symetric : projet régional pour le développement de la médecine systèmique
TRANSCRIPT

A. Gaignard - CHU de Nantes
projet régional pour le développement de la Médecine Systémique
portage scientifique : Jérémie Bourdon (LINA), Richard Redon (Inst. du Thorax)
SyMeTRIC

A. Gaignard - CHU de Nantes
Développer des approches prédictives, intégrer différentes sources d'information pour construire et valider des marqueurs et modèles bio-pathologiques.
pour une médecine personnalisée. identifier le bon traitement pour le bon groupe de patient, au bon moment, et à la bonne dose.
Acquisition, analyse, intégration de données massives, hétérogènes, cloisonnées.
“Systems Medicine”
2

A. Gaignard - CHU de Nantes
Acteurs régionaux
3
Tumorothèque
UMGC
FHU GOAL
LabCT

A. Gaignard - CHU de Nantes
Structuration
4
➡ discovery & validation de signatures / modèles
Education
Clinical care
Research
Society (innovation, public
policies, open data)
Computing infrastructure
Bio-informatics, systems bio-medicine,
data sciences & bio-statistics
Data access & publication
Data processing
Biological samples
Biologists
Clinicians
Mathematicians
Biom
arke
rs
disc
over
y
Tran
sfer
&
de
velo
pmen
t
*-omic data
Clinical data
Imaging data Bi
omar
kers
ev
aluat
ion
Computer scientists
colla
bora
tive
e-s
cienc
e

A. Gaignard - CHU de Nantes 5
RNA-seq : séquençage de tous les ARNs d’un échantillon pour mesurer différents niveaux d’expression des gènes
1 échantillon 300 échantillons 30 projets Données brutes 2x 17Go 10.2 To 306 To
Données produites 12 Go 3.6 To 108 To
CPU (1 core) 170 h 5.9 ans 177 ans
CPU (32 cores) 32 h 13 mois 32 ans
• Performance (algorithmique, parallélisme) • Stockage (et préservation ?) • Utilisation secondaire des données traitées (indexation sémantique) • Reproductibilité (qualité) des analyses de données
Aujourd’hui : preuves de concept
TopHat : alignement d’une séquence avec un génome de référence

A. Gaignard - CHU de Nantes
BiRD - Bioinformatics core facility
6
320 Cores 1.2 TB RAM150 TB storage
512 Cores 2 TB RAM80 TB storage
Infiniband
NFS
Bright Cluster Manager 7.0
Clu
ster
NG
S
BiR
D C
lust
er (G
alax
y +
clou
d)

A. Gaignard - CHU de Nantes
Démonstrateur RNA-seq
7
Web based
NGS data analysis X
A. Gaignard - CHU de Nantes
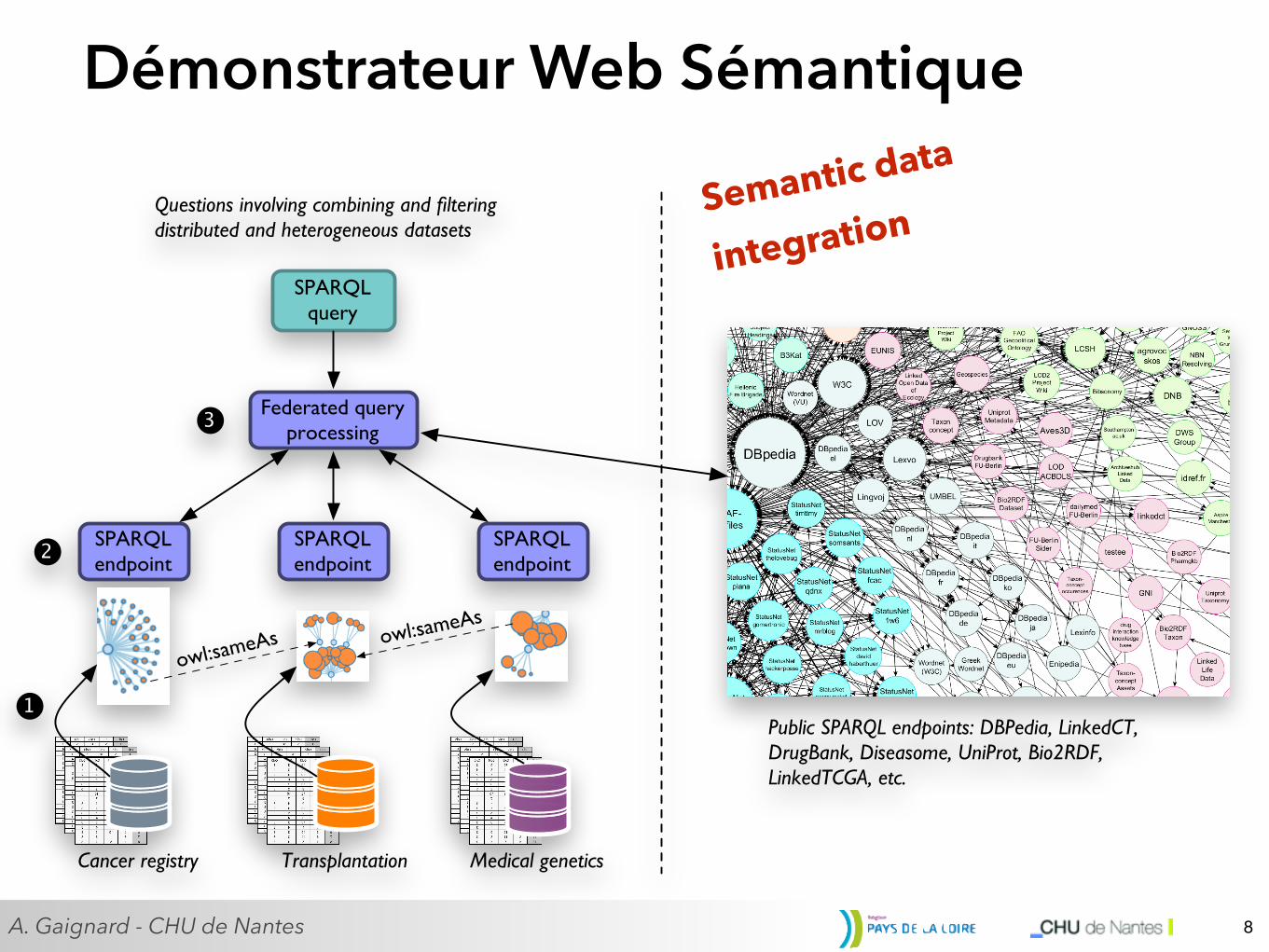
Démonstrateur Web Sémantique
8
��������� 17
SPARQL endpoint
SPARQL endpoint
SPARQL endpoint
Federated query processing
SPARQL query
owl:sameAs owl:sameAs
Cancer registry Transplantation Medical genetics
Public SPARQL endpoints: DBPedia, LinkedCT, DrugBank, Diseasome, UniProt, Bio2RDF, LinkedTCGA, etc.
Questions involving combining and filtering distributed and heterogeneous datasets
11
12
13
Figure 2: Interoperable and linked Cancer surveillance and biomedical datasets
2. Then, for each data sources, the corresponding curated data graphs (i.e. linked to referenceontologies and other datasets) are exposed through a standard SPARQL endpoint (Virtuoso,Fuseki19, Corese20, etc.) which serves data through the SPARQL21 semantic web query language.
3. On top of the available data sources, a federation engine is responsible for the distribution ofan input SPARQL query over distributed data sources. Main steps comprise the relevant datasources selection, query rewriting, distributed querying optimizations to reduce the amount oftransmitted results over the network, results filtering and linking so that they appear for the useras coming from a globally unified database. Federated SPARQL querying is still a very activeresearch field, however some federation engines such as Corese, FedX22, Anapsid23, or DARQ24
are already available with several focuses (query expressiveness, performance).
The development of this Linked Data demonstrator should rise some technical, regulatory or legalissues. We propose to systematically identify the obstacles so that data sharing and collaborativeresearch through SyMeTRIC will be made easier and more efficient.
The right part of figure 2 illustrates some of the publicly available SPARQL endpoint. By relying onSemantic Web standards, SyMeTRIC actors could benefit from massive open linked data (31+ billiontriples in September 2011). Conversely, using these standards opens interesting perspectives for Sy-MeTRIC actors, especially in the context of multi-centric studies when it comes to setup collaborationsinvolving data sharing.
Benefits are also expected in the direction of industrial partners. Lot of pharmaceutical and biotech-nology companies develop their own markers but do not have access to high-quality datasets. Suchinitiative would definitely help them in evaluating biomarker candidates and thus anticipate and eval-uate the risk of further developing a given biomarker.
19 http://jena.apache.org/documentation/serving_data20 https://wimmics.inria.fr/corese21 Query language similar to SQL, based on graph pattern matching, and possibly allowing reasoning.22 http://www.fluidops.com/en/company/training/open_source.php23 https://github.com/anapsid/anapsid24 http://darq.sourceforge.net
Semantic data
integration


W3C - PROV (provenance)

A. Gaignard - CHU de Nantes
• Incitation forte (Europe, gouvernements, société civile) à publier les données de la recherche (H2020 data management plans, agence européenne du médicament EMA)
• Contexte “Hôpital Numérique” ; “Conseil National du Numérique” ; projet de loi de santé (SNDS)
• “Open Data” = données brutes ≠ données inter-opérables≠ données intelligibles
Demain, une plateforme “données et modèles bio-médicaux”
11
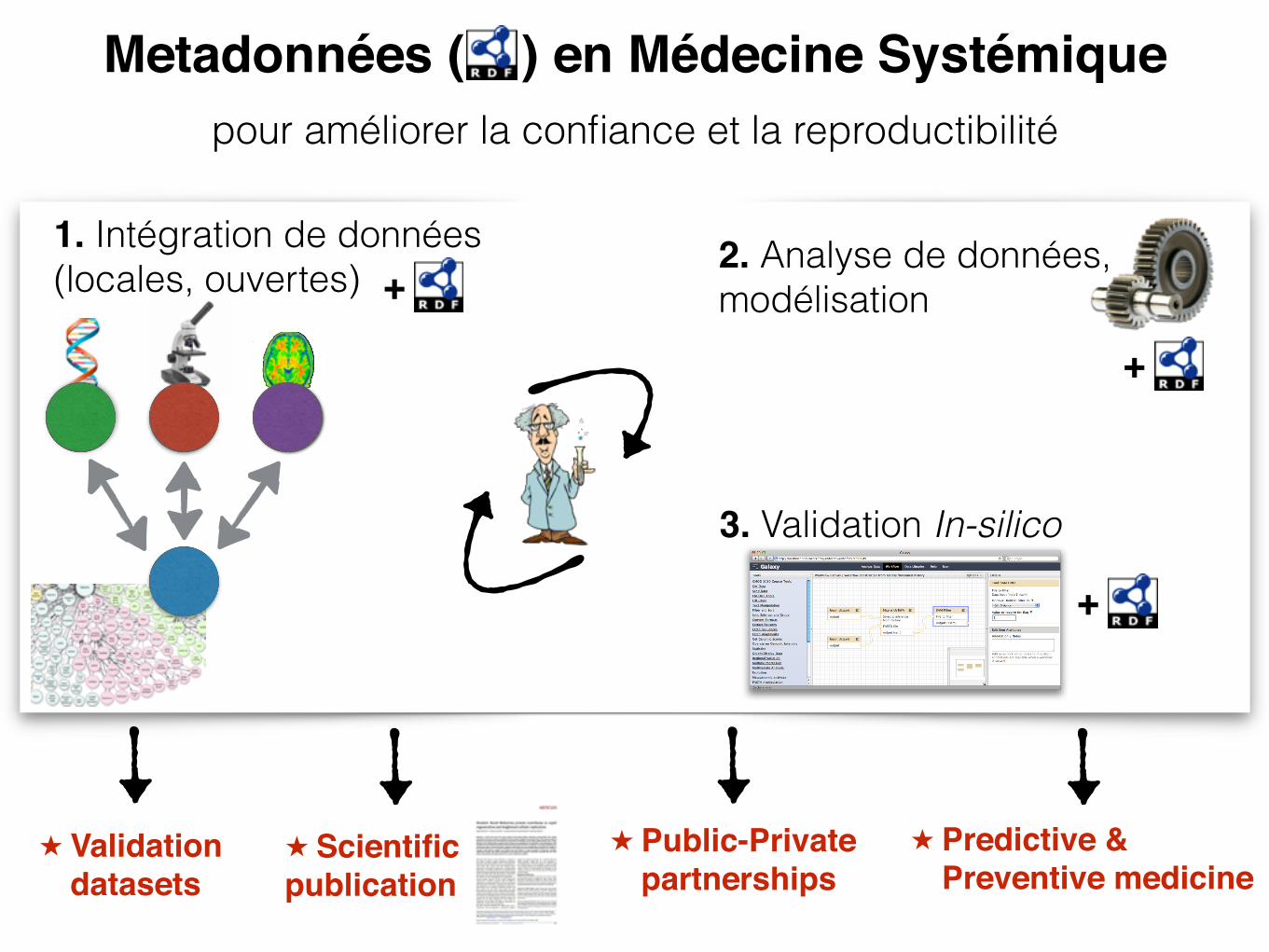
Metadonnées ( ) en Médecine Systémique
★ Scientific publication
1. Intégration de données (locales, ouvertes) 2. Analyse de données,
modélisation+
3. Validation In-silico
+
★ Predictive & Preventive medicine
pour améliorer la confiance et la reproductibilité
★ Public-Private partnerships
+
★ Validation datasets

A. Gaignard - CHU de Nantes
• WP1 : Inter-opérabilité des données cliniques et recherche, “privacy” + Exploitation de données publiques (Open Data, bases médico-administratives)
• WP2 : Production de données intelligibles et inter-opérables
• WP3 : Fédération d’infrastructures (clouds académiques, data centers universitaires)
Demain, une plateforme “données et modèles bio-médicaux”
13

A. Gaignard - CHU de Nantes
Contact : jéré[email protected] (LINA) [email protected] (Institut du Thorax) [email protected] (CHU de Nantes)
Questions ?