recherche des profils patients dépassant la durée …touati/sodas/exemples/sejour... ·...
TRANSCRIPT

1
2007 - 2008
Master MIAGE & DECISION Spécialité : Informatique décisionnelle
PROJET DATAMINING
Recherche des profils patients dépassant la durée
normale de séjour au centre hospitalier de
Poissy-St Germain en Laye
Etudiants :
Alpha Oumar BAH Aurel CRECIUN
Tuteur : Professeur Edwin DIDAY

2
SSOOMMMMAAIIRREE
Sommaire __________________________________________________________________ 2
INTRODUCTION ________________________________________________________________ 3
Première Partie4:Présentation du datamining et du logiciel sodas ________________________ 4
1 - Objectifs généraux du DATAMINING ____________________________________________ 4 1-1 Caractéristiques et ouvertures l’analyse des données symboliques ______________________________ 4 1-2 Avantages des objets symboliques ______________________________________________________ 5
2- Etude de marché des outils Datamining ____________________________________________ 6 2-1 Panorama des outils existant sur le marché (Benchmark) _____________________________________ 6 2-2 Le logiciel SODAS (Symbolic Official Data Analysis System) ________________________________ 7
3- Description sommaire du mode opératoire _________________________________________ 9 3-1 Les principaux onglets de Sodas ________________________________________________________ 9 3-2 Sélection d’une base d’étude __________________________________________________________ 10 3-3 Choix des méthodes à appliquer _______________________________________________________ 10
Partie 2 : ETUDE STATISTIQUE _________________________________________________ 14
II –1 Présentation de l’étude ______________________________________________________ 14 II –1-1 Contexte de l’étude et présentation des données ________________________________________ 14 II –1-2 L’analyse ______________________________________________________________________ 16
1. DB2SO : extraction de données symboliques de la base de données relationnelles _______________ 16
II-2 Présentation des méthodes et résultats __________________________________________ 21 II-2 -1 Méthode View __________________________________________________________________ 21
a- Présentation de la méthode __________________________________________________________ 21 b. Mise en oeuvre de la méthode View ___________________________________________________ 22
II-2 -2 La méthode STAT _______________________________________________________________ 25 a- Présentation de la méthode STAT_____________________________________________________ 25 b. Mise en oeuvre de la méthode STAT __________________________________________________ 26
II-2 -3 La méthode DIV : Divisive Clustering on Symbolic Objects _______________________________ 30 a- Présentation de la méthode DIV ______________________________________________________ 30 b- Mise en oeuvre de la méthode DIV ___________________________________________________ 31
II-2-4 La méthode TREE : Decision Tree ___________________________________________________ 34 a-Présentation de la méthode TREE _____________________________________________________ 34 b-Mise en oeuvre de la méthode TREE __________________________________________________ 34
II-2-5. La méthode PYR : Pyramical Clustering on Symbolic Objects _____________________________ 35 a- Présentation de la méthode PYR ______________________________________________________ 35 b- Mise en oeuvre de la méthode PYR ___________________________________________________ 36
II-2-6 PCA : Principal Component Analysis _________________________________________________ 36 a- Présentation de la méthode PCA ______________________________________________________ 36 b. Mise en oeuvre de la méthode PCA ___________________________________________________ 37
II-2-7 La méthode DISS/MATCH _________________________________________________________ 39 a- Présentation de la méthode _______________________________________________________ 39 b-Mise en oeuvre de la méthode ________________________________________________________ 39
II-2-8 Les méthodes clustering (SCLUST) __________________________________________________ 40 a- Présentation de la méthode _______________________________________________________ 40 b- Mise en œuvre de la méthode ________________________________________________________ 40
II-2-9 La méthode de SYKSOM __________________________________________________________ 42
Conclusion_______________________________________________________________45

3
INTRODUCTION
Désormais, le Datamining est au coeur de toutes les préoccupations du monde des
affaires. C’est un processus qui permet de découvrir, dans de grosses bases de données
consolidées, des informations jusque là inconnues mais qui peuvent être utiles et lucratives et
d'utiliser ces informations pour soutenir des décisions commerciales tactiques et stratégiques.
Les approches traditionnelles de la statistique ont des limites avec de grosses bases de
données, car en présence de milliers ou de millions d’individus et de centaines ou de milliers de
variables, on trouvera forcément un niveau élevé de redondance parmi ces variables. Les
techniques de datamining interviennent et offrent des réponses à l’analyse de données
volumineuse et nous permettra d’extraire des informations intéressantes et apportent de
nouvelles connaissances jusque là inconnues, que les méthodes statistiques classiques n’ont pas
mit en avant.
L’exploitation de ces nouvelles informations peut présenter un intérêt pour analyser et
interpréter les comportements d’individus et ensemble d’individus. Les résultats obtenus
s’insérant dans un dispositif d’analyse globale permettent alors de dresser dans des plans
stratégiques ou politiques les axes d’effort à respecter.
Les techniques du datamining sont regroupées dans deux principales catégories :
Les méthodes descriptives qui visent à structurer et à simplifier les données issues de
plusieurs variables, sans privilégier l'une d'entre elles en particulier, il s’agit notamment
de l'analyse en composantes principales (ACP), l'analyse factorielle des
correspondances (AFC), l'analyse des correspondances multiples (ACM) et des
méthodes de classification automatiques.
Les méthodes explicatives qui visent à expliquer une variable à l'aide de deux ou
plusieurs variables explicatives, les principales méthodes utilisées dans les enquêtes sont
la régression multiple, l'analyse discriminante et la segmentation (arbres de décision).
L’analyse des données symboliques prend actuellement de plus en plus d’importance, comme
en témoigne le développement du logiciel spécifique SODAS. C’est ce logiciel qui va être
utilisé dans le cadre de ce projet afin d’extraire les données concentrées dans une base de
donnée relationnelle de type ACCESS, SQL Server, BO et d’y appliquer les principales
méthodes d’analyse proposées dans SODAS.
L’étude datamining que nous réaliserons ici porte sur la recherche des profils patients
qui dépassent la durée normale de séjour dans un centre hospitalier
Le présent rapport est constitué de deux parties. La première est une présentation
générale du datamining et du logiciel SODAS. La deuxième partie portera sur la présentation de
méthodes, l’analyse et l’interprétation des résultats obtenus.

4
PREMIERE PARTIE
PRESENTATION DU DATAMINING ET DU LOGICIEL SODAS
1 - OBJECTIFS GENERAUX DU DATAMINING
Les progrès de la technologie informatique dans le recueil et le transport de données font
que dans tous les grands domaines de l’activité humaine, des données de toutes sortes
(numériques, textuelles, graphiques…) peuvent maintenant être réunies et en quantité souvent
très importante.
Les systèmes d’interrogation des données, qui n’étaient autrefois réalisables que via des
langages informatiques nécessitant l’intervention d’ingénieurs informaticiens de haut niveau,
deviennent de plus en plus simples d’accès et d’utilisation.
Résumer ces données à l’aide de concepts sous-jacents (une ville, un type de chômeur,
un produit industriel, une catégorie de panne …), afin de mieux les appréhender et d’en extraire
de nouvelles connaissances constitue une question cruciale. Ces concepts sont décrits par des
données plus complexes que celles habituellement rencontrées en statistique. Ces données sont
dites « symboliques », car elles expriment la variation interne inéluctable des concepts et sont
structurées.
Dans ce contexte, l’extension des méthodes de l’Analyse des Données Exploratoires et
plus généralement, de la statistique multidimensionnelle à de telles données, pour en extraire
des connaissances d’interprétation aisée, devient d’une importance grandissante.
L’analyse porte sur des « atomes », ou « unités » de connaissances (les individus ou
concepts munis de leur description) considérés au départ comme des entités séparées les unes
des autres et qu’il s’agit d’analyser et d’organiser de façon automatique.
1-1 Caractéristiques et ouvertures de l’analyse des données
symboliques
Par rapport aux approches classiques, l’analyse des données symboliques présente les
caractéristiques et ouvertures suivantes :
Elle s’applique à des données plus complexes. En entrée elle part de données
symboliques (variables à valeurs multiples, intervalle, histogramme, distribution de probabilité,
de possibilité, capacité …) munies de règles et de taxonomies et peut fournir en sortie des
connaissances nouvelles sous forme d’objets symboliques présentant les avantages qui sont
développés supra :
Elle utilise des outils adaptés à la manipulation d’objets symboliques de
généralisation et de spécialisation, d’ordre et de treillis, de calcul d’extension,
d’intention et de mesures de ressemblances ou d’adéquation tenant compte des
connaissances sous-jacentes basées sur les règles de taxonomies ;
Elle fournit des représentations graphiques exprimant, entre autres, la variation
interne des descriptions symboliques. Par exemple, en analyse factorielle, un objet
symbolique sera représenté par une zone (elle-même exprimable sous forme d’objet
symbolique) et pas seulement par un point ;

5
1-2 Avantages des objets symboliques
Les principaux avantages des objets symboliques peuvent se résumer comme suit :
Ils fournissent un résumé de la base, plus riche que les données agrégées habituelles
car ils tiennent compte de la variation interne et des règles sous-jacentes aux classes
décrites, mais aussi des taxonomies fournies. Nous sommes donc loin des simples
centres de gravité ;
Ils sont explicatifs, puisqu’ils s’expriment sous forme de propriétés des variables
initiales ou de variables significatives obtenues (axes factoriels), donc en termes
proches de l’utilisation ;
En utilisant leur partie descriptive, ils permettent de construire un nouveau tableau
de données de plus haut niveau sur lequel une analyse de données symboliques de
second niveau peut s’appliquer ;
Afin de modéliser des concepts, ils peuvent aisément exprimer des propriétés
joignant des variables provenant de plusieurs tableaux associés à différentes
populations. Par exemple, pour construire un objet symbolique associé à une ville,
on peut utiliser des propriétés issues d’une relation décrivant les habitants de chaque
ville et une autre relation décrivant les foyers de chaque ville.
Plutôt que de fusionner plusieurs bases pour étudier ensuite la base synthétique
obtenue, il peut être plus avantageux d’extraire d’abord des objets symboliques de
chaque base puis d’étudier l’ensemble des objets symboliques ainsi obtenus ;
Ils peuvent facilement être transformés sous forme de requête sur une Base de
Données.
Ils peuvent donc propager les concepts qu’ils représentent d’une base à une autre
(par exemple, d’un pays à l’autre de la communauté européenne, EUROSTAT ayant
fait un grand effort de normalisation des différents types d’enquête
sociodémographiques).
Alors qu’habituellement on pose des questions sous forme de requête à la base de
données pour fournir des informations intéressant l’utilisateur, les objets
symboliques formés à partir de la base par les outils de l’analyse des données
symboliques permettent à l’inverse de définir des requêtes et donc de fournir des
questions qui peuvent être pertinentes à l’utilisateurs.
6
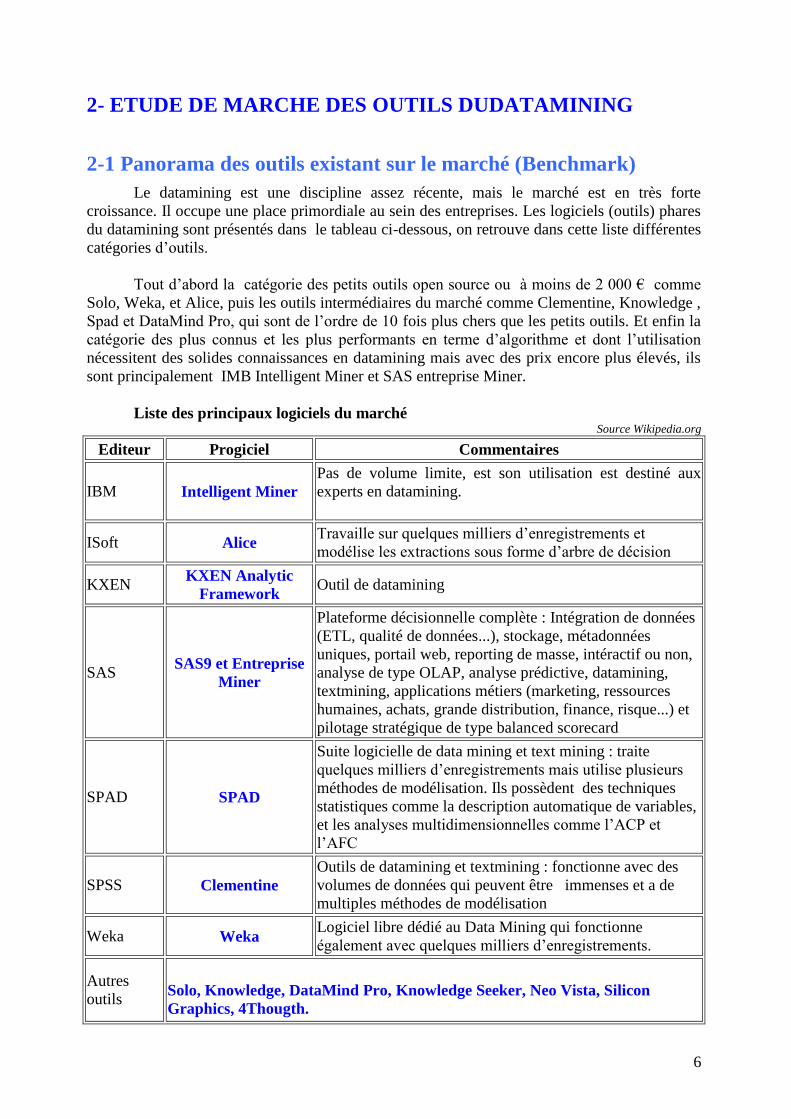
2- ETUDE DE MARCHE DES OUTILS DUDATAMINING
2-1 Panorama des outils existant sur le marché (Benchmark)
Le datamining est une discipline assez récente, mais le marché est en très forte
croissance. Il occupe une place primordiale au sein des entreprises. Les logiciels (outils) phares
du datamining sont présentés dans le tableau ci-dessous, on retrouve dans cette liste différentes
catégories d’outils.
Tout d’abord la catégorie des petits outils open source ou à moins de 2 000 € comme
Solo, Weka, et Alice, puis les outils intermédiaires du marché comme Clementine, Knowledge ,
Spad et DataMind Pro, qui sont de l’ordre de 10 fois plus chers que les petits outils. Et enfin la
catégorie des plus connus et les plus performants en terme d’algorithme et dont l’utilisation
nécessitent des solides connaissances en datamining mais avec des prix encore plus élevés, ils
sont principalement IMB Intelligent Miner et SAS entreprise Miner.
Liste des principaux logiciels du marché Source Wikipedia.org
Editeur Progiciel Commentaires
IBM Intelligent Miner
Pas de volume limite, est son utilisation est destiné aux
experts en datamining.
ISoft Alice Travaille sur quelques milliers d’enregistrements et
modélise les extractions sous forme d’arbre de décision
KXEN KXEN Analytic
Framework Outil de datamining
SAS SAS9 et Entreprise
Miner
Plateforme décisionnelle complète : Intégration de données
(ETL, qualité de données...), stockage, métadonnées
uniques, portail web, reporting de masse, intéractif ou non,
analyse de type OLAP, analyse prédictive, datamining,
textmining, applications métiers (marketing, ressources
humaines, achats, grande distribution, finance, risque...) et
pilotage stratégique de type balanced scorecard
SPAD SPAD
Suite logicielle de data mining et text mining : traite
quelques milliers d’enregistrements mais utilise plusieurs
méthodes de modélisation. Ils possèdent des techniques
statistiques comme la description automatique de variables,
et les analyses multidimensionnelles comme l’ACP et
l’AFC
SPSS Clementine
Outils de datamining et textmining : fonctionne avec des
volumes de données qui peuvent être immenses et a de
multiples méthodes de modélisation
Weka Weka Logiciel libre dédié au Data Mining qui fonctionne
également avec quelques milliers d’enregistrements.
Autres
outils
Solo, Knowledge, DataMind Pro, Knowledge Seeker, Neo Vista, Silicon
Graphics, 4Thougth.

7
2-2 Le logiciel SODAS (Symbolic Official Data Analysis System)
Sodas est un logiciel libre (gratuit) développé dans le cadre du projet Européen
EUROSTAT entre des établissements éducatifs et certaines sociétés commerciales. Il permet
l’extraction des connaissances à partir d’une base de données et l’analyse de données
symboliques définies par généralisation des propriétés des unités statistiques de premier ordre.
Il est téléchargeable à l’adresse suivante :
http://www.ceremade.dauphine.fr/~touati/sodas-pagegarde.htm
L’idée générale de SODAS est de construire, à partir d’une base de données
relationnelle, un tableau de données symboliques muni éventuellement de règles de taxonomies.
Le but étant de décrire des concepts résumant un vaste ensemble de données et d’analyser
ensuite ce tableau pour en extraire des connaissances par des méthodes d’analyse de données
symboliques.
SODAS est un logiciel polyvalent, permettant de faire aussi bien de l’analyse
symbolique et statistique que de classer les données par hiérarchie ou encore par arbre de
décision. Même s’il offre des richesses analytiques d’un niveau équivalent, SODAS n’est pas
un logiciel de statistiques classique dans la mesure où il manipule des données de type
complexe et permet de les représenter graphiquement. De plus, il est destiné à des utilisateurs
métiers, sans compétences statistiques ou informatiques, ce qui permet de se concentrer sur ce
qui est recherché et non sur la manière d’y parvenir.
On utilise SODAS afin d’extraire des informations à partir d’une base de données
(ACCESS….), ensuite on applique sur le fichier SODAS crée certaines méthodes d’analyse de
données symboliques tel que : l’analyse factorielle (AFC, ACP) la visualisations graphiques
(DStat, View), l’analyse discriminante (Tree), classification automatique, …etc..
Les différentes étapes d’analyse symbolique sous SODAS est résumée comme suit :
- Partir d’une base de données relationnelles (Access, Oracle, Sql Server…) ;
- Définir un contexte par :
- les individus, unités statistiques de premier niveau;
- les variables qui les décrivent ;
- les concepts, unités statistiques de second niveau.
- Construire le tableau de données symboliques sous forme d’un fichier sodas.
- Application des différentes méthodes SODAS et interprétation des résultats.
Chaque unité statistique de premier ordre est associée à un concept (unité statistique de second
ordre). Ce contexte est défini par une requête sur la base de données relationnelle.
Les nouvelles unités statistiques sont les concepts décrits par généralisation des
propriétés des unités statistiques de premier ordre qui leur sont associées.
Ainsi, chaque concept est décrit par des variables dont les valeurs peuvent être des
diagrammes de fréquences (variables qualitatives), des intervalles (variables numériques), des
valeurs uniques (éventuellement munies de règles et de taxonomies) selon le type de variables
8
et le choix de l’utilisateur. Une fois que le fichier de données symboliques est crée, on pourra
lui appliquer les différentes méthodes d’analyse de données symboliques de SODAS.
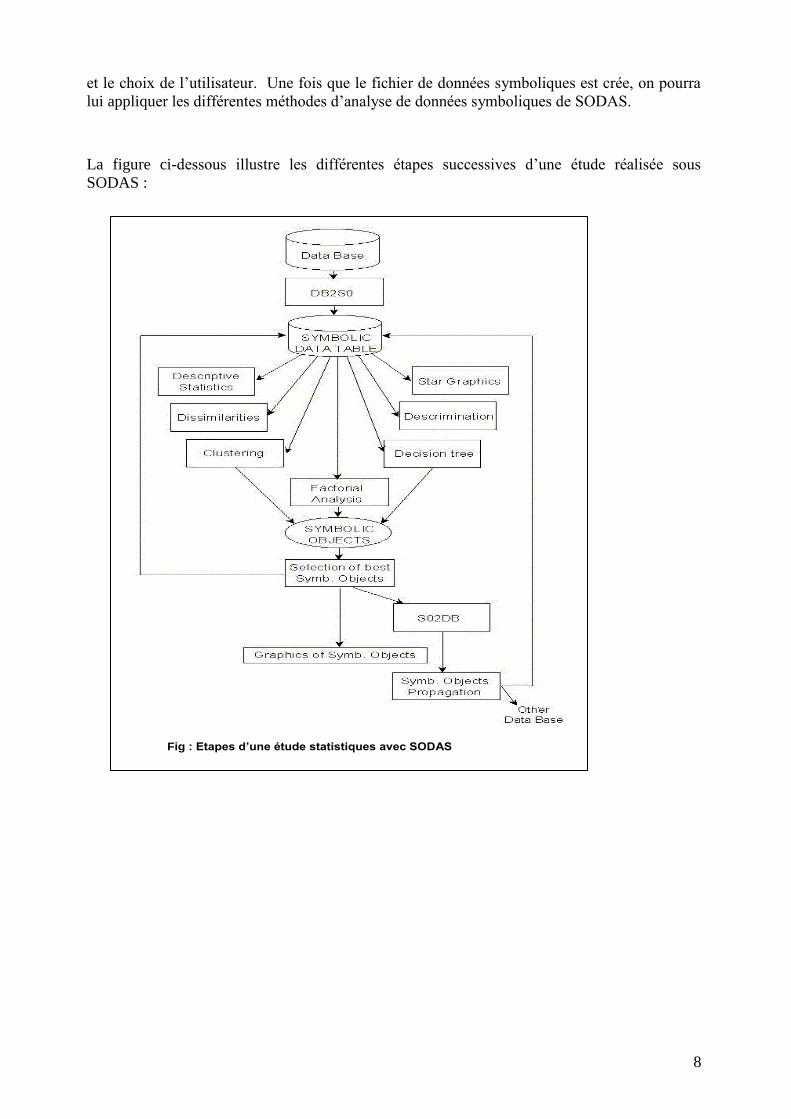
La figure ci-dessous illustre les différentes étapes successives d’une étude réalisée sous
SODAS :
Fig : Etapes d’une étude statistiques avec SODAS
9
3- DESCRIPTION SOMMAIRE DU MODE OPERATOIRE
3-1 Les principaux onglets de Sodas
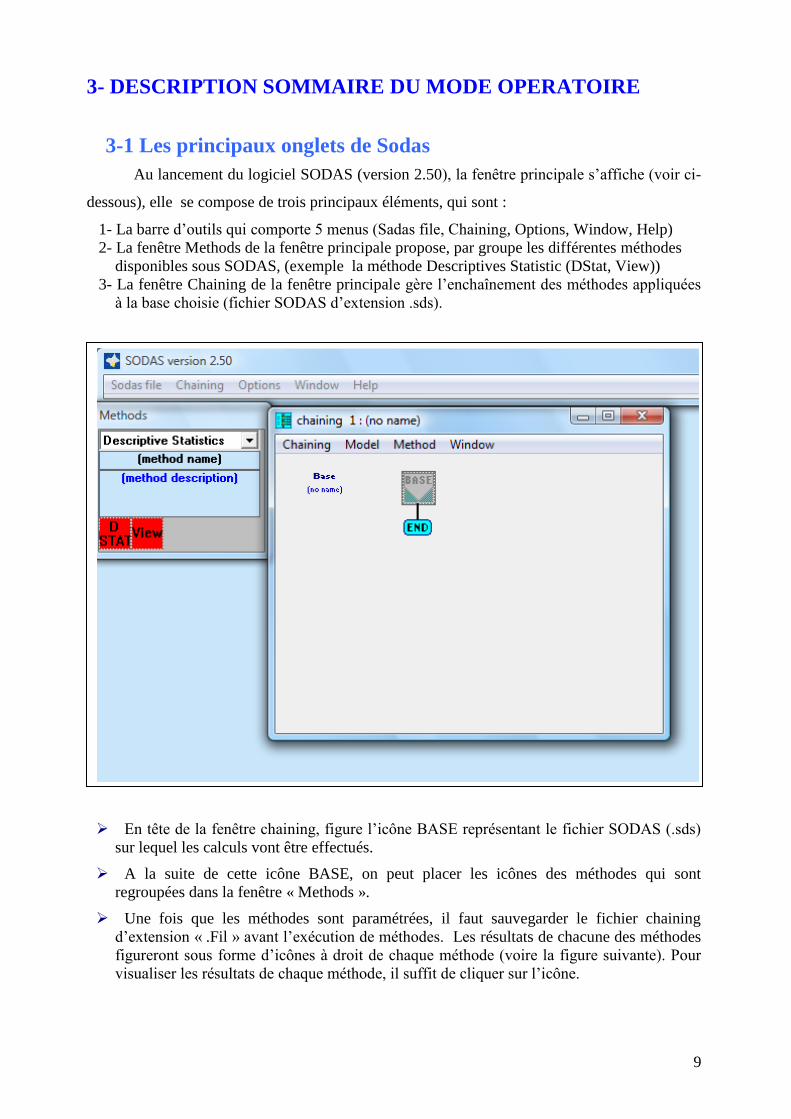
Au lancement du logiciel SODAS (version 2.50), la fenêtre principale s’affiche (voir ci-
dessous), elle se compose de trois principaux éléments, qui sont :
1- La barre d’outils qui comporte 5 menus (Sadas file, Chaining, Options, Window, Help)
2- La fenêtre Methods de la fenêtre principale propose, par groupe les différentes méthodes
disponibles sous SODAS, (exemple la méthode Descriptives Statistic (DStat, View))
3- La fenêtre Chaining de la fenêtre principale gère l’enchaînement des méthodes appliquées
à la base choisie (fichier SODAS d’extension .sds).
En tête de la fenêtre chaining, figure l’icône BASE représentant le fichier SODAS (.sds)
sur lequel les calculs vont être effectués.
A la suite de cette icône BASE, on peut placer les icônes des méthodes qui sont
regroupées dans la fenêtre « Methods ».
Une fois que les méthodes sont paramétrées, il faut sauvegarder le fichier chaining
d’extension « .Fil » avant l’exécution de méthodes. Les résultats de chacune des méthodes
figureront sous forme d’icônes à droit de chaque méthode (voire la figure suivante). Pour
visualiser les résultats de chaque méthode, il suffit de cliquer sur l’icône.

10
3-2 Sélection d’une base d’étude
Tout fichier SODAS possède l’extension .sds. C’est un fichier de ce type qui va constituer la
BASE de notre étude.
Pour sélectionner un tel fichier, il faut :
- double-cliquer sur l’icône BASE
- sélectionner notre fichier dans la liste de bases disponibles
- cliquer sur OK.
Notre filière a été modifiée et maintenant nous pouvons lire le nom de la base associée à
notre filière ainsi que son chemin d’accès sur le disque dur
3-3 Choix de la méthode à appliquer
Nous allons enrichir la filière définie précédemment grâce à des méthodes (Methods)
afin d’analyser les données de notre base.
Pour cela nous pouvons utiliser des filières prédéfinies (Model \ Predefined chaining) ou
bien composer nous-mêmes une filière en enchaînant des méthodes issues de la fenêtre
Methods.

11
Pour insérer de nouvelles méthodes, il suffit de choisir le menu Method et de cliquer sur
Insert Method. Un carré vide apparaît alors sous l’icône BASE ; nous sélectionnons ensuite
la méthode que nous souhaitons appliquer, dans la fenêtre Methods et nous la faisons glisser
jusqu’à l’emplacement vide.
Les méthodes constituant maintenant la filière sont affichées à la suite de l’icône BASE,
selon l’ordre défini par l’utilisateur, dans lequel elles vont s’enchaîner. Chaque méthode est
représentée par une icône à gauche de laquelle se trouve son nom ainsi qu’une description
sommaire.

12
Par défaut, les méthodes qui viennent d’être insérée sont grisées.
Chaque Méthodes est numérotées dans la filière : ce numéro apparaît dans une petite boîte
située à gauche de la méthodes.
La couleur de cette boîte indique le statut de la méthode :
- gris : la méthode ne peut être exécutée car elle n’est pas paramétrée
- vert : la méthode est exécutable car elle est paramétrée
- rouge : la méthode est désactivée. Elle est exécutable mais l’utilisateur en interdit
l’exécution (menu Methods puis Desactivate method).
Ensuite, il faut paramétrer la méthode. Il suffit de double cliquer sur l’icône de la
méthode. Alors, une fenêtre structurée en fiches à onglets s’ouvre ; elle regroupe l’ensemble des
différents paramètres de la méthode.
Après le paramétrage des diverses méthodes, l’affichage de la filière a changé. Toutes
les méthodes sont maintenant exécutables, car paramétrées (les icônes sont rouges).
Le paramétrage de toutes les méthodes de la filière étant terminé, nous pouvons l’exécuter.
Par contre, toute exécution d’une filière doit être obligatoirement précédée de sa sauvegarde
(Menu Chaining puis Save chaining as et saisie d’un nom dont l’extension est .FIL).
Une fois cette opération effectuée, nous exécutons la filière en cliquant sur les sous menus
Run chaining du menu Chaining.

13
Suite à l’exécution de la filière PROJET.FIL (dont le nom apparaît en haut à gauche de
la fenêtre), de nouvelles icônes sont apparues dans la fenêtre Chaining, à droite des icônes
Méthodes. Ces nouvelles icônes permettent d’accéder aux résultats numériques et, le cas
échéant, aux résultats graphiques de chaque Méthode exécutée.
1. un double-clic sur cette icône permet de d’accéder aux résultats numériques
(dans l’éditeur de texte, Wordpad) de la méthode SOE
2. cette icône permet d’accéder à l’éditeur graphique de la méthode SOE
3. un double-clic sur cette icône affiche une représentation graphique de la méthode
STAT suivant les paramètres saisis précédemment
4. cette icône entraîne l’affichage de la représentation graphique de la classification
pyramidale
Toutes ces méthodes, ainsi que d’autres, seront expliquées plus en détails dans la partie
suivante du présent rapport.

14
PARTIE 2 : ETUDE STATISTIQUE
II –1 PRESENTATION DE L’ETUDE
II –1-1 Contexte de l’étude et présentation des données
L’étude porte sur des données réelles du centre hospitalier de Poissy-Saint Germain
Laye, se sont des données de l’exercice 2007, on a procédé à un échantillonnage, les noms et
prénoms des patients on été supprimés pour des raisons de confidentialité et le modèle initial a
été simplifié pour réaliser cette étude.
Objectif de l’étude
Il s’agit d’étudier les caractéristiques des différentes groupes des malades par rapport à
leur durée de séjour, afin d’établir le lien entre les groupes et les malades, qui les composent.
Tous les malades ont été répartis en 11 groupes selon leur indice de performance de la durée de
séjour (IP_DMS). Cet indice se calcule comme le rapport de la durée de séjour d’un malade et
la durée de séjour de référence pour la même pathologie.
Ainsi, les groupes de séjours des malades ont été définies comme suit:
1. LONG_5 : dépassement de la DMS de référence plus de 3 fois
2. LONG_4 : dépassement de la DMS de référence entre 2 et 3 fois
3. LONG_3 : dépassement de la DMS de référence entre 50% et 200%
4. LONG_2 : dépassement de la DMS de référence entre 25% et 50%
5. LONG_1 : dépassement de la DMS de référence entre 10% et 25%
6. NORMAL : durée de séjour égale à la DMS de référence à 10% près
7. COURT_1 : durée de séjour inférieure à la DMS de référence de 10% à 25%
8. COURT_2 : durée de séjour inférieure à la DMS de référence de 25% à 50%
9. COURT_3 : durée de séjour inférieure à la DMS de référence de 50% à 200%
10. COURT_4 : durée de séjour inférieure à la DMS de référence de 2 à 3 fois
11. COURT_5 : durée de séjour inférieure à la DMS de référence de plus de 3 fois
Les individus sont représentés par les séjours.
Les concepts sont les 11 groupes de séjours cités précédemment.
Compte tenu de l’impossibilité d’utilisation directe de la base de données de l’hôpital et
du fait de la protection du modèle de données par les droits d’auteurs, nous avons procédé à une
extraction des données jugées pertinentes et les organiser sous forme d’étoile. Et donc ce
modèle est présenté ci-dessous.
- DimVILLE contient le nom et le département du domicile d’un patient
- Dim GHM contient le groupe homogène des maladies
- GHM le groupe homogène de maladie
- CMD_LIB libellé des catégories majeures de diagnostic
- N_DMS la durée normale (durée de référence en France) de séjours en nombre
jours.

15
- factSEJOURS : contient les séjours et leur caractéristique (NBR_PASS, N_DMS Age.
Sexe.. ……)
- dimUM : contient les libellés des unités médicales où le séjour à été effectué.
- dimIP_DMS : contient les libellés des groupes de séjours que nous considéré comme
concepts.
La variable d’insertion (single) se trouve dans la table VAR
16
II –1-2 L’analyse
1. DB2SO : extraction de données symboliques de la base de données
relationnelles
a. Généralités
DB2SO est le module du logiciel SODAS qui permet à l’utilisateur de créer un ensemble de
concepts à partir de données stockées dans une base de données relationnelles.
On présuppose bien évidemment qu’une série d’individus est stockée dans la base de données et
que ces individus sont répartis entre plusieurs groupes. Ainsi, DB2SO va pouvoir construire un
concept pour chaque groupe d’individus. Dans ce processus, les variables mères / filles ainsi
que les taxonomies sur les variables pourront également être associées avec les concepts créés.
b. Présentation de DB2SO
Le système de liaisons ODBC de SODAS lui permet d’accéder directement aux bases de
données et en particulier aux bases Microsoft Access.
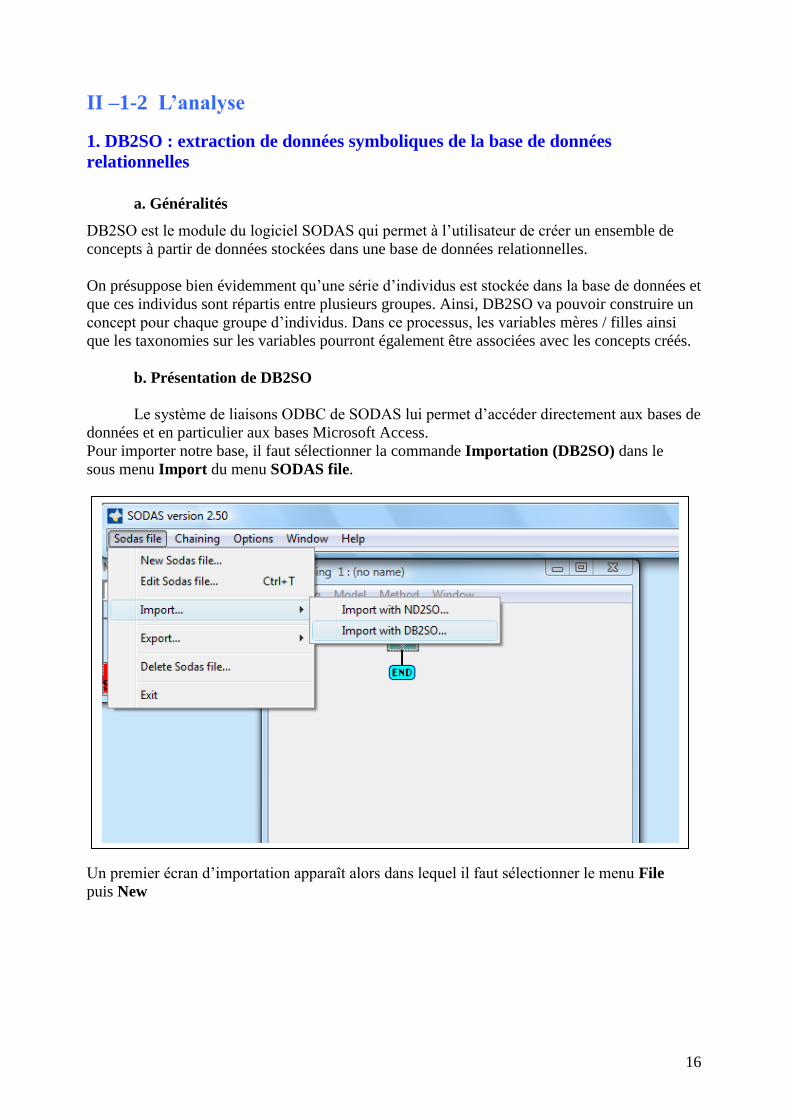
Pour importer notre base, il faut sélectionner la commande Importation (DB2SO) dans le
sous menu Import du menu SODAS file.
Un premier écran d’importation apparaît alors dans lequel il faut sélectionner le menu File
puis New

17
L’écran suivant nous invite à sélectionner une source de données machine. Dans notre
cas, il s’agit d’une base Microsoft Access.
Notre projet a en effet, pour objet l’étude d’une base de données Microsoft Access. Ce
SGBD inclut le driver ODBC permettant l’accès de DB2SO à la base de données
relationnelles.
SODAS ne propose aucun menu de connexion à la base de données car l’utilisateur est
automatiquement invité à s’y connecter quand cela est nécessaire, c’est-à-dire lorsqu’il
souhaite exécuter une requête. A tout moment, l’utilisateur peut décider de changer de base de
données en choisissant le menu File\Disconnect de l’écran ci-dessus. Il sera alors invité à
spécifier une nouvelle base de données.
18
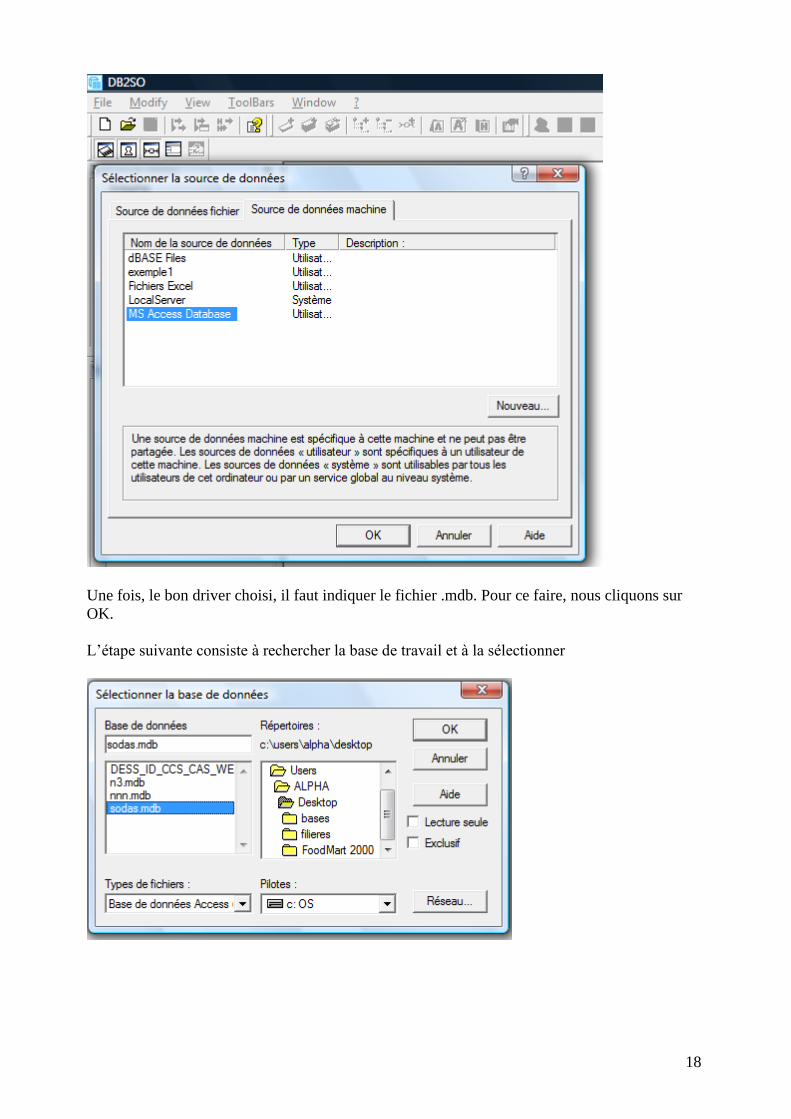
Une fois, le bon driver choisi, il faut indiquer le fichier .mdb. Pour ce faire, nous cliquons sur
OK.
L’étape suivante consiste à rechercher la base de travail et à la sélectionner

19
Lorsque ces étapes préliminaires ont été exécutées, nous allons procéder à l’extraction des
individus. Pour ce faire, il faut choisir la table qui est le résultat d’une requête préalablement
exécuté sous Access.
Résultat :
1ère colonne = individus
2nde colonne = concepts
3ème colonne et suivante = description des individus
Une fois que nous avons effectué toutes les manipulations dans le module DB2SO. Un résumé
de toutes les opérations apparaît dans l’écran principal suivant :

20

21
2-Présentation des méthodes et de l’analyse
Les filières des méthodes appliquées sont présentées dans la figure ci-dessous, la deuxième
filière utilise le fichier .sds résultat de DISS.
II-2 PRESENTATION DES METHODES ET RESULTATS
II-2 -1 Méthode View
a- Présentation de la méthode
L’éditeur d’objets symboliques View permet aux utilisateurs de visualiser, dans un
tableau, tous les objets symboliques présents dans un fichier SODAS et d’effectuer quelques
modifications sur les données. Cet éditeur permet aussi de visualiser des représentations
graphiques en 2 et 3 dimensions et une représentation SOL (Symbolic Object Language) de
chaque objet symbolique se trouvant dans le tableau.

22
Dans la table, il faut alors sélectionner les concepts (au moins 1) et les variables (au moins
3) que nous souhaitons voir représentés à l’écran. Ensuite, suivant notre choix nous voyons
apparaître à l’écran une étoile zoom, en 2 ou 3 dimensions.
Nous pouvons noter que les variables quantitatives sont représentées par des intervalles
et que les variables qualitatives sont représentées par des histogrammes.
Le bouton SOL, lui, renvoie une description SOL des objets symboliques sélectionnés
dans le tableau.
b. Mise en oeuvre de la méthode View
On remarque l’intervalle d’age dans les groupes est presque identique : 0-91(97) ans, ce
que ne permet pas de les distinguer. Par contre, la répartition par tranche d’âge et par sexe,
permet de remarquer qu’il y a plus d’hommes dans des séjours très longs (LONG_5) et plus des
femmes dans les séjours, qui dépassent 25% - 300% la durée moyenne de séjour de référence.

23
L’image suivante permet de comparer le groupe de séjours de durée normale (±10%) avec le
groupe des séjours LONG_5.
On remarque que ce sont plutôt des hommes âgés (>75 ans), qui peuvent avoir plus des
journées de réanimation (NBR_REA), plus de passage dans les services (NBR_PASS), plus
d’actes (NBR_ACTES) et des diagnostiques (NBR_DIAGS)
En transformant les nombres absolus des actes, diagnostics, journées de réanimation en
tranches, on remarque que les séjours de durée normale sont caractérisés par un nombre de
diagnostic inférieur aux séjours longs. Les séjours longs se caractérisent par plus d’actes. Cela
peut témoigné des raisons médicales pour lesquels les malades sont restés plus long temps en
hospitalisation. D’autre côté cela peut être interprété comme une difficulté de prise en charge
des malades chroniques par des structures spécialisées.
La description SOL caractérise les malades qui ont une durée de séjour normale :
NORMAL =
SEXE = M (0.43), F (0.57)
And NBR_PASS = 1 (0.68), 2 (0.30), 4 (0.02)
And CMD_LIB = diges (0.28), nerve (0.04), circu (0.23), obste (0.04), endoc (0.04), VIH
(0.02), muscu (0.08), respi (0.06), urolo (0.02), gynec (0.04), derma (0.04), hepat (0.08), orl
(0.04), cance (0.02)
And TR_AGE = 48_60 (0.15), 61_75 (0.19), 75plu (0.30), 18_25 (0.02), 26_37 (0.26), 38_47
(0.08)
And TR_ACTES = 12plu (0.04), 1 (0.43), 7_12 (0.09), 2_3 (0.32), 4_6 (0.11)
And TR_DIAG = 7plus (0.26), 4_6 (0.22), 1 (0.14), 2_3 (0.38)
And TR_REA = 12plu (0.04), 0 (0.94), 1_5 (0.02)
24
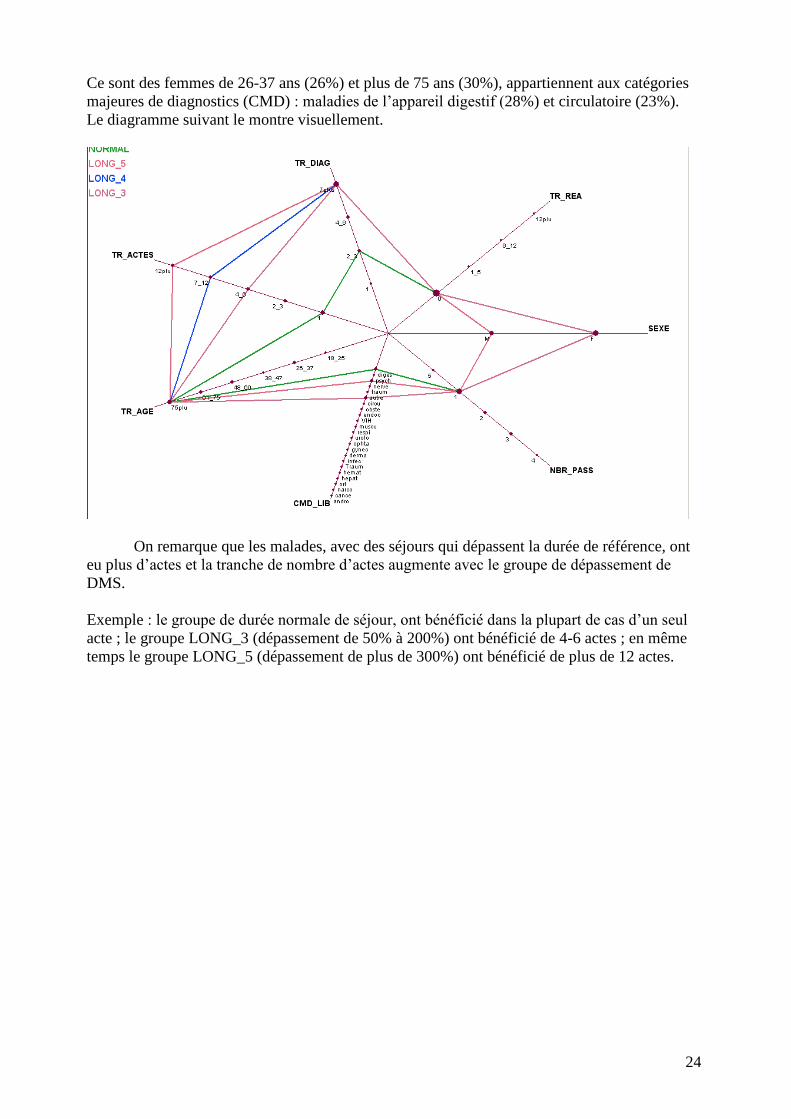
Ce sont des femmes de 26-37 ans (26%) et plus de 75 ans (30%), appartiennent aux catégories
majeures de diagnostics (CMD) : maladies de l’appareil digestif (28%) et circulatoire (23%).
Le diagramme suivant le montre visuellement.
On remarque que les malades, avec des séjours qui dépassent la durée de référence, ont
eu plus d’actes et la tranche de nombre d’actes augmente avec le groupe de dépassement de
DMS.
Exemple : le groupe de durée normale de séjour, ont bénéficié dans la plupart de cas d’un seul
acte ; le groupe LONG_3 (dépassement de 50% à 200%) ont bénéficié de 4-6 actes ; en même
temps le groupe LONG_5 (dépassement de plus de 300%) ont bénéficié de plus de 12 actes.

25
II-2 -2 La méthode STAT
a- Présentation de la méthode STAT
STAT permet d’appliquer des méthodes, habituellement utilisées pour des données
conventionnelles, à des objets symboliques représentés par leur description.
Ces méthodes dépendent du type des variables présentes dans la base SODAS avec
laquelle nous travaillons.
1. les fréquences relatives pour les variables multi nominales
2. les fréquences relatives pour les variables intervalles
3. les capacités et min/max/mean pour les variables multi nominales probabilistes
4. biplot pour les variables intervalles
Le format de sortie des données sera, suivant le choix de l’utilisateur, un listing ou bien un
graphique. Les graphiques peuvent être modifiés et personnalisés (figures, formes, couleurs,
texte, commentaires ...) par l’utilisateur et ils peuvent également être copiés et sauvegardés.
Les fréquences relatives pour les variables multi-nominales
Dans cette méthode, nous étudions la fréquence relative des différentes modalités de la
variable multi nominale en prenant en compte les éventuelles règles relatives à la base sur
laquelle nous travaillons. Le graphique associé à la distribution de la variable pourra, suivant le
choix de l’utilisateur, être soit un diagramme bâton, soit un diagramme en camembert.
Les fréquences relatives pour les variables intervalles
Cette méthode a besoin, en entrée, de 2 paramètres :
- une variable intervalle I
- un nombre de classes k
Nous pouvons construire un histogramme pour la variable I sur un intervalle [a,b] découpé en k
classes et où a représente la borne inférieure de I et b sa borne supérieure. La méthode va
permettre le calcul de la fréquence relative associée à la classe Ck tout en tenant compte du
recouvrement de cette classe Ck par les valeurs intervalles de I et ceci pour tous les objets
symboliques.
Les capacités et min/max/mean pour les variables multi nominales probabilistes
La méthode permet de construire un histogramme des capacités des différentes
modalités de la variable considérée. Dans l’histogramme capacité, la capacité d’une modalité
est représentée par l’union des différentes capacités. En ce qui concerne le graphique
min/max/mean, il associe un diagramme représentant l’étendue et la moyenne de la probabilité
de chaque modalité.
Biplot pour les variables intervalles
Ce graphique représente un objet symbolique par un rectangle dans le plan de 2
variables sélectionnées par l’utilisateur. La dimension de chaque côté du rectangle correspond à
l’étendue de la variation de l’objet symbolique relativement à la variable de l’axe considéré

26
b. Mise en oeuvre de la méthode STAT
Méthode DSTAT pour les variables intervalles
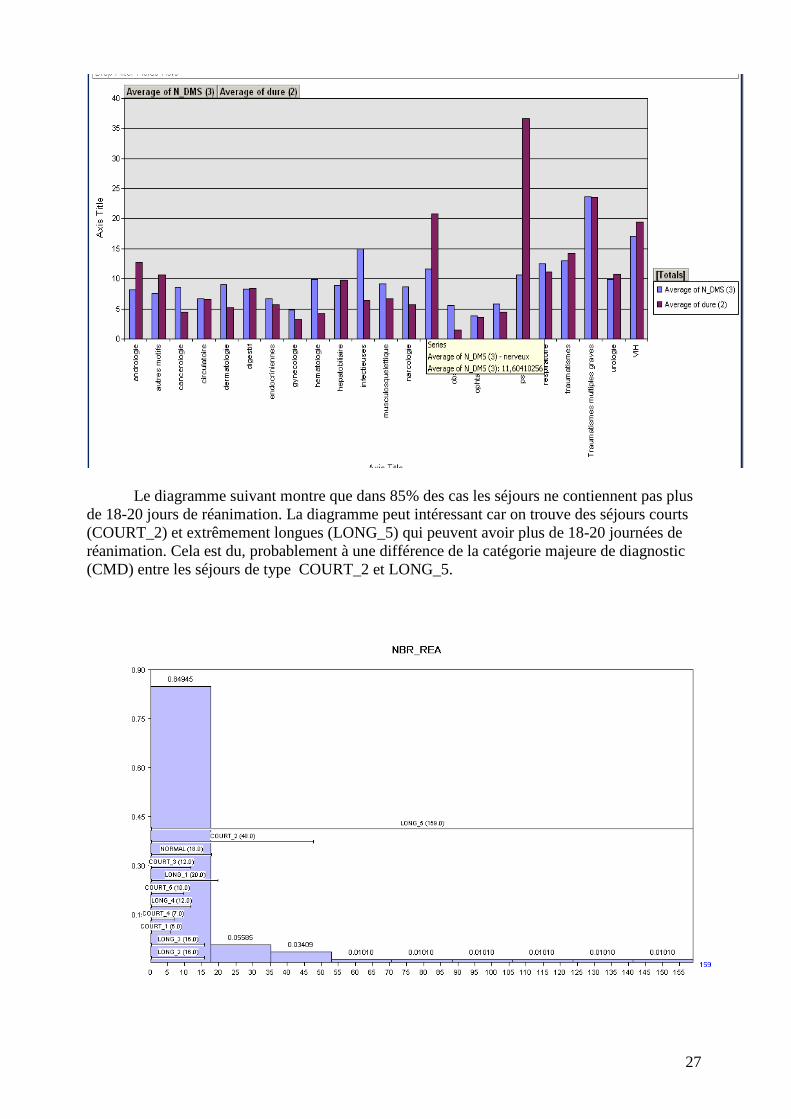
Les intervalles de nombre des actes représentés sur le diagramme suivant montre qu’un
nombre d’actes au delà de 66 est réservé aux séjours de longueur extrême (LONG_5). Vu que
celle ne concerne que 2 séjours, on s’obtiendra de conclusions avant une vérification sur un
échantillon plus large.
Les catégories majeures de diagnostic sont différentes elles aussi (figure ci-dessous).
Dans le groupe normale, sont affectés plutôt les appareilles digestif (28%) et circulatoire (23%).
Dans le groupe LONG_3 : circulatoire (20%) et musculo-squeletic (17%) Dans LONG_4 :
circulatoire (22%) et dans LONG_5 : nerveux (25%). Cella peut également indiquer les services
correspondants, qui ont besoin d’un accompagnement dans l’étude des flux de patients et une
optimisation d’utilisation du lit. Cette hypothèse se confirme quand on compare les durées
réelles (en bordeaux) et les durées de références (en bleue)
27
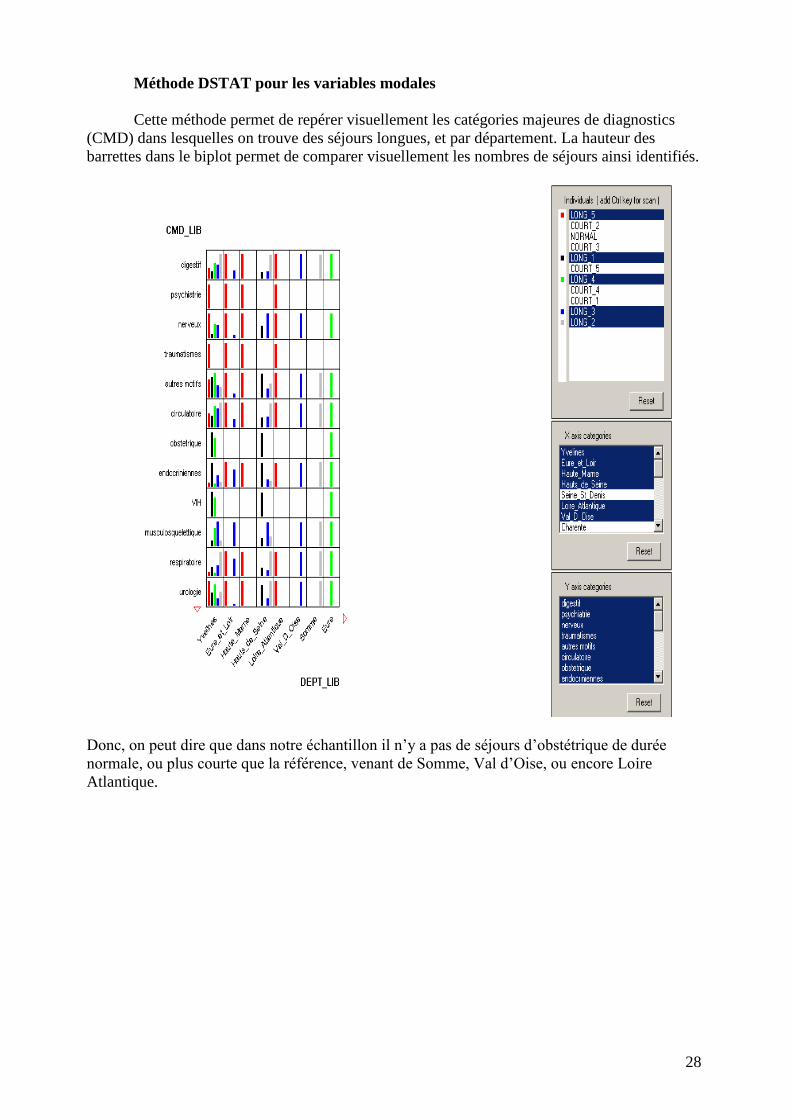
Le diagramme suivant montre que dans 85% des cas les séjours ne contiennent pas plus
de 18-20 jours de réanimation. La diagramme peut intéressant car on trouve des séjours courts
(COURT_2) et extrêmement longues (LONG_5) qui peuvent avoir plus de 18-20 journées de
réanimation. Cela est du, probablement à une différence de la catégorie majeure de diagnostic
(CMD) entre les séjours de type COURT_2 et LONG_5.
28
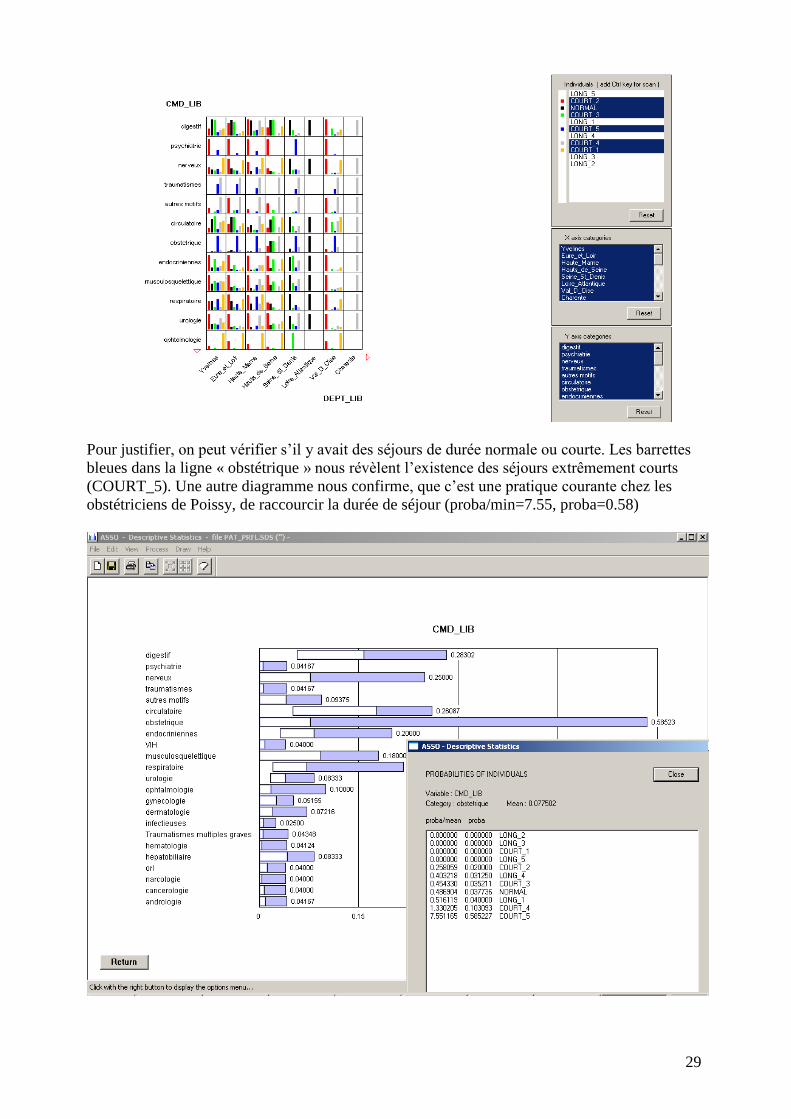
Méthode DSTAT pour les variables modales
Cette méthode permet de repérer visuellement les catégories majeures de diagnostics
(CMD) dans lesquelles on trouve des séjours longues, et par département. La hauteur des
barrettes dans le biplot permet de comparer visuellement les nombres de séjours ainsi identifiés.
Donc, on peut dire que dans notre échantillon il n’y a pas de séjours d’obstétrique de durée
normale, ou plus courte que la référence, venant de Somme, Val d’Oise, ou encore Loire
Atlantique.
29
Pour justifier, on peut vérifier s’il y avait des séjours de durée normale ou courte. Les barrettes
bleues dans la ligne « obstétrique » nous révèlent l’existence des séjours extrêmement courts
(COURT_5). Une autre diagramme nous confirme, que c’est une pratique courante chez les
obstétriciens de Poissy, de raccourcir la durée de séjour (proba/min=7.55, proba=0.58)

30
II-2 -3 La méthode DIV : Divisive Clustering on Symbolic Objects
a- Présentation de la méthode DIV
DIV est une méthode de classification hiérarchique qui part de tous les objets
symboliques réunis dans une seule classe et procède ensuite par division successive de chaque
classe. A chaque étape, une classe est divisée en deux classes suivant une question binaire ; ceci
permet d’obtenir le meilleur partitionnement en deux classes, conformément à l’extension du
critère d’inertie.
L’algorithme s’arrête après avoir effectuer k-1 division ; k étant le nombre de classes
donné, en entrée, à la méthode par l’utilisateur. Il ne s’agit pas du seul paramètre à saisir, en
entrée de la méthode. L’utilisateur doit également choisir les variables qui seront utilisées pour
calculer la matrice de dissimilarité, l’extension du critère d’inertie et pour définir l’ensemble
des questions binaires utiles pour effectuer le découpage.
Au moment de choisir nos variables, il faut être attentif à deux choses principales :
- le domaine de définition des variables doit être ordonné car dans le cas contraire, les
résultats obtenus seront totalement faux
- il n’est pas possible de mélanger des variables dont le domaine de définition est
continu avec des variables dont le domaine de définition est discret. Dans la fenêtre
de définition des paramètres de la méthode DIV du logiciel SODAS, l’utilisateur doit
choisir entre des variables qualitatives et des variables continues.
Trois paramètres doivent également être définis :
1 - la dissimilarité entre 2 objets peut être normalisée ou non. Elle peut être normalisée
en choisissant l’inverse de la dispersion ou bien l’inverse du maximum de la
déviation. La dispersion des variables est, ici, une extension aux objets symboliques
de la notion de variance.
2 - le nombre k de classes de la dernière partition. La division s’arrêtera après k-1
itérations et la méthode DIV aura calculer des partitions de la classe 2 à la classe k.
3 - la méthode DIV offre également la possibilité de créer un fichier partition ; il s’agit
d’un fichier texte contenant une matrice (aij) dans laquelle, chaque ligne i∈ [1,n]
correspond à un objet et chaque rangée j∈ [2,k-1] correspond à une partition en j
classes. Ainsi, (aij) signifie que l’objet j appartient à la classe k, dans la partition en j
classes.
Une fois ces différents paramètres définis, nous pouvons exécuter la méthode DIV. Nous
obtenons, en sortie, un listing contenant les informations suivantes :
- une liste de la « variance » des variables sélectionnées, à condition que ces variables
soient continues
- pour chaque partitions de 2 à k classes, une liste des objets contenus dans chaque
classe ainsi que l’inertie expliquée relative à la partition

31
- l’arbre de classification.
b- Mise en oeuvre de la méthode DIV
La méthode DIV va nous permettre de réaliser une classification hiérarchique des
Groupes de séjours par division successive de chaque classe, en partant d’une seule classe
réunissant tous les groupes de séjours.
Cette méthode ne permet pas d’étudier à la fois les variables qualitatives et les variables
quantitatives. Nous procéderons alors en deux temps correspondant à chacun des types de
variables
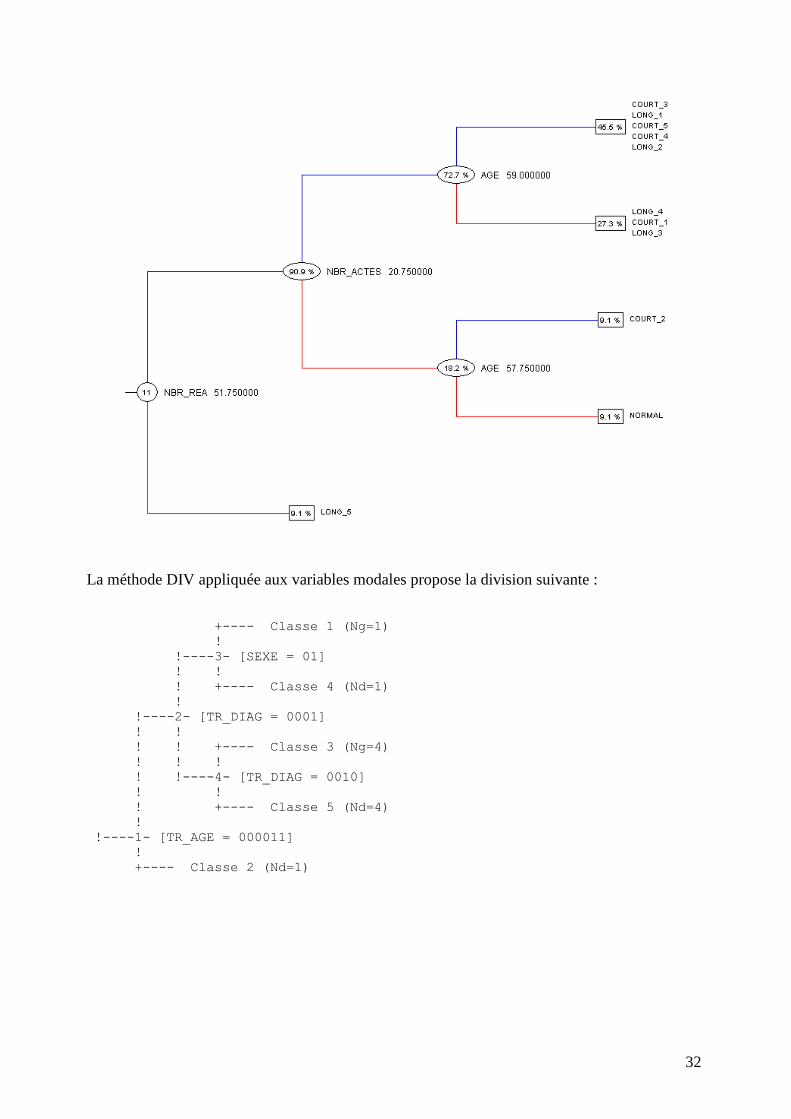
La classification divise propose une classification en 5 clausters avec une inertie expliqué de 96.779573. Cluster 1 :
IF 4- [AGE <= 59.000000] IS TRUE
AND 2- [NBR_ACTES <= 20.750000] IS TRUE
AND 1- [NBR_REA <= 51.750000] IS TRUE
Cluster 2 :
IF 1- [NBR_REA <= 51.750000] IS FALSE
Cluster 3 :
IF 3- [AGE <= 57.750000] IS TRUE
AND 2- [NBR_ACTES > 20.750000] IS FALSE
AND 1- [NBR_REA <= 51.750000] IS TRUE
Cluster 4 :
IF 3- [AGE <= 57.750000] IS FALSE
AND 2- [NBR_ACTES <= 20.750000] IS FALSE
AND 1- [NBR_REA <= 51.750000] IS TRUE
Cluster 5 :
IF 4- [AGE <= 59.000000] IS FALSE
AND 2- [NBR_ACTES <= 20.750000] IS TRUE
AND 1- [NBR_REA <= 51.750000] IS TRUE
+---- Classe 1 (Ng=5)
!
!----4- [AGE <= 59.000000]
! !
! +---- Classe 5 (Nd=3)
!
!----2- [NBR_ACTES <= 20.750000]
! !
! ! +---- Classe 3 (Ng=1)
! ! !
! !----3- [AGE <= 57.750000]
! !
! +---- Classe 4 (Nd=1)
!
!----1- [NBR_REA <= 51.750000]
!
+---- Classe 2 (Nd=1)
On constate que les séjours avec >20 actes et >51 journées de réanimation appartiennent au
concept LONG_5 (dépassent > 3 fois la durée de référence)
Les individus caractérisés par AGE <= 57.75; NBR_ACTES > 20.75 ; NBR_REA <= 51.75
appartiennent au concept NORMAL ou COURT_2. Le reste n’est pas divisible avec les
variables actuelles.
32
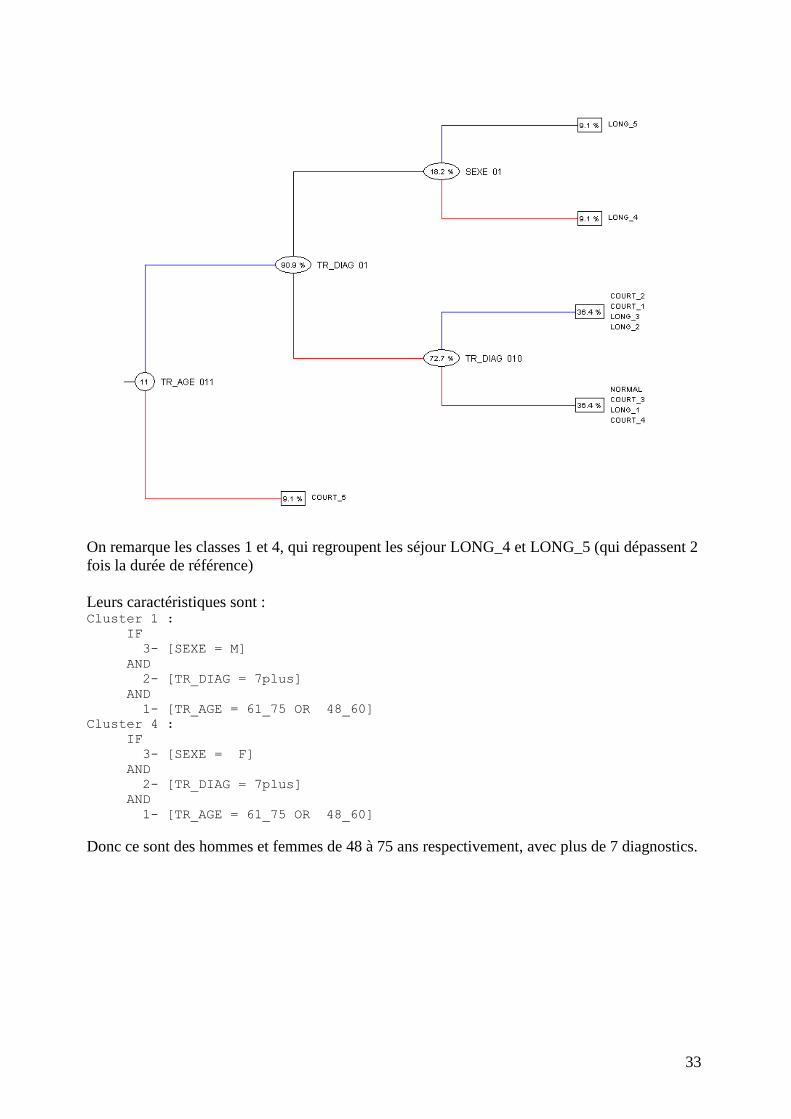
La méthode DIV appliquée aux variables modales propose la division suivante :
+---- Classe 1 (Ng=1)
!
!----3- [SEXE = 01]
! !
! +---- Classe 4 (Nd=1)
!
!----2- [TR_DIAG = 0001]
! !
! ! +---- Classe 3 (Ng=4)
! ! !
! !----4- [TR_DIAG = 0010]
! !
! +---- Classe 5 (Nd=4)
!
!----1- [TR_AGE = 000011]
!
+---- Classe 2 (Nd=1)
33
On remarque les classes 1 et 4, qui regroupent les séjour LONG_4 et LONG_5 (qui dépassent 2
fois la durée de référence)
Leurs caractéristiques sont : Cluster 1 :
IF
3- [SEXE = M]
AND
2- [TR_DIAG = 7plus]
AND
1- [TR_AGE = 61_75 OR 48_60] Cluster 4 :
IF
3- [SEXE = F]
AND
2- [TR_DIAG = 7plus]
AND
1- [TR_AGE = 61_75 OR 48_60]
Donc ce sont des hommes et femmes de 48 à 75 ans respectivement, avec plus de 7 diagnostics.

34
II-2-4 La méthode TREE : Decision Tree
a-Présentation de la méthode TREE
La méthode Tree nous propose un algorithme par agrandissement d’arbres, appliqué à des
données imprécises décrites par des concepts probabilistes. La procédure récursive de
partitionnement peut être vue comme une recherche itérative d’un ensemble organisé d’objets
symboliques, répondant au mieux aux données initiales. A chaque étape, le découpage optimal
est obtenu en utilisant une mesure générale, donnée en paramètre.
En sortie, nous obtenons une nouvelle liste d’objets symboliques qui permet éventuellement
d’assigner de nouveaux objets à une classe.
Avant d’exécuter la méthode, l’utilisateur doit choisir l’ensemble des variables prédictives
parmi :
- un ensemble de variables quantitatives ou de variables intervalles
- un ensemble de variables qualitative, multi valuées ou modales
Ensuite, nous obtenons en sortie un listing contenant les informations suivantes :
- la liste des variables utilisées
- la liste des objets symboliques appartenant à un « training set »
- la liste des objets symboliques appartenant à un « test set»
- la liste des noeuds ; chaque noeud étant décrit par une règle
- la liste des noeuds terminaux
b-Mise en oeuvre de la méthode TREE
Ci-dessous un extrait des sorties de l’exécution de la méthode TREE.
=======================================================================
| No | Nom |Leaf | Class | pas_lo | long | criterion|
| | | No | true | assig.| ( 1) | ( 2) | |
=======================================================================
| 1 | LONG_5 | 2 | 2 | 1 (*)| 100.00 | 0.00 | 0.36 |
| 2 | COURT_2 | 2 | 1 | 1 | 100.00 | 0.00 | 0.64 |
| 3 | NORMAL | 2 | 1 | 1 | 100.00 | 0.00 | 0.64 |
| 4 | COURT_3 | 2 | 1 | 1 | 100.00 | 0.00 | 0.64 |
| 5 | LONG_1 | 2 | 1 | 1 | 100.00 | 0.00 | 0.64 |
| 6 | COURT_5 | 2 | 1 | 1 | 100.00 | 0.00 | 0.64 |
| 7 | LONG_4 | 2 | 2 | 1 (*)| 100.00 | 0.00 | 0.36 |
| 8 | COURT_4 | 2 | 1 | 1 | 100.00 | 0.00 | 0.64 |
| 9 | COURT_1 | 2 | 1 | 1 | 100.00 | 0.00 | 0.64 |
| 10 | LONG_3 | 2 | 2 | 1 (*)| 100.00 | 0.00 | 0.36 |
| 11 | LONG_2 | 2 | 2 | 1 (*)| 100.00 | 0.00 | 0.36 |
=======================================================================
R(T)= 0.3636

35
CONFUSION MATRIX FOR TRAINNING SET
=================================================
| | pas_long | long | Total |
=================================================
| pas_long | 7 | 0 | 7 |
| long | 4 | 0 | 4 |
=================================================
| Total | 11 | 0 | 11 |
=================================================
L’arbre de décision
+ --- IF ASSERTION IS TRUE (up)
!
--- x [ ASSERTION ]
!
+ --- IF ASSERTION IS FALSE (down)
+---- < 2 >pas_long ( 5.87 4.00 )
!
!----1[ N_DMS <= 22.360001]
!
+---- < 3 >pas_long ( 1.13 0.00 )
II-2-5. La méthode PYR : Pyramical Clustering on Symbolic
Objects
a- Présentation de la méthode PYR
Il s’agit d’une classification pyramidale qui généralise la hiérarchisation en autorisant les
classes non disjointes à un niveau donné.
La pyramide constitue un modèle intermédiaire entre les arbres et les structures en
treillis. Cette méthode permet de classer des données plus complexes que ce que nous autorisait
le modèle tabulaire et ceci en considérant la variation des valeurs prises par les variables. La
pyramide est construite par un algorithme d’agglomération opérant du bas (les objets
symboliques) vers le haut (à chaque niveau, des classes sont agglomérées).
Dans une classification pyramidale, chaque classe formée est définie non seulement par
son extension (l’ensemble de ses éléments) mais aussi par un objet symbolique qui décrit ses
propriétés (l’intension de la classe). L’intension est héritée d’un prédécesseur vers son
successeur et nous obtenons ainsi une structure d’héritage.
La structure d’ordre permet l’identification de concepts intermédiaires ; c’est-à-dire de
concepts qui comblent un vide entre des classes bien identifiées. En entrée de cette méthode,
l’utilisateur doit choisir les variables qui seront utilisées pour construire la pyramide. Ces
variables peuvent être continues (des valeurs réelles), des intervalles de valeurs réelles ou bien
des histogrammes. L’utilisateur sera invité à choisir entre des variables qualitatives et continues
mais il lui est également possible de les mélanger.
36
b- Mise en oeuvre de la méthode PYR
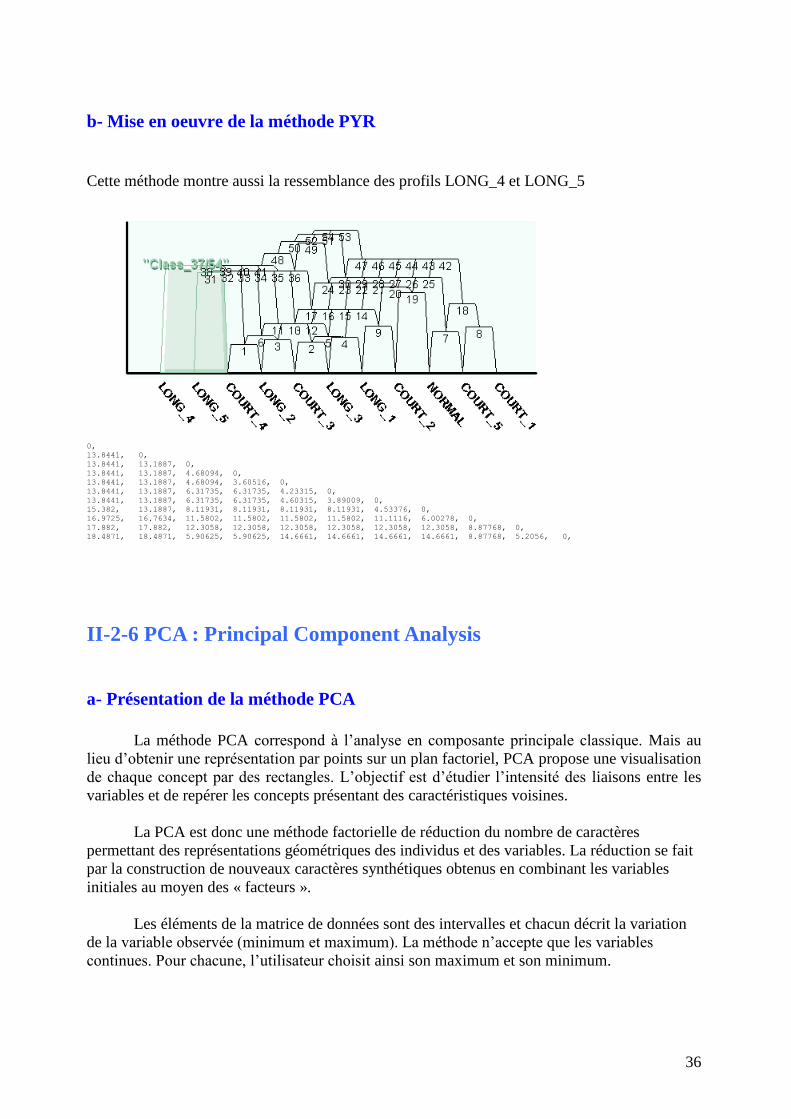
Cette méthode montre aussi la ressemblance des profils LONG_4 et LONG_5
0,
13.8441, 0,
13.8441, 13.1887, 0,
13.8441, 13.1887, 4.68094, 0,
13.8441, 13.1887, 4.68094, 3.60516, 0,
13.8441, 13.1887, 6.31735, 6.31735, 4.23315, 0,
13.8441, 13.1887, 6.31735, 6.31735, 4.60315, 3.89009, 0,
15.382, 13.1887, 8.11931, 8.11931, 8.11931, 8.11931, 4.53376, 0,
16.9725, 16.7634, 11.5802, 11.5802, 11.5802, 11.5802, 11.1116, 6.00278, 0,
17.882, 17.882, 12.3058, 12.3058, 12.3058, 12.3058, 12.3058, 12.3058, 8.87768, 0,
18.4871, 18.4871, 5.90625, 5.90625, 14.6661, 14.6661, 14.6661, 14.6661, 8.87768, 5.2056, 0,
II-2-6 PCA : Principal Component Analysis
a- Présentation de la méthode PCA
La méthode PCA correspond à l’analyse en composante principale classique. Mais au
lieu d’obtenir une représentation par points sur un plan factoriel, PCA propose une visualisation
de chaque concept par des rectangles. L’objectif est d’étudier l’intensité des liaisons entre les
variables et de repérer les concepts présentant des caractéristiques voisines.
La PCA est donc une méthode factorielle de réduction du nombre de caractères
permettant des représentations géométriques des individus et des variables. La réduction se fait
par la construction de nouveaux caractères synthétiques obtenus en combinant les variables
initiales au moyen des « facteurs ».
Les éléments de la matrice de données sont des intervalles et chacun décrit la variation
de la variable observée (minimum et maximum). La méthode n’accepte que les variables
continues. Pour chacune, l’utilisateur choisit ainsi son maximum et son minimum.

37
L’exécution de la méthode nous donne deux résultats :
1 - Le listing qui contient
- La description de la matrice de données par une table : chaque ligne correspond à une classe.
- Les valeurs propres, le pourcentage d’inertie et les premières composantes principales.
Chaque classe est caractérisée d’abord par deux composantes principales et visualisée dans un
plan factoriel par un rectangle.
- Les corrélations entre chaque variable descriptive et les composantes principales.
2 - Une représentation graphique des objets symboliques.
b. Mise en oeuvre de la méthode PCA
La méthode accepte seulement les variables continues, en entrée, et les sorties sont
présentées ci-dessous :
Corrélation entre variables et facteurs:
Var. Factor 1 Factor 2 Factor 3
AGE 0.48178 0.83659 0.96573
NBR_ACTES 0.28311 0.85143 0.68380
NBR_DIAGS 0.42866 0.79257 0.93141
PI_DMS -0.24888 0.31858 0.22126
NBR_REA 0.12778 0.68575 0.46858
N_DMS 0.51070 0.79866 0.96629
Contributions des objets symboliques aux axes (11 objs,3 fact)=
Objects Factor 1 Factor 2 Factor 3
LONG_5 0.83037 0.14827 0.09239
COURT_2 0.03150 0.32732 0.07828
NORMAL 0.01383 0.05343 0.12755
COURT_3 0.01760 0.03565 0.09853
LONG_1 0.01009 0.00992 0.06415
COURT_5 0.02877 0.01044 0.13129
LONG_4 0.00989 0.21906 0.05557
COURT_4 0.02376 0.02251 0.05684
COURT_1 0.01727 0.00478 0.12249
LONG_3 0.00906 0.16534 0.10732
LONG_2 0.00785 0.00329 0.06560
Qualité de représentation des objets symboliques (11 objs,3 fact)=
Objects Factor 1 Factor 2 Factor 3
LONG_5 0.86183 0.01809 0.08244
COURT_2 0.17327 0.21170 0.37026
NORMAL 0.08573 0.03894 0.67978
COURT_3 0.11772 0.02803 0.56651
LONG_1 0.11219 0.01296 0.61329
COURT_5 0.17020 0.00726 0.66768
LONG_4 0.09218 0.23998 0.44518
COURT_4 0.22224 0.02475 0.45712
COURT_1 0.12303 0.00401 0.75017
LONG_3 0.06008 0.12889 0.61174
LONG_2 0.08332 0.00411 0.59843
Le concept LONG_5 a une contribution de 83% au facteur 1. Le facteur 3 a bénéficié de la
contribution de reste des concepts. Les 3 premières axes cumulent 97.84% d’inertie.
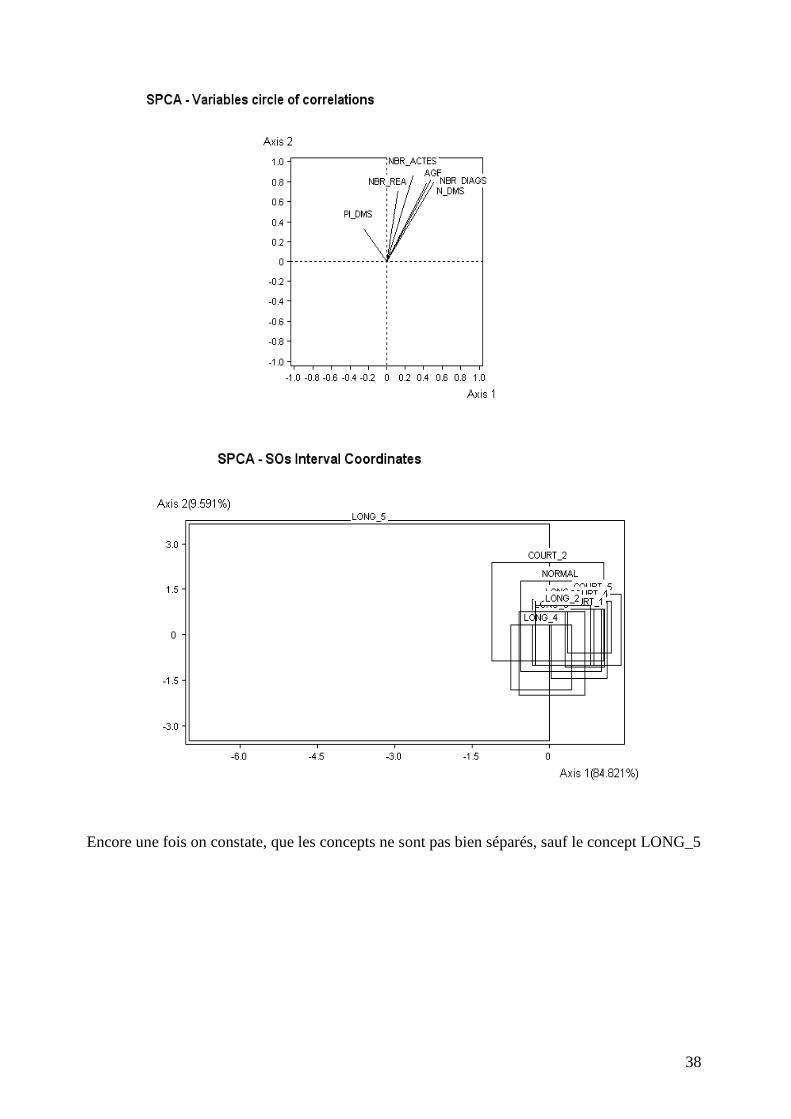
38
Encore une fois on constate, que les concepts ne sont pas bien séparés, sauf le concept LONG_5

39
II-2-7 La méthode DISS/MATCH
a- Présentation de la méthode
“Several data analysis techniques are based on defining and quantifying a dissimilarity
measure between the underlying objects. The method DI (Dissimilarities & Matching)
implements several dissimilarity measures between Boolean symbolic objects. The method DI
also implements a canonical and a flexible matching operator. Matching is the process of
comparing two or more structures to discover their likeness or difference. The definition of
matching operators for BSO is deemed important for the development of several symbolic data
analysis techniques, such as factor analysis”. Wikipedia
b-Mise en oeuvre de la méthode
On présente la matrice de dissimilarité qui sera utilisé pour la construction de la
pyramide. et
La représentation graphique de la matrice de dissimilarité
40
II-2-8 Les méthodes clustering (SCLUST)
a- Présentation de la méthode
Dans le cadre d’un problème de clustering, on dispose d’un ensemble de données qui
reprend une collection d’objets non étiquetés. Les classes sont encore inexistantes. L’objectif
est alors d’obtenir des clusters d’objets homogènes, en favorisant l’hétérogénéité entre ces
différents groupes.
La plupart des méthodes de clustering se basent sur une mesure de distance entre deux
objets. Ceux-ci étant caractérisés par les attributs, cette notion de distance devra se baser sur des
distinctions entre les valeurs prises par les attributs pour les différents objets.
On peut donc dire que toutes les techniques de clustering suivent un même principe général qui
consiste à minimiser la distance entre deux objets d’un même cluster et à maximiser la distance
entre deux objets de clusters distincts.
b- Mise en œuvre de la méthode
Extrait de description du concept: Prototype_1/5 =
AGE = [ 31.00 : 94.00 ]
And SEXE = M (0.54), F (0.46)
And NBR_ACTES = [ 1.00 : 111.00 ]
And NBR_DIAGS = [ 2.00 : 30.00 ]
And PI_DMS = [ 3.09 : 8.66 ]
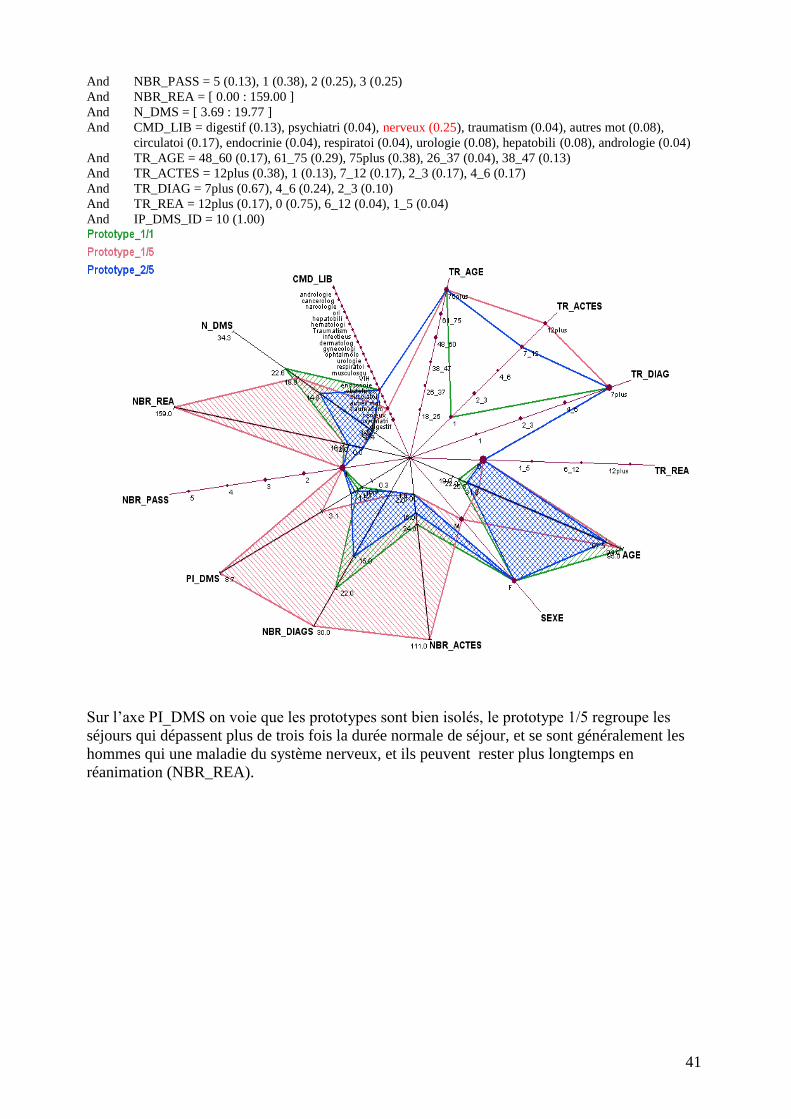
41
And NBR_PASS = 5 (0.13), 1 (0.38), 2 (0.25), 3 (0.25)
And NBR_REA = [ 0.00 : 159.00 ]
And N_DMS = [ 3.69 : 19.77 ]
And CMD_LIB = digestif (0.13), psychiatri (0.04), nerveux (0.25), traumatism (0.04), autres mot (0.08),
circulatoi (0.17), endocrinie (0.04), respiratoi (0.04), urologie (0.08), hepatobili (0.08), andrologie (0.04)
And TR_AGE = 48_60 (0.17), 61_75 (0.29), 75plus (0.38), 26_37 (0.04), 38_47 (0.13)
And TR_ACTES = 12plus (0.38), 1 (0.13), 7_12 (0.17), 2_3 (0.17), 4_6 (0.17)
And TR_DIAG = 7plus (0.67), 4_6 (0.24), 2_3 (0.10)
And TR_REA = 12plus (0.17), 0 (0.75), 6_12 (0.04), 1_5 (0.04)
And IP_DMS_ID = 10 (1.00)
Sur l’axe PI_DMS on voie que les prototypes sont bien isolés, le prototype 1/5 regroupe les
séjours qui dépassent plus de trois fois la durée normale de séjour, et se sont généralement les
hommes qui une maladie du système nerveux, et ils peuvent rester plus longtemps en
réanimation (NBR_REA).

42
Comme le montre les diagrammes, précédent, une partition en 5 classes n’a pas permis de
bien isoler les classes : les prototypes se chevauchent. Seul le prototype_1/5 se distingue par un
intervalle plus large de nombre d’actes et des journées de réanimation. Il se caractérise par un
l’indice PI_DMS compris entre 0.67 et 0.8, ce que veut dire que les durées de séjour, qui font
partie de cette classe constituent 67% - 80% de la durée de séjour de référence – ce sont des
séjours courtes. Il est composé principalement de malades avec pathologie digestive et musculo
– squelettique.
II-2-9 La méthode de SYKSOM
La méthode nous a proposé 25 prototypes ci-dessous un extrait.
Cluster 3 ( 1x3) Size 3
List of objects:
( 5) LONG_1
( 8) COURT_4
( 11) LONG_2
Cluster 8 ( 2x3) Size 5
List of objects:
( 4) COURT_3
( 6) COURT_5
( 7) LONG_4
( 9) COURT_1
( 10) LONG_3
Cluster 9 ( 2x4) Size 1
List of objects:
( 2) COURT_2
Cluster 10 ( 2x5) Size 1
List of objects:
( 1) LONG_5
Cluster 13 ( 3x3) Size 1
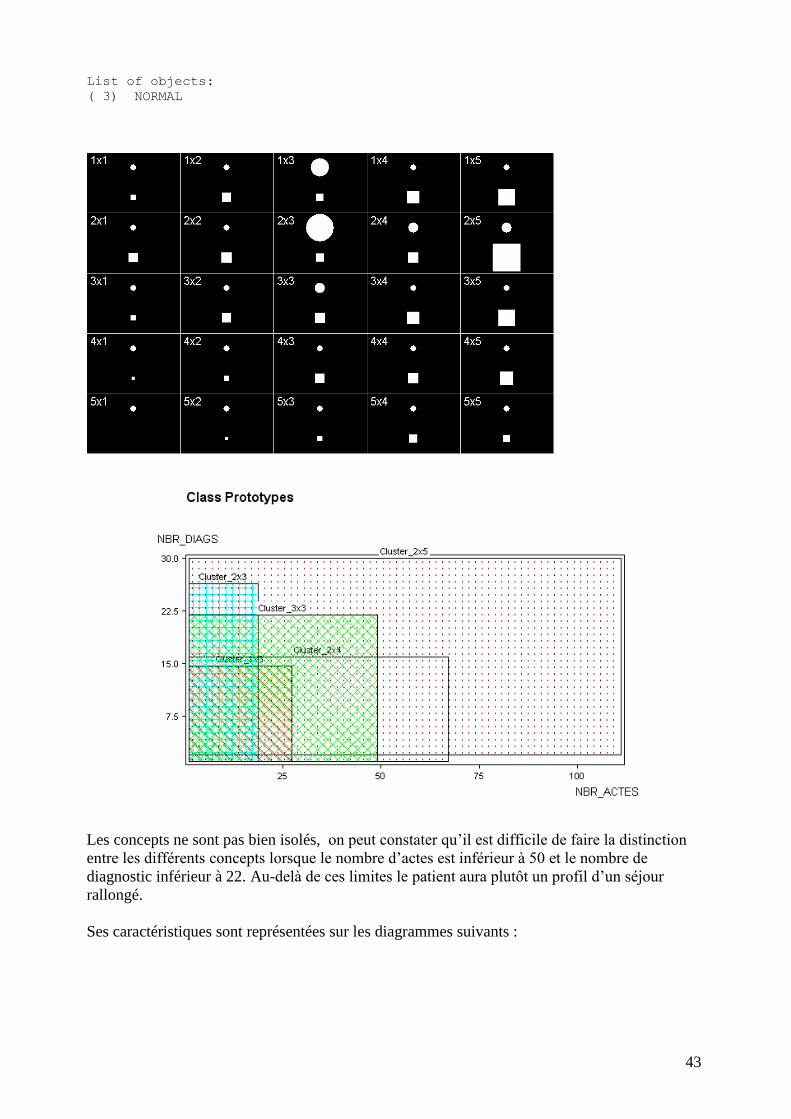
43
List of objects:
( 3) NORMAL
Les concepts ne sont pas bien isolés, on peut constater qu’il est difficile de faire la distinction
entre les différents concepts lorsque le nombre d’actes est inférieur à 50 et le nombre de
diagnostic inférieur à 22. Au-delà de ces limites le patient aura plutôt un profil d’un séjour
rallongé.
Ses caractéristiques sont représentées sur les diagrammes suivants :
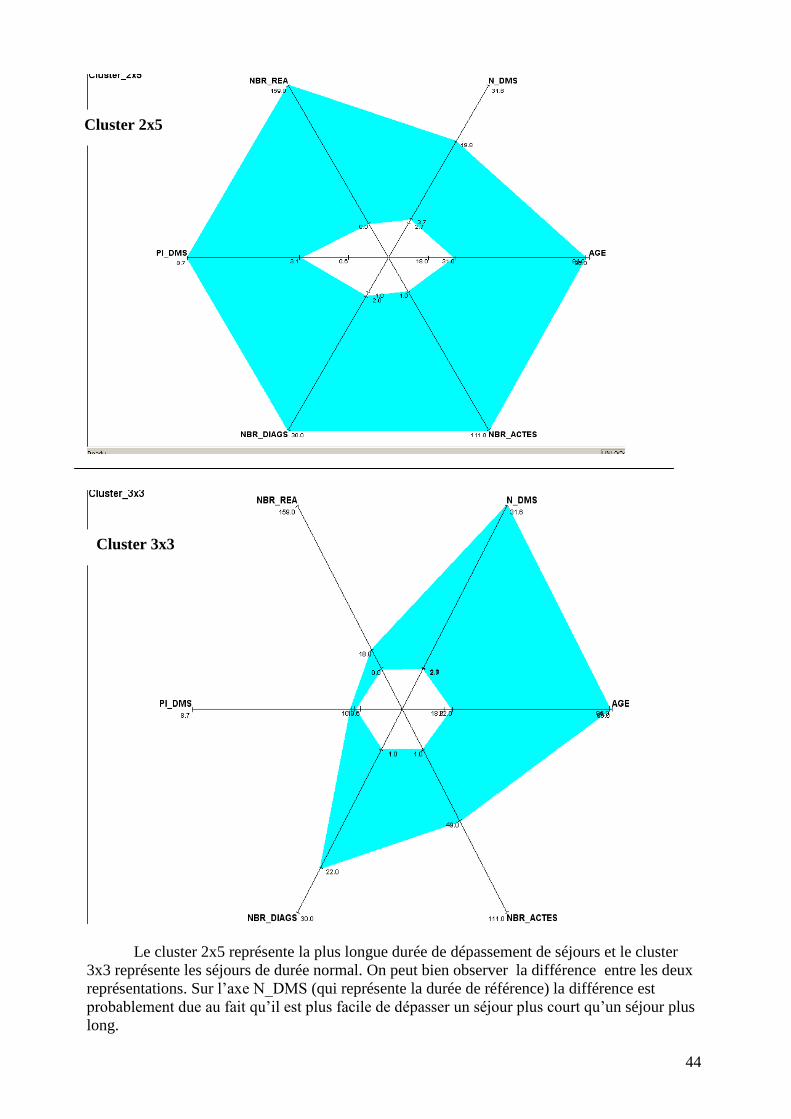
44
Le cluster 2x5 représente la plus longue durée de dépassement de séjours et le cluster
3x3 représente les séjours de durée normal. On peut bien observer la différence entre les deux
représentations. Sur l’axe N_DMS (qui représente la durée de référence) la différence est
probablement due au fait qu’il est plus facile de dépasser un séjour plus court qu’un séjour plus
long.
Cluster 2x5
Cluster 3x3

45
CONCLUSION
La réalisation de ce projet a été pour nous l’occasion de découvrir un logiciel puissant
d’analyse de données symboliques : le logiciel SODAS. Cet outil nous a permis d’extraire des
connaissances d’une importante base de données relationnelles.
La grande flexibilité de ce logiciel associée à la puissance de ses diverses représentations
graphiques a mis en évidence des résultats pertinents et facilement interprétables :
1- En utilisant les méthodes de datamining, sur un échantillon des individus extraits
de la base des données des dossiers médicaux, on a réussi d’établir le profil de
malades, qui dépassent la durée de séjour de référence.
2- Donc ce sont des hommes et femmes de 48 à 75 ans, avec plus de 7 diagnostics,
avec des maladies du système nerveux. Ils peuvent rester plus de temps en
réanimation et avoir plus d’actes que les autres catégories. Cella peut indiquer, que
le séjour est rallongé pour des raisons médicales, ou au cause d’insuffisance de
prise en charge des malades avec des maladies multiples et chroniques par des
structures spécialisés, comme le soin de suite.
3- La catégorie de malade âgés de plus de 59 ans, avec plus de 20 actes et plus de 51
jour de réanimation, dépasse toujours leur duré de séjour de référence.
4- Pour discriminer les autres catégories de malades, il sera nécessaire d’introduire
d’autres variables.
5- Il est possible, que le rallongement des séjours inférieur à 200% n’est pas du à un
profile de malades, mais est aléatoire et n’a pas des raisons médicales. Une étude
des flux de malades pourra relever les véritables causes de pétard dans leur durée
de séjour.
6- Le nombre d’actes et de diagnostics augmente avec l’age.
Enfin, réaliser ce projet en équipe a été tout à fait intéressant et productif. En effet, nous avons
pu confronter nos idées sur l’étude et effectuer ainsi une analyse plus détaillée

46
Bibliographie
- Stéphane Tuffery, Data Mining et Statistique Décisionnelle Nouv Edition, Technip, 2007,
ISBN-13: 978-2710808886
- Les logiciels de statistique et de data mining, http://data.mining.free.fr/cours/Logiciels.pdf , vu
le 18 mars 2008
- Étude statistique et préparation des données, http://data.mining.free.fr/cours/Donnees.pdf, vu
le 16 mars 2008
- De Hans Hermann Bock, E. Diday, Analysis of Symbolic Data Exploratory Methods for
Extracting, Springer, 2000, ISBN 3540666192, vu le 20 mars 2008 sur books.google.fr
www.ceremade.dauphine.fr/~touati/sodas-pagegarde.htm
- Téléchargement de SODAS
- Présentation des Méthodes
- Exemples des rapports et données
www.wikipedia.org