optimisation par essaim particulaire pour un problème d ... de projet 2007 rioland... · résumé...
TRANSCRIPT

INSTITUT SUPERIEUR
D’INFORMATIQUE
DE MODELISATION
ET DE LEURS APPLICATIONS
COMPLEXE DES CEZEAUX
BP 125 – 63173 AUBIERE CEDEX
Rapport de Projet 3ème année
Modélisation et Calcul Scientifique
Optimisation par essaim particulaire pour un
problème d’ordonnancement et d’affectation de
ressources
En vue de l’obtention du diplôme d’ingénieur
Pressente par : Arnaud Rioland
Alexandre Eudes
Responsable ISIMA : Michel Gourgand / Sylverin Kemmoé Durée : 150h
Date : 2007

INSTITUT SUPERIEUR
D’INFORMATIQUE
DE MODELISATION
ET DE LEURS APPLICATIONS
COMPLEXE DES CEZEAUX
BP 125 – 63173 AUBIERE CEDEX
Rapport de Projet 3ème année
Modélisation et Calcul Scientifique
Optimisation par essaim particulaire pour un
problème d’ordonnancement et d’affectation de
ressources
En vue de l’obtention du diplôme d’ingénieur
Pressente par : Alexandre Eudes
Arnaud Rioland
Responsable ISIMA : Michel Gourgand / Sylverin Kemmoé Durée : 150h
Date : 2007

Remerciements
Nous remercions Monsieur Sylverin Kemmoé et Monsieur Michel Gourgand
pour leur soutien et leur aide apportées tout au long de ce projet.

Résumé
Notre projet de dernière année d’école d’ingénieur consistait à étudier une méta
heuristique, l’optimisation par essaim particulaire. Cela consiste à trouver l’optimum d’une
fonction ou d’un problème donné en déplaçant des particules dans son ensemble de définition. Nous
l’avons implémenté pour des fonctions continues, et pour des problèmes de recherche
opérationnelle : de type flow shop et de type R.C.P .S.P. (Resource Constraint Project Scheduling
Problem). Ensuite, nous avons réalisé une interface graphique qui permet de visualiser les
résultats et de les commenter, mais qui pourra être aussi réutilisé pour d’autres problèmes
d’optimisation.
Mot clé : Optimisation, Essaim particulaire, Méta-heuristique, Recherche opérationnelle, flow shop,
R.C.P.S.P. , Interface graphique
Abstract
During our last Engineering School year, we have to study a meta-heuristic: the particular
swarm optimization (P.S.O.). It consists in finding the function or problem’s optimum. We have
programmed for continuous functions and for operations research problem which are flow shop and
R.C.P.S.P. (Resource Constraint Project Scheduling Problem). Then, we design a graphical
interface to be enabled to display results and to comment its, but it would be reused on other
optimization problem.
Keyword: Optimization, Particular swarm, Meta heuristic, Operations research, Flow shop,
R.C.P.S.P., graphical interface

Tables des Matières Introduction .......................................................................................................................................... 1
I. Présentations de l'algorithme d'optimisation par essaim de particules ........................................ 2
1. Définitions ................................................................................................................................. 2
2. Principe général de l'optimisation par essaim de particule ....................................................... 2
3. Optimisation continue ............................................................................................................... 4
4. Optimisation discrète ................................................................................................................... 6
a) Le flow-shop ............................................................................................................................ 6
b) Le RCPSP (Resource Constraint Project Scheduling Problem) .............................................. 9
II. Implémentation .......................................................................................................................... 12
1. L’application ........................................................................................................................... 12
2. Technologie XML ................................................................................................................... 13
3. Programmation de la méta heuristique.................................................................................... 13
1. Les classes génériques ..................................................................................................... 15
2. Classe spécifiques ............................................................................................................ 16
4) L’interface graphique ................................................................................................................. 18
Table des figures Figure 1 - Exemple de voisinage géographique ................................................................................... 3 Figure 2 - Deux cas de voisinage social ............................................................................................... 4 Figure 3 - Principe du déplacement d'une particule ............................................................................. 5 Figure 4 - Présentation des 2 cas pour le calcul du makespan ............................................................. 7 Figure 5 - Evaluation du makespan pour le RCPSP .......................................................................... 10 Figure 6– Flux et utilisation de l’XML .............................................................................................. 12
Figure 7 - Représentation UML de la partie calcul ............................................................................ 14 Figure 8 – Arbre d’héritage de la classe problème ............................................................................ 16
Figure 9 - Description de la partie édition de l’interface graphique .................................................. 19 Figure 10 - Description de la partie résultat de l’interface graphique ............................................... 20

1
Introduction
L’optimisation est omniprésente dans tous les domaines : dans l’industrie, dans l’économie,
dans la recherche scientifique, dans l’aérospatiale… C’est la recherche des compromis entre un
besoin et plusieurs contraintes : entre la résistance et le poids, entre les coûts, les ressources et les
temps de production par exemple. De très nombreuses techniques se sont développées au cours du
siècle dernier. Nous en avons étudié une : l’optimisation par essaim particulaire. Cet algorithme
était conçu à l’origine pour résoudre des problèmes définis dans sur des ensembles continus. Il
consiste en gros à déplacer un ensemble de particules dans l’espace de définition de la fonction que
l’on veut étudier et de mémoriser les coordonnées de la meilleure position.
A l’heure actuelle, la communauté scientifique travaille sur des problèmes dans un contexte
discret, des problèmes d’ordonnancement, d’affectation, de gestion de ressources comme le flow
shop et le R.C.P.S.P. (Resource Constraint Project Scheduling Problem). Il existe parfois des
algorithmes qui peuvent les traiter de manière exacte mais qui ont une complexité temporelle trop
grande. Des méthodes ont été mises en place pour résoudre ce type de problème par valeur
approchée et parmi elles, l’adaptation de l’optimisation par essaim particulaire. Elle a été imaginée
par Maurice Clerc, un chercheur qui travaille au sein de l’entreprise France Télécom, en 2000. On
remplace les points par des ordonnancements et les fonctions continues par des fonctions
d’évaluation.
Notre projet a consisté à mettre en place une interface graphique afin d’étudier les
différentes propriétés de l’optimisation par essaim particulaire. Nous avons donc programmé cet
algorithme pour optimiser une fonction continue, un problème de flow shop et un problème type
R.C.P.S.P. et grâce à l’outil de visualisation que nous avons produit, on a pu étudier les résultats
que nous avons obtenu.
Tout d’abord, nous allons vous présenter l’optimisation par essaim particulaire dans ses
deux contextes (continus et discret) et les problèmes du flow shop et du R.C.S.P.S.P. puis comment
nous avons implémenté les algorithmes d’optimisation et l’interface graphique. Enfin nous
disserterons sur les résultats que nous ont donné nos différents tests.

2
II.. PPrréésseennttaattiioonnss ddee ll''aallggoorriitthhmmee dd''ooppttiimmiissaattiioonn ppaarr eessssaaiimm ddee ppaarrttiiccuulleess
1. Définitions
En règle générale, on ne connaît pas toujours de méthode exacte pour trouver la solution
d'un problème d'optimisation en recherche opérationnelle. Dans ce cas on peut d'abord tenter de
voir si le problème que l'on étudie n'a pas de problème équivalent qui ont déjà été résolu. Si l'on n'a
toujours pas trouvé de méthode de résolution alors on utilise ce que l'on appelle une heuristique,
c'est-à-dire un algorithme qui donne une solution approchée. Ces algorithmes sont assez intuitifs ou
simples. On les déduits grâce à des observations et en faisant preuve de bon sens. Leur principe
consiste souvent à explorer un certain nombre de solutions et de mémoriser la meilleure. Ils peuvent
faire intervenir le hasard: cela permet de balayer un plus grand nombre de solution éventuelle, mais
il faut les exécuter plusieurs fois pour tendre au mieux vers la solution optimale.
Certaines heuristiques sont classées parmi les méta-heuristiques. Ce sont des algorithmes
dont le principe peut être réutilisé pour traiter différents problèmes d'optimisation. Ce sont des
principes génériques que l'on adapte selon le besoin. La plus utilisé des heuristiques et la plus
simple est la descente stochastique. Voici son fonctionnement dans le cas d'un problème de
minimisation : on choisit une solution initiale, on sélectionne au hasard un de ses voisins :
Si la valeur de la fonction objectif pour cette nouvelle solution est plus petite
alors on prend ce nouveau point comme point de référence et on observe ses
voisins.
Sinon on recherche un autre voisin.
On s'arrête quand on se rend compte que l'on ne trouve plus de meilleure solution.
2. Principe général de l'optimisation par essaim de particule
La méta-heuristique que nous avons étudiée dans le cadre de notre projet est l'optimisation
par essaim de particules. On dispose d'une fonction objectif à optimiser dans un sens ou dans l'autre.
Un essaim est un ensemble de particules positionnées dans l'espace de définition de la fonction
objectif. Le principe de l'algorithme consiste à déplacer ces particules dans l'espace de définition
afin de trouver la solution optimale.

3
Une particule est caractérisée par plusieurs attributs:
sa position actuelle: c'est-à-dire ses coordonnées dans l'ensemble de
définition et la valeur de la fonction objectif lui correspondant.
sa meilleure position : c’est la valeur obtenue par la particule et ses
coordonnées.
sa vitesse: cette donnée, recalculée à chaque itération de l'algorithme permet
de déduire la position suivante de la particule. Elle est fonction de la
meilleure position de la particule depuis le début de la recherche, du voisin le
mieux positionné à l'instant actuel et de la vitesse précédente de la particule.
ses voisins: c'est un ensemble de particule qui influe sur ses déplacements, en
particulier celui qui est le mieux positionné.
Il faut ensuite définir les voisinages et leur structure, il en existe de deux types :
les voisinages géographiques : les voisins d'une particule sont ses voisines
les plus proches. Ce type de voisinage impose l'utilisation d'une distance
pour recalculer à chaque itération (ou toutes les k itérations) les voisins de
chaque particule. Ci-dessous un exemple où les voisins d’une particule sont
les deux particules qui lui sont le plus proche.
Figure 1 - Exemple de voisinage géographique
Particule Voisins de la particule
colorée

4
Les voisinages sociaux : les voisinages sont établis à l'initialisation et ne sont
pas modifiés ensuite. Il existe différentes structures de voisinages sociaux,
nous allons vous en présenter quelques uns.
Si on utilise un voisinage en lignes et colonnes alors deux particules de l’essaim sont
voisines si elles appartiennent à la même ligne ou à la même colonne. Si on utilise un voisinage
en cercle, les voisines d’une particule sont, par exemple, les deux qui sont positionnées à sa
gauche et les deux qui sont positionnées à sa droite.
Le principe de l'optimisation par essaim particulaire a notamment été conçu à partir
de modèles sociaux. En effet, chacune des particules agit en fonction de sa propre expérience et
de celle de ses voisins. Pour se déplacer elle prend en compte son histoire (sa meilleure position)
et est attirée par la meilleure particule actuelle de son voisinage. C'est le modèle des
comportements d'individu au sein d'une tribu.
3. Optimisation continue
Dans un premier temps, pour nous familiariser avec la méta-heuristique et ses principes nous
l'avons utilisé dans son cadre originel : l'optimisation de fonctions continues.
Les particules sont dans un premier temps placées aléatoirement dans l'ensemble de
définition de la fonction objectif. Ensuite on calcule pour chacune de ses particules leur vitesse.
Dans ce but, on mémorise leur meilleure position depuis le début et on recherche celle de ses
voisins les plus proches à cet instant-là.
Voisinage en ligne et colonne Voisinage en cercle
Figure 2 - Deux cas de voisinage social

5
Où : et sont les vitesses de la particule aux itérations k et k+1.
est la meilleure position de la particule.
est la meilleure position d'un voisin à l'itération k.
est la position de la particule à l’itération k.
, et sont des coefficients fixés au début du programme ou générés aléatoirement.
Ensuite, on peut déterminer la position suivante de la particule grâce à la vitesse que l’on
vient de calculer :
Où : est la position de la particule à l'itération k.
est générée aléatoirement.
est nulle.
Les fonctions étant généralement définies dans un domaine borné, on doit donc gérer les
effets de bord i.e. les moments où la particule s'échappe de cet ensemble. Dans ce cas deux
optiques: on peut imaginer que la particule rebondit sur cette limite ou qu'elle reste bloqué sur la
limite et qu'elle ne puisse plus se mouvoir dans cette direction. Nous avons choisit la deuxième
solution, elle est plus simple à mettre en œuvre et permet d'être plus précis si la solution recherchée
se trouve sur les contours de l'ensemble de définition.
Position
actuelle de
la particule
Meilleure
position de
la particule
Position du
meilleur
voisin
Nouvelle position
Vitesse
actuelle
Figure 3 - Principe du déplacement d'une particule

6
4. Optimisation discrète
Au départ, les algorithmes d’optimisation par essaim particulaire était destinée
exclusivement pour des fonctions continues. En 2000, Maurice Clerc s'est rendu compte que cet
algorithme pouvait être utilisé à d'autres fins, et notamment pour résoudre des problèmes
d'ordonnancement, d'affectation ou de planification.
a) Le flow-shop
Dans un premier temps, nous avons dû adapter cette méta-heuristique au problème du flow
shop.
Le problème du flow shop est un problème d'ordonnancement. On a pièces à fabriquer et
machines. On va donc noter le temps de traitement de la pièce sur la
machine . Les pièces sont traitées par toutes les machines et on a qu'une seule gamme
(une gamme c'est l'ordre dans lequel les pièces parcourent la chaîne de production). L'objectif est de
déterminer l'ordonnancement de traitement des pièces qui minimise le makespan, c'est-à-dire le
temps total de traitement de l'ensemble des pièces.
1. Calcul du makespan pour un ordonnancement des pièces données :
On définit la fonction qui retourne la pièce traitée en ième
position et la date de
sortie de la pièce de la machine . On commence par placer la première pièce de
l’ordonnancement sur la première machine.
Ensuite, on calcule les dates de fin de traitement des pièces sur la première machine.
Il en est de même pour les dates de fin de traitement de la première pièce de
l’ordonnancement sur les différentes machines.
7
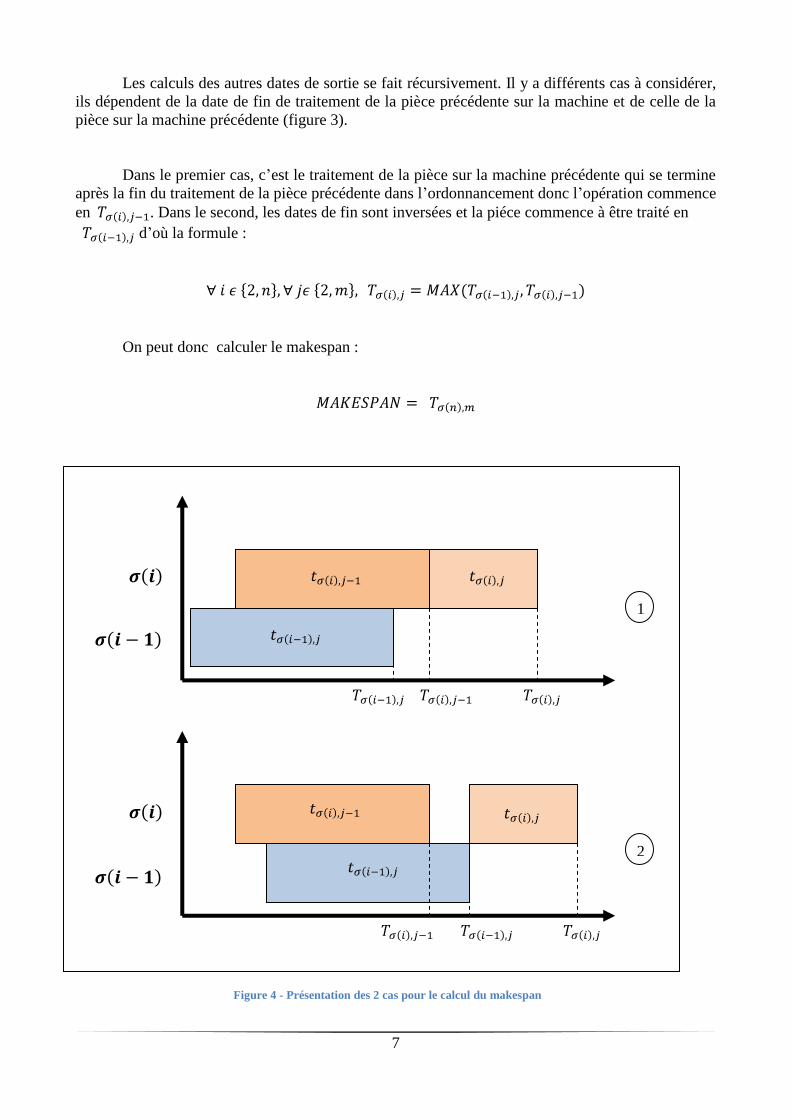
Les calculs des autres dates de sortie se fait récursivement. Il y a différents cas à considérer,
ils dépendent de la date de fin de traitement de la pièce précédente sur la machine et de celle de la
pièce sur la machine précédente (figure 3).
Dans le premier cas, c’est le traitement de la pièce sur la machine précédente qui se termine
après la fin du traitement de la pièce précédente dans l’ordonnancement donc l’opération commence
en . Dans le second, les dates de fin sont inversées et la piéce commence à être traité en
d’où la formule :
On peut donc calculer le makespan :
Figure 4 - Présentation des 2 cas pour le calcul du makespan
2
1

8
2. Notion de vitesse :
Le principal problème du passage du continu au discret réside dans les notions de position et
de vitesse. Une position dans l’ensemble de recherche correspond à un ordonnancement. Les
vitesses doivent permettre de passer d’un ordonnancement à un autre c’est pourquoi on les définit
comme un ensemble de permutation.
, et les deux soustractions ci-dessus correspondent à des vitesses. Les
, et sont des ordonnancements. Il faut donc redéfinir les
opérateurs et .
L’opérateur + permet d’appliquer à un ordonnancement un ensemble de permutation (une
vitesse).
Exemple :
L’opérateur est utilisé pour concaténé deux permutations.
Exemple :
L’opérateur est la multiplication par un scalaire positif d’une permutation. Si ce scalaire
est un entier alors on répète n fois les permutations. Si c’est un réel x compris entre 0 et 1, on enlève
certaines permutations, plus le nombre est petit et moins on en laisse. Pour les autres entiers positifs
on les écrit sous la forme n + x.
L’opérateur – retourne l’ensemble des permutations qui permettent de passer d’un
ordonnancement à un autre.
Exemple :
Nous disposons maintenant de tous les outils pour résoudre un problème de flow shop par la
méthode de l'optimisation par essaim particulaire. On peut suivre désormais le principe de la méta
heuristique.

9
3. No hope
La procédure «no hope
» (pas d’espoir en français) permet de relancer l’essaim quand on ne
parvient plus à améliorer la solution optimale du problème. Après un nombre important d’itération,
on réinitialise les particules afin de pouvoir analyser d’autres ordonnancements (cf .II.2.1)
b) Le RCPSP (Resource Constraint Project Scheduling Problem)
Le problème du R.C.P.S.P. est à la fois un problème d'ordonnancement et un problème de
planification. On dispose d'un nombre constant de ressource. On a n tâches à effectuer, chacune
nécessite un certain nombre de ressource pendant un temps de traitement donné. Il s'agit donc de
générer un planning qui minimise la durée totale nécessaire pour effectuer toutes les tâches.
On utilise les mêmes principes pour les positions et les vitesses que ceux du flow shop.
C'est lors du calcul du makespan que l'on détermine les dates de début et de fin des différentes
tâches. L'algorithme ne se contente pas de calculer la durée totale des opérations mais planifie
toutes les tâches.
1. Calcul du makespan :
On dispose d'un ordonnancement des tâches qui ne correspond pas à l'ordre dans lequel ces
tâches sont effectuées (contrairement au flow shop par exemple) mais plutôt à l'ordre d’insertion
des tâches dans le planning. En effet, on commence par sélectionner la première opération de
l'ordonnancement: on l'insère dans le planning au tout début du calendrier. On prend la deuxième
tâche et on regarde si l’on dispose d’assez de ressource à t=0 :
si oui alors on regarde si ces ressources restent disponibles pendant la durée de la tâche.
Sinon on recherche une autre date de début de la tâche (on recherche la date la plus petite
possible).
On continue à rentrer les tâches dans le planning au fur et à mesure. Pour récupérer le temps
total de traitement, on mémorise la plus grande des dates de fin de tâche, ce qui va nous permettre
d’évaluer les différents ordonnancements. Le passage du flow shop au R.C.P.S.P. s'est donc limité à
la modification de la fonction objectif.

10
Sur l’exemple ci-dessus, les pièces sont insérées dans l’ordre croissant.
2. Prise en compte des contraintes de précédence
A cela, nous devons ajouter les contraintes de précédence. La tâche i précède la tâche j si la
date de fin de la tâche i est inférieure à la date de début de la tâche j. Pour gérer ces contraintes, il
faut bien veiller à ce que dans les ordonnancements i est placé avant j pour toutes les contraintes
contenues dans ce problème et que la date de début d’une tâche soit supérieure à toutes les dates de
fin des tâches qui la précède.
Dans un premier temps, il faut adapter les ordonnancements à ces contraintes : si une tâche
en précède une autre, alors elle devra être placé devant dans l’ordonnancement. Pour cela, il faut
redéfinir l’opérateur qui permet d’appliquer une vitesse (c’est-à-dire un ensemble de
permutations) à un ordonnancement, ceci afin qu’aucune contrainte de précédence ne soit violée.
Prenons un exemple simple :
Exemple : avec la contrainte .
On veut permuter 2 et 5 sur l’ordonnancement ci-dessus. On ne peut pas les échanger
directement comme sur le flow shop car, dans ce cas, on violerait la contrainte , il faut donc
procéder pas à pas. La contrainte n’existe pas : on peut donc les permuter. De la même
manière on démontre que l’on peut intervertir 2 et 4 puis 2 et 5. 2 a pris la place de 5, on obtient
l’ordonnancement suivant : . Il faut maintenant ramener le 5 à la place du 2. On peut
Figure 5 - Evaluation du makespan pour le RCPSP
MAKESPAN
R
1 2 3 4

11
échanger 4 et 5. Ensuite, en principe, il faudrait permuter 3 et 5 mais cela violerait la contrainte :
dans ce cas là, on décide de laisser 5 à cette place.
Le principe général consiste donc à déplacer les deux tâches dans l’ordonnancement d’une
place à chaque fois, on commence par bouger vers la droite la première tâche dans
l’ordonnancement et on s’arête si on a atteint la place désirée ou si il y a une situation de blocage
dues aux contraintes de précédence. On opère de la même manière avec la seconde tâche à
échanger, mais en se déplaçant vers la gauche.
Il faut aussi prendre en compte cette contrainte au niveau du calcul du makespan. On peut
fixer la date minimale de début d’une tâche comme étant le maximum de toutes les dates de fins des
tâches qui la précède. On les connait toutes car grâce à l’ordonnancement car on les a déjà
calculées.
12
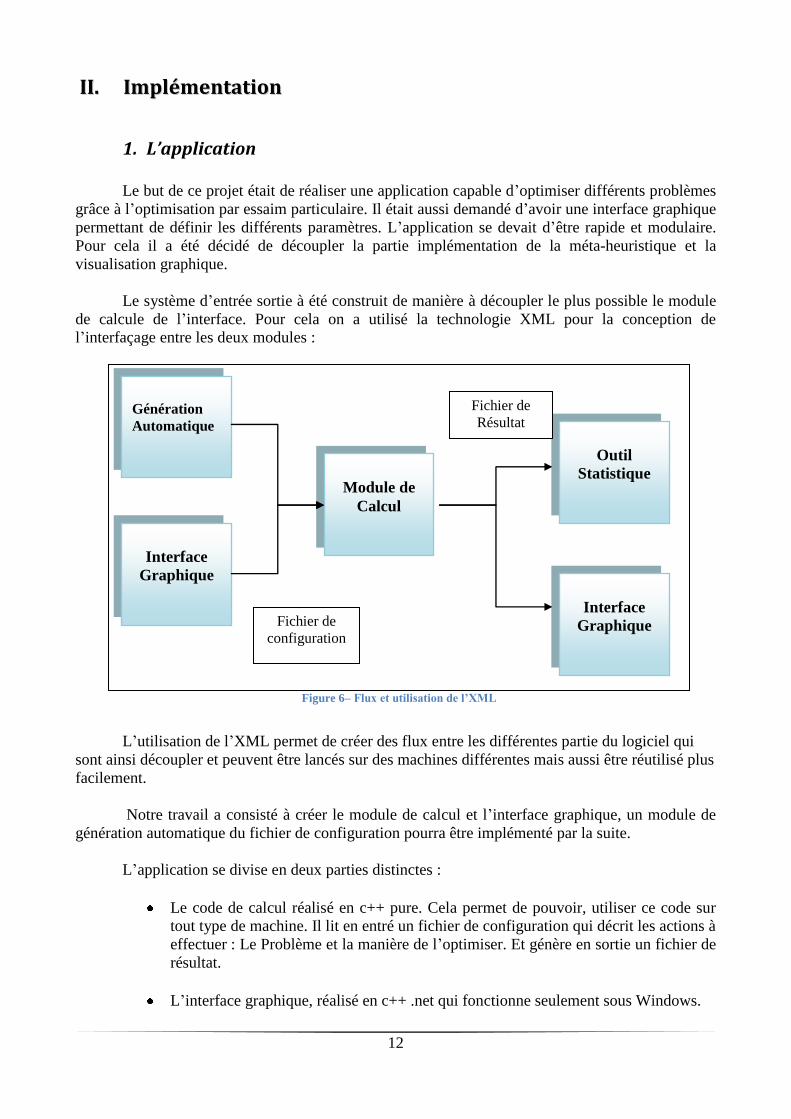
IIII.. IImmpplléémmeennttaattiioonn
1. L’application
Le but de ce projet était de réaliser une application capable d’optimiser différents problèmes
grâce à l’optimisation par essaim particulaire. Il était aussi demandé d’avoir une interface graphique
permettant de définir les différents paramètres. L’application se devait d’être rapide et modulaire.
Pour cela il a été décidé de découpler la partie implémentation de la méta-heuristique et la
visualisation graphique.
Le système d’entrée sortie à été construit de manière à découpler le plus possible le module
de calcule de l’interface. Pour cela on a utilisé la technologie XML pour la conception de
l’interfaçage entre les deux modules :
L’utilisation de l’XML permet de créer des flux entre les différentes partie du logiciel qui
sont ainsi découpler et peuvent être lancés sur des machines différentes mais aussi être réutilisé plus
facilement.
Notre travail a consisté à créer le module de calcul et l’interface graphique, un module de
génération automatique du fichier de configuration pourra être implémenté par la suite.
L’application se divise en deux parties distinctes :
Le code de calcul réalisé en c++ pure. Cela permet de pouvoir, utiliser ce code sur
tout type de machine. Il lit en entré un fichier de configuration qui décrit les actions à
effectuer : Le Problème et la manière de l’optimiser. Et génère en sortie un fichier de
résultat.
L’interface graphique, réalisé en c++ .net qui fonctionne seulement sous Windows.
Figure 6– Flux et utilisation de l’XML
Interface
Graphique
Module de
Calcul
Outil
Statistique
Fichier de
configuration
Fichier de
Résultat
Génération
Automatique
Interface
Graphique

13
Elle est capable de génère le fichier de configuration et de lire le fichier de données.
2. Technologie XML
La technologie Xml( Extensible Markup Language) provient des technologie web et permet
de construire, utiliser ,explorer des documents contenant des données structurées par un système de
balise. Ce format de fichier a l’avantage d’être facile à parser(lire le fichier et stocker ses
informations dans l’application)
Le fait de rendre compte de la structure des données, la rend parfaitement compatible avec le
concept d’objet des langages évolués actuels. Ces deux technologies se combinent parfaitement. Le
langage objet permet de créer les structures dynamiques et le XML apporte la partie transport,
stockage et conversion de l’information.
Puisque liée aux technologies web, cette technologie est en plein essor et de ce fait, son
utilisation est simplifiée par l’existence de parseur prêt à l’emploi. Dans notre cas nous avons utilisé
la bibliothèque Xerces qui a l’avantage d’être en c++ et de plus d’être portable. Cette bibliothèque
fournit un patron de conception d’un parseur Xml qui permet de créer son propre parseur adapté à
ses données.
3. Programmation de la méta heuristique
Nous avons choisi le C++ comme langage de programmation pour ce projet. Il a l’avantage
d’être orienté objet et cela nous a permis de factoriser le code et de n'écrire qu’une fois les principes
généraux de l’optimisation par essaim particulaire. De plus, la bibliothèque S.T.L. (standard
Template Library) contient des outils pour manipuler très facilement des listes utiles pour définir un
essaim ou des voisinages.
On peut partager en deux catégories les différentes classes que l'on a implémentées :
Les classes génériques, c'est-à-dire celles qui sont indépendantes du problème à résoudre:
Essaim : cette classe contient l'ensemble des particules et les voisinages, elle
contient la position de la valeur optimale trouvée.
Particule : c'est une composante de l'essaim qui se déplace dans l'espace de
définition de la fonction objectif. Elle contient sa position actuelle, sa meilleure
position et leurs valeurs.
14
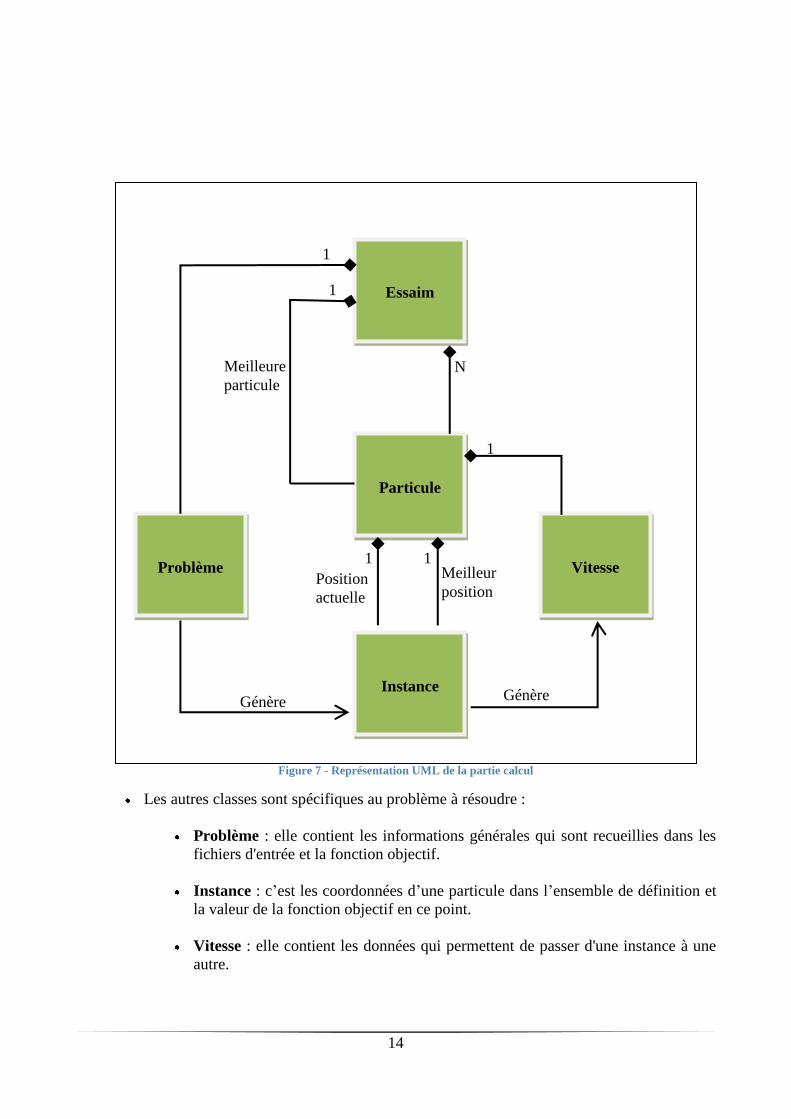
Les autres classes sont spécifiques au problème à résoudre :
Problème : elle contient les informations générales qui sont recueillies dans les
fichiers d'entrée et la fonction objectif.
Instance : c’est les coordonnées d’une particule dans l’ensemble de définition et
la valeur de la fonction objectif en ce point.
Vitesse : elle contient les données qui permettent de passer d'une instance à une
autre.
Figure 7 - Représentation UML de la partie calcul
Essaim
Particule
Problème
Instance
Vitesse
Génère Génère
N Meilleure
particule
1
1 1
Position
actuelle
Meilleur
position
1
1

15
1. Les classes génériques
La classe Essaim contient le nombre de particules et la liste les regroupant. Elles sont
stockées dans un vecteur de la S.T.L. (vector<Particule*>). On lui associe un Problème. Elle
possède aussi un attribut qui pointe sur la meilleure particule trouvée depuis le début de la recherche
de l’optimum et une particule par voisinage qui contient la meilleure position trouvée par le
voisinage. C’est à partir de cette classe que l’on gère l’avancée de l’algorithme. Elle ordonne le
déplacement des particules. A chacune on leur demande dans un premier temps de déterminer leur
nouvelle vitesse avant de les déplacer.
La classe Particule permet de représenter les points qui se déplacent dans l’espace de
définition de la fonction objectif. Elle contient deux éléments de la classe Instance, l’un contenant
la position actuelle de la particule, et l’autre la meilleure position visitée par cette même particule.
Elle est associée à une vitesse qui permettra de calculer la prochaine position.
La classe Essaim possède une méthode « No Hope » qui est activée si la meilleure position
n’est pas améliorée pendant les X dernières itérations. Elle consiste à, dans un premier temps, faire
revenir la particule à sa meilleure position. Et à partir de la a ce déplacer aléatoirement. Pour cela à
chaque itération on créé une nouvelle vitesse et on l’applique sur la particule. On s’arrête dans le
cas où la valeur de la particule s’est améliorée ou si l’on a effectué X itération. Cette procédure
permet de ressusciter une particule qui s’est orienté dans une direction n’offrant plus de valeurs
intéressantes et à restaurer la diversité au sein de l’essaim.
Le second problème concernant les voisinages concerne leur stockage. Nous avons testé
deux méthodes:
Pour chaque particule, on crée une liste où on mémorise l’adresse de chacun
des voisins. Pour rechercher le meilleur, on parcourt cette liste pour chacune
des particules et on retient le meilleur.
On définit tous les voisinages par rapport à l’essaim. On commence pour
chacun des voisinages par récupérer la meilleure position actuelle puis pour
toutes les particules, on sélectionne la meilleure position des voisinages
auxquelles elle appartient.
Nous avons commencé par mettre en place la première méthode puis nous nous sommes
rendu compte qu’en utilisant la deuxième on ne parcourt qu’une seule fois chaque voisinage par
itération, ce qui permet de gagner du temps en cas d’un nombre important de particule.

16
2. Classe spécifiques
Pour chaque problème à traiter par la méthode d’essaim particulaire, on implémente trois classes
spécifiques :
Une classe qui dérive de Problème qui contiendra les attributs spécifiques à chaque
problème et la fonction d’évaluation d’une Instance.
Une classe qui dérive de Instance qui contiendra spécificité des solutions du
problème et l’application d’une vitesse à une Instance.
Une classe qui dérive de Vitesse qui contiendra la représentation d’une vitesse et les
operateurs pour les manipuler entre elles.
L’arbre ci-dessus est aussi valable pour les classes Instance et Vitesse, en précisant que les classes
Vitesse spécifique au RCPSP et au flow shop sont identiques.
Figure 8 – Arbre d’héritage de la classe problème
RCPSP
Problème
Problème
Continu
Problème
Flow Shop
Problème

17
a) Le Problème continu
Dans le cas du Problème continu, il faut définir le problème, l’instance, la vitesse
correspondante. En continu, la définition du Problème revient à donner la fonction d’évaluation, le
domaine de validité, le nombre de dimensions. Une instance contient la position courante, un point
de , c'est-à-dire un tableau de réel. Elle doit vérifier que la position reste valide après chaque
déplacement (on reste dans les bornes). La vitesse est un vecteur de , donc un tableaux de
réel aussi.
b) Le Problème de Flowshop
Pour implémenter le problème du flow shop, une Instance est une liste qui contient l’ordre
dans lequel les pièces doivent être traitées. Les listes sont initialisées par l’intermédiaire de la
fonction random_shuffle( iterator deb, iterator fin) de la S.T.L. Cette fonction prend un élément de
la classe vector (son début et sa fin) en paramètre puis réordonne aléatoirement ses éléments.
La classe Instance contient aussi la valeur du makespan correspondant à l’ordonnancement.
Cette valeur est calculée dans la classe Problème, qui contient la fonction d’évaluation spécifique
au problème du flow shop explicitée dans au chapitre précédent, et elle contient aussi une méthode
permettant de lire et d’enregistrer les données des fichiers de données, qui sont le nombre de pièce,
le nombre de machines et tous les temps de traitement.
La classe Vitesse contient une liste qui stocke les permutations. On rentre les coordonnées
des points qui devront être intervertis. Cette liste contient 2n entiers, chaque permutation
correspondant à 2 entiers (les 2 à permuter). Ensuite, nous avons codé les opérateurs nécessaires
aux calculs. L’opérateur défini une simple concaténation, l’opérateur en répétant plusieurs
fois la liste ou en la scindant. L’opérateur – est en fait ici un constructeur : on lui fournit deux
ordonnancements d’entrée et il retourne une nouvelle instance de la classe Vitesse qui permet d’aller
d’un ordonnancement à un autre. Il ne reste plus qu’à appliquer ces permutations à la particule que
l’on va déplacer.
C) Le RCPSP
On est parti de l’existant pour le flow shop, on conserve la gestion des ordonnancements.
Seul change leur initialisation : on génère dans un premier temps une liste qui est commune pour
toutes les particules qui assure le respect des contraintes de précédence (pour cela on insère les
tâches une à une dans l’ordonnancement si leurs prédécesseurs sont déjà insérés dans la liste.
Ensuite pour chacune des particules on applique une vitesse générée aléatoirement, ce qui permet de
diversifier les particules avant de lancer l’optimisation.
Dans la classe Instance, on a modifié aussi l’opérateur +, celui que l’on utilise pour
appliquer une vitesse à une particule. On bouge à chaque fois d’une place les tâches dans
l’ordonnancement, afin de ne pas violer une contrainte de précédence quand on effectue une

18
permutation (cf. I.4.b.2). Quand on programme ces vitesses, on commence par déplacer vers la
droite la première tâche à permuter :
Si elle peut être positionnée à la place de l’autre tâche que l’on voulait
permuter alors décale cette autre tâche d’une case vers la droite, et il faut
prendre en compte ce décalage lorsqu’on va vouloir ramener cette tâche à la
place de la première.
Sinon, la deuxième tâche de la permutation n’a pas bougé et on la ramène à
partir de sa position initiale.
Enfin, dans la classe Problème, on récupère les données nécessaires contenues dans les
fichiers d’entrée, c’est-à-dire le nombre de tâche, leurs durées et leurs quantités de ressources
nécessaires, le nombre total de ressource disponible par unité de temps, le nombre maximum
d’itérations, et toutes les contraintes de précédence. Ces dernières sont stockées dans une matrice
PREC.
Reste ensuite à coder la fonction d’évaluation (cf. I.4.b.1) qui retourne le makespan, les
dates de début et de fin de chacune des tâches tout en prenant bien en compte les contraintes de
précédence. On a ajouté dans la classe Instance deux tableaux pour mémoriser ces données.
4) L’interface graphique
L’interface graphique est une surcouche permettant d’utiliser le code de calcul sans
programmer directement ou éditer les fichiers xml à la main. Son but est de simplifier la tâche de
l’utilisateur en lui donnant accès directement aux différents paramètres et en lui apportant une
visualisation graphique des résultats.
Elle a été programmée grâce à la technologie c++.net qui permet de créer relativement
simplement des interfaces graphiques pour Windows. Le choix du c++ s’imposait naturellement
pour garder une continuité avec le module de calcul.
Elle est composée de deux panneaux :
Le premier permet de générer le fichier de configuration en créant une liste de tâche
à effectuer. Elle donne la possibilité de charger ou d’exporter un fichier de configuration ou
d’exécuter le calcul directement.
Elle se présente comme suit (voir figure):
La première partie gère la configuration :
Un panneau permet d’ajouter une nouvelle tâche en définissant les paramètres :
- Nombre de réplication : le nombre de fois où l’on exécute la procédure
d’estimation. En effet les positions et les vitesses initiales dépendent d’un
générateur aléatoire. Pour être sûr que la méthode donne des résultats
dans tout les cas, il est nécessaire d’exécuter un grand nombre de fois la
méthode pour en garder que la tendance générale.
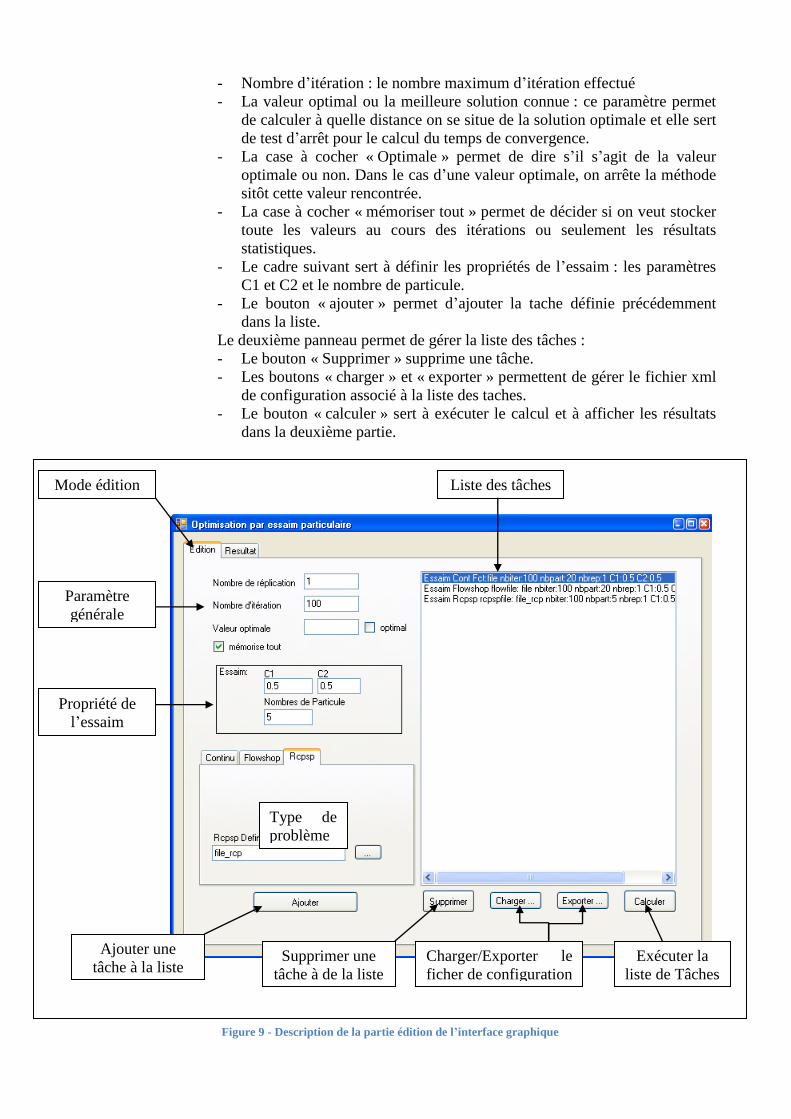
19
- Nombre d’itération : le nombre maximum d’itération effectué
- La valeur optimal ou la meilleure solution connue : ce paramètre permet
de calculer à quelle distance on se situe de la solution optimale et elle sert
de test d’arrêt pour le calcul du temps de convergence.
- La case à cocher « Optimale » permet de dire s’il s’agit de la valeur
optimale ou non. Dans le cas d’une valeur optimale, on arrête la méthode
sitôt cette valeur rencontrée.
- La case à cocher « mémoriser tout » permet de décider si on veut stocker
toute les valeurs au cours des itérations ou seulement les résultats
statistiques.
- Le cadre suivant sert à définir les propriétés de l’essaim : les paramètres
C1 et C2 et le nombre de particule.
- Le bouton « ajouter » permet d’ajouter la tache définie précédemment
dans la liste.
Le deuxième panneau permet de gérer la liste des tâches :
- Le bouton « Supprimer » supprime une tâche.
- Les boutons « charger » et « exporter » permettent de gérer le fichier xml
de configuration associé à la liste des taches.
- Le bouton « calculer » sert à exécuter le calcul et à afficher les résultats
dans la deuxième partie.
Type de
problème
Mode édition Liste des tâches
Ajouter une
tâche à la liste Supprimer une
tâche à de la liste
Charger/Exporter le
ficher de configuration
Exécuter la
liste de Tâches
Paramètre
générale
Propriété de
l’essaim
Figure 9 - Description de la partie édition de l’interface graphique
20
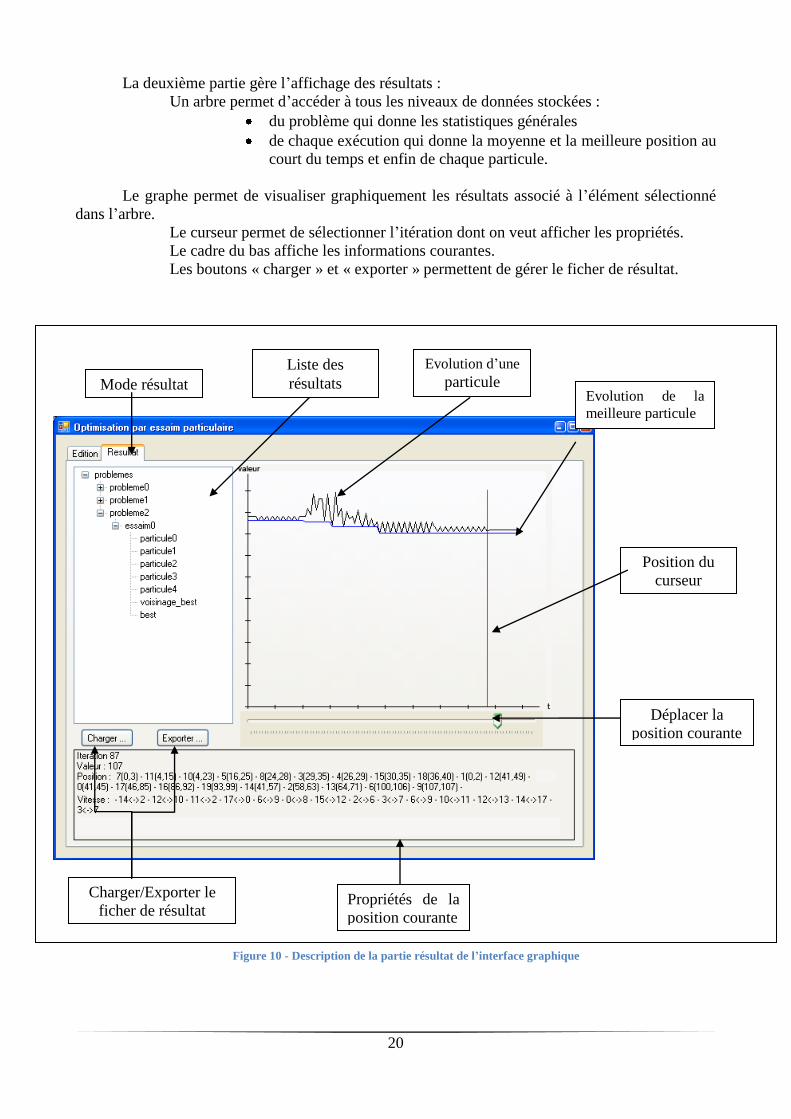
La deuxième partie gère l’affichage des résultats :
Un arbre permet d’accéder à tous les niveaux de données stockées :
du problème qui donne les statistiques générales
de chaque exécution qui donne la moyenne et la meilleure position au
court du temps et enfin de chaque particule.
Le graphe permet de visualiser graphiquement les résultats associé à l’élément sélectionné
dans l’arbre.
Le curseur permet de sélectionner l’itération dont on veut afficher les propriétés.
Le cadre du bas affiche les informations courantes.
Les boutons « charger » et « exporter » permettent de gérer le ficher de résultat.
Mode résultat
Liste des
résultats
Propriétés de la
position courante
Déplacer la
position courante
Charger/Exporter le
ficher de résultat
Position du
curseur
Evolution d’une
particule Evolution de la
meilleure particule
Figure 10 - Description de la partie résultat de l’interface graphique

21
5) Résultat
Optimisation de fonction continu :
Pour 30 réplications de 20 particules et 100 itérations avec C1=0.5 C2=0.5
fonction Nb
d’itération
moyen
Valeur
moyenne
objectif Minimum T moyen(s) Objectif
atteint
Norme² 22 0. 00569911 0.01 3*10-16
0.13 28
Rosenbrock
34.6333 150.926 100 3.2546e-013 0.13 19
Rastrigin
1.33333 0.000541188 100 0 0.13 30
Griewank 4.2 0.0195548 0.1 1.55312e-
011
0.13 20
shaffer 100 0.00245586 10-5
0.00245586 0.16
0
Pour 30 réplications de 20 particules et 100 itérations avec C1=0.2 C2=0.8
fonction Nb
d’itération
moyen
Valeur
moyenne
objectif minimum T moyen(s) Objectif
atteint
Norme² 10.7333 3.62173e-006
0.01 1.56636e-021 0.13 28
Rosenbrock
25.0667 32.5276 100 1.96272e-009 0.13 25
Rastrigin
1.06667 0.00377072
100 0.00377072 0.13 30
Griewank 11.6667 0.0396408 0.1 0.0396408 0.13 28
shaffer 100 0.0108516 10-5
0.00245586 0.16
0
On voit que l’optimisation par essaim particulaire optimise les fonctions objectifs. La valeur
objectif est atteint dans la plupart des cas et le minimum est très proche de 0.
L’influence des coefficients c1 et c2 est manifeste mais son influence dépend de la fonction la
certain jeu de coefficient améliore la solution de certain problème, ces coefficients en dégrade
d’autre.
22
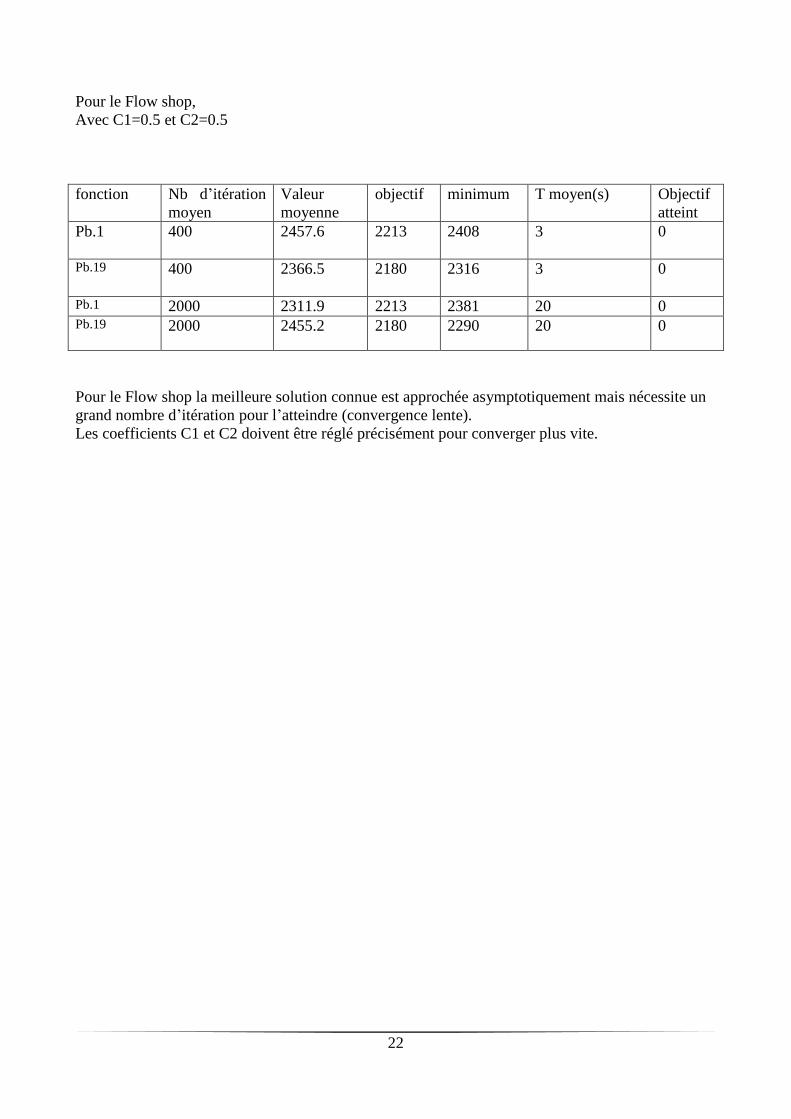
Pour le Flow shop,
Avec C1=0.5 et C2=0.5
fonction Nb d’itération
moyen
Valeur
moyenne
objectif minimum T moyen(s) Objectif
atteint
Pb.1 400 2457.6
2213 2408 3 0
Pb.19
400 2366.5
2180 2316 3 0
Pb.1 2000 2311.9 2213 2381 20 0 Pb.19
2000 2455.2 2180 2290 20 0
Pour le Flow shop la meilleure solution connue est approchée asymptotiquement mais nécessite un
grand nombre d’itération pour l’atteindre (convergence lente).
Les coefficients C1 et C2 doivent être réglé précisément pour converger plus vite.

23
Conclusion
Nous avons implémenté l’optimisation par essaim particulaire sur des fonctions définies
dans des domaines continus, et sur des problèmes de type flow shop ou R.C.P.S.P. Le point délicat
concerne la recherche des bons coefficients c1 et c2 (les constantes que l’on applique aux vitesses)
pour s’approcher au maximum des solutions optimales connues.
L’interface graphique que l’on a produite est extensible à tous les problèmes d’optimisation.
Ces algorithmes peuvent être coder en Fortran, par exemple, puis les résultats sont sauvegardés
dans un fichier XML. Ce dernier sera rechargé par notre interface graphique qui pourra afficher
toutes les données dont on a besoin.
On peut, de plus, générer un module statistique qui fait varier une constante de l’algorithme
d’optimisation, ce qui nous permet d’étudier différentes alternatives.
En partant de ce programme, on pourrait imaginer un logiciel qui pourrait appliquer
différentes méta heuristiques (recuit simulé, algorithme tabou…) à des problèmes de combinatoire,
d’affectation, d’ordonnancement et alors comparer chacune des méthodes sur un exemple précis.
Les graphiques permettraient de confronter les algorithmes et notamment leur vitesse de
convergence.

24
Bibliographie :
M.Clerc Discrete Particle Swarm Optimization illustrated by the Traveling Salesman Probleme
2003
David LEMOINE Optimisation par essaim particulaire (Examen probatoire
du diplôme d’ingénieur C.N.A.M.) 2004
Instance du flowshop http://www.cs.colostate.edu/sched/generatorNew/index.html
Instance du Rcpsp
http://129.187.106.231/psplib/