thˆse la phonologie des emprunts fran§ais non-anglicis©s en
TRANSCRIPT

U N I V E R S I T E P A R I S I V - S O R B O N N E
ÉCOLE DOCTORALE 5
(N° d’enregistrement attribué par la bibliothèque)
THÈSE pour l’obtention du grade de
DOCTEUR DE L’UNIVERSITÉ PARIS IV
La phonologie des emprunts français non-anglicisés
en anglais
Discipline : Linguistique
Présentée et soutenue publiquement par
Julie Quinio
Le 12 février 2009
Directeur de thèse : Michel Viel
_________________________________________
JURY
M. Dominique BELLION (Université Blaise Pascal, Clermont-Ferrand)
M. Jean BREUILLARD (Université Paris-Sorbonne)
M. Kevin MENDOUSSE (Université d’Auckland, Nouvelle-Zélande)
M. Michel VIEL (Université Paris-Sorbonne)


Remerciements
Je tiens à remercier tout particulièrement Michel Viel pour m’avoir guidée et avoir su
insuffler l’énergie nécessaire aux bons moments, Richard Lilly pour m’avoir donné confiance
et motivation tout au long de ce travail, ainsi que tous les membres de ma famille pour leur
soutien sans faille.


5
Sommaire
Introduction ............................................................................................................................... 9
1ère partie : Corpus et Base de données
I. Le corpus : les critères de sélection ..................................................................................... 19
A. Pourquoi un corpus ? .................................................................................................... 20
B. Les corpus disponibles.................................................................................................. 21
C. Trouver une méthode de sélection................................................................................ 24
D. Recherche des critères de sélection .............................................................................. 27
E. Le vocabulaire de l’emprunt ......................................................................................... 36
F. Limitation du corpus ..................................................................................................... 50
II. La sélection du corpus ........................................................................................................ 55
A. Travailler avec l’Oxford English Dictionary................................................................ 56
B. Application du critère orthographique.......................................................................... 59
C. Prononciation des emprunts.......................................................................................... 65
III. La base de données............................................................................................................ 85
A. Intérêt d’une base de données....................................................................................... 86
B. Les données .................................................................................................................. 86
C. Lecture des dictionnaires .............................................................................................. 94
D. Finalisation ................................................................................................................. 101
2ème partie : Suppression des variantes anglicisées
IV. Les suppressions.............................................................................................................. 105
A. Affiner la base de données ......................................................................................... 105
B. La méthode ................................................................................................................. 106

6 Sommaire
V. Etude de cas : niveau accentuel ........................................................................................ 111
A. Noms dissyllabiques accentués en finale ................................................................... 111
B. Noms dissyllabiques du type adjoint ou brassard ..................................................... 113
C. Verbes accentués 1 en finale....................................................................................... 114
D. Trissyllabes du type caramel...................................................................................... 117
E. Les emprunts qui héritent leur accent ......................................................................... 119
F. Mots composés et expressions .................................................................................... 120
VI. Etude de cas : niveau segmental...................................................................................... 125
A. Cas liés à la réduction vocalique ................................................................................ 105
B. Cas liés à la relation graphie-phonie........................................................................... 157
C. Cas liés aux règles de tension ..................................................................................... 173
D. Autres cas ................................................................................................................... 183
VII. Cas divers....................................................................................................................... 194
A. Quelques cas particuliers............................................................................................ 195
B. Des absents du corpus................................................................................................. 211
VIII. Correction du corpus .................................................................................................... 219
A. OED 3......................................................................................................................... 220
B. Adaptation ou adoption ?............................................................................................ 221
C. Les ajouts au corpus.................................................................................................... 224
D. Les suppressions du corpus ........................................................................................ 226
E. Les faiblesses de l’OED.............................................................................................. 230
IX. Les suppressions : conclusion ......................................................................................... 245
A. Base de Données Finale.............................................................................................. 245
B. Validation des critères de sélection ............................................................................ 246
C. Les emprunts anglicisés.............................................................................................. 246

Sommaire 7
3ème partie : Les emprunts non-anglicisés
X. Analyse des emprunts non-anglicisés............................................................................... 251
A. Comparaison des systèmes ......................................................................................... 254
B. Adaptation des phonèmes du français ........................................................................ 259
C. Adaptation des voyelles nasales ................................................................................. 327
XI. Vers une compréhension des emprunts non-anglicisés................................................... 351
A. Les marques de francité.............................................................................................. 352
B. Quelques cas particuliers ............................................................................................ 369
C. Quelques pistes de réflexion....................................................................................... 376
Conclusion............................................................................................................................. 385
Bibliographie ......................................................................................................................... 393
Annexes (Cédérom)
Base de Données Initiale
Base de Données Comparative
Base de Données Finale
Lexique Initial
Lexique Final


9
INTRODUCTION
En 1948, J. Orr commence une conférence radiophonique intitulée « L’empreinte du
français sur l’anglais »1 par cette remarque :
Tout Français qui se met à l’étude de l’anglais se trouve immédiatement en
pays de connaissance ; à chaque instant, il rencontre des mots qui lui sont
familiers, mots qui sont, en réalité, d’anciens émigrés, établis outre-Manche et
devenus d’authentiques citoyens anglais. (Orr, 241)
C’est cette même réflexion qui nous a guidée vers la présente étude. En effet, les
locuteurs francophones remarquent régulièrement certains mots ou expressions employés par
les anglophones, comme déjà-vu, cul-de-sac, filet mignon, espionage, souvenir : ils
reconnaissent des mots français, bien que ceux-ci ne soient pas prononcés exactement de la
même manière.
Nombreux sont les mots français qui ont été empruntés par la langue anglaise depuis
l’arrivée de Guillaume le Conquérant et de la noblesse normande au 11ème siècle. Pourtant,
beaucoup d’entre eux ne sont aujourd’hui plus identifiés par les locuteurs francophones. Quel
français reconnaîtra un mot de sa langue parmi les exemples suivants : chair, furniture,
damage, attorney ? En y regardant de plus près, on remarque évidemment la ressemblance
entre chaise et chair, entre fourniture et furniture ; mais pour beaucoup il ne s’agit que d’une
pure coïncidence.
Quelle différence y a-t-il alors entre les emprunts reconnus par les francophones et les
autres ? On observe que la forme graphique des emprunts identifiés par les francophones est
identique — ou presque — à celle des mêmes mots dans la langue française, tandis que les
autres ont une graphie différente. Cependant, les mots table, crime ou conscience font
1 Orr, John. « L’empreinte du français sur l’anglais. » Le Français Moderne 16 (1948): 241-247.

10 Introduction
également partie de la catégorie des emprunts qui ne sont plus identifiés par les francophones,
alors que leur graphie est identique à celle du français.
La véritable différence se situe donc au niveau de la prononciation. Les emprunts qui
sont identifiés par les francophones le sont parce que leur prononciation reste assez proche de
celle du français. Proche, mais pas identique. Les autres mots sont, pour des francophones,
prononcés ‘à l’anglaise’, c’est pourquoi on ne les remarque plus.
Nous touchons là au sujet même de notre étude. Nous souhaitons nous pencher sur
cette catégorie d’emprunts dont la prononciation reste particulière, car elle n’est ni totalement
‘anglaise’, ni vraiment étrangère. Les emprunts qui ne sont plus identifiés comme français
étant considérés comme ‘anglicisés’, les emprunts auxquels nous nous intéressons sont donc
phonologiquement ‘non-anglicisés’.
Nous nous sommes intéressée à ce sujet pour deux raisons. La première est qu’il réunit
deux langues que nous chérissons. En tant qu’angliciste, le travail sur les emprunts nous
attirait car il permettait de découvrir comment les apports étrangers sont traités par l’anglais.
En tant que francophone, nous étions curieuse et intriguée par ces mots que l’anglais avait
empruntés à la langue française et souhaitions comprendre quel statut ils avaient au sein de
cette langue.
La seconde raison est qu’alors que de nombreux linguistes ont commenté l’influence
des emprunts français sur la langue anglaise, il n’existe aucune étude approfondie de la
phonologie des emprunts français non-anglicisés. Le thème de la prononciation des emprunts
français est souvent abordé, mais il est en général rapidement traité, comme si les
informations étaient connues de tous et qu’il ne s’agissait que d’un rappel. Par exemple, Otto
Jespersen, dans le chapitre de son ouvrage Growth and Structure of the English Language2
2 Jespersen, Otto. Growth and Structure of the English Language. 1905. Stuttgart : Teubner Verlag, 1935. 9ème
éd. Oxford : Basil Blackwell, 1967.

Introduction 11
dédié aux apports du français, consacre seulement deux pages à l’influence du français sur la
phonologie anglaise, et une page à la prononciation de certains emprunts ‘récents’, sur les
vingt-sept pages que compte ce chapitre. De même P. Fijn van Draat, dans son article
« Aliens. Influx of French Words into English »3, résume en trois pages la phonologie des
emprunts français, comme s’il n’y avait guère plus à en dire.
L’intérêt de ce sujet réside donc dans l’étude exclusive et approfondie de la
phonologie des emprunts français. Il paraît nécessaire d’aller plus loin que ce qui a été fait
jusqu’à présent afin de comprendre ce qui différencie les emprunts non-anglicisés de ceux qui
se fondent aujourd’hui dans le vocable anglais sans qu’aucun locuteur autre que les
spécialistes puisse dire de quelle langue ils sont originaires, mais également de comprendre
quel est le statut particulier de ces mots qui puisse expliquer qu’ils soient traités à part au sein
de la langue anglaise. De manière plus générale, ce sujet permet également d’approfondir la
connaissance de la phonologie de l’anglais, ainsi que d’enrichir les recherches dans le
domaine du contact de langues.
En effet, l’emprunt symbolise la rencontre de deux langues, donc de deux systèmes
phonologiques, souvent différents ; son étude est de ce fait particulièrement importante pour
la linguistique car elle permet d’observer et de comprendre ce qui se passe quand deux
langues sont confrontées. Cet intérêt se situe aussi bien au niveau phonologique, grammatical
que sociologique et historique car un emprunt n’est pas le fruit du hasard : il se produit à un
moment donné, dans un milieu donné. Il représente en fait la rencontre de deux peuples, deux
cultures.
L’emprunt n’est d’ailleurs pas forcément lié à l’admiration d’un peuple pour un autre ;
on observe par exemple que la Guerre de Cent ans fut une période remarquable d’échanges
entre le français et l’anglais. De même, lorsque l’aristocratie anglaise parlait français, mais
3 Draat, P. Fijn van. « Aliens : Influx of French Words into English. » Englische Studien 72 (1938) : 321-342.

12 Introduction
que la majorité de la population s’exprimait en anglais, c’est le besoin de communication
entre ces deux mondes — par le biais des domestiques, par exemple — qui a donné lieu à des
échanges de vocables. Il est d’ailleurs fort probable que le dialecte français parlé par la
noblesse était mâtiné d’anglais, comme le laisse entendre Albert C. Baugh dans son ouvrage
A History of the English Language4 (Baugh, 123).
Certains linguistes tentent d’expliquer le phénomène de l’emprunt par la nécessité,
lorsqu’une notion est absente de la langue emprunteuse, ou par l’effet de mode, lorsque la
langue empruntée acquiert une certaine renommée. Mais nous voyons dans les exemples
précédents, par ailleurs illustratifs de la relation particulière entre ces deux langues, qu’il peut
être simplement le résultat d’un échange linguistique. Aucune langue n’étant dépourvue
d’emprunt, comme l’explique Louis Deroy dans l’Emprunt linguistique5 (Deroy, 7), il ne faut
peut-être y voir qu’un autre moyen d’enrichir le vocabulaire d’une langue, aux côtés de la
formation, de la dérivation, ou du néologisme.
Mais au fond, qu’entendons-nous exactement par ‘emprunt’ ? Il convient en effet de
définir précisément le terme, car tous les linguistes ne lui donnent pas le même sens. Par
exemple, certains linguistes en ont une vision assez restrictive, comme en témoignent cette
citation de Josette Rey-Debove et ce commentaire, tirés de l’article de John Humbley « Vers
une typologie de l’emprunt linguistique » 6 :
« L’emprunt lexical au sens strict du terme est le processus par lequel une
langue L1 dont le lexique est fini et déterminé dans l’instant T, acquiert un mot
M2 (expression et contenu) qu’elle n’avait pas et qui appartient au lexique
d’une Langue L2 (également fixe et déterminé). » […] Cette définition 4 Baugh, Albert C. and Thomas Cable. A History of the English Language. 1951. 5ème éd. London : Routledge,
2002.
5 Deroy, Louis. L’Emprunt linguistique. 1956. 2ème éd. Paris : Les Belles Lettres, 1980.
6 Humbley, John. « Vers une typologie de l’emprunt linguistique. » Cahiers de lexicologie 25/2 (1974) : 46-70.

Introduction 13
volontairement restrictive n’englobe pas l’emprunt du contenu sans l’emprunt
de l’expression (l’emprunt sémantique), ni le cas où l’expression est transférée
sans le contenu ou avec un contenu modifié. (Humbley, 52)
De même, Armand Boileau, cité par Andrée Tabouret-Keller dans son article « La
motivation des emprunts »7, considère qu’ « un vrai mot d’emprunt n’est plus considéré
comme un intrus » (Tabouret-Keller, 26), ce qui signifie qu’il ne considère comme emprunts
que les mots qui ne sont plus identifiés comme étant d’origine étrangère.
A l’inverse, Jean-Marc Chadelat, dans son ouvrage Valeur et fonctions des mots
français en anglais à l’époque contemporaine8, explique que « tous les mots anglais d’origine
française ne sont pas des emprunts français en anglais. […] L’anglais compte
approximativement 85% de termes d’origine française ou latine qui sont assimilés et dont
l’origine étrangère n’est souvent même pas perçue par les locuteurs » (Chadelat, 20). Selon
lui, seuls sont emprunts français les mots identifiés comme tels par les locuteurs anglophones.
Nous préférons au contraire observer l’emprunt dans son ensemble et en avoir une
vision très large, c’est pourquoi nous nous rapprochons de la définition générale proposée par
Haugen dans son article « The analysis of linguistic borrowing »9 :
The attempted reproduction in one language of patterns previously found in
another. (Haugen, 212)
Dans le cadre de notre étude, la définition qui correspond le mieux à notre point de vue
est celle proposée par Mossé dans son article « On the Chronology of French Loan-
Words »10 :
7 Tabouret-Keller, Andrée. « La Motivation des emprunts : un exemple pris sur le vif de l’apparition d’un sabir. »
La Linguistique I, (1969): 25-61.
8 Chadelat, Jean-Marc. Valeur et fonctions des mots français en anglais à l’époque contemporaine. Paris :
L’Harmattan, 2000.
9 Haugen, Einar. « The analysis of linguistic borrowing. » Language 26 (1950) : 210-231.

14 Introduction
A French loan-word is a word which whatever may be its etymology or
ultimate origin has been immediately borrowed from the French. (Mossé, 35)
Dans cette étude, nous limitons notre recherche aux mots empruntés par l’anglais
britannique au français parlé en France, en raison des relations historiques particulières entre
ces deux langues et ces deux pays, que nous avons déjà soulignées à plusieurs reprises. Nous
n’avons pas souhaité inclure l’anglais américain à notre étude, non seulement parce que sa
phonologie est un peu différente de celle de l’anglais britannique, mais aussi parce que
l’influence du français sur ce dialecte est sans doute diverse : par le biais de l’anglais
britannique d’une part, par le français de France d’autre part, mais également par le français
canadien, puisque Canada et États-Unis sont limitrophes. De même, dans l’anglais
britannique, nous limitons notre étude à l’anglais standard ou RP, même s’il nous arrive de
mentionner des phénomènes linguistiques associés à d’autres dialectes de l’anglais.
Nous présentons notre étude en trois grandes parties. La première est consacrée à la
sélection d’un corpus et l’élaboration d’une base de données d’emprunts français non-
anglicisés. Nous y détaillons la recherche d’une méthodologie de sélection des emprunts, ce
qui occasionne des discussions sur les termes employés dans le domaine de l’emprunt.
Dans la deuxième partie, nous procédons à l’affinage de la base de données, en
supprimant les variantes anglicisées. Ce travail nous amène à de nombreuse discussions sur la
phonologie de l’anglais afin de répondre à cette simple question : qu’est-ce qu’une variante
anglicisée ?
Enfin, la troisième et dernière partie présente l’analyse de la base de données finale,
composée uniquement de variantes non-anglicisées. Nous y présentons l’adaptation des
10 Mossé, Fernand. « On the Chronology of French Loan-Words in English. » English Studies XXV (1943) : 33-
40.

Introduction 15
phonèmes français en anglais et les principales caractéristiques des emprunts français non-
anglicisés.


1ère partie :
Corpus et base de données


19
I. LE CORPUS : LES CRITERES DE SELECTION
Table des matières
A. Pourquoi un corpus ? .......................................................................................................... 20
B. Les corpus disponibles........................................................................................................ 21
C. Trouver une méthode de sélection...................................................................................... 24
D. Recherche des critères de sélection .................................................................................... 27
1. Les méthodes de nos prédecesseurs .............................................................................. 27
2. Le choix d’une méthode ................................................................................................ 34
E. Le vocabulaire de l’emprunt ............................................................................................... 36
1. ‘Assimilé’, ‘inassimilé’ et ‘assimilation’ ...................................................................... 36
2. ‘Naturalisé’ et ‘anglicisé’ .............................................................................................. 38
3. Mot étranger et ‘xénisme’ ............................................................................................. 40
4. Pérégrinisme.................................................................................................................. 43
5. Les mots étiquetés ‘inassimilés’ dans l’OED................................................................ 47
F. Limitation du corpus ........................................................................................................... 50
1. Délimitation temporelle de l’étude................................................................................ 51
2. Le critère orthographique .............................................................................................. 52
3. Rappel des critères de sélection..................................................................................... 54

20 Le corpus : les critères de sélection
A. POURQUOI UN CORPUS ?
Tout travail d’analyse linguistique doit se baser sur un corpus. La première étape
consiste donc à rechercher un corpus qui va servir à l’analyse phonologique des emprunts
français en anglais. Deux possibilités s’offrent alors à nous : reprendre un corpus déjà existant
ou bien en construire un nouveau ; la contrainte étant que ce corpus doit contenir
essentiellement, sinon exclusivement, des emprunts non-anglicisés, c'est-à-dire ne suivant pas
les règles phonologiques de l’anglais.
Avant de rechercher si un corpus existant peut convenir à notre étude, il convient de
définir précisément l’objet de cette étude. Nous utilisons les termes ‘non-anglicisé’ ou
‘inassimilé’ par opposition aux termes ‘anglicisé’ ou ‘assimilé’ qui qualifient des emprunts
qui se fondent totalement dans la langue anglaise. Mais ces termes manquent de clarté.
Il n’existe pas de non-assimilation phonologique totale ; le locuteur adapte toujours
plus ou moins le nouveau mot, notamment quand il ne possède pas les mêmes traits
phonologiques ou les mêmes phonèmes que la langue d’origine de l’emprunt. En effet,
comme l’explique Haugen dans son article « The analysis of linguistic borrowing »11, deux
phénomènes accompagnent l’emprunt, l’importation et la substitution, qu’il définit ainsi :
If the loan is similar enough to the model so that a native speaker would accept
it as his own, the borrowing speaker may be said to have IMPORTED the model
into his language, provided it is an innovation in that language. But insofar as
he has reproduced the model inadequately he has normally SUBSTITUTED a
similar pattern from his own language. (Haugen, 212)
Ces phénomènes se retrouvent à tous les niveaux d’emprunt : « not only to a given
loan as a whole but to its constituent patterns as well, since different parts of the pattern may
be treated differently » (Haugen, 212). Au niveau phonologique, on va presque toujours 11 Op. cit. p. 13

Les corpus disponibles 21
observer une substitution de certains éléments notamment lorsque les systèmes des deux
langues sont différents, ce qui est généralement le cas.
En ce qui concerne notre étude, les emprunts qui nous intéressent subissent
probablement une substitution partielle accompagnée de l’importation de certains traits du
français, ce qui expliquerait que ces emprunts ne soient ni tout à fait prononcés comme les
mots d’origine, ni comme la plupart des mots anglais. L’assimilation totale étant la
substitution de tous les traits, nous recherchons en fait les emprunts qui sont les moins
substitués. Néanmoins dans cette étude, nous garderons les termes de ‘non-assimilé’ ou
‘inassimilé’ en gardant à l’esprit que ces termes ne signifient pas que l’emprunt n’a subit
aucune substitution, mais plutôt que cette substitution n’est pas totale.
B. LES CORPUS DISPONIBLES
Si de nombreux linguistes ont écrit sur les emprunts français en anglais, seuls
quelques-uns proposent leur corpus en annexe de leur étude : Alan Bliss, Esko V. Pennanen,
Laure Chirol, Jennifer Vince, Jennifer Speake ainsi que Jean-Marc Chadelat.
Dans le cas de Bliss et Speake, il ne s’agit pas réellement d’études sur les emprunts
français en anglais, mais de dictionnaires des mots étrangers. Ces dictionnaires fournissent
donc des listes de mots français. A première vue, cela semble convenir au type d’étude que
nous souhaitons mener, puisque le terme de ‘mot français’ semble pointer des emprunts
‘différents’ des autres, peut-être à cause de leur prononciation. Pour en être sûre, nous
étudions la méthode de sélection employée par ces éditeurs.
Bliss explique dans l’introduction de son Dictionary of Foreign Words and Phrases in
Current English12 ce qu’il entend par mot ‘étranger’ et de quelle manière il a fait sa sélection.
Pour lui, un mot ‘étranger’ est un mot qui n’a pas été anglicisé (Bliss, 7). Nous comprenons
12 Bliss, Alan. A Dictionary of Foreign Words and Phrases in Current English. London : Routledge, 1966.

22 Le corpus : les critères de sélection
qu’anglicisé signifie ‘totalement substitué’ ou ‘totalement assimilé’ phonologiquement.
Néanmoins il peut également s’agir de la forme orthographique comme le laisse comprendre
cette phrase : « The French words absorbed into English during the Middle Ages were fully
anglicized both in pronunciation and in form » (Bliss, 6). Les ‘mots étrangers’ seraient donc,
par opposition, tous les emprunts qui ne sont pas totalement substitués, ce qui semble bien
correspondre à ce que nous recherchons. Bliss reconnaît néanmoins qu’il est difficile de
définir ce qui caractérise un mot ‘étranger’ (Bliss, 8). Il propose alors une liste de critères
positifs et négatifs qui permettraient de mettre ces mots en évidence.
Les critères positifs permettent de repérer les mots étrangers. Ce sont l’utilisation de
l’italique (Bliss, 8), l’utilisation d’accents graphiques ou autres signes diacritiques, la présence
dans la prononciation de sons qui ne sont habituellement pas employés en anglais, la
correspondance graphie-phonie qui ne suit pas les habitudes de l’anglais (Bliss, 9) et
l’utilisation de formes féminines ou d’un pluriel différent du pluriel anglais (Bliss, 10). Les
critères négatifs, au contraire, permettent d’affirmer qu’un emprunt est anglicisé, et donc
qu’un mot ne suivant pas ces critères est étranger. Ces critères sont : l’existence de dérivés
formés en suivant les règles de l’anglais, l’utilisation d’une orthographe différente de celle du
mot d’origine (Bliss, 11) et un sens différent de celui de la langue d’origine (Bliss, 12).
Cependant, l’auteur admet que la plupart de ces critères peuvent être remis en
question. Par exemple, si l’italique permet souvent d’identifier un mot étranger, en revanche
tous les mots étrangers ne sont pas mis en italique. De même les accents graphiques
permettent d’identifier des mots étrangers, et particulièrement des mots d’origine française,
mais tous les mots empruntés n’ont pas forcément d’accent au départ. Bliss est donc forcé de
reconnaître qu’un certain nombre de mots étrangers ne pourront pas être identifiés à l’aide de
ces critères. C’est pour cette raison qu’il décide d’ajouter un critère totalement subjectif : « a
word is ‘foreign’ if it ‘feels’ foreign to the speaker or writer who uses it » (Bliss, 13). La

Les corpus disponibles 23
présence de ce critère subjectif est dérangeante car elle rend ce corpus peu ‘scientifique’,
d’autant que Bliss ajoute que « where objective criteria fail I have accepted as decisive my
own subjective judgement of the status of each word » (Bliss, 14), ce qui a pu avoir lieu très
souvent. Il paraît dangereux de ‘juger’ qu’un mot est étranger ou non sur son ‘ressenti’, car
chaque locuteur peut avoir un ressenti différent à l’égard des emprunts. De plus, l’auteur va
rejeter un mot comme machine, qui devrait figurer dans le dictionnaire puisque la
correspondance graphie-phonie ne suit pas les habitudes de l’anglais : « the strict application
of this criterion would class the word machine as ‘foreign’, a conclusion repugnant to
common sense » (Bliss, 10). Il considère sans doute ce mot comme anglicisé puisqu’il est
couramment employé. Néanmoins, nous ne l’aurions pas rejeté puisque sa prononciation ne
suit pas les règles de l’anglais.
Pour toutes ces raisons ― la sélection trop subjective des mots étrangers, ainsi qu’une
liste des critères imparfaite ― nous ne souhaitons pas utiliser ce corpus pour notre étude. Il
nous parait indispensable de travailler à partir d’un corpus réalisé scientifiquement et avec
objectivité. Laure Chirol13 et Jean-Marc Chadelat14, tous deux auteurs d’études
sociolinguistiques sur les emprunts français en anglais, reprennent simplement cette liste de
« mots français » pour réaliser leurs travaux ; en conséquence leurs corpus ne sont également
pas retenus.
Jennifer Speake, auteur de l’Oxford Dictionary of Foreign Words and Phrases15,
propose certains critères de sélection identiques à ceux de Bliss, mais elle ne les met pas en
perspective, ni ne détaille réellement sa démarche. Elle n’y définit pas non plus ce qu’elle
entend par ‘foreign’, ce qui est pourtant indispensable dans ce type d’étude. Pour cette raison,
13 Chirol, Laure. Les ‘mots français’ et le mythe de la France en anglais contemporain. Paris : Klincksieck, 1973.
14 Op. cit. p. 13
15 Speake, Jennifer, éd. The Oxford Dictionary of Foreign Words and Phrases. Oxford : Oxford UP, 1997.

24 Le corpus : les critères de sélection
nous ne retenons pas non plus sa liste de mots français.
Enfin, les corpus d’Esko V. Pennanen et de Jennifer Vince ne peuvent convenir car
l’un et l’autre se limitent à l’étude d’une période en particulier. En effet, le corpus d’Esko V.
Pennanen, dans son ouvrage On the Introduction of French Loan-Words in English16, se
cantonne à la période 1551-1700, alors que nous envisagions d’étudier les emprunts jusqu’à la
période contemporaine. Quant à Jennifer Vince, dans sa thèse de sociolinguistique « Les
emprunts de l’anglais au français à l’époque contemporaine »17, elle restreint son étude au
20ème siècle, ce qui nous semble une période trop limitée par rapport à l’histoire des emprunts
français en anglais.
Il semble ainsi qu’aucun corpus préétabli ne convienne à l’étude que nous souhaitons
mener. Le problème majeur est au fond qu’aucune de ces études ne prend en compte l’aspect
phonologique des emprunts. Par conséquent, il va nous falloir réaliser notre propre corpus
destiné à l’analyse phonologique des emprunts français inassimilés.
C. TROUVER UNE METHODE DE SELECTION
Différentes méthodes de sélection s’offrent à nous : sélectionner les emprunts
oralement à l’aide de corpus oraux ou bien de programmes audiovisuels ou radiophoniques ;
ou bien sélectionner les emprunts par écrit dans des journaux et magazines ou encore à l’aide
d’un dictionnaire. Nous décidons de tester ces différentes méthodes afin de déterminer celle
qui convient le mieux.
16 Pennanen, Esko V. On the Introduction of French Loan-Words into English. Acta Universitatis Tamperensis
ser.A 38. Tampere, Finland : Tampereen Yliopisto, 1971.
17 Vince, Jennifer. « Les Emprunts de l’anglais au français à l’époque contemporaine. » Thèse de Doctorat de
3ème cycle, Université Paris 7, 1984.

Trouver une méthode de sélection 25
Il existe un certain nombre de corpus oraux tels que le British National Corpus18 ou le
British Academic Spoken English corpus19. L’intérêt d’un travail sur un corpus oral est de
disposer d’une immense base de données de conversations qui permet d’observer l’emploi des
emprunts français à l’oral dans leur contexte. Mais l’inconvénient majeur d’un travail à partir
de corpus oraux est qu’ils sont tous transcrits par écrit. Cela rend la sélection des emprunts
totalement arbitraire puisque l’identification des emprunts se fait alors d’après leur forme,
mais sans aucune garantie d’une origine réellement française (elle peut être latine). Il est
surtout impossible de connaître la prononciation des mots et donc de mettre en évidence ceux
qui sont les moins assimilés. De plus, nous ne sommes pas certaine que les enregistrements
soient disponibles, ce qui obligerait à travailler à partir des transcriptions. Cette technique
laisse donc une trop grande part de subjectivité, ce qui ne nous semble pas être une bonne
démarche.
Le même problème est rencontré lors de la lecture de journaux ou magazines
britanniques. Bien que cette méthode ait l’avantage de sélectionner des emprunts de l’anglais
contemporain et de permettre de les observer en contexte ou d’en découvrir la fréquence
d’emploi, la sélection des emprunts reste liée à la subjectivité du lecteur et à sa connaissance
du vocabulaire français. Un emprunt peut en effet échapper à la sélection, simplement parce
que le lecteur n’a pas connaissance de ce terme en tant que mot français. Cette méthode n’est
donc pas suffisamment objective en plus du fait de retenir tous types d’emprunts, assimilés ou
non.
A première vue, la méthode de sélection à l’aide de programmes audiovisuels ou
radiophoniques semble la méthode à retenir : elle permet de relever les emprunts qui sont 18 Disponible sur internet : British National Corpus. University of Oxford. Novembre 2004.
http://www.natcorp.ox.ac.uk/.
19 The British Academic Spoken English (BASE) corpus. University of Warwick. Novembre 2004.
http://www2.warwick.ac.uk/fac/soc/al/research/projects/resources/base.

26 Le corpus : les critères de sélection
effectivement les moins assimilés et de noter dans quel contexte ils sont employés.
Néanmoins cette méthode n’est pas non plus suffisamment objective : pour relever les
emprunts, ils doivent être identifiés par l’auditeur, ce qui s’avère être très subjectif. Il est
nécessaire que l’auditeur connaisse et comprenne le mot. De plus, puisque cette étude a pour
but l’analyse de la phonologie des emprunts, il paraît finalement contradictoire d’utiliser des
critères phoniques comme point de départ de la sélection. Cela reviendrait à analyser la
phonologie avant même de sélectionner.
L’évaluation de ces différentes méthodes fait apparaître la nécessité d’utiliser des
critères de sélection objectifs, c'est-à-dire qui n’impliquent nullement le linguiste dans le
choix des emprunts, et qui ne se basent pas sur ce qui va être l’objet de l’étude, c'est-à-dire la
phonologie.
Dans cette optique, la méthode de sélection à l’aide d’un dictionnaire semble
finalement la plus adéquate. L’étymologie, notamment, permet d’identifier un mot comme
étant d’origine française indépendamment des connaissances du linguiste, ce qui est un point
de départ objectif. Cette méthode est certes critiquable, car elle a également ses
inconvénients : on y trouve plutôt les termes employés à l’écrit qu’à l’oral, la sélection va
dépendre d’une certaine manière du choix des éditeurs de faire figurer un mot ou un autre et il
est quasiment certain que les emprunts les plus récents n’y figureront pas puisqu’il faut
toujours un certain laps de temps avant qu’un mot nouveau n’entre dans un dictionnaire.
Néanmoins, il nous semble que cette méthode est celle qui va nous permettre de
travailler de la manière la plus ‘scientifique’. Il reste encore à trouver les critères précis qui
vont nous permettre de sélectionner le plus grand nombre d’emprunts non-assimilés.

Recherche des critères de sélection 27
D. RECHERCHE DES CRITERES DE SELECTION
Afin de trouver les critères les plus objectifs pour notre sélection, il semble utile
d’observer les méthodes de sélection des linguistes qui ont travaillé sur les emprunts français
en anglais.
1. Les méthodes de nos prédécesseurs
Cinq linguistes ont réalisé des études similaires des flux d’emprunts français en
anglais : Otto Jespersen, Albert C. Baugh, A. Koszul, Fernand Mossé et Esko V. Pennanen,
que nous avons déjà mentionnés. Tous ont décrit leur méthode pour relever les emprunts.
Jespersen est le premier à avoir réalisé une étude sur les flux d’emprunts français en
anglais et, à notre connaissance, l’un des premiers linguistes à s’être penché sur la question
des emprunts français en anglais. Dans son ouvrage Growth and Structure of the English
Language20, dont la première édition date de 1905, il réalise une étude qui a pour but de
montrer « the strength of the influx of French words at different periods » (Jespersen, 86).
Pensant qu’une sélection d’emprunts français reflètera l’ensemble des emprunts, il ne vise pas
à l’exhaustivité, mais décide de relever mille mots dans le New English Dictionary (NED)
(appelé aujourd’hui Oxford English Dictionary). Il garde les cent premiers mots des lettres A
à I et les cinquante premiers des lettres J et K (Jespersen, 86), les volumes suivants n’étant pas
encore parus. Il décide cependant d’exclure les dérivés, qui se sont formés au sein de la langue
anglaise, et les mots illustrés de moins de cinq citations par le NED car la plupart d’entre eux
« cannot really be said to have ever belonged to the English language » (Jespersen, 86). Cette
décision sera d’ailleurs remise en question par les linguistes qui vont reprendre cette étude,
20 Op. cit. p. 10

28 Le corpus : les critères de sélection
notamment Baugh et Koszul. Ses résultats montrent une période d’emprunts massifs entre
1250 et 1400 suivie d’une déclinaison progressive des emprunts.
Baugh reprend cette étude en 1935 dans son article intitulé « The chronology of
French Loan-Words in English »21. Le NED est à présent complet et Baugh réalise l’analyse
statistique sur l’ensemble du dictionnaire afin de voir si les résultats seront différents (Baugh,
90). Comme Jespersen, il sélectionne mille mots, mais sa méthode diffère légèrement : il
relève tous les mots d’origine française sur les pages numérotées -50 et -00 dans un premier
temps, puis, le nombre de mots étant insuffisant, sur les pages -20, -40, -60 et -80 (Baugh, 90).
De cette première sélection, il supprime les ‘nonce-words’ c’est-à-dire les mots inventés pour
une occasion particulière, et les mots désignés par le dictionnaire comme ‘inassimilés’,
« which clearly [have] never been a part of the English language in any real sense » (Baugh,
90-91). Le total s’élevant à 1031 emprunts, il ramène ‘arbitrairement’ la liste à mille emprunts
(Baugh, 91). Les dérivés ne sont pas inclus à cette liste, mais le mot de base, même s’il se
trouve sur une autre page, est ajouté. Par exemple, il note air pour représenter airily, airiness,
etc. (Baugh, 91). Ses résultats présentent quelques différences mineures par rapport à ceux de
Jespersen ― notamment sur les 18ème et 19ème siècles pour lesquels Baugh a des chiffres
supérieurs ― différences qui sont imputables à la méthode de sélection et non au fait que
Baugh ait travaillé sur l’ensemble du dictionnaire. En effet, Baugh pense que la décision de
Jespersen de supprimer les mots qui ne sont pas illustrés d’au moins cinq citations « works to
the disadvantage of late borrowings » (Baugh, 92), et que cette méthode lui aurait fait rejeter
des mots tels que « carton, chaise-longue, char-a-banc, chiffon » (Baugh, 92). On peut
remarquer que ces emprunts font partie de notre corpus, c’est pourquoi nous émettons la
même critique à l’égard de la méthode de Jespersen.
21 Baugh, Albert C. « The Chronology of French Loan-Words in English. » Modern Language Notes 50 (1935) :
90-93.

Recherche des critères de sélection 29
Un an plus tard, en 1936, Koszul reprend à son tour l’étude de Jespersen dans un
article intitulé « Statistique et Lecture. Note sur la courbe des emprunts de l’anglais au
français »22, mais cette fois pour la compléter, c'est-à-dire reprendre la méthode de son
prédécesseur et l’appliquer aux volumes M à W (Koszul, 80-81). On peut d’ailleurs noter que
Jespersen inclura les résultats de Koszul dans les éditions ultérieures de son ouvrage. Ces
résultats sont sensiblement les mêmes que ceux de Jespersen, c’est pourquoi Koszul en
conclut qu’effectivement l’analyse statistique d’un échantillon d’emprunts suffit à représenter
l’ensemble des emprunts (Koszul, 81). Néanmoins, il fait la même observation que Baugh23 :
La petite règle, en apparence si innocente, que nous nous sommes imposée
avec M. Jespersen, d’exclure de notre compte ‘those perfectly unimportant
words for which the NED gives less than five quotations’, joue de manière fort
inégale aux diverses périodes. (Koszul, 81-82)
Il remarque notamment que l’application de cette règle va faire supprimer plus de mots
aux périodes les plus récentes : « A la lettre p, un seul mot tombe au 13e siècle, deux au 14e,
mais six au 15e, une douzaine au 16e, une dizaine au 17e, et autant au 19e » (Koszul, 82). Nous
voyons ainsi que cette règle édictée par Jespersen peut être difficilement défendue car un
emprunt récent aura moins de chances d’être illustré par de nombreuses citations, puisque,
comme le fait remarquer Baugh, « the NED seldom gives as many as five quotations from the
same century, unless to illustrate various senses » (Baugh, 92). Par exemple pour espionage,
l’Oxford English Dictionary (OED)24 ne propose que quatre citations alors que ce mot a été
emprunté en 1793. Pourtant ce terme est courant en anglais. Le rejet de ces mots est donc
injustifié. 22 Koszul, A. « Statistique et Lecture. Note sur la courbe des emprunts de l’anglais au français. » Bulletin de la
Faculté des Lettres de Strasbourg 15 (1936) : 79-82.
23 Notons que Koszul ne fait pas référence à l’étude de Baugh, dont il n’a peut-être pas eu connaissance.
24 Oxford English Dictionary. 2ème éd. CD-ROM. Version 3.1. Oxford : Oxford UP, 2004.

30 Le corpus : les critères de sélection
Mossé décide également, en 1943, d’analyser les flux d’emprunts, dans un article
intitulé « On the Chronology of French Loan-Words »25, mais il choisit d’employer une
méthode différente. Après avoir rappelé les méthodes de ses prédécesseurs, Mossé ajoute
qu’elles sont parfois critiquables et que la seule procédure valable serait de prendre en compte
tous les emprunts français recensés par l’OED (Mossé, 34). Mossé ne va pas réaliser cette
étude complète, mais propose de tester sa méthode sur l’ensemble du volume A de l’OED
(Mossé, 34). Il ne sélectionne que les emprunts dont l’OED dit qu’ils sont « ‘adopted from’
the French » (Mossé, 34) et insère également les emprunts dont l’origine pourrait être le latin
ou le français (Mossé, 34). Ce problème de l’origine des mots est également évoqué par
Jespersen : il est parfois difficile de savoir si un emprunt vient du français ou du latin, car un
emprunt latin a fort bien pu parvenir à l’anglais par le biais du français, et le linguiste pourrait
être tenté de remettre en question l’étymologie donnée par le dictionnaire. Néanmoins Mossé,
tout comme Jespersen, décide de suivre les indications du dictionnaire (Mossé, 34 ; Jespersen,
86).
Mossé propose également sa définition d’un emprunt français :
A French loan-word is a word which whatever may be its etymology or
ultimate origin has been immediately borrowed from the French. (Mossé, 35)
Cette définition inclut comme emprunt français un emprunt originaire d’une autre
langue, mais qui serait arrivé en anglais par le biais du français. C’est une définition large et
qui a l’avantage de ne pas chercher à privilégier un mot qui aurait évolué au sein de la langue
― comme certains mots français venant du latin ― par rapport à des emprunts du français à
d’autres langues. A l’instar de ses prédécesseurs, il exclut les dérivés, formés au sein de la
langue. En revanche, il n’exclut pas les mots obsolètes ou rares, ainsi que les ‘nonce-words’,
mais les compte séparément (Mossé, 35). Comme Baugh, il préfère ne pas inclure les mots
25 Op. cit. p. 14

Recherche des critères de sélection 31
étiquetés par l’OED comme ‘inassimilés’, ajoutant toutefois que « such labelling is not always
clear » (Mossé, 35). Il se demande à ce propos : « Is aide-de-camp to be considered as really
‘unassimilated’? » (Mossé, 35), ce qui pose le problème du sens donné par les différents
linguistes au mot ‘inassimilé’. Faut-il le comprendre au sens d’assimilation phonologique, de
la forme orthographique ou bien de l’usage ? Il semble que Mossé le comprenne au sens de
l’usage puisque la forme orthographique est clairement française, et que la prononciation ―
[«EIdd´:kA)˘] dans l’English Pronouncing Dictionary26― ne suit pas les habitudes de l’anglais.
Malheureusement, il laisse la question en suspens, ce qui ne permet pas de donner de réponse
précise. En travaillant avec l’OED, nous constaterons nous-mêmes que cette étiquette n’est
pas clairement définie par le dictionnaire ; c’est pourquoi nous pensons qu’il est injustifié de
ne pas considérer ces mots comme des emprunts.
En 1971, Esko V. Pennanen27 poursuit les études des précédents linguistes sur les flux
d’emprunts français, mais il se concentre sur la période 1551-1700 pour laquelle les résultats
de ses prédécesseurs divergeaient. Il décide de suivre la méthode de Mossé à un détail près : il
ne rejette pas les emprunts ‘inassimilés’, mais les laisse étiquetés comme tels dans son corpus.
Travaillant sur l’OED complet, il relève en tout 4105 mots. Pennanen considère par
conséquent la méthode de Mossé comme étant la meilleure dans le cadre de son étude.
Jennifer Vince réalise en 1984 une étude sociolinguistique sur les emprunts français
dans sa thèse intitulée « Les emprunts de l’anglais au français à l’époque contemporaine »28.
L’objet de son étude est de comprendre pourquoi l’anglais emprunte au français et comment
ces emprunts sont employés au sein de la langue ; elle étudie la relation des locuteurs aux
26 Jones, Daniel. English Pronouncing Dictionary. Ed. Peter Roach, James Hartman et Jane Setter. 16ème éd.
Cambridge : Cambridge UP, 2003.
27 Op. cit. p. 24
28 Op. cit. p. 24

32 Le corpus : les critères de sélection
emprunts français. L’auteur concentre son étude sur les emprunts du 20ème siècle car cette
« période [est ] considérée à tort comme pauvre en emprunts de l’anglais au français » (Vince,
17). Elle ne suit pas la méthode de ses prédécesseurs bien qu’elle en ait connaissance. Vince
sélectionne tout d’abord son corpus à partir de deux dictionnaires, le Dictionary of Foreign
Words and Phrases in Current English de Bliss29 et le Dictionary of Modern English Usage de
Fowler30, et de l’ouvrage de Fraser Mackenzie, Les relations de l’Angleterre et de la France
d’après le vocabulaire31, tout en reconnaissant, comme nous l’avons fait, que cette méthode
est imparfaite :
Nous nous rendons compte du caractère particulier d’un corpus tiré de
dictionnaires, c’est-à-dire d’une langue qui est presque une métalangue, […] et
qui répond à un certain choix de la part des lexicographes […]. (Vince, 27)
Elle restreint par la suite son corpus en ne retenant que les termes trouvés dans la
presse afin de ne sélectionner que les emprunts les plus courants et d’observer leur usage au
sein de la langue. Vince suggère de vérifier l’origine de chaque mot dans la langue française
pour s’assurer qu’il s’agit bien d’emprunts au français et non au latin, par exemple
(Vince, 20). Elle inclut néanmoins dans son corpus des emprunts dont le français n’est qu’une
langue intermédiaire (Vince, 21), ainsi que les ‘faux-emprunts’ ou ‘pseudo-gallicismes’ qui
sont des mots « créé[s] à partir d’éléments lexicaux français, non par des locuteurs français
mais par les Anglais eux-mêmes » (Vince, 23). L’auteur donne pour exemple double-
entendre ou brise soleil32. Elle incorpore les faux-emprunts à son corpus « étant donné le
29 Op. cit. p. 21
30 Fowler, H. W. A Dictionary of Modern English Usage. 1926. 2ème éd. Sir Ernest Gowers, éd. Oxford : Oxford
UP, 1965.
31 Mackenzie, Fraser. Les relations de l’Angleterre et de la France d’après le vocabulaire. Vol. 2 : « Les
infiltrations de la langue et de l’esprit français en Angleterre : gallicismes anglais. » Paris : E. Droz, 1939.
32 Notons qu’il s’agit là d’un mauvais exemple car le brise-soleil est bien un mot français ; en effet, il s’agit

Recherche des critères de sélection 33
caractère français de ces mots et les questions qu’ils soulèvent » (Vince, 24). Cette thèse
expose en détail les problèmes soulevés par la sélection d’emprunts français et propose des
solutions aux nombreuses questions engendrées par ce type d’étude.
Enfin, en 2002, Bekim Bejta réalise une thèse sur « L’assimilation morpho-
phonologique des xénismes français en anglais et son traitement lexicographique »33. Son
travail a pour but d’étudier « l’assimilation, à différents niveaux linguistiques, des mots
français empruntés par l’anglais qui présentent, sous une forme ou une autre, des traits de la
langue source » (Bejta, 14). Ce travail est assez proche du nôtre, bien que nous n’étudions pas
‘l’assimilation’ à proprement parler, qui est le processus par lequel un emprunt passe du stade
de mot inassimilé au stade de mot totalement anglicisé, mais plutôt la prononciation des
emprunts inassimilés au sein de la langue. L’auteur choisit de relever dans le Longman
Pronunciation Dictionary34 toutes les entrées pour lesquelles la prononciation française est
proposée. En effet, dans un certain nombre de cas, l’éditeur a ajouté la prononciation d’origine
lorsque les mots « can either be pronounced in a way that imitates the foreign language or be
integrated into the English sound system » (LPD, xxi). Bejta établit donc un corpus de base de
519 emprunts qu’il considère comme non-assimilés du point de vue phonologique (Bejta, 16-
17). Toutefois il décide d’ajouter d’autres types d’emprunts à son corpus : « des emprunts
assimilés, de même que des items considérés comme assimilés, bien qu’ils ne soient pas
anglicisés à tous les niveaux, sont présentés afin de compléter l’analyse des formes qui
d’une invention de l’architecte Le Corbusier dans les années 1920 : « Le Déambulatoire ». Unité d’habitation
Le Corbusier Marseille : La Cité radieuse. 02 sept. 2008. http://www.marseille-
citeradieuse.org/chap1/11Deambulatoire.htm.
33 Bejta, Bekim. « L’assimilation morpho-phonologique des xénismes français en anglais et son traitement
lexicographique ». Thèse de doctorat, Université de Poitiers, 2002.
34 Wells, John Christopher. Longman Pronunciation Dictionary. 2ème éd. Harlow (GB) : Pearson Education, 2000.

34 Le corpus : les critères de sélection
comportent des caractéristiques xéniques » (Bejta, 17). Néanmoins il ne précise pas de quelle
manière sont sélectionnés ces ajouts.
2. Le choix d’une méthode
A première vue, la méthode de Bekim Bejta semble la plus appropriée pour notre
recherche, puisque c’est la seule étude axée sur la phonologie des emprunts, qui plus est des
emprunts inassimilés. Néanmoins, limiter la sélection aux entrées accompagnées de la
prononciation française nous semble trop restreint. En effet, pour un certain nombre
d’emprunts, comme par exemple accouchement, prononcé [´:ku˘SmÅ)] ou [´:ku˘SmA)˘] selon
le dictionnaire, la prononciation française n’est pas proposée ; pour autant nous considérerions
cet emprunt comme inassimilé du point de vue phonologique, notamment en raison de la
présence d’une voyelle nasale, inhabituelle en anglais. On trouve d’autres exemples de ce
type, comme apropos [«Qpr´:p´U], bateleur [«bQt´:lŒ˘], boudoir [:bu˘dwA˘] ou bouquet
garni [bU«kEIgA˘:ni˘]. Par conséquent, nous ne pouvons suivre cette méthode.
Celle de Jennifer Vince n’est pas non plus satisfaisante, car elle réalise son corpus
principalement à partir du dictionnaire de Bliss que nous avons déjà remis en question. De
plus, si l’idée de restreindre la sélection aux emprunts trouvés dans la presse semble justifiée
pour une étude sociolinguistique, elle n’est pas nécessaire dans le cadre de notre recherche. En
revanche, nous suivons son idée de prendre en compte les faux-emprunts. En effet, si ces mots
ne sont pas à proprement parler des emprunts puisque ce sont des créations de l’anglais à
partir d’éléments français, leur phonologie nous intrigue. On peut d’ailleurs mettre en doute
l’entière ‘création’ de ces mots, notamment à propos de double entendre, qui est souvent pris
comme exemple de pseudo-gallicisme. P. Fijn van Draat, dans son article « Aliens : Influx of

Recherche des critères de sélection 35
French Words into English »35 suggère qu’il s’agit de fautes dues à une mauvaise
connaissance de la langue française :
Wrong spellings, — impressement, châteleine, à l’Anglais, are not rare ; à
outrance is found corrupted into à l’outrance; double entente into double
entendre […]. (Draat, 323)
Qu’il s’agisse de fautes ou de créations, l’analyse des faux-emprunts paraît appropriée.
De tous les linguistes ayant travaillé sur les flux d’emprunts français en anglais, seule
la méthode de Mossé semble convenir pour notre travail, les autres n’ayant relevé qu’un
‘échantillon’ d’emprunts français. Nous décidons donc d’appliquer sa méthode sur l’ensemble
du dictionnaire OED. Comme Mossé et Vince (Mossé, 35 ; Vince, 21), nous ne rejetons pas
les mots qui n’ont fait que transiter par le français avant de parvenir à la langue anglaise. En
effet, il arrive souvent qu’un mot soit emprunté par le français à une autre langue, puis par
l’anglais au français. Agouti, par exemple, qui désigne un rongeur d’Amérique du Sud, est
originaire du guarani, langue du Paraguay, mais est passé en anglais par le biais du français.
Caracal, qui désigne cette fois un lynx d’Afrique, vient du turc, mais est passé en espagnol
puis en français, avant d’arriver dans la langue anglaise. Ces mots ne sont peut-être pas à
mettre sur le même plan que des emprunts du type attaché, souvenir ou lingerie puisque le
français les a lui-même empruntés, mais il ne faut cependant pas les négliger, notamment sur
le plan phonologique, car leur passage dans la langue française a pu influer sur leur forme
phonique en anglais.
A l’instar de Jespersen, Baugh et Mossé (Jespersen, 86 ; Baugh, 91 ; Mossé, 35), nous
ne retenons pas les dérivés — présentés dans l’étymologie comme ‘formed on’— qui ne sont
pas des emprunts puisque la dérivation se fait au sein de la langue anglaise. Nous excluons
également les ‘nonce-words’ et les mots obsolètes ou rares, car il est peu probable que nous
35 Op. cit. p. 11

36 Le corpus : les critères de sélection
trouvions leur prononciation. En revanche, contrairement à Mossé ou Jespersen (Mossé, 34 ;
Jespersen, 86), nous décidons de ne pas inclure au corpus les mots pour lesquels l’étymologie
est ‘French or Latin’ car il nous semble préférable de privilégier les emprunts pour lesquels
l’étymologie ne fait aucun doute.
Reste enfin la question des mots désignés comme ‘unassimilated’ par l’OED, soulevée
par Baugh et Mossé, et celle de la restriction de la sélection aux emprunts dont l’étymologie
est ‘adopted from French’, retenue par Mossé. Nous allons voir que ces problèmes sont liés
aux questions de vocabulaire et de définitions du domaine de l’emprunt.
E. LE VOCABULAIRE DE L’EMPRUNT
1. ‘Assimilé’, ‘inassimilé’ et ‘assimilation’
Baugh et Mossé font remarquer que le dictionnaire OED accompagne certains lexèmes
de la mention ‘unassimilated’. Ils décident tous deux de ne pas les inclure dans leur corpus,
Baugh déclarant que ces mots « clearly had never been a part of the English language in any
real sense » (Baugh, 91). Mossé ajoute tout de même que « such labelling is not always
clear » et se demande si aide-de-camp doit vraiment être considéré comme inassimilé
(Mossé, 35), sans toutefois répondre à la question.
Les termes ‘inassimilé’, ‘assimilé’ ou ‘assimilation’ sont des termes que l’on rencontre
très souvent dans la littérature de l’emprunt. Néanmoins, à la lecture des différents ouvrages et
articles sur le sujet, nous avons remarqué que tous les linguistes n’utilisaient pas ces termes
avec le même sens. La nécessité de donner une définition claire à chaque terme du domaine de
l’emprunt nous pousse à analyser le sens donné à ces termes par les différents linguistes qui
ont travaillé sur le sujet.
L’assimilation est le processus par lequel passe un emprunt, depuis le stade de mot
nouveau jusqu’au stade où il se mêle anonymement aux autres mots de la langue. Nous

Le vocabulaire de l’emprunt 37
remarquons que cette définition est en réalité sous-entendue par tous les linguistes
puisqu’aucun ne donne de définition de l’assimilation, excepté John Humbley dans son article
« Vers une typologie de l’emprunt linguistique »36, qui en donne une légèrement différente car
il lie ce terme à celui d’intégration : « par intégration nous entendons le processus qui vise
une conformité au système de la langue 1. L’assimilation est le résultat de ce processus »
(Humbley, 64). Cette assimilation peut avoir lieu à différents niveaux linguistiques, comme il
l’explique: « le processus d’assimilation s’effectue à tous les niveaux de langue, celui de la
prononciation, de l’orthographe, de la morphologie, du lexique et de la syntaxe »
(Humbley, 66). Un mot assimilé aura donc achevé ce processus soit à un ou plusieurs niveaux,
soit à tous les niveaux, auquel cas on pourra dire qu’il est ‘totalement assimilé’. Nous
pouvons remarquer que dans cette citation, Humbley parle de ‘processus d’assimilation’, ce
qui rejoint notre définition de départ. En réalité, Humbley donne au terme intégration le sens
que nous donnons à assimilation comme le montre cette citation : « Un mot qui contient des
phonèmes ou des combinaisons de phonèmes inusités en français, n’est pas intégré au niveau
phonétique » (Humbley, 66) ; nous pourrions aisément remplacer le terme ‘intégré’ par
‘assimilé’.
Si Humbley utilise le terme d’intégration pour le processus et d’assimilation pour le
résultat, Bekim Bejta37 préfère réserver le terme d’intégration au seul niveau lexical, comme
l’atteste cette citation : « L’assimilation (surtout phonologique) se déclenche, à un niveau
linguistique ou un autre, à partir du moment où un mot étranger est employé dans la langue
d’arrivée mais cela n’entraîne pas aussitôt l’intégration du mot en question au vocabulaire de
cette langue » (Bejta, 25). En effet, même si intégration et assimilation semblent synonymes,
il paraît pertinent de différencier l’intégration des emprunts au sein de la langue, c’est-à-dire
36 Op. cit. p. 12
37 Op. cit. p. 33

38 Le corpus : les critères de sélection
la présence ou non du mot dans le lexique de la langue, des autres niveaux d’assimilation. Une
réflexion de Bejta souligne l’importance de cette différenciation :
En dernière analyse, l’emprunt intégré peut, dans un schéma simplifié, se
présenter sous deux formes, c’est-à-dire l’emprunt qui est à la fois intégré au
vocabulaire de la langue cible et assimilé à tous ses niveaux linguistiques ;
ainsi que l’emprunt qui est intégré dans la langue cible sans qu’il soit assimilé
complètement à tous les niveaux linguistiques (phonologique,
morphosémantique, graphique, etc.). (Bejta, 26)
Dans l’ensemble, les linguistes sont d’accord sur le sens à donner au terme
‘assimilation’. En revanche, ils ne précisent pas toujours à quel niveau ils entendent les termes
assimilation ou (in)assimilé, ce qui peut créer des confusions, comme nous le montre cette
citation de Louis Deroy tirée de son ouvrage L’emprunt linguistique38 : « Tandis que match
est un emprunt assimilé, event est encore un mot à demi étranger » (Deroy, 17).
L’orthographe du mot match ne suit pas les conventions du français ; on peut en conclure que
ce mot n’est pas assimilé du point de vue orthographique. Le phonème /tS/ n’existant pas en
français, et la suite de phonèmes /t/ et /S/ n’étant pas habituelle en fin de mot, on peut
également en conclure que le mot n’est pas phonologiquement assimilé. Deroy entend donc
probablement le terme ‘assimilé’ au niveau de l’usage, match étant très courant. Suivant
l’usage de Bejta, nous aurions plutôt dit de ce mot qu’il est ‘intégré’ à la langue.
2. ‘Naturalisé’ et ‘anglicisé’
Laure Chirol39 commente ainsi la liste de mots français du dictionnaire de Bliss qu’elle
a utilisée pour son étude : « Bliss n’a pas relevé dans ses sources tous les mots d’origine 38 Op. cit. p. 12
39 Op. cit. p. 23

Le vocabulaire de l’emprunt 39
française — mais seulement les mots ‘français’, selon sa définition ce qui exclut les ‘mots
assimilés’. D’où l’exclusion de mots tels que bandit, banquet, etc. que l’auteur considère sans
doute comme naturalisés » (Chirol, 20-21). Dans ce cas-ci, on ne sait pas précisément de quel
niveau d’assimilation il s’agit. Il pourrait s’agir du niveau phonologique, leur prononciation
— [:bQndIt] et [:bQNkwIt] dans l’English Pronouncing Dictionary — étant visiblement
assimilée, mais ce pourrait également être le niveau lexical. On note cependant l’emploi du
terme ‘naturalisé’, qui, selon la citation de Chirol, serait synonyme d’assimilé (ou d’intégré).
Bliss précise qu’il ne s’intéresse qu’aux mots étrangers, qu’il oppose aux mots totalement
anglicisés (Bliss, 2 ; 7). Le terme ‘anglicisé’ correspond à celui d’assimilé dans le cas des
emprunts dans la langue anglaise. Nous pouvons rapprocher cela d’une autre phrase de Chirol
à propos de l’étude de Fraser Mackenzie, Les relations de l’Angleterre et de la France d’après
le vocabulaire40 : « Mackensie, dans sa préface, distingue très justement les mots étrangers
(alien words) des mots naturalisés (denizen words) » (Chirol, 15). Nous en déduisons
qu’assimilé, naturalisé et anglicisé sont synonymes.
La confusion qui règne sur le vocabulaire de l’emprunt vient, nous semble-t-il, de
l’utilisation d’un trop grand nombre de termes, rarement définis, et appliqués à différents
niveaux linguistiques, sans que cela ne soit jamais précisé.
Dans notre étude, qui s’intéresse uniquement à la phonologie des emprunts, nous
n’utiliserons au contraire les termes assimilé et anglicisé qu’au niveau phonologique. Si nous
souhaitons parler d’un autre niveau, comme celui de l’orthographe, dont nous verrons qu’il est
important dans le cadre des emprunts français, nous le préciserons.
40 Op. cit. p. 32

40 Le corpus : les critères de sélection
3. Mot étranger et ‘xénisme’
Mackenzie donne sa définition des denizen words, équivalents aux mots naturalisés :
« De nombreux emprunts français sont complètement absorbés dans la langue anglaise.
L’Anglais cultivé n’a aucune conscience du fait que carriage, marriage, coach, fritter,
pianist, pacifism ont été adoptés de la langue française. (En Angleterre les linguistes appellent
ces mots denizens) » (Mackenzie, 7). Si ces mots ne sont plus identifiés comme des emprunts,
c’est probablement parce qu’ils ont été assimilés aussi bien au niveau de la forme que de la
prononciation. Ce sont des emprunts que l’on peut considérer comme totalement assimilés ou
anglicisés. Mackenzie les oppose aux alien words ou mots étrangers : « D’autres mots
conservent à l’heure actuelle des souvenirs tantôt vagues tantôt sûrs de leurs origines
françaises (ceux-ci portent en Angleterre le nom alien) » (Mackenzie, 7), mais cette définition
manque de clarté. On peut néanmoins en déduire par opposition aux mots totalement
anglicisés, que ce sont ceux qui ne sont pas totalement anglicisés, c’est-à-dire ceux qui
gardent un caractère étranger. Bliss appelle ces mots ‘foreign’ ; Thierry Démory41, suivant la
définition de Tournier, leur donne le nom de ‘xénismes’ :
Il convient donc de distinguer les mots étrangers français perçus comme tels
aujourd’hui, et que Jean Tournier appelle des ‘xénismes’ (disons, les emprunts
‘qui se présentent à découvert’) de ceux qui ont été ‘naturalisés’, anglicisés,
dont l’origine française n’est plus perçue (disons les emprunts ‘qui avancent
masqués’). (Démory, 81)
Bejta considère les xénismes comme des emprunts non-assimilés (Bejta, 23),
probablement au niveau phonologique puisque son étude porte sur ce point. Il propose
toutefois la définition de Tournier : « Tant qu’il n’est pas assimilé, ou au moins en voie
41 Démory, Thierry. « Les emprunts français dans la langue anglaise. » CILL : Cahiers de l’Institut de
Linguistique de Louvain 27/3-4 (2001) : 79-87.

Le vocabulaire de l’emprunt 41
d’intégration, c'est-à-dire tant qu’il est perçu par l’usager comme un élément étranger, un
emprunt constitue ce que l’on appelle un xénisme » (Bejta, 34). Tournier, lui, parle de
‘perception’ de l’usager, ce qui rejoint le problème soulevé par Bliss lorsqu’il manque de
critères pour identifier les mots étrangers et qu’il choisit d’ajouter un critère subjectif :
A word is ‘foreign’ if it ‘feels’ foreign to the speaker or writer who uses it. […]
The objections to such a subjective criterion are obvious: no two speakers or
writers will agree at all points in the application of the criterion. The
apprehension of a word as ‘foreign’ will vary according to the education,
environment, and even the profession of the person who uses it. (Bliss, 13-14)
Louis Deroy42 évoque également le ressenti du locuteur : « On peut distinguer deux
catégories : les pérégrinismes ou xénismes, c'est-à-dire les mots sentis comme étrangers et en
quelque sorte cités (les Fremdwörter des linguistes allemands) et les emprunts proprement
dits ou mots tout à fait naturalisés (les Lehnwörter) » (Deroy, 224). Nous pouvons faire deux
observations à propos de cette citation : tout d’abord l’introduction d’un nouveau terme,
‘pérégrinisme’, considéré comme un synonyme de xénisme pour l’auteur ; ensuite nous
constatons qu’il oppose le xénisme à l’emprunt, qui pour lui se réduit à ce que nous nommons
‘emprunt naturalisé’, opinion que partage Humbley (Humbley, 65). Deroy affirme même que
les pérégrinismes devraient être exclus d’une étude des emprunts (Deroy, 224), point sur
lequel nous nous opposons. Nous préférons suivre l’avis de Mackenzie qui « englob[e] ces
mots dit aliens dans [sa] conception de l’emprunt » (Mackenzie, 7). En effet, d’une part nous
envisageons l’emprunt de manière très large et estimons que n’importe quelle utilisation d’un
mot étranger constitue un emprunt, d’autre part considérer que seuls les emprunts naturalisés
sont des emprunts à part entière aurait rendu notre étude absurde puisque nous nous
intéressons justement aux emprunts inassimilés, donc non-naturalisés. Deroy admet d’ailleurs
42 Op. cit. p. 12

42 Le corpus : les critères de sélection
qu’il est en pratique impossible de tracer une limite entre les emprunts et les pérégrinismes
(Deroy, 224).
Évoquer le ressenti du locuteur pour prouver qu’un mot est intégré ou non, ‘emprunt
réel’ ou non, est à notre sens non justifié. En effet, si l’on prend l’exemple de week-end en
français, probablement tous les locuteurs à qui l’on posera la question diront qu’il s’agit d’un
mot étranger, en l’occurrence d’un mot anglais. Pour autant cet emprunt est utilisé par tous et
aucun réel doublon n’existe en français. Ce type d’emprunt serait rejeté par Bliss, comme
nous l’avons vu pour l’exemple de machine, car pour lui, un mot si couramment employé ne
peut être considéré comme ‘étranger’. On voit ainsi qu’un mot peut être ressenti comme
étranger, mais être couramment employé, donc intégré (ex : weekend), ou bien avoir une
forme ou une prononciation qui ne suit pas les habitudes de la langue et pourtant n’être pas
ressenti comme étranger (ex : machine). Néanmoins, d’un point de vue strictement
linguistique, ces mots sont des emprunts, puisqu’ils sont originaires d’une autre langue, et des
emprunts ‘étrangers’ ou xénismes car leur forme phonique (et parfois également leur forme
orthographique) ne suit pas les règles de la langue d’accueil.
Sous le terme ‘xénisme’, nous trouvons finalement une vaste catégorie de mots. En
effet, un emprunt pourra être classé comme xénisme à partir du moment où il n’est pas
totalement assimilé. Dans notre étude, nous nous concentrerons sur le niveau phonologique et
parfois orthographique, mais en théorie, est xénisme tout emprunt qui n’est pas assimilé à tous
les niveaux. Mais, même au niveau phonologique, le xénisme peut se trouver à différents
stades d’assimilation ; il peut être très assimilé (proche de l’assimilation totale), comme très
peu assimilé, c'est-à-dire proche de la forme d’origine. Par exemple, la prononciation du mot
accolade [«Qk´:lEId] — avec la terminaison <ade> prononcé [EId] et l’alternance des syllabes
accentuées et inaccentuées — sera considérée comme très assimilée (presque totalement,
excepté l’accentuation) par rapport à celle de l’expression entente cordiale

Le vocabulaire de l’emprunt 43
[«A)˘ntA)˘ntkç˘dI:A˘l], avec ses voyelles nasales, son accent final et quasiment toutes les
voyelles pleines, ce qui est inhabituel en anglais. Dans notre étude, nous ne tenterons pas de
classer les xénismes pour ne sélectionner parmi eux que les moins assimilés, ce qui serait une
tâche bien trop complexe et peut-être inutile, mais nous nous intéresserons à tous les
xénismes, puisque le moindre caractère français dans la prononciation d’un mot peut être
important.
4. Pérégrinisme
Si Deroy considère que xénisme et pérégrinisme sont synonymes, tous les linguistes
ne sont pas de cet avis. Bejta nomme pérégrinisme un emprunt qui n’a pas été intégré au
lexique (Bejta, 24 ; 35-36). Tournier, cité par Bejta, en donne une définition plus précise :
« Un pérégrinisme est un emprunt passager à une langue étrangère, utilisé dans le discours
pour la couleur locale. Il n’est pas lexicalisé dans la langue d’accueil » (Bejta, 35), avec pour
exemple : « Most French workmen just can’t do without their daily dose of pinard » (Bejta,
35). On trouve dans la thèse de Bejta une définition assez semblable, tirée de La Grammaire
d’aujourd’hui43, mais appliquée au terme xénisme44 : « Utilisation épisodique d’un mot
étranger » (Bejta, 31). Les exemples fournis sont assez proches de celui de Tournier, mais
plus détaillés :
Les mots chinois liumang (traduit par ‘hooligan’ - autre mot étranger ! – et
‘traîne-savates’) et touji daoba (‘spéculation lucrative’), observés en 1984 dans
un article sur la Chine, étaient sans doute à cette date trop peu intégrés pour
être tenus pour des emprunts. On parle fréquemment, dans les cas de ce genre, 43 Arrivé, Michel, et al. La Grammaire d’aujourd’hui. Paris : Flammarion, 1986.
44 Nous observons une fois de plus les problèmes du vocabulaire de l’emprunt. Ayant déjà proposé notre
définition de ‘xénisme’, nous rapprochons celle-ci de ‘pérégrinisme’.

44 Le corpus : les critères de sélection
de xénisme. Inversement, dazibao (‘affiche murale’) avait subi, notamment
lors de la Révolution culturelle, au moins certains aspects du second moment :
par exemple, il prenait l’-s du pluriel (des dazibaos). Il pouvait sans doute être
tenu pour un emprunt. (Bejta, 31)
Selon ces exemples, liumang et touji daoba ne peuvent être considérés comme des
emprunts car ils ne sont pas intégrés à la langue ; en revanche, le fait que dazibao prenne le
pluriel du français signifie qu’il est intégré. Les auteurs pensent donc qu’une assimilation
flexionnelle est un signe d’intégration. Cependant, appliquer le pluriel chinois supposerait une
très bonne connaissance de la langue. Il est donc plus simple d’utiliser le pluriel du français. Il
ne semble pas improbable que liumang, dans un contexte pluriel, se verrait également
appliquer le pluriel du français. Par conséquent, ce n’est sans doute pas une véritable preuve
d’intégration lexicale. Peut-être n’y a-t-il finalement pas tant de différences entre les deux
exemples.
Les définitions, qui mentionnent les termes ‘épisodique’ ou ‘passager’, font plutôt
référence à la fréquence d’emploi. Un pérégrinisme serait donc un emprunt peu fréquent, qui
ne serait pas lexicalisé, selon Tournier. Nous en déduisons que la lexicalisation est liée à la
fréquence d’emploi d’un emprunt. Mais à partir de quelle fréquence peut-on considérer qu’un
emprunt est lexicalisé ? Nous voyons bien qu’il est périlleux de vouloir classer les emprunts
selon leur fréquence d’emploi ou leur intégration au vocabulaire. D’autant qu’un lexème peut
fort bien faire partie du vocabulaire d’un locuteur, mais pas d’un autre. Par exemple, un mot
faisant partie d’un lexique spécialisé, comme c’est souvent le cas avec les emprunts français,
pourra être fréquemment employé par un locuteur habitué à ce lexique et donc intégré, mais
apparaître comme un mot rare et non intégré pour un autre locuteur.
Tournier parle également de ‘couleur locale’ quant à l’utilisation des pérégrinismes.
Ces emprunts sont donc fortement liés à la langue et la culture d’un pays, et y font

Le vocabulaire de l’emprunt 45
directement référence. Ce procédé est souvent employé par les journalistes et les écrivains.
Quand Pierre Loti écrit Ramuntcho, roman qui se déroule dans le pays basque, il décide
d’inclure un certain nombre de mots de la langue basque pour plonger le lecteur dans le
monde des personnages. Si, dans ce cas, nous pouvons déjà parler d’emprunt, il est néanmoins
évident que si ces mots ne sont pas utilisés dans un autre contexte, leur vie au sein de la
langue emprunteuse sera fort limitée. C’est en ce sens que Tournier et les auteurs de La
Grammaire d’aujourd’hui parlent d’emprunt épisodique ou passager. Mais s’il est employé à
maintes reprises, comme le font souvent les journalistes lors d’un sujet d’actualité, perdra-t-il
pour autant sa référence d’origine ? Reprenons l’exemple de dazibao : si l’usage de ce terme
était fréquent au cours de la Révolution Culturelle chinoise, il était probablement connu d’un
certain nombre de locuteurs, fréquemment usité et donc considéré comme intégré, mais il
restait uniquement employé en référence à la Chine. Nous connaissons, dans la langue
française, nombre d’emprunts de ce type : Perestroïka, datcha, sushi, mozzarella, etc. La
définition de porridge dans le Trésor de la Langue Française45 en est un bon exemple :
« Bouillie de flocons d'avoine chaude, additionnée de lait et de sucre, couramment servie au
petit déjeuner dans les pays britanniques. » Ce terme est donc suffisamment employé pour
être intégré à un dictionnaire, mais il est toujours lié à la culture britannique dans l’esprit du
locuteur. C’est d’ailleurs peut-être cette conscience d’un lien avec la culture et par conséquent
la langue étrangère qui fait conserver à tous ces emprunts une forme phonique, et parfois aussi
une forme orthographique, proche de celle du mot d’origine. Nous pouvons avancer
l’hypothèse que ces emprunts vont être difficilement assimilés et pour ainsi dire ‘bloqués’ à
un certain stade d’assimilation, afin de toujours garder un fort caractère étranger.
Cette catégorie d’emprunt est donc particulièrement intéressante pour notre étude, bien
qu’il ne soit pas toujours évident de déclarer un emprunt ‘pérégrinisme’. En effet, nous
45 Trésor de la langue française informatisé. CD-ROM. Paris : CNRS Éditions, 2004.

46 Le corpus : les critères de sélection
pouvons envisager l’idée que le pérégrinisme perde un jour sa référence étrangère pour se
mêler ‘anonymement’ aux autres mots de la langue. Il passerait alors par une période au cours
de laquelle il serait probablement pérégrinisme pour certains, simple xénisme pour d’autres.
Cette fois encore, nous ne tenterons pas d’étiqueter les emprunts, mais nous pourrons parfois
supposer être en présence d’un pérégrinisme, pour expliquer sa prononciation peu assimilée.
Contrairement à beaucoup de linguistes, nous n’opposons pas les termes pérégrinisme
et xénisme, ces deux termes désignant, du point de vue phonologique, des emprunts
inassimilés. Nous considérons plutôt un ensemble ‘xénisme’, regroupant tous les emprunts
non-assimilés, parmi lesquels nous trouvons les ‘pérégrinismes’, qui présentent une
caractéristique supplémentaire.
Il ne faut d’ailleurs pas confondre un pérégrinisme, qui fait référence à une réalité
étrangère, et un xénisme, parfois ressenti comme étranger par le locuteur parce qu’il a
conservé des caractéristiques étrangères, notamment graphiques et phoniques. En outre,
certains mots peuvent être ressentis comme étrangers en raison de leur forme, et pourtant
n’être pas des emprunts ; c’est le cas les faux-emprunts, que nous avons déjà mentionnés46, et
pour lesquels nous trouvons de nombreux exemples en français : smoking, footing, parking ;
comme en anglais : grotesquerie, pot-et-fleur, faux-naïf. Enfin, comme nous l’avons déjà dit
à propos de machine, il est également possible qu’un emprunt ait gardé des caractéristiques
étrangères et ne soit pourtant pas ressenti comme étranger par les locuteurs. On trouve en
anglais les exemples de garage ou naïve47. Par conséquent, le critère du ‘ressenti’ du locuteur,
s’il peut avoir un intérêt sociolinguistique, n’a pas vraiment lieu d’être pour une étude
phonologique des emprunts.
46 Cf. p. 32
47 Ces exemples nous viennent de réflexions de locuteurs anglophones natifs.

Le vocabulaire de l’emprunt 47
5. Les mots étiquetés ‘inassimilés’ dans l’OED
Comment doit-on alors interpréter le terme ‘unassimilated’ dans le dictionnaire OED ?
En réalité, ce terme n’apparaît pas tel quel dans le dictionnaire. Mais on trouve le symbole ||
devant certains mots que les éditeurs considèrent comme « non-naturalized or partially
naturalized ». Nous en déduisons que Baugh et Mossé font référence à ces entrées. Dans
l’introduction du dictionnaire, les éditeurs expliquent la signification de ce symbole. Ils
classent les mots en quatre catégories : naturals, denizens, aliens et casuals.
NATURALS include all native words like father, and all fully naturalized
words like street, rose, knapsack, gas, parasol. DENIZENS are words fully
naturalized as to use, but not as to form, inflexion or pronunciation, as aide-de-
camp, locus, carte-de-visite, table d’hôte. ALIENS are names of foreign
objects, titles, etc., which we require often to use, and for which we have no
native equivalents, as shah, geyser, cicerone, targum, backsheeh, sepoy.
CASUALS are foreign words of the same class, not in habitual use, which for
special and temporary purposes occur in books of foreign travel, letters of
foreign correspondents, and the like. (OED, General Explanations, Main
words, I)
Ce que les éditeurs de l’OED appellent aliens et casuals nous nommons pérégrinisme,
les denizens sont pour nous des xénismes et les naturals sont l’équivalent des mots
naturalisés. Mais les auteurs ajoutent que tandis que les emprunts aux langues peu familières
sont rapidement naturalisés, les emprunts au français et aux langues savantes, notamment le
latin, « which are assumed to be known to all the polite », restent souvent dans la catégorie
denizen pendant des siècles (OED, General Explanations, Main words, I). Ils citent pour
exemple aide-de-camp, toujours traité comme un mot français, et dont Mossé se demandait

48 Le corpus : les critères de sélection
s’il devait être considéré comme inassimilé48. Ils ajoutent : « The words marked with || in the
Dictionary comprise denizens and aliens, and such casuals as approach, or formerly
approached, the position of these » (OED, General Explanations, Main words, I). En somme,
ce symbole signale des xénismes. Baugh est donc dans l’erreur lorsqu’il déclare que ces mots
n’ont jamais fait partie de la langue anglaise, puisque les denizens sont des mots assimilés au
niveau de l’usage. Nous concluons de cette citation, d’une part qu’il ne faut pas supprimer ces
entrées, contrairement à ce que Baugh et Mossé ont fait, et d’autre part que ce symbole
pourrait peut-être nous être utile pour la sélection des emprunts.
Cependant, l’utilisation de ce symbole par l’OED est assez inconstante. Parfois, on le
trouve devant l’entrée comme pour abbé, accouchement, acharnement, cheval, etc., mais
d’autres fois, on ne le trouve que devant une transcription, comme c’est le cas avec actualité :
le dictionnaire propose une variante /«QktSu˘QlI:tEI/ et une autre variante précédée du
symbole || /aktyalite/. Comment doit-on l’interpréter, puisque ce symbole est censé donner
une indication sur le mot, et non sur l’une de ses variantes ? En outre, il ne permet pas de
différencier clairement les xénismes au niveau phonologique des xénismes au niveau
orthographique. Par exemple, on trouve l’entrée alamort, || à la mort : seule la graphie serait
donc considérée comme non-naturalisée, mais pas la prononciation /Ql´:mç˘t/. Mais alors
comment interpréter les autres entrées précédées de ce symbole ? Est-ce une indication sur le
caractère étranger de la graphie, de la prononciation, des deux ? L’exemple d’actualité
pourrait laisser penser que lorsque le symbole se trouve devant le mot, c’est pour indiquer une
orthographe non-naturalisée, et lorsqu’il se trouve devant la transcription, pour indiquer une
prononciation non-naturalisée. Mais peut-on considérer l’orthographe d’actualité comme
naturalisée ? De plus, on trouve également des exemples tels qu’aiguillette /«EIgwI:lEt/, qui
48 Cf. p. 31

Le vocabulaire de l’emprunt 49
n’a ni une graphie, ni une prononciation habituelles en anglais, et qui n’est pourtant pas
précédé du symbole ; pourquoi n’est-il pas présent dans ce cas ? Nous voyons ainsi que ce
symbole n’est pas une indication fiable pour notre sélection d’emprunts ; c’est pourquoi nous
n’allons pas nous en servir dans cette étude.
Doit-on suivre Mossé dans sa décision de ne sélectionner que les entrées ‘adopted
from French’ dans l’OED ? Selon le dictionnaire, un mot, s’il n’est pas un descendant de la
langue germanique, peut être adopté (‘adopted’), adapté (‘adapted’) ou bien formé (‘formed’)
à partir d’une langue étrangère (OED, General Explanations, Main words, II) :
Adoption is essentially a popular process, at work whenever the speakers of
one language come into contact with the speakers of another, from whom they
acquire foreign things, or foreign ideas, with their foreign names. […]
Adaptation is essentially a learned or literary process; it consists in adapting a
foreign word to the ‘analogies of the language’, and so depriving it of its
foreign termination. […] Formation consists in the combination of existing
words or parts of words with each other, or with living formatives, i.e.
syllables which no longer exist as separate words, but yet have an appreciable
signification which they impart to the new product. (OED, General
Explanations, Main words, II)
Donna Lee Berg, dans son Guide to the Oxford English Dictionary49, explique que
pour James Murray, le premier éditeur de l’OED, adopted faisait référence à l’intégration
informelle et graduelle de choses, d’idées, de noms étrangers dans la langue anglaise. On
trouve dans cette catégorie des termes naturalisés ou partiellement naturalisés (Berg, 24). Elle
propose l’exemple de restaurant, qui est la forme naturalisée du mot, lequel a été emprunté
sans changement orthographique (Berg, 24). Elle donne également l’exemple de salad, dont 49 Berg, Donna Lee. A Guide to the Oxford English Dictionary. Oxford : Oxford UP, 1993.

50 Le corpus : les critères de sélection
les formes anciennes ont été empruntées au vieux-français salade, lui-même emprunté au
provençal salada (Berg, 24). Selon Berg, l’adaptation pour Murray est au contraire un
processus délibéré qui consiste à altérer un mot étranger pour lui faire suivre les structures de
l’anglais (Berg, 24). Cependant, elle souligne que la distinction entre les deux catégories n’est
pas clairement définie et que, depuis la seconde édition du dictionnaire, on utilise adopted
pour les mots entrés dans la langue sans changement, tandis que les mots qui ont été modifiés
d’une quelconque manière sont considérés comme adapted (Berg, 25). Néanmoins, Philip
Durkin, dans son article « Root and branch : revising the etymological component of the
Oxford English Dictionary »50, au sujet de la préparation de la 3ème édition du dictionnaire,
remarque qu’il peut également être difficile de différencier la catégorie adapted de la
catégorie formed (Durkin, 8). En effet, si un suffixe est adapté pour suivre la structure
habituelle de l’anglais, par exemple <–ism> à la place de <–isme> (ex : cubism, emprunté au
français cubisme), on peut légitimement se demander s’il s’agit d’une adaptation ou bien
d’une formation du radical étranger avec le suffixe anglais. Ce type de mots appartiendrait
alors à la catégorie formed.
Nous concluons de ces explications que les mots désignés comme ‘adopted’ sont ceux
qui restent le plus proche de la langue d’origine. La décision de Mossé nous paraît dès lors
appropriée et nous décidons de l’appliquer pour notre sélection d’emprunts français en
anglais.
F. LIMITATION DU CORPUS
Afin de sélectionner principalement des emprunts inassimilés, nous procédons à de
nouvelles restrictions dans notre sélection.
50 Durkin, Philip N. R. « Root and branch : revising the etymological component of the Oxford English
Dictionary. » Transactions of the Philological Society 97/1 (1999) : 1-49.

Limitation du corpus 51
1. Délimitation temporelle de l’étude
On trouve des emprunts français en anglais depuis l’invasion normande au 11ème siècle
jusqu’à nos jours. Néanmoins il paraît indispensable de limiter notre étude dans le temps car il
est fort probable que des emprunts très anciens soient totalement assimilés. D’ailleurs,
plusieurs linguistes qui ont étudié les emprunts français en anglais, comme Jespersen,
qualifient les mots du type de ceux que nous souhaitons relever d’emprunts ‘récents’.
En effet, si on observe les emprunts de la période du moyen anglais (de l’invasion
normande à 1500 environ), on trouve essentiellement des mots totalement anglicisés aussi
bien dans leur prononciation que dans leur forme graphique : crown, state, empire, realm,
chancellor, treasurer, count, sir, madam, mistress, cloak, coat, etc. (exemples tirés de
l’ouvrage de Baugh, A History of the English Language51, 169-171). Cette remarque est
confirmée par une citation de Manfred Görlach, trouvée dans son ouvrage Introduction to
Early Modern English52 :
In ME times it was common for loanwords from French and Latin to spread
from upper-class use to lower-class speech, becoming variously adapted in the
process. Such integration was much less effective with loans from
contemporary languages from the sixteenth century on. Many words, in
particular those derived from French and Italian, appear to have been left
unadapted because they were regarded as shibboleths of educated speech.
(Görlach, 156-157)
51 Op. cit. p. 12
52 Görlach, Manfred. Introduction to Early Modern English. Cambridge : Cambridge UP, 1991.

52 Le corpus : les critères de sélection
Une citation de Mary S. Serjeantson dans son ouvrage A History of Foreign Words in
English53 nous offre une explication linguistique :
By the end of the fifteenth century, the majority of the changes which
distinguished Modern from Middle English had taken place, so that, whereas
French words borrowed before 1450 or so had to undergo, with native words,
sound-changes which transformed them completely from what they had been
in their parent language, words adopted after this were too late for these
developments, or most of them, and were less completely divorced from their
original forms, such differences as there are being due more to sound-
substitution than to sound-change. (Serjeanton, 157)
Dès le 16ème siècle, c’est-à-dire le début de l’anglais moderne, nous observons
effectivement un certain nombre d’emprunts français qui ont gardé jusqu’à aujourd’hui une
forme phonique plus proche du mot d’origine : bourgeois, maître d’hôtel, moustache, potage,
etc. C’est pourquoi nous décidons de ne retenir pour notre étude que les emprunts introduits
en anglais depuis 1500.
2. Le critère orthographique
En observant le type d’emprunt que nous souhaitons relever : rendezvous, lingerie,
déjà-vu, cliché, naïve, nous remarquons que leur forme orthographique est souvent restée
identique à celle du français. Nous postulons alors que les emprunts qui gardent une
prononciation proche du mot d’origine sont également ceux dont l’orthographe n’a pas été
adaptée aux règles orthoépiques de l’anglais et qui, de ce fait, gardent un caractère français
dans leur forme graphique. Suivant cette idée, nous décidons de ne retenir que les emprunts à
la graphie identique en français et en anglais.
53 Serjeantson, Mary S. A History of Foreign Words in English. London: Routledge, 1935.

Limitation du corpus 53
Nous sommes consciente de l’aspect contestable de ce critère, mais dans le domaine
des emprunts français en anglais, il serait regrettable de rejeter l’aspect graphique, en
considérant qu’il n’est pas du ressort de la linguistique. En effet, il est fort probable que la
majorité des emprunts, notamment dans la période moderne, soient parvenus par la voie de
l’écrit :
Most of the new words entered English by way of the written language. They
are a striking evidence of the new force exerted by the printing press. They also
furnish a remarkable instance of the ease with which the printed word can pass
into everyday speech. For although many of the new words were of a distinctly
learned character in the beginning, they did not remain so very long […].
(Baugh, History, 233)
De plus, la forme graphique influe sans doute sur la prononciation, comme le montre
l’histoire du mot bourse qui a été emprunté une première fois au 16ème siècle et adapté sous la
forme burse, prononcé /:bŒ˘s/. A la fin du 18ème, cette forme est devenue obsolète. L’anglais a
alors réemprunté le mot bourse au 19ème siècle, cette fois sans changement : le mot se
prononce à présent /:bU´s/. Un autre exemple de l’influence de la graphie sur la prononciation
est celui de pied-à-terre prononcé [«pjEIdA˘:tE´] alors que le <d> de pied n’est jamais
prononcé [d] mais [t] en français.
Nous ne prétendons pas avoir trouvé un critère incontestable, mais celui-ci présente
l’avantage de sélectionner en grande partie des emprunts inassimilés et de laisser de côté des
emprunts totalement assimilés qui n’auraient pas eu d’intérêt dans notre étude, et cela sans
avoir pris un seul critère phonologique.

54 Le corpus : les critères de sélection
3. Rappel des critères de sélection
Nous avons donc décidé de sélectionner dans l’Oxford English Dictionary tous les
mots et expressions ‘adopted from French’ et introduits en anglais depuis 1500.
Nous allons ensuite restreindre la sélection aux seuls mots ayant une orthographe
identique en français et en anglais à l’aide du dictionnaire Trésor de la Langue Française
Informatisé (TLFi)54. Les accents, cédilles, traits d’unions, voire les espaces ne sont pas pris
en compte car ils peuvent être conservés ou non en anglais. Par exemple, rendez-vous est écrit
rendezvous, élite peut être écrit avec ou sans accent et garçon peut être écrit avec ou sans
cédille.
Enfin, nous relèverons les transcriptions de ces emprunts dans différents dictionnaires
de prononciation anglaise.
54 Op. cit. p. 45

55
II. LA SELECTION DU CORPUS
Table des matières
A. Travailler avec l’Oxford English Dictionary...................................................................... 56
B. Application du critère orthographique................................................................................ 59
1. Les dictionnaires employés ........................................................................................... 59
2. Emprunts de verbes et de formes verbales .................................................................... 60
3. Non-correspondance des mots....................................................................................... 61
4. Les expressions.............................................................................................................. 62
5. Les faux-emprunts ou pseudo-gallicismes .................................................................... 63
C. Prononciation des emprunts................................................................................................ 65
1. Les dictionnaires employés ........................................................................................... 66
2. Les systèmes de transcription des dictionnaires............................................................ 67
a) Les symboles identiques pour tous les dictionnaires .............................................. 67
b) Les symboles qui diffèrent ...................................................................................... 67
(1) Les symboles de l’ODP ................................................................................... 67
(2) Nos choix de symboles .................................................................................... 68
(3) Les symboles complémentaires ....................................................................... 70
(4) Les symboles typographiques de l’ODP.......................................................... 71
c) Les voyelles nasales ................................................................................................ 71
3. Transcriptions problématiques de l’OED...................................................................... 74
4. Les transcriptions françaises ......................................................................................... 76
a) Les symboles employés........................................................................................... 76
b) Transcription des verbes et participes..................................................................... 78
c) Transcription des expressions ................................................................................. 80
5. Les problèmes liés à l’orthographe ............................................................................... 82
6. De nouveaux emprunts ? ............................................................................................... 83
7. Le corpus final............................................................................................................... 83

56 La sélection du corpus
A. TRAVAILLER AVEC L’OXFORD ENGLISH DICTIONARY
L’Oxford English Dictionary fait autorité parmi les dictionnaires sur la langue
anglaise. Il retrace l’évolution de la langue depuis 1150 jusqu’à nos jours, offrant plus de
500 000 entrées et proposant des citations pour illustrer chaque sens. C’est un dictionnaire
unique sur l’histoire de la langue anglaise et une source d’informations extrêmement riche.
La version électronique sur CD-Rom facilite le travail du chercheur et lui permet de
réaliser des recherches multicritères. La version 3.1 réunit les 20 volumes de la seconde
édition imprimée du dictionnaire, publiés en 1989, les additions (volumes 1 à 3) publiées en
1993 et 1997, ainsi que près de 2000 entrées réalisées par l’équipe de révision, qui prépare la
3ème édition du dictionnaire55.
Les critères de recherche ne permettent cependant pas de sélectionner uniquement les
mots ‘adopted from French’ (a. F. ou a. Fr.). Nous sélectionnons alors les entrées comprenant
la mention ‘French’ dans l’étymologie et dont la date d’introduction est postérieure à 1500.
Nous incluons les emprunts à l’ancien français (OFr.) ou au moyen français (MFr. ou mid.F.).
Il est par la suite nécessaire de procéder à un passage en revue manuel de chaque entrée afin
de ne retenir que les entrées correspondant à notre sélection.
Nous rejetons toute entrée ‘adapted from French’ (ad. F.) ou ‘formed on French’
(f. F.), comme nous l’avons déjà indiqué, mais également ‘after F.’, puisqu’il ne s’agit alors
pas d’un emprunt direct ; ou lorsque l’on trouve la mention ‘cf. F.’ qui propose de comparer
avec un mot de la langue française. En général, il s’agit dans ce cas d’emprunts au latin.
Les emprunts à l’ ‘Anglo-French’, ou anglo-normand, ne sont pas retenus car il est
probable qu’il s’agisse d’emprunts au dialecte picard ou normand, par exemple, et non au
français.
55 L’OED 3 est accessible sur abonnement (ajouté au reste de l’OED 2) sur le site : www.oed.com.

Travailler avec l’Oxford English Dictionary 57
Nous retirons également les entrées présentées comme ‘French or Latin’ ou avec un
point d’interrogation, ce qui signifie que l’étymologie est incertaine. Nous trouvons en effet
préférable de ne garder que les emprunts dont l’étymologie ne fait aucun doute. Nous retirons
aussi les étymologies avec « = F. » car nous ne sommes pas certaine de l’interprétation à
donner à ce symbole, qui n’est pas mentionné dans l’introduction du dictionnaire. Il semble
que cela signifie ‘équivalent à’, mais cette indication ne donne pas de réelle information sur
l’étymologie.
Les mots rares (rare), obsolètes (obs. ou précédés du symbole ), archaïques (arch.)
ainsi que les ‘nonce-words’ sont supprimés de la sélection, d’une part parce que nous
travaillons sur l’anglais contemporain, et d’autre part parce qu’il est peu probable que nous
trouvions la transcription de ces mots dans les dictionnaires de prononciation.
Les ‘corruptions’ et ‘refashioning’ de mots français ne sont pas inclus car ces
changements ont lieu au sein de la langue anglaise.
Les mots dialectaux (écossais, canadiens, américains) ne sont pas non plus retenus, de
même que les mots originaires d’un français hors de France, tel que le français canadien, car
nous travaillons essentiellement sur l’anglais britannique et les emprunts du français de
France.
Enfin, nous supprimons les ‘modern formations’ (mod. f.). En effet, il s’agit souvent
de termes scientifiques, identiques la plupart du temps en anglais, français et allemand.
Comme expliqué dans l’introduction du dictionnaire, il serait aussi difficile qu’inutile
d’essayer de déterminer l’étymologie de ces termes, qui sont choisis par une communauté
scientifique et non par une langue (OED, General Explanations, Main words, II).
Si l’utilisation de critères aussi précis nous semble être une bonne méthode, nous nous
apercevons néanmoins du manque de constance du dictionnaire dans la présentation des
étymologies. Comme Phillip Durkin l’explique dans son article « Root and branch : revising

58 La sélection du corpus
the etymological component of the Oxford English Dictionary »56, ceci est dû au nombre
important d’équipes différentes ayant travaillé sur le dictionnaire, non seulement pour la
première édition, mais également pour la seconde, ainsi que pour les additions (Durkin, 6). Il
en résulte une inconstance qui rend parfois la tâche plus difficile qu’elle n’y paraît. Par
exemple, pour un certain nombre d’entrées, on ne trouve ni a. ni ad., mais seulement ‘F.’.
Nous trouvons l’explication dans le Guide to the Oxford English Dictionary de Berg57 :
« Note, however, that for non-naturalized words such as palus² it is usual to indicate simply
the language of origin (in this case, Latin) and, sometimes, the meaning of the word in that
language » (Berg, 24). Nous en déduisons qu’il s’agit d’adoptions, et incluons ces entrées à
notre sélection.
De plus, le principe de l’étymologie telle qu’elle est expliquée dans l’introduction du
dictionnaire n’est pas toujours suivi, puisqu’on trouve des exemples comme « absurdity : a. F.
absurdité ». Si le suffixe <–ité> est changé en <–ity>, il y a donc adaptation et non adoption.
Remarquons qu’on trouve également « contractility : ad. F. contractilité », où l’étymologie
suit la définition du dictionnaire. Le dictionnaire n’est donc pas constant puisque le même
changement est noté parfois comme adoption et parfois comme adaptation. De même, on
trouve « colorific : ad. F. colorifique ». Il s’agit bien d’une adaptation puisque <–ique>
devient <-ic>. Mais alors pourquoi trouve-t-on « caloric : a. F. calorique » ?
Cette constatation nous fait douter de notre décision de restreindre la sélection aux
seules adoptions. Peut-être aurait-il fallu inclure également les adaptations et affiner la
sélection par la comparaison orthographique avec le français ? Cependant, les étymologies
notées comme adaptations ne sont pas à remettre en question ; il y a toujours effectivement
56 Op. cit. p. 50
57 Op. cit. p. 49

Application du critère orthographique 59
adaptation58. Le problème de l’étymologie se situe uniquement au niveau des adoptions, qui
mériteraient parfois d’être notées comme adaptations. Le choix des adoptions est donc le bon,
même si cette présélection mérite d’être affinée à l’aide d’autres critères. Il faut ajouter que si
le dictionnaire avait été totalement constant et avait suivi précisément la définition d’adoption,
il n’aurait peut-être pas été nécessaire de faire la comparaison orthographique.
B. APPLICATION DU CRITERE ORTHOGRAPHIQUE
Après avoir sélectionné les emprunts français introduits depuis 1500, nous décidons de
comparer l’orthographe de chaque entrée avec celle du français à l’aide du Trésor de la
Langue française59. Si le mot est absent de ce dictionnaire, nous procédons à une seconde
recherche avec le Grand Robert électronique60.
1. Les dictionnaires employés
Le Trésor de la Langue française informatisé (TLFi) est une référence pour la langue
française et l’un des dictionnaires les plus riches puisqu’il compte 100 000 entrées avec les
différents sens de chaque mot, illustrés par des exemples. La version informatisée du
dictionnaire, disponible sur CD-Rom ou gratuitement sur Internet61, regroupe les 16 volumes
de la version imprimée. Elle permet une recherche rapide et efficace, puisqu’il est alors
possible de trouver un mot non seulement parmi les entrées, mais également à l’intérieur de
chaque article, ce qui se révèlera très utile pour la recherche des expressions.
58 Nous verrons par la suite qu’il existe quelques exceptions.
59 Op.cit. p. 45
60 Le Grand Robert. Ed. Alain Rey et Alain Duval. CD-ROM. Paris : Le Robert, Havas Interactive, 1994.
61 Trésor de la Langue française informatisé. ATILF, CNRS, Universités Nancy 1 et Nancy 2.
http://atilf.atilf.fr/tlf.htm.

60 La sélection du corpus
Le Grand Robert est également riche d’environ 100 000 entrées, mais la version
électronique étant ancienne62, elle ne permet qu’une recherche par entrée, de la même manière
que lorsqu’on travaille avec une version imprimée.
2. Emprunts de verbes et de formes verbales
Si ce travail de sélection ne présente pas de problèmes majeurs, il subsiste quelques
questionnements. Par exemple, comment doit-on traiter les participes présents tels que
accusant ? En effet, nous ne trouvons pas le mot sous cette forme dans une entrée, mais sous
la forme infinitive du verbe. Néanmoins, cette forme est bien attestée en français et nous ne
pouvons donc la supprimer. Il convient alors, dans le cas des participes présents, de regarder
la conjugaison du verbe afin de déterminer si les orthographes correspondent.
De même les verbes empruntés ne se présentent qu’extrêmement rarement sous la
forme infinitive <-er>63. Les emprunts se présentent sans le suffixe de l’infinitif : s’agit-il
alors d’une adaptation ou bien de l’emprunt de la forme conjuguée ? On peut supposer que la
forme infinitive du français pose problème à l’anglophone car le suffixe <–er> correspond au
nom d’agent en anglais. Mais nous ne pouvons savoir sous quelle forme le verbe est
emprunté. Dans le doute, nous considérons qu’il s’agit d’un emprunt de la forme conjuguée
— la plupart du temps, la 1ère ou 3ème personne du singulier — et nous observons donc la
conjugaison du verbe pour l’inclure ou non à la sélection.
Il est particulièrement judicieux de regarder la conjugaison dans le cas des verbes, car
l’orthographe de certains verbes (ex : desert, v.) correspond bien à un mot en français
(désert, n.), ce qui a priori nous ferait garder ce mot dans la sélection, mais ne correspond pas
62 Il existe depuis 2005 une nouvelle version électronique, reprenant les six volumes de l’édition imprimée de
2001.
63 Nous avons en effet remarqué que ce sont en général des verbes du 1er groupe qui sont empruntés.

Application du critère orthographique 61
à la forme conjuguée. En effet, to desert vient du verbe déserter, dont la forme conjuguée est
‘je déserte’. Les orthographes ne correspondent donc pas et il convient de supprimer cette
entrée. De la même manière, nous supprimons to chagrin, qui vient du verbe chagriner, et
dont la forme conjuguée est ‘je/il chagrine’.
3. Non-correspondance des mots
Il est en fait parfois nécessaire de regarder la catégorie grammaticale de l’emprunt afin
de vérifier si les emprunts correspondent. Par exemple pour le nom chocolate. Comme les
accents ne sont pas pris en compte, puisqu’il peuvent apparaître ou non en anglais, chocolate
pourrait être considéré comme ayant la même orthographe que chocolaté. Cependant, il s’agit
d’un nom, qui plus est emprunté au nom chocolat. Il y a donc adaptation et cet emprunt n’est
pas retenu.
Il peut également être préférable de vérifier l’emprunt d’origine dans l’étymologie du
dictionnaire. Le mot calender existe en français, mais nous remarquons une différence de
sens. En anglais, ce mot désigne une machine à presser du papier ou du tissu dans le but
d’aplanir ou de lustrer. En français, en revanche, il désigne un moine mendiant chez les
Musulmans. En regardant l’étymologie, nous nous apercevons que calender est en réalité
emprunté au français calandre. Ce mot aurait dû être noté comme adaptation et non adoption.
Par conséquent, nous le supprimons de la sélection.
Il n’est bien entendu pas possible ni nécessaire de procéder à une vérification de
l’étymologie et du sens pour chaque emprunt, non seulement parce que les sens sont parfois
différents, mais surtout parce que ce genre de problème est assez rare. Il nous arrive donc de
procéder à des vérifications de temps à autre et de supprimer certains emprunts de cette
manière.

62 La sélection du corpus
Une interrogation surgit néanmoins : n’aurait-il pas été préférable de comparer la
forme empruntée, figurant dans l’étymologie, à la forme finale en anglais ? Cela aurait
certainement permis d’identifier aussitôt les adaptations du type de calender. Cependant, cette
méthode nous aurait également fait rejeter des cas comme colonel, sur lequel nous
reviendrons en détail, qui a d’abord été emprunté sous la forme coronel, puis ré-adopté
lorsque la forme française était devenue colonel. Il existe en anglais un certain nombre de cas
de ré-adoptions de la nouvelle forme française qu’il eût été dommage de ne pouvoir
commenter.
4. Les expressions
Il reste à traiter le cas des expressions. La définition d’une expression d’après le Guide
to the Oxford English Dictionary64 de Berg est la suivante :
Phrase (phr.): A group of words held together by a preposition, conjunction,
adverb, or verb (and hence not a combination or a collocation) that has a more
specific meaning than the individual components might suggest. (Berg, 157)
Elle oppose ‘phrase’ à collocation : « In modern linguistic terminology, a collocation
is sometimes defined as the context, or the habitual way, in which a particular word is used
together with another word of group of words » (Berg, 101). Il est parfois difficile de
différencier l’une de l’autre — sauce béarnaise est-elle une expression ou une collocation,
puisqu’il existe également sauce allemande, et que le terme sauce peut être trouvé
isolément ? — c’est pourquoi nous avons préféré prendre le terme expression au sens large.
Afin de suivre notre critère orthographique, nous avons décidé de n’inclure les
expressions que lorsque tous les mots qui la composent sont d’origine française, par exemple :
haute cuisine, jeunesse dorée, je ne sais quoi. Nous n’avons alors pas toujours pris en
64 Op. cit. p. 49

Application du critère orthographique 63
compte les espaces pour inclure des cas tels que malapropos, à l’origine expression, devenu
par la suite adverbe en un seul mot.
L’autre problème des expressions est qu’on ne les trouve pas toujours dans les
dictionnaires, qui privilégient les entrées par mot. Néanmoins, devrait-on supprimer
l’expression film noir, genre cinématographique pourtant connu ? De même, devrait-on
supprimer de notre corpus l’expression succès de scandale, simplement parce qu’on ne la
trouve pas dans le dictionnaire ? Nous décidons dans certains cas de faire appel à Internet afin
d’en savoir plus. Nous trouvons effectivement plus de pages anglophones que francophones
présentant cette expression. Sur Wikipedia65, nous apprenons que ce terme employé dans le
domaine artistique — une œuvre qui doit son succès à un scandale, comme Le déjeuner sur
l’herbe de Manet — trouve son origine dans le Paris de la Belle Époque. Ceci est confirmé par
un texte français sur le scandale de l’œuvre de Manet, dans lequel nous retrouvons
l’expression66. Il est fort probable que cette expression a été usitée à cette époque et reprise en
anglais, par exemple par le biais de la presse. Nous avons ainsi choisi de garder ce type
d’expressions et, le cas échéant, nous avons signalé dans le Lexique67 que celles-ci ne
figuraient pas dans les dictionnaires ou dans les pages francophones sur Internet.
5. Les faux-emprunts ou pseudo-gallicismes
La recherche des expressions dans le dictionnaire nous a fait prendre conscience de
deux types de mots et expressions que nous regroupons sous le terme ‘faux-emprunts’.
65 « Succès de scandale. » Wikipedia, the Free Encyclopedia. 11 sept. 2008. Wikimedia Foundation. 4 oct. 2008.
http://en.wikipedia.org/wiki/Succ%C3%A8s_de_scandale.
66 Valensi, Louis. « 1863, un scandale au salon des indépendants. » CDI Garches. 9 nov. 2004. 4 oct. 2008.
http://cdigarches.free.fr/pdf/041109_1863-Scandale-au-Salon_site.pdf.
67 Cf. Annexes (Cédérom).

64 La sélection du corpus
Il existe une première catégorie d’emprunts qui, s’ils ne correspondent pas à de
véritables mots ou expressions en français, en sont très proches. Double-entendre est
l’expression qu’on présente le plus souvent pour ce type de cas. L’expression correcte en
français est double-entente. Pour autant, entendre est bien un mot français. Un autre exemple
est cri de cœur, au lieu de cri du cœur. Il s’agit bien d’emprunts donc, mais ‘mal empruntés’
en quelque sorte. P. Fijn van Draat mentionne ces erreurs d’emprunts dans son article
« Aliens : Influx of French Words into English »68 :
Faulty accents, such as apaché, affiché, crêche, cortége abound. Wrong
spellings, —impressement, châteleine, à l’Anglais, are not rare; à outrance is
found corrupted into à l’outrance; double entente into double entendre; an
officer is said to be en parole, where on is meant, and many others besides.
(Draat, 323)
La seconde catégorie de mots, moins importante que la première, a l’aspect d’un
emprunt français, mais ne l’est absolument pas puisque la formation a été réalisée au sein de
la langue anglaise. Il s’agit des faux-emprunts à proprement parler. Nous pouvons donner des
exemples tels que grotesquerie, blousée, boudoiresque, déjà entendu, essuyance. Il s’agit
parfois de dérivés d’emprunts français (boudoiresque) ou bien d’expressions copiées sur
d’autres déjà existantes (déjà entendu et déjà lu, d’après déjà vu), ou encore d’un mot formé
avec un radical bien assimilé dans la langue anglaise auquel on ajoute un suffixe ‘français’
(blousée, de blouse + -ée ; chocolatesque).
Nous avons décidé de sélectionner ces faux-emprunts pour l’intérêt qu’ils représentent.
La deuxième catégorie de faux-emprunts doit d’ailleurs être assez peu usitée car par la suite
nous n’avons trouvé que rarement la prononciation de ces mots et expressions.
68 Op. cit. p. 11

Prononciation des emprunts 65
C. PRONONCIATION DES EMPRUNTS
Une fois la sélection du corpus réduite aux seuls emprunts dont l’orthographe est
identique en français et en anglais, il nous faut rechercher la ou les transcriptions des
emprunts à l’aide de dictionnaires de prononciation.
Nous décidons d’utiliser trois dictionnaires afin d’obtenir le maximum d’informations
sur ces différents emprunts : l’English Pronouncing Dictionary69 de Daniel Jones, le Longman
Pronunciation Dictionary70 de John Wells, ainsi que l’Oxford Dictionary of Pronunciation for
Current English71.
Nous ajoutons également les prononciations trouvées dans l’Oxford English
Dictionary, bien que celles-ci soient à considérer avec précaution. En effet, les prononciations
proposées par l’OED dans sa deuxième édition incluent des prononciations de la première
édition qui n’ont pas été réactualisées (Durkin, 37). Dès lors, il est possible que certaines
entrées du volume A, par exemple, présentent des prononciations datant de la fin du 19ème
siècle. D’autre part, le système de transcription employé pour les emprunts français semble
parfois obscur, comme nous allons le voir. Néanmoins, toutes précautions gardées, ces
informations nous paraissent utiles pour notre étude.
En plus de nous fournir les transcriptions nécessaires à l’étude de la phonologie des
emprunts français, la présence de ces emprunts dans un des dictionnaires de prononciation
nous offre une indication de la fréquence d’emploi de ce mot. En effet, l’OED, à partir duquel
nous avons réalisé notre corpus, est un dictionnaire si riche qu’il compte nombre de mots peu
courants, malgré l’élimination des entrées présentées dans le dictionnaire comme rarement
69 Op. cit. p. 31.
70 Op. cit. p. 33.
71 Oxford Dictionary of Pronunciation for Current English. Ed. Clive Upton, William A. Kretzschmar, Jr et Rafal
Konopka. Oxford : Oxford UP, 2001.

66 La sélection du corpus
usitées. Les dictionnaires de prononciation, en revanche, privilégient les mots et expressions
les plus courants. La présence d’un emprunt dans un de ces dictionnaires nous indique de ce
fait une certaine fréquence d’emploi. Nous pouvons même aller plus loin en examinant la
présence d’un emprunt dans les différents dictionnaires. En effet, si l’emprunt est présent dans
les trois dictionnaires de prononciation, il pourra être considéré comme plus fréquent qu’un
emprunt présent dans un seul des dictionnaires, comme c’est parfois le cas. De plus, compte
tenu de la richesse exceptionnelle de l’OED, un emprunt présent uniquement dans ce
dictionnaire sera considéré comme plus rare qu’un emprunt présent dans un seul des
dictionnaires de prononciation.
Bien entendu, les emprunts pour lesquels aucune prononciation n’est disponible sont
supprimés du corpus, puisqu’il serait alors impossible de les étudier.
Pour finir, nous recherchons la transcription française de chaque emprunt retenu à
l’aide du dictionnaire TLFi ou à défaut du Grand Robert, afin de permettre des comparaisons
entre la forme anglaise et la forme française.
1. Les dictionnaires employés
L’English Pronouncing Dictionary (EPD) de Daniel Jones est l’un des dictionnaires de
référence pour la prononciation de l’anglais britannique. La 16ème édition, accompagnée d’un
CD-Rom, propose plus de 80 000 entrées et 215 000 prononciations actuelles.
Le Longman Pronunciation Dictionary (LPD) de John Wells est un autre dictionnaire
de référence pour l’anglais britannique. La seconde édition propose 135 000 transcriptions et
ajoute la prononciation d’origine pour les mots étrangers.
Enfin l’Oxford Dictionary of Pronunciation for Current English (ODP) est un
dictionnaire plus récent, mais qui compte 100 000 entrées et plus de 300 000 transcriptions. Il

Prononciation des emprunts 67
utilise un système de transcription API légèrement différent des deux autres, sur lequel nous
aurons l’occasion de revenir.
2. Les systèmes de transcription des dictionnaires
Les systèmes de transcription employés par les différents dictionnaires sont assez
similaires dans l’ensemble. Nous allons donc nous arrêter sur les quelques points de
différence.
a) Les symboles identiques pour tous les dictionnaires
Tous les dictionnaires utilisent les mêmes symboles pour les consonnes de l’anglais :
p, b, t, d, k, g, f, v, T, D, s, z, S, Z, h, tS, dZ, m, n, N, l, r, j, w.
En ce qui concerne les voyelles, la plupart sont représentées par les mêmes symboles :
I, √, Å, U, ´, i˘, A˘, ç˘, u˘, eI, çI, ´U, aU, I´, U´.
Cependant les dictionnaires divergent sur quelques symboles, sur lesquels nous allons
nous attarder.
b) Les symboles qui diffèrent
(1) Les symboles de l’ODP
Si en général les anglicistes sont assez d’accord sur les symboles à employer pour
transcrire l’anglais, l’Oxford Dictionary of Pronunciation (ODP) prend quelques distances
avec ses confrères.
Dans l’introduction, les éditeurs de l’ODP expliquent qu’ils ont choisi de représenter
dans le dictionnaire une variété de RP « younger, unmarked » et d’une certaine manière plus

68 La sélection du corpus
large que le RP habituellement représenté. Ils représentent « what is heard used by educated,
non-regionally-marked speakers rather than what is ‘allowed’ by a preconceived model »
(ODP, Intro, xiii). Ce choix de représenter un RP moderne a nécessité quelques changements
dans les conventions de transcriptions existantes (ODP, Intro, xiii) :
• La voyelle du mot cat est symbolisée par [a] et non plus [Q] car, selon les
éditeurs, elle est de nos jours prononcée dans une position plus ouverte
qu’auparavant.
• De même la voyelle de bed est représentée par [E] et non pas [e] pour refléter
son abaissement.
• La diphtongue de nice est représenté par [√I] et non plus [aI] car son point de
départ se situe aujourd’hui dans la zone de la voyelle de but.
• La voyelle de hair est notée [E˘] et non plus [E´] car les éditeurs estiment que
la diphtongue devrait aujourd’hui être considérée comme caractéristique d’un
RP marqué (U-RP) parlé par les classes les plus aisées (upper-class).
• Enfin, la voyelle de bird est symbolisée par [´˘] et non plus [Œ˘]. Les éditeurs
ont omis d’expliquer leur choix, mais nous supposons qu’ils considèrent que
cette voyelle est aujourd’hui plus centrale et moins arrondie. Il faut cependant
noter que ce symbole était utilisé dans les éditions antérieures à 1977 de l’EPD.
(LPD, Introduction, xix)
(2) Nos choix de symboles
Excepté pour le symbole [E], nous avons choisi de ne pas utiliser ce système car, tout
en ne remettant pas en question les décisions des éditeurs de l’ODP, nous ne souhaitons pas
entrer dans un débat sur les meilleurs symboles pour représenter les phonèmes de l’anglais.

Prononciation des emprunts 69
Les choix de l’ODP étant innovants mais peu répandus parmi les anglicistes, nous préférons
nous en référer aux décisions de l’API.
L’ODP est le seul dictionnaire, parmi ceux que nous avons consultés, à utiliser ces
symboles — mis à part [E], employé également par l’OED. Nous avons également choisi
d’utiliser [E] et non [e] pour une raison majeure : nous adhérons à la décision de Lilly et Viel
qui, dans leur ouvrage La Prononciation de l’anglais72, suivent la notation de l’English
Pronouncing Dictionary (EPD) excepté pour cette voyelle, qu’ils considèrent proche du [E] du
français de père (Lilly et Viel, 7). Notre étude nous amenant à comparer les prononciations
française et anglaise, il nous semble capital de ne pas confondre le [e] du français — qu’on
trouve dans thé — et le son de l’anglais de bed, transcrit le plus souvent [e] par convention
entre anglicistes, mais phonétiquement plus ouvert que le son français et situé dans la zone du
[E] français.
Nous employons donc le symbole [E] et de la même manière [EI] et [E´], les voyelles
de chain et chair. En utilisant le symbole [EI], nous nous opposons à tous les éditeurs de
dictionnaires, qui emploient tous [eI], y compris l’OED et l’ODP qui ont pourtant fait le choix
de [E]. En revanche, l’OED emploie le symbole [E´], ce qui est plus cohérent.
72 Lilly, Richard et Michel Viel. La prononciation de l’anglais : règles phonologiques et exercices de
transcription. 1977. Paris : Hachette, 1998.

70 La sélection du corpus
(3) Les symboles complémentaires
On trouve parfois des symboles complémentaires dans certains dictionnaires. Par
exemple, le LPD propose [ÅU] comme variante de [´U] ; et l’OED propose le symbole [ç´]
pour des mots tels que core.
Par ailleurs, l’EPD et le LPD ajoutent les symboles [i] et [u] — tandis que l’ODP
n’ajoute que le symbole [i]. Le dictionnaire EPD en donne une explication détaillée dans
l’introduction : de nos jours, pour beaucoup de locuteurs, la distinction entre [I] et [i˘] est
neutralisée. Par exemple, la voyelle finale de city n’est ni [I] ni [i˘]. Dans ce cas, les éditeurs
utilisent le symbole [i]. De la même manière, ils emploient le symbole [u]. De plus, ils
énoncent un certain nombre de règles pour l’emploi de ces symboles. Par exemple, [I] et [U]
n’apparaissent jamais en fin de mot ; dans les mots composés tels que busybody, on trouvera
[i] en milieu de mot ; enfin, on trouvera [i] et [u] devant une voyelle (sauf pour les
diphtongues ou triphtongues) (EPD, Introduction, xiv).
Le dictionnaire LPD emploie également ces symboles, sans toutefois les expliquer. On
remarque cependant une phrase de John Wells, éditeur du LPD, dans son blog du 22
novembre 2006 : « you can also think of the happY vowel ‘i’ as an abbreviatory convention
meaning either [I] or [i˘] »73, ce qui signifierait qu’il ne faut pas interpréter ce symbole de la
même manière que dans l’EPD. Néanmoins, on remarque dans la page « Key to phonetic
symbols for English » du LPD, que les symboles [i] et [u] sont employés dans les mêmes cas
que l’EPD ; nous les considérons donc comme ayant la même valeur.
73 Wells, John. « Dictionary Conventions. » John Wells’s phonetic blog. 22 nov. 2006. UCL Division of
Psychology and Language Sciences. 22 nov. 2006. http://www.phon.ucl.ac.uk/home/wells/blog0611b.htm.

Prononciation des emprunts 71
L’ODP, enfin, ne propose que le symbole [i] et le présente comme la voyelle de -y
dans happy. Ce symbole indique une plus grande tension que pour le [I] habituellement utilisé
en anglais dans cette position, mais également une plus grande longueur (ODP, Introduction,
xiv). L’ODP n’utilise pas le symbole [u], mais l’EPD fait remarquer que les cas où ce
symbole est employé sont rares.
Dans leur introduction, les éditeurs de l’EPD expliquent que ces symboles ne sont pas
au sens strict des symboles de phonèmes ; c’est la raison pour laquelle nous ne les inclurons
pas dans nos transcriptions. Il s’agit en effet d’un symbole phonétique, comme le symbole du
L sombre […] : il indique une réalisation différente dans certains contextes. Cette information
n’est pas nécessaire pour les transcriptions phonologiques (ou semi-phonologiques)
auxquelles nous avons affaire.
(4) Les symboles typographiques de l’ODP
L’ODP ajoute deux nouveaux symboles : [I] et [U] qui ont la valeur [I] ou [´], et [U]
ou [´] respectivement (ODP, Introduction, xiv). Ces symboles n’ont aucune valeur
phonétique, mais seulement typographique : deux variantes sont représentées par un seul
symbole. Cependant, pour notre étude, nous n’avons pas souhaité conserver ce symbole et
nous avons transcrit à chaque fois les différentes variantes représentées.
c) Les voyelles nasales
Bien que les voyelles nasales ne fassent pas partie des phonèmes habituels de
l’anglais, on les trouve dans tous les dictionnaires de prononciation, ainsi que l’OED. Il
semble que cette particularité soit réservée aux mots d’origine française.

72 La sélection du corpus
Dans l’introduction du dictionnaire, les éditeurs de l’EPD expliquent que les locuteurs
anglophones tentent de produire des sons semblables aux voyelles du français [E)], [A)], [ç)] et
[ø)] qu’on trouve dans les mots vin, restaurant, bon marché ou Verdun. Bien que beaucoup
de locuteurs produisent des sons éloignés des voyelles françaises, le principe adopté est
d’utiliser des symboles de voyelles anglaises auxquels est ajouté le signe de nasalisation
(EPD, Introduction, xi-xii). Les équivalences sont :
Figure 1. Équivalences entre les voyelles nasales françaises et anglaises dans l’EPD.
Le dictionnaire LPD ne propose, lui, que trois voyelles nasales. Les éditeurs
expliquent dans l’introduction que les locuteurs instruits ont généralement une certaine
connaissance du français et tentent alors de prononcer les noms français ‘à la française’. Ils
utilisent alors des voyelles nasales et d’autres caractéristiques du français pour prononcer les
mots qu’ils perçoivent comme français. Ainsi les sons représentés par [Å)], [Q)] et [Œ)˘] peuvent
être considérés comme des membres secondaires du système des voyelles du RP (LPD,
Introduction, xxi). [Å)] se trouve dans des mots comme grand prix et chanson et est donc
équivalent à la fois aux [A)] et [ç)] du français. [Q)] et [Œ)˘] ont la même correspondance que
dans l’EPD.
Le dictionnaire ODP n’aborde pas des voyelles nasales dans son introduction.
Néanmoins, le symbole de nasalisation est ajouté aux voyelles de l’anglais pour certains mots
Français Anglais
E) Q)
A) A)˘
ç) ç)˘
ø) Œ)˘

Prononciation des emprunts 73
d’origine française. Nous retrouvons en réalité les mêmes symboles que dans le LPD : [Å)]
dans chanson et [Q)] dans vingt-et-un. Seul [Œ)˘] est absent. On peut également noter la
présence du symbole [ç)˘] dans le mot bombe.
Le dictionnaire OED présente les voyelles nasales comme celles du français. Il inclut
cependant un symbole anglais parmi celles-ci (OED, Key to the pronunciation) :
Figure 2. Les voyelles nasales dans l’OED.
D’après ce tableau, il est impossible de savoir si ces symboles sont à prendre comme
ceux du français — car l’OED propose souvent la transcription française, comme nous allons
le voir dans la section suivante — ou bien des symboles qui représentent la tentative des
locuteurs anglophones de reproduire les sons du français.
Les différents dictionnaires n’emploient ainsi pas forcément les mêmes symboles pour
représenter les voyelles nasales. A ce stade, il nous semble prématuré — voire impossible —
de décider de suivre un système plutôt qu’un autre. En effet, l’analyse des voyelles nasales est
entièrement liée à l’analyse de la prononciation des emprunts, qui sera réalisée ultérieurement.
Dès lors, nous prenons la décision de transcrire les voyelles nasales selon le système de
chaque dictionnaire et de laisser pour l’analyse la discussion sur le choix des symboles et leur
valeur.
Œ), Q) as in French fin
A) as in French franc
ç) as in French bon
ø) as in French un

74 La sélection du corpus
3. Transcriptions problématiques de l’OED
Les prononciations de l’OED sont transcrites à l’aide du système API. Cependant, cela
n’a pas toujours été le cas. A l’origine, l’éditeur James Murray avait créé son propre système
de transcription, à une époque où l’Alphabet Phonétique International n’était pas encore un
système mondialement reconnu et utilisé. Le système de Murray continua à être utilisé dans
les Suppléments, jusqu’à l’élaboration de la deuxième édition. Néanmoins, dans celle-ci, peu
de prononciations ont été réactualisées. Pour l’essentiel du dictionnaire, le système de Murray
a été converti informatiquement en API (OED, Introduction, The translation of the phonetic
system). Ceci explique que certaines prononciations puissent encore dater de la première
édition.
Le cas des prononciations des emprunts français est particulier dans l’OED. On trouve
trois types de cas : l’utilisation de symboles anglais, l’utilisation de symboles français, ou bien
une combinaison de symboles anglais et français. Parfois, pour une même entrée, plusieurs
cas sont représentés. Par exemple pour l’entrée coussinet :
La première prononciation est transcrite à l’aide de symboles anglais et nous la
considérons comme la transcription anglaise. En revanche, la seconde prononciation est
transcrite à l’aide de symboles français. La mention ‘or as F.’ nous indique qu’il s’agit d’une
prononciation française. De plus, l’accentuation n’est pas notée, ce qui est souvent le cas pour
les transcriptions françaises, puisque l’accent est toujours placé sur la syllabe finale. Doit-on
considérer pour autant que les anglophones prononcent ainsi ? Il est probable que non,
puisque nous avons vu qu’une certaine adaptation phonétique était obligatoire, les systèmes
français et anglais étant différents. Il semble donc que cette transcription française ne soit pas
Coussinet /:kUsInEt/ or as F. /kusinE/

Prononciation des emprunts 75
à prendre en compte dans notre étude, quoiqu’elle tente de montrer une imitation de la
prononciation française de la part du locuteur anglophone.
Les mélanges des systèmes français et anglais dans les transcriptions sont plus
problématiques. Nous trouvons un exemple avec corbeau :
Le symbole [Å] fait partie du système anglais, mais le symbole [o˘] du système
français. En outre, l’accentuation n’est pas notée, comme pour la transcription française de
coussinet. Dès lors, comment traiter ce type de transcription ? Doit-on l’inclure à notre étude
ou non ?
L’exemple de cul-de-sac, enfin, résume assez bien le problème des transcriptions dans
l’OED :
La première prononciation est transcrite à l’aide de symboles anglais, la deuxième à
l’aide de symboles français, et la troisième en combinant les symboles français et anglais. A la
lecture de cette entrée, nous comprenons que l’OED tente de retracer l’évolution de la
prononciation, depuis une variante proche de celle du mot d’origine (transcription française),
jusqu’à une variante plus assimilée (transcription anglaise), en passant par une période
intermédiaire. Cependant, l’utilisation de symboles français pour représenter la prononciation
de locuteurs anglophones est problématique. L’idée que des anglophones puissent prononcer
le son [y] du français semble inenvisageable. En effet, [y] est une voyelle d’avant, fermée et
arrondie. Le système anglais ne possède pas de voyelle d’avant arrondie ; il est donc peu
probable que des anglophones puissent prononcer ce son. Dès lors, il se produit
Corbeau /kÅrbo˘/
Cul-de-sac /:k√ld´sQk/ ; formerly as F. /kydsak/ ; often /kyld´sQk/

76 La sélection du corpus
nécessairement une adaptation ; c’est pourquoi le symbole [y] ne peut être représentatif de la
prononciation des locuteurs.
Après consultation par e-mail du chef de l’équipe étymologie de l’OED, Philip
Durkin, qui nous confirme les difficultés d’interprétation de certaines transcriptions
d’emprunts français, nous décidons de ne pas tenir compte d’une transcription dès qu’elle
présente au moins un symbole du système français.
4. Les transcriptions françaises
a) Les symboles employés
Pour finir, nous ajoutons la transcription du mot d’origine, ce qui permettra des
comparaisons entre la prononciation de départ et celle d’arrivée. Nous utilisons
prioritairement le Trésor de la Langue Française informatisé (TLFi), mais également le Grand
Robert, en complément.
Les symboles employés par le TLFi sont ceux de l’API. Pour les consonnes : p, b, t,
d, k, g, f, v, s, z, S, Z, n, m, ¯, w, Á, j, l et {.74 Pour les voyelles : e, E, o, ç, y, u, O, ø, a, A, i,
´, et les consonnes nasales A), ç), E) et ø).
Le Grand Robert utilise en majorité les mêmes symboles que le TLFi, mais certains
symboles diffèrent. Voici les équivalences :
74 Il est à noter que le dictionnaire fait l’erreur d’employer le symbole [˜] au lieu de [¯]. Nous corrigeons cette
erreur dans les transcriptions.

Prononciation des emprunts 77
Figure 3. Équivalences entre les symboles du Grand Robert et ceux de l’API.
Dans les transcriptions, les symboles de dévoisement et d’allongement ne sont pas
notés car ils ne sont pas distinctifs en français. Il s’agit là de symboles phonétiques et non
phonologiques.
Le symbole utilisé par les dictionnaires TLFi et Grand Robert pour noter la consonne
du mot rue est [{]. Suivant la notation de ces dictionnaires, nous avons également utilisé ce
symbole. Cependant, on peut remettre en question ce choix. En effet, d’après le tableau des
consonnes de l’API, [{] correspond à une ‘consonne roulée uvulaire’. Or, la consonne de rue
n’est réalisée avec ce son que dans certains dialectes français, comme l’expliquent les auteurs
de l’article sur le français dans Handbook of the International Phonetic Association75 (HIPA,
80). La majorité des locuteurs francophones utilise une fricative uvulaire notée [“] dans l’API,
qui est précisément le symbole utilisé dans la présentation des sons du français dans cet
ouvrage (HIPA, 80). Il aurait donc été plus judicieux d’employer ce symbole. Nous pouvons 75 Handbook of the International Phonetic Association. Cambridge : Cambridge UP, 1999.
Grand Robert TLFi / API α A ό ç ∞ ø θ ´ ä A) ö ç) ü ø) ë E) Σ Z ƒ S ñ ˜

78 La sélection du corpus
néanmoins nous demander pourquoi les deux dictionnaires préfèrent utiliser [{]. Dans l’article
sur la lettre R du TLFi, les éditeurs expliquent qu’il a été décidé par convention de noter [{] la
consonne spirante (fricative), contrairement à la notation de l’API. Le Grand Robert, en
revanche, dans l’article sur la lettre R, affirme que c’est la fricative uvulaire qui est notée [{]
dans l’API et que la consonne roulée est notée [r], d’où le choix du symbole [{] dans les
transcriptions.
Nous recherchons les transcriptions dans le Grand Robert lorsqu’elles sont absentes du
TLFi ou que ce dictionnaire ne propose qu’une transcription dans un système autre que l’API.
En effet, lorsque la rédaction du TLF a été entreprise, au début des années soixante, la norme
API apparaissait tout juste ; c’est pourquoi certains articles du volume A ou B ne sont pas
transcrits en API76. Le système alors employé n’étant pas expliqué dans le dictionnaire, nous
préférons dans ces cas chercher la prononciation dans le Grand Robert.
b) Transcription des verbes et participes
La transcription des verbes pose problème puisque nous avons vu qu’en général,
l’anglais a emprunté une forme conjuguée. Or, dans le dictionnaire on ne trouve que la forme
infinitive.
Cependant, dans le TLFi, une transcription de la forme conjuguée à la première
personne du singulier est parfois disponible. Il est fort probable que la forme empruntée en
anglais corresponde justement à la première ou troisième personne du singulier en français,
qui sont identiques pour les verbes du premier groupe. Par exemple, le verbe to accouche,
76 Information issue d’une correspondance par mail avec Pascale Bernard, membre de l’équipe du TLFi.

Prononciation des emprunts 79
Dénaturer = denaty{ + e
Dénature = denaty{
vient du verbe français accoucher /akuSe/. Le TLFi propose la prononciation de j’accouche
/akuS/.On peut dans ce cas prendre cette transcription pour la base de données.
Cependant, il arrive que le dictionnaire ne propose pas de prononciation du verbe
conjugué. C’est le cas du verbe dénaturer dont la forme conjuguée a été empruntée en
anglais : to denature. Nous avons alors décidé d’analyser le verbe. En général, le verbe à la
1ère ou 3ème personne du singulier correspond au radical, sans le suffixe de l’infinitif <–
er> /e/ :
Figure 4. Analyse d’un verbe du 1er groupe.
Dans toutes les situations de ce type, nous procédons à la même analyse et retenons la
forme sans le suffixe d’infinitif.
Le même type de problème se pose pour la transcription des participes présents et
passés. Par exemple, pour un mot tel que interpellant, adjectif en anglais, mais emprunté au
participe présent du verbe interpeller, nous ne trouvons pas de transcription. Néanmoins il
nous est possible de reconstruire la prononciation puisque le participe présent est formé du
radical auquel est ajouté le suffixe du participe présent :
Figure 5. Analyse d’un participe présent.
Pour trouver le radical du verbe, nous procédons comme précédemment :
Interpellant = interpell- + -ant

80 La sélection du corpus
Nous ajoutons au radical, le suffixe <–ant> /A)/ :
Nous procédons de la même manière pour les participes passés, en ajoutant le suffixe
<-é> /e/ au radical du verbe.
c) Transcription des expressions
La transcription française des expressions est problématique car dans la plupart des
cas, il n’existe pas de transcription de l’expression telle quelle. En général, on trouve
l’expression sous l’article d’un mot, et c’est la transcription de ce mot qui est disponible.
La solution que nous proposons est de reconstruire la prononciation des expressions en
cherchant la transcription de chaque mot qui la compose. Dans la base de données, nous
indiquons que la prononciation a été reconstruite par un astérisque la précédant.
Par exemple pour l’expression affaire de cœur, nous cherchons la transcription de
chaque mot :
Figure 6. Reconstruction de la transcription d’affaire de cœur.
Interpeller : /E)tE{p´le/ ou /E)tE{pEle/ ou /E)tE{pele/
Radical = /E)tE{p´l/ ou /E)tE{pEl/ ou /E)tE{pel/
Transcription = /E)tE{p´lA)/ ou /E)tE{pElA)/ ou /E)tE{pelA)/
affaire : /afE{/
de : /d´/
cœur : /kø{/
affaire de cœur : * /afE{d´kø{/

Prononciation des emprunts 81
Néanmoins, cette technique n’est pas toujours satisfaisante. Par exemple pour
acte gratuit :
Nous observons ici une succession de quatre consonnes [ktg{] ce qui paraît
imprononçable et donc improbable. Il est alors vraisemblable qu’un schwa soit inséré entre [t]
et [g]. Nous préférons l’ajouter à la transcription, mais le notons entre parenthèses pour
indiquer que nous l’avons ajouté :
Le même type de problème est posé avec l’expression fines herbes. La reconstruction
donne le résultat :
Cette prononciation est gênante car elle ne rend pas la liaison, qui est d’autant plus
importante qu’elle n’est pas prononcée dans deux variantes anglaises de cette expression —
/«fi˘n:E´b/ et /«fi˘n:Œ˘b/. Ici encore, nous décidons d’ajouter la liaison, mais de la noter entre
parenthèses.
acte : /akt/ + gratuit : /g{atÁi/ acte gratuit : * /aktg{atÁi/
acte gratuit : * /akt(´)g{atÁi/
fines herbes : /fin/ + /E{b/ * /finE{b/
fines herbes : * /fin(z)E{b/

82 La sélection du corpus
5. Les problèmes liés à l’orthographe
Nous avons pris le parti de ne pas tenir compte des accents graphiques pour les
emprunts. Il est d’ailleurs fort courant de voir notés les accents dans une variante et pas dans
l’autre (ex : canapé, canape ; mélange, melange ; char-à-banc, char-a-banc), ou bien dans
un dictionnaire et pas dans l’autre. Dès lors, il peut y avoir confusion entre plusieurs mots qui
auraient la même orthographe sans accent. Par exemple, dans le corpus, réalisé à l’aide du
dictionnaire OED, nous trouvons l’entrée goût. Dans l’EPD, nous ne trouvons pas l’entrée
avec accent, mais le mot gout. S’agit-il pour autant du même mot ? Cette entrée est transcrite
/gaUt/, ce qui nous fait douter car nous avons remarqué que lorsque l’accent graphique est
présent, la prononciation avait tendance à garder des caractéristiques étrangères. D’ailleurs, la
transcription proposée par l’OED à l’entrée goût est /:gu˘/ En outre, dans l’OED il existe
également une entrée gout avec la même transcription. Nous en concluons que goût et gout ne
correspondent pas : l’entrée goût n’est donc pas présente dans l’EPD, c’est pourquoi nous ne
notons aucune transcription pour ce dictionnaire.
Parfois ce sont les différentes variantes orthographiques qui posent problème. Par
exemple, on a dans l’OED l’entrée quartet, quartette. Les deux variantes correspondent à des
mots différents en français. Pour noter la transcription française correspondant à l’emprunt, il
convient alors de regarder l’étymologie pour savoir quel mot a été emprunté. Ici, c’est
quartette qui a été emprunté, quartet n’étant qu’une variante graphique anglicisée.
Nous pouvons noter par ailleurs que toute nouvelle variante orthographique trouvée
dans un dictionnaire est ajoutée à l’entrée. En général, il s’agit de variantes avec ou sans
accents graphiques.

Prononciation des emprunts 83
6. De nouveaux emprunts ?
Au cours de notre recherche des transcriptions dans les dictionnaires de prononciation,
nous avons remarqué un certain nombre d’entrées qui ont une forme clairement identifiée
comme française, mais que nous n’avons pas trouvé dans l’OED : crème fraîche, danse
macabre, eau de Cologne, eau de nil, eau de parfum, eau de toilette. S’agit-il d’emprunts
trop récents pour figurer dans les dictionnaires de langue ? Sont-ils uniquement employés à
l’oral, ce qui expliquerait leur absence de l’OED, qui illustre ses entrées par des citations
écrites ? La seconde hypothèse semble peu probable étant donnée leur forme et le fait que les
emprunts français passent majoritairement par l’écrit. La première hypothèse est en revanche
plausible, mais elle ne pourra être vérifiée que dans quelques années, lors de la parution de
nouveaux volumes de l’OED.
7. Le corpus final
Après avoir relevé toutes les transcriptions, nous supprimons les entrées pour
lesquelles aucune transcription anglaise n’a été trouvée, ainsi que les entrées pour lesquelles
aucune transcription française n’a été trouvée puisqu’il serait alors impossible de confronter
les prononciations, notamment pour tenter de comprendre comment sont adaptés certains
phonèmes du français. Nous pouvons à ce propos signaler que tous les mots anglais emprunts
de noms propres français (ex : leotard) ont dû être supprimés, car la prononciation n’est pas
proposée dans les dictionnaires de noms propres.
Au final, nous obtenons un corpus de 3037 entrées. Il ne nous reste qu’à réaliser la
base de données qui sera la source du travail de recherche.


85
III. LA BASE DE DONNEES
Table des matières
A. Intérêt d’une base de données............................................................................................. 86
B. Les données ........................................................................................................................ 86
1. Transcriptions phonologiques ....................................................................................... 86
a) Les variantes anglaises ............................................................................................ 86
b) Informations complémentaires................................................................................ 88
c) Indication de l’origine française.............................................................................. 89
d) Transcriptions françaises......................................................................................... 90
2. Autres éléments ............................................................................................................. 91
a) Catégorie grammaticale........................................................................................... 91
b) Date d’emprunt ....................................................................................................... 91
c) Place de l’accent primaire ....................................................................................... 91
d) Nombre de syllabes................................................................................................. 92
3. Données additionnelles.................................................................................................. 92
a) Fréquence ................................................................................................................ 92
b) Commentaires ......................................................................................................... 93
c) Comparer ................................................................................................................. 93
d) Sondage................................................................................................................... 93
C. Lecture des dictionnaires .................................................................................................... 94
1. Usage du tiret................................................................................................................. 94
2. Phonèmes optionnels..................................................................................................... 95
3. Consonnes syllabiques .................................................................................................. 96
4. Coupe syllabique ........................................................................................................... 98
a) EPD ......................................................................................................................... 98
b) LPD ......................................................................................................................... 99
c) Décision................................................................................................................. 100
D. Finalisation ....................................................................................................................... 101

86 La base de données
A. INTERET D’UNE BASE DE DONNEES
Une fois le corpus sélectionné et les transcriptions de chaque emprunt relevées, nous
pouvons réaliser une base de données qui nous permettra d’exploiter ce corpus. Nous créons
alors un tableau informatisé intégrant différents champs de recherche et qui regroupe toutes
les informations nécessaires sur chaque mot du corpus77.
L’intérêt d’une base de données informatisée est de pouvoir mener une recherche
rapide et efficace. Il est possible de travailler sur un champ en particulier ou bien d’opérer des
sélections à partir de filtres. Cela permet, par exemple, de sélectionner tous les ‘substantifs’
dans le champ ‘catégorie grammaticale’, ou bien les ‘verbes dissyllabiques’ en filtrant le
champ ‘catégorie grammaticale’ ainsi que le champ ‘nombre de syllabes’.
B. LES DONNEES
Un certain nombre de données sont nécessaires à la recherche sur la phonologie des
emprunts français : les transcriptions des emprunts, leur catégorie grammaticale, leur date
d’entrée dans la langue anglaise, ainsi que le nombre de syllabes et la place de l’accent
primaire dans chaque variante.
1. Transcriptions phonologiques
a) Les variantes anglaises
Puisque le but est d’étudier la phonologie des emprunts, la transcription est
évidemment l’élément indispensable. Comme décrit au chapitre précédent, nous avons relevé
les transcriptions des différents emprunts dans trois dictionnaires de prononciation (EPD,
77 Cf. Annexes (Cédérom).

Les données 87
LPD, ODP) ainsi que dans l’OED. Afin de rendre la lecture de la base de données plus aisée,
nous avons décidé d’utiliser le même système de transcription pour toutes les variantes, ce qui
implique parfois l’adaptation du système employé par le dictionnaire — à l’exception
toutefois des voyelles nasales, pour lesquelles nous avons préféré laisser les symboles choisis
par les éditeurs du dictionnaire.
Pour chaque variante nous créons une entrée et numérotons la variante comme le
montre cet exemple :
Figure 7. Numérotation des variantes.
Nous ajoutons une colonne pour chaque dictionnaire et notons la variante dans la
colonne correspondante. Il est évidemment fort courant que plusieurs dictionnaires proposent
la même variante. Afin d’intégrer cette information — qui sera utile pour juger de la
fréquence de l’emprunt — sans toutefois alourdir la base de données, nous notons un signe =
dans la colonne correspondante :
Entrée EPD LPD ODP OED
attaché 1 ´:tQSEI = = =
attaché 2 Q:tQSEI
attaché 3 ´:tQSI
Extrait BD 1. Présentation des variantes identiques.
Dans cet exemple, nous trouvons la variante [´:tQSEI] dans tous les dictionnaires, la
variante [Q:tQSEI] uniquement dans l’EPD et enfin la variante [´:tQSI] uniquement dans le
LPD.
attaché 1 ´:tQSEI
attaché 2 Q:tQSEI
attaché 3 ´:tQSI
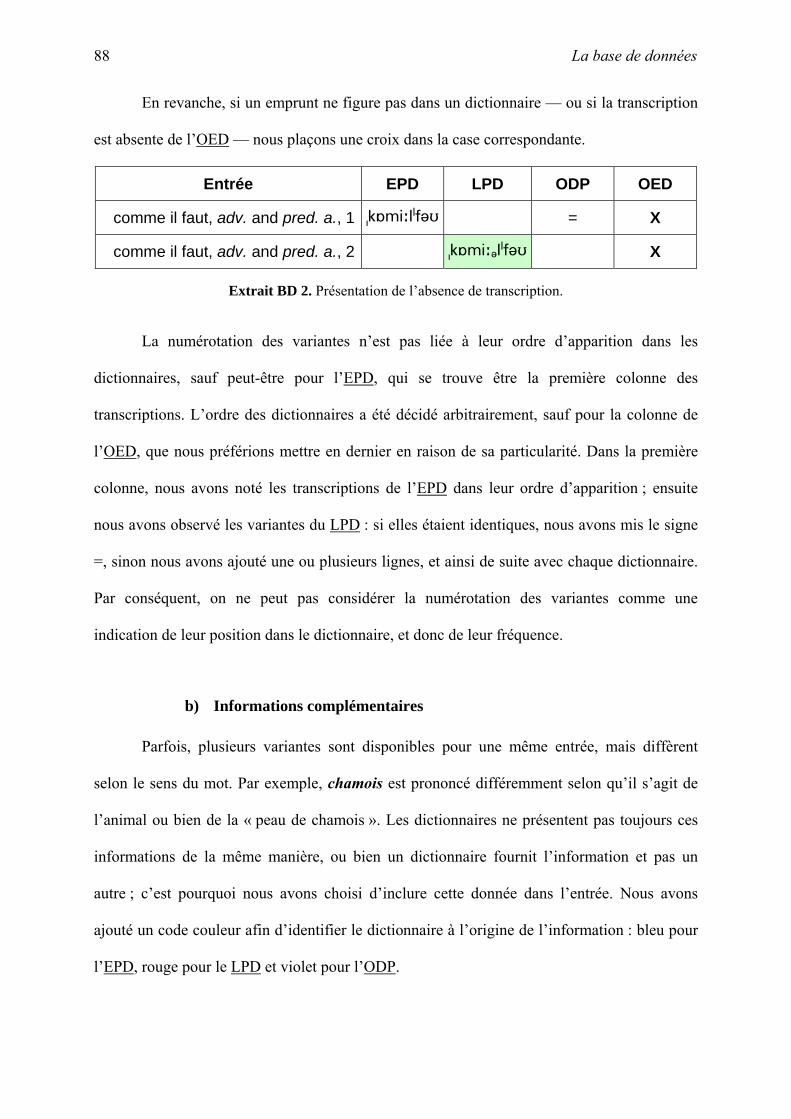
88 La base de données
En revanche, si un emprunt ne figure pas dans un dictionnaire — ou si la transcription
est absente de l’OED — nous plaçons une croix dans la case correspondante.
Entrée EPD LPD ODP OED
comme il faut, adv. and pred. a., 1 «kÅmi˘l:f´U = X
comme il faut, adv. and pred. a., 2 «kÅmi˘´l:f´U X
Extrait BD 2. Présentation de l’absence de transcription.
La numérotation des variantes n’est pas liée à leur ordre d’apparition dans les
dictionnaires, sauf peut-être pour l’EPD, qui se trouve être la première colonne des
transcriptions. L’ordre des dictionnaires a été décidé arbitrairement, sauf pour la colonne de
l’OED, que nous préférions mettre en dernier en raison de sa particularité. Dans la première
colonne, nous avons noté les transcriptions de l’EPD dans leur ordre d’apparition ; ensuite
nous avons observé les variantes du LPD : si elles étaient identiques, nous avons mis le signe
=, sinon nous avons ajouté une ou plusieurs lignes, et ainsi de suite avec chaque dictionnaire.
Par conséquent, on ne peut pas considérer la numérotation des variantes comme une
indication de leur position dans le dictionnaire, et donc de leur fréquence.
b) Informations complémentaires
Parfois, plusieurs variantes sont disponibles pour une même entrée, mais diffèrent
selon le sens du mot. Par exemple, chamois est prononcé différemment selon qu’il s’agit de
l’animal ou bien de la « peau de chamois ». Les dictionnaires ne présentent pas toujours ces
informations de la même manière, ou bien un dictionnaire fournit l’information et pas un
autre ; c’est pourquoi nous avons choisi d’inclure cette donnée dans l’entrée. Nous avons
ajouté un code couleur afin d’identifier le dictionnaire à l’origine de l’information : bleu pour
l’EPD, rouge pour le LPD et violet pour l’ODP.

Les données 89
Entrée EPD LPD ODP OED
chamois, n., 1 [leather ; (ii) ; leather] :SQmI = = =
chamois, n., 2 [goat-antelope ; (i) ; animal] :SQmwA˘ = =
chamois, n., 3 :SQmçI
Extrait BD 3. Présentation des informations complémentaires.
Nous ajoutons également en commentaire quelques annotations des dictionnaires à
propos des variantes, du type ‘formerly’, ou des précisions sur le sens ou le champ lexical de
la variante, comme pour assemblage prononcé [«QsÅm:blA˘Z] ‘with reference to wine
blending’ selon le LPD.
c) Indication de l’origine française
Dans les dictionnaires, nous trouvons souvent des informations relatives à l’origine du
mot ou à sa prononciation. Par exemple, dans l’EPD on trouve parfois la mention ‘as if
French’ précédant une variante. Les éditeurs commentent dans l’introduction du dictionnaire
la mention équivalente ‘as if Italian’ : « To indicate that this last pronunciation is aimed at
sounding Italian, it is marked in the entry as : as if Italian » (EPD, Introduction, vii). Nous
avons choisi d’indiquer cette mention par un fond de couleur jaune dans la cellule contenant la
variante en question.
De même, le LPD propose souvent la transcription dans la langue d’origine de
l’emprunt. Les éditeurs expliquent dans l’introduction que cette information est ajoutée
lorsque le mot « can either be pronounced in a way that imitates the foreign language or be
integrated into the English sound system » (LPD, Introduction, xxi). Nous l’avons indiqué par
un fond vert.
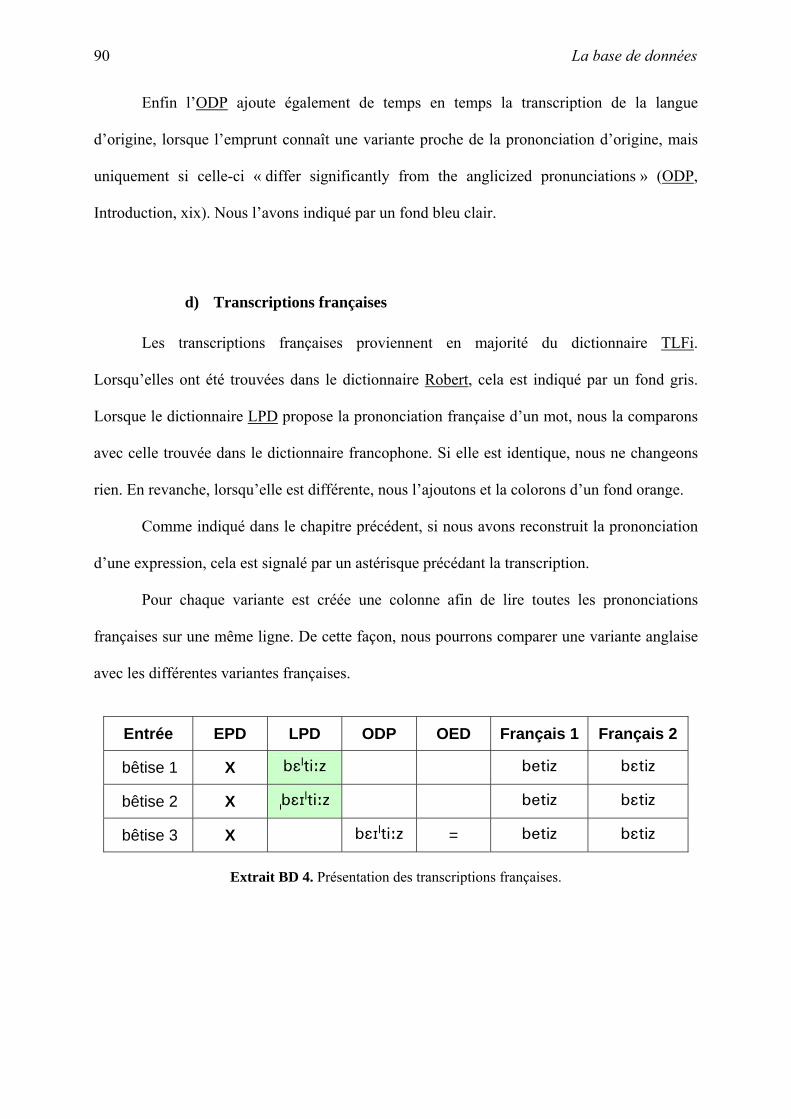
90 La base de données
Enfin l’ODP ajoute également de temps en temps la transcription de la langue
d’origine, lorsque l’emprunt connaît une variante proche de la prononciation d’origine, mais
uniquement si celle-ci « differ significantly from the anglicized pronunciations » (ODP,
Introduction, xix). Nous l’avons indiqué par un fond bleu clair.
d) Transcriptions françaises
Les transcriptions françaises proviennent en majorité du dictionnaire TLFi.
Lorsqu’elles ont été trouvées dans le dictionnaire Robert, cela est indiqué par un fond gris.
Lorsque le dictionnaire LPD propose la prononciation française d’un mot, nous la comparons
avec celle trouvée dans le dictionnaire francophone. Si elle est identique, nous ne changeons
rien. En revanche, lorsqu’elle est différente, nous l’ajoutons et la colorons d’un fond orange.
Comme indiqué dans le chapitre précédent, si nous avons reconstruit la prononciation
d’une expression, cela est signalé par un astérisque précédant la transcription.
Pour chaque variante est créée une colonne afin de lire toutes les prononciations
françaises sur une même ligne. De cette façon, nous pourrons comparer une variante anglaise
avec les différentes variantes françaises.
Entrée EPD LPD ODP OED Français 1 Français 2
bêtise 1 X bE:ti˘z betiz bEtiz
bêtise 2 X «bEI:ti˘z betiz bEtiz
bêtise 3 X bEI:ti˘z = betiz bEtiz
Extrait BD 4. Présentation des transcriptions françaises.

Les données 91
2. Autres éléments
a) Catégorie grammaticale
Il est important d’ajouter la catégorie grammaticale des emprunts car les règles
d’accentuation varient selon la partie du discours. Cela permet également de faire des
statistiques sur les catégories les plus empruntées.
Il arrive cependant assez souvent que l’emprunt appartienne à plusieurs catégories
grammaticales. Nous indiquons alors les différentes catégories, par exemple ‘adj. / n.’.
b) Date d’emprunt
La date d’emprunt est importante car on peut supposer qu’il y a des différences
d’assimilation selon l’ancienneté de l’emprunt ou sa période d’emprunt. Cela permettra peut-
être d’observer les différents degrés d’assimilation.
Nous pouvons ajouter qu’il ne s’agit pas forcément de la véritable date d’emprunt,
puisque le moment de l’emprunt est difficile à saisir (Haugen, 212), mais de la première
citation relevée par l’OED dans des écrits.
c) Place de l’accent primaire
Nous ajoutons une colonne qui indique la place de l’accent primaire pour chaque
variante. De cette façon nous pourrons observer si l’accent est majoritairement placé en finale
comme en français, ou bien sur une autre syllabe, ce qui est plus conforme aux habitudes de
l’anglais.

92 La base de données
d) Nombre de syllabes
Le nombre de syllabes va de pair avec la place de l’accent primaire car il convient de
dissocier les dissyllabes des mots de trois syllabes et plus, les règles d’accentuation appliquées
n’étant pas les mêmes pour ces deux catégories.
3. Données additionnelles
Nous ajoutons des informations trouvées dans les différents dictionnaires afin d’étoffer
la base de données et d’enrichir l’analyse des emprunts.
a) Fréquence
Nous n’obtenons pas cette donnée d’un dictionnaire de fréquence ; elle est déduite de
la présence d’un emprunt dans un ou plusieurs des dictionnaires de prononciation. Comme
nous l’avons exposé au chapitre précédent78, les dictionnaires de prononciation proposent les
transcriptions des mots les plus courants, tandis que l’OED compte également nombre de
mots moins usités. Nous en déduisons qu’un emprunt présent dans un seul des dictionnaires
de prononciation sera plus fréquent qu’un emprunt présent uniquement dans l’OED. De
même, un emprunt présent dans plusieurs, voire tous les dictionnaires de prononciation, sera
considéré comme plus fréquemment employé.
Dans cette colonne, nous notons donc le nombre de dictionnaires dans lesquels nous
trouvons l’emprunt. Étant donné la particularité de l’OED, nous notons en gras une
transcription trouvée seulement dans l’OED, car elle sera a priori moins fréquente qu’une
transcription trouvée dans un seul dictionnaire de prononciation.
78 Cf. p. 65

Les données 93
Entrée EPD LPD ODP OED Fréquence
abattoir :Qb´twA˘ = = = 4
abri X X X ´:bri˘ 1
acajou :Qk´Zu˘ X = X 2
accoutre, v. ´:ku˘t´ X = = 3
Extrait BD 5. Présentation de la fréquence des variantes.
b) Commentaires
Ces données proviennent de l’OED et nous informent sur l’histoire de la
prononciation, de l’accentuation ou encore de l’orthographe des emprunts. Elles peuvent donc
nous éclairer sur la forme ou sur la prononciation actuelle de certains emprunts.
c) Comparer
Nous ajoutons cette colonne pour indiquer qu’il existe un ou des mots très proches de
celui de l’entrée et avec lequel il serait intéressant de comparer la prononciation. Il s’agit
parfois de variantes orthographiques proches (ex : artist et artiste), de catégories
grammaticales différentes (ex : combat, n. et v.) ou de sens différents (ex : clavier, ‘keyboard’
et ‘instrument’).
d) Sondage
Ces informations proviennent du dictionnaire LPD. L’auteur a en effet réalisé deux
sondages, en 1988 et 1998, sur les préférences des locuteurs pour l’accentuation ou la
prononciation de certains mots (LPD, Introduction, xii). Ces résultats pourraient enrichir notre
analyse, c’est pourquoi nous souhaitons les inclure à la base de données.

94 La base de données
C. LECTURE DES DICTIONNAIRES
Tous les dictionnaires ne présentent pas les différentes variantes de la même manière.
Nous expliquons ici comment lire et interpréter les dictionnaires de prononciation, afin de
mieux comprendre notre base de données.
1. Usage du tiret
Les dictionnaires EPD, LPD et OED utilisent le tiret pour représenter une partie de la
variante précédente. Le LPD utilise parfois un point pour représenter une syllabe, dans les
variantes accentuelles. L’ODP, en revanche, préfère noter toutes les variantes en entier.
Néanmoins, il utilise parfois le signe + dans le cas des expressions.
Voici des exemples d’entrées dans les différents dictionnaires :
Figure 8. Exemples de transcriptions dans les dictionnaires.
Le tiret doit être interprété comme reprenant la ou les variantes précédentes. Ainsi une
entrée telle que chaise-longue doit être lue de cette manière :
EPD : gendarme :ZA)˘ndA˘m, :Zç)˘n–, :ZA˘n–
LPD : gendarme :ZÅndA˘m, :ZÅ)d–
langouste «lÅN:gu˘st, : • •
ODP : gendarme :ZÅndA˘m, :ZÅ)dA˘m
maître d’hôtel «mEItr´ d´U:tEl, «mEtr´ +

Lecture des dictionnaires 95
Figure 9. Interprétation de l’entrée chaise-longue.
2. Phonèmes optionnels
Les phonèmes optionnels sont symbolisés de manière différente selon les
dictionnaires. Dans l’EPD, ils sont représentés en italique (EPD, Introduction, xv). Dans le
LPD, ils sont représentés en italique ou en exposant, en considérant que le phonème en
italique peut être « optionally omitted », et que le phonème en exposant peut être « optionally
inserted » (LPD, Introduction, xviii), avec pour recommandation aux locuteurs étrangers
d’inclure le phonème en italique, mais d’exclure le phonème en exposant (LPD, 537). Enfin,
l’ODP et l’OED présentent les phonèmes optionnels entre parenthèses (ODP, Introduction, x).
Dans notre base de données, nous avons choisi de présenter les phonèmes optionnels
en italique :
Néanmoins, les dictionnaires utilisent très souvent ce symbole par souci d’économie
typographique, comme dans cet exemple :
chaise-longue «SEIz:lÅN, «SEz–, –:lÅNg, –:lç)˘Ng
variante «SEz– [–] = :lÅN «SEz:lÅN
variante –:lÅNg [–] = «SEIz «SEIz:lÅNg
[–] = «SEz «SEz:lÅNg
variante –:lç)˘Ng [–] = «SEIz «SEIz:lç)˘Ng
[–] = «SEz «SEz:lç)˘Ng
appellation contrôlée QpElQs«jç)˘Nkç)˘ntr´U:lEI
bureau bjU´:r´U

96 La base de données
Ici, il ne s’agit pas d’un phonème optionnel, mais d’une manière économique de
présenter deux phonèmes différents ; à la fois la monophtongue [U] : [bjU:r´U], et la
diphtongue [U´] : [bjU´:r´U]. Lorsque le phonème en italique est utilisé pour ce type de cas,
nous avons préféré présenter chaque variante séparément.
Nous avons également décidé de présenter les variantes séparément lorsque la
présence ou non du phonème en italique changeait le nombre de syllabes de la variante :
Ici, le schwa central est en italique (entre parenthèses dans l’ODP). La variante
/«vÅ)tr´Q:tE´/ compte quatre syllabes, tandis que la variante /«vÅ)trQ:tE´/ n’en compte que
trois. Il faut alors proposer deux variantes dans la base de données.
3. Consonnes syllabiques
Les consonnes syllabiques ne sont en général notées dans les dictionnaires que
lorsqu’il existe un risque d’ambiguïté, comme l’expliquent l’EPD (Introduction, xiv-xv) et
l’ODP (Introduction, xi).
Le LPD les lie aux phonèmes optionnels : « […] symbols written raised denote sounds
that are sometimes optionally inserted. Likely syllabic consonants are shown in this way,
since a syllabic consonant always has an optional variant involving [´] and a non-syllabic
consonant » (Introduction, xviii) :
cordon /:kç˘d´n/
ventre à terre /«vÅ)tr´Q:tE´/

Lecture des dictionnaires 97
Il existe en effet un cas particulier, celui des schwas notés en exposant dans l’EPD,
décrit ainsi dans l’introduction du dictionnaire : « The use of superscript schwa in words such
as :laIt´nIN should be interpreted as meaning that the schwa may be pronounced, or may be
omitted while giving its syllabic character to the following consonant » (EPD, Introduction,
xv).
Adoptant la méthode choisie par les éditeurs, nous avons décidé d’une part de ne noter
le symbole de syllabicité que lorsque le dictionnaire le notait, c’est-à-dire lorsqu’il existait un
risqué d’ambiguïté, d’autre part de garder le symbole schwa en exposant avec sa valeur
exposée dans l’EPD et le LPD. Dans l’ODP et l’OED, un schwa entre parenthèses —
optionnel — suivi de /m, n, N, l, r/ (les consonnes pouvant être syllabiques) correspond au
schwa exposant. Néanmoins, nous avons remarqué que le dictionnaire ODP privilégie les
variantes avec consonne syllabique uniquement.
Dans la base de données, nous avons choisi de présenter des variantes différentes selon
que le dictionnaire proposait une variante avec schwa en exposant, schwa uniquement, ou
consonne syllabique uniquement :
Entrée EPD LPD ODP OED
arrestation 1 «QrE:stEIS´n X
arrestation 2 X «QrE:stEISn
arrestation 3 X «QrE:stEIS´n
Extrait BD 6. Présentation des variantes avec schwa ou consonne syllabique.
Il reste cependant un cas, où le schwa apparait en exposant (ou entre parenthèses),
comme dans cet exemple :
agile /:QdZaI´l/

98 La base de données
Ici, si le schwa disparaît, la consonne /l/ ne devient pas pour autant syllabique. Il s’agit
en réalité d’un phonème optionnel. Nous trouvons un certain nombre d’exemples du même
type : automobile, canaille. Nous remarquons d’ailleurs que l’EPD transcrit souvent le schwa
en italique dans ce type de cas.
Nous avons souhaité noter différemment ce schwa optionnel, qui n’est pas tout à fait
comme les autres phonèmes optionnels. Lorsqu’il suit une diphtongue, comme dans agile, il
semble que l’on soit en présence d’une triphtongue, mais dans un exemple comme
automobile, le même type de schwa s’ajoute au phonème [i˘] sans toutefois changer sa nature.
C’est pourquoi nous avons préféré noter ce schwa en indice afin de le démarquer des schwas
en exposant, liés aux consonnes syllabiques, et des autres phonèmes optionnels :
4. Coupe syllabique
Les dictionnaires de prononciation ne font pas tous le même choix en ce qui concerne
la coupe syllabique, lorsqu’ils l’indiquent (l’ODP et l’OED ne l’indiquent pas). Pourtant la
syllabification est nécessaire pour le placement des accents. Pour notre base de données, il a
fallu décider d’un système cohérent de syllabification.
Nous avons tout d’abord examiné les méthodes employées par les dictionnaires EPD
et LPD.
a) EPD
Les éditeurs de l’EPD expliquent dans l’Introduction qu’il suivent le « Maximal Onset
Principle » ou principe d’attaque maximale (EPD, Introduction, xiii). Le maximum de
agile /:QdZaI´l/
automobile /:ç˘t´m´U«bi˘´l/

Lecture des dictionnaires 99
consonnes sont attribuées au début de la syllabe à droite, plutôt qu’à la fin de la syllabe à
gauche ; mais tout en respectant les règles phonotactiques anglaises. Ainsi, si l’application de
ce principe engendre une syllabe se terminant par I, E, Q, √, Å ou U, on considère que cela
viole les règles phonotactiques de l’anglais, et la première consonne intervocalique est
attribuée à la syllabe précédente. L’EPD coupe donc better /:bEt.´/ et beater /:bi˘.t´/. De plus,
E, Q et √ ne peuvent apparaître seuls en syllabe inaccentuée, contrairement à I, U et ´. Enfin,
les mots composés ne sont pas coupés selon ce principe, mais selon les bornes de mots.
Hardware ne sera pas coupé /:hA˘.dwE´/, mais /:hA˘d.wE´/. Cela s’applique aux composés
ouverts, fermés ou à trait d’union.
b) LPD
John Wells, éditeur du LPD, explique également dans l’Introduction du dictionnaire
ses décisions pour la coupe syllabique (LPD, Introduction, xix). Il commence par les mots
composés en considérant, comme l’EPD, que la frontière syllabique se situe à la borne de mot.
Il précise également que selon lui, une consonne ne peut appartenir qu’à une seule syllabe.
City pourra être coupé /:sI.tI/ ou /:sIt.I/, mais pas /:sIt.tI/. Il rejette donc le principe
d’ambisyllabicité, décrit notamment par Andrew Spencer dans son ouvrage Phonology79
(Spencer, 98).
La coupe syllabique doit autant que possible éviter de créer des groupes de consonnes
qu’on ne trouve jamais en début ou fin de mot. C’est ce qu’il appelle la contrainte
phonotactique. Par exemple, windy pourra être coupé /:wIn.dI/ ou /:wInd.I/, mais pas
/:wI.ndI/ car un mot anglais ne peut commencer par [nd].
79 Spencer, Andrew. Phonology : Theory and Description. Malden, MA, USA : Blackwell, 1996.

100 La base de données
Le principe adopté par le LPD est que les consonnes sont syllabifiées avec la voyelle
adjacente la plus fortement accentuée. Si les deux voyelles adjacentes sont inaccentuées, les
consonnes vont avec la voyelle de gauche. Enfin, une voyelle réduite compte comme moins
accentuée que toute autre voyelle non-réduite. Mais ce principe est sujet à la contrainte
phonotactique. Il ajoute qu’au sein d’un morphème, [tr] et [dr] ne sont pas séparés ; ainsi
petrol sera coupé /:pEtr.´l/.
Dans son article « Syllabification and Allophony »80, complémentaire de
l’Introduction du LPD, John Wells expose la méthode employée pour la coupe syllabique
dans le dictionnaire. Il y énonce ses différentes règles et traite effectivement [tr] et [dr]
comme des affriquées au même titre que [tS] et [dZ]. De plus, il précise que dans les mots
polymorphémiques, les consonnes sont attribuées à la syllabe du morphème auquel elles
appartiennent. Rat-race sera donc coupé /:rQt.rEIs/.
c) Décision
Après avoir consulté l’ouvrage d’Andrew Spencer, Phonology, nous avons décidé de
suivre le principe d’attaque maximale, suivi par l’EPD, mais en ne tenant pas compte de la
règle phonotactique selon laquelle une syllabe ne pourrait être ouverte si elle contient une
voyelle brève. Nous pensons en effet que cette règle est contestable. L’argument des
anglicistes est qu’on ne trouve pas de mot monosyllabique en syllabe ouverte avec voyelle
brève, mais il est tout à fait envisageable que les syllabes se comportent différemment dans un
80 Wells, John. « Syllabification and Allophony. » JC Wells homepage. Studies in the Pronunciation of English.
Susan Ramsaran, ed. London, New-York : Routledge, 1990 : 76-86. UCL Division of Psychology and
Language Sciences. Mars 2007. http://www.phon.ucl.ac.uk/home/wells/syllabif.htm

Finalisation 101
mot polysyllabique. De plus, dans le cadre des emprunts français, on peut remarquer que les
dictionnaires de prononciation envisagent eux-mêmes cette possibilité puisqu’on trouve des
cas comme bonhomie /«bÅnÅ:mI/, Chablis /SQ:blI/, petite bourgeoisie / p´«ti˘t«bç˘ZwA˘:zI/
ou comme ci, comme ça /kÅm«si˘kÅm:sQ/.
Notre choix est renforcé par les résultats des expériences de Caroline Bouzon pour sa
thèse « Rythme et structuration prosodique en anglais britannique contemporain »81. Elle y
réalise en effet des tests sur les locuteurs anglophones pour voir de quelle manière ils coupent
les syllabes. Ses résultats montrent qu’à 84%, les locuteurs coupent en syllabe ouverte, en
suivant le principe d’attaque maximale (Bouzon, 287).
C’est donc le principe que nous adoptons pour ce corpus, en gardant à l’esprit que
cette prise de décision relève essentiellement d’un besoin de cohérence pour la présentation de
la base de données.
D. FINALISATION
Une fois la base de donnée remplie, nous obtenons un tableau de 8986 lignes. Nous
créons dans un autre fichier un lexique des emprunts : en effet, le sens des mots est parfois
utile à l’analyse de la prononciation, mais il nous a semblé plus pratique de noter ces
informations dans un fichier différent à cause des différents sens que comptent parfois les
emprunts. De fait, un si grand nombre d’informations n’aurait pu être ajouté à la base de
données sans nuire à sa lisibilité.
Nous allons pouvoir à présent utiliser cette base de données pour étudier la phonologie
des emprunts français dans la langue anglaise.
81 Bouzon, Caroline. « Rythme et structuration prosodique en anglais britannique contemporain. » Thèse de
doctorat de 3ème cycle, Université Aix-Marseille I, 2004.


2ème partie :
Suppression des variantes anglicisées


105
IV. LES SUPPRESSIONS
Table des matières
A. Affiner la base de données ............................................................................................... 105
B. La méthode ....................................................................................................................... 106
1. Intérêt de la graphie..................................................................................................... 107
2. Exemples ..................................................................................................................... 109
A. AFFINER LA BASE DE DONNEES
La base de données que nous avons réalisée dans la première partie de cette thèse est
en réalité une base de données intermédiaire. En effet, nous avons pour but d’étudier les
emprunts qui ne sont pas totalement anglicisés, c'est-à-dire qui ne suivent pas toutes les règles
de l’anglais. Or, dans notre base de données actuelle, nous trouvons un certain nombre
d’emprunts dont la prononciation peut être expliquée par les règles de l’anglais. On peut donc
qualifier ces emprunts d’ ‘anglicisés’.
Nous décidons alors de supprimer les variantes anglicisées, qui ne vont pas nous être
utiles à la recherche de règles phonologiques pour les emprunts français non-anglicisés.
Nous choisissons de faire deux nouvelles bases de données issues de la première. Dans
une première base de données — que nous appellerons Base de Données Finale — nous

106 Les suppressions
supprimerons les variantes qui peuvent être entièrement expliquées par les règles de l’anglais,
c'est-à-dire les variantes anglicisées. C’est cette base de données qui servira à la recherche de
règles. Dans la seconde — que nous appellerons Base de Données Comparative — nous
retirerons uniquement les emprunts pour lesquels toutes les variantes sont anglicisées. Il
restera alors des emprunts qui comptent à la fois des variantes anglicisées et des variantes
non-anglicisées. Cette base de données nous permettra comparer les différentes variantes et
peut-être de mettre en évidence une évolution de l’anglicisation d’un emprunt.
B. LA METHODE
Pour ce type de tâche, il est nécessaire d’établir une méthode car les règles
phonologiques de l’anglais sont nombreuses et tous les linguistes ne sont pas en accord sur ce
sujet. Il convient donc de prendre une certaine position, tout en essayant de rester aussi
objectif et scientifique que possible.
Nous nous appuyons sur différents ouvrages pour établir une ‘liste’ de règles : d’une
part le Sound Pattern of English82 (SPE) de Chomsky et Halle, notamment au sujet de
l’accentuation, et d’autre part La prononciation de l’anglais83 de Lilly et Viel, pour la partie
phonographématique et les règles de tension. Mais nous faisons également appel à d’autres
ouvrages sur différents points précis sur lesquels nous reviendrons.
Dans cette thèse, nous ne proposerons pas la liste des règles, ce qui serait fastidieux,
mais préférons examiner un certain nombre de cas problématiques, illustratifs des difficultés
engendrées par cette tâche.
82 Chomsky, Noam et Morris Halle. The Sound Pattern of English. Cambridge, USA : MIT Press, 1968.
83 Op. cit. p. 69

La méthode 107
1. Intérêt de la graphie
Les éléments observés sont l’accentuation et la transcription phonémique. Par
exemple, dans le mot genre /:ZA)˘nr´/ on trouve une voyelle nasale, qui ne fait normalement
pas partie du système vocalique anglais, et le phonème [Z], qui fait bien partie du système
consonantique anglais, mais ne se trouve généralement pas à l’initiale d’un mot. Pour ces
raisons, cette variante sera retenue dans la base de données.
Cependant, ce type de cas, où la transcription seule suffit à montrer l’aspect étranger
de l’emprunt, n’est pas majoritaire dans ce corpus. Bien souvent, c’est la relation graphie-
phonie qu’il faut observer pour déterminer si l’emprunt est traité comme un mot anglais ou
comme un mot étranger.
L’aspect graphique n’est en effet pas à négliger. Lorsque le mot fête est prononcé
/:fEIt/, la prononciation en elle-même n’a rien d’inhabituel en anglais. En revanche, cette
prononciation correspond plutôt à l’orthographe <fate>. Inversement, en regardant la graphie
fête (indépendamment de l’accent), on pourrait s’attendre à la prononciation /:fi˘t/. De même
pour le mot chaise /:SEIz/. Cette prononciation pourrait exister en anglais, associée à la
graphie <shaze>. Mais c’est bien la correspondance entre <ch> et [S] qui ne suit pas les
habitudes de l’anglais.
Le fait que la graphie ait tant d’importance dans le cadre des emprunts français n’est
pas surprenant. En effet, la plupart de ces emprunts sont passés par la voie écrite, comme nous
l’avons déjà mentionné84. De plus, comme le signale Taillé dans son ouvrage Histoire de la
84 Cf. citation de Baugh p. 53

108 Les suppressions
Langue anglaise85, les emprunts de la période que nous étudions gardent la plupart du temps
leur forme orthographique française (Taillé, 38), ce qui semble être une de leurs particularités.
D’autre part, nous trouvons un certain nombre de mots dont l’histoire montre que leur
prononciation est liée à l’orthographe. C’est notamment le cas de critique86. Ce mot fut
emprunté au français au 17ème siècle sous la forme critic, avec l’accent sur la première syllabe,
conformément à la règle du suffixe <-ic>. Puis au 18ème siècle, le mot commença à être
orthographié critique, comme en français. Par la suite, la prononciation fut adaptée pour
paraître plus ‘française’ et le mot fut prononcé /krI:ti˘k/, prononciation toujours en usage
(OED, ‘critique’, ‘critic’).
Il n’est pas rare de trouver des exemples de ‘ré-emprunt’ de la forme orthographique
française. Parfois cela n’a pas d’incidence sur la prononciation — comme pour
colonel /:kŒ˘nl/, emprunté à l’origine sous la forme coronel (OED, ‘colonel’) — mais le plus
souvent la prononciation s’adapte à la nouvelle forme graphique, comme pour critique,
antique ou turquoise.
Il semble donc qu’adaptation phonique et adaptation graphique soient liées, dans un
sens comme dans l’autre. Autrement dit, lorsqu’un mot est anglicisé dans sa prononciation,
généralement sa graphie l’est aussi ; de même lorsque sa prononciation n’est pas anglicisée, sa
graphie ne l’est pas non plus. A moins que ce ne soit la conservation de l’orthographe
française qui fasse obstacle à l’anglicisation phonique.
Alors pourquoi l’orthographe française est-elle conservée, parfois jusqu’aux accents
graphiques ? Ou pourquoi est-elle ‘ré-empruntée’? Quelle est la relation entre la forme
graphique et la forme phonique ou l’accentuation ? C’est à ces questions que nous tenterons
de répondre dans cette étude. 85 Taillé, Michel. Histoire de la langue anglaise. Paris : Armand Colin, 1995.
86 Nous parlerons plus longuement de ce mot au chapitre 7.

La méthode 109
2. Exemples
La méthode consiste donc, pour chaque variante, à observer l’accentuation et la
prononciation et à les comparer avec les règles phonologiques de l’anglais RP, y compris la
relation graphie-phonie. Si la variante peut être entièrement expliquée par ces règles, elle est
déclarée anglicisée (0) ; dans le cas contraire, elle est déclarée non-anglicisée (1) dans une
colonne rajoutée à cet effet.
Prenons pour exemple la première variante de la base de donnée : abandon
/´:bQnd´n/. Pour l’accentuation, nous suivons la règle 50 (Main Stress Rule) de Chomsky et
Halle dans le Sound Pattern of English (SPE, 84) :
Figure 10. Main Stress Rule (50)87.
Abandon est un nom, c’est donc le cas b qui est appliqué, c’est-à-dire qu’on omet du
calcul de l’accent le cluster final comprenant une voyelle relâchée [´n]. Nous observons alors
le cluster précédent [Qnd] : il s’agit d’un cluster fort puisqu’il est composé d’une voyelle
relâchée suivie de deux consonnes ; c’est donc le cas ii qui est appliqué. L’accentuation
d’abandon suit donc la règle bii et peut être considérée comme anglicisée. Nous observons 87 Reproduction du Sound Pattern of English.

110 Les suppressions
ensuite la relation graphie-phonie : celle-ci est tout à fait régulière. Nous considérons alors
que cette variante est anglicisée ; elle pourra être supprimée de la base de données finale.
En revanche, la troisième variante du mot abandon est différente : /Qb´n:dÅN/.
L’accentuation ne suit pas les habitudes de l’anglais. En effet, dans un mot de trois syllabes et
plus, lorsque l’accent se trouve sur la syllabe finale, il subit une rétraction accentuelle vers
l’antépénultième par l’Alternating Stress Rule (Chomsky et Halle, 78). L’accent devrait donc
se trouver sur la première syllabe du mot et non sur la dernière, s’il suivait les règles de
l’anglais. De plus, le suffixe <-on> est prononcé [ÅN], ce qui est tout à fait inhabituel, puisque
ce suffixe est en général réduit à [´n] comme dans la première variante s’il est inaccentué, ou
bien prononcé [Ån] comme dans echelon, lexicon ou mastodon. Nous considérons donc cette
variante comme non-anglicisée.
Ce travail de suppressions des variantes anglicisées soulève rapidement de nombreuses
questions qui vont mener à de plus larges réflexions sur la phonologie de l’anglais et des
emprunts français en anglais.

111
V. ETUDE DE CAS : NIVEAU ACCENTUEL
Table des matières
A. Noms dissyllabiques accentués en finale ......................................................................... 111
B. Noms dissyllabiques du type adjoint ou brassard ........................................................... 113
C. Verbes accentués 1 en finale............................................................................................. 114
D. Trissyllabes du type caramel............................................................................................ 117
E. Les emprunts qui héritent leur accent ............................................................................... 119
F. Mots composés et expressions .......................................................................................... 120
Dans ce chapitre, nous allons développer certains points problématiques liés aux règles
d’accentuation de l’anglais.
A. Noms dissyllabiques accentués en finale
En général pour les règles d’accentuation, on différencie la catégorie grammaticale
(nom, verbe, ou adjectif). Chomsky et Halle présentent d’ailleurs les règles de cette manière
dans le SPE. On applique pour les noms les cas a (suffixe dérivationnel) ou b de la règle 50.
Mais ces cas ne peuvent être appliqués que lorsque le cluster final contient une voyelle
relâchée (ex : city, credit, tempest, infant, lantern), cluster qui sera omis pour le calcul de
l’accent. Or, nous trouvons dans la base de données un certain nombre de mots se terminant

112 Etude de cas : niveau accentuel
par une voyelle tendue : adage /´:dA˘Z/, affaire /´:fE´/, azote /´:z´Ut/, brigade /brI:gEId/,
etc.
Ces exemples peuvent être expliqués par le cas eii ; on pourrait alors estimer qu’ils ne
sont pas irréguliers. Néanmoins, suivant le point de vue de Deschamps, Duchet, Fournier et
O’Neil, dans leur Manuel de phonologie de l’anglais88, nous considérons que les noms ne sont
en général pas accentués en finale. Selon eux, l’accentuation générale des dissyllabes, toutes
catégories confondues, est /10/ (Deschamps et al., 54) — 0 ne représentant pas forcément une
syllabe réduite puisqu’on trouve des exemples tels que congress, diphthong, expert. Ils
classent comme exceptions des mots comme affaire, campaign, caprice, dessert, fatigue,
machine, etc. Nous remarquons d’ailleurs que parmi les 70 exemples d’exceptions proposées,
45 sont d’origine française, c'est-à-dire bien plus de la moitié. Cette constatation nous conduit
à penser qu’il s’agit là d’une particularité des emprunts français, puisque l’accent est fixe et
final en français.
Nous décidons néanmoins de vérifier l’assertion de Deschamps : nous relevons mille
noms dissyllabiques dans l’OED et observons la place de l’accent. Cette règle générale est
vérifiée : 85% des noms dissyllabiques sont accentués sur la 1ère syllabe. Par ailleurs, 25% des
noms accentués en finale sont des conversions de verbes ou bien homonymes d’un verbe
antérieur : l’accentuation existante a sans doute été maintenue pour le nom. Les verbes
préfixés pouvant être accentués en finale de manière régulière (Lilly et Viel, 49-50), c’est
probablement l’explication de cette accentuation. On remarque également parmi les noms
accentués en finale, 33% de mots originaires du français et dont l’accentuation pourrait être
expliquée par cette origine.
Nous en concluons que l’accentuation générale des noms dissyllabiques en anglais est
sur la première syllabe. On considère alors qu’une variante comme adage /´:dA˘Z/ ne suit pas
88 Deschamps, Alain et al. Manuel de phonologie de l’anglais. Paris : Didier-Erudition, 2000.

Noms dissyllabiques du type adjoint ou brassard 113
la règle anglaise ; elle sera notée (1). Néanmoins cela n’est valable que dans les cas où
l’origine française pourrait être la seule explication à la présence de l’accent en finale ; si le
nom est homonyme d’un verbe antérieur à l’emprunt, on peut légitimement penser que le
nouveau mot sera accentué de la même manière que celui qui était déjà présent dans la langue
(ex : allure, alose, annexe, entrain).
Nous estimons donc qu’un mot comme machine, considéré comme régulier par
Chomsky et Halle puisqu’expliqué par la règle 50eii, devrait être placé dans les exceptions au
même titre que giraffe /dZ´:rQf/, considéré comme exception par les auteurs puisque le
dernier cluster contient une voyelle relâchée et ne devrait normalement pas porter l’accent.
B. Noms dissyllabiques du type adjoint ou brassard
Il s’agit de noms dissyllabiques accentués 1– et contenant une voyelle tendue en
finale. Ici encore, c’est la règle d’accentuation de Chomsky et Halle qui est remise en
question, puisque s’ils suivaient la règle, ces mots devraient porter l’accent en finale par le cas
eii. Pour autant, peut-on les considérer comme des exceptions ? Il semble que non, puisque
l’accent primaire est placé selon la règle générale des dissyllabes. Mais le fait que la voyelle
finale reste tendue et ne soit pas réduite est-il conforme aux règles de l’anglais ?
Nous observons dans notre liste de mille mots dissyllabiques89 ceux qui sont accentués
sur la première syllabe et qui contiennent une voyelle tendue en finale. Ce groupe est loin
d’être majoritaire (22%, mots composés inclus), mais ne semble pour autant pas inhabituel en
anglais.
Le fait que la voyelle soit tendue ne fait pas entrer ce type de mots dans la catégorie
‘exceptions’. Parfois, on peut même considérer que la réduction est quasi-impossible, comme
89 Cf. discussion précédente.

114 Etude de cas : niveau accentuel
pour les mots contenant le digraphe <oi> (ex : adjoint, vocoid). Cependant, la tension est
parfois plus surprenante, notamment pour les mots comprenant le suffixe <–ard>, qui est en
général réduit comme dans mustard /:m√st´d/, awkward /:ç˘kw´d/, alors qu’ici on le trouve
avec une voyelle tendue comme pour brassard /:brQsA˘d/, brocard /:br´UkA˘d/. Le fait que
ce suffixe ne soit pas réduit est sans doute une caractéristique due à l’origine du mot. Nous
considérons alors les mots comprenant le suffixe <–ard> non réduit comme non-anglicisés.
De même, ampere /:QmpE´/ n’est pas anglicisé car la prononciation [E´] du suffixe <-ere>
n’est pas conforme aux règles de l’anglais (normalement [I´]).
En revanche, alcove /:Qlk´Uv/ sera considéré comme anglicisé, car les suffixes en
<-oCe> sont en général tendus (ex : bricole /:brIk´Ul/, console /:kÅns´Ul/, mangrove
/:mQNgr´Uv/). De même agile /:QdZaIl/ sera noté (0) car le suffixe <-ile> est très souvent
tendu (ex : docile /:d´UsaIl/, exile /:EksaIl/, fertile /:fŒ˘taIl/, mobile /:m´UbaIl/).
Il convient par conséquent d’observer chaque variante de ce type et de prendre une
décision au cas par cas.
C. Verbes accentués 1 en finale
Nous avons déjà mentionné la possibilité d’accentuer un verbe en finale, à condition
qu’il soit précédé de préfixes qui, si on les ôte, laissent un verbe monosyllabique, tel que
comprehend, represent, understand (Lilly et Viel, 49-50). Hormis dans le cadre de cette
règle, il n’est a priori pas possible de trouver un verbe accentué 1 en finale.
Tous les verbes de notre corpus accentués 1 en finale peuvent-ils être expliqués par
cette règle ? Voici quelques exemples :
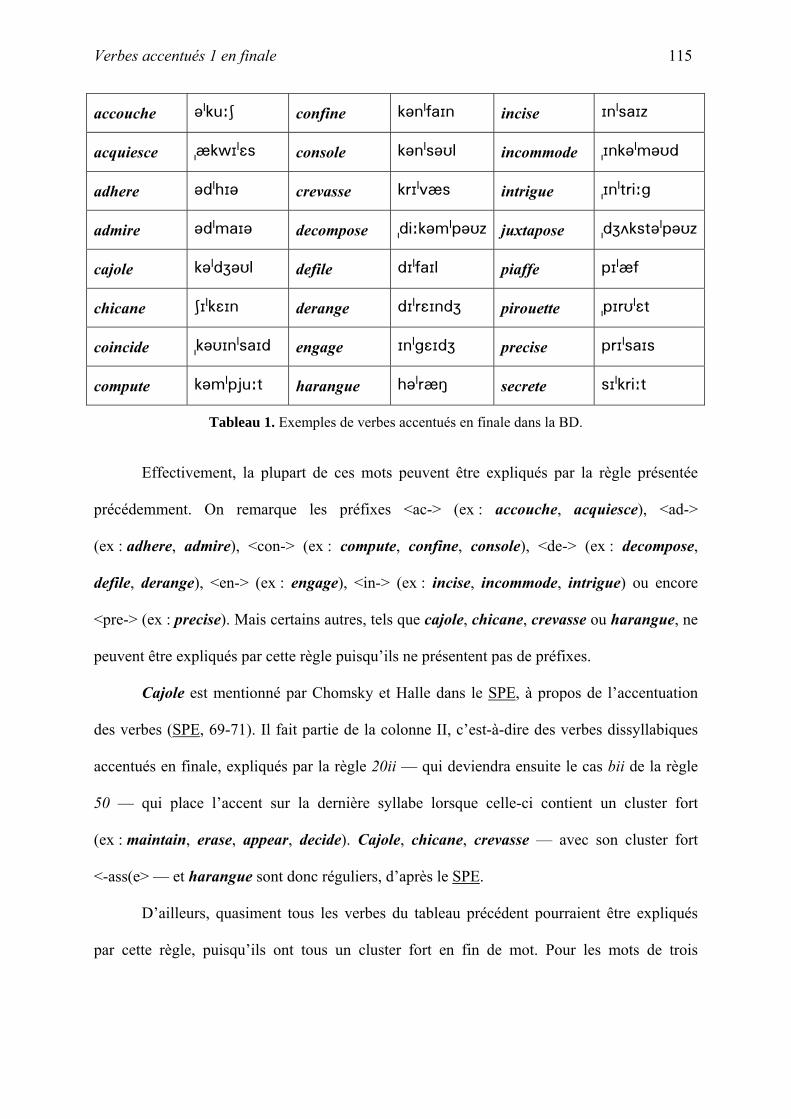
Verbes accentués 1 en finale 115
accouche ´:ku˘S confine k´n:faIn incise In:saIz
acquiesce «QkwI:Es console k´n:s´Ul incommode «Ink´:m´Ud
adhere ´d:hI´ crevasse krI:vQs intrigue «In:tri˘g
admire ´d:maI´ decompose «di˘k´m:p´Uz juxtapose «dZ√kst´:p´Uz
cajole k´:dZ´Ul defile dI:faIl piaffe pI:Qf
chicane SI:kEIn derange dI:rEIndZ pirouette «pIrU:Et
coincide «k´UIn:saId engage In:gEIdZ precise prI:saIs
compute k´m:pju˘t harangue h´:rQN secrete sI:kri˘t
Tableau 1. Exemples de verbes accentués en finale dans la BD.
Effectivement, la plupart de ces mots peuvent être expliqués par la règle présentée
précédemment. On remarque les préfixes <ac-> (ex : accouche, acquiesce), <ad->
(ex : adhere, admire), <con-> (ex : compute, confine, console), <de-> (ex : decompose,
defile, derange), <en-> (ex : engage), <in-> (ex : incise, incommode, intrigue) ou encore
<pre-> (ex : precise). Mais certains autres, tels que cajole, chicane, crevasse ou harangue, ne
peuvent être expliqués par cette règle puisqu’ils ne présentent pas de préfixes.
Cajole est mentionné par Chomsky et Halle dans le SPE, à propos de l’accentuation
des verbes (SPE, 69-71). Il fait partie de la colonne II, c’est-à-dire des verbes dissyllabiques
accentués en finale, expliqués par la règle 20ii — qui deviendra ensuite le cas bii de la règle
50 — qui place l’accent sur la dernière syllabe lorsque celle-ci contient un cluster fort
(ex : maintain, erase, appear, decide). Cajole, chicane, crevasse — avec son cluster fort
<-ass(e> — et harangue sont donc réguliers, d’après le SPE.
D’ailleurs, quasiment tous les verbes du tableau précédent pourraient être expliqués
par cette règle, puisqu’ils ont tous un cluster fort en fin de mot. Pour les mots de trois

116 Etude de cas : niveau accentuel
syllabes, tels qu’acquiesce, decompose ou incommode, c’est la présence de préfixes qui
explique que l’Alternating Stress Rule (ASR) ne soit pas appliquée.
Mais Chomsky et Halle proposent une autre explication à l’accentuation d’acquiesce.
Ils suggèrent que le <-e> final doit être pris en compte dans une forme sous-jacente
/-kwIEssE/, ce qui place l’accent 1 sur la voyelle précédente par le cas bii de la Main Stress
Rule. Ensuite une règle d’élision du [E] final intervient pour donner la forme finale, la
présence du préfixe <ac-> bloquant l’application de l’ASR. Cette règle est également
mentionnée pour d’autres mots tels que burlesque, coquette ou assemblage. Nous voyons
qu’il s’agit dans tous ces cas d’emprunts français. S’agit-il d’une règle propre à ces
emprunts ?
Nous relevons dans l’OED quelques verbes en <-esce> du même type qu’acquiesce :
accresce, coalesce, compesce, concresce, convalesce, defervesce, deliquesce, effervesce,
effloresce, etc. Nous remarquons d’une part qu’ils sont quasiment tous d’origine latine,
acquiesce étant donc une exception de ce point de vue, et d’autre part, que l’accent est
systématiquement placé en finale. Cette terminaison verbale est donc peut-être associée à un
accent final, quel que soit la morphologie du mot. D’ailleurs, en observant l’étymologie, on
s’aperçoit que dans de nombreux cas, le mot latin porte un accent sur cette syllabe, comme
intumesce, qui vient de intumēsc-ĕre ; cet accent final en anglais vient donc peut-être de
l’accentuation latine.
La règle du <-e> final proposée par Chomsky et Halle ne nous semble donc pas
satisfaisante pour expliquer l’accentuation d’acquiesce. De même, la règle qui dicte qu’un
verbe se terminant par un cluster fort prend l’accent en finale ne nous semble pas tout à fait
convaincante.
En effet, dans la colonne d’exemples dans laquelle se trouve cajole (SPE, 69), on
trouve à la fois des verbes préfixés comme decide, surmise, devote, et des verbes non-préfixés

Trissyllabes du type caramel 117
comme carouse, careen. Faut-il tous les traiter de la même manière ? Dans leur Manuel de
phonologie de l’anglais90, à propos des mots dissyllabiques, Deschamps, Duchet, Fournier et
O’Neil confortent l’idée selon laquelle seuls les verbes préfixés peuvent porter l’accent 1 en
finale, puisque, en définitive, il s’agit de monosyllabes (Deschamps et al., 48-58). Dans tous
les autres cas, l’accentuation régulière des verbes dissyllabiques est 10 ou 12, comme pour les
noms. Cette hypothèse est confirmée par les exemples de balance /:bQl´ns/, censure
/:sEntS´/ et ranger /:rEIndZ´/, relevés dans notre corpus et qui présentent une accentuation 10
pour des verbes non-préfixés.
Ainsi Chomsky et Halle ne devraient peut-être pas considérer que cajole est régulier.
S’il l’était, il serait accentué sur la première syllabe. Il est possible que ce soit son origine
française qui explique le maintien de l’accent en finale. Il devrait donc plutôt être classé
comme exception, de la même manière que machine doit être considéré comme exception et
non comme régulier.
D. Trissyllabes du type caramel
Certaines variantes telles que caramel /:kQr´mEl/ ou partisan /:pA˘tIzQn/ nous
interpellent : si elles peuvent être expliquées par le cas bi de la Main Stress Rule, elles sont
néanmoins très différentes des exemples qui illustrent ce cas dans le SPE (ex : America,
cinema, asparagus, venison, arsenal) qui présentent tous une voyelle réduite en finale. De
plus, s’il s’agit bien de mots de trois syllabes avec accent primaire sur l’antépénultième, la
voyelle finale n’est pas tendue comme dans les cas habituels de l’application de l’Alternating
Stress Rule (ASR). Il s’agit donc d’un autre cas de figure.
90 Op. cit. p. 106

118 Etude de cas : niveau accentuel
Comment expliquer ces variantes non-réduites en finale ? On remarque d’ailleurs que
caramel a également une variante réduite /:kQr´m´l/ ; il ne peut donc s’agir d’une règle
bloquant la réduction. On peut alors envisager que cette non-réduction soit due à l’origine
française des mots. En effet, pour que l’Alternating Stress Rule soit appliquée, il faut qu’un
accent 1 soit placé sur la dernière syllabe. L’hypothèse que nous proposons est que, dans nos
exemples, cet accent 1 est hérité du français. L’ASR peut alors être appliquée et l’on garde
une trace de l’ancien accent primaire dans la non-réduction de la voyelle finale. Dans la
variante caramel /:kQr´m´l/, la réduction de cette voyelle finale pourra être vue comme une
ultime anglicisation.
Nous trouvons plusieurs autres exemples de ce type :
aludel :QljUdEl
charlatan :SA˘l´tQn
argentan :A˘dZ´ntQn
caracal :kQr´kQl
cabochon :kQb´SÅn
calomel :kQl´mEl
artisan :A˘tIzQn
commandant :kÅm´ndQnt
fanfaron :fQnf´rÅn
Parmesan :pA˘mIzQn
Tableau 2. Exemples de trisyllabes non-réduits en finale dans la BD.
En revanche, certains mots qui a priori pourraient faire partie de cette catégorie, en
sont en réalité exclus. Analogue /:Qn´lÅg/, par exemple, doit être analysé comme

Les emprunts qui héritent leur accent 119
ana + logue ; de même discothèque /:dIsk´tEk/ comme disco + thèque, les éléments <-logue>
et <-thèque> ne pouvant être réduits ; avalanche /:Qv´lQntS/ ou catafalque /:kQt´fQlk/ ne
peuvent pas voir leur voyelle finale réduite à cause des clusters [tS] ou [lk] ; bric-à-brac
/:brIk´brQk/, enfin, est un mot composé et son dernier élément ne peut pas être réduit.
Par conséquent, il convient d’observer ces mots au cas par cas afin de déterminer s’ils
appartiennent à la catégorie de caramel, qui va être retenu dans la base de données, ou
d’avalanche, qui sera considéré comme anglicisé.
E. Les emprunts qui héritent leur accent
Certains emprunts sont associés au sein de l’anglais car l’un dérive de l’autre en
français. C’est le cas par exemple de bizarre et bizarrerie, canton et cantonal, gamine et
gaminerie, ou hotel et hotelier. Ces mots ne sont pas forcément empruntés au même moment,
mais ils sont souvent liés par leur prononciation et surtout leur accentuation, au moins pour
certaines variantes.
Bizarre /bI:zA˘/ est emprunté vers 1648 et bizarrerie /bI:zA˘r´rI/ en 1741. L’accent de
bizarre est inhabituel puisqu’il est en finale pour un nom dissyllabique. Nous pouvons
observer que cet accent inhabituel est maintenu dans bizarrerie.
De même hotel /h´U:tEl/ est emprunté dès 1644, tandis que hotelier /h´U:tElIEI/ ne
sera emprunté qu’en 1905. Ici encore, l’accent de hotel est irrégulier, et nous retrouvons cet
accent dans hotelier.
Gamine a deux variantes, l’une avec accentuation régulière /:gQmi˘n/ et l’autre avec
accentuation irrégulière /gQ:mi˘n/. C’est cette accentuation irrégulière que nous retrouvons

120 Etude de cas : niveau accentuel
dans l’emprunt postérieur gaminerie /g´:mi˘n´rI/.
Enfin, canton présente plusieurs variantes dont une avec accentuation régulière
/:kQntÅn/ et une totalement anglicisée /:kQnt´n/91, mais également une variante à
accentuation irrégulière /«kQn:tÅn/. C’est cette accentuation que nous retrouvons dans la
variante de cantonal /kQn:tÅn´l/ aux côtés de prononciations tout à fait régulières et
totalement anglicisées comme /:kQnt´n´l/.
Toutes les variantes qui reprennent un accent irrégulier seront traitées comme non-
anglicisées, puisque leur accentuation reste irrégulière.
F. Mots composés et expressions
Notre base de données regorge de mots composés et d’expressions. En voici quelques
exemples :
à la mode :Ql´m´Ud carte blanche «kA˘t:blA)˘ntS
au pair «´U:pE´ bric-à-brac :brIk´«brQk
beaux arts b´U:zA˘ chaise-longue «SEIz:lÅN
aide-de-camp :EIdd´«kÅN chargé d’affaires «SA˘ZEIdQ:fE´
agent provocateur «QZÅ)pr´«vÅk´:tŒ˘ comme ci, comme ça kÅm«si˘kÅm:sA˘
bête noire «bEt:nwA˘ coq au vin «kÅk´U:vQn
apropos «Qpr´:p´U cul-de-sac :k√ld´sQk
bon voyage «bç)˘NvçI:A˘Z double entendre «du˘bl2A)˘n:tA)˘ndr´
Tableau 3. Exemples de mots composés dans la BD.
91 Cf. Mots en <-on> p. 130.

Mots composés et expressions 121
Nous voyons que les composés se présentent sous plusieurs formes : parfois avec un
trait d’union, parfois un espace, parfois en un mot (ex : apropos, malapropos). Doit-on
d’ailleurs tous les classer comme composés ? Il nous semble que oui, car même si au sein de
la langue française certains éléments s’utilisent en collocation (par exemple café, qui peut être
café noir, café au lait, café sans sucre, etc.), une fois dans la langue anglaise, ces anciennes
collocations sont traitées comme un tout : on a donc les composés café au lait /«kQfEI´U:lEI/
et café noir /«kQfEI:nwA˘/.
La difficulté est alors de savoir si l’accentuation suit les règles de l’anglais ou non,
étant donnée la complexité de certains composés empruntés. En effet, rares sont les composés
simples, du type blackbird ou football, pour lesquels la règle est de placer l’accent 1 sur le
premier élément (Lilly et Viel, 56). Nous trouvons parfois des composés du type chargé
d’affaires, coco de mer, crème de la crème, embarras de richesse, jeunesse dorée, petit
bourgeois, enfant terrible, fait accompli, fin de siècle : la règle générale des composés
s’applique-t-elle pour ces emprunts ?
Nous nous reportons alors à la thèse de Claude Boisson intitulée L’accentuation des
composés en anglais contemporain92. Il y explique que « la quasi-totalité des composés
comportent seulement deux composants, et un bon nombre des autres peut du reste se ramener
au cas des composés binaires par une analyse en constituants immédiats appropriée »
(Boisson, 383) et qu’au final, le travail sur l’accentuation des composés se résume à savoir si
l’accent se place plutôt sur l’élément de gauche ou de droite (Boisson, 383).
Sur l’ensemble des composés, 64.5% sont gauches (accentués sur l’élément de gauche)
et 35.5% sont droits (accentués sur l’élément de droite) (Boisson, 383), ce qui correspond à la
règle générale des composés énoncée par Lilly et Viel. Cependant, Boisson ne veut se 92 Boisson, Claude. « L’accentuation des composés en anglais contemporain, avec quelques contributions à
l’accentologie générale ». Thèse de Doctorat d’État, Université Paris 7, 1980.

122 Etude de cas : niveau accentuel
contenter de cette généralité et approfondit sa recherche en travaillant par partie du discours,
notamment sur les composés nominaux et adjectivaux.
Les composés nominaux sont évidemment les plus nombreux. Dans son corpus,
Boisson trouve 72% de gauches et 28% de droits (Boisson, 394). Ici encore, on retrouve la
règle générale. Néanmoins, l’auteur choisit de détailler encore l’accentuation des nominaux
selon le type de composition (Nom + Nom, Adjectif + Nom, etc.). Il mentionne également les
composés nominaux d’origine étrangère (Boisson, 579) ; il relève de nombreux emprunts
français, quasiment tous accentués à droite. Au final, il considère que la normalité pour les
composés nominaux étrangers est d’être accentué à droite, et traite ceux accentués à gauche
comme des exceptions (Boisson, 583).
Cependant, si à première vue nos emprunts sont majoritairement accentués à droite,
nous trouvons tout de même un certain nombre de variantes accentuées à gauche, qui ne sont
sans doute pas à classer comme exceptions. De plus, il nous semble qu’en suivant la règle de
Boisson nous prendrions le problème à l’envers, puisqu’il s’agit plutôt d’observer quelles
variantes suivent la règle de l’anglais et lesquelles ne la suivent pas. Nous préférons donc
lister les règles de Boisson relatives aux composés anglais et observer si elles sont appliquées
à nos emprunts. Si oui, nous considérerons que la variante est anglicisée du point de vue de
l’accentuation, sinon nous la traiterons comme non-anglicisée.
Nous classons alors nos composés selon la partie du discours et observons
l’accentuation. Dans notre étude, nous ne chercherons pas à analyser plus finement les
composés, d’une part parce que cela pourrait être le sujet d’une nouvelle recherche, et d’autre
part, parce que nous ne sommes pas certaine que les locuteurs anglophones puissent analyser
ces composés. En effet, cela nécessiterait une excellente connaissance de la langue française.
De plus, la syntaxe française étant différente de celle de l’anglais, nous ne pourrions classer
certains composés de la même manière : par exemple, on trouve parmi nos emprunts

Mots composés et expressions 123
beaucoup de composés nominaux Nom + Adjectif (ex : carte blanche, chaise-longue) alors
que, si cette catégorie existe dans la typologie de Boisson, elle reste marginale. Nous
travaillerons donc uniquement sur les parties du discours (nom, adjectif, adverbe, etc.).
Qu’en est-il alors des autres parties du discours ? Contrairement aux composés
nominaux, les autres catégories sont majoritairement accentuées sur l’élément droit (Boisson,
567, 677, 704, 705, 706). La règle générale proposée par Lilly et Viel semble donc ne
correspondre qu’aux composés nominaux. Par conséquent, nous allons considérer qu’une
accentuation sur l’élément de droite est régulière pour les composés non-nominaux.
Néanmoins, nous ne considérerons pas qu’une accentuation à gauche est irrégulière, car il
nous semble tout de même qu’il s’agit d’une accentuation anglicisée. En effet, la catégorie des
noms est la plus répandue et la règle d’accentuation sur l’élément de gauche doit certainement
être ressentie comme très forte, ce qui doit expliquer certains cas d’accentuation à gauche
pour des adjectifs ou des adverbes.
Certains emprunts restent difficiles à classifier. Des entrées du type cherchez la
femme ; comme ci, comme ça ; chacun à son goût ; faites vos jeux ; plus ça change, ne sont
peut-être pas à ranger dans la catégorie des mots composés. Ces emprunts sont peut-être à
classer dans la catégorie ‘expressions’ qui est plus proche du syntagme que du mot composé.
Boisson note à ce propos que la frontière entre ces derniers est très mince (Boisson, 258).
Quoi qu’il en soit, on s’attend pour ces emprunts à une accentuation droite, puisque plus les
composés sont proches des syntagmes et plus l’accentuation est à droite, comme pour l’accent
de phrase (Boisson, 576).
En résumé, une accentuation à gauche sera toujours considérée comme anglicisée,
alors qu’une accentuation à droite ne sera considérée comme non-anglicisée que pour les
composés nominaux. Néanmoins, nous gardons à l’esprit les conclusions de Boisson, qui
explique que l’accentuation des composés est un sujet extrêmement complexe et qu’on devrait

124 Etude de cas : niveau accentuel
parler de tendances plutôt que de règles, tant les règles générales peuvent être contredites
lorsqu’on observe l’accentuation des sous-catégories de composés (Boisson, 809).

125
VI. ETUDE DE CAS : NIVEAU SEGMENTAL
Table des matières
A. Cas liés à la réduction vocalique ...................................................................................... 127
1. Les formes réduites de variantes irrégulières .............................................................. 127
2. Variantes à deux syllabes au lieu de trois.................................................................... 128
3. Mots en <-on> ............................................................................................................. 130
4. Variantes toutes voyelles pleines ................................................................................ 133
5. Variantes avec le suffixe <-ette> réduit ...................................................................... 137
6. Mots en <-ert>............................................................................................................. 138
7. Mots en <-uCe>........................................................................................................... 140
8. Mots en <-oC> ............................................................................................................ 141
a) <-oc> ..................................................................................................................... 142
b) <-ol>...................................................................................................................... 143
c) <-op> ..................................................................................................................... 144
d) <-or> ..................................................................................................................... 145
e) <-os> ..................................................................................................................... 147
f) <-ot> ...................................................................................................................... 148
g) Conclusion ............................................................................................................ 149
9. Mots en <-at> .............................................................................................................. 150
10. Mots en <-et> ............................................................................................................ 152
11. Syllabes prétoniques non-réduites............................................................................. 155
12. Mots en <-elle> ......................................................................................................... 156
B. Cas liés à la relation graphie-phonie................................................................................. 157
1. Présence du phonème [A˘]........................................................................................... 157
2. Mots en <-que> et <-gue>........................................................................................... 159
3. Terminaison <plosive + liquide + -e muet> ................................................................ 165
4. Cluster <plosive + liquide + -e muet> en milieu de mot............................................. 169
5. Mots en <qu-> ............................................................................................................. 172

126 Etude de cas : niveau segmental
C. Cas liés aux règles de tension ........................................................................................... 173
1. Mots en VCVC# : tension systématique ?................................................................... 173
2. Mots en <-é> : tension bloquée ? ................................................................................ 178
3. Mots avec suffixe <-ion> et assimilés......................................................................... 181
D. Autres cas ......................................................................................................................... 183
1. Variantes en [dZ] / [Z] ................................................................................................. 183
2. Variantes en [tS] / [S] ................................................................................................... 188
3. Les réduplications........................................................................................................ 189
4. Les mots perçus ou traités comme étrangers............................................................... 191
a) Origine latine ou grecque ...................................................................................... 191
b) Origine italienne ou espagnole.............................................................................. 192
c) Autres origines ...................................................................................................... 192
d) Décision ................................................................................................................ 193

Cas liés à la réduction vocalique 127
Dans ce chapitre, nous allons développer certains points problématiques liés à la
prononciation des emprunts (ex : réduction vocalique, règles de tension) et à la relation entre
graphie et phonie.
A. CAS LIES A LA REDUCTION VOCALIQUE
1. Les formes réduites de variantes irrégulières
Dans le mot bizarrerie /bI:zA˘r´rI/, le suffixe <-ie> est prononcé [I]. Doit-on le
considérer comme une réduction de [i˘] ? En effet, certains emprunts français en <-ie> ont
deux variantes pour le suffixe : [i˘] ou [I], comme causerie /:k´Uz´rI/ ou /:k´Uz´ri˘/.
Néanmoins, en observant les mots anglais en <-ie>, voire uniquement les emprunts de notre
sélection en <-ie>, nous remarquons que la prononciation la plus courante est [I] (ex : boogie,
calorie, brasserie, menagerie) ; la variante [i˘] est en fait assez rare. Nous pouvons alors
affirmer que la prononciation habituelle du suffixe <-ie> est [I] et que bizarrerie suit les
règles de l’anglais.
Mais dans le cas de causerie doit-on cette fois analyser la variante en [I] comme une
réduction de [i˘] ou comme une autre variante possible ? La prononciation [i˘] étant
considérée comme non-anglicisée, si [I] en est la réduction, considérera-t-on également la
variante réduite comme non-anglicisée ?
Un autre exemple est à rapprocher du cas de causerie : celui de bivouac. Le mot
présente trois variantes : /:bIvu˘Qk/, /:bIvUQk/ et /:bIvwQk/. Dans la première variante, la
prononciation [u˘] pour le digraphe <ou> ne suit pas la règle de l’anglais, qui donne

128 Etude de cas : niveau segmental
habituellement [aU] ; cette prononciation est donc non-anglicisée. Dans la deuxième variante,
la prononciation [U] ne peut être que la réduction de [u˘] (ou [U]), mais pas de [aU] ; la
correspondance irrégulière entre graphie et phonie est donc toujours présente et cette variante
va également être considérée comme non-anglicisée. Enfin, dans la troisième variante [w]
peut aussi être analysée comme la réduction de [U] et la variante comme non-anglicisée.
Revenons au cas de causerie : peut-on considérer que la prononciation [I] conserve
une correspondance graphie-phonie irrégulière ? Non, puisque nous avons vu que cette
terminaison est habituelle pour les mots en <-ie>. Cette variante peut donc être expliquée par
une règle de l’anglais. Nous allons alors noter la variante /:k´Uz´rI/ comme anglicisée.
Ainsi, lorsqu’une variante réduite ne conservera pas une relation graphie-phonie
irrégulière, ou qu’une règle de l’anglais permettra d’expliquer la prononciation, nous noterons
cette variante comme étant anglicisée. C’est le cas par exemple de débâcle /:dEb´k´l/,
variante de /:dEIbA˘k´l/ ; bustier /:b√stI´/, variante de /:b√stIEI/ ; ou bonhomie /:bÅn´mI/,
variante de /:bÅn´mi˘/.
2. Variantes à deux syllabes au lieu de trois
Nous trouvons dans la base de données un certain nombre d’emprunts pour lesquels il
existe une variante comptant deux syllabes alors que la majorité des variantes en compte trois.

Cas liés à la réduction vocalique 129
allemande :Ql´mQnd :QlmQnd
cafetière «kQf´:tjE´ «kQf:tjE´
bibelot :bIb´l´U :bIbl´U
vaudeville :vç˘d´vIl :vç˘dvIl
clavecin :klQv´sIn :klQvsIn
paletot :pQlIt´U :pQlt´U
Tableau 4. Exemples de variantes à 2 ou 3 syllabes dans la BD.
Doit-on analyser ces cas comme plus anglicisés ou bien comme essayant de refléter la
prononciation française courante ?
Comme le souligne Taillé dans Histoire de la langue anglaise93, l’anglais a tendance à
rendre muette les syllabes inaccentuées (Taillé, 29, 54). C’est ainsi que nourrice (OF. nurice)
est devenu nurse, que carabine est devenu carbine, ou encore que corselet est devenu corslet
(ces deux derniers mots faisant partie du corpus).
Gimson, dans son ouvrage An Introduction to the Pronunciation of English94,
mentionne également ce phénomène (Gimson, 237-238). Il précise que ce sont en général [´]
ou [I] qui s’élident. C’est effectivement ce que nous observons dans les exemples ci-dessus.
Même si nous ne pouvons être certaine que la prononciation française n’a pas
d’influence sur ces variantes en deux syllabes, il est possible de les expliquer par une règle de
l’anglais ; c’est pourquoi nous préférons les considérer comme anglicisées de ce point de vue
et les supprimer le cas échéant.
93 Op. cit. p. 108
94 Gimson, A. C. An Introduction to the Pronunciation of English.1962. 2ème éd. London : Edward Arnold, 1970.

130 Etude de cas : niveau segmental
3. Mots en <-on>
Nous trouvons dans le corpus un certain nombre d’emprunts se terminant par le
suffixe <-on>, tels que abandon, baton, blouson, chaudron, frisson, griffon ou papillon.
Pour certains, le suffixe <-on> est prononcé [Ån], ce qui ne semble pas être une prononciation
inhabituelle en anglais (ex : moron, pentagon, telethon, nylon). Mais doit-on considérer cette
prononciation du suffixe comme anglicisée, ou bien comme étant due à l’origine française des
mots ? En effet, il semble tout de même que le cas le plus courant en anglais soit la réduction
de la voyelle de ce suffixe, prononcé [´n] : mutton, person, felon, pardon, poison, cotton,
prison, reason, ribbon, etc.
Nous décidons alors de relever dans le dictionnaire EPD environ 200 variantes de
mots en <-Con> (type baton), hors accent 1 final, et d’observer leur prononciation ainsi que
leur étymologie. Chaque prononciation différente pour le suffixe <-on> correspond à une
variante, c’est-à-dire que carillon, prononcé /kQ:rIlj´n/ ou /k´:rIlj´n/, ne comptera que pour
une variante, mais que baton, prononcé /:bQt´n/ ou /:bQtÅn/ comptera pour deux variantes.
Figure 11. Mots en <-Con>.
Nombre total de variantes : 224 • variantes en [´n] (ou n syllabique) : 138 (62%)
• variantes en [Ån] : 70 (31%)
• variantes en [ç)˘N] : 10 (5%)
• variantes en [ÅN] : 3 (1%)
• autres : [√n] => megaton, stepson ; [´Un] => chaperon (var. chaperone) (1%)
Nombre total de mots : 176 • mots avec variantes [´n] et [Ån] : 36 (21%)
• mots avec variante [´n] uniquement: 100 (57%)
• mots avec variante [Ån] uniquement: 27 (15%)
• autres cas : 13 (7%)

Cas liés à la réduction vocalique 131
Nous notons effectivement une majorité de variantes en [´n] puisqu’elles atteignent
plus de 60%. Les variantes en [Ån] représentent un tiers des cas et on trouve également
quelques variantes en [ç)˘N] et [ÅN] (ex : piton /:pi˘tç)˘N/, pompon /:pÅmpÅN/ ou /:pÅmpç)˘N/,
salon /:sQlç)˘N/, soupçon /:su˘psç)˘N/ ou /:su˘psÅN/). Nous remarquons également que dans
20% des cas, on trouve à la fois une variante en [´n] et une en [Ån] (ex : mastodon, micron,
natron, oxymoron, pentagon, plankton), même si la plupart du temps on trouve une variante
unique en [´n] (ex : poison, salmon, silicon, treason, falcon) ou [Ån] (ex : synchrotron,
tampon, telethon, blouson, macron, chiffon).
Nous décidons de nous intéresser particulièrement à l’étymologie des mots prononcés
[Ån]. Nous dégageons rapidement deux groupes : d’une part des mots de vocabulaire savant
— botanique, physique, chimie, géométrie, biologie, etc. — en général d’origine grecque ou
latine (ex : mesotron, neuron, neutron, proton, noumenon) ; et d’autre part, des emprunts au
français (ex : mignon, mouflon, piton, saffron, tampon, caisson, chevron). Nous concluons
de cette recherche que la prononciation [Ån] du suffixe <-on> est probablement due à
l’origine française dans certains cas.
Cette idée est renforcée par l’observation des mots en <-Con> de la base de données.
Afin de comparer les résultats à ceux de la recherche précédente, nous excluons de la
sélection les expressions et variantes qui comptent un mot en <-Con> non final (ex : cordon
bleu, trahison des clercs, wagon-lit), car il est impossible de savoir comment ces mots
seraient accentués s’ils étaient pris isolément.

132 Etude de cas : niveau segmental
Figure 12. Mots en <-Con> dans la BD.
Nous constatons que les résultats sont différents de l’encadré précédent. On trouve ici
plus de variantes en [Ån] qu’en [´n], et encore plus si l’on ajoute les expressions et mots
composés.
Figure 13. Expressions et mots composés contenant <-Con> dans la BD.
De plus, on trouve beaucoup plus de variantes non-réduites parmi les emprunts
français que dans le lexique anglais général, puisque dans la base de données, on compte 65%
de variantes non réduites contre 38 % dans la première sélection.
Tous ces éléments confirment que la prononciation [Ån] du suffixe <-on> peut être
imputée à l’origine française de ces mots. C’est pourquoi nous décidons de ne pas considérer
ces variantes comme anglicisées et de les conserver dans la base de données.
Mots en <-Con> dans la BD
149 variantes hors accent 1 final
• variantes en [´n] / n syllabique : 52 (35%)
• variantes en [Ån] : 60 (40%)
• variantes en [ç)˘N] / [Å)] : 30 (20%)
• variantes en [ÅN] : 6 (4%)
• autre : caisson /:kEIsu˘n/ (1%)
Expressions et mots composés
22 variantes
• variantes en [´n] / n syllabique : 3
• variantes en [Ån] : 8
• variantes en [ç)˘N] / [Å)] : 10
• variantes en [ÅN] : 1

Cas liés à la réduction vocalique 133
Néanmoins, il nous faut remarquer certains emprunts de notre base de données, dont le
suffixe est prononcé [Ån], mais qui semblent plutôt appartenir à la catégorie ‘mots savants’
qu’à la catégorie ‘mots issus du français’, comme acron ou catholicon. Acron est en effet un
terme de zoologie, créé par un spécialiste à partir d’éléments de grec, et catholicon désigne un
remède médicinal et vient probablement du latin ou du grec. Le rapprochement avec le mot
catholic est, de plus, inévitable. Il est vraisemblable que ces mots ne sont pas identifiés par les
locuteurs comme étant d’origine française, et que leur prononciation n’est pas due à cette
origine. C’est pourquoi ces variantes seront exclues de la base de données.
Nous voyons ainsi qu’il est parfois nécessaire d’observer non seulement la
prononciation, mais également l’étymologie ou le sens de chaque emprunt afin de déterminer
à quelle catégorie il appartient.
4. Variantes toutes voyelles pleines
La langue anglaise préfère en général l’alternance de syllabes accentuées et
inaccentuées, comme dans adventure /´d:vEntS´/ ou comprehension /«kÅmprI:hEnS´n/. Bien
sûr, il est également possible de trouver plusieurs syllabes inaccentuées d’affilée, comme dans
ceremony /:sErIm´nI/ ou interestingly /:Intr´stINlI/. Il est, par contre, plus rare de trouver
plusieurs syllabes accentuées à la suite. Pourtant, lorsqu’on observe les emprunts français, on
remarque que c’est souvent le cas, et qu’on trouve même de nombreuses variantes pour
lesquelles toutes les voyelles sont pleines.
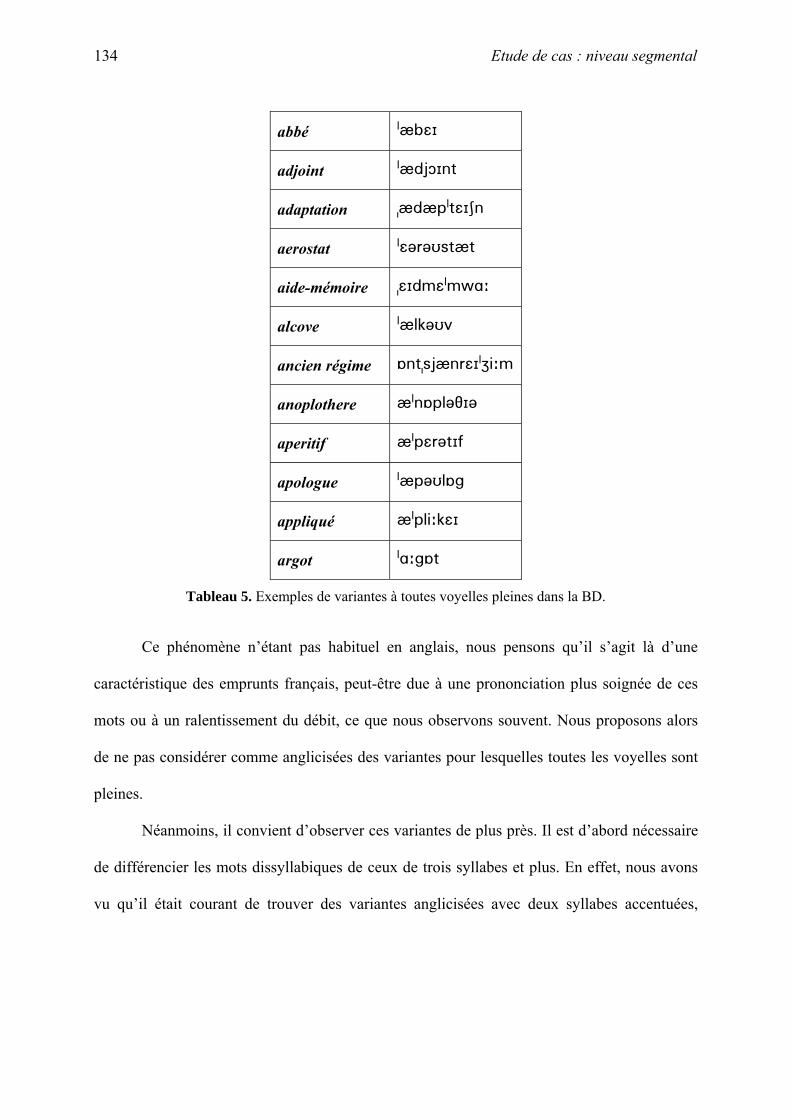
134 Etude de cas : niveau segmental
abbé :QbEI
adjoint :QdjçInt
adaptation «QdQp:tEISn
aerostat :E´r´UstQt
aide-mémoire «EIdmE:mwA˘
alcove :Qlk´Uv
ancien régime Ånt«sjQnrEI:Zi˘m
anoplothere Q:nÅpl´TI´
aperitif Q:pEr´tIf
apologue :Qp´UlÅg
appliqué Q:pli˘kEI
argot :A˘gÅt
Tableau 5. Exemples de variantes à toutes voyelles pleines dans la BD.
Ce phénomène n’étant pas habituel en anglais, nous pensons qu’il s’agit là d’une
caractéristique des emprunts français, peut-être due à une prononciation plus soignée de ces
mots ou à un ralentissement du débit, ce que nous observons souvent. Nous proposons alors
de ne pas considérer comme anglicisées des variantes pour lesquelles toutes les voyelles sont
pleines.
Néanmoins, il convient d’observer ces variantes de plus près. Il est d’abord nécessaire
de différencier les mots dissyllabiques de ceux de trois syllabes et plus. En effet, nous avons
vu qu’il était courant de trouver des variantes anglicisées avec deux syllabes accentuées,

Cas liés à la réduction vocalique 135
comme adjoint ou alcove95. Ce seront alors d’autres critères qui permettront d’affirmer
qu’abbé ou argot ne sont pas anglicisés.
En revanche, il semble inhabituel de trouver des mots de trois syllabes et plus ne
contenant pas de voyelles réduites ou présentant plusieurs voyelles pleines d’affilée. Pourtant,
nous en trouvons un nombre assez important dans la base de données. En regardant de près
ces variantes, nous remarquons que certaines seraient déclarées anglicisées si l’on ne tenait
pas compte des voyelles pleines. C’est le cas d’adaptation, aerostat, anoplothere ou
apologue.
Nous décidons alors d’examiner chaque variante afin d’expliquer ces prononciations
inhabituelles. Rapidement, on distingue un premier groupe de variantes dans lesquelles le
préfixe peut être réduit ou non : abstention /´b:stEnSn/ ou /Qb:stEnSn/ ; abstraction
/´b:strQkSn/ ou /Qb:strQkSn/ ; accessible /´k:sEs´bl/ ou /Qk:sEs´bl/ ; ou encore
adherence /´d:hI´r´ns/ ou /Qd:hI´r´ns/. Ces cas sont donc tout à fait réguliers.
On distingue ensuite un groupe de mots qui sont des constructions savantes, comme
aerogramme (aero + gramme) dans lequel le préfixe peut garder sa forme pleine :
/:E´r´UgrQm/. Font également partie de ce groupe des mots comme aerostat /:E´r´UstQt/,
anglophobe /:QNgl´Uf´Ub/, autoclave /:ç˘t´UklEIv/ ou bibliophile /:bIblI´UfaIl/. Il faut
noter que pour tous ces mots, il existe une variante dans laquelle on retrouve l’alternance
accentué / inaccentué : /:E´r´stQt/, /:QNgl´f´Ub/, /:bIblI´faIl/.
En étudiant les variantes qui pourraient être déclarées anglicisées, nous remarquons
que la plupart des mots concernés sont effectivement des mots « savants », en général
originaires du latin ou du grec — nous émettons même des doutes quant à leur transition par
95 Cf. p. 113

136 Etude de cas : niveau segmental
le français — et souvent employés dans des domaines particuliers comme la biologie, la
zoologie, l’archéologie, etc. Nous proposons alors l’hypothèse que, tout comme pour les mots
en <-on>, on pourrait classer ces variantes soit dans une catégorie ‘mots savants’, soit dans
une catégorie ‘mots français’. Des variantes comme alveole /:Qlvi˘´Ul/, anthracnose
/Qn:TrQkn´Us/, apogee /:Qp´UdZi˘/ ou azurine /:QzjU´raIn/ seraient en réalité des
prononciations ‘soignées’ ou ‘appliquées’ de ces mots savants.
Cette hypothèse est confirmée par une discussion de John Wells dans son blog96, à
propos de la prononciation d’osteoporosis, qui peut être prononcé /«ÅstI´Up´:r´UsIs/ ou
/-pç˘:r´UsIs/. Il explique que les locuteurs ont parfois le choix d’accentuer ou non une
syllabe, comme dans September ou November qui peuvent être prononcés /sEp-, n´U-/ ou
/s´p-, n´-/, ou encore –day dans les mots Sunday, Monday, birthday, etc., qui peut être
prononcé /-dEI/ ou /- dI/. Il ajoute que pour les termes techniques, il existe souvent une
variante avec voyelle pleine, que les spécialistes utilisent lorsqu’ils s’adressent au grand
public — par exemple quand un médecin aborde le sujet de l’ostéoporose avec son patient —,
et une variante avec voyelle réduite employée par les spécialistes entre eux.
Nous allons donc considérer les variantes entrant dans cette catégorie comme
anglicisées. En revanche, dans le cas des ‘mots français’, il s’agit d’une caractéristique propre
à ces emprunts. En général elle vient s’ajouter à d’autres critères de ‘francité’ comme c’est le
cas pour aide-mémoire /«EIdmE:mwA˘/, ancien régime /Ånt«sjQnrEI:Zi˘m/,
embourgeoisement /«ÅmbU´:ZwA˘zmÅ)/, ou encore wagon-lit /«vA˘gç)˘n:li˘/.
96 Wells, John. « Osteoporosis ». 18 dec. 2007. John Well’s phonetic blog. UCL Division of Psychology and
Language Sciences. 18 dec. 2007. http://www.phon.ucl.ac.uk/home/wells/blog0712b.htm.

Cas liés à la réduction vocalique 137
Nous supprimerons donc les variantes anglicisées de la base de données et ne
conserverons que les variantes entrant dans la catégorie ‘mots français’.
5. Variantes avec le suffixe <-ette> réduit
Parmi la classe de mots se terminant par le suffixe <-ette> — suffixe identifié comme
français de par sa forme — nous remarquons quelques variantes dans lesquelles ce suffixe est
réduit. Le nombre de mots concernés est assez limité ; en effet, ce suffixe porte généralement
l’accent primaire. Il est donc déjà rare de trouver l’accent placé sur une autre syllabe que la
finale. Néanmoins, nous trouvons cette liste de variantes avec suffixe réduit :
aigrette :EIgrIt
briquette, briquet :brIkIt
cossette, cosset :kÅsIt :kÅs´t
etiquette :EtIk´t :Et´k´t
omelet, omelette :Åml´t :ÅmlIt :Åm´lIt
palette :pQl´t :pQlIt
tablette :tQblIt
Tableau 6. Mots en <-ette> réduits dans la BD.
Remarquons que tous ces mots ont également une variante non-réduite, voire
accentuée en finale. Nous notons également que pour aigrette, briquette et tablette, la variante
réduite n’a été trouvée que dans l’OED, ce qui peut signifier qu’elle est plus rare ou plus
ancienne (tablette n’est d’ailleurs présent que dans l’OED).
Par ailleurs, tous les dictionnaires de prononciation présentent une variante réduite
pour etiquette, ce qui est une indication de sa fréquence. En ce qui concerne omelette, on
trouve plus de variantes réduites que non-réduites (une seule : /:ÅmlEt/), ce qui montre

138 Etude de cas : niveau segmental
également que la réduction du suffixe n’est pas chose exceptionnelle. Enfin, on remarque dans
le tableau qu’il existe parfois une variante orthographique <-et>, qui pourrait être une
représentation de la prononciation réduite. Néanmoins, la variante <cosset> doit être rare car
en cherchant sur Internet nous relevons uniquement l’orthographe <cossette> (avec le sens
‘betterave à sucre’)97. Pour <omelette> / <omelet>, nous obtenons un grand nombre
d’occurrences pour les deux orthographes. Enfin pour <briquette> / <briquet>, nous trouvons
les deux variantes, mais un plus grand nombre d’occurrences de <briquette>98.
Ajoutons que les sens de tablette correspondent à certains sens de tablet /:tQblIt/, ce
qui explique sans doute la prononciation réduite du mot.
Pour conclure, si la prononciation réduite du suffixe <-ette> est considérée comme
l’anglicisation maximale, nous estimons comme non-anglicisée une prononciation non-réduite
de ce suffixe, telle que omelette /:ÅmlEt/, aigrette /:EIgrEt/, épaulette /:Ep´lEt/ ou etiquette
/:EtIkEt/.
6. Mots en <-ert>
Le mot concert /:kÅnsŒ˘t/ nous interpelle : nous avons vu qu’un mot dissyllabique
accentué 1 sur la première syllabe et non-réduit en finale n’était pas inhabituel en anglais
(ex : adjoint), mais que cela dépendait de la terminaison ; brassard /:brQsA˘d/, par exemple,
n’est pas une prononciation anglicisée99. Alors la prononciation [Œ˘t] est-elle régulière ou
devrait-on plutôt s’attendre à une réduction en [´t] ?
97 D’après l’OED, une cossette est un morceau de betterave à sucre préparé pour l’extraction du jus.
98 Recherche du 29 octobre 2007. www.google.com.
99 Cf. p . 113
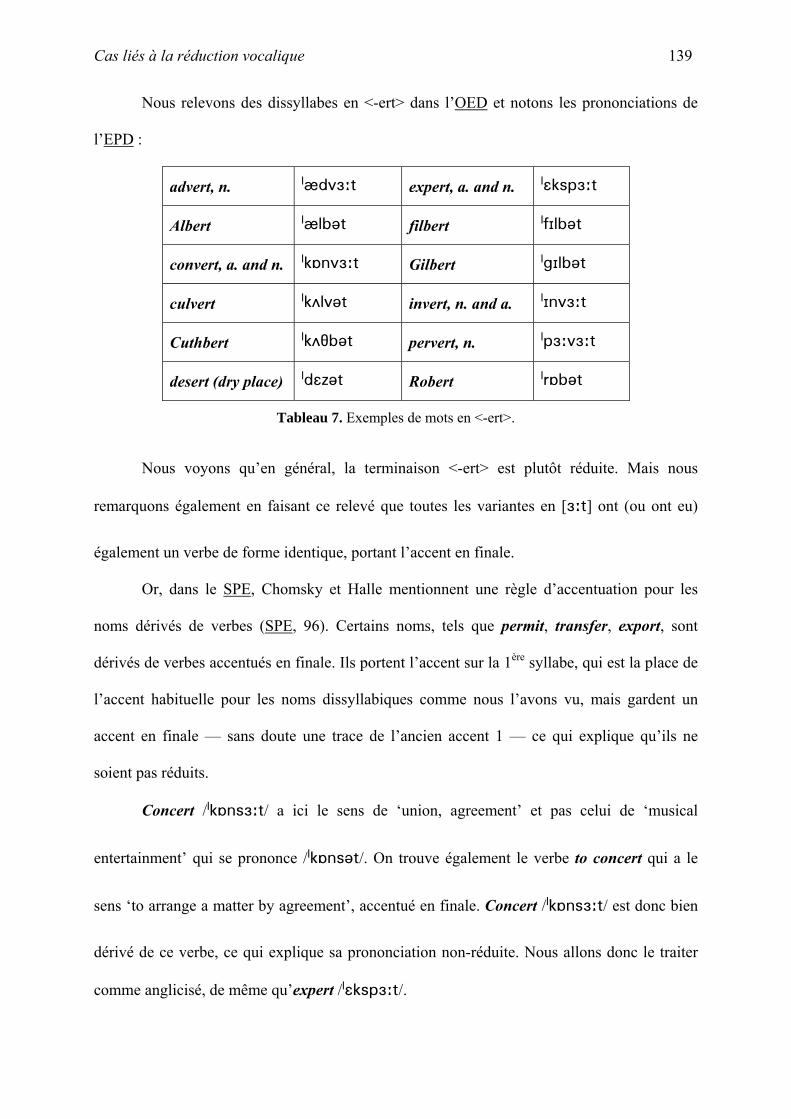
Cas liés à la réduction vocalique 139
Nous relevons des dissyllabes en <-ert> dans l’OED et notons les prononciations de
l’EPD :
advert, n. :QdvŒ˘t expert, a. and n. :EkspŒ˘t
Albert :Qlb´t filbert :fIlb´t
convert, a. and n. :kÅnvŒ˘t Gilbert :gIlb´t
culvert :k√lv´t invert, n. and a. :InvŒ˘t
Cuthbert :k√Tb´t pervert, n. :pŒ˘vŒ˘t
desert (dry place) :dEz´t Robert :rÅb´t
Tableau 7. Exemples de mots en <-ert>.
Nous voyons qu’en général, la terminaison <-ert> est plutôt réduite. Mais nous
remarquons également en faisant ce relevé que toutes les variantes en [Œ˘t] ont (ou ont eu)
également un verbe de forme identique, portant l’accent en finale.
Or, dans le SPE, Chomsky et Halle mentionnent une règle d’accentuation pour les
noms dérivés de verbes (SPE, 96). Certains noms, tels que permit, transfer, export, sont
dérivés de verbes accentués en finale. Ils portent l’accent sur la 1ère syllabe, qui est la place de
l’accent habituelle pour les noms dissyllabiques comme nous l’avons vu, mais gardent un
accent en finale — sans doute une trace de l’ancien accent 1 — ce qui explique qu’ils ne
soient pas réduits.
Concert /:kÅnsŒ˘t/ a ici le sens de ‘union, agreement’ et pas celui de ‘musical
entertainment’ qui se prononce /:kÅns´t/. On trouve également le verbe to concert qui a le
sens ‘to arrange a matter by agreement’, accentué en finale. Concert /:kÅnsŒ˘t/ est donc bien
dérivé de ce verbe, ce qui explique sa prononciation non-réduite. Nous allons donc le traiter
comme anglicisé, de même qu’expert /:EkspŒ˘t/.
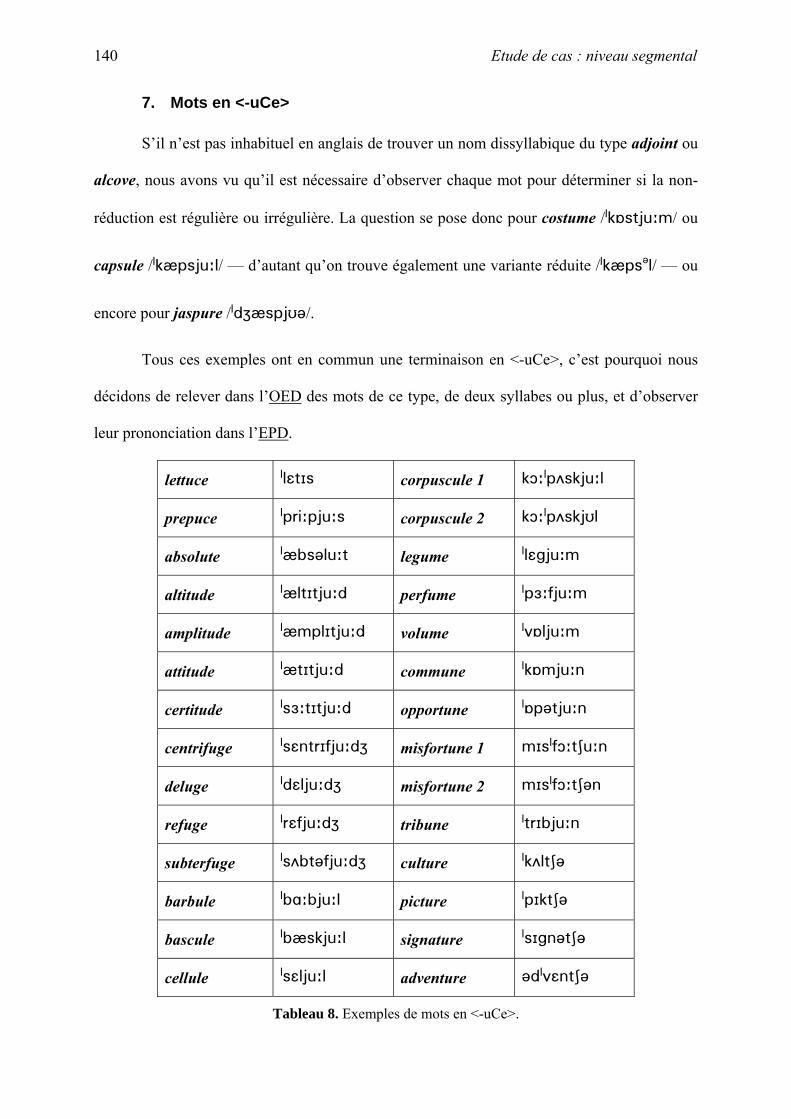
140 Etude de cas : niveau segmental
7. Mots en <-uCe>
S’il n’est pas inhabituel en anglais de trouver un nom dissyllabique du type adjoint ou
alcove, nous avons vu qu’il est nécessaire d’observer chaque mot pour déterminer si la non-
réduction est régulière ou irrégulière. La question se pose donc pour costume /:kÅstju˘m/ ou
capsule /:kQpsju˘l/ — d’autant qu’on trouve également une variante réduite /:kQps´l/ — ou
encore pour jaspure /:dZQspjU´/.
Tous ces exemples ont en commun une terminaison en <-uCe>, c’est pourquoi nous
décidons de relever dans l’OED des mots de ce type, de deux syllabes ou plus, et d’observer
leur prononciation dans l’EPD.
lettuce :lEtIs corpuscule 1 kç˘:p√skju˘l
prepuce :pri˘pju˘s corpuscule 2 kç˘:p√skjUl
absolute :Qbs´lu˘t legume :lEgju˘m
altitude :QltItju˘d perfume :pŒ˘fju˘m
amplitude :QmplItju˘d volume :vÅlju˘m
attitude :QtItju˘d commune :kÅmju˘n
certitude :sŒ˘tItju˘d opportune :Åp´tju˘n
centrifuge :sEntrIfju˘dZ misfortune 1 mIs:fç˘tSu˘n
deluge :dElju˘dZ misfortune 2 mIs:fç˘tS´n
refuge :rEfju˘dZ tribune :trIbju˘n
subterfuge :s√bt´fju˘dZ culture :k√ltS´
barbule :bA˘bju˘l picture :pIktS´
bascule :bQskju˘l signature :sIgn´tS´
cellule :sElju˘l adventure ´d:vEntS´
Tableau 8. Exemples de mots en <-uCe>.
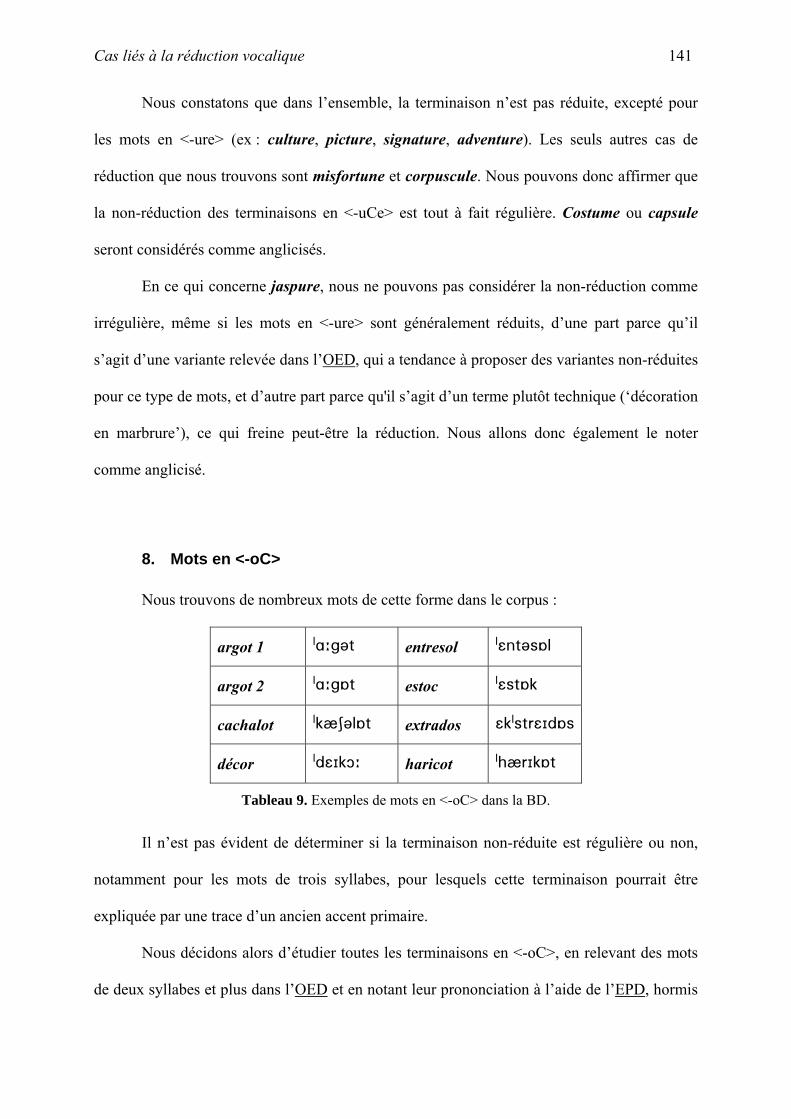
Cas liés à la réduction vocalique 141
Nous constatons que dans l’ensemble, la terminaison n’est pas réduite, excepté pour
les mots en <-ure> (ex : culture, picture, signature, adventure). Les seuls autres cas de
réduction que nous trouvons sont misfortune et corpuscule. Nous pouvons donc affirmer que
la non-réduction des terminaisons en <-uCe> est tout à fait régulière. Costume ou capsule
seront considérés comme anglicisés.
En ce qui concerne jaspure, nous ne pouvons pas considérer la non-réduction comme
irrégulière, même si les mots en <-ure> sont généralement réduits, d’une part parce qu’il
s’agit d’une variante relevée dans l’OED, qui a tendance à proposer des variantes non-réduites
pour ce type de mots, et d’autre part parce qu'il s’agit d’un terme plutôt technique (‘décoration
en marbrure’), ce qui freine peut-être la réduction. Nous allons donc également le noter
comme anglicisé.
8. Mots en <-oC>
Nous trouvons de nombreux mots de cette forme dans le corpus :
argot 1 :A˘g´t entresol :Ent´sÅl
argot 2 :A˘gÅt estoc :EstÅk
cachalot :kQS´lÅt extrados Ek:strEIdÅs
décor :dEIkç˘ haricot :hQrIkÅt
Tableau 9. Exemples de mots en <-oC> dans la BD.
Il n’est pas évident de déterminer si la terminaison non-réduite est régulière ou non,
notamment pour les mots de trois syllabes, pour lesquels cette terminaison pourrait être
expliquée par une trace d’un ancien accent primaire.
Nous décidons alors d’étudier toutes les terminaisons en <-oC>, en relevant des mots
de deux syllabes et plus dans l’OED et en notant leur prononciation à l’aide de l’EPD, hormis

142 Etude de cas : niveau segmental
les variantes accentuées 1 en finale. Nous procédons consonne par consonne, mais excluons
certaines terminaisons qui seraient improbables en français, telles que <-ok> ou <-ow>, ,
puisque ces terminaisons ne correspondent pas à l’orthoépie du français, ou encore des
terminaisons qui n’apparaissent pas ou peu dans nos emprunts, comme <-od> ou <-om> (seul
exemple : petit nom). Nous ne relevons pas non plus les mots en <-on> puisque cette
terminaison a déjà été étudiée.
a) <-oc>
La terminaison <-oc> n’offre pas beaucoup d’exemples :
Caradoc 1 k´:rQd´k
Caradoc 2 :kQr´dÅk
havoc :hQv´k
Languedoc :lA)˘Ng´dÅk
manioc :mQnIÅk
Médoc :mEIdÅk
Tremadoc trI:mQd´k
Tableau 10. Mots en <-oc>.
Sur ces quelques exemples, nous notons trois variantes en [´k] et quatre en [Åk].
Parmi les variantes réduites, nous remarquons le mot havoc, très courant, et les mots Caradoc
— qui a également une variante non-réduite — et Tremadoc. Ce sont deux termes de géologie
qui désignent des couches sédimentaires. Notons que c’est lorsque l’accent primaire est placé
sur la pénultième que la terminaison est réduite, tandis que la variante de Caradoc qui porte
l’accent primaire sur l’antépénultième n’est pas réduite en finale. La raison en est peut-être le
respect de l’alternance accentué / inaccentué caractéristique de l’anglais. Le placement de
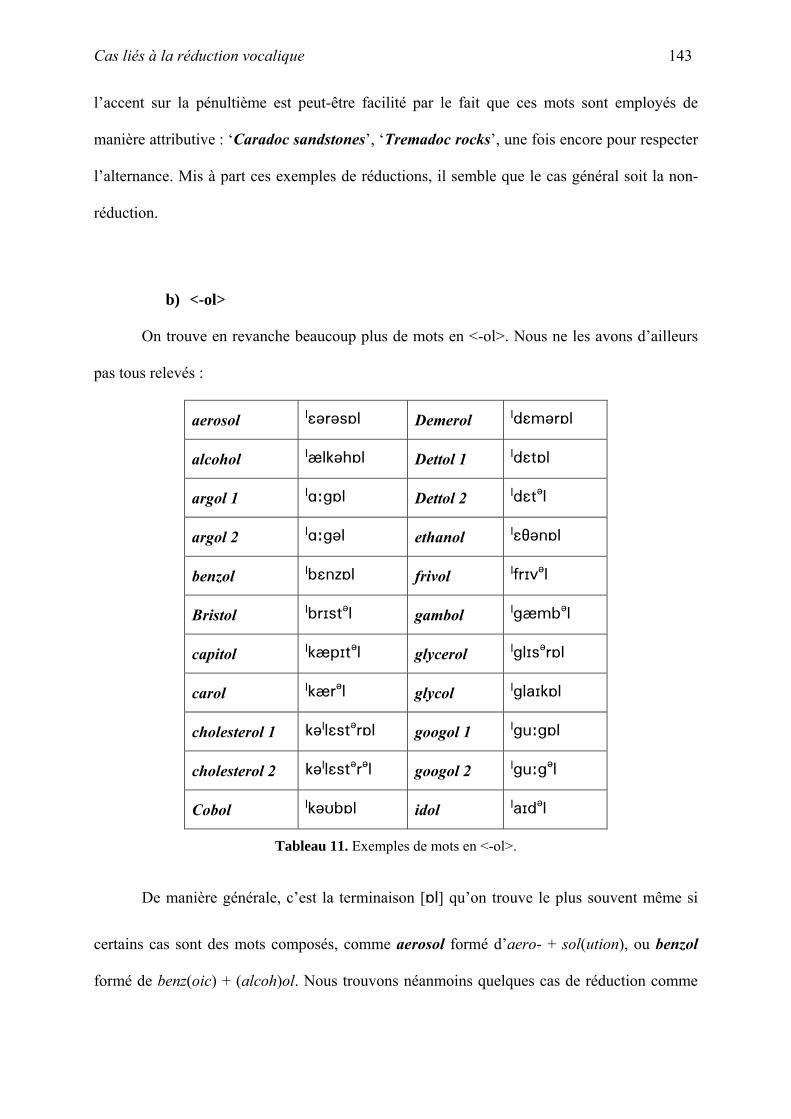
Cas liés à la réduction vocalique 143
l’accent sur la pénultième est peut-être facilité par le fait que ces mots sont employés de
manière attributive : ‘Caradoc sandstones’, ‘Tremadoc rocks’, une fois encore pour respecter
l’alternance. Mis à part ces exemples de réductions, il semble que le cas général soit la non-
réduction.
b) <-ol>
On trouve en revanche beaucoup plus de mots en <-ol>. Nous ne les avons d’ailleurs
pas tous relevés :
aerosol :E´r´sÅl Demerol :dEm´rÅl
alcohol :Qlk´hÅl Dettol 1 :dEtÅl
argol 1 :A˘gÅl Dettol 2 :dEt´l
argol 2 :A˘g´l ethanol :ET´nÅl
benzol :bEnzÅl frivol :frIv´l
Bristol :brIst´l gambol :gQmb´l
capitol :kQpIt´l glycerol :glIs´rÅl
carol :kQr´l glycol :glaIkÅl
cholesterol 1 k´:lEst´rÅl googol 1 :gu˘gÅl
cholesterol 2 k´:lEst´r´l googol 2 :gu˘g´l
Cobol :k´UbÅl idol :aId´l
Tableau 11. Exemples de mots en <-ol>.
De manière générale, c’est la terminaison [Ål] qu’on trouve le plus souvent même si
certains cas sont des mots composés, comme aerosol formé d’aero- + sol(ution), ou benzol
formé de benz(oic) + (alcoh)ol. Nous trouvons néanmoins quelques cas de réduction comme
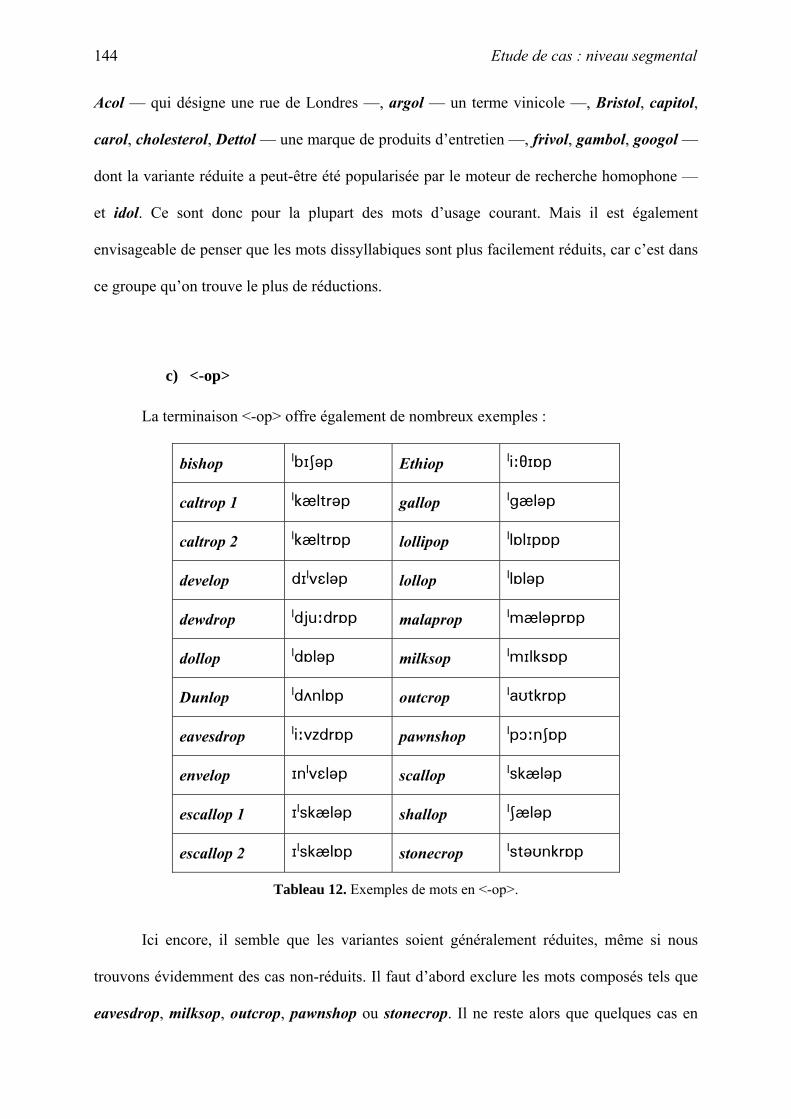
144 Etude de cas : niveau segmental
Acol — qui désigne une rue de Londres —, argol — un terme vinicole —, Bristol, capitol,
carol, cholesterol, Dettol — une marque de produits d’entretien —, frivol, gambol, googol —
dont la variante réduite a peut-être été popularisée par le moteur de recherche homophone —
et idol. Ce sont donc pour la plupart des mots d’usage courant. Mais il est également
envisageable de penser que les mots dissyllabiques sont plus facilement réduits, car c’est dans
ce groupe qu’on trouve le plus de réductions.
c) <-op>
La terminaison <-op> offre également de nombreux exemples :
bishop :bIS´p Ethiop :i˘TIÅp
caltrop 1 :kQltr´p gallop :gQl´p
caltrop 2 :kQltrÅp lollipop :lÅlIpÅp
develop dI:vEl´p lollop :lÅl´p
dewdrop :dju˘drÅp malaprop :mQl´prÅp
dollop :dÅl´p milksop :mIlksÅp
Dunlop :d√nlÅp outcrop :aUtkrÅp
eavesdrop :i˘vzdrÅp pawnshop :pç˘nSÅp
envelop In:vEl´p scallop :skQl´p
escallop 1 I:skQl´p shallop :SQl´p
escallop 2 I:skQlÅp stonecrop :st´UnkrÅp
Tableau 12. Exemples de mots en <-op>.
Ici encore, il semble que les variantes soient généralement réduites, même si nous
trouvons évidemment des cas non-réduits. Il faut d’abord exclure les mots composés tels que
eavesdrop, milksop, outcrop, pawnshop ou stonecrop. Il ne reste alors que quelques cas en
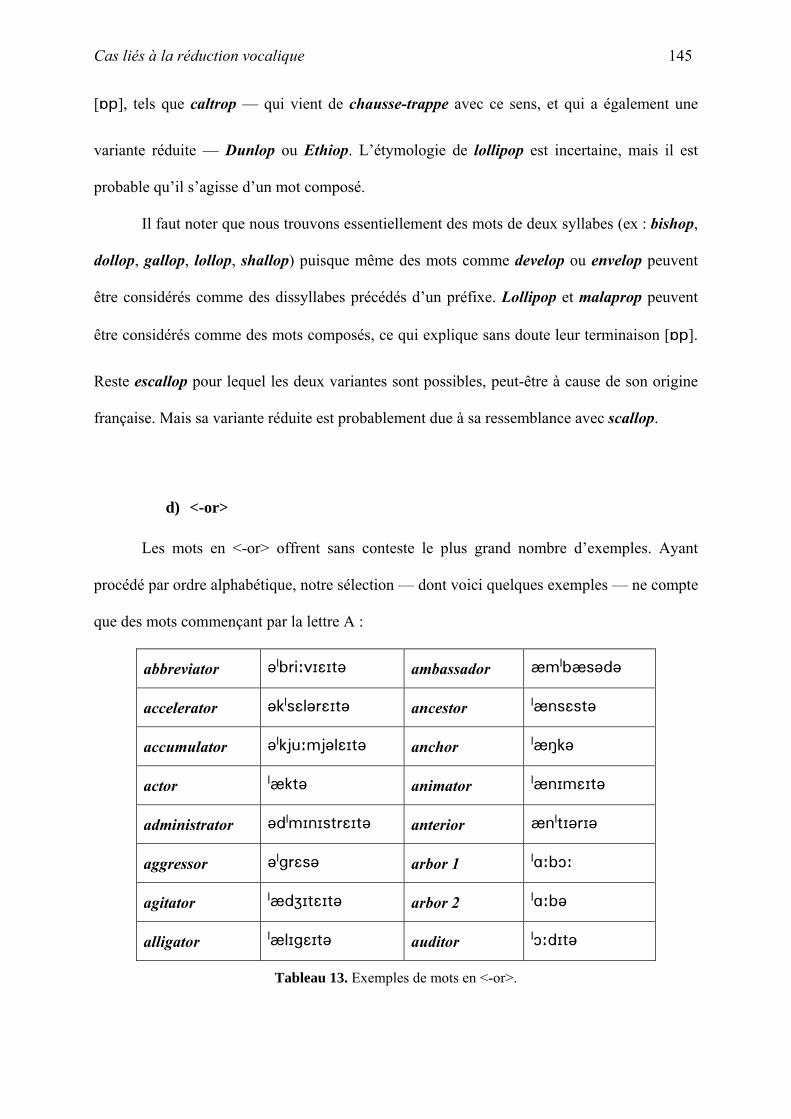
Cas liés à la réduction vocalique 145
[Åp], tels que caltrop — qui vient de chausse-trappe avec ce sens, et qui a également une
variante réduite — Dunlop ou Ethiop. L’étymologie de lollipop est incertaine, mais il est
probable qu’il s’agisse d’un mot composé.
Il faut noter que nous trouvons essentiellement des mots de deux syllabes (ex : bishop,
dollop, gallop, lollop, shallop) puisque même des mots comme develop ou envelop peuvent
être considérés comme des dissyllabes précédés d’un préfixe. Lollipop et malaprop peuvent
être considérés comme des mots composés, ce qui explique sans doute leur terminaison [Åp].
Reste escallop pour lequel les deux variantes sont possibles, peut-être à cause de son origine
française. Mais sa variante réduite est probablement due à sa ressemblance avec scallop.
d) <-or>
Les mots en <-or> offrent sans conteste le plus grand nombre d’exemples. Ayant
procédé par ordre alphabétique, notre sélection — dont voici quelques exemples — ne compte
que des mots commençant par la lettre A :
abbreviator ´:bri˘vIEIt´ ambassador Qm:bQs´d´
accelerator ´k:sEl´rEIt´ ancestor :QnsEst´
accumulator ´:kju˘mj´lEIt´ anchor :QNk´
actor :Qkt´ animator :QnImEIt´
administrator ´d:mInIstrEIt´ anterior Qn:tI´rI´
aggressor ´:grEs´ arbor 1 :A˘bç˘
agitator :QdZItEIt´ arbor 2 :A˘b´
alligator :QlIgEIt´ auditor :ç˘dIt´
Tableau 13. Exemples de mots en <-or>.
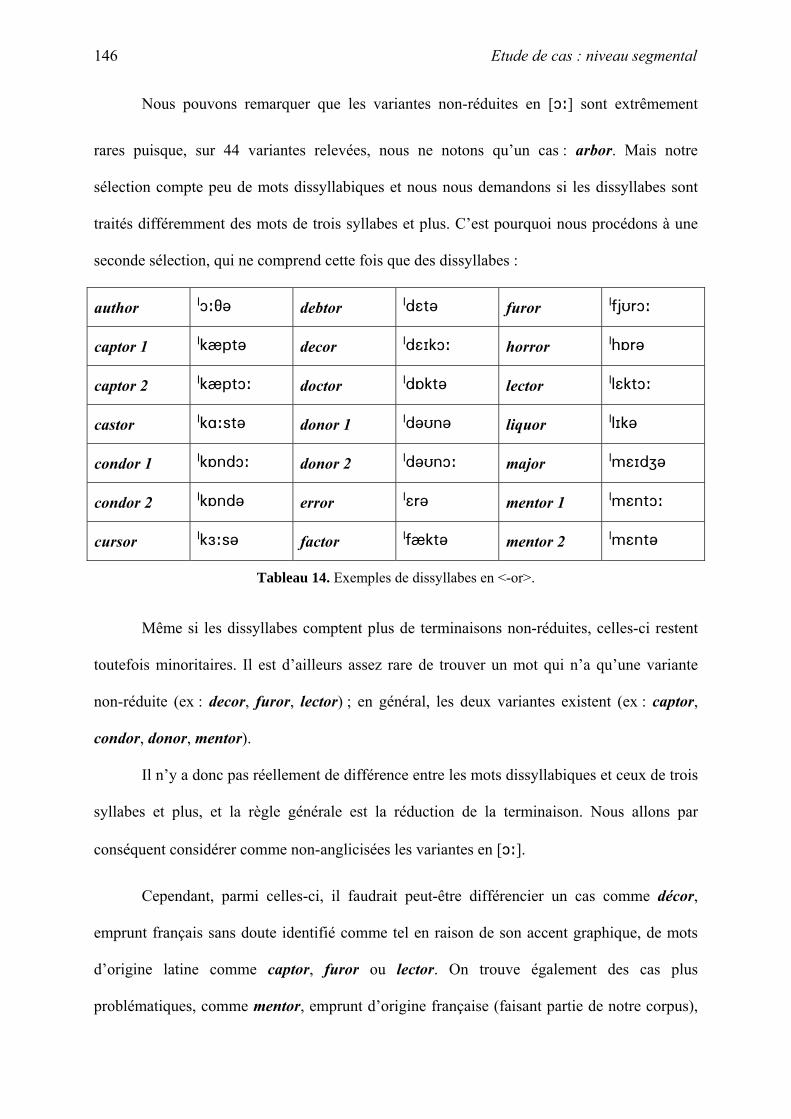
146 Etude de cas : niveau segmental
Nous pouvons remarquer que les variantes non-réduites en [ç˘] sont extrêmement
rares puisque, sur 44 variantes relevées, nous ne notons qu’un cas : arbor. Mais notre
sélection compte peu de mots dissyllabiques et nous nous demandons si les dissyllabes sont
traités différemment des mots de trois syllabes et plus. C’est pourquoi nous procédons à une
seconde sélection, qui ne comprend cette fois que des dissyllabes :
author :ç˘T´ debtor :dEt´ furor :fjUrç˘
captor 1 :kQpt´ decor :dEIkç˘ horror :hÅr´
captor 2 :kQptç˘ doctor :dÅkt´ lector :lEktç˘
castor :kA˘st´ donor 1 :d´Un´ liquor :lIk´
condor 1 :kÅndç˘ donor 2 :d´Unç˘ major :mEIdZ´
condor 2 :kÅnd´ error :Er´ mentor 1 :mEntç˘
cursor :kŒ˘s´ factor :fQkt´ mentor 2 :mEnt´
Tableau 14. Exemples de dissyllabes en <-or>.
Même si les dissyllabes comptent plus de terminaisons non-réduites, celles-ci restent
toutefois minoritaires. Il est d’ailleurs assez rare de trouver un mot qui n’a qu’une variante
non-réduite (ex : decor, furor, lector) ; en général, les deux variantes existent (ex : captor,
condor, donor, mentor).
Il n’y a donc pas réellement de différence entre les mots dissyllabiques et ceux de trois
syllabes et plus, et la règle générale est la réduction de la terminaison. Nous allons par
conséquent considérer comme non-anglicisées les variantes en [ç˘].
Cependant, parmi celles-ci, il faudrait peut-être différencier un cas comme décor,
emprunt français sans doute identifié comme tel en raison de son accent graphique, de mots
d’origine latine comme captor, furor ou lector. On trouve également des cas plus
problématiques, comme mentor, emprunt d’origine française (faisant partie de notre corpus),
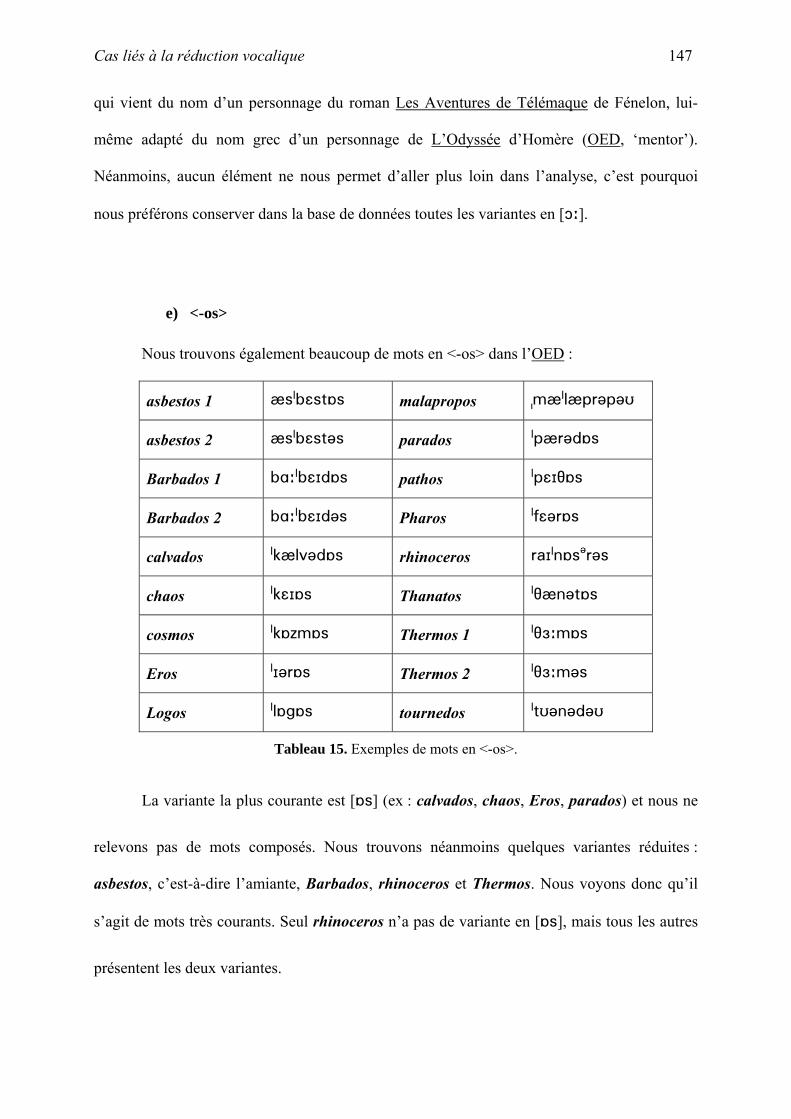
Cas liés à la réduction vocalique 147
qui vient du nom d’un personnage du roman Les Aventures de Télémaque de Fénelon, lui-
même adapté du nom grec d’un personnage de L’Odyssée d’Homère (OED, ‘mentor’).
Néanmoins, aucun élément ne nous permet d’aller plus loin dans l’analyse, c’est pourquoi
nous préférons conserver dans la base de données toutes les variantes en [ç˘].
e) <-os>
Nous trouvons également beaucoup de mots en <-os> dans l’OED :
asbestos 1 Qs:bEstÅs malapropos «mQ:lQpr´p´U
asbestos 2 Qs:bEst´s parados :pQr´dÅs
Barbados 1 bA˘:bEIdÅs pathos :pEITÅs
Barbados 2 bA˘:bEId´s Pharos :fE´rÅs
calvados :kQlv´dÅs rhinoceros raI:nÅs´r´s
chaos :kEIÅs Thanatos :TQn´tÅs
cosmos :kÅzmÅs Thermos 1 :TŒ˘mÅs
Eros :I´rÅs Thermos 2 :TŒ˘m´s
Logos :lÅgÅs tournedos :tU´n´d´U
Tableau 15. Exemples de mots en <-os>.
La variante la plus courante est [Ås] (ex : calvados, chaos, Eros, parados) et nous ne
relevons pas de mots composés. Nous trouvons néanmoins quelques variantes réduites :
asbestos, c’est-à-dire l’amiante, Barbados, rhinoceros et Thermos. Nous voyons donc qu’il
s’agit de mots très courants. Seul rhinoceros n’a pas de variante en [Ås], mais tous les autres
présentent les deux variantes.
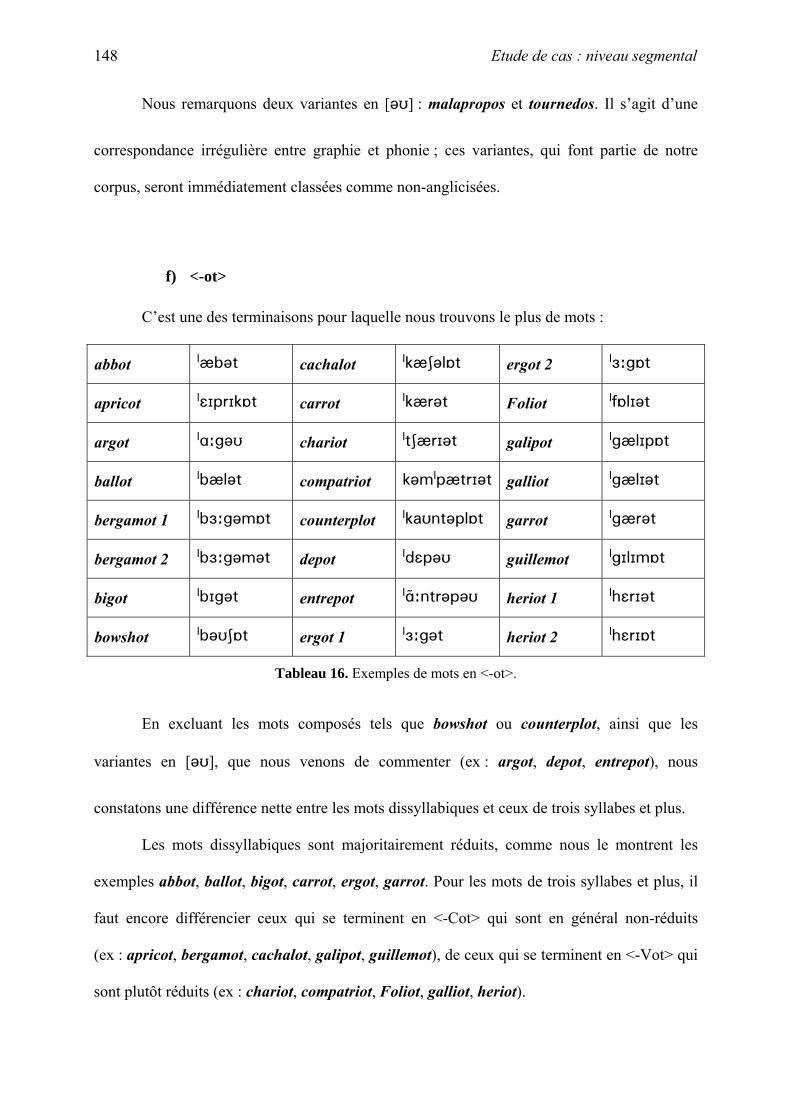
148 Etude de cas : niveau segmental
Nous remarquons deux variantes en [´U] : malapropos et tournedos. Il s’agit d’une
correspondance irrégulière entre graphie et phonie ; ces variantes, qui font partie de notre
corpus, seront immédiatement classées comme non-anglicisées.
f) <-ot>
C’est une des terminaisons pour laquelle nous trouvons le plus de mots :
abbot :Qb´t cachalot :kQS´lÅt ergot 2 :Œ˘gÅt
apricot :EIprIkÅt carrot :kQr´t Foliot :fÅlI´t
argot :A˘g´U chariot :tSQrI´t galipot :gQlIpÅt
ballot :bQl´t compatriot k´m:pQtrI´t galliot :gQlI´t
bergamot 1 :bŒ˘g´mÅt counterplot :kaUnt´plÅt garrot :gQr´t
bergamot 2 :bŒ˘g´m´t depot :dEp´U guillemot :gIlImÅt
bigot :bIg´t entrepot :A)˘ntr´p´U heriot 1 :hErI´t
bowshot :b´USÅt ergot 1 :Œ˘g´t heriot 2 :hErIÅt
Tableau 16. Exemples de mots en <-ot>.
En excluant les mots composés tels que bowshot ou counterplot, ainsi que les
variantes en [´U], que nous venons de commenter (ex : argot, depot, entrepot), nous
constatons une différence nette entre les mots dissyllabiques et ceux de trois syllabes et plus.
Les mots dissyllabiques sont majoritairement réduits, comme nous le montrent les
exemples abbot, ballot, bigot, carrot, ergot, garrot. Pour les mots de trois syllabes et plus, il
faut encore différencier ceux qui se terminent en <-Cot> qui sont en général non-réduits
(ex : apricot, bergamot, cachalot, galipot, guillemot), de ceux qui se terminent en <-Vot> qui
sont plutôt réduits (ex : chariot, compatriot, Foliot, galliot, heriot).

Cas liés à la réduction vocalique 149
Il est d’ailleurs possible que la terminaison <-VoC> — ou plus exactement <-ioC>
puisque c’est la seule voyelle que nous trouvions — soit en général réduite, puisque nous
trouvons également les exemples de period /:pI´rI´d/, axiom /:QksI´m/ ou idiom /:IdI´m/.
Cependant, nous relevons aussi des contre-exemples comme manioc /:mQnIÅk/ ou Ethiop
/:i˘TIÅp/.
g) Conclusion
Cette recherche nous permet de prendre des décisions pour tous les mots en <-oC> de
la base de données.
Certaines variantes sont non-réduites de façon régulière et seront considérées comme
anglicisées. C’est le cas des mots en :
• <-oc>
• <-ol>
• <-os>
• <-ot>, pour les mots de trois syllabes et plus en <-Cot>
Bien entendu, une variante réduite avec l’une de ces terminaisons sera également
traitée comme anglicisée.
En revanche, pour les autres terminaisons — <-op>, <-or> et <-ot> pour les
dissyllabes et mots de trois syllabes et plus en <-iot> —, on peut s’attendre à une réduction.
Une variante non-réduite sera donc considérée comme irrégulière. Néanmoins, une
vérification reste nécessaire, car il est possible que certains mots soient non-réduits en raison
de leur caractère savant, et non de leur origine française.

150 Etude de cas : niveau segmental
Des variantes comme decor /:dEIkç˘/ ou argot /:A˘gÅt/ seront donc considérées
comme non-anglicisées, tandis qu’estoc /:EstÅk/, galipot /:gQlIpÅt/ ou haricot /:hQrIkÅt/
seront traités comme anglicisés.
9. Mots en <-at>
Nous trouvons dans notre corpus quelques mots en <-at> dont la prononciation nous
interroge parfois :
assignat 1 «QsI:njA˘ concordat 1 kÅN:kç˘dQt
assignat 2 QsIg:nQt concordat 2 k´N:kç˘dQt
assignat 3 :QsIgnQt format :fç˘mQt
combat 1 :kÅmbQt hors de combat 1 «hç˘d´:kÅmbA˘
combat 2 :kÅmb´t hors de combat 2 «hç˘d´:kÅmbQt
Tableau 17. Exemples de mots en <-at> dans la BD.
Nous remarquons que seul combat a une variante réduite. Toutes les autres variantes,
en excluant celles accentuées 1 en finale, sont non-réduites. Serait-ce dû à leur origine
française ? Les variantes en [Qt] doivent-elles être considérées comme non-anglicisées ?
Nous sommes tentée de le croire, d’autant qu’un mot comme assignat compte deux variantes
accentuées 1 en finale. La non-réduction de la variante /:QsIgnQt/ est peut-être une trace de
l’ancien accent 1.
Pour s’en assurer, nous décidons de relever des mots en <-at> de deux syllabes et plus
dans l’OED et de chercher les transcriptions dans l’EPD, en excluant les mots accentués 1 en
finale, ainsi que les formations du type comsat :
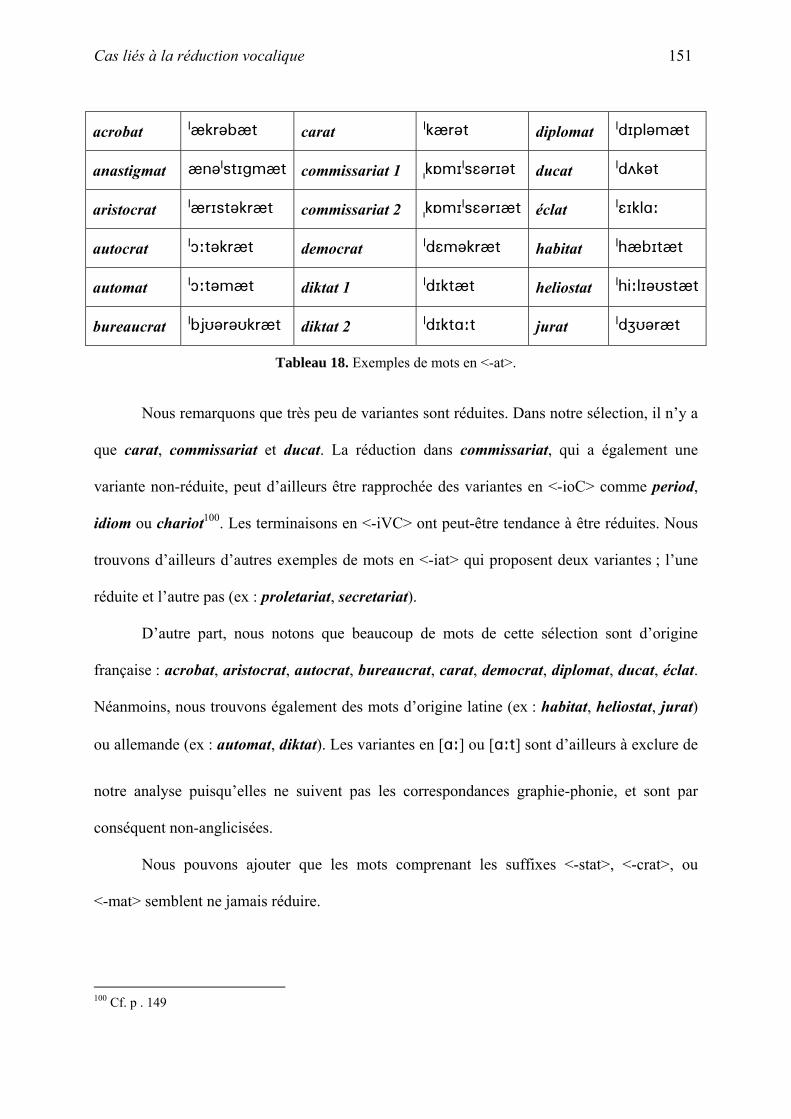
Cas liés à la réduction vocalique 151
acrobat :Qkr´bQt carat :kQr´t diplomat :dIpl´mQt
anastigmat Qn´:stIgmQt commissariat 1 «kÅmI:sE´rI´t ducat :d√k´t
aristocrat :QrIst´krQt commissariat 2 «kÅmI:sE´rIQt éclat :EIklA˘
autocrat :ç˘t´krQt democrat :dEm´krQt habitat :hQbItQt
automat :ç˘t´mQt diktat 1 :dIktQt heliostat :hi˘lI´UstQt
bureaucrat :bjU´r´UkrQt diktat 2 :dIktA˘t jurat :dZU´rQt
Tableau 18. Exemples de mots en <-at>.
Nous remarquons que très peu de variantes sont réduites. Dans notre sélection, il n’y a
que carat, commissariat et ducat. La réduction dans commissariat, qui a également une
variante non-réduite, peut d’ailleurs être rapprochée des variantes en <-ioC> comme period,
idiom ou chariot100. Les terminaisons en <-iVC> ont peut-être tendance à être réduites. Nous
trouvons d’ailleurs d’autres exemples de mots en <-iat> qui proposent deux variantes ; l’une
réduite et l’autre pas (ex : proletariat, secretariat).
D’autre part, nous notons que beaucoup de mots de cette sélection sont d’origine
française : acrobat, aristocrat, autocrat, bureaucrat, carat, democrat, diplomat, ducat, éclat.
Néanmoins, nous trouvons également des mots d’origine latine (ex : habitat, heliostat, jurat)
ou allemande (ex : automat, diktat). Les variantes en [A˘] ou [A˘t] sont d’ailleurs à exclure de
notre analyse puisqu’elles ne suivent pas les correspondances graphie-phonie, et sont par
conséquent non-anglicisées.
Nous pouvons ajouter que les mots comprenant les suffixes <-stat>, <-crat>, ou
<-mat> semblent ne jamais réduire.
100 Cf. p . 149
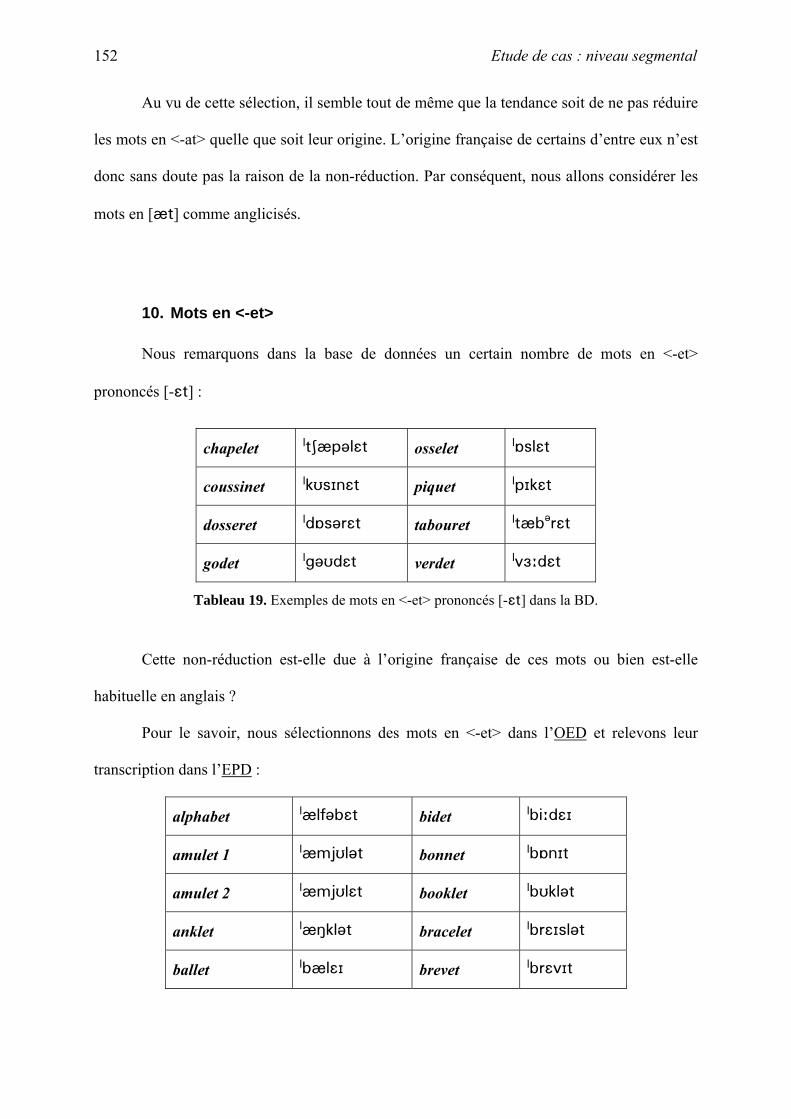
152 Etude de cas : niveau segmental
Au vu de cette sélection, il semble tout de même que la tendance soit de ne pas réduire
les mots en <-at> quelle que soit leur origine. L’origine française de certains d’entre eux n’est
donc sans doute pas la raison de la non-réduction. Par conséquent, nous allons considérer les
mots en [Qt] comme anglicisés.
10. Mots en <-et>
Nous remarquons dans la base de données un certain nombre de mots en <-et>
prononcés [-Et] :
chapelet :tSQp´lEt osselet :ÅslEt
coussinet :kUsInEt piquet :pIkEt
dosseret :dÅs´rEt tabouret :tQb´rEt
godet :g´UdEt verdet :vŒ˘dEt
Tableau 19. Exemples de mots en <-et> prononcés [-Et] dans la BD.
Cette non-réduction est-elle due à l’origine française de ces mots ou bien est-elle
habituelle en anglais ?
Pour le savoir, nous sélectionnons des mots en <-et> dans l’OED et relevons leur
transcription dans l’EPD :
alphabet :Qlf´bEt bidet :bi˘dEI
amulet 1 :QmjUl´t bonnet :bÅnIt
amulet 2 :QmjUlEt booklet :bUkl´t
anklet :QNkl´t bracelet :brEIsl´t
ballet :bQlEI brevet :brEvIt

Cas liés à la réduction vocalique 153
banquet :bQNkwIt cabaret :kQb´rEI
bayonet 1 :bEI´n´t cabinet :kQbIn´t
bayonet 2 :bEI´nEt carpet :kA˘pIt
Tableau 20. Exemples de mots en <-et>.
Nous remarquons immédiatement une divergence entre les mots dissyllabiques, qui
semblent majoritairement réduits, et ceux de trois syllabes et plus, qui semblent présenter plus
de cas de non-réduction.
Effectivement, pour les dissyllabes, nous trouvons les résultats suivants :
Figure 14. Prononciation des dissyllabes en <-et>.
On peut conclure de cette sélection que l’habitude en anglais est de réduire dans ce
contexte. Dès lors, toute variante en [Et] d’un mot dissyllabique sera considérée comme non-
anglicisée. Les variantes en [EI] sont, quant à elles, tout à fait irrégulières et font d’ailleurs
toutes partie de notre corpus.
En revanche, nous manquons de cas de trois syllabes pour vraiment en tirer quelque
conclusion que ce soit. C’est pourquoi nous procédons à une sélection supplémentaire, portant
uniquement sur les mots de trois syllabes et plus :
Mots 2 S : 50 mots
57 variantes 45 réduites
12 non-réduites
[EI] = 10 (ballet, beignet, beret, bidet, bouquet,
buffet, cachet, chalet, crochet, croquet)
[Et] = 2 (applet, chaplet)
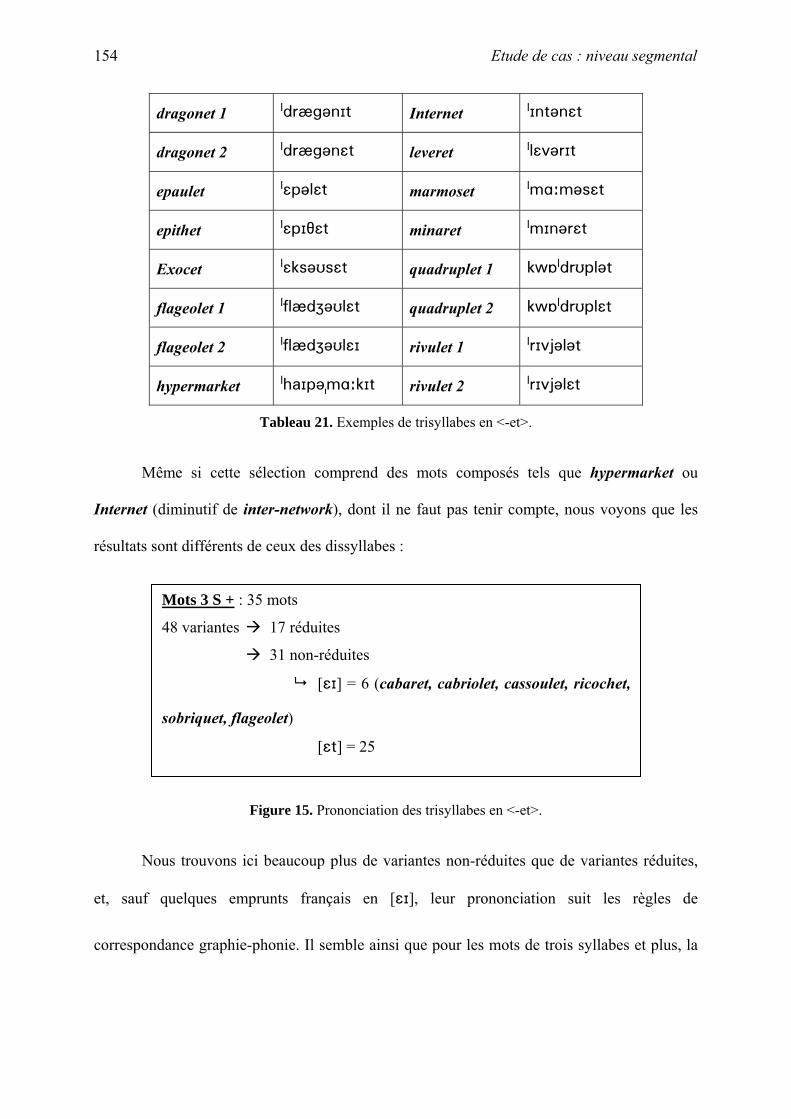
154 Etude de cas : niveau segmental
dragonet 1 :drQg´nIt Internet :Int´nEt
dragonet 2 :drQg´nEt leveret :lEv´rIt
epaulet :Ep´lEt marmoset :mA˘m´sEt
epithet :EpITEt minaret :mIn´rEt
Exocet :Eks´UsEt quadruplet 1 kwÅ:drUpl´t
flageolet 1 :flQdZ´UlEt quadruplet 2 kwÅ:drUplEt
flageolet 2 :flQdZ´UlEI rivulet 1 :rIvj´l´t
hypermarket :haIp´«mA˘kIt rivulet 2 :rIvj´lEt
Tableau 21. Exemples de trisyllabes en <-et>.
Même si cette sélection comprend des mots composés tels que hypermarket ou
Internet (diminutif de inter-network), dont il ne faut pas tenir compte, nous voyons que les
résultats sont différents de ceux des dissyllabes :
Figure 15. Prononciation des trisyllabes en <-et>.
Nous trouvons ici beaucoup plus de variantes non-réduites que de variantes réduites,
et, sauf quelques emprunts français en [EI], leur prononciation suit les règles de
correspondance graphie-phonie. Il semble ainsi que pour les mots de trois syllabes et plus, la
Mots 3 S + : 35 mots
48 variantes 17 réduites
31 non-réduites
[EI] = 6 (cabaret, cabriolet, cassoulet, ricochet,
sobriquet, flageolet)
[Et] = 25

Cas liés à la réduction vocalique 155
non-réduction soit tout à fait habituelle. Ces variantes seront donc considérées comme
anglicisées.
Évidemment, puisqu’un certain nombre de ces mots en <-et> sont d’origine française,
on ne peut exclure que celle-ci soit la cause de la non-réduction. Par exemple, des mots
comme epaulet ou flageolet présentent également une variante accentuée en finale, ce qui
laisse penser que la non-réduction est la trace d’un ancien accent primaire. Néanmoins,
puisque cette non-réduction semble généralisée pour les mots de trois syllabes et plus, nous ne
pouvons classer ces exemples comme non-anglicisés.
En résumé, nous allons considérer les mots dissyllabiques réduits en finale comme
anglicisés, et ceux non-réduits comme non-anglicisés, quelle que soit la prononciation. Pour
les mots de trois syllabes et plus, seule la prononciation [EI] sera considérée comme non-
anglicisée.
11. Syllabes prétoniques non-réduites
Aperitif /Q:pEr´tIf/ est-elle une variante anglicisée ? La question se pose par rapport à
la syllabe prétonique qui est pleine. Peut-on expliquer cette non-réduction par une règle de
l’anglais ?
La règle habituelle est la suivante : si l’on trouve deux consonnes à la jonction des
deux syllabes, il est possible d’accentuer la syllabe prétonique, qui sera alors pleine. Cette
règle permet d’expliquer les variantes suivantes de notre base de données : escalope
/E:skQl´p/, espalier /E:spQlI´/, extrados /Ek:strEId´s/, ou costumier /kÅ:stju˘mI´/. Elles
vont donc être traitées comme anglicisées.

156 Etude de cas : niveau segmental
En revanche, aperitif ne peut pas être expliqué par cette règle, ni habitué
/hQ:bItjUEI/, menagerie /mE:nQdZ´rI/, ou papeterie /pQ:pEt´rI/. Ces variantes seront donc
considérées comme non-anglicisées et maintenues dans la base de données.
12. Mots en <-elle>
Parmi les nombreux mots en <-elle> de la base de données, nous trouvons rubicelle
/:ru˘bIsEl/. Doit-on considérer que la non-réduction de la finale est une trace d’un ancien
accent primaire ou bien cette prononciation est-elle habituelle en anglais ? Une réduction en
finale serait-elle possible ?
Nous décidons de rechercher d’autres exemples en sélectionnant des mots en <-elle>
dans l’OED, puis en retenant ceux pour lesquels nous trouvons une transcription dans l’EPD,
hors accent 1 final, comme nous avons procédé pour les précédentes recherches.
Nous ne trouvons qu’un seul cas : pipistrelle /:pIpIstrEl/, qui compte également une
variante accentuée en finale. Nous reprenons alors notre base de données et observons les
mots en <-elle>. Ils sont assez nombreux, mais quasiment tous sont accentués en finale. Les
quelques cas accentués sur l’antépénultième sont :
chanterelle :tSA˘nt´«rEl
filoselle :fIl´sEl
mirabelle :mIr´bEl
pipistrelle :pIpIstrEl
rubicelle :ru˘bIsEl
Tableau 22. Mots en <-elle> accentués sur l’antépénultième dans la BD.

Cas liés à la relation graphie-phonie 157
Parmi ceux-ci, seuls filoselle et rubicelle ne proposent pas de variante accentuée en
finale.
Nous voyons ainsi que les mots en <-elle> sont tous d’origine française, quasiment
toujours accentués en finale, et jamais réduits. Nous ne pouvons donc considérer aucune de
ces variantes comme anglicisée, car il s’agit visiblement d’une terminaison identifiée comme
française.
B. CAS LIES A LA RELATION GRAPHIE-PHONIE
1. Présence du phonème [A˘]
Dans la variante d’aide-de-camp /«EIdd´:kA˘mp/, ce qui attire notre attention, c’est la
prononciation /kA˘mp/ de camp, habituellement prononcé /kQmp/. Est-ce dû à l’origine
française ? Nous observons d’autres emprunts et remarquons la présence du phonème [A˘] là
où l’on ne le trouve pas habituellement : broderie anglaise /«br´Ud´rI:A˘NglEIz/, cabiai
/:kA˘bIaI/ ou cadre /:kA˘d´/. En effet, les règles de l’anglais expliquent la présence du
phonème [A˘] par la transformation devant [r] (Q A˘ /— r , ex : card), ou devant [ns, ntS,
nt, nd] (ex : dance, demand) (Wells, vol. 1, 205), ainsi que devant les fricatives /f T s/
(ex : after, bath, glass) et occasionnellement /v D/ (Carney, 178)101. Wells, dans le premier
volume d’Accents of English102, propose à ce propos une explication :
101 Carney, Edward. A Survey of English Spelling. London, New-York : Routledge, 1994.
102 Wells, John. Accents of English. Vol. 1 : “An Introduction”. Cambridge: Cambridge UP, 1982.

158 Etude de cas : niveau segmental
Current RP also has [A˘] in many words where the vowel is followed by
[ns, ntS, nt, nd], such as dance, answer, branch, grant, demand. Some of
these had Middle English variants with [aU] (which would normally yield to
present-day [ç˘]); some are loanwords from French. (Wells, vol. 1, 205)
Il se pourrait donc que le [a] français soit souvent adapté en un [A˘] anglais. C’est sans
doute la raison pour laquelle on trouve ce phonème si souvent dans les emprunts français. Une
autre citation de Wells, du même ouvrage, vient appuyer cette hypothèse :
When foreign words are borrowed into English they are usually made to
conform to English patterns. Full integration implies a phonological
reinterpretation in terms of English phonemes arranged in patterns which
follow English phonotactic constraints. Thus for instance French façade
[fa:sad] is anglicized as RP /f´:sA˘d/, rhyming with card […]. (Wells, vol. 1,
102)
Enfin, une dernière citation, celle d’Andrew Carney dans son ouvrage A Survey of
English Spelling103, vient corroborer les précédentes : « Some recent French, Italian and
exotic borrowings have <a> ≡ /A˘/ before consonants which do not cause lengthening in §
Basic words » (Carney, 179).
Dans cette partie, nous allons considérer comme irrégulière la présence de [A˘] non-
expliquée par les règles anglaises citées précédemment, et noter ces variantes comme non-
anglicisées. Dans la partie suivante, nous tenterons de savoir s’il s’agit d’une caractéristique
des emprunts français en anglais et si [A˘] est l’adaptation la plus courante du [a] français.
103 Op. cit. p. 157
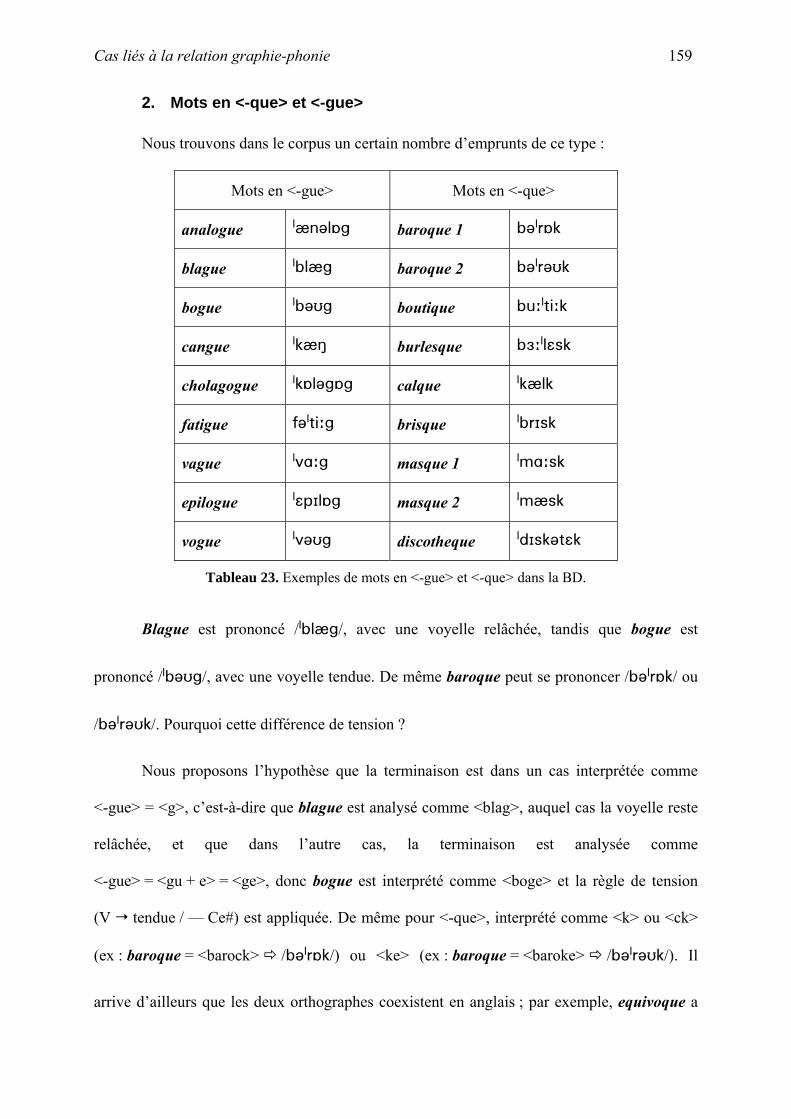
Cas liés à la relation graphie-phonie 159
2. Mots en <-que> et <-gue>
Nous trouvons dans le corpus un certain nombre d’emprunts de ce type :
Mots en <-gue> Mots en <-que>
analogue :Qn´lÅg baroque 1 b´:rÅk
blague :blQg baroque 2 b´:r´Uk
bogue :b´Ug boutique bu˘:ti˘k
cangue :kQN burlesque bŒ˘:lEsk
cholagogue :kÅl´gÅg calque :kQlk
fatigue f´:ti˘g brisque :brIsk
vague :vA˘g masque 1 :mA˘sk
epilogue :EpIlÅg masque 2 :mQsk
vogue :v´Ug discotheque :dIsk´tEk
Tableau 23. Exemples de mots en <-gue> et <-que> dans la BD.
Blague est prononcé /:blQg/, avec une voyelle relâchée, tandis que bogue est
prononcé /:b´Ug/, avec une voyelle tendue. De même baroque peut se prononcer /b´:rÅk/ ou
/b´:r´Uk/. Pourquoi cette différence de tension ?
Nous proposons l’hypothèse que la terminaison est dans un cas interprétée comme
<-gue> = <g>, c’est-à-dire que blague est analysé comme <blag>, auquel cas la voyelle reste
relâchée, et que dans l’autre cas, la terminaison est analysée comme
<-gue> = <gu + e> = <ge>, donc bogue est interprété comme <boge> et la règle de tension
(V tendue / — Ce#) est appliquée. De même pour <-que>, interprété comme <k> ou <ck>
(ex : baroque = <barock> /b´:rÅk/) ou <ke> (ex : baroque = <baroke> /b´:r´Uk/). Il
arrive d’ailleurs que les deux orthographes coexistent en anglais ; par exemple, equivoque a

160 Etude de cas : niveau segmental
une variante equivoke, monologue une variante monolog, et joke s’est autrefois écrit joque.
L’exemple de cangue /:kQN/ montre même que lorsque <-gue> est interprété comme <g>, on
applique la règle d’effacement du [g] après [N] en fin de mot.
Mais cela ne suffit pas à affirmer que ces variantes sont anglicisées ou non. Pour ce
faire, il nous faut observer la prononciation des mots en <-que> et <-gue> de la base de
données et voir si la correspondance graphie-phonie suit les règles de l’anglais.
Nous n’avons noté plusieurs variantes que si la terminaison <-Vgue> ou <-Vque>
différait au niveau de la prononciation, et non au niveau accentuel.

Cas liés à la relation graphie-phonie 161
Figure 16. Mots en <-gue>.
Mots en <-gue>
- ague : 4 variantes
[A˘g] nouvelle vague, vague
[Qg] blague
[EIg] vague
- igue : 4 variantes
[i˘g] fatigue, gigue, intrigue
[Ig] gigue
- ogue : 10 variantes
[Åg] analogue, apologue, catalogue raisonné, cholagogue,
epilogue, homologue, isologue, monologue
[´Ug] bogue, vogue
- ugue : 1 variante en [ju˘g] fugue
Autres : 16 variantes
-angue : 10 variantes
[QN] cangue, gangue, harangue
[A)˘N], [A˘Ng], [A˘N], [ÅN], [ÅNg] langue de chat
[Å)g] langue de chat, mauvaise langue
-ingue : [QN] meringue
-ongue : [ÅN], [ÅNg], [ç)˘Ng] chaise-longue
-ergue : [Œ˘g] exergue
-orgue : [ç˘g] morgue

162 Etude de cas : niveau segmental
La plupart de ces variantes vont être considérées comme anglicisées puisque la
correspondance graphie-phonie est régulière. Néanmoins on remarque des tensions
irrégulières : [i˘] pour <i> (la tension régulière étant [aI]) et [A˘] pour <a> (la tension
régulière étant [EI]) ; et des correspondances tout à fait irrégulières comme la terminaison
[QN] de meringue ou [Å)g] de mauvaise langue. Seuls ces cas irréguliers seront considérés
comme non-anglicisés.
Pour les terminaisons en <-que>, nous distinguons les cas en <-Vque> des cas en
<-Cque>, avec une étude particulière des mots en <-sque> qui sont assez nombreux.
Figure 17. Mots en <-Vque>.
Mots en <-que>
<-Vque>
-aque : 6 variantes
[Qk] claque, macaque, plaque
[A˘k] macaque, plaque
[EIk] plaque
-eque : 3 variantes en [Ek] cinematheque, discotheque, Pont l’Evêque
-ique : 21 variantes
[i˘k] boutique, caïque, clique, corps diplomatique, menu gastronomique,
moment critique, musique concrète, mystique, physique, pique, plastique,
pneumatique, politique, pose plastique, pratique, problematique, technique,
unique, veronique
[Ik] clique, pratique
-oque : 6 variantes
[Åk] baroque, coque, pendeloque
[´Uk] baroque, coque, toque

Cas liés à la relation graphie-phonie 163
Comme pour <-gue>, la plupart des mots en <-Vque> suivent les règles de l’anglais,
excepté ceux avec tension irrégulière en [A˘] et [i˘]. Les variantes appartenant à cette dernière
catégorie sont d’ailleurs les plus nombreuses. Toutes ces variantes irrégulières seront notées
comme non-anglicisées.
Figure 18. Mots en <-sque>.
Il existe en anglais une règle qui veut qu’un groupe consonantique soit précédé d’une
voyelle brève. Nous voyons ici que cette règle est en grande partie respectée, notamment pour
les mots en <-esque> qui sont tous, sans exception, prononcés [Esk]. De plus, toutes les
formes présentent au moins une variante avec voyelle relâchée. Nous allons donc considérer
qu’une variante à voyelle relâchée sera pour les mots en <-sque> anglicisée, à condition
toutefois que la correspondance graphie-phonie soit régulière. En effet, dans le cas de
brusque, la variante /:br√sk/ est régulière, tandis que la variante /:brUsk/ ne l’est pas, car la
correspondance <u> = [U] n’est pas habituelle en RP. Brusque /:brUsk/, de même que les
<-sque>
-asque : 13 variantes
[A˘sk] Basque, brasque, casque, flasque, masque, pas de basque
[Qsk] Basque, brasque, casque, flasque, masque, Monégasque, pas de basque
-esque : 8 variantes en [Esk] arabesque, Barbaresque, burlesque, gigantesque,
grotesque, Moresque, rocambolesque, soldatesque
-isque : 4 variantes
[i˘sk] bisque
[Isk] bisque, brisque, odalisque
-usque : [u˘sk], [Usk], [√sk] brusque

164 Etude de cas : niveau segmental
variantes tendues bisque /:bi˘sk/ et brusque /:bru˘sk/ seront donc notées comme non-
anglicisées.
Les mots en <-asque> sont à classer à part, car il existe en RP une règle qui transforme
[Q] en [A˘] devant le cluster [sk] (Lilly et Viel, 63) :
Figure 19. Règle de transformation du [Q].
Dès lors, on va considérer les variantes en [A˘sk] comme régulières puisque cette règle
est appliquée. En revanche, il est difficile de dire si les variantes en [Qsk] doivent être
considérées comme irrégulières parce qu’elles ignorent cette règle, ou régulières parce
qu’elles appliquent la règle précédente. Il nous semble néanmoins que c’est cette seconde
hypothèse qu’il faut retenir, c’est pourquoi nous les considérons également comme
anglicisées. Nous remarquons d’ailleurs que le problème de l’application ou non de cette règle
se retrouve régulièrement dans nos emprunts (ex : bastide, cadastral, lansquenet). Plus
largement, on remarque souvent des variantes avec [A˘] ou [Q] pour un même
emprunt (ex : chasse, lamé) et il n’est pas toujours facile de déterminer si ces variantes sont
anglicisées ou non. Dans la partie suivante, nous étudierons plus précisément l’adaptation de
<a> / [a] afin de clarifier ce problème.
Q A˘ / — {sp, st, sk, ft, T, D} (er, or, et) #

Cas liés à la relation graphie-phonie 165
Figure 20. Autres cas en <-que>.
Enfin, parmi les autres mots, on trouve à la fois des variantes régulières comme celles
des mots en <-alque>, <-arque> ou <-ecque>, et d’autres irrégulières comme celles des mots
en <-anque> ou la prononciation [I´k] de cirque. Ces dernières seront notées comme non-
anglicisées.
En conclusion, seules les variantes avec une tension irrégulière ou une correspondance
graphie-phonie inhabituelle en anglais seront considérées comme non-anglicisées et
conservées dans la base de données.
3. Terminaison <plosive + liquide + -e muet>
Notre base de données compte des mots se terminant en <-ble> prononcés tantôt [bl2]
comme tout ensemble /«tu˘tÅn:sÅmbl/, tantôt [bl´] comme enfant terrible
/«A)˘nfA)˘ntE:ri˘bl´/. De même, nous trouvons des mots en <-bre> prononcés tantôt [b´]
Autres :
-alque : [Qlk] calque, catafalque
-anque : [ÅNk] manque, pétanque
[Å)k] manque
[A)˘Nk] pétanque
-arque : [A˘k] marque, remarque
-irque : [Œ˘k], [I´k] cirque
-ecque : [Ek] Grecque
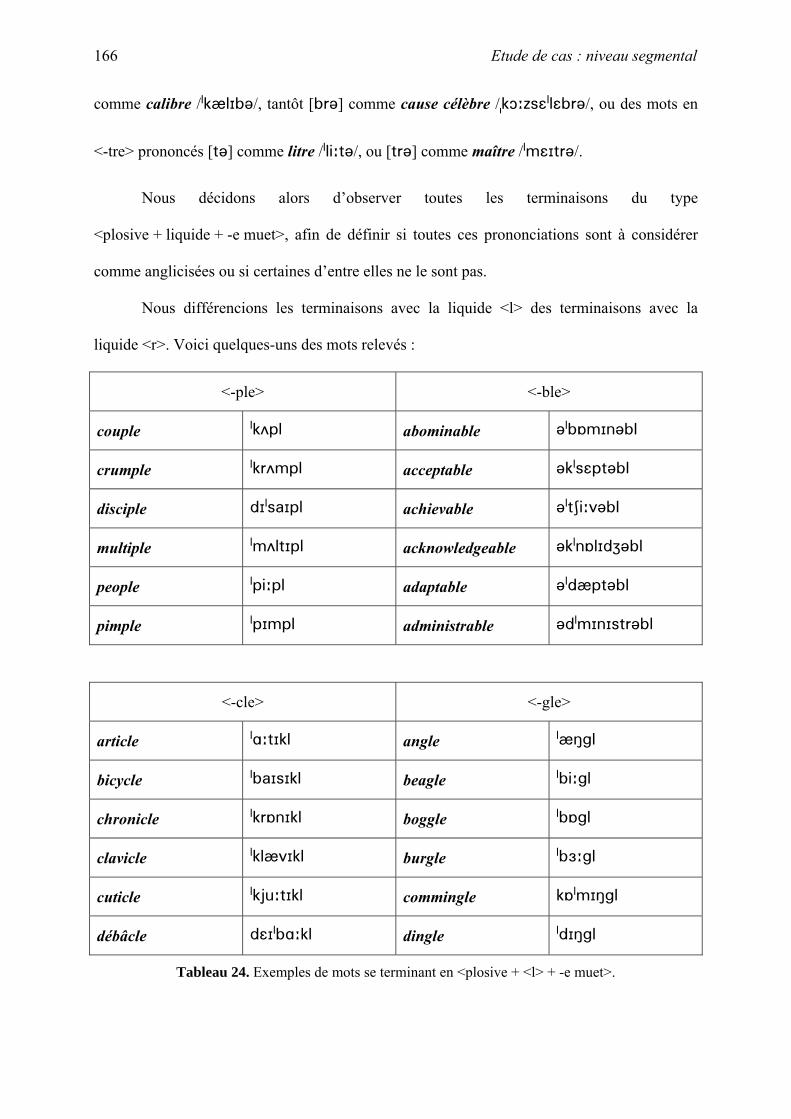
166 Etude de cas : niveau segmental
comme calibre /:kQlIb´/, tantôt [br´] comme cause célèbre /«kç˘zsE:lEbr´/, ou des mots en
<-tre> prononcés [t´] comme litre /:li˘t´/, ou [tr´] comme maître /:mEItr´/.
Nous décidons alors d’observer toutes les terminaisons du type
<plosive + liquide + -e muet>, afin de définir si toutes ces prononciations sont à considérer
comme anglicisées ou si certaines d’entre elles ne le sont pas.
Nous différencions les terminaisons avec la liquide <l> des terminaisons avec la
liquide <r>. Voici quelques-uns des mots relevés :
<-ple> <-ble>
couple :k√pl abominable ´:bÅmIn´bl
crumple :kr√mpl acceptable ´k:sEpt´bl
disciple dI:saIpl achievable ´:tSi˘v´bl
multiple :m√ltIpl acknowledgeable ´k:nÅlIdZ´bl
people :pi˘pl adaptable ´:dQpt´bl
pimple :pImpl administrable ´d:mInIstr´bl
<-cle> <-gle>
article :A˘tIkl angle :QNgl
bicycle :baIsIkl beagle :bi˘gl
chronicle :krÅnIkl boggle :bÅgl
clavicle :klQvIkl burgle :bŒ˘gl
cuticle :kju˘tIkl commingle kÅ:mINgl
débâcle dEI:bA˘kl dingle :dINgl
Tableau 24. Exemples de mots se terminant en <plosive + <l> + -e muet>.
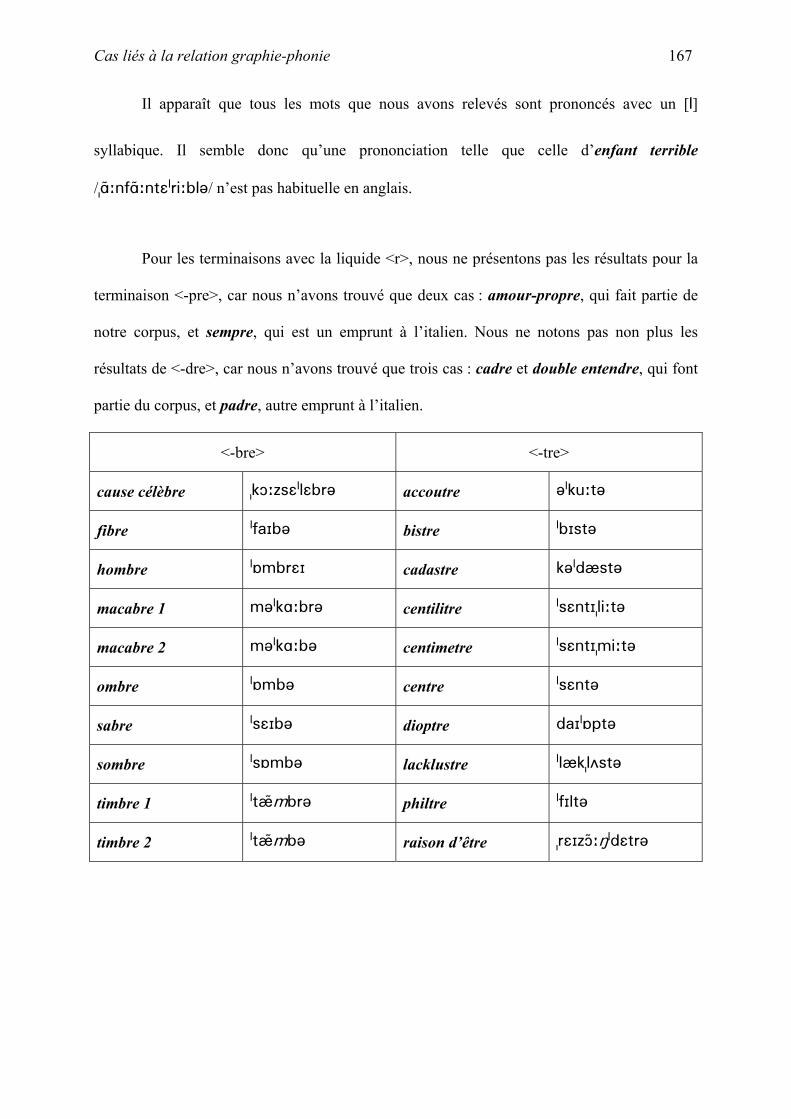
Cas liés à la relation graphie-phonie 167
Il apparaît que tous les mots que nous avons relevés sont prononcés avec un [l]
syllabique. Il semble donc qu’une prononciation telle que celle d’enfant terrible
/«A)˘nfA)˘ntE:ri˘bl´/ n’est pas habituelle en anglais.
Pour les terminaisons avec la liquide <r>, nous ne présentons pas les résultats pour la
terminaison <-pre>, car nous n’avons trouvé que deux cas : amour-propre, qui fait partie de
notre corpus, et sempre, qui est un emprunt à l’italien. Nous ne notons pas non plus les
résultats de <-dre>, car nous n’avons trouvé que trois cas : cadre et double entendre, qui font
partie du corpus, et padre, autre emprunt à l’italien.
<-bre> <-tre>
cause célèbre «kç˘zsE:lEbr´ accoutre ´:ku˘t´
fibre :faIb´ bistre :bIst´
hombre :ÅmbrEI cadastre k´:dQst´
macabre 1 m´:kA˘br´ centilitre :sEntI«li˘t´
macabre 2 m´:kA˘b´ centimetre :sEntI«mi˘t´
ombre :Åmb´ centre :sEnt´
sabre :sEIb´ dioptre daI:Åpt´
sombre :sÅmb´ lacklustre :lQk«l√st´
timbre 1 :tQ)mbr´ philtre :fIlt´
timbre 2 :tQ)mb´ raison d’être «rEIzç)˘N:dEtr´
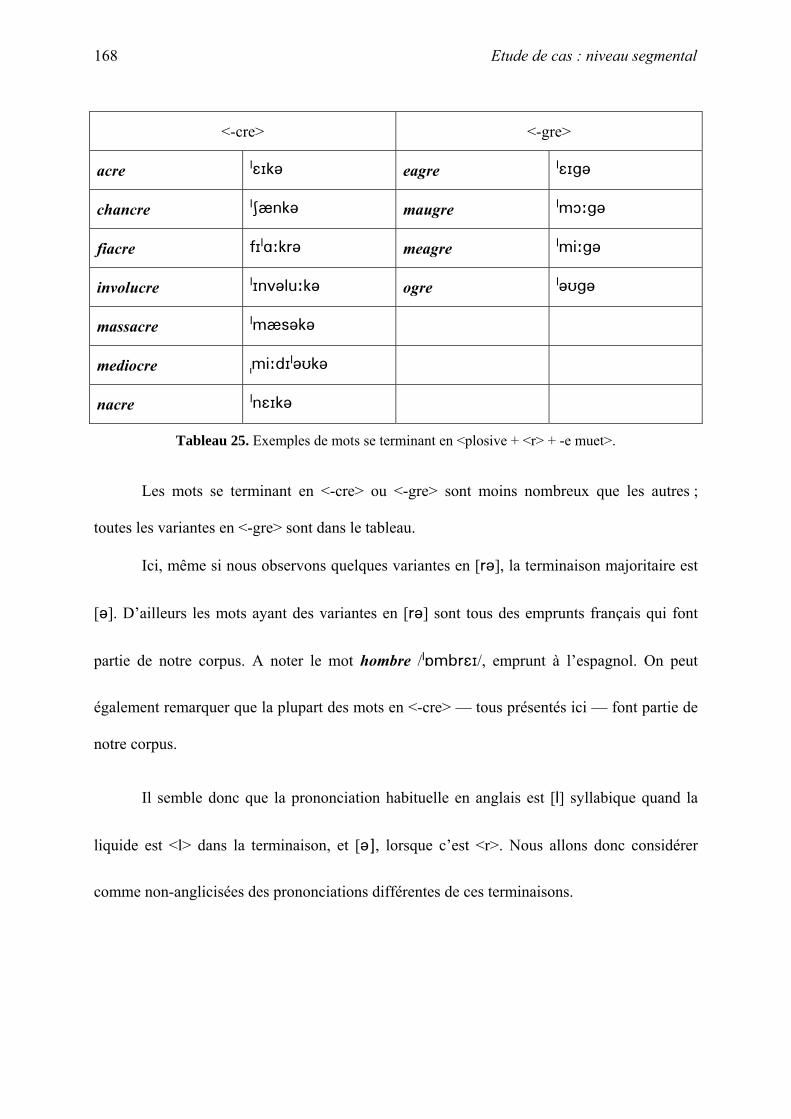
168 Etude de cas : niveau segmental
<-cre> <-gre>
acre :EIk´ eagre :EIg´
chancre :SQnk´ maugre :mç˘g´
fiacre fI:A˘kr´ meagre :mi˘g´
involucre :Inv´lu˘k´ ogre :´Ug´
massacre :mQs´k´
mediocre «mi˘dI:´Uk´
nacre :nEIk´
Tableau 25. Exemples de mots se terminant en <plosive + <r> + -e muet>.
Les mots se terminant en <-cre> ou <-gre> sont moins nombreux que les autres ;
toutes les variantes en <-gre> sont dans le tableau.
Ici, même si nous observons quelques variantes en [r´], la terminaison majoritaire est
[´]. D’ailleurs les mots ayant des variantes en [r´] sont tous des emprunts français qui font
partie de notre corpus. A noter le mot hombre /:ÅmbrEI/, emprunt à l’espagnol. On peut
également remarquer que la plupart des mots en <-cre> — tous présentés ici — font partie de
notre corpus.
Il semble donc que la prononciation habituelle en anglais est [l] syllabique quand la
liquide est <l> dans la terminaison, et [´], lorsque c’est <r>. Nous allons donc considérer
comme non-anglicisées des prononciations différentes de ces terminaisons.
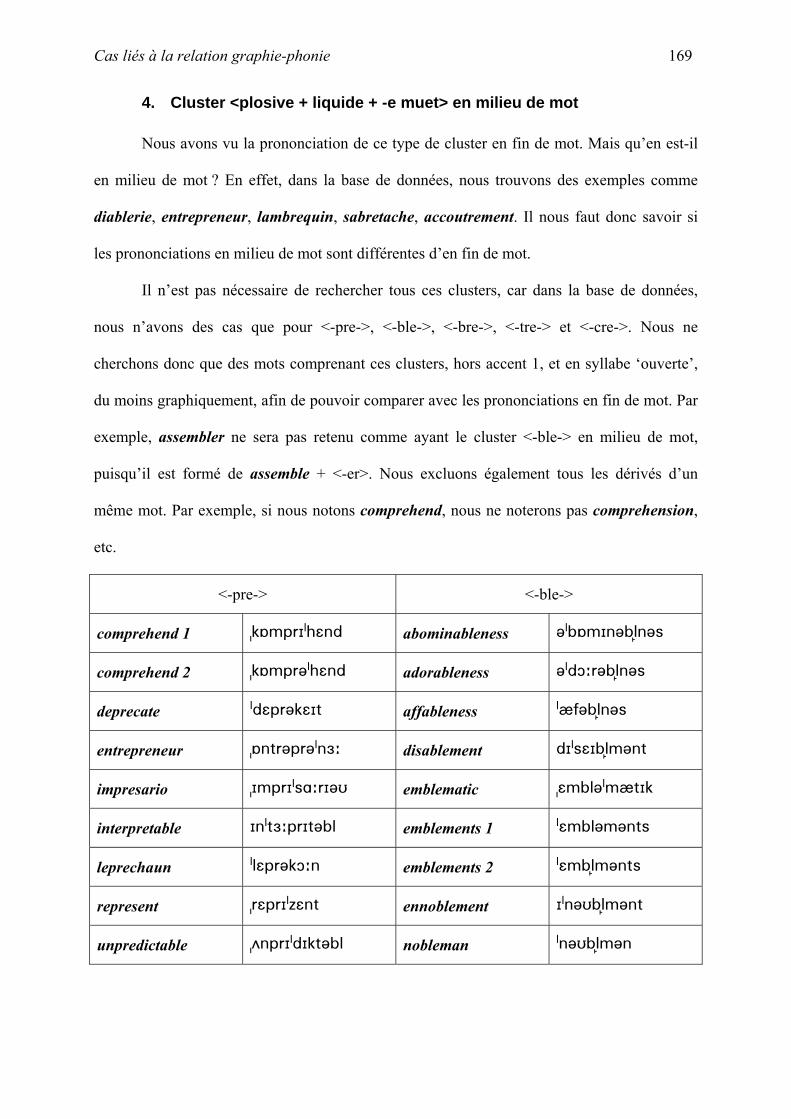
Cas liés à la relation graphie-phonie 169
4. Cluster <plosive + liquide + -e muet> en milieu de mot
Nous avons vu la prononciation de ce type de cluster en fin de mot. Mais qu’en est-il
en milieu de mot ? En effet, dans la base de données, nous trouvons des exemples comme
diablerie, entrepreneur, lambrequin, sabretache, accoutrement. Il nous faut donc savoir si
les prononciations en milieu de mot sont différentes d’en fin de mot.
Il n’est pas nécessaire de rechercher tous ces clusters, car dans la base de données,
nous n’avons des cas que pour <-pre->, <-ble->, <-bre->, <-tre-> et <-cre->. Nous ne
cherchons donc que des mots comprenant ces clusters, hors accent 1, et en syllabe ‘ouverte’,
du moins graphiquement, afin de pouvoir comparer avec les prononciations en fin de mot. Par
exemple, assembler ne sera pas retenu comme ayant le cluster <-ble-> en milieu de mot,
puisqu’il est formé de assemble + <-er>. Nous excluons également tous les dérivés d’un
même mot. Par exemple, si nous notons comprehend, nous ne noterons pas comprehension,
etc.
<-pre-> <-ble->
comprehend 1 «kÅmprI:hEnd abominableness ´:bÅmIn´bl2n´s
comprehend 2 «kÅmpr´:hEnd adorableness ´:dç˘r´bl2n´s
deprecate :dEpr´kEIt affableness :Qf´bl2n´s
entrepreneur «Åntr´pr´:nŒ˘ disablement dI:sEIbl2m´nt
impresario «ImprI:sA˘rI´U emblematic «Embl´:mQtIk
interpretable In:tŒ˘prIt´bl emblements 1 :Embl´m´nts
leprechaun :lEpr´kç˘n emblements 2 :Embl2m´nts
represent «rEprI:zEnt ennoblement I:n´Ubl2m´nt
unpredictable «√nprI:dIkt´bl nobleman :n´Ubl2m´n
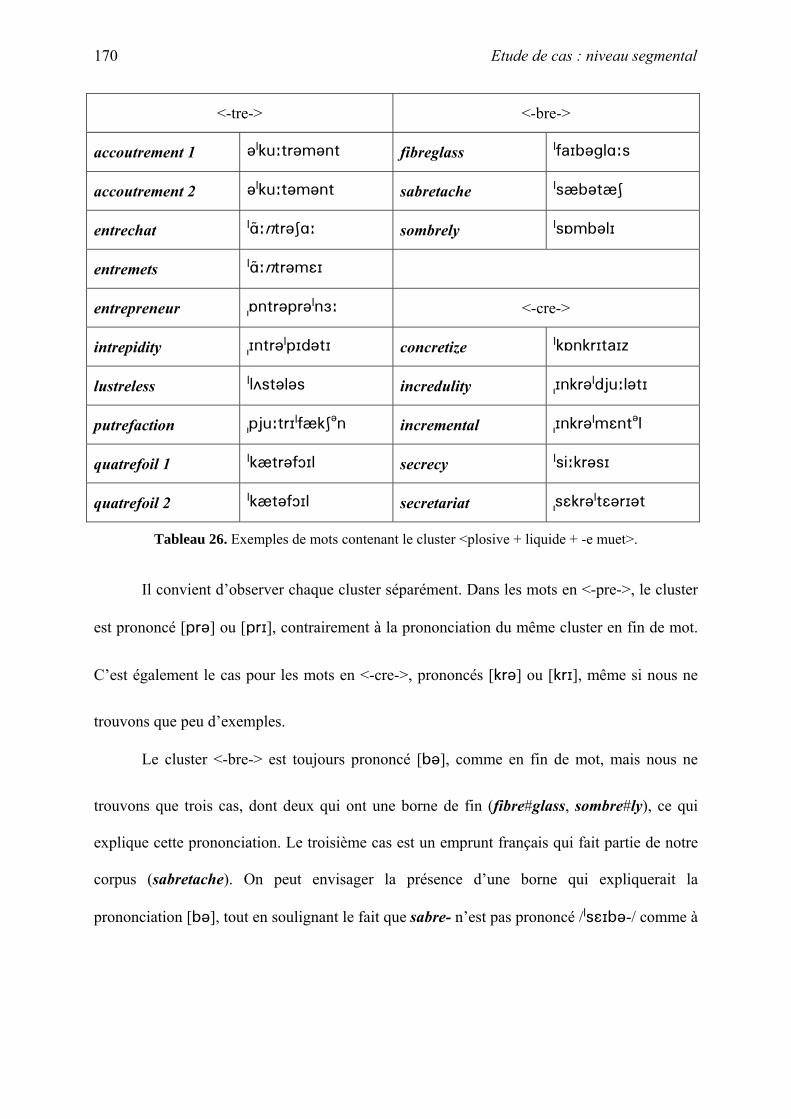
170 Etude de cas : niveau segmental
<-tre-> <-bre->
accoutrement 1 ´:ku˘tr´m´nt fibreglass :faIb´glA˘s
accoutrement 2 ´:ku˘t´m´nt sabretache :sQb´tQS
entrechat :A)˘ntr´SA˘ sombrely :sÅmb´lI
entremets :A)˘ntr´mEI
entrepreneur «Åntr´pr´:nŒ˘ <-cre->
intrepidity «Intr´:pId´tI concretize :kÅnkrItaIz
lustreless :l√st´l´s incredulity «Inkr´:dju˘l´tI
putrefaction «pju˘trI:fQkS´n incremental «Inkr´:mEnt´l
quatrefoil 1 :kQtr´fçIl secrecy :si˘kr´sI
quatrefoil 2 :kQt´fçIl secretariat «sEkr´:tE´rI´t
Tableau 26. Exemples de mots contenant le cluster <plosive + liquide + -e muet>.
Il convient d’observer chaque cluster séparément. Dans les mots en <-pre->, le cluster
est prononcé [pr´] ou [prI], contrairement à la prononciation du même cluster en fin de mot.
C’est également le cas pour les mots en <-cre->, prononcés [kr´] ou [krI], même si nous ne
trouvons que peu d’exemples.
Le cluster <-bre-> est toujours prononcé [b´], comme en fin de mot, mais nous ne
trouvons que trois cas, dont deux qui ont une borne de fin (fibre#glass, sombre#ly), ce qui
explique cette prononciation. Le troisième cas est un emprunt français qui fait partie de notre
corpus (sabretache). On peut envisager la présence d’une borne qui expliquerait la
prononciation [b´], tout en soulignant le fait que sabre- n’est pas prononcé /:sEIb´-/ comme à

Cas liés à la relation graphie-phonie 171
l’état isolé, mais /:sQb´-/. On peut alors également envisager que le mot soit pris comme un
tout et que le cluster <-bre-> puisse être prononcé [b´] en milieu de mot.
Les mots en <-ble-> et en <-tre-> nous montrent particulièrement l’importance de la
présence ou non d’une borne. La grande majorité des mots en <-ble-> sont des noms formés
d’un adjectif en <-able> + <-ness> (ex : abominable#ness, adorable#ness, affable#ness).
C’est pourquoi au cours de la sélection, nous avons décidé de ne plus relever ce type de mots.
Mais nous avons alors relevé plusieurs autres formations ; par exemple des mots se terminant
en <-ble> + le suffixe <-ment> (ex : disable#ment, ennoble#ment), ou des mots composés
(ex : noble#man). Tous sont prononcés [bl2], comme en fin de mot, sauf emblematic
/«Embl´:mQtIk/ et l’une des variantes d’emblements, prononcés [bl´]. Mais emblematic est
formé à partir d’emblem /:Embl´m/, ce qui explique sans doute la prononciation [bl´].
Emblements est, quant à lui, un terme juridique emprunté au vieux français. Il est
particulièrement intéressant puisqu’il présente deux variantes : /:Embl´m´nts/ et
/:Embl2m´nts/. On peut proposer l’hypothèse que la variante /:Embl2m´nts/ présente une
borne de fin (emble#ments) ce qui explique que la règle de prononciation du cluster en fin de
mot soit appliquée ; tandis que la variante /:Embl´m´nts/ ne contient pas de borne : le mot
est pris comme un tout et le cluster est prononcé [bl´].
De même, le cluster <-tre-> présente à la fois des prononciations [tr´] et [t´]. Deux
mots présentent les deux variantes : accoutrement et quatrefoil. Ici encore, nous proposons
l’hypothèse que la présence d’une borne explique la prononciation [t´], qui est celle du
cluster en fin de mot ; tandis que la prononciation [tr´] serait celle du mot pris comme un
tout. Toutefois, on s’aperçoit que beaucoup des mots relevés sont des emprunts français et que

172 Etude de cas : niveau segmental
le cluster <-tre-> y est généralement prononcé [tr´] (entrechat, entremets, entrepreneur,
etc.), même lorsque la présence d’une borne de fin peut être envisagée (ex : entre#chat,
entre#côte, entre#pôt). Or accoutrement et quatrefoil sont également des emprunts français.
On peut alors proposer une dernière hypothèse : la prononciation du cluster <-tre-> pour les
emprunts français identifiés comme tels est [tr´], et les prononciations /´:ku˘tr´m´nt/ ou
/:kQtr´fçIl/ sont des variantes portant une caractéristique d’emprunt français.
En conclusion, plusieurs hypothèses sont plausibles pour expliquer les différentes
prononciations de ces clusters en milieu de mot. Mais nous pouvons considérer dans tous les
cas qu’il y a toujours une règle de l’anglais pour expliquer la prononciation. Par conséquent,
aucune variante ne sera considérée comme non-anglicisée.
5. Mots en <qu->
Nous trouvons plusieurs transcriptions pour le mot questionnaire. La plus courante est
/«kwEstS´:nE´/, mais nous trouvons une variante /«kEstS´:nE´/. La prononciation [k] pour
<qu> en début de mot est-elle habituelle en anglais ?
Une rapide lecture des mots en <qu-> dans l’EPD nous confirme que la prononciation
courante est [kw] et non [k]. Cependant, nous trouvons un certain nombre de cas où le
digraphe est prononcé ainsi : quatorzain, quatrefoil, quay, Quebec, Quechua, quenelle,
Querétaro, quesadilla, Quesnel, Quetzalcoatl, Quezon City, quiche, Quinault, quint, Quito,
qui vive, etc. Nous remarquons dans cette liste un certain nombre d’emprunts français, et
d’une manière générale, nous pouvons dire que tous ces mots sont d’origine étrangère, ce qui
prouve que [kw] est bien la prononciation anglaise du digraphe. Les mots en <qu-> prononcé
[k] vont donc être considérés comme non-anglicisés.

Cas liés aux règles de tension 173
Cependant, en observant la prononciation du digraphe dans notre base de données,
nous remarquons le mot quai /kEI/, qui rappelle quay /ki˘/, lequel fait partie de la liste ci-
dessus. Or quay est un mot qu’on pourrait aisément qualifier d’anglicisé.
Quai doit-il alors être noté comme non-anglicisé ? Quay devrait-il également être
considéré comme non-anglicisé ? A moins que <qu-> ne puisse être prononcé [k] de manière
régulière lorsqu’il est suivi uniquement d’une voyelle. Bien que nous ne trouvions que peu
d’exemples, cette hypothèse est infirmée par les mots qua /kwEI/ /kwA˘/ et Quy /kwaI/. De
plus, on remarque une variante américaine de quay /kwEI/. Se pourrait-il alors que <qu-> se
prononce [k] devant [i˘] ? Cette hypothèse est également infirmée par les mots queen et
quean /kwi˘n/, queasy /:kwi˘zI/, etc.
Nous voyons ainsi que la prononciation de quay ne correspond pas aux habitudes de
l’anglais. L’explication se trouve dans son étymologie : le mot kay a été ré-orthographié
d’après le français quai (OED, ‘quay’).
Par conséquent, nous allons noter quai /kEI/ comme non-anglicisé, tout comme les
autres variantes dans lesquelles le digraphe <qu-> est prononcé [k].
C. CAS LIES AUX REGLES DE TENSION
1. Mots en VCVC# : tension systématique ?
Lorsque nous rencontrons les mots baton /:bQt´n/ et beton /:bEt´n/, nous nous
demandons pourquoi la voyelle n’est pas tendue comme dans bacon /:bEIk´n/ ou demon
/:di˘m´n/. En effet, on peut considérer que ces mots sont tendus par extension de la règle

174 Etude de cas : niveau segmental
V tendue / — Ce# ou V tendue / — CV# (Lilly et Viel, 58). Néanmoins, nous trouvons
d’autres mots de même forme avec une voyelle relâchée comme honour, canon, camel, civil
ou colour. Cette règle est-elle alors réellement appliquée ?
Nous décidons de relever dans l’EPD des mots dissyllabiques de forme VCVC#, en
excluant les digraphes comme première voyelle — puisqu’ils correspondent généralement à
des voyelles tendues —, afin d’observer si la règle de tension est appliquée:
Figure 21. Pourcentage de variantes tendues et relâchées.
Les premiers résultats nous montrent que l’application de cette règle est loin d’être
généralisée, puisqu’il y a quasiment 50% de variantes tendues et 50% de variantes relâchées.
Afin d’approfondir ces résultats, nous décidons d’observer les variantes voyelle par voyelle :
Sélection de 224 variantes
variantes tendues : 117 (52%)
variantes relâchées : 107 (48%)

Cas liés aux règles de tension 175
Figure 22. Variantes relâchées ou tendues selon la voyelle.
Ces résultats n’apportent guère plus de précisions. Hormis les voyelles <a> et <o> qui
présentent légèrement plus de variantes tendues, il semble que les variantes tendues et
relâchées soient assez également réparties. Il nous est alors difficile de déterminer quand la
règle de tension va s’appliquer.
<a>: 54 variantes relâchées, [Q] : 23 tendues: 31
[EI] / [E´] : 27 [A˘] : 4 (Cramer, Dalek, datum, Davos)
<e>: 44 variantes relâchées: 24
[E] : 22 [I] : 2 (Cecil, decor)
tendues: 20 [i˘] / [I´] : 15 [EI] : 5 (César, crépon, début, decor, detour)
<i> / <y>: 39 variantes relâchées : 20
[I] : 19 [√] : 1 (Cynon)
tendues : 19 [aI] / [aI´] : 16 [i˘] / [I´] : 3 (Chirac, Dijon, dinar)
<o> : 77 variantes relâchées : 33
[Å] : 24 [√] : 9 (dozen, coven, cover, covet, cozen, Comyn, colour / color,
comer) tendues, [´U] / [ç˘] : 44
<u> : 10 variantes relâchées, [√] : 3 (cumin, Curan, cutout) tendues, [(j)u˘] : 7

176 Etude de cas : niveau segmental
Après observation minutieuse de notre corpus, nous pouvons toutefois dégager
quelques hypothèses qui pourraient faire l’objet de recherches ultérieures. En étudiant les
suffixes, nous remarquons que les mots en <-ic> sont en général précédés d’une voyelle
relâchée :
chemic :kEmIk
chloric :klÅrIk
choric :kÅrIk
chronic :krÅnIk
civic :sIvIk
clinic :klInIk
conic :kÅnIk
Tableau 27. Mots en <-ic> de la sélection.
Cette hypothèse est confirmée par une règle de relâchement présentée dans l’ouvrage
de Lilly et Viel (p 61) :
Figure 23. Règle de relâchement devant certains suffixes.
Dans notre corpus, nous ne trouvons que deux exceptions à cette règle: Cretic /:kri˘tIk/
et chloric qui, en plus d’avoir une variante qui suit la règle, présente une variante avec voyelle
tendue /:klç˘rIk/.
Une autre hypothèse est qu’avant le suffixe <-al>, on trouve plutôt une voyelle
tendue :
V relâchée / — {-ic, -it, -id, -ish (v.)} (sauf <u>)

Cas liés aux règles de tension 177
chloral :klç˘r´l
clonal :kl´Un´l
choral :kç˘r´l
copal :k´Up´l
Tableau 28. Mots en <-al> de la sélection.
Mais les mots de ce type sont si peu nombreux qu’il est difficile de vraiment parler de
tendance. La seule exception dans notre sélection est coral /:kÅr´l/.
Enfin la dernière piste est celle de la consonne <-t->. En effet, il semble qu’on trouve
plutôt une voyelle tendue en présence de cette consonne, comme le montrent ces exemples :
cater :kEIt´ croton :kr´Ut´n
Cator :kEIt´ cutis :kju˘tIs
Chater :tSEIt´ dated :dEItId
chitin :kaItIn Datel :dEItEl
Coton :k´Ut´n datum :dEIt´m
crater :krEIt´ datum :dA˘t´m
Cretan :kri˘t´n detail :di˘tEIl
Tableau 29. Mots contenant <-t-> de la sélection.
Les seules exceptions sont les mots en <-ic> dont nous venons de parler, ainsi que le
mot cretin /:krEtIn/. Si cette tendance est réelle, cela classerait baton et beton dans les
exceptions. Néanmoins, en l’état, nous estimons qu’il n’est pas possible d’affirmer qu’il s’agit
d’un contexte d’application systématique de la règle de tension et nous préférons ne pas en
tenir compte dans notre travail de suppressions des variantes anglicisées. Nous allons donc

178 Etude de cas : niveau segmental
considérer baton et beton comme anglicisés puisque les variantes relâchées sont aussi
nombreuses que les variantes tendues. Seules les tensions irrégulières (telle que datum
/:dA˘t´m/ ou Dijon /:di˘Zç)˘N/) permettent de mettre en évidence les variantes non-
anglicisées.
2. Mots en <-é> : tension bloquée ?
Le mot glacé a une variante /:glQsI/ qui nous interpelle : est-elle anglicisée ou non ? Il
existe en effet la variante /:glQsEI/. La terminaison [I] est donc une variante réduite de [EI],
ce qu’on considère comme plus anglicisé. Mais la variante l’est-elle pour autant ?
La règle de tension de l’anglais V tendue / — Ce# s’applique quasi-
systématiquement. On peut citer des exemples tels que cane, sale, theme, scene, ride, file,
note, coke, duke ou tune (Lilly et Viel, 58). Il semble ici que lorsque l’accent graphique est
noté, la règle n’est plus appliquée. Dans ce cas, la variante /:glQsI/ doit être considérée
comme non-anglicisée.
Nous cherchons alors à savoir si la tension est toujours bloquée dans ce contexte, et
relevons tous les mots en <-é> de la base de données, afin d’observer si la voyelle est tendue
ou non :
blasé :blA˘zEI curé :kjU´rEI rosé :r´UzEI
broché :br´USEI jeté :ZEtEI rusé :ru˘zEI
café :kQfEI névé :nEvEI poché :pÅSEI
cloqué :kl´UkEI pré salé prEIsQ:lEI cliché :kli˘SEI
frisé 1 :fri˘zEI glacé 1 :glQsEI lamé 1 :lA˘mEI
frisé 2 :frIzEI glacé 2 :glA˘sEI lamé 2 :lQmEI
Tableau 30. Exemples de mots en <-é> dans la BD.

Cas liés aux règles de tension 179
Nous observons que les voyelles tendues sont très présentes. Il semble donc que la
règle de tension soit tout de même appliquée. Néanmoins, ce n’est pas systématique. Il
apparaît rapidement qu’il y a des différences selon la voyelle précédant la consonne, c’est
pourquoi nous décidons d’étudier les mots et leur transcription en fonction de cette voyelle.
Les mots en <-aCé> sont les plus nombreux104 :
Figure 24. Prononciation des mots en <-aCé>.
Il apparaît ici nettement que la règle de tension n’est pas appliquée le plus souvent, et
que lorsqu’elle l’est, la tension est irrégulière, puisque la tension régulière pour <a> est [EI].
Hormis pour blasé, les mots qui ont une variante tendue ont également une variante relâchée.
Il n’y a que deux mots en <-eCé> : jeté et névé, tous deux non-tendus en [E]. A noter
la variante /Z´:tEI/ de jeté, qui ne peut pas être prise en compte puisque la voyelle est réduite.
On trouve un peu plus d’exemples d’emprunts en <-iCé> :
Figure 25. Prononciation des mots en <-iCé>.
On constate ici que la règle de tension est en général appliquée, mais, comme pour
<a>, la tension est irrégulière. De plus, les mots ayant une variante relâchée ont toujours
également une variante tendue. 104 Les mots surlignés sont ceux qui ont à la fois une variante tendue et une autre non-tendue.
[A˘] : blasé, glacé, lamé, pâté
[Q] : café, enfant gâté, glacé, lamé, marron glacé, pâté, pâté de campagne,
pâté de foie gras, pâté en croûte, pâté maison, pousse-café, pré salé, ramé.
[i˘] : chiné, ciré, cliché, frisé, piqué, pisé, visé
[I] : frisé, pisé

180 Etude de cas : niveau segmental
Les mots en <-oCé> sont également tendus en général :
Figure 26. Prononciation des mots en <-oCé>.
On ne trouve qu’un seul mot avec une variante relâchée, qui ne présente pas d’autre
variante tendue. Mais dans le cas des mots en <-oCé>, on note que la tension est régulière.
Enfin, on ne compte que deux mots en <-uCé>, avec des variantes toutes tendues :
curé, prononcé /:kjU´rEI/ ou /:kjç˘rEI/, et rusé /:ru˘zEI/. Dans tous les cas, la tension est
régulière. En effet, U u˘ /— Ce# (ex : rusé) ; u˘ U´ /— r (ex : curé /:kjU´rEI/) et la
prononciation [ç˘] est une variante régulière de [U´].
En conclusion, nous ne pouvons pas dire que la règle de tension n’est pas appliquée
dans le contexte <–VCé>; cela dépend de la voyelle concernée. Nous avons noté que parfois
la tension est irrégulière et parfois régulière. Ne s’agirait-il pas en réalité de l’adaptation des
voyelles dans le cadre des emprunts français ? En effet, nous avons remarqué que le <i> est
souvent prononcé [i˘] (ex : abri, regime, aperitif, coulisse) et que le <o> est souvent prononcé
[´U] (ex : abricotine, apropos, bistro, godet). L’adaptation du <a> est moins claire pour
l’instant, mais il est en général prononcé [Q] ou [A˘] (ex : masque, cadastral, avalanche).
De plus, le <-é> n’est jamais muet, contrairement au <-e> de la règle anglaise (excepté
pour les variantes /:kQf/ et /:kEIf/ de café). En réalité, il semble que la règle de tension ne soit
pas appliquée en présence du <-é>, prononcé [EI] ou [I] ; on applique simplement les règles
d’adaptation des voyelles dans le cadre des emprunts français.
[´U] : broché, cloqué, posé, rosé, vin rosé
[Å] : poché

Cas liés aux règles de tension 181
Afin de répondre précisément à cette question, il nous faudrait d’abord étudier
l’adaptation de ces voyelles, ce qui sera réalisé dans la partie suivante de notre étude. A ce
stade, nous pouvons simplement affirmer que les variantes des mots en <-é> sont toutes non-
anglicisées en raison de la prononciation de leur terminaison, excepté la variante /:kEIf/ de
café, qui se prononce comme si le mot s’écrivait <cafe>, mais qui reste exceptionnelle.
3. Mots avec suffixe <-ion> et assimilés
On remarque dans la base de données certains mots se terminant par un suffixe du type
<-ion> et présentant deux variantes, l’une avec voyelle tendue, et l’autre avec voyelle
relâchée :
gavial :gEIvI´l :gQvI´l
glacier :glEIsI´ :glQsI´
glacial :glEIsI´l :glQsI´l
Tableau 31. Exemples de mots avec suffixe <-ion> ou assimilés dans la BD.
Or il existe en anglais une règle de tension de la voyelle précédant le suffixe <-ion> et
les suffixes assimilés (ex : -ial, -ier, -ien, -ia, -ium, etc.), excepté lorsque la voyelle est [I]
(Lilly et Viel, 60). Néanmoins, Lilly et Viel ajoutent que cette règle est moins systématique
que celle de l’accentuation des mots en <-ion>. Les variantes avec voyelle relâchée doivent-
elles également être considérées comme anglicisées ?
Nous décidons de relever dans l’EPD des mots en <-ion>, <-ial> et <-ier> — les trois
suffixes présents parmi les emprunts français — afin d’observer si la voyelle précédant le
suffixe est plutôt tendue ou si l’on trouve également des cas de non-tension.
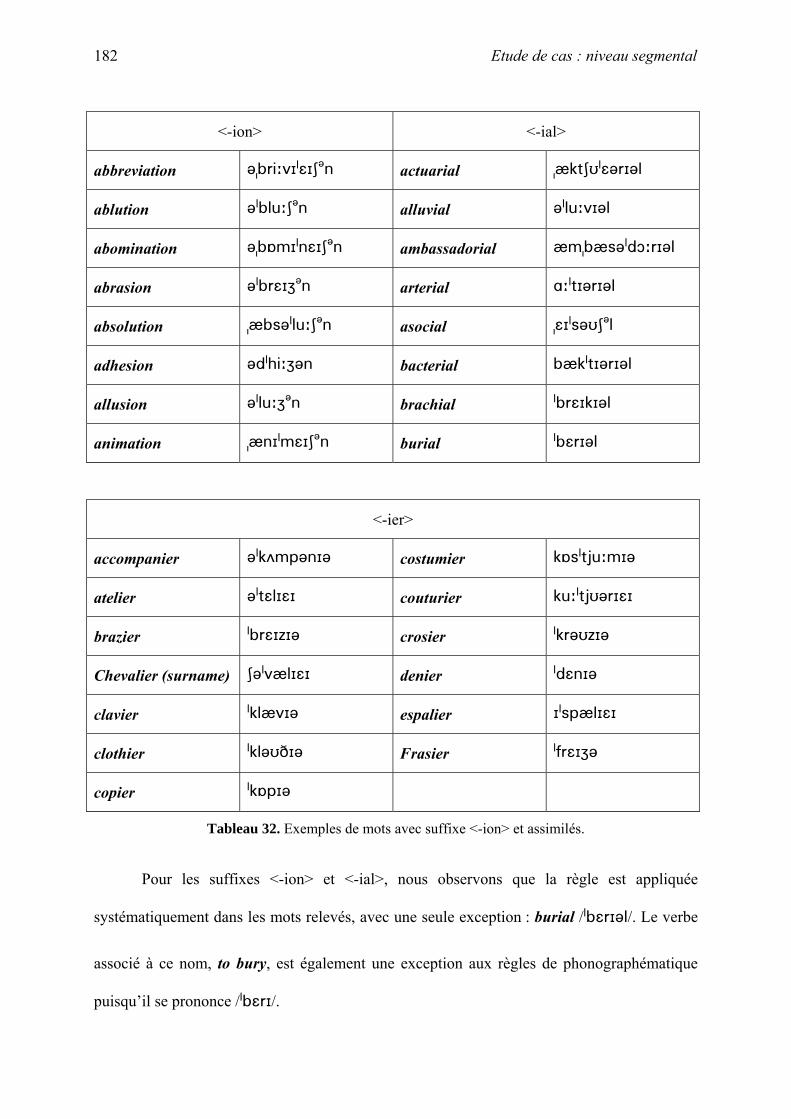
182 Etude de cas : niveau segmental
<-ion> <-ial>
abbreviation ´«bri˘vI:EIS´n actuarial «QktSU:E´rI´l
ablution ´:blu˘S´n alluvial ´:lu˘vI´l
abomination ´«bÅmI:nEIS´n ambassadorial Qm«bQs´:dç˘rI´l
abrasion ´:brEIZ´n arterial A˘:tI´rI´l
absolution «Qbs´:lu˘S´n asocial «EI:s´US´l
adhesion ´d:hi˘Z´n bacterial bQk:tI´rI´l
allusion ´:lu˘Z´n brachial :brEIkI´l
animation «QnI:mEIS´n burial :bErI´l
<-ier>
accompanier ´:k√mp´nI´ costumier kÅs:tju˘mI´
atelier ´:tElIEI couturier ku˘:tjU´rIEI
brazier :brEIzI´ crosier :kr´UzI´
Chevalier (surname) S´:vQlIEI denier :dEnI´
clavier :klQvI´ espalier I:spQlIEI
clothier :kl´UDI´ Frasier :frEIZ´
copier :kÅpI´
Tableau 32. Exemples de mots avec suffixe <-ion> et assimilés.
Pour les suffixes <-ion> et <-ial>, nous observons que la règle est appliquée
systématiquement dans les mots relevés, avec une seule exception : burial /:bErI´l/. Le verbe
associé à ce nom, to bury, est également une exception aux règles de phonographématique
puisqu’il se prononce /:bErI/.

Autres cas 183
Pour le suffixe <-ier>, en revanche, nous trouvons quelques cas avec la voyelle
relâchée. Accompanier est à exclure puisqu’il est formé du verbe accompany + suffixe <–er>,
et que la voyelle précédant le suffixe est réduite. Mais si nous étudions les cas à voyelle
relâchée, nous observons plusieurs emprunts de notre base de données (atelier, clavier,
espalier), un emprunt français antérieur au 16ème (denier) et un nom propre d’origine française
(Chevalier). Le dernier cas, copier, est formé du verbe to copy /:kÅpI/ et du suffixe <–er>.
Toutes les autres variantes présentent une voyelle tendue.
Nous en concluons que la règle de tension s’applique bien de manière quasi-
systématique, puisque les exceptions sont majoritairement des emprunts français. Nous allons
donc considérer comme non-anglicisées des variantes avec voyelle relâchée.
D. AUTRES CAS
1. Variantes en [dZ] / [Z]
Lors de la préparation de la base de données, nous avons examiné les transcriptions
des différents dictionnaires de prononciation. Nous avons décidé de noter les phonèmes
optionnels en italique sauf si cela avait pour conséquence une différence dans le nombre de
syllabes ou dans les phonèmes. En suivant cette règle [dZ] (avec [d] en italique, donc
optionnel) représente deux phonèmes différents : [dZ] et [Z].
Ainsi, nous devrions présenter un mot comme arrangement /´:rEIndZm´nt/ en deux
variantes : /´:rEIndZm´nt/ et /´:rEInZm´nt/. La seconde variante ne suivant pas la
correspondance habituelle <g> = [dZ], il nous faudrait alors la considérer comme non-
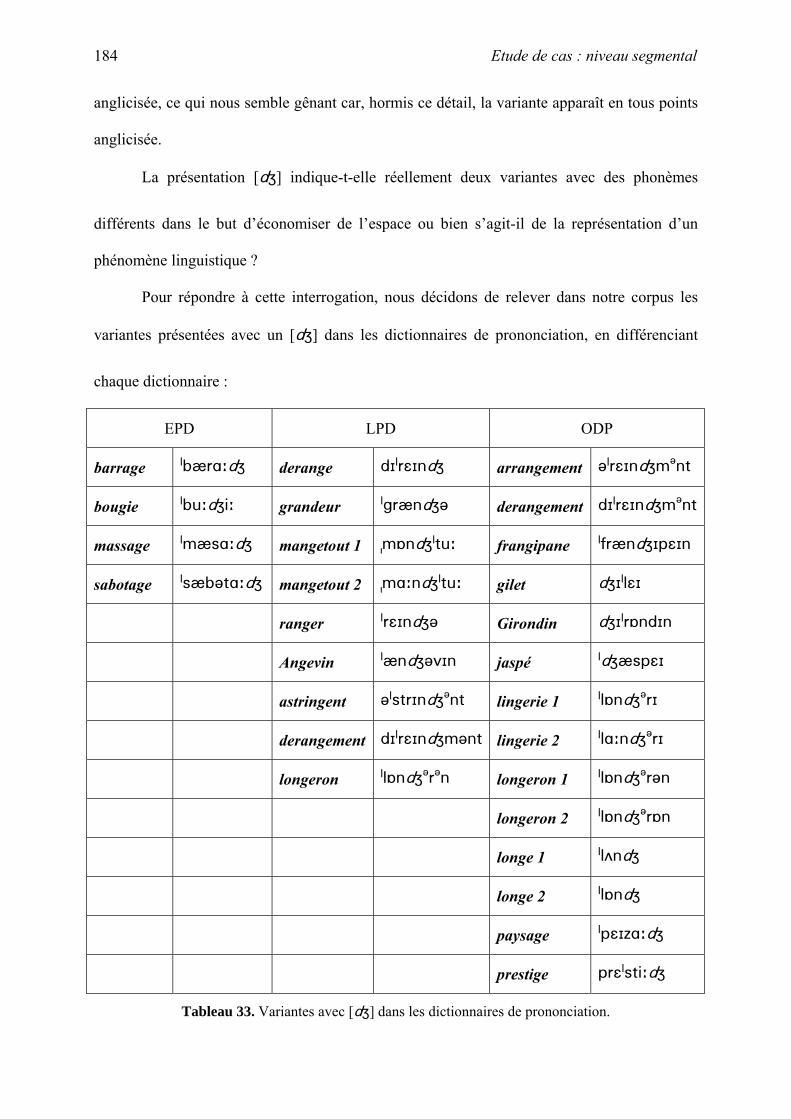
184 Etude de cas : niveau segmental
anglicisée, ce qui nous semble gênant car, hormis ce détail, la variante apparaît en tous points
anglicisée.
La présentation [dZ] indique-t-elle réellement deux variantes avec des phonèmes
différents dans le but d’économiser de l’espace ou bien s’agit-il de la représentation d’un
phénomène linguistique ?
Pour répondre à cette interrogation, nous décidons de relever dans notre corpus les
variantes présentées avec un [dZ] dans les dictionnaires de prononciation, en différenciant
chaque dictionnaire :
EPD LPD ODP
barrage :bQrA˘dZ derange dI:rEIndZ arrangement ´:rEIndZm´nt
bougie :bu˘dZi˘ grandeur :grQndZ´ derangement dI:rEIndZm´nt
massage :mQsA˘dZ mangetout 1 «mÅndZ:tu˘ frangipane :frQndZIpEIn
sabotage :sQb´tA˘dZ mangetout 2 «mA˘ndZ:tu˘ gilet dZI:lEI
ranger :rEIndZ´ Girondin dZI:rÅndIn
Angevin :QndZ´vIn jaspé :dZQspEI
astringent ´:strIndZ´nt lingerie 1 :lÅndZ´rI
derangement dI:rEIndZm´nt lingerie 2 :lA˘ndZ´rI
longeron :lÅndZ´r´n longeron 1 :lÅndZ´r´n
longeron 2 :lÅndZ´rÅn
longe 1 :l√ndZ
longe 2 :lÅndZ
paysage :pEIzA˘dZ
prestige prE:sti˘dZ
Tableau 33. Variantes avec [dZ] dans les dictionnaires de prononciation.

Autres cas 185
Dans l’EPD, nous relevons peu de variantes de ce type, et toutes ont des
caractéristiques françaises. Indépendamment de [dZ], ces variantes seraient classées comme
non-anglicisées. Nous pensons que dans le cadre de l’EPD, [dZ] représente bien les phonèmes
[dZ] et [Z], qui sont notés ainsi pour économiser de l’espace.
En revanche, dans les deux autres dictionnaires, nous trouvons à la fois des variantes
qui, [dZ] mis à part, seraient classées non-anglicisées, et d’autres qui seraient classées
anglicisées. [dZ] a-t-il la même valeur dans tous les cas ? La première remarque que nous
pouvons émettre, c’est que dans nombre de cas, [dZ] se trouve après une consonne nasale,
notamment dans les variantes a priori anglicisées (ex : derange, ranger, Angevin). Nous
avançons alors l’hypothèse que, dans le contexte [ndZ], il s’agit de la représentation d’une
assimilation et que la variante doit être considérée comme anglicisée.
Le phénomène de l’assimilation est décrit par de nombreux linguistes, dont Jones dans
l’ouvrage An Outline of English Phonetics105 ou Gimson dans An Introduction to the
Pronunciation of English106 : un son (A) est remplacé par un autre (B) sous l’influence d’un
troisième (C), qui se trouve à proximité (Jones, 217-218). L’assimilation est dite progressive
lorsque le son assimilé est influencé par un son précédent (Jones, 228) — comme dans dogs
où le [s] du pluriel devient [z] sous l’influence de la sonore [g] — ou bien régressive lorsque
le son assimilé est influencé par un son postérieur (Jones, 228), comme horse-shoe où le [s]
de horse devient parfois [S] sous l’influence de la palatale [S] de shoe.
105 Jones, Daniel. An Outline of English Phonetics. 1918. 9ème éd. Cambridge : W. Heffer and Sons, 1964. 106 Op. cit. p . 129

186 Etude de cas : niveau segmental
Dans le cas de [dZ], il s’agirait d’une élision du [d] due à la nasale [n] sans doute en
raison de leur même place d’articulation alvéolaire. Cette idée est renforcée par la notation du
LPD, qui différencie parmi les phonèmes optionnels ceux qui peuvent être optionnellement
insérés ou optionnellement omis. Dans tous les exemples de [dZ], il s’agit d’un phonème à
omettre optionnellement, peut-être selon que l’assimilation se produit ou non.
Mais il reste quelques cas problématiques comme mangetout /«mÅndZ:tu˘/ ou
/«mA˘ndZ:tu˘/, lingerie /:lÅndZ´rI/ ou /:lA˘ndZ´rI/, ou encore longeron /:lÅndZ´rÅn/, qui, sur
d’autres critères, ne peuvent être classés comme anglicisés. On ne peut donc pas considérer
tous les cas en [ndZ] comme anglicisés. Faut-il alors présenter ces variantes en deux sous-
variantes, ou bien s’agit-il ici aussi de la représentation de l’assimilation ?
Une autre des possibilités qui s’offrent à nous est d’observer chaque variante et de
décider si elle est anglicisée ou non en fonction de tous les critères hormis [dZ]. Si la variante
est, selon au moins un critère, non-anglicisée, nous considérons qu’il ne s’agit pas de
l’assimilation et qu’il faut la présenter dans la base de données avec les deux phonèmes [dZ]
et [Z]. Sinon, nous ne notons qu’une seule variante avec [dZ]. Ainsi, mangetout et lingerie
seront considérés comme non-anglicisés et notés en deux variantes. Mais il reste toujours un
cas particulier ; celui de longeron, dont la variante /:lÅndZ´rÅn/ sera notée /:lÅndZ´rÅn/ ou
/:lÅnZ´rÅn/, tandis que la variante /:lÅndZ´r´n/ sera laissée telle quelle. Ce résultat ne nous
semble pas satisfaisant.
En observant plus attentivement les dictionnaires LPD et ODP, nous remarquons que
le LDP n’utilise [dZ] que derrière une consonne nasale. Il s’agit donc probablement dans tous
les cas de l’assimilation, même si certaines variantes pourraient par ailleurs être classées

Autres cas 187
comme non-anglicisées. L’ODP est par conséquent le seul dictionnaire à utiliser cette notation
à la fois pour représenter l’assimilation, ou pour économiser de l’espace dans certains cas.
Suite à cette observation, nous concluons que lorsque [dZ] se trouve derrière une
consonne nasale, il s’agit de l’assimilation, quelle que soit la catégorie du mot ; les variantes
doivent être retranscrites telles que dans le dictionnaire, avec [d] en italique (ex : derange,
Angevin, lingerie, longeron). Dans les autres cas, il s’agit d’une économie d’espace : il
convient alors de représenter les deux variantes ; une avec [dZ] et l’autre avec [Z]
(ex : barrage, bougie, gilet, jaspé).
Il reste un cas lié à cette problématique : centrifuge. L’EPD ne propose que la
terminaison en [dZ], l’ODP propose [dZ] ([d] optionnel) et le LDP le présente en deux
variantes : [:sEntrIfju˘dZ] et [:sEntrIfju˘Z]. On remarque d’ailleurs que [dZ] ne suit pas une
nasale ; il ne s’agit donc pas d’un cas d’assimilation. Pourtant ce mot apparaît comme
anglicisé et il semble difficile à première vue de considérer la variante [:sEntrIfju˘Z] comme
non-anglicisée.
Nous retrouvons le mot centrifuge cité dans le blog de Jack Windsor Lewis107 comme
exemple de terminaison en [dZ] ou [Z], aux côtés de deluge et subterfuge. Ce billet vient en
réponse à celui de John Wells108, qui a remarqué la prononciation par les acteurs
shakespeariens du mot liege [:li˘Z]. Il observe d’autres exemples de variantes en [Z] : siege,
besiege, gamboge. L’une des hypothèses proposées par Wells est qu’il s’agit d’une
107 Lewis, Jack Windsor. « The pronunciation of liege, etc. » 20 sept. 2007. Phonetiblog. 24 sept. 2007.
http://www.yek.me.uk/archive5.html#blog048.
108 Wells, John. « My liege, we are besieged. » 20 sept. 2007. John Well’s phonetic blog. UCL Division of
Psychology and Language Sciences. 20 sept. 2007. http://www.phon.ucl.ac.uk/home/wells/blog0709.htm.

188 Etude de cas : niveau segmental
‘contamination’ due à des mots français comme prestige [prE:sti˘Z] ou beige [:bEIZ=]. Jack
Windsor Lewis confirme cette hypothèse en ajoutant que liege est peut-être ressenti comme
‘exotique’. Selon lui, cela expliquerait également qu’on entende souvent Beijing avec [Z], de
même que Gigli ou adagio. Il ajoute comme exemples de mots ‘influents’ cortege [kç˘:tEIZ]
ou noblesse oblige [n´U«blEs´U:bli˘Z].
Dès lors, nous pouvons considérer centrifuge [:sEntrIfju˘Z] comme étant influencé
par le français, directement ou indirectement, selon que le mot est ressenti comme français ou
simplement comme ‘exotique’ par les locuteurs. Nous allons donc traiter cette variante
comme non-anglicisée.
2. Variantes en [tS] / [S]
Le cas des variantes en [tS] / [S] est directement lié au point précédent. En effet, en
observant la variante avalanche /:Qv´lA˘ntS/ dans l’EPD, il nous semble qu’il s’agit du même
cas d’assimilation. Pourtant nous avons vu que l’EPD, dans le cas des variantes en [dZ],
n’utilisait le [d] italique que pour représenter deux phonèmes, dans un souci d’économie
d’espace. Par conséquent, il faudrait interpréter /:Qv´lA˘ntS/ comme représentant deux
variantes : /:Qv´lA˘ntS/ et /:Qv´lA˘nS/.
Cependant, nous trouvons dans l’introduction du dictionnaire un paragraphe à ce sujet.
Les éditeurs expliquent qu’ils différencient un cas comme ranger /:rEIndZ´/ — pour lequel le
[d] peut être omis en discours rapide selon les règles générales de simplification, ce qu’il n’est
pas nécessaire d’indiquer — de cas comme French et lunch, pour lesquels il est nécessaire

Autres cas 189
d’indiquer les différentes prononciations ([ntS] ou [nS]) car il s’agit de cas particuliers
d’insertion ou d’élision limités à un environnement phonologique particulier (EPD,
Introduction, Optional Sounds, xv).
Si nous suivons l’EPD et présentons avalanche en deux variantes, il nous faudra
garder la variante /:Qv´lA˘nS/ puisque la correspondance <ch> = [S] est irrégulière. Mais dans
un cas comme lunch, il parait difficile d’imputer la prononciation /:l√nS/ à l’origine du mot.
Un autre élément nous fait également penser qu’il s’agit bien du même cas
d’assimilation qu’avec [dZ] : dans le LPD, French, lunch, avalanche et ranger sont tous
présentés de la même manière, c’est-à-dire avec [t] ou [d] pouvant être optionnellement élidé.
Nous préférons donc traiter tous ces cas de la même manière, en ne les présentant
qu’en une seule variante avec phonème optionnel. Avalanche sera donc noté /:Qv´lA˘ntS/ et
ne sera pas conservé car la variante est en tous points anglicisée.
3. Les réduplications
Certains mots français sont formés de deux syllabes identiques. Parmi les emprunts
relevés, c’est le cas de cancan, bonbon, aye-aye, ha-ha, gaga ou loulou. Il est intéressant
d’observer comment sont traités ces mots par l’anglais.
cancan 1 :kQnkQn ha-ha 1 :hA˘hA˘
cancan 2 :kQNkQn ha-ha 2 hA˘:hA˘
bonbon 1 :bÅnbÅn gaga 1 :gA˘gA˘
bonbon 2 :bÅmbÅn gaga 2 :gQgA˘
aye-aye 1 :aIaI gaga 3 :gQg´
aye-aye 2 :aI«aI loulou :lu˘lu˘
Tableau 34. Les réduplications dans la BD.

190 Etude de cas : niveau segmental
La première remarque que nous pouvons faire, c’est que ces formes ne réduisent
quasiment jamais, mis à part une des variantes de gaga. D’autre part, l’accent est presque
toujours sur la 1ère syllabe, conformément à la règle des noms dissyllabiques — excepté pour
une variante de ha-ha, mais l’OED ajoute la note ‘formerly’ à cette variante.
Dans la majorité des cas, les deux syllabes sont prononcées de manière identique,
comme si une borne était présente en milieu de mot (ex : /:kQnkQn/, /:bÅnbÅn/, /:aIaI/,
/:hA˘hA˘/, /:gA˘gA˘/, /:lu˘lu˘/), mais parfois on remarque que le mot est pris en entier, par
exemple quand la nasale [n] de cancan devient [N] sous l’influence du [k] suivant, ou quand
la nasale [n] de bonbon devient [m] sous l’influence du [b] suivant. De même gaga /:gQgA˘/
est traité comme un seul bloc, et la variante /:gQg´/ présente une anglicisation totale.
Quant au travail de suppression des variantes anglicisées, il s’applique de la même
manière avec ces mots. Puisqu’ils semblent en général ne pas réduire, nous ne pouvons
considérer cette non-réduction comme régulière. Nous observons alors les correspondances et
supprimons celles qui suivent les règles de l’anglais. Des mots comme cancan, bonbon ou la
variante /:gQg´/ de gaga sont notées comme anglicisées. Quant à aye-aye, même si la
correspondance habituelle est <ai> = [EI], la forme <aye>, qui correspond à un ancien ‘oui’,
est prononcée [aI]. Il est fort probable qu’un locuteur voyant ce mot fasse l’association. Les
variantes qui seront conservées pour le travail ultérieur sont ha-ha, gaga /:gA˘gA˘/ et
/:gQgA˘/ et loulou.

Autres cas 191
4. Les mots perçus ou traités comme étrangers
Parmi les emprunts français, un certain nombre viennent eux-mêmes d’autres langues
ou bien ont une forme qui ne leur permet pas d’être identifiés comme emprunts français. Ils
sont alors traités différemment des mots français, mais parfois aussi différemment des mots
anglais. Nous pouvons les classer en plusieurs catégories selon leur origine réelle ou
supposée.
a) Origine latine ou grecque
L’anglais a énormément emprunté à ces deux langues classiques. Il n’est donc pas
surprenant que certains mots soient traités comme originaires du latin ou du grec, notamment
lorsque la forme le laisse penser. D’ailleurs, le français lui-même est issu en partie du latin et
a également emprunté au grec, raison pour laquelle on retrouve ces formes dans notre corpus.
Les emprunts traités comme des mots latins ou grecs sont par exemple
Bacchante /b´:kQntI/, harmonium /hA˘:m´UnI´m/, galimatias /«gQlI:mQtI´s/ ou
aeolipyle /:i˘´lIpaIl/. Si Bacchante et aeolipyle sont bien des mots latins à l’origine,
harmonium est une création française du 19ème siècle, sur une base gréco-latine. Quant à
galimatias, son origine est inconnue.
Les éléments phonologiques qui permettent de dire que ces mots sont traités comme
latins ou grecs sont notamment la prononciation [k] du digraphe <ch> dans Bacchante, ou la
prononciation [I] du <-e> final dans le même mot, ou encore la prononciation [i˘] du digraphe
<ae> dans aeolipyle (Lilly et Viel, 77-78). Pour galimatias et harmonium, c’est leur forme
graphique avec les terminaisons en <-ias> et <-ium> qui laisse penser que ces mots ne
peuvent pas être traités comme des emprunts français, mais plutôt comme ayant une origine
latine.

192 Etude de cas : niveau segmental
b) Origine italienne ou espagnole
Certains mots ont une forme orthographique qui laisse penser qu’ils sont d’origine
italienne ou espagnole, comme aioli /EI:´UlI/, chipolata /«tSIp´:lA˘t´/, ratafia /«rQt´:fi˘´/, ou
domino /:dÅmIn´U/, en raison de leur forme, notamment leurs terminaisons en <-i>, <-a> ou
<-o> — inhabituelles en français.
Au plan phonologique, on remarque dans chipolata la prononciation [tS] du digraphe
<ch> et [A˘] de <a>, habituelle pour les mots de cette origine (Lilly et Viel, 79). Il faut
remarquer qu’aioli a également une variante /aI:´UlI/, avec la correspondance <ai> = [aI] qui
n’est habituelle ni pour les mots anglais, ni pour les emprunts à l’italien ou l’espagnol. Nous
pensons que le mot est traité comme français dans ce cas, ce qui implique une connaissance de
la région d’origine de cette sauce, c’est-à-dire le sud de la France. Enfin, la prononciation
[i˘´] de ratafia se retrouve dans des mots d’origine espagnole comme les noms propres
Garcia /gA˘:si˘´/ et Maria /m´:ri˘´/, ou d’origine italienne comme pizzeria /«pi˘ts´:ri˘´/.
Quant à l’origine première de ces mots, elle ne correspond pas toujours à ce que leur
forme laisse supposer puisque, si chipolata vient bien de l’italien et domino de l’espagnol,
aioli vient du provençal, et ratafia du créole.
c) Autres origines
D’autres emprunts français ont eux-mêmes été empruntés à diverses langues, ce qui
explique leur forme inhabituelle. C’est le cas de kirsch /:kI´S/, d’origine allemande, de
kalanchoe /«kQl´n:k´UI/, formé sur le chinois, ou de mahaleb /:mA˘h´lEb/, d’origine arabe.

Autres cas 193
Ces mots ne sont pas traités comme des mots français, mais comme un mot allemand
dans le cas de kirsch — avec la correspondance <sch> = [S] — ou comme des mots
‘exotiques’ pour kalanchoe ou mahaleb.
d) Décision
Ces mots ne sont pas traités comme des mots français parce qu'ils ne sont pas
identifiés comme tels. Il serait alors inexact de les classer comme non-anglicisés, le cas
échéant, au même titre que des mots comme machine, cliché, lingerie ou camouflage. Nous
ne pouvons perdre de vue que nous étudions la phonologie des emprunts français en anglais,
et que des mots perçus comme venant d’autres langues, et traités comme tels, ne peuvent être
inclus dans une telle étude.
Au final, nous pouvons avancer que les emprunts français totalement anglicisés, que
nous excluons de notre prochaine étape de recherche, ne sont pas traités comme français
probablement parce qu'ils ne sont plus identifiés ou ressentis comme tels. C’est à ce titre que
les variantes traitées comme originaires d’autres langues peuvent rejoindre la catégorie des
mots ‘anglicisés’.

194
VII. CAS DIVERS
Table des matières
A. Quelques cas particuliers.................................................................................................. 195
1. Cas liés à des règles phonologiques ............................................................................ 195
a) Brut........................................................................................................................ 195
b) Commerce ............................................................................................................. 195
c) Calmant ................................................................................................................. 196
d) Bulletin.................................................................................................................. 198
e) Bombe ................................................................................................................... 199
f) Huron ..................................................................................................................... 199
g) Kermesse............................................................................................................... 200
h) Nougat................................................................................................................... 202
2. Cas liés à l’histoire du mot .......................................................................................... 203
a) Colonel .................................................................................................................. 203
b) Cartel ..................................................................................................................... 204
c) Morale ................................................................................................................... 205
d) Personnel............................................................................................................... 206
3. Autes cas...................................................................................................................... 207
a) Caisson .................................................................................................................. 207
b) Volte...................................................................................................................... 210
B. Des absents du corpus....................................................................................................... 211
1. Espionage .................................................................................................................... 212
2. Critique........................................................................................................................ 212
3. Turquoise..................................................................................................................... 213
4. Antique ........................................................................................................................ 214
5. Champagne.................................................................................................................. 216
6. Corps ........................................................................................................................... 217
7. Menage ........................................................................................................................ 218

Quelques cas particuliers 195
Dans ce chapitre, nous allons aborder certains cas minoritaires ou isolés qu’il nous
semblait important de commenter, en raison de leur intérêt phonologique ou historique, ou
parce qu’ils sont représentatifs de la complexité du travail sur l’emprunt.
A. QUELQUES CAS PARTICULIERS
1. Cas liés à des règles phonologiques
a) Brut
Brut, selon les trois dictionnaires de prononciation, se dit /:bru˘t/. Les règles de
l’anglais ne permettent pas d’expliquer cette tension, puisqu’il n’y a pas de <-e> final, auquel
cas cette prononciation aurait été tout à fait régulière. Une des hypothèses d’explication est
que le phonème [u˘] est celui qui est couramment employé pour adapter le [y] du français,
imprononçable pour les locuteurs anglophones.
Cependant cette hypothèse est à première vue difficile à vérifier, car dans beaucoup de
cas la tension est explicable par les règles de l’anglais. Nous trouvons néanmoins quelques cas
similaires à celui de brut : bustier /:bu˘stI´/, brusque /:bru˘sk/, de luxe /dI:lu˘ks/.
Dans la partie suivante, nous étudierons de plus près l’adaptation du [y] français afin
de confirmer ou infirmer cette hypothèse.
b) Commerce
La prononciation de commerce est /:kÅmŒ˘s/. La non-réduction de la dernière syllabe
est-elle régulière ou non ?

196 Cas divers
Nous cherchons d’autres exemples de mots en <-erce> dans l’OED afin d’observer
leur prononciation. Nous ne trouvons qu’un seul autre exemple : sesterce /:sEstŒ˘s/. Nous en
concluons alors que cette forme de mot est extrêmement rare en anglais et que c’est sans
doute la raison pour laquelle ces terminaisons ne sont pas réduites. De plus, la forme du mot
rend certainement la réduction difficile. Enfin, nous remarquons un verbe to commerce
prononcé /k´:mŒ˘s/, emprunté en même temps que le nom. Nous songeons alors à la règle
d’accentuation pour les noms dérivés de verbes, exposée par Chomsky et Halle dans le SPE,
et dont nous avons déjà fait mention109. L’accent 1 final du verbe est déplacé sur la première
syllabe pour le nom, tout en gardant une trace de l’ancien accent 1 : la syllabe finale ne se
réduit pas110.
Commerce est par conséquent issu d’une règle anglaise ; nous allons donc le traiter
comme anglicisé.
c) Calmant
Calmant a deux variantes : /:kA˘m´nt/ et /:kQlm´nt/. La première variante est tout à
fait régulière puisqu’elle suit la règle anglaise selon laquelle Q A˘ / — l {m, f}, ainsi que la
règle d’effacement du /l/ dans ce contexte, comme dans palm, calf, balm. Mais la seconde
variante doit-elle être considérée comme non-anglicisée ? Est-ce le suffixe <-ant> qui
empêche l’application des règles citées ?
Nous relevons dans l’OED des mots dérivés de mots en <-alm> ou <-alf> : balm,
calm, palm, calf, half.
109 Cf. p . 139
110 Par ailleurs, une note de l’OED atteste qu’à l’origine, l’accent était placé en finale.
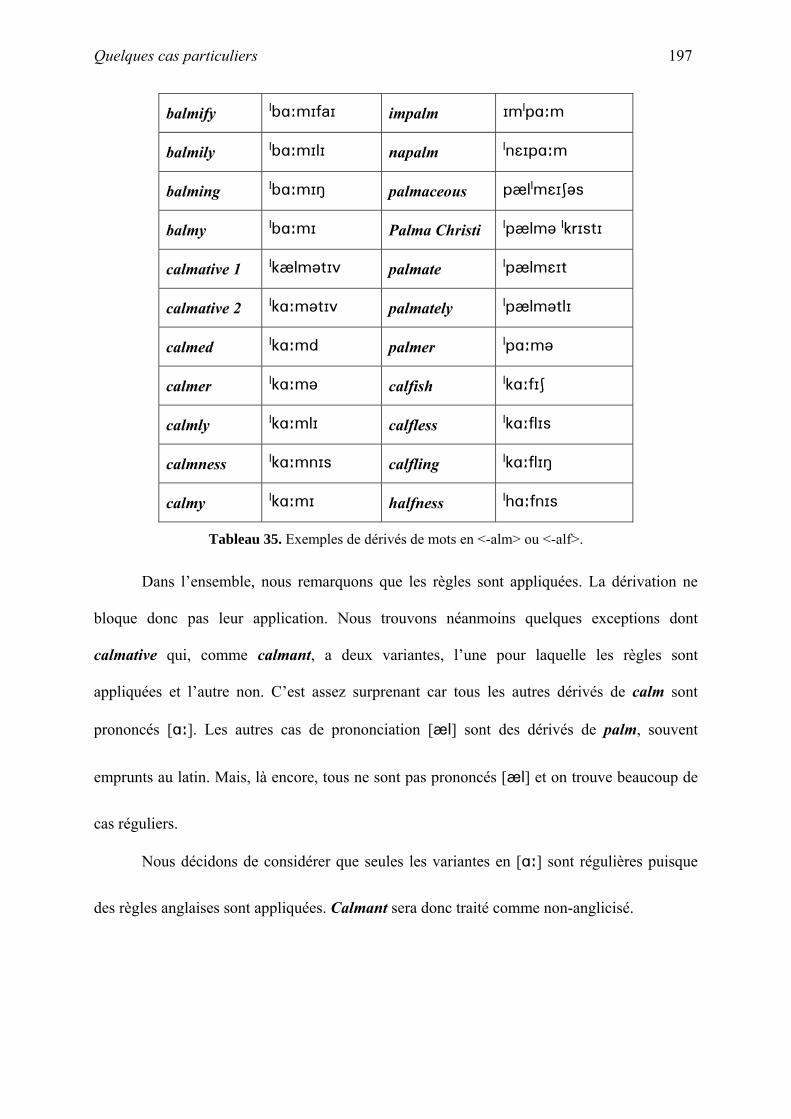
Quelques cas particuliers 197
balmify :bA˘mIfaI impalm Im:pA˘m
balmily :bA˘mIlI napalm :nEIpA˘m
balming :bA˘mIN palmaceous pQl:mEIS´s
balmy :bA˘mI Palma Christi :pQlm´ :krIstI
calmative 1 :kQlm´tIv palmate :pQlmEIt
calmative 2 :kA˘m´tIv palmately :pQlm´tlI
calmed :kA˘md palmer :pA˘m´
calmer :kA˘m´ calfish :kA˘fIS
calmly :kA˘mlI calfless :kA˘flIs
calmness :kA˘mnIs calfling :kA˘flIN
calmy :kA˘mI halfness :hA˘fnIs
Tableau 35. Exemples de dérivés de mots en <-alm> ou <-alf>.
Dans l’ensemble, nous remarquons que les règles sont appliquées. La dérivation ne
bloque donc pas leur application. Nous trouvons néanmoins quelques exceptions dont
calmative qui, comme calmant, a deux variantes, l’une pour laquelle les règles sont
appliquées et l’autre non. C’est assez surprenant car tous les autres dérivés de calm sont
prononcés [A˘]. Les autres cas de prononciation [Ql] sont des dérivés de palm, souvent
emprunts au latin. Mais, là encore, tous ne sont pas prononcés [Ql] et on trouve beaucoup de
cas réguliers.
Nous décidons de considérer que seules les variantes en [A˘] sont régulières puisque
des règles anglaises sont appliquées. Calmant sera donc traité comme non-anglicisé.

198 Cas divers
d) Bulletin
Bulletin est prononcé /:bUl´tIn/. Au départ, notre attention est attirée par le fait que le
<u> n’est pas prononcé /√/ comme la correspondance habituelle. Cependant, il existe une
règle pour les mots en <bull->, <pull-> et <full-> qui stipule que <u> se prononce /U/ dans ce
contexte (Lilly et Viel, 32). Cette règle s’applique-t-elle systématiquement ou bien peut-on
penser que cette prononciation est due à l’origine française, comme dans brusque /:brUsk/ ?
Nous relevons alors à l’aide de l’EPD des mots en <bull->, <pull-> et <full->, hormis
les mots composés avec bull, pull ou full.
bullace :bUlIs fuller :fUl´
Bullard :bUlA˘d Fullerton :fUl´t´n
Bulleid :bUli˘d fully :fUlI
Buller :b√l´ pullet :pUlIt
bullet :bUlIt pulley :pUlI
bully :bUlI pullulate :p√lj´lEIt
Tableau 36. Exemples de mots en <bull->, <pull->, <full->.
Nous ne trouvons que deux exceptions dans notre sélection : le nom propre Buller
/:b√l´/ et le verbe pullulate /:p√lj´lEIt / (et son dérivé pullulation /«p√lj´:lEIS´n/). Nous
pouvons donc considérer que la règle s’applique quasi-systématiquement et en conclure que
bulletin est certainement prononcé [U] par application de cette règle et non en raison de son
origine française. Nous le traitons donc comme anglicisé.

Quelques cas particuliers 199
e) Bombe
Bombe désigne un dessert glacé. On trouve trois variantes pour ce mot : /:bÅm/,
/:bÅmb/ et /:bç)˘b/. La deuxième variante est particulièrement surprenante. En effet, il existe
en anglais une règle d’effacement du [b] après [m] en fin de mot, comme dans climb, thumb,
comb ou lamb (Lilly et Viel, 75), et qui est d’ailleurs appliquée dans la première variante. Le
fait que le [b] ne soit pas effacé est donc tout à fait inhabituel. Nous pensons que c’est
l’origine française du mot qui en est la raison, c’est pourquoi nous allons considérer cette
variante comme non-anglicisée.
f) Huron
Nous trouvons plusieurs variantes pour ce mot : /:hjU´r´n/, /:hjU´rÅn/, /:jU´r´n/,
/:jU´rÅn/, /:hju˘r´n/, /:hju˘rÅn/. Certaines variantes n’ont pas le [h] à l’initiale. Or nous
avons remarqué que certains de nos emprunts n’ont pas de [h] initial, sans doute dans un souci
d’imitation du français. C’est le cas par exemple de hotel /´U:tEl/, hors d’œuvre /«ç˘:dŒ˘v/,
hors de combat /«ç˘d´:kç)˘mbA˘/, ou encore honnête homme /Å«nEt:Åm/.
Mais en anglais, il n’est pas rare que le [h] initial ne soit pas prononcé, phénomène qui
est appelé H-dropping, mais qui n’est pas caractéristique du RP (Wells, vol. 1, 253-256).
Cependant, nous trouvons devant les variantes /:jU´r´n/ et /:jU´rÅn/, issues du dictionnaire
LPD dont Wells est l’éditeur, le symbole § qui signifie « pronunciations which are widespread
among educated speakers of British English, but which are not considered, however, to belong
to RP » (LPD, Introduction, viii).

200 Cas divers
Alors s’agit-il d’un cas régulier, expliqué par une règle de l’anglais, ou bien d’une
imitation de la prononciation française ? Nous décidons de relever dans le LPD d’autres
variantes commençant par <h-> et précédées du symbole §. Nous observons que ce symbole
n’est pas uniquement présent devant les variantes avec H-dropping. En revanche, à chaque
absence du [h] initial d’un mot ‘anglais’, le symbole § précède la variante. Néanmoins, notre
observation nous montre que seuls les mots en <hu-> peuvent subir le H-dropping car nous ne
trouvons aucun cas de H-dropping parmi les autres voyelles (<ha->, <he->, <hi->, <ho->),
excepté les cas d’emprunts français déjà cités.
D’après le dictionnaire, ce phénomène ne se rencontre donc, chez les locuteurs
cultivés, que pour les mots commençant par <hu-> tels que huge, human, humid, humiliate,
humility, humour ou humus. Huron /:jU´r´n/ est par conséquent dû à une règle anglaise et
n’est pas une imitation du français. Nous allons donc traiter ces variantes comme anglicisées.
g) Kermesse
Kermesse /:kŒ˘mEs/ est-il régulier ou non ? Serait-il possible de réduire la dernière
syllabe ? Pour répondre à cette question, nous relevons des mots en <-esse> dans l’OED et
observons leur prononciation. Nous ne trouvons que peu de cas :
allegresse Qli˘:grEs duchesse 1 :d√tSIs
delicatesse dElIk´:tEs duchesse 2 :d√tSEs
finesse fI:nEs duchesse 3 du˘:SEs
maladresse mQl´:drEs noblesse n´U:blEs
Tableau 37. Mots en <-esse>.

Quelques cas particuliers 201
Quasiment toutes ces variantes sont accentuées en finale. Nous ne trouvons qu’un seul
cas de réduction : duchesse /:d√tSIs/. Cependant, la parenté avec duchess est évidente et c’est
sans doute la raison pour laquelle on trouve cette variante. Elle n’est donc pas à traiter comme
un cas de réduction du suffixe <-esse>.
Ainsi nous voyons que tous les mots en <-esse> sont des emprunts français et qu’ils
sont quasiment toujours accentués en finale. Cette terminaison est donc certainement
identifiée comme française. Par conséquent, nous ne pouvons considérer kermesse comme un
mot anglicisé.
Kermesse est également intéressant du point de vue de son sens. En effet, il ne porte
pas les sens les plus courants en français de « fête populaire » ou « fête de charité », mais
celui de « course cycliste ». Mais ce sens n’est pas présent dans les dictionnaires Robert ou
TLFi. S’agit-il d’un sens créé par l’anglais ?
L’étymologie de l’OED renvoie à kermis, emprunt au néerlandais et qui a le sens de
« fête périodique ou carnaval, célébré aux Pays-Bas et dans certaines régions d’Allemagne »,
ce qui se rapproche des sens français de kermesse, sans être toutefois identique.
D’après le TLFi, le premier sens de kermesse en français est celui de « fête patronale
célébrée en plein air et bruyamment, en Hollande, Belgique et dans le Nord de la France ».
Les sens de « fête populaire en plein air » et de « fête de bienfaisance » sont dérivés de ce
premier sens (TLFi, ‘Kermesse’). Par ailleurs, kermesse est noté comme étant un emprunt au
flamand.
Nous trouvons enfin l’explication du sens anglais dans un article de Wikipedia111 : il
s’agit d’une course cycliste qu’on appelle également criterium et qui est appelée kermesse par
111 ‘Kermesse’. Wikipedia, The Free Encyclopedia. Wikimedia Foundation. 11 janv. 2008.
http://en.wikipedia.org/wiki/Kermesse_%28Bicycle_Race%29

202 Cas divers
association à la fête populaire, car la course cycliste est souvent l’une des attractions de la
fête. Ce sens n’est donc pas une création de l’anglais.
h) Nougat
Nous trouvons dans tous les dictionnaires de prononciation une variante /:n√g´t/, à
comparer avec la première variante /:nu˘gA˘/. Cette variante semble anglicisée, pourtant la
correspondance <ou> = [√] n’est pas habituelle en anglais. Alors doit-on la traiter comme
non-anglicisée ?
Il existe tout de même certains mots anglais avec cette correspondance, comme
courage /:k√rIdZ/. Nous décidons alors de chercher s’il existe d’autres mots avec cette
correspondance. Nous sélectionnons dans l’EPD les mots contenant le phonème [√] et
observons ceux qui sont transcrits <ou> :
country :k√ntrI rough :r√f
couple :k√pl sough :s√f
courage :k√rIdZ touch :t√tS
cousin :k√z´n tough :t√f
double :d√bl trouble :tr√bl
nourish :n√rIS young :j√N
Tableau 38. Exemples de correspondances <ou> = [√].
Bien que minoritaire, nous remarquons que cette correspondance est présente en
anglais, dans des mots très courants. Nous dégageons néanmoins deux catégories : celle de la
correspondance <ough> = [√f] et le reste.

Quelques cas particuliers 203
En regardant l’étymologie, nous nous apercevons que tous les mots en <ough> sont
d’origine germanique, tandis que les autres — à l’exception de young, également d’origine
germanique — sont d’origine française. Ce sont tous des emprunts datant du 13ème au 14ème
siècle, à une époque où la graphie française n’était pas encore <ou>, mais <o> ou <u>,
comme le montre l’exemple de couple :
Figure 27. Étymologie de couple.
La prononciation avec [√] en anglais est sans doute issue d’une correspondance
antérieure à sa graphie <ou>— puisque [√] est une évolution de [U] (Wells, vol. 1, 132).
Néanmoins, il s’agit d’emprunts anciens et de mots très courants, c’est pourquoi il nous
semble que la correspondance actuelle ne peut être considérée comme non-anglicisée.
Nous en concluons que la prononciation [√] du digraphe <ou> doit être traitée comme
anglicisée. La variante /:n√g´t/, qui résulte simplement de l’application d’une correspondance
connue de longue date et qui présente une anglicisation totale, sera donc supprimée du corpus.
2. Cas liés à l’histoire du mot
a) Colonel
Colonel /:kŒ˘n´l/ est particulièrement illustratif de la complexité du travail sur
l’emprunt. L’orthographe et la prononciation actuelle semblent n’avoir rien en commun. Il
faut examiner l’histoire de ce mot pour comprendre cette particularité.
a. OF. cople, cuple, later couple.

204 Cas divers
A l’origine, c’est le mot coronel qui fut emprunté au français au 16ème siècle, sans
changement de forme. Puis, fin 16ème, le mot français changea de forme pour devenir colonel ;
cette nouvelle orthographe fut à nouveau empruntée par l’anglais. Les deux formes restèrent
en usage pendant un certain temps, <coronel> restant la forme principale jusqu’à 1630, puis la
forme orthographique <colonel> supplanta <coronel> vers 1650. Concernant la prononciation,
au 17ème siècle colonel était trissyllabique et souvent accentué en finale, puis fin 17ème,
commença à être réduit à deux syllabes. Mais coronel n’avait pas pour autant disparu de
l’usage populaire, comme en attestent des citations de 1710 /:k√r´UnEl/, 1766 /:kç˘nIl/ et
enfin 1780 /:kŒ˘nEl/, ce qui permet de comprendre la prononciation actuelle (OED, ‘colonel’).
Nous observons ainsi l’association curieuse d’une forme orthographique
correspondant au second emprunt à une forme phonique correspondant à l’emprunt initial,
dont l’usage n’a jamais cessé, et dont la prononciation s’est ‘usée’ au fil du temps. Il s’agit là
d’un cas extrêmement particulier, car si un ré-emprunt de la forme orthographique n’est pas
rare, en général la prononciation est alors modifiée pour se conformer à l’orthographe.
Nous décidons de supprimer colonel /:kŒ˘n´l/ puisque la variante, en regard de sa
graphie d’origine <coronel>, nous paraît anglicisée.
b) Cartel
Cartel est un emprunt au français datant du milieu du 16ème siècle. L’OED propose
deux variantes : /:kA˘t´l / et /kA˘:tEl /, en précisant que cette dernière est réservée aux sens 3c
et 3d. A la définition 3c « an agreement between two or more business houses », nous
trouvons la note ‘after G. Kartell’. Il s’agit donc d’un sens emprunté à l’allemand. La variante
reflète alors très probablement la prononciation allemande et n’est pas une imitation de la
prononciation française.

Quelques cas particuliers 205
Cependant le TLFi explique que le mot allemand Kartell est lui-même un emprunt au
français cartel (TLFi, ‘cartel’). Il est donc fort possible que la prononciation allemande imite
la prononciation française, notamment en conservant l’accent en finale — ce qui est inhabituel
en allemand, tout comme en anglais —, et que l’anglais, en empruntant le mot allemand, ait
conservé ces caractéristiques.
Cette hypothèse est confirmée par une citation de l’ouvrage de Marthe Philipp
Phonologie de l’allemand112 : « les signifiants empruntés au français portent toujours l’accent
principal sur la dernière syllabe » (Philipp, 150), avec pour exemples Séparée, Niveau,
Frikassee.
Il s’agit donc ici d’un cas tout à fait particulier puisque cette prononciation vient bien
du français, mais par le biais de l’allemand. On peut également noter que l’anglais n’a pas
conservé l’orthographe allemande <kartell>, mais a préféré reprendre l’orthographe <cartel>,
déjà existante.
Bien que cette variante soit en réalité originaire de l’allemand, nous allons prendre en
compte le fait que les caractéristiques françaises ont été conservées lors des deux emprunts
successifs, et traiter cartel /kA˘:tEl / comme non-anglicisé.
c) Morale
Morale est un cas un peu différent des autres. C’est un emprunt au mot français
morale qui date de 1752, avec comme premier sens « principes moraux, sens moral d’une
personne ». Ce sens est noté comme rare dans l’OED.
Il existe un deuxième sens, le plus courant en anglais aujourd’hui, qui est celui d’« état
mental ou émotionnel d’une personne ». L’OED explique dans l’étymologie que ce sens vient
112 Philipp, Marthe. Phonologie de l’Allemand. Paris : PUF, 1970.

206 Cas divers
du français moral, mais que l’orthographe avec <-e> en anglais est en partie due à la
confusion avec morale, et en partie un moyen de marquer l’accentuation sur la syllabe finale.
Même si cette orthographe ne correspond pas au mot français moral, nous préférons
conserver cet emprunt dans le corpus car il s’agit bien d’une adoption du mot morale au
départ. Nous considérons qu’il n’y a pas adaptation de moral, mais plutôt emprunt de sens.
d) Personnel
Personnel en anglais est un nom, mais est noté comme emprunt à l’adjectif français
personnel. Le sens principal est celui de l’ensemble des personnes appartenant à une même
profession ou un même corps. Ce sens est présent également en français pour le nom
personnel. Dès lors, il est surprenant de voir que l’étymologie suggère que l’anglais a
emprunté l’adjectif français plutôt que le nom.
Mais la première occurrence de cet emprunt en anglais date de 1819. Or ce sens
n’apparait en français qu’en 1831 d’après l’OED et le TLFi. L’OED propose alors deux
hypothèses pour expliquer cette curiosité : d’une part, l’anglais aurait employé personnel en
tant que nom par contraste avec le nom matériel ; d’autre part, l’anglais — tout comme le
français — aurait emprunté ce sens à l’allemand Personal. Cette hypothèse est également
avancée par le TLFi au sujet du nom français.
Il s’agit donc ici d’un cas un peu singulier, puisque la forme est bien empruntée au
français, mais que le sens est soit une création de l’anglais, soit un emprunt de sens à
l’allemand. Nous avons néanmoins choisi de conserver ce mot.

Quelques cas particuliers 207
3. Autres cas
a) Caisson
Caisson a deux variantes assez surprenantes /:kEIsu˘n/, trouvée dans l’OED, et
/k´:su˘n/, trouvée dans les trois dictionnaires de prononciation. L’EPD précise ‘sometimes in
engineering’. Ces variantes sont étonnantes, car la correspondance <on> = [u˘n] est tout à fait
inhabituelle. Nous trouvons alors une réponse dans l’OED : « which agrees with the usual
treatment of F. –on in the 18th c. » (OED, ‘caisson’).
Nous tentons de trouver d’autres exemples de cette adaptation des mots en <-on> :
dans notre corpus, nous trouvons le mot jargon, qui a une variante jargoon et pour lequel
l’OED propose les prononciations /:dZA˘g´n/ et /dZA˘:gu˘n/. Il s’agit effectivement d’un
emprunt français du 18ème siècle. On peut supposer que la variante /dZA˘:gu˘n/ correspond à
l’adaptation des mots en <-on> telle que décrite précédemment. La variante orthographique
<jargoon> est donc probablement issue d’un besoin de correspondance entre graphie et
phonie113. D’ailleurs, l’OED mentionne également pour caisson une orthographe <caissoon>
au 18ème siècle. Pour quelle raison la prononciation /:kEIsu˘n/ s’est-elle maintenue aux côtés
d’une graphie qui ne correspondait pas ?
Nous nous demandons alors si dans d’autres cas l’orthographe <-oon> n’aurait pas été
conservée avec la prononciation [u˘n]. Nous sélectionnons dans l’EPD des mots se terminant
par cette prononciation et observons dans l’OED l’étymologie de ceux qui s’écrivent <-oon>
ou <-on>. Nous trouvons alors un grand nombre d’emprunts français :
113 On peut d’ailleurs noter que dans l’ODP, la variante /:dZA˘g´n/ a été trouvée sous l’orthographe <jargon>,
tandis que la variante /dZA˘:gu˘n/ a été trouvée sous l’orthographe <jargoon>.
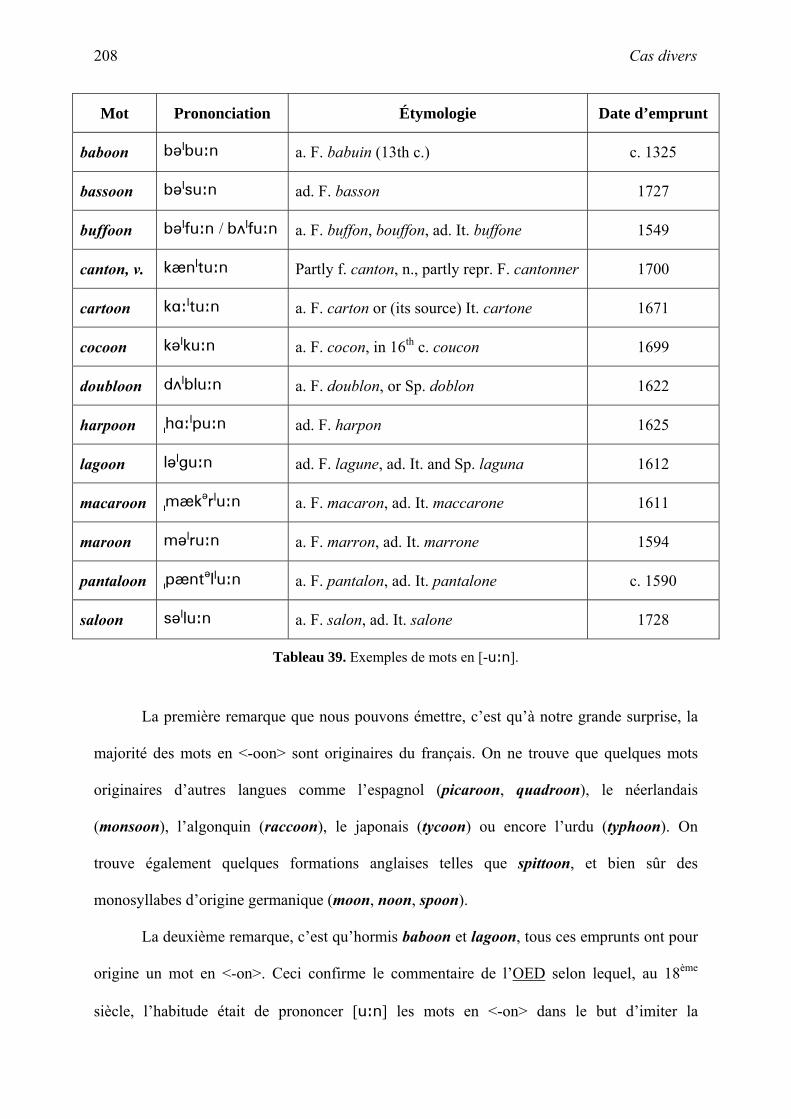
208 Cas divers
Mot Prononciation Étymologie Date d’emprunt
baboon b´:bu˘n a. F. babuin (13th c.) c. 1325
bassoon b´:su˘n ad. F. basson 1727
buffoon b´:fu˘n / b√:fu˘n a. F. buffon, bouffon, ad. It. buffone 1549
canton, v. kQn:tu˘n Partly f. canton, n., partly repr. F. cantonner 1700
cartoon kA˘:tu˘n a. F. carton or (its source) It. cartone 1671
cocoon k´:ku˘n a. F. cocon, in 16th c. coucon 1699
doubloon d√:blu˘n a. F. doublon, or Sp. doblon 1622
harpoon «hA˘:pu˘n ad. F. harpon 1625
lagoon l´:gu˘n ad. F. lagune, ad. It. and Sp. laguna 1612
macaroon «mQk´r:u˘n a. F. macaron, ad. It. maccarone 1611
maroon m´:ru˘n a. F. marron, ad. It. marrone 1594
pantaloon «pQnt´l:u˘n a. F. pantalon, ad. It. pantalone c. 1590
saloon s´:lu˘n a. F. salon, ad. It. salone 1728
Tableau 39. Exemples de mots en [-u˘n].
La première remarque que nous pouvons émettre, c’est qu’à notre grande surprise, la
majorité des mots en <-oon> sont originaires du français. On ne trouve que quelques mots
originaires d’autres langues comme l’espagnol (picaroon, quadroon), le néerlandais
(monsoon), l’algonquin (raccoon), le japonais (tycoon) ou encore l’urdu (typhoon). On
trouve également quelques formations anglaises telles que spittoon, et bien sûr des
monosyllabes d’origine germanique (moon, noon, spoon).
La deuxième remarque, c’est qu’hormis baboon et lagoon, tous ces emprunts ont pour
origine un mot en <-on>. Ceci confirme le commentaire de l’OED selon lequel, au 18ème
siècle, l’habitude était de prononcer [u˘n] les mots en <-on> dans le but d’imiter la

Quelques cas particuliers 209
prononciation française (OED, ‘patroon’). Nous pouvons d’ailleurs étendre cette période au
17ème siècle, voire à la fin du 16ème, car nous trouvons de nombreux mots en <-oon>
empruntés à cette époque114.
Enfin nous remarquons que tous ces mots sont accentués en finale (bien que
pantaloon ait une variante accentuée sur l’antépénultième). C’est sans doute une trace de
l’origine française qui s’est maintenue. Ce qui est particulièrement intéressant, c’est que
même les emprunts à d’autres langues sont accentués en finale. Nous pensons que
l’orthographe <-oon> a été associée à cette accentuation finale, si bien que tous les mots en
<-oon> sont automatiquement accentués de cette manière.
Un seul mot n’a pas été commenté : balloon. L’OED le note comme étant issu de
l’italien ballone. Or nous remarquons dans notre sélection que beaucoup de mots français en
<-on> sont originaires de mots italiens en <-one>. En revanche, aucun autre mot en <-oon>
n’est déclaré comme emprunt direct à l’italien. De plus, une note de l’OED précise : « Cf. F.
ballon (16th c.), which balloon subseq. followed in its senses. » Si nous examinons les
citations, nous voyons que les premières présentent <ballone> puis <balloon>. Il est donc
possible qu’il y ait eu un premier emprunt ballone à l’italien, puis un emprunt du français
ballon, adapté en balloon, conformément aux habitudes de l’époque.
Au regard de cette recherche, le maintien des correspondances caisson /k´:su˘n/ ou
canton, v. /k´n:tu˘n/ — relevé dans notre sélection et réservé au sens de « to provide
accommodation » — paraît assez extraordinaire. Nous allons évidemment les considérer
comme non-anglicisées, notamment en raison de l’accentuation, mais également de la non-
correspondance entre l’orthographe et la prononciation.
114 Nous pouvons également ajouter à cette liste le mot baton, pour lequel l’OED ajoute que la forme anglaise
habituelle aux 17ème et 18ème siècles était batoon.

210 Cas divers
b) Volte
L’OED propose deux variantes orthographiques <volte> et <volt>, mais le mot
français d’origine est volte. On trouve trois sens pour ce mot : le premier est une danse, mais
ce sens est obsolète ; le deuxième est un mouvement en escrime, et le dernier est un
mouvement exécuté par un cheval. Dans les citations, les deux variantes orthographiques sont
présentes pour tous les sens du mot.
L’EPD propose les orthographes <volte> et <volt>, cette dernière présentant deux
entrées différenciées par leur sens : d’une part l’unité d’électricité, qui vient du nom propre
Volta, et d’autre part un mouvement en escrime ou le mouvement d’un cheval, ce qui
correspond à notre emprunt. La transcription proposée est /:vÅlt/. Pour <volte> les
transcriptions sont plus surprenantes : /:vÅltEI/ ou /:vÅltI/.
Nous ne trouvons nulle part ailleurs ces transcriptions. Le LPD ne propose que
l’orthographe <volt> avec les transcriptions /:v´Ult/ ou /:vÅlt/. L’ODP propose les deux
orthographes, mais avec les mêmes transcriptions que le LPD. Tous les autres dictionnaires
consultés (Merriam-Webster115, The Free Dictionary116, Longman Dictionary of
Contemporary English117, American Heritage Dictionary118) proposent soit <volt>
uniquement, soit les deux orthographes — volte renvoyant alors à volt — avec les mêmes
transcriptions119.
115 Merriam-Webster Dictionary Online. http://www.merriam-webster.com/.
116 The Free Dictionary. Farlex. http://www.thefreedictionary.com/.
117 Longman Dictionary of Contemporary English Online. Pearson Education. http://www.ldoceonline.com/.
118 The American Heritage Dictionary of the English language. 4ème éd. Bartleby.com.
http://www.bartleby.com/61/.
119 Recherche Internet du 9 mai 2008.

Des absents du corpus 211
L’EPD est donc le seul dictionnaire à proposer les variantes /:vÅltEI/ et /:vÅltI/. Ces
prononciations sont particulièrement surprenantes car elles paraissent correspondre à une
orthographe <volté>. Or, le mot français d’origine est bien volte, et est prononcé /vçlt/.
En réalité, il semble que le mot soit traité selon l’EPD comme étant d’origine italienne.
En effet, on peut comparer ces variantes à celles de ces mots :
Bolognese «bÅl´:njEIzEI
Duce :du˘tSEI :du˘tSI
mascarpone «mQskA˘:p´UnEI
padre :pA˘drEI :pA˘drI
pianoforte pI«Qn´U:fç˘tEI pI«Qn´U:fç˘tI
Tableau 40. Exemples de mots d’origine italienne dans l’EPD.
Alors s’agit-il bien du même mot ? Il est en effet possible que l’EPD fasse référence à
un autre mot <volte> d’origine italienne. Cependant, nous n’en trouvons trace dans aucun
dictionnaire. Compte tenu des informations dont nous disposons, nous ne pouvons considérer
que ces variantes soient traitées comme françaises. C’est pourquoi, conformément à notre
décision sur les mots traités comme étant d’origine étrangère120, nous préférons ne pas les
conserver dans la base de données.
B. DES ABSENTS DU CORPUS
Au cours de notre travail, nous rencontrons certains mots, emprunts ou non, qui ne
font pas partie du corpus pour diverses raisons que nous allons expliquer, et qu’il nous semble
intéressant de commenter.
120 Cf. p . 193

212 Cas divers
1. Espionage
Espionage ne fait pas partie du corpus pour deux raisons : l’OED le note comme
adaptation, et son orthographe ne correspond pas tout à fait à l’orthographe française.
Effectivement, ce mot a été légèrement modifié à son arrivée en anglais. Au lieu de <nn>, on
ne trouve plus que <n>. Ce phénomène de simplification des doubles consonnes n’est pas
isolé. On en trouve d’autres exemples comme envelope ou concessionaire. Bliss l’a remarqué
et y voit une marque d’intégration : « Another systematic tendency, though one which serves
no very obvious purpose, is the simplification of double consonants in foreign languages
[…] » (Bliss, 12). Speake considère que cette simplification ne joue en rien sur la perception
du mot comme étranger (Speake, Préface, viii).
Sa prononciation n’est pourtant pas anglicisée : /:EspI´nA˘Z/, puisque le suffixe
<-age> est prononcé [A˘Z] et pas [IdZ]. Alors fallait-il l’inclure au corpus ? Non, si on s’en
tient à la règle stricte de l’orthographe identique en français et en anglais. Mais cela interpelle
tout de même sur les différents types d’adaptations graphiques et leurs conséquences, car
certains changements orthographiques vont induire une anglicisation de la prononciation,
alors que d’autres ne vont provoquer aucun changement, si ce n’est une forme graphique
légèrement plus conforme aux règles orthoépiques de l’anglais, comme c’est le cas avec
espionage.
2. Critique
Nous rencontrons critique lors de notre étude des mots en <-que>. L’OED lui donne
pour étymologie : « A gradual alteration of the 17-18th c. critick, critic, after French », raison
pour laquelle il ne fait pas partie de notre corpus. Un lien renvoie à l’entrée critic, et nous

Des absents du corpus 213
découvrons qu’il s’agit bien d’un emprunt français : « app. ad. F. critique ». Notons que
l’accent est alors sur la première syllabe.
L’OED détaille l’histoire de ce mot et explique qu’au 18ème siècle, il commence à être
orthographié <critique> en dépit de l’opposition exercée par certains auteurs et éditeurs de
dictionnaires. Mais c’est seulement au 19ème siècle que la prononciation change pour prendre
une forme imitant la prononciation française. C’est celle que nous connaissons de nos jours :
/krI:ti˘k/.
Critique est donc illustratif de l’histoire parfois complexe des emprunts. Il y a eu un
premier emprunt avec adaptation, puis un ré-emprunt de la forme orthographique et enfin un
changement phonique qui peut être considéré, soit comme un nouvel emprunt de la forme
phonique, soit comme une adaptation de la prononciation à la forme orthographique avec
l’application de règles réservées aux mots français.
3. Turquoise
Turquoise est un emprunt antérieur au 16ème siècle, c’est pourquoi il ne fait pas partie
du corpus. Mais, comme critique, il illustre parfaitement la complexité des emprunts.
Il est emprunté au 15ème siècle au vieux-français turqueise, -aise, sous la forme
adaptée turkeis, -keys. Suite à l’évolution des voyelles, il devient tur:kēse, -īse, puis par
déplacement de l’accent, comme dans les autres langues germaniques, :turkes, -as, -is. Mais
ces formes commencent dès avant 1600 à être remplacées par la nouvelle forme
orthographique française turquoise, turkois. Aux 17ème et 18ème siècles, il semble que l’accent
soit maintenu sur la première syllabe, mais à partir de la fin du 19ème siècle, on trouve l’accent
en finale. L’édition de 1911 du Webster propose tur:koiz ou :turkwoiz (OED, ‘Turquoise’).

214 Cas divers
Aujourd’hui, la prononciation est, d’après l’EPD, /:tŒ˘kwA˘z/ ou /:tŒ˘kwçIz/. L’accent
primaire est donc revenu en première syllabe, comme c’est généralement le cas pour les noms,
mais la prononciation s’est adaptée à la forme orthographique (/:tŒ˘kwçIz/), voire s’est
rapprochée de la forme française (/:tŒ˘kwA˘z/), puisque cette dernière variante est assez
proche du français /ty{kwaz/.
Nous observons ainsi que même après avoir emprunté un mot au français, l’anglais
reste attentif aux évolutions, notamment graphiques, de la forme française, et reprend souvent
cette nouvelle forme graphique. Il s’en suit généralement une modification de la prononciation
pour se conformer à cette nouvelle forme orthographique. On observe même parfois, comme
ici, un nouvel emprunt de la forme phonique, ou du moins d’une partie, car il semble, dans le
cas de turquoise, que seule la prononciation française du digraphe <oi> ait été empruntée.
L’une des difficultés du linguiste qui étudie les emprunts est alors d’interpréter s’il
s’agit d’un nouvel emprunt ou d’un emprunt de la forme graphique, d’un emprunt de la forme
phonique ou de l’application, au sein de la langue anglaise, de règles réservées aux mots
d’origine française. Il n’est d’ailleurs pas forcément possible d’affirmer qu’il s’agit de tel ou
tel cas ; nous ne pouvons que proposer des hypothèses.
4. Antique
Au sujet de l’étymologie d’antique, l’OED hésite entre une origine latine ou
française :
Figure 28. Étymologie d’antique.
ad. L antīqu-us, antīc-us ; or perh. immed. f. Fr. antique

Des absents du corpus 215
Lors de notre sélection du corpus, nous avons préféré exclure les mots dont
l’étymologie était incertaine, ce qui explique son absence du corpus.
Deux variantes sont proposées par le dictionnaire : /Qn:ti˘k/ et /:QntIk/.
Ce mot est à mettre en parallèle avec antic, qui a le sens de « grotesque » — et qui est
apparemment un emprunt à l’italien antico — parce que les deux mots s’écrivaient <antik(e>
ou <antick(e> au 16ème siècle.
Pendant un certain temps, on trouvait les variantes orthographiques <antic> ou
<antique> pour le mot correspondant au sens « relatif à une époque très ancienne », mais à
partir de 1700 <antique> prévalut. Cependant la prononciation resta pendant un moment
/:QntIk/, c’est-à-dire une forme correspondant à l’orthographe <antic> et conforme aux règles
habituelles de l’anglais. Ensuite la prononciation changea pour imiter le français et
correspondre à l’orthographe <antique> : /Qn:ti˘k/, avec l’accent primaire sur la dernière
syllabe. D’après l’OED, les poètes utilisent encore parfois la prononciation /:QntIk/.
Ce mot est intéressant car, comme pour critique ou turquoise, il met en évidence
l’importance du lien entre forme orthographique et prononciation. Il semble qu’il y ait un
besoin de la part du locuteur d’une certaine correspondance entre graphie et phonie. De plus,
il apparaît que certaines formes orthographiques sont identifiées ou ressenties comme
françaises ; la prononciation va alors avoir des caractéristiques particulières comme l’accent
primaire en finale, de manière à marquer l’origine française du mot. Il semble donc bien que
le locuteur anglophone applique un certain nombre de règles pour les mots d’origine
française, de façon à marquer cette origine.

216 Cas divers
5. Champagne
Lorsque nous commençons notre étude sur les emprunts français en anglais, un des
mots que nous nous attendons à rencontrer est champagne /SQm:pEIn/. La première citation
date de 1676 et est donc bien postérieure à 1500, l’un de nos critères de sélection. Les sens
proposés sont les mêmes qu’en français, c’est-à-dire la région française et le vin qui y est
produit. Mais dans l’OED, l’étymologie de ce mot renvoie simplement à champaign ou
campaign.
L’étymologie de champaign /:tSQmpEIn/ indique que ce mot vient du moyen-anglais
champayne, champaine, qui est un emprunt au vieux-français champaigne. Les premières
citations remontent à environ 1400. Ce mot serait une forme du centre de la France, et non du
nord ou du normand, comme c’est plus souvent le cas. D’après les commentaires de l’OED, la
prononciation [tS] et l’accentuation sur la première syllabe sont attestées dès le 14ème siècle
dans la poésie allitérative, mais au 19ème, on trouve occasionnellement un accent en finale. Le
commentaire ajoute : « Some even identify the word in pronunciation with champagne, as if it
were from modern French » (OED, ‘champaign’). C’est la seule relation à champagne que
nous trouvions dans cette entrée.
Campaign /kQm:pEIn/ est un emprunt du 17ème siècle au français campagne, qui au
16ème siècle en français avait remplacé le mot champagne (excepté pour le nom de la province
française). La première citation date de 1628. L’étymologie nous apprend qu’au 17ème siècle,
le mot a été utilisé dans tous les sens de champaign, mais que par la suite il a été réduit au
sens de « campagne militaire ».
Nous n’apprenons finalement rien de l’histoire du mot champagne en anglais. S’agit-il
d’un nouvel emprunt ? D’un ré-emprunt de la forme graphique qui a amené à changer la
prononciation ? Ce manque d’information ne nous permet donc pas de l’inclure au corpus.

Des absents du corpus 217
6. Corps
Un autre mot que nous nous attendions à trouver dans notre corpus est corps /:kç˘/, qui
est un terme militaire très courant. Il est en réalité absent de la sélection en raison de sa longue
présence au sein de la langue anglaise. Son histoire, liée à celle du mot corpse121, est aussi
complexe que passionnante.
A l’origine, l’anglais a emprunté le mot cors au vieux français. Puis, au 14ème siècle, le
français a changé la graphie en <corps> pour rappeler l’origine latine du mot (corpus).
L’anglais a emprunté cette nouvelle forme qui s’est maintenue aux côtés de cors pendant un
certain temps, avant de devenir la forme la plus courante bien que cors, orthographié <corse>
à partir du 16ème siècle, continue à être usité en tant que forme poétique.
En français, le <p> n’a jamais été prononcé. En anglais, il était également muet au
départ, puisque corps n’était qu’une variante orthographique de cors. Mais il a commencé à
être prononcé par certains locuteurs vers la fin du 15ème siècle, et cette pratique s’est ensuite
répandue, pour devenir tout à fait habituelle.
Le sens militaire de « corps d’armée » a été emprunté au français au début du 18ème
siècle : il s’agit donc d’un emprunt de sens mais pas de forme. On suppose qu’il s’est
prononcé /:kç˘ps/ au départ, mais dès la fin du 18ème siècle, il a été prononcé ‘à la française’,
c’est-à-dire sans prononcer le <p> ni le <s>, dont la prononciation avait alors disparu en
français (OED, ‘corps’).
Dès lors, il a été nécessaire de différencier ces deux sens, prononcés différemment
mais écrits de la même manière. C’est pourquoi une graphie avec -e final <corpse> est
apparue et est devenue la forme courante liée au sens de « corps d’un homme mort ».
121 L’étymologie de corps figure d’ailleurs sous l’ entrée corpse.

218 Cas divers
Corpse et corps ont donc une origine commune. Fallait-il inclure corps en raison de
l’origine française de son sens, et de sa prononciation ? Au regard de son histoire
étymologique, il nous a semblé qu’il s’agissait plutôt d’un emprunt de sens avec ré-emprunt
d’une forme phonique, d’où l’absence de corps de la sélection finale. Néanmoins nous
retrouvons ce mot dans les expressions corps d’élite, corps diplomatique et corps de ballet.
7. Menage
Menage est un très vieil emprunt puisqu’il date du 14ème siècle. C’est la raison pour
laquelle il ne fait pas partie de notre corpus. Cependant, sa prononciation actuelle /mEI:nA˘Z/
a toutes les caractéristiques d’un emprunt non-anglicisé. Or, en général, les emprunts les plus
anciens sont totalement anglicisés. Mais l’étymologie de l’OED précise que les citations du
17ème siècle et des siècles suivants sont probablement dues à un second emprunt.
Comme turquoise, cet exemple illustre l’une des difficultés du travail sur les
emprunts, qui est de déterminer quand il s’agit d’un second emprunt, d’un ré-emprunt de la
forme phonique, ou seulement d’un emprunt de sens. Aurait-il fallu inclure menage en ne
tenant compte que des citations postérieures au 17ème siècle ?
Nous préférons nous en tenir à nos critères de base car l’étymologie de l’OED n’est
pas absolument affirmative. De plus, il faut garder à l’esprit qu’il ne s’agit pas de faire une
liste exhaustive des emprunts français, mais bien de réaliser une sélection représentative des
emprunts non-anglicisés.

219
VIII. CORRECTION DU CORPUS
Table des matières
A. OED 3............................................................................................................................... 220
B. Adaptation ou adoption ?.................................................................................................. 221
C. Les ajouts au corpus.......................................................................................................... 224
D. Les suppressions du corpus .............................................................................................. 226
1. Fatiguable / fatigable ................................................................................................... 226
2. Forte............................................................................................................................. 227
3. Frigidaire ..................................................................................................................... 228
4. Negligée....................................................................................................................... 229
5. Saponin, saponine........................................................................................................ 230
E. Les faiblesses de l’OED.................................................................................................... 230
1. Lyonnais / Lyonnaise .................................................................................................. 231
2. Apache......................................................................................................................... 234
3. Pompon........................................................................................................................ 235
4. Variante orthographique ou autre entrée ? .................................................................. 237
a) Liana, liane ............................................................................................................ 237
b) Jargon, jargoon...................................................................................................... 238
c) Longe, lunge.......................................................................................................... 239
d) Caracol, caracole................................................................................................... 239
e) Corselet, corslet ..................................................................................................... 240
f) Gelatin, gelatine..................................................................................................... 241
g) Pavane, pavan........................................................................................................ 242
h) Telecabine, telecabin............................................................................................. 242

220 Correction du corpus
Au cours de ce travail de suppression, qui requiert non seulement d’observer la
prononciation, mais aussi parfois l’étymologie et le sens des mots, nous sommes amenée à
apporter quelques corrections au corpus initial.
A. OED 3
Nous avons travaillé essentiellement à l’aide de la version électronique de l’OED, qui
correspond à la 2ème édition. La 3ème édition, qui est une édition entièrement révisée du
dictionnaire, est en cours. Puisque seuls quelques volumes de la 3ème édition étaient prêts
lorsque nous avons commencé ce travail, nous avons préféré travailler avec la 2ème édition
complète. Néanmoins, il nous a semblé intéressant et utile de comparer notre sélection avec
les volumes disponibles de l’OED 3, notamment afin d’obtenir les transcriptions
contemporaines des mots.
Nous avons donc repris notre sélection initiale, avant suppression des mots n’ayant
aucune variante disponible, entre M et ramé (dernier emprunt de la partie révisée). Nous
avons pu ajouter certains emprunts pour lesquels aucune transcription en API n’était
disponible dans la 2ème édition, et nous avons comparé les transcriptions de l’OED 2 avec
celles de l’OED 3. Lorsqu’une transcription était identique dans les deux éditions, nous
l’avons surlignée en bleu ; lorsqu’elle n’était présente que dans l’OED 3, en rose. Si la
variante n’était présente que dans l’OED 2, nous l’avons laissée telle quelle. Ceci permet
d’identifier d’un coup d’œil les variantes contemporaines de l’OED, car, rappelons-le,
certaines variantes peuvent être très anciennes du fait de l’impossibilité de distinguer les
entrées de l’OED 1 de celles de l’OED 2.
Nous avons également apporté quelques corrections à notre corpus. Nous avons
supprimé certaines entrées qui étaient notées dans l’OED 3 comme obsolètes ou rares
(ex : maladresse, mangue, mondaine, parsemé) ou bien n’étant pas d’origine française

Adaptation ou adoption ? 221
(ex : major (esp.), minette (all.), pastel (it.), mensurable (lat.)), ou encore dont l’origine
française était incertaine (ex : manufacture, monocoque, palpitant, peau-de-soie),
conformément à nos critères de départ. Parfois, des citations plus anciennes étaient
disponibles, et nous avons pu ajuster les dates d’emprunt, voire supprimer un mot qui ne
correspondait plus au critère de date parce qu’antérieur au 16ème siècle (ex : page, noel, pavé,
phalange, planchette).
Enfin, nous avons ajouté certaines entrées, notamment des emprunts du 20ème siècle,
qui sont évidemment peu nombreux dans l’OED 2 (ex : maître à penser, mal du siècle,
maquisard, menu gastronomique, nouveau romancier, pain au chocolat). Notons que
certains d’entre eux sont des mots que nous avions remarqués dans les dictionnaires de
prononciation et dont nous nous demandions s’ils étaient trop récents pour figurer dans l’OED
(ex : crème fraîche)122.
B. ADAPTATION OU ADOPTION ?
Lors de la phase de sélection du corpus, nous avons décidé de ne garder que les
adoptions, c’est-à-dire les mots empruntés tels quels, sans changements graphiques
notamment. Nous avons également décidé de ne garder que les mots dont l’orthographe est
identique en français et en anglais. Nous avons alors été amenée à conserver des adjectifs dont
la forme en anglais correspond à une forme féminine en français, comme abusive, adhesive,
attentive, Benedictine, consanguine, corrective ou curative.
Après réflexion, nous pensons qu’il s’agit là d’une erreur. Si nous regardons
attentivement l’étymologie de ces mots dans l’OED, nous voyons que le mot d’origine est
bien l’adjectif, mais au masculin ou au féminin, comme dans ces exemples :
122 Cf. p. 83

222 Correction du corpus
Figure 29. Exemples d’étymologie de mots en <-ive> ou <-ine>.
Cependant, nous pensons qu’il ne s’agit pas ici de l’adoption de la forme féminine de
l’adjectif, mais plutôt d’une adaptation de l’adjectif au masculin auquel on ajouterait le suffixe
anglais de formation des adjectifs <–ive> ou <–ine>. Le fait que ce suffixe corresponde à la
forme féminine en français est donc d’une certaine manière un hasard.
En travaillant cas par cas, nous mettons au jour des situations plus complexes, comme
celle d’azurine. Sous cette entrée nous trouvons un adjectif et un nom. Mais l’étymologie
montre clairement qu’il y a adaptation :
Figure 30. Étymologie d’azurine.
L’adjectif, qui décrit une couleur bleu pâle, est l’emprunt initial. On trouve ensuite
deux sens pour le nom. Le premier correspond au ‘Blue Roach’, un poisson à la couleur
bleutée, et le second est une teinture de couleur noire bleutée. Or, en français, cette teinture est
appelée azurine. En revanche, nous n’avons pas trouvé de poisson appelé azurin ou azurine
dans nos dictionnaires.
Nous pouvons ainsi reconstituer l’histoire d’azurine : emprunt de l’adjectif azurin en
1600, avec adaptation en azurine, puis dérivation de l’adjectif en nom en 1832 pour désigner
un animal, la relation sémantique entre le nom et l’adjectif étant la couleur bleue, enfin
adoption du nom azurine en 1878 (les premières attestations en français datent de 1870),
abusive : a. Fr. abusif, -ive
adhesive : a. Fr. adhésif, -ive
attentive : a. Fr. attentif, -ive
consanguine : a. Fr. consanguin, -ine
a. F. azurin

Adaptation ou adoption ? 223
correspondant à une forme déjà existante en anglais. Toutefois, on peut également considérer
qu’il s’agit simplement d’un emprunt de sens.
Un autre cas complexe est celui de Benedictine. On trouve sous cette entrée un
adjectif et un nom. L’étymologie, ici aussi, suggère qu’il y a eu adaptation :
Figure 31. Étymologie de Benedictine.
Le nom est l’emprunt initial, avec le sens ‘one of the order of monks founded by St.
Benedict’. L’adjectif vient ensuite, avec le sens ‘belonging to this religious order’. Ce sens
existe en français, mais il est possible que la dérivation se soit faite au sein de la langue
anglaise, sans emprunt de sens au français.
Il existe également un autre sens au nom Benedictine : ‘a kind of liqueur’. Or en
français, ce sens correspond au nom Bénédictine. Il s’agit donc certainement d’un deuxième
emprunt ; cette fois une adoption du nom. Mais dans ce cas-ci, la différence étymologique est
reflétée par la prononciation. En effet, les dictionnaires EPD et LPD différencient les variantes
selon le sens du mot. La variante correspondant à la liqueur est /«bEnI:dIkti˘n/, alors que les
variantes correspondant aux moines sont /«bEnI:dIktIn/ ou /«bEnI:dIktaIn/. Nous remarquons
alors que l’emprunt tardif — la liqueur date de 1882, alors que le premier emprunt date de
1602 — est caractérisé par une prononciation du suffixe moins anglicisée et plus proche de la
prononciation française.
Ces exemples illustrent une nouvelle fois la complexité du travail des emprunts
puisqu’on se trouve très souvent en présence d’emprunts, puis de ré-emprunts — parfois de la
nouvelle forme française, parfois d’un mot qui a une forme déjà existante en anglais — ou
a. F. bénédictin

224 Correction du corpus
bien d’emprunts de sens. Il faut alors étudier attentivement l’histoire de chaque mot afin
d’identifier les différents événements qui se sont produits.
La décision prise à l’issue de ces observations est de ne pas conserver les adaptations,
conformément à la décision de départ lors de la sélection du corpus. Nous supprimons donc
du corpus des mots comme adhesive ou abusive, qui n’auraient jamais dû en faire partie.
Néanmoins, nous conservons les mots adoptés comme azurine ‘teinture noire bleutée’ ou
Benedictine ‘liqueur’ qui nous semblent correspondre aux critères de sélection.
C. LES AJOUTS AU CORPUS
Au cours de notre travail, nous avons rencontré des mots qui auraient dû faire partie du
corpus, mais qui en avaient été exclus pour différentes raisons que nous allons expliquer.
Nous avons décidé de rajouter ces quelques mots.
Plombière est noté comme formé sur le français Plombières-les-Bains, le nom d’un
village des Vosges, et désigne un dessert fait de crème glacée et de fruits. Nous ne l’avions
pas inclus au corpus en premier lieu, car nous ne gardons pas les formations. Mais il s’agit
d’une erreur du dictionnaire, car c’est en français que le mot a été formé à partir du nom du
village, et non en anglais (TLFi, ‘Plombières’)123. Par conséquent, plombière est très
certainement une adoption du nom français, c’est pourquoi nous avons décidé de l’inclure au
corpus.
L’OED propose à l’entrée serviette une citation remontant au 15ème siècle. Notre
critère étant de n’inclure que des emprunts postérieurs à 1500, nous ne l’avons pas
sélectionné. Mais un commentaire indique que les citations les plus anciennes du mot
correspondent exclusivement à un usage en écossais, et que le mot a été réintroduit au 19ème 123 On pourra remarquer la présence d’un <s> final en français, absent en anglais. Ce <s> vient du nom de la
commune. Néanmoins, le Robert précise qu’on trouve parfois la graphie <plombière>.

Les ajouts au corpus 225
siècle avec la forme orthographique française. Notre étude se focalisant sur l’anglais
britannique, nous ne devons alors pas tenir compte des premières citations, mais uniquement
de celles des 19ème et 20ème siècles. C’est pourquoi nous ajoutons ce mot au corpus.
Machine est un exemple connu d’emprunt français qui a gardé des caractéristiques
étrangères comme l’accent en finale ou la prononciation [i˘n] du suffixe <-ine>, et qui est
totalement intégré à la langue en ce sens que les locuteurs anglophones ne le considèrent pas
comme un mot français. Pour s’en convaincre, il suffit de lire cette remarque d’Alan Bliss
dans l’introduction de son Dictionary of Foreign Words and Phrases in Current English124 :
« the strict application of this criterion would class the word machine as ‘foreign’, a
conclusion repugnant to common sense » (Bliss, 10). Pourtant, il ne fait pas partie de notre
sélection initiale. La raison est simplement que l’OED le note comme adaptation du français.
Or il s’agit bien d’une adoption. Nous corrigeons cette erreur et l’incluons au corpus.
Grenadine, qui désigne un sirop de grenade, est un cas semblable à celui de machine.
L’OED indique qu’il s’agit d’une adaptation du français « (sirop de) grenadine », c’est
pourquoi il ne fait pas partie du corpus. Mais il s’agit ici encore d’une adoption, raison pour
laquelle nous l’ajoutons.
Suzerain est un cas semblable aux deux précédents. Il ne fait pas partie de la sélection
initiale, mais suzeraine y est, ce qui attire notre attention. Si suzerain a été exclu, ce n’est pas
en raison de sa date d’emprunt (1807), mais parce que l’étymologie le note ici aussi comme
‘adaptation’. Néanmoins il s’agit d’une adoption et nous l’ajoutons au corpus.
Manœuvre ne fait pas partie de la sélection initiale car dans l’OED 2, la première
citation date de 1479, ce qui l’exclut de notre corpus. Mais dans l’OED 3, on trouve deux
entrées pour manœuvre : une première avec la citation de 1479 et qui est classée comme
124 Op. cit. p. 21

226 Correction du corpus
obsolète et rare, et une deuxième dont la première citation date de 1759. Cette entrée
correspond en tous points à nos critères, c’est pourquoi nous décidons de l’inclure.
Enfin, l’étymologie étant absente de l’entrée de dans l’OED, il était impossible de
trouver dans la sélection initiale les expressions formées avec cette préposition et présentées
dans l’article du dictionnaire. Nous avons donc ajouté : de haut en bas, de nouveau, de
rigueur et de trop.
D. LES SUPPRESSIONS DU CORPUS
Nous avons décidé de supprimer certains emprunts pour différentes raisons que nous
allons décrire ici.
1. Fatiguable / fatigable
L’un de nos critères de sélection était une orthographe identique en anglais et en
français. Pour cela, nous avons regardé les différentes variantes orthographiques d’un mot et
si l’une de ces variantes correspondait au français, le mot était accepté dans le corpus.
Nous avons donc sélectionné fatiguable, qui a une variante fatigable, correspondant à
l’orthographe française. L’OED ne propose pas de transcription de ce mot, mais note l’accent
dans l’entrée. Ce qui surprend, c’est que fatiguable porte l’accent sur l’antépénultième, tandis
que fatigable porte l’accent sur la première syllabe. Nous trouvons dans l’ODP la variante
/f´:ti˘g´bl/ sous l’orthographe <fatiguable>. L’accentuation concorde avec celle donnée dans
l’OED.
Nous avons donc une transcription pour une orthographe qui ne correspond pas au
français, et une orthographe identique au français mais sans transcription. Fatiguable apparaît

Les suppressions du corpus 227
alors comme une adaptation, et semble même être traité comme dérivé de fatigue /f´:ti˘g/
puisqu’il garde le <u> après le <g> et surtout que l’accent est placé sur la même syllabe.
Pour cette raison, nous ne considérons pas qu’il s’agisse ici d’une adoption, et nous
préférons supprimer cette entrée du corpus.
2. Forte
Forte (n.) vient, d’après l’étymologie de l’OED, de fort, adjectif employé comme
substantif en français. Il semble donc qu’il s’agisse d’une adaptation. Mais le dictionnaire
indique ensuite « As in many other adoptions of Fr. adjs. used as ns., the fem. form has been
ignorantly substituted for the masc.; cf. locale, morale (of an army), etc. ». Doit-on alors le
considérer comme une adaptation ou comme une adoption de la forme féminine ?
Notre décision est de le considérer comme adaptation, car le nom français est bien
masculin ; la forme féminine n’existe que pour l’adjectif. Or cet emprunt, avec les sens de
« point fort d’une personne » ou « partie la plus résistante d’une lame » en escrime, n’a rien à
voir avec l’adjectif fort, forte. Il ne s’agit donc pas de l’emprunt de la forme féminine, mais
bien d’une adaptation, d’ailleurs assez surprenante, car l’utilisation de cette forme nécessite
une bonne connaissance de la langue française. En effet, il faut savoir que fort est la
substantivation de l’adjectif, et que la forme féminine de cet adjectif est forte.
Locale (n.) résulte peut-être du même phénomène, comme suggéré par le commentaire
de l’OED. Néanmoins, le dictionnaire ne détaille pas l’étymologie de ce mot. Il est juste noté
que locale est formé à partir de local (n.). Cependant, il s’agit très probablement d’une
adaptation. Selon le dictionnaire, le mot a été orthographié avec <-e> final pour représenter la
place de l’accent sur la dernière syllabe (/l´U:kA˘l/), à défaut de quoi le mot aurait été
confondu avec local /:l´Uk´l/. Locale est donc soit la forme féminine de l’adjectif, comme

228 Correction du corpus
suggéré par l’OED dans l’entrée forte, soit — hypothèse vers laquelle nous penchons — une
adaptation graphique ayant pour but une certaine représentation de la prononciation, et qui n’a
finalement aucun lien avec le féminin de l’adjectif.
Morale, quant à lui, ne résulte pas du même phénomène125. En effet, le mot est adopté
du mot français morale avec le sens de « principe moral, moralité » en 1752. Par la suite, on
trouve effectivement le sens « condition morale, disposition de l’esprit », qui correspond au
mot moral en français. Mais nous pensons que c’est parce que la forme morale existait déjà
que seul le sens de moral a été emprunté, et pas sa forme. Néanmoins, il existait également en
anglais une forme moral, adjectif et substantif. Alors pourquoi ne pas avoir simplement ajouté
le sens « condition morale, disposition de l’esprit » à cette forme identique ? Peut-être pour
indiquer l’origine française de ce sens.
Une fois encore, nous observons la complexité des emprunts et la difficulté à expliquer
leurs formes ou leurs prononciations. Quant à forte, puisque nous le considérons comme
adaptation, nous allons le supprimer du corpus. Notons qu’il n’est, en plus, pas traité
phonologiquement comme un mot français, mais plutôt comme un mot italien, avec des
variantes comme /:fç˘tEI/ ou /:fç˘tI/.
3. Frigidaire
Dans l’OED, l’étymologie de Frigidaire est « quasi-French », ce qui nous intrigue.
S’agit-il réellement d’un emprunt ? La définition nous indique qu’il s’agit du nom d’une
marque de réfrigérateur, ce qui explique la majuscule en début de mot. Ce dictionnaire
n’offrant pas plus de précisions, nous cherchons l’étymologie du mot dans le TLFi, qui nous
apprend qu’il s’agit d’une marque américaine. La marque a sans doute voulu créer un nom à
125 Cf. morale, p. 205.

Les suppressions du corpus 229
la consonance française, ce qui se ressent dans la prononciation /«frIdZI:dE´/, notamment en
raison de l’accent primaire en finale. Néanmoins, il ne s’agit pas d’un emprunt français, c’est
pourquoi nous le supprimons du corpus.
4. Negligée
L’étymologie de negligée indique qu’il vient du français négligé. Il s’agirait donc
d’une adaptation. Cette conclusion est renforcée par la note suivante : « rhyming evidence
suggests that in the 18th c. the final vowel was apparently [i˘] ».
Effectivement, les premières citations présentent la forme orthographique <negligee>.
Il est donc possible que l’accent graphique ait été rajouté ultérieurement, peut-être pour
maintenir une prononciation [EI]. On remarque en effet une graphie <neglejay> au 17ème
siècle, ce qui correspond très certainement à cette prononciation.
On peut alors postuler que cet emprunt s’est fait par le biais de l’oral, avec une
prononciation finale [EI], mais qu’il a été orthographié <negligee> soit par erreur, soit pour
angliciser le mot. Cette graphie <ee> a sans doute poussé certains locuteurs à prononcer la
terminaison [i˘]. C’est peut-être la raison pour laquelle on trouve l’accent graphique noté dans
la plupart des citations du 20ème siècle, sans doute pour rappeler l’origine française du mot.
Nous relevons également une citation de Bliss qui est à rapprocher du cas de
négligée : « So important is this final –é, in fact, that it is sometimes reinforced by an
additional, unetymological, e, as in rechauffée, soufflée for rechauffé, soufflé » (Bliss, 48).
Quoi qu’il en soit, puisqu’il s’agit d’un cas d’adaptation, nous ne pouvons conserver
cet emprunt dans notre corpus.

230 Correction du corpus
5. Saponin, saponine
L’entrée de l’OED propose deux variantes orthographiques. Le mot français d’origine
est <saponine>. Cependant, dans les dictionnaires de prononciation LPD et ODP, on ne trouve
que la forme <saponin>, ce qui laisse penser qu’il y a eu adaptation.
Parmi les citations de l’OED, on trouve effectivement les deux variantes
orthographiques, mais la dernière citation avec la forme <saponine> remonte à 1884. A priori,
la variante /:sQp´naIn/ proposée par l’OED correspond à cette forme orthographique, alors
que la seconde variante, /:sQp´nIn/, correspond sans doute plutôt à la forme <saponin>,
puisque c’est également la prononciation qu’on trouve dans les dictionnaires LPD et ODP
sous l’entrée <saponin>.
Il semble ainsi que la forme <saponine> n’est plus présente en anglais depuis la fin du
19ème siècle. Elle devrait donc être considérée comme obsolète, de même que la prononciation
/:sQp´naIn/. Par conséquent, saponin est considéré une adaptation du mot français
saponine, et il convient de le supprimer du corpus.
E. LES FAIBLESSES DE L’OED
Comme nous l’avons déjà fait remarquer à plusieurs reprises, l’OED est imparfait sur
certains points. Il nous arrive alors parfois d’éprouver des difficultés face à certaines entrées.
Nous avons vu précédemment, dans le cas des adaptations présentées comme des adoptions,
qu’il était parfois nécessaire d’observer très attentivement l’entrée du dictionnaire, son
étymologie, ses définitions et ses citations, et que dans certains cas, il aurait semblé utile de
proposer plusieurs entrées, afin de rendre compte des différents emprunts.
Nous allons ici décrire quelques cas qui ont particulièrement attiré notre attention et
ont engendré certaines modifications de notre part.

Les faiblesses de l’OED 231
1. Lyonnais / Lyonnaise
L’entrée de l’OED est « Lyonnais, n. and a. ». Mais sous l’onglet ‘Spellings’, on
découvre :
Figure 32. Détail de l’entrée Lyonnais.
Mais nous ne pouvons considérer comme équivalente l’orthographe <Lyon(n)ese>
puisqu’il s’agit d’une adaptation. En effet, le suffixe <-ais> du français est changé en son
équivalent anglais <-ese>. La prononciation /li˘´:ni˘z/ est conforme à cette orthographe.
Si l’on observe les citations, on s’aperçoit que l’orthographe <Lyonnais> est
minoritaire et n’apparaît pas avant le 20ème siècle. C’est la forme <Lyon(n)ese> (ou
éventuellement <Lyonnoise>, <Lionnoise>) qui est utilisée avant cette période.
Nous pouvons alors retranscrire une partie de l’histoire du mot : il y a eu un premier
emprunt, peut-être une adoption dans un premier temps, puisque la première citation présente
la forme <Lionnoise> ; puis une adaptation en <Lyon(n)ese> avec changement de
prononciation ; enfin au 20ème siècle a lieu un nouvel emprunt de la forme française, avec un
changement de prononciation en /li˘´:nEI/ afin de s’accorder avec la nouvelle orthographe
<Lyonnais>. Cependant, l’orthographe précédente n’est visiblement pas totalement
abandonnée, puisqu’on la trouve dans quelques citations de cette période.
Mais ce n’est pas le seul problème posé par cette entrée. En effet, le masculin et le
féminin sont mêlés dans les citations, comme dans les définitions. Par exemple, sous le sens
culinaire de « cuisiné ou servi avec des oignons », on trouve dans les citations la forme
Also Lyon(n)ese /li˘´:ni˘z/ ; (fem.) Lionnoise, Lyonnaise, Lyonoise

232 Correction du corpus
<Lyonnaise>, et cela dès la première citation, qui date de 1846. La forme féminine est donc
antérieure au masculin <Lyonnais>.
Il paraît alors nécessaire de présenter le masculin et le féminin dans deux entrées
différentes. Nous décidons donc d’observer chaque définition et chaque citation afin
d’analyser s’il s’agit du masculin ou du féminin.
La première définition est celle du nom et désigne d’une part les habitants de la région
de Lyon, et d’autre part le dialecte de cette région. Les premières citations présentent les
formes <Lionnoise> et <Lyonnoise>, qui sont des formes féminines d’après la note de
l’onglet ‘Spellings’. Nous trouvons ensuite des citations avec la forme <Lyon(n)ese>, qui ne
nous permet pas d’identifier s’il s’agit du féminin ou du masculin. Il est probable qu’elle ait
servi aux deux. Une citation désigne le dialecte <Lyonnais>, puis nous trouvons les formes
<Lyonnais> et <Lyonnaise> pour désigner les habitants. Nous pouvons donc noter le sens de
« habitants de la région de Lyon » sous les deux entrées, mais réserver le sens de « dialecte de
la région » à la forme <Lyonnais>.
La deuxième définition compte également deux sens, qu’il convient de séparer. Il
s’agit de l’adjectif, signifiant « relatif aux habitants de Lyon » d’une part, et désignant un type
de reliure d’autre part. Les citations relatives au type de reliure ne présentent que la forme
<Lyon(n)ese>. Les citations relatives aux habitants de Lyon présentent les formes
<Lyon(n)ese> ou <Lyonnais>. Il semble que la forme féminine <Lyonnaise> ne soit pas
employée dans ce sens.
Enfin la dernière définition est le terme culinaire que nous avons déjà mentionné.
Nous trouvons une fois la forme <Lyon(n)ese> et partout ailleurs <Lyonnaise>.
Nous pouvons donc mettre sous l’entrée <Lyonnais> le nom ainsi que l’adjectif
signifiant « relatif aux habitants de Lyon », et sous l’entrée <Lyonnaise> le nom désignant les
habitants de la région, et l’adjectif avec le sens culinaire. Mais où ranger la définition relative

Les faiblesses de l’OED 233
au type de reliure, puisque la forme <Lyon(n)ese> ne permet pas de déterminer s’il s’agit du
masculin ou du féminin ? De plus, faut-il inclure la variante /li˘´:ni˘z/ à la base de données, si
la variante orthographique <Lyon(n)ese> n’est plus employée ?
Afin de répondre à ces questions, nous cherchons les différentes variantes
orthographiques à l’aide du moteur de recherche Google126. Le nombre de pages résultant
devrait nous donner une indication de l’emploi des variantes :
Figure 33. Nombre de résultats dans Google selon l’orthographe.
Nous voyons à ces résultats que les variantes orthographiques <Lyonnais> et
<Lyonnaise> sont bien les plus courantes, même si on trouve encore la forme <Lyon(n)ese>.
Notons que pour la variante <Lyonnais>, on trouve essentiellement des pages sur la région
lyonnaise, l’équipe de football Olympique Lyonnais, et la banque Crédit Lyonnais. En
revanche, pour la variante <Lyonnaise>, nous trouvons essentiellement des pages relatives à
la cuisine, notamment ‘Lyonnaise potatoes’, mais aussi ‘Lyonnaise sauce’ ou ‘salad
Lyonnaise’. Le sens culinaire semble donc bien le plus courant.
Afin de trouver de l’aide pour les définitions correspondant à ces variantes masculine
et féminine, nous les cherchons dans d’autres dictionnaires127. Le Longman Dictionary of
Contemporary English (LDOCE) ne les recense pas, mais nous les trouvons dans le Merriam-
126 Recherche du 18 janv. 2008. www.google.com
127 Recherche du 18 janv. 2008.
<Lyonese> 4 000 pages
<Lyonnese> 2 750 pages
<Lyonnais> 708 000 pages
<Lyonnaise> 243 000 pages

234 Correction du corpus
Webster. La définition de <Lyonnaise> est « prepared with onions », et celle de <Lyonnais>
« former province SE central France », ce qui ne correspond pas à nos définitions ; il s’agit
plutôt du nom propre dans ce cas. Le Free Dictionary et l’American Heritage Dictionary
proposent les mêmes définitions128.
Mais cette recherche ne nous permet pas de classer la définition relative à la reliure
avec le féminin ou le masculin. Nous cherchons alors dans Google <Lyonese
bookbinding>129. Nous trouvons 159 pages, et la suggestion suivante « did you mean
Lyonnaise bookbinding ? ». En cherchant avec cette orthographe, nous trouvons
effectivement 917 pages, ce qui est nettement plus important. Nous décidons donc de ranger
cette définition sous l’entrée <Lyonnaise>.
En ce qui concerne la prononciation /li˘´:ni˘z/, même s’il est possible qu’elle ait
encore une existence, nous préférons ne pas l’inclure à la base de données car elle ne
correspond pas à une orthographe française.
Nous voyons ici que l’OED a sans doute fait une erreur en présentant Lyonnais et
Lyonnaise dans le même article, sans même faire apparaître la forme féminine dans l’entrée.
D’ailleurs, les dictionnaires de prononciation différencient ces deux mots. En effet, on ne
trouve Lyonnais que dans l’ODP, alors que Lyonnaise se trouve dans tous les dictionnaires.
Nous présentons donc deux entrées dans la base de données, ainsi que dans le lexique.
2. Apache
Nous avons relevé ce mot, mais il convient d’observer attentivement l’OED pour cette
entrée. En effet, le dictionnaire propose deux sens : le sens 1 désigne une tribu indienne du
128 Références des dictionnaires p. 210
129 Recherche du 18 janv. 2008. www.google.com

Les faiblesses de l’OED 235
sud des États-Unis, et le sens 2 un voyou parisien. L’OED ajoute que ce deuxième sens peut
être écrit avec une minuscule, et qu’il est originaire du français.
Une transcription est proposée pour le sens 2 : /´:pQS/, alors que la transcription
principale pour l’entrée est /´:pQtSi˘/. Mais l’étymologie donnée dans l’entrée est qu’Apache
est un emprunt à l’espagnol du Mexique.
Il convient donc de séparer les deux sens, et de les traiter comme des entrées
distinctes, car il s’agit de deux emprunts différents. Le premier ne nous concerne pas puisqu’il
s’agit d’un emprunt à l’espagnol. Seul le deuxième nous intéresse.
De même, en recherchant les transcriptions dans les dictionnaires de prononciation, il
convient de faire la différence. L’EPD et l’ODP, par exemple, proposent la prononciation
/´:pQtSI/, qui est très proche de celle proposée par l’OED pour le sens 1. De plus, nous
remarquons que le mot est écrit avec une majuscule. Nous en déduisons qu’il s’agit du sens 1
et préférons ne pas l’inclure à la base de données.
En revanche le LPD, s’il propose également la variante /´:pQtSI/ pour Apache, ajoute
« for the obsolete sense ‘ruffian’, the pronunciation was /´:pQS/ », ce qui correspond à la
transcription de l’OED pour le sens 2. Nous relevons donc uniquement cette transcription.
Une fois de plus, l’OED aurait gagné en clarté à présenter ce mot en deux entrées
distinctes, ce qui sera peut-être le cas dans la nouvelle édition.
3. Pompon
L’OED 2 propose l’entrée pompon, pom-pom, c’est pourquoi cet emprunt fait partie
de notre corpus. Cependant, l’OED 3 ne propose comme entrée que pompom, <pompon>
étant noté comme une graphie du 19ème siècle. Dans ce cas, il faudrait considérer ce mot

236 Correction du corpus
comme une adaptation et le supprimer de notre sélection. Néanmoins, nous remarquons que
pompon est présent dans tous les dictionnaires de prononciation, de même que pompom.
L’OED propose trois sens : (1) la touffe de laine qu’on attache à un vêtement pour le
décorer, (2) l’objet agité par les ‘cheerleaders’ ou ‘pom-pom girls’ (en français), et (3) la
variété de dahlia ou chrysanthème. D’après Wikipedia130, pom-pon ou pompon fait référence
à l’objet utilisé par les cheerleaders, tandis que pom-pom ou pompom fait référence à la
décoration en laine. De fait, lorsqu’on recherche l’orthographe <pompon> dans Google, on
trouve essentiellement des pages liées au cheerleading, tandis qu’en cherchant <pompom>, on
trouve des pages sur le pompon décoratif. Pourtant, le Free Dictionary attribue l’orthographe
<pompon> à l’objet de décoration, et <pompom> à celui des cheerleaders. Quant au Merriam-
Webster, il attribue l’orthographe <pom-pom> à l’objet décoratif ainsi qu’à celui utilisé par
les cheerleaders, et réserve l’orthographe <pompon> pour la fleur131.
En ce qui concerne la fleur, il semble bien que ce soit l’orthographe <pompon> qui lui
corresponde. Néanmoins, lorsqu’on recherche sur Google les deux orthographes associées au
mot ‘flower’, on se rend compte que l’orthographe <pompon> renvoie plutôt au dahlia-
pompon, tandis que l’orthographe <pompom> désigne des plantes dont la fleur ressemble à un
pompon, ce qui confirme que cette orthographe est associée à l’objet décoratif132.
Il apparaît ainsi que les dictionnaires se trompent sur l’usage de ces orthographes, ce
qui est assez surprenant. Il est également curieux que le français utilise le terme ‘pom-pom
girl’, alors que nous avons vu que l’usage de cette forme dans ce contexte est marginal. Ce
mot étant absent des dictionnaires français, nous n’en savons pas plus sur son étymologie.
130 ‘Pom-pon’. Wikipedia, the Free Encyclopedia. Wikimedia Foundation. 13 avr. 2008.
http://en.wikipedia.org/wiki/Pompon.
131 Recherche du 13 avr. 2008.
132 Recherche du 13 avr. 2008.

Les faiblesses de l’OED 237
Notre recherche nous permet par ailleurs d’affirmer que l’orthographe <pompon>
n’est pas obsolète, contrairement à ce que note l’OED, c’est pourquoi nous préférons
maintenir l’entrée pompon, pompom. Nous ajoutons exceptionnellement les variantes
associées à <pompom>, même s’il s’agit d’une adaptation, en raison de la particularité de
cette entrée.
4. Variante orthographique ou autre entrée ?
L’OED propose très souvent une ou plusieurs variantes orthographiques dans le titre
de l’entrée (‘headword’). Nous avons décidé, lors de la sélection du corpus, de noter les
différentes variantes orthographiques d’un mot, et de les inclure au corpus, dès lors que l’une
des variantes orthographiques était identique au français. Nous avons alors relevé les
transcriptions dans les dictionnaires en cherchant l’une ou l’autre des variantes
orthographiques, considérant qu’elles étaient équivalentes. Mais nous nous apercevons à
présent que l’orthographe peut avoir une incidence sur la prononciation. Il convient donc
d’analyser chaque cas de ce type.
a) Liana, liane
Pour liana, liane, l’OED propose les prononciations /lI:A˘n´/ ou /lI:A˘n/. Dans l’EPD,
on ne trouve que l’entrée liana, avec les transcriptions /lI:A˘n´/ ou /lI:Qn´/ ; dans le LPD, on
trouve liana avec les mêmes transcriptions, et liane prononcé /lI:A˘n/ ou /lI:Qn/. Enfin, dans
l’ODP, on trouve liana /lI:A˘n´/ et liane /lI:A˘n/ /lI:Qn/. Il semble donc que la prononciation
diffère selon l’orthographe du mot. En réalité, le problème vient de la présentation de l’OED
puisqu’en lisant l’étymologie, on réalise qu’il s’agit de deux mots différents. Liane est bien un

238 Correction du corpus
emprunt au français, tandis que liana a été dérivé de liane, soit pour latiniser le mot, soit
parce que le mot était pris comme étant d’origine espagnole. Même si liana et liane ont une
même origine, ce ne sont pas les deux variantes orthographiques d’un même mot. Par
conséquent, nous préférons ne conserver dans le corpus que liane, qui est le véritable emprunt
français. Nous supprimons donc liana et les variantes associées à ce mot.
b) Jargon, jargoon
Nous avons déjà mentionné l’entrée jargon, jargoon dans le paragraphe sur
caisson133. L’OED propose deux transcriptions, /:dZA˘g´n/ et /dZA˘:gu˘n/, mais dans les
dictionnaires EPD et LPD nous ne trouvons que jargon avec la prononciation /:dZA˘g´n/,
tandis que dans l’ODP, nous trouvons jargon prononcé /:dZA˘g´n/ et jargoon prononcé
/dZA˘:gu˘n/. Cette orthographe et cette prononciation sont donc très certainement liées, et la
variante jargoon devrait être supprimée du corpus. Toutefois, nous avons vu dans le
paragraphe sur caisson que les mots en <-on> avaient eu tendance à se prononcer [-u˘n], et
que c’était sans doute pour faire concorder orthographe et prononciation que la variante
orthographique <jargoon> avait été créée. Il n’est donc pas tout à fait impossible que l’OED
ait proposé la variante /dZA˘:gu˘n/ comme pouvant correspondre à l’orthographe <jargon>.
Pour cette raison, nous préférons conserver cette variante dans la base de données.
133 Cf. p. 207

Les faiblesses de l’OED 239
c) Longe, lunge
Longe, lunge est un cas un peu surprenant. Selon l’OED, la variante orthographique
principale est <lunge>, mais la variante correspondant à l’orthographe française est
évidemment <longe>. La transcription proposée par l’OED est /:l√ndZ/, ce qui paraît
surprenant pour une graphie <longe>. Nous sommes alors tentée de penser que cette graphie
n’est plus en cours, et que le mot n’a pas sa place dans le corpus. Cependant, d’une part on
remarque l’orthographe <longe> dans la plupart des citations, et d’autre part on trouve longe
dans le dictionnaire ODP avec les transcriptions /:l√ndZ/ et /:lÅndZ/, tandis que sous lunge, on
ne trouve que /:l√ndZ/. Il semble ainsi que longe puisse bel et bien être prononcé /:l√ndZ/.
Sur Internet, nous trouvons de nombreuses occurrences de longe avec le sens de
‘corde utilisée pour l’entraînement des chevaux’, ce qui correspond à notre entrée. En
revanche, lunge est plutôt associé à un exercice de musculation ; il s’agit visiblement d’un
autre mot134. Effectivement, dans l’OED, nous trouvons plusieurs entrées lunge. C’est peut-
être parce que longe ressemble à lunge que ce dernier est devenu une variante de longe, et
que la prononciation /:l√ndZ/ a été associée à la graphie <longe>. Il semble bien que ces
variantes orthographiques soient liées, c’est pourquoi nous les maintenons dans la base de
données.
d) Caracol, caracole
L’OED propose deux transcriptions pour caracol, caracole, n. : /:kQr´kÅl/ et
/:kQr´k´Ul/. Il semble que la première variante soit associée à l’orthographe <caracol>
134 Recherche du 17 janv. 2008. www.google.com.

240 Correction du corpus
puisqu’elle est prononcée [Ål], et que la seconde variante soit associée à l’orthographe
<caracole> puisque la règle de tension V tendue / — Ce# est appliquée. Dans l’EPD, le
LPD et l’ODP, on trouve caracole avec la terminaison [´Ul], ce qui confirme notre hypothèse.
Cependant, les deux variantes orthographiques sont possibles en français, ce qui nous oblige à
conserver ces deux graphies et les prononciations associées, sans toutefois faire de distinction
dans la base de données.
e) Corselet, corslet
Pour l’OED, corselet est la variante orthographique de corslet, mais seule la
prononciation /:kç˘slIt/ est présentée. Cependant, pour le sous-vêtement de femme, il propose
la variante corselette. Dans l’EPD et l’ODP, on trouve les orthographes <corslet> et
<corselet> avec pour transcriptions /:kç˘slIt/ ou /:kç˘sl´t/. Dans le LPD, on ne trouve que
l’orthographe <corselet>, avec les mêmes transcriptions, mais avec la note suivante : « but for
the undergarment, properly Corselette tdmk, /«kç˘s´:lEt/ ». On en conclut que cette variante
est liée à l’orthographe. Néanmoins, on peut noter que <corselette> est également présent
dans l’ODP mais avec les transcriptions /:kç˘slIt/ ou /:kç˘sl´t/.
En cherchant sur Internet, nous trouvons les variantes orthographiques <corslet> et
<corselet>, mais la première est plutôt utilisée dans le sens de pièce d’armure, tandis que la
deuxième est utilisée dans le sens de sous-vêtement féminin (la ‘gaine’), ou en zoologie.
Cependant, pour la gaine, on ne trouve pas autant d’occurrences de <corselette> que le
laissaient penser l’OED ou le LPD. On trouve plus souvent la forme <corselet>. On peut alors
envisager que la forme <corselette> soit apparue parce que l’accent était resté en finale dans
la variante /«kç˘s´:lEt/. A moins que cette variante /«kç˘s´:lEt/ ne soit apparue suite à une

Les faiblesses de l’OED 241
graphie <corselette>. Nous pouvons ajouter que le LPD mentionne Corselette comme une
marque, mais que nous trouvons plutôt un nom commun sur Internet135.
En conclusion, nous considérons que ces orthographes sont équivalentes : nous notons
les trois graphies et les trois prononciations.
f) Gelatin, gelatine
Gelatin, gelatine présente deux transcriptions dans l’OED : /:dZEl´tIn/ et /:dZEl´ti˘n/.
La première transcription semble être associée à <gelatin> tandis que la deuxième serait plutôt
associée à <gelatine>. Ces deux variantes orthographiques sont-elles équivalentes ?
Dans l’étymologie, on trouve la note suivante : « in popular use, the spelling is
commonly gelatine, and the pronunciation is often /dZEl´ti˘n/; in chemical use consistency
demands the form gelatin ». Notre hypothèse semble donc exacte. Dans les dictionnaires de
prononciation, on trouve les deux orthographes. Dans les trois dictionnaires, gelatin est
prononcé /:dZEl´tIn/, et gelatine est /:dZEl´ti˘n/, mais selon l’EPD gelatine peut aussi être
/:dZEl´tIn/. On ne peut donc pas séparer ces deux graphies puisqu’une des transcriptions est
identique pour les deux.
Par conséquent, nous considérons qu’il s’agit d’un même mot avec deux variantes
orthographiques. La graphie <gelatin> est plus anglicisée et est toujours associée à une
prononciation anglicisée. La variante orthographique <gelatine>, en revanche, a parfois une
prononciation anglicisée, mais le plus souvent non. Il s’agit tout de même d’un cas assez
particulier, puisque, d’après l’OED, ces deux graphies ne sont pas utilisées dans le même
135 Recherche du 12 sept. 2007. www.google.com.

242 Correction du corpus
contexte. Nous préférons alors conserver les deux variantes orthographiques dans notre
corpus.
g) Pavane, pavan
Dans l’OED, pavane, qui désigne une danse, n’a pas d’autre variante orthographique,
mais on trouve trois prononciations : /p´:vQn/, /p´:vA˘n/ et /:pQvn/. En revanche, les trois
dictionnaires de prononciation proposent la variante orthographique <pavan>. Cette graphie
est plus anglicisée, et la variante /:pQvn/, également anglicisée, semble lui correspondre,
tandis que les autres variantes, qui ne sont pas anglicisées, semblent correspondre à la graphie
<pavane>. Il est surprenant que l’OED ne propose pas la variante orthographique <pavan>,
qui est notée comme une graphie du 19ème siècle, mais que la variante anglicisée /:pQvn/ soit
tout de même présente. On peut supposer que c’est la prononciation /:pQvn/ qui a été à
l’origine de la graphie plus anglicisée, ce qui explique pourquoi aujourd’hui cette
prononciation est aussi associée à la graphie <pavane>. Nous gardons donc les deux graphies
dans la base de données puisqu’elles sont équivalentes.
h) Telecabine, telecabin
L’OED propose l’entrée telecabine avec la prononciation /«tElIkQ:bi˘n/, mais il
propose également une variante orthographique anglicisée telecabin associée à la
prononciation /:tElI«kQbIn/. Seule la première variante correspond au français, c’est pourquoi
nous envisageons de ne conserver que cette graphie et cette prononciation.
Cette décision est renforcée par le fait que toutes les citations de l’OED ne présentent
que la forme <telecabine>. En outre, une recherche de ces deux graphies dans Google révèle

Les faiblesses de l’OED 243
une présence beaucoup plus importante de <telecabine> — 26 000 pages contre 6 290 pour
<telecabin>136.
Nous maintenons alors la décision de n’inclure que la variante telecabine dans la base
de données.
136 Recherche du 2 mai 2008.


IX. LES SUPPRESSIONS : CONCLUSION
Table des matières
A. Base de Données Finale.................................................................................................... 245
B. Validation des critères de sélection .................................................................................. 246
C. Les emprunts anglicisés.................................................................................................... 246
A. BASE DE DONNEES FINALE
Une fois toutes les variantes anglicisées supprimées, nous obtenons la Base de
Données Finale comptant 5320 variantes pour 2065 emprunts. Cette base de données ne
comprend que des variantes considérées comme non-anglicisées d’après au moins un critère.
C’est cette base qui va nous servir à la recherche de règles phonologiques des emprunts
français en anglais.
A titre comparatif, nous allons conserver une seconde base de données présentant les
emprunts qui ont à la fois des variantes anglicisées et des variantes non-anglicisées. En effet,
il peut être intéressant de savoir qu’un emprunt compte aussi une ou plusieurs variantes

246 Les suppressions : conclusion
anglicisées, et de tenter de comprendre pourquoi. Cela permettra également de mettre en
évidence l’anglicisation progressive des emprunts, car certains mots présentent à la fois des
variantes anglicisées et des variantes très proches du français. De cette base de données
comparative seront exclus les emprunts pour lesquels toutes les variantes sont anglicisées.
B. VALIDATION DES CRITERES DE SELECTION
Pour vérifier la pertinence de nos critères de sélection, il nous faut savoir s’ils ont
effectivement permis de relever une majorité d’emprunts non-anglicisés. Pour ce faire, nous
comparons le nombre d’emprunts de la BD Initiale avec le nombre d’emprunts de la BD
Finale. Les emprunts absents de cette dernière sont donc des ‘emprunts anglicisés’, pour
lesquels toutes les variantes, ou la seule variante connue, sont anglicisées.
La BD Initiale, corrections et ajouts de l’OED 3 inclus, compte 3177 emprunts, contre
2065 dans la BD Finale. Nous avons donc supprimé 1110 emprunts, ce qui représente 35% du
corpus.
Nous en concluons que ces critères sont pertinents, puisque nous conservons les 2/3 du
corpus initial, mais ils restent sans doute perfectibles. Néanmoins nous sommes convaincue
que si le critère orthographique n’avait pas été pris en compte, le corpus aurait compté un
nombre bien plus grand d’emprunts anglicisés.
C. LES EMPRUNTS ANGLICISES
Les emprunts qui ont été supprimés à cette étape présentent donc uniquement des
variantes anglicisées. Mais qu’ont-ils en commun ? Et qu’est-ce qui les différencie des
emprunts non-anglicisés ? Peut-on expliquer pourquoi ces emprunts français ne gardent
aucune trace de leur origine ?

Les emprunts anglicisés 247
La grande majorité des variantes anglicisées sont celles de mots en <-ion>, <-ant>,
<-ance>, <-ent>, <-ence>, <-ible>, <-able>, <-al>, <-ment> ; c’est-à-dire des mots se
terminant par un suffixe extrêmement courant en anglais, et souvent d’origine latine ou
formés à partir d’éléments latins (ex : annihilation, clarification, incarceration, antecedent,
cerebral, coherence, petulance, sediment, etc.). Ces suffixes sont tellement connus des
locuteurs anglophones que les emprunts sont quasi-systématiquement anglicisés ; les
exceptions sont rares dans notre base de données, notamment pour <-ion> : demi-pension
/«dEmI:pÅ)sjÅ)/, en pension /«Å)pÅ):sjÅ)/, et œuvre de vulgarisation /:Œ˘vr´d´«v√lg´rIzQ:sjÅ)/ ;
<-ence> faience /faI:A)˘ns/ ; <-ent> malcontent /:mQlk´n«tEnt/, ou encore <-able>
formidable /«fç˘mI:dA˘b´l/.
En fait, ces emprunts anglicisés n’ont pas une forme graphique qui permet de déceler
leur origine française, c’est pourquoi ils ne sont pas traités comme tels. Aucun élément de leur
graphie ou de leur sens ne permet de les différencier d’autres mots anglais de même forme.
Ainsi, c’est très probablement la forme du mot qui va provoquer ou non son
anglicisation : moins un mot est identifié comme français et plus il a de chances d’être traité à
l’anglaise. On peut alors envisager qu’à l’inverse, plus il est identifié comme français et moins
il va être anglicisé. Nous pensons à ce propos que non seulement la forme graphique du mot a
de l’importance — comme les mots en <-elle> qui sont quasiment tous accentués en finale, et
jamais réduits — mais aussi son sens. En effet, si l’emprunt fait référence à la France, son
histoire, etc., il est fort probable qu’il sera moins anglicisé (ex : Savoyard, Provençal,
Renaissance, ancien régime, Directoire). Mais ce n’est pas toujours le cas, puisqu’on trouve
l’exemple de ministrable, terme qui d’après l’OED 3 est plutôt réservé à un contexte français
(« une personne qui est susceptible de devenir ministre du gouvernement ») et qui est
prononcé /:mInIstr´bl/. Ici la forme est plus ‘forte’ que le sens.

248 Les suppressions : conclusion
De plus, l’anglicisation passe sans doute par plusieurs chemins. Certains mots sont
probablement anglicisés dès l’emprunt, comme ceux que nous avons mentionnés
précédemment, et d’autres anglicisés progressivement. Nous observons en effet pour certains
emprunts des variantes qui semblent illustrer les différentes étapes de l’anglicisation. C’est un
sujet sur lequel nous reviendrons dans la dernière partie. On peut alors se poser les questions
suivantes : qu’est-ce qui provoque l’anglicisation progressive de ces emprunts ? La fréquence
d’emploi, l’ancienneté ? Et pourquoi d’autres emprunts semblent résister à l’anglicisation ?
En étudiant dans la partie suivante ces variantes non-anglicisées et en tentant de mettre
en évidence certaines règles de la phonologie des emprunts français, nous essaierons
également d’apporter des réponses à ces questions, afin de comprendre les mécanismes de
l’emprunt et de l’adaptation phonique.

3ème partie :
Les emprunts non-anglicisés


X. ANALYSE DES EMPRUNTS NON-ANGLICISES
Table des matières
A. Comparaison des systèmes ............................................................................................... 254
1. Le système phonologique du français ......................................................................... 254
2. Le système phonologique de l’anglais ........................................................................ 255
3. Points communs et différences.................................................................................... 257
B. Adaptation des phonèmes du français .............................................................................. 259
1. Mise en évidence de l’adaptation par les correspondances irrégulières...................... 259
2. Oral et écrit dans le cadre des emprunts français ........................................................ 259
3. Les voyelles................................................................................................................. 261
a) [i˘].......................................................................................................................... 261
b) [I´] ........................................................................................................................ 262
c) [wi˘]....................................................................................................................... 263
d) [A˘] ........................................................................................................................ 265
e) [wA˘] ..................................................................................................................... 270
f) [aI] ......................................................................................................................... 276
g) [Q] ........................................................................................................................ 279
h) [EI]......................................................................................................................... 287
i) [E´]......................................................................................................................... 287
j) [E]........................................................................................................................... 290
k) [u˘] ........................................................................................................................ 295
l) [U´] ........................................................................................................................ 299
m) [Œ˘] ....................................................................................................................... 302
n) [´U] ....................................................................................................................... 308
o) [Å].......................................................................................................................... 311

252 Analyse des emprunts non-anglicisés
4. Les consonnes.............................................................................................................. 312
a) [Z] .......................................................................................................................... 312
b) [S]........................................................................................................................... 314
c) [nj]......................................................................................................................... 315
5. Le cas particulier de la graphie <ll>............................................................................ 316
C. Adaptation des voyelles nasales ....................................................................................... 327
1. Les voyelles du système anglais.................................................................................. 328
a) [Å] .......................................................................................................................... 328
b) [A˘] ........................................................................................................................ 333
c) [Q]......................................................................................................................... 336
d) [ç˘] ........................................................................................................................ 338
e) [Œ˘]......................................................................................................................... 339
2. Les voyelles nasales anglaises..................................................................................... 339
a) [Å)] .......................................................................................................................... 340
b) [A)˘] ........................................................................................................................ 343
c) [ç)˘]......................................................................................................................... 345
d) [Q)] ........................................................................................................................ 347
e) [Œ)˘]......................................................................................................................... 348
3. Conclusion................................................................................................................... 349

Les emprunts anglicisés 253
Quelle est la particularité des emprunts français non-anglicisés ? En quoi sont-ils
différents des emprunts anglicisés, hormis le fait qu’ils ne suivent pas les règles de l’anglais ?
Lorsqu’on écoute la prononciation des emprunts français non-anglicisés, on note que dans la
plupart des cas elle ressemble à celle du mot d’origine, sans toutefois être identique. En effet,
il semble probable que les locuteurs tentent d’imiter la prononciation originale, et que c’est la
raison pour laquelle ces emprunts ne suivent pas les règles anglaises habituelles.
Nous avons vu que l’adaptation phonique est quasiment inévitable lors de l’emprunt
d’un mot137, cela en raison des différences entre les systèmes phonologiques des deux langues
concernées. De toute évidence, l’imitation est facilitée lorsque les deux systèmes ont des
phonèmes en commun ; c’est le phénomène d’importation décrit par Haugen138. En revanche,
si un phonème de la langue de départ est absent de la langue d’arrivée, il va falloir trouver le
moyen de ‘rendre’ ce phonème ; c’est le phénomène de substitution.
C’est pourquoi nous allons tout d’abord observer les systèmes français et anglais, et
regarder quels sont leurs points communs et leurs différences afin de comprendre où se situent
les difficultés des anglophones lors de l’emprunt de mots français. Nous montrerons ensuite
comment les phonèmes français sont adaptés en anglais.
137 Cf. p. 20
138 Op. cit. p. 13
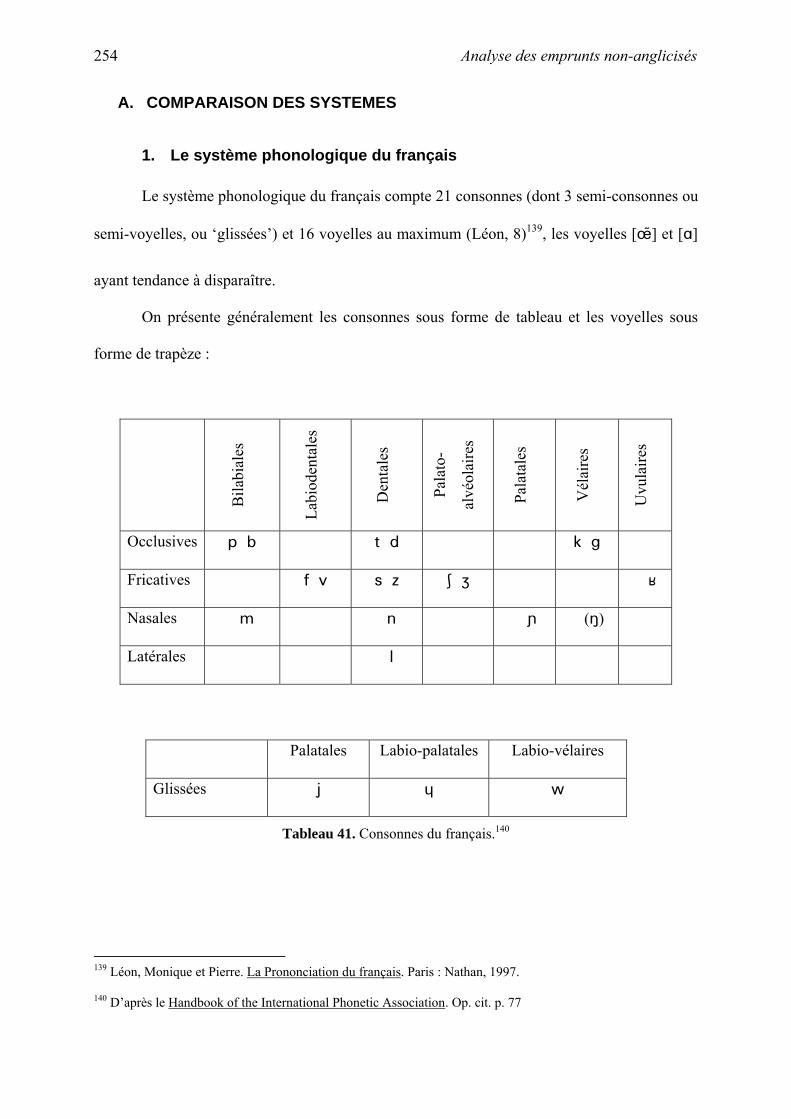
254 Analyse des emprunts non-anglicisés
A. COMPARAISON DES SYSTEMES
1. Le système phonologique du français
Le système phonologique du français compte 21 consonnes (dont 3 semi-consonnes ou
semi-voyelles, ou ‘glissées’) et 16 voyelles au maximum (Léon, 8)139, les voyelles [ø)] et [A]
ayant tendance à disparaître.
On présente généralement les consonnes sous forme de tableau et les voyelles sous
forme de trapèze :
Palatales Labio-palatales Labio-vélaires
Glissées j Á w
Tableau 41. Consonnes du français.140
139 Léon, Monique et Pierre. La Prononciation du français. Paris : Nathan, 1997.
140 D’après le Handbook of the International Phonetic Association. Op. cit. p. 77
Bila
bial
es
Labi
oden
tale
s
Den
tale
s
Pala
to-
alvé
olai
res
Pala
tale
s
Vél
aire
s
Uvu
laire
s
Occlusives p b t d k g
Fricatives f v s z S Z “
Nasales m n ¯ (N)
Latérales l

Comparaison des systèmes 255
Figure 34. Trapèze des voyelles du français.141
2. Le système phonologique de l’anglais
Le système phonologique de l’anglais compte 24 consonnes et 20 voyelles (dont 8
diphtongues), également présentées sous forme de tableau et de trapèze (Lilly et Viel,
Initiation, xi-xii)142 :
141 « Trapèze vocalique du français. » SFU : Introduction à la Linguistique. Simon Fraser University, Canada. 17
juil. 2008. http://www.sfu.ca/fren270/Phonetique/trapeze.html.
142 Lilly, Richard et Michel Viel. Initiation raisonnée à la phonétique de l’anglais. Paris : Hachette, 1975.
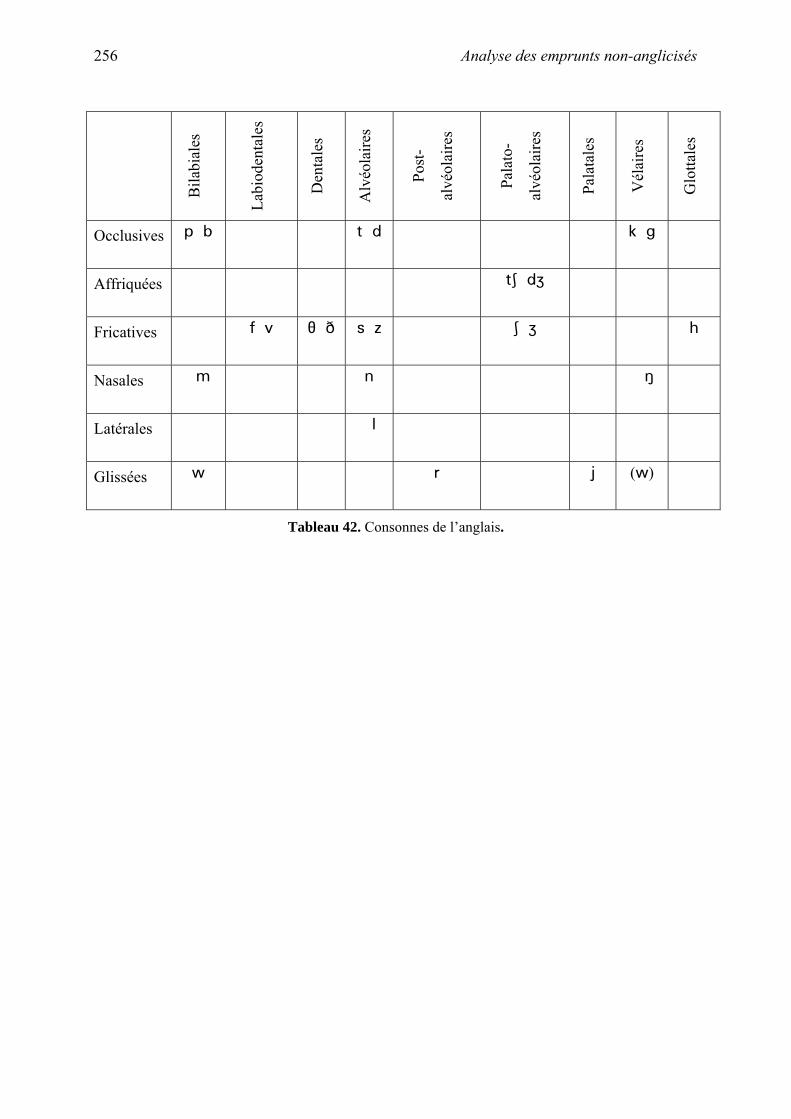
256 Analyse des emprunts non-anglicisés
Bila
bial
es
Labi
oden
tale
s
Den
tale
s
Alv
éola
ires
Post
-
alvé
olai
res
Pala
to-
alvé
olai
res
Pala
tale
s
Vél
aire
s
Glo
ttale
s
Occlusives p b t d k g
Affriquées tS dZ
Fricatives f v T D s z S Z h
Nasales m n N
Latérales l
Glissées w r j (w)
Tableau 42. Consonnes de l’anglais.
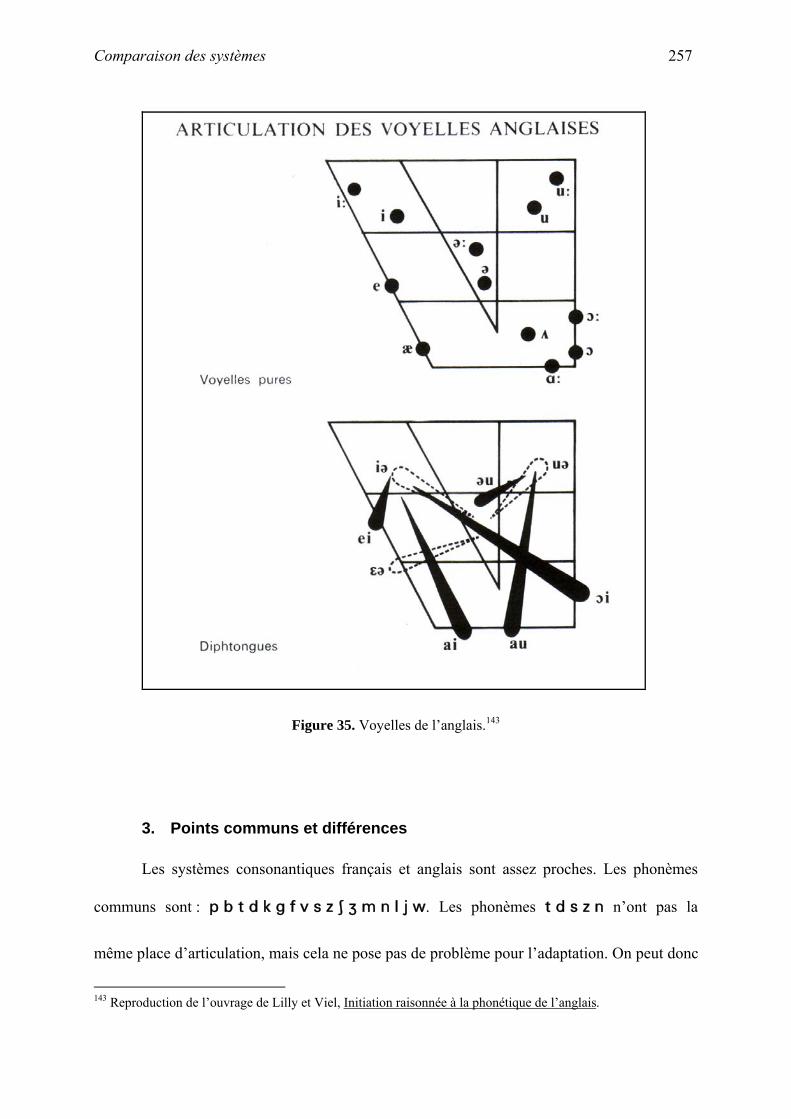
Comparaison des systèmes 257
Figure 35. Voyelles de l’anglais.143
3. Points communs et différences
Les systèmes consonantiques français et anglais sont assez proches. Les phonèmes
communs sont : p b t d k g f v s z S Z m n l j w. Les phonèmes t d s z n n’ont pas la
même place d’articulation, mais cela ne pose pas de problème pour l’adaptation. On peut donc
143 Reproduction de l’ouvrage de Lilly et Viel, Initiation raisonnée à la phonétique de l’anglais.

258 Analyse des emprunts non-anglicisés
considérer qu’ils sont communs aux deux systèmes. Le phonème [N] est présent dans le
système français, mais il est réservé aux mots d’origine anglaise, c’est pourquoi nous n’allons
pas considérer qu’il fait partie du système français habituel.
Les consonnes présentes dans le système français mais absentes du système anglais
sont la glissée labio-palatale [Á] et la nasale palatale [¯]. Toutefois, cette dernière tend à
disparaître et à être remplacée par le cluster [nj] (Walter, 227)144.
Les systèmes vocaliques sont plus complexes, et si certaines voyelles sont assez
proches dans le trapèze, il semble que seule la voyelle centrale [´] soit commune aux deux
systèmes. Rappelons que les points représentent une ‘zone’ dans laquelle se situe la voyelle.
Nous voyons ainsi que les zones du [E] français et du [E] anglais sont très proches, ce qui
justifie notre choix du symbole [E] en anglais, alors que le [e] est plus souvent employé par
les anglicistes145. Ajoutons que, contrairement à l’anglais, l’allongement des voyelles n’est
pas un trait pertinent en français ; il dépend du contexte. Enfin il faut remarquer les quatre
voyelles nasales, qui sont une des particularités du système français.
C’est donc essentiellement au niveau vocalique que les problèmes d’adaptation vont se
poser. Nous allons à présent observer de quelle manière l’anglais va réinterpréter des sons qui
ne font pas partie de son système.
144 Walter, Henriette. Le Français dans tous les sens. Paris : Robert Laffont, 1988.
145 C’est d’ailleurs le cas dans ce trapèze.

Adaptation des phonèmes du français 259
B. ADAPTATION DES PHONEMES DU FRANÇAIS
1. Mise en évidence de l’adaptation par les correspondances
irrégulières
Nous disposons à présent d’une base de données ne comptant que des variantes
considérées comme non-anglicisées puisqu’elles ne suivent pas toutes les règles
phonologiques de l’anglais. Il ne nous reste plus qu’à analyser cette base de données finale
afin de dégager les principales caractéristiques des emprunts français non-anglicisés.
Néanmoins, un nouveau problème apparaît : toutes ces variantes ont été conservées sur la base
d’un critère au minimum, mais ces critères sont très divers. Nous allons donc trouver à la fois
des variantes qui ont une prononciation qu’on pourrait qualifier d’anglicisée, mais dont
l’accentuation est irrégulière, et des variantes qui ont une accentuation régulière, mais une
prononciation non-anglicisée. Il paraît difficile de comparer ces deux types de variantes.
Nous choisissons alors de lister les critères pour lesquels ces variantes ont été
conservées dans cette base de données. Alors que le travail précédent consistait à supprimer
les variantes anglicisées, il s’agit à présent de comprendre pour quelles raisons ces variantes
ont été conservées. Nous avons à plusieurs reprises parlé de variantes ‘irrégulières’,
lorsqu’elles ne suivaient pas une règle phonologique de l’anglais. C’est donc à partir de ces
irrégularités que nous allons mettre en évidence certaines caractéristiques des emprunts
français non-anglicisés.
2. Oral et écrit dans le cadre des emprunts français
Avant toute chose, il nous paraît nécessaire d’aborder à nouveau le rapport entre oral
et écrit dans le cadre des emprunts français. En effet, si un locuteur imite la prononciation du
français au point, par exemple, de ne pas prononcer une consonne graphique finale, c’est

260 Analyse des emprunts non-anglicisés
probablement qu’il a déjà entendu le mot dans son contexte original, ou bien qu’il ne l’a
jamais vu écrit. Inversement, si un locuteur prononce cette consonne finale, c’est qu’il connaît
sa forme graphique, et pas forcément la prononciation originale.
Comment se déroule l’emprunt d’un mot ? Au départ, un contexte bilingue est
obligatoire, comme le rappelle Haugen dans son article « The Analysis of Linguistic
Borrowing »146 (Haugen, 210). Il faut qu’un locuteur de langue B (dans notre cas, l’anglais)
connaisse la langue A (ici, le français) pour pouvoir emprunter un mot avec son sens, sa
graphie et sa prononciation. Il est d’ailleurs fort probable qu’une adaptation ait déjà lieu à ce
stade, comme le suggère Haugen : « a bilingual speaker introduces a new loanword in a
phonetic form as near that of the model language as he can » (Haugen, 216). L’emprunt à
proprement parler se réalise lorsque ce locuteur utilise le nouveau terme dans sa langue natale,
et surtout que d’autres locuteurs utilisent à leur tour ce terme.
La complexité des emprunts français réside dans leur usage oral ou écrit. Si le locuteur
bilingue utilise l’emprunt au cours d’une conversation, et que son interlocuteur emploie à son
tour cet emprunt sans jamais l’avoir vu écrit, il reproduira ce qu’il aura entendu. S’il tente de
l’écrire, il appliquera les correspondances graphie-phonie de l’anglais. C’est ce qui se produit
dans les exemples de mange-tout, orthographié <monge-two>, et aubergines, orthographié
<obo-jeans>, relevés chez un marchand de légumes par John Wells et relatés dans son blog147.
Ce locuteur n’a visiblement pas identifié ces mots comme français ; il applique donc les
correspondances anglaises habituelles148.
146 Op. cit. p. 13
147 Wells, John. « Greengrocers’ spelling. » 6 juin 2008. John Well’s phonetic blog. UCL Division of Psychology
and Language Sciences. 27 juin 2008. http://www.phon.ucl.ac.uk/home/wells/blog0806a.htm.
148 Nous pouvons ajouter que ces graphies nous renseignent sur la prononciation du locuteur, qui prononce
visiblement aubergines /:´Ub´dZi˘nz/ et mange-tout /«mÅndZ:tu˘/.

Adaptation des phonèmes du français 261
De la même manière, si un locuteur rencontre un emprunt français lors d’une lecture et
qu’il tente de le prononcer, s’il n’a pas connaissance de la prononciation originale il se
contentera d’appliquer les correspondances graphie-phonie de l’anglais. C’est ce qui se
produit dans le cas des emprunts anglicisés que nous avons supprimés du corpus initial.
Pour qu’un locuteur anglophone n’ayant pas de connaissances du français prononce ‘à
la française’ un mot rencontré lors d’une lecture, ou qu’il orthographie correctement un
emprunt entendu lors d’une conversation, il faut donc réunir deux éléments : qu’il identifie le
mot comme étant d’origine française, et qu’il connaisse les correspondances graphie-phonie
réservées aux emprunts français.
Une fois encore, nous voyons que la graphie revêt une importance toute particulière
dans le cadre des emprunts français ; il paraît donc difficile de ne pas aborder ce sujet, bien
que notre domaine soit celui de la phonologie, donc de l’oral.
3. Les voyelles
a) [i˘]
La voyelle [i˘] est toujours associée à la graphie <i> :
Emprunt Anglais Français
affiche Q:fi˘S afiS
amandine «A˘m´n:di˘n amA)din
bidet :bi˘dEI bidE
camaraderie «kQm´:rA˘d´ri˘ kama{ad{i
debris :dEIbri˘ deb{i
fichu :fi˘Su˘ fiSy

262 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
maquisard «mQki˘:zA˘ makiza{
migraine :mi˘grEIn mig{En
petite p´:ti˘t p´tit
Tableau 43. Exemples de correspondances <i> = [i˘].
Nous observons que [i˘] correspond toujours au [i] français. Pour adapter [i], l’anglais
a théoriquement deux possibilités : [I] et [i˘], mais le choix de [i˘] peut s’expliquer par le fait
que c’est la voyelle qui est la plus proche de [i] dans le trapèze.
Si [i˘] est suivi d’une consonne finale muette en français (ex : abattis /abati/, Chablis
/Sabli/), la consonne est généralement muette en anglais aussi (/:Qb´ti˘/, /:SQbli˘/). On
remarque d’ailleurs que les terminaisons <i> + C muette sont en général <-is> (ex : louis,
maquis, parti pris, précis, semis, tant pis). Les autres cas sont <-it> (ex : maudit /m´U:di˘/),
<-ix> (ex : œil-de-perdrix /«çId´:pŒ˘dri˘/) ou <-iz> (ex : poudre de riz /«pu˘dr´d´:ri˘/).
b) [I´]
Cette prononciation est à rapprocher de [i˘], puisqu’on la trouve associée à la graphie
<ir> et qu’elle résulte de la transformation de [i˘] devant [r] :
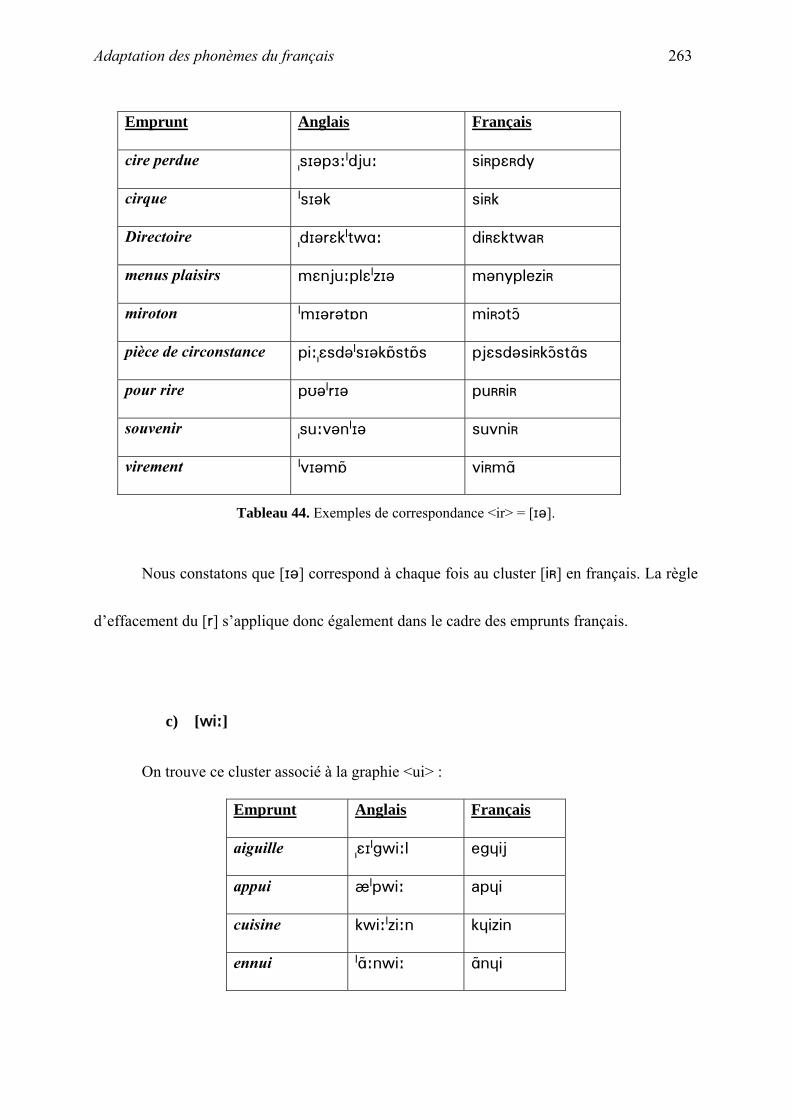
Adaptation des phonèmes du français 263
Emprunt Anglais Français
cire perdue «sI´pŒ˘:dju˘ si{pE{dy
cirque :sI´k si{k
Directoire «dI´rEk:twA˘ di{Ektwa{
menus plaisirs mEnju˘plE:zI´ m´nyplezi{
miroton :mI´r´tÅn mi{çtç)
pièce de circonstance pi˘«Esd´:sI´kÅ)stÅ)s pjEsd´si{kç)stA)s
pour rire pU´:rI´ pu{{i{
souvenir «su˘v´n:I´ suvni{
virement :vI´mÅ) vi{mA)
Tableau 44. Exemples de correspondance <ir> = [I´].
Nous constatons que [I´] correspond à chaque fois au cluster [i{] en français. La règle
d’effacement du [r] s’applique donc également dans le cadre des emprunts français.
c) [wi˘]
On trouve ce cluster associé à la graphie <ui> :
Emprunt Anglais Français
aiguille «EI:gwi˘l egÁij
appui Q:pwi˘ apÁi
cuisine kwi˘:zi˘n kÁizin
ennui :A)˘nwi˘ A)nÁi

264 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
menuisier mE:nwi˘zI´ m´nÁizje
nuit blanche «nwi˘:blÅ)S nÁiblA)S
Petit Suisse «pEtI:swi˘s p´tisÁis
suite :swi˘t sÁit
Tuileries :twi˘l´ri˘ tÁil{i
Tableau 45. Exemples de correspondance <ui> = [wi˘].
Nous observons que le cluster anglais [wi˘] représente le français [Ái]. Le français
possède en effet trois glissées, alors que l’anglais n’en présente que deux. La glissée [Á] est,
tout comme [w], une bilabiale, ce qui explique sans doute le choix de ce phonème anglais
pour adapter celui du français. On peut d’ailleurs remarquer que certains francophones ne
possèdent pas cette glissée, et qu’ils la remplacent par [w]. Par exemple huit /Áit/ sera
prononcé /wit/.
Dans les exemples de ce tableau, c’est donc en fait l’adaptation de [Á] qui est à relever,
puisque le <i> trouve sa correspondance habituelle pour les emprunts français : [i˘]. Si nous
pouvons mettre en évidence l’adaptation de [Á] par la graphie <ui>, c’est que ce phonème
apparaît le plus souvent devant [i] en français. Les seuls autres exemples sont suave prononcé
/:swA˘v/ ou (anciennement) /:swEIv/, et suede prononcé /:swEId/, adaptations du français
/sÁav/ et /sÁEd/.

Adaptation des phonèmes du français 265
d) [A˘]
Nous avons déjà mentionné la présence irrégulière de la voyelle [A˘], liée à la graphie
<a>, dans certaines variantes149. Nous les retrouvons donc dans la Base de Données Finale :
Emprunt Anglais Français
aide-de-camp «EIdd´:kA˘mp Edd´kA)
blasé :blA˘zEI blAze
camaraderie «kQm´:rA˘d´rI kama{ad{i
chapeau-bras «SQp´U:brA˘ Sapob{a
cor anglais «kç˘:rA˘NglEI kç{A)glE
femme fatale «fQmf´:tA˘l famfatal
formidable «fç˘mI:dA˘b´l fç{midabl
Gitane ZI:tA˘n Zitan
madame m´:dA˘m madam
Tableau 46. Exemples de variantes où [A˘] est irrégulier.
Nous observons dans deux cas (aide-de-camp et cor anglais) que la voyelle [A˘]
correspond à la voyelle nasale [A)] en français. Nous reviendrons sur ces cas lors de notre
analyse de l’adaptation des voyelles nasales.
Dans les autres cas, la voyelle [A˘] représente un [a] ou un [A] français. Il nous semble
utile de préciser que, même si le TLFi présente certaines variantes françaises avec [A], ou
propose les deux variantes [a]/[A], la voyelle [A] tend à disparaître en français et ne fait plus
partie du système de bon nombre de locuteurs francophones. D’ailleurs, le système du français
149 Cf. p . 157

266 Analyse des emprunts non-anglicisés
présenté dans le Handbook of the International Phonetic Alphabet150, qui est celui d’une jeune
locutrice parisienne, ne présente pas de [A], mais seulement un [a] plus centralisé que celui de
notre trapèze (Handbook, 78). Il paraît alors peu probable que les locuteurs anglophones
distinguent ces deux voyelles. C’est pourquoi nous préférons parler de l’adaptation de [a]
dans tous les cas, même si le TLFi ne propose qu’une variante avec [A].
D’après le tableau d’exemples, il apparaît que la voyelle [A˘] est employée pour
représenter le [a] français. Nous pensons également que l’emploi de cette voyelle est un
moyen de marquer l’origine française du mot, puisque comme nous allons le voir, elle est très
souvent présente dans des terminaisons où l’on attendrait plutôt une réduction ou une tension
en [EI].
En effet, nous remarquons l’utilisation de la voyelle [A˘] pour la terminaison <-age> :
Emprunt Anglais Français
badinage :bQdInA˘Z badinaZ
barrage :bQrA˘dZ bA{aZ
camouflage :kQm´flA˘Z kamuflaZ
dressage :drEsA˘Z d{EsaZ
lavage lQ:vA˘Z lavaZ
massage :mQsA˘dZ masaZ
maquillage «mQki˘:A˘Z makijaZ
sabotage :sQb´tA˘dZ sabçtaZ
Tableau 47. Exemples de terminaisons <-age> = [A˘Z] ou [A˘dZ].
150 Op. cit. p. 77

Adaptation des phonèmes du français 267
Le suffixe <-age> est prononcé [A˘Z] dans une version plus proche de la prononciation
originale [aZ], ou [A˘dZ] dans une version plus anglicisée avec la correspondance habituelle
<g> = [dZ]. Mais dans ce contexte, on s’attendrait plutôt à une tension en [EI] comme dans le
verbe engage /In:gEIdZ/ ou une réduction du suffixe, comme dans la version anglicisée de
garage /:gQrIdZ/.
On trouve également cette voyelle dans la terminaison <-ade> :
Emprunt Anglais Français
aubade ´U:bA˘d obad
charade S´:rA˘d Sa{ad
croustade kru˘:stA˘d k{ustad
esplanade «Espl´:nA˘d Esplanad
façade f´:sA˘d fasad
noyade nwA˘:jA˘d nwajad
parade p´:rA˘d pa{ad
promenade «prÅm´:nA˘d p{çmnad
roulade ru˘:lA˘d {ulad
Tableau 48. Exemples de terminaisons <-ade> = [A˘d].
La prononciation [A˘d] du suffixe <-ade> représente le cluster [ad] du français. Mais
on pourrait s’attendre à une prononciation [EId] dans ce contexte, comme dans l’autre
variante de charade /S´:rEId/, ou celle d’esplanade /«Espl´:nEId/.
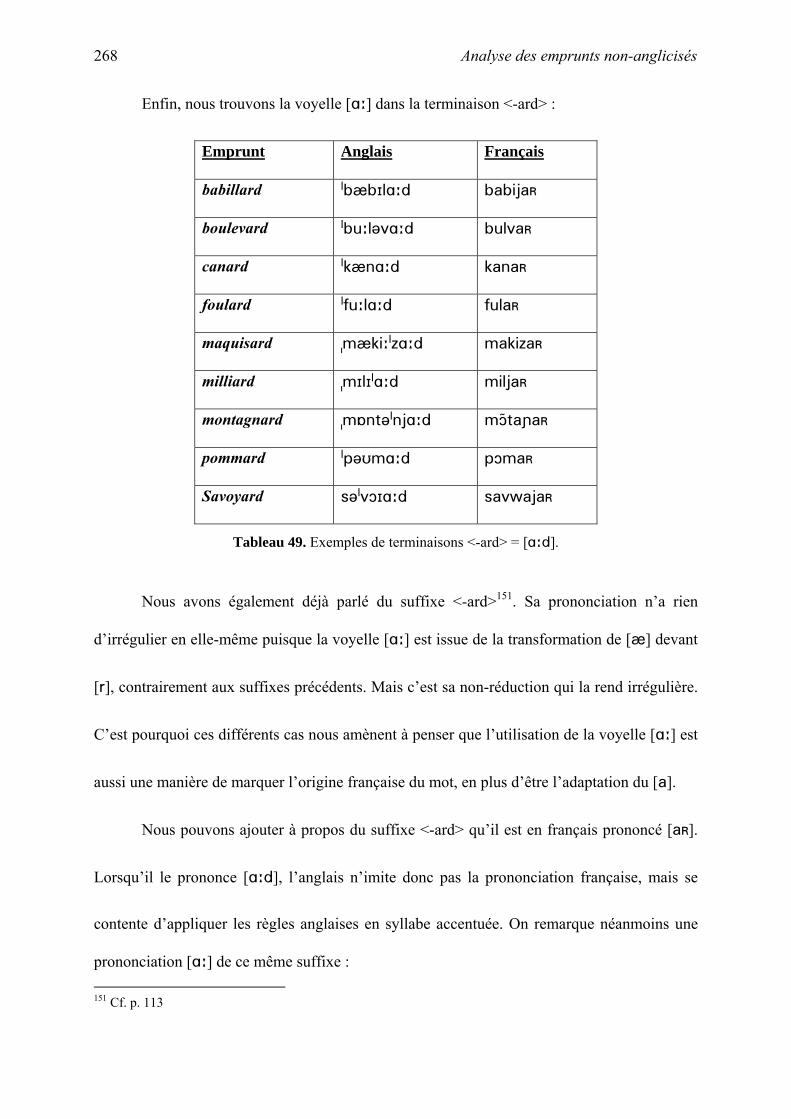
268 Analyse des emprunts non-anglicisés
Enfin, nous trouvons la voyelle [A˘] dans la terminaison <-ard> :
Emprunt Anglais Français
babillard :bQbIlA˘d babija{
boulevard :bu˘l´vA˘d bulva{
canard :kQnA˘d kana{
foulard :fu˘lA˘d fula{
maquisard «mQki˘:zA˘d makiza{
milliard «mIlI:A˘d milja{
montagnard «mÅnt´:njA˘d mç)ta¯a{
pommard :p´UmA˘d pçma{
Savoyard s´:vçIA˘d savwaja{
Tableau 49. Exemples de terminaisons <-ard> = [A˘d].
Nous avons également déjà parlé du suffixe <-ard>151. Sa prononciation n’a rien
d’irrégulier en elle-même puisque la voyelle [A˘] est issue de la transformation de [Q] devant
[r], contrairement aux suffixes précédents. Mais c’est sa non-réduction qui la rend irrégulière.
C’est pourquoi ces différents cas nous amènent à penser que l’utilisation de la voyelle [A˘] est
aussi une manière de marquer l’origine française du mot, en plus d’être l’adaptation du [a].
Nous pouvons ajouter à propos du suffixe <-ard> qu’il est en français prononcé [a{].
Lorsqu’il le prononce [A˘d], l’anglais n’imite donc pas la prononciation française, mais se
contente d’appliquer les règles anglaises en syllabe accentuée. On remarque néanmoins une
prononciation [A˘] de ce même suffixe : 151 Cf. p. 113
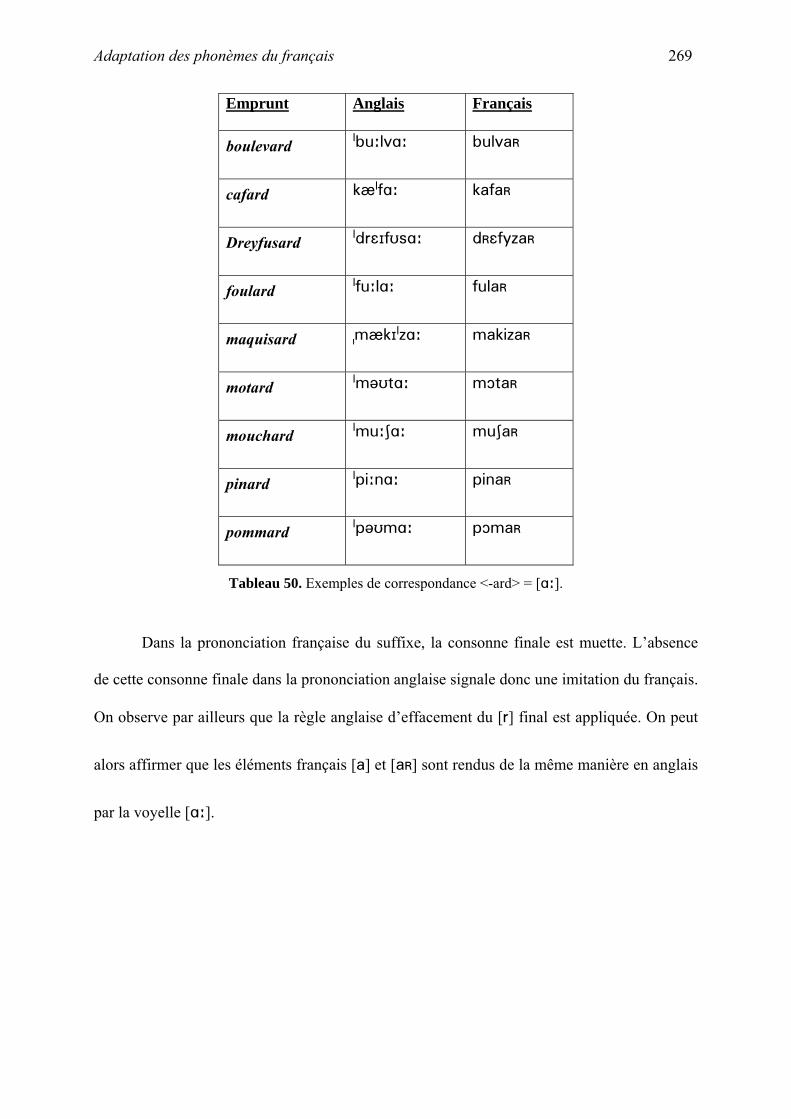
Adaptation des phonèmes du français 269
Emprunt Anglais Français
boulevard :bu˘lvA˘ bulva{
cafard kQ:fA˘ kafa{
Dreyfusard :drEIfUsA˘ d{Efyza{
foulard :fu˘lA˘ fula{
maquisard «mQkI:zA˘ makiza{
motard :m´UtA˘ mçta{
mouchard :mu˘SA˘ muSa{
pinard :pi˘nA˘ pina{
pommard :p´UmA˘ pçma{
Tableau 50. Exemples de correspondance <-ard> = [A˘].
Dans la prononciation française du suffixe, la consonne finale est muette. L’absence
de cette consonne finale dans la prononciation anglaise signale donc une imitation du français.
On observe par ailleurs que la règle anglaise d’effacement du [r] final est appliquée. On peut
alors affirmer que les éléments français [a] et [a{] sont rendus de la même manière en anglais
par la voyelle [A˘].
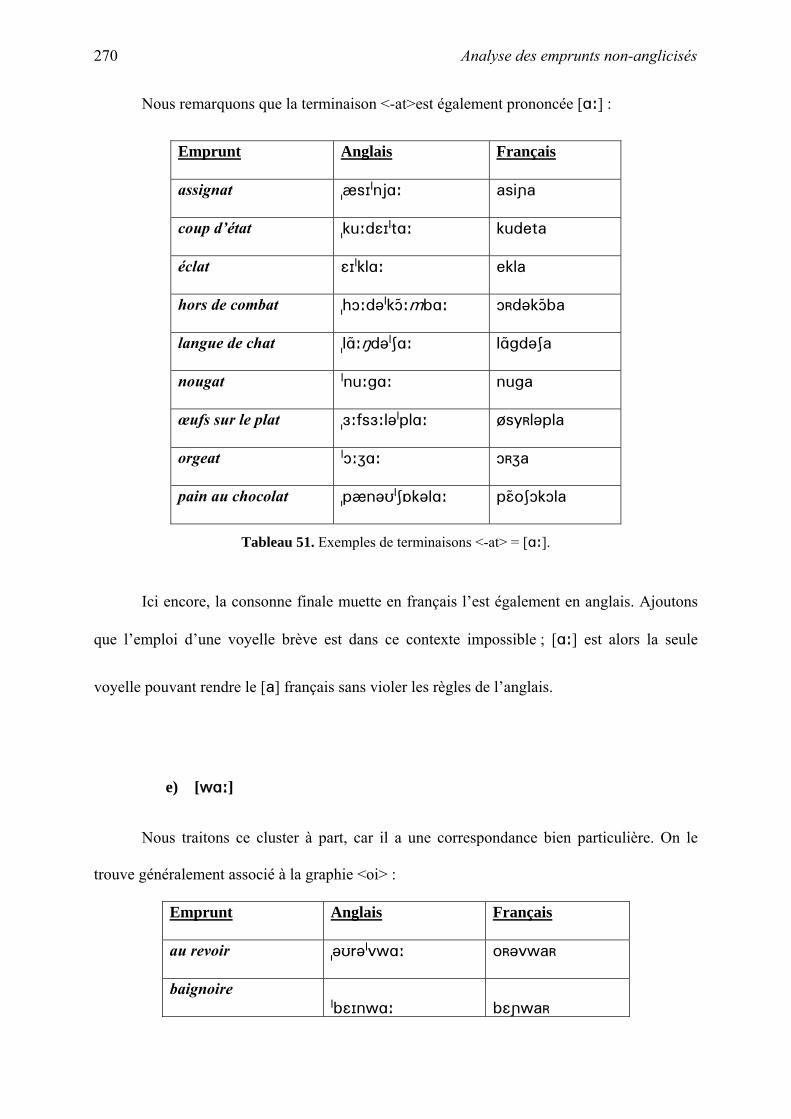
270 Analyse des emprunts non-anglicisés
Nous remarquons que la terminaison <-at>est également prononcée [A˘] :
Emprunt Anglais Français
assignat «QsI:njA˘ asi¯a
coup d’état «ku˘dEI:tA˘ kudeta
éclat EI:klA˘ ekla
hors de combat «hç˘d´:kç)˘mbA˘ ç{d´kç)ba
langue de chat «lA)˘Nd´:SA˘ lA)gd´Sa
nougat :nu˘gA˘ nuga
œufs sur le plat «Œ˘fsŒ˘l´:plA˘ Osy{l´pla
orgeat :ç˘ZA˘ ç{Za
pain au chocolat «pQn´U:SÅk´lA˘ pE)oSçkçla
Tableau 51. Exemples de terminaisons <-at> = [A˘].
Ici encore, la consonne finale muette en français l’est également en anglais. Ajoutons
que l’emploi d’une voyelle brève est dans ce contexte impossible ; [A˘] est alors la seule
voyelle pouvant rendre le [a] français sans violer les règles de l’anglais.
e) [wA˘]
Nous traitons ce cluster à part, car il a une correspondance bien particulière. On le
trouve généralement associé à la graphie <oi> :
Emprunt Anglais Français
au revoir «´Ur´:vwA˘ o{´vwa{
baignoire :bEInwA˘ bE¯wa{

Adaptation des phonèmes du français 271
Emprunt Anglais Français
chamois :SQmwA˘ Samwa
coiffeur kwA˘:fŒ˘ kwafø{
demoiselle «dEmwA˘:zEl d´mwazEl
droit de suite «drwA˘d´:swi˘t drwad´sÁit
macédoine «mQsI:dwA˘n masedwan
Niçoise ni˘:swA˘z niswaz
sang-froid «sA)˘N:frwA˘ sA)f{wA
Tableau 52. Exemples de correspondance <oi> = [wA˘].
Nous observons dans cette sélection que le cluster [wA˘] correspond au français [wa],
mais également à [wa{], associé à la graphie <oir>. En effet, en raison de l’effacement du [r]
final, la prononciation reste la même. On peut d’ailleurs noter que le cluster <oir> se trouve
plutôt en fin de mot (ex : abattoir, boudoir, manoir, peignoir, tamanoir), parfois écrit <oire>
(ex : armoire, conservatoire, Directoire, pourboire). Le seul cas en début de mot est soirée
/:swA˘rEI/, qu’on retrouve également dans l’expression soirée musicale
/:swA˘rEI«mju˘zI:kA˘l/. Ici le [r] est prononcé puisqu’il est l’attaque de la syllabe suivante.
Ici encore, nous remarquons que la consonne finale muette en français reste muette en
anglais, notamment pour les terminaisons en <-ois> comme chamois, bourgeois, Minervois,
Vaudois. On peut ajouter que les mots en <-oise>, pendant féminin du suffixe <-ois>, sont
toujours prononcé [wA˘z] (ex : bavaroise, méthode champenoise, ombres chinoises, petite
bourgeoise, vichyssoise).
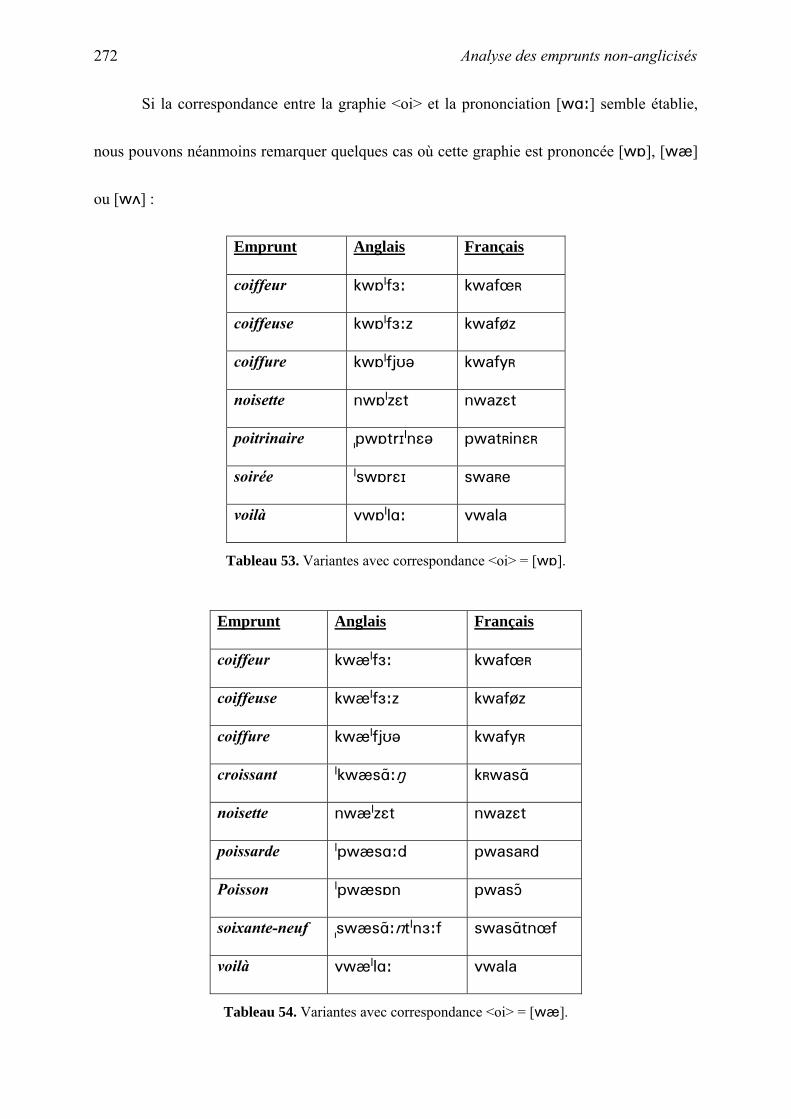
272 Analyse des emprunts non-anglicisés
Si la correspondance entre la graphie <oi> et la prononciation [wA˘] semble établie,
nous pouvons néanmoins remarquer quelques cas où cette graphie est prononcée [wÅ], [wQ]
ou [w√] :
Emprunt Anglais Français
coiffeur kwÅ:fŒ˘ kwafø{
coiffeuse kwÅ:fŒ˘z kwafOz
coiffure kwÅ:fjU´ kwafy{
noisette nwÅ:zEt nwazEt
poitrinaire «pwÅtrI:nE´ pwat{inE{
soirée :swÅrEI swa{e
voilà vwÅ:lA˘ vwala
Tableau 53. Variantes avec correspondance <oi> = [wÅ].
Emprunt Anglais Français
coiffeur kwQ:fŒ˘ kwafø{
coiffeuse kwQ:fŒ˘z kwafOz
coiffure kwQ:fjU´ kwafy{
croissant :kwQsA)˘N k{wasA)
noisette nwQ:zEt nwazEt
poissarde :pwQsA˘d pwasa{d
Poisson :pwQsÅn pwasç)
soixante-neuf «swQsA)˘nt:nŒ˘f swasA)tnøf
voilà vwQ:lA˘ vwala
Tableau 54. Variantes avec correspondance <oi> = [wQ].

Adaptation des phonèmes du français 273
Emprunt Anglais Français
cloisonné klw√:zÅnEI klwazçne
coiffeur kw√:fŒ˘ kwafø{
coiffure kw√:fjU´ kwafy{
croissant :krw√sÅ) k{wasA)
Poisson :pw√sÅn pwasç)
soixante-neuf «sw√sÅnt:nŒ˘f swasA)tnøf
voilà vw√:lA˘ vwala
Tableau 55. Variantes avec correspondance <oi> = [w√].
Nous remarquons tout d’abord que les prononciations [wÅ], [wQ] et [w√]
correspondent également à la prononciation [wa] en français. De plus, plusieurs de ces mots
sont présents dans les trois tableaux ci-dessus, mais ils pourraient également faire partie du
premier tableau puisqu’ils présentent tous une variante avec [wA˘] (sauf soixante-neuf).
Enfin, nous notons que ces prononciations ne se trouvent qu’en début de mot. En finale, on ne
peut donc trouver que la variante [wA˘].
La prononciation [wQ] s’explique car, comme nous allons le voir, [Q] peut également
être une adaptation de [a], bien qu’elle soit moins fréquente. La prononciation [wÅ] est issue
de [wQ], puisqu’il s’agit de la transformation de [Q] après [w], comme dans what /wÅt/,
wash /wÅS/ ou quality /:kwÅl´tI/ (Lilly et Viel, 65). Cette variante issue d’une règle anglaise
peut donc être considérée comme plus anglicisée. Néanmoins elle reste irrégulière par rapport
à la prononciation habituelle du digraphe <oi> [çI]. Enfin la prononciation [w√] est sans
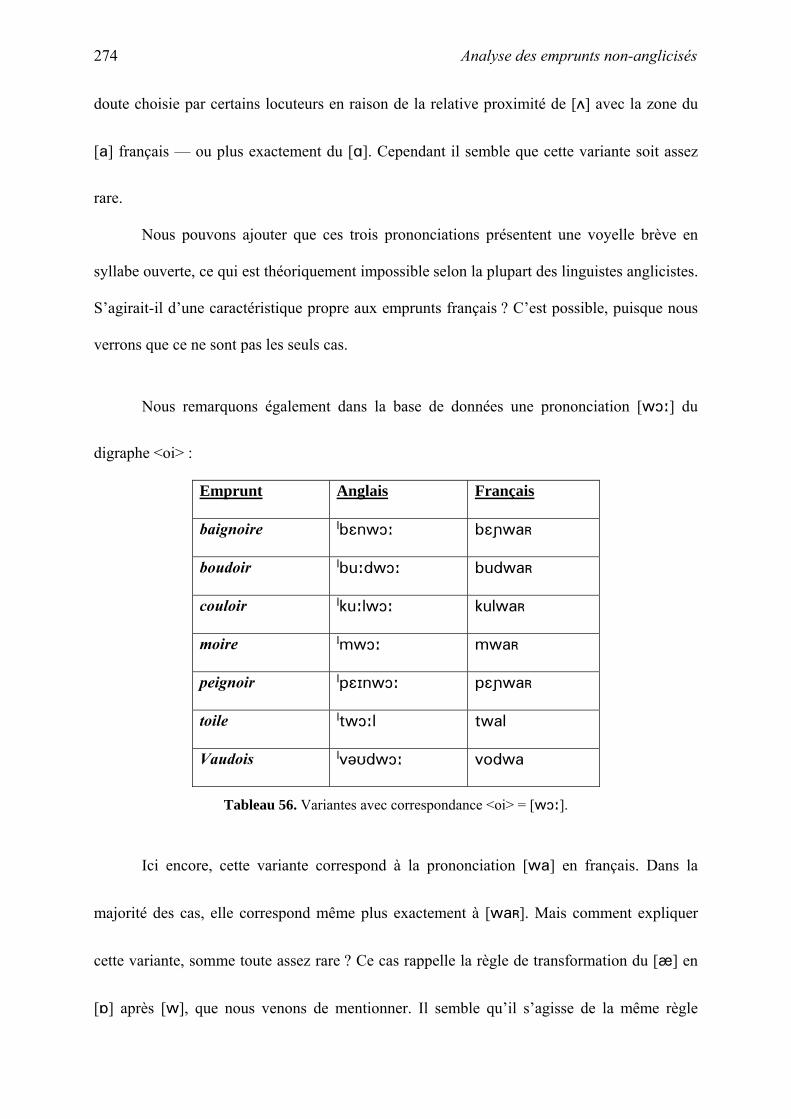
274 Analyse des emprunts non-anglicisés
doute choisie par certains locuteurs en raison de la relative proximité de [√] avec la zone du
[a] français — ou plus exactement du [A]. Cependant il semble que cette variante soit assez
rare.
Nous pouvons ajouter que ces trois prononciations présentent une voyelle brève en
syllabe ouverte, ce qui est théoriquement impossible selon la plupart des linguistes anglicistes.
S’agirait-il d’une caractéristique propre aux emprunts français ? C’est possible, puisque nous
verrons que ce ne sont pas les seuls cas.
Nous remarquons également dans la base de données une prononciation [wç˘] du
digraphe <oi> :
Emprunt Anglais Français
baignoire :bEnwç˘ bE¯wa{
boudoir :bu˘dwç˘ budwa{
couloir :ku˘lwç˘ kulwa{
moire :mwç˘ mwa{
peignoir :pEInwç˘ pE¯wa{
toile :twç˘l twal
Vaudois :v´Udwç˘ vodwa
Tableau 56. Variantes avec correspondance <oi> = [wç˘].
Ici encore, cette variante correspond à la prononciation [wa] en français. Dans la
majorité des cas, elle correspond même plus exactement à [wa{]. Mais comment expliquer
cette variante, somme toute assez rare ? Ce cas rappelle la règle de transformation du [Q] en
[Å] après [w], que nous venons de mentionner. Il semble qu’il s’agisse de la même règle

Adaptation des phonèmes du français 275
appliquée aux voyelles longues correspondantes. Philip Durkin, dans son article « Root and
branch : revising the etymological component of the Oxford English Dictionary »152, cite un
extrait de l’OED qui explique que lorsque memoir est prononcé /:mEmwç˘/, la terminaison
française subit le même traitement que <a> après [w] et devant [r] (Durkin, 38). Il existe donc
bien une règle transformant [A˘] en [ç˘] après [w], et ces variantes peuvent ainsi être
considérées comme plus anglicisées puisqu’elles appliquent une règle anglaise
supplémentaire.
Nous pouvons également mentionner ici la graphie <oy> parfois prononcée [wA˘j],
parfois [waI] :
Emprunt Anglais Français
bon voyage «bç)˘NvwaI:A˘Z bç)vwajaZ
foyer :fwaIEI fwaje
noyade nwA˘:jQd nwajad
noyau «nwA˘:j´U nwajo
voyeur vwA˘:jŒ˘ vwajø{
voyeuse vwA˘:jŒ˘z vwajOz
Tableau 57. Variantes avec correspondance <oy> = [wA˘j] ou [waI].
Dans ces emprunts, nous voyons que c’est le cluster français [waj] qui est représenté.
Les deux variantes proposées sont ainsi les deux possibilités offertes aux anglophones pour
adapter cette prononciation française ; soit une adaptation de chaque phonème : [a] + [j]
152 Op. cit. p. 50

276 Analyse des emprunts non-anglicisés
devient [A˘] + [j], soit l’utilisation de la diphtongue [aI], assez proche oralement du cluster
français. D’ailleurs, ces prononciations sont certainement très proches, hormis l’allongement
de [A˘]. Il ne faut pas oublier que ces symboles sont simplement une représentation de la
prononciation, et que certains anglicistes transcrivent la diphtongue [aI] par [aj]. En réalité, la
différence ne réside que dans la qualité de la voyelle. De plus, nous pouvons ajouter à ce
groupe la transcription de moyen-age /«mwQjE:nA˘Z/, qui utilise cette fois la prononciation
[wQj] pour rendre le français [waj]. Il semble que les éditeurs des dictionnaires essaient
surtout de trouver un moyen de retranscrire ces prononciations qui imitent celle du français.
Enfin, nous pouvons mentionner les deux cas où la graphie <oin> est prononcée
[wA˘n] : cointreau /:kwA˘ntr´U/et petits soins /«pEtI:swA˘n/. Il s’agit ici de la représentation
d’une voyelle nasale puisque ces mots se prononcent /kwE)t{o/ et /p´tiswE)/. Pourtant, il
semble que soit appliquée la correspondance <oi> = [wA˘] suivie de la nasale [n]. Nous
reviendrons sur l’adaptation des voyelles nasales dans la dernière partie de ce chapitre.
f) [aI]
La diphtongue [aI] est liée à la graphie <ai> :
Emprunt Anglais Français
aioli aI:´UlI ajçli
cabiai :kA˘bIaI kabjE
faience faI:A)˘ns fajA)s

Adaptation des phonèmes du français 277
Emprunt Anglais Français
médaillon :mEIdaIjÅ) medajç)
mitrailleuse «mItraI:Œ˘z mit{ajOz
paillette paI:jEt pajEt
quincaillerie kQ)kaIj´:rI kE)kaj{i
rocaille rÅ:kaI {çkaj
tirailleur «tIraI:Œ˘ ti{ajø{
Tableau 58. Exemples de correspondance <ai> = [aI].
Nous constatons que dans tous les cas sauf cabiai, la diphtongue [aI] correspond au
cluster [aj] en français. Nous venons de voir que ces deux clusters étaient oralement assez
proches. Cabiai résulte peut-être simplement de l’application de la correspondance <ai> =
[aI] dans le cadre des emprunts français.
Nous pouvons dégager deux groupes de ce tableau : celui des graphies <aï> en
français, auquel appartiennent aioli et faience puisqu’on trouve les variantes orthographiques
aïoli et faïence, et celui des graphies <aill>, majoritaire. Lorsque cette graphie est en milieu
de mot, certains éditeurs choisissent d’ajouter [j] à la diphtongue [aI] pour retranscrire le
français [aj], comme le montre l’exemple quincaillerie /kQ)kaIj´:rI/ ; d’autres non, comme
nous le voyons dans l’exemple tirailleur /«tIraI:Œ˘/. Ces exemples illustrent une fois encore la
difficulté des éditeurs à retranscrire des prononciations inhabituelles en anglais, dues à
l’imitation du français. Nous aurons d’ailleurs l’occasion de revenir sur le cas des mots en
<aill>.

278 Analyse des emprunts non-anglicisés
Nous pouvons également mentionner quelques cas de graphies <aï> associées à une
prononciation [aI:i˘] :
Emprunt Anglais Français
caïque kaI:i˘k kaik
naïf naI:i˘f naif
naïve naI:i˘v naiv
naïveté naI:i˘v´tEI naivte
Tableau 59. Variantes avec correspondance <aï> = [aI:i˘].
Dans ces variantes, l’anglais [aI:i˘] représente le cluster français [ai], lequel cause
peut-être une difficulté pour l’imitation. Nous observons alors deux correspondances mêlées :
<aï> = [aI] et <i> = [i˘]. Ajoutons que ces emprunts présentent également une variante en
[A˘:i˘]. Ces différentes variantes sont probablement le signe à la fois d’une difficulté des
éditeurs à retranscrire la prononciation des anglophones, mais aussi de la difficulté de ceux-ci
à imiter la prononciation française.
Pour finir, nous pouvons rappeler les deux cas de prononciation [waI] associés à la
graphie <oy> que nous avons mentionnés dans le paragraphe précédent : bon voyage
/«bç)˘NvwaI:A˘Z/ et foyer /:fwaIEI/.

Adaptation des phonèmes du français 279
g) [Q]
L’utilisation de la voyelle [Q] associée à la graphie <a> n’est a priori pas surprenante
puisqu’il s’agit d’une correspondance anglaise régulière. Cependant, nous remarquons un
certain nombre de cas où l’on attendrait une tension, ce qui rend la présence de [Q]
irrégulière :
Emprunt Anglais Français
apache ´:pQS apaS
carafe k´:rQf ka{af
engagé «ÅNgQ:ZEI A)gaZe
glacier :glQsI´ glasje
marron glacé «mQrÅn:glQsEI ma{ç)glase
mer de glace «mE´d´:glQs mE{d´glas
mise en page «mi˘zÅn:pQZ mizA)paZ
moustache m´:stQS mustaS
noyade nwA˘:jQd nwajad
Tableau 60. Exemples de variantes où [Q] est irrégulier.
Nous observons que la voyelle [Q] représente toujours un [a] français. Il s’agit donc
d’une autre voyelle anglaise servant à l’adaptation de [a]. Cependant, il semble que [Q] soit
moins fréquemment utilisé que [A˘]. D’ailleurs, la plupart des emprunts du tableau ci-dessus
présentent également une variante avec [A˘].
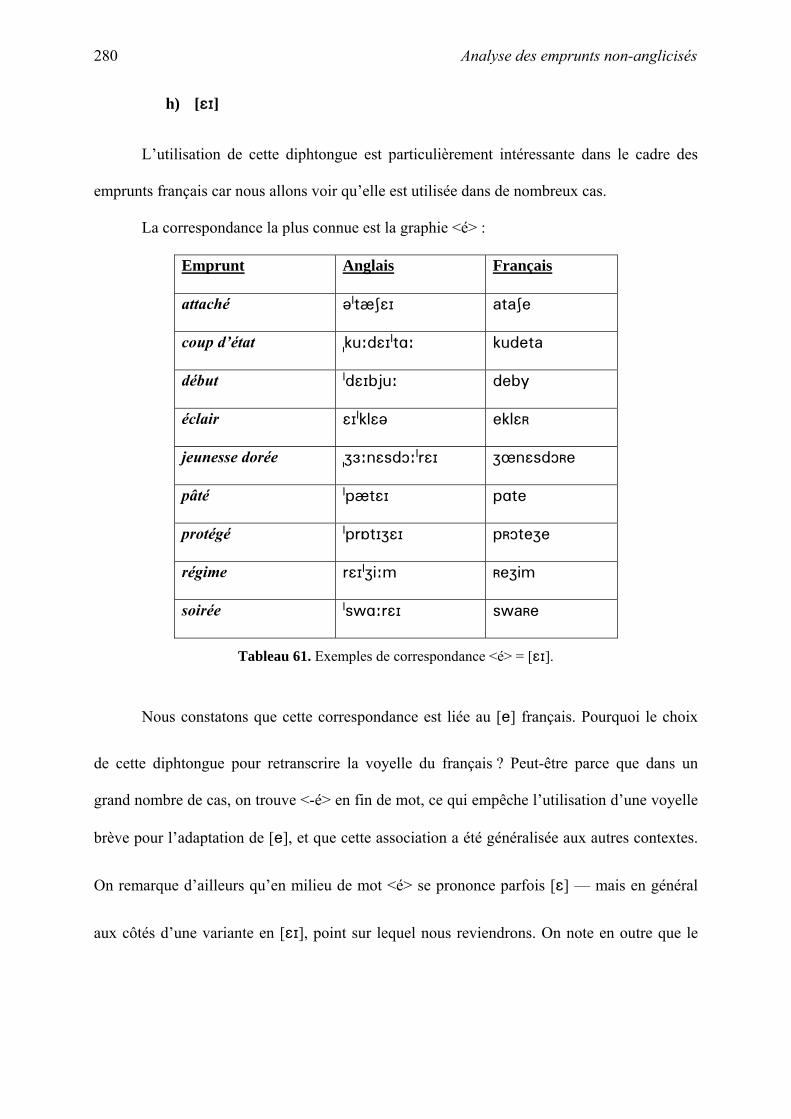
280 Analyse des emprunts non-anglicisés
h) [EI]
L’utilisation de cette diphtongue est particulièrement intéressante dans le cadre des
emprunts français car nous allons voir qu’elle est utilisée dans de nombreux cas.
La correspondance la plus connue est la graphie <é> :
Emprunt Anglais Français
attaché ´:tQSEI ataSe
coup d’état «ku˘dEI:tA˘ kudeta
début :dEIbju˘ deby
éclair EI:klE´ eklE{
jeunesse dorée «ZŒ˘nEsdç˘:rEI ZønEsdç{e
pâté :pQtEI pAte
protégé :prÅtIZEI p{çteZe
régime rEI:Zi˘m {eZim
soirée :swA˘rEI swa{e
Tableau 61. Exemples de correspondance <é> = [EI].
Nous constatons que cette correspondance est liée au [e] français. Pourquoi le choix
de cette diphtongue pour retranscrire la voyelle du français ? Peut-être parce que dans un
grand nombre de cas, on trouve <-é> en fin de mot, ce qui empêche l’utilisation d’une voyelle
brève pour l’adaptation de [e], et que cette association a été généralisée aux autres contextes.
On remarque d’ailleurs qu’en milieu de mot <é> se prononce parfois [E] — mais en général
aux côtés d’une variante en [EI], point sur lequel nous reviendrons. On note en outre que le

Adaptation des phonèmes du français 281
point de départ de la diphtongue [EI] est assez proche de la zone du [e] français, ce qui
pourrait être une autre explication.
La diphtongue [EI] est également associée à la graphie <è> :
Emprunt Anglais Français
cause célèbre «kç˘zsE:lEIbr´ kozselEb{
cortège kç˘:tEIZ kç{tEZ
crèche :krEIS k{ES
fin de siècle «fQ)d´sI:EIk´l fE)d´sjEkl
mise-en-scène «mi˘zÅn:sEIn mizA)sEn
procès-verbal «prÅsEIvŒ˘:bA˘l p{çsEvE{bal
roman à thèse r´U«mA)˘nA˘:tEIz {çmA)atEz
succès «sUk:sEI syksE
Tableau 62. Exemples de correspondance <è> = [EI].
Ici nous voyons que [EI] sert à adapter le [E] français. Comment expliquer qu’une
même diphtongue serve à rendre deux phonèmes différents ? Nous avons vu que le point de
départ de cette diphtongue se situait dans la zone du [e]. Mais on ne peut plus proposer cette
explication pour [E]. On peut cependant envisager que les anglophones ne distinguent pas
réellement ces deux phonèmes. En effet, en français ils sont en général en distribution
complémentaire : [e] en syllabe ouverte (ex : thé /te/) et [E] en syllabe fermée (ex : pelle
/pEl/). Il existe cependant des exceptions ; on trouve parfois [E] également en syllabe ouverte,
comme nous le voyons dans l’exemple succès. En revanche, [e] ne se trouve jamais en
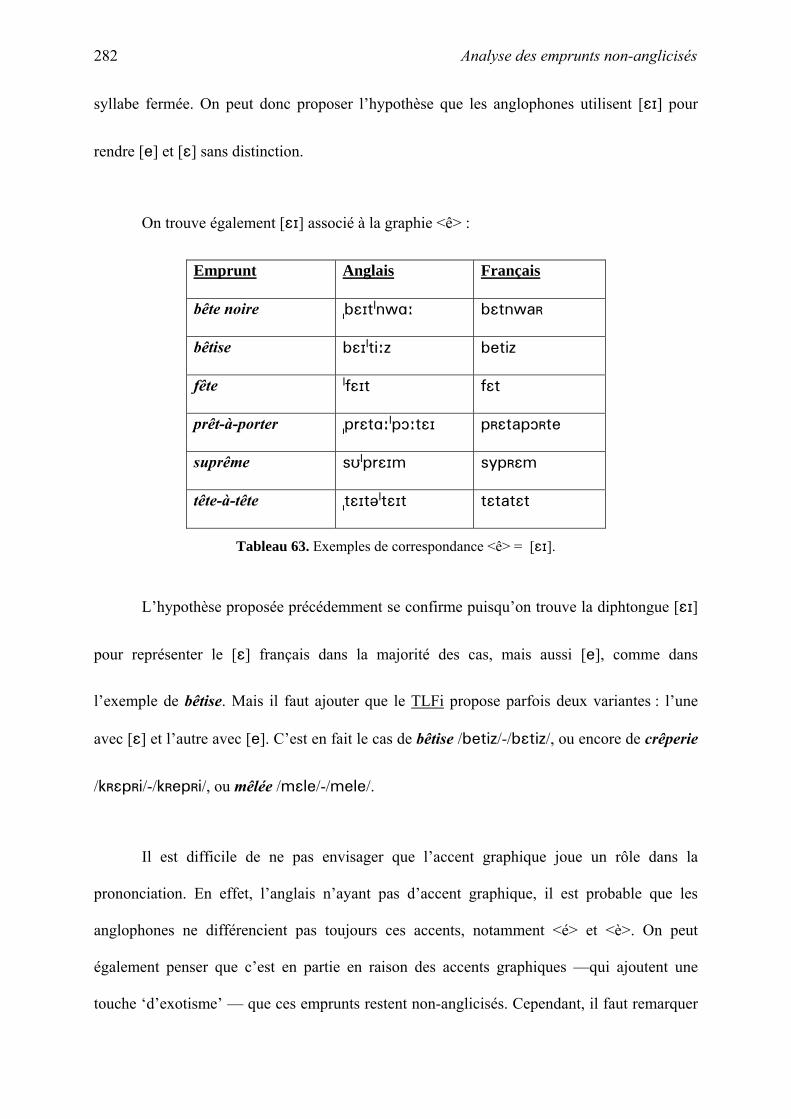
282 Analyse des emprunts non-anglicisés
syllabe fermée. On peut donc proposer l’hypothèse que les anglophones utilisent [EI] pour
rendre [e] et [E] sans distinction.
On trouve également [EI] associé à la graphie <ê> :
Emprunt Anglais Français
bête noire «bEIt:nwA˘ bEtnwa{
bêtise bEI:ti˘z betiz
fête :fEIt fEt
prêt-à-porter «prEtA˘:pç˘tEI p{Etapç{te
suprême sU:prEIm syp{Em
tête-à-tête «tEIt´:tEIt tEtatEt
Tableau 63. Exemples de correspondance <ê> = [EI].
L’hypothèse proposée précédemment se confirme puisqu’on trouve la diphtongue [EI]
pour représenter le [E] français dans la majorité des cas, mais aussi [e], comme dans
l’exemple de bêtise. Mais il faut ajouter que le TLFi propose parfois deux variantes : l’une
avec [E] et l’autre avec [e]. C’est en fait le cas de bêtise /betiz/-/bEtiz/, ou encore de crêperie
/k{Ep{i/-/k{ep{i/, ou mêlée /mEle/-/mele/.
Il est difficile de ne pas envisager que l’accent graphique joue un rôle dans la
prononciation. En effet, l’anglais n’ayant pas d’accent graphique, il est probable que les
anglophones ne différencient pas toujours ces accents, notamment <é> et <è>. On peut
également penser que c’est en partie en raison des accents graphiques —qui ajoutent une
touche ‘d’exotisme’ — que ces emprunts restent non-anglicisés. Cependant, il faut remarquer

Adaptation des phonèmes du français 283
que même lorsqu’il existe des variantes orthographiques sans accent — comme tête-à-tête /
tete-a-tete, fiancé / fiance, cortège / cortege — la prononciation proche du français se
maintient. Il serait d’ailleurs intéressant d’approfondir le sujet des accents graphiques et de
leur impact sur le locuteur : les anglophones utilisent-ils beaucoup les accents ou préfèrent-ils
les variantes orthographiques sans accent ? Différencient-ils ces accents (grave, aigu,
circonflexe) ? Identifient-ils un mot comme emprunt français si l’accent est absent ? Et
lorsque la variante graphique sans accent d’un emprunt devient la plus fréquente, la
prononciation a-t-elle tendance à s’angliciser ?
Néanmoins, même si nous pensons que l’accent graphique a une certaine importance,
nous observons que la diphtongue [EI] est également associée à des graphies sans accent,
comme la terminaison <-et> :
Emprunt Anglais Français
ballet :bQlEI balE
cabaret :kQb´rEI kaba{E
duvet :dju˘vEI dyvE
flageolet «flQdZ´U:lEI flaZçlE
mauvais sujet m´U:vEIsu˘:ZEI mçvEsyZE
parquet :pA˘kEI pa{kE
ricochet :rIk´SEI {ikçSE
sorbet :sç˘bEI sç{bE
Tableau 64. Exemples de correspondance <-et> = [EI].
Ici, nous observons que la diphtongue [EI] représente une terminaison [E] en français.
Dans ce contexte, on ne trouve pas la voyelle [e].
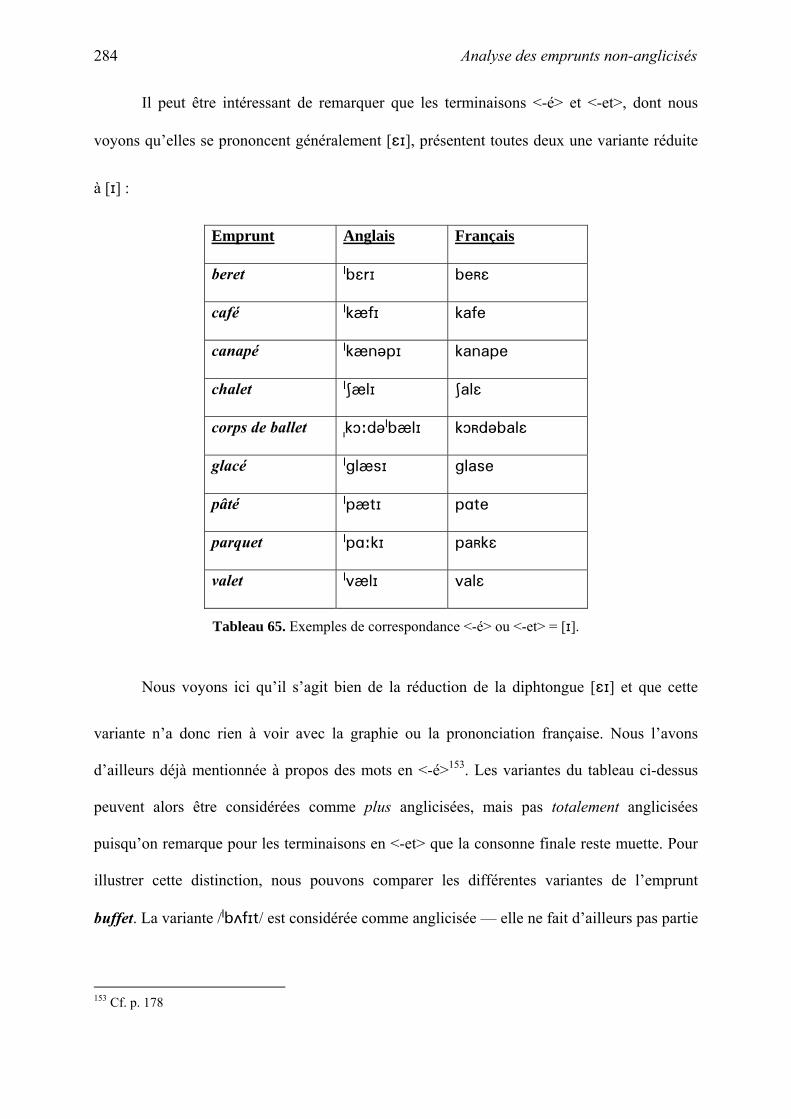
284 Analyse des emprunts non-anglicisés
Il peut être intéressant de remarquer que les terminaisons <-é> et <-et>, dont nous
voyons qu’elles se prononcent généralement [EI], présentent toutes deux une variante réduite
à [I] :
Emprunt Anglais Français
beret :bErI be{E
café :kQfI kafe
canapé :kQn´pI kanape
chalet :SQlI SalE
corps de ballet «kç˘d´:bQlI kç{d´balE
glacé :glQsI glase
pâté :pQtI pAte
parquet :pA˘kI pa{kE
valet :vQlI valE
Tableau 65. Exemples de correspondance <-é> ou <-et> = [I].
Nous voyons ici qu’il s’agit bien de la réduction de la diphtongue [EI] et que cette
variante n’a donc rien à voir avec la graphie ou la prononciation française. Nous l’avons
d’ailleurs déjà mentionnée à propos des mots en <-é>153. Les variantes du tableau ci-dessus
peuvent alors être considérées comme plus anglicisées, mais pas totalement anglicisées
puisqu’on remarque pour les terminaisons en <-et> que la consonne finale reste muette. Pour
illustrer cette distinction, nous pouvons comparer les différentes variantes de l’emprunt
buffet. La variante /:b√fIt/ est considérée comme anglicisée — elle ne fait d’ailleurs pas partie
153 Cf. p. 178

Adaptation des phonèmes du français 285
de la base de données finale — tandis que la variante /:b√fI/ est non-anglicisée car la voyelle
[I] est alors la réduction de [EI]. Quant aux terminaisons <-é>, comme nous l’avons
mentionné auparavant, nous considérons que la prononciation du <e> final, habituellement
muet en anglais, marque le mot comme non-anglicisé.
La diphtongue [EI] est également associée à la terminaison <-ier>, prononcée [IEI] ou
[jEI] :
Emprunt Anglais Français
atelier ´:tElIEI at´lje
bustier :b√stIEI bystje
costumier kÅ:stju˘mIEI kçstymje
dossier :dÅsIEI dosje
espalier I:spQlIEI Espalje
papier mâché «pQpjEI:mQSEI papjemASe
premier danseur «prEmIEIdÅn:sŒ˘ p{´mjedA)sø{
preux chevalier «prŒ˘S´vQ:ljEI p{OS´valje
sommelier sÅ:mElIEI sçm´lje
Tableau 66. Exemples de correspondance <-ier> = [IEI] ou [jEI].
Dans ce cas, la prononciation anglaise tente de rendre le cluster [je]. Nous constatons
donc à nouveau que [EI] sert indifféremment à représenter [E] ou [e]. A propos de la
terminaison <-ier>, nous pouvons simplement remarquer que l’anglais la prononce plus

286 Analyse des emprunts non-anglicisés
souvent en deux syllabes [IEI] qu’en une syllabe [jEI], pourtant plus proche de la
prononciation originale.
Pour finir, nous pouvons signaler deux cas de terminaison <-ie> prononcée [EI] :
lingerie /:lQ)nZ´rEI/ et cap-à-pie /«kQp´:pEI/. Comment expliquer cette prononciation [EI],
alors que la terminaison <-ie> se prononce généralement [I] ou, moins fréquemment, [i˘] ?
Ces variantes sont proposées par le LPD dans le cas de cap-à-pie, et par l’EPD et le LPD pour
lingerie, mais aucun commentaire n’est ajouté. Ajoutons que cap-à-pie présente également la
variante en [i˘], et lingerie les variantes [I] et [i˘]. L’hypothèse qu’on peut avancer pour
expliquer cette prononciation est celle d’une hypercorrection dans le cadre des emprunts
français.
En effet, le phénomène d’hypercorrection est assez répandu en anglais. John Wells le
mentionne dans le premier volume de son ouvrage Accents of English154, à propos des
locuteurs qui tentent de modifier leur accent. Il explique que changer d’accent consiste à
ajouter de nouvelles règles phonologiques à celles de l’accent de départ. Si la différence
d’accent est marquée seulement dans certains contextes, le changement sera plus facile s’il
suffit de généraliser la règle. Par exemple, un Canadien, pour lequel [aI] présente un
allophone [´I] dans un certain contexte, n’a qu’à utiliser [aI] dans tous les cas pour prendre
l’accent RP (Wells, vol. 1, 111-112). En revanche, l’inverse est plus difficile. Si un locuteur
RP cherche à prendre l’accent canadien, il va devoir apprendre à utiliser l’allophone [´I] dans
le bon contexte, c’est-à-dire devant une consonne sourde. S’il étend cette règle à tous les
154 Wells, John. C. Accents of English. Vol. 1 : “An Introduction”. Cambridge: Cambridge UP, 1982.

Adaptation des phonèmes du français 287
environnements, cela va générer des formes incorrectes, qu’on qualifie d’hypercorrections
(Wells, vol. 1, 112-113).
Dans le contexte des emprunts, Wells parle d’hyperforeignism :
Educated people are […] aware that words in or from foreign languages are
subject to somewhat different reading rules from those applying to English.
But they are often vague about them, and about the different rules applicable to
different foreign languages. Many resulting pronunciations are absurd in that
they reflect neither the reading rules of English nor those of the language from
which the word in question comes (Wells, vol. 1, 108).
Dans le cas de lingerie, on peut également évoquer l’influence de la prononciation
américaine puisque la variante en [EI] est la plus courante en anglais américain. Nous pouvons
d’ailleurs observer l’utilisation de cette variante dans deux vidéos trouvées sur Internet : l’une
avec une locutrice américaine155, et l’autre avec une locutrice britannique (tout début de la
vidéo)156.
i) [E´]
La diphtongue [E´] est à rapprocher de [EI] puisqu’elle est issue de la transformation
de [EI] devant [r]. On la trouve par exemple associée à la terminaison <-ère> :
155 « 60 Second Style : Lingerie. » VideoJug. 3 oct. 2008. VideoJug Corporation Limited. 14 oct. 2008.
http://www.videojug.com/film/60-second-style-lingerie.
156 « How to Choose a Well-Fitting Bra. » VideoJug. 20 fév. 2007. VideoJug Corporation Limited. 14 oct. 2008.
http://www.videojug.com/film/how-to-choose-a-well-fitting-bra.
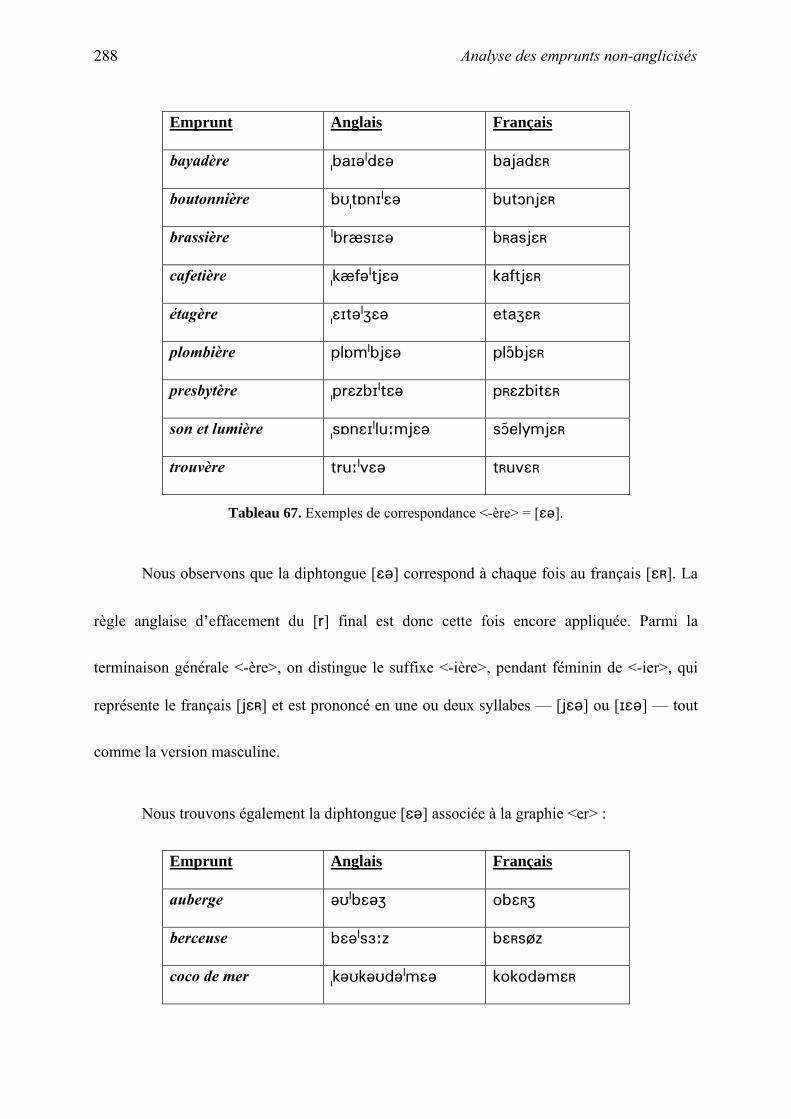
288 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
bayadère «baI´:dE´ bajadE{
boutonnière bU«tÅnI:E´ butçnjE{
brassière :brQsIE´ b{asjE{
cafetière «kQf´:tjE´ kaftjE{
étagère «EIt´:ZE´ etaZE{
plombière plÅm:bjE´ plç)bjE{
presbytère «prEzbI:tE´ p{EzbitE{
son et lumière «sÅnEI:lu˘mjE´ sç)elymjE{
trouvère tru˘:vE´ t{uvE{
Tableau 67. Exemples de correspondance <-ère> = [E´].
Nous observons que la diphtongue [E´] correspond à chaque fois au français [E{]. La
règle anglaise d’effacement du [r] final est donc cette fois encore appliquée. Parmi la
terminaison générale <-ère>, on distingue le suffixe <-ière>, pendant féminin de <-ier>, qui
représente le français [jE{] et est prononcé en une ou deux syllabes — [jE´] ou [IE´] — tout
comme la version masculine.
Nous trouvons également la diphtongue [E´] associée à la graphie <er> :
Emprunt Anglais Français
auberge ´U:bE´Z obE{Z
berceuse bE´:sŒ˘z bE{sOz
coco de mer «k´Uk´Ud´:mE´ kokod´mE{

Adaptation des phonèmes du français 289
Emprunt Anglais Français
divertissement «di˘vE´:ti˘smA)˘N divE{tismA)
famille verte f´«mi˘:vE´t famijvE{t
mer de glace «mE´d´:glQs mE{d´glas
Merlot :mE´l´U mE{lo
ouvert u˘:vE´ uvE{
recherché r´:SE´SEI {´SE{Se
Tableau 68. Exemples de correspondance <er> = [E´].
Ici encore, nous observons que la voyelle [E´] correspond au cluster français [E{]. La
correspondance est valable aussi bien au sein du mot (ex : auberge, divertissement,
recherché) qu’en finale (ouvert, coco de mer).
Enfin, nous pouvons mentionner trois cas où la diphtongue [E´] est associée à la
graphie <è> : barège /bQ:rE´Z/, cause célèbre /«kç˘zsI:lE´br´/ et chèvre /:SE´vr´/.
Cependant nous ne savons comment expliquer ces cas, puisque [E´] ne peut ici être issu d’une
transformation avec [r]. Ajoutons que chèvre est trouvé dans le LPD, tandis que barège et
cause célèbre sont trouvés dans l’ODP, mais que ces dictionnaires sont à chaque fois les seuls
à proposer cette variante. S’agit-il d’une erreur typographique ou bien d’un autre cas
d’hypercorrection ? Les deux hypothèses sont envisageables.
Reste une interrogation : si l’adaptation du français [E{] est [E´], cette prononciation
associée à la graphie <air(e> doit-elle être considérée comme anglicisée ou comme une
adaptation du français ? En effet, la correspondance <air> = [E´] suit les règles de l’anglais.

290 Analyse des emprunts non-anglicisés
C’est pourquoi nous avons supprimé par exemple l’emprunt maire /:mE´/ de la Base de
Données Initiale. Néanmoins, nous pourrions considérer qu’il s’agit d’une prononciation
imitant celle du français. Nous allons voir que cette interrogation surgit à plusieurs reprises au
cours de ce travail.
j) [E]
Nous trouvons parfois la voyelle [E] associée à la graphie <ai> :
Emprunt Anglais Français
baignoire :bEnwç˘ bE¯wa{
bouillabaisse «bu˘j´:bEs bujabEs
broderie anglaise «brÅd´rIA)˘N:glEz b{çd{iA)glEz
crème fraîche «krEm:frES k{Emf{ES
fait accompli «fEt´:kÅmpli˘ fEtakç)pli
maison :mEzÅ) mEzç)
maître d’hôtel «mEtr´d´U:tEl mEt{dotEl
mari complaisant «mQrI:kÅ)plEzÅ) ma{ikç)plEzA)
marraine mQ:rEn ma{En
Tableau 69. Exemples de correspondance <ai> = [E].
Nous observons dans tous les cas que le [E] anglais correspond à un [E] français. Ce
choix paraît tout à fait justifié, puisque la voyelle anglaise se situe dans la zone du [E]
français, d’où des symboles identiques. Il faut toutefois souligner que le TLFi propose parfois
une autre variante avec [e], comme pour maison /mEzç)/-/mezç)/, laissez-faire /lEsefE{/-

Adaptation des phonèmes du français 291
/lesefE{/, ou menus plaisirs /m´nyplezi{/-/m´nyplEzi{/. On peut alors considérer que le [E]
anglais représente ces deux voyelles françaises.
On trouve également dans quelques cas la voyelle [E] associée à la graphie <ei> :
Emprunt Anglais Français
madeleine mQd:lEn madlEn
monseigneur «mÅnsE:njŒ˘ mç)sE¯ø{
reine :rEn {En
seigneurial sE:njŒ˘rI´l sE¯ø{jal
treillis :trElji˘ t{Eji
Tableau 70. Variantes avec correspondance <ei> = [E].
Ici encore, le [E] anglais correspond à un [E] français. Mais nous trouvons également
quelques cas de variantes [E]/[e], comme seigneurial /sE¯ø{jal/-/se¯ø{jal/, ou treillis
/t{Eji/-/t{eji/.
Enfin, si trouver la voyelle [E] associée à une graphie <e> (avec ou sans accent) n’a a
priori rien de remarquable, puisque cela est conforme aux règles de l’anglais dans la plupart
des cas, nous constatons dans notre base de données un certain nombre de variantes avec [E]
au lieu d’une tension en [i˘] :

292 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
arête, arete Q:rEt a{Et
bête noire, bete noire «bEt:nwA˘ bEtnwa{
cortège, cortege kç˘:tEZ kç{tEZ
crème, creme :krEm k{Em
crêpe, crepe :krEp k{Ep
écu, ecu :Ekju˘ eky
flèche, fleche :flES flES
métier, metier :mEtIEI metje
Tableau 71. Exemples de variantes où [E] est irrégulier.
Nous avons cette fois ajouté les variantes sans accent graphique, car c’est en observant
ces variantes qu’on prend le mieux conscience de l’irrégularité. En effet, lors du travail de
suppression des variantes anglicisées, nous avons examiné la graphie des mots sans tenir
compte des accents. Ici encore, on peut penser que l’accent graphique joue un rôle sur la
prononciation, mais les variantes orthographiques rappellent que certains anglophones
orthographient ces mots sans accent, sans pour autant appliquer la règle de tension à l’oral.
Nous observons une fois de plus que la voyelle [E] représente en général le [E]
français, sauf dans écu ou métier, où elle représente un [e]. En fait, nous constatons dans les
transcriptions françaises de ce tableau que [e] est en syllabe ouverte, et [E] en syllabe fermée.
La voyelle anglaise [E] peut donc, tout comme [EI], servir aux représentations de [e] et [E]
sans distinction.
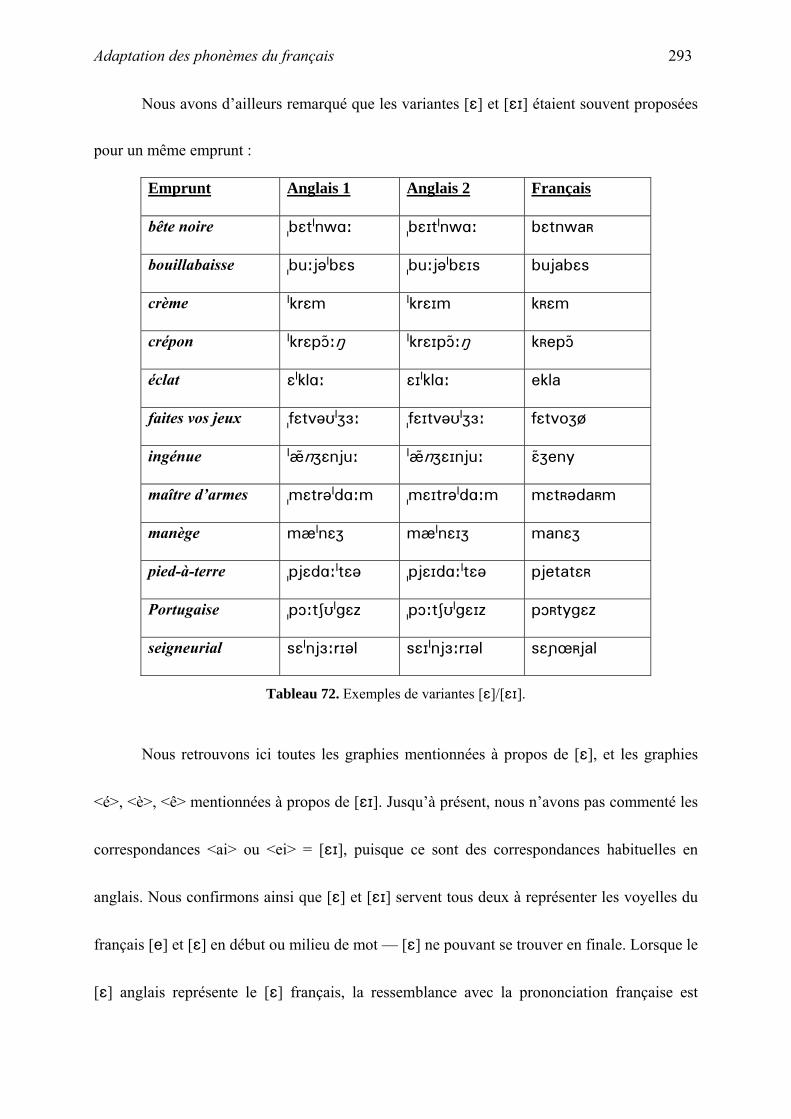
Adaptation des phonèmes du français 293
Nous avons d’ailleurs remarqué que les variantes [E] et [EI] étaient souvent proposées
pour un même emprunt :
Emprunt Anglais 1 Anglais 2 Français
bête noire «bEt:nwA˘ «bEIt:nwA˘ bEtnwa{
bouillabaisse «bu˘j´:bEs «bu˘j´:bEIs bujabEs
crème :krEm :krEIm k{Em
crépon :krEpç)˘N :krEIpç)˘N k{epç)
éclat E:klA˘ EI:klA˘ ekla
faites vos jeux «fEtv´U:ZŒ˘ «fEItv´U:ZŒ˘ fEtvoZO
ingénue :Q)nZEnju˘ :Q)nZEInju˘ E)Zeny
maître d’armes «mEtr´:dA˘m «mEItr´:dA˘m mEt{´da{m
manège mQ:nEZ mQ:nEIZ manEZ
pied-à-terre «pjEdA˘:tE´ «pjEIdA˘:tE´ pjetatE{
Portugaise «pç˘tSU:gEz «pç˘tSU:gEIz pç{tygEz
seigneurial sE:njŒ˘rI´l sEI:njŒ˘rI´l sE¯ø{jal
Tableau 72. Exemples de variantes [E]/[EI].
Nous retrouvons ici toutes les graphies mentionnées à propos de [E], et les graphies
<é>, <è>, <ê> mentionnées à propos de [EI]. Jusqu’à présent, nous n’avons pas commenté les
correspondances <ai> ou <ei> = [EI], puisque ce sont des correspondances habituelles en
anglais. Nous confirmons ainsi que [E] et [EI] servent tous deux à représenter les voyelles du
français [e] et [E] en début ou milieu de mot — [E] ne pouvant se trouver en finale. Lorsque le
[E] anglais représente le [E] français, la ressemblance avec la prononciation française est

294 Analyse des emprunts non-anglicisés
même parfois assez remarquable, comme le montre l’exemple de crème où la seule différence
marquante reste la prononciation du <r>. On se demande même dans ce type de cas pourquoi
certains locuteurs choisissent d’utiliser [EI]. La réponse est peut-être que ces locuteurs ne
connaissent pas la prononciation d’origine et se contentent d’appliquer la correspondance la
plus fréquente pour cette graphie.
On peut avancer une autre hypothèse pour expliquer ces variantes [E]/[EI] : la voyelle
[E] résulte peut-être d’une sorte de Smoothing, phénomène décrit par John Wells dans le
premier volume d’Accents of English157 à propos de chaos où la diphtongue [EI] peut parfois
être prononcée [E˘] (Wells, vol. 1, 238) ; c’est-à-dire devenir monophtongue. On pourrait
envisager que dans un contexte familier ou de prononciation moins soignée, la diphtongue
[EI] subisse un phénomène du même type qui aboutirait à la prononciation [E]. Néanmoins,
Wells décrit le phénomène du Smoothing dans un contexte prévocalique, ce qui n’est jamais
le cas ici.
Quoi qu’il en soit, il semble qu’il s’agisse d’une caractéristique de certains emprunts
français. Dès lors, nous pouvons nous demander si la décision de supprimer la variante de
fraise /:frEIz/, qui suit les correspondances anglaises habituelles, et de garder la variante /:frEz/
en raison de sa correspondance irrégulière, était la bonne. En observant la Base de Données
Comparative, nous trouvons d’autres cas de ce type : crêperie /:krEIp´rI/ a été conservé, mais
/:krEp´rI/ supprimé ; ecru /:EIkru˘/ conservé, mais /:Ekru˘/ supprimé ; madeleine /mQd:lEn/
conservé, mais /:mQdlEIn/ supprimé ; Médoc /:mEIdÅk/ conservé, mais /:mEdÅk/ supprimé.
Cependant, il est impossible de savoir si les variantes supprimées se prononcent ainsi parce
157 Op. cit. p. 286

Adaptation des phonèmes du français 295
que des règles anglaises sont appliquées ou parce qu’elles tentent d’imiter la prononciation
d’origine en appliquant des correspondances spécifiques aux emprunts français.
k) [u˘]
On trouve la voyelle [u˘] associée à la graphie <ou> :
Emprunt Anglais Français
bouquet :bu˘kEI bukE
coup de foudre «ku˘d´:fu˘dr´ kud´fud{
coupon :ku˘pÅn kupç)
mange-tout «mA)˘nZ:tu˘ mA)Ztu
nougat :nu˘gA˘ nuga
oubliette «u˘blI:Et ublijEt
rendez-vous :rÅndIvu˘ {A)devu
roux :ru˘ {u
soufflé :su˘flEI sufle
Tableau 73. Exemples de correspondances <ou> = [u˘].
Nous observons que la voyelle [u˘] représente dans tous ces cas le [u] français, ce qui
s’explique évidemment par la proximité de ces deux voyelles dans le trapèze.
Cependant, même si le digraphe <ou> est la plupart du temps associée à [u˘], on
remarque parfois qu’il est associé à la voyelle [U] :

296 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
accouchement ´:kUSm´nt akuSmA)
bouquet garni «bUkEIgA˘:ni˘ bukEga{ni
cassoulet «kQsU:lEI kasulE
coussinet :kUsInEt kusinE
couture kU:tjU´ kuty{
foulard fU:lA˘ fula{
mousquetaire «mUskI:tE´ musk´tE{
moustache mU:stA˘S mustaS
pas de bourrée «pA˘d´:bUrEI pAd´bu{e
Tableau 74. Exemples de correspondance <ou> = [U].
Ici aussi, nous constatons que la voyelle [U] correspond au [u] français. Cependant il
convient de dissocier les [U] sous accent des [U] inaccentués. En effet, les cas avec [U]
accentué (ex : accouchement, bouquet garni, coussinet, mousquetaire, pas de bourrée)
peuvent être vus comme une autre représentation du [u] français. En revanche, lorsque [U] est
en syllabe inaccentuée, on peut considérer qu’il s’agit de la réduction de [u˘]. Il est possible
également qu’il s’agisse de la réduction de [U], mais comme la correspondance <ou> = [U] est
beaucoup moins fréquente, nous pensons que c’est plus rarement le cas.
Nous pouvons également mentionner les quelques cas où la graphie <ou> est associée
à [w] :

Adaptation des phonèmes du français 297
Emprunt Anglais Français
bivouac :bIvwQk bivwak
bouillabaisse «bwi˘j´:bEs bujabEs
bouillon :bwi˘jç)˘N bujç)
fouetté :fwEtEI fwEte
gouache :gwA˘S gwaS
mouillé :mwi˘EI muje
oued :wEd wEd
oui :wi˘ wi
ratatouille «rQt´:twi˘ {atatuj
Zouave :zwA˘v zwav
Tableau 75. Variantes avec correspondance <ou> = [w].
Ce tableau regroupe deux cas de figure : soit la glissée [w] représente un [w] français,
soit le cluster [wi˘(j)] remplace un cluster [uj] en français. Dans le premier cas, il s’agit d’une
simple importation qui permet d’obtenir une prononciation très proche de celle d’origine. Le
deuxième cas est plus complexe ; nous l’observons lorsque la graphie est <ouill>. Il semble
que cette graphie soit mal interprétée ; on y retrouve la correspondance <i> = [i˘], alors que la
correspondance <ou> = [u˘] est ‘réduite’ à [w]. D’ailleurs, plusieurs autres exemples du
tableau ci-dessus, même s’ils présentent une prononciation proche du mot d’origine, peuvent
également être vus comme des réductions de variantes en [u˘], comme bivouac qui a
également une variante /:bIvu˘Qk/, fouetté une variante /:fu˘´tEI/, gouache une variante
/gu˘:A˘S/, ou Zouave une variante /:zu˘A˘v/. Dans ces dernières variantes, nous n’observons

298 Analyse des emprunts non-anglicisés
plus une réelle imitation de la prononciation française, mais plutôt une application des
correspondances les plus fréquentes pour les emprunts français.
Enfin, on trouve la voyelle [u˘] associée à la graphie <u>, ce qui dans bien des cas suit
tout à fait les règles de l’anglais. Cependant, on relève un certain nombre de cas irréguliers :
Emprunt Anglais Français
brusque :bru˘sk b{ysk
brut :bru˘t b{yt
bustier :bu˘stI´ bystje
charlotte russe «SA˘l´t:ru˘s Sa{lçt{ys
jus :Zu˘s Zy
luxe :lu˘ks lyks
mot juste «m´U:Zu˘st moZyst
Palais de Justice «pQlEId´Zu˘:sti˘s palEd´Zystis
Tartuffe tA˘:tu˘f ta{tyf
Tableau 76. Exemples de variantes où [u˘] est irrégulier.
Nous constatons que lorsque [u˘] est utilisé de façon irrégulière, il représente toujours
la voyelle [y] du français. Pourquoi le choix de [u˘] pour rendre cette voyelle d’avant fermée
et arrondie ? Il semble que ce soit le critère d’aperture qui est retenu puisque [u˘] est
également une voyelle fermée, bien que plus arrière et moins arrondie que [y]. Celle-ci pose
certainement un réel problème aux locuteurs qui cherchent à imiter la prononciation française
au plus proche.
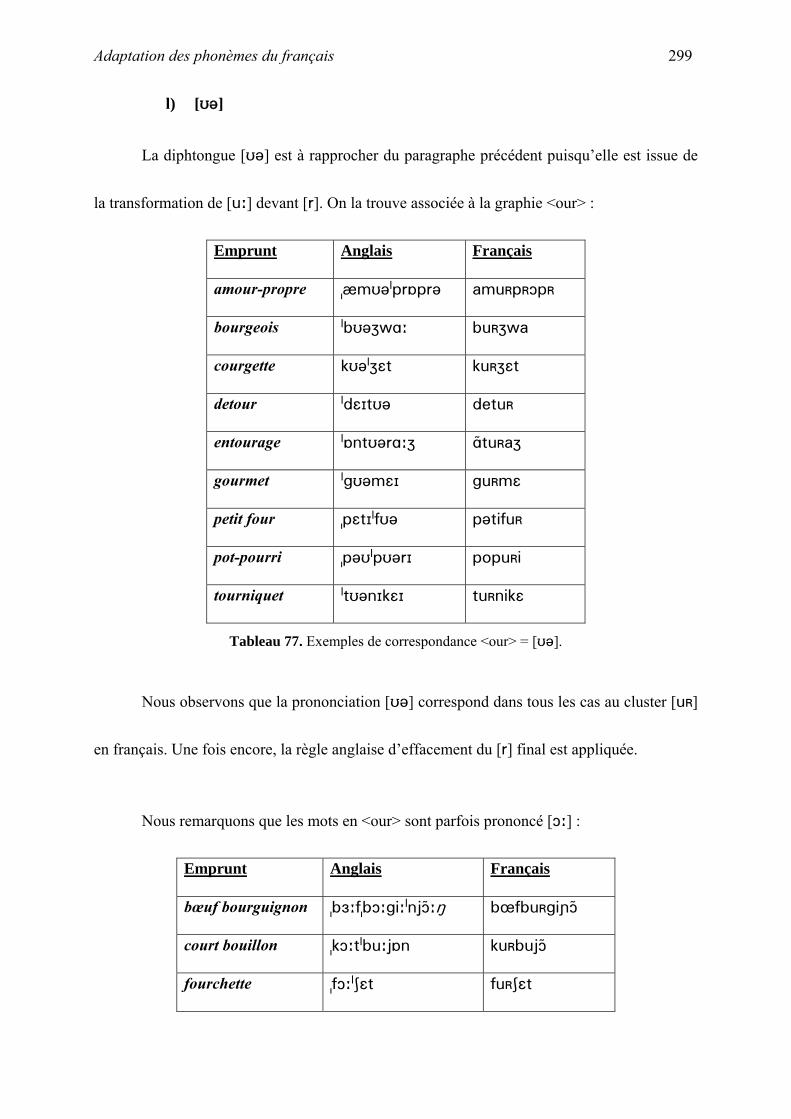
Adaptation des phonèmes du français 299
l) [U´]
La diphtongue [U´] est à rapprocher du paragraphe précédent puisqu’elle est issue de
la transformation de [u˘] devant [r]. On la trouve associée à la graphie <our> :
Emprunt Anglais Français
amour-propre «QmU´:prÅpr´ amu{p{çp{
bourgeois :bU´ZwA˘ bu{Zwa
courgette kU´:ZEt ku{ZEt
detour :dEItU´ detu{
entourage :ÅntU´rA˘Z A)tu{aZ
gourmet :gU´mEI gu{mE
petit four «pEtI:fU´ p´tifu{
pot-pourri «p´U:pU´rI popu{i
tourniquet :tU´nIkEI tu{nikE
Tableau 77. Exemples de correspondance <our> = [U´].
Nous observons que la prononciation [U´] correspond dans tous les cas au cluster [u{]
en français. Une fois encore, la règle anglaise d’effacement du [r] final est appliquée.
Nous remarquons que les mots en <our> sont parfois prononcé [ç˘] :
Emprunt Anglais Français
bœuf bourguignon «bŒ˘f«bç˘gi˘:njç)˘N bøfbu{gi¯ç)
court bouillon «kç˘t:bu˘jÅn ku{bujç)
fourchette «fç˘:SEt fu{SEt

300 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
petit bourgeois «pEtI:bç˘ZwA˘ p´tibu{Zwa
petit four «pEtI:fç˘ p´tifu{
pourparler «pç˘:pA˘lEI pu{pa{le
tour de force «tç˘d´:fç˘s tu{d´fç{s
tout court «tu˘:kç˘ tuku{
troubadour :tru˘b´dç˘ t{ubadu{
Tableau 78. Exemples de correspondance <our> = [ç˘].
La prononciation [ç˘] est une variante de [U´] qui a été considérée jusqu’à présent
comme une anglicisation. Cependant, son utilisation est particulièrement intéressante dans le
cadre des emprunts français, c’est pourquoi nous souhaitons la commenter ici. En effet, John
Wells explique dans le premier volume d’Accents of English158 que la variante [ç˘] est issue
d’une règle qu’il appelle ‘CURE Lowering’ — cure représentant la voyelle [U´] (Wells, vol. 1,
237). Par conséquent, l’obtention d’une variante [ç˘] pour nos emprunts implique une analyse
du mot qui va d’abord générer une prononciation [U´]. Or, nous venons de voir que [U´] est
issu de la transformation de [u˘] devant [r]. Puisqu’on considère [u˘] comme une imitation de
la prononciation française, et donc [U´] également, on peut finalement dire que [ç˘] est une
variante anglicisée issue d’une prononciation ‘française’.
Nous pouvons faire une autre remarque à propos des variantes en [ç˘]. Dans le
deuxième volume de son ouvrage Accent of English159, Wells affirme que cette règle de 158 Op. cit. p. 286
159 Wells, John C. Accents of English. Vol. 2 : « The British Isles ». Cambridge : Cambridge UP, 1982.

Adaptation des phonèmes du français 301
transformation de [U´] en [ç˘] ne semble pas être appliquée pour les mots étrangers :
« […] Ruhr, which as a foreign word is perhaps resistant to becoming a homophone of roar-
raw » (Wells, vol. 2, 288). Pourtant, nous voyons que cette règle est bien appliquée dans le
cas des emprunts français. Cela montre que les emprunts français forment une catégorie à part
dans les mots étrangers, ce qui leur permet dans certains cas de subir une anglicisation plus
importante.
Mais l’utilisation de cette règle anglaise est peut-être aussi facilitée par le fait que
certains mots en <our> comme tour /:tU´/-/:tç˘/ sont présents depuis longtemps dans la
langue anglaise. La correspondance <our> = [U´] n’est peut-être pas ressentie comme
française, ou peut-être ‘moins fortement’. On peut aussi signaler le mot four /:fç˘/ où la
prononciation [ç˘] est la seule connue, ce qui facilite peut-être la correspondance <our> =
[ç˘].
Nous pouvons enfin signaler deux cas particuliers où la graphie <our> est prononcée
[Œ˘] : tournedos /:tŒ˘n´d´U/ et tourniquet /:tŒ˘nIkEI/. On remarque que les trois dictionnaires
de prononciation proposent une variante avec [Œ˘] pour ces deux emprunts ; il ne s’agit donc
pas d’un cas isolé. Mais comment expliquer cette variante ? Car ni la graphie, ni la
prononciation française ne permettent d’expliquer le choix de ce phonème. En effet, cette
voyelle est plutôt employée lorsque la graphie est <ur>, mais il est peu probable que les
locuteurs ne tiennent pas comptent de la présence du <o>. De plus, cette prononciation est
assez éloignée de celle du français ; on peut donc exclure l’idée d’une imitation. Alors est-ce
le rapprochement avec l’anglais turn qui a fait naître cette prononciation ? Cette explication

302 Analyse des emprunts non-anglicisés
est envisageable, mais on remarque pourtant que les autres mots en <tourn-> (tournée,
tournette, tournure) ne présentent pas de variantes avec [Œ˘].
Nous trouvons une autre réponse dans le deuxième volume d’Accents of English160. Il
explique que [Œ˘] est parfois une variante de [U´], même si elle est assez rare, et propose les
exemples de pure /:pjŒ˘/, curious /:kjŒ˘rI´s/ et yours /:jŒ˘z/ (Wells, vol. 2, 288). Or
tournedos et tourniquet présentent également une variante avec [U´]. Cependant, Wells
précise que cette variante [Œ˘] apparaît uniquement derrière [j], or [j] est ici absent. Cet
ouvrage datant de 1982, on peut envisager que cette variante soit aujourd’hui plus fréquente et
que c’est une des explications de son utilisation pour ces emprunts, malgré l’absence de [j]
dont nous allons voir qu’elle est caractéristique des emprunts français.
La dernière explication à cette curiosité serait un rapprochement avec certains
emprunts plus anciens comme journey /:dZŒ˘nI/, journal /:dZŒ˘n´l/, bourbon (la boisson)
/:bŒ˘b´n/, ou courtesy /:kŒ˘t´sI/ (Lilly et Viel, 66).
m) [Œ˘]
On trouve la voyelle [Œ˘] associée à la graphie <eu> :
Emprunt Anglais Français
amuse-gueule ´:mju˘z«gŒ˘l amyzgøl
cordon bleu «kç˘dç)˘m:blŒ˘ kç{dç)blO
fauteuil :f´UtŒ˘I fotøj
160 Op. cit. p. 300

Adaptation des phonèmes du français 303
Emprunt Anglais Français
feuilleté fŒ˘:jEtEI føjte
jeunesse dorée «ZŒ˘nEsdç˘:rEI ZønEsdç{e
meuble :mŒ˘bl2 møbl
meunière «mŒ˘nI:E´ mOnjE{
mousseux mu˘:sŒ˘ musO
pas de deux «pA˘d´:dŒ˘ pAd´dO
Tableau 79. Exemples de correspondance <eu> = [Œ˘].
Nous observons dans ce tableau que la voyelle [Œ˘] représente tantôt le français [ø],
tantôt [O]. Ces deux phonèmes se trouvent en général en distribution complémentaire : [ø] en
syllabe fermée (ex : peur /pø{/) et [O] en syllabe ouverte (ex : peu /pO/). Cependant [ø]
peut parfois se trouver également en syllabe ouverte, comme le montre l’exemple jeunesse
dorée, pour lequel le TLFi propose deux variantes /ZønEsdç{e/-/ZOnEsdç{e/.
Oralement [ø] et [Œ˘] sont assez proches, bien que la voyelle anglaise soit plus
centrale, moins ouverte et non-arrondie. En revanche, [O] est oralement plus éloignée. On peut
cependant envisager, comme pour [e] / [E], que les locuteurs ne différencient pas ces deux
phonèmes, d’où l’utilisation d’une seule voyelle pour les adapter. De plus, la graphie étant
identique, la différence de prononciation n’est pas reflétée par l’orthographe.
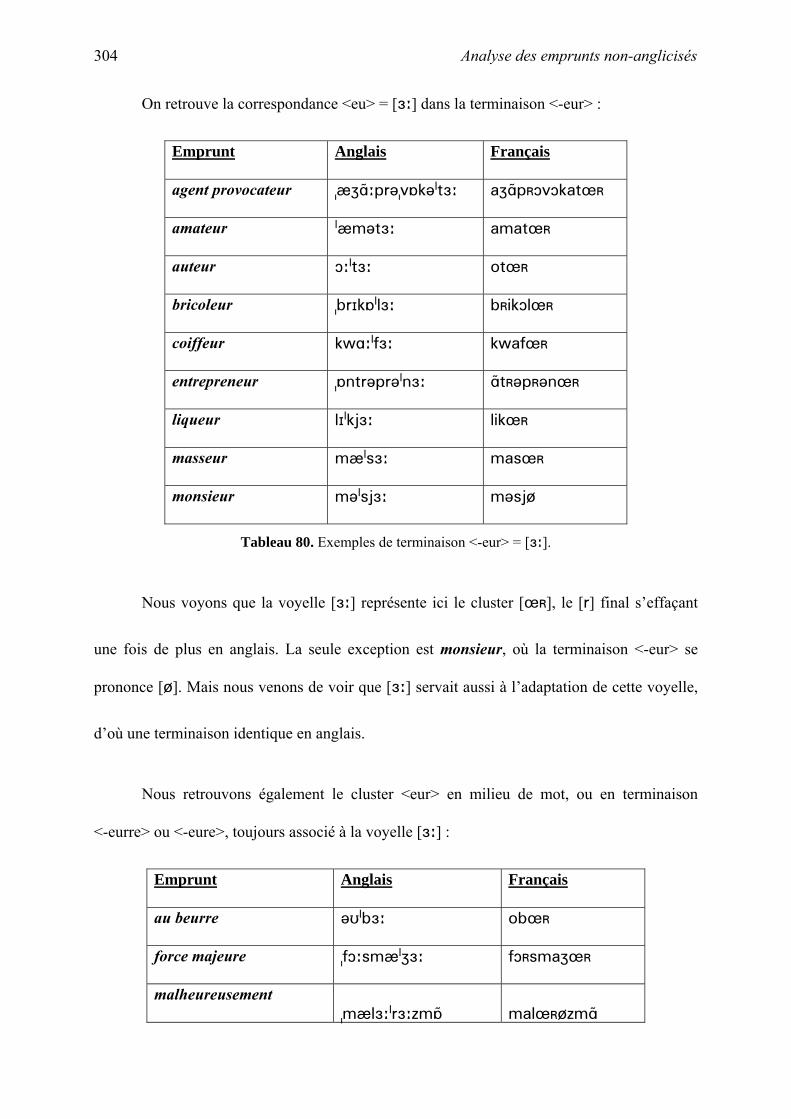
304 Analyse des emprunts non-anglicisés
On retrouve la correspondance <eu> = [Œ˘] dans la terminaison <-eur> :
Emprunt Anglais Français
agent provocateur «QZA)˘pr´«vÅk´:tŒ˘ aZA)p{çvçkatø{
amateur :Qm´tŒ˘ amatø{
auteur ç˘:tŒ˘ otø{
bricoleur «brIkÅ:lŒ˘ b{ikçlø{
coiffeur kwA˘:fŒ˘ kwafø{
entrepreneur «Åntr´pr´:nŒ˘ A)t{´p{´nø{
liqueur lI:kjŒ˘ likø{
masseur mQ:sŒ˘ masø{
monsieur m´:sjŒ˘ m´sjO
Tableau 80. Exemples de terminaison <-eur> = [Œ˘].
Nous voyons que la voyelle [Œ˘] représente ici le cluster [ø{], le [r] final s’effaçant
une fois de plus en anglais. La seule exception est monsieur, où la terminaison <-eur> se
prononce [O]. Mais nous venons de voir que [Œ˘] servait aussi à l’adaptation de cette voyelle,
d’où une terminaison identique en anglais.
Nous retrouvons également le cluster <eur> en milieu de mot, ou en terminaison
<-eurre> ou <-eure>, toujours associé à la voyelle [Œ˘] :
Emprunt Anglais Français
au beurre ´U:bŒ˘ obø{
force majeure «fç˘smQ:ZŒ˘ fç{smaZø{
malheureusement «mQlŒ˘:rŒ˘zmÅ) malø{OzmA)

Adaptation des phonèmes du français 305
Emprunt Anglais Français
mauvais quart d’heure m´U:vEI:kA˘:dŒ˘ mçvEka{dø{
messieurs mEI:sjŒ˘z mesjO
meurtrière «mŒ˘trI:E´ mø{t{ijE{
millefleurs «mi˘l:flŒ˘ milflø{
petit beurre «pEtI:bŒ˘ p´tibø{
seigneurial sE:njŒ˘rI´l sE¯ø{jal
Tableau 81. Variantes avec correspondance <eur> = [Œ˘].
En fin de mot, la graphie <-eure> ou <-eurre> correspond au cluster [ø{] comme vu
précédemment. On observe donc le même phénomène d’effacement du [r] final. L’exemple de
millefleurs est au pluriel, mais la marque graphique de pluriel ne se prononce pas à l’oral. Le
mot se terminant en [ø{] en français, il est donc à classer dans le même groupe. Cette fois
encore, messieurs est une exception puisqu’il se termine en [O] en français. De plus, le mot
est aussi au pluriel. Dans la variante présentée ci-dessus, la marque du pluriel est prononcée
en anglais, mais nous pouvons signaler une variante /mEI:sjŒ˘/, plus proche du français
puisque le pluriel n’y est pas prononcé. Nous aurons l’occasion de revenir sur la
prononciation du pluriel dans les emprunts de notre base de données.
Dans les exemples malheureusement et seigneurial, nous pouvons considérer qu’il ne
s’agit pas du cluster <eur>, mais de <eu>, puisque le [{] est l’attaque de la syllabe suivante et
n’est d’ailleurs pas effacé en anglais. Il existe même une variante française de
malheureusement /malO{OzmA)/ avec [O], phonème qu’on ne trouve qu’en syllabe ouverte.
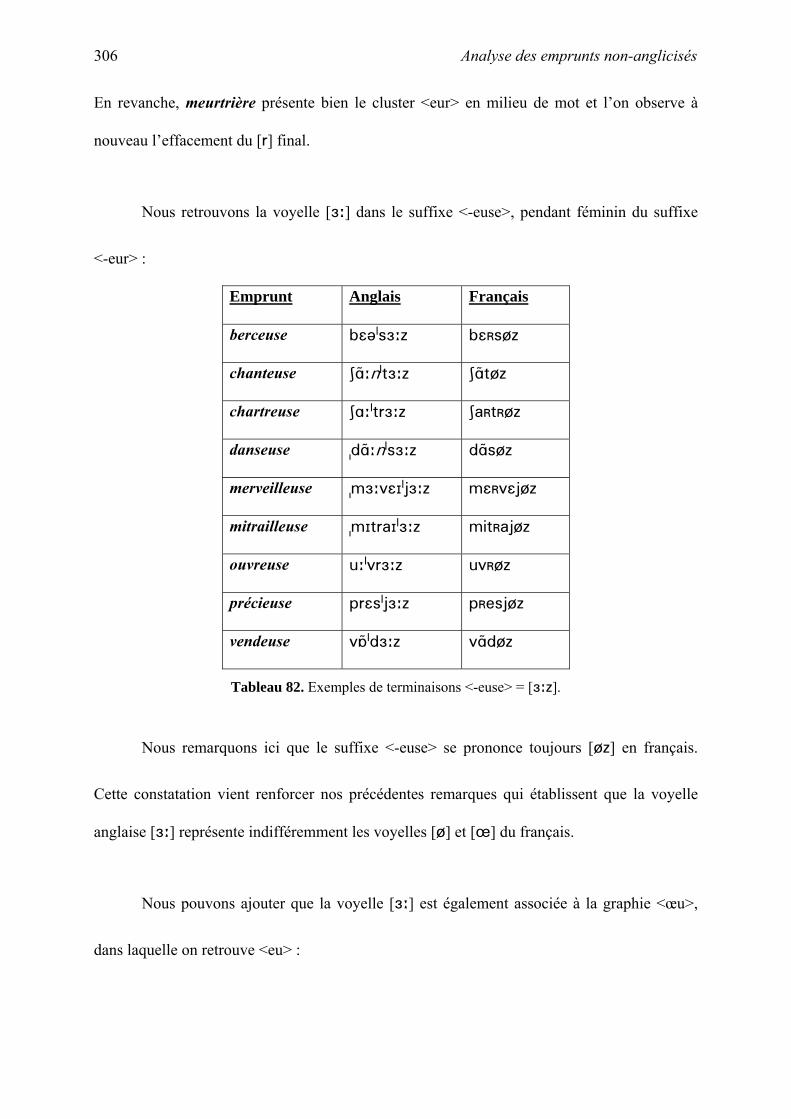
306 Analyse des emprunts non-anglicisés
En revanche, meurtrière présente bien le cluster <eur> en milieu de mot et l’on observe à
nouveau l’effacement du [r] final.
Nous retrouvons la voyelle [Œ˘] dans le suffixe <-euse>, pendant féminin du suffixe
<-eur> :
Emprunt Anglais Français
berceuse bE´:sŒ˘z bE{sOz
chanteuse SA)˘n:tŒ˘z SA)tOz
chartreuse SA˘:trŒ˘z Sa{t{Oz
danseuse «dA)˘n:sŒ˘z dA)sOz
merveilleuse «mŒ˘vEI:jŒ˘z mE{vEjOz
mitrailleuse «mItraI:Œ˘z mit{ajOz
ouvreuse u˘:vrŒ˘z uv{Oz
précieuse prEs:jŒ˘z p{esjOz
vendeuse vÅ):dŒ˘z vA)dOz
Tableau 82. Exemples de terminaisons <-euse> = [Œ˘z].
Nous remarquons ici que le suffixe <-euse> se prononce toujours [Oz] en français.
Cette constatation vient renforcer nos précédentes remarques qui établissent que la voyelle
anglaise [Œ˘] représente indifféremment les voyelles [O] et [ø] du français.
Nous pouvons ajouter que la voyelle [Œ˘] est également associée à la graphie <œu>,
dans laquelle on retrouve <eu> :
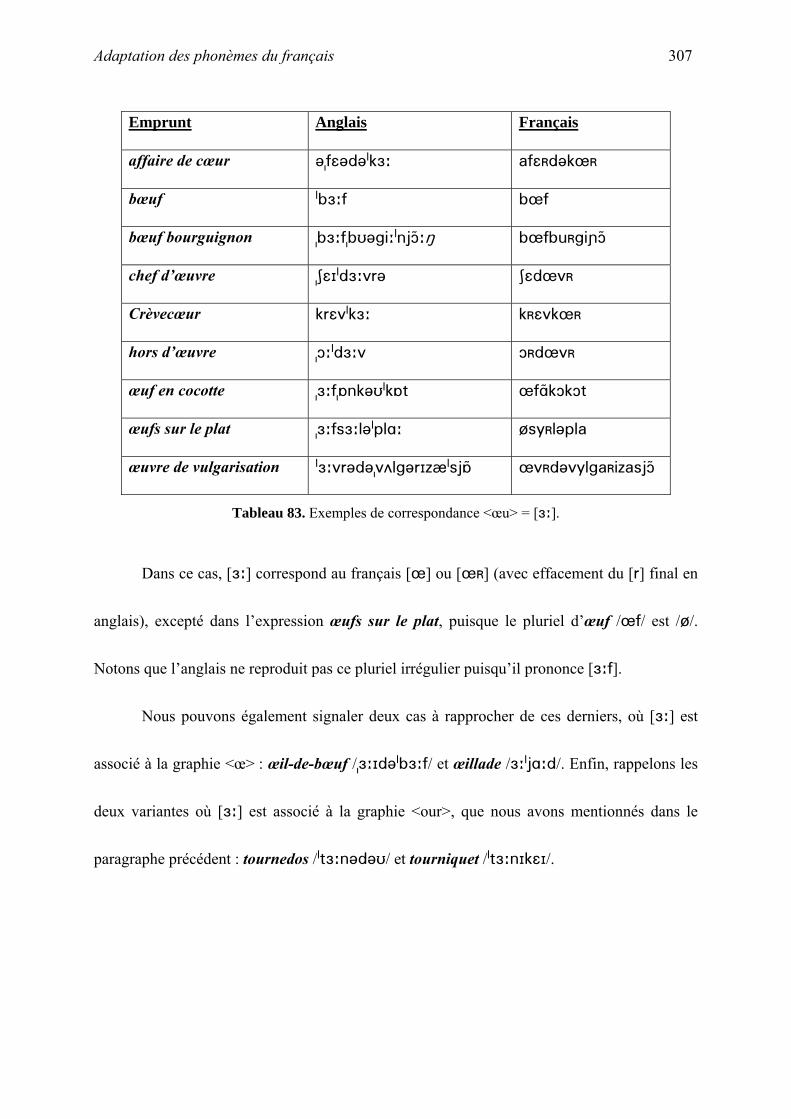
Adaptation des phonèmes du français 307
Emprunt Anglais Français
affaire de cœur ´«fE´d´:kŒ˘ afE{d´kø{
bœuf :bŒ˘f bøf
bœuf bourguignon «bŒ˘f«bU´gi˘:njç)˘N bøfbu{gi¯ç)
chef d’œuvre «SEI:dŒ˘vr´ SEdøv{
Crèvecœur krEv:kŒ˘ k{Evkø{
hors d’œuvre «ç˘:dŒ˘v ç{døv{
œuf en cocotte «Œ˘f«Ånk´U:kÅt øfA)kçkçt
œufs sur le plat «Œ˘fsŒ˘l´:plA˘ Osy{l´pla
œuvre de vulgarisation :Œ˘vr´d´«v√lg´rIzQ:sjÅ) øv{d´vylga{izasjç)
Tableau 83. Exemples de correspondance <œu> = [Œ˘].
Dans ce cas, [Œ˘] correspond au français [ø] ou [ø{] (avec effacement du [r] final en
anglais), excepté dans l’expression œufs sur le plat, puisque le pluriel d’œuf /øf/ est /O/.
Notons que l’anglais ne reproduit pas ce pluriel irrégulier puisqu’il prononce [Œ˘f].
Nous pouvons également signaler deux cas à rapprocher de ces derniers, où [Œ˘] est
associé à la graphie <œ> : œil-de-bœuf /«Œ˘Id´:bŒ˘f/ et œillade /Œ˘:jA˘d/. Enfin, rappelons les
deux variantes où [Œ˘] est associé à la graphie <our>, que nous avons mentionnés dans le
paragraphe précédent : tournedos /:tŒ˘n´d´U/ et tourniquet /:tŒ˘nIkEI/.
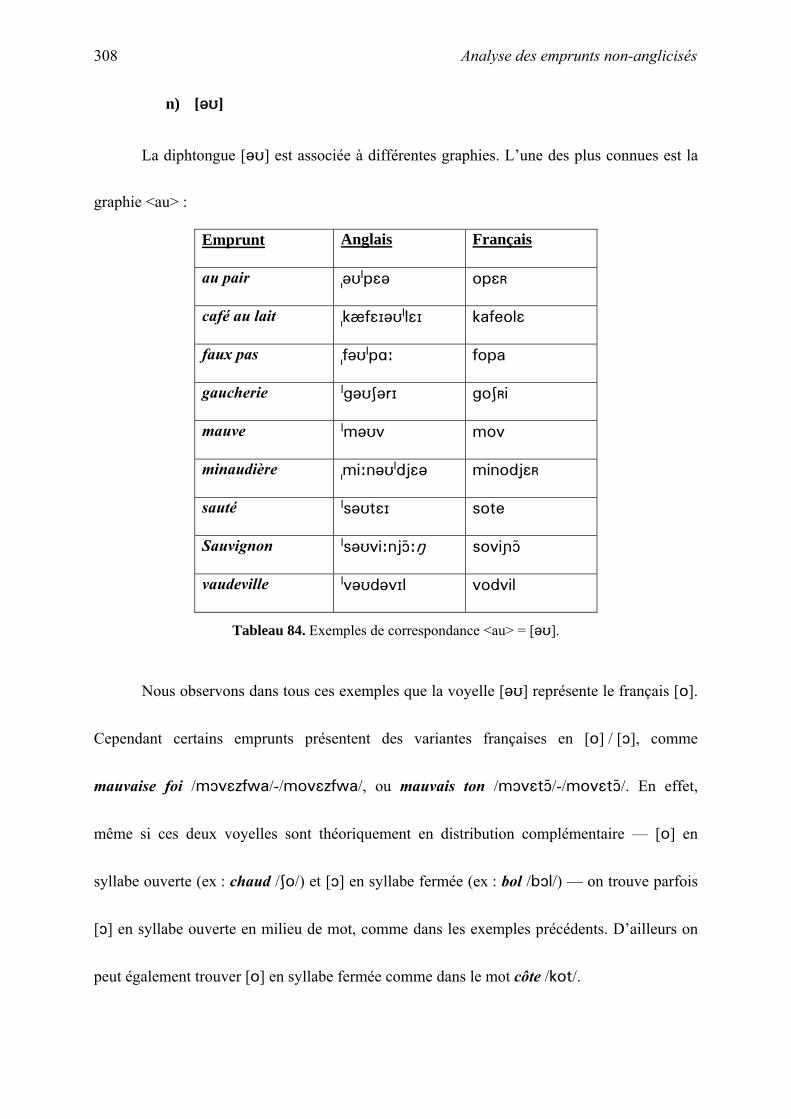
308 Analyse des emprunts non-anglicisés
n) [´U]
La diphtongue [´U] est associée à différentes graphies. L’une des plus connues est la
graphie <au> :
Emprunt Anglais Français
au pair «´U:pE´ opE{
café au lait «kQfEI´U:lEI kafeolE
faux pas «f´U:pA˘ fopa
gaucherie :g´US´rI goS{i
mauve :m´Uv mov
minaudière «mi˘n´U:djE´ minodjE{
sauté :s´UtEI sote
Sauvignon :s´Uvi˘njç)˘N sovi¯ç)
vaudeville :v´Ud´vIl vodvil
Tableau 84. Exemples de correspondance <au> = [´U].
Nous observons dans tous ces exemples que la voyelle [´U] représente le français [o].
Cependant certains emprunts présentent des variantes françaises en [o] / [ç], comme
mauvaise foi /mçvEzfwa/-/movEzfwa/, ou mauvais ton /mçvEtç)/-/movEtç)/. En effet,
même si ces deux voyelles sont théoriquement en distribution complémentaire — [o] en
syllabe ouverte (ex : chaud /So/) et [ç] en syllabe fermée (ex : bol /bçl/) — on trouve parfois
[ç] en syllabe ouverte en milieu de mot, comme dans les exemples précédents. D’ailleurs on
peut également trouver [o] en syllabe fermée comme dans le mot côte /kot/.
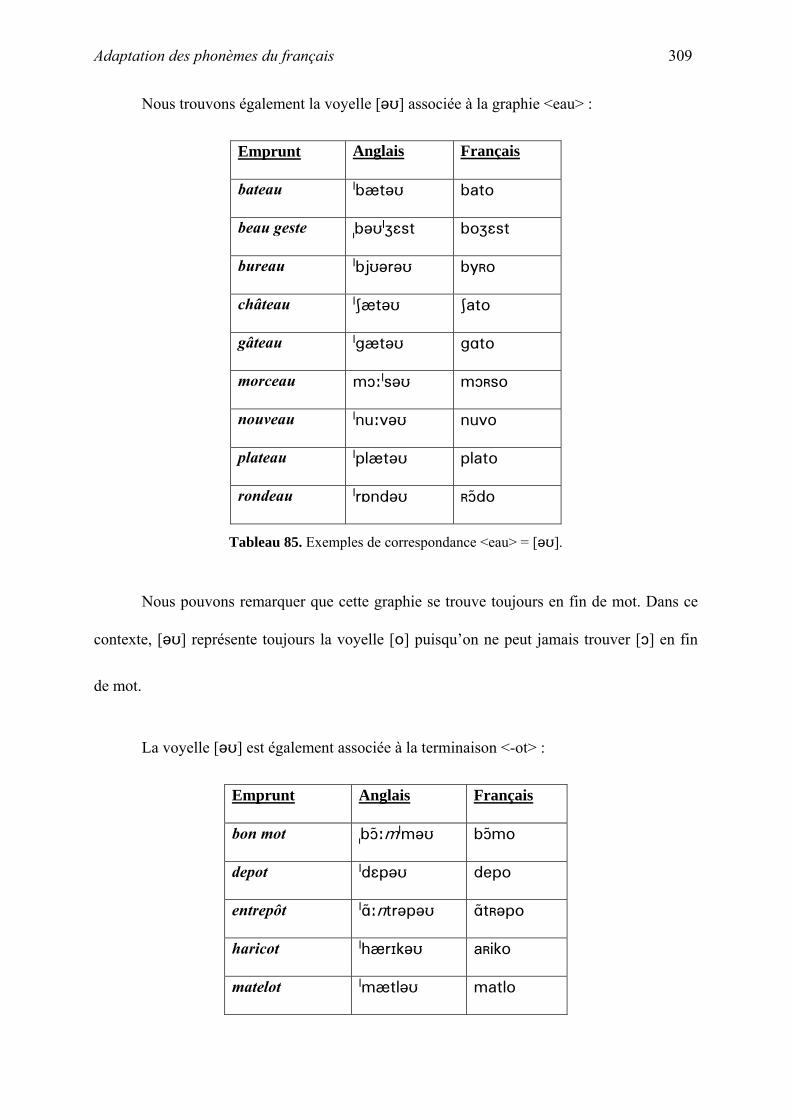
Adaptation des phonèmes du français 309
Nous trouvons également la voyelle [´U] associée à la graphie <eau> :
Emprunt Anglais Français
bateau :bQt´U bato
beau geste «b´U:ZEst boZEst
bureau :bjU´r´U by{o
château :SQt´U Sato
gâteau :gQt´U gAto
morceau mç˘:s´U mç{so
nouveau :nu˘v´U nuvo
plateau :plQt´U plato
rondeau :rÅnd´U {ç)do
Tableau 85. Exemples de correspondance <eau> = [´U].
Nous pouvons remarquer que cette graphie se trouve toujours en fin de mot. Dans ce
contexte, [´U] représente toujours la voyelle [o] puisqu’on ne peut jamais trouver [ç] en fin
de mot.
La voyelle [´U] est également associée à la terminaison <-ot> :
Emprunt Anglais Français
bon mot «bç)˘m:m´U bç)mo
depot :dEp´U depo
entrepôt :A)˘ntr´p´U A)t{´po
haricot :hQrIk´U a{iko
matelot :mQtl´U matlo

310 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
paletot :pQlIt´U palto
poule au pot «pu˘l´U:p´U pulopo
sabot :sQb´U sabo
tricot :tri˘k´U t{iko
Tableau 86. Exemples de terminaison <-ot> = [´U].
Ici encore [´U] représente la voyelle [o] puisque nous venons de voir qu’on ne peut
trouver [ç] en finale. Mais il est intéressant de noter que la consonne graphie finale est muette
en français et que l’anglais reproduit ce phénomène. On peut donc également considérer que
le <o> est final en anglais, ce qui oblige à tendre la dernière voyelle.
On trouve enfin la voyelle [´U] associée à la terminaison <-os> :
Emprunt Anglais Français
apropos «Qpr´:p´U ap{opo
dos-à-dos «d´UzA˘:d´U dozado
en gros «A)˘N:gr´U A)g{o
malapropos «mQ«lQpr´:p´U malap{opo
propos pr´:p´U p{opo
tournedos :tU´n´d´U tu{n´do
Tableau 87. Variantes avec terminaison <-os> = [´U].
Cette terminaison présente en fait peu de cas dont plusieurs variations sur le mot
propos (apropos, malapropos). Mais nous remarquons qu’ici aussi la consonne finale est

Adaptation des phonèmes du français 311
muette en français comme en anglais, et que la voyelle [´U] représente une fois encore le [o]
français. On peut alors en conclure que l’adaptation du [o] est [´U].
Nous nous demandons alors, à propos de certaines variantes supprimées de la Base de
Données Initiale, si un mot comme à gogo aurait dû être éliminé. En effet, il suit les règles de
l’anglais, raison pour laquelle nous l’avons supprimé. Cependant la transcription française est
/agogo/. On pourrait donc aussi considérer qu’il s’agit de l’adaptation du [o] dans le cadre
des emprunts français. Cette question peut en fait être posée chaque fois que la voyelle [´U]
est associée à la graphie <o> et que la tension est régulière. En réalité, nous ne nous posons
cette question que lorsque nous sommes face à une graphie marquée comme française comme
rôle /:r´Ul/ ou rôti /:r´UtI/, car en dehors de ces cas, nous ne doutons pas que la prononciation
[´U] soit issue d’une règle anglaise.
o) [Å]
Il n’est a priori pas surprenant de trouver la voyelle [Å] associée à la graphie <o>,
puisque c’est l’une des correspondances anglaises habituelles. En revanche, lorsqu’une
tension est attendue, cette prononciation devient irrégulière, comme c’est le cas avec les
emprunts suivants :
Emprunt Anglais Français
à la mode «Ql´:mÅd alamçd
belote b´:lÅt b´lçt
Boche :bÅS bçS
brioche brI:ÅS b{ijçS

312 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
cloche :klÅS klçS
compote :kÅmpÅt kç)pçt
papillote :pQpIlÅt papijçt
poché :pÅSEI pçSe
popote p´:pÅt pçpçt
roche moutonnée «rÅSmU:tÅnEI {çSmutçne
Tableau 88. Variantes où [Å] est irrégulier.
Nous constatons dans tous ces exemples que la voyelle [Å] représente le français [ç].
Nous remarquons notamment les terminaisons <-oche> prononcée [ÅS] et <-ote> prononcée
[Åt]. La non-tension sert donc à imiter la prononciation française, Mais on peut également
remarquer que [ç] et [Å] sont situés dans la même zone du trapèze des voyelles, ce qui
explique l’utilisation de [Å] pour rendre le [ç] français.
4. Les consonnes
a) [Z]
Le phonème [Z] est présent dans les systèmes anglais et français. Il ne pose donc
aucun problème d’adaptation. Toutefois, on remarque que [Z] est associé à des graphies
inhabituelles pour l’anglais, comme <j> :
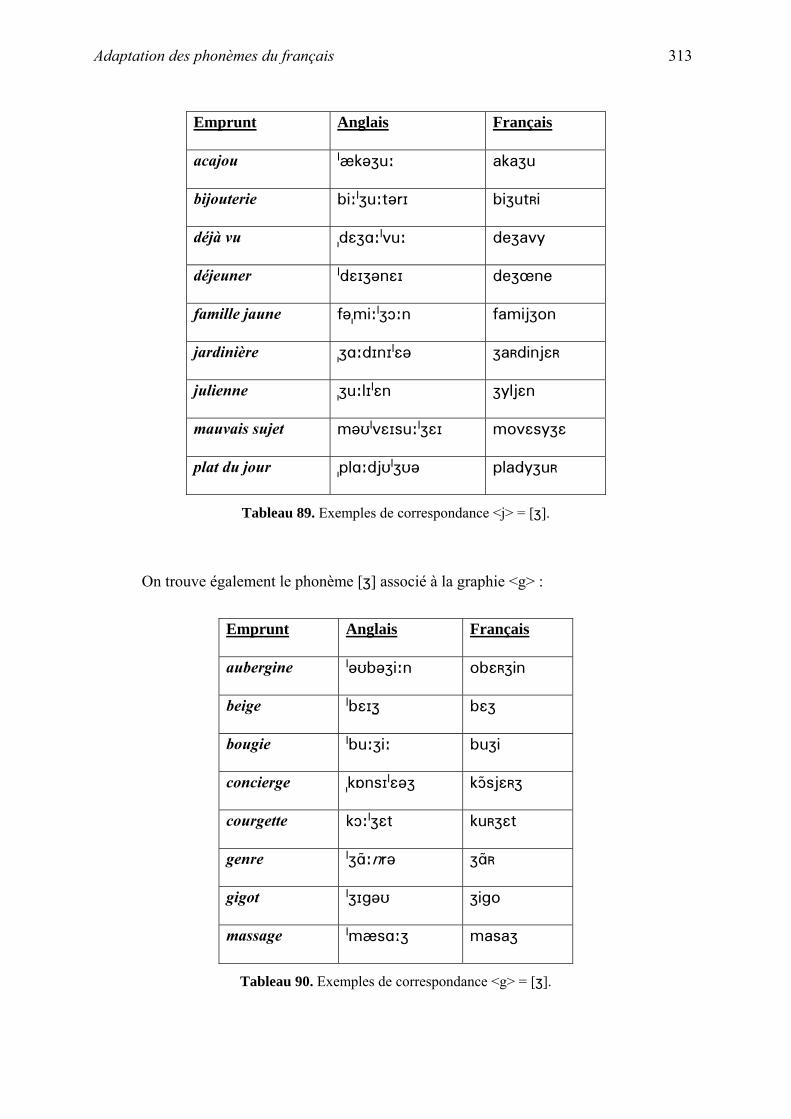
Adaptation des phonèmes du français 313
Emprunt Anglais Français
acajou :Qk´Zu˘ akaZu
bijouterie bi˘:Zu˘t´rI biZut{i
déjà vu «dEZA˘:vu˘ deZavy
déjeuner :dEIZ´nEI deZøne
famille jaune f´«mi˘:Zç˘n famijZon
jardinière «ZA˘dInI:E´ Za{dinjE{
julienne «Zu˘lI:En ZyljEn
mauvais sujet m´U:vEIsu˘:ZEI movEsyZE
plat du jour «plA˘djU:ZU´ pladyZu{
Tableau 89. Exemples de correspondance <j> = [Z].
On trouve également le phonème [Z] associé à la graphie <g> :
Emprunt Anglais Français
aubergine :´Ub´Zi˘n obE{Zin
beige :bEIZ= bEZ
bougie :bu˘Zi˘ buZi
concierge «kÅnsI:E´Z kç)sjE{Z
courgette kç˘:ZEt ku{ZEt
genre :ZA)˘nr´ ZA){
gigot :ZIg´U Zigo
massage :mQsA˘Z masaZ
Tableau 90. Exemples de correspondance <g> = [Z].

314 Analyse des emprunts non-anglicisés
En général, ces graphies sont plutôt associées à la fricative [dZ] (ex : judge, range).
En plus de ces correspondances irrégulières, nous remarquons une distribution inhabituelle en
anglais. En effet, le phonème [Z] se trouve en général en milieu de mot et est souvent issu de
la palatalisation de [z] devant [j] (ex : measure /:mEZ´/, allusion /´:lu˘Zn/). Or dans ces
emprunts, nous le trouvons souvent à l’initiale ou en finale de mot (ex : jardinière, julienne,
genre, gigot, concierge, massage).
En réalité, nous assistons ici à l’importation de correspondances et de distributions
françaises, alors que jusqu’à présent nous avions commenté les substitutions de phonèmes
français.
b) [S]
Comme [Z], la consonne [S] est présente dans les deux systèmes. Mais on la trouve ici
associée à la graphie <ch>, habituellement prononcée [tS] en anglais :
Emprunt Anglais Français
accouchement ´:ku˘SmÅ) akuSmA)
chandelier «SQnd´:lI´ SA)d´lje
chauffeur :S´Uf´ Sofø{
machine m´:Si˘n maSin
moustache m´:stA˘S mustaS
niche :ni˘S niS
parachute :pQr´Su˘t pa{aSyt
vichyssoise «vi˘SI:swA˘z viSiswaz
Tableau 91. Exemples de correspondance <ch> = [S].

Adaptation des phonèmes du français 315
Il s’agit donc également d’une importation de la correspondance. En revanche,
contrairement à [Z], on peut trouver [S] à l’initiale et en finale en anglais. La distribution est
donc tout à fait régulière.
c) [nj]
Nous trouvons ce cluster lié au digraphe <gn> :
Emprunt Anglais Français
champignon :SQmpi˘njç)˘ SA)pi¯ç)
chignon :Si˘njÅn Si¯ç)
cognac :kÅnjQk kç¯ak
Grand Guignol «grA)˘Ngi˘:njÅl g{A)gi¯çl
lorgnette lç˘:njEt lç{¯Et
mignardise «mInjA˘:di˘z mi¯a{diz
pâté de campagne «pQtEId´kÅm:pA˘nj´ pAted´kA)pa¯
pelure d’oignon p´«ljU´:dÅnjÅ) p´ly{dç¯ç)
vignette vI:njEt vi¯Et
Tableau 92. Exemples de correspondance <gn> = [nj].
Nous constatons que le cluster [nj] représente le phonème français [¯]. Mais nous
pouvons remarquer que cette consonne palatale tend à disparaître du français et à être
remplacée par [nj], ce qui justifie d’autant plus l’utilisation de ce cluster pour imiter la
prononciation française.

316 Analyse des emprunts non-anglicisés
Nous pouvons également signaler deux cas où le digraphe <gn> est prononcé [nw] :
baignoire /:bEInwA˘/ et peignoir /:pEInwA˘/. Cette prononciation s’explique par le fait que le
cluster français [wa{] est rendu par l’anglais [wA˘] ; un cluster [njwA˘] est alors impossible,
d’où l’effacement de la glissée [j].
Enfin, nous pouvons signaler deux variantes d’emprunts figurant dans le tableau ci-
dessus, dans lesquelles le digraphe <gn> est prononcé [n] : chignon /SI:nÅn/ et vignette
/vI:nEt/. Cette variante de chignon est d’ailleurs annotée comme étant ‘old-fashioned’ par
l’EPD. Mais comment expliquer cette prononciation ? La seule hypothèse que nous pouvons
proposer est celle de l’hypercorrection.
5. Le cas particulier de la graphie <ll>
La graphie <ll> est intéressante car elle n’a pas toujours la même valeur en français.
Parfois elle correspond au phonème [l] (ex : ville) et parfois au phonème [j] (ex : veille). En
anglais, sa correspondance habituelle est [l]. Ainsi, lorsqu’elle est associée à [j], cette
correspondance est irrégulière et on peut considérer qu’il s’agit de l’importation de la
correspondance française.
Mais si nous observons que lorsque <ll> = [l] en français, la correspondance est
identique en anglais, en revanche lorsque <ll> = [j] en français, la correspondance n’est pas
toujours la même. Nous allons voir que l’adaptation du [j] français est même assez complexe.
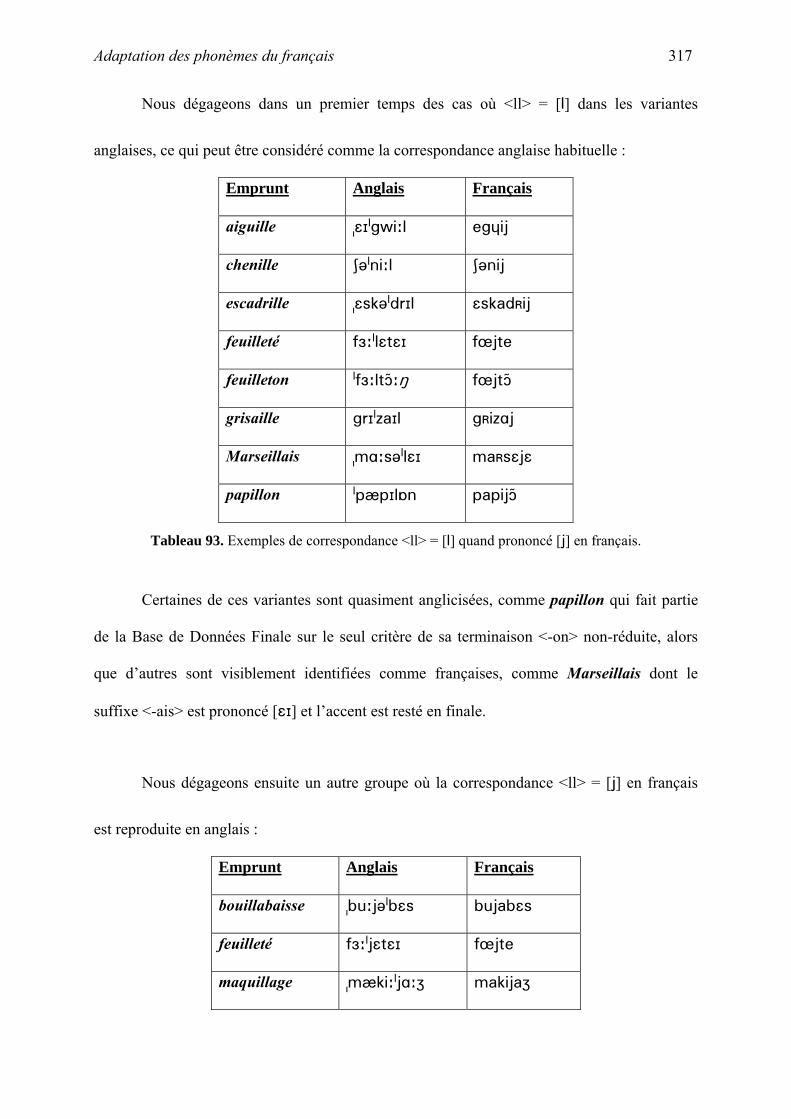
Adaptation des phonèmes du français 317
Nous dégageons dans un premier temps des cas où <ll> = [l] dans les variantes
anglaises, ce qui peut être considéré comme la correspondance anglaise habituelle :
Emprunt Anglais Français
aiguille «EI:gwi˘l egÁij
chenille S´:ni˘l S´nij
escadrille «Esk´:drIl Eskad{ij
feuilleté fŒ˘:lEtEI føjte
feuilleton :fŒ˘ltç)˘N føjtç)
grisaille grI:zaIl g{izAj
Marseillais «mA˘s´:lEI ma{sEjE
papillon :pQpIlÅn papijç)
Tableau 93. Exemples de correspondance <ll> = [l] quand prononcé [j] en français.
Certaines de ces variantes sont quasiment anglicisées, comme papillon qui fait partie
de la Base de Données Finale sur le seul critère de sa terminaison <-on> non-réduite, alors
que d’autres sont visiblement identifiées comme françaises, comme Marseillais dont le
suffixe <-ais> est prononcé [EI] et l’accent est resté en finale.
Nous dégageons ensuite un autre groupe où la correspondance <ll> = [j] en français
est reproduite en anglais :
Emprunt Anglais Français
bouillabaisse «bu˘j´:bEs bujabEs
feuilleté fŒ˘:jEtEI føjte
maquillage «mQki˘:jA˘Z makijaZ

318 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
Marseillais «mA˘sEI:jEI ma{sEjE
médaillon :mEIdaIjÅ) medajç)
merveilleuse «mŒ˘vEI:jŒ˘z mE{vEjOz
millefeuille «mi˘l:fŒ˘j´ milføj
paillette paI:jEt pajEt
papillon :pQpIjÅ) papijç)
quincaillerie kQ)kaIj´:rI kE)kaj{i
rillettes :ri˘jEt {ijEt
Tableau 94. Exemples de correspondances <ll> = [j].
Nous observons donc l’importation de la correspondance française. Cependant, nous
pouvons remarquer que dans les variantes anglaises, nous ne trouvons [j] qu’en position
d’attaque de syllabe. En effet, alors qu’en français [j] peut se trouver en position de coda, en
anglais [j] est toujours suivi d’une voyelle. Nous voyons dans certains des exemples du
tableau que pour respecter cette distribution, l’anglais va jusqu’à ajouter un schwa, donc au
final une syllabe supplémentaire, comme dans millefeuille /«mi˘l:fŒ˘j´/ ou quincaillerie
/kQ)kaIj´:rI/. Nous comprenons alors que c’est la position de coda de [j] qui pose problème
pour l’adaptation du mot.
Nous pouvons également remarquer que certains emprunts du premier tableau sont
également présents dans le deuxième, comme feuilleté, Marseillais ou papillon. On trouve
donc pour ces emprunts à la fois une variante imitant le français et une autre appliquant la
règle anglaise. Nous pouvons d’ailleurs signaler à propos de feuilleté que quelle que soit la

Adaptation des phonèmes du français 319
correspondance (française ou anglaise), la variante est prononcée en trois syllabes /fŒ˘:jEtEI/-
/fŒ˘:lEtEI/. Cette dernière variante serait-elle anglicisée à partir de la première ?
Nous remarquons également un troisième groupe, qui semble être à mi-chemin des
deux premiers, où <ll> se prononce [lj] :
Emprunt Anglais Français
carillon kQ:rIlj´n ka{ijç)
court bouillon «kç˘t:bu˘ljÅn ku{bujç)
paillette pQl:jEt pajEt
paillon :pQlj´n pajç)
treillis :trElji˘ t{Eji
Tableau 95. Variantes avec correspondance <ll> = [lj].
Nous différencions les exemples ci-dessus de cas comme cellulite /«sEljU:li˘t/, où la
prononciation [lj] s’explique par la présence régulière d’un [j] devant [U]. Ici, la prononciation
[lj] donne l’impression que le locuteur hésite entre l’application de la correspondance anglaise
ou française. Nous pouvons également voir ces variantes comme des exemples montrant
l’évolution vers l’anglicisation : plus tout à fait la correspondance française, mais pas encore
la correspondance anglaise. Notons néanmoins que ces cas sont assez rares.
Nous pouvons également commenter une autre variante de paillette, /«pQlI:Et/, qui
surprend car elle semble correspondre à une graphie <palliette>. Mais on peut également la
voir comme une variante de /pQl:jEt/ avec diérèse. Cette variante est à rapprocher de celle de
paillon /:pQlj´n/, qui semble en fait correspondre à une graphie <pallion>. S’agirait-il d’une

320 Analyse des emprunts non-anglicisés
erreur de lecture, les locuteurs étant habitués aux terminaisons en <-ion> ? Mais pour
paillette, cela ne peut venir du suffixe. Pourtant les deux variantes /pQl:jEt/ et /«pQlI:Et/
montrent que le <i> est traité comme suivant le digraphe <ll> et non le précédant, puisqu’elles
sont prononcées [pQ-]. Enfin, nous pouvons rapprocher de ces cas la variante de tenaillon
/tI:nQlI´n/, qui semble elle aussi correspondre à une graphie <tenallion>. Cette variante
présente les mêmes caractéristiques que celles de paillon et paillette que nous venons de
commenter.
Nous remarquons en fait que tous les exemples du tableau ci-dessus — ainsi que
tenaillon — présentent une graphie <ill>. Nous pouvons alors envisager l’hypothèse d’une
mauvaise interprétation de certains locuteurs qui croient lire <lli>, d’où la prononciation [lj],
qui ne serait alors pas le fruit d’une hésitation sur la correspondance à appliquer, mais d’une
erreur.
En plus de ces trois groupes principaux, nous trouvons une multitude de variantes dans
lesquelles [j] est absent. Nous avons déjà mentionné certains exemples à propos de la
diphtongue [aI], qui représente le français [aj] :
Emprunt Anglais Français
canaille 1 k´:naI kanaj
canaille 2 k´:nA˘I kanaj
grisaille grI:zaI g{izAj
mitraille mi˘:traI mit{aj
mitrailleuse «mItraI:Œ˘z mit{ajOz
passacaille 1 pQs´:kaI pasakaj

Adaptation des phonèmes du français 321
Emprunt Anglais Français
passacaille 2 «pQs´:kA˘I pasakaj
taille :taI taj
tirailleur «tIraI:Œ˘ ti{ajø{
Tableau 96. Exemples d’adaptations de [aj].
Dans tous ces exemples, le français [aj] est orthographié <aill>. Dans la plupart des
cas, ce cluster [aj] est en fin de mot. Or nous avons vu que cette position de [j] pose un
problème pour l’anglais. Le cluster est alors rendu soit par la diphtongue [aI], soit par un
cluster [A˘I] comme dans canaille ou passacaille, dans lequel on retrouve la correspondance
la plus fréquente pour le [a] français : [A˘], à laquelle s’ajoute un [I] qui représente le [j]
français. D’une certaine manière, on peut donc parler de ‘vocalisation’ de la glissée dans le
but de ne pas violer les règles de l’anglais.
Dans deux exemples de ce tableau, mitrailleuse et tirailleur, le cluster [aj] se trouve
au sein du mot. Il est rendu ici aussi par [aI]. Mais, alors qu’en français [j] est en position
d’attaque de syllabe — et nous avons vu jusqu’ici que, dans ce contexte, l’anglais conservait
la glissée — on remarque que ces deux variantes ne présentent pas de [j]. On peut d’ailleurs
comparer ces variantes à celles de paillon /:paIjÅ)/, paillette /paI:jEt/ ou médaillon
/:mEIdaIjÅ)/, dans lesquelles on trouve la correspondance [aI] pour le cluster [aj], à laquelle
s’ajoute une glissée en attaque de syllabe.

322 Analyse des emprunts non-anglicisés
Nous trouvons également des variantes sans [j] pour représenter le cluster français
[ij] :
Emprunt Anglais Français
aiguille «EI:gwi˘ egÁij
en famille «A)˘nfQ:mi˘ A)famij
maquillage «mQki˘:A˘Z makijaZ
maquillé :mQkIEI makije
pétillant :pEtIÅ) petijA)
pointillé «pçIntI:EI pwE)tije
Quatorze Juillet k´:tç˘zZwi˘:EI katç{zZÁijE
rillettes ri˘:Et {ijEt
Sémillon :sEmIÅ) semijç)
Tableau 97. Exemples d’adaptation de [ij].
Le cluster [ij] est toujours orthographié <ill>. Dans plusieurs de ces exemples, nous
retrouvons la correspondance <i> = [i˘]. En syllabe inaccentuée, [i˘] est réduit à [I]. Il semble
alors que le [j] soit en quelque sorte ‘intégré’ à la voyelle [i˘], que ce soit lorsque le cluster [ij]
est en fin de mot, comme dans aiguille ou en famille, ou en milieu de mot, comme dans
maquillage ou Quatorze Juillet, voire en début de mot comme dans rillettes, c'est-à-dire
même lorsque [j] est en attaque de syllabe. Nous pouvons cependant signaler que certains de
ces emprunts présentent également une variante avec [j], comme maquillage /«mQki˘:jA˘Z/,
maquillé /:mQkIjEI/, pétillant /:pEtIjÅ)/ ou rillettes /:ri˘jEt/. Nous remarquons pour plusieurs
d’entre eux que les variantes avec ou sans [j] proviennent de différents dictionnaires. Nous

Adaptation des phonèmes du français 323
pensons alors que ces divergences illustrent en fait la tentative des éditeurs de retranscrire ces
prononciations imitant le français, et que leurs réalisations ne sont peut-être pas si différentes.
Pourtant, on trouve parfois des variantes avec ou sans [j] dans le même dictionnaire, comme
c’est le cas pour maquillage et maquillé. Il est alors envisageable de penser que certains
locuteurs tentent d’imiter la prononciation française au plus près en prononçant un [j] marqué.
Nous remarquons également pour les mots en <-ille> que certains d’entre eux font
partie du premier tableau avec la correspondance anglaise, comme aiguille /«EI:gwi˘l/.
D’ailleurs plusieurs mots en <-ille> sont prononcés [i˘l], comme chenille /S´:ni˘l/, cheville
/S´:vi˘l/ ou vanille /v´:ni˘l/. Ces terminaisons qui mélangent correspondances anglaises et
françaises apparaissent comme plus anglicisées que les terminaisons en [i˘] d’aiguille ou en
famille, mais moins que des variantes comme espadrille /«Esp´:drIl/, qui présente une
anglicisation totale de la terminaison.
Nous ne trouvons que deux variantes sans [j] pour représenter le cluster français [Ej] :
Merveille du Jour /mŒ˘«vEId´:ZU´/, adaptation du français /mE{vEjdyZu{/, et Marseillaise
/«mA˘sEI:EIz/, adaptation de /ma{sEjEz/. Nous constatons que le cluster est orthographié
<eill> et rendu par la diphtongue [EI]. Dans les autres emprunts présentant ce cluster,
Marseillais /«mA˘sEI:jEI/, merveilleux /«mŒ˘vEI:jŒ˘/ et merveilleuse /«mŒ˘vEI:jŒ˘z/, nous
retrouvons cette diphtongue, en plus d’un [j]. Marseillaise présente d’ailleurs les deux
variantes, avec ou sans [j].

324 Analyse des emprunts non-anglicisés
Nous trouvons également quelques variantes sans [j] pour représenter le cluster
français [øj] :
Emprunt Anglais Français
feuilleton :fŒ˘Itç)˘N føjtç)
millefeuille «mi˘l:fçI milføj
portefeuille «pç˘t:fçI pç{t´føj
Tableau 98. Exemples d’adaptation de [øj].
Le cluster [øj] est toujours orthographié <euill>, mais ces cas sont évidemment moins
nombreux. La variante de feuilleton /:fŒ˘Itç)˘N/ est à rapprocher de celles de canaille et
passacaille en [A˘I]. Nous retrouvons la correspondance <eu> = [Œ˘] et le [j] est rendu par un
[I]. Mais nous pouvons la comparer avec la variante de feuilleté /fŒ˘:jEtEI/. Les deux mots ont
la même structure en français : / føjtç)/-/føjte/, mais sont traités de manière différente en
anglais. Nous constatons en fait que lorsque l’anglais ne possède pas de diphtongue
ressemblant au cluster français, il propose différentes solutions pour s’en rapprocher.
Les deux autres variantes présentent des variantes en [çI], ce qui est curieux puisqu’il
ne s’agit ni d’une correspondance anglaise, ni d’une prononciation proche de celle d’origine.
Mais nous venons de voir que l’anglais essayait le plus souvent de rendre les clusters français
avec [j] par une diphtongue. Il semble qu’il s’agisse bien ici d’une imitation du français, en ce
sens que l’anglais a tenté de représenter le cluster [øj] ; mais on peut également parler d’une
‘anglicisation orale’, puisque l’anglais a cherché à tout prix à rendre ce cluster par une
diphtongue anglaise, quitte à s’éloigner un peu plus de la prononciation d’origine.

Adaptation des phonèmes du français 325
Nous utilisons le terme ‘anglicisation orale’ puisqu’en général l’anglicisation
s’observe par l’application de correspondances graphie-phonie habituelles. Or ici, il s’agit
toujours d’une correspondance irrégulière. Il semble que ce phénomène soit le seul du genre,
mais on peut remarquer qu’il est présent dans les variantes des emprunts œil-de-bœuf
/«çId´:bŒ˘f/, œil-de-perdrix /«çId´:pŒ˘dri˘/ et trompe l’œil /«trÅmp:lçI/, où c’est la graphie
<œil> qui représente le cluster [øj].
Enfin, nous relevons des variantes sans [j] pour représenter le cluster français [uj] :
Emprunt Anglais Français
mouillé :mwi˘EI muje
nouille :nu˘I nuj
ratatouille 1 «rQt´:twi˘ {atatuj
ratatouille 2 «rQt´:tu˘I {atatuj
rouille :ru˘I {uj
Tableau 99. Exemples d’adaptation de [uj].
Le cluster [uj] est toujours représenté par la graphie <ouill>. Nous observons ici deux
prononciations différentes. La première, [u˘I], est à rapprocher de canaille et passacaille en
[A˘I] ou feuilleton en [Œ˘I], c'est-à-dire la correspondance <ou> = [u˘] suivi de la voyelle [I]
pour représenter [j]. Ce cluster est utilisé puisqu’aucune diphtongue de l’anglais ne peut
convenir. Ajoutons qu’on le trouve en fin de mot, tandis que lorsque le cluster français [uj] se
trouve en milieu de mot, on va trouver [j], comme dans bouilli /:bu˘jI/, bouillon /:bu˘jÅ)/ ou la
deuxième variante de mouillé /:mu˘jEI/.

326 Analyse des emprunts non-anglicisés
La seconde prononciation, [wi˘], est plus surprenante. Elle a déjà été partiellement
commentée dans le paragraphe sur [u˘]. Cette prononciation n’est pas une imitation du
français. Il ne s’agit pas non plus d’une prononciation anglicisée. En réalité, il semble qu’il
s’agisse d’une erreur d’interprétation, peut-être due à sa graphie particulièrement inhabituelle
en anglais. Au lieu d’appliquer les correspondances <ou> = [u˘] et <ill> = [j] ou [I], comme
nous l’observons dans les variantes précédentes, certains locuteurs appliquent la
correspondance <i> = [i˘], réduisant alors [u˘] à [w]. En finale, le [j] est ‘inclus’ dans la
voyelle [i˘], comme pour ratatouille /«rQt´:twi˘/, et en milieu de mot, [j] est présent en
attaque de syllabe, comme dans bouillon /:bwi˘jç)˘N/ ou bouillabaisse /«bwi˘j´:bEs/ —
excepté pour mouillé /:mwi˘EI/.
Dans ces derniers exemples, ce n’est donc pas l’adaptation du [j] français qui pose
problème, mais plutôt la graphie française, qui paraît peut-être complexe aux yeux de certains
locuteurs et les trouble au point qu’ils se trompent dans l’application des correspondances.
Quoi qu’il en soit, ces cas montrent que certains locuteurs ne connaissent visiblement pas la
prononciation originale, mais qu’ils ont connaissance de certaines correspondances à
appliquer dans le cadre des emprunts français.
Pourtant, ce qui intéressant dans le problème de la graphie <ll>, c’est que pour lui
donner la bonne correspondance, il faut nécessairement connaître la prononciation d’origine.
Il est évidemment possible d’appliquer la correspondance anglaise dans tous les cas, et donc
parfois de se tromper, mais il n’est pas possible d’appliquer la correspondance française à
chaque fois que le mot est identifié comme français. Nous remarquons d’ailleurs qu’on ne
trouve jamais la correspondance <ll> = [j] en anglais si elle n’est pas présente en français. Il

Adaptation des voyelles nasales 327
est donc surprenant, dans un exemple comme bouillabaisse /«bwi˘j´:bEs/, qu’un locuteur
applique la bonne correspondance pour <ll>, mais une mauvaise pour <ouill>.
C. ADAPTATION DES VOYELLES NASALES
Le français compte dans son système vocalique quatre voyelles nasales : [A)], [ç)], [E)] et
[ø)], quoique cette dernière fasse de moins en moins partie du système de nombreux
francophones. Elle tend à être remplacé par [E)].
L’anglais n’a pas de voyelles nasales dans son système ; ces voyelles vont donc poser
un problème pour l’imitation puisqu’elles comptent un trait qu’aucune voyelle anglaise ne
possède. Le moyen le plus simple de rendre ce trait de nasalité est de faire suivre la voyelle
d’une consonne nasale, et nous allons voir qu’il est souvent employé. Toutefois, nous avons
signalé dans la première partie que les dictionnaires proposent tous des voyelles nasales dans
leurs transcriptions161. Il semblerait donc que certains locuteurs anglophones parviennent à
réaliser des voyelles nasales, qui sont sans doute réservées au cadre des emprunts français.
Cependant, les dictionnaires n’utilisent pas tous les mêmes symboles pour retranscrire ces
voyelles nasales : ces différents symboles représentent-ils des prononciations différentes ou
bien ont-ils la même valeur ? L’EPD a-t-il raison de proposer quatre voyelles nasales alors
que bien souvent les francophones n’en utilisent que trois ?
En se servant des correspondances irrégulières, nous allons tenter de mettre en
évidence l’adaptation des voyelles nasales du français et de répondre à ces questions. Nous
allons cette fois encore partir de la voyelle anglaise et montrer dans quels contextes elle est
utilisée et quelle voyelle française elle représente. Même si les voyelles nasales françaises
161 Cf. p. 71

328 Analyse des emprunts non-anglicisés
sont souvent représentées par une voyelle anglaise suivie d’une consonne nasale, nous
présentons uniquement la voyelle dans le titre car, comme nous allons le voir, la consonne
suivante dépend souvent du contexte.
1. Les voyelles du système anglais
a) [Å]
La voyelle [Å] représente les cluster [Ån], [Åm] et [ÅN]. En général, la consonne
nasale dépend du contexte puisque [n] devient [m] devant [p] et [b], et [N] devant [k] et [g],
par le phénomène d’assimilation.
Nous trouvons la voyelle [Å] associée aux graphies <an> ou <am> (devant <p> ou
<b>). Pour simplifier, nous parlons de la graphie <an> et de la prononciation [Ån], mais en y
incluant leurs variantes contextuelles :
Emprunt Anglais Français
allemande :Ql´mÅnd almA)d
chanson :SÅnsÅ) SA)sç)
en passant «Ån:pQsÅn A)pasA)
flambé :flÅmbEI flA)be
langoustine «lÅNgU:sti˘n lA)gustin
langue de chat «lÅNd´:SA˘ lA)gd´Sa
mangetout «mÅndZ:tu˘ mA)Ztu
restaurant :rEst´rÅnt {Estç{A)
Tableau 100. Exemples de correspondances <an> = [Ån].

Adaptation des voyelles nasales 329
Nous voyons dans les exemples de ce tableau que le cluster [Ån] représente la voyelle
nasale [A)]. Nous pouvons remarquer que lorsqu’il s’agit de la terminaison <-ant>, prononcée
[A)] en français, nous trouvons des variantes avec la consonne finale prononcée, comme dans
restaurant /:rEst´rÅnt/, ou avec la consonne finale muette, comme dans en passant
/«Ån:pQsÅn/, ce qui est alors plus proche du français. Un même emprunt présente d’ailleurs
parfois les deux variantes comme pratiquant /«prQti˘:kÅnt/-/«prQti˘:kÅn/. Certains
dictionnaires présentent également la variante avec la consonne optionnelle comme croissant
dans l’EPD /:kwQsÅnt/. Mais la consonne finale peut également être muette dans d’autres
terminaisons comme le montrent les exemples grand mal /«grÅn:mQl/ ou Grand Prix
/«grÅn:pri˘/.
Dans la variante langue de chat /«lÅNd´:SA˘/, on constate que la consonne [n] devient
vélaire devant [g] — qui est d’ailleurs prononcé dans une autre variante /«lÅNgd´:SA˘/ —
lequel disparaît par la règle d’effacement du [g] final comme dans le mot king /:kIN/. La
variante sang-froid /«sÅN:frwA˘/ peut être expliquée de la même manière.
Cependant, nous relevons plusieurs variantes où <an> est prononcé [ÅN] sans que cela
puisse être expliqué par le contexte :
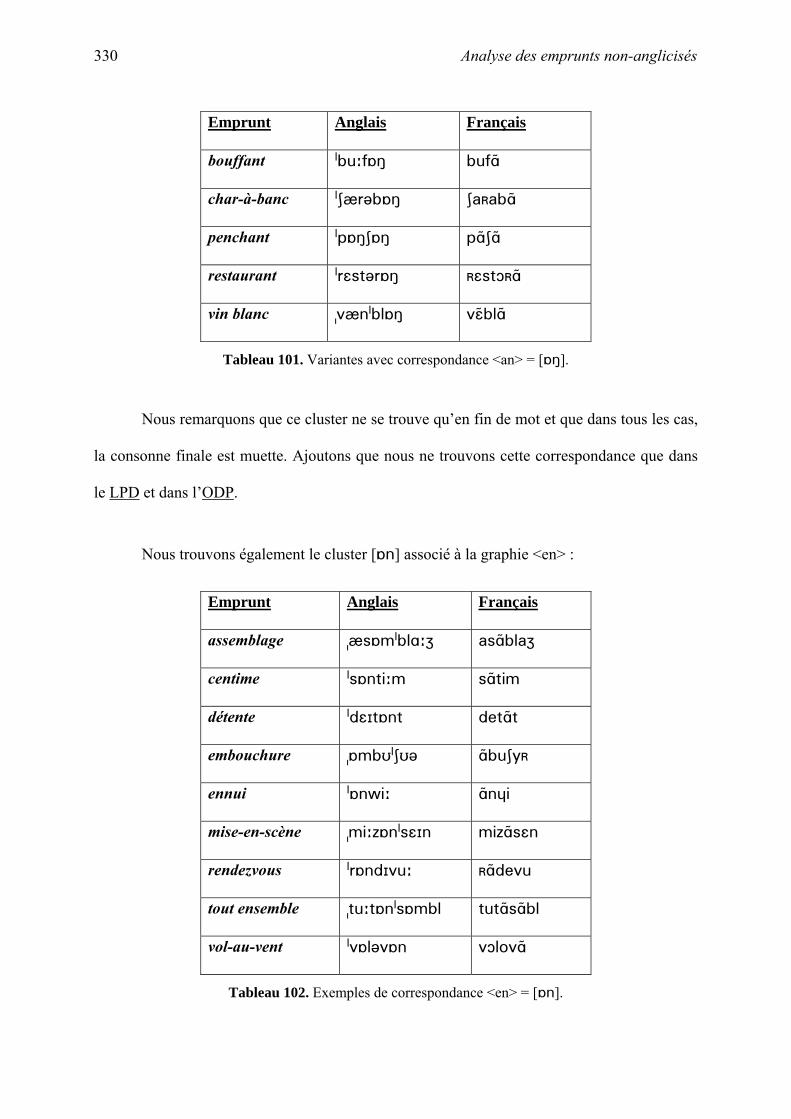
330 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
bouffant :bu˘fÅN bufA)
char-à-banc :SQr´bÅN Sa{abA)
penchant :pÅNSÅN pA)SA)
restaurant :rEst´rÅN {Estç{A)
vin blanc «vQn:blÅN vE)blA)
Tableau 101. Variantes avec correspondance <an> = [ÅN].
Nous remarquons que ce cluster ne se trouve qu’en fin de mot et que dans tous les cas,
la consonne finale est muette. Ajoutons que nous ne trouvons cette correspondance que dans
le LPD et dans l’ODP.
Nous trouvons également le cluster [Ån] associé à la graphie <en> :
Emprunt Anglais Français
assemblage «QsÅm:blA˘Z asA)blaZ
centime :sÅnti˘m sA)tim
détente :dEItÅnt detA)t
embouchure «ÅmbU:SU´ A)buSy{
ennui :Ånwi˘ A)nÁi
mise-en-scène «mi˘zÅn:sEIn mizA)sEn
rendezvous :rÅndIvu˘ {A)devu
tout ensemble «tu˘tÅn:sÅmbl tutA)sA)bl
vol-au-vent :vÅl´vÅn vçlovA)
Tableau 102. Exemples de correspondance <en> = [Ån].

Adaptation des voyelles nasales 331
Ici encore, le cluster [Ån] représente la voyelle nasale [A)]. Nous pouvons ajouter qu’il
existe une variante contretemps /:kÅntr´tÅm/ où la correspondance <em> = [Åm] n’est pas
expliquée par le contexte, à moins de considérer que [n] est transformé par le [p] muet.
D’ailleurs, nous trouvons une autre variante de contretemps /:kÅntr´tÅN/, cette fois
avec la correspondance <em> = [ÅN] qui ne peut pas non plus être expliquée
contextuellement. Nous pouvons rapprocher cette dernière variante d’un autre cas en [ÅN] :
rapprochement /rQ:prÅSmÅN/. Dans ces deux exemples, comme dans le tableau précédent,
[ÅN] représente un [A)] final, avec une consonne finale muette. Soulignons néanmoins que ces
cas sont rares.
Nous trouvons également la voyelle [Å] associée à la graphie <on>. Cette fois, nous ne
mentionnons que les cas où cette graphie est associée au cluster [ÅN], puisque le cluster [Ån]
peut être considéré comme anglicisé :
Emprunt Anglais Français
chacun à son goût «SQkŒ˘nQsÅN:gu˘ Sakø)asç)gu
chaise-longue «SEIz:lÅN SEzlç)g
jongleur ZÅN:glŒ˘ Zç)glø{
longueur lÅN:gŒ˘ lç)gø{
musique concrète mjU«zi˘kkÅN:krEt myzikkç)k{Et
Tableau 103. Variantes avec correspondance <on> = [ÅN].

332 Analyse des emprunts non-anglicisés
Nous observons que le cluster [ÅN] correspond cette fois à la voyelle nasale [ç)].
Cependant, toutes ces variantes peuvent être expliquées par le contexte. On peut donc
également les considérer comme anglicisées. Il convient alors de les distinguer des clusters
[ÅN] non-expliqués par le contexte :
Emprunt Anglais Français
abandon Qb´n:dÅN abA)dç)
chignon :Si˘njÅN Si¯ç)
cordon :kç˘dÅN kç{dç)
cordon bleu «kç˘dÅN:blŒ˘ kç{dç)blO
garçon :gA˘sÅN ga{sç)
nous verrons nu˘vE:rÅN nuverç))
pompon :pÅmpÅN pç)pç)
salon :sQlÅN salç)
soupçon :su˘psÅN supsç)
Tableau 104. Variantes avec correspondance <on> = [ÅN] non-expliquée.
Nous trouvons ce cluster [ÅN] irrégulier lorsque la voyelle nasale [ç)] est en fin de mot,
comme dans les précédents cas. Cependant, nous remarquons ici qu’il n’y a jamais de
consonne finale muette, excepté pour nous verrons. Il semble que ces variantes en [ÅN] soient
associées à une position finale de la voyelle nasale, avec ou sans consonne finale muette.

Adaptation des voyelles nasales 333
Enfin, nous trouvons le cluster [Ån] associé à la graphie <in> :
Emprunt Anglais Français
cointreau :kwÅntr´U kwE)t{o
ingénue :ÅnZ´nju˘ E)Zeny
lingerie :lÅnZ´rI lE)Z{i
Tableau 105. Variantes avec correspondance <in> = [Ån].
Dans ces variantes, le cluster [Ån] représente la voyelle nasale [E)]. Dans cointreau, il
s’agit du cluster [wE)] retranscrit par l’anglais [wÅn]. Ajoutons que ces variantes sont rares,
mais présentes dans les trois dictionnaires de prononciation.
Nous pouvons ainsi conclure que la voyelle [Å] peut servir à la représentation de trois
voyelles nasales du français : [A)], [ç)] et [E)], même si ces derniers cas sont très rares.
b) [A˘]
La voyelle [A˘] représente les cluster [A˘n], [A˘m] et [A˘N]. Nous trouvons le cluster
[A˘n] (et ses variantes contextuelles) associé aux graphies <an> et <am> notamment :
Emprunt Anglais Français
aide-de-camp «EIdd´:kA˘mp Edd´kA)
ambrette A˘m:brEt A)b{Et
blanc :blA˘Nk blA)
cor anglais «kç˘:rA˘NglEI kç{A)glE

334 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
enfant gâté «A˘nfA˘ngQ:tEI A)fA)gAte
flambé :flA˘mbEI flA)be
manqué :mA˘NkEI mA)ke
mélange mEI:lA˘nZ melA)Z
roman fleuve «r´UmA˘n:flŒ˘v {çmA)fløv
Tableau 106. Exemples de correspondance <an> = [A˘n].
Nous n’avons relevé que les cas où la présence de [A˘] était irrégulière, puisque dans
les autres cas cette correspondance est régulière. Nous voyons dans ces exemples que le
cluster représente la voyelle nasale française [A)]. Lorsqu’on trouve le cluster [A˘N], il s’agit
d’une variante contextuelle due à l’influence de la consonne vélaire suivante. Mais nous
pouvons ajouter l’exemple de restaurant /:rEst´rA˘N/ qui n’est pas expliqué par le contexte.
Cette variante n’est trouvée que dans l’EPD.
On trouve également le cluster [A˘n] associé à la graphie <en> :
Emprunt Anglais Français
centime :sA˘nti˘m sA)tim
crème de menthe «krEmd´:mA˘nt k{Emd´mA)t
en famille «A˘nfQ:mi˘ A)famij
enfant terrible «A˘nfA˘nt´:ri˘bl´ A)fA)tE{ibl
entente A˘n:tA˘nt A)tA)t
entrepreneur «A˘ntr´pr´:nŒ˘ A)t{´p{´nø{
faience faI:A˘nts fajA)s

Adaptation des voyelles nasales 335
Emprunt Anglais Français
genre :ZA˘nr´ ZA){
rentier :rA˘ntIEI {A)tje
Tableau 107. Exemples de correspondance <en> = [A˘n].
Ici encore, le cluster [A˘n] représente la voyelle nasale [A)]. Nous n’avons pas relevé de
variantes avec [A˘N] et une seule avec [A˘m] : embarras de richesse /«A˘mbQ«rA˘d´ri˘:SEs/.
D’une manière générale, nous remarquons que les variantes avec [A˘n], qu’elles soient
associées à la graphie <an> ou <en>, sont assez peu nombreuses.
Enfin, nous trouvons le cluster [A˘n] associé à la graphie <in> :
Emprunt Anglais Français
cointreau :kwA˘ntr´U kwE)t{o
lingerie :lA˘ndZ´rI lE)Z{i
petits soins «pEtI:swA˘n p´tiswE)
Tableau 108. Variantes avec correspondance <in> = [A˘n].
Nous ne trouvons que trois cas avec cette correspondance. Nous remarquons qu’ici le
cluster [A˘n] représente la voyelle nasale [E)]. Notons que ces variantes de cointreau et petits
soins ont déjà été mentionnées dans le paragraphe sur [wA˘] puisqu’on pourrait également
considérer qu’il s’agit de la correspondance <oi> = [wA˘] suivi de [n].
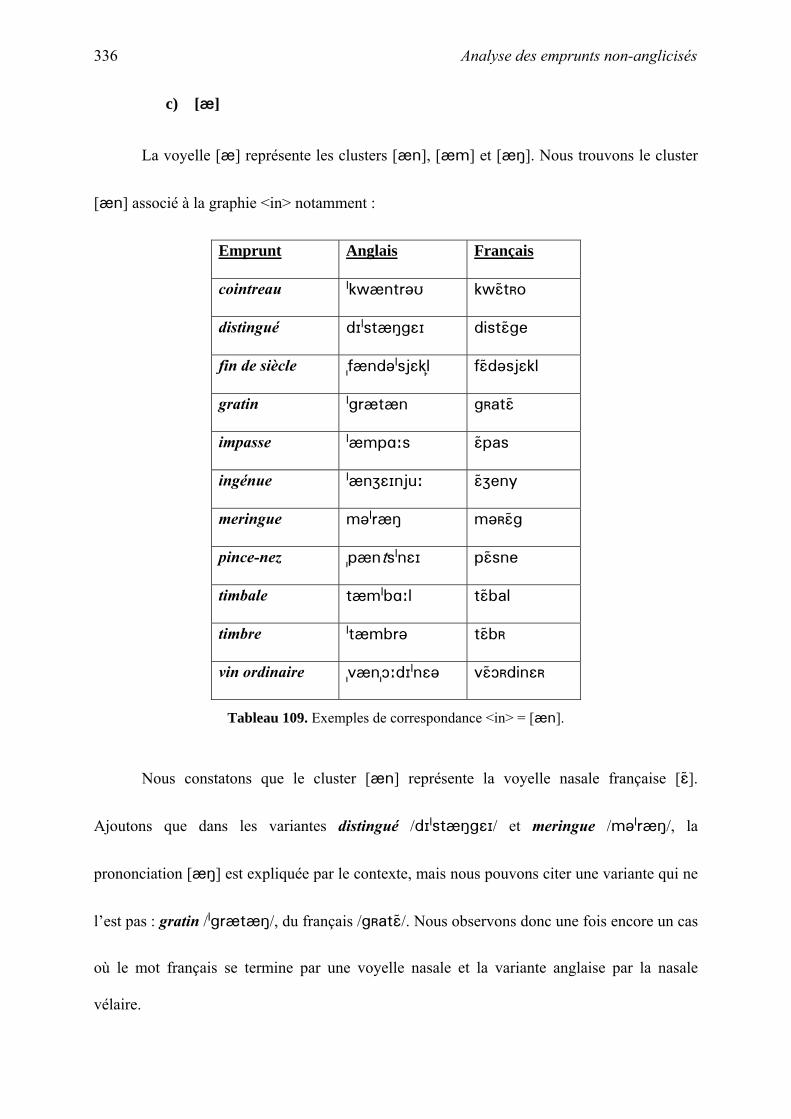
336 Analyse des emprunts non-anglicisés
c) [Q]
La voyelle [Q] représente les clusters [Qn], [Qm] et [QN]. Nous trouvons le cluster
[Qn] associé à la graphie <in> notamment :
Emprunt Anglais Français
cointreau :kwQntr´U kwE)t{o
distingué dI:stQNgEI distE)ge
fin de siècle «fQnd´:sjEkl2 fE)d´sjEkl
gratin :grQtQn g{atE)
impasse :QmpA˘s E)pas
ingénue :QnZEInju˘ E)Zeny
meringue m´:rQN m´{E)g
pince-nez «pQnts:nEI pE)sne
timbale tQm:bA˘l tE)bal
timbre :tQmbr´ tE)b{
vin ordinaire «vQn«ç˘dI:nE´ vE)ç{dinE{
Tableau 109. Exemples de correspondance <in> = [Qn].
Nous constatons que le cluster [Qn] représente la voyelle nasale française [E)].
Ajoutons que dans les variantes distingué /dI:stQNgEI/ et meringue /m´:rQN/, la
prononciation [QN] est expliquée par le contexte, mais nous pouvons citer une variante qui ne
l’est pas : gratin /:grQtQN/, du français /g{atE)/. Nous observons donc une fois encore un cas
où le mot français se termine par une voyelle nasale et la variante anglaise par la nasale
vélaire.

Adaptation des voyelles nasales 337
Le cluster [Qn] est également associé à la graphie <ain> :
Emprunt Anglais Français
bain-marie «bQnm´:ri˘ bE)ma{i
coup de main «ku˘d´:mQn kud´mE)
main en griffe «mQnÅn:gri˘f mE)A)g{if
pain au chocolat «pQn´U:SÅk´lA˘ pE)oSçkçla
pain de campagne «pQnd´kÅm:pQnj´ pE)d´kA)pa¯
pain de mie «pQnd´:mi˘ pE)d´mi
petitgrain :pEtIgrQn p´tig{E)
sainfoin :sQnfçIn sE)fwE)
Tableau 110. Variantes avec correspondance <ain> = [Qn].
Ici encore, nous observons que le cluster [Qn] représente la voyelle nasale [E)]. Les cas
ne sont pas nombreux puisqu’ils figurent tous dans le tableau ci-dessus. Nous pouvons
également ajouter un cas de correspondance <ain> = [QN] : main gauche /:mQN«g´US/, où le
[n] est transformé en [N] par assimilation.
Enfin, le cluster [Qn] est associé à la graphie <ein>, mais nous ne relevons que deux
cas de ce type : enceinte /Ån:sQnt/ du français /A)sE)t/, et serein /s´:rQn/ du français /s´{E)/.
Il s’agit donc encore de l’adaptation de la voyelle nasale [E)].

338 Analyse des emprunts non-anglicisés
Au final, nous voyons que ce cluster ne sert qu’à l’adaptation de [E)], mais qu’il s’agit
d’une variante minoritaire puisque nous ne trouvons que peu de cas. Cependant, il est
également probable que cette voyelle soit moins fréquente dans les emprunts français.
d) [ç˘]
La voyelle [ç˘] représente les clusters [ç˘n], [ç˘m] et [ç˘N], mais nous relevons en fait
peu de cas avec cette voyelle :
Emprunt Anglais Français
concierge «kç˘nsI:E´Z kç)sjE{Z
congé :kç˘nZEI kç)Ze
contretemps :kç˘ntr´tA)˘N kç)t{´tA)
demi-monde «dEmI:mç˘nd d´mimç)d
hors de combat «hç˘d´:kç˘mbA˘ ç{d´kç)ba
jongleur Zç˘N:glŒ˘ Zç)glø{
longueur lç˘N:gŒ˘ lç)gø{
son et lumière «sç˘nEI:lu˘mjE´ sç)elymjE{
Tableau 111. Variantes avec correspondance <on> = [ç˘n].
Nous constatons que le cluster [ç˘n] représente la voyelle nasale [ç)] et que les
variantes en [ç˘m] et [ç˘N] sont toujours expliquées par le contexte. Mais nous voyons que les
cas sont rares ; il s’agit donc d’une adaptation très minoritaire.

Adaptation des voyelles nasales 339
e) [Œ˘]
Nous trouvons enfin le cluster [Œ˘n] associé uniquement à la graphie <un> dans
seulement deux emprunts : chacun à son goût /«SQkŒ˘nA˘sç)˘N:gu˘/, adaptation du français
/Sakø)asç)gu/, et vingt-et-un /«vQ)ntEI:Œ˘n/, adapté du français /vE)teø)/. Nous trouvons
d’ailleurs une autre variante pour ce dernier emprunt /«vQ)tEI:Œ˘N/, avec le cluster [Œ˘N],
toujours dans le contexte de la voyelle nasale finale en français. Nous voyons ainsi que ce
cluster représente la voyelle nasale [ø)], qui est assez rare en français et tend à disparaître, ce
qui explique sans doute que nous trouvions si peu d’exemples parmi les emprunts français.
2. Les voyelles nasales anglaises
Nous avons vu dans la première partie de cette thèse que tous les dictionnaires de
prononciation utilisent des symboles de voyelles nasales pour certains emprunts français162. Il
s’agit de symboles de voyelles anglaises auxquelles on ajoute le signe de nasalisation, ou
tilde.
Nous avons bien entendu considéré comme irrégulière toute variante présentant une
voyelle nasale, puisque celles-ci n’existent théoriquement pas dans le système anglais. Nous
allons à présent observer les correspondances de ces voyelles nasales anglaises et voir quelles
voyelles nasales françaises elles représentent. Nous allons également observer quels symboles
sont utilisés par les différents dictionnaires et nous demander pourquoi l’EPD présente quatre
symboles alors que le LPD n’en présente que trois.
162 Cf. p. 71

340 Analyse des emprunts non-anglicisés
a) [Å)]
La voyelle [Å)] est sans doute l’une des plus fréquentes dans notre base de données. Il
faut remarquer qu’elle n’est pas présente dans l’EPD, mais dans les autres dictionnaires de
prononciation ainsi que l’OED, ce qui explique sans doute en partie sa fréquence.
Elle est associée notamment aux graphies <an> et <am> :
Emprunt Anglais Français
aide-de-camp «EIdd´:kÅ) Edd´kA)
ancien régime «Å)sIQ)rEI:Zi˘m A)sjE){eZim
au courant ´U:kUrÅ) oku{A)
Chambertin :SÅ)b´tQ) SA)bE{tE)
fête-champêtre «fEItSÅ):pEItr´ fEtSA)pEt{
fiancé fI:Å)sEI fijA)se
mésalliance mE:zQlIÅ)s mezaljA)s
penchant :pÅ)SÅ) pA)SA)
restaurant :rEst´rÅ) {Estç{A)
Tableau 112. Exemples de correspondance <an> = [Å)].
Nous constatons dans ces exemples que la voyelle [Å)] représente la voyelle nasale
française [A)]. Nous remarquons également que lorsque la consonne finale est muette en
français, elle l’est également en anglais comme le montrent les exemples au courant,
penchant et restaurant.

Adaptation des voyelles nasales 341
Nous trouvons également cette voyelle associée aux graphies <en> et <em> :
Emprunt Anglais Français
contretemps :kÅntr´tÅ) kç)t{´tA)
débridement dI«bri˘d:mÅ) deb{idmA)
embonpoint «Å)bÅn:pwQ) A)bç)pwE)
en route «Å):ru˘t A){ut
entrepot :Å)tr´p´U A)t{´po
genre :ZÅ)r´ ZA){
Provençal «prÅvÅ):sA˘l p{çvA)sal
tout ensemble «tu˘tÅ):sÅ)bl tutA)sA)bl
vol-au-vent :vÅl´vÅ) vçlovA)
Tableau 113. Exemples de correspondance <en> = [Å)].
Nous pouvons émettre ici les mêmes remarques que pour le tableau précédent : la
voyelle [Å)] représente la voyelle nasale française [A)] et lorsque la consonne finale est muette
en français, elle l’est également en anglais, comme nous le voyons dans les exemples
contretemps, débridement ou vol-au-vent. Nous pouvons ajouter, par rapport aux adaptations
avec voyelle + consonne nasale, qu’il n’y a pas d’exception lorsque [Å)] représente [A)] : on ne
trouve jamais de terminaison anglaise avec [Å)] suivi d’une consonne. On peut alors avancer
que lorsqu’un locuteur utilise la voyelle [Å)], il cherche à tout prix à reproduire la
prononciation française. De toute évidence, l’effort que représente la réalisation d’une voyelle
nasale pour un anglophone en est déjà la preuve.

342 Analyse des emprunts non-anglicisés
Nous trouvons encore cette voyelle associée à la graphie <on> :
Emprunt Anglais Français
bon vivant «bÅ):vi˘vÅ) bç)vivA))
chanson :SÅ)sÅ) SA)sç)
concierge :kÅ)sIE´Z kç)sjE{Z
embonpoint «Å)bÅ):pwQ) A)bç)pwE)
jongleur ZÅ):glŒ˘ Zç)glø{
montage mÅ):tA˘Z mç)taZ
Sauvignon :s´Uvi˘njÅ) sovi¯ç)
ton :tÅ) tç)
wagon-lit «vQgÅ):li˘ vagç)li
Tableau 114. Exemples de correspondance <on> = [Å)].
Nous voyons cette fois que la voyelle [Å)] représente la voyelle nasale française [ç)]. La
voyelle anglaise sert donc indifféremment à l’imitation de [A)] et [ç)], ce que nous pouvons
observer dans les exemples bon vivant / «bÅ):vi˘vÅ)/, chanson /:SÅ)sÅ)/ ou embonpoint
/«Å)bÅ):pwQ)/. Il semble donc que les locuteurs anglophones n’arrivent pas à produire deux
voyelles nasales différentes pour rendre [A)] et [ç)], mais il est également envisageable qu’ils
n’entendent pas la différence entre ces deux voyelles françaises.
Enfin, nous relevons deux exemples où la voyelle [Å)] est associée à la graphie <in> :
embonpoint /«ÅmbÅn:pwÅ)/, adaptation du français /A)bç)pwE)/, et lingerie /:lÅ)Z´rI/, adaptation
du français /lE)Z{i/. Dans ces deux cas, cette voyelle représente la voyelle nasale française [E)].

Adaptation des voyelles nasales 343
Or nous venons de voir que [Å)] sert également à représenter [A)] et [ç)]. Ainsi nous trouvons
une variante d’embonpoint /«Å)bÅ):pwÅ)/. Nous pouvons cependant penser que l’adaptation de
ce mot français présentant les trois voyelles nasales les plus courantes représente une
difficulté majeure pour les anglophones. Il n’est donc finalement pas si surprenant de voir que
certains locuteurs réalisent les trois voyelles nasales de manière uniforme.
b) [A)˘]
La voyelle [A)˘] est moins fréquente que [Å)] puisqu’on la trouve presque exclusivement
dans le dictionnaire EPD. On ne la trouve que rarement dans les autres dictionnaires et elle ne
figure d’ailleurs pas dans l’introduction du LPD.
Nous la trouvons associée notamment aux graphies <an> et <am> :
Emprunt Anglais Français
chambré :SA)˘mbrEI SA)b{e
carte blanche «kA˘t:blA)˘ntS ka{tblA)S
élan EI:lA)˘n elA)
fricandeau :frIkA)˘nd´U f{ikA)do
méthode champenoise mEI«tÅdSA)˘mp´n:wA˘z metçdSA)p´nwaz
nouveau roman «nu˘v´Ur´U:mA)˘N nuvo{çmA)
palais de danse :pQlEId´dA)˘s palEd´dA)s
pétanque pEI:tA)˘Nk petA)k
soi-disant «swA˘di˘:zA)˘N swadizA)
Tableau 115. Exemples de correspondance <an> = [A)˘].

344 Analyse des emprunts non-anglicisés
Nous constatons que la voyelle [A)˘] représente la voyelle nasale française [A)]. Nous
remarquons également qu’elle est souvent suivie d’une consonne nasale optionnelle. Il s’agit
en fait de la transcription choisie par l’EPD. Les autres dictionnaires n’ajoutent jamais de
consonne nasale comme le montre l’exemple palais de danse, relevé dans l’OED 3. Mais
l’observation de ces consonnes nasales optionnelles est tout de même intéressante car, si nous
remarquons la plupart du temps que cette consonne dépend du contexte, nous observons
également des cas où la consonne [N] n’est pas expliquée par le contexte, comme nous l’avons
déjà noté à plusieurs reprises. Nous l’observons par exemple dans la variante soi-disant
/«swA˘di˘:zA)˘N/ où la consonne finale est muette en français comme en anglais, ou nouveau
roman /«nu˘v´Ur´U:mA)˘N/. Il s’agit donc une fois encore d’emprunts qui se terminent par une
voyelle nasale en français. Ce phénomène est peut-être un moyen de marquer plus encore la
voyelle nasale, mais nous voyons qu’il n’est pas systématique puisque élan est transcrit
/EI:lA)˘n/.
La voyelle [A)˘] est également associée aux graphies <en> et <em> :
Emprunt Anglais Français
contretemps :kÅntr´tA)˘N kç)t{´tA)
dénouement dEI:nu˘mA)˘N denumA)
double entendre «du˘bl2A)˘n:tA)˘ndr´ dublA)tA)d{
employé A)˘m:plçIEI A)plwaje
en bloc «A)˘m:blÅk A)blçk
encore :A)˘Nkç˘ A)kç{
entrechat :A)˘ntr´SA˘ A)t{´Sa

Adaptation des voyelles nasales 345
Emprunt Anglais Français
mise-en-scène «mi˘zA)˘n:sEIn mizA)sEn
Provençal prÅvA)˘:sA˘l p{çvA)sal
Tableau 116. Exemples de correspondance <en> = [A)˘].
Nous constatons ici encore que la voyelle [A)˘] représente la voyelle nasale française
[A)]. Les graphies <an> et <en> étant les seules associées à cette voyelle, nous pouvons
affirmer que [A)˘] sert uniquement à l’imitation de [A)], ce qui est conforme à ce qu’annonce
l’EPD dans son introduction163. Nous émettons par ailleurs les mêmes remarques pour ce
tableau que pour le tableau précédent.
c) [ç)˘]
Comme pour [A)˘], nous ne trouvons la voyelle [ç)˘] que dans le dictionnaire EPD.
Nous ne trouvons qu’une exception : bombe /:bç)˘b/, relevée dans l’ODP. Cette voyelle est
notamment associée aux graphies <on> et <om> :
Emprunt Anglais Français
appellation contrôlée QpElQ«sjç)˘Nkç)˘ntr´U:lEI apElasjç)kç)t{ole
bon viveur «bç)˘NvI:vŒ˘ bç)vivø{
cordon bleu «kç˘dç)˘m:blŒ˘ kç{dç)blO
fait accompli «fEIt´:kç)˘mpli˘ fEtakç)pli
frisson :fri˘sç)˘N f{isç)
163 Cf. p. 72

346 Analyse des emprunts non-anglicisés
Emprunt Anglais Français
nom de guerre «nç)˘nd´:gE´ nç)d´gE{
pompon :pç)˘mpç)˘N pç)pç)
raconteur «rQkç)˘n:tŒ˘ {akç)tø{
soupçon :su˘psç)˘N supsç)
Tableau 117. Exemples de correspondance <on> = [ç)˘].
Nous constatons que la voyelle [ç)˘] représente la voyelle nasale française [ç)]. Comme
pour [A)˘], l’EPD ajoute une consonne nasale optionnelle, généralement expliquée par le
contexte, mais on retrouve [N] en fin de mot comme dans frisson, pompon ou soupçon.
Nous trouvons également cette voyelle associée à la graphie <en> dans trois cas :
centime /:sç)˘nti˘m/, adaptation du français /sA)tim/ ; gendarme /:Zç)˘ndA˘m/, du français
/ZA)da{m/, et Provençal(e /«prÅvç)˘n:sA˘l/, du français /p{çvA)sal/. Nous pouvons ajouter à
cette liste le mot employé /ç)˘m:plçIEI/, du français /A)plwaje/, dans lequel cette voyelle est
associée à la graphie <em>. Dans tous ces cas, nous voyons que la voyelle [ç)˘] représente la
voyelle nasale [A)], ce qui est assez surprenant. Ajoutons toutefois qu’il s’agit de cas rares
puisque nous ne relevons que quatre variantes de ce type. Nous excluons néanmoins qu’il
s’agisse d’erreurs puisque tous ces emprunts présentent également une variante avec [A)˘].
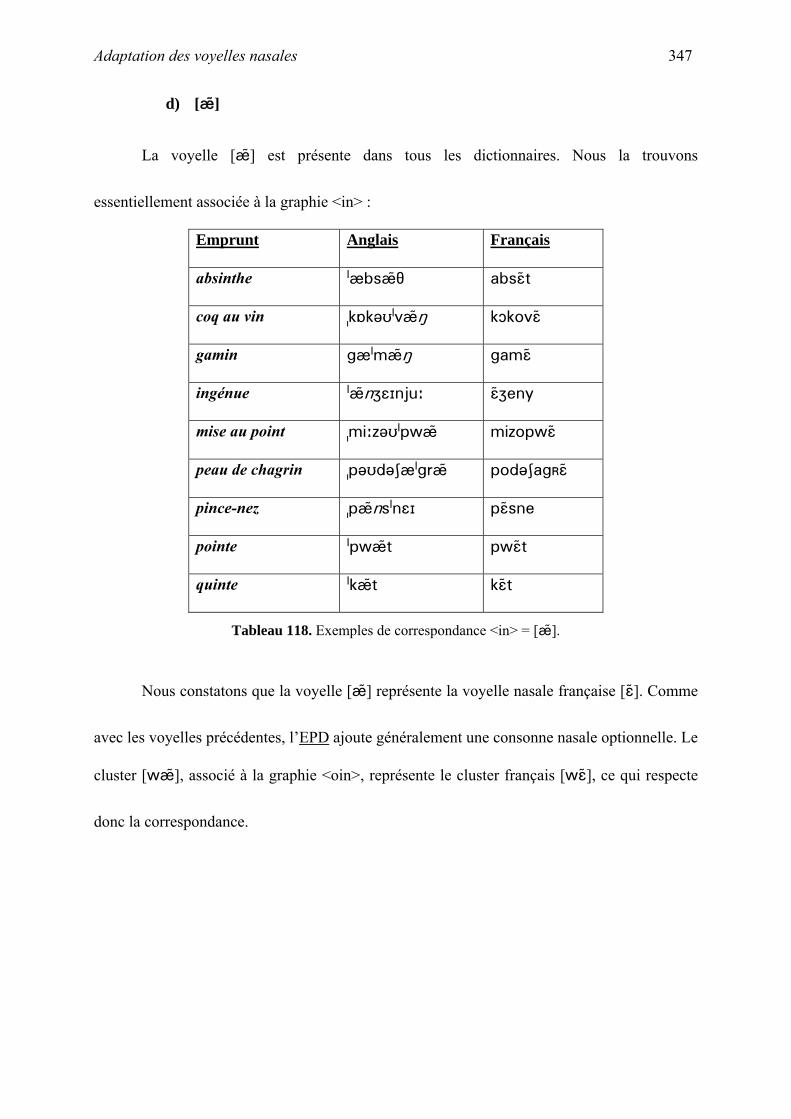
Adaptation des voyelles nasales 347
d) [Q)]
La voyelle [Q)] est présente dans tous les dictionnaires. Nous la trouvons
essentiellement associée à la graphie <in> :
Emprunt Anglais Français
absinthe :QbsQ)T absE)t
coq au vin «kÅk´U:vQ)N kçkovE)
gamin gQ:mQ)N gamE)
ingénue :Q)nZEInju˘ E)Zeny
mise au point «mi˘z´U:pwQ) mizopwE)
peau de chagrin «p´Ud´SQ:grQ) pod´Sag{E)
pince-nez «pQ)ns:nEI pE)sne
pointe :pwQ)t pwE)t
quinte :kQ)t kE)t
Tableau 118. Exemples de correspondance <in> = [Q)].
Nous constatons que la voyelle [Q)] représente la voyelle nasale française [E)]. Comme
avec les voyelles précédentes, l’EPD ajoute généralement une consonne nasale optionnelle. Le
cluster [wQ)], associé à la graphie <oin>, représente le cluster français [wE)], ce qui respecte
donc la correspondance.

348 Analyse des emprunts non-anglicisés
Cette voyelle est également associée à la graphie <ain> :
Emprunt Anglais Français
bain-marie bQ)mm´:ri˘ bE)ma{i
chatelain :SQt´lQ)N SAtlE)
coup de main «ku˘d´:mQ)N kud´mE)
pain de mie «pQ)d´:mi˘ pE)d´mi
petit grain :pEtIgrQ) p´tig{E)
Tableau 119. Exemples de correspondances <ain> = [Q)].
Ici encore, la voyelle [Q)] représente la voyelle nasale [E)]. Les cas ne sont pas
nombreux, mais les emprunts français présentant cette voyelle nasale ne sont pas nombreux. Il
est d’ailleurs possible que cette voyelle ne soit pas très fréquente en français.
Enfin, nous trouvons la voyelle [Q)] associée à la graphie <ein> dans quelques
emprunts : enceinte /«A)˘n:sQ)nt/, du français /A)sE)t/ ; plein jeu /«plQ):ZŒ˘/, du français /plE)ZO/,
et serein /s´:rQ)/, du français /s´{E)/. Une fois encore, cette voyelle représente la voyelle [E)],
si bien qu’on peut dire que [Q)] sert toujours à l’imitation de la voyelle nasale [E)].
e) [Œ)˘]
Nous ne trouvons cette voyelle que dans un seul emprunt : vingt-et-un /«vQ)tEI:Œ)˘/,
adaptation du français /vE)teø)/. La voyelle [Œ)˘] représente donc la voyelle nasale [ø)]. Nous
ne trouvons cette voyelle que dans l’EPD, qui ajoute la consonne nasale optionnelle [N], et le

Adaptation des voyelles nasales 349
LPD. Il n’est pas surprenant de ne trouver qu’un seul cas avec cette voyelle, puisque la
voyelle nasale française [ø)] est elle-même très rare en français, et à plus forte raison parmi
les emprunts de notre sélection.
3. Conclusion
En conclusion, nous pouvons établir les correspondances suivantes pour les clusters (la
flèche signifiant ‘représente’) :
• [Ån] [A)], [ç)] et parfois [Œ)]
• [A˘n] [A)] et parfois [Œ)]
• [ç˘n] [ç)]
• [Qn] [Œ)]
• [Œ˘n] [ø)]
Pour les voyelles nasales anglaises, nous pouvons établir les correspondances
suivantes :
• [Å)] [A)], [ç)] et parfois [Œ)]
• [A)˘] [A)]
• [ç)˘] [ç)] et parfois [A)]
• [Q)] [Œ)]
• [Œ)˘] [ø)]
Nous constatons alors une symétrie évidente entre les deux groupes.
D’une manière générale, les voyelles nasales anglaises semblent plus fréquentes dans
les transcriptions que les clusters voyelle + consonne nasale. Ainsi, d’après les éditeurs, les

350 Analyse des emprunts non-anglicisés
locuteurs anglophones parviennent souvent à réaliser une voyelle nasale. Mais, si on considère
à juste titre que ces voyelles nasales sont des tentatives de la part des locuteurs d’imiter la
prononciation française, on peut également considérer que ces différentes transcriptions
illustrent les tentatives des éditeurs de représenter ces imitations.
Nous voyons que les éditeurs de dictionnaires n’ont pas tous choisi les mêmes
symboles, ou que le LPD considère que les voyelles françaises [ç)] et [A)] sont représentées par
une seule et même voyelle anglaise [Å)], tandis que l’EPD considère que ces deux voyelles
sont rendues différemment en anglais. Quelle est la réalité ?
Pour les départager, il serait sans doute nécessaire de procéder à une expérimentation
phonétique sur de nombreux locuteurs anglophones. Nous ne pourrons dans notre étude
qu’écouter quelques exemples de ces réalisations dans des vidéos trouvées sur Internet, et
reconnaître la difficulté de retranscrire ces différentes prononciations.
Pour l’adaptation de la voyelle nasale française [A)], nous pouvons proposer les
exemples allemande164 ou croissant165 ; pour la voyelle [ç))] les exemples bourguignon166 et
court bouillon167 ; et pour la voyelle [E)] l’exemple gratin168.
164 « How to make Allemande Sauce. » VideoJug. 27 juil. 2006. VideoJug Corporation Limited. 15 oct. 2008.
http://www.videojug.com/film/how-to-make-allemande-sauce.
165 « How to make Croissants. » VideoJug. 3 avril. 2007. VideoJug Corporation Limited. 15 oct. 2008.
http://www.videojug.com/film/how-to-make-croissants.
166 « How to choose wine for beef bourguignon. » VideoJug. 23 août 2007. VideoJug Corporation Limited. 17
oct. 2008. http://www.videojug.com/film/how-to-choose-wine-for-beef-bourguignon.
167 « How to make lobster in court bouillon. » VideoJug. 27 sept. 2006. VideoJug Corporation Limited. 17 oct.
2008. http://www.videojug.com/film/how-to-make-lobster-in-court-bouillon.
168 « How to make celeriac and potato gratin. » VideoJug. 27 juil. 2006. VideoJug Corporation Limited. 18 oct.
2008. http://www.videojug.com/film/how-to-make-celeriac-and-potato-gratin.

XI. VERS UNE COMPREHENSION DES EMPRUNTS NON-
ANGLICISES
Table des matières
A. Les marques de francité.................................................................................................... 352
1. Non-réduction.............................................................................................................. 353
2. <h> muet ..................................................................................................................... 354
3. Consonnes finales muettes .......................................................................................... 355
4. Accentuation finale...................................................................................................... 356
5. Absence de [j] devant [u˘]........................................................................................... 358
6. Variantes toutes voyelles pleines ................................................................................ 360
7. Terminaisons <-ble>, <-pre>, <-tre>, <-dre>.............................................................. 362
8. Violation des règles anglaises ..................................................................................... 364
a) [j] final................................................................................................................... 364
b) [r] final .................................................................................................................. 365
c) Voyelle brève finale .............................................................................................. 366
d) Schwa sous accent................................................................................................. 367
9. Cumul des marques ..................................................................................................... 368
B. Quelques cas particuliers .................................................................................................. 369
1. Suffixe <-ier> .............................................................................................................. 369
2. Mots en <-ine> ............................................................................................................ 371
3. Traitement du schwa français...................................................................................... 373
C. Quelques pistes de réflexion............................................................................................. 376
1. Le pluriel ..................................................................................................................... 376
2. La liaison ..................................................................................................................... 377
3. Les étapes de l’anglicisation........................................................................................ 379

352 Vers une compréhension des emprunts non-anglicisés
Après avoir montré de quelle manière l’anglais adaptait les phonèmes français, nous
allons maintenant présenter quelques caractéristiques des emprunts français non-anglicisés et
tenter d’avancer dans la connaissance de ces emprunts.
A. LES MARQUES DE FRANCITE
En étudiant les emprunts de notre base de données, nous avons remarqué que non
seulement les locuteurs imitent la prononciation française, mais que souvent ils cherchent à
signaler l’origine française du mot. Ce que nous appelons des ‘marques de francité’, ce sont
donc tous les moyens employés par les locuteurs pour montrer que le mot prononcé est
d’origine française.
Nous allons nous concentrer ici sur les différentes marques de francité autres que les
correspondances irrégulières, décrites dans le chapitre précédent, et qui s’ajoutent souvent aux
prononciations imitant le français. Nous avons par exemple déjà évoqué l’utilisation de la
voyelle [A˘] comme indication de l’origine française du mot169, c’est pourquoi nous ne
reviendrons pas sur ce point.
Mais ces marques ne sont pas toutes au même niveau, n’ont pas toutes la même
‘force’. Alors que certaines sont à peine remarquées, d’autres sont le signe clair d’une volonté
du locuteur d’imiter au plus près la prononciation française, voire peut-être de montrer sa
connaissance de cette langue. Nous allons donc tenter de présenter ces marques de manière
progressive, de la moins forte à la plus forte, même si le but n’est pas de donner une valeur à
chacune de ces marques, mais plutôt de montrer que certains locuteurs vont signaler l’origine
française des mots sans trop bousculer la phonologie de l’anglais, alors que d’autres sont prêts
à en repousser les limites.
169 Cf. p. 266

Les marques de francité 353
1. Non-réduction
Nous avons vu dans la partie précédente à propos des mots en <-on>170 que l’habitude
était de réduire cette terminaison et que l’origine française était sans doute la raison de la non-
réduction pour nos emprunts. Nous pouvons donc considérer cette non-réduction comme un
moyen de marquer l’origine française. Cependant, d’autres mots en <-on> n’ayant pas une
origine française peuvent se prononcer [Ån]. C’est pourquoi cette marque peut être considérée
comme très faible car elle ne permet pas oralement d’identifier le mot comme étant d’origine
française.
Nous avons également mentionné d’autres cas de non-réduction : par exemple celle
des mots en <-ard> comme brassard /:brQsA˘d/ ou brocard /:br´UkA˘d/171, ou bien des
trissyllabes du type caramel /:kQr´mEl/ ou partisan /:pA˘tIzQn/172. Nous avons également
cité la non-réduction irrégulière des dissyllabes en <-op>, <-or> et <-ot> et des mots de trois
syllabes et plus en <-iot>173, et enfin celle des syllabes prétoniques comme dans aperitif
/Q:pEr´tIf/174.
Nous voyons donc que les cas de non-réduction sont multiples dans le cadre des
emprunts français. Il s’agit bel et bien d’une façon de marquer l’origine française, même si
elle est à peine visible puisqu’elle ne vient pas s’opposer de front aux règles de l’anglais.
170 Cf. p. 130
171 Cf. p. 113
172 Cf. p. 117
173 Cf. p. 149
174 Cf. p. 155

354 Vers une compréhension des emprunts non-anglicisés
2. <h> muet
En français, si on trouve toujours la graphie <h>, elle n’est plus prononcée depuis bien
longtemps. On trouve encore une trace du ‘h aspiré’ dans l’impossibilité de faire la liaison
devant des mots comme haricot ou hibou.
Il semble que les locuteurs anglophones ont remarqué cette particularité française du
<h> muet puisqu’on relève de nombreuses variantes où le <h> reste muet, alors qu’il est
habituellement prononcé en anglais :
Emprunt Anglais Français
de haut en bas d´«´UtÅ):bA˘ d´otA)bA
fines herbes «fi˘n:E´b finzE{b
haute couture «´UtkU:tjU´ otkuty{
honnête homme Å«nEt:Åm çnEtçm
hors d’œuvre «ç˘:dŒ˘v ç{døv{
hotel ´U:tEl otEl
malheureusement «mQlŒ˘:rŒ˘zmÅ) malø{OzmA)
table d’hôte «tA˘bl:d´Ut tabl´dot
trahison des clercs «trA˘I«zÅ)dEI:klE´ t{aizç)deklE{
Tableau 120. Exemples de correspondance <h> = ∅.
Bien entendu, le <h> muet n’est pas totalement inhabituel en anglais puisqu’on trouve
certains cas célèbres comme hour, honour, heir, mais il s’agit ici encore d’emprunts français,
certes très anciens. De plus, il existe le phénomène de H-dropping, dont nous avons déjà fait
mention175, mais qui n’est pas caractéristique du RP.
175 Cf. p. 199

Les marques de francité 355
Dans nos exemples, il s’agit visiblement d’un moyen d’imiter la prononciation
française. D’ailleurs on peut remarquer que la première variante de hotel proposée par l’EPD
est /h´U:tEl/, ce qui est sans doute le signe que ce mot est sur la voie de l’anglicisation, ou du
moins qu’il est un peu moins marqué comme étant d’origine française.
3. Consonnes finales muettes
Il s’agit d’un phénomène que nous avons remarqué et commenté à plusieurs reprises
dans le chapitre précédent. En voici à nouveau quelques exemples :
argot :A˘g´U chaud-froid :S´UfrwA˘
assignat «QsI:njA˘ cor anglais «kç˘:rÅNglEI
au jus ´U:Zu˘ coup :ku˘
boulevard :bu˘lvA˘ couvert ku˘:vE´
bourgeois :bU´ZwA˘ croissant :krwQsA)˘N
cabaret :kQb´rEI début :dEIbju˘
Chablis :SQbli˘ dénouement dEI:nu˘mA)˘N
chapeau-bras «SQp´U:brA˘ de trop d´:tr´U
Tableau 121. Exemples de variantes avec consonne finale muette.
En général, les consonnes finales sont prononcées en anglais. En revanche, en français
il est très courant que des consonnes finales graphiques soient muettes à l’oral. Elles
réapparaissent parfois grâce à la liaison. Le fait qu’une consonne soit muette dans la
prononciation anglaise est donc le signe évident d’une imitation de la prononciation française.
Ce phénomène témoigne également d’une bonne connaissance de la prononciation originale,

356 Vers une compréhension des emprunts non-anglicisés
puisqu’on remarque parfois une autre variante dans laquelle la consonne est prononcée,
comme pour boulevard /:bu˘lvA˘d/ ou au jus /´U:Zu˘s/.
4. Accentuation finale
L’accent anglais est libre et peut potentiellement tomber sur n’importe quelle syllabe,
bien que nous ayons vu qu’il existait des règles de placement. En revanche, en français,
l’accent est fixe et sur la dernière syllabe. Il semble que les locuteurs anglophones ont
remarqué cette caractéristique du français car nous avons noté que de nombreuses variantes
étaient accentuées en finale.
Dans la partie précédente, nous avons vu que les règles anglaises sont, pour les noms
et verbes non-préfixés dissyllabiques de porter l’accent sur la première syllabe, et pour les
mots de trois syllabes et plus de porter l’accent sur l’antépénultième, par l’application de
l’Alternating Stress Rule176. Mais ces règles semblent souvent ne pas être appliquées dans le
cadre des emprunts français.
Nous décidons de vérifier notre première constatation. Sur les 5325 variantes de la
base de données finale, nous observons les 5146 variantes de deux syllabes et plus.
Effectivement, 2988 variantes, soit près de 60%, sont accentuées en finale. Il existe donc bien
une prédominance de cet accent parmi les emprunts français non-anglicisés. Parmi les
dissyllabes, on note même 64% de variantes accentuées en finale, contre 55% pour les
trisyllabes, et 51% pour les mots de plus de trois syllabes.
En observant les emprunts présentant des variantes accentuées en finale, nous
remarquons certaines terminaisons. Nous proposons alors l’hypothèse que certaines
terminaisons sont identifiées comme françaises et ‘attirent’ l’accent en finale. Nous
176 Cf. p. 111 sqq.

Les marques de francité 357
sélectionnons alors ces terminaisons et observons la place de l’accent, ce qui confirme notre
hypothèse :
Figure 36. Terminaisons ‘attirant’ l’accent en finale.
Il est probable que ces terminaisons ‘marquent’ le mot comme étant d’origine
française, c’est pourquoi les locuteurs y associent une autre caractéristique française.
Nous sommes néanmoins surprise par les résultats de certaines terminaisons qui nous
semblent également marquer l’origine française du mot, à l’écrit comme à l’oral :
Figure 37. Terminaisons moins associées à l’accent final.
<-ette> sur 165 variantes, 157 sont accentuées en finale (95%)
<-elle> sur 52 variantes, 45 accentuées en finale (86%)
<-esse> sur 20 variantes, 18 accentuées en finale
<-enne> sur 12 variantes, 12 accentuées en finale
<-esque> sur 15 variantes, 15 accentuées en finale
<-iste> sur 8 variantes, 7 accentuées en finale
<-eur> sur 168 variantes, 144 accentuées en finale (85%)
<-euse> sur 40 variantes, 37 accentuées en finale
<-ois> sur 53 variantes, 33 accentuées en finale (62%)
<-oise> sur 14 variantes, 12 accentuées en finale
<-oir(e> sur 68 variantes, 32 accentuées en finale (47%)
<-ine> sur 120 variantes, 63 accentuées en finale (52%)
<-ier> sur 138 variantes, 43 accentuées en finale (31%)
<-ière> sur 54 variantes, 38 accentuées en finale (70%)

358 Vers une compréhension des emprunts non-anglicisés
Si la terminaison <-oise> reste très souvent accentuée, nous voyons que son pendant
masculin <-ois> l’est beaucoup moins. De même, seule la moitié des variantes en <-oir(e> ou
en <-ine> sont accentuées en finale. Mais le plus surprenant, c’est que si 70% des variantes en
<-ière> sont accentuées en finale, seulement un tiers des variantes en <-ier> portent l’accent
sur cette syllabe.
L’une des différences entre ces deux groupes est peut-être que ces dernières
terminaisons ont une prononciation qui permet d’identifier l’origine française, contrairement
aux mots en <-ette> par exemple, qu’il est peut-être nécessaire de marquer par l’accentuation
puisque leur prononciation n’offre pas d’indication particulière. Cependant, des mots en
<-eur> ou <-euse> ont également une prononciation qui laisse deviner leur origine, mais sont
pourtant souvent accentués en finale.
Quoi qu’il en soit, il apparaît que l’accentuation en finale sert à marquer l’origine
française d’un mot. Nous avons même retenu certaines variantes uniquement en raison de leur
accent final irrégulier (ex : alcove /Ql:k´Uv/, arcade /A˘:kEId/, cadene /k´:di˘n/). Il s’agit
donc d’une caractéristique importante qui, si elle ne viole pas les règles anglaises dans le sens
où un accent final n’est pas impossible en théorie, amène néanmoins à s’éloigner des
habitudes des langues germaniques qui ont tendance à préférer l’accent en début de mot.
5. Absence de [j] devant [u˘]
Lorsque <u> se prononce [u˘], il existe des règles qui dictent que [j] est obligatoire,
facultatif, ou interdit (Lilly et Viel, 59-60) :
• pas de [j] derrière [r S Z tS dZ Cl]
• [j] facultatif derrière [l]
• [j] obligatoire dans les autres cas.

Les marques de francité 359
Pour illustrer ces règles, nous pouvons proposer les exemples anglais de June
/:dZu˘n/, lucid /:lu˘sId/ ou /:lju˘sId/, et music /:mju˘zIk/. Cependant, dans notre corpus nous
trouvons des cas où [j] est absent alors qu’il est théoriquement obligatoire, comme dans
aperçu /«QpŒ˘:su˘/ ou mutilé /mu˘tI:lEI/.
Nous décidons alors d’étudier plus particulièrement les variantes avec [u˘] et
d’observer celles qui ne suivent pas la règle du [j] obligatoire. Sur 156 variantes, nous en
trouvons 76 irrégulières — c’est-à-dire qui auraient dû être précédées de [j] — soit la moitié
des cas. Nous réalisons le même travail sur les variantes avec [U´] et obtenons les mêmes
résultats : sur 25 variantes, une sur deux est irrégulière :
Emprunt Variante
couture ku˘:tU´
fondue :fÅndu˘
mal du pays «mQldu˘:pEI
nuance :nu˘A˘nts
pardessus :pA˘d´su˘
parfumerie pA˘:fu˘m´rI
pâte dure pA˘t:dU´
petite culture p´«ti˘tk√l:tU´
résumé :rEIzu˘mEI
Tableau 122. Exemples de variantes avec [j] absent.
Dès lors, nous pouvons parler d’une tendance à ne pas appliquer la règle dans le cadre
des emprunts français. Mais cela sert-il à mieux imiter le français ou plutôt à marquer la

360 Vers une compréhension des emprunts non-anglicisés
différence avec la règle anglaise habituelle afin de montrer l’origine française ? Nous
remarquons que dans la plupart des cas, on trouve à la fois une variante avec [ju˘] et une autre
avec [u˘] :
Emprunt Variante 1 Variante 2
amuse-bouche ´:mju˘z«bu˘S ´:mu˘z«bu˘S
battue bQ:tju˘ bQ:tu˘
charcuterie SA˘:kju˘t´rI SA˘:ku˘t´rI
couture ku˘:tjU´ ku˘:tU´
Tableau 123. Exemples de variantes avec ou sans [j].
L’absence de [j] témoigne sans doute de la volonté du locuteur de marquer l’origine
française du mot, en s’éloignant une fois de plus des règles habituelles de l’anglais. Mais il est
également envisageable que la non-application de cette règle soit liée à l’adaptation du [y],
puisque dans tous ces cas la voyelle [u˘] représente cette voyelle française.
Quelle que soit l’explication de ce phénomène, il s’agit bien d’une caractéristique liée
aux emprunts français en anglais, et donc d’une ‘marque de francité’.
6. Variantes toutes voyelles pleines
Dans la partie précédente, nous avons abordé cette particularité de certains emprunts
français de ne pas respecter l’alternance de syllabes accentuées et inaccentuées, en soulignant
toutefois que certains mots anglicisés peuvent également présenter ce phénomène177.
177 Cf. p. 133
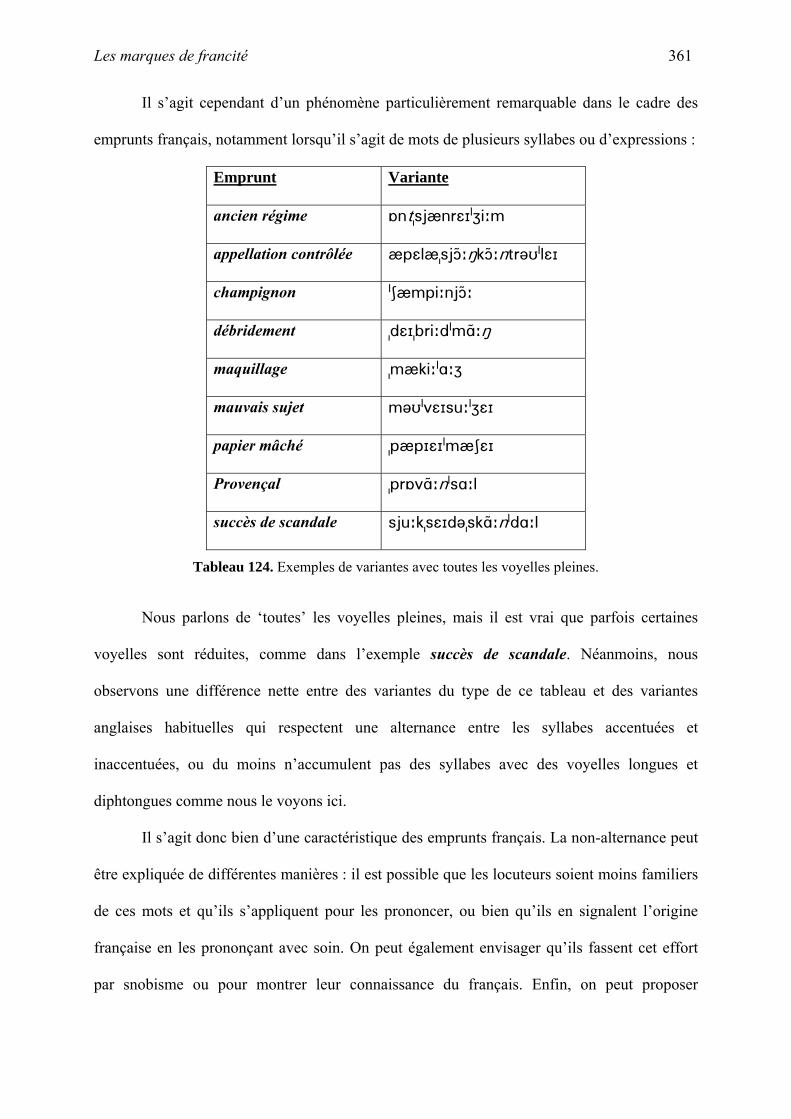
Les marques de francité 361
Il s’agit cependant d’un phénomène particulièrement remarquable dans le cadre des
emprunts français, notamment lorsqu’il s’agit de mots de plusieurs syllabes ou d’expressions :
Emprunt Variante
ancien régime Ånt«sjQnrEI:Zi˘m
appellation contrôlée QpElQ«sjç)˘Nkç)˘ntr´U:lEI
champignon :SQmpi˘njç)˘
débridement «dEI«bri˘d:mA)˘N
maquillage «mQki˘:A˘Z
mauvais sujet m´U:vEIsu˘:ZEI
papier mâché «pQpIEI:mQSEI
Provençal «prÅvA)˘n:sA˘l
succès de scandale sju˘k«sEId´«skA)˘n:dA˘l
Tableau 124. Exemples de variantes avec toutes les voyelles pleines.
Nous parlons de ‘toutes’ les voyelles pleines, mais il est vrai que parfois certaines
voyelles sont réduites, comme dans l’exemple succès de scandale. Néanmoins, nous
observons une différence nette entre des variantes du type de ce tableau et des variantes
anglaises habituelles qui respectent une alternance entre les syllabes accentuées et
inaccentuées, ou du moins n’accumulent pas des syllabes avec des voyelles longues et
diphtongues comme nous le voyons ici.
Il s’agit donc bien d’une caractéristique des emprunts français. La non-alternance peut
être expliquée de différentes manières : il est possible que les locuteurs soient moins familiers
de ces mots et qu’ils s’appliquent pour les prononcer, ou bien qu’ils en signalent l’origine
française en les prononçant avec soin. On peut également envisager qu’ils fassent cet effort
par snobisme ou pour montrer leur connaissance du français. Enfin, on peut proposer

362 Vers une compréhension des emprunts non-anglicisés
l’hypothèse que certains locuteurs ont remarqué que la réduction vocalique n’existait pas en
français et qu’ils ne réduisent pas en anglais pour imiter la prononciation française.
Oralement, il est probable que le débit du locuteur soit ralenti lorsqu’il prononce un
mot ou une expression de ce type, soit pour souligner une fois de plus l’origine française du
mot, soit parce que l’articulation de ce mot représente une difficulté. C’est peut-être
également parce que le locuteur ralentit son débit qu’il n’applique pas la réduction vocalique.
Ainsi la non-alternance des syllabes accentuées et inaccentuées constitue un moyen de
plus de marquer l’origine française d’un mot ; elle permet de différencier nettement ces
emprunts d’autres mots anglais. Elle permet également de mettre ces mots en évidence dans
un discours en marquant une rupture dans le rythme habituel de l’anglais.
7. Terminaisons <-ble>, <-pre>, <-tre>, <-dre>
Nous avons mentionné ces terminaisons dans la partie précédente en remarquant que
certains emprunts n’étaient pas prononcés comme la plupart des mots anglais178.
Commençons par la terminaison <-ble> :
Emprunt Anglais Français
amende-honorable Q«mÅ)dÅn´:rA˘bl´ amA)dçnç{abl
enfant terrible «A)˘nfA)˘ntE:ri˘bl´ A)fA)tE{ibl
quantité négligeable «kÅ)ntItEI«nEglI:ZA˘bl´ kA)titenegliZabl
Tableau 125. Variantes avec terminaison <-ble> = [bl´].
En français, un mot peut se terminer par le cluster plosive + liquide, comme ici [bl],
mais cela est impossible en anglais. Il ne s’offre à l’anglais que deux possibilités pour
178 Cf. p. 165

Les marques de francité 363
l’adaptation de ce cluster : soit appliquer la règle anglaise habituelle, qui rend la consonne [l]
syllabique, soit ajouter un schwa final pour rendre la syllabe valide.
Dans les trois exemples, c’est ce second choix qui a été fait. Cela résulte en une
syllabe qui ne viole pas les règles anglaises, et qui se rapproche du français en rendant la
terminaison moins ‘anglaise’.
Le même phénomène se produit avec les terminaisons présentant la liquide [{] en
français :
Emprunt Anglais Français
amour-propre «QmU´:prÅpr´ amu{p{çp{
cadre :kA˘dr´ kAd{
chypre :Si˘pr´ Sip{
coup de foudre «ku˘d´:fu˘dr´ kud´fud{
fête-champêtre «fEtSA)˘m:pEtr´ fEtSA)pEt{
maître :mEItr´ mEt{
nom de théâtre «nÅmd´tEI:A˘tr´ nç)d´teAt{
pâte tendre «pA˘t:tÅndr´ pAttA)d{
raison d’être «rEIzç)˘N:dEtr´ {Ezç)dEt{
Tableau 126. Exemples de terminaisons <-pre>, <-dre> et <-tre>.
Ici encore, les clusters français [p{], [t{] et [d{] sont adaptés en [pr´], [tr´] et [dr´].
Dans ces exemples, le fait de ne pas appliquer les règles anglaises habituelles rend la
prononciation de ces terminaisons curieuse. Ajoutons que ces cas ne sont pas si nombreux
dans la base de données ; cette prononciation des terminaisons n’est donc pas si courante et en
général, c’est la règle anglaise qui est appliquée.

364 Vers une compréhension des emprunts non-anglicisés
Ces variantes soulignent donc la volonté du locuteur de prononcer ces mots
différemment et montrent un désir de se rapprocher de la prononciation française. Il s’agit
clairement d’une façon de marquer l’origine du mot.
8. Violation des règles anglaises
Nous avons montré jusqu’à présent de quelles manières le locuteur pouvait indiquer
l’origine française du mot ou s’approcher de la prononciation originale tout en respectant plus
ou moins les règles de l’anglais. Nous allons voir à présent que certains locuteurs sont prêts à
repousser les limites des règles anglaises afin d’obtenir une prononciation la plus proche
possible du français. Ajoutons que les variantes que nous allons mentionner sont assez rares,
ce qui s’explique notamment par le fait que ces prononciations nécessitent une connaissance
de la langue française et un effort particulier de la part du locuteur.
a) [j] final
Nous avons vu dans le chapitre précédent que [j] peut se trouver en fin de mot en
français, mais que cela pose un problème d’adaptation en anglais, puisque cette glissée ne
peut se trouver que suivie d’une voyelle. En général, il est rendu par une diphtongue ou par un
[I].
Pourtant, nous relevons deux variantes se terminant par [j] : millefeuille /«mi˘l:fŒ˘j/ et
portefeuille /«pç˘t:fŒ˘j/. Nous pouvons d’ailleurs comparer cette variante de millefeuille avec
une autre variante /«mi˘l:fŒ˘j´/, où le schwa final permet de mettre [j] en position d’attaque de
syllabe, conformément à l’anglais.

Les marques de francité 365
Il est probable que ces deux variantes où [j] est en position de coda représentent la
prononciation de locuteurs tentant d’imiter la prononciation française.
b) [r] final
Nous venons de voir que l’anglais ne pouvait reproduire le cluster plosive + [{] du
français, et nous avons pu observer à plusieurs reprises la ‘force’ de la règle anglaise
d’effacement du [r] final. Pourtant, nous relevons un certain nombre de variantes présentées
avec un [r] final :
Emprunt Anglais Français
amour-propre «QmU´:prÅpr amu{p{çp{
cadre :kA˘dr kAd{
cause célèbre «kç˘zsE:lEbr kozselEb{
coup de théâtre «ku˘d´tEI:A˘tr kud´teAt{
fiacre fI:A˘kr fjak{
film noir «fIlm:nwA˘r filmnwa{
genre :ZA)˘nr ZA){
hors d’œuvre ç˘:dŒ˘vr ç{døv{
savoir vivre «sQvwA˘:vi˘vr savwa{viv{
Tableau 127. Exemples de variantes avec [r] final.
Ces exemples montrent que certains locuteurs vont jusqu’à violer cette règle pourtant
très forte de l’anglais pour se rapprocher le plus possible de la prononciation française.
L’exemple de film noir est particulièrement illustratif car c’est le seul du genre. Dans ce

366 Vers une compréhension des emprunts non-anglicisés
contexte, on trouve toujours une prononciation [wA˘]. D’ailleurs la première variante de cet
emprunt est /«fIlm:nwA˘/ ; il ne s’agit donc pas non plus d’une erreur typographique. Genre
est également particulier puisque tous les autres cas sont des terminaisons en plosive + [{] en
français. Contacté par e-mail, Clive Upton, l’éditeur de l’ODP, nous a d’ailleurs confirmé que
ces transcriptions représentaient bien les prononciations de certains locuteurs qui tentent
d’imiter le français.
c) Voyelle brève finale
Lorsque nous avons abordé le thème de la syllabification dans la première partie179,
nous avons commenté la théorie des anglicistes qui expliquent qu’une syllabe ne peut se
terminer par une voyelle brève puisqu’on ne trouve pas de mot anglais se terminant par une
voyelle brève sous accent.
Pourtant, dans notre base de données, nous en relevons un certain nombre :
Emprunt Variante
bonhomie «bÅnÅ:mI
Chablis SQ:blI
comme ci, comme ça kÅm«si˘kÅm:sQ
pain au chocolat «pQ)´U:SÅk´lQ
pensionnat :pÅ)sjÅnQ
petite bourgeoisie p´«ti˘t«bç˘ZwA˘:zI
quincaillerie kQ)kaIj´:rI
voilà vw√:lQ
Tableau 128. Exemples de variantes avec voyelle brève finale. 179 Cf. p. 98

Les marques de francité 367
Il ne peut s’agir d’erreurs typographiques car dans plusieurs cas, le même dictionnaire
propose également une variante avec voyelle longue.
Il est donc particulièrement intéressant d’observer que certains locuteurs sont capables
d’utiliser une voyelle brève sous accent en fin de mot, bien qu’il semble que ce soit réservé
aux voyelles [Q] et [I]. Ces variantes sont tout à fait exceptionnelles en regard des règles
phonologiques de l’anglais.
Les locuteurs qui produisent ces variantes le font sans doute avec l’idée qu’une voyelle
brève sera plus proche de la prononciation française qu’une voyelle longue.
d) Schwa sous accent
Il s’agit ici d’une violation ‘extrême’ des règles de l’anglais. En effet, la voyelle [´] est
par essence inaccentuée ; elle est liée au phénomène de réduction vocalique. Pourtant, nous
trouvons quelques exemples dans notre corpus, où le schwa est présenté sous accent :
Emprunt Anglais Français
de rigueur «d´rI:gŒ˘ d´{igø{
je ne sais quoi «Z´n´sEI:kwA˘ Z´nsekwa
relevé «r´l´:vEI {´l´ve
Tableau 129. Variantes où schwa est sous accent.
Nous comprenons à la vue de ce tableau qu’il s’agit en réalité d’un conflit de règles.
Nous trouvons un schwa en anglais parce qu’il y a un schwa en français, mais les règles de
l’anglais poussent à placer un accent sur cette même syllabe. Il en résulte néanmoins des
variantes qui violent les règles théoriques de l’anglais.

368 Vers une compréhension des emprunts non-anglicisés
Nous voyons alors que quelle que soit la force de certaines règles phonologiques, il est
dans certains cas possible de les repousser, mais que cela nécessite une volonté forte de la part
du locuteur.
9. Cumul des marques
Certaines variantes cumulent les marques de francité ; elles présentent non seulement
des correspondances irrégulières, mais également une ou plusieurs marques que nous venons
de décrire, comme l’accent final ou toutes les voyelles pleines. Voici quelques exemples :
acquis communautaire Q«ki˘k´«mu˘n´U:tE´
ancien régime «A)˘ntsIQ)nrEI:Zi˘m
crème de menthe «krEmd´:mÅnt
haute couture «´UtkU:tU´
première danseuse «prEmIE´dÅn:sŒ˘z
sauve-qui-peut «s´Uvki˘:pŒ˘
Tableau 130. Exemples de variantes cumulant les marques de francité.
Des variantes de ce type sont inévitablement identifiées comme étant d’origine
française ; on y retrouve l’essentiel des règles qui s’appliquent aux emprunts français en
anglais.
Deux réflexions découlent de cette observation : d’abord, si certaines variantes
cumulent plusieurs marques de francité, certaines au contraire n’en ont qu’une, par exemple
l’accent final. On trouve donc entre les deux toute une palette de variantes plus ou moins
anglicisées, ou plus ou moins ‘francisées’ selon le point de vue que l’on adopte.
La seconde réflexion est en fait une interrogation qui fait suite à cette première
réflexion : pourquoi certaines variantes restent-elles plus proches de la prononciation

Quelques cas particuliers 369
française, alors que d’autres se fondent quasiment parmi les emprunts totalement anglicisés ?
Il est sans doute difficile de répondre à cette question, qui n’est peut-être pas du ressort de la
phonologie, mais plutôt de la socio- ou de la psycholinguistique. En effet, il faudrait d’abord
comprendre pourquoi certains locuteurs ressentent tant le besoin de marquer l’origine
française de certains mots, d’imiter la prononciation d’origine, alors qu’ils pourraient tout
simplement prononcer ces mots comme tous les vocables anglais. C’est sans doute au fond
dans le ressenti du locuteur que se trouve la réponse à cette question.
B. QUELQUES CAS PARTICULIERS
Nous souhaitons à présent aborder certains points qui ont attiré notre attention lors de
l’analyse des emprunts non-anglicisées.
1. Suffixe <-ier>
Dans notre paragraphe sur l’accentuation finale, nous avons été surprise de noter que
seul un tiers des mots en <-ier> sont accentués en finale, alors que c’est un suffixe qui nous
semblait identifié comme français.
Nous décidons de nous pencher sur ces mots et d’observer leur prononciation :
Emprunt Variante
atelier ´:tElIEI
bombardier «bÅmb´:dI´
couturier ku˘:tjU´rIEI
dossier :dÅsIEI
fusilier «fju˘zI:lI´

370 Vers une compréhension des emprunts non-anglicisés
Emprunt Variante
grenadier «grEn´:dI´
métier :mEtIEI
plumassier «plu˘m´:sI´
sommelier sÅ:mElIEI
Tableau 131. Exemples de mots en <-ier>.
Nous dégageons rapidement deux groupes : un premier groupe, majoritaire, où le
suffixe <-ier> se prononce [IEI] ou [jEI], mais qui ne porte jamais l’accent et réduit à [I´] ; et
un second groupe où le suffixe <-ier> se prononce [I´], mais porte l’accent.
Le premier groupe étant majoritaire, cela explique pourquoi nous avons trouvé un
résultat d’accent primaire en finale si faible. Il s’explique par le fait que <-ier> est un suffixe
assimilé à <-ion> et qu’en général, l’accent tombe sur la syllabe précédente.
Mais comment expliquer les variantes accentuées en finale ? En observant les dates
d’emprunt de certains de ces mots, nous remarquons qu’ils sont parmi les plus anciens de
notre corpus. Nous décidons alors d’étudier le lien entre prononciation du suffixe et date
d’emprunt, en les notant par ordre chronologique.
Il ressort de cette étude que la plupart des mots en <-ier> prononcés [I´] et accentués
en finale sont des emprunts des 16ème et 17ème siècles, alors que les emprunts postérieurs à
cette époque sont en général prononcés [IEI]. Notre hypothèse est qu’à cette période les
emprunts en <-ier> étaient ainsi adaptés, c’est-à-dire avec une accentuation française, mais
une prononciation anglicisée. D’ailleurs, certains de ces emprunts ont eu une variante
graphique en <-eer>, comme grenadier ou cavalier. Après cette période, l’adaptation s’est

Quelques cas particuliers 371
faite avec une prononciation plus proche du français, mais une accentuation conforme aux
règles anglaises.
2. Mots en <-ine>
Dans la Base de Données Finale, nous avons retenu les emprunts en <-ine> prononcés
[i˘n], puisque la correspondance était irrégulière. Mais nous avons remarqué que certains
emprunts appartenaient à la catégorie des mots savants ou techniques, comme strychnine
/:strIkni˘n/. Cependant, nous doutons que la prononciation soit une marque de l’origine
française du mot dans ce cas. Alors se pourrait-il que cette correspondance irrégulière soit
couramment employée dans le cadre de mots savants, et que cela n’ait plus rien à voir avec
l’origine française ?
Nous décidons de relever les mots en <-ine> prononcés [i˘n] dans la Base de Données
Finale et d’observer le champ lexical auquel ils appartiennent. Voici une sélection de ces
mots :
abricotine cholerine kalicine muscardine
amandine crêpe de Chine langoustine pebrine
argentine crinoline lettrine routine
aubergine cuisine leucine strychnine
basquine figurine limousine sylvine
Benedictine fine machine tartine
bottine fumagine margarine usine
brigantine gelatine messaline veratrine
cambresine grenadine mousseline vitrine
Tableau 132. Exemples de mots en <-ine> = [i˘n].

372 Vers une compréhension des emprunts non-anglicisés
Nous pouvons remarquer que ce sont tous des noms, bien que certains puissent
également être adjectifs.
Nous notons que la majorité de ces emprunts appartiennent à des champs lexicaux
connus pour les emprunts français, comme la gastronomie (ex : cuisine, fine, praline, tartine)
ou l’habillement (ex : crinoline, bottine, mousseline), mais que certains font effectivement
partie d’un vocabulaire plus scientifique comme la chimie, la minéralogie, la botanique
(ex : fumagine, kalicine, leucine, pebrine, strychnine, veratrine). Il n’est donc pas certain
que le suffixe soit équivalent dans tous les cas.
L’OED distingue en fait plusieurs suffixes <-ine>, notamment ceux de formation des
adjectifs et ceux de formation des noms. Parmi ces derniers, l’OED mentionne un suffixe
utilisé dans le vocabulaire de la chimie, bien que l’article ne parle pas de la prononciation de
celui-ci (OED, ‘-ine, suffix5’). Le dictionnaire mentionne également un autre suffixe,
représentant le français <-ine>, utilisé notamment dans la formation de noms de substances :
Many of these have come into English, in the F. form –ine [i˘n], which has
consequently become a formative element, freely used in forming the names of
derivative products, and of things supposed to be derived from, resemble,
imitate, or commemorate those from which they are named, and thus in the
trade-names of new varieties of fabrics, cosmetics, patent medicines, and
proprietary articles generally. (OED, ‘-ine, suffix4’)
Le dictionnaire propose les exemples nectarine, brilliantine ou grenadine, mais on
pense également à argentine, qui fait partie de notre corpus, et désigne une matière imitant
l’argent. Grenadine fait également partie de notre corpus, et il est possible dans ce cas que la
prononciation [i˘n] ne soit pas due à l’origine française.
Le cas de margarine, dans notre sélection, est particulièrement intéressant. En effet,
s’il est aujourd’hui associé au domaine culinaire, au départ il s’agit d’un terme de chimie qui

Quelques cas particuliers 373
désigne une substance, comme le montre la citation française de l’OED : « Le corps gras
obtenu ci-dessus est composé, comme le beurre, de margarine, d’oléine et d’un peu d’huile
odorante » (OED, ‘margarine’). Reste à savoir si margarine est prononcé [i˘n] en raison de
son origine française ou parce qu’il s’agit d’un terme de chimie.
3. Traitement du schwa français
Le schwa français est une voyelle dont nous avons assez peu parlé jusqu’à présent.
Pourtant, il s’agit de la seule voyelle que les deux systèmes aient en commun. Leurs usages
sont néanmoins différents, puisqu’en anglais cette voyelle est liée au phénomène de réduction
vocalique, phénomène qui n’existe pas en français.
Nous avons vu que dans certaines variantes, le schwa se trouvait même sous accent, ce
qui est contraire aux règles anglaises. Nous avons remarqué que dans ces cas, le schwa anglais
représentait un schwa français. Il paraît donc intéressant d’observer comment le [´] français
est adapté dans les variantes anglaises.
En général, nous remarquons que le schwa français est également prononcé [´] en
anglais, ou bien avec une autre voyelle réduite :
Emprunt Anglais Français
accoutrement ´:ku˘tr´m´nt akut{´mA)
bretelle br´:tEl b{´tEl
carte-de-visite «kA˘td´vI:zi˘t ka{td´vizit
contretemps :kÅntr´tA)˘N kç)t{´tA)
de haut en bas d´«´UtÅ):bA˘ d´otA)bA
monsieur m´:sjŒ˘ m´sjO

374 Vers une compréhension des emprunts non-anglicisés
Emprunt Anglais Français
mousquetaire «mu˘skI:tE´ musk´tE{
Parmesan :pA˘mI«zQn pa{m´zA)
que voulez-vous k´«vu˘lEI:vu˘ k´vulevu
Tableau 133. Exemples de variantes où le schwa français est rendu par schwa.
Dans les expressions comme carte-de-visite, les mots atones comme de, qui sont
toujours prononcés avec schwa en français, le sont également en anglais.
Parfois, la syllabe avec schwa est effacée dans la variante anglaise :
Emprunt Anglais Français
acharnement Q:SA˘nmÅ) aSa{n´mA)
portefeuille «pç˘t:fçI pç{t´føj
volte-face «vÅlt:fQs vçlt´fas
Tableau 134. Variantes où le schwa français est effacé en anglais.
Ces cas sont assez rares puisque ce sont les seuls que nous ayons relevés. Pour
portefeuille et volte-face, il s’agit de mots composés et le <e> central, prononcé schwa en
français, est sans doute interprété comme un <e> muet par les locuteurs anglophones.
Enfin, dans certains cas, la voyelle représentant le schwa français est prononcée [E] :
Emprunt Anglais Français
atelier ´:tElIEI at´lje
chevalet «SEv´:lEI S´valE
chevrotain :SEvr´tEIn S´v{çtE)
demoiselle «dEmwA˘:zEl d´mwazEl

Quelques cas particuliers 375
Emprunt Anglais Français
grenadine :grEn´di˘n g{´nadin
hotelier h´U:tElIEI ot´lje
jeté :ZEtEI Z´te
peloton :pEl´tÅn p´lçtç)
velouté vE:lu˘tEI v´lute
Tableau 135. Exemples de variantes où le schwa français est rendu par [E].
Nous constatons que c’est le placement de l’accent qui oblige à prononcer la voyelle
pleine, puisque le schwa ne peut théoriquement se trouver sous accent — hormis dans les cas
que nous avons présentés précédemment. Les mots trisyllabiques notamment, lorsqu’ils
portent l’accent en finale, portent également un accent secondaire sur l’antépénultième, ce qui
oblige à rendre la voyelle pleine (ex : chevalet, chevrotain, demoiselle). Notons également
qu’atelier présente aussi une variante /:Qt´lIEI/, dans laquelle il semble que l’accent ait été
déplacé vers la première syllabe — contrairement à la règle du suffixe <-ion>, auquel <-ier>
est assimilé — afin de rester plus proche de la prononciation française, et notamment de
conserver le schwa.
On peut également comparer les variantes de jeté /:ZEtEI/ et /Z´:tEI/, la seconde étant
évidemment plus proche de la prononciation française. La première variante est plus
anglicisée ; l’accent primaire est placé sur la première syllabe, conformément à la règle des
noms dissyllabiques, ce qui oblige à prononcer la voyelle [E].
On peut enfin remarquer que lorsque la syllabe portant le schwa se trouve en contexte
prétonique en anglais, on trouve parfois une variante avec [E], comme velouté /vE:lu˘tEI/, ou
vedette /vE:dEt/.

376 Vers une compréhension des emprunts non-anglicisés
C. QUELQUES PISTES DE REFLEXION
Nous souhaitons pour finir aborder quelques points qui pourraient certainement faire
l’objet d’une étude approfondie.
1. Le pluriel
Lorsque nous avons recherché les transcriptions des emprunts, nous avons uniquement
noté la variante au singulier car il nous semblait d’une part qu’ajouter le pluriel risquerait de
rendre la base de données difficilement lisible, et d’autre part que l’étude du pluriel des
emprunts français pourrait faire l’objet d’une recherche ultérieure.
Néanmoins, certains emprunts se trouvent avoir pour unique forme le pluriel,
notamment certaines expressions. Nous disposons donc d’un échantillon d’emprunts au
pluriel, ce qui nous permet d’émettre quelques remarques :
Emprunt Anglais Français
bouchées :bu˘SEI buSe
crudités :kru˘dItEI k{ydite
faites vos jeux «fEItv´U:ZŒ˘ fEtvoZO
marrons glacés «mQr´n:glQsEI ma{ç)glase
mesdames mEI:dQmz medam
messieurs mEI:sjŒ˘z mesjO
œufs sur le plat «Œ˘fsŒ˘l´:plA˘ Osy{l´pla
petits chevaux «pEtIS´:v´Uz p´tiS´vo
petits pois «pEtI:pwA˘ p´tipwa
Tableau 136. Exemples d’emprunts au pluriel.

Quelques pistes de réflexion 377
En français, le pluriel n’est pas prononcé à l’oral, sauf lorsqu’il y a liaison ou bien que
le pluriel est irrégulier comme cheval/chevaux /S´val/-/S´vo/ ou œuf/œufs /øf/-/O/, pour
lesquels nous trouvons des illustrations dans nos exemples. Nous remarquons dans ce tableau
qu’en général le pluriel est également non marqué dans les variantes anglaises, comme pour
bouchées ou petits pois. Mais nous trouvons également des cas où il l’est, comme pour
mesdames ou messieurs. Remarquons cependant que ces emprunts présentent également des
variantes dans lesquelles le pluriel n’est pas marqué. Nous pouvons également relever la
variante de petits chevaux /«pEtIS´:v´Uz/, dans laquelle on entend l’imitation de la forme
irrégulière française, à laquelle s’ajoute la marque de pluriel anglaise. Enfin, on peut
remarquer que le pluriel irrégulier d’œuf dans l’expression œufs sur le plat n’est pas
reproduite puisque le <f> est prononcé [f].
Il pourrait donc être particulièrement intéressant de réaliser une étude sur le pluriel des
emprunts français : trouve-t-on plus souvent l’application du pluriel anglais ou du pluriel
français ? Y a-t-il un lien avec la fréquence du mot ? On peut effectivement supposer que plus
un mot est employé, plus les locuteurs auront tendance à lui adjoindre un pluriel régulier. Ou
bien y a-t-il un lien avec les marques de francité de l’emprunt ? En effet, on peut considérer
qu’appliquer la règle du pluriel français est une marque supplémentaire, mais qu’elle est peut-
être associée à des emprunts déjà fortement marqués comme étant d’origine française. Toutes
ces questions ne pourraient trouver de réponse que dans une étude approfondie de cette
flexion.
2. La liaison
La liaison est un phénomène de la langue française qui consiste à prononcer la
consonne finale d’un mot lorsqu’il est suivi d’un mot commençant par une voyelle, alors que

378 Vers une compréhension des emprunts non-anglicisés
lorsque le mot est à l’état isolé cette consonne est muette, comme le définit le Dictionnaire de
linguistique (‘Liaison’, 284)180.
Notre corpus comptant un bon nombre d’expressions et mots composés, nous trouvons
plusieurs illustrations de ce phénomène :
Emprunt Anglais Français
beaux arts b´U:zA˘ boza{
de haut en bas d´«´UtÅ):bA˘ d´otA)bA
dos-à-dos «d´UzA˘:d´U dozado
fines herbes «fi˘n:E´b finzE{b
metteur en scène mE«tŒ˘rÅn:sEIn mEtø{A)sEn
notes inégales «n´UtsInEI:gQl nçtzinegal
pied-à-terre «pjEIdA˘:tE´ pjetatE{
prêt-à-porter «prEtA˘:pç˘tEI p{Etapç{te
pur et dur «pU´rEI:dU´ py{edy{
Tableau 137. Exemples d’emprunts avec liaison en français.
Nous voyons dans ces exemples que la variante anglaise reproduit la liaison, excepté
pour fines herbes. Cependant, il existe une autre variante où la liaison est représentée
/«fi˘n:zE´b/. On peut même remarquer que les [r] effacés sont réintroduits dans metteur en
scène ou pur et dur. Néanmoins ce phénomène existe déjà en anglais, puisqu’il s’agit du
‘linking r’. Nous pouvons également remarquer une ‘erreur de liaison’ dans l’exemple pied-à-
terre. Alors qu’en français, la liaison se fait avec un [t], l’anglais fait la liaison avec un [d],
sans doute en raison de la graphie de pied.
180 Dubois, Jean, et al. Dictionnaire de linguistique. Paris : Larousse, 1994.

Quelques pistes de réflexion 379
Il serait donc également intéressant d’étudier le phénomène de liaison de manière
approfondie, pour voir s’il est reproduit en anglais ou non, et de tenter d’expliquer dans quels
cas il n’est pas reproduit. Est-ce le signe d’une anglicisation ? De l’application des
correspondances graphiques, puisque rien ne laisse deviner qu’une liaison se produit en
français ? Ce phénomène est également intéressant car il suppose une connaissance de la
prononciation d’origine. Relève-t-on d’autres erreurs du type de pied-à-terre ? Y a-t-il des cas
où l’anglais propose une liaison alors qu’elle n’est pas prononcée en français ? Une fois
encore, les question sur le sujet sont nombreuses et justifieraient qu’on s’y attarde.
3. Les étapes de l’anglicisation
Dans notre étude, nous avons observé la prononciation des variantes non-anglicisées.
Nous avons pu souligner le fait qu’il existait des disparités parmi celles-ci, certaines variantes
étant assez proches de l’anglicisation alors que d’autres en sont très éloignées. La différence,
nous l’avons dit, se situe dans le nombre plus ou moins important de marques de francité.
Nous pourrions presque classer les variantes de la moins anglicisée, c’est-à-dire présentant le
plus grand nombre de caractères français, à la plus proche de l’anglicisation totale.
Parmi les différentes variantes d’un même emprunt, on peut même parfois observer
différents degrés d’anglicisation. Si l’on observe les emprunts de la Base de Données
Comparative, on peut même observer des emprunts présentant à la fois des variantes
anglicisées et d’autres beaucoup plus proches de la prononciation française.

380 Vers une compréhension des emprunts non-anglicisés
Les différentes variantes du mot amateur, par exemple, semblent illustrer les étapes de
l’anglicisation :
Figure 38. Anglicisation progressive de l’emprunt amateur.
Notons que la dernière variante /:Qm´t´/ pourrait être placée sur la troisième ligne en
considérant qu’il s’agit simplement de la réduction de [Œ˘]. Nous pouvons ajouter que cette
variante est celle qui est en première position dans les dictionnaires de prononciation, c’est-à-
dire la variante la plus courante. Amateur est donc un emprunt qui s’est totalement anglicisé,
même si certains locuteurs continuent à le prononcer ‘à la française’.
/«Qm´:tŒ˘/ : Variante la moins anglicisée avec l’accent final et la correspondance <-eur> = [Œ˘] /:Qm´tŒ˘/ : Application de l’ASR qui place l’accent primaire sur l’antépénultième /:Qm´tjU´/ : Prononciation anglicisée de la terminaison <-eur> /:Qm´tj´/ : Réduction de la terminaison /:Qm´tS´/ : Palatalisation de [j] /:Qm´t´/ : Variante la plus anglicisée.

Quelques pistes de réflexion 381
Les différentes variantes de dressage semblent également montrer une anglicisation
progressive :
Figure 39. Anglicisation progressive de l’emprunt dressage.
A l’unanimité des dictionnaires de prononciation, la variante la plus courante est
/:drEsA˘Z/, c'est-à-dire une prononciation française avec une accentuation régulière. Même si
certains locuteurs prononcent ce mot de manière anglicisée, ils ne sont donc pas majoritaires.
Il serait intéressant de comprendre pourquoi la plupart des locuteurs préfèrent une variante qui
montre davantage l’origine française.
L’emprunt cordon présente également un intérêt :
Figure 40. Anglicisation progressive de l’emprunt cordon.
Cet exemple est un peu différent car, s’il montre bien une anglicisation progressive,
nous décrivons ces variantes non pas par l’application progressive de règles anglaises, mais
/drE:sA˘Z/ : Accent final, correspondance <-age> = [A˘Z], voyelle prétonique pleine. /dr´:sA˘Z/ : Réduction de la voyelle prétonique. /:drEsA˘Z/ : Accent sur la 1ère syllabe, conformément à la règle des dissyllabes. /:drEsA˘dZ/ : Correspondance anglaise <g> = [dZ] /:drEsIdZ/ : Réduction de la voyelle finale. Variante totalement anglicisée.
/:kç˘dÅ)/ : Utilisation d’une voyelle nasale, réservée aux emprunts français. /:kç˘dÅN/ : Utilisation de la consonne nasale [N] non expliquée par le contexte. /:kç˘dÅn/ : Non-réduction de la dernière syllabe. /:kç˘d´n/ : Réduction de la syllabe finale. Variante anglicisée.

382 Vers une compréhension des emprunts non-anglicisés
plutôt par les différentes marques de francité, de la plus ‘forte’ à la moins forte. Nous pouvons
ajouter que les trois premières variantes sont trouvées dans le dictionnaire LPD avec la
mention ‘in French words’. Les autres dictionnaires ne proposent que la variante anglicisée,
qui est donc la plus courante.
Un dernier exemple intéressant est celui de beret :
Figure 41. Anglicisation progressive de l’emprunt beret.
Nous pouvons remarquer que la variante la moins anglicisée se voit tout de même
appliquer la règle de réduction vocalique dans la première syllabe. Mais ce qui est
particulièrement intéressant avec cet exemple, c’est que la variante la plus anglicisée, relevée
dans le dictionnaire LPD est annotée ‘formerly’. Il s’agit donc d’une variante plus ancienne et
qui n’est probablement plus en usage.
Cela signifie que l’anglicisation ne suit pas un chemin linéaire comme nous l’avons
présenté dans ces tableaux. Un emprunt peut être anglicisé à une période puis être à nouveau
prononcé ‘à la française’. C’est un sujet que nous avons abordé à travers l’histoire de certains
mots, et qui a été également commenté par la linguiste Barbara Strang dans son ouvrage A
History of English181. Elle cite l’exemple de chivalry, emprunt de longue date, qui a
récemment pris une couleur plus française avec la correspondance <ch> = [S] alors qu’il se
prononçait [tS] depuis des siècles (Strang, 28-29). Selon elle, l’une des raisons de ces
181 Strang, Barbara M.H. A History of English. London: Methuen, 1970.
/b´:rEI/ : Accent final, correspondance <et> = [EI] /:bErEI/ : Accent sur la 1ère syllabe, conformément à la règle des dissyllabes. /:bErI/ : Réduction de la terminaison <-et> /:bErIt/ : Prononciation anglicisée et réduite de la terminaison <-et>. Variante anglicisée.

Quelques pistes de réflexion 383
changements récents est d’une part la scolarisation et l’apprentissage des langues, et d’autre
part la conscience des locuteurs de l’origine étrangère de ces mots (Strang, 28).
C’est donc certainement cette conscience des locuteurs qui explique également qu’ils
conservent des prononciations proches de celle d’origine, ou du moins marquées de
caractéristiques françaises. Mais alors, pour qu’un emprunt soit anglicisé, faut-il que les
locuteurs n’aient plus conscience de l’origine du mot ? Ou bien l’anglicisation est-elle le fruit
d’une volonté du locuteur d’intégrer le mot ? Il y a sans doute plus d’une explication au
phénomène d’anglicisation.
Il serait donc pertinent d’étudier ce phénomène, d’en comprendre les mécanismes, afin
de savoir pourquoi certains emprunts vont être anglicisés, alors que d’autres non, pourquoi
certains emprunts vont jusqu’à l’anglicisation totale, alors que d’autres semblent ‘bloqués’ à
un certain stade, ou quelles sont les règles anglaises qui vont être plus souvent appliquées lors
de l’anglicisation, ce qui serait une indication de l’importance de ces règles pour la langue
anglaise. Comprendre le phénomène d’anglicisation serait donc la clé pour comprendre la
phonologie des emprunts français, et peut-être même de tous les emprunts dans la langue
anglaise.


385
CONCLUSION
Au cours de cette étude, nous avons pu esquisser un portrait des emprunts français
non-anglicisés. Nous avons montré quelques-unes des caractéristiques de ces emprunts qui
forment une classe à part, non seulement au sein des emprunts français, mais également au
sein des emprunts de la langue anglaise. Mais au final, cette étude des emprunts français non-
anglicisés permet surtout d’en savoir plus sur la langue anglaise elle-même, sur ses habitudes,
ses règles. Elle permet de constater la force de certaines règles qui sont quasiment inviolables.
La première partie de notre travail, qui consistait à sélectionner les emprunts qui
allaient former notre corpus, a permis d’aborder le thème de l’emprunt en général, et a montré
sa complexité, illustrée notamment par la multiplicité des termes utilisés par les linguistes et
des sens qu’ils leur donnent. Mais ce travail a également été l’occasion d’une réflexion sur la
méthodologie à adopter pour la constitution d’un corpus. Nous nous sommes concentrée sur la
sélection d’emprunts français non-anglicisés phonologiquement, sans prendre en compte des
critères d’usage du mot ou de ressenti du locuteur, qui nous paraissaient être bien trop
subjectifs et finalement non-pertinents pour notre étude, puisque nous avons montré avec
l’exemple de machine qu’un emprunt peut être phonologiquement non-anglicisé, mais
pourtant n’être plus identifié ou ressenti comme étranger. Nous nous sommes attachée dans un
premier temps à ne pas utiliser de critères phonologiques pour la sélection, puisque cela allait
être l’objet de l’analyse. Nous ne prétendons pas avoir trouvé la meilleure méthodologie, mais
en avons proposé une qui nous semble justifiée puisqu’elle permettait de réaliser cette
sélection de manière objective. Or nous avons vu, notamment avec le corpus de Bliss, que
l’objectivité est difficile à conserver dans le domaine de l’emprunt.
Le travail de suppression des variantes anglicisées, qui constitue la deuxième partie de
cette étude, était nécessaire puisque nos critères de départ n’étaient pas suffisants pour obtenir
une base de données contenant uniquement des emprunts non-anglicisés. D’ailleurs, nous

386 Conclusion
avons vu que certains emprunts présentent à la fois des variantes anglicisées et non-
anglicisées, ce qui signifie que tous les emprunts ne peuvent être simplement classés dans les
catégories ‘anglicisé’ ou ‘non-anglicisé’. Il faudrait peut-être créer une troisième catégorie
d’emprunts ‘mixtes’. Il pourrait d’ailleurs être intéressant de se concentrer sur ces mots ; sont-
ils en cours d’assimilation ou sont-ils traités différemment selon les locuteurs qui les
emploient, et si oui pourquoi ? Ces emprunts ont peut-être un statut particulier qui les
différencie d’emprunts présentant uniquement des variantes non-anglicisées. Sont-ils plus
courants, c’est-à-dire connus d’un grand nombre de locuteurs et non réservés à des
spécialistes, ou bien sont-ils plus fréquemment employés ? Les questions sur cette catégorie
d’emprunts sont nombreuses.
Mais ce travail de suppression des variantes anglicisées nous a surtout permis
d’approfondir les connaissances de la phonologie de l’anglais, en nous demandant ce qu’était
une prononciation ‘anglicisée’. Dans le même temps, nous avons amorcé le travail d’analyse
des emprunts non-anglicisés, en dégageant certaines de leurs caractéristiques : en effet, pour
déclarer qu’une variante est non-anglicisée, il est nécessaire d’expliquer ce qui la différencie
d’une variante anglicisée.
Enfin, la dernière partie nous a permis de synthétiser les caractéristiques des emprunts
non-anglicisés en partant de l’idée que leur prononciation imite celle du mot français d’origine
et en montrant comment l’anglais s’y prend pour adapter la prononciation française. Nous
avons également montré qu’en plus de prononciations imitant celles du français, les locuteurs
usent de moyens linguistiques pour marquer l’origine française de ces mots, moyens qui vont
de la simple non-réduction jusqu’à la violation de règles pourtant très fortes de l’anglais, en
passant par l’accentuation en finale — caractéristique du français. Nous avons appelé ces
moyens linguistiques des ‘marques de francité’, puisqu’il s’agit de phénomènes linguistiques
indiquant que le mot est d’origine française. Selon la connaissance du locuteur de l’origine

Conclusion 387
française du mot et sa volonté de montrer cette origine, il va utiliser plus ou moins de
marques. Certains locuteurs vont même jusqu’à franchir les limites imposées par la
phonologie de leur langue, en utilisant des variantes théoriquement impossibles.
Nous pouvons considérer que ces correspondances irrégulières et ces marques de
francité représentent en fait un sous-système phonologique de l’anglais, avec ses propres
règles, et réservé aux seuls emprunts français. Selon nous, il ne s’agit pas d’un système
‘coexistant’ pour deux raisons : d’une part puisqu’on retrouve les phonèmes de l’anglais —
les seuls phonèmes nouveaux étant les voyelles nasales — et d’autre part parce qu’on
remarque fréquemment des variantes combinant les règles habituelles de l’anglais et celles de
ce ‘système des emprunts français’. Cela va générer des variantes mi-anglaises mi-françaises
comme auberge /´U:bŒ˘Z/ ou cerclage /sŒ˘:klA˘Z/, où la correspondance anglaise <er> = [Œ˘]
se mêle aux correspondances des emprunts français, ou encore tirade /taI:rA˘d/ où le <i> est
tendu ‘à l’anglaise’ et la terminaison <-ade> prononcée ‘à la française’, en plus de l’accent
final.
Si nous nous sommes jusqu’à présent opposée à l’utilisation du ‘ressenti’ du locuteur
comme critère de sélection, nous devons nous rendre à l’évidence que cet élément a tout de
même son importance dans le domaine de l’emprunt. Dans bien des cas, c’est sans doute cette
‘conscience’ de l’origine française du mot — terme employé par Barbara Strang dans son
ouvrage A History of English182 — qui explique que l’anglicisation d’un emprunt est difficile
voire impossible. Dans la première partie, nous avons parlé des pérégrinismes, en définissant
ces emprunts comme étant sémantiquement liés à la France et à sa culture (ex : bouillabaisse,
cognac, château), sa géographie (ex : Provençal, Midi, mistral) ou son histoire (ex : ancien
régime, Directoire, Dreyfusard) ; les locuteurs employant des pérégrinismes ont donc
182 Op. cit. p. 382.

388 Conclusion
forcément conscience d’employer des mots relatifs à la France et cela explique sans doute
pourquoi ils utilisent ces règles phonologiques propres aux emprunts français.
Pourtant, cette conscience de l’origine du mot ne permet pas d’expliquer tous les cas,
puisque des mots comme machine ou police ne sont pas considérés comme étrangers, en dépit
de l’utilisation évidente de règles réservées aux emprunts français. Il reste donc à comprendre
pourquoi ces mots conservent une prononciation proche du mot d’origine qui n’est pas due à
une conscience de l’origine ou à une volonté de montrer sa connaissance de la langue
française.
L’une des difficultés de l’étude des emprunts est que ce domaine empiète sur plusieurs
autres. Nous avons ici réalisé un travail de phonologie, mais avons à présent compris que les
réponses à certaines questions étaient à chercher du côté de la psycholinguistique ou de la
sociolinguistique : quel est le ressenti du locuteur par rapport à ce mot ? A-t-il conscience
d’utiliser un mot français ? Le prononce-t-il de cette manière intentionnellement ?
Il semble à présent évident qu’il est impossible d’occulter l’importance du contexte
d’emploi de l’emprunt, des connotations qui y sont associées. Laure Chirol183 cite l’exemple
du mot accouchement qui est « réservé aux naissances royales et princières. Il relève moins
de la médecine que de l’expression des relations sociales dans l’aristocratie » (Chirol, 18). Cet
emprunt est donc employé dans un contexte particulier et n’est certainement pas connu de
l’ensemble de la population, contrairement à souvenir par exemple. Nous avons vu que
beaucoup d’emprunts appartiennent à des champs lexicaux très spécialisés et sont donc de ce
fait employés par une minorité de locuteurs, alors que d’autres font partie du vocabulaire
courant. Il faut d’ailleurs ajouter que ces derniers semblent les moins nombreux, ce qui donne
une indication sur les locuteurs qui emploient des mots français, c’est-à-dire essentiellement
des spécialistes de certains domaines (gastronomie, art, architecture, mode, histoire) et des
183 Op. cit. p. 23

Conclusion 389
locuteurs d’un niveau de langue assez soutenu. Mais ces champs lexicaux sont également
révélateurs de l’image de la France pour les anglophones, ce que montre l’étude de Laure
Chirol. On parle d’ailleurs souvent du ‘prestige’ de la langue française, notamment pour
expliquer la quantité impressionnante d’emprunts au français, et Barbara Strang explique que
cela peut-être une motivation d’emprunt — et donc d’usage d’emprunts : « borrowing can
result from […] the desire to associate oneself with a prestige group » (Strang, 34).
Nous avons apporté à cette étude notre point de vue de phonologue angliciste, mais
notre expertise ne peut suffire à répondre aux questions qui nécessitent des connaissances
dans les autres champs couverts par le domaine de l’emprunt. Pour réellement avancer dans
l’analyse de la phonologie des emprunts non-anglicisés, il faudrait en fait réunir un collège
d’experts en sociolinguistique, psycholinguistique, contact des langues ou même histoire, afin
d’avoir toutes les clés pour comprendre les mécanismes de l’emprunt et de l’anglicisation.
Nous ne pouvons donc proposer qu’une analyse partielle, et de nombreuses questions
restent en suspens à l’issue de ce travail. Mais il ouvre cependant de nombreuses perspectives
de recherches futures, dans tous les domaines que nous avons cités. Sur le plan phonologique,
il paraît nécessaire d’une part de vérifier les résultats que nous avons tirés des dictionnaires
auprès de locuteurs anglophones, en réalisant des expérimentations. De même, plusieurs
études phonétiques pourraient être réalisées, sur la prononciation des voyelles nasales, ou bien
l’observation du débit des locuteurs lorsqu’ils utilisent des emprunts non-anglicisés, afin de
vérifier notre hypothèse d’un ralentissement voire d’une courte pause avant certains emprunts.
Enfin et surtout, il serait nécessaire de réaliser une étude sociologique afin de mieux
comprendre la relation des locuteurs aux emprunts français.
En effet, il semble que la relation des locuteurs anglophones face aux emprunts
français soit particulièrement importante, car elle n’est jamais neutre. On explique parfois
l’emploi des emprunts par la mode, ou bien on qualifie cet emploi de ‘snobisme’, comme le

390 Conclusion
souligne Jespersen dans Growth and Structure of the English Language184 (Jespersen, 85). Les
emprunts sont donc vus positivement ou négativement, selon le point de vue adopté. Mais
dans la plupart des cas, il n’existe pas de neutralité du locuteur à l’égard des emprunts
français, du moins lorsque ceux-ci ont été identifiés.
Nous retrouvons parfois ce manque de neutralité chez certains linguistes, qui tentent
d’expliquer la nécessité des emprunts, en les classant dans différentes catégories selon leur
‘utilité’. Chirol présente par exemple les catégories proposées par Fowler, comme les « mots
acceptés comme pratiquement anglais bien que non indispensables », les « ornements
prétentieux » ou les « substituts inutiles pour des termes anglais » (Chirol, 23). Mackenzie
classe également les emprunts en différentes catégories comme les « expressions pour
lesquelles il n’existe pas d’équivalent anglais », les « expressions qui constituent un tour de
phrase particulièrement heureux » ou les « expressions qui acquièrent une vogue temporaire et
deviennent rapidement désuètes » — avec comme exemple boutique (Chirol, 23-26). Nous
constatons que ces linguistes portent un jugement sur les emprunts, ce qui n’est pourtant pas
leur rôle. D’ailleurs, Fowler va encore plus loin en classant les emprunts français en trois
catégories : mots permis, mots à utiliser avec prudence, et mots interdits (Chirol, 21). De
même, Draat écrit un article sur l’influence des emprunts français en anglais185, mais les juge
très sévèrement, comme le montre cette citation : « Very often they serve no useful purpose,
introduced as they are for mere ornament, display, ostentation, or to lend a touch of distinction
to affect higher culture » (Draat, 322-323), ou encore celle-ci : « Others maintain themselves,
[…] in spite of their patent uselessness » (Draat, 323).
Une citation de Barbara Strang reflète notre point de vue sur ces classements des
emprunts selon leur nécessité :
184 Op. cit. p. 10
185 Op. cit. p. 11

Conclusion 391
However, it will not do to class some loans as necessary and other as bids for
prestige or expressions of snobbery. It is people who use words according to
pressures from within or without, and as their tastes and knowledge permit. On
the one hand it is foolish to suppose that all borrowings are necessary in the
sense that they fill gaps in the lexical repertoire; on the other hand it is foolish
to class as unnecessary the borrowings which depend on the gratification of
human feelings no less profound than the desire for adequate expression of
message-content. In this sense every borrowing is a necessary one […].
(Strang, 34-35)
Ce jugement de la part de certains linguistes, qui illustre en fait un rejet des emprunts,
n’est pas réservé aux emprunts français en anglais. Nous observons aujourd’hui le même type
de réactions à l’égard des emprunts anglais en français, et quelques siècles plus tôt, ce sont les
emprunts italiens en français qui étaient visés. Nous comprenons finalement que l’emprunt est
un sujet sensible, au point que même des linguistes, qui se doivent pourtant d’avoir une
position neutre et objective sur des faits de langue, en oublient parfois leur rôle. Ils se placent
dans la peau du locuteur, avec son ressenti, ses émotions. L’un des avantages de notre position
est que nous sommes angliciste et non anglophone, ce qui permet peut-être de garder un peu
plus de neutralité en étudiant la phonologie de l’anglais. Cependant, nous ne pouvons nier que
nous sommes francophone, et que c’est aussi pour cette raison que nous avons choisi d’étudier
ces emprunts.
Nous voyons alors qu’il est difficile de conserver une position neutre face au sujet des
emprunts car il est lié, au moins pour certains, à l’idée d’une langue ‘pure’ qui serait entachée
par les apports étrangers. Cette idée fait parfois dériver certains linguistes vers une sorte de
protectionnisme de la langue, ce qui nous paraît excessif et injustifié. Heureusement, la réalité
linguistique montre qu’il est aussi inutile qu’impossible de vouloir empêcher le phénomène de

392 Conclusion
l’emprunt. Au final, cette étude des emprunts français en anglais nous fait prendre conscience
que la linguistique est bien une science humaine.

393
BIBLIOGRAPHIE
Dictionnaires
The American Heritage Dictionary of the English language. 4ème éd. Bartleby.com.
http://www.bartleby.com/61/.
Bliss, Alan. A Dictionary of Foreign Words and Phrases in Current English. London :
Routledge, 1966.
Dubois, Jean, et al. Dictionnaire de linguistique. Paris : Larousse, 1994.
Fowler, H. W. A Dictionary of Modern English Usage. 1926. 2ème éd. Sir Ernest Gowers, éd.
Oxford : Oxford UP, 1965.
The Free Dictionary. Farlex. http://www.thefreedictionary.com/.
Le Grand Robert. Ed. Alain Rey et Alain Duval. CD-ROM. Paris : Le Robert, Havas
Interactive, 1994.
Jones, Daniel. English Pronouncing Dictionary. Ed. Peter Roach, James Hartman et Jane
Setter. 16ème éd. Cambridge : Cambridge UP, 2003.
Longman Dictionary of Contemporary English Online. Pearson Education.
http://www.ldoceonline.com/.
Merriam-Webster Dictionary Online. http://www.merriam-webster.com/.
Oxford BBC Guide to Pronunciation. Ed. Lena Olausson et Catherine Sangster. Oxford :
Oxford UP, 2006.
Oxford Dictionary of Pronunciation for Current English. Ed. Clive Upton, William A.
Kretzschmar, Jr et Rafal Konopka. Oxford : Oxford UP, 2001.

394 Bibliographie
Oxford English Dictionary. 2ème éd. CD-ROM. Version 3.1. Oxford : Oxford UP, 2004.
Oxford English Dictionary. 3ème éd. Juin 2008. Oxford UP. Mai 2007–août 2008.
www.oed.com.
Speake, Jennifer, ed. The Oxford Dictionary of Foreign Words and Phrases. Oxford : Oxford
UP, 1997.
Trésor de la langue française informatisé. CD-ROM. Paris : CNRS Éditions, 2004.
Wells, John Christopher. Longman Pronunciation Dictionary. 2ème éd. Harlow (GB) : Pearson
Education, 2000.
Ouvrages
Arrivé, Michel, et al. La Grammaire d’aujourd’hui. Paris : Flammarion, 1986.
Baugh, Albert C. and Thomas Cable. A History of the English Language. 1951. 5ème éd.
London : Routledge, 2002.
Berg, Donna Lee. A Guide to the Oxford English Dictionary. Oxford : Oxford UP, 1993.
Carney, Edward. A Survey of English Spelling. London, New-York: Routledge, 1994.
Chadelat, Jean-Marc. Valeur et fonctions des mots français en anglais à l’époque
contemporaine. Paris : L’Harmattan, 2000.
Chevillet, François. Histoire de la langue anglaise. Que sais-je ? n°1265. Paris : PUF, 1994.
Chirol, Laure. Les ‘mots français’ et le mythe de la France en anglais contemporain. Paris :
Klincksieck, 1973.
Chomsky, Noam et Morris Halle. The Sound Pattern of English. Cambridge, USA : MIT
Press, 1968.

Bibliographie 395
Crépin, André. Deux mille ans de langue anglaise. Paris : Nathan, 1994.
Deroy, Louis. L’Emprunt linguistique. 1956. 2ème éd. Paris : Les Belles Lettres, 1980.
Deschamps, Alain et al. Manuel de phonologie de l’anglais. Paris : Didier-Érudition, 2000.
Garde, Paul. L’accent. Paris : PUF, 1968.
Gimson, A. C. An Introduction to the Pronunciation of English. 1962. 2ème éd. London :
Edward Arnold, 1970.
Görlach, Manfred. Introduction to Early Modern English. Cambridge : Cambridge UP, 1991.
Handbook of the International Phonetic Association. Cambridge : Cambridge UP, 1999.
Harris, John. English Sound Structure. Oxford : Blackwell, 1994.
Jespersen, Otto. Growth and Structure of the English Language. 1905. Stuttgart : Teubner
Verlag, 1935. 9ème éd. Oxford : Basil Blackwell, 1967.
Jones, Daniel. The Pronunciation of English. 1909. 4ème éd. Cambridge : Cambridge UP,
1956.
Jones, Daniel. An Outline of English Phonetics. 1918. 9ème éd. Cambridge : W. Heffer and
Sons, 1964.
Léon, Monique et Pierre. La prononciation du français. Paris : Nathan, 1997.
Lilly, Richard et Michel Viel. Initiation raisonnée à la phonétique de l’anglais. Paris :
Hachette, 1975.
Lilly, Richard et Michel Viel. La prononciation de l’anglais : règles phonologiques et
exercices de transcription. 1977. Paris : Hachette, 1998.

396 Bibliographie
Mackenzie, Fraser. Les relations de l’Angleterre et de la France d’après le vocabulaire. Vol.2 :
« Les infiltrations de la langue et de l’esprit français en Angleterre : gallicismes
anglais. » Paris : E. Droz, 1939.
Pennanen, Esko V. On the Introduction of French Loan-Words into English. Acta
Universitatis Tamperensis ser.A 38. Tampere, Finlande : Tampereen Yliopisto, 1971.
Philipp, Marthe. Phonologie de l’Allemand. Paris : PUF, 1970.
Resplandy, Franck. My rendez-vous with a femme fatale : les mots français dans les langues
étrangères. Paris : Bartillat, 2006.
Serjeantson, Mary S. A History of Foreign Words in English. London : Routledge, 1935.
Spencer, Andrew. Phonology : Theory and Description. Malden, MA, USA : Blackwell, 1996.
Strang, Barbara M.H. A History of English. London : Methuen, 1970.
Taillé, Michel. Histoire de la langue anglaise. Paris : Armand Colin, 1995.
Walter, Henriette. Honni soit qui mal y pense : l’incroyable histoire d’amour entre le français
et l’anglais. Paris : Robert Laffont, 2001.
Walter, Henriette. Le Français dans tous les sens. Paris : Robert Laffont, 1988.
Wells, John. Accents of English. Vol. 1 : “An Introduction”. Cambridge: Cambridge UP,
1982.
Wells, John. Accents of English. Vol. 2 : “The British Isles”. Cambridge : Cambridge UP,
1982.

Bibliographie 397
Articles
Baggioni, Daniel. « Schuchardt et la mixité des langues. » Cercle linguistique d’Aix-en-
Provence. L’Emprunt. Centre des sciences du langage. Aix-en-Provence : Publications
de l’Université de Provence (1994) : 23-37.
Baugh, Albert C. « The Chronology of French Loan-Words in English. » Modern Language
Notes 50 (1935) : 90-93.
Crépin, André. « Réflexion sur la coupe syllabique. » Colloque d’avril sur l’anglais oral :
réalités et didactique. Université Paris-Nord (1982) : 55-62.
Darbelnet, Jean. « De l’emprunt au néologisme. » Les relations entre la langue anglaise et la
langue française : actes du colloque international de terminologie. Paris, mai 1975.
Conseil international de langue française. Québec : l’Éditeur officiel du Québec
(1978) : 109-121.
Démory, Thierry. « Les emprunts français dans la langue anglaise. » CILL : Cahiers de
l’Institut de Linguistique de Louvain 27/3-4 (2001) : 79-87.
Deroy, Louis. « Vingt ans après L’Emprunt linguistique : critiques et réflexions. » L’emprunt
linguistique. Colloque international organisé par Hubert Le Bourdellès, C. Buridant et
R. Lilly. Cahiers de l’Institut de linguistique de Louvain 6 (1980) : 7-18.
Draat, P. Fijn van. « Aliens. Influx of French Words into English. » Englische Studien 72
(1938) : 321-342.
Durand-Deska, Anna et Pierre Durand. « La forme sonore des emprunts : les mot anglais en
polonais et en français. » L’emprunt. Cercle Linguistique d’Aix-en-Provence (1994) :
79-105.

398 Bibliographie
Durkin, Philip N. R. « Root and branch : revising the etymological component of the Oxford
English Dictionary. » Transactions of the Philological Society 97/1 (1999) : 1-49.
Haugen, Einar. « The analysis of linguistic borrowing. » Language 26 (1950) : 210-231.
Humbley, John. « Vers une typologie de l’emprunt linguistique. » Cahiers de lexicologie 25/2
(1974) : 46-70.
Humbley, John. « L’intégration phonétique des mots d’emprunt français en anglais. »
L’emprunt linguistique. Colloque international organisé par Hubert le Bourdellès, C.
Buridant et R. Lilly. Cahiers de l’Institut de linguistique de Louvain 6 (1980) : 193-
206.
Koszul, A. « Statistique et Lecture. Note sur la courbe des emprunts de l’anglais au français. »
Bulletin de la Faculté des Lettres de Strasbourg 15 (1936) : 79-82.
Mossé, Fernand. « On the Chronology of French Loan-Words in English. » English Studies
XXV (1943) : 33-40.
Orr, John. « L’empreinte du français sur l’anglais. » Le Français Moderne 16 (1948) : 241-
247.
Tabouret-Keller, Andrée. « La Motivation des emprunts : un exemple pris sur le vif de
l’apparition d’un sabir. » La Linguistique I, (1969): 25-61.
Touratier, Christian. « Les problèmes de l’emprunt. » Cercle linguistique d’Aix-en-Provence.
L’Emprunt. Centre des sciences du langage. Aix-en-Provence : Publications de
l’Université de Provence (1994) : 11-22.

Bibliographie 399
Thèses
Bejta, Bekim. « L’assimilation morpho-phonologique des xénismes français en anglais et son
traitement lexicographique. » Thèse de doctorat, Université de Poitiers, 2002.
Boisson, Claude. « L’accentuation des composés en anglais contemporain, avec quelques
contributions à l’accentologie générale ». Thèse de Doctorat d’État, Université Paris 7,
1980.
Bouzon, Caroline. « Rythme et structuration prosodique en anglais britannique
contemporain. » Thèse de doctorat de 3ème cycle, Université Aix-Marseille I, 2004.
Vince, Jennifer. « Les Emprunts de l’anglais au français à l’époque contemporaine. » Thèse
de Doctorat de 3ème cycle, Université Paris 7, 1984.
Sources électroniques
The British Academic Spoken English (BASE) corpus. University of Warwick. Novembre
2004. http://www2.warwick.ac.uk/fac/soc/al/research/projects/resources/base.
(anciennement) <http://www.rdg.ac.uk/slals/base/>.
British National Corpus. University of Oxford. Novembre 2004.
http://www.natcorp.ox.ac.uk/.
« Le Déambulatoire. » Unité d’habitation Le Corbusier Marseille : La Cité radieuse. 02 sept.
2008. http://www.marseille-citeradieuse.org/chap1/11Deambulatoire.htm.
« How to choose a well-fitting bra. » VideoJug. 20 fév. 2007. VideoJug Corporation Limited.
14 oct. 2008. http://www.videojug.com/film/how-to-choose-a-well-fitting-bra.

400 Bibliographie
« How to choose wine for beef bourguignon. » VideoJug. 23 août 2007. VideoJug
Corporation Limited. 17 oct. 2008. http://www.videojug.com/film/how-to-choose-
wine-for-beef-bourguignon.
« How to make Allemande Sauce. » VideoJug. 27 juil. 2006. VideoJug Corporation Limited.
15 oct. 2008. http://www.videojug.com/film/how-to-make-allemande-sauce.
« How to make celeriac and potato gratin. » VideoJug. 27 juil. 2006. VideoJug Corporation
Limited. 18 oct. 2008. http://www.videojug.com/film/how-to-make-celeriac-and-
potato-gratin.
« How to make croissants. » VideoJug. 3 avril. 2007. VideoJug Corporation Limited. 15 oct.
2008. http://www.videojug.com/film/how-to-make-croissants.
« How to make lobster in court bouillon. » VideoJug. 27 sept. 2006. VideoJug Corporation
Limited. 17 oct. 2008. http://www.videojug.com/film/how-to-make-lobster-in-court-
bouillon.
‘Kermesse’. Wikipedia, The Free Encyclopedia. Wikimedia Foundation. 11 janv. 2008.
http://en.wikipedia.org/wiki/Kermesse_%28Bicycle_Race%29
Lewis, Jack Windsor. « The pronunciation of liege, etc. » 20 sept. 2007. Phonetiblog. 24 sept.
2007. http://www.yek.me.uk/archive5.html#blog048.
‘Pom-pon’. Wikipedia, the Free Encyclopedia. Wikimedia Foundation. 13 avr. 2008.
http://en.wikipedia.org/wiki/Pompon.
« 60 Second Style : Lingerie. » VideoJug. 3 oct. 2008. VideoJug Corporation Limited. 14 oct.
2008. http://www.videojug.com/film/60-second-style-lingerie.
« Succès de scandale. » Wikipedia, the Free Encyclopedia. 11 sept. 2008. Wikimedia
Foundation. 4 oct. 2008. http://en.wikipedia.org/wiki/Succ%C3%A8s_de_scandale.

Bibliographie 401
« Trapèze vocalique du français. » SFU : Introduction à la Linguistique. Simon Fraser
University, Canada. 17 juil. 2008. http://www.sfu.ca/fren270/Phonetique/trapeze.html.
Trésor de la Langue française informatisé. ATILF, CNRS, Universités Nancy 1 et Nancy 2.
http://atilf.atilf.fr/tlf.htm.
Valensi, Louis. « 1863, un scandale au salon des indépendants. » CDI Garches. 9 nov. 2004. 4
oct. 2008. http://cdigarches.free.fr/pdf/041109_1863-Scandale-au-Salon_site.pdf.
Wells, John. « Syllabification and Allophony. » JC Wells homepage. Publié dans Studies in
the Pronunciation of English. Susan Ramsaran, ed. London, New-York : Routledge,
1990 : 76-86. UCL Division of Psychology and Language Sciences. Mars 2007.
http://www.phon.ucl.ac.uk/home/wells/syllabif.htm.
Wells, John. « Dictionary Conventions. » John Wells’s phonetic blog. 22 nov. 2006. UCL
Division of Psychology and Language Sciences. 22 nov. 2006.
http://www.phon.ucl.ac.uk/home/wells/blog0611b.htm.
Wells, John. « My liege, we are besieged. » 20 sept. 2007. John Well’s phonetic blog. UCL
Division of Psychology and Language Sciences. 20 sept. 2007.
http://www.phon.ucl.ac.uk/home/wells/blog0709.htm.
Wells, John. « Osteoporosis ». 18 dec. 2007. John Well’s phonetic blog. UCL Division of
Psychology and Language Sciences. 18 dec. 2007.
http://www.phon.ucl.ac.uk/home/wells/blog0712b.htm.
Wells, John. « Greengrocers’ spelling. » 6 juin 2008. John Well’s phonetic blog. UCL
Division of Psychology and Language Sciences. 27 juin 2008.
http://www.phon.ucl.ac.uk/home/wells/blog0806a.htm.

RÉSUMÉ en français
Ce travail porte sur la phonologie des emprunts français non-anglicisés, c’est-à-dire qui ne suivent pas toutes les
règles de l’anglais et conservent des caractéristiques françaises. Dans la première partie, nous décrivons la
méthodologie employée pour la sélection du corpus, ce qui nous amène à étudier la terminologie utilisée dans la
linguistique de l’emprunt, et présentons la base de données qui servira à l’analyse de ces emprunts. Dans la seconde
partie, nous supprimons de cette base de données initiale toutes les variantes anglicisées, ce qui donne lieu à de
nombreuses discussions sur la phonologie de l’anglais. Enfin, la dernière partie présente l’analyse de la base de
données finale, ne contenant que des variantes non-anglicisées. En partant de l’idée que ces emprunts imitent la
prononciation française, nous montrons comment les phonèmes français sont adaptés en anglais, et de quelle
manière les locuteurs anglophones signalent l’origine française d’un mot.
TITRE en anglais
The Phonology of Non-Anglicized French Loanwords
RÉSUMÉ en anglais
This study focuses on the phonology of non-anglicized French loanwords, i.e. those which do not follow all English
rules and retain French characteristics. The first part describes the methodology used for the selection of the corpus,
which brings about discussions on loanword terminology, and presents the database that will be used in the analysis
of these loanwords. The second part is dedicated to the deletion of the anglicized variants remaining in the
database, which brings about many discussions on English phonology. Finally, the last part presents the analysis of
the final database, containing only non-anglicized variants. Starting with the idea that these loanwords imitate the
French pronunciation, we show how French phonemes are adapted into English, and how English speakers indicate
the French origin of a word.
DISCIPLINE
Phonologie ; Linguistique ; Phonologie de l’anglais
MOTS CLEFS
Emprunts ; phonologie ; anglicisation ; adaptation ; phonologie de l’anglais ; phonologie du français
INTITULÉ ET ADRESSE DE L’ÉCOLE DOCTORALE
ED Concepts et Langage
Université Paris-Sorbonne, Maison de la Recherche, rue Serpente, 75005 PARIS