troisiÈme partie : le cadre mÉthodologique chapitre … · thèse de doctorat/philippe de...
TRANSCRIPT

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 170
TROISIÈME PARTIE : LE CADRE MÉTHODOLOGIQUE
Chapitre 2
L’étude du contenu représentationnel
Dans ce chapitre, nous présentons les méthodes et techniques que nous avons utilisées pour l’étude
du phénomène représentationnel.
1 Le questionnaire d’évocation et l’analyse prototypique et catégorielle
1.1 L’organisation de la représentation
Il existe deux grandes catégories de mesure : les mesures classiques (aussi appelées « explicites »
ou « directes ») et les mesures d’accessibilité (ou encore « implicites » ou « indirectes »). Les
mesures implicites sont destinées à réduire au maximum les effets liés à la désirabilité sociale. Elles
sont basées sur l’accessibilité en mémoire et donc sur le temps de réponse. L’association libre fait
partie des techniques associatives de recueil « indirect » des représentations.
Le principe consiste à demander à un participant de donner par écrit, à partir d’un mot inducteur (la
représentation étudiée), les mots qui lui viennent spontanément à l’esprit. On considère que la
production spontanée de l’individu fait référence à un partage social d’une conception de l’objet et
donc, que cette production correspondrait à une description groupale de l’objet de représentation.
Le principe de l’association libre s’inscrit dans les travaux réalisés sur les associations catégorielles
et le fonctionnement associatif de la mémoire. Inspirée de la psychologie clinique, elle permet de
répertorier les stéréotypes qu’un groupe entretient vis-à-vis d’un autre ou bien d’accéder au contenu
d’une représentation sociale. Les éléments constitutifs des stéréotypes présents en mémoire forment
un réseau. Ainsi, l’activation d’une représentation donnée (« Préhistoire ») modifie l’accessibilité
des éléments qui lui sont associés dans le réseau (activation des éléments « mammouth » et
« homme préhistorique » par exemple).
L’analyse prototypique et catégorielle a pour objectif d’étudier comment s’organisent les
associations libres en différenciant les éléments centraux des éléments périphériques (Vergès, 1992-
1995). On travaille directement à partir des évocations recueillies sans analyse de contenu préalable.
Toutefois, un travail de catégorisation thématique est nécessaire afin de pouvoir regrouper les

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 171
termes sur la base de leur proximité lexicale et sémantique (Flament et Rouquette, 1992 ; Dany,
Urdapilleta et Lo Monaco, 2014).
On procède d’abord à une analyse prototypique qui consiste à croiser rang d’apparition et fréquence
d’apparition. Le croisement de ces deux critères fait apparaître un tableau à 4 cases « rang-
fréquences » (voir tableau 13).
Tableau 13 : rang-fréquences.
Rang moyen faible Rang moyen élevé
Fréquence élevée
Case 1 : Zone du noyau
Case 2 : Zone de changement potentiel
Fréquence basse
Case 3 : Zone de changement potentiel
Case 4 : Périphérie
La case 1 regroupe les éléments les plus saillants et signifiants et contient ceux qui forment le noyau
central de la représentation.
Les cases 2 et 3 contiennent des éléments contradictoires puisque soit la fréquence est importante et
le rang est aussi important, soit c’est l’inverse. Selon Vergès (1994), il s’agit d’une zone
potentiellement déséquilibrante, source de changement possible de la représentation. Les éléments
de la case 2 en particulier (fréquence élevée) peuvent être considérés comme des éléments qui
pourront potentiellement venir fusionner avec ceux de la case 1 (Flament, 1994).
La case 4 comporte des éléments à la fois peu présents et peu importants.
Cette technique part du principe que les idées les plus importantes sont énoncées les premières
(rang d’apparition). L’ordre d’apparition refléterait l’accessibilité des termes, ce qui renseignerait
sur la force des associations de chacun de ceux-ci avec la catégorie proposée : plus un terme
apparaîtrait rapidement dans la liste, plus ce dernier serait fortement associé au label catégoriel du
mot inducteur. Or des études (Jones, 1958 ; Winnick et Kressel, 1965) ont montré que les idées
importantes apparaissent souvent dans un deuxième temps. Pour pallier ce problème, Abric (2003)
propose de remplacer le rang d’apparition par le rang d’importance : on demande aux personnes
interrogées de hiérarchiser en classant elles-mêmes leur production en fonction du poids qu’elles
accordent à chaque terme pour définir l’objet de la représentation. Le croisement de la fréquence
des évocations (critère quantitatif) et de leur rang d’importance (critère qualitatif) constitue un
indicateur de la centralité, de la nécessité des éléments produits. Le croisement des deux critères
(fréquence et importance) permet de produire un tableau à quatre cases « importance-fréquences »
qui correspond aux quatre zones de la représentation (voir tableau 14).

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 172
Tableau 14 : importance-fréquences.
Rang moyen faible Rang moyen élevé Fréquence élevée
Case 1 : Zone du noyau
Case 2 : 1ère périphérie
Fréquence basse
Case 3 : Éléments contrastés
Case 4 : 2ème périphérie
La case 1 contient les éléments potentiellement centraux de la RS sur la base de leur fréquence et de
leur importance. Certains éléments présents dans cette case peuvent ne pas faire partie du noyau
central, mais les éléments qui constituent le système central sont présents.
La case 2 regroupe les éléments périphériques les plus importants mais peu fréquents.
La case 3 constitue la zone des éléments contrastés. Selon Abric, cela peut révéler l’existence d’un
sous-groupe minoritaire dont les éléments du noyau se trouveraient dans cette case. Ce peut aussi
être un complément de la première périphérie.
Enfin, la case 4 contient les éléments rares et avec une moindre importance, c’est la 2e périphérie.
Une comparaison des deux tableaux (Dany et al., 2014) a révélé que les cases 1 et 4 restent assez
bien circonscrites : les éléments les plus saillants en case 1 et les moins saillants en case 4. Par
contre, selon la méthode utilisée, le statut des éléments de la case 2 diffère. L’utilisation conjointe
des deux techniques semble des plus intéressantes car « tous ces éléments montrent qu’entre la
déclaration spontanée des termes et leur classement, nous assistons à une modification des
représentations » (Ibid., p.20) qui agit aussi bien sur la zone du noyau comme sur les zones
périphériques.
En effet, dans le cas de la technique « rang-fréquence », c’est le consensus qui fait apparaître tel ou
tel terme à tel emplacement. Dans le cas de la technique « importance-fréquence », on peut
considérer que le critère devient plus qualitatif car il est le résultat d’un choix ordinal a posteriori
des personnes interrogées. Or ce qui importe pour déterminer si un élément est central ou pas c’est
son caractère non négociable, c’est-à-dire une caractéristique plutôt qualitative. À ce sujet, Moliner
(1994) propose de distinguer la centralité qualitative qui correspondrait au caractère symbolique de
l’élément (i.e., son caractère non négociable dans l’attribution de sens à l’objet), de la centralité
quantitative qui renverrait à la saillance de l’élément qui serait toutefois moins décisif en termes
d’allocation de signification concernant l’objet sous étude. La technique importance-fréquence
permet donc de recueillir un contenu qui n’est pas seulement le résultat d’une récupération
mnésique, mais bien celui d’une attribution de sens (Dany, id.).

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 173
Le point faible de la technique importance-fréquence reste le problème de la désirabilité sociale qui
fait qu’un groupe peut être amené à répondre d’une façon plutôt qu’une autre. On sait que les élèves
(Gilly, 1974, 1980 ; Elbers, 1986 ; Grossen, 1986 ; Schubaueur-Leoni, 1986 ; Ecalle, 1998) sont
particulièrement sensibles aux situations de communication avec l’adulte (le rôle de l’enseignant,
ses attentes à leur égard) et que leurs représentations à ce sujet déterminent la façon dont ils vont
eux-mêmes se comporter.
Il apparaît donc utile, sinon indispensable, de combiner les deux techniques pour identifier les
éléments qui vont changer de ceux qui vont perdurer, ceux qui vont muter d’une case à l’autre.
Sachant que les éléments du noyau sont ceux qui sont les plus stables (Abric, 1993, 2001 ; Voir
Rateau et Lo Monaco, 2013 ; Rateau, Moliner, Guimelli et Abric, 2011 pour une revue), une
comparaison des résultats des deux techniques appliquées au même corpus produit par les mêmes
participants permet d’identifier ces éléments. Cette information, ajoutée à celle fournie par l’analyse
prototypique classique, permet de mieux préciser les hypothèses concernant les éléments qui ont
une forte probabilité de constituer le système central de la représentation.
Enfin, rappelons que ces deux techniques ne permettent pas de déterminer formellement les
éléments du noyau mais seulement un repérage. Il faudrait pour cela compléter l’analyse avec le
modèle des schèmes cognitifs de base (SCB), la technique de mise en cause (MEC) ou le test
d’indépendance au contexte (TIC ) sachant que les deux premiers sont impossibles à mettre en
œuvre auprès d’enfants.
1.2 Le traitement des données
1.2.1 Le traitement prototypique
L’ensemble des mots produit par les élèves de chaque classe interrogée a été enregistré au sein d’un
fichier « brut » Excel dans lequel nous avons fait apparaître en colonne nos variables et en ligne nos
observations (élèves) et à l’intersection les données sous une forme textuelle : chaque mot choisi
par les élèves.
La saisie doit respecter certains impératifs : un trait d’union entre les mots composés pour qu’ils
soient considérés comme un seul terme, le remplacement des mots de deux lettres par des
équivalents car le programme ne sait pas traiter les termes très courts, la suppression des accents et

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 174
de la ponctuation. Le fichier Excel est transformé en fichier « csv » puis importé dans le programme
Evoc 20001 conçu par Vergès2 (comme le montre la figure 23).
Figure 23 : fichier « csv ».
Une fonction « nettoie » (voir figure 24) permet d’afficher l’ensemble des évocations et de procéder
à des corrections orthographiques. Il est aussi possible de supprimer certaines données comme les
« hors sujets » pour qu’elles ne soient pas prises en compte dans l’analyse. En ce qui nous concerne,
nous avons privilégié un nettoyage direct dans les fichiers bruts « Excel » et « csv » pour éviter la
multiplication des manipulations déjà très nombreuses et disposer de fichiers de travail à jour
uniques.
1 Le programme Windows (Delphi) a été réalisé par Stéphane Scano et par Christian Junique (MMSH, Université d’Aix en Provence). 2 Toutes les données des analyses Evoc figurent dans l’annexe 17 (DVD).

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 175
Figure 24 : interface « NETTOIE » d’Evoc 2000.
Le logiciel calcul pour chaque mot la fréquence (la quantité) et le rang (ordre d’apparition). La
fonction « RANGMOT » permet d’obtenir après traitement, un listing de la distribution des rangs
pour tous les mots. Cette distribution suit une loi logarithmique (loi de ZIPFF). Elle permet
d’identifier trois zones de fréquences : celle où les mots sont très peu nombreux, celle où les mots
sont peu nombreux pour une même fréquence et la zone où le nombre de mots est très important
pour une même fréquence. Tandis que le rang moyen est calculé automatiquement par le
programme, c’est au chercheur de choisir une fréquence minimale qui corresponde au seuil à partir
duquel un mot est considéré comme fréquent. Il doit aussi définir une fréquence moyenne : ce seuil
va déterminer la position des évocations dans un tableau à 4 cases en fonction du rapport rang-
fréquence (« RANGFRQ »). La distribution des rangs peut lui fournir des indications et l’aider à
choisir (voir figure 25).

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 176
Figure 25 : interface « RANGFRQ » d’Evoc 2000.
Enfin, la fonction « AIDECAT » permet d’identifier les mots qui apparaissent ensemble
(cooccurrence) et ceux qui apparaissent avant un autre (préférence). Selon Vergès, « la forte
cooccurrence peut vouloir dire deux choses : soit elle montre que deux mots font partie de la même
catégorie, soit elle indique l’existence d’une relation entre deux catégories associées à des
dimensions différentes de l’objet évoqué »3.
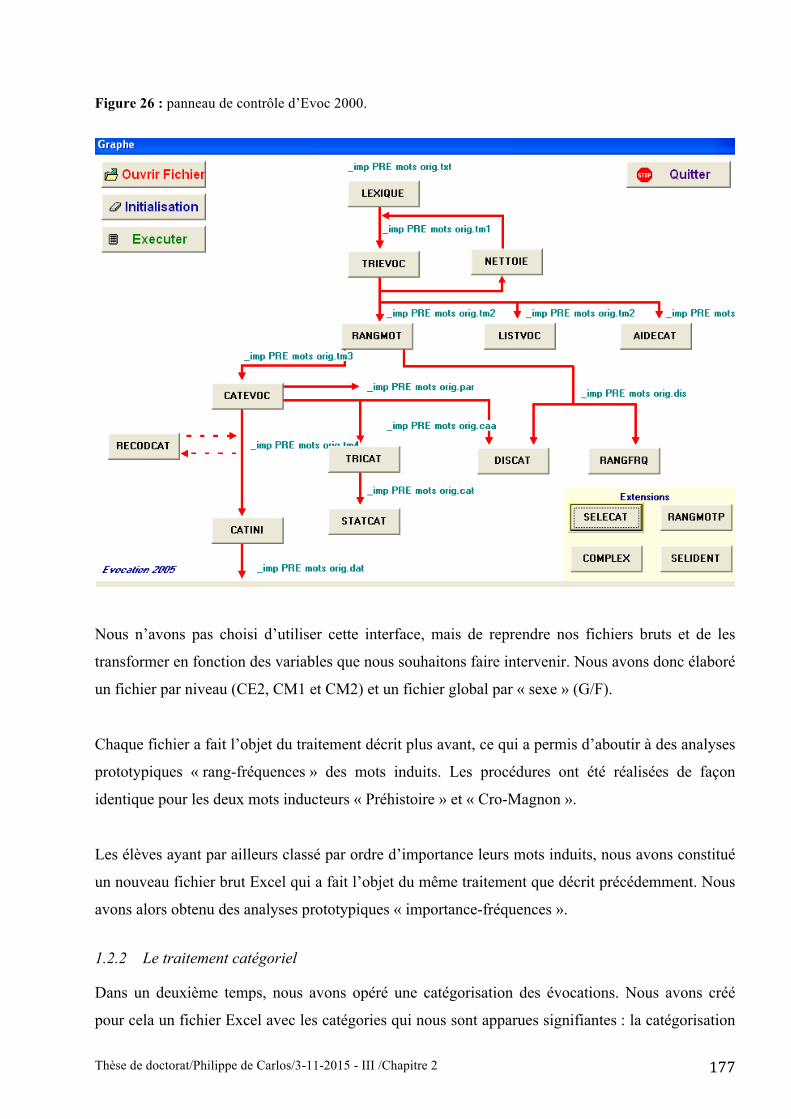
L’interface du programme Evoc 2000 permet également des analyses en fonction des variables. Il
faut pour cela à l’aide du bouton « SELECAT » associer un code à une variable puis opérer avec le
bouton « COMPLEX » (voir figure 26) au croisement entre deux variables. Il n’est pas possible de
croiser plus de deux variables.
3 Manuel Evoc 2005, version 06/2006 : paragraphe 7.4. (P. Vergès).
Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 177
Figure 26 : panneau de contrôle d’Evoc 2000.
Nous n’avons pas choisi d’utiliser cette interface, mais de reprendre nos fichiers bruts et de les
transformer en fonction des variables que nous souhaitons faire intervenir. Nous avons donc élaboré
un fichier par niveau (CE2, CM1 et CM2) et un fichier global par « sexe » (G/F).
Chaque fichier a fait l’objet du traitement décrit plus avant, ce qui a permis d’aboutir à des analyses
prototypiques « rang-fréquences » des mots induits. Les procédures ont été réalisées de façon
identique pour les deux mots inducteurs « Préhistoire » et « Cro-Magnon ».
Les élèves ayant par ailleurs classé par ordre d’importance leurs mots induits, nous avons constitué
un nouveau fichier brut Excel qui a fait l’objet du même traitement que décrit précédemment. Nous
avons alors obtenu des analyses prototypiques « importance-fréquences ».
1.2.2 Le traitement catégoriel
Dans un deuxième temps, nous avons opéré une catégorisation des évocations. Nous avons créé
pour cela un fichier Excel avec les catégories qui nous sont apparues signifiantes : la catégorisation

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 178
obéit à une logique interprétative des items avec un regroupement forcé sur une base sémantique.
L’intérêt de cette méthode est de pouvoir disposer d’une double lecture des mêmes données brutes
en conservant une proximité avec le corpus d’origine. En effet, les termes inducteurs renvoient à
des notions très diverses avec des mots qui peuvent, tout en ayant été cités que très rarement,
recouvrir un même champ sémantique. Alors que dans l’analyse prototypique, nous n’avions pris en
compte qu’une partie des données (seuils de fréquences), le regroupement catégoriel à l’avantage de
prendre en compte la quasi totalité des évocations. Il permet aussi de faire apparaître des relations
significatives là où des évocations isolées n’auraient pu le faire dans le cadre d’une analyse
prototypique.
Les données des fichiers bruts de chaque mot inducteur ont donc été transformées en fichiers
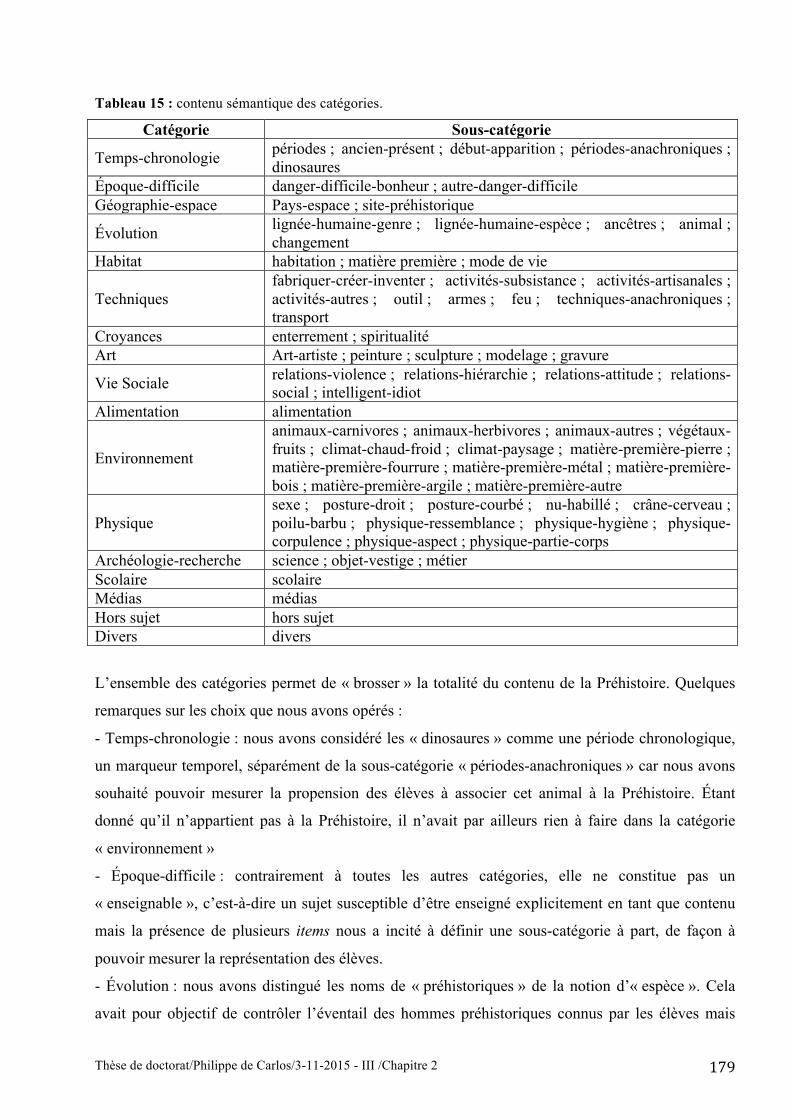
catégoriels. Toutes les évocations ont été redistribuées au sein de 17 catégories (voir tableau 15) :
temps-chronologie ; époque-difficile ; géographie-espace ; évolution ; habitat ; techniques ;
croyances ; art ; vie sociale ; alimentation ; environnement ; physique ; archéologie ; recherche ;
scolaire ; médias ; hors sujet ; divers. Les deux dernières catégories, qui ne concernent qu’un
nombre infime des évocations, ont systématiquement été supprimées pour ne pas générer de biais
dans les analyses.
Sur l’ensemble des 17 catégories retenues et en fonction du seuil de fréquences minimal, 15
catégories ont été retenues pour les 1178 évocations (dont 300 types4) de « Préhistoire » et 14 pour
les 957 évocations (dont 283 types) de « Cro-Magnon ». La répartition des items dans les
différentes catégories est présentée en détail en annexe (voir annexes 7 et 8).
À l’origine, nous avions divisé chaque catégorie en sous-catégories (tableau 15) de façon à procéder
à des analyses thématiques plus fines mais la complexité des traitements et des interprétations entre
niveau prototypique, niveau sous-catégoriel et niveau catégoriel nous a obligé à simplifier notre
approche dans le cadre de l’analyse d’évocation hiérarchisée. Nous sommes toutefois convaincus
qu’une telle démarche demande à être explorée. Ce travail à toutefois permis de définir de façon
précise chaque catégorie et donc d’opérer une redistribution le plus objectivement possible et
similaire des évocations des deux corpus « Préhistoire » et « Cro-Magnon » en vue d’une
comparaison. Elle permettra également de se référer d’un point de vue qualitatif au contenu des
évocations et donc de préciser les résultats.
4 Un mot unique.
Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 179
Tableau 15 : contenu sémantique des catégories.
Catégorie Sous-catégorie
Temps-chronologie périodes ; ancien-présent ; début-apparition ; périodes-anachroniques ; dinosaures
Époque-difficile danger-difficile-bonheur ; autre-danger-difficile Géographie-espace Pays-espace ; site-préhistorique
Évolution lignée-humaine-genre ; lignée-humaine-espèce ; ancêtres ; animal ; changement
Habitat habitation ; matière première ; mode de vie
Techniques fabriquer-créer-inventer ; activités-subsistance ; activités-artisanales ; activités-autres ; outil ; armes ; feu ; techniques-anachroniques ; transport
Croyances enterrement ; spiritualité Art Art-artiste ; peinture ; sculpture ; modelage ; gravure
Vie Sociale relations-violence ; relations-hiérarchie ; relations-attitude ; relations-social ; intelligent-idiot
Alimentation alimentation
Environnement
animaux-carnivores ; animaux-herbivores ; animaux-autres ; végétaux-fruits ; climat-chaud-froid ; climat-paysage ; matière-première-pierre ; matière-première-fourrure ; matière-première-métal ; matière-première-bois ; matière-première-argile ; matière-première-autre
Physique sexe ; posture-droit ; posture-courbé ; nu-habillé ; crâne-cerveau ; poilu-barbu ; physique-ressemblance ; physique-hygiène ; physique-corpulence ; physique-aspect ; physique-partie-corps
Archéologie-recherche science ; objet-vestige ; métier Scolaire scolaire Médias médias Hors sujet hors sujet Divers divers
L’ensemble des catégories permet de « brosser » la totalité du contenu de la Préhistoire. Quelques
remarques sur les choix que nous avons opérés :
- Temps-chronologie : nous avons considéré les « dinosaures » comme une période chronologique,
un marqueur temporel, séparément de la sous-catégorie « périodes-anachroniques » car nous avons
souhaité pouvoir mesurer la propension des élèves à associer cet animal à la Préhistoire. Étant
donné qu’il n’appartient pas à la Préhistoire, il n’avait par ailleurs rien à faire dans la catégorie
« environnement »
- Époque-difficile : contrairement à toutes les autres catégories, elle ne constitue pas un
« enseignable », c’est-à-dire un sujet susceptible d’être enseigné explicitement en tant que contenu
mais la présence de plusieurs items nous a incité à définir une sous-catégorie à part, de façon à
pouvoir mesurer la représentation des élèves.
- Évolution : nous avons distingué les noms de « préhistoriques » de la notion d’« espèce ». Cela
avait pour objectif de contrôler l’éventail des hommes préhistoriques connus par les élèves mais

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 180
aussi leur capacité à mentionner le concept censé les réunir. La sous-catégorie « ancêtres » réunit
tous les termes qui relient la notion d’« homme » à celle de « passé » (ex : « avant-dernier-homme »
ou « prédécesseur »). C’est à ce titre que le terme « homme-préhistorique » a été classé dans cette
sous-catégorie.
- Habitat : il nous a paru intéressant de distinguer les différents modes de vie des « nomades » et des
« sédentaires » puisqu’il s’agit là d’un concept structurant pour différencier les deux époques de la
préhistoire « Paléolithique « et « Néolithique ». Les deux modes de vie devraient se retrouver dans
les évocations de « Préhistoire » alors que c’est surtout celui lié aux nomades qui devrait apparaître
plus saillant dans les évocations de « Cro-Magnon ». Il en est de même pour les types d’habitations.
Ces données pouvent être confrontées.
- Croyances : nous savons à cause des études qui ont été réalisées (Semonsut, 2009) et par notre
expérience du terrain que la question des croyances est peu abordée à l’école. Cette catégorie doit
permettre d’évaluer le poids des évocations liées à ce thème.
- Art : nous avons souhaité contrôler si les élèves ont une représentation de base de l’art
préhistorique, c’est-à-dire essentiellement construite autour d’un terme prototypique « art » ou s’ils
envisagent les créations d’un point de vue différentiel qui ne se résume pas non plus à la peinture.
- Vie sociale : de même que l’époque-difficile, ce thème n’est pas susceptible de faire l’objet d’une
forte transmission de la part de l’enseignant d’autant qu’il est presque totalement absent de manuels
scolaires.
- Environnement : c’est la catégorie qui regroupe le plus de sous-catégories. Elle réunit à la fois les
items liés au climat, à la faune, à la flore et aux matières premières susceptibles d’être présentes
et/ou utilisées. L’environnement est un sujet complexe difficile à aborder pour l’enseignant.
- Physique : il s’agit de tout ce qui touche à la représentation physique des préhistoriques et de Cro-
Magnon en particulier. On s’attend à avoir plus d’évocations pour cette catégorie dans les
évocations de « Cro-Magnon ».
- Archéologie-Recherche : cette catégorie permet d’envisager si la Préhistoire est reliée à la
question de la recherche et de la science chez les élèves. Il s’agit par ailleurs d’un contenu
d’enseignement dans le cadre de la Préhistoire.
- Scolaire : il s’agit des termes qui renvoient au domaine scolaire « élève », « école »… Ces termes
sont marginaux, mais reflètent une représentation de la Préhistoire du point de vue du métier de
l’élève, c’est pourquoi nous avons décidé de les traiter.
Des termes comme « électricité » ou « sport » ont été mis dans la catégorie « hors sujet » et d’autres
comme « fatiguer » dans la catégorie « divers » car nous ne savions pas quoi en faire. Ces
catégories n’ont pas été prises en compte dans les analyses. Elles sont très marginales.

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 181
Chaque catégorie (à part «époque-difficile ») est susceptible d’être un thème enseigné à l’école dans
le cadre du cours de préhistoire. Une analyse quantitative des catégories permettra de disposer du
poids de chacune d’entre elles et de comparer les proportions obtenues avec celles des manuels
scolaires.
Le cumul des analyses parallèles prototypiques et catégorielles a enfin donné la possibilité de
vérifier la question des enchaînements élément central versus élément périphérique au sein d’un
même fichier et entre les fichiers « prototypiques » et « catégoriels ».
2 Le questionnaire de caractérisation et l’analyse de similitudes (l’arbre
maximum)5
L’analyse de similitudes formalisée par Flament en 1962 a pour objectif d’identifier les liens
qu’entretiennent les éléments entre eux puisqu’au sein d’une RS les éléments sont considérés
comme liés les uns aux autres. Elle met donc en correspondance la théorie des graphes et la théorie
des représentations sociales et permet une représentation topographique et relationnelle sous la
forme d’arbres de similitude. Elle fait partie de l’analyse structurale puisqu’elle met en relief les
relations fortes entre éléments sur des critères de proximité et de distance.
« On admet que deux items seront d’autant plus proches dans la représentation, qu’un nombre
d’autant plus élevé de sujets les traite de la même façon (soit les acceptent tous les deux, soit les
rejettent tous les deux) » (Flament, 1986).
Parmi les techniques existantes pour le recueil de l’information, nous avons opté pour celle des
choix successifs par blocs. Elle est particulièrement simple à mettre en œuvre, en particulier auprès
d’enfants de cycle 3 et offre la possibilité d’une analyse relativement fine et aisée à réaliser.
Le questionnaire dit de caractérisation est composé d’une liste d’items divisibles par le nombre
d’items à retenir successivement. Les élèves ont été invités à lire et/ou à regarder les items, à
sélectionner ceux qui correspondaient le plus à l’objet de représentation, puis parmi les items restant
ceux qui correspondaient le moins. Les enfants ont chaque fois reporté le numéro des items dans des
cases vierges.
La liste d’items a varié selon le thème de 9 (climat, action et attitude) à 12 (objet et environnement).
Si le nombre de départ est 9, on a les 3 items les plus caractéristiques, les 3 items les moins
caractéristiques et les 3 items non choisis, soit 3 blocs de 3 items. Chaque item est codé selon trois
5 Toutes les données des analyses liées aux questionnaires de caractérisations figurent dans l’annexe 18 (DVD).

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 182
modalités de 1 à 3 : 1 s’il a été considéré comme non caractéristique, 2 s’il n’a pas été choisi et 3
s’il a été choisi comme caractéristique,
« Ce processus repose sur un modèle statistique équiprobable : la probabilité d’être codé 1 (ou 2 ou
3) est de 0,33. On se trouve donc devant ce que l’on peut appeler un Q-sort rectangulaire. Il diffère
du Q-sort classique qui veut se rapprocher d’une loi de gauss en constituant trois groupes inégaux
d’items privilégiant la classe centrale (...) En effet, ce qui nous intéresse c’est une distribution
dissymétrique qui privilégie la dimension « caractéristique » ou « non-caractéristique ». (Pierre
Vergès, 2002, p.539)
Dans ce modèle, trois notions sont importantes :
- L’indice de similitude : il permet d’évaluer l’intensité d’une relation à travers un coefficient de
corrélation.
- La matrice de similitude : elle comprend l’ensemble des valeurs de similitude obtenue pour tous
les couples d’éléments.
- L’arbre maximum : un graphe constitué d’un ensemble minimum de relations considérées comme
les plus importantes. C’est un arbre connexe, valué et sans cycle (il ne se ferme pas) (Degenne et
Vergès, 1973, p. 472-473 ; Moliner, et al., 2002, p. 147). Cette dernière propriété est quelquefois
difficile à respecter.
Grâce à l’analyse de similitudes, il est donc possible de construire un graphe, appelé « arbre
maximum », composé de relations qui relient deux à deux les éléments d’un système afin de mettre
en évidence la proximité ou l’antagonisme de ces éléments. Quand deux arêtes de même valeur sont
reliées à un même item, il est délicat de choisir laquelle supprimer ; il faut alors essayer les
variantes possibles et décider laquelle semble la plus pertinente. L’arbre se construit en partant des
items qui présentent les indices les plus élevés. Les graphes peuvent être composés d’une seule
chaîne ou bien être séparés. Certaines valeurs qui relient deux items peuvent être négatives et ainsi
caractériser une opposition marquée. En plus de l’indice de distance, la moyenne attribuée à chaque
item permet aussi de situer celui-ci en fonction de son importance (de « caractéristique » à « non
caractéristique »). Le modèle postule que les éléments de cet « arbre maximum » appartiennent au
noyau de la représentation dès lors qu’ils sont reliés à au moins trois autres items de cet arbre
(Rouquette et Rateau, 1998 ; Aïssani, 1991 6 ). Selon Bonadi et Roussiau (2014), il serait
envisageable, sans que cela ait été pour le moment validé empiriquement d’observer une graduation
6 Selon la proposition d’Aïssani (1991), une évocation peut être considérée comme importante si elle est reliée à au moins trois autres items, qui plus est s’ils sont localisés dans l’arbre « maximum » de similitude en début de chaîne.

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 183
dans l’organisation de la représentation sur la base des coefficients de similitudes, ce à quoi nous
nous attacherons.
Toutefois l’analyse de similitudes ne permet pas de contrôler la centralité des éléments mis en
avant. En effet, les éléments centraux correspondent parfois au sommet de « l’arbre maximum » de
similitudes mais ce n’est pas toujours le cas, c’est pourquoi il est indispensable de compléter cette
approche par des analyses complémentaires.
Toutes nos matrices de similitudes ont été créées à partir de « macros » Excel fournies par le
Laboratoire de Psychologie Sociale EA849 d’Aix-Marseille.
3 Les courbes de fréquences
Selon la théorie des graphes7, il est non seulement possible comme nous l’avons vu, de réaliser pour
chaque thématique un arbre maximum, mais aussi de classer chaque item de chaque thématique sur
une échelle de trois degrés (plus caractéristique, non choisis et moins caractéristique) et de réaliser à
partir de cette échelle une courbe caractéristique de sa position dans l’organisation structurale de la
représentation (Vergès, 2001). Un élément ayant une courbe en J8 aura de fortes probabilités
d’appartenir à la zone du noyau. La courbe en ∩9 (« cloche ») indique que les éléments ont une
relation périphérique avec l’objet de représentation et la courbe en ∪10 (« u ») pourrait signifier
l’appartenance à une zone contrastée avec éventuellement l’existence de sous-groupes. Nous
ajoutons une quatrième et une cinquième genre, les courbes quasi J et quasi ∩. Pour les courbes
quasi J, nous reprenons la formule de Konstantinos Grivopoulos (2014) : « les items concernés,
inclinant plutôt vers le statut central, sont ceux pour lesquels la différence entre les scores du « non
choisi » et du « moins caractéristique » (notés nc et mc), ∆ (nc-mc), est supérieure à la différence
entre les « caractéristiques » et « non choisi » : ∆ (nc-mc) > ∆ (pc-nc)11 ». Pour les courbes quasi ∩,
nous avons appliqué le même raisonnement et créé un critère identique : les items concernés sont
ceux dont les scores du « non choisi » et du « moins caractéristique » sont inférieurs à la différence
entre les « caractéristiques » et « non choisi ».
En appliquant cette procédure à chaque élément d’une thématique, il est possible d’obtenir des
informations microscopiques et de les comparer aux résultats macroscopiques des analyses
7 Théorie définie par Koening, 1925 et introduite en France par Berge, 1970. 8 Le score de la modalité « caractéristique » est supérieur à celui de la modalité « non choisi » qui à son tour est supérieur au score du « moins caractéristique ». 9 De type gaussien, le score de la modalité « non choisi » est supérieur aux autres. 10 Le résultat de la modalité « non choisi » est le plus faible des trois modalités. Cette courbe témoigne d’une dichotomie de la population à l’égard de l’item concerné, donc d’une dissonance à l’égard de sa centralité. 11 Pour une démonstration de cette condition, cf. annexe 9.

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 184
factorielles et des arbres maximum tout en ayant une vision générale inter-thématiques ce qui
permet de dégager une représentation globale de la Préhistoire.
4 L’analyse de classification hiérarchique (le dendrogramme)
À partir des données issues des questionnaires de caractérisations, nous avons procédé à la
construction de dendrogrammes basés sur la méthode de Ward, c’est-à-dire une variance minimum
à l’intérieur de chaque groupe.
Cette technique fait partie des procédures de classification utilisées notamment par les biologistes
pour organiser le vivant. Elle consiste à classer les éléments par un système d’inclusions
successives, en fonction de leurs liens de distance respective.
Il s’agit en règle générale de calculer la distance euclidienne, c’est-à-dire géométriques normales
entre les éléments dans l’espace en calculant la somme des différences au carré des indices
correspondant pour chaque paire d’items. On constitue sur cette base une matrice. À partir de cette
matrice, on effectue des regroupements d’items en fonction de leur distance respective. Le résultat
correspond à un arbre ou dendrogramme.
Le dendrogramme est un diagramme qui permet d’illustrer l’arrangement des groupes générés par le
regroupement hiérarchique agglomératif. Le groupement (« clustering ») est une analyse
multidimensionnelle dont l’objectif est de partitionner un ensemble d’objets et de les reclasser de
façon ascendante (du plus fin au moins fin) de sorte que chaque objet n’appartienne qu’à un groupe
et que ces groupes s’excluent mutuellement. Chaque nœud correspond à une valeur égale à la
distance entre les deux éléments qu’il réunit. Grâce aux nœuds, on connaît le niveau de
rapprochement entre ces classes.
Un dendrogramme fournit donc une classification des éléments lorsque l’on se donne une « hauteur
de coupe » de l’arbre. Plus l’arbre est coupé « bas » (proche des éléments initiaux) plus la
classification obtenue est fine (moins de perte d’inertie interclasse).
L’intérêt comparatif entre les arbres et les dendrogrammes réside dans leur complémentarité. En
effet, l’indice de distance utilisé par l’analyse de similitudes est une fonction inverse (correction de
-1) de la distance euclidienne utilisée par la méthode de Ward qui aboutit à un indice qui varie dans
l’intervalle [-1; 1]. Les résultats similaires sont donc le fait d’un calcul tout à fait comparable, mais
juste inversé pour générer un pôle négatif et rendre visibles les arêtes négatives qui aboutissent à la
formation des sous-graphes dans l’analyse de similitudes tandis que dans le dendrogramme certains
éléments seront agrégés alors qu’ils n’étaient pas proches « physiquement » dans l’arbre maximum.
Le dendrogramme permet d’éclairer les positions des éléments au sein de la structure de la

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 185
représentation mais aussi de confirmer ou pas la stabilité des classes par comparaison avec les
résultats des analyses factorielles et de similitudes.
L’ACH (Analyse de Classification Hiérarchique) « permet de repérer des groupements d’opinions
que l’on peut interpréter en référence à la notion de champ proposée par l’approche
sociogénétique » (Moliner et Guimelli, 2015).
Pour effectuer ces opérations, nous avons utilisé le logiciel « Statistica » fourni par le Laboratoire
de Psychologie Sociale EA849 d’Aix-Marseille.
5 L’analyse factorielle des correspondances
Ce type d’analyse a été mis en œuvre par Lo Monaco qui a démontré dans son étude sur le vin tout
l’intérêt que l’on pouvait en tirer. L’AFC est une méthode multidimensionnelle qui permet :
− De repérer à la fois les similitudes mais aussi les oppositions entre les modalités ; elle vise la
mise en évidence d’associations en termes de fréquence en fonction de variables indépendantes.
Elle révèle des correspondances entre les modalités des variables indépendantes et les modalités
des observations.
− D’accéder à un résumé des données : elle facilite l’extraction d’une structure particulière d’un
ensemble de données qui restitue l’essentiel de l’information tout en réduisant la masse de ces
données.
− L’identification des axes factoriels les plus significatifs (constitués par les modalités des
variables indépendantes mobilisées)
« L’utilisation de l’AFC dans le cadre des données issues de la technique de caractérisation présente
l’avantage de faire apparaître dans le plan (représentation géométrique) à quelles modalités de
variables se trouve le plus fortement associée telle ou telle modalité de réponse à propos de tel ou
tel item » (Lo Monaco, 2008). Parmi les deux facteurs, le facteur 1 est celui qui explique le
maximum d’informations. Il est généralement placé sur l’axe des abscisses et répartit les données
expliquées de part et d’autre du point d’origine. Le facteur 2 explique une autre partie de
l’information répartie sur l’axe des ordonnées. Généralement, les deux facteurs n’expliquent pas la
totalité de l’information. Cette façon de procéder autorise la mise en évidence d’ancrages sociaux et
à partir de quelles variables s’opèrent ces ancrages (Lo Monaco, 2008)
La structure des écarts à l’indépendance est mesurée par le calcul de la contribution au Chi2. Le test
du Chi2 est une mesure des écarts entre des fréquences observées et des fréquences théoriques et
doit déterminer si cette différence est due au hasard (hypothèse nulle) ou pas. G. Mialaret (1991)
indique qu’une des restrictions principales à l’utilisation de la technique de calcul du Chi2 est liée à

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 186
l’effectif minimum. En principe, dans un tableau de contingence, chaque case des effectifs
théoriques doit avoir un effectif supérieur ou égal à cinq. En effet, le test interprète de façon
significative, alors que cela ne l’est pas, le choix qui peut être fait par une minorité de sujets (moins
de 5). C’est pourquoi, nous avons procédé à un nettoyage des données en supprimant dans les
tableaux de contingence celles dont les effectifs étaient inférieurs à 5.
Pour réaliser ces opérations, nous avons utilisé le logiciel Statistica. Nous sommes partis d’un
fichier Excel dans lequel nous avons fait apparaître en colonne nos variables indépendantes et
dépendantes et en ligne nos observations (élèves) et à l’intersection l’effectif sous la forme d’une
donnée numérique : le choix (1 ou 2 ou 3) réalisé dans le cadre du questionnaire de caractérisation.
Comme le calcul du Chi2 est réalisé sur la base d’une table de contingence, nous avons transformé
notre fichier de données brutes en une table de fréquences (contingence) appelée table de Burt.
C’est à partir de cette table de Burt que nous avons ensuite effectué notre analyse factorielle des
correspondances. À l’issue de cette analyse, nous avons obtenu deux tableaux avec les coordonnées
et les contributions à l’inertie pour les lignes et pour les colonnes puisque cette méthode calcule les
coordonnées (les vecteurs propres) de chaque modalité des lignes et de chaque modalité des
colonnes pour chaque dimension du tableau que l’on appelle les axes factoriels. Pour sélectionner
les modalités et les observations en fonction de l’importance de leur contribution à la constitution
des dimensions (axes), il faut définir une valeur qui permet de définir si telle observation ou
modalité contribue de manière signifiante. Selon Deschamps (2003), une observation ou modalité
contribue à un facteur si elle présente une contribution par facteur supérieur à la contribution par
facteur moyen. Comme dans le programme Statistica, 100 % est égal à 1, on divise donc 1 par le
nombre de modalités pour les variables et par le nombre de « mots » pour les observations : par
exemple, 1/5 (variables) et 1/36 (observations) pour le fichier « AFC nourriture ». Sur la base des
modalités et des observations retenues, on construit alors un nuage de points que l’on transforme
graphiquement en carte AFC. Le pourcentage d’inertie est la part de l’information représentée par
chaque axe. Plus la valeur est importante, plus elle rend compte du pouvoir explicatif de l’axe. Pour
l’analyse AFC de « nourriture », nous avons un pourcentage cumulé des deux principaux axes de
92,09 %. Notre nuage de points est donc expliqué à 92,09 % par ces deux axes, ce qui est très élevé.
6 L’analyse des variations significatives (chi2)
Le test de Chi2 est un test statistique qui permet de se prononcer sur le lien entre deux variables
qualitatives, autrement dit si elles ont, une relation statistique entre elles. Toutes nos analyses ont
été réalisées sur le site : http://www.aly-abbara.com/utilitaires/statistiques/chi_carre.html

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 187
Dans le cadre des analyses que nous avons réalisées, nous avons retenu trois seuils significatifs :
• Chi2 avec p < 0,05* soit 99,5 % de chances de ne pas se tromper ou bien 0,5 % de chance de se
tromper.
• Chi2 avec p < 0,01** soit 99,99 % de chances de ne pas se tromper ou bien 0,01 % de chance
de se tromper.
• Chi2 avec p < 0,001*** soit 99,999 % de chances de ne pas se tromper ou bien 0,001 % de
chance de se tromper.
Plus p (p-value) est petit, plus la variation est significative. Par convention, on accepte l’hypothèse
de dépendance (d’un lien significatif entre les variables) lorsque l'on a au maximum 5 % de chance
de se tromper.
Les résultats sont notés de la façon suivante : Chi2 = ***7,812 ; ddl 2 ; p < 0,001 soit Chi2 =
résultat du chi carré ; nombre de lignes x nombre de colonnes (ddl) ; alpha probabilité ou p-value
(p).
Lorsque nous comparons plusieurs niveaux de classes, nous indiquons pour quel niveau la variable
n’est pas significative en associant le niveau au résultat, par exemple : « les CE2 et les CM1 citent
plus fréquemment la toundra printemps en tant que les CM2 « non-caractéristique (CE2/Chi2 =
3,578; ddl 2 ; p<0,05 et CM1/Chi2 = 3,8; ddl 2 ; p<0,05) ».
7 Le questionnaire classique
7.1 Les types d’analyses
Le questionnaire classique n’est pas conçu, comme les questionnaires d’évocation ou de
caractérisation, pour identifier structuralement les éléments d’une représentation. Toutefois son
intérêt est fondamental, car il permet d’apporter des informations sur ces représentations en
résonance avec celles qui seront produites par les questionnaires d’évocation et de caractérisation ce
qui, en plus de les compléter, autorisera des comparaisons. Par rapport aux questionnaires
d’évocation et de caractérisation, le questionnaire classique (voir tableau 16) apporte une plus-value
notable du point de vue de la taille de l’échantillon, de la répartition géographique, du type de
pédagogie et des périodes de passations.

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 188
Tableau 16 : comparaisons des corpus.
Questionnaire classique Questionnaires d’évocation et de caractérisation
- 725 élèves ; 35 classes ; 20 écoles - 319 élèves ; 13 classes ; 7 écoles
- Élèves de province, de banlieue parisienne et de Paris des XIVe, XVe, XVIIIe et XIXe arrondissements
- Élèves de Paris des XIe, XIIe et IVe arrondissements
- Différents types de pédagogies : Éducation nationale, Decroly, Freinet, Montessori, Émilie Brandt et Éducation Nouvelle
- Uniquement de l’Éducation nationale
- Une passation en 2004-2006 - Une passation en 2012-2013
- Une passation en 2012-2013
- Une triple passation pour les CE2 - Une passation unique en fin d‘année scolaire
Le questionnaire classique permet donc :
-‐ Une analyse plus fine sur la base de variables comme : le sexe, le niveau scolaire (l’âge/la
connaissance) et la catégorie socioprofessionnelle des parents.
-‐ Une analyse comparative sur la base de la variable « type de pédagogie ».
-‐ Une analyse diachronique concernant les élèves de CE2 qui ont été interrogés trois fois.
L’ensemble des analyses est opéré à partir du logiciel « Sphinx Lexica »12. Il s’agit d’un logiciel
destiné à l’analyse de contenu et à l’analyse lexicale. Il permet de saisir, dépouiller et explorer les
données enregistrées tout en intégrant des techniques d’analyse multidimensionnelle (analyse
factorielle, typologie, etc.) de fichiers contenant des nombres et/ou des textes. La version « Lexica »
offre des fonctionnalités qui autorisent le traitement des questions ouvertes.
L’utilisation du logiciel Sphinx implique la mise en œuvre automatique de tests statistiques adaptés
au type de données analysées (voir tableau 17). La population est analysée à travers différents types
de données (numérique, nominale et texte) au niveau des individus et au niveau des strates (une
strate est un ensemble d’individus regroupés selon un ou plusieurs critères : par exemple, les
garçons et les CE2). Les analyses sont univariées (description d’une variable à la fois), bivariées
(mise en relations de deux variables) ou multi variées (analyses simultanée de plusieurs variables).
Le tableau 2 ci-dessous indique les méthodes utilisées en fonction des types de données pour les
questions fermées (ou ouvertes lorsqu’elles ont été recodées) :
12 Toutes les données des analyses Sphinx figurent dans l’annexe 10 (DVD).

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 189
Tableau 17 : la nature des données analysées détermine la méthode.
Manuel Sphinx 2006, p.209
Le logiciel calcule automatiquement les Chi2 et réalise les AFC (analyse bi variée). Pour le Chi2, il
précise le niveau de dépendance (Non Significatif, Significatif, Très Significatif), indique la valeur,
la « ddl » et la « p-value » tout en alertant si certains effectifs théoriques venaient à être inférieurs à
5. Pour les variables numériques, Sphinx calcule le coefficient de corrélation (r). « Le coefficient de
corrélation (r) établit la qualité de l’ajustement entre deux variables V1 et V2. Sa valeur absolue (ou
r2) est comprise entre 0 et 1 » (Manuel Sphinx 2006, p. 212). Nous avons considéré qu’il existait
une bonne relation entre les variables lorsque le coefficient est supérieur à 0,8. Lorsqu’il s’agit de
traiter des données à la fois numériques et nominales, nous avons procédé à des analyses de la
variance. Le test de Fisher est utilisé pour les analyses de la variance multiple (Manova) : deux
variables nominales et une numérique. Le programme permet aussi de réaliser à partir de nos
tableaux croisés ou des moyennes des AFC et des ACP. Toutes les questions fermées ont fait l’objet
d’un recodage. Nous avons défini pour chaque modalité une valeur numérique et établis ainsi un
barème entre 0 et 1. La valeur est attribuée en fonction de la « bonne réponse » attendue13. On
13 Voir le fichier Sphinx : annexe 10.

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 190
obtient ainsi pour chaque question un score. L’analyse de scoring offre la possibilité de comparer
les résultats des élèves, mais aussi entre les différentes passations pour les CE2. Les tableaux de
résultats à plat produits par Sphinx font l’objet d’une mesure de cohérence interne par
l’intermédiaire du coefficient alpha de Cronbach. Nous avons considéré que l’alpha était significatif
à partir de 0,6 et très significatif à partir de 0,8.
En ce qui concerne les questions ouvertes, nous avons procédé à deux types de recodages :
- Certaines questions fermées pouvaient être complétées par une question ouverte. Les réponses ont
été recodées en « bonne » ou « mauvaise » réponse de façon à pouvoir établir des moyennes et
produire une analyse de scoring.
- Le deuxième type de traitement a consisté à définir dans des dictionnaires (un dictionnaire par
question ouverte) l’ensemble des termes que nous souhaitions récupérer à l’intérieur du corpus
produit par les élèves. Par exemple pour la question 70 du questionnaire standard qui porte sur le
Néolithique, nous avons défini des catégories autour de termes principaux : le mot « agriculture »
est la catégorie qui comprend le terme « agriculture » mais aussi « cultiver », « champ », etc. Cette
méthode permet de faire ressortir les termes significatifs. Les résultats offrent un éclairage qualitatif
complémentaire de ceux produits par les autres analyses.
Enfin, le contenu a été analysé sous la forme d’arbres de décision14. Chaque branche de l’arbre
correspond à une population et à une modalité de réponse : l’ensemble de la population va être
réparti en deux branches selon la réponse fournie à une question (bonne ou mauvaise). Le nœud de
séparation correspond au profil qui sert à décomposer la population : ceux qui ont donné la bonne
réponse et ceux qui ont donné la mauvaise. Il est ensuite possible à partir de chaque branche
d’établir un second nœud et donc de créer deux autres branches en introduisant une seconde
question. Chaque branche donne le pourcentage de la population précédente qui a répondu à l’une
ou l’autre modalité du profil (bonne ou mauvaise réponse). On sait donc combien d’élèves (sur la
population totale) ont donné la bonne réponse à la définition du mot « sédentaire » et combien
parmi ceux-là ont su, par exemple, choisir dans un dessin les bonnes maisons de sédentaires. Le
croisement de plusieurs questions sur une même thématique permet de vérifier la cohérence des
réponses fournies. Chaque thème fait l’objet d’un nombre important de questions réparties dans des
thèmes. Les questions, qui sont posées à des moments différents, se croisent pour se compléter ou
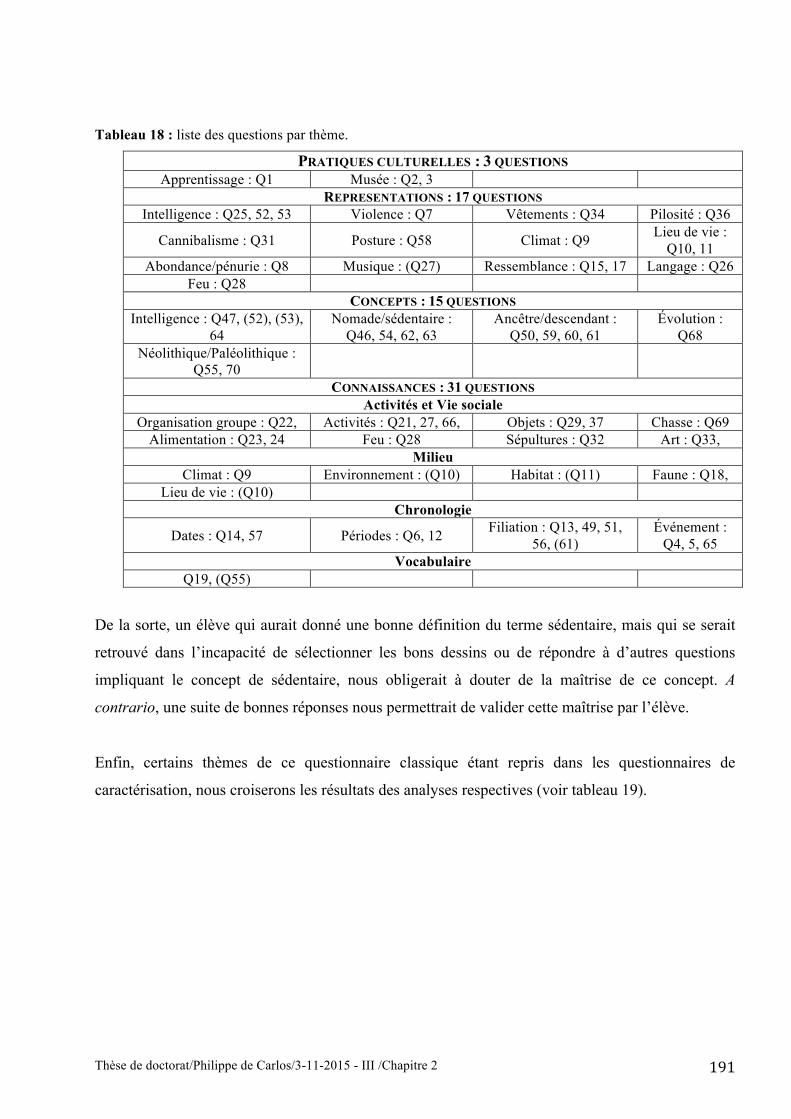
vérifier la cohérence des réponses fournies (voir tableau 18) comme c’est le cas pour
nomade/sédentaire (Q46, 54, 62 et 63), chronologie (Q14, 57 et 65), néolithique (Q55 et 70) et
ancêtre/descendant (Q50, 59, 60 et 61). 14 Annexes 12 à 15.
Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 191
Tableau 18 : liste des questions par thème.
PRATIQUES CULTURELLES : 3 QUESTIONS Apprentissage : Q1 Musée : Q2, 3
REPRESENTATIONS : 17 QUESTIONS Intelligence : Q25, 52, 53 Violence : Q7 Vêtements : Q34 Pilosité : Q36
Cannibalisme : Q31 Posture : Q58 Climat : Q9 Lieu de vie : Q10, 11
Abondance/pénurie : Q8 Musique : (Q27) Ressemblance : Q15, 17 Langage : Q26 Feu : Q28
CONCEPTS : 15 QUESTIONS Intelligence : Q47, (52), (53),
64 Nomade/sédentaire :
Q46, 54, 62, 63 Ancêtre/descendant :
Q50, 59, 60, 61 Évolution :
Q68 Néolithique/Paléolithique :
Q55, 70
CONNAISSANCES : 31 QUESTIONS Activités et Vie sociale
Organisation groupe : Q22, Activités : Q21, 27, 66, Objets : Q29, 37 Chasse : Q69 Alimentation : Q23, 24 Feu : Q28 Sépultures : Q32 Art : Q33,
Milieu Climat : Q9 Environnement : (Q10) Habitat : (Q11) Faune : Q18,
Lieu de vie : (Q10) Chronologie
Dates : Q14, 57 Périodes : Q6, 12 Filiation : Q13, 49, 51, 56, (61)
Événement : Q4, 5, 65
Vocabulaire Q19, (Q55)
De la sorte, un élève qui aurait donné une bonne définition du terme sédentaire, mais qui se serait
retrouvé dans l’incapacité de sélectionner les bons dessins ou de répondre à d’autres questions
impliquant le concept de sédentaire, nous obligerait à douter de la maîtrise de ce concept. A
contrario, une suite de bonnes réponses nous permettrait de valider cette maîtrise par l’élève.
Enfin, certains thèmes de ce questionnaire classique étant repris dans les questionnaires de
caractérisation, nous croiserons les résultats des analyses respectives (voir tableau 19).

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 192
Tableau 19 : croisements entre le questionnaire classique et les questionnaires de caractérisation.
Questionnaires de caractérisation
Attitude
Questionnaire classique
Questionnaires de caractérisation
Animaux
Questionnaire classique
items questions items questions 1 Q58 1 Q69 2 Q36 2 Q69 3 Q7 3 (Q18) 4 Q25 4 (Q18) 6 Q34 5 Q69 (Q18) 7 Q25 6 (Q18) 8 Q7 7 (Q18) 9 Q34 8 Q69
11 Q17 9 Q69 12 Q58 10 (Q18)
11 (Q69) 12 Q69 (Q18)
Questionnaires de caractérisation
Action
Questionnaire classique
Questionnaires de caractérisation
Climat
Questionnaire classique
items questions items questions 1 Q21 2 Q10 2 Q21 3 Q10 5 Q21 4 Q10 9 Q21 5 Q10 6 Q10 8 Q10 9 Q10
7.2 Les variables Sphinx
Dans le cadre des analyses Sphinx, nous avons utilisé plusieurs variables :
− Des variables « brutes » : le sexe (garçon ou fille), le niveau (CE2, CM1, CM2), la CSP
(supérieure, moyenne, inférieure), le type de pédagogie (Éducation nationale ou pédagogies
différentes), la géographie (Paris, banlieue, province), la classe, l’école. Ces variables sont
directement issues des données recueillies.
− Des variables « reconstruites » : nous avons recodé certaines informations et construit des
variables complémentaires.
• L’établissement (regroupement de plusieurs classes au sein d’une école).
• Les contenus (voir tableau 2) : les concepts (regroupement des questions qui traitent de
concepts comme « nomade » ou « évolution »), les représentations (regroupement des
questions qui sont plus orientées vers l’imaginaire comme la pilosité des préhistoriques),
les connaissances (regroupement des questions qui traitent de connaissances comme

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 193
situer un hominidé sur une frise du temps). Les connaissances ont elles-mêmes été
subdivisées en quatre sous-variables : les activités et la vie sociale, le milieu, la
chronologie et le vocabulaire. La Préhistoire est vaste et le questionnaire prend en
compte la variété des contenus qui la constituent. Il s’agit dès lors d’opérer une analyse
qui permette de rendre compte de cette diversité et de vérifier si les résultats peuvent
différer selon le type de contenu.
• La méthode : les questions ont été regroupées en 10 types : les QCM simples, les QCM à
double niveau, les QCM avec une question ouverte, les questions ouvertes, les dessins à
choisir, les dessins à relier, les textes à relier, les tableaux à double entrée et les frises.
Nous avons souhaité tester l’influence des types de questions sur les résultats des élèves
pour déterminer s’il existe un biais.
Les variables « sexe et classe » sont aussi utilisées dans les analyses d’évocations hiérarchisées et
de similitudes. Elles permettront de comparer les résultats issus des différentes techniques. Dans
certains cas, la variable géographie a été réduite à deux ensembles, Paris et Province, car les
établissements situés en banlieue sont exclusivement des établissements issus des pédagogies
différentes. Cela pourrait constituer un biais. Il y a eu aussi du sens à réunir Paris et sa banlieue
proche. Du point de vue des types de pédagogies, nous avons considéré que l’Éducation nationale
constituait un tout assez homogène même si nous n’ignorons pas que cette homogénéité n’est pas
synonyme de similarité. Sous le vocable de pédagogies différentes, nous avons rassemblé des
classes issues d’écoles différentes, la différence s’exprimant par rapport à l’Éducation nationale à
travers l’usage de pédagogies spécifiques. Pour compenser une lecture globale du point de vue
géographique ou du type de pédagogie, nous avons utilisé une variable classe/école destinée à faire
apparaître les particularités qui pourraient exister au sein d’une même zone géographique ou au sein
d’une pédagogie.
8 Conclusion du chapitre
Il faut rappeler que les trois techniques que nous avons mis en œuvre (sphinx, évocation,
caractérisation) ne permettent pas de déterminer formellement les éléments du noyau mais
seulement un repérage et une organisation. Il faudrait pour cela compléter l’analyse avec le modèle
des schèmes cognitifs de base (SCB), la technique de mise en cause (MEC) ou le test
d’indépendance au contexte (TIC) sachant que les deux premiers sont impossibles à mettre en

Thèse de doctorat/Philippe de Carlos/3-11-2015 - III /Chapitre 2 194
œuvre auprès d’enfants. Toutes ces techniques sont adaptées aux élèves du collège et du lycée mais
pas aux élèves du primaire. Cela revient-il pour autant à faire le deuil de l’identification du noyau
central ? En fait, c’est la pluri-méthodologie et la triangulation (Apostolidis, 2003) qui va permettre
de déterminer la structure de la représentation et s’approcher de la structuration du système central.
École Decroly CM1