optimisation · 2010-05-03 · chapitre 1 introduction ce cours traite les concepts de base li´es...
TRANSCRIPT

1
Universite Joseph FourierMagistere de Mathematique, 1ere annee
OPTIMISATIONAnalyse convexe
Theorie de programmation non-lineaire
Notes de cours
Anatoli Iouditski
http://www-lmc.imag.fr/lmc-sms/Anatoli.Iouditski/teaching/magistere.htm

2
Certaines enoncees du cours (theoremes, propositions, lemmes, exemples (si ces derniers
contiennent des conjectures) sont marquees par des indices∗
ou+. Les enonces qui ne sont
pas marquees sont obligatoires : vous devez connaitre le resultat et la preuve. Les enonces
marquees par∗sont semi-obligatoires : vous etes supposes connaitre le resultat sans la preuve
(normalement, cette derniere accompagne le resultat), mais il est preferable, bien entendu, de
lire egalement la preuve. Les preuves des conjectures marques par+ne sont pas donnees dans le
texte ; vous etes supposes d’etre capable de les demontrer, et ces resultats font partie d’exercices.Le sillabus du cours est le suivant :Objectifs : Introduction a la Theorie de Programmation Non-lineaire et Algorithmes d’Optimisation
Continue.Duree : 14 semaines, 2 heures par semaine.Prerequis : : Algebre Lineaire elementaire (vecteurs, matrices, espaces Euclidiens) ; connaissances
de base en Analyse (gradients et Hessians de fonctions multi-variees) ; habilite d’ecrire un simple code enMatlab ou Scilab.
Contenu :1ere Partie. Elements d’Analyse Convexe et Conditions d’Optimalite
10 semaines1-2. Ensembles affines et convexes (definitions, proprietes de base, theoremes de Caratheodory-Radon-
Helley)3-4. Theoreme de separation des ensembles convexes (Lemme de Farkas, Separation, Theoreme sur
l’alternative, Points extremaux, Theoreme de Krein-Milman dans Rn, structure des ensembles polyhe-draux, theorie de Programmation Lineaire)
5. Fonctions convexes (definition, caracterisations differentielle, operations que preservent la convexite)6. Les programmes de Programmation Mathematique et dualite de Lagrange en Programmation
Convexe (Theoreme de Dualite en Programmation Convexe avec l’applications a la Programmation Qua-dratique avec des contraintes lineaires)
7. Conditions d’optimalite en optimisation sans contraintes et avec des contraintes (Regle de Fermat ;Conditions de Karush-Kuhn-Tucker dans le cas regulier ; conditions d’optimalite necessaires/suffisantesde second ordre pour le cas sans contraintes)
2nde Partie. Algorithmes de Programmation Nonlineaire4 semaines
8. Minimisation sans contraintes univariee (Methode de Bi-section, Recherche lineaire)9. Minimisation sans contraintes multi-variee (Methode de Descente en Gradient, et Methode de
Newton).

Table des matieres
1 Introduction 71.1 Espace lineaire Rn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.1.1 Rn : structure lineaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.1.2 Rn : Structure Euclidienne . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.2 Combinaisons Lineaires, Sous-espaces Lineaires, Dimension . . . . . . . . . . . . 141.2.1 Combinaisons lineaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.2.2 Sous-espaces lineaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.2.3 Generateurs, Ensembles lineairement independants, Dimension . . . . . . 17
1.3 Ensembles affines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221.3.1 Ensembles affines et Enveloppes affines . . . . . . . . . . . . . . . . . . . 221.3.2 Generateurs affines, Ensembles independents affinement, Dimension affine 25
1.4 Description duale des sous-espaces lineaires et d’ensembles affines . . . . . . . . . 281.4.1 Ensembles affines et systemes d’equations lineaires . . . . . . . . . . . . . 291.4.2 Structure des simples ensembles affines . . . . . . . . . . . . . . . . . . . . 31
1.5 Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2 Ensembles convexes : Introduction 352.1 Definition, Exemples, Description interne, Proprietes algebriques . . . . . . . . . 35
2.1.1 Ensembles convexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.1.2 Examples d’ensembles convexes . . . . . . . . . . . . . . . . . . . . . . . . 362.1.3 Description interne d’ensembles convexes : Combinaisons convexes et en-
veloppes convexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.1.4 Plus d’exemples d’ensembles convexes : le polytope et le cone . . . . . . . 402.1.5 Proprietes algebriques d’ensembles convexes . . . . . . . . . . . . . . . . . 422.1.6 Proprietes topologiques d’ensembles convexes . . . . . . . . . . . . . . . . 42
2.2 Theoremes classiques sur ensembles convexes . . . . . . . . . . . . . . . . . . . . 482.2.1 Theoreme de Caratheodory . . . . . . . . . . . . . . . . . . . . . . . . . . 482.2.2 Theoreme de Radon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 492.2.3 Theoreme de Helley . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
2.3 Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3 Theoreme de separation Theorie d’inegalites lineaires 553.1 Theoreme de separation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.1.1 Necessite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 573.1.2 Suffisance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 583.1.3 Separation forte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.2 Theorie de systemes finis d’inegalites lineaires . . . . . . . . . . . . . . . . . . . . 64
3

4 TABLE DES MATIERES
3.2.1 Preuve de la partie ”necessite” du Theoreme sur l’Alternative . . . . . . . 683.3 Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4 Points Extremes. Structure d’Ensembles Polyhedraux 73
4.1 Description externe d’un ensemble convexe ferme. Plans de support . . . . . . . . 734.2 Representation minimale d’ensembles convexes : points extremes . . . . . . . . . 75
4.3 Structure d’ensembles polyhedraux . . . . . . . . . . . . . . . . . . . . . . . . . . 784.3.1 Theorie de Programmation Lineaire . . . . . . . . . . . . . . . . . . . . . 80
4.4 Structure d’ensembles polyhedraux : preuves . . . . . . . . . . . . . . . . . . . . 854.4.1 Points extremes d’un ensemble polyhedral . . . . . . . . . . . . . . . . . . 85
4.4.2 Structure d’un polyhedre borne . . . . . . . . . . . . . . . . . . . . . . . . 864.4.3 Structure d’un ensemble polyhedral general : fin de la preuve . . . . . . . 89
4.5 Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
5 Fonctions Convexes 95
5.1 Fonctions convexes : premier abord . . . . . . . . . . . . . . . . . . . . . . . . . . 955.1.1 Definitions et Exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
5.1.2 Proprietes elementaires de fonctions convexes . . . . . . . . . . . . . . . . 975.1.3 Quelle est la valeur d’une fonction convexe en dehors de son domaine ? . . 98
5.2 Comment detecter la convexite . . . . . . . . . . . . . . . . . . . . . . . . . . . . 985.2.1 Operations preservant la convexite des fonctions . . . . . . . . . . . . . . 99
5.2.2 Critere differentiel de convexite . . . . . . . . . . . . . . . . . . . . . . . . 1015.3 Inegalite du Gradient . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
5.4 Bornitude et la propriete de Lipschitz des fonctions convexes . . . . . . . . . . . 1055.5 Maximum et minimum de fonctions convexes . . . . . . . . . . . . . . . . . . . . 108
5.6 Exrecices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
6 Programmation Convexe et Dualite de Lagrange 1156.1 Programme de Programmation Mathematique . . . . . . . . . . . . . . . . . . . . 115
6.2 Convex Programming program and Duality Theorem . . . . . . . . . . . . . . . . 1166.2.1 Theoreme sur l’Alternative Convexe . . . . . . . . . . . . . . . . . . . . . 116
6.2.2 Fonction de Lagrange et dualite de Lagrange . . . . . . . . . . . . . . . . 1206.2.3 Conditions d’Optimalite en Programmation Convexe . . . . . . . . . . . . 122
6.3 Dualite pour la Programmation Lineaire et Quadratique convexe . . . . . . . . . 1266.3.1 La dualite en Programmation Lineaire . . . . . . . . . . . . . . . . . . . . 126
6.3.2 La dualite en Programmation Quadratic . . . . . . . . . . . . . . . . . . . 1276.4 Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
7 Conditions d’Optimalite 133
7.1 Conditions d’Optimalite du Premier Ordre . . . . . . . . . . . . . . . . . . . . . . 1357.2 En guise de conclusion... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
7.3 Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
8 Methodes d’Optimisation : Introduction 149
8.1 Preliminaires sur les Methodes d’Optimisation . . . . . . . . . . . . . . . . . . . 1508.1.1 Classification des Problemes et des Methodes d’Optimisation Non-Lineaire 150
8.1.2 Nature iterative des Methodes d’Optimisation . . . . . . . . . . . . . . . . 1508.1.3 Convergence des Methodes d’Optimisation . . . . . . . . . . . . . . . . . . 151

TABLE DES MATIERES 5
8.1.4 Solutions globales et locales . . . . . . . . . . . . . . . . . . . . . . . . . . 1548.2 Recherche Lineaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
8.2.1 Recherche lineaire d’ordre zero . . . . . . . . . . . . . . . . . . . . . . . . 1568.2.2 Dichotomie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1618.2.3 Approximation de courbes . . . . . . . . . . . . . . . . . . . . . . . . . . . 1638.2.4 Recherche Lineaire Inexacte . . . . . . . . . . . . . . . . . . . . . . . . . . 166
8.3 Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
9 Methode de Descente de Gradient et Methode de Newton 1719.1 Descente de Gradient . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
9.1.1 L’idee . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1719.1.2 Implementations Standards . . . . . . . . . . . . . . . . . . . . . . . . . . 1729.1.3 Convergence de la Descente de Gradient . . . . . . . . . . . . . . . . . . . 1739.1.4 Vitesses de convergence . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1769.1.5 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
9.2 Methode de Newton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1899.2.1 Version “de base” de la methode de Newton . . . . . . . . . . . . . . . . 189
9.3 Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191

6 TABLE DES MATIERES

Chapitre 1
Introduction
Ce cours traite les concepts de base lies a la theorie et aux algorithmes d’optimisationpour resoudre des problemes extremaux avec un nombre fini de variables – ce qui s’appelleProgrammation Mathematique. Nos objectifs sont
– (A) comprendre quand un point x∗ est une solution du probleme de Programmation Non-lineaire
f(x) → min | gi(x) ≤ 0, i = 1, ...,m;hj(x) = 0, j = 1, ..., k,
ou toutes fonctions impliquees dependent de n variables reelles formant le vecteur dedecision x ;
– (B) apprendre des algorithmes numeriques capables pour rapprocher la solution.
(A) est le sujet de la premiere partie purement theorique du cours dans laquelle on vise adevelopper des conditions necessaires/suffisantes d’optimalite. Ces conditions sont tres impor-tantes par les deux raisons suivantes :
– d’abord, dans certains cas les conditions necessaires/suffisantes pour l’optimalite per-mettent d’obtenir une solution en ”forme analytique” ; si tel est le cas, nous obtenonsbeaucoup d’information importante – nous avons dans notre disposition non seulementla solution elle-meme, mais egalement la possibilite pour analyser comment la solutiondepend des donnees. Dans des situations reelles, cette comprehension est souvent plusprecieuse que que la solution elle-meme ;
– en second lieu, les conditions d’optimalite sont a la base de la majorite d’algorithmesnumeriques pour trouver les solutions approximatives dans les situations quand une so-lution en “forme analytique” est indisponible (et elle n’est “presque jamais” disponible).Dans ces algorithmes, nous verifions a chaque etape les conditions d’optimalite pour l’ite-ration courante ; naturellement, elles sont violes, mais il s’avere que les resultats de notreverification permettent d’obtenir une nouvelle iteration qui est, dans un sens, meilleureque la precedente. Ainsi, les conditions d’optimalite forment une base pour la deuxiemepartie du cours consacre aux algorithmes numeriques.
En fait, la premiere partie (“theorique”) du cours – elements d’analyse convexe – est bien plusambitieuse qu’elle soit declaree dans (A) : nous etudierons beaucoup de choses qui n’ont aucunerelation directe aux conditions d’optimalite et aux algorithmes d’optimisation. D’autre part,nous obtiendrons un certain nombre d’occasions d’appliquer dans notre – contexte simple “endimension finie” quelques resultats de l’analyse fonctionnelle et de la theorie d’operateurs.
7

8 CHAPITRE 1. INTRODUCTION
1.1 Espace lineaire Rn
Nous sommes interesses a resoudre des problemes extremaux avec un nombre fini de variablesde design ; en resolvant un probleme, nous devrions choisir “quelque chose de optimal” d’unespace des vecteurs. Ainsi, l’univers ou tous les evenements ont lieu est un espace vectoriel,ou, plus precisement, un espace vectoriel n-dimensionnel Rn. Vous etes cense savoir ce qu’estl’espace depuis les cours d’algebre ; neanmoins, essayons de rafraichir nos connaissances.
1.1.1 Rn : structure lineaire
Soit n un entier positif. Considerez l’ensemble qui consiste de tous vecteurs n-dimensionnels– les ensembles ordonnes x = (x1, ..., xn) de n reels (n-uplets) ; nous equipons cet ensemble desoperations suivantes :
– l’addition, qui met en correspondance a une paire de vecteurs n-dimensionnels x =(x1, ..., xn), y = (y1, ..., yn) un nouveau vecteur du meme type – leur somme
x+ y = (x1 + y1..., xn + yn),
et– la multiplication par des reels, qui met en correspondance a un λ reel et a un vecteurx = (x1, ..., xn) n-dimensionnel un nouveau vecteur n-dimensionnel – le produit de λ et dex, defini en tant que
λx = (λx1..., λxn).
La structure que nous obtenons – l’ensemble de tous les vecteurs n-dimensionnels avec les deuxoperations qu’on vient de definir – s’appelle l’espace vectoriel reel Rn n-dimensionnel.
Remarque 1.1.1 pour menager de l’espace, nous notons habituellement un vecteur en arran-geant ses entrees dans la ligne : x = (x1, > ..., xn). On devra se rappeler, cependant, que les
conventions d’Algebre Lineaire exigent des entrees d’etre arrangees en colonne : x =
⎛⎝ x1....xn
⎞⎠.
C’est la seule maniere d’etre compatible avec les definitions de multiplication de vecteur par unematrice et d’autres operations d’Algebre Lineaire.Essayez SVP de ne pas oublier cette petite contradiction !
Tant que l’addition et la multiplication par des reels sont concernes, “l’arithmetique de la struc-ture que nous obtenons est absolument semblable a celle des reels. Par exemple (ci-dessousemploie des lettres latines pour noter les vecteurs n-dimensionnels, et des lettres grecs pournoter des reels) :
– le vecteur nul 0 = (0, ..., 0) joue le role du zero reel :
x+ 0 = 0 + x = x
for all x ;– the a l’oppose −α du reel α (α + (−α) = 0) correspond la negation vectorielle
x = (x1, ..., xn) �→ −x = (−1)x = (−x1, ...,−xn)
(x+ (−x) = 0) ;

1.1. ESPACE LINEAIRE RN 9
– nous pouvons utiliser les regles standards de manipulation avec des expressions du type
λx+ μy + νz + ...
– changer l’ordre :λx+ μy + νz = νz + μy + λx,
– ouvrir les parentheses :
(λ− μ)(x− y) = λx− λy − μx+ μy,
– rassembler les termes similaires et simplifier les termes opposes :
3x+ 7y + z − 8x+ 3y − z = −5x+ 10y,
etc.Tous ces resultats sont des consequences immediates du fait que les regles correspondantesagissent sur des reels et que notre arithmetique vectoriel est “element-par-element” – pour ajou-ter des vecteurs et pour les multiplier par des reels signifie d’effectuer les operations semblablesavec leurs entrees. La seule chose que nous “ne savons pas” faire pour le moment est de multiplierdes vecteurs par des vecteurs.
Un etudiant curieux pourrait demander ce qui est la vraie signification des mots“arithmetique des vecteurs est completement semblable a l’arithmetique des reels”. Lareponse est suivante : la definition des operations que nous l’avons presentee impliqueimmediatement que les axiomes suivants sont satisfaits :
– Axiomes d’addition :– associativite : x+ (y + z) = (x+ y) + z ∀x, y, z ;– commutativite : x+ y = y + x ∀x, y ;– existence de zero : il existe un vecteur zero, note 0, tel que x+ 0 = x ∀x ;– existence de negation : pour chaque vecteur x, il existe un vecteur, note −x, tel quex+ (−x) = 0.
– Axiomes de multiplication :– unitarite : 1 · x = x pour tout x ∈ E ;– associativite :
λ · (μ · x) = (λμ) · xpour tous les reels λ, μ et tous les vectors x ;
– Axiomes d’addition-multiplication :– distributivite par rapport aux reels :
(λ+ μ) · x = (λ · x) + (μ · x)pour tous les reels λ, μ et tout vecteur x ;
– distributivite par rapport aux vecteurs :
λ · (x+ y) = (λ · x) + (λ · y)pour tout reel λ et tous les vecteurs x, y.
Tous ces axiomes, naturellement, ont lieu egalement pour l’addition et la multiplication
habituelles des reels. Il en decoule que toutes les regles de l’arithmetique reelle habituelle qui
sont des consequences des axiomes indiques seulement et n’emploient aucune autre propriete
des reels – et ce sont fondamentalement toutes les regles “d’arithmetique elementaire d’ecole”,
a l’exception de celles qui traitent la division – sont verifiees automatiquement pour des
vecteurs.

10 CHAPITRE 1. INTRODUCTION
1.1.2 Rn : Structure Euclidienne
La vie dans notre univers Rn serait plutot lassante s’il n’y avait aucune autre structure dansl’espace que la structure lineaire, donnee par l’addition et la multiplication par des reels. Heu-reusement, nous pouvons equiper Rn par la structure Euclidienne donne par le produit scalaire(ou interieur) standard. Le produit scalaire est l’operation qui met dans la correspondance a unepaire x, y de vecteurs n-dimensionnels le reel
xT y =n∑
i=1
xiyi.
Le produit interieur possede les proprietes fondamentales suivantes qui decoulent directementde la definition :
– bilinearite, i.e., la linearite partielle par rapport aux premier et second arguments :
(λx+ μy)T z = λ(xT z) + μ(yT z), xT (λy + μz) = λ(xT y) + μ(xT z);
– symetrie :
xT y = yTx;
– positivite :
xTx =n∑
i=1
x2i ≥ 0,
ou ≥ devient = si et seulement si x = 0.
Notez que cette linearite du produit scalaire en ce qui concerne le premier et du deuxiemeargument permet d’ouvrir des parentheses dans les produits scalaires des expressions complexes :
(λx+ μy)T (νz + ωw) = λxT (νz + ωw) + μyT (νz + ωw) =
= λνxT z + λωxTw + μνyT z + μωyTw,
ou, en forme generale,
(p∑
i=1
λixi)T
q∑j=1
μjyj) =p∑
i=1
q∑j=1
λiμjxTi yj.
Notez que dans la derniere relation xi et yj sont les vecteurs n-dimensionnels et pas, commeavant, les elements d’un vecteur.
La structure Euclidienne engendre certains concepts importants.
Formes lineaires sur Rn
Tout d’abord, la structure Euclidienne permet d’identifier des formes lineaires sur Rn avecdes vecteurs. Ceci signifie la chose suivante :
une forme lineaire sur Rn est une fonction a valeurs reelles f(x) telle que
f(x+ y) = f(x) + f(y); f(λx) = λf(x)
pour tous les vecteurs x, y et tout reel λ. Etant donne un vecteur f ∈ Rn, nous pouvons luiassocier la fonction
f(x) = fTx

1.1. ESPACE LINEAIRE RN 11
laquelle, grace a la bilinearite du produit scalaire, est une forme lineaire.
Ce qui est bien plus interessant, vice versa, chaque forme lineaire f(x) sur Rn peut etreobtenue de cette facon a partir d’un certain (uniquement defini par la forme) vecteur f . Pour levoir, supposons que ei, i = 1, ..., n, les vecteurs standards de base de Rn ; tous les entrees de eison nuls, excepte le i-eme, qui est 1. Evidemment, pour tout vecteur x = (x1, ..., xn) :
x = x1e1 + ...+ xnen. (1.1)
Alors, pour une forme lineaire f(·), calculons ses valeurs
fi = f(ei), i = 1, ..., n,
sur les vecteurs de base et regardons le vecteur f = (f1, ..., fn). Je pretends que ca soit exactementle vecteur qui “engendre” la forme f(·) :
f(x) = fTx ∀x.
En effet,
f(x) = f(∑n
i=1 xiei) [regardez (1.1)]=
∑ni=1 xif(ei) [du a la linearite de f(·)]
=∑n
i=1 xifi [l’origine de fi]= fTx [la definition du produit scalaire]
Ainsi, chaque forme lineaire f(·) est en effet le produit scalaire avec un vecteur fixe. Le fait quece vecteur est uniquement defini par la forme est immediat : si f(x) = fTx = (f ′)Tx pour tous xalors (f − f ′)tx = 0 pour tous x ; en substituant x = f − f ′, nous obtenons (f − f ′)t(f − f ′) = 0,qui, du a la positivite du produit scalaire, implique f = f ′.
Ainsi, le produit scalaire permet d’identifier les formes lineaires sur Rn avec des vecteurs del’espace : prenant le produit scalaire d’un vecteur variable avec un vecteur fixe, nous obtenons uneforme lineaire, et chaque forme lineaire peut etre obtenue de cette facon d’un vecteur uniquementdefini.
pour ceux qui se rappellent “encore” ce qui est un espace lineaire abstrait j’ajouterait le
suivant. Des formes lineaires sur un espace vectoriel E peuvent etre naturellement arrangees
en un espace vectoriel : ajouter deux formes lineaires et multiplier ces formes par des reels
signifie, respectivement, les ajouter et les multiplier par des reels, comme fonctions sur E ; le
resultat encore sera une forme lineaire sur E. Ainsi, chaque espace lineaire E a une “contre-
parties” – l’espace lineaire E∗ qui consiste en des formes lineaires sur E et appele l’espace
conjugue E. Les considerations ci-dessus indiquent que le produit scalaire sur Rn permet
d’identifier l’espace Rn avec son conjugue. Proprement parlant, notre identification est iden-
tification des ensembles, pas celui des espaces lineaires. Cependant, on voit immediatement
qu’en fait l’identification en question preserve des operations lineaires (l’addition et la mul-
tiplication des formes par des reels correspondent aux memes operations avec les vecteurs
representant les formes) et est un isomorphisme des espaces lineaires.
La metrique Euclidienne
Des notions tres importantes qui arrivent avec la structure Euclidienne sont ceux demetrique :

12 CHAPITRE 1. INTRODUCTION
– la norme Euclidienne d’un vecteur x :
|x| =√xTx =
√√√√ n∑i=1
x2i ;
– la metrique sur Rn – une distance entre une paire de points :
dist(x, y) ≡ |x− y| =√√√√ n∑
i=1
(xi − yi)2.
La norme Euclidienne possede les trois proprietes suivantes (qui sont par ailleurs des proprietescaracteristiques de la notion generale d’une “norme sur un espace lineaire”) :
– positivite :|x| ≥ 0,
ou ≥ est = ssi x = 0 ;– homogeneite :
|λx| = |λ||x|;– inegalite de triangle :
|x+ y| ≤ |x|+ |y|.Les deux premieres proprietes decoulent immediatement de la definition ; l’inegalite de triangledemande une preuve moins triviale, et cette preuve est tres instructive : son resultat “collateral”est l’inegalite fondamentale de Cauchy
|xT y| ≤ |x||y| ∀x, y (1.2)
– “la valeur absolue du produit scalaire de deux vecteurs est moins ou egale que le produit desnormes des vecteurs”, avec l’inegalite etant egalite si et seulement si x et y sont colineaires,c.-a-d., si x = λy ou y = λx avec un reel λ convenablement choisi.
Etant donne l’inegalite de Cauchy, nous pouvons immediatement demontrer l’inegalitede triangle :
|x+ y|2 = (x + y)T (x+ y) [par definition]= xTx+ yT y + 2xT y [en ouvrant les parentheses]= |x|2 + |y|2 + 2xT y [par definition]≤ |x|2 + |y|2 + 2|x||y| [par l’inegalite de Cauchy]= (|x| + |y|)2 [comme nous nous rappelons de l’ecolel].
Le point interessant est, evidemment, de prouver l’inegalite de Cauchy. La preuve estextremement elegante : etant donne deux vecteurs x, y, considerons la fonction
f(λ) = (λx − y)T (λx − y) = λ2xTx− 2λxT y + yT y.
On ignore le cas trivial quand x = 0 (dans ce cas-ci l’inegalite de Cauchy est evidente), desorte que f soit une forme quadratique de λ avec le principal coefficient positif xTx. Enraison de la positivite du produit scalaire, cette forme est non negative sur l’axe entier, desorte que son discriminant
(2xT y)2 − 4(xTx)(yT y)
est non positive, et on arrive a l’inegalite desiree :
(xT y)2 ≤ (xTx)(yT y) [≡ (|x||y|)2].

1.1. ESPACE LINEAIRE RN 13
L’inegalite devient egalite si et seulement si le discriminant est 0, c.-a-d., si et seulement si
f possede une racine reelle λ∗ (de multiplicite 2) ; mais encore du a la positivite du produit
interieur, f(λ∗) = 0 signifie exactement ce que λ ∗ x− y = 0, c.-a-d., exactement que x et y
sont colineaires.
Des proprietes indiquees de la norme Euclidienne decoule immediatement que la metriquedist(x, y) = |x − y| que nous avons defini en effet est une metrique – il satisfait les proprietescaracteristiques suivantes :
– positivite :dist(x, y) ≥ 0,
avec ≥ etant = ssi x = y ;– symetrie :
dist(x, y) = dist(y, x);
– inegalite de triangle :dist(x, z) ≤ dist(x, y) + dist(y, z).
Equipe de cette metrique, Rn devient un espace metrique, et nous pouvons employer toutes lesnotions relatives d’Analyse :
– convergence : une suite {xi ∈ Rn} est appelee convergeante vers un point x ∈ Rn, et xest appele la limite de la suite [notation : x = limi→∞ xi], si
dist(xi, x) ≡ |xi − x| → 0, i→ ∞;
notez que la convergence est en fait une notion de “coordonnee-par-coordonnee” : xi → x∗,i→ ∞, si et seulement si (xi)j → x∗j pour tous les indices de coordonnees j = 1, ..., n (ici,naturellement, (xi)j est la j-eme coordonnee xi, et, pareillement, pour x∗j ;
– ensemble ouvert : un ensemble U ⊂ Rn s’appelle ouvert, s’il contient, avec chaque de sespoints x, un voisinage de ce point – une boule centree en x d’un certain rayon positif :
∀x ∈ U ∃r > 0 : U ⊃ Br(x) ≡ {y | |y − x| ≤ r}(notez que l’ensemble vide, en accord avec cette definition, est ouvert) ;
– ensemble ferme : un ensemble F ⊂ Rn est appele ferme, s’il contient des limites de toutessuites convergeantes d’elements de F :
{xi ∈ F, i = 1, 2, ...} & {x∗ = limi→∞
xi} ⇒ x∗ ∈ F
(notez que l’ensemble vide, en accord avec cette definition, est ferme).On le voit facilement que les ensembles fermes sont exactement les complements a lesouverts.
Notez que la convergence est compatible avec les structures lineaires et Euclidiennes de Rn.Precisement :
– si deux suite de vecteurs {xi}, {yi} convergent vers x, resp., y, et deux suites de reels {λi}and {μi} convergent vers λ, resp., μ, alors la suite {λixi + μiyi} converge, et la limite estλx+μy. Ainsi, on peut passer a la limite terme-par-terme dans des sommes finies commeλx+ μy + νz + ... ;
– si deux suites {xi} and {yi} de vecteurs convergent vers x, resp., y, alors
xTi yi → xT y, i→ ∞ & dist(xi, yi) → dist(x, y), i→ ∞.

14 CHAPITRE 1. INTRODUCTION
Des notions de convergence et des ensembles ouverts/fermes peuvent etre associe a n’importequel espace metrique, non seulement avec Rn. Cependant, en ce qui concerne ces proprietes Rn
possede la propriete fondamentale suivante :
Proposition 1.1.1 [Compacite des sous-ensembles bornes et fermes de Rn] Un sous-ensembleferme et borne F de Rn est compact, c.-a-d., possede les deux proprietes suivantes equivalentes :
(i) Toute suite {xi ∈ F} possede une sous-suite {xit}∞t=1 qui converge vers un point de F ;
(ii) Toute famille (pas forcement finie) d’ouverts {Uα} couvrant F (F ⊂ ∪αUα) possede unesous-famille finie qui encore couvre F .
On le voit facilement que, vice versa, un ensemble compact dans Rn (et en fait, un
compact dans tout espace metrique) est borne et ferme. Autrement dit, Proposition 1.1.1
donne la caracterisation des ensembles compacts dans Rn : ceux-ci sont exactement les
ensembles fermes et bornes.
La propriete exprimee dans Proposition sera extremement importante pour nous : la compacitedes sous-ensembles bornes et fermes de notre univers est a la base de la majorite des resultatsque nous sommes sur le point d’obtenir. Notez que c’est une caracteristique tres “personnelle”des espaces Rn comme membres d’une famille beaucoup plus nombreuse d’espaces vectoriels to-pologiques. Les problemes d’optimisation dans ces espaces plus vastes sont egalement d’un grandinteret (ils surgissent, par exemple, dans la Commande a temps continue). La theorie de cesproblemes est beaucoup plus compliquee techniquement que la theorie des problemes d’optimi-sation sur Rn, principalement puisqu’il y a des difficultes avec la compacite. Proposition 1.1.1est la raison principale du fait que nous limitons nos considerations aux espaces de dimensionfini.
1.2 Combinaisons Lineaires, Sous-espaces Lineaires, Dimension
1.2.1 Combinaisons lineaires
Soit x1, ..., xk un vecteur n-dimensionnel et soit λ1, ..., λk reels. Un vecteur de type
x = λ1x1 + ...+ λkxk
est appele combinaison lineaire des vecteurs x1, ..., xk avec des coefficients λ1, ..., λk .
1.2.2 Sous-espaces lineaires
Un ensemble non vide L ⊂ Rn est appele sous-espace lineaire, s’il est ferme par rapport auxoperations lineaires :
x, y ∈ L, λ, μ ∈ R ⇒ λx+ μy ∈ L.Une definition equivalente, bien evidemment, est : un sous-espace lineaire est un sous-ensemblenon vide de Rn qui contient toutes les combinaisons lineaires de ses elements.
Par exemple, les sous-ensembles suivants de Rn sont clairement des sous-espaces :
– le sous-ensemble {0} compris du vecteur 0 ;– Rn entier ;– l’ensemble de tous les vecteurs avec la premiere entree egale a 0.

1.2. COMBINAISONS LINEAIRES, SOUS-ESPACES LINEAIRES, DIMENSION 15
Notez que chaque sous-espace lineaire pour sur contient zero (en effet, il est non vide pardefinition ; si x ∈ L, alors egalement par definition, L devrait contenir le vecteur 0x = 0).Une consequence immediate de cette observation insignifiante est celle-ci :
l’intersection L = ∩αLα d’une famille arbitraire des sous-espaces lineaires de Rn est encore unsous-espace lineaire
En effet, L n’est pas vide – tous les Lα sont les sous-espaces lineaires et contiennent donc 0, desorte que L contienne egalement 0. Et chaque combinaison lineaire des vecteurs de L est contenuedans chaque Lα (comme combinaison des vecteurs de Lα) et, par consequent, est contenu dansL de sorte que L soit ferme en ce qui concerne des combinaisons lineaires.
Enveloppe lineaire
Soit X un sous-ensemble non vide arbitraire de Rn. Il existent des sous-espaces lineairesdans Rn qui contiennent X – par exemple, le Rn entier. En prenant l’intersection de tous cessous-espaces, nous obtenons, comme nous savons deja, un sous-espace lineaire. Ce sous-espacelineaire s’appelle enveloppe lineaire deX et est note Lin(X). Par construction, l’eveloppe lineairepossede les deux proprietes suivantes :
– il contient X ;– il est le plus petit sous-espace lineaire contenant X : si L est un sous-espace lineaire etX ⊂ L, alors, egalement, Lin(X) ⊂ L.
Il est facile a voir quels sont les elements de l’enveloppe lineaire de X :
Proposition 1.2.1 [Linear span]
Lin(X) = {l’ensemble de toutes combinaisons lineaires de vecteurs de X}.En effet, toutes les combinaisons lineaires des vecteurs de X devrait appartenir a chaque sous-espace lineaire L qui contient X, en particulier, a Lin(X). Il reste pour demontrer que chaqueelement de Lin(X) est une combinaison lineaire des vecteurs de X. Pour cela notons par Ll’ensemble de toutes ces combinaisons ; tout ce que nous avons besoin de montrer que L lui-meme est un sous-espace lineaire. En effet, en supposant ceci et en remarquant que X ⊂ L(comme 1x = x, de sorte que chaque vecteur de X soit une combinaison lineaire triviale desvecteurs de X), nous pourrions conclure que L ⊃ Lin(X), puisque Lin(X) est le plus petit parmides sous-espaces lineaires contenant X.
Il reste a verifier que L est un sous-espace, c.-a-d., que la combinaison lineaire∑
i λiyi descombinaisons lineaires yi =
∑j μijxj des vecteurs xj ∈ X est encore une combinaison lineaire
des vecteurs de X, ce qui est evident :∑i
λi∑j
μijxj =∑j
(∑i
λjμij)xj .
Vous etes invite a preter l’attention a cette preuve simple et a penser a elle jusqu’a ce quevous “ sentiez” la construction “en entier” plutot que comprendre la preuve point par point –nous emploierons le meme raisonnement en parlant des enveloppes convexes.
Somme des sous-espaces lineaires
Etant donne deux ensembles arbitraires de vecteurs X,Y ⊂ Rn, nous pouvons former leursomme arithmetique – l’ensemble
X + Y = {x+ y | x ∈ X, y ∈ Y }

16 CHAPITRE 1. INTRODUCTION
compris de toutes sommes par paire – un terme de X et un autre de Y .Un fait important sur cette addition des ensembles est donne par la proposition suivante
Proposition 1.2.2+La somme arithmetique L+M de deux sous-espaces lineaires L,M ⊂ Rn
est un sous-espace lineaire qui n’est rien d’autre que l’enveloppe lineaire Lin(L ∪M) de l’uniondes sous-espaces.
Exemple 1.2.1 On associe un sous-espace LI de Rn avec un sous-ensemble I d’indices 1, ..., nde facon que LI est compris de tous les vecteurs x avec les elements xi indexes par i �∈ I egalesa 0 :
LI = {x | xi = 0 ∀i �∈ I}.On peut voir facilement que
LI + LJ = LI∪J .
Remarque 1.2.1 Comme pour la somme arithmetique d’ensembles de vecteurs, nous pouvonsformer le produit
ΛX = {λx | λ ∈ Λ, x ∈ X}d’un ensemble Λ ⊂ R de reels et d’un ensemble X ⊂ Rn de vecteurs.
Cette “arithmetique des ensembles” n’est rien d’autre qu’un notation commode, et nousl’emploierons de temps en temps. Bien que cette arithmetique ressemble fort a celle de vecteurs 1,quelques lois arithmetiques importantes ne sont pas vraies pour des ensemble ; par exemple, d’unemaniere generale
{2}X �= X +X; X + {−1}X �= {0}.Soyez vigilant !
Somme directe. Soit L et M deux sous-espaces lineaires. Par la definition de la sommearithmetique, chaque vecteur x ∈ L +M est une somme de certains vecteurs xL de L et dexM de M :
x = xL + xM . (1.3)
Une question importante est : dans quelle mesure x predetermine-t-il xL et xM ? Le “degrede liberte” qu’il y a ici est evident : vous pouvez ajouter a xL un vecteur arbitraire d del’intersection L ∩M et soustraire le meme vecteur de xM , et c’est tout.
En effet, pour un d de x = xL + xM nous avons x = (xL + d >)+ (xM − d), et les termesdans la nouvelle decomposition appartiennent encore a L et aM (puisque d ∈ L∩M et L,Msont des sous-espaces lineaires). Vice versa, si
(I) x = xL + xM , (II) x = x′L + x′M
sont deux decompositions du type en question,
x′L − xL = xM − x′M . (1.4)
1. par exemple,– nous pouvons ecrire sans les parentheses les expressions comme Λ1X1+...+ΛkXk – l’ensemble qu’en resulte
est independant de la facon dont nous inserons des parentheses, et nous pouvons reordonner les termesdans ces relations ;
– {1}X = X ;– nous avons l’associativite (ΛΞ)X = Λ(ΞX) ;– nous avons la “distributivite restreinte”
{λ}(X + Y ) = {λ}X + λY ; (Λ + Ξ){x} = Λ{x}+ Ξ{x};– il existe le zero additif – l’ensemble {0}.

1.2. COMBINAISONS LINEAIRES, SOUS-ESPACES LINEAIRES, DIMENSION 17
Si on note par d la valeur commune de ces deux expressions, nous voyons que d ∈ L∩M(en effet, le cote gauche de (1.4) indique que d ∈ L, et le cote droit que d ∈ M). Ainsi,la decomposition (ii) en effet est obtenue a partir (i) en ajoutant un vecteur de L ∩M aucomposant dans L et en soustrayant le meme vecteur du composant dans M .
Nous voyons que d’une maniere generale – quand L∩M contient des vecteurs non nul –les composants de decomposition (1.3) ne sont pas uniquement definis par x. Par contre,
si L ∩M = {0}, alors les composants xL et xM sont uniquement definis par x.
Dans le dernier cas la somme L +M s’appelle la somme directe ; pour x ∈ L +M , xL estappele la projection parallele a M de x sur L et xM s’appelle la projection parallele a Lde x sur M . Quand L +M est une somme directe, les projections dependent lineairementde x ∈ L +M : quand nous ajoutons/multiplions par des reels les vecteurs projetes, leursprojections sommes sujets aux memes operations.
par exemple, dans la situation de l’Exemple 1.2.1 la somme LI + LJ est une somme
directe (c.-a-d., LI ∩ LJ = {0}) si et seulement si le seul vecteur x dans Rn avec les indices
des entrees non nul appartenant a I et a J est le vecteur nul ; en d’autres termes, la somme
est directe si et seulement si I ∩J = ∅. Dans ce cas-ci les projections de x ∈ LI +LJ = LI∪J
sur LI et LJ sont tres simples : xLI a les memes entrees que x pour i ∈ I et a les entrees
restantes nulles, et de meme pour xLJ .
1.2.3 Generateurs, Ensembles lineairement independants, Dimension
Soit L ⊂ Rn un sous-espace lineaire.
Generateur
On appele un ensemble X ⊂ L generateur de L, si chaque vecteur de L peut etre representecomme une combinaison lineaire des vecteurs deX. Ou, ce qui est identique, si L = Lin(X). Dansce cas nous disons egalement que X genere (ou engendre) L et L est est genere (ou engendre)par X.
Par exemple, (1.1) dit que la collection e1, ..., en des vecteurs de base canonique de Rn
engendre tout l’espace.
Independence lineaire
Une collection x1, ..., xk des vecteurs n-dimensionnels s’appele lineairement independante, sichaque combinaison lineaire non triviale (avec au moins un coefficient non nul) des vecteurs estnon nulle :
(λ1, ..., λk) �= 0 ⇒k∑
i=1
λixi �= 0.
Parfois il est plus commode d’exprimer la meme propriete sous la forme (equivalente) suivante :un ensemble de vecteurs x1, ..., xk est lineairement independant si et seulement si la seule com-binaison lineaire nulle des vecteurs est triviale :
k∑i=1
λixi = 0 ⇒ λ1 = ... = λk = 0.
Par exemple, les vecteurs de la base canonique de Rn sont lineairement independants : puisqueles entrees dans le vecteur
∑ni=1 λiei sont exactement λ1..., λn, le vecteur est zero si et seulement
si tous les coefficients λi sont zero.

18 CHAPITRE 1. INTRODUCTION
L’essence de la notion de l’independance lineaire est donnee par le simple resultat suivant(qui est en fait une definition equivalente de l’independance lineaire) :
Corollaire 1.2.1+Soit x1, ..., xk lineairement independents. Alors les coefficients λi de la com-
binaison lineaire
x =k∑
i=1
λixi
des vecteurs x1, ..., xk sont uniquement definis par la valeur x de la combinaison.
Notez que, par definition, un ensemble vide de vecteurs est lineairement independant (en effet,vous ne pouvez pas presenter une combinaison lineaire non triviale des vecteurs de cet ensemblequi est nulle – vous ne pouvez pas presenter une combinaison lineaire des vecteurs d’un ensemblevide du tout !)
Dimension
En Algebre nous avons le resultat fondamental suivant :
Proposition 1.2.3 [Dimension] Soit L (different de {0}) un sous-espace lineaire non trivial deRn. Alors les deux quantites suivantes sont des nombres entiers finis qui sont egaux entre eux :
(i) le nombre minimal des elements dans les sous-ensembles de L qui engendre L ;(ii) le nombre maximal des elements des sous-ensembles finis lineairement independants de
L.La valeur commune de ces deux nombres entiers s’appelle la dimension de L (notation : dim (L)).
Une consequence directe de Proposition 1.2.3 set le theoreme suivant :
Theoreme 1.2.1 [Bases] Soit L un sous-espace lineaire non trivial dans Rn.
A. Soit X ⊂ L. Les trois proprietes suivantes de X sont equivalentes :(i) X est un ensemble lineairement independant qui engendre L ;(ii) X est lineairement independant et contient dim L elements ;(iii) X engendre L et contient dim L elements.
Un sous-ensemble X de L possedant les proprietes indiquees d’equivalent entre elles s’appelleun basis de L.
B. Chaque collection lineairement independante de vecteurs de L soit elle-meme est une basede L, ou peut etre complete a une telle base en ajoutant de nouveaux vecteurs. En particulier,la existe une base de L.
C. Etant donne un ensemble X qui engendre L, on peut toujours en extraire une base de L.
La preuve :(i) → (ii) : supposons que X , a la fois, engendre L et soit lineairement independant.
Puisque X engendre L il contient au moins dim L elements (Proposition 1.2.3), et puisqueX est lineairement independant, il contient au plus dim L elements (la meme proposition).Ainsi, X contient exactement dim L elements, comme il est exige par (ii).
(ii) → (iii) : soit X lineairement independant de dim L elements x1, ..., xdim L. Nousdevons montrer que X engendre L. Supposons, au contraire, que ce n’est pas le cas, et doncil existe un vecteur y ∈ L qui ne peut pas etre represente comme une combinaison lineaire desvecteurs xi, i = 1, ..., dim L. Je pretends qu’en ajoutant y aux vecteurs x1, ..., xdim L, nousobtenons toujours un ensemble lineairement independant (ceci impliquerait la contradiction

1.2. COMBINAISONS LINEAIRES, SOUS-ESPACES LINEAIRES, DIMENSION 19
desiree, puisque cet ensemble contient plus que dim L vecteurs de L, et ceci est interditpar Proposition 1.2.3). Si y, x1, ..., xdim L etaient lineairement dependants, il existerait unecombinaison lineaire non triviale des vecteurs egale a zero :
λ0y +
dim L∑i=1
λixi = 0. (1.5)
Le coefficient λ0 n’est surement nul (sinon notre combinaison serait une combinaison lineairenon triviale nulle de vecteurs x1, ..., xdim L lineairement independant (l’hypothese)). Commeλ0 �= 0, nous pouvons resoudre (1.5) par rapport a y :
y =
dim L∑i=1
(−λi/λ0)xi,
et obtenir une representation de y comme combinaison lineaire de xi’s, ce qu’on a supposeimpossible.
Remarque 1.2.2 en montrant l’implication (ii) → (iii), nous avons etabli le resultat sui-vant :
N’importe lequel ensemble lineairement independant {x1..., xk} de vecteurs de L qui n’est pasun generateur de L peut etre augmente a un ensemble lineairement independant plus granden ajoutant un vecteur de L convenablement choisi( a savoir, en ajoutant tout vecteur y ∈ Lqui n’est pas une combinaison lineaire x1, ..., xk).
Ainsi, en commencant par un ensemble lineairement independant arbitraire dans L qui n’en-gendre pas L, nous pouvons l’augmenter point par point, preservant l’independance lineaire,jusqu’a ce qu’il devienne generateur ; ceci se produit surement a une etape, puisque dansnotre processus nous obtenons tous le temps des sous-ensembles lineairement independantsde L et Proposition 1.2.3 indique qu’un tel ensemble ne contient pas plus de dim L elements.Ainsi, nous avons montre que
n’importe quel sous-ensemble de L lineairement independant peut etre enveloppe d’un sous-ensemble generateur lineairement independant (c.-a-d., a une base de L)
s’appliquant le dernier resultat au sous-ensemble vide de L nous voyons cela :
N’importe quel sous-espace lineaire de Rn possede une base.
les resultats ci-dessus sont exactement ceux annonces dans B.
(iii) → (i) : soit X un sous-ensemble generateur de L qui contient dim L elementsx1, ..., xdim L ; nous devrions montrer que x1, ..., lexdim L sont lineairement independant. Sup-posons qu’au contraire, ce n’est pas le cas ; puis, comme dans la preuve de l’implicationprecedente, un de nos vecteurs, par exemple x1, est une combinaison lineaire du restant desxi. J’affirme qu’en supprimant de X le vecteur x1, nous obtenons toujours un ensemble quiengendre L (c’est la contradiction desiree, puisque l’ensemble generateur qui reste contientmoins de dim L vecteurs, et ceci est interdit par Proposition 1.2.3). En effet, chaque vecteury dans L est une combinaison lineaire de x1, ..., xdim L ( X est un generateur !) ; en substi-tuant dans cette combinaison la representation de x1 par l’intermediaire des xi restants, nousrepresentons y comme combinaison lineaire de x2, ..., xdim L, de sorte que le dernier ensemblede vecteurs en effet engendre L.
Remarque 1.2.3 En montrant (iii) ⇒ (i), nous avons egalement prouve C :
Si X engendre L il existe alors un sous-ensemble lineairement independant X ′ de X qui soitegalement generateur de L et qui est donc une base de L. En particulier, Lin(X) a une basequi consiste en des elements de X.

20 CHAPITRE 1. INTRODUCTION
en effet, vous pouvez prendre comme X ′ un ensemble lineairement independant maximal(avec le nombre maximum autorise d’elements) dans X (puisque, par Proposition 1.2.3, n’im-porte quel sous-ensemble lineairement independant dans L contient au plus dim L elements,un tel sous-ensemble existe). Par extremalite de cet ensemble, en ajoutant a X ′ un elementarbitraire y de X , nous obtenons un ensemble lineairement dependant ; maintenant, commedans la preuve de l’implication (ii) → (iii), il suit que y est une combinaison lineaire desvecteurs de X ′. Ceci, come dans la preuve de l’implication (iii) → (i), implique que chaquecombinaison lineaire des vecteurs de X est en fait egale a une combinaison lineaire desvecteurs de X ′, de sorte que X et X ′ engendrent le meme sous-espace lineaire L.
Jusqu’ici nous avons defini la notion de la base et de la dimension pour des sous-espaces de Rn
non triviaux – differents de {0}. Afin d’eviter des remarques triviales dans ce qui va suivre, onassigne par definition la dimension 0 au sous-espace lineaire trivial {0}, et on traite l’ensemblevide comme base de ce sous-espace lineaire.
Dimension de Rn et de ses sous-espaces
En illustrant les notions d’ensemble generateur et celle d’ensemble lineairement de independant,nous avons mentionne que la collection des vecteurs de base canonique e1, ..., en est a la fois ungenerateur de l’espace et un ensemble lineairement independant. Selon le theoreme 1.2.1, il suitque
la dimension de Rn est n, et les vecteurs de base canonique forment une base dans Rn.
Ainsi, la dimension de Rn est n. Et que diriez-vous des dimensions des sous-espaces ? Natu-rellement, elle est tout au plus n, en raison de la simple proposition suivante :
Proposition 1.2.4 Soit L ⊂ L′ une paire de sous-espaces lineaires de Rn. Alors dim L ≤dim L′, et l’inegalite devient l’egalite si et seulement si L = L′. En particulier, la dimension dechaque sous-espace propre de Rn (different du Rn entier) est < n.
En effet, choisissons une base x1, ..., xdim L de L. C’est un ensemble lineairementindependant dans L et le nombre dim L d’elements de cet ensemble est ≤ dim L′ par Propo-sition 1.2.3 ; ainsi, dim L ≤ dimL′. Il reste pour prouver que si cette inegalite est une egalite,alors L = L′. Mais c’est evident : dans ce cas-ci x1, ..., xdim L est un ensemble lineairementindependant dans L′ qui contient dim L′ d’elements, et donc il engendre L′ par Theoreme1.2.1.A. Nous avons donc
L = Lin(x1, ..., xdim L) = L′.
Formule de dimension
Nous savons deja que si L etM sont des sous-espaces lineaires dansRn, alors leur intersectionL ∩ M et leur somme arithmetique L + M sont des sous-espaces lineaires. Il existe une tressympathique formule de dimension :
dim L+ dim M = dim (L ∩M) + dim (L+M). (1.6)
La preuve : Soit l = dim L, m = dim M , k = dim (L ∩M), et soit c1, ..., ck une basede L ∩M . Selon Theoreme 1.2.1, on peut etendre la collection c1, ..., ck avec les vecteursf1, ..., fl−k a une base de L, le meme que l’etendre par les vecteurs d1, ..., dm−k a une basede M . Pour montrer la formule de dimension, il suffit de verifier que m + l − k vecteursf1, ..., fl−k, d1, ..., dm−k, c1, ..., ck forment une base de L +M – dans ce cas la dimension dela somme sera m+ l − k = dim L+ dim M − dim (L ∩M), comme demande.

1.2. COMBINAISONS LINEAIRES, SOUS-ESPACES LINEAIRES, DIMENSION 21
Pour montrer que les vecteurs ci-dessus forment une base dans L +M nous devrionsmontrer qu’ils engendrent cet espace et sont lineairement independant. Le premier est evident– les vecteurs en question par construction engendrent L etM et enjambent donc leur sommeL+M . Pour prouver l’independance lineaire, supposons que
{∑p
λpfp}+ {∑q
μqcq}+ {∑r
νrdr} = 0 (1.7)
et montrons que dans ce cas tous les coefficients λp, μq, νr sont nuls. En effet, en notant les
sommes entre les parentheses par sL, sL∩M et sM , respectivement, nous voyons de l’equation
que sL (qui est par sa construction un vecteur dans L) est moins la somme de sL∩M et
sM , lesquels sont tous les deux vecteurs de M . Ainsi, sL appartient a L ∩M et peut etre
donc represente comme combinaison lineaire de c1, ..., ck. Maintenant nous obtenons deux
representations de sL comme combinaison lineaire des vecteurs c1, ..., ck, f1, ..., fl−k lesquels,
par construction, forment une base de L : celui donne par la definition de sL et qui n’implique
que les vecteurs f , et l’autre impliquant seulement c. Puisque les vecteurs de la base sont
lineairement independant, les coefficients des deux combinaisons sont uniquement definis par
sL (Corollaire 1.2.1) et devraient etre identiques. Cela est possible seulement s’ils sont nuls ;
ainsi, tous les λ’s sont nuls et sL = 0. Par le raisonnement semblable, tous les ν’s sont
zero et sM = 0. Maintenant (1.7) implique que sL∩M = 0, et tous les μ’s sont zero du a
l’independance lineaire de c1, ..., ck.
Coordonnees dans une base
Soit L un sous-espace lineaire dans Rn de dimension k > 0, et soit f1, ..., fk une base dans L.Comme l’ensemble f1, ..., fk engendre L, tout x ∈ L peut etre represente en combinaison lineairede f1, ..., fk :
x =k∑
i=1
ξifi.
Les coefficients ξi de cette representation sont uniquement definis par x, puisque f1, ..., fk sontlineairement independant (Corollaire 1.2.1). Ainsi, en fixant une base f1, ..., fk dans L nousassocions a chaque vecteur x ∈ L la collection ordonnee uniquement definie ξ(x) de k coefficientsdans la representation de x comme combinaison lineaire des vecteurs de la base ; ces coefficientss’appellent les coordonnees de x en base f . En tant que chaque collection ordonnee de k reels,ξ(x) est un vecteur k-dimensionnel. On le voit immediatement que transformation de L sur Rk
donne parx �→ ξ(x)
est un isomorphisme lineaire de L et Rk, i.e., est une transformation un-vers-un qui preserve lesoperations lineaires.
On observe que tant que des operations lineaires sont concernes, il n’y a aucune differenceentre un sous-espace L de Rn et Rk. L peut etre identifiee avec Rk de multiple facons – chaquechoix d’une base dans L a comme consequence une telle identification. Pouvons nous choisirl’isomorphisme pour preserver aussi la structure Euclidienne, c.-a-d., pour assurer que
xT y = ξT (x)ξ(y) ∀x, y ∈ L ?
Oui, on peut le faire facilement : a cet effet il suffit de choisir la base f1, ..., fk orthonormale,c.-a-d., une base qui possede la propriete additionnelle
fTi fj =
{0, i �= j1, i = j

22 CHAPITRE 1. INTRODUCTION
(dans l’Algebre ils montrent qu’une telle base existe toujours). En effet, si f1, ..., fk est une baseorthonormale, puis pour x, y ∈ L nous avons
xT y = (∑k
i=1 ξi(x)fi)T (
∑kj=1 ξj(y)fj) [definition des coordonnees]
=∑k
i=1
∑kj=1 ξi(x)ξj(y)f
Ti fj [bilinearity du produit scalaire]
=∑k
i=1 ξi(x)ξi(y) [orthonormalite de la base]= ξT (x)ξ(y).
Ainsi, chaque sous-espace lineaire L de Rn de la dimension positive k est, dans un sens, Rk :vous pouvez preciser une correspondance lineaire entre les vecteurs de L et les vecteurs de Rn
de telle maniere que toutes les operations arithmetiques avec des vecteurs de L – addition etmultiplication par des reals – correspondent aux memes operations avec leurs images dans Rk, etles produits scalaires (et par consequent - des normes) des vecteurs de L seront identiques que lesquantites correspondantes pour leurs images. Notez que la correspondance mentionnee ci-dessusn’est pas unique – il y a autant de manieres de l’etablir que de choisir une base orthonormalede L.
Jusqu’ici nous parlions des sous-espaces de dimension positive. Nous pouvons enlever cetterestriction en introduisant l’espace de dimension nulle R0 ; le seul vecteur de cet espace est 0,et, naturellement, par definition 0 + 0 = 0 et λ0 = 0 pour tout λ reel. La structure Euclidiennesur R0 est, naturellement, egalement triviale : 0T 0 = 0. Ajoutant cet espace triviale a la familledes autres Rn, nous pouvons dire que n’importe quel sous-espace lineaire L dans n’importe quelRn est equivalent, dans le sens mentionne ci-dessus, a Rdim L.
1.3 Ensembles affines
Plusieurs evenements a venir auront lieu pas dans Rn entier, mais dans ses le sous-ensemblesaffines lesquels, geometriquement, sont des plans de differentes dimensions dans Rn.
1.3.1 Ensembles affines et Enveloppes affines
Definition d’Ensemble affine
Geometriquement, un sous-espace lineaire L de Rn est un plan special – celui qui passe parl’origine de l’espace (c.-a-d., contenant le vecteur zero). Pour obtenir un “plan special” approprieL a une translation – ajouter a tous les points de L un vecteur fixe de decalage a. Cette intuitiongeometrique mene a la definition suivante :
Definition 1.3.1 [Ensemble affine] Un ensemble affine (un plan) M dans Rn est un ensemblede la forme
M = a+ L = {y = a+ x | x ∈ L}, (1.8)
ou L est un sous-espace lineaire de Rn et a est un vecteur de Rn 2).
Par exemple, decalant le sous-espace lineaire L qui consiste en les vecteurs avec la premiereentree nulle par un vecteur a = (a1, ..., an), nous obtenons l’ensemble M = a + L de tous lesvecteurs x avec x1 = a1 ; selon notre terminologie, c’est un ensemble affine.
2. )d’apres notre convention sur le calcul des ensembles, j’aurais du ecrire dans (1.8) {a} + L a la place dea+L. D’habitude on ignore cette difference et omette les parentheses en notant le singleton dans les expressionssemblables : nous ecrirons a+ L au lieu de {a}+ L, Rd a la place de R{d}, etc.

1.3. ENSEMBLES AFFINES 23
La question immediate au sujet de la notion d’un ensemble affine est : quels sont les “degresde liberte” dans la decomposition (1.8) – M determine-t-il a et L ? La reponse est suivante :
Proposition 1.3.1 Le sous-espace lineaire L dans la decomposition (1.8) est uniquement definipar M et est l’ensemble de toutes les differences des vecteurs de M :
L =M −M = {x− y | x, y ∈M}. (1.9)
Le vecteur de decalage a n’est pas uniquement defini par M et peut etre choisi comme un vecteurarbitraire de M .
Preuve : commencons par le premier resultat. Un vecteur de M , par definition, est de la formea + x, d’ou x est un vecteur L. La difference de deux vecteurs a + x, a + x′ de ce type estx − x′ et donc elle appartient a L (puisque x, x′ ∈ L et L est un sous-espace lineaire). Ainsi,M −M ⊂ L. Pour obtenir l’inclusion inverse, notez que n’importe quel vecteur x de L est unedifference de deux vecteurs deM , a savoir, des vecteurs a+x et a = a+0 (rappel que le vecteurzero appartient a n’importe quel sous-espace lineaire).
Pour prouver la deuxieme conjecture, nous devrions verifier que si M = a+ L, alors a ∈Met nous avons egalement M = a′ + L pour chaque a′ ∈ M . Le premier fait est evident – depuis0 ∈ L, nous avons a = a + 0 ∈ M . Pour etablir le deuxieme, notons d = a′ − a (ce vecteurappartient a L car a′ ∈M) remarquons que
a+ x = a′ + x′, x′ = x− d;
quand x parcourt L. Alors, le vecteur a gauche de notre identite parcourt a+ L, et, comme x′
parcourt L, le vecteur a droite parcourt a′ + L. Nous en concluons que a+ L = a′ + L.
Intersections d’ensembles affines
Une conclusion immediate de Proposition 1.3.1 est suivante :
Corollaire 1.3.1 Soit {Mα} une famille arbitraire d’ensembles affines dans Rn. Supposons quel’ensemble M = ∩αMα n’est pas vide. Alors M est un ensemble.
Preuve. Choisissons a ∈ M (cet ensemble n’est pas vide). Alors a ∈ Mα pour tout α, et donc,par Proposition 1.3.1,
Mα = a+ Lα
pour certains sous-espaces lineaires Lα. Maintenant il est claire que
M = a+ (∩αLα),
et, comme ∩αLα est un sous-espace lineaire, M est un ensemble affine.
Combinaisons et enveloppes affines
Une consequence de Corollaire 1.3.1 est que pour chaque sous-ensemble non vide Y de Rn
il existe le plus petit ensemble affine contenant Y – l’intersection de tous les ensembles affinescontenant Y . Ce plus petit ensemble affine contenant Y s’appelle l’enveloppe affine de Y (onnote Aff(Y )).
Tout ceci ressemble beaucoup a l’histoire des enveloppes lineaires. Pouvons nous etendrecette analogie pour obtenir une description de l’enveloppe affine Aff(Y ) en termes d’elements de

24 CHAPITRE 1. INTRODUCTION
Y que ressemble a celle de l’etendus lineaire (l’enveloppe linear de X est l’ensemble de toutesles combinaisons lineaires des vecteurs de X) ? Bien sur !
Choisissons un point y0 ∈ Y , et considerons l’ensemble
X = Y − y0.
Tout ensemble effine contenant Y devrait contenir egalement y0 et donc, par Proposition 1.3.1,peut etre represente comme M = y0 + L, L etant un sous-espace lineaire. Il est evident qu’unensemble affine M = y0 + L contienne Y si et seulement si le sous-espace L contient X, et queplus grand est L, le plus grand est M :
L ⊂ L′ ⇒M = y0 + L ⊂M ′ = y0 + L′.
Ainsi pour trouver le plus petit parmi les ensembles affines contenant Y , il suffit de trouver leplus petit parmi des sous-espaces lineaires contenant X et de decaler ce dernier sous-espace pary0 :
Aff(Y ) = y0 + Lin(X) = y0 + Lin(Y − y0). (1.10)
On sais ce qui est Lin(Y − y0) – un ensemble de toutes combinaisons lineaires de vecteurs deY − y0, et l’element generique de Lin(Y − y0) est
x =k∑
i=1
μi(yi − y0) [k peut dependre de x]
avec yi ∈ Y et les coefficients reels μi. Il en decoule que l’element generique de Aff(Y ) est
y = y0 +k∑
i=1
μi(yi − y0) =k∑
i=0
λiyi,
ouλ0 = 1−
∑i
μi, λi = μi, i ≥ 1.
On observe qu’un element generique de Aff(Y ) est une combinaison lineaire des vecteurs deY . Notons, cependant, que les coefficients λi dans cette combinaison ne sont pas completementarbitraires : leur somme est egale a 1. Les combinaisons lineaires de ce type – avec la somme decoefficients egale a 1 – ont un nom special – elles s’appellent les combinaisons affines.
Nous avons vu que n’importe quel vecteur de Aff(Y ) est une combinaison affine des vecteursde Y . Est-ce que l’inverse est vrai, c.-a-d., est-ce que Aff(Y ) contient toute combinaison affinedes vecteurs de Y ? La reponse a cette question est positive. En effet, si
y =k∑
i=1
λiyi
est une combinaison affine des vecteurs de Y , alors en utilisant l’identite∑
i λi = 1, nous pouvonsl’ecrire egalement comme
y = y0 +k∑
i=1
λi(yi − y0),
y0 etant “le vecteur marque” que nous avons utilise dans notre raisonnement precedent, Mais levecteur de ce type, comme nous savons deja, appartient a Aff(Y ). Ainsi, nous venons au suivant

1.3. ENSEMBLES AFFINES 25
Proposition 1.3.2 [Structure d’enveloppe affine]
Aff(Y ) = {l’ensemble de toutes les combinaisons des vecteurs de Y }.Quand Y lui-meme est un ensemble affine, il coincide avec son enveloppe affine et la propositionci-dessus mene au
Corollaire 1.3.2 Un ensemble affine M est ferme par rapport a la prise des combinaisonsaffines de ses membres – n’importe quelle combinaison de ce type est un vecteur de M . Et,vice versa, un ensemble non vide qui est ferme en par rapport aux combinaisons affines de sesmembres est un ensemble affine.
1.3.2 Generateurs affines, Ensembles independents affinement, Dimension af-fine
Ensembles affines sont etroitement lies aux sous-espaces lineaires, et les notions de base lieesaux sous-espaces lineaires ont leurs analogues affines naturels. Presentons ces notions et leursproprietes de base. Je vais sauter les preuves : elles sont tres simples et repetent fondamentale-ment les preuves de Section 1.2
Generateurs affines
Soit M = a+ L ensemble affine. On dit que un sous-ensemble Y de M est generateur affinede M (on dit aussi que Y engendre M affinement, ou que M et affinement engendre par Y ), siM = Aff(Y ), ou, ce qui est la meme chose du a Proposition 1.3.2, si tout point de M est unecombinaison affine des points de Y . La consequence immediate du raisonnement dans la sectionprecedente est suivante :
Proposition 1.3.3 SoitM = a+L ensemble affine et Y un sous-ensemble deM , et soit y0 ∈ Y .L’ensemble Y engendre M affinement – M = Aff(Y ) – ssi l’ensemble
X = Y − y0
engendre le sous-espace L : L = Lin(X).
Ensemble affinement independent
Rappelons nous qu’un ensemble lineairement independant x1, ..., xk est un ensemble telsqu’aucune combinaison lineaire non triviale des x1, ..., xk est nulle. Une definition equivalenteest donnee par Corollaire 1.2.1 : x1, ..., xk sont lineairement independant, si les coefficients λidans leurs combinaison lineaire
x =k∑
i=1
λixi
sont uniquement definis par la valeur x de la combinaison. Cette forme equivalente reflete l’es-sence de la matiere – de ce que nous avons besoin en effet, est l’unicite des coefficients. Enconsequence, cette forme equivalente est le prototype pour la notion d’un ensemble affinementindependant : nous voulons presenter cette notion de telle maniere que les coefficients λi dansune combinaison affine
y =k∑
i=0
λiyi

26 CHAPITRE 1. INTRODUCTION
des vecteur d’un ensemble “affinement independent” de vecteurs y0, ..., yk soit uniquement definispar y. Non-unicite impliquerait que
k∑i=0
λiyi =k∑
i=0
λ′iyi
pour deux vecteurs differents de coefficients λi et λ′i avec la somme des coefficients egale a 1 ; si
tel est le cas, alorsm∑i=0
(λi − λ′i)yi = 0,
et yi’s sont lineairement dependent. De plus, il existe leur combinaison nulle non trivial avec lasomme de coefficients nulle (car
∑i(λi − λ′i) =
∑i λi −
∑i λ
′i = 1− 1 = 0). Notre raisonnement
peut etre inverse – si il existe une combinaison lineaire non triviale de yi’s avec la somme nullede coefficients qui est nulle, alors les coefficients dans la representation d’un vecteur par unecombinaison d’affine de yi’s ne sont pas uniquement definis. Ainsi, afin de nous obtenir a unicitenous devrions interdire les relations
k∑i=0
μiyi = 0
avec des coefficients μi non triviaux dont la somme est nulle.
Definition 1.3.2 [Ensemble affinement independant] Une collection y0, ..., yk de vecteurs n-dimensionnels est appelee affinement independante si il n’existe pas d’une combinaison lineairenulle de ces vecteurs que soit non trivial et dont la somme des coefficients soit nulle :
k∑i=1
λiyi = 0,k∑
i=0
λi = 0 ⇒ λ0 = λ1 = ... = λk = 0.
Avec cette definition nous obtenons le resultat completement similaire au Corollaire 1.2.1 :
Corollaire 1.3.3 Soit y0, ..., yk affinement independants. Alors les coefficients λi d’une combi-naison affine
y =k∑
i=0
λiyi [∑i
λi = 1]
des vecteurs y0, ..., yk sont uniquement definis par la valeur y de la combinaison.
La verification de l’independance affine d’un ensemble peut etre immediatement reduite a laverification de l’independance lineaire de la collection etroitement liee :
Proposition 1.3.4 k+ 1 vecteurs y0, ..., yk sont affinement independants si et seulement si lesk vecteurs (y1 − y0), (y2 − y0), ..., (yk − y0) sont lineairement independants.
De la derniere proposition il decoule, par exemple, que la collection 0, e1..., en qui consiste del’origine et des vecteurs de base canonique est affinement independante. Notez que cette collec-tion est lineairement dependante (en tant que toute collection contenant zero).
Vous devriez identifier de facon definitive la difference entre les deux notions de l’independanceque nous discutons : l’independance lineaire signifie qu’aucune combinaison lineaire non trivialedes vecteurs ne peut etre zero, tandis que l’independance affine signifie qu’aucune combinaisonlineaire non triviale d’une certaine classe restreinte (i.e., avec la somme de coefficients nulle) nepeut etre zero. Par consequent, il y a plus d’ensembles affinement independants que lineairementindependants : un ensemble lineairement independant est pour sur affinement independant, maisl’inverse n’est pas vrai.

1.3. ENSEMBLES AFFINES 27
Bases affines et dimension affine
Avec de l’aide des Propositions 1.3.2 et 1.3.3 on arrive a reduire les notions de generateuraffine/ensemble affinement independant a ceux de generateur lineaire/independance lineaire. Encombinant avec Proposition 1.2.3 et Theoreme 1.2.1, on obtient des analogues suivants de cesderniers resultats :
Proposition 1.3.5 [Dimension affine] Soit M = a + L un ensemble affine dans Rn. Alors lesdeux quantites suivantes sont des entiers positifs qui sont egaux :
(i) nombre minimal d’elements de sous-ensembles de M qui engendre M affinement ;(ii) nombre maximal d’elements dans un sous-ensemble de M affinement independant.
Cette valeur commune est egale a la dimension dim L de L plus 1.
Par definition, la dimension affine d’un ensemble affine M = a + L est la dimension dim L deL. Ainsi, si M est de dimension affine k, alors la cardinalite minimale des generateurs affines deM , memes que la cardinalite maximale des sous-ensembles affinement independants de M , estk + 1.
Theoreme 1.3.1 [Bases affines] Soit M = a+ L un ensemble affine dans Rn.
A. Soit Y ⊂M . Les trois proprietes suivantes de Y sont equivalentes :(i) Y est un ensemble affinement independant qui engendre M affinement ;(ii) Y est affinement independant et contient 1 + dim L elements ;(iii) Y engendre M affinement and contient 1 + dim L elements.Le sous-ensemble Y deM possedant ces proprietes est appele base affine deM . Basses affines
de M sont exactement des ensembles y0, ..., ydim L tels que y0 ∈M et (y1 − y0), ..., (ydim L − y0)est une base de L.
B. Chaque collection de vecteurs de M affinement independante soit elle-meme est une baseaffine de M , ou peut etre augmentee a une telle base en ajoutant de nouveaux vecteurs. Enparticulier, il existe la base affine de M .
C. Etant donne un ensemble Y qui engendre affinement M , on peut toujours extraire de cetensemble une base affine de M .
Nous savons deja que la base canonique e1, ..., en forme une base de l’espaceRn. Mais quelles sontles bases affines de Rn ? Selon Theoreme 1.3.1.A, on peut choisir comme telle base l’ensemblee0, e0 + e1, ..., e0 + en, e0 etant un vecteur arbitraire.
Coordonnees Barycentriques
Soit M un ensemble affine, et soit y0, ..., yk soient une base affine de M . Comme la base,par definition, engendre affinement M , chaque vecteur y de M est une combinaison affine desvecteurs de la base :
y =k∑
i=0
λiyi [k∑
i=0
λi = 1],
et puisque les vecteurs de la base affine sont affinement independants, les coefficients de cettecombinaison sont uniquement definis par y (Corollaire 1.3.3). Ces coefficients s’appellent co-ordonnees barycentriques de y par rapport a la base affine en question. Contrairement auxcoordonnees habituelles par rapport a une base (lineaire), les coordonnees barycentriques nepourraient pas etre tout a fait arbitraires : leur somme devrait etre egale a 1.

28 CHAPITRE 1. INTRODUCTION
1.4 Description duale des sous-espaces lineaires et d’ensemblesaffines
Nous avons introduit les notions du sous-espace lineaire et de l’ensemble affine et avonspresente un schema pour produire ces entites : pour obtenir, par exemple, un sous-espace lineaire,on peut commencer a partir d’un ensemble non vide arbitraire X ⊂ Rn et ajouter toutes lescombinaisons lineaires des vecteurs de X. En remplacant des combinaisons lineaires avec lescombinaisons affines, on obtient une methode de produire des ensembles affines.
La maniere indiquee de produire des sous-espaces lineaires/ensembles affines ressemble al’approche d’un macon construisant une maison : il commence par la base et puis ajoute denouveaux elements jusqu’a ce que la maison soit prete. Il existe, neanmoins, une approched’artiste creant une sculpture : il prend quelque chose de grand et puis supprime les partiessuperflus. Y a-t-il quelque chose comme “la maniere artistique” pour representer des sous-espaceslineaires et des ensembles affines ? La reponse est positive et tres instructive. Pour la comprendre,nous avons besoin de quelques outils techniques.
Complement orthogonal
Deux vecteurs x, y ∈ Rn sont orthogonaux, si leur produit scalaire est 0 :
xT y = 0.
Etant donne un sous-ensemble non vide X de Rn, on definit son complement orthogonal X⊥
comme l’ensemble de tous vecteurs qui sont orthogonaux a tout vecteur de X :
X⊥ = {y ∈ Rn | yTx = 0 ∀x ∈ X}.Le complement orthogonal est non vide (il contient zero) et est clairement ferme par rapporta l’addition de ses membres et la multiplication par des reels : en raison de la bilinearite duproduit scalaire que nous avons
yTx = 0, zTx = 0 ∀x ∈ X ⇒ (λy + μz)Tx = 0 ∀x ∈ X [∀λ, μ ∈ R].
Autrement dit, le complement orthogonal est un sous-espace lineaire.Que se passe-t-il si on prend le complement orthogonal deux fois – en passant deX a (X⊥)⊥ ?
Tout d’abord, on obtient un sous-espace lineaire. De plus, ce sous-espace contient X (le produitscalaire est symetrique et chaque element de X⊥ est orthogonal a tout x ∈ X, x, a son tour, estorthogonal a tous les vecteurs de X⊥ et appartient a (X⊥)⊥). Ainsi, (X⊥)⊥ est un sous-espacelineaire subspace qui contient X et donc il contient l’enveloppe lineaire Lin(X) de X. Un resultatutile d’Algebre Lineaire dit que (X⊥)⊥ est exactement Lin(X) :
(∀X ⊂ Rn,X �= ∅) : (X⊥)⊥ = Lin(X). (1.11)
En particulier, si X est un sous-espace lineaire (X = Lin(X)) alors le “double” complementorthogonal de X est X lui-meme :
X est un sous-espace lineaire ⇒ X = (X⊥)⊥. (1.12)
Dans le dernier cas, il y a egalement une relation simple entre les dimensions de X et X⊥ : onle prouve dans l’algebre lineaire que la somme de ces dimensions est exactement la dimension nde l’espace entier :
X est un sous-espace lineaire ⇒ dim X + dim (X⊥) = n. (1.13)

1.4. DESCRIPTIONDUALE DES SOUS-ESPACES LINEAIRES ET D’ENSEMBLES AFFINES29
Une consequence utile de ces faits est
Proposition 1.4.1 Soit L un sous-espace lineaire dans Rn. Alors Rn est la somme directede L et L⊥. Ainsi, chaque vecteur x de Rn peut etre represente de facon unique commeune somme d’un vecteur de L (appele la projection orthogonale de x sur L et d’un vecteurorthogonal a L (appele la composante de x orthogonale a L).
En effet, l’intersection de L et L⊥ est compose du seul vecteur 0 (un vecteur de l’intersectiondevrait etre orthogonal a lui-meme, et de la positivite du produit interieur nous savons queil existe exactement un tel vecteur - zero). Nous voyons que la somme L + L⊥ est directe,et tout ce que nous avons besoin a montrer que cette somme est le Rn entier. Ceci estimmediatement donne par (1.13) et la formule de dimension (1.6) :
dim (L+ L⊥) = dim L+ dim L⊥ − dim (L ∩ L⊥) = n− dim {0} = n;
et on sait deja que le seul sous-espace de Rn de dimension n est Rn lui-meme.
1.4.1 Ensembles affines et systemes d’equations lineaires
Soit L un sous-espace lineaire. Selon (1.12), c’est un complement orthogonal – notamment,le complement orthogonal a le sous-espace lineaire L⊥. Soit maintenant a1, ..., am un generateurde L⊥. Un vecteur x qui est orthogonal a a1, ..., am est orthogonal a L⊥ (parce que chaquevecteur de L⊥ est une combinaison lineaire de a1, ..., am et le produit interieur est bilineaire).Naturellement, vice versa, un vecteur orthogonal au L⊥ est orthogonal a a1, ..., am. Nous voyonsque
L = (L⊥)⊥ = {a1, ..., am}⊥ = {x | aTi x = 0, i = 1, ..., k}. (1.14)
Ainsi, nous obtenons le resultat tres important :
Proposition 1.4.2 [Description “externe” d’un sous-espace lineaire]Tout sous-espace lineaire L dans Rn est un ensemble de solutions d’un systeme homogene d’equa-tions lineaires :
aTi x = 0, i = 1, ...,m, (1.15)
ou, coordonnee par coordonnee,
a11x1 + ...+ a1nxn = 0............
ak1x1 + ...+ aknxn = 0(1.16)
(aij est j-eme element de ai) pour un m et des vecteurs a1, ..., am proprement choisis.
Par definition d’un sous-espace lineaire, vice versa, l’ensemble de solutions d’un systeme ho-mogene des equations lineaires avec n variables est un sous-espace lineaire dans Rn. Une autremaniere de le voir est de noter que l’ensemble de solutions du systeme (1.15) est exactement lecomplement orthogonal de l’ensemble {a1..., am}, et le complement orthogonal est toujours unsous-espace lineaire.
A partir de Proposition 1.4.2 utilisant de ce que nous connaissons deja sur la dimension nouspouvons facilement deriver plusieurs consequences importantes :
– Les systemes (1.15) qui definissent un sous-espace lineaire donne L sont exactement lessystemes donnes par les vecteurs a1, ..., am qui engendre L⊥ 3)
3. )le raisonnement qui nous a mene jusqu’a Proposition 1.4.2 dit que [a1, ..., am engendre L⊥] ⇒ [(1.15) definitL] ; maintenant on dit que l’inverse est egalement vra

30 CHAPITRE 1. INTRODUCTION
– Le plus petit nombre m d’equations dans (1.15) est la dimension de L⊥, c.-a-d., par (1.13),est egale a codim L ≡ n− dim L 4)
– Un sous-espace lineaire dans Rn est toujours un ensemble ferme (en effet, l’ensemble desolutions (1.14) est clairement ferme).
Maintenant, un ensemble affine M est, par definition, un decalage d’un sous-espace lineaire :M = a + L. Comme nous savons deja, les vecteurs x de L sont exactement les solutions d’uncertain systeme homogene d’equations lineaires
aTi x = 0, i = 1, ...,m.
Il est evident qu’en ajoutant a ces vecteurs un vecteur fixe a, on obtient exactement l’ensemblede solution du systeme lineaire soluble non homogene
aTi x = bi ≡ aTi a, i = 1, ...,m.
Vice versa, l’ensemble de solutions du systeme soluble d’equation lineaires
aTi x = bi, i = 1, ...,m,
avec n variables est la somme d’une solution particuliere du systeme et d’ensemble de solutionsdu systeme homogene correspondant (ce dernier est un sous-espace lineaire dans Rn), i.e., estun ensemble affine.
Proposition 1.4.3 [Description “externe” d’ensemble affine]
Tout ensemble affine M = a + L dans Rn est un ensemble de solutions d’un systeme lineairesoluble d’equations
aTi x = bi, i = 1, ...,m, (1.17)
oua11x1 + ...+ a1nxn = b1
............ak1x1 + ...+ aknxn = bm
(1.18)
(aij est la j-eme entree de ai) avec un m et des vecteurs a1, ..., am proprement choisis.
Vice versa, l’ensemble de toutes les solutions d’un systeme soluble d’equations lineaires avecn variables est un sous-espace affine de Rn.
Le sous-espace lineaire L qui est associe a M est exactement l’ensemble de solutions de laversion homogene (avec la partie droite etant 0) du systeme (1.17).
Nous voyons, en particulier, qu’un ensemble affine est toujours ferme.
Commentaire : la description “externe” d’un sous-espace lineaire/ensemble affine – “celui desartistes”– est dans beaucoup de cas plus utile que la description “interne” par l’intermediaire descombinaisons lineaires/affinse (“ celle des macons”). Par exemple, avec la description externe ilest tres facile de verifier si un vecteur donne appartient ou n’appartient pas a un sous-espace
4. ) pour rendre ce resultat juste dans le cas extreme quand L = Rn (c.-a-d., quand codim L = 0), nousferons dorenavant une convention que un ensemble vide d’equations ou d’inegalites definit, comme l’ensemble desolutions, l’espace entier

1.4. DESCRIPTIONDUALE DES SOUS-ESPACES LINEAIRES ET D’ENSEMBLES AFFINES31
lineaire/ensemble affine, ce qui n’est pas facile du tout a partir de sa description interne 5). En faitles deux descriptions sont “complementaire” entre eux et travaillent parfaitement en parallele :ce qui est difficile a voir avec l’une d’entre elles, est clair avec l’autre. L’idee d’employer lesdescriptions “interne” et “externe” des entites que nous rencontrons – des sous-espaces lineaires,ensembles affines, ensembles convexes, problemes d’optimisation – l’idee generale de dualite –est, je dirais, la force principale de l’analyse et de l’optimisation convexes, et dans la suite nousallons rencontrer des differentes realisations de cette idee fondamentale.
1.4.2 Structure des simples ensembles affines
Cette petite sous-section traite principalement de la terminologie. Selon leur dimension, lesensembles affines dans Rn sont appeles differemment :
– Ensembles de dimension 0 sont des translations du seul sous-espace lineaire de dimension0 – de {0}, c.-a-d., sont des singletons – vecteurs de Rn. Ces ensembles s’appellent despoints ; un point est une solution d’un systeme carre d’equations lineaires avec la matricenon singuliere.
– Ensembles de dimension 1 (droites). Ces ensembles sont des translations des sous-espaceslineaires unidimensionnels de Rn. Un sous-espace lineaire unidimensionnel a une base d’unelement donnee par un vecteur non nul d et est compose de tous les multiples de ce vecteur.En consequence, la ligne est un ensemble de la forme
{y = a+ td | t ∈ R}donne par une paire de vecteurs a (l’origine de la droite) et d (la direction de la droite),d �= 0. L’origine de la droite et sa direction ne sont pas uniquement definies par la droites ;vous pouvez choisir comme origine n’importe quel point sur la droite et multiplier unedirection particuliere par des reels non nuls.dans les coordonnees barycentriques une droite est decrite de facon suivante :
l = {λ0y0 + λ1y1 | λ0 + λ1 = 1} = {λy0 + (1− λ)y1 | λ ∈ R},ou y0, y1 est une base affine de l ; vous pouvez choisir comme telle base n’importe quellepaire de points distincts sur la droite.La description “externe” d’une droite est suivante : c’est l’ensemble de solutions d’unsysteme lineaire avec n variables et n− 1 equations lineairement independantes.
– Ensembles de dimension > 2 et < n− 1 n’ont aucun nom special ; parfois on les appellentdes plans affines de telle ou telle dimension.
– Ensembles affines de dimension n− 1, grace au role important qu’ils jouent dans l’analyseconvexe, ont un nom special – ils s’appellent des hyperplans. La description externe d’unhyperplan est qu’un hyperplan est l’ensemble de solution d’une equation lineaire
aTx = b
avec partie droite non triviale(a �= 0). En d’autres mots, un hyperplan est un ensemble deniveau a(x) = const d’une forme lineaire nonconstant a(x) = aTx.
– Ensemble affine le “plus grand possible” – celui de dimension n – est unique et est le Rn
entier. Cet ensemble est donne par un systeme vide d’equations lineaires.
5. )il n’est pas difficile de certifier qu’un point donne appartient, par exemple, a un sous-espace lineaire donnecomme enveloppe lineaire d’un certain ensemble – il suffit de preciser une representation du point comme com-binaison lineaire des vecteurs de l’ensemble. Mais comment pourriez vous certifier que un point n’appartient pasau subspace ?

32 CHAPITRE 1. INTRODUCTION
1.5 Exercices
Exercice 1.1 Marquez par ”o” les enonces qui sont toujours justes, avec ”n” ceux qui poursur sont faux, et par ” ?” – ceux qui sont parfois justes et sont parfois faux, selon les entites yparticipant :
– Tout sous-espace lineaire L de Rn contient le vecteur nul– Tout sous-espace lineaire L de Rn contient un vecteur non nul– L’union L ∪M des deux sous-espaces lineaires de Rn est un sous-espace lineaire– L’ntersection de toute famille de sous-espaces lineaires de Rn est un sous-espace lineaire– Pour toute paire L, M de sous-espaces lineaires de Rn, dim (L+M) = dim L+ dim M– Pour toute paire L, M de sous-espaces lineaires avec L ∩ M = {0}, dim (L + M) =
dim L+ dim M– Pour toute paire L, M de sous-espaces lineaires avec dim (L+M) = dim L+dim M nous
avons L ∩M = {0}– L’ensemble de vecteurs 3-dimensionnels (1,−1, 0), (0, 1,−1), (−1, 0, 1) engendre R3
– L’ensemble des vecteurs (1,−1, 0), (0, 1,−1), (−1, 0, 1) engendre le sous-espace lineaire L ={x ∈ R3 : x1 + x2 + x3 = 0}
– L’ensemble des vecteurs (1,−1, 0), (0, 1,−1), (−1, 0, 1) est une base du sous-espace lineaireL = {x ∈ R3 : x1 + x2 + x3 = 0}
– Si L ⊂ M sont deux sous-espace lineaires de Rn, alors dim L ≤ dim M , avec une egalitessi L =M
– Si X ⊂ Y sont deux ensembles non vides dans Rn, then dim Lin(X) ≤ dim Lin(Y ), avecune egalite ssi X = Y
– Un ensemble affine M dans Rn contient le vecteur nul– Tout ensemble affine L dans Rn contient un vecteur non nul ;– L’union L ∪M des deux ensembles affines dans Rn est un ensemble affine– L’intersection de toute famille des sous-ensembles affines de Rn est un ensemble affine– L’ensemble des vecteurs (0, 0, 0), (1, 1,−1), (−1, 1, 1), (1,−1, 1) engendre affinement tout
R3
– L’ensemble des vecteurs (1, 1,−1), (−1, 1, 1), (1,−1, 1) engendre affinement L = {x ∈ R3 :x1 + x2 + x3 = 1}
– L’ensemble des vecteurs (1, 1,−1), (−1, 1, 1), (1,−1, 1) est une base affine de L = {x ∈R3 : x1 + x2 + x3 = 1}
– Si L ⊂M sont deux ensembles affines dans Rn, alors la dimension affine de L est ≤ quecelle de M , avec une egalite ssi L =M
– Si X ⊂ Y sont deux ensembles non vides dans Rn, alors la dimension de Aff(X) est ≤que celle de Aff(Y ), avec une egalite ssi X = Y
Exercice 1.2 Montrez la loi du parallelogramme :
|x+ y|2 + |x− y|2 = 2(|x|2 + |y|2).
Exercice 1.3 Trouver une description externe de Lin(X) pour
X = {(1, 1, 1, 1), (1, 1,−1,−1)} ⊂ R4.
Pourrait-une description contenir moins de 2 equations ? Plus de 2 equations lineairementindependantes ?

1.5. EXERCICES 33
Exercice 1.4 Quelles sont les dimensions des ensemble affines– (A) :
2x1 + 3x2 + 4x3 + 5x4 = 13x1 + 4x2 + 5x3 + 6x4 = 24x1 + 5x2 + 6x3 + 7x4 = 3
dans R4 ?– (B) :
2x1 + 3x2 + 4x3 + 5x4 = 13x1 + 4x2 + 5x3 + 6x4 = 44x1 + 5x2 + 6x3 + 7x4 = 9
dans R4 ?– (C) :
n∑j=1
(i+ j)xj = i, i = 1, ...,m
dans Rn (2 ≤ m ≤ n) ?– (D) :
n∑j=1
(i+ j)xj = i2, i = 1, ...,m
dans Rn (3 ≤ m ≤ n) ?
Exercice supplementaire
Exercice 1.5 Soit M un sous-ensemble non vide de Rn. Prouvez que M est un ensemble affinesi et seulement s’il contient, avec tout couple de points x, y ∈M , la droite
{λx+ (1− λ)y | λ ∈ R}
engendree par ces points

34 CHAPITRE 1. INTRODUCTION

Chapitre 2
Ensembles convexes : Introduction
Les sous-espaces lineaires et les ensembles affines sont “trop simples” pour satisfaire a tousles besoins d’analyse convexe. Ce qui nous interesse reellement sont les ensembles convexes dansRn.
2.1 Definition, Exemples, Description interne, Proprietes algebriques
2.1.1 Ensembles convexes
A l’ecole on a appris qu’une figure s’appelle convexe si elle contient, avec n’importe quellepaire de ses points x, y, le segment entier [x, y] liant ces points. C’est exactement la definition d’unensemble convexe dans le cas multidimensionnel ; il suffit d’exprimer en language mathematiquele sens de la phrase “le segment [x, y] liant les points x, y ∈ Rn”.
Definition 2.1.1 [Convex set]
1) Soit x, y deux points dans Rn. L’ensemble
[x, y] = {z = λx+ (1− λ)y | 0 ≤ λ ≤ 1}
est appele segment avec les extremites x, y.
2) Un sous-ensemble M de Rn est appele convexe, s’il contient avec toute paire de pointsx, y, le segment entier [x, y] :
x, y ∈M, 0 ≤ λ ≤ 1 ⇒ λx+ (1− λ)y ∈M.
Commentaire : Comme nous savons de la Section 1.4.2, ensemble de tous les combinaisonsaffines {z = λx + (1 − λ)y | λ ∈ R} de deux vecteurs donnes est leur enveloppe affine qui estune droite, a condition que x �= y. Quand le parametre λ de la combinaison est 0, nous obtenonsun des points x, y (notamment, y), et quand λ = 1 – l’autre (x). Et le segment [x, y], en accordavec l’intuition geometrique, est compose de des combinaisons affines de x, y avec ces extremiteset toutes les valeurs intermediaires du parametre λ.
Notez que par cette definition un ensemble vide est convexe (par convention, ou, plutot, parle sens exact de la definition : pour l’ensemble vide, vous ne pouvez pas presenter un contre-exemple pour prouver qu’il n’est pas convexe).
35

36 CHAPITRE 2. ENSEMBLES CONVEXES : INTRODUCTION
2.1.2 Examples d’ensembles convexes
les exemples les plus simples d’ensembles convexes non vides sont des singletons (points) etl’espace entier Rn. Un exemple beaucoup plus interessant est le suivant :
Exemple 2.1.1 L’ensemble de solution d’un systeme (peut-etre infini) d’inegalites lineaires
aTαx ≤ bα, α ∈ A
de n inconnus x, c.-a-d. l’ensemble
M = {x ∈ Rn | aTαx ≤ bα, α ∈ A}
est convexe.En particulier, l’ensemble de solutions d’un systeme fini
Ax ≤ b
de m inegalites avec n inconnus (A et une matrice m×n) est convexe ; ce type d’ensemble portele nom de polyhedre.
En effet, soit x, y deux solutions du systeme ; il faut montrer que tout point z = λx+ (1 − λy)avec λ ∈ [0, 1] est aussi une solution du systeme. Cela est evident car pour tout α ∈ A on a
aTαx ≤ bαaTαy ≤ bα.
Par consequence, en multipliant les inegalites par les reels non negatif λ et 1−λ et en faisant lasomme :
λaTαx+ (1− λ)aTαy ≤ λbα + (1− λ)bα = bα,
et ce qui est sur la gauche est exactement aTαz.
Remarque 2.1.1 Remarquez que tout ensemble de l’Example 2.1.1 est aussi ferme (pourquoi ?)
Comme nous nous rappelons du cours precedent, tout ensemble affine dans Rn (et en par-ticulier, tout sous-espace lineaire) est l’ensemble de toutes les solutions a un certain systemed’equations lineaires. Maintenant, un systeme d’equations lineaires est equivalent a un systemed’inegalites lineaires (vous pouvez d’une maniere equivalente representer une egalite lineaire parune paire d’inegalites lineaires opposees). Il suit qu’un ensemble affine est un cas particulier d’unensemble polyhedral et donc est un ensemble convexe. Naturellement, nous pourrions obtenircette conclusion directement : la convexite d’un ensemble signifie qu’il est ferme par rapport auxcertaines combinaisons affines – notamment, les combinaisons des paires de ces elements avecles poids non negatifs ; et un ensemble affine est ferme par rapport a toutes les combinaisonsaffines de ses elements (Proposition 1.3.2).
Exemple 2.1.2 [‖ · ‖-boule] Soit ‖ · ‖ une norme sur Rn c.-a-d. une fonction reelle sur Rn
qui satisfait les trois proprietes caracteristiques de la norme, mentionnees dans la Section 1.1.2.Alors la boule unite dans cette norme – l’ensemble
{x ∈ E | ‖ x ‖≤ 1},

2.1. DEFINITION, EXEMPLES, DESCRIPTION INTERNE, PROPRIETESALGEBRIQUES37
ainsi que toute autre boule-‖ · ‖{x | ‖ x− a ‖≤ r}
(a ∈ Rn et r ≥ 0 sont fixes) est convexe.En particulier, boules Euclidiennes (boules-|·| associees avec la norme Euclidienne ‖ · ‖= |·|)
sont convexe.
En effet, soit V = {x | ‖ x − a ‖≤ r} et x, y ∈ V . Nous avons a verifier que si λ ∈ [0, 1],alors z = λx + (1− λ)y ∈ V . Ceci est donne par le calcul suivant :
‖ z − a ‖ = ‖ [λx+ (1− λ)y]− a ‖= ‖ [λ(x− a)] + [(1− λ)(y − a)] ‖≤ ‖ λ(x− a) ‖ + ‖ (1 − λ)(y − a) ‖ [inegalite de triangle - definition de la norme]= λ ‖ x− a ‖ +(1− λ) ‖ y − a ‖ [homogeneite - definition de la norme]≤ λr + (1− λ)r = r [since x, y ∈ V ]
Les exemples basiques des normes sur Rn sont les normes Lp :
‖ x ‖p={(∑n
i=1 |xi|p)1/p , 1 ≤ p <∞max1≤i≤n |xi|, p = ∞ .
Ces sont reellement des normes (ce qui n’est pas evident au depart). Quand p = 2, nousobtenons la norme Euclidienne ; bien sur, vous sauriez dessiner la boule Euclidienne. Quandp = 1, nous obtenons
‖ x ‖1=n∑
i=1
|xi|,
et la boule unite est un hyperoctaedron
V = {x ∈ Rn |n∑
i=1
|xi| ≤ 1}
Quand p = ∞, nous obtenons‖ x ‖∞= max
1≤i≤n|xi|,
et la boule unite est un hypercube
V = {x ∈ Rn | −1 ≤ xi ≤ 1, 1 ≤ i ≤ n}.
Il sera bien utile de dessiner les boules unite de normes ‖ · ‖1 et ‖ · ‖∞ dans R2.
Exemple 2.1.3 [Ellipsoid] Soit Q une matrice n × n symetrique (Q = QT ) et positive definie(xTQx ≥ 0, avec ≥ etant = si et seulement si x = 0). Alors, pour tout r non negatif, leQ-ellipsoid du rayon r centre en a – l’ensemble
{x | (x− a)TQ(x− a) ≤ r2}est convexe.
La facon la plus simple de prouver qu’un ellipsoid est convexe est la suivante : etantdonne une matrice symetrique definie positive Q, on peut lui associer le produit scalaire :
〈x, y〉 = xTQy
qui, qu’on le voit immediatement, satisfait les proprietes caracteristiques – bilinearite,symetrie et positivite – du produit scalaire standard xT y (en fait ces trois proprietes du

38 CHAPITRE 2. ENSEMBLES CONVEXES : INTRODUCTION
produit scalaire associe a Q, prises ensemble, sont exactement equivalent a la symetrie etpositivite de la matrice Q). Il suit que la Q-norme, c.-a-d. la fonction
|x|Q =√xTQx,
est une norme : en montrant que la norme Euclidienne standard est une norme (section 1.1.2),
nous avons employe la bilinearite, la symetrie et la positivite du produit scalaire standard
seulement, et aucunes autres proprietes specifiques). On voit maintenant qu’un Q-ellipsoid
n’est qu’une boule dans la norme | · |Q, de sorte que sa convexite soit prouve dans l’Example
2.1.2.
Exemple 2.1.4+[ε-voisinage d’un ensemble convexe]
Soit M un ensemble convexe dans Rn, et soit ε > 0. Alors, quelque soit la norme ‖ · ‖ sur Rn,le ε-voisinage de M , c.-a-d. l’ensemble
Mε = {y ∈ Rn | dist‖·‖(y,M) ≡ infx∈M
‖ y − x ‖≤ ε}
est convexe.
2.1.3 Description interne d’ensembles convexes : Combinaisons convexes etenveloppes convexes
Combinaisons convexes
Nous avons defini la notion de combinaison lineaire y d’un ensemble donne de vecteursy1, ..., ym - c’est un vecteur represente comme
y =m∑i=1
λiyi,
ou λi sont certains coefficients reels. A partir de cette definition, nous sommes venus a la notion decombinaison affine – une combinaison lineaire avec la somme de coefficients egale a 1. Maintenantnous presentons la notion suivante dans le genre : celle de combinaison convexe.
Definition 2.1.2 Une combinaison convexe des vecteurs y1, ..., ym est leur combinaison affineavec des coefficients non negatifs. Ou, ce qui est identique, une combinaison lineaire
y =m∑i=1
λiyi
avec des coefficients non negatifs avec la somme de coefficients egale a 1 :
λi ≥ 0,m∑i=1
λi = 1.
Le resultat suivant ressemble a ceux qui nous avons obtenu pour des sous-espaces lineaires etensembles affines :
Proposition 2.1.1 Un ensemble M dans Rn est convexe si et seulement s’il est ferme parrapport a toutes les combinaisons convexes de ses elements, c.-a-d., si et seulement si n’importequelle combinaison convexe des vecteurs de M est encore un vecteur de M .

2.1. DEFINITION, EXEMPLES, DESCRIPTION INTERNE, PROPRIETESALGEBRIQUES39
Preuve.partie ”si” (la suffisance) : supposons que M contient toutes les combinaisons convexes des
elements de M . Alors, avec deux points quelconques x, y ∈M , M contient egalement le vecteurλx + (1 − λ)y pour tout λ ∈ [0, 1], puisque c’est une combinaison convexe de x et y ; ainsi, Mest convexe.
partie ”seulement si” (la necessite) : supposez que M est convexe ; nous devrions montrerqu’alors M contient n’importe quelle combinaison convexe
(∗) y =m∑i=1
λiyi
de vecteurs yi ∈ M . La preuve est donnee par recurrence en m. Le cas de m = 1 est evident(puisque la seule combinaison convexe d’un terme est 1 · y1 = y1 ∈ M). Supposons que noussavons deja que n’importe quelle combinaison convexe de m − 1 vecteurs, m ≥ 2, de M estencore un vecteur de M , et montrons que ce resultat demeure valide egalement pour toutesles combinaisons convexes de m vecteurs de M . Soit (*) une telle combinaison. Nous pouvonssupposer que 1 > λm, puisqu’autrement il n’y a rien a demontrer. En supposant λm < 1, nouspouvons ecrire
y = (1− λm)[m−1∑i=1
λi1− λm
yi] + λmym.
Ce qui est entre les parentheses est une combinaison convexe de m−1 points deM et, par notrehypothese inductive c’est un point, disons z, de M ; nous avons
y = (1− λm)z + λmym
avec z et ym ∈M , et y ∈M par la definition du convexe M .
Enveloppe convexe
Comme pour les sous-espaces lineaires et ensemble affines nous avons le fait fondamental(bien qu’evident) suivant :
Proposition 2.1.2 [Convexite d’intersections] Soit {Mα}α une famille d’ensembles convexesde Rn. Alors l’intersection
M = ∩αMα
est convexe.
En effet, si les bouts d’un segment [x, y] appartiennent a M , ils appartient egalement au chaqueMα ; en raison de la convexite de Mα, le segment [x, y] lui-meme appartient au chaque Mα, et,par consequent, a leur intersection, c.-a-d., a M .
Une consequence immediate de cette proposition (cf. les resultats analogues pour des sous-espaces lineaires et ensembles affines dans le Chapitre 1) est comme suit :
Corollaire 2.1.1 [Enveloppe convexe]Soit M un sous-ensemble non vide dans Rn. Alors parmi tous les ensembles convexes conte-nant M (ces ensembles existent, par exemple, Rn lui-meme) il existe le plus petit, a savoir,l’intersection de tous les ensembles convexes contenant M .
Cet ensemble s’appelle enveloppe convexe de M [ notation : Conv(M)].

40 CHAPITRE 2. ENSEMBLES CONVEXES : INTRODUCTION
Enveloppe lineaire de M est l’ensemble de toutes les combinaisons lineaires des vecteurs deM , enveloppe affine est l’ensemble de toutes les combinaisons affines des vecteurs deM . Commevous devinez,
Proposition 2.1.3 [Enveloppe convexe par combinaisons convexes] Pour M ⊂ Rn non vide :
Conv(M) = {l’ensemble de tous les combinaisons convexes de vecteurs de M}.
Preuve : selon la Proposition 2.1.1, tout ensemble convexe contenant M (en particulier,Conv(M)) contient toutes les combinaisons convexes des vecteurs de M . Il reste a verifier queConv(M) ne contient rien d’autre. A cet effet il suffit de montrer que l’ensemble de toutes lescombinaisons convexes des vecteurs deM , nous l’appelons M∗, lui-meme est convexe (en tenantcompte du fait que Conv(M) est le plus petit ensemble convexe contenant M , nous realisonsnotre but – l’inclusion Conv(M) ⊂ M∗). Montrer que M∗ est convexe est la meme chose quede montrer que n’importe quelle combinaison convexe νx+(1− ν)y de deux points quelconquesx =
∑i λixi, y =
∑i μixi deM
∗ – deux combinaisons convexes des vecteurs xi ∈M – est encoreune combinaison convexe des vecteurs de M . C’est evident :
νx+ (1− ν)y = ν∑i
λixi + (1− ν)∑i
μixi =∑i
ξixi, ξi = νλi + (1− ν)μi,
et les coefficients ξi sont bien non negatifs avec la somme egale 1.La Proposition 2.1.3 nous fournit une description (“de macon”) interne d’un ensemble
convexe. Bientot nous obtiendrons egalement une description (d’“artiste”) externe extremementutile des ensembles convexes ferme : nous montrerons que tous ces ensembles sont donnes parl’Example 2.1.1 – ils sont exactement les ensembles de toutes les solutions aux systemes (proba-blement, infinis) d’inegalites lineaires “non strictes” 1).
2.1.4 Plus d’exemples d’ensembles convexes : le polytope et le cone
Notre “ approche de macon” a produire des ensembles convexes nous fournit deux exemplesapparemment nouveaux : un polytope et un cone.
Un polytope est, par definition, l’enveloppe convexe d’un un ensemble fini non vide dans Rn,c.-a-d. l’ensemble de forme
Conv({u1, ..., uN}) = {N∑i=1
λiui | λi ≥ 0,∑i
λi = 1}.
Un cas important d’un polytope est le simplex : l’enveloppe convexe de n+1 points v1, ..., vn+1
affinement independants de Rn :
M = Conv({v1, ..., vn+1}) = {n+1∑i=1
λivi | λi ≥ 0,n+1∑i=1
λi = 1};
les points v1, ..., vn+1 s’appellent les sommets du simplex.
1. ) L’ensemble de solutions de n’importe quel systeme d’inegalites lineaires non strictes est un ensemble fermeet convexe – ceci nous deja savons de l’exemple 2.1.1 et remarquons 2.1.1. L’inverse est aussi vrai, mais il nousfaudra de montrer que n’importe quel ensemble convexe ferme est l’ensemble de solutions d’un systeme d’inegaliteslineaires

2.1. DEFINITION, EXEMPLES, DESCRIPTION INTERNE, PROPRIETESALGEBRIQUES41
Nous decouvrirons sous peu qu’un polytope n’est rien d’autre qu’un ensemble polyhedralborne, c.-a-d. un ensemble borne donne par un nombre fini d’inegalites lineaires. L’equivalencede ces deux definitions – interne et externe — d’un polytope est l’un des faits les plus profondsde l’Analyse Convexe.
Un cone Un sous-ensemble non vide M de Rn s’appelle conique, s’il contient, avec chaquepoint x ∈M , le rayon entier Rx = {tx | t ≥ 0} engendre par le point :
x ∈M ⇒ tx ∈M ∀t ≥ 0.
Un ensemble conique convexe s’appelle cone 2).
Proposition 2.1.4+Le sous-ensemble non vide M de Rn est un cone si et seulement s’il
possede les proprietes suivantes :
– il est conique : x ∈M, t ≥ 0 ⇒ tx ∈M ;– il contient des sommes de ses elements : x, y ∈M ⇒ x+ y ∈M .
Comme consequence immediate, nous obtenons qu’un cone est ferme par rapport aux combinai-sons lineaires avec des coefficients non negatifs de ces elements. Et vice versa, un ensemble nonvide ferme par rapport a ces combinaisons est un cone.
Exemple 2.1.5+L’ensemble de solutions d’un systeme homogene (peut-etre infini)
aTαx ≤ 0, α ∈ A
d’inegalites lineaires avec n inconnus x, c.-a-d. l’ensemble
K = {x | aTαx ≤ 0 ∀α ∈ A},
est un cone.
En particulier, l’ensemble de solutions d’un systeme homogene fini de m inegalites lineaires
Ax ≤ 0
(A est une matrice m× n) est un cone ; un cone de ce dernier type s’appelle polyhedral.
Notez note que les cones donnes par des systemes d’inegalites homogenes lineaires non strictessont necessairement fermes. Nous verrons bientot que, vice versa, chaque cone convexe ferme estl’ensemble de solutions d’un tel systeme, de sorte que l’Exemple 2.1.5 soit l’exemple generiqued’un cone convexe ferme.
Les cones forment une famille tres importante d’ensembles convexes, et on peutdevelopper la theorie de cones absolument semblable (et dans un sens, equivalente) a celle desensembles convexes. Par exemple, en introduisant la notion de combinaison conique des vec-teurs x1, ..., xk comme combinaison lineaire des vecteurs avec des coefficients non negatifs,vous pouvez facilement montrer les resultats suivants completement analogues a ceux quiconcernent les ensembles convexes generaux, avec la combinaison conique jouant le role dela combinaison convexe :
2. )certains appellent cones ce que nous appelons ensembles coniques et cones convexes ce que nous appelonscones

42 CHAPITRE 2. ENSEMBLES CONVEXES : INTRODUCTION
– Un ensemble est un cone si et seulement s’il est non vide et est ferme par rapport atoutes les combinaisons coniques de ses elements ;
– L’intersection de n’importe quelle famille des cones est encore un cone ; en particulier,pour tout ensemble non vide M ⊂ Rn il existe le plus petit cone contenant M – sonenveloppe conique Cone (M), et cette enveloppe conique est compose de toutes lescombinaisons coniques des vecteurs de M .
En particulier, l’enveloppe conique d’un ensemble fini non vide M = {u1, ..., uN} devecteurs dans Rn est le cone
Cone (M) = {N∑i=1
λiui | λi ≥ 0, i = 1, ..., N}.
Un fait fondamental (cf. l’histoire ci-dessus au sujet des polytopes) est que c’est la description
(interne) generique d’un cone polyhedral – d’un ensemble donne par (description externe)
un nombre fini d’inegalites lineaires homogenes.
2.1.5 Proprietes algebriques d’ensembles convexes
Le resultat suivant est une consequence directe de la definition de l’ensemble convexe.
Proposition 2.1.5+Les operations suivantes preservent la convexite des ensembles :
– Somme arithmetique et multiplication par des reels : si M1, ...,Mk sont convexes dans Rn
et λ1, ..., λk sont des reels, alors l’ensemble
λ1M1 + ...+ λkMk = {k∑
i=1
λixi | xi ∈Mi, i = 1, ..., k}
est convexe.– Prendre l’image par transformation affine : si M ⊂ Rn est convexe et x �→ A(x) ≡ Ax+ b
est une transformation affine de Rn dans Rm (A est une matrice m × n, b est un m-vecteur), alors l’ensemble
A(M) = {y = A(x) ≡ Ax+ a | x ∈M}
dans Rm est convexe.– Prendre l’image inverse par transformation affine : si M ⊂ Rn est convexe et y �→ Ay+ b
est une transformation affine de Rm vers Rn (A est une matrice n×m, b est un vecteura n dimensions), alors l’ensemble
A−1(M) = {y ∈ Rm | A(y) ∈M}
dans Rm est convexe.
2.1.6 Proprietes topologiques d’ensembles convexes
Les ensembles convexes et les objets etroitement lies - fonctions convexes - jouent le rolecentral dans l’optimisation. Pour jouer ce role correctement, seule la convexite ne suffit pas ;nous avons besoin en plus de la convexite la fermeture. Dans le Chapitre 1 nous avons deja parleau sujet des notions les plus fondamentales de topologie – convergence des suites de vecteurs,fermes et ouverts dans Rn. Voici trois notions supplementaires dont nous avons besoin :

2.1. DEFINITION, EXEMPLES, DESCRIPTION INTERNE, PROPRIETESALGEBRIQUES43
Fermeture Il est claire de la definition d’un ensemble ferme que l’intersection de n’importequelle famille des ensembles fermes dans Rn est egalement fermee. De ce fait il decoule, commed’habitude, que pour n’importe quel sous-ensemble M de Rn il existe le plus petit ensembleferme contenant M ; cet ensemble s’appelle fermeture de M et est note clM . Dans l’analyse ilsdemontrent la description (“interne”) suivante de la fermeture d’un ensemble dans un espacemetrique (et, en particulier, dans Rn) :
La fermeture d’un ensemble M ⊂ Rn est exactement l’ensemble de tous les point limites detoutes suites convergeantes d’elements de M .
Maintenant il est facile a demontrer que, par exemple, la fermeture d’une boule Euclidienneouverte
{x | |x− a| < r} [r > 0]
est la boule fermee {x | |x− a| ≤ r}. Une autre application utile est l’exemple de fermeture del’ensemble
M = {x | aTαx < bα, α ∈ A}donne par un systeme strict d’inegalites lineaires : si un tel ensemble n’est pas vide, alors safermeture est donnee par des versions non strictes des memes inegalites :
clM = {x | aTαx ≤ bα, α ∈ A}.
La condition que M soit non vide dans le dernier exemple est essentielle : l’ensemble Mdonne par deux inegalites strictes
x < 0, −x < 0
dans R est vide, ainsi que sa fermeture ; par contre, en appliquant formellement la regleci-dessus, on aurait la reponse fausse :
clM = {x | x ≤ 0, x ≥ 0} = {0}.
L’interieur. Soit M ⊂ Rn. On dit qu’un point x ∈ M est un point interieur de M , si uncertain voisinage de x est contenu dans M , c.-a-d. qu’il existe une boule, centree en x de rayonpositif qu’appartient a M :
∃r > 0 Br(x) ≡ {y | |y − x| ≤ r} ⊂M.
L’ensemble de tous les points interieurs de M s’appelle interieur de M [ notation : int M ].
Par exemple,
– l’interieur d’un ensemble ouvert est l’ensemble lui-meme ;– l’interieur de la boule fermee {x | |x − a| ≤ r} est la boule ouverte {x | |x − a| < r}
(pourquoi ?)– l’interieur d’un ensemble polyhedral {x | Ax ≤ b} avec la matrice A ne contenant pas de
lignes nulles est l’ensemble {x | Ax < b} (pourquoi ?)
le dernier resultat n’est pas valide pour des ensembles de solutions des systemesinfinis d’inegalites lineaires. Par exemple, le systeme
x ≤ 1
n, n = 1, 2, ...

44 CHAPITRE 2. ENSEMBLES CONVEXES : INTRODUCTION
dans R a comme ensemble de solutions le rayon nonpositive R− = {x ≤ 0} ; l’interieurde ce rayon est le rayon negatif {x < 0}. En meme temps, les versions strictes de nosinegalites
x <1
n, n = 1, 2, ...
definissent le meme rayon nonpositive, pas le rayon negatif.
Il est facile a voir egalement (et c’est vrai pour les espaces metriques arbitraires, pas pour Rn
seulement), que– l’interieur d’un ensemble arbitraire est ouvert
L’interieur d’un ensemble, naturellement, est contenu dans l’ensemble, qui, alternativement, estcontenu dans sa fermeture :
int M ⊂M ⊂ clM. (2.1)
Le complement de l’interieur dans la fermeture – l’ensemble
∂M = clM\ int M
s’appelle frontiere de M , et les points de ∂M s’appellent des points de frontiere de M (aver-tissement : ces points n’appartiennent pas necessairement a M , parce que M peut etre moinsque clM ; en fait, tous les points de frontiere appartiennent a M si et seulement si M = clM ,c.-a-d., si et seulement si M est ferme).
La frontiere d’un ensemble est fermee (comme intersection de deux ensembles fermes clMet de Rn\ int M ; le dernier ensemble est ferme etant le complement d’un ensemble ouvert, voirChapitre 1). De la definition de la frontiere,
M ⊂ int M ∪ ∂M [= clM ],
de sorte qu’un point de M est soit un point interieur de M ou un point de frontiere de M .
Interieur relatif. Plusieurs objets qu’on verra dans la suite possedent des bonnes proprietesseulement dans l’interieur de l’ensemble lie a leur construction et peuvent perdre ces proprietesaux points de frontiere de l’ensemble ; c’est pourquoi dans beaucoup de cas nous sommes par-ticulierement interesses par les points interieurs des ensembles et voulons que l’ensemble de cespoints soit assez “ massif”. Que faire si ce n’est pas le cas, par exemple, s’il n’y a aucun pointinterieur du tout (considerez a un segment dans un plan) ? Il s’avere que dans ces cas nouspouvons employer un bon substitut de l’interieur “normal” – interieur relatif defini comme suit :
Definition 2.1.3 [Interieur relatif] Soit M ⊂ Rn. Nous disons qu’un point x ∈ M estrelativement interieur pour M , si M contient l’intersection d’une assez petite boule centreeen x avec Aff(M) :
∃r > 0 Br(x) ∩Aff(M) ≡ {y | y ∈ Aff(M), |y − x| ≤ r} ⊂M.
L’ensemble de tous les points relativement interieurs de M s’appelle son interieur relatif [nota-tion : riM ].
Par exemple l’interieur relatif d’un singleton est le singleton lui-meme (puisqu’un point dansl’espace 0-dimensional est identique comme boule de n’importe quel rayon positif) ; de meme,l’interieur relatif d’un ensemble affine est l’ensemble lui-meme. L’interieur d’un segment [x, y](x �= y) dans Rn est vide des que n > 1 ; contrairement a ceci, son interieur relatif est non vide

2.1. DEFINITION, EXEMPLES, DESCRIPTION INTERNE, PROPRIETESALGEBRIQUES45
independamment de n et est l’intervalle (x, y) – le segment avec des points extremaux supprimes.Geometriquement parlant, l’interieur relatif est l’interieur que nous obtenons en considerant Mcomme sous-ensemble de son enveloppe affine (le dernier, geometriquement, n’est rien que Rk,k etant la dimension affine de Aff(M)).
Nous pouvons jouer avec la notion de l’interieur relatif de la meme maniere qu’avec celle del’interieur, a savoir :
– comme Aff(M) est ferme (Chapitre 1, Section 1.4.1) et contient M , il contient egalementle plus petit parmi les ensembles fermes contenant M , c.-a-d, clM . Ainsi nous avons lesanalogues suivants d’inclusions (2.1) :
riM ⊂M ⊂ clM [⊂ Aff(M)]; (2.2)
– nous pouvons definir frontiere relative ∂riM = clM\riM qui est un ensemble fermecontenu dans Aff(M), et, comme pour le “vrai” interieur et la “vraie” frontiere, nousavons
riM ⊂M ⊂ clM = riM + ∂riM.
Naturellement, si Aff(M) = Rn, alors l’interieur relatif devient l’interieur habituel, de memepour la frontiere ; ce pour sur est le cas quand int M �= ∅ (car alors M contient une boule B, etdonc l’enveloppe affine de M est le Rn entier, qui est l’enveloppe affine de B).
Bonnes proprietes topologiques d’ensembles convexes
Un ensembleM dansRn peut posseder une topologie tres “pathologique” : les deux inclusionsdans la chaine
riM ⊂M ⊂ clM
peuvent etre tres “peu denses”. Par exemple, si M est l’ensemble de nombres rationnels dusegment [0, 1] ⊂ R. Alors riM = int M = ∅ – puisque n’importe quel voisinage de chaque reelrationnel contient des reels irrationnels – tandis que clM = [0, 1]. Ainsi, riM est “incompara-blement plus petit” que M , clM est “incomparablement plus grand”, et M est contenu dans safrontiere relative (d’ailleurs, qu’est-ce que cette frontiere relative ?).
La proposition suivante montre que la topologie d ensembles convexes est bien meilleurequ’elle pourrait etre pour un ensemble arbitraire.
Theoreme 2.1.1 Soit M un ensemble convexe dans Rn. Alors
(i)+L’interieur int M , la fermeture clM et l’interieur relatif riM sont convexes ;
(ii) si M est non vide, alors son interieur relatif est non vide ;(iii) la fermeture de M est identique a la fermeture de son interieur relatif :
clM = cl riM
(en particulier, chaque point de clM est la limite d’une suite des points de riM)
(iv) l’interieurs relatif reste inchange quand nous remplacons M avec sa fermeture clM :
riM = ri clM.
Preuve :(ii) soit M un ensemble convexe non vide, montrons que riM �= ∅. Il suffit de considerer le
cas quand Aff(M) est l’espace entier Rn. En effet, par translation de M nous pouvons toujours

46 CHAPITRE 2. ENSEMBLES CONVEXES : INTRODUCTION
supposer que Aff(M) contient 0, c.-a-d. est un sous-espace lineaire. Comme nous savons duchapitre precedent, un sous-espace lineaire dans Rn, en ce qui concerne les operations lineaireset la structure Euclidienne, est equivalent a un certain Rk. Puisque la notion d’interieur relatiftraite seulement les structures lineaires et Euclidiennes, nous ne perdons rien en identifiantAff(M) a Rk et le prenant en tant que notre univers au lieu de l’univers original Rn. Ainsi, dansle reste de la preuve (ii) nous supposons que Aff(M) = Rn, et ce que nous devrions prouver estque l’interieur de M (ce qui dans le cas en question est identique a l’interieur relatif) est nonvide.
Selon Theorem 1.3.1, Aff(M) = Rn possede une base a0, ..., an affine qui consiste en desvecteurs de M . Puisque a0, ..., an appartiennent a M et M est convexe, l’enveloppe convexeentiere des vecteurs – le simplex Δ avec les sommets a0, ..., an – est contenue dans M . Enconsequence, un point interieur du simplex est certainement un point interieur de M ; ainsi,afin de montrer que int M �= ∅, il suffit de montrer que l’interieur de Δ est non vide, comme ildevrait etre selon l’intuition geometrique.
La preuve du dernier fait est comme suit : comme a0, ..., an est, par sa construction, unebase affine de Rn, chaque point x ∈ Rn est une combinaison affine des points de la base. Lescoefficients λi = λi(x) de la combinaison – les coordonnees barycentriques de x par rapport a labase – sont des solutions du systeme suivant des equations :
n∑i=0
λiai = x;n∑
i=0
λi = 1,
ou, coordonnee par coordonnee,
a01λ0 + a11λ1 + ... + an1λn = x1a02λ0 + a12λ1 + ... + an2λn = x2..... ..... ..... ..... = ...
a0nλ0 + a1nλ1 + ... + annλn = xnλ0 + λ2 + ... + λn = 1
; (2.3)
(apq est la q-eme entree du vecteur ap). C’est un systeme lineaire de n + 1 equations a n + 1inconnus. Le systeme homogene correspondant a seulement la solution triviale – en effet, unesolution non triviale du systeme homogene nous donnerait une combinaison lineaire non trivialenulle de ai avec la somme de coefficients nulle ce qui contredit a l’independance affine de a0, ..., an(ils sont affinement independants puisqu’ils forment une base affine de Rn). Il en suit que si A estla matrice du systeme, elle est non singuliere, de sorte que la solution λ(x) depende lineairement(et, par consequent, de facon continue) de la partie droite, c.-a-d. de x.
Maintenant prenons n’importe quel x = x0 avec λi(x0) > 0, par exemple, le centre du
simplex :
x0 = (n+ 1)−1n∑
i=0
ai.
Par continuite des λi(·), il y a un voisinage de x0 – la boule Br(x0) centre en x0 du rayon positif
r - ou les fonctions λi sont encore positives :
x ∈ Br(x0) ⇒ λi(x) ≥ 0, i = 0, ..., n.
et la derniere relation signifie que chaque x ∈ Br(x0) est une combinaison affine de ai avec des
coefficients positifs, c.-a-d. est une combinaison convexe des vecteurs, et donc x appartient a Δ.Ainsi, Δ contient un voisinage de x0, de sorte que x0 soit un point interieur de Δ.

2.1. DEFINITION, EXEMPLES, DESCRIPTION INTERNE, PROPRIETESALGEBRIQUES47
(iii) : On doit montrer que la fermeture de riM est exactement la meme que la fermeture deM . En fait, on va montrer encore plus :
Lemme 2.1.1 Soit x ∈ riM et y ∈ clM . Alors tous les points du demi-segment [x, y),
[x, y) = {z = (1− λ)x+ λy | 0 ≤ λ < 1}
appartiennent a l’interieur relatif de M .
Preuve du Lemme. Soit Aff(M) = a+ L, L etant un sous-espace lineaire ; alors
M ⊂ Aff(M) = x+ L.
Soit B une boule unite dans L :
B = {h ∈ L | ‖ h ‖≤ 1}.
Comme x ∈ riM , il existe un rayon positif r tel que
x+ rB ⊂M. (2.4)
Par ailleurs, comme y ∈ clM , nous avons y ∈ Aff(M) (voir (2.2)). De plus, pour tout ε > 0 ilexiste y′ ∈ M tel que |y′ − y| ≤ ε ; comme y′ et y sont dans Aff(M), le vecteur y − y′ est dansL, et donc dans εB. Ainsi
(∀ε > 0) : y ∈M + εB. (2.5)
Maintenant, soit z ∈ [x, y), alors
z = (1− λ)x+ λy
avec un certain λ ∈ (0, 1). Il nous faut demontrer que z est relativement interieur pourM , c.-a-d.que il existe r′ > 0 tel que
z + r′B ⊂M. (2.6)
Grace a (2.5), pour tout ε > 0 nous avons
z+εB ≡ (1−λ)x+λy+εB ⊂ (1−λ)x+λ[M+εB]+εB = (1−λ)[x+ λε
1 − λB+
ε
1− λB]+λM. (2.7)
Notons que pour tous t′, t′′ non negatifs
t′B + t′′B ⊂ (t′ + t′′)B.
En effet, si u ∈ t′B et v ∈ t′′B, c.-a-d. ‖ u ‖≤ t′ et ‖ v ‖≤ t′′, alors, par l’inegalite de triangle,‖ u+ v ‖≤ t′ + t′′, c.-a-d. u+ v ∈ (t′ + t′′)B. A partir de cette inclusion on obtient de (2.7)
z + εB ⊂ (1− λ)
[x+
(1 + λ)ε
1− λB
]+ λM
pour tout ε > 0. En choisissant ε assez petit, nous pouvons rendre le coefficient devant B dansla partie droite ≤ r (voir (2.4)) ; pour ce choix de ε, nous avons, par (2.4),
x+(1 + λ)ε
1− λB ⊂M,

48 CHAPITRE 2. ENSEMBLES CONVEXES : INTRODUCTION
et on arrive a
z + εB ⊂ (1− λ)M + λM =M
(la derniere egalite est du a la convexite de M). Ainsi, z ∈ riM .
Notre Lemme implique immediatement (iii). Effectivement, cl riM ne peut etre que pluspetite que clM : cl riM ⊂ clM , de sorte que tout ce que nous avons besoin a montrer estl’inclusion inverse : clM ⊂ cl riM c.-a-d. que chaque point y ∈ clM est une limite d’une suitede points de riM . C’est immediat : nous pouvons supposerM non vide (autrement, les ensemblesen question sont vides et coincident l’un avec l’autre), de sorte que par (ii) il existe un pointx ∈ riM . Selon le Lemme, le demi-segment [x, y) appartient a riM , et y est la limite d’une suitedes points de ce demi-segment, par exemple, de la suite xi =
1nx+ (1− 1
n)y.
Une consequence interessante du Lemme 2.1.1 est suivante :
Corollaire 2.1.2+Soit M un ensemble convexe. Alors toute combinaison convexe∑
i
λixi
des points xi ∈ clM ou au moins un terme avec le coefficient positif correspond a un xi ∈ riMest un point de riM .
(iv) : Le resultat est evidemment vrai quandM est vide, ainsi supposons queM est non vide.L’inclusion riM ⊂ ri clM est evident, et tout ce que nous avons besoin a montrer est l’inclusioninverse. Alors soit z ∈ ri clM , et montrons que z ∈ riM . Soit x ∈ riM (nous savons deja que ledernier ensemble est non vide). Considerez le segment [x, z] ; puisque z est dans l’interieur relatifde clM , nous pouvons prolonger un peu ce segment par le point z sans quitterclM , c.-a-d. qu’ilexiste y ∈ clM tel que z ∈ [x, y). Et maintenant, z ∈ [x, y), avec x ∈ riM , y ∈ clM , on obtientpar Lemme 2.1.1 que z ∈ riM .
Nous voyons de la preuve du Theoreme 2.1.1 que pour obtenir la fermeture d’un ensemble
convexe (non vide), il suffit le soumettre “a la fermeture radiale”, c.-a-d. choisir un point
x ∈ riM et prendre tous les rayons dans Aff(M) commencant par x et regarder l’intersection
de ce rayon (disons, l) avec M . Une telle intersection sera un ensemble convexe sur la droite
qui contient un demi-voisinage x, c.-a-d. soit un segment [x, yl], ou le rayon entier l, ou un
demi-intervalle [x, yl). Dans les deux premiers cas nous n’avons rien a faire ; dans le dernier
cas nous ajoutons yl aM . Apres avoir parcouru tous les rayons, quand tous les points finaux
”manques” yl sont ajoutes a M , nous obtenons la fermeture de M . Pour voir le role qui joue
la convexite dans cette construction, on peut considerer l’ensemble non convexe de nombres
rationnels de [0, 1] ; l’interieur (≡ l’interieur relatif) de cet ensemble est vide, la fermeture
est [0, 1], et il n’y a aucune possibilite de reconstituer la fermeture a partir de l’interieur.
2.2 Theoremes classiques sur ensembles convexes
2.2.1 Theoreme de Caratheodory
Appelons dimension d’un ensemble M convexe non vide (notation : dim M) la dimensionaffine de Aff(M).
Theoreme 2.2.1 [Caratheodory] Soit M ⊂ Rn, et soit dim ConvM = m. Alors tout pointx ∈ ConvM est une combinaison convexe d’au plus m+ 1 points de M .

2.2. THEOREMES CLASSIQUES SUR ENSEMBLES CONVEXES 49
Preuve : Soit x ∈ ConvM . Par Proposition 2.1.3 sur la structure de l’enveloppe convexe, x estune combinaison convexe de certains points x1, ..., xN de M :
x =N∑i=1
λixi, [λi ≥ 0,N∑i=1
λi = 1].
Choisissons parmi toutes ces representations de x celle avec le plus petit possible nombre N decoefficients non nuls, et supposons que c’est la combinaison ci-dessus. J’affirme que N ≤ m+ 1(cette affirmation mene au resultat desire). En effet, si N > m + 1, alors les points x1, ..., xNne sont pas affinement independants (puisque n’importe quel ensemble affinement independantdans Aff(M) ⊃ M est compose d’au plus de dim Aff(M) + 1 = m + 1 points, cf. Proposition1.3.5). Ainsi, certaine combinaison non triviale de x1, ..., xN avec la somme zero de coefficientsest nulle :
N∑i=1
δixi = 0, [N∑i=1
δi = 0, (δ1, ..., δN ) �= 0].
Il en suit que pour tout t la combinaison affine
(∗)N∑i=1
[λi + tδi]xi = x.
Ici a gauche nous avons une combinaison affine des xi. Quand t = 0, c’est une combinaisonconvexe – tous les coefficients sont non negatifs. Quand t est grand, ce n’est pas une combinaisonconvexe, puisque certains δi sont negatifs (en effet, pas tous les δi sont zero, et la somme de δiest 0). Il existe, evidemment, le plus grand t pour lequel la combinaison (*) a des coefficientsnon negatifs, a savoir
t∗ = mini:δi<0
λi|δi| .
Pour cette valeur de t, la combinaison (*) a tous les coefficients non negatifs, et au moins un descoefficients est zero. Ainsi, nous avons represente x comme une combinaison convexe de moinsde N vecteurs de M .
2.2.2 Theoreme de Radon
Theoreme 2.2.2 [Radon] Soit S ensemble d’au moins n + 2 points x1, ..., xN dans Rn. Alorscet ensemble peut etre divise en deux ensembles non vides S1 et S2 dont les enveloppes convexesont un point commun : il existe une partition I ∪ J = {1, ..., N}, I ∩ J = ∅, de l’ensembled’indices {1, ..., N} en deux ensemble non vides I et J et les combinaisons convexe des points{xi, i ∈ I}, {xj , j ∈ J} qui coincident, c.-a-d. qu’il existe αi, i ∈ I, and βj , j ∈ J , tels que∑
i∈Iαixi =
∑j∈J
βjxj;∑i
αi =∑j
βj = 1; αi, βj ≥ 0.
Preuve. Comme N > n+1, les points x1, ..., xN ne sont pas affinement independants (car dansRn tout ensemble affinement independant contient au plus n + 1 elements). Ainsi, il existe uncombinaison non triviale de xi egale 0 avec la somme nulle des coefficients :
N∑i=1
λixi = 0, [N∑i=1
λi = 0, (λ1, ..., λN ) �= 0].

50 CHAPITRE 2. ENSEMBLES CONVEXES : INTRODUCTION
Soit I = {i | λi ≥ 0}, J = {i | λi < 0} ; alors I et J ne sont pas vides et forment une partitionde {1, ..., N}. Nous avons
a ≡∑i∈I
λi =∑j∈J
(−λj) > 0
(rappelez-vous que la somme des λi est nulle et tous les λi ne sont pas zeros). Si on pose
αi =λia, i ∈ I, βj =
−λja, j ∈ J,
on obtient
αi ≥ 0, βj ≥ 0,∑i∈I
αi = 1,∑j∈J
βj = 1,
et
[∑i∈I
αixi]− [∑j∈J
βjxj ] = a−1
⎛⎝[∑i∈I
λixi]− [∑j∈J
(−λj)xj ]⎞⎠ = a−1
N∑i=1
λixi = 0.
2.2.3 Theoreme de Helley
Theoreme 2.2.3 [Helley, I] Soit F une famille finie d’ensembles convexes dans Rn. On supposeque n’importe quels n+1 ensembles de la famille ont un point commun. Alors tous les ensemblesont un point commun.
Preuve : montrons le resultat par recurrence en nombre N d’ensembles dans la famille. Le casde N ≤ n+1 est evident. Supposons maintenant que nous avons prouve le theoreme pour toutesles familles avec un certain nombre N ≥ n+ 1 d’ensembles, et soit S1, ..., SN , SN+1 une famillede N + 1 ensembles convexes qui satisfait les conditions du Theoreme de Helley ; nous devrionsmontrer que l’intersection des ensembles S1, ..., SN , SN+1 est non vide.
En supprimant de notre famille de N+1 ensembles l’ensemble Si, nous obtenons la famille deN ensemble qui satisfait les conditions du Theoreme de Helley et ainsi, par l’hypothese inductive,possede une intersection non vide de ses membres :
(∀i ≤ N + 1) : T i = S1 ∩ S2 ∩ ... ∩ Si−1 ∩ Si+1 ∩ ... ∩ SN+1 �= ∅.
Choisissons un point xi dans chaque ensemble Ti (non vide). Nous obtenons N + 1 ≥ n + 2points de Rn. Comme nous le savons du Theoreme de Radon, nous pouvons diviser l’ensembled’indices {1, ..., n+1} en deux sous-ensembles non vides I et J de telle maniere qu’une certainecombinaison convexe x des points xi, i ∈ I, soit simultanement une combinaison convexe despoints xj, j ∈ J . Pour accomplir la preuve il suffit de verifier que x appartient a tous les ensemblesS1, ..., SN+1. En effet, soit i∗ un indice de notre ensemble d’indices, montrons que x ∈ Si∗ . Nousavons i∗ ∈ I, ou i∗ ∈ J . Dans le premier cas tous les ensembles Tj, j ∈ J , sont contenus dans Si∗
(puisque Si∗ participe a toutes les intersections qui donnent T i avec i �= i∗). En consequence,tous les points xj , j ∈ J , appartiennent a Si∗ , et donc x, qui est une combinaison convexe de cespoints, appartient egalement a Si∗ (tous nos ensembles sont convexes !), comme requis. Dans ledeuxieme cas le raisonnement semblable indique que tous les points xi, i ∈ I, appartiennent aSi∗ , et donc x, qui est une combinaison convexe de ces points, appartient a Si∗ .
Dans la version mentionnee ci-dessus du Theoreme de Helley nous avons traite les famillesfinies d’ensembles convexes. Pour etendre ce resultat au cas des familles infinies, nous devonsrenforcer legerement les conditions :

2.2. THEOREMES CLASSIQUES SUR ENSEMBLES CONVEXES 51
Theoreme 2.2.4∗
[Helley, II] Soit F une famille d’ensembles convexes dans Rn. Suppo-sons que
(a) tous les n+ 1 ensembles de la famille on un point commun,et
(b) chaque ensemble de la famille est ferme, et l’intersection des ensembles d’une certainesous-famille finie est bornee (par exemple, un des ensembles dans la famille est borne).Alors tous les ensembles de la famille on un point commun.
Preuve∗
: Par le theoreme precedent, tous les sous-familles finies de F ont les intersectionsnon vides, et ces intersections sont convexes (puisque l’intersection de n’importe quelle familledes ensembles convexes est convexe par Theoreme 2.1.2) ; grace a (a) ces intersections sontegalement fermees. Ajoutant a F toutes les intersections des sous-familles finies de F , nousobtenons une famille plus nombreuse F ′ qui consiste en des ensembles convexes fermes, etn’importe quel sous-famille finie de cette famille plus nombreuse a encore une intersectionnon vide. Par ailleurs, (b) implique que cette nouvelle famille contient un ensemble borne Q.Puisque tous les ensembles sont fermes, la famille d’ensembles
{Q ∩Q′ | Q′ ∈ F}
est une famille emboitee d’ensembles compacts (c.-a-d. une famille d’ensembles compacts avec
l’intersection non vide de toute sous-famille finie) ; par le theoreme bien connu d’analyse, une
telle famille a une intersection non vide 3).
3. )voici la preuve de ce theoreme : supposez, au contraire, que les ensembles compacts Qα, α ∈ A en questionont l’intersection vide. Choisissez un ensemble Qα∗ de la famille ; pour chaque x ∈ Qα∗ il y a un ensemble Qx dansla famille qui ne contient pas x – autrement x serait un point commun de tous nos ensembles. PuisqueQx est ferme,il y a une boule ouverte Vx centree en x qui n’intersecte pas Qx. Les boules Vx, x ∈ Qα∗ , forment une couvertureouverte de l’ensemble compact Qα∗ , et donc on peut en extraire une sous-couverture Vx1 , ..., VxN finie de Qα∗ .Puisque Qxi n’intersecte pas Vxi , nous en concluons que l’intersection de la sous-famille fini Qα∗ , Qx1 , ..., QxN estvide, qui est une contradiction

52 CHAPITRE 2. ENSEMBLES CONVEXES : INTRODUCTION
2.3 Exercices
Exercice 2.1 Lesquels parmi les ensembles ci-dessous sont convexes :
– {x ∈ Rn | ∑ni=1 x
2i = 1}
– {x ∈ Rn | ∑ni=1 x
2i ≤ 1}
– {x ∈ Rn | ∑ni=1 x
2i ≥ 1}
– {x ∈ Rn | maxi=1,...,n xi ≤ 1}– {x ∈ Rn | maxi=1,...,n xi ≥ 1}– {x ∈ Rn | maxi=1,...,n xi = 1– {x ∈ Rn | mini=1,...,n xi ≤ 1}– {x ∈ Rn | mini=1,...,n xi ≥ 1}– {x ∈ Rn | mini=1,...,n xi = 1}
Faites selon votre choix au moins 3 parmi 5 exercices suivants 2.2 - 2.6 :
Exercice 2.2 Prouvez la Proposition 2.1.4.
Exercice 2.3 Prouvez le resultat contenu dans l’Exemple 2.1.5.
Exercice 2.4 Prouvez la Proposition 2.1.5.
Exercice 2.5 Prouvez la partie (i) du Theoreme 2.1.1.
Exercice 2.6 Prouvez le Corollaire 2.1.2.
Exercice 2.7 Δ 4) Prouvez le resultat suivant(Theoreme de Kirchberger) :
Supposons que X = {x1, ..., xk} et Y = {y1, ..., ym} sont des ensembles finis dans Rn, aveck + m ≥ n + 2, et que tous les points x1, ..., xk , y1, ..., ym sont distincts. Supposons aussi quequelque soit le sous-ensemble S ⊂ X ∪ Y compris de n + 2 points, les enveloppes convexes desensembles X ∩ S et Y ∩ S ont l’intersection vide. Alors les enveloppes convexes de X et de Yont aussi l’intersection vide.
Indication : supposez, au contraire, que les enveloppes convexes de X et de Y intersectent, desorte que
k∑i=1
λixi =m∑j=1
μjyj
pour certains λi,∑
i λi = 1, et certains μj ,∑
j μj = 1, non negatives. Maintenant, regardezl’expression de ce type avec le plus petit possible nombre de coefficients non nuls λi, μj.
Exercice 2.8 Δ Montrez le theoreme suivant (de Grunbaum) sur la partition de masse :
Soit x1, ..., xN des points de Rn, et chaque point xi est assigne une masse non negative μi, lasomme des masses de tous les points etant egaux a 1. Alors il existe un point x∗ tel que n’importequel hyperplan {x | aTx = aTx∗}, a �= 0, passant par le point x∗ coupe l’espace Rn en deux
4. ) les exercices marques Δ sont d’une nature toute particuliere. Trois de ces exercices suffisent pour obtenirune excellente note a l’examen theorique

2.3. EXERCICES 53
demi-espaces fermes de la masse au moins 1n+1 chacun, c.-a-d. que pour n’importe quel a �= 0
on a ∑i| aT xi≤aT x∗
μi ≥ 1
n+ 1
et ∑i| aT xi≥aT x∗
μi ≥ 1
n+ 1.
Indication : considerez la famille de tous les demi-espaces fermes de μ-measure > n/(n + 1).Montrez que la famille satisfait les hypotheses du Theoreme de Helley et verifiez que n’importequel point qui appartient a l’intersection des ensembles de la famille satisfait la conclusion dutheoreme de Grunbaum.

54 CHAPITRE 2. ENSEMBLES CONVEXES : INTRODUCTION

Chapitre 3
Theoreme de separation Theoried’inegalites lineaires
Dans ce chapitre nous allons repondre a la question suivante : supposons que nous avonsdeux ensembles convexes dans Rn, quand pouvons-nous les separer par un hyperplan, c.-a-d.trouver une forme lineaire non nulle qui en tout point d’un des ensembles est superieur ouegal a sa valeur en n’importe quel point de l’autre ensemble ? Nous verrons que la reponse acette question forme, dans un sens, le coeur de l’analyse convexe ; elle est a la base de tous nosdeveloppements ulterieurs.
3.1 Theoreme de separation
Un hyperplan M dans Rn (un ensemble affine de dimension n − 1), comme nous le savonsde la Section 1.4.2, est un ensemble de niveau d’une forme lineaire non triviale :
∃a ∈ Rn, b ∈ R, a �= 0 : M = {x ∈ Rn | aTx = b}.
Nous pouvons, par consequent, associer a l’hyperplan (ou a la forme lineaire associee a, qui estdefinie uniquement, a la multiplication par un reel non nul pres) les ensembles suivants :
– les demi-espaces ouverts ”haut” et ”bas” M++ = {x ∈ Rn | aTx > b}, M−− = {x ∈ Rn |aTx < b} ;ces ensembles sont convexes, et puisqu’une forme lineaire est continue, et ces ensemblessont donnes par des inegalites strictes sur la valeur d’une fonction continue, ils sont eneffet ouverts.Notez que puisque a est uniquement defini par M , a la multiplication par un reel non nulpres, ces demi-espaces ouverts sont uniquement defini par l’hyperplan, a la permutationdu ”haut” et du ”bas” pres (qu’un demi-espace est le ”haut”, depend du choix particulierde a) ;
– les demi-espaces ”haut” et ”bas” fermes M+ = {x ∈ Rn | aTx ≥ b}, M− = {x ∈ Rn |aTx ≤ b} ;Ceux-ci sont egalement les ensembles convexes, fermes (puisqu’ils sont donnes par desinegalites non-strictes sur la valeur d’une fonction continue). On le voit facilement quele demi-espace superieur ou inferieur ferme est la fermeture du demi-espace ouvert cor-respondant, et M lui-meme est la frontiere (c.-a-d. le complement de l’interieur dans lafermeture) de chacun des quatre demi-espaces.
55

56 CHAPITRE 3. THEOREME DE SEPARATION THEORIE D’INEGALITES LINEAIRES
Il est evident que nos demi-espaces et M lui-meme donnent une partition de Rn :
Rn =M−− ∪M ∪M++
(partition par des ensembles disjoints),
Rn =M− ∪M+
(M est une intersection des ensembles a droite).Maintenant nous definissons la notion de base de separation propre de deux ensembles
convexes T et S par un hyperplan.
Definition 3.1.1 [Separation propre] On dit qu’un hyperplan
M = {x ∈ Rn | aTx = b} [a �= 0]
separe proprement deux ensembles convexes (non vides) S et T , si(i) les ensembles appartiennent aux demi-espaces fermes opposes definis par M ,
et(ii) au moins un des ensembles n’est pas contenu dans M .Nous disons que S et T peuvent etre proprement separes, s’il existe un hyperplan qui separe
proprement S et T , c.-a-d. si il existe a ∈ Rn tel que
supx∈S
aTx ≤ infy∈T
aT y
etinfx∈S
aTx < supy∈T
aT y.
Par exemple,– l’hyperplane donne par aTx ≡ x2 − x1 = 1 dans R2 separe proprement les ensembles
convexes polyhedraux T = {x ∈ R2 | 0 ≤ x1 ≤ 1, 3 ≤ x2 ≤ 5} et S = {x ∈ R2 | x2 =0;x1 ≥ −1} ;
– l’hyperplane aTx ≡ x = 1 dans R1 separe proprement les ensembles convexes S = {x ≤ 1}et T = {x ≥ 1} ;
– l’hyperplane aTx ≡ x1 = 0 in R2 separe proprement les ensembles S = {x ∈ R2 | x1 <0, x2 ≥ −1/x1} et T = {x ∈ R2 | x1 > 0, x2 > 1/x1} ;
– l’hyperplane aTx ≡ x2 − x1 = 1 does not separe proprement les ensembles convexesS = {x ∈ R2 | x2 ≥ 1} et T = {x ∈ R2 | x2 = 0} ;
– l’hyperplane aTx ≡ x2 = 0 in R2 separe les ensembles S = {x ∈ R2 | x2 = 0, x1 ≤ −1} etT = {x ∈ R2 | x2 = 0, x1 ≥ 1}, mais ne les separe pas proprement.
Notez que la partie de la definition 3.1.1 commencant par ”c.-a-d.” contient un certain
resultat (notamment, que la description verbale de la separation est identique a la description
”analytique” indiquee). Je n’ai aucun doute que vous comprenez que ces deux descriptions
sont equivalentes.
Parfois nous sommes interesses egalement par une notion plus forte de separation :
Definition 3.1.2 [Separation forte] Nous disons que deux ensembles non vides S et T dans Rn
peuvent etre separes fortement, si il existent deux hyperplans paralleles distincts qui separent Set T , c.-a-d. s’il existe a ∈ Rn tel que
supx∈S
aTx < infy∈T
aT y.

3.1. THEOREME DE SEPARATION 57
Il est evident que le
Separation forte → separation propre
Nous pouvons immediatement produire des exemples d’ensembles qui peuvent etre separesproprement sans pouvoir etre separes fortement, par exemple, les ensembles {x ∈ R2 | x1 >0, x2 ≥ 1/x1} and {x ∈ R2 | x1 < 0, x2 ≥ −1/x1}.
On arrive maintenant a la question :
quand une paire d’ensembles convexes non vides S et T dans Rn peut etre separee [propre-ment ou fortement] ?
La question plus importante est celle sur la possibilite de separation propre. La reponse estsuivante :
Theoreme 3.1.1 [Theoreme de separation] Deux ensembles convexes non vides S et T dansRn peuvent etre separe proprement si et seulement si leurs interieurs relatifs sont disjoints :
riS ∩ riT = ∅.
Nous allons maintenant demontrer ce theoreme fondamental.
3.1.1 Necessite
La necessite de la propriete indiquee (la partie ”seulement si” du theoreme) est plus ou moinsevidente. En effet, supposez que les ensembles sont proprement separables, de sorte que pour uncertain a ∈ Rn non nul
supx∈S
aTx ≤ infy∈T
aT y; infx∈S
aTx < supy∈T
aT y. (3.1)
Nous devrions mener a une contradiction l’hypothese que riS et riT ont un certain point communx. Supposons que c’est le cas ; alors de la premiere inegalite dans (3.1) il est evident que xmaximise la fonction lineaire f(x) = aTx sur S et donne simultanement le minimum cettefonction sur T . Maintenant, nous avons le simple resultat suivant :
Lemme 3.1.1 La fonction lineaire f(x) = aTx peut atteindre son maximum ouminimum sur un ensemble convexe Q dans un point x ∈ riQ si et seulement si lafonction est constante sur Q.
Preuve : la partie ”si” est evidente. Pour prouver la partie ”seulement si”,supposons que x ∈ riQ est le minimiseur de f(x) sur Q et y est un point arbitrairede Q ; nous devrions montrer que f(x) = f(y). Il n’y a rien a prouver si y = x, ainsinous pouvons supposer que y �= x. Comme x ∈ riQ le segment [y, x], qui est contenudans Q, peut etre prolonge un peu par le point x, sans quitter Q, de sorte qu’il existez ∈ Q tel que x ∈ [y, z), c.-a-d. x = (1− λ)z + λy avec un certain λ ∈ (0, 1]. Commey �= x, nous avons en fait λ ∈ (0, 1). Et puisque f est lineaire, nous avons
f(x) = (1− λ)f(z) + λf(y).
Comme f(x) ≤ min{f(y), f(z)} et 0 < λ < 1, cette relation peut etre satisfaiteseulement si f(x) = f(y) = f(z).

58 CHAPITRE 3. THEOREME DE SEPARATION THEORIE D’INEGALITES LINEAIRES
Revenant a nos considerations liees a (3.1), nous concluons du Lemme que sous notre hy-pothese (∃x ∈ riS ∩ riT , c.-a-d. quand f(x) = aTx atteint son maximum sur S et son minimumT en x) f est constante (et egale a aT x) sur les deux ensembles S et T ; mais ceci contredit ladeuxieme inegalite dans (3.1).
Ainsi, nous avons montre que la condition riS ∩ riT = ∅ est necessaire pour la separationpropre de S et T .
3.1.2 Suffisance
La preuve de la partie suffisance du theoreme de separation est beaucoup plus instructif. Ily a plusieurs manieres de la prouver, et nous allons suivre le chemin qui passe par Lemme deFarkas.
Lemme de Farkas Homogene
Soit a1, ..., aN et a des vecteurs de Rn. On s’interesse a la question : quand a appartient-il aucone engendre par les vecteurs a1, ..., an. Autrement dit, quand est-ce que a peut etre representecomme une combinaison lineaire ai avec des coefficients non negatifs ? Une condition necessairepour ceci est evidente : si
a =n∑
i=1
λiai [λi ≥ 0, i = 1, ..., N ]
alors tout vecteur h qui a des produits scalaires non negatifs avec tous les ai doit aussi avoir leproduit scalaire non negatif avec a :
a =∑i
λiai & λi ≥ 0∀i & hT ai ≥ 0∀i⇒ hTa ≥ 0.
Le Lemme de Farkas Homogene dit que cette condition est aussi suffisante :
Lemme 3.1.2 [Lemme de Farkas Homogene] Soit a, a1, ..., aN vecteurs de Rn. Le vecteur a estune combinaison conique des vecteurs ai si et seulement si tout vecteur h qui satisfait hT ai ≥ 0,i = 1, ..., N , satisfait aussi hTa ≥ 0.
Preuve : La necessite – la partie “seulement si”– est evidente. Pour prouver la suffisance de lacondition du lemme supposons que chaque vecteur h satisfaisant hT ai ≥ 0 ∀i satisfait egalementhTa ≥ 0, et montrons que a est une combinaison conique des vecteurs ai.
Il n’y a rien a montrer quand a = 0 – le vecteur zero naturellement est une combinaisonconique des vecteurs ai. Ainsi, dorenavant nous supposons que a �= 0.
10. SoitΠ = {h | aTh = −1},
et soitAi = {h ∈ Π | aTi h ≥ 0}.
Π est un hyperplan dans Rn, et chaque Ai est un ensemble polyhedral contenu dans cet hyper-plan.
20. Nous savons que l’intersection de tous les ensembles Ai, i = 1, ..., n, est vide (puisqu’unvecteur h de l’intersection aurait les produits interieurs non negatifs avec tout le ai et le produitinterieur −1 avec a, et on sait qu’un tel h n’existe pas). Choisissons la plus petite, en nombred’elements, sous-famille de la famille A1, ..., AN qui a toujours l’intersection vide de ses membres.

3.1. THEOREME DE SEPARATION 59
Sans perte de generalite nous pouvons supposer que c’est la famille A1, ..., Ak. Ainsi, l’intersectionde tous les k ensembles A1, ..., Ak est vide, mais l’intersection de n’importe quels ensembles dek − 1 de la famille A1, ..., Ak est non vide.
30. J’affirme que– A. a ∈ Lin({a1, ..., ak}) ;– B. Les vecteurs a1, ..., ak sont lineairement independants.
A. est facile : en supposant que a �∈ E = Lin({a1..., ak}), nous obtenons que laprojection orthogonale f du vecteur a sur le complement orthogonal E⊥ de E est nonnul. Le produit scalaire de f et de a est identique que fTf , c.-a-d. est positif, alorsque fTai = 0, i = 1, ..., k. Si on pose h = −(fTf)−1f , nous voyons que hTa = −1et hTai = 0, i = 1, ..., k. En d’autres termes, h appartient a chaque ensemble Ai,i = 1, ..., k, par la definition de ces ensembles, et donc l’intersection des ensemblesA1, ..., Ak est non vide, qui est une contradiction.
La preuve de B. est donne par le Theoreme de Helley I. En effet, supposonsque a1, ..., ak sont lineairement dependants, et menons cette supposition a unecontradiction. Comme a1, ..., ak sont lineairement dependants, la dimension m deE = Lin({a1, ..., ak}) est pour sur < k. Nous savons deja du A. que a ∈ E. Soitmaintenant A′
i = Ai ∩E. J’affirme que toutes les familles de k − 1 des ensembles A′i
ont une intersection non vide, alors que tous ces k ensembles ont l’intersection vide.La deuxieme affirmation est evidente – puisque A1, ..., Ak ont l’intersection vide, lememe est le cas avec leurs parties A′
i. La premiere affirmation est egalement facile-ment verifiable : prenons par exemple k− 1 des ensembles “a trait” A′
1, ..., A′k−1. Par
la construction, l’intersection de A1, ..., Ak−1 est non vide ; soit h un vecteur de cetteintersection, c.-a-d. un vecteur avec les produits scalaires non negatifs avec a1, ..., ak−1
et le produit−1 avec a. En remplacant h avec sa projection orthogonale h′ sur E, nousne changeons pas tous ces produits interieurs, puisque ce sont des produits avec desvecteurs de E ; ainsi, h′ est egalement un point commun de A1, ..., Ak−1, et puisquec’est un point de E, c’est aussi bien un point commun des ensembles A′
1, ..., A′k−1.
Maintenant nous pouvons accomplir la preuve du B. : les ensembles A′1, ..., A
′k sont
les ensembles convexes appartenant a l’hyperplan Π′ = Π∩E = {h ∈ E | aTh = −1}(Π′ est en effet un hyperplan dans E car 0 �= a ∈ E) dans le sous-espace lineaire m-dimensionnel E. Π′ est un ensemble affine de dimension l = dim E−1 = m−1 < k−1(dans notre cas m = dim E < k), et tous l + 1 ≤ k − 1 des sous-ensembles convexesA′
1,...,A′k de Π′ ont une intersection non vide. Du Theoreme de Helley I (qui naturel-
lement est valide pour les sous-ensembles convexes d’un ensemble affine, la dimensionaffine de l’ensemble jouant le role de n dans la formulation originale) il decoule quetous les ensembles A′
1, ..., A′k ont un point commun, ce qui, comme nous le savons,
n’est pas le cas. Ainsi, par contradiction, on obtient que a1, ..., ak sont lineairementindependant.
40. Le A. et le B. etant dans notre disposition, nous pouvons facilement finir la preuve de lapartie“si” du lemme de Farkas comme suit : par A. nous avons
a =k∑
i=1
λiai
avec des coefficients reels λi, et tous ce que nous avons a montrer est que ces coefficients nesont pas negatifs. Supposons, au contraire, que, par exemple λ1 < 0. Augmentons le systeme

60 CHAPITRE 3. THEOREME DE SEPARATION THEORIE D’INEGALITES LINEAIRES
(lineairement independant par B.) des vecteurs a1, ..., ak par les vecteurs f1, ..., fn−k a une basedans Rn (ce qui est possible par Theoreme 1.2.1). Soit maintenant ξi(x) soit les coordonneesd’un vecteur x dans cette base (ξ1 correspond a a1). La fonction ξ1(x) est une forme lineaire dex et donc, selon la Section 1.1.2, est le produit interieur avec un certain vecteur :
ξ1(x) = fTx ∀x.
Nous avons
fTa = ξ1(a) = λ1 < 0
et
fTai =
{1, i = 1,0, i = 2, ..., k,
ainsi fTai ≥ 0, i = 1, ..., k. On en deduit par la normalisation appropriee de f que le vecteur|λ1|−1f , appartient aux A1, ..., Ak , ce qui est la contradiction desiree – par la construction, cetteintersection est vide.
Remarque 3.1.1 Une consequence immediate du Lemme de Farkas Homogene est que l’enve-loppe conique
Cone ({a1, ..., aN}) = {a =N∑i=1
λiai | λi ≥ 0, i = 1, ..., N}
d’un ensemble fini non vide est l’ensemble de toutes les solutions d’un certain systeme d’inegaliteslineaires homogenes non strictes, notamment,
{hT a ≥ 0 ∀(h : hT ai ≥ 0, i = 1, ..., N)}.
Ainsi, l’enveloppe conique d’un ensemble fini de vecteurs est convexe et ferme.
Du Lemme de Farkas au Theoreme de separation
Maintenant nous sommes enfin equipes pour prouver la partie suffisance du Theoreme deSeparation.
Etape 1. Separation d’un polytope convexe et d’un point exterieur au polytope.Commencons par le cas apparemment tres particulier du theoreme, ou un des ensembles est unpolytope – l’enveloppe convexe de l’ensemble fini de points x1, ..., xN – et l’autre est un singletonT = {x}. Nous devrions montrer que si x �∈ S = Conv({x1..., xN}), il existe alors une formelineaire qui separe proprement x et S. En fait, nous prouverons meme l’existence de la separationforte.
Associons aux vecteurs n-dimensionnels x1, ..., xN , x les vecteurs a =
(x1
)et ai =
(xi1
)(n + 1)-dimensionnels, i = 1, ..., n. J’affirme que a n’appartient pas a l’enveloppe conique dea1, ..., an. En effet, si a serait representable comme une combinaison lineaire de a1, ..., aN avecdes coefficients non negatifs, alors, en regardant la (n + 1)-eme coordonnee dans une tellerepresentation, on deduirait que la somme des coefficients devrait etre 1, de sorte que cetterepresentation, en realite, est une combinaison convexe de x1, ..., xn avec la valeur x, ce qu’on asuppose impossible.

3.1. THEOREME DE SEPARATION 61
Comme a n’appartient pas a l’enveloppe conique de a1, ..., aN , par le Lemme de Farkas
Homogene, il existe un vecteur h =
(fα
)∈ Rn+1 qui “separe” a et a1, ..., aN , c.-a-d. que
hTa > 0, hT ai ≤ 0, i = 1, ..., N.
Ainsi, bien sur,hTa > max
ihTai.
Puisque les composants dans tous les produits scalaires hTa, hT ai qui proviennent des (n + 1)-emes coordonnees sont egaux entre eux, nous en concluons que le composant n-dimensionnel fde h separe x et x1, ..., xN :
[hT a− α =] fTx > maxifTxi [= max
ihT ai − α].
Comme pour toute combinaison convexe y =∑
i λixi des points xi on a fTy ≤ maxi fTxi, on
conclut, finalement, quefTx > max
y∈Conv({x1,...,xN})fTy,
et f separe fortement T = {x} et S = Conv({x1, ..., xN}).Remarque 3.1.2 Un sous-produit de notre raisonnement est qu’un polytope – l’enveloppeconvexe
Conv({v1, ..., vN})d’un ensemble non vide fini de vecteurs – est l’ensemble de solutions d’un systeme d’inegaliteslineaires non strictes, notamment, du systeme
{fTx ≤ maxi=1,...,N
fTvi ∀f}.
Il en suit que un polytope est non seulement convexe, mais egalement ferme.
Etape 2 Separation d’un ensemble convexe et d’un point exterieur. Soit maintenantS un ensemble non vide convexe arbitraire et T = {x} est un singleton exterieur a S (a ladifference avec l’Etape 1 est que maintenant on ne suppose pas que S soit un polytope).
Tout d’abord, sans perte de generalite nous pouvons supposer que S contient 0 (si ce n’estpas le cas, nous pouvons soumettre S et T a la translation S �→ S − a, T �→ T − a avec a ∈ S).Soit L l’enveloppe lineaire de S. Si x �∈ L, la separation est facile : en prenant comme f lacomposante de x orthogonale a L, nous obtenons
fTx = fTf > 0 = maxy∈S
fTy,
et f separe fortement S et T = {x}.Il nous reste le cas x ∈ L. Comme S ⊂ L, x ∈ L et x �∈ S, L est un sous-espace lineaire
different de 0. Soit Σ = {h ∈ L | |h| = 1} la sphere unite dans L. C’est un ensemble ferme etborne dans Rn (la fermeture vient du fait que | · | est continu et L est ferme, cf. la section 1.4.1).En consequence, Σ est un ensemble compact (Proposition 1.1.1). Montrons qu’il existe f ∈ Σqui separe x et S dans le sens que
fTx ≥ supy∈S
fTy. (3.2)

62 CHAPITRE 3. THEOREME DE SEPARATION THEORIE D’INEGALITES LINEAIRES
Supposons, au contraire, qu’un tel f n’existe pas. Sous notre hypothese pour chaque h ∈ Σ ilexiste yh ∈ S tel que
hT yh > hTx.
Puisque l’inegalite est stricte, il existe un voisinage Uh du vecteur h tels que
(h′)T yh > (h′)Tx ∀h′ ∈ Uh. (3.3)
La famille d’ensembles ouverts {uh}h∈Σ que nous obtenons est une couverture de Σ ; puisqueΣ est compact, nous pouvons en extraire une couverture finie Uh1 , ..., UhN
de Σ. Soit y1 =yh1 , y2 = yh2 , ..., yN = yhN
les points correspondants et soit le polytope S′ = Conv({y1, ..., yN})est engendre par ces points. En raison de l’origine de yi, ils sont tous des points de S ; puisque Sest convexe, le polytope S′ est contenu dans S et, par consequent, ne contient pas x. Par Etape1, x peut etre fortement separe de S′ : il existe a tels que
aTx > supy∈S′
aT y. (3.4)
Comme x et S′ ⊂ S appartiennent a L, nous pouvons supposer que a ∈ L (il suffit de remplacer aavec sa projection orthogonale sur L, ce qui ne change pas les deux cotes de (3.4)). En normalisanta, nous pouvons egalement avoir |a| = 1, de sorte que a ∈ Σ. Maintenant nous obtenons unecontradiction : comme a ∈ Σ et Uh1 , ..., UhN
forment une couverture de Σ, a appartient a uncertain Uhi
. Or, par la construction de Uhi(regardez (3.3) nous avons
aT yi ≡ aT yhi> aTx,
ce qui contredit (3.4) car yi ∈ S′.La contradiction que nous obtenons montre que il existe f ∈ Σ qui satisfait (3.2). Montrons
qu’en fait f separe proprement S et {x} : etant donne (3.2), tout ce que nous avons a montrer estque la forme lineaire f(z) = fT z n’est pas constante sur S. C’est evident : par notre hypotheseinitiale, 0 ∈ S, de sorte que si f(z) etaient constants sur S, f soit orthogonal a n’importequel vecteur de S et par consequent a L = Lin(S), ce qui est impossible, puisque, encore parconstruction, f ∈ L and |f | = 1.
Un lecteur curieux pourrait remarquer qu’avec le raisonnement de l’Etape 2 nous sommesentres dans un monde completement nouveau. En effet, toutes nos considerations a partir dudebut de ce chapitre jusqu’au l’Etape 2 ont ete ceux d’algebre rationnelle – nous n’avons ja-mais employe des notions comme la convergence, la compacite, etc., en employant seulementl’arithmetique rationnelle (pas de racines carrees, etc.). Ceci signifie que tous les resultatsde la presente partie, y compris le Lemme de Farkas Homogene et ceux de l’Etape 1, de-meurent valides si nous remplacons, par exemple, notre univers Rn avec l’espace Qn desvecteurs rationnels de dimension n (ceux avec des coordonnees rationnelles ; naturellement,la multiplication devrait etre limitee a la multiplication par des nombres rationnels dans cetespace). La version “rationnelle” du Lemme de Farkas ou du theoreme sur la separation d’unvecteur rationnel d’un polytope “rationnel” par une forme lineaire rationnelle sont certai-nement d’interet (par exemple, en Programmation en Nombres Entiers). Contrairement aces “considerations d’algebre rationnelle”, dans l’etape 2 nous avons employe la compacite– quelque chose exploitant fortement le fait que notre univers est Rn et pas, par exemple,Qn (dans le dernier espace les ensembles bornes et fermes ne sont pas necessairement com-pacts). Notez egalement que nous ne pourrions pas eviter des “choses” comme cet argumentde compacite a l’Etape 2, puisque le resultat meme que nous prouvons est vrai dans Rn maisil est faut, par exemple, dans Qn. En effet, considerez “le plan rationnel” – l’univers de tous

3.1. THEOREME DE SEPARATION 63
les vecteurs a deux dimensions avec les coordonnees rationnelles, soit S le demi-plan dans ceplan rationnel donne par l’inegalite lineaire
x1 + αx2 ≤ 0,
avec α irrationnel. Bien sur, S est “convexe” en Q2 ; mais on peut le voir immediatement
qu’un point exterieur a cet ensemble ne peut pas etre separe de S par une forme lineaire
rationnelle.
Etape 3. Separation de deux ensembles convexes non vides disjoints Maintenantnous sommes en mesure de montrer que deux ensembles non vides et convexes d’intersectionvide S et T peuvent etre proprement separes. A cet effet considerons la difference arithmetique
Δ = S − T = {x− y | x ∈ S, y ∈ T}.
Nous savons de la Proposition 2.1.5 que Δ est un ensemble convexe (et, naturellement, nonvide) ; comme S ∩ T = ∅, Δ ne contient pas 0. Par Etape 2, nous pouvons proprement separerΔ et {0} : il existe h tels que
fT0 = 0 ≥ supz∈Δ
fT z & fT0 > infz∈Δ
fT z.
Autrement dit,
0 ≥ supx∈S,y∈T
[fTx− fTy] & 0 > infx∈S,y∈T
[fTx− fT y],
ce qui signifie que f separe proprement S et T .
Etape 4. Separation d’ensembles convexes non vides avec les interieurs relatifs dis-joints. Soit S et T deux ensembles convexes non vides avec les interieurs relatifs dont l’in-tersection est vide. Nous devrions montrer que S et T peuvent etre proprement separes. C’estimmediat : comme nous savons du Theoreme 2.1.1, les ensembles S′ = riS et T ′ = riT sont nonvides et convexes ; puisque nous sommes donnes que leur intersection est vide, ils peuvent etreproprement separes par Etape 3 : il existe f tels que
infx∈T ′ f
Tx ≥ supy∈S′
fTx & supx∈T ′
fTx > infy∈S′ f
Tx. (3.5)
On peut voir facilement que f separe proprement S et T . En effet, les quantites sur les cotesgauches et droits de la premiere inegalite de (3.5) ne changent pas si nous remplacons S′ avecclS′ et T ′ avec clT ′ ; par Theoreme 2.1.1, clS′ = clS ⊃ S and clT ′ = clT ⊃ T , et nousobtenons infx∈T fTx = infx∈T ′ fTx, et, de la meme facon, supy∈S fTy = supy∈S′ fTy. Ainsi,nous obtenons de (3.5)
infx∈T
fTx ≥ supy∈S
fT y.
Il suffit de remarquer que T ′ ⊂ T , S′ ⊂ S, et la seconde inegalite dans (3.5) implique
supx∈T
fTx > infy∈S
fTx.

64 CHAPITRE 3. THEOREME DE SEPARATION THEORIE D’INEGALITES LINEAIRES
3.1.3 Separation forte
Nous savons du Theoreme de Separation ce qui sont les conditions necessaires et suffi-santes simples pour la separation propre de deux ensembles convexes - leurs interieurs relatifsdevraient etre disjoints. Il y a egalement une condition necessaire et suffisante simple pourque deux ensembles soient fortement separables :
Proposition 3.1.1∗
Deux ensembles convexe non vides S et T dans Rn peuvent etresepares fortement si et seulement si la “distance entre ces ensembles est positive” :
ρ(S, T ) = infx∈S,y∈T
|x− y| > 0.
Ceci est, en particulier, le cas quand un des ensembles est compact, l’autres est ferme et lesensembles sont disjoints.
Preuve∗. La necessite est evidente : si S et T peuvent etre separes proprement, c.-a-d. que
pour un certain a on aα ≡ sup
x∈SaTx < β ≡ inf
y∈TaT y,
alors pour toute paire (x, y) avec x ∈ S et y ∈ T on a
|x− y| ≥ β − α
|a|(autrement on aurait par l’inegalite de Cauchy (1.2)
aT y − aTx = aT (y − x) ≤ |a||y − x| < β − α,
qui est impossible).Pour prouver la suffisance, considerons l’ensemble Δ = S−T . C’est un ensemble convexe
qui ne contient pas de vecteurs de longueur plus petite que ρ(S, T ) > 0 ; par consequent, iln’intersecte pas la boule B d’un certain rayon positif r centre a l’origine. En consequence,par le Theoreme de Separation Δ peut etre separe proprement de B : il existe a tel que
infz∈B
aT z ≥ supx∈S,y∈T
aT (x− y) & supz∈B
aT z > infx∈S,y∈T
aT (x− y). (3.6)
Du seconde inegalite nous obtenons que a �= 0 ; ainsi infz∈B aT z < 0, et la premiere inegalite
dans (3.6) dit que a separe fortement S et T .
La partie “en particulier” de l’enonce de la proposition est un simple exercice d’analyse :
deux sous-ensembles deRn fermes disjoints non vides dont un est compact sont a une distance
positive l’un de l’autre.
3.2 Theorie de systemes finis d’inegalites lineaires
Le theoreme de separation et l’outil principal que nous avons developpe en le prouvant –le Lemme de Farkas homogene sont des resultats les plus utiles et les plus utilises de l’analyseconvexe. En ce moment nous emploierons le Lemme de Farkas pour obtenir un des resultats lesplus importants de la theorie de systemes (finis) d’inegalites lineaires – le Theoreme General surl’Alternative.
Un systeme fini d’inegalites lineaires peut etre ecrit comme
(I)Sx < pNx ≤ q

3.2. THEORIE DE SYSTEMES FINIS D’INEGALITES LINEAIRES 65
ou x ∈ Rn est le vecteur d’inconnus, S (”stricte”) and N (”non-stricte”) sont des matrices fixesde n colonnes et de certains nombres de lignes, et p, q sont les vecteurs fixes des dimensionsappropriees. Notez que nous pouvons aussi considerer dans ce cadre les egalites lineaires, enrepresentant chaque egalite par une paire d’inegalites opposees non strictes.
La question principale liee au systeme (I) est si le systeme est soluble. Si nous savons repondrea une telle question, nous savons egalement repondre a beaucoup d’autres questions, par exemple,
– si une inegalite lineaire donnee aTx<≤=b est une consequence de (I), c.-a-d. est satisfait
par toutes les solutions du systeme (I)(une inegalite est une consequence de (I) si et seulement si le systeme (I) augmente par lanegation de cette inegalite n’a aucune solution) ;
– si un point donne x qui satisfait (I) minimise la forme lineaire donnee aTx sur l’ensemblede solutions de (I)(en effet, repondre a cette question est la meme chose que dire si le systeme (I) augmented’inegalite aTx < aT x n’a aucune solution) ;etc.
Il est clair comment certifier que (I) a une solution – nous devrions simplement la montrer.Ce qui est bien moins clair, est comment certifier que (I) n’a aucune solution 1. Heureusement,dans notre probleme il existe la condition suffisante pour (I) a etre insoluble :
(*) si vous pouvez deriver a partir des relations du systeme une inegalite evidemment fausse,alors (I) est clairement insoluble.
(*) est une remarque “philosophique”, pas un vrai resultat. Essayons de donner a cetteremarque un sens mathematique : la maniere la plus simple de deriver de (I) une inegalite-consequence est de combiner les inequalities/equations du systeme d’une facon lineaire, c.-a-d.
– multiplier les inegalites strictes par des reels non negatifs et ajouter les inegalitesresultantes, ce qui nous amene a l’inegalite
σTSx ≤ σT p;
ici σ ≥ 0 est le vecteur de nos reels non negatifs. Notez que si σ �= 0, nous avons droit deremplacer dans l’inegalite resultante ≤ avec < ;
– de la meme facon, nous pouvons multiplier les inegalites non strictes par des reels nonnegatifs et ajouter les inegalites resultantes, obtenant l’inegalite
νTNx ≤ νT q;
ici ν ≥ 0 est le vecteur correspondant des reels non negatifs ;– faire la somme des inegalites obtenues, en arrivant a l’inegalite
(σTS + νTN)x ? σT p+ νT q, (3.7)
ou ? doit etre remplace par ≤ dans le cas σ = 0 et par < dans le cas σ �= 0.
1. c’est un phenomene bien connu de la vie quotidienne : il est facile de certifier que vous avez fait quelquechose, par exemple, avez appris le Russe : vous pouvez simplement parler en Russe. Mais comment pourriez-vouscertifier que vous n’avez pas fait quelque chose, par exemple, jamais etudie le Russe ? Un des avantages principauxdu systeme judiciaire dans “des bons pays democratiques”, est que ce n’est pas a vous de montrer que vous n’etespas coupable de quelque chose, c’est les autres qui devraient montrer que vous l’etes

66 CHAPITRE 3. THEOREME DE SEPARATION THEORIE D’INEGALITES LINEAIRES
Nous pouvons faire l’observation suivante
(**) si l’inegalite obtenue (3.7) n’a aucune solution, alors le systeme (I) n’a egalement aucunesolution.
Le fait que notre observation est juste est completement evident de l’origine de (3.7) : parla construction, toute solution a (I) doit satisfaire (3.7).
Maintenant, quand est-ce que l’inegalite lineaire (3.7) n’a aucune solution ? Ceci est le casseulement si son cote gauche est 0 et ne depend pas de la valeur de x, autrement l’inegalite seraitsoluble, independamment de la valeur du cote droit. Ainsi, nous devrions avoir [σTS+νTN ]x = 0pour tout x, ou, ce qui est identique,
STσ +NT ν = 0.
Nos autres conclusions dependent de la valeur de σ : si σ = 0, alors le signe dans l’inegalite est≤, et il n’a aucune solution si le cote droit est strictement negatif ; dans le cas σ �= 0 le signedans l’inegalite est <, et il n’a aucune solution si son cote droit est nonpositive. Ainsi, nousavons etabli le principe suivant :
Pour certifier que (I) n’a pas de solution il suffit de montrer la condition suivante :
( !) : Ils existent des vecteursσ ≥ 0, ν ≥ 0
de dimensions egales au nombre des lignes dans S et N respectivement, tels que
STσ +NT ν = 0,
et, de plus,– dans le cas σ �= 0 : σT p+ νT q ≤ 0 ;– dans le cas σ = 0 : νT q < 0.
Le fait crucial pour la theorie d’inegalites lineaires est que la condition ( !) est non seulementsuffisante, comme nous le venons d’observer, mais egalement necessaire pour que (I) soit unecontradiction :
Theoreme 3.2.1 [Theoreme General sur l’Alternative ] ( !) est necessaire et suffisant pour que(I) n’ait aucune solution.
Nous prouverons la partie “necessite” de ce theoreme (la partie de “suffisance” est deja prouvee)a la fin de cette section. Pour le moment je voudrais faire quelques remarques.
– L’avantage principal du Theoreme 3.2.1 est qu’il reformule un certain resultat negatif –“(I) n’a aucune solution” – comme un resultat positif : existence de certains vecteurs σet ν satisfaisant un certain nombre de relations explicites et verifiables. C’est pourquoi cetheoreme est la clef des nombreux resultats utiles, par exemple, du Theoreme de Dualitepour la Programmation Lineaire.
– Il y a beaucoup de corollaires, ou, plutot, cas particuliers du Theoreme 3.2.1 (nousenumererons certains de ces corollaires ci-dessous). Tous ces cas sont obtenues en specifiantexplicitement la condition ( !) pour la forme particuliere des donnees de (I). Je ne pensepas que vous devriez apprendre “par coeur” toutes les formes particulieres du theoreme ; ilest beaucoup plus facile de se rappeler quelle est la signification reelle du theoreme – “unsysteme des inegalites lineaires n’a aucune solution si et seulement si en combinant d’une

3.2. THEORIE DE SYSTEMES FINIS D’INEGALITES LINEAIRES 67
facon lineaire les inegalites du systeme un peut obtenir une inegalite contradictoire” – etregarder (c’est toujours tout a fait claire) ce qui ce ”recu” signifie dans le cas particulierdans le ca en question.
– La partie la plus importante, celle de la necessite, du Theoreme 3.2.1 est liee fortement aufait que le systeme (I) en question est compose d’inegalites lineaires. Malheureusement,sa generalisation naturelle au cas des inegalites plus generales, par exemple, les inegalitesquadratiques, n’est pas juste. Par exemple, le systeme d’inegalites quadratiques
x2 ≤ 1; y2 ≤ 1; −(x+ y)2 ≤ −5
avec deux inconnus x et y n’a aucune solution ; mais il n’y a pas de combinaison lineairede ces inegalites avec des coefficients non negatifs qui est “clairement contradictoire”, c.-a-d. est de la forme 0 ≤ −1. C’est reellement un desastre – en fait c’est la raison del’existence des problemes combinatoires compliques pour lesquels aucun algorithme desolution “efficace” n’est connu.
Nous allons maintenant formuler quelques cas particuliers du Theoreme 3.2.1 qui sont souventemployes ; c’est un bon exercice de deriver ces corollaires du Theoreme General sur l’Alternative.
Le premier cas est
Theoreme 3.2.2 [Theoreme de Gordan sur l’Alternative] Un des systemes d’inegalites
(I) Ax < 0, x ∈ Rn,
(II) AT y = 0, 0 �= y ≥ 0, y ∈ Rm,
A etant une matrice m× n, a une solution si et seulement si l’autre n’a aucune solution.
Le deuxieme cas particulier est le Lemme de Farkas Homogene qui nous est deja connu. Sa“nouvelle forme” (equivalente a l’original) est suivante :
Theoreme 3.2.3 [Lemme de Farkas Homogene] L’inegalite lineaire homogene
aTx ≤ 0 (3.8)
est une consequence d’un systeme d’inegalites lineaires homogenes
Nx ≤ 0 (3.9)
si et seulement si
a = AT ν
pour un certain vecteur ν non negatif.
Notez que l’implication ”Theoreme 3.2.1⇒Lemme de Farkas Homogene” est sans interet reel –nous n’avons toujours pas montrer la partie de necessite du theoreme ; en fait notre preuve serabasee exactement sur le Lemme de Farkas homogene.
Le cas suivant est
Theoreme 3.2.4 [Lemme de Farkas Non-homogene] Une inegalite lineaire
aTx ≤ p (3.10)

68 CHAPITRE 3. THEOREME DE SEPARATION THEORIE D’INEGALITES LINEAIRES
est une consequence d’un systeme soluble d’inegalites lineaires
Nx ≤ q (3.11)
si est seulement si elle est une “consequence lineaire” du systeme et de l’inegalite triviale
0Tx ≤ 1.
Autrement dit, si elle peut etre obtenue en prenant la somme ponderee, avec des coefficients nonnegatifs, d’inegalites du systeme et de cette inegalite triviale.
La formulation algebrique de cet enonce : (3.10) est une consequence du systeme soluble(3.11) si et seulement si
a = NT ν
pour un vecteur ν non negatif tel queνT q ≤ p.
Le dernier exemple est
Theoreme 3.2.5 [Theoreme de Motzkin sur l’Alternative] Le systeme
Sx < 0, Nx ≤ 0
n’a pas de solutions si et seulement si le systeme
STσ +NT ν = 0, σ ≥ 0, ν ≥ 0, σ �= 0
a une soultion.
3.2.1 Preuve de la partie ”necessite” du Theoreme sur l’Alternative
Nous derivons le resultat du Lemme de Farkas Homogene. La situation est suivante :nous savons que le systeme
(I)Sx < pNx ≤ q
n’a pas de solutions, et nous avons a demontrer l’existence de σ et ν exiges par ( !).A cet effet nous allons etendre notre espace des variables x par trois variables, u, v et t.
On considere le systeme suivant d’inegalites non strictes homogenes :
(I′)
Sx+ ue− vp ≤ 0Nx− vq ≤ 0−u+ t ≤ 0−v + t ≤ 0
,
e etant le vecteur de uns e = (1, ..., 1) de dimension egale au nombre de lignes de S.J’affirme que (I′) implique l’inegalite homogene lineaire
(I′′) t ≤ 0.
En effet, s’il existait une solution (x, u, v, t) de (I′) avec t > 0, on obtiendrait des deuxdernieres inegalites de (I′) u ≥ t > 0, v ≥ t > 0 ; alors les deux premieres inegalites dedans(I′) impliqueraient
Sx
v≤ p− u
ve < p, N
x
v≤ q,

3.2. THEORIE DE SYSTEMES FINIS D’INEGALITES LINEAIRES 69
c.-a-d. (I) serait soluble, ce qui n’est pas le cas par hypothese.Ainsi, (I′) implique (I′′). Par le Lemme de Farkas Homogene, ils existent des vecteurs
non negatifs σ, ν et des reels α, β non negatif tels que le vecteur des coefficients⎛⎜⎝0x0u0v1t
⎞⎟⎠dans la partie gauche de l’inegalite (I′′) (l’indice marque ici la dimension du vecteur corres-pondant) est egal a la matrice transposee du systeme (I) fois le vecteur⎛⎜⎝
σναβ
⎞⎟⎠ .
C.-a-d., ⎛⎜⎝ST NT 0 0eT 0 −1 0−pT −qT 0 −10 0 1 1
⎞⎟⎠⎛⎜⎝σναβ
⎞⎟⎠ =
⎛⎜⎝0x0u0v1t
⎞⎟⎠ .
Autrement dit,
STσ +NT ν = 0; eTσ = α; pTσ + qT ν = −β; α+ β = 1. (3.12)
Montrons que σ et ν sont bien les vecteurs exiges par ( !), ceci accomplira la preuve. En effet,nous savons que σ, ν, (α et β) sont des vecteurs (respectivement, des reels) non negatifs parconstruction ; et nous venons d’etablir que STσ +NT ν = 0.
Maintenant, si σ = 0, alors de la deuxieme relation de (3.12) nous avons α = 0, d’ou,
grace a la quatrieme relation, β = 1. Ainsi, de la troisieme relation, qT ν = pTσ + qT ν < 0,
comme requis dans ( !). Si σ �= 0, alors les conditions de ( !) sont donnes par la troisieme
relation de (3.12).

70 CHAPITRE 3. THEOREME DE SEPARATION THEORIE D’INEGALITES LINEAIRES
3.3 Exercices
Exercice 3.1 Lesquelles des paires (S, T ) d’ensembles ci-dessous sont (a) proprement separeset (b) fortement separes par la forme lineaire f(x) = x1 :
– S = {x ∈ Rn | ∑ni=1 x
2i ≤ 1}, T = {x ∈ Rn | x1 + x2 ≥ 2, x1 − x2 ≥ 0} ;
– S = {x ∈ Rn | ∑ni=1 x
2i ≤ 1}, T = {x ∈ Rn | x1 + x2 ≥ 2, x1 − x2 ≥ −1} ;
– S = {x ∈ Rn | ∑ni=1 |xi| ≤ 1}, T = {x ∈ Rn | x1 + x2 ≥ 2, x1 − x2 ≥ 0} ;
– S = {x ∈ Rn | maxi=1,...,n xi ≤ 1}, T = {x ∈ Rn | x1 + x2 ≥ 2, x1 − x2 ≥ −1} ;– S = {x ∈ Rn | x1 = 0}, T = {x ∈ Rn | x1 ≥
√x22 + ...+ x2n} ;
– S = {x ∈ Rn | x1 = 0}, T = {x ∈ Rn | x1 = 1} ;– S = {x ∈ Rn | x1 = 0, x22 + ...+ x2n ≤ 1}, T = {x ∈ Rn | x1 = 0, x2 ≥ 100} ;– S = {x ∈ R2 | x1 > 0, x2 ≥ 1/x1}, T = {x ∈ R2 | x1 < 0, x2 ≥ −1/x1}.
Faites au moins deux exercices de votre choix parmi les Exercices 3.2 - 3.4 :
Exercice 3.2 Deriver le Theoreme de Gordan sur l’Alternative (Theoreme 3.2.2) du TheoremeGeneral sur l’Alternative
Exercice 3.3 Deriver le Lemme de Farkas Non homogene (Theorem 3.2.4) du TheoremeGeneral sur l’Alternative
Exercice 3.4 Deriver Theoreme de Motzkin sur l’Alternative (Theorem 3.2.5) du TheoremeGeneral sur l’Alternative
Exercice 3.5 Marquer parmi les systemes suivants d’inegalites lineaires avec deux inconnusceux ont des solutions par “s”, ceux qui n’ont pas de solutions par “a” (pour les systemes quisont solubles, precisez une solution ; pour les systemes non soluble, expliquez pourquoi ils lesont) :
–
⎧⎨⎩x+ y ≥ 22x− y ≥ 1−5x+ y ≥ −5
–
⎧⎨⎩x+ y ≥ 22x− y ≥ 1−5x+ y ≥ −4
–
⎧⎨⎩x+ y ≥ 22x− y ≥ 1−5x+ y ≥ −3.5
Exercice 3.6 Considerez l’inegalite lineaire
x+ y ≤ 2
et le systeme d’inegalites lineaires {x ≤ 1−x ≤ −100
Notre inegalite est clairement une consequence du systeme – elle est satisfaite a chaque solutiondu systeme (simplement parce qu’il n’y a aucune solution du systeme du tout). Selon le Lemmede Farkas Non homogene, l’inegalite devrait etre une consequence lineaire du systeme et del’inegalite triviale 0 ≤ 1, c.-a-d. il devrait exister ν1, ν2 non negatifs tels que(
11
)= ν1
(10
)+ ν2
(−10
), ν1 − 100ν2 ≤ 2,

3.3. EXERCICES 71
ce qui n’est certainement pas le cas. Quelle est la raison de la “contradiction” observee ?
Exercice 3.7 � Montrer le resultat suivant :
Soit S un ensemble convexe non vide et ferme de Rn, et soit T = {x} etre unsingleton en dehors de S (x �∈ S). Considerez le programme
min{|x− y| | y ∈ S}.
Le programme est soluble et a une solution unique y∗, et la forme lineaire aTh,a = x− y∗, separe fortement T et S :
supy∈S
aT y = aT y∗ = aTx− |a|2.
Remarque : le resultat ci-dessus est un argument principal de la preuve alternative duTheoreme de Separation. C’est un excellent exercice de deriver le Theoreme de Separation dece resultat.

72 CHAPITRE 3. THEOREME DE SEPARATION THEORIE D’INEGALITES LINEAIRES

Chapitre 4
Points Extremes. Structured’Ensembles Polyhedraux
Le Theoreme de Separation nous permet de mieux comprendre la geometrie d’ensemblesconvexes.
4.1 Description externe d’un ensemble convexe ferme. Plans desupport
Tout d’abord, nous allons prouver la caracterisation “externe” d’un ensemble convexe fermeannoncee dans le Chapitre 2.
Theoreme 4.1.1 Tout ensemble convexe ferme M dans Rn est l’ensemble de solutions d’unsysteme (infini) d’inegalites lineaire non strictes.
Geometriquement : chaque ensemble convexe ferme M ⊂ Rn qui differe du Rn entier est l’in-tersection de demi-espaces fermes, notamment, de tous les demi-espaces fermes qui contiennentM .
Preuve : est deja prete par le Theoreme de Separation. En effet, si M est vide, il n’y a riena prouver – un ensemble vide est une intersection des deux demi-espaces fermes appropries.Si M est l’espace entier, nous avons rien a montrer non plus – selon notre convention, notreespace est la solution du systeme vide d’inegalites lineaires. Maintenant, supposons que M estconvexe, ferme, non vide et different de l’espace entier. Soit x �∈ M ; alors x est a une distancepositive de M parce que M est ferme, et donc il existe un hyperplan approprie qui separe x etM (Proposition 3.1.1) :
∀x �∈M ∃ax : aTxx > αx ≡ supy∈M
aTx y.
Pour tout x �∈ M le demi-espace ferme Hx = {y | aTx y ≤ αx} contient M et ne contient pas x ;par consequent,
M = ∩x �∈MHx
etM n’est pas plus grand (et, bien sur, pas plus petit) que l’intersection de tous les demi-espacesfermes qui contiennent M .
Parmi les demi-espaces fermes qui contiennent un ensembleM ferme convexe et propre (c.-a-d. non vide et different de l’espace entier) les plus interessants sont les demi-espaces “extremes”
73

74 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
– ceux dont l’hyperplan de frontiere toucheM . Cette notion a un sens pour un ensemble convexearbitraire (non necessaire ferme), mais nous l’employons pour un ensemble ferme seulement, etnous allons inclure la condition de fermeture dans le definition :
Definition 4.1.1 [Plan de support] Soit M un ensemble convexe ferme dans Rn, et soit x unpoint de la frontiere relative de M . Un hyperplan
Π = {y | aT y = aTx} [a �= 0]
est appele plan de support de M en x, s’il separe proprement M et {x}, c.-a-d. si
aTx ≥ supy∈M
aT y & aTx > infy∈M
aT y. (4.1)
Notez que puisque x est un point de la frontiere relative de M et donc appartient a clM =M ,la premiere inegalite dans (4.1) est en fait une egalite. Ainsi, une definition equivalente d’unplan de support est comme suit :
Soit M un ensemble ferme convexe et x un point de la frontiere relative de M .L’hyperplan {y | aT y = aTx} est appele plan de support de M en x, si la formelineaire a(y) = aT y atteint en x son maximum sur M et n’est pas constante M .
Par exemple, l’hyperplan {x1 = 1} dans Rn est plan de support a la boule Euclidienne {x ||x| ≤ 1} en x = e1 = (1, 0, ..., 0).
La propriete la plus importante du plan de support est son existence :
Proposition 4.1.1 [Existence de l’hyperplan de support] Soit M un ensemble convexe fermedans Rn et x un point de la frontiere relative de M . Alors
(i) il existe au moins un hyperplan de support de M en x ;
(ii) si Π est plan de support de M en x, alors l’intersection M ∩Π est d’une dimension affinemoindre que celle de M (rappelez vous que la dimension affine d’un ensemble est, par definition,la dimension de son enveloppe affine).
Preuve : (i) est facile : si x est un point de la frontiere relative de M , alors il est exterieur al’interieur relatif de M , et donc {x} et riM peuvent etre separes proprement par le Theoremede Separation ; l’hyperplan de separation est exactement l’hyperplan de support de M en xhyperplan.
Pour prouver (ii) notez que si Π = {y | aT y = aTx} est plan de support de M en x ∈ ∂riM ,alors l’ensemble M ′ =M ∩Π est ensemble convexe non vide (il contient x), et la forme lineaireaT y est constante sur M ′ et donc (pourquoi ?) sur Aff(M ′). En meme temps, la forme n’est pasconstante sur M par definition de plan de support. Ainsi, Aff(M ′) est un sous-ensemble propre(plus petit que Aff(M) entier) de Aff(M), et la dimension affine de Aff(M ′) (c.-a-d. la dimensionaffine de M ′) est plus petite que la dimension de Aff(M) (= la dimension affine de M). 1).
1. ) dans le dernier raisonnement nous avons utilise le fait suivant : si P ⊂ Q sont deux ensemble affines, alorsla dimension affine de P est ≤ que celle de Q, avec ≤ etant = si et seulement si P = Q. Nous connaissons unresultat semblable pour les sous-espaces lineaires (voir Chapitre 1) ; prouvez svp que ce resultat (immediat) estaussi valide pour les ensembles affines

4.2. REPRESENTATIONMINIMALE D’ENSEMBLES CONVEXES : POINTS EXTREMES75
4.2 Representation minimale d’ensembles convexes : pointsextremes
Plan de support est un outil tres utile pour prouver l’existence de points extremes d’unensemble convexe. Geometriquement, un point extreme d’un ensemble convexe M est un pointdeM qui ne peut pas etre obtenu comme une combinaison convexe d’autres points de l’ensemble ;l’importance de cette notion vient du fait (qu’on va prouver entre temps) que l’ensemble de tousles point extremes d’un “assez bon” ensemble convexe M est la “plus courte instruction dumacon pour batir l’ensemble” – c’est le plus petit ensemble de points dont M est l’enveloppeconvexe.
La definition exacte d’un point extreme est comme suit :
Definition 4.2.1 [Point extreme] Soit M un ensemble convexe non vide dans Rn. Un pointx ∈ M s’appelle un point extreme de M , si il n’existe aucun segment [u, v] ∈ M de longueurpositive pour qui x est un point interieur, c.-a-d. si la relation
x = λu+ (1− λ)v
avec un certain λ ∈ (0, 1) et u, v ∈M est possible si et seulement si
u = v = x.
Par exemple, les points extremes d’un segment sont exactement ses extremites ; les pointsextremes d’un triangle sont ses sommets ; les points extremes d’un disque (ferme) dans R2
sont les points du cercle.Nous avons une definition equivalente de points extremes :
Proposition 4.2.1+Un point x d’un ensemble convexe M est extreme si et seulement si l’en-
semble M\{x} est convexe.
Il est clair qu’un ensemble convexeM ne possede pas necessairement de points extremes – prenezcomme exemple la boule unite ouverte dans Rn. Cet exemple n’est pas vraiment interessant –l’ensemble en question n’est pas ferme. En remplacant la boule ouverte avec sa fermeture, onobtient un ensemble (la boule fermee) avec plein de points extremes – ces sont tous les pointsde la frontiere. Ils existent, cependant, des ensembles convexes fermes qui ne possedent pas depoints extremes – par exemple, une droite ou un ensemble affine d’une dimension plus elevee.Un fait bien sympathique est que l’absence de points extremes d’un ensemble M convexe fermea toujours une raison standard – l’ensemble contient une droite. Ainsi, un ensemble convexe Mferme et non vide qui ne contient pas de droites pour sur possede un point extreme. Et si M estnon vide convexe et, en plus, compact, alors il possede un ensemble tout a fait representatif depoints extremes – leur enveloppe convexe est l’ensemble M entier.
Theoreme 4.2.1 Soit M un ensemble convexe ferme et non vide dans Rn. Alors(i) l’ensemble Ext(M) de points extremes de M est non vide si et seulement si M ne contient
pas de droites ;(ii) si M est borne, alors M est l’enveloppe convexe de ses points extremes :
M = Conv(Ext(M)),
de sorte que chaque point de M est une combinaison convexe des points de Ext(M).

76 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
Notez que la partie (ii) de ce theoreme est la version “en dimension finie” du celebre Theoremede Krein-Milman.
Preuve : Commencons par (i). La partie ”seulement si” est facile.
Lemme 4.2.1 Soit M un ensemble convexe ferme dans Rn. Supposons que pourun certain x ∈M et h ∈ Rn M contient le rayon
{x+ th | t ≥ 0}
partant de x et ayant h comme direction. Alors M contient egalement tous les rayonsparalleles commencant en points de M :
(∀x ∈M) : {x+ th | t ≥ 0} ⊂M.
En particulier, si M contient une certaine droite, alors il contient egalement toutesles droites paralleles passant par les points de M .
Commentaire. Pour un ensemble convexe M , l’ensemble de toutes les directionsh tels que x + th ∈ M pour un certain x ∈ M et tous t ≥ 0 (par le lemme, tel quex+ th ∈ M pour tout x ∈ M et tout t ≥ 0) s’appelle cone recessif de M [notation :Rec(M) ]. Avec le Lemme 4.2.1 on voit immediatement (prouvez-le !) que Rec(M)est en effet un cone, et que
M +Rec(M) =M.
Les directions de Rec(M) sont appelees directions recessives pour M .
Preuve du lemme est immediate : si x ∈M et x+ th ∈M pour tout t ≥ 0, alors,du a la convexite, pour tout τ ≥ 0 fixe nous avons
ε(x+τ
εh) + (1− ε)x ∈M
pour tout ε ∈ (0, 1). Quand ε→ +0, l’expression dans le cote gauche tend vers x+τh,et, comme M est ferme, x+ τh ∈M pour tout τ ≥ 0.
Le Lemme 4.2.1 resout nos problemes avec la partie ”seulement si”. En effet, ici nous devonsmontrer que si M possede des points extremes, alors M ne contient pas de droites, ou, ce quiest identique, que si M contient des droites, alors il n’a aucun point extreme. Mais le dernierresultat est immediat : si M contient une droite, alors, par le lemme, il y a toute une droitedans M passant par n’importe quel point donne de M , de sorte qu’aucun point ne puisse etreextreme.
Il nous reste a prouver la partie ”si” de (i). Ainsi, dorenavant nous supposons que M necontient pas de droites ; notre but est de montrer qu’alors M possede des points extremes.Commencons par le suivant
Lemme 4.2.2 Soit Q un ensemble convexe ferme non vide, soit x un point de lafrontiere relative de Q et Π un hyperplan de support a Q en x. Alors tous les pointsextremes de l’ensemble convexe ferme non vide Π∩Q sont aussi les points extremesde Q.
Preuve du lemme : D’abord, l’ensemble Π ∩ Q est ferme et convexe (commel’intersection des ensembles possedant ces proprietes) ; il n’est pas vide, puisqu’il

4.2. REPRESENTATIONMINIMALE D’ENSEMBLES CONVEXES : POINTS EXTREMES77
contient x (Π contient x du a la definition d’un plan de support, et Q contient x dua la fermeture de Q). Deuxiemement, soit a la forme lineaire liee a Π :
Π = {y | aT y = aT x},tel que
infx∈Q
aTx < supx∈Q
aTx = aT x (4.2)
(voir Proposition 4.1.1). Supposons que y est un point extreme de Π∩Q ; nous avonsa montrer que y est un point extreme de Q, c.-a-d. que la decomposition
y = λu+ (1− λ)v
pour certains u, v ∈ Q et λ ∈ (0, 1) est possible seulement si y = u = v. Pour celail suffit de verifier que sous les hypotheses ci-dessus u, v ∈ Π ∩Q c.-a-d. de montrerque u, v ∈ Π, car on sait deja que u, v ∈ Q). En effet nous savons que y est un pointextreme de Π ∩Q, alors la relation y = λu+ (1− λ)v avec λ ∈ (0, 1) et u, v ∈ Π∩Qimplique y = u = v.
Pour montrer que u, v ∈ Π, notez que comme y ∈ Π on a
aT y = aT x ≥ max{aTu, aT v}(la derniere inegalite resulte de (4.2)). Par ailleurs,
aT y = λaTu+ (1− λ)aT v;
en combinant ces observations avec le fait que λ ∈ (0, 1), on deduit que
aT y = aTu = aT v.
Mais ces egalites impliquent exactement que u, v ∈ Π.
Equipes avec le lemme, nous pouvons facilement prouver (i) par induction en dimension del’ensemble M (rappelons, qui c’est la dimension de l’enveloppe affine de M , c.-a-d. la dimensiondu sous-espace lineaire L tel que Aff(m) = a+ L).
Il n’y a rien a montrer si la dimension de M est zero, c.-a-d. si M est un point – alors,naturellement, M = Ext(M). Maintenant, supposons que nous avons deja prouve que Ext(T )est non vide pour tout ensemble T convexe non vide ferme qui ne contient pas de droites dedimension k, et prouvons que le meme resultat est valide pour les ensembles de dimension k+1.Soit M un tel ensemble de dimension k+1. Puisque M est de dimension positive et ne contientpas de droites, il est different de Aff(M) et donc possede un point de frontiere relative x 2). SelonProposition 4.1.1, il existe un hyperplan Π = {x | aTx = aT x} qui supporte M en x :
infx∈M
aTx < maxx∈M
aTx = aT x.
2. )En effet, il existe z ∈ Aff(M)\M , de sorte que le point
xλ = x+ λ(z − x)
(x est un point fixe arbitraire de M) n’appartient pas a M pour un certain λ ≥ 1, tandis que x0 = x appartienta M . L’ensemble des λ ≥ 0 pour lesquels xλ ∈ M est donc non vide et borne au-dessus ; cet ensemble est ferme(puisque M est ferme). Alors, il existe le plus grand λ = λ∗ pour lequel xλ ∈ M . J’affirme que xλ∗ est un pointde la frontiere relative de M . En effet, par construction c’est un point de M . Si xλ∗ est un point de l’interieurde M , alors tout le point xλ avec une valeur λ proche de λ∗ et plus grand que λ∗ appartient a M aussi, ce quicontredit a l’origine λ∗

78 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
Par la meme proposition, l’ensemble T = Π ∩M (qui est ferme, convexe et non vide) est dedimension affine plus petite que celle deM , c.-a-d., de dimension ≤ k. Evidement, T ne contientpas de droites (puisque l’ensemble M plus grand n’en contient pas). Par l’hypothese inductive,T possede un point extreme, et par le Lemme 4.2.2 ce point est aussi extreme pour M . L’etapeinductive est maintenant completee, et (i) est prouve.
Montrons (ii). Ainsi, soit M non vide, convexe, ferme et borne ; nous devons prouver que
M = Conv(Ext(M)).
Il est evident que par convexite de M , l’ensemble a droite est contenu dans celui a gauche. Ilnous reste a prouver que tout x ∈ M est une combinaison convexe des points de Ext(M). Iciencore nous employons l’induction sur la dimension de M . Le cas de dimension 0 (quand Mest un point) est trivial. Supposons que le resultat en question est juste pour tout ensemble k-dimensionnel convexe ferme et borne. Soit M un ensemble convexe ferme et borne de dimensionk + 1. Soit x ∈ M ; pour representer x comme une combinaison convexe des point de Ext(M),dressons a travers x une droite arbitraire l = {x + λh | λ ∈ R} (h �= 0) dans l’enveloppe affineAff(M). En se deplacant le long de cette droite a partir de x dans chacune des deux directionspossibles, nous allons certainement quitter M (puisque M est borne). Comme c’est expliquedans le preuve de (i), cela signifie que il existe λ+ et λ− non negatifs tel que les points
x± = x+ λ±h
appartiennent a la frontiere relative de M . Il nous reste a verifier que x± sont des combinaisonsconvexes des points extremes de M (ca complete la preuve, puisque x est clairement une com-binaison convexe des point x±). En effet, M admet un hyperplan Π de support en x+ ; commec’est explique dans la preuve de (i), l’ensemble Π∩M (qui est convexe, ferme et borne) est d’unedimension plus petite que celle deM ; par l’hypothese inductive, le point x+ de cet ensemble estune combinaison convexe des points extremes de cet ensemble, et par le Lemme 4.2.2 tout cespoints soin aussi les points extremes de M . Ainsi, x+ est une combinaison convexe des pointsextremes de M . Le meme raisonnement est valide pour x−.
4.3 Structure d’ensembles polyhedraux
Comme le premier fruit de notre developpement, nous allons etablir un resultat extremementimportant sur la structure d’un ensemble polyhedral (qui forme la base de la theorie de Pro-grammation Lineaire).
Selon notre definition (Chapitre 2), un ensemble polyhedral M est l’ensemble de solutionsd’un systeme fini d’inegalites lineaires non strices :
M = {x ∈ Rn | Ax ≤ b}, (4.3)
A est une matrice de n colonnes et m lignes et b est un vecteur m-dimensionnel. Ceci est ladescription externe (“artistique”) d’un ensemble polyhedral ; et quelle est sa description interne(“maconnique”) ?
Pour repondre a cette question, considerons la construction suivante. Prenons deux ensemblesde vecteurs fini non vide S (“sommets”) et R (“rayons”) et construisons l’ensemble
M(S,R) = Conv(S) + Cone (R) = {∑s∈S
λss+∑r∈R
μrr | λs ≥ 0, μr ≥ 0,∑s
λs = 1}.

4.3. STRUCTURE D’ENSEMBLES POLYHEDRAUX 79
Ainsi, nous prenons tout vecteur qui peut etre representer comme une somme d’une combinaisonconvexe des points de S et d’une combinaison conique des points de R. L’ensemble M(S,R) estconvexe (comme la somme arithmetique des deux ensembles convexe Conv(S) et Cone (R)). Ladescription interne promise de la structure de l’ensemble polyhedral est suivante :
Theoreme 4.3.1 [Structure d’ensemble polyhedral] Les ensembles de la forme M(S,R) sontexactement les ensembles polyhedraux non vides : M(S,R) est polyhedral, et chaque ensemblepolyhedral non vide M est M(S,R) pour S et R proprement choisis.
Les polytopes M(S, {0}) = Conv(S) sont exactement les ensembles polyhedraux non videset bornes. Les ensembles du type M({0}, R) sont exactement les cones polyhedraux (ensemblesdonnes par un nombre fini d’inegalites lineaires non strictes homogenes).
Remarque 4.3.1 En plus des resultats du theoreme, on peut prouver (nous ne le ferons paspour sauver du temps) que dans la representation d’un ensemble polyhedral non vide M commeM = Conv(S) + Cone (R)
– la partie “conique” Cone (R) (mais pas l’ensemble R lui-meme !) peut etre determine defacon unique parM et est exactement le cone recessif deM (voir le commentaire apres le Lemme4.2.1) ;
– si M ne contient pas de droites, alors S peut etre choisi comme l’ensemble de tous lespoints extremes de M .
Nous allons remettre la preuve du theoreme jusqu’a la fin du chapitre ; en ce moment permettez-moi expliquer pourquoi ce theoreme est si important – pourquoi c’est tellement bien de connaitreles deux descriptions interne et externe de l’ensemble polyhedral.
Nous pouvons se poser plusieurs questions naturelles :– A. Est-il vrai que l’image inverse d’un ensemble polyhedral M ⊂ Rn par une transforma-
tion affine y �→ P(y) = Py + p : Rm → Rn, c.-a-d. l’ensemble
P−1(M) = {y ∈ Rm | Py + p ∈M}
est polyhedral ?– B. Est-il vrai que l’image d’un ensemble polyhedralM ⊂ Rn par une transformation affinex �→ y = P(x) = Px+ p : Rn → Rm, c.-a-d. l’ensemble
P(M) = {Px+ p | x ∈M}
est polyhedral ?– C. Est-il vrai que l’intersection des deux ensembles polyhedraux est aussi un ensemble
polyhedral ?– D. Est-il vrai que la somme arithmetique des deux ensembles polyhedraux est a nouveau
un ensemble polyhedral ?Les reponses a toutes ces question sont, comme nous allons voir, positives ; ce qui est tresinstructif, c’est comment ces reponses sont obtenues.
Il est facile de repondre affirmativement a la question A. a partir de la definition originale –externe – d’un ensemble polyhedral : si M = {x | Ax ≤ b}, alors, naturellement,
P−1(M) = {y | A(Py + p) ≤ b} = {y | (AP )y ≤ b−Ap}
et donc P−1(M) est un ensemble polyhedral.

80 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
Si vous essayez de repondre affirmativement a B. par l’intermediaire de la meme definition,vous risquez de tomber en panne – on ne connait pas de facon simple de mettre a jour les inegaliteslineaires definissant un ensemble polyhedral pour obtenir ceux definissant son image, et il n’estabsolument pas clair pourquoi l’image en question serait donnee par un nombre fini d’inegaliteslineaires. Notez, cependant, que on n’a aucune difficulte pour repondre affirmativement a B.en utilisant la description interne d’un ensemble polyhedral non vide : si M = M(S,R), alors,evidemment,
P(M) =M(P(S), PR),
ou PR = {Pr | r ∈ R} est l’image de R par l’action de la partie homogene de P.De la meme facon, la reponse positive a C. devient evident, si on emploie la description
externe d’un ensemble polyhedral : prendre l’intersection des ensembles de solution des deuxsystemes d’inegalites lineaires non strictes, est exactement la meme chose que simplement mettreensemble toutes les inegalites des deux systemes originaux. Et il est tres difficile de repondre aD. en utilisant la description externe d’un polyhedre – que se passe-t-il avec les inegalites quandon ajoute les solutions des deux systemes ? Contrairement a cela, la description interne donnela reponse immediatement :
M(S,R) +M(S′, R′) = Conv(S) + Cone (R) + Conv(S′) + Cone (R′)= [Conv(S) + Conv(S′)] + [Cone (R) + Cone (R′)]= Conv(S + S′) + Cone (R ∪R′)= M(S + S′, R ∪R′).
Notez que dans ce calcul nous avons utilise deux regles qui doivent etre justifiees : Conv(S) +Conv(S′) = Conv(S + S′) and Cone (R) + Cone (R′) = Cone (R ∪ R′). La seconde est evidentepar la definition de l’enveloppe conique, et seulement la premiere doit etre verifiee. Pour lademontrer, notez que Conv(S) + Conv(S′) est un ensemble convexe qui contient S + S′ et ainsicontient Conv(S + S′). L’inclusion inverse est montree de facon suivante : si
x =∑i
λisi, y =∑j
λ′js′j
sont des combinaisons convexes des points de S, et de S′ respectivement, alors, (verifiez, svp !),
x+ y =∑i,j
λiλ′j(si + s′j)
est la somme a droite est une combinaison convexe des points de S + S′.Nous observons qu’il est extremement utile de garder dans l’esprit les deux description d’en-
sembles polyhedraux – ce qui est difficile a voir avec l’un est absolument clair avec l’autre.Pour une application apparemment “plus importante” de la theorie qu’on vient de developper
considerons la problematique de Programmation Lineaire.
4.3.1 Theorie de Programmation Lineaire
Un probleme general de Programmation Lineaire est celui de maximisation d’un objectif –fonction lineaire sur un ensemble polyhedral :
(P) cTx→ max | x ∈M = {x ∈ Rn | Ax ≤ b};ici c est un vecteur n-dimensionnel donne qu’on appelle objectif, A est unematrice de contraintesm×n donnee et b ∈ Rm vecteur (terme) a droite. On appelle (P) le “programme de Programma-tion Lineaire sous forme canonique” ; il existe d’autres formulations equivalentes du probleme.

4.3. STRUCTURE D’ENSEMBLES POLYHEDRAUX 81
Existence de solutions d’un programme de Programmation Lineaire
Selon la terminologie de Programmation Lineaire, (P) est appele– admissible (faisable), si le systeme Ax ≤ b etre soluble, et non admissible (infaisable)
autrement ;– borne, si il est admissible l’objectif est borne superieurement sur l’ensemble de faisabilite
(l’ensemble de solutions de Ax ≤ b), et non borne, si il est admissible, mais l’objectif n’estpas borne sur l’ensemble de faisabilite ;
– soluble, s’il est faisable et la solution optimale existe – l’objectif atteint son maximum surl’ensemble faisable.
Si le probleme est borne, alors la borne superieure de la valeur de l’objectif sur l’ensemble defaisabilite est un reel ; ce reel est appele valeur optimale du probleme et est note par c∗. Il estcommode d’associer une valeur optimale aux problemes infinies et infaisables – pour un problemenon borne, par definition, cette valeur est +∞, et pour un probleme infaisable elle est −∞.
Notez que notre terminologie vise le probleme de maximisation ; si le probleme est de trouverle minimum de l’objectif, la terminologie peur etre mise a jour de facon evidente : en definissantle probleme borne/non borne, nous devons parler de la borne inferieure plutot que de la bornesuperieure, etc. Par exemple, la valeur optimale infinie pour un probleme de minimisation nonborne sera −∞, et +∞ pour un probleme infaisable. Cette terminologie est conformee avecla maniere habituelle de convertir un probleme de minimisation en un probleme equivalent demaximisation en remplacant l’objectif original c avec −c : les proprietes de faisabilite telles quela bornitude et la solubilite restent inchangees, et la valeur optimale change son signe.
Un fait interessant au sujet de la terminologie de Programmation Lineaire est que lesspecialistes emploient les expressions “programme LP infaisable”, “programme LP non borne”,mais ne parlent jamais de “programme LP borne”, seulement du “programme soluble”. Le pointici est que un programme LP borne est toujours soluble bien que cela n’est absolument pasevident en avance. Avec les outils que nous disposons nous sommes maintenant capable deprouver ce resultat fondamental de Programmation Lineaire.
Theoreme 4.3.2(i) un programme LP est soluble si et seulement s’il est borne.(ii) si le programme est soluble et l’ensemble faisable du probleme ne contient pas de droites,
alors au moins une des solutions optimales est un point extreme de l’ensemble faisable.
Preuve : (i) : la partie “seulement si” du resultat n’est qu’une tautologie : la definition de lasolubilite inclue la bornitude. Ce que nous devons prouver est la partie “ si” – que tout problemeborne est soluble. C’est donne immediatement par la description interne de l’ensemble admissibleM du probleme : c’est un ensemble polyhedral, et comme il n’est pas vide (notre probleme estborne), nous pouvons le representer comme
M(S,R) = Conv(S) + Cone (R)
pour certains ensembles finis non vides S and R. J’affirme tout d’abord que puisque (P) estborne, le produit scalaire de c avec tout vecteur de R est non positif. En effet, autrement ilexiste r ∈ R avec cT r > 0 ; puisque M(S,R) clairement contient avec chaque point x le rayon{x+ tr | t ≥ 0}, et l’objectif est illimite sur ce rayon, il est non borne superieurement sur M , cequi n’est pas le cas.
Maintenant choisissons dans l’ensemble S fini et non vide un point, appele s∗, qui maximisel’objectif sur S. J’affirme que s∗ est une solution optimale de (P), c.-a-d. que (P) est soluble.

82 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
Et je peux justifier immediatement mon affirmation : s∗ appartient a M ; maintenant, un pointgenerique de M =M(S,R) est
x =∑s∈S
λss+∑r∈R
μrr
avec des λs et μr non negatifs et∑
v λv = 1. Ainsi,
cTx =∑
s λscT s+
∑r μrc
T r≤ ∑
s λscT s [car μr ≥ 0 and cT r ≤ 0, r ∈ R]
≤ ∑s λsc
T s∗ [comme λs ≥ 0 et cT s ≤ cT s∗]= cT s∗ [car
∑s λs = 1]
(ii) : si l’ensemble admissible de (P), appelons le M , ne contient pas de droites, est convexeet ferme (tant qu’un ensemble polyhedral) il possede un point extreme. Il en suit que (ii) estvalide dans le cas trivial quand l’objectif de (P) est constant sur l’ensemble admissible, car dansce cas on peut prendre tout point extreme de M comme solution optimale. Le cas d’objectifnonconstant sur M peut etre immediatement reduit au cas trivial ci-dessus : si x∗ est unesolution optimal de (P) et la forme lineaire cTx n’est pas constante sur M , alors l’hyperplanΠ = {x | cTx = c∗} est celui de support a M en x∗ ; l’ensemble Π ∩M est ferme, convexe, nonvide et ne contient pas de droites, il possede donc un point extreme x∗∗ qui, d’une part, est,bien evidement, une solution optimale de (P), et, d’autre part, est un point extreme de M parle Lemme 4.2.2.
Nous allons etablir maintenant le deuxieme resultat fondamental sur Programmation Lineaire– le Theoreme de Dualite ; mis a part des problemes concernant le calcul, on peut dire que LPconsiste, essentiellement, en Theoreme 4.3.2 et Theoreme de Dualite.
Theoreme de dualite pour Programmation Lineaire
On considere un programme LP faisable.En parlant de la valeur optimale de (P), nous faisons en fait certaines affirmations au sujet
d’admissibilite/non admissibilite d’un systeme d’inegalites lineaires. Par exemple, quand on ditque la valeur optimale de (P) est egal a c∗ ∈ R, on dit en fait que le systeme d’inegalites lineaires
(Sα) :cTx > αAx ≤ b
est n’est pas soluble pour α ≥ c∗ et est soluble pour α < c∗.Le Theoreme sur l’Alternative de Chapitre 3 nous dit que la solubilite d’un systeme fini
d’inegalites lineaires est etroitement liee avec l’insolubilite d’un autre systeme d’inegaliteslineaires. Quel sera cet “autre systeme” pour (Sα) ? Non admissibilite de (Sα) pour un certainα signifie que l’inegalite cTx ≤ α est une consequence du systeme soluble d’inegalites Ax ≤ b ;par le Lemme de Farkas Non homogene, c’est le cas si et seulement si le systeme
(S∗α) :
bT y ≤ αAT y = c
y ≥ 0
avec le vecteur d’inconnus y ∈ Rm est soluble. Ainsi, si (P) est faisable, alors

4.3. STRUCTURE D’ENSEMBLES POLYHEDRAUX 83
(*) (Sα) est non soluble pour un α donne si et seulement si (S∗α) est soluble pour cet α.
En consequence, la solubilite du systeme (S∗α) peut aussi etre interprete en termes d’un
certain programme LP, notamment, le programme dual a (P) :
(D) bT y → min | y ∈M∗ = {y ∈ Rm | AT y = c, y ≥ 0}
Precisement, la solubilite de (S∗α) veut dire exactement que (D) est faisable et la valeur optimale
de ce probleme est ≤ α. En fait, nous avons “plus ou moins etabli”
Theoreme 4.3.3 [Theoreme de Dualite en Programmation Lineaire]
(i) (P) est borne si et seulement si (D) est soluble ; (D) est borne si et seulement si (P) estsoluble. Ainsi les deux probleme (P) et (D) sont solubles si et seulement si l’un des deux estborne. Si (P) et (D) sont solubles, alors
(i.1) les valeurs optimales des deux problemes sont egales ;
(i.2) une paire x, y de solutions faisables des problemes est composee de solutions optimales siet seulement si
yT (b−Ax) = 0 [“condition de complementarite”], (4.4)
ou, de facon equivalente, si et seulement si
bT y − cTx = 0 [“saut de dualite nul”] (4.5)
(ii) si (P) n’est pas borne, alors (D) n’est pas admissible ; si (D) n’est pas borne, alors (P)n’est pas admissible.
Remarque 4.3.2 Notez que ”si... alors...” dans (ii) ne peut pas etre remplacer avec ”si etseulement si” – il se peut que les deux (P) et (D) ne sont pas faisables, comme c’est le cas dansl’exemple
(P ) x1 − x2 → max | x1 + x2 ≤ 0, −(x1 + x2) ≤ −1,
(D) − y2 → min y1 − y2 = 1, y1 − y2 = −1, y1, y2 ≥ 0.
Notez egalement que l’enonce de (i) du Theoreme de Dualite implique en fait qu’un programmeLP borne est soluble (en effet, si (P) est borne, alors, par (i), (D) est soluble et donc est borne ;mais si (D) est borne, alors (P), par le meme (i), est soluble). Ainsi, le Theoreme de Dualitecontient en fait l’enonce du (i) du Theoreme d’Existence 4.3.2.
Preuve. (i) : supposons que (P) est borne avec la valeur optimale c∗. Cela signifie que le systeme(Sα) est soluble quelque soit α < c∗ et n’est pas soluble quelque soit α ≥ c∗ ; Comme on sait de(*), ceci signifie exactement que (S∗
α) est soluble quelque soit α ≥ c∗ et n’est pas soluble quelquesoit α < c∗. En d’autres termes, (D) est soluble avec la valeur optimale c∗.
Maintenant on peut repeter ce raisonnement en permutant les roles de (P) et (D). Supposonsque (D) est borne avec la valeur optimal c∗, et montrons que alors (P) est soluble avec la memevaleur optimale. Nos hypotheses a propos de (D) disent exactement que le systeme d’inegaliteslineaires
bT y < αAT y = c
y ≥ 0

84 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
est soluble pour α > c∗ et n’est pas soluble sinon. Afin d’appliquer, comme dans le cas ci-dessus,le Lemme de Farkas Non homogene, nous ecrivons le systeme dans sous la forme equivalente :
(Tα) bT y < α
By ≡⎛⎝ AT
−AT
−I
⎞⎠ y ≤ q ≡⎛⎝ c−c0
⎞⎠ou I est la matrice identite de la meme dimension que b et y. Dire que (Tα) n’est pas soluble estle meme que dire que l’inegalite −bT y ≤ −α est une consequence du systeme By ≤ q. Puisquele probleme dual est faisable, le systeme By ≤ q est soluble ; donc par le Lemme de Farkas nonhomogene, l’inegalite −bT y ≤ −α est une consequence du systeme si et seulement si il exister
un vecteur non negatif σ =
⎛⎝ uvw
⎞⎠ tel que b = σTB et σT q ≤ −α, ou, en d’autres termes, si et
seulement si
−b = Au−Av − w; cT (u− v) ≤ −α.On peut voir immediatement (posez x = v−u) que u, v et w non negatifs qui satisfont la dernierrelation existent si et seulement s’il existe x tel que Ax ≤ b et cTx ≥ α. Ainsi, si (D) est borneavec la valeur optimale c∗, c.-a-d. que le systeme (Tα) est soluble pour α > c∗ et n’est pas solublesinon, alors le systeme d’inegalite
Ax ≤ b, cTx ≥ α
est soluble si α ≤ c∗ et n’est pas soluble sinon. Alors, (P) est soluble avec la valeur optimale c∗.Pour prouver (i.2), supposons qu’un des problemes est soluble ; dans ce cas, selon la partie
deja etablie du resultat, les deux problemes (P) et (D) sont solubles avec la meme valeur optimalec∗. Puisque (P) est un probleme de maximisation et (D) est celui de minimisation, nous avons
cTx ≤ c∗ ≤ bT y
pour toute paire x, y de solutions faisables de (P) et (D) ; par consequent, le saut de dualite
bT y − cTx = [bT y − c∗] + [c∗ − cTx]
sur une telle paire est toujours non negatif et devient nul si et seulement si x est une solutionoptimale de (P) et y est optimale pour (D), comme cela est dit dans (4.5).
(4.4) est une consequence immediate de (4.5) par le raisonnement suivant (ici x est faisablepour (P) et y est faisable pour (D)) :
yT (b−Ax) = yT b− (AT y)x= yT b− cTx [car y est faisable pour (D)]
(ii) : montrons d’abord que si (P) est non borne, alors (D) est infaisable. Non bornitude de(P) signifie exactement que le systeme (Sα) est soluble pour chaque α reel, d’ou, comme on saitdeja de (*), (S∗
α) n’est pas soluble pour tout α ; mais ceci est le meme que de dire que (D) estinfaisable.
Par un raisonnement semblable avec (Tα) jouant le role de (Sα) on demontre que si (D) n’estpas borne, alors (P) est infaisable.

4.4. STRUCTURE D’ENSEMBLES POLYHEDRAUX : PREUVES 85
Dans la preuve du theoreme, nous n’avons pas utilise la symetrie entre le probleme primal
(P) et le dual (D), bien que la dualite LP est completement symetrique : le probleme dual au
dual “est” le meme probleme primal (ici “est” signifie “ est equivalent”). Pourquoi je n’ai pas
profite de cette symetrie est clair – a cause des guillemets dans dans “est” – j’ai prefere de ne
pas gaspiller le temps pour ecrire des formes differentes du programme dual au programme
LP.
4.4 Structure d’ensembles polyhedraux : preuves
Seulement la Section 4.4.1 ci-dessous est obligatoire
4.4.1 Points extremes d’un ensemble polyhedral
Soit
K = {x ∈ Rn | Ax ≤ b},ensemble polyhedral, ou A est une matrice m × n et b un vecteur de Rm. Que sont les pointsextremes de K ?
Theoreme 4.4.1 [Points extremes d’un ensemble polyhedral]
Soit x ∈ K. Le vecteur x est un point extreme de K si et seulement si n certains inegaliteslineairement independantes du systeme Ax ≤ b (c.-a-d., avec les vecteurs de coefficientslineairement independants) sont egalites en x.
Preuve : soit ai, i = 1, ...,m, les lignes de A.
La partie “seulement si” : soit x un point extreme de K, et soit I l’ensemble d’indices i pourlesquels aTi x = bi ; nous avons a prouver que l’ensemble F de vecteurs {ai | i ∈ I} contientexactement n vecteurs lineairement independants, c.-a-d. que Lin(F ) = Rn. Supposez que cen’est pas le cas ; alors le complement orthogonal de F contient un vecteur h non nul (puisquele dimension F⊥ est egal a n − dim Lin(F ), voir Chapitre 1, et donc est positive). Considerezle segment δε = [x− εh, x+ εh], ou ε > 0 est le parametre de notre construction. Puisque h estorthogonal aux vecteurs “actifs” ai – ceux avec i ∈ I, tout point y de ce segment satisfait larelation aTi y = aTi x = bi. Maintenant, si i est un indice “inactif” – celui avec aTi x < bi – alorsaTi y ≤ bi pour tout y ∈ Δε, a condition que ε soit assez petit. Puisque il y a seulement un nombrefini d’indices inactifs, nous pouvons choisir ε > 0 de telle maniere que tout y ∈ Δε satisfait toutesles inegalites “inactives” aTi x ≤ bi, pour i �∈ I. Puisque y ∈ Δε satisfait, comme nous avons vu,aussi toutes les inegalites “actives”, on en conclut que ce choix de ε permet d’obtenir δε ⊂ K,qui est une contradiction : ε > 0 et h �= 0, de sorte que δε est un segment non trivial avec lepoint x ∈ ri δε, et aucun tel segment ne peut pas etre contenu dans K, puisque x etre un pointextreme de K.
Pour prouver la partie “si”, supposons que x ∈ K est tel que parmi les inegalites aTi x ≤ biqui sont des egalites en x il y a n qui sont lineairement independantes, par exemple, ceux avecles indices 1...., n, et montrons que x est un point extreme de K. C’est immediat : en supposantque x n’est pas un point extreme, nous obtiendrions l’existence d’un vecteur non nul h tels quele x± h ∈ K. En d’autres termes, pour i = 1, ..., n nous obtiendrions bi ± aTi h ≡ aTi (x± h) ≤ bi,ce qui est possible seulement si aTi h = 0, i = 1, ..., n. Mais le seul vecteur qui est orthogonalaux n vecteurs lineairement independants de Rn est le vecteur nul, et nous avons h = 0, et ona suppose que ce n’est pas le cas. .

86 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
Corollaire 4.4.1 L’ensemble de points extremes d’un ensemble polyhedral est fini
En effet, selon le theoreme ci-dessus, chaque point extreme d’un ensemble polyhedral K = {x ∈Rn | Ax ≤ b} est donne par le choix d’un sous-ensemble de n inegalites du systeme originalqui sont devenu les egalites, la matrice de ce sous-ensemble etant non singuliere. Ainsi, un pointextreme est uniquement defini par le sous-ensemble correspondant, de sorte que le nombre depoints extremes n’excede pas le nombre Cn
m de sous-matrices n× n de la matrice A.Notez que Cn
m n’est qu’une borne superieure (generalement tres conservatrice) sur le nombrede points extremes d’un ensemble polyhedral donne par m inegalites dans Rn : les sous-matricesn×n de A peuvent etre singulieres et, ce qui est bien plus important, la majorite des matrices nonsingulieres produisent normalement “des candidats” qui ne satisfont pas certaines des inegalitesrestantes.
Remarque 4.4.1 Le resultat du Theoreme 4.4.1 est tres important, en particu-lier, pour la theorie de la Methode de Simplex – l’outil de calcul traditionnel pourla Programmation Lineaire. Une fois applique au programme de LP sous la formecanonique 3)
cTx→ min | Px = p, x ≥ 0 [x ∈ Rn],
avec la matrice P k × n, le resultat du Theoreme 4.4.1 est que les points extremesde l’ensemble faisable sont exactement les solutions faisables de base du systemePx = p, c.-a-d., les vecteurs non negatifs x tels que Px = p et l’ensemble de co-lonnes de P lie aux entrees positives de x est lineairement independant. Puisquel’ensemble faisable d’un programme LP sous la forme standard ne contient pas desdroites, parmi les solutions optimales (si en existe une) d’un programme LP sous saforme canonique au moins un est un point extreme de l’ensemble faisable (Theorem4.3.2.(ii)). Ainsi, en principe nous pourrions tester l’ensemble fini de tous les pointsextremes de l’ensemble faisable (≡ a toutes les solutions faisables de base) et choisircelui avec la meilleure valeur de l’objectif. Cette recette permet de trouver une solu-tion faisable en nombre fini d’operations arithmetiques, a condition que le problemesoit soluble, est ce que fait la Methode de Simplex ; cette derniere parcourt les solu-tions faisables de base d’une maniere tres futee qui permet de tester seulement unepartie negligeable de solutions candidates.
Une autre consequence utile du Theoreme 4.4.1 est que si toutes les donneesdans un programme de LP sont rationnelles, alors n’importe quel point extremedu domaine faisable du programme est un vecteur avec les entrees rationnelles. Enparticulier, un programme soluble de LP dans la forme standard avec des donneesrationnelles a au moins une solution optimale rationnelle.
4.4.2 Structure d’un polyhedre borne
Maintenant nous pouvons prouver une partie importante du Theoreme 4.3.1 – celle quidecrit la structure d’ensembles polyhedraux bornes.
Theoreme 4.4.2 [structure d’ensembles polyhedraux bornes] Un ensemble polyhedral bornenon vide M dans Rn est un polytope, c.-a-d., une enveloppe convexe d’un ensemble non videfini :
M =M(S, {0}) = Conv(S);
on peut choisir comme S l’ensemble de tous les points extremes de M .
3. )plutot une des formes canoniques, cf. le probleme dual (D) au probleme LP dans la Section 4.3.1

4.4. STRUCTURE D’ENSEMBLES POLYHEDRAUX : PREUVES 87
Vice versa – un polytope est un ensemble polyhedral borne et non vide.
Preuve : la premiere partie du resultat – qu’un ensemble polyhedral non vide borne est unpolytope – decoule du Theoreme de Krein-Milman combine avec le Corollaire 4.4.1. En effet,un ensemble polyhedral est toujours ferme (comme ensemble donne par des inegalites nonstrictes impliquant des fonctions continues) et convexe ; s’il est egalement borne et non vide,il est, par le Theoreme de Krein-Milman, l’enveloppe convexe de l’ensemble S de ses pointsextremes ; S est fini par Corollary 4.4.1.
Maintenant prouvons la partie plus difficile du resultat – qu’un polytope est un ensemblepolyhedral borne. Le fait que l’enveloppe convexe d’un ensemble fini est borne est evident.Ainsi, tout ce que nous avons a montrer est que l’enveloppe convexe d’un ensemble finiede points est un ensemble polyhedral. La preuve passe par un concept geometrique tresinteressant et utile – le polaire d’un ensemble.
Le polaire d’un ensemble convexe
SoitM ⊂ Rn un ensemble convexe ferme qui contient 0. Le polaire deM (note Polar (M))est defini comme ensemble de tous les vecteurs f qui ont les produits scalaires avec tous lesvecteurs de M n’excedant pas 1 :
Polar (M) = {f | fTx ≤ 1 ∀x ∈M}.Le polaire d’un ensemble est non vide – il contient 0. Notez egalement que le polaire est uneextension naturelle de la notion de complement orthogonal a un sous-espace lineaire : si Mest un tel sous-espace, alors Polar (M), comme on le voit immediatement, est exactementM⊥
(puisqu’une forme lineaire peut etre bornee par 1 sur un sous-espace lineaire si et seulement sielle est identiquement nulle sur le sous-espace). Nous avons l’extension suivante de la formule
(L⊥)⊥ = L [L est un sous-espace lineaire] :
Lemme 4.4.1 Pour tout ensemble convexe ferme M qui contient 0 son polaire Polar (M)est egalement un ensemble convexe et contenant 0, et
Polar (Polar (M)) =M. (4.6)
Preuve : soit M ferme, convexe et 0 ∈M .Le fait que Polar (M) est convexe et ferme, est evident – c’est l’ensemble donne par un
systeme (infini) d’inegalites lineaires non strictes xT f ≤ 1 parametrees par x ∈M , et chaqueensemble de ce type, comme nous le savons, est ferme et convexe. Nous avons deja mentionneque Polar (M) contient 0.
Il reste a verifier (4.6). Il est absolument clair de la definition du polaire que M ⊂Polar (Polar (M)) (si x ∈ M , puis xT f ≤ 1 pour tout le f ∈ Polar (M) par la constructionde Polar (M), d’ou, encore par la construction, x ∈ Polar (Polar (M))). Ainsi, il nous restea montrer que Polar (Polar (M)) ne contient que des points de M . Suppose, au contraire,qu’un element z de Polar(M) tel que z �∈ M , existe. Puisque M est ferme, convexe, n’estpas vide et z �∈M , M et {z} peuvent etre fortement separes (Proposition 3.1.1) : il existe φtel que
φT z > α ≡ supx∈M
φTx.
Comme 0 ∈M , α ≥ 0, il existe β positif, disons, β = 12 (φ
T z + α), tel que
φT z > β > supx∈M
φTx.
Et si on divise par β > 0 et on pose f = β−1φ, nous avons
fT z > 1 > supx∈M
fTx.

88 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
Ici l’inegalite a droite implique que f ∈ Polar (M) ; mais dans ce cas l’inegalite a gauchecontredit a l’origine de z qui est un point de Polar (Polar (M)).
Remarque 4.4.2 La notion du polaire a un sens pour un ensemble non videarbitraire M , pas necessairement ferme, convexe ou contenant zero. Pour M nonvide arbitraire nous avons
Polar (M) = Polar (cl Conv(M ∪ {0})).Cette identite combinee avec (4.6) conduit a l’identite
Polar (Polar (M)) = clConv(M ∪ {0}) [M �= ∅],qui est de nature bien similaire a l’identite pour le complement orthogonal :
(M⊥)⊥ = Lin(M) [M �= ∅].Si M est un ensemble convexe ferme contenant zero, alors Polar (M) se rappelle de tout
M (M peut etre reconstitue par l’intermediaire de son polaire en appliquant la polarite denouveau, voir (4.6)). Il est tres utile de savoir quelles sont les proprietes du polaire respon-sables de telles et de telles proprietes de l’ensemble. Voici un exemple simple d’un resultatdans ce genre :
Proposition 4.4.1+Soit M un ensemble convexe ferme dans Rn et 0 ∈ M . Alors 0 ∈
int M si et seulement si Polar (M) est borne.
Fin de la preuve du Theoreme 4.4.2
Maintenant nous pouvons accomplir la preuve du Theoreme 4.4.2. Pour rendre notreterminologie plus compacte, nous allons provisoirement appeler les polytopes – les enveloppesconvexes des ensembles finis non vides – S-ensembles (“S” du “sommet”), et les ensemblesnon vides polyhedraux bornes – PB-ensembles (“P” du “polyhedral” et “B”, du “borne”).De la partie deja prouvee du theoreme nous savons que chaque PB-ensemble est aussi un S-ensemble, et ce que nous devrions prouver est que chaque S-ensembleM est un PB-ensemble.
Soit M = Conv({s1..., sn}) un S-ensemble, montrons qu’il est un PB-ensemble. Commed’habitude, nous pouvons supposer sans perte de generalite que l’ensemble est de dimensionn 4). Ainsi, nous pouvons supposer que int M �= ∅. Par translation, nous pouvons egalementnous assurer que 0 ∈ int M . Maintenant regardons le polaire M∗ = Polar (M) de M . Selonla Proposition 4.4.1, cet ensemble est borne. J’affirme que cet ensemble est egalement po-lyhedral. En effet, un point f appartient a M∗ si et seulement si fTx ≤ 1 pour tous les xqui sont des combinaisons convexes des points s1..., sn, ou,ce qui est identique, f ∈ M∗ siet seulement si fT si ≤ 1, i = 1..., n. Ainsi, M∗ est donne par un systeme fini d’inegaliteslineaires non strictes
sTi f ≤ 1, i = 1, ..., N
et donc polyhedral.Maintenant nous sommes faits. M∗ est PB-ensemble, et donc, comme nous savons deja,
il est S-ensemble. Par ailleurs, M∗ est le polaire d’un ensemble borne et donc 0 est unpoint interieur de M∗ (Proposition 4.4.1). Mais nous venons de montres que le polaire deS-ensemble avec 0 dans son interieur est un PB-ensemble. Ainsi, le polaire a M∗ – et c’estM par le Lemme 4.4.1 – est un PB-ensemble.
4. ) et voici la justification : par un decalage de M , nous pouvons supposer que M contient 0 ; en remplacantRn par Lin(M) nous obtenons la situation quand l’interieur de M est non vide. Etant donne que le resultat quenous prouvons est valide dans le cas particulier quand S-ensemble en question possede l’interieur non vide, nouspouvons conclure que M , comme un sous-ensemble de L, est defini par un systeme fini d’inegalites lineaires nonstrictes. En ajoutant a ces inegalites les inegalites lineaires qui definissent L – nous savons du Chapitre 1 qu’unsous-espace lineaire est un ensemble polyhedral – nous obtenons la description polyhedral desiree de M commeun sous-ensemble de Rn.

4.4. STRUCTURE D’ENSEMBLES POLYHEDRAUX : PREUVES 89
4.4.3 Structure d’un ensemble polyhedral general : fin de la preuve
Maintenant prouvons le Theoreme 4.3.1 dans le cas general. La preuve suit les lignes decelle du Theoreme 4.4.2, mais avec une difference significative : maintenant nous n’avonsplus de Theoreme de Krein-Milman pour nous debarrasser d’une partie de difficultes.
Comme ci-dessus, pour simplifier notre language nous allons appeler SR-ensemble (“S” du“sommet”, “R” du “rayon”) les ensembles de la formeM(S,R), et P-ensembles les ensemblespolyhedraux non vides. Nous devrions montrer que chaque P-ensemble est SR-ensemble, etvice versa. Nous commencons par montrer que chaque P-ensemble est un SR-ensemble.
Implication P⇒SR
P⇒SR, Etape 1 : reduction au cas quand le P-ensemble ne contient pasde droites. Soit M un P-ensemble, de sorte que M est l’ensemble de toutes les solutionsd’un systeme soluble d’inegalites lineaires :
M = {x ∈ Rn | Ax ≤ b} (4.7)
avec une matrice A m × n . Un tel ensemble peut contenir des droites ; si h est la directiond’une droite dans M , alors A(x + th) ≤ b pour certains x et tout t ∈ R, qui est possibleseulement si Ah = 0. Vice versa, si h est dans le noyau de A, c.-a-d., si Ah = 0, alors ladroite x+Rh avec x ∈M est contenue dans M . ainsi, nous venons au suivant
Lemme 4.4.2 L’ensemble polyhedral non vide (4.7) contient des droites si etseulement si le noyau de A est non trivial, et les vecteurs non nuls du noyau sontexactement les directions des droites contenues dans M : si M contient une droitedirigee par h, alors h ∈ KerA, et, reciproquement, si 0 �= h ∈ KerA et x ∈ Malors M contient la droite entiere x+Rh.
Etant donne un ensemble non vide (4.7), notons L = KerA le noyaux de A et L⊥ lecomplement orthogonal du noyau. Soit M ′ la section transversale de M par L⊥ :
M ′ = {x ∈ L⊥ | Ax ≤ b}.L’ensemble M ′ ne contient pas de droites (car le vecteur-directeur de n’importe quelle droitedans M ′, d’une part, devrait appartenir a L⊥ en raison M ′ ⊂ L⊥, et d’autre part, devraitappartenir a L = KerA, puisqu’une droite dans M ′ ⊂M est une droite dans M aussi bien).L’ensemble M ′ est non vide et, de plus, M = M ′ + L. En effet, M ′ contient les projectionsorthogonales de tous les points deM sur L⊥ (car pour projeter un point sur L⊥, vous devriezvous deplacer de ce point suivant une certaine droite avec la direction dans L, et tous cesdeplacements qui commencent dans M , restent dans M par le Lemme) Ainsi M ′ est nonvide, et tel que M ′ + L ⊃ M . D’autre part, M ′ ⊂ M et M + L = M par le Lemme 4.4.2,d’ou M ′ + L ⊂M , et, effectivement, M ′ + L =M .
Les resultats de nos efforts sont comme suit : etant donne un P-ensemble arbitraire M ,nous l’avons represente comme une somme d’un P-ensemble M ′ ne contenant pas de droiteset un sous-espace lineaire L Avec cette decomposition dans l’esprit nous voyons qu’afin derealiser notre objectif – montrer que chaque P-ensemble est SR-ensemble – il suffit de montrerce resultat pour des P-ensembles qui ne contiennent pas de droites. En effet, siM ′ =M(S,R′)en notant par R′ l’ensemble fini tels que L = Cone (R′) (pour obtenir R′, prenez l’ensemblede 2 dim L vecteurs ±ai, i = 1, ..., dim L ou a1, ..., adim L est une base de L) nous obtenons
M = M ′ + L= [Conv(S) + Cone (R)] + Cone (R′)= Conv(S) + [Cone (R) + Cone (R′)]= Conv(S) + Cone (R ∪R′)= M(S,R ∪R′)
(la quatrieme egalite evidente dans la chaine nous est deja connue).

90 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
P⇒SR, etape 2 : P-ensemble ne contient pas de droites. Nous sommes donnesun P-ensemble dans Rn ne contenant pas de droites et nous devons montrer que c’est un SR-ensemble. Nous prouverons ce resultat par induction sur la dimension n de l’espace. Le casde n = 0 est trivial. Supposons maintenant que le resultat en question est valide pour n ≤ k,et essayons de montrer qu’il est valide egalement pour n = k + 1. Soit M un P-ensemble enquestion dans Rk+1 :
M = {x ∈ Rk+1 | aTi x ≤ bi, i = 1, ...,m}. (4.8)
Sans perte de generalite nous pouvons supposer que tous les ai sont des vecteurs non nul(comme M est non vide, les inegalites avec ai = 0 sont satisfaites sur Rn entier, et en lesenlevant du systeme, nous ne changeons pas l’ensemble de solutions). Notez que m > 0, carautrement M contiendrait des droites, pour k ≥ 0.
10. Supposons que M n’est pas borne, car autrement le resultat desire est donne parTheorem 4.4.2. J’affirme qu’il existe une direction recessive de M (voir le commentaire auLemme 4.2.1). En effet, soit x ∈ M , et soit xi ∈ M une suite des vecteurs avec les normesconvergeant vers ∞ (une telle suite existe, si M n’est pas borne). Considerez la suite devecteurs unitaires
ri = |xi − x|−1(xi − x).
puisque la boule unite dans Rn est compacte, en passant a une subsequence nous pouvonssupposer que les vecteurs ri convergent vers un vecteur unitaire r non nul. Ce vecteur r estla direction demandee. En effet, si t ≥ 0, alors les vecteurs
xti = x+ tri = x+t
|xi − x| (xi − x)
pour tout i assez grand (ceux pour lesquels |xi − x| ≥ t) sont les combinaisons convexes dex et xi et appartiennent donc a M . Comme i → ∞, ces vecteurs convergent vers x + tr,et comme M est ferme, nous concluons que x + tr ∈ M pour tout t non negatif. Ainsi, Mcontient le rayon {x+ tr | t ≥ 0}, d’ou, par le Lemme 4.2.1, M +Cone ({r}) =M .
20. Pour chaque i ≤ m, m etant le nombre de lignes de A dans (4.8), c.-a-d., le nombred’inegalites lineaires dans la description de M , notons par Mi la “facette” correspondantede M – l’ensemble polyhedral indique par le systeme d’inegalites (4.8) dans lequel l’inegaliteaTi x ≤ bi est remplace par l’egalite aTi x = bi. Certaines de ces “facettes” peuvent etre vides ;soit I l’ensemble d’indices i de facettes Mi non vides.
Quand i ∈ I, l’ensemble Mi est un ensemble polyhedral non vide, c.-a-d., un P-ensemble– qui ne contient pas de droites (puisque Mi ⊂ M et M ne contient pas de droites). Parailleurs, Mi appartient a l’hyperplan {aTi x = bi}, c.-a-d., est en fait un P-ensemble dans Rk.Par l’hypothese inductive, nous avons des representations
Mi =M(Si, Ri), i ∈ I,
pour les ensembles Si et Ri non vides finis correctement choisis. Je pretends que
M =M(∪i∈ISi,∪i∈IRi ∪ {r}), (4.9)
ou r est la direction recessive de M trouve dans 10 ; pour completer notre preuve inductiveil nous reste a verifier cette affirmation,
Pour montrer (4.9), notez, tout d’abord, que l’ensemble sur le cote droit de cette relationest contenu dans celui a gauche. En effet, comme Mi ⊂M et Si ⊂Mi, nous avons Si ⊂ M ,et, egalement, S = ∪iSi ⊂M ; puisque M est convexe, nous avons
Conv(S) ⊂M. (4.10)
De plus, si r′ ∈ Ri, alors r′ est une direction recessive de Mi ; et comme Mi ⊂ M , r′ est
une direction recessive de M par le Lemme 4.2.1. Ainsi, chaque vecteur de ∪i∈IRi est une

4.4. STRUCTURE D’ENSEMBLES POLYHEDRAUX : PREUVES 91
direction recessive pour M , de meme pour r ; ainsi, chaque vecteur de R = ∪i∈IRi ∪ {r} estune direction recessive de M , d’ou, encore par le Lemme 4.2.1,
M +Cone (R) =M.
En combinant cette relation avec (4.10), nous obtenons M(S,R) ⊂M , comme demande.Il nous reste a montrer que M est contenu dans l’ensemble sur le cote droit de (4.9).
Soit x ∈ M , deplacons-nous a partir de x dans la direction (−r), c.-a-d., le long du rayon{x − tr | t ≥ 0}. Pour un t assez grand le point x − tr quitte M (en effet, autrement lerayon avec la direction −r qui commence en x serait contenu dans M , alors que le rayonoppose pour sur est contenu dans M puisque r est une direction recessive de M ; maisc’aurait dit que M contient une droite, qui n’est pas le cas par hypothese.) Comme le rayon{x − tr | t ≥ 0} quite M et M est ferme, il existe le plus grand t, que l’on appelle t∗, telsque x′ = x − t∗r appartient encore a M . Il est absolument clair qu’en x′ une des inegaliteslineaires definissant M devienne egalite, autrement nous pourrions legerement augmenterle parametre t∗ en restant toujours dans M . Ainsi, x′ ∈ Mi pour un certain i ∈ I. Enconsequence,
x′ ∈ Conv(Si) + Cone (Ri),
et x = x′ + t∗r ∈ Conv(Si) + Cone (Ri ∪ {r}) ⊂M(S,R), comme demande.
SR⇒P
Nous savons deja que chaque P-ensemble est un SR-ensemble. Maintenant nous mon-trerons que chaque SR-ensemble est un P-ensemble, de ce fait accomplissant la preuve duTheoreme 4.3.1. Comme dans la preuve du Theoreme 4.4.2, ceci sera fait en utilisant lanotion de l’ensemble polaire.
Ainsi soit M un SR-ensemble :
M =M(S,R), S = {s1..., sN}, R = {r1..., rM};
nous devons montrer que c’est un P-ensemble. Sans perte de generalite nous pouvons supposerque 0 ∈M .
10. Soit M∗ le polaire de M . J’affirme que M∗ est un P-ensemble. En effet, f ∈M∗ si etseulement si fTx ≤ 1 pour chaque x de la forme
(combinaison convexe de si) + (combinaison conique de rj),
c.-a-d., si et seulement si fT rj ≤ 0 pour tous j (autrement fTx n’est pas borne sur M) etfT si ≤ 1 pour tous i. Ainsi,
M∗ = {f | sTi f ≤ 1, i = 1..., N, rTj f ≤ 0, j = 1..., n}
est un P-ensemble.20. Maintenant nous sommes faits : M∗ est un P-ensemble, et par consequent - nous le
savons deja – est SR-ensemble. Par 10, le polaire d’un SR-ensemble est un P-ensemble ; ainsi,
M = Polar (M∗) [voir (4.6)]
est un P-ensemble.
Le Theoreme 4.3.1 dit egalement que les ensembles du type M(S, {0}) sont exactementles ensembles polyhedraux bornes (nous avons deja verifie ceci dans le Theoreme 4.4.2) etque les ensembles du type M({0}, R) sont exactement les cones polyhedraux, c.-a-d., ceuxdonnes par des systemes finis d’inegalites lineaires homogenes non strictes. Ce dernier faitest tout ce que nous avons encore a prouver. C’est facile :

92 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
D’abord, montrons qu’un cone polyhedralM peut etre represente commeM({0}, S) pourcertain S . Comme tout ensemble polyhedral, M peut etre represente comme
M = Conv(S) + Cone (R); (4.11)
puisque, pour des raisons evidentes, Conv(S) ⊂ Cone (S), on obtient
M ⊂ Cone (S) + Cone (R) = Cone (S ∪R). (4.12)
Puisque M , etant un cone, contient 0, et, d’autre part,
M +Cone (R) = Conv(S) + Cone (R) + Cone (R) = Conv(S) + Cone (R) =M
(puisque Cone (R) + Cone (R) est identique au Cone (R)), nous obtenons
Cone (R) = 0 + Cone (R) ⊂M +Cone (R) =M ;
comme Cone (R) ⊂ M par (4.11) et S ⊂ M , le cote droit de (4.12) est l’enveloppe coniquedes vecteurs deM et donc un sous-ensemble du cone M . Ainsi, l’inclusion dans (4.12) est enfait egalite, et M =M({0}, S ∪R), comme exige.
Il reste a demontrer que l’ensemble du type M = M({0}, R) – qui est clairement uncone – est un cone polyhedral. En tant qu’un SR-ensemble, M est donne par un systeme finid’inegalites,
aTi x ≤ bi, i = 1, ...,m,
et tout ce que nous devrions prouver est que on peut choisir les inegalites homogenes (avec
bi = 0) dans le systeme. C’est immediat : comme M est un cone, pour n’importe quelle
solution x du systeme ci-dessus tous les vecteurs tx, t ≥ 0, sont egalement des solutions, ce
qui est possible si et seulement si bi ≥ 0 pour tous i et aTi x ≤ 0 pour toutes les i et toutes les
solutions x du systeme. Il suit qu’en “renforcant” le systeme, c.-a-d., en remplacant bi ≥ 0
par bi = 0, et de ce fait rendant le systeme homogene, nous ne changeons pas l’ensemble de
solutions.

4.5. EXERCICES 93
4.5 Exercices
Exercice 4.1 Prouver la Proposition 4.2.1.
Exercice 4.2 Soit M ensemble convexe dans Rn et x un point extreme de M . Montrez que si
x =m∑i=1
λixi
est une representation de x comme une combinaison convexe des points xi ∈ M avec des poidspositifs λi, alors x = x1 = ... = xm.
Exercice 4.3 Soit M ensemble convexe ferme dans Rn et x un point de M . Montrez que s’ilexiste une forme lineaire aTx telle que x est le minimiseur unique de la forme sur M , alors xest un point extreme de M .
Exercice 4.4 Trouvez tous les points extremes de l’ensemble
{x ∈ R2 | −x1 + 2x2 ≤ 8, 2x1 + x2 ≤ 9, 3x1 − x2 ≤ 6, x1, x2 ≥ 0}.Exercice 4.5 Marquez avec ”o” les enonces justes ci-dessous :
– si M est un ensemble convexe non vide dans Rn qui ne contient pas de droites, alors Mpossede un point extreme ;
– si M est un ensemble convexe dans Rn qui a un point extreme, alors M ne contient pasde droites ;
– si M est un ensemble convexe ferme et non vide dans Rn qui ne contient pas de droites,alors M a un point extreme ;
– si M est un ensemble convexe ferme dans Rn qui possede un point extreme, alors M necontient pas de droites ;
– si M est un ensemble convexe non vide borne dans Rn, alors M est l’enveloppe convexede Ext(M)
– si M est un ensemble convexe non vide borne et ferme dans Rn, alors M est l’enveloppeconvexe de Ext(M)
– si M est un ensemble convexe non vide ferme dans Rn qui est egal a l’enveloppe convexede Ext(M), alors M est borne.
Exercice facultatif : Theoreme de Birkhoff
Exercice 4.6 Une matrice π n×n s’appelle double stochastique, si toutes ses entrees sont nonnegatives, et les sommes d’entrees dans chaque ligne et chaque colonne sont egales a 1, commec’est le cas avec la matrice identite ou, plus generalement, avec une matrice de permutation –celle qui a exactement une entree non nulle (egale a 1) dans chaque colonne et chaque ligne,par exemple,
π =
⎛⎝ 0 1 00 0 11 0 0
⎞⎠ .
Les matrices double stochastiques d’un ordre donne n forment un ensemble polyhedral convexeborne et non vide D dans Rn×n. Quels sont les points extremes de cet ensemble ? La reponseest donnee par le suivant

94 CHAPITRE 4. POINTS EXTREMES. STRUCTURE D’ENSEMBLES POLYHEDRAUX
Theoreme 4.5.1 (Birkhoff) Les points extremes du polytope D de matrices double stochastiquen× n sont exactement les matrices de permutation d’ordre n.
Essayez de prouver le Theoreme.
Le Theoreme de Birkhoff est la source des nombreuses inegalites importantes ; certaines de cesinegalites seront le sujet d’exercices facultatifs des prochains chapitres.

Chapitre 5
Fonctions Convexes
5.1 Fonctions convexes : premier abord
5.1.1 Definitions et Exemples
Definition 5.1.1 [Fonction convexe] Fonction f : Q → R defini sur un sous-ensemble Q nonvide de Rn a valeurs reelles s’appelle convexe, si
le domaine Q de la fonction est convexe ;– pour tous x, y ∈ Q et chaque λ ∈ [0, 1],
f(λx+ (1− λ)y) ≤ λf(x) + (1− λ)f(y). (5.1)
Si l’inegalite ci-dessus est stricte quelques soient x �= y et 0 < λ < 1, la fonction f s’appellestrictement convexe.
Fonction f telle que −f est convexe s’appelle concave ; le domaine Q d’une fonction concavedoit etre convexe, et la fonction elle-meme doit satisfaire l’inegalite opposee de (5.1) :
f(λx+ (1− λ)y) ≥ λf(x) + (1− λ)f(y), x, y ∈ Q,λ ∈ [0, 1].
L’exemple le plus simple d’une fonction convexe est la fonction affine
f (x) = aTx+ b
– la somme d’une forme lineaire et d’une constante. Cette fonction est convexe sur l’espaceentier, et le “d’inegalite de convexite” devient egalite pour cette fonction ; la fonction affine estegalement concave. On montre facilement que la fonction qui est convexe et concave sur l’espaceentier est une fonction d’affine.
Voici quelques exemples elementaires des fonctions convexes de “non-lineaires” d’une va-riable :
– fonctions convexes sur l’axe entier :x2p, p etant un entier positif ;exp{x} ;
– fonctions convexes sur le rayon non negatif :xp, 1 ≤ p ;−xp, 0 ≤ p ≤ 1 ;x lnx ;
95

96 CHAPITRE 5. FONCTIONS CONVEXES
– fonctions convexe sur le rayon positif :1/xp, p > 0 ;− lnx.
Pour l’instant il n’est pas clair pourquoi ces fonctions sont convexes ; nous allons bientotderiver un critere analytique simple pour detecter la convexite qui nous permettra de montrerimmediatement que les fonctions ci-dessus sont en effet convexes.
Une definition equivalente tres commode d’une fonction convexe est donnee en termes de sonepigraph. Etant donne une fonction a valeurs reelles f , definie sur un sous-ensemble non vide Qde Rn, nous definissons son epigraph comme ensemble
Epi(f) = {(t, x) ∈ Rn+1 | x ∈ Q, t ≥ f(x)};geometriquement, pour definir l’epigraph, vous devez prendre le graphe de la fonction – la surface{t = f(x), x ∈ Q} dans Rn+1 – et ajouter a cette surface tous les points qui sont “au-dessus”.La definitions geometrique (equivalente) d’une fonction convexe est donne par
Proposition 5.1.1+
[Definition de la convexite en termes d’epigraph] La fonction f definiesur un sous-ensemble de Rn est convexe si et seulement si son epigraph est un ensemble convexenon vide dans Rn+1.
Plus d’exemples de fonctions convexes : les normes. En utilisant la Proposition 5.1.1,nous pouvons prolonger notre liste initiale de fonctions convexes (certaines fonctions unidimen-sionnelles et affine) avec des normes. Comme nous nous rappelons du Chapitre 1, une fonctiona valeurs reelles π(x) sur Rn s’appelle une norme, si elle est non negative partout etant nulleseulement en zero, est homogene :
π(tx) = |t|p(x)et satisfait l’inegalite de triangle
π(x+ y) ≤ π(x) + π(y).
Pour l’instant nous connaissons trois exemples de normes – la norme Euclidienne |x| =√xTx,
la norme-1 |x|1 =∑
i |xi| et la norme-infty |x|∞ = maxi |xi|. Il etait aussi reclame (bien quepas verifie) que ces sont trois membres d’une famille infinie de, de normes
|x|p =(
n∑i=1
|xi|p)1/p
, q ≤ p ≤ ∞
(|x| est exactement |x|2, et la partie a droite dans cette relation avec p = ∞ est par definition,maxi |xi|).
Nous sommes sur le point de montrer que chaque norme est convexe :
Proposition 5.1.2 Soit π(x) une fonction a valeurs reelles sur Rn qui est positivement ho-mogene de degre 1 :
π(tx) = tπ(x) ∀x ∈ Rn, t ≥ 0.
π est convexe si et seulement si elle est sous-additive :
π(x+ y) ≤ π(x) + π(y) ∀x, y ∈ Rn.
En particulier, une norme (qui par definition est positivement homogene de degre 1 et est sous-additive) est convexe.

5.1. FONCTIONS CONVEXES : PREMIER ABORD 97
Preuve est immediate : l’epigraph d’une fonction π positivement homogene du degre 1 estun ensemble conique : (t, x) ∈ Epi(π) → λ(t, x) ∈ Epi(π) pour tous λ ≥ 0. Maintenant, parProposition 5.1.1 π est convexe si et seulement si epi(π) est convexe. De la Proposition 2.1.4nous savons qu’un ensemble conique est convexe (c.-a-d., est un cone) si et seulement s’il contientla somme de chaque paire de ses elements ; cette derniere propriete est satisfaite pour l’epigraphd’une fonction a valeurs reelles si et seulement si la fonction est sous-additif (evident).
5.1.2 Proprietes elementaires de fonctions convexes
Inegalite de Jensen
Proposition 5.1.3 [l’inegalite de Jensen] Soit f fonction convexe et soit Q le domaine de f .Alors pour n’importe quelle combinaison convexe
N∑i=1
λixi
des points de Q on a
f(N∑i=1
λixi) ≤N∑i=1
λif(xi).
La preuve est immediate : les points (f(xi), xi) appartiennent clairement a l’epigraph de f ;comme f est convexe, son epigraph est un ensemble convexe, de sorte que la combinaison convexe
N∑i=1
λi(f(xi), xi) = (N∑i=1
λif(xi),N∑i=1
λixi)
de ces points appartient egalement a Epi(f). Par la definition de l’epigraph, ca implique∑Ni=1 λif(xi) ≥ f(
∑Ni=1 λixi).
Notez que la definition de la convexite d’une fonction f est exactement la condition que fsatisfait l’inegalite de Jensen dans le cas de N = 2 ; nous voyons que satisfaire cette inegalitepour N = 2 est la meme chose que la satisfaire pour tout N .
Convexite d’ensembles de niveau d’une fonction convexe
L’observation simple suivante est egalement tres utile :
Proposition 5.1.4 [Convexite d’ensembles de niveau] Soit f une fonction convexe avec le do-maine Q. Alors, pour tout reel α, l’ensemble
levα(f) = {x ∈ Q | f(x) ≤ α}– l’ensemble de niveau α de f – est convexe.
La preuve prend une ligne : si x, y ∈ levα(f) et λ ∈ [0, 1], alors f(λx+ (1− λ)y) ≤ λf(x) + (1−λ)f(y) ≤ λα+ (1− λ)α = α, de sorte que λx+ (1− λ)y ∈ levα(f).
Notez que la convexite des ensembles de niveau ne caracterise pas les fonctions convexes ; il ya des fonctions non convexes qui partagent cette propriete (par exemple, toute fonction monotoned’une variable). La caracterisation “correcte” des fonctions convexes en termes d’ensemblesconvexes est donnee par Proposition 5.1.1 – les fonctions convexes sont exactement les fonctionsavec les epigraphes convexes. La convexite des ensembles de niveau definie une famille plus largedes fonctions, celle qu’on appelle fonctions quasi-convexes.

98 CHAPITRE 5. FONCTIONS CONVEXES
5.1.3 Quelle est la valeur d’une fonction convexe en dehors de son domaine ?
Litteralement, cette question n’a pas de sens. Neanmoins, en parlant au sujet des fonctionsconvexes, il est extremement commode de penser que la fonction a une valeur egalement endehors de son domaine, a savoir, la valeur +∞ ; avec cette convention, nous pouvons dire que
une fonction convexe sur Rn est une fonction a valeurs sur l’axe etendue R ∪ {+∞} tels que ledomaine domf de la fonction – l’ensemble des x ou f(x) est fini – est non vide, et pour tous lesx, y ∈ Rn et tout λ ∈ [0, 1] on a
f(λx+ (1− λ)y) ≤ λf(x) + (1− λ)f(y). (5.2)
Si l’expression dans le cote droit contient des valeurs infinies, sa valeur est determinee selon
les conventions standard et raisonnables sur ce qui sont des operations arithmetiques sur “l’axereelle etendue” R ∪ {+∞} ∪ {−∞} :
– les operations arithmetiques avec des reels sont comprises dans leur sens habituel ;– la somme de +∞ et d’un reel, de meme que la somme de +∞ et de +∞ est +∞ ; La
somme d’un reel et de −∞, meme que la somme de −∞ et de −∞ est −∞. La somme de+∞ et de −∞ est non definie ;
– le produit d’un reel et de +∞ est +∞, 0 ou −∞, si le reel est positif, zero ou negatif, dememe pour le produit d’un reel et de −∞. Le produit de deux “infinis” est encore infini,avec la regle habituelle pour determiner le signe du produit.
Note that it is not clear in advance that our new definition of a convex function is equivalentto the initial one : initially we included into the definition requirement for the domain to beconvex, and now we omit explicit indicating this requirement. In fact, of course, the definitionsare equivalent : convexity of Dom f – i.e., the set where f is finite – is an immediate consequenceof the “convexity inequality” (5.2).
Il est commode de penser a une fonction convexe comme a quelque chose qui est definiepartout, puisque ca permet d’economiser beaucoup de mots. Par exemple, avec cette conventionje peux ecrire f + g (quand f et g sont deux fonctions convexes sur Rn), et tout le mondecomprendra ce qui cela signifie ; sans cette convention, j’aurais du ajouter a cette expressionl’explication comme suit : “f + g est une fonction avec le domaine etant l’intersection de ceuxde f et de g, et dans cette intersection elle est definie comme (f + g)(x) = f(x) + g(x)”.
5.2 Comment detecter la convexite
Dans un probleme d’optimisation
f(x) → min | gj(x) ≤ 0, j = 1, ...,m
la convexite de l’objectif f et des contraintes gi est cruciale : il s’avere que les problemes aveccette propriete possedent les proprietes theoriques tres agreables (par exemple, les conditionslocales necessaires d’optimalite pour ces problemes sont suffisantes pour l’optimalite globale) ;et ce qui est beaucoup plus important, des problemes convexes peuvent etre resolus efficacement(dans le sens theorique et, dans une certaine mesure, dans le sens pratique de ce mot), ce quin’est pas, malheureusement, le cas pour des problemes non convexes generaux. C’est pourquoiil est si important de savoir comment detecter la convexite d’une fonction donnee.

5.2. COMMENT DETECTER LA CONVEXITE 99
Le plan de notre recherche est typique pour des mathematiques. Commencons par l’exempleque vous connaissez de l’Analyse. Comment detectez-vous la continuite d’une fonction ? Natu-rellement, il y a une definition de continuite en termes de ε et δ, mais ce serait vraiment undesastre si chaque fois que nous devons prouver la continuite d’une fonction, nous etions obligesre-demontrer que “pour tout ε positif il existe δ positif tels que...”. En fait nous employons uneautre approche : nous enumerons une fois pour toutes un certain nombre d’operations standardqui preservent la continuite, comme l’addition, la multiplication, des superpositions, etc., etprecisons un certain nombre d’exemples standards des fonctions continues. Pour montrer queles operations dans la liste preservent la continuite, de meme que montrer que les fonctionsstandards sont continues, ceci demande un certain effort, et les preuves sont faites en termes deε− δ ; mais apres que cet effort soit une fois fourni, nous n’avons normalement aucune difficultea prouver la continuite d’une fonction donnee : il suffit de demontrer que la fonction peut etreobtenue, en nombre fini d’etapes, de nos ”matieres premieres” – fonctions standards qui sontcontinues – en appliquant nos “machines” – les regles de combinaison qui preservent la conti-nuite. Normalement cette demonstration est effectuee par un mot simple ”evident” ou meme estcomprise par defaut.
C’est exactement le cas avec la convexite. Ici nous devrions egalement preciser la listed’operations qui preservent la convexite et un certain nombre de fonctions convexes standards.
5.2.1 Operations preservant la convexite des fonctions
Ces operations sont comme suit :
– [Stabilite par rapport aux sommes ponderees] si f et g sont des fonctions convexes surRn, alors leur combinaison lineaire λf + μg avec des coefficients non negatifs est encoreconvexe, a condition que elle soit finie au moins dans un point ;[ceci est donne par la verification directe de la definition]
– [Stabilite par rapport aux substitutions affines de l’argument] La superposition f(Ax+ b)d’une fonction convexe f sur Rn et d’une transformation affine x �→ Ax+ b de Rm dansRn est convexe, a condition que il soit fini au moins en un point.[ vous pouvez le prouver directement en verifiant la definition ou en notant que l’epigraphde la superposition, si il est non vide, est l’image inverse de l’epigraph de f sous unetransformation affine]
– [Stabilite par rapport a la maximisation] la borne superieure supα fα(·) de n’importe quellefamille des fonctions convexes sur Rn est convexe, a condition que cette borne soit finieau moins en un point.[pour le comprendre, notez que l’epigraph de la borne superieure est bien l’intersectiondes epigraphes des fonctions de la famille ; rappelez-vous que l’intersection de n’importequelle famille d’ensembles convexes est convexe]
– [“Superposition convexe monotone”] Soit f(x) = (f1(x), ..., fk(x)) fonction vectorielle surRn avec les composants fi convexes, et soit F une fonction convexe sur Rk qui est mono-tone, c.-a-d., tels que z ≤ z′ implique toujours F (z) ≤ F (z′). Alors la superposition
φ(x) = F (f(x)) = F (f1(x), ..., fk(x))
est convexe sur Rn, a condition qu’elle est finie au moins en un point.Remarque 5.2.1 L’expression F (f1(x), ..., fk(x)) n’a pas de sens au point x ou certainesdes fi sont +∞. Par definition, dans ce point on assigne la valeur +∞ a la superposition.

100 CHAPITRE 5. FONCTIONS CONVEXES
[Pour justifier cette regle, notez que si λ ∈ (0, 1) et x, x′ ∈ Dom φ, alors z = f(x), z′ = f(x′)sont les vecteurs dans Rk qui appartiennent au DomF , et par la convexite des composantsde f nous avons
f(λx+ (1− λ)x′) ≤ λz + (1− λ)z′;
en particulier, nous avons sur la gauche un vecteur de Rk qui n’a pas d’entrees infinies, etnous pouvons user la monotonie de F :
φ(λx+ (1− λ)x′) = F (f(λx+ (1− λ)x′)) ≤ F (λz + (1− λ)z′).
Maintenant, on utilise la convexite de F :
F (λz + (1− λ)z′) ≤ λF (z) + (1− λ)F (z′)
pour obtenir la relation demandee
φ(λx+ (1− λ)x′) ≤ λφ(x) + (1− λ)φ(x′).
](Imaginez combien de mots supplementaires seraient necessaires ici s’il n’y avait aucune conven-tion sur la valeur d’une fonction convexe en dehors de son domaine !)
nous avons deux regles supplementaires :– [stabilite sous la minimisation partielle] si f(x, y) : Rn
x × Rmy est convexe comme
fonction de z = (x, y) et la fonction
g(x) = infyf(x, y)
est dite propre, c.-a-d., est > −∞ partout et est fini au moins en un point, alors g estconvexe[ceci peut etre montre comme suit. Nous devrions prouver que si x, x′ ∈ Dom g et x′′ =λx+(1−λ)x′ avec λ ∈ [0, 1], alors x′′ ∈ Dom g et g(x′′) ≤ λg(x) + (1−λ)g(x′). Etantdonne ε positif nous pouvons trouver y et y′ tels que (x, y) ∈ Dom f , (x′, y′) ∈ Dom fet g(x) + ε ≥ f(x, y), g(x′) + ε ≥ f(x′, y′). En prenant la somme ponderee de ces deuxinegalites, nous obtenons
λg(x) + (1− λ)g(y) + ε ≥ λf(x, y) + (1− λ)f(x′, y′) ≥(car f est convexe)
≥ f(λx + (1− λ)x′, λy + (1− λ)y′) = f(x′′, λy + (1− λ)y′)
(le dernier ≥ suit a nouveau de la convexite de f). La derniere quantite dans la chaineest ≥ g(x′′), et nous obtenons g(x′′) ≤ λg(x) + (1 − λ)g(x′) + ε. En particulier, x′′ ∈Dom g (on a suppose que g prend seulement les valeurs dans R et la valeur +∞).De plus, puisque l’inegalite resultante est valide pour tout le ε > 0, nous venons aug(x′′) ≤ g(x)λ + (1− λ)g(x′), comme exige.]
– la “transformation conique” d’une fonction convexe f sur Rn, c.-a-d. la fonctiong(y, x) = yf(x/y), est convexe dans le demi-espace y > 0 de Rn+1.
Maintenant nous savons quelles sont les operations de base preservant la convexite. Voyonsquelles peuvent les fonctions simples auxquelles ces operations peuvent etre appliquees. Nousavons deja un certain nombre d’exemples, mais nous ne savons toujours pas pourquoi les fonctionsdans les exemples sont convexes. La facon habituelle de verifier la convexite d’une fonction“simple” est basee sur le critere differentiel de convexite.

5.2. COMMENT DETECTER LA CONVEXITE 101
5.2.2 Critere differentiel de convexite
De la definition de la convexite d’une fonction il suit immediatement que la convexite estune propriete “unidimensionnelle” : une fonction propre f sur Rn (c.-a-d., finie au moins en unpoint) qui prend ses valeurs dans R ∪ {+∞} est convexe si et seulement si sa restriction surn’importe quelle droite, c.-a-d., n’importe quelle fonction du type g(t) = f(x+ th) sur la droite,est soit convexe, soit identiquement +∞.
Il en decoule que pour detecter la convexite d’une fonction, il suffit, en principe, de savoirdetecter la convexite des fonctions d’une variable. Cette derniere question peut etre resolue parles outils standard de calcul. A savoir, dans le calcul on a prouve
Proposition 5.2.1 [Condition necessaire et suffisant de convexite pour des fonctions regulieressur la droite] Soit (a, b) un intervalle sur l’axe reelle (nous n’excluons pas le cas de a = −∞et/ou b = +∞). Alors
(i) Une fonction f qui est differentiable partout sur (a, b) est convexe sur (a, b) si et seulementsi sa derivee f ′ est monotone non decroissante sur (a, b) ;
(ii) Une fonction f deux fois differentiable sur (a, b) est convexe sur (a, b) si et seulement saderivee seconde f ′′ est non negatif partout sur (a, b).
Avec la proposition, on peut immediatement verifier que les fonctions enumerees commeexemples des fonctions convexes dans la Section 5.1.1 sont en effet convexes. La seule difficultequ’on rencontre est que certaines de ces fonctions (par exemple, xp, p ≥ 1, et −xp, 0 ≤ p ≤ 1ont ete annoncees d’etre convexes sur le mi-intervalle [0,+∞), alors que la proposition parlede la convexite des fonctions sur des intervalles ouverts. Pour surmonter cette difficulte, on vaemployer le fait suivant :
Proposition 5.2.2 SoitM un ensemble convexe et f une fonction avec Dom f =M . Supposonsque f est convexe sur riM et continu sur M , c.-a-d.
f(xi) → f(x), i→ ∞,
pour toutes suite convergeante (xi) vers x dans M . Alors f est convexe sur M .
Preuve de la Proposition 5.2.1 :(i), necessite. Suppons que f est differentiable et convexe sur (a, b) ; nous devrions montrer
qu’alors f ′ monotone non decroissante. Soient x < y deux points de (a, b), et montrons quef ′(x) ≤ f ′(y). En effet, soit z ∈ (x, y). Nous avons la representation suivante de z commecombinaison convexe de x et y :
z =y − z
y − xx+
x− z
y − xy,
d’ou, par convexite,
f(z) ≤ y − z
y − xf(x) +
x− z
y − xf(y),
d’ouf(z)− f(x)
x− z≤ f(y)− f(z)
y − z.
Passant ici a la limite quand z → x+ 0, nous obtenons
f ′(x) ≤ f(y)− f(x)
y − x,

102 CHAPITRE 5. FONCTIONS CONVEXES
et en passant dans la meme inegalite a la limite en z → y − 0, nous obtenons
f ′(y) ≥ f(y)− f(x)
y − x,
d’ou f ′(x) ≤ f ′(y), comme promis.(i), suffisance : nous devons montrer que si f est differentiable sur (a, b) et f ′ non mo-
notone non decroissante sur (a, b), alors f est convexe sur (a, b). Il suffit de verifier que six < y, x, y ∈ (a, b), et z = (1− λ)x + λy avec 0 < λ < 1, alors
f(z) ≤ (1− λ)f(x) + λf(y),
ou, ce qui est la meme chose (il suffit d’ecrire f(z) comme λf(z) + (1− λ)f(z)), que
f(z)− f(x)
λ≤ f(y)− f(z)
1− λ.
Notez que z − x = λ(y − x) et y − z = (1 − λ)(y − x), nous voyons que l’inegalite que nousdevrions prouver est equivalent a
f(z)− f(x)
z − x≤ f(y)− f(z)
y − z.
Mais sous cette forme equivalente l’inegalite est evidente : par le Theoreme de valeur in-termediaire de Lagrange, le cote gauche est f ′(ξ) avec un certain ξ ∈ (x, z), alors que le cotedroit est f ′(η) avec un certain η ∈ (z, y). Puisque f ′ est non decroissante et ξ ≤ z ≤ η, nousavons f ′(ξ) ≤ f ′(η).
(ii) est consequence immediate de (i), puisque, comme nous savons, une fonctiondifferentiable – dans le cas en question, c’est f ′, est monotone non decroissante sur unintervalle si et seulement si son derivee est non negatif sur cet intervalle.
En fait, pour les fonctions d’une variable il y a un critere differentiel de la convexite qui“ne presume pas” de regularite (nous l’acceptons sans preuve) :
Proposition 5.2.3 [Critere de convexite pour des fonctions univariees]Soit g : R → R∪{+∞} une fonction. Supposons que son domaine δ = {t | g(t) <∞} est
un ensemble convexe qui n’est pas un singleton, c.-a-d.. un intervalle (a, b) avec probablementun ou deux les deux extremites (−∞ ≤ a < b ≤ ∞). Alors g est convexe si et seulement s’ilrepond aux 3 exigences suivantes :
1) g est continu sur (a, b) ;2) g est differentiable partout sur (a, b), a l’exclusion de’un ensemble denombrable de
points, et la derivee g′(t) est non decroissante sur son domaine ;3) a chaque extremite u de l’intervalle (a, b) qui appartient a δ g est semi-continu
superieure :g(u) ≥ lim supt∈(a,b),t→ug(t).
Preuve de la Proposition 5.2.2 : Soit x, y ∈ M et z = λx + (1 − λ)y, λ ∈ [0, 1]. Nousdevons prouver que
f(z) ≤ λf(x) + (1− λ)f(y).
Comme nous savons du Theoreme 2.1.1.(iii), ils existent des suites convergeantes xi ∈ riMet yi ∈ riM , respectivement vers x et y. Alors zi = λxi + (1 − λ)yi converge vers z quandi→ ∞, et comme f est convexe sur riM , nous avons
f(zi) ≤ λf(xi) + (1− λ)f(yi);
En passant a la limite, comme xi, yi, zi convergent, quand i→ ∞, vers x, y, lez ∈M respec-
tivement et f continu sur M , nous obtenons l’inegalite exigee.

5.2. COMMENT DETECTER LA CONVEXITE 103
Des Propositions 5.2.1.(ii) et 5.2.2 nous obtenons la conditions necessaire et suffisante suivantpour la convexite de la fonction reguliere de n variables :
Corollaire 5.2.1 [Critere de convexite pour des fonctions regulieres sur Rn]Soit f : Rn → R ∪ {+∞} une fonction. Supposons que le domaine Q de f est un ensemble
convexe avec un interieur non vide et que f est– continu sur le Q– deux fois differentiable sur l’interieur de Q.
Alors f est convexe si et seulement si son Hessian est semidefinite positif sur l’interieur de Q :
hT f ′′(x)h ≥ 0 ∀x ∈ int Q ∀h ∈ Rn.
Preuve :∗
La partie “seulement si” est evidente : si f est convexe et x ∈ Q′ = int Q,alors la fonction d’une variable g(t) = f(x + th), ou h est une direction arbitraire dansRn, est convexe dans un certain voisinage du point t = 0 sur l’axe reelle (les substitutionsaffines d’arguments conservent la convexite). Puisque f est deux fois differentiable dansun voisinage de x, g est deux fois differentiable dans un voisinage de t = 0, de sorte queg′′(0) = hT f ′′(x)h ≥ 0 par Proposition 5.2.1.
Il nous reste de prouver la partie “si”. Supposons alors que nous soyons donneshT f ′′(x)h ≥ 0 pour chaque x ∈ int Q et chaque h ∈ Rn. Nous devons montrer que fest convexe.
Montrons d’abord que f est convexe sur l’interieur Q′ du domaine Q. Comme nous savonsdu Theoreme 2.1.1, Q′ est un ensemble convexe. Tout ce que nous devons prouver est quechaque version unidimensionnelle
g(t) = f(x+ t(y − x)) 0 ≤ t ≤ 1
avec x et y dans Q′ est convexe sur le segment 0 ≤ t ≤ 1. Puisque f est continu sur Q ⊃ Q′, gest continu sur le segment ; et puisque f est deux fois differentiable sur Q′, g est differentiablesur (0, 1) avec la deuxieme derivee
g′′(t) = (y − x)T f ′′(x+ t(y − x))(y − x) ≥ 0.
En consequence, g est convexe sur [0, 1] (Propositions 5.2.1.(ii) et 5.2.2). Ainsi, f est convexe
sur Q′. Il reste pour noter que f , etant convexe sur Q′ et continu sur Q, est convexe sur Q
par Proposition 5.2.2.
En appliquant les regles de combinaison qui preservent la convexite aux fonctions simples quipassent le test “infinitesimal” de convexite, nous pouvons prouver la convexite des fonctionscomplexes. Considerons, par exemple, un posynome exponentiel – la fonction
f(x) =N∑i=1
ci exp{aTi x}
avec les coefficients positifs ci (c’est pourquoi la fonction s’appelle posynomiale). Commentpourrions-nous montrer que la fonction est convexe ? C’est immediat :
exp{t} est convexe (puisque sa derivee seconde est positive et donc la premiere derivee estmonotone) ;
par consequent, toutes les fonctions exp{atix} sont convexes (la stabilite de la convexite parrapport aux substitutions affines d’argument) ;
par consequent, f est convexe (stabilite de la convexite par rapport aux combinaisons lineairesavec des coefficients non negatifs).
Et si nous etions censes de montrer que le maximum des trois posynomes est convexe ? Etbien, nous pourrions ajouter a nos trois etapes le quatrieme, qui se rapporte a la stabilite de laconvexite sous p la maximisation ponctuelle.

104 CHAPITRE 5. FONCTIONS CONVEXES
5.3 Inegalite du Gradient
Une propriete extremement importante d’une fonction convexe est donnee par la propositionsuivante :
Proposition 5.3.1 [Inegalite du gradient] Soit f une fonction a valeurs finies et valeur +∞,et soit x un point interieur du domaine de f et soit Q soit un ensemble convexe contenant x.On suppose que
– f est convexe sur Q,– f est differentiable en x.
Soit ∇f(x) le gradient de la fonction en x. Alors nous avons l’inegalite suivante :
(∀y ∈ Q) : f(y) ≥ f(x) + (y − x)T∇f(x). (5.3)
Geometriquement : le graph
{(y, t) ∈ Rn+1 | y ∈ Dom f ∩Q, t = f(y)}de la fonction f limitee a l’ensemble Q est au-dessus du graph
{(y, t) ∈ Rn+1 | t = f(x) + (y − x)T∇f(x)}de la forme lineaire tangente a f en x.
Preuve : Soit y ∈ Q. Il n’y a rien a prouver si y �∈ Dom f (puisque le cote droit dans l’inegalitede gradient est +∞), meme qu’il n’y a rien a montrer quand y = x. Ainsi, nous pouvons supposerque y �= x et y ∈ Dom f . Posons
yτ = x+ τ(y − x), 0 < τ ≤ 1,
de sorte que y1 = y et yτ soit un point interieur du segment [x, y] pour 0 < τ < 1. Maintenantnous utilisons le lemme suivant :
Lemme 5.3.1 Soit x, x′, x′′ trois points distincts avec x′ ∈ [x, x′′], et soit fconvexe et fini sur [x, x′′]. Alors
f(x′)− f(x)
‖ x′ − x ‖ ≤ f(x′′)− f(x)
‖ x′′ − x ‖ . (5.4)
Preuve du Lemme : Nous avons
x′ = x+ λ(x′′ − x), λ =‖ x′ − x ‖‖ x′′ − x ‖ ∈ (0, 1)
oux′ = (1− λ)x+ λx′′.
Par la convexite de f ,f(x′) ≤ (1− λ)f(x) + λf(x′′),
ouf(x′)− f(x) ≤ λ(f(x′′)− f(x′)).
En divisant par λ et en soumettant dans cette formule la valeur de λ, nous obtenons(5.4).

5.4. BORNITUDE ET LA PROPRIETE DE LIPSCHITZ DES FONCTIONS CONVEXES105
En appliquant le lemme au triplet x, x′ = yτ , x′′ = y, nous obtenons
f(x+ τ(y − x))− f(x)
τ ‖ y − x ‖ ≤ f(y)− f(x)
‖ y − x ‖ ;
quand τ → +0, le cote gauche de cette inegalite, par la definition du gradient, tend vers ‖y − x ‖−1 (y − x)T∇f(x), et nous avons
‖ y − x ‖−1 (y − x)T∇f(x) ≤‖ y − x ‖−1 (f(y)− f(x)).
Autrement dit,(y − x)T∇f(x) ≤ f(y)− f(x);
ce qui est exactement l’inegalite (5.3).
Pour conclure l’histoire de l’Inegalite du Gradient, il est utile de noter que dans lecas quand Q est un ensemble convexe avec l’interieur non vide et f est continu sur Q etdifferentiable sur int Q, alors f est convexe sur Q si et seulement si l’Inegalite du Gradient(5.3) est verifiee pour chaque paire x int Q et y ∈ Q.
En effet, la partie “seulement si”, c.-a-d., l’implication
la convexite de f → Inegalite du Gradient pour tout x ∈ int Q et tout y ∈ Q
est donnee par la Proposition 5.3.1. Pour prouver la partie “si”, c.-a-d., pour etablir l’impli-cation reciproque, supposons que f satisfait l’inegalite de gradient pour tout le x ∈ int Q ettout le y ∈ Q, et verifions que f est convexe sur Q. Il suffit de montrer que f est convexe surl’interieur Q′ de l’ensemble Q (voir la Proposition 5.2.2). Pour montrer que f est convexe surQ′, notez que Q′ est convexe (Theoreme 2.1.1) et que, en raison de l’Inegalite du Gradient,sur Q′ f est la borne superieure de la famille affine (et donc convexe) des fonctions :
f(y) = supx∈Q′
fx(y), fx(y) = f(x) + (y − x)T∇f(x).
5.4 Bornitude et la propriete de Lipschitz des fonctions
convexes
Les fonctions convexes possedent des tres bonnes proprietes locales.
Theoreme 5.4.1 [Bornitude et continuite de Lipschitz de fonctions convexes]Soit f une fonction convexe et soit K un ensemble ferme et borne contenu dans l’interieur
relatif du domaine domf de f . Alors f est Lipschitzienne sur K, c.-a-d. qu’il existe laconstante L, nommee la constante de Lipschitz de f sur K, tels que
|f(x)− f(y)| ≤ L|x− y| ∀x, y ∈ K. (5.5)
En particulier, f est bornee sur K.
Remarque 5.4.1 Chacune des trois conditions sur K – (1) la fermeture, (2) la bornitudeet (3) K ⊂ ri Dom f– sont essentielles, ce qu’on peut voir dans les trois exemples suivants :
– f(x) = 1/x, Dom f = (0,+∞), K = (0, 1]. Nous avons (2), (3) mais pas (1) ; f n’estni bornee, ni Lipschitzienne sur K.
– f(x) = x2, Dom f = R, K = R. Nous avons (1), (3) mais pas (2) ; f n’est ni borneeni Lipschitz sur K.
– f(x) = −√x, Dom f = [0,+∞), K = [0, 1]. Nous avons (1), (2) et pas (3) ; f n’est pas
Lipschitzienne sur K 1), bien qu’elle soit bornee. Nous pourrions construire egalement
1. )en effet, nous avons limt→+0f(0)−f(t)
t= limt→+0 t
−1/2 = +∞, alors que pour une fonction f Lipschitzienneles ratios t−1(f(0)− f(t)) devraient etre bornees

106 CHAPITRE 5. FONCTIONS CONVEXES
une fonction convexe f de deux variables qui n’est pas bornee, avec un domaine com-pact non-polyhedral (par exemple, avec Dom f etant le disque unite), pour lequel (1)et (2) sont verifier, mais pas (3).
Remarque 5.4.2 Theoreme 5.4.1 dit qu’une fonction convexe f est bornee sur tout sous-ensemble compact de l’interieur relatif de Dom f . En fait il y a un resultat bien plus fort surla borne inferieure de f : f est bornee inferieurement sur tout sous-ensemble borne de Rn !
Preuve du Theoreme 5.4.1. Nous commencerons par la version locale suivante dutheoreme.
Proposition 5.4.1 Soit f une fonction convexe, et soit x un point de l’interieur relatif dudomaine Dom f de f . Alors
(i) f est bornee en x : il existe un r positif tels que f est bornee dans le r-voisinage Ur(x)de x dans l’enveloppe affine de Dom f :
∃r > 0, C : |f(x)| ≤ C ∀x ∈ Ur(x) = {x ∈ Aff(Dom f) | ‖ x− x ‖≤ r};
(ii) f est Lipschitzienne en x, c.-a-d., il existe un ρ positif et une constante L tels que
|f(x)− f(x′)| ≤ L ‖ x− x′ ‖ ∀x, x′ ∈ Uρ(x).
Implication “Proposition 5.4.1 ⇒ Theoreme 5.4.1” est donne par un raisonnementstandard d’Analyse. Tout ce que nous avons besoin de montrer que si K est un sous-ensembleborne et ferme (c.-a-d., un ensemble compacte) de ri Dom f , alors f est Lipschitzienne K(la bornitude de f sur K est une consequence evidente de la propriete de Lipschitz sur K etde la bornitude de K). Supposons, au contraire, que f n’est pas Lipschitzienne sur K ; alorspour chaque entier i il existe une paire de points xi, yi ∈ K tels que
f(xi)− f(yi) ≥ i|xi − yi|. (5.6)
PuisqueK est compact, en passant a une sous-suite nous pouvons supposer que le xi → x ∈ Kde et yi → y ∈ K. Par la Proposition 5.4.1 le cas x = y est impossible – f est Lipschitziennedans un voisinage B de x = y ; comme xi → x et yi → y, ce voisinage devrait contenir tousles xi et yi avec i assez grands ; mais alors, grace a la propriete de Lipschitz de f dans B,les rapports (f(xi) − f(yi))/|xi − yi| forment une suite bornee, ce qui n’est pas le cas parhypothese.
Le cas x �= y est “encore moins” possible – puisque, par la proposition, f est continusur Dom f , en deux points x et y (notez que la propriete de Lipschitz en un point impliqueclairement la continuite de la fonction), de sorte que nous ayons f(xi) → f(x) et f(yi) → f(y)quand i → ∞. Ainsi, le cote gauche de (5.6) reste borne quand i→ ∞. Dans le cote droit itend vers ∞, et le facteur |xi − yi| a une limite de non nulle |x− y|, ainsi le cote droit tendvers ∞ avec i, ce qui mene a la contradiction.Preuve de la Proposition 5.4.1.
10. Nous commencons par montrer que la fonction f est bornee au-dessus dans un voisi-nage de x. C’est immediat : nous savons qu’il existe un voisinage Ur(x) qui est contenu dansDom f (puisque, par hypothese, x est un point de l’interieur relatif de Dom f). Maintenant,nous pouvons trouver un petit simplex Δ de dimension m = dim Aff(Dom f) avec les som-mets x0, .., xm dans Ur(x) de telle maniere que x soit une combinaison convexe des vecteursxi avec des coefficients positifs, et meme avec les coefficients 1/(m+ 1) :
x =
m∑i=0
1
m+ 1xi
2).
2. )pour voir qu’un tel Δ existe, nous pouvons agir comme suit : d’abord, le cas de Dom f etant un singletonest evident, ainsi nous pouvons supposer que Dom f est un ensemble convexe de dimension m ≥ 1. Prenons une

5.4. BORNITUDE ET LA PROPRIETE DE LIPSCHITZ DES FONCTIONS CONVEXES107
Nous savons que x est le point de l’interieur relatif de Δ (regarder la preuve du Theoreme2.1.1.(ii)) ; puisque Δ engendre le meme ensemble affine que Dom f (m est bien la dimensionde Aff(Dom f) !), cela signifie que Δ contient Ur(x) avec certain r > 0. Maintenant, dans
Δ = {m∑i=0
λixi | λi ≥ 0,∑i
λi = 1}
f est bornee superieurement par max0≤i≤m f(xi) grace a l’inegalite de Jensen :
f(
m∑i=0
λixi) ≤m∑i=0
λif(xi) ≤ maxif(xi).
En consequence, f est bornee superieurement (par la meme quantite) dans Ur(x).20. Montrons que si f est bornee superieurement par un certain C dans Ur(x), alors elle
est bornee inferieurement dans ce voisinage (et, par consequent, est tout simplement borneedans Ur). En effet, soit x ∈ Ur, de sorte que x ∈ Aff(Dom f) et ‖ x − x ‖≤ r. En posantx′ = x − [x − x] = 2x − x, on obtient x′ ∈ Aff(Dom f) et ‖ x′ − x ‖=‖ x − x ‖≤ r. Ainsix′ ∈ Ur. Comme x = 1
2 [x+ x′], nous avons
2f(x) ≤ f(x) + f(x′),
d’ouf(x) ≥ 2f(x)− f(x′) ≥ 2f(x)− C, x ∈ Ur(x),
et, effectivement, f est bornee inferieurement dans Ur, ce qui est (i).30. (ii) est une consequence immediate de (i) et du Lemme 5.3.1. En effet, montrons que
f est Lipschitzienne dans le voisinage Ur/2(x), ou r > 0 est tel que f est bornee dans Ur(x)(nous savons deja de (i) que un tel r existe). Soit |f | ≤ C dans Ur, et soit x, x′ ∈ Ur/2,x �= x′. Nous pouvons eteindre le segment [x, x′] au travers du point x′ jusqu’il atteint lafrontiere (relative) de Ur en un certain point x′′ ; alors nous aurons
x′ ∈ (x, x′′); ‖ x′′ − x ‖= r.
Du (5.4) nous avons
f(x′)− f(x) ≤‖ x′ − x ‖ f(x′′)− f(x)
‖ x′′ − x ‖ .
base affine y0..., ym arbitraire dans M = Aff(Dom f) et puis passons de cette base a l’ensemble z0 = y0, z1 =y0+ ε(y1−y0), z2 = y0+ ε(y2−y0)..., zm = y0+ ε(ym−y0) avec un certain ε > 0. Bien evidemment, les vecteurs ziappartiennent a M et forment une base affine (du fait que les vecteurs zi − z0, i = 1..., m, sont ε fois les vecteursyi − y0, et ces derniers forment une base dans le sous-espace lineaire L tel que M = y0 +L, cf. le Theoreme 1.3.1.Par consequent, les vecteurs zi − z0, i = 1..., m, forment egalement une base dans L d’ou, par le meme Corollaire,z0, ..., zm forment la base affine de M). Un choisissant epsilon > 0 assez petit, nous pouvons imposer que tousles vecteurs z0..., zm soyons dans le (r/10)-voisinage du vecteur z0. Maintenant, soit Δ′ l’enveloppe convexe dez0, ..., zm ; c’est un simplex avec les sommets contenus dans le voisinage de z0 du rayon r/10 (naturellement, nousparlons de la boule dans M). Ce voisinage est une intersection d’une boule Euclidienne, qui est un ensembleconvexe, et de M , qui est egalement convexe ; donc ce voisinage est convexe. Puisque les sommets de Δ′ sontcontenus dans ce voisinage, Δ′ entier est contenu dans le voisinage. Posons maintenant z = (m + 1)−1
∑m
i=0zi ;
evidemment, Δ′ est contenu dans le voisinage de z dans M du rayon 2×(r/10) = r/5. Le choix de Δ = [x− z]+Δ′,nous permet d’obtenir le simplex avec les sommets xi = zi+ x− z qui est contenu dans le r/5-voisinage de x dansM et tel que (m+ 1)−1
∑m
i=0xi ≡ (m+ 1)−1
∑m
i=0[zi + x− z] = z + x− z = x, comme requis.
J’ai donne cet horrible “explication” pour montrer combien de mots nous avons besoin pour rendre rigoureusela recette evidente “prenons un petit simplex avec la moyenne de sommets egale a x”. Les “explications” de cetype n’ont pas lieu d’etre (et seront omises), parce que en faisant cela on risque de tuer meme le raisonnement leplus clair. Notez, en tous cas, que dans les mathematiques nous devrions pouvoir expliquer, si on nous demande,ce qui signifie “prendre un petit simplex” et comment peut-on le “prendre”. Inutile de dire que vous etes censespouvoir effectuer ce travail routine par vous-memes ; a cet effet vous devriez vous rappeler ce qui est la significationexacte des mots que nous employons et ce qui sont les relations de base entre le concepts.

108 CHAPITRE 5. FONCTIONS CONVEXES
Le deuxieme facteur du cote droit n’excede pas la quantite (2c)/(r/2) = 4c/r ; en effet, lenumerateur est, en valeur absolue, au plus 2C (puisque |f | est bornee par C dans Ur et x, x′′
sont dans Ur) et le denominateur est au moins r/2 (en effet, x est a la distance tout au plusr/2 de x, et x′′ est a la distance exactement r de x, de sorte que la distance entre x et x′′,par l’inegalite de triangle, soit au moins r/2). Ainsi, nous avons
f(x′)− f(x) ≤ (4C/r) ‖ x′ − x ‖, x, x′ ∈ Ur/2;
en permutant x et x′, on arrive a
f(x)− f(x′) ≤ (4C/r) ‖ x′ − x ‖,
d’ou|f(x)− f(x′)| ≤ (4C/r) ‖ x− x′ ‖, x, x′ ∈ Ur/2,
comme exige par (ii).
5.5 Maximum et minimum de fonctions convexes
Nous avons deja mentionne que les problemes d’optimisation impliquant des fonctionsconvexes possedent des bonnes proprietes theoriques. Une des plus importantes est donne parle theoreme suivant :
Theoreme 5.5.1 [“Unimodalite”] Soit f une fonction convexe sur un ensemble convexe Q ⊂Rn, et soit x∗ ∈ Q ∩Dom f un minimiseur local de f sur Q :
(∃r > 0) : f(y) ≥ f(x∗) ∀y ∈ Q, ‖ y − x ‖< r. (5.7)
Alors x∗ est un minimiseur global de f sur Q :
f(y) ≥ f(x∗) ∀y ∈ Q. (5.8)
De plus, l’ensemble ArgminQ f de tous les minimiseurs locaux (≡ globaux) de f sur Q estconvexe.
Si f est strictement convexe (c.-a-d. que l’inegalite de convexite f(λx+(1− λ)y) ≤ λf(x)+(1−λ)f(y) est stricte quelques soient x �= y et λ ∈ (0, 1)), alors soit cet ensemble est vide empty,soit il est un singleton.
Preuve : 1) Soit x∗ un minimiseur local de f sur Q et y ∈ Q, y �= x∗ ; on doit montrer quef(y) ≥ f(x∗). Il n’y a rien a montrer si f(y) = +∞, ainsi on peut supposer que y ∈ Dom f .Notez que, surement, x∗ ∈ Dom f – par la definition d’un minimiseur local.
Pour tout τ ∈ (0, 1) nous avons par le Lemme 5.3.1,
f(x∗ + τ(y − x∗))− f(x∗)τ ‖ y − x∗ ‖ ≤ f(y)− f(x∗)
‖ y − x∗ ‖ .
Comme x∗ est un minimiseur local de f , le cote gauche de cette inegalite est non negatif pourtout τ > 0 assez petit. On en deduit que le cote droit est non negatif, c.-a-d., f(y) ≥ f(x∗).
2) Le convexite de ArgminQ f , vient du fait que ArgminQ f n’est rien d’autre que l’ensemblede niveau levα(f) de f associe a la valeur minimale minQ f de f sur Q ; comme tout ensemblede niveau d’une fonction convexe, cet ensemble est convexe (Proposition 5.1.4).

5.5. MAXIMUM ET MINIMUM DE FONCTIONS CONVEXES 109
3) Pour montrer que l’ensemble ArgminQ f lie a une fonction f strictement convexe est,si non vide, un singleton, notez que s’il y avait deux minimizers distincts x′, x′′, alors, de laconvexite stricte, nous aurions
f(1
2x′ +
1
2x′′) <
1
2[f(x′) + f(x′′)] = min
Qf,
ce qui est impossible – l’argument dans le cote gauche est un point de Q !Un autre fait plaisant est celui dans le cas de fonctions convexes differentiables la condition
necessaire d’optimalite (la regle de Fermat) est suffisant pour l’optimalite globale :
Theoreme 5.5.2 [Condition necessaire et suffisante d’optimalite pour une fonction convexedifferentiable]
Soit f une fonction convexe sur l’ensemble convexe Q ⊂ Rn, et soit x∗ un point interieurde Q. Supposons que f est differentiable en x∗. Alors x∗ est un minimizer de f sur Q si etseulement si
∇f(x∗) = 0.
Preuve : comme condition necessaire pour l’optimalite locale, la relation ∇f(x∗) = 0 est connuede l’Analyse ; elle n’a rien en commun avec la convexite. L’essence de la matiere est, naturelle-ment, la suffisance de cette condition pour l’optimalite globale de x∗ dans le cas de f convexe.Cette suffisance est donnee par l’Inegalite du Gradient (5.3) : en vertu de cette inegalite et enraison de ∇f(x∗) = 0,
f(y) ≥ f(x∗) + (y − x∗)∇f(x∗) = f(x∗)
pour tout y ∈ Q.
Remarque 5.5.1 On pourrait se poser la question naturelle suivante : que se passe-t-il si x∗
dans la condition ci-dessus n’est pas necessairement un point interieur deQ. Ainsi, supposons quex∗ est un point arbitraire d’un ensemble convexe Q et que f est convexe sur Q et differentiableen x∗ (ce qui veut dire exactement que Dom f contient un voisinage de x∗ et f est derivable enx∗). Dans ces conditions, quand est-ce que x∗ est un minimiseur de f sur Q ?
La reponse est comme suit : soit
TQ(x∗) = {h ∈ Rn | x∗ + th ∈ Q ∀ assez petit t > 0}
soit le cone tangent de Q en x∗. Geometriquement, c’est l’ensemble de toutes les directionsmenant de x∗ vers l’interieur de Q, de sorte qu’un assez petit deplacement positive de x∗ le longde cette direction garde le point dans Q. De la convexite de Q on conclut que le cone tangent esten effet un cone convexe (mais pas necessairement ferme). Par exemple, quand x∗ est un pointinterieur de Q, le cone tangent a Q en x∗ est Rn entier. Un exemple plus interessant est le conetangent a un ensemble polyhedral
Q = {x | aTi x ≤ bi, i = 1, ...,m}; (5.9)
Pour x∗ ∈ Q le cone tangent correspondant est le cone polyhedral
{h | aTi h ≤ 0 ∀i : aTi x∗ = bi} (5.10)
qui correspond aux contraintes aTi x ≤ bi de la description de Q qui sont actives en x∗ (c.-a-d.,ceux parmi les inegalites qui sont egalites en x∗ plutot que des inegalites strictes(Pourquoi ?))

110 CHAPITRE 5. FONCTIONS CONVEXES
Maintenant, pour les fonctions convexes sur Q et differentiables a x∗ la condition necessaireet suffisante pour x∗ d’etre un minimiseur de f sur Q est comme suit :
(*) la derivee de f prise en x∗ le long de chaque direction de TQ(x∗) doit etre non negative :
hT∇f(x∗) ≥ 0 ∀h ∈ TQ(x∗).
Preuve est immediate. La necessite est evidente, ce qui n’a rien a voir avec la convexite :en supposant que x∗ est un minimiseur local de f sur Q, nous notons que s’il y avait unedirection h ∈ TQ(x
∗) avec hT∇f(x∗) < 0, alors nous aurions
f(x∗ + th) < f(x∗)
pour tout t > 0 assez petit. D’autre part, x∗ + th ∈ Q pour tout t > 0 assez petit du ah ∈ TQ(x
∗). Combinant ces observations, nous concluons que dans chaque voisinage de x∗ ily a des points de Q avec une valeur de f strictement plus petite que f(x∗) ; ceci contreditl’hypothese que x∗ est un minimiseur local de f sur Q.
La suffisance est une consequence de l’Inegalite du Gradient, exactement comme dans le
cas quand x∗ est un point interieur de Q.
La condition (*) indique que si f est convexe sur Q et differentiable en x∗ ∈ Q, la conditionnecessaire et suffisante pour que x∗ soit un minimiseur de f sur Q est que la forme lineairedonnee par le gradient ∇f(x∗) de f en x∗ doit etre non negative sur toutes les directions ducone tangent TQ(x
∗). Les formes lineaires non negatives sur toutes les directions du cone tangentforment egalement un cone (Verifiez cela !) ; ce cone s’appelle le cone normal a Q en x∗ et est noteNQ(x
∗). Ainsi, (*) dit que la condition necessaire et suffisante pour que x∗ donne le minimumde f sur Q est l’inclusion ∇f(x∗) ∈ NQ(x
∗). Ce qui cette condition veut dire reellement, dependde ce qui est le cone normal : si nous avons une description explicite du cone normal, nous avonsune forme explicite de la condition d’optimalite.
Par exemple, quand TQ(x∗) = Rn (autrement dit, quand x∗ est un point interieur de Q),
alors le cone normal est compose des formes lineaires non negatives sur l’espace entier, c.-a-d.,c’est le cone trivial {0} ; par consequent, dans ce cas en la condition d’optimalite devient la regle∇f(x∗) = 0 de Fermat.
Quand Q est l’ensemble polyhedral (5.9), le cone tangent est le cone polyhedral (5.10) ; il estcompose de toutes les directions qui ont les produits scalaires non positifs avec tous les vecteursai des inegalites actives en x∗. Le cone normal est compose de tous les vecteurs qui ont lesproduits scalaires non negatifs avec toutes ces directions, c.-a-d., il contient des vecteurs a telsque l’inegalite hTa ≥ 0 est une consequence des inegalites hTai ≤ 0, i ∈ I(x∗) ≡ {i | aTi x∗ = bi}.Nous concluons du Lemme de Farkas Homogene que le cone normal est simplement l’enveloppeconique des vecteurs −ai, i ∈ I(x∗). Ainsi, dans le cas en question (*) lit :
x∗ ∈ Q est un minimiseur de f sur Q si et seulement si il existent des reels non negatifs λ∗iassocies “aux indices actifs” i (ceux dans I(x∗)) tels que
∇f(x∗) +∑
i∈I(x∗)
λ∗i ai = 0.
Ceux-ci sont les celebres conditions d’optimalite de Karush-Kuhn-Tucker ; dans le chapitre sui-vant nous montrerons que ces conditions sont necessaires et suffisantes d’optimalite dans unesituation bien plus generale.

5.5. MAXIMUM ET MINIMUM DE FONCTIONS CONVEXES 111
Les resultats ci-dessus montrent que le fait qu’un point x∗ ∈ Dom f est un minimizer globald’une fonction convexe f ne depend que du comportement local de f en x∗. Ce n’est pas le casavec des maximums d’une fonction convexe. Tout d’abord, un tel maximum, s’il existe, danstous les cas non triviaux devrait appartenir a la frontiere du domaine de la fonction :
Theoreme 5.5.3 Soit f convexe, et soit Q le domaine de f . Supposons que f atteint sonmaximum sur Q en un point x∗ de l’interieur relatif de Q. Alors f est constante sur Q.
Preuve : soit y ∈ Q ; nous devons prouver que f(y) = f(x∗). Il n’y a rien a prouver si y = x∗,ainsi nous allons supposer que y �= x∗. Puisque, par hypothese, x∗ ∈ riQ, nous pouvons prolongerle segment [x∗, y] par le point final x∗, tout en gardant l’extremite gauche du segment dans Q.En d’autres termes, il existe un point y′ ∈ Q tels que x∗ est un point interieur du segment [y′, y] :
x∗ = λy′ + (1− λ)y
pour un certain λ ∈ (0, 1). Par definition de convexite
f(x∗) ≤ λf(y′) + (1− λ)f(y).
Comme f(y′) et f(y) son inferieurs a f(x∗) (x∗ est un maximiseur de f sur Q !) et les poids λ et1−λ sont strictement positifs, cette inegalite n’est peut etre valide que si f(y′) = f(y) = f(x∗).
Dans certains cas nous pouvons etre encore plus precis :
Theoreme 5.5.4 Soit f une fonction convexe sur Rn et E un sous-ensemble de Rn. Alors
supConvE
f = supEf. (5.11)
En particulier, si S ⊂ Rn est un ensemble convexe compact, alors la borne superieure de f surS est egale a la borne superieure de f sur l’ensemble Ext(S) des points extremes de S :
supSf = sup
Ext(S)f (5.12)
Preuve : pour montrer (5.11), supposons que x ∈ ConvE, de facon que x est une combinaisonconvexe des points de E (Theoreme 2.1.3 sur la structure de l’enveloppe convexe) :
x =∑i
λixi [xi ∈ E, λi ≥ 0,∑i
λi = 1].
En appliquant l’inegalite de Jensen (Proposition 5.1.3), nous obtenons
f(x) ≤∑i
λif(xi) ≤∑i
λi supEf = sup
Ef.
Ainsi le cote gauche de (5.11) est ≤ le cote droit ; l’inegalite reciproque est evidente, car ConvE ⊃E.
Pour obtenir (5.12) de (5.11), il suffit de noter que par le Theoreme de Krein-Milman(Theoreme 4.2.1) pour S convexe nous avons S = Conv Ext(S).
Le dernier theoreme sur des maximum des fonctions convexes est comme suit :

112 CHAPITRE 5. FONCTIONS CONVEXES
Theoreme 5.5.5∗Soit f une fonction convexe tels que le domaine Q de f est ferme et ne
contient pas de droites. Alors(i) si l’ensemble de maximiseurs globaux de f
ArgmaxQ
f ≡ {x ∈ Q | f(x) ≥ f(y)∀y ∈ Q}
est non vide, alors il rencontre l’ensemble Ext(Q) des points extremes de Q, de sorte qu’aumoins un des maximiseurs de f soit un point extreme de Q ;
(ii) si l’ensemble Q est polyhedral et f est bornee superieurement sur Q, alors le maximumde f sur Q est atteint : ArgmaxQ f �= ∅.Preuve : nous commencons par (i). Nous prouverons ce resultat par induction sur ladimension de Q. Le cas dim Q = 0, c.-a-d., le cas d’un singleton Q, est trivial, car iciQ = ExtQ = ArgmaxQ f . Supposons maintenant que le resultat en question est valide pourle cas de dim Q ≤ p, et montrons qu’il est valide egalement pour le cas de dim Q = p + 1.Verifions d’abord que l’ensemble ArgmaxQ f rencontre la frontiere (relative) de Q. En effet,soit x ∈ ArgmaxQ f . Il n’y a rien a prouver si x lui-meme est un point de la frontiere relativede Q ; et si x n’est pas un point de frontiere, alors, par Theoreme 5.5.3, f est constant sur Q,de sorte que ArgmaxQ f = Q ; et puisque Q est ferme, n’importe quel point de la frontiererelative de Q (un tel point existe, puisque Q ne contient pas de droites et est de dimensionpositive) est un maximiseur de f sur Q, de sorte que la encore ArgmaxQ f rencontre ∂riQ.
Ainsi, parmi les maximiseurs de f il existe au moins un, disons x, qui appartient a lafrontiere relative de Q. Alors, soit H un hyperplan de support de Q en x (voir la Section4.1), et soit Q′ = Q ∩H . L’ensemble Q′ est ferme et convexe (car Q et H le sont), non vide(il contient x) et ne contient pas de droites (puisque Q ne contient pas de droites). Nousavons maxQ f = f(x) = maxQ′ f (notez qui Q′ ⊂ Q), d’ou
∅ �= ArgmaxQ′
f ⊂ ArgmaxQ
f.
Comme dans la preuve du Theoreme de Krein-Milman (Theoreme 4.2.1), nous avonsdim Q′ < dim Q. En raison de cette inegalite nous pouvons appliquer a f et a Q′ notrehypothese inductive pour obtenir
Ext(Q′) ∩ ArgmaxQ′
f �= ∅.
Comme Ext(Q′) ⊂ Ext(Q), et, comme nous venons de voir ArgmaxQ′ f ⊂ ArgmaxQ f , nousconcluons que Ext(Q)∩ArgmaxQ f n’est pas plus petit que le Ext(Q′)∩ArgmaxQ′ f et doncest non vide, comme exige.
Pour prouver (ii), nous utilisons le resultat sur la structure de l’ensemble polyhedral :
Q = Conv(S) + Cone (R),
ou S et R sont les ensembles finis. Nous sommes sur le point de montrer que la bornesuperieure de f sur Q est exactement le maximum de f sur l’ensemble fini S :
∀x ∈ Q : f(x) ≤ maxs∈S
f(s). (5.13)
Ceci signifiera, en particulier, que f atteint son maximum sur Q – par exemple, dans le pointou f atteint son maximum sur S.
Pour prouver ce resultat, nous allons montrer d’abord que si f bornee superieurementsur Q, alors chaque direction r ∈ Cone (R) est celle de descente pour f , c.-a-d., est telle quetoute deplacement dans cette direction prise dans n’importe quel point x ∈ Q diminue f :
f(x+ tr) ≤ f(x) ∀x ∈ Q∀t ≥ 0. (5.14)

5.5. MAXIMUM ET MINIMUM DE FONCTIONS CONVEXES 113
En effet, si, au contraire, il y avait x ∈ Q, r ∈ R et t ≥ 0 tels que f(x + tr) > f(x), nousaurions t > 0 et, par le Lemme 5.3.1,
f(x+ sr) ≥ f(x) +s
t(f(x+ tr) − f(x)), s ≥ t.
Somme x ∈ Q et r ∈ Cone (R), x + sr ∈ Q pour tout s ≥ 0, et puisque f est borneesuperieurement sur Q, le cote gauche dans la derniere inegalite est borne, tandis que laquantite a droite tend a +∞ quand s→ ∞ en raison de f(x+ tr >) > f(x).
Maintenant pour montrer (5.13) il suffit de remarquer qu’un point generique x ∈ Q peutetre represente en comme
x =∑s∈S
λss+ r [r ∈ Cone (R);∑s
λs = 1, λs ≥ 0],
et nous avons
f(x) = f(∑
s∈S λss+ r)≤ f(
∑s∈S λss) [par (5.14)]
≤ ∑s∈S λsf(s) [par l’inegalite de Jensen]
≤ maxs∈S f(s)

114 CHAPITRE 5. FONCTIONS CONVEXES
5.6 Exrecices
Exercice 5.1 Marquez par ”c” celles parmi les fonctions ci-dessous qui sont convexes sur lesdomaines indiques :
– f(x) ≡ 1 sur R– f(x) = x sur R– f(x) = |x| sur R– f(x) = −|x| sur R– f(x) = −|x| sur R+ = {x ≥ 0}– exp{x} sur R– exp{x2} sur R– exp{−x2} sur R– exp{−x2} sur {x | x ≥ 100}
Exercice 5.2 Montrer que les fonctions suivantes sont convexes :– x2
y sur {(x, y) ∈ R2 | y > 0}– ln(exp{x}+ exp{y}) sur le plan R2.
Exercice 5.3 Une fonction reelle f definie sur un ensemble convexe Q est appelee log-convexesur Q, si elle est a valeurs positives sur Q et la fonction ln f est convexe sur Q. Montrez que
– une fonction log-convexe sur Q est convexe sur Q– la somme (et plus generalement, toute combinaison lineaire avec des coefficients positifs)
des deux fonctions log-convexes sur Q est aussi log-convexe sur Q.Indication : utilisez le resultat de l’exercice precedent et votre connaissance d’operationspreservant la convexite
Exercice 5.4 On considere un programme de Programming Lineaire
cTx→ min | Ax ≤ b
avec une matrice A m×n. Soit x∗ une solution optimale du probleme, c.-a-d., x∗ est un minimi-seur d’une fonction convexe differentiable f(x) = cTx sur l’ensemble convexe Q = {x | Ax ≤ b}et, ainsi, selon la Remarque 5.5.1, ∇f(x∗) doit appartenir au cone normal de Q en x∗ – c’estla condition necessaire et suffisante d’optimalite de x∗. Que veut dire cette condition en termesde A, b et c ?

Chapitre 6
Programmation Convexe et Dualitede Lagrange
Dans ce chapitre nous touchons a notre objectif principal – les conditions d’optimalite, nousobtiendrons ces conditions pour le cas le plus favorable de programmation convexe.
6.1 Programme de Programmation Mathematique
Un programme de Programmation Mathematique (sous contraintes) est un probleme commesuit :
(P) min {f(x) | x ∈ X, g(x) ≡ (g1(x), ..., gm(x)) ≤ 0, h(x) ≡ (h1(x), ..., hk(x)) = 0} . (6.1)
La terminologie standardisee liee a (6.1) est suivante :– [domaine] X s’appelle domaine du probleme– [objectif] f s’appelle l’objectif– [ contraintes ] gi, i = 1, ...,m, s’appellent contraintes (fonctionnelles) d’inegalite ; hj , j =
1, ..., k, s’appellent contraintes d’egalite 1)
Dans la suite, si l’oppose n’est pas dit explicitement, il est toujours suppose que l’objectif et lescontraintes sont bien definis sur X.
– [solution faisable] un point x ∈ Rn s’appelle la solution faisable de (6.1), si x ∈ X,gi(x) ≤ 0, i = 1, ...,m, et hj(x) = 0, j = 1, ..., k, c.-a-d., si x satisfait toutes les restrictionsimposees par la formulation du probleme– [ensemble faisable] l’ensemble de toutes les solutions faisables s’appelle ensemble faisable
du probleme– [probleme faisable] un probleme avec un ensemble faisable non vide (c.-a-d., celui qui
admet les solutions faisables) s’appelle faisable (ou consistant)– [ contraintes actives ] une contrainte gi(·) ≤ 0 d’inegalite s’appelle active en une solution
faisable donnee x, si cette contrainte est satisfaite en ce point comme une egalite plutotqu’une inegalite stricte, c.-a-d., si
gi(x) = 0.
1. )rigoureusement parlant, les contraintes ne sont pas les functions gi, hj , mais les relations gi(x) ≤ 0,hj(x) = 0 ; en fait le mot “contraintes” est employe dans ces deux sens, et il est toujours clair ce qu’il signifie. Parexemple, en disant que x satisfait les contraintes, nous sous-entendons les relations, et en disant que les contraintessont differentiables, nous sous-entendons que les functions
115

116 CHAPITRE 6. PROGRAMMATION CONVEXE ET DUALITE DE LAGRANGE
Une contrainte d’egalite de hi(x) = 0 est active par definition en chaque solution faisablex.
– [valeur optimale] la valeur
f∗ ={infx∈X:g(x)≤0,h(x)=0 f(x), le probleme faisable+∞, le probleme infaisable
s’appelle la valeur optimale du probleme– [bornitude] le probleme s’appelle borne inferieurement, si son valeur optimale est > −∞,
c.-a-d., si l’objectif est borne inferieurement sur l’ensemble faisable– [solution optimale] un point x ∈ Rn s’appelle solution optimale de (6.1), si x est faisable
et f(x) ≤ f(x′) pour n’importe quelle autre solution faisable x′, c.-a-d., si
x ∈ Argminx′∈X:g(x′)≤0,h(x′)=0
f(x′)
– [probleme soluble] un probleme s’appelle soluble, s’il admet des solutions optimales– [ensemble optimal] l’ensemble de toutes les solutions optimales d’un probleme s’appelle
son ensemble optimalResoudre le probleme sous-entend trouver une solution optimale ou detecter qu’il n’existe aucunesolution optimale.
6.2 Convex Programming program and Duality Theorem
Un programme (P) de Programmation Mathematique s’appelle convexe (ou programme deProgrammation Convexe), si
– X est sous-ensemble convexe de Rn
– f, g1..., gm sont des fonctions convexes a valeurs reelles sur X,et
– il n’y a aucune contrainte d’egalite du tout.On note qu’au lieu de dire qu’il n’y a aucune contrainte d’egalite, on pourrait indiquer que lesseules contraintes de ce type qui sont admises sont des contraintes lineaires ; ce dernier cas peutetre immediatement reduit au cas sans contraintes d’egalite en remplacant Rn avec l’ensembleaffine donne par les contraintes (lineaires) d’egalite.
6.2.1 Theoreme sur l’Alternative Convexe
Le cas le plus simple d’un programme convexe est, naturellement, un programme de Pro-grammation Lineaire – celui ou X = Rn et l’objectif et tous les contraintes sont lineaires. Noussavons deja ce qui sont des conditions d’optimalite pour ce cas particulier – elles sont donneespar le Theoreme de Dualite pour la Programmation Lineaire dans le Chapitre 4. Commentavons-nous obtenu ces conditions ?
Nous avons commence par l’observation que le fait qu’un point x∗ est une solution optimalepeut etre exprime en termes de solubilite/insolubilite des certains systemes d’inegalites : enutilisant notre notation “modernes”, ces systemes sont
x ∈ G, f(x) ≤ c, gj(x) ≤ 0, j = 1, ...,m (6.2)
etx ∈ G, f(x) < c, gj(x) ≤ 0, j = 1, ...,m; (6.3)

6.2. CONVEX PROGRAMMING PROGRAM AND DUALITY THEOREM 117
ou c est un parametre. L’optimalite de x∗ pour ce probleme signifie exactement que pour cconvenablement choisi (ce choix, naturellement, est c = f(x∗)) le premier de ces systemes estsoluble et x∗ est sa solution, alors que le deuxieme systeme est insoluble. En partant de cetteobservation triviale, nous avons converti “sa partie negative” – l’affirmation que (6.3) est inso-luble – en un resultat positif, en utilisant le Theoreme General sur l’Alternative, et ceci nous amene au Theoreme de Dualite de LP.
Maintenant nous allons employer la meme approche. Ce que nous avons besoin est un “ana-logue convexe” du Theoreme sur l’Alternative. Autrement dit, on cherche quelque chose commece dernier resultat mais pour le cas quand les inegalites en question sont donnees par des fonctionsconvexes plutot que par des fonctions lineaires (et, de plus, nous avons une inclusion convexex ∈ X).
Le resultat dont on a besoin est facile a deviner. Comment sommes-nous venus a la formu-lation du Theoreme sur l’Alternative ? Nous nous sommes pose la question : comment exprimerd’une facon affirmative le fait qu’un systeme d’inegalites lineaires n’a pas de solution ; et nousavons observe que si nous pouvons combiner, d’une facon lineaire, les inegalites du systemeet obtenir une inegalite evidemment fausse comme 0 ≤ −1, alors le systeme est insoluble ;cette condition contient une certaine affirmation sur les poids avec lesquels nous combinons lesinegalites originales.
Maintenant, le schema du raisonnement ci-dessus n’a rien en commun avec la linearite (etmeme avec la convexite) des inegalites en question. En effet, considerez un systeme arbitraired’inegalites du type (6.3) :
(I)f(x) < cgj(x) ≤ 0, j = 1, ...,m
x ∈ X;
nous supposons que X soit un sous-ensemble non vide de Rn et f, g1, ..., gm sont des fonctionsa valeurs reelles sur X. Il est absolument evident que
s’il existent λ1, ..., λm non negatifs tels que l’inegalite
f(x) +m∑j=1
λjgj(x) < c (6.4)
n’a aucune solution dans X, alors (I) n’a egalement aucune solution.
En effet, une solution de (I) est clairement une solution de (6.4) – la derniere inegalite n’est rienqu’une combinaison des inegalites de (I) avec les poids 1 (pour la premiere inegalite) et λj (pourle reste).
Maintenant, que signifie-t-il que (6.4) n’a aucune solution ? Une condition necessaire et suf-fisant pour ceci est que l’infinum du cote gauche de (6.4) en x ∈ X est ≥ c. Ainsi, nous venonsau
Proposition 6.2.1 [condition suffisant pour l’insolubilite de (I)] Considerons un systeme (I)avec des donnees arbitraires et supposons que le systeme
(II)
infx∈X[f(x) +
∑mj=1 λjgj(x)
]≥ c
λj ≥ 0, j = 1, ...,m
avec des inconnus λ1, ..., λm a une solution. Alors (I) est insoluble.

118 CHAPITRE 6. PROGRAMMATION CONVEXE ET DUALITE DE LAGRANGE
Il est important de se rappeler que ce resultat est completement general : il n’exige aucunehypothese sur les entites impliquees.
Le resultat que nous avons obtenu, malheureusement, ne nous aide pas : la force du Theoremesur l’Alternative (et le fait que nous avons utilise pour prouver le Theoreme de Dualite pourla Programmation Lineaire) n’etait pas la suffisance de la condition dans la proposition pourl’insolubilite de (I), mais la necessite de cette condition. La justification de la necessite de lacondition en question n’a rien en commun avec le raisonnement evident qui donne la suffisance.Nous avons etabli la necessite pour le cas lineaire (quand X = Rn et f , g1..., gm sont lineaires)dans le Chapitre 4 par l’intermediaire du Lemme de Farkas. Nous allons prouver la necessitede la condition pour le cas convexe, et deja dans ce cas nous avons besoin d’une hypotheseadditionnelle ; et dans le cas non convexe general la condition en question n’est simplement pasnecessaire pour l’insolubilite de (I)
Ce “preface” explique ce que nous devrions faire. Nous commencons par l’hypothesesupplementaire de regularite mentionnee ci-dessus.
Definition 6.2.1 [Condition de Slater] Soit X ⊂ leRn et g1..., gm des fonctions a valeurs reellessur X. Nous disons que ces fonctions satisfont la condition de Slater sur X, s’il existe x ∈ Xtel que gj(x) < 0, j = 1, ...,m.
On dit qu’un probleme avec des contraintes d’inegalites
(IC) f(x) → min | gj(x) ≤ 0, j = 1, ...,m, x ∈ X
(f, g1, ..., gm sont des fonctions reelles sur X) satisfait la condition de Slater, si g1, ..., gm satis-font cette condition sur X.
nous sommes sur le point d’etablir le fait fondamental suivant :
Theoreme 6.2.1 [Theoreme sur l’Alternative Convexe]Soit X ⊂ Rn convexe, et soient f, g1, ..., gm des fonctions reelles convexes sur X. De plus, onsuppose que g1, ..., gm satisfont la condition de Slater sur X. Alors le systeme (I) est soluble siet seulement si le systeme (II) est insoluble.
Une partie du resultat – “si (II) a une solution, alors (I) n’a aucune solution”– est donnepar la Proposition 6.2.1. Ce que nous avons a montrer est l’implication inverse. Ainsi noussupposons que (I) n’a aucune solution, et nous allons montrer qu’alors (II) a une solution.
Sans perte de generalite nous pouvons supposer que X est de dimension “complete” :riX = int X (en effet, autrement nous pourrions remplacer notre “univers Rn avec l’enve-loppe d’affine de X).
10. On pose
F (x) =
⎛⎜⎝f(x)g1(x)...
gm(x)
⎞⎟⎠et on considere deux ensembles dans Rm+1 :
S = {u = (u0, ..., um) | ∃x ∈ X : F (x) ≤ u}et
T = {(u0, ..., um) | u0 < c, u1 ≤ 0, u2 ≤ 0, ..., um ≤ 0}.J’affirme que
– (i) S et T sont les ensembles convexes non vides ;

6.2. CONVEX PROGRAMMING PROGRAM AND DUALITY THEOREM 119
– (ii) S et T sont disjoints.En effet, convexite de T est evidente, ainsi que le fait que S et T ne sont pas vides. Laconvexite de S est une consequence immediate du fait que X et f, g1, ..., gm sont convexes.En effet, supposant que u′, u′′ ∈ S, on conclue que ils existent x′, x′′ ∈ X tels que F (x′) ≤ u′
et F (x′′) ≤ u′′, d’ou, pour chaque λ ∈ [0, 1]
λF (x′) + (1− λ)F (x′′) ≤ λu′ + (1− λ)u′′.
Le cote gauche dans cette inegalite, due a la convexite de X et de f, g1, ..., gm, est ≥ F (y),y = λx′ + (1−λ)x′′. Alors, pour le point v = λu′ +(1− λ)u′′, il existe y ∈ X avec F (y) ≤ v,d’ou v ∈ S. Ainsi, S est convexe.
Le fait que S∩T = ∅ est une reformulation equivalente du fait que (I) n’a aucune solution.20. Comme S et T sont des ensembles convexes non vides avec l’intersection vide, selon
le Theoreme de Separation ils peuvent etre separes par une forme lineaire : il existe a =(a0, ..., am) �= 0 tel que
infu∈S
m∑j=0
ajuj ≥ supu∈T
m∑j=0
ajuj . (6.5)
30. Etudions les proprietes du vecteur a. J’affirme que, en premier,
a ≥ 0. (6.6)
et, en second,a0 > 0. (6.7)
En effet, pour prouver (6.6) notons que si quelques ai etaient negatifs, alors le cote droitdans (6.5) serait +∞ 2) , ce qui est interdit par (6.5).
Ainsi, a ≥ 0 ; alors, nous pouvons immediatement calculer le cote droit de (6.5) :
supu∈T
m∑j=0
ajuj = supu0<c,u1,...,um≤0
m∑j=0
ajuj = a0c.
Puisque pour chaque x ∈ X le point F (x) appartient a S, le cote gauche dans (6.5) n’est pasmoins que
infx∈X
⎡⎣a0f(x) + m∑j=1
ajgj(x)
⎤⎦ ;
et en combinant nos observations, nous concluons que (6.5) implique
infx∈X
⎡⎣a0f(x) + m∑j=1
ajgj(x)
⎤⎦ ≥ a0c. (6.8)
Montrons maintenant que a0 > 0. Ce fait crucial est une consequence immediate de lacondition de Slater. En effet, soit x ∈ X le point donne par cette condition, de sorte quegj(x) < 0. De (6.8) nous concluons que
a0f(x) +
m∑j=0
ajgj(x) ≥ a0c.
Si a0 etait 0, alors de cote droit de cette inegalite nous aurions 0, alors que le gauche seraitla combinaison
∑mj=0 ajgj(x) des reels gj(x) negatifs avec les coefficients aj non negatifs
2. )regardez ce qui se produit quand toutes les coordonnees dans u, excepte la i-eme, sont fixees aux valeurspermises par la description de T et ui est un “grand” reel negatif

120 CHAPITRE 6. PROGRAMMATION CONVEXE ET DUALITE DE LAGRANGE
et pas tous egaux a 0 3), de facon que le cote gauche est strictement negatif ce qui est lacontradiction recherchee.
40. Maintenant nous pouvons terminer la preuve : comme a0 > 0, on peut diviser lesdeux cotes de (6.8) par a0 pour obtenir
infx∈X
⎡⎣f0(x) + m∑j=1
λjgj(x)
⎤⎦ ≥ c, (6.9)
ou λj = aj/a0 ≥ 0. Ainsi, (II) a une solution.
6.2.2 Fonction de Lagrange et dualite de Lagrange
Le resultat du Theoreme sur l’Alternative Convexe attire notre attention a la fonction
L(λ) = infx∈X
⎡⎣f0(x) + m∑j=1
λjgj(x)
⎤⎦ , (6.10)
ainsi qu’a l’agregat
L(x, λ) = f0(x) +m∑j=1
λjgj(x) (6.11)
qui est a l’origine de cette fonction. L’agregat (6.11) a un nom special – il s’appelle fonction deLagrange du programme d’optimisation sous contraintes d’inegalite
(IC) f(x) → min gj(x) ≤ 0, j = 1, ...,m, x ∈ X.
La fonction de Lagrange d’un programme d’optimisation est une entite tres importante : laplupart de conditions d’optimalite sont exprimees en termes de cette fonction. Commencons parla traduction de ce que nous savons deja en langage de fonction de Lagrange.
Theoreme de dualite pour la programmation convexe
Theoreme 6.2.2 Considerons un programme d’optimisation contraint par des inegalites arbi-traires (IC). Alors
(i) l’infinumL(λ) = inf
x∈XL(x, λ)
de la fonction de Lagrange en x ∈ X est, pour chaque λ ≥ 0, une borne inferieure pour la valeuroptimale de (IC), de sorte que la valeur optimale du programme d’optimisation
(IC∗) supλ≥0
L(λ)
est egalement une borne inferieure pour la valeur optimale de (IC) ;(ii) [Theoreme de Dualite Convexe ] Si (IC)– est convexe,– est borne inferieurement,
et– satisfait la condition de Slater,
3. )en effet, des le debut on sait que a = 0, ainsi si a0 = 0, alors pas tous les aj , j ≥ 1, sont nuls

6.2. CONVEX PROGRAMMING PROGRAM AND DUALITY THEOREM 121
alors la valeur optimale de (IC∗) est atteint et est egal a la valeur optimale de (IC).
Preuve : (i) n’est rien que la Proposition 6.2.1 (comprenez svp pourquoi) ; cependant, il serautile de repeter le raisonnement sous-jacent :
Soit λ ≥ 0 ; afin de prouver que
L(λ) ≡ infx∈X
L(x, λ) ≤ c∗ [L(x, λ) = f(x) +m∑j=1
λjgj(x)],
c∗ etant la valeur optimale de (IC), notons que si x est faisable pour (IC), alors,evidemment, L(x, λ) ≤ f(x), de sorte que l’infinum de L dans x ∈ X soit ≤ la valeurminimale c∗ de f sur l’ensemble faisable de (IC).
(ii) est une consequence immediate du Theoreme sur l’Alternative Convexe. En effet, soit c∗
la valeur optimale de (IC). Alors le systeme
f(x) < c∗, gj(x) ≤ 0, j = 1, ...,m
n’a pas de solutions dans X, et par le theoreme ci-dessus le systeme (ii) lie a c = c∗ a unesolution, c.-a-d., il existe λ∗ ≥ 0 tel que L(λ∗) ≥ c∗. Mais nous savons de (i) que l’inegalitestricte ici est impossible et, par ailleurs, L(λ) ≤ c∗ pour chaque λ ≥ 0. Ainsi, L(λ∗) = c∗ et λ∗
est le maximiseur de L sur λ ≥ 0.
Programme Dual
Theoreme 6.2.2 etablit un certain lien entre deux programmes d’optimisation – le programme“primal”
(IC) f(x) → min | gj(x) ≤ 0, j = 1, ...,m, x ∈ X.et son Dual de Lagrange
(IC∗) supλ≥0
L(λ), [L(λ) = infx∈X
L(x, λ)]
(les variables λ du probleme dual s’appellent les multiplicateurs de Lagrange du probleme pri-mal). Le theoreme indique que la valeur optimale dans le probleme dual est ≤ celle du primal,et dans certaines circonstances favorables (le probleme primal est convexe, borne inferieurementet satisfait la condition de Slater) les valeurs optimales dans les deux programmes sont egales.
Dans notre formulation il y a une certaine asymetrie entre les programmes primal et dual.En fait les deux programmes sont lies a la fonction de Lagrange d’une maniere tout a faitsymetrique. En effet, considerez le programme
minx∈X
L(x), L(x) = supλ≥0
L(λ, x).
L’objectif dans ce programme est +∞ en chaque point x ∈ X qui n’est pas faisable pour (IC)et est egale a f(x) sur l’ensemble faisable de (IC), de sorte que ce programme soit equivalent a(IC). Nous voyons que les programmes primal et dual viennent de la fonction de Lagrange : dansle probleme primal, on minimise sur X du resultat de la maximisation de L(x, λ) sur λ ≥ 0, etdans le programme dual on maximise sur λ ≥ 0 le resultat de la minimisation de L(x, λ) surx ∈ X. C’est un exemple particulier (et le plus important) du jeu de deux personnes a sommenulle.

122 CHAPITRE 6. PROGRAMMATION CONVEXE ET DUALITE DE LAGRANGE
Nous avons dit que les valeurs optimales de (IC) et de (IC∗) sont egales entre elles sousquelques conditions de convexite et de regularite. Il y a egalement une autre maniere de dire queces valeurs optimales sont egales – c’est toujours le cas quand la fonction de Lagrange possedeun point-selle, c.-a-d. qu’il existe une paire x∗ ∈ X, λ∗ ≥ 0 telle L(x, λ) atteint sur cette paireson minimum en fonction de x ∈ X et atteint son maximum en fonction de λ ≥ 0 :
L(x, λ∗) ≥ L(x∗, λ∗) ≥ L(x∗, λ) ∀x ∈ X,λ ≥ 0.
On peut facilement demontrer (faites-le par vous-meme) que
Proposition 6.2.2 (x∗, λ∗) est un point-selle de la fonction de Lagrange L du probleme (IC)si et seulement si x∗ est une solution optimale de (IC), λ∗ est une solution optimale de (IC∗) etles valeurs optimales dans les deux problemes sont egales entre elles.
Notre but maintenant sera d’extraire de ce que nous savons deja sur la fonction de Lagrangeles conditions d’optimalite pour des programmes convexes.
6.2.3 Conditions d’Optimalite en Programmation Convexe
Nous commencons avec la formulation point-selle des conditions d’optimalite.
Theoreme 6.2.3 [Formulation point-selle des Conditions d’Optimalite en ProgrammationConvexe]
Soit (IC) un programme d’optimisation, L(x, λ) sa fonction de Lagrange, et x∗ ∈ X. Alors,
(i) une condition suffisante pour que x∗ soit une solution optimale de (IC) est l’existence duvecteur de multiplicateurs de Lagrange λ∗ ≥ 0 tels que (x∗, λ∗) est un point-selle de la fonctionde Lagrange L(x, λ). C.-a-d., un point ou L(x, λ) atteint son minimum en fonction de x ∈ X etatteint son maximum en fonction de λ ≥ 0 :
L(x, λ∗) ≥ L(x∗, λ∗) ≥ L(x∗, λ) ∀x ∈ X,λ ≥ 0. (6.12)
(ii) De plus, si le probleme (IC) est convexe et satisfait la condition de Slater, alors cettecondition est aussi necessaire pour l’optimalite de x∗ : si x∗ est optimal pour (IC), alors il existeλ∗ ≥ 0 tels que (x∗, λ∗) est un point-selle de la fonction de Lagrange.
Preuve : (i) : supposons que pour un x∗ ∈ X donne il existe λ∗ ≥ 0 tel que (6.12) est satisfait ;montrons qu’alors x∗ est optimal pour (IC). Tout d’abord, x∗ est faisable : en effet, si gj(x
∗) > 0pour certains j, alors, immediatement, supλ≥0 L(x
∗, λ) = +∞ (regardez ce qui se produit quandtous les λ’s, excepte λj, sont fixes, et λj → +∞) ; mais supλ≥0 L(x
∗, λ) = +∞ est interdit parla deuxieme inegalite de (6.12).
Puisque x∗ est faisable, supλ≥0 L(x∗, λ) = f(x∗), et nous concluons de la deuxieme inegalite
de (6.12) que L(x∗, λ∗) = f(x∗). Maintenant la premiere inegalite dans (6.12) dit que
f(x) +m∑j=1
λ∗jgj(x) ≥ f(x∗) ∀x ∈ X.
La derniere inegalite implique immediatement que x∗ est optimal : en effet, si x est faisable pour(IC), alors le cote gauche dans la derniere inegalite est ≤ f(x) (rappellons-nous que λ∗ ≥ 0), etl’inegalite implique que f(x) ≥ f(x∗).

6.2. CONVEX PROGRAMMING PROGRAM AND DUALITY THEOREM 123
(ii) : supposons que (IC) est un programme convexe, x∗ est sa solution optimale et le problemesatisfait la condition de Slater ; nous devrions montrer qu’il existe alors λ∗ ≥ 0 tel que (x∗, λ∗)est un point-selle de la fonction de Lagrange, c.-a-d. que (6.12) est satisfait. Comme nous savonsdu Theoreme de Dualite Convexe (Theoreme 6.2.2.(ii)), le probleme dual (IC∗) a une solutionλ∗ ≥ 0 et la valeur optimale du probleme dual est egale a la valeur optimale du primal, c.-a-d.,a f(x∗) :
f(x∗) = L(λ∗) ≡ infx∈X
L(x, λ∗). (6.13)
Nous en concluons immediatement que
λ∗j > 0 ⇒ gj(x∗) = 0
(ceci s’appelle condition de complementarite : les multiplicateurs de Lagrange positifs peuventetre associes seulement aux contraintes actives (celles qui sont satisfaites en x∗ comme egalites).En effet, de (6.13) nous avons
f(x∗) = infx∈X
L(x, λ∗) ≤ L(x∗, λ∗) = f(x∗) +m∑j=1
λ∗jgj(x∗);
les termes de la∑
j dans le cote droit sont nonpositifs (puisque x∗ est faisable pour (IC)), et lasomme elle-meme est non negative due a notre inegalite, ce qui est possible si et seulement sitoutes les termes dans la somme sont zero, et c’est exactement la complementarite.
Des conditions de complementarite nous concluons immediatement que f(x∗) = L(x∗, λ∗),et donc (6.13) ait comme consequence
L(x∗, λ∗) = f(x∗) = infx∈X
L(x, λ∗).
D’autre part, puisque x∗ est faisable pour (IC), nous avons L(x∗, λ) ≤ f(x∗) si λ ≥ 0. Encombinant nos observations, nous concluons que
L(x∗, λ) ≤ L(x∗, λ∗) ≤ L(x, λ∗)
pour tout le x ∈ X et tout le λ ≥ 0.Notons que (i) est valide pour un programme d’optimisaton avec des contraintes inegalites
arbitraire, pas necessairement convexe. C’est une toute autre histoire que dans le cas non convexela condition suffisante d’optimalite, donnee par (i), est “tres loin d’etre necessaire” et n’est“presque jamais” satisfaite. Contrairement a ceci, dans le cas convexe la condition en questionest non seulement suffisante, mais egalement “presque necessaire” – il l’est certainement quand(IC) est un programme convexe satisfaisant la condition de Slater.
Le Theoreme 6.2.3 est la condition d’optimalite la plus forte pour un programme de pro-grammation convexe, mais c’est, dans un sens, une “condition implicite” – elle est exprimee entermes de point-selle de la fonction de Lagrange, et il est peu clair comment verifier que quelquechose est le point-selle de la fonction de Lagrange. Essayons de comprendre la signification dufait que (x∗, λ∗) est un point de selle de la fonction de Lagrange. Par definition, cela signifie que
– (A) L(x∗, λ) atteint son maximum en λ ≥ 0 dans λ = λ∗
– (B) L(x, λ∗) atteint son minimum en x ∈ X dans x = x∗.Il est facile a voir que signifie (A) : il signifie exactement que
x∗ est faisable pour (IC) et les conditions de complementarite
λ∗jgj(x∗) = 0

124 CHAPITRE 6. PROGRAMMATION CONVEXE ET DUALITE DE LAGRANGE
sont satisfaites (c.-a-d., les valeurs de λ∗j positives ne peuvent etre associees que avec descontraintes gj(x) ≤ 0 actives en x∗).
Effectivement, la fonction
L(x∗, λ) = f(x∗) +m∑j=1
λjgj(x∗)
est affine en λ, et nous comprenons quand et ou une telle fonction atteint son maximum surl’orthant non negatif : elle est borne superieurement sur l’orthant si et seulement si tous lescoefficients devants λj sont non positifs (c.-a-d., si et seulement si x∗ est faisable pour (IC)), etsi c’est le cas, alors l’ensemble de maximiseurs est exactement l’ensemble
{λ ≥ 0 | λjgj(x∗) = 0, j = 1, ...,m}.Maintenant, que signifie-t-il que la fonction L(x, λ∗) atteint son minimum sur X en x∗ ? La
reponse depend de la “bonte” de la fonction de Lagrange comme fonction de x. Par exemple, si(IC) est un convexe programme, alors
L(x, λ∗) = f(x) +m∑j=1
λ∗jgj(x)
est convexe en x ∈ X (rappellez-vous que λ∗ ≥ 0) ; quand f, g1, ..., gm sont differentiables enx∗, ainsi l’est L(x, λ∗). Rappelez-vous maintenant que nous savons ce qui sont les conditionsnecessaires et suffisantes pour qu’une fonction convexe atteint son minimum sur l’ensembleconvexe X en x∗ ∈ X ou la fonction est differentiable : le gradient de la fonction en x∗ doitappartenir au cone normal de l’ensemble X en x∗ (voir la Remarque 5.5.1 du Chapitre 5.1.1).D’ailleurs, nous connaissons au moins deux cas quand ce “appartenir au cone normal” peut etretraduit dans des mots tout a fait explicites ; ce sont les cas quand
– (a) X est un ensemble convexe arbitraire et x∗ ∈ int X. Dans ce cas precis “appartenir aucone normal” veut dire simplement d’etre zero ;
– (b) X est un ensemble convexe polyhedral :
X = {x ∈ Rn | aTi x− bi ≤ 0, i = 1...,M}et x∗ est un point arbitraire de X. Dans ce cas “appartenir au cone normal de X en x∗”signifie “etre une combinaison, avec des coefficients nonpositifs, des vecteurs “actifs” ai –ceux avec aTi x
∗ = bi.Considerons maintenant un “melange” de ces deux cas : supposons que X dans (IC) est l’inter-section d’un ensemble convexe arbitraire X ′ et d’un ensemble convexe de polyhedral X ′′ :
X = X ′ ∩X ′′,
X ′′ = {x | gi+m(x) ≡ aTi x− bi ≤ 0 i = 1...,M}.Soit x∗ une solution faisable de (IC) qui est un point interieur de X ′, et soit f, g1..., gm desfonctions convexes et differentiables en x∗. Quand x∗ est optimal pour (IC) ?
Comme nous le savons deja, la condition suffisante (qui est egalement necessaire si g1..., gmsatisfont la condition de Slater surX) est qu’ils existent des multiplicateurs de Lagrange λ∗1..., λ∗mnon negatifs tels que
λ∗jgj(x∗) = 0, j = 1, ...,m (6.14)

6.2. CONVEX PROGRAMMING PROGRAM AND DUALITY THEOREM 125
et
x∗ ∈ ArgminX
[f(x) +m∑j=1
λ∗jgj(x)] (6.15)
Maintenant essayons de comprendre ce que signifie reellement cette condition. On sait que x∗
est un point interieur de X ′. Il en suit que si x∗ est un minimizer de la fonction φ(x) = f(x) +∑mj=1 λ
∗jgj(x) sur X, c’est egalement un minimizer local de la fonction sur X ′′ ; puisque φ est
convexe, x∗ est egalement un minimizer global de φ sur X ′′. Vice versa, si x∗ est un minimizer deφ sur X ′′, c’est, naturellement, un minimizer de la fonction sur l’ensemble plus petit X. Ainsi,(6.15) dit exactement que φ atteint en x∗ son minimum sur l’ensemble polyhedral X ′′. Maisnous savons de la Remarque 5.5.1 quand une fonction convexe et differentiable φ atteint sonminimum par rapport a x sur un ensemble polyhedral : c’est le cas si et seulement si
∇φ(x∗) +∑i∈I
μ∗i ai = 0 (6.16)
ou μ∗i ≥ 0 et I est l’ensemble d’indices des contraintes lineaires gm+i(x) ≡ aTi x− b ≥ 0 dans ladescription de X ′′ qui sont actives (sont satisfaites comme egalites) en x∗.
Mettons maintenant λ∗m+i = μ∗i pour i ∈ I et λ∗m+i = 0 pour i �∈ I, i ≤ M . Avec cettenotation, nous avons
λ∗j ≥ 0, λ∗jgj(x∗) = 0, j = 1, ...,m +M, (6.17)
tandis que (6.16 dit que
∇f(x∗) +m+M∑i=1
λ∗j∇gj(x∗) = 0. (6.18)
Recapitulons : nous avons montre sous les conditions ci-dessus (le probleme est convexe, lesdonnees sont differentiables en x∗, la solution faisable x∗ est un point interieur X ′) que lacondition suffisante (et necessaire et suffisante, si g1, ..., gm satisfont la condition de Slater surX) de l’optimalite de x∗ est l’existence des multiplicateurs de Largange λ∗j , j = 1, ...,m +M ,satisfaisant (6.17) et (6.18).
Notez que cette condition d’optimalite a“l’aire” comme si nous traitions les contraintesg1(x) ≤ 0, ..., gm(x) ≤ 0 et les contraintes lineaires definissant X ′′ en tant que contraintesfonctionnelles, et on traite X ′, et pas X = X ′ ∩ X ′′, comme domaine du probleme. Mais ily a une difference importante : avec cette nouvelle interpretation des donnees, afin d’obtenirla necessite de notre condition d’optimalite, nous avons ete censes de supposer que toutes lesm+M de nos nouvelles contraintes fonctionnelles satisfaisaient la condition de Slater : il existex ∈ X ′ tel que gj(x) < 0, j = 1, ...,m+M . Avec notre approche nous avons obtenu la necessitesous une hypothese plus faible : il devrait exister x ∈ X ′ ou les contraintes “compliquees”g1(x) ≤ 0, ..., gm(x) ≤ 0 sont satisfaits en tant qu’inegalites strictes, alors que les contraintes“simples” lineaires gm+1(x) ≤ 0¿..., gm+M (x) ≤ 0 simplement sont satisfaites.
Les resultats de nos considerations meritent certainement d’etre formules comme un theoreme(ou nous changeons legerement la notation : ce qui sera m et X, dans les considerations ci-dessusetaient m+M et X ′) :
Theoreme 6.2.4 [Conditions d’Optimalite de Karush-Kuhn-Tucker dans le cas Convexe]
Soit (IC) un programme convexe, x∗ ∈ X une solution faisable interieure de (IC) (x∗ ∈int X), et soit f, g1..., gm differentiables en x∗.
(i) [Suffisance] la condition de Karush-Kuhn-Tucker :

126 CHAPITRE 6. PROGRAMMATION CONVEXE ET DUALITE DE LAGRANGE
Ils existent des multiplicateurs nonnegatifs de Lagrange, λ∗j , j = 1...,m, tels que
λ∗jgj(x∗) = 0, j = 1, ...,m [complementarite] (6.19)
et
∇f(x∗) +m∑j=1
λ∗j∇gj(x∗) = 0, (6.20)
est suffisante pour que x∗ soit une solution optimale de (IC).(ii) [Necessite et suffisance ] sous la “condition de Slater restrante” :
il existe x ∈ X tel que les gj non lineaires sont strictlement negatives, et gjlineaires sont nonpositives en x ∈ X
la condition de Karush-Kuhn-Tucker de (i) est necessaire et suffisante pour que x∗ soit unesolution optimale de (IC).
Notez que les conditions d’optimalite du Chapitre 5 (cf. le Theoreme 5.5.2 et la Remarque 5.5.1)sont des cas particuliers du Theoreme ci-dessus pour le cas quand m = 0.
6.3 Dualite pour la Programmation Lineaire et Quadratique
convexe
Le role fondamental qui joue la fonction de Lagrange et la dualite de Lagrange dans l’opti-misation n’est pas limitee au Theoreme 6.2.3 seulement. Il y a plusieurs cas quand nous pouvonsdecrire “explicitement” le probleme dual, et toutes les fois quand c’est le cas, nous obtenonsune paire de programmes d’optimisation etroitement lies – la paire primal-dual ; en analysantles deux problemes simultanement, nous obtenons plus d’informations sur leurs proprietes (ainsiqu’une possibilite de resoudre les problemes numeriquement d’une maniere plus efficace) que sinous nous limitions seulement a un probleme de la paire. La recherche detaillee sur la dualitedans le cas de Programmation Convexe “bien structure”, quand nous pouvons explicitementecrire les problemes primal et dual, va au dela de la portee de notre cours (principalement parceque la dualite de Lagrange n’est pas la meilleure approche ici ; dans ce cas la Dualite de Fenchelest un meilleur outil – quelque chose de semblable, mais non identique). Il y a, cependant, descas simples quand deja la dualite de Lagrange est tout a fait appropriee. Nous allons etudierdeux de tels cas.
6.3.1 La dualite en Programmation Lineaire
Commencons par une observation generale. Notez que la condition de Karush-Kuhn-Tuckersous hypotheses du Theoreme ((IC) est convexe, x∗ est un point interieur de X, f, g1..., gm sontdifferentiables en x∗) est exactement la condition que (x∗, λ∗ = (λ∗1..., λ∗m)) est un point-selle dela fonction de Lagrange
L(x, λ) = f(x) +m∑j=1
λjgj(x) : (6.21)
(6.19) indique que L(x∗, λ) atteint en λ∗ son maximum en λ ≥ 0, et (6.20) dit que L(x, λ∗)atteint en x∗ son minimum en x.
Considerons maintenant le cas particulier de (IC) ou X = Rn est l’espace entier, l’objectiff est convexe et differentiable partout et les contraintes g1..., gm sont lineaires. Dans ce cas, le

6.3. DUALITE POUR LA PROGRAMMATION LINEAIRE ET QUADRATIQUE CONVEXE127
Theoreme 6.2.4 nous dit que la condition KKT (Karush-Kuhn-Tucker) est necessaire et suffisantepour l’optimalite de x∗ ; comme nous avons juste explique, c’est identique a dire que la conditionnecessaire et suffisante de l’optimalite de x∗ est que x∗ avec certain λ∗ ≥ 0 forment un point-sellede la fonction de Lagrange. Combinant ces observations avec la Proposition 6.2.2, nous obtenonsle resultat suivant :
Proposition 6.3.1 Soit (IC) un programme convexe avec X = Rn, l’objectif f qui est differen-tiable partout et les contraintes lineaires g1..., gm. Alors x∗ est la solution optimale de (IC) si etseulement s’il existe λ∗ ≥ 0 tel que (x∗, λ∗) est un point-selle de la fonction de Lagrange (6.21)(consideree comme la fonction de x ∈ Rn et de λ ≥ 0). En particulier, (IC) est soluble si etseulement si L possede des points-selle, et si c’est le cas, alors (IC) avec son dual de Lagrange
(IC∗) : L(λ) → max | λ ≥ 0
sont solubles avec des valeurs optimales egales.
Regardons que cette proposition indique dans le cas de Programmation Lineaire, c.-a-d., quand(IC) est le programme
(P ) f(x) = cTx→ min | gj(x) ≡ bj − aTj x ≤ 0, j = 1, ...,m.
Afin d’obtenir le dual de Lagrange, nous devrons former la fonction de lagrange
L(x, λ) = f(x) +m∑j=1
λjgj(x) = [c−m∑j=1
λjaj ]Tx+
m∑j=1
λjbj
de (IC) et pour le minimiser en x ∈ Rn ; ceci nous donnera l’objectif dual. Dans notre cas laminimisation en x est immediate : la valeur minimale est −∞, si c−∑m
j=1 λjaj �= 0, et∑m
j=1 λjbjsinon. Nous voyons que le dual de Lagrange est
(D) bTλ→ max |m∑j=1
λjaj = c, λ ≥ 0.
Le probleme (D) que nous obtenons est le dual LP de (P ) habituel, et la Proposition 6.3.1 estune des formes equivalentes du Theoreme de Dualite en Programmation Lineaire du Chapitre5.
6.3.2 La dualite en Programmation Quadratic
Considerons maintenant le cas quand le probleme original est quadratique convexe avec descontraintes lineaires :
(P ) f(x) =1
2xTDx+ cTx | gj(x) ≡ bj − aTj x ≤ 0, j = 1, ...,m,
ou l’objectif est une forme quadratique strictement convexe, de sorte que D = DT soit unematrice definie positive : xTDx > 0 quelque soit x �= 0. Il est commode de reecrire les contraintessous une forme vectorielle :
g(x) = b−Ax ≤ 0, b =
⎛⎝ b1...bm
⎞⎠ , A =
⎛⎝ aT1...aTm
⎞⎠ .

128 CHAPITRE 6. PROGRAMMATION CONVEXE ET DUALITE DE LAGRANGE
Afin de former le dual de Lagrange au programme (P ), nous ecrivons la fonction de Lagrange :
L(x, λ) = f(x) +∑m
j=1 λjgj(x)
= cTx+ λT (b−Ax) + 12x
TDx= 1
2xTDx− [ATλ− c]Tx+ bTλ
et la minimisons en x. Puisque la fonction est convexe et differentiable en x, le minimum, siexiste, est donne par la regle de Fermat :
∇xL(x, λ) = 0,
qui dans notre situation devientDx = [ATλ− c].
Comme D est definie positive, elle est non singuliere, de sorte que l’equation de Fermat a unesolution unique qui est le minimiseur recherche de L(·, λ) ; cette solution est
x = D−1[ATλ− c].
Substituant la valeur de x dans l’expression pour la fonction de Lagrange, nous obtenons l’ob-jectif dual :
L(λ) = −1
2[ATλ− c]TD−1[ATλ− c] + bTλ,
et le probleme dual est a maximiser cet objectif sur l’orthant non negatif. Habituellement onreecrit ce probleme dual d’une maniere equivalente en ajoutant des variables supplementaires
t = −D−1[ATλ− c] [[ATλ− c]TD−1[ATλ− c] = tTDt];
apres cette manipulation le probleme dual devient
(D) − 1
2tTDt+ bTλ→ max | ATλ+Dt = c, λ ≥ 0.
Nous observons que le probleme dual est egalement un Programme Quadratique convexe avecdes contraintes lineaires.
Notez egalement que dans notre cas dans un probleme faisable (P ) est automatiquementsoluble 4)
Avec cette observation, nous obtenons de la Proposition 6.3.1
Theoreme 6.3.1 [Theoreme de Dualite en Programmation Quadratique]Soit (P ) un Programme Quadratique faisable avec la matrice symetrique definie positive D dansl’objectif. Alors (P ) et (D) sont solubles, et les valeurs optimales de ces deux problemes sontegales entre elles.
La paire (x; (λ, t)) des solutions feasables des problemes est composee des solutions optimales(i) si et seulement si l’objectif primal en x est egal a l’objectif dual en (λ, t) [condition
d’optimalite de “saut de dualite nul”]ou, ce qui est le meme
(ii) si et seulement si
λi(Ax− b)i = 0, i = 1, ...,m, et t = −x. (6.22)
4. )car son objectif, en raison de la positivite de D, va a l’infini avec |x| → ∞ et grace au fait general suivant :Soit (IC) un programme faisable avec le domaine ferme X, objectif et contraintes continus sur X, et tel quef(x) → ∞ que x ∈ X “tend a l’infini” (c.-a-d. |x| → ∞). Alors (IC) est soluble.Vous etes invites a prouver ce petit resultat (il se trouve parmi les exercices accompagnant ce chapitre)

6.3. DUALITE POUR LA PROGRAMMATION LINEAIRE ET QUADRATIQUE CONVEXE129
Preuve (i) : nous savons de la Proposition 6.3.1 que la valeur optimale dans le probleme (P )de minimisation est egale a la valeur optimale dans le probleme (D) de maximisation. Il en suitque la valeur de l’objectif primal en n’importe quelle solution faisable primale est ≥ la valeur del’objectif dual en n’importe quelle solution faisable duale, et l’egalite est possible si et seulementsi ces valeurs coincident avec les valeurs optimales des problemes, comme c’est affirme dans (i).
(ii) : calculons la difference Δ entre la valeur de l’objectif primal en une solution faisableprimale x et celle de l’objectif dual en une solution faisable duale (λ, t) :
Δ = cTx+ 12x
TDx− [bTλ− 12t
TDt]= [ATλ+Dt]Tx+ 1
2xTDx+ 1
2tTDt− bTλ
[comme ATλ+Dt = c]= λT [Ax− b] + 1
2 [x+ t]TD[x+ t]
Comme Ax− b ≥ 0 et λ ≥ 0 grace a la faisabilite (primale) de x et la faisabilite (duale) de (λ, t),les deux termes dans l’expression finale de Δ sont non negatifs. Ainsi, Δ = 0 (ce qui, grace a(i), est equivalent a l’optimalite de x pour (P ) et l’optimalite de (λ, t) pour (D)) si et seulementsi
∑mj=1 λj(Ax − b)j = 0 et (x + t)TD(x + t) = 0. Comme λ ≥ 0 et Ax ≥ b, la premiere de ces
egalites, est equivalente a λj(Ax− b)j = 0, j = 1...,m. De plus, comme la matrice D est positivedefinie, la seconde egalite est equivalente a x+ t = 0.

130 CHAPITRE 6. PROGRAMMATION CONVEXE ET DUALITE DE LAGRANGE
6.4 Exercices
Exercice 6.1 Montrez le resultat suivant :Soit le programme d’optimisation
f(x) → min | gj(x) ≤ 0, j = 1, ...,m, hl(x) = 0, l = 1, ..., k, x ∈ X ⊂ Rn
faisable, avec le domaine X ferme, et soient f, g1, ..., gm, h1, ..., hk des fonctions continues surX. Supposons, de plus, que le probleme est “coercive” , c.-a-d., il existe une fonction s(t) → ∞,t→ ∞, sur le rayon non negatif tel que
max{f(x), g1(x), ..., gm(x), |h1(x)|, ..., |hk(x)|} ≥ s(|x|) ∀x ∈ X.
Alors le probleme est soluble.
Indication : considerez ce qu’on appelle suite relaxante {xi}, c.-a-d., une suite de solutionsfaisables au probleme avec les valeurs de l’objective qui convergent quand i → ∞ a la valeuroptimale du probleme. Montrez que la suite est bornee et possede donc des points limites ; verifiezque chaque tel point est une solution optimale du probleme.
Exercice 6.2 Trouver la solution le minimiseur de la fonction lineaire
f(x) = cTx
sur l’ensemble
Vp = {x ∈ Rn |n∑
i=1
|xi|p ≤ 1};
ici p, 1 < p <∞, est un parametre.
Exercice 6.3 Considerez la fonction
I(u, v) =k∑
i=1
ui ln(ui/vi)
vue comme une fonction de u ∈ Rk non negatif et de v ∈ Rk positif ; ici 0 ln 0 = 0.1) Montrez que la fonction est convexe en (u, v) sur l’ensemble en question2) Prouvez que si u, v ∈ Δ = {z ∈ Rk
+ :∑
i zi = 1} et u ≥ 0, alors
I(u, v) ≥ 0,
avec l’inegalite etant stricte a condition que u �= v.
Indication : appliquer l’inegalite de Jensen a la fonction strictement convexe − ln t sur (0,∞).Commentaire : un vecteur z ∈ Δ peut etre considere comme la distribution de probabilite
sur l’ensemble de k points : zi est la probabilite assignee a l’i-eme element de l’ensemble. Aveccette interpretation, I(u, v) est une sorte de “distance dirige” entre les lois de probabilite : il placeen correspondance a une paire ordonnee des distributions un reel non negatif qui est positif siles distributions sont distinctes, et est zero sinon. Cette quantite s’appelle distance de Kullback-Leibler (ce n’est pas une distance dans le sens de notre definition du Chapitre 1, puisqu’elle n’estpas symetrique : I(u, v) n’est pas identique a I(v, u)). La distance de Kullback-Leibler entre lesdistributions joue un role important dans la Theorie de Decisions Statistiques.

6.4. EXERCICES 131
Exercice 6.4 Montrez le theoreme suivant de Karhu-Bonnenblast :
Soit X ⊂ Rk un ensemble convexe et f1, ..., fm des fonctions convexes a valeurs reelles sur X.Prouvez que
– ou le systeme d’inegalites strictes
(∗) fi(u) < 0, i = 1, ...,m,
a une solution dans X,– ou ils existent μi ≥ 0 dont la somme fait 1 tels que la fonction
m∑i=1
μifi(u)
est non negative pour tout x ∈ X.
Indicaton : Considerer le programme
(S) t→ min | f0(x)− t ≤ 0, f1(x)− t ≤ 0, ..., fN (x)− t ≤ 0, x ∈ X.
C’est un programme convexe avec la valeur optimale
t∗ = minx∈X
maxi=0,...,N
fi(x)
(notez que (t, x) est faisable pour (S) si et seulement si x ∈ X et t ≥ maxi=0,...,N fi(x)).
Exercice 6.5 Prouvez le resultat suivant :si r > 0 et μ ∈ Rk sont un reel et un vecteur donnes, alors
infv∈Rk
[r ln
(k∑
i=1
exp{vi})− μT v]
est propre (different de −∞) si et seulement si
μ ≥ 0,∑i
μi = r,
et si c’est le cas, alors le inf indique est 0 (dans le cas r = 0), ou est
−k∑
i=1
μi ln(μi/r) [0 ln 0 = 0].
Indication : on voit immediatement que μ ≥ 0 est la condition necessaire pour que l’infinum enquestion soit fini. Pour accomplir la preuve de la necessite, vous devriez verifier que inf est −∞egalement dans le cas du μ ≥ 0 et
∑ki=1 μi �= r ; pour voir ceci, regardez ce qui se passe quand
vi = t, i = 1, ..., k, et t parcourt R.Pour prouver la suffisance et obtenir la representation requise de la valeur optimale, supposez
d’abord que tous les μi sont positifs et utilisez la regle de Fermat pour trouver le minimiseurexacte, ensuite pensez comment eliminer les composants zero de μ, s’ils sont presents.

132 CHAPITRE 6. PROGRAMMATION CONVEXE ET DUALITE DE LAGRANGE

Chapitre 7
Conditions d’Optimalite
Ce chapitre, dernier dans la partie theorique du cours, est consacre aux conditions d’optima-lite du premier ordre pour des programmes de Programmation Mathematiques de type general
(P ) f(x) → min | g(x) ≡ (g1(x), g2(x), ..., gm(x)) ≤ 0, h(x) = (h1(x), ..., hk(x)) = 0, x ∈ X.
La question que nous interesse est suivante :– supposons que nous sommes donnes une solution faisable x∗ de (P ). Quelles sont les
conditions (necessaires, suffisantes, necessaires et suffisantes) pour que x∗ soit optimale ?Nous allons repondre a cette question sous les conditions suivantes sur les donnees du probleme :
– A. x∗ est un point interieur du domaine X du probleme ;– B. les fonctions f, g1, ..., gm, h1, ...hk sont lisses en x∗ (au moins une fois continument
differentiables dans un voisinage du point ; si necessaire, nous aurons besoin de plus deregularite).
Il est important que, contrairement a ce qui a ete fait dans la conference precedente, on n’imposeaucune contrainte structurelle telle que convexite.
Avant de venir aux considerations “techniques”, considerons quelques questions “philoso-phiques” suivantes :
– Quelle sorte des conditions nous interesse ?– Pourquoi sommes nous interesses par ces conditions ?
La reponse a la premiere question est comme suit : nous sommes interesses par des conditionsd’optimalite locales et verifiables. La localite signifie que les conditions devraient etre exprimeesen termes de proprietes locales des donnees – en termes de valeurs et derivees (du premier, se-cond... ordre) des fonctions f, g1..., gm, h1..., hk en x∗. La verifiabilite signifie que etant donne lesvaleurs et les derivees en x∗ des fonctions indiquees, nous devrions pouvoir verifier efficacementsi la condition est ou n’est pas satisfaite.
Ces specifications – tout a fait raisonnables – pour les conditions a deriver menent auxconsequences plutot desagreables :
Nous pouvons esperer d’obtenir des conditions necessaires pour l’optimalite de x∗
et des conditions suffisantes pour l’optimalite local de x∗, mais pas de conditionssuffisantes d’optimalite global de x∗.
Essayons de voir que signifie optimalite “local” et “globale”, et, en second lieu, pourquoi l’affir-mation ci-dessus est vraie.
L’optimalite globale de x∗ n’est rien d’autre que l’optimalite “reelle” : x∗ est une solutionfaisable de (P ) avec la plus petite valeur de l’objectif. Contrairement a ceci, l’optimalite locale
133

134 CHAPITRE 7. CONDITIONS D’OPTIMALITE
de x∗ signifie que x∗ est la solution faisable qui n’est pas plus mauvaise, du point de vue desvaleurs de l’objectif, que d’autres solutions faisables assez proches de x∗. La definition formelleest suivante :
Une solution faisable x∗ de (P ) s’appelle localement optimale, s’il existe un voisinage U dex∗ tel que x∗ est solution optimale de la version (P ) “limitee a U”, c.-a-d., si
x ∈ U, g(x) ≤ 0, h(x) = 0 ⇒ f(x) ≥ f(x∗).
Notez que dans la derniere relation j’ai saute l’inclusion x ∈ X ; c’est parce que nous avonssuppose que x∗ est un point interieur de X, de sorte que en resserrant U , nous pouvons toujoursle rendre une partie de X et rendre ainsi l’inclusion x ∈ X une consequence de l’inclusion x ∈ U).
Dans le cas convexe l’optimalite locale est equivalente a l’optimalite globale (cf. Theoreme5.5.1 combinee avec le fait que l’ensemble faisable d’un programme convexe est convexe). Dansle cas general ces deux notions sont differentes – une solution globalement optimale est, naturel-lement, localement optimale, mais pas vice versa : regardez quelque chose comme le probleme
f(x) = 0.1x2 + sin2 x→ min;
ici il y a plusieurs minimiseurs locaux x∗k de l’objectif, mais seulement un d’entre eux – x∗ = 0– est son minimiseur global.
Notez que puisqu’une solution globalement optimale pour sur est localement optimale, lacondition necessaire d’optimalite locale est aussi necessaire pour l’optimalite global.
Maintenant, il est claire pourquoi dans le cas general il est impossible de preciser une condi-tion locale qui soit suffisante pour l’optimalite globale : parce que l’information locale sur unefonction f en un minimiseur local x∗ de la fonction ne permet pas comprendre que ce minimiseurest seulement local et pas global. En effet, prenons f ci-dessus et x∗k �= 0 ; c’est seulement unminimiseur local, pas global, de f . En meme temps nous pouvons facilement changer f en dehorsd’un voisinage de x∗k et rendre x∗k minimiseur global de la fonction modifiee (tracez le graphede f pour le voir). Notez que nous pouvons facilement rendre la fonction modifiee f aussi lisseque nous le souhaitons. Maintenant, l’information locale – la valeur et les derivees en x∗k – estidentique pour la fonction originale f et la fonction modifiee f , puisque les fonctions coincidentdans un voisinage de x∗. Elle en suit qu’il n’y a aucun test qui prend l’information locale sur leprobleme en x∗ et rend correctement la reponse a la question si x∗ est ou n’est pas un minimiseurglobal de l’objectif, meme si nous assumons que l’objectif soit tres reguliere. En effet, un tel testne peut pas distinguer f et f dans l’exemple precedent, et une fois demande aurait donne deuxfois la meme reponse. Cette reponse est forcement fausse dans un de ces deux cas !
La difficulte que nous avons decrite est intrinseque pour l’optimisation non convexe : nonseulement il n’existe pas de “test local efficace” pour l’optimalite globale ; egalement, il n’existepas, comme nous le verrons dans les chapitres suivants, d’algorithme efficace capable d’approcherle minimiseur global d’un probleme de Programmation Mathematique de type general, memeun probleme avec des donnees tres lisses.
En raison de cette propriete desagreable et inevitable des problemes de programmationmathematiques de type general, la reponse a la seconde des questions annoncees – commentnous allons utiliser les conditions d’optimalite dans la Programmation Mathematique – n’estpas aussi optimiste que nous pourrions souhaiter. En ce qui concerne des conditions de l’op-timalite globale, nous pouvons esperer avoir des conditions necessaires seulement ; en d’autrestermes, nous pouvons esperer avoir un test qui est capable nous indiquer que ce que nous avonsn’est pas une solution globalement optimale. Puisqu’il n’y a pas de condition (locale) suffisante

7.1. CONDITIONS D’OPTIMALITE DU PREMIER ORDRE 135
de l’optimalite globale, nous n’avons aucun espoir de concevoir un test local capable nous direque ce qui nous avons est la solution “reelle” – globale – du probleme. Le maximum de ceque nous pouvons esperer dans cette direction est une condition suffisante de l’optimalite local,c.-a-d., un test local capable de dire que ce que nous avons ne peut pas etre ameliore par des“petites modifications”. C’est la raison principale pourquoi je ne parle pas des conditions suffi-sants de l’optimalite locale dans ce cours. Ceux de vous qui sont interessee par ce sujet devraients’adresser a un texte traditionnel sur la Programmation Mathematique.
Le pessimisme provoque par les remarques ci-dessus a cependant ses limites. Une conditionnecessaire d’optimalite est une certaine relation qui doit etre satisfaite par la solution optimale.Si nous sommes assez intelligents pour produire – sur le papier ou algorithmiquement – tousles candidats x∗ qui satisfont cette relation, et si la liste de ces candidats s’avere finie, nouspouvons parcourir la liste et choisir la meilleur, du point de vue de l’objectif, solution faisabledans cette liste, ce qui va nous donner la solution globalement optimale (etant donne qu’elleexiste). Inutile de dire que la possibilite decrite est rencontree seulement dans les cas parti-culierement simples, mais deja ces cas sont parfois extremement importantes (nous discuteronsun exemple de ce type a la fin de ce chapitre). Une autre maniere d’utiliser des conditionsnecessaires et/ou suffisantes de’optimalite local est de les employer en tant que “le guide” pourdes algorithmes d’optimisation. Ici nous produisons une suite des solutions approximatives etles soumettons au test d’optimalite locale donne par notre condition d’optimalite. Si l’iterationcourante passe le teste, nous terminons avec une solution localement optimale du probleme ; sice n’est pas le cas, alors la condition d’optimalite (qui est viole sur l’iteration courante) indiquenormalement comment mettre a jour l’iteration afin de reduire la “violation” de la condition.Par ces mises a jour sequentielles nous obtenons une suite d’iterations qui, sous des conditions“raisonnables”, converge a une solution localement optimale du probleme. Comme nous le ver-rons dans les prochains chapitres, cette idee est a la base de toutes les methodes traditionnellesde Programmation Mathematique. Naturellement, dans ce cadre il est en principe impossiblede garantir la convergence a une solution globalement optimale (imaginez que on part d’unesolution localement optimale qui n’est pas globalement optimale ; selon le schema decrit nousterminons immediatement !) Bien que ce soit un inconvenient grave de cette approche, il netue pas les methodes traditionnelles basees sur les conditions d’optimalite. D’abord, il peut seproduire que nous sommes chanceux et il n’y a aucune solution locale qui ne soit pas globale ;alors le schema ci-dessus rapprochera la solution optimale (bien que nous ne saurons jamais quec’est le cas...) En second lieu, dans beaucoup de situations pratiques nous sommes interesses enune “amelioration significative” d’une solution initiale donnee du probleme plutot qu’a trouverla “meilleure solution”, et les methodes traditionnelles permettent de realiser ce but restreint.
7.1 Conditions d’Optimalite du Premier Ordre
L’idee des conditions d’optimalite du premier ordre est extremement simple. Soit (P ) unprobleme d’optimisation, et soit x∗ une solution faisable au probleme. Deriver une conditionnecessaire d’optimalite locale de x∗ est equivalent a trover les consequences du fait qui x∗ estlocalement optimal ; chaque telle consequence est, naturellement, une condition necessaire d’op-timalite. Supposons ainsi qui x∗ est localement optimal pour (P ), et essayons de deviner cequi peut etre derive de ce fait. L’idee la plus directe est comme suit : approchons l’objectif etles contraintes du probleme reel (P ) dans un voisinage de x∗ par des fonctions “simples”, dece fait en venant a une “approximation” (P ) du probleme (P ). Nous pouvons esperer que si

136 CHAPITRE 7. CONDITIONS D’OPTIMALITE
l’approximation est assez bonne localement, alors la propriete locale de (P ) que nous interesse– ce que x∗ est une solution localement optimale de (P ) – sera heritee par (P ). Si
– (A) (P ) est aussi simple que nous sommes capable de dire “de maniere constructive” cequi signifie le fait que x∗ est localement optimal pour (P ),et
– (B) nous pouvons montrer que notre hypothese
“ si x∗ est localement optimal pour (P ), il est localement optimal pour (P )aussi bien”
est vrai,alors la condition donnee par (A) sera necessaire pour l’optimalite locale de x∗ pour (P ).
Il y a, fondamentalement, seulement une facon “naturelle” d’implementer cette idee, etantdonne que nous sommes interesses par des conditions d’optimalite du premier ordre et, parconsequent, que (P ) devrait etre pose en termes de valeurs et des gradients de l’objectif et descontraintes originales en x∗ seulement. Cette facon consiste a lineariser l’objectif et les contraintesoriginales en x∗ et de rendre les fonction affines qui en resultent, respectivement, l’objectif et lescontraintes de (P ). Les linearisations en question sont
f(x) = f(x∗) + (x− x∗)T∇f(x∗),gi(x) = gi(x
∗) + (x− x∗)T∇gi(x∗), i = 1, ...,m,hi(x) = hi(x
∗) + (x− x∗)T∇hj(x∗), j = 1, ..., k,
ce qui donne le probleme de Programmation Lineaire (P ) :
(P ) :min f(x∗) + (x− x∗)T∇f(x∗)s.t.
gi(x∗) + (x− x∗)T∇gi(x∗) ≤ 0, i = 1, ...,m
(x− x∗)T∇hj(x∗) = 0, j = 1, ..., k
(j’ai laisse tomber hj(x∗) – elles sont nulles, car x∗ est faisable).
Maintenant, le Theoreme de Dualite pour la Programmation Lineaire nous dit quand x∗
est une solution optimale au programme LP (P ). Puisque nous n’avons pas etabli ce theoremepour la forme particuliere du programme de LP qui nous interesse maintenant (celle avec descontraintes d’egalite et pas seulement des contraintes d’inegalite), nous allons deriver la conditiond’optimalite explicitement de la source du Theoreme de Dualite pour LP – du Lemme de FarkasHomogene.
Supposons que x∗ (qui est faisable pour (P ) – rappelez-vous que x∗ est faisable pour (P ))est optimal pour (P ). Soit I(x∗) l’ensemble d’indices de toutes les contraintes d’inegalite de (P )qui sont actives (satisfaites comme egalites) en x∗, et considerons l’ensemble
K = {d | dT∇gi(x∗) ≤ 0, i ∈ I(x∗), dT∇hj(x∗) = 0, j = 1, ..., k}.
Il est claire que si d ∈ K, alors tout vecteur xt = x∗+ td qui correspond a un assez petit t positifest faisable pour (P ). Comme x∗ est optimal pour ce dernier probleme, on doit avoir
f(x∗) + (xt − x∗)T∇f(x∗) ≥ f(x∗)
pour ce t, d’ou dT∇f(x∗) ≥ 0. Ainsi,

7.1. CONDITIONS D’OPTIMALITE DU PREMIER ORDRE 137
(*) si x∗ est optimal pour (P ), alors dT∇f(x∗) ≥ 0 pour tout d ∈ K ;
en realite “si ... alors ...” peut etre remplace par “si et seulement si” (pourquoi ?).Ensuite, par le Lemme de Farkas Homogene (cf. Chapitre 3) l’affirmation (*) est equivalente
a une possibilite de representer
∇f(x∗) = −∑
i∈I(x∗)
λ∗i∇gj(x∗)−k∑
j=1
μ∗j∇hj(x∗) (7.1)
avec certains λ∗i non negatifs et certains μ∗j reels. Pour le voir, notez que K est exactement lecone polyhedral
{d | dT∇gi(x∗) ≤ 0, i ∈ I(x∗), dT∇hj(x∗) ≤ 0, dT (−∇hj(x∗)) ≤ 0, j = 1, ..., k},et (*) dit que le vecteur ∇f(x∗) a le produit scalaire non negatif avec tout vecteur de K, i.e.,avec tout vecteur qui a le produit scalaire non negatif avec les vecteur de l’ensemble fini
A = {−∇gi(x∗), i ∈ I(x∗),±∇hj(x∗), j = 1, ..., k}.Par le Lemme de Farkas Homogene ceci est le cas si et seulement si ∇f(x∗) est une combinaisonde vecteurs de A avec des coefficients non negatifs :
∇f(x∗) = −∑
i∈I(x∗)λ∗i∇gi(x∗) +
k∑j=1
[μ∗j,+ − μ∗j,−]∇hj(x∗)
avec λ∗j , μ∗j,+, μ∗j,− non negatifs. Et dire que ∇f(x∗) est representable sous cette derniere formeest la meme chose qu’il soit representable comme exige dans (7.1).
Pour l’instant λ∗i sont definis pour i ∈ I(x∗) seulement. Nous allons poser λ∗i = 0 pouri �∈ I(x∗) et en elargissant la somme du cote droit de (7.1) sur i = 1...,m. Notez egalement quemaintenant nous avons des relations de complementarite λ∗i gi(x∗) = 0, i = 1...,m.
Nous avons etabli le resultat conditionnel suivant :
Proposition 7.1.1 Soit x∗ localement optimal pour (P ) et tel que l’hypothese (B) est verifiee :x∗ demeure une solution optimale pour le programme linearise (P ) egalement. Alors ils existentλ∗i non negatifs et μ∗j reels tels que
λ∗i gi(x∗) = 0, i = 1, ...,m [complementary slackness]
∇f(x∗) +∑mi=1 λ
∗i∇gi(x∗) +
∑kj=1 μ
∗j∇hj(x∗) = 0 [Euler’s Equation]
(7.2)
La propriete de x∗ d’etre faisable pour (P ) et de satisfaire la condition “ils existent λ∗i nonnegatifs et ... tels que...” dans la proposition ci-dessus s’appelle Condition d’Optimalite deKarush-Kuhn-Tucker ; nous connaissons deja une version de cette condition pour des problemescontraints par des inegalites. Le point x∗ qui satisfait la condition d’optimalite de KKT s’appelleun point KKT de (P ) (quelquefois ce nom est employe pour la paire (x∗;λ∗, μ∗), c.-a-d., pourle point x∗ avec le certificat qu’il satisfait la condition de KKT).
De la discussion ci-dessus il decoule que tout ce que nous pouvons esperer est que lacondition de KKT soit necessaire pour l’optimalite locale de x∗ ; la Proposition 7.2 indiqueque c’est en effet le cas, mais sous une condition supplementaire implicite : “x∗ reste...”.Le probleme, par consequent, est de convertir cette pretention implicite en quelque chose deverifiable ou d’eliminer cette condition. Le dernier, malheureusement, est impossible, ce qu’onvoit de l’exemple elementaire suivant (ou le probleme est meme convexe) :

138 CHAPITRE 7. CONDITIONS D’OPTIMALITE
f(x) ≡ x→ min | g1(x) ≡ x2 ≤ 0.
La solution optimale (la seule solution faisable) est x∗ = 0. Neanmoins, x∗ = 0 n’est pas unpoint KKT – il est impossible de trouver λ∗1 non negatif tel que
∇f(0) + λ∗1∇g1(0) ≡ 1 + λ∗1 × 0 = 0.
Ainsi, nous avons besoin d’une “condition de regularite” pour rendre la condition de KKTnecessaire a l’optimalite locale. La condition la plus generale de ce type s’appelle “qualificationdes contraintes”.
Qualification des contraintes indique reellement que l’ensemble faisable du probleme actuel(P ) “est proche” a l’ensemble faisable du probleme linearise (P ) dans un voisinage de x∗ “auxterme d’ordre superieur en |x−x∗| pres”, de la meme facon que les donnees des problemes. Pourdonner la definition precise, nous allons ecrire
θ(t) = o(ts)
(θ est une fonction sur le rayon non negatif, s > 0), si θ(t)t−s → 0 quand t → +0 et θ(0) = 0.Et nous dirons que le probleme (P ) a la propriete de Qualification de Contraintes en solutionfaisable x∗, s’il existe une fonction θ(t) = o(t) telle que
pour toute solution faisable x du probleme linearise (P ) il existe une solution faisablex′ du probleme actuel (P ) telle que
|x− x′| ≤ θ(|x− x∗|)– la distance entre x et x′ diminue plus vite que la distance entre x et x∗ quandx→ x∗.
La condition de Qualification des Contraintes dit que l’ensemble faisable du probleme linearise(P ) ne peut pas etre (localement, naturellement) “beaucoup plus large” que l’ensemble faisablede (P ) : pour chaque x pres de x∗ et faisable pour (P ) il existe un x′ “tres proche” a x et faisablepour (P ). Notez que dans le “ mauvais” exemple ci-dessus nous avons exactement l’oppose :l’ensemble faisable de (P ) est la droite entiere (puisque la contrainte dans le probleme lineariseest 0 × x ≤ 0), qui est “un ensemble beaucoup plus large”, meme localement, que l’ensemblefaisable {0} de (P ).
On voit facilement que sous l’hypothese de Qualification de Contraintes l’optimalite localede x∗ pour (P ) implique l’optimalite globale de x∗ pour (P ), de sorte que cette condition rendla condition de KKT necessaire pour l’optimalite :
Proposition 7.1.2 Soit x∗ localement optimal pour (P ), ou (P ) satisfait la condition de Qua-lification de Contraintes en x∗. Alors x∗ est optimal pour (P ) et, par consequent, est un pointKKT de (P ).
Preuve. Soit x∗ localement optimal pour (P ) ; nous devrions montrer qu’alors x∗ est optimalpour (P ). Supposez, au contraire, que x∗ n’est pas optimal pour (P ). Puisque x∗ est faisablepour (P ), la “non optimalite” de x∗ pour le dernier probleme signifie qu’il existe une solutionfaisable x de (P ) avec plus petite valeur de l’objective linearisee f(x∗) + (x − x∗)T∇f(x∗) quela valeur de cet objectif en x∗. Posons d = x− x∗, nous obtenons donc
dT∇f(x∗) < 0.

7.1. CONDITIONS D’OPTIMALITE DU PREMIER ORDRE 139
Maintenant, soitxt = x∗ + t(x− x∗), 0 ≤ t ≤ 1.
Les points xt sont des combinaisons convexes de deux solutions faisables de (P ) et sont doncegalement les solutions faisables du dernier (c’est un programme LP). Par Qualification desContraintes, ils existent des solutions faisables x′t du probleme actuel (P ) tels que
|xt − x′t| ≤ θ(|xt − x∗|) = θ(t|x− x∗|) ≡ θ(tq), q = |x− x∗|, (7.3)
avec θ(t) = o(t). Maintenant, f est continument differentiable dans un voisinage de x∗ (c’est lacondition que nous avons accepte une fois pour toutes au debut de ce chapitre). Il en decouleque (c’est une consequence immediate du Theoreme de Valeur Intermediaire de Lagrange) f estlocalement Lipschitzienne en x∗ : il existe un voisinage U de x∗ et une constante C < ∞ telsque
|f(x)− f(y)| ≤ C|x− y|, x, y ∈ U. (7.4)
Quand t→ +0, nous avons xt → x∗, et comme
|x′t − xt| ≤ θ(tq) → 0, t→ 0,
x′t converge egalement vers x∗ quand t → 0. En particulier, xt et x′t appartiennent a U pourtout t assez petit positif. De plus, de l’optimalite locale de x∗ et du fait que x′t converge vers x∗
quand t→ +0 et est faisable pour (P ) pour tout t nous concluons que
f(x′t) ≥ f(x∗)
quelque soit t positif assez petit. Ainsi pour t petit positif nous avons
0 ≤ t−1[f(x′t)− f(x∗)]≤ t−1[f(xt)− f(x∗)] + t−1[f(x′t)− f(xt)]≤ t−1[f(xt)− f(x∗)] + t−1C|x′t − xt| [see (7.4)]≤ t−1[f(xt)− f(x∗)] + t−1Cθ(tq) [see (7.3)]
= f(x∗+td)−f(x∗)t + t−1Cθ(tq).
Comme t→ 0, la derniere expression dans la chaine tend vers dT∇f(x∗) < 0 (car θ(tq) = o(t)),alors que elle doit etre non negative. C’est la contradiction desiree.
La Proposition 7.1.2 ressemble beaucoup a un pleonasme : on s’est pose la question quand lacondition de KKT est necessaire pour l’optimalite locale, et la reponse que nous avons maintenantdit que ce pour sur est le cas quand (P ) satisfait la condition de Qualification des Contraintesen x∗. Si on gagne quelque chose avec cette reponse, ce quelque chose est en effet tres mince– nous ne savons pas certifier si la Qualification des Contraintes a lieu. Il y a un cas trivial –celui quand les contraintes de (P ) sont lineaires ; dans ce cas-ci l’ensemble faisable du problemelinearise est simplement le meme que l’ensemble faisable du probleme initial (en fait il suffit desupposer la linearite des contraintes actives en x∗ seulement ; dans ce cas les ensembles faisablesde (P ) et de (P ) coincident l’un avec l’autre dans un voisinage de x∗, ce qui est bien suffisantpour la Qualification de Contraintes).
Parmi les certificats plus generaux – conditions suffisantes – pour la Qualification desContraintes 1) le plus frequemment utilise est l’hypothese de regularite de x∗ pour (P ) :
1. ) regardez ce que nous faisons : nous discutons une condition suffisante pour quelque chose, notamment, laQualification des Contraintes, qui n’est a son tour, rien d’autre qu’une condition suffisante pour rendre quelquechose d’autre – le KKT – une condition necessaire pour l’optimalite locale. C’est une qualite tout a fait im-pressionnante d’un etre humain d’etre capable de comprendre ce genre de “conditions des condition” et de lesmanipuler !

140 CHAPITRE 7. CONDITIONS D’OPTIMALITE
(Regularite)
l’ensemble des gradients de toutes contraintes actives de (P ) en x∗ est un ensemblelineairement independant
(rappelons qu’une contrainte est active en x∗ si elle est satisfaite en ce point commeegalite ; en particulier, toutes les contraintes d’egalite sont actives en chaque solutionfaisable).
Le Theoreme fondamental suivant (c’est l’une des formes du Theoreme de Fonction Implicite)montre pourquoi (Regularite) implique la Qualification des Contraintes :
Theoreme 7.1.1 Soit x∗ un point de Rn et soit φ1..., φl des fonction k ≥ 1 continumentdifferentiables dans un voisinage de x∗ qui sont egales a 0 a x∗ et sont telles que leurs gra-dients ∇φi(x∗) en x∗¿, i = 1, ..., l, forment un ensemble lineairement independant.
Alors il existe
– un voisinage X du point x∗ dans Rn
– un voisinage Y d’origine dans Rn
– un isomorphisme y �→ S(y) de Y sur X qui transforme y = 0 en x∗ : S(0) = x∗
– tel que
– (I) S est k fois continument differentiables dans Y , et son inverse S−1(x) est k foiscontinument differentiables dans X ;
– (II) les fonctions
ψi(y) ≡ φi(S(y))
dans Y sont les fonctions-coordonnees yi, i = 1, ..., l.
Corollaire 7.1.1 Soit x∗, φ1, ..., φl satisfont les hypotheses du Theoreme 7.1.1, q ≤ l, X unvoisinage de x∗ donne par le theoreme, et soit Φ l’ensemble de solutions du systeme
φi(x) ≤ 0, i = 1, ..., q; φi(x) = 0, i = q + 1, ..., l.
Il existe alors un voisinage U ⊂ X de x∗ tel que la distance d’un point x ∈ U jusqu’au Φ estbornee superieurement par un facteur proportionnel a la norme du “vecteur de violation”
δ(x) =
⎛⎜⎜⎜⎜⎜⎜⎜⎝
max{φ(x), 0}...
max{φq(x), 0}|φq+1(x)|
...|φl(x)|
⎞⎟⎟⎟⎟⎟⎟⎟⎠.
C.-a-d., qu’il existe une constante D <∞ tel que pour chaque x ∈ U il existe x′ ∈ Φ avec
|x− x′| ≤ D|δ(x)|. (7.5)
Preuve. Soit V une boule fermee du rayon positif r centre a l’origine et contenue dans Y .Puisque S est au moins une fois continument differentiable dans un voisinage de l’ensemblecompact V , ses premiers derivees sont bornees dans V et donc S est Lipschitzienne dans V avecune certaine constante D > 0 :
|S(y′)− S(y′′)| ≤ D|y′ − y′′| ∀y′, y′′ ∈ V.

7.1. CONDITIONS D’OPTIMALITE DU PREMIER ORDRE 141
Puisque S−1 est continu et S−1(x∗) = 0, il existe un voisinage U ⊂ X de x∗ tels que S−1 renvoiece voisinage dans V .
Maintenant, soit x ∈ U , et considerons le vecteur y = S−1(x). En raison de l’origine de U , cevecteur appartient a V , et en raison de l’origine de S, les l premieres coordonnees du vecteur sontexactement φi(x), i = 1, ..., l (puisque x = S(y), et nous savons que φi(S(y)) = yi, i = 1, ..., l).Considerons maintenant le vecteur y′ avec les coordonnees
y′i =
⎧⎨⎩min{yi, 0}, i = 1, ..., q0, i = q + 1, ..., lyi, i = l + 1, ..., n
.
Il est claire que– (a) |y′| ≤ |y|, de sorte que y′ ∈ V ainsi que y ;– (b) les l premieres coordonnees du vecteur y′ − y forme le vecteur δ(x) de violation, et les
coordonnees restantes de y′ − y sont zero, ainsi |y′ − y| = |δ(x)|.Maintenant posons x′ = S(y′). Puisque les l premieres coordonnees de y′ = S−1(x′) sont exac-tement φi(x
′), i = 1, ..., l, nous voyons que les valeurs de φ1..., φq en x′ sont non positives, et lesvaleurs des autre φs sont zero, de sorte que x′ ∈ Φ. D’autre part,
|x− x′| ≡ |S(y)− S(y′)| ≤ D|y − y′| = D|δ(x)|
(nous avons utilise la propriete de Lipschitz de S dans V ), comme requis.
Conditions d’Optimalite du Premier Ordre Maintenant nous pouvons atteindre notrecible – etablir les Conditions d’Optimalite du Premier Ordre.
Theoreme 7.1.2 [Conditions d’Optimalite du Premier Ordre en Programmation Mathematique]Considerons le programme (P ) d’optimisation avec une solution faisable x∗. Supposons quef, g1, ..., gm, h1, ..., hk sont continument differentiables dans un voisinage de x∗ et que
– soit toutes les contraintes de (P ) qui sont en activite a x∗ sont lineaires,– ou (Regularite) a lieu, c.-a-d. que les gradients des contraintes actives en x∗ forme un
ensemble lineairement independant.Alors la condition de KKT est necessaire pour que x∗ soit une solution locale optimale de (P ). Deplus, si (Regularite) a lieu et x∗ est une solution locale optimale de (P ), alors les multiplicateursλ∗i et μ∗j de Lagrange, certifiant l’optimalite sont uniquement definis.
Du a la Proposition 7.1.2, tout ce que nous avons besoin de verifier est que(i) (P ) satisfait la Qualification des Contraintes en x∗ (ceci impliquera que si x∗ est localement
optimal pour (P ), alors c’est un point KKT du probleme)et
(ii) si (Regularite) a lieu et x∗ est localement optimal pour (P ), de sorte que, d’apres (i),c’est un point KKT du probleme, alors les multiplicateurs de Lagrange correspondants sontuniquement definis.
(ii) est immediat : les multiplicateurs de Lagrange qui correspondent aux contraintesd’inegalite inactives en x∗ doivent etre 0 par complementarite, et les multiplicateurs restants,par l’equation d’Euler (7.1), sont les coefficients de la representation de −∇f(x∗) comme unecombinaison lineaire des gradients des contraintes actives en x∗. Sous (Regularite), ces gradientssont lineairement independants, de sorte que les coefficients dans la combinaison ci-dessus soientuniquement definis.

142 CHAPITRE 7. CONDITIONS D’OPTIMALITE
Nous allons maintenant verifier (i). Il n’y a aucun probleme d’etablir (i) dans le cas quandtoutes les contraintes de (P ) actif en x∗ sont lineaires – dans ce cas la Qualification desContraintes est evidente. Ainsi, nous devons deriver la propriete de Qualification des Contraintesen supposant que (Regularite) ait lieu. A cet effet on note {φ1..., φl} le groupe des contraintesd’inegalite actives en x (les q premieres fonctions du groupe) et toutes les contraintes d’egalite(les l − q fonctions restantes). Ce groupe avec x∗, satisfait les conditions du Corollaire 7.1.1 ;selon le corollaire, il existe un voisinage U de x∗ et une constante D <∞ tels que
∀x ∈ U ∃x′ : |x− x′| ≤ D|δ(x)|, φi(x′) ≤ 0, i = 1, ..., q; φi(x′) = 0, i = q + 1, ..., l. (7.6)
De plus, il existe un voisinage W de x∗ tel que toutes les contraintes d’inegalite qui ne sont pasactives en x∗ sont satisfaites dans W entier (en effet, toutes les fonctions de contraintes sontcontinues en x∗, et les contraintes inactives en x∗, etant des inegalites strictes en ce point, restentsatisfaites dans un voisinage de x∗). Considerez maintenant une transformation
x �→ x′(x)
suivante : pour x ∈ U , x′(x) est le vecteur x′ donne par (7.6), si le dernier vecteur appartient aW . Sinon, comme dans le cas x �∈ U , on pose x′(x) = x∗. Notez qu’avec cette definition x′(x) esttoujours une solution faisable de (P ) (pourquoi ?) De plus, comme x → x∗, le vecteur de viola-tions δ(x) tend vers 0, et x′ donne par (7.6) tend egalement vers x∗ et donc devienne par la suiteun vecteur deW . D’ou pour tout x assez proche de x∗, le vecteur x′(x) est exactement le vecteurdonne par (7.6). En recapitulant nos observations, nous venons aux conclusions suivantes :
nous avons defini une transformation qui met en correspondance a un x ∈ Rn arbi-traire une solution faisable x′(x) de (P ). Cette transformation est bornee, et dansun certain voisinage Q de x∗ est tel que
|x′(x)− x| ≤ D|δ(x)|. (7.7)
Supposons maintenant que x soit une solution faisable du probleme lineairise (P ). Notons quele vecteur φ(x) = (φ1(x), ..., φl(x)) admet la representation
φ(x) = φlin(x) + φrem(x),
ou φlin vient des linearisations des fonctions φi en x∗ – c.-a-d., des fonction-contraintes de (P ),
et φrem vient des restes des developpements de Taylor du premier ordre de φi en x∗. Puisquex est faisable pour (P ), les q premieres coordonnees de φlin(x) sont non positives, et les autrescoordonnees sont egales a 0. Il en decoule que si x est faisable pour (P ), alors la norme du vecteurde violations δ(x) n’excede pas la norme du vecteur φrem(x) (regardez la definition du vecteurde violations), et la derniere norme est ≤ θ(|x− x∗|) pour certain θ(t) = o(t), En effet, le restedu developpement de Taylor du premier ordre d’une fonctions continument differentiable dansun voisinage de x∗ est o(|x− x∗|), x etant le point ou le developpement est evalue. Combinantcette observation avec (7.7), nous concluons qu’il y a un voisinage Z de x∗ tels que si x ∈ Z estfaisable pour (P ), alors
|x′(x)− x| ≤ D|δ(x)| ≤ D|φrem(x)| ≤ Dθ(|x− x∗|) (7.8)
pour certain θ(t) = o(t). Hors Z le cote gauche est borne par D′|x − x∗| pour un certain D′
(rappelez-vous que x′(x) est borne). En modifiant la definition de θ(t) d’une facon appropriee endehors d’un voisinage de t = 0, on peut assurer que (7.8) soit valide quelque soit x faisable pour(P ). Comme x′(x), par construction, est faisable pour (P ), (7.8) demontre que la Qualificationdes Contraintes a lieu.

7.2. EN GUISE DE CONCLUSION... 143
7.2 En guise de conclusion...
Nous avons annonce dans la preface de ce cours et de ce chapitre que les conditions d’optima-lite permettent dans certains cas de trouver les solutions explicites aux problemes d’optimisation.Il est temps maintenant d’expliquer comment peut-on les employer pour resoudre un probleme“sur le papier”. Le schema est tres simple. Etant donne un probleme (P ) d’optimisation, nouspouvons noter les conditions d’optimalite de KKT avec les conditions de faisabilite :
∇f(x∗) +∑mi=1 λ
∗i∇gi(x∗) +
∑kj=1 μ
∗j∇hj(x∗) = 0 [n = dim x equations]
λ∗i gi(x∗) = 0, i = 1, ..., .m [m equations]
hj(x∗) = 0, j = 1, ..., k [k equations]
gi(x∗) ≤ 0, i = 1, ...,mλ∗i ≥ 0, i = 1, ...,m
La partie “egalite” de ce systeme est un systeme de n+m+k equations non-lineaires avec n+m+kinconnus – les coordonnees de x∗, λ∗, μ∗. Normalement un tel systeme a seulement un nombrefini de solutions. Si nous sommes assez intelligents pour trouver toutes ces solutions et si pourune raison nous savons que la solution optimale existe et satisfait en effet la condition de KKT(par exemple, les hypotheses du Theoreme 7.1.2 sont verifiees en chaque solution faisable), alorsnous pouvons etre surs qu’en regardant toutes les solutions du systeme KKT et en choisissantparmi elles celle qui est faisable et qui a la meilleure valeur de l’objectif, nous pouvons etresurs que nous finirons avec la solution optimale du probleme. Dans ce processus, nous pouvonsemployer la partie “inegalite” du systeme pour eliminer des candidats de la liste qui ne satisfontpas les inegalites, ce qui permet d’eviter une analyse plus detaillee de ces candidats.
L’approche de ce type est particulierement fructueuse si (P ) est convexe (c.-a-d., quef, g1..., gm sont convexes et h1..., hk sont lineaires). Dans ce cas-ci les conditions de KKT sontsuffisantes pour l’optimalite globale (nous le savons du chapitre precedent). Ainsi, si le problemeest convexe et nous pouvons calculer une solution du systeme KKT, alors nous pouvons etresurs que c’est une solution optimale globale de (P ), et nous ne devrions pas prendre la peine derechercher d’autres points KKT et de les comparer les uns aux autres.
Malheureusement, le programme decrit peut etre realise seulement dans des cas simples ; lesysteme non-lineaire de KKT est trop difficile a etudier analytiquement. Considerons maintenantun de ces cas simples (mais tres instructif).
Minimisation d’une forme quadratique homogene sur la boule unite. Nous consideronsle probleme
(Q) f(x) ≡ xTAx→ min | g1(x) ≡ xTx− 1 ≤ 0,
A etant une matrice symetrique n× n. Essayons de lister toutes solutions localement optimalesdu probleme.
Etape 0. Notons f∗ la valeur optimale. Puisque x = 0 est clairement une solution faisableet f(0) = 0, nous avons f∗ ≤ 0. Il y a, par consequent, deux cas possibles :
Cas (A) : f∗ = 0 ;
Cas (B) : f∗ < 0.
Etape 1 : Cas (A). Le cas (A) a lieu si et seulement si xTAx ≥ 0 pour tous x, |x| ≤ 1, ou,du a la homogeneite de f(x), si et seulement si
xTAx ≥ 0 ∀x.

144 CHAPITRE 7. CONDITIONS D’OPTIMALITE
Nous savons que les matrices symetriques avec cette propriete portent un nom special – elless’appellent symetriques semi-definie positives (nous avons rencontre ces matrices dans le criterede convexite pour des fonctions deux fois differentiables). Dans l’Algebre Lineaire il y a des testspour cette propriete, par exemple, la regle de Silvester 2) : une matrice symetrique est semi-definie positive si et seulement si tous ses mineurs principaux – ceux constitues par des lignes etdes colonnes avec les memes indices – soient non negatifs. Maintenant, quelles sont les solutionslocalement optimales du probleme dans le cas de A semi-definie positive ? Ce sont exactementles points x de la boule unite (l’ensemble faisable du probleme) qui appartiennent au noyau deA, c.-a-d., tels que
Ax = 0
(on note Ker(A)) : tout d’abord, si x ∈ Ker(A) alors xTAx = 0 = f∗, de sorte que x∗ soitmeme globalement optimal. Vice versa, supposons que x est localement optimal, et prouvonsque Ax = 0. La contrainte dans notre probleme est convexe ; l’objectif est egalement convexe(rappelez-vous le critere de la convexite pour des fonctions regulieres et notez que f ′′(x) = 2A),de sorte qu’une solution localement optimale soit en fait optimale. Ainsi, x est localement optimalsi et seulement si xTAx = 0. En particulier, si x est localement optimal, alors x′ = x/2, parexemple, l’est egalement. En cette nouvelle solution optimale, la contrainte est satisfaite commeinegalite stricte, de sorte que x′ soit un minimizer local sans contrainte de fonction f(·), et parla regle de Fermat nous obtenons ∇f(x′) ≡ 2Ax′ = 0 et Ax = 0.
Etape 2 : Cas (B). Considerons maintenant le cas de f∗ < 0, c.-a-d., le cas quand il existeh, |h| ≤ 1, tel que
(#) hTAh < 0.
Que sont les solutions localement optimales x∗ du probleme dans ce cas ?
Que disent les conditions d’optimalite du premier ordre. Logiquement, il y a deux possibilites :la premiere quand |x∗| < 1, et la seconde quand |x∗| = 1.
Montrons d’abord que la premiere situation est en fait impossible. En effet, dans le cas|x∗| < 1 x∗ devrait etre localement optimal pour le probleme sans contraintes f(x) → min |x ∈ Rn avec l’objectif regulier. Par la condition necessaire du second degre d’optimalite localesans contraintes, le Hessian f ′′ en x∗ (qui est egale a 2A) devrait etre semi-defini positif, ce quicontredit (#).
Ainsi, dans le cas en question une solution localement optimale x∗ est forcement sur lafrontiere de la boule unite, et la contrainte g1(x) ≤ 0 est active en x∗. Le gradient 2x∗ de cettecontrainte est donc non nul en x∗, et (par Theorem 7.1.2) x∗ est un point KKT :
∃λ∗1 ≥ 0 : ∇f(x∗) + λ∗1∇g1(x∗) = 0,
ou, ce qui est identique,
Ax∗ = −λ∗1x∗.Ainsi, x∗ devrait etre un vecteur propre 3) de A avec une valeur propre nonpositive λ ≡ −λ∗1. Etc’est tout ce que nous pouvons tirer des conditions necessaires d’optimalite du premier ordre.
En regardant l’exemple
A = Diag(1, 0,−1,−2,−3...,−8)
2. )a ne pas confondre avec S. Stallone.
3. ) un vecteur propre d’une matrice carree M est un vecteur non nul e tels que Me = se pour un certain sreel (ce reel s’appelle la valeur propre de M , associe au vecteur propre e)

7.2. EN GUISE DE CONCLUSION... 145
dans R10, nous observons que les conditions necessaires d’optimalite du premier ordre sont satis-faites par 18 vecteurs ±e2,±e3...,±e10, ou ei, i = 1....10, sont les orths de la base canonique deR10. Tous ces 18 vecteurs sont des points de Karush-Kuhn-Tucker du probleme, et les conditionsd’optimalite du premier ordre ne permettent pas de comprendre lesquels parmi ces 18 candidatssont localement optimaux et lesquels ne le sont pas.
Remarque 7.2.1 Un produit secondaire de notre raisonnement est le resultat qui dit que unematrice symetrique A qui satisfait (#) possede un vecteur propre ((Q) pour sur est soluble,et la condition necessaire du premier ordre indique, comme nous avons vu, qu’une solutionoptimale doit etre un vecteur propre). Notez qu’il est loin d’etre claire a l’avance pourquoi unematrice symetrique devrait avoir un vecteur propre. Naturellement, notre raisonnement etablitl’existence d’un vecteur propre seulement sous la condition (#), mais on peut immediatementeliminer cette contrainte (etant donne une matrice symetrique arbitraire A′, on peut appliquernotre raisonnement a la matrice A = A′ − TI qui, pour un T grand, satisfait surement (#), etdemontrer l’existence d’un vecteur propre de A ; naturellement, celui sera egalement un vecteurpropre de A′).
L’existence d’un vecteur propre d’une matrice symetrique est, naturellement, un faitelementaire bien connu d’Algebre Lineaire ; voici sa preuve en quelques lignes :
Montrons d’abord qu’une matrice arbitraire A, meme avec les entrees complexes, possedeune valeur propre complexe. En effet, λ est une valeur propre de A si et seulement si il existeun vecteur (complexe) non nul z tels que (A−λI)z = 0, c.-a-d., si et seulement si la matriceλI −A est singuliere, ou, ce qui est identique, le determinant de la matrice est nul. D’autrepart, le determinant de la matrice λI−A est clairement un polynome nonconstant de λ, et untel polynome, selon le Theoreme Fondamental de l’Algebre (FTA) – a une racine (complexe) ;une telle racine est une valeur propre de A.
Maintenant on doit montrer que si A est symetrique et reelle, alors il existe une valeurpropre reelle et un vecteur propre reel. C’est immediat : montrons que toutes les valeurspropres de A sont reelles. En effet, si λ est une valeur propre de A (consideree commematrice complexe) et z est le vecteur propre correspondant (complexe), alors l’expression
n∑i,j=1
Aijzjz∗i
(on note par ∗ la conjugaison complexe) est reelle (considerez son conjugue !) ; d’autre part,pour le vecteur propre z nous avons
∑j Aijzj = λzi, de sorte que notre expression devient
λ∑n
i=1 ziz∗i = λ
∑ni=1 |zi|2 ; comme z �= 0, cette derniere expression est reelle si et seulement
si λ est reelle.
Enfin, quand on sait qu’une valeur propre λ d’une matrice symetrique reelle (consideree
comme une matrice avec les entrees complexes) est en fait reelle, on peut immediatement
montrer que le vecteur propre lie a cette valeur propre peut etre choisi pour etre reel : en
effet, la matrice reelle λI −A est singuliere et a donc un noyau non trivial.
Ainsi, dans notre exemple particulier la Theorie d’Optimisation avec ses Conditions d’Optimaliteest, dans un sens, superflue. Cependant, on devrait noter deux choses :
– que la preuve d’Algebre Lineaire de l’existence d’un vecteur propre est basee sur le FTAqui annonce l’existence de la racine (complexe) d’un polynome. Pour obtenir le memeresultat sur l’existence d’un vecteur propre, dans notre preuve (et dans toutes les preuvessur lesquelles elle se base) nous n’avons jamais parle de quelque chose comme FTA ! Toutce que nous avons utilise de l’Algebre etait la theorie elementaire de systemes d’equations

146 CHAPITRE 7. CONDITIONS D’OPTIMALITE
lineaires, et nous n’avons jamais pense aux nombres complexes, aux racines des polynomes,etc. !
– Il est utile de noter que la Theorie d’Optimisation (qui semble etre superflue pour etablirl’existence d’un vecteur propre d’une matrice symetrique) devient inevitable si on cherchea montrer une generalisation en dimension infinie de ce fait – le Theoreme de Hilbertqui dit qu’un operateur lineaire symetrique compact dans un espace de Hilbert possedeun vecteur propre [et, en conclusion, meme une base orthonormee de vecteurs propres].Je ne vais pas expliquer ce que signifient tous ces mots ; en gros, on dit qu’une matricesymetrique de dimension infinie peut etre diagonalisee dans une base orthonormale propre-ment choisie (par exemple, un operateur integral f(s) �→ ∫ 1
0 K(t, s)f(s)ds avec K(·, ·) pastres mauvais (par exemple, carre integrable) symetrique (K(t, s) = K∗(s, t)), possede unsysteme orthonormal complet dans L2[0, 1] des fonctions propres. Ce fait, en particulier,explique pourquoi les spectres atomiques sont discrets plutot que continus). En prouvantce theoreme extremement important, on ne peut pas utiliser les outils d’Algebre Lineaire(il n’y a desormais aucun determinant ou polynome), mais on peut toujours employerceux d’Optimisation (la compacite de l’operateur implique la solubilite du probleme cor-respondant (Q), et la condition necessaire d’optimalite du premier ordre qui dans le casen question indique que la solution est un vecteur propre de l’operateur, contrairement aFTA, demeure valide dans le cas de dimension infinie).

7.3. EXERCICES 147
7.3 Exercices
Exercice 7.1 Considerez le probleme de minimisation de la forme lineaire
f(x) = x2 + 0.1x1
sur le plan 2D sur le triangle avec les sommets (1, 0), (0, 1), (0, 1/2) (faites le dessin !).1) Verifiez que la solution optimale x∗ = (1, 0) est unique.2) Verifiez que le probleme peut etre ecrit comme le programme LP :
x2 + 0.1x1 → min | x1 + x2 ≤ 1, x1 + 2x2 ≥ 1, x1, x2 ≥ 0.
Montrez que dans cette formulation du probleme la condition necessaire d’optimalite de KKTest satisfaite en x∗.Quelles sont les contraintes actives en x∗ ? Quels sont les multiplicateurs de Lagrange corres-pondants ?
3) Verifiez que le probleme peut etre reecrit comme Programme Non-lineaire avec lescontraintes d’inegalite :
x2 + 0.1x1 → min | x1 ≥ 0, x2 ≥ 0, (x1 + x2 − 1)(x1 + 2x2 − 1) ≤ 0.
La condition d’optimalite de KKT est-elle satisfaite en x∗ ?
Exercice 7.2 Considerez le probleme elementaire suivant :
f(x1, x2) = x21 − x2 → min | x2 = 0
avec la solution optimale unique evidente (0, 0). La condition de KKT est-elle satisfaite en cettesolution ?
Reecrivez le probleme d’une maniere equivalente comme
f(x1, x2) = x21 − x2 → min | x22 = 0.
Que diriez-vous de la condition de KKT dans ce probleme equivalent ? Qu’empeche d’appliquerle Theoreme 7.1.2 ?
Exercice 7.3 Considerez un probleme d’optimisation
f(x) → min | gi(x) ≤ 0, i = 1, ...,m.
Supposez que x∗ est une solution localement optimale, f, gi sont continument differentiablesdans un voisinage de x∗ et les contraintes gi sont concaves dans ce voisinage. Montrez que laQualification des Contraintes a lieu en ce point. x∗ est-il un point de KKT du probleme ?
Exercice 7.4 Soit a1, ..., an positifs reels, et 0 < s < r sont des entiers. Trouver le maximumet le minimum de la fonction
n∑i=1
aix2ri
sur la surfacen∑
i=1
x2si = 1.

148 CHAPITRE 7. CONDITIONS D’OPTIMALITE
Exercice 7.5 Soit p(x) un polynome de degre n > 0. Sans perte de generalite nous pouvonssupposer que p(x) = xn + ..., c.-a-d. le coefficient du monome de degre le plus eleve est 1.
Considerez maintenant le module |p(z)| en fonction de l’argument complexe z ∈ C. Prouvezque cette fonction a un minimum, et que le minimum est zero.Indication : comme |p(z)| → +∞ si |z| → +∞, la fonction continue |p(z)| doit atteindre unminimum sur un plan complexe.
Soit z un point du plan complexe. Prouvez que pour le petit h complexe
p(z + h) = p(z) + hkck +O(|h|k+1)
pour certains k, 1 ≤ k ≤ n et ck �= 0. Maintenant, si p(z) �= 0 il y a un choix (lequel ?) de hpetit tel que |p(z + h)| < |p(z)|.

Chapitre 8
Methodes d’Optimisation :Introduction
On commence avec ce chapitre la deuxieme partie de notre cours ; ce que nous interessedorenavant sont des methodes numeriques pour l’optimisation continue non-lineaire, c.-a-d., lesalgorithmes pour resoudre des problemes du type
minimiser f(x) s.t. gi(x) ≤ 0, i = 1, ...,m; hj(x) = 0, j = 1, ..., k. (8.1)
ici x varie sur Rn, et l’objectif f(x), ainsi que les fonctions gi et hj , sont assez regulieres(normalement nous les supposons etre au moins une fois continument differentiables). On appelleles contraintes
gi(x) ≤ 0, i = 1, ...,m; hj(x) = 0, j = 1, ..., k
les contraintes fonctionnelles, divisees de facon evidente en contraintes d’inegalite et d’egalite.Nous appelons (8.1) le probleme d’optimisation non-lineaire afin de distinguer ces problemes
des programmes de Programmation Lineaires ; les derniers correspondent au cas quand toutesles fonctions f, gi, hj sont lineaires. Et nous parlons de l’optimisation continue dans la descrip-tion de notre sujet pour faire la distinction avec l’optimisation discrete, ou nous recherchons unesolution sur un ensemble discret, par exemple, celui des vecteurs avec des coordonnees entiers(programmation en nombres entiers), les vecteurs avec les coordonnees dans {0, 1} (program-mation booleenne), etc...
Les problemes (8.1) surgissent dans une variete d’applications, en gros, toutes les fois queles gens prennent des decisions, ils essayent de les faire d’une facon “optimale”. Si la situa-tion est assez simple, quand les decisions possibles puissent etre parametrisees par des vecteursde dimension finie, et la qualite de ces decisions puisse etre caracterisee par un ensemble finide criteres “calculables”, le concept de la decision “optimale” prend typiquement la forme duprobleme (8.1). Notez que dans des applications reelles cette phase preliminaire – modelisationdu probleme reel de decision comme probleme d’optimisation avec l’objectif et les contraintescalculables – est, normalement, beaucoup plus difficile et creatrice que la phase suivante ou nousresolvons le probleme qui en resulte. Dans notre cours, de toute facon, nous ne touchons pas laphase de modelisation, et nous nous concentrons sur la technique de resolution des programmesd’optimisation.
Rappelez-vous que nous avons developpe des conditions d’optimalite pour les problemes (8.1)dans les Chapitres 6 et 7. Nous nous rappelons qu’on peut former un systeme carre d’equationsnon-lineaires et un systeme d’inegalites qui definissent un certain ensemble – celui des points de
149

150 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
Karush-Kuhn-Tucker – qui, sous certaines conditions de regularite, contient toutes les solutionsoptimales du probleme. D’habitude, le systeme de Karush-Kuhn-Tucker a un nombre fini desolutions, et si nous sommes assez intelligents pour trouver toutes les solutions analytiquement,alors nous pourrions en selectionner la meilleure, la solution optimale, toujours sous une formeanalytique. La difficulte, cependant, est qu’en regle generale nous ne sommes pas assez intelli-gents pour resoudre analytiquement le systeme de Karush-Kuhn-Tucker, et nous ne savons pastrouver analytiquement une solution optimale par d’autres moyens. Dans tous ces cas “difficiles”– et tous les problemes d’optimisation venant de vraies applications du monde sont difficiles dansce sens – tout ce que nous pouvons esperer est une routine numerique, un algorithme qui permetde approcher numeriquement les solutions qui nous interessent. Ainsi, les methodes numeriquesd’optimisation forment l’outil principal pour resoudre des problemes d’optimisation.
8.1 Preliminaires sur les Methodes d’Optimisation
Il faut souligner qu’on ne peut pas esperer de concevoir une methode d’optimisation capableresoudre efficacement tous les problemes d’optimisation non-lineaire – ces problemes sont tropdivers. En fait il y a de nombreuses methodes, et chacune d’elles est oriente vers une certainefamille restreinte des problemes d’optimisation.
8.1.1 Classification des Problemes et des Methodes d’Optimisation Non-Lineaire
Traditionnellement, des problemes d’optimisation non-lineaire (8.1) sont divises en deuxgrandes classes :
– Problemes sans contraintes – aucune contrainte inegalite ou egalite n’est presente. La formegenerique d’un probleme sans contrainte, par consequent, est
minimize f(x) s.t. x ∈ Rn, (8.2)
ou f est une fonction reguliere (au moins une fois continument differentiable) sur Rn ;– Problemes contraints, qui impliquent au moins une contrainte d’inegalite ou d’egalite.
Les problemes contraints, a leur tour, sont subdivises en plusieurs classes, selon qu’il y a descontraintes non-lineaires, contraintes d’inegalite, et ainsi de suite.
Selon la classification decrite des problemes d’optimisation, les methodes d’optimisation sontprincipalement divisees en celles pour l’optimisation sans contrainte et celles pour l’optimisationsous contraintes. Bien que les problemes sans contrainte plus simples ne soient pas tres frequentsdans les applications, les methodes d’optimisation sans contrainte jouent le role tres important :elles sont employees directement pour resoudre des problemes sans contrainte et indirectement,comme modules, dans beaucoup de methodes de minimisation sous contraintes.
8.1.2 Nature iterative des Methodes d’Optimisation
Les methodes de resolution numeriques des problemes d’optimisation non-lineaire sont, enleur essence, des routines iteratives : pour le probleme (8.1), une methode ne peut pas typi-quement trouver la solution exacte en temps fini. En fait, la methode genere une suite infini{xt} de solutions approximatives. L’iteration suivante xt+1 est formee, selon certaines regles,sur la base de l’information locale sur le probleme, collectee sur l’iteration precedente. La partied’information It obtenue sur l’iteration courante xt est un vecteur qui consiste en des valeurs

8.1. PRELIMINAIRES SUR LES METHODES D’OPTIMISATION 151
de l’objectif et des contraintes xt et, probablement, celles des gradients ou meme des derivessuperieures de ces fonctions en xt. Ainsi, quand il s’agit de former xt+1, la methode “connait”les valeurs et les derivees, jusqu’a un certain ordre fixe, de l’objectif et des contraintes sur lesprecedentes iterations x1..., xt. Et cette information est exactement toute l’information sur leprobleme disponible a la methode quand elle produit l’iteration xt+1. En consequence, cetteiteration est une certaine fonction d’information accumulee jusqu’ici :
xt+1 = Xt+1(I1,I2, ...,It).
L’ensemble de regles de recherche Xt(·) predetermine le comportement de la methode sur unprobleme arbitraire ; par consequent, la methode elle-meme peut etre identifiee avec la collection{Xt}∞t=1. Notez que la liste d’arguments deXt est composee des (t−1) parts d’information locale ;en particulier, la liste d’arguments de la toute premiere regle de recherche X1 est vide, de sorteque cette “fonction” soit simplement un vecteur fixe donne par la description de la methode –point initial.
Il decoule du schema general decrit ce-dessus d’une routine iterative que les methodes d’op-timisation peuvent etre classifiees non seulement selon les types de problemes que les methodesresolvent, mais egalement selon le type d’information locale qu’elles emploient. De ce point devue d’“information”, les methodes sont divisees en
– routines d’ordre zero, qui utilisent seulement des valeurs de l’objectif et des contraintes etpas leurs derives ;
– routines du premier ordre, celle qui utilisent les valeurs et les gradients de l’objectif et descontraintes ;
– routines du second ordre, qui utilisent les valeurs, les gradients et les Hessians (c.-a-d.,matrices des derivees secondes) de l’objectif et des contraintes.
En principe, naturellement, nous pourrions parler aussi des methodes d’ordres plus eleve ; cesmethodes, cependant, ne sont jamais employees dans la pratique. En effet, pour employer unemethode d’ordre k, on devrait avoir une possibilite de calculer les derives partiels de l’objectif etdes contraintes jusqu’a l’ordre k. Dans le cas multidimensionnel ce n’est pas exactement facilememe pour k = 1 et meme quand vos fonctions sont donnees par des expressions analytiquesexplicites (ce qui n’est pas toujours le cas). Et il y a une “explosion” de difficultes dans le calculdes derivees d’ordre superieur : pour une fonction de n variables, il y a n premieres deriveesa calculer, n(n+1)
2 derivees secondes, n(n+1)(n+2)2×3 de derivees troisiemes, etc. ; en consequence,
meme dans le cas d’un probleme d’echelle moyenne avec n ∼ quelques dizaines, les difficultesavec la programmation, temps de calcul et la memoire requise pour traiter les derives eleveesrend excessivement chere l’exploitation de ces derivees. Par ailleurs, des methodes d’ordre pluseleve que 2 ne possede aucun avantage theorique, ainsi il n’y a aucune compensation pour l’effortde calcul de ces derives.
8.1.3 Convergence des Methodes d’Optimisation
Nous ne pouvons pas nous attendre a ce qu’un probleme non-lineaire soit resolu de faconexacte en nombre fini d’etapes ; tout ce que nous pouvons esperer est que la suite d’iterations {xt}produite par la methode en question converge vers l’ensemble de solution du probleme quandt→ ∞. Dans la theorie d’optimisation numerique, la convergence d’une methode d’optimisationsur certaine famille des problemes est exactement ce qui donne le droit a la methode d’etrequalifie comme un outil pour resoudre des problemes de la famille. La convergence n’est pas la

152 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
seule caracteristique d’une methode, mais c’est la propriete qu’en fait une routine d’optimisationtheoriquement valide.
Vitesses de convergence
La convergence d’une methode numerique d’optimisation (et tout autre) est la propriete laplus faible qui donne a la methode le droit d’exister. En principe, il y a autant de methodesavec cette propriete que vous voulez, et la question est comment ranger ces methodes et les-quelles parmi elles sont a recommander pour l’utilisation pratique. En Optimisation Non-lineairetraditionnelle ce probleme est generalement “resolu” en comparant le taux asymptotique deconvergence mesure comme suit.
Supposons que la methode pour le probleme P produit une suite d’iterationsqui converge vers l’ensemble de solutions du probleme X∗
P . Pour definir le taux deconvergence, nous introduisons d’abord la fonction d’erreur err(x) qui mesure laqualite d’une solution approximative x ; cette fonction doit etre positive en dehorsde X∗
P et zero sur X∗P .
Il y a plusieurs choix raisonnables de la fonction d’erreur. Par exemple, nouspouvons toujours utiliser la distance entre la solution approximative et l’ensemblede solutions :
distP (x) = infx∗∈X∗
P
|x− x∗|;
un autre choix serait l’erreur residuelle en termes de l’objectif et des contraintes :
resP (x) = max{f(x)− f∗; [g1(x)]+; ...; [gm(x)]+; |h1(x)|; ...; |hk(x)|},f∗ etant la valeur optimale de P et [a]+ = max(a, 0) etant partie positive du reel a,etc.
Pour une fonction d’erreur correctement choisie (par exemple, pour distP ), laconvergence des iterations vers l’ensemble de solutions implique que la suite scalaire
rt = err(xt)
converge vers 0, et nous mesurons la “qualite de la convergence” par la vitesse aveclaquelle les reels non negatifs rt tendent vers zero.
Il existe une classification standard des vitesses de convergences :– [convergence lineaire] une suite {rt ≥ 0} tels que pour un certain q ∈ (0, 1), C < ∞ et
tout t on art ≤ Cqt
s’appelle convergeante lineairement vers 0 avec le taux q ; l’exemple le plus simple etantrt = Cqt. La limite inferieure des qs pour lesquels {rt} converge lineairement vers 0 avecle taux q de convergence s’appelle taux de convergence de la suite.Par exemple, pour la suite rt = Cqt, ainsi que pour la suite {rt = C(q+εt)
t}, de εt → 0 t →∞, le taux de convergence est q, bien que la deuxieme suite, d’une maniere generale, neconverge pas vers 0 avec le taux q (elle converge lineairement avec le taux q′ de convergencepour n’importe quel q′ ∈ (q, 1)).On voit immediatement qu’une condition suffisante pour qu’une suite {rt > 0} convergelineairement avec le taux q ∈ (0, 1) est que
lim supt→∞rt+1
rt< q.

8.1. PRELIMINAIRES SUR LES METHODES D’OPTIMISATION 153
– [convergence sous- et super-lineaire] Supposons qu’une suite converge vers 0, mais neconverge pas lineairement (par exemple, la suite rt = t−1), dans ce cas on dit que lasuite converge sous-lineairement.Une suite qui converge lineairement vers zero avec n’importe quel taux positif (de sorteque le taux de convergence de la suite soit 0) converge super-lineairement (par exemple,la suite rt = t−t).Une condition suffisante pour qu’une suite {rt > 0} converge super-lineairement est
limt→∞
rt+1
rt= 0.
– [convergence d’ordre p > 1] On dit qu’une suite {rt ≥ 0} est convergeante d’ordre p > 1vers 0, si pour un certain C et tout t assez grand on a
rt+1 ≤ Crpt .
La borne superieure des p pour lesquels le suite converge vers 0 avec l’ordre p s’appelleordre de convergence de la suite.Par exemple, la suite rt = a(p
t) (a ∈ (0, 1), p > 1) converge vers zero d’ordre p, carrt+1/r
pt = 1. Les suites convergeantes vers 0 d’ordre 2 ont un nom special – on dit qu’elles
convergent quadratiquement.Naturellement, une suite convergeante vers 0 d’ordre p > 1 converge super-lineairementvers 0 (mais, d’une maniere generale, pas vice versa).
Traditionnellement, le taux de convergence des routines numeriques iteratives est mesure par lerang de la suite correspondante d’erreurs {rt = err(xt)} dans l’echelle ci-dessus ; en particulier, onparle de methodes sous-lineaires, lineaires, super-lineaires, quadratique ou de methodes d’ordrep > 1. On pense souvent que meilleur est le taux de convergence d’une methode, plus preferableest la methode elle-meme. Par exemple, une methode qui converge lineairement soit meilleureque une methode sous-lineaire ; parmi deux methodes lineaire, celle avec le taux plus petitde convergence soit preferable ; une methode super-lineaire soit preferee a une methode quipossede une convergence lineaire. Naturellement, toutes ces preferences sont “conditionnees”par l’absence de differences significatives dans la complexite numerique des iterations, etc.
On devrait souligner que le taux de la convergence, ainsi que la propriete meme de la conver-gence, est une caracteristique asymptotique de la suite d’erreurs ; il n’indique pas que quand “ar-rive” le taux annonce de convergence, c.-a-d., ce que sont les valeurs de C ou/et “assez grandesvaleurs” de t mentionnes dans les definitions correspondantes. Pour des methodes concretes, lesbornes de ces quantites typiquement peuvent etre extraites a partir des preuves de convergence,mais ca n’aide pas beaucoup – ces bornes sont habituellement tres compliquees, grossieres etdependent des caracteristiques quantitatives “invisibles” du probleme comme les magnitudes desderivees d’ordre eleve, le conditionnement du Hessian, etc. A partir de ces observations (com-binees avec le fait que notre vie est finie) il decoule que on ne devrait pas surestimer l’importancedu taux de convergence des methodes. Cette approche traditionnelle donne une sorte d’orienta-tion, rien d’avantage ; malheureusement, il ne semble y avoir aucune maniere purement theoriqued’obtenir un “rangement” detaille des methodes numeriques d’optimisation. En consequence,les recommandations pratiques concernant des methodes a employer sont basees sur differentesconsiderations theoriques et empiriques : taux theorique de convergence, comportement reel surdes problemes d’essai, stabilite numerique, simplicite et robustesse, etc.

154 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
8.1.4 Solutions globales et locales
La difficulte intrinseque et cruciale dans l’Optimisation Non-lineaire est que nous ne pou-vons pas nous attendre a ce qu’une methode numerique d’optimisation approche une solutionglobalement optimale du probleme.
Cette difficulte a ses racines en la nature locale d’information sur le probleme qui est dis-ponible aux methodes. Supposez, par exemple, que notre tache est de minimiser la fonctionmontree sur l’image :
x’ x’’
La fonction a deux minimiseurs locaux, x′ et x′′. Il est impossible de deviner qu’il existe enfait un autre minimiseur en observant un voisinage assez petit de chaque de ces minimizers.En consequence, n’importe quelle methode “normale” d’optimisation non-lineaire lancee sur leprobleme en question avec le point de depart dans un petit voisinage du “faux minimiseur”(local, pas global) x′, convergera vers x′ – l’information locale sur f disponible pour la methodene laisse pas deviner que x′′ existe !
Il serait errone de dire que la difficulte est absolument unsurmountable. Nous pourrions lancerla methode avec les differents points de depart, ou meme regarder les valeurs de l’objectif sur unesuite des point qui est dense dans R 1) et definir xt en tant que meilleur, en termes de valeurs def , des premiers t points de la suite. Cette derniere “methode” peut etre facilement etendue auxproblemes multi-dimensionnels avec des contraintes generales ; on peut immediatement prouversa convergence vers la solution globale ; la methode est simple dans l’execution, etc. Il y aseulement un petit inconvenient de la methode : le nombre enorme d’evaluations de fonctionrequises pour resoudre un probleme avec l’inexactitude ε.
On peut voir facilement que la methode decrite, appliquee au probleme
f(x) → min | x ∈ Rn, g1(x) = |x|2 ≤ 1
avec l’objectif f Lipschitzien, avec la constante de Lipschitz 1 :
|f(x)− f(y)| ≤ |x− y|,
exige, dans le pire cas, au moins ε−n de pas pour trouver un point xε avec l’erreurresiduelle – la quantite f(xε)−min|x|≤1 f – n’excedant pas ε.
1. )c.-a-d. qui visite tout voisinage arbitrairement petit de chaque point de R, comme le fait, par exemple,la suite de tous les nombres rationnels (pour ranger des nombres rationnels dans une suite simple, enumerez-les selon la somme de valeurs absolues du numerateur et du denominateur dans les fractions correspondantes :d’abord ceux avec la somme ci-dessus egale a 1 (le seul rationnel 0 = 0/1), puis ceux avec la somme egale a 2(−1 = −1/1, 1 = 1/1), puis ceux avec la somme egale a 3 (−2/1,−1/2, 1/2, 2/1), etc.)

8.2. RECHERCHE LINEAIRE 155
Quand ε = 0.01 et n = 20 (des conditions tres modestes de precision et dedimension), le nombre d’iterations devient > 1040, 2) et ceci est la borne inferieurede complexite !
D’ailleurs, pour la famille des problemes en question la borne inferieure ε−n surle nombre d’evaluations de la fonction necessaire pour garantir l’erreur residuel exigeε est valide pour une methode arbitraire d’optimisation qui utilise seulement l’infor-mation locale sur l’objectif.
Ainsi, nous pouvons approcher, avec n’importe quelle erreur donnee ε > 0, la solution global den’importe quel probleme d’optimisation ; mais dire que au mieux ca nous coutera 1020 anneesde calculs pour ε = 0.01, n = 20, est pire que ne rien dire du tout.
Suite aux considerations ci-dessus, nous venons a la conclusion importante, bien quedesesperee :
Il ne semble pas raisonnable de s’attendre a ce qu’une methode d’optimisationpuisse approcher, avec une erreur raisonnable en un temps raisonnable, une solutiona tous les problemes d’optimisation global d’une taille donne (meme assez moderee)
En fait, tout ce que nous pouvons esperer faire en temps raisonnable est de trouver des bonnesapproximations d’un certain (et pas necessairement correspondant a la solution optimale) pointde Karush-Kuhn-Tucker du probleme d’optimisation (dans le cas sans contrainte – a un pointcritique de l’objectif). Dans les cas simples nous pouvons esperer egalement d’approcher unesolution localement optimale, sans aucune garantie de son optimalite globale.
Il y a, en tous cas, un “cas soluble” quand nous pouvons approcher une solution globalementoptimal d’un probleme d’optimisation par une solution de complexite raisonnable. C’est le casquand le probleme est convexe (c.-a-d., les fonctions f et gi, i = 1, ...,m, sont convexes, alorsque hj , si presentes, sont lineaires). Proprietes des problemes convexes d’optimisation et desmethodes numeriques pour ces problemes forme le sujet de la Programmation Convexe. LaProgrammation Convexe est, en sa nature, plus simple et, par consequent, beaucoup plus avanceeque l’Optimisation Non-lineaire generale. En particulier, dans la Programmation Convexe nouspouvons concevoir des methodes avec un taux global (pas asymptotique !)de convergence tout afait raisonnable, capables de garantir (avec un cout numerique raisonnable) des approximationsde grande precision pour des solutions globalement optimales, meme pour dans le cas d’unprogramme convexe general.
Personnellement, j’aimerais limiter le reste de notre cours au monde sympathique de laProgrammation Convexe, mais nous ne pouvons pas nous le permettre : dans des applicationsreelles, malheureusement, nous rencontrons trop souvent des problemes non convexes, et nousn’avons d’autre choix que de les resoudre – meme au prix d’affaiblir la notion de la “solutionoptimal” jusqu’a considerer comme telle un point de Karush-Kuhn-Tucker.
8.2 Recherche Lineaire
Le reste de ce chapitre est consacre a l’optimisation unidimensionnelle sans contraintes, c.-a-d., aux methodes numeriques pour resoudre des problemes de type
f(x) → min | x ∈ R, (8.3)
2. ) Supposons qu’on dispose du super-ordinateur le plus rapid du moment – il s’agit du NEC Earth Simulator/5120, capable approximativement de 35000 Gflops (c.-a-d. de 3.5 ∗ 1013 operations numeriques elementaires parseconde. Cette machine aura besoin alors de O(1020) annees pour accomplir cette tache !

156 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
f etant une fonction au moins continue sur l’axe ; d’habitude, on appelle ces methodes recherchelineaire.
Notre interet pour la recherche lineaire ne vient pas seulement du fait que dans les appli-cations on rencontre, naturellement, des problemes unidimensionnels, mais plutot du fait quela recherche lineaire est un composant fondamental de toutes les methodes traditionnelles d’op-timisation multi-dimensionnelle. D’habitude, nous avons le schema suivant d’une methode deminimisation sans contraintes multi-dimensionnelle : en regardant le comportement local del’objectif f sur l’iteration courante xt, la methode choisit la “direction du movement” dt (qui,normalement, est une direction de descente de l’objectif : dTt ∇f(xt) < 0) et execute un pas danscette direction :
xt �→ xt+1 = xt + αtdt
afin de realiser un certain progres en valeur de l’objective, c.-a-d., pour assurer que f(xt+1) <f(xt). Et dans la majorite des methodes le pas dans la direction dt est choisie par la minimisationunidimensionnelle de la fonction
φ(α) = f(xt + αdt).
Ainsi, la technique de recherche lineaire est une brick de base fondamentale de toute methodemulti-dimensionnelle.
8.2.1 Recherche lineaire d’ordre zero
Nous commencons par la recherche lineaire d’ordre zero, c.-a-d., par des methodes pourresoudre (8.3) qui utilisent des valeurs de f seulement, pas ces derivees.
Les methodes que nous sommes sur le point de developper resolvent pas le probleme (8.3)tel qi’il est, mais le probleme
f(x) → min | a ≤ x ≤ b (8.4)
de minimisation de l’objectif sur un segment fini donne [a, b] (−∞ < a < b < ∞). Pour assurerque le probleme soit bien conditionne, nous faisons l’hypothese suivante :
f est unimodale sur [a, b], c.-a-d., possede un minimum local unique x∗ sur le segment.
Cette hypothese, comme on le voit facilement, implique qui f strictement decroissante sur [a, b]a gauche de x∗ :
a ≤ x′ < x′′ ≤ x∗ ⇒ f(x′) > f(x′′) (8.5)
et est strictement croissante sur [a, b] a droite de x∗ :
x∗ ≤ x′ < x′′ ≤ b⇒ f(x′) < f(x′′). (8.6)
En effet, si (8.5) etaient faux, il existerait x′ et x′′ tels que
a ≤ x′ < x′′ ≤ x∗, f(x′) ≤ f(x′′).
Il suit que l’ensemble de minimiseurs de f sur [a, x′′] contient un minimiseur, x∗, qui estdifferent de x′′ 3). Comme x∗ est un minimiseur de f sur [a, x′′] et x∗ differe de x′′, x∗ est
un minimiseur local de f sur [a, b], alors qu’on a suppose que le minimizer local unique de f
sur [a, b] est x∗ ; ceci donne la contradiction desiree. On a (8.6) de facon analogue.
3. )regardez : si x′′ soi-meme n’est pas un minimiseur de f sur [a, x′′], alors tout minimiseur de f sur [a, x′′]peut etre choisi comme x∗ ; si x′′ est un minimizer de f sur [a, x′′], alors x′ est egalement un minimiseur, carf(x′) ≤ f(x′′), et nous pouvons poser x∗ = x′

8.2. RECHERCHE LINEAIRE 157
Notez que les relations (8.5) et (8.6), a leur tour, impliquent qui f est unimodal sur [a, b] etmeme sur chaque segment [a′, b′] ⊂ [a, b] plus petit.
Etant donne que f est unimodal sur [a, b], nous pouvons preciser une strategie pour approcherx∗ : choisissons deux points x− et x+ dans (a, b),
a < x− < x+ < b,
et calculons les valeurs f(x−) et f(x+). On observe que
si [cas A] f(x−) ≤ f(x+), alors x∗ se trouve a gauche de x+ [en effet, si x∗ etait a droite dex+, on aurait f(x−) > f(x+) d’apres (8.5)], et si [ cas B ] f(x−) ≥ f(x+), x∗ est alors a droitede x− [raisonnement “symetrique”].
En consequence, dans le cas A nous pouvons remplacer le “segment d’incertitude” initial Δ0 =[a, b] par le nouveau segment d’incertitude Δ1 = [a, x+], et dans le cas B par le segment Δ1 =[x−, b] ; dans les deux cas les nouveau “segment d’incertitude” Δ1 couvre x∗ et est strictementplus petit que Δ0. Puisque, l’objectif, etant unimodal sur le segment initial Δ0 = [a, b], estunimodal egalement sur le segment plus petit Δ1 ⊂ Δ0, nous pouvons reiterer ce procede –choisir deux points dans Δ1, calculer les valeurs de l’objectif en ces points, comparez les resultatset remplacez Δ1 par un plus petit segment Δ2, contenant la solution desiree x∗, et ainsi de suite.
Ainsi, nous venons a
Algorithme 8.2.1 [la minimisation d’ordre zero de fonction unimodale sur [a, b] ]Initialisation : Poser δ0 = [a, b], t = 1Etape t : Etant donne le segment precedent Δt−1 = [at−1, bt−1] d’incertitude,
– choisir les points de recherche x−t , x+t : at−1 < x−t < x+t < bt−1 ;
– calculer f(x−t ) et f(x+t ) ;
– definir le nouveau segment incertain : si f(x−t ) ≤ f(x+t ), poser Δt = [at−1, x+t ], poser
Δt = [x−t , bt−1] sinon ;– remplacer t par t+ 1 et boucler.
On voit immediatement que nous pouvons assurer la convergence lineaire des longueurs dessegments d’incertitude vers 0, ce qui nos donne un algorithme lineairement convergeant versx∗. Par exemple, si x−t , x
+t sont choisis pour couper Δt−1 en trois parts egales, nous obtenons
|Δt+1| = 23 |Δt| (|Δ| represente la longueur d’un segment Δ), ce qui nous donne un algorithme
qui converge lineairement, avec le taux√2/3 :
|x∗ − xk| ≤(2
3
) k/2�|b− a|, (8.7)
k etant le # d’evaluations de fonction executees jusqu’ici et xk etant un point arbitraire dusegment d’incertitude Δ k/2�, forme apres k evaluations de la fonction.
L’estimation (8.7) est tres bonne – nous avons la convergence lineaire non-asymptotique avecle taux de convergence qui ne depend pas de la fonction f . Existe-il quelque chose de mieux ?
La reponse est “oui”. Une facon d’ameliorer le taux de convergence est de noter qu’un desdeux points de recherche employes pour passer de Δt au Δt+1 se trouve certainement en interieurde Δt+1, et nous pourrions essayer de l’utiliser pour passer de Δt+1 a Δt+2. Avec cette strategie,le cout de la mise a jour de Δt en Δt+1 sera une evaluation de fonction, et pas deux (exceptele tout premier Δ0 → Δ1, qui coute toujours deux evaluations de fonction). Il y a deux faconde mettre en application cette nouvelle strategie – l’optimale (recherche de Fibonacci) et lasous-optimale (“recherche d’or”).

158 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
Recherche de Fibonacci
La recherche de Fibonacci peut etre employee quand nous savons a l’avance le nombreN > 2 d’evaluations de fonction que nous allons executer.
Etant donne N , on considere la suite des N + 1 premiers nombres entiers de FibonacciF0, F1, F2..., Fn definis par la recurrence
F0 = F1 = 1; Fk = Fk−1 + Fk−2
(les 10 premiers elements de la suite sont 1, 1, 2, 3, 5, 8, 13, 21, 34, 55).La methode que nous allons utiliser est suivante : etant donne Δ0 = [a, b], on pose
d0 = |b− a|,
on choisit les deux premiers points x−1 et x+1 de recherche a la distance
d1 =FN−1
FNd0
de l’extremite droite et de l’extremite gauche de Δ0 respectivement (comme FN/FN−1 =(FN−1+FN−2)/FN−1 = 1+FN−2/FN−1 < 2, nous avons d1 > d0/2, de sorte que x
−1 < x+1 ).
La longueur du nouveau segment Δ1 d’incertitude est alors d1.En suite on reitere l’etape ci-dessus, avec N remplace N − 1. Ainsi, maintenant nous
devrions evaluer f en deux points x−2 , x+2 du segment Δ1 places a la distance
d2 =FN−2
FN−1d1 [=
FN−2
FN−1
FN−1
FNd0 =
FN−2
FNd0] (8.8)
des bouts droit et gauche de Δ1. Le fait crucial (qui resulte des proprietes arithmetiques desnombres de Fibonacci) est queun de ces deux points ou f devrait etre calcule est deja traite – celui parmi les deux pointsprecedents qui appartient a l’interieur de Δ1.
En effet, supposons, sans perte de generalite, que Δ1 = [a, x+1 ] (le cas Δ1 = [x−1 , b] estcompletement analogue), de sorte que x−1 ∈ int Δ1. Nous avons
x−1 − a = (b− d1)− a = (b− a)− d1 = d0 − d1 = d0
(1− FN−1
FN
)=
[comme FN = FN−1 + FN−2 et d2 = FN−2
FNd0]
= d0FN−2
FN= d2.
Ainsi, seulement un des deux points exiges de Δ1 est reellement “nouveau”, et l’autre vientde l’etape precedente ; par consequent, afin de mettre a jour Δ1 vers Δ2 nous avons besoind’une seule evaluation de fonction. Apres cette nouvelle evaluation de fonction, nous pouvonsremplacer Δ1 avec Δ2. Pour traiter Δ2, nous agissons exactement comme ci-dessus, mais avecN remplace par N − 2 ; ici nous devons evaluer f aux deux points de Δ2 a la distance
d3 =FN−3
FN−2d2 [=
FN−3
FNd0, see (8.8)]
des extremites du segment, et, a nouveau, un de ces point est deja traite.Au bout des iterations nous venons au segment ΔN−1 qui couvre x∗ ; la longueur du
segment est
dN−1 =F1
FNd0 =
b− a
FN,

8.2. RECHERCHE LINEAIRE 159
et le nombre total d’evaluations de f requis pour obtenir ce segment est N (nous avonsbesoin de 2 evaluations de f pour passer de Δ0 vers Δ1, et chacune des N − 2 mises a joursuivantes Δt �→ Δt+1 necessite une evaluation de f).
Si on prend comme approximation de x∗ n’importe quel point xN du segment ΔN−1,nous avons
|xN − x∗| ≤ |ΔN | = b− a
FN. (8.9)
Pour comparer (8.9) avec l’evaluation de precision (8.7) de notre methode initiale – peusophistiquee – notez que
Ft =1
λ+ 2
[(λ+ 1)λt + (−1)tλ−t
], λ =
1 +√5
2> 1. 4) (8.10)
En consequence, de (8.9) nous obtenons
|xN − x∗| ≤ λ+ 2
λ+ 1λ−N |b− a|(1 + o(1)), (8.11)
ou on note o(1) une fonction de N qui converge vers 0 quand N → ∞).Nous voyons que le taux de convergence pour la recherche de Fibonacci est
λ−1 =2
1 +√5= 0.61803...
qui est bien meilleur que le taux√
2/3 = 0.81649... donne par (8.7).On peut montrer que la recherche de Fibonacci est une methode optimale (dans un
certain sens precis) d’ordre zero, en termes de precision garantie apres N evaluations defonction. Malgre ces bonnes proprietes theoriques, la methode n’est pas tres commode dupoint de vue pratique : nous devrions choisir a l’avance le nombre d’evaluations de fonction aexecuter (c.-a-d., pour ajuster la methode a une certaine precision, choisie a l’avance), ce quiest parfois assez desagreable. La methode de recherche d’or que nous sommes sur le point depresenter est exempte de cette imperfection et, en meme temps, pour des N pas trop petits,aussi efficace que la recherche de Fibonacci originale.
L’idee de la methode de recherche d’or est tres simple : a l’etape k de recherche de larecherche de Fibonacci a N pas, nous choisissons deux points de recherche dans le segmentΔk−1, et chacun de ces points divise le segment (entre l’extremite plus proche et la pluseloignee) en rapport
[1− FN−k/FN−k+1] : [FN−k/FN−k+1] ,
4. )voici le calcul : les nombres de Fibonacci satisfont l’equation homogene en differences finies :
xt − xt−1 − xt−2 = 0
avec la condition initiale x0 = x1 = 1. Pour resoudre une equation homogene en differences finies, on doitd’abord chercher ses solutions fondamentales – ceux du type xt = λt. En substituant xt = λt dans l’equation,nous obtenons une equation quadratique pour λ :
λ2 − λ− 1 = 0,
et nous venons aux deux solutions fondamentales :
x(i)t = λt
i, i = 1, 2, avec λ1 =1 +
√5
2> 1, λ2 = −1/λ1.
N’importe quelle combinaison lineaire de ces solutions fondamentales est encore une solution de l’equation, et pourobtenir {Ft}, il reste de choisir les coefficients de la combinaison pour satisfaire les conditions initiales F0 = F1 = 1.En consequence, nous venons au (8.10). Surprise : l’expression pour les quantites entieres Ft implique les nombresirrationnels !

160 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
c.-a-d., en rapport FN−k−1 : FN−k. Selon (8.10), ce rapport pour les grands N−k est proche
de 1/λ, λ = (1 +√5)/2. Dans la recherche d’or on utilise ce rapport sur chaque etape, et
c’est tout !
Recherche d’or
Soit λ = (1 +√5)/2 (aussi appele le “nombre d’or”). Dans l’implementation de recherche
d’or de l’Algorithme 8.2.1 nous choisissons a chaque etape les points de recherche x−t et x+t pourdiviser le segment precedent de l’incertitude Δt−1 = [at−1, bt−1] dans le rapport 1/λ :
x−t =λ
1 + λat−1 +
1
1 + λbt−1; x+t =
1
1 + λat−1 +
λ
1 + λbt−1. (8.12)
On voit facilement que pour t ≥ 2, un des points de recherche exiges pour mettre a jour Δt−1
vers Δt est deja traite en cours de la mise a jour de Δt−2 vers Δt−1. Pour le verifier, il suffit deconsiderer le cas quand Δt−2 = [α, β] et Δt−1 = [α, x+t−1] (le cas “symetrique” Δt−1 = [x−t−1, β]est completement analogue). Notons d = β − α, nous avons
x−t−1 = α+1
1 + λd, x+t−1 = α+
λ
1 + λd. (8.13)
Maintenant, nous sommes dans la situation Δt−1 = [α, x+t−1], de sorte que le second des deuxpoints de recherche requis pour mettre a jour Δt−1 vers Δt soit
x+t = α+λ
1 + λ(x+t−1 − α) = α+
λ2
(1 + λ)2d
(voyez la deuxieme egalite dans (8.13)). La derniere quantite, dues a la premiere egalite dans(8.13) et a l’equation caracteristique λ2 = 1 + λ qui donne λ, n’est rien d’autre que x−t−1 :
λ2 = 1 + λ⇔ 1
1 + λ=
λ2
(1 + λ)2.
Ainsi, dans la recherche d’or chaque mise a jour Δt−1 �→ Δt, excepte la toute premiere, exigeune evaluation de fonction. La longueur du segment d’incertitude est reduite par chaque mise ajour par le facteur
λ
1 + λ=
1
λ,
c.-a-d.,
|Δt| = λ−t(b− a).
Apres N ≥ 2 evaluations de fonction (apres t = N − 1 etapes de recherche d’or) nous pouvonsapprocher x∗ par le point xN du segment ΔN−1, est l’imprecision sera bornee par
|xN − x∗| ≤ |ΔN−1| ≤ λ1−N (b− a). (8.14)
Ainsi, nous observons une convergence lineaire avec le meme taux λ−1 = 0.61803... que pour larecherche de Fibonacci, mais maintenant la methode est “stationnaire” – nous pouvons executerautant de pas que nous le souhaitons.

8.2. RECHERCHE LINEAIRE 161
8.2.2 Dichotomie
L’avantage theorique des methodes d’ordre zero, comme la recherche de Fibonacci et larecherche d’or, est que ces methodes n’utilisent du’une information minimale sur l’objectif –ses valeurs seulement. De plus, ces methodes ont un champ des applications tres large – laseule condition imposee sur l’objectif est d’etre unimodal sur un segment donne qui localise leminimiseur a approcher. Et meme dans ce cadre, tres large, ces methodes convergent lineairementavec le taux de convergence independant de l’objectif ; d’ailleurs, les evaluations d’efficacite (8.11)et (8.14) sont non-asymptotiques : elles ne contiennent pas des facteurs constants “incertains”et sont valides pour toutes valeurs de N . En meme temps, souvent notre objectif “se comportemieux” qu’une fonction unimodale generale, par exemple, la fonction f peut etre lisse. En seservant de ces proprietes additionnelles de l’objectif, nous pouvons ameliorer le comportementdes methodes de recherche lineaire.
Voyons ce qui se produit si nous resolvons le probleme (8.4) avec un objectif lisse(continument differentiable). Comme ci-dessus, supposons que l’objectif est unimodal sur [a, b].En fait nous faisons une hypothese un peu plus forte :
(A) : le minimiseur x∗ de f sur [a, b] est un point interieur du segment, et f ′(x) change sonsigne en x∗ :
f ′(x) < 0, x ∈ [a, x∗); f ′(x) > 0, x ∈ (x∗, b]
[notez que unimodalite + derivabilite impliquent seulement f ′(x) ≤ 0 sur [a, x∗) et f ′(x) ≥ 0sur (x∗, b]].
Supposons, en plus, comme c’est normalement le cas, que nous pouvons calculer non seule-ment la valeur, mais egalement la derivee de l’objectif en un point donne.
Sous ces hypotheses nous pouvons resoudre (8.4) par la methode la plus simple possible – ladichotomie : calculons f ′ au point median x1 de Δ0 = [a, b]. Il y a trois cas possibles :
– f ′(x1) > 0. Ce cas, selon (A), est possible si et seulement si x∗ < x1, et nous pouvonsremplacer le segment initial d’incertitude par [x1, b], reduisant ainsi la longueur du segmentd’incertitude par le facteur 2 ;
– f ′(x1) < 0. Comme dans le cas precedant, cette inegalite est possible si et seulement six∗ > x1, et nous pouvons remplacer le segment initial d’incertitude par [a, x1], reduisantde nouveau la longueur du segment d’incertitude par le facteur 2 ;
– f ′(x1) = 0. Selon (A), c’est possible si et seulement si x1 = x∗, et nous pouvons termineravec le minimiseur exact actuel.
Dans les deux premiers cas notre objectif possede clairement la propriete (A) par rapport aunouveau segment d’incertitude, et nous pouvons reiterer notre construction. Ainsi, nous venonsa
Algorithme 8.2.2 [Dichotomie]
Initialisation : poser Δ0 = [a, b], t = 1
Etape t : Etant donne le segment Δt−1 = [at−1, bt−1],
– definir le point courant de recherche xt comme le milieu de Δt−1 :
xt =at−1 + bt−1
2;
– calculer f ′(xt) ;

162 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
– dans le cas f ′(xt) = 0 terminer et sortir une solution exacte xt de (8.4). Autrement, poser
Δt =
{[at−1, xt], f ′(xt) > 0[xt, bt−1], f ′(xt) < 0
remplacer t par t+ 1 et boucler.
Des considerations ci-dessus nous amenent a
Proposition 8.2.1 [Convergence lineaire de la Dichotomie]Sous hypothese (A), pour n’importe quel t ≥ 1, soit la Dichotomie termine en cours des tpremieres etapes avec la solution exacte x∗, ou le t-eme segment d’incertitude Δt est bien defini,couvre x∗ et est de longueur 2−t(b− a).
Ainsi, la methode de dichotomie converge lineairement avec le taux de convergence 0, 5.
Remarque 8.2.1 Le taux de convergence de l’algorithme de Dichotomie est meilleur que0,61803... pour la recherche de Fibonacci ou la recherche d’or. Il n’y a aucune contradictionavec l’optimalite annoncee de la recherche de Fibonacci : le dernier est optimal parmi toutes lesmethodes d’ordre zero de minimisation de fonctions unimodales, alors que la dichotomie est unemethode du premier ordre.
Remarque 8.2.2 La methode de Dichotomie peut etre vue comme “le cas limite” de l’algo-rithme d’ordre zero 8.2.1 : quand, dans le dernier algorithme, nous posons les deux points derecherche x−t et x+t pres du milieu du segment Δt−1, le resultat de comparaison entre f(x−t ) etf(x+t ) qui regit le choix du nouveau segment d’incertitude dans l’algorithme 8.2.1 est donne parle signe de f ′ au point du milieu de Δt−1.
Remarque 8.2.3 Notez que l’hypothese (A) peut etre affaiblie. En effet, supposons que f ′
change son signe sur le segment [a, b] : f ′(a) < 0, f ′(b) > 0 ; et on ne suppose rien au sujet de laderivee sur (a, b), excepte sa continuite. Dans ce cas-ci nous pouvons encore utiliser la methodede dichotomie avec succes pour rapprocher un point critique de f dans (a, b), c.-a-d., un pointou f ′(x) = 0. En effet, de la description de la methode on voit que ce que la methode produitune suite de segments “emboites” Δ0 ⊃ Δ1 ⊃ Δ2 ⊃ ..., avec le segment suivant etant deux foisplus petit que le precedent, avec la propriete que f ′ change son signe de − a + en passant del’extremite gauche de chaque segment Δt a son extremite droite. Ce processus peut etre termineseulement dans le cas quand xt est un point critique de f . Si cet evenement ne se produit pas,alors les segments emboites Δt ont un point commun unique x∗, et puisque dans n’importe quelvoisinage du point il y a des points avec des valeurs positives et negatives de f ′, nous avonsf ′(x∗) = 0 (f ′ est continu !). C’est le point critique de f et l’algorithme converge lineairementvers x∗ avec le taux de convergence 0, 5.
La remarque ci-dessus explique la nature de l’algorithme de dichotomie. C’est un algorithmepour trouver le zero de la fonction f ′ plutot que pour minimiser f (sous l’hypothese (A), natu-rellement, c’est la meme chose). Et l’idee de la methode est triviale : etant donne que le zero def ′ est encadre par le segment initial Δ0 = [a, b] (c.-a-d., que f ′ aux points extremes du segmentest de signe different), nous produisons une suite des segments inclus, qui encadrent egalementle zero de f ′ : nous avons scinde le segment precedent Δt = [at−1, bt−1] par son milieu xt endeux sous-segments [at−1, xt] et [xt, bt−1]. Comme f ′ change son signe en passant de at−1 a bt−1,il change son signe soit en passant de at−1 a xt, soit en passant de xt a bt−1 (a condition quef ′(xt) �= 0, de sorte que nous puissions parler du signe de f ′(xt) ; si f ′(xt) = 0, nous sommes

8.2. RECHERCHE LINEAIRE 163
faits). Nous detectons sur lequel des deux sous-segments f ′ changent en fait son signe et leprenons comme nouveau segment Δt d’incertitude ; par la construction, il encadre egalement lezero de f ′.
8.2.3 Approximation de courbes
Les methodes de recherche lineaire considerees jusqu’ici possedent, sous l’hypothese d’uni-modalite, l’excellente propriete de convergence lineaire globale. Pouvons-nous esperer quelquechose de mieux ? Naturellement, oui : on aimerait bien avoir une methode de convergence super-lineaire. Si l’objectif se comporte “bien”, autrement dit, est assez regulier, nous avons de bonneschances d’accelerer la convergence, au moins sur la phase finale, en utilisant l’approximationde courbe, c.-a-d., en approchant l’objectif par une fonction simple dont le minimum peut etretrouve de facon explicite. Par exemple, on peut approcher f par un polynome, en choisissant lescoefficients du polynome afin de l’adapter aux valeurs observees (et a celles des derivees, si ellessont disponibles) de f en des iterations “les plus prometteuses”. Une iteration d’un algorithme“pur” d’approximation de courbe est suivante :
– au debut de l’iteration, nous avons un certain ensemble de “points de travail” ou nous avonsdeja calcule les valeurs et, probablement, certains derivees de l’objectif. Avec ces donnees,nous calculons le polynome d’approximation courant p qui devrait avoir les memes valeurset les meme derivees aux points de travail que ceux de l’objectif ;
– apres avoir calcule le polynome p, nous trouvons analytiquement son minimiseur et leprenons comme le nouveau point de recherche ;
– nous calculons la valeur (et, probablement, les derivees) de l’objectif en ce point de re-cherche et mettons a jour l’ensemble de points de travail, en ajoutant le dernier point derecherche (ainsi que l’information sur l’objectif en ce point) et en excluant de cet ensemblele “plus mauvais” des points de travail precedents ;et on boucle.
L’idee sous-jacente est tres simple : si nous somme capable obtenir la convergence de cettemethode, les points de travail seront eventuellement a une petite distance d du minimiseur de f .Si f est assez lisse, l’erreur qu’on commet en approchant f par p dans le d-voisinage des pointsde travail sera de l’ordre de dq+1, q etant le degre de p, et l’erreur de l’approximation de f ′ par p′
sera de l’ordre de dq. En consequence, nous pouvons esperer que la distance entre le minimiseurde p (c.-a-d., le zero de p′) et le minimiseur de f (le zero de f ′) sera de l’ordre de dq, ce qui nousdonne “de bonnes chances” d’obtenir la convergence super-lineaire.
Naturellement, ce qui est dit n’est rien de plus qu’une idee tres approximative. Voyons unerealisation standard de cette idee.
Methode de Newton
Supposons que nous resolvons le probleme (8.3) avec l’objectif f deux fois continumentdifferentiable, et que, etant donne x, nous pouvons calculer f(x), f ′(x) et f ′′(x). Sous ces hy-potheses nous pouvons appliquer au probleme la Methode suivante de Newton :
Algorithme 8.2.3 [Methode de Newton unidimensionnelle]
Initialisation : choisir le point initial x0Etape t : etant donne l’iteration precedente xt−1,

164 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
– calculer f(xt−1), f′(xt−1) et f
′′(xt−1) et approcher f autour de xt−1 par son developpementde Tailor du second ordre :
p(x) = f(xt−1) + f ′(xt−1)(x− xt−1) +1
2f ′′(xt−1)(x− xt−1)
2;
– choisir comme xt le minimiseur de la fonction quadratique p(·) :
xt = xt−1 − f ′(xt−1)
f ′′(xt−1),
remplacer t avec t+ 1 et boucler.
La methode de Newton, si initialisee pres d’un minimiseur local non-degenere x∗ de f (c.-a-d.,pres d’un point x∗ satisfaisant la condition suffisante d’optimalite du second ordre : f ′(x∗) = 0,f ′′(x∗) > 0), converge vers x∗ quadratiquement :
Proposition 8.2.2 [Convergence quadratique locale de la Methode de Newton] Soit x∗ ∈ R unminimiseur local non-degenere de la fonction reguliere f , c.-a-d., un point tels que f est troisfois continument differentiable dans un voisinage de x∗ avec f ′(x∗) = 0, f ′′(x∗) > 0. Alors lesiteration de Newton convergent vers x∗ quadratiquement, a condition que le point de depart x0soit assez proche de x∗.
Preuve. Soit g(x) = f ′(x), de sorte que g(x∗) = 0, g′(x∗) > 0 et
xt = xt−1 − g(xt−1)
g′(xt−1).
Puisque g = f ′ est deux fois continument differentiable dans un voisinage de x∗ et g′(x∗) > 0,ils existent des constantes positives K1, K2 et r tels que
|x′ − x∗|, |x′′ − x∗| ≤ r ⇒ |g′(x′)− g′(x′′)| ≤ k1|x′ − x′′|, g′(x′) ≥ k2. (8.15)
Maintenant, soit
ρ = min{r; k2k1
}. (8.16)
Supposons que pour un certain t l’iteration xt−1 appartient au ρ-voisinage
Uρ = [x∗ − ρ, x∗ + ρ]
de x∗. Alors g′(xt−1) ≥ k2 > 0 (grace a (8.15) ; notez que ρ ≤ r), ainsi l’iteration de Newtonxt−1 �→ xt est bien definie. Nous avons
xt − x∗ = xt−1 − x∗ − g(xt−1)
g′(xt−1)=
[car g(x∗) = 0]
= xt−1 − x∗ − g(xt−1)− g(x∗)g′(xt−1)
=g(x∗)− g(xt−1)− g′(xt−1)(x
∗ − xt−1)
g′(xt−1).

8.2. RECHERCHE LINEAIRE 165
Le numerateur dans la fraction a droite est le reste du developpement de Taylor d’ordre 1 deg en xt−1 ; par (8.15), et comme |xt−1 − x∗| ≤ ρ ≤ r, il ne depasse pas en valeur absolue12k1|x∗ − xt−1|2. Le denominateur, par le meme (8.15), est au moins k2. D’ou,
xt−1 ∈ Uρ ⇒ |xt − x∗| ≤ k12k2
|xt−1 − x∗|2. (8.17)
Grace a l’origine de ρ, (8.17) implique
|xt − x∗| ≤ |xt−1 − x∗|/2.
On observe que la trajectoire de la Methode de Newton, apres avoir une fois atteint Uρ, nequite jamais ce voisinage et converge vers x∗ lineairement avec le taux 0.5. C’est surement lecas quand x0 ∈ Uρ, et nous allons specifier “assez proche de” dans l’enonce de la propositioncomme l’inclusion x0 ∈ Uρ. Avec cette specification, nous obtenons que la trajectoire convergevers x∗ lineairement, et on deduit de (8.17) que l’ordre de convergence est (au moins) 2.
Remarque 8.2.4 Les deux hypotheses – que f ′′(x∗) > 0 et que x0 est assez pres de x∗ sontessentielles 5). Par exemple, pour la fonction convexe reguliere f(x) = x4 (avec le minimiseurdegenere x∗ = 0), la methode devient
xt = xt−1 − 1
3xt−1 =
2
3xt−1;
dans cet exemple la methode converge, mais la convergence est lineaire plutot que quadratique.
Appliquee a la fonction reguliere strictement convexe f(x) =√1 + x2 avec le minimizer local
(et global) unique (et non-degenere x∗ = 0), la methode devient, comme on voit immediatement,
xt = −x3t−1;
cette suite converge (tres rapidement : avec l’ordre 3) vers 0 a condition que le point de departsoit dans (−1, 1), et diverge a l’infini – aussi rapidement – si |x0| > 1.
En fait la Methode de Newton est une Methode de Linearisation pour trouver le zero de f ′ :etant donne l’iteration precedente xt−1, nous “linearisons” g = f ′ en ce point et prenons commext la solution a la linearisation
g(xt−1) + g′(xt−1)(x− xt−1) = 0
de l’equation actuelle g(x) = 0.
5. )en fait, la condition f ′′(x∗) > 0 peut etre remplace par f ′′(x∗) < 0, puisque la trajectoire de la methodene change pas si on remplace f par −f (en d’autres termes, la Methode de Newton ne distingue pas les minimalocaux et les maxima locaux de l’objectif). On parle du cas de f ′′(x∗) > 0, pas celui de f ′′(x∗) < 0, simplementparce que le premier est le seul important pour la minimisation.

166 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
f’(x)
xt
xt-1
Methode de Newton comme recherche de zero
8.2.4 Recherche Lineaire Inexacte
Comme nous l’avons remarque, l’application principale des methodes de recherche lineaireest en interieur des algorithmes d’optimisation multi-dimensionnelle. Dans ces algorithmes onadmet seulement un petit nombre d’etapes du sous-programme de recherche lineaire a chaqueiteration de l’algorithme principal, sinon la complexite globale de la methode principale seratrop importante. D’ailleurs, souvent dans l’algorithmique multi-dimensionnels nous n’avons pasbesoin de solutions tres precises des sous-problemes unidimensionnels ; ce qui est important pourla methode principale, est de garantir un progres raisonnable sur l’objectif du sous-probleme.Si tel est le cas, nous pouvons terminer la recherche lineaire relativement loin de la solutionoptimale du sous-probleme en question, en utilisant certains tests simples pour du “progresraisonnable”. Nous allons presenter deux tests le plus populaires de ce type.
La regle d’Armijo
On considere la situation qui est typique pour l’application de la technique de recherchelineaire a l’interieur de la methode principale multi-dimensionnelle. Sur une iteration de laderniere methode nous avons l’iteration courante x ∈ Rn et la direction de recherche d ∈ Rn
qui est direction de descente pour notre objectif f(·) : Rn → R :
dT∇f(x) < 0. (8.18)
Le but est de reduire “de facon importante” la valeur de l’objectif par un pas
x �→ x+ γ∗d
de x dans la direction d.
Supposons que f est continument differentiable. Alors la fonction
φ(γ) = f(x+ γd)
d’une variable est egalement une fois continument differentiable ; d’ailleurs, en raison de (8.18),nous avons
φ′(0) < 0,

8.2. RECHERCHE LINEAIRE 167
de sorte que pour le petit γ positif on a
φ(γ)− φ(0) ≈ γφ′(0) < 0.
Nous desirons de choisir un pas “raisonnablement grand” γ∗ > 0 qui a comme consequence leprogres φ(γ∗) − φ(0) sur l’objectif “de l’ordre de γ∗φ′(0)”. Le test d’Armijo de cette conditionest construit de facon suivante :
Test d’Armijo :on fixe une fois pour toutes les constantes ε ∈ (0, 1) (un choix populaire est ε = 0.2) et η > 1(disons, η = 2 ou η = 10) et on dit que la valeur candidate γ > 0 est appropriee, si les deuxconditions suivantes sont satisfaites :
φ(γ) ≤ φ(0) + εγφ′(0) (8.19)
[cette partie du test dit que le progres en valeur de φ donne par le pas γ est “de l’ordre deγφ′(0)”]
φ(ηγ) ≥ φ(0) + εηγφ′(0) (8.20)
[cette partie du test dit que γ est un pas “de l’ordre de grandeur maximal” qui satisfait encore(8.19) – si on multiplie γ par η, la nouvelle valeur ne satisfait plus (8.19), comme une inegalitestricte]
Sous l’hypothese (8.18) et la condition (tres naturelle) que f (et, par consequent, φ) est borneinferieurement, le test d’Armijo est consistant : ils existent des valeurs de γ > 0 qui passent letest. Pour le voir, il suffit de remarquer que
A. (8.19) est satisfait pour tout γ positif assez petit.En effet, puisque φ est differentiable, nous avons
0 > φ′(0) = limγ→+0
φ(γ)− φ(0)
γ,
d’ou
εφ′(0) ≥ φ(γ) − φ(0)
γ
pour tout assez petit γ positif (comme εφ′(0) > φ′(0) du a φ′(0) < 0, ε ∈ (0, 1)). L’inegalite finaleest equivalente a (8.19) ;
B. (8.19) n’est pas verifiee pour toutes valeurs γ assez grandes.En effet, le cote droit de (8.19) tend vers −∞ quand γ → ∞, du a φ′(0) < 0, mais son cotegauche est borne inferieurement.
Nous pouvons choisir un γ = γ0 positif et verifier s’il satisfait (8.19). Si c’est le cas, onremplace cette valeur par γ1 = ηγ0, γ2 = ηγ1, etc., verifiant chaque fois si la nouvelle valeur deγ passe (8.19). Selon B , ceci ne peut pas durer toujours : pour un certain s ≥ 1, γs ne satisfaitsurement pas (8.19). Quand cela se produit pour la premiere fois, la quantite γs−1 satisfait (8.19),alors que la quantite γs = ηγs−1 ne satisfait pas (8.19), ce qui signifie que γ = γs−1 passe le testd’Armijo.
Notez que la preuve presentee donne en fait un algorithme explicite (et rapide) pour trouverle pas qui passe le test d’Armijo, et cet algorithme peut etre utilise (et il est, en effet, souventemploye) dans la recherche d’Armijo au lieu des methodes de recherche lineaire plus precises(et, normalement, plus fastidieuses).

168 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
Test de Goldstein
Un autre test populaire pour le “progres suffisant” pour la recherche lineaire est le testde Goldstein suivant :
on fixe ε ∈ (0, 1/2) et on dit que la valeur candidat γ > 0 est appropriee, si
φ(0) + (1− ε)γφ′(0) ≤ φ(γ) ≤ φ(0) + εγφ′(0). (8.21)
Ici encore la relation (8.18) et la bornitude de f impliquent la consistance du test.

8.3. EXERCICES 169
8.3 Exercices
Exercice 8.1 [Recherche d’or] Codez la recherche d’or et testez la sur quelques fonctions uni-modales de votre choix.
Exercice 8.2 [Dichotomie] Codez la methode de dichotomie et tester la sur quelques fonctionsunimodales de votre choix.
Lancer 50 pas de l’algorithme de dichotomie sur la fonction (non-unimodale)
f(x) = − sin
(2π
217 + x
)[x ≥ 0]
avec le segment initial (a) [0, 1] ; (b) [0, 4], prenant comme resultat le point central du segmentfinal. Pourquoi les resultats sont-ils differents ?
Exercice 8.3 [Recherche d’or contre le dichotomie] Supposons que le probleme (8.4) a resoudresatisfait l’hypothese (A) (Section 8.2.2), et que les derivees de l’objectif sont disponibles. Quedevrait etre prefere – la recherche d’or ou la dichotomie ?
Naturellement, la dichotomie a une meilleure convergence (taux 0.5 contre 0.618... pour larecherche d’or), mais cette comparaison est injuste : la recherche d’or n’utilise pas des derives,et en excluant la partie du code qui calcul f ′, on doit economiser du temps de calcul, malgre unnombre plus grand d’etapes requises dans la recherche d’or pour realiser la meme precision.
La raison reelle de preferer le bisection est que cette methode est plus stable numeriquement.En effet, supposons que nous devons resoudre (8.4) et toutes les valeurs de f, f ′, f ′′ dans [a, b],memes que a et b eux-memes, sont des “reels normaux” – ceux de l’ordre de 1. Supposons aussique nous cherchons a obtenir le segment d’incertitude final de la longueur ε. Quelles sont lesvaleur de ε que nous pouvons obtenir reellement en utilisant les ordinateurs reels avec leurserreurs d’arrondie ?
Je vous propose le raisonnement approximatif suivant : pour implementer la recherche d’or,nous devrions comparer des valeurs de l’objectif sur les etapes finales – aux points a la distanceO(ε) du minimiseur. En ces points, les valeurs de f different de la valeur optimale (et, parconsequent, l’un de l’autre) de O(ε2). Afin d’assurer la comparaison correcte des valeurs (etla comparaison incorrecte rend tous les calculs suivants errones), l’erreur d’arrondie absolue ε∗
de la representation d’ordinateur d’un nombre de l’ordre de 1 (pour les machines actuelles ε∗
de double precision Fortran/C est quelque chose comme 10−16) devrait etre moins que O(ε2).Ainsi, les valeurs de ε que nous pouvons atteindre dans la recherche d’or devraient etre d’ordrede O(
√ε∗).
Dans la methode de dichotomie, nous devrions comparer les valeurs de f ′ a 0 ; si tous lesresultats intermediaires dans le code qui calcule la derivee sont de l’ordre de 1, la derivee est cal-culee avec l’erreur absolue ≤ cε∗, avec une certaine constante c. Si f ′′(x∗), x∗ etant le minimiseurde f sur [a, b], est positif de l’ordre de 1 (le minimiseur est numeriquement “bien conditionne”),alors a la distance ≥ Cε de x∗ les valeurs reelles de f ′ sont, en valeurs absolues, au moins C ′ε,C ′ etant une certaine constante. Nous voyons que si x se trouve a la distance ε de x∗ et ε est telque C ′ε > cε∗ (c.-a-d., la grandeur de f ′(x) est plus grande que l’erreur absolue dans le calcul def ′(x)), alors le signe de f ′(x) reellement calcule considera avec le signe exact de f ′(x), et l’etapede dichotomie sera correcte. Ainsi, dans les conditions ci-dessus, nous pouvons compter que ladichotomie pourra atteindre une precision ε = c(C ′)−1ε∗ = O(ε∗) (comparez avec O(
√ε∗) pour
la recherche d’or).

170 CHAPITRE 8. METHODES D’OPTIMISATION : INTRODUCTION
Afin de valider ce raisonnement, j’ai tester la recherche d’or et la dichotomie sur le probleme
f(x) = (x+ 1)2 → min | −2 ≤ x ≤ 1.
A ma surprise (je suis peu experimente dans l’analyse d’erreur !), les deux methodes ont resolule probleme avec la precision sur x de O(10−16). Apres une reflection, j’ai compris ce qui n’allaitpas et pu modifier l’objectif pour observer le phenomene decrit.
Pourriez-vousa) deviner ce qui ne va pas avec mon exemple ?b) corriger l’exemple et observez le phenomene ?
Exercice 8.4 [Methode de Newton] Tester la Methode de Newton sur les fonctions1) f(x) = 1
2x2 − x− 1
2 exp{−2x} (point initial 0.5)2) f(x) = x4 exp{−x/6} (point initial 1.0)

Chapitre 9
Methode de Descente de Gradient etMethode de Newton
Dans cette partie du cours nous etudions des methodes d’optimisation sans contraintes.
f(x) → min | x ∈ Rn. (9.1)
Nous faisons maintenant une fois pour toutes l’hypothese suivante :– (A) l’objectif f dans (9.1) est continument differentiable ;– (B) le probleme en question est soluble : l’ensemble
X∗ = ArgminRn
f
est non vide.
9.1 Descente de Gradient
Cette section est consacree a la methode pour resoudre (9.1) la plus ancienne et la pluslargement connue - Descente de Gradient .
9.1.1 L’idee
L’idee de la methode est tres simple. Supposez que nous sommes en un certain point x, et quenous avons calcule f(x) et ∇f(x). Supposez que x n’est pas un point critique de f : ∇f(x) �= 0(c’est la meme chose que dire que x n’est pas un point de Karush-Kuhn-Tucker du probleme).Alors g = −∇f(x) est une direction de descente de f en x :
d
dγ|γ=0f(x− γ∇f(x)) = −|∇f(x)|2 < 0.
De plus, c’est la meilleure parmi les directions h de descente (normalisees pour avoir la memelongueur que celle de g) de f en x : pour tout h, |h| = |g|, on a
d
dγ|γ=0f(x+ γh) = hT∇f(x) ≥ −|h||∇f(x)| = −|∇f(x)|2
(par l’inegalite de Cauchy, qui devient egalite si et seulement si h = g).
171

172CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
L’observation indiquee demontre qu’afin d’ameliorer x – pour former un nouveau point avecune plus petite valeur de l’objectif – on peur effectuer un deplacement (pas)
x �→ x+ γg ≡ x− γ∇f(x)a partir de x dans la direction de l’antigradient ; un tel deplacement avec la longueur de pas γ > 0correctement choisi assure la decroissance de f . La methode de Descente de Gradient consiste,tout simplement, de reiterer ce pas. Ainsi, le schema generique de la methode est suivant :
Algorithme 9.1.1 [Descente de Gradient ]Initialisation : choisir le point initial x0 et mettre t = 1.Etape t : au debut de l’etape t nous avons la precedente iteration xt−1. On
– calcule f(xt−1) et ∇f(xt−1)– choisit (d’une facon ou d’une autre) un pas positif γt et on pose
xt = xt−1 − γt∇f(xt−1), (9.2)
on remplace t avec t+ 1 et on boucle.
Ainsi, la methode generique de Descente de Gradient est la repetition de (9.2) avec une certaineregle pour choisir les pas γt > 0 ; normalement, les pas sont donnes par une sorte de recherchelineaire, applique a la fonction univariee
φt(γ) = f(xt−1 − γ∇f(xt−1)).
9.1.2 Implementations Standards
Les differentes versions de la recherche lineaire resultent dans differentes versions de lamethode de Descente de Gradient. Parmi ces versions, on devrait mentionner
– DAr [ Descente de Gradient avec la recherche lineaire d’Armijo] : le pas γt > 0 a l’iterationt ou ∇f(xt−1) �= 0 est choisi selon le test d’Armijo (Section 8.2.4) :
f(xt−1 − γt∇f(xt−1)) ≤ f(xt−1)− εγt|∇f(xt−1)|2;f(xt−1 − ηγt∇f(xt−1)) ≥ f(xt−1)− εηγt|∇f(xt−1)|2, (9.3)
ε ∈ (0, 1) et η > 1 sont des parametres de la methode. Et si xt−1 est un point critiquede f , c.-a-d., ∇f(xt−1) = 0, le choix de γt > 0 n’a absolument aucune importance :independamment de la valeur de γt, (9.2) aura comme consequence xt = xt−1.
– PRD [“Steepest Descent” (la Plus Rapide Descente)] : γt minimise f le long du rayon{xt−1 − γ∇f(xt−1) | γ ≥ 0} :
γt ∈ Argminγ≥0
f(xt−1 − γ∇f(xt−1)). (9.4)
Evidemment, la Plus Rapide Descente est un genre d’idealisation : dans des cas non triviauxnous ne savons pas trouver un minimum exacte de l’objectif le long un rayon. D’ailleurs, pourrendre cette idealisation valide, nous devrions supposer que les pas correspondants sont biendefinis, c.-a-d., que
Argminγ≥0
f(x− γ∇f(x)) �= ∅
pour le chaque x ; dans ce qui suit, ceci est suppose “par defaut” toutes les fois que nous parlonsau sujet de la Plus Rapide Descente.
Contrairement a la Plus Rapide Descente, la Descente de Gradient avec la la recherche lineaired’Armijo est tout a fait “constructive” – nous savons de la Section 8.2.4 comment trouver unpas γt qui passe le test d’Armijo.

9.1. DESCENTE DE GRADIENT 173
9.1.3 Convergence de la Descente de Gradient
Theoreme General de Convergence
Nous commencons par etablir, sous des conditions peut restrictives, la convergence globalede la Descente de Gradient vers l’ensemble des points critiques de f , c.-a-d. vers l’ensemble :
X∗∗ = {x ∈ Rn | ∇f(x) = 0}.
Theoreme 9.1.1 [Convergence globale de Descente de Gradient] Les methodes PRD et DArverifient :
(i) si la trajectoire {xt} de la methode est bornee, alors cette trajectoire possede des pointslimites, et tous ces points sont des points critiques de f ;
(ii) si l’ensemble de niveau
S = {x ∈ Rn | f(x) ≤ f(x0)}
de l’objectif est borne, alors la trajectoire de la methode est bornee (et, par consequent, tous sespoints limites, d’apres (i), appartiennent a X∗∗).
Preuve : (ii) est une consequence immediate de (i), puisque DAr et PRD sont clairement desmethodes de descente :
xt �= xt−1 ⇒ f(xt) < f(xt−1). (9.5)
Par consequent, la trajectoire, pour chacune des methodes, est contenue dans l’ensemble S deniveau ; puisque sous l’hypothese de (ii) cet ensemble est borne, la trajectoire egalement estbornee, selon (ii).
Il nous reste de prouver (i). Ainsi, supposons que la trajectoire {xt} soit bornee, et quex∗ est un point limite de la trajectoire ; nous devons montrer que ∇f(x∗) = 0. Supposons, aucontraire, que ce n’est pas le cas, et menons cette hypothese a une contradiction. L’idee de cequi suit est tres simple : comme ∇f(x∗) �= 0, un pas de la methode a partir de x∗ doit diminuerla valeur de f d’une certaine quantite positive δ ; c’est absolument clair de la construction dupas. Ce qui est tres probable (on devrait, naturellement, le prouver, et nous le ferons dans uninstant) que il existe un petit voisinage U de x∗ tels qu’un pas de la methode a partir d’unpoint arbitraire x ∈ U ameliore egalement l’objectif au moins par la quantite positive fixe δ′.Il n’est absolument pas important pour nous ce qui est ce δ′, tout ce que nous avons besoin asavoir que cette quantite est positive et independante du choix particulier de x ∈ U . Supposezque nous avons deja montre que de tels U et δ′ existent. Sous cette hypothese, nous obtenonsimmediatement une contradiction : puisque x∗ est un point limite de la trajectoire, la trajectoirevisite U un nombre infini de fois. Chaque fois qu’elle visite U , le pas correspondant diminue f aumoins de δ′ > 0, et aucun pas de la methode n’augmente l’objectif. Ainsi, en cours de la methodenous diminuons l’objectif par δ′ un nombre infini de fois et ne l’augmentons jamais, de sorteque l’objectif devrait diverger vers −∞ le long de notre trajectoire ; le dernier est impossible,puisqu’on a assume que l’objectif est borne inferieurement.
Maintenant il est temps de prouver notre argument principal – celui sur l’existence de U etde δ′ necessaires dans la construction ci-dessus. Je voudrais souligner qu’il y a la quelque chosea prouver, malgre le fait deja connu (la propriete de “descente”) que l’objectif est ameliore parchaque pas a partir d’un point non critique de f (et de tous points assez proches de x∗ noncritique, qui ne sont egalement pas critiques, puisque ∇f est continu). La difficulte est que leprogres dans f sur un pas depend du point a partir du quel nous avons fait le pas ; en principe

174CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
il peut arriver qu’un pas de chaque point d’un voisinage de x∗ ameliore l’objectif, mais il n’ya aucune borne inferieure positive δ′ pour les ameliorations qui soitindependante du point. Etdans le raisonnement ci-dessus nous avons besoin en effet du ‘’progres uniforme” – autrementil serait possible que les visites consecutives de U par la trajectoire ont comme consequencede plus en plus petites ameliorations de f , dont la somme est finie. Cette possibilite tuerait leraisonnement ci-dessus completement.
Evidemment, de tels U et δ′ existent. Il suffit le prouver pour DAr seulement – il estabsolument clair que le progres dans l’objectif sur un pas de PRD soit au moins celui de DAr, les deux pas etant prises a partir du meme point. La preuve pour le cas de DAr est commesuit :
Puisque f est continument differentiable et ∇f(x∗) �= 0, il existent r, P et p positifs telsque
|x− x∗| < r ⇒ p ≤ |∇f(x)| ≤ P ;
Pour les memes raisons, il existe r′ ∈ (0, r) tel que nous avons dans le r′-voisinage V de x∗ :
|∇f(x′)−∇f(x′′)| ≤ ζ ≡ (1 − ε)P−1p2.
Soit U le r′/2-voisinage de x∗. J’affirme que
(*) si x ∈ U , le pas sx donne par la recherche lineaire d’Armijo pour la fonction
φx(s) = f(x− s∇f(x)) [φ′x(0) = −|∇f(x)|2]
est au moins
s∗ =1
2r′η−1P−1.
Notez que (*) est tout ce que nous avons besoin. En effet, le progres dans l’objectif dans larecherche lineaire d’Armijo pour une fonction φ et ayant pour resultat un pas s au moinsεs|φ′(0)|. En appliquant cette observation a un pas de DAr pris a partir d’un point x ∈ Uet en utilisant (*), nous venons a la conclusion que le progres dans l’objectif sur ce pas estau moins εs∗|∇f(x)|2 ≥ εs∗p2, et cette derniere quantite (qui est positive et est independantde x ∈ U) peut nous servir de δ′.
Il nous reste a prouver (*), ce qui est immediat : en supposant que x ∈ U et sx < s∗, entenant compte de la construction du test d’Armijo, nous obtenons
φx(ηsx)− φx(0) > εηsxφ′(0). (9.6)
Maintenant, comme sx < s∗, la longueur du segment [x, x − ηsx∇f(x)] est au plus ηs∗P ≤r′/2, et puisqu’une extremite du segment appartient a U , le segment lui-meme appartient aV . En consequence, la derivee de f le long du segment change tout au plus de ζ, de sorteque la derivee de φ change sur le segment [0, ηsx] tout au plus de
|∇f(x)|ζ ≤ Pζ = (1− ε)p2.
D’autre part, du theoreme de valeur intermediaire de Lagrange on sait que
φ(ηsx)− φ(0) = ηsxφ′(ξ) ≤ ηsxφ
′(0) + ηsx(1− ε)p2;
Ici ξ est un certain point sur le segment [0, ηsx]. En combinant cette inegalite avec (9.6),nous obtenons
ηsx(1− ε)p2 > −(1− ε)ηsxφ′(0) ≡ (1− ε)ηsx|∇f(x)|2 ≥ (1− ε)ηsxp
2,
qui est une contradiction.

9.1. DESCENTE DE GRADIENT 175
Essayons de bien comprendre la preuve ci-dessus : sa structure est typique pour des preuvesde convergence dans l’optimisation traditionnelle : nous savons a l’avance que le processus iteratifen question possede une certaine fonction de Lyapunov L – qui diminue le long de la trajectoiredu processus et est bornee inferieurement (dans la preuve ci-dessus cette fonction est f elle-meme) ; nous supposons que la trajectoire soit bornee, et que l’ensemble de niveau de la fonctionde Lyapunov, associe a la valeur de la fonction au point initial de la trajectoire est borneaussi (alors, evidemment, la trajectoire est surement bornee – puisque la fonction de Lyapunovn’augmente jamais le long de la trajectoire, cette derniere ne peut pas quitter l’ensemble deniveau). Supposez maintenant que les trois entites – (1) la fonction de Lyapunov, (2) notreprocessus iteratif, et (3) l’ensemble X∗ qui est l’ensemble de solutions de notre probleme – sontlies par la relation suivante :
(**) si un point de la trajectoire n’appartient pas a X∗, alors le pas de processusa partir de ce point fait decroitre strictement la fonction de Lyapunov
Normalement (**) est evident de la construction du processus et de la fonction de Lyapunov ;par exemple, dans la preuve ci-dessus ou L est l’objectif, le processus est DAr ou PRD et X∗ estl’ensemble des points critiques de l’objectif, vous ne devriez pas ouvrer trop dur afin de montrerque le pas d’un point non critique diminue l’objectif. Maintenant, etant donne tout ceci, noussommes interesses de montrer que la trajectoire du processus converge vers X∗ ; quel est le pointprincipal de la preuve ? Naturellement, un equivalent de (*), c.-a-d., “une version localementuniforme de (**)” – nous devrions montrer qu’un point n’appartenant pas a X∗ possede unvoisinage tel que chaque fois que la trajectoire visite ce voisinage, le progres dans la fonctionde Lyapunov sur le pas correspondant est separe de zero. Apres que nous ayons prouve ce faitcrucial, nous pouvons immediatement appliquer le schema de la preuve ci-dessus pour montrerque la trajectoire converge vers X∗.
J’ai une bonne raison d’investir en explication de la “squelette” de cette preuve de conver-gence : dorenavant, je sauterai les preuves semblables, puisque je crois que vous avez comprisce principe general, et les details techniques ne sont pas d’un grand interet. J’espere que main-tenant il devient clair pourquoi dans le test d’Armijo nous avons besoin du plus grand pas (aufacteur η pres) qui permet d’obtenir un “progres significatif” dans l’objectif. Si nous sautonscette condition “maximale”, nous admettons des pas arbitrairement petits meme a partir despoints qui sont loin de l’ensemble des solutions. En consequence, (*) n’ai plus lieu, et nous seronsincapables d’assurer la convergence du processus (et elle sera en effet perdue).
Points limites de la Descente de Gradient
Nous avons montre que les versions standards de la Descente de Gradient, sous l’hypotheseque la trajectoire est bornee, convergent vers l’ensemble X∗∗ des points critiques de l’objectif. Cetensemble contient certainement l’ensemble X∗ de minimiseurs globaux de f , ainsi que l’ensemblede minimiseurs locaux de l’objectif, mais ce n’est pas tout : X∗∗ contient egalement tous lesmaximiseurs locaux de f et les points selles de la fonction. Une question importante est si unpoint limite de la trajectoire de la descente de gradient peut etre quelque chose que ne nousinteresse pas – un point critique qui n’est pas un minimiseur local de l’objectif. Ce qui peut etreaffirmer est le suivant : un maximiseur local x∗ non degenere de f (c.-a-d., un point critique de ftels que f ′′(x∗) est defini negative) ne peut pas etre un point limite de la trajectoire de DAr et dePRD , a l’exclusion du cas quand, justement, x∗ s’avere etre un point de la trajectoire ; ceci peutse produire dans DAr (bien qu’il est “pratiquement impossible”), et il ne se produit jamais dansPRD , excepte le cas “trivial” (et egalement “pratiquement impossible”) quand la trajectoire

176CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
commence en x∗. En parlant “officieusement”, il est “tres improbable” qu’un point limite de latrajectoire est un point selle de l’objectif. Ainsi, de point de vue “pratique”, des points limitesde la trajectoire de la Descente de Gradient sont des minimiseurs locaux de l’objectif.
9.1.4 Vitesses de convergence
Vitesse de convergence globale : cas de C1,1 general
Comme nous le savons deja, sous l’hypothese de (ii) du Theoreme 9.1.1 (c.-a-d., quandl’ensemble de niveau S = {x | f(x) ≤ f(x0)} est borne), les versions de la Descente de Gradientcitees dans le Theoreme convergent vers l’ensemble X∗∗ de points critiques de f . Que peut etredit au sujet de la vitesse non-asymptotique de convergence ? La reponse depend de la facon dontnous mesurons la precision (ou l’imprecision). Si nous employons quelque chose comme
dist(x,X∗∗) = miny∈X∗∗ |y − x|
d’une solution approximative x a X∗∗, il n’y a aucune evaluation non triviale d’efficacite : laconvergence des quantites dist(xt,X
∗∗) vers 0 peut etre arbitrairement lente, meme lorsque fest convexe. Il y a, cependant, une autre mesure d’exactitude,
εf (x) = |∇f(x)|2,
bien plus appropriee. Notez que l’ensemble X∗∗ vers lequel la trajectoire converge est exactementl’ensemble ou εf (·) = 0, de sorte que εf (x) en effet puisse etre vu comme quelque chose qui mesurele “residu de l’inclusion x ∈ X∗∗”. Et il s’avere que nous pouvons preciser le taux auquel ce residuconverge vers 0 :
Proposition 9.1.1 [Vitesse Non-asymptotique de convergence de Descente de Gradient]Supposons que l’objectif f est une fonction de C1,1, c.-a-d., il est continument differentiable avecle gradient Lipschitzien :
|∇f(x)−∇f(y)| ≤ Lf |x− y|, ∀x, y ∈ Rn. (9.7)
Alors pour tout entier N > 0 :(i) Pour la trajectoire {xt} de PRD avec le point du depart x0 nous avons
εf [t] ≡ min0≤t<N
|∇f(xt)|2 ≤ 2Lf
N[f(x0)−min f ]. (9.8)
(ii) Pour la trajectoire {xt} de DAr avec le point du depart x0 nous avons
εf [t] ≡ min0≤t<N
|∇f(xt)|2 ≤ ηLf
2ε(1 − ε)N[f(x0)−min f ], (9.9)
ε ∈ (0, 1), η > 1 etant les parametres du test d’Armijo.
Preuve :10. On commence avec le lemme fondamental suivant :
Lemme 9.1.1 Sous l’hypothese du Theoreme on a
f(y) ≤ f(x) + (y − x)T∇f(x) + Lf
2|y − x|2, ∀x, y ∈ Rn. (9.10)

9.1. DESCENTE DE GRADIENT 177
Preuve du Lemme. Soit φ(γ) = f(x+γ(y−x)). Notez que φ est continument differentiable(comme f l’est) et
|φ′(α) − φ′(β)| = |(y − x)T (∇f(x+ α(y − x))−∇f(x+ β(y − x))| ≤[par l’inegalite de Cauchy]
≤ |y − x||∇f(x + α(y − x)) −∇f(x+ β(y − x))| ≤[(9.7)]
≤ |y − x|2Lf |α− β|.Ainsi,
|φ′(α)− φ′(β)| ≤ Lf |y − x|2|α− β|, ∀α, β ∈ R. (9.11)
Nous avons
f(y)− f(x)− (y − x)T∇f(x) = φ(1)− φ(0)− φ′(0) =∫ 1
0
φ′(α)dα − φ′(0) =
=
∫ 1
0
[φ′(α)− φ′(0)]dα ≤
[cf. (9.11)]
≤∫ 1
0
|y − x|2Lfαdα =Lf
2|y − x|2,
comme requit dans (9.10).20. Nous somme en mesure de prouver (i). Par construction de la Plus Rapide Descente,
f(xt) = minγ≥0
f(xt−1 − γ∇f(xt−1)) ≤
[par Lemme 9.1.1]
≤ minγ≥0
[f(xt−1) + [−γ∇f(xt−1)]
T∇f(xt−1) +Lf
2|γ∇f(xt−1)|2
]=
= f(xt−1) + |∇f(xt−1)|2 minγ≥0
[−γ +
Lf
2γ2
]= f(xt−1)− 1
2Lf|∇f(xt−1)|2.
Ainsi, on arrive a l’inegalite importante :
f(xt−1)− f(xt) ≥ 1
2Lf|∇f(xt−1)|2 (9.12)
– le progres dans l’objectif sur un pas de la Plus Rapide Descente est au moins de l’ordre dela norme carree du gradient sur l’iteration precedente.
Maintenant, pour conclure la preuve, il suffit de noter que, en raison de la monotoniede la methode, le progres “total” sur l’objectif sur un une suite des pas de la methode nepeut pas depasser l’erreur initial f(x0)−min f en valeur de l’objective ; par consequent, dansune long suite, il doit y etre un pas avec le petit progres, c.-a-d., avec la petite norme dugradient. Pour rendre ce raisonnement quantitatif, prenons la somme des inegalites (9.12)sur t = 1, ..., n, venant a
1
2Lf
N−1∑t=0
|∇f(xt)|2 ≤ f(x0)− f(xN ) ≤ f(x0)−min f.
La partie a gauche est ≥ N2Lf
min0≤t<N |∇f(xt)|2, et nous obtenons (9.8).

178CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
30. La preuve de (ii) est un peu plus compliquee, mais suit la meme idee fondamentale : leprogres sur un pas de DAr peut etre petit seulement si le gradient sur l’iteration precedenteest petit, et dans une suite de pas on doit obligatoirement avoir un certain pas sur lequel leprogres est petit, puisque tout le progres ne peut pas exceder l’erreur initial.
Decrivons maintenant ce raisonnement quantitatif. Tout d’abord, le progres dans l’objec-tif sur l’iteration t de DAr n’est pas trop petit, a condition que γt et |∇f(xt−1)|2 ne soientpas trop petits :
f(xt−1)− f(xt) ≥ εγt|∇f(xt−1)|2. (9.13)
C’est une consequence immediate de la premiere inegalite de (9.3). Deuxiemement, γt n’estpas trop petit. En effet, par le Lemme 9.1.1 applique a x = xt−1, y = xt−1 − ηγt∇f(xt−1)nous avons
f(xt−1 − ηγt∇f(xt−1)) ≤ f(xt−1)− ηγt|∇f(xt−1)|2 + Lf
2η2γ2t |∇f(xt−1)|2,
tandis que par la deuxieme inegalite de (9.3)
f(xt−1 − ηγt∇f(xt−1)) ≥ f(xt−1)− εηγt|∇f(xt−1)|2.
En combinant ces inegalites, nous obtenons
(1− ε)ηγt|∇f(xt−1)|2 ≤ Lf
2η2γ2t |∇f(xt−1)|2.
Comme γt > 0, dans le cas ∇f(xt−1) �= 0 nous obtenons
γt ≥ 2(1− ε)
ηLf; (9.14)
et dans le cas de ∇f(xt−1) = 0, comme on se le rappelle, γt peut etre choisi de la manierearbitraire sans influencer la trajectoire (cette derniere de toute facon satisfera xt−1 = xt =xt+1 = ...), et nous pouvons supposer que γt toujours satisfait (9.14).
En combinant (9.13) et (9.14), nous venons a l’inegalite suivante (comparez a (9.12) :
f(xt−1)− f(xt) ≥ 2ε(1− ε)
ηLf|∇f(xt−1)|2. (9.15)
Nous pouvons maintenant accomplir la preuve exactement comme dans le cas de la Plus
Rapide Descente.
Remarque 9.1.1 L’evaluation d’efficacite donnee par la Proposition 9.1.1 donne une bornesuperieure non-asymptotique sous-lineaire de convergence vers 0 des “imprecisions” εf (·). Notez,neanmoins, que c’est une borne sur l’erreur de la le meilleure (avec la plus petite norme dugradient) iteration produite en cours des N premieres etapes de la methode, pas sur l’erreurde la derniere iteration xN (les quantites |∇f(xt)|2 peuvent osciller, contrairement aux valeursf(xt) de l’objectif).
Vitesse de convergence globale : cas C1,1 convexe
Le Theoreme 9.1.1 dit que sous une hypothese assez faible de regularite, la trajectoire deDAr et PRD convergent vers l’ensemble X∗∗ de points critiques de f . Si nous supposons, enoutre, que f est convexe, de sorte que l’ensemble de points critiques de f coincide avec l’ensemblede minimiseurs globaux de la fonction, nous pouvons affirmer que la trajectoire de la methodeconvergent vers l’ensemble optimal du probleme. De plus, dans le cas de l’objectif convexe

9.1. DESCENTE DE GRADIENT 179
C1,1 (voir la Proposition 9.1.1) nous pouvons obtenir des caracterisations non-asymptotiquesd’efficacite en termes de residus f(xt) − min f , et sous l’hypothese supplementaire disant quel’objectif est non degenere (voir ci-dessous) – aussi en termes de distances |xt−x∗| de l’iterationsxt a la solution optimale.
Pour simplifier les developpements et les rendre plus “pratiques”, dans ce qui suit nousconsiderons seulement la version d’Armijo de la Descente de Gradient DAr .
Cas C1,1 convexe :
Proposition 9.1.2 [Vitesse de convergence globale de DAr dans le cas C1,1 convexe]
Soit le parametre ε dans la methode de DAr ≥ 0.5, et soit f fonction C1,1 convexe avec unensemble non vide X∗ de minimiseurs globaux. Alors
(i) la trajectoire {xt} de DAr converge vers un certain point x∗ ∈ X∗ ;(ii) pour chaque N ≥ 1 nous avons
f(xN )−min f ≤ ηLf dist2(x0, x
∗)4(1− ε)N
, (9.16)
ou Lf est la constante de Lipschitz de ∇f(·) et
dist(x,X∗) = miny∈X∗ |y − x|. (9.17)
Preuve.10. Soit x∗ un point de X∗, regardons comments les distances
d2t = |xt − x∗|2
varient avec t. Nous avons
d2t = |xt − x∗|2 ≡ |[xt−1 − γt∇f(xt−1)]− x∗|2 = |[xt−1 − x∗]− γt∇f(xt−1)|2 =
= |xt−1 − x∗|2 − 2γt(xt−1 − x∗)T∇f(xt−1) + γ2t |∇f(xt−1)|2. (9.18)
Comme f est convexe, par l’Inegalite de Gradient
f(y) ≥ f(x) + (y − x)T∇f(x) ∀x, y ∈ Rn
nous obtenons :
(xt−1 − x∗)T∇f(xt−1) ≥ f(xt−1)− f(x∗) = f(xt−1)−min f.
Cette inegalite, combinee avec (9.18) resulte en
d2t ≤ d2t−1 − γt[2εt−1 − γt|∇f(xt−1)|2
], εs ≡ f(xs)−min f ≥ 0. (9.19)
Selon (9.13), nous avons
γt|∇f(xt−1)|2 ≤ 1
ε[f(xt−1)− f(xt)] =
1
ε[εt−1 − εt].
En combinant la derniere inegalite avec (9.19), nous obtenons
d2t ≤ d2t−1 − γt[(2− ε−1)εt−1 + ε−1εt
]. (9.20)

180CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
Comme, par notre hypothese de depart, 1/2 ≤ ε, et, clairement, εs ≥ 0, la quantite entre lesparentheses dans la partie droite est non negative. Nous savons aussi de (9.14) que
γt ≥ γ =2(1− ε)
ηLf,
ainsi par (9.20) nous obtenons
d2t ≤ d2t−1 − γ[(2 − ε−1)εt−1 + ε−1εt
]. (9.21)
On en deduit que(*) Les distances entre les points xt et un point (quelconque) x∗ ∈ X∗ n’augmentent pas
avec t. Et, en particulier, la trajectoire de la methode est bornee.
De (*) il en suit immediatement que {xt} converge vers un certain point x∗ ∈ X∗, commec’est affirme dans (i). En effet, par le Theoreme 9.1.1 la trajectoire, etant bornee, a tous sespoints limites dans l’ensemble X∗∗ de points critiques de f , ou, ce qui est identique (f estconvexe !), dans l’ensemble X∗ de minimiseurs globaux de f . Soit x∗ un de ces points limites,et montrons qu’en fait {xt} converge vers x∗. Pour cela notez que 0 est un point limite de lasuite non-croissante |xt − x∗| ; par consequent, la suite converge vers 0, de sorte que xt → x∗
quand t→ ∞.Il nous reste a verifier (9.16). En prenant la somme d’inegalites (9.21) entre t = 1 et
t = N , nous obtenons
Nγ[(2− ε−1)εt−1 + ε−1εt
] ≤ d20 − d2N ≤ d20 ≡ |x0 − x∗|2.Comme ε0 ≥ ε1 ≥ ε2 ≥ ... (notre methode est celle de descente – elle n’augmente jamais lesvaleurs de l’objectif !), le cote gauche dans la derniere inegalite ne sera que plus petit si nousremplacons tout les εt avec εN ; ainsi, nous avons
2NγεN ≤ |x0 − x∗|2. (9.22)
Et en substituant l’expression pour γ,
εN ≤ ηLf |x0 − x∗|24(1− ε)N
.
Comme cette derniere inegalite reste valide pour tout x∗ ∈ X∗, ceci implique (9.16).
Cas C1,1 fortement convexe. Dans la Proposition 9.1.2 nous traitons le cas de la fonctionf reguliere et convexe, mais on n’a fait aucune hypothese sur le conditionnement du minimum– le minimiseur pourrait etre non-unique, et le graphe de f pourrait etre tres “plat” autour deX∗. Sous condition supplementaire de convexite forte de f nous pouvons obtenir des resultatsde convergence bien meilleurs. Nous avons la definition suivante :
Definition 9.1.1 [Fonctions fortement convexes] Une fonction f : Rn → R s’appelle fortementconvexe avec les parametres (lf , Lf ) de convexite forte, 0 < lf ≤ Lf ≤ ∞, si f est continumentdifferentiable et satisfait les inegalites
f(x)+(y−x)T∇f(x)+ lf2|y−x|2 ≤ f(y) ≤ f(x)+(y−x)T∇f(x)+Lf
2|y−x|2, ∀x, y ∈ Rn. (9.23)
Dans l’optimisation “traditionnelle” les fonctions fortement convexes jouent le role des “bons”objectifs, et c’est la famille sur laquelle l’analyse theorique de convergence des methodes d’opti-misation habituellement est fait. Il est important de savoir comment detecter la convexite forte

9.1. DESCENTE DE GRADIENT 181
et quelles sont les proprietes fondamentales des fonctions fortement convexes ; c’est la tache quenous interesse maintenant.
La condition suffisant la plus utile plus de la convexite forte est donne par la propositionsuivante :
Proposition 9.1.3 [Critere de la convexite forte pour des fonctions deux fois continumentdifferentiables]Soit f : Rn → R une fonction deux fois continument differentiable, et soit (lf , Lf ), 0 < lf ≤Lf < ∞, deux reels donnes. f est fortement convexe avec les parametres lf , Lf si et seulementsi le spectre de la matrice d’Hessian de f en chaque point x ∈ Rn est contenu dans le segment[lf , Lf ] :
lf ≤ λmin(∇2f(x)) ≤ λmax(∇2f(x)) ≤ Lf ∀x ∈ Rn, (9.24)
ou λmin(A), λmax(A) est, respectivement, la plus petite et la plus grande valeur propre de lamatrice symetrique A and ∇2f(x) est l’Hessian (la matrice de derivees secondes) de f en x.
Exemple 9.1.1 La forme quadratique convexe
f(x) =1
2xTAx− bTx+ c,
A etant une matrice symetrique positive definie, est fortement convexe avec les parametres lf =λmin(A), Lf = λmax(A).
Voici les proprietes les plus importantes (pour nous) de fonctions fortement convexes :
Proposition 9.1.4 Soit f fortement convexe avec les parametres (lf , Lf ). Alors(i) Les ensembles de niveau {x | f(x) ≤ a} de f sont compactes pour tout reel a ;(ii) f attaint son minimum global sur Rn, et son minimiseur x∗ est unique ;(iii) ∇f(x) est Lipschitzien avec la constante de Lipschitz Lf .
Maintenant nous revenons a la Descente de Gradient. La proposition suivante indique quepour un f fortement convexe la methode converge lineairement :
Proposition 9.1.5 [Convergence lineaire de DAr applique a la fonction f fortement convexe]Soit une fonction f fortement convexe, avec les parametres (lf , Lf ). Pour minimiser f on utilisela methode DAr , initialisee en un certain point x0, et soit le parametre ε du test d’Armijo≥ 1/2. Alors, pour tout entier N ≥ 1, nous avons
|xN − x∗| ≤ θN |x0 − x∗|, θ =
√Qf − (2− ε−1)(1 − ε)η−1
Qf + (ε−1 − 1)η−1, (9.25)
ou x∗ est le minimiseur (unique, selon la Proposition 9.1.4.(ii)) de f et
Qf =Lf
lf(9.26)
est le conditionnement de f .De plus,
f(xN )−min f ≤ θ2NQf [f(x0)−min f ]. (9.27)
Ainsi, la methode possede une vitesse globale lineaire de convergence avec le taux θ (notez queθ ∈ (0, 1) grace a ε ∈ [1/2, 1)).

182CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
Preuve.10. Selon la Proposition 9.1.4, f est une fonction C1,1 convexe qui atteint son minimum, et legradient de f est Lipschitzien avec la constante Lf . En consequence, toutes les conclusionsde la preuve de la Proposition 9.1.2 sont valides, en particulier, la relation (9.20) :
d2t ≡ |xt−x∗|2 ≤ d2t−1− γ[(2 − ε−1)εt−1 + ε−1εt
], γ =
2(1− ε)
ηLf, εs = f(xs)−min f. (9.28)
En appliquant (9.23) au couple (x = x∗, y = xs), nous obtenons (car ∇f(x∗) = 0)
εs ≥ lf2|xs − x∗|2 =
lf2d2s;
ainsi, grace a (9.28),
d2t ≤ d2t−1 −γlf2
[(2− ε−1)d2t−1 + ε−1d2t
],
ou, en substituant l’expression pour γ,
d2t ≤ θ2d2t−1, (9.29)
avec θ donne par (9.25), d’ou (9.25).Il nous reste a prover (9.27). Pour cela il suffit de noter que, due a la premiere inegalite
dans (9.23), appliquee a x = x∗, y = x0, nous avons
|x0 − x∗|2 ≤ 2
lf[f(x0)− f(x∗)] =
2
lf[f(x0)−min f ], (9.30)
tandis que la seconde inegalite dans (9.23), appliquee a x = x∗, y = xN nous dit que
f(xN )−min f ≡ f(xN )− f(x∗) ≤ Lf
2|xN − x∗|2.
En consequence,
f(xN )−min f ≤ Lf
2|xN − x∗|2 ≤
[cf. (9.25)]
≤ Lf
2θ2N |x0 − x∗|2 ≤
[cf. (9.30)]
≤ Lf
lfθ2N [f(x0)−min f ],
comme requis dans (9.27).
Vitesse de convergence globale dans le cas C1,1 convexe : le resume. Les resultatsdonnes par Propositions 9.1.2 et 9.1.5 peuvent etre recapitules de facon suivante. Supposez quenous resolvons
f(x) → min
avec l’objectif C1,1 convexe (c.-a-d., ∇f(x) est un champ de vecteur Lipschitzien), tel que l’en-semble X∗ de minimiseurs globaux de f est non vide. Supposez de plus que pour minimiser fnous utilisons la methode DAr avec le parametre ε correctement choisi, a savoir, 1/2 ≤ ε < 1.Alors

9.1. DESCENTE DE GRADIENT 183
– A. Dans le cas general, ou on n’impose aucune convexite forte de f , la trajectoire {xt} de lamethode converge vers certain x∗ ∈ X∗, et les residus en termes d’objectif – les quantitesεn = f(xN )−min f – convergent vers zero au moins comme O(1/N). Autrement dit, nousavons l’estimation
εN ≤ ηLf dist2(x0,X
∗)4(1− ε)
1
N. (9.31)
Notez que– aucun resultat quantitatif sur la vitesse de convergence des distances |xn − x∗| ne peutetre donnee ; tout ce que nous savons, c’est que ces quantites convergent vers 0, mais laconvergence peut etre aussi lente qu’on veut. C.-a-d., etant donne une suite decroissantarbitraire {dt}, qui converge vers 0, on peut exhiber une fonction C1,1 convexe f sur leplan 2D tels que dist(x0, x
∗) = d0 et dist(xt, x∗) ≥ dt pour tout t ;
– l’estimation (9.31) donne un ordre correct de la vitesse convergence vers 0 des erreursen termes d’objectif : pour la fonction C1,1 convexe correctement choisie f sur le plan2D, on a
εN ≥ α
N, N = 1, 2, ...
avec un certain α positif.– B. Si f est fortement convexe avec les parametres (lf , Lf ), alors la methode converge
lineairement :
|xN − x∗| ≤ θN |x0 − x∗|, f(xN)−min f ≤ Qfθ2N [f(x0)−min f ],
θ =
√Qf − (2− ε−1)(1− ε)η−1
Qf + (ε−1 − 1)η−1, (9.32)
Qf = Lf/lf etant le conditionnement de f .Notez que le taux de convergence θ (ou θ2, selon la mesure de precision – la distance de l’iterationxt a l’ensemble optimal ou le residu f(xt)− f∗ en termes d’objectif – que nous employons) tendvers 1 quand le conditionnement du probleme tend vers l’infini (on dit, quand le probleme devientmal conditionne). Quand Qf est grand, nous avons,
θ ≈ 1− pQ−1f , p = (1− ε)η−1, (9.33)
de sorte que pour baisser la borne superieure (9.32) sur |x· − x∗| par un facteur constant, parexemple, par le facteur 10 (un chiffre supplementaire dans l’ecriture decimale de x∗), il nous fautO(Qf ) iterations de la methode. En d’autres termes, (9.32) nous dit que
(**) le nombre d’iterations de la methode ayant pour resultat le progres dans la precision donnea l’avance (c.-a-d., diminuer la distance initiale de l’ensemble optimal par un facteur donne, parexemple, 106), est proportionnel au conditionnement Qf de l’objectif.
Evidemment, cette conclusion est obtenue a partir de la boirne superieure de l’erreur ; il sepeut que nos bornes superieures “sous-estiment” la precision “reelle” de la methode. Il s’avere,pourtant, que nos bornes sont assez justes, et notre conclusion est valide :
le nombre d’iterations de la Descente de Gradient requis pour reduire l’erreurinitiale (mesuree comme distance de l’ensemble optimal ou comme residu en termesd’objectif) par un facteur donne est, en general, proportionnel au conditionnementde f .
Pour justifier cette affirmation, regardons ce qui se produit dans le cas de l’objectif quadra-tique.

184CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
Vitesse de convergence dans le cas quadratique
Nous considerons maintenant la Descente de Gradient appliquee au cas d’un objectif qua-dratique fortement convexe
f(x) =1
2xTAx− bTx+ c.
A etant une matrice symetrique positive definie. Comme nous le savons de l’exemple 9.1.1, fest fortement convexe avec les parametres lf = λmin(A), Lf = λmax(A) (les valeurs propresminimale et maximale de A, respectivement).
Il est plus facile d’etudier la Plus Rapide Descente, plutot que la descente d’Armijo (dans ledernier cas que nos considerations souffriraient de l’incertitude dans le choix de longueurs despas).
Nous avons les relations suivantes :– Le gradient de la fonction f est donne par la relation
g(x) ≡ ∇f(x) = Ax− b; (9.34)
en particulier, le minimiseur unique x∗ de f est donne par (la regle de Fermat)
Ax∗ = b. (9.35)
Notez aussi que, comme on le voit d’une ligne de calculs,
f(x) = E(x) + f(x∗), E(x) =1
2(x− x∗)TA(x− x∗); (9.36)
notez que E(·) n’est rien d’autre que l’erreur en termes d’objectif.– La trajectoire de la Plus Rapide Descente est donnee par la recurrence
xt+1 = xt − γt+1gt, gt ≡ g(xt) ≡ ∇f(xt) = Axt − b = A(xt − x∗), (9.37)
ou γt+1 est le minimiseur de la fonction quadratique fortement convexe φ(γ) = f(xt−γgt)de variable reelle γ. La solution de l’equation φ′(γ) = 0 est
γt+1 =gTt gtgTt Agt
; (9.38)
ainsi, (9.37) devient
xt+1 = xt − gTt gt
gTt Agtgt. (9.39)
– Les calculs explicites donnent 1)
E(xt+1) =
{1− (gTt gt)
2
[gTt Agt][gTt A
−1gt]
}E(xt). (9.40)
1. Voici ces calculs : comme φ(γ) est une forme quadratique convexe et γt+1 est son minimiseur, nous avons
φ(0) = φ(γt+1) +1
2γ2t+1φ
′′;
grace a l’origine de φ, nous obtenons φ′′ = gTt Agt, d’ou
E(xt)− E(xt+1) ≡ f(xt)− f(xt+1) ≡ φ(0)− φ(γt+1) =1
2γ2t+1[g
Tt Agt],
ou, due a (9.38),
E(xt)− E(xt+1) =(gTt gt)
2
2gTt Agt.
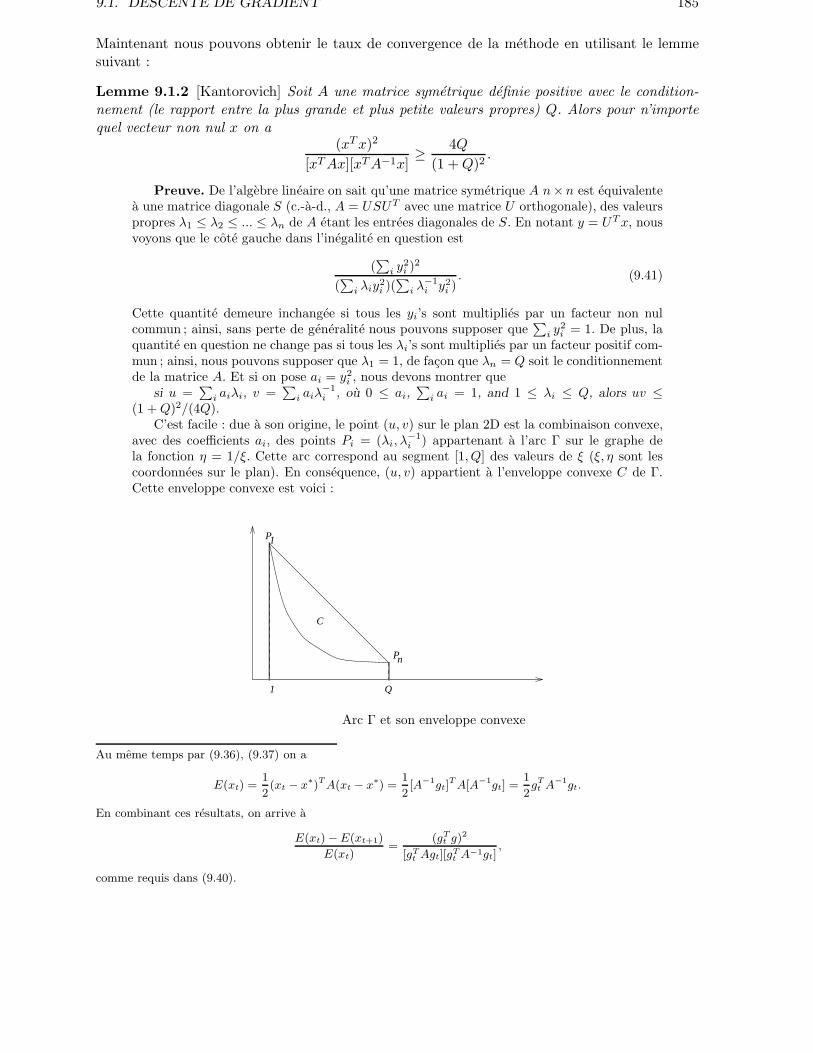
9.1. DESCENTE DE GRADIENT 185
Maintenant nous pouvons obtenir le taux de convergence de la methode en utilisant le lemmesuivant :
Lemme 9.1.2 [Kantorovich] Soit A une matrice symetrique definie positive avec le condition-nement (le rapport entre la plus grande et plus petite valeurs propres) Q. Alors pour n’importequel vecteur non nul x on a
(xTx)2
[xTAx][xTA−1x]≥ 4Q
(1 +Q)2.
Preuve. De l’algebre lineaire on sait qu’une matrice symetrique A n×n est equivalentea une matrice diagonale S (c.-a-d., A = USUT avec une matrice U orthogonale), des valeurspropres λ1 ≤ λ2 ≤ ... ≤ λn de A etant les entrees diagonales de S. En notant y = UTx, nousvoyons que le cote gauche dans l’inegalite en question est
(∑
i y2i )
2
(∑
i λiy2i )(
∑i λ
−1i y2i )
. (9.41)
Cette quantite demeure inchangee si tous les yi’s sont multiplies par un facteur non nulcommun ; ainsi, sans perte de generalite nous pouvons supposer que
∑i y
2i = 1. De plus, la
quantite en question ne change pas si tous les λi’s sont multiplies par un facteur positif com-mun ; ainsi, nous pouvons supposer que λ1 = 1, de facon que λn = Q soit le conditionnementde la matrice A. Et si on pose ai = y2i , nous devons montrer que
si u =∑
i aiλi, v =∑
i aiλ−1i , ou 0 ≤ ai,
∑i ai = 1, and 1 ≤ λi ≤ Q, alors uv ≤
(1 +Q)2/(4Q).C’est facile : due a son origine, le point (u, v) sur le plan 2D est la combinaison convexe,
avec des coefficients ai, des points Pi = (λi, λ−1i ) appartenant a l’arc Γ sur le graphe de
la fonction η = 1/ξ. Cette arc correspond au segment [1, Q] des valeurs de ξ (ξ, η sont lescoordonnees sur le plan). En consequence, (u, v) appartient a l’enveloppe convexe C de Γ.Cette enveloppe convexe est voici :
C
1 Q
P1
Pn
Arc Γ et son enveloppe convexe
Au meme temps par (9.36), (9.37) on a
E(xt) =1
2(xt − x∗)TA(xt − x∗) =
1
2[A−1gt]
TA[A−1gt] =1
2gTt A
−1gt.
En combinant ces resultats, on arrive a
E(xt)−E(xt+1)
E(xt)=
(gTt g)2
[gTt Agt][gTt A−1gt]
,
comme requis dans (9.40).

186CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
La plus grande, sur (u, v) ∈ C, valeur de produit uv correspond au cas quand (u, v)appartient au segment [P1, Pn] limitant C d’en haut, de sorte que
uv ≤ max0≤a≤1
[(a+ (1− a)Q)(a+1− a
Q)];
le maximum de l’expression sur le cote droit peut etre calcule explicitement (il correspond a
a = 1/2), sa valeur est (Q+ 1)2/(4Q).
En combinant le Lemme 9.1.2 et (9.40), nous venons au resultat suivant :
Proposition 9.1.6 [Taux de convergence pour la Plus Rapide Descente appliquee a la formequadratique fortement convexe]La methode de la Plus Rapide Descente, utilisee pour minimiser une forme quadratique fortementconvexe f avec le conditionnement Q, converge lineairement avec le taux de convergence au pire
1− 4Q
(Q+ 1)2=
(Q− 1
Q+ 1
)2
, (9.42)
notamment, pour tout N on a
f(xN )−min f ≤(Q− 1
Q+ 1
)2N
[f(x0)−min f ]. (9.43)
Notez que la proposition ci-dessus indique que le taux de convergence est au pire (Q− 1)2(Q+1)−2 ; le taux reel de convergence depend du point initial x0. Il se trouve que (9.43) donnela description correcte du taux de convergence : pour “presque tous” les points de depart, leprocessus converge en effet avec le taux proche de la borne superieure indiquee. Puisque le tauxde convergence donne par Proposition est 1 − O(1/Q) (cf. (9.33)), la conclusion quantitative(**) de la sous-section precedente est en effet valide, meme dans le cas f quadratique fortementconvexe.
Vitesse de convergence locale de la Plus Rapide Descente. La relation (9.43) est uneestimation non-asymptotique d’efficacite de la methode de la Plus Rapide Descente dans lecas quadratique. Dans le cas non-quadratique non-degenere la methode admet une estimationasymptotique d’efficacite semblable. C.-a-d. qu’on peut montrer le resultat suivant :
Theoreme 9.1.2 [Vitesse locale de convergence de la Plus Rapide Descente]Supposons que la trajectoire {xt} de la Plus Rapide Descente pour f converge vers un point x∗
qui est un minimiseur local non-degenere de f , c.-a-d., est tel que f est deux fois continumentdifferentiable dans un voisinage de x∗ et l’Hessian ∇2f(x∗) de l’objectif est definie positif en x∗.
Alors la trajectoire converge vers x∗ lineairement, et le taux de convergence de la suite f(xt)−f(x∗) des residus en termes d’objectif est au pire(
Q− 1
Q+ 1
)2
,
Q etant le conditionnement de ∇2f(x∗) :
(∀ε > 0 ∃Cε <∞) : f(xN )− f(x∗) ≤ Cε
(Q− 1
Q+ 1+ ε
)2N
, N = 1, 2, ... (9.44)

9.1. DESCENTE DE GRADIENT 187
9.1.5 Conclusions
Essayons de recapituler ce que nous avons appris sur la Descente de Gradient. Nous savonsque
– dans le cas general, sous les hypotheses assez faibles de regularite, PRD et DAr convergentvers l’ensemble des points critiques de l’objectif (voir le Theoreme 9.1.1), et il y a unecertaine vitesse garantie (sous-lineaire) de convergence globale en termes de quantites|∇f(xN )|2 (voir la Proposition 9.1.1) ;
– dans le cas convexe C1,1, DAr converge vers un minimiseur global de l’objectif (a condi-tion que un tel minimiseur existe), et il y une certaine vitesse garantie (sous-lineaire) deconvergence globale en termes d’erreur f(xN)−min f dans la valeur de l’objectif (voir laProposition 9.1.2) ;
– dans le cas fortement convexe, DAr converge vers le minimiseur unique de l’objectif, et lesdistances au minimiseur et les erreurs en termes d’objectif admettent les bornes superieuresglobales, qui convergent lineairement vers zero. Le taux de convergence correspondant estdonne par le conditionnement Q de l’objectif (voir la Proposition 9.1.5) et est du type1 − O(1/Q), de sorte que le nombre d’iteration necessaire pour diminuer l’erreur initialepar un facteur donne soit proportionnel aQ (c’est une borne superieure, mais generalementelle reflete le comportement reel de la methode) ;
– La methode PRD converge lineairement (globalement, dans le cas quadratique, et asymp-totiquement dans le cas non-quadratique) avec le taux de convergence 1 − O(1/Q), Qetant le conditionnement de l’Hessian de l’objectif en minimiseur vers lequel la methodeconverge (dans le cas quadratique, naturellement, cet Hessian est simplement la matricede notre forme quadratique).
C’est ce que nous savons. Quelles devraient etre des conclusions – est-ce une methode bonne oumauvaise ? Comme c’est d’habitude le cas dans l’optimisation numerique, nous ne sommes pascapable donner une reponse exacte : il y a trop de differents criteres a prendre en compte. Noussommes pourtant capable d’enumerer des avantages et des inconvenients de la methode. Unetelle liste nous fournit une sorte d’orientation : quand nous nous savons ce qui sont les pointsforts et faibles d’une methode d’optimisation, etant donnes une application particuliere qui nousinteresse, nous pouvons decider si “les points forts sont assez forts et les points faibles sont assezfaibles” dans le cas en question, ce qui doit nous permettre de choisir la solution mieux adaptee ala situation. En ce qui concerne la Descente de Gradient, les points forts evidents de la methodesont
– une large famille des problemes pour lesquels nous pouvons garantir la convergence globalevers un point critique (normalement - a un minimiseur local) de l’objectif ;
– simplicite d’une iteration de la methode : nous avons besoin d’une evaluation simple de ∇fet un nombre restreint d’evaluations de f (les evaluations de f sont exigees par la recherchelineaire ; si on emploie DAr avec la recherche lineaire simplifiee, decrite dans la Section8.2.4, ce nombre est en effet petit). Notez que chaque evaluation de f est accompagneepar d’un petit nombre (normalement, O(n), n etant la dimension du vecteur de decision)d’operations arithmetiques.
Le point de faible le plus important de la methode est sa vitesse relativement basse de conver-gence : meme dans le cas quadratique fortement convexe, la methode converge lineairement. Cen’est pas si mauvais en soit ; ce qui est en effet tres mauvais, est que le taux de convergence esttrop sensible au conditionnement Q de l’objectif. Comme nous le savons, le nombre d’iterationsde la methode, pour un progres donne sur la precision, est proportionnel a Q. Et c’est vraiment

188CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
trop mauvais, puisque dans les applications nous rencontrons souvent des problemes mal condi-tionnes, avec des conditionnements d’ordre des milliers et des millions ; et si c’est le cas, nousne pouvons attendre de rien de bon de la Descente de Gradient, au moins quand ces sont dessolutions de grande precision qui nous interessent.
Il est utile de comprendre la geometrie qui conditionne le ralentissement de la Descente deGradient dans le cas de l’objectif mal conditionne. Considerons le cas de f quadratique fortementconvexe. Les surfaces de niveau
Sδ = {x | f(x) = min f + δ}de f sont les ellipsoides homothetiques centres en minimiseur x∗ de f ; les carres des “demi-axes”de ces ellipsoides sont inversement proportionnelles aux valeurs propres de A = ∇2f . En effet,comme nous savons de (9.36),
f(x) =1
2(x− x∗)TA(x− x∗) + min f,
de sorte que en coordonnees orthogonales xi, associees a la base de vecteurs propres de A avecl’origine placee en x∗ nous avons
f(x) =1
2
∑i
λix2i +min f,
ou λi sont les valeurs propres de A. En consequence, l’equation de Sδ en coordonnees indiqueesest ∑
i
λix2i = 2δ.
Maintenant, si A est mal conditionnee, les ellipsoides Sδ deviennent un genre de “vallees” – ilssont relativement etroits dans certaines directions (ceux liees aux plus petites demi-axes d’ellip-soides) et relativement etendus dans d’autres directions (liees aux plus grandes demi-axes). Legradient – qui est orthogonal a la surface de niveau – sur la grande partie de cette surface regarde“presque a travers la vallee”, et puisque la vallee est etroite, les pas de la methode s’averent etretres courts. En consequence, la trajectoire de la methode est une sorte de mouvement en petitszigzags avec une lente tendance globale vers le minimiseur.
On doit souligner que dans ce cas le probleme lui-meme n’est pas intrinsequement mauvais ;toutes les difficultes viennent du fait que nous relions l’objectif aux coordonnees initiales malchoisies. Sous une transformation lineaire des coordonnees appropriee (passez de xi a yi =
√λixi)
l’objectif devient parfaitement conditionne – il devient la somme de carres des coordonnees,de sorte que le conditionnement soit egale a 1, et la Descente de Gradient, lancee dans cesnouvelles coordonnees, ira tout droit sur le minimiseur. Le probleme, naturellement, est que laDescente de Gradient est associe aux coordonnees Euclidiennes initiales, fixees une fois pourtoutes (puisque la notion fondamentale du gradient est une notion Euclidienne : les differentesstructures Euclidiennes ont comme consequence differents vecteurs de gradient de la memefonction au meme point). Si ces coordonnees initiales sont mal choisies pour un objectif f donne(de sorte que le conditionnement de f dans ces coordonnees soit grand), la Descente de Gradientsera lente, bien que si nous etions assez intelligents pour executer d’abord une mis a echelleapproprie – une transformation non-orthogonale lineaire des coordonnees – et lancer ensuite laDescente de Gradient dans ces nouvelles coordonnees, on aurait obtenu une convergence rapide.Dans le prochain chapitre nous considererons la celebre Methode de Newton qui, dans un sens,n’est rien d’autre une Descente de Gradient, “mise a echelle localement” de facon optimale, avecl’echelle qui varie de une iteration a l’autre.

9.2. METHODE DE NEWTON 189
9.2 Methode de Newton
On continu l’etude de methodes de minimisation sans contraintes pour le probleme
f(x) → min | x ∈ Rn.
Ce qui est a notre ordre du jour est la celebre Methode de Newton basee sur le modele quadra-tique local de f . Pour pouvoir parler de ce modele, nous supposons dorenavant que f est deuxfois continument differentiable.
9.2.1 Version “de base” de la methode de Newton
L’idee de la methode est tres simple, nous l’avons deja employe cette idee dans le cas uni-varie (Chapitre 8). Etant donne la valeur f(x), le gradient ∇f(x) et la matrice d’Hessian∇2f(x) de l’objectif en iteration courante x, nous rapprochons f dans le voisinage de x parson developpement de Taylor de second ordre :
f(y) ≈ f(x) + (y − x)T∇f(x) + 1
2(y − x)T [∇2f(x)](y − x)
et prenons en tant que prochaine iteration le minimiseur en y de la forme quadratique a droite.Pour obtenir ce minimiseur, nous derivons la forme en y et mettons le gradient a 0, ce qui nousdonne l’equation pour y :
[∇2f(x)](y − x) = −∇f(x).C’est un systeme lineaire par rapport a y ; en supposant que la matrice du systeme (l’Hessian∇2f(x)) est inversible, nous pouvons ecrire la solution comme
y = x− [∇2f(x)]−1∇f(x).Dans la version “de base” de methode de Newton, on applique cette simple iteration :
Algorithme 9.2.1 [Methode de Newton] Etant donne le point de depart x0, faire
xt = xt−1 − [∇2f(xt−1)]−1∇f(xt−1). (9.45)
La methode ci-dessus n’est pas necessairement bien definie (par exemple, que faire quand l’Hes-sian en xt−1 est singulier ?) Nous adresserons cette difficulte, ainsi que plusieurs autres problemeslies a la methode, plus tard. Notre but en ce moment est d’etablir le resultat fondamental surla methode – sa convergence locale quadratique dans le cas non-degenere :
Theoreme 9.2.1 [Convergence Locale Quadratique de la methode de Newton dans le cas non-degenere ]Supposons que f est trois fois continument differentiable dans un voisinage de x∗ ∈ Rn, et quex∗ est un minimiseur local non-degenere de f , c.-a-d., ∇f(x∗) = 0 et la matrice ∇2f(x∗) estdefinie positive. Alors la methode de Newton, etant lancee “assez pres de x∗”, converge vers x∗
quadratiquement.
Preuve : Soit U un voisinage convexe de x∗ ou les derives partiels du troisieme ordre de f (c.-a-d., les derives partiels du second degre des composants de ∇f) sont bornees. Par consequent,dans ce voisinage,
| − ∇f(y)−∇2f(y)(x∗ − y)| ≡ |∇f(x∗)−∇f(y)−∇2f(y)(x∗ − y)| ≤ β1|y − x∗|2 (9.46)

190CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
avec un certain β1 (nous avons utilise la borne superieure standard pour du reste dudeveloppement de Taylor d’ordre 1 pour les composants de ∇f : si g(·) est une fonction scalaireavec les derivees secondes bornees dans U , alors
|g(x) − g(y) −∇g(y)(x− y)| ≤ β|y − x|2
pour un certain β <∞ 2) et tout x, y ∈ U).Puisque ∇2f(x∗) est non singuliere et ∇2f(x) est continu en x = x∗, il existe un (plus petit)
voisinage U ′ ⊂ U de x∗, qu’on supposera une boule centre en x∗ du rayon r > 0, tel que
y ∈ U ′ ⇒ |[∇2f(y)]−1| ≤ β2 (9.47)
pour un certain constant beta2. Ici et dans ce qui suit, on note |A| la norme d’operateur de lamatrice A :
|A| = max|h|≤1
|Ah|,
les normes a droite etant les normes Euclidiennes sur les espaces vectoriels correspondants.Supposez maintenant qu’un certain point xt de la trajectoire de la methode de Newton pour
f soit assez proche de x∗, c.-a-d. est tel que
xt ∈ U ′′, U ′′ = {x | |x− x∗| ≤ ρ ≡ min[1
2β1β2, r]}. (9.48)
Nous avons|xt+1 − x∗| = |xt − x∗ − [∇2f(xt)]
−1∇f(xt)| == |[∇2f(xt)]
−1[∇2f(xt)(xt − x∗)−∇f(xt)
]| ≤ |[∇2f(xt)]
−1|| − ∇f(xt)−∇2f(xt)(x∗ − xt)| ≤
[by (9.47) and (9.46)]≤ β1β2|xt − x∗|2.
Ainsi, on arrive a
xt ∈ U ′′ ⇒ |xt+1 − x∗| ≤ β1β2|xt − x∗|2 [≤ (β1β2|xt − x∗|)|xt − x∗| ≤ 0.5|xt − x∗|] . (9.49)
On observe que la nouvelle iteration xt+1 est au moins deux fois plus proche de x∗ que xt et,par consequent, xt+1 ∈ U ′′. Ainsi, une fois le voisinage U ′′ atteint (ceci se produit surement sila trajectoire est commencee dans U ′′), la trajectoire ne quite jamais ce voisinage de x∗, et
|xt+1 − x∗| ≤ β1β2|xt − x∗|2 ≤ 0.5|xt − x∗|, t ≥ t,
de sorte que la trajectoire converge vers x∗ quadratiquement.Le theoreme ci-dessus etablit la convergence rapide – quadratique – locale de la methode
de Newton vers un minimizer local non-degenere de f , ce qui est tres bien. En meme temps,nous nous rappelons du Chapitre 8 que meme dans le cas univarie et pour l’objectif convexeet regulier, la methode de Newton peut diverger si le point initial n’est pas “assez” pres duminimiseur. On en conclue que nous ne pouvons pas compter sur cette methode sous sa formepresente dans des calculs reels – ainsi comment pourrions nous savoir que le point de departest “assez pres” du minimiseur ? Nous voyons que certaines modifications sont necessaires pourrendre la methode globalement convergeante.
2. notez que β est de l’ordre de l’amplitude des derivees secondes de g dans U

9.3. EXERCICES 191
9.3 Exercices
Exercice 9.1 Montrez que dans la Plus Rapide Descente les directions des deux mouvementssuccessifs quelconques sont mutuellement orthogonales. Derivez de ceci que dans le cas 2D toutesles directions des pas paires sont colineaires, et ceux des pas impaires sont egalement colineaires.
Exercice 9.2 Ecrivez le code mettant en oeuvre DAr (ou PRD , selon votre choix) et l’appliquezaux problemes suivants :
– Probleme de Rosenbrock
f(x) = 100(x2 − x21)2 + (1− x1)
2 → min | x = (x1, x2) ∈ R2,
avec le point initial x0 = (−1.2, 1).Le probleme de Rosenbrock est un exemple bien connu de test : son point critique uniqueest x∗ = (1, 1) (le minimizer global de f) ; les courbes de niveau de la fonction sont lesvallees en forme de banane, et la fonction est non convexe et plutot mal conditionnee
– Probleme Quadratique de
fα(x) = x21 + αx22 → min | x = (x1, x2) ∈ R2.
Testez les valeur suivants de α :
10−1; 10−4; 10−6
et pour chaque valeur testez les points de depart
(1, 1); (√α, 1); (α, 1).
Combien de temps prend de diviser l’erreur initiale sur en termes de l’objectif par le facteurde 10 ?
– Probleme Quadratique
f(x) =1
2xTAx− bTx, x ∈ R4,
avec
A =
⎛⎜⎜⎝0.78 −0.02 −0.12 −0.14−0.02 0.86 −0.04 0.06−0.12 −0.04 0.72 −0.08−0.14 0.06 −0.08 0.74
⎞⎟⎟⎠ , b =
⎛⎜⎜⎝0.760.081.120.68
⎞⎟⎟⎠ , x0 = 0.
Lancez la methode jusque’a ce que la norme du gradient sur l’iteration courante soit ≤10−6. Est-ce que la convergence est rapide ?Ceux qui emploient MATLAB ou SCILAB peuvent calculer le spectre de A et comparer laborne superieure theorique sur la vitesse de convergence avec la vitesse observee.
– Experimentations avec la matrice de Hilbert. Soit H(n) la matrice n× n de Hilbert :
(H(n))ij =1
i+ j − 1, i, j = 1, ..., n.
C’est une matrice symetrique definie positive (car xTH(n)x =∫ 10 (
∑ni=1 xit
i−1)2dt ≥ 0,l’inegalite etant stricte pour x �= 0).Pour n = 2, 3, 4, 5 realiser les experiences suivants :

192CHAPITRE 9. METHODEDE DESCENTEDEGRADIENT ETMETHODEDE NEWTON
– choisissez un vecteur non nul x∗ de dimension n, par exemple, x∗ = (1, ..., 1)T ;– calculez b = H(n)x∗ ;– appliquent votre code de Descente de Gradient a la fonction quadratique
f(x) =1
2xTH(n)x− bTx,
avec le point initial x0 = 0. Notez que x∗ est le minimizer unique de f .– Terminez la methode quand vous obtenez |xn − x∗| ≤ 10−4, ne lui permettant pas, de
toute facon, de faire plus de 104 iterations.Quels sont vos conclusions ?Ceux qui emploient MATLAB ou SCILAB peuvent essayer de calculer le conditionnement dematrices de Hilbert en question.
Si vous utilisez la methode DAr , jouez avec les parametres ε et η de la methode pour obtenir lameilleure convergence.