!bd**2!:! desbdàbd - myuuu.frmyuuu.fr/cours/mbds/immersionbdetinfostructure/mbdsbigdata2013… ·...
TRANSCRIPT

Bases de Données et BIG DATA(BD2
BD**2 : Des BD à BD
(des Bases de Données à BIG DATA)
) :
« De BIG Brother à …BIG DATA »
Pr Serge Miranda Directeur Master MBDS (www.mbds-‐fr.org)
Conférence MBDS 2013 Big Data 2013 Pr Serge Miranda, Univ de
Nice Sophia AnHpolis

World is changing :
Tiepolo (Un Nouveau Monde; Venise) Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

« Big » DATA ?
• • IDC 2012 : 1.8 Ze;a octets – 10**24 ont été produits en 2011 (50% de croissance par an)
• Big data doesn’t look like it’s just an IT trend, either. Gartner forecasts 4.4m IT jobs will be created globally by 2015 to support big data.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

VOLUME : Exa-‐octets /seconde! • « Entre les débuts de la
culture humaine et 2003, l’humanité a produit 5 exa-‐octets (10**18; 1000 peta) d’informaYon Aujourd’hui nous produisons autant d’informaYon tous les 2 jours » – Eric Schmidt (CEO de Google), Davos 2010
• En 2013 : chaque 10
minutes ! • En 2015 chaque 10
secondes (UC BERKELEY report, 2013), en 2020…
(UC BERKELEY Study)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

De -‐300 ans à 2013 !
• Bibliothèque d’Alexandrie : – tout le savoir Humain !
• Chaque terrien 2013 aurait (en moyenne) 300 fois la collecHon de ceee bibliothèque! – 1200 EXAOCTETS – 5 piles de CD de la Terre à la Lune (VIKT2013)
• En 2000 : ¼ des infos du monde étaient numérisées – Doublement tous les ans – En 2013 : 98%!

VOLUME BIG DATA ? Chaque Seconde en 2012 sur
Internet: • 300 000 requêtes sur Google (3 millions de mails par sec; 10 sites créés par sec)
• 300 000 SMS • 50 000 Mails échangés • 3000 visites sur Facebook ( 1 milliard « d’amis ») • > 1 heure de video sur YOUTUBE (hébergement d’1,5 milliard de videos) • 4000 tweets (140 M/jour) • 20 Applicafons smartphones téléchargées • 2 CV postés sur Linkedin (188 Millions de CV)…et
….. • 1 usurpafon d’idenfté
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

« DATAFICATION » (mise en donnée numérique; géoloc) ? • CORRELATION (Comment?) >> CAUSALITE (Pourquoi ?) ! – GOOGLE et l’algorithme de la grippe (NATURE, 2009)
• 1 milliard de recherches Google par jour analysées aux USA
– PrévenHon des incendies à New York • Pb des immeubles en sous locaHon et vétustes • Moins de risques sur ceux qui ont eu un ravalement !
• « COURTIER de données » (Acxiom, Experian,…)

EvoluHon société ? • « La vie des sociétés dans lesquelles règne le mode de produc9on…
s’annonce comme une immense accumulaYon de marchandises » – Karl Marx Le Capital (1867) – RévoluHon industrielle
• « …comme une immense accumulaYon de SPECTACLES » – Guy Debord (1967) – (images, TV, Top Down/BROADCAST) – UHlisateur PASSIF
• « …comme une Immense accumulaYon d’ INFORMATIONS temps réel » – Réseaux sociaux, NFC et Big Data – BOTTOM UP/Narrowcast – UHlisateur InteracHf et proacHf

Plan • DATA ecosystem (Mobiquitous informaHon systems; Social network) • BIG DATA
– OPEN DATA, – LINKED DATA (Web Séman9que), – WEB DATA
• DATA SYSTEMS – SQL (et ODMG) – NO SQL
• Hadoop (Ex en Annexe du MBDS2012) – NEW SQL
• Stonebraker (2011) • Oracle BIG DATA for the enterprise • Microsoq BIG DATA • IBM, Teradata …
• RESEARCH Areas • References
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

« DATA » roots/key words? 1) « DATA X » :
– DATA base (19/8/1968 : Ted Codd et Modèle RelaYonnel), DBMS • DATA bank
– DATA warehouse (ETL/DATA Pumping, ..) • DATA mart • DATA mining (OLAP, CorrélaHons, ..), Data AnalyHcs, DATA Pumping
– DATA Systems (« SQL », « NO SQL », « NEW SQL » en 2011) – DATA mash up – DATA SCIENCE
2) « Y DATA »: -‐ Linked DATA, Web DATA (DBpedia, Web SémanHque) -‐ Meta DATA -‐ Open DATA
è BIG Data (« Data Science » + « Data Business »)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

VOLUME le début d’un « tsunami DATA »
• Vers le YOTTA De Données
– 20 petaoctets (10**15) de données traitées chaque jour sur Google (20 fois contenu BNF!) • Datawarehouse de WALMART et BD …. De la CIA
– (IDC) 35 zeea octets dans le monde numérique en 2020 – 1000 Milliards d’objets tagués en 2020 (1 tera) – Ambifon NSA (Service Renseignement USA) : analyse simultanée d’un yo;aoctet (10**32) è Vers 10**99 = « Google »>
• Les nouveaux réseaux communautaires spacio temporels TEMPS REEL ++ – d’entreprises (« Zero mail » chez Atos et Bluekiwi en 2012, Microsoq et) – Entre individus (PATH, PAIR , Google+,..) – SANTE, TRANSPORT, TOURISME,…
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Un nouvel ESPACE DATA
• « Déluge » de DATA – – BOTTOM UP – – TEMP REEL (2.0, Tags, ..) – – Non structurées (linked data) – Gouvernement (Open Data) ….
– è « DATA DELUGE SCIENCE…massively interdisciplinary coopera9on…towards a global approach for interoperability « G.Glinos, EC 2012
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

UN NOUVEAU MONDE mobiquitaire !
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
« Futur mobiquitaire » et « Écosystème endogène du Smartphone » (de la producHon d’info à la consommaHon d’info)
En 2011, plus d’abonnements au mobile que d’habitants sur la planète 2015 : La moiHé de la planète aura un smartphone (50% NFC) 1000 Milliards d’objets tagués en 2020 USERWARE Instagram (Photo),..
MOBIQUITE : MOBIlité et ubiQUITE

Le Futur n’est plus ce qu’il était ! • « WEB ?
– au cube » • DATA WEB + Capteurs + TAGS
– « SOLOMO » (SOcial-‐LOcal-‐MObile)
• Déferlante /Déluge BOTTOM UP (crowdsourcing, ..) – Approches communautaires 2.0 « dynamiques, géolocalisées, contextuelles, temporelles » : tourisme, transport, santé,…
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
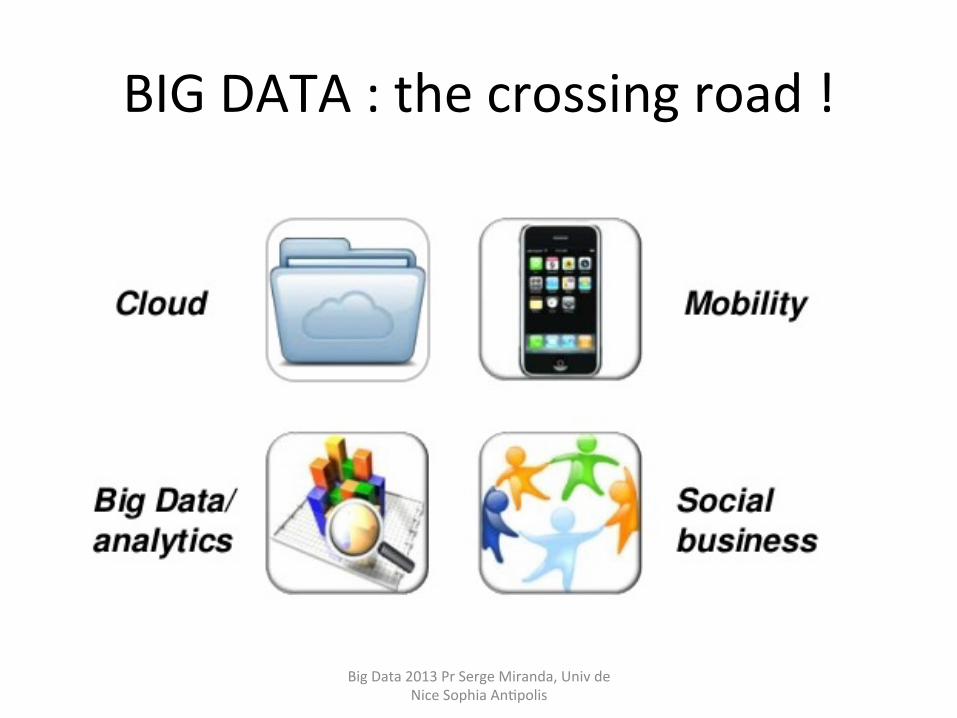
BIG DATA : the crossing road !
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

BIG DATA ?
• « BIG DATA Refers to data sets whose size is beyond the capabiliYes of the current DB (SQL) technology »
• C. Thanos , April 2012, Ercim News
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

BIG DATA (Wikipedia) • Big data (« grosse donnée » ou données massives) est une expression
anglophone u9lisée pour désigner des ensembles de données qui deviennent tellement volumineux qu'ils en deviennent difficiles à travailler avec des ou9ls classiques de ges9on de base de données. Dans ces nouveaux ordres de grandeur, la capture, le stockage, la recherche, le partage, l'analyse et la visualisa9on des données doivent être redéfinis. Les perspec9ves du traitement des big data sont énormes, notamment pour l'analyse d'opinions ou de tendances industrielles, la génomique, l'épidémiologie ou la luQe contre la criminalité ou la sécurité2.
• Le phénomène Big data est considéré comme l'un des grands défis informaYques de la décennie 2010-‐2020. Il engendre une dynamique importante tant par l'administra9on3, que par les spécialistes sur le terrain des technologies ou des usages4.
• OuHl adapté : Graph Databases (en), framework : MapReduce ou Hadoop et systèmes de gesHon de bases de données comme BigTable.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

BIG DATA : Les 3 « V » de M. Stonebraker (2011) et les 4V De
Popescu (Variability) • « Il y a beaucoup de bruit autour du Big Data. Ce concept a
plusieurs significa9ons en fonc9on du type de personnes. Selon moi, la meilleure façon de considérer le Big Data est de penser au concept de trois V. Big Data peut être synonyme de gros Volume. Du teraoctet au petaoctet. Il peut également signifier la rapidité [Velocity] de traitement de flux con9nus de données. Enfin, la troisième significa9on : vous avez à manipuler une grande Variété de données, de sources hétérogènes. Vous avez à intégrer entre mille et deux mille sources de données différentes et l’opéra9on est un calvaire. La vérité est que le Big Data a bien trois significa9ons et que les éditeurs n’en abordent qu’une à la fois. Il est important de connaître leur posi9onnement pour leur poser les bonnes ques9ons.”
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

BIG DATA and « 4V »
• VOLUME : Massively distributed architecture required to store data – EX : Google, Amazon, Facebook,… with 10 to 100 K servers
• VELOCITY (real Hme)with Extreme query Workload – Indicators >> Precise answers
• Variety – Unstructured data (linked data RDF, Open data,..) – Semi structured data (XML)
• Variability – Schema EVOLUTION (flexibility, ..)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

DefiniHon BIG DATA by IDC : 5th V !
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

2012
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
Google* indexe 20 milliards de pages par jour pour répondre à 3,3 milliards de requêtes quo9diennes . Google, c’est aussi 425 millions d’u9lisateurs de sa messagerie Gmail, disposant chacun d’un espace de stockage de 10 Go, soit 4,25 « Eo ». Google compte 250 millions de membres sur le réseau social Google+. YouTube recense 800 millions d’u9lisateurs qui passent 4 milliards d’heures à regarder des vidéos chaque mois Les u9lisateurs de youtube envoient 72 heures de vidéos par minute pour 1,3 milliard de vidéos hébergées en tout.
*GOOGLE vient du chiffre mathémaYque 1 suivi de 100 Zeros

VARIETY du « BIG » Data [FERM2012] • WEB DATA : réseaux sociaux (TWITTER, FB, Instagram, ..),
– e-‐commerce, indexaHon, stockage de photos (Instagram), de vidéos, linked data, etc. – ex: Google traitait 24 petaoctets de données par jour avec MapReduce en 2009)
• OPEN DATA données publiques (open data). • LINKED DATA (Web Sémanfque) • MOBIQUITOUS /TAGGED OBJECT DATA : Internet et objets communicants: RFID,
NFC, réseaux de capteurs,
journaux des appels en téléphonie; • Données des sciences: génomique, astronomie, physique subatomique
– ex: le CERN annonce produire 15 petaoctets de données par an avec le LHC climatologie – ex: le centre de recherche allemand sur le climat gère une base de données de 60
petaoctets… • données commerciales
– ex: historique des transacHons dans une chaîne d’hypermarchés • données personnelles
– ex: dossiers médicaux;
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Besoins mobiquitaires
• OLTP/OLCP Temps Réel – Géolocalisafon (ContextualisaHon, Temporalité) – Réseaux sociaux spacio –temporels temps réel (électeurs, spectateurs, ..)
• Approche décisionnelle/OLTP temps réel (DATA ANALYTICS) BOTTOM UP – Jeux, MarkeHng, CommunicaHon – Réseaux sociaux (Twieer, Facebook,..) – TAGS NFC, …
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Infographie BIG DATA (Dec 2012)
• hep://www.siliconrepublic.com/strategy/item /30640-‐the-‐future-‐of-‐big-‐data-‐inf
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

WEB et rêve de Laplace !
• « Le Web con9ent une descrip9on exhaus9ve du monde passé et présent » Julien Laugel (MFG Labs)
• Rêve de LAPLACE – « Une enYté connaitra parfaitement l’état du monde passé et présent pour prévoir son évoluYon »
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Grands Domaines d’applicafon BIG DATA et Projets du MBDS 2012-‐2015:
du moteur de recherche au moteur de LA recherche
• GénéHque (découverte de 4 gènes liés au cancer du foie,..) • médecine (neurosciences : localisaHon migraine,…) • Epidémies, Pandémies, Catastrophes (Ex SANDY en Oct
2012 avec cartographie inondaHons via analyse tweets) • Climatologie, Astronomie • Océanographie (Expert planton, méduses,..)Chimie • LinguisHque, Macro-‐Economie • Transport (Projet VAMP) • Cartographie temps réel AIDE SOCIALE (Projet FIRST Inde) • COMMERCE, TOURISME (Projet MATRIUM, REVE,
IMAJEANS); – Projet CITY WALLET avec Nice, Vitoria (Espagne) et Bruxelles
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Recherche scienHfique AVANT Big Data
• PROBLEME – Etat de l’art
• INTUITION • VALIDATION par Expérience, simulaHon, calculs,…
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Recherche scienHfique avec BIG DATA
• Analyse informaHque de BIG DATA – IdenHficaHon de CORRELATIONS nouvelles
• Générateur d ’ hypothèses – Émergence de DECOUVERTES (avec ou pas expérimentaHons)
• SCIENCE demain ? – Mise en relief de corrélaHons – Recherche de modèles expliquant les corrélaHons
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
GeneraHons Share Differently
• 1930-50’s era generation – Focus on society – Friendships are forged through adversity
• 1960-70’s era generation – Focus on community – Friendships forged through identification with a cause
• 1980-90’s era generation – Focus on the individual – Friendships forged through individual goal accomplishment
• 2000’s era generation – Focus on common interests and SHARING
– Des rapports de FORCE aux rapports de FLUX (Joel de Rosnay 2012 “SURFER LA VIE”)
– Friendships are created or thrive virtually…
IOGDC Open Data Tutorial

BIG DATA et « Village TERRE »!
• « D’une distance de 6 à une distance de 2 » (UC BERKELEY) – « Expert » (financier, médecin, professeur, guide,..) + « ExperHse » (Data AnalyHcs) !
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

EX1 : Big data et Neurosciences
• Projet BrainScanr de Jessica et Bradley VOYTEK – Analyse de 3,5 millions d’arHcles en neurosciences – Carte de « proximité staHsHque » entre termes neuroscienHfiques
• Générateur automaHque d’hypothèses – Proximité entre « sérotonine » et « migraine » (2943 arHcles) – Proximité entre « striatum » (région cerveau) et « migraine » (4782 arHcles)
» è RéorientaHon des travaux de recherche !
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Ex2: BIG DATA et psycho-‐linguisHque
• « Emergence des mots chez le bébé ? » • Deb ROY du MIT a enregistré et filmé son propre bébé pendant 3 ans (jour et nuit !) – (90 000H de video et 140 000 H audio) – <200 teraoctets> – 70 Millions de mots prononcés
• Approche d’analyse psycho linguisfque d’assimilafon et d’évolufon du langage chez l’être humain (et modèle contextuel) !
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

« Profil numérique et BIG DATA »
Exemple: MOODMeter !

MOOC ? (Massively Open Online Courses)
• Concept né en 2008 • Mise en Oeuvre à l’été 2011 à l Université de Stanford aux USA avec une approche pédagogique essenHellement portée sur le contenu de l’enseignement diffusé – 1 cours gra9uit en Intelligence Ar9ficielle a été suivi par 160 000 étudiants (finalisé par 23 000)
• Andrew Ng l’un des pionniers, le MOOC répond à une problémaHque simple « La demande dans le monde est bien trop grande et notre société est incapable de construire assez d’universités pour y répondre ».

MOOC, Mobiquité et BIG DATA
• Retour temps réel pour professeurs sur ATTENTION des étudiants (eye tracking, émofons, ..)
• Retour temps réel sur exercices • Retour temps réel sur Intérêt des cours (au dela de l évaluafon… finale)
• Echanges 2.0 entre étudiants

vers les M200C !
M2OOC : Mobiquitous
MOOC

Autres Exemples BIG DATA • Déforestafon : projet PlanetarySKIN (7 tera de données satellites)
• Suivi astronomique en direct : Projet LSST (30 Tera chaque nuit)
• Micro-‐organismes marins: Projet GOS (2 teraoctets) • Bio Chimie sur 100 millions de molécules : Projet BSrC • Cancer du foie :projet ICGC (200 teraoctets) analyse des BD sur 25000 tumeurs de 5O types de cancers
• Détecfon épidémies en temps réel : Projet Healthmap (1 teraoctets) : Suivi progression cholera en HaiH avec 2 semaines d’avance (cholera, grippe, dengue, ..)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

OPEN DATA
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Open Data (Wikipedia)
• « Une donnée ouverte (en anglais open data) est une informa9on publique brute, qui a voca9on à être librement accessible et réu9lisable. La philosophie pra9que de l'open data préconise une libre disponibilité pour tous et chacun, sans restric9on de copyright, brevets ou d'autres mécanismes de contrôle. »
• Big Data 2013 Pr Serge Miranda, Univ de
Nice Sophia AnHpolis

Les données ouvertes dans le ‘Web des données’ (Wikipedia)
• Les principaux problèmes de l'exploita9on des données ouvertes sont de l'ordre
technique car les données en masse ne peuvent pas être traitées humainement. Le concept de Web des données appliqué aux données ouvertes met en œuvre 3 mécanismes :
– permeQre l'existence de la donnée sur le réseau à travers une URI unique(cela inclut les URL). – diminuer le coût de transforma9on de la données en apportant des formats standards lisible
par les machines (comme avec RDF,RDFa ou les Microdonnée dans le HTML5) ; – améliorer la qualité de la donnée pour éviter qu'un traitement de mise à disposi9on ne puisse
les altérer. Un entrepôt de données même avec des erreurs est préférable qu'un entrepôt biaisé. Ainsi, des mécanisme pour la fréquence et l’automa9sa9on des mises à jour de la donnée par les producteurs des données est possible avec un service SPARQL sur ces données.
• Les données ouvertes ne sont pas contrôlables par leurs producteurs (contrôle des
mises à jours) et réellement exploitables par d'autres qu'à la condi9on d'u9liser ces 3 mécanismes.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

What Makes DATA “OPEN”? Data Open
• Open Format – The US Government through the Open Government DirecHve (hep://www.whitehouse.gov/omb/assets/memoranda_2010/m10-‐06.pdf ) defines an open format as “one that is pla�orm independent, machine readable, and made available to the public without restricHons that would impede the re-‐use of that informaHon.”
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

OPEN (DATA) FORMAT ?
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
What Forman
• Example Open Formats: – PDF for documents (but not data) – CSV for data (Excel) – Web standards for publishing, sharing or linking
• HTML, XML, RDF
– Web standards for syndicaHon • RSS, Atom, JSON
IOGDC Open Data Tutorial

Links to OPEN DATA community
– W3C eGovernment Interest Group • hep://www.w3.org/egov/wiki/Main_Page
– Open Data InnovaHon Network on LinkedIn • hep://bit.ly/ODNetwork
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
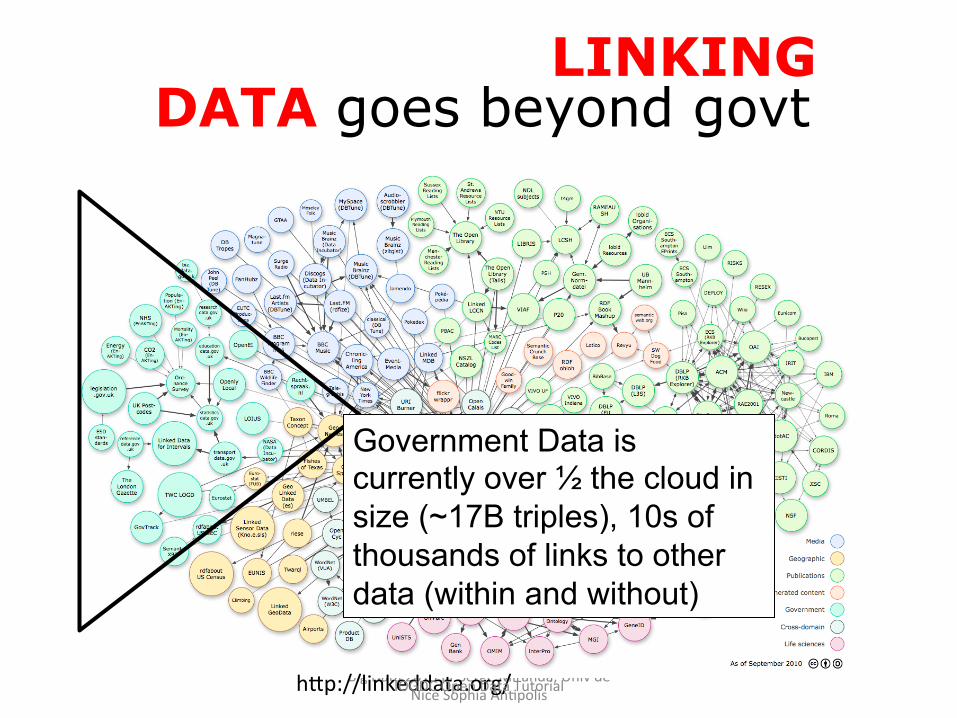
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
“Linking” Data LINKING DATA goes beyond govt
hep://linkeddata.org/
Government Data is currently over ½ the cloud in size (~17B triples), 10s of thousands of links to other data (within and without)
IOGDC Open Data Tutorial

« 5 star » LINKED OPEN DATA
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
En 2010, Tim Berners-‐Lee a donné une échelle de qualité des données ouvertes qui va de zéro à 5 étoiles.

Data analyfcs
• AnalyHcs based on over 1,000,000 datasets from around the world can be seen at – hep://logd.tw.rpi.edu/iogds_data_analyHcs
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

(Open) Linked DATA/ Semanfc WEB
• Variante Open Data issue du Web Séman9que : Open Linked Data
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Tim Berners-‐Lee, (Weaving the Web, 2001) on “SEMANTIC WEB”
“I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web — the content, links, and transac9ons between people and computers. A “Seman9c Web”, which should make this possible, has yet to emerge, but when it does, the day-‐to-‐day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The “intelligent agents” people have touted for ages will finally materialize”
Big Data 2013 Pr Serge Miranda, Univ de
Nice Sophia AnHpolis

« WEB SémanYque » du W3C hep://www.w3.org/2001/sw/
• Le Web séman9que est un mouvement collabora9f mené par le World Wide Web Consor9um(W3C) 1 qui favorise des méthodes communes pour échanger des données.
• Le Web séman9que vise à aider l'émergence de nouvelles connaissances en s'appuyant sur les connaissances déjà présentes sur Internet. Pour y parvenir, le Web séman9que met en œuvre le Web des données qui consiste à lier et structurer l'informa9on sur Internet pour accéder simplement à la connaissance qu'elle con9ent déjà2.
• Selon le W3C, « le Web séman9que fournit un framework qui permet aux données d'être partagées et réu9lisées entres plusieurs applica9ons, entreprises et groupes d'u9lisateurs ».2
• Le Web séman9que propose des langages spécialement conçus pour les données : le RDF (Resource Descrip9on Framework), le OWL(Web Ontology Language), et le XML (eXtensible Markup Language). HTML décrit les documents et les liens entre eux. RDF, OWL, et XML, en revanche, peuvent décrire également des choses, comme des personnes, des réunions, ou des pièces d'avion.< WIKIPEDIA>
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

WEB SEMANTIQUE ?
• è Un Modele de Données ! – un FORMAT Commun (Structures des données)
• Des idenHfiants universels de ressources du Web (URI/URL)
• Un Format unique : RDF • Un schéma : RDF
– Un langage de Manipulafon • SPARQL • OWL
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

« Linked DATA » , RDF format and SPARQL [BENE2006] To make data machine processable : -‐ Unambiguous names for resources (that may also bind data to real world objects): URIs (URL) -‐ common data structures to access, connect, describe the resources: RDF (Resource Descripfon Framework) -‐ Access to that data: SPARQL -‐ Define common vocabularies: RDFS, OWL, SKOS -‐ Reasoning logics: OWL, Rules
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

RDF (2008) • Defined by W3C January 15th, 2008
– Info representaHon in the WWW – Inherits XML Syntax – Exploits URI to idenHfy Resources
• An RDF graph is a set of triples to describe WEB resources – RDF/XML is the W3C recommendaHon – Simple triple: <subject predicate object>
• (cf Minsky et linguisYque sur triplet <Sujet><Verbe> <Complément>)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

RDFS (RDF Schema)
• To specify vocabularies in RDF – Classes/subclasses – Resources – Range – Domain
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Sparql : SQL-‐like syntax • SPARQL queries for RDF graphs
• PREFIX dc: hep://purl.org/dc/elements/1.1/ <URI abrégé> SELECT ?ftle WHERE { <h;p://example.org/book/book1> dc:ftle ?ftle } <
liste des triplets> FROM Name of the RDF graph Note : Jena is a Java framework for building Seman9c Web applica9ons; provides an environment for RDF, RDFS and OWL, SPARQL and includes a rule-‐ based inference engine
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

< http://fr.wikipedia.org/wiki/Bill_Gates > Sujet < http://www.w3.org/pim/contact#mailbox> Prédicat
« [email protected] » Objet
Exemple RDF [MAEV2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia
Antipolis

• Langage d’interrogation, ajout, modiSication et suppression de données RDF.
• Exemple : Quels sont les Auteurs français nés en 1900 ?
Exemple SPARQL [MAEV2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia
Antipolis
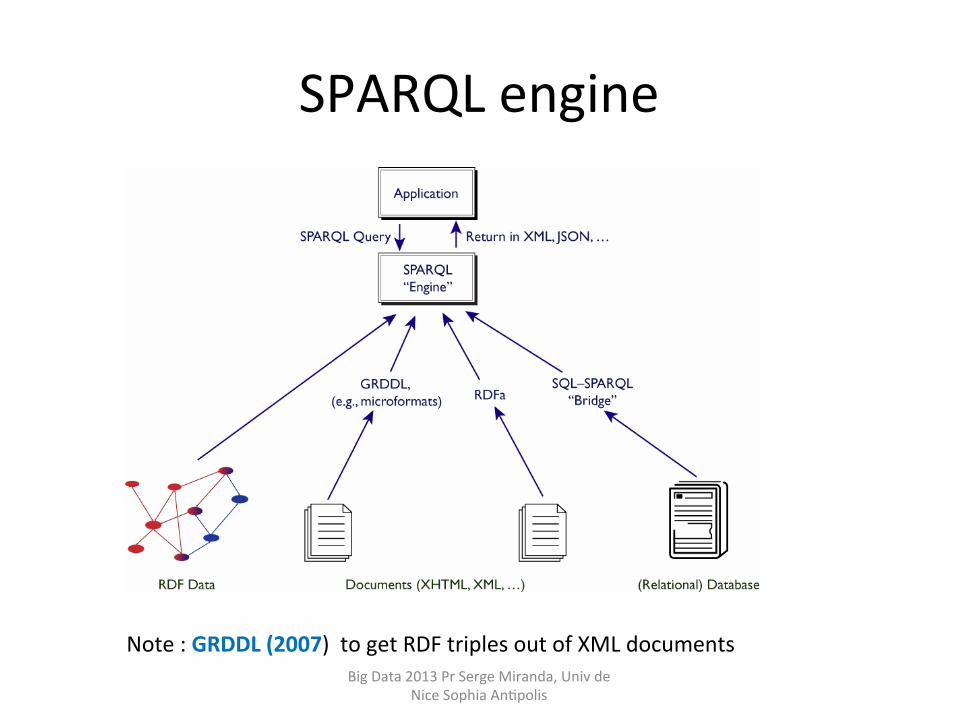
SPARQL engine
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
Note : GRDDL (2007) to get RDF triples out of XML documents

OWL (Ontology Web Language)
• Declarafve logic-‐based language based on RDF – Programs (reasoners) to
• Verify consistency of knowledge • Discover implicit knowledge
– OWL Object properHes
• SemanHc inherent approach with resasoning capability
• Appropriate for DATA Exchange (protocols) – Cf [ALIMI2012] to model the SE of Global Pla�orm
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

DATA WEB (web de données)
• livre de David Wood ¨Linking Government Data¨ en 2011: – le Web des données est passé de quelques 40 millions de triplets RDF au sein de quatre entrepôts de données en 2007
à – 203 entrepôts avec plus de 25 milliards de triplets avec 395 millions de liens à la fin 2010.
Big Data 2013 Pr Serge Miranda, Univ de
Nice Sophia AnHpolis

EX : Dataset GOVtrack (USA)
• GovTrack provides SPARQL access to data on the U.S. Congress -‐ Contains over 13,000,000 triples about legislators, bills, and votes
-‐ h;p://www.govtrack.us/
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

EX (GovTrack) : Find Senate bills that either John McCain or Barack Obama sponsored and the other cosponsored
[CORNO2008] PREFIX bill: <hep://www.rdfabout.com/rdf/schema/usbill/> PREFIX dc: <hep://purl.org/dc/elements/1.1/> foaf: <hep://xmlns.com/foaf/0.1/> SELECT ?Htle ?sponsor ?status WHERE { { ?bill bill:sponsor ?mccain ; bill:cosponsor ?obama . } UNION { ?bill bill:sponsor ?obama ; bill:cosponsor ?mccain . } ?bill a bill:SenateBill ; bill:status ?status ; bill:sponsor ?sponsor ; dc:Htle ?Htle . ?obama foaf:name "Barack Obama" . ?mccain foaf:name "John McCain" .}
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Dataset « DBPEDIA » ? • DBPEDIA : Données extraites de Wikipedia sous forme RDF • DBPedia is an RDF version of informafon from Wikipedia which : -‐ Contains data derived from Wikipedia’s
infoboxes, category hierarchy, arHcle, abstracts, and various external links -‐ Contains over 130 million triples
-‐ Dataset: h;p://dbpedia.org/
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

DBPEDIA [GAND2012] Projets 2012 [GAND2012]):
– Dataliq.org (ANR) – Kolflow (ANR) – pluggable to any RDF store (SparQL1.1) – ERWAN (visualisafon de données RDF/XML) – Mobile DB PEDIA ? è Tourisme mobiquitaire et guide temps réel
Moteur KGRAM/Corese en Open Source • VERROUS ? -‐ Modeles pour meta données ? -‐ Architectures logicielles ouvertes (stockage, acces,..)
• fr.dbpedia.org/sparql
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

DATA SYSTEMS for BIG DATA
SQL (SQL2/SQL3) • NO SQL (NOT ONLY SQL) • NEWSQL
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
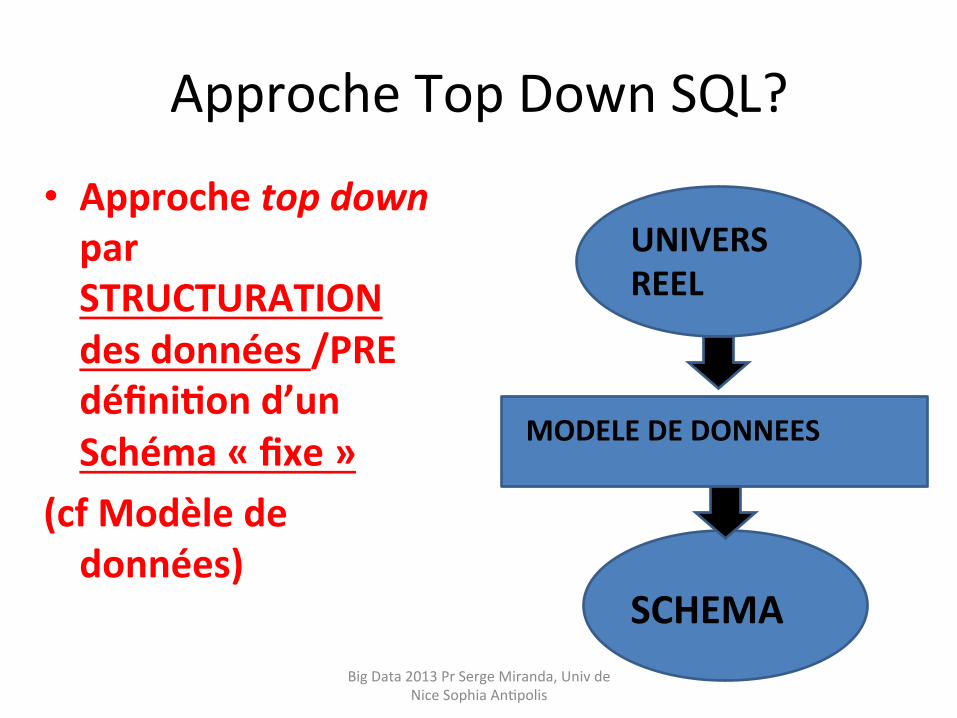
Approche Top Down SQL?
• Approche top down par STRUCTURATION des données /PRE définifon d’un Schéma « fixe »
(cf Modèle de données)
UNIVERS REEL
MODELE DE DONNEES
SCHEMA Big Data 2013 Pr Serge Miranda, Univ de
Nice Sophia AnHpolis

Approche Top DOWN SQL (données Structurées)
• 3 phases pour mise en place BD SQL : – 1) CONCEPTION (UML,..) puis – 2) Schéma (figé) puis – 3) CREATION BD
• SQL (SQL3) ou ODMG • ApplicaHons TRANSACTIONNELLES (OLTP)
– Propriétés TIPS – Propriétés ACID
• ApplicaHons décisionnelles (OLCP) top down – DATAWAREHOUSE – DATA MINING
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Rappels Modèle de données « relaHonnel » (de CODD) support SQL • « Modèle relafonnel de CODD » – è Prérequis à SQL2
• « Modèle OR de Chris Date » (3rd manifesto) – è Prérequis à SQL3 et ODMG
• Modèle de Codd (19/8/1968) – DOMAINES – RELATIONS
• Aeributs/CP/CE • Double définiHon formelle
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Apports des BD SQL2 et SQL3
• Propriétés « TIPS » de l’approche BD SQL – TransacHons, – Interface non procédurale (SQL), – Persistance, – StructuraHon (SCHEMA)
• « T » : « TRANSACTIONS » – Propriétés « ACID » : Atomicité, Cohérence, IsolaHon, Durabilité – OLTP (On line Transac9on Processing)
• Data Warehouse/data Mining (et OLCP : On Line Complex Processing)
è Approche TOP DOWN
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Marché BD SQL et standards OR ? (Stonebraker 96 et Gartner)
SGBD- R SGBD-OR
Traitements
SQL
Non SQL
(1) (2)
SGF SGBD- OO (3)
(1) : 10 G$ <licences *> en 2010 (20 % de croissance, 60 G $ en 2020) (3) : 1/100 de (1) en 2010 et 2020 (2) : 2x (3) en 2010 ; 2*(1) en 2020 ! * Marché de 27 G dollars avec services et support en 2010
SQL2 G/P/D SQL3 /Mobiquité
ODMG /CAO
Simples Complexes Données
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Une dichotomie « data system »BIG DATA /SQL ou une intégrafon ?
• SQL/ DATA BASE MANAGEMENT SYSTEMS (DBMS) et TIPS – Données structurées (Tables, Objets, ) : Schéma et modèle Objet RelaHonnel – Approche TOP DOWN – ApplicaHons transacHonnelles avec cohérence ACID et Propriétés TIPS – Schema fixe et données structurées – Systèmes centralisés et SCALABILITE VERTICALE (Serveur ++ et transacHonnel ACID) – Interface SQL avec réponses précises – Gesfon/PRODUCTION/DECISION (Datawarehouse)
• Standards SQL3/0DMG (See [ORACLE12] )
• NO SQL (Not Only SQL) – Données non structurées (accessibles sur le WEB par URL,..) – Approche BOTTOM UP – Systèmes réparfs et SCALABILITE HORIZONTALE (10K + Servers ) – Schema VARIABLE ou pas de Schéma et données non structurées (TEXT), semi-‐structurées (XML) ou liées
(RDF) – ApplicaHons DECISIONNELLES avec Données temps réel et SCALABILITE HORIZONTALE (Propriétés BASE et
Thèorème CAP) – InterrogaHon par machine avec indicaHons de réponses et ONTOLOGIES – Collaborafon/PARTAGE communautaire/CARTOGRAPHIE TEMPS REEL
• Standards (Linked data : RDF, SPARQL, OWL,…)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Les 4 « V » de Popescu pour BIG DATA [POPE2012]
Alex Popescu, (comme Forrester Research), enrichit les 3 V de Stonebraker pour définir BIG DATA :
-‐ Volume: les données dépassent les limites de la scalabilité verHcale des ouHls classiques, nécessitant des soluHons de stockage distribués et des ouHls de traitement parallèles. -‐ Variété: les données sont hétérogènes ce qui rend leur intégraHon complexe et coûteuse. -‐ Vélocité: les données doivent être traitées et analysées rapidement eu égard à la vitesse de leur capture. -‐ Variabilité: le format (Schéma) et le sens des données peut varier au fil du temps.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Propriétés « BASE » transacHonnelles de Big Data
• BASE : – Basically – Available – Scalability – Eventually consistent
• Replica consistency; Cross Node Consistency • CAP Theorem
– Consistency, SQL – Availability, – Parffoning NO SQL
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

•
Données « COMPLEXES » : SQL3, NO SQL et NEWSQL? (MIRA2013)
SGBD-OR SQL
Traitements
SQL
Non SQL
SGBD- OO
SQL3
ODMG
Complexes Structurées Top Down
Complexes Non Structurées
Temps Réel Bottom Up BIG DATA
Données
NO SQL
NEW SQL
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

12
Une approche non SQL permeeant la gesHon de données de type BIG DATA cf 4 « V » de POPESCU
NO SQL (Not Only SQL)
(1998)
+
VARIABILITE
+
VOLUME
+
VELOCITE
+
VARIETE
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

NO SQL et les leaders du Web (logiciels Open Source)
• Google – MapReduce et BigTable,
• Yahoo! – Hadoop, S4,
• Amazon – Dynamo, S3,
• Facebook – Cassandra, Hive,
• Twieer : Storm, FlockDB, • LinkedIn : Ka�a, SenseiDB, Voldemort, etc.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

FondaHon APACHE
• Hadoop, • Lucene/Solr, • Hbase, Hive, Pig, Cassandra, Mahout, Zookeeper, S4, Storm, Ka�a, Flume, Hama, Giraph
• Start ups autour de Hadoop en 2012 : Cloudera (76M$ levés), Hortonworks (~20M$), Datameer (12M$), ZeQaset, Drawntoscale,…
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Types de SGBD « NO SQL » • Les bases NoSQL visent à passer à l’échelle (SCALABILITY)
de manière horizontale en relâchant les condi9ons fortes de transac9onnalité (ACID ) aQendues des bases SQL (BASE), et en renonçant au modèle rela9onnel.
• 4 types de base NoSQL: – Clé-‐valeur (ex: Hadoop, Cassandra, ..) < table de hachage> – “Orientées colonne” (Ex : BigTable”,..) < stockage par COLONNES pas par lignes>
– “Orientées document” (ex: CouchDB, MongoDB,..) • DOC = record; Pas de schéma; Ensemble de CLE-‐VALEUR;
– Graphe (ex: Neo4j) pour réseaux sociaux. • Nœuds/liens/propriétés; pas d opérateurs ensemblistes mais parcours de graphes
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

NO SQL/ Data Systems [Noel2011]
“Platonic architecture of a DATA SYSTEM” ? • 1) “BATCH LAYER” : HADOOP (arbitrary computaHons, horizontal scalability, map reducHon,..)
• 2) “SPEED LAYER” :
– RIAK, CASSANDRA (NO SQL DB), MONGO DB (NO SQL), H-‐BASE (incremental algorithms, subset of big data,..) :
Conclusion : one store both for operafonal data and analyfcs, REAL TIME in the pocket
Big Data 2013 Pr Serge Miranda, Univ de
Nice Sophia AnHpolis

MAP REDUCE et HADOOP
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

MAP REDUCE (Google 2004) • MapReduce est à l’origine une technique de programmaHon connue de longue date en programmaHon foncHonnelle, mais surtout un framework développé par Google pour le CALCUL DISTRIBUE
• implémentafons en open source: – Hadoop (Yahoo! puis Fondafon Apache), – Disco (Nokia), MrJob (Yelp!), etc.
• Autres implémenta9ons de MapReduce intégrées dans les bases de données No SQL: CouchDB, MongoDB, Riak, …
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
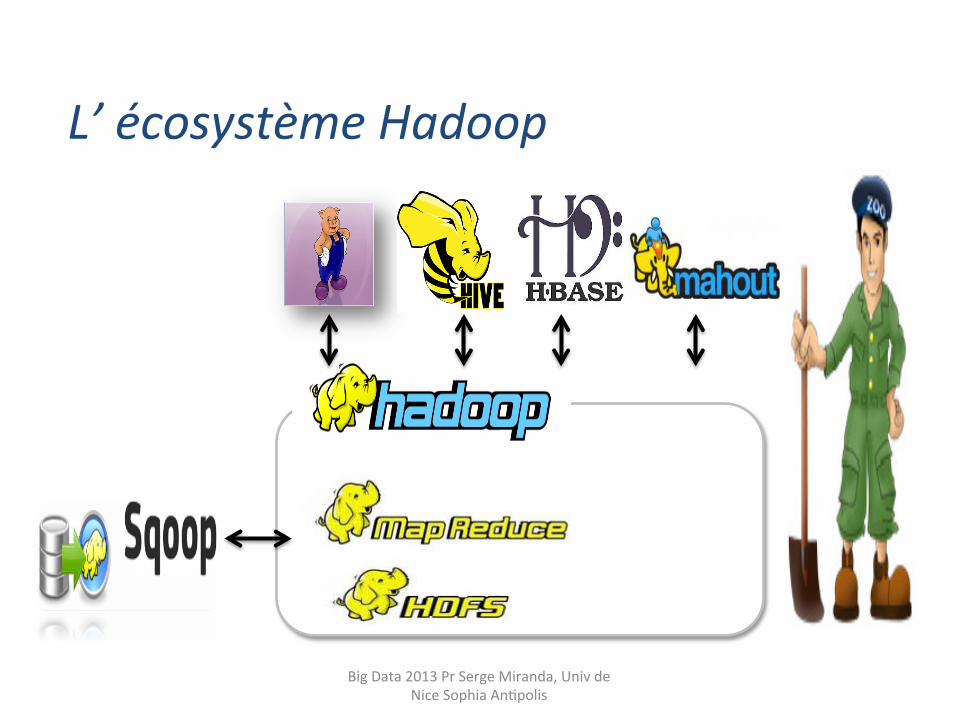
L’ écosystème Hadoop
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

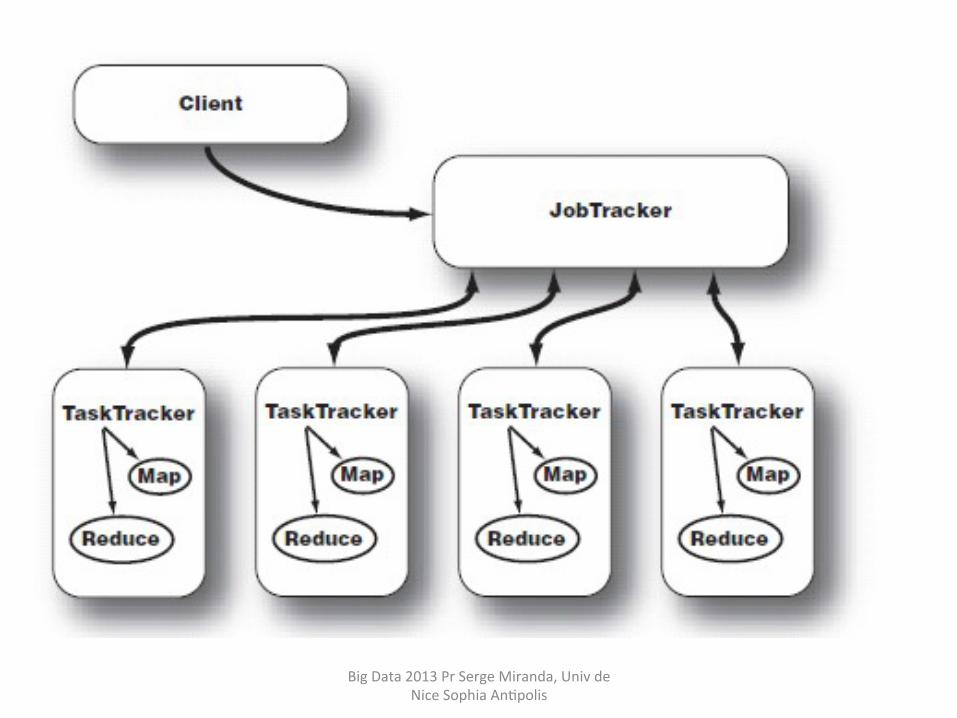
§ Son rôle consiste à diviser le traitement en 2 étapes :
Map : étape d’ingesHon et de transformaHon des données sous la forme de paires clé/valeur
Reduce : étape de fusion des enregistrements par clé pour former le résultat final.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Résumé MAP REDUCE Les différentes étapes du traitement vont donc être:
-‐ Découper les données d'entrée (« spli�ng ») en « morceaux » parallélisables
-‐ Mapper chacun des « morceaux » pour produire des valeurs associées à des clefs.
-‐ Grouper (« shuffling ») ces couples clef-‐valeur par clef.
-‐ Réduire (Reduce) les groupes indexés par clef en une forme finale, avec une valeur pour chaque clef.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
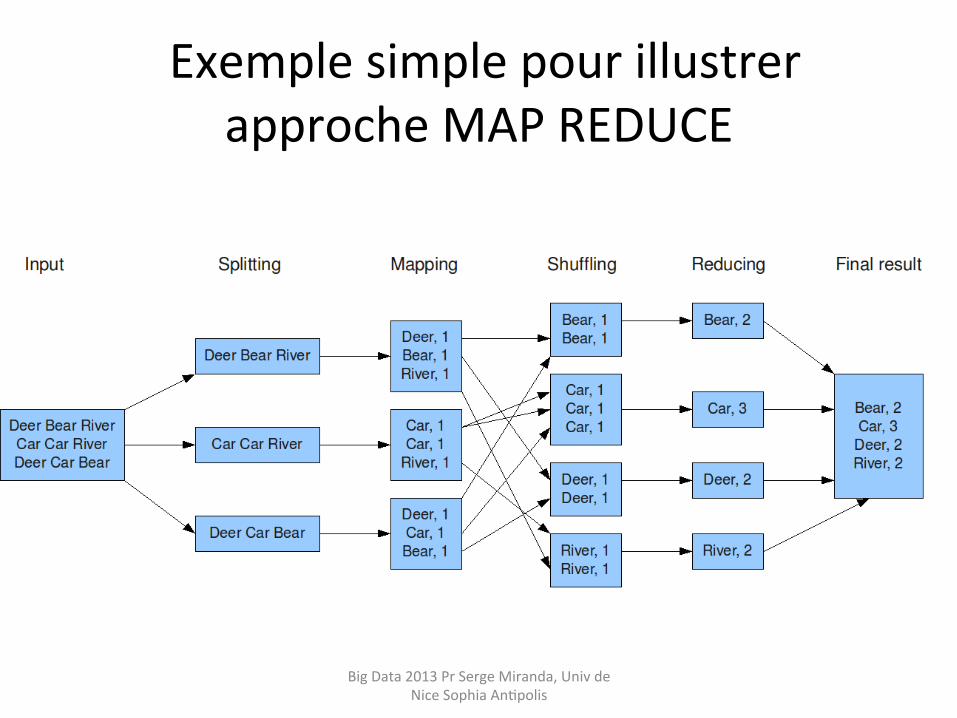
Exemple simple pour illustrer approche MAP REDUCE
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

• Enfin, il nous rester à programmer notre opérafon REDUCE, qui va recevoir la liste des groupes construits après l'opérafon MAP.
• Dans notre cas, l'opérafon REDUCE va simplement consister à – addifonner les valeurs associées à chaque clef – comme nous avons associé une valeur de « 1 » à chaque présence d'un mot dans MAP
– è cela nous donnera à terme le nombre d’occurrences des mots du texte.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

NEW SQL ?
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

« From NO SQL to NEW SQL »
• “Replacing real SQL ACID with either no ACID or “ACID lite” just pushes consistency problems into the applica9ons where they are far harder to solve. Second, the absence of SQL makes queries a lot of work”
• M.Stonebraker
• Avec HADOOP, l administrateur est …L u9lisateur !
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Verrous MeHssage
• Systèmes amphibiens :Passerelles entre SGBD/Datawarehouse TOP DOWN (SQL) et décisionnel/analyHcs BOTTOM UP (NOSQL) – MainHen ACID approche SQL – Interface SQL++ (Complexité cachée) – MainHen Performances boQom up et scalabilité approches NOSQL
– è « NEW SQL »
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

« From NO SQL to NEW SQL » [RICH2012] ([STON2011]
• “NEW SQL” (on top of SQL) : – VoltDB de Stonebraker – MYSQL – Scale DB, – NimbusDB, – (open Source, in memory RDB), – Clustrix, – + TERADATA BIG DATA, Oracle BIG DATA, Microso� BIG DATA, IBM Big Data…
• “Future is polyglot persistence” Big Data 2013 Pr Serge Miranda, Univ de
Nice Sophia AnHpolis

VOLTDB (Stonebraker 2011) • www.voldtb.com : Designed by DBMS pioneer Mike Stonebraker
for organiza9ons that have reached the price/performance limita9ons of general purpose SQL databases, VoltDB is a NewSQL database that combines the proven power of rela9onal processing with blazing speed, linear scalability and uncompromising fault tolerance. VoltDB is the ideal solu9on for high velocity database applica9ons that require 100% accuracy and real-‐9me analy9cs.
• JUIN 2012 : VOLTDB Processes 686 000 TransacYon par seconde sur Cloud Amazon
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

CTO de Teradata Stephen Brobst (Oct 2012)
• « Désormais, vous pouvez bénéficier de la puissance de MapReduce et de la facilité d’usage de SQL ,…
• Avant, avec Hadoop, les seules personnes capables d’extraire des données étaient celles qui les avaient placées »
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Big Data Teradata • « Unified Data Architecture », avec
– intégraHon Hadoop. • – système de fichiers HDFS (Hadoop Distributed File System), au moyen du langage de requêtage SQL, un langage très familier dans le monde des bases de données.
• – HCatalog, un framework de métadonnées Open Source développé par Hortonworks,
• et SQL-‐H, qui permet d’analyser des données stockées sur un filesystem HDFS en uHlisant SQL.
– ASTER, propriété de Teradata, avait inventé et breveté SQL-‐MapReduce, qui greffe à SQL des
foncHonnalités de MapReduce. – L’appliance Teradata-‐Aster Big Analyfcs
• plus de 50 applicaHons analyHques pré-‐intégrées. • 15 petabytes de données, réparHes entre les deux bases,
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

NEW SQL (ORACLE and BIG DATA)
Oct 2011
•
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
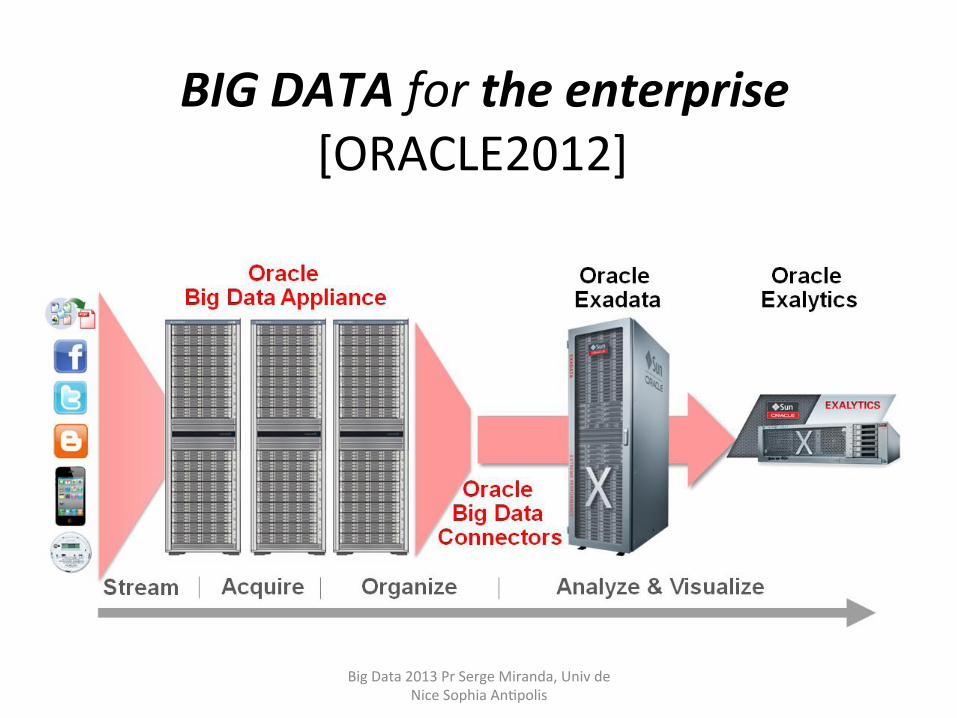
BIG DATA for the enterprise [ORACLE2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Oracle BIG DATA for enterprise • HADOOP and ORACLE
– Apache Hadoop allows large data volumes to be organized and processed while keeping the data on the original data storage cluster.
– Hadoop Distributed File System (HDFS) is the long-‐term storage system for web logs for example. These web logs are turned into browsing behavior (sessions) by running MapReduce programs on the cluster and generaHng aggregated results on the same cluster.
These aggregated results are then loaded into a Relafonal DBMS system.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Oracle SoluHon Spectrum • Many new technologies have emerged to address the IT infrastructure
requirements outlined above. • At last count, there were over 120 open source key-‐value databases for
acquiring and storing big data, with Hadoop emerging as the primary system for organizing big data and relafonal databases expanding their reach into less structured data sets to analyze big data. These new systems have created a divided solufons spectrum comprised of: – Not Only SQL (NoSQL) soluHons: developer-‐centric specialized systems – SQL soluHons: the world typically equated with the manageability, security
and trusted nature of relaHonal database management systems (RDBMS)
• NoSQL systems are designed to capture all data without categorizing and parsing it upon entry into the system, and therefore the data is highly varied.
• SQL systems, on the other hand, typically place data in well-‐defined structures and impose metadata on the data captured to ensure consistency and validate data types.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
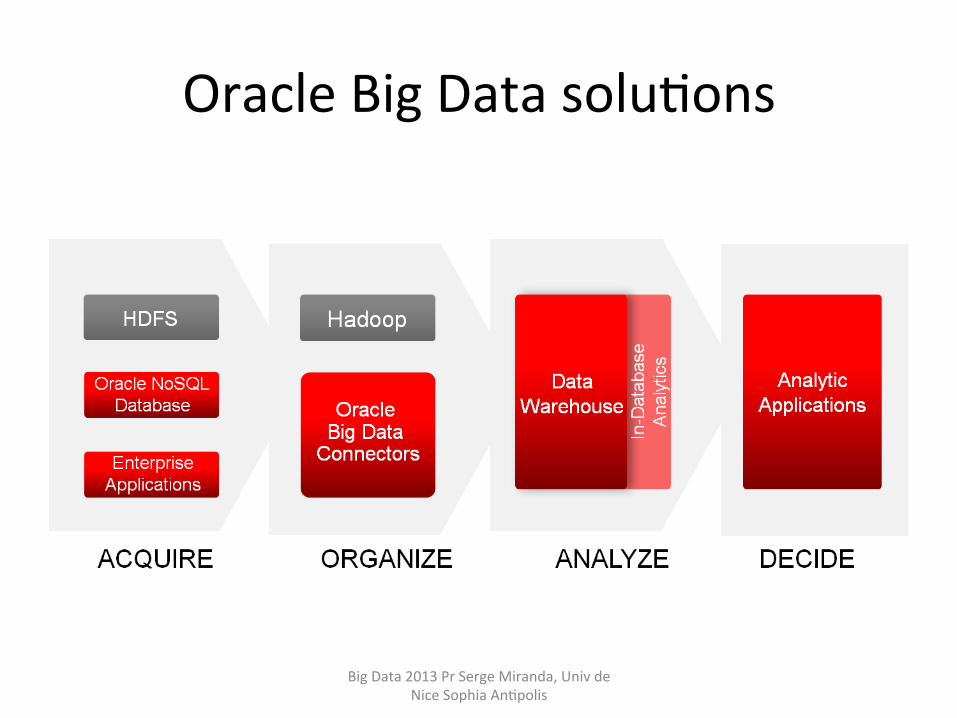
Oracle Big Data soluHons
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
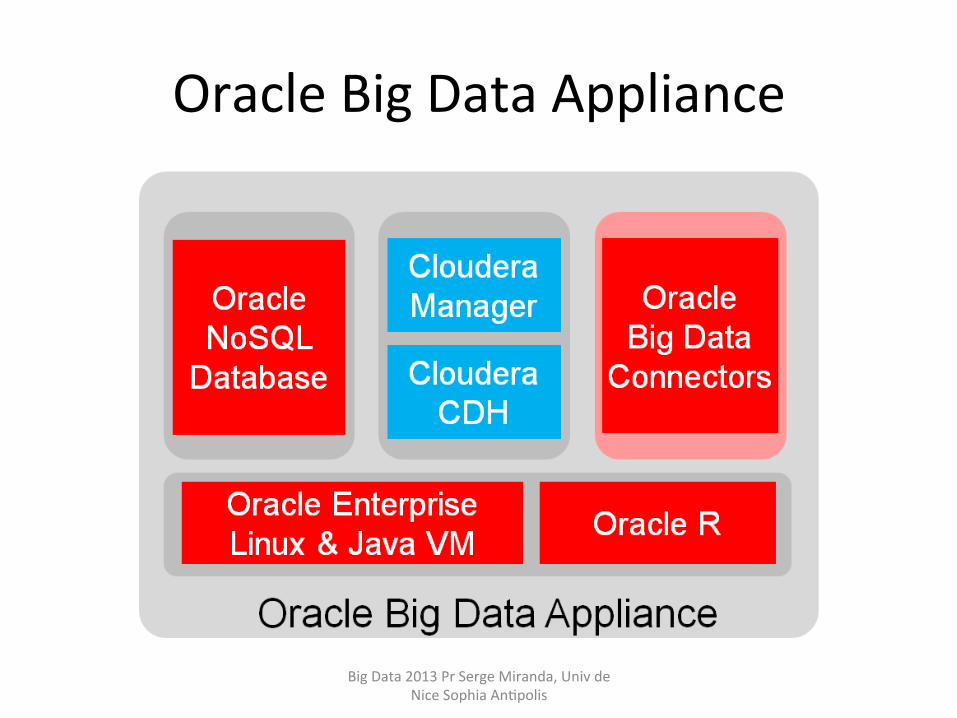
Oracle Big Data Appliance
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Oracle In-‐Database AnalyHcs
• Oracle R Enterprise (staHsHcs; predicHon) • In-‐Database Data Mining (predicHve analyHcs) • In-‐Database Text Mining (senHment analysis) • In-‐Database SemanHc Analysis (Graphs) • In-‐Database SpaHal (data ploeed on a map) • In-‐Database MapReduce (procedural logic)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

NEW SQL
(Microso� SQL Server 2012 et BIG DATA)
• Microso� a annoncé en novembre 2011 l’arrêt de son projet interne de MapReduce pour Azure (bap9sé “Dryad”) au profit d’Hadoop
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Big Data dans SQL SERVER 2012
• SQL SERVER intègre la composante Hadoop, • L’éditeur lance ainsi une seconde version d’Hadoop pour Azure et Windows Server.
• Interface Excel à Hadoop – le projet Apache Sqoop, – la mise à disposiHon de Mahoot (ouHls de datamining pour Hadoop)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
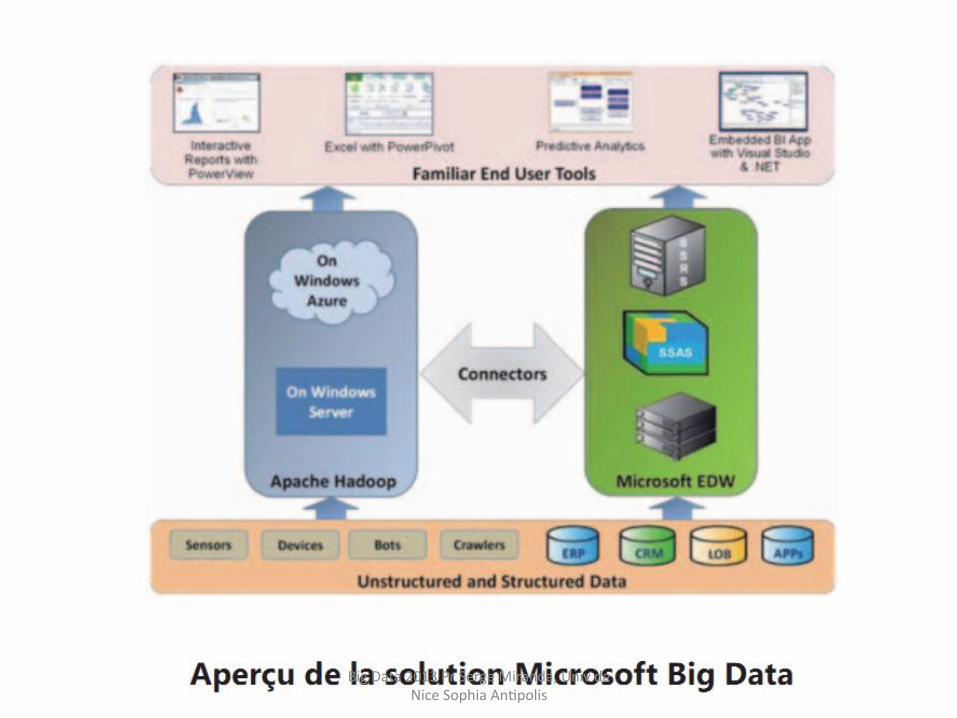
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Et GOOGLE en 2013: BIG QUERY (avec interface SQL)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
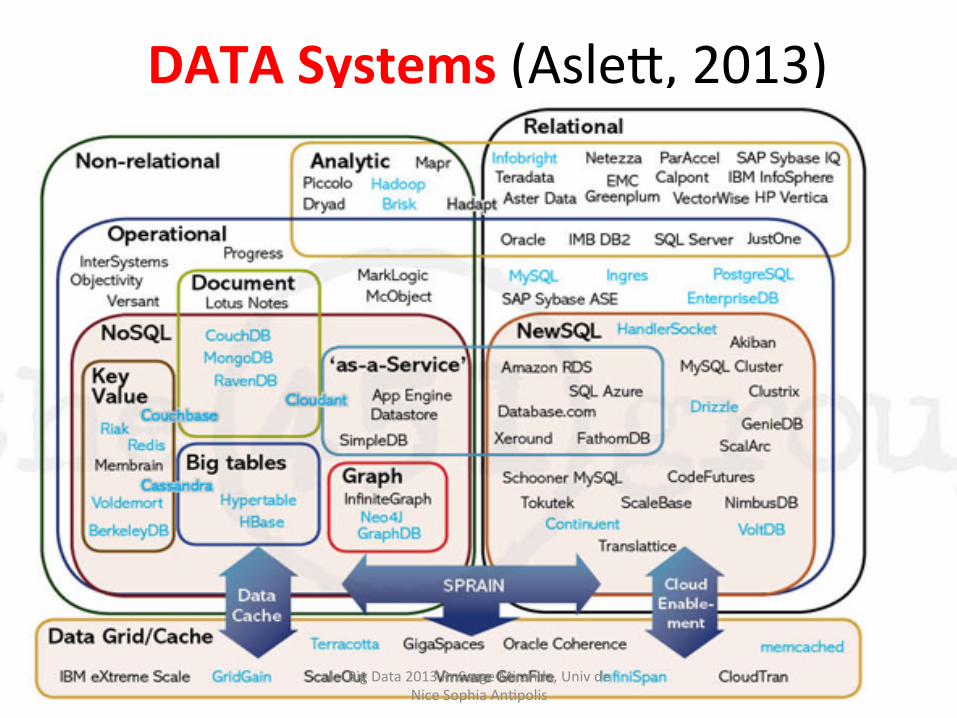
DATA Systems (Aslee, 2013)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Conclusion BIG DATA et recherche scienffique?
• Risque de prédire sans expliquer ? • La fin d’un monde scienHfique tradiHonnel ?
– il n’ y a : • Plus d’hypothèses à formuler Avant ! • Plus d’expérimentaHon à faire pendant ! • Plus de compréhension après !
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Conclusion BIG DATA : évolufon des méthodes scienffiques
• Méthode logique d’Aristote (330 a JC) • Méthode expérimentale de Roger Bacon (1250) • Méthode théorique de Newton(1700) • Méthode de simulafon d’Enrico Forni (1950) • Méthode d’analyse des liens de Google ? Twieers? TAGS NFC? Apres une science des traitements : Vers une SCIENCE • DES DONNEES ? • DES SERVICES ?
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Conclusion : Recherches Informafques BD**2
• ISSUES NEW SQL /BIG DATA : DATA MODELING? DATA PROCESSING (QL) ? DATA ANALYSIS? DATA CONSISTENCY? – Data uncertainty mngt? Data contextual Info mngt? Data quality
• Passerelles NEW SQL (entre SQL et NOSQL): – Modèles (Modèle commun?), concepHon, algorithmique (requetes,
ACID, BASE), systèmes, Middleware, OLTP Temps reel, OLCP Temps réel
– SQL-‐BIG (SQL-‐H, SQL-‐B, ..) • Réseaux sociaux spaHo temps réel et communautaires • GénéraHon informaHon temps réel mobiquitaires (contextuelles,
géolocalisées, ..) • ApplicaHons innovantes décisionnelles autour de données Temps
réel (Interfaces Réseaux sociaux, tag mining)
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

ANR et BIG DATA • L’ANR (Agence Na9onale de la Recherche) indique dans son document de programma9on 2012 ses
aQentes en termes de Big Data: Cet axe théma9que regroupe une classe de problèmes où le volume et la complexité des données manipulées et traitées cons9tuent un verrou majeur.
• Ces données sont caractérisées par leur nature différente (temporelle, spa9ale, hybride, etc.), leur forme (signaux, déstructurées, semi structurées, etc.), leur représenta9on matérielle et logicielle, leur ges9on à grande échelle (transport, stockage, vola9lité, acuité, pérennité, etc.). Concernant la simula9on, tous les aspects de la ges9on des données impliquées dans les cycles de simula9on sont concernés. Les données du processus de simula9on doivent être modélisées, stockées, traitées et manipulées par des algorithmes robustes, performants, et adaptés aux supports répar9s.
• Elle précise également les sous-‐thèmes qui l’intéressent: Les sous thèmes importants sont, de façon non exhaus9ve, le stockage, la gesYon et le traitement de BigData, i.e. très grands volumes de données (web, smart grids, wireless sensor networks) avec notamment le stream compu9ng (traitement en flux tendu des données) dans lequel le stockage classique est irréalisable voire non souhaitable (p.ex. caméras de vidéo protec9on), les techniques innovantes de modélisaYon par les données, de pré et post traitement, de fouille des données, d’interpréta9on… provenant notamment de disposi9fs ubiquitaires de collecte d’informa9ons fixes et mobiles qui sont « enfouis » et « omniprésents » toujours en plus grand nombre dans le monde réel (assistants personnels, téléphones cellulaires, traceurs GPS, caméras de vidéo protec9on, Réseaux RFID, etc.).
• Concernant l’open source, sans exclure de financer le développement de logiciels propriétaires, l’ANR affiche clairement des arguments en faveur de l’open source: [Le programme] s''intéresse à la produc9on et la fourniture de logiciels libres (i.e., « open source »). Ces deux modes vont économiquement cohabiter dans le futur mais le logiciel libre a voca9on à faciliter l''accès, la connaissance et l''u9lisa9on à coût modéré de résultats de R&D accessibles directement par l’Internet et donc partout sur la planète.
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

QuesHons ?
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

References • [ORACLE2012] White Paper Oracle, January 2012 « Oracle BIG DATA for the enterprise » • [DAVIS2009] Ian Davis « 30 Minute Guide to RDF and Linked Data” 2009 , Slide Share • [RICH2012] Chris Richardon “SQL, NO SQL and NEW SQL”Feb 2012 SLIDE SHARE • [STON2011] Mike Stonebraker, “New SQL: An Alternative to NoSQL and Old SQL for New
OLTP Apps » ACM, Juin 2011 • [FERM2012] Fermigier Stéphane « BIG DATA et Open Source, Une convergence inévitable »
White Paper, Version 1.0, Mars 2012 • [NOEL2011] Steven Noels, « BIG DATA”, SAI 7 April 2011 • [BEEM2012] Wim Von Leuven« Open Data Tutorial », Hadley Beeman et al, IOGDC, 2012 • [BERN2006] Tim Berners-Lee “SPARQL will make a huge difference”, May 2006 • [CORNO2008] Corno et al , « SPARQL - QueryLanguage for RDF » • [BASSM2012] Bassma Ben Dhouma « Implémentation d’une application pour pour la gestion
des données de type Big Data sous un Hadoop Cluster en utilisant une base de données Nosql » Rapport MBDS, Univ Manouba , Tunisie, Oct 2012
• [MAEVA2012] Maeva Antoine, Rapport MBDS2012, INRIA Sophia, Equipe OASIS • [MIRA2013] S. Miranda , AM Lesas« Livre sur Systemes d’information mobiquitaires et
standard NFC » < A paraitre 2013> • [GAND2012] Fabien Gandon « Recherches Web Sémantqiue » Juin 2012 • [BUFFA2012] Michel Buffa, Proposition recherche Fui VAMP
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

References NO SQL (BEN 2013 ) Benjamin Renaut “Introduction à HADOOP” Cours MBDS, 2013 Université de Nice Sophia Antipolis [POPE2012] Alex Popescu “Big Data Causes Concern and Big Confusion. A Big Data Definition to Help Clarify the Confusion”, 27 février 2012
<http://nosql.mypopescu.com/post/18376617501/big-data-causes-concern-and-big- confusion-a-big-data>. [Sharma 2012] SQLand NoSQL Databases « , VaHka Sharma, Meenu Dave Volume 2, Issue 8, August 2012 ISSN: 2277 128X InternaHonal Journal of Advanced Research in Computer Science and Soqware Engineering Research Paper , Available online at: www.ijarcsse.com SQL SilvanWeber, “ NoSQLDatabases ”
– hep://www.christof-‐strauch.de /nosqldbs.pdf MarHn Fowler and Pramod Sadalage Rendered, “NoSQLdbs-‐ “, February8,2012,11:26,
– hep://marHnfowler.com/arHcles/nosql-‐intro.pdf An Oracle White Paper, “Oracle NoSQL Database”, September2011, hep://www.oracle.com/technetwork/database/nosqldb/learnmore/nosql-‐database-‐498041.pdf Luis Ferreira Universidade do Minho, “Bridging the gap between SQL and NoSQL”,
– hepsikhote.files.wordpress.com201105arHgo-‐mi-‐star1.pdf
Andrew J. Brust, Blue Badge Insights, Inc., “NoSQL and the Windows Azure pla�orm”, April 25, 2011 DAMA -‐ Philadelphia / Delaware Valley, the “Role of Data Architecture in NOSQL”, Wednesday January 11th, 2012,
– hep://www.damaphila.org/HaugheyNOSQL.pdf
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Annexe : Projet MBDS Tunis (Univ de La Manouba), 2012
ApplicaYon Hadoop pour Maroc Telecom [BASSM2012]
" Système d’exploitation: Unix - Ubuntu
" Langage de programmation: JAVA
" Outils de travail: - Hadoop 0.20 - Sqoop - Pig
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
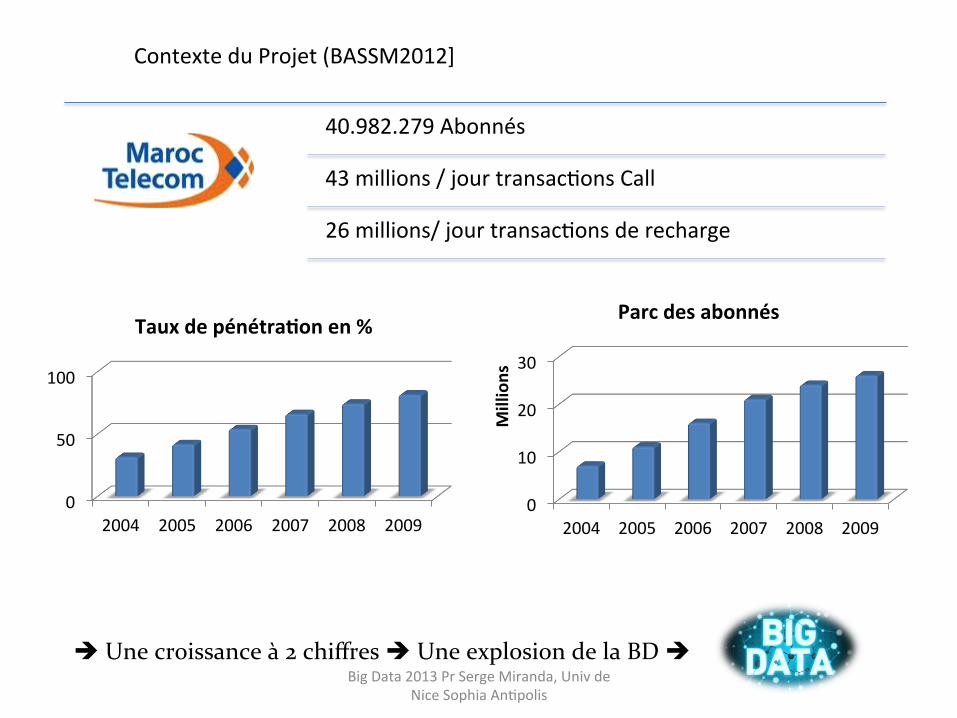
40.982.279 Abonnés
43 millions / jour transacHons Call
26 millions/ jour transacHons de recharge
0
50
100
2004 2005 2006 2007 2008 2009
Taux de pénétrafon en %
0
10
20
30
2004 2005 2006 2007 2008 2009 Millions
Parc des abonnés
è Une croissance à 2 chiffres è Une explosion de la BD è
Contexte du Projet (BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Probléma9que BIG DATA du Projet [BASSM2012]
Quanftés de données à stocker et données inexploitables par SQL simple
Coût de stockage
Temps de traitement
100 GB è 10 min 1 TB è 2 heures 1 PB è 3 mois
Compléxité et lourdeur des requêtes SQL
137 tables
SQL ne permet pas de répondre aux besoins de Maroc
telecom en terme de gestion BIG DATA Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
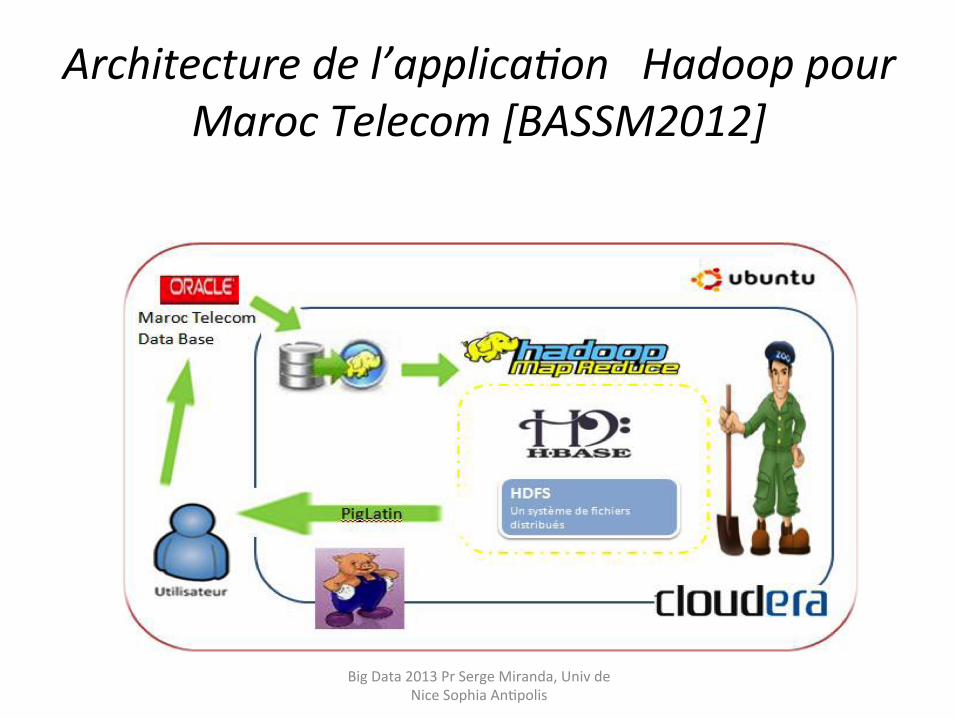
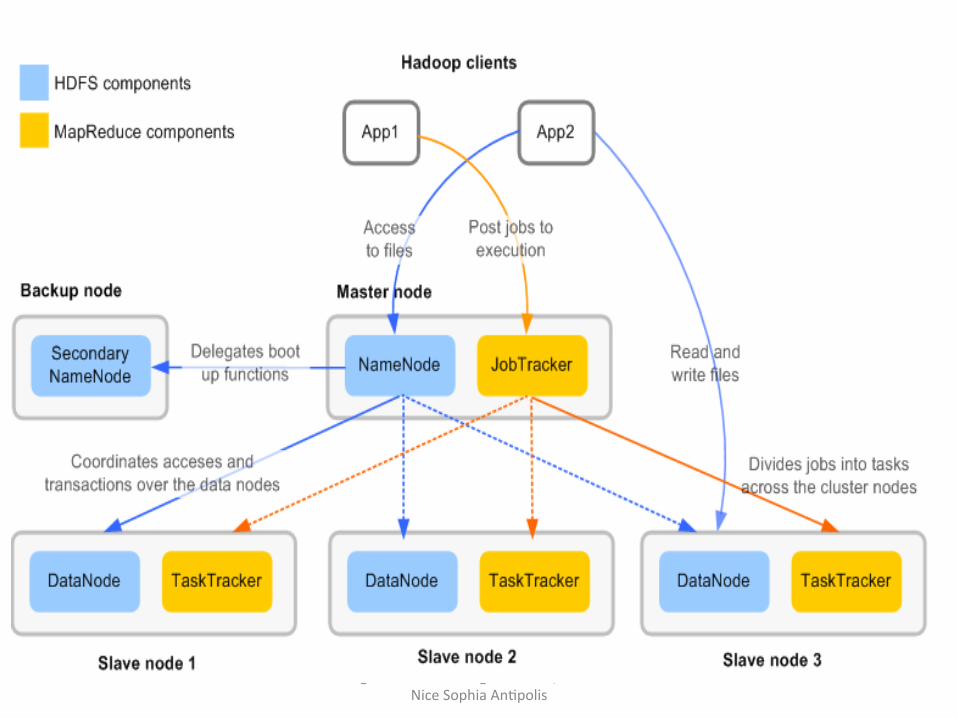
Architecture de l’applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
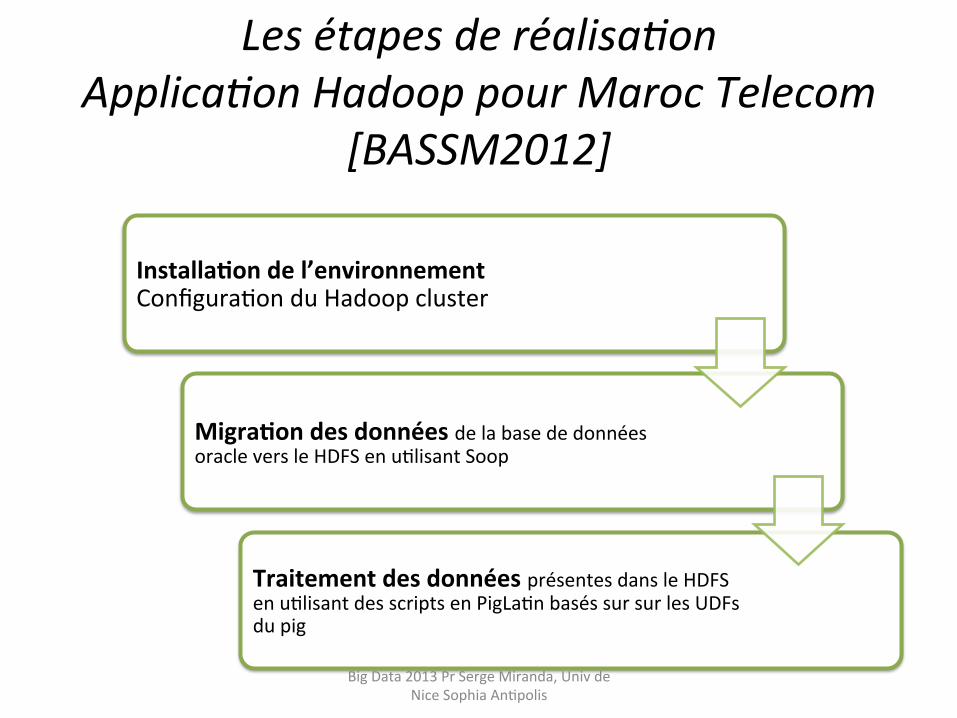
Les étapes de réalisa9on Applica9on Hadoop pour Maroc Telecom
[BASSM2012]
Installafon de l’environnement ConfiguraHon du Hadoop cluster
Migrafon des données de la base de données oracle vers le HDFS en uHlisant Soop
Traitement des données présentes dans le HDFS en uHlisant des scripts en PigLaHn basés sur sur les UDFs du pig
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
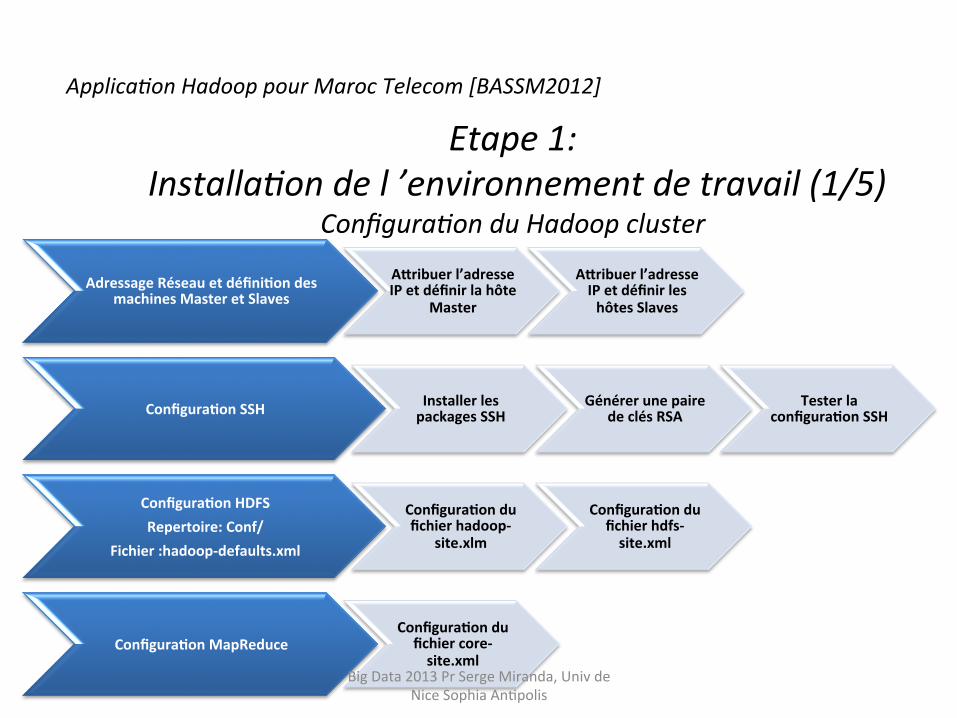
Adressage Réseau et définifon des machines Master et Slaves
A;ribuer l’adresse IP et définir la hôte
Master
A;ribuer l’adresse IP et définir les hôtes Slaves
Configurafon SSH Installer les packages SSH
Générer une paire de clés RSA
Tester la configurafon SSH
Configurafon HDFS Repertoire: Conf/
Fichier :hadoop-‐defaults.xml
Configurafon du fichier hadoop-‐
site.xlm
Configurafon du fichier hdfs-‐site.xml
Configurafon MapReduce Configurafon du fichier core-‐site.xml
Etape 1: Installa9on de l ’environnement de travail (1/5)
Configura9on du Hadoop cluster
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
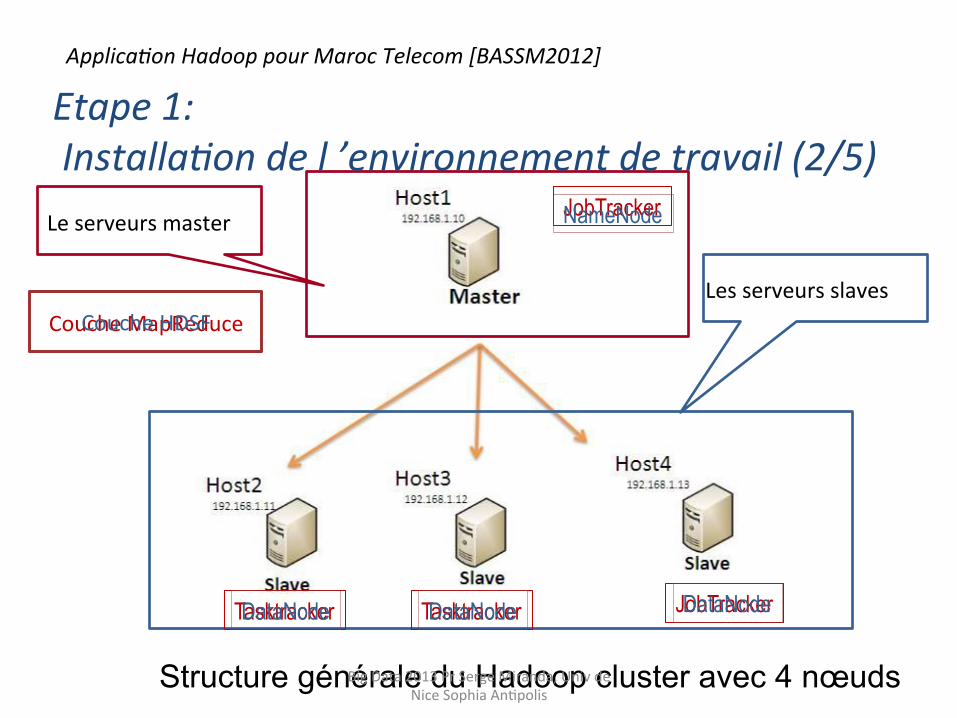
Structure générale du Hadoop cluster avec 4 nœuds
Les serveurs slaves
Le serveurs master
Etape 1: Installa9on de l ’environnement de travail (2/5)
Couche MapReduce
Tasktracker Tasktracker
JobTracker
JobTracker DataNode DataNode
NameNode
DataNode
Couche HDSF
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
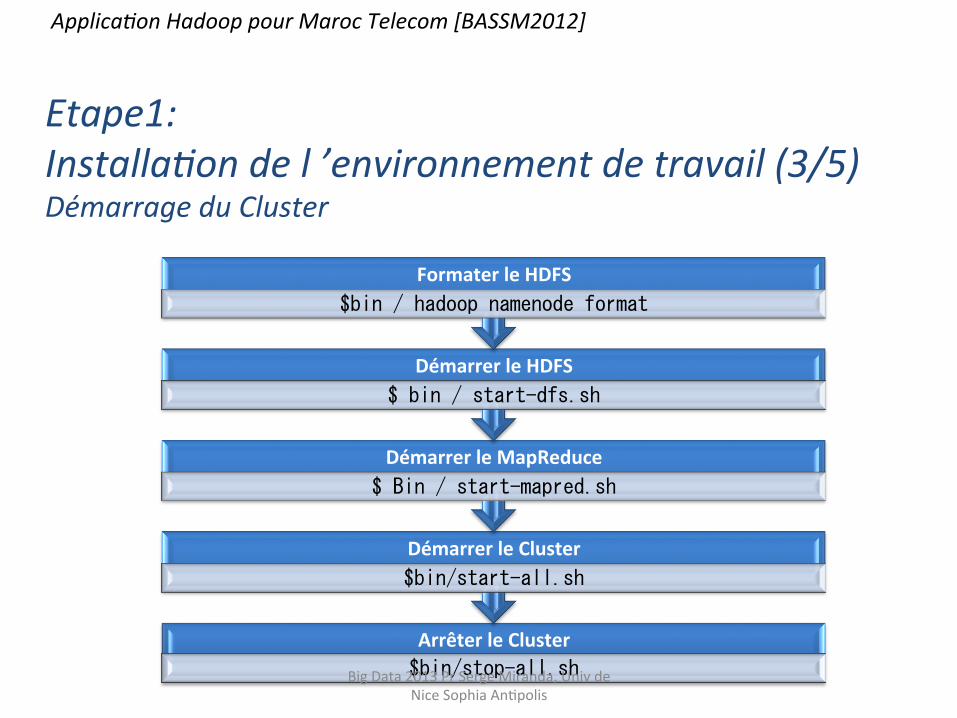
Arrêter le Cluster $bin/stop-all.sh
Démarrer le Cluster $bin/start-all.sh
Démarrer le MapReduce $ Bin / start-mapred.sh
Démarrer le HDFS $ bin / start-dfs.sh
Formater le HDFS $bin / hadoop namenode format
Etape1: Installa9on de l ’environnement de travail (3/5) Démarrage du Cluster
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

L’interface Web Du NameNode
Récapitulatif du cluster
nœuds actifs et morts Capacité totale
hep://localhost:50070
Etape1: Installa9on de l ’environnement de travail (4/5)
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
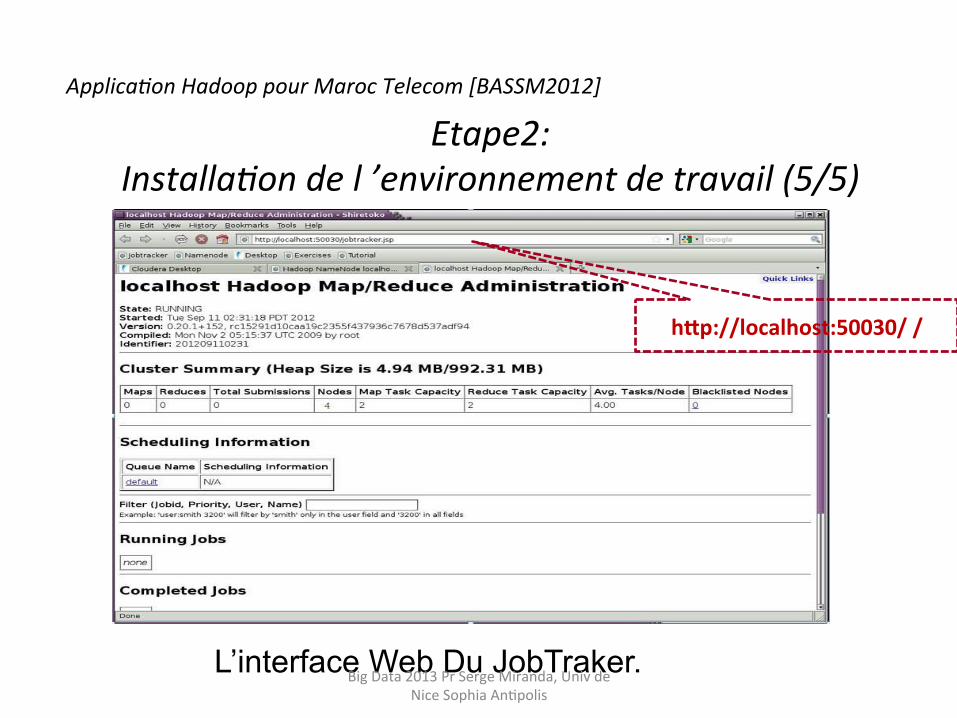
L’interface Web Du JobTraker.
h;p://localhost:50030/ /
Etape2: Installa9on de l ’environnement de travail (5/5)
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Extrait de la base de données Maroc Telecom : Les tables quotidiennes
Etape2: Migra9on des données (1/4)
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
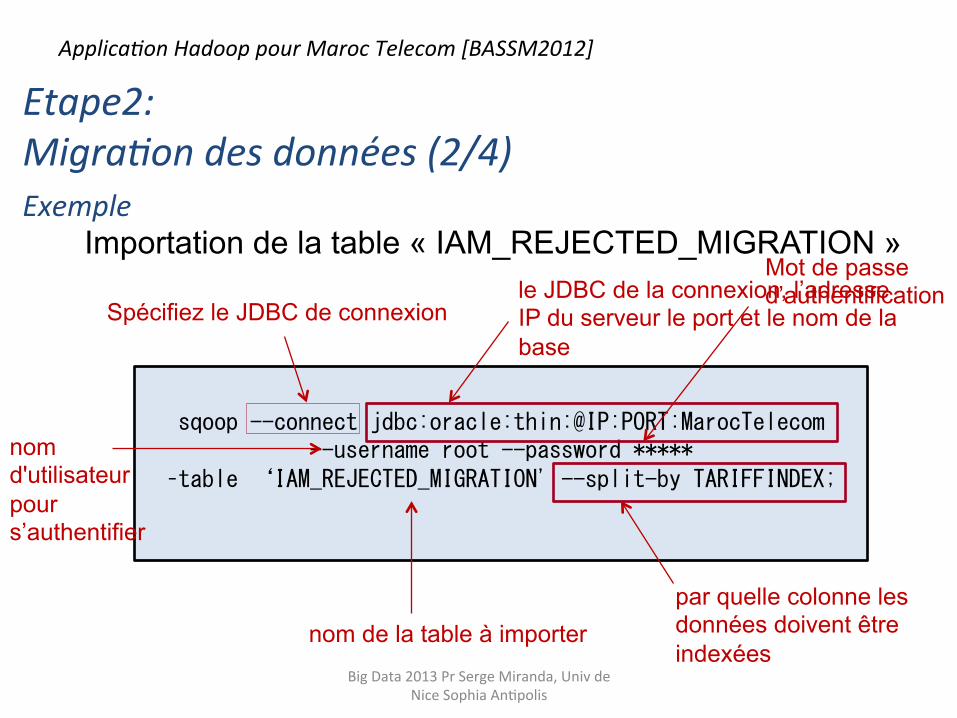
sqoop --connect jdbc:oracle:thin:@IP:PORT:MarocTelecom --username root --password *****
–table ‘IAM_REJECTED_MIGRATION' --split-by TARIFFINDEX;
Importation de la table « IAM_REJECTED_MIGRATION » le JDBC de la connexion, l’adresse IP du serveur le port et le nom de la base
nom d'utilisateur pour s’authentifier
Mot de passe d’authentification
nom de la table à importer par quelle colonne les données doivent être indexées
Spécifiez le JDBC de connexion
Etape2: Migra9on des données (2/4) Exemple
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Etape2: Migra9on des données (3/4)
Lancement de la commande d’importation
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
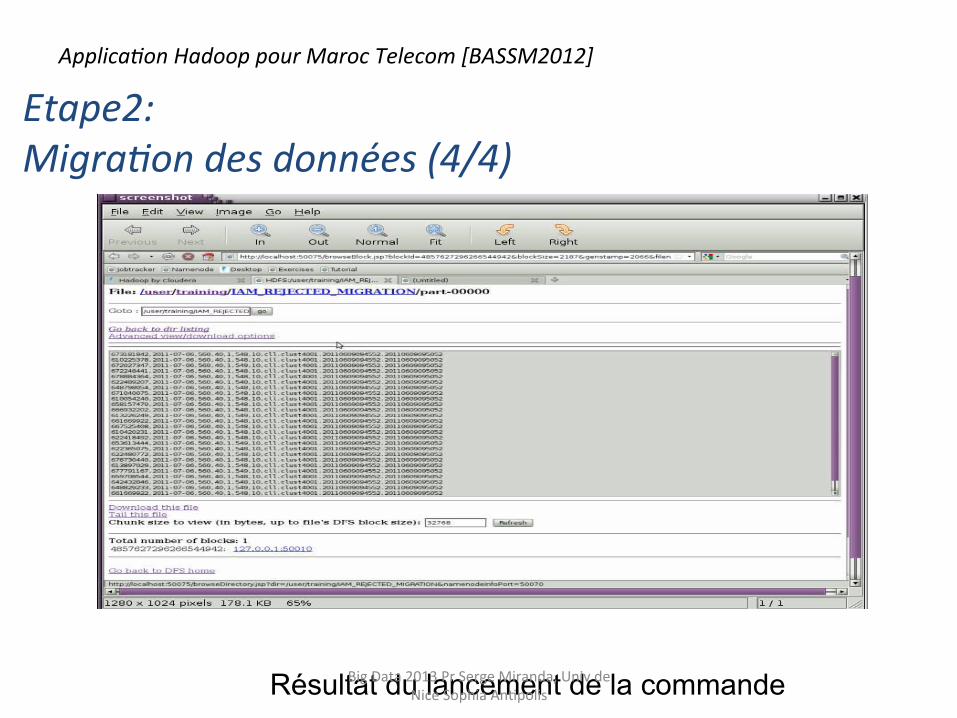
Résultat du lancement de la commande
Etape2: Migra9on des données (4/4)
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Etape3: Migra9on des données (1/4) Objec9fs § Gestion de données de types complexes
§ Réduction du temps de réponse des requêtes SQL lourdes et complexes
§ Des requêtes en langage naturel pour du filtrage dynamique (idem sans in-‐memory)
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Etape3: Traitement des données migrées (2/4) Exemple
SELECT TO_NUMBER (TO_CHAR (TIMESTAMP, 'yyyymmdd')),TARIFFINDEX, SUBSTR(BEARER_FLAG,1,1),COUNT(DISTINCT MSISDN),FORFAIT FROM IAM_CALL2 WHERE TARIFFINDEX IN (1,2,3,5,6,9,15,16,21,22,24,25,26,27,18)
GROUP BY TO_NUMBER (TO_CHAR (TIMESTAMP, 'yyyymmdd')), TARIFFINDEX, SUBSTR(BEARER_FLAG,1,1),FORFAIT;
Requêtes SQL à traduire en PigLatin
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis

Etape3: Traitement des données migrées (3/4)
Script PigLatin
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis
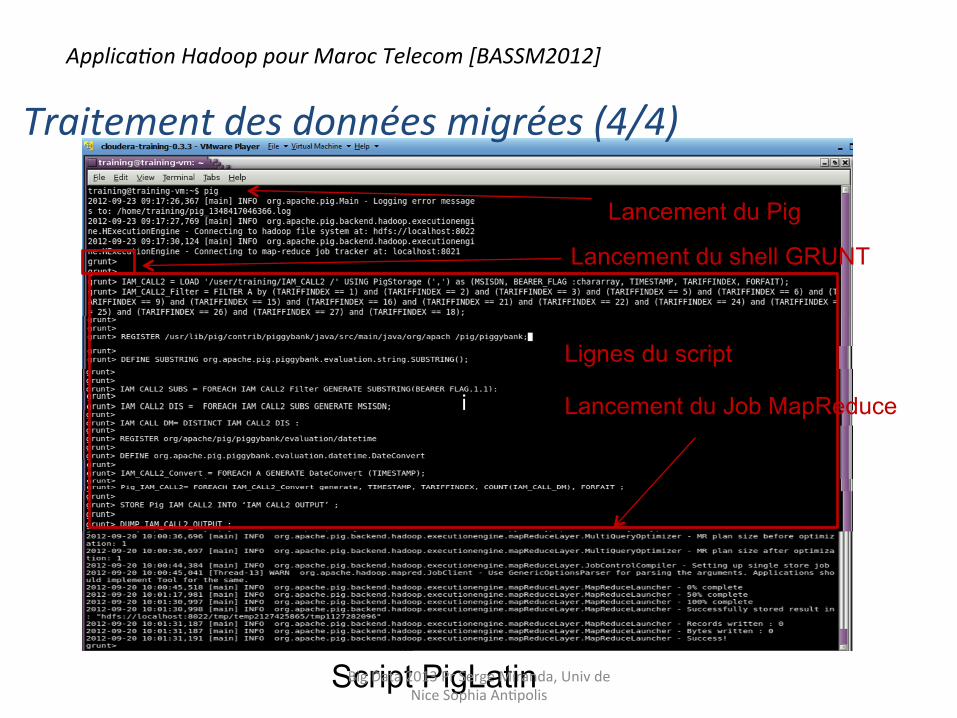
Traitement des données migrées (4/4)
Script PigLatin
Lancement du Job MapReduce
Lancement du Pig
Lancement du shell GRUNT
i
Lignes du script
Applica9on Hadoop pour Maroc Telecom [BASSM2012]
Big Data 2013 Pr Serge Miranda, Univ de Nice Sophia AnHpolis