rapport d'activite et projet scientifique … · d’informations (mrim) responsable :...
TRANSCRIPT

- 1 -
RAPPORT D'ACTIVITE
et PROJET SCIENTIFIQUE
Equipe Modélisation et Recherched’Informations (MRIM)
Responsable : Catherine Berrut, Professeur, Université Joseph Fourier
1 PERSONNEL
Chercheurs : Philippe Mulhem, Georges Quénot.Enseignants-chercheurs : Catherine Berrut, Christophe Brouard, Marie-France Bruandet,Jean-Pierre Chevallet, Yves Chiaramella, Jacques Courtin, Nathalie Denos, Marie-ChristineFauvet, Anne Guérin-Dugué.Ingénieurs :Doctorants : 23
Nombre d'équivalents chercheurs (NE) : 17,4
La liste détaillée des membres de l'équipe est fournie en annexe 1.
2 BILAN DES ACTIVITES DE RECHERCHE 02-05
2.1 Thématique scientifique et objectifs généraux
2.1.1 Présentation générale
La recherche d’information a pour objectif la définition de modèles et de systèmes dédiées àla représentation des documents (de tous média), permettant l’accès par le contenu (signal etsymbolique) de ces documents en vue de satisfaire les besoins d’information des usagers.Cette définition situe au cœur du problème la nécessité d’intégrer au modèle de recherched'informations les usagers du système notamment en mettant en œuvre une pertinence« système » la plus proche possible de la pertinence « usager ». Dans ce contexte oùl’interaction homme-système est primordiale, l’objectif du groupe est d’étendre la notion demodèle de recherche d’information, de même que les réalisations qui en sont dérivées, à laprise en compte plus large de la « recherche d’information interactive ». Cet objectif implique
LIG — Dossier de contractualisation 583

MRIM- 2 -
d’intégrer l’utilisateur au cœur de nos réflexions. Il explique aussi pleinement notreparticipation à des programmes d’expérimentation de haut niveau conformes aux standardsdu domaine qui confrontent nos approches à la réalité des documents et des problèmeseffectifs des usagers.L'éventail applicatif des SRIs est très vaste, depuis les systèmes grand public jusqu'auxsystèmes dédiés à des experts. Nous intégrons également dans nos travaux la problématiqueapporté par le filtrage d’informations.En ce qui concerne la recherché d’informations, nous nous sommes depuis longtempsintéressés à ces derniers que nous appelons les systèmes orientés précision. Leur objectif estd’obtenir une représentation détaillée du contenu des documents, une interprétation fidèle derequêtes complexes, favorisant un fort taux de précision. Cette activité est centrée sur ladéfinition de modèles de recherche d’information prenant en compte des éléments complexes(multimédia, structure, expressivité des contenus et des requêtes).L’ensemble des travaux de l’équipe est présentée dans ce rapport selon trois axes :
• La modélisation des données multimédia pour le filtrage ou la recherche d’informations• La définition de systèmes personnalisés de filtrage ou de recherche d’informations• L’évaluation des systèmes.
Avant de detailler les travaux de recherche de l’équipe, rappelons que notre équipe estfortement associée avec le laboratoire IPAL (FRE 2339) de Singapour. Ce laboratoire a étécréé par Philippe Mulhem en 1998, il en a assuré la direction jusqu’en 2003. Depuis 2003,Jean-Pierre Chevallet a pris la direction de ce laboratoire. Le rapport d’activité de l’IPAL estjoint au rapport d’activité du CLIPS (UMR 5524).
2.1.2 Modélisation des données multimédia pour le filtrage et la recherched’informations
Participants : Catherine Berrut, Georges Quénot, Philippe Mulhem, Jean-Pierre Chevallet,Marie-France Bruandet, Yves Chiaramella, Anne Guérin-Dugué, Hatem Haddad, MathiasGéry, Ho-Bao Quoc, Jean Martinet, Leïla Kefi, Mohammed Belkhatir, Mbarek Charhad, LeXuan Hung, Stéphane Ayache, Saïd Radhouani, Caroline Tambellini, Agatha Manolova,Khaled Khelif, Sébastien Marquez, Reda Mechtri, Loïc Maisonnasse, Isavela Dioletti,Alexandre François, Delphine Verbyst.
Mots-clés : représentation, description, modélisation, extraction de caractéristiques, langagesstructurés et syntagmes, graphes conceptuels
2.1.2.1 RésuméUne grande partie des travaux de l'équipe MRIM se base sur la modélisation etl'expérimentation de l'indexation et de la recherche de documents suivant une approcheclassique :
1. les documents sont atomiques, c'est-à-dire qu'ils sont estimés comme pertinents ou nonpertinents dans leur totalité,
2. les indexations sont statiques, c'est-à-dire que nous nous intéressons à établir unereprésentation du contenu des documents qui n'évolue pas au cours du temps, et ellesne dépendent pas d'un utilisateur ou d'un groupe d'utilisateurs particuliers,
3. les besoins des utilisateurs sont hors contexte, c'est-à-dire que l'on ne tient pas compted'un contexte d'utilisation de recherche d'information.
Malgré les limitations des approches classiques de Recherche d'Information, les problèmes
LIG — Dossier de contractualisation 584

- 3 -
qui se posent sur le choix des vocabulaires d'indexation en particulier sont encore loin d'êtrerésolus. Les travaux que nous menons sur ces aspects de représentation du contenu desdocuments se déclinent en 4 directions principales, allant de descriptions simples (des termes)à des représentations complexes (des graphes), en passant par des séquences de termes et deslangages structurés. L'éventail que nous étudions est vaste, et permet de couvrir l'ensembledes problèmes inhérents à la mise en place d'indexations de documents textuels, visuels, et decombinaisons de ces média :
Les travaux menés sur les termes visent d'un côté à déterminer quels termes (ou quellescaractéristiques) sont nécessaires et suffisantes pour une bonne indexation desdocuments, et d'un autre côté à modéliser les manières d'extraire ces termes à partir desdocuments. Ces problèmes se posent surtout sur des données visuelles comme lesimages et les vidéos
Les travaux menés sur des séquences de termes, particulièrement dans le cadre dedocuments parlés, se situent dans le domaine, nouveau en recherche d'information, del'indexation et la recherche par des modèles de langues.
Lorsque l'on désire gagner en finesse de représentation du contenu sémantique dedocuments comme le texte, le passage à des descriptions structurées comme dessyntagmes nominaux sont nécessaire. Le choix de ces descriptions et des processusd'extractions ont un impact très important sur le succès de ces approches, et nousétudions théoriquement et expérimentalement ces aspects
Dans le cas de traitement de documents visuels, l'équipe MRIM a montré depuis desannées que l'utilisation de graphes est nécessaire. A partir de cette hypothèse, le choixdes éléments à représenter doit être étudié. Nous recherchons donc en particulier àdéfinir des modèles théoriques robustes et à les implanter. Comme ces modèles doivent,comme dans toute approche en recherche d'information, permettre l'intégration depondérations qui représentent l'importance d'éléments d'indexation pour les documents,nous proposons des avancées sur ces aspects.
2.1.2.2 Description détailléea ) Etiquetage de document multimédia
Contrairement aux documents textuels, les documents multimédia ne possèdent pas d’indicesnaturels comme les mots (ou les groupes de mots) qui peuvent servir à représenter leurcontenu et à partir desquels on peut les retrouver. De plus, dans le cas des documents audio ouvidéo, on souhaite plus souvent retrouver un passage particulier plutôt que le document dansson ensemble. On peut assez souvent se ramener au cas du texte en utilisant une transcriptionde la piste audio produite par un système de reconnaissance automatique de la parole maiscela laisse de côté une part importante du contenu des documents même dans le cas desdocuments purement audio. Pour représenter le contenu non textuel des documentsmultimédia, on utilise des « descripteurs ». Ceux-ci peuvent être associés au document dansson ensemble ou à une partie seulement de ces documents. On en distingue de deux types : lesdescripteurs dits de niveau signal (en général numériques) et les descripteurs de niveausémantiques (en général symboliques). Nous conduisons de nombreux travaux sur l’extractionde tels descripteurs et sur la façon dont on peut les utiliser dans les systèmes de recherche parle contenu.
a.1 Extraction de caractéristiques au niveau signal.Nous avons développé des outils pour : l’extraction de caractéristiques de couleur
LIG — Dossier de contractualisation 585

MRIM- 4 -
(histogrammes 3D) et de texture (filtres de gabor), la segmentation en plans, l’extractiond’images-clés, l’extraction des mouvements de caméra et la segmentation des objets mobiles.Nous avons aussi travaillé sur la réduction de la dimensionnalité des descripteurs par analyseen composantes principales.
a.2 Extraction de caractéristiques au niveau sémantique.Nous avons développé des détecteurs spécifiques pour :
• la segmentation des documents vidéo en histoires: l'originalité de ce travail réside dansl'exploitation du contenu multimodal de la vidéo. Jusqu'à huit critères différents, issusdirectement de l'audio (signal brut), de la transcription de l'audio, ou de l'image ont étécombinés par une expression booléenne pour obtenir une segmentation optimale. Parexemple, au niveau du signal audio brut, on détecte les silences, les jingles et leschangements de locuteur, au niveau de la trancription, on détecte les fins de reportagepar des patrons linguistiques appropriés et au niveau du signal image, on détecte leschangements de plan.
• la segmentation et la catégorisation sémantique par analyse lexicale : le problème estici le découpage d'un texte en segments ayant une unité sémantique et d'attribuer uneou plusieurs catégories a chacun de ces segments. Le découpage est effectué par ladétection des changements de vocabulaire dans la séquence de mots composant letexte. Pour la catégorisation, l'approche utilisée repose sur la constitution etl'utilisation de vocabulaires spécifiques à des thèmes (par exemple politique ou sport)ou à des concepts (par exemple rocher ou verdure).
• la catégorisation sémantique à partir du contenu visuel : nous avons développé uneméthode travaillant à partir de caractéristiques dites de bas niveau (couleur, texture)exploitées localement et par apprentissage (par Machines à Vecteurs de Support) àpartir d'exemples positifs et négatifs. Pour améliorer sa performance et sa généralité,nous utilisons des interactions croisées (renforcement ou inhibition) entre conceptsdétectés.
• la détection de l'identité du locuteur : celle-ci se fait par l'intermédiaire de patronslinguistiques (par exemple : c'était [prénom nom] depuis [ville] pour [CNN|ABC])appliqués à la transcription de l'audio.
• la détection de l'état émotionnel du locuteur : celle-ci se fait par classification devecteurs de caractéristiques (par exemple anlyse spectrale) extraits directement dusignal audio. Les catégories recherchées incluent : neutre, colère, surprise, joie et peur.
a.3 Exploitation dans un système de recherche par le contenu.Nous avons développé un système qui intègre un certain nombre des caractéristiques extraitesde niveaux bas et haut. Ce système permet une recherche dans une base de documents vidéosuivant cinq modalités :
1) par mots-clés à partir de la transcription de la piste audio2) à partir d’images exemples (par similarité visuelle : couleur et texture)3) à partir de concepts pré-indexés4) par proximité temporelle avec des images sélectionnées parmi les résultats précédents5) par similarité visuelle avec des images sélectionnées parmi les résultats précédents
Le choix de ces cinq modalités intègre les extractions de caractéristiques que nous proposonset propose en même temps des interactions simples pour les manipuler par un utilisateureffectuant une tâche de recherche. Ces cinq modalités peuvent être combinées dans desproportions choisies par l’utilisateur. Un bouclage de pertinence peut être utilisé à volonté.
LIG — Dossier de contractualisation 586
- 5 -
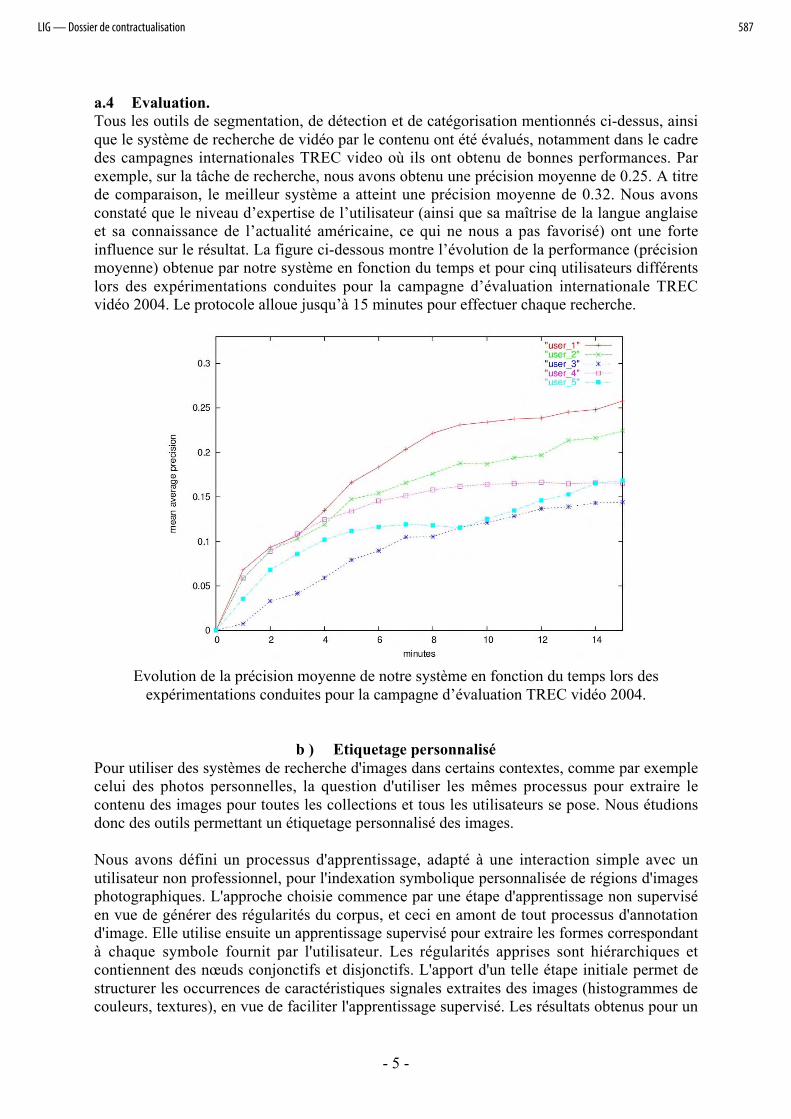
a.4 Evaluation.Tous les outils de segmentation, de détection et de catégorisation mentionnés ci-dessus, ainsique le système de recherche de vidéo par le contenu ont été évalués, notamment dans le cadredes campagnes internationales TREC video où ils ont obtenu de bonnes performances. Parexemple, sur la tâche de recherche, nous avons obtenu une précision moyenne de 0.25. A titrede comparaison, le meilleur système a atteint une précision moyenne de 0.32. Nous avonsconstaté que le niveau d’expertise de l’utilisateur (ainsi que sa maîtrise de la langue anglaiseet sa connaissance de l’actualité américaine, ce qui ne nous a pas favorisé) ont une forteinfluence sur le résultat. La figure ci-dessous montre l’évolution de la performance (précisionmoyenne) obtenue par notre système en fonction du temps et pour cinq utilisateurs différentslors des expérimentations conduites pour la campagne d’évaluation internationale TRECvidéo 2004. Le protocole alloue jusqu’à 15 minutes pour effectuer chaque recherche.
Evolution de la précision moyenne de notre système en fonction du temps lors desexpérimentations conduites pour la campagne d’évaluation TREC vidéo 2004.
b ) Etiquetage personnaliséPour utiliser des systèmes de recherche d'images dans certains contextes, comme par exemplecelui des photos personnelles, la question d'utiliser les mêmes processus pour extraire lecontenu des images pour toutes les collections et tous les utilisateurs se pose. Nous étudionsdonc des outils permettant un étiquetage personnalisé des images.
Nous avons défini un processus d'apprentissage, adapté à une interaction simple avec unutilisateur non professionnel, pour l'indexation symbolique personnalisée de régions d'imagesphotographiques. L'approche choisie commence par une étape d'apprentissage non superviséen vue de générer des régularités du corpus, et ceci en amont de tout processus d'annotationd'image. Elle utilise ensuite un apprentissage supervisé pour extraire les formes correspondantà chaque symbole fournit par l'utilisateur. Les régularités apprises sont hiérarchiques etcontiennent des nœuds conjonctifs et disjonctifs. L'apport d'un telle étape initiale permet destructurer les occurrences de caractéristiques signales extraites des images (histogrammes decouleurs, textures), en vue de faciliter l'apprentissage supervisé. Les résultats obtenus pour un
LIG — Dossier de contractualisation 587

MRIM- 6 -
ensemble de 15 étiquettes sur un ensemble de 750 photographies personnelles sont uneprécision de 35% et un rappel de 35%, ce qui est pour la précision un incrément de +34% parrapport à une classification de référence connue (1-NN) et pour le rappel un incrément de+13%. Nous avons de plus comparé sur des données synthétiques les résultats de notreapproche avec celle de machines à vecteur de support (SVM) avec une amélioration declassification correcte de +28%.
Ce travail sera utilisé par la suite pour créer la représentation du contenu des images commenous le proposons dans la partie ci-dessus.
c ) Langage structuré et syntagme
Les spécialistes d’un domaine utilisent généralement un vocabulaire très précis pour décrireleurs problèmes et leurs solutions (Médecine, Politique, Droit, Physique, etc). Lorsqu’ils ontbesoin de faire une recherche d’information, leurs besoins sont très ciblés et leurs requêtessont alors très précises. Le nombre de documents recherchés peut alors être assez réduit, carune recherche précise et ciblée réduit le nombre potentiel de documents pertinents. Cescaractéristiques conduisent à la définition de Recherche d’Information Précise, dans laquelleles mesures de rappel et de précision sont à interpréter de manières différentes. En effet, dansle cas où très peu de documents sont pertinents (à la limite un seul), un rappel proche de 100%peut être indispensable à une recherche réussie. La qualité du système est alors sa faculté àproposer ces quelques documents en tête de classement : la mesure pertinente pour ce type desystème est alors la taille de la réponse pour obtenir 100% de rappel, et la précision obtenue àce point.
Notre approche dans cet axe de travail comporte les pistes suivantes : il s’agit d’une part deprendre en compte de la terminologie spécifique et complexe d’un domaine pour augmenter laqualité du système de recherche. Le second axe de travail consiste à tenir compte du terme etde son rôle dans la phrase et le document en général. Des informations de nature syntaxiquesont alors nécessaires pour construire un index structuré à partir de l’analyse syntaxique dudocument. D’autre part, il nous parait nécessaire de disposer d’informations extérieures audocument pour rendre compte des connaissances du domaine spécifique sur lequel porte cesdocuments. Ces informations peuvent être des ontologies de domaine (comme UMLS UnifiedMedical Language System http://www.nlm.nih.gov/research/umls/), qui servent à mieuxinterpréter les termes des documents et des requêtes et cibler les réponses. Des informationscomplémentaires peuvent être obtenue par l’analyse des collections elles mêmes comme parexemple des thésaurus d’associations. Finalement, il semble important de tester des approchesd’indexation ayant pour objectif de transformer les termes en concepts lorsque les ressourceslinguistiques sont disponibles. Ce type d’indexation conceptuelle permet d’obtenir unereprésentation pivot naturellement interlangue, elle permet également une fois l’index obtenude s’affranchir des problèmes d’homonymie et de synonymie. Cependant, le manque d’outilset de ressources linguistiques disponibles limite encore la portée de ce type d’approche. Maisles perspectives semblent prometteuses (comme le montrent les réusltats obtenus lors del’expérience d’indexation multilingue pour la participation à CLEF 2005 avec l’Université deGenève).
Indexation par multi-termes structurés : ce travail considère le terme commel’élément central de l’indexation précise. Un terme se définit comme un élément d’uneterminologie, c'est-à-dire un syntagme nominal qui désigne un concept unique dans undomaine donné (ex : « malformations vasculaires du système nerveux central »). La
LIG — Dossier de contractualisation 588

- 7 -
particularité de ce type d’indexation réside dans la fonction de correspondance qui doitétablir des liens entre des variations de termes. Ce travail a fait l’objet de la thèse de MrBao Quoc. Il a proposé que la correspondance par dérivation de termes soit évaluée par unréseau Bayesien. Cette proposition a été appliquée à un système de Recherched’Information bilingue (Français, Vietnamien). A l’occasion, un système de détection dessyntagmes nominaux a été construit pour le Vietnamien. Son travail fusionne uneindexation par termes structurés et d’autres types informations extraites des documents oudes requêtes des utilisateurs. En effet, il semble nécessaire d’aider la fonction decorrespondance entre les termes structurés par des informations complémentaires.
Indexation par dépendances syntaxiques : L’étape pour continuer à exploiter lesinformations linguistiques des documents, consiste à utiliser les dépenses syntaxiquesextraites par un analyseur de surface. Il est nécessaire de se limiter pour l’instant, à cesstructures arborescentes simples si l’on veut maintenir un processus d’indexationautomatique. En effet, des structures plus complexes ont déjà été étudiées pour desapplications de recherche d’information, comme les logiques terminologiques ou lesgraphes conceptuels. Mais l’impossibilité actuelle de les extraire automatiquement delarges corpus de textes dans des temps raisonnables empêche leur usage pour l’indexation.Actuellement le travail a essentiellement porté sur l’extraction de nouveaux descripteurs àpartir des résultats d’analyseurs syntaxiques de surface. L’utilisation des dépendancessyntaxique en RI à ainsi été évaluée. Une dépendance représente le lien syntaxico-sémantique entre deux mots : le dépendant et son recteur (i.e. le mot dont il dépend). Cesdépendances sont conservées sous forme de terme d’indexations semi-complexes quiconsistent en des n-uplets composés de termes et du type de la relation syntaxique.
Indexation sémantique : Une étape supplémentaire à la syntaxe, consiste à remplacerles termes par leur image dans une structure sémantique. Sans aller jusqu’aux structures degraphe conceptuels, il existe des structures comme les vecteurs conceptuels, qui permettentde projeter une indexation initiale de termes dans des dimensions sémantiques. La qualitéde l’indexation est directement liée à la qualité des vecteurs sémantiques disponibles etégalement liée au processus de désambiguïsation. Une première ébauche de ce type desolution a été mise en oeuvre et testé lors de la campagne CLEF 2005.
Indexation par dimensions sur des ontologies : Certaines requêtes précises exprimentexplicitement des contraintes par rapport à des dimensions d’une ontologie. Nous appelonsdimension d’une ontologie, les sous arbres de sa structure hiérarchique. Par exemple, enmédecine, une requête peut faire explicitement référence à une anatomie et une pathologie.Traiter ces dimensions dans le système de recherche permet de répondre plus précisément àce type de requête. Les premiers résultats de ce type d’approche ont été présentés au forumCLEF 2005 pour la piste d’indexation des images médicales.
Les expérimentations utilisant des informations syntaxiques, ont montré la nécessité d’avoirun modèle qui prenne en compte les différences entre les divers descripteurs utilisés. Pourcela, un modèle de langue intégrant les lemmes et les dépendances semble être une voieintéressante à explorer. Les expérimentations qui ont été faites (par exemple dans le cadre duprojet PRISM), ont aussi montrés le besoin de la prise en compte de la variation syntaxiquelors de l’utilisation des dépendances.Finalement, la recherche de sens pour l’indexation textuelle passe par l’utilisation d’outilslinguistiques performants et de ressources à large couverture. Au fur et à mesure que ceséléments deviennent disponibles et suffisamment performants pour être utilisés dans desapplications de recherche d’information, nous pouvons poursuivre la définition etl’expérimentation d’un système de recherche d’information orienté vers la précision des
LIG — Dossier de contractualisation 589

MRIM- 8 -
réponses. La frontière mouvante entre de tels systèmes et des systèmes de réponse à desquestions demande en permanence à être redéfinie. Il n’est cependant pas à exclure que cesdeux domaines se rejoignent à l'avenir.
d ) Graphes conceptuels
Lorsque l'on souhaite indexer des documents, le problème du pouvoir d'expression nécessaireet suffisant se pose. En particulier, un cadre formel intéressant permettant à la fois de prendreen compte différentes facettes des informations et une certaine complexité de représentationnous a amenés à considérer le formalisme des graphes conceptuels. La versatilité de ceformalisme nous permet de l'employer avec succès dans différents contextes. Nos travaux sebasent donc sur le formalisme des graphes conceptuels sans pour autant que les résultatsobtenus ne soient contraints par ce cadre.
Nos travaux portent sur des modélisations du contenu des images fixes et des documentsvidéo pour la recherche d'information. Ces travaux incluent la prise en compte des éléments àreprésenter et la prise en compte des pondérations associées à ces éléments. D'autre part, larecherche d'information à pour objectif de traiter des corpus de taille importante, et cet aspectest également l'objet de certains de nos travaux. Nous décrivons ces points dans la suite.
De manière plus précise, une partie de nos travaux se sont portés sur la modélisation ducontenu d'images photographiques par l'utilisation de symboles pour représenter les objetsvisibles et également les caractéristiques signal comme les textures et les couleurs. Nousintégrons dans un modèle formel clair les éléments liés aux objets visibles, aux couleurs deces objets, aux textures de ces objets, ainsi que les éléments liés aux relations entre ces objets,ce qui est déjà un gros travail théorique. D’un point de vue expérimental, nous montrons surune collection de 48817 images (tirée de la campagne internationale TREC vidéo) que nostravaux fournissent des résultats qui dépassent largement l’état de l’art existant (entre +30% et+100%) pour les systèmes exploitant uniquement l'information visuelle.
Un autre aspect moins formel porte sur la manière de pondérer les objets visibles dans unereprésentation du contenu d’une image. Nous avons conduit des expérimentations impliquant30 participants pour déterminer parmi quatre critères (la taille des objets visibles, la positiondes objets dans une image, l'éclatement des objets, et l'homogénéité de l’image) lesquelsapparaissent statistiquement significatifs. Nous avons déduit de cette étude que tous cescritères sont effectivement significatifs excepté l'éclatement des objets (nombre d'objets d'unmême type). Une fois ce constat établi, nous avons formalisé un schéma de pondération pourles objets visibles des images, modèle que nous avons implanté puis évalué avec succès.
Nous avons étudié une manière de diminuer la complexité du traitement des graphesconceptuels pendant la phase de recherche. Notre proposition utilise des graphes simples,appelés graphes étoiles, pour représenter des images. L’utilisation de ces graphes simples etnon de graphes complexes comme dimensions d’un espace vectoriel, amène une réductiond'un facteur 6 sur le temps de réponse par rapport à une méthode de projection de graphe déjàoptimisée, tout en conservant une qualité de réponses similaire.
Nous avons également développé un modèle basé sur des relations conceptuelles pour ladescription fine du contenu des documents vidéo. Ce modèle est une extension et uneadaptation à la vidéo du modèle EMIR_ précédemment développé pour les images fixes. Lebut est de permettre une intégration homogène des éléments d'indexation associés auxdifférentes pistes du média (son, image et texte) et d'éléments externes (bases deconnaissances) aussi bien au niveau signal qu'au niveau sémantique.
LIG — Dossier de contractualisation 590

- 9 -
2.1.3 Systèmes personnalisés pour le filtrage et la recherche d’informations
Participants : Marie-France Bruandet, Catherine Berrut, Philippe Mulhem, Nathalie Denos,Anne Guérin-Dugué, Christophe Brouard, Jean-Christophe Bottraud, Razan Taher, StéphaneBissol, An-Te Nguyen, Cédric Bisiaux, Stéphane Ayache.
Mots-clés : assistant adaptatif, recherche collaborative, étiquetage personnalisé, profil.2.1.3.1 RésuméUne part importante de l'activité de recherche de l'équipe MRIM porte sur la conception desystèmes de RI novateurs. Comme le montre la section précédente, la recherche sur lesmodèles traditionnels de RI, posant les questions de la représentation des documents et desrequêtes et de leur mise en correspondance, reste un thème majeur de l'équipe. Pourtant latendance est à l'intégration, dans ces systèmes, d'informations propres aux utilisateurs : onparle alors de systèmes de RI personnalisés. Il s'agit d'inventer des modes d'interactionefficaces dépassant la durée d'un simple échange requête-résultat et permettant aux utilisateursde communiquer aux systèmes le plus d'informations possibles sur leur besoin d'information.Il s'agit aussi d'intégrer dans ces systèmes des méthodes d'apprentissage donnant aux systèmesla capacité de s'adapter automatiquement aux utilisateurs.
On peut considérer deux grands types de situations d'interaction entre utilisateurs et système.Ou bien l'utilisateur est considéré comme isolé des autres utilisateurs et l'interaction etl'apprentissage se réalisent indépendamment pour les différents utilisateurs. Ou bien aucontraire on se place dans une situation de recherche collaborative.
Différents travaux portant sur la personnalisation des système de RI ont été menés parl'équipe, dans différentes situations d'interaction, soit individuelle soit collaborative, et surdifférents média. Plus particulièrement ces travaux ont porté sur :
- L'étude de différentes situations d'interaction comme l'aide personnalisée à l'utilisateurdans le cas d'une recherche collaborative (en s'appuyant sur les recherches desutilisateurs ayant des centre d'intérêts communs), l'assistance à la recherche dedocuments disponibles sur le Web à partir des documents présents chez l'utilisateur etde la tâche en cours.
- La mise au point d'une méthode apprentissage combinant apprentissage supervisé et nonsupervisé pour l'étiquetage personnalisé d'images.
- La mise au point de méthodes d'apprentissage pour le filtrage de documents textuelsbasés le retour de pertinence des utilisateurs dans une situation de rechercheindividuelle ou collaborative.
- L’étude de la notion de communauté et sa mise en œuvre dans les systèmes de filtragedans l'optique d'utiliser ces communautés pour enrichir les profils utilisateurs.
- La mise au point d'une méthode d'apprentissage basée sur un retour de pertinence pourla navigation dans une base d'images.
- La recherche d'une définition générale de la notion de "profil utilisateur" dépassant lesimple critère de contenu, identifiant et organisant les différents autres critèresutilisateurs potentiels.
2.1.3.2 Description détailléea ) Recherche collaborative
En général, les approches de recherche d’information collaborative proposent des interfacespour supporter la collaboration et non pas des outils de recherche d’information pour fournir
LIG — Dossier de contractualisation 591

MRIM- 10 -
des résultats adaptés aux besoins et aux désirs de chaque utilisateur au cours d’une session derecherche collaborative. Les hypothèses sous-jacentes à ce travail sont que les utilisateursayant choisi de travailler ensemble c’est-à-dire de façon collaborative diminuent la durée deleur session de recherche sur les moteurs de recherche et améliorent au final la qualité desrésultats obtenus. La qualité des résultats ici s’entend sur la convergence plus rapide vers desrésultats satisfaisants et correspondant à leur objectif commun de recherche. La définitiond’une recherche d’information collaborative est fondée sur la mise en commun des donnéesissues des recherches d'information individuelles (requêtes, documents retrouvés, jugementsde pertinence émis sur les documents, etc.). L’idée est d’augmenter l’efficacité de la rechercheafin de construire collectivement un résultat mieux approprié en trouvant des informationscomplémentaires correspondant à des facettes différentes du problème traité et d’obtenir aufinal un meilleur recouvrement du domaine d'information recherché. En d’autre terme, ils’agit de répondre au problème classique en recherche d’information à savoir de préciser viaune requête à un moteur de recherche un besoin d’information souvent mal défini.
Nous avons construit un environnement collaboratif afin d’aider les utilisateurs lors de leurssessions de recherche en leur permettant d’obtenir une aide personnalisée. Un utilisateur aucours de sa session de recherche pourra, s’il le désire, connaître les autres pistes explorées parles autres membres du groupe, les résultats obtenus par la personne qu’il estime la pluscompétente dans le domaine de recherche ou les résultats obtenus par des utilisateursformulant des requêtes totalement différentes des siennes. En d’autres termes, il s’agit lorsquel’utilisateur le désire, de répondre à certaines situations qui se produisent lors d’une session derecherche individuelle. L’on peut en faire la typologie suivante, l’utilisateur peut :
- se trouver bloquer ou être désorienté (i.e. l'utilisateur ne parvient pas à un résultatsatisfaisant et ne sait plus quelle requête reformuler)
- douter de ses résultats (i.e. l’utilisateur a obtenu un résultat satisfaisant, mais il n’est passûr de la qualité intrinsèque de celui-ci)
- être curieux de l’état d’avancement des autres (i.e. l'utilisateur n’a pas de problèmeparticulier, mais veut se positionner par rapport aux autres pour éventuellement êtreréconforté !)
Pour que ce travail soit satisfaisant, il faut, bien entendu, que chaque membre du groupeaccepte de juger les résultats qu’il obtient afin que l’on ait une évaluation de la qualité desrésultats obtenus par une requête donnée. Nous obtenons ainsi, en quelque sorte, uneévaluation de la performance de la requête pour l’objectif choisi. Le système pourra ainsiconstruire une requête à partir des différentes requêtes ayant obtenu les meilleurs résultats dupoint de vue des utilisateurs du groupe ainsi que construire une réponse collective au besoind’information posé. Le système doit donc « apprendre » de la collaboration afin d’aiderl’utilisateur dans les différentes étapes de recherche (expression du besoin d’information,évaluation du résultat obtenu et reformulation de sa requête).
Nous avons construit un prototype correspondant à cet environnement collaboratif. La partiela plus délicate du travail a été la validation de nos hypothèses de travail auprès d’un groupetravaillant individuellement puis en collaboration afin de vérifier si un tel environnement estun apport ou au contraire un frein. La difficulté est la mise en place d’un protocole devalidation. Nous devons avouer que l’expérience bien que limitée nous a encouragé car lesutilisateurs étaient plutôt satisfaits devant l’obtention du résultat global et de l’aide apportée.
b ) Assistant adaptatifAprès avoir analysé les problèmes que pose aux utilisateurs l’usage des services de recherchedisponibles sur le World Wide Web, nous avons proposé une vision plus ouverte d’unsystème de recherche d’information de façon à mieux prendre en compte ses besoins. L’idée
LIG — Dossier de contractualisation 592

- 11 -
sous-jacente est d’intégrer l’utilisateur comme un élément important d’un système derecherche d’information. Nous pensons que le processus de recherche doit prendre en compteun ensemble d’informations contextuelles, associées à l’utilisateur et représentant ses centresd’intérêt. C’est pourquoi, nous avons proposé un assistant personnel de recherche, chargé decollecter et de maintenir des informations sur l’utilisateur et son activité, mais surtout derecevoir la demande de l’utilisateur et de l’enrichir, afin de personnaliser les résultats obtenusvia un service de recherche.
Parallèlement, il nous a semblé souhaitable d’étudier les bases d’un protocole decommunication entre ces assistants et les services de recherche, en spécifiant trois typesd’information : un objectif de recherche, un contexte de tâches et un profil personnel ; nousavons étudié différentes façons d’organiser cette information dans le cadre des assistants derecherche.
Notre approche est centrée sur la définition de ce que nous appelons un « contexte derecherche ». Ce contexte est construit autour de deux éléments : un profil de l’utilisateur,déduit des documents que ce dernier gère, et une représentation de ses activités, centrée sur lanotion de tâche « documentaire ». Le contexte de recherche peut ainsi améliorer la définitiondes objectifs de recherche d’information d’un utilisateur donné.Notre approche se distingue d’approches comparables par plusieurs éléments :• L’assistant de recherche construit le profil de l’utilisateur (c'est-à-dire la représentation
des centres d’intérêt de l’utilisateur) indépendamment de toute recherche. L’assistantexploite la bibliothèque de références gérées par l’utilisateur, et disponible dans sonenvironnement. L’utilisateur peut entraîner explicitement le système, et en obtenir del’aide dès sa première requête.
• Ce profil de l’utilisateur est défini comme une hiérarchie de classes, ces dernières étantconstruites à partir d’une classification des références fournies pour élaborer le profil. Leprofil est organisé autour de deux éléments : un profil conceptuel, gérant les informationsnécessaires à l’organisation et à l’évolution du profil, et un profil opérationnel,correspondant à une description du profil utilisable dans les processus de recherche.
• L’activité de l’utilisateur est observée en permanence de façon à pouvoir construire à toutun instant une représentation des tâches en cours. Cette représentation peut ensuite êtrecombinée au profil pour construire un contexte de recherche.
• Des stratégies de recherche nouvelles, utilisant des algorithmes d’apprentissage pourgénérer des requêtes de façon à préciser les objectifs de la recherche sans intervention del’utilisateur ont également été développées et testées.
Ce travail se situe à la frontière des deux domaines de recherche que sont l’apprentissage enintelligence artificielle (IA) et la recherche d’information (RI). Les points forts de ce travailsont, d’une part, l’adaptation et l’évolution des profils de l’utilisateur pour la partie IA et,d’autre part la construction et l’utilisation d’un profil hiérarchisé de l’utilisateur ainsi que lagénération automatique de requêtes dépendant de son profil pour la partie RI.Afin de rendre opérationnel l’assistant de recherche, nous avons proposé une architecturegénérale et une plate-forme logicielle pour ce type d’assistants. Cette architecture permet declairement identifier les différents composants et algorithmes nécessaires à la mise en œuvrede ces systèmes. Elle met également en évidence le grand nombre de variations possibles et ladifficulté soulevée par l’évaluation et la comparaison de ces variations. Nous avons égalementconstruit un système fournissant à la fois les composants de base, le cadre nécessaire àl’assemblage des assistants et les mécanismes permettant d’utiliser simultanément plusieursagents pour pouvoir les comparer.
Les différents tests et expériences réalisés ont également permis de montrer les limites de la
LIG — Dossier de contractualisation 593

MRIM- 12 -
solution proposée pour évaluer les performances des assistants. Parfaitement utilisable dans lecas d’un petit nombre d’assistants, elle demande un trop grand investissement de la part desobservateurs lorsque ce nombre devient trop important.
c ) Filtrage adaptatif pour les documents textuelsLa problématique du filtrage adaptatif se situe au confluent de l'apprentissage machine et dela Recherche d'Information. Il s'agit de donner aux systèmes de Recherche d'Information lacapacité d'apprendre. De l'apprentissage machine, on retient le principe général del'induction dans lequel il s'agit de généraliser (par l'extraction de règles ou la construction degroupes par exemple) à partir d'un ensemble d'exemples (classés ou non, selon quel'apprentissage est dit "supervisé" ou "non supervisé") pour pouvoir, par exemple, classerd'éventuels nouveaux exemples. Le filtrage adaptatif ne se limite cependant pas à uneméthode d'apprentissage. En effet, des modèles d'évaluation de pertinence propres à laRecherche d'Information, doivent être combinés aux méthodes d'apprentissage.
On peut distinguer deux grandes catégories de systèmes adaptatifs selon qu'un moded'apprentissage supervisé ou non supervisé est considéré. Ces deux modes d'apprentissage ontdonné lieu à des recherches dans l'équipe.
c.1 Cas d'un apprentissage superviséLes travaux de l'équipe ont porté sur le cas d'apprentissage supervisé le plus évident et le plusrépandu qui consiste à tenir compte de l'ensemble des retours de pertinence d'un utilisateurpour lui proposer parmi les nouveaux documents ceux qui sont susceptibles de l'intéresser(voir figure ci-dessous).
En particulier, les travaux de l'équipe ont porté sur :
- La définition d'un nouveau système de filtrage adaptatif mettant en oeuvre un nouveaumodèle de pertinence.
Le système proposé fonctionne sur le principe de la mise à jour d'une liste de mots clépondérés (aussi appelé profils) représentant le besoin d'information de l'utilisateur (ce queproposent la majorité des systèmes existants). Une méthode de mise à jour des poids ainsiqu'une méthode d'évaluation de la pertinence basée sur l'idée de résonance dans un réseau ontété proposées et évaluées lors de campagnes internationales.
- La prise en compte des dépendances entre termes d'indexation.
Flux de documents
Système defiltrage
adaptatifSélection du document
Retour de pertinence del'utilisateur
Rejet du document
Utilisateur
LIG — Dossier de contractualisation 594

- 13 -
L'apprentissage automatique d'une liste de mots clé pondérés pose de façon plus accentuéeencore le problème de la dépendance des termes d'indexation (toujours présent en Recherched'Information) puisque les termes sont ajoutés sans contrôle.
- La prise en compte de groupe de mots
La présence d'un mot clé dans un document peut être une bonne indication de la pertinenced'un document sans pour autant être sûr que ce mot soit utilisé dans le bon contexte. Lareprésentation du besoin d'information par une liste de groupe de mots clés pondérés et nonune simple liste de mots clés pondérés permet de vérifier que le mot est utilisé dans le boncontexte. Une méthode d'apprentissage permettant de trouver les groupes pertinents doitcependant faire face à des problèmes d'explosion combinatoire (quel groupe choisir ?) et à desproblèmes de dépendances (forte dépendance entre le groupe de termes et les termesd'indexation le composant).
c.2 Cas d'un apprentissage non supervisé et filtrage collaboratifLes travaux de l'équipe ont aussi porté sur le cas d'un apprentissage non supervisé dans lequelil s'agit de construire des groupes d'utilisateurs sur la base de leur retour de pertinence sur lesdifférents documents. Les documents peuvent ensuite être filtrés en tenant compte à la fois desretours de pertinence de l'utilisateur et de son appartenance à une communauté d'utilisateurs :c'est le principe des systèmes de filtrage collaboratif, qui ont constitué le principal objetd'étude sur la « Qualité des systèmes de filtrage ».
c.3 Interaction de l'utilisateur avec un système de filtrage d'informationDe façon classique, l'interaction avec les systèmes de filtrage se fait par l'intermédiaire deretours de pertinence émis par l'utilisateur vers un système qu'il perçoit comme une boîtenoire. Ce cadre d'interaction limité peut être enrichi de façon à étendre la capacité dessystèmes à s'adapter à l'utilisateur, y compris dans des situations où l'approche du retour depertinence classique échoue à rendre compte des changements advenus dans le besoin del'utilisateur.
L'interaction de l'utilisateur avec un système de filtrage a fait l'objet de travaux de recherchedans l'équipe, notamment au travers du projet TIPS où l'objectif était d'intégrer dans unsystème d'accès à l'information une fonctionnalité de filtrage collaboratif avec des moyenspour chacun de percevoir les autres utilisateurs du système (plateforme COCoFil,Community-Oriented Collaborative Filtering).
Ce travail s'est prolongé en développant la notion de communauté dans les systèmes defiltrage pour la mettre au coeur de l'interaction. En particulier, ces travaux ont porté sur lamise au point de méthodes de construction et de visualisation de « communautés » selon descritères de regroupement variés, dans l'optique d'utiliser ces communautés pour enrichir lesprofils utilisateurs.
d ) Reformulation adaptative pour les imagesCompte tenu du décalage sémantique entre les informations « signal » d’un système derecherche d’images par le contenu et les informations « symboliques » préhensibles parl’utilisateur, nous proposons dans le cadre du projet SCoPIe un modèle d’interaction pour unsystème de navigation dans une base d’images indexées par le contenu. Le modèle met enadéquation à travers un processus de bouclage de pertinence (ou feedback), les besoins del’utilisateur exprimés pendant la session de recherche avec les informations de bas niveaureprésentant les images.Le modèle proposé permet une prise en compte de l’usager selon trois axes :
LIG — Dossier de contractualisation 595

MRIM- 14 -
- la modélisation de la pertinence, formalisée par une méthode à noyaux, attribue àchaque image et par caractéristique une valeur traduisant son adéquation avec l’usager,
- la fusion des caractéristiques couleur, texture et forme qui décrivent une image.Plusieurs heuristiques sont mises en œuvre afin d’apprendre les poids associés àchaque caractéristiques selon les choix de l’usager,
- la prise en compte de l’évolution des besoins de l’utilisateur pendant la session derecherche. Le système propose plusieurs « profils temporels » à l’utilisateur selon sonparcour (mémoire, oubli, constant).
La combinaison de ces trois critères aboutit à une métrique adaptée à l’utilisateur de la formesuivante :
€
DistUtilisateur i, j( ) = wcDistc i, j( )Φ pi(c )( )c∑
où i, j sont des images, c une caractéristique de bas niveau,
€
wcc∑ =1 et Φ est une fonction
décroissante.La figure ci-dessous montre l’interface de ce système de reformulation.
Le modèle a été testé sur une base de 4000 images, nous avons évalué chacune descomposantes du modèle, et montrons à l’aide de tests statistiques le gain significatif apportépar le modèle en terme de satisfation de l’usager.
e ) Profil d’utilisateurDans le cadre de la problématique générale de l’accès à l’information, nous avons pourobjectif de fournir les informations les plus pertinentes en fonction de chaque utilisateur, dansune forme la mieux adaptée, en répondant à des exigences de qualité, et en assurant le suivi del’utilisateur tant dans ses besoins que dans ses préférences.
Nous abordons cette problématique au travers de la notion de profil, que l’on définit commeun ensemble de préférences spécifiées par l’utilisateur ou dérivées de son activité passée. Lorsde l’accès à l’information, la requête est évaluée via le prisme du profil, et exploite lesdonnées du profil aux différentes étapes de son cycle de vie : reformulation, exécution,présentation des résultats.Ces dernières années, les travaux de l’équipe ont consisté :
- à contribuer à cette définition englobante du profil en tant que vecteur essentiel de lapersonnalisation,
- à explorer la variété des critères d’accès à l’information, notamment les facteurs liés auxcaractéristiques de qualité des documents qui véhiculent l’information, qu’il s’agissede caractéristiques internes (lisibilité, longueur, niveau d’illustration, etc.), de
LIG — Dossier de contractualisation 596

- 15 -
caractéristiques externes (réputation de l’auteur, processus de publication, etc.) ou decaractéristiques d’usage (évaluations explicites ou implicites des utilisateurs)
- à étudier en théorie et en pratique ce que ces nouveaux critères d’accès impliquent entermes d’indexation des documents
- à explorer les possibilités d’interaction de l’utilisateur avec les profils utiles en filtragecollaboratif et filtrage hybride
2.1.4 Evaluation des systèmes de filtrage et de recherche d’informations
Participants : Catherine Berrut, Georges Quénot, Jean-Pierre Chevallet, Nathalie Denos,Philippe Mulhem, Stéphane Ayache, Mbarek Charhad, Lizbeth Gallard, Delphine Verbyst,Frédérik Colin.
Mots-clés : qualité, campagnes d’évaluation, passage à l’échelle.2.1.4.1 RésuméQue ce soit en amont par la construction de tableaux de bord permettant le suivi de la qualitédes systèmes, ou en aval par la participation aux campagnes d’évaluation des systèmes, ouencore par l’analyse d’usage de systèmes dédiés, l’équipe participe activement à la validationde ces travaux. Cet axe de recherche est fondamental, à notre sens, dans nos activités. C’estégalement un axe exigeant en temps de développement et de mise enœuvre. Nous ledéveloppons ici en trois parties :
• La qualité des systèmes de filtrage• Usages• Campagnes d’évaluation
2.1.4.2 Description détailléea ) Qualité des systèmes de filtrage
Les systèmes de filtrage d’information envoient aux utilisateurs les informations quirépondent à leur profil, sans même qu’ils aient à formuler de requête. Très souvent, le systèmes’adapte pour tenir compte de l’évolution du besoin de l’utilisateur, en exploitant son retourde pertinence sur les informations fournies.La capacité d’un système de filtrage à s’adapter dépend fortement du comportement del’utilisateur : par exemple sa motivation à fournir du retour au système peut faiblir ou sonretour peut être orienté de telle façon que le système ne peut en faire bon usage.Pour contrer ce type de problème, on peut envisager de raffiner les fonctionnalitésd’adaptation du système en le dotant d’une capacité à détecter les dysfonctionnementspendant son exploitation. Cette approche conduit à une problématique nouvelle : le contrôlede la qualité d’un système de filtrage en exploitation.Ces dernières années, les travaux de l’équipe ont consisté :
- à définir un modèle de qualité d’un système de filtrage collaboratif en exploitation,- à le mettre en œuvre au travers d’une couche de contrôle qui mesure la qualité et en fait
la synthèse dans un tableau de bord
b ) Analyse d’usages : usage familial, nomadismeb.1 Usage familiale de materiel dédié à la recherché d’images : le projet AnnapurnaLe projet Annapurna (pour Annotation Automatique d’Images pour la Recherche et laNavigation) a été conçu dans le contexte de l’explosion de la photo numérique et de laconvergence avec la télévision.
LIG — Dossier de contractualisation 597

MRIM- 16 -
Ayant fait ce constat, le projet Annapurna avait comme objectifs principaux (i) de sélectionnerle meilleur des techniques d’indexation d’images par le contenu, telles que l’annotationsémantique automatique et la navigation par proximité sémantique (ii) de les améliorer et deles adapter au contexte grand-public, caractérisé par l’environnement familial domestique etun téléviseur amélioré, équipé de moyens de stockage, et (iii) de les démontrer à travers lescénario d’usage de la gestion d’une collection de photos personnelles.
L’approche retenue consistait à développer un prototype logiciel comportant un moteurd’annotation automatique qui ajoute des mots-clés descriptifs aux images (mer, neige,paysage, ville, intérieur, bébé, groupe de personnes…), ainsi qu’une application de navigationpar similarité sémantique et/ou visuelle. Ce prototype a été porté sur une plate-forme grand-public (de type décodeur avec disque dur), caractérisée par une contrainte forte sur lapuissance et le coût des algorithmes mis en œuvre. Enfin une étude d’usage des techniquesd’annotation automatique d’images, dans le contexte de la gestion d’une collection de photospersonnelles, avec le support de la plate-forme expérimentale développée a été menée.
Au sein du laboratoire CLIPS, ce travail a été effectué en collaboration avec Multicom.
b.2 Accès Mobile à de l’Information MultimédiaLe développement récent des technologies de communication mobile, permet d’envisager denouvelles applications d’accès à l’information. En particulier, les téléphones portables avecappareil photo intégré sont actuellement très répandus. Le rapport entre leur capacité detraitement (processeur et mémoire), et leur compacité en fait un outil privilégié pour l’accèsmobile à de l’information multimédia.
Nous pensons alors qu’il faut mettre en place un nouveau paradigme pour la recherched’information, en prenant en compte la personnalisation du terminal d’accès (téléphonemobile personnel), son extrême mobilité (on l’a toujours sur soi), ses capacités de calculs, saconnexion au réseau (ex : GRPS), et ses possibilités multimodales d’acquisition et deprésentation de l’information (caméra, micro, clavier, mini écran, haut-parleur). Cettepersonnalisation doit prendre en compte également des éléments de contexte, comme laposition géographique ou une information sur la tâche de l’utilisateur éventuellementdisponible dans l’agenda électronique du téléphone.Pour construire ce nouveau paradigme de Recherche d’Information, nous avons choisi detravailler sur une tâche particulière d’accès à l’information, mettant en œuvre une image prisesur l’appareil photo, pour servir de requête à un système d’information décrivant des lieuxtouristiques. L’extrême simplicité de la requête, permet d’envisager une utilisation trèsconviviale, car il suffit de pointer l’objectif photographique de son téléphone pour recevoirune description textuelle et audio du monument ou du bâtiment observé. Le prototype
LIG — Dossier de contractualisation 598

- 17 -
Snap2Tell (voir figure) qui permet de tester cette approche, s’apparente à un systèmed’identification d’objets (des bâtiments et des monuments), à partir de leur apparence visuelle.Contrairement aux systèmes de Recherche d’Images par le contenu (Content Base ImageRetrieval), ce n’est pas une description textuelle qui permet de retrouver une image, mais c’estune image qui permet d’accéder à un contenu textuel et audio. L’approche pour l’indexationdes monuments consiste non pas à donner des termes clés, mais à décrire l’objet par unensemble d’images (voir ci-dessous).
Images index du musée des civilisationsLe problème posé est alors un problème d’appariement d’image entre l’image requête et lesimages index des documents. Les techniques d’extraction d’indices visuels peuvent alors êtreutilisées, cela peut aller de simples histogrammes par zone, aux techniques de calculs detextures et de détection de contours. La contrainte dans ce genre de système provient de lacapacité réduite en calcul et en mémoire du terminal portable, et de la limitation desinformations à transmettre à cause du coût de la communication.L’intérêt de l’étude réside également dans l’originalité de la base d’image. En effet, unensemble d’image index est fournit au système pour décrire un seul objet. Il devient alorspossible de mettre en place un apprentissage sur cet ensemble, pour découvrir descaractéristiques uniques à cet ensemble, et s’en servir pour augmenter le taux dereconnaissance.De manière expérimentale, nous avons mis en place la base d’image STOIC (SingaporeTourist Object Identification Collection), comportant plus de 3000 images de monuments etbâtiments de Singapour.Ce travail est un résultat de la collaboration entre le CLIPS (UJF-CNRS) et l’Institute forInfocomm Research (I2R A-STAR), dans le cadre du laboratoire IPAL.
c ) Campagnes nationales et internationales d’évaluationc.1 TRECNous avons participé à plusieurs campagnes internationales d’évaluation des systèmes deRecherche d’Information. Nous avons participé à toutes les campagnes TREC vidéo de 2001 à2005 inclus. Nous avons participé à toutes les tâches proposées (segmentation en plans,segmentation en histoires, détection de concepts et recherche en mode manuel ou interactif) etnous y avons obtenu de très bonnes performances (cf. section 2.1.1).Nous avons participé a ces évaluation en tant que participants mais nous avons égalementparticipé à l’organisation de ces évaluations pour la définition des tâches, la préparation desdonnées, et la mise au point des outils d’évaluation (définition des métriques et écritures desprogrammes de comparaison notamment).
c.2 TECHNOVISIONNous participons également à l’organisation de la campagne ARGOS (campagne d'évaluationd'outils d'analyse des contenus vidéo) sur le même thème dans le cadre du programmenational TechnoVision. Notre contribution concerne la définition des métriques et ledéveloppement d’outils permettant la mesure des performances des systèmes.
LIG — Dossier de contractualisation 599

MRIM- 18 -
c.3 CLEF : Recherche d’Information Multi langueL’objectif des campagnes CLEF (Cross-Language Evaluation Forum http://clef.iei.pi.cnr.it/)organisées par le réseau d’excellence Européen DELOS ( Network of Excellence for DigitalLibraries ), est de développer une infrastructure pour l’évaluations de modèles et techniquesde recherche d’Information traitant des langues européennes. Cette évaluation concerne à lafois des interrogations monolingues et multilingues, et a produit des collections de testsuniques. Ces collections sont l’occasion d’expérimenter de nouvelles techniques, à la fois entenant compte des particularités des langues nouvellement introduites, mais également endéveloppant et testant la robustesse de ces techniques par rapport aux langues.Dans cette campagne, notre objectif est de tester l’usage de traitement de la langue pour destâches de recherche d’informations précise. Nous pensons en effet, que les techniques detraitement de la langue naturelle sont suffisamment matures pour être mise en place sur delarges collections. D’autre part, notre travail est également tourné vers l’usage deconnaissances externes aux collections (thésaurus, ontologie), mais également desinformations extraites des collections elle-même par des techniques de « text mining ».Notre première participation nous a permis de tester l’usage d’un thésaurus d’associationextrait automatiquement des textes en anglais et français. Ce thésaurus d’association construità base de calculs de co-occurrences, est utilisé pour réaliser des extensions de requêtes. Nousavons réalisé des tests à la fois en mono-lingue et en bilingue. Dès cette participation, nousavons utilisé les résultats d’un analyseur de surface de la langue( Xip shallow parser).L’analyseur nous a servit uniquement pour la sélection des termes sur les parties du discours.La partie multilingue a consisté en la construction d’un dictionnaire de traduction par fusionde multiples ressources linguistiques. Nous avons obtenu des résultats dans la moyenne desparticipants avec 33% de précision moyenne en monolinque Français, contre 54% pour lesmeilleurs résultats, mais nous avons obtenu un rappel important (92%). L’usage non contrôléd’un large dictionnaire a fait baissé la précision à 14%. Ce type de résultat illustre la difficultédans l’utilisation de techniques linguistiques, plus précises que celle employées classiquementen Recherche d’Information. Par exemple, nous n’avons pas employé de technique deracinisation.Pour notre deuxième participation, nous avons travaillé sur plus de langues : le français,l’anglais, le russe et le finnois. Pour toutes ces langues, nous avons encore employé unanalyseur de surface. Cela s’est avéré intéressant pour le finnois notamment car il s‘agit d’unelangue agglutinative, et un analyseur permet de fournir au système d’indexation des termesdésagglutiné pour permettre la correspondance. Nous avons également mis en œuvre unenouvelle mesure statistique (Deviation from Randomness) qui a donné de bons résultats : 44%pour le monolingue français, 53% pour le finnois et 35% pour le russe. Pour la partietraduction, nous avons testé le filtrage des variantes par utilisation du contexte. Le contexte aété fournit pare la construction d’un thésaurus d’association. Cette technique dedésambiguïsation et la faible taille de nos dictionnaires ont fait chuter les résultats de manièreimportante. Au vu des résultats des autres participants, il semble la conservation de bonrésultats au passage de monolingue en multilingue, est directement liée à la qualité desressources linguistiques. Il faut noter que nous avons été les seuls dans cette participation àutiliser des analyseurs.Nous avons participé cette année pour la troisième fois à la campagne CLEF avec uneparticipation à la tâche multilingue, monolingue et images médicales. Les expérimentationsdes années précédentes ont été poursuivies pour intégrer dans l’indexation plus d’informationssyntaxiques. Le travail a essentiellement porté sur l’extraction de nouveaux descripteurs àpartir des résultats d’analyseurs syntaxiques de surface. L’utilisation des dépendancessyntaxique en RI à ainsi été évaluée. Une dépendance représente le lien syntaxico-sémantiqueentre deux mots : le dépendant et son recteur (i.e. le mot dont il dépend). Ces dépendances
LIG — Dossier de contractualisation 600
- 19 -
sont extraites et conservées sous forme de terme d’indexations semi-complexes qui consistenten des n-uplets composés par des mots et par le type de relation qui relie ces mots. Lesexpérimentations sur différent corpus des collections CLEF nous ont permis de montrer quel’utilisation des dépendances avait un impact sur la précision de la RI pour certaines requêtes.Elles tendent à montrer que se descripteur peut être complémentaire avec un descripteur deniveaux lexical tel que le lemme. Une autre direction a été explorée en collaboration avecl’Université de Genève. Il s’agit de l’usage d’une ontologie multilingue. Cette techniqueélimine l’étape de traduction des requêtes, car elle permet de transformer à la fois lesdocuments et les requêtes dans une représentation commune. Cette cohérence dansl’indexation élimine également l’étape de fusion nécessaire dans le cas d’une indexationséparée des langues. Cette technique a donnée d’honnêtes résultats (entre 10 et 16%), mais esttoutefois liées à la disponibilité et qualités de ressources ontologiques multilingues.
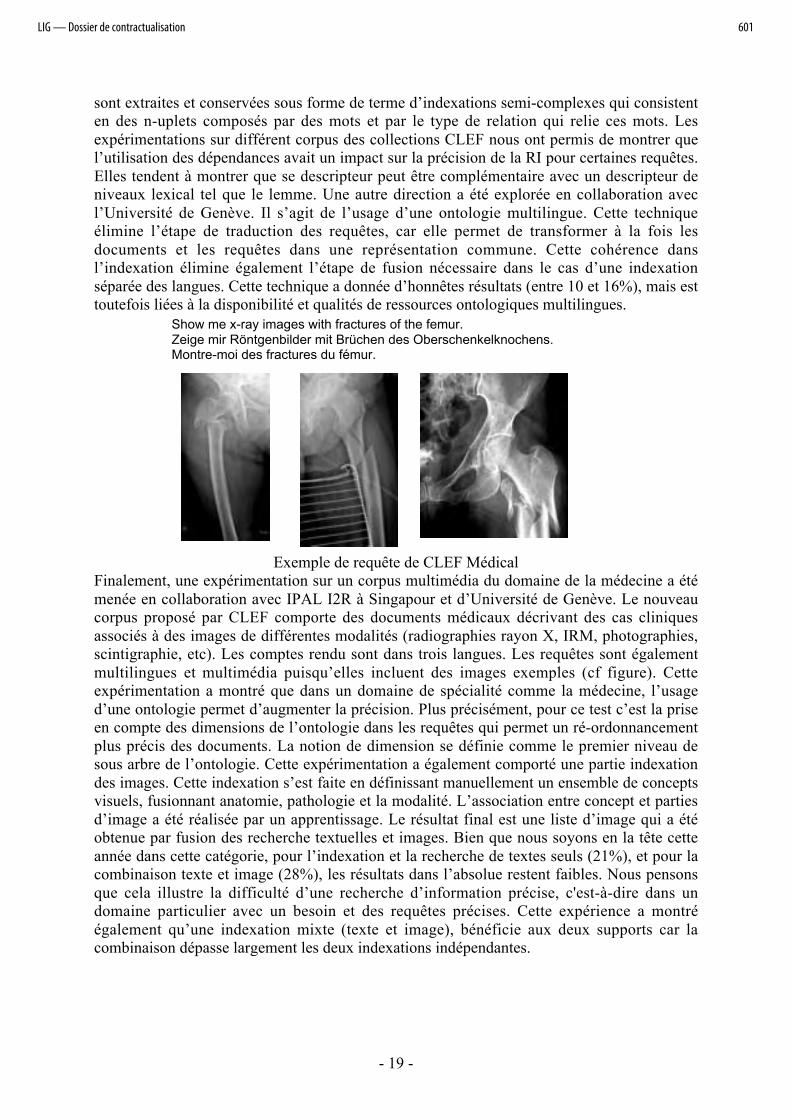
Exemple de requête de CLEF MédicalFinalement, une expérimentation sur un corpus multimédia du domaine de la médecine a étémenée en collaboration avec IPAL I2R à Singapour et d’Université de Genève. Le nouveaucorpus proposé par CLEF comporte des documents médicaux décrivant des cas cliniquesassociés à des images de différentes modalités (radiographies rayon X, IRM, photographies,scintigraphie, etc). Les comptes rendu sont dans trois langues. Les requêtes sont égalementmultilingues et multimédia puisqu’elles incluent des images exemples (cf figure). Cetteexpérimentation a montré que dans un domaine de spécialité comme la médecine, l’usaged’une ontologie permet d’augmenter la précision. Plus précisément, pour ce test c’est la priseen compte des dimensions de l’ontologie dans les requêtes qui permet un ré-ordonnancementplus précis des documents. La notion de dimension se définie comme le premier niveau desous arbre de l’ontologie. Cette expérimentation a également comporté une partie indexationdes images. Cette indexation s’est faite en définissant manuellement un ensemble de conceptsvisuels, fusionnant anatomie, pathologie et la modalité. L’association entre concept et partiesd’image a été réalisée par un apprentissage. Le résultat final est une liste d’image qui a étéobtenue par fusion des recherche textuelles et images. Bien que nous soyons en la tête cetteannée dans cette catégorie, pour l’indexation et la recherche de textes seuls (21%), et pour lacombinaison texte et image (28%), les résultats dans l’absolue restent faibles. Nous pensonsque cela illustre la difficulté d’une recherche d’information précise, c'est-à-dire dans undomaine particulier avec un besoin et des requêtes précises. Cette expérience a montréégalement qu’une indexation mixte (texte et image), bénéficie aux deux supports car lacombinaison dépasse largement les deux indexations indépendantes.
Show me x-ray images with fractures of the femur.Zeige mir Röntgenbilder mit Brüchen des Oberschenkelknochens.Montre-moi des fractures du fémur.
LIG — Dossier de contractualisation 601

MRIM- 20 -
2.1.5 Interactions entre applications accessibles via Internet
Participants : Ali Aït-Bachir, Faryel Allouti, Helga Duarte, Marie-Christine Fauvet,Jacqueline Konaté, Youssef Roummieh, Yehia Taher
2.1.5.1 RésuméL'Internet a remis en cause la manière dont les systèmes d'information interagissent au traversdes réseaux, et la façon dont les applications sont développées. En effet, l'Internet fournit unmoyen universel aux organisations pour composer leurs services, partager leurs ressources etsavoir-faire, afin de minimiser leurs coûts, d'offrir de nouvelles applications à valeur ajoutée,sans pour autant perdre de leur autonomie. Dans ce contexte, la construction d'applicationss'appuie de plus en plus sur l'intégration ou la composition de services accessibles parInternet. Ainsi, la technologie des services web est devenue incontournable pourl'automatisation des interactions complexes entre les systèmes d'information distribués surInternet, qu'ils soient intra ou inter organisations.
L'objectif de notre travail est de proposer des modèles et des langages de haut niveau pourgérer efficacement des intéractions entre des ressources (applications et/ou informations)disponibles sur l'Internet, c'est-à-dire accessibles via des services web. Plus précisemment, cesmodèles et langages permettront la description, la localisation et l'intégration de servicesexistants ainsi que la composition de nouveaux services donnant ainsi aux organisations lapossibilité de composer leurs services et de partager leurs ressources.
2.1.5.2 Description détailléeUn service web est dit composé ou composite lorsque son exécution implique des interactionsavec d'autres services web afin de faire appel à leurs fonctionnalités. La composition deservices web spécifie quels services ont besoin d'être invoqués, dans quel ordre et commentgérer les conditions d'exception. Les composants d'un service web composé restentindépendants du service composé. Des modèles d'orchestration permettent de gérer l'ordre desappels des opérations des services web.
Certains services web, en particulier dans le domaine du commerce électronique, ont despropriétés transactionnelles inhérentes. Ceci est le cas notamment des services associés à lagestion de ressources (au sens large), comme par exemple la réservation de chambres d'hôtel,de places de spectacle, de services professionnels, etc. En principe, les propriétéstransactionnelles de ces services peuvent être exploitées lors de leur composition pourrépondre à des contraintes et des préférences établies par le concepteur et l'utilisateur final.Aujourd'hui cependant, les langages et outils disponibles permettant de programmer destransactions sur des services web ne fournissent pas de concepts de haut niveau pour~: (i)exprimer les propriétés transactionnelles désirées au niveau du service composé ; (ii) assurerces propriétés de façon automatisée en exploitant les propriétés transactionnelles des servicescomposants.
Nous avons défini les prémisses d'un modèle de composition permettant la prise en comptedes propriétés d'atomicité des services composants afin d'assurer des propriétés d'atomicité surle service composite. En particulier, l'opérateur permet l'expression de contraintes deminimalité et de maximalité sur les services participant dans une transaction donnée, c'est-à-dire qu'il est possible d'exprimer des contraintes telles que entre X et Y services doivent êtreexécutés ou alors aucun ne doit être exécuté. L'opérateur opère sur destypes de services,c'est-à-dire des ensembles de services alternatifs fournissant une capacité donnée, et non passur des servicess pécifiques. De plus, l'opérateur est paramétré par des fonctions derestrictionet de préférence qui guident la sélection des options de composition au moment del'exécution.
LIG — Dossier de contractualisation 602

- 21 -
2.2 Résultats majeursNous citons ici certains des prototypes que nous avons développés :
2.2.1 Plexir
Plexir (PLateform for Experimenting Information Retrieval) est le nom d'un projet visant àmettre en place un instrument d’expérimentation pour la recherche d'information sous laforme d'une plateforme permettant de regrouper et de mettre à la disposition desscientifiques, les ressources informatiques et humaines nécessaires à l’accès et l’explorationdes informations dans le cadre de leurs travaux. Une première maquette réalisée encollaboration avec d'autres laboratoires de recherche (irit,erss,irin,lip6,limsi) permettant delancer des évaluation de RI à distance a été réalisée.
2.2.2 Aira.
Dans le cadre de sa thèse, J.C Bottraud a réalisé un prototype d'assistant personnel derecherche nommé AIRA. Le système AIRA utilise les références documentaires rassembléespar l’utilisateur pour construire un profil le représentant. Ce profil est ensuite exploité pourinterpréter et filtrer les résultats proposés par les moteurs de recherche. Le système réalisé estmulti-plateforme et interagit avec l'utilisateur au moyen d'une interface Web.
2.2.3 Torii
Torii(http://torii.info) est le portail Web développé dans le cadre du projet TIPS. Il permet unaccès personnalisé aux archives ouvertes comme arXiv, offrant des fonctionnalités derecherche, de filtrage basé sur le contenu, de filtrage collaboratif, et d’annotation/évaluationcollective de documents. L’équipe a particulièrement contribué à ces deux dernièresfonctionnalités.
2.2.4 COCoFil
COCoFil est une plateforme de filtrage collaboratif orientée vers la perception descommunautés. On y trouve non seulement les fonctionnalités classiques du filtragecollaboratif, mais aussi des fonctionnalités tournées vers l’intégration de la prise deconscience des communautés d’utilisateurs notamment via un carnet d’adresses articulé avecla possibilité de connaître les évaluations des autres utilisateurs et les utilisateurs dont le profilest proche.
2.2.5 PENG
Peng est un système d’accès personnalisé aux informations d’actualité, destiné auxjournalistes ; il concrétise un scénario de type push/pull, où le journaliste surveille lesnouvelles informations en provenance des agences de presse, et peut décider d’approfondir surun sujet en élargissant le spectre des sources d’informations sollicitées (le Web, les archivesde sa compagnie, etc.). Le système est fortement personnalisable, autour d’un profild’utilisateur composé de « centres d’intérêt » adaptatifs. L’équipe a spécialement contribué àla conception et réalisation d’une première version du module de présentation del’information, par lequel passe toute interaction de l’utilisateur avec le système.
LIG — Dossier de contractualisation 603

MRIM- 22 -
3 ACTIVITES D’ENCADREMENT
3.1 Thèses et HDR soutenues depuis le 01/10/01
La liste des thèses et HDR est fournie dans le tableau en annexe 2.
3.2 Thèses et HDR en cours1. AÏT-BACHIR Ali, Vers un modèle de conversation pour la spécification dynamique des
interactions entre services web, ED MSTI, UJF, allocation MENRT, première inscription10/05
2. AYACHE Stéphane, Indexation par concepts des documents vidéo par fusion descaractéristiques audio, image et texte, ED MSTI, INPG, allocation MENRT, premièreinscription 10/03
3. BELKHATIR Mohamed, Etude de l'intégration Signal/Sémantique pour l'indexation et larecherche d'images fixes. Application à un corpus de photographies personnelles et aucorpus clés TRECVID2004, ED MSTI, UJF, allocation MENRT, première inscription10/02
4. BISSOL Stéphane, Indexation symbolique d'images : une approche fondée surl'apprentissage non supervisé de régularités, ED MSTI, UJF, bourse étrangère puis ATER,première inscription 10/01
5. CHARHAD Mbarek, Modèles des documents vidéo pour l'indexation et la recherche parle contenu sémantique, ED MSTI, INPG, bourse étrangère, première inscription 10/02
6. DUARTE Helga, Vers un modèle transactionnel pour la composition de services web, EDMSTI, UJF, bourse étrangère, première inscription 10/03
7. KEFI Leila, Système de recherche de corpus pour utilisateurs experts. Application à desdocuments techniques, ED MSTI, UJF, allocation MENRT, première inscription 10/02
8. LE Thi-Hoang-Diem, Indexation pivot conceptuelle multilingue par combinaison deconnaissances ontologiques et pragmatique, ED MSTI, UJF, co-tutelle, premièreinscription 10/04
9. LE Xuan-Hung, Indexation des éléments non linguistiques dans la bande son desdocuments audiovisuels en vue de la recherche par le contenu, ED MSTI, INPG, co-tutelle, première inscription 10/03
10. MAISONNASSE Loïc, Vers un modèle théorique de recherche d'information précisemultilingue, basée sur une indexation relationnelle des documents, ED MSTI, UJF,allocation MENRT, première inscription 10/04
11. NGUYEN An-Te, COCoFil : un nouveau système de filtrage collaboratif, ED MSTI, UJF,co-tutelle, première inscription 10/02
12. RADHOUANI Saïd, Etude de l'utilisation des ontologies pour la Recherched’Informations, ED MSTI, UJF, co-tutelle, première inscription 10/03
13. TAHER Yehia, Vers un modèle de médiation dans une plate-forme de composition deservices Web, ED Informatique, UCB Lyon I, allocation de la région Rhône-Alpes,première inscription 10/05
14. TAMBELLINI Caroline, Recherche et filtrage d'informations bruitées. Application auxréunions téléphoniques, ED MSTI, UJF, allocation MENRT, première inscription 10/03
15. VERBYST Delphine, Indexation et Recherche de documents structurés en contexte, ED
LIG — Dossier de contractualisation 604

- 23 -
MSTI, UJF, contrat industriel, première inscription 10/05
4 COLLABORATION ET VALORISATION
4.1 Principales relations scientifiques hors contrats
1. Université de Genève : co-tutelle de thèses (RADHOUANI Saïd, TURKI Slim)2. Université de Ho Chi Minh-Ville : co-tutelle de thèses (LE Thi-Hoang-Diem, NGUYEN
An-Te, HO Bao-Quoc)3. Université de Hanoï: co-tutelle de thèse (LE Xuan-Hung)4. Université de Tunis : accueil de Chiraz Lattiri lors de plusieurs séjours au CLIPS, accueil
de Pr Ali Jaoua, professeur invité à l’UJF en juin 2004.5. Queensland University of Technology, Brisbane, Australie : accueil de DUARTE Helga à
Brisbane (10/2004), accueil de Marie-Christine Fauvet à Brisbane (07/2005)6. National Institute of Informatics (NII), Tokyo, Japon : accueil de Koji Eguchi au CLIPS
(novembre 2004 - février 2005), accueil de Stéphane Ayache au NII (avril-juin 2005, août2005)
7. Centre de Recherche Xerox de Meylan (Isère) : co-encadrement de Masters, de thèse.
4.2 Contrats institutionnels
La liste des contrats institutionnels est fournie dans le tableau en annexe 4.
4.3 Contrats (co)financés par un industriel
La liste des contrats à financement industriel est fournie dans le tableau en annexe 4.
5 PUBLICATIONS (01-05)
On trouvera en annexe 3 des indicateurs de production scientifique
Articles dans des revues avec comité de lecture internationales et nationales (ACL)
Revues internationales :Année 2003
LIG — Dossier de contractualisation 605

MRIM- 24 -
1. Lim J.H., Tian Q., Mulhem P. , Home Photo Content Modeling for Personalized Event-Based Retrieval, IEEE Multimedia, vol10, no4, pp28-37, October-December, 2003.
2. Mulhem P., Martin H., From Database to Web multimedia documents, InternationalJournal on Multimedia Tools and Applications, Kluwer Publisher, vol20, no3, pp263-282, August, 2003.
3. Mulhem P., Kankanhalli M., Hassan H., Yi J., Pivot Vector Space Approach for Audio-Video Mixing, IEEE Multimedia, vol10, no2, pp28-40, April-June, 2003.
Année 20044. Brouard C., Nie J.Y., Relevance as Resonance: A New Theoretical Perspective and a
Practical Utilization in Information Filtering, Information Processing andManagement, vol40, no1, pp1-19, janvier, 2004.
5. Dumas M., Fauvet M.-C., Scholl P.-C., TEMPOS: A Platform for Developing TemporalApplications on top of Object DBMS, IEEE Journal on Transactions on Knowledgeand Data Engineering, vol16, no3, 2004.
6. Le Borgne H., Guérin-Dugué A., Antoniadis A., Representation of images forclassification with independent features, Pattern Recognition Letters (PRL), vol25,pp141-154, 2004.
Revues nationales :Année 2002
7. Brouard C., RELIEFS : un système d'inspiration cognitive pour le filtrage adaptatif dedocuments textuels, Revue Technologies et Sciences de l'Information, vol7, no1/2,pp157-182, 2002
8. Géry M. Un modèle d'hyperdocument en contexte pour la recherche d'informationstructurée sur le Web, Revue ISI (Ingéniérie des Systèmes d'Information), vol7, no1,pp11-44, 10, 2002.
9. Mulhem P, Indexation par apprentissage local et global pour la recherche symboliqued'images fixes, Revue ISI (Ingénierie des Systèmes d'Information), vol7, no1-2, pp183-205, 2002.
Année 200310. Fauvet M.-C., Baina S., Cooperative evaluation of queries on semi-structured
distributed data, Ingénierie des Systèmes d'Information, vol8, no5-6, pp27-48, 2003.11. Mulhem P., Gensel J., Martin H., Modèles pour résumés adaptatifs de vidéos, Revue
Ingénierie des Systèmes d'Information, vol7, no5-6, pp91-118, 2003.12. Thevenin T., Fauvet M.-C., Josselin D., A Spatio-temporal model for public transports
(in French), Revue Internationale de Géomatique, vol13, no2, pp157-180, 2003.
Année 200413. Gallardo-López L., Denos N., Berrut C. , Une approche pour le contrôle de la qualité
des Systèmes de Filtrage Collaboratif, International Journal of Info & Com Sciencesfor Decision Making, no13, pp10, février, 2004.
14. Latiri Cherif C., Chevallet J.P., Elloumi S., Jaoua A., Une Extension de la Connexionde Galois Floue pour la Recherche d'Information, Revue I3 : Information - Interaction- Intelligence, vol3, no2, 2004.
Année 200515. Duarte H., Fauvet M.-C., Dumas M., Benatallah B., Vers un modèle de composition de
services Web avec propriétés transactionnelles, Revue Ingénierie des Systèmes
LIG — Dossier de contractualisation 606

- 25 -
d'Information, vol10, no3/2005, 2005.
Articles dans des revues sans comité de lecture (SCL)
Conférences invitées (INV)
Conférences d'audience internationaleAnnée 2001
1. Berrut C., Indexation et Recherche d ’informations, Atelier Stic-franco-marocain"Mutimedia et communisation", du 28 au 30 mai 2001.
Année 20032. Chevallet J.P., La Recherche d'Information sur le WEB , Conférence invitée donnée à la
conférence GEI'2003 de Mahdia Tunisie le 19 mars , 2003.3. Chevallet J.P.,, Traitement de la langue pour l'extraction de connaissances pour la
recherche d'information , Tutoriel à la conférence GEI'2003 de Mahdia Tunisie le 17mars, 2003
4. Chiaramella Y., Indexing and Retrieving Structured Documents, Conférence à ESSIR03(European Summer School on Information Retrieval) Aussois - Savoie - Franceseptembre 2003
5. Guérin-Dugué A., Berrut C., Signal, perception, images, Conférence à ESSIR03(European Summer School on Information Retrieval) Aussois - Savoie - Franceseptembre 2003
6. Quénot G., Indexing and Retrieving Video documents, Conférence à ESSIR03(European Summer School on Information Retrieval) Aussois - Savoie - Franceseptembre 2003
Conférences d'audience nationaleAnnée 2003
7. Berrut C., Bachimont B., Indexation multimédia : enjeux et difficultés, 2003, Les jeudisdu Numérique, Lyon 20 mars 2003.
8. Fauvet M.C., Composition de Services Web, Tutoriel du Congrès INFORSID (Nancy,France), 2003.
Communications avec actes internationales et nationales (ACT)
Conférences d'audience internationaleAnnée 2001
1. Chen J., Tan T., Mulhem P., A Method for Photograph Indexing using SpeechAnnotations, in IEEE Pacific-RIM Conference on Multimedia, Beijing, China, pp867-872, October, 2001.
2. Géry M., Chevallet J.P., Toward a Structured Information Retrieval System on the Web:Automatic Structure Extraction of Web Pages, International Workshop on WebDynamics, 3 janvier, 2001
3. Le Borgne H., Guérin-Dugué A, Sparse-Dispersed Coding and Images Discriminationwith Independent Component Analysis, in Third International Conference onIndependent Component Analysis and Signal Separation (ICA 2001), San Diego,
LIG — Dossier de contractualisation 607

MRIM- 26 -
California, December 9-13, 2001.4. Haddad H., Mulhem P., Association Rules for Symbolic Indexing of Still Images, in
International Conference Conference on Artificial Intelligence (IC-AI) 2001, LasVegas, USA, pp469-475, June, 2001.
5. Mulhem P., Leow W.K., Lee Y.K., Fuzzy Conceptual Graphs for Matching Images ofNatural Scenes, in 17th International Joint Conference on Artificial Intelligence(IJCAI-01), Seattle, USA, pp1397-1402, 4-10 August, 2001.
6. Mulhem P., Tan T., Impact of Labeling Processes on Symbolic Images, in IASTEDInternational Conference on Signal and Image Processing, Waikiki, USA, pp7-11,August, 2001.
7. Paulin D., Kumar D., Bhaskar R., Quénot G., Recovering Camera Motion and MobileObjects in Video Documents, in International Workshop on Content-Based MultimediaIndexing, Brescia, Italy, 19-21, 2001
8. Quénot G., Particle Image Velocimetry using Dynamic Programming, in Particle ImageVelocimetry Challenge Workshop, Göttingen, Germany, 14-15 September, 2001.
9. Quénot G., Simple and Accurate PIV Camera Calibration using a Single Target Imageand Camera Focal Length, in Fourth International Symposium on Particle ImageVelocimetry, Göttingen, Germany, pp. paper 1040, 17-19 September, 2001.
10. Quénot G., TREC-10 Shot Boundary Detection Task: CLIPS System Description andEvaluation, in 10th Text Retrieval Conference, Gaithersburg, MD, USA, pp142-150,13-16 November, 2001.
11. Tan T., Mulhem P., Image Query System using Object Probes, in IEEE InternationalConference on Image Processing (ICIP) 2001, Tessaloniki, Greece, pp701-704,October, 2001.
12. Vaufreydaz D., Géry M., Internet evolution and progress in full automatic frenchlanguage modelling, in IEEE Workshop on Automatic Speech Recognition andUnderstanding (ASRU01), Madonna di Campiglio Trento (Italie), 2001.
13. Zhang J., Tan T., Wu J., Mulhem P., Multiple Indexing and Retrieval of Still ImageChinese Speech Annotations, in International Conference on Chinese Computing,Singapore, Singapore, pp180-187, November, 2001.
Année 200214. Achanta R., Kankanhalli M., Mulhem P., Compressed Domain Object Tracking for
Automatic Indexing of Objects in MPEG Home Videos, in IEEE InternationalConference on Multimedia and Expo (ICME) 2002, Lausanne, Switzerland, pp983-986, 2002.
15. Brouard C., CLIPS at TREC-11: Experiments in Filtering, in 11th Text REtrievalConference, november, 2002.
16. Chen J., Tan T., Mulhem P., SmartAlbum - Toward Unification of Approaches forImage Retrieval, in IEEE International Conference on Pattern Recognition, Québec,pp983-986, august, 2002.
17. Chevallet J.P., Building Thesaurus from Manual Sources and Automatic ScannedTexts, in The 2nd International Conference Adaptive Hypermedia and Adaptive WebBased Systems, Malaga, Spain, pp95-104, may, 2002.
18. Codina M., Tan T., Mulhem P., Silhouette Extraction and Human PostureClassification on still Images, in DICTA, Australia, pp230-235, january, 2002.
19. Denos N., QCT and SF services in Torii: Human Evaluations of Documents Benefit tothe Community, in Proceedings of the 2nd International Conference on AdaptiveHypermedia and Adaptive Web Based Systems (AH2002) Workshop on"Personalization Techniques in Electronic Publishing on the Web: Trends and
LIG — Dossier de contractualisation 608

- 27 -
Perspectives", Stefano Mizzaro and Carlo Tasso (Eds.), Malaga, Spain, pp105-114,29/5-31/5, 2002.
20. Géry M., Considering HyperDocuments and Context for Indexing the Web, inInternational Conference on Artificial Intelligence (IC-AI'02), Las Vegas, Nevada,United States, 24-27 juin, 2002.
21. Géry M., Haddad H., Vaufreydaz D., Web as Huge Information Source for NounPhrases Integration in the Information Retrieval Process, in International Conferenceon Information and Knowledge Engineering (IKE'02), Las Vegas, Nevada, UnitedStates, 24-27 juin, 2002.
22. Haddad H., Combining Text Mining and NLP for Information Retrieval , inInternational Conference on Artificial Intelligence (IC-AI'02), Las Vegas, Nevada,United States, 24-27 juin, 2002.
23. Latiri Cherif C., Chevallet J.P., Elloumi S., Galois connection based InformationRetrieval model, in EUROFUSE Workshop on Information Systems , Villa Monastero,Varenna, Italy, September 23-25, 2002.
24. Lusseyran F., Rambert A., Gougat P., Fraigneau Y, Elcafsi A., Quénot G.,Relationship between Fourier-Modes and Spatial-Structures in a Cavity-BoudaryLayer Interaction at Moderate Reynolds Numbers, in 11th International Symposiumon the Applications of Laser Techniques to Fluid Mechanics, Lisbon, Portugal, pp.paper 34.3, 8-11 July, 2002.
25. Mulhem P., Lim J.H., Symbolic Photograph Content-Based Retrieval, in ACMConference on Information and Knowledge Management (CIKM) 2002, Virginia,USA, pp94-101, 2002.
26. Rambert A., Lusseyran F., Gougat P., Quénot G., 3D Velocity measurements byOptical Flow PIV based on a simple and accurate camera calibration, in 11thInternational Symposium on the Applications of Laser Techniques to Fluid Mechanics,Lisbon, Portugal, pp. paper 24.2, 8-11 July, 2002.
27. Rambert A., Lusseyran F., Gougat P, Quénot G., Mesure 3D de vitesse par PIV FlotOptique basée sur un étalonnage simplifié des caméras, in 8ème CongrèsFrancophone de Vélocimétrie Laser, Orsay, France, pp. papier 57, 17-20 Septembre,2002.
28. Quénot G., Moraru D., Besacier L., Mulhem P., CLIPS at TREC-11: Experiments inVideo Retrieval, in 11th Text Retrieval Conference, Gaithersburg, MD, USA, 19-22November, 2002.
29. Tan T., Jiayi C., Mulhem P., Kankanhalli M., A Multi-Modal Photo AnnotationSystem, in ACM Multimedia (Demonstration), Juan les Pins, France, pp87-88,December, 2002.
30. Wang J. , Kankanhalli M., Mulhem P., Abdulredha H., Face Detection using DCTCoefficients in MPEG Videos, in International Workshop on AdvancedImageTechnology, Hualien, Taiwan, ROC, pp66-70, january, 2002.
Année 200331. Ayache S., Moraru D., Besacier L., Quénot G., Video Story Segmentation with Multi-
Modal Features: Experiments on TRECvid 2003, in 6th ACM SIGMM InternationalWorkshop on Multimedia Information Retrieval (MIR'04), New York, NY, USA,October 15-16, 2004.
32. Bissol S., Mulhem P., Chiaramella Y., Dynamic Learning of Indexing Concepts forHome Image Retrieval, in Content-Based Multimedia Indexing (CBMI2003), Rennes(France), pp87-93, 22-24 septembre, 2003.
33. Bottraud J.C, Bisson G., Bruandet M.F., An Adaptive Information Research Personal
LIG — Dossier de contractualisation 609

MRIM- 28 -
assistant., in Workshop AI2IA (Artificial Intelligence, Information Access and MobileComputing) of IJCAI (International Joint Conference on Artificial Intelligence),Acapulco, Mexico, pp8 pages, Août, 2003.
34. Charhad M., Quénot G., Semantic Video Content Indexing and Retrieval usingConceptual Graphs, in ICTTA, Damascus, Syria, 19-23 Avril, 2004.
35. Chen J., Tan T., Mulhem P., An Improved Method for Image Retrieval using SpeechAnnotation, in International Conference on Multimedia Modeling (MMM'03), Taipei,Taiwan, pp15-32, 8-10 January, 2003.
36. Chevallet J.P., Sérasset G., Simple Translations of Monolingual Queries Expandedthrough an Association Thesaurus. X-IOTA IR system used for CLIPS BilingualExperiments., in CLEF 2003, 2003.
37. Guérin-Dugué A., Ayache S., Berrut C., Image retrieval : a first step for a humancentered approach, in Fourth Pacific-Rim Conference on Multimedia (ICICS-PCM2003), Singapore, 15-18 December 2003, 2003.
38. Guyader N., Le Borgne H., Hérault J., Guérin-Dugué A., Towards the introduction ofhuman perception in a natural scene classification system, in IEEE Internationalworkshop on Neural Network for Signal Processing (NNSP'2002), Martigny Valais,Suisse, 4-6 septembre, 2003.
39. Jiayi C., Tan T., Mulhem P., Using speech annotation for home digital image indexingand retrieval, in Content Based Multimedia Indexing Conference, CBMI 2003,Rennes, France, pp195-200, 22-24 juillet, 2003.
40. Latiri C., Ben Yahia S., Chevallet J.P., Jaoua A., Query expansion using fuzzyassociation rules between terms, in JIM'2003 conference Journées de l'InformatiqueMessine, Metz , France, September 3-6, 2003.
41. Latiri C., Elloumi S., Chevallet J.P., Jaoua A., Extension of Fuzzy Galois Connectionfor Information Retrieval using a Fuzzy Quantifier, in ACS/IEEE InternationalConference on Computer Systems and Applications (AICCSA'03), Tunis, Tunisia, July14-18, 2003.
42. Le Borgne H., Guyader N., Guérin-Dugué A., Hérault J., Classification of images:ICA filters Vs Human Perception, in Seventh International Symposium on SignalProcessing and its Applications (IEEE catalog N°03EX714C, ISBN 0-7803-7947-0)(ISSPA 2003), Paris, France, pp251-254, 1-4 Juillet, 2003.
43. Lim J.H., Li J., Mulhem P., Tian Q., Content-Based Summarization for PersonalImage Library, in Joint Conference on Digital Libraries, Houston, USA, pp393, 27-31May, 2003.
44. Lim J.H., Mulhem P., Qi T., Event-Based Home Photo Retrieval, in IEEEInternational Conference on Multimedia and Expo 2003, Baltimore, USA, pp33-36,July, 2003 [Vol. II]
45. Lusseyran F., Quénot G., LIMSI-CNRS and CLIPS-IMAG at the 2nd PIV Challenge.,in International PIV Challenge 2003, Pusan, Corea, 19-20 Sep., 2003.
46. Madhwacharyula C., Jun W., Weiqi Y., Yi J., Radhakrishna A.S.V., Bissol S., Yu J.C.,Qiuying Z., Srinivasna S.H., Abdulredha H.H., Mulhem P., Kankanhalli M., AnInformation-integration Approach to Designing Digital Video Albums, in FourthInternational Conference on Information, Communications & Signal Processing andFourth Pacific-Rim Conference on Multimedia (ICICS-PCM 2003), Singapore, 15-18December, 2003.
47. Martinet J., Chiaramella Y., Mulhem P., Ounis I., Photograph indexing and retrievalusing star-graphs, in Third International Workshop on Content-Based MultimediaIndexing (CBMI'03), Rennes, France, pp335-341, 22-24 September, 2003.
48. Mulhem P., Lim J.H.,, Home Photo Retrieval: Time Matters, in Conference on Image
LIG — Dossier de contractualisation 610

- 29 -
and Video Retrieval, Urbana Champain, USA, pp321-330, July, 2003.49. Quénot G., Moraru D., Besacier L., CLIPS at TRECvid: Shot Boundary Detection and
Feature Detection, in TRECVID’2003 Workshop, Gaithersburg, MD, USA,, 17-18November, 2003.
50. So Yu J.J., Kankanhalli M., Mulhem P., Semantic Video Summarization inCompressed Domain MPEG Video, in IEEE International Conference on Multimediaand Expo 2003, Baltimore, USA, pp329-332, July, 2003. [Vol. III]
51. Wang J., Achanta R., Kankanhalli M., Mulhem P., A Hierarchical Framework forFace Tracking using State Vector Fusion for Compressed Video, in IEEEInternational Conference on Acoustics, Speech, and Signal Processing, Hong-Kong,pp209-212, April , 2003.
52. Zhang Q., Kankanhalli M., Mulhem P., Semantic Video Annotation and Vague Query,in International COnference on Multimedia Modeling (MMM'03), Taipei, Taiwan,pp190-208, 8-10 January, 2003.
Année 200453. Ayache S., Moraru D., Besacier L., Quénot G, Video Story Segmentation with Multi-
Modal Features: Experiments on TRECvid 2003, in 6th ACM SIGMM InternationalWorkshop on Multimedia Information Retrieval (MIR'04), New York, NY, USA,October 15-16, 2004.
54. Belkhatir M., Mulhem P., Chiaramella Y., Integrating Perceptual Signal Featureswithin a Multi-facetted Conceptual Model for Automatic Image Retrieval, in ECIR,Sunderland, pp267-282, April, 2004.
55. Belkhatir M., Mulhem P., Chiaramella Y., The Outline of an 'Intelligent' ImageRetrieval Engine , in ICWI, Madrid, Octobre, 2004.
56. Bissol S., Mulhem P., Chiaramella Y., Towards Personalized Image Retrieval, in 2ndInternational Workshop on Adaptive Multimedia Retrieval , Valencia, Spain, pp89-102, August, 2004.
57. Charhad M., Quénot G., Semantic Video Content Indexing and Retrieval usingConceptual Graphs, in ICTTA, Damascus, Syria, 19-23 Avril, 2004.
58. Chevallet J.P., X-IOTA: An Open XML Framework for IR ExperimentationApplication on Multiple Weighting Scheme Tests in a Bilingual Corpus, Lecture Notesin Computer Science (LNCS), AIRS'04 Conference Beijing, vol3211, pp263-280, 2004.
59. Daassi C., Nigay L., Fauvet M.C., Visualization process of Temporal Data, inDatabase and Expert Systems Applications (DEXA 2004), Zaragoza, Spain, pp914-924, August-September, 2004.
60. Le X.H.,, Quénot G., Castelli E.,, Speaker-Dependent Emotion Récognition For AudioDocument Indexing, International Conference on Electronics, Information, AndCommunications (ICEIC'04), 2004.
61. Le X.H., Quénot G., Castelli E., Recognizing Emotions for Audio-Visual DocumentIndexing, in 9th IEEE Symposium on Computers and Ccommunications (ISCC'04),Alexandria, Egypt , June 28 - July 1, 2004.Lim J.H., Chevallet J.P., Merah S.N.,SnapToTell: Ubiquitous Information Access from Camera. A Picture-Driven TouristInformation Directory Service, in Mobile & Ubiquitous Information Access (MUIA'04)Workshop as part of the conference Mobile Human Computer Interaction with MobileDevices and Services (Mobile HCI 04), Glasgow University of Strathclyde, Scotland,pp21-27, 13 September, 2004.
62. Lim J.H., Chevallet J.P., VisMed: A Visual Vocabulary Approach for Medical ImageIndexing and Retrieval, in Asia Information Retrieval Symposium AIRS2005, JejuIsland, Korea, 13-15 October, to appear, 2005.
LIG — Dossier de contractualisation 611

MRIM- 30 -
63. Madhwacharyula C., Kankanhalli M., Mulhem P., Content Based Editing of SemanticVideo Data, in IEEE International Conference on Multimedia and Expo (ICME 2004),Taipei, Taiwan, pp-, July, 2004.
64. Quénot G., Moraru D., Ayache S., Charhad M., Besacier L., Mulhem P., GuironnetM., Pellerin D., Gensel J., Carminati L., CLIPS-LIS-LSR-LABRI Experiments atTRECVID 2004, in TRECVID'2004 Workshop, Gaithersburg, MD, USA, November15-16, 2004.
65. Qiu B., Xiong W., Tian Q., Xu C., Ong S.H., Foong K., Chevallet J.P., MultiPRE : ANovel Framework With Multiple Parallel Retrieval Engines For ContentBased ImageRetrieval, in ACM Multimedia, Singapore, 6-11 Novembre, to appear, 2005.
66. Sérasset G., Chevallet J.P., Using surface-syntactic parser and Deviation fromRandomness. X-IOTA IR system used for CLIPS Mono & Bilingual Experiments forCLEF 2004., in Cross Language Evaluation Forum CLEF 2004, LNC3491, Springer-Verlag, Bath, United Kindom, pp38-49, 15-17 September, 2004.
Année 200567. Ayache S., Quénot G., Satoh S., CLIPS and NII at TRECvid: Shot segmentation and
feature extraction, in TREC Workshop on Video Retrieval Evaluation, Gaithersburg,MD, USA, 14-15 November, to appear, 2005.
68. Belkhatir M., Combining semantics and texture characterizations for precision-oriented automatic image retrieval, in European Conference on Information Retrieval(ECIR), Santiago de Compostela, Espagne, pp457-474, 2005.
69. Charhad M., Moraru D., Ayache S., Quénot G., Speaker Identity Indexing In Audio-Visual Documents, in Content-Based Multimedia Indexing (CBMI2005), Riga, Latvia,pp: actes sur CD, June 21-23, 2005.
70. Charhad M., Zrigui M., Quénot G., Une Approche Conceptuelle pour la Modélisationet la Structuration Sémantique des Documents Vidéos, in In IEEE Int. Conf. onSciences of Electronic, Technologies of Information and Telecommunications,(SETIT), Sousse, Tunisia, pp: actes sur CD, 27-31 mars, 2005.
71. Chevallet J.P., Lim J.H Leong M.K., Object Identification and Retrieval from EfficientImage Matching. Snap2Tell with the STOIC dataset, in Asia Information RetrievalSymposium (AIRS 2005), Jeju Island, Korea, pp97-112, 13-15 October, 2005.
72. Chevallet J.P., Lim J.H, Radhouani S., Using Ontology Dimensions and NegativeExpansion to solve Precise Queries in CLEF Medical Task, in CLEF Workhop,Working Notes Medical Image Track, Vienna, Austria , 21-23 September, to appear,2005.
73. Fauvet M.C., Duarte H., Dumas M., Benatallah M., Handling TransactionalProperties in Web Service Composition, in WISE2005 International Conference, NewYork City (NY), ppP. 273-289, November, 2005.
74. Lim J.H., Chevallet J.P., VisMed: A Visual Vocabulary Approach for Medical ImageIndexing and Retrieval, in Asia Information Retrieval Symposium AIRS2005, JejuIsland, Korea, 13-15 October, 2005.
75. Lim J.H., Chevallet J.P., A Structured Learning Approach for Medical Image Indexingand Retrieval, in CLEF Workhop, Working Notes Medical Image Track, Vienna,Austria , 21-23 September, 2005.
76. Lusseyran F., Quénot G., LIMSI-CNRS and CLIPS-IMAG at the 3rd PIV Challenge, inInternational PIV Challenge 2005, Pasadena, CA, USA, September 19-20, 2005.
77. Maisonnasse L., Sérasset G., Chevallet J.P., Using Syntactic Dependency andLanguage Model X-IOTA IR System for CLIPS Mono & Bilingual Experiments in
LIG — Dossier de contractualisation 612

- 31 -
CLEF 2005, in Workshop CLEF 2005, Vienne, Autriche, 21-23 September, 2005.78. Martinet J., Chiaramella Y., Mulhem P., A Model for Weighting Image Objects in
Home Photographs, in CIKM'05, Bremen, Germany, 2005.79. Qiu B., Xiong W., Tian Q., Xu C., Ong S.H., Foong K., Chevallet J.P., MultiPRE : A
Novel Framework With Multiple Parallel Retrieval Engines For ContentBased ImageRetrieval, in ACM Multimedia, Singapore, 6-11 Novembre, to appear, 2005.
80. Ramnath V., Lim J.H., Chevallet J.P., Zhang D., Harnessing Location-Context forContent-based Services in Vehicular Systems, in IEEE 61st Semiannual VehicularTechnology Conference VTC2005-Spring, Stockholm, Sweden, 2005.
Conférences d'audience nationaleAnnée 2001
81. Brouard C., Nie J.Y., RELIEFS: un système pour le filtrage adaptatif de documentstextuels basé sur la notion de résonance, INFORSID, Genève, pp267-278, 2001.
82. Chevallet J.P., Haddad H., Proposition d'un modèle relationnel d'indexationsyntagmatique : mise en oeuvre dans le système iota, INFORSID 2001, Genève-Martigny, pp465, 483, 2001.
83. Haddad H., Mulhem P., Utilisation de Fouille de Données pour l'IndexationAutomatique des Images, in INFORSID 2001, Genève, Suisse, pp405-418, 2001.
84. Rambert A., Lusseyran F., Gougat P., Elcafsi A., Quénot G., StructuresTourbillonnaires dans une Cavité en Interaction avec une Couche Limite : P.I.V. parFLOT optique, in XVème Congrès Français de Mécanique, Nancy, France, pp. papier703, 3-7 Septembre, 2001.
Année 200285. Géry M., Chemins de lecture en contexte : Indexation sémantique de la structure du
Web, in 20ème Congrès INFORSID'02 (Informatique des Organisations et Systèmesd'Information et de Décision), Nantes, France, pp123-138, 4-7 juin, 2002.
86. Haddad H., Géry M., Vaufreydaz D., Le Web : une source d'information pourl'intégration de multi-termes dans un processus de Recherche d'information, inJournées francophones d'accès intelligents aux documents multimédia sur l'Internet(MediaNet 2002), Sousse, Tunisie , 17-21 Juin, 2002.
87. Martinet J., Chiaramella Y., Mulhem P., Un modèle vectoriel étendu de recherched'information adapté aux images, in 20ème Congrès INFORSID'02 (Informatique desOrganisations et Systèmes d'Information et de Décision), Nantes, France, pp337-348,4-7 juin, 2002.
Année 200388. Bottraud J.C, Bisson G., Bruandet M.F., Apprentissage de profils pour un agent de
recherche d'information, in Conférence d'Apprentissage (CAp), Laval, pp31-46, 1-2juillet, 2003.
89. Bottraud J.C, Bisson G., Bruandet M.F. , Une aide personnalisée et adaptative pour larecherche d'information sur le Web, in conférence INFORSID (INFormatique desORganisations et Systèmes d'Information et de Décision), Nancy, ppP 235-250, 3-6Juin, 2003.
90. Belkhatir M., EMIR3: Intégration d'un formalisme de description signal au sein d'unmodèle symbolique de recherche d'images, in INFORSID 2003, Nancy, pp105-120,Juin, 2003.
91. Gallardo-Lopez L., Berrut C., Denos N., Une approche pour le contrôle de la qualité
LIG — Dossier de contractualisation 613

MRIM- 32 -
des Systèmes de Filtrage Collaboratif, in MAJECSTIC'2003, Polytechnique deMarseille, France, pp7, 29-31 octobre, 2003.
92. Ho B.Q., Chevallet J.P., Bruandet M.F., Mise en place d'un Système de Recherched’Informations en vietnamien, in TALN 2003 Traitement Automatique des LanguesNaturelles, Atelier "multilinguisme", Batz-sur-Mer, France, 11-14 juin , 2003.
93. Kefi L., Berrut L., Gaussier E., Modèle d’indexation de données peu symboliques dansdes documents structurés : L’exemple du graphique dans un corpus de documentstechniques, in XXI congrés Inforsid, Nancy, pp69-86, juin, 2003.
94. Radhouani S., Chevallet J.P., Utiliser les liens pour adapter les moteurs de rechercheaux spécificités du WEB, in MAJECSTIC'2003 Maniferstation des Jeunes ChercheursSTIC, Polytechnique de Marseille, France, pp6, 29-31 Octobre, 2003.
Année 200495. Bottraud J.C., Bisson G., Bruandet M.F., Expansion de requêtes par apprentissage
automatique dans un assistant pour la recherche d’information, in CORIA'04,Toulouse, France, 10-12 Mars, 2004.
96. Chardonnel C., du Mouza C., Fauvet M.C., Josselin D., Rigaux P., Patrons demobilité quotidienne : représentation et interrogation, in Journées CASSINI,Grenoble, 2004.
97. Chevallet J.P., X-IOTA Une plateforme distribuée ouverte pour l'expérimentation enRecherche d'Information, in COnférence en Recherche Information et ApplicationsCORIA'2004, Toulouse, pp287-304, 10 - 12 mars, 2004.
98. Daassi C., Nigay L., Fauvet M.C., Composant logiciel vs physique pour interagir avecun espace de valeurs temporelles, in 16e Conférence Francophone sur l'IHM, Namur,Belgique, Août, 2004.
99. Debanne E., Mulhem P., Query by Example for Symbolic Still Image Retrieval, inPremière Conférence en Recherche d'Information et Applications - CORIA'04,Toulouse, pp363-376, 10-12 Mars, 2004.
100. Denos N., Berrut C., Gallardo-Lopez L., Nguyen A.T.,, COCoFil - une plateformede filtrage collaboratif orientée vers la communauté, COnférence en RechercheInformation et Applications CORIA'2004, Toulouse, pp9-26, 10 - 12 mars, 2004.
101. Ho B.Q., Chevallet J.P., Bruandet M.F., Recherche d’Information Bilinguefrançais-vietnamien, in Recherche Informatique Vietnam & Francophonie (RIVF’04),02-05 Février 2004, Hanoi, Vietnam, pp179-186, 2004.
102. Radhouani S., Chevallet J.P., Géry M., Un modèle à base de chemin de lecturepour la Recherche d’Informations précises sur le Web, in COnférence en RechercheInformation et Applications CORIA'2004, Toulouse - France, 10 - 12 mars, 2004.
103. Radhouani S., Chevallet J.P., Géry M., Extraction et indexation de chemins delecture pour la Recherche d’Information sur le WEB., in Eight MaghrebianConference on Software Engineering and Artificial Intelligence MCSEAI'04, Sousse,Tunisie, pp173 - 186, 9-12 mai, 2004.
104. Taher R., Recherche d’Information Collaborative, Quatrième ColloqueVSST’2004 (Veille Stratégique Scientifique & Technologique), Toulouse, pp67-77, 25-29 octobre, 2004.
105. Taher R., Soutien Personnalisé pour la Recherche d’Information Collaborative, in2ème Congrès MAJECSTIC'04, Calais, France, 13-15 octobre, 2004.
106. Tambellini C., Berrut C., Brouard C., Une Analyse préalable à l'indexation detranscriptions de conversations téléphoniques, in CORIA'04, Toulouse, pp307-331,10-12 mars , 2004.
LIG — Dossier de contractualisation 614

- 33 -
Année 2005107. Charhad M., Quénot G., Approche par patrons linguistiques pour la détection
automatique du locuteur : application à l'indexation par le contenu des journauxtélévisés, Compression et Représentation des Signaux Audiovisuels (CORESA’05), 7 -8 Nov. , to appear, 2005.
108. Chevallet J.P., Lim J.H., SnapToTell : Accès ubiquitaire à de l’informationmultimédia à partir d’un téléphone portable. Application sur une base d’images deSingapour, CORIA05 COnférence en Recherche Information, Grenoble (France),pp245-260, 9-11 mars, 2005.
109. Kefi L., Berrut C., Gaussier E., Indexation Complexe de documents: vers unevérification qualitative, Inforsid, Grenoble, pp521-538, 24-27 mai, 2005.
110. Maisonnasse L., Vers l’exploitation d'analyse de dépendance en recherched’information précise, INFORSID 2005, Grenoble, 26/05/2005, 2005.
111. Maisonnasse L., Tambellini C., Dépendances syntaxiques et méthodes dedétection de passages pour une segmentation sur le locuteur et le thème, in DEFT2005, TALN 2005 tome 2, Dourdan , pp155-164, 6-10 juin, 2005.
112. Nguyen A.T., Denos N., Berrut C., Cartes de communautés pour l’adaptationinteractive de profils dans un système de filtrage d’information, Inforsid 2005,Grenoble, pp253-268, 24-27 mai, 2005.
Communications sans actes (COM)
audience internationaleAnnée 2002
1. Géry M., Non-linear reading for a structured Web indexation, 25th International ACMSIGIR Conference on Research and Development Information Retrieval, SIGIR'02(Poster Session), Tampere, Finland, 11-15 août, 2002.
Année 20032. Martinet J., Ounis I., Chiaramella Y., Mulhem P., A weighting scheme for star-graphs,
25th BCS-IRSG European Conference on Information Retrieval Research (ECIR’03) -Poster Session, Pise, Italie, pp 546-554, 2003.
Année 20043. Tambellini C., Berrut C., Brouard C., Information filtering and retrieval applied to
delocalized meetings, ECIR'04 Sunderland, 2004.
Année 20054. Ayache A., Quénot G., Charhad M., Video shots classification using lexical context,
ECIR'05, 2005.5. Chevallet J.P., Lim J.H., Vasudha R., SnapToTell : a Singapore Image Test Bed for
Ubiquitous Information Access from Camera, Poster on European Conference onInformation Retrieval ECIR'05, pp 530-532, 2005.
audience nationaleAnnée 2002
6. Gallardo-Lopez L., Une première approche de la qualité dans les Systèmes de FiltrageCollaboratif, INFORSID, 2002.
LIG — Dossier de contractualisation 615

MRIM- 34 -
7. Taher R., Fusion de Requête pour la Recherche d’Information Collaborative etSynchrone, in 20ème Congrès INFORSID'02 (Informatique des Organisations etSystèmes d'Information et de Décision), Nantes, France, pp431-432, 4-7 juin, 2002.
Année 20038. Kefi L., vers une indexation des graphiques, Majecstic'03, Marseille, France, pp 119,
29-31 octobre, 2003.9. Taher R., Recherche d’Information Collaborative, in 1er Congrès Francophone
MAJECSTIC’03 (MAnifestation des JEunes Chercheurs STIC), Marseille, France, pp105, 29-31 octobre , 2003.
Année 200410. Charhad M., Un modèle d'indexation et de recherche de documents vidéos basé sur le
formalisme des graphes conceptuels, 22ème Congrès INFORSID'04 (Informatique desOrganisations et Systèmes d'Information et de Décision), Biarritz, France, 25-28 Mai,2004.
11. Duarte-Amaya H., Vers un modèle transactionnel pour des services Web, CongrèsINFORSID, Biarritz, 2004.
12. Kefi L., Recherche d’information contextualisée : L’exemple de la documentationtechnique et de ses utilisateurs, 22ème Congrès INFORSID'04 (Informatique desOrganisations et Systèmes d'Information et de Décision), Session jeuneschercheurs:Poster, Biarritz, France, 25-28 Mai, 2004.
Ouvrages scientifiques (ou chapitres) (OS)
audience internationaleAnnée 2002
1. Benatallah B., Dumas M., Fauvet M.C., Rabhi F., Towards Patterns of Web ServicesComposition, Patterns and Skeleton for Parallel and Distributed Computing (F. Rabhiand S. Gorlatch Ed.), Springer Verlag (UK), chapter 10, pp28, 2002, [ISBN: 1-85233-506-8]
2. Kefti A., Gensel J., Martin H., Mulhem P., An Object Approach for Web Presentations,Mutilmedia Mining - A high Way to Intelligent Multimedia Documents, Kluwer,chapter 8, pp161-177, 2002.
3. Quénot G., Mulhem P., Paulin D., Kumar D., Bhaskar B., Bhusnurmath A., RecoveringCamera Motion and Mobile Objects in Video Documents, Multimedia Mining: AHighway to Intelligent Multimedia Documents, Kluwer Academic Publishers, ISBN 1-4020-7247-3, chapter 5, pp83-112, 2002.
Année 20034. Mulhem P., Lim J.H., Leow W.K., Kankanhalli M., Advances in Digital Home Image
Albums, Multimedia Systems and Content-Based Image Retrieval, Idea Publishing,chapter IX, pp201-226, 2003.
5. Mulhem P., Gensel J., Martin H., Adaptive Video Summarization, Handbook on VideoDatabases, CRC Press, chapter 11, pp279-298, 2003.
audience nationaleAnnée 2001
LIG — Dossier de contractualisation 616

- 35 -
6. Urdapilleta I., Brouard C., Analyse de Profils Sensoriels par une Méthode basée sur lePrincipe de Diffusion et la Théorie des Ensembles Flous, Traité d'évaluationsensorielle, Aspects cognitifs et métrologiques des perceptions, Dunod, pp125-146,2001.
Année 20027. Chevallet J.P., Nigay L., Les interfaces pour la Recherche d'Information, Interaction
homme-machine et recherche d'information, Hermes Science, Lavoisier ISBN 2-7462-0426-6, chapter 2, pp65-102, 2002.
Année 20038. Berrut C., Denos N., Filtrage collaboratif, Assistance intelligente à la recherche
d'informations, Hermes - Lavoisier, chapter 8, pp30, 2003.9. Bruandet M.F., Chevallet J.P., Utilisation et construction de bases de connaissances
pour la Recherche d'Informations, Assistance Intelligente à la Recherched’Information , M.-H. Stefanini, E. Gaussier, Hermes, chapter 3, pp85-118, 2003.
Année 200410. Chevallet J.P., Modélisation logique pour la recherche d'information, Les systèmes de
recherche d'information, Hermes, chapter 5, pp105-138, 2004.
Ouvrages de vulgarisation (ou chapitres) (OV)
Directions d’ouvrages (DO)
Edition de livres
Année 20021. Berrut C., Boughanem M., Recherche et filtrage d'informations, Hermès (eds), 2002,
[ISBN: 2-7462-0519-X]
Autres publications (AP)
Thèses et habilitations
Année 20021. Géry M., Indexation et interrogation de chemins de lecture en contexte pour la
Recherche d'Information Structurée sur le Web, thèse de doctorat, Université JosephFourier, 24 octobre 2002.
2. Haddad H., Extraction et Impact des connaissances sur les performances des Systèmesde Recherche d'Information, thèse de doctorat, Université Joseph Fourier, 24septembre 2002.
LIG — Dossier de contractualisation 617

MRIM- 36 -
3. Mulhem P., Vers l'Indexation et la Recherche Interprétative de Documents Multimedia,HDR soutenue le 26 novembre 2002.
Année 20044. Bottraud J.C., Un assistant adaptatif pour la recherche d'information : AIRA (
Adaptative Information Retrieval Assistant), thèse de doctorat, Université JosephFourier, 21 décembre 2004.
5. Ho B.Q., Vers une indexation structurée, basée sur des syntagmes nominaux. Impact surun SRI en vietnamien et la RI multilingue., thèse de doctorat, Université JosephFourier, 18 novembre 2004.
6. Martinet J., Un modèle vectoriel relationnel de recherche d'information adapté auximages, thèse de doctorat, Université Joseph Fourier, 22 décembre 2004.
7. Taher R., Recherche d’Information Collaborative, thèse de doctorat, Université JosephFourier - GRENOBLE I, 5 mars 2004.
Année 20058. Gallardo-Lopez L., Accès à l’information par un filtrage collaboratif contrôlé, thèse de
doctorat, Université Joseph Fourier, 31 janvier 2005.9. Turki S., Des hyperclasses aux composants pour l'ingénierie des systèmes
d'informations, thèse de doctorat, Université Joseph Fourier, Université de Genève, 7juillet 2005.
6 PRINCIPALES RESPONSABILITES SCIENTIFIQUES ETADMINISTRATIVES
Catherine BerrutDirectrice adjointe du CLIPS-IMAGPrésidente de la Commission de Spécialistes 27è de l’UJF (2003-2006), vice-présidente
de cette Commission (2000-2003)Co-Présidente de l’Ecole Européenne de Recherche d’Information (2003) et de son
Steering Committee (2005-2007)Responsable de la filière Ingénieur Technologie de l’Informations pour la Santé (TIS)
de Polytech’Grenoble (depuis septembre 2005), responsable adjointe de cette formation(2000-2005)
Membre élue du Conseil d’Administration de l’Université Joseph FourierPrésidente de la section disciplinaire de l’Université Joseph Fourier (depuis septembre
2005), vice-présidente de cette section (2002-2005)
Christophe BrouardCo-responsable de la licence professionnelle 3ID de l'iut2 de Grenoble.
Marie-France BruandetResponsable du Master 2ème année Recherche Systèmes d’Informations (jusqu’en 2004)Présidente du comité de programme de la conférence nationale CORIA 2004
Jean-Pierre ChevalletDirecteur de l’IPAL (FRE 2339), depuis novembre 2003.
LIG — Dossier de contractualisation 618

- 37 -
Yves ChiaramellaDirection de la Fédération de Recherche IMAG (FR 71)Responsable du cluster recherche Région Rhône-Alpes "Informatique, Signal, LogicielsEmbarqués"Coordonateur recherche du secteur STIC pour l'UJF, de juin 2002 à juillet 2005Co-Président de l’Ecole Européenne de Recherche d’Information (2003) et de son
Steering Committee (2005-2007)
Jacques CourtinJusqu'à octobre 2005Directeur adjoint de l'IUT2 de l’Université Pierre Mendes France (UPMF), membre duconseil de direction de l'IUT2,Chargé des personnels enseignants (recrutement, carrière...) à l’Université PierreMendes France (UPMF)Membre du Conseil d’Administration de l'IUT2Membre de la CAPA des agrégés au rectorat de Grenoble
De 1996 à 2001, Vice-Président de l’Université Pierre Mendes France (UPMF)De 2003 à 2004, Chargé de mission à la présidence de l’Université Pierre MendesFrance (UPMF)De 1988 à 2002, au CUEFA-CNAM, responsable de formation des ingénieurs cnam eninformatique
Nathalie DenosResponsable des enseignements d’informatique de l’UFR ESE – UPMF Grenoble 2, etseule en poste jusqu’à cette rentrée (septembre 2005), 1200 étudiants.Responsable pédagogique du CIB-C2i (Certificat Informatique et Internet) à l’UPMF.
Marie-Christine FauvetResponsable du Master 2ème année Recherche Systèmes d’Informations (depuis 2004)Responsable de l'Ecole d'Informatique, UFR-IMA, UJF (depuis septembre 2003).Membre élu du Conseil Scientifique de l'UJF (1999 à 2003).Membre nommé (représentant UJF) du Conseil Scientifique de l'Université Stendhal(Grenoble 3) depuis juin 2005
Anne Guérin-DuguéResponsable de l'IUP MIAGE de sept 2001- sept 2005
Philippe MulhemDirecteur de l’IPAL (FRE 2339), Singapour de 1998 à novembre 2003.Président du comité d'organisation de la conférence nationale CORIA 05.
Georges Quénot.Membre du Comité de Direction de TREC-Vidéo
7 PERSPECTIVES DE RECHERCHE 06-10
LIG — Dossier de contractualisation 619

MRIM- 38 -
7.1 Poursuivre nos travaux sur l’indexation et la recherched’informations multimédia
Nous avons des résultats actuels très intéressants et reconnus dans ce domaine. Ces travaux nepeuvent que se poursuivre pour que notre équipe continue à produire les résultats de qualitééquivalente à ceux produits actuellement.
Nous souhaitons par ailleurs enrichir nos approches, notamment sur les axes suivants :
• Données multimédia, multilingues, structurésLa généralisation des données électroniques, ainsi que l’accès à des ressources électroniquesfiables, nous permettent d’appliquer nos travaux, de les renforcer ou de construire denouvelles solutions sur tout type de média.
• Indexation adaptative des données multimédiaLes processus d'indexations sont non paramétrés actuellement : il y a par exemple peu de priseen compte de la nature, l’usage, voire la qualité des documents en vue de l'extraction de leurcontenu. Cet axe de recherche doit être en mesure de proposer des solutions générales à ceproblème.
• Le passage à l’échelleLa confrontation des systèmes actuels avec de gros corpus (plusieurs téra-octets dedocuments) amène à une réflexion sur l’efficience (rapidité) et l’efficacité (qualité) dessystèmes. Les campagnes telles que Trec TeraByte nous donnent la possibilité effective devalider de telles approches.
• Modèles formels de recherche d’informationsL’équipe a depuis de nombreuses années développé des recherches sur cet axe : modèlelogique, graphes conceptuels, etc. Nous souhaitons continuer ce travail de recherche, et ce enamont de tous nos autres travaux.
7.2 Evaluation de systèmesLà aussi, notre équipe a fourni de gros efforts durant ces 4 dernières années pour l ‘évaluationdes systèmes. La participation aux campagnes internationales et nationales constituera encoreun de nos objectif importants pour les prochaines années. Ce travail est – répétons-le –exigeant pour une équipe de recherche. Il nécessite beaucoup de moyens (humains etmatériels). En contrepartie, il n’amène pas forcément à un retour académique sur nos travaux(publications notamment). Quoi qu’il en soit, nous pensons qu’une équipe dans notre domainene peut faire une recherche de qualité sans validation de ce type.
7.3 Contextualisation de la recherche ou du filtrageInitialement la problématique de la RI était de mettre en correspondance une requête et undocument. On évolue actuellement vers une personnalisation de la RI en intégrant les retoursde pertinence de l'utilisateur, sa proximité avec d'autres utilisateurs ou encore les documentsprésents dans son espace personnels, etc ... D'autres critères de pertinence qui ne sont pasnécessairement liés au contenu thématique du document ont aussi été identifiés (longueur desdocuments, lisibilité, niveau d'illustration, réputation de l'auteur, etc...) et pourraient être
LIG — Dossier de contractualisation 620

- 39 -
intégrés à l'évaluation de la pertinence des documents. L'ouverture de la RI au contexte sepoursuit naturellement en tentant de tenir compte de la situation toute entière c'est-à-dire enintégrant l'activité de l'utilisateur, son environnement (par exemple, l'appareil dont il disposepour visualiser les documents), éventuellement son rôle dans le groupe échangeantl'information ou encore l'historique ayant amené à cette situation. De nombreux critèressemblent pouvoir avoir un impact important dans le cadre de la sélection d'information. Cescritères doivent être identifiés et intégrés adéquatement. Un moyen d'atteindre cet objectif estd'intégrer les systèmes de RI dans des environnements complexes et réels dans lesquels cescritères pourraient avoir un impact important. L'intégration d'un SRI à un outil d'aide à laréunion téléphonique est l'exemple d'un environnement complexe pour lequel de premierséléments de réflexion ont été dégagés. Bien évidemment, nous souhaitons continuer àdévelopper des systèmes dit ‘nomades’ : Snap2Tell nous a permis d’en faire une premièreapproche.
7.4 ApprentissageDe nombreuses méthodes d'apprentissage ont été développées dans le cadre de l'apprentissagemachine (arbres de décision, réseaux de neurones, SVM, ...). Nombre de ces méthodes ont étéappliquées à la RI.Les résultats montrent que l'efficacité des méthodes varient selon le type de tâches c'est-à-direpar exemple la précision de la recherche (allant de la classification en grands thèmes à larecherche de réponses à des questions précises) , la taille de la bases d'apprentissage et le typede données (base d'articles, news, ...). Cette efficacité reste de plus difficilement prédictible.Un travail de recherche visant à mettre en évidence les conditions d'applications desdifférentes méthodes semble porteur. Ce travail constituerait un retour intéressant de la RIpour l'apprentissage machine. La mise en ligne d'un système de filtrage adaptatif sur le web,permettant l'expérimentation de différentes méthodes sur différentes tâches de RI permettantl'accès à une grande variété de données semble un moyen intéressant de testerexpérimentalement différents critères de choix.
7.5 Interactions entre applications accessibles via Internet
Généralisation du modèle : nous avons considéré uniquement la composition de services quis'exécutent en parallèle et qui se synchronisent lors de la phase de validation/obtention deressources. Le modèle doit être étendu dans la perspective de prendre en compte d'autresdépendances d'exécution (la séquence, l'alternative, etc.).
Médiation de données et d'interactions : le modèle de données et le modèle d'interaction d'unservice composite sont déterminés par ceux des services composants. L'opérateur decomposition doit donc intégrer des mécanismes pour exprimer les dépendances entre cesmodèles, par exemple au moyen de fonctions d'agrégation. Par ailleurs, les participants à unecomposition ont chacun leur modèle d'orchestration permettent de gérer l'ordre des appels desopérations qu'ils offrent, indépendamment des autres participants. Dans ce contexte, lesinteractions entre des services qui n'ont pas de connaissances a priori les uns des autres est unproblème ouvert. Notre objectif est de définir un modèle de conversation permettant à desservices d'exposer leurs offres et leurs attentes afin de pouvoir définir, au moment del'exécution, leur schéma d'interactions. Le processus de médiation (données et interactions)doit pouvoir être conduit dynamiquement car les services entrant dans une composition sontconnus au moment de l'exécution.
LIG — Dossier de contractualisation 621

MRIM- 40 -
Gestion des exceptions : les applications visées sont le plus souvent conçues pour exécuter unprocessus de manière autonome. Des mécanismes de traitement des erreurs sont prévus etintégrés au processus. Dans le cas où une action spécifique est requise (une procédureautomatique ou une intervention huamine), celle-ci est modélisée et prise en compte dans leprocessus lui-même. Nous voulons étudier la possibilité d'exécution d'action(s) dans le cas desituations exceptionnelles au cours de l'exécution d'une application s'appuyant sur unensemble de services web. La question qui se pose naturellement dans ces situations est quedoit-il être fait ? La réponse peut être fournie par le biais d'opérations, éventuellementinteractives, telles que la suspension de l'exécution, sa reprise, le ``retour arrière'', l'annulation,la compensation, etc.
LIG — Dossier de contractualisation 622
- 41 -
Annexe 1 - liste détaillée des membres de l'équipe
NOM Prénom Section Etab. Grade %Recherche QuotitéChercheursQUENOT Georges 07 CNRS CR1 100% 1MULHEM Philippe 07 CNRS CR1 100% 1
Enseignants-chercheursBERRUT Catherine 27 UJF PR2 100% 1BROUARD Christophe 27 UPMF MCF 100% 1BRUANDET Marie-France
27 UJF PR1 (retraite enjanvier 2005)
100% 1
CHEVALLET Jean-Pierre
27 UPMF MCF (délégationCNRS)
100% 1
CHIARAMELLA Yves 27 UJF PRCE 50% 1COURTIN Jacques 27 UPMF PRCE (retraite en
septembre 2005)20% 1
DENOS Nathalie 27 UPMF MCF 100% 1F A U V E T M a r i e -Christine
27 UJF PR2 100% 1
GUERIN-DUGUE Anne 27 UJF PR2 (départ auL I S a u 1er
septembre 2005)
100% 0,6
Personnels sous contratGRIZOLLE Bénédicte UJF Ingénieur expert
(depuis mai 2005pour 17 mois)
100% 1
LE CORVEC Caroline UJF Ingénieur expert(depuis septembre2005 pour 6 mois)
100% 0,7
LOUIS Laurent UJF Ingénieur expert(depuis octobre2005 pour 6 mois)
100% 1
LISTE DES DOCTORANTS AU 01/09/2005NOM Prénom Etablissement Financement PartenaireAÏT BACHIR Ali UJF Allocataire MENRTAYACHE Stéphane INPG Allocataire MENRTBELKHATIR Loïc UJF Allocataire MENRTBISSOL Stéphane UJF Bourse gvt étranger, puis
ATERSingapour
CHARHAD Mbarek INPG Bourse gvt étranger TunisieDUARTE Helga UJF Bourse gvt étranger ColombieKEFI Leila UJF Allocataire MENRT C e n t r e d e
RechercheXerox
LE Thi-Hoang-Diem UJF Co-tutelle Vietnam Université HôChi Minh-Ville
LIG — Dossier de contractualisation 623
MRIM- 42 -
Chi Minh-VilleLE Xuan-Hung INPG Co-tutelle Vietnam Université
HanoïMAISONNASSE Loïc UJF Allocataire MENRTNGUYEN An-Te UJF Co-tutelle Vietnam Université Hô
Chi Minh-VilleRADHOUANI Saïd UJF Co-tutelle Suisse Université
GenèveTAHER Yehia UCB (Lyon I) Allocataire Région Liris (Lyon)TAMBELLINI Caroline UJF Allocataire MENRTVERBYST Delphine UJF Contrat industriel France Telecom
LIG — Dossier de contractualisation 624
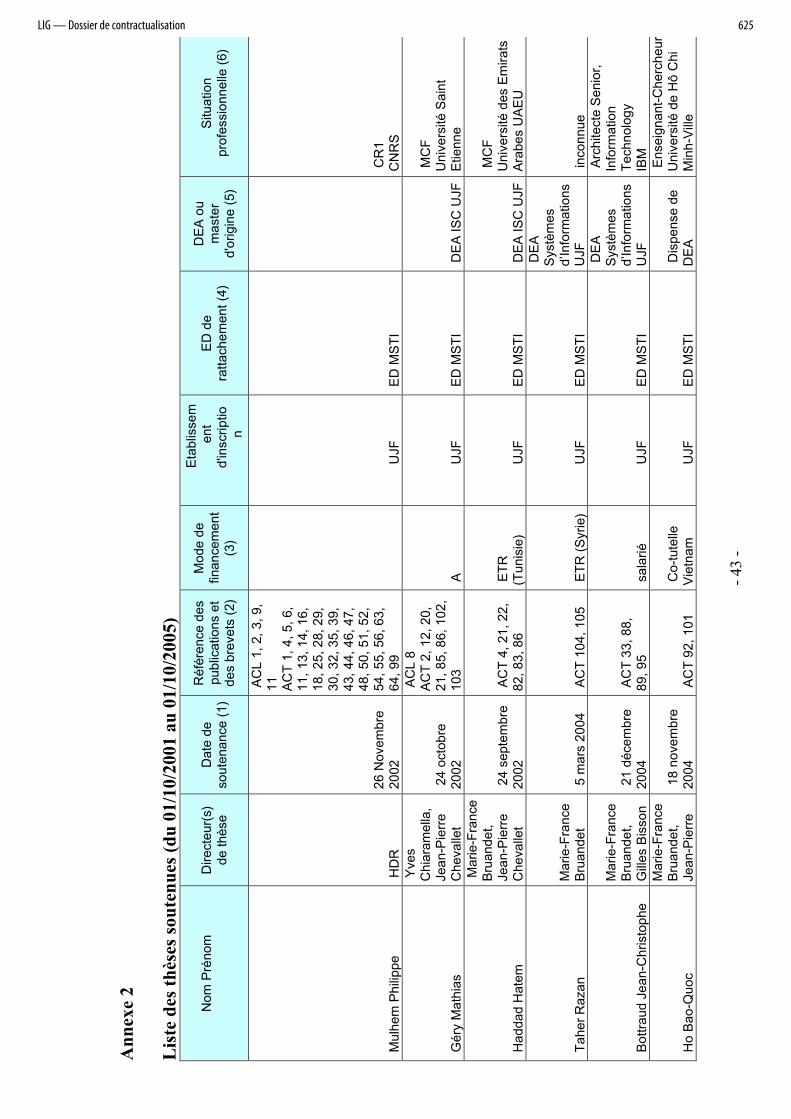
- 43
-
Ann
exe
2
Lis
te d
es t
hèse
s so
uten
ues
(du
01/1
0/20
01 a
u 01
/10/
2005
)
Nom
Pré
nom
Dire
cteu
r(s)
de th
èse
Dat
e de
sout
enan
ce (
1)
Réf
éren
ce d
espu
blic
atio
ns e
tde
s br
evet
s (2
)
Mod
e de
finan
cem
ent
(3)
Eta
blis
sem
ent
d'in
scrip
tion
ED
de
ratta
chem
ent (
4)
DE
A o
um
aste
rd'
orig
ine
(5)
Situ
atio
npr
ofes
sion
nelle
(6)
Mul
hem
Phi
lippe
HD
R26
Nov
embr
e20
02
AC
L 1,
2, 3
, 9,
11 AC
T 1
, 4, 5
, 6,
11, 1
3, 1
4, 1
6,18
, 25,
28,
29,
30, 3
2, 3
5, 3
9,43
, 44,
46,
47,
48, 5
0, 5
1, 5
2,54
, 55,
56,
63,
64, 9
9
UJF
ED
MS
TI
CR
1C
NR
S
Gér
y M
athi
as
Yve
sC
hiar
amel
la,
Jean
-Pie
rre
Che
valle
t 2
4 oc
tobr
e20
02
AC
L 8
AC
T 2
, 12,
20,
21, 8
5, 8
6, 1
02,
103
A U
JF E
D M
ST
I D
EA
ISC
UJF
MC
FU
nive
rsité
Sai
ntE
tienn
e
Had
dad
Hat
em
Mar
ie-F
ranc
eB
ruan
det,
Jean
-Pie
rre
Che
valle
t 2
4 se
ptem
bre
2002
AC
T 4
, 21,
22,
82, 8
3, 8
6 E
TR
(Tun
isie
) U
JF E
D M
ST
I D
EA
ISC
UJF
MC
FU
nive
rsité
des
Em
irats
Ara
bes
UA
EU
Tah
er R
azan
Mar
ie-F
ranc
eB
ruan
det
5 m
ars
2004
AC
T 1
04, 1
05 E
TR
(S
yrie
) U
JF E
D M
ST
I
DE
AS
ystè
mes
d’In
form
atio
nsU
JF in
conn
ue
Bot
trau
d Je
an-C
hris
toph
e
Mar
ie-F
ranc
eB
ruan
det,
Gill
es B
isso
n 2
1 dé
cem
bre
2004
AC
T 3
3, 8
8,89
, 95
sal
arié
UJF
ED
MS
TI
DE
AS
ystè
mes
d’In
form
atio
nsU
JF
Arc
hite
cte
Sen
ior,
Info
rmat
ion
Tec
hnol
ogy
IBM
Ho
Bao
-Quo
c
Mar
ie-F
ranc
eB
ruan
det,
Jean
-Pie
rre
Che
valle
t
18
nove
mbr
e20
04 A
CT
92,
101
Co-
tute
lleV
ietn
am U
JF E
D M
ST
I D
ispe
nse
deD
EA
Ens
eign
ant-
Che
rche
urU
nive
rsité
de
Hô
Chi
Min
h-V
ille
LIG — Dossier de contractualisation 625
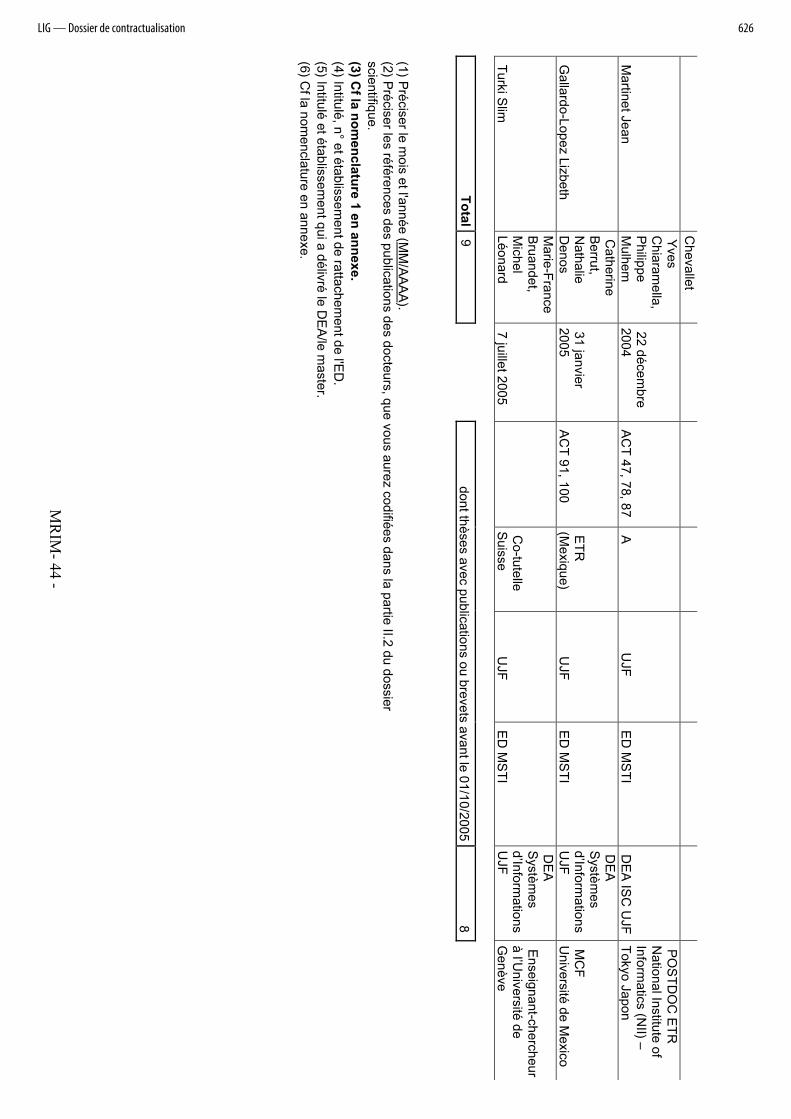
MR
IM- 44 -
Chevallet
Martinet Jean
Yves
Chiaram
ella,P
hilippeM
ulhem 22 décem
bre2004
AC
T 47, 78, 87
A U
JF E
D M
ST
I D
EA
ISC
UJF
PO
ST
DO
C E
TR
National Institute of
Informatics (N
II) –T
okyo Japon
Gallardo-Lopez Lizbeth
Catherine
Berrut,
Nathalie
Denos
31 janvier2005
AC
T 91, 100
ET
R(M
exique) U
JF E
D M
ST
I
DE
AS
ystèmes
d’Informations
UJF
MC
FU
niversité de Mexico
Turki S
lim
Marie-F
ranceB
ruandet,M
ichelLéonard
7 juillet 2005
Co-tutelle
Suisse
UJF
ED
MS
TI
DE
AS
ystèmes
d’Informations
UJF
Enseignant-chercheur
à l’Université de
Genève
To
tal 9
dont thèses avec publications ou brevets avant le 01/10/20058
(1) Préciser le m
ois et l'année (MM
/AA
AA
).(2) P
réciser les références des publications des docteurs, que vous aurez codifiées dans la partie II.2 du dossierscientifique.(3) C
f la no
men
clature 1 en
ann
exe.(4) Intitulé, n° et établissem
ent de rattachement de l'E
D.
(5) Intitulé et établissement qui a délivré le D
EA
/le master.
(6) Cf la nom
enclature en annexe.
LIG — Dossier de contractualisation 626
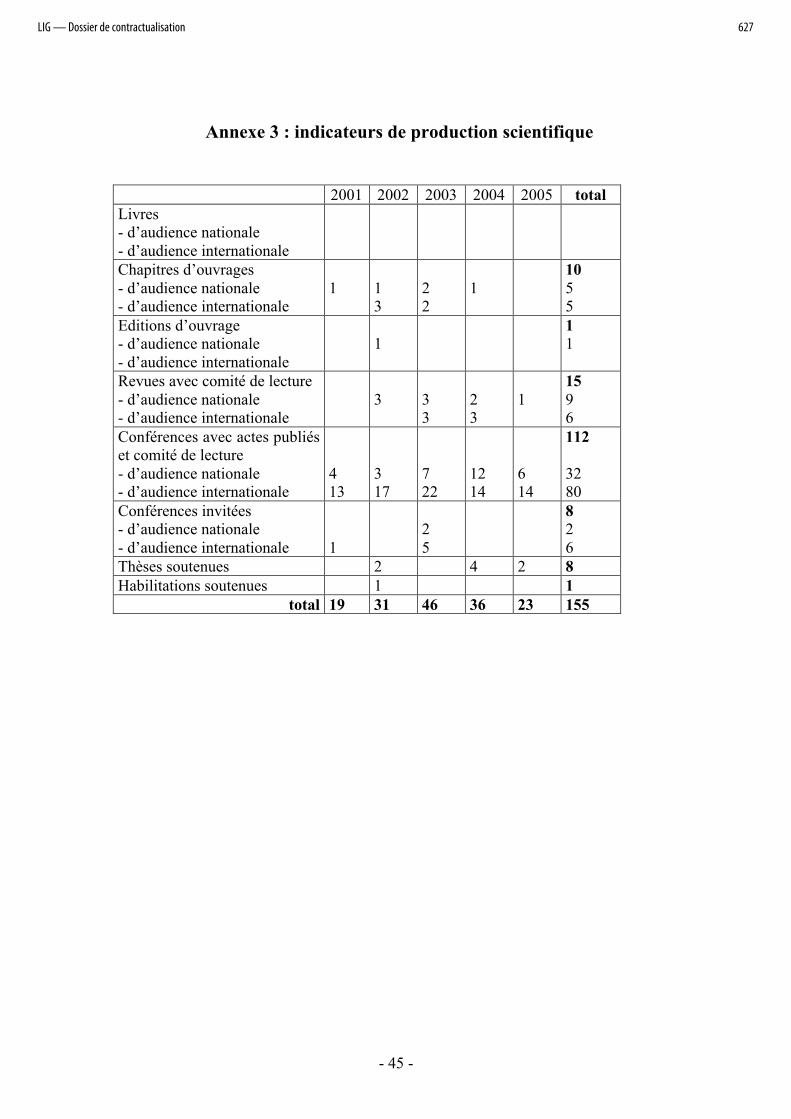
- 45 -
Annexe 3 : indicateurs de production scientifique
2001 2002 2003 2004 2005 totalLivres- d’audience nationale- d’audience internationaleChapitres d’ouvrages- d’audience nationale- d’audience internationale
1 13
22
11055
Editions d’ouvrage- d’audience nationale- d’audience internationale
111
Revues avec comité de lecture- d’audience nationale- d’audience internationale
3 33
23
11596
Conférences avec actes publiéset comité de lecture- d’audience nationale- d’audience internationale
413
317
722
1214
614
112
3280
Conférences invitées- d’audience nationale- d’audience internationale 1
25
826
Thèses soutenues 2 4 2 8Habilitations soutenues 1 1
total 19 31 46 36 23 155
LIG — Dossier de contractualisation 627
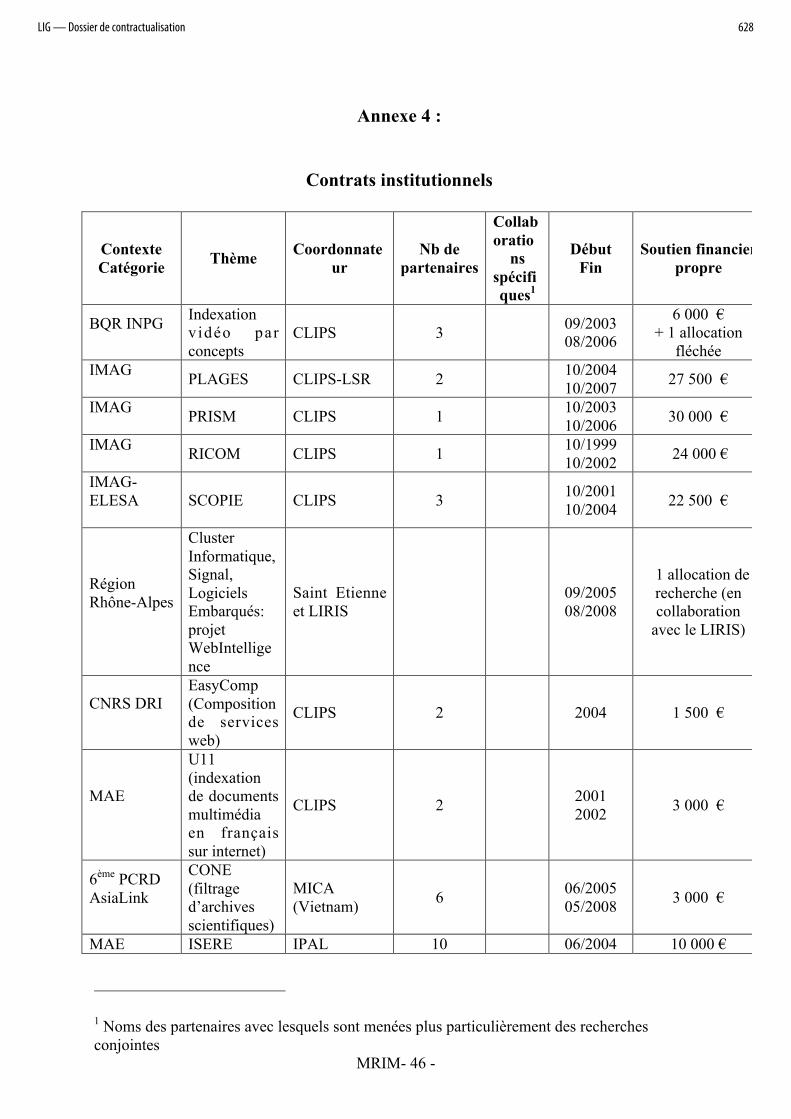
MRIM- 46 -
Annexe 4 :
Contrats institutionnels
ContexteCatégorie
ThèmeCoordonnate
urNb de
partenaires
Collaboratio
nsspécifiques1
DébutFin
Soutien financierpropre
BQR INPGIndexationvidéo parconcepts
CLIPS 309/200308/2006
6 000 €+ 1 allocation
fléchéeIMAG
PLAGES CLIPS-LSR 210/200410/2007
27 500 €
IMAGPRISM CLIPS 1
10/200310/2006
30 000 €
IMAGRICOM CLIPS 1
10/199910/2002
24 000 €
IMAG-ELESA SCOPIE CLIPS 3
10/200110/2004
22 500 €
RégionRhône-Alpes
ClusterInformatique,Signal,LogicielsEmbarqués:projetWebIntelligence
Saint Etienneet LIRIS
09/200508/2008
1 allocation derecherche (encollaboration
avec le LIRIS)
CNRS DRIEasyComp(Compositionde servicesweb)
CLIPS 2 2004 1 500 €
MAE
U11(indexationde documentsmultimédiaen françaissur internet)
CLIPS 220012002
3 000 €
6ème PCRDAsiaLink
CONE(filtraged’archivesscientifiques)
MICA(Vietnam)
606/200505/2008
3 000 €
MAE ISERE IPAL(Singapour)
10 06/2004 10 000 €
1 Noms des partenaires avec lesquels sont menées plus particulièrement des recherchesconjointes
LIG — Dossier de contractualisation 628
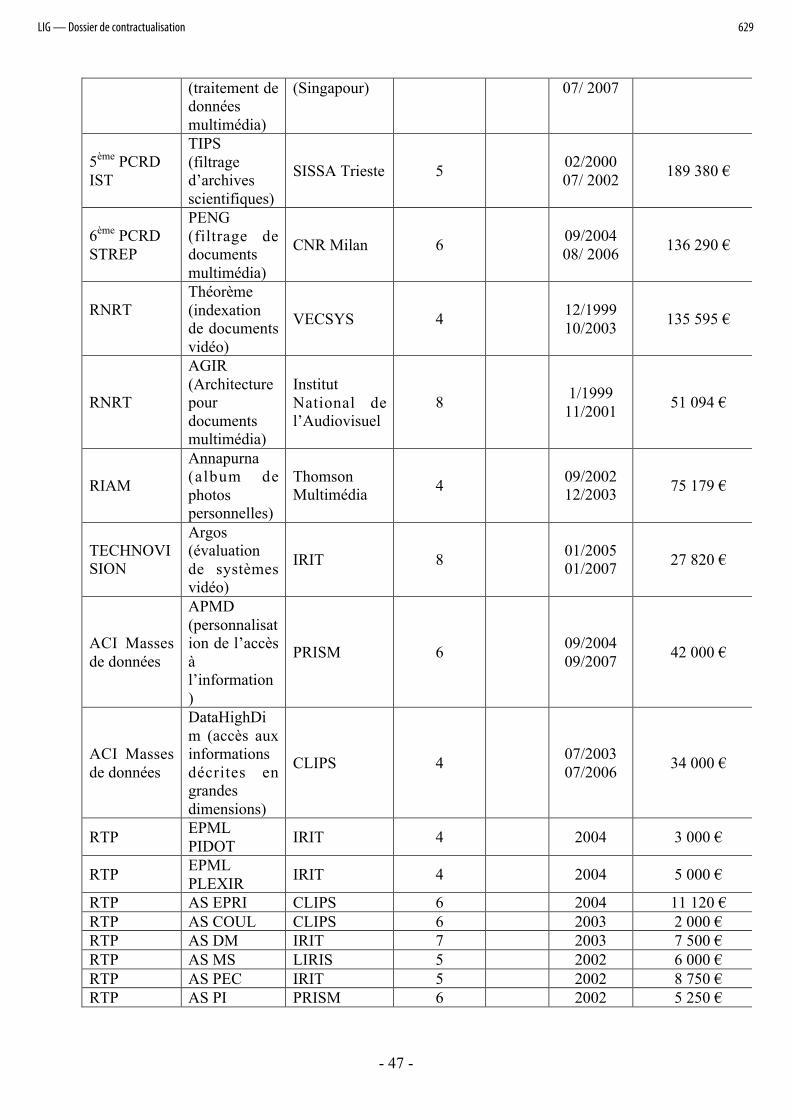
- 47 -
(traitement dedonnéesmultimédia)
(Singapour) 07/ 2007
5ème PCRDIST
TIPS(filtraged’archivesscientifiques)
SISSA Trieste 502/200007/ 2002
189 380 €
6ème PCRDSTREP
PENG(filtrage dedocumentsmultimédia)
CNR Milan 609/200408/ 2006
136 290 €
RNRTThéorème(indexationde documentsvidéo)
VECSYS 412/199910/2003
135 595 €
RNRT
AGIR(Architecturepourdocumentsmultimédia)
InstitutNational del’Audiovisuel
81/1999
11/200151 094 €
RIAM
Annapurna(album dephotospersonnelles)
ThomsonMultimédia 4
09/200212/2003 75 179 €
TECHNOVISION
Argos(évaluationde systèmesvidéo)
IRIT 801/200501/2007 27 820 €
ACI Massesde données
APMD(personnalisation de l’accèsàl’information)
PRISM 609/200409/2007
42 000 €
ACI Massesde données
DataHighDim (accès auxinformationsdécrites engrandesdimensions)
CLIPS 407/200307/2006
34 000 €
RTPEPMLPIDOT
IRIT 4 2004 3 000 €
RTPEPMLPLEXIR
IRIT 4 2004 5 000 €
RTP AS EPRI CLIPS 6 2004 11 120 €RTP AS COUL CLIPS 6 2003 2 000 €RTP AS DM IRIT 7 2003 7 500 €RTP AS MS LIRIS 5 2002 6 000 €RTP AS PEC IRIT 5 2002 8 750 €RTP AS PI PRISM 6 2002 5 250 €
LIG — Dossier de contractualisation 629
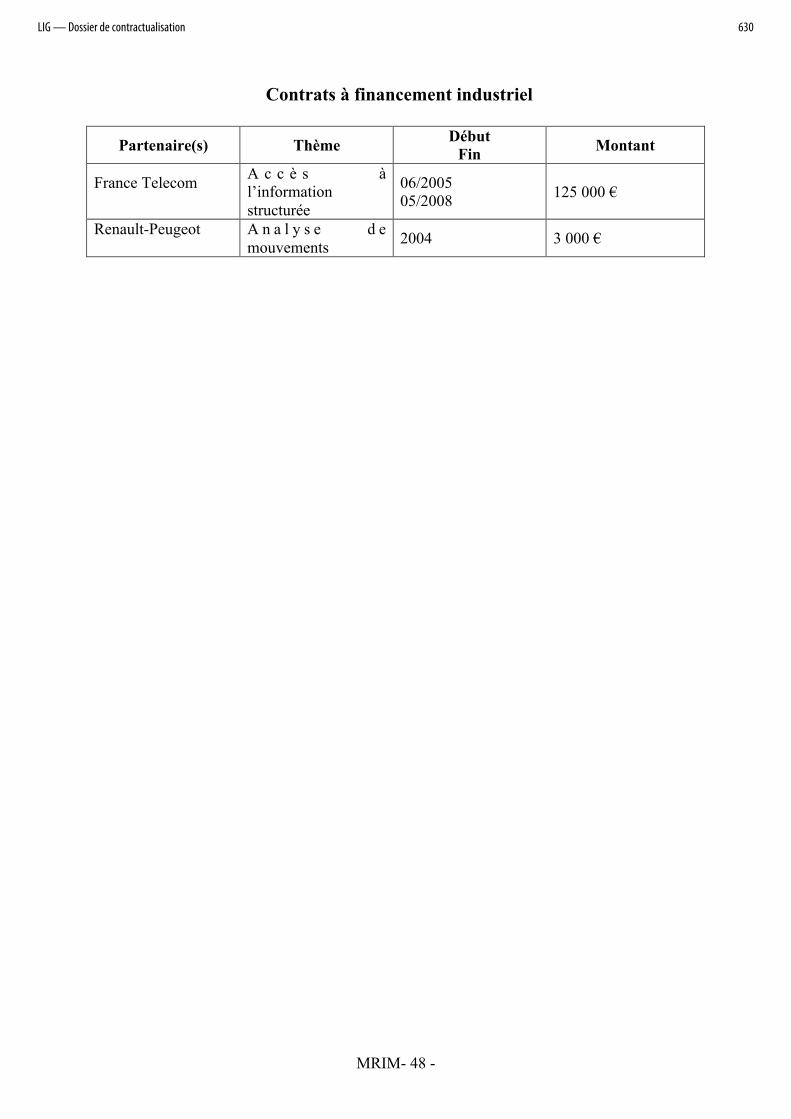
MRIM- 48 -
Contrats à financement industriel
Partenaire(s) ThèmeDébut
Fin Montant
France TelecomA c c è s àl’informationstructurée
06/200505/2008 125 000 €
Renault-Peugeot A n a l y s e d emouvements
2004 3 000 €
LIG — Dossier de contractualisation 630
- 49
-
Ann
exe
5
Lis
te d
es b
reve
ts p
rior
itai
res
fran
çais
ou
euro
péen
s (O
EB
: o
ffic
e eu
ropé
en d
es b
reve
ts)
Typ
e de
dép
ôt(I
NP
I, O
EB
) (1
)N
° de
dépô
tD
ate
dedé
pôt
Titr
e du
bre
vet
N°
depu
blic
atio
nD
ate
depu
blic
atio
nD
épos
ants
(2)
Co-
dépo
sant
s(2
)Li
cenc
e(n
ombr
e)In
vent
eurs
Ext
ensi
on O
EB
ou
PC
T (
pate
nt c
oope
rati
on t
reat
y) d
es b
reve
ts p
rior
itai
res
fran
çais
ou
euro
péen
sT
ype
d'ex
tens
ion
(OE
B, P
CT
, )
Pay
sd'
exte
nsio
n(U
S, J
PN
,...
)
N°
de d
épôt
du p
rem
ier
dépô
tT
itre
du b
reve
tN
° de
dép
ôtpo
url'e
xten
sion
Dat
e d
edé
pôt d
el'e
xten
sion
N°
depu
blic
atio
n de
l'ext
ensi
on
Dép
osan
ts(2
)C
o-dé
posa
nts
(2)
Lice
nce
(no
mbr
e)In
vent
eurs
Log
icie
ls
Dat
e de
dép
ôtD
épos
ants
(2)
Co-
dépo
sant
s(2
)F
inal
ité d
u lo
gici
el
LIG — Dossier de contractualisation 631