all cours rezo 430 pages
DESCRIPTION
All Cours Rezo 430 PagesTRANSCRIPT

RESEAUX
Les modèles
Le modèle TCP/IP
1 - Introduction
2 - Description du modèle 2.1 - Un modèle en 4 couches 2.2 - La couche hôte réseau 2.3 - La couche internet 2.4 - La couche transport 2.5 - La couche application
3 - Comparaison avec le modèle OSI et critique 3.1 - Comparaison avec le modèle OSI 3.2 - Critique 4 - Discussion autour de la documentation 5 - Suivi du document
1 - Introduction
TCP/IP désigne communément une architecture réseau, mais cet acronyme désigne en fait 2 protocoles étroitement liés : un protocole de transport, TCP (Transmission Control Protocol) qu'on utilise "par-dessus" un protocole réseau, IP (Internet Protocol). Ce qu'on entend par "modèle TCP/IP", c'est en fait une architecture réseau en 4 couches dans laquelle les protocoles TCP et IP jouent un rôle prédominant, car ils en constituent l'implémentation la plus courante. Par abus de langage, TCP/IP peut donc désigner deux choses : le modèle TCP/IP et la suite de deux protocoles TCP et IP.
Le modèle TCP/IP, comme nous le verrons plus bas, s'est progressivement imposé comme modèle de référence en lieu et place du modèle OSI. Cela tient tout simplement à son histoire. En effet, contrairement au modèle OSI, le modèle TCP/IP est né d'une implémentation ; la normalisation est venue ensuite. Cet historique fait toute la particularité de ce modèle, ses avantages et ses inconvénients. L'origine de TCP/IP remonte au réseau ARPANET. ARPANET est un réseau de télécommunication conçu par l'ARPA
(Advanced Research Projects Agency), l'agence de recherche du ministère américain de la défense (le DOD : Department of Defense). Outre la possibilité de connecter des réseaux hétérogènes, ce réseau devait résister à une éventuelle guerre nucléaire, contrairement au réseau téléphonique habituellement utilisé pour les télécommunications mais considéré trop vulnérable. Il a alors été convenu qu'ARPANET utiliserait la technologie de commutation par paquet (mode datagramme), une technologie émergeante promettante. C'est donc dans cet objectif et ce choix technique que les protocoles TCP et IP furent inventés en 1974. L'ARPA signa alors plusieurs contrats avec les constructeurs (BBN principalement) et l'université de Berkeley qui développait un Unix pour imposer ce standard, ce qui fut fait.
2 - Description du modèle
2.1 - Un modèle en 4 couches
Le modèle TCP/IP peut en effet être décrit comme une architecture réseau à 4 couches :

Le modèle OSI a été mis à côté pour faciliter la comparaison entre les deux modèles.
2.2 - La couche hôte réseau
Cette couche est assez "étrange". En effet, elle semble "regrouper" les couches physique et liaison de données du modèle OSI. En fait, cette couche n'a pas vraiment été spécifiée ; la seule contrainte de cette couche, c'est de permettre un hôte d'envoyer des paquets IP sur le réseau. L'implémentation de cette couche est laissée libre. De manière plus concrète, cette implémentation est typique de la technologie utilisée sur le réseau local. Par
exemple, beaucoup de réseaux locaux utilisent Ethernet ; Ethernet est une implémentation de la couche hôte-réseau.
2.3 - La couche internet
Cette couche est la clé de voûte de l'architecture. Cette couche réalise l'interconnexion des réseaux (hétérogènes) distants sans connexion. Son rôle est de permettre l'injection de paquets dans n'importe quel réseau et l'acheminement des ces paquets indépendamment les uns des autres jusqu'à destination. Comme aucune connexion n'est établie au préalable, les paquets peuvent arriver dans le désordre ; le contrôle de l'ordre de
remise est éventuellement la tâche des couches supérieures. Du fait du rôle imminent de cette couche dans l'acheminement des paquets, le point critique de cette couche est le routage. C'est en ce sens que l'on peut se permettre de comparer cette couche avec la couche réseau du modèle OSI.
La couche internet possède une implémentation officielle : le protocole IP (Internet Protocol).
Remarquons que le nom de la couche ("internet") est écrit avec un i minuscule, pour la simple et bonne raison que le mot internet est pris ici au sens large (littéralement, "interconnexion de réseaux"), même si l'Internet (avec un grand I) utilise cette couche.
2.4 - La couche transport
Son rôle est le même que celui de la couche transport du modèle OSI : permettre à des entités paires de soutenir
une conversation. Officiellement, cette couche n'a que deux implémentations : le protocole TCP (Transmission Control Protocol) et le protocole UDP (User Datagram Protocol). TCP est un protocole fiable, orienté connexion, qui permet l'acheminement sans erreur de paquets issus d'une machine d'un internet à une autre machine du même internet. Son rôle est de fragmenter le message à transmettre de manière à pouvoir le faire passer sur la couche internet. A l'inverse, sur la machine destination, TCP replace dans l'ordre les fragments transmis sur la couche internet
pour reconstruire le message initial. TCP s'occupe également du contrôle de flux de la connexion.

UDP est en revanche un protocole plus simple que TCP : il est non fiable et sans connexion. Son utilisation présuppose que l'on n'a pas besoin ni du contrôle de flux, ni de la conservation de l'ordre de remise des paquets. Par exemple, on l'utilise lorsque la couche application se charge de la remise en ordre des messages. On se souvient que dans le modèle OSI, plusieurs couches ont à charge la vérification de l'ordre de remise des messages. C'est là une avantage du modèle TCP/IP sur le modèle OSI, mais nous y reviendrons plus tard. Une
autre utilisation d'UDP : la transmission de la voix. En effet, l'inversion de 2 phonèmes ne gêne en rien la compréhension du message final. De manière plus générale, UDP intervient lorsque le temps de remise des
paquets est prédominant.
2.5 - La couche application
Contrairement au modèle OSI, c'est la couche immédiatement supérieure à la couche transport, tout simplement parce que les couches présentation et session sont apparues inutiles. On s'est en effet aperçu avec l'usage que les logiciels réseau n'utilisent que très rarement ces 2 couches, et finalement, le modèle OSI dépouillé de ces 2 couches ressemble fortement au modèle TCP/IP.
Cette couche contient tous les protocoles de haut niveau, comme par exemple Telnet, TFTP (trivial File Transfer Protocol), SMTP (Simple Mail Transfer Protocol), HTTP (HyperText Transfer Protocol). Le point important pour cette couche est le choix du protocole de transport à utiliser. Par exemple, TFTP (surtout utilisé sur réseaux locaux) utilisera UDP, car on part du principe que les liaisons physiques sont suffisamment fiables et les temps de transmission suffisamment courts pour qu'il n'y ait pas d'inversion de paquets à l'arrivée. Ce choix rend TFTP plus rapide que le protocole FTP qui utilise TCP. A l'inverse, SMTP utilise TCP, car pour la remise du courrier électronique, on veut que tous les messages parviennent intégralement et sans erreurs.
3 - Comparaison avec le modèle OSI et critique
3.1 - Comparaison avec le modèle OSI
Tout d'abord, les points communs. Les modèles OSI et TCP/IP sont tous les deux fondés sur le concept de pile de protocoles indépendants. Ensuite, les fonctionnalités des couches sont globalement les mêmes.
Au niveau des différences, on peut remarquer la chose suivante : le modèle OSI faisait clairement la différence entre 3 concepts principaux, alors que ce n'est plus tout à fait le cas pour le modèle TCP/IP. Ces 3 concepts sont les concepts de services, interfaces et protocoles. En effet, TCP/IP fait peu la distinction entre ces concepts, et ce malgré les efforts des concepteurs pour se rapprocher de l'OSI. Cela est dû au fait que pour le modèle TCP/IP, ce sont les protocoles qui sont d'abord apparus. Le modèle ne fait finalement que donner une justification théorique aux protocoles, sans les rendre véritablement indépendants les uns des autres.
Enfin, la dernière grande différence est liée au mode de connexion. Certes, les modes orienté connexion et sans connexion sont disponibles dans les deux modèles mais pas à la même couche : pour le modèle OSI, ils ne sont disponibles qu'au niveau de la couche réseau (au niveau de la couche transport, seul le mode orienté connexion n'est disponible), alors qu'ils ne sont disponibles qu'au niveau de la couche transport pour le modèle TCP/IP (la couche internet n'offre que le mode sans connexion). Le modèle TCP/IP a donc cet avantage par rapport au modèle OSI : les applications (qui utilisent directement la couche transport) ont véritablement le choix entre les
deux modes de connexion.
3.2 - Critique
Une des premières critiques que l'on peut émettre tient au fait que le modèle TCP/IP ne fait pas vraiment la distinction entre les spécifications et l'implémentation : IP est un protocole qui fait partie intégrante des spécifications du modèle. Une autre critique peut être émise à l'encontre de la couche hôte réseau. En effet, ce n'est pas à proprement
parler une couche d'abstraction dans la mesure où sa spécification est trop floue. Les constructeurs sont donc obligés de proposer leurs solutions pour "combler" ce manque. Finalement, on s'aperçoit que les couches physique et liaison de données sont tout aussi importantes que la couche transport. Partant de là, on est en droit de proposer un modèle hybride à 5 couches, rassemblant les points forts des modèles OSI et TCP/IP :

Modèle hybride de référence C'est finalement ce modèle qui sert véritablement de référence dans le monde de l'Internet. On a ainsi gardé la plupart des couches de l'OSI (toutes, sauf les couches session et présentation) car correctement spécifiées. En revanche, ses protocoles n'ont pas eu de succès et on a du coup gardé ceux de TCP/IP.
Le modèle OSI
1 - Introduction 2 - Les différentes couches du modèle 2.1 - Les 7 couches 2.2 - La couche physique 2.3 - La couche liaison de données 2.4 - La couche réseau
2.5 - Couche transport 2.6 - La couche session 2.7 - La couche présentation 2.8 - La couche application 3 - Transmission de données au travers du modèle OSI 4 - Critique du modèle OSI 4.1 - Ce n'était pas le bon moment
4.2 - Ce n'était pas la bonne technologie 4.3 - Ce n'était pas la bonne implémentation 4.4 - Ce n'était pas la bonne politique 5 - L'avenir d'OSI 6 - Discussion autour de la documentation 7 - Suivi du document
1 - Introduction
Les constructeurs informatiques ont proposé des architectures réseaux propres à leurs équipements. Par exemple, IBM
a proposé SNA, DEC a proposé DNA... Ces architectures ont toutes le même défaut : du fait de leur caractère propriétaire, il n'est pas facile des les interconnecter, à moins d'un accord entre constructeurs. Aussi, pour éviter la multiplication des solutions d'interconnexion d'architectures hétérogènes, l'ISO (International Standards Organisation), organisme dépendant de l'ONU et composé de 140 organismes nationaux de normalisation, a développé un modèle de
référence appelé modèle OSI (Open Systems Interconnection). Ce modèle décrit les concepts utilisés et la démarche suivie pour normaliser l'interconnexion de systèmes ouverts (un réseau est composé de systèmes ouverts lorsque la modification, l'adjonction ou la suppression d'un de ces systèmes ne modifie pas le comportement global du réseau). Au moment de la conception de ce modèle, la prise en compte de l'hétérogénéité des équipements était fondamentale. En effet, ce modèle devait permettre l'interconnexion avec des systèmes hétérogènes pour des raisons historiques et économiques. Il ne devait en outre pas favoriser un fournisseur particulier. Enfin, il devait permettre de s'adapter à
l'évolution des flux d'informations à traiter sans remettre en cause les investissements antérieurs. Cette prise en compte de l'hétérogénéité nécessite donc l'adoption de règles communes de communication et de coopération entre les équipements, c'est à dire que ce modèle devait logiquement mener à une normalisation internationale des protocoles. Le modèle OSI n'est pas une véritable architecture de réseau, car il ne précise pas réellement les services et les protocoles à utiliser pour chaque couche. Il décrit plutôt ce que doivent faire les couches. Néanmoins, l'ISO a écrit ses
propres normes pour chaque couche, et ceci de manière indépendante au modèle, i.e. comme le fait tout constructeur.

Les premiers travaux portant sur le modèle OSI datent de 1977. Ils ont été basés sur l'expérience acquise en matière de grands réseaux et de réseaux privés plus petits ; le modèle devait en effet être valable pour tous les types de réseaux. En 1978, l'ISO propose ce modèle sous la norme ISO IS7498. En 1984, 12 constructeurs européens, rejoints en 1985 par les grands constructeurs américains, adoptent le standard.
2 - Les différentes couches du modèle
2.1 - Les 7 couches
Le modèle OSI comporte 7 couches :
Les principes qui ont conduit à ces 7 couches sont les suivants : - une couche doit être créée lorsqu'un nouveau niveau d'abstraction est nécessaire, - chaque couche a des fonctions bien définies, - les fonctions de chaque couche doivent être choisies dans l'objectif de la normalisation internationale des protocoles,
- les frontières entre couches doivent être choisies de manière à minimiser le flux d'information aux interfaces,
- le nombre de couches doit être tel qu'il n'y ait pas cohabitation de fonctions très différentes au sein d'une même couche et que l'architecture ne soit pas trop difficile à maîtriser. Les couches basses (1, 2, 3 et 4) sont nécessaires à l'acheminement des informations entre les extrémités concernées et dépendent du support physique. Les couches hautes (5, 6 et 7) sont responsables du traitement de l'information relative à la gestion des échanges entre systèmes informatiques. Par ailleurs, les couches 1 à 3
interviennent entre machines voisines, et non entre les machines d'extrémité qui peuvent être séparées par plusieurs routeurs. Les couches 4 à 7 sont au contraire des couches qui n'interviennent qu'entre hôtes distants.
2.2 - La couche physique
La couche physique s'occupe de la transmission des bits de façon brute sur un canal de communication. Cette couche doit garantir la parfaite transmission des données (un bit 1 envoyé doit bien être reçu comme bit valant 1). Concrètement, cette couche doit normaliser les caractéristiques électriques (un bit 1 doit être représenté par une tension de 5 V, par exemple), les caractéristiques mécaniques (forme des connecteurs, de la topologie...), les
caractéristiques fonctionnelles des circuits de données et les procédures d'établissement, de maintien et de libération du circuit de données.

L'unité d'information typique de cette couche est le bit, représenté par une certaine différence de potentiel.
2.3 - La couche liaison de données
Son rôle est un rôle de "liant" : elle va transformer la couche physique en une liaison a priori exempte d'erreurs de transmission pour la couche réseau. Elle fractionne les données d'entrée de l'émetteur en trames, transmet ces trames en séquence et gère les trames d'acquittement renvoyées par le récepteur. Rappelons que pour la couche physique, les données n'ont aucune signification particulière. La couche liaison de données doit donc être capable
de reconnaître les frontières des trames. Cela peut poser quelques problèmes, puisque les séquences de bits utilisées pour cette reconnaissance peuvent apparaître dans les données. La couche liaison de données doit être capable de renvoyer une trame lorsqu'il y a eu un problème sur la ligne de transmission. De manière générale, un rôle important de cette couche est la détection et la correction d'erreurs intervenues sur la couche physique. Cette couche intègre également une fonction de contrôle de flux pour éviter l'engorgement du récepteur.
L'unité d'information de la couche liaison de données est la trame qui est composées de quelques centaines à quelques milliers d'octets maximum.
2.4 - La couche réseau
C'est la couche qui permet de gérer le sous-réseau, i.e. le routage des paquets sur ce sous-réseau et l'interconnexion des différents sous-réseaux entre eux. Au moment de sa conception, il faut bien déterminer le mécanisme de routage et de calcul des tables de routage (tables statiques ou dynamiques...).
La couche réseau contrôle également l'engorgement du sous-réseau. On peut également y intégrer des fonctions de comptabilité pour la facturation au volume, mais cela peut être délicat.
L'unité d'information de la couche réseau est le paquet.
2.5 - Couche transport
Cette couche est responsable du bon acheminement des messages complets au destinataire. Le rôle principal de la couche transport est de prendre les messages de la couche session, de les découper s'il le faut en unités plus petites et de les passer à la couche réseau, tout en s'assurant que les morceaux arrivent correctement de l'autre côté. Cette couche effectue donc aussi le réassemblage du message à la réception des morceaux. Cette couche est également responsable de l'optimisation des ressources du réseau : en toute rigueur, la couche transport crée une connexion réseau par connexion de transport requise par la couche session, mais cette couche
est capable de créer plusieurs connexions réseau par processus de la couche session pour répartir les données, par exemple pour améliorer le débit. A l'inverse, cette couche est capable d'utiliser une seule connexion réseau pour transporter plusieurs messages à la fois grâce au multiplexage. Dans tous les cas, tout ceci doit être transparent pour la couche session. Cette couche est également responsable du type de service à fournir à la couche session, et finalement aux utilisateurs du réseau : service en mode connecté ou non, avec ou sans garantie d'ordre de délivrance, diffusion
du message à plusieurs destinataires à la fois... Cette couche est donc également responsable de l'établissement et du relâchement des connexions sur le réseau. Un des tous derniers rôles à évoquer est le contrôle de flux. C'est l'une des couches les plus importantes, car c'est elle qui fournit le service de base à l'utilisateur, et c'est par
ailleurs elle qui gère l'ensemble du processus de connexion, avec toutes les contraintes qui y sont liées.
L'unité d'information de la couche réseau est le message.
2.6 - La couche session
Cette couche organise et synchronise les échanges entre tâches distantes. Elle réalise le lien entre les adresses logiques et les adresses physiques des tâches réparties. Elle établit également une liaison entre deux programmes d'application devant coopérer et commande leur dialogue (qui doit parler, qui parle...). Dans ce dernier cas, ce
service d'organisation s'appelle la gestion du jeton. La couche session permet aussi d'insérer des points de reprise dans le flot de données de manière à pouvoir reprendre le dialogue après une panne.
2.7 - La couche présentation
Cette couche s'intéresse à la syntaxe et à la sémantique des données transmises : c'est elle qui traite l'information de manière à la rendre compatible entre tâches communicantes. Elle va assurer l'indépendance entre l'utilisateur et le transport de l'information.

Typiquement, cette couche peut convertir les données, les reformater, les crypter et les compresser.
2.8 - La couche application
Cette couche est le point de contact entre l'utilisateur et le réseau. C'est donc elle qui va apporter à l'utilisateur les services de base offerts par le réseau, comme par exemple le transfert de fichier, la messagerie...
3 - Transmission de données au travers du modèle OSI
Le processus émetteur remet les données à envoyer au processus récepteur à la couche application qui leur ajoute un en-tête application AH (éventuellement nul). Le résultat est alors transmis à la couche présentation. La couche présentation transforme alors ce message et lui ajoute (ou non) un nouvel en-tête (éventuellement nul). La couche présentation ne connaît et ne doit pas connaître l'existence éventuelle de AH ; pour la couche présentation, AH fait en fait partie des données utilisateur. Une fois le traitement terminé, la couche présentation envoie le nouveau
"message" à la couche session et le même processus recommence. Les données atteignent alors la couche physique qui va effectivement transmettre les données au destinataire. A la réception, le message va remonter les couches et les en-têtes sont progressivement retirés jusqu'à atteindre le processus récepteur :
Le concept important est le suivant : il faut considérer que chaque couche est programmée comme si elle était vraiment horizontale, c'est à dire qu'elle dialoguait directement avec sa couche paire réceptrice. Au moment de dialoguer avec sa couche paire, chaque couche rajoute un en-tête et l'envoie (virtuellement, grâce à la couche sous-jacente) à sa couche paire.
4 - Critique du modèle OSI
La chose la plus frappante à propos du modèle OSI est que c'est peut-être la structure réseau la plus étudiée et la plus unanimement reconnue et pourtant ce n'est pas le modèle qui a su s'imposer. Les spécialistes qui ont analysé cet échec en ont déterminé 4 raisons principales.
4.1 - Ce n'était pas le bon moment

David Clark du MIT a émis la théorie suivant quant à l'art et la manière de publier une norme au bon moment. Pour lui, dans le cycle de vie d'une norme, il y a 2 pics principaux d'activité : la recherche effectuée dans le domaine couvert par la norme, et les investissements des industriels pour l'implémentation et la mise en place de la norme. Ces deux pics sont séparés par un creux d'activité qui apparaît être en fait le moment idéal pour la publication de la norme : il n'est ni trop tôt par rapport à la recherche et on peut donc assurer une certaine
maîtrise, et il n'est ni trop tard pour les investissements et les industriels sont prêts à utiliser des capitaux pour l'implémenter.
Le modèle OSI était idéalement placé par rapport à la recherche, mais hélas, le modèle TCP/IP était déjà en phase d'investissement prononcé (lorsque le modèle OSI est sorti, les universités américaines utilisaient déjà largement TCP/IP avec un certain succès) et les industriels n'ont pas ressenti le besoin d'investir dessus.
4.2 - Ce n'était pas la bonne technologie
Le modèle OSI est peut-être trop complet et trop complexe. La distance entre l'utilisation concrète (l'implémentation) et le modèle est parfois importante. En effet, peu de programmes peuvent utiliser ou utilisent
mal l'ensemble des 7 couches du modèle : les couches session et présentation sont fort peu utilisées et à l'inverse les couches liaison de données et réseau sont très souvent découpées en sous-couches tant elles sont complexes. OSI est en fait trop complexe pour pouvoir être proprement et efficacement implémenté. Le comité rédacteur de la norme a même du laisser de côté certains points techniques, comme le la sécurité et le codage, tant il était délicat de conserver un rôle bien déterminé à chaque couche ainsi complétée. Ce modèle est également redondant (le contrôle de flux et le contrôle d'erreur apparaissent pratiquement dans chaque couche). Au niveau de
l'implémentation, TCP/IP est beaucoup plus optimisé et efficace. La plus grosse critique que l'on peut faire au modèle est qu'il n'est pas du tout adapté aux applications de télécommunication sur ordinateur ! Certains choix effectués sont en désaccord avec la façon dont les ordinateurs et les logiciels communiquent. La norme a en fait fait le choix d'un "système d'interruptions" pour signaler les événements, et sur des langages de programmation de haut niveau, cela est peu réalisable.
4.3 - Ce n'était pas la bonne implémentation
Cela tient tout simplement du fait que le modèle est relativement complexe, et que du coup les premières implémentations furent relativement lourdes et lentes. A l'inverse, la première implémentation de TCP/IP dans l'Unix de l'université de Berkeley (BSD) était gratuite et relativement efficace. Historiquement, les gens ont donc eu une tendance naturelle à utiliser TCP/IP.
4.4 - Ce n'était pas la bonne politique
Le modèle OSI a en fait souffert de sa trop forte normalisation. Les efforts d'implémentation du modèle étaient
surtout "bureaucratiques" et les gens ont peut-être vu ça d'un mauvaise oeil. A l'inverse, TCP/IP est venu d'Unix et a été tout de suite utilisé, qui plus est par des centres de recherches et les universités, c'est-à-dire les premiers a avoir utilisé les réseaux de manière poussée. Le manque de normalisation de TCP/IP a été contre-balancé par une implémentation rapide et efficace, et une utilisation dans un milieu propice à sa propagation.
5 - L'avenir d'OSI
Au niveau de son utilisation et implémentation, et ce malgré une mise à jour du modèle en 1994, OSI a clairement perdu la guerre face à TCP/IP. Seuls quelques grands constructeurs dominant conservent le modèle mais il est amené à disparaître d'autant plus vite qu'Internet (et donc TCP/IP) explose.
Le modèle OSI restera cependant encore longtemps dans les mémoires pour plusieurs raisons. C'est d'abord l'un des
premiers grands efforts en matière de normalisation du monde des réseaux. Les constructeurs ont maintenant tendance à faire avec TCP/IP, mais aussi le WAP, l'UMTS etc. ce qu'il devait faire avec OSI, à savoir proposer des normalisations dès le départ. OSI marquera aussi les mémoires pour une autre raison : même si c'est TCP/IP qui est concrètement utilisé, les gens ont tendance et utilisent OSI comme le modèle réseau de référence actuel. En fait, TCP/IP et OSI ont des structures très proches, et c'est surtout l'effort de normalisation d'OSI qui a imposé cette "confusion" générale entre les 2 modèles. On a communément tendance à considérer TCP/IP comme l'implémentation
réelle de OSI.
Les Rfc
Les Rfc (Requests for Comments) sont des documents officiels spécifiant les différentes implémentations, standardisations, normalisations représentant alors la définition de TcpIp. Ces documents sont utilisés par Ietf
(Internet Engineering Task Force) ainsi que d'autre organismes de normalisation. Depuis 1969, plus de 3500 documents ont été rédigés. Les Rfc sont classées, selon cinq classifications qui sont obligatoire, recommandé, facultatif, limitée, non recommandé ainsi que trois niveaux de maturité qui sont standard proposé, standard brouillon, standard internet. Lorsqu'un document est publié, un numéro de Rfc lui est attribué et en cas d'évolution, un nouveau

document sera publié sous une autre référence. Une Rfc très intéressante relate les divers fonctionnement de toute cette partie administrative. La Rfc 3160 nommé Tao de l'Ietf traite des sujets tels que le processus de standardisation des Rfcs, les rôles des différentes organisations, le fonctionnement interne de l'Ietf et etc.
Voici la liste des différentes Rfc référencées sur le site FrameIP.
TAO
Rfc 3160 RFC : A Novice's Guide to the Internet Engineering Task Force
Rfc 3160-fr RFC : Un guide pour la participation aux travaux de l'Internet Engineering Task Force
ATM
Rfc 1483 RFC : Multiprotocol Encapsulation over ATM Adaptation Layer 5
Rfc 2684 RFC : Multiprotocol Encapsulation over ATM Adaptation Layer 5
Ethernet
Rfc 894 RFC : Un Standard pour la Transmission des Datagrammes IP sur les Réseaux Ethernet
Rfc 894-err RFC : Errata de la RFC 894
Rfc 3580 RFC : IEEE 802.1X Remote Authentication Dial In User Service (RADIUS) Usage Guidelines
Rfc 3748 RFC : Extensible Authentication Protocol (EAP)
PPP
Rfc 1661 RFC : The Point-to-Point Protocol (PPP)
Rfc 2153 RFC : PPP Vendor Extensions
PPPOE
Rfc 2516 RFC : A Method for Transmitting PPP Over Ethernet (PPPoE)
Rfc 2516-fr RFC : Une méthode pour la transmission du PPP sur ethernet
PPTP
Rfc 2637 RFC : Point-to-Point Tunneling Protocol (PPTP)
Rfc 2637-fr RFC : Protocole de transmission sous tunnel point à point
IP
Rfc 791 RFC : Internet Protocol
Rfc 791 fr RFC : Internet Protocol
Rfc 815 RFC : Ip Datagram Reassembly Algorithms
Rfc 1071 RFC : Computing the Internet Checksum
Rfc 1340 RFC : Assigned Numbers (Remplacé par la RFC 1700)
Rfc 1700 RFC : Assigned Numbers
Rfc 1349 RFC : Type of Service in the Internet Protocol Suite
Rfc 1517 RFC : Applicability Statement for the Implementation of Classless Inter-Domain Routing (CIDR)
Rfc 1518 RFC : An Architecture for IP Address Allocation with CIDR
Rfc 1519 RFC : Classless Inter-Domain Routing (CIDR): an Address Assignment and Aggregation Strategy
Rfc 1631 RFC : The IP Network Address Translator (NAT)
Rfc 1878 RFC : Variable Length Subnet Table For IPv4
Rfc 1918 RFC : Address Allocation for Private Internets

IPv6
Rfc 2460 RFC : Internet Protocol, Version 6 (IPv6) - Specification
Rfc 4302 RFC : IP Authentication Header
Rfc 4303 RFC : IP Encapsulating Security Payload (ESP)
ARP/RARP
Rfc 826 RFC : An Ethernet Address Resolution Protocol
Rfc 5227 RFC : IPv4 Address Conflict Detection
Rfc 903 RFC : A Reverse Address Resolution Protocol
IGMP
Rfc 1112 RFC : Host Extensions for Ip Multicasting
Rfc 2236 RFC : Internet Group Management Protocol, Version 2
ICMP
Rfc 792 RFC : Internet Control Message Protocol
Rfc 792-fr RFC : Internet Control Message Protocol
Rfc 1256 RFC : Icmp Router Discovery Messages
TCP
Rfc 793 RFC : Transmission Control Protocol
Rfc 793-fr RFC : Transmission Control Protocol
Rfc 896 RFC : Congestion Control in Ip/Tcp Internetworks
Rfc 1071 RFC : Computing the Internet Checksum
Rfc 1340 RFC : Assigned Numbers
Rfc 1323 RFC : TCP Extensions for High Performance
Rfc 2018 RFC : TCP Selective Acknowledgment Options
UDP
Rfc 768 RFC : User Datagram Protocol
Rfc 768-fr RFC : User Datagram Protocol
Rfc 1071 RFC : Computing the Internet Checksum
Rfc 1340 RFC : Assigned Numbers
DHCP
Rfc 951 RFC : Bootstrap Protocol (Bootp)
Rfc 951-fr RFC : Protocole d'amorçage (Bootp)
Rfc 1497 RFC : Bootp Vendor Information Extensions
Rfc 1541 RFC : Dynamic Host Configuration Protocol
Rfc 1542 RFC : Clarifications and Extensions for the Bootstrap Protocol
Rfc 2131 RFC : Dynamic Host Configuration Protocol
Rfc 2131-fr RFC : Protocole de configuration dynamique de machine (DHCP)
Rfc 2132 RFC : Dhcp Options and Bootp Vendor Extensions
Rfc 2132-fr RFC : Options DHCP et Extensions fournisseur BOOTP
IPSEC
Rfc 2401 RFC : Security Architecture for the Internet Protocol
Rfc 2401-fr RFC : Architecture de sécurité pour IP
Rfc 2402 RFC : IP Authentication Header
Rfc 2406 RFC : IP Encapsulating Security Payload (ESP)
Rfc 2408 RFC : Internet Security Association and Key Management Protocol (ISAKMP)
Rfc 2409 RFC : The Internet Key Exchange (IKE)
Rfc 3095 RFC : Robust Header Compression (ROHC)
L2TP
Rfc 2661 RFC : Layer Two Tunneling Protocol "L2TP"
DNS
Rfc 1033 RFC : Domain adminstrators operations guide
Rfc 1034 RFC : Domain Names - Concepts and facilities
Rfc 1034-fr RFC : Domain Name Server (Concepts de base)
Rfc 1035 RFC : Domain Names - Implementation and specification
Rfc 1591 RFC : Domain Name System Structure and Delegation
rfc 5358 Preventing Use of Recursive Nameservers in Reflector Attacks
SIP
Rfc 3261 RFC : SIP: Session Initiation Protocol
Rfc 3265 Session Initiation Protocol (SIP)-Specific Event Notification
Rfc 3853 S/MIME Advanced Encryption Standard (AES) Requirement for the Session Initiation Protocol (SIP)
Rfc 4320 Actions Addressing Identified Issues with the Session Initiation Protocol's (SIP) Non-INVITE Transaction
Rfc 4916 Connected Identity in the Session Initiation Protocol (SIP)
Rfc 5393 Addressing an Amplification Vulnerability in Session Initiation Protocol (SIP) Forking Proxies
Rfc 2327 SDP: Session Description Protocol
RTP
Rfc 3550 RFC : RTP: A Transport Protocol for Real-Time
Rfc 2032 RFC : RTP Payload Format for H.261 Video
Rfc 3711 RFC : The Secure Real-time Transport Protocol (SRTP)
MPLS
Rfc 2547 RFC : BGP/MPLS VPNs
NNTP
Rfc 977 RFC : Network News Transfer Protocol
NTP
Rfc 868 RFC : Time Protocol
Rfc 1059 RFC : Network Time Protocol (Version 1)
Rfc 1119 RFC : Network Time Protocol (Version 2)
Rfc 1305 RFC : Network Time Protocol (Version 3)
Rfc 4330 RFC : Simple Network Time Protocol (SNTP) Version 4
SNMP

Rfc 1155 RFC : V1 - Structure and identification of management information for TCP/IP-based internets
Rfc 1441 RFC : v2c - Introduction to version 2 of the Internet-standard Network Management Framework
Rfc 1901 RFC : V2 - Introduction to Community-based SNMPv2
Rfc 3411 RFC : V3 - An Architecture for Describing SNMP Management Frameworks
Rfc 3826 RFC : The Advanced Encryption Standard (AES) in the SNMP User-based Security Model
SSL - TLS
draft xxx RFC : The SSL Protocol Version 2.0
draft 302 RFC : The SSL Protocol Version 3.0
Rfc 2246 RFC : The TLS Protocol Version 1.0
Rfc 3546 RFC : Transport Layer Security (TLS) Extensions
Rfc 4366 RFC : Transport Layer Security (TLS) Extensions
STUN
Rfc 3489
RFC : STUN - Simple Traversal of User Datagram Protocol (UDP) Through Network Address Translators (NATs)
Rfc 5389 RFC : Session Traversal Utilities for NAT (STUN)
FTP
Rfc 959 RFC : File Transfert Protocol (FTP)
HTTP
Rfc 2616 RFC : Hypertext Transfer Protocol -- HTTP/1.1
Rfc 2109 RFC : HTTP State Management Mechanism
HSRP
Rfc 2281 RFC : Cisco Hot Standby Router Protocol (HSRP)
Divers
Rfc 822 RFC : Standard for the format of ARPA Internet text messages
Les entêtes
Entête Ethernet
1 - L'histoire 2 - Définition du protocole 3 - CSMA/CD
4 - Structure de l'entête 5 - Définition des différents champs 5.1 - Préambule 5.2 - SFD 5.3 - Adresse destination 5.4 - Adresse source 5.5 - Ether Type
5.6 - 802.1Q 5.6.1 - Priorité 5.6.2 - CFI 5.6.3 - VLAN ID 5.6.4 - EtherType

5.7 - Données 5.8 - FCS 6 - Les types d'équipements 6.1 - Le répéteur (Repeater) 6.2 - Le HUB (Concentrateur)
6.3 - Le commutateur (Switch) 6.4 - Le pont (Bridge)
6.5 - Le routeur (Gateway) 6.6 - Synthèse des équipements 7 - Discussion autour de la documentation 8 - Suivi du document
1 - L'histoire
Le premier LAN Ethernet fut conçu au milieu des années 1970 par Robert Metcalfe et son assistant David Boggs. Le débit original était de 2,94 Mbps. Robert Metcalfe était un membre de la direction de recherche pour Xerox. Il travaillait au centre de recherche Palo Alto au USA (PARC : Palo Alto Research Center) où certains des premiers PC ont été construits. Il quitta Xerox en 1979 pour promouvoir l'utilisation du PC (personal computer) et du LAN (Local Areas Network). Il a réussit à convaincre les entreprises Digital Equipment, Intel et Xerox de travailler ensemble pour promouvoir l'Ethernet comme un standard.
Jusqu'au début des années 1990, Ethernet n'était qu'une technologie parmi d'autres bien d'autres tel que Token Ring (IEEE 802.5), FDDI (802.7), ATM et etc. La technologie Ethernet a conquis depuis la majeure partie du marché. Cela grâce aux point suivants :
- Première technologie LAN haut débit grand public - Les autres technologies sont sensiblement plus complexes - Usage d'un protocol entièrement décentralisé (CSMA/CD) synonyme de simplicité. Toutes les stations sont égales vis-à-vis du réseau, il n'y a pas d'équipement maître de contrôle du réseau - il est possible de connecter ou retirer une machine du réseau sans perturber le fonctionnement de l'ensemble - Un coût de l'équipement beaucoup plus faible que ses technologies concurrentes
De plus, Ethernet paraît être en bonne position pour conserver son statut de technologie prédominante pendant encore de nombreuses années.
Une RFC spécifique a été écrite spécialement pour l'interaction entre Ethernet et un datagramme IP. (Un Erratumest paru)
2 - Définition du protocole
La technologie Ethernet se décline dans de nombreuses variantes tel que :
- Deux topologies différentes qui sont bus et étoile - Multi supports permettant d'être capable de faire usage de câbles coaxiaux, de fils en cuivre à paires torsadées ou de fibres optiques. - Une Offre d'une large gamme de débit avec 10 Mbps, 100 Mbps, 1 Gbps et 10 Gbps
L'Ethernet est basé sur un principe de dialogue sans connexion et donc sans fiabilité. Les trames sont envoyées par l'adaptateur sans aucune procédure de type « handshake » avec l'adaptateur destinataire. Le service sans connexion
d'Ethernet est également non-fiable, ce qui signifie qu'aucun acquittement, positif ou négatif, n'est émis lorsqu'une trame passe le contrôle CRC avec succès ou lorsque celle-ci échoue. Cette absence de fiabilité constitue sans doute la clé de la simplicité et des coûts modérés des systèmes Ethernet. Ce service de couche 2 du modèle OSI est similaire au service en mode datagramme de couche 3 assuré par IP et au service sans connexion de couche 4 d'UDP.

3 - CSMA/CD
Les noeuds d'un réseau LAN Ethernet sont reliés les uns aux autres par un canal à diffusion. Lorsqu'un adaptateur transmet une trame, tous les autres adaptateurs la reçoivent. Ethernet repose sur un algorithme d'accès multiple
CSMA/CD, signifiant Carrier Sense Multiple Access with Collision Detection C'est un protocole permettant la discussion sur un réseau de type Ethernet.
Voici les règles schématiques du protocole de discussion CSMA/CD :
- Les adaptateurs peuvent commencer à transmettre à n'importe quel moment - Les adaptateurs ne transmettent jamais lorsqu'ils détectent une activité sur le canal - Les adaptateurs interrompent leur transmission dès qu'ils détectent l'activité d'un autre adaptateur au sein du canal (détection de collisions) - Avant de procéder à la retransmission d'une trame, les adaptateurs patientent pendant une durée aléatoire relativement courte
Voici le fonctionnement détaillé étape par étape du dialogue sur un réseau Ethernet :
1- L'adaptateur Ethernet obtient un datagramme de la couche Réseau. Il prépare alors une trame en ajoutant les entêtes Ethernet avant et après ce datagramme. Puis il place cette trame Ethernet dans sa mémoire tampon 2 - Si l'adaptateur Ethernet ne détecte aucune activité sur le média physique, il commence à transmettre la trame préparée. Si le média est occupé, il se met en attente jusqu'à la fin du signal d'énergie (plus 96 fois la durée d'un bit) et commence alors la transmission de la trame
3 - Pendant la transmission, l'adaptateur continu de surveiller qu'il n'y a aucun autre signal en provenance d'un autre adaptateur. Si c'est le cas, il poursuit la transmission de la trame jusqu'au bout
4 - Si l'adaptateur Ethernet détecte le début d'une autre transmission, il interrompt la sienne et envoie un signal de brouillage de 48 bits
5 - Après cette interruption, l'adaptateur entre dans une phase d'attente exponentielle appelée "exponential backoff phase". Après la nième collision consécutive au cours de la transmission d'une trame, un adaptateur choisit de façon aléatoire une valeur K dans l'ensemble {0, 1, 2,..., 2m-1}, dans lequel m=min(n,10). Il attend ensuite K x 512 fois la durée d'un bit, puis revient à l'étape 2. Ce tirage aléatoire permet d'éviter que les deux adaptateurs transmettent de nouveau ensemble.
Voici les astuces et avantages employés par le protocole CSMA/CD :
- Le rôle des signaux de brouillage est d'informer tous les autres adaptateurs des collisions qui se produisent sur le média - La norme Ethernet impose des limites à la distance entre 2 stations au sein d'un LAN. Cette limite permet de garantir que si un adaptateur choisit une valeur de K inférieure à celle de tous les autres adaptateurs impliqués dans une collision, il pourra transmettre sa trame sans risquer une nouvelle collision - L'avantage d'une attente exponentielle est que cela permet de s'adapter au nombre d'adaptateurs impliqués dans une collision
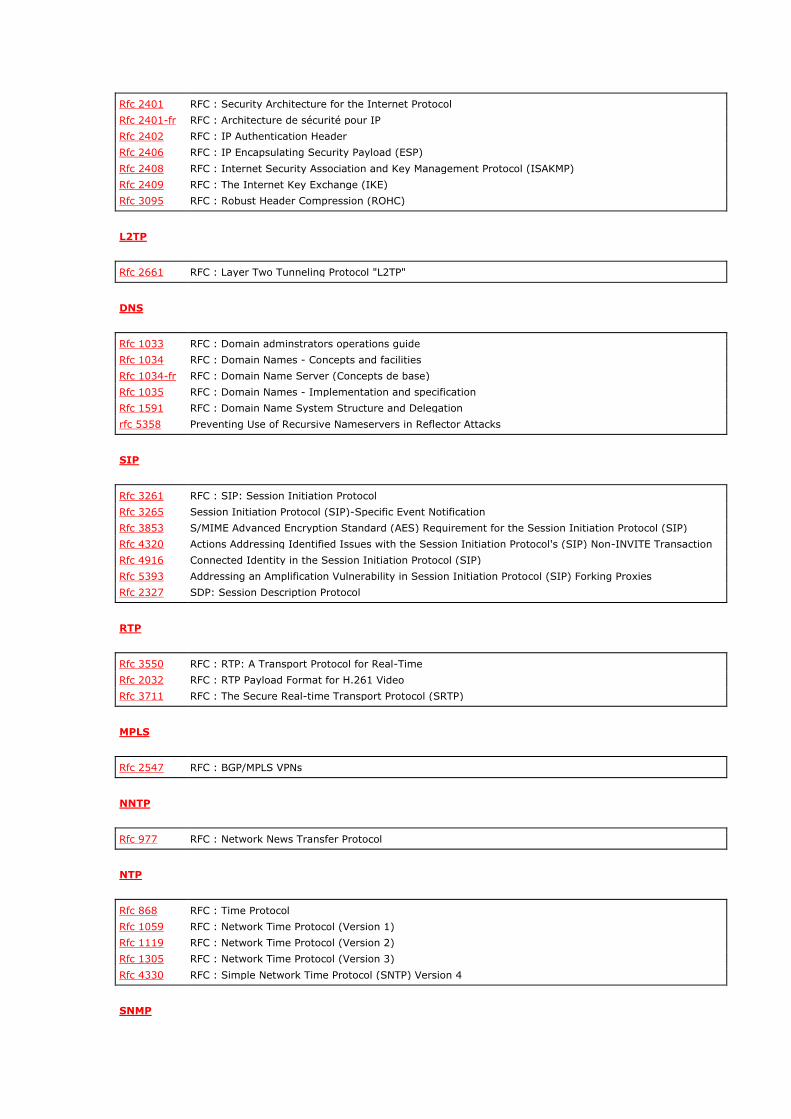
4 - Structure de l'entête
Voici un exemple d'une trame Ethernet saisie avec Ethereal. Vous trouverez ci-dessous sa structure basé sur 14 octets.
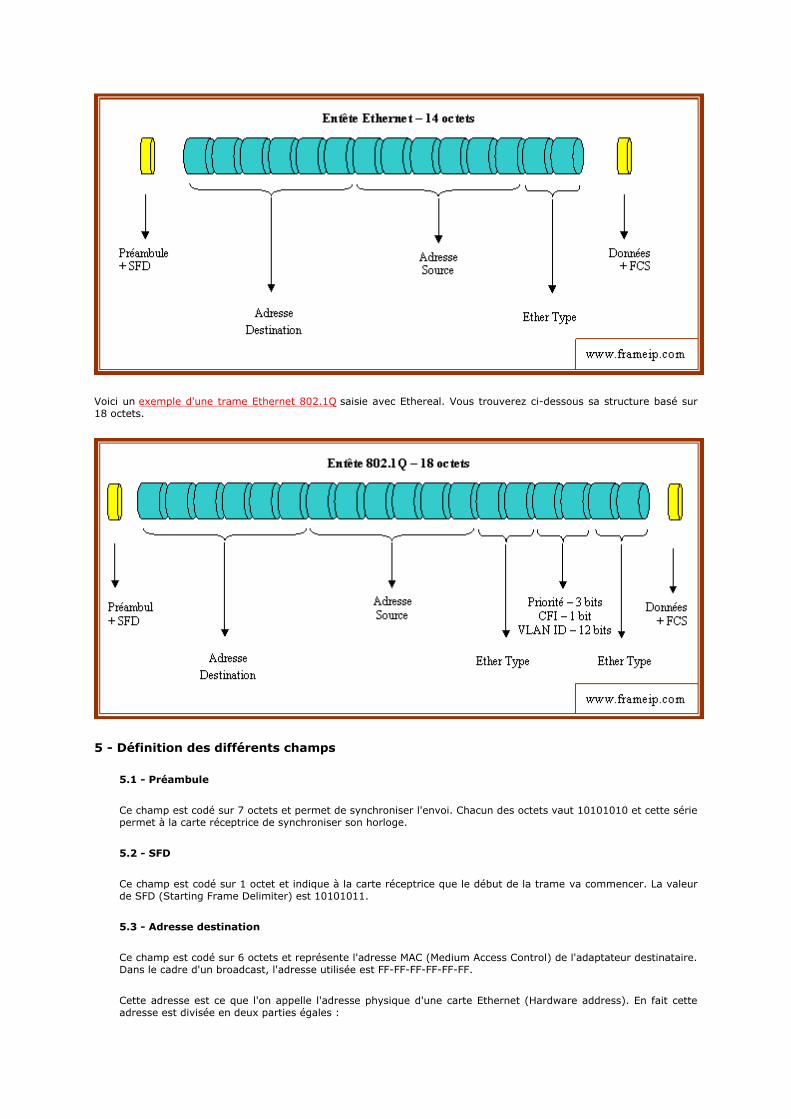
Voici un exemple d'une trame Ethernet 802.1Q saisie avec Ethereal. Vous trouverez ci-dessous sa structure basé sur 18 octets.
5 - Définition des différents champs
5.1 - Préambule
Ce champ est codé sur 7 octets et permet de synchroniser l'envoi. Chacun des octets vaut 10101010 et cette série permet à la carte réceptrice de synchroniser son horloge.
5.2 - SFD
Ce champ est codé sur 1 octet et indique à la carte réceptrice que le début de la trame va commencer. La valeur de SFD (Starting Frame Delimiter) est 10101011.
5.3 - Adresse destination
Ce champ est codé sur 6 octets et représente l'adresse MAC (Medium Access Control) de l'adaptateur destinataire. Dans le cadre d'un broadcast, l'adresse utilisée est FF-FF-FF-FF-FF-FF.
Cette adresse est ce que l'on appelle l'adresse physique d'une carte Ethernet (Hardware address). En fait cette adresse est divisée en deux parties égales :

- Les trois premiers octets désignent le constructeur. C'est le l'organisation OUI (Organizationally Unique Identifier) gérer par l'IEEE, qui référence ces correspondances. - Les trois derniers octets désignent le numéro d'identifiant de la carte, dont la valeur est laissée à l'initiative du constructeur qui possède le préfixe
L'association de l'IEEE et du constructeur assure ainsi l'unicité de l'attribution des numéros d'adresse MAC.
5.4 - Adresse source
Ce champ est codé sur 6 octets et représente l'adresse MAC (Medium Access Control) de l'adaptateur émetteur.
Cette adresse est ce que l'on appelle l'adresse physique d'une carte Ethernet (Hardware address). En fait cette adresse est divisée en deux parties égales :
- Les trois premiers octets désignent le constructeur. C'est le l'organisation OUI (Organizationally Unique Identifier) gérer par l'IEEE, qui référence ces correspondances. - Les trois derniers octets désignent le numéro d'identifiant de la carte, dont la valeur est laissée à l'initiative du constructeur qui possède le préfixe
L'association de l'IEEE et du constructeur assure ainsi l'unicité de l'attribution des numéros d'adresse MAC.
5.5 - Ether Type
Ce champ est codé sur 2 octets et indique le type de protocole inséré dans le champ donnée. Voici un extrait des différentes correspondances :
0x6000 - DEC 0x0609 - DEC 0x0600 - XNS 0x0800 - IPv4
0x0806 - ARP 0x8019 - Domain 0x8035 - RARP 0x809B - AppleTalk 0x8100 - 802.1Q 0x86DD - IPv6
Dans le cadre d'une trame VLAN taggé 802.1Q, ce champs doit être à 0x8100 afin de spécifier l'ajout des 4 octets suivants.
5.6 - 802.1Q
5.6.1 - Priorité
Ce champ est codé sur 3 bits et représente une information sur la priorité de la trame. Il y a donc 8 niveaux où 000 représente une priorité basse et 111 une haute.
5.6.2 - CFI
Ce champ est codé sur 1 bit et doit être marqué à 0. CFI (canonical format indicator) est utilisé pour des raisons de compatibilité entre les réseaux Ethernet et les réseaux de type Token ring.
5.6.3 - VLAN ID
Ce champ est codé sur 12 bits et représente le numéro du VLAN. Il est donc possible d'intégrer la trame dans 1 VLAN parmi 4096 possibilités. La valeur 0 indique qu'il n'y a pas de VLAN, c'est souvent utilisée dans le cas où l'on désire appliquer une priorité sans avoir besoin de la notion de VLAN.
5.6.4 - EtherType
Ce champ est codé sur 2 octets et indique le type de protocole inséré dans le champ donnée. Voici un extrait des différentes correspondances :
0x6000 - DEC 0x0609 - DEC

0x0600 - XNS 0x0800 - IPv4 0x0806 - ARP 0x8019 - Domain 0x8035 - RARP
0x809B - AppleTalk 0x86DD - IPv6
5.7 - Données
Ce champ est codé entre 46 et 1500 octets et contient les données de la couche 3. Dans le cas de TCP/IP, c'est ici que vient se loger le datagramme IP. L'unité de transfert maximale est le MTU (Maximale Transfer Unit) et sa valeur est classiquement de 1500 octets. Si la taille des données est inférieure à 46 octets, alors elle devra être complétée avec des octets de bourrage (padding) et c'est la couche réseau qui sera chargée de les éliminer.
5.8 - FCS
Ce champ est codé sur 4 octets et représente la séquence de contrôle de trame. Il permet à l'adaptateur qui
réceptionnera cette trame de détecter toute erreur pouvant s'être glissée au sein de la trame.
Les erreurs binaires sont principalement créées par les variations d'affaiblissement du signal et l'induction électromagnétique parasite dans les câbles Ethernet ou les cartes d'interface. La valeur de FCS (Frame Check Sequence) est le résultat d'un calcul polynomial appelé CRC (Cyclic Redundancy Code). A la réception de la trame, la couche liaison effectue le même calcul et compare les deux résultats qui doivent être égaux afin de valider la conformité de la trame reçue.
6 - Les types d'équipements
6.1 - Le répéteur (Repeater)
Cet équipement agît au niveau 1 du modèle OSI. Sa fonction est de répéter un signal électrique en le régénérant. L'avantage est de pouvoir augmenter la distance physique, cependant, l'inconvénient est qu'il répète aussi le bruit du fait qu'il n'applique aucun filtre ni contrôle.
6.2 - Le HUB (Concentrateur)
Cet équipement agît au niveau 1 du modèle OSI. Sa fonction est d'interconnecter plusieurs cartes d'interfaces ensembles. Ainsi, chaque signal électrique reçu est rediffusé sur tous les autres ports du HUB.
Dans le cadre d'un HUB 100Mbps, on obtient un débit partagé de 100Mbps pour l'ensemble de équipement Ethernet raccordé.
6.3 - Le commutateur (Switch)

Cet équipement agît au niveau 2 du modèle OSI. Identiquement à un HUB, sa fonction est d'interconnecter plusieurs cartes d'interfaces ensembles. Cependant, lorsqu'il réceptionne une trame, il compare l'adresse MAC de destination avec sa table de correspondance. Ainsi, il ne diffuse cette trame uniquement sur le port physique concerné.
Dans le cadre d'un Switch 100Mbps, on obtient un débit dédié de 100Mbps par équipement Ethernet raccordé. les caractéristiques principales à vérifier lors de la sélection d'un Switch sont :
- Le nombre d'adresse MAC maximum qui peuvent mise en mémoire
- Le nombre de paquet par seconde (PPS) que la matrice de fond de panier peux commuter
6.4 - Le pont (Bridge)
Cet équipement agît au niveau 2 du modèle OSI. Il permet d'interconnecter deux réseaux de Liaison différente. Par exemple, on trouvera fréquemment des ponts permettant de relier des réseaux :
- Ethernet et WIFI - Ethernet et Token Ring
6.5 - Le routeur (Gateway)
Cet équipement agît au niveau 3 du modèle OSI. Il permet de relier plusieurs réseau IP différents. Pour cela, lorsqu'il reçoit une trame, il compare l'adresse IP destination du datagramme avec sa table de routage et route ce
datagramme sur l'interface de sortie correspondante.
6.6 - Synthèse des équipements
Voici une synthèse comparative des différents équipements Ethernet :

Entête IP
1 - Définition du protocole 2 - Structure de l'entête
3 - Définition des différents champs 3.1 - Vers 3.2 - IHL 3.3 - Service 3.4 - Longueur totale 3.5 - Identification 3.6 - Flags
3.7 - Position fragment 3.8 - TTL 3.9 - Protocole 3.10 - Checksum
3.11 - Adresse IP source 3.12 - Adresse IP destination 3.13 - Options
3.14 - Bourrage 4 - Discussion autour de la documentation 5 - Suivi du document
1 - Définition du protocole IP
IP signifie "Internet Protocol", protocole Internet. Il représente le protocole réseau le plus répandu. Il permet de
découper l'information à transmettre en paquets, de les adresser, de les transporter indépendamment les uns des autres et de recomposer le message initial à l'arrivée. Ce protocole utilise ainsi une technique dite de commutation de paquets. Il apporte, en comparaison à Ipx/Spx et Netbeui, l'adressage en couche 3 qui permet, par exemple, la fonction principale de routage. Il est souvent associé à un protocole de contrôle de la transmission des données appelé TCP, on parle ainsi du protocole TCP/IP. Cependant, TCP/IP est un ensemble de protocole dont voici les plus connu.
- IP - Internet Protocol - Couche 3 - IP natif. - ARP - Address Resolution Protocol - Couche 3 - Résolution d'adresse IP en adresse MAC. - RARP - Reverse Address Resolution Protocol - Couche 3 - Résolution d'adresse MAC en adresse IP. - ICMP - Internet Control Message Protocol - Couche 3 - Gestion des messages du protocole IP. - IGMP - Internet Group Management Protocol - Couche 3 - Protocole de gestion de groupe.
- TCP - Transmission Control Protocol - Couche 4 - Transport en mode connecté.
- UDP - User Datagram Protocol - Couche 4 - Transport en mode non connecté. Vous trouverez tous les détails du protocole IP dans la Rfc 791.
2 - Structure de l'entête
Voici la structure de l'entête IP basé sur 20 octets.

Voici le complément de l'entête IP qui est optionnel basé sur 4 octets.
3 - Définition des différents champs
3.1 - Le champ Vers
Le champ version est codé sur 4 bits. Il représente le numéro de version du protocole IP. Il permet aux piles IP réceptionnant la trame de vérifier le format et d'interpréter correctement la suite du paquet. C'est d'ailleurs pour cette raison qu'il est placé au début, une version inconnue par un équipement conduit au rejet direct.
Voici la liste des différent codes. - 00 - Réservé - 01 - Non assigné - 02 - Non assigné
- 03 - Non assigné - 04 - IP V4 - 05 - ST Datagram Mode - 06 - IP V6 - 07 - Non assigné - 08 - Non assigné - 09 - Non assigné
- 10 - Non assigné - 11 - Non assigné - 12 - Non assigné

- 13 - Non assigné - 14 - Non assigné - 15 - Réservé
3.2 - IHL
IHL signifie "Internet header lengh". ce champ est codé sur 4 bits et représente la longueur en mots de 32 bits de l'entête IP. Par défaut, il est égal à 5 (20 octets), cependant, avec les options de l'entête IP, il peut être compris entre 6 et 15.
Le fait que le codage soit sur 4 bits, la taille maximum de l'entête IP est donc de 15*32bits = 60 octets
3.3 - Service
Le champs service "Type Of Service" est codé sur 8 bits, il permet la gestion d'une qualité de service traitée directement en couche 3 du modèle OSI. Cependant, la plupart des équipements de Backbone, ne tiennent pas compte de ce champ et même certain le réinitialise à 0.
Voici la composition du champ Service :
Vous trouverez tous les détails du champ Service TOS "Type Of Service" dans la Rfc 1349.
3.3.1 - Priorité
Le champ Priorité "Precedence" est codé sur 3 bits. Il indique la priorité que possède la paquet. Voici les correspondances des différentes combinaisons :
- 0 - 000 - Routine - 1 - 001 - Prioritaire
- 2 - 010 - Immédiat - 3 - 011 - Urgent - 4 - 100 - Très urgent - 5 - 101 - Critique
- 6 - 110 - Supervision interconnexion - 7 - 111 - Supervision réseau
3.3.2 - Délai
Le champ Délai "Delay" est codé sur 1 bit. Il indique l'importance du délai d'acheminement du paquet. Voici les correspondances des différentes combinaisons : - 0 - Normal - 1 - Bas

3.3.3 - Débit
Le champ Débit "Throughput" est codé sur 1 bit. Il indique l'importance du débit acheminé. Voici les correspondances des différentes combinaisons :
- 0 - Normal - 1 - Haut
3.3.4 - Fiabilité
Le champ Fiabilité "Reliability" est codé sur 1 bit. Il indique l'importance de la qualité du paquet. Voici les correspondances des différentes combinaisons : - 0 - Normal - 1 - Haute
3.3.5 - Coût
Le champ Coût "Cost" est codé sur 1 bit. Il indique le coût du paquet. Voici les correspondances des
différentes combinaisons : - 0 - Normal - 1 - Faible
3.3.6 - MBZ
Le champ MBZ "Must Be Zero" est codé sur 1 bit. Comme son nom l'indique, il doit être mis à 0.
3.4 - Longueur totale
Le champ Longueur totale est codé sur 16 bits et représente la longueur du paquet incluant l'entête IP et les Data associées. La longueur totale est exprimée en octets, ceci permettant de spécifier une taille maximum de 216 =
65535 octets. La longueur des Data est obtenu par la combinaison des champs IHL et Longueur totale : Longueur_des_data = Longueur_totale - ( IHL * 4 );
3.5 - Identification
Le champ Identification est codé sur 16 bits et constitue l'identification utilisée pour reconstituer les différents fragments. Chaque fragment possède le même numéro d'identification, les entêtes IP des fragments sont
identiques à l'exception des champs Longueur totale, Checksum et Position fragment. Vous trouverez tous les détails des mécanismes de fragmentation et de réassemblage dans la Rfc 815.
3.6 - Flags
Le champ Flags est codé sur 3 bits et indique l'état de la fragmentation. Voici le détail des différents bits constituant ce champ.
3.6.1 - Reserved
Le premier bit est réservé et positionné à 0.
3.6.2 - DF
Appelé DF "Don't Fragment", le second bit permet d'indiqué si la fragmentation est autorisée. Si un Datagramme devant être fragmenté possède le flag DF à 1, alors, il sera alors détruit.
3.6.3 - MF
Appelé MF "More Fragments", le troisième bit indique s'il est à 1 que le fragment n'est pas le dernier.
3.7 - Position fragment

Le champ Position fragment est codé sur 13 bits et indique la position du fragment par rapport à la première trame. Le premier fragment possède donc le champ Position fragment à 0.
3.8 - TTL
Le champ TTL (Time To Live) est codé sur 8 bits et indique la durée de vie maximale du paquet. Il représente la durée de vie en seconde du paquet. Si le TTL arrive à 0, alors l'équipement qui possède le paquet, le détruira. Attention, à chaque passage d'un routeur le paquet se verra décrémenté de une seconde. De plus, si le paquet
reste en file d'attente d'un routeur plus d'une seconde, alors la décrémentation sera plus élevée. Elle sera égale au nombre de seconde passé dans cette même file d'attente. Par défaut, si les temps de réponse sont corrects, alors on peut, entre guillemet, en conclure que le Time To Live représente le nombre de saut maximum du niveau. Le but du champ TTL est d'éviter de faire circuler des trames en boucle infinie.
3.9 - Protocole
Le champ Protocole est codé sur 8 bits et représente le type de Data qui se trouve derrière l'entête IP.
Vous trouverez tous les détails des types de protocole dans la Rfc 1700 qui remplace désormais la Rfc 1340. Voici la liste des protocoles les plus connu : - 01 - 00001 - ICMP - 02 - 00010 - IGMP
- 06 - 00110 - TCP - 17 - 10001 - UDP
3.10 - Checksum
Le champ Checksum est codé sur 16 bits et représente la validité du paquet de la couche 3. Pour pouvoir calculer le Checksum, il faut positionner le champ du checksum a 0 et ne considérer que l'entête IP. Donc par exemple, si deux trames ont la même entête IP (y compris le champ length) et deux entêtes ICMP et Data différentes (mais
de même longueur), le checksum IP sera alors le même. Voici un exemple de fonction permettant le calcul du checksum IP
unsigned short calcul_du_checksum(bool liberation, unsigned short *data, int taille)
{ unsigned long checksum=0; // ******************************************************** // Complément à 1 de la somme des complément à 1 sur 16 bits // ******************************************************** while(taille>1)
{ if (liberation==TRUE) liberation_du_jeton(); // Rend la main à la fenêtre principale checksum=checksum+*data++; taille=taille-sizeof(unsigned short); }
if(taille) checksum=checksum+*(unsigned char*)data;
checksum=(checksum>>16)+(checksum&0xffff); checksum=checksum+(checksum>>16); return (unsigned short)(~checksum);
}
Vous trouverez tous les détails du Checksum IP dans la Rfc 1071.
Tous les équipements de niveau 3, tel que les routeurs, devront recalculer le Checksum, car il décrémente le champs TTL. De plus, toutes les fonctions de niveau 3 à 7, tel que la NAT, le PAT, modifiant le contenu de l'entête IP ou des Data, devront recalculer le Checksum.
3.11 - Adresse IP source
Le champ IP source est codé sur 32 bits et représente l'adresse IP source ou de réponse. Il est codé sur 4 octets qui forme l'adresse A.B.C.D.

3.12 - Adresse IP destination
Le champ IP destination est codé sur 32 bits et représente l'adresse IP destination. Il est codé sur 4 octets qui forme l'adresse A.B.C.D.
3.13 - Options
Le champ Options est codé entre 0 et 40 octets. Il n'est pas obligatoire, mais permet le "Tuning de l'entête IP". Afin de bien gérer les Options, cela doit commencer par un octets de renseignement. Voici le détail de cette octet :
3.13.1 - Copie
Le champ Copie est codé sur 1 bit et indique comment les options doivent être traitées lors de la fragmentation. Cela signifie que lorsqu'il est positionné à 1, il faut recopier les options dans chaque paquet fragmenté.
3.13.2 - Classe
Le champ Classe est codé sur 2 bits et indique les différentes catégorie d'options existantes. Voici la liste des différentes classe possible : - 0 - 00 - Supervision de réseau - 1 - 01 - Non utilisé
- 2 - 10 - Debug et mesures - 3 - 11 - Non utilisé
3.13.3 - Numéro
Le champ Numéro est codé sur 5 bits et indique les différentes options existantes. Voici la liste des différents numéros possibles par Classe : Classe 0, - 0 - 00000 - Fin de liste d'option. Utilisé si les options ne se terminent pas à la fin de l'en-tête (bourrage).
- 1 - 00001 - Pas d'opération. Utilisé pour aligner les octets dans une liste d'options. - 2 - 00010 - Restriction de sécurité et de gestion. Destiné aux applications militaires. - 3 - 00011 - Routage lâche défini par la source. - 7 - 00111 - Enregistrement de route. - 8 - 01000 - Identificateur de connexion. - 9 - 01001 - Routage strict défini par la source.
Classe 2, - 4 - 00100 - Horodatage dans l'Internet.

3.14 - Bourrage
Le champ Bourrage est de taille variable comprise entre 0 et 7 bits. Il permet de combler le champ option afin d'obtenir une entête IP multiple de 32 bits. La valeur des bits de bourrage est 0.
Entête Arp
1 - Définition du protocole 2 - Structure de l'entête 3 - Définition des différents champs
3.1 - Hardware type 3.2 - Protocol type 3.3 - Hardware Address Length 3.4 - Protocol Address Length 3.5 - Operation 3.6 - Sender Hardware Address
3.7 - Sender Internet Address 3.8 - Target Hardware Address 3.9 - Target Internet Address 4 - Fonctionnement 4.1 - Arp Request 4.2 - Arp Reply 4.3 - Le cache
4.3.1 - Le cache des hôtes 4.3.2 - Le cache dans la Rfc 5 - Discussion autour de la documentation 6 - Suivi du document
1 - Définition du protocole
Le protocole Arp, signifiant Address Resolution Protocol, fonctionne en couche Internet du modèle TCP/IPcorrespondant à la couche 3 du modèle Osi. L'objectif de Arp est de permettre la résolution d'une adresse physique par l'intermédiaire de l'adresse IP correspondante d'un host distant. Le protocole Arp apporte un mécanisme de « translation » pour résoudre ce besoin. Vous trouverez tous les détails du protocole Arp dans la RFC 826 "An Ethernet Address Resolution Protocol". Un complément est sortie en juillet 2008 avec la RFC 5227 "IPv4 Address Conflict Detection".
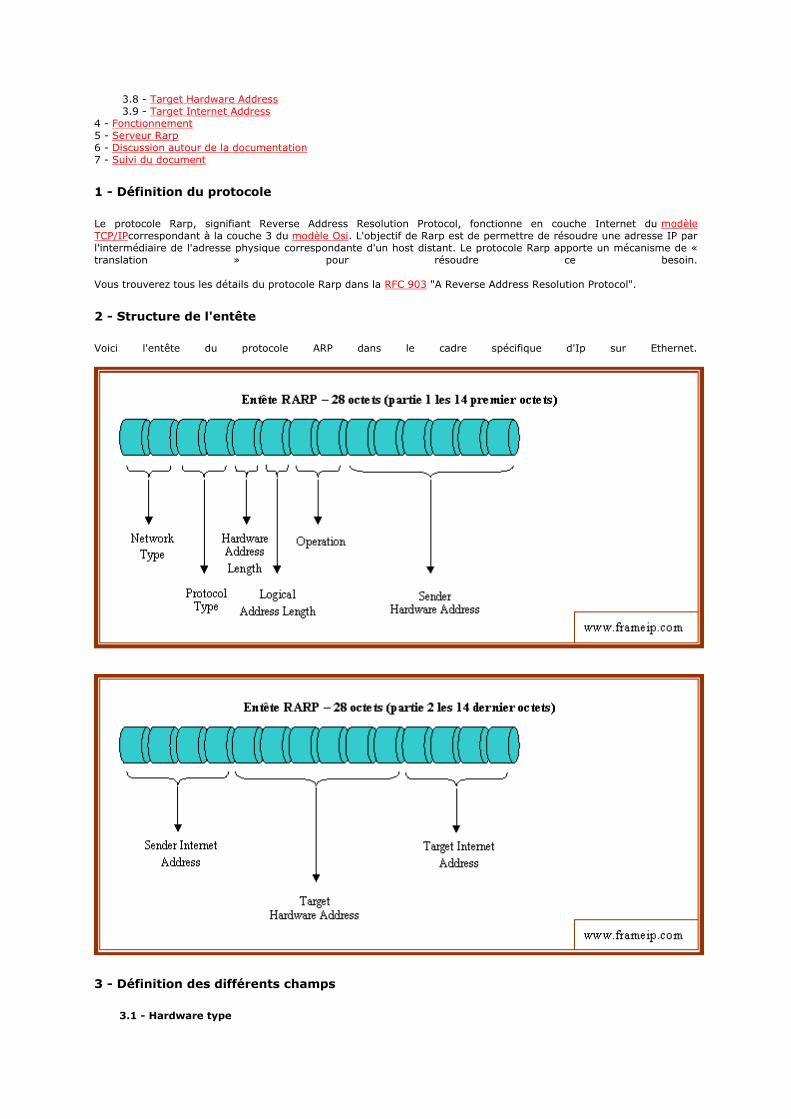
2 - Structure de l'entête
Voici l'entête du protocole ARP dans le cadre spécifique d'Ip sur Ethernet.

3 - Définition des différents champs
3.1 - Hardware type
Ce champs est placé en premier afin d'indiquer quel est le format de l'entête Arp. Voici les différentes valeurs possibles.
- 01 - Ethernet (10Mb) [JBP] - 02 - Experimental Ethernet (3Mb) [JBP] - 03 - Amateur Radio AX.25 [PXK] - 04 - Proteon ProNET Token Ring [Doria] - 05 - Chaos [GXP] - 06 - IEEE 802 Networks [JBP]
- 07 - ARCNET [JBP] - 08 - Hyperchannel [JBP] - 09 - Lanstar [TU] - 10 - Autonet Short Address [MXB1] - 11 - LocalTalk [JKR1] - 12 - LocalNet (IBM PCNet or SYTEK LocalNET) [JXM] - 13 - Ultra link [RXD2]
- 14 - SMDS [GXC1] - 15 - Frame Relay [AGM] - 16 - Asynchronous Transmission Mode (ATM) [JXB2] - 17 - HDLC [JBP] - 18 - Fibre Channel [Yakov Rekhter] - 19 - Asynchronous Transmission Mode (ATM) [RFC2225] - 20 - Serial Line [JBP]
- 21 - Asynchronous Transmission Mode (ATM) [MXB1] - 22 - MIL-STD-188-220 [Jensen] - 23 - Metricom [Stone]
- 24 - IEEE 1394.1995 [Hattig] - 25 - MAPOS [Maruyama] - 26 - Twinaxial [Pitts]
- 27 - EUI-64 [Fujisawa] - 28 - HIPARP [JMP] - 29 - IP and ARP over ISO 7816-3 [Guthery] - 30 - ARPSec [Etienne] - 31 - IPsec tunnel [RFC3456] - 32 - InfiniBand (TM) [Kashyap] - 33 - TIA-102 Project 25 Common Air Interface (CAI) [Anderson]
On remarquera tout particulièrement que le numéro 1 qui le plus fréquents. En effet ces architectures sont principalement utilisées dans les réseaux d'entreprises, Wifi, et Metro.
3.2 - Protocol type

Ce champs indique quel est le type de protocole couche 3 qui utilise Arp. Voici la valeur propre à Ip. - 0x0800 - IP
3.3 - Hardware Address Length
Ce champ correspond à la longueur de l'adresse physique. La longueur doit être prise en octets. Voici des exemples de valeurs courantes.
- 01 - Token Ring - 06 - Ethernet
3.4 - Protocol Address Length
Ce champ correspond à la longueur de l'adresse réseau. La longueur doit être prise en octets. Voici des exemples de valeurs courantes. - 04 - IP v4
- 16 - IP v6
3.5 - Operation
Ce champ permet de connaître la fonction du message et donc son objectif. Voici les différentes valeurs possibles. - 01 - Request [RFC 826] - 02 - Reply [RFC 826]
3.6 - Sender Hardware Address
Ce champ indique l'adresse physique de l'émetteur. Dans le cadre spécifique d'Ethernet, cela représente l'adresse Mac source.
3.7 - Sender Internet Address
Ce champ indique l'adresse réseau de l'émetteur. Dans le cadre spécifique de TCP/IP, cela représente l'adresse Ip de source.
3.8 - Target Hardware Address
Ce champ indique l'adresse physique du destinataire. Dans le cadre spécifique d'Ethernet, cela représente l'adresse Mac destination. Si c'est une demande Arp, alors, ne connaissant justement pas cette adresse, le champs sera mis à 0.
3.9 - Target Internet Address
Ce champ indique l'adresse réseau du destinataire. Dans le cadre spécifique de TCP/IP, cela représente l'adresse Ip de destination.
4 - Fonctionnement
Pour envisager une discussion entre deux Host se situant dans le même Lan, les deux hosts doivent avoir connaissance des adresses physiques des machines avec lesquelles elles discutent. De ce mécanisme découle une table de conversion contenant à la fois les adresses Ip et Mac. L'alimentation de cette table peut s'effectuer de deux manières, automatique via Arp ou manuelle via l'administrateur. Considérons que ces deux hosts n'ont jamais discuté ensemble.
Voici la réponse suite à la commande « arp -a » correspondante à ces deux hosts montrant le contenu du cache local.

La machine source ne connaissant pas l'adresse physique de la machine destinatrice, celle-ci va émettre une trame Broadcast de niveau 2 s'adressant à toutes les hôtes du réseau, comportant sa propre adresse physique et la question demandée. Puis, l'hôte de destination va se reconnaître et répondre en Unicast.
4.1 - Arp Request
La question de type Arp Request se présente sous cette forme : "Je suis l'hôte « 00 08 54 0b 21 77», Est-ce que l'hôte possédant l'adresse Ip 192.168.0.1 peut me retourner son adresse physique ?". Voici la traduction de cette
requête saisie grâce à Ethereal.
4.2 - Arp Reply
L'hôte destinataire qui va se reconnaître va pouvoir d'un coté alimenter sa table de conversion et répondre à l'hôte source en envoyant une trame comportant son adresse physique. Voici la traduction de cette réponse saisie grâce à Ethereal.
4.3 - Le cache

4.3.1 - Le cache des hôtes
Par la forme de la question et de la réponse, on s'aperçoit que la table Arp des deux hôtes ont été alimenté. Voici la table Arp de la machine 192.168.0.3.
Voici la table Arp de la machine 192.168.0.1.
4.3.2 - Le cache dans la Rfc
Les mises en caches sont systématiques et obligatoires. Le fonctionnement du cache est bien caché dans le Rfc 826, mais l'on retrouve trois références.
La première concerne l'envoi. Elle se trouve dans le chapitre "An Example:" dont voici un extrait :
An Example: -----------
... Machine X gets the reply packet from Y, forms the map from <ET(IP), IPA(Y)> to EA(Y), notices the packet is a reply and throws it away. The next time X's Internet module tries to send
a packet to Y on the Ethernet, the translation will succeed, and
the packet will (hopefully) arrive. If Y's Internet module then wants to talk to X, this will also succeed since Y has remembered the information from X's request for Address Resolution.
Cette exemple spécifie que l'émetteur, après réception de la réponse, met en cache la correspondance @mac @ip afin de la réutiliser la prochaine fois sans émettre de nouvelle requête. La seconde concerne la réception. Elle se trouve dans le chapitre "Packet Reception:" dont voici un extrait :
Packet Reception: ----------------- When an address resolution packet is received, the receiving Ethernet module gives the packet to the Address Resolution module which goes through an algorithm similar to the following.
Negative conditionals indicate an end of processing and a

discarding of the packet. ?Do I have the hardware type in ar$hrd? Yes: (almost definitely)
[optionally check the hardware length ar$hln]
?Do I speak the protocol in ar$pro? Yes: [optionally check the protocol length ar$pln] Merge_flag := false If the pair <protocol type, sender protocol address> is
already in my translation table, update the sender hardware address field of the entry with the new information in the packet and set Merge_flag to true.
Cette explication du fonctionnement basé sur le conditionnel aboutit, si le récepteur possède déjà l'entrée
dans son cache, à mettre l'entrée obligatoirement à jour. Et ça, quelle soit ou pas identique au cache actuel. Cette dernière réflexion est très importante pour comprendre la faiblesse de ce process qui vise à privilégier l'économie et la rapidité à l'encontre de la sécurité. La troisième référence concerne aussi la réception. Elle se trouve dans le chapitre "An Example:" dont voici un extrait :
An Example: ----------- Let there exist machines X and Y that are on the same 10Mbit
Ethernet cable. They have Ethernet address EA(X) and EA(Y) and DOD Internet addresses IPA(X) and IPA(Y) . Let the Ethernet type of Internet be ET(IP). Machine X has just been started, and
sooner or later wants to send an Internet packet to machine Y on the same cable. X knows that it wants to send to IPA(Y) and tells the hardware driver (here an Ethernet driver) IPA(Y). The driver consults the Address Resolution module to convert <ET(IP),
IPA(Y)> into a 48.bit Ethernet address, but because X was just started, it does not have this information. It throws the Internet packet away and instead creates an ADDRESS RESOLUTION packet with (ar$hrd) = ares_hrd$Ethernet (ar$pro) = ET(IP)
(ar$hln) = length(EA(X)) (ar$pln) = length(IPA(X)) (ar$op) = ares_op$REQUEST (ar$sha) = EA(X) (ar$spa) = IPA(X) (ar$tha) = don't care (ar$tpa) = IPA(Y)
and broadcasts this packet to everybody on the cable. Machine Y gets this packet, and determines that it understands the hardware type (Ethernet), that it speaks the indicated protocol (Internet) and that the packet is for it ((ar$tpa)=IPA(Y)). It enters (probably replacing any existing entry) the information that <ET(IP), IPA(X)> maps to EA(X).
Cette exemple confirme bien la mise en cache systématique quelque soit l'état du cache actuel. Traduction mot à mot de la dernière phrase : "Elle écrit (remplaçant probablement toute entrée existante) l'information qui < ET(ip), des cartes d'cIpa(x) > à EA(x)."
Entête Rarp
1 - Définition du protocole 2 - Structure de l'entête 3 - Définition des différents champs 3.1 - Hardware type 3.2 - Protocol type
3.3 - Hardware Address Length 3.4 - Protocol Address Length 3.5 - Operation 3.6 - Sender Hardware Address 3.7 - Sender Internet Address
3.8 - Target Hardware Address 3.9 - Target Internet Address 4 - Fonctionnement 5 - Serveur Rarp 6 - Discussion autour de la documentation
7 - Suivi du document
1 - Définition du protocole
Le protocole Rarp, signifiant Reverse Address Resolution Protocol, fonctionne en couche Internet du modèle TCP/IPcorrespondant à la couche 3 du modèle Osi. L'objectif de Rarp est de permettre de résoudre une adresse IP par l'intermédiaire de l'adresse physique correspondante d'un host distant. Le protocole Rarp apporte un mécanisme de « translation » pour résoudre ce besoin.
Vous trouverez tous les détails du protocole Rarp dans la RFC 903 "A Reverse Address Resolution Protocol".
2 - Structure de l'entête
Voici l'entête du protocole ARP dans le cadre spécifique d'Ip sur Ethernet.
3 - Définition des différents champs
3.1 - Hardware type

Ce champs est placé en premier afin d'indiquer quel est le format de l'entête Arp. Voici les différentes valeurs possibles. - 01 - Ethernet (10Mb) [JBP] - 02 - Experimental Ethernet (3Mb) [JBP]
- 03 - Amateur Radio AX.25 [PXK] - 04 - Proteon ProNET Token Ring [Doria]
- 05 - Chaos [GXP] - 06 - IEEE 802 Networks [JBP] - 07 - ARCNET [JBP] - 08 - Hyperchannel [JBP] - 09 - Lanstar [TU] - 10 - Autonet Short Address [MXB1] - 11 - LocalTalk [JKR1]
- 12 - LocalNet (IBM PCNet or SYTEK LocalNET) [JXM] - 13 - Ultra link [RXD2] - 14 - SMDS [GXC1] - 15 - Frame Relay [AGM] - 16 - Asynchronous Transmission Mode (ATM) [JXB2] - 17 - HDLC [JBP] - 18 - Fibre Channel [Yakov Rekhter]
- 19 - Asynchronous Transmission Mode (ATM) [RFC2225] - 20 - Serial Line [JBP] - 21 - Asynchronous Transmission Mode (ATM) [MXB1] - 22 - MIL-STD-188-220 [Jensen] - 23 - Metricom [Stone] - 24 - IEEE 1394.1995 [Hattig]
- 25 - MAPOS [Maruyama] - 26 - Twinaxial [Pitts] - 27 - EUI-64 [Fujisawa] - 28 - HIPARP [JMP]
3.2 - Protocol type
Ce champs indique quel est le type de protocole couche 3 qui utilise Rarp. Voici la valeur propre à Ip.
- 0x0800 - IP
3.3 - Hardware Address Length
Ce champ correspond à la longueur de l'adresse physique. La longueur doit être prise en octets. Voici des exemples de valeurs courantes. - 01 - Token Ring - 06 - Ethernet
3.4 - Protocol Address Length
Ce champ correspond à la longueur de l'adresse réseau. La longueur doit être prise en octets. Voici des exemples de valeurs courantes. - 04 - IP v4 - 16 - IP v6
3.5 - Operation
Ce champ permet de connaître la fonction du message et donc son objectif. Voici les différentes valeurs possibles. "There are two opcodes: 3 ('request reverse') and 4 ('reply reverse')." - 03 - Request [RFC 903] - 04 - Reply [RFC 903]
3.6 - Sender Hardware Address
Ce champ indique l'adresse physique de l'émetteur. Dans le cadre spécifique d'Ethernet, cela représente l'adresse Mac source.
3.7 - Sender Internet Address

Ce champ indique l'adresse réseau de l'émetteur. Dans le cadre spécifique de TCP/IP, cela représente l'adresse Ip de source.
3.8 - Target Hardware Address
Ce champ indique l'adresse physique du destinataire. Dans le cadre spécifique d'Ethernet, cela représente l'adresse Mac destination. Si c'est une demande Arp, alors, ne connaissant justement pas cette adresse, le champs sera mis à 0.
3.9 - Target Internet Address
Ce champ indique l'adresse réseau du destinataire. Dans le cadre spécifique de TCP/IP, cela représente l'adresse Ip de destination.
4 - Fonctionnement
Rarp étant un protocole de niveau 3, il s'appui sur une entête Ethernet à 14 octets. On y retrouvera spécifiquement le flag "type de protocole" égale 0x8035. (0x0806 pour ARP)
5 - Serveur Rarp
Voici RARPD 1.15 qui est un serveur RARP. Fonctionnant sous NT/Win2K. En plus de l'exe, vous y trouverez la source en C.
/*
RARPD.CPP: Free software Copyright (c) 1999-2003 Lew Perin */
/* Revision History: Version Date Reason ------- --------
1.00 10/31/99 Forked from billgpc.cpp. 1.01 11/27/99 Lazy automatic reinitialization of the RARP table when it has been changed on disk, removal of lots of chatter from the log and main window. 1.02 1/17/00 Faster retrieval of IP address via qsort/bsearch. 1.03 6/3/00 Bugs in automatic reinitialization, handle usage, error messages fixed; thanks, Ury Jamshy!
1.04 8/12/00 Fixed recognition of directory with embedded spaces from command line; thanks, Jiri Medlen! 1.05 9/17/00 Fixed TCP Registry navigation for Windows 2000. 1.06 1/15/01 Made some minor type/constness changes to satisfy modern C++ compilers. Fixed bug that could destroy adapterName when excluding subnets. 1.07 5/17/01 In Win2K we now probe devices to see if they're
really there. 1.08 6/18/01 Minor debug logging changes.
1.09 7/23/01 Fixed bug recognizing Registry key for adapter where one adapter is good and a subsequent one is *almost* OK. 1.10 12/18/01 In Win2K/XP we now no longer check first for direct
connection to Tcpip in checking for a useful adapter. 1.10.1 3/3/02 We no longer assume a ("useless" non-physical) adapter will have an Ndi\Interfaces subkey. Temporarily, we ignore whether a 2K/XP adapter is connected to Tcpip. 1.10.2 3/20/02 Now using new driver version for 2K/XP compatibility. Delay response slightly in loopback testing. 1.11 4/13/03 Logic for subnet exclusion now considers DHCP-based
Registry subnet parameters too. 1.12 4/20/03 Cleaned up logic for when checkStack() fails. 1.13 4/29/03 Fixed getValue() length bug in getSubnetMask(). 1.14 6/6/03 Now require driver version 1.02 1.15 10/12/03 Compute our IP address the Winsock way if the Registry fails us. */

#if !defined(_MT) // Symantec seems to need this to believe we're multithreaded //#define _MT #endif
#define WIN32_LEAN_AND_MEAN #include <windows.h> #include <process.h> #include <wincon.h>
#include <ctype.h> #include <limits.h> #include <stdio.h> // for sscanf; sorry! #include <iostream.h> #include <strstrea.h> #include <fstream.h> #include <iomanip.h>
#include <string.h> #include <stdlib.h> #include <winioctl.h> #include <winsock.h> #include <time.h> #include "shared.h" #include "resource.h"
#define VERSION "1.15" #define TEST_VERSION 0 // if nonzero, annoying messagebox #define WM_REALLY_CLOSE WM_APP BOOL quiescing = FALSE; // set by GUI, obeyed by threads
/* This class will create a list of pseudo-IP addresses for subnets from a RARPD command line and return them one by one with the overloaded array indexing operator, returning zero if you've gone beyond the last one. */
class SubnetHolder { size_t count; long* subnets; public: SubnetHolder() { count = 0; } ~SubnetHolder() { if (count) delete[] subnets; } void init(char* acmdLine);
long operator[] (size_t a) { return (a < count) ? subnets[a] : 0; } }; void SubnetHolder::init(char* acmdLine) { const char* sentinel = "/XS"; if (count) {
delete[] subnets; count = 0; } for (char* next = acmdLine; (next = strstr(next, sentinel)) != NULL; count++) {
next += strlen(sentinel); long* newSubnets = new long[count + 1]; newSubnets[count] = inet_addr(next); if (count) { memcpy(newSubnets, subnets, count * sizeof(long)); delete[] subnets; }
subnets = newSubnets; } } /* What OS are we running on? Only NT's acceptable.
*/ enum OSType { W95, WNT };

OSType os = W95; DWORD osMajorVersion, osMinorVersion; UINT mbType = MB_APPLMODAL;
HDESK mainWindowDesktop = NULL; // used in NT desktop switching /* Navigating the registry: */
// Table listing info on legal root keys: struct { char* name; HKEY handle; } rootKeys[] = {
{ "HKEY_CLASSES_ROOT", HKEY_CLASSES_ROOT }, { "HKEY_CURRENT_USER", HKEY_CURRENT_USER }, { "HKEY_LOCAL_MACHINE", HKEY_LOCAL_MACHINE }, { "HKEY_USERS", HKEY_USERS }, { "HKEY_DYN_DATA", HKEY_DYN_DATA }, { NULL, NULL } };
/* These are the names of the registry keys we use the most: */ char* tcpKeyName = ""; // filled in by configureForOS()
/* We'll often need to know if a key is a root key because if so we'd better not close its handle. */ BOOL isRootKey(HKEY h)
{ for (int i = 0; rootKeys[i].name != NULL; i++) { if (rootKeys[i].handle == h) return TRUE; } return FALSE; }
/* It's impossible to get a handle for a non-root key; you have to start with its root key and work outward. */ HKEY getRootKey(const char* apath) {
for (int i = 0; rootKeys[i].name != NULL; i++) { size_t rkiLen = strlen(rootKeys[i].name); if (!strncmp(apath, rootKeys[i].name, rkiLen)) { if ((apath[rkiLen] == '\0') || (apath[rkiLen] == '\\')) { return rootKeys[i].handle; }
} } return NULL; } ofstream outFile;
enum { logLineLen = 500, // Use this in ostrstreams for listbox string. msgLen = 500, // Use this for message boxes. ObjectNameLen = logLineLen / 2 // Use this for desktop names. }; /*
If we have two handles to NT desktops, the objects may be the same even if the handles are different. That's what we test here. */

BOOL differentObjects(HANDLE ahandleA, HANDLE ahandleB) { BOOL result = FALSE; char objectNameA[ObjectNameLen];
char objectNameB[ObjectNameLen];
DWORD ignoreLenNeeded; if ((GetUserObjectInformation(ahandleA, UOI_NAME, objectNameA, ObjectNameLen, &ignoreLenNeeded)) && (GetUserObjectInformation(ahandleB, UOI_NAME, objectNameB, ObjectNameLen, &ignoreLenNeeded))) {
result = strcmp(objectNameA, objectNameB); } else outFile << "Can't get object name" << GetLastError() << endl; return result; } /*
Send the main window's listbox one line of text. After we send the line we select it to make sure it's visible, and then we deselect it so it won't call attention to itself. If we're in a desperate hurry, though - dump() is, due to its responsibility in promiscuous mode - we do without the visibility manipulation. By the way, while this function would run faster using PostMessage() than with SendMessage(), the data wouldn't get through reliably.
There's a kink here that was introduced when we made it possible to run, launched by an NT service at boot time, trying to grab a desktop we wouldn't normally have (WinLogon.) Since we can't execute SetThreadDesktop once we already have a window, we need the ability to log messages without a main window, i.e. straight to rarpd.log. */
void logLine(HWND amainWindow, const char* aline, BOOL ahurry = FALSE) { if (!amainWindow) { outFile << aline << endl; return;
} static HWND dlg = HWND(INVALID_HANDLE_VALUE); if (dlg == INVALID_HANDLE_VALUE) dlg = GetDlgItem(amainWindow, IDC_LOGBOX); SendMessage(dlg, LB_ADDSTRING, 0, (LPARAM)aline); if (!ahurry) { LONG lastLine = SendMessage(dlg, LB_GETCOUNT, 0, 0) - 1; SendMessage(dlg, LB_SETCARETINDEX, WPARAM(lastLine), MAKELPARAM(FALSE, 0));
UpdateWindow(dlg); } } /* This is a convenience function for the cases where we just have a string to put out together with Windows's wisdom on what might have happened.
Just to be tidy, we strip the trailing CRLF in the Windows error message. */ void logLastError(HWND amainWindow, char* aline) { char* errMsgBuf = "";
char* msgBuf = new char[logLineLen]; ostrstream msgOss(msgBuf, logLineLen); FormatMessage(FORMAT_MESSAGE_ALLOCATE_BUFFER | FORMAT_MESSAGE_FROM_SYSTEM, NULL, GetLastError(), MAKELANGID(LANG_NEUTRAL, SUBLANG_DEFAULT), // Default language (LPTSTR) &errMsgBuf, 0, NULL); char* crLoc = strchr(errMsgBuf, '\r');
if (crLoc) *crLoc = '\0'; msgOss << aline << ": " << errMsgBuf << ends; logLine(amainWindow, msgBuf); LocalFree(errMsgBuf); } /*
Running under NT, launched by a service, things get complicated. Originally our aproach involved a window of 0 to go along with our MB_APPLMODAL | MB_SERVICE_NOTIFICATION style. But we like to make the whole context of the rarp transaction, i.e. the log in our main window,

available when things get bad enough for us to put up a message box. So we devised a scheme that allowed us to switch desktops temporarily back to the one our main window lives in, and then restore the current input desktop once the message box is dismissed. If this seems bizarre, consider
that the situation really does arise when the following events
transpire: - rarpd is launched by its service before anyone logs on and puts its main window where it can be seen, i.e. in the Winlogon desktop;
- someone logs on before rarpd finishes, so the Default desktop becomes current and rarpc's main window becomes invisible; - rarpd learns of something that requires the user's attention and wants to put up a message box anchored by the main window. By the way, there's plenty of time for the second event in this sequence
to interpose itself between the first and third when the third is a rarp failure, i.e. a timeout. */ int ourMessageBox(HWND hwnd, char* amsg, UINT atype) { int result;
ShowWindow(hwnd, SW_RESTORE); if (os == WNT) { HDESK newDesktop = OpenInputDesktop(0, FALSE, DESKTOP_SWITCHDESKTOP); if (!newDesktop) logLastError(hwnd, "Can't open input desktop"); if (differentObjects(mainWindowDesktop, GetThreadDesktop(GetCurrentThreadId()))) { if (!SetThreadDesktop(mainWindowDesktop)) {
logLastError(hwnd, "SetThreadDesktop for main window"); } } if ((mainWindowDesktop && newDesktop) && differentObjects(mainWindowDesktop, newDesktop)) { if (SwitchDesktop(mainWindowDesktop)) {
result = MessageBox(hwnd, amsg, "rarpd", atype); if (!result) logLastError(hwnd, "MessageBox"); if (!SwitchDesktop(newDesktop)) { logLastError(hwnd, "Couldn't switch back to new desktop"); } return result; }
else logLastError(hwnd, "Couldn't switch to old desktop"); } // else fall through } // end of NT-specific logic result = MessageBox(hwnd, amsg, "rarpd", atype); if (!result) logLastError(hwnd, "MessageBox"); return result; }
/* Two functions, alert() and fail(), centralize our error messages and ensure that when an error message goes up on the screen the listbox is visible so the user has some context for the message. A third, yesOrNo(), does something similar when the user must decide. These
functions also make sure messages and responses get logged. */ /* Here we've reached a point where we can't go on. This is a convenience function removing some Windows GUI clutter. For those cases in which we think it's OK without alarming the user, there's an optional Boolean
allowing this. */ void fail(HWND amainWindow, char* amsg, BOOL asilent = FALSE) { if (!asilent) ourMessageBox(amainWindow, amsg, MB_ICONSTOP); logLine(amainWindow, "**Fatal error:");
logLine(amainWindow, amsg); if (amainWindow) SendMessage(amainWindow, WM_CLOSE, 0, 0); else exit(-1); }

/* Here we need to alert the user to something that might not be fatal. */
void alert(HWND amainWindow, char* amsg) { ourMessageBox(amainWindow, amsg, MB_ICONEXCLAMATION); logLine(amainWindow, amsg); }
/* Here we need to ask the user a yes-or-no question. */ int yesOrNo(HWND amainWindow, char* amsg) {
int result; result = ourMessageBox(amainWindow, amsg, MB_YESNO); logLine(amainWindow, "**Query:"); logLine(amainWindow, amsg); logLine(amainWindow, ((result == IDYES) ? "[yes]" : "[no]")); return result; }
/* This class will create a list RARP table entries from rarpd.tbl and return pointers to them one by one with the overloaded array indexing operator, returning NULL if you've gone beyond the last one. */
struct RarpTblEntry { UCHAR macAddress[MacAddressSize]; UINT ipAddress; }; int rarpTblEntryCmp(const void* aleft, const void* aright)
{ const RarpTblEntry* left = (const RarpTblEntry*)aleft; const RarpTblEntry* right = (const RarpTblEntry*)aright; return memcmp(left->macAddress, right->macAddress, MacAddressSize); } /*
Our RARP table class encapsulates a lazy reinitialization behavior in response to the table having changed on disk. We only consider reinitializing the table when the caller is accessing the first entry in the table; then we check the file only if it has been at least a minute since the last check. We reinitialize then if the file has been written since the last initialization. */
class RarpTbl { size_t count; RarpTblEntry* entries; HWND mainWindow; time_t timeOfLastFileCheck;
FILETIME timeOfLastInit; void considerInit(); public: RarpTbl(HWND amainWindow) : mainWindow(amainWindow), count(0), timeOfLastFileCheck(0) { timeOfLastInit.dwLowDateTime = timeOfLastInit.dwHighDateTime = 0; init();
} ~RarpTbl() { if (count) delete[] entries; } void init(); RarpTblEntry* operator[] (size_t a) { if (a == 0) considerInit(); return (a < count) ? &entries[a] : NULL; }
RarpTblEntry* find(const unsigned char* akey) { considerInit(); return (RarpTblEntry*)bsearch(akey, entries, count, sizeof(RarpTblEntry), rarpTblEntryCmp);

} }; void RarpTbl::considerInit()
{
time_t now = time(NULL); if (UINT(now - timeOfLastFileCheck) > 60) { timeOfLastFileCheck = now; HANDLE fh = CreateFile("RARPD.TBL", GENERIC_READ, 0, // Not interested if it's being edited
NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL); if (fh != INVALID_HANDLE_VALUE) { FILETIME timeLastWritten; BOOL gotFileTime = GetFileTime(fh, NULL, NULL, &timeLastWritten); CloseHandle(fh); if (gotFileTime) { if (CompareFileTime(&timeOfLastInit, &timeLastWritten) < 0) init();
} } } } void RarpTbl::init() {
GetSystemTimeAsFileTime(&timeOfLastInit); ifstream inFile("RARPD.TBL", ios::in | ios::nocreate); logLine(mainWindow, "Initializing RARP table"); if (!inFile.ipfx()) fail(mainWindow, "Can't open RARPD.TBL"); if (count) { delete[] entries; count = 0;
} char buf[200]; for (size_t lineNo = 1; inFile.ipfx(); lineNo++) { RarpTblEntry next; next.ipAddress = INADDR_NONE; inFile.getline(buf, sizeof(buf));
// logLine(mainWindow, buf); if (!isalnum(buf[0])) continue; char ipAddr[200]; int digits[MacAddressSize]; if (sscanf(buf, "%02x.%02x.%02x.%02x.%02x.%02x %s", digits, digits + 1, digits + 2, digits + 3, digits + 4, digits + 5, ipAddr) == 7) {
for (size_t byteNo = 0; byteNo < MacAddressSize; byteNo++) { next.macAddress[byteNo] = UCHAR(digits[byteNo]); } next.ipAddress = inet_addr(ipAddr); } if (next.ipAddress == INADDR_NONE){ strcat(buf, ": bad");
logLine(mainWindow, buf); continue; } RarpTblEntry* newEntries = new RarpTblEntry[count + 1]; memcpy(&newEntries[count], &next, sizeof(RarpTblEntry)); if (count) {
memcpy(newEntries, entries, count * sizeof(RarpTblEntry)); delete[] entries; } entries = newEntries; count++; } qsort(entries, count, sizeof(RarpTblEntry), rarpTblEntryCmp);
} /* Here, since we know we're running on NT, we do what's necessary to make ourselves useful should we be running launched by a service before logon. (This is after all the best way to run rarpd on NT.) We see if we're already running on the input desktop and, if not, try to seize it. If
we do switch desktops we make sure our window won't be minimized, because in our experience a minimized window on the NT Winlogon desktop is a dead duck. */

void setNTDesktop(int& acmdShow, const OSVERSIONINFO& avInfo) { char* msgBuf = new char[logLineLen];
ostrstream msgOss(msgBuf, logLineLen);
mbType = (avInfo.dwMajorVersion < 4) ? // Service notification MB_TASKMODAL | 0x00040000 : MB_TASKMODAL | 0x00200000; enum { ObjectNameLen = logLineLen / 2 }; char oldDesktopName[ObjectNameLen]; char newDesktopName[ObjectNameLen];
DWORD ignoreLenNeeded; HWINSTA windowStation = GetProcessWindowStation(); if (windowStation) { char stationName[ObjectNameLen]; if (GetUserObjectInformation(windowStation, UOI_NAME, stationName, ObjectNameLen, &ignoreLenNeeded)) { msgOss << "Window station name: " << stationName << ends;
logLine(0, msgBuf); msgOss.seekp(0); } else logLastError(0, "Can't get window station name"); } else logLastError(0, "Can't get window station"); HDESK oldDesktop = GetThreadDesktop(GetCurrentThreadId());
if (oldDesktop) { if (GetUserObjectInformation(oldDesktop, UOI_NAME, oldDesktopName, ObjectNameLen, &ignoreLenNeeded)) { msgOss << "Old desktop name: " << oldDesktopName << ends; logLine(0, msgBuf); msgOss.seekp(0); }
else logLastError(0, "Can't get old desktop name"); } else logLastError(0, "Can't get thread desktop"); HDESK newDesktop = OpenInputDesktop(0, TRUE, DESKTOP_CREATEWINDOW | DESKTOP_SWITCHDESKTOP); if (newDesktop) {
if (GetUserObjectInformation(newDesktop, UOI_NAME, newDesktopName, ObjectNameLen, &ignoreLenNeeded)) { msgOss << "New desktop name: " << newDesktopName << ends; logLine(0, msgBuf); msgOss.seekp(0); } else logLastError(0, "Can't get new desktop name");
if (strcmp(oldDesktopName, newDesktopName)) { if (SetThreadDesktop(newDesktop)){ acmdShow = SW_SHOWNORMAL; mainWindowDesktop = newDesktop; } else logLastError(0, "SetThreadDesktop"); }
else { mainWindowDesktop = oldDesktop; logLine(0, "Already have the input desktop"); } } else logLastError(0, "Can't open input desktop");
} /* The handles for dealing with the NT RARP driver: */ SC_HANDLE scmHandle = NULL;
SC_HANDLE srvHandle = NULL; HANDLE ntRarpHandle = INVALID_HANDLE_VALUE; HINSTANCE ourInstance = HINSTANCE(INVALID_HANDLE_VALUE); /* Normally the driver doesn't already exist as a service when we're called, but if it already exists that's OK. We know the current directory has been
set to the directory rarpd was loaded from. The call to GetFileAttributes is necessary because CreateService will vacuously succeed even if it fails to find the driver. */

BOOL installNTDriver(SC_HANDLE ascmHandle) { BOOL result = FALSE;
char driverPath[logLineLen];
*driverPath = 0; GetCurrentDirectory(logLineLen, driverPath); wsprintf(driverPath + strlen(driverPath), "\\RARP.SYS"); if (GetFileAttributes(driverPath) != 0xffffffff) {
SC_HANDLE srvHandle = CreateService(ascmHandle, "RARP", "RARP Support", SERVICE_ALL_ACCESS, SERVICE_KERNEL_DRIVER, SERVICE_DEMAND_START, SERVICE_ERROR_NORMAL, driverPath,
NULL, NULL, NULL, NULL, NULL); if (srvHandle == NULL) { if (GetLastError() == ERROR_SERVICE_EXISTS) { logLine(0, "RARP.SYS already existed"); result = TRUE; } else logLastError(0, "Couldn't install RARP.SYS");
} else { logLine(0, "Created service for RARP.SYS"); result = TRUE; CloseServiceHandle(srvHandle); // 0.54.2 } }
else logLine(0, "Can't find RARP.SYS"); return result; } /* Here we wait for success (in which case we return TRUE) or either of two
kinds of failure: - we get an error from StartService() other than an indication that the service database is still locked; - the user gives up. In either error condition we log an error message and return FALSE. */
BOOL APIENTRY startServiceDialogProc(HWND hDlg, UINT message, UINT wParam, LONG /* lParam */) { switch (message) { case WM_INITDIALOG: {
SetDlgItemText(hDlg, IDC_EDIT_WAIT_SCM, "Windows NT has reported to rarpd that the " "service database is locked. This means that " "rarpd's device driver cannot yet be started. " "Normally this is " "a temporary situation, especially when rarpd "
"is being used to configure a new workstation.\r\n" "Unless you press the button below, rarpd will " "continue trying to start its driver until it " "succeeds.\r\n" "If you press the button, rarpd will try to reach " "the rarp server without the use of its device " "driver. You are strongly urged to wait.");
SetTimer(hDlg, 0, 5000, NULL); } break; case WM_COMMAND: if (wParam == IDC_BUTTON_STOP) { SetLastError(ERROR_SERVICE_DATABASE_LOCKED); logLastError(0, "Couldn't start RARP service");
return EndDialog(hDlg, FALSE); } break; case WM_TIMER:

if (StartService(srvHandle, 0, NULL)) return EndDialog (hDlg, TRUE); else { DWORD error = GetLastError(); if (error != ERROR_SERVICE_DATABASE_LOCKED) {
SetLastError(error);
logLastError(0, "Couldn't start RARP service"); return EndDialog (hDlg, FALSE); } } break;
} return FALSE; } /* Because our call to StartService() can be frustrated by a transitory lock on the service database held by some other process, we keep trying to
start our driver periodically while displaying a dialog that allows the user to give up. */ void ourStartService() { BOOL result = FALSE;
if (StartService(srvHandle, 0, NULL)) result = TRUE; else { DWORD error = GetLastError(); if (error == ERROR_SERVICE_DATABASE_LOCKED) { result = DialogBox(ourInstance, MAKEINTRESOURCE(DIALOG_WAIT_SCM), 0, (DLGPROC)startServiceDialogProc); }
else { SetLastError(error); logLastError(0, "Couldn't start RARP service"); } } if (result) logLine(0, "Started RARP service");
} void connectToNTDriver() { scmHandle = OpenSCManager(NULL, NULL, SC_MANAGER_ALL_ACCESS); if (scmHandle == NULL) fail(0, "OpenSCManager"); if (installNTDriver(scmHandle)) {
srvHandle = OpenService(scmHandle, "RARP", SERVICE_ALL_ACCESS); if (srvHandle != NULL) ourStartService(); else logLastError(0, "Couldn't open RARP service"); } } void disconnectFromNTDriver()
{ if (ntRarpHandle != INVALID_HANDLE_VALUE) { if (!CloseHandle(ntRarpHandle)) { logLastError(0, "Can't close RARP device"); } }
if (srvHandle != NULL) { SERVICE_STATUS serviceStatus; SC_HANDLE stopHandle = OpenService(scmHandle, "RARP", SERVICE_ALL_ACCESS); if (stopHandle == NULL) logLastError(0, "OpenService stopping RARP"); else { if (!ControlService(stopHandle, SERVICE_CONTROL_STOP, &serviceStatus)) {
logLastError(0, "ControlService SERVICE_STOP"); } CloseServiceHandle(stopHandle); } SC_HANDLE removeHandle = OpenService(scmHandle, "RARP", SERVICE_ALL_ACCESS); if (removeHandle == NULL) logLastError(0, "OpenService removing RARP");
else { if (!DeleteService(removeHandle)) { logLastError(0, "DeleteService for RARP"); }

CloseServiceHandle(removeHandle); } CloseServiceHandle(srvHandle); }
if (scmHandle != NULL) CloseServiceHandle(scmHandle);
} void shutdown() { if (os == WNT) disconnectFromNTDriver();
char dateStr[80], timeStr[80]; GetDateFormat(LOCALE_USER_DEFAULT, 0, NULL, "yyyy'-'MM'-'dd", dateStr, sizeof(dateStr)); GetTimeFormat(LOCALE_USER_DEFAULT, TIME_FORCE24HOURFORMAT, NULL, "HH':'mm':'ss", timeStr, sizeof(timeStr)); outFile << "rarpd finished " << dateStr << " " << timeStr << endl; outFile.close();
} BOOL ctrlHandler(DWORD actrlChar) { switch(actrlChar) { case CTRL_SHUTDOWN_EVENT:
case CTRL_LOGOFF_EVENT: shutdown(); return FALSE; // Quit the program. default: break; } return TRUE; // Don't quit.
} /* Since we run under two different operating systems, there are some things we need to set up depending on which one it is. We keep an enumerator for the OSes we tolerate.
*/ DWORD transportValueType = REG_SZ; char* subnetMaskString = "IPMask"; char* dhcpSubnetMaskString = "DhcpIPMask"; void configureForOS(int& acmdShow)
{ char* msgBuf = new char[logLineLen]; ostrstream msgOss(msgBuf, logLineLen); char* osString = ""; OSVERSIONINFO vinfo; vinfo.dwOSVersionInfoSize = sizeof(vinfo); GetVersionEx(&vinfo);
osMajorVersion = vinfo.dwMajorVersion; osMinorVersion = vinfo.dwMinorVersion; switch(vinfo.dwPlatformId) { case VER_PLATFORM_WIN32_NT: os = WNT; osString = "NT";
tcpKeyName = "HKEY_LOCAL_MACHINE\\System\\CurrentControlSet\\" "Services\\Tcpip\\Parameters"; transportValueType = REG_MULTI_SZ; subnetMaskString = "SubnetMask"; dhcpSubnetMaskString = "DhcpSubnetMask"; setNTDesktop(acmdShow, vinfo); #if 0 // Control handler doesn't get called at system shutdown: why??
if (!SetConsoleCtrlHandler((PHANDLER_ROUTINE)ctrlHandler, TRUE)) { fail(0, "Can't install shutdown handler"); } #endif connectToNTDriver(); break; default:
fail(0, "This program requires Windows NT"); break; } msgOss << "Running under Windows " << osString << " "

<< osMajorVersion << "." << osMinorVersion << "." << ends; logLine(0, msgBuf); }
/*
Here we can't proceed because a registry key we need doesn't exist. */ void abortOnBadKey(const char* apath, HWND amainWindow) {
char* msgBuf = new char[logLineLen]; ostrstream msgOss(msgBuf, logLineLen); msgOss << "Can't find key" << endl << " " << apath << endl << "in registry.\n" << "Make sure Microsoft TCP/IP is properly installed" << " and that you have Registry write access for IP."
<< ends; fail(amainWindow, msgBuf); } /* As we navigate outward from the root to the key we seek, we make sure to close all intermediate keys. While navigating we ask only read access
but at our destination we want to be able to modify things. */ HKEY getKey(const char* apath, HWND amainWindow, BOOL asilent = FALSE) { HKEY thisKeyHandle = getRootKey(apath); if (thisKeyHandle == NULL) abortOnBadKey(apath, amainWindow);
char subKeyName[80]; const char* separatorP = apath + strcspn(apath, "\\"); while (*separatorP) { const char* nextSubKeyP = separatorP + 1; size_t subKeyLen = strcspn(nextSubKeyP, "\\"); memcpy(subKeyName, nextSubKeyP, subKeyLen);
subKeyName[subKeyLen] = '\0'; separatorP = nextSubKeyP + subKeyLen; HKEY nextKeyHandle; if (RegOpenKeyEx(thisKeyHandle, subKeyName, 0, KEY_READ, &nextKeyHandle)!= ERROR_SUCCESS) { if (!asilent) {
char* msgBuf = new char[logLineLen]; ostrstream msgOss(msgBuf, logLineLen); msgOss << "Failure on " << apath << " at subkey: " << subKeyName << " with read access." << ends; logLine(amainWindow, msgBuf); } RegCloseKey(thisKeyHandle);
return NULL; } RegCloseKey(nextKeyHandle); if (RegOpenKeyEx(thisKeyHandle, subKeyName, 0, KEY_READ | KEY_SET_VALUE, &nextKeyHandle)!= ERROR_SUCCESS) {
if (!asilent) { char* msgBuf = new char[logLineLen]; ostrstream msgOss(msgBuf, logLineLen); msgOss << "Failure on " << apath << " at subkey: " << subKeyName << " with full access." << ends; logLine(amainWindow, msgBuf); }
RegCloseKey(thisKeyHandle); return NULL; } if (!isRootKey(thisKeyHandle)) RegCloseKey(thisKeyHandle); thisKeyHandle = nextKeyHandle; } return thisKeyHandle;
} /* Sometimes we just need to know if a Registry key exists...

*/ BOOL keyExists(const char* apath, HWND amainWindow) {
BOOL result = FALSE;
HKEY keyHandle = getKey(apath, amainWindow, TRUE); if (keyHandle != NULL) { RegCloseKey(keyHandle); result = TRUE; }
return result; } /* If we can find a value corresponding to the key name and expected name, return TRUE and stow its length. The argument "alength" is used a la Microsoft, i.e. both as input and output. We don't leave a non-root
key handle open. */ BOOL getValue(const char* akeyName, char* anexpectedName, BYTE* abuf, DWORD& alength, DWORD atype, HWND amainWindow) { HKEY keyHandle = getKey(akeyName, amainWindow);
BOOL result = FALSE; DWORD regType; // value's type if (keyHandle == NULL) abortOnBadKey(akeyName, amainWindow); if (RegQueryValueEx(keyHandle, anexpectedName, NULL, ®Type, abuf, &alength) == ERROR_SUCCESS) { if (regType == atype) result = TRUE; else {
size_t bufLen = strlen(anexpectedName) + strlen(akeyName) + 100; char* msgBuf = new char[bufLen]; ostrstream msgOss(msgBuf, bufLen); msgOss << "Unexpected value type in registry for" << endl << " key: " << akeyName << endl << " value name: " << anexpectedName << ends;
alert(amainWindow, msgBuf); } } if (!isRootKey(keyHandle)) RegCloseKey(keyHandle); return result; }
/* The timeout that the receiver thread itself uses to quit on a read from RARP is made shorter than the one the worker thread uses to kill the receiver thread by the initialization of ReceiverParams. */ struct ReceiverParams {
HWND mainWindow; DWORD timeout; UINT ourIpAddress; BOOL& quiescing; UCHAR ourMacAddress[MacAddressSize]; USHORT ourHwType;
UCHAR ourHwLen; RarpTbl& tbl; ReceiverParams(HWND amainWindow, DWORD atimeout, RarpTbl& atbl, UINT anipAddress, BOOL& aquiescing) : mainWindow(amainWindow), timeout((atimeout > 2000) ? (atimeout - 2000) : 1000 ), tbl(atbl), ourIpAddress(anipAddress), quiescing(aquiescing) { }
BOOL getntRarpHardwareAddress(); }; struct WorkerParams { HWND mainWindow; BOOL dumpDriver; // dump the driver? SubnetHolder& excludedSubnets; // Subnets we ignore searching for netcard
DWORD rxTimeout; // how long we wait for reply (msec.) char* transportKeyName; // card-specific TCP transport key name char* adapterName; // e.g. "Elnk31" WorkerParams(HWND amainWindow,

BOOL adumpDriver, DWORD arxTimeout, SubnetHolder& anexcludedSubnets) : mainWindow(amainWindow), dumpDriver(adumpDriver), rxTimeout(arxTimeout),
excludedSubnets(anexcludedSubnets),
transportKeyName(NULL), adapterName(NULL) { }; ~WorkerParams() { if (transportKeyName) delete transportKeyName; if (adapterName) delete adapterName; };
void dumpDriverMemory(); char* findNT4NetcardTCPParams(); char* findNT5NetcardTCPParams(); BOOL isSubnetExcluded(char* atcpParamsKeyName); void openntRarp(); BOOL checkStack(); UINT ourIpAddress();
BOOL probeAdapter(char* anadapterName); }; /* If we get something from the netcard that looks fishy, we want to dump it. */
void dump(HWND amainWindow, UINT asize, BYTE* abufP, char* alegend) { logLine(amainWindow, alegend); for (UINT offset = 0; offset < asize; offset += 16) { char* msgBuf = new char[logLineLen]; ostrstream msgOss(msgBuf, logLineLen); msgOss << hex << setw(3) << setfill('0') << offset << ":";
for (UINT incr = 0; incr < 16; incr++) { if (offset + incr >= asize) break; if ((incr % 4) == 0) msgOss << " "; msgOss << hex << setw(2) << setfill('0') << WORD(abufP[offset + incr]); } msgOss << ends;
logLine(amainWindow, msgBuf, TRUE); } } BOOL ReceiverParams::getntRarpHardwareAddress() { char allZeroes[6] = { 0 };
DWORD length; BYTE hwType; BOOL result = FALSE; if (DeviceIoControl(ntRarpHandle, DIOC_RarpGetMacAddress, NULL, 0, ourMacAddress, MacAddressSize, &length, NULL) && memcmp(ourMacAddress, allZeroes, sizeof(allZeroes))) { DWORD hwLength;
if (DeviceIoControl(ntRarpHandle, DIOC_RarpGetHWType, NULL, 0, &hwType, 1, &hwLength, NULL)) { result = TRUE; ourHwLen = UCHAR(length); ourHwType = htons(hwType); }
} return result; } /* The receiver thread exits when it detects a good reply (params->success TRUE) or when the socket fails (FALSE.)
*/ void rarpReceiver(void* aparams) { ReceiverParams& params = *((ReceiverParams*)aparams); if (!params.getntRarpHardwareAddress()) { fail(params.mainWindow, "Couldn't get hardware address.");
} RarpBuf rxBuf, txBuf; txBuf.ap.hwType = params.ourHwType; txBuf.ap.protType = htons(ProtocolTypeIP);

txBuf.ap.hwLen = params.ourHwLen; txBuf.ap.protLen = 4; txBuf.ap.op = htons(RarpOpReply); memcpy(txBuf.ap.senderMacAddress, params.ourMacAddress, MacAddressSize);
txBuf.ap.senderProtAddress = params.ourIpAddress;
while (!params.quiescing) { OVERLAPPED ovrlp = {0,0,0,0,0}; DWORD bytesReturned; BOOL gotIt = FALSE;
if ((ovrlp.hEvent = CreateEvent(0, FALSE, 0, NULL)) == 0) { fail(params.mainWindow, "Windows is out of resources."); } else if (ReadFile(ntRarpHandle, &rxBuf, sizeof(RarpBuf), &bytesReturned, &ovrlp)) gotIt = TRUE; else if (GetLastError() == ERROR_IO_PENDING) { while (!gotIt && !params.quiescing) {
if (WaitForSingleObject(ovrlp.hEvent, params.timeout) == WAIT_OBJECT_0) { GetOverlappedResult(ntRarpHandle, &ovrlp, &bytesReturned, FALSE); gotIt = TRUE; } } }
else { logLastError(params.mainWindow, "Can't read from RARP"); CloseHandle(ovrlp.hEvent); break; } if (gotIt) { // It's for us. if (ntohs(rxBuf.ap.op) == RarpOpRequest) {
memcpy(txBuf.ap.targetMacAddress, rxBuf.ap.targetMacAddress, MacAddressSize); RarpTblEntry* entryP = params.tbl.find(rxBuf.ap.targetMacAddress); if (entryP) { txBuf.ap.targetProtAddress = entryP->ipAddress; memcpy(txBuf.remoteMacAddress, rxBuf.remoteMacAddress,
MacAddressSize); if (memcmp(params.ourMacAddress, rxBuf.remoteMacAddress, MacAddressSize) == 0) { // loopback testing! Sleep(50); // Give client time to dump its own request. } OVERLAPPED txOvrlp = { 0 }; DWORD bytesSent;
if ((txOvrlp.hEvent = CreateEvent(0, FALSE, 0, NULL)) == 0) { fail(params.mainWindow, "Can't create event for WriteFile"); } else if (!WriteFile(ntRarpHandle, &txBuf, sizeof(txBuf), &bytesSent, &txOvrlp)) { if (GetLastError() == ERROR_IO_PENDING) { GetOverlappedResult(ntRarpHandle, &txOvrlp, &bytesSent, TRUE);
} else logLastError(params.mainWindow, "WriteFile"); } CloseHandle(txOvrlp.hEvent); } }
else if (ntohs(rxBuf.ap.op) != RarpOpReply) { dump(params.mainWindow, bytesReturned, (UCHAR*)&rxBuf, "Buffer but not a RARP request"); } } CloseHandle(ovrlp.hEvent); }
_endthread(); } /* This function returns the last segments of a Registry key, starting with the character after the backslash, if there is a backslash. Usually we just want the last one segment, but we may want more than that.
*/ char* keyNameTail(char* akeyName, int atailSegments = 1) {

char* p; for (p = akeyName + strlen(akeyName) - 1; ; p--) { if (p == akeyName) return p; // no backslash; simple keyname if ((*p == '\\') && (--atailSegments <= 0)) break;
}
return (p + 1); } /* Here we log everything we wrote to the listbox.
*/ void writeLog(HWND hDlg) { enum { lineBufLen = 500 }; char* lineBuf = new char[lineBufLen]; LRESULT lineLen;
for (USHORT lineNo = 0; (lineLen = SendDlgItemMessage(hDlg, IDC_LOGBOX, LB_GETTEXTLEN, lineNo, 0)) != LB_ERR; lineNo++) { if (lineLen < lineBufLen) { SendDlgItemMessage(hDlg, IDC_LOGBOX, LB_GETTEXT, lineNo, (LPARAM)lineBuf);
lineBuf[lineLen] = '\0'; outFile << lineBuf << endl; } else outFile << "**Listbox line too long: " << lineLen << endl; } delete lineBuf; }
void WorkerParams::openntRarp() { enum { SYSVersionMin = 102, SYSVersionMax = 102 }; if (srvHandle != NULL) { // Service exists char rarpDeviceName[80];
wsprintf(rarpDeviceName, "\\\\.\\RARP%s", adapterName); char openMsg[120]; wsprintf(openMsg, "Opening %s", rarpDeviceName); logLine(mainWindow, openMsg); ntRarpHandle = CreateFile(rarpDeviceName, GENERIC_READ | GENERIC_WRITE, 0, NULL, OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL | FILE_FLAG_OVERLAPPED, NULL); if (ntRarpHandle != INVALID_HANDLE_VALUE) { logLine(mainWindow, "Opened RARP device"); UINT sysVersion; DWORD bytesReturned; if (DeviceIoControl(ntRarpHandle, DIOC_RarpGetVersion,
NULL, 0, &sysVersion, sizeof(sysVersion), &bytesReturned, NULL)) { if ((sysVersion < SYSVersionMin) || (sysVersion > SYSVersionMax)) { logLine(mainWindow, "Wrong version of RARP.SYS"); CloseHandle(ntRarpHandle); ntRarpHandle = INVALID_HANDLE_VALUE;
} else { char* msgBuf = new char[logLineLen]; ostrstream msgOss(msgBuf, logLineLen); msgOss << "Using RARP.SYS version " << (sysVersion / 100) << "." << setw(2) << setfill('0') << (sysVersion % 100) << ends;
logLine(mainWindow, msgBuf); } } else { logLine(mainWindow, "Can't get version of RARP.SYS"); CloseHandle(ntRarpHandle); ntRarpHandle = INVALID_HANDLE_VALUE;
} } else logLastError(mainWindow, "Opening RARP device"); }

} /* Can we find the subnet for this TCP parameters key among those excluded?
*/
long getSubnetMask(char* atcpParamsKeyName, HWND amainWindow) { char buf[80]; long addr;
long result = 0; DWORD addrLength = sizeof(buf), maskLength = sizeof(buf); if (!getValue(atcpParamsKeyName, "IPAddress", (BYTE*)buf, addrLength, REG_MULTI_SZ, amainWindow)) { fail(amainWindow, "No IPAddr for TCP params key"); } addr = inet_addr(buf);
if (addr != 0) { // static or BOOTP logLine(amainWindow, "...static IP"); // ***temp if (!getValue(atcpParamsKeyName, subnetMaskString, (BYTE*)buf, maskLength, REG_MULTI_SZ, amainWindow)) { fail(amainWindow, "No Subnet Mask for TCP params key"); } result = inet_addr(buf) & addr;
} else { // DHCP addrLength = sizeof(buf); if (getValue(atcpParamsKeyName, "DhcpIPAddress", (BYTE*)buf, addrLength, REG_SZ, amainWindow)) { addr = inet_addr(buf); logLine(amainWindow, "...DHCP IP"); // ***temp
maskLength = sizeof(buf); if (!getValue(atcpParamsKeyName, dhcpSubnetMaskString, (BYTE*)buf, maskLength, REG_SZ, amainWindow)) { fail(amainWindow, "No DHCP Subnet Mask for TCP params key"); } result = inet_addr(buf) & addr;
} } char maskMsg[80]; // ***temp in_addr mask; // ***temp mask.S_un.S_addr = result; // ***temp sprintf(maskMsg, "...mask = %s", inet_ntoa(mask)); // ***temp logLine(amainWindow, maskMsg); // ***temp
return result; } BOOL WorkerParams::isSubnetExcluded(char* atcpParamsKeyName) { long mask = getSubnetMask(atcpParamsKeyName, mainWindow); for (size_t subnetNo = 0;
(excludedSubnets[subnetNo]) != 0; subnetNo++) { if (excludedSubnets[subnetNo] == mask) { logLine(mainWindow, "...excluded"); return TRUE; }
} return FALSE; } /* Windows NT TCP Registry navigation, pre-NT 5:
The "Bind" value of the Tcpip Linkage key has a series of strings of the form \Device\adaptername, where if adaptername begins with "NdisWan" it's a Dial-up pseudo-adapter. We want one entry to remain. If so, that adapter's Parameters\Tcpip key name is what we return. While we're at it we also allocate and fill adapterName so we can find the MAC address later.
The string we return is the caller's responsibility to delete. */

char* WorkerParams::findNT4NetcardTCPParams() { char* tcpLinkageKeyName = "HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\" "Services\\Tcpip\\Linkage";
char* srvKeyPrefix = "HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\"
"Services\\"; char* tcpParamSuffix = "\\Parameters\\Tcpip"; DWORD bindBufLen = 1000; char* bindBuf = new char[bindBufLen]; if (!getValue(tcpLinkageKeyName, "Bind", (BYTE*)bindBuf, bindBufLen,
REG_MULTI_SZ, mainWindow)){ fail(mainWindow, "Registry failure"); } size_t nTCPKeys = 0; // Want to end up with 1 char* result = ""; for (CHAR* thisValue = bindBuf; *thisValue;
thisValue += (strlen(thisValue) + 1)) { if (strstr(thisValue, "NdisWan")) continue; // Not interested in Dial-up! char* resultSave = result; result = new char[strlen(srvKeyPrefix) + strlen(keyNameTail(thisValue)) + strlen(tcpParamSuffix) + 1]; strcpy(result, srvKeyPrefix); strcat(result, keyNameTail(thisValue));
strcat(result, tcpParamSuffix); if (isSubnetExcluded(result)) { delete[] result; result = resultSave; continue; } else if (++nTCPKeys > 1) break; // Bail out if more than one!
else { adapterName = new char[strlen(keyNameTail(thisValue)) + 1]; strcpy(adapterName, keyNameTail(thisValue)); } } if (nTCPKeys > 1) fail(mainWindow,
"No unique Registry key for TCP/IP over LAN"); else if (nTCPKeys == 0) fail(mainWindow, "Can't find Registry key for LAN TCP/IP"); else openntRarp(); delete bindBuf; return result; }
/* In Windows 2000 we resort to the overkill of issuing the MACADDR ioctl against the actual device because our Registry navigation still can't eliminate some ghost devices. Probably the poorly documented Setup API will get us out of that; Win2K ipconfig appears to use it. */
BOOL WorkerParams::probeAdapter(char* anadapterName) { char queryResult[512]; char deviceName[80]; BOOL result = FALSE;
BOOL createdDevice = FALSE; // resorted to DefineDosDevice? BOOL foundDevice = BOOL(QueryDosDevice(anadapterName, queryResult, sizeof(queryResult))); if ((!foundDevice) && (GetLastError() == ERROR_FILE_NOT_FOUND)) { strcpy(deviceName, "\\Device\\"); strcat(deviceName, anadapterName); createdDevice = DefineDosDevice(DDD_RAW_TARGET_PATH, anadapterName,
deviceName); } if (foundDevice || createdDevice) { char macFileName[80]; strcpy(macFileName, "\\\\.\\"); strcat(macFileName, anadapterName);
HANDLE hMAC = CreateFile(macFileName, GENERIC_READ, FILE_SHARE_READ | FILE_SHARE_WRITE, NULL, OPEN_EXISTING, 0, INVALID_HANDLE_VALUE); if (hMAC != INVALID_HANDLE_VALUE) {

UCHAR addrData[80]; ULONG ethAddrCode = 0x01010102; ULONG trAddrCode = 0x02010102; DWORD returnedCount = DWORD(-1); // impossible value
BOOL ioctlOK = FALSE; // assume failure
DWORD queryIoctl = CTL_CODE(FILE_DEVICE_PHYSICAL_NETCARD, 0, METHOD_OUT_DIRECT, FILE_ANY_ACCESS); if (DeviceIoControl(hMAC, queryIoctl /* IOCTL_NDIS_QUERY_GLOBAL_STATS */, ðAddrCode, sizeof(ethAddrCode), addrData, sizeof(addrData), &returnedCount, NULL)) {
ioctlOK = TRUE; } else if (DeviceIoControl(hMAC, queryIoctl, &trAddrCode, sizeof(trAddrCode), addrData, sizeof(addrData), &returnedCount, NULL)) { ioctlOK = TRUE; }
if (ioctlOK && (returnedCount == 6)) result = TRUE; else logLine(mainWindow, "... couldn't ioctl device"); // ***temp** if (createdDevice) { // Get rid of it! DefineDosDevice(DDD_RAW_TARGET_PATH | DDD_REMOVE_DEFINITION | DDD_EXACT_MATCH_ON_REMOVE, anadapterName, deviceName); } CloseHandle(hMAC);
} } else logLine(mainWindow, "... couldn't query or define device"); // ***temp** if (result) logLine(mainWindow, "...probed OK"); // ***temp*** return result; }
/* Windows NT TCP Registry navigation, NT 5: We're interested in the network adapters enumerated below the key for the network adapter class, which in NT 5 involves a GUID. For each one, we're only interested if it's bound above to TCP/IP and below to Ethernet
or Token Ring, and we're only interested if there's one and only one meeting our criteria. Then computing the keyname is easy after we open the corresponding RARP device. */ char* WorkerParams::findNT5NetcardTCPParams() {
char* result = ""; char* netcardClassKeyName = "HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\Control\\Class\\" "{4D36E972-E325-11CE-BFC1-08002BE10318}"; char* tcpParamsPrefix = "HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\" "Parameters\\Interfaces\\";
enum { KeyNameBufLen = 1000, ValueBufLen = 1000 }; DWORD valueBufLen; char* valueBuf = new char[ValueBufLen]; char* keyNameBuf = new char[KeyNameBufLen]; size_t nTCPKeys = 0; // Want to end up with 1 HKEY netcardClassHandle = getKey(netcardClassKeyName, mainWindow);
if (netcardClassHandle == NULL) { abortOnBadKey(netcardClassKeyName, mainWindow); } for (DWORD adapterNo = 0; ; adapterNo++) { char netcardSubKeyName[80]; // e.g. "0001" DWORD netcardSubKeyNameSize = sizeof(netcardSubKeyName);
FILETIME lastUpdate; LONG rc = RegEnumKeyEx(netcardClassHandle, adapterNo, netcardSubKeyName, &netcardSubKeyNameSize, NULL, NULL, NULL, &lastUpdate); if (rc != ERROR_SUCCESS) break; // No more subkeys.
strcpy(keyNameBuf, netcardClassKeyName); strcat(keyNameBuf, "\\"); strcat(keyNameBuf, netcardSubKeyName); // e.g. "0000" logLine(mainWindow, keyNameBuf); // ***temp***

size_t cardKeyNameLen = strlen(keyNameBuf); // length so far... valueBufLen = ValueBufLen; strcpy(keyNameBuf + cardKeyNameLen, "\\Ndi\\Interfaces"); if (!keyExists(keyNameBuf, mainWindow)) continue; // not physical...
// If our driver could handle ALL media we'd use Characteristics of x84
// as our test of the physicality of the adapter. if (getValue(keyNameBuf, "LowerRange", (BYTE*)valueBuf, valueBufLen, REG_SZ, mainWindow) && ((!stricmp(valueBuf, "ethernet")) || (!stricmp(valueBuf, "token ring")))) {
logLine(mainWindow, "...is a physical netcard"); // ***temp*** valueBufLen = ValueBufLen; keyNameBuf[cardKeyNameLen] = '\0'; if (getValue(keyNameBuf, "NetCfgInstanceId", (BYTE*)valueBuf, valueBufLen, REG_SZ, mainWindow)) { logLine(mainWindow, valueBuf); // ***temp*** char* resultSave = result;
result = new char[strlen(tcpParamsPrefix) + strlen(keyNameTail(valueBuf)) + 1]; strcpy(result, tcpParamsPrefix); strcat(result, keyNameTail(valueBuf)); #if 0 // ***temp 1.10.1*** HKEY tcpParamsKey = getKey(result, mainWindow); if (tcpParamsKey != NULL) {
logLine(mainWindow, "...bound to TCP/IP"); RegCloseKey(tcpParamsKey); } else { delete[] result; result = resultSave; continue;
} #endif valueBufLen = ValueBufLen; // Is the NTEContextList stuff needed? char physSignature[ValueBufLen]; // signature of physical netcard if (!getValue(result, "NTEContextList", (BYTE*)physSignature,
valueBufLen, REG_MULTI_SZ, mainWindow) || isSubnetExcluded(result) || !probeAdapter(keyNameTail(valueBuf))) { delete[] result; result = resultSave; continue; }
else if (++nTCPKeys > 1) break; else { adapterName = new char[strlen(keyNameTail(valueBuf)) + 1]; strcpy(adapterName, keyNameTail(valueBuf)); } } }
} RegCloseKey(netcardClassHandle); if (nTCPKeys > 1) fail(mainWindow, "No unique Registry key for TCP/IP over LAN");
else if (nTCPKeys == 0) fail(mainWindow, "Can't find Registry key for LAN TCP/IP"); else openntRarp(); delete valueBuf; delete keyNameBuf; return result;
} /* When the Registry fails us we try to get our IP address this way. */ UINT getWinsockLocalIp()
{ UINT result = 0; WSAData wsaData; if (WSAStartup(MAKEWORD(1, 1), &wsaData) == 0) {

char hostName[200]; if (gethostname(hostName, sizeof(hostName)) == 0) { struct hostent *phe = gethostbyname(hostName); if (phe != NULL) {
for (int i = 0; result == 0 && phe->h_addr_list[i] != 0; ++i) {
struct in_addr& ipAddr = *((struct in_addr*)phe->h_addr_list[i]); result = ipAddr.s_addr; } }
} WSACleanup(); } return result; } UINT WorkerParams::ourIpAddress()
{ UINT result = 0; char valueBuf[80]; DWORD valueBufLen1 = sizeof(valueBuf), valueBufLen2 = sizeof(valueBuf); if (getValue(transportKeyName, "IPAddress", (BYTE*)valueBuf, valueBufLen1, transportValueType, mainWindow)) { if ((strlen(valueBuf) != 0) && strcmp(valueBuf, "0.0.0.0")) {
result = inet_addr(valueBuf); } } else if (getValue(transportKeyName, "DhcpIPAddress", (BYTE*)valueBuf, valueBufLen2, transportValueType, mainWindow)) { if ((strlen(valueBuf) != 0) && strcmp(valueBuf, "0.0.0.0")) { result = inet_addr(valueBuf);
} } return (result ? result : getWinsockLocalIp()); // 10/12/03 } /*
Here we check if the machine we're running on really uses the Microsoft IP stack. We also make sure it isn't set up for DHCP. */ BOOL WorkerParams::checkStack() { transportKeyName = ((osMajorVersion < 5) ? findNT4NetcardTCPParams() :
findNT5NetcardTCPParams()); return BOOL(transportKeyName[0] != '\0'); } /* Diagnostic dump of the driver */
void WorkerParams::dumpDriverMemory() { if (os == WNT) { if (ntRarpHandle == INVALID_HANDLE_VALUE) { fail(mainWindow, "Driver dump requires RARP.SYS");
} else { enum { BufSize = 2000 }; BYTE* buf = new BYTE[BufSize]; DWORD bytesReturned; if (DeviceIoControl(ntRarpHandle, DIOC_RarpDumpDriver, NULL, 0, buf, BufSize,
&bytesReturned, NULL)) { dump(mainWindow, bytesReturned, buf, "Driver context:"); } else logLine(mainWindow, "Can't dump RARP.SYS"); delete buf; } }
_endthread(); } enum { ThreadStackSize = 8192 };

/* We use _beginthread() and _endthread() rather than the nicer CreateThread() etc. because Microsoft says using the latter in a program perverse enough
to use the C runtime library causes a memory leak. Whether or not that's
a bug, to ignore the hint would be to punish Microsoft for its candor. Wouldn't that be the wrong thing to punish them for? */ void worker(void* aparams)
{ WorkerParams& params = *((WorkerParams*)aparams); RarpTbl rarpTbl(params.mainWindow); if (params.checkStack()) { if (params.dumpDriver) params.dumpDriverMemory(); ReceiverParams receiverParams(params.mainWindow, params.rxTimeout, rarpTbl,
params.ourIpAddress(), quiescing); HANDLE receiverHandle = HANDLE(_beginthread(rarpReceiver, ThreadStackSize, &receiverParams)); while (!quiescing) Sleep(1000); logLine(params.mainWindow, "Quiescing..."); WaitForSingleObject(receiverHandle, INFINITE); }
SendMessage(params.mainWindow, WM_REALLY_CLOSE, 0, 0); _endthread(); } int APIENTRY mainDialogProc(HWND hDlg, UINT message, UINT wParam, LONG lParam) {
switch (message) { case WM_CLOSE: quiescing = TRUE; return 1; case WM_REALLY_CLOSE:
writeLog(hDlg); EndDialog (hDlg, 0); DestroyWindow(hDlg); PostQuitMessage(0); return 1; default: break;
} return DefWindowProc (hDlg, message, wParam, lParam); } /* Here we set up the GUI. The use of ShowWindow() is probably inept, but it's the only way I could figure out that would allow the nCmdShow arg
to WinMain() to coerce this program into running minimized if the user wants it that way. The problem seems to be that nCmdShow is always the same (SW_SHOWDEFAULT == decimal 10) no matter what the Win95 Shortcut Run property is. Am I missing something or what? Another idisyncrasy here is that we disable the Close item on the control
menu if we're running under NT with the NT driver. This is because we want to be sure any outstanding read gets successfully canceled so the driver can be dismissed. This isn't appropriate, though, in case we want the user to see the window and dismiss it only after he's seen enough, so we make it an option. */
BOOL initGUI(HINSTANCE hInstance, HWND& amainWindow, int nCmdShow, BOOL allowClose) { static char appName[] = "RARPD"; WNDCLASS wndclass; wndclass.style = CS_HREDRAW | CS_VREDRAW; wndclass.lpfnWndProc = (WNDPROC)mainDialogProc;
wndclass.cbClsExtra = 0; wndclass.cbWndExtra = DLGWINDOWEXTRA; wndclass.hInstance = hInstance; wndclass.hIcon = LoadIcon(hInstance, "ICON_3");

wndclass.hCursor = LoadCursor (NULL, IDC_ARROW); wndclass.hbrBackground = (HBRUSH)(COLOR_BTNFACE+1); wndclass.lpszMenuName = NULL; wndclass.lpszClassName = appName;
RegisterClass(&wndclass);
amainWindow = CreateDialog(hInstance, MAKEINTRESOURCE(DIALOG_MAIN), NULL, (DLGPROC)mainDialogProc); if (amainWindow) { #if 0 if ((srvHandle != NULL) && !allowClose) {
HMENU ctrlMenuH = GetSystemMenu(amainWindow, FALSE); if (ctrlMenuH != NULL) { EnableMenuItem(ctrlMenuH, SC_CLOSE, MF_BYCOMMAND | MF_GRAYED); } } #endif ShowWindow(amainWindow,
((nCmdShow == SW_SHOWDEFAULT) ? SW_SHOWMINIMIZED : nCmdShow)); return TRUE; } else { char* complaint = "Couldn't create main window"; logLastError(0, complaint); MessageBox(0, complaint, "rarpd", MB_ICONSTOP);
return FALSE; } } /* Here we extract the /t<seconds> option, returning a millisecond value, or, failing that, return the default 30,000 milliseconds.
*/ DWORD getTimeout(char* acmdLine) { DWORD result = 30000; if (acmdLine != NULL) {
char* optionP = strstr(acmdLine, "/t"); if (optionP == NULL) optionP = strstr(acmdLine, "/T"); if (optionP != NULL) { int secs = atoi(optionP + 2); if (secs > 0) result = secs * 1000; } }
return result; } /* We want to set the current directory to the one we were launched from. This can be tricky because if we were launched by the rarpd Launcher our full file path is encased in quotes in the command line. Then we can
open the logfile according to whether the user wants to overwrite any old logfile or append to it. If we were launched from the command line without an explicit path, there's no need to set the current directory. */ void openLog(char* cmdLine)
{ const char* progNameSentinels = (cmdLine[0] == '"') ? "\\\"" : "\\ "; char* lastBackslash = strchr(cmdLine, '\\'); while (lastBackslash != NULL) { size_t nextSentinelLoc = strcspn(lastBackslash + 1, progNameSentinels); char sentinel = lastBackslash[nextSentinelLoc + 1]; if (sentinel != '\\') break;
lastBackslash += (nextSentinelLoc + 1); } char dirPath[MAX_PATH]; if (lastBackslash != NULL) { char* cmdLineDirStart = cmdLine + strspn(cmdLine, "\""); size_t dirPathLen = lastBackslash - cmdLineDirStart; memcpy(dirPath, cmdLineDirStart, dirPathLen);
dirPath[dirPathLen] = '\0'; SetCurrentDirectory(dirPath); } if ((strstr(cmdLine, "/a") != NULL) || (strstr(cmdLine, "/A") != NULL)) {

outFile.open("RARPD.LOG",ios::out | ios::app); } else outFile.open("RARPD.LOG", ios::out | ios::trunc); char dateStr[80], timeStr[80];
GetDateFormat(LOCALE_USER_DEFAULT, 0, NULL,
"yyyy'-'MM'-'dd", dateStr, sizeof(dateStr)); GetTimeFormat(LOCALE_USER_DEFAULT, TIME_FORCE24HOURFORMAT, NULL, "HH':'mm':'ss", timeStr, sizeof(timeStr)); outFile << "rarpd " VERSION " started " << dateStr << " " << timeStr << endl;
outFile << "Command line: " << cmdLine << endl; } /* Here we marshall the options entered from the command line. We also set the current directory to be the one from which the program was loaded.
Originally we set the current directory so we could find the VxD even if we'd been started from the Registry key HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Run. This reason became obsolete when RARP.vxd became an NDIS protocol installed so that it gets loaded by the OS from the system directory, but we left the logic in because it made rarpd.log much easier to find when a remote user sent email complaining that the program didn't
work. */ int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR /* lpCmdLine */, int nCmdShow) { ourInstance = hInstance;
HWND mainWindow = 0; // our main window; 0 means not yet ready BOOL dumpDriver = FALSE; // dump the driver? SubnetHolder excludedSubnets; char* cmdLine = GetCommandLine(); if ((cmdLine != NULL) && (*cmdLine != '\0')) { openLog(cmdLine);
strupr(cmdLine); dumpDriver = BOOL(strstr(cmdLine, "/D") != NULL); excludedSubnets.init(cmdLine); } else { MessageBox(0, "Can't get command line", "rarpd", MB_ICONSTOP); exit(-1);
} configureForOS(nCmdShow); // Do this before any screen I/O! if ((!hPrevInstance) && initGUI(hInstance, mainWindow, nCmdShow, dumpDriver)) { logLine(mainWindow, "RARPD Version " VERSION); logLine(mainWindow, "Free software copyright (C) 1996-2003 Lew Perin"); WorkerParams workerParams(mainWindow, dumpDriver,
getTimeout(cmdLine), excludedSubnets); _beginthread(worker, ThreadStackSize, &workerParams); MSG msg; while (GetMessage(&msg, NULL, 0, 0)) { if (!IsDialogMessage(mainWindow, &msg)) {
TranslateMessage(&msg); DispatchMessage(&msg); } } } shutdown(); return 0;
}
Entête ICMP
1 - Définition du protocole 2 - Structure de l'entête 3 - Définition des différents champs

3.1 - Type et Code 3.1.1 - Type=0,8 - Le Ping 3.1.2 - Type=3 - Destination non valide 3.1.3 - Type=4 - Volume de donnée trop importante 3.1.4 - Type=5 - Redirection
3.1.5 - Type=9,10 - découverte de routeur 3.1.6 - Type=11 - Temps excédé
3.1.7 - Type=12 - Erreur d'entête 3.1.8 - Type=13,14 - Marqueur temporel 3.1.9 - Type=15,16,17,18 - Demande d'information 3.2 - Checksum 3.3 - Identifiant 3.4 - Numéro de séquence 4 - Discussion autour de la documentation
5 - Suivi du document
1 - Définition du protocole
Le protocole ICMP (Internet Control Message Protocol) permet de gérer les informations relatives aux erreurs du protocole IP. Il ne permet pas de corriger ces erreurs, mais d'en informer les différents émetteurs des Datagrammes en erreurs. Chaque pile IP, que ce soit des routeurs ou des stations de travail, gèrent ICMP par défaut.
Ce protocole est considéré comme faisant partie de l'ensemble des protocoles TCP/IP. Cependant, contrairement à TCP et UDP, il se situe en couche 3 et donc, il est encapsulé dans IP. Le mot "Encapsulation" relate clairement la confusion du placement d'ICMP dans les 7 couches OSI. Les messages d'erreur ICMP sont transportés sur le réseau sous forme de Datagramme, comme n'importe quelle donnée. Ainsi, les messages d'erreurs peuvent eux-mêmes être sujet aux erreurs. Toutefois, en cas d'erreur sur un
message ICMP, aucune trame d'erreur n'est délivrée pour éviter un effet "boule de neige".
Vous trouverez tous les détails du protocole ICMP dans la Rfc 792.
2 - Structure de l'entête
Voici la structure de l'entête ICMP basé sur 8 octets.
Les deux champs Identifiant et Numéro de séquence ne sont présent que dans le cas d'un paquet de type Ping sinon les champs reste présent mais en tant que bourrage et donc non utilisés.
3 - Définition des différents champs
3.1 - Type et Code
Les champs Type et Code sont codés respectivement sur 8 bits ce qui donne un totale de 2 octets. Ils représentent la définition de message d'erreur contenu. Voici la liste des principales combinaison entre les champs Type et Code :

Type Code Description
0 0 Réponse à une demande d'écho
3 0 Réseau inaccessible
3 1 Hôte inaccessible
3 2 Protocole inaccessible
3 3 Port inaccessible
3 4 Fragmentation nécessaire mais interdite
3 5 Echec de routage par la source
3 6 Réseau de destination inconnu
3 7 Hôte de destination inconnue
3 8 Machine source isolée
3 9 Réseau de destination interdit administrativement
3 10 Hôte de destination interdite administrativement
3 11 Réseau inaccessible pour ce type de service
3 12 Hôte inaccessible pour ce type de service
3 13 Communication interdite par un filtre
3 14 Host Precedence Violation
3 15 Precedence cutoff in efect
4 0 Volume de donnée trop importante
5 0 Redirection pour un hôte
5 1 Redirection pour un hôte et pour un service donné
5 2 Redirection pour un réseau
5 3 Redirection pour un réseau et pour un service donné
8 0 Demande d'écho
9 0 Avertissement routeur
10 0 Sollicitation routeur
11 0 Durée de vie écoulée avant d'arrivée à destination
11 1 Temps limite de réassemblage du fragment dépassé
12 0 En-tête IP invalide
12 1 Manque d'une option obligatoire
12 2 Mauvaise longueur
13 0 Requête pour un marqueur temporel
14 0 Réponse pour un marqueur temporel
15 0 Demande d'adresse réseau
16 0 Réponse d'adresse réseau
17 0 Demande de masque de sous réseau
18 0 Réponse de masque de sous réseau
3.1.1 - Type=0,8 - Le Ping
Le principe du Ping étant, à la base, de valider la présence d'un Hote IP. Pour cela, l'application Ping utilisera
la séquence 8-0 afin d'émettre une demande d'écho. Les données reçues dans un message d'écho doivent
être réémises dans la réponse. Ainsi, si le message de retour correspond à l'émission, on en déduit que l'Hote est présent. De plus, on peux en déduire d'autres services, tel que le temps de réponse, la taille paquet maximum la durée de vie et etc. L'identificateur et le numéro de séquence peuvent être utilisés par l'émetteur du message d'écho afin d'associer facilement l'écho et sa réponse. Par exemple, l'identificateur peut être utilisé comme l'est un port pour TCP ou UDP, identifiant ainsi une session. Et le numéro de séquence peut être incrémenté pour chaque
message d'écho envoyé. L'hôte de destination respectera ces deux valeurs pour le retour.
3.1.2 - Type=3 - Destination non valide
Ce type de message est émis dans le cas où un routeur ou un hôte ne puisse pas router un paquet.

3.1.3 - Type=4 - Volume de donnée trop importante
Un routeur ou hôte peut être amené à détruire un Datagramme s'il manque de mémoire pour bufferiser. Dans ce cas, le routeur émettra un message à destination de la source du Datagramme détruit, un paquet
ICMP de type 4. Cela peut ce produire dans un second cas. Quand le Datagramme arrive trop rapidement pour qu'il puisse être traité le message ICMP peut donc constituer une demande de diminution de débit de transfert.
3.1.4 - Type=5 - Redirection
Ces types de messages sont émis afin d'indiquer que le chemin emprunté n'est pas le bon pour la destination demandé. La réception de ce type de message d'erreur peut être interprétée par la modification de la table de routage locale. C'est plus communément appelé "Icmp Redirect".
3.1.5 - Type=9,10 - découverte de routeur
Au démarrage d'une station, plutôt que de configurer manuellement les routes statiques, surtout si elle sont susceptibles de changer et que le nombre de stations est grands, il peut être intéressant de faire de la
découverte automatique de routeurs. Pour cela, il y a deux possibilités. La première est l'envoi régulier de messages ICMP de type 9 "Avertissement routeur" d'annonces de routes par les routeurs. La seconde possibilité est qu'une station sollicite les routeurs avec un message de type 10 "Sollicitation routeur". La découverte de routeur n'est pas un protocole de routage, son objectif est bien moins ambitieux , juste obtenir une route par défaut.
Vous trouverez tous les détails du "découverte de routeur" dans la Rfc 1256.
3.1.6 - Type=11 - Temps excédé
Lorsqu'un routeur traitant un Datagramme est amené à mettre à jour le champ Durée de Vie de l'en-tête IP et que ce champ atteint une valeur zéro, le Datagramme sera détruit. Le routeur peut alors envoyer un message d'erreur "Time To Live expiré". Ce message ICMP peux être émis aussi dans le cas où le temps de réassemblage expire et le Datagramme ne peux donc être reconstitué à temps.
3.1.7 - Type=12 - Erreur d'entête
Si un routeur rencontre un problème avec un paramètre d'en-tête IP l'empêchant de finir son traitement, le datagramme sera alors détruit. Un message d'erreur de type 12 sera donc alors émis.
3.1.8 - Type=13,14 - Marqueur temporel
Le but de ce type de message est de s'échanger des données temporelles pour, par exemple, synchroniser les horloges.
3.1.9 - Type=15,16,17,18 - Demande d'information
Ce type de message est envoyé vers une adresse constituée du numéro de réseau dans le champ source de l'en-tête IP et un champ destinataire à 0. La pile IP qui répondra pourra alors envoyer une réponse avec les
adresses entièrement renseignées.
3.2 - Checksum
Le champ Checksum est codé sur 16 bits et représente la validité du paquet de la couche 3 ICMP. Pour pouvoir calculer le Checksum, il faut positionner le champ du checksum a 0. Ce calcul est strictement le même que celui du protocole IGMP.
Voici un exemple de fonction permettant le calcul du checksum ICMP.
unsigned short calcul_du_checksum(bool liberation, unsigned short *data, int taille) { unsigned long checksum=0;
// ******************************************************** // Complément à 1 de la somme des complément à 1 sur 16 bits // ******************************************************** while(taille>1)

{ if (liberation==TRUE) liberation_du_jeton(); // Rend la main à la fenêtre principale checksum=checksum+*data++;
taille=taille-sizeof(unsigned short);
} if(taille) checksum=checksum+*(unsigned char*)data;
checksum=(checksum>>16)+(checksum&0xffff); checksum=checksum+(checksum>>16); return (unsigned short)(~checksum); } unsigned short calcul_du_checksum_icmp(bool liberation, struct icmp icmp_tampon,char data_tampon[65535])
{ char tampon[65535]; unsigned short checksum; // ******************************************************** // Initialisation du checksum // ********************************************************
icmp_tampon.checksum=0; // Doit être à 0 pour le calcul // ******************************************************** // Calcul du ICMP // ******************************************************** memcpy(tampon,(unsigned short *)&icmp_tampon,sizeof(struct icmp)); memcpy(tampon+sizeof(struct icmp),data_tampon,strlen(data_tampon));
checksum=calcul_du_checksum(liberation,(unsigned short*)tampon,sizeof(struct icmp)+strlen(data_tampon)); return(checksum); }
3.3 - Identifiant
Le champ identifiant est codé sur 16 bits et définit l'identifiant de l'émetteur. Pour cela, il est conseillé d'assigner le numéro du processus assigné (PID) à l'application lors de l'exécution. Cela permet de le rendre unique inter application. Cela ressemble beaucoup aux numéros de port pour les protocole TCP et UDP.
3.4 - Numéro de séquence
Le champ Séquence est codé sur 16 bits et permet au récepteur, d'identifier si il manque un paquet. Le plus
classique étant une incrémentation linéaire de 1. Ainsi, si le récepteur reçoit la séquence 1 puis 3, il peut en déterminer une perte d'un paquet. Néanmoins, ce n'est pas normalisé, donc personne n'à la garantie que l'émetteur utilisera cette méthode. Cela peut aussi permettre à l'émetteur d'envoyer multiples paquets et de pouvoir distinguer les retours.
Entête IGMP
1 - Définition du protocole
2 - Structure de l'entête 3 - Définition des différents champs 3.1 - Type 3.2 - Temps de réponse max 3.3 - Checksum 3.4 - Adresse du groupe
4 - Discussion autour de la documentation 5 - Suivi du document
1 - Définition du protocole
Le protocole IGMP (Internet Group Management Protocol) permet de gérer les déclarations d'appartenance à un ou plusieurs groupes auprès des routeurs Multicast. Les inscriptions sont soit spontanées soit après requête du routeur. Pour cela, l'hôte envoi une trame IGMP destinées à ce ou ces groupes. Il existe 2 version du protocole IGMP.
Vous trouverez tous les détails du protocole IGMP version 1 dans la Rfc 1112.

Vous trouverez tous les détails du protocole IGMP version 2 dans la Rfc 2236.
2 - Structure de l'entête
Voici la structure de l'entête IGMP V2 basé sur 8 octets.
De la même manière qu'ICMP, IGMP est un protocole de couche 3. Il est encapsulé dans IP afin d'être véhiculé sur un réseau IP. Le terme "Encapsulé" relate pourquoi ce protocole est en couche 3 et non pas en niveau 4.
3 - Définition des différents champs
3.1 - Type
Le champ Type est codé sur 8 bits et détermine la nature du message IGMP. Voici les 4 types de messages existant : - 11 - 00001011 - Requête pour identifier les groupes ayant des membres actifs. - 12 - 00001100 - Rapport d'appartenance au groupe émis par un membre actif du groupe (IGMP version 1) - 16 - 00010000 - Rapport d'appartenance au groupe émis par un membre actif du groupe (IGMP version 2)
- 17 - 00010001 - Un membre annonce son départ du groupe
3.2 - Temps de réponse max
Ce champ n'est utilisé que pour les messages de type 11. Il indique le temps d'attente maximum pour un client avant l'émission du rapport d'appartenance. L'unité utilisée est le 1/10 de seconde. Pour les autres types, ce champ est marqué à 0.
3.3 - Checksum
Le champ Checksum est codé sur 16 bits et représente la validité du paquet de la couche 3 IGMP. Pour pouvoir
calculer le Checksum, il faut positionner le champ du checksum a 0. Ce calcul est strictement le même que celui du protocole ICMP. Voici un exemple de fonction permettant le calcul du checksum IGMP :
unsigned short calcul_du_checksum(bool liberation, unsigned short *data, int taille) { unsigned long checksum=0; // ******************************************************** // Complément à 1 de la somme des complément à 1 sur 16 bits // ********************************************************
while(taille>1) {

if (liberation==TRUE) liberation_du_jeton(); // Rend la main à la fenêtre principale checksum=checksum+*data++; taille=taille-sizeof(unsigned short);
}
if(taille) checksum=checksum+*(unsigned char*)data; checksum=(checksum>>16)+(checksum&0xffff);
checksum=checksum+(checksum>>16); return (unsigned short)(~checksum); } unsigned short calcul_du_checksum_igmp(bool liberation, struct igmp igmp_tampon,char data_tampon[65535]) {
char tampon[65535]; unsigned short checksum; // ******************************************************** // Initialisation du checksum // ******************************************************** igmp_tampon.checksum=0; // Doit être à 0 pour le calcul
// ******************************************************** // Calcul du IGMP // ******************************************************** memcpy(tampon,(unsigned short *)&igmp_tampon,sizeof(struct igmp)); memcpy(tampon+sizeof(struct igmp),data_tampon,strlen(data_tampon)); checksum=calcul_du_checksum(liberation,(unsigned short*)tampon,sizeof(struct igmp)+strlen(data_tampon));
return(checksum); }
3.4 - Adresse du groupe
Le champ Adresse du groupe est codé sur 32 bits et contient une adresse IP. Celle ci représente l'adresse du groupe d'appartenance ou 0 si l'inscription n'a pas encore eu lieu. Le type 11 place ce champ à 0 et les autres types marquent l'IP.
Entête TCP
1 - Définition du protocole
2 - Structure de l'entête 3 - Mode de transfert 3.1 - Ouverture de session 3.2 - Transfert des données 3.3 - Fermeture de session 3.4 - Fermeture brutale de connexion 4 - La fenêtre coulissante
5 - Définition des différents champs 5.1 - Port source
5.2 - Port destination 5.3 - Numéro de séquence 5.4 - Numéro de l'accusé de réception 5.5 - Offset
5.6 - Réservé 5.7 - Flags 5.8 - Fenêtre 5.9 - Checksum 5.10 - Pointeur de donnée urgente 5.11 - Options 5.12 - Bourrage
6 - Discussion autour de la documentation 7 - Suivi du document
1 - Définition du protocole
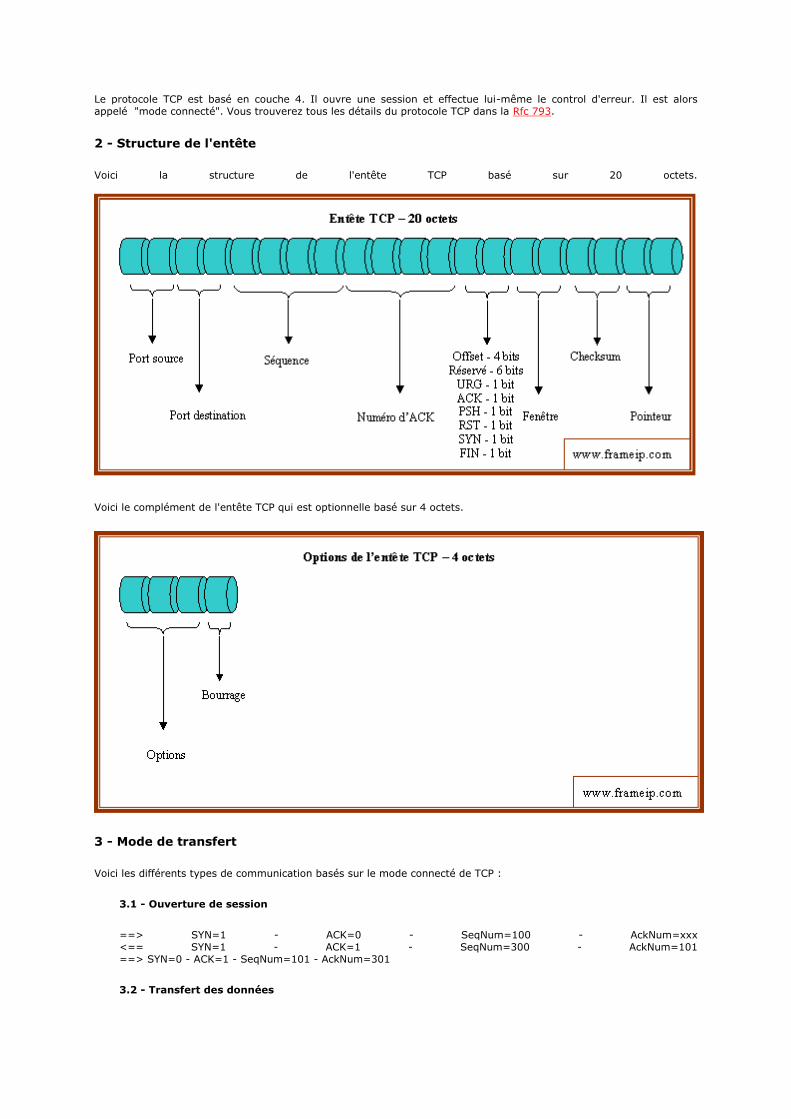
Le protocole TCP est basé en couche 4. Il ouvre une session et effectue lui-même le control d'erreur. Il est alors appelé "mode connecté". Vous trouverez tous les détails du protocole TCP dans la Rfc 793.
2 - Structure de l'entête
Voici la structure de l'entête TCP basé sur 20 octets.
Voici le complément de l'entête TCP qui est optionnelle basé sur 4 octets.
3 - Mode de transfert
Voici les différents types de communication basés sur le mode connecté de TCP :
3.1 - Ouverture de session
==> SYN=1 - ACK=0 - SeqNum=100 - AckNum=xxx <== SYN=1 - ACK=1 - SeqNum=300 - AckNum=101 ==> SYN=0 - ACK=1 - SeqNum=101 - AckNum=301
3.2 - Transfert des données

==> ACK=1 - SeqNum=101 - AckNum=301 - Data=30 octets <== ACK=1 - SeqNum=301 - AckNum=131 - Data=10 octets ==> ACK=1 - SeqNum=131 - AckNum=311 - Data=5 octets <== ACK=1 - SeqNum=311 - AckNum=136 - Data=10 octets
3.3 - Fermeture de session
<== ACK=1 - FIN=1 - SeqNum=321 - AckNum=136 ==> ACK=1 - FIN=0 - SeqNum=136 - AckNum=321
3.4 - Fermeture brutale de connexion
1ère cas possible : ==> ACK=1 - RST=0 - SeqNum=200 - AckNum=400 <== ACK=0 - RST=1 - SeqNum=400 - ACKNum=xxx 2nd cas possible :
<== ACK=0 - RST=0 - SeqNum=200 - Data=30 octets ==> ACK=0 - RST=1 - SeqNum=230 - Data=xxx
4 - La fenêtre coulissante
La fenêtre coulissante, plus connue sous le nom de "Sliding Windows" est employée pour transférer des données entre
les hôtes. La fenêtre définit le volume de données susceptibles d'être passées via une connexion TCP, avant que le récepteur n'envoie un accusé de réception. Chaque ordinateur comporte une fenêtre d'émission et une fenêtre de réception qu'il utilise pour buffériser les données en continu, sans devoir attendre un accusé de réception pour chaque
paquet. Cela permet au récepteur de recevoir les paquets dans le désordre et de profiter des délais d'attente pour réorganiser les paquets. La fenêtre émettrice contrôle les données émises, si elle ne reçoit pas d'accusé de réception au bout d'un certain temps, elle retransmet le paquet.
Considérations sur le débit :
TCP a été conçu pour offrir des performances optimales en présence de conditions de liaison variées et les systèmes d'exploitations comportent des améliorations telles que celles prenant en charge la RFC 1323. Le débit réel d'une liaison dépend d'un certain nombre de variables, mais les facteurs les plus importants sont les suivants :
Vitesse de la liaison (bits par seconde pouvant être transmis)
Retard de propagation
Dimension de la fenêtre (quantité de données n'ayant pas fait l'objet d'un accusé de réception et qui peuvent
être en attente sur une connexion TCP)
Fiabilité de la liaison
Encombrement du réseau et des périphériques intermédiaires
MTU du parcours
Voici quelques considérations fondamentales sur le calcul du débit TCP : La capacité d'un canal de communication est égale à la bande passante multipliée par le temps de transmission aller-
retour. Elle est connue sous le nom de produit bande passante-retard. Si la liaison est fiable, pour obtenir des performances optimales, la dimension de la fenêtre doit être supérieure ou égale à la capacité du canal de
communication, de manière à permettre à la pile d'envoi de le remplir. La plus grande dimension de fenêtre pouvant être spécifiée, en raison du champ de 16 bits de l'en-tête TCP, est de 65535. Des fenêtres plus larges peuvent toutefois être négociées grâce au redimensionnement des fenêtres.
Le débit ne peut jamais excéder la taille de la fenêtre divisée par le temps de transmission aller-retour. Si la liaison n'est pas fiable ou est encombrée et que des paquets sont perdus, l'utilisation fenêtre de taille supérieure ne garantit
pas nécessairement un meilleur débit. Windows 2000 prend en charge non seulement le dimensionnement des fenêtres, mais également les accusés de réception sélectifs (SACK, décrits dans la RFC 2018) pour améliorer les performances au sein d'environnements qui présentent des pertes de paquets. Il prend également en charge l'horodatage (décrit dans la RFC 1323) pour une meilleure évaluation RTT.
Le retard de propagation dépend de la vitesse de la lumière, des latences de l'équipement de transmission, etc. Le retard de transmission dépend donc de la vitesse du support.
Pour un parcours spécifique, le retard de propagation est fixe, mais le retard de transmission dépend de la taille du
paquet. À des vitesses réduites, le retard de transmission constitue un facteur limitatif. À des vitesses élevées, le retard de propagation peut devenir un facteur de limitation.

En résumé, les piles TCP/IP peuvent s'adapter à la plupart des conditions de réseau et fournir dynamiquement le meilleur débit et la meilleure fiabilité possibles pour chaque connexion. Les essais de mise au point manuelle sont souvent contre-productifs, sauf lorsqu'un ingénieur réseau qualifié procède préalablement à une étude précise du flux de données.
5 - Définition des différents champs
5.1 - Port source
Le champ Port source est codé sur 16 bits et correspond au port relatif à l'application en cours sur la machine source.
5.2 - Port destination
Le champ Port destination est codé sur 16 bits et correspond au port relatif à l'application en cours sur la machine de destination.
Vous trouverez la liste des ports TCP officialisées par l'IANA, organisation gérant mondialement les adressage IP.
5.3 - Numéro de séquence
Le champ Numéro de séquence est codé sur 32 bits et correspond au numéro du paquet. Cette valeur permet de situer à quel endroit du flux de données le paquet, qui est arrivé, doit se situer par rapport aux autres paquets.
5.4 - Numéro de l'accusé de réception
Le champ Numéro de séquence est codé sur 32 bits et définit un acquittement pour les paquets reçus. Cette valeur signale le prochain numéro de paquet attendu. Par exemple, si il vaut 1500, cela signifie que tous les Datagrammes <1500 ont été reçus
5.5 - Offset
Le champ Offset est codé sur 4 bits et définit le nombre de mots de 32 bits dans l'entête TCP. Ce champ indique donc où les données commencent.
5.6 - Réservé
Le champ Réservé est codé sur 6 bits et il servira pour des besoins futurs. Ce champ doit être marqué à 0. Au jour d'aujourd'hui, on peut considérer que les besoins futurs se transforment en un champ non utilisé.
5.7 - Flags
- Le champ URG est codé sur 1 bit et indique que le champ Pointeur de donnée urgente est utilisé. - Le champ ACK est codé sur 1 bit et indique que le numéro de séquence pour les acquittements est valide. - Le champ PSH est codé sur 1 bit et indique au récepteur de délivrer les données à l'application et de ne pas attendre le remplissage des tampons. - Le champ RST est codé sur 1 bit et demande la réinitialisation de la connexion. - Le champ SYN est codé sur 1 bit et indique la synchronisation des numéros de séquence.
- Le champ FIN est codé sur 1 bit et indique fin de transmission.
5.8 - Fenêtre
Le champ Fenêtre "Windows" est codé sur 16 bits et correspond au nombre d'octets à partir de la position marquée dans l'accusé de réception que le récepteur est capable de recevoir. Le destinataire ne doit donc pas envoyer les paquets après Numéro de séquence + Window.
5.9 - Checksum
Le champ Checksum est codé sur 16 bits et représente la validité du paquet de la couche 4 TCP.
Le Checksum est constitué en calculant le complément à 1 sur 16 bits de la somme des compléments à 1 des octets de l'en-tête et des données pris deux par deux (mots de 16 bits). Si le message entier contient un nombre impair d'octets, un 0 est ajouté à la fin du message pour terminer le calcul du Checksum. Cet octet supplémentaire n'est pas transmis. Lors du calcul du Checksum, les positions des bits attribués à celui-ci sont marquées à 0.

Le Checksum couvre de plus, une pseudo en-tête de 96 bits préfixée à l'en-tête TCP. Cette pseudo en-tête comporte les adresses Internet sources et destinataires, le type de protocole et la longueur du message TCP (incluant la data). Ceci protège TCP contre les erreurs de routage.
La longueur TCP compte le nombre d'octets de l'en-tête TCP et des données du message, en excluant les 12
octets de la pseudo en-tête. Voici un exemple de fonction permettant le calcul du checksum TCP. Elle est identique à celle de UDP.
struct pseudo_entete { unsigned long ip_source; // Adresse ip source unsigned long ip_destination; // Adresse ip destination char mbz; // Champs à 0 char type; // Type de protocole (6->TCP et 17->UDP)
unsigned short length; // htons( Taille de l'entete Pseudo + Entete TCP ou UDP + Data ) }; unsigned short calcul_du_checksum(bool liberation, unsigned short *data, int taille) { unsigned long checksum=0; // ********************************************************
// Complément à 1 de la somme des complément à 1 sur 16 bits // ******************************************************** while(taille>1) { if (liberation==TRUE) liberation_du_jeton(); // Rend la main à la fenêtre principale checksum=checksum+*data++;
taille=taille-sizeof(unsigned short);
} if(taille) checksum=checksum+*(unsigned char*)data;
checksum=(checksum>>16)+(checksum&0xffff); checksum=checksum+(checksum>>16); return (unsigned short)(~checksum); } unsigned short calcul_du_checksum_tcp(bool liberation, unsigned long ip_source_tampon, unsigned long
ip_destination_tampon, struct tcp tcp_tampon, char data_tampon[65535]) { struct pseudo_entete pseudo_tcp; char tampon[65535]; unsigned short checksum; // ********************************************************

// Initialisation du checksum // ******************************************************** tcp_tampon.checksum=0; // Doit être à 0 pour le calcul
// ********************************************************
// Le calcul du Checksum TCP (Idem à UDP) // ******************************************************** // Le calcul passe par une pseudo entete TCP + l'entete TCP + les Data pseudo_tcp.ip_source=ip_source_tampon; pseudo_tcp.ip_destination=ip_destination_tampon;
pseudo_tcp.mbz=0; pseudo_tcp.type=IPPROTO_TCP; pseudo_tcp.length=htons((unsigned short)(sizeof(struct tcp)+strlen(data_tampon))); memcpy(tampon,&pseudo_tcp,sizeof(pseudo_tcp)); memcpy(tampon+sizeof(pseudo_tcp),&tcp_tampon,sizeof(struct tcp)); memcpy(tampon+sizeof(pseudo_tcp)+sizeof(struct tcp),data_tampon,strlen(data_tampon)); checksum=calcul_du_checksum(liberation,(unsigned short*)tampon,sizeof(pseudo_tcp)+sizeof(struct
tcp)+strlen(data_tampon)); return(checksum); }
5.10 - Pointeur de donnée urgente
Le champ Pointeur de donnée urgente est codé sur 16 bits et communique la position d'une donnée urgente en donnant son décalage par rapport au numéro de séquence. Le pointeur doit pointer sur l'octet suivant la donnée urgente. Ce champ n'est interprété que lorsque le Flag URG est marqué à 1. Dès que cet octet est reçu, la pile TCP doit envoyer les données à l'application.
5.11 - Options
Les champs d'options peuvent occuper un espace de taille variable à la fin de l'en-tête TCP. Ils formeront toujours un multiple de 8 bits. Toutes les options sont prises en compte par le Checksum. Un paramètre d'option commence toujours sur un nouvel octet. Il est défini deux formats types pour les options: - Cas 1 - Option mono-octet. - Cas 2 - Octet de type d'option, octet de longueur d'option, octet de valeur d'option.
La longueur d'option prend en compte l'octet de type, l'octet de longueur lui-même et tous les octets de valeur et est exprimée en octet. La liste d'option peut être plus courte que ce que l'offset de données pourrait le faire supposer. Un octet de remplissage "Bourrage" devra être dans ce cas rajouté après le code de fin d'options.
5.12 - Bourrage
Le champ Bourrage est de taille variable comprise entre 0 et 7 bits. Il permet de combler le champ option afin d'obtenir une entête TCP multiple de 32 bits. La valeur des bits de bourrage est 0.
Entête UDP
1 - Définition du protocole 2 - Structure de l'entête 3 - Définition des différents champs 3.1 - Port source 3.2 - Port destination
3.3 - Longueur 3.4 - Checksum 4 - Discussion autour de la documentation 5 - Suivi du document
1 - Définition du protocole
Le protocole UDP est basé en couche 4. Il n'ouvre pas de session et n'effectue pas de control d'erreur. Il est alors appelé "mode non connecté". Il est donc peut fiable, cependant, il permet aux applications d'accéder directement à un service de transmission de Datagrammes rapide. UDP est utilisé pour transmettre de faibles quantités de données où le coût de la création de connexions et du maintient de transmissions fiables s'avèrent supérieur aux données à émettre. UDP peut également être utilisé pour les

applications satisfaisant à un modèle de type "interrogation réponse". La réponse étant utilisée comme un accusé de réception à l'interrogation. On y trouve classiquement Snmp et Dns. UDP est aussi utilisé dans un second cas, tel que la voix sur IP. L'envoi en temps réel est primordiale, donc si une trame n'arrivait pas, la retransmission serait inutile Vous trouverez tous les détails du protocole UDP dans la Rfc 768.
2 - Structure de l'entête
Voici la structure de l'entête UDP basé sur 8 octets.
3 - Définition des différents champs
3.1 - Port source
Le champ Port source est codé sur 16 bits et correspond au port relatif à l'application en cours sur la machine
source.
3.2 - Port destination
Le champ Port destination est codé sur 16 bits et il correspond au port relatif à l'application en cours sur la machine de destination.
Vous trouverez la liste des ports TCP officialisées par l'IANA, organisation gérant mondialement les adressage IP.
3.3 - Longueur
Le champ Longueur est codé sur 16 bits et il représente la taille de l'entête et des données. Sont unité est l'octet
et sa valeur maximale est 64 Koctets (216).
3.4 - Checksum
Le champ Checksum est codé sur 16 bits et représente la validité du paquet de la couche 4 UDP. Le Checksum est constitué en calculant le complément à 1 sur 16 bits de la somme des compléments à 1 des octets de l'en-tête et des données pris deux par deux (mots de 16 bits). Si le message entier contient un nombre
impair d'octets, un 0 est ajouté à la fin du message pour terminer le calcul du Checksum. Cet octet supplémentaire n'est pas transmis. Lors du calcul du Checksum, les positions des bits attribués à celui-ci sont marquées à 0. Le Checksum couvre de plus, une pseudo en-tête de 96 bits préfixée à l'en-tête UDP. Cette pseudo en-tête comporte les adresses Internet source et destinataires, le type de protocole et la longueur du message UDP. Ceci protège UDP contre les erreurs de routage.

La longueur UDP compte le nombre d'octets de l'en-tête UDP et des données du message, en excluant les 12 octets de la pseudo en-tête. Voici un exemple de fonction permettant le calcul du checksum UDP. Elle est identique à celle de TCP.
struct pseudo_entete { unsigned long ip_source; // Adresse ip source unsigned long ip_destination; // Adresse ip destination char mbz; // Champs à 0
char type; // Type de protocole (6->TCP et 17->UDP) unsigned short length; // htons( Taille de l'entete Pseudo + Entete TCP ou UDP + Data ) }; unsigned short calcul_du_checksum(bool liberation, unsigned short *data, int taille) {
unsigned long checksum=0; // ******************************************************** // Complément à 1 de la somme des complément à 1 sur 16 bits // ******************************************************** while(taille>1) { if (liberation==TRUE)
liberation_du_jeton(); // Rend la main à la fenêtre principale checksum=checksum+*data++; taille=taille-sizeof(unsigned short); } if(taille) checksum=checksum+*(unsigned char*)data;
checksum=(checksum>>16)+(checksum&0xffff); checksum=checksum+(checksum>>16); return (unsigned short)(~checksum); }
unsigned short calcul_du_checksum_udp(bool liberation, unsigned long ip_source_tampon, unsigned long ip_destination_tampon, struct udp udp_tampon, char data_tampon[65535]) { struct pseudo_entete pseudo_udp; char tampon[65535]; unsigned short checksum;
// ******************************************************** // Initialisation du checksum // ******************************************************** udp_tampon.checksum=0; // Doit être à 0 pour le calcul // ********************************************************

// Le calcul du Checksum UDP (Idem à TCP) // ******************************************************** // Le calcul passe par une pseudo entete UDP + l'entete UDP + les Data pseudo_udp.ip_source=ip_source_tampon;
pseudo_udp.ip_destination=ip_destination_tampon;
pseudo_udp.mbz=0; pseudo_udp.type=IPPROTO_UDP; pseudo_udp.length=htons((unsigned short)(sizeof(struct udp)+(unsigned short)strlen(data_tampon))); memcpy(tampon,&pseudo_udp,sizeof(pseudo_udp)); memcpy(tampon+sizeof(pseudo_udp),&udp_tampon,sizeof(struct udp));
memcpy(tampon+sizeof(pseudo_udp)+sizeof(struct udp),data_tampon,strlen(data_tampon)); checksum=calcul_du_checksum(liberation,(unsigned short*)tampon,sizeof(pseudo_udp)+sizeof(struct udp)+strlen(data_tampon)); return(checksum); }
Entête IPv6
1 - Définition du protocole 2 - Structure de l'entête 3 - Définition des différents champs 3.1 - Version (Version) 3.2 - Classe (Traffic Class) 3.3 - Label (Flow Label) 3.4 - Longueur (Payload Length)
3.5 - Entête suivante (Next Header) 3.6 - Saut maximum (Hop Limit) 3.7 - Adresse source (Source Address) 3.8 - Adresse destination (Destination Address) 4 - Structure des options de l'entête 4.1 - Sauts après sauts (Hop-by-Hop) 4.2 - Routage (Routing)
4.3 - Fragmentation (Fragment) 4.4 - Destination (Destination) 4.5 - AH (Authentication) 4.6 - ESP (Encapsulating Security Payload) 5 - Définition des différentes champs des Options 5.1 - Sauts après sauts (Hop-by-Hop)
5.2 - Routage (Routing) 5.3 - Fragmentation (Fragment) 5.4 - Destination (Destination) 5.5 - AH (Authentication) 5.6 - ESP (Encapsulating Security Payload) 6 - Discussion autour de la documentation 7 - Suivi du document
1 - Définition du protocole
Lorsque le protocole Internet IPv4 a été lancé, Internet était minuscule est relativement privé. Il semblait inimaginable d'atteindre les près de 4.300.000 adresses disponibles. Aujourd'hui, Internet est victime de son succès et l'espace
d'adressage d'IPv4 est incapable de répondre à la forte demande d'adresse à travers le monde. En effet, personne n'imaginait à l'époque d'utiliser un jour une adresse IP pour téléphoner, jouer, naviguer sur Internet avec un téléphone
portable ou bien un assistant personnel. On compte aujourd'hui plus d'objets intelligents connectés que d'être humain sur Terre.
C'est à cette pénurie d'adresses que doivent faire face aujourd'hui les RIR. Bien sûr des solutions ont été développé, ce qui à considérablement ralentit le déploiement industrielle d'IPv6. Voici la liste de ces solutions :
DHCP, Dynamic Host Configuration Protocol, permet d'allouer dynamiquement les adresses seulement quand
les machines sont connectées.
HTTP 1.1, permettant, principalement, d'héberger plusieurs site web avec une seule adresse IP.
NAT, Network Address Translation, permet de réduire le nombre d'adresses publiques utilisées en proposant de réaliser grâce à une fonction de routeur, la translation des adresses privées d'un site.
Cet emploi généralisé des NAT a conduit à une complexification de la gestion des réseaux et à un alourdissement des
mécanismes de routage. Cela nuit également au développement d'application Peer to Peer temps réel comme la VoIP. De plus, associé à la sécurité et à la mobilité, ces services sont des raisons supplémentaires au besoin d'IPv6.

IPv6 est définit par la RFC 2460.
2 - Structure de l'entête
Voici la structure de l'entête IP basé sur 40 octets.
3 - Définition des différents champs
L'entête qui était de 20 octets en IPv4 passe à 40 octets en IPv6. Certains champs d'IPv4 ont été supprimés, ou sont maintenant optionnels, ceci afin de réduire le coût de traitement des paquets et de bande passante des entêtes IPv6.
3.1 - Version (Version)
Le champ "Version" est codé sur 4 bits. Il représente le numéro de version du Protocole Internet. Sa valeur est donc égale à 6 (0110 base 2). Ce champ est identique à la pile IPV4, il sert justement à identifier le protocole de couche 3 du modèle OSI. Voici la liste des différent codes :
- 00 - Réservé - 01 - Non assigné - 02 - Non assigné - 03 - Non assigné - 04 - IP V4 - 05 - ST Datagram Mode

- 06 - IP V6 - 07 - Non assigné - 08 - Non assigné - 09 - Non assigné - 10 - Non assigné
- 11 - Non assigné - 12 - Non assigné
- 13 - Non assigné - 14 - Non assigné - 15 - Réservé
3.2 - Classe (Traffic Class)
Le champ "Classe" est codé sur 8 bits. Il définit la priorité du datagramme afin que des noeuds origines et des routeurs transmetteurs puissent identifier et distinguer la classe ou la priorité du paquets IPv6 en question.
3.3 - Label (Flow Label)
Le champ "Label" est codé sur 20 bits. Il peut être utilisé par une source pour nommer des séquences de paquets pour lesquels un traitement spécial de la part des routeurs IPv6 est demandé. Ce traitement spécial pourrait être une qualité de service différente du service par défaut ou un service "temps réel".
3.4 - Longueur (Payload Length)
Le champ "Longueur" est codé sur 16 bits. Le champ "Longueur" de l'entête IPV4 indiquait la longueur des données incluant l'entête IPV4. Contrairement à cela, cette fois le champ "Longueur" de l'entête IPv6 indique le nombre d'octet des données qui suivent cette entête IPv6. Il faut noté que les options de l'entête IPv6 sont
considérés comme de la donnée et font donc partie du calcul du champ "Longueur".
3.5 - Entête suivante (Next Header)
Le champ "Entête suivante" est codé sur 8 bits. Il identifie le type de la Data ou de l'option qui se trouve derrière l'entête IPv6. Les valeurs employées sont identiques au champ "Protocole" de l'entête IPV4. Vous trouverez tous les détails des types de protocole dans la RFC 1700 qui remplace désormais la RFC 1340.
Voici la liste des protocoles les plus connu :
- 01 - 00000001 - ICMP - 02 - 00000010 - IGMP - 06 - 00000110 - TCP - 17 - 00010001 - UDP - 58 - 00111010 - ICMPV6
Voici la liste des options de l'entête IPv6 vues plus bas :
- 00 - Option Sauts après sauts - 60 - Option Destination - 43 - Option Routage - 44 - Option Fragmentation - 51 - Option AH - 50 - Option ESP
3.6 - Saut maximum (Hop Limit)
Le champ "Saut maximum" est codé sur 8 bits. Il indique le nombre de routeur maximum que le datagramme pourra traverser. Identiquement au champ "TTL" de l'entête IPV4, il est décrémenté de 1 par chaque noeud que le paquet traverse.
3.7 - Adresse source (Source Address)
Le champ "Adresse source" est codé sur 128 bits. Il représente l'adresse IP de l'émetteur.
3.8 - Adresse destination (Destination Address)
Le champ "Adresse destination" est codé sur 128 bits. Il représente l'adresse IP du destinataire.
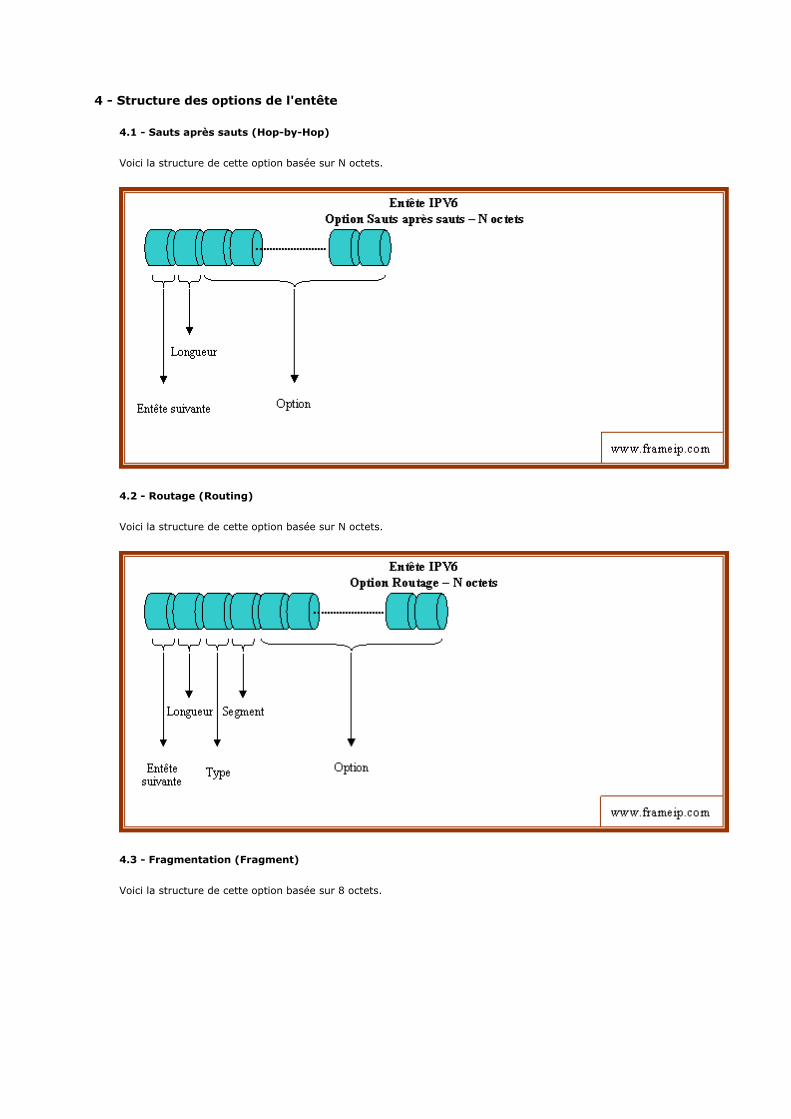
4 - Structure des options de l'entête
4.1 - Sauts après sauts (Hop-by-Hop)
Voici la structure de cette option basée sur N octets.
4.2 - Routage (Routing)
Voici la structure de cette option basée sur N octets.
4.3 - Fragmentation (Fragment)
Voici la structure de cette option basée sur 8 octets.
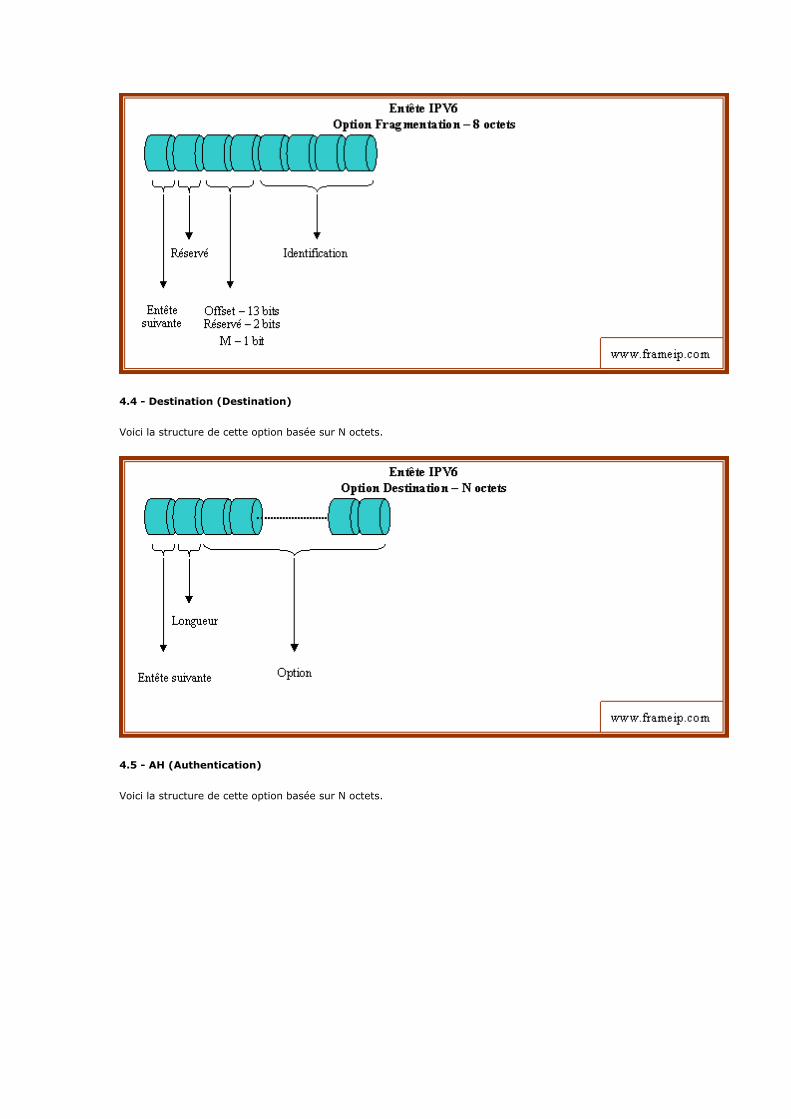
4.4 - Destination (Destination)
Voici la structure de cette option basée sur N octets.
4.5 - AH (Authentication)
Voici la structure de cette option basée sur N octets.

4.6 - ESP (Encapsulating Security Payload)
Voici la structure de cette option basée sur N octets.
5 - Définition des différentes champs des Options
Lors de l'utilisation de plusieurs extensions, il est recommandé d'utiliser l'ordre suivant :
Entête IPv6
Option Sauts après sauts
Option Destination
Option Routage
Option Fragmentation
Option AH
Option ESP
Option Destination
Entête de couche supérieure
5.1 - Sauts après sauts (Hop-by-Hop)

L'option "Sauts après sauts" est utilisée pour transporter des informations optionnelles qui doivent être examinées par chaque noeud le long du chemin emprunté par le paquet. Cette Option est codé 0 et est définie par la RFC 2460.
5.1.1 - Entête suivante (Next Header)
Le champ "Entête suivante" est codé sur 8 bits. Il identifie le type de la Data ou de l'option qui se trouve derrière cette option de l'entête IPv6. tous les détails sont dans la définition du champ "Entête suivante" de l'entête IPv6 en paragraphe 3.5.
5.1.2 - Longueur (Hdr Ext Len)
Le champ "Longueur" est codé sur 8 bits. Il représente la taille de cette Option "Sauts après sauts". L'unité de mesure est les mots de 8 octets sans compter les 8 premiers octets.
5.1.3 - Options (Options)
Le champ "Options" est codé sur N bits. Il contient le contenu de l'option à spécifier.
5.2 - Routage (Routing)
L'option de "Routage" est utilisée par une source IPv6 pour lister au moins un noeud intermédiaire à aller voir sur
le chemin emprunté par le paquet vers la destination. Cette fonction est très similaire aux options de "Loose Source" ou "Record Route" de l'entête IPV4. Cette Option est codé 43 et est définie par la RFC 2460.
5.2.1 - Entête suivante (Next Header)
Le champ "Entête suivante" est codé sur 8 bits. Il identifie le type de la Data ou de l'option qui se trouve derrière cette option de l'entête IPv6. tous les détails sont dans la définition du champ "Entête suivante" de l'entête IPv6 en paragraphe 3.5.
5.2.2 - Longueur (Hdr Ext Len)
Le champ "Longueur" est codé sur 8 bits. Il représente la taille de cette Option "Routage". L'unité de mesure est les mots de 8 octets sans compter les 8 premiers octets.
5.2.3 - Type (Routing Type)
Le champ "Type" est codé sur 8 bits. Il identifie la variante particulière de l'entête de routage.
5.2.4 - Segment (Segments Left)
Le champ "segment" est codé sur 8 bits. Il indique le nombre de segments de chemin restant. C'est à dire le nombre de noeuds intermédiaires listés explicitement qu'il reste à traverser avant d'atteindre la destination finale.
5.1.5 - Données (type-specific data)
Le champ "Données" est codé sur N bits. Il contient le contenu de l'option à spécifier.
5.3 - Fragmentation (Fragment)
L'option de "Fragmentation" est utilisée par une source IPv6 pour envoyer un paquet plus large que celui qui tiendrait dans le MTU vers la destination. Attention, contrairement à l'entête IPV4, la fragmentation dans IPv6 n'est réalisée que par les noeuds sources et non par les routeurs le long d'un chemin emprunté par le paquet. Cette Option est codé 44 et est définie par la RFC 2460.
5.2.1 - Entête suivante (Next Header)
Le champ "Entête suivante" est codé sur 8 bits. Il identifie le type de la Data ou de l'option qui se trouve derrière cette option de l'entête IPv6. tous les détails sont dans la définition du champ "Entête suivante" de l'entête IPv6 en paragraphe 3.5.

5.2.2 - Réservé (Reserved)
Le champ "Réservé" est codé sur 8 bits. Il est prévu pour des besoins futurs, en attendant, sa valeurs doit être positionnée à 0 pour l'émission et il doit être ignoré pour la réception.
5.2.3 - Offset (Fragment Offset)
Le champ "Offset" est codé sur 13 bits. Il indique l'offset des données suivant cette entête, en nombre de
mots de 8 octets, par rapport au début de la partie fragmentable du paquet original.
5.2.4 - Réservé (Res)
Le champ "Réservé" est codé sur 2 bits. Il est prévu pour des besoins futurs, en attendant, sa valeurs doit être positionnée à 0 pour l'émission et il doit être ignoré pour la réception.
5.2.5 - M (M)
Le champ "M" est codé sur 1 bit. Il peux prendre deux valeurs. 0 pour indiquer que c'est le dernier fragment et 1 pour signifier que ce n'est pas terminé.
5.1.6 - Identification (Identification)
Le champ "Identification" est codé sur 32 bits. Pour chaque paquet devant être fragmenté, le noeud source génère une valeur d'Identification. L'Identification doit être différente de tout autre identification de paquet fragmenté envoyé récemment avec les mêmes Adresse Source et Adresse Destination. Si un entête de routage est présent, l'Adresse Destination concernée est celle de la destination finale.
5.4 - Destination (Destination)
L'option de "Destination" est utilisée pour transporter des informations optionnelles qui ont besoin d'être examinées uniquement par les noeuds destination du paquet. Cette Option est codé 60 et est définie par laRFC 2460.
5.4.1 - Entête suivante (Next Header)
Le champ "Entête suivante" est codé sur 8 bits. Il identifie le type de la Data ou de l'option qui se trouve derrière cette option de l'entête IPv6. tous les détails sont dans la définition du champ "Entête suivante" de l'entête IPv6 en paragraphe 3.5.
5.4.2 - Longueur (Hdr Ext Len)
Le champ "Longueur" est codé sur 8 bits. Il représente la taille de cette Option "Destination". L'unité de mesure est les mots de 8 octets sans compter les 8 premiers octets.
5.4.3 - Options (Options)
Le champ "Options" est codé sur N bits. Il contient le contenu de l'option à spécifier.
5.5 - AH (Authentication)
L'option "AH" est utilisée pour fournir un mécanisme permettant au destinataire de s'assurer de l'identité de la source et de l'intégrité des données. Cela fournit surtout une bonne protection contre les rejeux et les spoofing IP. Cette Option est codé 51 et est définie par la RFC 4302.
5.5.1 - Entête suivante (Next Header)
Le champ "Entête suivante" est codé sur 8 bits. Il identifie le type de la Data ou de l'option qui se trouve derrière cette option de l'entête IPv6. tous les détails sont dans la définition du champ "Entête suivante" de l'entête IPv6 en paragraphe 3.5.

5.5.2 - Longueur (Payload Len)
Le champ "Longueur" est codé sur 8 bits. Il représente la taille de cette Option "AH". L'unité de mesure est les mots de 4 octets avec une valeur minimale de 2.
5.5.3 - Réservé (Reserved)
Le champ "Réservé" est codé sur 16 bits. Il est prévu pour des besoins futurs, en attendant, sa valeurs doit
être positionnée à 0 pour l'émission et il doit être ignoré pour la réception.
5.5.4 - SPI (Security Parameters Index)
Le champ "SPI" est codé sur 32 bits. Il permet au destinataire d'identifier l'association de sécurité (SA) avec le datagramme entrant.
5.5.5 - Séquence (Sequence Number Field)
Le champ "Séquence" est codé sur 32 bits. Il contient le numéro de séquence du SA. Il est incrémenté à chaque datagramme.
5.5.6 - ICV (Integrity Check Value-ICV)
Le champ "ICV" est codé sur N bits. Il contient la valeur du résultat d'un procédé cryptographique sur les données. Cela permet de protéger et vérifier l'intégrité de celles-ci.
5.6 - ESP (Encapsulating Security Payload)
L'option "ESP" est utilisée après l'entête IP et avant les données (l'entête de couche supérieur). Elle complète l'option 'AH" afin d'offrir la confidentialité des données. Elle permet en plus de chiffrer l'ensemble des paquets
incluant ou pas l'entête IPv6. Cette Option est codé 50 et est définie par la RFC 4303.
5.6.1 - SPI (Security Parameters Index)
Le champ "SPI" est codé sur 32 bits. Il permet au destinataire d'identifier l'association de sécurité (SA) avec le datagramme entrant.
5.6.2 - Séquence (Sequence Number)
Le champ "Séquence" est codé sur 32 bits. Il contient le numéro de séquence du SA. Il est incrémenté à chaque datagramme.
5.6.3 - Données utiles (Payload Data)
Le champ "Données utiles" est codé sur N bits. Il contient les données chiffrées.
5.6.4 - Remplissage (Padding)
Le champ "Remplissage" est codé sur N bits. Il permet de combler l'entête de données non intéressante afin d'obtenir une taille de multiple. La longueur maximum possible est 255 octets.
5.6.5 - Longueur (Pad Length)
Le champ "Longueur" est codé sur 8 bits. Il représente la taille du champ "Remplissage".
5.6.6 - Entête suivante (Next Header)
Le champ "Entête suivante" est codé sur 8 bits. Il identifie le type de la Data ou de l'option qui se trouve derrière cette option de l'entête IPv6. tous les détails sont dans la définition du champ "Entête suivante" de l'entête IPv6 en paragraphe 3.5.

5.6.7 - ICV (Integrity Check Value)
Le champ "ICV" est codé sur N bits. Il contient le Hash de l'entête ESP.
Le fonctionnement
La Nat
1 - Introduction 1.1 - Objet de ce cours 1.2 - Réutilisation de ce cours 1.3 - Décharge 1.4 - Votre travail 2 - Définitions
2.1 - L'identification des machines 2.2 - L'adressage IP 2.3 - Qu'est-ce que la NAT ? 3 - La NAT statique 3.1 - Le principe 3.2 - Pourquoi je ne peux pas accéder à Internet avec une adresse privée ? 3.3 - Le fonctionnement de la NAT statique
3.4 - Avantages et inconvénients de la NAT statique 3.5 - Problèmes de routage liés à l'utilisation de la NAT statique (proxy ARP) 3.6 - Problèmes de routage liés à l'utilisation de la NAT statique (routage sur la passerelle)
4 - La NAT dynamique 4.1 - Le principe 4.2 - Le fonctionnement de la NAT dynamique 4.3 - Avantages et inconvénients de la NAT dynamique
4.4 - Problèmes liés à la NAT dynamique (ICMP) 4.5 - Problèmes liés à la NAT dynamique (FTP) 5 - Statique ou dynamique ? 5.1 - Quand faire de la NAT statique ? 5.2 - Quand faire de la NAT dynamique ? 5.3 - Puis-je combiner ces deux méthodes ?
6 - Comment rendre joignables les machines de mon réseau local alors que je n'ai qu'une seule adresse publique ? 6.1 - Explication du problème 6.2 - Le port forwarding, qu'est-ce que c'est ? 6.3 - Le port mapping, qu'est-ce que c'est ? 6.4 - Les limites du port forwarding 7 - Les proxys 7.1 - Qu'est-ce qu'un proxy ?
7.2 - Qu'est-ce qu'un proxy n'est pas ? 8 - Vaut-il mieux faire de la NAT ou avoir un proxy ? 8.1 - Avantages du proxy 8.2 - Avantages de la NAT 8.3 - Alors ? NAT ou proxy ? 9 - La sécurité et la NAT 9.1 - La NAT dynamique permet-elle d'améliorer ma sécurité ?
9.2 - Est-ce utile pour la sécurité d'utiliser un proxy ? 9.3 - La NAT est elle compatible avec IPSEC ?
10 - Utilitaires pour faire de la NAT 10.1 - Sous windows 10.2 - Sous Unix 11 - Mini lexique
11.1 - Modèle OSI 11.2 - IP 11.3 - TCP 11.4 - SNAT ou Source NAT 11.5 - DNAT ou Destination NAT 12 - Annexes 12.1 - Ressources utilisées
12.2 - Remerciements 13 - Conclusion 14 - Discussion autour de la documentation 15 - Suivi du document
1 - Introduction

1.1 - Objet de ce cours
Avec le développement croissant du monde de l'internet, et notamment des liaisons à connexions permanentes comme le câble ou l'ADSL, de plus en plus de particuliers utilisent de la NAT pour partager leur accès Internet,
parfois même sans le savoir ;-) Il m'a donc semblé opportun de faire un petit cours rassemblant les idées principales qui tournent autour de la NAT, et d'essayer de les clarifier. Ce cours se limitera à l'étude de la NAT sur le modèle TCP/IP. Pour comprendre les mécanismes mis en oeuvre dans la NAT, vous aurez besoin d'avoir quelques connaissances sur le modèle TCP/IP, et notamment sur les couches 3 et 4 du modèle OSI (IP et
TCP/UDP).
1.2 - Réutilisation de ce cours
Vous êtes libre d'utiliser de courts extraits de ce cours dans la mesure où vous incluez un lien permettant d'avoir accès à l'ensemble du document. Ceci dans le but de permettre à vos lecteurs d'obtenir facilement un complément d'information. De même, vous êtes libre de copier le cours dans son intégralité, à condition cependant d'en avertir l'auteur, et que cette utilisation soit exempte de tout caractère commercial (bannières publicitaires incluses). Cette restriction étant principalement due au plus élémentaire des respects : celui du temps que j'ai consacré à la
rédaction de ce cours. Toute autre utilisation devra faire l'objet d'un accord préalable avec l'auteur.
1.3 - Décharge
L'auteur décline toute responsabilité concernant la mauvaise utilisation ou compréhension du cours qui engendrerait l'écroulement de votre réseau ;-)
1.4 - Votre travail
La seule et unique tâche que je vous demanderai d'accomplir sera de corriger mes erreurs (aussi bien dans la
cohérence des éléments avancés que pour l'orthographe), me donner des conseils sur ce qui est mal expliqué
pour le rendre plus accessible, ajouter des éléments qui ont attrait à la NAT et rendent l'exposé plus complet, combler tout manque pour améliorer ce cours.
2 - Définitions
2.1 - L'identification des machines
Pour envoyer du courrier à un ami, vous utilisez son adresse postale. Ainsi vous êtes sûr que le paquet que vous
envoyez arrivera à la bonne personne. Et bien pour les ordinateurs, c'est pareil. Quand vous connectez votre ordinateur à un réseau (Internet par exemple), il possède une adresse qui l'identifie d'une façon unique pour que les autres ordinateurs du réseau puissent lui envoyer des informations.
2.2 - L'adressage IP
Nous avons parlé d'adresses pour les machines, il est temps maintenant de définir ces adresses. On parle d'adresse IP (Internet protocol), car il s'agit du protocole qui permet d'identifier les machines et de router les
informations sur Internet. Ces adresses sont codées sur 4 octets, soit 32 bits. Ce qui nous permet d'avoir 2^32 adresses disponibles (un peu plus de 4 milliards d'adresses). Même si ce chiffre dépasse de loin le nombre de machines présentes sur Internet, nous allons bientôt manquer d'adresses disponibles, notamment parce qu'un grand nombre de ces adresses sont gâchées. En attendant un nouveau standard d'adressage qui permette d'avoir plus d'adresses disponibles (IPv6), il a fallu trouver des solutions temporaires. La NAT a notamment été une réponse à cette future pénurie d'adresses. Nous allons voir en quoi elle consiste, et quels sont ses avantages et inconvénients.
2.3 - Qu'est-ce que la NAT ?
Le terme barbare NAT représente les initiales de "Network Address Translation", ou "Traduction d'Adresse réticulaire" en français. Mais il est souvent utilisé pour représenter différents concepts que nous allons différencier, notamment NAT statique, NAT dynamique, PAT, IP masquerading... Si l'on s'en tient intrinsèquement à la définition du terme NAT, cela représente la modification des adresses IP dans l'en-tête d'un datagramme IP effectuée par un routeur. On verra par la suite quelles sont les différentes applications possibles. On parlera de SNAT quand c'est l'adresse source du paquet qui est modifiée, et de DNAT quand il s'agit de l'adresse destination.
3 - La NAT statique
3.1 - Le principe

La NAT statique, se base sur l'association de n adresses avec n adresses. C'est à dire qu'à une adresse IP interne, on associe une adresse IP externe. Dans ce cas, la seule action qui sera effectuée par le routeur sera de remplacer l'adresse source ou destination par l'adresse correspondante.
3.2 - Pourquoi je ne peux pas accéder à Internet avec une adresse privée ?
On prend l'exemple suivant: Machine 1 - 10.0.0.1/24
| | Interface interne routeur - 10.0.0.254/24 <ROUTEUR> Interface externe routeur - 193.22.35.42/24 | |
Internet La machine 1 veut envoyer un paquet sur Internet, vers www.ohmforce.com, par exemple. Donc dans l'en-tête IP, l'adresse en destination est celle de www.ohmforce.com, et en source c'est 10.0.0.1. Si jamais il n'y avait pas de translation d'adresse, le paquet arriverait bien a la machine www.ohmforce.com, mais celle-ci essaierait de renvoyer sa réponse a 10.0.0.1 qui n'est pas une adresse routée sur Internet !! (Elle fait partie d'une classe d'adresses réservées pour les réseaux privés). Et notre machine 1 n'obtiendrait jamais de réponse... Ainsi, une
machine ayant une adresse privée ne pourra pas recevoir de réponse à ses requêtes sans un mécanisme supplémentaire.
3.3 - Le fonctionnement de la NAT statique
Nous avons vu qu'une machine ayant une adresse privée ne pouvait pas dialoguer sur Internet avec celle-ci, donc
pour résoudre ce problème, on va lui donner une adresse publique virtuelle qui va lui permettre d'accéder à Internet. Ainsi, un routeur (la plupart du temps la passerelle d'accès à Internet) va modifier dans l'en-tête IP du
paquet l'adresse source 10.0.0.1 pour mettre une adresse valide sur Internet 193.22.35.43 (dans notre exemple). Le paquet va donc arriver à sa destination, et celle-ci va pouvoir le renvoyer à 193.22.35.43 qui est une adresse valide sur Internet. Le paquet va arriver jusqu'au routeur qui a fait l'association entre 193.22.35.43 et 10.0.0.1, il va donc modifier l'adresse destination 193.22.35.43 et mettre à la place 10.0.0.1, et renvoyer le paquet sur le réseau local. Ainsi, la machine 1 est vue de l'Internet avec l'adresse 193.22.35.43. S'il s'agit d'un serveur web, il suffit d'envoyer une requête HTTP vers cette adresse pour obtenir le site web.
La NAT statique nous a permis de rendre une machine accessible sur Internet alors qu'elle possédait une adresse privée. On a simplement fait une association entre une adresse privée et une adresse publique: 10.0.0.1 <--> 193.22.35.43
3.4 - Avantages et inconvénients de la NAT statique
En associant une adresse IP publique à une adresse IP privée, nous avons pu rendre une machine accessible sur Internet. Par contre, on remarque qu'avec ce principe, on est obligé d'avoir une adresse publique par machine voulant accéder à Internet. Cela ne va pas régler notre problème de pénurie d'adresses IP... D'autre part, tant
qu'à donner une adresse publique par machine, pourquoi ne pas leur donner cette adresse directement plutôt que de passer par un intermédiaire ? A cette question, on peut apporter plusieurs éléments de réponse. D'une part, il est souvent préférable de garder un adressage uniforme en interne et de ne pas mêler les adresses publiques aux adresses privées. Ainsi, si on doit faire des modifications, changements, interventions sur le réseau local, on peut facilement changer la correspondance entre les adresse privées et les adresses publiques pour rediriger les requêtes vers un serveur en état de marche. D'autre part, on gâche un certain nombre d'adresses lorsqu'on
découpe un réseau en sous-réseaux (adresse de réseau, adresse de broadcast...), comme lorsqu'on veut créer
une DMZ pour rendre ses serveurs publiques disponibles. Avec la NAT statique, on évite de perdre ces adresses. Malgré ces quelques avantages, le problème de pénurie d'adresses n'a toujours pas été réglé. Pour cela, on va se pencher sur la NAT dynamique (Pour ceux qui ne veulent pas rentrer dans les détails techniques, vous pouvez directement passer au paragraphe 4)
3.5 - Problèmes de routage liés à l'utilisation de la NAT statique (proxy ARP)
Les problèmes montrés ne sont pas toujours rencontrés lors de l'implémentation de la NAT statique. Si celle-ci est bien faite, tous les mécanismes décrits devraient être implémentés de façon transparente pour l'utilisateur. Ce qui va suivre demande d'avoir quelques notions sur le fonctionnement de la pile TCP/IP. Un premier problème rencontré est celui de la redirection d'un paquet vers l'adresse virtuelle de la NAT statique. On considèrera l'exemple précédent auquel on ajoute le premier routeur rencontré sur Internet. Machine 1 - 10.0.0.1/24
| | Interface interne routeur - 10.0.0.254/24

<ROUTEUR> Interface externe routeur - 193.22.35.42/24 | | Interface interne - 193.22.35.254/24
<Routeur Internet> Interface externe
| | Internet La machine 1 fait une requête vers le site www.ohmforce.com. Le paquet est NATé au niveau du routeur avec comme adresse source 193.22.35.43, ainsi, le site web www.ohmforce.com renvoie sa réponse vers cette adresse. Le paquet est routé sur Internet et arrive sur le routeur Internet (celui qui précède le routeur de
l'entreprise ou du particulier). Celui-ci regarde l'adresse de destination et observe qu'elle se situe sur le même réseau qu'une de ses interfaces. Ainsi, elle a maintenant besoin de l'adresse MAC de la machine 193.22.35.43 pour lui envoyer le paquet. Elle fait donc une requête ARP en demandant "Quelle est l'adresse MAC de la machine ayant 193.22.35.43 comme adresse IP ?". Or, sur ce réseau, aucune machine n'a cette adresse puisqu'il s'agit d'une adresse virtuelle. Il faut donc que le routeur (193.22.35.42) réponde lui-même à cette requête ARP. C'est ce que l'on appelle faire proxy ARP. Quand vous faites de la NAT statique, le proxy ARP est souvent automatiquement implémenté, cependant, il est bon de connaître ce mécanisme si ce n'est pas le cas.
Il y a plusieurs façon de pallier à ce problème. Soit mettre en place soit même un mécanisme de proxy ARP sur la machine faisant la NAT statique. - Soit ajouter une entrée statique dans la table ARP du routeur Internet (pas le routeur faisant la NAT, mais le premier routeur rencontré après celui-ci sur Internet). Commande arp sous windows :
arp -s 193.22.35.43 @MAC_routeur - Soit ajouter une route host statique pour chacune des adresses virtuelles. Sous windows: Route add -p 193.22.35.43 mask 255.255.255.255 193.22.35.42
3.6 - Problèmes de routage liés à l'utilisation de la NAT statique (routage sur la passerelle)
Un second problème peur survenir sur l'équipement qui fait la NAT. Revenons à l'exemple précédent. Le routeur Internet envoie le paquet au routeur de l'entreprise. Celui-ci reçoit la trame Ethernet, voit que c'est son adresse
MAC qui est en destination, il envoie donc le contenu des données à la couche IP. Celle-ci voit que c'est l'adresse 192.22.35.43 (l'adresse virtuelle de notre machine) qui est en destination. Il va voir dans la table de routage, et là, il peut y avoir un problème... Soit une route spécifique existe pour cette adresse pour rediriger le paquet vers le réseau interne, soit ce n'est pas le cas, et il sera renvoyé sur l'interface externe du routeur, vu que l'adresse de destination appartient au même réseau que son interface externe 193.22.35.42 !! Pour que la NAT fonctionne, il faut donc qu'il y ait une route spécifique vers le réseau interne. Dans notre cas:
Route add -p 193.22.35.43 mask 255.255.255.255 10.0.0.1 Ainsi, quand le routeur recevra un paquet à destination de l'adresse virtuelle 193.22.35.43, il le redirigera bien vers l'adresse réelle de la machine, 10.0.0.1. Et hop, ça marchera ;-)
4 - La NAT dynamique
4.1 - Le principe
La NAT dynamique est aussi appelée IP masquerading. Contrairement à la NAT statique, la NAT dynamique associe une seule adresse à n adresses (ou pour être plus précis, M adresses à N adresses, les adresses pour
sortir étant choisies dans un pool). Ainsi, on peut associer une adresse publique à n adresses privées et permettre ainsi à un grand nombre de machines ayant des adresses privées d'accéder à Internet !! Par contre, nous verrons que cette méthode possède quelques inconvénients. Et contrairement à la NAT statique, le routeur qui effectue la
NAT devra à la fois modifier les adresses IP mais aussi les ports TCP/UDP (que l'on appelle PAT, Port Address Translation).
4.2 - Le fonctionnement de la NAT dynamique
Le fonctionnement est un peu différent de celui de la NAT statique. Nous allons notamment voir pourquoi il faut faire de la PAT et non pas une simple traduction des adresses IP. Reprenons l'exemple précédent: Machine 1- 10.0.0.1/24
| | Interface interne routeur - 10.0.0.254/24 <ROUTEUR> Interface externe routeur - 193.22.35.42/24 |

| Internet Cette fois, c'est l'adresse publique de l'interface externe du routeur 193.22.35.42 qui va être utilisée pour sortir. Ainsi, lorsque le paquet arrive à la machine de destination, www.ohmforce.com par exemple, celle-ci le renvoie
vers l'adresse 193.22.35.42. Le routeur reçoit donc ce paquet et voit que l'adresse de destination est lui-même !! Comment peut-il alors savoir si le paquet est pour lui ou une machine en interne ?
C'est grâce aux ports TCP/UDP qu'il va pouvoir faire la différence. Ainsi, si une machine en interne fait une requête avec comme port TCP source 2356, le routeur pourra savoir que lorsqu'il recevra un paquet avec comme port destination 2356, il faut le rediriger vers la machine en interne qui a initialisé la connexion. Mais je vois déjà pointer les questions: "oui, mais si deux machines du réseau interne initialisent des connexions avec le même port TCP/UDP ?hein ? alors ? comment qu'on fait pour savoir qui est qui ? hein ? alors ?"
Et vous auriez raison de vous les poser ! Mais tout a été prévu pour pallier à ce problème. En fait, le routeur remplace le port TCP/UDP source par un nouveau qu'il choisit lui-même. Ainsi, comme c'est lui qui les choisit, il n'en choisira pas deux identiques, et pourra identifier chacune des connexions, magisme... On reprend donc depuis le début le fonctionnement. La machine 10.0.0.1 veut se connecter au site www.ohmforce.com, elle envoie donc un paquet avec comme adresse source la sienne, 10.0.0.1, et comme port source un port quelconque supérieur à 1024, soit par exemple
5987. Le paquet arrive au routeur qui fait la NAT, il remplace donc l'adresse IP source par la sienne 193.22.35.42, et la PAT en remplaçant le port TCP/UDP source 5987 par un de son choix, 10000 par exemple. Il garde ces informations de correspondance bien au chaud dans une table NAT. Le paquet arrive a www.ohmforce.com qui le renvoie a 193.22.35.42. Le paquet arrive au routeur, il voit que l'adresse destination est lui-même, il regarde donc le port destination TCP/UDP qui est 10000. Il va regarder dans la table NAT pour avoir la correspondance, et bingo !! il sait qu'il faut envoyer ce paquet à 10.0.0.1, tout en ayant modifié le port destination 10000 en 5987 qui
est le port sur lequel 10.0.0.1 a initialisé la connexion. Et voilà. On peut ainsi masquer autant de machines que l'on veut derrière une seule adresse publique !
4.3 - Avantages et inconvénients de la NAT dynamique
Comme nous l'avons vu, la NAT dynamique permet à des machines ayant des adresses privées d'accéder à Internet. Cependant, contrairement à la NAT statique, elle ne permet pas d'être joint par une machine de l'Internet. Effectivement, si la NAT dynamique marche, c'est parce que le routeur qui fait la NAT reçoit les
informations de la machine en interne (Adresse IP, port TCP/UDP). Par contre, il n'aura aucune de ces informations si la connexion est initialisée de l'extérieur... Le paquet arrivera avec comme adresse de destination le routeur, et le routeur ne saura pas vers qui rediriger la requête en interne. La NAT dynamique ne permet donc que de sortir sur Internet, et non pas d'être joignable. Elle est donc utile pour partager un accès Internet, mais pas pour rendre un serveur accessible. De plus, étant donné que l'on peut "cacher" un grand nombre de machines derrière une seule adresse publique, cela permet de répondre à notre
problème de pénurie d'adresses. Par contre, les machines n'étant pas accessibles de l'extérieur, cela donne un petit plus au niveau de la sécurité ;-)
4.4 - Problèmes liés à la NAT dynamique (ICMP)
La NAT dynamique demande l'utilisation des ports TCP/UDP, cependant, tous les protocoles utilisés sur un réseau
n'utilisent pas obligatoirement ces ports, notamment les protocoles ICMP, PPTP, Netbios... Prenons par exemple le protocole ICMP. Se limitant à la couche 3 il n'utilise pas de ports TCP ou UDP. Il n'est donc pas possible de faire de la NAT dynamique de façon classique.
Une méthode spécifique doit être implémentée pour permettre la NAT du trafic ICMP. Pour cela, au lieu de se baser sur les ports TCP/UDP, on peut se baser sur l'identifiant ICMP présent dans l'en-tête du message ICMP. Ainsi, le mécanisme est exactement le même, mis à part que l'on utilise cet identifiant, plutôt que les ports
TCP/UDP. Il faut donc implémenter spécifiquement ce type de NAT pour le protocole ICMP. Par ailleurs, certains paquets ICMP contiennent dans leur payload des informations concernant les datagrammes IP qui ont causé l'erreur. Le routeur faisant la NAT doit donc aussi modifier les informations contenues dans le payload pour que l'information apportée à la machine émettrice soit pertinente.
4.5 - Problèmes liés à la NAT dynamique (FTP)
Le protocole ftp a un fonctionnement un peu particulier. Il utilise deux connexions en parallèle. L'une pour le contrôle de la connexion, l'autre pour le transfert des données. Le ftp peut fonctionner selon deux modes
différents, actif ou passif. En mode passif, pas de problème, les connexions sont initialisées de l'intérieur pour chacun de ces deux canaux. Par contre, pour le mode actif, la connexion de contrôle est d abord initialisée de l intérieur, et quand des données sont demandées, c'est le serveur qui initialise la connexion de données à partir de l'extérieur. Et comme nous le savons, il n'est pas possible d'initialiser de connexions à partir de l'extérieur du réseau avec de la NAT dynamique. Un autre problème du protocole ftp est qu'il contient des données se rapportant aux adresses des machines. Ainsi quand les adresses sont NATées, cela pose problème... Donc pour

que le ftp puisse fonctionner, on est obligés d'utiliser un module qui soit capable de lire les informations contenues dans les données ftp. Pour faire cela, on utilise un proxy (Voir paragraphe 7) qui sera capable de suivre la connexion et de modifier les données ftp pour la rendre possible. Dans un cas comme celui-ci, ce n'est plus un simple module NAT à ajouter, mais un proxy à part entière.
5 - Statique ou dynamique ?
5.1 - Quand faire de la NAT statique ?
Nous avons vu que la NAT statique permettait de rendre disponible une machine sur Internet, mais qu'il fallait par contre une adresse IP pour que ce serveur soit joignable. Il est donc utile d'utiliser la NAT statique quand vous voulez rendre une application disponible sur Internet, comme un serveur web, mail ou un serveur FTP.
5.2 - Quand faire de la NAT dynamique ?
La NAT dynamique permet d'une part de donner un accès à Internet à des machines possédant des adresses
privées, et d'autre part d'apporter un petit plus en terme de sécurité. Elle est donc utile pour économiser les adresse IP, donner un accès à Internet à des machines qui n'ont pas besoin d'être joignables de l'extérieur (comme la plupart des utilisateurs). D'autre part, même quand on possède assez d'adresses IP, il est souvent préférable de faire de la NAT dynamique pour rendre les machines injoignables directement de l'extérieur. Par exemple, pour un usage personnel de partage de l'ADSL ou du câble, on utilise souvent la NAT dynamique pour partager sont accès, étant donné que les machines n'ont pas besoin d'être jointes de l'extérieur.
5.3 - Puis-je combiner ces deux méthodes ?
Oui, et c'est même souvent la meilleure solution lorsque l'on a à la fois des machines offrant un service, et
d'autres qui n'ont besoin que de se connecter à Internet. Ainsi, on économisera les adresses IP grâce aux machines NATées dynamiquement, et on utilisera exactement le bon nombre d'adresses IP publiques dont on a besoin. Il est donc très intéressant de combiner ces deux méthodes.
6 - Comment rendre joignables les machines de mon réseau local alors que je n'ai qu'une
seule adresse publique ?
6.1 - Explication du problème
Nous avons vu que dans le cas de la NAT dynamique, les machines du réseau local ne pouvaient pas être jointes de l'extérieur. Cela est plutôt un plus pour la sécurité, mais si on doit offrir des services comme un serveur FTP ou web, ça devient problématique. C'est notamment le cas quand on possède un accès ADSL ou câble, une seule
adresse publique vous est fournie, et il devient alors compliqué de rendre disponibles plusieurs serveurs du réseau local. Une solution à ce problème est le port forwarding.
6.2 - Le port forwarding, qu'est-ce que c'est ?
Le port forwarding consiste à rediriger un paquet vers une machine précise en fonction du port de destination de ce paquet. Ainsi, lorsque l'on n'a qu'une seule adresse publique avec plusieurs machines derrière en adressage
privé. On peut initialiser une connexion de l'extérieur vers l'une de ses machines (une seule par port TCP/UDP). Prenons l'exemple précédent et disons que la machine 10.0.0.1 possède un serveur FTP. Maintenant, on configure
le routeur pour qu'il redirige les connexions arrivant sur le port 21 vers la machine 10.0.0.1. Et hop, on rend notre machine ayant une adresse privée disponible depuis l'extérieur !! Ainsi, le port forwarding nous a permis de rendre nos machines du réseau local joignables d'Internet, même si l'on ne possède qu'une seule adresse IP publique !!
6.3 - Le port mapping, qu'est-ce que c'est ?
Le port mapping est un peu équivalent au port forwarding. Il consiste simplement à rediriger la requête sur un port différent que celui demandé. Par exemple, si on fait tourner un serveur web sur le réseau local sur le port 8080 et qu'on veut le rendre accessible pour les internautes. On redirige le port 80 vers notre serveur sur le port 8080. Ainsi, les clients externes auront l'impression de s'adresser à un serveur sur le port usuel pour le web, 80.
6.4 - Les limites du port forwarding
Hé oui, le port forwarding ne peut pas non plus répondre parfaitement à toutes les questions qu'amène la NAT dynamique. Ainsi, on a vu que l'on ne pouvait associer qu'une adresse de machine à un port donné. Si l'on

possède plusieurs serveurs FTP en local et que l'on veut les rendre accessibles, il faudra trouver une autre astuce...
7 - Les proxys
7.1 - Qu'est-ce qu'un proxy ?
Un proxy est un mandataire pour une application donnée. C'est à dire qu'il sert d'intermédiaire dans une connexion entre le client et le serveur pour relayer la requête qui est faite. Ainsi, le client s'adresse toujours au
proxy, et c'est lui qui s'adresse ensuite au serveur. Une proxy fonctionne pour une application donnée, http, ftp, smtp, etc. Il peut donc modifier les informations à envoyer au serveur, ainsi que celles renvoyées par celui-ci. La contrepartie est qu'il faut un proxy par application. Cependant, beaucoup de proxys sont en fait des multi-proxys qui sont capables de comprendre la plupart des applications courantes.
7.2 - Qu'est-ce qu'un proxy n'est pas ?
Un amalgame est souvent fait entre les fonctionnalités qu'on peut apporter à un proxy, et au proxy lui-même.
Ainsi, on pense souvent qu'un proxy doit faire de la NAT, ou serveur de cache, mais ce ne sont que des fonctionnalités ajoutées. Effectivement, il est souvent utile d'ajouter des fonctions de cache à un proxy vu que c'est lui qui centralise l'accès au web. Ainsi, si 15 personnes demandent le même site web, il ne sera chargé qu'une fois puis gardé dans le cache du proxy. D'autre part, la NAT est elle aussi souvent indispensable pour qu'un proxy fonctionne, vu qu'il est censé être un intermédiaire, il faudra qu'il modifie l'adresse source du paquet pour que la réponse passe par lui. Cependant, même si c'est ce qui est le plus souvent utilisé, ce n'est pas obligatoire. Si ces fonctionnalités sont souvent utiles et utilisées, ce n'est pas pour autant qu'il faut penser qu'elles
sont synonymes de proxy.
8 - Vaut-il mieux faire de la NAT ou avoir un proxy ?
8.1 - Avantages du proxy
Comme nous l'avons vu, un proxy est dédié à un protocole (une application) particulier. Ainsi, il est capable d'interpréter le trafic et notamment de cacher les informations. On diminue ainsi le trafic et augmente la bande
passante de la même occasion. On peut aussi autoriser ou non l'accès à certaines partie d'un site, à certaines fonctionnalités, etc. On a donc un bon contrôle de ce qui transite sur le réseau, et on sait quels protocoles peuvent circuler.
8.2- Avantages de la NAT
Contrairement au proxy, la NAT est indépendante des applications utilisées. On peut donc faire passer la plupart des protocoles que l'ont veut.
8.3 - Alors ? NAT ou proxy ?
La réponse est bien sur... ça dépend !! Vous êtes déçus ? Il ne faut pas, car si vous avez bien lu et compris ce qui précède, vous devriez être en mesure de faire votre choix vous même en fonction de ce que vous avez (adresses, matériel, etc.) et de ce que vous voulez faire (applications, politique de sécurité, etc.). Personnellement, j'ai une petite préférence pour la NAT car elle ne limite pas ce que je peux faire sur le réseau, je n'ai donc pas de mauvaises surprises quand j'utilise un nouveau protocole un peu exotique ;-)
9 - La sécurité et la NAT
9.1 - La NAT dynamique permet-elle d'améliorer ma sécurité ?
La NAT dynamique permet de rendre les machines d'un réseau local inaccessibles directement de l'extérieur, on peut donc voir cela comme une sécurité supplémentaire. Mais cela n'est pas suffisant et il est indispensable d'utiliser un filtrage si l'on veut obtenir un bon niveau de sécurité. La NAT dynamique seule ne peut pas être considérée comme une sécurité suffisante.
9.2 - Est-ce utile pour la sécurité d'utiliser un proxy ?
Un proxy travaille au niveau 7 du modèle OSI, c'est à dire qu'il est capable d'interpréter et de modifier les informations du protocole sur lequel il travaille. Ainsi, il peut vérifier le contenu de ce qui est reçu de la part du serveur et en interdire ou modifier le contenu selon la politique choisie. L'utilisation d'un proxy pour des protocoles critiques est donc souvent utile si on veut avoir une bonne vision de ce qui se passe.
9.3 - La NAT est elle compatible avec IPSEC ?

Si on veut être précis, la réponse est oui. Cependant, la norme IPSEC ayant différentes implémentations, ce n'est pas toujours le cas. D'ailleurs la plupart des constructeurs ont créé leur propres solutions IPSEC pour traverser de la NAT. Le problème vient de l'encryption de l'en-tête IP par les participants au tunnel IPSEC. Si l'adresse IP est modifiée pendant le trajet du paquet, elle ne sera pas la même à l'arrivée que celle qui a été encryptée au départ, et après comparaison, le paquet sera détruit. Cependant, en se plaçant en mode ESP et en faisant du tunneling,
c'est la totalité du paquet qui est encryptée, et une nouvelle en-tête est ajoutée à celui-ci. Ainsi, la comparaison ne se fera pas sur l'en-tête modifiée, mais sur celle contenue dans les données du paquet. Mais cette solution
n'est pas toujours possible. Je ne crois pas qu'il existe de norme pour résoudre ce problème, mais une solution semble apporter une réelle satisfaction au problème cité. Elle est aujourd'hui utilisée par beaucoup de constructeurs, la NAT traversal ou NAT-T. Il s'agit d'encapsuler les données dans un tunnel UDP. Ainsi, de la même façon qu'en mode tunnel et ESP, l'en-tête modifiée par la NAT ne sera pas utilisée pour le test d'authentification. Ainsi, il est souvent possible de mettre en place un VPN IPSEC, même si on utilise de la NAT.
10 - Utilitaires pour faire de la NAT
10.1 - Sous windows
Voici quelques noms de produits qui permettent entre autres de faire de la NAT, une présentation plus précise sera peut-être faite par la suite si cela s'avère utile. Je n'ai pas testés ces produits, vos remarques et expériences sont donc les bienvenues ;-)
Wingate, winroute lite, NAT32, TCPrelay...
10.2 - Sous Unix
IPchains, ipfilter, netfilter...
11 - Mini lexique
11.1 - Modèle OSI
Le modèle OSI a été créé dans le but d'uniformiser les réseaux et de permettre l'interopérabilité entre systèmes hétérogènes. Il définit sept couches ayant chacune un rôle spécifique. Ces couches permettent donc de rendre un service les unes par rapport aux autres, tout en étant chacune indépendante des autres.
11.2 - IP
IP est un protocole de couche 3 qui permet principalement d'identifier les machines à l'aide d'adresses et de router les informations entre réseaux logiques. Il permet aussi de faire de la fragmentation de paquets.
11.3 - TCP
TCP est un protocole de couche 4 qui permet d'identifier et de contrôler les connexions entre machines. La gestion des flux et des erreurs est aussi intégrée à ce protocole.
11.4 - SNAT ou Source NAT
Le Source NAT correspond à la modification de l'adresse source dans un paquet translaté. Il est notamment utilisé pour la NAT dynamique, mais aussi pour la NAT statique lorsqu'on veut sortir du réseau local.
11.5 - DNAT ou Destination NAT
Le Destination NAT correspond à la modification de l'adresse destination dans un paquet translaté. Il est utilisé pour la NAT statique, lorsqu'on veut accéder à un serveur sur un réseau local.
12 - Annexes
12.1 - Ressources utilisées
Je n'ai pas utilisé beaucoup de documents aussi bien en ligne que sur papier. Les réponses et connaissances
apportées proviennent en majeure partie des informations que j'ai pu glaner en furetant sur le net, et notamment sur les newgroups fr.comp.reseaux.ip et fr.comp.reseaux.ethernet. Je me suis quand même inspiré de la RFC 1631. Et notamment de l'excellente faq sur les firewalls de Stéphane

Catteau dont je me suis inspiré pour la mise en forme. Disponible sur: http://fr.comp.securite.free.fr/firewall.txt N'hésitez pas à la consulter, on y apprend plein de choses.
12.2 - Remerciements
Je remercie notamment les personnes suivantes pour leur lecture assidue de la faq durant sa réalisation et leurs conseils précieux. Diane Guinnepain, Pep, Ifragu, Cédric Blancher.
13 - Conclusion
La NAT est aujourd'hui un élément important en réseau étant donné son énorme déploiement à travers le monde suite à l'annonce de la pénurie d'adresses IPv4. J'ai essayé de rendre la compréhension de cette technique la plus accessible possible. Cependant, il faut impérativement avoir quelques notions en réseau pour pouvoir bien comprendre les points délicats qu'elle engendre. Il y a et il y aura sûrement encore beaucoup de choses à dire sur le sujet. Vos remarques sont donc encore et toujours les bienvenues, aussi bien pour y ajouter des idées, que pour enlever le superflu.
Maintenant, si je revois passer des questions sur la NAT, j'aurai au minimum un droit de flagellation sur les personnes incriminées ;-)
Le routage
1 - Introduction 1.1 - Objet de ce cours 1.2 - Pré requis 1.3 - Réutilisation de ce cours
1.4 - Décharge
1.5 - Votre travail 2 - Une communication, comment ça marche ? 2.1 - Que faut-il pour dialoguer ? 2.2 - Analogie de la parole 2.3 - Et Internet dans tout ça ?
3 - Définitions 3.1 - Le modèle OSI 3.2 - L'encapsulation 3.3 - Retour à Internet 4 - La couche physique (couche 1) 4.1 - Le rôle de la couche 1 5 - La couche liaison de données (couche 2)
5.1 - Les rôles de la couche 2 5.2 - L'adressage des machines 5.3 - Le protocole Ethernet 5.4 - Format d'une trame Ethernet 5.5 - Dialogue entre deux machines 6 - La couche réseau (couche 3) 6.1 - Les rôles de la couche 3
6.2 - Quelles adresses pour la couche 3 ? 6.3 - Pourquoi encore une adresse alors que nous avons déjà l'adresse MAC ? 6.4 - Comment déterminer qu'une machine est sur mon réseau ? 6.5 - Qu'est ce que la table de routage ? 6.6 - Qu'est-ce qu'une route par défaut ? 6.7 - Mais si l'on met une route par défaut, peut-on en mettre plusieurs ?
6.8 - Puis-je mettre l'adresse d'un routeur n'étant pas sur mon réseau comme passerelle ?
6.9 - Vu que ma machine a plusieurs interfaces, dois-je avoir plusieurs tables de routage ? 6.10 - Format d'un datagramme IP 6.11 - Cas particulier des liaisons point à point 7 - Les interactions entre les couches 2 et 3 7.1 - Trame et datagramme, qu'est-ce qui circule sur le réseau ? 7.2 - L'organisation de l'encapsulation
7.3 - Qu'est-ce que le protocole ARP ? 8 - Dialogue entre deux machines distantes 8.1 - Présentation du dialogue 8.2 - Emission du message par A 8.3 - Réception du message par le routeur 1 intermédiaire 8.4 - Réception du message par la machine B 8.5 - Quelques remarques
9 - Mini lexique 9.1 - Adresse IP 9.2 - Réseau logique 9.3 - Connexion/interconnexion 9.4 - Sous-réseau 9.5 - ARP

10 - Annexes 10.1 - Ressources utilisées 10.2 - Remerciements 11 - Conclusion 12 - Discussion autour de la documentation
13 - Suivi du document
1 - Introduction
1.1 - Objet de ce cours
Le but de ce document est de vous présenter comment les informations peuvent transiter d'un ordinateur à l'autre sur Internet. Nous nous limiterons aux aspects réseau du dialogue. Tous les aspects applicatifs seront donc mis de coté (gestion des noms de machines, protocoles applicatifs, etc.) L'étude se limitera donc aux couches 2 et 3 du modèle OSI, soit Ethernet et IPv4 dans notre cas. Oups... ces mots sont du charabia pour vous, je vous invite
alors à continuer la lecture du document qui vous présentera plus en détail chacun de ces concepts évoqués.
1.2 - Pré requis
Pour une meilleure compréhension de ce cour, il sera nécessaire d'avoir quelques bases en ce qui concerne l'adressage IPv4 et les sous-réseaux. Pour cela, je vous conseillerai la lecture de la faq sur les masques de sous réseau
1.3 - Réutilisation de ce cours
Vous êtes libre d'utiliser de courts extraits de ce cours, dans la mesure où vous incluez un lien permettant d'avoir
accès à l'ensemble du document. Ceci dans le but de permettre à vos lecteurs d'obtenir facilement un complément
d'information. De même, vous êtes libre de copier ce cours dans son intégralité, à condition cependant d'en avertir l'auteur, et que cette utilisation soit exempte de tout caractère commercial (bannières publicitaires incluses). Cette restriction étant principalement due au plus élémentaire des respects : celui du temps que j'ai consacré à la rédaction de ce cours. Toute autre utilisation devra faire l'objet d'un accord préalable avec l'auteur.
1.4 - Décharge
L'auteur décline toute responsabilité concernant la mauvaise utilisation ou compréhension du document qui
engendrerait l'écroulement de votre réseau ;-)
1.5 - Votre travail
La seule et unique tâche que je vous demanderai d'accomplir sera de corriger mes erreurs (aussi bien dans la cohérence des éléments avancés que pour l'orthographe), me donner des conseils sur ce qui est mal expliqué pour le rendre plus accessible, ajouter des éléments qui ont trait aux masques et rendent l'exposé plus complet, combler tout manque pour améliorer ce cours. Mais maintenant, entrons dans le vif du sujet...
2 - Une communication, comment ça marche ?
2.1 - Que faut-il pour dialoguer ?
"Peux tu me passer le sel s'il te plait ?"
"Oui, tiens, le voici" Il apparaît souvent très simple de dialoguer, cependant, un dialogue nécessite une multitude de normes à mettre
en place pour que chacun puisse s'exprimer et comprendre l'autre. "Peux tu me passer le sel s'il te plait ?" "Excuse me, but I don't understand what you're talking about" "Pardon ? je te demande le SEL ! tu me comprends pas ou quoi ?" Et bien non, il ne comprend pas puisqu'ils n'utilisent pas le même moyen pour communiquer. On voit donc qu'il est nécessaire de se mettre d'accord sur des normes pour pouvoir dialoguer.
2.2 - Analogie de la parole
Nous avons vu précédemment que deux personnes devaient utiliser la même langue pour se comprendre, ou du moins, que chacun d'eux comprenne la langue utilisée par l'autre. Mais le dialogue par la parole ne se limite pas à cela. Le dialogue met en place deux interlocuteurs, chacun à leur tour émetteur puis récepteur. Ils doivent donc avoir chacun un moyen d'écouter, et un moyen de parler. Il faudra par ailleurs un moyen de transmission de l'information.

L'émetteur sera les cordes vocales. Le récepteur le tympan. Le moyen de transmission sera les ondes sonores. Le support de transmission sera l'air. Il faudra aussi se mettre d'accord sur une langue à utiliser, qui elle-même sera régie par des règles, etc. Nous voyons donc qu'il est nécessaire de mettre en place tout un nombre de normes pour communiquer.
2.3 - Et Internet dans tout ça ?
Effectivement, vous ne voyez peut-être toujours pas le rapport que tout cela peut avoir avec Internet ? Et bien de
la même façon que nous communiquons par la parole, nous souhaitons faire communiquer des machines par Internet. Si l'on suit le même raisonnement que précédemment, il apparaît nécessaire de mettre en place des normes permettant de décrire la façon dont les ordinateurs vont communiquer entre eux. Et effectivement, lors de la création d'Internet, un modèle décrivant les normes à mettre en place a été choisi, il s'agit du modèle OSI (open systems interconnection)
3 - Définitions
Ce chapitre va nous permettre de présenter plusieurs notions qu'il sera nécessaire de bien comprendre pour pouvoir poursuivre la lecture du cours sans problèmes.
3.1 - Le modèle OSI
En se basant sur les observations précédentes, on voit que chacun des éléments en jeu (tympans, cordes vocales, etc,.) remplit une tâche particulière. Le modèle OSI est basé sur ce principe. Il part de l'observation des tâches
que nous avons à accomplir et associe ces tâches à des couches. Le modèle est organisé en sept couches ayant chacune un ou plusieurs rôles précis.
Représentation: Couche 7: Application Couche 6: Présentation
Couche 5: Session Couche 4: Transport Couche 3: Réseau Couche 2: Liaison de données Couche 1: Physique
Chaque couche a donc un rôle précis séparé des autres. Les couches peuvent communiquer avec les couches directement adjacentes (la couche 2 pourra avoir des échanges avec les couches 1 et 3). Ainsi, l'utilisation de l'ensemble de ces couches permet de réaliser une suite de tâches qui, regroupées, permettent la communication. Un message à envoyer parcourt les couches de la couche 7 à la couche 1 qui représente le support de transmission. L'analogie avec la parole serait le cerveau qui crée le message de la couche 7, jusqu'au support de transmission qui est l'air et qui représente la couche 1. Tout cela en passant par les couches intermédiaires
représentées par les nerfs, les cordes vocales, les ondes, etc. Chacune des couches formate donc bien le message et l'envoi à la couche suivante (du cerveau aux nerfs, des nerfs aux cordes vocales, etc.)
3.2 - L'encapsulation
Au cours de son passage par chacune des couches, des informations relatives à chacune d'entre elles sont
ajoutées pour lui permettre d'effectuer la tâche qui lui incombe, on appelle cela l'en-tête. Cela permet d'avoir un
certain nombre d'informations nécessaires à chaque couche pour effectuer son travail, et que ces informations circulent avec le message à transmettre. ++++++++++++++++++++++ couche 7 | Info à transmettre | ++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++ couche 6 | en-tête couche 6 | Info à transmettre | +++++++++++++++++++++++++++++++++++++++++ ++++++++++++++++++++++++++++++++++++++++++++++ couche 5 | en-tête 5 | en-tête 6 | Info à transmettre |
++++++++++++++++++++++++++++++++++++++++++++++ ... et ainsi de suite ... jusqu'au paquet final ++++++++++++++++++++++++++++++++++++++++++++++

Couche 1 | en-tête 1 | ... | e-t 5 | en-tête 6 | Info | ++++++++++++++++++++++++++++++++++++++++++++++ Chaque couche ajoute donc sa propre en-tête à l'information d'origine. Ce procédé s'appelle l'encapsulation. Ces notions seront présentées plus en détail par la suite. Lorsqu'une machine reçoit le message, il parcourt les
couches dans le sens inverse, de la couche 1 à la couche 7 qui représente l'application qui doit recevoir le message. De la même façon que lors de la réception d'un message auditif (ondes transportées par l'air, qui font
vibrer les tympans, les tympans envoient l'information reçue par l'intermédiaire des nerfs au cerveau).
3.3 - Retour à Internet
Maintenant que nous connaissons le modèle en couche et les principes qu'il représente, nous allons pouvoir nous pencher sur l'implémentation de ce modèle en couches pour la communication de machines sur Internet. Dans ce document, nous présenterons les couches 2 et 3 qui permettent d'acheminer les données d'un ordinateur à un autre. La couche 2 permet à deux machines directement connectées de dialoguer, on dit alors que les machines sont sur un même réseau (avec la définition de réseau présentée dans le lexique) La couche 3 permet le
dialogue entre réseaux, ce que l'on appelle le routage. On remarque ainsi que deux machines sur un même réseau pourront dialoguer directement, mais pour parler à une machine située sur un réseau distant, il faudra passer par des machines intermédiaires qui feront la liaison entre les réseaux (on appellera ces machines intermédiaires des routeurs).
4 - La couche physique (couche 1)
4.1 - Le rôle de la couche 1
Nous ne nous attarderons pas longtemps sur la couche 1 car son rôle est simple et ne demande pas de connaissance particulières (du moins, si l'on n'entre pas dans les détails ;-)
La couche 1 concerne le support physique de transport des données. Cela peut aller du simple câble transportant un signal électrique, à la fibre optique, en passant par les ondes radio. Le rôle de la couche 1 est donc d'offrir un support de transmission permettant d'acheminer les données d'un point à un autre.
5 - La couche liaison de données (couche 2)
5.1 - Les rôles de la couche 2
La couche liaison de données a pour rôle de transmettre les données de façon fiable entre des équipements directement connectés. D'autres rôles lui incombent, mais leur connaissance ne nous sera pas utile pour comprendre le transport des informations.
Nous allons donc voir dans ce chapitre comment deux machines directement liées vont faire pour dialoguer. Sur un réseau, il y a souvent plusieurs machines connectées, il faut alors pouvoir les différencier les unes par rapport aux autres. Pour cela, nous allons les identifier individuellement grâce à des adresses.
5.2 - L'adressage des machines
Pour la couche 2, ce sont les adresses MAC.
Les adresses MAC sont codées sur 6 octets, soit 48 bits donc 2^48 = ... plusieurs milliers de milliards d'adresses possibles ! Elles sont la plupart du temps écrites par octet sous forme hexadécimale, séparés par le caractère ":" Ce qui donne par exemple 3C:AB:35:48:FF:D2 qui est une adresse MAC. Nous pouvons ainsi identifier chaque interface de machine individuellement. Il nous faut maintenant définir les règles qui permettront aux machines de
dialoguer. Pour cela nous allons définir un protocole.
5.3 - Le protocole Ethernet
Le protocole Ethernet définit le format des messages échangés. Le message de base utilisé par Ethernet est la trame. La trame est composée d'une en-tête et d'une "charge utile" contenant les informations à transmettre. L'en-tête Ethernet contient les informations nécessaires au bon fonctionnement de la couche 2 qui pourront permettre la transmission des informations. Nous y retrouvons notamment les adresses MAC des machines participant au dialogue.
5.4 - Format d'une trame Ethernet
La description suivante ne prend en compte que les informations qui nous intéressent et n'est pas le format
complet d'une trame Ethernet. La trame est composée d'une en-tête contenant les informations du protocole Ethernet, et d'un payload contenant les informations à transporter.

Trame Ethernet ++++++++++++++++++++----------------------------- | En-tête Ethernet | Informations à transporter | ++++++++++++++++++++-----------------------------
Nous allons voir plus en détail ce que contient l'en-tête Ethernet.
En-tête Ethernet ++++++++++++++++++++++++++++++++++++++++++++++++++++ | @ MAC source | @ MAC destination | Protocole sup | ++++++++++++++++++++++++++++++++++++++++++++++++++++ L'adresse MAC source est l'adresse de la machine qui envoi la trame. L'adresse MAC destination est celle de la machine qui doit recevoir la trame (jusqu'ici ce n'est pas bien sorcier :-)
Le protocole sup est le protocole utilisé par la couche supérieure (la couche 3 dans notre cas puisque Ethernet est un protocole de couche 2) Ceci est utile car quand la couche 2 reçoit le message, elle doit savoir à quel protocole de couche 3 envoyer les informations reçues (il est possible sur une machine d'utiliser plusieurs protocoles pour une même couche).
5.5 - Dialogue entre deux machines
Prenons l'exemple d'une machine A qui veut envoyer le message "Bonjour" à une machine B située sur le même réseau. Il lui suffit de connaître l'adresse MAC de B pour lui envoyer le message. Ainsi, en lui envoyant la trame
suivante, elle devrait pouvoir lui envoyer le message: ++++++++++++++++++++++++++++++++++------------------ | @MAC A| @MAC B | protocole sup | XXXXX | Bonjour | ++++++++++++++++++++++++++++++++++------------------
B reçoit la trame et voit que c'est son adresse MAC qui est en destination, elle lit donc le reste des informations. Il
s'agit des informations des couches supérieures (XXXXX), et enfin, du message "Bonjour". Nous avons donc réussi grâce à la couche 2 à faire dialoguer deux machines connectées sur un même réseau. Nous allons maintenant voir comment faire communiquer deux machines appartenant à des réseaux différents.
6 - La couche réseau (couche 3)
6.1 - Les rôles de la couche 3
La couche réseau a pour rôle d'acheminer les informations d'un réseau à un autre. C'est ce que l'on appelle le routage. Les réseaux sont donc reliés entre eux par des machines que l'on appelle routeurs. Ces routeurs vont donc recevoir les paquets sur un réseau, et les renvoyer sur l'autre. Ils ont donc une connexion sur chaque réseau. Tous les réseaux ne pouvant pas être reliés entre eux, il va souvent falloir passer par des réseaux intermédiaires pour pouvoir envoyer un paquet d'un réseau à un autre.
La couche réseau a d'autres fonctionnalités auxquelles nous ne nous intéresserons pas ici. Principe de fonctionnement: Machine A Machine B | |
---------- ---------- ---------- |Réseau 1|--Routeur1--|Réseau 2|--Routeur2--|Réseau 3| ---------- ---------- ----------
Lorsque la machine A veut envoyer un message à B, le paquet va d'abord passer par le réseau 1. Puis le routeur 1 qui est connecté à ce réseau va le récupérer pour le renvoyer vers le réseau 2, et ainsi de suite jusqu'au réseau 3
où la machine B va pouvoir le recevoir. Cela est bien joli, mais comment ça marche ? Comment le routeur 1 sait-il qu'il faut envoyer le paquet sur le réseau 2 pour qu'il puisse atteindre B ??? Et puis on sait maintenant envoyer une trame d'une machine à une autre sur un même réseau, mais sur deux réseaux différents ? Nous allons essayer de répondre à ces questions dans les paragraphes suivant.
6.2 - Quelles adresses pour la couche 3 ?
Je vous invite à lire le paragraphe 2.2 de la faq sur les masques pour comprendre l'intérêt de l'adresse IP et du masque qui lui est associé. Une adresse IP est donc codée sur 4 octets. Elle s'écrit en décimal séparés par des
points. Par exemple, 192.168.0.1 est une adresse IP.
6.3 - Pourquoi encore une adresse alors que nous avons déjà l'adresse MAC ?

Il est nécessaire de différencier les adresses de couche 2 et de couche 3, car l'adressage au niveau de chacune de ces couches n'a pas le même rôle. L'adressage MAC en couche 2 permet d'identifier les machines SUR UN MEME RESEAU. L'adressage IP en couche 3 permet d'adresser les machines SUR DES RESEAUX DISTINCTS.
Peut-on alors utiliser pour ces deux couches une seule de ces deux adresses ? La réponse est malheureusement non. Les adresses de couche 2 sont en rapport avec le matériel réseau utilisé (le protocole de couche 2 est géré
au niveau de la carte connectée au réseau et non pas par le système d'exploitation comme les couches supérieures) il est donc difficile de modifier les adresses MAC qui sont censées être codées directement sur la carte réseau. Cela est notamment du au fait que chaque adresse MAC doit être unique sous peine de conflit matériel, et que cette adresse doit être accessible très tôt lors du boot d'une machine. Les adresses de couche 3 quant à elles demandent une certaine souplesse d'utilisation car on ne connaît pas à priori l'adresse du réseau sur lequel une machine va se trouver. Il y a donc une incompatibilité d'utilisation d'une adresse de couche 2 pour une adresse de couche 3, et vice versa.
Enfin, les protocoles réseau évoluant au fil du temps, il est nécessaire que chaque couche soit indépendante des autres. Il y a d'autres raisons qui nous obligent à utiliser des adresses différentes pour des couches différentes, mais ceci n'étant pas partie intégrante du sujet, nous ne nous y attarderons pas ici, d'autant plus que les arguments présentés devraient vous avoir convaincus :-)
6.4 - Comment déterminer qu'une machine est sur mon réseau ?
Si vous avez compris la faq sur les masques de sous réseau, vous savez que le masque permet notamment à une
machine de savoir quelles sont les autres machines de son réseau. Ainsi, quand une machine veut dialoguer avec une autre, elle va d'abord regarder si cette machine est sur son propre réseau, ou si elle va devoir passer par des routeurs intermédiaires pour lui envoyer son paquet. Ceci va être possible grâce à la table de routage.
6.5 - Qu'est ce que la table de routage ?
La table de routage est un regroupement d'informations permettant de déterminer le prochain routeur à utiliser pour accéder à un réseau précis sur lequel se trouvera la machine avec laquelle nous souhaitons dialoguer. Ainsi,
si l'on reprend l'exemple du §6.1, le routeur 1 doit savoir que pour atteindre le réseau 1, il devra envoyer les informations sur son interface de gauche sur le schéma, que pour atteindre le réseau 2, il devra envoyer les informations sur son interface de droite, et enfin, pour atteindre le réseau 3, il devra envoyer les informations sur son interface de droite vers le routeur 2. La table de routage doit pouvoir regrouper toutes ces informations. Elle les regroupe par ligne en indiquant pour un réseau donné par où il faut passer. Pour le routeur 1 par exemple, sa table de routage doit être:
vers réseau 1 -> utiliser interface gauche vers réseau 2 -> utiliser interface droite vers réseau 3 -> utiliser interface droite vers routeur 2 En fait, la réalité est un peu plus précise. Les interfaces peuvent être identifiés par leurs adresses ou leur type, et les réseaux sont identifiés par l'adresse du réseau et le masque associé.
Ainsi, cela se traduit en: Réseau Masque Interface Passerelle 192.168.0.0 255.255.255.0 ethernet 1 ethernet 1 172.16.0.0 255.255.0.0 ethernet 2 ethernet 2
10.0.0.0 255.0.0.0 ethernet 2 172.16.0.254 Où 192.168.0.0, 172.16.0.0 et 10.0.0.0 représentent les réseaux 1, 2 et 3. Et 172.16.0.254 représente l'adresse de l'interface de gauche du routeur 2. Ainsi, pour atteindre la machine d'adresse 10.0.0.45 située sur le réseau 3,
le routeur va voir dans la table de routage quelle entrée correspond au réseau contenant cette adresse. Il s'agit du réseau 10.0.0.0/255.0.0.0, et pour atteindre ce réseau, il est dit d'envoyer le paquet par l'interface ethernet 2, vers l'adresse 172.16.0.254. Et voilà !
Ce système semble très bien, mais on en voit vite les limites sachant que le réseau Internet est composé de plusieurs millions de réseaux... Cela voudrait dire qu'il faut connaître la route vers chacun de ces réseaux pour pouvoir dialoguer avec eux. Heureusement, une solution a été mise en place pour répondre à ce problème. Il s'agit de la route par défaut.
6.6 - Qu'est-ce qu'une route par défaut ?
La route par défaut est la route qui sera utilisée lorsque aucune route spécifique pour aller vers la destination
spécifiée n'aura été trouvée. Ainsi, dans le cas précédent, si je voulais atteindre l'adresse 193.253.25.46, aucune entrée de ma table de routage ne m'aurait indiqué comment y aller... Ce qui fait que ma machine n'aurait pas su vers qui envoyer le paquet et qu'il serait allé directement à la poubelle :-( En indiquant en plus une route par défaut, cela aurait permis à ma machine d'avoir une destination, même quand aucune entrée de la table de routage ne correspondait à l'adresse demandée. J'aurais donc envoyé mon paquet

vers ma route par défaut, en fait vers le prochain routeur à utiliser, et c'est ce prochain routeur qui se serait occupé de continuer à router le paquet. Si lui non plus n'avait pas eu de route spécifiée pour l'adresse de destination demandée, il aurait envoyé le paquet à son propre routeur par défaut, et ainsi de suite jusqu'à tomber sur un routeur connaissant la route !
Cela peut sembler un peu aléatoire comme stratégie, mais aujourd'hui, Internet est fait de telle façon que les routeurs qui le composent connaissent les routes vers toutes les destinations. Cela est mis en place grâce à des
protocoles évolués permettant d'échanger des informations de routage en temps réel ! Mais ceci sort un peu de notre objectif :-) La table de routage pour le routeur 1 devient alors: Réseau Masque Interface Passerelle 192.168.0.0 255.255.255.0 ethernet 1 ethernet 1
172.16.0.0 255.255.0.0 ethernet 2 ethernet 2 10.0.0.0 255.0.0.0 ethernet 2 172.16.0.254 défaut 0.0.0.0 ethernet 2 172.16.0.254 Cette ligne peut parfois être aussi écrite: 0.0.0.0 0.0.0.0 ethernet 2 172.16.0.254
NB: On peut se rendre compte dans notre exemple que la route vers le réseau 10.0.0.0 n'est plus nécessaire, vu que la route par défaut pointe vers le même routeur.
6.7 - Mais si l'on met une route par défaut, peut-on en mettre plusieurs ?
Cela n'a pas d'intérêt dans l'absolu, et sera traité différemment selon les systèmes. Disons qu'une table de routage normale ne devrait avoir qu'une route par défaut.
6.8 - Puis-je mettre l'adresse d'un routeur n'étant pas sur mon réseau comme passerelle ?
Non ! Et d'ailleurs, cela n'aurait pas de sens, puisqu'une passerelle est censée nous indiquer un chemin pour sortir de notre réseau. Si on indique l'adresse d'une machine en dehors de notre réseau, c'est que l'on en est déjà sorti ! La conséquence est que les passerelles indiquées dans une table de routage devront toujours appartenir à mon propre réseau, ou du moins, à l'un des réseaux auxquels appartiennent mes interfaces, si j'en ai plusieurs.
6.9 - Vu que ma machine a plusieurs interfaces, dois-je avoir plusieurs tables de routage ?
Là encore la réponse est non. La table de routage est censée contenir toutes les informations de routage pour
votre machine (ou routeur) quel que soient le nombre d'interfaces. D'ailleurs, vous avez pu voir dans la table de routage du routeur 1 que les routes contenaient des informations sur ses deux interfaces. Il existe cependant des fonctions avancées de routage avec plusieurs table, mais nous n'en sommes pas là ;-) Mais maintenant que nous savons comment une machine fait pour aiguiller un paquet, il nous reste à savoir quelles informations de couche 3 ce paquet devra contenir pour que le routage puisse être effectué. Le message de base utilisé par IP est le datagramme.
6.10 - Format d'un datagramme IP
De la même façon qu'avec Ethernet, la couche IP (couche 3) va nécessiter un certain nombre d'informations pour pouvoir effectuer les tâches qui lui incombent comme le routage. A la manière de la trame Ethernet, le datagramme IP se compose d'une en-tête IP, et d'un payload contenant les informations à transporter.
Datagramme IP
********************----------------------------- | En-tête IP | Informations à transporter | ********************----------------------------- Nous allons voir plus en détail ce que contient l'en-tête IP, même si nous ne décrivons pas l'ensemble de l'en-tête, mais juste les informations qui nous intéressent.
En-tête IP **************************************************** | @ IP source | @ IP destination | Protocole sup | **************************************************** Celle-ci ressemble fort à ce que nous avons vu précédemment pour Ethernet, nous ne détaillerons donc pas son contenu. Maintenant que nous avons décrit la couche 3, nous allons pouvoir voir plus en détail comment se fait
l'interface avec la couche 2.

6.11 - Cas particulier des liaisons point à point
Il existe cependant des cas où l'utilisation d'une table de routage est un peu différente, et où la précision d'une passerelle n'est pas nécessaire. C'est quand deux machines sont reliées directement l'une à l'autre. On parle alors
de liaison point à point. Dans ce cas, nous sommes sûrs qu'un paquet envoyé par une des machines à une extrémité de la connexion va être reçu par l'autre machine. Il suffit alors dans la table de routage de spécifier l'interface de sortie.
7 - Les interactions entre les couches 2 et 3
7.1 - Trame et datagramme, qu'est-ce qui circule sur le réseau ?
Et bien oui, nous avons vu que les couches 2 et 3 avaient chacune leur propre format de message utilisé pour transporter l'information, mais le quel des deux circule vraiment sur le réseau ? Si nous répondons la trame, cela voudra dire que notre trame sera contrainte de rester sur le réseau local, puisque la couche 2 ne permet pas d'aller d'un réseau à l'autre. Si nous répondons le datagramme, de la même façon, nous ne serons pas capables
de dialoguer avec les machines de notre réseau, et donc pas avec les routeurs à utiliser pour aller vers d'autres réseaux. Donc la réponse semble être: ni l'un ni l'autre... Ou plutôt: l'un et l'autre ! Effectivement, nous avons parlé au §3.2 d'encapsulation des informations. C'est exactement le principe qui va être utilisé ici. Les informations de couche 2 et 3 vont être mises ensemble avec les informations à transmettre.
Le paquet ainsi formé contiendra ainsi l'ensemble des informations nécessaires au transport de l'information. C'est donc une trame qui circulera sur le réseau, et cette trame Ethernet contiendra le datagramme IP. ++++++++++++++++++++++++++++++++++++++++++++++ | en-tête 2 | e-t 3 | ... | en-tête 6 | Info | ++++++++++++++++++++++++++++++++++++++++++++++
<--------- Datagramme IP -------->
<-------------- Trame Ethernet --------------> Maintenant, comment est organisée cette encapsulation pour que chaque couche retrouve facilement ses informations ?
7.2 - L'organisation de l'encapsulation
Comme nous l'avons vu au §3.2, lors de l'émission d'une information, chaque couche ajoute son en-tête. Le
paquet final ainsi formé contient donc les informations de toutes les couches, ainsi que l'information d'origine. La dernière couche ayant apporté son en-tête est la couche 2 (la couche 1 n'a pas besoin d'apporter de l'information, ou du moins, cela est transparent pour nous). Ainsi, quand le paquet arrive à sa destination, ce sont les informations de couche 2 qui sont accessibles en premier, et ça tombe bien puisque ce sont elles dont nous avons besoin en premier pour recevoir le message ! La réception d'un message se passe donc ainsi:
La carte réseau de ma machine reçoit la trame suivante ++++++++++++++++++++++++++++++++++++++++++++++ Couche 2 | en-tête 2 | e-t 3 | ... | en-tête 6 | Info | ++++++++++++++++++++++++++++++++++++++++++++++
La couche 2 regarde l'adresse MAC de destination et si cela correspond bien à notre machine, elle envoi les informations à la couche 3 en prenant soin d'enlever l'en-tête Ethernet, qui ne servira plus.
++++++++++++++++++++++++++++++++++++++++++++++ Couche 3 | en-tête 3 | e-t 4 | ... | en-tête 6 | Info | ++++++++++++++++++++++++++++++++++++++++++++++
De la même façon, la couche 3 regarde l'adresse IP de destination, et si cela correspond bien à UNE DES adresses IP de notre machines, elle envoi les informations à la couche 4, et ainsi de suite. Si par contre, le datagramme est à destination d'une autre adresse IP, notre machine va router ce paquet vers sa vraie destination (cela n'est vrai que si le routage est activé sur la machine, mais c'est normalement le cas pour un routeur :-) En fin de chaîne, l'application impliquée dans le dialogue va recevoir les informations qu'elle attend:
++++++++++++++++++++++ couche 7 | Info à transmettre | ++++++++++++++++++++++ Tout cela semble marcher parfaitement comme une machine bien huilée. Cependant, il nous manque encore quelques informations pour pouvoir avoir une compréhension globale du fonctionnement du routage. Par exemple, nous savons déterminer l'adresse IP du prochain routeur à utiliser, mais c'est de l'adresse MAC dont nous avons
besoin pour dialoguer avec lui directement sur notre réseau... Il faut donc pouvoir récupérer une adresse MAC en

fonction d'une adresse IP. Pour cela, nous allons devoir utiliser un protocole particulier, dédié à cette fonction, que l'on appelle ARP.
7.3 - Qu'est-ce que le protocole ARP ?
Le protocole ARP permet d'obtenir une adresse MAC en fonction d'une adresse IP. Reprenons notre problème. Le routeur 1 veut envoyer un paquet vers l'adresse 10.0.0.45 du réseau 3. Comme nous l'avons vu
précédemment, le routeur regarde dans sa table de routage pour savoir où il va devoir envoyer le paquet. La table de routage lui dit que pour atteindre le réseau 10.0.0.0/255.0.0.0 qui contient l'adresse 10.0.0.45, il faut passer par le routeur dont l'une des adresses d'interface est 172.16.0.254. Le nouveau travail du routeur est donc d'envoyer le paquet vers 172.16.0.254. Cette adresse IP étant sur son propre réseau (notre routeur a une interface dans le réseau 172.16.0.0./255.255.0.0), il faut connaître son adresse MAC pour pouvoir lui envoyer le paquet. Pour connaître son adresse MAC, l'idéal serait de lui demander, mais pour lui demander, il faudrait connaître son adresse MAC !!!
Et on tourne en rond :-( Vu qu'aucune autre machine du réseau n'est censée connaître l'adresse MAC de 172.16.0.254, nous ne pouvons pas non plus leur demander. Il faut donc trouver un moyen de s'adresser à l'adresse MAC de 172.16.0.254 sans la connaître ! Et si vous vous rappelez bien du cours sur les masques de sous réseau, vous avez peut-être deviné que nous avons un mécanisme à notre disposition nous permettant de faire cela... Il s'agit du principe de broadcast ! En
envoyant ma question à tout le monde, je suis sûr que la machine 172.16.0.254 va le recevoir. Je peux donc envoyer à tout le monde ma requête ARP demandant: - Qui a l'adresse IP 172.16.0.254 ? et quelle est son adresse MAC ? Toutes les machines reçoivent cette question, mais seule 172.16.0.254 va me répondre: - Je suis 172.16.0.254 et mon adresse MAC est 04:CF:65:84:C5:E2
J'ai ainsi pu récupérer l'adresse MAC de 172.16.0.254, et je peux désormais lui envoyer le paquet à transmettre. Nous avons ainsi réussi à faire la liaison souhaitée entre l'adresse IP connue et l'adresse MAC recherchée :-) Une question se pose quand même, car si toutes les machines doivent envoyer des messages à tout le monde à chaque fois qu'elles souhaitent communiquer, on va vite encombrer le réseau...
Pour répondre à ce problème, ARP utilise une solution de cache local. C'est à dire que lorsqu'une requête ARP va être effectuée, la réponse à cette requête va être gardée pendant un certain temps pour pouvoir être réutilisée. Ce temps est paramétrable, et est souvent de l'ordre de quelques minutes. Ainsi, si mes machines continuent de dialoguer ensemble, il n'y aura plus besoin de faire des broadcasts ARP, il suffira d'aller chercher dans le cache ARP l'information. D'ailleurs, le fonctionnement de ARP veut que le système aille d'abord regarder dans le cache ARP si l'information s'y trouve, avant de faire le broadcast ARP (ce qui semble normal :-)
Bon, et bien nous avons maintenant en notre possession toutes les connaissances devant nous permettre de comprendre en partie le dialogue entre deux machines distantes. Allons-y !
8 - Dialogue entre deux machines distantes
8.1 - Présentation du dialogue
Nous allons reprendre le même type de schéma que nous avons vu précédemment, avec une machine A souhaitant envoyer un message à une machine B sur Internet.
Machine A (193.25.25.25/24) (232.32.32.32) Machine B | | ---------- ---------- ----------
|Réseau 1|--Routeur1--|Internet|--Routeur2--|Réseau 3| ---------- ---------- ---------- Interface gauche routeur 1: 193.25.25.254/24 Interface droite routeur 1: 140.40.40.14/28 La partie Internet n'est pas mise en détail mais représente quelques de routeurs successifs avant le routeur 2.
NB: Comme petit exercice, vous pouvez vous demander pourquoi je n'ai pas précisé le masque de sous réseau pour la machine B ?
8.2 - Emission du message par A
La machine A veut envoyer le message "bonjour" à B. Comme nous l'avons vu à travers le modèle OSI, ce message va traverser les différentes couches du modèle pour que chacune y apporte l'information nécessaire à l'accomplissement de sa tâche. Dans le modèle TCP/IP utilisé sur Internet, les couches 5 et 6 ne sont pas utilisées

(on peut en déduire que les fonction effectuées par ces couches ne sont pas nécessaires, ou qu'elles sont prises en charge par une autre couche) Le message passe donc par la couche 4 qui, une fois son en-tête ajoutée, envoi le paquet à la couche 3. La couche 3 reçoit le paquet (segment TCP) et l'adresse de destination 232.32.32.32. Elle va voir dans sa table de
routage (celle de la machine sur laquelle on est, cad A) à qui envoyer les informations.
Table de routage de A: Réseau Masque Interface Passerelle 193.25.25.0 255.255.255.0 ethernet 1 ethernet 1 défaut 0.0.0.0 ethernet 1 193.25.25.254 Elle n'a pas de route spécifique pour l'adresse 232.32.32.32, ce sera donc la route par défaut qui sera utilisée.A
doit donc maintenant envoyer le paquet à l'interface 193.25.25.254 du routeur 1. A retourne voir dans sa table de routage par quel interface sortir pour envoyer le datagramme à 193.25.25.254.Elle doit maintenant connaître l'adresse MAC de l'interface 193.25.25.254. Pour cela, elle va voir dans son cache ARP si elle ne trouve pas l'information. Si c'est le cas, elle connaît l'adresse MAC, sinon, il faut qu'elle fasse un broadcast ARP pour la trouver.Maintenant que la couche 3 connaît l'adresse MAC destination, elle peut envoyer le datagramme IP (en-tête IP + segment TCP) et l'adresse MAC destination à la couche 2.
En-tête IP **************************************************-------- | IP SRC 193.25.25.25 | IP DST 232.32.32.32 | ps | infos | **************************************************-------- <----------------------Datagramme IP--------------------->
La couche 2 reçoit le datagramme et y ajoute son en-tête Ethernet. La trame est maintenant prête à être envoyée sur le réseau. En-tête Ethernet
++++++++++++++++++++++++++++++++++++++++++++++++-------- | MACSRC MAC A | MACDST MAC 193.25.25.254 | ps | infos | ++++++++++++++++++++++++++++++++++++++++++++++++--------
<---------------------Trame Ethernet-------------------> La trame circule sur le réseau jusqu'à sa destination qui est l'adresse MAC de 193.25.25.254.
8.3 - Réception du message par le routeur 1 intermédiaire
Le routeur 1 intermédiaire reçoit la trame. La couche 2 regarde l'adresse MAC en destination, et comme c'est l'adresse MAC de l'interface 193.25.25.254, le datagramme IP est envoyé à la couche 3.
La couche 3 reçoit le datagramme et regarde l'adresse IP de destination. Ce n'est l'adresse d'aucune des interfaces du routeur 1, donc le paquet devra être routé vers sa destination. Le routeur va donc voir sa table de routage pour voir vers qui renvoyer le paquet. Table de routage du routeur 1:
Réseau Masque Interface Passerelle 193.25.25.0 255.255.255.0 ethernet 1 ethernet 1 140.40.40.0 255.255.255.240 ethernet 2 ethernet 2 défaut 0.0.0.0 ethernet 2 140.40.40.13 Il n'y a pas de route spécifique pour l'adresse 232.32.32.32. C'est donc la route par défaut qui sera utilisée. La prochaine machine à qui envoyer le paquet est donc 140.40.40.13. Le routeur retourne voir dans sa table de
routage par quel interface sortir pour atteindre 140.40.40.13. C'est la seconde ligne de la table qui contient l'information et l'interface à utiliser est l'interface 2.De la même façon que précédemment, il faut trouver son adresse MAC pour lui envoyer la trame contenant les informations nécessaires. On la trouve facilement grâce aux mécanismes ARP. Le routeur 1 peut donc envoyer la trame vers le prochain routeur. Nous n'allons pas détailler la suite, le passage par chaque routeur étant identique à celui-ci. Les informations arrivent donc jusqu'au routeur 2 grâce aux mécanismes de routage d'Internet :-) Celui-ci va
comme précédemment renvoyer le paquet qui ne lui est pas destiné vers la machine B qui est sur son réseau.
8.4 - Réception du message par la machine B
La trame arrive donc sur l'interface de la machine B. L'adresse MAC en destination est bien celle de cette interface (Cette adresse MAC aura été trouvée grâce au mécanisme ARP mis en oeuvre par le routeur 2, vous suivez bien ?) La couche 2 renvoi donc le datagramme IP à la couche 3 IP. La couche 3 reçoit le datagramme et regarde l'adresse IP de destination. C'est bien l'adresse d'une des interfaces de la machine ! La couche 3 va donc pouvoir
envoyer les informations à la couche 4, qui enverra elle-même le message "bonjour" à la couche 7 applicative. Et hop, nous avons réussi ainsi à envoyer le message "bonjour" de la machine A à la machine B !!! Magisme...

Bien sûr, certains points n'ont pas été détaillés et demandent des connaissances plus poussées pour pouvoir être expliqués. Mais cela fera l'objet d'un autre cours ;-)
8.5 - Quelques remarques
Et bien oui, même si tout s'est bien déroulé dans notre dialogue, et que vous avez tout parfaitement compris, il est bon de mettre en valeur certains aspects de la communication. - Les adresses MAC source et destination sont modifiées à chaque passage par un routeur
Oui, et c'est normal. Ces adresses MAC sont relatives à la couche 2 dont le rôle principal est le dialogue sur un réseau local. Donc les adresses MAC utilisées dans une trame doivent être en relation avec le réseau sur lequel on se situe, pas celui d'à coté ;-) Que se passerait-il si une adresse MAC de destination était celle d'une interface étant sur un autre réseau ? Ca ne marcherait plus :-( car la trame serait envoyée sur le réseau local (en couche 2) et ne trouverait pas de machine
ayant cette adresse MAC. La trame serait donc perdue. Les adresses MAC contenues dans une trame Ethernet doivent donc toujours être en rapport avec le réseau local. C'est ce qui explique qu'elles doivent être modifiées à chaque passage sur un nouveau réseau. - Par contre, les adresses IP source et destination n'ont pas été modifiées durant le transport de A à B Oui, et cela est encore normal ! La couche 3 concerne les informations de routage, donc sur des adresses
appartenant à des réseaux distants. Ces adresses représentent donc les deux extrémités du dialogue et ne doivent pas être modifiées. Que se serait-il passé si on avait modifié les adresses IP source et destination à chaque passage d'un routeur ? Ici encore, nous aurions eu des problèmes. Le datagramme IP serait bien arrivé jusqu'au routeur 1, et lui l'aurait renvoyé vers le prochain routeur sur Internet en mettant comme adresse IP destination 140.40.40.13. Le routeur
ayant cette adresse 140.40.40.13 aurait bien reçu le datagramme, mais voyant que c'était lui l'adresse IP de
destination, il aurait pris le paquet pour lui et la communication se serait arrêtée là (la couche 4 n'aurait pas reconnu ce paquet comme appartenant à une connexion valide) et badaboum... Il est donc impératif de ne pas modifier les adresses IP lors du transport du datagramme. Le dialogue IP se fait de bout en bout entre les réseaux distants, alors que le dialogue Ethernet se fait de proche en proche sur chacun des réseaux traversés. Voici un petit dessin pour schématiser les deux principes que nous venons d'évoquer.
Machine A Machine B | | ---------- ---------- ---------- |Réseau 1|--Routeur1--|Internet|--Routeur2--|Réseau 3| ---------- ---------- ---------- <---------------- Dialogue IP ---------------->
<--- DE ---><-------- DE ---------><--- DE ---> Avec DE = Dialogue Ethernet NB: Il est cependant possible que les adresses IP source et destination soient modifiées dans le cas de la traduction d'adresse. Ceci ne faisant pas partie intégrante du sujet, je vous invite à lire la faq sur la nat(traduction
d'adresse) - Une autre remarque que nous pouvons faire, est la foultitude d'étapes qui ont été utilisées pour un simple envoi de "bonjour" Et encore, ce n'est rien, en rentrant plus dans le détail, il y a encore bon nombre d'autres communications que nous n'avons pas détaillées qui sont nécessaires au dialogue. Et dire que tout cela se fait en quelques
millisecondes et est complètement transparent pour l'utilisateur final... C'est quand même bô Internet :-))
9 - Mini lexique
9.1 - Adresse IP
L'adresse IP est un numéro codé sur 4 octets permettant d'identifier une machine de façon unique sur le réseau.
9.2 - Réseau logique
On appelle réseau logique un ensemble d'adresses IP appartenant à une même plage d'adresses. Cette plage est notamment définie par l'adresse de réseau et le masque associé.
9.3 - Connexion/interconnexion

Ces deux termes sont souvent employés indifféremment, à tort ! On parle de connexion de machines au sein d'un même réseau, et d'interconnexion de réseaux entre eux. La connexion se rapporte alors à une notion de couche 2, alors que l'interconnexion est une notion de couche 3.
9.4 - Sous-réseau
On définit un sous-réseau comme un sous-ensemble d'une plage d'adresses réseau. C'est grâce au masque que l'on peut définir un sous-réseau au sein d'un réseau, et ainsi découper un réseau en plusieurs sous-réseaux.
9.5 - ARP
ARP est un protocole permettant de déterminer une adresse MAC en fonction d'une adresse IP.
10 - Annexes
10.1 - Ressources utilisées
Je me suis inspiré des connaissances que j'ai pu glaner un peu partout depuis que je fais du réseau, sans m'appuyer sur un document en particulier. Je dois cependant avouer que j'en ai beaucoup appris depuis que je
donne des cours en école d'ingénieur et qu'il faut répondre aux multiples questions de ces petites têtes blondes :-) Ca m'a permis de me remettre en question et d'approfondir des sujets que je pensais maîtriser. La route vers le savoir est encore longue ! :-) Pour aller plus loin sur le sujet, je vous conseillerai la lecture du livre de Richard Stevens "Le TCP/IP illustré" qui est une mine d'or pour comprendre les mécanismes TCP/IP.
Et sans oublier l'excellente faq sur les firewalls de Stéphane Catteau dont je me suis inspiré pour la mise en
forme. Disponible sur: http://fr.comp.securite.free.fr/firewall.txt N'hésitez pas à la consulter, on y apprend plein de choses.
10.2 - Remerciements
Je remercie notamment les personnes suivantes pour leur lecture assidue du cours durant sa réalisation et leurs conseils précieux.
David Blevin, Eric Belhomme, Annie D.
11 - Conclusion
Arf... je vois le bout du tunnel... Je dois bien avouer que j'ai du tourner le problème dans tous les sens afin de trouver une façon cohérente d'aborder
les principes de routage. J'espère que le résultat est à la hauteur de mes attentes, et surtout qu'il vous aura permis de comprendre un peu mieux le fonctionnement d'un des principes majeur d'Internet. La compréhension en profondeur du routage n'est vraiment pas une chose aisée. D'ailleurs, il me reste un bon nombre de questions en suspend auxquelles je vais essayer de répondre. Peut être dans une suite du cours :-) En tout cas, je compte sur vous pour me faire un retour efficace sur ce document. Je manipule beaucoup des concepts abordés tous les jour. Mon oeil sur le sujet n'est donc pas très neuf, et il est probable que je n'explique pas bien certaines notions. Si des éléments ne vous semblent
pas clair lors de la lecture du document, je vous invite à me contacter à l'adresse spécifiée dans l'en-tête du document pour me faire part de vos remarques. Ne négligez pas vos remarques, elles me sont extrêmement utiles pour améliorer ce document, ainsi que ma compréhension personnelle. Merci de votre attention, vous pouvez éteindre votre
ordinateur.
Petit cours sur les masques de sous-réseau
1 - Introduction 1.1 - Objet de ce cours
1.2 - Réutilisation de ce cours 1.3 - Décharge 1.4 - Votre travail 2 - Définitions 2.1 - L'identification des machines 2.2 - La segmentation des réseaux
2.3 - Une seule adresse pour le prix de deux 2.4 - Définition empirique du masque 2.5 - Pourquoi maîtriser les masques ? 3 - Adresse IP et masque

3.1 - L'adressage IP 3.2 - Nombre de machines 3.3 - La séparation grâce au masque 3.4 - Le couple adresse IP et masque 4 - Le codage
4.1 - Le codage binaire 4.2 - Pourquoi un codage binaire pour les ordinateurs ?
4.3 - Qu'est-ce qu'un octet ? 4.4 - Ecriture binaire de l'adresse IP 5 - Les masques 5.1 - Récapitulatif 5.2 - Comment représente-t-on un masque ? 5.3 - Comment le masque et l'adresse IP sont ils associés ? 5.4 - Adresses spécifiques (réseau, broadcast)
5.5 - Les bits à 1 et à 0 doivent ils être contigus ? 5.6 - Quelles adresses pour les masques ? 5.7 - Faire fi de l'écriture 5.8 - Quelle est cette notation avec un /, comme /24 ? 6 - Comment bien choisir son masque ? 6.1 - Partir de l'existant 6.2 - En fonction du nombre de machines
6.3 - Comment déterminer la plage d'adresses à partir du masque et d'une adresse ? 6.4 - Une méthode simple pour trouver les adresses de réseau possibles 6.5 - Comment définir une plage réseau quelconque comme somme de plusieurs plages ? 6.6 - Plages réservées (RFC 1918) 7 - Comment découper une plage d'adresses en plusieurs sous-réseaux ? 7.1 - Comment Déterminer les masques pour chacun des sous-réseaux ?
7.2 - Comment déterminer les plages d'adresses des sous-réseau ? 7.3 - Le résultat 8 - Que sont les classes d'adresses A, B, C, D... ? 8.1 - Historique
8.2 - Définition 8.3 - Y a-t-il un pénurie d'adresses IPv4 ? 8.4 - Le système d'adressage par classes est-il viable ?
8.5 - Qu'est-ce que l'adressage CIDR ? 9 - Trucs et astuces avec les masques 9.1 - Comment déterminer qu'une machine appartient à mon réseau ? 9.2 - Des machines sur un même réseau peuvent elles avoir des masques différents ? 9.3 - Puis-je utiliser un outil qui calcule pour moi ? 9.4 - Tout ça c'est bien, mais quand est ce que je l'utilise ce masque moi ? 10 - Mini lexique
10.1 - Adresse IP 10.2 - Réseau logique 10.3 - sous-réseau 10.4 - Le ET logique 11 - Annexes 11.1 - Ressources utilisées
11.2 - Remerciements 12 - Conclusion 13 - Discussion autour de la documentation 14 - Suivi du document
1 - Introduction
1.1 - Objet de ce cours
Dans le monde des réseaux, on utilise souvent des termes inintelligibles pour le commun des mortels n'ayant pas une formation informatique poussée. Les masques en font partie, d'autant plus que leur compréhension et leur utilisation n'est pas toujours simple (au départ ;-) ) Le but de ce cours est de présenter de façon la plus compréhensible possible ce que sont les masques, à quoi ils servent, comment bien les utiliser et se familiariser avec. Pour cela, nous traiterons aussi quelques sujets annexes qui nous permettront de mieux comprendre l'utilité des masques, comme les réseaux logiques, quelques notions de routage, etc.
1.2 - Réutilisation de ce cours
Vous êtes libre d'utiliser de courts extraits de ce cours, dans la mesure où vous incluez un lien permettant d'avoir accès à l'ensemble du document. Ceci dans le but de permettre à vos lecteurs d'obtenir facilement un complément d'information. De même, vous êtes libre de copier ce cours dans son intégralité, à condition cependant d'en avertir l'auteur, et que cette utilisation soit exempte de tout caractère commercial (bannières publicitaires incluses). Cette restriction étant principalement due au plus élémentaire des respects : celui du temps que j'ai consacré à la rédaction de ce cours. Toute autre utilisation devra faire l'objet d'un accord préalable avec l'auteur.
1.3 - Décharge

L'auteur décline toute responsabilité concernant la mauvaise utilisation ou compréhension du document qui engendrerait l'écroulement de votre réseau ;-)
1.4 - Votre travail
La seule et unique tâche que je vous demanderai d'accomplir sera de corriger mes erreurs (aussi bien dans la cohérence des éléments avancés que pour l'orthographe), me donner des conseils sur ce qui est mal expliqué pour le rendre plus accessible, ajouter des éléments qui ont trait aux masques et rendent l'exposé plus complet, combler tout manque pour améliorer ce cours.
2 - Définitions
2.1 - L'identification des machines
Pour envoyer du courrier à un ami, vous utilisez son adresse postale. Ainsi vous êtes sûr que le paquet que vous envoyez arrivera à la bonne personne. Et bien pour les ordinateurs, c'est pareil. Quand vous connectez votre ordinateur à un réseau (Internet par exemple), il possède une adresse qui l'identifie d'une façon unique pour que
les autres ordinateurs du réseau puissent lui envoyer des informations.
2.2 - La segmentation des réseaux
Imaginez un énorme réseau comme Internet où chacune des machines serait obligée de connaître l'ensemble des millions d'autres machines (et notamment leurs adresses) et de savoir comment y accéder. Cela obligerait nos pauvres ordinateurs à avoir des tables énormes contenant l'ensemble de ces informations. Cela induirait aussi des temps de réponses très grands pour parcourir cette table.
Pour répondre à cette problématique, on a segmenté cet énorme réseau en différents petits réseaux. Et c'est au
sein de ces petits réseaux que l'on donne des adresses aux machines pour leur envoyer l'information. Ainsi, il suffit de connaître l'adresse du réseau pour envoyer l'information à une machine de celui-ci, et c'est à l'intérieur de ce réseau que l'information sera redirigée vers la bonne machine. C'est exactement comme lorsque vous envoyez un paquet par la poste, vous mettez le nom de la ville, le paquet arrive à la poste de la ville, et c'est elle qui distribue le paquet à la bonne adresse.
2.3 - Une seule adresse pour le prix de deux
Comme vous l'avez compris, il nous faut deux adresses pour identifier une machine, une pour le réseau et une pour la machine elle-même. Cependant, l'adressage qui a été choisi pour les machines ne définit qu'une seule adresse. Vous me direz que ce n'est pas suffisant. Et bien si ! Il suffit de segmenter cette adresse en deux parties distinctes, l'une pour le réseau, et l'autre pour la machine. C'est là où le masque entre en jeu, c'est lui qui joue le rôle de séparateur entre ces deux adresses.
2.4 - Définition empirique du masque
Le masque est un séparateur entre la partie réseau et la partie machine d'une adresse IP.
2.5 - Pourquoi maîtriser les masques ?
L'utilisation et la maîtrise des masques doivent pouvoir vous permettre d'une part, de savoir ce que vous manipulez, et d'autre part d'optimiser le fonctionnement de votre réseau. Effectivement, l'utilisation des masques
vous permettra de segmenter de la façon la plus correcte l'adressage de votre réseau, et ainsi de séparer les machines sensibles du reste du réseau, limiter les congestions, et prévoir l'évolution de votre réseau, etc.
Malheureusement, la séparation d'un réseau en plusieurs sous-réseaux n'a pas que des avantages. L'un des inconvénients majeurs est notamment la complexification des tables de routage étant donné le plus grand nombre de réseaux à router.
3 - Adresse IP et masque
3.1 - L'adressage IP
Nous avons parlé d'adresses pour les machines, il est temps maintenant de définir ces adresses. On parle d'adresse IP (Internet protocol), car il s'agit du protocole qui permet d'identifier les machines et de router les informations sur Internet. Ces adresses sont codées sur 4 octets (voir chapitre 4 sur le codage binaire) et sont la plupart du temps écrites en numérotation décimale en séparant les octets par des points. Ca donne quelque chose comme ça: 192.168.132.24

3.2 - Nombre de machines
En y regardant d'un peu plus près, on peut calculer le nombre de machines que l'on peut identifier à l'aide de cet adressage. Ainsi, on utilise 4 octets, soit 32 bits, soit encore 2^32 adresses (2 exposant 32 adresses) Or 2^32 =
4 294 967 296, on peut donc définir un peu plus de 4 milliards d'adresses !!!
3.3 - La séparation grâce au masque
Cependant, nous avons vu qu'il fallait séparer cette adresse en deux parties pour pouvoir identifier à la fois le réseau et l'adresse. Mais comment se fait cette séparation ? En fait, le masque comme l'adresse IP est une suite
de 4 octets, soit 32 bits. Chacun des ces bits peut prendre la valeur 1 ou 0. Et bien il nous suffit de dire que les bits à 1 représenteront la partie réseau de l'adresse, et les bits à 0 la partie machine. Ainsi, on fera une association entre une adresse IP et un masque pour savoir dans cette adresse IP quelle est la partie réseau et quelle est la partie machine de l'adresse.
3.4 - Le couple adresse IP et masque
Le masque servant à faire la séparation en deux parties sur une adresse IP, il est donc indissociable de celle-ci. Une adresse seule ne voudra rien dire puisqu'on ne saura pas quelle est la partie réseau et quelle est la partie
machine. De la même façon, un masque seul n'aura pas de valeur puisqu'on n'aura pas d'adresse sur laquelle l'appliquer. L'adresse IP et le masque sont donc liés l'un a l'autre, même si l'on peut choisir l'un indépendamment de l'autre.
4 - Le codage
4.1 - Le codage binaire
Nous utilisons tous les jours un système de numération décimale. Avec donc 10 symboles (0123456789) qui nous permettent d'énumérer toute sorte de nombres en les plaçant dans un certain ordre. Cette place est primordiale puisqu'elle représente le passage aux dizaines, centaines, milliers, etc. Ainsi, tout nombre peut se décomposer en puissances de 10, par exemple: 324 = 300 + 20 +4 = 3*10^2 + 2*10^1 + 4*10^0
Cependant, il existe d'autres modes selon la base dans laquelle on se place. Lorsque l'on utilise la base 2, on se place en numération binaire où seuls deux symboles sont utilisés (01) On peut, de la même façon, décomposer tout nombre en puissance de 2. 324 = 256 + 64 + 4 = 1*2^8 + 0*2^7 + 1*2^6 + 0*2^5 + 0*2^4
+ 0*2^3 + 1*2^2 + 0*2^1 + 0*2^0
4.2 - Pourquoi un codage binaire pour les ordinateurs ?
Pour les ordinateurs, c'est ce choix du codage binaire qui a été fait. Pourtant, il aurait été plus simple d'utiliser la base 10 avec laquelle nous sommes familiers. Cependant, les informations liées aux ordinateurs circulent sur des fils électriques. Sur ces fils, il est difficile de distinguer plus de deux états pour le signal, on peut par exemple choisir un état à 0 volt, et un autre pour 5 volts. On se retrouve donc avec deux valeurs possibles. C'est pour cela qu'on a choisi un codage binaire avec deux valeurs possibles, 0 et 1.
4.3 - Qu'est-ce qu'un octet ?
Un octet est une séquence de huit bits. C'est donc un nombre codé avec huit bits. Ainsi, si on transpose sa valeur en décimal, on obtient un nombre qui peut varier entre 0 et 255. Donc, dans une adresse IP, on ne pourra pas trouver d'autres nombres que ceux compris entre 0 et 255. Une adresse comme 192.65.25.428 ne peut pas être une adresse IP valide vu que son dernier octet n'est pas compris entre 0 et 255.
4.4 - Ecriture binaire de l'adresse IP
Nous avons vu que l'adresse IP était composée de 4 octets écrits en notation décimale, séparés par des points,
par exemple: 192.168.25.132 Cette adresse peut aussi bien s'écrire en binaire: 11000000.10101000.00011001.10000100 192 . 168 . 25 . 132
Nous verrons par la suite pourquoi il est utile de revenir à cette notation pour bien comprendre le fonctionnement des masques.
5 - Les masques
5.1 - Récapitulatif
Nous avons déjà vu plusieurs aspects importants des masques qu'il faudra toujours essayer de garder à l'esprit: - Codés sur 4 octets, soit 32 bits, - Ils permettent de faire la séparation entre la partie réseau et la partie machine de l'adresse IP,
- La partie réseau est représentée par des bits à 1, et la partie machine par des bits à 0, - Le masque ne représente rien sans l'adresse IP à laquelle il est associé.
5.2 - Comment représente-t-on un masque ?
Comme le masque est codé sur 32 bits, voici un exemple possible de masque: __________Réseau__________ _Machine
| | | | 11111111.11111111.11111111.00000000 Ce qui s'écrit en décimal 255.255.255.0 Maintenant, plusieurs questions peuvent se poser. Jusqu'ici je comprends, mais comment je peux associer ce masque à une adresse IP, et quel sera le résultat ? Pourquoi les bits à 1 sont séparés de ceux à 0 ?
5.3 - Comment le masque et l'adresse IP sont-ils associés ?
Prenons par exemple une machine qui a pour adresse IP 192.168.25.147. Il nous faut lui associer un masque pour savoir quelle partie de cette adresse représente le réseau. Associons-lui le masque précédent 255.255.255.0. On
remarque que les bits des trois premiers octets sont à 1, ils représentent donc la partie réseau de l'adresse, soit 192.168.25, le 147 permettant d'identifier la machine au sein de ce réseau. Dans cet exemple, on remarque qu'un octet a été réservé pour l'adresse machine, ce qui nous donne 2^8 = 256 adresses disponibles pour les machines sur le réseau 192.168.25. Les adresses disponibles pour les machines seront donc:
192.168.25.0 (réservée pour le réseau, voir 5.4) 192.168.25.1 ... 192.168.25.254 192.168.25.255 (réservée pour le broadcast, voir 5.4)
On observe donc que c'est le masque qui détermine le nombre de machines d'un réseau. Ainsi, on verra par la suite qu'on choisira le masque en fonction du nombre de machines que l'on veut installer.
5.4 - Adresses spécifiques (réseau, broadcast)
Il existe des adresses spécifiques au sein d'un réseau. La première adresse d'une plage ainsi que la dernière ont un rôle particulier. La première adresse d'une plage représente l'adresse du réseau. Celle-ci est très importante car c'est grâce à elle qu'on peut identifier les réseaux et router les informations d'un réseau à un autre. La
dernière adresse d'une plage représente ce que l'on appelle l'adresse de broadcast. Cette adresse est celle qui permet de faire de la diffusion à toutes les machines du réseau. Ainsi, quand on veut envoyer une information à toutes les machines, on utilise cette adresse. Dans notre exemple, l'adresse de réseau sera donc 192.168.25.0, et l'adresse de broadcast 192.168.25.255. On remarque donc qu'il ne nous reste plus que 254 adresses pour identifier nos machines. Ainsi, à chaque fois que
l'on choisira un masque en fonction du nombre de machines que l'on veut adresser, il faudra tenir compte de ces
deux adresses...
5.5 - Les bits à 1 et à 0 doivent ils être contigus ?
Dans l'exemple de masque que nous avons choisi, nous avons vu que les bits à 0 et à 1 étaient regroupés. Cela n'est pas une obligation, mais cela facilite énormément l'exploitation du réseau. En conservant la contiguïté des bits, les adresses de nos machines au sein du réseau se suivent. Ce ne serait pas le cas si l'on avait choisi un masque avec des bits non contigus.
Exemple, si on choisit le masque suivant: 11111111.11111111.11111110.00000001 Ici, on a comme précédemment 8 bits qui représentent la partie machine, par contre, ils ne sont plus à la même place. Cela se traduit en décimal par le masque suivant 255.255.254.1. On voit donc que les adresses dont le
dernier bit est a 1 ne seront pas dans le même réseau que celles dont le dernier bit est a 0. Ce qui veut dire que les adresses dont le dernier octet est impair ne seront pas dans le même réseau que les adresses paires. Dans cet

exemple, cela reste encore facile de différencier les adresses paires et impaires, mais lorsque l'on fait des mélanges plus compliqués entre les bits significatifs, cela devient très vite inextricable. On conservera donc toujours la contiguïté des bits significatifs !!!
5.6 - Quelles adresses pour les masques ?
Etant donné que l'on conserve la contiguïté des bits, on va toujours rencontrer les mêmes nombres pour les octets du masque. Ce sont les suivants:
11111111 11111110 11111100 ... 10000000 00000000
Soit en décimal: 255, 254, 252, 248, 240, 224, 192, 128, et 0. Ainsi, on peut tout de suite dire si un masque semble valide au premier coup d'oeil. Un masque en 255.255.224.0 sera correct alors qu'un masque en 255.255.232.0 ne le sera pas (à moins de ne pas vouloir respecter la contiguïté des bits)
Vous pouvez aller voir tous les masques possibles dans la RFC suivante: Rfc 1878
5.7 - Faire fi de l'écriture par octets
L'écriture de l'adresse IP selon 4 octets séparés par un point est facile à utiliser. Mais quand on se penche sur le
problème d'un peu plus près, on se rend compte qu'elle n'est pas très adaptée... Elle a deux défauts principaux:
- Ecriture en décimal alors que l'on raisonne en binaire - Séparation des octets par des points Ainsi, lorsqu'on utilise des masques où la séparation réseau/machine se fait sur un octet (tous les bits des octets sont soit à 1, soit à 0) cela est simple. Prenons par exemple le réseau 192.168.25.0/255.255.255.0. Toutes les machines commençant par 192.168.25 appartiendront à ce réseau. Si l'on prend le réseau 192.168.25.32/255.255.255.248 et je vous demande si la machine 192.168.25.47 appartient à ce réseau ? ça
devient plus compliqué... Pour bien comprendre, il faut alors revenir en binaire. Etant donné que les trois premiers octets du masque ont tous leurs bits à 1, c'est sur le quatrième que va se faire la différentiation. Il s'écrit 248, soit 11111000 en binaire. Donc les 5 premiers bits de cet octet représenteront la partie réseau. Pour notre réseau, le dernier octet vaut 32, soit 00100000, pour notre machine, il vaut 47, soit 00101111. On voit
que les 5 premiers bits de ces deux octets ne sont pas identiques (00100 != 00101) et donc que ces deux adresses n'appartiennent pas au même réseau. Cela peut sembler très compliqué, mais on verra par la suite des méthodes simples pour déterminer rapidement l'appartenance à un réseau.
5.8 - Quelle est cette notation avec un /, comme /24 ?
Une autre notation est souvent utilisée pour représenter les masques. On la rencontre souvent car elle est plus rapide à écrire. Dans celle-ci, on note directement le nombre de bits significatifs en décimal, en considérant que la
contiguïté est respectée. Ainsi, pour notre exemple 192.168.25.0/255.255.255.0, on peut aussi écrire
192.168.25.0/24, car 24 bits sont significatifs de la partie réseau de l'adresse. De même, les écritures suivantes sont équivalentes: 10.0.0.0/255.0.0.0 = 10.0.0.0/8 192.168.25.32/255.255.255.248 = 192.168.25.32/29
Etant donné que le masque détermine le nombre de machines qu'il pourra y avoir sur un réseau, c'est souvent de cette information que l'on part pour choisir le masque. Etant donné que l'on travail en binaire, le nombre de machines possible au sein d'un réseau sera une puissance de 2. Pour un nombre de machines donné, il faudra donc choisir la puissance de 2 supérieure pour pouvoir adresser les machines. De plus, il faudra prévoir un certain nombre d'adresses supplémentaires pour accueillir de nouvelles machines.
Ainsi, disons que l'on possède le réseau 193.225.34.0/255.255.255.0 et que l'on veut faire un réseau de 60 machines au sein de celui-ci. On veut 60 machines, il faut ajouter deux adresses pour le réseau et le broadcast, ce qui fait 62 adresses au total. La puissance de 2 supérieure à 62 est 64, mais cela ne nous laisserait que 2 adresses pour évoluer, ce qui est un peu juste. On préfèrera donc un réseau de 128 adresses. Pour identifier 128 adresses, il nous faut 7 bits (128 = 2^7) Donc dans notre masque, 7 bits seront à 0 pour identifier la partie machine, et les 25 bits restants seront à 1. Ce qui donne:

11111111.11111111.11111111.10000000 et en décimal 255.255.255.128.
6 - Comment bien choisir son masque ?
6.1 - Partir de l'existant
La plupart du temps, le choix de l'adressage se fait en fonction des besoins exprimés, et des limites de ce que l'on a le droit de faire. Une certaine plage vous est allouée par votre fournisseur d'accès. Vous pourrez alors découper cette plage en différents réseaux, mais ne surtout pas dépasser celle-ci. Ainsi, si vous possédez une plage de 128 adresses et que vous voulez adresser 500 machines, vous aurez quelques petits problèmes...
6.2 - En fonction du nombre de machines
Etant donné que le masque détermine le nombre de machines qu'il pourra y avoir sur un réseau, c'est souvent de
cette information que l'on part pour choisir le masque. Etant donné que l'on travaille en binaire, le nombre de machines possible au sein d'un réseau sera une puissance de 2. Pour un nombre donné de machines, il faudra donc choisir la puissance de 2 immédiatement supérieure pour pouvoir adresser les machines. De plus, il faudra prévoir un certain nombre d'adresses supplémentaires pour accueillir de nouvelles machines. Ainsi, disons que l'on possède le réseau 193.225.34.0/255.255.255.0 et que l'on veut faire un réseau de 60 machines au sein de celui-ci. On veut 60 machines, il faut ajouter deux adresses pour le réseau et le broadcast, ce
qui fait 62 adresses au total. La puissance de 2 supérieure à 62 est 64, mais cela ne nous laisserait que 2 adresses pour évoluer, ce qui est un peu juste. On préfèrera donc un réseau de 128 adresses. Pour identifier 128 adresses, il nous faut 7 bits (128 = 2^7) Donc dans notre masque, 7 bits seront à 0 pour identifier la partie machine, et les 25 bits restants seront à 1. Ce qui donne:
11111111.11111111.11111111.10000000
et en décimal 255.255.255.128
6.3 - Comment déterminer la plage d'adresses à partir du masque et d'une adresse ?
Nous avons vu précédemment que le masque devait être associé à une adresse IP pour avoir une valeur. Le choix de la plage d'adresses sur laquelle il s'applique est donc tout aussi important !! Nous avons choisi un masque qui nous permettra d'identifier 128 machines. Mais nous possédons une plage de 256 adresses. Où faut-il placer nos 128 adresses dans cette plage ? Peut-on les placer n'importe où ?
La réponse est bien sûr non. Nous n'avons que deux possibilités pour choisir notre plage, les adresses de 0 à 127, et les adresses de 128 à 255. Choisir une plage de 32 à 160 serait une erreur, et le réseau ne fonctionnerait pas. Voici l'explication: La différenciation du réseau va se faire sur le premier bit du dernier octet (vu que nos trois premiers octets sont
fixés à 193.225.34) Si ce bit est à 0, cela correspond aux adresses de 0 à 127. S'il est à 1, cela correspond aux adresses de 128 à 255. Ainsi, si l'on choisit une plage d'adresses de 32 à 160, les adresses de 32 à 127 auront le premier bit de leur dernier octet à 0, alors que les adresses de 128 à 160 auront ce même bit à 1, elles seront alors considérées comme étant dans deux réseaux différents !!! Ainsi, quel que soit le nombre de machines à placer dans une plage, on ne peut pas choisir l'adressage n'importe comment.
PS: Dans notre cas, les deux choix possibles sont identiques, mais l'on verra par la suite que ce n'est pas toujours le cas pour des plages plus petites...
6.4 - Une méthode simple pour trouver les adresses de réseau possible
Il n'est pas toujours évident de savoir si une adresse correspond bien à celle d'un réseau selon le masque que l'on a choisi. Avec la méthode suivante, vous devriez pouvoir vous en sortir. Il faut avant tout que vous ayez
déterminé le masque selon le nombre de machines dont vous avez besoin. Ensuite, selon l'octet significatif (qui n'est pas à 0 ou 255) faites 256-cet_octet=X. L'adresse de réseau devra alors être un multiple de X. Un petit exemple pour être un peu plus clair. On veut par exemple 50 machines, on choisit donc un masque en 255.255.255.192. C'est le dernier octet qui est significatif, on fait donc 256-192=64. Il faut donc que le dernier octet de l'adresse de réseau soit un multiple de 64. Si on prend la plage 10.0.0.0/255.255.255.0, on pourra choisir les adresses de réseau suivantes:
10.0.0.0, 10.0.0.64,

10.0.0.128, 10.0.0.192.
6.5 - Comment découper une plage réseau quelconque comme somme de plusieurs plages ?
Nous avons vu qu'une plage réseau ne pouvait pas être choisie n'importe comment. Etant donné que les masques et les adresses IP se basent sur un codage binaire, les chiffres utilisés dans les adresses résultantes ne pourront être que des multiples de puissances de 2 en accord avec le masque. Ainsi, une plage 70.0.0.0 ne pourra pas avoir un masque qui définisse plus de deux chiffres sur le premier octet, car 70 est un multiple de 2, mais pas de
4. Ce n'est pas clair ? un exemple devrait vous aider à mieux comprendre.Disons que l'on veut décrire la plage d'adresses allant de 69.0.0.0 à 79.255.255.255.
La question est de savoir quel masque associé à quelle adresse de réseau nous permettra de définir cette plage. Le premier octet varie de 69 à 79. Il prend donc 11 valeurs. 11 n'étant pas une puissance de 2, on sait d'ores et déjà que l'on ne pourra pas définir cette plage avec un seul réseau, mais qu'il va falloir la découper en une somme de plusieurs réseaux. Le but est cependant d'optimiser cette somme de réseaux pour en avoir le moins possible. On pourrait simplement utiliser 11 réseaux avec des masques 255.0.0.0, mais on doit sûrement pouvoir faire plus propre et regrouper plusieurs de ces réseaux en un seul.
La première puissance de 2 inférieure à 11 est 8. Il faut maintenant savoir si l'on peut placer un réseau, dont le premier octet décrira 8 valeurs, dans cette plage. Le seul multiple de 8 de cette plage est 72. On décrirait alors un réseau dont le premier octet varierait de 72 à 79, ce qui est bien compris dans notre plage d'origine. Le réseau 72.0.0.0/248.0.0.0 est donc bien adapté pour décrire notre plage, mais il reste encore à décrire les adresses de 69.0.0.0 à 71.255.255.255.
On effectue le même raisonnement. (Ici le premier octet prend 3 valeurs, la puissance de 2 inférieure à 3 est 2, et le multiple de 2 de cette plage est 70) On trouve donc le réseau 70.0.0.0/254.0.0.0 Il ne nous reste plus qu'à décrire la plage 69.0.0.0 à 69.255.255.255 qui peut être définie par 69.0.0.0/255.0.0.0.
Et voilà !! Nous avons découpé notre plage d'origine qui allait de 69.0.0.0 à 79.255.255.255 en trois sous-réseaux: 69.0.0.0/255.0.0.0 70.0.0.0/254.0.0.0 et 72.0.0.0/248.0.0.0
6.6 - Plages réservées (Rfc 1918)
Certaines plages d'adresses ont été réservées pour une utilisation locale. Ainsi, pour configurer un réseau local quand on n'a pas de plage d'adresses publiques à disposition, on doit utiliser ces plages d'adresses privées. Si vous voulez avoir plusieurs réseaux, c'est à vous de faire le découpage au sein de ces plages comme bon vous semble.
Voici ces plages d'adresses: 10.0.0.0/255.0.0.0 soit plus de 16 millions d'adresses 192.168.0.0/255.255.0.0 soit près de 65000 adresses
172.16.0.0/255.240.0.0 soit plus d'un million d'adresses Si après vous ne trouvez pas votre bonheur, c'est que vous avez un sacrément grand réseau, ou que vous vous y
prenez mal... Rfc 1918
7 - Comment découper une plage d'adresses en plusieurs sous-réseaux ?
7.1 - Détermination des masques pour chacun des réseaux
Il est souvent nécessaire de découper une plage d'adresses en plusieurs sous-réseaux. Pour cela, il vaut souvent mieux envisager le découpage des réseaux dans son ensemble plutôt que de les faire chacun séparément et de se rendre compte à la fin qu'ils sont incompatibles... Ainsi nous allons encore partir du nombre de machines dans chacun des réseaux. Prenons l'exemple précédent du réseau 193.225.34.0/255.255.255.0. On désire comme précédemment faire un sous-réseau de 60 machines, mais

aussi un réseaux de 44 machines et un dernier de 20 machines. De la même façon que nous l'avons vu précédemment, pour 44 machines, il faudra réserver 64 adresses, soit un masque 255.255.255.192. Pour 20 machines, il faudra réserver 32 adresses, soit un masque 255.255.255.224.
7.2 - Détermination des plages réseau
Nous allons donc devoir placer trois plages de 128, 64 et 32 adresses dans une plage de 256 adresses, cela ne devrait pas poser de problème.
On commence par la plage la plus grande de 128 adresses. Si on commençait par la plus petite et qu'on la plaçait n'importe où, cela pourrait poser problème. Imaginons que l'on place la plage de 32 adresses de 0 à 31, et celle de 64 adresses de 128 à 192, il ne nous resterai plus de place pour la plage de 128 adresses !!! On a donc deux choix pour cette plage de 128 adresses, soit les adresses de 0 à 127, soit de 128 à 255. A priori, les deux choix sont possibles et non déterminants. On choisit de 0 à 127. Ainsi, notre sous-réseau sera caractérisé par 193.225.34.0/255.255.255.128.
Pour la seconde plage de 64 adresses, il nous reste deux plages d'adresses possibles, de 128 à 191, et de 192 à 255. Là encore le choix n'est pas déterminant. On choisit de 128 à 191. Ainsi, notre sous-réseau sera caractérisé par 193.225.34.128/255.255.255.192 (ici, la première adresse de notre plage (l adresse du réseau)est celle en 128 et le dernier octet du masque en 192 nous indique que ce sous-réseau contient 64 adresses)
Enfin, pour la dernière plage de 32 adresses, il nous reste encore deux possibilités de 192 à 223 ou de 224 à 255. On choisit de 192 à 223. Ainsi, notre sous-réseau sera caractérisé par 193.225.34.192/255.255.255.224
7.3 - Le résultat
Nous avons donc découpé notre réseau d'origine 193.225.34.0/255.255.255.0 en trois sous-réseaux
193.225.34.0/255.255.255.128
193.225.34.128/255.255.255.192 193.225.34.192/255.255.255.224 Il nous reste même une plage de 32 adresses non utilisées de 224 à 255.
8 - Que sont les classes d'adresses A, B, C, D... ?
8.1 - Historique
Comme nous l'avons vu dans le paragraphe 2, le masque de sous-réseau permet de segmenter l'ensemble des adresses de l'Internet en différents réseaux. Mais cette segmentation ne s'est pas faite n'importe comment ! On a découpé la plage d'adresses disponible en cinq parties distinctes. Les classes A, B, C, D et E, que l'on appelle aussi adresses globales.
8.2 - Définition
Classe A: Premier bit de l'adresse à 0, et masque de sous-réseau en 255.0.0.0. Ce qui donne la plage d'adresse 0.0.0.0 à 126.255.255.255 soit 16 777 214 adresses par réseau de classe A Classe B: Deux premiers bits de l'adresse à 10 (1 et 0), et masque de sous-réseau en 255.255.0.0. Ce qui donne
la plage d'adresse 128.0.0.0 à 191.255.255.255 soit 65 534 adresses par réseau de classe B Classe C: Trois premiers bits de l'adresse à 110, et masque de sous-réseau en 255.255.255.0. Ce qui donne la
plage d'adresse 192.0.0.0 à 223.255.255.255 soit 255 adresses par réseau de classe C Classe D: Quatre premiers bits de l'adresse à 1110, et masque de sous-réseau en 255.255.255.240. Ce qui donne la plage d'adresse 224.0.0.0 à 239.255.255.255 soit 255 adresses par réseau de classe D Classe E: Quatre premiers bits de l'adresse à 1111, et masque de sous-réseau en 255.255.255.240. Ce qui donne
la plage d'adresse 240.0.0.0 à 255.255.255.255 Les classes A, B et C, sont réservées pour les utilisateurs d'Internet (entreprises, administrations, fournisseurs d'accès, etc) La classe D est réservée pour les flux multicast et la classe E n'est pas utilisée aujourd'hui (du moins, je n'en ai pas connaissance...) Ainsi, une entreprise demandant 80 000 adresses se voyait attribuer un réseau de classe A, et gâchait par la
même occasion (16 777 214 - 80 000=) 16 697 214 adresses !!! Inutile alors de vous montrer combien d'adresses étaient perdues de la sorte...

8.3 - Y a-t-il une pénurie d'adresses IPv4 ?
La réponse est non.
Il n'y a pas aujourd'hui de pénurie d'adresses IP. Cependant, il est certain qu'étant donné le développement rapide d'Internet, on va vite arriver à une situation critique. C'est aussi pour cela qu'une nouvelle version d'IP a été créée et sera bientôt déployée.
8.4 - Le système d'adressage par classes est-il viable ?
La réponse est encore non, et a déjà été depuis bien longtemps étudié et transformé. Nous avons vu qu'en se basant sur ce système de classes, nous risquons de gâcher un très grand nombre d'adresses. Les classes d'adresses globales se sont donc rapidement avérées obsolètes et on a du créer un nouveau modèle, l'adressage CIDR
8.5 - Qu'est-ce que l'adressage CIDR ?
Etant donné que l'adressage par classes s'est avéré incompatible avec l'évolution d'Internet, il a fallu imaginer un nouveau modèle qui simplifie à la fois le routage et permette un adressage plus fin. Pour cela, on a créé
l'adressage CIDR (Classless Inter-Domain Routing). Cet adressage ne tient pas compte des classes globales et autorise l'utilisation de sous-réseaux au sein de toutes les classes d'adresses. Ainsi, une entreprise désirant 80 000 adresses ne se verra plus attribuer une classe A complète, mais un sous-réseau de cette classe A. Par exemple, on lui fournira non plus 16 millions d'adresses, mais 130 000 (la puissance de deux supérieure à 80 000) Ainsi les 16 millions d'adresses restantes pourront être utilisées pour d'autres entités. L'adressage CIDR ne tient donc plus du tout compte des masques associés aux classes d'adresses globales. On
s'affranchit ainsi du découpage arbitraire et peu flexible en classes. On peut très bien trouver un réseau de classe B avec un masque de classe C, par exemple 164.23.0.0/255.255.255.0.
9 - Trucs et astuces avec les masques
9.1 - Comment déterminer qu'une machine appartient à mon réseau ?
C'est très simple. pour cela, il va falloir déterminer si l'adresse de la machine appartient à la plage d'adresses
définie par mon adresse et mon masque. Pour cela, je fais un ET logique entre mon adresse et mon masque réseau, j'en déduis donc l'adresse de mon réseau (pour une explication du ET logique, regarder le paragraphe 10.4) Je fais pareil avec l'adresse de l'autre machine et MON masque réseau, et j'obtiens une adresse de réseau. Si les deux adresses de réseau sont les mêmes, ça veut dire que la machine appartient bien au même réseau.
Disons par exemple que ma machine ait pour adresse 192.168.0.140/255.255.255.128 et je veux savoir si les machines A et B ayant pour adresses 192.168.0.20(A) et 192.168.0.185(B) sont sur le même réseau ? Je fais 192.168.0.140 ET 255.255.255.128 -------------------
= 192.168.0.128 de même avec les deux autres adresses Pour A 192.168.0.20 ET 255.255.255.128
-------------------
= 192.168.0.0 et pour B 192.168.0.185 ET 255.255.255.128
------------------- = 192.168.0.128 On voit ainsi que les nombres obtenus sont les mêmes pour ma machine et B. On en déduit donc que B est sur le même réseau, et que A est sur un réseau différent.
9.2 - Des machines sur un même réseau peuvent-elles avoir des masques différents ?
A priori, la réponse est non. Cependant, il peut y avoir des cas dans lesquels une telle configuration peut être
utile.

Pour comprendre cela, il faut comprendre ce qui se passe au niveau de la communication entre machines, et notamment sur le fonctionnement du modèle TCP/IP. Celui-ci ne faisant pas partie de l'objet du cours, nous ne ferons que survoler le sujet. En fait, ce ne sont pas les mêmes mécanismes qui gèrent une communication entre deux machines sur un même
réseau, et deux machines sur deux réseaux distincts. Une communication a lieu dans les deux sens, c'est à dire que pour communiquer ensemble, une machine A doit voir une machine B _ET_ la machine B doit voir la machine
A. Prenons l'exemple de trois machines A, B et C et de la plage d'adresses 192.168.0.0/24. A doit pouvoir communiquer avec B et C, mais B ne doit pas pouvoir communiquer avec C. Pour cela, on peut jouer sur les masques des machines et les plages d'adresses réseau auxquelles elles appartiennent. Grâce aux masques, on peut découper cette plage en deux, et on obtient ainsi, non plus une plage d'adresses...
mais trois ! La 1ere: 192.168.0.0/255.255.255.0 soit de 192.168.0.0 à 192.168.0.255 La 2ieme: 192.168.0.0/255.255.255.128 soit de 192.168.0.0 à 192.168.0.127 La 3ieme: 192.168.0.128/255.255.255.128 soit de 192.168.0.128 à 192.168.0.255
En fait, la première plage englobe les deux autres, ainsi, une machine de la première plage pourra voir toutes les autres machines des autres plages, mais une machine de la seconde plage ne pourra pas voir toutes les machines de la première plage (seulement la moitié des adresses...) Ce n'est pas clair ? regardons alors un exemple:
On donne les adresses suivantes aux machines A, B et C. A: 192.168.0.129/255.255.255.0 Plage 1
B: 192.168.0.130/255.255.255.128 Plage 2
C: 192.168.0.1/255.255.255.0 Plage 1 D'après ce que l'on a vu précédemment, la plage 2 sera englobée dans la plage 1, et donc A et C considèreront que la machine B est sur leur réseau. A ayant une adresse dans la même plage que B (plage 2), B verra A comme étant aussi dans son réseau. Par contre, B ne considèrera pas que C est dans réseau car l'adresse de C n'appartient pas à la plage 2. Ainsi, C peut envoyer un paquet à B (C voit bien B comme étant dans son réseau) mais B ne pourra pas lui répondre. Cette configuration correspond donc bien à ce que l'on cherchait à faire.
Cependant, une telle configuration n'est pas conseillée et ne doit être utilisée que s'il n'y a pas d'autres solutions. En dehors de cas exotiques comme celui exposé, on ne doit jamais avoir deux machines appartenant à un même réseau ayant des masques différents !
9.3 - Puis-je utiliser un outil qui calcule pour moi ?
Non !!! Enfin si, mais bon, vous me décevriez beaucoup ;-) Car après ce que nous avons vu, vous devriez être capable de calculer n'importe quel masque correct aussi vite qu'une machine. Et il est toujours mieux de bien
maîtriser ce qu'on utilise. À force d'utiliser des automates, on perd les notions de ce que l'on manipule. D'autre part, un logiciel ne corrigera pas vos erreurs ! La plupart des logiciels de calcul de masque ne font qu'un calcul bête et méchant qui peut s'avérer faux. Prenons l'exemple du 6.3, ou l'on veut une plage commençant en 192.168.0.32, et une centaine de machines. Un mauvais logiciel vous sortira le réseau 192.168.0.32/255.255.255.128, et hop, ça marchera pas...
9.4 - Tout ça c'est bien, mais quand est ce que je l'utilise ce masque moi ?
Effectivement, quand vous allez sur Internet, vous utilisez un masque sans le savoir. Sous Windows, que vous soyez connecté à un réseau local, ou directement par un modem, vous pourrez voir les propriétés de vos interfaces réseau en allant dans une fenêtre DOS et en entrant la commande "ipconfig /all" Vous pouvez aussi modifier ces propriétés en allant dans les propriétés de votre carte réseau, puis propriétés TCP/IP, et là, vous devriez voir votre adresse IP, ainsi que le masque associé, et votre passerelle par défaut. Vous pouvez modifier ces informations, mais votre réseau risque de ne plus fonctionner (et en plus il faudra rebooter sous 98..) donc attention !!
Le masque définit donc les machines (ou plus précisément, les interfaces) appartenant à un même réseau. Pour dialoguer avec ces machines, vous utiliserez un des mécanismes de couche 2 du modèle OSI, alors que pour dialoguer avec les machines d'un autre réseau, vous aurez besoin d'utiliser des mécanismes de couche 3 qui permettent notamment de faire du routage... Il est donc primordial de ne pas se tromper dans le choix du masque.
Mais ça, ça ne fait pas partie intégrante du sujet ;-)

10 - Mini lexique
10.1 - Adresse IP
L'adresse IP est un numéro codé sur 4 octets permettant d'identifier une machine de façon unique sur le réseau.
10.2 - Réseau logique
On appelle réseau logique un ensemble d'adresses IP appartenant à une même plage d'adresses. Cette plage est notamment définie par l'adresse de réseau et le masque associé.
10.3 - sous-réseau
On définit un sous-réseau comme un sous-ensemble d'une plage d'adresses réseau. C'est grâce au masque que l'on peut définir un sous-réseau au sein d'un réseau, et ainsi découper un réseau en plusieurs sous-réseaux.
10.4 - Le ET logique
La fonction de ET logiques est souvent utilisée dans les masques. Elle se base en binaire sur le principe suivant:
0 ET 0 = 0 1 ET 0 = 0 0 ET 1 = 0 1 ET 1 = 1 On peut donc en déduire au niveau des masques 192.168.0.140 ET 255.255.255.128 décomposé en:
11000000.10101000.00000000.10001100 ET 11111111.11111111.11111111.10000000 ------------------------------------------------ = 11000000.10101000.00000000.10000000 soit 192 . 168 . 0 . 128
Ici, on voit que les trois premiers octets du masque ont tous leurs bits à 1, donc les trois premiers octets du résultat ne seront pas modifiés par rapport à l'adresse d'origine, et on obtient facilement 192.168.0. Pour le dernier octet, il faut regarder plus en détail.
11 - Annexes
11.1 - Ressources utilisées
Je n'ai pas utilisé beaucoup de documents aussi bien en ligne que sur papier. Les réponses et connaissances apportées proviennent en majeure partie des informations que j'ai pu glaner en furetant sur le net, et notamment sur les newgroups fr.comp.reseaux.ip et fr.comp.reseaux.ethernet. Je me suis quand même inspiré de quelques documents:
Les RFCs 943 (remplacé en 1992 par la Rfc 1340), 1517, 1518, 1519, 1878. Le site http://www.captage.com/tajan/articles/ip.htm
Et l'excellente faq sur les firewalls de Stéphane Catteau dont je me suis inspiré pour la mise en forme. Disponible sur: http://fr.comp.securite.free.fr/firewall.txt N'hésitez pas à la consulter, on y apprend plein de choses.
11.2 - Remerciements
Je remercie notamment les personnes suivantes pour leur lecture assidue du cours durant sa réalisation et leurs
conseils précieux. Jad Chantiri, Pierrick Vodoz, Laurent de Soras, Stéphane Catteau, Cédric Blancher, Ohmforce, Franck Bacquet, Olivier Lamer, Diane Guinnepain, JC, Alain Winestel, thierry Bellemare, Alex A, Hubert Quarantel-Colombani, Tony.
12 - Conclusion
J'ai fait de mon mieux pour rendre la notion de masques la plus abordable possible et traiter le sujet de la meilleure façon. Je me rends compte que ce cours est assez fourni en information et pas toujours facile à digérer. Vos remarques sont donc encore et toujours les bienvenues, aussi bien pour y ajouter des idées, que pour enlever le superflu.

Maintenant, si je revois passer des questions sur les masques, j'aurai au minimum un droit de flagellation sur les personnes incriminées ;-)
IP sur BlueTooth
1 - Introduction 1.1 - Historique 1.2 - Présentation de bluetooth 2 - Présentation de Bluetooth du point de vue technique
2.1 - Bluetooth Radio et Baseband / Link Controller 2.1.1 - Liaison à connexion synchrone orientée (SCO) 2.1.2 - Liaison à connexion asynchrone (ACL) 2.2 - L2CAP 2.3 - SDP (Service discovery Protocol) 2.3.1 - Mode de détection
2.3.2 - Stockage des informations 2.3.3 - Contrôle des erreurs 3 - GAP profile 4 - Bluetooth IP 4.1 - RFCOMM 4.2 - Utilisation de BNEP 4.3 - Poste mobile esclave
4.4 - Poste mobile maître 4.5 - Adaptation de la couche IP pour périphériques mobiles 4.6 - Adaptation de la couche IP pour la station de base 5 - Références 6 - Discussion autour de la documentation 7 - Suivi du document
1 - Introduction
1.1 - Historique
Février 1998 : Création du Bluetooth SIG, les principaux constructeurs présents dans ce groupe sont Ericsson, IBM, Intel, Nokia, Toshiba
Mai 1998 : Annonce publique du Bluetooth SIG
Juillet 1999 : Le groupe Bluetooth SIG publie la spécification 1.0A
Décembre 1999 : Sortie de la version 1.0B
Décembre 1999 : Le groupe Bluetooth SIG compte maintenant 9 société après que 3COM, Lucent, Microsoft, Motorola les ai rejoint.
En 2004 : Le groupe Bluetooth SIG compte maintenant plus de 2000 sociétés.
1.2 - Présentation de bluetooth
Présentation du domaine d'application de Bluetooth en informatique :

Bluetooth voit aussi son application pour la télévision et également dans d'autres domaines où les câbles sont très utilisés. La suite de ce document sera surtout axé sur l'utilisation de Bluetooth dans l'informatique.
Buts et caractéristiques de cette technologie :
Il s'agit d'une technologie destinée à remplacer les câbles.
Dans sa version 1 le débit ne dépasse pas 1Mb/s (La version 2 fonctionnera à 10Mb/s).
La portée est de l'ordre de 10m dans la version 1 (Le version 2 prévoie des distances de 100m).
Pourquoi ne pas utiliser Wi-fi étant données les performances de Bluetooth : Bluetooth offre l'avantage de la
consommation, en effet la connexion sans fil est surtout utilisée pour les appareils mobiles, et donc n'étant pas
reliés directement au secteur. Bluetooth est à plus faible consommation que Wi-fi. Le second avantage de cette technologie est le prix. La création de Bluetooth SIG ( ) en 1998 regroupait les plus grands constructeurs Ericsson, IBM, Intel, Nokia, Toshiba. En 2004 on peut compter plus de 2000 sociétés qui participent au Bluetooth SIG. Au lancement, le pari de cette technologie était de réussir à produire des puce Bluetooth à moins de 5$.
2 - Présentation de Bluetooth du point de vue technique
Représentation des couches Bluetooth :

Dans cette partie, je vais expliquer les différentes couches qui composent Bluetooth.
2.1 - Bluetooth Radio et Baseband / Link Controller
La couche Bluetooth radio est une couche totalement matérielles. L'avantage de Bluetooth en terme radio par rapport aux autres technologies est l'adaptation qu'il peut réaliser en effectuant des sauts de fréquences 1600 fois par seconde. La bande Bluetooth s'étend de 2.402 GHz à 2.480GHz. Cela représente 79 canaux d'une largeur de
1MHz. En France il est possible d'utiliser uniquement 23 canaux. Ces sauts de fréquences permettent de limiter les collisions. Un réseau Bluetooth est composé d'un Maître et de plusieurs esclaves. Un maître peut avoir jusqu'a 7 esclaves. Pour permettre la création de grands réseaux, un maître peut être esclave d'un autre réseau. Dans la norme Bluetooth un maître et ses esclaves sont appelés piconet. Représentation des piconets :

Les éléments Bluetooth d'un même piconet utilisent le même canal. Pour permettre la discussion de tous les éléments du piconet, il y a une répartition en time slots de 625 micro secondes. Chronogramme d'une discussion entre éléments Bluetooth :
2.1.1 - Liaison à connexion synchrone orientée (SCO)
Ce type de liaison est utilisé pour la transmission de voix, puisqu'il y a besoin de "temps réel" pour ce type d'application. Bluetooth utilise dans ce cas des créneaux réservés afin de réduire au maximum le délai. Si l'on est en fonctionnement mode "Point To Point", la transmission sera Bidirectionnelle. Ce type de connexion fonctionnant en mode "Temps réel" il n'y a pas de retransmission possible. Il est possible d'atteindre 64Kb/s afin de respecter la norme de codage, sachant qu'un maître peut gérer jusqu'à 3 liens de ce type.
2.1.2 - Liaison à connexion asynchrone (ACL)
Ce type de connexion a été conçu pour échanger des données. Avec ce type de connexion il est possible
d'effectuer un broadcast. Les débits de ce type de connexion sont de 723.2 Kbps en sortie avec un entrant à
57.6 Kb/s. En mode symétrique on peut aller jusqu'à 433.9Kb/s.
2.2 - L2CAP
Le couche L2CAP a pour rôle de transformer les données en paquets pour la couche Baseband. Son rôle est également la gestion des connexions logiques entre plusieurs éléments Bluetooth. Encapsulation à partir de L2CAP :
2.3 - SDP (Service discovery Protocol)
SDP est la couche chargée de la découverte d'éléments Bluetooth. Son rôle est la détection et l'intégration de nouveaux éléments Bluetooth dans le réseau.
2.3.1 - Mode de détection
Schéma de l'architecture.

Pour faciliter la découverte d'éléments Bluetooth, les opérations de découvertes sont faites entre serveurs de clients. Un élément Bluetooth peut être à la fois client et serveur. Un client va donc contacter un serveur Bluetooth et ce serveur Bluetooth va lui envoyer la liste des éléments Bluetooth qu'il connaît avec les services découverts.
2.3.2 - Stockage des informations
2.3.3 - Contrôle des erreurs
Au niveau du contrôle d'erreurs il en existe de deux types sur bluetooth.
3 - GAP profile
Tout périphérique Bluetooth est obligatoirement placé dans un profil. Les profiles ont été mis en place pour faciliter les connexions et l'interopérabilité entre les matériels. Un profil va définir les couches qui vont être utilisées (RFCOMM, BNEP, TCS,...) Il existe 13 profiles, GAP (Generic Access Profile) qui permet de détecter des produits Bluetooth, et le SDAP (Service
Discovery Access Profile ) qui a pour but de connaître les services disponibles dans les produits qui ont été détectés par le GAP. Citons les autres rapidement :
Cordless Telephony Profile
Intercom Profil
Serial Port Profile
Headset Profile
Dial-up Networking Profile
Fax Profile
LAN Access Profile
Generic Object Exchange Profile (GOEP)
Object Push Profile
File Transfer Profile
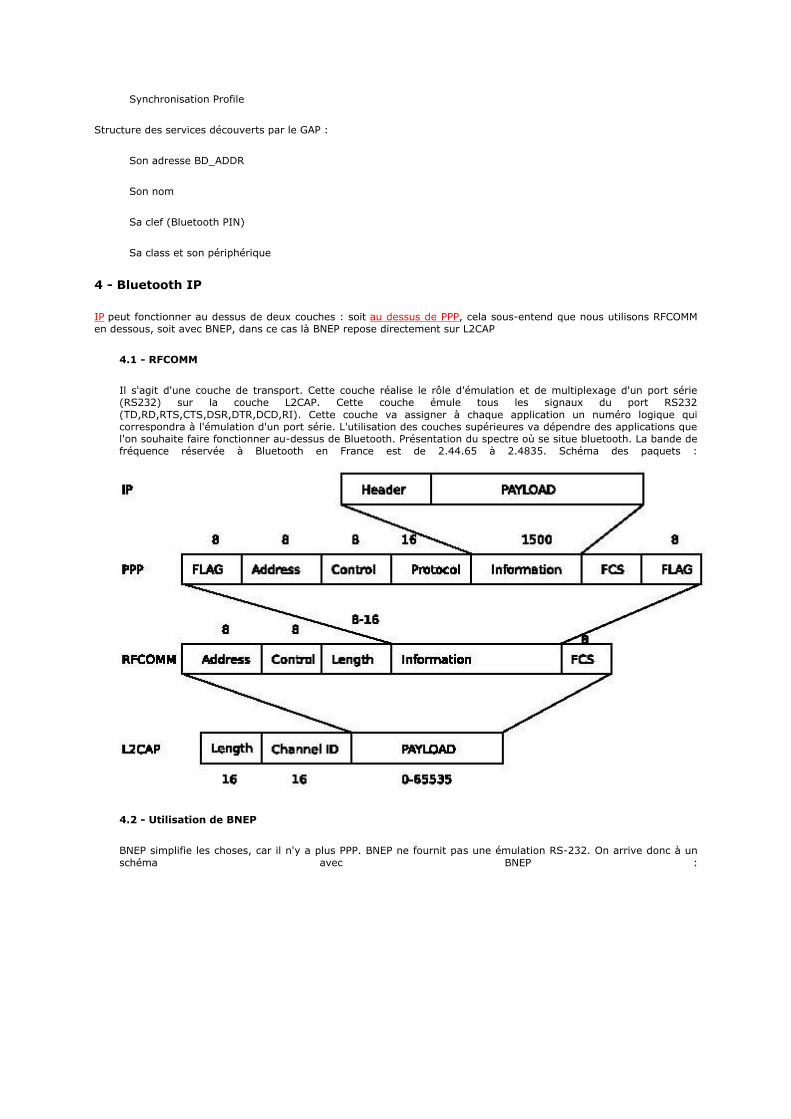
Synchronisation Profile
Structure des services découverts par le GAP :
Son adresse BD_ADDR
Son nom
Sa clef (Bluetooth PIN)
Sa class et son périphérique
4 - Bluetooth IP
IP peut fonctionner au dessus de deux couches : soit au dessus de PPP, cela sous-entend que nous utilisons RFCOMM en dessous, soit avec BNEP, dans ce cas là BNEP repose directement sur L2CAP
4.1 - RFCOMM
Il s'agit d'une couche de transport. Cette couche réalise le rôle d'émulation et de multiplexage d'un port série (RS232) sur la couche L2CAP. Cette couche émule tous les signaux du port RS232
(TD,RD,RTS,CTS,DSR,DTR,DCD,RI). Cette couche va assigner à chaque application un numéro logique qui correspondra à l'émulation d'un port série. L'utilisation des couches supérieures va dépendre des applications que l'on souhaite faire fonctionner au-dessus de Bluetooth. Présentation du spectre où se situe bluetooth. La bande de fréquence réservée à Bluetooth en France est de 2.44.65 à 2.4835. Schéma des paquets :
4.2 - Utilisation de BNEP
BNEP simplifie les choses, car il n'y a plus PPP. BNEP ne fournit pas une émulation RS-232. On arrive donc à un
schéma avec BNEP :
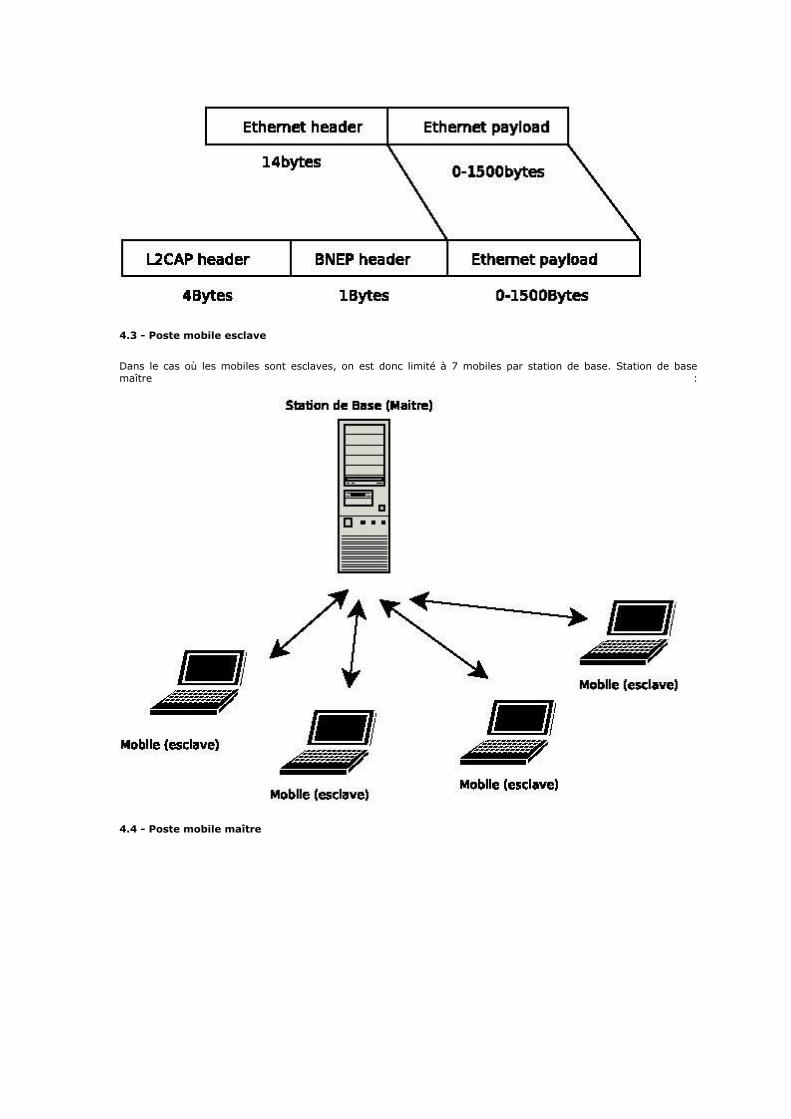
4.3 - Poste mobile esclave
Dans le cas où les mobiles sont esclaves, on est donc limité à 7 mobiles par station de base. Station de base maître :
4.4 - Poste mobile maître

Dans ce cas précis, la station de base est esclave d'autant de Mobile. Station de base esclave :
4.5 - Adaptation de la couche IP pour périphériques mobiles
La couche IP a trois états possibles :
Discovery : Le périphérique est dans cet état au démarrage. C'est dans cette étape qu'il va chercher les stations de base les plus proches dont il a généralement aucune information. Il y a une procédure permettant d'obtenir uniquement les stations de base. Cette procédure va être répétée tant qu'une station
de base n'a pas été trouvée. Une procédure de connexion est déclenchée pour passer dans l'état Configuration.
Configuration : La station de base va donner un état de maître ou esclave au mobile. Le mobile va ensuite établir une connexion bidirectionnelle L2CAP sur la connexion existante. C'est à cette étape que la MTU des datagrammes de la couche L2CAP est négociée. La station de base va envoyer un datagramme contenant la MTU maximum qu'il peut accepter. Le mobile va ensuite confirmer la valeur en la renvoyant. A ce moment là si il n'y a pas eu d'erreur, on passe en phase Connected.
Connected : Une fois arrivé dans cette étape pour la première fois, il faut affecter une IP au mobile. Pour cela DHCP peut être utilisé, ou alors, si Mobile IP est activé il n'y aura pas de configuration à modifier sur le
Mobile.
Etats de Bluetooth IP pour l'éléments mobile :

Il faut aussi gérer la perte de lien. Pour détecter cela, la spécification Bluetooth propose "Link supervision timer". Ce compteur est fixé à une certaine valeur et est remis à sa valeur initiale à chaque réception de paquet. Si aucun
paquet n'est arrivé avant l'arrivée à 0 de ce timer, une alerte est déclenchée. Cette valeur est fixée par défaut à 20 minutes, il faut choisir une bonne valeur pour ce timer car une trop faible valeur peut provoquer beaucoup d'erreurs, et donc une perte de temps en reconnexion. Une valeur trop grande va laisser trop de Mobiles connectés alors qu'ils ne sont plus dans la zone, ou autre.
4.6 - Adaptation de la couche IP pour la station de base
La couche pour la station de base est plus simple que pour le Mobile (figure suivante). De ce côté on retrouve
uniquement deux états. Son but principal est de maintenir la connexion. Cette couche a aussi pour but de découvrir de nouveaux éléments Bluetooth
Configuration : Cet état a pour but de configurer et d'établir la connexion. Durant cette phase, la station de base est maître et le nouvel élément est esclave. A la fin de cet état, suivant la configuration décidée, la station de base peut passer esclave. Durant cette phase de configuration, le canal L2CAP est créé et configuré. La configuration du canal est initiée par la station de base. Comme expliqué précédemment, la station de base va donner sa MTU. La station de base passera ensuite dans l'état connecté après
confirmation de cette MTU.
Connected : On retrouve une base de correspondance entre le numéro de canal au niveau de L2CAP avec l'IP associé.

Etats de Bluetooth IP pour la station de base :
5 - Références
STMicroelectronics, Technical Note Bluetooth Tutorial[en ligne], 2001. Disponible sur : <http ://www.st.com/stonline/prodpres/dedicate/bluetoot/document/tutorial.pdf> (consulté le 24.04.2004).
Simon Baatz, Matthias Frank, Rolf Göpffarth et al , Handoff Support for Mobility with IP Bluetooth[en ligne], 2000. Disponible sur : <http ://web.informatik.uni-bonn.de/IV/Mitarbeiter/baatz/LCN2000_rp.pdf> (consulté le 24.04.2004).
ATMEL Corporation, The Bluetooth Wireless Technology White Paper, 2000. Disponible sur : <http
://www.atmel.com/dyn/resources/prod_documents/DOC1991.PDF>(consulté le 24.04.2004).
David Kammer, Gordon McNutt, Brian Senese, Bluetooth Application Developer's Guide. Syngress Media, Janvier 2002. 520 Pages. ISBN 1928994423.
Michael Miller, Discovering Bluetooth. Sybex, Juillet 2001. 304 Pages. ISBN : 0-7821-2972-2.
Les services
Dhcp
1 - Définition 2 - Références

3 - Fonctionnement 4 - Les baux 5 - Dynamique ou pas ? 6 - Les requêtes et les messages DHCP 7 - Les messages DHCP
7.1 - Dialogue avec le serveur 7.2 - Format de la trame BOOTP/DHCP
7.3 - Passage d'options 8 - Le serveur Dhcp 8.1 - Où trouver un serveur DHCP ? 8.2 - Compilation du serveur 8.3 - Le fichier dhcpd.conf 8.3.1 - Les paramètres globaux 8.3.2 - shared-network
8.3.3 - subnet 8.3.4 - host 8.3.5 - group 8.3.6 - Les options 8.3.7 - Exemple de fichier dhcpd.conf 8.4 - Lancer le démon dhcpd 8.5 - Exécuter le démon à chaque démarrage (pour Linux)
8.6 - Documentation 9 - Configuration des clients 9.1 - Tout pour contrôler, réparer etc 9.2 - Windows 95/98 9.2.1 - Configuration 9.2.2 - Vérification
9.3 - Windows NT4/2000/XP 9.3.1 - Configuration 9.3.2 - Vérification 9.4 - Linux
9.4.1 - Configuration 9.4.2 - Vérifiez l'état de votre connexion 9.4.3 - Particularités du client DHClient
10 - Savoir "Sniffer" 10.1 - En-têtes de trames 10.2 - Détail des trames 10.2.1 - Le DHCP Discover 10.2.2 - Un petit ping... 10.2.3 - Offre d'un nouveau bail 10.2.4 - Demande du Bail de la part du client
10.2.5 - Le serveur est d'accord 10.3 - Notes supplémentaires 10.3.1 - Duplication d'adresse 10.3.2 - Pas de réponse 10.4 - Renouvellement d'un bail en cours de validité 10.4.1 - Quand ça se passe bien...
10.4.2 - Et quand ça se passe mal 11 - Discussion autour de la documentation 12 - Suivi du document
1 - Définition
DHCP signifie Dynamic Host Configuration Protocol. Il s'agit d'un protocole qui permet à un ordinateur qui se connecte
sur un réseau local d'obtenir dynamiquement et automatiquement sa configuration IP. Le but principal étant la simplification de l'administration d'un réseau. On voit généralement le protocole DHCP comme distribuant des adresses
IP, mais il a été conçu au départ comme complément au protocole BOOTP (Bootstrap Protocol) qui est utilisé par exemple lorsque l'on installe une machine à travers un réseau (on peut effectivement installer complètement un ordinateur, et c'est beaucoup plus rapide que de le faire en à la main). Cette dernière possibilité est très intéressante pour la maintenance de gros parcs machines. Les versions actuelles des serveurs DHCP fonctionne pour IPv4 (adresses IP sur 4 octets). Une spécification pour IPv6 (adresses IP sur 16 octets) est en cours de développement par l'IETF.
2 - Références
Les incontournables RFCs : - RFC951 : Bootp - RFC1497 : Options vendor extensions
- RFC1541 : Définition du protocole Dhcp - RFC1542 : Interaction entre Bootp et Dhcp - RFC2131 : Complément à la Rfc 1541 - RFC2132 : Complément aux options vendor extensions Spécifications et API Java : dhcp.org

Le site de l'ISC : http://www.isc.org Le site de Microsoft : BOOTP, DHCP, DNS servers (en anglais)
3 - Fonctionnement
DHCP fonctionne sur le modèle client-serveur : un serveur, qui détient la politique d'attribution des configurations IP, envoie une configuration donnée pour une durée donnée à un client donné (typiquement, une machine qui vient de démarrer). Le serveur va servir de base pour toutes les requêtes DHCP (il les reçoit et y répond), aussi doit-il avoir une
configuration IP fixe. Dans un réseau, on peut donc n'avoir qu'une seule machine avec adresse IP fixe : le serveur DHCP. Le protocole DHCP s'appuie entièrement sur BOOTP : il en reprend le mécanisme de base (ordre des requêtes, mais aussi le format des messages). DHCP est une extension de BOOTP. Quand une machine vient de démarrer, elle n'a pas de configuration réseau (même pas de configuration par défaut), et pourtant, elle doit arriver à émettre un message sur le réseau pour qu'on lui donne une vraie configuration. La
technique utilisée est le broadcast : pour trouver et dialoguer avec un serveur DHCP, la machine va simplement émettre un paquet spécial, dit de broadcast, sur l'adresse IP 255.255.255.255 et sur le réseau local. Ce paquet particulier va être reçu par toutes les machines connectées au réseau (particularité du broadcast). Lorsque le serveur DHCP reçoit ce paquet, il répond par un autre paquet de broadcast contenant toutes les informations requises pour la configuration. Si le client accepte la configuration, il renvoit un paquet pour informer le serveur qu'il garde les paramètres, sinon, il fait une nouvelle demande.
Les choses se passent de la même façon si le client a déjà une adresse IP (négociation et validation de la configuration), sauf que le dialogue ne s'établit plus avec du broadcast.
4 - Les baux
Pour des raisons d'optimisation des ressources réseau, les adresses IP sont délivrées pour une durée limitée. C'est ce qu'on appelle un bail (lease en anglais). Un client qui voit son bail arriver à terme peut demander au serveur un
renouvellement du bail. De même, lorsque le serveur verra un bail arrivé à terme, il émettra un paquet pour demander
au client s'il veut prolonger son bail. Si le serveur ne reçoit pas de réponse valide, il rend disponible l'adresse IP. C'est toute la subtilité du DHCP : on peut optimiser l'attribution des adresses IP en jouant sur la durée des baux. Le problème est là : si toutes les adresses sont allouées et si aucune n'est libérée au bout d'un certain temps, plus aucune requête ne pourra être satisfaite. Sur un réseau où beaucoup d'ordinateurs se connectent et se déconnectent souvent (réseau d'école ou de locaux
commerciaux par exemple), il est intéressant de proposer des baux de courte durée. A l'inverse, sur un réseau constitué en majorité de machines fixes, très peu souvent rebootées, des baux de longues durées suffisent. N'oubliez pas que le DHCP marche principalement par broadcast, et que cela peut bloquer de la bande passante sur des petits réseaux fortement sollicités.
5 - Dynamique ou pas ?
Un serveur DHCP est censé fournir des adresses dynamiques (un même ordinateur peut recevoir successivement 2 adresses différentes), mais il peut fournir une adresse IP fixe à un client bien particulier. Ceci ne doit être utilisé que de manière modérée, sinon, le serveur DHCP ne sert à peu près plus à rien, mais cela peut se révéler utile pour fournir l'adresse IP au serveur TFTP qui va servir pour le boot à distance des machines.
6 - Les requêtes et les messages DHCP
On pourrait croire qu'un seul aller-retour peut suffire à la bonne marche du protocole. En fait, il existe plusieurs messages DHCP qui permettent de compléter une configuration, la renouveler... Ces messages sont susceptibles d'être émis soit par le client pour le ou les serveurs, soit par le serveur vers un client :

La valeur entre parenthèses est utilisées pour identifier ces requêtes dans les messages DHCP. Voir les options DHCP.
La première requête émise par le client est un message DHCPDISCOVER. Le serveur répond par un DHCPOFFER, en particulier pour soumettre une adresse IP au client. Le client établit sa configuration, demande éventuellement d'autres
paramètres, puis fait un DHCPREQUEST pour valider son adresse IP. Le serveur répond simplement par un DHCPACK avec l'adresse IP pour confirmation de l'attribution. Normalement, c'est suffisant pour qu'un client obtienne une configuration réseau efficace, mais cela peut être plus ou moins long selon que le client accepte ou non l'adresse IP ou demande des infos complémentaires...
Pour demander une nouvelle adresse, le chronogramme-type est le suivant :

Pour renouveler une adresse, le fonctionnement est le suivant (les 2 serveurs connaissent le client) :

7 - Les messages DHCP
7.1 - Dialogue avec le serveur
Les messages DHCP sont transmises via UDP. Bien que peu fiable, ce protocole suffit au transport des paquets simples sur réseau local, et surtout il est très léger, donc intéressant pour les petits systèmes (du genre le micro bout de programme qui fait la requête DHCP lorsque le PC se met en route). De facto, DHCP fonctionne aussi en
mode non connecté. Le client n'utilise que le port 68 pour envoyer et recevoir ses messages de la même façon, le serveur envoie et reçoit ses messages sur un seul port, le port 67.
7.2 - Format de la trame BOOTP/DHCP
La trame DHCP est en fait la même que BOOTP, et a le format suivant (les chiffres entre parenthèses indique la taille du champ en octets) :
- op : vaut 1 pour BOOTREQUEST (requête client), 2 pour BOOTREPLY (réponse serveur)

- htype : type de l'adresse hardware (adresse MAC, par exemple. Voir Rfc 1340) - hlen : longueur de l'adresse hardware (en octet). C'est 6 pour une adresse MAC - hops : peut être utilisé par des relais DHCP - xid : nombre aléatoire choisi par le client et qui est utilisé pour reconnaître le client - secs : le temps écoulé (en secondes) depuis que le client a commencé sa requête
- flags : flags divers - ciaddr : adresse IP du client, lorsqu'il en a déjà une
- yiaddr : la (future ?) adresse IP du client - siaddr : adresse IP du (prochain) serveur à utiliser - giaddr : adresse IP du relais (passerelle par exemple) lorsque la connexion directe client/serveur n'est pas possible - chaddr : adresse hardware du client - sname : champ optionnel. Nom du serveur - ile : nom du fichier à utiliser pour le boot
- options : Champs réservé pour les options (voir Rfc 2132). Dans une précédente RFC, la taille de ce champ était limitée (limité à 64 octets par exemple pour la première version de Bootp) ; maintenant, il n'y a plus de limitation. Dans tous les cas, un client DHCP doit être prêt à recevoir au minimum 576 octets, mais la possibilité lui est offerte de demander au serveur de restreindre la taille de ses messages.
7.3 - Passage d'options
Le passage de paramètres (nom de la machine...) se fait par l'intermédiaires d'options. Les options sont documentées dans la Rfc 2132. Elles portent toutes un numéro qui les identifie. Par exemple, l'option 15 est celle
qui permet de donner au client le nom de domaine du réseau. Il est bien entendu possible d'envoyer plusieurs options dans le même message DHCP ; dans tous les cas, que l'on ne transmette qu'une seule option utile ou plusieurs, on doit toujours finir la zone d'options par une option 255 (end). Le format des options est le suivant :
Le numéro de l'option n'est codé que sur 1 octet, donc il ne peut y avoir que 256 options possibles. L'octet 2 code la longueur du champ de données qui suit. Il ne tient donc pas compte des 2 octets de code d'option et de longueur. Certaines options ne comportent pas de données complémentaires, comme l'option 255. Dans ce cas, il n'y a ni
champ de longueur ni champ de données. Les messages DHCP vus dans le chapitre précédent (DHCPACK...) sont tout simplement une option ! Il s'agit de l'option 53 qui comporte un champ de données de longueur 1 contenant le numéro identifiant la requête (1 pour DHCPDISCOVER...). Les 4 premiers octets du champ d'options doivent être initialisés respectivement avec les valeurs 99, 130, 83 et 99 (valeurs en décimal). Cette séquence est appelée le "magic cookie" (gateau magique en français).
Le client DHCP a la possibilité d'imposer au serveur DHCP une taille maxi pour le champ d'options (option 57). La conséquence d'une telle limitation est que le serveur peut manquer de place pour envoyer toutes les options souhaitées. Pour répondre à ce problème, le serveur est autorisé à utiliser les champs sname et filepour finir son envoi. Le client est averti de cet usage par un option 52 dans la zone d'options.
8 - Le serveur Dhcp
8.1 - Où trouver un serveur DHCP ?
L'Internet Software Consortium développe un serveur DHCP pour le monde du logiciel libre. C'est le serveur DHCP le plus répandu, et celui qui "suit" au mieux les Rfcs. La dernière version en date est la 3.0 et elle est encore en version bêta. Les versions antérieures marchent toutefois très bien, bien que l'ISC sortent beaucoup de patchs. L'une des principales innovations de la version 3 est la possibilité de mettre à jour un DNSdynamiquement en fonction des adresses IP fournies par le serveur DHCP. Pour information, le première draft sur le DNS dynamique date de mars 1996... Microsoft a bien entendu son propre serveur DHCP pour Windows. Seule la version pour
Windows 2000 Server permet de mettre à jour les DNS dynamiquement avec DHCP. Le reste de cette section traite de l'installation et de la configuration d'un serveur DHCP sous système Unix. L'exemple pris est celui d'un serveur fourni par l'ISC.
8.2 - Compilation du serveur
La première étape de la réalisation d'un serveur DHCP est bien entendu sa compilation. Allez sur le site de l'ISC et téléchargez une version d'un serveur DHCP ou téléchargez simplement ma version qui, bien que vieille, prend en charge la mise a jour de DNS. Copier le fichier dans un répertoire.
Décompressez l'archive : tar xzf dhcp-2.0b1pl6.tar.gz

Déplacez-vous dans le répertoire (commande cd), et tapez : ./configure Cela va générer les fichiers Makefile correspondant à votre système. Tapez ensuite make pour compiler le serveur et enfin make install pour installer le serveur.
Avant de faire le ./configure, il est hautement recommandé de lire le fichier README qui explique comment installer correctement le serveur. Par exemple, pour ma version, tapez ./configure --with-nsupdate pour compiler
le serveur avec le support Dynamic DNS update. make install copiera les fichiers perl dans le répertoire /usr/local/DHCP-DNS-0.52mdn.
8.3 - Le fichier dhcpd.conf
Ce fichier est la base de la configuration du serveur. Par défaut, il se trouve dans le répertoire /etc/, mais vous pouvez le mettre n'importe où. il est composé de plusieurs sections, chacune limitée par des accolades { et } : - des paramètres globaux qui s'appliquent à tout le fichier,
- shared-network, - subnet, - host, - group. Chaque section peut contenir des paramètres et des options. Une section group peut contenir des sections host. Au début du fichier, on peut placer des paramètres globaux, comme par exemple la durée des baux, les adresses
des DNS... Chaque ligne du fichier de configuration doit se terminer par un ;, sauf lorsqu'il y a une accolade. Les commentaires sont possibles en ajoutant un # en début de ligne.
8.3.1 - Les paramètres globaux
Ils peuvent être un peu tout et n'importe quoi, pourvu qu'ils aient une signification applicable à toutes les
déclarations du fichier. Par exemple, on peut redéfinir la durée des baux (max-lease-time et default-lease-time), empêcher le serveur de répondre à des requêtes venant d'hôtes non déclarés (deny unknown-clients;), indiquer le nom de domaine que les machines doivent utiliser, les serveurs DNS... Voir un exemple.
8.3.2 - shared-network
Ce paramètre est utilisé pour regrouper plusieurs zones subnet lorsque ceux-ci concerne le même réseau physique. Les paramètres rentrés en début de zone seront utilisés pour le boot des clients provenant des sous-réseaux déclarés, à moins de spécifier pour certains hôtes de ne pas booter (zone host). Son utilisation
se rapproche de celle de host ; il faut toutefois l'utiliser systématiquement que le réseau est divisé en différents sous-réseaux administrés par le serveur DHCP. Syntaxe : shared-network FOO-BAR
{ filename "boot"; subnet 192.168.2.0 netmask 255.255.255.224 { range 192.168.2.10 192.168.2.30; }
subnet 192.168.2.32 netmask 255.255.255.224 {
range 192.168.2.40 192.168.2.50; } }
8.3.3 - subnet
subnet permet de définir les sous-réseaux sur lesquels le serveur DHCP doit intervenir. C'est la partie la plus
importante du fichier de configuration du serveur DHCP ; sans ça, votre serveur ne marchera jamais. La syntaxe exacte pour cette zone est comme suit : subnet numero_sous-reseau netmask netmask {
[ paramètres globaux... ] [ déclarations... ] }

numero_sous-reseau et netmask sont donnés sous format adresse IP pointées. Un exemple se trouve juste au dessus, dans la partie décrivant la zone shared-network. On peut bien entendu commencer la zone par des paramètres globaux qui ne seront appliqués que pour les ordinateurs de ce sous-réseau. Par exemple, le nom de domaine à appliquer sur ce sous-réseau (option
domain-name). Ensuite, on peut ajouter des déclarations d'hôtes. Le paramètre global indispensable est :
range [ dynamic-bootp ] adresse_inferieure [ adresse_superieure ] qui définit la zone d'adresses IP (limitée par adresse_inferieure et adresse_superieure) que le DHCP peut distribuer. Plusieurs range peuvent se suivre. On peut ne pas spécifier d'adresse supérieure, cela revient à ne considérer qu'une seule adresse IP distribuable (celle indiquée, bien sûr). dynamic-bootp doit être mis pour indiquer que le DHCP doit répondre aux requêtes BOOTP en donnant une adresse de cette plage.
8.3.4 - host
Ce mot permet de déclarer des machines que le DHCP doit connaître et leur appliquer une configuration particulière. Vous n'êtes pas obligé d'utiliser cette zone, mais elle est par exemple indispensable lorsque vous avez déclaré deny unknown-clients; en début de fichier pour empêcher le serveur DHCP de répondre à des
requêtes provenant d'hôtes non déclarés. host est utilisé de la façon suivante : host nom { paramètres...
} Un hôte peut être reconnu de deux façons : en utilisant son nom (le nom qui suit le mot clé host) ou en utilisant son adresse hardware (ethernet ou token-ring). Dans ce dernier cas, il faut ajouter une ligne dans la déclaration host : hardware ethernet|token-ring adresse-hardware;. Il est fortement recommandé
d'authentifier les ordinateurs à partir de leur adresse hardware plutôt que leur nom, surtout qu'il sont
supposés ne pas posséder de véritable nom Internet et que l'on peut redéfinir ce nom. Un point important : c'est dans une déclaration host que l'on décide d'attribuer une adresse fixe ou non à un hôte. Il suffit alors d'utiliser une ligne comme celle-ci : fixed-address 192.168.2.4;. ATTENTION ! Toute adresse IP attribuée de manière fixe ne doit pas faire partie des zones d'adresses IP déclarées avec range... (zone subnet).
8.3.5 - group
Cette zone est simplement utilisée pour rassembler plusieurs déclarations (de toute sorte, y compris d'autres déclarations group) pour leur appliquer des différents paramètres. Exemple :
group { option domain-name "bar.org"; option routers 192.168.1.254; host foo1
{ ... } host foo2 {
...
} }
8.3.6 - Les options
Les paramètres qui doivent commencer avec option sont les options définies dans la Rfc 2132. Il y en a environ 60 définies dans la Rfc, mais le serveur peut en gérer jusqu'à 254 (les options 0 et 255 sont réservées). Pour trouver les options possibles et leur nom, vous pouvez consulter le fichier common/tables.c des sources du serveur. ATTENTION ! les noms des options peut varier d'une version de serveur à une autre.
Le format des valeurs des options est donné dans ce même fichier au début ("format codes:"). Les options plus utiles sont les suivantes : - subnet-mask (option 1) qui indique le masque de sous-réseau pour la configuration IP, - routers (option 3) qui indique les routeurs à utiliser, - domain-name-servers (option 6) qui indique les DNS à utiliser. On peut aussi bien donner le nom que

l'adresse IP (!) - host-name (option 12) qui indique au client quel nom d'hôte il doit prendre, - domain-name (option 15) qui fournit au client le nom du domaine arpa dans lequel il se trouve, - broadcast-address (option 28) qui indique l'adresse de broadcast en vigueur sur le réseau, - dhcp-lease-time (option 51) qui indique au client la durée de validité du bail.
- D'autres options (60 en particulier) permettent de personnaliser les messages DHCP circulant sur le réseau.
8.3.7 - Exemple de fichier dhcpd.conf
- max-lease-time 240;
- default-lease-time 240; - deny unknown-clients; - option domain-name "bar.com"; - option domain-name-servers foo1.bar.com, foo2.bar.com; subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.2 192.168.1.100; range 192.168.1.110 192.168.1.254; option broadcast-address 192.168.1.255; } group {
option routers 192.168.2.101; host foo3 { hardware ethernet 00:c0:c3:11:90:23;
option host-name pc3;
} host foo4 { hardware ethernet 00:c0:c3:cc:0a:8f; fixed-address 192.168.1.105; }
} host foo5 { hardware ethernet 00:c0:c3:2a:34:f5; server-name "bootp.bar.com";
filename "boot"; } Explications : Les cinq premières lignes définissent les paramètres globaux. Les 2 premiers concernent les baux (leases).
La ligne suivante dit au serveur de ne pas répondre aux requêtes DHCP venant d'hôtes qu'il ne connaît pas (i.e. non définis dans dhcpd.conf). On définit enfin les paramètres du domaine du réseau (nom de domaine et serveurs DNS). On définit ensuite le sous-réseau sur lequel le serveur DHCP est censé intervenir : c'est la ligne "subnet...".
Dans ce sous-réseau, on dit au serveur de ne fournir des adresses IP que dans les plages d'adresses définies par les lignes "range...". la dernière ligne de la section définit l'adresse de broadcast à utiliser sur le sous-
réseau. On crée ensuite un groupe dont le but est uniquement de fournir des adresses de passerelles à des machines bien déterminées (par leur adresse MAC). On remarque que foo4.bar.com obtiendra une adresse IP fixe. foo5, enfin, sera une machine qui bootera à travers le réseau, en se connectant au serveur TFTP bootp.bar.com, et booter avec le fichier boot.
8.4 - Lancer le démon dhcpd
Pour lancer le serveur, il faut d'abord être root sur le système. Il suffit ensuite de taper la commande suivante : dhcpd -lf fichier_de_leases -cf fichier_de_config adpateur1 adapteur2... le serveur DHCP va alors se lancer sur les adaptateurs réseau adapteur1, adapteur2..., en trouvant sa
configuration dans le fichier fichier_de_config et en utilisant le fichier fichier_de_leases pour stocker ses baux.

Sans tous les arguments, le serveur DHCP va aller chercher ses fichiers dans des emplacements déterminés au moment de la compilation, dans le fichier includes/dhcpd.h et utiliser eth0 comme interface par défaut. Vous pouvez bien entendu modifier tout ça.
8.5 - Exécuter le démon à chaque démarrage (pour Linux)
Pour lancer le démon au démarrage de votre machine, il faut d'abord placer un script shell de lancement du démon dans le répertoire /etc/rc.d/init.d/. Ce script va en fait gérer le démarrage et l'arrêt de dhcpd. Ce fichier n'est hélas par fourni avec les archives de l'ISC. Vous pouvez le créer vous même en vous inspirant des autres
scripts figurant dans le répertoire ou simplement reprendre: # Source networking configuration. . /etc/sysconfig/network # Check that networking is up. [ ${NETWORKING} = "no" ] && exit 0
[ -f /usr/sbin/dhcpd ] || exit 0 [ -f /etc/dhcpd.conf ] || exit 0 [ -f /var/dhcpd/dhcpd.leases ] || touch /var/dhcpd/dhcpd.leases # See how we were called. case "$1" in
start) # Start daemons. echo -n "Starting dhcpd: " daemon /usr/sbin/dhcpd -lf /var/dhcpd/dhcpd.leases -cf /etc/dhcpd.conf eth0 touch /var/lock/subsys/dhcpd ;;
stop)
# Stop daemons. echo -n "Shutting down dhcpd: " killproc dhcpd echo rm -f /var/lock/subsys/dhcpd ;;
restart) $0 stop $0 start ;; status) status dhcpd ;;
*) echo "Usage: dhcpd {start|stop|restart|status}" exit 1 esac exit 0
Faites un chmod 755 dhcpd pour mettre les bons droits. Il faut maintenant dire à GNU/Linux d'exécuter ce script au démarrage. Cela se fait en créant des liens symboliques dans les répertoires /etc/rc.d/rcx.d/ avec x un entier correspondant au runlevel auquel le démon doit être lancé. Faites simplement chkconfig --add dhcpd, cela va créer les liens symboliques pour vous.
Vous pouvez maintenant redémarrer votre ordinateur, le serveur DHCP sera lancé automatiquement. ATTENTION ! Il se peut que linuxconf prenne le contrôle du serveur DHCP. Si vous voulez garder indéprendante la gestion de votre serveur DHCP (comme c'est par exemple le cas pour moi car j'ai modifié la script /etc/rc.d/init.d/dhcpd), désactivez la prise en charge de dhcpd dans linuxconf.
8.6 - Documentation
La commande make install a dû installer sur votre système les manuels du serveur. Pour y accéder, tapez
simplement : - man dhcpd pour connaître le fonctionnement du démon dhcpd, - man dhcpd.conf pour savoir comment écrire et configurer le fichier dhcpd.conf, - man dhcpd.leases pour avoir des informations sur les baux du serveur DHCP.
Cette doc n'est toutefois ni très simple ni complète. Les options ne sont par exemple pas détaillées. La meilleure documentation est finalement de loin la Rfc qui pour une fois a la bonne idée d'être claire et concise.

9 - Configuration des clients
Vous devez aller dans la configuration TCP/IP, enlever tout ce qu'il y a concernant l'IP, le masque de sous réseau, DNS, passerelle et juste dire que vous voulez une configuration dynamique (DHCP). Relancez vos services réseaux, la
méthode la plus simple et la plus bestiale étant le "reboot", et voilà. Une fois le système remonté, vous devez avoir hérité d'une configuration automatique.
9.1 - Tout pour contrôler, réparer etc
Dans cette partie nous verrons, suivant le système employé, - Windows 95/98 - Windows NT4/2000/Xp - Linux (Mandrake 9)
quels sont les outils pour contrôler l'état du client DHCP. Je demande aux utilisateurs de Be/OS, de MAC/OS et de tous ceux que j'oublie, de bien vouloir m'excuser de ne pas leur apporter mon soutien. J'ai déjà dans mon petit bureau (4 M2) trois PC dont un sur lequel sont installés trois systèmes, je n'ai plus de place...
9.2 - Windows 95/98
9.2.1 - Configuration
Par le panneau de configuration, icône "réseau", cliquez sur "TCP/IP -> <votre carte réseau>. L'adresse IP doit être configurée dynamiquement, c'est d'ailleurs le choix par défaut à l'installation.
9.2.2 - Vérification
Si vous avez un bail en cours de validité, la commande "winipcfg" vous affiche les choses suivantes:
ATTENTION! Windows 95 et 98 installent également le client PPP dont nous n'avons rien à faire... Ce client apparaît également dans la liste des interfaces réseau.
Vérifiez bien que vous pointez sur votre carte Ethernet et pas sur le client PPP...
Si vous cliquez sur le bouton "Plus d'info>>":

Ici, c'est le bouton "Renouveler" qui sera votre seul secours en cas de problèmes. Notez que les rubriques "Bail obtenu" et "Expiration du bail" contiennent des valeurs calculées par votre machine. Le serveur DHCP ne donne que la durée.
9.3 - Windows NT4/2000/XP
9.3.1 - Configuration
La configuration se fait dans le panneau de configuration, icône "réseau", onglet "protocoles", puis "propriétés" de TCP/IP. Là, vous avez indiqué que la carte doit recevoir une adresse IP dynamiquement.
9.3.2 - Vérification
Tapez dans une console, la commande "ipconfig"
Votre adresse doit être affichée. Si vous voulez tous les détails, utilisez la commande "ipconfig /all":

La commande "ipconfig" permet également: - De résilier le bail: "ipconfig /release" - De renouveler le bail: "ipconfig /renew"
C'est cette commande qui est à utiliser pour essayer de récupérer une adresse IP lorsque vous avez des problèmes. Notes. - Les rubriques "Bail obtenu" et "Expiration du bail" contiennent des valeurs calculées par votre machine.
Le serveur DHCP ne donne que la durée. - La commande en mode graphique "winipcfg" n'existe pas nativement sous Windows NT mais vous pouvez la récupérer dans le kit de ressources techniques (téléchargeable sur le site MS en cherchant bien :-). N'essayez pas d'utiliser celle de Windows 95/98, les dll winsock32 utilisées ici ne sont pas compatibles.
9.4 - Linux
9.4.1 - Configuration
Avec cet OS c'est beaucoup plus compliqué, parce qu'il y a beaucoup plus de configurations possibles. La
configuration utilisée dans l'exposé est la suivante:
- Un portable Compaq équipé d'une carte réseau D-LINK PCMCIA MANDRAKE 8.2 Eth0 et configurée avec DHClient. Notez que DHClient n'est pas le seul client possible. Vous pouvez parfaitement le remplacer par PUMP, DHCPXD ou par DHCPCD. Tous ces clients sont disponibles dans la distribution Mandrake, qui installe
d'ailleurs DHCPCD par défaut, et non pas celui que j'utilise. - DHCPCD semble avoir la préférence du distributeur. Je n'ai jamais rencontré de problèmes avec, mais je ne l'utilise normalement pas pour la raison suivante: Son paramétrage ne se fait que par la ligne de commande, ce qui oblige à aller modifier des scripts pas toujours faciles à trouver si l'on veut par exemple utiliser son propre DNS à la place de celui proposé dans le bail. - PUMP Fonctionne également sans problèmes, il dispose d'un fichier de configuration /etc/pump.conf dans
le quel on peut par exemple spécifier très simplement que l'on ne veut pas modifier le paramétrage du DNS avec l'information récupérée par DHCP. (Le ou les DNS sont inscrits dans le fichier /etc/resolv.conf). - Je n'ai pas vraiment étudié DHCPXD qui fonctionne lui aussi sans difficultés. Il dispose d'un répertoire /etc/dhcpxd dans lequel vous trouverez quelques fichiers qui vous donneront toutes les indications sur le bail

en cours. DHCLIENT a ma préférence. Il est écrit par ISC (les auteurs de BIND le fameux DNS et DHCPD lque nous utilisons ici, c'est dire qu'ils savent de quoi ils parlent :). Ce client cumule à mon sens tous les avantages:
- Un fichier de configuration /etc/dhclient.conf, sans doute encore plus performant que celui de PUMP. Notez que ce fichier n'existe pas dans la distribution Mandrake, il vous faudra éventuellement le créer si vous
ne voulez pas vous contenter du fonctionnement par défaut. - Des scripts optionnels exécutés automatiquement avant l'obtention du bail et après l'obtention du bail, avec à disposition des variables contenant toutes les informations recueillies par le client auprès du serveur. Très pratique par exemple pour vous envoyer par mail l'adresse courante de votre machine si celle-ci change; dans le cas par exemple où vous avez besoin de vous y connecter à distance par telnet ou ssh. - Il tient un historique des baux obtenus dans le fichier /var/lib/dhcp/dhclient.leases
Son seul inconvénient est sa richesse. Il n'est pas le plus facile à mettre en oeuvre.
9.4.2 - Vérifiez l'état de votre connexion
Dans /etc/sysconfig/network-scripts, il y a un fichier intitulé : ifcfg-eth0. Il doit contenir au moins ces lignes : DEVICE="eth0" BOOTPROTO="dhcp" IPADDR="" NETMASK="" ONBOOT="yes"
C'est assez parlant pour ne pas nécessiter d'explications particulières. La commande "ifconfig eth0" devrait vous donner quelque chose comme ceci :
Si rien n'apparaît, c'est que votre interface n'est pas activée. Essayez alors ifup eth0 :

Cette commande affiche l'état de Eth0, mais elle ne donne pas toutes les informations que l'on obtient sous Windows avec winipcfg ou ipconfig. Si vous voulez tout savoir, il faut aller dans le répertoire "/var/lib/dhcp" et regarder le fichier dhclient.leases. Celui-ci contient l'historique des dialogues DHCP : lease
{ interface "eth0"; fixed-address 192.168.0.8;
option subnet-mask 255.255.255.0; option routers 192.168.0.253; option dhcp-lease-time 3600; option dhcp-message-type 5;
option domain-name-servers 192.168.0.253; option dhcp-server-identifier 192.168.0.253; option domain-name "maison.mrs"; renew 2 2002/12/10 08:49:42; rebind 2 2002/12/10 09:14:05; expire 2 2002/12/10 09:21:35;
} Notez que ce fichier peut être beaucoup plus long. Cherchez dedans le dernier bail obtenu. Constatez que vous avez bien la trace de toutes les informations que notre serveur DHCP est capable d'envoyer à ses clients.
9.4.3 - Particularités du client DHClient
Grâce aux informations conservées dans ce fichier dhclient.leases, ce client adopte un comportement un peu particulier, que l'on ne retrouve pas dans celui de Microsoft, par exemple.
Lorsqu'un hôte a obtenu un premier bail de la part du DHCP, l'adresse du serveur DHCP est conservée et, même après extinction et redémarrage de l'hôte au bout d'un temps bien supérieur à la durée de son bail, le client commencera par envoyer directement un DHCP request au serveur qu'il connaît. Cette particularité peut dérouter lorsque l'on espionne les dialogues DHCP sur le réseau.
10 - Savoir "Sniffer"
Un "sniffer" n'est pas un outil pour se "shooter", mais pour analyser les données qui se trimbalent sur le réseau. C'est un outil d'administrateur, qui est capable du meilleur comme du pire. Si vous voulez jouer avec, il en existe un tout à fait convenable et gratuit, aussi bien en version Linux que Windows, c'est Ethereal. Il nécessite l'installation de la librairie libpcap, disponible elle aussi sous Linux comme sous Windows. Nous allons juste ici analyser une capture de trames correspondant au dialogue DHCP, et constater que, lorsque ça va bien, ça se passe comme c'est dit dans les livres, ce qui est un peu réconfortant.
La manipulation est faite avec un client sous Windows XP.
10.1 - En-têtes de trames

1 - Notre client se réveille, il n'a pas d'IP et utilise 0.0.0.0 pour faire un "broadcast général (255.255.255.255)". C'est le DHCP Discover. 2 - Notre serveur DHCP, qui a l'intention d'offrir à ce client l'IP 192.168.0.9, fait un ping sur cette adresse, histoire de voir si elle est réellement disponible sur le réseau. 3 - Comme il ne reçoit pas de réponse à son ping, il offre cette adresse au client.
4 - Le client fait alors un DHCP Request 5 - Le serveur accepte 6 - Le client fait un broadcast ARP pour vérifier de son côté que l'IP 192.168.0.9 n'est pas dupliquée sur le réseau. 7 - idem 8 - idem 9 - Là, commence le verbiage propre aux réseaux Microsoft...
Note à propos du ping. Ce ping fait "perdre" une seconde au processus d'attribution d'un bail. En effet, le serveur attend pendant une
seconde une éventuelle réponse. Si vous êtes absolument sûr de votre réseau, vous pouvez désactiver ce ping dans le fichier de configuration de DHCPd, mais je ne vous le conseille pas.
10.2 - Détail des trames
Ce qui suit représente l'interprétation exhaustive des trames par le "sniffer". Il est évident qu'en lecture directe sur le réseau, on ne verrait qu'une suite d'octets difficilement interprétable par l'esprit humain. La lecture en est certes un peu fastidieuse, mais elle est riche d'enseignements... Les points les plus importants sont marqués en gras.

10.2.1 - Le DHCP Discover


10.2.2 - Un petit ping...
Pas de réponse au ping, on peut continuer tranquille...

10.2.3 - Offre d'un nouveau bail


Le serveur DHCP vient de proposer une configuration au client.
10.2.4 - Demande du Bail de la part du client
Il faut aussi, maintenant que le client fasse une demande explicite pour ce bail. N'oublions pas qu'il pourrait y avoir plusieurs DHCP qui répondent, il faut donc qu'il y ait une confirmation au serveur choisi par le client.


C'est presque fini, il ne reste plus au serveur qu'à confirmer l'attribution de ce bail.

10.2.5 - Le serveur est d'accord


Pas besoin de regarder de près ce qu'il se passe dans les broadcasts ARP que le client fait par la suite.
10.3 - Notes supplémentaires
10.3.1 - Duplication d'adresse
Que se serait-il passé, si l'adresse proposée par le serveur (ici 192.168.0.9) avait été déjà utilisée par un autre noeud du réseau ? Je ne vous assommerai pas encore une fois avec un sniff, croyez-moi sur parole, j'ai fait la manip pour
vérifier. Dans ce cas, le serveur recevra un "echo reply" de la part du noeud utilisant cette IP et ne répondra pas au Discover. Le client, ne recevant pas de réponse, enverra un nouveau discover et le serveur lui proposera une autre IP.
10.3.2 - Pas de réponse
Et si le client qui a pris l'IP 192.168.0.9 ne répond pas aux pings ? Ce sera la catastrophe annoncée. Le bail sera alloué et il y aura une duplication de l'IP sur le réseau. Mais les
broadcast ARP fait par le client qui a reçu l'IP dupliquée mettra à jour cette duplication et la configuration échouera. Cette situation ne devrait pas se produire sur un réseau proprement configuré. Elle ne devrait apparaître que s'il y a un utilisateur malveillant sur le réseau, qui force une configuration statique quand il ne le faut pas et
qui bloque volontairement les échos ICMP.
Pour ceux qui n'ont pas peur de se plonger dans les Rfcs, vous trouverez celle qui traite du protocole Dhcp la Rfc 2131.
10.4 - Renouvellement d'un bail en cours de validité
Lorsque la durée du bail est inférieure à " l'uptime" du client, autrement dit, si votre client reste connecté plus longtemps que la durée de validité de son bail, il va devoir le renouveler. Pour visualiser cette procédure, nous faisons un petit test, en diminuant la durée de vie du bail à quatre minutes,
et nous sniffons :
10.4.1 - Quand ça se passe bien...
Ca semble suffisamment parlant, au bout d'environ 120 secondes, soit 50% de la durée de vie du bail, le client essaye de le renouveler. Ca se passe bien, puisque le serveur répond toute de suite et ça repart pour 4 minutes. Inutile de regarder le détail des trames.
10.4.2 - Et quand ça se passe mal
Nous allons faire la même chose, mais en simulant une panne de serveur DHCP :

Mais elle aurait pu mal finir, si ça avait été une bonne, vraie, grosse panne du serveur. En effet, une fois le bail expiré, le client perd bel et bien son IP et est éjecté de fait du réseau... Du temps où les câblés Wanadoo fonctionnaient sur ce système, ils n'ont pas manqué d'assister quelques fois à ce désolant spectacle.
Dns
1 - Introduction
2 - Historique 3 - Les formats 3.1 - Le transport 3.2 - L'entête 3.3 - Les RR 4 - Les zones
4.1 - Structure arborescente de l'espace de noms 4.2 - Formation des zones 4.3 - Principes des zones 4.4 - Description techniques pour les zones 4.5 - Type de serveurs et autorités 4.6 - La diffusion des modifications 4.7 - Les pannes
5 - Recherche de ressources 5.1 - Les Résolveurs 5.2 - Les Requêtes 5.3 - Les Requêtes inverses 6 - La sécurité 6.1 - Fragilité

6.2 - Sécurisation 7 - Conclusion 8 - Discussion autour de la documentation 9 - Suivi du document
1 - Introduction
Dans le monde de l'Internet, les machines du réseau sont identifiées par des adresses Ip. Néanmoins, ces adresses ne
sont pas très agréables à manipuler, c'est pourquoi, on utilise les noms. L'objectif a alors été de permettre la résolution des noms de domaines qui consiste à assurer la conversion entre les noms d'hôtes et les adresses Ip. La solution actuelle est l'utilisation des Dns (Domain Name System) ce que nous allons vous présenter dans ce document. Le travail présenté ici s'appuie particulièrement sur les Rfcs 1034 et 1035. Les Rfc (Request For Comment) sont des documents de l'IETF (Internet Engineering Task Force) qui ont vocation à être les standards d'Internet. Dans une
première partie nous ferons une introduction à la notion de Dns, en présentant un bref historique et en nous penchant sur sa structure. Nous nous intéresserons ensuite plus précisément aux serveurs de noms et pour finir nous parlerons du système de recherches des ressources et plus précisément des requêtes Dns.
Vous pouvez regarder une très bonne vidéo en ligne relatant de manière pédagogique le fonctionnement de DNS.
2 - Historique
Jusqu'en 1984, sur la suite des protocoles TcpIp, la transcription de noms d'hôtes en adresses Internet s'appuyait sur une table de correspondance maintenue par le Network Information Center (NIC), et ce dans un fichier .txt, lequel était transmis par Ftp à tous les hôtes. Il n'était à l'époque pas compliqué de stocker les adresses puisque le nombre de machines était très réduit. Par ailleurs, avec la croissance exponentielle d'Internet il a fallu trouver une autre solution, car les problèmes se sont multipliés :
La mise à jour des fichiers : En effet il fallait retransmettre le fichier de mise à jour à tous les hôtes, ce qui encombrait fortement la bande passante du NIC.
L'autonomie des organismes : Avec l'évolution de l'Internet, les architectures ont été transformées, ainsi des organismes locaux ont eu la possibilité de créer leur propres noms et adresses, et ils étaient alors obligés d'attendre que le NIC prenne en compte leurs nouvelles adresses avant que les sites ne puissent être visibles par tous sur Internet. Le souhait était alors que chacun puisse gérer ses adresses avec une certaine autonomie.
Tous ces problèmes ont fait émerger des idées sur l'espace des noms et sa gestion. Les propositions ont été diverses, mais l'une des tendances émergentes a été celle d'un espace de noms hiérarchisé, et dont le principe hiérarchique s'appuierait autant que possible sur la structure des organismes eux-mêmes, et où les noms utiliseraient le caractère
"." pour marquer la frontière entre deux niveaux hiérarchiques. En 1983-1984, Paul Mockapetris et John Postel proposent et développent une solution qui utilise des structures de base de données distribuée : les Domain Name System, Rfcs 882 et 883 devenue obsolète par la Rfc 1034. Les spécification des Dns ont été établies en 1987.
Paul Mockapetris Jon Postel
3 - Les formats
3.1 - Le transport
3.1.1 - Utilisation d'Udp
Le port serveur utilisé pour l'envoi des datagrammes en Udp est 53. Les datagrammes Dns en Udp sont
limités à 512 octets (valeur représentant les données sans l'entête Udp et Ip). Les datagramme plus long doivent être tronqué à l'aide du champ Tc.

L'utilisation d'Udp n'est pas recommandé pour les transfert de zone, mais uniquement pour les requêtes standards.
3.1.2 - Utilisation de Tcp
Le port serveur utilisé pour l'envoi des datagrammes en Tcp est 53. Le datagramme inclus alors un champ de deux octets nommé "longueur", il permet de spécifier la la longueur total des données indépendamment de la fragmentation. La longueur est calculé sans les 2 octets de ce même champ.
3.2 - L'entête
Voici la structure de l'entête Dns basé sur 12 octets.
3.2.1 - Id
Codé sur 16 bits, doit être recopié lors de la réponse permettant à l'application de départ de pouvoir identifier le datagramme de retour.
3.2.2 - Qr
Sur un 1 bit, ce champ permet d'indiquer s'il s'agit d'une requête (0) ou d'une réponse (1).
3.2.3 - Opcode
Sur 4 bits, ce champ perme de spécifier le type de requête :
0 - Requête standard (Query)
1 - Requête inverse (Iquery)
2 - Status d'une requête serveur (Status)
3-15 - Réservé pour des utilisations futurs
3.2.4 - Aa
Le flag Aa, sur un bit, signifie "Authoritative Answer". Il indique une réponse d'une entité autoritaire.

3.2.5 - Tc
Le champ Tc , sur un bit, indique que ce message a été tronqué.
3.2.6 - Rd
Le flag Rd, sur un bit, permet de demander la récursivité en le mettant à 1.
3.2.7 - Ra
Le flag Ra, sur un bit, indique que la récursivité est autorisée.
3.2.8 - Z
Le flag Z, sur un bit, est réservé pour une utilisation futur. Il doit être placé à 0 dans tout les cas.
3.2.9 - Rcode
Le champ Rcode, basé sur 4 bits, indique le type de réponse.
0 - Pas d'erreur
1 - Erreur de format dans la requête
2 - Problème sur serveur
3 - Le nom n'existe pas
4 - Non implémenté
5 - Refus
6-15 - Réservés
3.2.10 - Qdcount
Codé sur 16 bits, il spécifie le nombre d'entrée dans la section "Question".
3.2.11 - Ancount
Codé sur 16 bits, il spécifie le nombre d'entrée dans la section "Réponse".
3.2.12 - Nscount
Codé sur 16 bits, il spécifie le nombre d'entrée dans la section "Autorité".
3.2.13 - Arcount
Codé sur 16 bits, il spécifie le nombre d'entrée dans la section "Additionnel".
3.3 - Les RR
La base de données des serveurs de noms (fichier de domaine et fichiers de résolution inverse) est constituée
"d'enregistrements de ressources", "Ressource Records" (RRs). Ces enregistrements sont répartis en classes. La seule classe d'enregistrement usuellement employée est la classe Internet (IN). L'ensemble d'informations de ressources associé à un nom particulier est composé de quatre enregistrements de ressources séparés (RR). Voici les différents champs d'un RR que vous pouvez aussi retrouver dans la Rfc 1035 au chapitre 3.2.1 :

3.3.1 - Nom
Nom du domaine où se trouve le RR. Ce champ est implicite lorsqu'un RR est en dessous d'un autre, auquel
cas le champ owner est le même que celui de la ligne précédente.
3.3.2 - Type
Ce champ type, codé sur 16 bits, spécifie quel type de donnée sont utilisés dans le RR. Voici les différents types disponibles:
Entrée Valeur Désignation
A 01 Adresse de l'hôte
NS 02 Nom du serveur de noms pour ce domaine
MD 03 Messagerie (obselete par l'entrée MX)
MF 04 Messagerie (obselete par l'entrée MX)
CNAME 05 Nom canonique (Nom pointant sur un autre nom)
SOA 06 Début d'une zone d'autorité (informations générales sur la zone)
MB 07 Une boite à lette du nom de domaine (expérimentale)
MG 08 Membre d'un groupe de mail (expérimentale)
MR 09 Alias pour un site (expérimentale)
NULL 10 Enregistrement à 0 (expérimentale)
WKS 11 Services Internet connus sur la machine
PTR 12 Pointeur vers un autre espace du domaine (résolution inverse)
HINFO 13 Description de la machine
MINFO 14 Groupe de boite à lettres
MX 15 Mail exchange (Indique le serveur de messagerie. Voir [Rfc-974] pour plus de détails
TXT 16 Chaîne de caractère
3.3.3 - Classe
Une valeur encodée sur 16 bits identifiant une famille de protocoles ou une instance d'un protocole. Voici les
classes de protocole possible :
Entrée Valeur Désignation
In 01 Internet
Cs 02 Class Csnet (obselete)

Ch 03 Chaos (chaosnet est un ancien réseau qui historiquement a eu une grosse influence sur le développement de l'Internet, on peut considérer à l'heure actuelle qu'il n'est plus utilisé)
Hs 04 Hesiod
3.3.4 - Ttl
C'est la durée de vie des RRs (32 bits, en secondes), utilisée par les solveurs de noms lorsqu'ils ont un cache des RRs pour connaître la durée de validité des informations du cache.
3.3.5 - Longueur
Sur 16 bits, ce champ indique la longueur des données suivantes.
3.3.6 - Données
Données identifiant la ressource, ce que l'on met dans ce champs dépend évidemment du type de ressources que l'on décrit.
A : Pour la classe IN, une adresse IP sur 32 bits. Pour la classe CH, un nom de domaine suivi d'une adresse octale Chaotique sur 16 bits.
Cname : un nom de domaine.
Mx : une valeur de préférence sur 16 bits (la plus basse possible) suivie d'un nom d'hôte souhaitant servir d'échangeur de courrier pour le domaine de l'owner.
Ptr : Une adresse IP sous forme d'un nom.
Ns : Un nom d'hôte.
Soa : Plusieurs champs.
Voici un exemple montrant les différents champs saisies par Ethereal :
4 - Les zones
4.1 - Structure arborescente de l'espace de noms
Le Dns utilise la gestion hiérarchique des noms. On distingue deux domaines pour le classement des noms.
4.1.1 - Les domaines géographiques (Codes ISO 3166)
.ac - Ascension .gm - Gambie .np - Nepal

.ad - Andorre
.ae - Emirats Arabes Unis
.af - Afganistan
.ag - Antigua And Barbuda
.ai - Anguilla
.al - Albania
.am - Arménie
.an - Netherlands Antilles
.ao - Angola
.aq - Antartique
.ar - Argentine
.as - American Samoa
.at - Autriche
.au - Australie
.aw - Aruba
.az - Azerbaijan
.ba - Bosnie Herzégovine
.bb - Barbades
.bd - Bangladesh
.be - Belgique
.bf - Burkina Faso
.bg - Bulgarie
.bh - Bahrain
.bi - Burundi
.bj - Benin
.bm - Bermudes
.bn - Brunei Darussalam
.bo - Bolivie
.br - Brésil
.bs - Bahamas
.bt - Bhutan
.bv - Bouvet Island
.bw - Botswana
.by - Belarus
.bz - Belize
.ca - Canada
.cc - Cocos (Keeling) Islands
.cd - République du Congo
.cf - République d'Afrique Centrale .cg - Congo .ch - Suisse .ci - Cote d'Ivoire .ck - Iles Cook
.cl - Chili
.cm - Cameroun
.cn - Chine
.co - Colombie
.cr - Costa Rica
.cu - Cuba
.cv - Cap Vert
.cx - Christmas Island
.cy - Chypre
.cz - République Tchèque
.de - Allemagne
.dj - Djibouti
.dk - Danmark
.dm - Dominica
.do - République Dominicaine
.dz - Algérie
.ec - Equateur
.ee - Estonie
.eg - Egypte
.eh - Sahara occidental
.er - Erytrée
.es - Espagne
.et - Ethiopie
.fi - Finlande
.fj - Fiji
.fk - Iles Fakland (Malouines)
.fm - Micronesie (Etat Fédéral)
.fo - Iles Faroe
.fr - France
.fx - France Métropoliotaine
.ga - Gabon
.gn - Guinée
.gp - Guadeloupe
.gq - Guinéee Equatoriale
.gr - Grèce
.gs - South Georgia and the South Sandwich
Islands .gt - Guatemala .gu - Ile de Guam .gw - Guiné-Bissau .gy - Guyane
.hk - Hong Kong
.hm - Heard and McDonald Islands
.hn - Honduras
.hr - Croatie/Hrvatska
.ht - Haiti
.he - Hongrie
.hu - Hongarie
.id - Indonésie
.ie - Irelande
.il - Israel
.im - Isle of Man
.in - Inde
.io - Territoire Anglais de l'Océan Indien
.iq - Irak
.ir - Iran (Islamic Republic of)
.is - Islande
.it - Italie
.je - Jersey
.jm - Jamaïque
.jo - Jordanie
.jp - Japon
.ke - Kenya
.kg - Kyrgyzstan
.kh - Cambodge
.ki - Kiribati
.km - Iles Comores
.kn - Saint Kitts and Nevis
.kp - République Démocratique populaire de Corée .kr - République de Corée .kw - Koweit .ky - Iles Cayman .kz - Kazakhstan .la - République Démocratique populaire du
Laos .lb - Liban .lc - Sainte Lucie .li - Liechtenstein .lk - Sri Lanka .lr - Liberia .ls - Lesotho
.lt - Lituanie
.lu - Luxembourg
.lv - Latvia
.ly - Libyan Arab Jamahiriya
.ma - Maroc
.mc - Monaco
.md - République de Moldavie
.mg - Madagascar
.mh - Iles Marshall
.mk - Macédoine, ex République Yougoslave
.ml - Mali
.mm - Myanmar
.mn - Mongolie
.mo - Macao
.mp - Iles Mariannes du Nord
.mq - Martinique
.mr - Mauritanie
.ms - Montserrat
.mt - Malte
.mu - Ile Maurice
.mv - Maldives
.mw - Malawi
.mx - Mexique
.my - Malaisie
.nr - Nauru
.nu - Niue
.nz - Nouvelle Zélande
.om - Oman
.pa - Panama
.pe - Pérou
.pf - Polynésie Française
.pg - Papouasie Nouvelle Guinée
.ph - Philippines
.pk - Pakistan
.pl - Pologne
.pm - Saint Pierre et Miquelon
.pn - Pitcairn Island
.pr - Porto Rico
.ps - Territoires Palestiniens
.pt - Portugal
.pw - Palau
.py - Paraguay
.qa - Qatar
.re - L'Ile de la Réunion
.ro - Roumanie
.ru - Fédération Russe
.rw - Rwanda
.sa - Arabie Saoudite
.sb - Iles Salomon
.sc - Seychelles
.sd - Soudan
.se - Suède
.sg - Singapour
.sh - Sainte Hélène
.si - Slovanie
.sj - Svalbard and Jan Mayen Islands .sk - Slovaquie .sl - Sierra Leone .sm - San Marino .sn - Sénégal
.so - Somalie
.sr - Surinam
.st - Sao Tome and Principe
.sv - Salvador
.sy - Syrie
.sz - Swaziland
.tc - Iles Turques et Caicos
.td - Tchad
.tf - Territoire Français du Sud
.tg - Togo
.th - Thailande
.tj - Tajikistan
.tk - Tokelau
.tm - Turkmenistan
.tn - Tunisie
.to - Iles Tonga
.tp - Timor Oriental
.tr - Turquie
.tt - Trinité et Tobago
.tv - Tuvalu
.tw - Taiwan
.tz - Tanzanie
.ua - Ukraine
.ug - Ouganda
.uk - Royaume Uni
.um - US Minor Outlying Islands
.us - United States
.uy - Uruguay
.uz - Uzbekistan
.va - Vatican
.vc - Iles Grenadines et St Vincent .ve - Vénézuela .vg - Iles Vierges Anglaises
.vi - Iles Vierges Américaines
.vn - VietNam
.vu - Vanuatu
.wf - Iles de Wallis et Futuna

.gb - Grande Bretagne
.gd - Grenade
.ge - Géorgie
.gf - Guyane Française
.gg - Guernesey
.gh - Ghana
.gi - Gibraltar
.gl - Groenland
.mz - Mozambique
.na - Namibie
.nc - Nouvelle Calédonie
.ne - Niger
.nf - Iles Norfolk
.ng - Nigeria
.ni - Nicaragua
.nl - Hollande
.no - Norvège
.ws - Samoa
.ye - Yemen
.yt - Mayotte
.yu - Yougoslavie
.za - Afrique du sud
.zm - Zambie
.zw - Zimbabwe
4.1.2 - Les domaines génériques
Cette liste est définie par la Rfc 1591 - Domain Name System Structure and Delegation .com - Commerciaux .edu - Organismes d'éducation américaine .net - Organismes de gestion de réseaux .org - Organismes non-commerciaux
.int - Organismes internationaux
.gov - Organismes gouvernementaux USA
.mil - Organismes militaires USA
.arpa - Transition ARPAnet-> Internet + traduction inverse
L'arborescence des noms de domaine est constituée :
d'une racine
de noeud identifiés par des labels dont les informations sont stockées dans une base de données
Les labels portés par les noeuds font entre 0 et 63 octets, sachant que l'identifiant de longueur zéro est réservé à la racine. Deux noeuds " frère " ne peuvent pas porter le même identifiant, néanmoins, deux noeuds peuvent avoir le même label dans le cas où il n'on aucun lien de " fratrie ". Le nom de domaine d'un noeud est constitué des identifiants situés entre ce noeud à la racine de l'arborescence. Lorsqu'un utilisateur doit entrer un nom de domaine, la longueur de chaque identifiant est omise et les identifiants devront être séparés par des points ("."). Un nom de domaine complet atteignant toujours la racine, la forme écrite exacte de tout domaine entièrement
qualifié se termine par un point. Nous utiliserons cette propriété pour distinguer les cas :
d'une chaîne de caractères représentant un nom de domaine complet (souvent appelé "absolu" ou "entièrement qualifié"). Par exemple, "www.FRAMEIP.COM"
d'une chaîne de caractères représentant les premiers identifiants d'un nom de domaine incomplet, et devant être complété par l'application locale avec un complément absolu (expression appelée "relative"). Par exemple, "www", à utiliser relativement au domaine FRAMEIP.COM.
4.2 - Formation des zones
La base de données est divisée en sections appelées zones, lesquelles sont distribuées sur l'ensemble des serveurs de noms. De plus, elle est divisée selon deux méthodes : en classes et par "découpage" de l'espace des noms de domaines. La partition en classes est assez simple. La base de données est organisée, déléguée, et maintenue séparément
pour chacune des classes. Comme par convention, l'espace de noms est identique quel que soit la classe, la séparation par classe peut conduire à voir l'espace de domaines comme un tableau d'arbres de noms parallèles.
Notez que les données attachées aux noeuds des arbres seront différentes dans chaque arbre.

4.3 - Principes des zones
Dans une classe, des "coupes" dans l'espace de noms peuvent être faites entre deux noeuds adjacents quelconques. Un fois toutes les coupes définies, chaque groupe de noeuds interconnectés devient une zone
indépendante. La zone est alors définie comme étant la "sphère d'autorisation" pour tout nom à l'intérieur de la zone. Notez que les "coupes" dans l'espace de noms peuvent être à des endroits différents de l'arbre suivant la classe, les serveurs de noms associés peuvent être différents, etc. Ces règles signifient que chaque zone doit avoir au moins un noeud, et donc un nom de domaine, pour lequel il est "autorisé", et que tous les noeuds d'une zone particulière sont connectés. Du fait de la structure d'arbre,
chaque zone contient un noeud "de plus haut niveau" qui est plus proche de la racine que tous les autres noeuds de cette zone. Le nom de ce noeud est souvent utilisé pour identifier la zone elle-même. Selon ce concept, il est possible, bien que pas forcément utile, de découper l'espace de noms de telle façon que chaque nom de domaine se retrouve dans une zone séparée ou au contraire que tous les noeuds se retrouvent dans une zone unique.
4.4 - Description techniques pour les zones

Les données qui décrivent chaque zone sont organisées en quatre parties :
Les données générales sur chaque noeud de la zone
Les données qui définissent le noeud supérieur de la zone
Les données qui décrivent les sous-zones
Les données qui permettent d'accéder aux serveurs de noms qui gèrent les sous-zones
Toutes ces données sont stockées dans des RRs, donc une zone peut être entièrement décrite par un jeu de RRs. Les informations sur des zones entières peuvent donc être transmises d'un serveur à l'autre, tout simplement en
échangeant ces RRs. Les plus importants des RRs sont ceux qui décrivent le noeud principal d'une zone. Ils sont de deux sortes : des RRs qui répertorient l'ensemble des serveurs de noms de la zone, et un RR de type SOA qui décrit les paramètres de gestion de la zone. Les RRs contenant des informations sur les sous zones sont de type NS. Il faut des informations pour connaître
l'adresse d'un serveur dans la sous zone, ceci pour pouvoir y accéder. Ce genre de données est conservé dans d'autres RRs. Tout est fait pour que dans la structure en zones, toute zone puisse disposer localement de toutes les données nécessaires pour communiquer avec les serveurs de noms de chacune de ses sous-zones.
4.5 - Type de serveurs et autorités
Par le découpage en zone on a donc trois types de serveurs de noms.
4.5.1 - Le serveur primaire
Le serveur primaire est serveur d'autorité sur sa zone : il tient à jour un fichier appelé "fichier de zone", qui établit les correspondances entre les noms et les adresses IP des hosts de sa zone. Chaque domaine possède un et un seul serveur primaire.
4.5.2 - Le serveur secondaire
Un serveur de nom secondaire obtient les données de zone via le réseau, à partir d'un autre serveur de nom
qui détient l'autorité pour la zone considérée. L'obtention des informations de zone via le réseau est appelé transfert de zone (voir partie 2.4). Il est capable de répondre aux requêtes de noms Ip (partage de charge), et de secourir le serveur primaire en cas de panne. Le nombre de serveurs secondaires par zone n'est pas limité. Ainsi il y a une redondance de l'information. Le minimum imposé est un serveur secondaire et le pré requis mais pas obligatoire est de le situer sur un segment différent du serveur primaire. Un serveur qui effectue un transfert de zone vers un autre serveur est appelé serveur maître. Un serveur
maître peut être un serveur primaire ou un serveur secondaire. Un serveur secondaire peut disposer d'une liste de serveurs maîtres (jusqu'à dix serveurs maîtres). Le serveur secondaire contacte successivement les serveurs de cette liste, jusqu'à ce qu'il ait pu réaliser son transfert de zone.
4.5.3 - Le serveur cache
Le serveur cache ne constitue sa base d'information qu'à partir des réponses des serveurs de
noms. Il inscrit les correspondances nom / adresse IP dans un cache avec une durée de validité limitée (Ttl) ; il n'a aucune autorité sur le domaine : il n'est pas responsable de la mise à jour des informations contenues dans son cache, mais il est capable de répondre aux requêtes des clients
Dns. De plus on peut distinguer les serveurs racine : ils connaissent les serveurs de nom ayant autorité sur tous les domaines racine. Les serveurs racine connaissent au moins les serveurs de noms pouvant résoudre le premier niveau (.com, .edu, .fr, etc.) C'est une pierre angulaire du système Dns : si les serveurs racine sont inopérationnels, il n'y a plus de communication sur l'Internet, d'où multiplicité des serveurs racines (actuellement il y en a 14). Chaque serveur racine reçoit environ
100 000 requêtes par heure.
Un serveur de nom, en terme de physique, peux très bien jouer le rôle de plusieurs de ces fonctions. On trouvera par exemple, beaucoup d'entreprise qui héberge leurs domaine sur le serveur Dns primaire servant aussi de cache pour les requêtes sortantes des utilisateurs interne.
4.6 - La diffusion des modifications

"Le transfert de zones" Pour chaque zone Dns, le serveur servant de référence est le Dns maître ou Dns primaire. Les Dns esclaves ou secondaires servant cette zone vont récupérer les informations du Dns maître. Cette récupération d'information est appelée transfert de zone. Seuls les Dns secondaires ont besoin d'être autorisés à effectuer cette opération,
mais assez souvent aucune restriction n'est présente. Ceci permettant à n'importe qui de se connecter via nslookup et d'utiliser l'argument ls -d permettant l'affichage du contenu d'une zone.
Lorsque des changements apparaissent sur une zone, il faut que tous les serveurs qui gèrent cette zone en soient informés. Les changements sont effectués sur le serveur principal, le plus souvent en éditant un fichier. Après avoir édité le fichier, l'administrateur signale au serveur qu'une mise à jour a été effectuée, le plus souvent au moyen d'un signal (SIGINT). Les serveurs secondaires interrogent régulièrement le serveur principal pour savoir si les données ont changé depuis la dernière mise à jour. Ils utilisent un numéro constitué de la date au format américain: année, mois, jour; version du jour, il est donc toujours incrémenté. Donc pour la mise a jour ils
comparent le champ SERIAL du RR SOA de la zone donnée par le serveur principal contenant le numéro à celui qu'ils connaissent. Si ce numéro a augmenté, ils chargent les nouvelles données.
4.7 - Les pannes
Lorsqu'un serveur primaire est indisponible, le serveur secondaire ne reçoit pas de réponse à ses interrogations sur le numéro de version du fichier de zone. Il continue ses tentatives jusqu'à expiration de la validité des enregistrements de son fichier de zone ('Expire Time'). Lorsqu'un serveur primaire redevient disponible, aucun mécanisme de synchronisation entre le fichier de zone des serveurs secondaires et celui du serveur primaire n'a
été normalisé.
5 - Recherche de ressources
5.1 - Les Résolveurs
Les "résolveurs" sont des programmes qui interfacent les applications utilisateur aux serveurs de noms de domaines. En effet, ce n'est pas l'utilisateur qui effectue les requêtes directement. Dans le cas le plus simple, un
résolveur reçoit une requête provenant d'une application (ex., applications de courrier électronique, Telnet, Ftp) sous la forme d'un appel d'une fonction de bibliothèque, d'un appel système etc., et renvoie une information sous une forme compatible avec la représentation locale de données du système. Le résolveur est situé sur la même machine que l'application recourant à ses services, mais devra par contre consulter des serveurs de noms de domaines sur d'autres hôtes. Comme un résolveur peut avoir besoin de
contacter plusieurs serveurs de noms, ou obtenir les informations directement à partir de son cache local, le temps de réponse d'un résolveur peut varier selon de grandes proportions, depuis quelques millisecondes à plusieurs secondes. L'une des raisons les plus importantes qui justifient l'existence des résolveurs est d'éliminer le temps d'acheminement de l'information depuis le réseau, et de décharger simultanément les serveurs de noms, en répondant à partir des données cachées en local. Il en résulte qu'un cache partagé entre plusieurs processus,
utilisateurs, machines, etc., sera incomparablement plus efficace qu'une cache non partagé.
5.2 - Les Requêtes
La principale activité d'un serveur de noms est de répondre aux requêtes standard. La requête et sa réponse sont toutes deux véhiculées par un message standardisé décrit dans la Rfc 1035. La requête contient des champs QTYPE, QCLASS, et QNAME, qui décrivent le(s) type(s) et les classes de l'information souhaitée, et quel nom de domaine cette information concerne. Les requêtes sont des messages envoyés aux serveurs de noms en vue de consulter les données stockées par le serveur. Par exemple avec Internet, on peut utiliser aussi
bienUdp que Tcp pour envoyer ces requêtes.
5.2.1 - Structure des requêtes
Parmi les champs fixes on trouve 4 bits très importants appelé code d'opération (OPCODE). Le code d'opération permet de donner des informations sur la nature du message (requête, réponse, ...). Les quatre possibilités sont :
Question, Contient la question (nom d'hôte ou de domaine sur lequel on cherche des renseignements et type de renseignements recherchés).
Answer, Contient les RRs qui répondent à la question.
Authority, Contient des RRs qui indiquent des serveurs ayant une connaissance complète de cette
partie du réseau.
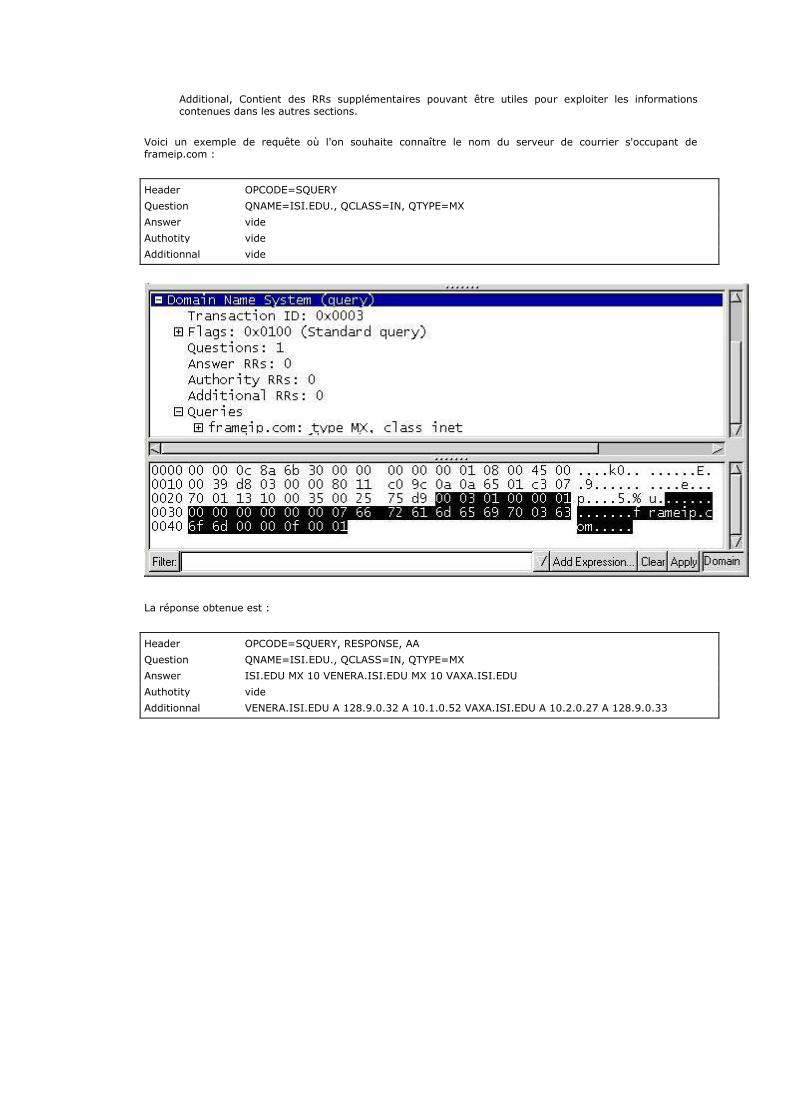
Additional, Contient des RRs supplémentaires pouvant être utiles pour exploiter les informations contenues dans les autres sections.
Voici un exemple de requête où l'on souhaite connaître le nom du serveur de courrier s'occupant de
frameip.com :
Header OPCODE=SQUERY
Question QNAME=ISI.EDU., QCLASS=IN, QTYPE=MX
Answer vide
Authotity vide
Additionnal vide
La réponse obtenue est :
Header OPCODE=SQUERY, RESPONSE, AA
Question QNAME=ISI.EDU., QCLASS=IN, QTYPE=MX
Answer ISI.EDU MX 10 VENERA.ISI.EDU MX 10 VAXA.ISI.EDU
Authotity vide
Additionnal VENERA.ISI.EDU A 128.9.0.32 A 10.1.0.52 VAXA.ISI.EDU A 10.2.0.27 A 128.9.0.33
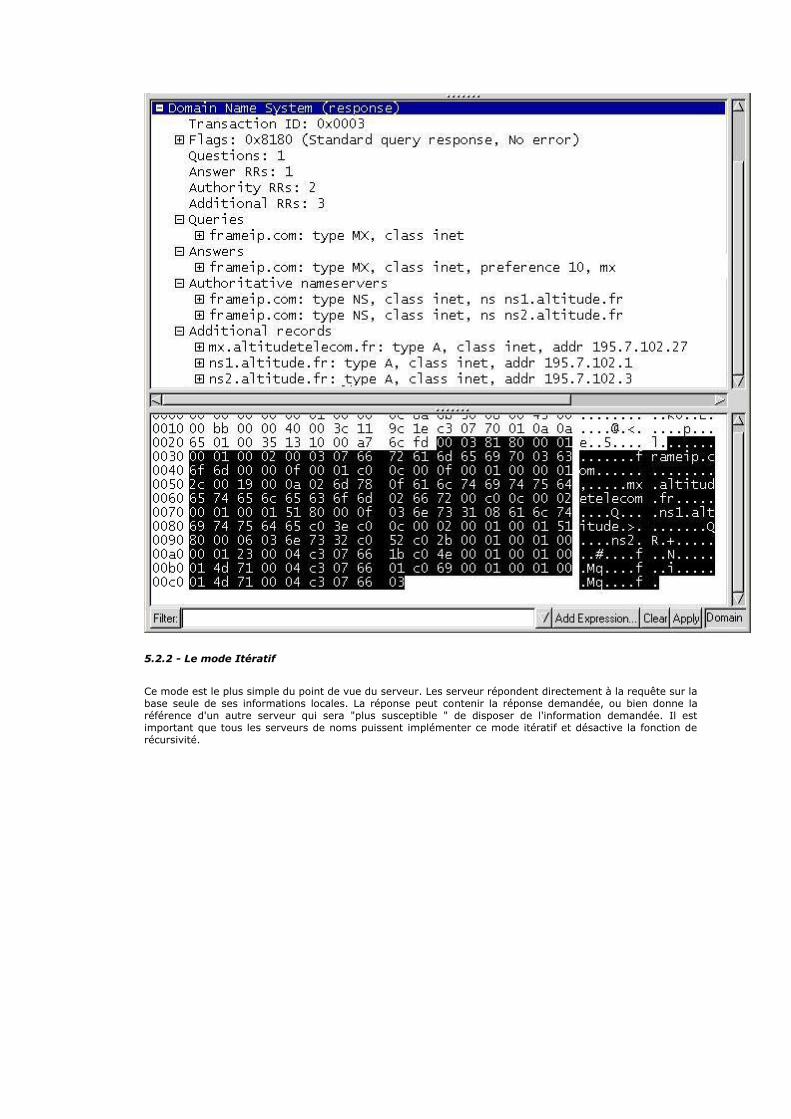
5.2.2 - Le mode Itératif
Ce mode est le plus simple du point de vue du serveur. Les serveur répondent directement à la requête sur la base seule de ses informations locales. La réponse peut contenir la réponse demandée, ou bien donne la référence d'un autre serveur qui sera "plus susceptible " de disposer de l'information demandée. Il est important que tous les serveurs de noms puissent implémenter ce mode itératif et désactive la fonction de récursivité.

Les avantages d'une résolution itérative :
Dans le cas d'une implémentation simplifiée d'un résolveur qui ne sait exploiter d'autres réponses
qu'une réponse directe à la question.
Dans le cas d'une requête qui doit passer à travers d'autres protocoles ou autres "frontières" et doit pouvoir être envoyée à un serveur jouant le rôle d'intermédiaire.
Dans le cas d'un réseau dans lequel intervient une politique de cache commun plutôt qu'un cache individuel par client.
Le service non-récursif est approprié si le résolveur est capable de façon autonome de poursuivre sa
recherche et est capable d'exploiter l'information supplémentaire qui lui est envoyée pour l'aider à résoudre
son problème.
5.2.3 - Le mode Récursif
Le mode récursif une fois est plus simple du point de vue du client. Dans ce mode, le premier serveur prend le rôle de résolveur.

L'utilisation du mode récursif est limité aux cas qui résultent d'un accord négocié entre le client et le serveur. Cet accord est négocié par l'utilisation de deux bits particuliers des messages de requête et de réponse :
Le bit Ra (Récursion admissible), est marqué ou non par le serveur dans toutes les réponses. Ce bit est marqué si le serveur accepte à priori de fournir le service récursif au client, que ce dernier l'ait demandé ou non. Autrement dit, le bit RA signale la disponibilité du service plutôt que son utilisation.
Les requêtes disposent d'un bit Rd (pour "récursion désirée"). Ce bit indique que le requérant désire utiliser le service récursif pour cette requête. Les clients peuvent demander le service récursif à n'importe quel serveur de noms, bien que ce service ne puisse leur être fourni que par les serveurs qui
auront déjà marqué leur bit RA, ou des serveurs qui auront donné leur accord pour ce service par une négociation propriétaire ou tout autre moyen hors du champ du protocole Dns.
Le mode récursif est mis en oeuvre lorsqu'une requête arrive avec un bit RD marqué sur un serveur
annonçant disposer de ce service, le client peut vérifier si le mode récursif a été utilisé en constatant que les deux bits Ra et Rd ont été marqués dans la réponse. Notez que le serveur de noms ne doit pas utiliser le service récursif s'il n'a pas été explicitement demandé
par un bit RD, car cela interfère avec la maintenance des serveurs de noms et de leurs bases de données. Lorsque le service récursif est demandé et est disponible, la réponse récursive à une requête doit être l'une des suivantes :
La réponse à la requête, éventuellement préfacée par un ou plusieurs RR CNAME qui indiquent les alias trouvés pendant la recherche de la réponse.
Une erreur de nom indiquant que le nom demandé n'existe pas. Celle-ci peut inclure des RR CNAME qui indiquent que la requête originale pointait l'alias d'un nom qui n'existe pas.
Une indication d'erreur temporaire.

Si le service récursif n'est pas requis, ou n'est pas disponible, la réponse non-récursive devra être l'une des suivantes :
Une réponse d'erreur "autorisée" indiquant que le nom n'existe pas.
Une indication temporaire d'erreur.
Une combinaison : - Des RR qui répondent à la question, avec indication si les données sont extraites d'une zone ou
d'un cache. - D'une référence à un serveur de noms qui gère une zone plus "proche" du nom demandé que le serveur qui a été contacté.
Les RR que le serveur de nom pense être utile au requérant pour continuer sa recherche.
5.2.4 - Exemple de résolution de noms
Nous allons voir avec un exemple comment se fait le parcours de l'arborescence pour la résolution de noms. On prend par exemple l'adresse suivante : www.frameip.com Il faut alors :
Trouver le NS de la racine
Interroger pour trouver le NS des .com
Poser la question finale au NS de frameip.com qui identifiera l'entrée www
5.3 - Les Requêtes inverses
5.3.1 - Fonctionnement
Dans le cas d'une requête inverse, le solveur envoie une demande à un serveur de noms afin que celui-ci renvoie le nom d'hôte associé à une adresse Ip connue. C'est utile surtout pour des questions de sécurité, pour savoir avec qui on échange. La mise en place de la résolution inverse est un peu plus compliquée, car l'adressage par nom est basé sur la notion de domaine qui souvent n'a rien à voir avec la structure des adresses Ip. Par conséquent, seule une recherche approfondie portant sur tous les domaines peut garantir l'obtention d'une réponse exacte. Deux moyens existent pour convertir une adresse IP en nom d'hôte :
l'usage de requêtes Dns inversées (Au sens Opcode=Iquery où Iquery = 1) ou les requêtes Dns de type Ptr (Classe IN et Opcode=Query). En effet, dans le premier cas, on envoie un message Dns contenant une réponse et on demande toutes les questions pouvant conduire à cette réponse, alors que les requêtes Ptr posent la question de façon explicite : Qui est l'adresse a.b.c.d ?
Une requête Dns inversée a la particularité d'avoir le champ Question vide, et de contenir une entrée dans le champ Answer. Pour que le serveur Dns comprenne le sens de la requête, le champ Opcode des en-têtes du message Dns doit être à la valeur Iquery. Voici une représentation extraite de la Rfc 1035 :
Header OPCODE=IQUERY, ID=997
Question "EMPTY"
Answer "ANYNAME" A IN 10.1.0.52
Authotity "EMPTY"
Additionnal "EMPTY"
Pour répondre aux requêtes inverses en évitant des recherches exhaustives dans tous les domaines, un domaine spécial appelé in-addr.arpa a été créé. Une fois le domaine in-addr.arpa construit, des enregistrements de ressources spéciaux sont ajoutés pour associer les adresses IP au noms d'hôte qui leur correspondent. Il s'agit des enregistrements pointeurs (PTR), ou enregistrements de références. Par exemple pour connaître le nom de la machine dont l'adresse est 137.194.206.1, on envoie une requête dont la
question contient QNAME=1.206.194.137.IN-ADDR.ARPA.
5.3.2 - Exemple
Ligne de commande permettant d'établir la requête
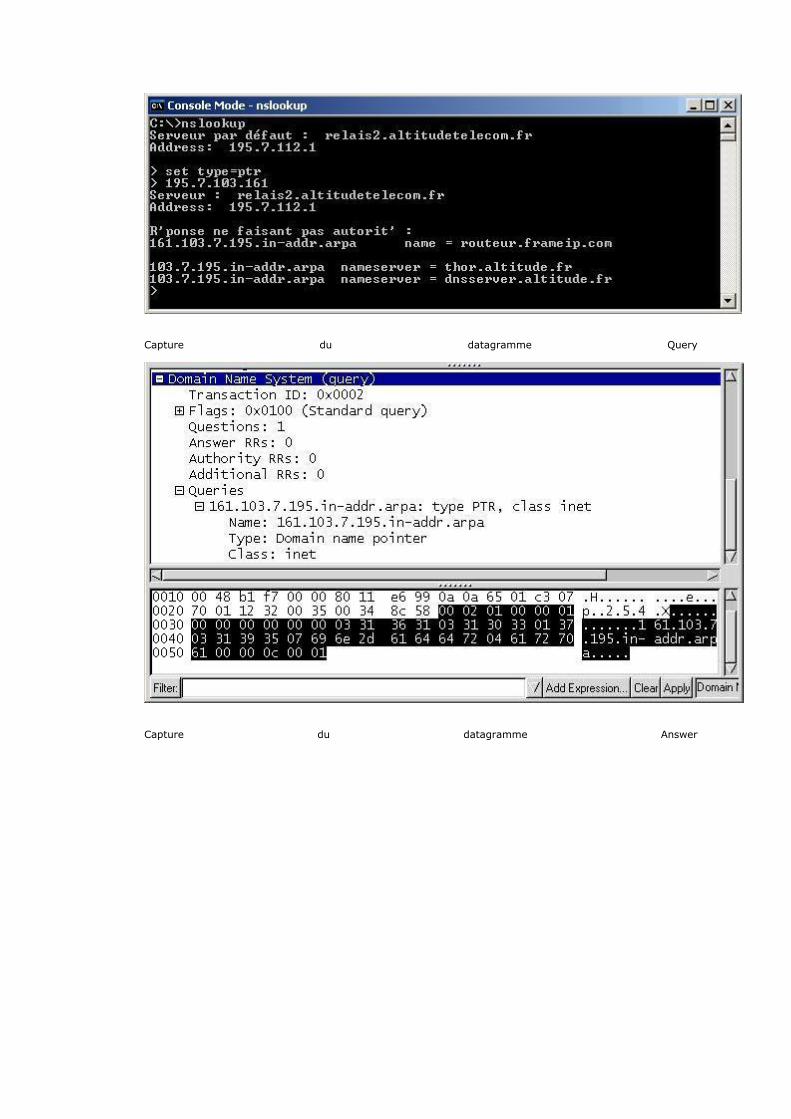
Capture du datagramme Query
Capture du datagramme Answer

6 - La sécurité
6.1 - Fragilité
Sans le Dns, la majorité des applications d'Internet s'arrêtent! De plus le Dns est souvent la cible favorite desdénis de service (Dos) des pirates. Il y a aussi un exemple simple avec le système de requêtes inversées vu précédemment qui entraîne une fuite d'information (ceci représentant la partie découverte de l'attaque). Jusqu'ici,
nous n'avons utilisés les requêtes Dns inversées que pour faire la correspondance entre une adresse Ip et l'hostname associé (Requête de classe IN et de type A). Or, nous pouvons faire des recherches inversées sur d'autres types de ressources. Par exemple, nous pourrions émettre une requête inverse au sujet des champs HINFO1 pour se chercher toutes les machines tournant sous une version vulnérable d'un certain système d'exploitation. En effet, le champs Hinfo est sensé contenir le type et version du Système d'Exploitation de la machine.
6.2 - Sécurisation
Les normes de sécurisation du Dns portent sur la certification de l'origine des données, l'authentification des transactions et des requêtes. Elles ne portent pas sur la confidentialité des informations : les données échangées ne sont pas chiffrées avant d'être transportées par le réseau et n'apporte aucune protection aux en-têtes des messages Dns, ou aux trames de commandes (requêtes Dns). La sécurisation du Dns doit assurer l'authentification d'une transaction, c'est à dire que le Resolver reçoit une
réponse provenant bien du serveur à qui il a envoyé une requête, qu'il s'agit de la réponse correspondant effectivement à sa requête, que la trame n'a pas été "diddled" (dupé) lors de son transport par le réseau. L'authentification de transaction est assurée par le rajout d'un "Enregistrement de Signature" (SIG RR) à la fin de la trame de réponse. La signature est créée à partir d'une concaténation entre la réponse du serveur et la requête du client. La clef privée utilisée pour la signature appartient au serveur qui émet le message signé, et non à la zone. Les clefs publiques utilisées dans les mécanismes de sécurisation du Dns sont contenues dans des
"Enregistrements de Clefs" (Key RR) stockés dans la base de données du Dns. Ces clefs publiques peuvent être destinées à une zone, à un host ou autre. Un KEY RR est authentifié par un SIG RR comme n'importe quel autre enregistrement.

7 - Conclusion
Le système de gestion de noms Dns est efficace et unificateur. De plus, comme tous les systèmes cruciaux d'Internet, il y a au moins une implémentation efficace et gratuite. C'est portable et très complet.
Bind est le gestionnaire de Dns le plus connu et probablement un des plus complets. Il fonctionne sous Unix et Windows. Nouvelle syntaxe des fichiers de configuration sur la dernière version 9 avec un système de log flexible par
catégories, une liste d'accès par adresse Ip sur les requêtes, transfert de zones et mises a jours pour chaque zone, transfert de zones plus efficaces et enfin des meilleures performances pour les serveurs gérant des milliers de zones. Récemment est apparue le DnsSEC. DnsSEC est un ensemble de protocoles utilisant de la cryptographie symétrique et/ou asymétrique incorporant un système de stockage et de publication des clés publiques. Ainsi, il permet de résoudre les différents problèmes de sécurité lors des transferts de zone, des mises à jour (update dynamique par
exemple) et de rendre inopérant le Dns spoofing (détournement de flux entre deux machines à l'avantage du pirate). A ces nouveautés s'ajoute la compatibilité avec IPv6 et surtout l'interopérabilité des deux systèmes d'adressages, ce qui en fait un système très complexe. Les dernières versions de Bind 9 incorporent ces dernières possibilités, mais il faudrait un déploiement à l'échelle mondiale pour que le système soit réellement utilisable.
NTP
1 - Introduction 2 - Nécessité d'avoir un temps précis et fiable
3 - Bref historique 3.1 - TP 3.2 - NTP 3.3 - SNTP 4 - Objectifs 5 - Architecture système et réseau, NTP v3
5.1 - Références de temps 5.2 - Précision 5.3 - Structure d'un réseau NTP 5.4 - Fonctionnement d'un serveur NTP : cinq modes différents 6 - Mécanismes de synchronisation 6.1 - Gestion des messages 6.2 - Traitements internes
6.3 - Réglage de l'horloge 7 - Exemple de trame NTP 8 - Les serveurs NTP d'Internet 9 - Conclusion 10 - Les liens 11 - Discussion autour de la documentation 12 - Suivi du document
1 - Introduction
Actuellement tout équipement informatique dispose d'une horloge matérielle ou logicielle à laquelle il est fait référence pour horodater des fichiers, des transactions, des courriers électroniques, etc... Cette horloge, bien que conçue autour d'un oscillateur à quartz, dérive comme toute montre ordinaire.
Ceci est d'autant plus gênant lorsque les machines sont en réseau et partagent des ressources communes comme des
systèmes de fichiers. Par exemple, certains outils de développement, comme la commande Unix "make", basent leur travail sur la comparaison des dates de modification de fichiers. De même, la cohérence et la comparaison de
messages de "logs" de plusieurs systèmes devient très difficile s'ils ne sont pas à la même heure.
La nécessité de synchroniser des équipements en réseau paraît alors évidente. C'est la finalité du protocole Network Time Protocol (NTP), qui synchronise les machines et les routeurs des réseaux. Au cours des 20 dernières années de recherches sur ce sujet sensible, trois protocoles ont vu le jour, avec pour aboutissement la version actuelle de NTP
utilisée par les systèmes.
Nous allons passer rapidement sur ces précurseurs du protocole NTP. Nous définirons ensuite les buts du protocole. Puis nous verrons les différentes architectures qui implémentent ce protocole. Nous détaillerons enfin les mécanismes de synchronisation mis en place dans NTP.
2 - Nécessité d'avoir un temps précis et fiable
Bases de données distribuées : transactions, journalisation, logs
Estampilles de documents sécurisés : certification et cryptographie
Aviation : contrôle de trafic et enregistrement de positions

Programmation télévision et radio
Multimédia : synchronisation pour les téléconférences en temps réel
Gestion des réseaux
...
3 - Bref historique
Le temps légal défini par la seconde légale a été basé :
Sur le temps universel (TU) jusqu'en 1956.
Sur le temps des éphémérides (TE) de 1956 à 1967.
Sur le temps atomique à jet de césium à partir de 1967.
Jusqu'en 1956 la seconde légale était définie comme la 86400ème partie du jour solaire moyen. A partir de 1956 la seconde des éphémérides a été définie par le comité international des poids et mesure comme étant la fraction 1/31556925.9747 de l'année tropique pour 1900 janvier 0 à 12 heures de temps des éphémérides. Depuis 1967 la seconde légale est définie comme la durée de 9 192 631 770 périodes de la radiation correspondant à la transition entre les deux niveaux hyperfins de l'état fondamental de l'atome de césium 133.
Afin de de synchroniser les systèmes à travers les réseaux, plusieurs protocoles ont vu le jour avant l'arrivée de la version de NTP actuellement utilisée.
3.1 - TP
En 1983, un premier protocole, le Time Protocole est réalisé RFC 868. Il est rapidement popularisé et repris sur les systèmes Unix au travers du démons timed et de la commande rdate. Cependant ses limites sont vite atteintes
car, d'une part, il n'offre qu'une précision de l'ordre de la seconde, et d'autre part, il n'implémente aucun mécanisme pour compenser la dérive des horloges.
3.2 - NTP
Dans le même temps, les toutes premières versions de NTP sont élaborées sous le nom d'Internet Clock Service.
On voit cette implémentation utilisée dans le protocole de routage HELLO. Cependant, la première version de NTP à proprement parlé apparaît en 1988 et ses spécifications sont relatées dans le RFC 1059. Dans cette version sont déjà présents les modes de communication client/serveur et symétrique pour la distribution du temps. Un an plus tard (1989), apparaît la deuxième version de NTP RFC 1119 qui introduit un aspect sécuritaire car il permet de crypter les paquets de communication grâce à un algorithme de chiffrage à clé secrète (DES-CBS). De son coté, la Digital Equipment Corporation (DEC) met au point le Digital Time Synchronisation Service (DTSS). Se basant alors
sur les bonnes idées de ce dernier et sur NTPv2, une troisième version de NTP voit le jour en 1992 RFC 1305. C'est la plus utilisée jusqu'à ce jour. Depuis 1994, une nouvelle spécification de NTP est à l'étude pour prendre en compte les changements de l'Internet comme le support d'IPv6 ou bien encore le chiffrement des paquets avec un système à clé publique. Bien que cette dernière spécification n'ai toujours pas été rendue publique, une implémentation de cette version est déjà disponible. Pour le moment elle est très peu répandue bien qu'elle assure comme ses prédécesseurs une compatibilité ascendante. On la trouve surtout sur le réseau "DCnet Research Network" où son comportement est mis à l'épreuve. Bien évidemment, chaque version de NTP a apporté
son lot d'améliorations quant à l'efficacité des algorithmes afin d'obtenir une meilleure fiabilité et disponibilité du système.
3.3 - SNTP
En dernier lieu, une version simplifiée du protocole NTP est développée en parallèle. Il s'agit du Simple Network Time Protocol (SNTP) spécifié dans la RFC 4330 et qui en est déjà à sa quatrième version. SNTP est destiné à des réseaux où la précision de l'ordre de la seconde est suffisante (exemple : workstations). A la base, SNTP amène un allègement des algorithmes de traitement des paquets NTP, ce qui permet d'envisager SNTP sur des systèmes
embarqués où la capacité de calculs, notamment à virgule flottante, est généralement très limité. L'objectif de ce nouveau protocole est de faciliter l'implémentation d'un client NTP n'ayant pas besoin de beaucoup de précision tout en étant capable de dialoguer avec des serveurs NTP standards. Cependant, l'utilisation de SNTP doit rester limitée pour ne pas perturber et fausser le réseau NTP. En fait, il est vivement recommandé de n'utiliser SNTP qu'en bout de chaîne dans les échange NTP, c'est à dire directement sur une horloge de référence (horloge atomique) ou bien sur les systèmes clients exclusivement. On doit ainsi éviter de faire d'un système réglé par
SNTP, une référence pour un autre système.
4 - Objectifs
Ce à quoi sert NTP
donner la meilleure précision possible compte tenu des conditions matérielles

résister à une multitude de pannes (y compris les bugs d'implémentation)
optimiser l'utilisation de la diversité et de la redondance présentes sur Internet
organiser de manière automatique la topologie d'un sous-réseau afin d'avoir une précision et une fiabilité optimales
réaliser l'authentification cryptographique basée sur des infrastructures de clefs symétriques et de clefs publiques
Ce à quoi ne sert pas NTP
temps local : le noyau le fait
contrôle d'accès : firewall
non-répudiation : utiliser un protocole spécifique si besoin
5 - Architecture système et réseau, NTP v3
NTP est un protocole basé sur les protocoles UDP et IP. C'est donc un protocole Internet basé sur l'adressage IP, en mode non connecté avec User Datagram Protocol sur le port 123.
La synchronisation de l'heure est diffusée depuis des serveurs primaires dans une arborescence en réseau. Près de 200 000 clients et serveurs utilisent NTP sur internet.
NTP a été porté sur la plupart des plateformes dont Windows, Linux, Unix,... La version 3 de NTP, dont nous parlons
ici, est utilisée depuis 1992.
5.1 - Références de temps
Elles sont toutes dérivées plus ou moins directement d'horloges atomiques. On peut citer :
les horloges pilotées par des signaux radio émis par des émetteurs spécialisés comme DCF77 en
Allemagne
les horloges pilotées par des émetteurs de radio-diffusion publiques transmettant, en plus de leur programme, des informations horaires comme l'émetteur TDF d'Allouis diffusant France-Inter
les systèmes de positionnement, comme le GPS, constituent d'excellentes sources de référence
5.2 - Précision
Le protocole NTP fournit différents niveaux de précision :
de l'ordre d'une dizaine de millisecondes sur les réseaux WAN
inférieure à la milliseconde sur les réseaux LAN
inférieure à la microseconde lorsqu'on utilise une référence de temps de type GPS (sur les LAN)
L'architecture de NTPv4 permet d'atteindre une précision 10 fois plus grande, de l'ordre de la microseconde sur les
nouveaux réseaux plus performants.
5.3 - Structure d'un réseau NTP
L'une des caractéristiques principales d'un réseau NTP est sa structure pyramidale. Un certain nombre de sources de référence, dites primaires, synchronisées par la radio ou un réseau filaire sur les standards nationaux, sont connectées à des ressources largement accessibles, comme des passerelles de backbone et des serveurs de temps primaires.
Le but de NTP est de transporter ces informations de temps de ces serveurs vers d'autres serveurs de temps
reliés à Internet. Il vérifie aussi les horloges pour minimiser les erreurs dues aux problèmes de propagation sur le réseau.
Quelques machines ou passerelles des réseaux locaux, agissant en tant que serveurs de temps secondaires, font tourner NTP, en connexion avec un ou plusieurs serveurs primaires.
Dans l'optique de réduire le trafic engendré par le protocole, les serveurs de temps secondaires distribuent le temps via NTP aux machines restantes sur le réseau local.

Dans un souci de fiabilité, certaines machines peuvent être équipées avec des horloges moins précises, mais aussi moins chères, afin d'être utilisées pour des sauvegardes, en cas de défaillance des serveurs de temps (primaires ou secondaires) ou des chemins réseaux.
Pour résumer : des références de temps synchronisent des serveurs NTP qui leur sont directement raccordés. Ceux-ci constituent la « strate 1 » et ils vont synchroniser chacun plusieurs dizaines d'autres serveurs qui vont constituer la « strate 2 » et ainsi de suite jusqu'aux clients terminaux. Ce principe permet de bien répartir la charge des serveurs tout en conservant une distance aux sources de référence relativement faible. Relations entre
serveurs NTP :
5.4 - Fonctionnement d'un serveur NTP : cinq modes différents
Sauf dans le mode broadcast, une association est créée quand deux machines échangent des messages. Une
association peut fonctionner dans un des cinq modes suivants :
Mode symétrique actif
Un serveur fonctionnant dans ce mode envoie périodiquement des messages, sans se soucier de l'état de ses voisins (joignables, serveurs primaires ou secondaires, clients). Il indique ainsi sa « volonté » de synchroniser d'autres serveurs et d'être synchroniser par eux.
Mode symétrique passif ce type d'association est généralement créée lors de l'arrivée sur le serveur d'un message d'un autre serveur (en mode symétrique actif). Le serveur annonce son intention de synchroniser et d'être
synchronisé. Seulement il ne le fait qu'après avoir été sollicité par un autre serveur.
Mode client
La machine envoie des messages régulièrement, sans se préoccuper de l'état de ses voisins. La station (typiquement, elle appartient à un réseau LAN) indique ainsi sa « volonté » d'être synchronisée.
Mode serveur
L'association de ce mode est créée lors de la réception d'une requête (un message) d'une station en mode client.
Mode broadcast
Destiné aux réseaux locaux, il se limite à une diffusion d'informations horaires pour des clients pouvant être soit passifs, soit découvrant ainsi les serveurs avec lesquels ils vont se synchroniser.
La fiabilité du système est assurée par la redondance des serveurs et l'existence de plusieurs chemins dans un
réseau, pour aller d'un point à un autre.
Les serveurs primaires (strate 1) se synchronisent sur des horloges de référence par radio, ou autre. Il en existe environ 230 dans le monde. Les clients et serveurs communiquent en mode client/serveur, symétrique ou multicast, avec ou sans cryptage.
Les serveurs secondaires (environ 4500)(ex : serveurs de campus universitaires) se synchronisent sur plusieurs serveurs primaires en mode client/serveur, et avec d'autres serveurs secondaires en mode symétrique.
D'une manière générale, les serveurs d'une strate se synchronisent sur plusieurs serveurs de la strate supérieure en mode client/serveur, et avec d'autres serveurs de la même strate en mode symétrique.

Les simples clients se synchronisent en mode client/serveur s'ils sont isolés, ou en mode multicast s'ils font partie d'un réseau (ex : machines universitaires se synchronisant sur plusieurs serveurs de strate 3, comme les serveurs des départements universitaires).
Une station en mode client envoie de temps en temps un message NTP à une station en mode serveur, généralement peu de temps après avoir redémarré. Le serveur n'a pas besoin d'enregistrer des informations sur l'état du client, puisque c'est le client qui décide quand envoyer une requête, en fonction de son état en local. Dans ce mode, le fonctionnement pourrait être simplifié en un mécanisme de RPC sans perdre de précision ni de
robustesse, surtout dans le cadre d'un réseau LAN à haut débit.
Dans les modes symétriques, la distinction client/serveur disparaît. Le mode passif est destiné aux serveurs de temps qui se trouvent près de la racine du système de synchronisation (les serveurs de la strate 1 ou 2).
Le mode symétrique actif est destiné aux serveurs de temps qui se trouvent près des feuilles du réseau de synchronisation, sur les strates les plus élevées. La fiabilité du service de temps peut être généralement assurée avec deux stations sur le niveau au-dessus (strate plus petite) et une station sur le même niveau. Normalement, une station fonctionne en mode actif (symétrique, client ou broacast) avec une configuration donnée au
démarrage, alors que les autres sont en mode passif (symétrique ou serveur) sans configuration préalable.
Cependant une erreur intervient lorsque deux stations qui communiquent sont dans le même mode, sauf pour le mode symétrique actif. Dans ce cas, chaque station ignore les messages de l'autre et l'association créée par cet échange n'est rompue qu'en cas de coupure de réseau entre les deux stations.
Le mode broadcast est surtout destiné aux réseaux locaux avec beaucoup de stations et où la précision requise n'est pas très importante. Le déroulement classique est le suivant : un ou plusieurs serveurs de temps du réseau envoie régulièrement des broacasts aux stations, pour déterminer l'heure, avec une latence de l'ordre de quelques
millisecondes.
Comme dans le mode client/serveur, le protocole utilisé peut être simplifié. Ainsi, un système basé sur l'algorithme de sélection d'horloge peut être utilisé dans le cas où on dispose de multiples serveurs de temps, afin d'optimiser la fiabilité.
NTP intègre un système d'exploration du réseau pour découvrir automatiquement de nouveaux serveurs NTP, par différentes méthodes :
Multicast : - Les serveurs inondent périodiquement le réseau local par un message multicast. - Les clients utilisent le mode client/serveur lors du premier contact pour mesurer le temps de
propagation puis restent en écoute.
Manycast : (mode plus précis)
- Les clients inondent le réseau local par un message multicast. - Les serveurs répondent en multicast. - Les clients communiquent ensuite avec les serveurs comme s'ils avaient été configurés en unicast.
Des contrôles de time-out et de TTL garantissent le bon déroulement de la configuration.
6 - Mécanismes de synchronisation
6.1 - Gestion des messages
Comme beaucoup de systèmes distribués sur un réseau, les hôtes NTP (clients ou serveurs) utilisent des messages pour communiquer.
Voici les champs contenus dans un paquet NTP :
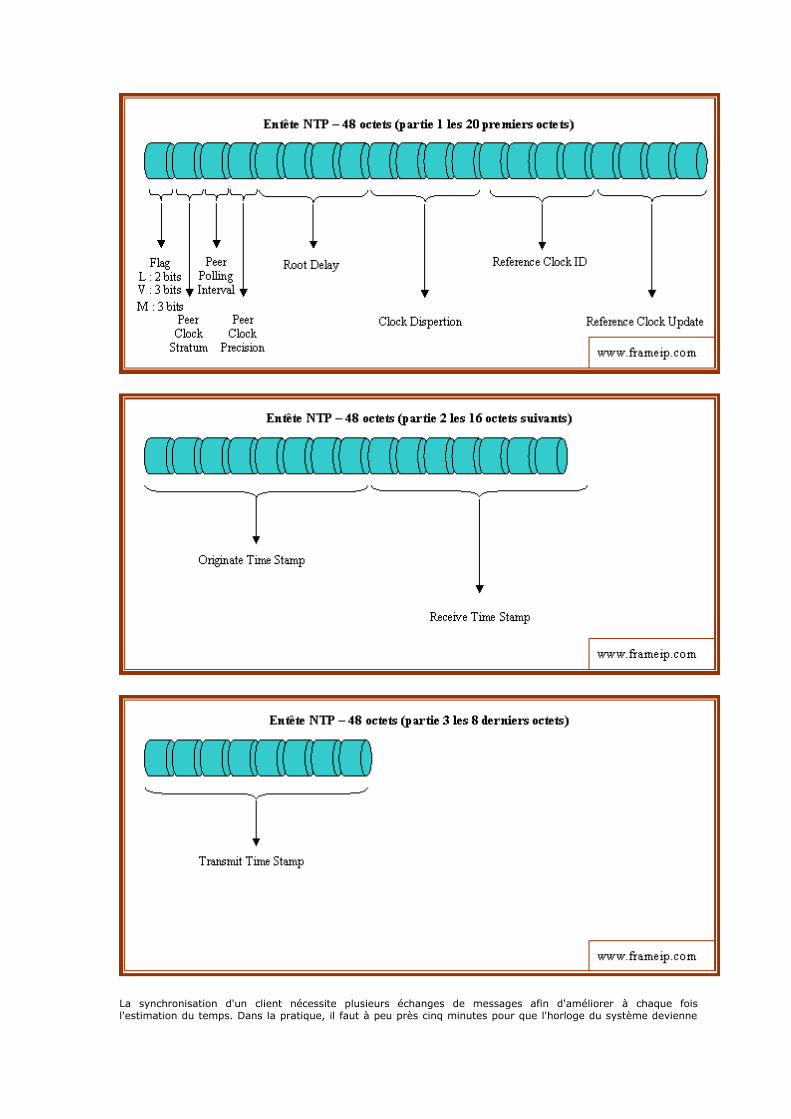
La synchronisation d'un client nécessite plusieurs échanges de messages afin d'améliorer à chaque fois l'estimation du temps. Dans la pratique, il faut à peu près cinq minutes pour que l'horloge du système devienne

fiable. Une fois cette synchronisation effectuée, le client pourra devenir à son tour un système de référence. De plus, plus le client échange des messages avec ses serveurs de référence, plus il est capable de discerner, parmi eux, ceux qui amènent une certaine part d'erreur dans la détermination du temps. Le cas échéant, il peut décider de ne plus faire appel à ces systèmes appelés « falsetickers ».
L'échange de messages conduisant à la synchronisation suit la procédure suivante :
Le système désirant être synchronisé envoie d'abord un paquet dans lequel il initialise le champ «
Originate timestamp » avec sa propre heure système.
Le serveur stocke ensuite l'heure de réception du paquet dans le champ « Receive timestamp » du
même paquet.
Ensuite il effectue un contrôle de validité du paquet pour s'assurer qu'il doit bien effectuer le traitement (vérification du stratum du client, authentification, ...).
Avant de retourner le paquet à l'expéditeur, le champ « Transmit timestamp » est renseigné avec l'heure courante du serveur.
Le client enregistre l'heure de réception de la réponse afin de pouvoir estimer le temps de trajet du
paquet. En supposant que les délais de transmission des messages sont symétriques, le temps de trajet correspond à la moitié du temps d'attente total moins le temps de traitement sur la machine distante. (NTP implémente un algorithme de Huff&Puff pour compenser les délais de transmission asymétriques)
Le client lui aussi vérifie la validité de la réponse pour savoir si elle doit être prise en compte.
Le système client peut alors estimer le décalage de son horloge avec le système de référence.
6.2 - Traitements internes
Une fois la réponse du serveur obtenue, un ensemble d'algorithmes prend le relais afin de déterminer le décalage de l'horloge locale avec le système distant.
On peut représenter la suite des traitements comme ci-dessous :
Les premières étapes à franchir servent à assurer la sécurité du protocole :
Les filtres éliminent les réponses non conformes aux attentes du protocole.
L'algorithme de sélection détecte les données erronées afin de lutter contre les comportements byzantins
des serveurs.
Ensuite l'algorithme de combinaison compare les réponses des différents serveurs entres elles et avec les réponses précédentes pour déterminer le mieux possible le décalage de l'horloge locale.
Enfin l'algorithme de contrôle de l'horloge utilisera les méthodes qui sont à sa disposition pour recaler l'horloge.
6.3 - Réglage de l'horloge
Une fois que le décalage a été déterminé, il faut agir sur l'horloge pour se synchroniser. Plusieurs possibilités d'action s'offrent alors au processus qui interagit avec l'horloge:
Il peut changer brutalement l'heure système. Cette technique est à éviter car elle perturbe les
applications utilisant l'horloge du système et peut même engendrer une certaine instabilité.
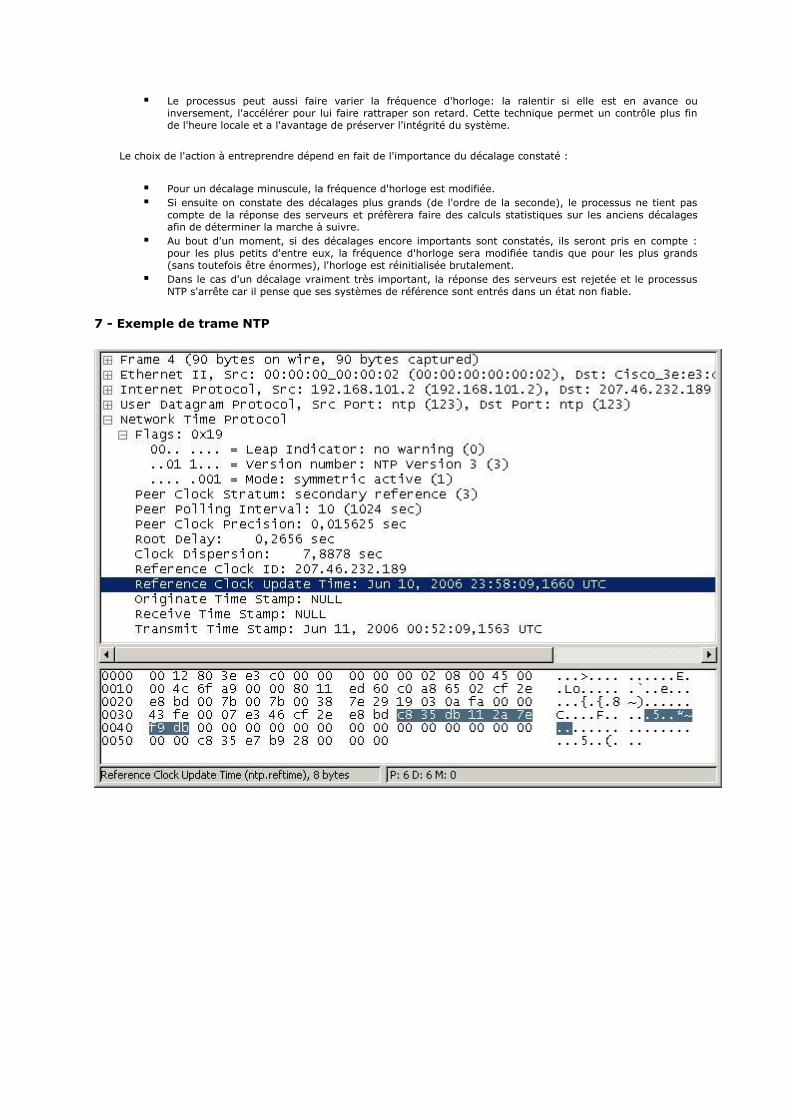
Le processus peut aussi faire varier la fréquence d'horloge: la ralentir si elle est en avance ou inversement, l'accélérer pour lui faire rattraper son retard. Cette technique permet un contrôle plus fin de l'heure locale et a l'avantage de préserver l'intégrité du système.
Le choix de l'action à entreprendre dépend en fait de l'importance du décalage constaté :
Pour un décalage minuscule, la fréquence d'horloge est modifiée.
Si ensuite on constate des décalages plus grands (de l'ordre de la seconde), le processus ne tient pas
compte de la réponse des serveurs et préfèrera faire des calculs statistiques sur les anciens décalages afin de déterminer la marche à suivre.
Au bout d'un moment, si des décalages encore importants sont constatés, ils seront pris en compte :
pour les plus petits d'entre eux, la fréquence d'horloge sera modifiée tandis que pour les plus grands (sans toutefois être énormes), l'horloge est réinitialisée brutalement.
Dans le cas d'un décalage vraiment très important, la réponse des serveurs est rejetée et le processus
NTP s'arrête car il pense que ses systèmes de référence sont entrés dans un état non fiable.
7 - Exemple de trame NTP
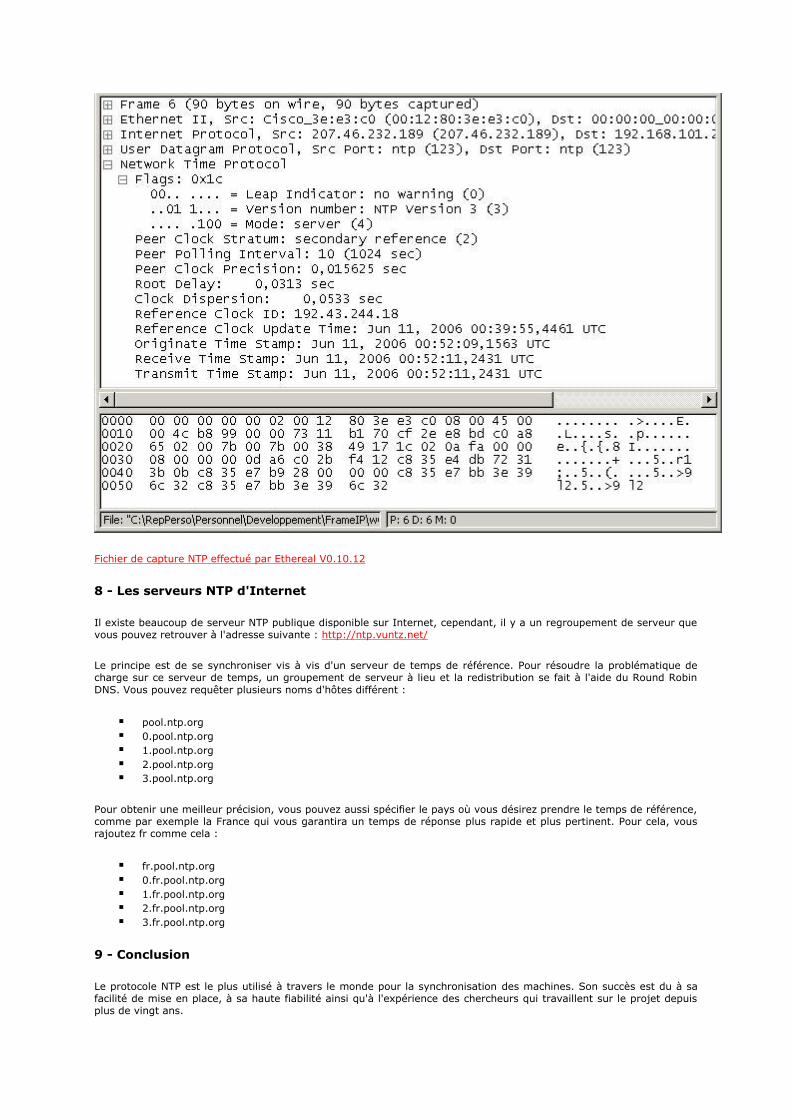
Fichier de capture NTP effectué par Ethereal V0.10.12
8 - Les serveurs NTP d'Internet
Il existe beaucoup de serveur NTP publique disponible sur Internet, cependant, il y a un regroupement de serveur que vous pouvez retrouver à l'adresse suivante : http://ntp.vuntz.net/
Le principe est de se synchroniser vis à vis d'un serveur de temps de référence. Pour résoudre la problématique de charge sur ce serveur de temps, un groupement de serveur à lieu et la redistribution se fait à l'aide du Round Robin
DNS. Vous pouvez requêter plusieurs noms d'hôtes différent :
pool.ntp.org
0.pool.ntp.org
1.pool.ntp.org
2.pool.ntp.org
3.pool.ntp.org
Pour obtenir une meilleur précision, vous pouvez aussi spécifier le pays où vous désirez prendre le temps de référence, comme par exemple la France qui vous garantira un temps de réponse plus rapide et plus pertinent. Pour cela, vous rajoutez fr comme cela :
fr.pool.ntp.org
0.fr.pool.ntp.org
1.fr.pool.ntp.org
2.fr.pool.ntp.org
3.fr.pool.ntp.org
9 - Conclusion
Le protocole NTP est le plus utilisé à travers le monde pour la synchronisation des machines. Son succès est du à sa facilité de mise en place, à sa haute fiabilité ainsi qu'à l'expérience des chercheurs qui travaillent sur le projet depuis plus de vingt ans.

La quatrième version du protocole permettra encore plus de fiabilité et de précision dans la détermination du temps. Mais la version actuellement utilisée en fait déjà un protocole incontournable que tout bon informaticien devrait connaître.
SNMP
1 - Introduction 2 - SNMP (Simple Network Management Protocol) 2.1- Présentation générale
2.2- Fonctionnement 2.3- Les MIBS 3 - Présentation, évolution des versions de SNMP 4 - SNMPv1 et v2 4.1- Les faiblesses de SNMPv1 4.2- Les améliorations de SNMPv2c
5 - SNMP v3 5.1 - User Security Module (USM) 5.1.1 - L'authentification 5.1.2 - Le cryptage 5.1.3 - L'estampillage de temps 5.2 - VACM (View Access Control Model) 5.3 - La trame de SNMPv3
6 - Exemple de trame SNMP 7 - Conclusion 8 - Discussion autour de la documentation 9 - Suivi du document
1 - Introduction
L'informatique est de plus en plus présent dans notre vie de tous les jours. On compte désormais sur les services offerts par les réseaux pour le fonctionnement de l'outil informatique, que ce soit en entreprise, lors de transactions bancaires, lors de téléconférences, etc. Les services offerts sont devenus quasi-indispensables. Pour assurer que ces services soient convenables, il est nécessaire de surveiller le réseau et d'agir quand une erreur se produit.
Sur les réseaux physiques de nombreuses composantes sont donc à surveiller : l'utilisation de la largeur de bande, l'état de fonctionnement des liens, les éventuels goulets d'étranglement, les problèmes de câblage, le bon cheminement de l'information entre les machines, etc. Pour ce faire différents points stratégiques sont à observer
comme les routeurs, les concentrateurs, les liens, les postes, les imprimantes.
Ainsi, en cas de panne ou de mauvais fonctionnement sur le réseau, l'administrateur doit pouvoir interpréter l'information reçue pour identifier la source du problème. Un protocole de gestion est nécessaire pour exercer les fonctions de gestion sur un réseau. Il doit être capable de dialoguer avec tous les éléments de celui-ci.
2 - SNMP (Simple Network Management Protocol)
2.1- Présentation générale
SNMP (Simple Network Management Protocol) est le protocole de gestion de réseaux proposé par l'IETF. Il est actuellement le protocole le plus utilisé pour la gestion des équipements de réseaux. SNMP est un protocole relativement simple. Pourtant l'ensemble de ses fonctionnalités est suffisamment puissant
pour permettre la gestion des réseaux hétérogènes complexes. Il est aussi utilisé pour la gestion à distance des applications: les bases de données, les serveurs, les logiciels, etc.
L'environnement de gestion SNMP est constitué de plusieurs composantes : la station de supervision, les éléments
actifs du réseau, les variables MIB et un protocole. Les différentes composantes du protocole SNMP sont les suivantes:
Les éléments actifs du réseau sont les équipements ou les logiciels que l'on cherche à gérer. Cela va d'une station de travail à un concentrateur, un routeur, un pont, etc. Chaque élément du réseau dispose d'une entité dite agent qui répond aux requêtes de la station de supervision. Les agents sont des modules qui résident dans les éléments réseau. Ils vont chercher l'information de gestion comme par exemple le nombre de paquets en reçus ou
transmis.
La station de supervision (appelée aussi manager) exécute les applications de gestion qui contrôlent les éléments réseaux. Physiquement, la station est un poste de travail.
La MIB (Management Information Base) est une collection d'objets résidant dans une base d'information
virtuelle. Ces collections d'objets sont définies dans des modules MIB spécifiques.

Le protocole, qui permet à la station de supervision d'aller chercher les informations sur les éléments de réseaux et de recevoir des alertes provenant de ces mêmes éléments.
2.2- Fonctionnement
Le protocole SNMP est basé sur un fonctionnement asymétrique. Il est constitué d'un ensemble de requêtes, de
réponses et d'un nombre limité d'alertes. Le manager envoie des requêtes à l'agent, lequel retourne des réponses. Lorsqu'un événement anormal surgit sur l'élément réseau, l'agent envoie une alerte (trap) au manager.
SNMP utilise le protocole UDP [RFC 768]. Le port 161 est utilisé par l'agent pour recevoir les requêtes de la station de gestion. Le port 162 est réservé pour la station de gestion pour recevoir les alertes des agents.
Les requêtes SNMP Il existe quatre types de requêtes: GetRequest, GetNextRequest, GetBulk, SetRequest.
La requête GetRequest permet la recherche d'une variable sur un agent.
La requête GetNextRequest permet la recherche de la variable suivante.
La requête GetBulk permet la recherche d'un ensemble de variables regroupées.
La requête SetRequest permet de changer la valeur d'une variable sur un agent.
Les réponses de SNMP À la suite de requêtes, l'agent répond toujours par GetResponse. Toutefois si la variable demandée n'est pas disponible, le GetResponse sera accompagné d'une erreur noSuchObject.
Les alertes (Traps, Notifications)
Les alertes sont envoyées quand un événement non attendu se produit sur l'agent. Celui-ci en informe la station de supervision via une trap. Les alertes possibles sont: ColdStart, WarmStart, LinkDown, LinkUp, AuthentificationFailure.
2.3- Les MIBS
La MIB (Management Information base) est la basé de données des informations de gestion maintenue par l'agent, auprès de laquelle le manager va venir pour s'informer.
Deux MIB publics ont été normalisées: MIB I et MIB II (dite 1 et 2)
Un fichier MIB est un document texte écrit en langage ASN.1 (Abstract Syntax Notation 1) qui décrit les variables, les tables et les alarmes gérées au sein d'une MIB.
La MIB est une structure arborescente dont chaque noeud est défini par un nombre ou OID (Object Identifier). Elle contient une partie commune à tous les agents SNMP en général, une partie commune à tous les agents SNMP d'un même type de matériel et une partie spécifique à chaque constructeur. Chaque équipement à superviser possède sa propre MIB. Non seulement la structure est normalisée, mais également les appellations
des diverses rubriques.
Ces appellations ne sont présentes que dans un souci de lisibilité. En réalité, chaque niveau de la hiérarchie est repéré par un index numérique et SNMP n'utilise que celui-ci pour y accéder.
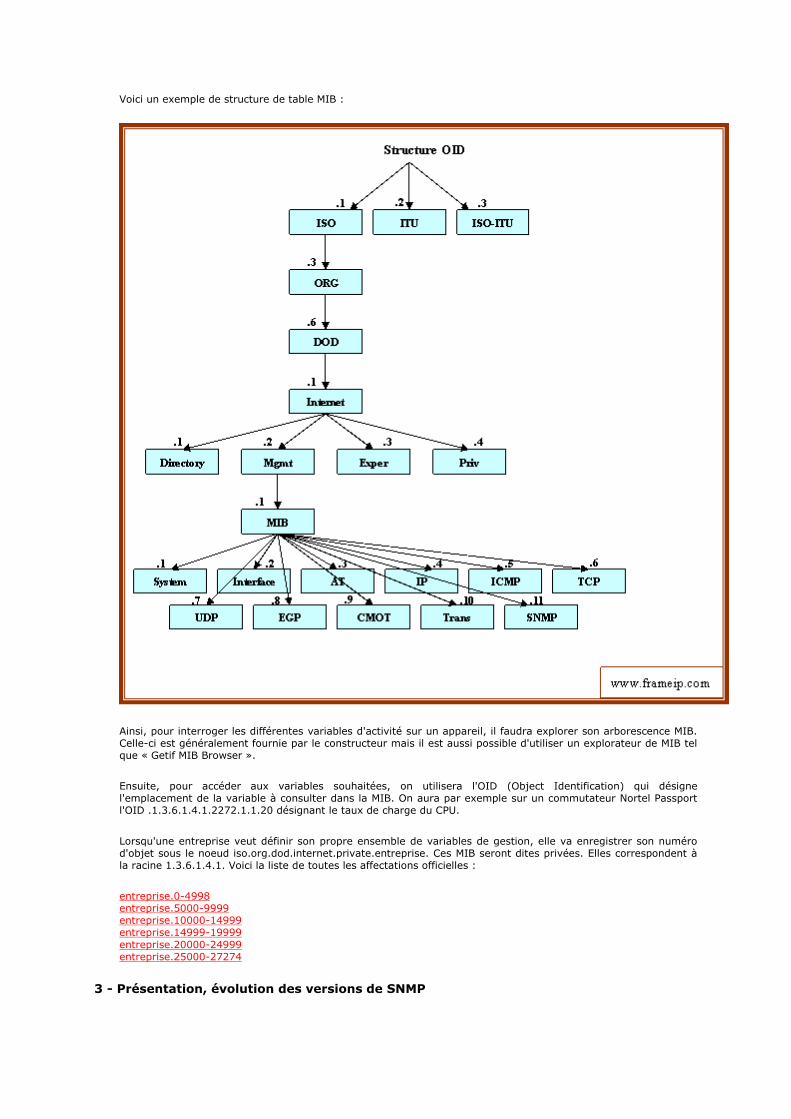
Voici un exemple de structure de table MIB :
Ainsi, pour interroger les différentes variables d'activité sur un appareil, il faudra explorer son arborescence MIB. Celle-ci est généralement fournie par le constructeur mais il est aussi possible d'utiliser un explorateur de MIB tel que « Getif MIB Browser ».
Ensuite, pour accéder aux variables souhaitées, on utilisera l'OID (Object Identification) qui désigne
l'emplacement de la variable à consulter dans la MIB. On aura par exemple sur un commutateur Nortel Passport l'OID .1.3.6.1.4.1.2272.1.1.20 désignant le taux de charge du CPU.
Lorsqu'une entreprise veut définir son propre ensemble de variables de gestion, elle va enregistrer son numéro d'objet sous le noeud iso.org.dod.internet.private.entreprise. Ces MIB seront dites privées. Elles correspondent à la racine 1.3.6.1.4.1. Voici la liste de toutes les affectations officielles :
entreprise.0-4998 entreprise.5000-9999 entreprise.10000-14999 entreprise.14999-19999
entreprise.20000-24999 entreprise.25000-27274
3 - Présentation, évolution des versions de SNMP

Voici les différentes versions de SNMP:
SNMPv1 (ancien standard): Ceci est la première version du protocole, tel que définie dans le RFC 1157.. On dit que la sécurité de cette version est triviale, car la seule vérification qui est faite est basée sur la chaîne de
caractères " community ". SNMPsec (historique): Cette version ajoute de la sécurité au protocole SNMPv1. La
sécurité est basée sur des groupes. Très peu ou aucun manufacturiers n'a utilisé cette version qui est maintenant largement oubliée. RFC 1155
SNMPv2p (historique): Beaucoup de travaux on été exécutés pour faire une mise à jour de SNMPv1. Ces
travaux ne portaient pas seulement sur la sécurité. Le résultat est une mise à jour des opérations du protocole, des nouvelles opérations, des nouveaux types de données. La sécurité est basée sur les groupes de SNMPsec.
SNMPv2c (expérimental): Cette version du protocole est appelé " community stringbased SNMPv2 ". Ceci est
une amélioration des opérations de protocole et des types d'opérations de SNMPv2p et utilise la sécurité par chaîne de caractères "community " de SNMPv1. RFC - 1441
SNMPv2u (expérimental): Cette version du protocole utilise les opérations, les types de données de SNMPv2c et la sécurité basée sur les usagers.
SNMPv2* (expérimental): Cette version combine les meilleures parties de SNMPv2p et SNMPv2u. Les documents qui décrivent cette version n'ont jamais été publiés dans 12 les RFC. Des copies de ces documents peuvent être trouvées sur le site web et SNMP Research (un des premiers à défendre de cette version).
RFC - 1901
SNMPv3 (standard actuel): Cette version comprend une combinaison de la sécurité basée sur les usagers et les types et les opérations de SNMPv2p, avec en plus la capacité pour les " proxies ". La sécurité est basée
sur ce qui se trouve dans SNMPv2u et SNMPv2*.
RFC - 3411
4 - SNMPv1 et v2
La trame SNMPv1 est complètement encodée en ASN.1 [ISO 87]. Les requêtes et les réponses ont le même format
La version la plus utilisée est encore la version 1. Plusieurs versions 2 ont été proposées par des documents
de travail, mais malheureusement, aucune d'entre elles n'a jamais été adoptée comme standard. La version 3 est actuellement en voie d'être adoptée. On place la valeur zéro dans le champ version pour SNMPv1, et la valeur 3 pour SNMPv3.
La communauté permet de créer des domaines d'administration. La communauté est décrite par une chaîne de caractères. Par défaut, la communauté est « PUBLIC».
Le PDU (Packet Data Unit).

Le « PDU type » décrit le type de requête, de réponse ou d'alerte. Le Tableau 2 donne les valeurs associées à ces champs.
Le « Request ID » permet à la station de gestion d'associer les réponses à ses requêtes. Le « Error Status » est l'indicateur du type d'erreur. Si aucune erreur ne s'est produite, ce champ est mis à zéro. Les réponses négatives possibles sont décrites dans le tableau suivant :
4.1- Les faiblesses de SNMPv1

Une des plus grandes faiblesses du protocole SNMPv1 est l'absence d'un mécanisme adéquat pour assurer la confidentialité et la sécurité des fonctions de gestion. Les faiblesses comprennent aussi l'authentification et le cryptage, en plus de l'absence d'un cadre administratif pour l'autorisation et le contrôle d'accès. Ce problème rend la sécurité sur SNMPv1 du type : "SHOW-AND-TELNET", c'est à dire qu'on utilise SNMP pour l'acquisition des données de gestion, mais pas pour effectuer le contrôle on utilise le protocole Telnet.
Le groupe de travail de l'IETF qui a oeuvré sur SNMPv2 a voulu inclure la sécurité dans la nouvelle version. Malheureusement, ce groupe n'a pas pu atteindre un consensus sur le fonctionnement du mécanisme de sécurité.
Partant de là, deux propositions ont été développées (SNMPv2u et SNMPv2*). La plupart des experts s'entendent pour dire que deux standards SNMP ne peuvent pas coexister, et que ceci n'est pas une solution à long terme.
Tous les consensus du groupe de travail ont été rassemblés (uniquement les améliorations qui ne portaient pas sur la sécurité), et le groupe de travail SNMPv2 de l'IETF a terminé ses travaux en publiant une version de SNMPv2 (on l'appelle SNMPv2c, RFC 1901, RFC 1905 et RFC 1906) sans sécurité.
4.2- Les améliorations de SNMPv2c
SNMPv2c a introduit quelques nouveaux types, mais sa nouveauté majeure est l'opération GETBULK, qui permet à
une plate forme de gestion, de demander en bloc de plusieurs variables consécutives dans la MIB de l'agent. Généralement, on demande autant de variables que l'on peut mettre dans un paquet SNMP. Ceci règle un problème majeur de performance dans SNMPv1. Avec la version 1, la plate forme est obligée de faire un GETNEXT et d'attendre la réponse pour chaque variable de gestion.
5 - SNMP v3
Cette nouvelle version du protocole SNMP vise essentiellement à inclure la sécurité des transactions. La sécurité comprend l'identification des parties qui communiquent et l'assurance que la conversation soit privée, même si elle passe par un réseau public.
Cette sécurité est basée sur 2 concepts :
USM (User-based Security Model)
VACM (View- based Access Control Model)
5.1 - User Security Module (USM)
Trois mécanismes sont utilisés. Chacun de ces mécanismes a pour but d'empêcher un type d'attaque.
L'authentification : Empêche quelqu'un de changer le paquet SNMPv3 en cours de route et de valider le mot de passe de la personne qui transmet la requête.
Le cryptage : Empêche quiconque de lire les informations de gestions contenues dans un paquet SNMPv3.
L'estampillage du temps : Empêche la réutilisation d'un paquet SNMPv3 valide a déjà transmis
par quelqu'un.
5.1.1 - L'authentification
L'authentification a pour rôle d'assurer que le paquet reste inchangé pendant la transmission, et que le mot de passe est valide pour l'usager qui fait la requête.
Pour construire ce mécanisme, on doit avoir connaissance des fonctions de hachage à une seule direction. Des exemples de ces fonctions sont : MD5 et SHA-1. Ces fonctions prennent en entrée une chaîne de
caractères de longueur indéfinie, et génèrent en sortie une chaîne d'octets de longueur finie (16 octets pour MD5, 20 octets pour SHA-1).
Pour authentifier l'information qui va être transmise, on doit aussi avoir un mot de passe qui est « partagé ». Le mot de passe ne doit donc être connu que par les deux entités qui s'envoient les messages, et préférablement par personne d'autre.
La figure ci dessous montre le mécanisme d'authentification :

Les étapes d'authentification sont les suivantes :
Le transmetteur groupe des informations à transmettre avec le mot de passe.
On passe ensuite ce groupe dans la fonction de hachage à une direction.
Les données et le code de hachage sont ensuite transmis sur le réseau.
Le receveur prend le bloc des données, et y ajoute le mot de passe.
On passe ce groupe dans la fonction de hachage à une direction.
Si le code de hachage est identique à celui transmis, le transmetteur est authentifié.
Avec cette technique, le mot de passe est validé sans qu'il ait été transmis sur le réseau. Quelqu'un qui saisit
les paquets SNMPv3 passants sur le réseau ne peut pas facilement trouver le mot de passe.
Pour ce qui est de SNMPv3, l'authentification se fait à l'aide de HMAC-MD5-96 ou de HMAC-SHA- 96, qui est un peu plus compliqué que ce qui a été décrit ici. Le résultat de la fonction de hachage est placé dans le bloc paramètres de sécurité du paquet SNMPv3.
L'authentification se fait sur tout le paquet.
L'étape d'authentification ne vise pas à cacher l'existence du paquet ou à le crypter. Si l'on utilise
uniquement l'authentification, les personnes qui saisissent les paquets passants sur le réseau peuvent encore en voir le contenu. Toutefois, elles ne peuvent pas changer le contenu sans connaître le mot de passe.
5.1.2 - Le cryptage
Le cryptage a pour but d'empêcher que quelqu'un n'obtienne les informations de gestion en écoutant sur le réseau les requêtes et les réponses de quelqu'un d'autre.
Avec SNMPv3, le cryptage de base se fait sur un mot de passe « partagé » entre le manager et l'agent. Ce mot de passe ne doit être connu par personne d'autre. Pour des raisons de sécurité, SNMPv3 utilise deux mots de passe : un pour l'authentification et un pour le cryptage. Ceci permet au système d'authentification et au système de cryptage d'être indépendants. Un de ces systèmes ne peut pas compromettre l'autre.
SNMPv3 se base sur DES (Data Encryption Standard) pour effectuer le cryptage.

On utilise une clé de 64 bits (8 des 64 bits sont des parités, la clé réelle est donc longue de 56 bits) et DES encrypte 64 bits à la fois. Comme les informations que l'on doit encrypter sont plus longues que 8 octets, on utilise du chaînage de blocs DES de 64 bits.
Une combinaison du mot de passe, d'une chaîne aléatoire et d'autres informations forme le « Vecteur
d'initialisation ». Chacun des blocs de 64 bits est passé par DES et est chaîné avec le bloc précédent avec un XOR. Le premier bloc est chaîné par un XOR au vecteur d'initialisation. Le vecteur d'initialisation est transmis avec chaque paquet dans les « Paramètres de sécurité », un champs qui fait partie du paquet SNMPv3.
Contrairement à l'authentification qui est appliquée à tout le paquet, le cryptage est seulement appliquée sur le PDU.
La RFC 3826 "The Advanced Encryption Standard (AES) Cipher Algorithm in the SNMP User-based Security
Model" relate l'intégration d'AES dans SNMP. Celui renforce le chiffrement en remplacement du DES. Cependant, pour le moment, cette RFC est en cours de validation et donc pas encore officialisée.
5.1.3 - L'estampillage de temps
Si une requête est transmise, les mécanismes d'authentification et de cryptage n'empêchent pas quelqu'un de saisir un paquet SNMPv3 valide du réseau et de tenter de le réutiliser plus tard, sans modification.
Par exemple, si l'administrateur effectue l'opération de remise à jours d'un équipement, quelqu'un peut saisir ce paquet et tenter de le retransmettre à l'équipement à chaque fois que cette personne désire faire une mise à jour illicite de l'équipement. Même si la personne n'a pas l'autorisation nécessaire, elle envoie un paquet, authentifié et encrypté correctement pour l'administration de l'équipement.
On appelle ce type d'attaques le « Replay Attack ». Pour éviter ceci, le temps est estampillé sur chaque paquet. Quand on reçoit un paquet SNMPv3, on compare le temps actuel avec le temps dans le paquet. Si la différence est plus que supérieur à 150 secondes, le paquet est ignoré.
SNMPv3 n'utilise pas l'heure normale. On utilise plutôt une horloge différente dans chaque agent. Ceux-ci gardent en mémoire le nombre de secondes écoulées depuis que l'agent a été mis en circuit. Ils gardent également un compteur pour connaître le nombre de fois où l'équipement a été mis en fonctionnement. On appelle ces compteurs BOOTS (Nombre de fois ou l'équipement a été allumé) et TIME (Nombre de secondes
depuis la dernière fois que l'équipement a été mis en fonctionnement).
La combinaison du BOOTS et du TIME donne une valeur qui augmente toujours, et qui peut être utilisée pour l'estampillage. Comme chaque agent a sa propre valeur du BOOTS/TIME, la plate-forme de gestion doit garder une horloge qui doit être synchronisée pour chaque agent qu'elle contacte. Au moment du contact initial, la plateforme obtient la valeur du BOOTS/TIME de l'agent et synchronise une horloge distincte.
5.2 - VACM (View Access Control Model)
Permet le contrôle d'accès au MIB. Ainsi on a la possibilité de restreindre l'accès en lecture et/ou écriture pour un
groupe ou par utilisateur.
5.3 - La trame de SNMPv3

Le format de la trame SNMPv3 est très différent du format de SNMPv1. Ils sont toutefois codés tous deux dans le format ASN.1 [ISO 87]. Ceci assure la compatibilité des types de données entres les ordinateurs d'architectures différentes.
Pour rendre plus facile la distinction entre les versions, le numéro de la version SNMP est placé tout au début du paquet. Toutefois, le contenu de chaque champ varie selon la situation. Selon que l'on envoie une requête, une réponse, ou un message d'erreur, les informations placées dans le paquet respectent des règles bien définies dans le standard. Voici comment les champs d'un paquet SNMPv3 sont remplis :
Version SNMP Pour SNMPv3, on place la valeur 3 dans ce champ. On place 0 pour un paquet SNMPv1.
Identificateur de message Ce champ est laissé à la discrétion du moteur SNMP. On retrouve souvent des algorithmes, où le premier message de requête est envoyé avec un nombre aléatoire et les suivants avec les incréments de 1. Les paquets qui sont émis en réponse à une requête portent la même identification que le paquet de la requête.
Taille maximale
Le moteur choisit la taille maximale d'une réponse à une requête selon ses capacités en mémoire tampon et ses limites à décoder de longs paquets. Quand on envoie une réponse à une requête, on doit veiller à ne pas dépasser la taille maximale.
Drapeaux Trois bits sont utilisés pour indiquer : - Si une réponse est attendue à la réception de ce paquet. (Reportable Flag) - Si un modèle de cryptage a été utilisé (Privacy Flag)
- Si un modèle d'authentification a été utilisé (Authentification Flag)
Le modèle de sécurité Ce module identifie le type de sécurité qui est utilisé pour encrypter le reste du paquet. Cet identificateur doit identifier de façon unique chaque module de sécurité. Actuellement, l'algorithme de cryptage DES (Data Encryption Standard) et l'algorithme d'authentification HMAC-MD5-96 ont été choisis comme algorithmes utilisés dans SNMPv3. HMAC-SHA-96 est optionnel.
Les informations de sécurité Ces informations ne sont pas décrites dans le standard SNMPv3, ce bloc est laissé au soin des modules de sécurité. D'un module de sécurité à un autre, ces informations seront différentes. Le module de sécurité DES a standardisé le contenu de ce bloc.
Les identificateurs de contextes Avec SNMPv1, il était possible d'avoir une seule base d'informations (MIB) par agent. Ceci n'est pas suffisant pour certains équipements qui peuvent contenir plusieurs fois les mêmes variables. Par exemple, un commutateur ATM
contient plusieurs cartes qui ont chacune leurs propres bases d'informations. Le contexte permet de distinguer entre plusieurs bases d'informations et même plusieurs agents. On distingue entre des agents, par exemple, quand on a un moteur qui agit comme passerelle entre SNMPv3 et du SNMPv1. On envoie donc un paquet SNMPv3 en identifiant à quel agent SNMPv1 on désire que le paquet soit retransmis.
6 - Exemple de trame SNMP
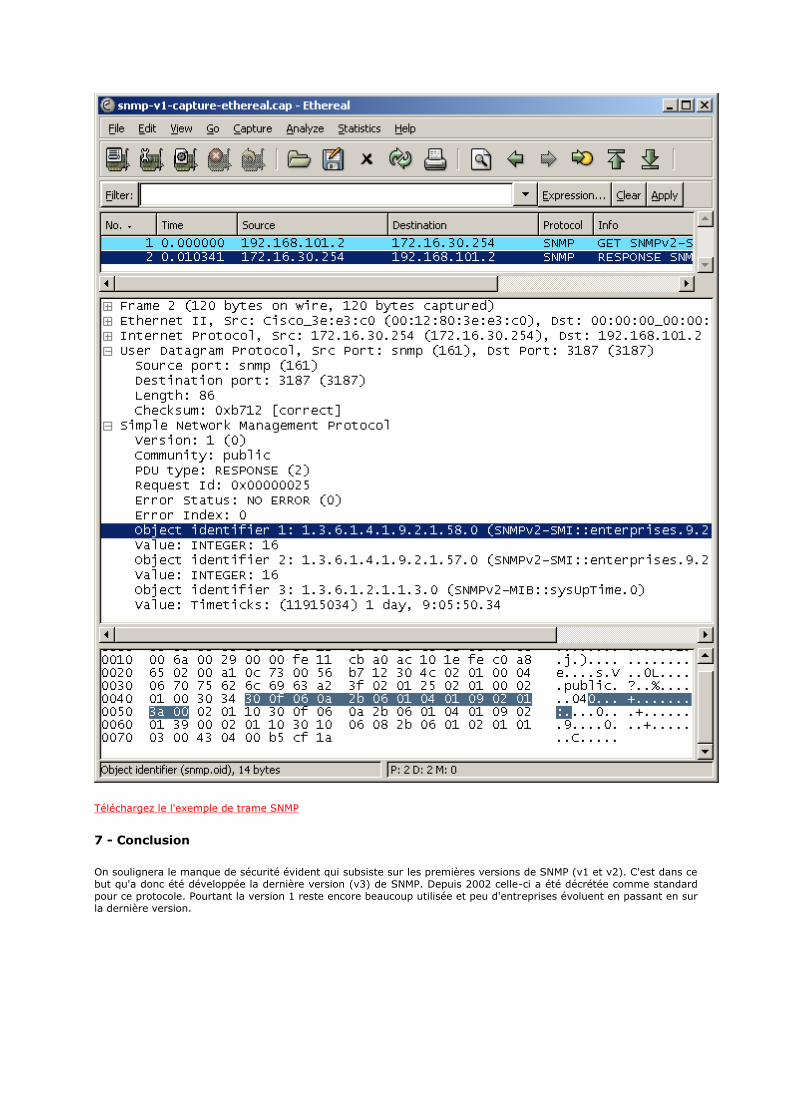
Téléchargez le l'exemple de trame SNMP
7 - Conclusion
On soulignera le manque de sécurité évident qui subsiste sur les premières versions de SNMP (v1 et v2). C'est dans ce but qu'a donc été développée la dernière version (v3) de SNMP. Depuis 2002 celle-ci a été décrétée comme standard pour ce protocole. Pourtant la version 1 reste encore beaucoup utilisée et peu d'entreprises évoluent en passant en sur la dernière version.

La VoIP
Téléphonie sur IP - TOIP
1 - Bilan 2 - Généralités sur la transmission 3 - Synoptique d'une architecture raccordé avec un PABX traditionnel 4 - Les différents codecs et taux de compression 5 - Les différents protocoles 5.1 - H323 5.2 - SIP
5.3 - MGCP 6 - L'alimentation des postes IP 7 - La migration d'une installation 8 - Les 8 arguments plaidant pour 9 - Les 6 faiblesses qui rebutent les entreprises 10 - Les failles du protocole H.323 11 - Les différents éléments pouvant composer un réseau
12 - La réglementation dans certains pays 13 - Le panorama des produits 13.1 - 3COM 13.2 - ALCATEL 13.3 - AVAYA 13.4 - WellX
13.5 - CISCO 13.6 - NORTEL 13.7 - QUESCOM 13.8 - MITEL
13.9 - SIEMENS 13.10 - EADS-TELECOM 13.11 - ERICSSON
13.12 - CENTILE 13.13 - TENOVIS 13.14 - TIPTEL 13.15 - FRANCE TELECOM 13.16 - ALSATEL 13.17 - IC TELECOM 13.18 - PACWAN
13.19 - Panasonic 13.20 - TechTelecom 13.21 - 3CX 13.22 - Keyyo 13.23 - Open Source 14 - Discussion autour de la documentation
15 - Suivi du document
1 - Bilan
Qui n'a pas entendu parler de téléphonie sur Ip ou de voix sur Ip ? Bilan : beaucoup de monde à l'heure actuelle. Nous avons tous de près ou de loin entendu parler d'un projet de déploiement ou même de participer à un projet de téléphonie sur IP. Laissons le terme "Voix sur IP" à son utilisation,
c'est à dire : technologie utilisée pour transporter le service de téléphonie sur Ip (transport de la voix sur un Backbone
ou autre MAN/WAN). N'hésitez pas à visiter cette page afin d'en savoir un peu plus sur IP. La téléphonie sur Ip est un service de téléphonie fourni sur un réseau de télécommunications ouvert au public ou privé utilisant principalement le protocole de réseau IP. Cette technologie permet d'utiliser une infrastructure existante de réseau Ip pour raccorder des terminaux Ip que l'on nomme IP-PHONE, ainsi que des logiciels sur PC raccordés sur le même réseau Ip que l'on nomme SOFTPHONE. La téléphonie sur Ip peut :
1) se rajouter en complément sur un réseau téléphonique traditionnel existant avec une passerelle (voir le synoptique en bas de page) 2) s'utiliser en full-Ip pour une nouvelle infrastructure (nouvel immeuble par exemple avec uniquement du câblage catégorie 5 ou 6)
3) s'utiliser en multi sites full Ip avec l'aide d'un opérateur adéquat et parfois des serveurs centralisés 4) s'utiliser sur un ordinateur relié au réseau Internet à destination d'un autre ordinateur relié lui aussi au réseau Internet, mais en utilisant absolument le même logiciel (les communications seront donc gratuites de PC à PC). Cette technologie est proposé par de multiples constructeurs avec parfois des solutions clés en mains ou des intégrateurs spécialisés dans ce domaine. Je vous recommande fortement d'analyser vos besoins en réalisant une

petite étude avant de vous décider ou de vous engager avec un seul constructeur ou intégrateur. Pour les visiteurs pressés et désireux de comparer tout de suite une partie des offres de ToIP disponibles sur le marché français, voici une page qui offre un petit panorama des solutions actuelles de téléphonie sur IP. La téléphonie sur Ip est une transmission de la voix en mode paquets au format TCP/UDP. Pour comprendre le
traitement complexe de la voix analogique (signaux électriques) en signaux binaires, voici un synoptique explicatif :
Explications du synoptique : La bande voix qui est un signal électrique analogique utilisant une bande de fréquence de 300 à 3400 Hz, elle est d'abord échantillonné numériquement par un convertisseur puis codé sur 8 bits, puis compressé par les fameux codecs ( il s'agit de processeurs DSP ) selon une certaine norme de compression variable selon les codecs utilisés, puis ensuite on peut éventuellement supprimer les pauses de silences observés lors d'une conversation, pour être ensuite habillé RTP,UDP et enfin en IP. Une fois que la voix est transformée en paquets IP, ces petits paquets Ip identifiés et numérotés peuvent transités sur n'importe quel réseau Ip (ADSL, Ethernet,
Satellite,routeurs, switchs, PC, Wifi, etc...)
2 - Généralités sur la transmission
Tout d'abord, il s'agit de parler de commutation par paquets ( au lieu de commutation par circuit : PBX, ce qui est le cas d'un réseau téléphonique traditionnel). Le transport des signaux voix numérisés par paquets impose des contraintes majeures :
1) Optimisation de la bande passante (attention aux autres applications informatiques qui monopolise la majeure partie de la bande passante disponible comme Microsoft Exchange). Pour un bon partage de la bande passante, il faut connaître l'ensemble des flux pouvant avoir une influence importante sur le transport de la voix.
2) Délai de transmission (très important dans des cahiers des charges : temps de transfert des paquets), il comprend le codage, le passage en file d'attente d'émission, la propagation dans le réseau, la bufférisation en réception et le décodage. Le délai de transmission optimal est de 150 ms (UIT-T G114). Les délais parfois
tolérables sont entre 150 et 400 ms.
3) Le phénomène d'écho (réverbération du signal). C'est le délai entre l'émission du signal et la réception de ce même signal en réverbération. Cette réverbération est causée par les composants électroniques des parties analogiques. Un écho < 50 ms n'est pas perceptible. Plus il est décalé dans le temps plus il est insupportable.
4) La gigue ou Jitter (variation de l'écart initial entre deux paquets émis). Correspond à des écarts de délais de transmission entre des paquets consécutifs. Nécessite la mise en place de buffers en réception qui lissent ces
écarts pour retrouver le rythme de l'émission. Effet nefaste des buffers de réception ==> augmentation du délai de transmission.
5) La gestion de la qualité de service des réseaux Ip de transport d'un bout à l'autre. Elle peut-être une solution propriétaire (Qos constructeur), DiffServ, RSVP ou MPLS. Rappelons enfin que le mode de fonctionnement de l'acheminement sur l'Internet est du type Best Effort : chaque équipement constituant le réseau (en particulier les routeurs) fait de son mieux pour acheminer les informations.
En conclusion, le transport de la téléphonie sur l'Ip ne doit souffrir d'aucun retard de transmission, ni d'altérations
(attention aux firewall), ni de perte de paquets.
3 - Synoptique d'une architecture raccordé avec un PABX traditionnel

Ci-dessus, un synoptique d'une solution "ToIP" avec interconnexion avec un PBX existant (QSIG ou E&M) et une liaison vers le réseau public à partir de la passerelle (gateway) qui peut servir soit en permanence, soit dans certains cas (routage international ou opérateur différent du PBX). Dans notre cas ci-dessus, les composants sont :
Un switch,
Deux postes Ip ( Cisco 7960 ),
Une application SoftPhone sur PC,
Un routeur servant de passerelle vers le PBX et vers le PSTN,
Un serveur de communications Ip (le serveur peut être intégré dans un seul et même élément).
4 - Les différents codecs et taux de compression
Les codecs sont des chipsets qui font office de codeurs/décodeurs. Certains terminaux IP-PHONES n'acceptent qu'une partie ou même un seul codec, tout dépend du modèle de terminal et du constructeur. Le principe de fonctionnement de ces codecs vous ont été expliqués sur la page précédente. Les principaux taux de compression de la voix sont les codecs officiels suivants :
Méthode de compression Débit en KBits/s
G.711 PCM 64
G.726 AD PCM 32
G.728 LD CELP 16
G.729 CS ACELP 8
G.729 x 2 Encodings 8
G.729 x 3 Encodings 8
G.729a CS ACELP 8
G.723.1 MPMLQ 6,3
G.723.1 ACELP 5,3
5 - Les différents protocoles utilisés

Les différents protocoles non propriétaires sont les trois suivants :
5.1 - H323
Le protocole H323 est le plus connu et se base sur les travaux de la série H.320 sur la visioconférence sur RNIS. C'est une norme stabilisée avec de très nombreux produits sur le marché (terminaux, gatekeeper, gateway, logiciels). Il existe actuellement 5 versions du protocole (V1 à V5). Vous trouverez plus de renseignement sur H323 ici.
5.2 - SIP
Le protocole SIP est natif du monde Internet (HTTP) et est un concurrent direct de l'H323. A l'heure actuelle, il est moins riche que H.323 au niveau des services offerts, mais il suscite actuellement un très grand intérêt dans la communauté Internet et télécom. Vous trouverez plus de renseignement sur SIP ici.
5.3 - MGCP
Le protocole MGCP est complémentaire à H.323 ou SIP, et traite des problèmes d'interconnexion avec le monde téléphonique (SS7, RI).
6 - L'alimentation des postes IP
He oui, un poste Ip (ou ip-phone) a besoin d'une alimentation externe DC de 48Volts ou d'une télé alimentation par le port ethernet. Il y a deux solutions pour se passer d'un petit transformateur 220V~/48VDC pouvant être facilement oublié et débranché avec une fausse manip.. Ces deux solutions ont été normalisés par un document officiel de IEEE Computer Society (norme : 802.3af) et elles sont décrites ci-dessous:
Dans le premier cas à gauche ici, les téléphones Ip sont directement connectés aux switchs d'étages qui intégrent l'alimentation 48 V nécessaire sur les paires LIBRES ! C'est donc un switch dernière
génération compatible 802.3af Dans notre 2° cas à gauche, le switch n'étant pas équipés, il a
fallu installer un PATCH POWER PANEL pour pouvoir alimenter quand même les téléphones IP. Les cordons réseaux sortent du switch, vont au power panel puis ressortent sur un autre port vers le PC de l'étage.
Si vous n'avez pas un switch qui assure la téléalimentation ou un power patch panel, il est obligatoire de disposer d'un transformateur externe par téléphone Ip (IP-PHONE). Il est à noter qu'en cas de panne secteur, il n'y a plus de téléphone ( c'est normal ) et aucun appel d'urgences n'est donc possible.
7 - La migration d'une installation
Cette migration d'un réseau existant doit respecter absolument certaines règles, les voici :
1 - Mettre à niveau le réseau étendu
2 - Dimensionner le réseau local (s'assurer d'une très bonne bande passante et surtout de son utilisation)
3 - Récupérer l'existant en téléphonie classique (comme les fax par exemple ou les liens opérateurs analogiques ou numériques)
4 - Conférer une certaine autonomie aux sites distants

5 - Intégrer la téléphonie sans fil (soit DECT, soit WIFI)
6 - Autoalimenter les postes téléphoniques (norme 802.3af)
7 - Assurer la sécurité
8 - Calculer le retour sur investissement (ROI)
8 - Les 8 arguments plaidant pour
1 - Économiser sur la facture télécom
2 - Pérenniser l'investissement 3 - Simplifier les infrastructures 4 - Faciliter l'administration et la mobilité 5 - Homogénéiser les services téléphoniques sur un ensemble de sites 6 - Faciliter l'intégration avec le système d'information 7 - Évoluer plus facilement
8 - Regrouper les équipes et se passer d'un prestataire
9 - Les 6 faiblesses qui rebutent les entreprises
1) Fiabilité 2) Une qualité de son médiocre 3) Améliorer l'utilisation
4) Localisation 5) Standards 6) Support administratif
10 - Les failles du protocole H.323
He oui, même ce protocole n'est pas à l'abri de failles de sécurité. Ces trous de sécurité pourraient être exploites pour exécuter des commandes arbitraires ou provoquer un deni de service sur le système
vulnérable. La criticité de ces problèmes sur les différents équipements/logiciels semble varier d'un produit a l'autre. Les systèmes touchés sont les téléphones Ip et les visioconférences IP.
11 - Les différents éléments pouvant composer un réseau
- Le PABX-IP, c'est lui qui assure la commutation des appels et leurs autorisations, il peut servir aussi de routeur ou de switch dans certains modèles, ainsi que de serveur DHCP. Il peut posséder des interfaces de type analogiques (fax),
numériques (postes), numériques (RNIS,QSIG) ou opérateurs (RTC-PSTN ou EURO-RNIS). Il peut se gérer par Ip en intranet ou par un logiciel serveur spécialisé que ce soit en interne ou depuis l'extérieur. Il peut s'interconnecter avec d'autres PABX-IP ou PABX non Ip de la même marque (réseau homogène) ou d'autres PABX d'autres marques (réseau hétérogène). - Le serveur de communications (exemple : Call Manager de Cisco), il gère les autorisations d'appels entre les
terminaux Ip ou softphones et les différentes signalisations du réseau. Il peut posséder des interfaces réseaux opérateurs (RTC-PSTN ou RNIS), sinon les appels externes passeront par la passerelle dédiée à cela (gateway). - La passerelle (gateway), c'est un élément de routage équipé de cartes d'interfaces analogiques et/ou numériques pour s'interconnecter avec soit d'autres PABX (en QSIG,RNIS ou E&M), soit des opérateurs de télécommunications local, national ou international. Plusieurs passerelles peuvent faire partie d'un seul et même réseau, ou l'on peut
également avoir une passerelle par réseau local (LAN). La passerelle peut également assurer l'interface de postes
analogiques classiques qui pourront utiliser toutes les ressources du réseau téléphonique Ip (appels internes et externes, entrants et sortants). - Le routeur, il assure la commutation des paquets d'un réseau vers un autre réseau. - Le switch, il assure la distribution et commutation de dizaines de port Ethernet à 10/100 voire 1000 Mbits/s. Suivant les modèles, il peut intégrer la téléalimentation des ports Ethernet à la norme 802.3af pour l'alimentation des IP-
phones ou des bornes WIFI en 48V. - Le gatekeeper, il effectue les translations d'adresses (identifiant H323 et @ Ip du référencement du terminal) et gère la bande passante et les droits d'accès. C'est le point de passage obligé pour tous les équipements de sa zone d'action. - Le MCU, est un élément optionnel et gère les conférences audio vidéo.
- L'IP-PHONE, c'est un terminal téléphonique fonctionnant sur le réseau LAN Ip à 10/100 avec une norme soit propriétaire, soit SIP, soit H.323. Il peut y avoir plusieurs codecs pour l'audio, et il peut disposer d'un écran monochrome ou couleur, et d'une ou plusieurs touches soit programmables, soit préprogrammées. IL est en général doté d'un hub passif à un seul port pour pouvoir alimenter le PC de l'utilisateur (l'IP-PHONE se raccorde sur la seul

prise Ethernet mural et le PC se raccorde derrière l'IP-PHONE). - Le SOFTPHONE, c'est un logiciel qui assure toutes les fonctions téléphoniques et qui utilise la carte son et le micro du PC de l'utilisateur, et aussi la carte Ethernet du PC. Il est géré soit par le Call Manager, soit par le PABX-IP.
12 - La réglementation dans certains pays
Le présent tableau est fondé sur les résultats de l'enquête de l'UIT sur la réglementation ( Edition 2000 ) et sur des
études de cas réalisées par l'UIT. Les états membres n'y ont apporté ni modifications ni éclaircissements en vue du troisième Forum Mondial des politiques de télécommunications. Notes : selon que la transmission des signaux s'effectue ou non "en temps réel", la réglementation afférente à la téléphonie classique peut s'appliquer à divers degrés. On ne dispose pas pour tous les pays d'informations réglementaires permettant de déterminer si le service est assuré ou non en temps réel.
Pays Description de la réglementation
Angola Antigua-et-Barbuda (1) Bhoutan Congo
Costa Rica Dominicaine (Rép.) Estonie (2) Etats-Unis (3) Gambie Guatemala
Madagascar
Malte Mexique Mongolie (2) Nouvelle-Zélande Ouganda Pologne
Sainte-Lucie (1) Saint-Vincent (4) Slovaquie Tonga Vietnam
Pas d'interdiction spécifique pour la téléphonie/télécopie sur l'Internet public.
Notes : (1) Antigua-et-Barbuda et Sainte Lucie : l'utilisation de l'Internet public n'est pas interdite
pour la téléphonie et la télécopie, mais on ne dispose d'aucune donnée sur l'utilisation des réseaux Ip pour ces services. (2) En Estonie, les communications téléphoniques nationales et internationales acheminées par des réseaux Ip étaient interdites jusqu'au 31 décembre 2000. La
téléphonie Ip publique était également interdite jusqu'à la même date. En Mongolie, les communications téléphoniques internationales étaient interdites jusqu'à cette même date.
(3) Les Etats-Unis autorisent la téléphonie Ip sans aucune condition, c'est à dire qu'elle n'est pas assujettie au régime des règlements internationaux. (4) Saint-Vincent : l'utilisation de réseaux Ip n'est pas interdite, mais on ne dispose d'aucune donnée concernant l'utilisation de l'Internet public pour la téléphonie et la télécopie.
Pays de l'Union Européenne (5) Hongrie (6) Islande
Autorisée ou non réglementée si la transmission n'est pas en temps réel ( n'est pas assimilée à de la téléphonie vocale ). (5) L'Union Européenne regroupe les 15 pays suivants : Allemagne, Autriche, Belgique,
Danemark, Espagne, Finlande, France, Grèce, Irlande, Italie, Luxembourg, Pays-bas, Portugal, Royaume Uni et Suède. (6) Hongrie : lorsque le temps mort de transmission est =/> 250 ms et la perte de paquets >1%.
Hong-Kong (RAS de) Japon République Tchèque (7) Singapour
Suisse
Autorisée. Dans le cas d'une transmission en temps réel, assortie de conditions peu contraignantes ( obligation de notification ou d'enregistrement, autres dispositions de base de la réglementation de la téléphonie vocale classique ).
(7) Exception : de téléphone à téléphone dans le cas autre que l'opérateur établi.
Australie Canada Chine Corée (Rép.) Malaisie
Autorisée. Lorsque la transmission de fait en temps réel, assimilée aux autres services de télécommunication vocale ( sous réserve d'octroi de licences et visée par les dispositions détaillées de la réglementation applicable à la téléphonie vocale classique )
Voici les pays qui autorisent les services téléphoniques/de télécopie, soit sur Internet public, soit sur des réseaux Ip ( mais pas sur les deux à la fois ).
Pays Utilisation de Internet public Utilisation des réseaux IP
Argentine Interdite Non interdite
Chypre Interdite Non interdite
Ethiopie Interdite Non interdite
Kenya Interdite ( services téléphoniques, rappel et
reroutage compris ) Non interdite

Kirghizistan Non interdite Interdite ( jusqu'en 2003 pour la téléphonie Ip )
Moldova Non interdite Interdite ( jusqu'en 2003 pour la téléphonie Ip )
Pérou Interdite ( les services téléphoniques sont interdits puisqu'ils sont assimilés à des services de téléphonie vocale )
Non interdite
Philippines Interdite Non interdite
Sri Lanka Non interdite Interdite ( services téléphoniques )
Ce présent tableau est fondé sur les résultats de l'enquête de l'UIT sur la réglementation ( Edition 2000 ) et sur des études de cas réalisées par l'UIT. Les états membres n'y ont apporté ni modifications ni éclaircissements en vue du troisième Forum Mondial des politiques de télécommunications.
La réglementation de la téléphonie sur Ip dans certains pays ( ter ). Voici les pays qui interdisent l'utilisation de l'Internet public et des réseaux Ip pour les services de téléphonie ou de télécopie.
Pays Informations données
Albanie Services téléphoniques sur réseaux Ip interdits jusqu'en 2003
Azerbaïdjan
Belize Tous les services sont interdits
Botswana Téléphonie interdite sur l'Internet public
Cambodge Téléphonie interdite indéfiniment
Cameroun Téléphonie interdite sur l'Internet public
Côte d'Ivoire Téléphonie interdite sur l'Internet public jusqu'en 2004
Croatie
Cuba Téléphonie interdite sur l'Internet public et les réseaux Ip à la différence de la télécopie
Equateur Téléphonie interdite sur l'Internet public. Téléphonie temporairement interdite sur les réseaux IP
Erytrhée Téléphonie interdite pendant encore plusieurs années ( à la fois sur l'Internet public et sur les réseaux Ip )
Gabon Téléphonie interdite ( à la fois sur l'Internet public et sur les réseaux Ip )
Inde Ce pays interdit l'utilisation de services téléphoniques sur l'Internet public, mais n'a pas répondu à la question concernant les réseaux IP
Indonésie Téléphonie interdite sur l'Internet public. Réglementation en cours d'élaboration pour
autoriser la téléphonie sur les réseaux IP.
Israël Téléphonie interdite sur l'Internet public. Téléphonie et télécopie interdites sur les réseaux IP
Jordanie Téléphonie interdite sur l'Internet public. Services téléphoniques et de télécopie interdits sur les réseaux Ip jusqu'a la fin de l'année 2004
Lettonie
Lituanie Téléphonie interdite sur l'Internet public et sur les réseaux Ip jusqu'au 31 décembre 2002
Maroc
Mozambique Téléphonie et télécopie interdites sur l'Internet public et sur les réseaux IP
Myanmar
Nicaragua Services téléphoniques interdits sur l'Internet public et sur les réseaux IP
Nigéria Téléphonie et télécopie interdites à l'heure actuelle sur les réseaux IP
Pakistan Services de terminaison téléphoniques interdits sur l'Internet public. Téléphonie
interdite sur les réseaux IP
Paraguay Téléphonie interdite sur l'Internet public et les réseaux IP
Qatar Téléphonie et télécopie interdites sur l'Internet public et sur les réseaux IP, mais la

situation sera réexaminée
Roumanie Téléphonie interdite sur l'Internet public. Services téléphoniques interdits au moins jusqu'au 1er janvier 2003
Sénégal Téléphonie interdite sur l'Internet public
Seychelles
Téléphonie et télécopie interdites sur l'Internet public; néanmoins, la téléphonie Internet, qui est considérée comme une application Internet plutôt que comme service de télécommunication assuré par un fournisseur de services Internet, est autorisée. Tous les services sur les réseaux Ip sont interdits
Swaziland
Thaïlande Téléphonie et télécopie interdites sur l'Internet public et sur les réseaux IP
Togo
Trinité-et-Tobago Téléphonie interdite sur les réseaux Ip
Tunisie
Turquie Téléphonie interdite sur l'Internet public et les réseaux IP
Ce présent tableau est fondé sur les résultats de l'enquête de l'UIT sur la réglementation ( Edition 2000 ) et sur des études de cas réalisées par l'UIT. Les états membres n'y ont apporté ni modifications ni éclaircissements en vue du
troisième Forum Mondial des politiques de télécommunications.
13 - Le panorama des produits
Les informations contenues dans cette page n'engagent ni la responsabilité du webmaster, ni les différents constructeurs auquel il faut se référer en cas d'étude précise sur la téléphonie sur IP. Les images proviennent des images existantes sur les sites des constructeurs. Work in progress. Travaux en cours. Mise à jour du 13 juin2004. Le
panorama n'est pas classé selon les qualités des constructeurs, il est classé aléatoirement.
13.1 - 3COM
Site Internet : www.3com.fr Produits Téléphonie et Applications, cliquez ici Le produit 3Com® NBX® 100 Communications System est disponible dans 61 pays et dans 11 langages différents.
La connectivité PSTN possible est Loop-start analog, T1/PRI, E1/PRI et ISDN BRI-ST. Les capacités maximum sont : 400 heures de messagerie vocale, 720 PSTN et 1500 devices ( PSTN + postes ). Le système d'exploitation est VxVorks. Autre produit : 3 NBX 1200 postes IP maxi du type Basic ou Business
13.2 - ALCATEL

Site Internet : www.alcatel.fr Alcatel OmniPcx Office, cliquez ici. Alcatel Office, cliquez ici. La voix sur Ip est native sur le produit OmniPcx.
Le système d'exploitation est Linux, la messagerie unifiée est disponible, le nombre de postes Ip maximum est de 4000 pour l'OmniPcx 4400 et de 200 sur l'Omnipcx Office. Le nombre maximum de boites vocales est de 15000.
L'Ip Sotfphone est disponible.
13.3 - AVAYA
Site Internet : www.avaya.fr Avaya Ip 401 Compact Office
et Avaya IP¨403 Office et aussi l'Ip 6000
Le système d'exploitation est propriétaire, la messagerie unifiée est disponible, le nombre de boites vocales est illimité, et le nombre de postes Ip maximum est de 90 pour l'Ip 403 Office et de 4 pour l'Ip 403 Compact Office. Deux autres modèles :Definity One sous windows NT H323, 240 postes IP maxi du type 4600 ou softphone IP + Definity sous OS proprietaire, H323, 5000 postes IP maxi du type 4600 ou softphone IP
13.4 - WellX
Site Internet : www.wellx.com Pour plus d'informations, cliquez ici.
WellX Office est une solution PCBX (PC industriel équipé de cartes de Télécommunications). Le système d'exploitation est Windows 2000.

WellX Office est conforme au protocole SIP (stack OsIP et proxy Partysip) et gère indifféremment des terminaux analogiques et des terminaux SIP (IP-Phone -par ex. SIEMENS en photo à droite-, MSN Messenger, SIP Phone, postes USB,....) mais aussi des "Access Device" type Mediatrix (www.mediatrix.com).
Jusqu'à 200 postes Ip et 256 postes analogiques.
Applications disponibles : Administration Web, Serveur vocal, Enregistreur de communications, Gestion des appels CTI ( montée de fiches, client Web ), messagerie vocale et unifiée, commandes vocales, ACD, interfaces TAPI ( possibilité de développer une application 'téléphonie' avec VBA, VB, ASP, HTML, ou C++ ).
Client CTI
13.5 - CISCO
Site Internet : www.cisco.com
Caractéristiques des postes IP Phone de Cisco, cliquez ici. Démonstration d'un poste 7960, cliquez ici. Possibilité de développement XML. Cisco Unity : messagerie unifiée et messagerie vocale.

Le serveur de convergence média Cisco 7835-1266 peut gérer 2500 postes IP, tandis que le serveur de convergence média Cisco 7835-1133 peut gérer 1000 postes Ip ( par serveur ) avec possibilité de les monter en grappe . Ils intègrent le serveur Call Manager. Le logiciel de traitement d'appels Cisco CallManager Manager 3.2 peut gérer un maximum de 10 000 postes Ip par grappe..
La version 4.0 du Call Manager est sortie.. Ils sont tous compatibles H323, MGCP, SIP, SCCP.
Quelques modèles : MCS7845 sous windows 2000, 30 000 postes IP maxi du type switch, XML, couleur, sans fil MCS7835 sous windows 2000, 10 000 postes IP maxi du type switch, XML, couleur, sans fil MCS7825 sous windows 2000, 4000 postes IP maxi du type switch, XML, couleur, sans fil MCS7815 sous windows 2000, 400 postes IP maxi du type switch, XML, couleur, sans fil Call manager express , OS temps réel, 120 postes IP maxi du type switch, XML, sans fil
Caractéristiques des postes IP Phone de Cisco, cliquez ici. Démonstration d'un poste 7960, cliquez ici. Possibilité de développement XML

13.6 - NORTEL
Site Internet : www.nortelnetworks.com
Le système d'exploitation est VxVorks. Le nombre de postes IP maximum est de 1000 pour le Call Server de base ( Succession Communication Server for Enterprise (CSE) 1000 ) et de 10 000 avec des serveurs en grappe.
Quelques modèles : Business Communication Manager 3.5 sous windows NT, EUROISDN, H323, QSIG, SIP, maxi inconnu, du type i2004, i2002 et i2050 Succession 1000 sous Vx-Works, EUROISDN, H323, QSIG, 1000 postes IP maxi du type i2004, i2002 et i2050 Succession 1000M sous Vx-Works, EUROISDN, H323, QSIG, 10 000 postes IP maxi du type i2004, i2002 et i2050 Caractéristiques des postes IP Phone, cliquez ici.
13.7 - QUESCOM
Site Internet : http://www.quescom.com/
Le produit QUESCOM 400 intègre les éléments suivants : Serveur de voix sur IP, Serveur de messagerie et de téléphonie, Serveur d'appels RNIS et IP. Ce produit permet d'interconnecter un PABX existant avec une solution de VOIX SUR Ip et dispose d'une option GSM. Il est compatible avec les téléphones Ip de Cisco et accepte jusqu'à 32 communications Ip simultanées.

13.8 - MITEL
Site Internet : http://www.mitel.fr/ Le produit 3300 ICP intègre la messagerie vocale ( jusqu'à 750 boites ), un standard automatique et la distribution automatique des appels ( ACD ). La connectivité PSTN est possible ainsi que PRI ( QSIG et Euro Isdn ), et BRI. L'IP Sotfphone est disponible ainsi que des téléphones WI-FI. MITEL propose plus de 6 téléphones Ip et
le nombre d'utilisateurs maximum peut dépasser les 700 avec un montage en cluster des contrôleurs.
Deux gammes : MN 3340, sous Vx-Works, 40 postes IP maxi, du type 5201, 5205 MN 3300, sous Vx-Works, 100, 250 et 700 postes IP maxi, du type 5201, 5205
13.9 - SIEMENS
Site Internet : http://www.siemens.fr/ HiPath 3300 sous windows NT/2000, ETSI, ISO, CE, IP, 96 postes IP maxi, du type nc HiPath 3350 sous windows NT/2000, ETSI, ISO, CE, IP, 96 postes IP maxi, du type nc HiPath 3500 sous windows NT/2000, ETSI, ISO, CE, IP, 192 postes IP maxi, du type nc HiPath 3550 sous windows NT/2000, ETSI, ISO, CE, IP, 192 postes IP maxi, du type nc HiPath 3700 sous windows NT/2000, ETSI, ISO, CE, IP, 500 postes IP maxi, du type nc
HiPath 3750 sous windows NT/2000, ETSI, ISO, CE, IP, 500 postes IP maxi, du type nc
13.10 - EADS-TELECOM
Plusieurs modèles : NexspanCommunicationServer sous windows 2000 et IRMX, 950 postes ip maxi, du type i740, i760, i780, i2052, H323

M6501 IP PBX sous IRMX, 250 postes IP maxi, du type i740, i760, i780, i2052 softphone M6540 IP PBX sous IRMX, 250 postes IP maxi, du type i740, i760, i780, i2052 softphone M6550 IP PBX sous IRMX, 9500 postes IP maxi, du type i740, i760, i780, i2052 softphone Nexspan C sous IRMX, 0 postes IP maxi Nexspan S sous IRMX, 250 postes IP maxi, du type i740, i760, i780, i2052 softphone
Nexspan L sous IRMX, 250 postes IP maxi, du type i740, i760, i780, i2052 softphone
13.11 - ERICSSON
Site Internet : http://www.ericsson.fr/ Webswitch 2000 3.1 OS proprietaire, 128 à 1500 postes IP maxi, du type Dialog 3413, IP , softphone
13.12 - CENTILE
Site internet : http://www.centile.com/ Centile a développé deux types de produits:
- le PABX hébergé (hosted iPBX), - ainsi que le PABX local (LAN PBX). Le PABX hébergé est destiné a des Opérateurs télécoms, ISP afin qu'ils opèrent le service. Cette solution logicielle s'installe sur Solaris et LINUX et contient toutes les fonctionnalités attendues d'un PABX:
- Serveur d'IVRs (boite vocale, conférence, ACD...) - Serveur CTI pour les interfaces utilisateurs (Flash) - Stacks protocolaires (SIP, MGCP, SCCP, H323) - Gestion des codecs (G729, G723, G711)
- Media serveur - Call Control engine
Sur un serveur, plusieurs PABX peuvent être crées avec un nombre d'utilisateurs differents afin d'attaquer le marché de la PME a la grande entreprise. Les API pour les couches applicatives et services sont à la disposition des clients afin de développer des services personnalisés. Le LAN PABX est destiné à des entreprises multi-sites, pour des centres d'affaires ou tout simplement pour une entreprise qui veut avoir l'équipement en local.
13.13 - TENOVIS
Site Internet : http://www.tenovis.com/
ICC sous proprietaire et LINUX, H323, 5000 postes ip maxi, du type compatible H323 I5 IP sous proprietaire et LINUX, H323, 48 postes ip maxi, du type compatible H323
13.14 - TIPTEL
Site Internet : http://www.tiptel.fr/ IP400 sous windows , H323, 200 postes ip max, du type compatible H323 IP3000-30 sous windows , H323, 1000 postes ip max, du type compatible H323
13.15 - FRANCE TELECOM
Site Internet : http://www.francetelecom.com/fr/ e-DIATONIS Mx sous IRMX , 250 postes IP maxi, du type propriétaire e-DIATONIS Lx sous IRMX , 250 postes IP maxi, du type propriétaire e-DIATONIS S sous LINUX , 200 postes IP maxi, du type propriétaire
e-DIATONIS M sous LINUX , 200 postes IP maxi, du type propriétaire e-DIATONIS L sous LINUX , 200 postes IP maxi, du type propriétaire
13.16 - ALSATEL
Site Internet : http://www.alsatel.fr/ Irma VPM IPBX Orienté Centres de sécurité ou d'alertes sous windows NT/XP, SIP, H323, postes IP phones, TIPPHONE
13.17 - IC Telecom

IC TELECOM permet d'améliorer votre productivité tout en réduisant vos coûts. Avec IC CENTREX, IC TELECOM propose une solution complète et modulaire de télécommunication d'entreprise : voix, data, mobile. Plus besoin d'acheter ou de louer un PABX, plus d'abonnement à l'opérateur historique. C'est l'avantage d'avoir un guichet unique donc un seul et même interlocuteur. Un accompagnement vous est dédié tout au long de notre collaboration.
Aussi, IC TELECOM vous offre de nombreux autres produits et services avec IC CONVERGENCE qui combine la téléphonie fixe et mobile, IC OFFICE permet de bénéficier d'une solution de messagerie avancée, conviviale et
sécurisée via une interface web 2.0 depuis n'importe quelle borne wifi. IC BACKUP vous donne la possibilité de sauvegardé en ligne vos données sans limite de stockage tout en bénéficiant d'une architecture sécurisée. Enfin, IC 800 qui grâce à son SVI vous apporte la possibilité de ne plus perdre d'appels, de réduire le temps d'attente de vos clients et fournisseurs en orientant intelligemment vos appels.
Avantages IC CENTREX :
- Pas de location ni d'achat de PABX - Suppression des abonnements
- Un seul interlocuteur téléphonique - Forfait illimité pour vos appels - Une maintenance technique 24h /24h 7j/7j - Communications inter sites gratuites et illimitées - Une facture unique pour l'internet, la téléphonie fixe et mobile - Service de maintenance et de formation
13.18 - PACWAN
Site internet : http://www.pacwan.fr/
PACWAN propose deux solutions : VoxDSL : les solutions professionnelles de voix sur IP pour les entreprises. De 1 à 999 postes, disposez immédiatement de nos solutions prêt à brancher VoxDSL et des télécommunications gratuites et illimitées (vers
les téléphones fixes de la France métropolitaine, hors numéros spéciaux ou surtaxés). Votre central téléphonique d'entreprise complet à partir de 22 euros par mois... communications incluses ! La technologie de voix sur IP pour les petites entreprises. La convergence de la voix et des données pour de très grosses économies à la clé ! VoaDSL : La voix sur IP n'est plus synonyme de multinationales. Vous aussi accédez dès maintenant au futur des télécommunications, et ne payez plus un centimes sur vos appels téléphoniques !
La voix sur ADSL c'est le téléphone et l'Internet dans un seul abonnement. C'est d'importantes économies et une nouvelle façon de penser le travail et l'organisation de votre entreprise. Vous télétravaillez, vous gérez une agence locale, vous dépensez des fortunes en téléphone ? La solution VoADSL adaptée à vos besoin existe déjà chez PacWan! Un équipement simple a installer (Plug & call), un support technique prêt à vous aider et des tarifs d'abonnement équivalents à ceux de l'ADSL classique.
13.19 - Panasonic
Site internet :
KX-TD208FR OS nc, max nc, type nc
KX-TD612SP OS nc, max nc, type nc KXt-TDA100 OS propriétaire, max nc, type nc KXt-TDA200 OS propriétaire, max nc, type nc
13.20 - TechTelecom
Site Internet : www.techtelecom.fr La solution de téléphonie sur IP e-phone® a la particularité de s'intégrer directement dans l'environnement de
messagerie du client. Avec son combiné USB, son casque USB ou son oreillette Bluetooth, il est possible d'émettre ou de recevoir des appels directement à partir de sa messagerie. Cette nouvelle offre construite autour de serveurs standard Windows a de plus l'avantage d'utiliser toutes les possibilités de l'informatique : - Annuaires centralisés, - Messagerie unifiée, - Serveur vocal,
- Lien TAPI...
Document au format Pdf
13.21 - 3CX
Site internet : http://www.3cx.fr/
Faites évoluer vos moyens de communications avec 3CX PABX-IP for Windows
Un autocom qui remplace entièrement votre PABX propriétaire, compatible avec téléphones/softphones SIP standard, les services VoIP et les lignes RTC traditionnelles. 3CX PABX-IP est bien moins onéreux qu'un PABX traditionnel et peut vous aider à faire des économies importantes sur le coût des appels en utilisant un fournisseur de services VoIP. Son administration web rend facile la gestion du système téléphonique. 3CX PABX-IP élimine le
réseau de branchements téléphoniques et permet aux utilisateurs d'avoir un poste direct en prenant tout simplement leur téléphone.

13.22 - Keyyo
Site internet : www.keyyo.fr
Le standard téléphonique évolutif Keyyo grâce à son mode hébergé IPCentrex vous affranchit de toute installation de PABX et de câblage. Vous mutualisez votre réseau informatique et telecom. Vos téléphones IP se branchent directement sur votre réseau informatique. Avec Keyyo c'est simple : Branchez/ téléphonez/ Gérez d'un simple clic !
Keyyo c'est plus de flexibilité pour une meilleure maîtrise des coûts Vous gérez en toute autonomie vos lignes et forfaits poste par poste depuis votre compte web Keyyo
13.23 - Open Source
La ToIP Open Source
Voix sur IP - VOIP
1 - Introduction
2 - Le Réseau Téléphonique Commuté 2.1 - Histoire de la téléphonie 2.2 - Principe du Rtc 2.3 - Architecture du réseau 3 - Les enjeux de la téléphonie sur Ip 4 - Les avantages 4.1 - Réduction des coûts
4.2 - Standards ouverts et interopérabilité multi-fournisseurs 4.3 - Choix d'un service opéré 4.4 - Un réseau voix, vidéo et données (triple play) 4.5 - Un service PABX distribué ou centralisé 4.6 - Evolution vers un réseau de téléphonie sur Ip 4.7 - Intégration des services vidéo 5 - L'Architecture Voip
5.1 - Les schémas 5.2 - Gateway et Gatekeeper 6 - Standards VoIP 6.1 - Protocole H323

6.1.1 - Introduction 6.1.2 - Fonctionnement 6.1.3 - H323 dans le modèle Osi 6.1.4 - La visioconférence sur Ip 6.1.5 - Avantages et inconvénients
6.1.6 - Comparaison avec Sip 6.1.7 - Conclusion
6.2 - Protocole Sip 6.2.1 - Introduction 6.2.2 - Fonctionnement 6.2.3 - Sécurité et Authentification 6.2.4 - Comparaison avec H323 6.2.5 - Conclusion 6.3 - Transport Rtp et Rtcp
6.3.1 - Introduction 6.3.2 - Les fonctions de Rtp 6.3.3 - Entête Rtp 6.3.4 - Les fonctions de Rtcp 6.3.5 - Entête Rtcp 6.3.6 - Conclusion 6.4 - H261
6.5 - Audio 7 - Problème et QoS 7.1 - Latence 7.2 - Perte de paquets 7.3 - Gigue 8 - Etat du marché
9 - Conclusion 10 - Discussion autour de la documentation 11 - Suivi du document
1 - Introduction
La voix sur IP (Voice over IP) est une technologie de communication vocale en pleine émergence. Elle fait partie d'un
tournant dans le monde de la communication. En effet, la convergence du triple play (voix, données et vidéo) fait partie des enjeux principaux des acteurs de la télécommunication aujourd'hui. Plus récemment l'Internet s'est étendu partiellement dans l'Intranet de chaque organisation, voyant le trafic total basé sur un transport réseau de paquets IP surpasser le trafic traditionnel du réseau voix (réseau à commutation de circuits). Il devenait clair que dans le sillage de cette avancée technologique, les opérateurs, entreprises ou organisations et fournisseurs devaient, pour bénéficier de l'avantage du transport unique IP, introduire de nouveaux services voix et vidéo. Ce fût en 1996 la naissance de la première version voix sur IP appelée H323. Issu de l'organisation de standardisation européenne ITU-T sur la base de
la signalisation voix RNIS (Q931), ce standard a maintenant donné suite à de nombreuses évolutions, quelques nouveaux standards prenant d'autres orientations technologiques. Pour être plus précis et néanmoins schématique, le signal numérique obtenu par numérisation de la voix est découpé en paquets qui sont transmis sur un réseau IP vers une application qui se chargera de la transformation inverse (des paquets vers la voix). Au lieu de disposer à la fois d'un réseau informatique et d'un réseau téléphonique commuté (RTC), l'entreprise peux donc, grâce à la VoIP, tout fusionner sur un même réseau. Ca par du fait que la téléphonie
devient de la "data". Les nouvelles capacités des réseaux à haut débit devraient permettre de transférer de manière fiable des données en temps réel. Ainsi, les applications de vidéo ou audioconférence ou de téléphonie vont envahir le monde IP qui, jusqu'alors, ne pouvait raisonnablement pas supporter ce genre d'applications (temps de réponse important, jigue-jitter, Cos-Qos,...). Jusque vers le milieu des années 90, les organismes de normalisation ont tenté de transmettre les données de manière toujours plus efficace sur des réseaux conçus pour la téléphonie. A partir de cette date, il y a eu changement. C'est sur les réseaux de données, que l'on s'est évertué à convoyer la parole. Il a donc
fallu développer des algorithmes de codage audio plus tolérants et introduire des mécanismes de contrôle de la qualité de service dans les réseaux de données. Faire basculer différents types de données sur un même réseau permet en
plus, de simplifier son administration. Comme toute innovation technologique qui se respecte, la VoIP doit non seulement simplifier le travail mais aussi faire économiser de l'argent. Les entreprises dépensent énormément en communications téléphoniques, or le prix des communications de la Toip (Téléphonie sur Ip) est dérisoire en comparaison. En particulier, plus les interlocuteurs sont
éloignés, plus la différence de prix est intéressante. De plus, la téléphonie sur IP utilise jusqu'à dix fois moins de bande passante que la téléphonie traditionnelle. Ceci apportant de grand intérêt pour la voix sur réseau privée. Il semblerait que les entreprises après avoir émis un certain nombre de doutes sur la qualité de services soient désormais convaincues de la plus grande maturité technologique des solutions proposées sur le marché. Qu'il s'agisse d'entreprises mono-site ou multisites, les sondages montrent que le phénomène de migration vers les systèmes de téléphonie sur IP en entreprise est actuellement engagé.
Les premières technologies de VoIP imaginées étaient propriétaires et donc très différentes les unes des autres. Pourtant, un système qui est censé mettre des gens et des systèmes en relation exige une certaine dose de standardisation. C'est pourquoi sont apparus des protocoles standards, comme le H323 ou le SIP.
2 - Le Réseau Téléphonique Commuté

Mais qu'est-ce que le RTC? Le RTC est tout simplement le réseau téléphonique que nous utilisons dans notre vie de tous les jours et qui nous donne accès à de multiple fonction. En effet outre le fait de pouvoir téléphoner, le RTC nous permet d'utiliser de multiples services tel que la transmission et réception de fax, l'utilisation d'un minitel, accéder à Internet etc... Il représente donc l'un des protocole de discussion utilisé sur la paire de cuivre boucle locale.
2.1 - Histoire de la téléphonie
Du premier télégraphe de Chappe en 1790 au RTC actuelle, l'histoire des communications à connu de grands moments et de grandes avancés dû à l'ingéniosité de certains et aux progrès technologique et électronique. Nous
retiendrons quelques grandes dates tel que :
1837 Premier télégraphe électrique inventé par Samuel Morse
1889 Almon B. Strowger (USA) invente le premier « sélecteur » automatique et donne ainsi naissance à la commutation téléphonique automatique
1938 Alec Reeves (Français) dépose le brevet des futurs systèmes à modulation par impulsion et codage (MIC) : quantification et échantillonnage du signal à intervalles réguliers, puis codage sous forme binaire.
1962 Les premiers systèmes de transmission multiplex de type MIC apparaissent aux Etats-Unis ils
permettent une liaison à 24 voies entre centraux téléphonique, à la même époque en France on installe des MIC à 32 voies.
1970 Un nouveau pas est franchi dans le domaine de la commutation électronique avec la mise en service en France, par le CNET, des premiers centraux téléphoniques publics en commutation électronique temporelle.
1979 Lancement du minitel en France
1987 Le RNIS est mis en service en France.
1990 De nouveaux concepts apparaissent tel que la commutation temporelle asynchrone (ATM) et la hiérarchie numérique synchrone.
2.2 - Principe du Rtc
Le réseau téléphonique public (RTPC, Réseau Téléphonique Public Commuté ou simplement RTC) a essentiellement pour objet le transfert de la voix. Le transport des données n'y est autorisé, en France, que depuis 1964. Utilisant le principe de la commutation de circuits, il met en relation deux abonnés à travers une
liaison dédiée pendant tout l'échange.
On distingue deux grandes parties dans ce réseau :
Le réseau capillaire ou de distribution, c'est le raccordement depuis chez l'abonné à un point d'entrée du réseau. Cette partie du réseau est analogique.

Le réseau de transit, effectue pour sa part le transport des communications entre les noeuds de transit concentrateurs / commutateurs). Cette portion du réseau est actuellement numérique.
La numérisation offre plusieurs avantages. Puisqu'il ne s'agit que de 0 et de 1, la qualité du signal est préservée,
quelle que soit la distance entre les convertisseurs (analogique numérique et numérique analogique). Ce n'est pas le cas des communications analogiques où le signal est pollué à chaque manipulation. La gestion générale du réseau discerne trois fonctions :
La distribution, celle-ci comprend essentiellement la liaison d'abonné ou boucle locale (paire métallique torsadée) qui relie l'installation de l'abonné au centre de transmission de rattachement. Cette ligne assure la transmission de la voix (fréquence vocale de 300 à 3 400 Hz), de la numérotation (10 Hz pouf la numérotation décimale -au cadran- et 697 à 1633 Hz pour la numérotation fréquentielle) et de la signalisation générale (boucle de courant, fréquences supra vocales)
La commutation, c'est la fonction essentielle du réseau, elle consiste à mettre en relation deux abonnés, maintenir la liaison pendant tout l'échange et libérer les ressources à la fin de celui-ci. C'est le réseau qui
détermine les paramètres de taxation et impute le coût de la communication à l'appelant
La transmission, c'est la partie support de télécommunication du réseau, cette fonction est remplie soit par un système filaire cuivre (en voie de disparition), de la fibre optique ou des faisceaux hertziens. Aujourd'hui, le réseau est pratiquement intégralement numérisé, seule la liaison d'abonné reste analogique.
2.3 - Architecture du réseau
Le réseau téléphonique commuté a une organisation hiérarchique à trois niveaux. Il est structuré en zones
correspondant à un niveau de concentration.
On distingue :
Zone à Autonomie d'Acheminement (ZAA), cette zone, la plus basse de la hiérarchie, comporte un ou plusieurs Commutateurs à Autonomie d'Acheminement (CAA) qui eux-mêmes desservent des
Commutateurs Locaux (CL). Les commutateurs locaux ne sont que de simples concentrateurs de lignes auxquels sont raccordés les abonnés finals. La ZAA (Zone à Autonomie d'Acheminement) est un réseau étoilé, elle constitue le réseau de desserte;
Zone de Transit Secondaire (ZTS), cette zone comporte des Commutateurs de Transit Secondaires (CTS). Il n'y a pas d'abonnés reliés aux CTS (Commutateurs de Transit Secondaires). Ils assurent le brassage des circuits lorsqu'un CAA (Commutateur à Autonomie d'Acheminement) ne peut atteindre le CAA destinataire directement (réseau imparfaitement maillé);

Zone de Transit Principal (ZTP), cette zone assure la commutation des liaisons longues distances. Chaque ZTP (Zone de Transit Principal) comprend un Commutateur de Transit Principal (CTP), L'un des commutateurs de transit principal (CTP) est relié au commutateur international de transit.
3 - Les enjeux de la téléphonie sur Ip
Dans cette partie, nous allons voir pourquoi la téléphonie IP est devenue importante pour les entreprises. L'enjeu est de réussir à faire converger le réseau de donnée IP et le réseau téléphonique actuel. Voici les principales motivations pour déployer la téléphonie sur IP (Source Sage Research 2003, sondage auprès de 100 décisionnaires IT).
Motivations Pourcentage
Réduction de coûts 75 %
Nécessité de standardiser l'équipement 66 %
Hausse de la productivité des employés 65 %
Autres bénéfices de productivité 64 %
Hausse du volume d'appels à traiter 46 %
Autres facteurs 50 %
La téléphonie sur IP exploite un réseau de données IP pour offrir des communications vocales à l'ensemble de l'entreprise sur un réseau unique voix et données. Cette convergence des services de communication données, voix, et
vidéo sur un réseau unique, s'accompagne des avantages liés à la réduction des coûts d'investissement, à la simplification des procédures d'assistance et de configuration, et à l'intégration accrue de filiales et de sites distants aux installations du réseau d'entreprise.
Les coûts généraux de l'infrastructure de réseau sont réduits. Le déploiement d'un unique réseau convergé voix et données sur tous les sites permet de réaliser des économies sur les investissements productifs, l'ordre d'idée en 2004-2005 atteint les 50% si l'on prend on compte les communications inter-site. De plus, comme le téléphone et le PC partagent le même câble Ethernet, les frais de câblage sont réduits. Les frais d'administration du réseau sont également minimisés. Il est ainsi possible de réaliser des économies à court et à long terme sur de nombreux postes : administration d'un seul réseau, fournisseur d'accès unique, unique contrat de maintenance, câblage commun, gratuité
des communications interurbaines, réduction de la complexité de l'intégration d'applications. Enfin, la migration de la solution actuelle vers la Téléphonie sur IP s'effectue en douceur. Les solutions de téléphonie sur Ip sont conçues pour dégager une stratégie de migration à faible risque à partir de l'infrastructure existante. Le scénario vers lequel va s'orienter la téléphonie sur Ip dépend beaucoup de l'évolution du réseau lui-même. En effet, si Internet reste à peu près dans sa configuration actuelle où il est essentiellement dimensionné en fonction d'une qualité de service moyenne pour la transmission des données, il est fort probable que la téléphonie sur Ip restera un
marché réservé au réseau de type Frame, Mpls. Les seules exceptions seraient alors les cas d'interconnexion de PBX d'entreprises, commerce électronique, applications nouvelles associant la voix pour une véritable utilisation multimédia d'Internet. En effet, ce qui ralenti considérablement l'explosion de ce secteur est le fait qu'il y ait encore trop peu de déploiements opérationnels en France et même dans le monde. De nombreuses entreprises connaissent la téléphonie sur IP, mais toutes en sont au même stade : le test. De plus, il faut savoir que la plupart des déploiements opérationnels de téléphonie sur IP ont été réalisés pour des universités, or, les universités n'ayant pas les mêmes exigences qu'une entreprise, ces déploiements ne sont pas réellement pris en compte.
Les applications et les services Ip intégrés améliorent la productivité et le soin de la clientèle. Les bénéfices récurrents
seront apportés par les gains de productivité liés à l'utilisation de nouveaux services et de nouveaux applicatifs tels que la messagerie unifiée qui permettent de libérer, selon les spécificités des métiers, entre 25 et 40 minutes de temps de travail par collaborateur, les assistants personnels qui permettent au collaborateur de personnaliser sur l'Intranet toutes les fonctions avancées de renvoi d'appel en fonction de son agenda propre ou partagé et les applications «
d'eLearning », qu'il convient de faire apparaître dans une démarche de démonstration de retour sur l'investissement à court et moyen terme. De plus, les fonctions simplifiées de création, de déplacement et de modification réduisent le temps nécessaire pour ajouter de nouveaux utilisateurs au réseau. Le déploiement de nouveaux services est accéléré. L'utilisation d'une infrastructure IP commune et d'interfaces standard ouvertes permet de développer et de déployer très rapidement des applications innovantes. Enfin, les utilisateurs accèdent à tous les services du réseau partout où ils peuvent s'y connecter notamment à travers l'extention mobility (substitution de postes).
4 - Les avantages
La VoIP offre de nombreuses nouvelles possibilités aux opérateurs et utilisateurs qui bénéficient d'un réseau basé sur Ip. Les avantages les plus marqués sont les suivants.
4.1 - Réduction des coûts

En déplaçant le trafic voix Rtc vers le réseau privé WAN/IP les entreprises peuvent réduire sensiblement certains coûts de communications. Réductions importantes mises en évidence pour des communications internationales, ces réductions deviennent encore plus intéressantes dans la mutualisation voix/données du réseau IP inter-sites (WAN). Dans ce dernier cas, le gain est directement proportionnel au nombre de sites distants.
4.2 - Standards ouverts et interopérabilité multi-fournisseurs
Trop souvent par le passé les utilisateurs étaient prisonniers d'un choix technologique antérieur. La VoIP a
maintenant prouvé tant au niveau des réseaux opérateurs que des réseaux d'entreprises que les choix et les évolutions deviennent moins dépendants de l'existant. Contrairement à nos convictions du début, nous savons maintenant que le monde VoIP ne sera pas uniquement H323, mais un usage multi-protocoles selon les besoins de services nécessaires. Par exemple, H323 fonctionne en mode "peer to peer" alors que MGCP fonctionne en mode centralisé. Ces différences de conception offrent immédiatement une différence dans l'exploitation des terminaisons considérées.
4.3 - Choix d'un service opéré
Les services opérateurs ouvrent les alternatives VoIP. Non seulement l'entreprise peut opérer son réseau privéVoIP en extension du réseau RTC opérateur, mais l'opérateur lui-même ouvre de nouveaux services de transport VoIP qui simplifient le nombre d'accès locaux à un site et réduit les coûts induits. Le plus souvent les entreprises opérant des réseaux multi-sites louent une liaison privée pour la voix et une pour la donnée, en conservant les connexions RTC d'accès local. Les nouvelles offres VoIP opérateurs permettent outre les accès RTC
locaux, de souscrire uniquement le média VoIP inter-sites.
4.4 - Un réseau voix, vidéo et données (triple play)
En positionnant la voix comme une application supplémentaire du réseau IP, l'entreprise ne va pas uniquement substituer un transport opérateur RTC à un transport IP, mais simplifier la gestion des trois réseaux (voix, données et vidéo) par ce seul transport. Une simplification de gestion, mais également une mutualisation des efforts financiers vers un seul outil. Concentrer cet effort permet de bénéficier d'un réseau de meilleure qualité, plus facilement évolutif et plus disponible, pourvu que la bande passante du réseau concentrant la voix, la vidéo
et les données soit dimensionnée en conséquence.

4.5 - Un service PABX distribué ou centralisé
Les PABX en réseau bénéficient de services centralisés tel que la messagerie vocale, la taxation, etc... Cette même centralisation continue à être assurée sur un réseau VoIP sans limitation du nombre de canaux. A l'inverse, un certain nombre de services sont parfois souhaités dans un mode de décentralisation. C'est le cas du centre d'appels où le besoin est une centralisation du numéro d'appel (ex : numéro vert), et une décentralisation des agents du centre d'appel. Difficile à effectuer en téléphonie traditionnelle sans l'utilisation d'un réseau IP pour le
déport de la gestion des ACD distants. Il est ainsi très facile de constituer un centre d'appel ou centre de contacts (multi canaux/multi-médias) virtuel qui possède une centralisation de supervision et d'informations. Il convient pour en assurer une bonne utilisation de dimensionner convenablement le lien réseau. L'utilisation de la VoIP met en commun un média qui peut à la fois offrir à un moment précis une bande passante maximum à la
donnée, et dans une autre période une bande passante maximum à la voix, garantissant toujours la priorité à celle-ci.
4.6 - Evolution vers un réseau de téléphonie sur Ip
La téléphonie sur IP repose totalement sur un transport VoIP. La mise en oeuvre de la VoIP offre là une première brique de migration vers la téléphonie sur IP.
4.7 - Intégration des services vidéo
La VoIP intègre une gestion de la voix mais également une gestion de la vidéo. Si nous excluons la configuration des "multicasts" sur les composants du réseau, le réseau VoIP peut accueillir des applications vidéo de type vidéo conférence, vidéo surveillance, e-learning, vidéo on demand,..., pour l'ensemble des utilisateurs à un coût
d'infrastructure réseau supplémentaire minime.
5 - L'Architecture Voip
5.1 - Les schémas
Voici le schéma générale de l'utilisation de la Voip en entreprise :

La VoIP étant une nouvelle technologie de communication, elle n'a pas encore de standard unique. En effet,chaque constructeur apporte ses normes et ses fonctionnalités à ses solutions. Il existe tout de même des références en la matière. Je vais décrire les trois principales que sont H.323, SIP et MGCP/MEGACO. Tous les acteurs de ce marché utilisent comme base pour leur produit une ou plusieurs de ces trois architectures. Il existe donc plusieurs approches pour offrir des services de téléphonie et de visiophonie sur des réseaux IP. Certaines
placent l'intelligence dans le réseau alors que d'autres préfèrent une approche peer to peer avec l'intelligence répartie à la périphérie (terminal de téléphonie IP, passerelle avec le réseau téléphonique commuté...). Chacune a ses avantages et ses inconvénients. Le schéma ci-dessus, décrit de façon générale la topologie d'un réseau de téléphonie IP. Elle comprend toujours des terminaux, un serveur de communication et une passerelle vers les autres réseaux. Chaque norme a ensuite ses propres caractéristiques pour garantir une plus ou moins grande qualité de service. L'intelligence du réseau
est aussi déportée soit sur les terminaux, soit sur les passerelles/Gatekeeper (contrôleur de commutation). On retrouve les éléments communs suivants :
Le routeur : Il permet d'aiguiller les données et le routage des paquets entre deux réseaux. Certains routeurs, comme les Cisco 2600, permettent de simuler un gatekeeper grâce à l'ajout de cartes spécialisées supportant les protocoles VoIP.
La passerelle : il s'agit d'une interface entre le réseau commuté et le réseau IP.
Le PABX : C'est le commutateur du réseau téléphonique classique. Il permet de faire le lien entre la passerelle ou le routeur et le réseau RTC. Une mise à jour du PABX est aussi nécessaire. Si tout le réseau devient IP, il n'y a plus besoin de ce matériel.
Les Terminaux : Des PC ou des téléphones VoIP.
Pour transmettre les paquets, on utilise RTP, standardisé en 1996. Il est un protocole adapté aux applications présentant des propriétés temps réel. Il permet ainsi de reconstituer la base de temps des flux (horodatage des paquets : possibilité de re-synchronisation des flux par le récepteur), de détecter les pertes de paquets et en
informer la source, et d'identifier le contenu des données pour leurs associer un transport sécurisé. En revanche, ce n'est pas "la solution" qui permettrait d'obtenir des transmissions temps réel sur IP. En effet, il ne procure pas de réservation de ressources sur le réseau (pas d'action sur le réseau de type RSVP, diffserv, Policeur), de fiabilisation des échanges (pas de retransmission automatique, pas de régulation automatique du débit) et de garantie dans le délai de livraison (seules les couches de niveau inférieur le peuvent) et dans la continuité du flux temps réel. Bien qu'autonome, RTP peut être complété par RTCP. Ce dernier apporte un retour d'informations sur la transmission et sur les éléments destinataires. Ce protocole de contrôle permet de renvoyer à la source des
informations sur les récepteurs et ainsi lui permettre, par exemple, d'adapter un type de codage ou encore de modifier le débit des données.
5.2 - Gateway et Gatekeeper

Pour commencer je vais parler d'un des éléments clefs d'un réseau VoIP, la passerelle et leurs « Gatekeepers » associés. Les passerelles ou gateways en téléphonie IP sont des ordinateurs qui fournissent une interface où se fait la convergence entre les réseaux téléphoniques commutés (RTC) et les réseaux basés sur la commutation de paquets TCP/IP. C'est une partie essentielle de l'architecture du réseau de téléphonie IP. Le gatekeeper est l'élément qui fournit de l'intelligence à la passerelle. Comme nous l'avons déjà fait remarqué, nous pouvons
séparer les parties matérielles et logicielles d'une passerelle. Le gatekeeper est le compagnon logiciel de la gateway.
Une gateway permet aux terminaux d'opérer en environnements hétérogènes. Ces environnements peuvent être très différents, utilisant diverses technologies tels que le Numéris, la téléphonie commutée ou la téléphonie IP. Les gateways doivent aussi être compatible avec les terminaux téléphoniques analogiques. La gateway fournit la possibilité d'établir une connexion entre un terminal analogique et un terminal multimédia (un PC en général). Beaucoup de sociétés fournissent des passerelles mais cela ne signifie pas qu'elles fournissent le même service. Les gateways (partie physique) et les gatekeepers (partie logicielle) font l'objet de deux sections séparées pour
bien cerner la différence. Certaines sociétés vendent un produit " gateway ", mais en réalité, elles incorporent une autre gateway du marché avec leur gatekeeper pour proposer une solution commerciale. La plus-value ne se fait pas sur la gateway mais sur le gatekeeper car c'est sur celui-ci qu'on peut faire la différence. Un gatekeeper deux services principaux : la gestion des permission et la résolution d'adresses. La gatekeeper est aussi responsable de la sécurité. Quand un client veut émettre un appel, il doit le faire au travers du gatekeeper. C'est alors que celui-ci fournit une résolution d'adresse du client de destination. Dans le cas où il y a plusieurs
gateways sur le réseau, il peut rediriger l'appel vers un autre couple gateway/gatekeeper qui essaiera à son tour de router l'appel. Pendant la résolution d'adresse, le gatekeeper peut aussi attribuer une certaine quantité de bande passante pour l'appel. Il peut agir comme un administrateur de la bande passant disponible sur le réseau. Le gatekeeper répond aux aspects suivant de la téléphonie IP :
Le routage des appels : en effet, le gatekeeper est responsable de la fonction de routage. Non seulement, il doit tester si l'appel est permis et faire la résolution d'adresse mais il doit aussi rediriger l'appel vers le bon
client ou la bonne passerelle.
Administration de la bande passante : le gatekeeper alloue une certaine quantité de bande passant pour un appel et sélectionne les codecs à utiliser. Il agit en tant que régulateur de la bande passante pour prémunir le réseau contre les goulots d'étranglement (bottle-neck).
Tolérance aux fautes, sécurité : le gatekeeper est aussi responsable de la sécurité dans un réseau de téléphonie IP. Il doit gérer les redondances des passerelles afin de faire aboutir tout appel. Il connaît à tout moment l'état de chaque passerelle et route les appels vers les passerelles accessibles et qui ont des ports
libres.
Gestion des différentes gateways : dans un réseau de téléphonie IP, il peut y avoir beaucoup de gateways. Le gatekeeper, de par ses fonctionnalités de routage et de sécurité, doit gérer ces gateways pour faire en sorte que tout appel atteigne sa destination avec la meilleure qualité de service possible.
Ainsi, le gatekeeper peut remplacer le classique PABX. En effet, il est capable de router les appels entrant et de les rediriger vers leur destination ou une autre passerelle. Mais il peut gérer bien d'autres fonctions telles que la conférence ou le double appel. Il n'existe pas les mêmes contraintes avec un gatekeeper qu'avec un PABX. En
effet, ce dernier est constitué par du logiciel et l'opérateur peut implémenter autant de services qu'il le désire. Alors qu'avec un PABX, l'évolutivité est limitée par le matériel propriétaire de chaque constructeur, avec le gatekeeper, l'amélioration des services d'un réseau de téléphonie IP n'a pas de limites. Le grand bénéfice du développement d'un gros gatekeeper est de remplacer le PABX classique. En effet, chaque PABX utilise son propre protocole pour communiquer avec les postes clients, ce qui entraîne un surcoût. Avec le couple gateway/gatekeeper, ce problème n'existe pas. Il utilise des infrastructures qui existent, le LAN et des protocoles
tel qu'IP.
6 - Standards VoIP
6.1 - Protocole H323
6.1.1 - Introduction
Avec le développement du multimédia sur les réseaux, il est devenu nécessaire de créer des protocoles qui supportent ces nouvelles fonctionnalités, telles que la visioconférence : l'envoi de son et de vidéo avec un soucis de données temps réel. Le protocole H.323 est l'un d'eux. Il permet de faire de la visioconférence sur des réseaux IP.
H.323 est un protocole de communication englobant un ensemble de normes utilisés pour l'envoi de données audio et vidéo sur Internet. Il existe depuis 1996 et a été initié par l'ITU (International Communication Union), un groupe international de téléphonie qui développe des standards de communication. Concrètement, il est utilisé dans des programmes tels que Microsoft Netmeeting, ou encore dans des équipements tels que les routeurs Cisco. Il existe un projet OpenH.323 qui développe un client H.323 en logiciel libre afin que les

utilisateurs et les petites entreprises puissent avoir accès à ce protocole sans avoir à débourser beaucoup d'argent.
6.1.2 - Fonctionnement
Le protocole H.323 est utilisé pour l'interactivité en temps réel, notamment la visioconférence (signalisation, enregistrement, contrôle d'admission, transport et encodage). C'est le leader du marché pour la téléphonie Ip. Il s'inspire du protocole H.320 qui proposait une solution pour la visioconférence sur un réseau numérique à intégration de service (Rnis ou Isdn en anglais), comme par exemple le service numéris proposé par France Telecom. Le protocole H.323 est une adaptation de H.320 pour les réseaux Ip. A l'heure actuelle, la visioconférence sur liaison Rnis est toujours la technique la plus déployée. Elle existe depuis 1990. Les
réseaux utilisés sont à commutation de circuits. Ils permettent ainsi de garantir une Qualité de Service (QoS) aux utilisateurs (pas de risque de coupure du son ou de l'image). Aujourd'hui, c'est encore un avantage indiscutable. Par contre, comme pour le téléphone, la facturation est fonction du débit utilisé, du temps de communication et de la distance entre les appels. H.323 définit plusieurs éléments de réseaux :
Les terminaux - Dans un contexte de téléphonie sur IP, deux types de terminaux H.323 sont
Aujourd'hui disponibles. Un poste téléphonique IP raccordés directement au réseau Ethernet de l'entreprise. Un PC multimédia sur lequel est installé une application compatible H.323.
Les passerelles (GW: Gateway) - Elles assurent l'interconnexion entre un réseau Ip et le réseau téléphonique, ce dernier pouvant être soit le réseau téléphonique public, soit un Pabx d'entreprise. Elles assurent la correspondance de la signalisation et des signaux de contrôle et la cohésion entre les médias. Pour ce faire, elles implémentent les fonctions suivantes de transcodage audio (compression, décompression), de modulation, démodulation (pour les fax), de suppression d'échos, de suppression
des silences et de contrôle d'appels. Les passerelles sont le plus souvent basées sur des serveurs informatiques standards (Windows NT, Linux) équipés d'interfaces particuliers pour la téléphonie
(interfaces analogiques, accès de base ou accès primaire RNIS, interface E1, etc.) et d'interfaces réseau, par exemple de type Ethernet. La fonctionnalité de passerelle peut toutefois être intégrée directement dans le routeur ainsi que dans les Pbx eux-mêmes.
Les portiers (GK: Gatekeeper) - Ils sont des éléments optionnels dans une solution H.323. Ils ont pour
rôle de réaliser la traduction d'adresse (numéro de téléphone - adresse Ip) et la gestion des autorisations. Cette dernière permet de donner ou non la permission d'effectuer un appel, de limiter la bande passante si besoin et de gérer le trafic sur le Lan. Les "gardes-barrière" permettent également de gérer les téléphones classiques et la signalisation permettant de router les appels afin d'offrir des services supplémentaires. Il peuvent enfin offrir des services d'annuaires.
Les unités de contrôle multipoint (MCU, Multipoint Control Unit) - Référence au protocole T.120 qui permet aux clients de se connecter aux sessions de conférence de données. Les unités de contrôle
multipoint peuvent communiquer entre elles pour échanger des informations de conférence.
Dans un contexte de téléphonie sur IP, la signalisation a pour objectif de réaliser les fonctions suivantes :
Recherche et traduction d'adresses - Sur la base du numéro de téléphone du destinataire, il s'agit de trouver son adresse IP (appel téléphone . PC) ou l'adresse IP de la passerelle desservant le destinataire. Cette fonction est prise en charge par le Gatekeeper. Elle est effectuée soit localement soit par requête vers un annuaire centralisé.
Contrôle d'appel - L'équipement terminal (« endpoint » = terminal H.323 ou passerelle) situé à
l'origine de l'appel établit une connexion avec l'équipement de destination et échange avec lui les informations nécessaires à l'établissement de l'appel. Dans le cas d'une passerelle, cette fonction implique également de supporter la signalisation propre à l'équipement téléphonique à laquelle elle est raccordée (signalisation analogique, Q.931, etc.) et de traduire cette signalisation dans le format défini dans H.323. Le contrôle d'appel est pris en charge soit par les équipements terminaux soit par le Gatekeeper. Dans ce cas, tous les messages de signalisation sont routés via le Gatekeeper, ce
dernier jouant alors un rôle similaire à celui d'un PBX. Services supplémentaires : déviation, transfert d'appel, conférence, etc.
Trois protocoles de signalisation sont spécifiés dans le cadre de H.323 à savoir :
RAS (Registration, Admission and Status) - Ce protocole est utilisé pour communiquer avec un Gatekeeper. Il sert notamment aux équipements terminaux pour découvrir l'existence d'un Gatekeeper et s'enregistrer auprès de ce dernier ainsi que pour les demandes de traduction d'adresses. La signalisation RAS utilise des messages H.225.0 6 transmis sur un protocole de
transport non fiable (Udp, par exemple).
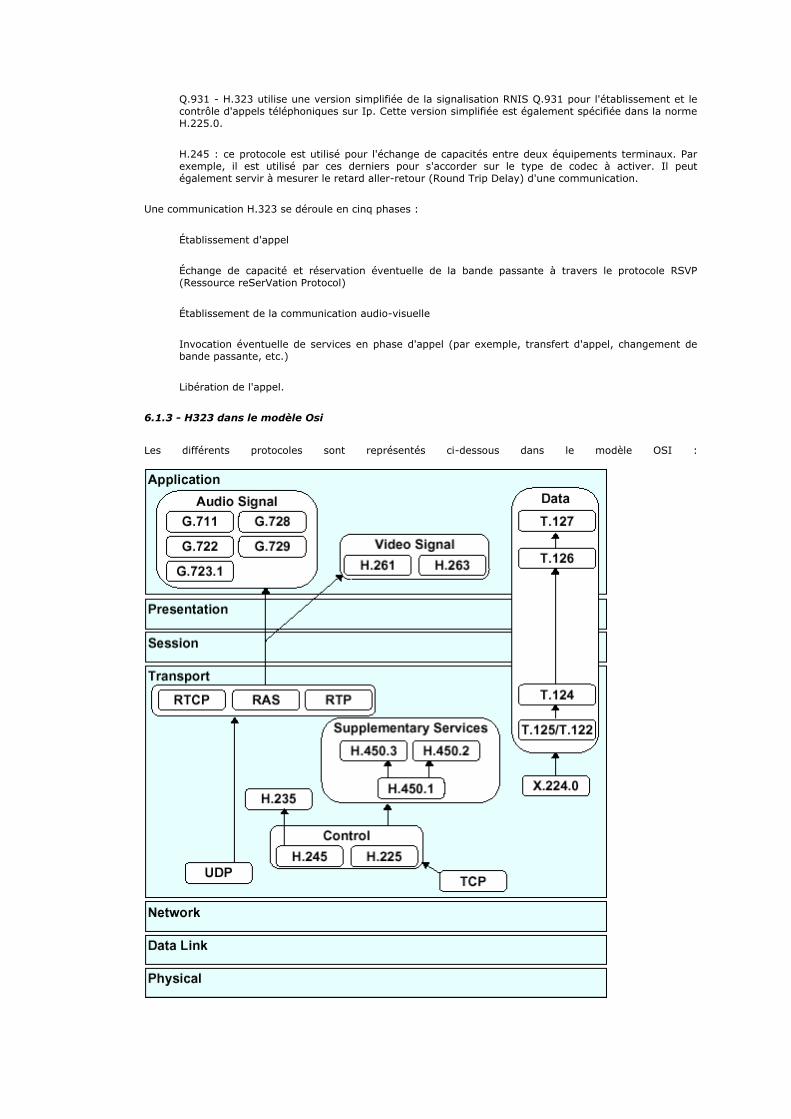
Q.931 - H.323 utilise une version simplifiée de la signalisation RNIS Q.931 pour l'établissement et le contrôle d'appels téléphoniques sur Ip. Cette version simplifiée est également spécifiée dans la norme H.225.0.
H.245 : ce protocole est utilisé pour l'échange de capacités entre deux équipements terminaux. Par exemple, il est utilisé par ces derniers pour s'accorder sur le type de codec à activer. Il peut également servir à mesurer le retard aller-retour (Round Trip Delay) d'une communication.
Une communication H.323 se déroule en cinq phases :
Établissement d'appel
Échange de capacité et réservation éventuelle de la bande passante à travers le protocole RSVP (Ressource reSerVation Protocol)
Établissement de la communication audio-visuelle
Invocation éventuelle de services en phase d'appel (par exemple, transfert d'appel, changement de bande passante, etc.)
Libération de l'appel.
6.1.3 - H323 dans le modèle Osi
Les différents protocoles sont représentés ci-dessous dans le modèle OSI :

6.1.4 - La visioconférence sur Ip
Tout d'abord, au niveau économique, la visioconférence sur Ip s'avère moins coûteuse que celle sur liaison RNIS car d'un côté, l'équipement d'un PC est relativement peu cher : ce système ne nécessite pas
l'installation de prises RNIS spéciales. D'autre part, une liaison Rnis a un coût calculé selon la longueur de l'appel, le débit, et la distance. Alors que dans une liaison IP, le prix est forfaitaire selon le débit. En fin de compte, la visioconférence par Ip s'avère souvent moins onéreuse que par liaison Rnis. Ensuite, qualitativement parlant, la visioconférence sur Ip peut utiliser des débits supérieurs et ainsi avoir une image et un son meilleurs qu'avec une liaison Rnis. En effet, la visioconférence sur Numeris utilise des
débits allant de 128Kb/s à 384Kb/s, alors qu'en mutualisant certaines liaisons Ip, on peut obtenir des lignes haut débit allant jusqu'à plusieurs Mb/s. Malheureusement, le problème majeur de la visioconférence sur Ip est l'absence d'une Qualité de Service (QoS) sur les réseaux Ip. C'est également ce qui fait l'avantage des réseaux Rnis. Cependant, avec l'évolution des réseaux Ip, on sait désormais qu'il est possible qu'on puisse disposer d'une QoS sur ceux-ci tel que Rsvp, Diffserv, gestion de file d'attente. On pourrait donc avoir des flux avec priorité sur ces réseaux.
En dehors du protocole H.323, il existe des normes de visioconférence sur Ip ayant des possibilités analogues à H.323 telles que Ip multicast, qui est particulièrement adaptés au téléenseignement et à la diffusion de séminaires et conférences car il permet la connexion de plusieurs dizaines de sites voire plus. Il existe également le système Vrvs qui est utilisé dans certaines communautés scientifiques, notamment la physique, en raison de sa convivialité. Il intègre Ip multicast et H.323. Pour pouvoir suivre une visioconférence, il faut bien entendu le matériel adéquat. Ce peut être un matériel
dédié contenant tout ce qu'il faut : moniteur, micro, et caméra vidéo. Ou alors, un ensemble matériel et logiciel sur un poste de travail normal (PC, etc.). Si la visioconférence ne compte que deux interlocuteurs, alors la liaison est point à point comme illustré sur le schéma ci-dessous :
Dans le cas où il y a plus de deux interlocuteurs, la visioconférence nécessite l'utilisation d'un pont multipoint comme illustré sur le schéma ci-dessous :

Pour se connecter entre eux, les interlocuteurs sont identifiés par un numéro ou une adresse E.164. Elle est
composée de numéros et est structurée comme un numéro de téléphone. En particulier, un numéro de téléphone est une adresse E.164. « E.164 » est le nom de la norme qui définit ces adresses. Pour router un appel H.323 dans le réseau, il est nécessaire d'avoir un « GateKeeper ». C'est un élément logiciel qui fonctionne dans un PC, ou encore dans un pont multipoint ou dans un routeur IP (Exemple dans
les routeurs Cisco). En fonction de l'adresse destinataire contenue dans l'appel H.323, les différents GateKeeper vont établir la communication entre émetteur et destinateur et mettre en place le routage. Par ailleurs, le protocole H.323 intègre la norme T.120 qui permet le partage d'applications. On peut, par exemple, afficher des documents sur les postes de travail des autres interlocuteurs.
6.1.5 - Avantages et inconvénients
Les réseaux IP sont à commutation de paquets, les flux de données transitent en commun sur une même liaison. La visioconférence IP mise sur une disponibilité de ces liaisons. Les débits des réseaux IP doivent donc être adaptés en fonction du trafic afin d'éviter tout risque de coupure du son et de la vidéo. Tous les
sites n'ont pas le même débit. Plus le débit sera élevé et plus le risque de coupure sera faible. Par ailleurs, tant que la Qualité de Service n'existera pas dans les réseaux IP, la fiabilité des visioconférences sur les lignes à faible débit sera basse. A l'heure actuelle, la compatibilité entre les différentes normes de visioconférence est assez faible. La visioconférence H.323 et H.320 sont compatibles mais elles nécessitent l'emploi de passerelles H.320/H.323. En ce qui concerne les différentes normes pour la visioconférence sur Ip, H.323 et Ip Multicast ne sont, en
règle générale, pas compatibles, sauf dans le cadre de VRVS qui permet un certain degré d'interopérabilité, mais ne gère pas la norme T.120.
Voici les principaux bénéfices qu'apporte la norme H.323 sont les suivants :
Codec standards : H.323 établit des standards pour la compression et la décompression des flux audio et vidéo. Ceci assure que des équipements provenant de fabricants différents ont une base commune
de dialogue.
Interopérabilité : Les utilisateurs veulent pouvoir dialoguer sans avoir à se soucier de la compatibilité du terminal destinataire. En plus d'assurer que le destinataire est en mesure de décompresser l'information, H.323 établit des méthodes communes d'établissement et de contrôle d'appel.
Indépendance vis à vis du réseau : H.323 est conçu pour fonctionner sur tout type d'architecture réseau. Comme les technologies évoluent et les techniques de gestion de la bande passante s'améliorent, les solutions basées sur H.323 seront capables de bénéficier de ces améliorations
futures.

Indépendance vis à vis des plates-formes et des applications : H.323 n'est lié à aucun équipement ou système d'exploitation.
Support multipoint : H.323 supporte des conférences entre trois points terminaux ou plus sans
nécessiter la présence d'une unité de contrôle spécialisée.
Gestion de la bande passante : Le trafic audio et vidéo est un grand consommateur de ressources réseau. Afin d'éviter que ces flux ne congestionnent le réseau, H.323 permet une gestion de la bande passante à disposition. En particulier, le gestionnaire du réseau peut limiter le nombre simultané de
connexions H.323 sur son réseau ou limiter la largeur de bande à disposition de chaque connexion. De telles limites permettent de garantir que le trafic important ne soit pas interrompu.
Support multicast : H.323 supporte le multicast dans les conférences multipoint. Multicast envoie chaque paquet vers un sous-ensemble des destinataires sans réplication, permettant une utilisation optimale du réseau.
A l'heure actuelle, le standard de fait pour les systèmes de téléphonie sur IP est la norme H.323 de l'UIT. Indispensable pour permettre un minimum d'interopérabilité entre équipements de fournisseurs différents, ce
standard présente toutefois les inconvénients suivants :
Protocole complexe, créé initialement pour les conférences multimédia et qui incorpore des mécanismes superflus dans un contexte purement téléphonique. Ceci a notamment des incidences au niveau des terminaux H.323 (téléphones IP, par exemple) qui nécessitent de ce fait une capacité mémoire et de traitement non sans incidence au niveau de leur coût.
Comprend de nombreuses options susceptibles d'être implémentées de façon différentes par les constructeurs et donc de poser des problèmes d'interopérabilité ou de plus petit dénominateur
commun (dans le choix du codec, par exemple) ; D'autre part, comme le seul codec obligatoire est le
codec G.711 (64 Kps) et que le support des autres codecs plus efficaces est optionnel, l'interopérabilité entre produits provenant de constructeurs différents ne signifie pas qu'ils feront un usage optimal de la bande passante. En effet, dans le cas où les codecs à bas débits sont différents, le transport de la voix se fera à 64 Kbps, ce qui, en terme de bande passante, ne présente guère d'avantages par rapport à un système téléphonique classique.
6.1.6 - Comparaison avec Sip
Sip est un autre protocole pour l'interactivité en temps réel. Il a été développé par l'IETF et s'inspire du
protocole Http alors que H.323 s'inspire de la téléphonie. Sip est plus modulaire et peut fonctionner avec d'autres protocoles. Il est donc plus souple que H.323.
6.1.7 - Conclusion
Le protocole H.323 est une des normes envisageables pour la visioconférence sur Ip. Cependant, elle est pour l'instant surtout employé par des programmes propriétaires (Microsoft, etc.). La documentation est difficile d'accès car l'ITU fait payer les droits d'accès aux derniers développements de cette technologie, en dehors des efforts faits par le projet OpenH.323 pour rendre cette technologie accessible à tous. Cet ensemble de normes ne s'avèrent pas toujours compatibles avec d'autres protocoles à cause de son développement inspiré de la téléphonie, ce qui peut rendre son utilisation un peu "rigide".
6.2 - Protocole SIP
6.2.1 - Introduction
Le protocole Sip (Session Initiation Protocole) a été initié par le groupe MMUSIC (Multiparty Multimedia Session Control) et désormais repris et maintenu par le groupe SIP de l'IETF donnant la Rfc 3261 rendant obsolète la Rfc 2543. Sip est un protocole de signalisation appartenant à la couche application du modèle Osi. Son rôle est d'ouvrir, modifier et libérer les sessions. L'ouverture de ces sessions permet de réaliser de l'audio ou vidéoconférence, de l'enseignement à distance, de la voix (téléphonie) et de la diffusion multimédia sur Ip essentiellement. Un utilisateur peut se connecter avec les utilisateurs d'une session déjà ouverte. Pour ouvrir une session, un utilisateur émet une invitation transportant un descripteur de session
permettant aux utilisateurs souhaitant communiquer de s'accorder sur la compatibilité de leur média, Sip permet donc de relier des stations mobiles en transmettant ou redirigeant les requêtes vers la position courante de la station appelée. Enfin, SIP possède l'avantage de ne pas être attaché à un médium particulier et est sensé être indépendant du protocole de transport des couches basses.
6.2.2 - Fonctionnement
Sip intervient aux différentes phases de l'appel :

Localisation du terminal correspondant,
Analyse du profil et des ressources du destinataire,
Négociation du type de média (voix, vidéo, données...) et des paramètres de communication,
Disponibilité du correspondant, détermine si le poste appelé souhaite communiquer, et autorise l'appelant à le contacter.
Etablissement et suivi de l'appel, avertit les parties appelant et appelé de la demande d'ouverture de session, gestion du transfert et de la fermeture des appels.
Gestion de fonctions évoluées : cryptage, retour d'erreurs, ...
Avec Sip, les utilisateurs qui ouvrent une session peuvent communiquer en mode point à point, en mode diffusif ou dans un mode combinant ceux-ci. Sip permet donc l'ouverture de sessions en mode :
Point-à-point - Communication entre 2 machines, on parle d'unicast.
Diffusif - Plusieurs utilisateurs en multicast, via une unité de contrôle M.C.U (Multipoint Control Unit)
Combinatoire - Plusieurs utilisateurs pleinement interconnectés en multicast via un réseau à maillage complet de connexions.
Voici les différents éléments intervenant dans l'ouverture de session :
Suivant nature des échanges, choix des protocoles les mieux adaptés (Rsvp, Rtp, Rtcp, Sap, Sdp).
Détermination du nombre de sessions, comme par exemple, pour véhiculer de la vidéo, 2 sessions doivent être ouvertes (l'une pour l'image et l'autre pour la vidéo).
Chaque utilisateur et sa machine est identifié par une adresse que l'on nomme Url Sip et qui se présente comme une Url Mailto.
Requête Uri permettant de localiser le proxy server auquel est rattaché la machine de l'appelé.
Requête Sip, une fois le client (machine appelante) connecté à un serveur Sip distant, il peut lui adresser une ou plusieurs requêtes Sip et recevoir une ou plusieurs réponses de ce serveur. Les réponses contiennent certains champs identiques à ceux des requêtes, tels que : Call-ID, Cseq, To et From.
Les échanges entre un terminal appelant et un terminal appelé se font par l'intermédiaire de requêtes :
Invite - Cette requête indique que l'application (ou utilisateur) correspondante à l'Url Sip spécifié est
invité à participer à une session. Le corps du message décrit cette session (par ex : média supportés par l'appelant ). En cas de réponse favorable, l'invité doit spécifier les médias qu'il supporte.
Ack - Cette requête permet de confirmer que le terminal appelant a bien reçu une réponse définitive à
une requête Invite.
Options - Un proxy server en mesure de contacter l'UAS (terminal) appelé, doit répondre à une requête Options en précisant ses capacités à contacter le même terminal.
Bye - Cette requête est utilisée par le terminal de l'appelé à fin de signaler qu'il souhaite mettre un
terme à la session.
Cancel - Cette requête est envoyée par un terminal ou un proxy server à fin d'annuler une requête non validée par une réponse finale comme, par exemple, si une machine ayant été invitée à participer à une session, et ayant accepté l'invitation ne reçoit pas de requête Ack, alors elle émet une requête Cancel.
Register - cette méthode est utilisée par le client pour enregistrer l'adresse listée dans l'URL TO par le serveur auquel il est relié.

Une réponse à une requête est caractérisée, par un code et un motif, appelés code d'état et raison phrase respectivement. Un code d'état est un entier codé sur 3 bits indiquant un résultat à l'issue de la réception d'une requête. Ce résultat est précisé par une phrase, textbased (UTF-8), expliquant le motif du refus ou de l'acceptation de la requête. Le code d'état est donc destiné à l'automate gérant l'établissement des sessions Sip et les motifs aux programmeurs. Il existe 6 classes de réponses et donc de codes d'état, représentées
par le premier bit :
1xx = Information - La requête a été reçue et continue à être traitée
2xx = Succès - L'action a été reçue avec succès, comprise et acceptée
3xx = Redirection - Une autre action doit être menée afin de valider la requête
4xx = Erreur du client - La requête contient une syntaxe éronnée ou ne peut pas être traitée par ce serveur
5xx = Erreur du serveur - Le serveur n'a pas réussi à traiter une requête apparemment correcte
6xx = Echec général - La requête ne peut être traitée par aucun serveur
Dans un système Sip on trouve deux types de composantes, les users agents (UAS, UAC) et un réseau de
serveurs :
L'UAS (User Agent Server) - Il représente l'agent de la partie appelée. C'est une application de type serveur qui contacte l'utilisateur lorsqu'une requête Sip est reçue. Et elle renvoie une réponse au nom de l'utilisateur.
L'U.A.C (User Agent Client) - Il représente l'agent de la partie appelante. C'est une application de type client qui initie les requêtes.
Le relais mandataire ou PS (Proxy Server), auquel est relié un terminal fixe ou mobile, agit à la fois comme
un client et comme un serveur. Un tel serveur peut interpréter et modifier les messages qu'il reçoit avant de les retransmettre :
Le RS (Redirect Server) - Il réalise simplement une association (mapping) d'adresses vers une ou plusieurs nouvelles adresses. (lorsqu'un client appelle un terminal mobile - redirection vers le PS le plus proche - ou en mode multicast - le message émis est redirigé vers toutes les sorties auxquelles sont reliés les destinataires). Notons qu'un Redirect Server est consulté par l'Uac comme un simple
serveur et ne peut émettre de requêtes contrairement au Ps.
Le LS (Location Server) - Il fournit la position courante des utilisateurs dont la communication traverse les Rs et PS auxquels il est rattaché. Cette fonction est assurée par le service de localisation.
Le RG (Registrar) - C'est un serveur qui accepte les requêtes Register et offre également un service de localisation comme le LS. Chaque PS ou RS est généralement relié à un Registrar.
6.2.3 - Sécurité et Authentification
Les messages Sip peuvent contenir des données confidentielles, en effet le protocole Sip possède 3
mécanismes de cryptage :
Cryptage de bout en bout du Corps du message Sip et de certains champs d'en-tête sensibles aux
attaques.
Cryptage au saut par saut (hop by hop) à fin d'empêcher des pirates de savoir qui appelle qui.
Cryptage au saut par saut du champ d'en-tête Via pour dissimuler la route qu'a emprunté la requête.
De plus, à fin d'empêcher à tout intrus de modifier et retransmettre des requêtes ou réponses Sip, des mécanismes d'intégrité et d'authentification des messages sont mis en place. Et pour des messages Sip transmis de bout en bout, des clés publiques et signatures sont utilisées par Sip et stockées dans les champs d'en-tête Autorisation.
Une autre attaque connue avec Tcp ou Udp est le « deny of service », lorsqu'un Proxy Server intrus renvoie une réponse de code 6xx au client (signifiant un échec général, la requête ne peut être traitée). Le client peut ignorer cette réponse. Si il ne l'ignore pas et émet une requête vers le serveur "régulier" auquel il était

relié avant la réponse du serveur "intrus", la requête aura de fortes chances d'atteindre le serveur intrus et non son vrai destinataire.
6.2.4 - Comparaison avec H323
Voici les avantages du protocole H.323 :
Il existe de nombreux produits (plus de 30) utilisant ce standard adopté par de grandes entreprises telles Cisco, IBM, Intel, Microsoft, Netscape, etc.
Les cinq principaux logiciels de visioconférence Picturel 550, Proshare 500, Trinicon 500, Smartstation et Cruiser 150 utilisent sur Ip la norme H.323.
Un niveau d'interopérabilité très élevé, ce qui permet à plusieurs utilisateurs d'échanger des données
audio et vidéo sans faire attention aux types de média qu'ils utilisent.
Voici les avantages du protocole Sip :
Sip est un protocole plus rapide. La séparation entre ses champs d'en-tête et son corps du message facilite le traitement des messages et diminue leur temps de transition dans le réseau.
Nombre des en-têtes est limité (36 au maximum et en pratique, moins d'une dizaine d'en-têtes sont utilisées simultanément), ce qui allège l'écriture et la lecture des requêtes et réponses.
Sip est un protocole indépendant de la couche transport. Il peut aussi bien s'utiliser avec Tcp que Udp.
De plus, il sépare les flux de données de ceux la signalisation, ce qui rend plus souple l'évolution "en direct" d'une communication (arrivée d'un nouveau participant, changement de paramètres...).
SIP H323
Nombre échanges pour établir
la connexion 1,5 aller-retour 6 à 7 aller-retour
Maintenance du code protocolaire
Simple par sa nature textuelle à l'exemple de Http
Complexe et nécessitant un compilateur
Evolution du protocole Protocole ouvert à de nouvelles fonctions
Ajout d'extensions propriétaires sans concertation entre vendeurs
Fonction de conférence Distribuée Centralisée par l'unité MC
Fonction de téléservices Oui, par défaut H.323 v2 + H.450
Détection d'un appel en boucle Oui Inexistante sur la version 1 un appel routé sur l'appelant provoque une infinité de requêtes
Signalisation multicast Oui, par défaut Non
6.2.5 - Conclusion
La simplicité, la rapidité et la légèreté d'utilisation, tout en étant très complet, du protocole Sip sont autant
d'arguments qui pourraient permettre à Sip de convaincre les investisseurs. De plus, ses avancées en matière de sécurité des messages sont un atout important par rapport à ses concurrents.
6.3 - Transport Rtp et Rtcp
6.3.1 - Introduction
Rtp est un protocole qui a été développé par l'IETF afin de facilité le transport temps réel de bout en bout des flots données audio et vidéo sur les réseaux Ip, c'est à dire sur les réseaux de paquets. Rtp est un protocole qui se situe au niveau de l'application et qui utilise les protocoles sous-jacents de transport Tcp ou Udp. Mais l'utilisation de Rtp se fait généralement au-dessus de Udp ce qui permet d'atteindre plus facilement le temps
réel. Les applications temps réels comme la parole numérique ou la visio-conférence constitue un véritable problème pour Internet. Qui dit application temps réel, dit présence d'une certaine qualité de service (QoS)

que Rtp ne garantie pas du fait qu'il fonctionne au niveau Applicatif. De plus Rtp est un protocole qui se trouve dans un environnement multipoint, donc on peut dire que Rtp possède à sa charge, la gestion du temps réel, mais aussi l'administration de la session multipoint. Rtp et Rtcp sont définis, depuis juillet 2003, par la Rfc 3550 rendant obsolète la version précédente Rfc 1889.
6.3.2 - Les fonctions de Rtp
Le protocole Rtp, Real Time Transport Protocol, standardisé en 1996, a pour but d'organiser les paquets à l'entrée du réseau et de les contrôler à la sortie. Ceci de façon à reformer les flux avec ses caractéristiques de départ. Rtp est géré au niveau de l'application donc ne nécessite pas l'implémentation d'un Kernel ou de
librairies. Comme nous l'avons dit dans l'introduction, Rtp est un protocole de bout en bout. Rtp est volontairement incomplet et malléable pour s'adapter aux besoins des applications. Il sera intégré dans le noyau de l'application. Rtp laisse la responsabilité du contrôle aux équipements d'extrémité. Rtp, est un protocole adapté aux applications présentant des propriétés temps réel. Il permet ainsi de :
Reconstituer la base de temps des flux (horodatage des paquets : possibilité de resynchronisation des flux par le récepteur)
Mettre en place un séquencement des paquets par une numérotation et ce afin de permettre ainsi la détection des paquets perdus. Ceci est un point primordial dans la reconstitution des données. Mais il faut savoir quand même que la perte d'un paquet n'est pas un gros problème si les paquets ne sont pas perdus en trop grands nombre. Cependant il est très important de savoir quel est le paquet qui a été perdu afin de pouvoir pallier à cette perte. Et ce par le remplacement par un paquet qui se compose d'une synthèse des paquets précédent et suivant.
Identifier le contenu des données pour leurs associer un transport sécurisé.
L'identification de la source c'est à dire l'identification de l'expéditeur du paquet. Dans un multicast l'identité de la source doit être connue et déterminée.
Transporter les applications audio et vidéo dans des trames (avec des dimensions qui sont dépendantes des codecs qui effectuent la numérisation). Ces trames sont incluses dans des paquets afin d'être transportées et doivent de ce fait être récupérées facilement au moment de la phase de dépaquétisation afin que l'application soit décodée correctement.
En revanche, ce n'est pas "la solution" qui permettrait d'obtenir des transmissions temps réel sur IP. En effet, il ne procure pas de :
Réservation de ressources sur le réseau (pas d'action sur le réseau, cf. RSVP);
Fiabilité des échanges (pas de retransmission automatique, pas de régulation automatique du débit);
Garantie dans le délai de livraison (seules les couches de niveau inférieur le peuvent) et dans la continuité du flux temps réel.
6.3.3 - Entête Rtp
L'entête d'un paquet Rtp est obligatoirement constitué de 16 octets. Cette entête précède le "payload" qui
représente les données utiles.

6.3.3.1 - V
Ce champ, codé sur 2 bits, permet d'indiquer la version de Rtp. Actuellement, V=2.
6.3.3.2 - P
Ce bit indique, si il est à 1, que les données possèdent une partie de bourrage.
6.3.3.3 - X
Ce bit spécifie, si il est à 1, que l'entête est suivie d'une entête supplémentaire.
6.3.3.4 - CC
Ce champ, codé sur 4 bits, représente le nombre de CSRC qui suit l'entête.
6.3.3.5 - M
Ce bit, lorsqu'il est à 1, définie que l'interprétation de la Marque est par un profil d'application.
6.3.3.6 - PT
Basé sur 7 bits, ce champ identifie le type du payload (audio, vidéo, image, texte, html, etc.).
6.3.3.7 - Numéro de séquence
Ce champ, d'une taille de 2 octets, représente le numéro d'ordre d'émission des paquets. Sa valeur initiale est aléatoire et il s'incrémente de 1 à chaque paquet envoyé, il peut servir à détecter des paquets perdus.
6.3.3.8 - Timestamp
Ce champ horodatage, de 4 octets, représente l'horloge système ou l'horloge d'échantillonnage de
l'émetteur. Elle doit être monotone et linéaire pour assurer la synchronisation des flux.
6.3.3.9 - SSRC
Basé sur 4 octets, ce champ identifie de manière unique la source de synchronisation, sa valeur est choisie de manières aléatoire par l'application.

6.3.3.10 - CSRC
Ce champ, sur 4 octets, identifie les sources de contribution. La liste des participants ayant leur contribution (audio, vidéo) aux donnée du paquet.
6.3.4 - Les fonctions de Rtcp
Le protocole Rtcp est fondé sur la transmission périodique de paquets de contrôle à tous les participants
d'une session. C'est le protocole Udp (par exemple) qui permet le multiplexage des paquets de données Rtp et des paquets de contrôle Rtcp. Le protocole Rtp utilise le protocole Rtcp, Real-time Transport Control Protocol, qui transporte les informations supplémentaires suivantes pour la gestion de la session :
Les récepteurs utilisent Rtcp pour renvoyer vers les émetteurs un rapport sur la QoS. Ces rapports comprennent le nombre de paquets perdus, le paramètre indiquant la variance d'une distribution (plus communément appelé la gigue : c'est à dire les paquets qui arrivent régulièrement ou irrégulièrement) et le délai aller-retour. Ces informations permettent à la source de s'adapter, par
exemple, de modifier le niveau de compression pour maintenir une QoS.
Une synchronisation supplémentaire entre les médias. Les applications multimédias sont souvent transportées par des flots distincts. Par exemple, la voix, l'image ou même des applications numérisées sur plusieurs niveaux hiérarchiques peuvent voir les flots gérées suivre des chemins différents.
L'identification car en effet, les paquets Rtcp contiennent des informations d'adresses, comme
l'adresse d'un message électronique, un numéro de téléphone ou le nom d'un participant à une conférence téléphonique.
Le contrôle de la session, car Rtcp permet aux participants d'indiquer leur départ d'une conférence téléphonique (paquet Bye de Rtcp) ou simplement de fournir une indication sur leur comportement.
Le protocole Rtcp demande aux participants de la session d'envoyer périodiquement les informations citées ci-dessus. La périodicité est calculée en fonction du nombre de participants de l'application. On peut dire que les paquets Rtp ne transportent que les données des utilisateurs. Tandis que les paquets Rtcp ne
transportent en temps réel, que de la supervision. On peut détailler les paquets de supervision en 5 types:
200 : rapport de l'émetteur
201 : rapport du récepteur
202 : description de la source
203 : au revoir
204 : application spécifique
Ces différents paquets de supervision fournissent aux noeuds du réseau les instructions nécessaires à un
meilleur contrôle des applications temps réel.
6.3.5 - Entête Rtcp
Ce protocole défini cinq paquets de contrôle :
200 - SR (Sender Report) : Ce rapport regroupe des statistiques concernant la transmission (pourcentage de perte, nombre cumulé de paquets perdus, variation de délai (gigue), ...Ces rapports sont issus d'émetteurs actifs d'une session.
201 - RR (Receiver Report) : Ensemble de statistiques portant sur la communication entre les participants. Ces rapports sont issus des récepteurs d'une session.
202 - SDES (Source Description) : Carte de visite de la source (nom, e-mail, localisation).
203 - BYE : Message de fin de participation à une session.
204 - APP : Fonctions spécifiques à une application.

Voici l'en-tête commun à tous les paquets Rtcp.
6.3.5.1 - V
Ce champ, codé sur 2 bits, permet d'indiquer la version de Rtp, qui est la même que dans les paquets Rtcp. Actuellement, V=2.
6.3.5.2 - P
Ce bit indique, si il est à 1, que les données possèdent une partie de bourrage.
6.3.5.3 - RC
Ce champ, basé sur 5 bits, indique le nombre de blocs de rapport de réception contenus en ce paquet. Une valeur de zéro est valide.
6.3.5.4 - PT
Ce champ, codé sur 1 octet, est fixé à 200 pour identifier ce datagramme Rtcp comme SR.
6.3.5.5 - Longueur
Ce champ de 2 octets, représente la longueur de ce paquet Rtcp incluant l'entête et le bourrage.
6.3.5.6 - SSRC
Basé sur 4 octets, ce champ, représente l'identification de la source pour le créeateur de ce paquet SR.
6.3.6 - Conclusion
Rtp nécessite le protocole de transport Udp, (en-tête 8 octets), qui fournira les numéros de port source et destination nécessaire à la couche application. Pour l'instant le protocole Rtp se trouve au dessus de Udp, tandis que dans le futur, on aura une indépendance vis à vis des couches réseaux. En résumant, ces deux protocoles sont adaptés pour la transmission de données temps réel. Cependant, ils
fonctionnent en stratégie bout à bout et donc ne peuvent contrôler l'élément principal de la communication : le réseau. Ces protocoles sont principalement utilisés en visioconférence où les participants sont tour à tour émetteurs ou récepteurs. Pour le transport de la voix, ils permettent une transmission correcte sur des réseaux bien ciblés. C'est-à-dire, des réseaux qui implémentent une qualité de service adaptée. Des réseaux bien dimensionnés (bande passante, déterminisme des couches sous-jacentes, Cos, ...) peuvent aussi se servir de
cette solution.

6.4 - H261
Le protocole H.261 est décrit dans la RFC 2032, cette norme décrit le transport d'un flux vidéo sur Rtp. Le format de l'en-tête est le suivant :
SBIT (Start Bit) - Basé sur 3 bits, ce champ représente le nombre de bits de poids forts à ignorer dans le premier
octet de données. EBIT (End Bit) - Basé sur 3 bits, ce champ représente le nombre de bits de poids faible à ignorer dans le dernier octet de données. I (Intra-frame encoded data flag) - Basé sur 1 bit, ce flag doit être mis à 1 si il contient seulement des intra-frame codé.
V (Motion Vector) - Basé sur 1 bit, ce flag indique si le Motion Vector est utilisé ou pas. GOBN (GOB number) - Basé sur 4 bits, ce champ code le nombre de GOB actif au début du paquet. Placez à 0 si le paquet commence par un en-tête de GOB. MBAP (Macroblock Address Predictor) - Basé sur 5 bits, ce champ code le prédicteur d'adresse de Macroblock.
Placez à 0 si le paquet commence par un en-tête de GOB. QUANT (Quantizer) - Basé sur 5 bits, ce champ représente la valeur actif avant le début de ce paquet. HMVD (Horizontal Motion Vector Data) - Basé sur 5 bits, ce champ doit être à 0 si le flag V est à 0 ou si le paquet commence avec une entête Gob.
VMVD (Vertical Motion Vector Data) - Basé sur 5 bits, ce champ doit être à 0 si le flag V est à 0 ou si le paquet commence avec une entête Gob.
6.5 - Audio
Le transport de la voix sur un réseau IP nécessite au préalable tout ou une partie des étapes suivantes :
Numérisation : dans le cas où les signaux téléphoniques à transmettre sont sous forme analogique, ces derniers doivent d'abord être convertis sous forme numérique suivant le format PCM (Pulse Code
Modulation) à 64 Kbps. Si l'interface téléphonique est numérique (accès RNIS, par exemple), cette fonction est omise.
Compression : le signal numérique PCM à 64 Kbps est compressé selon l'un des formats de codec (compression / décompression) (Tableau 3-3) puis inséré dans des paquets IP. La fonction de codec est le plus souvent réalisée par un DSP (Digital Signal Processor). Selon la bande passante à disposition, le signal voix peut également être transporté dans son format originel à 64 Kbps.
Décompression : côté réception, les informations reçues sont décompressées .il est nécessaire pour cela
d'utiliser le même codec que pour la compression- puis reconverties dans le format approprié pour le destinataire (analogique, PCM 64Kbps, etc.).
L'objectif d'un codec est d'obtenir une bonne qualité de voix avec un débit et un délai de compression le plus faibles possibles. Le coût du DSP est lié à la complexité du codec utilisé. Le Tableau ci-dessous présente les caractéristiques des principaux codecs standards de l'UIT. Les codecs les plus souvent mis en oeuvre dans les solutions VoIP sont G.711, G.729 et G.723.1.
La qualité d'un codec est mesurée de façon subjective en laboratoire par une population test de personnes. Ces dernières écoutent tout un ensemble de conversations compressées selon les différents codecs à tester et les
évaluent qualitativement selon la table suivante : Tableau : Echelle utilisé pour l'évaluation de la qualité de voix
Qualité de la parole Score
Excellente 5
Bonne 4
Correcte 3
Pauvre 2
Insuffisante 1
Sur la base des données numériques des appréciations, une opinion moyenne de la qualité d'écoute (Mean Opinion Score . MOS) est ensuite calculée pour chaque codec. Les résultats obtenus pour les principaux codecs sont résumés dans le tableau ci-dessous :
Tableau : Score MOSdes différents codecs
Codec VoIP Débit (Kbps) Score MOS
G.711 (PCM) 64 4.1
G.726 32 3.85
G.729 8 3.92
G.723.1 6.4 3.9
G.723.1 5.3 3.65
GSM 13 3.5
G.729 x2 3.27
G.729 x3 2.68
G.729 x GSM 3.17
Deux observations principales peuvent être tirées du Tableau 3-5 :
La qualité de la voix obtenue par les codecs G.729 et G.723.1 (à 6.4Kbps) est très proche de celle du service téléphonique actuel, et ce pour des débits entre 8 et 10 fois inférieurs. Ces deux codecs présentent une meilleure qualité que celle des réseaux téléphoniques cellulaires (GSM).
Le cumul, dans une même communication, d'opérations de compression/décompression conduit à une rapide dégradation de la qualité. Les solutions mises en oeuvre doivent éviter des configurations en tandem dans lesquelles un PBX reçoit un appel d'un poste distant à travers une liaison VoIP et le redirige vers une autre liaison semblable.
Offrant une qualité de voix très proche, les codecs G.729 et G.723.1 se distinguent essentiellement par la bande passante qu'ils requièrent et par le retard que chacun introduit dans la transmission. Le choix d'un équipement implémentant l'un ou l'autre de ces codecs devra donc être fait selon la situation, en fonction notamment de la bande passante à disposition et du retard cumulé maximum estimé pour chaque liaison (selon les standards de l'UIT, le retard aller (« one-way delay ») devrait être inférieur à 150 ms). Le facteur du jitter est primordiale pour une bonne écoute de la Voip.
7 - Problème et QoS
7.1 - Latence
La maîtrise du délai de transmission est un élément essentiel pour bénéficier d'un véritable mode conversationnel et minimiser la perception d'écho (similaire aux désagréments causés par les conversations par satellites, désormais largement remplacés par les câbles pour ce type d'usage).
Or la durée de traversée d'un réseau IP dépend de nombreux facteurs:

Le débit de transmission sur chaque lien
Le nombre d'éléments réseaux traversés
Le temps de traversée de chaque élément, qui est lui même fonction de la puissance et la charge de ce dernier, du temps de mise en file d'attente des paquets, et du temps d'accès en sortie de l'élément
Le délai de propagation de l'information, qui est non négligeable si on communique à l'opposé de la terre. Une transmission par fibre optique, à l'opposé de la terre, dure environ 70 ms.
Noter que le temps de transport de l'information n'est pas le seul facteur responsable de la durée totale de
traitement de la parole. Le temps de codage et la mise en paquet de la voix contribuent aussi de manière importante à ce délai. Il est important de rappeler que sur les réseaux IP actuels (sans mécanismes de garantie de qualité de service), chaque paquet IP « fait sont chemin » indépendamment des paquets qui le précèdent ou le suivent: c'est ce qu'on appelle grossièrement le « Best effort » pour signifier que le réseau ne contrôle rien. Ce fonctionnement est fondamentalement différent de celui du réseau téléphonique où un circuit est établi pendant toute la durée de la
communication. Les chiffres suivants (tirés de la recommandation UIT-T G114) sont donnés à titre indicatif pour préciser les classes de qualité et d'interactivité en fonction du retard de transmission dans une conversation téléphonique. Ces chiffres concernent le délai total de traitement, et pas uniquement le temps de transmission de l'information sur le réseau.
Classe n° Délai par sens Commentaires
Classe n° Délai par sens Commentaires
1 0 à 150 ms Acceptable pour la plupart des conversations
2 150 à 300 ms Acceptable pour des communications faiblement interactives
3 300 à 700 ms Devient pratiquement une communication half duplex
4 Au delà de 700 ms Inutilisable sans une bonne pratique de la conversation half duplex
En conclusion, on considère généralement que la limite supérieure "acceptable" , pour une communication téléphonique, se situe entre 150 et 200 ms par sens de transmission (en considérant à la fois le traitement de la voix et le délai d'acheminement).
7.2 - Perte de paquets
Lorsque les buffers des différents élément réseaux IP sont congestionnés, ils « libèrent » automatiquement de la bande passante en se débarrassant d'une certaine proportion des paquets entrant, en fonction de seuils
prédéfinis. Cela permet également d'envoyer un signal implicite aux terminaux TCP qui diminuent d'autant leur débit au vu des acquittements négatifs émis par le destinataire qui ne reçoit plus les paquets. Malheureusement, pour les paquets de voix, qui sont véhiculés au dessus d'UDP, aucun mécanisme de contrôle de flux ou de retransmission des paquets perdus n'est offert au niveau du transport. D'où l'importance des protocoles RTP et RTCP qui permettent de déterminer le taux de perte de paquet, et d'agir en conséquence au niveau applicatif. Si aucun mécanisme performant de récupération des paquets perdus n'est mis en place (cas le plus fréquent dans
les équipements actuels), alors la perte de paquet IP se traduit par des ruptures au niveau de la conversation et une impression de hachure de la parole. Cette dégradation est bien sûr accentuée si chaque paquet contient un
long temps de parole (plusieurs trames de voix de paquet). Par ailleurs, les codeurs à très faible débit sont généralement plus sensibles à la perte d'information, et mettent plus de temps à « reconstruire » un codage fidèle.
Enfin connaître le pourcentage de perte de paquets sur une liaison n'est pas suffisant pour déterminer la qualité de la voix que l'on peut espérer, mais cela donne une bonne approximation. En effet, un autre facteur essentiel intervient; il s'agit du modèle de répartition de cette perte de paquets, qui peut être soit « régulièrement » répartie, soit répartie de manière corrélée, c'est à dire avec des pics de perte lors des phases de congestion, suivies de phases moins dégradées en terme de QoS.
7.3 - Gigue
La gigue est la variance statistique du délai de transmission. En d'autres termes, elle mesure la variation
temporelle entre le moment où deux paquets auraient dû arriver et le moment de leur arrivée effective. Cette irrégularité d'arrivée des paquets est due à de multiples raisons dont: l'encapsulation des paquets IP dans les protocoles supportés, la charge du réseau à un instant donné, la variation des chemins empruntés dans le réseau, etc...

Pour compenser la gigue, on utilise généralement des mémoires tampon (buffer de gigue) qui permettent de lisser l'irrégularité des paquets. Malheureusement ces paquets présentent l'inconvénient de rallonger d'autant le temps de traversée global du système. Leur taille doit donc être soigneusement définie, et si possible adaptée de manière dynamique aux conditions du réseau.
La dégradation de la qualité de service due à la présence de gigue, se traduit en fait, par une combinaison des
deux facteurs cités précédemment: le délai et la perte de paquets; puisque d'une part on introduit un délai supplémentaire de traitement (buffer de gigue) lorsque l'on décide d'attendre les paquets qui arrivent en retard, et que d'autre part on finit tout de même par perdre certains paquets lorsque ceux-ci ont un retard qui dépasse le délai maximum autorisé par le buffer.
8 - Etat du marché
On compte une bonne vingtaine de firmes sur le marché. Les principaux sont Cisco, Clarent, Avaya, Alcatel, Nortel Network, Siemens, Ténovis, 3COM ... Ce qu'il faut souligner, c'est le fait qu'il y ait peu de concurrents car comme je l'ai dit précédemment, la téléphonie sur Ip est un marché très jeune et très novateur. D'ailleurs, le fait que la téléphonie sur IP soit un marché chevauchant 2 secteurs qui se rapprochent et étaient complètement différent auparavant, la téléphonie et l'informatique, nous assistons ici à une concurrence ayant des origines différentes. En effet, nous retrouvons le géant de l'équipement réseaux Cisco en concurrence avec des entreprises de téléphonies tel que Alcatel ou Siemens. Mais Cisco et Clarent arrivent largement en tête, sur un marché qui de 259 millions de dollars cette année
pourrait atteindre 2,89 milliards en 2006. La téléphonie sur IP propose 3 types de terminaux différents : Les hardphones qui sont des téléphones physiques IP, les softphones qui sont des logiciels permettant de téléphoner sur IP au travers d'un PC et les téléphones IP Wi-fi qui sont des téléphones sans-fil IP. Mais la plupart des concurrents proposent ces 3 produits qui sont plutôt homogènes. Un softphone Cisco et un Softphone Siemens sont quasi-identiques. Seule l'interface graphique les distingue. Pour le client, le produit des 2 concurrents est identique dans la mesure où il apporte les mêmes services.
Voici une documentation complémentaire sur la téléphonie sur IP en Open Source.
9 - Conclusion
Actuellement, il est évident que la téléphonie IP va continuer de se développer dans les prochaines années. Le marché de la téléphonie IP est très jeune mais se développe à une vitesse fulgurante. C'est aujourd'hui que les entreprises doivent investir dans la téléphonie IP si elles veulent y jouer un rôle majeur.
Le fait est que IP est maintenant un protocole très répandu, qui a fait ses preuves et que beaucoup d'entreprises disposent avantage de la téléphonie IP, car elle demande un investissement relativement faible pour son déploiement. La téléphonie IP ouvre la voie de la convergence voix/données et celle de l'explosion de nouveaux services tels que les CTI.
Maintenant que la normalisation a atteint une certaine maturité, il n'est plus dangereux de miser sur le standard H323 qui a été accepté par l'ensemble de la communauté. La téléphonie IP est une bonne solution en matière d'intégration, de fiabilité, d'évolutivité et de coût. Elle fera partie intégrante des Intranets d'entreprises dans les années à venir et apparaîtra aussi dans la téléphonie publique pour permettre des communications à bas coût.
Enfin, le développement de cette technologie représente-t-il un risque ou une opportunité pour les opérateurs traditionnels ? La réponse n'est pas tranchée. D'un coté, une stagnation des communications classiques; d'un autre coté l'utilisation massive d'Internet va augmenter le trafic et développer de nouveaux services que pourront développer les opérateurs. Bientôt nous téléphonerons tous sur IP... On peut ainsi vraisemblablement penser que le protocole IP deviendra un jour un standard unique permettant l'interopérabilité des réseaux mondialisés. C'est pourquoi l'intégration de la voix sur IP n'est qu'une étape vers EoIP :
Everything over IP.
Triple Play
1 - Introduction 2 - Triple Play par ADSL 2.1 - La technologie ADSL 2.2 - La Set-Top-Box
2.3 - Accès à Internet 2.3.1 - Connexion à l'abonné 2.3.2 - Connexion à la Set-Top-Box 2.3.3 - Débit IP 2.4 - Téléphonie 2.4.1 - POTS 2.4.2 - Voice over IP
2.4.3 - Voice over ATM

2.5 - Télévision par ADSL 2.5.1 - Fonctionnement 2.5.2 - Bande passante et encodage 2.5.3 - Vidéo à la demande 3 - Triple Play par câble
3.1 - Origine 3.2 - Hybride Fiber Coax
3.3 - Modem Câble 3.4 - DVB/DAVIC 3.5 - DOCSIS et PacketCable 4 - Offres des différents opérateurs 5 - Evolution 5.1 - WiMax 5.2 - UMA (Unlicensed Mobile Acces)
6 - Conclusion 7 - Discussion autour de la documentation 8 - Suivi du document
1 - Introduction
Les FAI (Fournisseur d'Accès Internet) proposent depuis maintenant près de deux ans de nouvelles offres. Il s'agit
d'offres « Triple Play » qui permettent à l'utilisateur de bénéficier d'un accès Internet haut débit, de la téléphonie et de la télévision par Internet.
Après avoir réalisé une présentation générale de cette technologie, une présentation plus spécifiques des différentes technologies utilisées sera réalisée. Puis nous exposerons les différentes offres proposés actuellement par les FAI. Ce document sera clôturé par une présentation des évolutions possibles de cette technologie.
2 - Triple Play par ADSL
L'ADSL (Asymmetric Digital Subscriber Line) est la technologie la plus utilisée actuellement pour l'accès à Internet par les particuliers. Bien que ça ne fut pas historiquement sur ce type de technologie que les offres Triple Play ont été développées, c'est aujourd'hui le premier fournisseur de ce genre d'offres.
Avant d'expliquer le fonctionnement de ces offres via ADSL, nous allons effectuer une brève description de cette technologie.
2.1 - La technologie ADSL
L'ADSL est une technologie développée pour pouvoir faire passer des données informatiques au travers des lignes téléphoniques (cela permet alors de réutiliser un réseau de câble déjà existant). Pour ce faire, elle utilise les bandes de hautes fréquences, non utilisées par la téléphonie (300-3400Hz), en utilisant des techniques de multiplexage et de modulation adaptées aux lignes téléphoniques. Le fait d'utiliser les fréquences hautes de la ligne téléphonique implique cependant l'utilisation d'un filtre de part et d'autre de la ligne téléphonique afin que les signaux de téléphonie ne viennent pas perturber les signaux ADSL (et inversement).
Les flux sont asymétriques, ce qui signifie qu'en ADSL, un abonné peut envoyer des données (voie montante) à un débit plus faible qu'il peut en recevoir (voie descendante). Cela est particulièrement adapté à une utilisation de la connexion par un particulier qui reçoit plus souvent des données qu'il n'en envoie (bien que l'asymétrie de l'ADSL soit plus dû à une contrainte technique qu'à un réel choix).
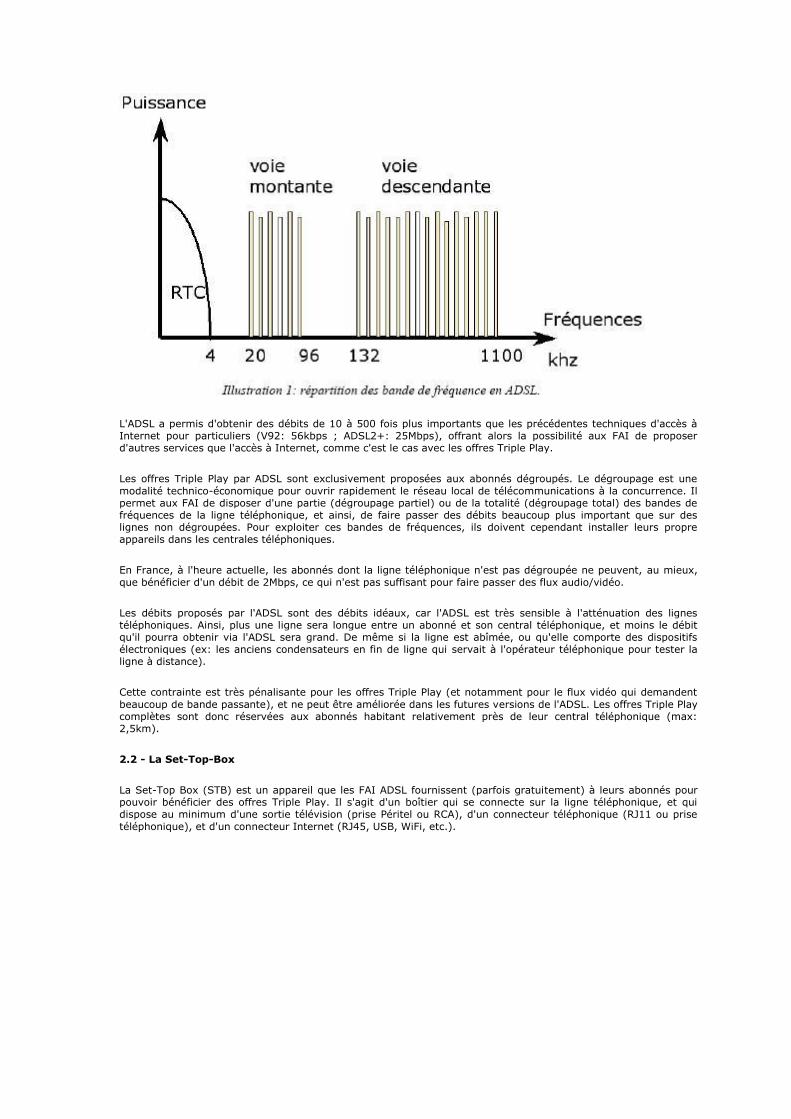
L'ADSL a permis d'obtenir des débits de 10 à 500 fois plus importants que les précédentes techniques d'accès à Internet pour particuliers (V92: 56kbps ; ADSL2+: 25Mbps), offrant alors la possibilité aux FAI de proposer d'autres services que l'accès à Internet, comme c'est le cas avec les offres Triple Play.
Les offres Triple Play par ADSL sont exclusivement proposées aux abonnés dégroupés. Le dégroupage est une
modalité technico-économique pour ouvrir rapidement le réseau local de télécommunications à la concurrence. Il permet aux FAI de disposer d'une partie (dégroupage partiel) ou de la totalité (dégroupage total) des bandes de fréquences de la ligne téléphonique, et ainsi, de faire passer des débits beaucoup plus important que sur des lignes non dégroupées. Pour exploiter ces bandes de fréquences, ils doivent cependant installer leurs propre appareils dans les centrales téléphoniques.
En France, à l'heure actuelle, les abonnés dont la ligne téléphonique n'est pas dégroupée ne peuvent, au mieux,
que bénéficier d'un débit de 2Mbps, ce qui n'est pas suffisant pour faire passer des flux audio/vidéo.
Les débits proposés par l'ADSL sont des débits idéaux, car l'ADSL est très sensible à l'atténuation des lignes téléphoniques. Ainsi, plus une ligne sera longue entre un abonné et son central téléphonique, et moins le débit qu'il pourra obtenir via l'ADSL sera grand. De même si la ligne est abîmée, ou qu'elle comporte des dispositifs électroniques (ex: les anciens condensateurs en fin de ligne qui servait à l'opérateur téléphonique pour tester la ligne à distance).
Cette contrainte est très pénalisante pour les offres Triple Play (et notamment pour le flux vidéo qui demandent
beaucoup de bande passante), et ne peut être améliorée dans les futures versions de l'ADSL. Les offres Triple Play complètes sont donc réservées aux abonnés habitant relativement près de leur central téléphonique (max: 2,5km).
2.2 - La Set-Top-Box
La Set-Top Box (STB) est un appareil que les FAI ADSL fournissent (parfois gratuitement) à leurs abonnés pour pouvoir bénéficier des offres Triple Play. Il s'agit d'un boîtier qui se connecte sur la ligne téléphonique, et qui dispose au minimum d'une sortie télévision (prise Péritel ou RCA), d'un connecteur téléphonique (RJ11 ou prise
téléphonique), et d'un connecteur Internet (RJ45, USB, WiFi, etc.).

La STB est en quelque sorte un mini-ordinateur capable de communiquer via ADSL avec le FAI, et de proposer des services avancés aux abonnés.
Certaines STB disposent de services supplémentaires (parfois payant) comme des fonctionnalités de partages de connexion Internet (routage IP/NAT), de lecteur multimédia (à destination de la télévision), de streaming
multipostes (i.e., recevoir plus d'une chaîne de télévision), etc.
2.3 - Accès à Internet
L'accès à Internet est le premier type de service qui a été proposé à travers l'ADSL. Les autres services d'une
offre Triple Play par ADSL étant dépendant de celui là, nous allons nous intéresser au fonctionnement de ce service dans un premier temps.
2.3.1 - Connexion à l'abonné
La connexion entre l'utilisateur et la STB peut généralement s'effectuer de trois façons différentes:
Connexion USB: il s'agit d'une liaison série qui permet à l'utilisateur de connecter directement son ordinateur à la STB. Elle ne spécifie aucun protocole de communication particulier à utiliser.
Cependant, la communication avec la STB se fait, la plupart du temps, en utilisant soit le protocole ATM, soit le protocole Ethernet. Il se peut aussi que la STB ne fonctionne que comme un modem ADSL classique en utilisant ce type de connexion, obligeant alors l'utilisation du protocole PPP au dessus d'ATM (PPPoA) ou d'Ethernet (PPPoE) dans ce cas.
Connexion Ethernet: il s'agit en fait d'une connexion Fast Ethernet (100 Mbit/s) qui permet à
l'utilisateur de se connecter à la STB au moyen d'une carte réseau.
Connexion WiFi: la plupart du temps, il s'agit d'un module optionnel payant qui permet à
l'utilisateur de se connecter à la STB au moyen d'une connexion sans fils, type 802.11b/g.
Bien évidemment, le protocole réseau utilisé ici es t le protocole IP. Sa configuration au niveau de l'ordinateur de l'utilisateur est effectuée à l'aide d'un serveur DHCP, soit implémenté dans la STB, soit se situant dans les locaux du FAI.
En général, les FAI ne procurent qu'une seule adresse IP par abonné (l'abonné peut cependant en obtenir d'autre en payant, mais ce n'est pas fréquent avec tous les FAI). Cette dernière peut d'ailleurs changer dans
le temps (IP dynamique), mais étant donné la nature quasi permanente des connexions ADSL, les IP dynamiques n'offrent aucun avantage aux FAI.
Pour partager la connexion Internet entre différent ordinateurs, il existe généralement deux solutions:
soit la STB permet d'effectuer du routage IP (et plus précisément, du routage NAT), et dans ce cas,
il suffit de la configurer de manière à ce qu'elle partage la connexion Internet (ou, plus exactement, qu'elle partage l'adresse IP publique de cette connexion). Si on veut pouvoir se connecter en Ethernet à Internet, il faut alors prévoir des appareils de partage du lien Ethernet (hub ou switch). En WiFi, le lien est naturellement partagé. Enfin, en utilisant la connexion USB, on doit posséder un appareil qui fasse la passerelle entre le lien USB et un lien réseau (principalement Ethernet), et qui

soit compatible avec les drivers USB de la STB. Cela ne peut bien sur pas fonctionner si la connexion à Internet dépend du protocole PPP. Ce type de partage de connexion permet de pouvoir utiliser en même temps les trois types d'accès à la STB pour se connecter à Internet.
sinon, on doit utiliser un appareil externe à la STB capable d'effectuer le routage NAT. Cela peut
être un appareil dédié, ou un ordinateur. Là cependant, on ne peut plus utiliser qu'un seul des trois
type de connexion à la STB pour accéder à Internet.
2.3.2 - Connexion à la Set-Top-Box
La STB est connectée à la ligne téléphonique de l'utilisateur. A l'autre bout de la ligne téléphonique se trouve le DSLAM qui a pour tâche de faire la passerelle entre les équipements des utilisateurs (via la STB) et le réseau du FAI. Le DSLAM se situe au niveau du central téléphonique local (plus techniquement appelé le Noeud de Raccordement Abonné), et peut être un équipement appartenant au FAI ou à l'opérateur historique, France Télécom (cela dépend du niveau de dégroupage de l'abonné). Un même DSLAM est connecté à un ensemble d'abonnés (du même FAI). Le nombre d'abonnés par DSLAM varie en fonction du
fabricant (ex: 1008 abonnés par DSLAM pour Free).
La communication entre la STB et le DSLAM est effectuée en utilisant la technologie ADSL. Cette technologie provenant des télécommunications, elle implique quasiment tout le temps l'utilisation du protocole ATM au dessus, ce dernier étant suffisamment simple pour être implémenté facilement dans des appareils de télécommunication et offrant une très bonne gestion de la QoS. Dans le cas d'une offre Triple Play, il peut aussi s'agir d'une extension du protocole ATM qui est utilisée (RFC 2684), afin de permettre le transport de
plusieurs flux (protocoles) différents via ATM. Ces flux sont généralement au nombre de quatre: un pour les données audio (téléphonie), un pour les données vidéo (télévision), un pour les données Internet, et un
dernier pour les données de contrôle des trois flux précédents.
Enfin, au dessus d'ATM, on peut trouver un certain nombre de protocoles, mais pour ce qui nous intéresse (l'accès à Internet), il s'agit bien évidemment du protocole IP (qui peut être encapsulé dans de l'Ethernet chez certains FAI pour faciliter l'interfaçage avec le réseau interne de ces FAI).
Le DSLAM peut contenir certains services IP, comme un service DHCP par exemple, pour configurer les STB.
Ça n'est cependant pas courant.
La connexion entre le DSLAM et le réseau du FAI est effectuée à l'aide d'une ou plusieurs fibres optiques. A ce niveau, les technologies utilisées sont SDH ou DWDM, couplées à un protocole pouvant supporter le très haut débit, type ATM ou Gigabit Ethernet. Dans ce dernier cas, les fonctions de routages sont effectuées par la pile TCP/IP, le protocole IP étant inévitablement utilisé dans tous les cas pour pouvoir interagir avec Internet et les services IP du FAI (e-mails, newsgroup, proxy Web, etc.).

2.3.3 - Débit IP
Le débit en ADSL dépend du contrat de l'abonné, mais surtout, de la distance entre l'installation de l'utilisateur et le central téléphonique où se trouve le DSLAM auquel il est connecté. Actuellement, cela va de 128 kbit/s à 25 Mbit/s (ADSL2+) pour le flux descendant (download), et de 128 kbit/s à 1 Mbit/s (ADSL2+) pour le flux montant (upload), sachant que seuls les utilisateurs habitant prés de leur central téléphonique peuvent bénéficier des meilleurs débits. Les limites de débits par utilisateur sont effectuées au niveau du
DSLAM.
Ainsi, en ADSL, le débit vendu n'est que rarement garanti. De plus, il est spécifié par un débit ATM, qui ne correspond pas au débit IP, et, de fait, encore moins au débit utile disponible pour l'utilisateur.
On notera enfin que la totalité du débit ADSL vendu n'est pas totalement dédié à l'accès à Internet dans une offre Triple Play. En effet, ce débit est partagé entre le flux de données (Internet), le flux audio (téléphonie)
et le flux vidéo (télévision), sachant que ce dernier est extrêmement gourmand. Ce partage est cependant adaptatif, c'est à dire que, tant qu'un flux est tout seul à utiliser la connexion, il peut jouir de la totalité du
débit (c'est une spécificité d'ATM).
2.4 - Téléphonie
La téléphonie au travers d'une ligne ADSL (parfois nommée Voice over xDSL) peut être effectuée de plusieurs manières, même si aujourd'hui, les FAI ADSL semble tous adopter la même technologie pour mettre en place leurs services de téléphonie.
2.4.1 - POTS
Le Plain Old Telephone Service correspond en fait à la façon traditionnelle de faire de la téléphonie, c'est-à-dire, en se servant classiquement des fréquences basses de la ligne téléphonique de l'abonné pour y faire passer de la voix de manière analogique. C'est un système encore utilisé par les opérateurs téléphoniques, et
qui, dans le cas de l'ADSL, est une façon logique de transporter de la voix, les lignes téléphoniques ayant été prévues initialement pour cela. Les conversations téléphoniques sont alors possibles sans ajout de matériel

spécifique chez l'abonné, et sont directement transmises par le RTC classique (via le réseau d'un opérateur de téléphonie).
Fournir un service téléphonique de ce type nécessite d'avoir accès aux fréquences basses de la ligne
téléphonique. Cela n'est possible que si le FAI a effectué un dégroupage total de la ligne téléphonique de l'abonné, ou si le FAI est en plus un opérateur de téléphonie alternatif.
Aujourd'hui, seuls les opérateurs de téléphonie qui se sont lancés par la suite dans la proposition de services Internet utilisent encore ce système. Les FAI qui ne proposaient pas initialement de services de téléphonie
ont quant à eux préférés ne pas avoir à utiliser directement le RTC pour faire passer leurs services de téléphonie (et donc, payer les services d'un opérateur de téléphonie), mais plutôt, utiliser leur réseau informatique interne pour réduire les coûts.
2.4.2 - Voice over IP
La voix sur IP est un mécanisme qui permet de faire passer des conversations audio entre plusieurs appareils interconnectés entre eux via un réseau informatique supportant le protocole IP. Dans le monde ADSL, on peut aussi le retrouver sous l'acronyme VoMSDN (Voice over MultiService Data Networks).
Il se compose essentiellement de trois modules:
un module de numérisation de la voix, qui a pour tâche de convertir la voix analogique en données
numériques (et inversement), en utilisant éventuellement des algorithmes de compression.
un protocole de contrôle de la conversation, qui permet d'établir une conversation entre plusieurs
participant, et qui se charge de négocier les différents paramètres de configuration de cette conversation.
un protocole de transport des données audio, qui encapsule la voix numérisée dans des paquets IP
afin de la transporter à travers le réseau, en utilisant éventuellement un mécanisme de QoS.
La VoIP est une technique rentable pour les FAI, car elle réutilise leur réseau interne (initialement destiné aux services Internet) pour faire passer leurs services de téléphonie. De plus, cela permet de supprimer la notion de distance dans le coût des appels téléphoniques étant donné que le trafic IP n'est pas facturé à la distance, mais à la quantité de données transférées, et que les réseaux des FAI s'étendent sur la quasi-
totalité du territoire français. Enfin, les circuits électroniques de numérisation de la voix étant aujourd'hui peu coûteux (du fait qu'il s'agisse d'une technologie amortie, et qu'ils sont maintenant produit en masse), cela permet d'inclure directement dans les STB de tels circuits à moindre frais. Ainsi, c'est ce type de technique qui est presque exclusivement utilisé par les FAI français pour proposer leurs services de téléphonie.
La VoIP ne reste cependant qu'un concept, et il en existe aujourd'hui plusieurs implémentations incompatibles entres elles. Elles fonctionnent cependant globalement avec les mêmes types d'éléments réseaux:
les terminaux: cela peut être soit un ordinateur disposant d'une connexion IP, soit un téléphone IP, soit un appareil permettant de numériser les signaux d'un téléphone classique (le cas d'une STB par exemple). C'est par eux que les utilisateurs initialisent et reçoivent les conversations téléphoniques.
les registres: ils permettent d'associer un terminal (via son adresse IP) à un identifiant plus simple à utiliser, et connu par les utilisateurs désirant contacter ce terminal. Cette association peut s'effectuer à l'aide d'un mécanisme d'identification plus ou moins complexe.
les proxy: ce sont des éléments qui permettent la mise en relation de deux terminaux qui ne se
connaissent pas (i.e., le terminal appelant ne connaît pas l'adresse IP du terminal à appeler). Ils sont généralement liés aux registres (voire confondus), et peuvent controler les accès d'un terminal
en fonction d'une politique de gestion de droits.
les passerelles: elles assurent l'inter-connexion entre un réseau VoIP spécifique et un autre type de réseau téléphonique (RTC, VoIP, VoATM, etc.).
les unités de contrôle multi-points (Multipoint Control Unit): elles permettent de gérer les
communications qui comportent plus de deux participants.
Ces implémentations permettent généralement d'effectuer trois types de conversations:
point à point: les terminaux qui veulent communiquer (à hauteur de deux terminaux maximum par
conversation) se connectent directement entre eux, en effectuant une phase de négociation pour déterminer les paramètres de la communication. Un fois la communication initialisée, les données (uniquement audio dans le cas de la VoIP) peuvent circuler entre les deux terminaux, à l'aide d'un protocole de transfert de données isochrones. Ce type de communication nécessite de connaître
l'adresse IP du terminal qu'un utilisateur veut joindre, ce qui n'est pas toujours possible (surtout quand un des deux participants se situe derrière un routeur NAT).
point à point, via un proxy: ici, tous les terminaux s'enregistrent avec le registre afin d'être associé avec un identifiant connus des utilisateurs susceptibles de les appeler. Quand un terminal a besoin
d'en contacter un autre, il utilise alors le proxy en lui donnant l'identifiant du terminal qu'il veut

contacter. Le proxy se sert alors du registre pour déterminer l'adresse IP du terminaux à joindre, et détermine si ce terminal est libre et accessible par le terminal appelant. Le cas échéant, la communication entre les deux terminaux s'effectue en point à point.
multi-points: dans le cadre d'une communication entre plus de deux terminaux, une MCU est
utilisée pour gérer la mise en relation des différents participants. Elle permet de spécifier le nombre
maximum de participants, les débits de la communication, l'identifiant de la communication, etc. La MCU est utilisée par le proxy. Le reste de la communication s'effectue de la même manière qu'en point à point, via un proxy, à ceci près que c'est la MCU qui est le destinataire de tous les flux (elle les redirige vers les autres participant en utilisant du multicast IP en général).
Les implémentations actuelles de VoIP ont été pensées, non pas pour effectuer des conversations audio seulement, mais pour gérer et transporter des communications multimédia, pouvant comporter autant de la
voix que de la vidéo ou des données (texte, dessins, etc.). Il existe aujourd'hui deux grandes normes qui sont utilisées pour effectuer de la VoIP:
H.323: cette norme regroupe un ensemble de protocoles de communication de la voix, de l'image
et de données sur IP. C'est un protocole qui fut développé par l'UIT-T en 1996. Il est dérivé du protocole H.320 utilisé sur RNIS. Il se base sur le fonctionnement de la téléphonie classique (de l'époque), et est de fait assez complexe et très rigide. Il est de plus en plus remplacé par leprotocole SIP, plus simple à utiliser et bien plus modulaire.
SIP (Session Initiation Protocol): c'est un protocole normalisé et standardisé par l'IETF (RFC 3261)
qui a été conçu pour établir, modifier et terminer des sessions multimedia. Il se charge de l'authentification et la localisation des multiples participants. Il se charge également de la négociation sur les types de média utilisables par les différents participants. SIP ne transporte pas les données échangées durant la session comme la voix ou la vidéo. SIP étant indépendant de la transmission des données, tout type de données et de protocoles peut être utilisé pour cet échange.
La plupart du temps, c'est le protocole RTP (Real Time Protocol) qui est utilisé pour transporter les données audio, que ça soit en H.323 (norme d'où provient RTP) ou en SIP. Ce protocole encapsule les données de la
conversation en ajoutant des informations temporelles qui permettent d'effectuer une synchronisation temporelle des flux au niveau du récepteur. RTP reposant sur UDP, il ne permet pas de s'assurer de la fiabilité de la transmission (mais seul UDP peut être utilisé pour des applications temps réel, TCP ajoutant une latence non négligeable).
Il peut être associé au protocole RTCP (Real Time Control Protocol) qui permet d'avoir un retour de la part du
récepteur sur, entre autre, le nombre de données reçues et perdues, afin d'adapter dynamiquement les paramètres de la communication, et effectuer ainsi de la QoS.
Les FAI fournissant des services de téléphonie par VoIP utilisent généralement le protocole SIP, en association avec d'autres protocoles de signalétique qui permettent d'adapter simplement les signaux de la téléphonie classique (provenant du RTC ou d'un simple téléphone classique) à des signaux de contrôles VoIP. Ainsi, on peut par exemple trouver les protocoles SIP-T (Session Initiation Protocol for Telephones) et MGCP
(Multimedia Gateway Control Protocol) dans le dispositif VoIP du FAI Free.
Le protocole SIP-T permet d'adapter les signaux provenant (ou à destination) du RTC pour les utiliser en VoIP, et MGCP permet d'adapter les signaux provenant (ou à destination) d'un téléphone classique pour que la STB puisse les utiliser en VoIP, sans effectuer un trop gros travail de conversion.

Dans le cas de Free, les commutateurs XC jouent à le fois le rôle de passerelle (vers le RTC ou les réseau d'autres FAI), de proxy et de registre (en se servant de la base de données des abonnées). Ils
communiquent entre eux à l'aide du protocole SIP-T.
Les STB (appelées Freebox chez Free) communiquent quant à elles avec un commutateur XC (toujours le
même pour une Freebox donnée) à l'aide du protocole MGCP. Chaque Freebox est associée (géographiquement) à un commutateur dont elle dépend pour passer et recevoir des appels.
Les commutateurs ont besoin de communiquer entre eux pour acheminer un appel, soit en provenance (ou à destination) d'un autre réseau, soit en provenance (ou à destination) de deux Freebox ne dépendant pas du même commutateur.
Les données audio voyagent par le protocole RTP, entre une Freebox et un commutateur, dans le cas d'une communication inter-réseaux, ou directement entre deux Freebox, dans le cas d'une communication entre
deux abonnés de Free. On notera, dans le premier cas, qu'un seul commutateur XC est concerné par les paquets RTP: le commutateur qui fait la passerelle avec le réseau du second participant de la communication.
La VoIP est donc un technique particulièrement adaptée à la téléphonie dans les offres Triple Play, de part son faible coût (dû principalement au fait qu'elle ré-utilise le réseau du FAI) et sa simplicité d'intégration dans les STB.
2.4.3 - Voice over ATM
La VoATM (aussi connue sous le nom Voice Trafic over ATM) est une technique qui permet de tirer partie des fonctionnalités de transport multi-flux de l'ATM. Les DSLAM étant la plupart du temps reliés par des liaisons
ATM au FAI, il peut sembler plus judicieux d'utiliser de la VoATM pour faire passer le flux audio ADSL plutôt que de se servir du protocole VoIP. De plus, l'ATM permet de faire de la réservation de débit, ce que n'offre pas IP, cela pouvant être un gros problème dans les transferts de type isochrone.
Cependant, en France, la VoATM n'est pas utilisée par les FAI ADSL qui proposent des services de téléphonie, probablement pour des raisons d'évolutions improbables. C'est pourquoi cette technologie est citée ici uniquement à titre informatif, et ne sera pas développée plus (se référer aux références bibliographiques pour plus de détails, et notamment, celles de l'IEC).
On notera enfin que cette technologie reste cependant utilisée par certains FAI américains.
2.5 - Télévision par ADSL
On peut trouver aujourd'hui de chaîne de télévision en ligne. Ces chaînes transmettent leurs programmes en temps réel. C'est ce que l'on appelle du streaming accessible grâce à des logiciels particuliers (le plus souvent Windows Media Player). Il s'agit alors d'un simple flux disponible sur son écran d'ordinateur. Avec de système il faut posséder à haut débit constant pour assurer une bonne réception.

La télévision par l'ADSL permet quand à elle d'accéder à un bouquet de chaîne télévisé directement sur son poste de télévision.
2.5.1 - Fonctionnement
Sur le câble et le satellite toutes les chaînes sont transmises aux abonnés. C'est alors au décodeur de faire le tri. Le fonctionnement est différent par le ADSL. Le débit sur la boucle locale étant limité, le DSLAM ne transmet qu'une seule chaîne au domicile de l'abonné. Il n'est donc pas possible de regarder deux chaînes simultanément, ou d'enregistrer une chaîne sur son magnétoscope pendant que vous en regardez une autre.
Lorsque l'utilisateur veut changer de chaîne, la set-top-box transmet la demande au DSLAM. Celui-ci à la charge de sélectionner le bon flux. Mais le DSLAM non plus ne reçoit pas toutes les chaînes. Il ne reçoit que
les chaînes qu'il transmet à ce moment à ces abonnés, et cela pour ne pas saturer le réseau.
Donc quand un abonné zappe, le DSLAM vérifie s'il ne reçoit pas déjà la chaîne désirée. Ce serait le cas s'il la transmet à un autre abonné. Si c'est la cas il duplique le flux pour l'envoyer aux différents abonnés. Dans le cas contraire il doit aller le rechercher à la tête du réseau. Cela peut entraîner un délai lors du changement de chaîne.
La set-top-box reçoit enfin le flux vidéo. Il se charge de le séparer des autres flux éventuellement reçus (Internet ou téléphonie). Puis le décodeur numérique traduit le signal à la volée. Il envoie ce signal à la
télévision (ou magnétoscope ...).
Avant de délivrer des programmes payant le DSLAM consulte le serveur de gestion des droits d'accès situé sur le centre de diffusion, pour vérifier que le client a bien souscrit l'abonnement correspondant.
2.5.2 - Bande passante et encodage
La télévision est le service le plus critique en matière de bande passante pour les offres Triple play de l'ADSL. En effet elle est gourmande en bande passante, et requiert un débit garanti pour une bonne visualisation. Il faut donc trouver un compromis entre qualité de l'image et contraintes dues au débit.
Ainsi les opérateurs réservent environ 4 à 5 Mbps de bande passante pour le flux vidéo, même si le support est utilisé en même temps pour d'autre technologie (Internet, téléphonie ..). Cette bande passante allouée à
la télévision sur ADSL devrait ainsi permettre d'obtenir une qualité d'images très correcte.
Le type d'encodage retenue est généralement le MPEG2. Il permet de diffuser le flux vidéo dans la bande passante réservé, tout en conservant une bonne qualité d'image. Une compression trop importante pourrait bien sur entraîner une perte de qualité d'image ou de fluidité. Ce taux de compression et le débit garanti de 3,5 à 4 Mbps permettent d'attendre une définition de 576;480 points.
Le passage en MPEG4 est aujourd'hui envisagé. Cela permettrai d'obtenir une meilleure qualité dans un bande passante diminué de moitié. Les FAI pourrait alors envisagé de permettre à l'abonné de recevoir deux
chaînes simultanément.
Les fournisseurs de contenu (TPS, Canal Satellite ou autres) livrent leurs contenues en direct au FAI. Ceux-ci encodent en direct ces flux audio-vidéo en MPEG2. C'est une partie délicate qui peut être à l'origine d'une grande perte de qualité. Mais cet encodage est indispensable pour ramener le flux numérique à des dimensions permettant la transmission via l'ADSL. Une fois cet encodage réalisé, le flux peut être envoyé sur le réseau.
2.5.3 - Vidéo à la demande
Le service VOD (Video On Demande) proposé par les FAI permet à un utilisateur de louer une vidéo sans
bouger de chez lui, et de la visionné à partir de son écran de télévision. L'utilisation est très simple pour l'abonné .Il peut de sélectionner dans un catalogue les films, documentaires ou archives télévisuels que lui propose son FAI. Il utilise pour cela son équipement, connexion et settop-box. Il effectue son choix sur sa télévision grâce à la télécommande de sa set-top-box. Il peut ainsi sélectionner une vidéo et la visionner moyennant finance.
Le FAI Propose à ses abonnés une série de vidéo. Ces vidéos sont détenus par des fournisseurs de contenus, les sociétés gérant les droits de ces vidéos. Ce sont eux qui sont chargés de la compression des vidéo. Cet
encodage est réalisé en MPEG2 ou MPEG4. Ils peuvent également réaliser une encryption du flux vidéo, afin de protéger les vidéos contre la copie. Le plus utilisé pour réalisé cet encryption est la technologie DRM, Data Rigth Management, de Microsoft. Les fichiers diffusés sont alors cryptés avant leur diffusion sur Internet. Le client doit posséder une clé, ou licence, pour le lire. Cette clé est unique et définit l'usage que faire de cette vidéo l'utilisateur et notamment le nombre de lecture et la durée de validité.

Une fois ces opérations effectuées, le FAI se charge de l'acheminement de ces flux de donnés vers l'abonné. Grâce à la technologie Multicast le fournisseur peut alléger la charge de transmission sur le réseau. Il installera partout sur son réseau des serveurs vidéo relais. Ce sont des ordinateurs dotés de très grandes capacités de stockage et d'interfaces très rapides. Ils peuvent envoyer simultanément plusieurs instance d'une même vidéo vers différents abonnés.
D'après le débit de la ligne deux techniques peuvent être utilisé par les FAI. Si le débit vers l'abonné est suffisant la vidéo peut être envoyée en streaming au décodeur. Le client peut donc lire la vidéo en simultané.
Si le débit est insuffisant le FAI proposera certain film préalablement envoyé sur le disque dur de l'abonné. Le fait que les vidéos soient cryptés empêche l'abonné de réaliser des copies de ces vidéos.
Au début de la séance le client effectue le règlement. Il reçoit alors une clé de décodage lui permettant de visualiser le film.
3 - Triple Play par câble
3.1 - Origine
A l'origine le câble a été développé pour véhiculer des émissions de télévision : il était donc analogique, unidirectionnel et déployé dans les zones résidentielles. La télévision devenant numérique les cablo-opérateurs ont voulu suivre. Ils ont alors rapidement voulu développer leur offre pour offrir à leurs abonnés l'Internet et la téléphonie. Le câble devient alors bidirectionnel et se déploiera dans le zones industrielles pour s'ouvrir aux entreprises.
A l'origine les réseaux desservant l'abonné était constitué de câble coaxiaux TV. Ils ont une impédance de 75
ohms et offrent une largeur de bande de 400 Mhz environ. Leurs taux d'affaiblissement est important. Le nombre
de répéteur nécessaires au transport du signal viennent limiter la bande passante.
Afin d'augmenter cette bande passante une nouvelle architecture a été construite : l'architecture HFC, Hybride Fiber Coax.
3.2 - Hybride Fiber Coax
L'architecture HFC combine les deux supports de transmission que sont la fibre optique et le câble coaxial. Le câble coaxial est alors utilisé pour le dernier kilomètre vers l'abonné. Cette architecture s'oppose à un réseau en
coaxial de bout en bout et à l'architecture FTTH, Fiber To The Home, ou seul le dernier mètre est en coaxial.
Le câble était prévu au départ pour faire uniquement arriver la télévision chez l'abonné. Il fonctionnait donc en mode half-duplex, du fournisseur vers l'abonné. Les communications dans le sens inverse n'étaient possible que via une ligne téléphonique. Ce système était performant pour l'acheminement de la télévision seul. Mais le half-duplex n'est pas adapté pour les services Internet ou la téléphonie. Les cablo-opérateurs ont donc largement investi pour passer en full-duplex, en développant des architectures HFC. Ils mettent ainsi en service la voie de
retour de leurs câbles, qui auparavant servait à la maintenance ou aux tests. Cela permet d'obtenir des débits de 27 à 36 Mbps en voie descendante et de 320 Kbps à 10 Mbps en voie montante. Ces lignes full-duplex offrent donc à présent des débits suffisants pour permettre aux fournisseurs de proposer à leurs abonnés Internet et téléphonie.
Pour l'architecture HFC les artères sont donc en fibre optique, et la distribution jusqu'à l'abonné passe par du coaxiale. Le câble coaxial ne sert donc plus que pour le dernier kilomètre au plus. Un noeud de réseau HFC dessert entre 500 et 1500 abonnés. Au contraire de l'ADSL la bande passante doit être partagée par tous. Ce
système, logique pour la distribution de la télévision uniquement, peut poser des problèmes de vitesse de transmission. Ainsi il y a le plus souvent une limitation en download pour les abonnés.
De plus cela signifie que l'ensemble des abonnés sur un noeud reçoivent l'ensemble des messages. Pour assurer un minimum de sécurité des données, il faut donc que l'opérateur crypte ces données et que seul l'abonné destinataire soit en mesure de le décrypter.
L'avantage de cette solution est de bénéficier du réseau TV câblé déjà mis en place. Mais ce réseau ce limite aux grandes agglomérations, et il est financièrement lourd a déployé. La communication s'effectue grâce à un modem
câblé situé chez l'abonné.
3.3 - Modem Câble
Il est indispensable de disposer d'un modem câble pour pouvoir bénéficier de l'Internet et de la téléphonie via le câble. En effet les signaux de données numériques sont transmis à travers des signaux de spectre de fréquence radio sur le câble. Les modems câbles permettent de convertir les données numériques en signal modulé de fréquence radio et inversement.

Les modems câbles sont bidirectionnelles et permettent l'envoie et la réception de données IP en même temps. Ce modems peuvent atteindre des vitesse de 43 Mbps en montant et 10 Mbps en descendant. Ils utilisent pour cela des techniques QAM (Quadrature Amplitude Modulation) ou PSK (Phase Shift Keying).
Le modem câble sert donc de convertisseur de modulation entre réseaux câblés et réseau Ethernet. Les données sont transmises sur des fréquences du réseau câblé différentes de celles utilisées par la TV. Pour transmettre la voix les opérateurs ont choisi de s'appuyer sur les technologies existantes. C'est donc via la voix sur IP que s'est implanté la téléphonie chez les cablo-opérateur.
Les téléphones IP, les fax, les ordinateurs et les téléviseurs sont reliés a au modem câble via un bus Ethernet. Un couche application DOCSIS permet de relier le réseau HFC à un réseau IP via le Headend ou CMTS (Cable Modem Termination System). C'est l'équipement de tête de réseau. Il est situé dans la station locale et connecte l'ensemble des abonnés de la zone. Il va donc convertir les données du réseau IP en en signal radio fréquence pour les transmettre sur le réseau HFC. Il va également procéder à l'opération inverse. Il permet ainsi de faire communiquer le réseau HFC avec d'autres réseaux comme Internet ou le réseau CATV analogique. Le CMTS est l'équivalent du DSLAM pour les technologies xDSL.
Typiquement pour les consommateurs domestiques la vitesse du flux de données avales est limitée entre 512 kbit/s à 10 Mbit/s, et le flux amont entre 256 kbit/s et 1 Mbit/s. Il faut distinguer trois types de communication qui se propagent sur un réseau câblé :
Downstream Broadcast Channel : permettant la diffusion de la télévision.
Downstream Interactive Channel : communication de l'opérateur vers l'abonné.
Upstream Return Channel : communication de l'abonné vers l'opérateur.

Les bandes passantes Upstream Return et Downstream Interactive sont réparties par le CMTS pour les différents abonnés.
3.4 - DVB/DAVIC
La technologie de Digital Video Broadcast (DVB) et de Digital Audio Video Council (DAVIC) représente le standard européen pour la télévision numérique. Elles présentent l'interet d'être conforme aux directives et normes européennes.
La spécification DVD 2,0 appelé également DVD-RCC (Return Channel for Cable) est standardisé sous la
dénomination ETSS 200800. Le standard s'appuie sur une couche ATM utilisant LLC/SNAP (RFC 1483) et une couche d'adaptation AAL5 pour encapsuler les paquet IP (IP switching permettant un routage IP sur un commutateur ATM). Pour la communication entre le terminal abonné (STM) et les équipements de la station locale (TDR), il utilise le protocole de signalisation ATM ou alors un proxy avec DSMCC.
3.5 - DOCSIS et PacketCable
Le consortium CableLabs a été créé en mai 1988 et regroupe des opérateurs, acteurs ou industriels de la télévision par câble. Il a établi plusieurs spécifications pour le transport de paquet IP : DOCSIS et PacketCable.
Le standard américain DOCSIS (Data Over Cable Service Interface Specification) définit les exigences relatives aux interfaces des modems câbles utilisés pour la diffusion de données à grandes vitesse par téléréseau.
En mars 1998 l'ITU (Union Internationale des Télécommunications) accepte DOCSIS comme standard pour les modems câbles sous l'appellation ITU J,112 ou DOCSIS 1.0. Pour délivrer les services de données DOCSIS sur un réseau câblé, un canal de fréquence radio de 6MHz dans la bande de fréquence 50-750 MHz est alloué pour le trafic descendant et un autre canal de 6 Mhz dans la bande de fréquence 5-42MHz pour le trafic montant.
Un équipement de tête de réseau CMTS communique à travers ces canaux avec les modems câbles situés chez
l'abonné. Ce sont des équipement externes qui se connectent aux ordinateurs par l'intermédiaire d'une carte Ethernet ou d'une interface USB.
DOCSIS emploie la méthode TDMA(Time Division Multiple Access)/SCDMA(Synchronous Code Division Multiple Access). Cette méthode d'accès diffère du système d' Ethernet, car le système DOCSIS n'éprouve aucune collision.
La phase d'initialisation logicielle en DOCSIS est généralement la suivante (fortement simplifiée) :
Le modem envoie une requête DHCP de façon a connaitre la configuration réseau à utiliser.
Le CMTS renvoie son adresse IP locale (a ne pas confondre avec l'adresse IP de l'ordinateur sur
Internet), sa passerelle, et plus spécifiquement l'adresse IP du serveur TFTP et le nom du fichier de configuration a aller y chercher.
Le modem se connecte au serveur TFTP et demande le fichier de configuration nommé précédemment.
Ce fichier contient entre autre les informations relative a la vitesse de connexion du modem, sa priorité sur le réseau, et le nombre d'ordinateurs autorisés a accéder au modem en même temps.
Le modem informe le CMTS qu'il a bien reçu le fichier, et qu'il est prêt a opérer (phase de
synchronisation).
Après ceci, le ou les ordinateurs branchés au modem peuvent eux-même demander leurs informations de connexion via le DHCP, et agir comme sur un réseau local tout a fait conventionnel.
En avril 1999 CableLabs a écrit une nouvelle spécification : DOCSIS 1.1. Elle ajoute quelques éléments clés par rapport au standard d'origine : qualité supérieurs, systèmes de sécurité, gestion priorité des paquets destinés aux communications vocales ... L'objectif est de supporter la téléphonie et les autres services temps réel.
Enfin en février 2002 arrive DOCSIS 2.0. Cette nouvelle norme apporte une symétrie de la bande passante entre les voies montantes et descendantes. Cette évolution est due à l'évolution de l'utilisation d'Internet par les internautes avec les l'avènement du peer-to-peer, de la voix sur IP, de la vidéo-conférence ...
La version européenne de DOCSIS s'appelle EuroDOCSIS. La différence principale est que les canaux de câble en Europe sont de 8 MHz de large (PAL), tandis qu'en Amérique du Nord les canaux sont de 6 MHz de large (NTSC). Ceci permet d'assigner plus de largeurs de bande à la circulation de données aval. Il existe également un DOCSIS
spécifique pour le Japon.
Le projet PacketCable a pour ambition d'implanter des services audio et vidéo IP sur le câble. Ces services incluent TV, téléphonie, vidéo-conférence, unifiées sur la couche réseau IP. Ce projet s'appuie sur plusieurs protocole. Il utilise DOCSIS 1.1 pour le transport des données sur le réseau câblé. IPsec doit assurer la sécurité
des donnés en dehors du réseau câblé. H.263 pour la compression vidéo et G.711, G.726 et G.729 pour la compression audio. Enfin pour la gestion centralisée de la signalisation téléphonique inter-réseau CableLabs utilise MGCP. MGCP (Medio Gateway Control Protocol) permet d'assurer la signalisation des services de téléphonie sur les réseaux câblés.
4 - Offres des différents opérateurs
Voici un tableau comparatif des différents opérateurs proposant du Triple play. Nous avons deux catégories: les
opérateurs proposant du Triple play à travers le téléphone (ADSL), et les opérateurs passant par le câble.
90 % des français sont abonnés aux fournisseurs téléphoniques utilisant l'ADSL. En faisant une comparaison des différentes offres, nous trouvons une offre moyenne pour l'ADSL correspondant à 16Megabit par seconde avec un coût d'environ 30 euro par mois.
En ce qui concerne les offres passant par le câble, les offres des deux fournisseurs étaient pendant longtemps très ressemblantes, mais UPC-Noos à depuis peu augmenté le débit de 4Mégabit à 10Megabit. Nous avons une offre
moyenne de 7Megabit par seconde de débit avec un coût d'environ 60 euros par mois.
Nous voyons que les offres ADSL proposent un débit plus élevé avec un coût inférieur par rapport aux fournisseurs câble. Mais les facteurs de choix ne s'arrêtent pas la. Le débit de l'Internet pour les clients ADSL peut changer dans le cas ou ils regardent la télévision, alors que le débit Internet des offres câble est fixe. Il faut également prendre en compte l'offre et le débit des différents fournisseurs proposés selon le lieu d'habitation, ce qui varie beaucoup d'une localisation à une autre.
5 - Evolution
Un des grandes évolutions de ces dernières années est la fusion des technologies telecoms avec celle de l'Internet dans des offres dites convergentes. En d'autre terme, cela signifie pour le client une facturation unique, et la possibilité de retrouver les mêmes services chez lui mais aussi en mobilité (vidéo, musique, communication...)
Depuis le début de l'année 2005, les offres de convergence se multiplient en Europe et dans le monde. Ces offres sont basées sur différentes technologies, principalement sur Cell-ID (France, Suisse, Allemagne) et UMA (Angleterre, Suède
et Finlande). NTT DoCoMo, opérateur mobile au Japon, a lancé une offre entreprise permettant à ses clients d'utiliser de la VoIP grâce à un terminal bi-mode Wi-Fi.
La technologie Cell-ID permet à un opérateur mobile de localiser un client (précision de la cellule GSM). Cette information est utilisée pour une facturation différenciée. Cette solution qui est "pur mobile" souffre d'un manque de précision en milieu urbain et de coûts importants de développements. Elle ne répond pas aux attentes en termes d'intégration et de haut débit mais permet de répondre aux attentes clients concernant des offres d'abondance domestique. C'est pourquoi on continu à chercher d'autres solutions de convergence.
Afin d'adapter ces nouvelles technologies, il est nécessaire de faire évoluer les technologies de réseau sans fil comme le Wi-Fi ou le WiMAX aux téléphones mobiles.

5.1 - WiMax
Le WiMAX (Worldwide Interoperability for Microwave Access) est l'évolution du Wi-Fi. Cette norme est basée sur le standard de transmission radio 802.16. Elle a été validée en 2001 par l'organisme international de normalisation
IEEE (Institute of Electrical and Elecronic Engeneers), et fut poussée par un consortium d'une cinquantaine de membres, dont Intel, Nokia, Fujitsu, Cisco, Atmel, Siemens, Motorola, Alcatel, France Telecom, etc.
WiMAX est une réponse pour des connexions sans-fil à haut débit. Elle porte sur des zones de couvertures de plusieurs kilomètres, permettant des usages en situation fixe ou mobile. Avec sa couverture de réseau de 20 km
et le débit de 70 Mbit/s, il est par la suite envisageable de fournir un accès haut débit aux endroits ruraux n'ayant pas l'ADSL ni le câble.
Il y a très peu de temps, le 12 décembre 2005, l'organisme IEEE a standardisé la variante mobile de la technologie WiMAX, le WiMAX mobile. Elle a un débit de 30 Megabit/seconde avec une portée de 3-4 kilomètres, ce qui est largement plus que les réseaux téléphonique. Le G3 peut actuellement transiter entre 400 et 700 Kilobit/seconde et par utilisateur. C'est la concurrent direct du réseau téléphonique.
Pour le moment les composants compatibles avec le WiMAX mobile commencent tout juste à être fabriqués. On
estime la sortie en masse des ces composants en 2008. Avec cette technologie on pourrait peut être un jour remplacer le réseau mobile actuel, à condition d'avoir une couverture total du pays.
Les licences d'exploitation du WiMAX sont aujourd'hui en cours d'attribution au niveau régional, sachant que seuls 2 opérateurs pourront se partager une région. C'est l'ARCEP (Autorité de Régulation des Communications Electroniques et des Postes), anciennement ART (Autorité de Régulation des Télécoms), qui a pour charge de déterminer les ayant droits.
Il existe aussi une seule licence d'exploitation nationale qui a été attribuée à la société Altitude Telecom
(récemment renommée IFW suite à son acquisition par le FAI Free) qui aurait déjà commencé à déployer son
réseau WiMAX avec des équipements « 802.16e ready ».
Une Autre évolution se fait au niveau des services proposés par le Triple play. Il existe aujourd'hui plusieurs concepts et technologies en cours de développement par les différents fournisseurs. Afin de gagner des parts du marché, ils proposent des services et des fonctionnalités supplémentaires. Une des services qui est en plein essor est le Quadruple play. Le Quadruple play est un Triple play auquel on ajoute de la téléphonie mobile.
Dès qu'on entre dans la zone du STB de la maison ou du bureau, la communication mobile passe par le réseau haut débit via de la VoIP. Pour que cela fonctionne, il faut avoir des opérateurs qui proposent cette fonctionnalité, ainsi que des téléphones mobiles compatibles.
Grâce au développement des technologies sans fil, le Wi-Fi et le WiMAX, ainsi que des téléphones compatibles Wi-Fi via la VoIP, le Quadruple play sera envisageable. La plupart des téléphones mobiles en construction intègrent le support de la VoIP. Aujourd'hui il y a un certain nombre de téléphones sortis avec le support de la VoIP. Il y a notamment Skype qui présente, en partenariat avec Netgear, le premier téléphone Skype Wi-Fi VoIP. Il y a
également Senao, société taïwanaise, qui propose un téléphone Wi-Fi 802.11b/g pour la VoIP. Un autre exemple est NTT DoCoMo, opérateur mobile au Japon, qui introduit son téléphone 3G/Wi-Fi.
En ce qui concerne les fournisseurs d'accès, ils sont un pas en avance. Il y a, pour le moment, déjà deux fournisseurs proposant le concept du Quadruple play, mais les autres ne tarderont pas à suivre. Nous faisons par la suite une brève explications de ces deux offres.
5.2 - UMA (Unlicensed Mobile Acces)
Le téléphone compatible avec la technologie UMA utilise un accès haut débit sans fil à la maison ou au bureau.
Puis il bascule, sans interruption de service, sur le réseau mobile à l'extérieur et en mobilité. L'utilisation du réseau fixe ou mobile devient transparente pour l'utilisateur. Ce dernier pourrait alors utiliser un seul téléphone et un seul numéro au lieu d'avoir un numéro fixe et un deuxième pour le téléphone mobile.
Le protocole dont se sert l'UMA permet d'utiliser des services concernant les téléphones mobiles tel que GSM et GPRS, à travers des technologies comme le Bluetooth et le Wi-Fi (802.11b/g). Il est également compatible avec les réseaux IP sans fil comme les réseaux WiMAX.
Le fonctionnement de cette technologie est relativement simple. Dès qu'un téléphone mobile UMA entre dans la zone de couverture d'un point d'accès Wi-Fi ou Bluetooth, il peut recevoir et établir une communication par paquet IP. Ces paquets sont alors transmis jusqu'au contrôleur UMA grâce au réseau IP de la maison ou de l'entreprise. Ce contrôleur envoie les données nécessaires vers le réseau de l'opérateur mobile. Il authentifie de cette même manière l'utilisateur avant sa connexion au réseau cellulaire.

Une fois que cette technologie sera sortie de la phase tests, elle sera intégrée à la Livebox afin d'offrir le Quadruple play aux clients de Wanadoo.
Le deuxième fournisseur proposant le Quadruple play est Neuf Télécom. Il propose le Beautiful Phone . C'est un téléphone de nouvelle génération qui permet lui aussi de téléphoner en Wi-Fi à la maison grâce à la Neufbox, et
de basculer vers une connexion GSM à l'extérieur, en utilisant le réseau de l'opérateur SFR. Actuellement le Beautiful Phone est en cours de tests par des clients volontaires. Après cette période d'essais le fournisseur devrait ajouter la téléphonie mobile à ses offres, et le Triple play se transformera en Quadruple play.
Avec ces nouvelles technologies qui ne cessent d'évoluer, utilisant de plus en plus de bande passante, le débit doit également suivre. A la suite de ADSL 2+, voici maintenant le VDSL (Very High Rate Digital Subscriber line). Basée sur la même technologie que l'xDSL, les signaux VDSL sont transportés sur une paire de cuivre, simultanément et sans interférence avec la voix téléphonique. Cette technologie permet d'atteindre de très hauts débits. VDSL
promet un débit vers l'internaute atteignant 50 Mbit/s, et depuis l'abonné vers Internet de l'ordre de 3 Mbit/s. L'évolution de cette technologie, le VDSL 2, peut même fonctionner jusqu'à 100 Mbit/s dans les deux sens (en théorie).
Cette technologie utilise une bande de fréquences allant jusqu'à 12 MHz en VDSL 1 et 30 MHz pour le VDSL 2, tandis que l'ADSL 2+ utilise une bande de fréquences de 2,2 MHz. La plage de fréquences étant plus large et la consommation d'énergie plus importante, les opérateurs doivent adapter leurs équipements réseaux. Alors qu'une
carte ADSL 2+, insérée dans un multiplexeur d'accès pour lignes d'abonnés numériques (DSLAM), peut desservir jusqu'à 72 clients, une carte VDSL n'accepterait pas plus de 24 clients pour l'instant. Club Internet est l'un des rares FAI à disposer déjà de DSLAM équipés aussi bien de cartes ADSL 2+ que VDSL. L'objectif est de fournir des débits en VDSL aux abonnés situés à 1500 m du répartiteur et de l'ADSL 2+ aux personnes résidant à plus de 1,5 km.
Une autre technologie en cours de développement est la FTTH (Fiber To The Home) ; la fibre optique à la maison/immeuble. Elle permet l'accès à Internet à des débits atteignant souvent 100 Mbit/s. Comparable au câble
dans son installation, puisqu'elle nécessite la pose de fibres jusque chez l'abonné, la FTTH est principalement utilisé dans les zones urbanisées de la Corée du Sud, du Japon et des Etats-Unis, ainsi que dans quelques agglomérations européennes. Elle est cependant en phase de tests dans certaines grandes villes françaises (telles Lyon ou Paris), par différentes sociétés (Cite Fibre, France Télécom, etc.).
6 - Conclusion
Les grands axes de convergence technologique s'effectuent principalement entre le monde des télécommunications et celui de l'informatique. Cela se voit notamment avec l'arrivée de solutions concernant la téléphonie sur IP. La convergence des opérateurs de télécommunication avec les FAI, s'effectue entre le téléphone fixe, le mobile, l'Internet ainsi que la télévision à travers les offres Quadruple play. L'objectif principale de la téléphonie sur IP est de réduire les coûts de fonctionnement. En effet, avec cette offre, l'utilisateur n'est plus dépendant de l'opérateur téléphonique pour des appels internes. On diminue de même les frais sur les appels longue distance en passant par le réseau IP.

Afin de garder leur clientèle, et de gagner plus de part du marché, les FAI et les câblo-opérateurs ne cessent pas de développer des services supplémentaires. En parallèle avec le Quadruple play, on parle également de Quintuple play. Ce dernier présente différents services selon le fournisseur. Le cinquième service peut être: le jeu en ligne, des services à travers le réseau Wi-Fi ou bien le CPL (Courant Porteur en Ligne).
Demain, notre téléphone mobile basculera de manière automatique, en fonction du lieu d'utilisation et sans que nous le sachions, sur les modes de télécommunications les plus adaptés, comme le Wi-Fi et le WiMAX.
Les IpVpn
Réseaux Privés Virtuels - Vpn
1 - Introduction 2 - Principe de fonctionnement 2.1 - Principe général 2.2 - Fonctionnalités des Vpn 2.2.1 - Le Vpn d'accès
2.2.2 - L'intranet Vpn 2.2.3 - L'extranet Vpn 2.2.4 - Bilan des caractéristiques fondamentales d'un Vpn 3 - Protocoles utilisés pour réaliser une connexion Vpn 3.1 - Rappels sur Ppp 3.1.1 - Généralités 3.1.2 - Format d'une trame Ppp
3.1.3 - Les différentes phases d'une connexion Ppp 3.2 - Le protocole Pptp 3.3 - Le protocole L2tp 3.3.1 - Concentrateurs d'accès L2tp (Lac : L2tp Access Concentrator) 3.3.2 - Serveur réseau L2tp (Lns : L2tp Network Server) 3.4 - Le protocole Ipsec
3.4.1 - Vue d'ensemble 3.4.2 - Principe de fonctionnement 3.4.3 - Le protocole Ah (Authentication Header) 3.4.4 - Protocole Esp (Encapsulating Security Payload) 3.4.5 - La gestion des clefs pour Ipsec : Isakmp et Ike 3.4.6 - Les deux modes de fonctionnement de Ipsec 3.5 - Le protocole Mpls
3.5.1 - Principe de fonctionnement de Mpls 3.5.2 - Utilisation du Mpls pour les Vpn 3.5.3 - Sécurité 3.6 - Le protocole Ssl 3.6.1 - Fonctionnement 4 - Comparaison des différents protocoles 4.1 - Vpn-Ssl, une nouveauté marketing ?
4.2 - Pptp 4.3 - L2tp / Ipsec 4.4 - Mpls 4.5 - Mpls / Ipsec 5 - Conclusion 6 - Discussion autour de la documentation
7 - Suivi du document
1 - Introduction
Les applications et les systèmes distribués font de plus en plus partie intégrante du paysage d'un grand nombre d'entreprises. Ces technologies ont pu se développer grâce aux performances toujours plus importantes des réseaux locaux. Mais le succès de ces applications a fait aussi apparaître un de leur écueil. En effet si les applications
distribuées deviennent le principal outil du système d'information de l'entreprise, comment assurer leur accès sécurisé au sein de structures parfois réparties sur de grandes distances géographiques ? Concrètement comment une succursale d'une entreprise peut-elle accéder aux données situées sur un serveur de la maison mère distant de plusieurs milliers de kilomètres ? Les Vpn ont commencé à être mis en place pour répondre à Ce type de problématique. Mais d'autres problématiques sont apparues et les Vpn ont aujourd'hui pris une place importante dans les réseaux informatique et l'informatique distribuées. Nous verrons ici quelles sont les principales caractéristiques des Vpn à travers un certain nombre d'utilisation type. Nous nous intéresserons ensuite aux protocoles permettant leur
mise en place.
2 - Principe de fonctionnement

2.1 - Principe général
Un réseau Vpn repose sur un protocole appelé "protocole de tunneling". Ce protocole permet de faire circuler les informations de l'entreprise de façon cryptée d'un bout à l'autre du tunnel. Ainsi, les utilisateurs ont l'impression
de se connecter directement sur le réseau de leur entreprise. Le principe de tunneling consiste à construire un chemin virtuel après avoir identifié l'émetteur et le destinataire. Par la suite, la source chiffre les données et les achemine en empruntant Ce chemin virtuel. Afin d'assurer un
accès aisé et peu coûteux aux intranets ou aux extranets d'entreprise, les réseaux privés virtuels d'accès simulent un réseau privé, alors qu'ils utilisent en réalité une infrastructure d'accès partagée, comme Internet. Les données à transmettre peuvent être prises en charge par un protocole différent d'Ip. Dans Ce cas, le protocole de tunneling encapsule les données en ajoutant une en-tête. Le tunneling est l'ensemble des processus d'encapsulation, de transmission et de désencapsulation.
2.2 - Fonctionnalités des Vpn
Il existe 3 types standard d'utilisation des Vpn. En étudiant ces schémas d'utilisation, il est possible d'isoler les fonctionnalités indispensables des Vpn.
2.2.1 - Le Vpn d'accès
Le Vpn d'accès est utilisé pour permettre à des utilisateurs itinérants d'accéder au réseau privé. L'utilisateur se sert d'une connexion Internet pour établir la connexion Vpn. Il existe deux cas:
L'utilisateur demande au fournisseur d'accès de lui établir une connexion cryptée vers le serveur distant : il communique avec le Nas (Network Access Server) du fournisseur d'accès et c'est le Nas qui établit la connexion cryptée.
L'utilisateur possède son propre logiciel client pour le Vpn auquel cas il établit directement la communication de manière cryptée vers le réseau de l'entreprise.
Les deux méthodes possèdent chacune leurs avantages et leurs inconvénients :
La première permet à l'utilisateur de communiquer sur plusieurs réseaux en créant plusieurs tunnels, mais nécessite un fournisseur d'accès proposant un Nas compatible avec la solution Vpn choisie par l'entreprise. De plus, la demande de connexion par le Nas n'est pas cryptée Ce qui peut poser des problèmes de sécurité.
Sur la deuxième méthode Ce problème disparaît puisque l'intégralité des informations sera cryptée dès l'établissement de la connexion. Par contre, cette solution nécessite que chaque client transporte
avec lui le logiciel, lui permettant d'établir une communication cryptée. Nous verrons que pour pallier Ce problème certaines entreprises mettent en place des Vpn à base de Ssl, technologie implémentée dans la majorité des navigateurs Internet du marché.
Quelle que soit la méthode de connexion choisie, Ce type d'utilisation montre bien l'importance dans le Vpn d'avoir une authentification forte des utilisateurs. Cette authentification peut se faire par une vérification "login / mot de passe", par un algorithme dit "Tokens sécurisés" (utilisation de mots de passe aléatoires) ou
par certificats numériques.

2.2.2 - L'intranet Vpn
L'intranet Vpn est utilisé pour relier au moins deux intranets entre eux. Ce type de réseau est particulièrement utile au sein d'une entreprise possédant plusieurs sites distants. Le plus important dans Ce type de réseau est de garantir la sécurité et l'intégrité des données. Certaines données très sensibles peuvent être amenées à transiter sur le Vpn (base de données clients, informations financières...). Des techniques de cryptographie sont mises en oeuvre pour vérifier que les données n'ont pas été altérées. Il s'agit d'une authentification au niveau paquet pour assurer la validité des données, de l'identification de leur
source ainsi que leur non-répudiation. La plupart des algorithmes utilisés font appel à des signatures numériques qui sont ajoutées aux paquets. La confidentialité des données est, elle aussi, basée sur des algorithmes de cryptographie. La technologie en la matière est suffisamment avancée pour permettre une sécurité quasi parfaite. Le coût matériel des équipements de cryptage et décryptage ainsi que les limites légales interdisent l'utilisation d'un codage " infaillible ". Généralement pour la confidentialité, le codage en lui-même pourra être moyen à faible, mais sera combiné avec d'autres techniques comme l'encapsulation Ip
dans Ip pour assurer une sécurité raisonnable.
2.2.3 - L'extranet Vpn
Une entreprise peut utiliser le Vpn pour communiquer avec ses clients et ses partenaires. Elle ouvre alors son réseau local à ces derniers. Dans Ce cadre, il est fondamental que l'administrateur du Vpn puisse tracer les clients sur le réseau et gérer les droits de chacun sur celui-ci.
2.2.4 - Bilan des caractéristiques fondamentales d'un Vpn
Un système de Vpn doit pouvoir mettre en oeuvre les fonctionnalités suivantes :
Authentification d'utilisateur. Seuls les utilisateurs autorisés doivent pouvoir s'identifier sur le réseau virtuel. De plus, un historique des connexions et des actions effectuées sur le réseau doit être conservé.
Gestion d'adresses. Chaque client sur le réseau doit avoir une adresse privée. Cette adresse privée doit rester confidentielle. Un nouveau client doit pourvoir se connecter facilement au réseau et recevoir une adresse.
Cryptage des données. Lors de leurs transports sur le réseau public les données doivent être protégées par un cryptage efficace.

Gestion de clés. Les clés de cryptage pour le client et le serveur doivent pouvoir être générées et régénérées.
Prise en charge multiprotocole. La solution Vpn doit supporter les protocoles les plus utilisés sur les
réseaux publics en particulier Ip.
Le Vpn est un principe : il ne décrit pas l'implémentation effective de ces caractéristiques. C'est pourquoi il existe plusieurs produits différents sur le marché dont certains sont devenus standard, et même considérés comme des normes.
3 - Protocoles utilisés pour réaliser une connexion Vpn
Nous pouvons classer les protocoles que nous allons étudier en deux catégories:
Les protocoles de niveau 2 comme Pptp et L2tp.
Les protocoles de niveau 3 comme Ipsec ou Mpls.
Il existe en réalité trois protocoles de niveau 2 permettant de réaliser des Vpn : Pptp (de Microsoft), L2F (développé
par CISCO) et enfin L2tp. Nous n'évoquerons dans cette étude que Pptp et L2tp : le protocole L2F ayant aujourd'hui quasiment disparut. Le protocole Pptp aurait sans doute lui aussi disparut sans le soutien de Microsoft qui continue à l'intégrer à ses systèmes d'exploitation Windows. L2tp est une évolution de Pptp et de L2F, reprenant les avantages des deux protocoles. Les protocoles de couche 2 dépendent des fonctionnalités spécifiées pour Ppp (Point to Point Protocol), c'est pourquoi nous allons tout d'abord rappeler le fonctionnement de Ce protocole.
3.1 - Rappels sur Ppp
Ppp (Point to Point Protocol) est un protocole qui permet de transférer des données sur un lien synchrone ou asynchrone. Il est full duplex et garantit l'ordre d'arrivée des paquets. Il encapsule les paquets Ip, Ipx et Netbeui dans des trames Ppp, puis transmet ces paquets encapsulés au travers de la liaison point à point. Ppp est employé généralement entre un client d'accès à distance et un serveur d'accès réseau (Nas). Le protocole Ppp est défini dans la Rfc 1661 appuyé de la Rfc 2153.
3.1.1 - Généralités
Ppp est l'un des deux protocoles issus de la standardisation des communications sur liaisons séries (Slip étant le deuxième). Il permet non seulement l'encapsulation de datagrammes, mais également la résolution
de certains problèmes liés aux protocoles réseaux comme l'assignation et la gestion des adresses (Ip, X25 et autres). Une connexion Ppp est composée principalement de trois parties :
Une méthode pour encapsuler les datagrammes sur la liaison série. Ppp utilise le format de trame Hdlc (Hight Data Level Control) de l'ISO (International Standartization Organisation).
Un protocole de contrôle de liaison (Lcp - Link Control Protocol) pour établir, configurer et tester la
connexion de liaison de données.
Plusieurs protocoles de contrôle de réseaux (Ncps - Network Control Protocol) pour établir et configurer les différents protocoles de couche réseau.

3.1.2 - Format d'une trame Ppp
Fanion - Séparateur de trame égale à la valeur 01111110. Un seul drapeau est nécessaire entre 2 trames. Adresse - Ppp ne permet pas un adressage individuel des stations donc Ce champ doit être à 0xFF (toutes les stations). Toute adresse non reconnue entraînera la destruction de la trame.
Contrôle - Le champ contrôle doit être à 0x03 Protocole - La valeur contenue dans Ce champ doit être impaire (l'octet de poids fort étant pair). Ce champ identifie le protocole encapsulé dans le champ informations de la trame. Les différentes valeurs utilisables
sont définies dans la Rfc « assign number » et représentent les différents protocoles supportés par Ppp (Osi, Ip, Decnet IV, Ipx...), les Ncp associés ainsi que les Lcp. Données - De longueur comprise entre 0 et 1500 octets, Ce champ contient le datagramme du protocole supérieur indiqué dans le champ "protocole". Sa longueur est détectée par le drapeau de fin de trame, moins deux octets de contrôle. Fcs (Frame Check Sequence) - Ce champ contient la valeur du checksum de la trame. Ppp vérifie le contenu du Fcs lorsqu'il reçoit un paquet. Le contrôle d'erreur appliqué par Ppp est conforme à X25.
3.1.3 - Les différentes phases d'une connexion Ppp
Toute connexion Ppp commence et finit par une phase dite de "liaison morte". Dès qu'un événement externe
indique que la couche physique est prête, la connexion passe à la phase suivante, à savoir l'établissement de la liaison. Comme Ppp doit être supporté par un grand nombre d'environnements, un protocole spécifique a été élaboré et intégré à Ppp pour toute la phase de connexion ; il s'agit de Lcp (Link Control Protocol). Lcp est un protocole utilisé pour établir, configurer, tester, et terminer la connexion Ppp. Il permet de manipuler des tailles variables de paquets et effectue un certain nombre de tests sur la configuration. Il permet notamment de détecter un lien bouclé sur lui-même.
La connexion Ppp passe ensuite à une phase d'authentification. Cette étape est facultative et doit être spécifiée lors de la phase précédente. Si l'authentification réussie ou qu'elle n'a pas été demandée, la connexion passe en phase de "Protocole
réseau". C'est lors de cette étape que les différents protocoles réseaux sont configurés. Cette configuration s'effectue séparément pour chaque protocole réseau. Elle est assurée par le protocole de contrôle de réseau (Ncp) approprié. A Ce moment, le transfert des données est possible. Les NPC peuvent à tout moment ouvrir
ou fermer une connexion. Ppp peut terminer une liaison à tout moment, parce qu'une authentification a échouée, que la qualité de la ligne est mauvaise ou pour toute autre raison. C'est le Lcp qui assure la fermeture de la liaison à l'aide de paquets de terminaison. Les Ncp sont alors informés par Ppp de la fermeture de la liaison.
3.2 - Le protocole Pptp
Pptp, définit par la Rfc 2637, est un protocole qui utilise une connexion Ppp à travers un réseau Ip en créant un
réseau privé virtuel (Vpn). Microsoft a implémenté ses propres algorithmes afin de l'intégrer dans ses versions de windows. Ainsi, Pptp est une solution très employée dans les produits Vpn commerciaux à cause de son intégration au sein des systèmes d'exploitation Windows. Pptp est un protocole de niveau 2 qui permet l'encryptage des données ainsi que leur compression. L'authentification se fait grâce au protocole Ms-Chap de Microsoft qui, après la cryptanalyse de sa version 1, a révélé publiquement des failles importantes. Microsoft a corrigé ces défaillances et propose aujourd'hui une version 2 de Ms-Chap plus sûre. La partie chiffrement des données s'effectue grâce au protocole Mppe (Microsoft Point-to-Point Encryption).

Le principe du protocole Pptp est de créer des paquets sous le protocole Ppp et de les encapsuler dans des datagrammes IP. Pptp crée ainsi un tunnel de niveau 3 défini par le protocole Gre (Generic Routing Encapsulation). Le tunnel Pptp se caractérise par une initialisation du client, une connexion de contrôle entre le client et le serveur ainsi que par la clôture du tunnel par le serveur. Lors de l'établissement de la connexion, le
client effectue d'abord une connexion avec son fournisseur d'accès Internet. Cette première connexion établie une connexion de type Ppp et permet de faire circuler des données sur Internet. Par la suite, une deuxième connexion
dial-up est établie. Elle permet d'encapsuler les paquets Ppp dans des datagrammes IP. C'est cette deuxième connexion qui forme le tunnel Pptp. Tout trafic client conçu pour Internet emprunte la connexion physique normale, alors que le trafic conçu pour le réseau privé distant, passe par la connexion virtuelle de Pptp.
Plusieurs protocoles peuvent être associés à Pptp afin de sécuriser les données ou de les compresser. On retrouve évidement les protocoles développés par Microsoft et cités précédemment. Ainsi, pour le processus
d'identification, il est possible d'utiliser les protocoles Pap (Password Authentification Protocol) ou MsChap. Pour l'encryptage des données, il est possible d'utiliser les fonctions de Mppe (Microsoft Point to Point Encryption). Enfin, une compression de bout en bout peut être réalisée par Mppc (Microsoft Point to Point Compression). Ces divers protocoles permettent de réaliser une connexion Vpn complète, mais les protocoles suivants permettent un niveau de performance et de fiabilité bien meilleur.
3.3 - Le protocole L2tp
L2tp, définit par la Rfc 2661, est issu de la convergence des protocoles Pptp et L2F. Il est actuellement développé
et évalué conjointement par Cisco Systems, Microsoft, Ascend, 3Com ainsi que d'autres acteurs clés du marché des réseaux. Il permet l'encapsulation des paquets Ppp au niveau des couches 2 (Frame Relay et Atm) et 3 (Ip). Lorsqu'il est configuré pour transporter les données sur IP, L2tp peut être utilisé pour faire du tunnelling sur Internet. L2tp repose sur deux concepts : les concentrateurs d'accès L2tp (Lac : L2tp Access Concentrator) et les serveurs réseau L2tp (Lns : L2tp Network Server). L2tp n'intègre pas directement de protocole pour le chiffrement des données. C'est pourquoi L'IETF préconise l'utilisation conjointe d'Ipsec et L2tp.
Une documentation dédié à L2TP est présent sur le site de FrameIP.
3.3.1 - Concentrateurs d'accès L2tp (Lac : L2tp Access Concentrator)
Les périphériques Lac fournissent un support physique aux connexions L2tp. Le trafic étant alors transféré sur les serveurs réseau L2tp. Ces serveurs peuvent s'intégrer à la structure d'un réseau commuté Rtc ou alors à un système d'extrémité Ppp prenant en charge le protocole L2tp. Ils assurent le fractionnement en canaux de tous les protocoles basés sur Ppp. Le Lac est l'émetteur des appels entrants et le destinataire des appels sortants.
3.3.2 - Serveur réseau L2tp (Lns : L2tp Network Server)
Les serveurs réseau L2tp ou Lns peuvent fonctionner sur toute plate-forme prenant en charge la terminaison
Ppp. Le Lns gère le protocole L2tp côté serveur. Le protocole L2tp n'utilise qu'un seul support, sur lequel arrivent les canaux L2tp. C'est pourquoi, les serveurs réseau Lns, ne peuvent avoir qu'une seule interface de réseau local (Lan) ou étendu (Wan). Ils sont cependant capables de terminer les appels en provenance de n'importe quelle interface Ppp du concentrateur d'accès Lac : async., Rnis, Ppp sur Atm ou Ppp sur relais de trame. Le Lns est l'émetteur des appels sortants et le destinataire des appels entrants. C'est le Lns qui sera responsable de l'authentification du tunnel.

3.4 - Le protocole Ipsec
Ipsec, définit par la Rfc 2401, est un protocole qui vise à sécuriser l'échange de données au niveau de la couche réseau. Le réseau Ipv4 étant largement déployé et la migration vers Ipv6 étant inévitable, mais néanmoins
longue, il est apparu intéressant de développer des techniques de protection des données communes à Ipv4 et Ipv6. Ces mécanismes sont couramment désignés par le terme Ipsec pour Ip Security Protocols. Ipsec est basé sur deux mécanismes. Le premier, AH, pour Authentification Header vise à assurer l'intégrité et l'authenticité des datagrammes IP. Il ne fournit par contre aucune confidentialité : les données fournies et transmises par Ce
"protocole" ne sont pas encodées. Le second, Esp, pour Encapsulating Security Payload peut aussi permettre l'authentification des données mais est principalement utilisé pour le cryptage des informations. Bien qu'indépendants ces deux mécanismes sont presque toujours utilisés conjointement. Enfin, le protocole Ike permet de gérer les échanges ou les associations entre protocoles de sécurité. Avant de décrire ces différents protocoles, nous allons exposer les différents éléments utilisés dans Ipsec. Une documentation dédié à IPSEC est présente sur le site de FrameIP.
3.4.1 - Vue d'ensemble
Les mécanismes mentionnés ci-dessus font bien sûr appel à la cryptographie et utilisent donc un certain
nombre de paramètres (algorithmes de chiffrement utilisés, clefs, mécanismes sélectionnés...) sur lesquels les tiers communicants doivent se mettre d'accord. Afin de gérer ces paramètres, Ipsec a recours à la notion d'association de sécurité (Security Association, SA). Une association de sécurité Ipsec est une "connexion" simplexe qui fournit des services de sécurité au trafic qu'elle transporte. On peut aussi la considérer comme une structure de données servant à stocker l'ensemble des paramètres associés à une communication donnée.
Une SA est unidirectionnelle ; en conséquence, protéger les deux sens d'une communication classique requiert deux associations, une dans chaque sens. Les services de sécurité sont fournis par l'utilisation soit
de AH soit de Esp. Si AH et Esp sont tout deux appliqués au trafic en question, deux SA (voire plus) sont créées ; on parle alors de paquet (bundle) de SA.
Chaque association est identifiée de manière unique à l'aide d'un triplet composé de:
L'adresse de destination des paquets,
L'identifiant du protocole de sécurité utilisé (AH ou Esp),
Un index des paramètres de sécurité (Security Parameter Index, SPI). Un SPI est un bloc de 32 bits inscrit en clair dans l'en-tête de chaque paquet échangé ; il est choisi par le récepteur.
Pour gérer les associations de sécurités actives, on utilise une "base de données des associations de sécurité" (Security Association Database, SAD). Elle contient tous les paramètres relatifs à chaque SA et sera consultée pour savoir comment traiter chaque paquet reçu ou à émettre. Les protections offertes par Ipsec sont basées sur des choix définis dans une "base de données de politique de sécurité" (Security Policy Database, SPD). Cette base de données est établie et maintenue par un utilisateur, un administrateur système ou une application mise en place par ceux-ci. Elle permet de décider,
pour chaque paquet, s'il se verra apporter des services de sécurité, s'il sera autorisé à passer ou rejeté.
3.4.2 - Principe de fonctionnement
Le schéma ci-dessous représente tous les éléments présentés ci-dessus (en bleu), leurs positions et leurs interactions.

On distingue deux situations :
Trafic sortant Lorsque la "couche" Ipsec reçoit des données à envoyer, elle commence par consulter la base de données des politiques de sécurité (SPD) pour savoir comment traiter ces données. Si cette base lui indique que le trafic doit se voir appliquer des mécanismes de sécurité, elle récupère les caractéristiques requises pour la SA correspondante et va consulter la base des SA (SAD). Si la SA
nécessaire existe déjà, elle est utilisée pour traiter le trafic en question. Dans le cas contraire, Ipsec fait appel à IKE pour établir une nouvelle SA avec les caractéristiques requises.
Trafic entrant Lorsque la couche Ipsec reçoit un paquet en provenance du réseau, elle examine l'en-tête pour savoir si Ce paquet s'est vu appliquer un ou plusieurs services Ipsec et si oui, quelles sont les références de la SA. Elle consulte alors la SAD pour connaître les paramètres à utiliser pour la vérification et/ou le déchiffrement du paquet. Une fois le paquet vérifié et/ou déchiffré, la Spd est consultée pour savoir si
l'association de sécurité appliquée au paquet correspondait bien à celle requise par les politiques de sécurité.
Dans le cas où le paquet reçu est un paquet Ip classique, la Spd permet de savoir s'il a néanmoins le droit de passer. Par exemple, les paquets IKE sont une exception. Ils sont traités par Ike, qui peut envoyer des
alertes administratives en cas de tentative de connexion infructueuse.
3.4.3 - Le protocole Ah (Authentication Header)
L'absence de confidentialité permet de s'assurer que Ce standard pourra être largement répandu sur Internet, y compris dans les endroits où l'exportation, l'importation ou l'utilisation du chiffrement dans des buts de confidentialité est restreint par la loi.
Son principe est d'adjoindre au datagramme Ip classique un champ supplémentaire permettant à la réception de vérifier l'authenticité des données incluses dans le datagramme. Ce bloc de données est appelé "valeur de vérification d'intégrité" (Intégrity Check Value, Icv). La protection contre le rejet se fait grâce à un numéro de séquence.

3.4.4 - Protocole Esp (Encapsulating Security Payload)
Esp peut assurer au choix, un ou plusieurs des services suivants :
Confidentialité (confidentialité des données et protection partielle contre l'analyse du trafic si l'on utilise le mode tunnel).
Intégrité des données en mode non connecté et authentification de l'origine des données, protection contre le rejeu.
La confidentialité peut être sélectionnée indépendamment des autres services, mais son utilisation sans intégrité/authentification (directement dans Esp ou avec AH) rend le trafic vulnérable à certains types
d'attaques actives qui pourraient affaiblir le service de confidentialité.
Le champ bourrage peut être nécessaire pour les algorithmes de chiffrement par blocs ou pour aligner le texte chiffré sur une limite de 4 octets.
Les données d'authentification ne sont présentes que si Ce service a été sélectionné. Voyons maintenant comment est appliquée la confidentialité dans Esp. L'expéditeur :
Encapsule, dans le champ "charge utile" de Esp, les données transportées par le datagramme original et éventuellement l'en-tête Ip (mode tunnel).

Ajoute si nécessaire un bourrage.
Chiffre le résultat (données, bourrage, champs longueur et en-tête suivant).
Ajoute éventuellement des données de synchronisation cryptographiques (vecteur d'initialisation) au début du champ "charge utile".
3.4.5 - La gestion des clefs pour Ipsec : Isakmp et Ike
Les protocoles sécurisés présentés dans les paragraphes précédents ont recours à des algorithmes cryptographiques et ont donc besoin de clefs. Un des problèmes fondamentaux d'utilisation de la cryptographie est la gestion de ces clefs. Le terme "gestion" recouvre la génération, la distribution, le stockage et la suppression des clefs.
IKE (Internet Key Exchange) est un système développé spécifiquement pour Ipsec qui vise à fournir des mécanismes d'authentification et d'échange de clef adaptés à l'ensemble des situations qui peuvent se présenter sur l'Internet. Il est composé de plusieurs éléments : le cadre générique Isakmp et une partie des protocoles Oakley et Skeme. Lorsqu'il est utilisé pour Ipsec, IKE est de plus complété par un "domaine d'interprétation" pour Ipsec.
3.4.5.1 - Isakmp (Internet Security Association and Key Management Protocol)
Isakmp a pour rôle la négociation, l'établissement, la modification et la suppression des associations de sécurité et de leurs attributs. Il pose les bases permettant de construire divers protocoles de gestion des clefs
(et plus généralement des associations de sécurité). Il comporte trois aspects principaux :
Il définit une façon de procéder, en deux étapes appelées phase 1 et phase 2 : dans la première, un
certain nombre de paramètres de sécurité propres à Isakmp sont mis en place, afin d'établir entre les deux tiers un canal protégé ; dans un second temps, Ce canal est utilisé pour négocier les associations de sécurité pour les mécanismes de sécurité que l'on souhaite utiliser (AH et Esp par exemple).
Il définit des formats de messages, par l'intermédiaire de blocs ayant chacun un rôle précis et permettant de former des messages clairs.
Il présente un certain nombre d'échanges types, composés de tels messages, qui permettant des négociations présentant des propriétés différentes : protection ou non de l'identité, perfect forward secrecy...
Isakmp est décrit dans la Rfc 2408.
3.4.5.2 Ike (Internet Key Exchange)
IKE utilise Isakmp pour construire un protocole pratique. Il comprend quatre modes :
Le mode principal (Main mode)
Le mode agressif (Aggressive Mode)
Le mode rapide (Quick Mode)
Le mode nouveau groupe (New Groupe Mode)
Main Mode et Aggressive Mode sont utilisés durant la phase 1, Quick Mode est un échange de phase 2. New Group Mode est un peu à part : Ce n'est ni un échange de phase 1, ni un échange de phase 2, mais il ne peut avoir lieu qu'une fois qu'une SA Isakmp est établie ; il sert à se mettre d'accord sur un nouveau groupe pour de futurs échanges Diffie-Hellman.
a) Phase 1 : Main Mode et Aggressive Mode Les attributs suivants sont utilisés par Ike et négociés durant la phase 1 : un algorithme de chiffrement, une fonction de hachage, une méthode d'authentification et un groupe pour Diffie-Hellman. Trois clefs sont générées à l'issue de la phase 1 : une pour le chiffrement, une pour l'authentification et une pour la dérivation d'autres clefs. Ces clefs dépendent des cookies, des aléas échangés et des valeurs
publiques Diffie-Hellman ou du secret partagé préalable. Leur calcul fait intervenir la fonction de hachage choisie pour la SA Isakmp et dépend du mode d'authentification choisi. Les formules exactes sont décrites dans la Rfc 2409.

b) Phase 2 : Quick Mode Les messages échangés durant la phase 2 sont protégés en authenticité et en confidentialité grâce aux éléments négociés durant la phase 1. L'authenticité des messages est assurée par l'ajout d'un bloc Hash
après l'en-tête Isakmp et la confidentialité est assurée par le chiffrement de l'ensemble des blocs du message.
Quick Mode est utilisé pour la négociation de SA pour des protocoles de sécurité donnés comme Ipsec. Chaque négociation aboutit en fait à deux SA, une dans chaque sens de la communication. Plus précisément, les échanges composant Ce mode ont le rôle suivant :
Négocier un ensemble de paramètres Ipsec (paquets de SA)
Échanger des nombres aléatoires, utilisés pour générer une nouvelle clef qui dérive du secret généré
en phase 1 avec le protocole Diffie-Hellman. De façon optionnelle, il est possible d'avoir recours à un nouvel échange Diffie-Hellman, afin d'accéder à la propriété de Perfect Forward Secrecy, qui n'est pas fournie si on se contente de générer une nouvelle clef à partir de l'ancienne et des aléas.
Optionnellement, identifier le trafic que Ce paquet de SA protégera, au moyen de sélecteurs (blocs optionnels IDi et IDr ; en leur absence, les adresses Ip des interlocuteurs sont utilisées).
c) Les groupes : New Groupe Mode
Le groupe à utiliser pour Diffie-Hellman peut être négocié, par le biais du bloc SA, soit au cours du Main Mode, soit ultérieurement par le biais du New Group Mode. Dans les deux cas, il existe deux façons de désigner le groupe à utiliser :
Donner la référence d'un groupe prédéfini : il en existe actuellement quatre, les quatre groupes Oakley (deux groupes MODP et deux groupes EC2N).
Donner les caractéristiques du groupe souhaité : type de groupe (MODP, ECP, EC2N), nombre premier
ou polynôme irréductible, générateurs...
d) Phases et modes Au final, le déroulement d'une négociation IKE suit le diagramme suivant :

3.4.6 - Les deux modes de fonctionnement de Ipsec
Le mode transport prend un flux de niveau transport (couche de niveau 4 du modèle OSI) et réalise les
mécanismes de signature et de chiffrement puis transmet les données à la couche Ip. Dans Ce mode, l'insertion de la couche Ipsec est transparente entre Tcp et Ip. Tcp envoie ses données vers Ipsec comme il les enverrait vers IPv4. L'inconvénient de Ce mode réside dans le fait que l'en-tête extérieur est produit par la couche Ip c'est-à-dire sans masquage d'adresse. De plus, le fait de terminer les traitements par la couche Ip ne permet pas de
garantir la non-utilisation des options Ip potentiellement dangereuses. L'intérêt de Ce mode réside dans une relative facilité de mise en oeuvre. Dans le mode tunnel, les données envoyées par l'application traversent la pile de protocole jusqu'à la couche Ip incluse, puis sont envoyées vers le module Ipsec. L'encapsulation Ipsec en mode tunnel permet le masquage d'adresses. Le mode tunnel est utilisé entre deux passerelles de sécurité (routeur, firewall, ...) alors que le mode transport se situe entre deux hôtes.

3.5 - Le protocole Mpls
Le protocole Mpls est un brillant rejeton du "tout ip". Il se présente comme une solution aux problèmes de routage des datagrammes Ip véhiculés sur Internet. Le principe de routage sur Internet repose sur des tables de routage. Pour chaque paquet les routeurs, afin de déterminer le prochain saut, doivent analyser l'adresse de destination du paquet contenu dans l'entête de niveau 3. Puis il consulte sa table de routage pour déterminer sur quelle interface doit sortir le paquet. Ce mécanisme de recherche dans la table de routage est consommateur de temps Cpu et
avec la croissance de la taille des réseaux ces dernières années, les tables de routage des routeurs ont constamment augmenté. Le protocole Mpls fut initialement développé pour donner une plus grande puissance aux commutateurs Ip, mais avec l'avènement de techniques de commutation comme Cef (Cisco Express Forwarding) et la mise au point de nouveaux Asic (Application Specific Interface Circuits), les routeurs Ip ont vu leurs performances augmenter sans le recours à Mpls.
3.5.1 - Principe de fonctionnement de Mpls
Le principe de base de Mpls est la commutation de labels. Ces labels, simples nombres entiers, sont insérés entre les en-têtes de niveaux 2 et 3, les routeurs permutant alors ces labels tout au long du réseau jusqu'à destination, sans avoir besoin de consulter l'entête Ip et leur table de routage.
3.5.1.1 - Commutation par labels
Cette technique de commutation par labels est appelée Label Swapping. Mpls permet de définir des piles de
labels (label stack), dont l'intérêt apparaîtra avec les Vpn. Les routeurs réalisant les opérations de label swapping sont appelés Lsr pour Label Switch Routers.
Les routeurs Mpls situés à la périphérie du réseau (Edge Lsr), qui possèdent à la fois des interfaces Ip traditionnelles et des interfaces connectées au backbone Mpls, sont chargés d'imposer ou de retirer les labels des paquets Ip qui les traversent. Les routeurs d'entrée, qui imposent les labels, sont appelés Ingress Lsr,
tandis que les routeurs de sortie, qui retirent les labels, sont appelés Egress Lsr.

3.5.1.2 - Classification des paquets
A l'entrée du réseau Mpls, les paquets Ip sont classés dans des Fec (Forwarding Equivalent Classes). Des paquets appartenant à une même Fec suivront le même chemin et auront la même méthode de forwarding.
Typiquement, les Fec sont des préfixes Ip appris par l'Igp tournant sur le backbone Mpls, mais peuvent aussi être définis par des informations de Qos (Quality Of Services). La classification des paquets s'effectue à l'entrée du backbone Mpls, par les Ingress Lsr. A l'intérieur du backbone Mpls, les paquets sont label-switchés, et aucune reclassification des paquets n'a lieu. Chaque Lsr affecte un label local, qui sera utilisé en entrée, pour chacune de ses Fec et le propage à ses voisins. Les Lsr voisins sont appris grâce à l'Igp. L'ensemble des Lsr utilisés pour une Fec, constituant un chemin à travers le réseau, est appelé Label Switch
Path (Lsp). Il existe un Lsp pour chaque Fec et les Lsp sont unidirectionnels.
3.5.2 - Utilisation du Mpls pour les Vpn
Pour satisfaire les besoins des opérateurs de services Vpn, la gestion de Vpn-IP à l'aide des protocoles Mpls a
été définie dans une spécification référencée Rfc 2547. Des tunnels sont créés entre des routeurs Mpls de périphérie appartenant à l'opérateur et dédiés à des groupes fermés d'usagers particuliers, qui constituent des Vpn. Dans l'optique Mpls/Vpn, un Vpn est un ensemble de sites placés sous la même autorité administrative, ou groupés suivant un intérêt particulier.
3.5.2.1 - Routeurs P, Pe et Ce
Une terminologie particulière est employée pour désigner les routeurs (en fonction de leur rôle) dans un environnement Mpls / Vpn :
P (Provider) : ces routeurs, composant le coeur du backbone Mpls, n'ont aucune connaissance de la
notion de Vpn. Ils se contentent d'acheminer les données grâce à la commutation de labels ;
Pe (Provider Edge) : ces routeurs sont situés à la frontière du backbone Mpls et ont par définition une ou plusieurs interfaces reliées à des routeurs clients ;
Ce (Customer Edge) : ces routeurs appartiennent au client et n'ont aucune connaissance des Vpn ou même de la notion de label. Tout routeur « traditionnel » peut être un routeur Ce, quel que soit son type ou la version d'OS utilisée.

Le schéma ci-dessous montre l'emplacement de ces routeurs dans une architecture Mpls :
3.5.2.2 - Routeurs Virtuels : VRF
La notion même de Vpn implique l'isolation du trafic entre sites clients n'appartenant pas aux mêmes Vpn. Pour réaliser cette séparation, les routeurs Pe ont la capacité de gérer plusieurs tables de routage grâce à la notion de Vrf (Vpn Routing and Forwarding). Une Vrf est constituée d'une table de routage, d'une Fib
(Forwarding Information Base) et d'une table Cef spécifiques, indépendantes des autres Vrf et de la table de routage globale. Chaque Vrf est désignée par un nom (par ex. RED, GREEN, etc.) sur les routeurs Pe. Les noms sont affectés localement et n'ont aucune signification vis-à-vis des autres routeurs. Chaque interface de Pe, reliée à un site client, est rattachée à une Vrf particulière. Lors de la réception de paquets Ip sur une interface client, le routeur Pe procède à un examen de la table de routage de la Vrf à laquelle est rattachée l'interface et donc ne consulte pas sa table de routage globale. Cette possibilité
d'utiliser plusieurs tables de routage indépendantes permet de gérer un plan d'adressage par sites, même en cas de recouvrement d'adresses entre Vpn différents.
3.5.3 - Sécurité
La séparation des flux entre clients sur des routeurs mutualisés supportant Mpls est assurée par le fait que seul la découverte du réseau se fait au niveau de la couche 3 et qu'ensuite le routage des paquets est effectué en s'appuyant uniquement sur le mécanisme des labels (intermédiaire entre la couche 2 et la couche 3). Le niveau de sécurité est le même que celui de Frame Relay avec les Dlci au niveau 2.
Le déni de service est en général effectué au niveau 3 (Ip). Ici, les paquets seront quand même routés jusqu'au destinataire au travers du réseau Mpls en s'appuyant sur les LSPs.
3.6 - Le protocole Ssl
Récemment arrivé dans le monde des Vpn, les Vpn à base de Ssl présente une alternative séduisante face aux technologies contraignantes que sont les Vpn présentés jusque ici. Les Vpn Ssl présentent en effet le gros
avantage de ne pas nécessiter du coté client plus qu'un navigateur Internet classique. En effet le protocole Ssl utilisé pour la sécurisation des échanges commerciaux sur Internet est implémenté en standard dans les navigateurs modernes.

Ssl est un protocole de couche 4 (niveau transport) utilisé par une application pour établir un canal de communication sécurisé avec une autre application. Ssl a deux grandes fonctionnalités : l'authentification du serveur et du client à l'établissement de la connexion et
le chiffrement des données durant la connexion.
3.6.1 - Fonctionnement
Le protocole Ssl Handshake débute une communication Ssl. Suite à la requête du client, le serveur envoie
son certificat ainsi que la liste des algorithmes qu'il souhaite utiliser. Le client commence par vérifier la validité du certificat du serveur. Cela se fait à l'aide de la clé publique de l'autorité de certification contenue dans le navigateur du client. Le client vérifie aussi la date de validité du certificat et peut également consulter une CRL (Certificate Revocation List). Si toutes les vérifications sont passées, le client génère une clé symétrique et l'envoie au serveur. Le serveur peut alors envoyer un test au client, que le client doit signer avec sa clé privée correspondant à son propre certificat. Ceci est fait de façon à Ce que le serveur puisse authentifier le client.
De nombreux paramètres sont échangés durant cette phase : type de clé, valeur de la clé, algorithme de chiffrage ... La phase suivante consiste en l'échange de données cryptées (protocole Ssl Records). Les clés générées avec le protocole Handshake sont utilisées pour garantir l'intégrité et la confidentialité des données échangées. Les différentes phases du protocole sont :
Segmentation des paquets en paquets de taille fixe
Compression (mais peu implémenté dans la réalité)
Ajout du résultat de la fonction de hachage composé de la clé de cryptage, du numéro de message, de la longueur du message, de données ...
Chiffrement des paquets et du résultat du hachage à l'aide de la clé symétrique générée lors du Handshake.
Ajout d'un en-tête Ssl au paquet.

4 - Comparaison des différents protocoles
Chaque protocole présenté permet de réaliser des solutions performantes de Vpn. Nous allons ici aborder les points forts et les points faibles de chacun de ses protocoles.
4.1 - Vpn-Ssl, une nouveauté marketing ?
Présentée comme la solution miracle pour permettre aux itinérants de se connecter aux applications réparties de l'entreprise les Vpn-Ssl souffrent de problèmes principalement liés aux navigateurs web utilisés.
Le but d'utiliser des navigateurs web est de permettre aux utilisateurs d'utiliser un outil dont ils ont l'habitude et qui ne nécessite pas de configuration supplémentaire. Cependant lorsqu'un certificat expire l'utilisateur doit aller manuellement le renouveler. Cette opération peut poser problème aux utilisateurs novices. De plus sur la majorité des navigateurs web la consultation des listes de certificats révoqués n'est pas activée par défaut : toute la sécurité de Ssl reposant sur ces certificats ceci pose un grave problème de sécurité.
Rien n'empêche de plus le client de télécharger une version modifiée de son navigateur pour pouvoir utiliser de nouvelles fonctionnalités (skins, plugins...). Rien ne certifie que le navigateur n'a pas été modifié et que son autorité de certification en soit bien une. Enfin Un autre problème lié à l'utilisation de navigateurs web comme base au Vpn est leur spécificité au monde web. En effet par défaut un navigateur n'interceptera que des communication Https ou éventuellement Ftps.
Toutes les communications venant d'autre type d'applications (MS Outlook, ou une base de données par exemple) ne sont pas supportées. Ce problème est généralement contourné par l'exécution d'une applet Java dédiée dans le navigateur. Mais ceci implique également la maintenance de cette applet (s'assurer que le client possède la bonne version, qu'il peut la re-télécharger au besoin) L'idée suivant laquelle le navigateur web est une plate-forme idéale pour réaliser des accès Vpn est donc sérieusement à nuancer.
4.2 - Pptp
Pptp présente l'avantage d'être complètement intégré dans les environnements Windows. Ceci signifie en particulier que l'accès au réseau local distant pourra se faire via le système d'authentification de Windows NT : RADIUS et sa gestion de droits et de groupe. Cependant comme beaucoup de produit Microsoft la sécurité est le point faible du produit :
Mauvaise gestion des mots de passe dans les environnements mixtes win 95/NT
Faiblesses dans la génération des clés de session : réalisé à partir d'un hachage du mot de passe au lieu d'être entièrement générées au hasard. (facilite les attaques « force brute »)
Faiblesses cryptographiques du protocole MsCHAP 1 corrigées dans la version 2 mais aucun contrôle sur cette version n'a été effectué par une entité indépendante.
Identification des paquets non implémentée : vulnérabilité aux attaques de type « spoofing »
4.3 - L2tp / Ipsec
Les mécanismes de sécurité mis en place dans Ipsec sont plus robustes et plus reconnus que ceux mis en place
par Microsoft dans Pptp. Par défaut le protocole L2tp utilise le protocole Ipsec. Cependant si le serveur distant ne
le supporte pas L2tp pourra utiliser un autre protocole de sécurité. Il convient donc de s'assurer que l'ensemble des équipements d'un Vpn L2tp implémente bien le protocole Ipsec. Ipsec ne permet d'identifier que des machines et non pas des utilisateurs. Ceci est particulièrement problématique pour les utilisateurs itinérants. Il faut donc prévoir un service d'authentification des utilisateurs. Dans le cas de connexion dial-up c'est l'identifiant de connexion qui sera utilisé pour authentifier l'utilisateur. Mais dans le cas de
connexion via Internet il faudra prévoir une phase d'authentification supplémentaire à l'établissement du tunnel. D'autre part Ipsec n'offre aucun mécanisme de Qos Ce qui limite ses applications : toutes les applications de voix sur Ip ou de vidéo sur Ip sont impossibles ou seront amenées à être complètement dépendantes des conditions de traffic sur l'internet public.
Enfin Ipsec à cause de la lourdeur des opérations de cryptage/décryptage réduit les performances globales des réseaux. L'achat de périphériques dédiés, coûteux est souvent indispensable.
4.4 - Mpls

Mpls est aujourd'hui la solution apparaissant comme la plus mature du marché. La possibilité d'obtenir une Qos garantie par contrat est un élément qui pèse fortement dans la balance des décideurs. Cependant, seuls des opérateurs spécialisés fournissent Ce service Ce qui peut poser de nouveaux problèmes. Tout d'abord, Ce sont ces opérateurs de services qui fixent les prix. Ce prix inclus forcement une marge pour le fournisseur de service. D'autre part certaines entreprise ne souhaitent pas sous traiter leurs communications à un seul opérateur. En
effet l'explosion de la bulle boursière autour des valeurs technologiques a suscité une vague de faillite d'opérateurs réseaux et de nombreuses entreprises ont vu leurs connexions coupées du jour au lendemain. Ce
risque est aujourd'hui fortement pris en compte par les décideurs informatiques. Cependant utiliser plusieurs opérateurs pour la gestion du Vpn complique d'autant la gestion et la configuration de celui-ci. Enfin l'étendu d'un Vpn-Mpls est aujourd'hui limité par la capacité de l'opérateur de service à couvrir de vastes zones géographiques.
4.5 - Mpls / Ipsec
Mpls Ipsec
Qualité de service Permet d'attribuer des priorités au trafic par le biais de classes de service
Le transfert se faisant sur l'Internet public, permet seulement un service "best effort"
Coût Inférieur à celui des réseaux Frame Relay et Atm mais supérieur à celui des autres Vpn IP.
Faible grâce au transfert via le domaine Internet public
Sécurité Comparable à la sécurité offerte par les réseaux Atm et Frame Relay existants.
Sécurité totale grâce à la combinaison de
certificats numériques et de Pki pour l'authentification ainsi qu'à une série d'options
de cryptage, triple DES et AES notamment
Applications compatibles
Toutes les applications, y compris les logiciels d'entreprise vitaux exigeant une qualité de service élevée et une faible latence et les
applications en temps réel (vidéo et voix sur IP)
Accès à distance et nomade sécurisé. Applications sous IP, notamment courrier électronique et Internet. Inadapté au trafic en
temps réel ou à priorité élevée
Etendue Dépend du réseau Mpls du fournisseur de services
Très vaste puisque repose sur l'accès à Internet
Evolutivité
Evolutivité élevée puisque n'exige pas une interconnexion d'égal à égal entre les sites et que les déploiements standard peuvent prendre en charge plusieurs dizaines de milliers de
connexions par Vpn
Les déploiements les plus vastes exigent une planification soigneuse pour répondre notamment aux problèmes d'interconnexion site à site et de peering
Frais de gestion du réseau
Aucun traitement exigé par le routage Traitements supplémentaires pour le cryptage et le décryptage
Vitesse de déploiement
Le fournisseur de services doit déployer un routeur Mpls en bordure de réseau pour permettre l&148;accès client
Possibilité d'utiliser l'infrastructure du réseau Ip existant
Prise en charge
par le client Non requise. Le Mpls est une technologie réseau Logiciels ou matériels client requis
5 - Conclusion
Cette étude des solutions Vpn, met en évidence une forte concurrence entres les différents protocoles pouvant être
utilisés. Néanmoins, il est possible de distinguer deux rivaux sortant leurs épingles du jeu, à savoir Ipsec et Mpls. Ce dernier est supérieur sur bien des points, mais il assure, en outre, simultanément, la séparation des flux et leur confidentialité. Le développement rapide du marché pourrait bien cependant donner l'avantage au second. En effet, la mise en place de Vpn par Ip entre généralement dans une politique de réduction des coûts liés à l'infrastructure réseau des entreprises. Les Vpn sur Ip permettent en effet de se passer des liaisons louées de type Atm ou Frame Relay. Le
coût des Vpn Ip est actuellement assez intéressant pour motiver de nombreuses entreprises à franchir le pas. A performance égales un Vpn Mpls coûte deux fois moins cher qu'une ligne Atm. Mais si les solutions à base de Mpls prennent actuellement le devant face aux technologies Ipsec c'est principalement grâce à l'intégration possible de solution de téléphonie sur Ip. La qualité de service offerte par le Mpls autorise en effet Ce type d'utilisation. Le marché des Vpn profite donc de l'engouement actuel pour ces technologies qui permettent elles aussi de réduire les coût des infrastructures de communication. Les Vpn sont donc amenés à prendre de plus en plus de place dans les réseaux informatiques.

IPsec
1 - Introduction
2 - Les services offerts par IPsec 2.1 - Les deux modes d'échange IPsec 2.2 - Les protocoles à la base d'IPsec 2.2.1 - AH (authentication header) 2.2.2 - ESP (encapsulating security payload)
2.2.3 - Implantation d'IPsec dans le datagramme IP 3 - Architectures de sécurité 3.1 - Associations de sécurité 3.2 - Architectures supportées 3.2.1 - Dialogue entre deux hôtes protégeant le trafic eux-mêmes 3.2.2 - Dialogue entre deux LANs à l'aide de passerelles de sécurité
3.2.3 - Dialogue entre deux hôtes traversant deux passerelles de sécurité 3.2.4 - Dialogue entre un hôte et une passerelle de sécurité 4 - Gestion des clefs 5 - La compression des en-têtes 6 - Problèmes divers 6.1 - Limitations dûes à la gestion manuelle des clefs 6.2 - Broadcast et multicast
6.3 - Firewalls 6.4 - NATs 6.5 - Protocoles autres qu'IP 6.5.1 - PPTP 6.5.2 - L2TP 6.5.3 - PPTP ou L2TP ? 7 - Quelques implémentations actuelles
7.1 - Windows
7.2 - Linux 7.3 - NetBSD 7.4 - FreeBSD 7.5 - OpenBSD 7.6 - Solutions hardware
8 - Les écueils 9 - Discussion autour de la documentation 10 - Suivi du document
Cet article présente le fonctionnement du protocole IPsec, qui permet de créer des réseaux privés virtuels de manière conforme aux spécifications de l'IETF. Les services offerts par IPsec et leurs limitations y sont détaillés, de même que les problèmes d'interopérabilité, tant avec d'autres protocoles qu'entre applications différentes. Enfin, quelques implémentations sont présentées, et un rapide aperçu de leur conformité aux standards est donné.
1 - Introduction
Le protocole IPsec est l'une des méthodes permettant de créer des VPN (réseaux privés virtuels), c'est-à-dire de relier entre eux des systèmes informatiques de manière sûre en s'appuyant sur un réseau existant, lui-même considéré comme non sécurisé. Le terme sûr a ici une signification assez vague, mais peut en particulier couvrir les notions d'intégrité et de confidentialité. L'intérêt majeur de cette solution par rapport à d'autres techniques (par exemple les
tunnels SSH) est qu'il s'agit d'une méthode standard (facultative en IPv4, mais obligatoire en IPv6), mise au point dans ce but précis, décrite par différentes RFCs, et donc interopérable. Quelques avantages supplémentaires sont l'économie de bande passante, d'une part parce que la compression des en-têtes des données transmises est prévue par ce standard, et d'autre part parce que celui-ci ne fait pas appel à de trop lourdes techniques d'encapsulation, comme par
exemple les tunnels PPP sur lien SSH. Il permet également de protéger des protocoles de bas niveau comme ICMP et IGMP, RIP, etc...
IPsec présente en outre l'intérêt d'être une solution évolutive, puisque les algorithmes de chiffrement et d'authentification à proprement parler sont spécifiés séparément du protocole lui-même. Elle a cependant l'inconvénient inhérent à sa flexibilité : sa grande complexité rend son implémentation délicate. Les différents services offerts par le protocole IPsec sont ici détaillés. Les manières de les combiner entre eux que les implémentations sont tenues de supporter sont ensuite présentées. Les moyens de gestion des clefs de chiffrement et signature sont étudiés et les problèmes d'interopérabilité associés sont évoqués. Enfin, un aperçu rapide de quelques implémentations IPsec, en s'intéressant essentiellement à leur conformité aux spécifications est donné.
2 - Les services offerts par IPsec
2.1 - Les deux modes d'échange IPsec
Une communication entre deux hôtes, protégée par IPsec, est susceptible de fonctionner suivant deux modes différents : le mode transport et le mode tunnel. Le premier offre essentiellement une protection aux protocoles

de niveau supérieur, le second permet quant à lui d'encapsuler des datagrammes IP dans d'autres datagrammes IP, dont le contenu est protégé. L'intérêt majeur de ce second mode est qu'il rend la mise en place de passerelles de sécurité qui traitent toute la partie IPsec d'une communication et transmettent les datagrammes épurés de leur partie IPsec à leur destinataire réel réalisable. Il est également possible d'encapsuler une communication IPsec en mode tunnel ou transport dans une autre communication IPsec en mode tunnel, elle-même traitée par une
passerelle de sécurité, qui transmet les datagrammes après suppression de leur première enveloppe à un hôte traitant à son tour les protections restantes ou à une seconde passerelle de sécurité.
2.2 - Les protocoles à la base d'IPsec
2.2.1 - AH (authentication header)
AH est le premier et le plus simple des protocoles de protection des données qui font partie de la spécification IPsec. Il est détaillé dans la Rfc 2402. Il a pour vocation de garantir :
L'authentification : les datagrammes IP reçus ont effectivement été émis par l'hôte dont l'adresse IP est indiquée comme adresse source dans les en-têtes.
L'unicité (optionnelle, à la discrétion du récepteur) : un datagramme ayant été émis légitimement et enregistré par un attaquant ne peut être réutilisé par ce dernier, les attaques par rejeu sont ainsi évitées.
L'intégrité : les champs suivants du datagramme IP n'ont pas été modifiés depuis leur émission : les données (en mode tunnel, ceci comprend la totalité des champs, y compris les en-têtes, du datagramme IP encapsulé dans le datagramme protégé par AH), version (4 en IPv4, 6 en IPv6), longueur de l'en-tête (en IPv4), longueur totale du datagramme (en IPv4), longueur des données (en IPv6), identification, protocole ou en-tête suivant (ce champ vaut 51 pour indiquer qu'il s'agit du protocole AH), adresse IP de l'émetteur, adresse IP du destinataire (sans source routing).
En outre, au cas où du source routing serait présent, le champ adresse IP du destinataire a la valeur que
l'émetteur a prévu qu'il aurait lors de sa réception par le destinataire. Cependant, la valeur que prendrontles champs type de service (IPv4), indicateurs (IPv4), index de fragment (IPv4), TTL (IPv4), somme de contrôle d'en-tête (IPv4), classe (IPv6), flow label (IPv6), et hop limit (IPv6) lors de leur réception n'étant pas prédictible au moment de l'émission, leur intégrité n'est pas garantie par AH. L'intégrité de celles des options IP qui ne sont pas modifiables pendant le transport est assurée, celle des autres options ne l'est pas.
Attention, AH n'assure pas la confidentialité : les données sont signées mais pas chiffrées. Enfin, AH ne spécifie pas d'algorithme de signature particulier, ceux-ci sont décrits séparément, cependant, une implémentation conforme à la Rfc 2402 est tenue de supporter les algorithmes MD5 et SHA-1.
2.2.2 - ESP (encapsulating security payload)
ESP est le second protocole de protection des données qui fait partie de la spécification IPsec. Il est détaillé dans la Rfc 2406. Contrairement à AH, ESP ne protège pas les en-têtes des datagrammes IP utilisés pour transmettre la communication. Seules les données sont protégées. En mode transport, il assure :
La confidentialité des données (optionnelle) : la partie données des datagrammes IP transmis est chiffrée.
L'authentification (optionnelle, mais obligatoire en l'absence de confidentialité) : la partie données des datagrammes IP reçus ne peut avoir été émise que par l'hôte avec lequel a lieu l'échange IPsec, qui
ne peut s'authentifier avec succès que s'il connaît la clef associée à la communication ESP. Il est également important de savoir que l'absence d'authentification nuit à la confidentialité, en la rendant plus vulnérable à certaines attaques actives.
L'unicité (optionnelle, à la discrétion du récepteur).
L'integrité : les données n'ont pas été modifiées depuis leur émission.
En mode tunnel, ces garanties s'appliquent aux données du datagramme dans lequel est encapsulé le trafic utile, donc à la totalité (en-têtes et options inclus) du datagramme encapsulé. Dans ce mode, deux avantages supplémentaires apparaissent:
Une confidentialité, limitée, des flux de données (en mode tunnel uniquement, lorsque la confidentialité est assurée) : un attaquant capable d'observer les données transitant par un lien n'est pas à même de déterminer quel volume de données est transféré entre deux hôtes particuliers. Par exemple, si la communication entre deux sous-réseaux est chiffrée à l'aide d'un tunnel ESP, le volume

total de données échangées entre ces deux sous-réseaux est calculable par cet attaquant, mais pas la répartition de ce volume entre les différents systèmes de ces sous-réseaux.
La confidentialité des données, si elle est demandée, s'étend à l'ensemble des champs, y compris les
en-têtes, du datagramme IP encapsulé dans le datagramme protégé par ESP).
Enfin, ESP ne spécifie pas d'algorithme de signature ou de chiffrement particulier, ceux-ci sont décrits séparément, cependant, une implémentation conforme à la Rfc 2406 est tenue de supporter l'algorithme de chiffrement DES en mode CBC, et les signatures à l'aide des fonctions de hachage MD5 et SHA-1.
2.2.3 - Implantation d'IPsec dans le datagramme IP
La figure 1 montre comment les données nécessaires au bon fonctionnement des formats AH et ESP sont
placées dans le datagramme IPv4. Il s'agit bien d'un ajout dans le datagramme IP, et non de nouveaux datagrammes, ce qui permet un nombre théoriquement illimité ou presque d'encapsulations IPsec : un datagramme donné peut par exemple être protégé à l'aide de trois applications successives de AH et de deux encapsulations de ESP.
3 - Architectures de sécurité
3.1 - Associations de sécurité
La Rfc 2401 (Security Architecture for the Internet Protocol) décrit le protocole IPsec au niveau le plus élevé. En particulier, elle indique ce qu'une implémentation est censée permettre de configurer en termes de politique de sécurité (c'est-à-dire quels échanges IP doivent être protégés par IPsec et, le cas échéant, quel(s) protocole(s) utiliser). Sur chaque système capable d'utiliser IPsec doit être présente une SPD (security policy database), dont la forme précise est laissée au choix de l'implémentation, et qui permet de préciser la politique de sécurité à
appliquer au système. Chaque entrée de cette base de données est identifiée par un SPI (security parameters index) unique (32 bits) choisi arbitrairement. Une communication protégée à l'aide d'IPsec est appelée une SA (security association). Une SA repose sur une unique application de AH ou sur une unique application de ESP. Ceci n'exclut pas l'usage simultané de AH et ESP entre deux systèmes, ou par exemple l'encapsulation des datagrammes AH dans d'autres datagrammes AH, mais plusieurs SA devront alors être activées entre les deux systèmes. En outre, une SA est unidirectionnelle. La
protection d'une communication ayant lieu dans les deux sens nécessitera donc l'activation de deux SA. Chaque SA est identifiée de manière unique par un SPI, une adresse IP de destination (éventuellement adresse de broadcast ou de multicast), et un protocole (AH ou ESP). Les SA actives sont regroupées dans une SAD (security association database). La SPD est consultée pendant le traitement de tout datagramme IP, entrant ou sortant, y compris les
datagrammes non-IPsec. Pour chaque datagramme, trois comportements sont envisageables : le rejeter,
l'accepter sans traitement IPsec, ou appliquer IPsec. Dans le troisième cas, la SPD précise en outre quels traitements IPsec appliquer (ESP, AH, mode tunnel ou transport, quel(s) algorithme(s) de signature et/ou chiffrement utiliser). Les plus importants de ces termes sont récapitulés dans le tableau suivant :
SPD base de données définissant la politique de sécurité
SA une entrée de la SPD
SAD liste des SA en cours d'utilisation
Les règles de la SPD doivent pouvoir, si l'adminsitrateur du système le souhaite, dépendre des paramètres suivants :

adresse ou groupe d'adresses IP de destination
adresse ou groupe d'adresses IP source
nom du système (DNS complète, nom X.500 distingué ou général)
protocole de transport utilisé (typiquement, TCP ou UDP)
nom d'utilisateur complet, comme [email protected] (ce paramètre n'est toutefois pas obligatoire sur certains types d'implémentations)
importance des données (ce paramètre n'est toutefois pas obligatoire sur certains types d'implémentations)
ports source et destination (UDP et TCP seulement, le support de ce paramètre est facultatif)
Certains paramètres peuvent être illisibles à cause d'un éventuel chiffrement ESP au moment où ils sont traités, auquel cas la valeur de la SPD les concernant peut le préciser, il s'agit de :
l'identité de l'utilisateur
le protocole de transport
les ports source et destination
Il est donc possible de spécifier une politique de sécurité relativement fine et détaillée. Cependant, une politique
commune pour le trafic vers un ensemble de systèmes permet une meilleure protection contre l'analyse de trafic qu'une politique extrêmement détaillée, comprenant de nombreux paramètres propres à chaque système particulier. Enfin, si l'implémentation permet aux applications de préciser elles-mêmes à quelle partie du trafic appliquer IPsec et comment, l'administrateur doit pouvoir les empêcher de contourner la politique par défaut.
3.2 - Architectures supportées
Le protocole IPsec permet théoriquement n'importe quelle combinaison, en un nombre quasiment illimité de niveaux d'encapsulation, c'est-à-dire d'accumulations de SA. Néanmoins, les implémentations ne sont pas tenues
d'offrir une telle flexibilité. Les architectures qu'une application conforme à la Rfc 2401 doivent supporter, au nombre de quatre, sont décrites ci-dessous.
3.2.1 - Dialogue entre deux hôtes protégeant le trafic eux-mêmes
Deux hôtes engagent une communication IPsec, en encapsulant le protocole de haut niveau dans : en mode transport :
des datagrammes AH
des datagrammes ESP
ou des datagrammes ESP encapsulés dans des datagrammes AH
en mode tunnel :
des datagrammes AH
ou des datagrammes ESP
3.2.2 - Dialogue entre deux LANs à l'aide de passerelles de sécurité
Ici, deux passerelles de sécurité gèrent les conversations entre les hôtes de deux LANs différents, IPsec s'appliquant de manière transparente pour les hôtes. Les deux passerelles de sécurité échangent des datagrammes en mode tunnel, à l'aide de AH ou ESP (après routage, ceci correspond simplement à la deuxième partie du cas précédent), puis transmettent les datagrammes obtenus après traitement IPsec aux hôtes destinataires. Ainsi, les datagrammes IP émis par un système de l'un des deux LANs sont encapsulés
dans d'autres datagrammes IP+IPsec par la passerelle du "LAN émetteur", encapsulation supprimée par la passerelle du "LAN récepteur" pour obtenir de nouveau les datagrammes IP originaux.

3.2.3 - Dialogue entre deux hôtes traversant deux passerelles de sécurité
Le troisième cas n'ajoute pas vraiment de prérequis sur les implémentations IPsec. Ainsi, une passerelle de sécurité doit avoir la capacité de transmettre dans un tunnel IPsec du trafic déjà sécurisé par IPsec. Celà
autorise les dialogues IPsec entre deux hôtes situés eux-mêmes dans des LANs reliés par des passerelles de sécurité.
3.2.4 - Dialogue entre un hôte et une passerelle de sécurité
Le dernier cas est celui d'un hôte externe se connectant à un LAN protégé par une passerelle de sécurité. Les documentations techniques désignent souvent un tel hôte sous le nom de road warrior. Il engage une conversation IPsec avec un système du LAN en mode transport, le tout encapsulé dans un tunnel IPsec établi entre le road warrior lui-même et la passerelle de sécurité. Dans ce cas, les datagrammes du tunnel sont de type AH ou ESP et les datagrammes utilisés en mode transport doivent pouvoir être de type AH, ESP, ou ESP encapsulé dans AH.
4 - Gestion des clefs
Les services de protection offerts par IPsec s'appuient sur des algorithmes cryptographiques, et reposent donc sur des clefs. Si celles-ci sont gérables manuellement dans le cas où peu d'hôtes seront amenés à engager des conversations IPsec, ceci devient un véritable cauchemar quand le système commence à prendre un peu d'extension (le nombre de couples de clefs augmentant de manière quadratique avec le nombre de systèmes). C'est pourquoi la spécification
IPsec propose également des procédés d'échange automatique de clefs, dont les aspects les plus importants sont ici évoqués. Une présentation complète de cette procédure dépasse toutefois le cadre de cet article. La Rfc 2401 précise qu'une implémentation IPsec est tenue de supporter la gestion manuelle de clefs et la méthode d'échange automatique de clefs IKE, bien que d'autres algorithmes existent. Un point important est que la gestion de clefs automatique est considérée comme plus sûre que la gestion manuelle.
Le protocole IKE (internet key exchange) est décrit par la Rfc 2409. Il permet l'échange de clefs entre deux hôtes d'adresses IP connues préalablement ou inconnues selon le mode d'échange de clefs sélectionné. Parmi ses avantages figure le mode agressif (cette caractéristique n'est pas obligatoire), qui permet d'accélérer la négociation, au prix de la protection d'identité. L'identité est toutefois protégée dans le cas d'une négociation IKE authentifiée à l'aide de signatures à clef publique. Deux manières d'échanger des clefs sont abondamment utilisées : les clefs pré-partagées, et les certificats X.509 (dans ce dernier cas, deux systèmes d'adresses initialement inconnues pourront protéger leurs échanges).
La seconde manière de procéder a l'avantage de permettre à des clients d'adresses IP dynamiques et changeant éventuellement de créer des SAs, mais n'est pas obligatoirement supportée par les implémentations conformes à laRfc 2409. Enfin, une définition qui peut s'avérer utile lors de la lecture de documentations techniques sur IPsec : la PFS (perfect forward secrecy) est définie par la Rfc 2409 comme la notion selon laquelle la compromission d'une clef ne permettra
l'accès qu'aux données protégées par cette clef, mais ne sera pas suffisante pour déchiffrer tout l'échange IPsec, seule la partie de la communication protégée par la clef corrompue sera déchiffrable.
5 - La compression des en-têtes
La Rfc 3095 décrit un protocole de compression d'en-têtes pouvant s'appliquer à RTP, UDP, et ESP sur IP. La compression des données elles-mêmes n'est malheureusement pas couverte par cette spécification, il n'est donc pas
prévu, à l'heure actuelle, de les compresser. En revanche, il est conçu pour s'accommoder des taux d'erreurs de transmission importants des communications par voie hertzienne. Enfin, la compression décrite s'appuie sur une couche de liens garantissant la transmission des données dans leur ordre d'émission et sans duplication, ce qui peut rendre dangereuse son utilisation sur certains réseaux. Enfin, la couche de liens doit permettre la négociation des
paramètres ROHC (robust header compression), cette négociation peut cependant se faire à priori ou en s'appuyant sur d'autres protocoles.
6 - Problèmes divers
L'utilisation simultanée d'IPsec et d'autres protocoles ou de certains équipements réseau pose, dans certains cas, quelques problèmes. En outre, la gestion manuelle de clefs introduit quelques restrictions sur les usages possibles du protocole.
6.1 - Limitations dues à la gestion manuelle des clefs
Les services d'unicité offerts par AH et ESP s'appuient sur des numéros de séquence initialisés à 0 lors de la
création d'une SA et incrémentés lors de l'envoi de chaque datagramme. Ces numéros de séquence sont stockés dans un entier de 32 bits, qui ne doit jamais être diminué. Le nombre maximal de datagrammes qu'une SA peut permettre d'échanger est donc de l'ordre de quatre milliards. Passé cette limite, il est nécessaire de créer une nouvelle SA et donc une nouvelle clef. Ceci rend pénible la mise en oeuvre simultanée de la gestion manuelle de

clefs et de la protection contre la duplication de datagrammes. Cette dernière étant optionnelle, il est possible de la désactiver, auquel cas le numéro de séquence peut être annulé lorsqu'il a atteint sa valeur maximale.
6.2 - Broadcast et multicast
L'utilisation d'IPsec pour l'envoi et la réception de datagrammes multicast et broadcast pose quelques problèmes dont certains ne sont pas encore résolus. Des problèmes de performances d'une part, et des difficultés qu'une simple augmentation de la puissance de calcul ne saurait résoudre, comme la vérification des numéros de séquence. Le service de protection contre la duplication des données n'est donc pas utilisable en environnement
multicast et broadcast à l'heure actuelle.
6.3 - Firewalls
Le filtrage de datagrammes IPsec est délicat pour deux raisons :
les RFCs ne précisent pas si, sur un système remplissant simultanément les fonctions de passerelle de sécurité et de firewall, le décodage de l'IPsec doit avoir lieu avant ou après l'application des règles de firewalling
il n'est pas possible au code de firewalling de lire certaines données, par exemple des numéros de port,
dans des données chiffrées, ou transmises dans un format qu'il ne connaît pas
Il est donc important de lire la documentation de l'implémentation IPsec utilisée sur les systèmes destinés à gérer simultanément IPsec et firewalling. Il est également utile de noter que les systèmes qui appliquent les règles de firewalling avant le décodage IPsec sont néanmoins souvent capables de filtrer les datagrammes décodés en utilisant des outils de tunneling comme ipip et gif, ou en filtrant au niveau de l'interface de sortie des données. Enfin, AH utilise le numéro de protocole 51 et ESP le numéro de protocole 50. Quant à IKE, il utilise le numéro de
port UDP 500. Ces informations sont indispensables lors de la configuration d'un firewall qui doit laisser passer ou
bloquer les échanges IPsec.
6.4 - NATs
Théoriquement, toute translation d'adresse sur un datagramme IPsec devrait être évitée, car ce type d'opération modifie le contenu des datagrammes, ce qui est incompatible avec les mécanismes de protection de l'intégrité des données d'IPsec. Il existe une solution à ce problème, proposée par SSH Communications Security : l'IPsec NAT-Traversal. Il s'agit d'un draft, donc encore incomplet, mais suffisant pour envisager ce que l'avenir réserve.
Certains équipement permettent d'ailleurs déjà de traverser des NAT, en utilisant des protocoles plus ou moins normalisés et avec plus ou moins de bonheur. Comme il ne s'agit que d'un draft, il est décrit dans des documents dont le nom et l'adresse changent souvent, mais un moyen simple de le retrouver est d'entrer la chaîne draft-stenberg-ipsec-nat-traversal dans votre moteur de recherche favori. Enfin, ce protocole ne peut être mis en oeuvre que si le protocole IKE est utilisé simultanément.
6.5 - Protocoles autres qu'IP
Un inconvénient d'IPsec est que ce protocole ne prévoit que le convoyage sécurisé de datagrammes IP. Ceci n'est
pas suffisant, car d'autres standards comme IPX et NetBIOS sont utilisés sur un grand nombre de réseaux. Il existe cependant une solution à ce problème : encapsuler les données à protéger dans du PPP, lui-même transporté par IPsec. Le rôle de PPP est en effet de permettre la transmission de différents protocoles au-dessus d'un lien existant. Ceci implique de pouvoir encapsuler PPP dans les datagrammes IPsec, cette opération est décrite dans les paragraphes suivants.
6.5.1 - PPTP
La première solution permettant cette encapsulation est le protocole PPTP, décrit par la Rfc 2637. PPTP offre ainsi à un client, dit PAC (PPTP access concentrator), la possibilité d'établir un lien PPP avec un serveur dit PNS (PPTP network server), encapsulé dans des datagrammes IP. Si le client a préalablement établi une SA
avec une passerelle de sécurité (éventuellement distincte du PNS), qui lui permet de protéger ces datagrammes IP, les données PPP seront donc également sécurisées, de même que les protocoles de niveau supérieur s'appuyant sur le lien PPP. Deux points s'avèrent importants lors de la configuration d'un firewall placé entre un PAC et un PNS :
PPTP s'appuie sur le protocole d'encaspulation général GRE, auquel l'IANA a attribué le numéro 47
un lien PPTP est contrôlé par une connexion TCP vers le port 1723 du PNS
Enfin, PPTP seul, c'est-à-dire sans IPsec, peut être et a été utilisé pour crééer des VPNs, assurant des échanges authentifiés, en protégeant les mots de passes utilisés d'un éventuel attaquant, mais sans chiffrer le reste de la communication. Cependant, ce système offre une authentification nettement moins fiable que

ce qu'il est possible d'obtenir avec IPsec. En outre, de nombreuses implémentations de ce protocole, notamment celles de Microsoft, ont fait l'objet de découvertes de vulnérabilités et d'incapacité à protéger efficacement les mots de passe des utilisateurs. Aussi l'usage de ce système est-il risqué.
6.5.2 - L2TP
Une deuxième solution d'encapsulation de PPP dans IP est le protocole L2TP, décrit par la Rfc 2661. Il permet la transmission de PPP à l'aide des protocoles de niveau 2 comme ethernet. Il offre également un mécanisme d'encapsulation de PPP dans UDP. Ainsi, il est possible de protéger PPP à l'aide d'UDP encapsulé dans IPsec. L2TP offre en outre une architecture plus modulaire que PPTP : on suppose le client capable d'échanger des trames par l'intermédiaire d'un protocole de niveau 2 ou des datagrammes UDP avec un LAC (L2TP access
concentrator), qui transmet les données à un LNS (L2TP network server). Si le LAC et le LNS sont situés physiquement sur le même système, celui-ci joue alors exactement le même rôle que le PNS de PPTP. Un détail important lors du paramétrage d'un firewall : le L2TP encapsulé dans UDP utilise le port 1701.
6.5.3 - PPTP ou L2TP ?
L'utilisation de PPTP ou L2TP ne change pas grand-chose du point de vue de la sécurité, celle-ci étant assurée par la couche inférieure IPsec. La question qui se pose est donc celle de la consommation de bande passante, parce que toutes ces encapsulations commencent à représenter un volume de données non négligeable. Dans le cas d'un client se connectant à un ISP et établissant ensuite le tunnel vers un réseau destination, PPTP
devrait permettre d'économiser les en-têtes UDP. En revanche, dans le cas d'un client se connectant, par exemple à l'aide d'un modem ou d'une ligne ISDN, directement sur le réseau privé, et disposant donc d'un lien de niveau 2 vers ce réseau, L2TP semble plus économe. Un dernier point à prendre compte est que l'os tournant sur le serveur imposera parfois des limitations :
pour Windows 2000 et ultérieures, Microsoft semble privilégier très fortement L2TP
les versions précédentes de Windows ne supportent pas L2TP
les Unix-like libres semblent accuser un léger retard en matière de support L2TP
7 - Quelques implémentations actuelles
Cette partie donne un aperçu des capacités de quelques OS populaires en matière de support IPsec. Les informations fournies constituent une synthèse des sites des OS, des éditeurs et des FAQs des logiciels concernés : de plus amples détails sont donc disponibles sur ces sites.
7.1 - Windows
Windows XP et 2000 incluent un support du mode transport d'IPsec et de l'échange de clefs à l'aide de certificats en natif. Il existe de très nombreux logiciels permettant de créer des VPN sous Windows, y compris un serveur VPN en option sous Windows 2000 et XP, capable de mettre en place des tunnels IPsec/L2TP. D'autre part, Windows 95, 98 et NT 4 disposent d'une grande quantité d'implémentations IPsec commerciales et à peu près toutes les versions de Windows depuis 95 sont capables de créer des tunnels PPTP. Une solution intéressante est également proposée par SSH Communications Security. Leur implémentation est à l'heure actuelle l'une des rares à supporter IPsec NAT-Traversal. Le client est disponible pour les versions 95, 98, Me, NT 4, 2000 et XP de
Windows.
7.2 - Linux
L'implémentation IPsec la plus utilisée sous Linux est sous licence GPL, il s'agit de FreeS/WAN. La partie kernel de cette implémentation s'appelle KLIPS. Sont notamment supportés :
l'échange dynamique de clefs IKE à l'aide du logiciel pluto, qui permet l'utilisation de clefs pré-partagées aussi bien que de certificats
la protection des connexions d'un road warrior à un LAN, même si son adresse IP est attribuée dynamiquement et est susceptible de changer
la création de tunnels PPTP (côté serveur), grâce au logiciel PoPToP
la création de tunnels PPTP (côté client), grâce au logiciel PPTP-linux
la création de tunnels L2TP, grâce au logiciel l2tpd

le chiffrement opportuniste, qui permet la protection des données échangées entre deux systèmes totalement étrangers jusqu'alors (les clefs publiques sont alors échangées à l'aide de la DNS)
Les principaux problèmes connus lors de l'écriture de ce document étaient :
KLIPS présente une très légère fuite de mémoire
si plusieurs connexions sont établies entre deux passerelles de sécurité, la compression d'en-têtes doit être activée pour toutes ou aucune de ces connexions
KLIPS ne gère pas les datagrammes dans lesquels des options IP sont présentes
Enfin, FreeS/WAN décode les paquets IPsec avant de les transmettre au code de firewalling. Les règles de firewalling peuvent néanmoins tester si les datagrammes ont été envoyés en clair ou non.
7.3 - NetBSD
NetBSD utilise KAME, une implémentation IPsec (et plus généralement IPv6) sous licence BSD. La foire aux questions concernant IPsec pour NetBSD. Sont notamment supportés :
l'utilisation simultanée d'IPsec en mode tunnel ou transport avec IPv6, au moins pour la version courante de NetBSD
la configuration socket par socket (à l'aide de l'appel système setsockopt(2))
la création de tunnels IPsec grâce aux ports pptp et pptp-server
un nombre quasiment illimité de SA imbriquées
l'échange dynamique de clefs IKE, en utilisant soit racoon, qui peut fonctionner à l'aide de clefs pré-partagées ou de certificats, soit isakmpd, qui en est encore à son stade alpha, et supporte également ces deux méthodes
Les principaux problèmes connus lors de l'écriture de ce document étaient :
les clefs associées à une SA mise en place à l'aide de l'appel setsockopt(2) ne peuvent être négociées par racoon
le protocole AH en mode tunnel ne fonctionne pas correctement
Enfin, lors d'une utilisation conjointe de KAME et IPfilter sous NetBSD, les datagrammes sont traités par le firewall avant d'être décodés par KAME.
7.4 - FreeBSD
FreeBSD s'appuie également KAME. L'utilisation d'IPsec sous FreeBSD est documentée. Sont notamment supportés :
l'utilisation simultanée d'IPsec en mode tunnel ou transport avec IPv6, au moins pour la version courante de FreeBSD
la création de tunnels PPTP (côté client)
la création de tunnels PPTP (côté serveur), grâce au logiciel PoPToP
la création de tunnels L2TP, grâce au logiciel (dont le portage sous FreeBSD en est encore au stade
alpha) l2tpd
l'échange dynamique de clefs IKE, en utilisant racoon
7.5 - OpenBSD

A l'instar de FreeBSD et NetBSD, OpenBSD utilise KAME. La documentation relative à l'utilisation d'IPsec sousOpenBSD. Sont notamment supportés :
l'échange dynamique de clefs ISAKMP grâce au logiciel isakmpd, qui supporte le mode agressif et
l'utilisation de certificats comme de clefs pré partagées, et la création de SAs avec des clients d'adresse IP variables et attribuées dynamiquement, photuris peut également être employé, mais il est encore en stade alpha et peu documenté
la création de tunnels PPTP (côté client), grâce au port pptp
la création de tunnels PPTP (côté serveur), grâce au logiciel PoPToP
l'échange dynamique de clefs selon le standard Photuris, en s'appuyant sur le logiciel photurisd
7.6 - Solutions hardware
Si de nombreuses SA doivent être maintenues, compte tenu de la forte charge CPU liée au chiffrement, il sera peut-être nécessaire d'avoir recours à l'une des multiples solutions hard disponibles dans le commerce (Redcreek, Timestep).
8 - Les écueils
Nous conclurons cet article sur une mise en garde : il est fondamental, lors de la mise en place de VPNs à l'aide d'IPsec de parfaitement comprendre à quoi la protection va s'appliquer. Il est en effet très facile de commettre des erreurs aux conséquences extrêmement graves. Par exemple, placer une passerelle de sécurité derrière un firewallet configurer ce dernier pour laisser passer tout trafic IPsec implique un paramétrage soigneux de la passerelle de sécurité, pour éviter qu'un attaquant l'utilise pour contourner le firewall. Notamment, si cette passerelle met en oeuvre le chiffrement
opportuniste de l'implémentation FreeS/WAN, le firewall peut ne plus être d'aucune utilité. Il est de manière générale recommandé d'appliquer des règles de firewalling après au même titre qu'avant les traitements IPsec (pour fixer les idées, une manière simple bien qu'exorbitante d'appliquer ce conseil est de placer un premier firewall avant la passerelle de sécurité et un second après cette passerelle). En outre, le chiffrement des données ne doit pas créer l'illusion de la sécurité, comme SSL l'a trop souvent fait : chiffrer n'est pas authentifier (un attaquant peut très bien engager une conversation chiffrée avec une passerelle de
sécurité), et authentifier le système émetteur d'un datagramme à l'aide du protocole AH ne suffit pas nécessairement à assurer la sécurité : si un administrateur utilise un protocole permettant une authentification en clair comme telnet, en encapsulant les données dans des datagrammes protégés par AH, un attaquant pourra lire son mot de passe, et s'il est ensuite possible d'établir des connexions non authentifiées à l'aide d'IPsec vers le système, ce dernier peut alors être considéré comme compromis.
Ces deux exemples illustrent la complexité de la mise en place d'IPsec. Cette complexité ne saurait que difficilement s'accommoder de solutions soi-disant magiques et clefs en mains, paramétrées en quelques clics de souris. IPsec est excessivement complexe, et masquer cette complexité derrière des interfaces graphiques n'appelant pas les choses par leurs noms est aussi dangereux qu'irresponsable (serait-il grand temps de mettre un terme à l'anarchie dans le vocabulaire ?-D).
Architecture L2TP - Layer 2 Tunneling Protocol
1 - Introduction
2 - Histoire
2.1 - Rappel du contexte technico-économique 2.2 - Les différentes connexions "Haut débit" par modem xDSL 2.3 - L'alternative PPPoE 2.4 - Statut de PPP over Ethernet 3 - Le protocole PPP
3.1 - Introduction 3.2 - Format de l'entête 3.3 - Etablissement d'une connexion 3.4 - LCP - Link Control Protocol 3.5 - NCP - Network Control Protocols 3.6 - Authentification 4 - Le protocole PPPoE
4.1 - Introduction 4.2 - L'histoire 4.3 - Format de l'entête 4.4 - Les étapes 4.5 - Sécurité 5 - Le protocole L2TP 5.1 - Introduction

5.2 - Format de l'entête 5.3 - Les concentrateurs d'accès - LAC 5.4 - Les serveurs réseau - LNS 5.5 - Avantages et inconvénients 6 - L'architecture PPP - L2TP
6.1 - Architecture IP 6.2 - Les encapsulations
6.3 - Les tailles maximums de l'OverHead 6.4 - Problématique liée au MTU 7 - Conclusion 8 - Discussion autour de la documentation 9 - Suivi du document
1 - Introduction
La première partie du dossier est un peu théorique. Après un bref rappel du contexte technico-économique et des différentes problématiques rencontrées par les fournisseurs d'accès à Internet (ISP) avec les connexions « Haut Débit » chez le particulier (technologies xDSL ou liaison câble), le protocole PPPoE sera présenté en détail ainsi que PPP afin d'aborder L2TP. La seconde partie du document est plus orientée pratique. Elle décrit la mise en place d'une solution L2TP et présente les différentes encapsulations et taille des trames.
L2TP, définit par la Rfc 2661, est issu de la convergence des protocoles PPTP et L2F. Il est actuellement développé et évalué conjointement par Cisco Systems, Microsoft, Ascend, 3Com ainsi que d'autres acteurs clés du marché des réseaux. Il permet l'encapsulation des paquets PPP au niveau des couches 2 (Frame Relay et ATM) et 3 (Ip). Lorsqu'il est configuré pour transporter les données sur IP, L2TP peut être utilisé pour faire du tunnelling sur Internet. L2TP repose sur deux concepts : les concentrateurs d'accès L2TP (LAC : L2TP Access Concentrator) et les serveurs réseau L2TP (LNS : L2TP Network Server). L2TP n'intègre pas directement de protocole pour le chiffrement des données. C'est pourquoi L'IETF préconise l'utilisation conjointe d'IPSEC et L2TP.
2 - Histoire
2.1 - Rappel du contexte technico-économique
Les services Internet proposés au particulier et aux petites entreprises sont de plus en plus nombreux (connexion via un fournisseur d'accès, travail à distance, services à valeur ajoutée tels que l'e-mail, serveur Web hébergé, VPN, etc.). Cette population appelée communément SOHO (Small Office / Home Office) est la cible des grands de
l'industrie du réseau (opérateurs, constructeurs, etc.). En effet, le besoin de connexion à « Haut-débit » est de plus en plus fort, mais face à des technologies de plus en plus complexes, les déploiements sont ralentis car trop coûteux (liens fibres optiques, terminaux de connexion ATM), trop spécifiques (encapsulations multiples des protocoles pour interfacer PC et modem) ou encore trop difficiles à mettre en place par les opérateurs (configuration, formation des utilisateurs).
Différentes propositions ont été faites afin de « standardiser » et « simplifier » le mode de connexion entre un micro-ordinateur personnel PC et un modem de type xDSL ou modem câble. Ces différentes solutions sont présentées en paragraphe II.2. Rappelons que les objectifs qui animent ces recherches sont la facilité et la vitesse de déploiement des connexions « Haut débit » chez les consommateurs SOHO, et de surcroît à moindre coût !
2.2 - Les différentes connexions "Haut débit" par modem xDSL
Dans le cas de connexion par RTC (Réseau Téléphonique Commuté), les utilisateurs finaux (SOHO ou particuliers
pour un usage privé) sont habitués à utiliser un matériel « banalisé » comme un modem analogique fonctionnant en bande téléphonique analogique (30Hz -> 3,6 KHz), dont le coût d'achat est faible, et surtout dont la configuration est minimale (utilisation des protocoles PPP, SLIP, RAS, etc. nativement gérés par les systèmes d'exploitations les plus répandus du marché).
Dans le cadre des connexions « Haut-débit », un matériel plus sophistiqué de type modem xDSL ou modem câble est nécessaire. Son coût d'acquisition est plus élevé que dans le cas précédent, et la configuration est plus complexe car elle s'appuie sur des technologies plus élaborées. Les recherches menées par l'industrie du réseau et des télécommunications ont abouti à plusieurs propositions d'architecture décrites ci-après, chacune basée sur les technologies ATM sur xDSL. Un des objectifs étant la
simplicité de configuration, le protocole PPP a été retenu comme point de départ. Chacune des solutions diffère sur le mode de connexion entre le micro-ordinateur et le modem xDSL.
2.2.1 - ATM sur interface xDSL
Le schéma suivant présente la première proposition de configuration.

Une carte d'interface xDSL est implantée directement dans le micro-ordinateur, sur lequel sont installés un driver PPP et un driver ATM. L'avantage principal est l'utilisation de PPP pour l'utilisateur, donc la configuration et la procédure de connexion est connue car identique à celle utilisée dans le cas de connexion analogique par RTC. La connexion PPP s'effectue au travers de la boucle locale jusqu'au réseau de données régional vers un POP (Point-Of-Presence) de fournisseur d'accès.
Deux inconvénients majeurs à cette architecture :
Le marché des interfaces xDSL n'en est qu'à ses premiers pas et le manque d'inter-opérabilité entre les différents équipements xDSL ne permet pas la réalisation d'économies d'échelles nécessaires pour la production d'interfaces xDSL standards à coût réduit.
La ligne xDSL ne peut être utilisée que par un seul micro-ordinateur à la fois, ce qui limite l'intérêt de ce type de connexion pour les SOHO.
2.2.2 - Interface ATM et modem xDSL
La seconde proposition d'architecture est présentée dans le schéma ci-dessous.
Les limites reconnues d'une interface xDSL, les approches suivantes, dont celle-ci, s'appuient sur un équipement xDSL externe (modem). La configuration proposée ici repose sur un lien ATM entre le micro-ordinateur et le modem xDSL. A cet effet, une interface ATM est implantée dans le PC. Les inconvénients de cette proposition sont les suivants :
Les interfaces ATM sont peu répandues chez les utilisateurs finaux. Cette configuration était la
première hypothèse des opérateurs pour le déploiement des connexions « Haut débit » chez le consommateur. Pour rappel, elle n'a pas été retenue pour des raisons économiques. De plus, ce type d'interface est difficile à installer et à configurer par l'utilisateur. Cette complexité risque de ralentir le déploiement et l'acceptation de la technologie xDSL chez les consommateur.
Il n'existe pas d'interface ATM pour les micro-ordinateurs portables, ce qui est un inconvénient pour les SOHO, le plus souvent nomades.

Le partage d'une telle connexion nécessite l'utilisation d'un commutateur ATM, ce qui rend difficile, voir quasi impossible le déploiement d'un telle solution.
2.2.3 - Interface Ethernet, L2TP sur IP et modem xDSL
La troisième solution est présentée dans le schéma suivant.
Cette architecture est plus « ouverte » dans la mesure où le lien entre le micro-ordinateur et l'équipement xDSL repose sur une technologie éprouvée : Ethernet. En effet, le modem xDSL dispose d'un banal
connecteur Ethernet qui peut être soit attaché directement à une carte Ethernet implantée dans le client PC (liaison à l'aide d'un câble « croisé » ou « droit » ), soit indirectement via un Hub (ou Switch) Ethernet. Le micro-ordinateur doit être configuré comme sur un réseau local d'entreprise (LAN : Local Area Network), c'est à dire : posséder un driver de carte réseau (NIC Ethernet), une pile de protocole TCP/IP, et une couche logicielle permettant la gestion de sessions PPP (pour la connexion à l'ISP). Cette topologie a l'avantage de permettre le partage de la connexion xDSL au travers d'un réseau. Autre
avantage d'un telle architecture : le coût peu élevé de l'équipement. A noter quand même les quelques inconvénients suivants :
Cette configuration n'intègre pas nativement ce qui est nécessaire au départ, à savoir un mécanisme de transport et de gestion de sessions PPP au travers d'Ethernet. L'utilisation d'un protocole de « tunneling » comme L2TP (ou PPTP) peut s'avérer un moyen pour assurer le transport de PPP sur IP, mais ajoute une complexité à la configuration.
Le modem xDSL doit, dans ce type de solution, posséder une adresse IP (configurable de préférence)
pour la communication au niveau du réseau Ethernet. Le client PC a donc quant à lui deux adresses IP : la première pour la connexion au réseau Ethernet (afin d'établir correctement le tunnel L2TP), la seconde pour la liaison PPP vers un ISP.
Quelles adresses IP utiliser pour établir le tunnel L2TP entre le client PC et le modem xDSL ? Une des réponses possibles à cette problématique est l'implantation et l'utilisation combinée de mécanismes comme NAT (Network Address Translation : translation d'adresses IP d'un réseau vers un autre)
etDHCP (attribution dynamique d'une adresse IP à un client, à partir de plages définies). Même si ces
techniques sont connues et maîtrisées dans le monde du réseau, elles sont loin d'être à la portée des utilisateurs finaux.
2.2.4 - Interface Ethernet, ATM sur BMAP et modem xDSL
La quatrième et dernière architecture proposée est la suivante.

Les inconvénients apportés par l'utilisation d'un protocole de « tunneling » comme L2TP pour transporter du PPP sur de l'Ethernet ont entraîné le développement d'un nouveau protocole baptisé BMAP (Broadband Modem Access Protocol). Dans l'approche qui est présentée sur le schéma ci-avant, la configuration reprend le principe de PPP sur ATM, mais le transport entre le client PC et le modem xDSL sur Ethernet, est assuré par ce protocole BMAP. La configuration de l'équipement xDSL est nettement simplifiée, mais cette solution
apporte d'autres inconvénients que ceux cités auparavant :
La pile de protocole au niveau du client PC est bien plus complexe que le modèle Dial-up standard. Alors que ce dernier consiste à adresser directement le modem analogique à partir du protocole PPP,
le modèle présenté ici introduit un réseau Ethernet et de l'ATM cohabitant avec du BMAP pour transporter le protocole PPP vers le modem xDSL. La complexité d'un telle configuration est donc une fois de plus mise en avant.
Concernant le partage de la connexion : la nature du protocole BMAP est telle que si plusieurs clients
PC veulent accéder au modem xDSL (donc à la même ligne) au même moment, un des micro-ordinateurs du réseau doit être défini pour fonctionner en mode passerelle, relayant ainsi le trafic des autres postes vers le modem. Cet aspect augmente encore le niveau de complexité de cette solution.
Pas ou peu d'équipement xDSL intègre la gestion du protocole BMAP. De plus, il n'y a pas encore de drivers BMAP disponibles pour les systèmes d'exploitations Windows.
2.2.5 - Conclusion
En conclusion de la présentation de ces quatre propositions, il apparaît chaque fois plus d'inconvénients que d'avantages. D'un côté la configuration à mettre en place est soit trop coûteuse ou soit trop complexe pour l'utilisateur final, d'un autre côté les équipements n'intègrent pas les fonctionnalités nécessaires. C'est pour
cette raison qu'aucune d'entre elles n'a été retenue.
2.3 - L'alternative PPPoE
La solution qui a été retenue a donné naissance à un nouveau protocole baptisé PPPoE : PPP over Ethernet. Comme son nom l'indique, cette technique repose sur le meilleur des deux mondes :
Le protocole PPP pour la communication avec un ISP au travers de l'architecture xDSL mise en place. Respectant un des objectifs majeurs initiaux, la solution se rapproche du modèle Dial-Up bien connu.
L'utilisateur final a déjà une connaissance de l'utilisation et de la configuration de ce mode de connexion.
La topologie Ethernet pour le partage du modem xDSL au travers d'un réseau local bâti autour de Hub (ou Switch) ou de rattachement direct au client PC dans lequel est implantée une carte d'interface Ethernet (NIC), s'appuyant ainsi sur un standard de l'industrie.
Le schéma suivant présente l'architecture PPPoE :

Le modem xDSL peut être préconfiguré par l'opérateur (CVP pour le lien opérateur), réduisant ainsi le temps d'installation d'une telle solution chez l'utilisateur final. Ce dernier n'a plus que quelques étapes à réaliser pour finaliser sa connexion « Haut débit » :
Implanter une carte d'interface Ethernet dans le ou les clients PC. Connecter la carte directement au modem xDSL ou sur un Hub Ethernet (dans le cas du partage de la connexion).
Installer le driver Ethernet de la carte correspondant au système d'exploitation du client
Installer le driver PPPoE qui fera le lien PPP entre le client et le modem xDSL.
Créer une connexion à un ISP de façon tout à fait classique.
Le résultat d'une demande de connexion est l'établissement d'une session PPP over Ethernet. Le modem xDSL joue un rôle de pont MAC/LLC qui se contente de faire transiter du flux PPP encapsulé dans des trames Ethernet d'un côté, vers du flux PPP circulant dans un CVP ATM sur support xDSL de l'autre. Le CVP ATM défini permet la connexion directe à un POP via la boucle locale « Haut débit ». Ce dernier doit être équipé de telle manière à
accepter des connexions PPP sur ce canal virtuel. L'ISP voit quand à lui arriver une demande de connexion PPP des plus classiques. Lors du partage de connexion, il n'est pas nécessaire de définir de CVP supplémentaires. En effet, le multiplexage de sessions PPP se réalise de manière transparente. Redback Networks est une des sociétés qui a activement participé à l'élaboration du protocole PPPoE. Elle propose un équipement complet pour les POP s'appuyant sur un serveur SMS1000.
Le schéma suivant résume une solution mettant en oeuvre PPPoE et le serveur de RedBack.

2.4 - Statut de PPP over Ethernet
Depuis son développement initial, PPPoE a été soumis en Août 1998 à l'IETF (Internet Engineering Task Force) comme Internet Draft. Une session BOF (Birds Of a Feather) a abouti à la mise à jour de l'Internet Draft initial.
Les sociétés qui ont participé à l'élaboration de PPPoE (RedBack Networks, UUNET, Routerware) ont demandé à
l'IETF d'inclure PPPoE dans les RFC (Request for Comment), proposition qui a été retenue et qui fait référence à la RFC 2516.
3 - Le protocole PPP
3.1 - Introduction
Le protocole Point à Point (PPP) propose une méthode standard pour le transport de datagrammes multi-protocoles sur une liaison simple point à point. PPP comprend trois composants principaux:
Une méthode pour encapsuler les datagrammes de plusieurs protocoles.
Un protocole de contrôle du lien "Link Control Protocol" (LCP) destiné à établir, configurer, et tester la liaison de données.
Une famille de protocoles de contrôle de réseau "Network Control Protocols" (NCPs) pour l'établissement et
la configuration de plusieurs protocoles de la couche "réseau".Dans notre cas nous n'utilisons que NCP/IP.
Nous présentons l'organisation et les méthodes utilisées par PPP, ainsi que l'encapsulation effectuée par ce protocole, un mécanisme extensible de négociation d'options spécifique à son utilisation capable de négocier une large gamme de paramètres de configuration et apportant des fonctions étendues de gestion. Dans cette présentation Nous étudierons les spécificités de son utilisation dans une cession de type PPPoE.
3.2 - Format de l'entête
La trame PPP est constituée d'un en-tête et d'un bloc de données. Cette encapsulation nécessite l'usage d'un tramage dont le but principal est d'indiquer le début et la fin de l'encapsulation. Les champs ci-dessous sont toujours transmis de gauche à droite.

Flag - Indicateur de début ou fin de trame (Valeur = 01111110).
Adresse - Adresse de broadcast standard (Valeur = 11111111), car PPP n'attribue pas d'adresse d'hôte (Couche 2).
Contrôle - Fourniture d'un service non orienté connexion (semblable au LLC) (Valeur = 00000011).
Protocole - Identification du protocole encapsulé (LCP=Cxxx, NCP=8xxx,Protocole de niveau 3=0xxx).
Code Protocole
8021 IP
8023 OSI
8025 XNS, Vines
8027 DECnet
8029 AT
8031 Bridge
Données - Contient soit la valeur zéro, soit des données (1500 octets maximum).
FCS - Séquence de contrôle de trame pour une vérification des erreurs.
3.3 - Etablissement d'une connexion
Pour établir une connexion sur un lien Point à Point, chaque extrémité doit dans un premier temps émettre des paquets LCP pour configurer et tester le support de liaison.
Ensuite, PPP envoie des paquets NCP pour choisir et configurer un ou plusieurs protocoles réseau disponibles. Une fois ces protocoles configurés, les datagrammes peuvent être envoyés sur la liaison. Celle-ci reste disponible jusqu'à ce que des paquets LCP ou NCP spécifiques ne la ferment explicitement.

Dead - Une communication débute et se termine nécessairement dans cet état. Le passage à la phase d'établissement s'effectue lorsque le niveau physique est prêt à accueillir la connexion.
Etablissement - Grâce au protocole LCP, les équipements distants s'échangent des paquets de configuration par l'intermédiaire desquels ils négocient les paramètres de la connexion. Au cours de cette phase, tout paquet non-LCP est ignoré.
Authentification - Par défaut, l'authentification n'est pas demandée mais sur certaines liaisons, elle peut
être indispensable. Dans ce cas, c'est lors de la phase d'établissement que le protocole d'authentification doit être spécifié.
Connexion - le protocole réseau utilisé (IP, IPX ou Apple Talk) doit être configuré via le protocole NCP. Le trafic sur le lien peut alors avoir lieu.
Fin - la fermeture de la liaison peut survenir suite à plusieurs événements comme la perte de la porteuse, la chute d'une temporisation d'attente ou plus fréquemment suite à la demande d'un utilisateur.
Voici un exemple appliqué dans le cadre d'une connexion d'un internaute à un provider:
3.4 - LCP - Link Control Protocol
LCP transporte les paquets permettant d'établir, de maintenir et de terminer PPP. Pour l'établissement de PPP, il
faut négocier de paramètres de fonctionnement. LCP gère les options PPP indépendantes des protocoles de la couche réseau. Les premiers paquets envoyés par les extrémités PPP négocient les options configurables au début d'une connexion. Il existe trois classes de paquets LCP :

Les paquets de Configuration de Liaison utilisés pour établir et configurer une communication (Requête-Configuration, Configuration-Acquittée, Configuration-NonAcquittée et Configuration-Rejetée).
Les paquets de Fermeture de Liaison utilisés pour couper une communication (Requête-Fermeture et
Fermeture-Acquittée).
Les paquets de Maintenance de Liaison utilisés pour gérer et déterminer une liaison (Code-Rejeté, Protocole-Rejeté, Requête-Echo, Réponse-Echo, et Requête-Elimination).
Lorsque le champ Protocole du paquet PPP indique une valeur hexadécimale c021 (Link Control Protocol). Format
d'un paquet LCP :
Code - Le champ Code comporte un octet, et identifie le type de paquet LCP.
Valeur Nom Signification
1 Configure-Request Départ de la connexion, définie et négocie la configuration
2 Configure-Ack Accusé de la réception d'un Configure-Request
3 Configure-Nak Réponse négative à la réception d'un Configure-Request
4 Configure-Reject Options de configurations non reconnaissables
5 Terminate-Request Fermeture de la connexion
6 Terminate-Ack Accusé de la réception d'un Terminate-Request
7 Code-Reject Code reçu inconnu
Identificateur - Le champ Identificateur comporte un octet, et fournit un moyen d'associer requêtes et réponses. Lorsqu'un paquet présente un Identificateur invalide, il est ignoré sans affecter l'automate.
Longueur - Le champ Longueur comporte deux octets, et donne la longueur du paquet LCP, y compris l'octet de Code, d'Identificateur, le champ Longueur lui-même et le champ Données. La longueur ne doit pas excéder l'U R M de la liaison.
Données - Le champ Données comporte zéro ou un nombre quelconque d'octets, selon l'indication du champ Longueur. Le format interne du champ Données dépend de la valeur présente dans le champ Code.
Options de LCP pour PPPoE:
Recommandé : numéro magique, MRU (<=1492 Octets).
Non recommandé : Compression des champs (PFC).

Non utilisation : Vérification du séquencement des champs (FCS), Compression des champs adresse et contrôle (ACFD); Table des caractères de contrôle asynchrones (ACCM).
3.5 - NCP - Network Control Protocols
L'état réseau d'une connexion PPP suit soit l'état d'authentification, soit l'état d'établissement. A ce stade, LCP a déjà établi toutes les options de PPP. La connexion est active et presque prête à transporter les données de l'utilisateur. Le NCP configure les protocoles de la couche réseau que la connexion PPP va transporter (IP pour PPPoE). Il existe trois classes de paquets NCP :
Les paquets de Configuration, utilisés pour établir et configurer une communication (Requête-Configuration, Configuration-Acquittée, Configuration-NonAcquittée et Configuration-Rejetée).
Les paquets de Fermeture, utilisés pour couper une communication (Requête-Fermeture et Fermeture-Acquittée).
Le paquet erreur (Code-Rejeté).
Détail du paquet NCP :
Code - Le champ Code comporte un octet, et identifie le type de paquet NCP.
Valeur Nom Signification
1 Configure-Request Départ de la connexion, définie et négocie la configuration
2 Configure-Ack Accusé de la réception d'un Configure-Request
3 Configure-Nak Réponse négative à la réception d'un Configure-Request
4 Configure-Reject Options de configurations non reconnaissables
5 Terminate-Request Fermeture de la connexion
6 Terminate-Ack Accusé de la réception d'un Terminate-Request
7 Code-Reject Code reçue inconnue
8 Protocol-Reject Réception avec une valeur de protocole inconnu
9 Echo-Request Loopback pour la détermination de la qualité du lien
10 Echo-Reply Réponse au Echo-Request
11 Discard-Request Ignore la requête reçue
Identificateur - Le champ Identificateur comporte un octet, et fournit un moyen d'associer requêtes et réponses. Lorsqu'un paquet présente un Identificateur invalide, il est ignoré sans affecter l'automate.

Longueur - Le champ Longueur comporte deux octets, et donne la longueur du paquet NCP.
Données - Le champ Données comporte zéro ou un nombre quelconque d'octets, selon l'indication du champ Longueur. Le format interne du champ Données dépend de la valeur présente dans le champ Code.
3.6 - Authentification
PPP peut supporter les opérations d'authentifications au début d'une connexion. L'état d'authentification fait suite à l'état d'établissement si l'une ou l'autre des extrémités est d'accord pour
utiliser un protocole d'authentification. La négociation de cette option s'effectue lors de la montée du niveau LCP. Les deux protocoles d'authentifications :
Password Authentication Protocol (PAP) - PAP implémente la méthode traditionnelle avec l'utilisation d'un nom d'utilisateur et d'un mot de passe. Sur demande d'un authentificateur , le récepteur répond avec le nom et le mot de passe, l'authentificateur valide l'information et envoie un accusé de réception positif ou négatif.
Challenge Handshake Authentification Protocol (CHAP) - CHAP implémente une authentification utilisant un
nom d'utilisateur et une chaîne aléatoire CHAP. L'authentificateur envoie son nom et sa chaîne aléatoire, le récepteur transforme cette chaîne par un algorithme de calcul et une clé CHAP secrète. Il envoie ensuite le résultat avec son propre nom, l'authentificateur compare la réponse avec sa propre copie de la clé secrète. Enfin, il envoie un accusé de réception indiquant un échec ou un succès.
4 - Le protocole PPPoE
4.1 - Introduction
Les technologies d'accès modernes font face à quelques problèmes et buts contradictoires. Il est souhaitable de connecter des hôtes multiples à un site distant à travers un même dispositif d'accès client. Un autre but est de fournir un contrôle d'accès et facturer selon la même méthode que celle utilisée par PPP sur réseau commuté. Dans beaucoup de technologies d'accès, la méthode la plus avantageuse financièrement pour rattacher des hôtes multiples à un dispositif d'accès client est l'utilisation d'Ethernet. Enfin, la minimisation des coûts est importante ; il faut utiliser la plus petite configuration possible ou mieux aucune configuration.
PPP sur Ethernet (PPPoE) fournit la capacité de connecter un réseau d'hôtes vers un concentrateur d'accès distant à travers un simple dispositif d'accès ponté. Avec ce modèle, chaque hôte utilise sa propre pile PPP et l'utilisateur garde une interface familière. Le contrôle d'accès, la facturation et les autres services peuvent être réalisés par un utilisateur final plutôt que par un site final (la base).
Pour fournir une connexion point à point à travers Ethernet, chaque session PPP doit apprendre l'adresse Ethernet de la machine distante afin d'établir et d'identifier une session unique. PPPoE inclut donc un protocole de découverte.
4.2 - L'histoire
Ce document présente le protocole de communication baptisé PPPoE (Point to Point over Ethernet) permettant de véhiculer du flux PPP (Point to Point Protocol) encapsulé dans des trames Ethernet. Cette technologie (1998-99) est née d'un travail conjoint de UUNET Technologies Inc., RedBack Networks Inc., et RouterWare Inc. Elle fait
l'objet de la Rfc 2516 qui sera décrite au cours de l'étude du protocole PPPoE, suivi d'une traduction en français.
4.3 - Format de l'entête

L'entête pour PPPoE se définie comme suit :
Version - 4 bits qui doivent être à la valeur 0x1 pour cette version de la spécification PPPoE.
Type - 4 bits qui doivent être à la valeur 0x1 pour cette version de la spécification PPPoE.
Code - 8 bits définis plus bas pour l'étape de découverte et l'étape de la session PPP.
Id - Valeur non signée sur 16 bits. C'est la valeur définie lors de l'étape de la découverte. Cette valeur est fixée pour une session PPP donnée entre l'adresse Ethernet source et l'adresse Ethernet destination. La
valeur 0xffff est réservée pour un usage futur et ne doit pas être utilisée.
Longueur - 16 bits indiquant la longueur de la charge utile PPPoE. Cela n'inclut pas la longueur des en-têtes Ethernet ou PPPoE.
Voilà comment l'entête Ethernet spécifie l'intégration de PPP
Adresse de destination - Ce champs, basé sur 6 octets contient soit une adresse Ethernet unicast soit une broadcast (0xFFFFFFFFFFFF). Pour les paquets de découverte, la valeur peux être soit unicast soit
broadcast. Pour le trafic de session PPP, ce champ doit contenir l'adresse unicast du peer distant qui a été déterminée lors de l'étape Découverte.
Adresse source - Ce champs, basé sur 6 octets, doit contenir l'adresse MAC de l'équipement source.

Type Ethernet - Ce champ codé sur 16 bits doit être configuré à 0x8863 pour l'étape Découverte et 0x8864 pour la session PPP.
CRC - Ce champ permet en 4 octets de valider la conformité de la trame.
4.4 - Les étapes
PPPoE est composé de deux étapes distinctes : la découverte et la session PPP. Quand un hôte veut initier une session PPPoE, il doit tout d'abord lancer une requête de découverte afin d'identifier l'adresse Ethernet MAC de son vis à vis puis définir un identificateur de session PPPoE. Alors que PPP définit une liaison de bout en bout, la
phase de découverte correspond à un rapport client-serveur. Lors du processus de découverte, un hôte (le client) découvre un concentrateur d'accès (le serveur). Selon la topologie du réseau, il peut y avoir plus d'un concentrateur d'accès avec lequel l'hôte peut communiquer. L'étape de la découverte permet à l'hôte de découvrir tous les concentrateurs d'accès et d'en sélectionner un. Quand la découverte s'achève avec succès, l'hôte et le concentrateur d'accès sélectionné possèdent les informations qu'ils emploieront pour construire leur connexion point à point sur Ethernet.
L'étape de la découverte attend alors jusqu'à ce qu'une session PPP soit établie. Une fois qu'une session PPP est établie, l'hôte et le concentrateur d'accès doivent allouer les ressources pour une interface virtuelle PPP.
4.4.1 - Découverte
L'étape de découverte s'effectue en quatre temps. Quand elle s'achève, chaque vis à vis connaît l'identificateur de session PPPoE ainsi que les adresses Ethernet des extrémités; cela suffit pour définir une session PPPoE. Les étapes sont :
Emission par diffusion d'un paquet d'initialisation par l'hôte.
Emission de paquets d'offres par un ou plusieurs concentrateurs d'accès.
Emission adressée d'un paquet de demande de session par l'hôte.
Emission d'un paquet de confirmation par le concentrateur d'accès sélectionné.
Quand l'hôte reçoit le paquet de confirmation, il peut passer à l'étape suivante : la session PPP. Toutes les trames de découvertes Ethernet ont la valeur 0x8863 dans le champ « Type Ethernet ». La charge utile PPPoE contient zéro ou plusieurs TAGs. Un TAG est un ensemble type-longueur-valeur (TLV) construit et défini comme suit :
Type - 16 bits. L'annexe A contient une liste de tous les types et de leurs valeurs.
Longueur - Valeur non-signée sur 16 bits indiquant en octets la longueur de « Valeur ».
Si un paquet de découverte est reçu avec un TAG de type inconnu, il doit être ignoré à moins qu'il n'en soit spécifié autrement dans ce document. Ceci fournira une compatibilité ascendante lorsque de nouveaux TAGs seront ajoutés. Lorsque de nouveaux TAGs indispensables seront ajoutés, le numéro de version sera incrémenté. Voici un exemple appliqué dans le cadre de l'ADSL. En effet lors de connexion PPPoE, le client pourra choisir
l'équipement de connexion pour soit aller vers son provider, soit vers un serveur multicast ou établir deux
sessions simultanées.

Le paquet de découverte « Initialisation » (PADI)
Les hôtes envoient le paquet PADI (PPPoE Active Discovery Initition) en plaçant l'adresse de diffusion dans le
champ « Adresse de destination ». Le champ « Code » contient 0x09 et le champ « Identificateur de session » contient 0x0000. Le paquet PADI doit contenir un TAG de type « Nom du service » indiquant le service que l'hôte demande ainsi qu'un nombre quelconque de TAGs d'autres types. Un paquet PADI entier (incluant l'en-
tête PPPoE) ne doit pas dépasser 1484 octets afin de laisser la place suffisante pour qu'un agent relais puissent ajouter un TAG « Identificateur de session relais ».
Le paquet de découverte « Offre » (PADO)
Quand le concentrateur d'accès reçoit un PADI qu'il peut servir, il répond en envoyant un paquet PADO (PPPoE Active Discovery Offer). L'adresse de destination est l'adresse de l'hôte telle qu'envoyée dans le PADI. Le champ « Code » est fixé à 0x07 et le champ « Identificateur de session » à 0x0000. Le paquet PADO doit contenir exactement un TAG « Concentrateur d'accès-Nom » contenant le nom du concentrateur d'accès, un TAG « Nom du service » identique à celui contenu dans le PADI et un nombre quelconque d'autres TAGs «
Nom du service » indiquant les autres services offerts par le concentrateur d'accès. Si le concentrateur d'accès ne peut pas servir le PADI, il ne doit pas répondre avec un PADO.

Le paquet de découverte « Requête » (PADR)
Puisque le PADI a été envoyé en diffusion, l'hôte peut recevoir plusieurs PADO. L'hôte examine les paquets PADO reçus et en choisit un. Le choix peut être basé sur le nom du concentrateur d'accès ou sur les services offerts. L'hôte envoie alors un paquet PADR (PPPoE Active Discovery Request) au concentrateur d'accès
sélectionné. Le champ « Adresse de destination » est l'adresse Ethernet du concentrateur d'accès qui a été envoyée par le PADO. Le champ « Code » contient 0x19 et le champ « Identificateur de session » la valeur
0x0000. Le paquet PADR doit contenir exactement un TAG de type « Nom du service » indiquant le nom du service que l'hôte a demandé et un nombre quelconque de TAGs d'autres types.
Le paquet de découverte « Confirmation de session » (PADS)
Quand le concentrateur d'accès reçoit un paquet PADR, il se prépare à commencer une session PPP. Il génère un identificateur de session unique pour la session PPPoE et répond à l'hôte avec un paquet PADS (PPPoE Active Discovery Session-confirmation). Le champ « Adresse de destination » est l'adresse Ethernet de l'hôte qui a envoyé le PADR. Le champ « Code » contient 0x65 et le champ « Identificateur de session » doit être mis à la valeur unique générée pour cette session PPPOE. Le paquet PADS contient exactement un TAG de
type « Nom du service » indiquant le nom du service sous lequel le concentrateur d'accès a accepté la session PPPoE et un nombre quelconque de TAGs d'autres types. Si le concentrateur d'accès n'accepte pas le service proposé dans le PADR, il doit répondre avec un PADS contenant un TAG de type « Nom du service-Erreur ». (et un nombre quelconque de TAGs d'autres types). Dans ce cas le champ « Identificateur de session » doit contenir 0x0000.

Le paquet de découverte « Terminaison » (PADT)
Ce paquet peut être envoyé à n'importe quel moment après qu'une session ait été établie pour indiquer que
la session PPPoE est terminée. Il peut être envoyé soit par l'hôte, soit par le concentrateur d'accès. Le champ « Adresse de destination » est une adresse Ethernet fixée, le champ « Code » contient 0xa7 et le champ «
Identificateur de session » doit indiquer quelle session se termine. Aucun TAG n'est nécessaire. Quand un paquet PADT (PPPoE Active Discovery Terminate) est reçu, aucun autre trafic PPP utilisant cette session ne peut être envoyé. Même les paquets normalement utilisés pour terminer une session PPP ne doivent pas être envoyés après réception d'un PADT. Une extrémité PPP devrait utiliser le protocole PPP lui-même pour arrêter
une session PPPoE, mais le paquet PADT peut être utilisé quand PPP ne le peut pas.
4.4.2 - Session PPP
Une fois que la session PPPoE est ouverte, les données PPP sont envoyées comme dans n'importe quelle autre encapsulation PPP. Tous les paquets Ethernet contiennent une adresse fixe. Le champ « Type Ethernet » vaut 0x8864. Le champ « Code » de PPPoE doit contenir 0x00. Le champ « Identificateur de session » ne doit pas changer pour cette session PPPoE et doit être à la même valeur que celle assignée lors de l'étape de découverte. La charge utile PPPoE contient une trame PPP. La trame commence avec l'identificateur de protocole de PPP.

Quand un hôte ne reçoit pas de paquet PADO au bout d'un laps de temps déterminé, il doit renvoyer le paquet PADI et doubler la période d'attente. Cela peut se répéter autant de fois que souhaité et désiré. Si l'hôte attend pour recevoir un paquet PADS, un mécanisme similaire de temps mort doit être employé, avec l'hôte renvoyant le PADR. Après un nombre déterminé d'essais, l'hôte doit alors renvoyer un paquet PADI. Les valeurs du champ « Type Ethernet » employées dans ce document (0x8863 et 0x8864) ont été assignées par l'IEEE pour l'utilisation de PPPoE. L'utilisation de ces valeurs et le champ « Version » sont les seuls identifiants du protocole.
4.5 - Sécurité
Afin de se protéger contre d'éventuels actes de piratage, le point d'accès (AC : Access Concentrator) peut utiliser le TAG AC-Cookie. Ce dernier doit être en effet capable de générer de manière unique une valeur de TAG basée
sur l'adresse MAC source d'une requête PADR, identifiant l'hôte émetteur. Cet identifiant permettra ainsi au point d'accès de limiter le nombre de sessions simultanées pour un hôte donné. L'algorithme utilisé pour la génération d'un identifiant unique à partir de l'adresse MAC est laissé au choix des constructeurs (détail d'implémentation). L'algorithme HMAC (Keyed-Hashing for Message Authentication) peut par exemple être mis en place. Il nécessite
une clé privée qui n'est connue que du point d'accès. Attention toutefois à l'utilisation du TAG AC-Cookie, car il est une méthode de protection contre certaines attaques, mais il n'offre pas une garantie de sécurité totale. Certains point d'accès ne souhaitent pas forcément diffuser l'ensemble des services qu'ils implémentent à des hôtes non authentifiés. Dans ce cas, deux stratégies peuvent être employées :
Ne jamais refuser une requête basée sur le TAG Service-Name, et toujours lui retourner la valeur du service demandé. Il y a donc correspondance entre le service demandé et le service retourné à l'hôte
émetteur.
N'accepter que les requêtes Service-Name ayant une longueur de TAG nulle (indiquant n'importe quel service). L'hôte émetteur et le point d'accès connaissent déjà le type de service utilisé pour cette session. L'information sur le service ne circule donc plus sur le réseau.
5 - Le protocole L2TP
5.1 - Introduction
L2TP a été conçu pour transporter des sessions PPP au travers d'un réseau IP, et de terminer physiquement les
sessions PPP en un point de concentration déterminé dans le réseau. Le protocole L2TP (Layer 2 Tunneling Protocol), développé à partir du protocole point à point PPP, est sans conteste l'une des pierres angulaires des réseaux privés virtuels d'accès. Il rassemble en effet les avantages de
deux autres protocoles L2F et PPTP. L2TP est une norme préliminaire de l'IETF (Engineering Task Force) actuellement développée et évaluée conjointement par Cisco Systems, Microsoft, Ascend, 3Com et d'autres acteurs clés du marché des réseaux. Le protocole L2TP est un protocole réseau qui encapsule des trames PPP pour les envoyer sur des réseaux IP, X25, relais de trames ou ATM. Lorsqu'il est configuré pour transporter les données sur IP, le protocole L2TP peut être utilisé pour faire du tunnelling sur Internet. Dans ce cas, le protocole L2TP transporte des trames PPP dans
des paquets IP. La maintenance du tunnel est assurée à l'aide de messages de commandes au format L2TP tandis que le protocole UDP est utilisé pour envoyer les trames PPP au sein de trames L2TP.
5.2 - Format de l'entête

T - 1 bit indiquant le type de message. 0 si c'est un message de données, 1 si c'est un message de contrôle.
L - 1 bit qui positionné à 1, indique la présence du champ longueur. Ce bit doit être mis à 1 dans les messages de contrôle.
0 - 2 bits réservés pour des extensions futures. Pour l'instant ces bits sont mis à 0 et ignorés.
S - 1 bit qui positionné à 1 indique la présence des champs Ns et Nr. Ce bit doit être à 1 dans les messages de contrôle.
0 - 1 bit réservé pour des extensions futures. Pour l'instant ce bit est mis à 0 et ignoré.
O - 1 bit qui positionné à 1, indique la présence du champ Offset Size. Ce bit doit être à 0 pour les messages de contrôle.
P - 1 bit qui positionné à 1, considère ce message comme prioritaire. Exemple : messages LCP echo request utilisés par les extrémités PPP pour le maintien de la session PPP.
0 - 4 bits réservés pour des extensions futures. Pour l'instant ces bits sont mis à 0 et ignorés.
Version - 4 bits indique la version du tunnel employé. Il doit être à 2 pour le L2TP RFC 2661. La valeur 1
représenterait un paquets L2F.
Longueur - 16 bits. Ce champ est optionnel et représente la longueur totale du message en octet. Ce champ n'existe que si le flag L est positionné à 1.
Tunnel ID - 16 bits représentant l'identifiant du tunnel, qui a une signification locale. Le Tunnel ID d'un message est celui du destinataire.
Session ID - 16 bits représentant l'identification pour une session dans un tunnel. La signification est également purement locale. La session ID d'un message est celui du destinataire.
Ns - 16 bits correspondant au numéro de séquence pour ce message.
Nr - 16 bits correspondant au numéro de séquence attendu lors de la réception du prochain message.
Offset Size - 16 bits représentant la longueur de la fin de l'entête L2TP.
5.3 - Les concentrateurs d'accès - LAC
Les concentrateurs d'accès L2TP, signifiant L2TP Access Concentrateur (LAC), peuvent être intégrés à la structure d'un réseau commuté comme le réseau téléphonique commuté (RTC) ou encore associés à un système

d'extrémité PPP prenant en charge le protocole L2TP. Le rôle du concentrateur d'accès LAC se limite à fournir un support physique qui sera utilisé par L2TP pour transférer le trafic vers un ou plusieurs serveurs réseau L2TP (LNS). Il assure le fractionnement en canaux pour tout protocole basé sur PPP. Le concentrateur d'accès LAC joue le rôle de serveur d'accès, il est à l'origine du
tunnel et est responsable de l'identification du VPN.
5.4 - Les serveurs réseau - LNS
Les serveurs réseau L2TP, signifiant L2tp Network Server (LNS), peuvent fonctionner sur toute plate-forme prenant en charge la terminaison PPP. Les serveurs réseaux L2TP gèrent le protocole L2TP côté serveur. Les serveurs LNS sont les émetteurs des appels sortants et les destinataires des appels entrants. Ils sont responsables de l'authentification du tunnel.
5.5 - Avantages et inconvénients
L2TP repose sur UDP qui lui même repose sur IP. Au total, l'empilement total des couches protocolaires est le suivant (en partant du backbone) : IP/PPP/L2TP/UDP/IP/Couche2. A cela se rajoutent TCP/HTTP si l'utilisateur
surfe sur le web. L'ensemble n'est donc pas très léger, et une attention particulière doit être portée sur ce qui est de l'accordement de MRU (pour PPP) avec la MTU de tous les équipements IP traversés, de telle façon à éliminer la fragmentation sur les paquets de grande taille. L'overhead représente donc l'inconvénient de L2TP. L2TP permettant de terminer des sessions PPP n'importe où. Cela permet à un opérateur ou plus généralement au propriétaire d'un réseau d'accès (boucle locale) de collecter pour le compte d'un tiers des connexions et de lui laisser le soin de terminer les sessions PPP associées. C'est vraiment la fonction VPN de L2TP : permettre à un
utilisateur mobile de se connecter à un réseau particulier, éventuellement privé, tout en utilisant une infrastructure publique et partagée. Ainsi un salarié d'une entreprise peut être sûr de se connecter à un VPN particulier de son entreprise (correspondant à son groupe de travail), quelque soit le POP de son entreprise auquel il se connecte. Il peut ainsi conserver les droits, et les restrictions définies par son profil. Les concepts de mobilité
et de Wholesale représentent donc les avantages de L2TP.
6 - L'architecture PPP - L2TP
6.1 - Architecture IP
Voici l'architecture PPP transporté sur un réseau d'infrastructure IP via L2TP :
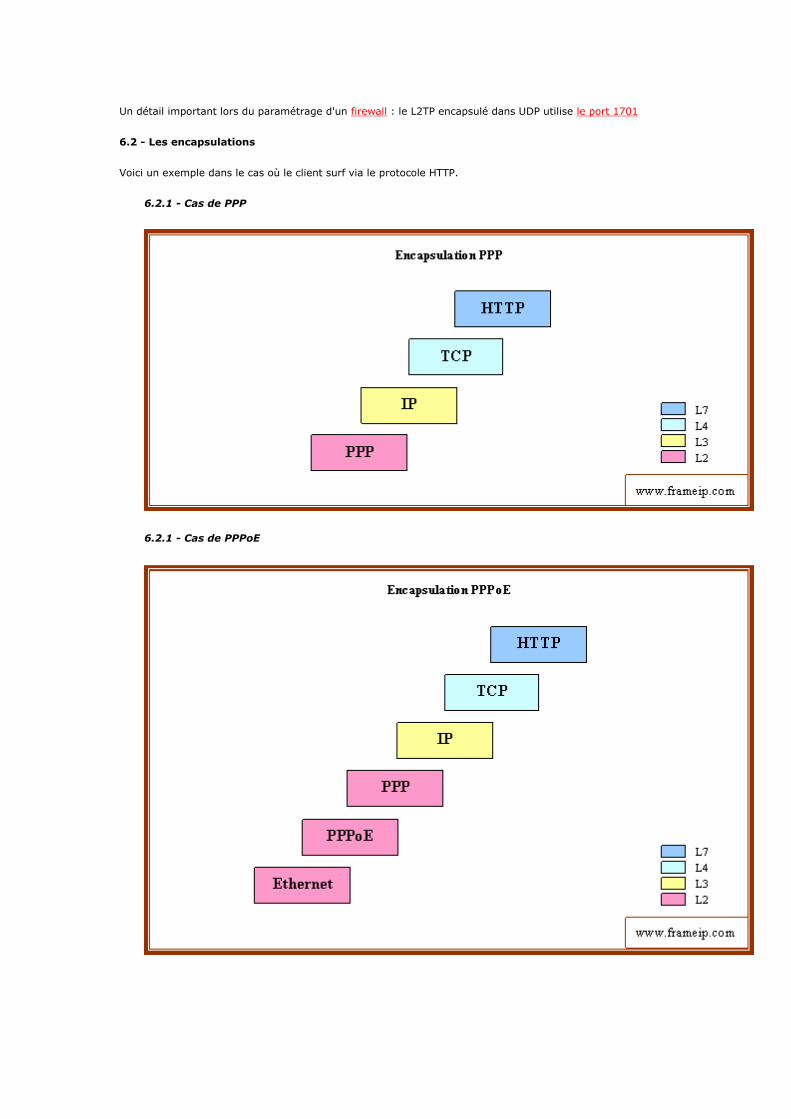
Un détail important lors du paramétrage d'un firewall : le L2TP encapsulé dans UDP utilise le port 1701
6.2 - Les encapsulations
Voici un exemple dans le cas où le client surf via le protocole HTTP.
6.2.1 - Cas de PPP
6.2.1 - Cas de PPPoE

6.2.1 - Cas de L2TP
6.3 - Les tailles maximums de l'OverHead
6.3.1 - Cas de PPP
OverHead = PPP
La surcouche des entêtes est donc de 8 octets. Voici la représentation en pourcentage dans le cadre de paquet non fragmenté :
Taille de datagramme Pourcentage relatif
70 11,4 %
1300 0,6 %
1500 0,5 %
6.3.2 - Cas de PPPoE
OverHead = PPP + PPPoE La surcouche des entêtes est donc de 8+6=14 octets. Voici la représentation en pourcentage dans le cadre de paquet non fragmenté :
Taille de datagramme Pourcentage relatif

70 20 %
1300 1,1 %
1500 0,9 %
6.3.2 - Cas de L2TP
OverHead = PPP + L2TP + UDP + IP
La surcouche des entêtes est donc de 8+6+8+20=42 octets. Voici la représentation en pourcentage dans le cadre de paquet non fragmenté :
Taille de datagramme Pourcentage relatif
70 60 %
1300 3,2 %
1500 2,8 %
6.4 - Problématique liée au MTU
Si l'infrastructure de l'opérateur est basée sur Ethernet, alors un Overhead de 42 octets demande une gestion de
trame Ethernet de 1518+42 soit 1560 octets pour ne pas fragmenter. Je ne compte pas en plus si cette infrastructure Ethernet gère les VLAN. L'utilisation de la VOIP devient dans ce cadre assez difficile à maîtriser.
Mpls
1 - Introduction à MPLS 2 - MPLS: Objectifs et Missions 3 - Le routage classique 4 - La commutation de labels 5 - Principes MPLS
6 - Label 7 - Implicit Routing (LDP) 8 - Explicit Routing 9 - Support de la QoS 9.1 - Signalisation et QoS 9.2 - Routage et QoS 9.3 - Architecture pour la QoS
10 - VPN 11 - Traffic Engineering 12 - Agrégation de flux 13 - Applications 14 - Discussion autour de la documentation 15 - Suivi du document
1 - Introduction à MPLS
MPLS (Multi-Protocol Label Switching) est une technique réseau en cours de normalisation à l'IETF dont le rôle principal est de combiner les concepts du routage IP de niveau 3, et les mécanismes de la commutation de niveau 2 telles que implémentée dans ATM ou Frame Relay. MPLS doit permettre d'améliorer le rapport performance/prix des équipements de routage, d'améliorer l'efficacité du routage (en particulier pour les grands réseaux) et d'enrichir les services de
routage (les nouveaux services étant transparents pour les mécanismes de commutation de label, ils peuvent être déployés sans modification sur le coeur du réseau). Les efforts de l'IETF portent aujourd'hui sur Ipv4. Cependant, la technique MPLS peut être étendue à de multiples protocoles (IPv6, IPX, AppleTalk, etc,). MPLS n'est en aucune façon restreint à une couche 2 spécifique et peut fonctionner sur tous les types de support permettant l'acheminement de paquets de niveau 3.
MPLS traite la commutation en mode connecté (basé sur les labels); les tables de commutation étant calculées à partir d'informations provenant des protocoles de routage IP ainsi que de protocoles de contrôle. MPLS peut être considéré comme une interface apportant à IP le mode connecté et qui utilise les services de niveau 2 (PPP, ATM, Ethernet, ATM, Frame Relay, SDH ...).

La technique MPLS a été voulue par l'IETF relativement simple mais très modulaire et très efficace. Certains points clé sont maintenant mis en avant par l'IETF et par certains grands constructeurs dominés par Cisco, ainsi que par les fournisseurs de services aux premiers desquels se trouvent les opérateurs de réseaux. Un grand effort pour aboutir à une normalisation a été consentie par les différents acteurs, ce qui semble mener à une révolution des réseaux IP.
2 - MPLS: Objectifs et Missions
L'un des objectifs initiaux était d'accroître la vitesse du traitement des datagrammes dans l'ensemble des équipements intermédiaires. Cette volonté, avec l'introduction des gigarouteurs, est désormais passée au second plan. Depuis, l'aspect "fonctionnalité" a largement pris le dessus sur l'aspect "performance", avec notamment les motivations suivantes :
Intégration IP/ATM
Création de VPN
Flexibilité : possibilité d'utiliser plusieurs types de media (ATM, FR, Ethernet, PPP, SDH).
Differential Services (DiffServ)
Routage multicast
MPLS pourra assurer une transition facile vers l'Internet optique. MPLS n'étant pas lié à une technique de niveau 2 particulière, il peut être déployé sur des infrastructures hétérogènes (Ethernet, ATM, SDH, etc.). Avec la prise en charge de la gestion de contraintes molles et dures sur la qualité de service (DiffServ, Cisco Guaranteed Bandwidth). Avec la possibilité d'utiliser simultanément plusieurs protocoles de contrôle, MPLS peut faciliter
l'utilisation de réseaux optiques en fonctionnant directement sur WDM.
Traffic Engineering permettant de définir des chemins de routage explicites dans les réseaux IP (avec RSVP ou CR-LDP). L'ingénierie des flux est la faculté de pouvoir gérer les flux de données transportés au dessus d'une infrastructure réseau. Aujourd'hui, cette ingénierie des flux est essentiellement faite à l'aide d'ATM, avec comme conséquence une grande complexité de gestion (en effet IP et ATM sont deux techniques réseaux totalement différentes, avec parfois des contraintes non compatibles). Avec l'intégration de cette fonctionnalité, MPLS va permettre une simplification radicale des réseaux.
Les labels peuvent être associés à un chemin, une destination, une source, une application, un critère de qualité de service, etc. ou une combinaison de ces différents éléments. Autrement dit, le routage IP est considérablement enrichi sans pour autant voir ses performances dégradées (à partir du moment ou un datagrame est encapsulé, il est acheminé en utilisant les mécanismes de commutation de niveau 2). On peut imaginer qu'un des services les plus importants sera la possibilité de créer des réseaux privés virtuels (VPN) de niveau 3. Ainsi, des services de voix sur IP, de multicast ou d'hébergement de serveurs web pourront coexister sur une même infrastructure. La modularité de
MPLS et la granularité des labels permettent tous les niveaux d'abstraction envisageables.
3 - Le routage classique
IP est un protocole de niveau réseau fonctionnant dans un mode non connecté, c'est-à-dire que l'ensemble des paquets (ou datagrammes) constituant le message sont indépendants les uns des autres : les paquets d'un même message peuvent donc emprunter des chemins différents utilisant des protocoles IGP (interior gateway protocol), tels que RIP
(routing information protocol) de type "Vecteur de distance", et OSPF (open shortest path first) de type "Etat de liens"
, ou bien des protocoles EGP (exterior gateway protocol), tel que BGP (border gateway protocol). Chaque routeur maintient une table de routage, dans laquelle chaque ligne contient un réseau de destination, un port de sortie, et le prochain routeur relaie vers ce réseau de destination.

A la réception d'un datagramme, les noeuds intermédiaires (ou routeurs) déterminent le prochain relais (ou next-hop) le plus approprié pour que le paquet rallie sa destination. Ensuite l'adresse mac destination (niveau 2 du model OSI) du datagramme est remplacée par l'adresse mac du routeur relaie (ou next-hop), et l'adresse mac source du datagramme est remplacée par l'adresse mac du routeur courant, laissant sans changement les adresses ip (niveau 3 du model OSI) du datagramme afin que le prochain routeur effectue les même opérations sur le paquet pour les sauts suivants. Ce calcul fastidieux est effectué sur tous les datagrammes d'un même flux, et cela autant de fois qu'il y a de routeurs
intermédiaires à traverser. Il est donc gourmand en terme de ressource machine. Le mode non connecté du protocole IP, qui était initialement l'un de ses atouts, en particulier pour sa scalabilité, est devenu aujourd'hui un frein à son évolution.
4 - La commutation de labels
Lorsqu'un paquet arrive dans un réseau MPLS (1). En fonction de la FEC auquelle appartient le paquet, l'ingress node
consulte sa table de commutation (2) et affecte un label au paquet (3), et le transmet au LSR suivant (4).

Lorsque le paquet MPLS arrive sur un LSR [1] interne du nuage MPLS, le protocole de routage fonctionnant sur cet équipement détermine dans la base de données des labels LIB (Label Base Information), le prochain label à appliquer à
ce paquet pour qu'il parvienne jusqu'à sa destination [2]. L'équipement procède ensuite à une mise à jour de l'en-tête
MPLS (swapping du label et mise à jour du champ TTL, du bit S) [3], avant de l'envoyer au noeud suivant (LSR ou l'egress node) [4]. Il faut bien noter que sur un LSR interne, le protocole de routage de la couche réseau n'est jamais sollicité.
Enfin, une fois que le paquet MPLS arrive à l'egress node [1], l'équipement lui retire toute trace MPLS [2] et le
transmet à la couche réseau.

5 - Principes MPLS
Basée sur la permutation d'étiquettes, un mécanisme de transfert simple offre des possibilités de nouveaux paradigmes de contrôle et de nouvelles applications. Au niveau d'un LSR (Label Switch Router) du nuage MPLS, la permutation
d'étiquette est réalisée en analysant une étiquette entrante, qui est ensuite permutée avec l'étiquette sortante et finalement envoyée au saut suivant. Les étiquettes ne sont imposées sur les paquets qu'une seule fois en périphérie du réseau MPLS au niveau du Ingress E-LSR (Edge Label Switch Router) où un calcul est effectué sur le datagramme afin de lui affecter un label spécifique. Ce qui est important ici, est que ce calcul n'est effectué qu'une fois. La première fois que le datagramme d'un flux arrive à un Ingress E-LSR. Ce label est supprimé à l'autre extrémité par le Egress E-LSR.
Donc le mécanisme est le suivant: Le Ingress LSR (E-LSR) recoit les paquets IP, réalise une classification des paquets, y assigne un label et transmet les paquets labellisés au nuage MPLS. En se basant uniquement sur les labels, les LSR du nuage MPLS commutent les paquets labellisés jusqu'à l'Egress LSR qui supprime les labels et remet les paquets à leur destination finale. L'affectation des étiquettes aux paquets dépend des groupes ou des classes de flux FEC (forwarding équivalence classes). Les paquets appartenant à une même classe FEC sont traités de la même manière. Le chemin établi par MPLS
appelé LSP (Label Switched Path) est emprunté par tous les datagrammes de ce flux. L'étiquette est ajoutée entre la couche 2 et l'en-tête de la couche 3 (dans un environnement de paquets) ou dans le champ VPI/VCI (identificateur de chemin virtuel/identificateur de canal virtuel dans les réseaux ATM). Le switch LSR du nuage MPLS lit simplement les étiquettes, applique les services appropriés et redirige les paquets en fonction des étiquettes. Ce schéma de consultation et de transfert MPLS offre la possibilité de contrôler explicitement le routage en fonction des adresses source et destination, facilitant ainsi l'introduction de nouveaux services IP. Un flux MPLS est vu comme un flux de
niveau 2.5 appartenant niveau 2 et niveau 3 du modèle de l'OSI.

6 - Label
Un label a une signification locale entre 2 LSR adjacents et mappe le flux de trafic entre le LSR amont et la LSR aval. A chaque bond le long du LSP, un label est utilisé pour chercher les informations de routage (next hop, lien de sortie, encapsulation, queueing et scheduling) et les actions à réaliser sur le label : insérer, changer ou retirer. La figure ci dessous, décrit la mise en oeuvre des labels dans les différentes technologies ATM, Frame Relay, PPP, Ethernet et
HDLC. Pour les réseaux Ethernet, un champ appelé shim a été introduit entre la couche 2 et la couche 3. Sur 32 bits, il a une signification d'identificateur local d'une FEC. 20 bits contiennent le label, un champ de 3 bits appelé Classe of Service (CoS) sert actuellement pour la QoS, un bit S pour indiquer s'il y a empilement de labels et un dernier champ, le TTL sur 8 bits (même signification que pour IP). L'empilement des labels permet en particulier d'associer plusieurs contrats de service à un flux au cours de sa traversé du réseau MPLS.
7 - Implicit Routing (LDP)
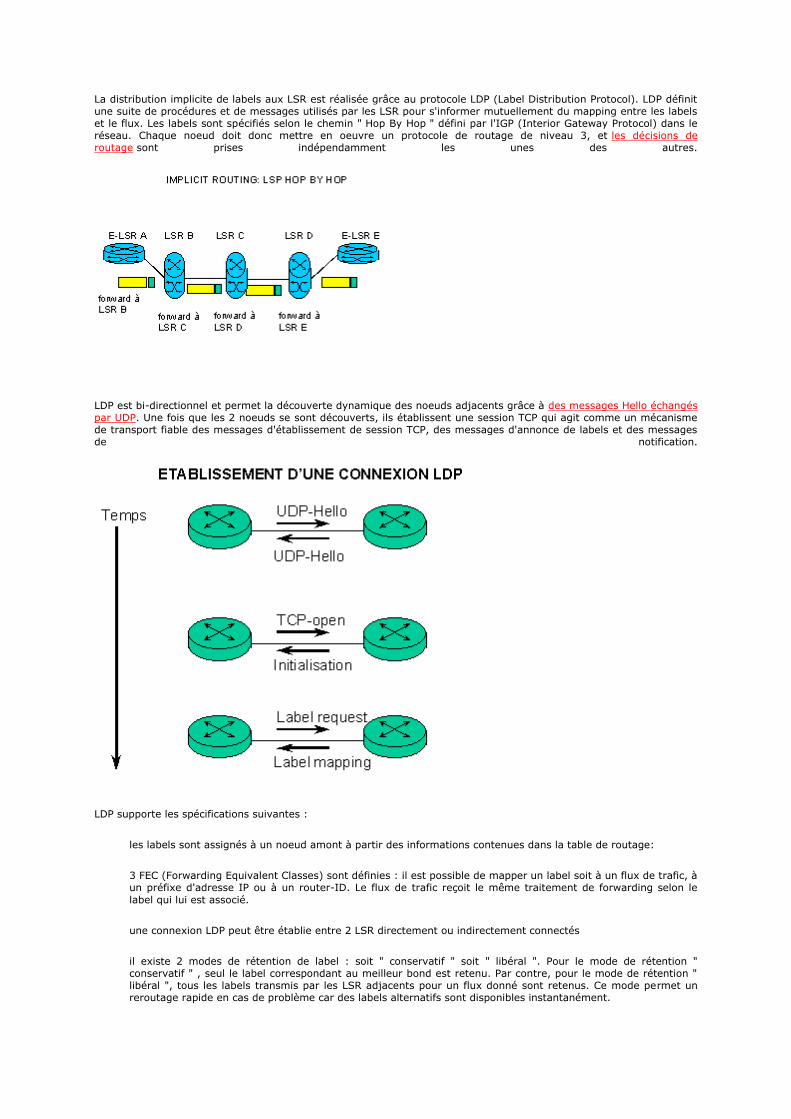
La distribution implicite de labels aux LSR est réalisée grâce au protocole LDP (Label Distribution Protocol). LDP définit une suite de procédures et de messages utilisés par les LSR pour s'informer mutuellement du mapping entre les labels et le flux. Les labels sont spécifiés selon le chemin " Hop By Hop " défini par l'IGP (Interior Gateway Protocol) dans le réseau. Chaque noeud doit donc mettre en oeuvre un protocole de routage de niveau 3, et les décisions de routage sont prises indépendamment les unes des autres.
LDP est bi-directionnel et permet la découverte dynamique des noeuds adjacents grâce à des messages Hello échangés par UDP. Une fois que les 2 noeuds se sont découverts, ils établissent une session TCP qui agit comme un mécanisme de transport fiable des messages d'établissement de session TCP, des messages d'annonce de labels et des messages de notification.
LDP supporte les spécifications suivantes :
les labels sont assignés à un noeud amont à partir des informations contenues dans la table de routage:
3 FEC (Forwarding Equivalent Classes) sont définies : il est possible de mapper un label soit à un flux de trafic, à un préfixe d'adresse IP ou à un router-ID. Le flux de trafic reçoit le même traitement de forwarding selon le
label qui lui est associé.
une connexion LDP peut être établie entre 2 LSR directement ou indirectement connectés
il existe 2 modes de rétention de label : soit " conservatif " soit " libéral ". Pour le mode de rétention " conservatif " , seul le label correspondant au meilleur bond est retenu. Par contre, pour le mode de rétention " libéral ", tous les labels transmis par les LSR adjacents pour un flux donné sont retenus. Ce mode permet un reroutage rapide en cas de problème car des labels alternatifs sont disponibles instantanément.

8 - Explicit Routing
L'Explicit Routing est la solution MPLS pour faire du Traffic Engineering dont l'objectif est le suivant :
utiliser efficacement des ressources du réseau
éviter les points de forte congestion en répartissant le trafic sur l'ensemble du réseau. En effet, le plus court chemin déterminé par le routage classique IP pour atteindre une destination peut ne pas être le seul chemin possible et certains chemins alternatifs peuvent être sous-utilisés alors que le plus court chemin est sur-utilisé.
Historiquement, le Traffic Engineering a été réalisé grâce à des métriques de liens associées à des protocoles de routage internes (RIP, OSPF, IS-IS). A la fin des années 90, il a également été possible de faire du Traffic Engineering avec des technologies de niveau 2 telles que ATM et Frame Relay. Aujourd'hui, MPLS émerge comme un nouveau mécanisme de Traffic Engineering en offrant une plus grande flexibilité de routage IP (bande passante, QoS,...), grâce à l'Explicit Routing. Dans ce cas, le LSP n'est plus déterminé à chaque bond comme pour l'implicit routing : c'est l'ingress node qui choisit le chemin de bout en bout. Au niveau des LSR en coeur de réseau, seul le label MPLS est
analysé (pas l'en-tête du datagramme IP).
L'Explicit Routing permet à un opérateur de faire du Traffic Engineering en imposant au réseau des contraintes sur les
flux, du point source jusqu'au point destination. Ainsi, des routes autres que le plus court chemin peuvent être utilisées. Le réseau détermine lui-même le chemin en suivant les étapes ci-dessous :
connaissance de l'état du réseau : topologie, bande passante réelle d'un lien, bande passante utilisée, bande passante restante. Des extensions ont été apportées aux protocoles de routage OSPF et IS-IS car la distribution dynamique des bases de données était limitée aux noeuds adjacents et à une seule métrique.
calcul d'un chemin répondant aux contraintes spécifiées. Les extensions d'OSPF et d'IS-IS sont nécessaires.
établissement du ER-LSP (Explicitly Routed Path). La source connaît le chemin complet de l'ingress node à l'egress node et c'est elle qui spécifie les LSR à l'intérieur du LSP. Deux options de signalisation spécifiées pour l'établissement du LSP : RSVP ou CR-LDP (Constraint-Based Routing LDP) :
CR-LDP est l'alternative à RSVP; il est jugé plus fiable dans la mesure où il met en oeuvre TCP (orienté connexion). De plus, CR-LDP peut interfonctionner avec LDP et utilise les messages LDP pour signaler les différentes contraintes. Les fonctions de CR-LDP sont réalisées par des instructions matérielles (asics) ne
nécessitant pas de fréquents rafraîchissements, contrairement à RSVP dont les fonctions sont réalisées par le
logiciel nécessitant de fréquents messages de rafraîchissement.
envoi du trafic sur le chemin trouvé
supervision de l'état des LSP et le transmet à l'IGP
ré-optimisation des LSP quand nécessaire

Les fonctions supportées par ER-LDP sont :
ER-LSP de bout en bout
strict/loose explicit routing : dans un LSP routé de manière " stricte ", chaque bond est spécifié. Une section du LSP peut être routée de manière " imprécise " lorsque sont introduits 2 LSR non directement connectés.
spécification d'une classe de service
réservation de bande passante
route pinning : dans une section de ER-LSP routée de manière " imprécise ", les bonds sont sélectionnés selon une transmission bond par bond
ER-LSP preemption : établissement/maintien de priorité
9 - Support de la QoS
9.1 - Signalisation et QoS
L'intérêt principal de MPLS est de permettre de se passer des couches inférieures ATM, Ethernet, PPP, Frame Relay et de fournir directement à la couche IP un mode connecté. Vu les similitudes qu'il y a entre traiter un "
label " et traiter un champ VPI/VCI de cellule ATM, la majorité des premières implémentations réutilisent un coeur de commutateur ATM. De fait, pour les constructeurs d'équipements, il est relativement facile de transformer un commutateur PNNI/ATM, en commutateur/routeur MPLS/IP de coeur de réseau : ceci revient à remplacer la couche logicielle du plan de commande par une " couche logicielle MPLS ", c'est à dire remplacer PNNI Signalling par LDP (Label Distribution Protocol) et PNNI Routing par OSPF (ou IS-IS, etc.).
LDP est le protocole de signalisation qui permet d'affecter des labels à un chemin au sein d'un réseau. En ce sens, il correspond à un protocole de signalisation et d'un point de vue fonctionnel s'apparente à PNNI Signalling. Cependant, LDP ne contient pas de paramètres permettant de formuler une demande de ressources à l'établissement d'un LSP (même s'il est possible de demander un traitement spécifique pour tous les paquets empruntant un même LSP, selon le modèle DiffServ).
Deux approches ont été retenues à l'IETF pour permettre d'associer des ressources et de garantir de la QoS sur un LSP : CR-LDP pour Constraint based Routing LDP, définit des extensions à LDP, et RSVP-Tunnels, définit des extensions à RSVP pour la commande de LSP. L'IETF a décidé de ne pas trancher entre ces deux approches concurrentes et de laisser ce soin au marché. Elles permettent toutes les deux d'associer de la ressource à un LSP. La première peut le faire selon les deux modèles " QoS ATM " (catégorie de service, paramètres de trafic et de QoS), et " QoS IP " (modèle Intserv), alors que la deuxième permet essentiellement de la " QoS IP ".

Une utilisation combinée de LDP+CR-LDP, ou de RSVP-Tunnels permet donc d'établir des LSP en leur associant de la bande passante.
9.2 - Routage et QoS
Dans son expression la plus simple, MPLS utilise les fonctions de routage IP pour établir un LSP : le message d'établissement est alors routé comme le serait n'importe quel autre paquet IP contenant la même adresse destination. Dans ce cas, le routage se fait " hop by hop ", chaque routeur décidant par lui même de l'interface de sortie vers laquelle il envoie le message, indépendamment de ce que les routeurs précédent ont pu choisir. Ce
mode de fonctionnement permet à un opérateur d'établir simplement un LSP entre deux extrémités de son réseau (pratique dans le cadre des VPNs). De plus, un tel mode de fonctionnement permet de sécuriser des LSP en autorisant leur reroutage en cas de faute dans le réseau (comme pour des Soft PVC en PNNI). L'inconvénient d'un routage " hop by hop " dans un environnement dynamique est qu'il y a un risque de création de boucles. Le problème des boucles en MPLS a fait l'objet de divers documents, sans que de réelle solution soit trouvée : en routage " hop by hop ", on sait détecter des boucles, on ne sait pas les éviter complètement. Au
cours de l'établissement, quand RSVP-Tunnels ou CR-LDP est utilisé, MPLS permet d'établir des LSP avec ressources associées, automatiquement à travers le réseau. En MPLS, un LSP auquel on veut associer de la bande passante, s'il est routé via le protocole de routage IP, suivra la même route que n'importe quel autre LSP vers la même destination : la route qui minimise la somme des poids administratifs (seul paramètre déclaré par OSPF). Dans le cas de MPLS, les routeurs choisissent la route et vérifient a posteriori que la ressource nécessaire à l'établissement du LSP est effectivement présente sur cette
route. La probabilité que la route retenue ne dispose pas de la ressource est plus importante en MPLS qu'en PNNI. OSPF et IS-IS n'ont pas été définis pour router des trafics nécessitant un certain niveau de QoS, ou un minimum de bande passante. Ils ne fournissent donc pas à un routeur IP les informations dont celui-ci aurait besoin pour router un LSP en fonction de ce qui est signalé en RSVP-Tunnels ou CR-LDP. Pour surmonter ces insuffisances, des extensions ont été proposées pour OSPF et IS-IS (par exemple OSPF-TE: une extension au traffic engeneering )
pour leur permettre de diffuser au sein d'un réseau IP les informations de QoS dont les routeurs pourraient avoir
besoin pour router des LSP.
9.3 - Architecture pour la QoS
Deux types d'architectures sont étudiées pour définir la QoS IP :
Integrated Services (IntServ)
Differential Services (DiffServ)
IntServ suppose que pour chaque flux demandant de la QoS, les ressources nécessaires sont réservées à chaque
bond entre l'émetteur et le récepteur. IntServ requiert une signalisation de bout en bout, assurée par RSVP, et doit maintenir l'état de chaque flux (messages RSVP, classification, policing et scheduling par flux de niveau 4). IntServ permet donc une forte granularité de QoS par flux et pour cette raison, est plutôt destiné à être implémenté à l'accès. IntServ définit 2 classes de services :
Guaranteed : garantie de bande passante, délai et pas de perte de trafic
Controlled Load : fournit différents niveaux de services en best effort
DiffServ, quant à lui, est davantage destiné à être appliqué en coeur de réseau opérateur. Les différents flux, classifiés selon des règles prédéfinies, sont agrégés selon un nombre limité de classes de services, ce qui permet de minimiser la signalisation. DiffServ ne peut pas offrir de QoS de bout en bout et a un comportement " Hop By Hop ".
DiffServ définit 2 classifications de service (Expedited, Assured) qui peuvent être corrélées aux classifications de service IntServ (Guaranteed, Controlled Load). DiffServ utilse les 6 premiers bits du champ TOS de l'entête IP afin de classifier le trafic dans des classes ou contrats au niveau de l'Ingress-LSR. Ce champ s'appellera DS-Field dans DiffServ. Voir la comparaison dans les deux figures ci dessus entre ces deux champs. Au niveau des LSR, DiffServ définit des PHB (Per Hop Behaviors) afin de construire ces LSPs. Ainsi au niveau des Edges LSR, DiiServ utilise le champs DS-Field, et à l'intérieur du
corps MPLS, il invoque les PHBs.
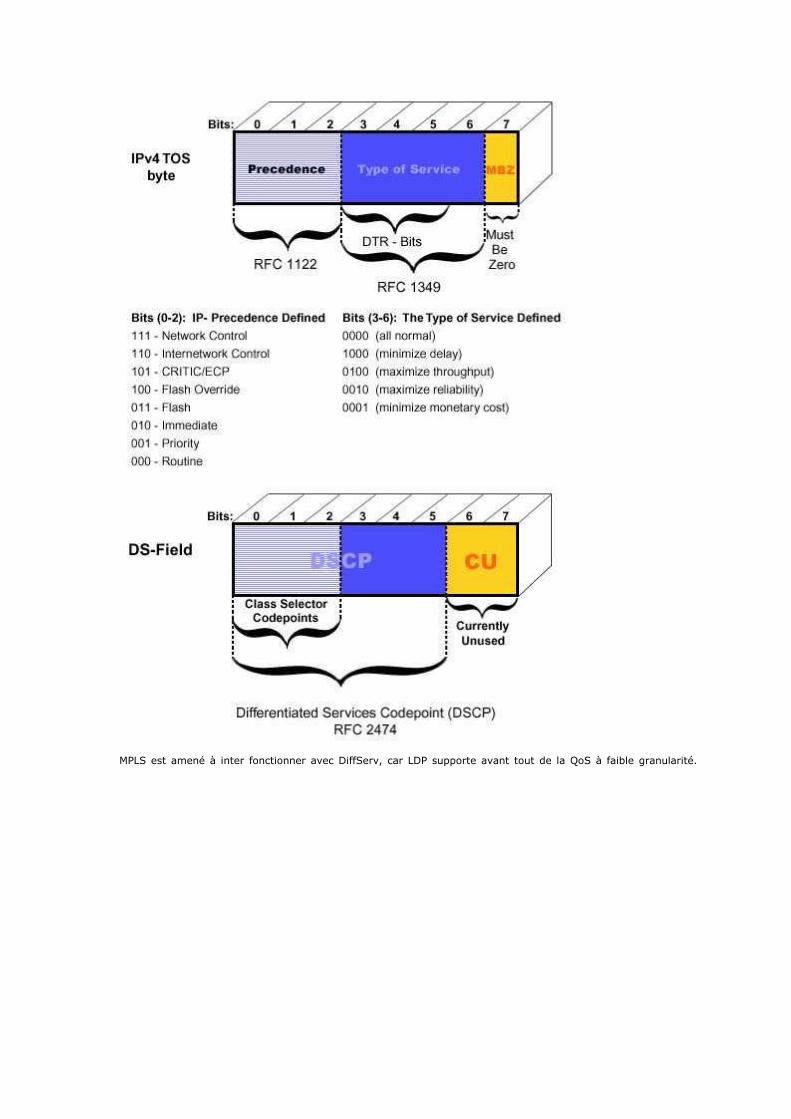
MPLS est amené à inter fonctionner avec DiffServ, car LDP supporte avant tout de la QoS à faible granularité.
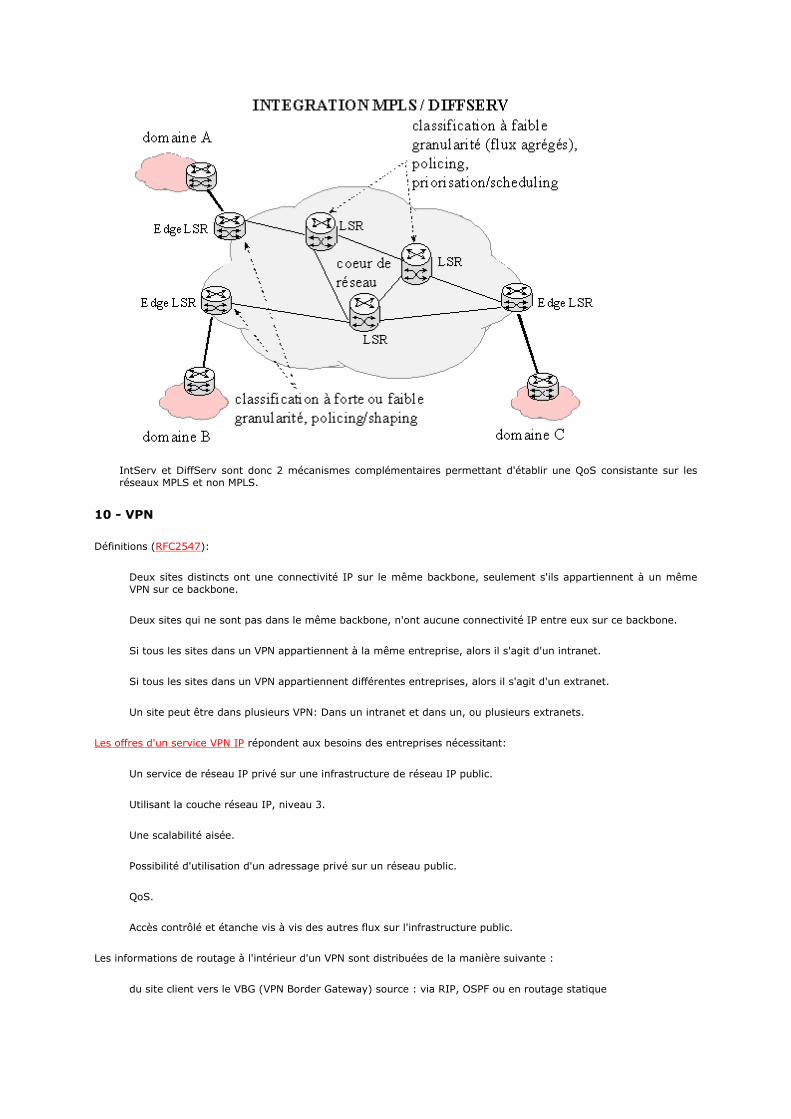
IntServ et DiffServ sont donc 2 mécanismes complémentaires permettant d'établir une QoS consistante sur les
réseaux MPLS et non MPLS.
10 - VPN
Définitions (RFC2547):
Deux sites distincts ont une connectivité IP sur le même backbone, seulement s'ils appartiennent à un même
VPN sur ce backbone.
Deux sites qui ne sont pas dans le même backbone, n'ont aucune connectivité IP entre eux sur ce backbone.
Si tous les sites dans un VPN appartiennent à la même entreprise, alors il s'agit d'un intranet.
Si tous les sites dans un VPN appartiennent différentes entreprises, alors il s'agit d'un extranet.
Un site peut être dans plusieurs VPN: Dans un intranet et dans un, ou plusieurs extranets.
Les offres d'un service VPN IP répondent aux besoins des entreprises nécessitant:
Un service de réseau IP privé sur une infrastructure de réseau IP public.
Utilisant la couche réseau IP, niveau 3.
Une scalabilité aisée.
Possibilité d'utilisation d'un adressage privé sur un réseau public.
QoS.
Accès contrôlé et étanche vis à vis des autres flux sur l'infrastructure public.
Les informations de routage à l'intérieur d'un VPN sont distribuées de la manière suivante :
du site client vers le VBG (VPN Border Gateway) source : via RIP, OSPF ou en routage statique
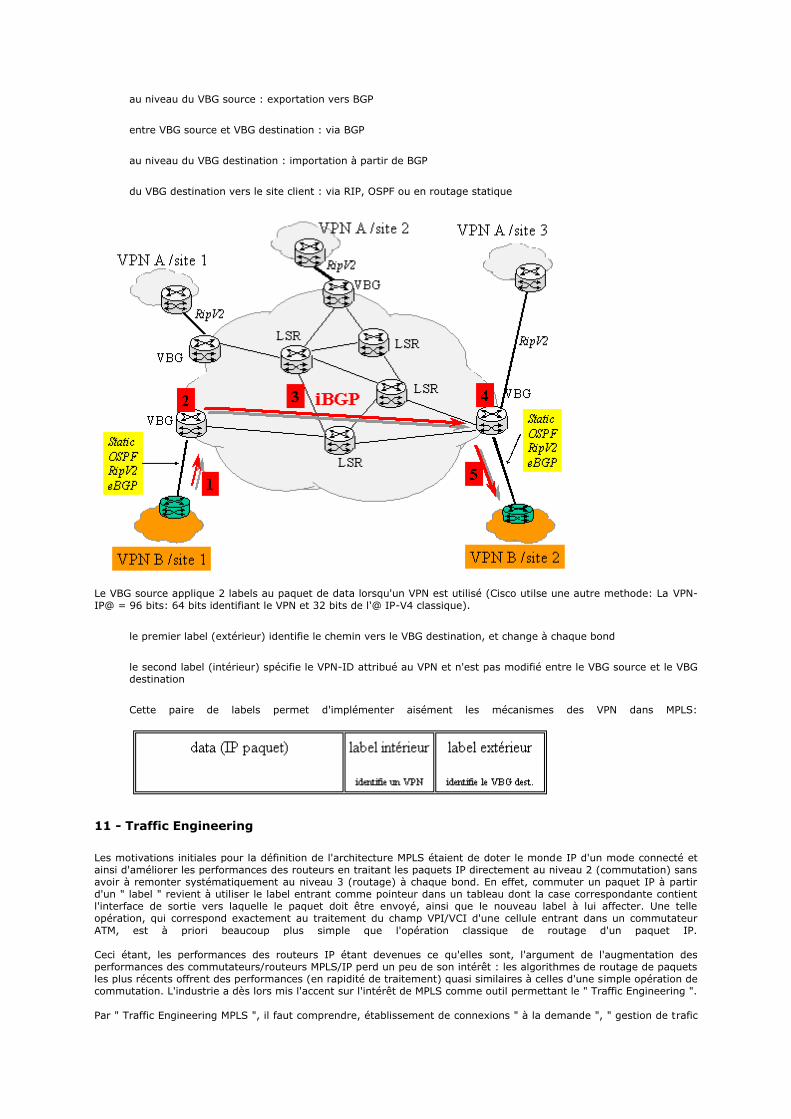
au niveau du VBG source : exportation vers BGP
entre VBG source et VBG destination : via BGP
au niveau du VBG destination : importation à partir de BGP
du VBG destination vers le site client : via RIP, OSPF ou en routage statique
Le VBG source applique 2 labels au paquet de data lorsqu'un VPN est utilisé (Cisco utilse une autre methode: La VPN-IP@ = 96 bits: 64 bits identifiant le VPN et 32 bits de l'@ IP-V4 classique).
le premier label (extérieur) identifie le chemin vers le VBG destination, et change à chaque bond
le second label (intérieur) spécifie le VPN-ID attribué au VPN et n'est pas modifié entre le VBG source et le VBG destination
Cette paire de labels permet d'implémenter aisément les mécanismes des VPN dans MPLS:
11 - Traffic Engineering
Les motivations initiales pour la définition de l'architecture MPLS étaient de doter le monde IP d'un mode connecté et ainsi d'améliorer les performances des routeurs en traitant les paquets IP directement au niveau 2 (commutation) sans avoir à remonter systématiquement au niveau 3 (routage) à chaque bond. En effet, commuter un paquet IP à partir d'un " label " revient à utiliser le label entrant comme pointeur dans un tableau dont la case correspondante contient l'interface de sortie vers laquelle le paquet doit être envoyé, ainsi que le nouveau label à lui affecter. Une telle opération, qui correspond exactement au traitement du champ VPI/VCI d'une cellule entrant dans un commutateur
ATM, est à priori beaucoup plus simple que l'opération classique de routage d'un paquet IP. Ceci étant, les performances des routeurs IP étant devenues ce qu'elles sont, l'argument de l'augmentation des performances des commutateurs/routeurs MPLS/IP perd un peu de son intérêt : les algorithmes de routage de paquets les plus récents offrent des performances (en rapidité de traitement) quasi similaires à celles d'une simple opération de commutation. L'industrie a dès lors mis l'accent sur l'intérêt de MPLS comme outil permettant le " Traffic Engineering ".
Par " Traffic Engineering MPLS ", il faut comprendre, établissement de connexions " à la demande ", " gestion de trafic

", gestion des routes, gestion des ressources, gestion de l'écoulement de flux de trafic à travers un réseau IP. La possibilité de faire suivre à des paquets IP un chemin à travers le réseau ne correspondant pas forcément au chemin que ces mêmes paquets auraient suivi s'ils avaient été routés au niveau 3 (c'est à dire à partir des informations issues du protocole de routage interne du réseau, i.e. RIP, OSPF, IS-IS, EIGRP, etc.), ceci afin de mieux gérer les ressources du réseau ". En effet, via un Label Switched Path (LSP), MPLS permet d'imposer le chemin que les paquets IP doivent
suivre pour atteindre une destination donnée. Un LSP est donc unidirectionnel.
MPLS et ses LSPs constituent dès lors un outil de gestion et d'optimisation de l'utilisation des ressources d'un réseau IP : les LSP sont montés par voie de gestion à l'avance par l'opérateur selon un chemin que celui-ci peut avoir préalablement choisi et déterminé.... Une utilisation " Traffic Engineering " de LSP MPLS s'apparente à la fonction Soft PVC unidirectionnel (contrairement à un LSP, un VC peut aussi être bidirectionnel) qui existe en commutation ATM. Pour établir un Soft PVC, l'opérateur se contente généralement d'identifier par voie de gestion les extrémités qu'il veut joindre. La connexion est ensuite
établie automatiquement entre ces deux extrémités, la route que cette connexion suit à travers le réseau étant déterminée par les éléments de coeur de réseau. Dans le cas de PNNI, la spécification laisse le routage d'un Soft PVC sous la responsabilité des noeuds ATM. Ceci étant, la majorité des MIB propriétaires permettent à un opérateur de spécifier lui-même s'il le désire le chemin qu'un Soft PVC doit suivre à travers le réseau. La principale différence entre un LSP MPLS et un Soft PVC ATM est qu'il est possible d'associer à un Soft PVC une catégorie de service ATM, ainsi que des paramètres de trafic et de QoS. Dans un réseau MPLS simple, établir des LSP
revient alors à établir des Soft PVC UBR unidirectionnels : on marque un chemin à travers le réseau sans lui associer de ressources.
12 - Agrégation de flux
L'une des forces annoncées de MPLS est sa capacité d'agrégation de flux : la possibilité de réunir le trafic entrant dans un routeur via plusieurs LSP dans un seul et unique LSP sortant. Une telle configuration correspond à monter une
connexion multi-point à point (fonction de VC merge en ATM), comparable à un arbre inversé dont le routeur de sortie serait la racine. Cette fonction permet de réduire au maximum le nombre de connexions que les routeurs de coeur de
réseau ont à gérer. Dans ce même but, MPLS introduit un concept de hiérarchie au niveau des LSP et d'empilement des labels. Il est donc possible de construire des LSP, encapsulés dans un autre LSP, lui-même encapsulé dans un LSP, etc. Ce concept
d'encapsulation rappelle évidemment la possibilité en ATM de mettre des VC dans des VP. Cependant, en MPLS, le nombre de niveau d'encapsulation (ou de hiérarchie) n'est a priori pas limité à 2.
13 - Applications
Les applications les plus courantes du MPLS sont les suivantes :
L'ingénierie de trafic est activée par des mécanismes MPLS permettant de diriger le trafic via un chemin
spécifique, qui n'est pas nécessairement le chemin le moins coûteux. Les administrateurs de réseau peuvent mettre en oeuvre des politiques visant à assurer une distribution optimale du trafic et à améliorer l'utilisation globale du réseau.
La bande passante garantie constitue une amélioration à forte valeur ajoutée par rapport aux mécanismes d'ingénierie de trafic traditionnels. MPLS permet aux fournisseurs de services d'allouer des largeurs de bande passante et des canaux garantis. La bande passante garantie permet également la comptabilité des ressources QoS (qualité de service) de manière à organiser le trafic 'prioritaire' et 'au mieux', tels que la voix et les
données.
Le reroutage rapide permet une reprise très rapide après la défaillance d'une liaison ou d'un noeud. Une telle
rapidité de reprise empêche l'interruption des applications utilisateur ainsi que toute perte de données.
Les réseaux privés virtuels MPLS simplifient considérablement le déploiement des services par rapport aux VPN IP traditionnels. Lorsque le nombre de routes et de clients augmente, les VPN MPLS peuvent facilement monter en charge, tout en offrant le même niveau de confidentialité que les technologies de niveau 2. Ils peuvent également transporter des adresses IP non-uniques à travers un domaine public.
La fonction Classe de service (CoS) MPLS assure que le trafic important est traité avec la priorité adéquate sur le réseau et que les exigences de latence sont respectées. Les mécanismes de qualité de service IP peuvent être mis en oeuvre de façon transparente dans un environnement MPLS.
Implémentation Mpls avec Cisco
1 - Introduction 2 - Matériel et configurations utilisés

3 - Principes généraux - Terminologie 3.1 - Réseau de démonstration 3.2 - Commutation par labels 3.3 - Classification des paquets 3.4 - Mode trame et mode cellule
3.5 - Distribution des labels (TDP / LDP) 3.6 - Tables MPLS: TIB et TFIB
3.6.1 - Rôle de la TIB (Tag Information Base) 3.6.2 - Rôle de la TFIB (Tag Forwarding Information Base) 3.7 - Penultimate Hop Popping 3.8 - Rétention des labels 3.9 - MPLS sur ATM 3.10 - Pile de labels (label stacking) 3.11 - Description de l'entête MPLS
3.12 - Configuration d'un routeur LSR 3.12.1 - Configuration de CEF 3.12.2 - Configuration d'un IGP 3.12.3 - Configuration de TDP / LDP 4 - Virtual Private Networks (VPN) 4.1 - Réseau de démonstration 4.2 - Routeurs P, PE et CE
4.3 - Routeurs virtuels : VRF 4.4 - Multiprotocol BGP (MP-BGP) 4.4.1 - Notion de RD (Route Distinguisher) 4.4.2 - Notion de RT (Route Target) 4.4.3 - Configuration d'une VRF 4.4.4 - Updates MP-BGP
4.4.5 - Configuration MP-BGP d'un PE 4.4.6 - Vérification du fonctionnement de MP-BGP 4.5 - Echange des routes avec les CE 4.5.1 - Configuration eBGP
4.5.2 - Configuration RIPv2 4.6 - Transmission des paquets IP 4.7 - Accès Internet
4.7.1 - Route par défaut statique (Static Default Route) 4.7.2 - Route par défaut dynamique (Dynamic Default Route) 4.7.3 - Routage optimal (Optimum Routing) 4.8 - Signalisation Inter-AS (MP-eBGP) 5 - Traffic Engineering (TE) 5.1 - Introduction 5.2 - Types de tunnels
5.3 - Critères de bande passante 5.4 - Etablissement d'un tunnel 5.5 - Réoptimisation 5.6 - Configuration IOS 5.6.1 - Activation globale de Traffic Engineering 5.6.2 - Configuration de l'IGP
5.6.3 - Configurations des interfaces 5.6.4 - Création d'un tunnel explicite 5.6.5 - Création d'un tunnel dynamique 5.7 - Utilisation avec MPLS/VPN 6 - Conclusion 7 - Annexe I: Configurations MPLS simples 8 - Annexe II: Configurations MPLS/VPN
9 - Discussion autour de la documentation 10 - Suivi du document
1 - Introduction
Dans les réseaux IP traditionnels, le routage des paquets s'effectue en fonction de l'adresse de destination contenue dans l'entête de niveau 3. Chaque routeur, pour déterminer le prochain saut (next-hop), consulte sa table de routage
et détermine l'interface de sortie vers laquelle envoyer le paquet. Le mécanisme de recherche dans la table de routage est consommateur de temps CPU, et avec la croissance de la taille des réseaux ces dernières années, les tables de routage des routeurs ont constamment augmenté. Il était donc nécessaire de trouver une méthode plus efficace pour le routage des paquets. Le but de MPLS était à l'origine de donner aux routeurs IP une plus grande puissance de commutation, en basant la décision de routage sur une information de label (ou tag) inséré entre le niveau 2 (Data-Link Layer) et le niveau 3 (Network Layer). La transmission des paquets était ainsi réalisée en switchant les paquets en fonction du label, sans avoir à consulter l'entête de niveau 3 et la table de routage.
Toutefois, avec le développement de techniques de commutation comme CEF (Cisco Express Forwarding) et la mise au point de nouveaux ASIC (Application Specific Interface Circuits), les routeurs IP ont vu leurs performances améliorées sans le recours à MPLS. L'intérêt de MPLS n'est actuellement plus la rapidité mais l'offre de services qu'il permet, avec notamment les réseaux privés virtuels (VPN) et le Traffic Engineering (TE), qui ne sont pas réalisables sur des infrastructures IP traditionnelles. Ce document se focalise principalement sur la présentation des principes de MPLS et
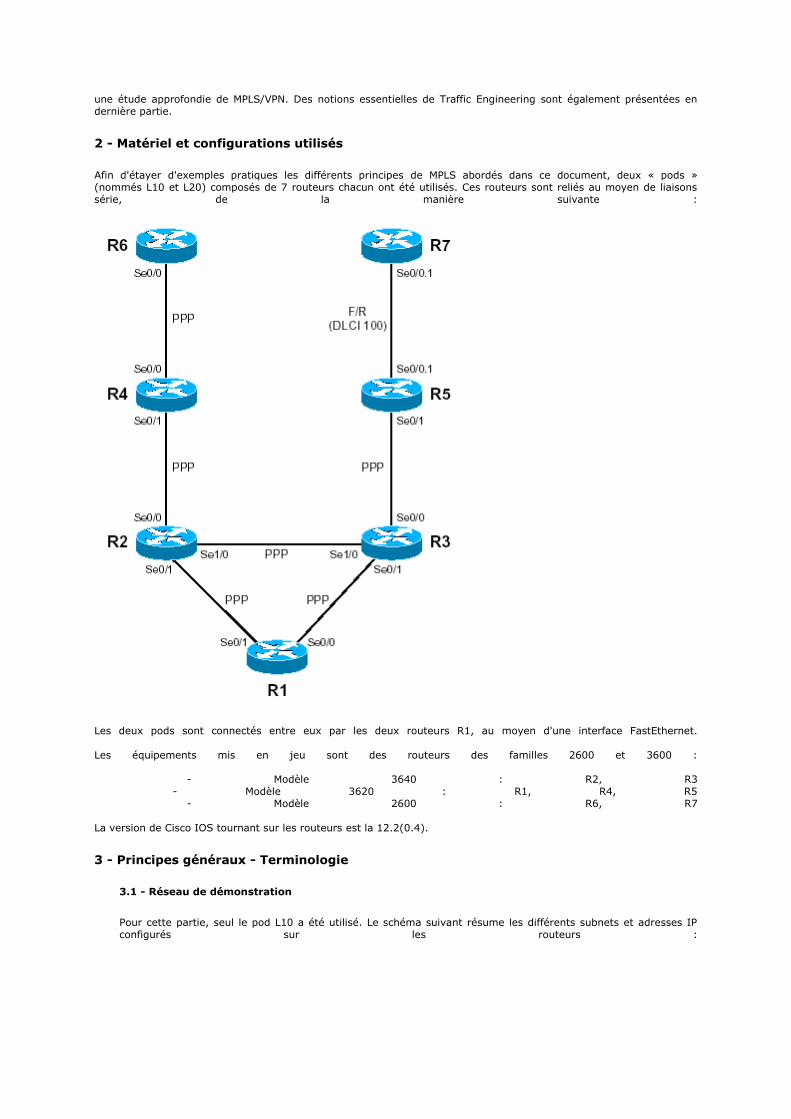
une étude approfondie de MPLS/VPN. Des notions essentielles de Traffic Engineering sont également présentées en dernière partie.
2 - Matériel et configurations utilisés
Afin d'étayer d'exemples pratiques les différents principes de MPLS abordés dans ce document, deux « pods » (nommés L10 et L20) composés de 7 routeurs chacun ont été utilisés. Ces routeurs sont reliés au moyen de liaisons série, de la manière suivante :
Les deux pods sont connectés entre eux par les deux routeurs R1, au moyen d'une interface FastEthernet.
Les équipements mis en jeu sont des routeurs des familles 2600 et 3600 : - Modèle 3640 : R2, R3
- Modèle 3620 : R1, R4, R5 - Modèle 2600 : R6, R7
La version de Cisco IOS tournant sur les routeurs est la 12.2(0.4).
3 - Principes généraux - Terminologie
3.1 - Réseau de démonstration
Pour cette partie, seul le pod L10 a été utilisé. Le schéma suivant résume les différents subnets et adresses IP configurés sur les routeurs :
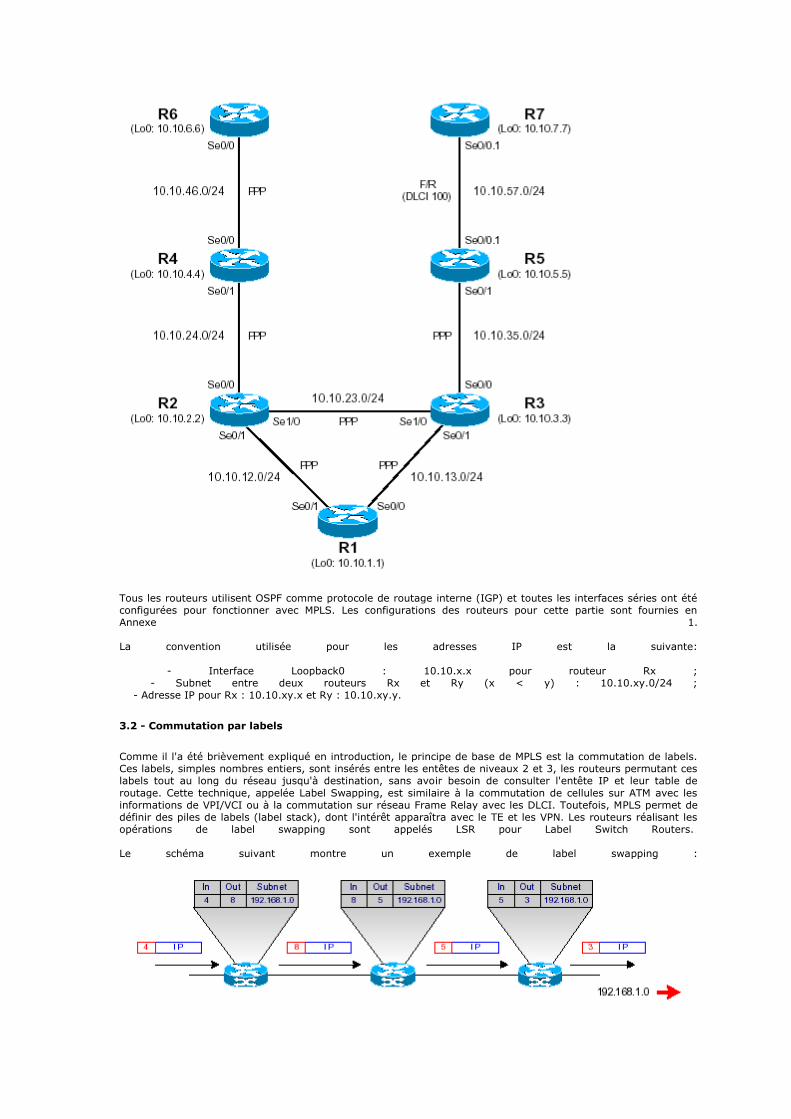
Tous les routeurs utilisent OSPF comme protocole de routage interne (IGP) et toutes les interfaces séries ont été configurées pour fonctionner avec MPLS. Les configurations des routeurs pour cette partie sont fournies en Annexe 1. La convention utilisée pour les adresses IP est la suivante:
- Interface Loopback0 : 10.10.x.x pour routeur Rx ; - Subnet entre deux routeurs Rx et Ry (x < y) : 10.10.xy.0/24 ; - Adresse IP pour Rx : 10.10.xy.x et Ry : 10.10.xy.y.
3.2 - Commutation par labels
Comme il l'a été brièvement expliqué en introduction, le principe de base de MPLS est la commutation de labels. Ces labels, simples nombres entiers, sont insérés entre les entêtes de niveaux 2 et 3, les routeurs permutant ces labels tout au long du réseau jusqu'à destination, sans avoir besoin de consulter l'entête IP et leur table de
routage. Cette technique, appelée Label Swapping, est similaire à la commutation de cellules sur ATM avec les informations de VPI/VCI ou à la commutation sur réseau Frame Relay avec les DLCI. Toutefois, MPLS permet de définir des piles de labels (label stack), dont l'intérêt apparaîtra avec le TE et les VPN. Les routeurs réalisant les opérations de label swapping sont appelés LSR pour Label Switch Routers. Le schéma suivant montre un exemple de label swapping :
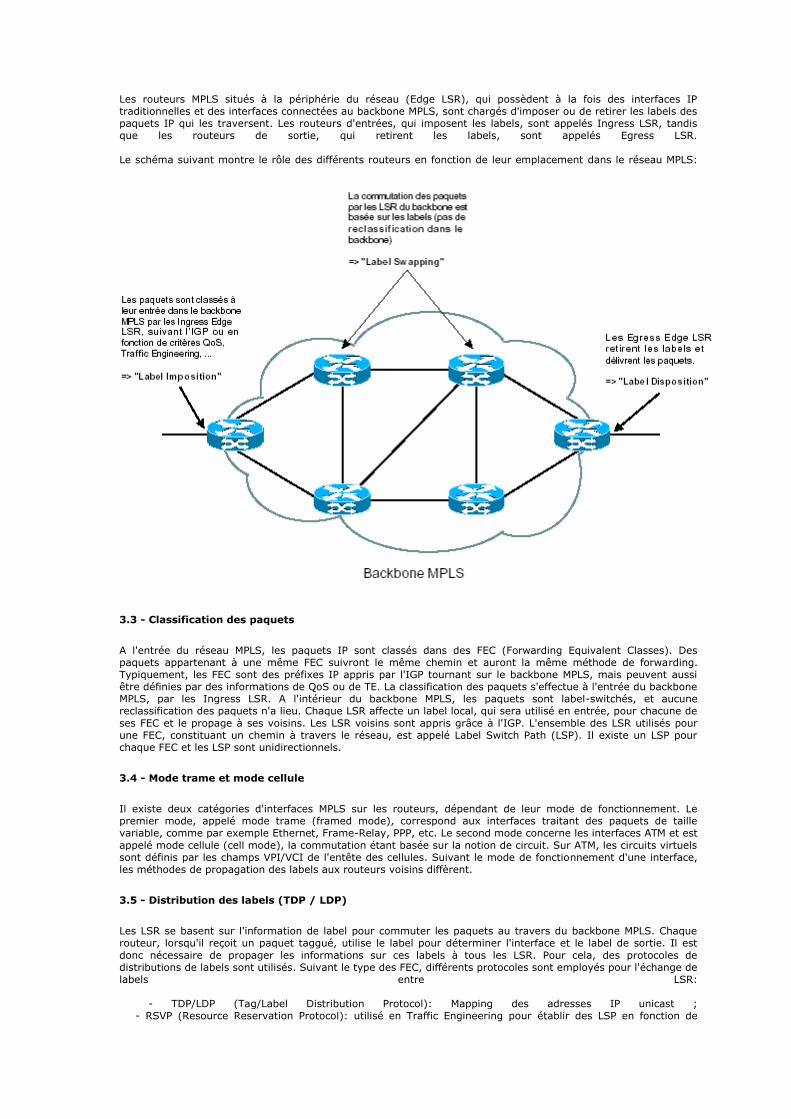
Les routeurs MPLS situés à la périphérie du réseau (Edge LSR), qui possèdent à la fois des interfaces IP traditionnelles et des interfaces connectées au backbone MPLS, sont chargés d'imposer ou de retirer les labels des paquets IP qui les traversent. Les routeurs d'entrées, qui imposent les labels, sont appelés Ingress LSR, tandis que les routeurs de sortie, qui retirent les labels, sont appelés Egress LSR.
Le schéma suivant montre le rôle des différents routeurs en fonction de leur emplacement dans le réseau MPLS:
3.3 - Classification des paquets
A l'entrée du réseau MPLS, les paquets IP sont classés dans des FEC (Forwarding Equivalent Classes). Des paquets appartenant à une même FEC suivront le même chemin et auront la même méthode de forwarding. Typiquement, les FEC sont des préfixes IP appris par l'IGP tournant sur le backbone MPLS, mais peuvent aussi être définies par des informations de QoS ou de TE. La classification des paquets s'effectue à l'entrée du backbone MPLS, par les Ingress LSR. A l'intérieur du backbone MPLS, les paquets sont label-switchés, et aucune reclassification des paquets n'a lieu. Chaque LSR affecte un label local, qui sera utilisé en entrée, pour chacune de
ses FEC et le propage à ses voisins. Les LSR voisins sont appris grâce à l'IGP. L'ensemble des LSR utilisés pour une FEC, constituant un chemin à travers le réseau, est appelé Label Switch Path (LSP). Il existe un LSP pour chaque FEC et les LSP sont unidirectionnels.
3.4 - Mode trame et mode cellule
Il existe deux catégories d'interfaces MPLS sur les routeurs, dépendant de leur mode de fonctionnement. Le premier mode, appelé mode trame (framed mode), correspond aux interfaces traitant des paquets de taille variable, comme par exemple Ethernet, Frame-Relay, PPP, etc. Le second mode concerne les interfaces ATM et est
appelé mode cellule (cell mode), la commutation étant basée sur la notion de circuit. Sur ATM, les circuits virtuels sont définis par les champs VPI/VCI de l'entête des cellules. Suivant le mode de fonctionnement d'une interface, les méthodes de propagation des labels aux routeurs voisins diffèrent.
3.5 - Distribution des labels (TDP / LDP)
Les LSR se basent sur l'information de label pour commuter les paquets au travers du backbone MPLS. Chaque routeur, lorsqu'il reçoit un paquet taggué, utilise le label pour déterminer l'interface et le label de sortie. Il est
donc nécessaire de propager les informations sur ces labels à tous les LSR. Pour cela, des protocoles de distributions de labels sont utilisés. Suivant le type des FEC, différents protocoles sont employés pour l'échange de labels entre LSR: - TDP/LDP (Tag/Label Distribution Protocol): Mapping des adresses IP unicast ; - RSVP (Resource Reservation Protocol): utilisé en Traffic Engineering pour établir des LSP en fonction de
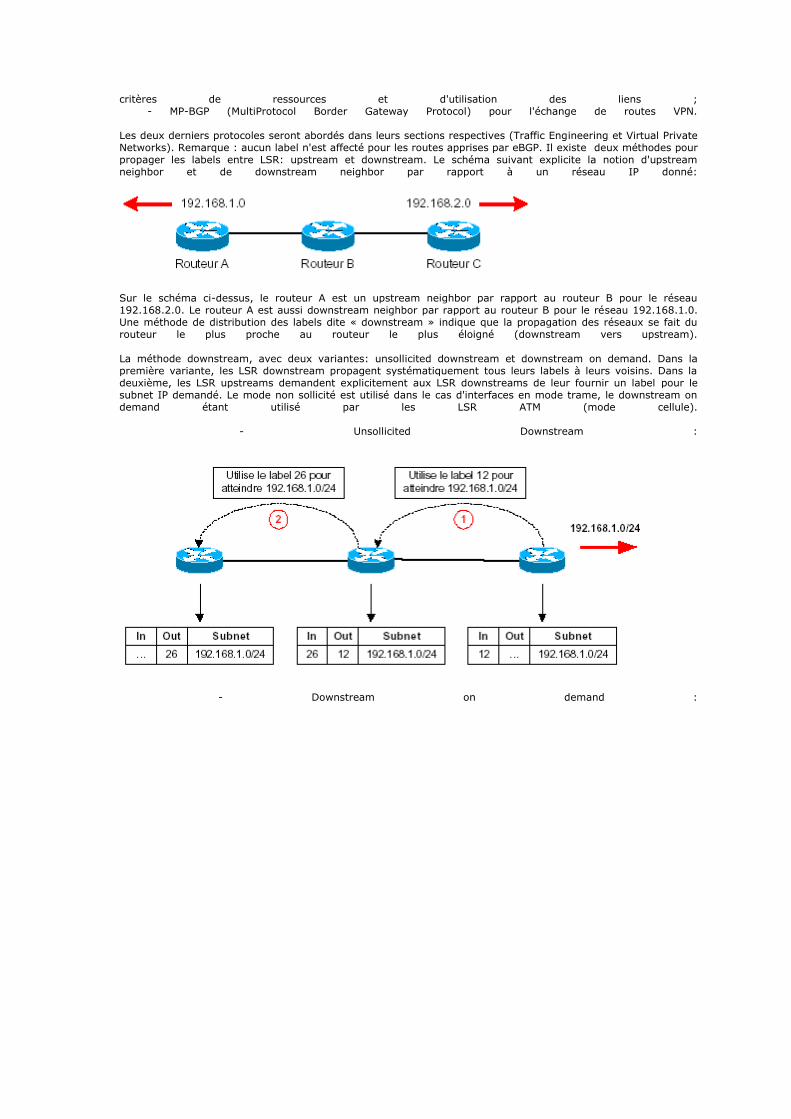
critères de ressources et d'utilisation des liens ; - MP-BGP (MultiProtocol Border Gateway Protocol) pour l'échange de routes VPN. Les deux derniers protocoles seront abordés dans leurs sections respectives (Traffic Engineering et Virtual Private Networks). Remarque : aucun label n'est affecté pour les routes apprises par eBGP. Il existe deux méthodes pour
propager les labels entre LSR: upstream et downstream. Le schéma suivant explicite la notion d'upstream neighbor et de downstream neighbor par rapport à un réseau IP donné:
Sur le schéma ci-dessus, le routeur A est un upstream neighbor par rapport au routeur B pour le réseau 192.168.2.0. Le routeur A est aussi downstream neighbor par rapport au routeur B pour le réseau 192.168.1.0. Une méthode de distribution des labels dite « downstream » indique que la propagation des réseaux se fait du routeur le plus proche au routeur le plus éloigné (downstream vers upstream).
La méthode downstream, avec deux variantes: unsollicited downstream et downstream on demand. Dans la première variante, les LSR downstream propagent systématiquement tous leurs labels à leurs voisins. Dans la deuxième, les LSR upstreams demandent explicitement aux LSR downstreams de leur fournir un label pour le subnet IP demandé. Le mode non sollicité est utilisé dans le cas d'interfaces en mode trame, le downstream on demand étant utilisé par les LSR ATM (mode cellule). - Unsollicited Downstream :
- Downstream on demand :
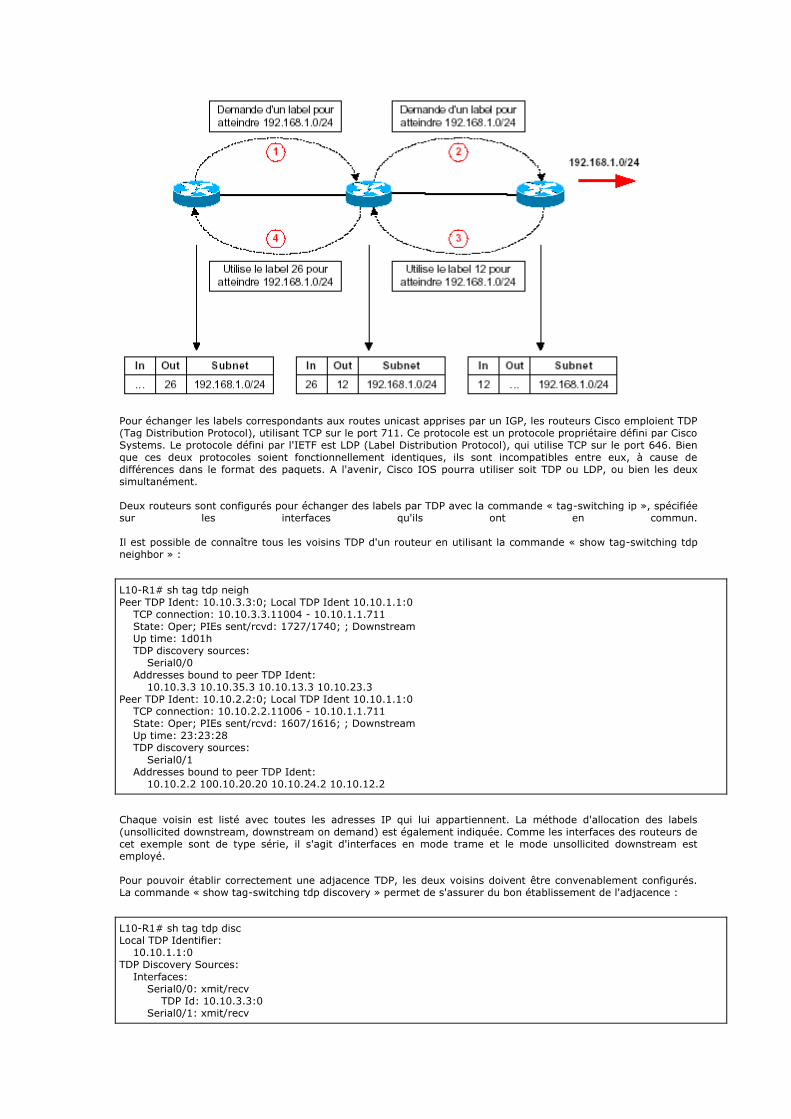
Pour échanger les labels correspondants aux routes unicast apprises par un IGP, les routeurs Cisco emploient TDP (Tag Distribution Protocol), utilisant TCP sur le port 711. Ce protocole est un protocole propriétaire défini par Cisco Systems. Le protocole défini par l'IETF est LDP (Label Distribution Protocol), qui utilise TCP sur le port 646. Bien
que ces deux protocoles soient fonctionnellement identiques, ils sont incompatibles entre eux, à cause de différences dans le format des paquets. A l'avenir, Cisco IOS pourra utiliser soit TDP ou LDP, ou bien les deux
simultanément. Deux routeurs sont configurés pour échanger des labels par TDP avec la commande « tag-switching ip », spécifiée sur les interfaces qu'ils ont en commun.
Il est possible de connaître tous les voisins TDP d'un routeur en utilisant la commande « show tag-switching tdp neighbor » :
L10-R1# sh tag tdp neigh
Peer TDP Ident: 10.10.3.3:0; Local TDP Ident 10.10.1.1:0 TCP connection: 10.10.3.3.11004 - 10.10.1.1.711 State: Oper; PIEs sent/rcvd: 1727/1740; ; Downstream Up time: 1d01h TDP discovery sources: Serial0/0
Addresses bound to peer TDP Ident: 10.10.3.3 10.10.35.3 10.10.13.3 10.10.23.3 Peer TDP Ident: 10.10.2.2:0; Local TDP Ident 10.10.1.1:0 TCP connection: 10.10.2.2.11006 - 10.10.1.1.711 State: Oper; PIEs sent/rcvd: 1607/1616; ; Downstream Up time: 23:23:28 TDP discovery sources:
Serial0/1 Addresses bound to peer TDP Ident: 10.10.2.2 100.10.20.20 10.10.24.2 10.10.12.2
Chaque voisin est listé avec toutes les adresses IP qui lui appartiennent. La méthode d'allocation des labels
(unsollicited downstream, downstream on demand) est également indiquée. Comme les interfaces des routeurs de cet exemple sont de type série, il s'agit d'interfaces en mode trame et le mode unsollicited downstream est employé. Pour pouvoir établir correctement une adjacence TDP, les deux voisins doivent être convenablement configurés. La commande « show tag-switching tdp discovery » permet de s'assurer du bon établissement de l'adjacence :
L10-R1# sh tag tdp disc Local TDP Identifier: 10.10.1.1:0 TDP Discovery Sources:
Interfaces: Serial0/0: xmit/recv TDP Id: 10.10.3.3:0 Serial0/1: xmit/recv

TDP Id: 10.10.2.2:0
Chaque voisin doit être marqué « xmit/recv » (émission / réception) pour que l'échange des labels puisse avoir lieu.
3.6 - Tables MPLS: TIB et TFIB
A partir des informations apprises par TDP / LDP, les LSR construisent deux tables, la TIB et la TFIB. De manière générale, la TIB contient tous les labels appris des LSR voisins, tandis que la TFIB, utilisée pour la commutation proprement dite des paquets, est un sous-ensemble de la TIB.
3.6.1 - Rôle de la TIB (Tag Information Base)
La première table construite par le routeur MPLS est la table TIB (Tag Information Base). Elle contient pour
chaque subnet IP la liste des labels affectés par les LSR voisins. Il est possible de connaître les labels affectés à un subnet par chaque LSR voisin en utilisant la commande "show tag tdp bindings". Un exemple de résultat de cette commande est donné ci-dessous:
L10-R1# sh tag tdp bind 10.10.4.4 255.255.255.255
tib entry: 10.10.4.4/32, rev 31 local binding: tag: 24 remote binding: tsr: 10.10.3.3:0, tag: 20 remote binding: tsr: 10.10.2.2:0, tag: 21
On remarque que le routeur a affecté le label local 24 pour atteindre le réseau 10.10.4.4/32, et que les routeurs L10-R2 (10.10.2.2) et L10-R3 (10.10.3.3) ont respectivement affecté les label 21 et 20 pour
atteindre le subnet 10.10.4.4/32. Il est à noter qu'IOS emploie le terme TSR pour « Tag Switch Router », qui est équivalent à celui de LSR. Pour les interfaces ATM (fonctionnant en mode cellule), la commande à utiliser est « show tag atm-tdp bindings » :
ATM-LSR# show tag-switching atm-tdp bindings Destination: 193.12.161.1/32 Tailend Switch XTagATM162 241/33 Active -> Terminating Active, VCD=2 Destination: 194.16.16.4/32
Transit XTagATM161 240/91 Active -> XTagATM162 241/276 Active
Les labels entre ATM LSR sont échangés au moyen d'un VC de contrôle MPLS, par défaut configuré sur VPI/VCI = 0/32.
3.6.2 - Rôle de la TFIB (Tag Forwarding Information Base)
A partir de la table TIB et de la table de routage IP, le routeur construit une table TFIB, qui sera utilisée pour commuter les paquets. Chaque réseau IP est appris par l'IGP, qui détermine le prochain saut ("next-hop")
pour atteindre ce réseau. Le LSR choisit ainsi l'entrée de la table TIB qui correspond au réseau IP et sélectionne comme label de sortie le label annoncé par le voisin déterminé par l'IGP (plus court chemin). Il est possible d'afficher le contenu de la table TFIB grâce à la commande "show tagswitching forwarding". Le résultat de cette commande sur le routeur utilisé précédemment est donné ci-dessous:
L10-R1# sh tag for 10.10.4.4 Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 24 21 10.10.4.4/32 0 Se0/1 point2point
On remarque ainsi que le routeur L10-R1 a sélectionné pour le réseau 10.10.4.4/32 l'entrée de la TIB créée par le voisin 10.10.2.2 (connecté à L10-R1 par l'interface Serial0/1), qui a la meilleure métrique du point de vue de l'IGP (plus court chemin). Ainsi, pour chaque paquet reçu ayant comme label 24, le routeur commutera le paquet sur l'interface de sortie Serial0/1, et en permutant le label 24 par 21. La sélection de L10-R2 comme next-hop est confirmée en consultant l'entrée 10.10.4.4/32 de la table de routage:
L10-R1# sh ip route 10.10.4.4 Routing entry for 10.10.4.4/32 Known via "ospf 10", distance 110, metric 1601, type intra area
Last update from 10.10.12.2 on Serial0/1, 23:16:16 ago Routing Descriptor Blocks:

* 10.10.12.2, from 10.10.4.4, 23:16:16 ago, via Serial0/1 Route metric is 1601, traffic share count is 1
Le routeur, lorsqu'il reçoit un paquet taggué, se base sur la TFIB pour forwarder le paquet. A partir d'un label
d'entrée (local tag), il en déduit l'interface et le label de sortie (Outgoing interface et Outgoing tag or VC). Pour pouvoir utiliser la TFIB, le routeur doit employer CEF comme technique de commutation, qui doit être activée globalement et pour chaque interface recevant des paquets taggués. CEF est en effet le seul mode de commutation capable d'utiliser la TFIB. Les anciens modes (fastswitching, optimum switching, etc.) ne sont
pas conçus pour gérer cette table. Il est possible de consulter la table CEF d'un routeur avec la commande « show ip cef ». Tous les préfixes IP connus seront alors affichés avec leur interface de sortie et l'adresse du next-hop. Il est possible d'obtenir des informations plus détaillées sur un subnet particulier avec la commande « show ip cef subnet netmask ». Il est ainsi aisé de connaître le(s) label(s) de sortie utilisés pour atteindre ce réseau, l'interface de sortie et le next-hop IP, comme le montre l'exemple suivant :
L10-R1# sh ip cef 10.10.4.4 10.10.4.4/32, version 594, cached adjacency to Serial0/1 0 packets, 0 bytes
tag information set local tag: 24 fast tag rewrite with Se0/1, point2point, tags imposed: {21} via 10.10.12.2, Serial0/1, 0 dependencies next hop 10.10.12.2, Serial0/1 valid cached adjacency tag rewrite with Se0/1, point2point, tags imposed: {21}
L'interface de sortie à emprunter pour atteindre le subnet 10.10.4.4/32 est donc Serial0/1, avec comme
adresse de next-hop 10.10.12.2 (routeur L10-R2). Le tag local affecté par le routeur L10-R1 est 24 et le tag utilisé en sortie est 21 (appris de L10-R2 par TDP).
Sur L10-R2, le contenu de la TIB pour 10.10.4.4/32 est reproduit ci-dessous :
L10-R2# sh tag tdp bind 10.10.4.4 255.255.255.255 tib entry: 10.10.4.4/32, rev 26
local binding: tag: 21 remote binding: tsr: 10.10.4.4:0, tag: imp-null remote binding: tsr: 10.10.1.1:0, tag: 24
On retrouve donc bien comme tag d'entrée le tag 21 pour atteindre le réseau 10.10.4.4. A partir de la version IOS 12.1(5)T, il est possible de connaître les labels d'un chemin servant à atteindre une destination précise, avec la commande « traceroute » :
L10-R7# trace 10.10.6.6 Type escape sequence to abort. Tracing the route to 10.10.6.6 1 10.10.57.5 [MPLS: Label 29 Exp 0] 120 msec 116 msec 116 msec 2 10.10.35.3 [MPLS: Label 22 Exp 0] 105 msec 108 msec 104 msec
3 10.10.23.2 [MPLS: Label 23 Exp 0] 92 msec 100 msec 96 msec
4 10.10.24.4 [MPLS: Label 29 Exp 0] 89 msec 92 msec 84 msec 5 10.10.46.6 40 msec * 40 msec
Le label MPLS affiché pour chaque hop correspond au label en entrée du routeur. Le champ « Exp » (codé sur 3 bits) est similaire au champ TOS de l'entête IP, mais n'est pas employé ici. Dans cet exemple, le chemin pour atteindre R6 à partir de R7 est { R5, R3, R2, R4, R6 }. Le schéma suivant montre comment les paquets sont acheminés de R7 jusqu'à R6 :

Les routeurs R5, R3, R2 et R4 commutent les paquets uniquement sur l'entête MPLS : l'entête IP n'est pas examinée, et les routeurs ne consultent que leur table TFIB (leur table de routage n'est pas utilisée). On constate que les paquets arrivant sur le routeur R6 pour le réseau 10.10.6.6 ne sont pas taggués. Ce phénomène, appelé Penultimate Hop Popping, permet au routeur auquel sont rattachés des réseaux sur des interfaces non MPLS d'éviter un lookup dans la table TFIB. Le Penultimate Hop Popping est
décrit plus précisement dans le paragraphe suivant.
3.7 - Penultimate Hop Popping
Un LSR "egress" annonçant un réseau, qui lui est soit directement connecté, soit rattaché (appris par IGP, EGP, routage statique...) par une interface non tagguée, n'a pas besoin de recevoir de paquets taggués pour atteindre ce réseau. En effet, si les paquets reçus étaient taggués, le routeur egress devrait d'abord déterminer l'interface de sortie grâce à la table TFIB, puis effectuer une recherche dans la table de routage IP. L'opération de recherche sur le label dans la TFIB est inutile, car dans tous les cas le routeur devra effectuer une recherche dans la table de
routage. Le routeur egress annonce donc ces réseaux IP avec le label "implicit-null" à ses voisins. Un LSR ayant comme label de sortie "implicit-null" aura ainsi pour but de dépiler le premier label du paquet et de faire suivre le paquet sur l'interface de sortie spécifiée. Le routeur egress n'aura alors plus qu'une recherche à faire dans sa table de routage.

Un exemple de Penultimate Hop Popping entre L10-R1 et L10-R2 est donné ci-dessous:
L10-R1# sh tag for 10.10.2.2 Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 23 Pop tag 10.10.2.2/32 145198 Se0/1 point2point
L10-R1# sh ip cef 10.10.2.2 10.10.2.2/32, version 593, cached adjacency to Serial0/1 0 packets, 0 bytes tag information set local tag: 23 via 10.10.12.2, Serial0/1, 0 dependencies next hop 10.10.12.2, Serial0/1
valid cached adjacency tag rewrite with Se0/1, point2point, tags imposed: {}
Le réseau 10.10.2.2/32 correspond à l'interface Loopback0 du routeur L10-R2, connecté par un lien série à L10-
R1. On constate que le tag de sortie (Outgoing tag) pour 10.10.2.2/32 est déclaré sous le terme « pop tag » pour signaler l'action de dépilement du premier label.
3.8 - Rétention des labels
Afin d'accélérer la convergence du réseau lors d'un changement de topologie (lien défectueux, dysfonctionnement d'un routeur), les LSR conservent dans leur table TIB la liste des labels annoncés pour chaque réseau IP par leurs voisins TDP, y compris de ceux n'étant pas les next-hops choisis par l'IGP. Ainsi, en cas de perte d'un lien ou d'un
noeud, la sélection d'un nouveau label de sortie est immédiate : en effet, il suffit au routeur d'élire un nouveau
next-hop et de sélectionner l'entrée correspondante dans la TIB, puis de mettre à jour la TFIB. Ce mode de fonctionnement est appelé mode libéral (liberal mode). L'avantage de ce procédé est naturellement une convergence plus rapide lorsque les informations de routage au niveau 3 changent, avec pour inconvénients que davantage de mémoire est allouée dans les routeurs et que des labels supplémentaires sont utilisés. Le mode libéral est appliqué dans le cas d'interfaces fonctionnant en mode trame. Il existe un autre mode appelé mode conservatif, qui correspond au downstream on demand, utilisé par les LSR
ATM. Pour atteindre un subnet donné au-delà d'une interface de type « cellule », les LSR ATM demandent à leurs voisins downstream de leur fournir un label pour chaque couple (interface d'entrée, subnet IP). La problématique des réseaux ATM est abordée dans le paragraphe suivant.
3.9 - MPLS sur ATM
Il existe deux manières d'implémenter MPLS sur des réseaux de type ATM. La première consiste à mettre en place un backbone constitué de switches purement ATM, c'est-à-dire sans aucune connaissance de MPLS ou du routage
IP. Dans ce cas, des PVCs sont simplement établis entre les routeurs MPLS et les labels sont alors encapsulés entre l'entête LLC/SNAP et l'entête IP. La deuxième méthode consiste à mettre en oeuvre MPLS sur des switches
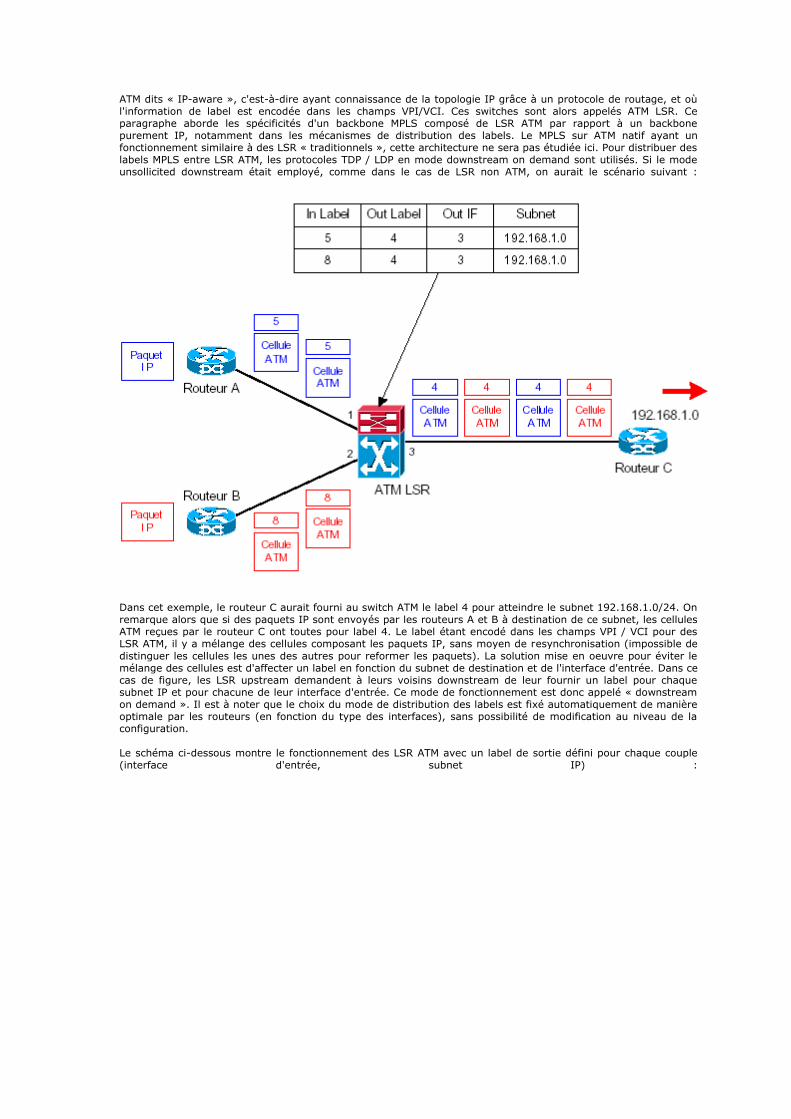
ATM dits « IP-aware », c'est-à-dire ayant connaissance de la topologie IP grâce à un protocole de routage, et où l'information de label est encodée dans les champs VPI/VCI. Ces switches sont alors appelés ATM LSR. Ce paragraphe aborde les spécificités d'un backbone MPLS composé de LSR ATM par rapport à un backbone purement IP, notamment dans les mécanismes de distribution des labels. Le MPLS sur ATM natif ayant un fonctionnement similaire à des LSR « traditionnels », cette architecture ne sera pas étudiée ici. Pour distribuer des
labels MPLS entre LSR ATM, les protocoles TDP / LDP en mode downstream on demand sont utilisés. Si le mode unsollicited downstream était employé, comme dans le cas de LSR non ATM, on aurait le scénario suivant :
Dans cet exemple, le routeur C aurait fourni au switch ATM le label 4 pour atteindre le subnet 192.168.1.0/24. On remarque alors que si des paquets IP sont envoyés par les routeurs A et B à destination de ce subnet, les cellules ATM reçues par le routeur C ont toutes pour label 4. Le label étant encodé dans les champs VPI / VCI pour des LSR ATM, il y a mélange des cellules composant les paquets IP, sans moyen de resynchronisation (impossible de
distinguer les cellules les unes des autres pour reformer les paquets). La solution mise en oeuvre pour éviter le mélange des cellules est d'affecter un label en fonction du subnet de destination et de l'interface d'entrée. Dans ce cas de figure, les LSR upstream demandent à leurs voisins downstream de leur fournir un label pour chaque subnet IP et pour chacune de leur interface d'entrée. Ce mode de fonctionnement est donc appelé « downstream on demand ». Il est à noter que le choix du mode de distribution des labels est fixé automatiquement de manière optimale par les routeurs (en fonction du type des interfaces), sans possibilité de modification au niveau de la configuration.
Le schéma ci-dessous montre le fonctionnement des LSR ATM avec un label de sortie défini pour chaque couple (interface d'entrée, subnet IP) :
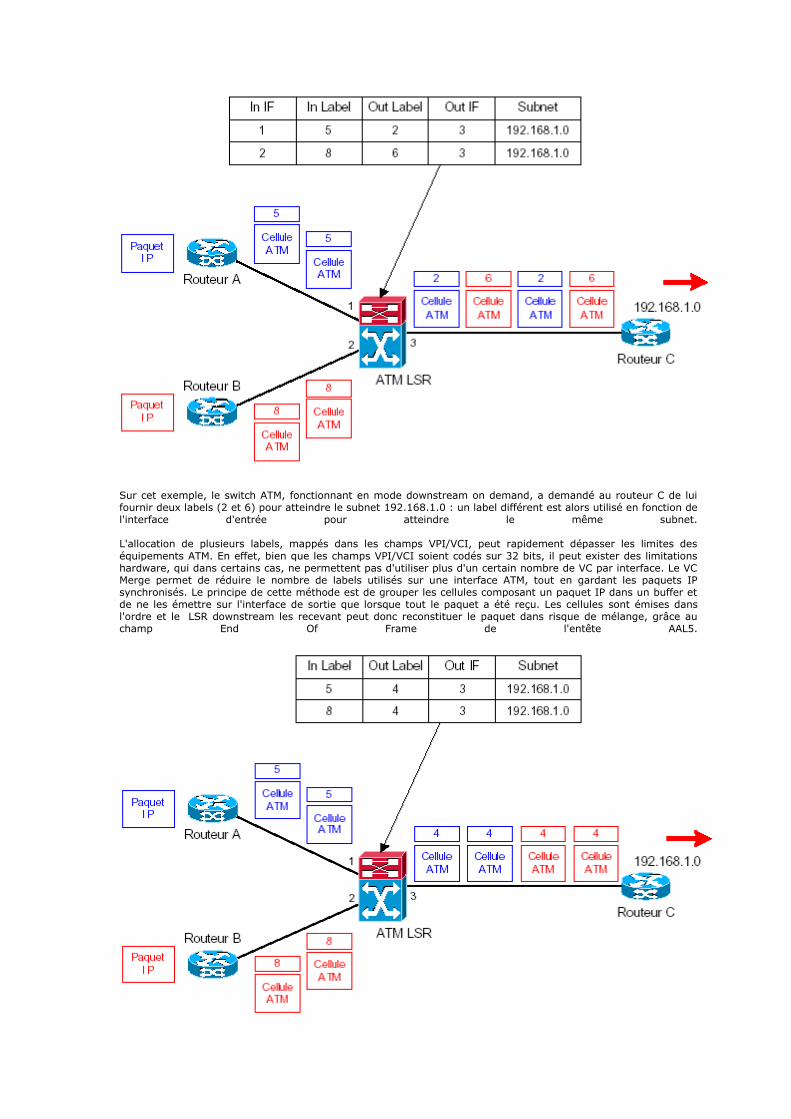
Sur cet exemple, le switch ATM, fonctionnant en mode downstream on demand, a demandé au routeur C de lui fournir deux labels (2 et 6) pour atteindre le subnet 192.168.1.0 : un label différent est alors utilisé en fonction de l'interface d'entrée pour atteindre le même subnet. L'allocation de plusieurs labels, mappés dans les champs VPI/VCI, peut rapidement dépasser les limites des
équipements ATM. En effet, bien que les champs VPI/VCI soient codés sur 32 bits, il peut exister des limitations hardware, qui dans certains cas, ne permettent pas d'utiliser plus d'un certain nombre de VC par interface. Le VC Merge permet de réduire le nombre de labels utilisés sur une interface ATM, tout en gardant les paquets IP synchronisés. Le principe de cette méthode est de grouper les cellules composant un paquet IP dans un buffer et de ne les émettre sur l'interface de sortie que lorsque tout le paquet a été reçu. Les cellules sont émises dans l'ordre et le LSR downstream les recevant peut donc reconstituer le paquet dans risque de mélange, grâce au champ End Of Frame de l'entête AAL5.

L'avantage de cette méthode est de pouvoir affecter un label unique pour chaque subnet IP traité. Toutefois, la bufferisation des paquets augmente la latence de transmission des paquets, et le débit de l'interface risque d'être limité.
3.10 - Pile de labels (label stacking)
Chaque paquet MPLS est susceptible de transporter plusieurs labels, formant ainsi une pile de labels, qui sont
empilés et dépilés par les LSR. Cette possibilité d'empiler des labels, désignée sous le terme de Label Stacking, est utilisée par le Traffic Engineering et MPLS / VPN. Lorsqu'un LSR commute un paquet, seul le premier label est traité, comme le montre la figure suivante:
3.11 - Description de l'entête MPLS
Un label MPLS occupe 4 octets (32-bits) et se présente sous la forme:
La signification des différents champs est données ci-dessous: - Label (20 bits) - Exp (3 bits): Champ expérimental, utilisé pour la QoS. Equivalent au champ TOS de l'entête IP ;
- S (1 bit): Champ "bottom of stack". Lorsque ce bit est à 1, le bas de la pile est atteint, et l'entête de niveau 3
est placé juste après. - TTL (8 bits): Ce champ a le même rôle que le champ TTL de l'entête IP. Le format des labels MPLS est générique et peut notamment être utilisé sur Ethernet, 802.3, PPP, Frame-Relay et sur des PVC ATM (backbone ATM natif). En cas d'emploi d'un médium non supporté (par ex. ISDN), des tunnels
GRE peuvent être mis en place. L'adjacence TDP peut alors s'établir entre les deux extrémités du tunnel et les paquets labellisés sont encapsulés dans IP.
3.12 - Configuration d'un routeur LSR
Cette partie, axée sur la configuration IOS, indique la liste des différentes étapes devant être suivies pour configurer MPLS sur un backbone IP. Les configurations résultantes sont fonctionnelles bien que dénuées d'intérêt pratique, aucun service spécifique à MPLS n'étant mis en oeuvre. Elles permettent toutefois d'appréhender les changements induits par MPLS au niveau des commandes IOS par rapport à des routeurs purement IP. Les
configurations minimales MPLS ainsi décrites peuvent être consultées en Annexe 1 de ce document.

3.12.1 - Configuration de CEF
La première opération à effectuer pour utiliser MPLS est d'activer CEF (Cisco Express Forwarding) comme méthode de commutation sur tous les routeurs du backbone. En effet, CEF est la seule méthode de routage
capable d'utiliser la TFIB pour commuter les paquets. En cas d'oubli, MPLS ne sera pas fonctionnel. CEF se configure avec la commande globale: "ip cef [distributed]". Le mot-clé optionnel "distributed" permet d'activer CEF de manière distribuée sur les routeurs disposant de cartes de routage et de cartes filles comme les cartes VIP des routeurs 7500. Ce type de carte fait tourner une version réduite d'IOS et a une certaine autonomie de fonctionnement car disposant d'un processeur et de mémoire dédiée.
3.12.2 - Configuration d'un IGP
Un protocole de routage interne doit être utilisé sur le backbone pour pouvoir diffuser les labels MPLS. Il est conseillé d'utiliser un protocole "link-state", tel que OSPF ou IS-IS, qui sont les seuls à permettre le Traffic Engineering. Il est bien entendu nécessaire de s'assurer que la connectivité est établie partout sur le
backbone avant de procéder à la configuration de MPLS.
3.12.3 - Configuration de TDP / LDP
Pour permettre à un routeur d'établir une adjacence TDP avec un voisin sur une interface donnée, cette interface doit être configurée avec la commande "tagswitching ip". Bien que le protocole LDP (standard de l'IETF) ne soit pas encore supporté, la commande "mpls ip" (correspondant à LDP) existe dans la version 12.1(5)T. Toutefois, cette commande a le même effet que "tag-switching ip".
4 - Virtual Private Networks (VPN)
Actuellement, il est très courant qu'une entreprise soit constituée de plusieurs sites géographiques (parfois très
éloignés) et dont elle souhaite interconnecter les réseaux informatiques à travers un WAN (Wide Area Network). La solution la plus connue et la plus employée consiste à relier les sites au moyen de liaisons spécialisées, dédiées à l'entreprise. Toutefois, le coût prohibitif de ces liaisons, et éventuellement la non aisabilité technique, par exemple avec des sites séparés de plusieurs centaines de km, amènent à rechercher des solutions plus abordables. Les fournisseurs d'accès Internet disposent de backbones étendus, et couvrant la plupart du temps une large portion de territoire. Il est donc plus simple pour une entreprise de relier ses sites aux points de présence (POP) de l'opérateur
et mettre en place une solution VPN (Virtual Private Networks). MPLS/VPN fournit une méthode de raccordement de sites appartenant à un ou plusieurs VPN, avec possibilité de recouvrement des plans d'adressage IP pour des VPN différents. En effet, l'adressage IP privé (voir RFC 1918) est très employé aujourd'hui, et rien ne s'oppose à ce que plusieurs entreprises utilisent les mêmes plages d'adresses (par exemple 172.16.1.0/24). MPLS/VPN permet d'isoler le trafic entre sites n'appartenant pas au même VPN, et en étant
totalement transparent pour ces sites entre eux. Dans l'optique MPLS/VPN, un VPN est un ensemble de sites placés sous la même autorité administrative, ou groupés suivant un intérêt particulier. Cette partie aborde les concepts de MPLS/VPN, en particulier avec les notions de routeurs virtuels (VRF) et le protocole MP-BGP, dédié à l'échange de routes VPN. Dans les documents présentant MPLS/VPN, les VPN sont généralement définis avec des noms de couleurs (red, blue, etc.). Cette convention sera conservée dans ce rapport.
4.1 - Réseau de démonstration
Dans cette partie, le réseau de démonstration est constitué du pod L10, avec R6 et R7 comme placés en tant que
routeurs clients. Afin de séparer le plan d'adressage du backbone MPLS (adresses en 10.x.y.z), les adresses utilisées par les VPN sont du type 100.x.y.z, avec les mêmes conventions que précédemment. Par exemple, l'interface Loopback0 du routeur L10-R6 sera 100.10.6.6.
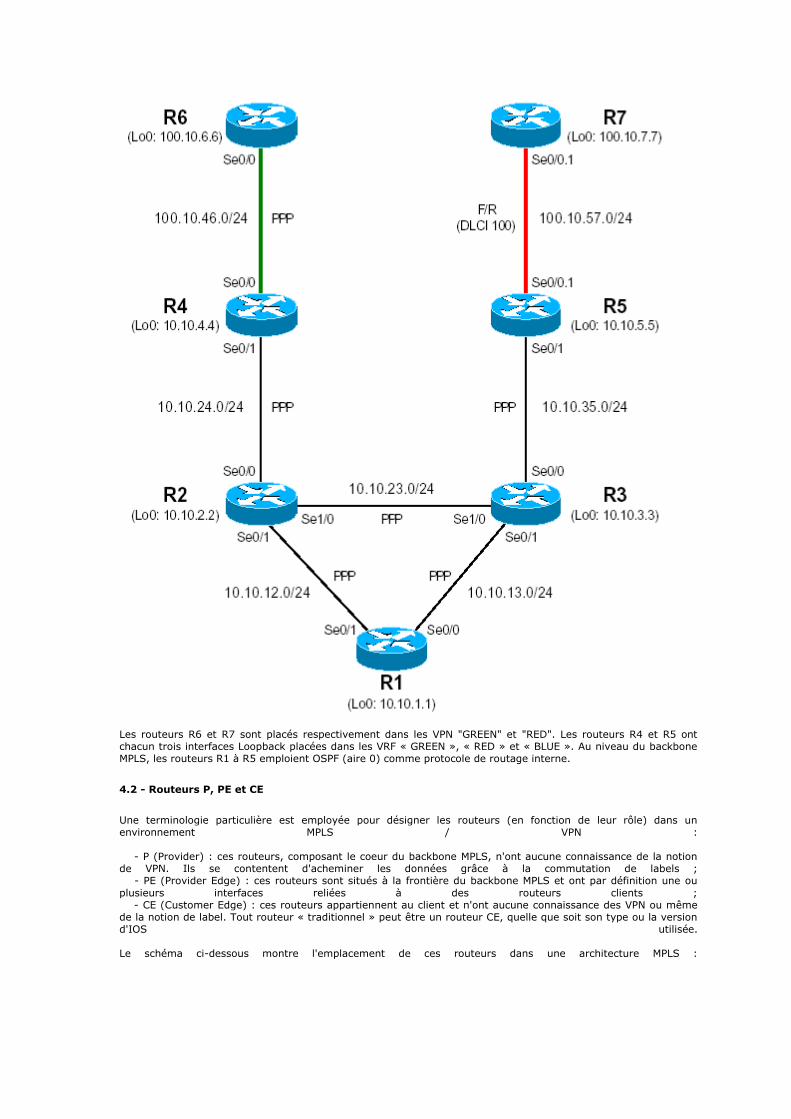
Les routeurs R6 et R7 sont placés respectivement dans les VPN "GREEN" et "RED". Les routeurs R4 et R5 ont chacun trois interfaces Loopback placées dans les VRF « GREEN », « RED » et « BLUE ». Au niveau du backbone MPLS, les routeurs R1 à R5 emploient OSPF (aire 0) comme protocole de routage interne.
4.2 - Routeurs P, PE et CE
Une terminologie particulière est employée pour désigner les routeurs (en fonction de leur rôle) dans un environnement MPLS / VPN : - P (Provider) : ces routeurs, composant le coeur du backbone MPLS, n'ont aucune connaissance de la notion de VPN. Ils se contentent d'acheminer les données grâce à la commutation de labels ; - PE (Provider Edge) : ces routeurs sont situés à la frontière du backbone MPLS et ont par définition une ou
plusieurs interfaces reliées à des routeurs clients ; - CE (Customer Edge) : ces routeurs appartiennent au client et n'ont aucune connaissance des VPN ou même de la notion de label. Tout routeur « traditionnel » peut être un routeur CE, quelle que soit son type ou la version d'IOS utilisée. Le schéma ci-dessous montre l'emplacement de ces routeurs dans une architecture MPLS :

4.3 - Routeurs virtuels : VRF
La notion même de VPN implique l'isolation du trafic entre sites clients n'appartenant pas aux mêmes VPN. Pour réaliser cette séparation, les routeurs PE ont la capacité de gérer plusieurs tables de routage grâce à la notion de VRF (VPN Routing and Forwarding). Une VRF est constituée d'une table de routage, d'une FIB (Forwarding Information Base) et d'une table CEF spécifiques, indépendantes des autres VRF et de la table de routage globale. Chaque VRF est désignée par un nom (par ex. RED, GREEN, etc.) sur les routeurs PE. Les noms sont affectés
localement, et n'ont aucune signification vis-à-vis des autres routeurs. Chaque interface de PE reliée à un site client est rattachée à une VRF particulière. Lors de la réception de paquets IP sur une interfaces client, le routeur PE procède à un examen de la table de routage de la VRF à laquelle est rattachée l'interface, et donc ne consulte pas sa table de routage globale. Cette possibilité d'utiliser plusieurs tables de routage indépendantes permet de gérer un plan d'adressage par sites, même en cas de recouvrement d'adresses entre VPN différents. Par exemple, L10-R4 est configuré de la manière suivante pour ses interfaces Loopback :
interface Loopback1 ip vrf forwarding BLUE ip address 100.10.4.4 255.255.255.255
! interface Loopback2
ip vrf forwarding RED ip address 100.10.4.4 255.255.255.255 ! interface Loopback3 ip vrf forwarding GREEN
ip address 100.10.4.4 255.255.255.255 !
La commande « ip vrf forwarding <vrf> » permet de placer une interface dans la VRF spécifiée. Comme le montre
l'exemple ci-dessus, la même adresse IP peut être affectée plusieurs fois à différentes interfaces, car celles-ci sont placées dans des VRF différentes. Pour construire leurs tables VRF, les PE doivent s'échanger les routes correspondant aux différents VPN. En effet, pour router convenablement les paquets destinés à un PE nommé PE-1, relié au site CE-1, le routeur PE-2 doit connaître les routes VPN de PE- 1. L'échange des routes VPN s'effectue grâce au protocole MP-BGP, décrit dans le paragraphe suivant. Les configurations des VRF ne comportant que des paramètres relatifs à MP-BGP (notamment
pour l'export et l'import des routes), la syntaxe IOS et des exemples pratiques seront donc donnés dans les paragraphes suivants. Les VRF disposant de tables de routage et de tables CEF spécifiques, il est possible de les

consulter grâce à une extension des commandes classiques. Par exemple, pour consulter la table de routage de la VRF « RED » sur L10-R4, il suffit d'employer la commande « show ip route vrf <vrf> » :
L10-R4# sh ip route vrf RED
Gateway of last resort is not set
100.0.0.0/8 is variably subnetted, 6 subnets, 2 masks B 100.10.57.0/24 [200/0] via 10.10.5.5, 01:10:46 B 100.10.7.7/32 [200/0] via 10.10.5.5, 01:10:46 B 100.10.5.5/32 [200/0] via 10.10.5.5, 01:10:46 C 100.10.4.4/32 is directly connected, Loopback2 B 100.10.172.0/24 [200/0] via 10.10.5.5, 01:10:46
B 100.10.171.0/24 [200/0] via 10.10.5.5, 01:10:46
Si l'on examine la table de routage globale de L10-R4, on constate qu'il s'agit bien d'une table complètement différente et indépendante :
L10-R4# sh ip route Gateway of last resort is not set 10.0.0.0/8 is variably subnetted, 11 subnets, 2 masks O 10.10.5.5/32 [110/2401] via 10.10.24.2, 01:04:51, Serial0/1
O 10.10.3.3/32 [110/1601] via 10.10.24.2, 01:04:51, Serial0/1 O 10.10.1.1/32 [110/1601] via 10.10.24.2, 01:04:51, Serial0/1 O 10.10.2.2/32 [110/801] via 10.10.24.2, 01:04:51, Serial0/1 C 10.10.4.4/32 is directly connected, Loopback0 O 10.10.12.0/24 [110/1600] via 10.10.24.2, 01:04:51, Serial0/1 O 10.10.13.0/24 [110/2400] via 10.10.24.2, 01:04:51, Serial0/1 O 10.10.23.0/24 [110/1600] via 10.10.24.2, 01:04:51, Serial0/1
C 10.10.24.0/24 is directly connected, Serial0/1
C 10.10.24.2/32 is directly connected, Serial0/1 O 10.10.35.0/24 [110/2400] via 10.10.24.2, 01:04:51, Serial0/1
La table CEF d'une VRF peut également être examinée, au moyen de la commande « show ip cef vrf <vrf> <subnet> » :
L10-R4# sh ip cef vrf RED 100.10.7.7 100.10.7.7/32, version 24, cached adjacency to Serial0/1
0 packets, 0 bytes tag information set local tag: VPN-route-head fast tag rewrite with Se0/1, point2point, tags imposed: {27 30} via 10.10.5.5, 0 dependencies, recursive next hop 10.10.24.2, Serial0/1 via 10.10.5.5/32
valid cached adjacency tag rewrite with Se0/1, point2point, tags imposed: {27 30}
La table CEF permet donc de déterminer le Next-Hop, l'interface de sortie et les labels utilisés pour atteindre un subnet particulier.
4.4 - Multiprotocol BGP (MP-BGP)
Le protocole MP-BGP est une extension du protocole BGP 4, et permettant d'échanger des routes Multicast et des
routes VPNv4. MP-BGP adopte une terminologie similaire à BGP concernant le peering : - MP- BGP : peering entre routeurs d'un même AS ; - MP-eBGP : peering entre routeurs situés dans 2 AS différents.
4.4.1 - Notion de RD (Route Distinguisher)
Des sites appartenant à des VPN isolés ayant la possibilité d'utiliser des plans d'adressage recouvrants, les
routes échangées entre PE doivent être rendues uniques au niveau des updates BGP. Pour cela, un identifiant appelé RD (Route Distinguisher), codé sur 64 bits, est accolé à chaque subnet IPv4 d'une VRF donnée. Le RD s'écrit sous la forme « ASN:nn » ou « IP-Address:nn ». Dans les exemples de configuration fournis avec ce document, le paramètre ASN a été fixé arbitrairement à 100, et « nn » choisi en fonction de la VRF, quel que soit le routeur. Il est toutefois conseillé de choisir un RD unique par routeur et par VRF. Une route VPNv4, formé d'un RD et d'un préfixe IPv4, s'écrit ainsi sous la forme RD:Subnet/Masque. Exemple : 100:1:100.10.5.5/32. Lors de la création d'une VRF sur un PE, un RD doit être configuré. Les routes apprises
soit localement (routes statiques, Loopback sur le PE), soit par les CE rattachés au PE seront ainsi exportées

dans les updates MP-BGP avec ce RD. Les RD affectés aux différentes VRF existantes sur un PE peuvent être consultés au moyen de la commande « show ip vrf » :
L10-R4# sh ip vrf
Name Default RD Interfaces
BLUE 100:1 Loopback1 GREEN 100:3 Serial0/0 Loopback3 RED 100:2 Loopback2
On constate que les interfaces connectées aux VRF sont également listées par cette commande.
4.4.2 - Notion de RT (Route Target)
Le RD permet de garantir l'unicité des routes VPNv4 échangées entre PE, mais ne définit pas la manière dont les routes vont être insérées dans les VRF des routeurs PE. L'import et l'export de routes sont gérés grâce à une communauté étendue BGP (extended community) appelée RT (Route Target). Les RT ne sont rien de plus que des sortes de filtres appliqués sur les routes VPNv4. Chaque VRF définie sur un PE est configurée pour exporter ses routes suivant un certain nombre de RT. Une route VPN exportée avec un RT donné sera ajoutée dans les VRF des autres PE important ce RT. Par exemple, si la route VPN 2000:1:192.168.1.0/24 est
exportée par un routeur PE avec comme liste de RT 2000:500 et 2000:501, tous les autres routeurs PE ayant une ou plusieurs VRF important au minimum un de ces deux RT ajouteront cette route dans leurs VRF concernées. La configuration simple pour un VPN consiste à appliquer la règle : RT_import = RT_export = RT_VPN
(Avec RT_VPN choisi comme identifiant spécifique au VPN).
Sur la figure ci-dessus, les 3 sites rouges appartiennent au même VPN. Pour échanger les routes entre tous
les sites, chaque PE importe et exporte le RT 500:1000. Le schéma suivant indique la marche à suivre pour créer une topologie de type « hub and spoke » :

Dans ce exemple, le site vert est un site central (par ex. pour l'administration des différents VPN). Chacun des 3 sites, appartenant à un VPN différent (Rouge, Violet et Bleu) importe les routes du site central (RT 500:1001). Réciproquement, le site central importe les routes de tous les sites clients (RT 500:1000). Bien que le site central ait accès à tous les sites clients, ceux-ci ne peuvent se voir entre eux. En effet, aucune relation de RT n'est définie entre les sites clients (aucun site n'importe ou n'exporte de route vers un autre).
Naturellement, comme le site vert « voit » les 3 sites clients, le plan d'adressage de ces sites doit être compatible (c'est-à-dire non recouvrant) au niveau des routes échangées pour garantir l'unicité des routes vis-à-vis du site central.
4.4.3 - Configuration d'une VRF
Les VRF sont configurées sur les routeurs PE avec les paramètres suivants : - Nom de VRF (case-sensitive) ; - RD (Route Distinguisher) ; - RT exportés ;
- RT importés ; - Filtres sur l'import et l'export des routes (optionnel). Le paramétrage d'une VRF « TEST » (avec un RD de 500:1000), exportant ses routes avec les RT 500:1 et 500:2 et important les routes avec les RT 500:1 et 500:3, serait le suivant :
ip vrf TEST rd 500:1000 route-target export 500:1 route-target export 500:2 route-target import 500:1
route-target import 500:3 !
4.4.4 - Updates MP-BGP
En plus du RD et des RT, les updates MP-BGP contiennent d'autres informations, telles que le Site d'Origine (SOO), l'adresse IP du PE annonçant la route (PE nexthop) et le label VPN affecté par ce PE.

4.4.5 - Configuration MP-BGP d'un PE
La configuration d'un routeur PE pour échanger des routes VPNv4 se présente sous la forme suivante :
router bgp 10 no synchronization bgp log-neighbor-changes
neighbor 10.10.1.1 remote-as 10 neighbor 10.10.1.1 update-source Loopback0 no neighbor 10.10.1.1 activate no auto-summary ! address-family vpnv4 neighbor 10.10.1.1 activate
neighbor 10.10.1.1 send-community extended no auto-summary exit-address-family !
On remarque la présence d'une section supplémentaire par rapport à une configuration BGP traditionnelle, introduite par la commande « address-family vpnv4 ». Cette partie de la configuration BGP contient tous les voisins tournant MP-BGP. Pour pouvoir ajouter un voisin dans la configuration VPNv4, ce voisin doit être préalablement déclaré dans la configuration globale de BGP (commande « remote- s » et autres). Pour éviter qu'un voisin ne soit actif à la fois pour BGP et MP-BGP, la ligne « no neighbor <neighbor> activate » doit être insérée globalement. Naturellement, il est tout à fait possible pour un routeur d'être actif pour BGP et MP-
BGP simultanément. Par exemple, le BGP traditionnel servira à propager les routes Internet aux routeurs PE, tandis que MP-BGP servira à la propagation des routes VPN. Pour propager les Route-Target (RT), qui définissent l'appartenance aux VPN et qui sont des communautés étendues BGP, la ligne « neighbor <neighbor> sendcommunity extended » doit être utilisée.
Dans le réseau de démonstration MPLS/VPN, le routeur L10-R1 fait office de Route Reflector BGP. Sa
configuration est la suivante :
router bgp 10 no synchronization
no bgp default route-target filter bgp log-neighbor-changes bgp cluster-id 10 neighbor iBGP peer-group no neighbor iBGP activate neighbor iBGP remote-as 10
neighbor iBGP update-source Loopback0 neighbor iBGP soft-reconfiguration inbound no auto-summary ! address-family vpnv4 neighbor iBGP activate neighbor iBGP route-reflector-client
neighbor iBGP send-community extended

neighbor 10.10.2.2 peer-group iBGP neighbor 10.10.3.3 peer-group iBGP neighbor 10.10.4.4 peer-group iBGP neighbor 10.10.5.5 peer-group iBGP
no auto-summary
exit-address-family !
Afin de faciliter l'ajout de nouveaux voisins, la notion de « peer-group » a été utilisée. Un peer group est défini par un nom, et il est possible de fixer certaines propriétés pour ce groupe : AS distant (remote-as), interface source pour les updates (update-source), etc. Chaque voisin est ensuite ajouté dans ce groupe avec un commande du type: « neighbor 10.10.5.5 peer-group iBGP ». Dans cet exemple, toutes les commandes appliquées au groupe « iBGP » le seront pour le voisin 10.10.5.5.
4.4.6 - Vérification du fonctionnement de MP-BGP
Plusieurs commandes existent pour s'assurer du bon fonctionnement de BGP sur les routeurs. Par exemple, pour connaître toutes les routes apprises par MP-BGP sur un routeur donné, la commande « show ip bgp vpnv4 all » peut être utilisée :
L10-R4# sh ip bgp vpnv4 all BGP table version is 129, local router ID is 10.10.4.4 Status codes: s suppressed, d damped, h history, * valid, > best, i -
internal Origin codes: i - IGP, e - EGP, ? - incomplete Network Next Hop Metric LocPrf Weight Path Route Distinguisher: 100:1 (default for vrf BLUE)
*> 100.10.4.4/32 0.0.0.0 0 32768 ? *>i100.10.5.5/32 10.10.5.5 0 100 0 ?
Route Distinguisher: 100:2 (default for vrf RED) *> 100.10.4.4/32 0.0.0.0 0 32768 ? *>i100.10.5.5/32 10.10.5.5 0 100 0 ? *>i100.10.7.7/32 10.10.5.5 0 100 0 102 i *>i100.10.57.0/24 10.10.5.5 0 100 0 ? *>i100.10.171.0/24 10.10.5.5 0 100 0 102 i *>i100.10.172.0/24 10.10.5.5 0 100 0 102 i
Route Distinguisher: 100:3 (default for vrf GREEN) *>i100.10.3.3/32 10.10.3.3 0 100 0 ? *> 100.10.4.4/32 0.0.0.0 0 32768 ? *>i100.10.5.5/32 10.10.5.5 0 100 0 ? *> 100.10.6.6/32 100.10.46.6 1 32768 ? *> 100.10.46.0/24 0.0.0.0 0 32768 ?
*> 100.10.46.6/32 0.0.0.0 0 32768 ? *> 100.10.161.0/24 100.10.46.6 1 32768 ? *> 100.10.162.0/24 100.10.46.6 1 32768 ? Route Distinguisher: 100:2000 *>i100.10.3.3/32 10.10.3.3 0 100 0 ?
Si l'on souhaite se restreindre à une VRF donnée, la commande « show ip bgp vpnv4 vrf <vrf> » peut être employée :
L10-R4# sh ip bgp vpnv4 vrf RED BGP table version is 129, local router ID is 10.10.4.4 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal Origin codes: i - IGP, e - EGP, ? - incomplete Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 100:2 (default for vrf RED) *> 100.10.4.4/32 0.0.0.0 0 32768 ? *>i100.10.5.5/32 10.10.5.5 0 100 0 ? *>i100.10.7.7/32 10.10.5.5 0 100 0 102 i *>i100.10.57.0/24 10.10.5.5 0 100 0 ? *>i100.10.171.0/24 10.10.5.5 0 100 0 102 i
*>i100.10.172.0/24 10.10.5.5 0 100 0 102 i
Les labels fournis dans les updates MP-BGP peuvent être affichés au moyen de la commande « sh ip bgp vpnv4 [vrf <vrf> | all] tags » :
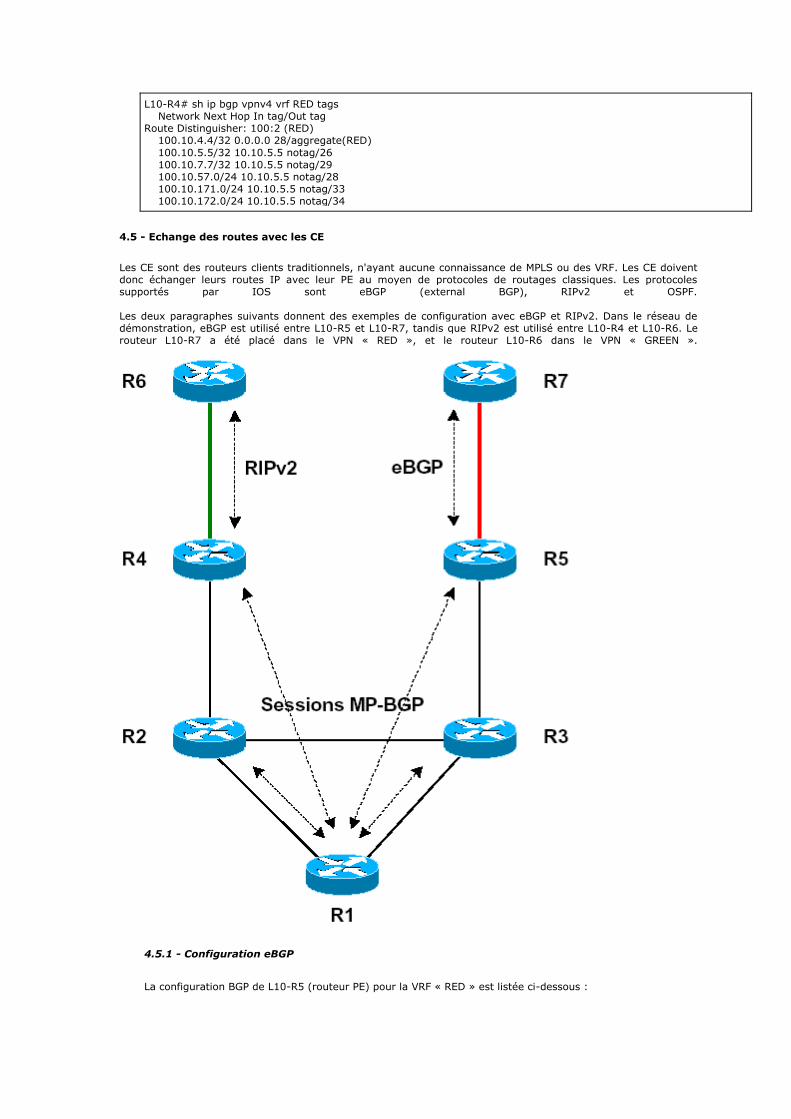
L10-R4# sh ip bgp vpnv4 vrf RED tags Network Next Hop In tag/Out tag Route Distinguisher: 100:2 (RED) 100.10.4.4/32 0.0.0.0 28/aggregate(RED)
100.10.5.5/32 10.10.5.5 notag/26
100.10.7.7/32 10.10.5.5 notag/29 100.10.57.0/24 10.10.5.5 notag/28 100.10.171.0/24 10.10.5.5 notag/33 100.10.172.0/24 10.10.5.5 notag/34
4.5 - Echange des routes avec les CE
Les CE sont des routeurs clients traditionnels, n'ayant aucune connaissance de MPLS ou des VRF. Les CE doivent donc échanger leurs routes IP avec leur PE au moyen de protocoles de routages classiques. Les protocoles supportés par IOS sont eBGP (external BGP), RIPv2 et OSPF.
Les deux paragraphes suivants donnent des exemples de configuration avec eBGP et RIPv2. Dans le réseau de démonstration, eBGP est utilisé entre L10-R5 et L10-R7, tandis que RIPv2 est utilisé entre L10-R4 et L10-R6. Le routeur L10-R7 a été placé dans le VPN « RED », et le routeur L10-R6 dans le VPN « GREEN ».
4.5.1 - Configuration eBGP
La configuration BGP de L10-R5 (routeur PE) pour la VRF « RED » est listée ci-dessous :

router bgp 10 ! [...] address-family ipv4 vrf RED
redistribute connected
neighbor 100.10.57.7 remote-as 102 neighbor 100.10.57.7 activate no auto-summary no synchronization exit-address-family
[...] !
L'interface reliant L10-R5 et L10-R7 étant paramétrée comme suit (sur L10-R5):
interface Serial0/0.1 point-to-point description Vers L10-R7 bandwidth 125 ip vrf forwarding RED
ip address 100.10.57.5 255.255.255.0 frame-relay interface-dlci 100
Chaque voisin devant être actif en eBGP dans une VRF donné doit donc être configuré dans la section « address-family ipv4 vrf <vrf> » correspondante. A titre indicatif, la configuration BGP de L10-R7 est fournie
ci-dessous:
router bgp 102
bgp log-neighbor-changes
network 100.10.7.7 mask 255.255.255.255 network 100.10.171.0 mask 255.255.255.0 network 100.10.172.0 mask 255.255.255.0 neighbor 100.10.57.5 remote-as 10 !
On constate donc que la configuration du routeur CE est tout à fait classique, sans présence de VRF ou de toute autre notion de VPN.
4.5.2 - Configuration RIPv2
La configuration RIPv2 avec un routeur CE suit le même principe qu'une configuration eBGP, mais les routes apprises par RIP doivent être réinjectées dans MP-BGP et réciproquement :
router rip version 2 ! address-family ipv4 vrf GREEN version 2
redistribute bgp 10 metric 1 network 100.0.0.0 no auto-summary
exit-address-family ! [...]
router bgp 10 [...] address-family ipv4 vrf GREEN redistribute connected redistribute rip no auto-summary no synchronization
exit-address-family ! [...]
L'interface reliant L10-R4 et L10-R6 est paramétrée de la manière suivante (sur L10-R4):

interface Serial0/0 description Vers L10-R6 bandwidth 125 ip vrf forwarding GREEN
ip address 100.10.46.4 255.255.255.0
encapsulation ppp no fair-queue clockrate 125000 end
4.6 - Transmission des paquets IP
La transmission des paquets IP provenant des CE sur le backbone MPLS emploie la notion de label stacking. Pour atteindre un site donné, le PE source encapsule deux labels : le premier sert à atteindre le PE de destination, tandis que le second détermine l'interface de sortie sur le PE, à laquelle est reliée le CE. Le second label est appris grâce aux updates MP-BGP. Les tables CEF des routeurs peuvent être consultées pour déterminer les labels
utilisées. Par exemple, supposons que l'on souhaite connaître les tags employés pour atteindre l'adresse de Loopback 100.10.5.5 configurée sur le routeur L10-R5, et placée dans la VRF « RED ». La consultation de la table de routage de la VRF « RED » sur L10-R4 montre que le next-hop est bien L10-R5 (10.10.5.5):
L10-R4# sh ip route vrf RED Gateway of last resort is not set 100.0.0.0/8 is variably subnetted, 6 subnets, 2 masks B 100.10.57.0/24 [200/0] via 10.10.5.5, 00:01:45 B 100.10.7.7/32 [200/0] via 10.10.5.5, 00:01:46
B 100.10.5.5/32 [200/0] via 10.10.5.5, 00:01:46
C 100.10.4.4/32 is directly connected, Loopback2 B 100.10.172.0/24 [200/0] via 10.10.5.5, 00:01:46 B 100.10.171.0/24 [200/0] via 10.10.5.5, 00:01:46
Le label utilisé pour atteindre L10-R5 est déterminé grâce à la table CEF globale du routeur :
L10-R4# sh ip cef 10.10.5.5 10.10.5.5/32, version 41, cached adjacency to Serial0/1
0 packets, 0 bytes tag information set local tag: 17 fast tag rewrite with Se0/1, point2point, tags imposed: {27} via 10.10.24.2, Serial0/1, 7 dependencies next hop 10.10.24.2, Serial0/1
valid cached adjacency tag rewrite with Se0/1, point2point, tags imposed: {27}
L10-R4 imposera donc le label 27 pour atteindre L10-R5, le prochain saut étant le routeur L10-R2 (10.10.24.2). Le deuxième label (dit label VPN), servant à sélectionner l'interface de sortie sur L10-R5, peut être déterminé
grâce à la table CEF de la VRF « RED », indépendante de la table CEF globale :
L10-R4# sh ip cef vrf RED 100.10.5.5 100.10.5.5/32, version 23, cached adjacency to Serial0/1
0 packets, 0 bytes tag information set local tag: VPN-route-head fast tag rewrite with Se0/1, point2point, tags imposed: {27 26} via 10.10.5.5, 0 dependencies, recursive next hop 10.10.24.2, Serial0/1 via 10.10.5.5/32 valid cached adjacency
tag rewrite with Se0/1, point2point, tags imposed: {27 26}
Le label VPN est donc 26. Pour joindre l'adresse IP 100.10.5.5 de la VRF « RED », le routeur L10-R4 imposera donc la pile de label { 27 26 }. Sur le backbone MPLS, la commutation se fera uniquement en fonction du premier
label, comme le montre le résultat de la commande traceroute :
L10-R4# trace vrf RED 100.10.5.5
1 10.10.24.2 [MPLS: Labels 27/26 Exp 0] 72 msec 72 msec 68 msec

2 10.10.23.3 [MPLS: Labels 23/26 Exp 0] 56 msec 60 msec 60 msec 3 100.10.57.5 28 msec * 28 msec
On remarque que seul le premier label a été modifié, le label VPN ayant été conservé intact pendant tout le
cheminement sur le backbone. La copie d'écran suivante montre quel aurait été le résultat de la commande traceroute pour atteindre l'adresse de Loopback 10.10.5.5 (adresse globale) à partir de L10-R4 :
L10-R4# trace 10.10.5.5 1 10.10.24.2 [MPLS: Label 27 Exp 0] 68 msec 68 msec 64 msec 2 10.10.23.3 [MPLS: Label 23 Exp 0] 52 msec 56 msec 56 msec 3 10.10.35.5 28 msec * 24 msec
Il apparaît clairement que la présence du label VPN n'a pas d'effet sur les routeurs P du backbone : ceux-ci switchent les paquets entre routeurs PE et n'ont aucune information sur les labels VPN. Rappelons que les labels VPN, appris par MP-BGP, peuvent être affichés au moyen de la commande « show ip bgp
vpnv4 vrf <vrf> tags » :
L10-R4# sh ip bgp vpnv4 vrf RED tags Network Next Hop In tag/Out tag
Route Distinguisher: 100:2 (RED) 100.10.4.4/32 0.0.0.0 28/aggregate(RED) 100.10.5.5/32 10.10.5.5 notag/26 100.10.7.7/32 10.10.5.5 notag/30 100.10.57.0/24 10.10.5.5 notag/28 100.10.171.0/24 10.10.5.5 notag/31
100.10.172.0/24 10.10.5.5 notag/32
On retrouve bien le label 26 pour atteindre le subnet 100.10.5.5/32 sur le routeur L10-R5. Si l'on effectue un traceroute vers l'adresse 100.10.7.7, appartenant à L10-R7, on obtient le résultat suivant :
L10-R4# trace vrf RED 100.10.7.7 Type escape sequence to abort. Tracing the route to 100.10.7.7
1 10.10.24.2 [MPLS: Labels 27/30 Exp 0] 96 msec 92 msec 92 msec 2 10.10.23.3 [MPLS: Labels 23/30 Exp 0] 84 msec 88 msec 84 msec 3 100.10.57.5 [MPLS: Label 30 Exp 0] 76 msec 76 msec 72 msec 4 100.10.57.7 36 msec * 36 msec
On constate la présence du Penultimate Hop Popping, entre les routeurs L10-R3 (10.10.24.3) et L10-R5. (100.10.57.5). En effet, L10-R3 a retiré le premier label 23, servant à atteindre L10-R5. Ce fonctionnement est confirmé en consultant la table TFIB de L10-R3 :
L10-R3# sh tag for Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface
16 Untagged 10.10.13.1/32 0 Se0/1 point2point 17 Untagged 10.10.35.5/32 0 Se0/0 point2point 18 Untagged 10.10.23.2/32 0 Se1/0 point2point
20 Pop tag 10.10.1.1/32 1693 Se0/1 point2point 21 Pop tag 10.10.2.2/32 0 Se1/0 point2point 22 20 10.10.4.4/32 3020 Se1/0 point2point 23 Pop tag 10.10.5.5/32 5821 Se0/0 point2point 26 Pop tag 10.10.12.0/24 0 Se1/0 point2point Pop tag 10.10.12.0/24 0 Se0/1 point2point 27 Pop tag 10.10.24.0/24 2304 Se1/0 point2point
29 Aggregate 100.10.3.3/32[V] 0
L10-R3# sh ip cef 10.10.5.5 10.10.5.5/32, version 34, cached adjacency to Serial0/0
0 packets, 0 bytes tag information set
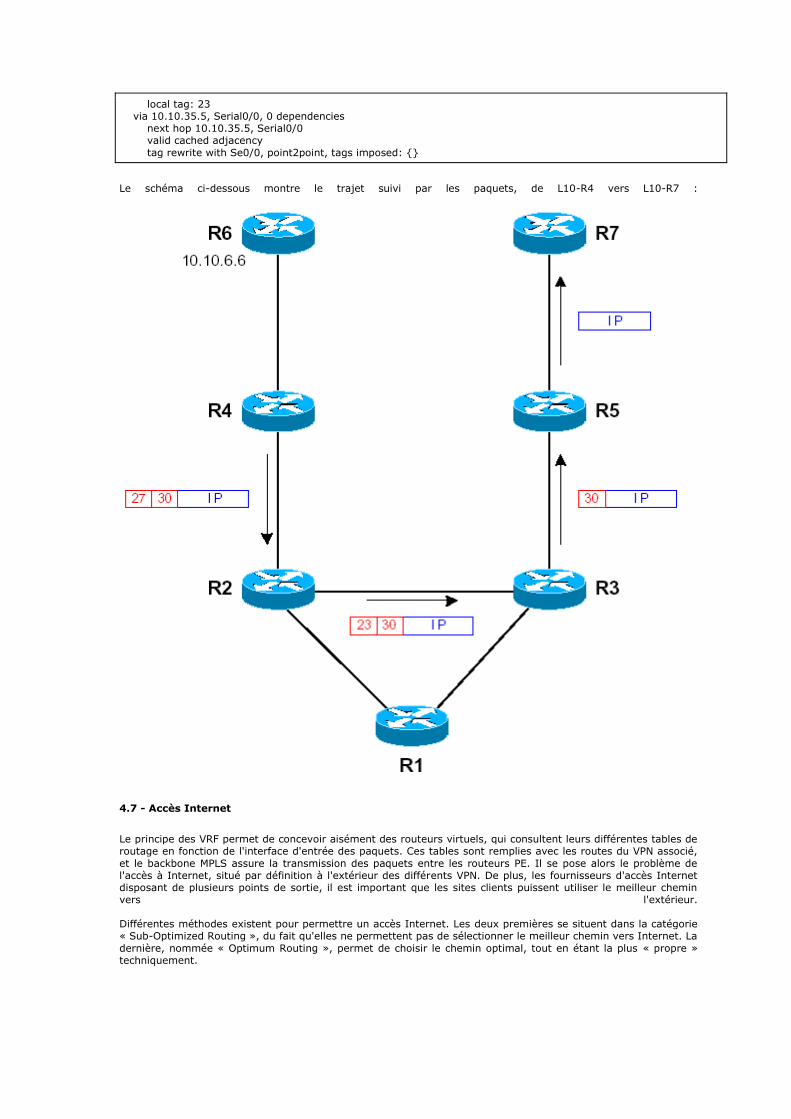
local tag: 23 via 10.10.35.5, Serial0/0, 0 dependencies next hop 10.10.35.5, Serial0/0 valid cached adjacency
tag rewrite with Se0/0, point2point, tags imposed: {}
Le schéma ci-dessous montre le trajet suivi par les paquets, de L10-R4 vers L10-R7 :
4.7 - Accès Internet
Le principe des VRF permet de concevoir aisément des routeurs virtuels, qui consultent leurs différentes tables de routage en fonction de l'interface d'entrée des paquets. Ces tables sont remplies avec les routes du VPN associé,
et le backbone MPLS assure la transmission des paquets entre les routeurs PE. Il se pose alors le problème de l'accès à Internet, situé par définition à l'extérieur des différents VPN. De plus, les fournisseurs d'accès Internet disposant de plusieurs points de sortie, il est important que les sites clients puissent utiliser le meilleur chemin vers l'extérieur. Différentes méthodes existent pour permettre un accès Internet. Les deux premières se situent dans la catégorie « Sub-Optimized Routing », du fait qu'elles ne permettent pas de sélectionner le meilleur chemin vers Internet. La
dernière, nommée « Optimum Routing », permet de choisir le chemin optimal, tout en étant la plus « propre » techniquement.

4.7.1 - Route par défaut statique (Static Default Route)
La première méthode (la plus ancienne) consiste à une utiliser une extension de la commande « ip route » pour définir une route par défaut dans les VRF des routeurs PE, au moyen de la commande :
ip route vrf GREEN 0.0.0.0 0.0.0.0 PE-Internet global
où PE-Internet est l'adresse globale du PE fournissant l'accès à Internet. Pour que le retour des paquets puisse être effectif vers le CE concerné, les routes VPN du CE doivent être déclarées globalement sur son PE de rattachement, et propagées au PE-Internet (IGP, iBGP, etc.). Par exemple, si un réseau 120.2.1.0/24 est connecté à un CE 120.1.1.1 appartenant au VPN « GREEN », le PE doit contenir les deux lignes suivantes :
ip route vrf GREEN 0.0.0.0 0.0.0.0 120.1.1.2 global ip route 120.2.1.0 255.255.255.0 120.1.1.1
Dans cet exemple, on a supposé que PE-Internet a pour adresse 120.1.1.2. Lorsque le PE recevra un paquet sur la VRF « GREEN », il effectuera un lookup dans la table de routage de cette VRF. Si aucune entrée n'est trouvée pour la destination IP, la route par défaut injectée au moyen de la commande « ip route » sera utilisée. Il est à noter que la table de routage globale du routeur est examinée pour atteindre PEInternet, et que les paquets traversent le backbone MPLS sans label VPN (seul le label de
PE-Internet est accolé par le PE). Naturellement, ce type de routage n'est pas optimal, car si plusieurs PE disposent d'un accès Internet, seul le PE déclaré dans la route par défaut sera employé. De plus, cette méthode « casse » la notion de VRF avec la déclaration des routes VPN de manière globale sur les PE. Enfin, tous les PE doivent être configurés de cette manière, avec pour chacun la route par défaut et la mise en place dans la table de routage globale des routes
VPN.
4.7.2 - Route par défaut dynamique (Dynamic Default Route)
Une solution plus propre techniquement pour propager une route par défaut à tous les PE est d'utiliser la
notion de VPN avec une topologie « Hub and Spoke ». Sur le routeur PE-Internet, une VRF particulière est configurée pour annoncer la route par défaut (apprise par un autre routeur, généralement avec eBGP). Si l'on souhaite propager manuellement cette route à un certains sites de différents VPN, il suffit d'employer la politique d'attribution des RT du schéma ci-dessous :
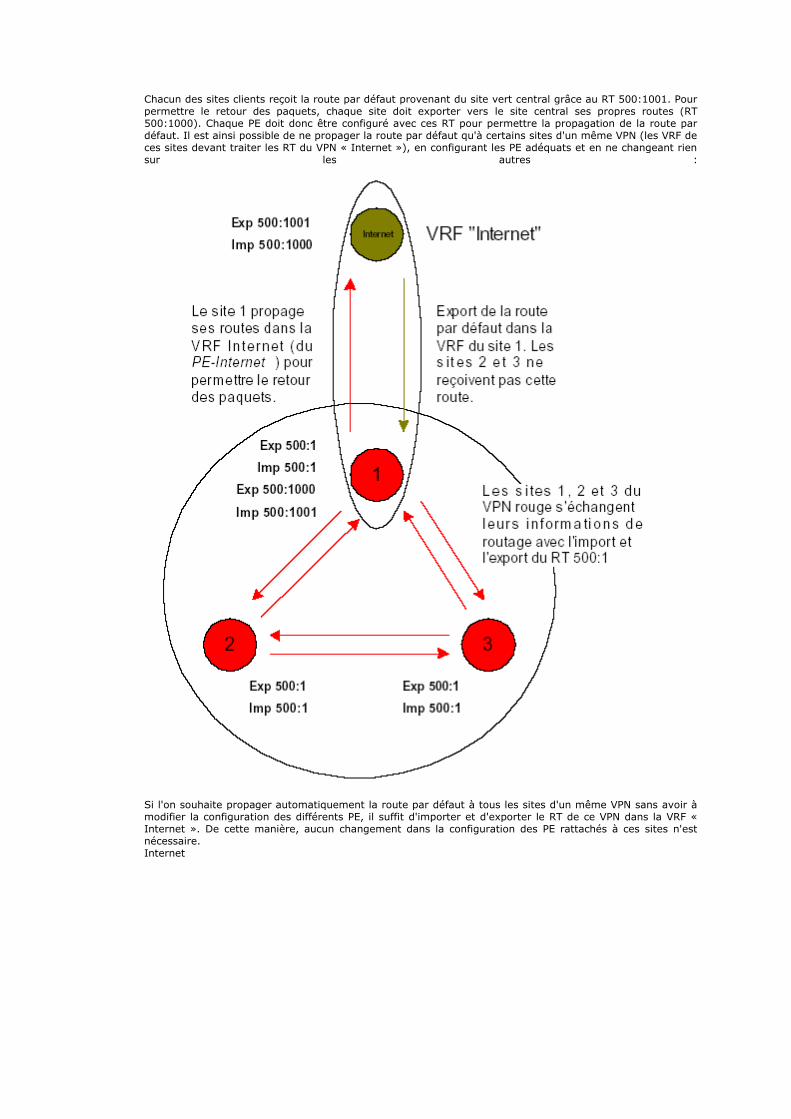
Chacun des sites clients reçoit la route par défaut provenant du site vert central grâce au RT 500:1001. Pour permettre le retour des paquets, chaque site doit exporter vers le site central ses propres routes (RT 500:1000). Chaque PE doit donc être configuré avec ces RT pour permettre la propagation de la route par défaut. Il est ainsi possible de ne propager la route par défaut qu'à certains sites d'un même VPN (les VRF de ces sites devant traiter les RT du VPN « Internet »), en configurant les PE adéquats et en ne changeant rien
sur les autres :
Si l'on souhaite propager automatiquement la route par défaut à tous les sites d'un même VPN sans avoir à modifier la configuration des différents PE, il suffit d'importer et d'exporter le RT de ce VPN dans la VRF « Internet ». De cette manière, aucun changement dans la configuration des PE rattachés à ces sites n'est nécessaire. Internet

4.7.3 - Routage optimal (Optimum Routing)
La méthode dite « Optimum Routing » permet aux sites clients d'accéder à Internet, tout en sélectionnant le meilleur chemin si plusieurs PE sont passerelles vers l'extérieur. Le concept clé de l'Optimum Routing est de propager l'ensemble des routes Internet sur tous les PE du
backbone MPLS. Naturellement, il n'est pas possible de propager ces routes dans chaque VPN : en supposant que l'on compte 100000 routes Internet ; propager ces routes dans 100 VPN différents (soit 10 millions de routes au total) n'est évidemment pas réalisable. Les routes Internet sont donc échangées entre PE grâce au protocole BGP standard (sessions iBGP entre les PE), et ce sont les tables de routage globales des PE qui contiennent ces routes. Pour permettre aux sites d'accéder à l'extérieur, les CE sont reliés de deux manières au backbone de
l'opérateur : la première connexion permet l'accès aux routes Internet globales, tandis que la seconde permet l'accès aux autres sites du VPN, avec l'utilisation d'une VRF.

La mise en place d'une double liaison avec le CE (une avec VRF, l'autre sans) peut être réalisée au moyen de deux sous-interfaces (2 VLAN sur trunk Ethernet, 2 DLCI sur Frame Relay, 2 VC sur ATM, etc.) ou avec un tunnel GRE. Exemple de configuration avec une interface Frame-Relay :
interface Serial1/0 no ip address encapsulation frame-relay !
interface Serial1/0.1 description Interface pour accès Internet ip address 100.2.1.1 255.255.255.252 frame-relay interface-dlci 100 ! interface Serial1/0.2 description Interface pour accès VPN
ip vrf forwarding RED ip address 10.2.1.1 255.255.255.252 frame-relay interface-dlci 200 !
Exemple de configuration avec une interface Ethernet en mode trunk :
interface FastEthernet0/0 no ip address
! interface FastEthernet0/0.1 description Interface pour accès Internet ip address 100.1.1.1 255.255.255.252 encapsulation isl 1 ! interface FastEthernet0/0.2
description Interface pour accès VPN ip vrf forwarding GREEN ip address 10.1.1.1 255.255.255.252 encapsulation isl 2 !

Sur le CE, deux approches sont possibles pour accéder à la fois aux autres sites du VPN et à Internet. La première, la plus classique, consiste à sélectionner l'interface de sortie grâce au Policy Routing, au moyen des commandes route-map. La seconde consiste à employer la notion de VRF sur le routeur CE lui-même, mais sans utilisation de MP-BGP. Les VRF peuvent en effet être mises en place sur un routeur, indépendamment de MPLS/VPN. L'exemple suivant montre comment implémenter le Policy Routing sur un CE
(en reprenant l'exemple du PE ci-dessus, connecté au CE par une interface FastEthernet) avec translation d'adresse (NAT) :
interface FastEthernet0/0 description Vers site client ip address 10.2.0.1 255.255.255.0
ip policy route-map ACCESS ip nat inside ! interface FastEthernet1/0 no ip address ! interface FastEthernet1/0.1
description Interface pour accès Internet ip address 100.1.1.2 255.255.255.252 encapsulation isl 1 ip nat outside ! interface FastEthernet1/0.2 description Interface pour accès VPN
ip address 10.1.1.2 255.255.255.252 encapsulation isl 2 ! ip classless ip route 0.0.0.0 0.0.0.0 10.1.1.1
! route-map ACCESS permit 10
match ip address 100 set ip next-hop 100.1.1.1 ! ip nat inside source list 101 interface FastEthernet1/0.1 overload access-list 100 deny ip any 10.0.0.0 0.255.255.255 access-list 100 permit ip any any
access-list 101 permit ip 10.0.0.0 0.255.255.255 any !
Pour cet exemple, il est supposé que le VPN client emploie le réseau 10.0.0.0/8 dans son plan d'adressage IP interne. Le route-map « ACCESS » permet de rediriger le trafic destiné à Internet (c'est-à-dire n'étant pas
dirigé vers une adresse en 10.x.y.z, voir liste d'accès 100) sur l'interface « Internet », FastEthernet1/0.1. Pour pouvoir communiquer avec l'extérieur, une translation des adresses source en 10.0.0.0/8 (voir liste d'accès 101) du site doit également avoir lieu. Cette action est réalisée avec les commandes « ip nat [...] ». Remarque: en cas d'utilisation des VRF sur un routeur CE, il est important de garder à l'esprit que certaines fonctions (par exemple NAT, HSRP, etc.) peuvent ne pas être supportées avec des interfaces VRF.
4.8 - Signalisation Inter-AS (MP-eBGP)
A partir de la version 12.1(5)T, il devient possible de créer relier des sites d'un 3ême VPN à travers des
Autonomous Systems différents. En effet, l'annonce des routes VPNv4 inter-AS est fonctionnelle, ainsi que la
transmission des paquets labellisés entre plusieurs backbones. Le peering MP-eBGP se fait de manière similaire au peering MP-iBGP, à l'exception naturellement du numéro d'AS et du format des updates MP-eBGP, qui subit quelques légères adaptations. Chaque routeur d'interconnexion entre deux AS va annoncer les routes VPNv4 à ses voisins externes avec un seul label. Ce label sera utilisé entre les 2 AS pour la transmission des paquets.
Des tests ont été effectués lors du Workshop MPLS avec les versions 12.1(5)T et 12.2(0.4) pour étudier le fonctionnement de MP-eBGP. Pour cela, les deux pods, L10 et L20, ont été raccordés au moyen d'une liaison FastEthernet entre les deux routeurs R1. La signalisation MP-BGP est alors la suivante :
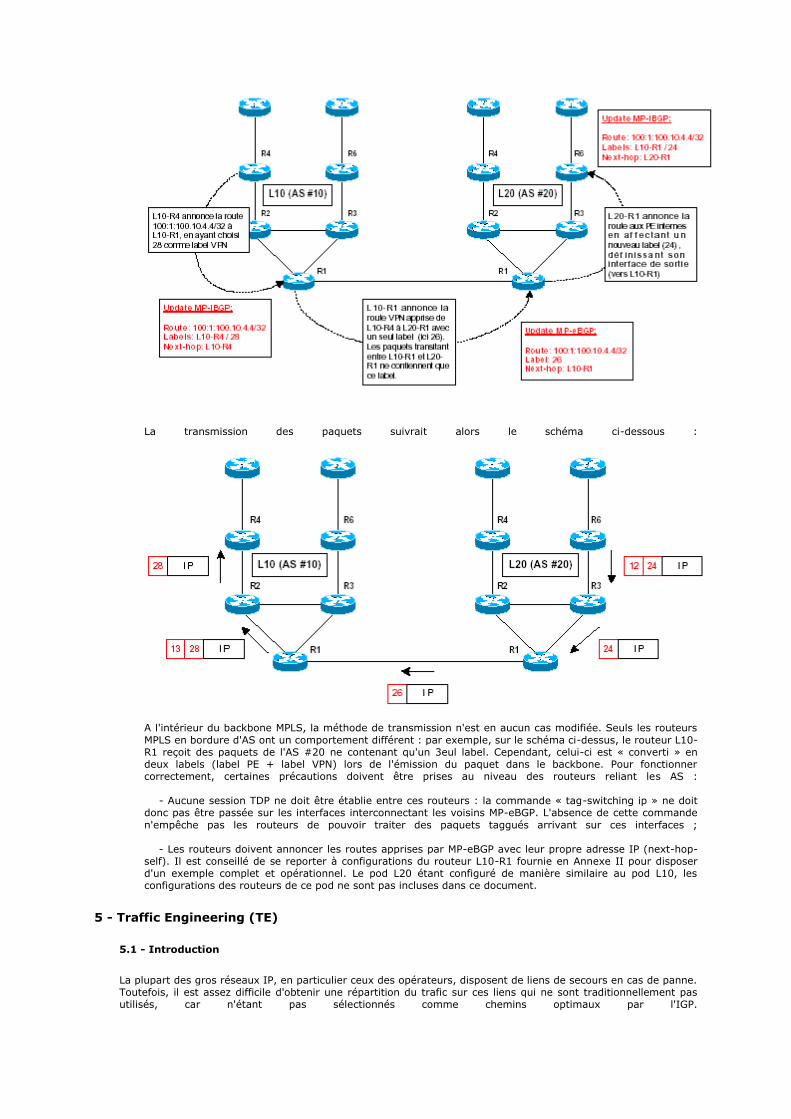
La transmission des paquets suivrait alors le schéma ci-dessous :
A l'intérieur du backbone MPLS, la méthode de transmission n'est en aucun cas modifiée. Seuls les routeurs
MPLS en bordure d'AS ont un comportement différent : par exemple, sur le schéma ci-dessus, le routeur L10-R1 reçoit des paquets de l'AS #20 ne contenant qu'un 3eul label. Cependant, celui-ci est « converti » en deux labels (label PE + label VPN) lors de l'émission du paquet dans le backbone. Pour fonctionner correctement, certaines précautions doivent être prises au niveau des routeurs reliant les AS :
- Aucune session TDP ne doit être établie entre ces routeurs : la commande « tag-switching ip » ne doit donc pas être passée sur les interfaces interconnectant les voisins MP-eBGP. L'absence de cette commande
n'empêche pas les routeurs de pouvoir traiter des paquets taggués arrivant sur ces interfaces ; - Les routeurs doivent annoncer les routes apprises par MP-eBGP avec leur propre adresse IP (next-hop-self). Il est conseillé de se reporter à configurations du routeur L10-R1 fournie en Annexe II pour disposer d'un exemple complet et opérationnel. Le pod L20 étant configuré de manière similaire au pod L10, les configurations des routeurs de ce pod ne sont pas incluses dans ce document.
5 - Traffic Engineering (TE)
5.1 - Introduction
La plupart des gros réseaux IP, en particulier ceux des opérateurs, disposent de liens de secours en cas de panne. Toutefois, il est assez difficile d'obtenir une répartition du trafic sur ces liens qui ne sont traditionnellement pas utilisés, car n'étant pas sélectionnés comme chemins optimaux par l'IGP.

Le Trafic Engineering permet un meilleur emploi des liaisons, puisqu'il permet aux administrateurs réseau d'établir des tunnels LSP à travers le backbone MPLS, indépendamment de l'IGP.
5.2 - Types de tunnels
Les tunnels MPLS (appelés également trunks) peuvent être créés en indiquant la liste des routeurs à emprunter (méthode explicite) ou bien en utilisant la notion d'affinité (méthode dynamique). La notion d'affinité est simplement une valeur sur 32 bits spécifiée sur les interfaces des routeurs MPLS. La sélection du chemin s'effectue alors en indiquant (sur le routeur initiant le tunnel) une affinité et un masque.
5.3 - Critères de bande passante
Pour permettre une gestion plus souple du trafic, chaque interface MPLS susceptible d'être un point de transit pour des tunnels MPLS dispose d'une notion de priorité, définie sur 8 niveaux. Lors de l'établissement d'un nouveau tunnel, si celui-ci a une priorité plus grande que les autres tunnels et que la bande passante totale utilisable pour le TE est insuffisante, alors un tunnel moins prioritaire sera fermé. Ce mode de fonctionnement est appelé préemption.
Les niveaux de priorité sont codés avec valeur de 0 à 8, 0 correspondant à la priorité plus élevée et 8 à la priorité la plus basse. Chaque interface MPLS/TE doit être configurée avec un débit maximum alloué pour le Traffic Engineering. Par exemple, il est possible de n'autoriser que 50 Kb/s pour les tunnels sur une interface ayant un débit de 128 Kb/s. Pour bien comprendre la notion de préemption, considérons l'exemple suivant : un tunnel de priorité 3 avec une bande passante (BW) de 50 Kb/s est déjà établie sur une interface autorisant 100 Kb/s de tunnels MPLS. Le
routeur autorisera l'établissement d'un tunnel de priorité inférieure (>= 3) jusqu'à un débit de 50 Kb/s, c'est-à-dire la bande passante disponible. Par contre, si une demande pour l'établissement d'un tunnel de priorité supérieure survient (< 3), alors le routeur considère que la bande passante disponible est de 100 Kb/s. Le nouveau tunnel sera ainsi établi, et des tunnels de priorité moindre seront fermés si besoin est (préemption). Il
est important de garder à l'esprit que créer un tunnel MPLS ne garantit pas la présence de la bande passante tout au long du réseau. En effet, les interfaces des routeurs sont configurées pour allouer un certain débit au TE ; mais
en cas de congestion d'un lien avec du trafic hors tunnel, les tunnels n'auront pas de bande passante garantie.
5.4 - Etablissement d'un tunnel
Pour permettre au Trafic Engineering de fonctionner, le protocole de routage interne (IGP) doit être un protocole à état de liens (link-state). En effet, pour déterminer le chemin à emprunter par un tunnel, les routeurs doivent avoir la connaissance complète de la topologie du réseau. Les seuls protocoles supportant le TE sont donc OSPF et ISIS. Des extensions ont été rajoutés à ces deux protocoles pour gérer les critères de bande passante et de priorité sur les liens du réseau. Pour OSPF, des Opaque LSA ont été mis en place et pour IS-IS de nouveaux
enregistrements TLV ont été créés. Pour choisir le meilleur chemin correspondant aux critères de bande passante spécifiés, l'algorithme de SPF de ces protocoles a été modifié pour tenir compte de ces contraintes. Cet algorithme de calcul du meilleur chemin pour les tunnels LSP est appelé PCALC et permet donc le Constrained Based Routing. L'algorithme PCALC est le suivant :
- Supprimer les liens qui ne disposent pas de la bande passante suffisante ; - Supprimer les liens qui ne correspondent pas à l'affinité demandé ; - Exécuter l'algorithme de Dijkstra sur la topologie restante (avec les métriques de l'IGP) ; - Si plusieurs chemins subsistent, maximiser la valeur V, définie comme étant le minimum des valeurs de bande passante disponible sur chaque lien du chemin. Cela permet de load-balancer les tunnels de mêmes
critères sur plusieurs chemins différents ;
- S'il existe encore plusieurs chemins, sélectionner celui-ci avec le nombre minimal de sauts (hops) ; - Enfin, si plusieurs chemins sont encore présents, en choisir un aléatoirement. L'établissement d'un tunnel, après exécution de l'algorithme PCALC, est réalisé au moyen du protocole RSVP, auquel des extensions ont été rajoutées pour permettre le TE. Chaque noeud du chemin vérifie si les critères demandés sont compatibles avec son état actuel ; dans le cas contraire, la signalisation RSVP déclenche une annulation et le noeud « floode » son état pour en informer ses voisins.
5.5 - Réoptimisation
Un mécanisme important du Traffic Engineering est le fait de pouvoir réoptimiser les chemins empruntés par les tunnels LSP. Pour éviter une rupture dans le routage, un nouveau tunnel est établi parallèlement de celui déjà ouvert. Dès que l'établissement du tunnel de remplacement est réussie, le premier tunnel est fermé.
5.6 - Configuration IOS
Ce paragraphe présente les différentes étapes de configurations permettant d'activer le Traffic Engineering sur un backbone MPLS déjà en place.

5.6.1 - Activation globale de Traffic Engineering
Pour qu'un LSR puisse gérer le TE, la commande « mpls traffic-eng tunnels » doit être saisie en mode de configuration globale.
5.6.2 - Configuration de l'IGP
Suivant l'IGP (OSPF ou IS-IS), la méthode de configuration diffère :
- OSPF :
router ospf 10
network 10.0.0.0 0.255.255.255 area 0 mpls traffic-eng router-id Loopback0 mpls traffic-eng area 0 !
- IS-IS :
router isis net 49.0020.4444.4444.4444.00
metric-style wide mpls traffic-eng router-id Loopback0 mpls traffic-eng level-1 !
5.6.3 - Configurations des interfaces
Chaque interface MPLS devant permettre le Traffic Engineering doit être configurée de la manière analogue à l'exemple ci-dessous :
interface serial 0/0 ip address 10.20.24.4 255.255.255.0
no ip directed-broadcast bandwidth 125 encapsulation ppp tag-switching ip mpls traffic-eng tunnels ip rsvp bandwidth 100 100
!
La commande « mpls traffic-eng tunnels » permet d'autoriser le passage de tunnels LSP à travers cette interface.
La commande « ip rsvp bandwidth » indique quel débit en Kb/s peut être utilisé pour les tunnels.
5.6.4 - Création d'un tunnel explicite
En prenant comme exemple le pod L20 avec l'établissement d'un tunnel entre L20-R4 et L20-R3, la configuration de L20-R4 serait la suivante :
interface Tunnel1
ip unnumbered Loopback0 no ip directed-broadcast no ip route-cache cef tunnel destination 10.20.3.3 tunnel mode mpls traffic-eng tunnel mpls traffic-eng autoroute announce tunnel mpls traffic-eng bandwidth 10
tunnel mpls traffic-eng path-option 1 explicit name WAY1 ! ip explicit-path name WAY1 enable next-address 10.20.24.2 next-address 10.20.12.1 next-address 10.20.13.3 !

La liste des hops, définie par le chemin explicite « WAY1 » est ainsi : - L20-R2 (10.20.24.2) - L20-R1 (10.20.12.1) - L20-R3 (10.20.13.3)
5.6.5 - Création d'un tunnel dynamique
La création d'un tunnel dynamique est relativement similaire à la création d'un tunnel explicite. Ici, l'affinité est fixée à 0x10, avec un masque de 0x11.
interface Tunnel2 ip unnumbered Loopback0 no ip directed-broadcast no ip route-cache cef tunnel destination 10.20.3.3
tunnel mode mpls traffic-eng tunnel mpls traffic-eng autoroute announce tunnel mpls traffic-eng bandwidth 10 tunnel mpls traffic-eng affinity 0x10 mask 0x11 tunnel mpls traffic-eng path-option 1 dynamic
5.7 - Utilisation avec MPLS/VPN
Pour assurer un bon fonctionnement du Traffic Engineering avec MPLS/VPN, les deux extrémités des tunnels doivent établir une adjacence TDP. Pour cela, deux tunnels LSP doivent être établis (un pour chaque direction) et la commande « tagswitching ip » passée sur les interfaces Tunnels.
Au niveau de la transmission des paquets, 3 labels sont utilisés : un label correspondant au tunnel sera placé en première position, les deux labels MPLS/VPN (label PE + label VPN) étant placés après. Le label de tunnel est naturellement retiré par l'extrémité terminale du tunnel, et les paquets sont ensuite forwardés normalement.
6 - Conclusion
- A l'origine développé pour la rapidité, la commutation de paquets par tag switching a permis la mise en oeuvre de solutions de plus haut niveau, comme les VPN ou le Traffic Engineering. MPLS rassemble en une seule entité l'efficacité des protocoles de niveau 3, alliée à la vitesse de commutation de niveau 2.
7 - Annexe I: Configurations MPLS simples
Configuration de L10-R1 :
! version 12.2 no service single-slot-reload-enable
service timestamps debug uptime service timestamps log uptime no service password-encryption !
hostname L10-R1 ! boot system flash slot0:c3620-js-mz.122-0.4.bin
logging rate-limit console 10 except errors enable secret 5 $1$AKNE$ZjooLX5ZFP7nbGr6E/ejh/ ! ip subnet-zero ! no ip finger no ip domain-lookup
! ip cef no ip dhcp-client network-discovery call rsvp-sync ! interface Loopback0
ip address 10.10.1.1 255.255.255.255 ! interface Serial0/0

description Vers L10-R3 bandwidth 125 ip address 10.10.13.1 255.255.255.0 encapsulation ppp
clockrate 125000
! interface Serial0/1 description Vers L10-R2 bandwidth 125 ip address 10.10.12.1 255.255.255.0
encapsulation ppp clockrate 125000 ! router ospf 10 log-adjacency-changes passive-interface Ethernet0/0 network 10.0.0.0 0.255.255.255 area 0
! ip classless no ip http server ! line con 0 exec-timeout 0 0 transport input none
line aux 0 line vty 0 4 exec-timeout 0 0 password cisco login ! end
Configuration de L10-R2 :
! version 12.2 no service single-slot-reload-enable service timestamps debug uptime service timestamps log uptime
no service password-encryption ! hostname L10-R2 ! boot system flash flash:c3640-js-mz.122-0.4.bin logging rate-limit console 10 except errors enable secret 5 $1$M7Ig$NBWKag8D2u7Q9sOU9xDfm/
! ip subnet-zero ! no ip finger no ip domain-lookup ! ip cef
no ip dhcp-client network-discovery call rsvp-sync
! interface Loopback0 ip address 10.10.2.2 255.255.255.255 !
interface Serial0/0 description Vers L10-R4 bandwidth 125 ip address 10.10.24.2 255.255.255.0 encapsulation ppp clockrate 125000 !
interface Serial0/1 description Vers L10-R1 bandwidth 125 ip address 10.10.12.2 255.255.255.0 encapsulation ppp ! interface Serial1/0
description Vers L10-R3

bandwidth 125 ip address 10.10.23.2 255.255.255.0 encapsulation ppp clockrate 125000
!
router ospf 10 log-adjacency-changes network 10.0.0.0 0.255.255.255 area 0 ! ip classless
no ip http server ! line con 0 exec-timeout 0 0 transport input none line aux 0 line vty 0 4
exec-timeout 0 0 password cisco login ! end
Configuration de L10-R3 :
!
version 12.2 no service single-slot-reload-enable service timestamps debug uptime
service timestamps log uptime no service password-encryption ! hostname L10-R3
! boot system flash slot0:c3640-js-mz.122-0.4.bin logging rate-limit console 10 except errors enable secret 5 $1$3Paa$QoFQfhYLZLCidMokHBanf1 ! ip subnet-zero
! no ip finger no ip domain-lookup ! ip cef no ip dhcp-client network-discovery call rsvp-sync
! interface Loopback0 ip address 10.10.3.3 255.255.255.255 ! interface Serial0/0 description Vers L10-R5 bandwidth 125
ip address 10.10.35.3 255.255.255.0 encapsulation ppp
clockrate 125000 ! interface Serial0/1 description Vers L10-R1
bandwidth 125 ip address 10.10.13.3 255.255.255.0 encapsulation ppp ! interface Serial1/0 description Vers L10-R2 bandwidth 125
ip address 10.10.23.3 255.255.255.0 encapsulation ppp ! router ospf 10 log-adjacency-changes network 10.0.0.0 0.255.255.255 area 0 !
ip classless

no ip http server ! line con 0 exec-timeout 0 0
transport input none
line aux 0 line vty 0 4 exec-timeout 0 0 password cisco login
! end
Configuration de L10-R4 :
! version 12.2 no service single-slot-reload-enable service timestamps debug uptime
service timestamps log uptime no service password-encryption ! hostname L10-R4 ! boot system flash slot0:c3620-js-mz.122-0.4.bin logging rate-limit console 10 except errors
enable secret 5 $1$mLZz$9KLAmd1tA023Bd5Z5mV.s1 ! ip subnet-zero
! no ip finger no ip domain-lookup !
ip cef no ip dhcp-client network-discovery call rsvp-sync ! interface Loopback0 ip address 10.10.4.4 255.255.255.255
! interface Serial0/0 description Vers L10-R6 bandwidth 125 ip address 10.10.46.4 255.255.255.0 encapsulation ppp no fair-queue
clockrate 125000 ! interface Serial0/1 description Vers L10-R2 bandwidth 125 ip address 10.10.24.4 255.255.255.0 encapsulation ppp
! router ospf 10
log-adjacency-changes network 10.0.0.0 0.255.255.255 area 0 ! ip classless
no ip http server ! line con 0 exec-timeout 0 0 transport input none line aux 0 line vty 0 4
exec-timeout 0 0 password cisco login ! end
Configuration de L10-R5 :

! version 12.2 no service single-slot-reload-enable service timestamps debug uptime
service timestamps log uptime
no service password-encryption ! hostname L10-R5 ! boot system flash flash:c3620-js-mz.122-0.4.bin
logging rate-limit console 10 except errors enable secret 5 $1$m80i$NykiaSFf0D9EdTDAjJozu. ! ip subnet-zero ! no ip finger no ip domain-lookup
! ip cef no ip dhcp-client network-discovery frame-relay switching call rsvp-sync ! interface Loopback0
ip address 10.10.5.5 255.255.255.255 ! interface Serial0/0 no ip address encapsulation frame-relay clockrate 125000 frame-relay lmi-type cisco
frame-relay intf-type dce ! interface Serial0/0.1 point-to-point description Vers L10-R7 bandwidth 125 ip address 10.10.57.5 255.255.255.0
frame-relay interface-dlci 100 ! interface Serial0/1 description Vers L10-R3 bandwidth 125 ip address 10.10.35.5 255.255.255.0 encapsulation ppp
! router ospf 10 log-adjacency-changes network 10.0.0.0 0.255.255.255 area 0 ! ip classless no ip http server
! line con 0 exec-timeout 0 0 transport input none line aux 0 line vty 0 4
exec-timeout 0 0 password cisco login ! end
Configuration de L10-R6 :
!
version 12.2 no service single-slot-reload-enable service timestamps debug uptime service timestamps log uptime no service password-encryption ! hostname L10-R6
!

boot system flash flash:c2600-js-mz.122-0.4.bin logging rate-limit console 10 except errors enable secret 5 $1$bZ2c$wdF872FRcLXaObuYJD90u1 !
ip subnet-zero
! no ip finger no ip domain-lookup ! ip cef
no ip dhcp-client network-discovery call rsvp-sync ! interface Loopback0 ip address 10.10.6.6 255.255.255.255 ! interface Serial0/0
description Vers L10-R4 bandwidth 125 ip address 10.10.46.6 255.255.255.0 encapsulation ppp no fair-queue ! router ospf 10
log-adjacency-changes network 10.0.0.0 0.255.255.255 area 0 ! ip classless no ip http server ! line con 0
exec-timeout 0 0 transport input none line aux 0 line vty 0 4 exec-timeout 0 0 password cisco
login line vty 5 15 login ! end
Configuration de L10-R7 :
!
version 12.2 no service single-slot-reload-enable service timestamps debug uptime service timestamps log uptime no service password-encryption ! hostname L10-R7
! boot system flash flash:c2600-js-mz.122-0.4.bin
logging rate-limit console 10 except errors enable secret 5 $1$Fgps$hTMFn1J6vXX9P3Dh9JDaK/ ! ip subnet-zero
! no ip finger no ip domain-lookup ! ip cef no ip dhcp-client network-discovery call rsvp-sync
! interface Loopback0 ip address 10.10.7.7 255.255.255.255 ! interface Serial0/0 no ip address encapsulation frame-relay
frame-relay lmi-type cisco

! interface Serial0/0.1 point-to-point description Vers L10-R5 bandwidth 125
ip address 10.10.57.7 255.255.255.0
frame-relay interface-dlci 100 ! router ospf 10 log-adjacency-changes network 10.0.0.0 0.255.255.255 area 0
! ip classless no ip http server ! line con 0 exec-timeout 0 0 transport input none
line aux 0 line vty 0 4 password cisco login line vty 5 15 login !
end
8 - Annexe II: Configurations MPLS/VPN
Configuration de L10-R1 :
! version 12.2
no service single-slot-reload-enable service timestamps debug uptime service timestamps log uptime no service password-encryption ! hostname L10-R1 !
boot system flash slot0:c3620-js-mz.122-0.4.bin logging rate-limit console 10 except errors enable secret 5 $1$AKNE$ZjooLX5ZFP7nbGr6E/ejh/ ! ip subnet-zero !
no ip finger no ip domain-lookup ! ip cef no ip dhcp-client network-discovery call rsvp-sync !
interface Loopback0 ip address 10.10.1.1 255.255.255.255
! interface Ethernet0/0 ip address 200.1.112.1 255.255.255.0 half-duplex !
interface Serial0/0 description Vers L10-R3 bandwidth 125 ip address 10.10.13.1 255.255.255.0 encapsulation ppp clockrate 125000
tag-switching ip ! interface Serial0/1 description Vers L10-R2 bandwidth 125 ip address 10.10.12.1 255.255.255.0 encapsulation ppp
clockrate 125000

tag-switching ip ! interface FastEthernet1/0 ip address 50.50.50.1 255.255.255.0
duplex auto
speed auto ! router ospf 10 log-adjacency-changes passive-interface FastEthernet1/0
network 10.0.0.0 0.255.255.255 area 0 ! router bgp 10 no synchronization no bgp default route-target filter bgp log-neighbor-changes bgp cluster-id 10
neighbor iBGP peer-group no neighbor iBGP activate neighbor iBGP remote-as 10 neighbor iBGP update-source Loopback0 neighbor iBGP soft-reconfiguration inbound neighbor 50.50.50.2 remote-as 20 no neighbor 50.50.50.2 activate
no auto-summary ! address-family vpnv4 neighbor iBGP activate neighbor iBGP route-reflector-client neighbor iBGP send-community extended neighbor iBGP route-map NH_Rewrite out
neighbor 10.10.2.2 peer-group iBGP neighbor 10.10.3.3 peer-group iBGP neighbor 10.10.4.4 peer-group iBGP neighbor 10.10.5.5 peer-group iBGP neighbor 50.50.50.2 activate neighbor 50.50.50.2 send-community extended
no auto-summary exit-address-family ! route-map NH_Rewrite permit 10 match as-path 1 set ip next-hop peer-address !
route-map NH_Rewrite permit 20 ! ip as-path access-list 1 deny ^$ ip as-path access-list 1 permit .* ! ip classless no ip http server
! line con 0 exec-timeout 0 0 transport input none line aux 0 line vty 0 4
exec-timeout 0 0 password cisco login ! end
Configuration de L10-R2 :
!
version 12.2 no service single-slot-reload-enable service timestamps debug uptime service timestamps log uptime no service password-encryption ! hostname L10-R2
!

boot system flash flash:c3640-js-mz.122-0.4.bin logging rate-limit console 10 except errors enable secret 5 $1$M7Ig$NBWKag8D2u7Q9sOU9xDfm/ !
ip subnet-zero
! no ip finger no ip domain-lookup ! ip cef
no ip dhcp-client network-discovery call rsvp-sync ! interface Loopback0 ip address 10.10.2.2 255.255.255.255 ! interface Ethernet0/0
no ip address shutdown half-duplex ! interface Serial0/0 description Vers L10-R4 bandwidth 125
ip address 10.10.24.2 255.255.255.0 encapsulation ppp clockrate 125000 tag-switching ip ! interface Serial0/1 description Vers L10-R1
bandwidth 125 ip address 10.10.12.2 255.255.255.0 encapsulation ppp tag-switching ip ! interface Ethernet1/0
no ip address shutdown half-duplex ! interface Serial1/0 description Vers L10-R3 bandwidth 125
ip address 10.10.23.2 255.255.255.0 encapsulation ppp clockrate 125000 tag-switching ip ! router ospf 10 log-adjacency-changes
network 10.0.0.0 0.255.255.255 area 0 ! router bgp 10 no synchronization bgp log-neighbor-changes neighbor 10.10.1.1 remote-as 10
neighbor 10.10.1.1 update-source Loopback0 no auto-summary ! address-family vpnv4 neighbor 10.10.1.1 activate neighbor 10.10.1.1 send-community extended no auto-summary
exit-address-family ! ip classless no ip http server ! line con 0 exec-timeout 0 0
transport input none line aux 0 line vty 0 4 exec-timeout 0 0

password cisco login ! end
Configuration de L10-R3 :
! version 12.2 no service single-slot-reload-enable service timestamps debug uptime service timestamps log uptime
no service password-encryption ! hostname L10-R3 ! boot system flash slot0:c3640-js-mz.122-0.4.bin logging rate-limit console 10 except errors enable secret 5 $1$3Paa$QoFQfhYLZLCidMokHBanf1
! ip subnet-zero ! no ip finger no ip domain-lookup ! ip cef
no ip dhcp-client network-discovery call rsvp-sync !
ip vrf ADMIN rd 100:2000 route-target export 100:2000 route-target import 100:2001
! interface Loopback0 ip address 10.10.3.3 255.255.255.255 ! interface Loopback10 description Interface de Management
ip vrf forwarding ADMIN ip address 100.10.3.3 255.255.255.255 ! interface Ethernet0/0 no ip address shutdown half-duplex
! interface Serial0/0 description Vers L10-R5 bandwidth 125 ip address 10.10.35.3 255.255.255.0 encapsulation ppp clockrate 125000
tag-switching ip !
interface Serial0/1 description Vers L10-R1 bandwidth 125 ip address 10.10.13.3 255.255.255.0
encapsulation ppp tag-switching ip ! interface Ethernet1/0 no ip address shutdown half-duplex
! interface Serial1/0 description Vers L10-R2 bandwidth 125 ip address 10.10.23.3 255.255.255.0 encapsulation ppp tag-switching ip
!

router ospf 10 log-adjacency-changes network 10.0.0.0 0.255.255.255 area 0 !
router bgp 10
no synchronization neighbor 10.10.1.1 remote-as 10 neighbor 10.10.1.1 update-source Loopback0 no neighbor 10.10.1.1 activate no auto-summary
! address-family ipv4 vrf ADMIN redistribute connected no auto-summary no synchronization exit-address-family !
address-family vpnv4 neighbor 10.10.1.1 activate neighbor 10.10.1.1 send-community extended no auto-summary exit-address-family ! ip classless
no ip http server ! line con 0 exec-timeout 0 0 transport input none line aux 0 line vty 0 4
exec-timeout 0 0 password cisco login ! end
Configuration de L10-R4 :
! version 12.2 no service single-slot-reload-enable service timestamps debug uptime service timestamps log uptime no service password-encryption !
hostname L10-R4 ! boot system flash slot0:c3620-js-mz.122-0.4.bin logging rate-limit console 10 except errors enable secret 5 $1$mLZz$9KLAmd1tA023Bd5Z5mV.s1 ! memory-size iomem 10
ip subnet-zero !
no ip finger no ip domain-lookup ! ip cef
no ip dhcp-client network-discovery call rsvp-sync ! ip vrf BLUE rd 100:1 route-target import 100:1 route-target export 100:1
! ip vrf RED rd 100:2 route-target import 100:2 route-target export 100:2 ! ip vrf GREEN
rd 100:3

route-target import 100:3 route-target export 100:3 route-target import 100:2000 route-target export 100:2001
!
interface Loopback0 ip address 10.10.4.4 255.255.255.255 ! interface Loopback1 ip vrf forwarding BLUE
ip address 100.10.4.4 255.255.255.255 ! interface Loopback2 ip vrf forwarding RED ip address 100.10.4.4 255.255.255.255 ! interface Loopback3
ip vrf forwarding GREEN ip address 100.10.4.4 255.255.255.255 ! interface Ethernet0/0 no ip address shutdown !
interface Serial0/0 description Vers L10-R6 bandwidth 125 ip vrf forwarding GREEN ip address 100.10.46.4 255.255.255.0 encapsulation ppp no fair-queue
clockrate 125000 ! interface Serial0/1 description Vers L10-R2 bandwidth 125 ip address 10.10.24.4 255.255.255.0
encapsulation ppp tag-switching ip ! router ospf 10 log-adjacency-changes network 10.0.0.0 0.255.255.255 area 0 !
router rip version 2 ! address-family ipv4 vrf GREEN version 2 redistribute bgp 10 metric 1 network 100.0.0.0
no auto-summary exit-address-family ! router bgp 10 no synchronization bgp log-neighbor-changes
neighbor 10.10.1.1 remote-as 10 neighbor 10.10.1.1 update-source Loopback0 no neighbor 10.10.1.1 activate no auto-summary ! address-family ipv4 vrf BLUE redistribute connected
no auto-summary no synchronization exit-address-family ! address-family ipv4 vrf RED redistribute connected no auto-summary
no synchronization exit-address-family ! address-family ipv4 vrf GREEN

redistribute connected redistribute rip no auto-summary no synchronization
exit-address-family
! address-family vpnv4 neighbor 10.10.1.1 activate neighbor 10.10.1.1 send-community extended no auto-summary
exit-address-family ! ip classless no ip http server ! line con 0 exec-timeout 0 0
transport input none line aux 0 line vty 0 4 exec-timeout 0 0 password cisco login !
end
Configuration de L10-R5 :
!
version 12.2 no service single-slot-reload-enable service timestamps debug uptime service timestamps log uptime
no service password-encryption ! hostname L10-R5 ! boot system flash flash:c3620-js-mz.122-0.4.bin logging rate-limit console 10 except errors
enable secret 5 $1$m80i$NykiaSFf0D9EdTDAjJozu. ! ip subnet-zero ! no ip finger no ip domain-lookup !
ip cef no ip dhcp-client network-discovery frame-relay switching call rsvp-sync ! ip vrf BLUE rd 100:1
route-target import 100:1 route-target export 100:1
! ip vrf RED rd 100:2 route-target import 100:2
route-target export 100:2 route-target import 100:2000 route-target export 100:2001 ! ip vrf GREEN rd 100:3 route-target import 100:3
route-target export 100:3 ! interface Loopback0 ip address 10.10.5.5 255.255.255.255 ! interface Loopback1 ip vrf forwarding BLUE
ip address 100.10.5.5 255.255.255.255

! interface Loopback2 ip vrf forwarding RED ip address 100.10.5.5 255.255.255.255
!
interface Loopback3 ip vrf forwarding GREEN ip address 100.10.5.5 255.255.255.255 ! interface Ethernet0/0
no ip address half-duplex ! interface Serial0/0 no ip address encapsulation frame-relay clockrate 125000
frame-relay lmi-type cisco frame-relay intf-type dce ! interface Serial0/0.1 point-to-point description Vers L10-R7 bandwidth 125 ip vrf forwarding RED
ip address 100.10.57.5 255.255.255.0 frame-relay interface-dlci 100 ! interface Serial0/1 description Vers L10-R3 bandwidth 125 ip address 10.10.35.5 255.255.255.0
encapsulation ppp tag-switching ip ! router ospf 10 log-adjacency-changes network 10.0.0.0 0.255.255.255 area 0
! router bgp 10 no synchronization bgp log-neighbor-changes neighbor 10.10.1.1 remote-as 10 neighbor 10.10.1.1 update-source Loopback0 no neighbor 10.10.1.1 activate
no auto-summary ! address-family ipv4 vrf BLUE redistribute connected no auto-summary no synchronization exit-address-family
! address-family ipv4 vrf RED redistribute connected neighbor 100.10.57.7 remote-as 102 neighbor 100.10.57.7 activate no auto-summary
no synchronization exit-address-family ! address-family ipv4 vrf GREEN redistribute connected no auto-summary no synchronization
exit-address-family ! address-family vpnv4 neighbor 10.10.1.1 activate neighbor 10.10.1.1 send-community extended no auto-summary exit-address-family
! ip classless no ip http server !

line con 0 exec-timeout 0 0 transport input none line aux 0
line vty 0 4
exec-timeout 0 0 password cisco login ! end
Configuration de L10-R6 :
! version 12.2 no service single-slot-reload-enable service timestamps debug uptime service timestamps log uptime no service password-encryption
! hostname L10-R6 ! boot system flash flash:c2600-js-mz.122-0.4.bin logging rate-limit console 10 except errors enable secret 5 $1$bZ2c$wdF872FRcLXaObuYJD90u1 !
ip subnet-zero ! no ip finger
no ip domain-lookup ! ip cef no ip dhcp-client network-discovery
call rsvp-sync ! interface Loopback0 ip address 100.10.6.6 255.255.255.255 ! interface Ethernet0/0
no ip address half-duplex ! interface Serial0/0 description Vers L10-R4 bandwidth 125 ip address 100.10.46.6 255.255.255.0
encapsulation ppp no fair-queue ! interface FastEthernet1/0 no ip address duplex auto speed auto
! interface FastEthernet1/0.1
encapsulation dot1Q 161 ip address 100.10.161.6 255.255.255.0 no ip redirects !
interface FastEthernet1/0.2 encapsulation dot1Q 162 ip address 100.10.162.6 255.255.255.0 no ip redirects ! router rip version 2
network 100.0.0.0 ! ip classless no ip http server ! line con 0 exec-timeout 0 0
transport input none

line aux 0 line vty 0 4 exec-timeout 0 0 password cisco
login
line vty 5 15 login ! end
Configuration de L10-R7 :
! version 12.2 no service single-slot-reload-enable service timestamps debug uptime service timestamps log uptime no service password-encryption !
hostname L10-R7 ! boot system flash flash:c2600-js-mz.122-0.4.bin logging rate-limit console 10 except errors enable secret 5 $1$Fgps$hTMFn1J6vXX9P3Dh9JDaK/ ! ip subnet-zero
! no ip finger no ip domain-lookup
! ip cef no ip dhcp-client network-discovery call rsvp-sync
! interface Loopback0 ip address 100.10.7.7 255.255.255.255 ! interface Ethernet0/0 no ip address
half-duplex ! interface Serial0/0 no ip address encapsulation frame-relay frame-relay lmi-type cisco !
interface Serial0/0.1 point-to-point description Vers L10-R5 bandwidth 125 ip address 100.10.57.7 255.255.255.0 frame-relay interface-dlci 100 ! interface FastEthernet1/0
no ip address duplex auto
speed auto ! interface FastEthernet1/0.1 encapsulation dot1Q 171
ip address 100.10.171.7 255.255.255.0 no ip redirects ! interface FastEthernet1/0.2 encapsulation dot1Q 172 ip address 100.10.172.7 255.255.255.0 no ip redirects
! router bgp 102 bgp log-neighbor-changes network 100.10.7.7 mask 255.255.255.255 network 100.10.171.0 mask 255.255.255.0 network 100.10.172.0 mask 255.255.255.0 neighbor 100.10.57.5 remote-as 10
!

ip classless no ip http server ! line con 0
exec-timeout 0 0
transport input none line aux 0 line vty 0 4 password cisco login
line vty 5 15 login ! no scheduler allocate end
Les sockets
Winsock
1 - L'histoire de Winsock 2 - L'architecture
3 - Les compatibilités 3.1 - Winsock 3.2 - Le mode Raw 3.3 - Les options 4 - Le mode non connecté
5 - Le mode connecté 6 - Le mode brut 7 - Les liens 8 - Discussion autour de la documentation 9 - Suivi du document
1 - L'histoire de Winsock
Depuis des années, les applications se sont tournées vers une communication réseaux afin d'interagir entre elles. La Socket Windows, ou plus couramment appelé Winsock, est une API (Application Programming Interface) procurant des fonctions d'accès aux protocoles réseaux. Winsock représente donc une interface API permettant l'utilisation du protocole TCP/IP sur une interface Windows.
Winsock 1.1 à été publié le 20 janvier 1993 afin de créer un standard universel pour les applications TCP/IP. Les auteurs des Windows Socket 1.1 ont limité les possibilités à l'utilisation d'un seul protocole, TCP/IP, contrairement à la version 2.0 qui propose en plus, la suite des protocoles ATM, IPX/SPX, DECnet et le sans fil. Le passage à Winsock 2.0 s'est fait en gardant 100% de compatibilité permettant aux applications déjà développées de continuer à fonctionner.
2 - L'architecture
L'architecture Winsock 2 est conforme à WOSA (Windows Open System Architecture).
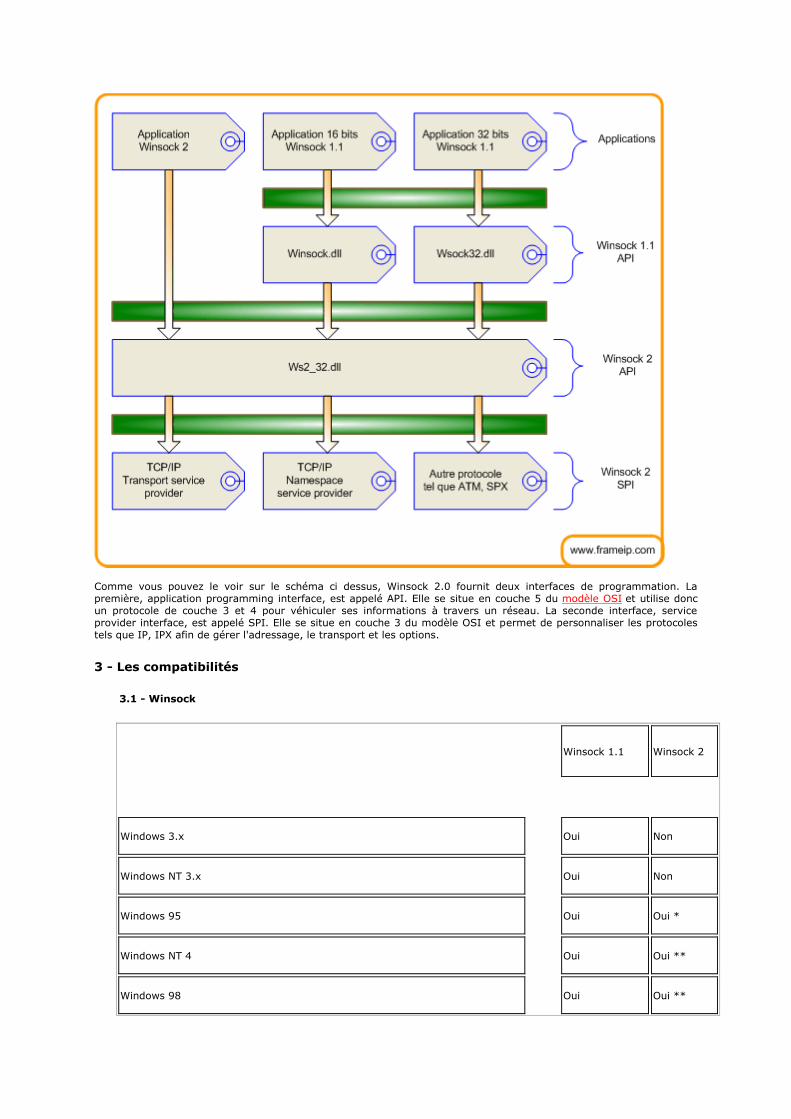
Comme vous pouvez le voir sur le schéma ci dessus, Winsock 2.0 fournit deux interfaces de programmation. La première, application programming interface, est appelé API. Elle se situe en couche 5 du modèle OSI et utilise donc un protocole de couche 3 et 4 pour véhiculer ses informations à travers un réseau. La seconde interface, service provider interface, est appelé SPI. Elle se situe en couche 3 du modèle OSI et permet de personnaliser les protocoles tels que IP, IPX afin de gérer l'adressage, le transport et les options.
3 - Les compatibilités
3.1 - Winsock
Winsock 1.1 Winsock 2
Windows 3.x
Oui Non
Windows NT 3.x
Oui Non
Windows 95
Oui Oui *
Windows NT 4
Oui Oui **
Windows 98
Oui Oui **

Windows 2000
Oui Oui
Windows XP
Oui Oui
Windows 2003
Oui Oui
* Windows 95 est livré de base avec Winsock 1.1. Il est possible d'installer Winsock 2 à l'aide d'un add-on Microsoft disponible à cette l'Url.
3.2 - Le mode Raw
Le mode Raw est disponible à partir de la version 2.0 de Winsock. ** Malgré le support du mode Raw, Win98 et Nt4 ne sont pas compatibles avec l'option IP_HDRINCL permettant de spécifier l'entête IP.
3.3 - Les options
Vous trouverez la liste des compatibilités de toutes les options.
4 - Le mode non connecté
Le mode non connecté est basé sur UDP qui ne garanti pas la transmission de donnée. Voici le schéma d'une relation entre deux hosts IP en mode non connecté.
5 - Le mode connecté
Le mode connecté est basé sur l'ouverture d'une session TCP afin de garantir, au niveau 4, la transmission de donnée. Voici le schéma d'une relation entre deux hosts IP en mode connecté.

6 - Le mode brut
Le mode brut est plus communément appelé mode raw. Compatible uniquement avec la version 2 de Winsock, il permet de spécifier un protocole de couche 3 tel que ATM, SPX, IP et autres. Dans le cadre d'IP, il existe une option appelée IP_HDRINCL apportant la possibilité de spécifier l'entête IP entière. Pour avoir accès aux options du mode raw, il faut posséder les droits d'administrateur local. Microsoft l'impose pour des raisons de sécurité, mais propose de
contourner cette restriction à l'aide de la modification du registre explicité dans la Q195445.
Mode connecte en C++
1 - Schéma d'une relation client serveur 2 - Initialisation de la socket 2.1 - Commande WSAStartup() 2.2 - Commande socket()
2.3 - Commande setsockopt() 3 - Ecoute du port TCP 3.1 - Commande bind() 4 - Etablissement de la session TCP 4.1 - Commande connect() 4.2 - Commande listen() 4.3 - Commande accept()
5 - Echange des données 5.1 - Commande send() 5.2 - Commande recv() 6 - Fermeture de la session TCP 6.1 - Commande shutdown() 7 - Libération de la socket
7.1 - Commande closesocket()
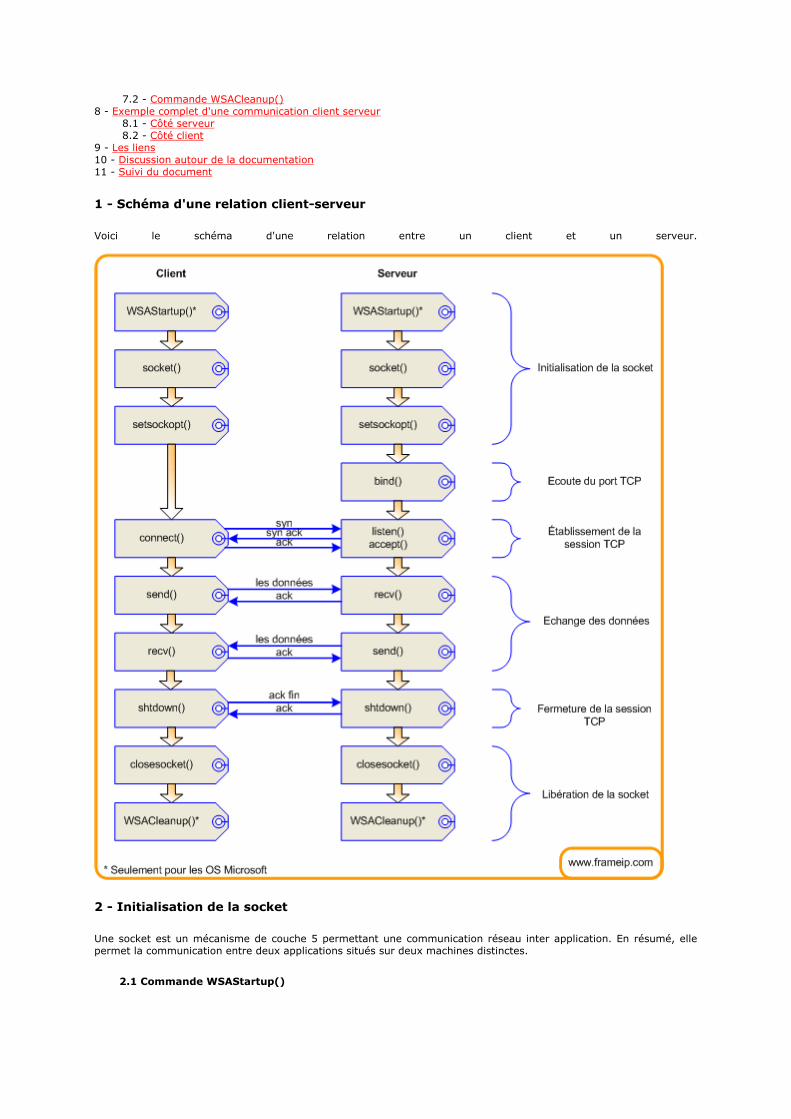
7.2 - Commande WSACleanup() 8 - Exemple complet d'une communication client serveur 8.1 - Côté serveur 8.2 - Côté client 9 - Les liens
10 - Discussion autour de la documentation 11 - Suivi du document
1 - Schéma d'une relation client-serveur
Voici le schéma d'une relation entre un client et un serveur.
2 - Initialisation de la socket
Une socket est un mécanisme de couche 5 permettant une communication réseau inter application. En résumé, elle permet la communication entre deux applications situés sur deux machines distinctes.
2.1 Commande WSAStartup()

Windows se basant sur Winsock, nous devons initialiser cette API, contrairement à Linux. Pour cela, nous allons utiliser la fonction WSAStartup(). L'utilisation de cette fonction est donc obligatoire pour un système d'exploitation Windows. Si vous utilisez un autre OS, alors passez directement à l'étape suivante. Voici un exemple d'utilisation pour le côté client et serveur.
// ******************************************************** // Déclaration des variables // ******************************************************** WSADATA initialisation_win32; // Variable permettant de récupérer la structure d'information sur l'initialisation int erreur; // Variable permettant de récupérer la valeur de retour des fonctions utilisées
// ******************************************************** // Initialisation de Winsock // ******************************************************** erreur=WSAStartup(MAKEWORD(2,2),&initialisation_win32); if (erreur!=0) printf("\nDesole, je ne peux pas initialiser Winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else
printf("\nWSAStartup : OK");
- Le premier paramètre indique la version de Winsock que nous demandons. - Le second paramètre est l'adresse d'une structure de type WSADATA qui contient toutes les informations nécessaires résultant de l'initialisation.
- La fonction devra renvoyer 0 pour indiquer que sont exécution c'est correctement déroulée. Voici la fiche Msdn concernant la fonction WSAStartup().
2.2 - Commande socket()
La création d'une socket est obligatoire afin d'obtenir un identifiant unique. Cela permettra aux prochaines fonctions de toutes ce référencer au même id, donc à la même socket. Voici un exemple d'utilisation pour le côté
client et serveur.
// ******************************************************** // Déclaration des variables // ********************************************************
SOCKET id_de_la_socket; // Identifiant de la socket // ******************************************************** // Ouverture d'une Socket // ******************************************************** id_de_la_socket=socket(AF_INET,SOCK_STREAM,0);
if (id_de_la_socket==INVALID_SOCKET) printf("\nDesole, je ne peux pas creer la socket du a l'erreur : %d",WSAGetLastError()); else printf("\nsocket : OK");
- Le premier paramètre indique que vous désirez crée une socket basé sur le protocole IPv4. - Le second paramètre sélectionne le mode connecté via TCP, cela nécessitera alors une ouverture de session. - La fonction retournera l'identifiant de la socket si elle s'est exécutée correctement. Sinon, elle indiquera la valeur INVALID_SOCKET.
Voici la fiche Msdn concernant la fonction socket().
2.3 - Commande setsockopt()
La configuration des options de la socket n'est pas obligatoire. Vous devez l'utilisez que si vous avez un besoin spécifique. Voici un exemple d'utilisation pour le côté client et serveur.
// ********************************************************
// Déclaration des variables // ******************************************************** int tempo; // Variable temporaire de type int // ******************************************************** // Activation de l'option permettant d'activer l'algorithme de Nagle
// ******************************************************** tempo=1; erreur=setsockopt(id_de_la_socket,IPPROTO_TCP,TCP_NODELAY,(char *)&tempo,sizeof(tempo));

if (erreur!=0) printf("\nDesole, je ne peux pas configurer cette options du à l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nsetsockopt : OK");
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket(). - Le second paramètre spécifie le niveau de l'option. - Le troisième paramètres indique l'option à configurer. Dans cette exemple, la passage à 1, de TCP_NODELAY,
permet d'activer l'algorithme de Nagle décrit dans la RFC 896. Il apportera une meilleur gestion dans le cadre d'envoi de très petite donnée. - Le quatrième paramètre indique la valeur de l'option que l'on spécifie. - Le cinquième paramètre spécifie uniquement la taille du quatrième. - La fonction devra renvoyer 0 pour indiquer que sont exécution c'est correctement déroulée. Voici la fiche Msdn concernant la fonction setsockopt().
3 - Ecoute du port TCP
3.1 - Commande bind()
La commande bind permet de lier la socket à un port et adresse IP d'écoute. Voici un exemple d'utilisation pour le côté serveur.
// ******************************************************** // Déclaration des variables // ******************************************************** SOCKADDR_IN information_sur_la_source; // Déclaration de la structure des informations lié à l'écoute
// ******************************************************** // Lie la socket à une ip et un port d'écoute // ******************************************************** information_sur_la_source.sin_family=AF_INET; information_sur_la_source.sin_addr.s_addr=INADDR_ANY; // Ecoute sur toutes les IP locales information_sur_la_source.sin_port=htons(33333); // Ecoute sur le port 33333
erreur=bind(id_de_la_socket,(struct sockaddr*)&information_sur_la_source,sizeof(information_sur_la_source)); if (erreur!=0) printf("\nDesole, je ne peux pas ecouter ce port : %d %d",erreur,WSAGetLastError()); else printf("\nbind : OK");
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket(). - Le second argument est la structure comprenant les informations sur le port et l'adresse IP à se lier. - Le troisième paramètre spécifie uniquement la taille de la structure du second. - La fonction devra renvoyer 0 pour indiquer que sont exécution c'est correctement déroulée.
Voici la fiche Msdn concernant la fonction bind().
4 - Établissement d'une session TCP
Le client doit utiliser la fonction connect() afin d'amorcer l'ouverture de session TCP. Et le serveur doit appeler la fonction accept() pour valider l'ouverture. Le but de ces fonctions est de créer la session TCP basé sur trois trames
S,AS,A. Cette étape n'est donc nécessaire que dans le cadre de l'utilisation du mode connecté.
4.1 - Commande connect()
La commande connect permet d'initier et d'établir la session TCP avec le serveur. Voici un exemple d'utilisation pour le côté client.
// ******************************************************** // Déclaration des variables // ******************************************************** SOCKADDR_IN information_sur_la_destination; // Déclaration de la structure des informations lié au serveur // ******************************************************** // Ouverture de la session TCP sur destination de l'adresse IP 10.10.10.10 et du port 80
// ******************************************************** information_sur_la_destination.sin_family=AF_INET; information_sur_la_destination.sin_addr.s_addr=inet_addr("10.10.10.10"); // Indiquez l'adresse IP de votre serveur

information_sur_la_destination.sin_port=htons(80); // Port écouté du serveur (33333) erreur=connect(id_de_la_socket,(struct sockaddr*)&information_sur_la_destination,sizeof(information_sur_la_destination)); if (erreur!=0)
printf("\nDesole, je n'ai pas pu ouvrir la session TCP : %d %d",erreur,WSAGetLastError());
else printf("\nsetsockopt : OK");
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket(). - Le second argument est la structure comprenant les informations sur la destination du port et sur l'adresse IP. - Le troisième paramètre spécifie uniquement la taille de la structure du second. - La fonction devra renvoyer 0 pour indiquer que son exécution c'est correctement déroulée. Voici la fiche Msdn concernant la fonction connect().
4.2 - Commande listen()
La commande listen permet d'écouter les demandes d'ouvertures de session TCP arrivant sur le port et adresse IP sélectionné par la commande bind(). Voici un exemple d'utilisation pour le côté serveur.
// ********************************************************
// Attente d'ouverture de session // ******************************************************** erreur=99; // Initiation de erreur pour être sur que l'on va rentrer dans la boucle while(erreur!=0) // Boucle tant qu'une demande de session (SYN) tcp n'a pas été reçu erreur=listen(id_de_la_socket,1); printf("\nlisten : OK");
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket(). - Le second argument représente le nombre maximum de demande d'ouverture de session simultanée accepté. - La fonction devra renvoyer 0 pour indiquer qu'une session TCP a été établie.
Voici la fiche Msdn concernant la fonction listen().
4.3 - Commande accept()
La commande accept permet d'indiquer, après réception du SYN (demande d'ouverture de session TCP), l'acceptation de l'établissement complète de la session. Voici un exemple d'utilisation pour le côté serveur.
// ******************************************************** // Déclaration des variables // ******************************************************** SOCKET id_de_la_nouvelle_socket; // Identifiant de la nouvelle socket SOCKADDR_IN information_sur_la_source; // Déclaration de la structure des informations lié à l'écoute
// ******************************************************** // Acceptation de la demande d'ouverture de session // ******************************************************** printf("\nAttente de la reception de demande d'ouverture de session tcp (SYN)"); tempo=sizeof(information_sur_la_source); // Passe par une variable afin d'utiliser un pointeur id_de_la_nouvelle_socket=accept(id_de_la_socket,(struct sockaddr*)&information_sur_la_source,&tempo);
if(id_de_la_nouvelle_socket==INVALID_SOCKET)
printf("\nDesole, je ne peux pas accepter la session TCP du a l'erreur : %d",WSAGetLastError()); else printf("\naccept : OK");
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket(). - Le second argument est la structure comprenant les informations sur la source du port et de l'adresse IP qui ont été récupérées. - Le troisième paramètre spécifie uniquement la taille de la structure du second. - La fonction renverra le descripteur d'une nouvelle socket permettant l'envoi des données via la session TCP ouverte.
Voici la fiche Msdn concernant la fonction accept().
5 - Echange des données
5.1 - Commande send()

La commande send permet l'envoi d'une chaîne de caractère à destination du serveur ayant établi la session TCP. Voici un exemple d'utilisation pour le côté client.
// ********************************************************
// Déclaration des variables
// ******************************************************** int nombre_de_caractere; // Indique le nombre de caractères qui a été reçu ou envoyé char buffer[65535]; // Tampon contenant les données reçues ou envoyées // ******************************************************** // Envoi des données
// ******************************************************** strcpy(buffer,"Coucou, je suis les donnees. www.frameip.com"); // Copie la chaine de caractère dans buffer nombre_de_caractere=send(id_de_la_socket,buffer,strlen(buffer),0); if (nombre_de_caractere==SOCKET_ERROR) printf("\nDesole, je n'ai pas envoyer les donnees du a l'erreur : %d",WSAGetLastError()); else printf("\nsend : OK");
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket(). - Le second argument est le buffer contenant les données à envoyer. - Le troisième paramètre spécifie uniquement la taille du buffer. - La fonction renverra le nombre de caractère qui a été émis.
Voici la fiche Msdn concernant la fonction send().
5.2 - Commande recv()
La commande recv permet de recueillir dans un buffer les données reçues sur une socket. Voici un exemple d'utilisation pour le côté serveur.
// ******************************************************** // Reception des données // ******************************************************** nombre_de_caractere=recv(id_de_la_nouvelle_socket,buffer,1515,0); if (nombre_de_caractere==SOCKET_ERROR)
printf("\nDesole, je n'ai pas recu de donnee"); else { buffer[nombre_de_caractere]=0; // Permet de fermer le tableau après le contenu des data, car la fonction recv ne le fait pas printf("\nVoici les donnees : %s",buffer);
}
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction accept(). - Le second argument est le buffer contenant les données à recevoir. - Le troisième paramètre représente le nombre maximum de caractère attendu.
- La fonction renverra le nombre de caractère qui a été reçu. Voici la fiche Msdn concernant la fonction recv().
6 - Fermeture de la session TCP
6.1 Commande shutdown()
La fermeture de session TCP n'est pas obligatoire dû fait que vous aurez déjà obtenue les services attendus. Cependant ces très fortement conseillé pour un développement propre et une utilisation respectueuse duprotocole IP. Voici un exemple d'utilisation pour le côté client et serveur.
// ******************************************************** // Fermeture de la session TCP Correspondant à la commande connect() // ******************************************************** erreur=shutdown(id_de_la_socket,2); // 2 signifie socket d'émission et d'écoute if (erreur!=0) printf("\nDesole, je ne peux pas fermer la session TCP du a l'erreur : %d %d",erreur,WSAGetLastError());
else printf("\nshutdown : OK");

- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket(). - Le second argument indique si l'on doit fermer l'émission, la réception ou les deux. - La fonction devra renvoyer 0 pour indiquer que sont exécution c'est correctement déroulée. Voici la fiche Msdn concernant la fonction shutdown().
7 - Libération de la socket
7.1 Commande closesocket()
Cette fonction permet de libérer proprement l'accès à la socket. Durement conseillé pour le respect d'un développement propre et d'une utilisation saine du système d'exploitation. Voici un exemple d'utilisation pour le côté client et serveur.
// ******************************************************** // Fermeture de la socket correspondant à la commande socket() // ******************************************************** erreur=closesocket(id_de_la_socket); if (erreur!=0) printf("\nDesole, je ne peux pas liberer la socket du a l'erreur : %d %d",erreur,WSAGetLastError());
else printf("\nclosesocket : OK");
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket().
- La fonction devra renvoyer 0 pour indiquer que sont exécution c'est correctement déroulée. Voici la fiche Msdn concernant la fonction closesocket().
7.2 Commande WSACleanup()
Cette étape n'est utile et fonctionnelle que dans le cadres du système d'exploitation Microsoft. Cette fonction permet de libérer l'accès à Winsock. Attention, dans un environnement multiprocess, l'utilisation de cette commande fermera les accès de tous les process. Voici un exemple d'utilisation pour le côté client et serveur.
// ******************************************************** // Quitte proprement le winsock ouvert avec la commande WSAStartup // ********************************************************
erreur=WSACleanup(); // A appeler autant de fois qu'il a été ouvert. if (erreur!=0) printf("\nDesole, je ne peux pas liberer winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nWSACleanup : OK");
- La fonction devra renvoyer 0 pour indiquer que sont exécution c'est correctement déroulée. Voici la fiche Msdn concernant la fonction WSACleanup().
8 - Exemple complet d'une communication client serveur
8.1 - Côté serveur
Voici un exemple de code fonctionnel qui permet d'écouter sur le port TCP 33333 et d'afficher les données reçues. Le fichier cpp est disponible ici.
// ******************************************************** // Les includes // ******************************************************** #include <winsock2.h> // pour les fonctions socket #include <cstdio> // Pour les Sprintf
// ******************************************************** // Les librairies // ******************************************************** #pragma comment(lib,"ws2_32.lib") // ********************************************************

// Définition des variables // ******************************************************** WSADATA initialisation_win32; // Variable permettant de récupérer la structure d'information sur l'initialisation int erreur; // Variable permettant de récupérer la valeur de retour des fonctions utilisées
int tempo; // Variable temporaire de type int
int nombre_de_caractere; // Indique le nombre de caractères qui a été reçu ou envoyé char buffer[65535]; // Tampon contenant les données reçues ou envoyées SOCKET id_de_la_socket; // Identifiant de la socket SOCKET id_de_la_nouvelle_socket; // Identifiant de la nouvelle socket SOCKADDR_IN information_sur_la_source; // Déclaration de la structure des informations lié à l'écoute
int main (int argc, char* argv[]) { printf("\nBonjour, vous etes du cote serveur. www.frameip.com\n"); // ******************************************************** // Initialisation de Winsock
// ******************************************************** erreur=WSAStartup(MAKEWORD(2,2),&initialisation_win32); if (erreur!=0) printf("\nDesole, je ne peux pas initialiser Winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nWSAStartup : OK");
// ******************************************************** // Ouverture d'une Socket // ******************************************************** id_de_la_socket=socket(AF_INET,SOCK_STREAM,0); if (id_de_la_socket==INVALID_SOCKET) printf("\nDesole, je ne peux pas creer la socket du a l'erreur : %d",WSAGetLastError()); else
printf("\nsocket : OK"); // ******************************************************** // Activation de l'option permettant d'activer l'algorithme de Nagle // ******************************************************** tempo=1;
erreur=setsockopt(id_de_la_socket,IPPROTO_TCP,TCP_NODELAY,(char *)&tempo,sizeof(tempo)); if (erreur!=0) printf("\nDesole, je ne peux pas configurer cette options du à l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nsetsockopt : OK"); // ********************************************************
// Lie la socket à une ip et un port d'écoute // ******************************************************** information_sur_la_source.sin_family=AF_INET; information_sur_la_source.sin_addr.s_addr=INADDR_ANY; // Ecoute sur toutes les IP locales information_sur_la_source.sin_port=htons(33333); // Ecoute sur le port 33333 erreur=bind(id_de_la_socket,(struct sockaddr*)&information_sur_la_source,sizeof(information_sur_la_source)); if (erreur!=0)
printf("\nDesole, je ne peux pas ecouter ce port : %d %d",erreur,WSAGetLastError()); else printf("\nbind : OK"); // ******************************************************** // Attente d'ouverture de session
// ******************************************************** erreur=99; // Initiation de erreur pour être sur que l'on va rentrer dans la boucle while(erreur!=0) // Boucle tant qu'une demande de session (SYN) tcp n'a pas été reçu erreur=listen(id_de_la_socket,1); printf("\nlisten : OK"); // ********************************************************
// Acceptation de la demande d'ouverture de session // ******************************************************** printf("\nAttente de la reception de demande d'ouverture de session tcp (SYN)"); tempo=sizeof(information_sur_la_source); // Passe par une variable afin d'utiliser un pointeur id_de_la_nouvelle_socket=accept(id_de_la_socket,(struct sockaddr*)&information_sur_la_source,&tempo); if(id_de_la_nouvelle_socket==INVALID_SOCKET) printf("\nDesole, je ne peux pas accepter la session TCP du a l'erreur : %d",WSAGetLastError());
else printf("\naccept : OK"); // ********************************************************

// Reception des données // ******************************************************** nombre_de_caractere=recv(id_de_la_nouvelle_socket,buffer,1515,0); if (nombre_de_caractere==SOCKET_ERROR)
printf("\nDesole, je n'ai pas recu de donnee");
else { buffer[nombre_de_caractere]=0; // Permet de fermer le tableau après le contenu des data, car la fonction recv ne le fait pas printf("\nVoici les donnees : %s",buffer);
} // ******************************************************** // Fermeture de la session TCP Correspondant à la commande connect() // ******************************************************** erreur=shutdown(id_de_la_nouvelle_socket,2); // 2 signifie socket d'émission et d'écoute if (erreur!=0)
printf("\nDesole, je ne peux pas fermer la session TCP du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nshutdown : OK"); // ******************************************************** // Fermeture des deux socket correspondant à la commande socket() et accept() // ********************************************************
erreur=closesocket(id_de_la_nouvelle_socket); if (erreur!=0) printf("\nDesole, je ne peux pas liberer la socket du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nclosesocket : OK"); erreur=closesocket(id_de_la_socket); if (erreur!=0)
printf("\nDesole, je ne peux pas liberer la socket du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nclosesocket : OK"); // ******************************************************** // Quitte proprement le winsock ouvert avec la commande WSAStartup
// ******************************************************** erreur=WSACleanup(); // A appeler autant de fois qu'il a été ouvert. if (erreur!=0) printf("\nDesole, je ne peux pas liberer winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nWSACleanup : OK"); }
8.2 - Côté client
Voici un exemple de code fonctionnel qui permet d'envoyer des données sur le port TCP 33333, n'oubliez pas de changer l'IP de destination pour correspondre à votre serveur. Le fichier cpp est disponible ici.
// ******************************************************** // Les includes // ******************************************************** #include <winsock2.h> // pour les fonctions socket
#include <cstdio> // Pour les Sprintf // ******************************************************** // Les librairies // ******************************************************** #pragma comment(lib,"ws2_32.lib")
// ******************************************************** // Définition des variables // ******************************************************** WSADATA initialisation_win32; // Variable permettant de récupérer la structure d'information sur l'initialisation int erreur; // Variable permettant de récupérer la valeur de retour des fonctions utilisées int tempo; // Variable temporaire de type int
int nombre_de_caractere; // Indique le nombre de caractères qui a été reçu ou envoyé char buffer[65535]; // Tampon contennant les données reçues ou envoyées SOCKET id_de_la_socket; // Identifiant de la socket SOCKADDR_IN information_sur_la_destination; // Déclaration de la structure des informations lié au serveur int main (int argc, char* argv[])

{ printf("\nBonjour, vous etes du cote client. www.frameip.com\n"); // ********************************************************
// Initialisation de Winsock
// ******************************************************** erreur=WSAStartup(MAKEWORD(2,2),&initialisation_win32); if (erreur!=0) printf("\nDesole, je ne peux pas initialiser Winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else
printf("\nWSAStartup : OK"); // ******************************************************** // Ouverture d'une Socket // ******************************************************** id_de_la_socket=socket(AF_INET,SOCK_STREAM,0); if (id_de_la_socket==INVALID_SOCKET)
printf("\nDesole, je ne peux pas creer la socket du a l'erreur : %d",WSAGetLastError()); else printf("\nsocket : OK"); // ******************************************************** // Activation de l'option permettant d'activer l'algorithme de Nagle // ********************************************************
tempo=1; erreur=setsockopt(id_de_la_socket,IPPROTO_TCP,TCP_NODELAY,(char *)&tempo,sizeof(tempo)); if (erreur!=0) printf("\nDesole, je ne peux pas configurer cette options du à l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nsetsockopt : OK");
// ******************************************************** // Etablissement de l'ouverture de session // ******************************************************** information_sur_la_destination.sin_family=AF_INET; information_sur_la_destination.sin_addr.s_addr=inet_addr("10.10.10.10"); // Indiquez l'adresse IP de votre serveur
information_sur_la_destination.sin_port=htons(33333); // Port écouté du serveur (33333) erreur=connect(id_de_la_socket,(struct sockaddr*)&information_sur_la_destination,sizeof(information_sur_la_destination)); if (erreur!=0) printf("\nDesole, je n'ai pas pu ouvrir la session TCP : %d %d",erreur,WSAGetLastError()); else printf("\nsetsockopt : OK");
// ******************************************************** // Envoi des données // ******************************************************** strcpy(buffer,"Coucou, je suis les donnees. www.frameip.com"); // Copie la chaine de caractère dans buffer nombre_de_caractere=send(id_de_la_socket,buffer,strlen(buffer),0); if (nombre_de_caractere==SOCKET_ERROR)
printf("\nDesole, je n'ai pas envoyer les donnees du a l'erreur : %d",WSAGetLastError()); else printf("\nsend : OK"); // ******************************************************** // Fermeture de la session TCP Correspondant à la commande connect()
// ******************************************************** erreur=shutdown(id_de_la_socket,2); // 2 signifie socket d'émission et d'écoute if (erreur!=0) printf("\nDesole, je ne peux pas fermer la session TCP du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nshutdown : OK");
// ******************************************************** // Fermeture de la socket correspondant à la commande socket() // ******************************************************** erreur=closesocket(id_de_la_socket); if (erreur!=0) printf("\nDesole, je ne peux pas liberer la socket du a l'erreur : %d %d",erreur,WSAGetLastError()); else
printf("\nclosesocket : OK"); // ******************************************************** // Quitte proprement le winsock ouvert avec la commande WSAStartup

// ******************************************************** erreur=WSACleanup(); // A appeler autant de fois qu'il a été ouvert. if (erreur!=0) printf("\nDesole, je ne peux pas liberer winsock du a l'erreur : %d %d",erreur,WSAGetLastError());
else
printf("\nWSACleanup : OK");
Mode non connecte en C++
1 - Schéma d'une relation client serveur 2 - Initialisation de la socket 2.1 - Commande WSAStartup() 2.2 - Commande socket()
3 - Ecoute du port UDP 3.1 - Commande bind() 4 - Echange des données 4.1 - Commande sendto() 4.2 - Commande recvfrom() 5 - Libération de la socket
5.1 - Commande closesocket() 5.2 - Commande WSACleanup() 6 - Exemple complet d'une communication client serveur 6.1 - Côté serveur 6.2 - Côté client 7 - Les liens 8 - Discussion autour de la documentation
9 - Suivi du document
1 - Schéma d'une relation client-serveur

Voici le schéma d'une relation entre un client et un serveur.
2 - Initialisation de la socket
Une socket est un mécanisme de couche 5 permettant une communication réseau inter application. En résumé, elle permet la communication entre deux applications situés sur deux machines distinctes.
2.1 Commande WSAStartup()
Windows se basant sur Winsock, nous devons initialiser cette API contrairement à Linux. Pour cela, nous allons utiliser la fonction WSAStartup(). L'utilisation de cette fonction est donc obligatoire pour un système d'exploitation Windows. Si vous utilisez un autre OS, alors passez directement à l'étape suivante. Voici un exemple d'utilisation
pour le côté client et serveur.
// ******************************************************** // Déclaration des variables // ******************************************************** WSADATA initialisation_win32; // Variable permettant de récupérer la structure d'information sur l'initialisation int erreur; // Variable permettant de récupérer la valeur de retour des fonctions utilisées
// ********************************************************
// Initialisation de Winsock // ******************************************************** erreur=WSAStartup(MAKEWORD(2,2),&initialisation_win32); if (erreur!=0) printf("\nDesole, je ne peux pas initialiser Winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else
printf("\nWSAStartup : OK");

- Le premier paramètre indique la version de Winsock que nous demandons. - Le second paramètre est l'adresse d'une structure de type WSADATA qui contient toutes les informations nécessaires résultant de l'initialisation. - La fonction devra renvoyer 0 pour indiquer que sont exécution c'est correctement déroulée.
Voici la fiche Msdn concernant la fonction WSAStartup().
2.2 - Commande socket()
La création d'une socket est obligatoire afin d'obtenir un identifiant unique. Cela permettra aux prochaines fonctions de toutes ce référencer au même id, donc à la même socket. Voici un exemple d'utilisation pour le côté client et serveur.
// ******************************************************** // Déclaration des variables // ******************************************************** SOCKET id_de_la_socket; // Identifiant de la socket // ******************************************************** // Ouverture d'une Socket
// ******************************************************** id_de_la_socket=socket(AF_INET,SOCK_DGRAM,0); if (id_de_la_socket==INVALID_SOCKET) printf("\nDesole, je ne peux pas creer la socket du a l'erreur : %d",WSAGetLastError()); else printf("\nsocket : OK");
- Le premier paramètre indique que vous désirez crée une socket basé sur le protocole IPv4.
- Le second paramètre sélectionne le mode connecté via UDP, cela nécessitera alors une ouverture de session. - La fonction retournera l'identifiant de la socket si elle s'est exécutée correctement. Sinon, elle indiquera la valeur INVALID_SOCKET.
Voici la fiche Msdn concernant la fonction socket().
3 - Ecoute du port UDP
3.1 - Commande bind()
La commande bind permet de lier la socket à un port et adresse IP d'écoute. Voici un exemple d'utilisation pour le
côté serveur.
// ******************************************************** // Déclaration des variables // ********************************************************
SOCKADDR_IN information_sur_la_source; // Déclaration de la structure des informations lié à l'écoute // ******************************************************** // Lie la socket à une ip et un port d'écoute // ******************************************************** information_sur_la_source.sin_family=AF_INET;
information_sur_la_source.sin_addr.s_addr=INADDR_ANY; // Ecoute sur toutes les IP locales information_sur_la_source.sin_port=htons(33333); // Ecoute sur le port 33333
erreur=bind(id_de_la_socket,(struct sockaddr*)&information_sur_la_source,sizeof(information_sur_la_source)); if (erreur!=0) printf("\nDesole, je ne peux pas ecouter ce port : %d %d",erreur,WSAGetLastError()); else printf("\nbind : OK");
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket(). - Le second argument est la structure comprenant les informations sur le port et l'adresse IP à se lier. - Le troisième paramètre spécifie uniquement la taille de la structure du second.
- La fonction devra renvoyer 0 pour indiquer que sont exécution c'est correctement déroulée. Voici la fiche Msdn concernant la fonction bind().
4 - Echange des données
4.1 - Commande sendto()

La commande sendto permet l'envoi d'une chaîne de caractère à destination du serveur précisé comme argument de la fonction. Voici un exemple d'utilisation pour le côté client.
// ********************************************************
// Déclaration des variables
// ******************************************************** int nombre_de_caractere; // Indique le nombre de caractères qui a été reçu ou envoyé char buffer[65535]; // Tampon contenant les données reçues ou envoyées // ******************************************************** // Envoi des données
// ******************************************************** information_sur_la_destination.sin_family=AF_INET; // Indiquez l'utilisation d'IPV4 information_sur_la_destination.sin_addr.s_addr=inet_addr("10.10.10.10"); // Indiquez l'adresse IP de votre serveur information_sur_la_destination.sin_port=htons(33333); // Port TCP 33333 à destination du serveur strcpy(buffer,"Coucou, je suis les donnees. www.frameip.com"); // Copie la chaine de caractère dans buffer nombre_de_caractere=sendto(id_de_la_socket,buffer,strlen(buffer),0,(struct sockaddr*)&information_sur_la_destination,sizeof(information_sur_la_destination));
if (nombre_de_caractere==SOCKET_ERROR) printf("\nDesole, je ne peux pas envoyer les donnees du a l'erreur : %d",WSAGetLastError()); else printf("\nsend : OK");
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket(). - Le second argument est le buffer contenant les données à envoyer. - Le troisième paramètre spécifie uniquement la taille du buffer. - Le quatrième fait référence à la structure comprenant les informations sur le port et l'adresse IP de destination. - Le cinquième indique la taille de la structure précédente. - La fonction renverra le nombre de caractère qui a été émis.
Voici la fiche Msdn concernant la fonction sendto().
4.2 - Commande recvfrom()
La commande recvfrom permet de recueillir dans un buffer les données reçues sur une socket. Voici un exemple d'utilisation pour le côté serveur.
// ******************************************************** // Reception des données // ******************************************************** tempo=sizeof(information_sur_la_source); // Passe par une variable afin d'utiliser un pointeur nombre_de_caractere=recvfrom(id_de_la_socket,buffer,1515,0,(struct
sockaddr*)&information_sur_la_source,&tempo); buffer[nombre_de_caractere]=0; // Permet de fermer le tableau après le contenu des data, car la fonction recvfrom ne le fait pas printf("\nVoici les donnees : %s",buffer);
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction accept(). - Le second argument est le buffer contenant les données à recevoir. - Le troisième paramètre représente le nombre maximum de caractère attendu. - Le quatrième fait référence à la structure comprenant les informations sur le port et l'adresse IP en écoute. - Le cinquième indique la taille de la structure précédente.
- La fonction renverra le nombre de caractère qui a été reçu.
Voici la fiche Msdn concernant la fonction recvfrom()
5 - Libération de la socket
5.1 Commande closesocket()
Cette fonction permet de libérer proprement l'accès à la socket. Durement conseillé pour le respect d'un
développement propre et d'une utilisation saine du système d'exploitation. Voici un exemple d'utilisation pour le côté client et serveur.
// ******************************************************** // Fermeture de la socket correspondant à la commande socket()
// ******************************************************** erreur=closesocket(id_de_la_socket);

if (erreur!=0) printf("\nDesole, je ne peux pas liberer la socket du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nclosesocket : OK");
- Le premier argument est l'identifiant de la socket que vous avez récupéré grâce à la fonction socket(). - La fonction devra renvoyer 0 pour indiquer que sont exécution c'est correctement déroulée.
Voici la fiche Msdn concernant la fonction closesocket().
5.2 Commande WSACleanup()
Cette étape n'est utile et fonctionnelle que dans le cadres du système d'exploitation Microsoft. Cette fonction permet de libérer l'accès à Winsock. Attention, dans un environnement multiprocess, l'utilisation de cette commande fermera les accès de tous les process. Voici un exemple d'utilisation pour le côté client et serveur.
// ******************************************************** // Quitte proprement le winsock ouvert avec la commande WSAStartup // ******************************************************** erreur=WSACleanup(); // A appeler autant de fois qu'il a été ouvert. if (erreur!=0)
printf("\nDesole, je ne peux pas liberer winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nWSACleanup : OK");
- La fonction devra renvoyer 0 pour indiquer que sont exécution c'est correctement déroulée.
Voici la fiche Msdn concernant la fonction WSACleanup().
6 - Exemple complet d'une communication client serveur
6.1 - Côté serveur
Voici un exemple de code fonctionnel qui permet d'écouter sur le port UDP 33333 et d'afficher les données reçues.
Le fichier cpp est disponible ici.
// ******************************************************** // Les includes
// ******************************************************** #include <winsock2.h> // pour les fonctions socket #include <cstdio> // Pour les Sprintf // ******************************************************** // Les librairies // ********************************************************
#pragma comment(lib,"ws2_32.lib") // ******************************************************** // Définition des variables // ********************************************************
WSADATA initialisation_win32; // Variable permettant de récupérer la structure d'information sur l'initialisation
int erreur; // Variable permettant de récupérer la valeur de retour des fonctions utilisées int tempo; // Variable temporaire de type int int nombre_de_caractere; // Indique le nombre de caractères qui a été reçu ou envoyé char buffer[65535]; // Tampon contenant les données reçues ou envoyées SOCKET id_de_la_socket; // Identifiant de la socket SOCKADDR_IN information_sur_la_source; // Déclaration de la structure des informations lié à l'écoute
int main (int argc, char* argv[]) { printf("\nBonjour, vous etes du cote serveur. www.frameip.com\n"); // ******************************************************** // Initialisation de Winsock // ********************************************************
erreur=WSAStartup(MAKEWORD(2,2),&initialisation_win32); if (erreur!=0) printf("\nDesole, je ne peux pas initialiser Winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else

printf("\nWSAStartup : OK"); // ******************************************************** // Ouverture d'une Socket
// ********************************************************
id_de_la_socket=socket(AF_INET,SOCK_DGRAM,0); if (id_de_la_socket==INVALID_SOCKET) printf("\nDesole, je ne peux pas creer la socket du a l'erreur : %d",WSAGetLastError()); else printf("\nsocket : OK");
// ******************************************************** // Lie la socket à une ip et un port d'écoute // ******************************************************** information_sur_la_source.sin_family=AF_INET; information_sur_la_source.sin_addr.s_addr=INADDR_ANY; // Ecoute sur toutes les IP locales information_sur_la_source.sin_port=htons(33333); // Ecoute sur le port 33333
erreur=bind(id_de_la_socket,(struct sockaddr*)&information_sur_la_source,sizeof(information_sur_la_source)); if (erreur!=0) printf("\nDesole, je ne peux pas ecouter ce port : %d %d",erreur,WSAGetLastError()); else printf("\nbind : OK"); // ********************************************************
// Reception des données // ******************************************************** tempo=sizeof(information_sur_la_source); // Passe par une variable afin d'utiliser un pointeur nombre_de_caractere=recvfrom(id_de_la_socket,buffer,1515,0,(struct sockaddr*)&information_sur_la_source,&tempo); buffer[nombre_de_caractere]=0; // Permet de fermer le tableau après le contenu des data, car la fonction recvfrom ne le fait pas
printf("\nVoici les donnees : %s",buffer); // ******************************************************** // Fermeture de la socket correspondante à la commande socket() // ******************************************************** erreur=closesocket(id_de_la_socket);
if (erreur!=0) printf("\nDesole, je ne peux pas liberer la socket du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nclosesocket : OK"); // ******************************************************** // Quitte proprement le winsock ouvert avec la commande WSAStartup
// ******************************************************** erreur=WSACleanup(); // A appeler autant de fois qu'il a été ouvert. if (erreur!=0) printf("\nDesole, je ne peux pas liberer winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nWSACleanup : OK"); }
6.2 - Côté client
Voici un exemple de code fonctionnel qui permet d'envoyer des données sur le port UDP 33333, n'oubliez pas de
changer l'IP de destination pour correspondre à votre serveur. Le fichier cpp est disponible ici.
// ******************************************************** // Les includes // ********************************************************
#include <winsock2.h> // pour les fonctions socket #include <cstdio> // Pour les Sprintf // ******************************************************** // Les librairies // ******************************************************** #pragma comment(lib,"ws2_32.lib")
// ******************************************************** // Définition des variables // ******************************************************** WSADATA initialisation_win32; // Variable permettant de récupérer la structure d'information sur l'initialisation int erreur; // Variable permettant de récupérer la valeur de retour des fonctions utilisées

int tempo; // Variable temporaire de type int int nombre_de_caractere; // Indique le nombre de caractères qui a été reçu ou envoyé char buffer[65535]; // Tampon contennant les données reçues ou envoyées SOCKET id_de_la_socket; // Identifiant de la socket
SOCKADDR_IN information_sur_la_destination; // Déclaration de la structure des informations lié au serveur
int main (int argc, char* argv[]) { printf("\nBonjour, vous etes du cote client. www.frameip.com\n");
// ******************************************************** // Initialisation de Winsock // ******************************************************** erreur=WSAStartup(MAKEWORD(2,2),&initialisation_win32); if (erreur!=0) printf("\nDesole, je ne peux pas initialiser Winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else
printf("\nWSAStartup : OK"); // ******************************************************** // Ouverture d'une Socket // ******************************************************** id_de_la_socket=socket(AF_INET,SOCK_DGRAM,0); if (id_de_la_socket==INVALID_SOCKET)
printf("\nDesole, je ne peux pas creer la socket du a l'erreur : %d",WSAGetLastError()); else printf("\nsocket : OK"); // ******************************************************** // Envoi des données // ********************************************************
information_sur_la_destination.sin_family=AF_INET; // Indiquez l'utilisation d'IPV4 information_sur_la_destination.sin_addr.s_addr=inet_addr("10.10.10.10"); // Indiquez l'adresse IP de votre serveur information_sur_la_destination.sin_port=htons(33333); // Port TCP 33333 à destination du serveur strcpy(buffer,"Coucou, je suis les donnees. www.frameip.com"); // Copie la chaine de caractère dans buffer nombre_de_caractere=sendto(id_de_la_socket,buffer,strlen(buffer),0,(struct
sockaddr*)&information_sur_la_destination,sizeof(information_sur_la_destination)); if (nombre_de_caractere==SOCKET_ERROR) printf("\nDesole, je ne peux pas envoyer les donnees du a l'erreur : %d",WSAGetLastError()); else printf("\nsend : OK"); // ********************************************************
// Fermeture de la socket correspondant à la commande socket() // ******************************************************** erreur=closesocket(id_de_la_socket); if (erreur!=0) printf("\nDesole, je ne peux pas liberer la socket du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nclosesocket : OK");
// ******************************************************** // Quitte proprement le winsock ouvert avec la commande WSAStartup // ******************************************************** erreur=WSACleanup(); // A appeler autant de fois qu'il a été ouvert. if (erreur!=0)
printf("\nDesole, je ne peux pas liberer winsock du a l'erreur : %d %d",erreur,WSAGetLastError()); else printf("\nWSACleanup : OK"); }
Mode connecte et non connecté en VB
1 - Le composant Winsock en VB 2 - Les propriétés, les procédure et les évènements de Winsock
3 - Mode connecté 3.1 - Schéma d'une relation client serveur 3.2 - Le mode client 3.3 - Le mode serveur 3.3.1 - Sur une feuille

3.3.2 - Dans une classe 3.4 - Exemple complet d'une communication client serveur 4 - Mode non connecté 4.1 - Schéma d'une relation client serveur 4.2 - Le mode client et serveur
4.3 - Exemple complet d'une communication client serveur 5 - Les liens
6 - Discussion autour de la documentation 7 - Suivi du document
1 - Le composant Winsock en VB
Le contrôle Winsock VB de Microsoft permet d'envoyer des datagrames facilement à un autre ordinateur ou tout autre équipement Ip. Ce contrôle ne supporte que
deux mode de connexion qui sont Tcp et Udp. On peut utiliser ce contrôle sous deux formes. La première comme composant et la seconde comme référence. Quand vous voulez utiliser Winsock dans votre application, vous devez l'ajouter comme composant "Microsoft Winsock Control 6.0" ou comme référence "%WinDir%\System\mswinsck.ocx".
2 - Les propriétés, les procédures et les évènements de Winsock
Voici la liste des propriétés ayant rapport à la configuration de Winsock. Leurs effets et les valeurs qu'ils peuvent prendre et évidemment, elle peuvent aussi en retourner.
Nom Effet Valeurs acceptées
Name *(Quand il est sur une feuille) Le nom du contrôle Une chaîne de caractères correcte pour un nom d'objet
Index *(Quand il est sur une feuille) Son index si il fait partit d'une collection de contrôles
rien=pas dans une collection;un chiffre de 0 à (limite du type entier)
Left *(Quand il est sur une feuille) La position du côté gauche du contrôle un chiffre
LocalPort Port à écouter pour recevoir des paquets ou des demandes de connexion
un chiffre de 0 à 65 000
Protocol Protocole à utiliser 0 pour TCP et 1 pour UDP
RemoteHost L'adresse de l'hôte auquel il faut envoyer des paquets (UDP) une adresse ip: 192.168.0.1, 125.124.368.14, ... ou un DNS.
RemotePort Le port de l'hôte auquel il faut envoyer des paquets (UDP) un chiffre de 0 à 65 000
Tag *(Quand il est sur une feuille) Une propriété pour stocker des
données, ce que l'on veut ce que l'on veut
Top *(Quand il est sur une feuille) La position du haut du contrôle un chiffre
Voici la liste des propriétés de Winsock retournant une valeur en lecture seule.
Nom Résultat
BytesReceived Nombre de BYTES reçus
LocalHostName Nom d'hôte de cet ordinateur
RemoteHostIP Adresse IP de l'hôte auquel on est connecté
SocketHandle
Le handle du socket qui est utilisé (la section que l'API winsock a dû lui réserver)
State L'état du socket (connecté, erreur, attente de connexion, ...)
Voici la liste des évènements que Winsock peut déclencher. Normalement, tout va bien dans une feuille, mais pour la classe, vous devez utiliser Withevents puis lui créer un instance et il n'y aura pas de problème.
Nom Description des arguments Description
Close() Fermeture d'une connexion
(TCP)

Connect()
Connexion réussie (TCP)
ConnectionRequest(ByVal requestID As Long) l'ID d'une requête de
connexion)
Demande de connexion
(TCP)
DataArrival(ByVal bytesTotal As Long) Le nombre de bytes qui arrivent
Arrivée de données
Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean)
Informations relatives à l'erreur (numéro, description, ...)
Erreur!!!!!!
SendComplete()
Envoi des données terminé
SendProgress(ByVal bytesSent As Long, ByVal bytesRemaining As Long)
Nombre de bytes envoyées Nombre de bytes qui reste à envoyer
Envoi des données en cours ...
Avec c'est différentes méthodes et propriétés, vous serez capables de créer des applications utilisant Winsock.
3 - Mode connecté
3.1 - Schéma d'une relation client serveur

3.2 - Le mode client
Voici le code expliqué d'un client en Tcp. Il est bien sur requis une feuille avec un bouton command1 et un contrôle socket.
Private Sub Command1_Click() socket.Connect "www.google.com", 80 'On se connecte à www.google.com sur le port
80 End Sub Private Sub socket_Close() 'Fin de la connexion MsgBox "connexion terminée!" socket.Close 'Fermeture du socket End Sub Private Sub socket_Connect() 'Connexion établie MsgBox "connexion réessie!" socket.SendData "GET / HTTP/1.0" &
vbCrLf & "Accept: */*" & vbCrLf & "User-Agent: Winsock" & vbCrLf & vbCrLf 'On envoie des données au serveur, ici c'est une requête HTTP End Sub Private Sub socket_DataArrival(ByVal bytesTotal As Long) 'Arrivée de données Dim data As String If socket.State <> sckConnected Then Exit Sub 'Juste au cas où ça a buggé socket.GetData data, vbString 'On récupère les données 'DONNÉES DANS DATA MsgBox data End Sub
Private Sub socket_Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) Err.Clear 'On ignore l'erreur End Sub
Voici comment créer un client http sans utiliser le contrôle Winsock, mais plutôt l'objet référence.
Public WithEvents socket As Winsock 'Pour les évènements
Private Sub Command1_Click() socket.Connect "www.google.com", 80 'On se connecte à www.google.com sur le port 80 End Sub
Private Sub Form_QueryUnload(Cancel As Integer, UnloadMode As Integer) Set socket = Nothing 'On vide l'objet winsock End Sub
Private Sub socket_Close() 'Fin de la connexion MsgBox "connexion terminée!" socket.Close 'Fermeture du socket End Sub
Private Sub socket_Connect() 'Connexion établie MsgBox "connexion réessie!" socket.SendData "GET / HTTP/1.0" & vbCrLf & "Accept: */*" & vbCrLf & "User-Agent: Winsock" & vbCrLf & vbCrLf 'On envoie des données au serveur, ici c'est une requête HTTP End Sub
Private Sub socket_DataArrival(ByVal bytesTotal As Long) 'Arrivée de données Dim data As String If socket.State <> sckConnected Then Exit Sub 'Juste au cas où ça a buggé socket.GetData data, vbString 'On récupère les données 'DONNÉES DANS DATA MsgBox data End Sub
Private Sub socket_Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) Err.Clear 'On ignore l'erreur End Sub
Private Sub Form_Load() Set socket = New Winsock 'On initialise winsock 'With socket '.param1=??? '.param2=??? 'End With End Sub
3.3 - Le mode serveur
3.3.1 - Sur une feuille
Voici le code expliqué d'un serveur avec un seul client Tcp simultané. Il est bien sur requis une feuille avec un bouton command1 et un contrôle Winsock socket.
Private Sub Command1_Click() socket.Close 'UN SOCKET DOIT ÊTRE FERMER AVANT D'ÊTRE MIS EN ÉCOUTE!!! socket.LocalPort = 95 'écoute port 95 socket.Listen End Sub
Private Sub socket_Close() 'Fermeture du socket MsgBox "connexion terminée!" socket.Close 'S'assurer que le
socket se ferme car sinon, ça peut être très drôle ;-) Command1_Click End Sub
Private Sub socket_ConnectionRequest(ByVal requestID As Long) 'Demande de connexion MsgBox "Demande de

connexion!" socket.Close 'UN SOCKET DOIT ÊTRE FERMER AVANT D'ACCEPTER UNE CONNEXION!!! 'Bon, ya u gros problème. c'est une connexion par socket. QUE FAIRE!!! socket.Accept requestID 'Une autre contrôle winsock peut très bien accepter cette demande... End Sub
Private Sub socket_DataArrival(ByVal bytesTotal As Long) 'Arrivée des données Dim data As String If
socket.State <> sckConnected Then Exit Sub 'En cas de problèmes ... on ne sait pas socket.GetData data, vbString MsgBox data 'Ce que le client dit (on s'en fiche tu :-) 'Ce qu'on lui répond : Dim envoie As String envoie = "<html><head><title>Salut</title></head><body>Allo</body></html>" 'La réponse à envoyer socket.SendData "HTTP/1.0 200 OK" & vbCrLf & "Server: Winsock/6.0" & vbCrLf & "Content-Type: text/html" & vbCrLf & "Content-Lenght: " & Len(envoie) & vbCrLf & vbCrLf & envoie 'Une réponse HTTP ^ End Sub
Private Sub socket_Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source
As String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) Err.Clear 'En cas d'erreur, ignorer End Sub
Private Sub socket_SendComplete() socket.Close 'On ferme End Sub
Voici la partie serveur multi-clients. il est bien sur requis une feuille avec un bouton command1 et deux
contrôles Winsock socket et écoute.
Private Sub Command1_Click() 'Le socket est ouvert et il restera ouvert If ecoute.State = 2 Then Exit Sub 'Si on écoute déjà, on quitte la procédure ecoute.LocalPort = 95 ecoute.Listen End Sub
Private Sub ecoute_ConnectionRequest(ByVal requestID As Long) 'LE TRÈS GROS MORCEAU Dim nb As Integer nb = socket.Count 'Le nombre de socket dans la collection. Comme le 0 compte, pas besoins de rajouter +1. Load socket(nb) 'On ajoute ajoute un autre socket dans la collection de ce contrôle socket(nb).Accept requestID 'CE contrôle fesant partit de la collection accepte la requête Debug.Print "Client ajouté : " &
socket(nb).RemoteHostIP End Sub
Private Sub ecoute_Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) Err.Clear 'En cas
d'erreur, ignorer End Sub
Private Sub socket_Close(Index As Integer) socket_SendComplete Index 'Si le socket se ferme, fait comme si l'envoie serait fini End Sub
Private Sub socket_DataArrival(Index As Integer, ByVal bytesTotal As Long) 'NOTEZ BIEN L'ARGUMENT INDEX. IL RETOURE L'INDEX DE CE SOCKET DANS LA COLLECTION 'Ce que le client dit (on s'en fiche tu :-) 'Ce qu'on lui répond : Dim envoie As String envoie = "<html><head><title>Salut</title></head><body>a" & String$(10000, "l") & "o</body></html>" 'La réponse à envoyer Debug.Print "Envoie du socket # " & Index & "
à " & Now socket(Index).SendData "HTTP/1.0 200 OK" & vbCrLf & "Server: Winsock/6.0" & vbCrLf & "Content-Type: text/html" & vbCrLf & "Content-Lenght: " & Len(envoie) & vbCrLf & "Pragma: no-cache" & vbCrLf & vbCrLf & envoie 'Une réponse HTTP ^ End Sub
Private Sub socket_Error(Index As Integer, ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) Err.Clear 'En cas d'erreur, ignorer End Sub
Private Sub socket_SendComplete(Index As Integer) socket(Index).Close 'Fermer le socket Debug.Print "Fermeture du socket # " & Index & " à " & Now If Index <> 0 Then Unload socket(Index) 'Si le socket n'est pas
le 0 (celui de base), on le FLUSH End Sub
3.3.2 - Dans une classe
Pour un serveur avec un seul client, c'est la même chose que sur une feuille sauf qu'il faut utiliser Winsock comme référence et le déclarer avec Withevents. Pour un serveur multi-clients, c'est plus complexe.
Voici la partie cliente Classe 1.
Public WithEvents socket As Winsock
Public MyNum As Long
Private Sub Class_Initialize() Set socket = New Winsock End Sub

Private Sub Class_Terminate() Set socket = Nothing End Sub
Private Sub socket_Close() Form1.Killsocket MyNum 'S'assurer que le socket se ferme car sinon, ça peut être très drôle ;-) End Sub
Private Sub socket_DataArrival(ByVal bytesTotal As Long) 'Ce qu'on lui répond : Debug.Print "OK" Dim envoie As
String envoie = "<html><head><title>Salut</title></head><body>A" & String$(1000, "l") & "o</body></html>" 'La réponse à envoyer socket.SendData "HTTP/1.0 200 OK" & vbCrLf & "Server: Winsock/6.0" & vbCrLf & "Content-Type: text/html" & vbCrLf & "Content-Lenght: " & Len(envoie) & vbCrLf & vbCrLf & envoie 'Une réponse HTTP ^ End Sub
Private Sub socket_Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) Err.Clear 'En cas
d'erreur, ignorer End Sub
Private Sub socket_SendComplete() socket.Close 'On ferme End Sub
Voici la partie clients Classe 2.
Private WithEvents socket As Winsock Public Sockets As New Collection Public Num As Long
Private Sub Class_Initialize() Set socket = New Winsock With socket .LocalPort = 95 .Listen End With End Sub
Private Sub Class_Terminate() Set Sockets = Nothing Set socket = Nothing End Sub
Private Sub socket_ConnectionRequest(ByVal requestID As Long) Dim buf As New Client buf.socket.Accept requestID buf.MyNum = Num Num = Num + 1 Sockets.Add buf End Sub
Private Sub socket_Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) Err.Clear End Sub
Voici la définition de la feuille que l'on peux, au passage, se passer.
Private Clients As Clients
'JUSTE POUR DÉMARRER ET NETTOYER CAR J'AI PAS ENVIE DE ME CASSER LA TÊTE
Private Sub Form_Load() Set Clients = New Clients End Sub
Private Sub Form_QueryUnload(Cancel As Integer, UnloadMode As Integer) Set Clients = Nothing End Sub
Sub Killsocket(MyNum As Long) For i = 1 To Clients.Sockets.Count If Clients.Sockets.MyNum = MyNum Then Clients.Sockets.Remove i Next End Sub
3.4 - Exemple complet d'une communication client serveur
C'est très simple, le serveur commence à écouter un port pour attendre une connexion Tcp. Dès qu'un client envoie une demande de connexion, le serveur l'accepte et établit l'ouverture de session avec le client. Le serveur et le client sont maintenant connectés et peuvent donc envoyer et recevoir des données. Quand le serveur arrête la connexion, le client s'en rend compte grâce à l'évènement socket_close. La fermeture de la session TCP peux
être demandé par le client ou par le serveur. Les sources et l'exe peuvent être téléchargé ici.
Private Sub CheckState_Timer() If Clients.ListCount = 0 Then send.Enabled = False Else: send.Enabled = True 'Si il n'y a pas de client, pourquoi envoyer un message? If Ecoute.State = 0 Then Go.Caption = "Écouter" Else: Go.Caption = "Arrêter le serveur" 'Placer le texte du bouton Go End Sub
Private Sub Clients_MouseUp(Button As Integer, Shift As Integer, X As Single, Y As Single)

If Button = vbRightButton And Clients.ListIndex <> -1 Then 'Si on clique avec le bouton droit et qu'on a sélectionner un ip dans la liste, on affiche le menu PopupMenu pop End If
End Sub
Private Sub Decon_Click() 'ON LE BOOT!! Dim col col = Split(Clients.List(Clients.ListIndex), ":") 'On récuprère son # de socket (après le ":") Socket_Close (CInt(col(1))) 'On fait comme s'il aurait quitté
End Sub Private Sub Ecoute_ConnectionRequest(ByVal requestID As Long) 'Demande de connexion Dim Nb As Integer Nb = Socket.Count '# de la prochaince socket disponible (LIMITE : 65535 CAR TYPE INTEGER = SUR 4 OCTETS (FFFF)) Load Socket(Nb) 'On charge ce socket
Socket(Nb).Accept requestID 'On fait accepter la connexion recep.Text = recep.Text & recep.Text & "<system> : Connexion établie avec " & Socket(Nb).RemoteHostIP & " !" & vbCrLf & vbCrLf 'On dit que le client c'est connecté Clients.AddItem Socket(Nb).RemoteHostIP & ":" & Nb 'On met son IP suivit de ":" et son 1 de socket dans la liste End Sub Private Sub Ecoute_Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As
String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) 'Erreur! MsgBox "Erreur avec le socket! & vbcrlf # " & Number & vbCrLf & Description Ecoute.Close End Sub Private Sub Form_Load() CheckState_Timer 'On fait faire une première vérification avec le timer
End Sub Private Sub Go_Click() 'On appuie sur le bouton Go On Error Resume Next If Ecoute.State = 2 Then 'Si on écoutait, ben on ferme Ecoute.Close
For i = 1 To Socket.Count - 1 'On décharge tout les sockets Socket(i).Close Unload Socket(i) 'On détruit l'objet créer (0 ne peut pas être unloadé) Next Else 'Sinon ben on écoute Ecoute.LocalPort = Port.Text 'Le port Ecoute.Listen 'On écoute
If Err.Number <> 0 Then 'ERREUR, POURQUOI ON PEUT PAS ÉCOUTER (sûrement que le port est occupé) MsgBox "Erreur avec le socket! & vbcrlf # " & Err.Number & vbCrLf & Err.Description 'On dit pourquoi Err.Clear 'On nettoie l'erreur End If End If End Sub
Private Sub send_Click() 'Envoie du message, comme avec le client recep.Text = recep.Text & "<you> : " & vbCrLf & Emission.Text & vbCrLf & vbCrLf For i = 1 To Socket.Count - 1 Socket(i).SendData Emission.Text Next Emission.Text = ""
End Sub Private Sub Socket_Close(Index As Integer) 'Le client vient de quitter ou il s'est fait booter Dim col For i = 0 To Clients.ListCount - 1 'On cherche son # de socket pour l'enlever de la liste col = Split(Clients.List(i), ":") If col(1) = Index Then
Socket(col(1)).Close Unload Socket(col(1)) 'On kill le socket recep.Text = recep.Text & recep.Text & "<system> : Connexion terminée avec " & col(0) & " !" & vbCrLf & vbCrLf 'On dit qu'il quitte Clients.RemoveItem i 'On l'enlève de la liste Exit For 'Pas besoins de continuer End If
Next End Sub Private Sub Socket_DataArrival(Index As Integer, ByVal bytesTotal As Long) 'Arrivée des données, comme avec le

client Dim data As String Socket(Index).GetData data, vbString recep.Text = recep.Text & "<" & Socket(Index).RemoteHostIP & "> : " & vbCrLf & data & vbCrLf & vbCrLf
End Sub
4 - Mode non connecté
4.1 - Schéma d'une relation client serveur
4.2 - Le mode client et serveur
Udp est orienté sans connexion, donc il nécessite peu de code. C'est le même fonctionnement que Tcp, mais il n'y a pas de session, donc pas de fermeture de connexion. Il est bien sur requis deux Sockets en tant que contrôle ou objet socket1 et socket2 avec le protocole Udp de sélectionné!
'SOCKET 1 EST LE "CLIENT" ET LE 2 EST LE "SERVEUR"
Private Sub Form_Load() On Error Resume Next 'UDP PLANTE DESFOIS!!! socket2.Bind 98, "0.0.0.0" 'PORT À ÉCOUTER socket1.RemoteHost = "127.0.0.1" 'Adresse auquel il faut envoyer le(s) datagramme(s) socket1.RemotePort = 98 'Port auquel il faut envoyer le(s) datagramme(s) socket1.SendData "drole" 'Envoyer les données End Sub
Private Sub Form_Unload(Cancel As Integer) socket2.Close 'Arrêter d'écouter le port UDP 98 End Sub
Private Sub socket1_Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) Err.Clear 'Ignorer l'erreur End Sub
Private Sub socket2_DataArrival(ByVal bytesTotal As Long) Dim data As String socket2.GetData data, vbString

'Prendre les données comme avec tcp MsgBox "Message de " & socket2.RemoteHostIP & " : " & data End Sub
Private Sub socket2_Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) Err.Clear 'Ignorer l'erreur End
Sub
4.3 - Exemple complet d'une communication client serveur
Le principe d'Udp est simple. Premièrement, un "serveur" décide de commencer à écouter un port et attend l'arrivée de paquets de données. Un client lui envoie un datagramme en spécifiant à l'adresse ip et ports de
destination ainsi que la correspondance de retour. Le client utilise LocalPort=le_#_du_port pour spécifier le port sur lequel il attend une réponse, pus communément appelé port source. Quand le serveur reçoit un paquet, il détermine les coordonnées de l'émetteur et peut ainsi lui répondre. Il n'y a pas de session donc pas de fermeture de connexion, cela permet d'effectuer des échanges courts et rapides. Les sources et l'exe peuvent être téléchargé ici.
Option Explicit Private Sub CheckState_Timer() If Socket.State = 1 Then Go.Caption = "Arrêter" Else: Go.Caption = "Écouter"
End Sub Private Sub Go_Click() On Error Resume Next If Socket.State <> 1 Then Socket.Close Socket.Bind port.Text, addr.Text
If Err.Number <> 0 Then 'ERREUR, POURQUOI ON PEUT PAS ÉCOUTER (sûrement que le port est occupé) MsgBox "Erreur avec le socket! & vbcrlf # " & Err.Number & vbCrLf & Err.Description 'On dit pourquoi Err.Clear 'On nettoie l'erreur End If Else Socket.Close End If
End Sub Private Sub send_Click() On Error Resume Next If Socket.State <> 1 Then 'On prend 1 port pour recevoir les messages du recépteur
Socket.LocalPort = 0 'N'IMPORTE QUEL PORT LIBRE End If Socket.RemoteHost = sendaddr.Text 'L'adresse où ilo faut envoyer les données Socket.RemotePort = sendport.Text 'Le port où ilo faut envoyer les données Socket.SendData Emission.Text 'On envoie (ÇA PEUT BOGUER POUR RIEN!!!) recep.Text = recep.Text & "<you> : " & vbCrLf & Emission.Text & vbCrLf & vbCrLf 'Pour savoir ce qu'on a envoyer Emission.Text = "" 'On fait de la place pour un nouveau message
End Sub Private Sub Socket_DataArrival(ByVal bytesTotal As Long) Dim data As String Socket.GetData data, vbString 'On les met dans la variable data recep.Text = recep.Text & "<" & Socket.RemoteHostIP & "> : " & vbCrLf & data & vbCrLf & vbCrLf 'Pour dire qui à
envoyer le message
sendaddr.Text = Socket.RemoteHostIP 'On garde son adresse et on peut lui répondre sendport.Text = Socket.RemotePort 'On garde son port et on peut lui répondre Beep End Sub Private Sub Socket_Error(ByVal Number As Integer, Description As String, ByVal Scode As Long, ByVal Source As
String, ByVal HelpFile As String, ByVal HelpContext As Long, CancelDisplay As Boolean) 'ERREUR!!! ON AFFICHE L'ERRREUR ET ON FERME LE SOCKET MsgBox "Erreur avec le socket! & vbcrlf # " & Number & vbCrLf & Description Socket.Close End Sub
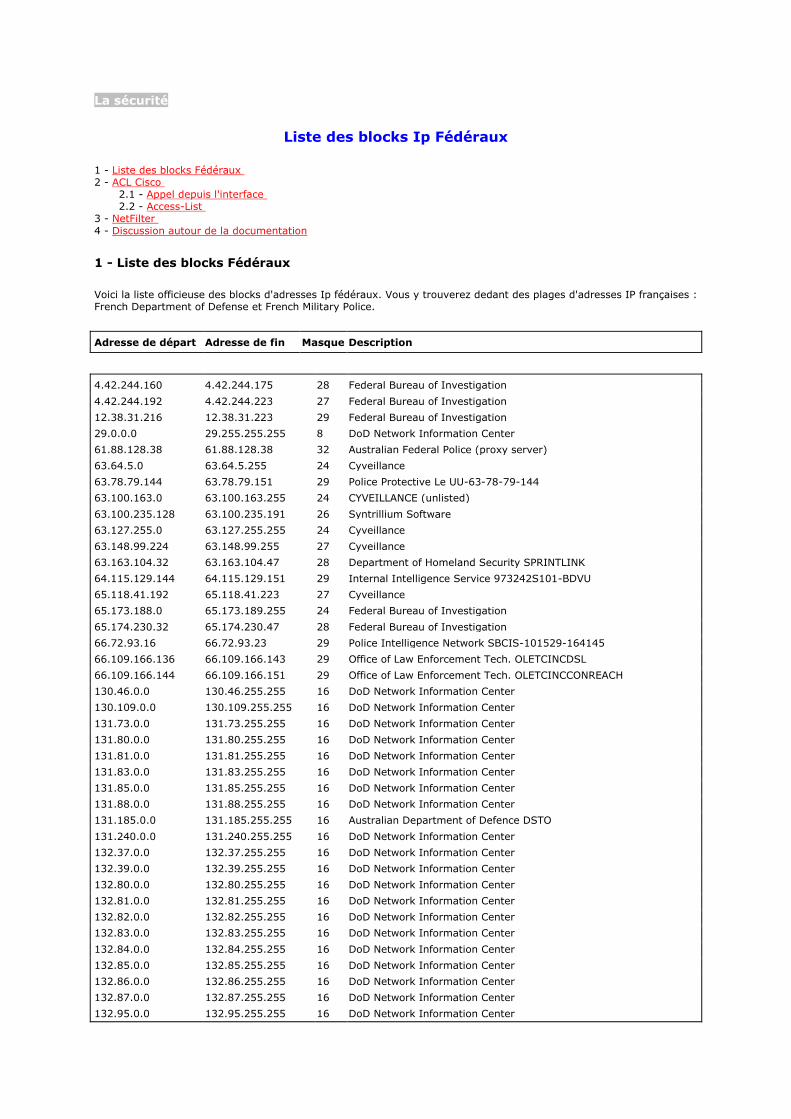
La sécurité
Liste des blocks Ip Fédéraux
1 - Liste des blocks Fédéraux 2 - ACL Cisco 2.1 - Appel depuis l'interface 2.2 - Access-List 3 - NetFilter
4 - Discussion autour de la documentation
1 - Liste des blocks Fédéraux
Voici la liste officieuse des blocks d'adresses Ip fédéraux. Vous y trouverez dedant des plages d'adresses IP françaises : French Department of Defense et French Military Police.
Adresse de départ Adresse de fin Masque Description
4.42.244.160 4.42.244.175 28 Federal Bureau of Investigation
4.42.244.192 4.42.244.223 27 Federal Bureau of Investigation
12.38.31.216 12.38.31.223 29 Federal Bureau of Investigation
29.0.0.0 29.255.255.255 8 DoD Network Information Center
61.88.128.38 61.88.128.38 32 Australian Federal Police (proxy server)
63.64.5.0 63.64.5.255 24 Cyveillance
63.78.79.144 63.78.79.151 29 Police Protective Le UU-63-78-79-144
63.100.163.0 63.100.163.255 24 CYVEILLANCE (unlisted)
63.100.235.128 63.100.235.191 26 Syntrillium Software
63.127.255.0 63.127.255.255 24 Cyveillance
63.148.99.224 63.148.99.255 27 Cyveillance
63.163.104.32 63.163.104.47 28 Department of Homeland Security SPRINTLINK
64.115.129.144 64.115.129.151 29 Internal Intelligence Service 973242S101-BDVU
65.118.41.192 65.118.41.223 27 Cyveillance
65.173.188.0 65.173.189.255 24 Federal Bureau of Investigation
65.174.230.32 65.174.230.47 28 Federal Bureau of Investigation
66.72.93.16 66.72.93.23 29 Police Intelligence Network SBCIS-101529-164145
66.109.166.136 66.109.166.143 29 Office of Law Enforcement Tech. OLETCINCDSL
66.109.166.144 66.109.166.151 29 Office of Law Enforcement Tech. OLETCINCCONREACH
130.46.0.0 130.46.255.255 16 DoD Network Information Center
130.109.0.0 130.109.255.255 16 DoD Network Information Center
131.73.0.0 131.73.255.255 16 DoD Network Information Center
131.80.0.0 131.80.255.255 16 DoD Network Information Center
131.81.0.0 131.81.255.255 16 DoD Network Information Center
131.83.0.0 131.83.255.255 16 DoD Network Information Center
131.85.0.0 131.85.255.255 16 DoD Network Information Center
131.88.0.0 131.88.255.255 16 DoD Network Information Center
131.185.0.0 131.185.255.255 16 Australian Department of Defence DSTO
131.240.0.0 131.240.255.255 16 DoD Network Information Center
132.37.0.0 132.37.255.255 16 DoD Network Information Center
132.39.0.0 132.39.255.255 16 DoD Network Information Center
132.80.0.0 132.80.255.255 16 DoD Network Information Center
132.81.0.0 132.81.255.255 16 DoD Network Information Center
132.82.0.0 132.82.255.255 16 DoD Network Information Center
132.83.0.0 132.83.255.255 16 DoD Network Information Center
132.84.0.0 132.84.255.255 16 DoD Network Information Center
132.85.0.0 132.85.255.255 16 DoD Network Information Center
132.86.0.0 132.86.255.255 16 DoD Network Information Center
132.87.0.0 132.87.255.255 16 DoD Network Information Center
132.95.0.0 132.95.255.255 16 DoD Network Information Center

132.96.0.0 132.96.255.255 16 DoD Network Information Center
132.97.0.0 132.97.255.255 16 DoD Network Information Center
132.98.0.0 132.98.255.255 16 DoD Network Information Center
132.99.0.0 132.99.255.255 16 DoD Network Information Center
132.100.0.0 132.100.255.255 16 DoD Network Information Center
132.101.0.0 132.101.255.255 16 DoD Network Information Center
132.102.0.0 132.102.255.255 16 DoD Network Information Center
132.103.0.0 132.103.255.255 16 DoD Network Information Center
132.133.0.0 132.133.255.255 16 DoD Network Information Center
132.134.0.0 132.134.255.255 16 DoD Network Information Center
132.135.0.0 132.135.255.255 16 DoD Network Information Center
132.136.0.0 132.136.255.255 16 DoD Network Information Center
132.137.0.0 132.137.255.255 16 DoD Network Information Center
132.138.0.0 132.138.255.255 16 DoD Network Information Center
132.139.0.0 132.139.255.255 16 DoD Network Information Center
132.140.0.0 132.140.255.255 16 DoD Network Information Center
132.141.0.0 132.141.255.255 16 DoD Network Information Center
132.142.0.0 132.142.255.255 16 DoD Network Information Center
132.143.0.0 132.143.255.255 16 DoD Network Information Center
132.144.0.0 132.144.255.255 16 DoD Network Information Center
134.194.0.0 134.194.255.255 16 DoD Network Information Center
134.229.0.0 134.229.255.255 16 DoD Network Information Center
134.230.0.0 134.230.255.255 16 DoD Network Information Center
134.232.0.0 134.232.255.255 16 DoD Network Information Center
134.254.0.0 134.254.255.255 16 DoD Network Information Center
136.188.0.0 136.188.255.255 16 DoD Network Information Center
136.189.0.0 136.189.255.255 16 DoD Network Information Center
136.190.0.0 136.190.255.255 16 DoD Network Information Center
136.191.0.0 136.191.255.255 16 DoD Network Information Center
136.192.0.0 136.192.255.255 16 DoD Network Information Center
136.193.0.0 136.193.255.255 16 DoD Network Information Center
136.194.0.0 136.194.255.255 16 DoD Network Information Center
136.195.0.0 136.195.255.255 16 DoD Network Information Center
136.196.0.0 136.196.255.255 16 DoD Network Information Center
136.197.0.0 136.197.255.255 16 DoD Network Information Center
136.208.0.0 136.208.255.255 16 DoD Network Information Center
136.211.0.0 136.211.255.255 16 DoD Network Information Center
136.212.0.0 136.212.255.255 16 DoD Network Information Center
136.213.0.0 136.213.255.255 16 DoD Network Information Center
136.214.0.0 136.214.255.255 16 DoD Network Information Center
136.222.0.0 136.222.255.255 16 DoD Network Information Center
137.130.0.0 137.130.255.255 16 DoD Network Information Center
137.191.0.0 137.191.255.255 16 Irish Department of Defense
137.209.0.0 137.209.255.255 16 DoD Network Information Center
137.210.0.0 137.210.255.255 16 DoD Network Information Center
137.211.0.0 137.211.255.255 16 DoD Network Information Center
137.212.0.0 137.212.255.255 16 DoD Network Information Center
137.231.0.0 137.231.255.255 16 DoD Network Information Center
137.232.0.0 137.232.255.255 16 DoD Network Information Center
137.233.0.0 137.233.255.255 16 DoD Network Information Center
137.234.0.0 137.234.255.255 16 DoD Network Information Center
137.235.0.0 137.235.255.255 16 DoD Network Information Center
137.246.0.0 137.246.255.255 16 DoD Network Information Center
137.247.0.0 137.247.255.255 16 DoD Network Information Center
138.60.0.0 138.60.255.255 16 DoD Network Information Center
138.135.0.0 138.135.255.255 16 DoD Network Information Center
138.136.0.0 138.136.255.255 16 DoD Network Information Center

138.150.0.0 138.150.255.255 16 DoD Network Information Center
138.151.0.0 138.151.255.255 16 DoD Network Information Center
138.153.0.0 138.153.255.255 16 DoD Network Information Center
138.159.0.0 138.159.255.255 16 DoD Network Information Center
138.170.0.0 138.170.255.255 16 DoD Network Information Center
139.77.0.0 139.77.255.255 16 DoD Network Information Center
139.233.0.0 139.233.255.255 16 DoD Network Information Center
139.234.0.0 139.234.255.255 16 DoD Network Information Center
139.235.0.0 139.235.255.255 16 DoD Network Information Center
139.236.0.0 139.236.255.255 16 DoD Network Information Center
139.237.0.0 139.237.255.255 16 DoD Network Information Center
139.238.0.0 139.238.255.255 16 DoD Network Information Center
139.239.0.0 139.239.255.255 16 DoD Network Information Center
139.240.0.0 139.240.255.255 16 DoD Network Information Center
139.241.0.0 139.241.255.255 16 DoD Network Information Center
139.242.0.0 139.242.255.255 16 DoD Network Information Center
139.243.0.0 139.243.255.255 16 DoD Network Information Center
139.244.0.0 139.244.255.255 16 DoD Network Information Center
139.245.0.0 139.245.255.255 16 DoD Network Information Center
139.246.0.0 139.246.255.255 16 DoD Network Information Center
139.247.0.0 139.247.255.255 16 DoD Network Information Center
139.248.0.0 139.248.255.255 16 DoD Network Information Center
139.249.0.0 139.249.255.255 16 DoD Network Information Center
139.250.0.0 139.250.255.255 16 DoD Network Information Center
139.251.0.0 139.251.255.255 16 DoD Network Information Center
139.252.0.0 139.252.255.255 16 DoD Network Information Center
139.253.0.0 139.253.255.255 16 DoD Network Information Center
139.254.0.0 139.254.255.255 16 DoD Network Information Center
140.1.0.0 140.1.255.255 16 DoD Network Information Center
140.2.0.0 140.2.255.255 16 DoD Network Information Center
140.3.0.0 140.3.255.255 16 DoD Network Information Center
140.4.0.0 140.4.255.255 16 DoD Network Information Center
140.5.0.0 140.5.255.255 16 DoD Network Information Center
140.6.0.0 140.6.255.255 16 DoD Network Information Center
140.7.0.0 140.7.255.255 16 DoD Network Information Center
140.8.0.0 140.8.255.255 16 DoD Network Information Center
140.9.0.0 140.9.255.255 16 DoD Network Information Center
140.10.0.0 140.10.255.255 16 DoD Network Information Center
140.11.0.0 140.11.255.255 16 DoD Network Information Center
140.12.0.0 140.12.255.255 16 DoD Network Information Center
140.13.0.0 140.13.255.255 16 DoD Network Information Center
140.15.0.0 140.15.255.255 16 DoD Network Information Center
140.16.0.0 140.16.255.255 16 DoD Network Information Center
140.17.0.0 140.17.255.255 16 DoD Network Information Center
140.18.0.0 140.18.255.255 16 DoD Network Information Center
140.19.0.0 140.19.255.255 16 DoD Network Information Center
140.20.0.0 140.20.255.255 16 DoD Network Information Center
140.21.0.0 140.21.255.255 16 DoD Network Information Center
140.22.0.0 140.22.255.255 16 DoD Network Information Center
140.23.0.0 140.23.255.255 16 DoD Network Information Center
140.24.0.0 140.24.255.255 16 DoD Network Information Center
140.25.0.0 140.25.255.255 16 DoD Network Information Center
140.26.0.0 140.26.255.255 16 DoD Network Information Center
140.27.0.0 140.27.255.255 16 DoD Network Information Center
140.28.0.0 140.28.255.255 16 DoD Network Information Center
140.29.0.0 140.29.255.255 16 DoD Network Information Center
140.30.0.0 140.30.255.255 16 DoD Network Information Center
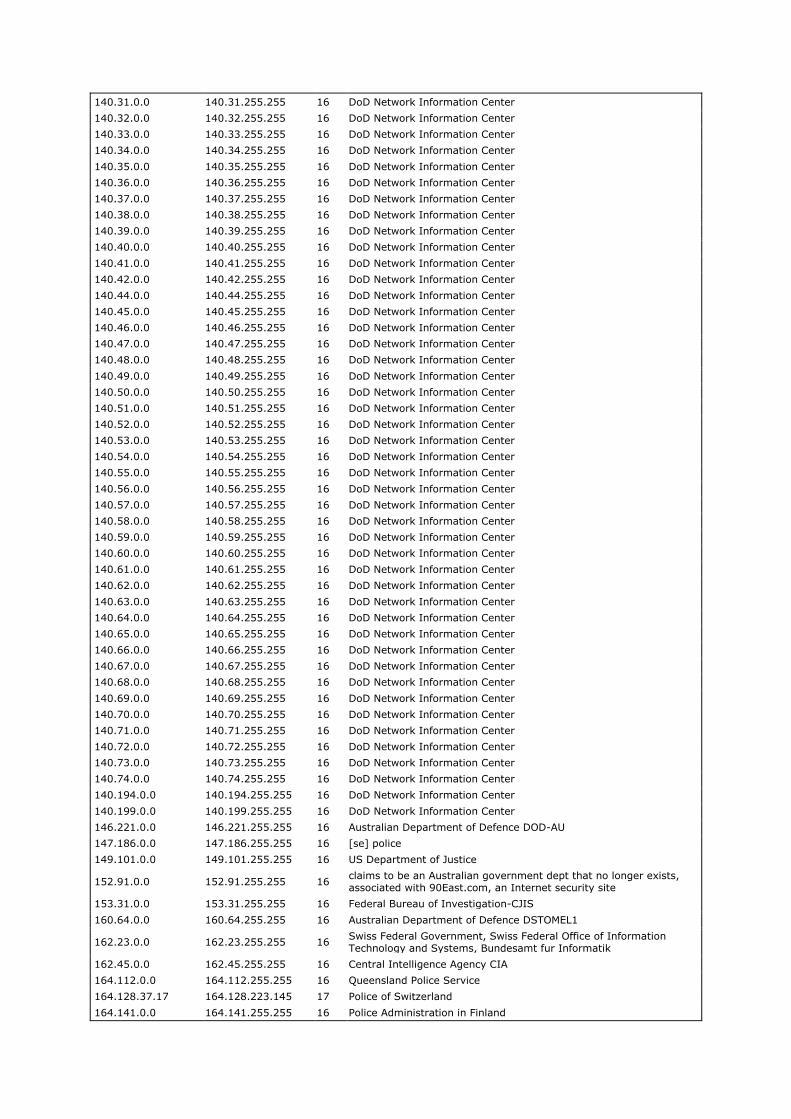
140.31.0.0 140.31.255.255 16 DoD Network Information Center
140.32.0.0 140.32.255.255 16 DoD Network Information Center
140.33.0.0 140.33.255.255 16 DoD Network Information Center
140.34.0.0 140.34.255.255 16 DoD Network Information Center
140.35.0.0 140.35.255.255 16 DoD Network Information Center
140.36.0.0 140.36.255.255 16 DoD Network Information Center
140.37.0.0 140.37.255.255 16 DoD Network Information Center
140.38.0.0 140.38.255.255 16 DoD Network Information Center
140.39.0.0 140.39.255.255 16 DoD Network Information Center
140.40.0.0 140.40.255.255 16 DoD Network Information Center
140.41.0.0 140.41.255.255 16 DoD Network Information Center
140.42.0.0 140.42.255.255 16 DoD Network Information Center
140.44.0.0 140.44.255.255 16 DoD Network Information Center
140.45.0.0 140.45.255.255 16 DoD Network Information Center
140.46.0.0 140.46.255.255 16 DoD Network Information Center
140.47.0.0 140.47.255.255 16 DoD Network Information Center
140.48.0.0 140.48.255.255 16 DoD Network Information Center
140.49.0.0 140.49.255.255 16 DoD Network Information Center
140.50.0.0 140.50.255.255 16 DoD Network Information Center
140.51.0.0 140.51.255.255 16 DoD Network Information Center
140.52.0.0 140.52.255.255 16 DoD Network Information Center
140.53.0.0 140.53.255.255 16 DoD Network Information Center
140.54.0.0 140.54.255.255 16 DoD Network Information Center
140.55.0.0 140.55.255.255 16 DoD Network Information Center
140.56.0.0 140.56.255.255 16 DoD Network Information Center
140.57.0.0 140.57.255.255 16 DoD Network Information Center
140.58.0.0 140.58.255.255 16 DoD Network Information Center
140.59.0.0 140.59.255.255 16 DoD Network Information Center
140.60.0.0 140.60.255.255 16 DoD Network Information Center
140.61.0.0 140.61.255.255 16 DoD Network Information Center
140.62.0.0 140.62.255.255 16 DoD Network Information Center
140.63.0.0 140.63.255.255 16 DoD Network Information Center
140.64.0.0 140.64.255.255 16 DoD Network Information Center
140.65.0.0 140.65.255.255 16 DoD Network Information Center
140.66.0.0 140.66.255.255 16 DoD Network Information Center
140.67.0.0 140.67.255.255 16 DoD Network Information Center
140.68.0.0 140.68.255.255 16 DoD Network Information Center
140.69.0.0 140.69.255.255 16 DoD Network Information Center
140.70.0.0 140.70.255.255 16 DoD Network Information Center
140.71.0.0 140.71.255.255 16 DoD Network Information Center
140.72.0.0 140.72.255.255 16 DoD Network Information Center
140.73.0.0 140.73.255.255 16 DoD Network Information Center
140.74.0.0 140.74.255.255 16 DoD Network Information Center
140.194.0.0 140.194.255.255 16 DoD Network Information Center
140.199.0.0 140.199.255.255 16 DoD Network Information Center
146.221.0.0 146.221.255.255 16 Australian Department of Defence DOD-AU
147.186.0.0 147.186.255.255 16 [se] police
149.101.0.0 149.101.255.255 16 US Department of Justice
152.91.0.0 152.91.255.255 16 claims to be an Australian government dept that no longer exists, associated with 90East.com, an Internet security site
153.31.0.0 153.31.255.255 16 Federal Bureau of Investigation-CJIS
160.64.0.0 160.64.255.255 16 Australian Department of Defence DSTOMEL1
162.23.0.0 162.23.255.255 16 Swiss Federal Government, Swiss Federal Office of Information Technology and Systems, Bundesamt fur Informatik
162.45.0.0 162.45.255.255 16 Central Intelligence Agency CIA
164.112.0.0 164.112.255.255 16 Queensland Police Service
164.128.37.17 164.128.223.145 17 Police of Switzerland
164.141.0.0 164.141.255.255 16 Police Administration in Finland

165.142.0.0 165.142.255.255 16 Department of Justice AUVICDJUST
165.187.0.0 165.187.255.255 16 Western Australian Police Department WAPOL
166.64.0.0 166.64.255.255 16 New South Wales Police Service NSWPOLICE
168.152.0.0 168.152.255.255 16 Australian Federal Police AFP-AU-B1
192.58.200.0 192.58.203.255 22 Department of Justice GOVDOJBLS01
192.84.170.0 192.84.170.255 24 Federal Bureau of Investigation
192.190.61.0 192.190.61.255 24 Tasmania Police Department TASPOL
192.190.66.0 192.190.66.255 24 Australian Institute of Criminology AIC
192.251.207.0 192.251.207.255 24 Australian Army Support Agency SYS-SPT-ARMY
193.77.9.0 193.77.9.255 24 Hacker from Slovenia
193.121.83.1 193.121.83.255 24 Federale politie - Police federale (BELGIUM)
193.172.176.0 193.172.177.255 24 Dutch Government
193.191.209.192 193.191.209.207 28 Belgium Federal Government
193.252.72.142 193.252.72.142 32 French Department of Defense
193.252.228.0 193.252.228.255 24 Prefecture de police de Paris
194.89.205.0 194.89.205.255 24 Finnish Police
195.46.218.178 195.46.218.178 32 French Military Police
195.76.172.0 195.76.172.255 24 Direccion General de la Policia (SPAIN)
195.76.204.0 195.76.204.255 24 Ministerio del Interior (Spain)
195.162.203.0 195.162.203.7 29 Politie-Belgium (Federal Computer Crime Unit)
198.61.8.0 198.61.15.255 21 Tasmania Police Department NETBLK-TASPOL
198.137.240.0 198.137.241.255 24 Executive Office Of The President USA
198.165.21.64 198.165.21.79 28 Department of Justice GT-198-165-21-64-CX
198.190.209.0 198.190.209.255 24 Federal Bureau of Investigation
199.75.96.0 199.75.107.255 21 Organization of American States (www.ftaa-alca.org)
199.123.80.0 199.123.80.255 24 US Army Criminal Investigation Command ACIRS-DEV
199.212.192.0 199.212.216.255 19 Department of Justice DOJ-GC-CA
199.227.159.64 199.227.159.95 27 Epic EPIC-200309091608751 (NET-199-227-159-64-1)
203.25.230.0 203.25.231.255 24 Victoria Police Centre
204.75.224.0 204.75.224.255 24 Office of the Sheriff, Rusk County, Texas
204.91.138.0 204.91.138.255 24 EPIC EPIC2-NET (NET-204-91-138-0-1)
205.128.1.240 205.128.1.255 28 Office of the Inspector General OIG-1-05
205.229.233.0 205.229.233.255 24 Federal Bureau of Investigation
206.212.128.0 206.212.191.255 18 New York City Police Department NYPD-GOV
206.218.64.0 206.218.127.255 18 Office of the Attorney General, State of Texas
206.241.30.0 206.241.31.255 24 US Customs
207.43.55.0 207.43.55.255 24 Federal Bureau of Investigation
207.132.172.0 207.132.175.255 22 Office of the Judge Advocate General, US Navy
207.132.176.0 207.132.191.255 20 Office of the Judge Advocate General, US Navy
207.155.128.0 207.155.255.255 17 NetPD
212.31.111.172 212.31.111.175 30 Cyprus Police
214.0.0.0 214.255.255.255 8 DoD Network Information Center
215.0.0.0 215.255.255.255 8 DoD Network Information Center (More)
216.118.66.0 216.118.66.255 24 Brussel politie - Police bruxelles
216.146.85.224 216.146.85.255 27 Federal Bureau of Investigation
217.167.182.0 217.167.182.255 24 French Department of Defense
2 - ACL Cisco
Voici un exemple d'Access List Cisco, permettant de dropper toutes les trames vennant de l'un de ces réseaux.
2.1 - Appel depuis l'interface
Vous devez appeler l'Access-List à partir de votre interface Wan et lui indiquer de dropper les paquets matchés par cette Acl.
Interface Wan

ip access-group ACL_ENTRANTE in
2.2 - Access-List
Voici l'Acl se terminant bien évidement par un permit Any.
ip access-list extended ACL_ENTRANTE
deny ip 4.42.244.160 0.0.0.15 any deny ip 4.42.244.192 0.0.0.31 any deny ip 12.38.31.216 0.0.0.7 any deny ip 29.0.0.0 0.255.255.255 any deny ip 61.88.128.38 0.0.0.0 any deny ip 63.64.5.0 0.0.0.255 any
deny ip 63.78.79.144 0.0.0.7 any deny ip 63.100.163.0 0.0.0.255 any deny ip 63.100.235.128 0.0.0.63 any deny ip 63.127.255.0 0.0.0.255 any deny ip 63.148.99.224 0.0.0.31 any deny ip 63.163.104.32 0.0.0.15 any deny ip 64.115.129.144 0.0.0.7 any
deny ip 65.118.41.192 0.0.0.31 any deny ip 65.173.188.0 0.0.0.255 any deny ip 65.174.230.32 0.0.0.15 any deny ip 66.72.93.16 0.0.0.7 any deny ip 66.109.166.136 0.0.0.7 any deny ip 66.109.166.144 0.0.0.7 any deny ip 130.46.0.0 0.0.255.255 any
deny ip 130.109.0.0 0.0.255.255 any
deny ip 131.73.0.0 0.0.255.255 any deny ip 131.80.0.0 0.0.255.255 any deny ip 131.81.0.0 0.0.255.255 any deny ip 131.83.0.0 0.0.255.255 any deny ip 131.85.0.0 0.0.255.255 any deny ip 131.88.0.0 0.0.255.255 any
deny ip 131.185.0.0 0.0.255.255 any deny ip 131.240.0.0 0.0.255.255 any deny ip 132.37.0.0 0.0.255.255 any deny ip 132.39.0.0 0.0.255.255 any deny ip 132.80.0.0 0.0.255.255 any deny ip 132.81.0.0 0.0.255.255 any
deny ip 132.82.0.0 0.0.255.255 any deny ip 132.83.0.0 0.0.255.255 any deny ip 132.84.0.0 0.0.255.255 any deny ip 132.85.0.0 0.0.255.255 any deny ip 132.86.0.0 0.0.255.255 any deny ip 132.87.0.0 0.0.255.255 any deny ip 132.95.0.0 0.0.255.255 any
deny ip 132.96.0.0 0.0.255.255 any deny ip 132.97.0.0 0.0.255.255 any deny ip 132.98.0.0 0.0.255.255 any deny ip 132.99.0.0 0.0.255.255 any deny ip 132.100.0.0 0.0.255.255 any deny ip 132.101.0.0 0.0.255.255 any deny ip 132.102.0.0 0.0.255.255 any
deny ip 132.103.0.0 0.0.255.255 any deny ip 132.133.0.0 0.0.255.255 any deny ip 132.134.0.0 0.0.255.255 any deny ip 132.135.0.0 0.0.255.255 any deny ip 132.136.0.0 0.0.255.255 any deny ip 132.137.0.0 0.0.255.255 any
deny ip 132.138.0.0 0.0.255.255 any deny ip 132.139.0.0 0.0.255.255 any deny ip 132.140.0.0 0.0.255.255 any deny ip 132.141.0.0 0.0.255.255 any deny ip 132.142.0.0 0.0.255.255 any deny ip 132.143.0.0 0.0.255.255 any deny ip 132.144.0.0 0.0.255.255 any
deny ip 134.194.0.0 0.0.255.255 any deny ip 134.229.0.0 0.0.255.255 any deny ip 134.230.0.0 0.0.255.255 any deny ip 134.232.0.0 0.0.255.255 any deny ip 134.254.0.0 0.0.255.255 any deny ip 136.188.0.0 0.0.255.255 any

deny ip 136.189.0.0 0.0.255.255 any deny ip 136.190.0.0 0.0.255.255 any deny ip 136.191.0.0 0.0.255.255 any deny ip 136.192.0.0 0.0.255.255 any
deny ip 136.193.0.0 0.0.255.255 any
deny ip 136.194.0.0 0.0.255.255 any deny ip 136.195.0.0 0.0.255.255 any deny ip 136.196.0.0 0.0.255.255 any deny ip 136.197.0.0 0.0.255.255 any deny ip 136.208.0.0 0.0.255.255 any
deny ip 136.211.0.0 0.0.255.255 any deny ip 136.212.0.0 0.0.255.255 any deny ip 136.213.0.0 0.0.255.255 any deny ip 136.214.0.0 0.0.255.255 any deny ip 136.222.0.0 0.0.255.255 any deny ip 137.130.0.0 0.0.255.255 any deny ip 137.191.0.0 0.0.255.255 any
deny ip 137.209.0.0 0.0.255.255 any deny ip 137.210.0.0 0.0.255.255 any deny ip 137.211.0.0 0.0.255.255 any deny ip 137.212.0.0 0.0.255.255 any deny ip 137.231.0.0 0.0.255.255 any deny ip 137.232.0.0 0.0.255.255 any deny ip 137.233.0.0 0.0.255.255 any
deny ip 137.234.0.0 0.0.255.255 any deny ip 137.235.0.0 0.0.255.255 any deny ip 137.246.0.0 0.0.255.255 any deny ip 137.247.0.0 0.0.255.255 any deny ip 138.60.0.0 0.0.255.255 any deny ip 138.135.0.0 0.0.255.255 any deny ip 138.136.0.0 0.0.255.255 any
deny ip 138.150.0.0 0.0.255.255 any deny ip 138.151.0.0 0.0.255.255 any deny ip 138.153.0.0 0.0.255.255 any deny ip 138.159.0.0 0.0.255.255 any deny ip 138.170.0.0 0.0.255.255 any deny ip 139.77.0.0 0.0.255.255 any
deny ip 139.233.0.0 0.0.255.255 any deny ip 139.234.0.0 0.0.255.255 any deny ip 139.235.0.0 0.0.255.255 any deny ip 139.236.0.0 0.0.255.255 any deny ip 139.237.0.0 0.0.255.255 any deny ip 139.238.0.0 0.0.255.255 any deny ip 139.239.0.0 0.0.255.255 any
deny ip 139.240.0.0 0.0.255.255 any deny ip 139.241.0.0 0.0.255.255 any deny ip 139.242.0.0 0.0.255.255 any deny ip 139.243.0.0 0.0.255.255 any deny ip 139.244.0.0 0.0.255.255 any deny ip 139.245.0.0 0.0.255.255 any deny ip 139.246.0.0 0.0.255.255 any
deny ip 139.247.0.0 0.0.255.255 any deny ip 139.248.0.0 0.0.255.255 any deny ip 139.249.0.0 0.0.255.255 any deny ip 139.250.0.0 0.0.255.255 any deny ip 139.251.0.0 0.0.255.255 any deny ip 139.252.0.0 0.0.255.255 any
deny ip 139.253.0.0 0.0.255.255 any deny ip 139.254.0.0 0.0.255.255 any deny ip 140.1.0.0 0.0.255.255 any deny ip 140.2.0.0 0.0.255.255 any deny ip 140.3.0.0 0.0.255.255 any deny ip 140.4.0.0 0.0.255.255 any deny ip 140.5.0.0 0.0.255.255 any
deny ip 140.6.0.0 0.0.255.255 any deny ip 140.7.0.0 0.0.255.255 any deny ip 140.8.0.0 0.0.255.255 any deny ip 140.9.0.0 0.0.255.255 any deny ip 140.10.0.0 0.0.255.255 any deny ip 140.11.0.0 0.0.255.255 any deny ip 140.12.0.0 0.0.255.255 any
deny ip 140.13.0.0 0.0.255.255 any deny ip 140.15.0.0 0.0.255.255 any deny ip 140.16.0.0 0.0.255.255 any deny ip 140.17.0.0 0.0.255.255 any

deny ip 140.18.0.0 0.0.255.255 any deny ip 140.19.0.0 0.0.255.255 any deny ip 140.20.0.0 0.0.255.255 any deny ip 140.21.0.0 0.0.255.255 any
deny ip 140.22.0.0 0.0.255.255 any
deny ip 140.23.0.0 0.0.255.255 any deny ip 140.24.0.0 0.0.255.255 any deny ip 140.25.0.0 0.0.255.255 any deny ip 140.26.0.0 0.0.255.255 any deny ip 140.27.0.0 0.0.255.255 any
deny ip 140.28.0.0 0.0.255.255 any deny ip 140.29.0.0 0.0.255.255 any deny ip 140.30.0.0 0.0.255.255 any deny ip 140.31.0.0 0.0.255.255 any deny ip 140.32.0.0 0.0.255.255 any deny ip 140.33.0.0 0.0.255.255 any deny ip 140.34.0.0 0.0.255.255 any
deny ip 140.35.0.0 0.0.255.255 any deny ip 140.36.0.0 0.0.255.255 any deny ip 140.37.0.0 0.0.255.255 any deny ip 140.38.0.0 0.0.255.255 any deny ip 140.39.0.0 0.0.255.255 any deny ip 140.40.0.0 0.0.255.255 any deny ip 140.41.0.0 0.0.255.255 any
deny ip 140.42.0.0 0.0.255.255 any deny ip 140.44.0.0 0.0.255.255 any deny ip 140.45.0.0 0.0.255.255 any deny ip 140.46.0.0 0.0.255.255 any deny ip 140.47.0.0 0.0.255.255 any deny ip 140.48.0.0 0.0.255.255 any deny ip 140.49.0.0 0.0.255.255 any
deny ip 140.50.0.0 0.0.255.255 any deny ip 140.51.0.0 0.0.255.255 any deny ip 140.52.0.0 0.0.255.255 any deny ip 140.53.0.0 0.0.255.255 any deny ip 140.54.0.0 0.0.255.255 any deny ip 140.55.0.0 0.0.255.255 any
deny ip 140.56.0.0 0.0.255.255 any deny ip 140.57.0.0 0.0.255.255 any deny ip 140.58.0.0 0.0.255.255 any deny ip 140.59.0.0 0.0.255.255 any deny ip 140.60.0.0 0.0.255.255 any deny ip 140.61.0.0 0.0.255.255 any deny ip 140.62.0.0 0.0.255.255 any
deny ip 140.63.0.0 0.0.255.255 any deny ip 140.64.0.0 0.0.255.255 any deny ip 140.65.0.0 0.0.255.255 any deny ip 140.66.0.0 0.0.255.255 any deny ip 140.67.0.0 0.0.255.255 any deny ip 140.68.0.0 0.0.255.255 any deny ip 140.69.0.0 0.0.255.255 any
deny ip 140.70.0.0 0.0.255.255 any deny ip 140.71.0.0 0.0.255.255 any deny ip 140.72.0.0 0.0.255.255 any deny ip 140.73.0.0 0.0.255.255 any deny ip 140.74.0.0 0.0.255.255 any deny ip 140.194.0.0 0.0.255.255 any
deny ip 140.199.0.0 0.0.255.255 any deny ip 146.221.0.0 0.0.255.255 any deny ip 147.186.0.0 0.0.255.255 any deny ip 149.101.0.0 0.0.255.255 any deny ip 152.91.0.0 0.0.255.255 any deny ip 153.31.0.0 0.0.255.255 any deny ip 160.64.0.0 0.0.255.255 any
deny ip 162.23.0.0 0.0.255.255 any deny ip 162.45.0.0 0.0.255.255 any deny ip 164.112.0.0 0.0.255.255 any deny ip 164.128.37.17 0.0.127.255 any deny ip 164.141.0.0 0.0.255.255 any deny ip 165.142.0.0 0.0.255.255 any deny ip 165.187.0.0 0.0.255.255 any
deny ip 166.64.0.0 0.0.255.255 any deny ip 168.152.0.0 0.0.255.255 any deny ip 192.58.200.0 0.0.3.255 any deny ip 192.84.170.0 0.0.0.255 any

deny ip 192.190.61.0 0.0.0.255 any deny ip 192.190.66.0 0.0.0.255 any deny ip 192.251.207.0 0.0.0.255 any deny ip 193.77.9.0 0.0.0.255 any
deny ip 193.121.83.1 0.0.0.255 any
deny ip 193.172.176.0 0.0.0.255 any deny ip 193.191.209.192 0.0.0.15 any deny ip 193.252.72.142 0.0.0.0 any deny ip 193.252.228.0 0.0.0.255 any deny ip 194.89.205.0 0.0.0.255 any
deny ip 195.46.218.178 0.0.0.0 any deny ip 195.76.172.0 0.0.0.255 any deny ip 195.76.204.0 0.0.0.255 any deny ip 195.162.203.0 0.0.0.7 any deny ip 198.61.8.0 0.0.7.255 any deny ip 198.137.240.0 0.0.0.255 any deny ip 198.165.21.64 0.0.0.15 any
deny ip 198.190.209.0 0.0.0.255 any deny ip 199.75.96.0 0.0.7.255 any deny ip 199.123.80.0 0.0.0.255 any deny ip 199.212.192.0 0.0.31.255 any deny ip 199.227.159.64 0.0.0.31 any deny ip 203.25.230.0 0.0.0.255 any deny ip 204.75.224.0 0.0.0.255 any
deny ip 204.91.138.0 0.0.0.255 any deny ip 205.128.1.240 0.0.0.15 any deny ip 205.229.233.0 0.0.0.255 any deny ip 206.212.128.0 0.0.63.255 any deny ip 206.218.64.0 0.0.63.255 any deny ip 206.241.30.0 0.0.0.255 any deny ip 207.43.55.0 0.0.0.255 any
deny ip 207.132.172.0 0.0.3.255 any deny ip 207.132.176.0 0.0.15.255 any deny ip 207.155.128.0 0.0.127.255 any deny ip 212.31.111.172 0.0.0.3 any deny ip 214.0.0.0 0.255.255.255 any deny ip 215.0.0.0 0.255.255.255 any
deny ip 216.118.66.0 0.0.0.255 any deny ip 216.146.85.224 0.0.0.31 any deny ip 217.167.182.0 0.0.0.255 any permit ip any any
3 - NetFilter
Voici un exemple de règle IpTables, permettant de dropper toutes les trames vennant de l'un de ces réseaux. Cette règle se termine bien évidemant par un -j ACCEPT.
iptables -A INPUT -i interface_wan -s 4.42.244.160/28 -p ip -j DROP iptables -A INPUT -i interface_wan -s 4.42.244.192/27 -p ip -j DROP iptables -A INPUT -i interface_wan -s 12.38.31.216/29 -p ip -j DROP iptables -A INPUT -i interface_wan -s 29.0.0.0/8 -p ip -j DROP iptables -A INPUT -i interface_wan -s 61.88.128.38/32 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 63.64.5.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 63.78.79.144/29 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 63.100.163.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 63.100.235.128/26 -p ip -j DROP iptables -A INPUT -i interface_wan -s 63.127.255.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 63.148.99.224/27 -p ip -j DROP iptables -A INPUT -i interface_wan -s 63.163.104.32/28 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 64.115.129.144/29 -p ip -j DROP iptables -A INPUT -i interface_wan -s 65.118.41.192/27 -p ip -j DROP iptables -A INPUT -i interface_wan -s 65.173.188.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 65.174.230.32/28 -p ip -j DROP iptables -A INPUT -i interface_wan -s 66.72.93.16/29 -p ip -j DROP iptables -A INPUT -i interface_wan -s 66.109.166.136/29 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 66.109.166.144/29 -p ip -j DROP iptables -A INPUT -i interface_wan -s 130.46.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 130.109.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 131.73.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 131.80.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 131.81.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 131.83.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 131.85.0.0/16 -p ip -j DROP

iptables -A INPUT -i interface_wan -s 131.88.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 131.185.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 131.240.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.37.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 132.39.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 132.80.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.81.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.82.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.83.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.84.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 132.85.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.86.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.87.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.95.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.96.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.97.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.98.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 132.99.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.100.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.101.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.102.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.103.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.133.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.134.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 132.135.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.136.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.137.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.138.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.139.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.140.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.141.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 132.142.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.143.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 132.144.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 134.194.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 134.229.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 134.230.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 134.232.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 134.254.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.188.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.189.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.190.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.191.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.192.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 136.193.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.194.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.195.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.196.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.197.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.208.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.211.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 136.212.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.213.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.214.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 136.222.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.130.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.191.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 137.209.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.210.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.211.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.212.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.231.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.232.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.233.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 137.234.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.235.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.246.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 137.247.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 138.60.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 138.135.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 138.136.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 138.150.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 138.151.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 138.153.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 138.159.0.0/16 -p ip -j DROP

iptables -A INPUT -i interface_wan -s 138.170.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.77.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.233.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.234.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 139.235.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 139.236.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.237.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.238.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.239.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.240.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 139.241.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.242.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.243.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.244.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.245.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.246.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.247.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 139.248.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.249.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.250.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.251.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.252.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.253.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 139.254.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.1.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.2.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.3.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.4.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.5.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.6.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.7.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.8.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.9.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.10.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.11.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.12.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.13.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.15.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.16.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.17.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.18.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.19.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.20.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.21.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.22.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.23.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.24.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.25.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.26.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.27.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.28.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.29.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.30.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.31.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.32.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.33.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.34.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.35.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.36.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.37.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.38.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.39.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.40.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.41.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.42.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.44.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.45.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.46.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.47.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.48.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.49.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.50.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.51.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.52.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.53.0.0/16 -p ip -j DROP

iptables -A INPUT -i interface_wan -s 140.54.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.55.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.56.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.57.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.58.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.59.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.60.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.61.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.62.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.63.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.64.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.65.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.66.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.67.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.68.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.69.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.70.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 140.71.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.72.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.73.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.74.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.194.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 140.199.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 146.221.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 147.186.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 149.101.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 152.91.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 153.31.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 160.64.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 162.23.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 162.45.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 164.112.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 164.128.37.17/17 -p ip -j DROP iptables -A INPUT -i interface_wan -s 164.141.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 165.142.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 165.187.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 166.64.0.0/16 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 168.152.0.0/16 -p ip -j DROP iptables -A INPUT -i interface_wan -s 192.58.200.0/22 -p ip -j DROP iptables -A INPUT -i interface_wan -s 192.84.170.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 192.190.61.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 192.190.66.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 192.251.207.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 193.77.9.0/24 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 193.121.83.1/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 193.172.176.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 193.191.209.192/28 -p ip -j DROP iptables -A INPUT -i interface_wan -s 193.252.72.142/32 -p ip -j DROP iptables -A INPUT -i interface_wan -s 193.252.228.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 194.89.205.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 195.46.218.178/32 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 195.76.172.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 195.76.204.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 195.162.203.0/29 -p ip -j DROP iptables -A INPUT -i interface_wan -s 198.61.8.0/21 -p ip -j DROP iptables -A INPUT -i interface_wan -s 198.137.240.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 198.165.21.64/28 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 198.190.209.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 199.75.96.0/21 -p ip -j DROP iptables -A INPUT -i interface_wan -s 199.123.80.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 199.212.192.0/19 -p ip -j DROP iptables -A INPUT -i interface_wan -s 199.227.159.64/27 -p ip -j DROP iptables -A INPUT -i interface_wan -s 203.25.230.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 204.75.224.0/24 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 204.91.138.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 205.128.1.240/28 -p ip -j DROP iptables -A INPUT -i interface_wan -s 205.229.233.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 206.212.128.0/18 -p ip -j DROP iptables -A INPUT -i interface_wan -s 206.218.64.0/18 -p ip -j DROP iptables -A INPUT -i interface_wan -s 206.241.30.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 207.43.55.0/24 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 207.132.172.0/22 -p ip -j DROP iptables -A INPUT -i interface_wan -s 207.132.176.0/20 -p ip -j DROP iptables -A INPUT -i interface_wan -s 207.155.128.0/17 -p ip -j DROP iptables -A INPUT -i interface_wan -s 212.31.111.172/30 -p ip -j DROP

iptables -A INPUT -i interface_wan -s 214.0.0.0/8 -p ip -j DROP iptables -A INPUT -i interface_wan -s 215.0.0.0/8 -p ip -j DROP iptables -A INPUT -i interface_wan -s 216.118.66.0/24 -p ip -j DROP iptables -A INPUT -i interface_wan -s 216.146.85.224/27 -p ip -j DROP
iptables -A INPUT -i interface_wan -s 217.167.182.0/24 -p ip -j DROP
iptables -A INPUT -j ACCEPT
Dos Cisco
1 - Le concept
2 - Le fonctionnement 2.1 - Schéma 2.2 - Envoi 2.3 - Réception 2.4 - Multiples réceptions 3 - Les conseils et astuces 4 - Les liens
5 - Les outils 6 - La conclusion 7 - Discussion autour de la documentation 8 - Suivi du document
1 - Le concept
L'envoi de paquet spécifique sur une interface Cisco provoque le blocage de la réception sur cette même interface
réalisant ainsi un DOS. Ces trames doivent avoir un formatage spécial en spécifiant un type de protocole et une valeur de temps de vie.
2 - Le fonctionnement
2.1 - Schéma
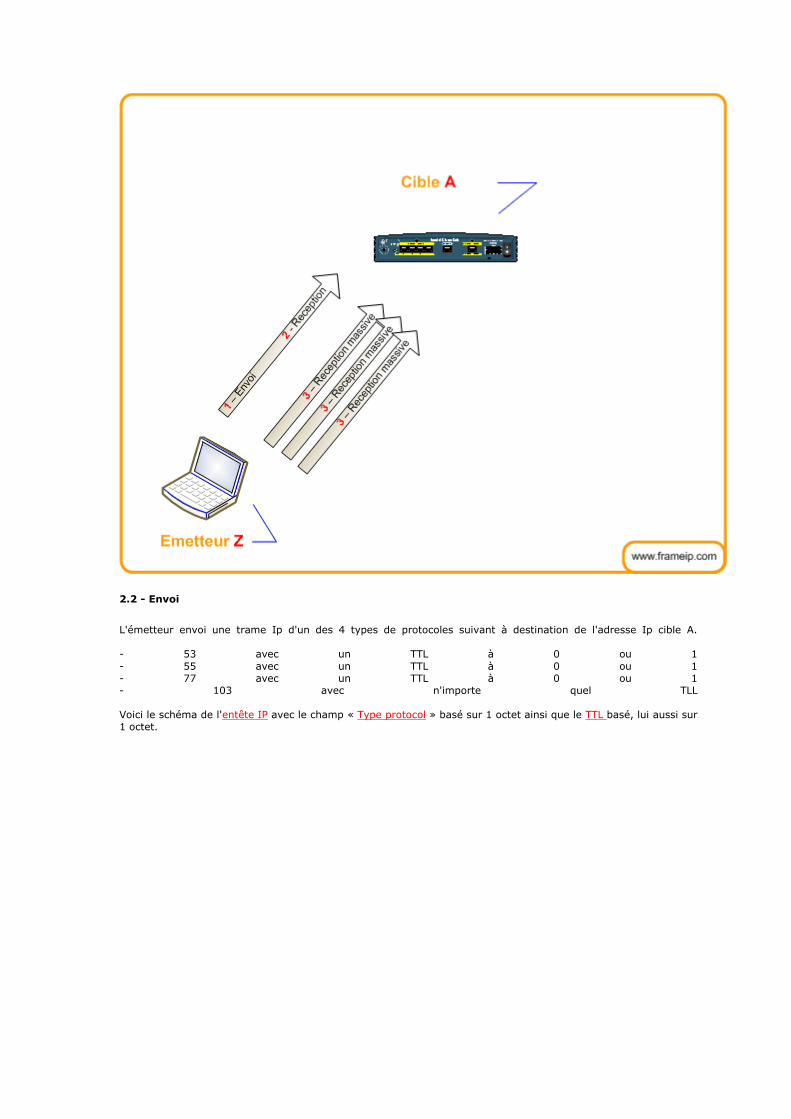
2.2 - Envoi
L'émetteur envoi une trame Ip d'un des 4 types de protocoles suivant à destination de l'adresse Ip cible A. - 53 avec un TTL à 0 ou 1
- 55 avec un TTL à 0 ou 1 - 77 avec un TTL à 0 ou 1 - 103 avec n'importe quel TLL Voici le schéma de l'entête IP avec le champ « Type protocol » basé sur 1 octet ainsi que le TTL basé, lui aussi sur 1 octet.

2.3 - Réception
A la réception de l'un des paquets malicieux, l'équipement Cisco le positionne dans son Buffer d'interface. De là, le paquet reste bloqué dans ce tampon. Vous pouvez en voir le contenu grâce la commande « show buffers input-interface ethernet 0 packet »
On peut remarqué la présence d'une trame bloquée dans le buffer de l'interface Ethernet 0. Attention, toutes les trames reçues transitent via le buffer qui représente la file d'attente de l'interface. Donc vous pouvez très bien appliquer la commande au moment où un paquet entre dans le buffer sans qu'il est le temps d'en sortir. Effectuez donc plusieurs fois la commande afin de confirmer le blocage des trames visualisées.
2.4 - Multiples réceptions
L'attaque est de type Dos (Deny Of Service) via un Buffer Over Flow, cela signifie donc que le blocage massif de trame saturera la capacité du buffer. L'interface sera alors dans l'incapacité de recevoir de trames
supplémentaires.
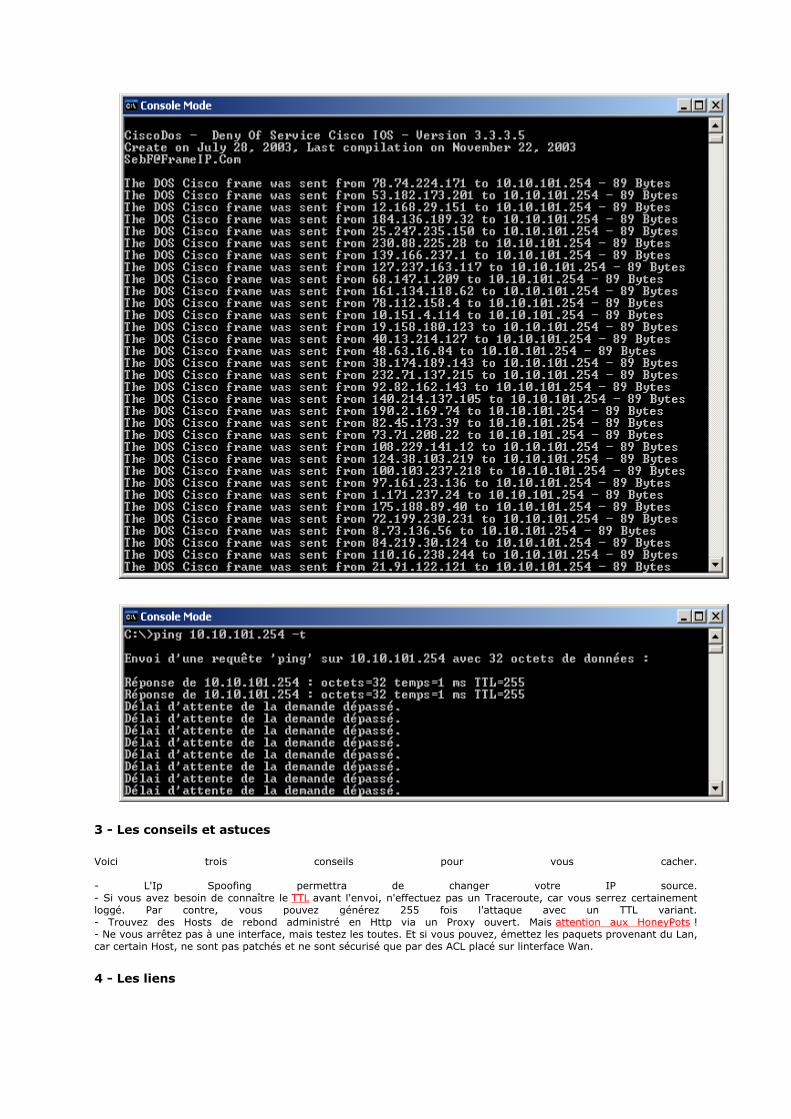
3 - Les conseils et astuces
Voici trois conseils pour vous cacher. - L'Ip Spoofing permettra de changer votre IP source.
- Si vous avez besoin de connaître le TTL avant l'envoi, n'effectuez pas un Traceroute, car vous serrez certainement loggé. Par contre, vous pouvez générez 255 fois l'attaque avec un TTL variant. - Trouvez des Hosts de rebond administré en Http via un Proxy ouvert. Mais attention aux HoneyPots ! - Ne vous arrêtez pas à une interface, mais testez les toutes. Et si vous pouvez, émettez les paquets provenant du Lan, car certain Host, ne sont pas patchés et ne sont sécurisé que par des ACL placé sur linterface Wan.
4 - Les liens

- La description par Cisco - L'information de « CERT Coordination Center »
5 - Les outils
- FrameIP est un générateur de trames IP. Il vous permettra de personnaliser les champs des différentes entêtes réseaux. - CiscoDos, c'est un outils spécifique pour l'attaque Cisco. Il vous permettra d'effectuer de l'Ip Spoofing.
6 - La conclusion
C'est une attaque violente du fait qu'elle s'effectue en une seule trame et ne peut donc pas être arrêtée par une IDS classique (sauf IDS double patte transparente). Ce n'est pas la peine de vous acharner après les grands noms de l'Internet, car il y de très forte chance qu'ils aient
appliqués le patch. Néanmoins, sachant que l'IOS est le second Operating System de la planète après Windows, cela nous apporte la certitude que le parc est loin d'être patché...
Les Firewalls
1 - Pourquoi un firewall 2 - Les différents types de filtrages 2.1 - Le filtrage simple de paquet (Stateless)
2.1.1 - Le principe 2.1.2 - Les limites 2.2 - Le filtrage de paquet avec état (Stateful)
2.2.1 - Le principe 2.2.2 - Les limites 2.3 - Le filtrage applicatif (ou pare-feu de type proxy ou proxying applicatif) 2.3.1 - Le principe
2.3.2 - Les limites 2.4 - Que choisir 3 - Les différents types de firewall 3.1 - Les firewall bridge 3.1.1 - Avantages 3.1.2 - Inconvénients
3.2 - Les firewalls matériels 3.2.1 - Avantages 3.2.2 - Inconvénients 3.3 - Les firewalls logiciels 3.3.1 - Les firewalls personnels 3.3.2 - Les firewalls plus « sérieux » 4 - Attaques, outils, défenses
4.1 - Scénarios d'attaques (Pénétrations de réseaux) 4.1.1 - Premier cas : Pas de protection 4.1.2 - Deuxième cas : Filtrer les flux entrants illégaux 4.1.3 - Troisième cas : Bloquer les flux entrants et sortants 4.1.4 - Quatrième cas : Protection locale via un Firewall personnel 4.2 - Les techniques et outils de découvertes de Firewall 4.2.1 - Firewalk
4.2.2 - Nmap 4.2.3 - HPING2
4.2.4 - NESSUS 4.3 - Configuration théorique des défenses 4.4 - Les réactions des firewalls aux attaques classiques 4.5 - Un exemple pratique : netfilter
5 - Conclusion 6 - Discussion autour de la documentation 7 - Suivi du document
1 - Pourquoi un firewall
De nos jours, toutes les entreprises possédant un réseau local possèdent aussi un accès à Internet, afin d'accéder à la
manne d'information disponible sur le réseau des réseaux, et de pouvoir communiquer avec l'extérieur. Cette ouverture vers l'extérieur est indispensable... et dangereuse en même temps. Ouvrir l'entreprise vers le monde signifie aussi laisser place ouverte aux étrangers pour essayer de pénétrer le réseau local de l'entreprise, et y accomplir des actions douteuses, parfois gratuites, de destruction, vol d'informations confidentielles, ... Les mobiles sont nombreux et dangereux. Pour parer à ces attaques, une architecture sécurisée est nécessaire. Pour cela, le coeur d'une tel architecture est basé

sur un firewall. Cette outil a pour but de sécuriser au maximum le réseau local de l'entreprise, de détecter les tentatives d'intrusion et d'y parer au mieux possible. Cela représente une sécurité supplémentaire rendant le réseau ouvert sur Internet beaucoup plus sûr. De plus, il peut permettre de restreindre l'accès interne vers l'extérieur. En effet, des employés peuvent s'adonner à des activités que l'entreprise ne cautionne pas, le meilleur exemple étant le jeu en ligne. En plaçant un firewall limitant ou interdisant l'accès à ces services, l'entreprise peut donc avoir un
contrôle sur les activités se déroulant dans son enceinte.
Le firewall propose donc un véritable contrôle sur le trafic réseau de l'entreprise. Il permet d'analyser, de sécuriser et de gérer le trafic réseau, et ainsi d'utiliser le réseau de la façon pour laquelle il a été prévu et sans l'encombrer avec des activités inutiles, et d'empêcher une personne sans autorisation d'accéder à ce réseau de données.
2 - Les différents types de filtrages
2.1 - Le filtrage simple de paquet (Stateless)
2.1.1 - Le principe
C'est la méthode de filtrage la plus simple, elle opère au niveau de la couche réseau et transport dumodèle
Osi. La plupart des routeurs d'aujourd'hui permettent d'effectuer du filtrage simple de paquet. Cela consiste à accorder ou refuser le passage de paquet d'un réseau à un autre en se basant sur : - L'adresse IP Source/Destination. - Le numéro de port Source/Destination. - Et bien sur le protocole de niveau 3 ou 4.
Cela nécessite de configurer le Firewall ou le routeur par des règles de filtrages, généralement appelées des ACL (Access Control Lists).
2.1.2 - Les limites
Le premier problème vient du fait que l'administrateur réseau est rapidement contraint à autoriser un trop grand nombre d'accès, pour que le Firewall offre une réelle protection. Par exemple, pour autoriser les connexions à Internet à partir du réseau privé, l'administrateur devra accepter toutes les connexions Tcpprovenant de l'Internet avec un port supérieur à 1024. Ce qui laisse beaucoup de choix à un éventuel pirate.
Il est à noter que de définir des ACL sur des routeurs haut de gamme - c'est à dire, supportant un débit important - n'est pas sans répercussion sur le débit lui-même. Enfin, ce type de filtrage ne résiste pas à certaines attaques de type IP Spoofing / IP Flooding, la mutilation de paquet, ou encore certainesattaques de type DoS. Ceci est vrai sauf dans le cadre des routeurs fonctionnant en mode distribué. Ceci permettant de gérer les Acl directement sur les interfaces sans remonter à la carte de traitement central. Les performances impactées par les Acl sont alors quasi nulles.
2.2 - Le filtrage de paquet avec état (Stateful)
2.2.1 - Le Principe
L'amélioration par rapport au filtrage simple, est la conservation de la trace des sessions et des connexions
dans des tables d'états internes au Firewall. Le Firewall prend alors ses décisions en fonction des états de connexions, et peut réagir dans le cas de situations protocolaires anormales. Ce filtrage permet aussi de se protéger face à certains types d'attaques DoS.
Dans l'exemple précédent sur les connexions Internet, on va autoriser l'établissement des connexions à la demande, ce qui signifie que l'on aura plus besoin de garder tous les ports supérieurs à 1024 ouverts. Pour les protocoles Udp et Icmp, il n'y a pas de mode connecté. La solution consiste à autoriser pendant un certain
délai les réponses légitimes aux paquets envoyés. Les paquets Icmp sont normalement bloqués par le Firewall, qui doit en garder les traces. Cependant, il n'est pas nécessaire de bloquer les paquets Icmp de type 3 (destination inaccessible) et 4 (ralentissement de la source) qui ne sont pas utilisables par un attaquant. On peut donc choisir de les laisser passer, suite à l'échec d'une connexion Tcp ou après l'envoi d'un paquet Udp.

Pour le protocole Ftp (et les protocoles fonctionnant de la même façon), c'est plus délicat puisqu'il va falloir gérer l'état de deux connexions. En effet, le protocole Ftp, gère un canal de contrôle établi par le client, et un canal de données établi par le serveur. Le Firewall devra donc laisser passer le flux de données établi par le
serveur. Ce qui implique que le Firewall connaisse le protocole Ftp, et tous les protocoles fonctionnant sur le même principe. Cette technique est connue sous le nom de filtrage dynamique (Stateful Inspection) et a été inventée par Checkpoint. Mais cette technique est maintenant gérée par d'autres fabricants.
2.2.2 - Les limites
Tout d'abord, il convient de s'assurer que les deux techniques sont bien implémentées par les Firewalls, car certains constructeurs ne l'implémentent pas toujours correctement. Ensuite une fois que l'accès à un service a été autorisé, il n'y a aucun contrôle effectué sur les requêtes et réponses des clients et serveurs. Un
serveur Http pourra donc être attaqué impunément (Comme quoi il leur en arrive des choses aux serveurs WEB !). Enfin les protocoles maisons utilisant plusieurs flux de données ne passeront pas, puisque le système de filtrage dynamique n'aura pas connaissance du protocole.
2.3 - Le filtrage applicatif (ou pare-feu de type proxy ou proxying applicatif)
2.3.1 - Le principe
Le filtrage applicatif est comme son nom l'indique réalisé au niveau de la couche Application. Pour cela, il faut bien sûr pouvoir extraire les données du protocole de niveau 7 pour les étudier. Les requêtes sont traitées par des processus dédiés, par exemple une requête de type Http sera filtrée par un processus proxy Http. Le pare-feu rejettera toutes les requêtes qui ne sont pas conformes aux spécifications du protocole. Cela
implique que le pare-feu proxy connaisse toutes les règles protocolaires des protocoles qu'il doit filtrer.
2.3.2 - Les limites
Le premier problème qui se pose est la finesse du filtrage réalisé par le proxy. Il est extrêmement difficile de pouvoir réaliser un filtrage qui ne laisse rien passer, vu le nombre de protocoles de niveau 7. En outre le fait de devoir connaître les règles protocolaires de chaque protocole filtré pose des problèmes d'adaptabilité à de nouveaux protocoles ou des protocoles maisons. Mais il est indéniable que le filtrage applicatif apporte plus de sécurité que le filtrage de paquet avec état,
mais cela se paie en performance. Ce qui exclut l'utilisation d'une technologie 100 % proxy pour les réseaux à gros trafic au jour d'aujourd'hui. Néanmoins d'ici quelques années, le problème technologique sera sans doute résolu.
2.4 - Que choisir

Tout d'abord, il faut nuancer la supériorité du filtrage applicatif par rapport à la technologie Stateful. En effet les proxys doivent être paramétrés suffisamment finement pour limiter le champ d'action des attaquants, ce qui nécessite un très bonne connaissance des protocoles autorisés à traverser le firewall. Ensuite un proxy est plus susceptible de présenter une faille de sécurité permettant à un pirate d'en prendre le contrôle, et de lui donner un accès sans restriction à tout le système d'information.
Idéalement, il faut protéger le proxy par un Firewall de type Stateful Inspection. Il vaut mieux éviter d'installer les
deux types de filtrage sur le même Firewall, car la compromission de l'un entraîne la compromission de l'autre. Enfin cette technique permet également de se protéger contre l'ARP spoofing.
3 - Les différents types de firewall
3.1 - Les firewall bridge
Ces derniers sont relativement répandus. Ils agissent comme de vrais câbles réseau avec la fonction de filtrage en plus, d'où leur appellation de firewall. Leurs interfaces ne possèdent pas d'adresse Ip, et ne font que transférer les paquets d'une interface a une autre en leur appliquant les règles prédéfinies. Cette absence est particulièrement utile, car cela signifie que le firewall est indétectable pour un hacker lambda. En effet, quand une requête ARP est émise sur le câble réseau, le firewall ne répondra jamais. Ses adresses Mac ne circuleront jamais sur le réseau, et comme il ne fait que « transmettre » les paquets, il sera totalement invisible sur le réseau. Cela rend impossible toute attaque dirigée directement contre le firewall, étant donné qu'aucun paquet ne sera traité par ce dernier
comme étant sa propre destination. Donc, la seule façon de le contourner est de passer outre ses règles de drop. Toute attaque devra donc « faire » avec ses règles, et essayer de les contourner. Dans la plupart des cas, ces derniers ont une interface de configuration séparée. Un câble vient se brancher sur une troisième interface, série ou même Ethernet, et qui ne doit être utilisée que ponctuellement et dans un environnement sécurisé de préférence.
Ces firewalls se trouvent typiquement sur les switchs.
3.1.1 - Avantages
Impossible de l'éviter (les paquets passeront par ses interfaces)
Peu coûteux
3.1.2 - Inconvénients
Possibilité de le contourner (il suffit de passer outre ses règles)
Configuration souvent contraignante
Les fonctionnalités présentes sont très basiques (filtrage sur adresse IP, port, le plus souvent en Stateless).
3.2 - Les firewalls matériels

Ils se trouvent souvent sur des routeurs achetés dans le commerce par de grands constructeurs comme Cisco ou Nortel. Intégrés directement dans la machine, ils font office de « boite noire », et ont une intégration parfaite avec le matériel. Leur configuration est souvent relativement ardue, mais leur avantage est que leur interaction avec les autres fonctionnalités du routeur est simplifiée de par leur présence sur le même équipement réseau. Souvent relativement peu flexibles en terme de configuration, ils sont aussi peu vulnérables aux attaques, car présent dans
la « boite noire » qu'est le routeur. De plus, étant souvent très liés au matériel, l'accès à leur code est assez difficile, et le constructeur a eu toute latitude pour produire des système de codes « signés » afin d'authentifier le
logiciel (système RSA ou assimilés). Ce système n'est implanté que dans les firewalls haut de gamme, car cela évite un remplacement du logiciel par un autre non produit par le fabricant, ou toute modification de ce dernier, rendant ainsi le firewall très sûr. Son administration est souvent plus aisée que les firewall bridges, les grandes marques de routeurs utilisant cet argument comme argument de vente. Leur niveau de sécurité est de plus très bon, sauf découverte de faille éventuelle comme tout firewall. Néanmoins, il faut savoir que l'on est totalement dépendant du constructeur du matériel pour cette mise à jour, ce qui peut être, dans certains cas, assez contraignant. Enfin, seules les spécificités prévues par le constructeur du matériel sont implémentées. Cette
dépendance induit que si une possibilité nous intéresse sur un firewall d'une autre marque, son utilisation est impossible. Il faut donc bien déterminer à l'avance ses besoin et choisir le constructeur du routeur avec soin.
3.2.1 - Avantages
Intégré au matériel réseau
Administration relativement simple
Bon niveau de sécurité
3.2.2 - Inconvénients
Dépendant du constructeur pour les mises à jour
Souvent peu flexibles.
3.3 - Les firewalls logiciels
Présents à la fois dans les serveurs et les routeurs « faits maison », on peut les classer en plusieurs catégories :
3.3.1 - Les firewalls personnels
Ils sont assez souvent commerciaux et ont pour but de sécuriser un ordinateur particulier, et non pas un
groupe d'ordinateurs. Souvent payants, ils peuvent être contraignants et quelque fois très peu sécurisés. En effet, ils s'orientent plus vers la simplicité d'utilisation plutôt que vers l'exhaustivité, afin de rester accessible à l'utilisateur final.
3.3.1.1 - Avantages
Sécurité en bout de chaîne (le poste client)
Personnalisable assez facilement
3.3.1.2 - Inconvénients
Facilement contournable
Difficiles a départager de par leur nombre énorme.
3.3.2 - Les firewalls plus « sérieux »
Tournant généralement sous linux, car cet OS offre une sécurité réseau plus élevée et un contrôle plus adéquat, ils ont généralement pour but d'avoir le même comportement que les firewalls matériels des routeurs, à ceci prêt qu'ils sont configurables à la main. Le plus courant est iptables (anciennement ipchains),
qui utilise directement le noyau linux. Toute fonctionnalité des firewalls de routeurs est potentiellement réalisable sur une telle plateforme.

3.3.2.1 - Avantages
Personnalisables
Niveau de sécurité très bon
3.3.2.2 - Inconvénients
Nécessite une administration système supplémentaire
Ces firewalls logiciels ont néanmoins une grande faille : ils n'utilisent pas la couche bas réseau. Il suffit donc de passer outre le noyau en ce qui concerne la récupération de ces paquets, en utilisant une librairie spéciale, pour récupérer les paquets qui auraient été normalement « droppés » par le firewall. Néanmoins, cette faille induit de s'introduire sur l'ordinateur en question pour y faire des modifications... chose qui induit déjà une intrusion dans le réseau, ou une prise de contrôle physique de l'ordinateur, ce qui est déjà Synonyme d'inefficacité de la part du firewall.
4 - Attaques, outils, défenses
4.1 - Scénarios d'attaques (Pénétrations de réseaux)
Qu'est-ce qu'une backdoor ? Une backdoor est un accès (« caché ») sur votre système qui permet à un pirate d'en prendre le contrôle à distance. Il existe une multitude de sortes de backdoor, et en général dans ce domaine, l'imagination des pirates rivalise avec l'incrédulité des utilisateurs. Voici quelques scénarios d'attaques plus ou moins classique.
4.1.1 - Premier cas : Pas de protection
Considérons un ordinateur victime sur lequel on a installé une backdoor en exploitant une des failles du
système. L'attaquant a alors la possibilité d'utiliser tous les services présents sur cet ordinateur. Il lui suffit d'envoyer ses ordres à la backdoor et de récupérer les réponses.
4.1.2 - Deuxième cas : Filtrer les flux entrants illégaux
La sécurité de notre système ne nous semblant pas infaillible, nous décidons alors d'installer un Firewall avec états (Un Firewall sans état nous semblant quelque peu léger). Le trafic entrant est maintenant stoppé
comme il se doit. Malheureusement, le pirate étant rusé et malicieux, il a pris soin de s'arranger pour que sa
backdoor initie elle-même les sessions. Du coup le Firewall laisse passer les requêtes de l'attaquant qui sont considérées comme des réponses par celui-ci.

4.1.3 - Troisième cas : Bloquer les flux entrants et sortants
Dans le cas précédent, le problème était dû aux flux sortants qui permettait au cheval de Troie d'initier les sessions avec la machine de l'attaquant. Il s'agit donc de bloquer les flux sortants. Pour cela la défense
insère donc un proxy afin de contrôler ce qui sort du réseau. Malheureusement le trojan peut encore sortir, certes avec plus de difficultés puisqu'il devra se renseigner sur les flux autorisés à sortir par le proxy, et les utiliser pour passer le proxy. Par exemple on peut encapsuler des ordres dans du HTTP (Ip over Http),dans du SSL (Ip over Ssl), DNS (Ip over Dns), Smtp (Ip over Smtp). Dans le cas d'un proxy avec authentification, le pirate fera preuve de grande imagination en réalisant un
trojan capable de profiter des applications (comme IE par exemple) qui une fois qu'elles se sont authentifiées sont utilisées pour passer le proxy.
4.1.4 - Quatrième cas : Protection locale via un Firewall personnel
L'idée du Firewall personnel est de surveiller le trafic entrant et sortant de la machine infectée.
Malheureusement ceux-ci sont fortement attaquables, on peut :
Passer au-dessus du Firewall via une application autorisée. ® Appel de CreateRemoteThread permettant de l'injection de code à la volée sous Windows.
Passer en dessous du Firewall via une bibliothèque adaptée (Winpcap sous Windows ou pcap sous Linux).
Attaquer le Firewall lui-même en tant qu'applicatif (Arrêt du processus).
4.1.5 - Cinquième cas : piratage de VPN
Imaginons qu'un pirate mal intentionné installe un trojan sur l'ordinateur d'un commercial. L'ordinateur possédant entre autre un système Windows et un client VPN. Normalement, le client VPN fonctionne de telle sorte que toutes les liaisons réseaux n'étant pas dans le VPN ne fonctionnent pas. Malheureusement, il s'agit
du même problème que pour les Firewall personnels et le trojan permet à l'attaquant d'accéder au réseau de l'entreprise via le VPN.
On peut se rendre compte de l'importance de la robustesse du système d'exploitation, sur lequel est installé le VPN. Après une attaque réussie et la prise de contrôle en root de la machine par le pirate, celui-ci va essayer d'installer ce que l'on appelle un rootkit.
Il existe deux types de rootkit, les rootkit simples et les rootkit noyaux. Les rootkit simples se contentent de remplacer toute une collection de programmes système (ps, netstat, ifconfig, ....) lui permettant d'effacer les

traces de son passage et ainsi masquer complètement sa backdoor. Un simple outils tel que Tripwire permet de vérifier l'intégrité des commandes, en enregistrant de façon cryptée les signatures (générées par une fonction de hashage) des fichiers de commandes en question. Les rootkit noyaux sont beaucoup plus difficiles à détecter, puisqu'ils modifient le noyau et donc modifient
son comportement. Par exemple rendre invisible un processus à chaque appel (non pas de la commande ps) mais des fonctions systèmes du noyau, qui elles même sont appelées par la commande ps. Evidemment un
rootkit noyau modifie en plus les routines de journalisassions du système, masque les connexions réseaux, ... Pour se protéger des rootkit noyaux, le plus simple est de s'en prémunir. Pour cela, l'idéal est de patcher son noyau pour empêcher l'installation d'un rootkit, et de désactiver les LKM (Loadable Kernel Modules qui permettent au root d'introduire un nouveau code dans le système d'exploitation pendant que ce dernier est en cours d'exécution), malheureusement cela ne suffit pas toujours (voir kinsmod.c). Il existe un outil pour Linux capable d'un certain nombre de vérification de modules de backdoor. Cet outil s'appelle rkscan et permet de détecter les versions de rootkits les plus populaires.
4.2 - Les techniques et outils de découvertes de Firewall
Il existe beaucoup d'outils et beaucoup de techniques permettant d'identifier un Firewall. L'objectif de ce paragraphe est d'en exposer quelques-uns et quelques-unes. Il est évident que la plupart des outils utilisés par les pirates pour découvrir les Firewall sont utilisables pour une activité tout aussi louable telle que la vérification du bon fonctionnement du firewall et de la robustesse du réseau. Dans un premier temps il convient de localiser le ou les Firewalls. La localisation du firewall ne pose pas de gros
problèmes, un simple traceroute (ou tracert.exe) suffira, bien que dans certains cas netcat apporte de meilleurs résultats. Exemple :
C:> nc -v -n 10.10.1.8 25
(UNKNOWN) [10.10.1.8] 25 (?) open 421 10.10.1.8 Sorry, the firewall does not provide mail service to you.
Ensuite l'attaquant cherchera à identifier le Firewall, soit en espérant exploiter une faille même du Firewall, soit il cherchera à identifier les règles du Firewall afin d'y détecter une faille dans le filtrage de paquet. Pour identifier les règles d'un Firewall, il faut utiliser un scanner de port. Il existe de nombreux scanner de ports, les plus connus sont Firewalk, Nmap et Hping2 :
4.2.1 - Firewalk
Le Firewalking est une technique qui permet de déterminer les règles de filtrages de niveau 4 (Transport) sur les équipements (routeurs, Firewall, passerelles) qui acheminent des paquets de niveau 3 (Réseau). Le principe de cette technique repose sur le champ Ttl (Time To Live) des en-têtes IP des paquets. C'est à
dire le nombre d'équipement (routeur) que peut traverser le paquet. Le logiciel traceroute utilise aussi la technique du Ttl. Lorsque l'on envoie un paquet Udp avec un Ttl de 1, le premier routeur recevant le paquet émettra un paquet Icmp Ttl-exceeded. Et l'on répète le procédé en augmentant le Ttl de 1 à chaque fois. En fait ce procédé peut être réalisé avec d'autres protocoles de niveau 4 comme Tcp ou de niveau 3 comme Icmp. Firewalk fonctionne en construisant des paquets avec un IP Ttl calculé de façon à expirer sur un segment
situé après le firewall. En fait si le paquet est autorisé par le firewall, il pourra le passer et expirera comme prévu en envoyant un message "Icmp Ttl expired in transit". A l'inverse, si le paquet est bloqué par l'ACL du firewall, il sera abandonné et aucune réponse ne sera envoyée ou bien un paquet de filtre admin Icmp de type 13 sera envoyé.
Il est possible de bloquer les paquets Icmp Ttl EXPIRED au niveau de l'interface externe, mais le problème
est que ses performances risquent d'en prendre un sérieux coup car des clients se connectant légitimement ne sauront jamais ce qui est arrivé à leur connexion.
4.2.2 - Nmap
Nmap (Network Mapper) est certainement le scanner de port le plus célèbre disponible sous linux, Windows et même MAC. En règle générale, Nmap vérifie que l'hôte à scanner est connecté au réseau. Il réalise pour cela à la fois un Tcp ping sur le port 80 et un ping Icmp normal. Ce comportement peut être détecté par un IDS (Inspection Detection System) et pour cela on peut changer le comportement de Nmap. Nmap permet d'effectuer différents types de scans, en voici les exemples principaux :
Tcp connect : option -sT Principe : une connexion Tcp habituelle est tentée sur chaque port.
Inconvénient, ce genre de scan est visible dans les logs des firewalls. Les noms de services sont associés aux ports ouverts par le fichier Nmap-services et non /etc/services. Il n'est donc pas exclu

que le service désigné soit faux. Avantage, possibilité de déterminer l'utilisateur sous lequel est lancé un démon via Ident.
Syn scan : option -sS Principe : Seul un paquet Syn est envoyé. Si le port est ouvert, un Syn|ACK est
renvoyé, sinon un RST est renvoyé. En cas de port ouvert Nmap renvoie un paquet RST pour fermer la connexion immédiatement. Avantages, rapide et moins détectable. Fait une différence entre les ports filtrés et ouverts. Inconvénient, impossibilité de déterminer l'utilisateur via Ident.
IDLE scan : option -sI @zombie:port zombie Principe : Une machine "zombie" permet de masquer la
source du scan. Avantages, quasiment impossible à tracer, permet de déterminer les règles du firewall à partir du zombie plutôt que de la machine qui initie le scan. Inconvénients, pas de prise d'empreinte d'OS, ni d'utilisation de Ident.
(0) S'assurer que la machine zombie n'est pas trop chargée pour permettre de bien mesurer l'incrémentation (un petit calibrage avant le scan est donc nécessaire en envoyant une dizaine de
paquets Syn). (1) et (6) Envoi d'un paquet Syn|ACK au zombie pour récupérer l'IP ID (le numéro de séquence). (2) et (7) Réponse à (1) et (6) par un paquet RST contenant l'IP ID du zombie. (3) Envoi d'un paquet Syn à la cible avec comme adresse source celle du zombie. (4) Si le port est ouvert, la cible répond en envoyant un paquet Syn | ACK au zombie, sinon par un paquet RST.
(5) Le zombie incrémente son IP ID, et répond à la cible en envoyant un paquet RST à la cible. (8) Il est aussi conseillé de tester plusieurs fois chaque port pour éviter les faux-positifs.
FIN, XMAS et NULL scans : options -sF, -sX et -sN Principe : envoi respectivement de paquet FIN, de paquet FIN| URG |PSH et de paquet sans aucun flag Tcp activé. Avantages, contournement de certains Firewalls. Inconvénient, ne fonctionne pas contre certains OS qui n'appliquent pas les normes à la lettre (comme Windows, IRIX, ...)
SCAN Udp : option -sU Principe : Envoi d'un paquet Udp vide sur chaque port. Les ports fermés
retournent un paquet Icmp port unreachable. Avantage, permet d'avoir des informations sur NFS, TFtp et certaines backdoor. Inconvénient, très lent.
Scan RPC (Remote Procedure Call) : option -sR Principe : envoi de commandes SunRPC. Avantage,
détermine s'il s'agit bel et bien de port RPC et si oui, de quel programme et/ou version il s'agit. Inconvénient, assez voyant.
ACK et Window scan : option -sA et sW principe : Envoie respectivement un paquet ACK avec un numéro de séquence aléatoire et un paquet ayant une taille de fenêtre non valide. Les ports qui ne
répondent pas par un RST sont filtrés. Avantage, permet de vérifier si un port est filtré et s'il l'est avec une règle stateful. Inconvénient, Le Window scan ne fonctionne pas sur tous les systèmes d'exploitation.
Scans personnalisés : option --scanflags L'utilisateur spécifie les flags Tcp qu'il souhaite activer.
Scan de protocoles : option -sO Permet de déterminer quels sont les protocoles supportés par le système scanné, généralement un routeur.
Il n'est pas difficile de scanner dans l'anonymat :

Changer la vitesse du scan, grâce à l'option -T suivie des arguments Paranoïd, Sneaky, Polite, Normal, Aggressive or Insane. Nmap attend 5 minutes entre chaque paquet envoyé en mode Paranoïd et 15 secondes en mode Sneaky.
Utiliser des leurres (decoys, option -D) en envoyant d'autres paquets IP spoofés et semblant provenir d'une autre adresse. Sur un réseau local on peut spoofer (option -S) l'adresse source, et récupérer les réponses par sniffage en mode promiscuous. Sur la technique de l'IDLE scan.
L'auteur de Nmap, Fyodor, décrit sa technique de prise d'empreinte du système d'exploitation (fingerprinting)
dans l'article « Détection d'OS distante par prise d'empreinte de pile Tcp/IP » traduit en français par ArHuman, et l'original en anglais « Remote OS detection via Tcp/IP Stack FingerPrinting ». Le principe repose sur le test de différentes particularités des piles Tcp/IP des différents systèmes d'exploitation, lesquelles sont :
Le type d'incrémentation du numéro de séquence initiale (ISN).
La présence ou non du flag IP Don't Fragment.
Des tests sur les tailles de fenêtres.
Le type de service (ToS).
Différents tests sur des paquets Tcp.
Différents tests au niveau Icmp, comme la limite de vitesse d'envoi de certains types de paquets Icmp d'erreurs.
Nmap utilise l'option -O pour effectuer une prise d'empreinte du système, et en général on associe l'option -v (Verbose) pour obtenir des informations supplémentaires comme les ports servant à effectuer les tests de la prise d'empreinte.
Il m'a semblé important de remarquer le fait que de scanner un Firewall ou un système protégé par un Firewall prend plus de temps qu'un système non protégé.
4.2.3 - HPING2
HPING2 est différent de Nmap d'abord parce qu'il est beaucoup plus configurable. On peut facilement modifier n'importe quel octet de l'entête TcpIP. Cela permet d'être réellement créatif au niveau des techniques de balayage à des fins de reconnaissance. On peut bien sûr insérer des données malveillantes dans les paquets (buffer overflow, trojan, ...) et les utiliser pour pénétrer des réseaux.
HPING2 permet de :
tester les règles de Firewall,
de faire du scan sophistiqué,
de tester les performances d'un réseau utilisant différents protocoles, le ToS et la fragmentation,
de faire du firewalk,
de l'empreinte de système d'exploitation.
Actuellement, la version HPING3 est en train d'être développé par Salvatore SanFilippo, et d'autres
volontaires. Selon son site Web, Hping3 sera nettement supérieur à l'actuelle version. Il y aura des améliorations d'installation, des outputs plus lisibles, et sera exploitable par script. Le statut actuel du projet peut être suivi ici. Il existe aussi des outils d'évaluation de vulnérabilité :
Les payants : Retina (eEye) , NetRecon (Symantec), ISS Internet Scanner (ISS), Cybercop Scanner (Network Associates).
Les freeware : Nessus (Renaud Deraison).

4.2.4 - NESSUS
Nessus a été écrit par Renaud Deraison (depuis début 1998), un grand maître de Linux et de la sécurité. Nessus est devenu le Linux de l'évaluation de la vulnérabilité, il surpasse certains de ses concurrents
commerciaux. Nessus emploie un modèle de plug-in extensible qui permet à la sécurité d'ajouter à la demande des modules d'exploration. Nessus utilise un langage de script NASL (Nessus Attack Script Language) pour écrire des tests de sécurité rapidement et facilement. Nessus est basé sur une architecture client-Serveur, le serveur réalise les attaques et tourne sur un système UNIX; les clients initialisent les attaques et existent sur différentes plates-formes X11, Win32 et un client Java. Le fait d'être open source et d'utiliser des plug-in permet à Nessus d'être mis à jour régulièrement au niveau de sa base de données
d'attaques et d'être à la pointe de la technologie. Nessus compte à l'heure actuel plus de 500 contrôles de vulnérabilités, dont certains ne sont pas disponibles dans les scanners commerciaux.
4.3 - Configuration théorique des défenses
La configuration d'un firewall est l'élément clef de son efficacité. Un firewall mal configuré peut être tout aussi efficace... qu'aucun firewall du tout. C'est la clef de son bon fonctionnement et de son efficacité. Il existe deux politiques de configurations différentes en ce qui concerne la « base » du firewall :
Tout autoriser sauf ce qui est dangereux : cette méthode est beaucoup trop laxiste. En effet, cela laisse toute latitude à l'imagination des intrus de s'exprimer. Et à moins d'avoir tout prévu de façon exhaustive, on laissera forcément des portes ouvertes, des failles béantes dans notre système. A éviter absolument. Tout interdire sauf ce dont on a besoin et ce en quoi on a confiance : cette politique est beaucoup plus sécuritaire. En effet, les services sont examinés avant d'être autorisés à passer le firewall, et sont donc tous soumis à un examen plus ou moins approfondi. Ainsi, pas de mauvaise surprise sur un service que l'on pensait ne pas avoir
installé, plus d'oubli : tout service autorisé est explicitement déclaré dans le firewall. Cette politique s'accompagne de la création de deux zones : une zone interne et l'extérieur. On peut considérer que tout ce qui est dans notre réseau local est autorisé, sans prendre de trop gros risques : le firewall est là pour nous protéger des attaques
extérieures, pas des attaques internes pour lesquelles il ne peut rien. Cette facette peut changer suivant la politique de l'entreprise (interdire l'accès à certains, jeux, etc.). La zone externe est par contre considérée comme « non sûre », et donc toute requête envoyée sur un service non explicitement déclaré comme accessible de
l'extérieur sera interceptée et ignorée. La configuration de la DMZ est ici très importante, et sa gestion aussi. Cette politique s'accompagne de plusieurs points à noter : Plus de services sont ouverts, plus vulnérable est le système. C'est logique, car plus le nombre de logiciels accessibles de l'extérieur est grand, plus le risque qu'un intrus exploite ces dits logiciels pour s'introduire dans le système est important. C'est ainsi que, par exemple, si on utilise un serveur Web qui interface déjà le serveur de base de donnée, il est inutile d'autoriser le trafic entrant vers le serveur de base de données... vu que le serveur
Web joue le rôle d'interface. Suivant la politique de l'entreprise, l'accès ou non à certains services peut être bloqué dans les deux sens. Cela peut servir, par exemple, à empêcher le jeu en ligne, ou autres activités que l'entreprise ne désire pas voir se dérouler sur ses propres infrastructures. Certains protocoles sont assez difficiles à autoriser, notamment le Ftp. Le comportement du protocole Ftp est
assez atypique et mérite que l'on s'y attarde. Le fonctionnement du Ftp prévoit que ce soit le serveur qui initie la connexion sur le client pour lui transmettre le fichier. Un exemple concret :
Le client demande le fichier index.txt
Le serveur envoie un message au client « accepte la connexion sur le port 2563 »
Le client attend une connexion sur ce port et renvoie un ACK au serveur
Le serveur initie la connexion et lance le transfert de données.
Ce comportement implique que le serveur, dans la zone « externe », initie une connexion sur un port choisi par lui-même sur le client. Or, nous avons explicitement interdit ce genre de manipulation via notre politique. Il y a donc deux solutions :
Interdire le Ftp.
Forcer le client à utiliser la commande PASV, qui indique que le serveur doit adopter un comportement passif, et accepter la connexion du client sur un port spécifié par ce dernier. C'est donc le client qui initiera la connexion, et donc, la connexion sera autorisée par le firewall. Avec la commande PASV, l'échange se
passe donc ainsi : - Le client envoie la commande PASV - Le serveur répond avec l'adresse et le port auquel le client peut se connecter - Le client demande le fichier index.txt (RETR index.txt)

- Le serveur envoie un reçu et attend la connexion du client - Le client se connecte et reçoit le fichier
La configuration efficace d'un firewall n'est pas chose évidente, et implique une grande rigueur, la moindre erreur
ouvrant une brèche exploitable par les hackers.
4.4 - Les réactions des firewalls aux attaques classiques
4.4.1 - IP spoofing
L'IP spoofing consiste à modifier les paquets IP afin de faire croire au firewall qu'ils proviennent d'une adresse IP considérée comme « de confiance ». Par exemple, une IP présente dans le réseau local de l'entreprise. Cela laissera donc toute latitude au hacker de passer outre les règles du firewall afin d'envoyer
ses propres paquets dans le réseau de l'entreprise. Les derniers firewalls peuvent offrir une protection contre ce type d'attaque, notamment en utilisant un protocole VPN, par exemple IPSec. Cela va crypter les entêtes des paquets, et ainsi rendre impossible leur modification par un intrus, et surtout, l'intrus ne pourra générer de paquets comme provenant de ce réseau local, ce dernier n'ayant pas la clé nécessaire au cryptage. Les algorithmes utilisés dans de tels protocoles sont de type RSA.
4.4.2 - DOS et DDOS
Le DOS, ou Denial Of Service attack, consiste à envoyer le plus de paquets possibles vers un serveur, générant beaucoup de trafic inutile, et bloquant ainsi l'accès aux utilisateurs normaux. Le DDOS, pour Distributed DOS, implique venir de différentes machines simultanées, cette action étant le plus souvent
déclenchée par un virus : ce dernier va d'abord infecter nombre de machines, puis à une date donnée, va envoyer depuis chaque ordinateur infecté des paquets inutiles vers une cible donnée. On appelle aussi ce type d'attaque « flood ». Les firewalls ici n'ont que peu d'utilité. En effet, une attaque DOS ou DDOS utilise le plus souvent des adresses sources différentes (le but n'est pas de récupérer une réponse ici) et souvent,
impossible de distinguer ces paquets des autres... Certains firewalls offrent une protection basique contre ce genre d'attaque, par exemple en droppant les paquets si une source devient trop gourmande, mais généralement, ces protections sont inutiles. Cette attaque brute reste un des gros problèmes actuels, car elle
est très difficilement évitable.
4.4.3 - Port scanning
Ceci constitue en fait une « pré-attaque » (Etape de découverte). Elle consiste à déterminer quels ports sont ouverts afin de déterminer quelles sont les vulnérabilités du système. Le firewall va, dans quasiment tous les cas, pouvoir bloquer ces scans en annoncent le port comme « fermé ». Elles sont aussi aisément détectables car elles proviennent de la même source faisant les requêtes sur tous les ports de la machine. Il suffit donc au firewall de bloquer temporairement cette adresse afin de ne renvoyer aucun résultat au scanner.
4.4.4 - Exploit
Les exploits se font en exploitant les vulnérabilités des logiciels installés, par exemple un serveur Http, Ftp, etc. Le problème est que ce type d'attaque est très souvent considéré comme des requêtes tout a fait « valides » et que chaque attaque est différente d'une autre, vu que le bug passe souvent par reproduction de
requêtes valides non prévues par le programmeur du logiciel. Autrement dit, il est quasiment impossible au firewall d'intercepter ces attaques, qui sont considérées comme des requêtes normales au système, mais exploitant un bug du serveur le plus souvent. La seule solution est la mise à jour périodique des logiciels utilisés afin de barrer cette voie d'accès au fur et à mesure qu'elles sont découvertes.
4.5 - Un exemple pratique : netfilter
Le réseau est assez basique et est installé comme suit :

Le firewall dispose donc de deux cartes réseau, nommées sous linux eth0 et eth1. Nous allons donc définir deux variables décrivant quelle interface est reliée au réseau local et laquelle est reliée au WAN. Nous préciseront aussi le nom de l'interface de loopback (qui redirige vers le routeur lui même) :
IN="eth1" EXT="eth0" LO="lo"
Viennent ensuite plusieurs variables permettant de décrire dans l'ordre le réseau actuel, les réseaux considérés comme locaux, le chemin vers le binaire d'iptables et une commande permettant de récupérer l'IP associée à l'interface externe, donc notre IP sur le WAN :
NETIN="192.168.0.1" PRIVATE_NETS="10.0.0.0/8 172.16.0.0/12 192.168.0.0/16" IPTABLES="/sbin/iptables" EXTIP=`/sbin/ifconfig $EXT | grep inet | cut -d : -f 2 | cut -d \ -f 1`
Ensuite, comme nous voulons que nos machines en local puissant accéder au WAN via le Nat, nous allons l'activer :
echo 1 > /proc/sys/net/ipv4/ip_forward
Enfin vient la configuration en elle même des règles du firewall. Iptables repose sur un système de tables qui correspondent aux différents types de trafic. Ici, nous allons utiliser deux tables, filter et nat. La table nat regroupe tout le trafic émis en local, tandis que filter lui va regrouper les trafics entrants non expressément demandés en local. A chaque table est associé différentes chaînes correspondant aux étapes majeures du routage
interne effectué pour ce type de trafic : Pour la table filter : INPUT et OUTPUT, si les paquets sont destinés au routeur, à un de ses processus, alors il va d'abord passer par la chaîne INPUT, puis être délivré au processus local, qui va émettre ou non une réponse. La réponse, si émise,
devra être conforme aux règles de la chaîne OUTPUT. FORWARD, si le paquet est destiné à un autre hôte du réseau, alors ce dernier devra passer par cette chaîne.
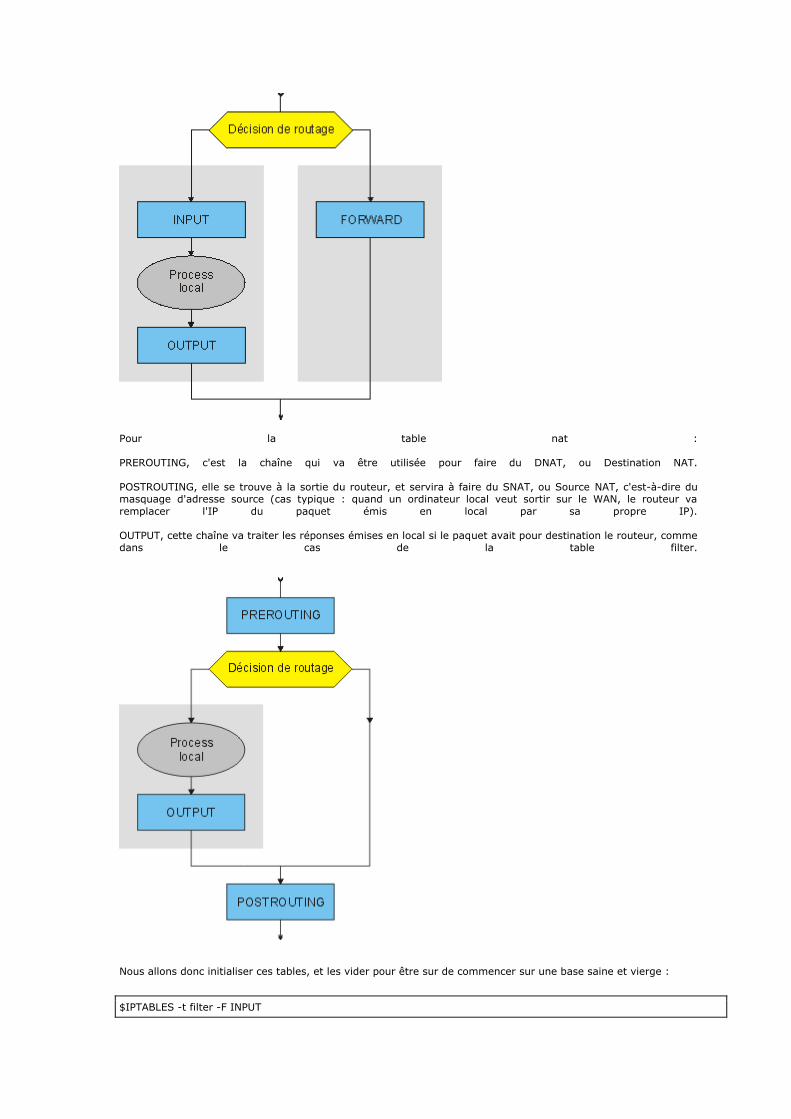
Pour la table nat : PREROUTING, c'est la chaîne qui va être utilisée pour faire du DNAT, ou Destination NAT.
POSTROUTING, elle se trouve à la sortie du routeur, et servira à faire du SNAT, ou Source NAT, c'est-à-dire du masquage d'adresse source (cas typique : quand un ordinateur local veut sortir sur le WAN, le routeur va
remplacer l'IP du paquet émis en local par sa propre IP). OUTPUT, cette chaîne va traiter les réponses émises en local si le paquet avait pour destination le routeur, comme dans le cas de la table filter.
Nous allons donc initialiser ces tables, et les vider pour être sur de commencer sur une base saine et vierge :
$IPTABLES -t filter -F INPUT

$IPTABLES -t filter -F FORWARD $IPTABLES -t filter -F OUTPUT $IPTABLES -t nat -F PREROUTING
$IPTABLES -t nat -F OUTPUT
$IPTABLES -t nat -F POSTROUTING
A ce stade, nous avons un système vierge où toutes les chaînes sont vides, c'est à dire ou aucune règle n'est en
vigueur. Nous allons donc créer ces règles. Par défaut, comme décrit auparavant, nous allons interdire tout trafic de la table filter qui ne soit pas expressément autorisé. Ces règles vont être les politiques « par défaut », gérant le cas où aucune règle de la chaîne ne s'applique au paquet concerné.
$IPTABLES -t filter -P INPUT DROP $IPTABLES -t filter -P FORWARD DROP $IPTABLES -t filter -P OUTPUT DROP
Par contre, comme nous avons confiance en nos utilisateurs, nous allons autoriser le trafic vers l'extérieur
demandé en interne. Il nous suffirait de calquer notre politique sur celle de la table filter pour obtenir le même type de sécurité et fermer des services à nos utilisateurs locaux :
$IPTABLES -t nat -P PREROUTING ACCEPT
$IPTABLES -t nat -P OUTPUT ACCEPT $IPTABLES -t nat -P POSTROUTING ACCEPT $IPTABLES -t nat -A POSTROUTING -o $EXT -j MASQUERADE
Néanmoins, lorsqu'un de nos utilisateurs locaux va demander par exemple une page Http, la réponse va passer par la table filter et va donc être jetée. Nous devons donc autoriser les réponses à revenir à leur destinataire :
$IPTABLES -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
$IPTABLES -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT $IPTABLES -A OUTPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
Maintenant, nous allons commencer à sélectionner les paquets qui vont être autorisés à rentrer dans notre
réseau. Comme nous allons autoriser des services, nous devons d'abord être sûrs que ces derniers sont autorisés à rentrer. C'est le but de cette commande qui va jeter tous les paquets qui nous sont parvenus dont l'adresse de destination n'est pas la notre :
if [ -n "$EXTIP" ]; then
$IPTABLES -t nat -A PREROUTING -i $EXT -d ! $EXTIP -j LOG --log-prefix "FW abnormal prerouting: " $IPTABLES -t nat -A PREROUTING -i $EXT -d ! $EXTIP -j DROP fi
La loopback est aussi quelque chose que nous pouvons autoriser, il n'y a aucun danger à ce que le routeur émette des paquets pour lui même :
$IPTABLES -A INPUT -i $LO -j ACCEPT
$IPTABLES -A OUTPUT -o $LO -j ACCEPT
Ensuite, nous allons autoriser tout le trafic expressément émis par le routeur. Il est assez sûr d'autoriser cela, car on imagine que l'administrateur système et réseau, si il fait son propre firewall en iptables, sait ce qu'il installe sur son routeur :
$IPTABLES -A OUTPUT -j ACCEPT $IPTABLES -t nat -A OUTPUT -j ACCEPT
Comme nous avons encore confiance en nos utilisateurs, nous allons autoriser tout le trafic qu'ils génèrent vers le routeur :
$IPTABLES -A INPUT -m state --state NEW -i $IN -j ACCEPT $IPTABLES -A OUTPUT -m state --state NEW -o $IN -j ACCEPT

Et nous allons accepter toute redirection de trafic de notre réseau local vers l'extérieur.
$IPTABLES -A FORWARD -m state --state NEW -i $IN -o $EXT -j ACCEPT
A ce stade, tous les paquets entrants passeront par la table filter, et devront donc être droppés. Nous avons coupé tout accès entrant non expressément autorisé. Typiquement, c'est la configuration bastion ou l'entreprise ne propose aucun service Http ou Ftp, mais veut permettre à ses employés de sortir sur le WAN. Nous avons autorisé tout trafic considéré comme sûr, et si aucune règle ne s'applique au paquet, il subira la politique par défaut : si il est interne il est autorisé, si il est externe il est interdit.
Enfin, nous allons autoriser expressément les services que nous ouvrons à l'extérieur, par exemple le trafic Http, qui est de type Tcp sur le port 80 :
$IPTABLES -A INPUT -m state --state NEW -i $EXT -p Tcp --dport 80 -j ACCEPT
Il nous suffit ainsi de répéter cette commande, en mettant le numéro de port et le type de trafic ad hoc pour ouvrir nos services à l'extérieur.
Ce firewall est très robuste et permet ainsi un niveau de sécurité assez élevé, largement suffisant dans le cas d'un réseau local.
5 - Conclusion
Nous avons vu, dans cette publication, les différents types de firewalls, les différentes attaques et parades. Il ne faut pas perdre de vue qu'aucun firewall n'est infaillible et que tout firewall n'est efficace que si bien configuré. De plus, un
firewall n'apporte pas une sécurité maximale et n'est pas une fin en soi. Il n'est qu'un outil pour sécuriser et ne peut en
aucun cas être le seul instrument de sécurisation d'un réseau. Un système comportant énormément de failles ne deviendra jamais ultra-sécurisé juste par l'installation d'un firewall. Toutes ces technologies sont et seront en pleine évolution, car la base même de tout cela est de jouer au chat et à la souris entre les hackers et les programmeurs de firewall ainsi que les administrateurs. Une grande bataille d'imagination qui n'aura certainement jamais de fin.
Saturation du processeur
1 - Le concept 2 - Le fonctionnement 2.1 - Schéma 2.2 - Calcul du Checksum IP 2.3 - Calcul du Checksum TCP
2.4 - Calcul du Checksum UDP 3 - Les conseils et astuces 4 - Les liens 5 - Les outils 6 - La conclusion 7 - Discussion autour de la documentation 8 - Suivi du document
1 - Le concept
Le but est de saturer le processeur de la cible en lui demandant d'effectuer des calculs de checksum. L'attaque peut être émise à partir d'un poste ou plusieurs simultanément. Dans le premier cas, vous aurez très souvent vous-même besoin d'un bon processeur afin de surpasser celui de la cible, excepté, si vous utilisez des checksums pré calculés. Dans le second cas, vous émettez alors l'attaque à partir de N postes et disposant ainsi d'une puissance processeur
supérieur à votre cible, d'une bande passante supérieur et des points d'accès non concentrés et donc plus difficile à stopper.
2 - Le fonctionnement
2.1 - Schéma
Le fonctionnement est de générer une trame IP sans application spécifique afin d'obliger la cible à calculer le
checksum de l'entête IP afin de valider la conformité.
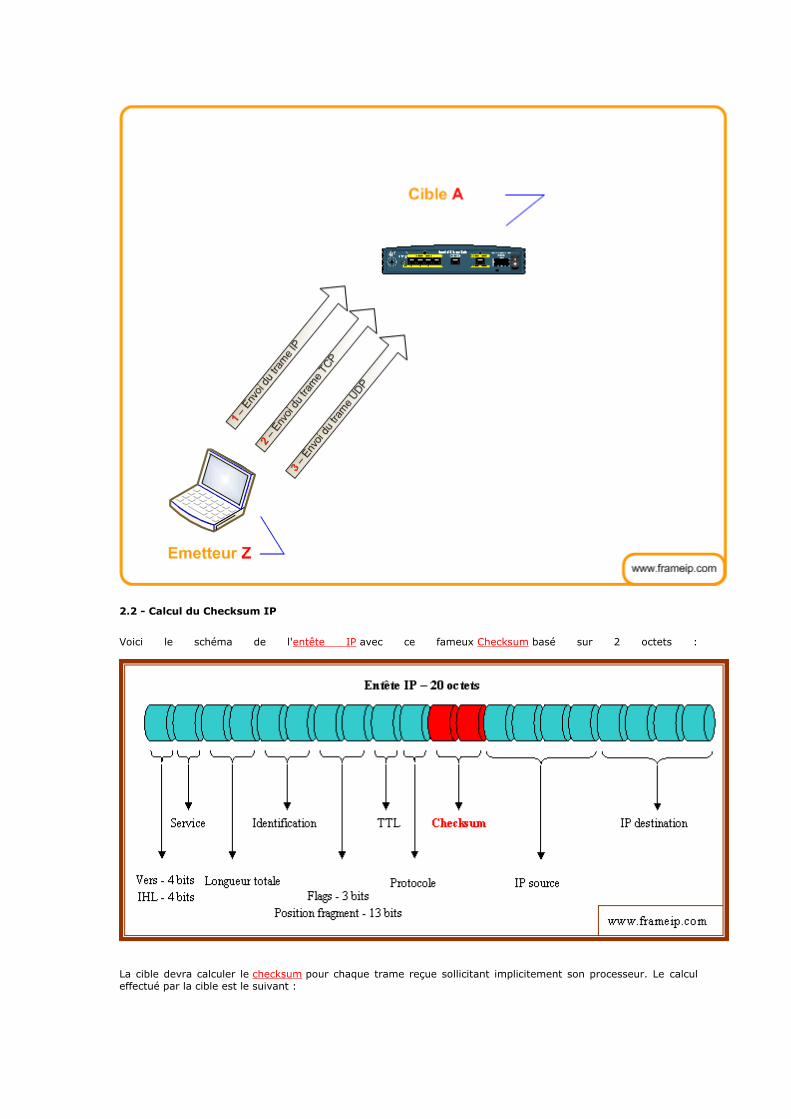
2.2 - Calcul du Checksum IP
Voici le schéma de l'entête IP avec ce fameux Checksum basé sur 2 octets :
La cible devra calculer le checksum pour chaque trame reçue sollicitant implicitement son processeur. Le calcul effectué par la cible est le suivant :

unsigned short calcul_du_checksum(bool liberation, unsigned short *data, int taille) { unsigned long checksum=0; // ********************************************************
// Complément à 1 de la somme des complément à 1 sur 16 bits
// ******************************************************** while(taille>1) { if (liberation==TRUE) liberation_du_jeton(); // Rend la main à la fenêtre principale
checksum=checksum+*data++; taille=taille-sizeof(unsigned short); } if(taille) checksum=checksum+*(unsigned char*)data;
checksum=(checksum>>16)+(checksum&0xffff); checksum=checksum+(checksum>>16); return (unsigned short)(~checksum); }
L'avantage de cette méthode est d'être portable sur toutes piles IP, même si aucun port n'est en écoute.
2.3 - Calcul du Checksum TCP
Le fonctionnement est de générer une trame TCP afin d'obliger la cible à calculer le checksum de l'entête IP et TCP afin de valider la conformité. Voici le schéma de l'entête TCP avec le Checksum basé sur 2 octets :
La cible devra calculer le checksum de l'entête IP puis celui de l'entête TCP pour chaque trame reçue sollicitant implicitement son processeur. Le calcul effectué par la cible pour le Checksum TCP est le suivant :
struct pseudo_entete { unsigned long ip_source; // Adresse ip source unsigned long ip_destination; // Adresse ip destination char mbz; // Champs à 0 char type; // Type de protocole (6->TCP et 17->UDP)
unsigned short length; // htons( Taille de l'entete Pseudo + Entete TCP ou UDP + Data ) }; unsigned short calcul_du_checksum_tcp(bool liberation, unsigned long ip_source_tampon, unsigned long ip_destination_tampon, struct tcp tcp_tampon, char data_tampon[65535]) { struct pseudo_entete pseudo_tcp;
char tampon[65535];

unsigned short checksum; // ******************************************************** // Initialisation du checksum
// ********************************************************
tcp_tampon.checksum=0; // Doit être à 0 pour le calcul // ******************************************************** // Le calcul du Checksum TCP (Idem à UDP) // ********************************************************
// Le calcul passe par une pseudo entete TCP + l'entete TCP + les Data pseudo_tcp.ip_source=ip_source_tampon; pseudo_tcp.ip_destination=ip_destination_tampon; pseudo_tcp.mbz=0; pseudo_tcp.type=IPPROTO_TCP; pseudo_tcp.length=htons((unsigned short)(sizeof(struct tcp)+strlen(data_tampon))); memcpy(tampon,&pseudo_tcp,sizeof(pseudo_tcp));
memcpy(tampon+sizeof(pseudo_tcp),&tcp_tampon,sizeof(struct tcp)); memcpy(tampon+sizeof(pseudo_tcp)+sizeof(struct tcp),data_tampon,strlen(data_tampon)); checksum=calcul_du_checksum(liberation,(unsigned short*)tampon,sizeof(pseudo_tcp)+sizeof(struct tcp)+strlen(data_tampon)); return(checksum); }
L'utilisation du checksum TCP permet d'obtenir de meilleur résultat, car implicitement, il est combiné au checksum IP.
2.4 - Calcul du Checksum UDP
Le fonctionnement est identique à la méthode TCP, pour cela, il faut générer une trame UDP afin d'obliger la cible à calculer le checksum de l'entête IP et UDP afin de valider la conformité. Voici le schéma de l'entête UDPavec le Checksum basé sur 2 octets :
La cible devra calculer le checksum de l'entête IP puis celui de l'entête UDP pour chaque trame reçue sollicitant
implicitement son processeur. Le calcul effectué par la cible pour le Checksum UDP est le suivant :
struct pseudo_entete {
unsigned long ip_source; // Adresse ip source unsigned long ip_destination; // Adresse ip destination char mbz; // Champs à 0 char type; // Type de protocole (6->TCP et 17->UDP) unsigned short length; // htons( Taille de l'entete Pseudo + Entete TCP ou UDP + Data ) };
unsigned short calcul_du_checksum_udp(bool liberation, unsigned long ip_source_tampon, unsigned long

ip_destination_tampon, struct udp udp_tampon, char data_tampon[65535]) { struct pseudo_entete pseudo_udp; char tampon[65535];
unsigned short checksum;
// ******************************************************** // Initialisation du checksum // ******************************************************** udp_tampon.checksum=0; // Doit être à 0 pour le calcul
// ******************************************************** // Le calcul du Checksum UDP (Idem à TCP) // ******************************************************** // Le calcul passe par une pseudo entete UDP + l'entete UDP + les Data pseudo_udp.ip_source=ip_source_tampon; pseudo_udp.ip_destination=ip_destination_tampon;
pseudo_udp.mbz=0; pseudo_udp.type=IPPROTO_UDP; pseudo_udp.length=htons((unsigned short)(sizeof(struct udp)+(unsigned short)strlen(data_tampon))); memcpy(tampon,&pseudo_udp,sizeof(pseudo_udp)); memcpy(tampon+sizeof(pseudo_udp),&udp_tampon,sizeof(struct udp)); memcpy(tampon+sizeof(pseudo_udp)+sizeof(struct udp),data_tampon,strlen(data_tampon)); checksum=calcul_du_checksum(liberation,(unsigned short*)tampon,sizeof(pseudo_udp)+sizeof(struct
udp)+strlen(data_tampon)); return(checksum); }
3 - Les conseils et astuces
- L'astuce de l'émetteur est d'envoyer des trames préconstruites afin de ne pas calculer soit même le checksum gagnant ainsi un temps considérable. - L'utilisation de smurf augmentera fortement le nombre de checksum à calculer.
- Le choix de la taille des données est important. Si les trames sont grandes, du style 65535 octets, alors le calcul du checksum sera plus long et sollicitera plus de processeur.
4 - Les liens
5 - Les outils
- FrameIP est un générateur de trames IP. Il vous permettra de personnaliser les champs des différentes entêtes réseaux. Vous aurez la possibilité grâce à cet outils de pré calculer les checksum. - PingIcmp permet d'effectuer des Ping Icmp sans interruption.
6 - La conclusion
La puissance de calcul est tel maintenant, que même la combinaison Checksum IP et TCP n'écroulera pas les récents
processeurs. Cependant, destiné à des petits chipset tel que des boîtiers d'impression, des routeurs de particulier et autres, la gêne occasionnée peut être conséquente.
SynFlood
1 - Le concept 2 - Le Fonctionnement 2.1 - Schéma
2.2 - Envoi du SYN 2.3 - Réception par la cible A 2.4 - Réponse de la cible A 2.5 - Réponse de la cible B 3 - Les conseils et astuces 4 - Les liens 5 - Les outils
6 - La conclusion 7 - Discussion autour de la documentation 8 - Suivi du document

1 - Le concept
L'attaque SynFlood est basée sur l'envoi massif de demande d'ouverture de session TCP. Les buts recherchés peuvent être :
- Le Buffer Overflow du process écoutant le port TCP de destination. - La saturation du nombre d'ouverture de session TCP en cours.
2 - Le fonctionnement
2.1 - Schéma
2.2 - Envoi du SYN
Le fonctionnement est de générer une trame TCP de demande de synchronisation à destination de la cible. Cette demande de synchronisation SYN est la première étape d'une ouverture de session TCP. Voici le schéma de l'entête TCP avec ce fameux flag SYN basé sur 1 bit :
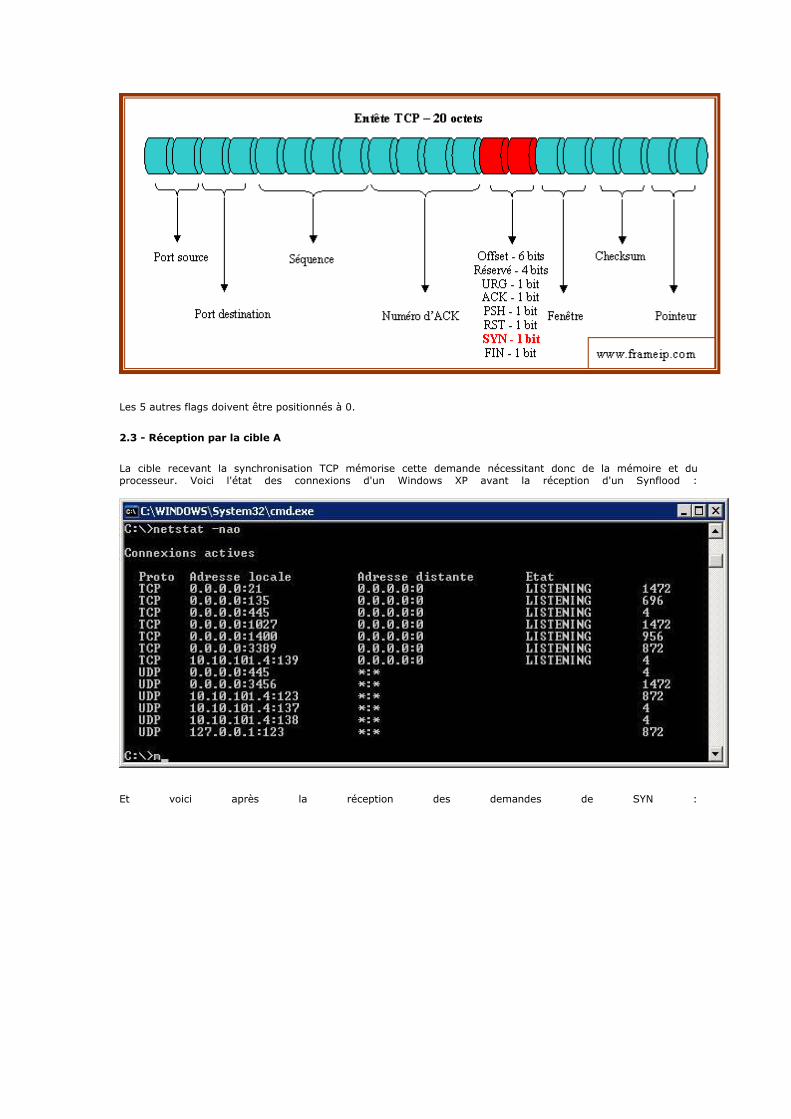
Les 5 autres flags doivent être positionnés à 0.
2.3 - Réception par la cible A
La cible recevant la synchronisation TCP mémorise cette demande nécessitant donc de la mémoire et du
processeur. Voici l'état des connexions d'un Windows XP avant la réception d'un Synflood :
Et voici après la réception des demandes de SYN :
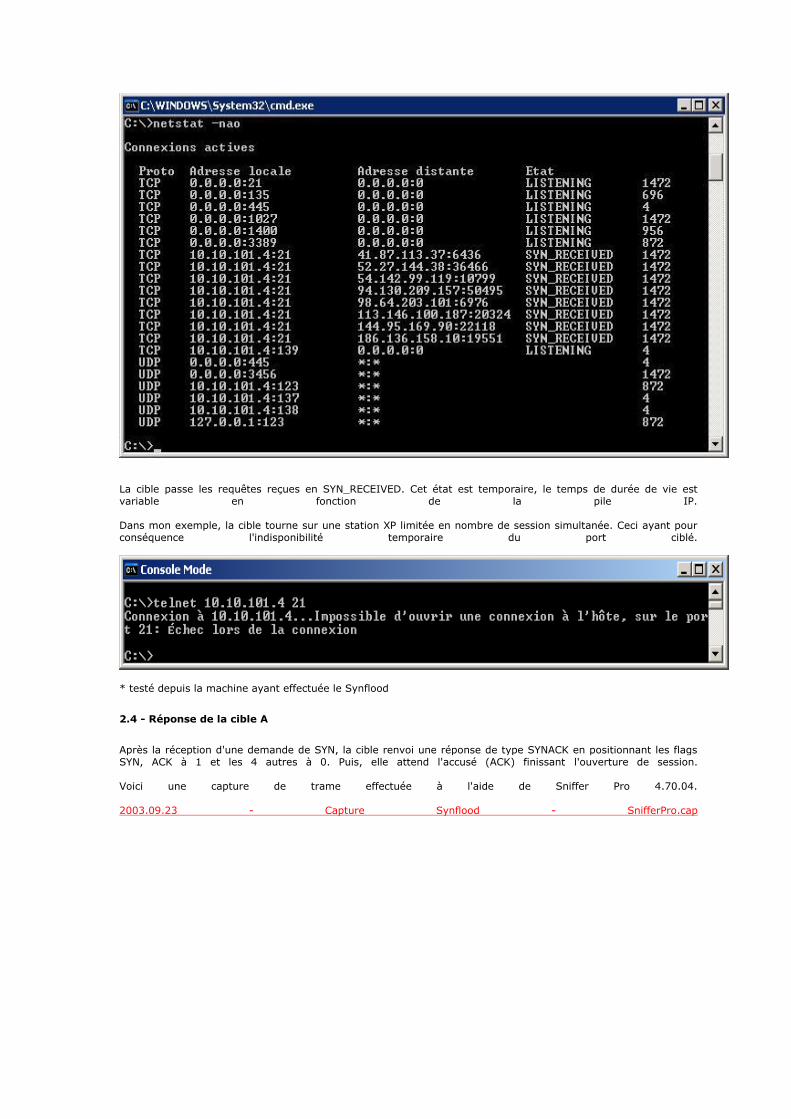
La cible passe les requêtes reçues en SYN_RECEIVED. Cet état est temporaire, le temps de durée de vie est variable en fonction de la pile IP. Dans mon exemple, la cible tourne sur une station XP limitée en nombre de session simultanée. Ceci ayant pour conséquence l'indisponibilité temporaire du port ciblé.
* testé depuis la machine ayant effectuée le Synflood
2.4 - Réponse de la cible A
Après la réception d'une demande de SYN, la cible renvoi une réponse de type SYNACK en positionnant les flags SYN, ACK à 1 et les 4 autres à 0. Puis, elle attend l'accusé (ACK) finissant l'ouverture de session. Voici une capture de trame effectuée à l'aide de Sniffer Pro 4.70.04.
2003.09.23 - Capture Synflood - SnifferPro.cap

* 10.10.101.4 - Correspond à la Cible A Vous pourrez remarquer que les 11 premières réponses de la cible sont des SYNACK et que les suivantes sont des
ACKRST ! De plus, dans cet exemple, on peut s'apercevoir que Windows n'ayant pas eu c'est 11 ACK finalisant les ouvertures de session, réémets ses 11 premiers SYNACK au cas où les trames n'auraient pas aboutis. Cela relève purement du fonctionnement normal de TCP, du mode connecté apportant la garantie de transfert. Mais cela peut servir dans le cadre d'une attaque spoofée à l'attention d'une seconde cible.
2.5 - Réponse de la cible B
Trois hypothèses en fonction de l'Ip source que vous aurez .
- Le premier cas, correspond à ne pas utiliser l'Ipspoofing et donc de faire correspondre la cible B à l'émetteur originel. Vous recevrez donc alors le SYNACK de la cible A et vous en ferrez ce que vous désirez. - La seconde hypothèse est de spécifier une IP non attribuée. La réponse de la cible A n'aboutira donc pas et n'engendra donc pas de trafic supplémentaire. La durée en état d'attente d'établissement de session sur la cible sera au maximum. Excepté le cas où un routeur informe la cible A via ICMP du drop du paquet ou de l'Ip non routable.
- La troisième possibilité est de spécifier une correspondance à un Hôte. Alors celui-ci répondra certainement (cela est dépendant de la pile IP) un RST indiquant : « Je ne comprend pas ce que tu veux, je n'ai jamais rien demandé, alors ferme cette demande d'ouverture de session qui n'existe pas ! ». Intéressant, ce point de vue qui génère encore du trafic supplémentaire. Voici une capture de trame effectuée à l'aide de Sniffer Pro 4.70.04.
2003.09.23 - Capture 2 Synflood - SnifferPro.cap
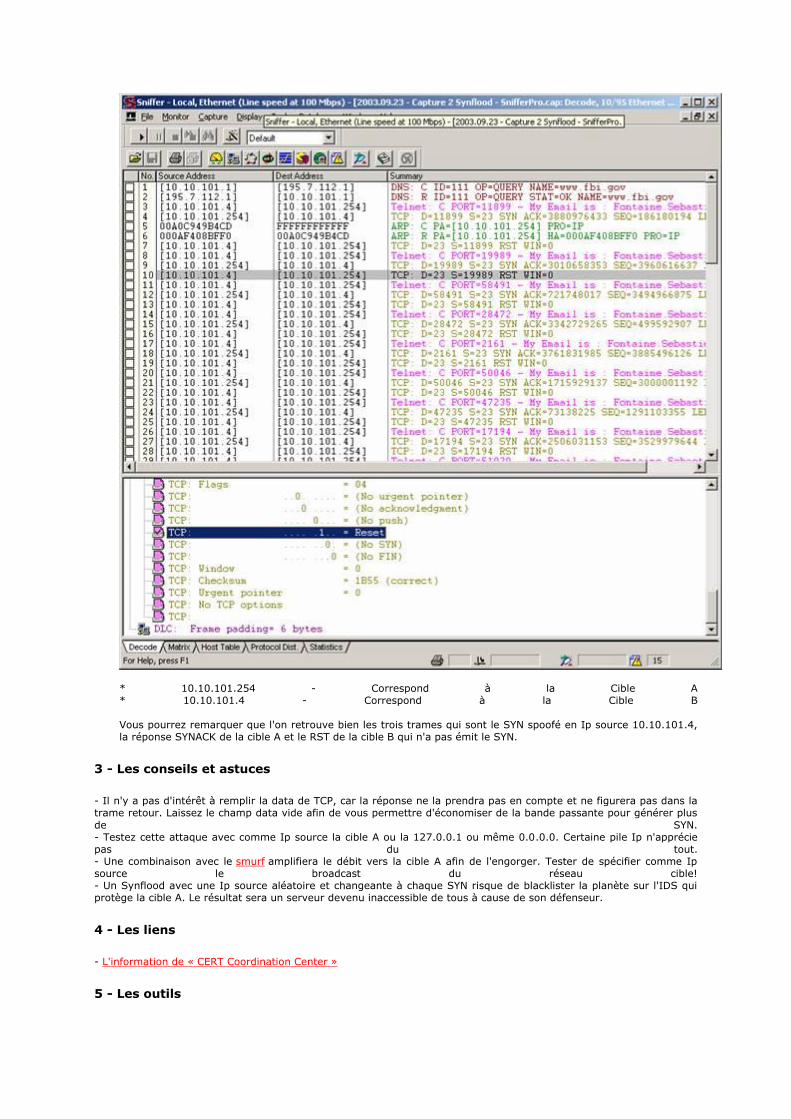
* 10.10.101.254 - Correspond à la Cible A * 10.10.101.4 - Correspond à la Cible B
Vous pourrez remarquer que l'on retrouve bien les trois trames qui sont le SYN spoofé en Ip source 10.10.101.4, la réponse SYNACK de la cible A et le RST de la cible B qui n'a pas émit le SYN.
3 - Les conseils et astuces
- Il n'y a pas d'intérêt à remplir la data de TCP, car la réponse ne la prendra pas en compte et ne figurera pas dans la trame retour. Laissez le champ data vide afin de vous permettre d'économiser de la bande passante pour générer plus
de SYN. - Testez cette attaque avec comme Ip source la cible A ou la 127.0.0.1 ou même 0.0.0.0. Certaine pile Ip n'apprécie pas du tout. - Une combinaison avec le smurf amplifiera le débit vers la cible A afin de l'engorger. Tester de spécifier comme Ip source le broadcast du réseau cible! - Un Synflood avec une Ip source aléatoire et changeante à chaque SYN risque de blacklister la planète sur l'IDS qui protège la cible A. Le résultat sera un serveur devenu inaccessible de tous à cause de son défenseur.
4 - Les liens
- L'information de « CERT Coordination Center »
5 - Les outils

- SynFlood est un outil spécifique pour l'envoi massif de SYN. De plus, vous pourrez changer l'Ip source à volonté. - Frameip vous permettra de générer tous type de paquet IP. Ainsi, vous pourrez émettre les SYN à volonté.
6 - La conclusion
Cette méthode à pour but de saturer le nombre de session de la cible. Il peut s'avérer sur certaine pile Ip que le résultat soit le crash du daemon écoutant le port ciblé.
Le smart-spoofing IP
1 - Introduction 2 - L'ARP cache poisoning 3 - Le filtrage IP 4 - Le spoofing IP 5 - Le smart-spoofing IP 5.1 - Quelques cas de figure
6 - Comment se protéger 6.1 - Sécurité passive 6.2 - Sécurité active 7 - Discussion autour de la documentation 8 - Suivi du document
1 - Introduction
Cet article a pour but de présenter une nouvelle technique de spoofing IP réduisant de manière importante la confiance que l'on peut avoir dans les solutions de sécurité basées sur le filtrage IP source. Cet article ne présente pas une
nouvelle vulnérabilité, le concept du spoofing IP existant depuis longtemps. Toutefois, la technique employée, basée sur de l'ARP cache poisoning associée à de la translation d'adresse, simplifie très nettement sa mise en oeuvre, rendant de ce fait les solutions de filtrage IP source incertaines, voire inutiles.
2 - L'ARP cache poisoning
Cette technique vise à modifier le routage au niveau 2, et permet de jouer l'attaque de l'intercepteur (Man In The Middle) sur un LAN. Le protocole ARP est le protocole assurant la correspondance sur un LAN entre les adresses de niveau 2 (adresses Ethernet) et les adresses de niveau 3 (adresses IP). En modifiant les associations, il est possible de faire croire à une machine que l'adresse IP de son correspondant se trouve en fait à l'adresse Ethernet d'une machine pirate. Le protocole ARP (RFC 826) a été créé sans prendre en compte les aspects d'authentification des machines, de
sorte que n'importe quelle machine sur un réseau est capable de s'annoncer comme propriétaire d'une adresse IP. L'utilisation d'un protocole non sécurisé, associé à de mauvaises implémentations dans les systèmes d'exploitation, fait qu'à ce jour, quasiment tous les systèmes sont vulnérables à de l'ARP cache poisoning. Bien que la RFC définisse le format des messages, il est possible de les envoyer sous de multiples formes. Ainsi, une trame ARP peut être codée de 8 façons différentes (broadcast ou unicast, whois ou reply, gratuitous ou pas). Selon le résultat que l'on veut obtenir (création d'une entrée en table, mise à jour), il est possible d'employer ou de combiner ces messages. Des tests menés
sur de nombreux OS (Unix, Linux, BSD, Windows, IOS, IPSO...) montrent qu'il existe toujours une forme de requête permettant de les "cache poisoner". Sur certains OS, Windows 9x, NT et 2000, il est même possible de modifier des entrées définies en statique. Ce ne sont pas les seuls. Des tests menés sur un Solaris 8 ont permis d'identifier que cet OS était également vulnérable à de l'ARP cache poisoning sur des entrées définies en statique en utilisant des requêtes de type gratuitous. Les attaques mettant en oeuvre le protocole ARP sont nombreuses et vont de l'écoute réseau sur un réseau switché au
déni de service, en passant par le spoofing et l'attaque de l'intercepteur.
3 - Le filtrage IP
Le filtrage IP consiste en la mise en place de règles de contrôle d'accès portant sur l'adresse IP source des paquets entrant dans un équipement ou une application, qui a alors la possibilité de comparer l'adresse IP source du paquet entrant avec une liste d'adresses autorisées (adresses unitaires ou réseau tout entier). Le paquet IP sera accepté
seulement si l'adresse fait partie de cette liste. Dans le cas contraire, le paquet sera rejeté (émission d'un refus ou poubellisation). A noter que d'autres contrôles ou traitements sur le paquet peuvent être appliqués avant de l'accepter définitivement, mais ceci est hors de ce propos. Le concept de filtrage IP est également à la base de la notion de cloisonnement des réseaux : telle machine ne peut communiquer qu'avec telle autre machine. Le filtrage IP est donc un composant de sécurité de base, simple et performant, que l'on retrouve dans nombre d'équipements et de logiciels :
- Firewall avec utilisation de règles intégrant l'IP source - Routeurs avec Access List (ACL) - Filtres intégrés dans les piles IP des systèmes d'exploitation

- TCP Wrapper sur les systèmes unix - Filtrage IP effectué au sein des applications afin de limiter les communications entre deux machines (transfert de zone pour un serveur DNS, relais SMTP, serveur Web...) - ...
4 - Le spoofing IP
La méthode du spoofing d'IP source permet de contourner ce filtrage. Elle existe depuis longtemps et certaines
histoires célèbres font état de cette technique. Le concept est simple, les techniques pour y parvenir plus complexes. Il suffit d'usurper l'adresse IP d'une machine autorisée pour profiter de ses privilèges. Pour y parvenir, seules les techniques basées sur la construction manuelle de paquets IP étaient jusqu'alors connues. Jumelées à de l'écoute réseau, cela permettait au mieux de créer une pseudo communication avec la machine visée. La pile IP du système d'exploitation de la machine pirate était dans ce cas inutilisée. Des outils comme dsniff ou ettercap mettent en oeuvre ce principe.
Les mises en oeuvre de cette méthode sont les suivantes : - Construction de paquets en aveugle. Les paquets sont construits et envoyés sur le réseau, sans savoir ce que l'autre machine va répondre. En TCP, cela nécessite de prédire les numéros de séquence échangés. - Hijacking de connexion TCP. Il s'agit d'attendre l'établissement d'une connexion par une source autorisée, puis de la voler. Cela nécessite d'être sur le chemin réseau, d'écouter le trafic et de s'insérer dans la connexion. Cette méthode permet de profiter des privilèges de la source, le hijacking étant effectué après la phase d'authentification.
- Ecoute du réseau et construction de paquets. Il s'agit d'une méthode similaire au hijacking, mais en créant une nouvelle connexion. Les paquets sont écrits et lus sur le réseau sans passer par la pile IP de la machine, permettant de spoofer l'adresse de la source. Restera à jouer la phase d'authentification. Cf l'article "IP-spoofing Demystified" Les méthodes présentées ici sont possibles, mais difficilement exploitables, pour cause d'absence d'outillage évolué.
5 - Le smart-spoofing IP
La technique présentée ici abandonne les principes d'écoute du réseau et de forgeage de paquets. Elle permet de
spoofer une adresse IP de façon "propre", en permettant à n'importe quelle application exécutée de "profiter" de cette nouvelle identité. Cette méthode a été nommée le "smart-spoofing IP". Dans la suite de l'article, nous appellerons "Paris" la machine sur laquelle le filtrage IP est effectué, "Londres" la machine autorisée à se connecter sur Paris et "Evil" la machine opérant le smart-spoofing IP. Evil se doit d'être sur le chemin réseau entre Paris et Londres. Deux routeurs Rp et Rl sont positionnés. Ils correspondent aux "next hops" permettant à Evil de joindre respectivement Paris et Londres. Selon que Evil se situe dans le même réseau que Paris ou Londres, Rp et Rl pourront se confondre avec
Paris ou Londres. Les explications suivantes continueront à identifier Rp et Rl afin de traiter le cas général.
Le smart-spoofing IP consiste à opérer dans un premier temps un ARP cache poisoning de Rp afin d'insérer dans la chaîne de routage niveau 2 des paquets circulant entre Londres et Paris. Il est nécessaire d'activer le routage sur Evil afin que Londres continue à recevoir les paquets qui lui sont destinés. Dans le cas où Evil se situe sur le même LAN que
Paris, un blocage des ICMP redirect sur Evil empêchera de laisser trop de traces permettant une détection de l'attaque. Les ICMP redirect ne constituent toutefois pas une gêne fonctionnelle car le routage a seulement été détourné au niveau 2 (les ICMP redirect agissant au niveau 3). Enfin, il est nécessaire d'empêcher Rl d'effectuer des requêtes ARP en broadcast, vers d'autres machines. Ces broadcast auraient l'inconvénient de repositionner la véritable adresse ARP

de Rl dans le cache de Rp. Pour ce faire, on remplit le cache ARP de Rl avec l'ensemble des adresses MAC pouvant se trouver sur le réseau. Il est à noter que seul l'ARP cache poisoning de Rp est nécessaire.
Une fois ceci réalisé, l'ensemble des paquets circulant de Paris vers Londres passera par Evil. La deuxième étape consiste à mettre en place un mécanisme de translation d'adresse source (SNAT) sur Evil, de sorte
que les connexions créées vers Paris le soit avec l'adresse source de Londres. Les paquets en retour seront naturellement traités par le processus de SNAT et renvoyés dans la pile IP de Evil.
La dernière étape consiste à utiliser le logiciel client de l'application protégée par le filtrage IP source (telnet, browser, ftp, console d'administration...) afin d'accéder à Paris en se faisant passer pour Londres. Le logiciel client peut être exécuté sur Evil lui-même ou sur Evil2, une machine sous Windows (pour profiter des GUI spécifiques à cet OS) située
dans un réseau juste derrière Evil. Ce concept a été mis en oeuvre sur une plate forme Linux 7.3 de base, équipée de l'outil arp-sk pour opérer l'ARP cache poisoning ainsi que de iptables pour la gestion SNAT. L'outil arp-fillup est utilisé afin de saturer le cache ARP de Rl. L'utilisation de VMWare permet de créer sur Evil une machine Evil2 sous Windows, ainsi que le réseau dédié associé. Cette méthode n'apporte rien de techniquement nouveau. Le spoofing IP était déjà réalisable auparavant. Les risques
pour les systèmes étaient existants. La nouveauté réside ici dans la simplicité de sa mise en oeuvre, dans la souplesse
d'utilisation qui en suit (utilisation d'une simple application cliente, telle un browser), et dans le nombre d'équipements contre qui cette méthode peut être menée. L'utilisation du filtrage IP devient quasiment inutile compte tenu de la facilité de le contourner. Un certain nombre de réflexions s'en suit, pouvant remettre en question quelques certitudes dans le domaine de la sécurité. Notamment la réponse à cette question : Que vaut réellement une règle de filtrage IP source positionnée sur Paris (qu'il soit un firewall, un routeur, une
application...) et n'autorisant que l'adresse IP de Londres ? Globalement, il faut considérer que la règle en question correspond à autoriser toutes les machines des réseaux situés sur le chemin entre Paris et Londres. Ces machines ont en effet la possibilité d'effectuer un ARP cache poisoning de leur Rp, et donc de se faire passer pour Londres. Ce n'est sans doute pas ce que l'on vous avait expliqué lors de votre formation sur la création de règles sur votre firewall. Ceci est d'autant plus inquiétant que les réseaux traversés ne sont pas tous sous votre contrôle (réseau du partenaire, réseau de l'opérateur...) Il est à noter certaines techniques
(par exemple le spoofing DNS) permettent de s'insérer sur un chemin réseau (modification du routage au niveau 3 cette fois ci)

5.1 - Quelques cas de figure
- Votre architecture d'accès à Internet impose le passage par un proxy HTTP incluant des fonctions d'authentification, de filtrage d'URL, de contrôle de contenu, de contrôle antivirus et de traçabilité. Ce proxy est situé sur le réseau interne. Il est le seul à être autorisé à passer le firewall. Pensez-vous encore maintenant que cet investissement en matière de sécurité soit le garant de votre politique de sécurité, alors qu'il est si facile de le contourner ? Il est essentiel de reconsidérer son positionnement dans votre réseau (le placer dans une nouvelle
DMZ par exemple). Le positionnement de telles passerelles ne devrait plus être préconisé sur le réseau interne.
- Le réseau de votre entreprise a été cloisonné pour des raisons de sécurité (présence de serveurs critiques, de bases de données sensibles, interconnexion avec un partenaire, client ou fournisseur...), de performance ou fonctionnelles (réseau de production, réseau de développement). Des routeurs équipés d'ACL "qui vont bien" permettent, selon vous, d'assurer la sécurité car ils contrôlent les flux échangés.
- Les équipements (routeurs, switchs, firewalls, appliance...) de votre réseau sont administrables via telnet et HTTP. Des ACLs limitent l'accès depuis une machine bien précise située dans votre bureau, seule autorisée à s'y connecter. En êtes-vous si sûr ? La récupération des mots de passe d'accès relève de la même technique (ARP cache poisoning). Dès lors, que reste-t-il à votre routeur pour se protéger si à la fois l'authentification et le filtrage IP sont tombés ? - Il en va de même des applications protégées par un TCP Wrapper (SSH, Telnet, FTP...), d'un serveur Web
possédant une arborescence spécifique, accessible uniquement depuis certaines adresses IP, d'un serveur DNS maître, n'autorisant le transfert de zone que depuis un serveur secondaire bien précis, d'un serveur de mail n'autorisant le flux incoming qu'en provenance d'un relais bien précis, du processus d'anti-relaying d'un relais de mails basé sur une résolution inverse de l'adresse IP source. Il doit encore être possible de trouver bon nombre d'autres exemples plus inquiétants les uns que les autres.
6 - Comment se protéger
Le filtrage IP n'a jamais été considéré comme un élément permettant de sécuriser un système. Tout au plus est-il un frein. Ce document a montré que ce frein est en fait virtuel dans bien des situations. Il n'est d'ailleurs jamais (est-ce bien sûr ?) considéré comme unique protection d'accès à un équipement ou une ressource. L'accès nécessite généralement une phase d'authentification (par mot de passe...).
Le problème posé ici est issu de l'aspect non sécurisé de la couche niveau 2 du réseau. Comme celui-ci n'a pas intégré lors de sa conception (RFC 826) de mécanisme d'authentification forte des extrémités, il est nécessaire de remonter cette sécurité dans les couches supérieures. L'authentification forte des extrémités doit donc être effectuée au niveau 3, ou au niveau applicatif. L'utilisation systématique de protocoles comme IPSec, SSL, SSH et plus généralement les VPNs est donc le seul moyen efficace de protection contre le spoofing IP. Par ailleurs, le chiffrement induit par l'utilisation de ces technologies permet de supprimer le problème lié à l'écoute sur le réseau. Encore faut-il que cette
cryptographie soit mise en oeuvre correctement, mais ceci est un autre débat. Par ailleurs, il est également possible de renforcer la sécurité en empêchant l'ARP cache poisoning. Le seul moyen d'y parvenir est de travailler à partir d'un référentiel de ce que devraient être les associations adresses IP/MAC. Il s'agit en général de mesures lourdes à administrer, et dont l'efficacité est toute relative. Elle n'a comme portée que le segment réseau du LAN. Si le paquet a traversé un réseau non maîtrisé, alors rien ne vous prouve qu'il ne provient pas de la machine Evil.
6.1 - Sécurité passive

Il s'agit de mesures visant à empêcher l'ARP cache poisoning, en figeant l'association IP/MAC sur les OS (utilisation des entrées statiques des tables ARP). Ceci est lourd et pratiquement inexploitable à grande échelle. Qui plus est, certains OS gèrent mal ces entrées statiques qui peuvent être alors corrompues. C'est le cas des Windows 9x, NT et 2000 (XP a corrigé le problème). Ces OS sont donc fondamentalement vulnérables à ce type d'attaque et font profiter de leur faiblesse les logiciels (firewall, proxy, serveurs web...) qui leur sont dédiés.
Le verrouillage IP/MAC peut également être pris en charge au niveau applicatif. Par exemple, certains firewalls
(dont iptables) sont capables de contrôler l'association IP/MAC des paquets entrants. L'utilisation de commutateurs de niveau 3, capables de gérer l'association MAC/IP/port est également une solution au problème.
6.2 - Sécurité active
Lorsqu'il n'est pas réaliste de verrouiller les entrées ARP de chaque machine, il est possible de mettre en oeuvre une solution de détection centralisée, qui agit comme une sonde de détection. Certaines sondes sont d'ailleurs capables de détecter des paquets ARP anormaux, susceptibles de signifier un ARP cache poisoning. Cependant, cette attaque étant réalisable avec des paquets normaux, la sonde n'a que peu d'intérêt. L'utilisation de logiciels
comme arpwatch permet de centraliser les associations MAC/IP, et de contrôler en temps réel les messages ARP pour vérifier qu'un poisoning n'est pas en cours. Des alertes sont alors générées en cas de divergence. Il pourrait même être envisagé un système de contre mesure consistant à repositionner la bonne association MAC/IP sur une machine venant de se faire poisoner. Ce repositionnement pourrait s'effectuer par le même processus que celui qui a permis l'attaque : par ARP cache poisoning !
Smurf
1 - Le concept 2 - Le fonctionnement 2.1 - Schéma
2.2 - Envoi 2.3 - Réception sur le réseau cible A 2.4 - Réponse du réseau cible A 3 - Les conseils et astuces
4 - Les liens 5 - Les outils 6 - La conclusion 7 - Discussion autour de la documentation 8 - Suivi du document
1 - Le concept
Le concept est d'émettre une trame de type ICMP à une adresse IP de Broacast réseau. Cela permettant de s'adresser à plusieurs host simultanément appelé « Amplificateur ». Le résultat vous multiplie l'attaque par n fois.
2 - Le fonctionnement
2.1 - Schéma
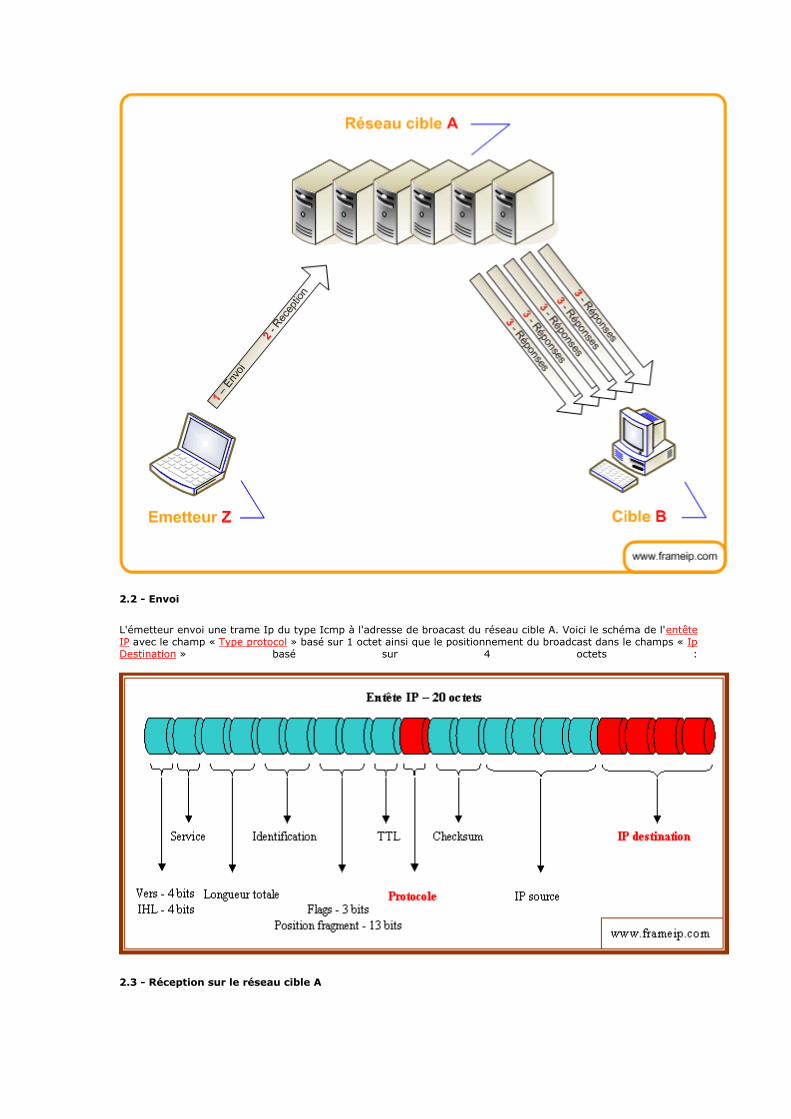
2.2 - Envoi
L'émetteur envoi une trame Ip du type Icmp à l'adresse de broacast du réseau cible A. Voici le schéma de l'entête IP avec le champ « Type protocol » basé sur 1 octet ainsi que le positionnement du broadcast dans le champs « Ip Destination » basé sur 4 octets :
2.3 - Réception sur le réseau cible A
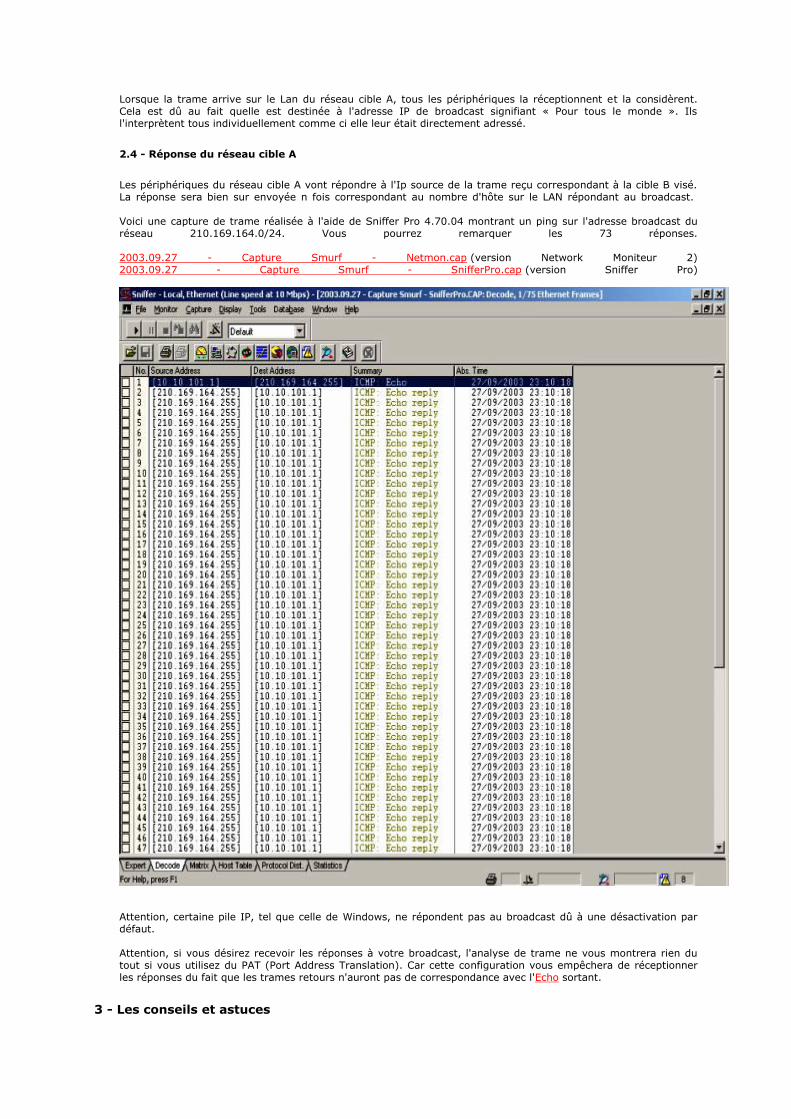
Lorsque la trame arrive sur le Lan du réseau cible A, tous les périphériques la réceptionnent et la considèrent. Cela est dû au fait quelle est destinée à l'adresse IP de broadcast signifiant « Pour tous le monde ». Ils l'interprètent tous individuellement comme ci elle leur était directement adressé.
2.4 - Réponse du réseau cible A
Les périphériques du réseau cible A vont répondre à l'Ip source de la trame reçu correspondant à la cible B visé. La réponse sera bien sur envoyée n fois correspondant au nombre d'hôte sur le LAN répondant au broadcast.
Voici une capture de trame réalisée à l'aide de Sniffer Pro 4.70.04 montrant un ping sur l'adresse broadcast du réseau 210.169.164.0/24. Vous pourrez remarquer les 73 réponses. 2003.09.27 - Capture Smurf - Netmon.cap (version Network Moniteur 2) 2003.09.27 - Capture Smurf - SnifferPro.cap (version Sniffer Pro)
Attention, certaine pile IP, tel que celle de Windows, ne répondent pas au broadcast dû à une désactivation par défaut. Attention, si vous désirez recevoir les réponses à votre broadcast, l'analyse de trame ne vous montrera rien du tout si vous utilisez du PAT (Port Address Translation). Car cette configuration vous empêchera de réceptionner les réponses du fait que les trames retours n'auront pas de correspondance avec l'Echo sortant.
3 - Les conseils et astuces

- Vous pourrez multipliez une attaque si vous visez deux réseaux broadcast IP. Pour cela, vous spécifiez le premier en IP destination et le second en IP source. L'effet sera ravageur. - Vous pouvez utilisez un autre protocole que ICMP comme UDP basé sur le port 7 (echo). Le principe reste le même, sauf que le nom de l'attaque se nomme alors « Fraggle ».
4 - Les liens
- Un article du journal Zdnet
- The White Paper - L'information de « CERT Coordination Center »
5 - Les outils
- 2003.09.27 - Liste des IP - Smurf.xls représente la liste des blocs d'adresses IP ouverts au Smurf. - Pingicmp permet d'envoyer un paquet Icmp très rapidement et bien sûr à des adresses de Broadcast.
- Synflood, permet de générer une attaque basé sur le SYN TCP et bien sur à des adresses de Broadcast. - FrameIP, permet de générer des trames IP et à destination d'un Broadcast, vous ferez ce que vous voulez.
6 - La conclusion
Ce concept permet d'amplifier une attaque et vous aidera à générer le nombre de trame nécessaire à une liaison de type Dial et xDsl.