présenté par : wafa chaib et yasmina ben dania dania.pdf · a la fin de l’année 2003, mpls...
TRANSCRIPT

République Algérienne Démocratique Et Populaire Ministère de l’Enseignement Supérieur et de Recherche
Scientifique
Université Kasdi Merbah-Ouargla
Faculté des Nouvelles Technologies de l’Information et de la Communication
Département d'Informatique et Technologie de l'information
Mémoire Master Professionnel
Domaine : Informatique et Technologie de l'Information
Filière : Informatique
Spécialité : Réseaux convergence et sécurité
Présenté par : Wafa CHAIB et Yasmina BEN DANIA
Thème
Président Dr. Idriss KORICHI Maître, UKM Ouargla
Examinateur Fares KHELSNAN Maître, UKM Ouargla
Rapporteur Mohamed Kamel BEN KADDOUR Maître, UKM Ouargla
Année universitaire 2014/2015

Remerciements
Nous adressons en premier lieu notre reconnaissance à notre DIEU
tout puissant, de m’avoir permis d’arriver là, car sans lui rien n’est possible.
Nous tenons tout d'abord à remercier Mr Ben Kaddour Mohamed Kamel notre encadreur de mémoire, pour tout le soutien, l'aide, l'orientation, la guidance qu'il m'a apportés durant le mémoire, ainsi que pour ses précieux conseils et ses encouragements lors de la réalisation de notre mémoire.
Nous tenons ensuite à remercier nos parents pour le soutien inconditionnel dont ils ont fait preuve depuis que notre projet professionnel est défini. Merci pour le soutien financier, moral, psychologique et matériel. Si nous avons ici aujourd'hui, c'est grâce à vous!
Nous souhaitons aussi remercier nos frères et nos sœurs pour leur accompagnement durant ces cinq années et leur soutien sans faille.
Nous voulons bien entendu remercier également Zineb, Ftahia et Samira, et tous les autres.
Nous remercions tous les professionnels qui ont participé à la réalisation de ce mémoire de fin d'études et plus particulièrement Mme. Maarif.
Enfin, nous remercions nos amis et nos camarades de promotion pour ces deux années passées ensemble, dans les meilleurs moments comme dans les pires.

Dédicaces
A l’homme de ma vie, mon exemple éternel, mon soutien
moral et source de joie et de bonheur, celui qui s’est toujours
sacrifié pour me voir réussir, que dieu te garde dans son vaste
paradis, à toi mon père.
A la lumière de mes jours, la source de mes efforts, la flamme
de mon cœur, ma vie et mon bonheur ; maman que j’adore.
Aux personnes dont j’ai bien aimé la présence dans ce jour, à
tous mes frères et mes sœurs, mes nièces
amani,khairo,ridha,hamodi,ilias,malak,mouhamed,anis,fatom
a,safaa,iad,ikram,fatima,israa,abd essamia, naofal ,abir.
Aux personnes qui m’ont toujours aidé et encouragé, qui
étaient toujours à mes côtés, et qui m’ont accompagnaient
durant mon chemin d’études supérieures, mes aimables amis,
sifou,hakim,walid;mouhamed,saadia,fadila,saida,afaf,marwa,
amina.et spécialement le groupe RCS.
Je dédie ce modeste travail à frères de mon cœur Hadji yahia.

Dédicaces
Je dédie ce modeste travail à : A mes parents .Aucun
hommage ne pourrait être à la hauteur de l’amour Dont ils ne
cessent de me combler. Que dieu leur procure bonne santé et
longue vie.
A celui que j’aime beaucoup et qui m’a soutenue tout au long
de ce projet : A mes frères ayoub. Zakaria et slimen et mes
sœurs yamina et khadidja.
A toute ma famille, et mes amis, A mon binôme YASMINA
et toute la famille CHAIB et HAFSSI. Et à tous ceux qui ont
contribué de près ou de loin pour que ce projet soit possible, je
vous dis merci.

Sommaire
I
Titre page Liste des Figures………….………….………….………….………….………….……. III Liste des tableaux………….………….………….……….………….………….……... IV
Résumé………….………….………….………….………….………….…………………….. V Introduction générale………….………….………….………….………….…………............ VI
Chapitre I : Généralité sur NGN
I. Introduction………….……….………….………….………….………….………... 2 I.1.Définition de réseau NGN………………….………….………….………………. 2 I.2.Les principes de NGN.………….………….………….………….………………. 3 I.2.1.Premier Principe .…………….……….………….………………………....... 3 I.2.2. Deuxième Principe ………………………………………...………………... 3 I.2.3. Troisième principe …………………………………………………………... 4 I.3. Conditions préalables à l’utilisation d’un NGN………………………………….. 4 I.4. Les facteurs incitatifs……………………………………………………………... 4 I.4.1. Facteurs économiques……………………………………………………….. 4 I.4.2. Facteurs technologiques ……………………………………………………. 5 I.4.3. Facteurs sociaux…………………………………………………………….. 5 I.5.Types de NGN ……………………………………………………………………. 5 I.5.1 Les NGN Class 4 et Class 5 ………………………………………………….. 5 I.5.2.Le NGN Multimédia ………………………………………………………… 6 I.6. Avantages de réseau NGN ………………………………………………………. 6 I.7. Les limites du NGN………………………………………………………………. 7 I.8. La convergence et les NGN………………………………………………………. 7 I.9Modèle d’architecture en couche………………………………………………….. 8 I.9.1. La couche d’accès………………………………………………………….. 8 I.9.2. La couche de transport ………………………………………………………. 8 I.9.3. La couche de contrôle ……………………………………………………… 8 I.9.4. La couche d’exécution des services …………………………………………. 9 I.9.5. La couche applications ……………………………………………………. 9 I.10. Typologie des scénarios de migration ………………………………………….. 10 I.11. Principaux équipements d’un réseau NGN …………………………………….. 10 I.11.1. Le Signalling Gateway (SG) ……………………………………………….. 10 I.11.2. Le Media Gateway Controller (MGC) …………………………………….. 10 I.12. Le réseau RMS d’ALGERIE TELECOM …………………………………….. 11 Conclusion …………………………………………………………………………….. 12
Chapitre II : Qualité de service II. Introduction ………………………………………………………………………. 14 II.1.Définition de la qualité de service ……………………………………………… 14 II.1.1. Qualité de service vue par l'utilisateur ……………………………………… 14 II.1.2. Qualité de service vue par le gestionnaire du réseau ……………………….. 14 II.1.3. Qualité de service vue par l'exploitant du réseau …………………………… 14 II.2. Critères de la qualité de service ………………………………………………… 15 II.2.1. La bande passante ………………………………………………………….. 15 II.2.2. Le délai de transport ……………………………………………………….. 15 II.2.3. La gigue ……………………………………………………………………. 15 II.2.4. le taux de perte………………………………………………………………. 15 II.3. Exigence des applications en métrique de la QoS ……………………………… 15 II.4. Qualité de Service et Sécurité ………………………………………………….. 16 II.5. Les modèles d’implémentation de la qualité du service ……………………… 16 II.5.1. Le modèle best effort ……………………………………………………….. 16

Sommaire
II
II.5.2. Modèle à intégration de service (IntServ) …………………………………... 17 II.5.3. Modèle à différenciation de service (DiffServ) …………………………….. 19 II.6. La gestion de la QoS ……………………………………………………………. 22 II.6.1.Plan de données ……………………………………………………………… 23 II.6.2. Plan de contrôle ……………………………………………………………... 31 II.7. QoS IP et MPLS ………………………………………………………………… 33
Conclusion …………………………………………………………………………….. 33
Chapitre III : MPLS et Qualité de Service
III. Introduction ……………………………………………………………………… 35
III.1. Présentation de MPLS ………………………………………………………. 35 III.2. Eléments de domaine MPLS ………………………………………………… 36 III.2.1. LSR (Label Switch Router) ……………………………………………. 36 III.2.2. LER (Label Edge Router) ………………………………………………… 36 III.2.3. Classe d’Equivalence pour l’Acheminement ……………………………… 36 III.2.4. Le LSP (Label Switch Path) ……………………………………………. 37 III.3. Architecture MPLS …………………………………………………………… 37 III.3.1. Le plan de contrôle ……………………………………………………… 37 III.3.2. Le plan de données ………………………………………………………… 37 III.4. Structures de données des labels ……………………………………………… 38 III.5. Les labels …………………………………………………………………….. 39 III.5.1. Definition ………………………………………………………………… 39 III.5.2. Pile de labels (Label Stack) ………………………………………………. 39 III.5.3. Fonctionnement de label …………………………………………………… 39 III.5.4. Distribution des labels …………………………………………………….. 40 III.6. Aspects avancés et applications ……………………………………………… 40 III.6.1. Ingénierie de trafic ………………………………………………………. 41
III.6.2. Qualité de service ………………………………………………………… 41 Conclusion …………………………………………………………………………… 43
Chapitre IV : Application IV. Introduction ………………………………………………………………………… 45
IV.1. Présentation des logiciels utilisés …………………………………………… 45
IV.1.1. Logiciels utilisés pour la réalisation de la maquette ……………………… 45 IV.1.2. Logiciel utilisés pour la supervision de la maquette …………………… 46 IV.1.3. Logiciel utilisé pour générer le trafic ……………………………………… 46 IV.2. Réalisation de la maquette …………………………………………………… 46 IV.2.1. Description de la maquette ………………………………………………… 46 IV.2.2.Topologie et plan d’adressage …………………………………………… 46 IV.2.3.Configuration ………………………………………………………………… 46 IV.2.4. Évaluation de la qualité de service sur la maquette (réseau IP/MPLS) …… 48 IV.2.5. Etude du réseau sans qualité de service …………………………………… 49 IV.2.6. Etude du réseau avec qualité de service …………………………………… 52 Conclusion générale…………………………………………………………………. VII
Référence et bibliographie ………………………………………………………….. XI

Liste des figures
III
N° Titre de figure Page I.1 convergence des services dans les réseaux de nouvelle génération 3 I.2 La convergence et les NGN 8 I.3 Architecture générale d’un réseau NGN 9 I.4 Architecture de BACKBONE RMS ALGERIE TELECOM 12 II.1 les exigences de quelques applications en termes de QoS 16 II.2 Fonctionnalités dans un routeur IntServ 17 II.3 Processus RSVP 18 II.4 Fonctionnement du protocole RSVP 19 II.5 Principe DiffServ 20 II.6 Le champ DS dans l’en-tête IPv4 20 II.7 Figure II.7 : Architecture DiffServ 22 II.8 Mécanismes de conditionnement 23 II.9 Algorithme seau percé. 25 II.10 Principe du Token Bucket 25 II.11 L’algorithme FIFO 25 II.12 Principe du traitement des paquets par priorités 26 II.13 L’algorithme FQ 26 II.14 L’algorithme WFQ 27 II.15 L’ordonnancement CBQ 27 II.16 L’ordonnancement CBWFQ 28 II.17 L’ordonnancement LLQ 28 II.18 Tail Drop 29 II.19 Probabilité d’élimination avec RED 30 II.20 Probabilité de rejet avec WRED 31 II.21 Eléments d’une gestion de politique 32 III.1 Couche MPLS 35 III.2 Architecture d’un domaine MPLS 36 III.3 Architecture d’un routeur LSR 37 III.4 Structures de données des labels dans une architecture LSR 38 III.5 Structure de shim MPLS 39 II.6 Exemple d’utilisation du champ STACK 39 III.7 La commutation de label 40 III.8 Intégration MPLS avec le modèle DiffServ 42 III.9 MPLS et DiffServ (E-LSP) 42
III.10 MPLS et DiffServ (L-LSP) 43 IV.1 Topologie de maquette 47 IV.2 L’échange de labels entre les routeurs de domaine MPLS 48 IV.4 Variation de délai dans un seul sens (voix seule) 49
IV.5 Variation de Jitter (voix seule) 50
IV.5 Variation de délai dans un seul sens (voix+FTP) 50
IV6 Paramètres de la voix avec la présence du flux FTP 51
IV.7 champ DSCP et EXP dans un paquet FTP 53
IV.8 Lechamp DSCP et EXP dans un paquet VoIP (UDP) 53
IV.9 Variation de délai dans un seul sens (voix+FTP) 54
IV.10 Variation de Jitter (voix+FTP) 54

Liste des Tableaux
IV
N° Titre de Tableau page II.1 les exigences de quelques applications en termes de QoS 16 IV.1 Les exigences de la VoIP en métrique de qualité de service 49 IV.2 Paramètre de la voix seul 50 IV.3 Paramètres de la voix avec la présence du flux FTP 54

Résumé
V
Résumé
A la fin de l’année 2003, MPLS (Multi Protocol Label Switching) est devenu un sujet de rechercher très
convoités par la communauté scientifique. MPLS est une architecture réseau qui permet d’acheminer des
données en utilisant un système de « Label » qui permet de fournir un service basé sur la commutation de
paquets et qui unifie le transport des données. Dans le monde les télécommunications, La qualité de
service QoS dans les réseaux téléphoniques a toujours tenu une place importante voire prépondérante
dans la conception des architectures de réseaux.
Dans ce travail nous avons menés des études sur deux solutions différentes qui correspondent aux
modèles Intserv et Diffserv. Les résultats obtenu dans le cadre de ce mémoire ont montré l’influence de
l’approche diffserv en fonction du délai et de la gigue appliquée au service VoIP et FTP testé en
absence et présence de QoS. L’implémentation et les tests ont été réalisés au moyen du simulateur GNS3
et Ixchariot respectivement sur différentes topologies de réseaux. Les résultats obtenus montrent
nettement l’importance d’une garantie de la QoS et sa réaction à la réception de l’information.
Les mot clés : NGN , MPLS ,la qualité de service QoS ,diffserv , Intserv , GNS3.
2003 MPLS ) ( .MPLS
" " .
.
Intserv Diffserv.
diffserv
)QoS . (
GNS3 IxChariot .
.
:NGN , MPLS , QoS ,diffserv , Intserv , GNS3.
Abstract
At the end of 2003, MPLS (Multi Protocol Label Switching) has become a subject of search coveted by
the scientific community. MPLS is a network architecture that can route data using a system of
"Label" which allows to provide a service based on packet switching and unifies the data transport. In
the telecommunications world, the QoS in telephone networks has always been important or even
predominant in the design of network architectures.
In this work we conducted studies on two different solutions that match the Intserv and Diffserv
models. The results obtained in the framework of this memore showed the influence of diffserv
approach based on the delay and jitter applied to VoIP and FTP service tested in the absence and
presence of QoS. The implementation and the tests were performed using the simulator GNS3 and
IxChariot respectively on different network topologies. The results clearly show the importance of
guaranteed QoS and its reaction to the receipt of the information.

Introduction générale
VI
Introduction
Les réseaux actuels sont assujettis à certaines critiques, notamment lorsque le trafic de
données qui les traverse se diversifie (Internet par exemple). Internet est un réseau à
commutation de paquets qui fournit un service d’acheminement des paquets « au mieux »,
plus connu sous l’appellation « Best-Effort ». Par cela, nous entendons que le réseau n’est pas
capable d’assurer une garantie de service aux paquets, soit en délai , en débit, et en pertes .
Tous les types de trafic qui traversent le réseau sont par conséquent traités de la même
manière. Pour les applications qui circulaient aux débuts de l’Internet, ces limitations
n’étaient pas incommodantes en raison de l’insensibilité aux variations temporelles des
applications (le courrier électronique, ou le transfert de fichiers par exemple) ; d’autre part, la
charge des réseaux était bornée ce qui laissait suffisamment de bande-passante disponible
pour le trafic en circulation. Mais aujourd’hui, la naissance de nouvelles applications a fait
d’Internet un réseau à usage plus hétérogène en terme de type de données et par conséquent
plus délicat face à la garantie de service attendue par les utilisateurs. Ainsi, la vidéo et l’audio
sont venus se substituer aux autres applications. Cependant, ces dernières ont des
caractéristiques, sur le réseau, différentes de celles des applications insensibles au délai. De ce
fait, il en découle deux principales catégories de trafic qui traversent couramment les réseaux :
les applications que nous qualifions d’élastiques, caractérisées par une insensibilité à
la métrique « temps » (telles que les e-mails); ce type de trafic devient alors plus
«gourmand » en terme de débit ;
les applications moins sensibles en débit mais exigeantes en délai, que nous qualifions
de non-élastiques ; la vidéoconférence et la téléphonie sur Internet en sont les
exemples les plus répandus.
Ces deux métriques sont, entres autres, à la base d’un besoin de garantie minimum à
percevoir. La notion de Qualité de Service (ou QoS) intervient à cet effet, puisque pour
satisfaire les besoins de ces applications, il est nécessaire de pouvoir leur fournir une qualité
de service qui leur soit adaptée.
Depuis l’apparition de cette revendication, d’importants travaux sont menés dans le domaine
de la qualité de service pour proposer des solutions remédiant aux insuffisances constatées.
En particulier, les groupes de l’IETF (The Internet Engineering for Task Force) se sont

Introduction générale
VII
penchés sur deux idées. Tout d’abord, un premier groupe, IntServ (Integrated Services) qui a
proposé une architecture à base de réservation de ressources pour chaque flot. Cette dernière
s’effectue au moyen du protocole RSVP (Resource Reservation Setup Protocol) pour gérer
cette réservation au niveau de chaque flot, et ainsi fournir de manière individuelle la ressource
requise par l’application demandeuse de qualité de service. Cependant, cette solution s’est
avérée insuffisante pour des réseaux à large dimensionnement.
C’est pourquoi un second groupe de travail a abordé le problème en proposant une garantie se
service basée sur la différenciation de service. Le groupe DiffServ (Differentiated Services)
fonde son concept sur une gestion de trafic par classe, sur des méthodes de conditionnement
du trafic à l’entrée du réseau et sur le marquage de celui-ci en fonction de son appartenance à
une classe, pour un traitement spécifique.
Nous avons choisi d’articuler notre étude autour de quatre chapitres principaux.
Le premier chapitre est consacré à la présentation générale des réseaux de prochaine
génération (NGN ou Next Generation Network en anglais), avec leur architecture répartie,
avantages et leurs caractéristiques.
Nous consacrons, dans un second temps, un chapitre à la qualité de service en définissant
tout d’abord la notion en tant que telle, puis en présentant les paramètres qui garantissent la
qualité de service dans un réseau. Nous exposons, de même, les différentes techniques
développées par les communautés de recherches, à savoir les modèles à intégration de service
IntServ, puis les modèles à différenciation de service DiffServ. Pour chacun de ces modèles,
nous détaillons les architectures et les différents services offerts qui permettent d’assurer la
qualité de service du trafic sur le réseau.
le troisième chapitre est consacré à la présentation des concepts de base de la technologie
MPLS et leur mécanisme de fonctionnement , ainsi que la relation entre MPLS et la QoS .
La dernière partie est consacrée à l’implémentation des algorithmes ainsi qu’aux diverses
simulations réalisées pour tester et valider les mécanisme d’ordonnancement. Pour ce faire,
nous avons brièvement présenté la plate-forme de test, en l’occurrence l’outil de simulation
GNS3 et les outils de supervision et de test.
Enfin, la conclusion générale résumera les résultats obtenus et donnera quelques
perspectives sur des travaux futurs.

Chapitre I : Généralité sur NGN

Chapitre I Généralité sur NGN
2
I. Introduction
L’ensemble des architectures de communication est actuellement en train d’évoluer vers une infrastructure globale basée sur IP : les réseaux de nouvelle génération (NGN ou Next Generation Network). Cette évolution s’explique par le fort pouvoir intégrateur d’IP qui est en mesure d’offrir un mode d’acheminement des données indépendant, d’une part, du type de technologies des réseaux sous-jacentes et d’autre part, du type de données véhiculées. L’objectif des opérateurs de télécommunications est ainsi de réaliser, à travers ces futurs réseaux, le support de multiples services (téléphonie, vidéo, données) au sein d’une unique infrastructure tirant parti de l’hétérogénéité des technologies réseaux.
Les NGN sont définis par une série de principes. Sous cette appellation entrent un ensemble de changement qui modifient déjà la structure des réseaux et guident l’industrie dans un tournant qu’il lui faut prendre à une vitesse dictée par les besoins de différentes organisations. Il est une caractéristique commune sur laquelle tout le monde s’accorde à propos des NGN, c’est la flexibilité nécessaire aux opérateurs établis pour fournir aux usagers professionnels des services fixes et mobiles propres à améliorer leur manière de travailler, et aux usagers résidentiels, tout un éventail de services de loisir.
I.1. Définition de réseau NGN [38]
Tout d’abord, rappelons que l’acronyme NGN (Next Generation Network) est un terme générique qui englobe différentes technologies visant à mettre en place un concept, celui d’un réseau convergent multiservices. En particulier, il n’existe pas de définition normalisée d’un NGN. La terminologie employée pour décrire les NGN est propre à chaque organisme de normalisation et emprunte à la fois au lexique des réseaux et des télécommunications.
L’UIT (Union internationale des télécommunications) définit un réseau de prochaine génération (NGN) comme un réseau en mode paquet qui est en mesure d’assurer des services de télécommunication et d’utiliser de multiples technologies de transport à large bande, à qualité de service imposée et dans lequel les fonctions liées aux services sont indépendantes des technologies sous-jacentes liées au transport.
Pour l'ITU-T, un réseau NGN est un réseau qui remplit les conditions générales suivantes:
Le réseau est en mesure d'assurer des services de télécommunication au public Son plan de transfert est exploité en mode paquet.
Il peut utiliser de multiples technologies de transport à large bande, pourvu qu'elles soient capables d'assurer une qualité de service de bout en bout.
Il permet un accès non restreint par les utilisateurs aux opérateurs de leur choix (notion d'interopérabilité et de libre concurrence) et à de multiples services (concept de réseau unique polyvalent)
Il peut supporter de multiples technologies d'accès (le dernier kilomètre peut être DSL, Fibre Optique, Câble, Wimax...)
Il prend en charge la notion de mobilité généralisée (accès aux services et cohérence des services quel que soit le lieu ou la technologie d'accès fixe ou mobile)
Chapitre I Généralité sur NGN
3
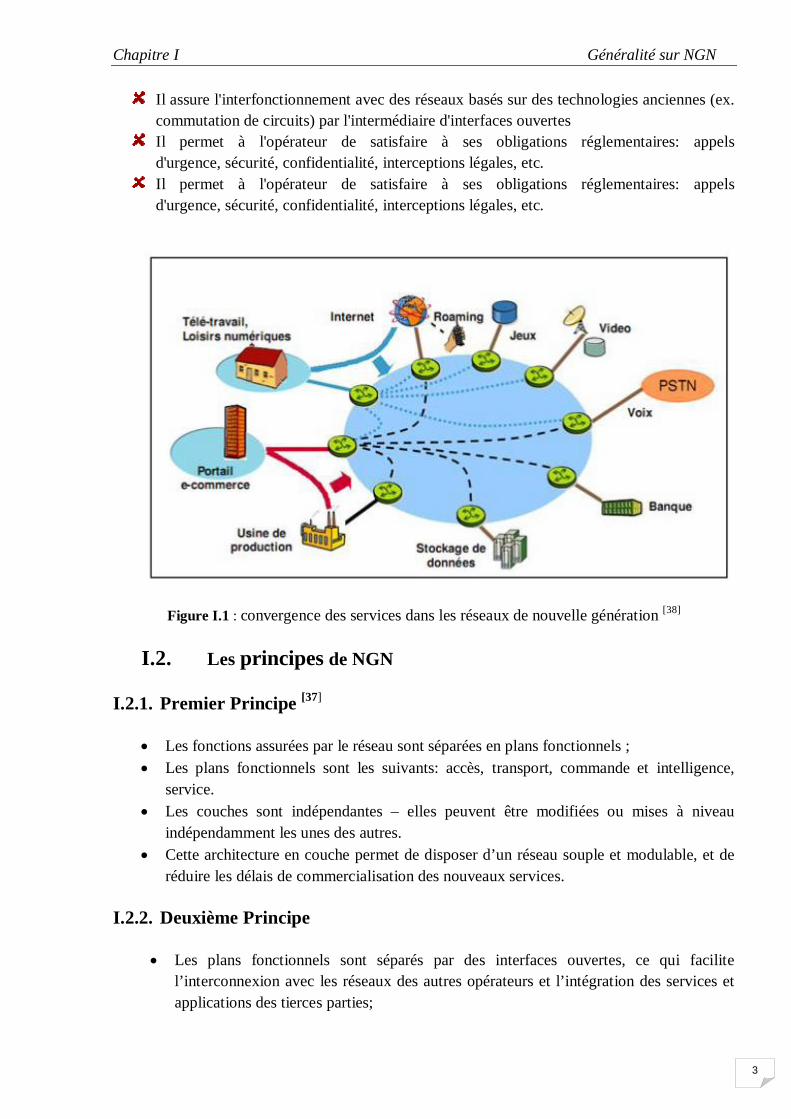
Il assure l'interfonctionnement avec des réseaux basés sur des technologies anciennes (ex. commutation de circuits) par l'intermédiaire d'interfaces ouvertes
Il permet à l'opérateur de satisfaire à ses obligations réglementaires: appels d'urgence, sécurité, confidentialité, interceptions légales, etc.
Il permet à l'opérateur de satisfaire à ses obligations réglementaires: appels d'urgence, sécurité, confidentialité, interceptions légales, etc.
Figure I.1 : convergence des services dans les réseaux de nouvelle génération [38]
I.2. Les principes de NGN
I.2.1. Premier Principe [37]
Les fonctions assurées par le réseau sont séparées en plans fonctionnels ; Les plans fonctionnels sont les suivants: accès, transport, commande et intelligence,
service. Les couches sont indépendantes – elles peuvent être modifiées ou mises à niveau
indépendamment les unes des autres. Cette architecture en couche permet de disposer d’un réseau souple et modulable, et de
réduire les délais de commercialisation des nouveaux services.
I.2.2. Deuxième Principe
Les plans fonctionnels sont séparés par des interfaces ouvertes, ce qui facilite l’interconnexion avec les réseaux des autres opérateurs et l’intégration des services et applications des tierces parties;

Chapitre I Généralité sur NGN
4
Il est ainsi possible d’étendre la portée de l’opérateur et de ses services et de permettre aux utilisateurs finals d’accéder à un plus grand nombre de services.
I.2.3. Troisième Principe [37]
Les NGN sont des réseaux multiservices (c’est-à-dire qu’ils assurent des services multiples, contrairement aux réseaux traditionnels spécialisés);
Un réseau multiservice offre aux opérateurs la possibilité de proposer aussi bien les services issus de la convergence que les nouveaux services
I.3. Conditions préalables à l’utilisation d’un NGN [4]
Avant de pouvoir établir une communication avec d’autres usagers, un terminal NGN doit remplir une série de conditions préalables:
L’usager doit souscrire à un abonnement, comme il le fait pour le réseau fixe ou mobile ou pour l’Internet.
Le terminal doit activer la connexion avec le réseau d’accès IP (fibre optique, DSL, UMTS, CATV, WiFi, WiMAX, LTE, etc.). Cette procédure comprend également l’attribution d’une adresse IP.
Le terminal lance ensuite la procédure de découverte du serveur P-CSCF, qui sera son point d’entrée dans le réseau et son serveur Proxy SIP pour toute la durée du futur enregistrement au niveau du NGN. Cette procédure est initiée, typiquement, lorsqu’on allume le terminal.
Ensuite, le terminal s’enregistre dans le NGN, au niveau SIP. Le NGN est maintenant en mesure d’authentifier l’usager, de mettre en place des tunnels sécurisés et d’autoriser l’établissement de sessions.
I.4. Les facteurs incitatifs
I.4.1. Facteurs économiques [44]
Érosion des recettes de la téléphonie sur lignes fixes ; Concurrence des nouveaux arrivants sur les secteurs du marché à forte marge (longue
distance, international) et des opérateurs intégrés verticalement (offres triples) ; Saturation des services de téléphonie fixe et mobile ; Désir de retenir, étendre et fidéliser la clientèle. Capacité de s’étendre sur de nouveaux segments de marché Possibilité d’ “échelle d’investissement”: investir par phases en ciblant d’abord les
zones les plus densément peuplées pour s’étendre progressivement aux autres zones

Chapitre I Généralité sur NGN
5
I.4.2. Facteurs technologiques [44]
Obsolescence des réseaux historiques, coût et complexité de la gestion de plusieurs réseaux historiques.
Moindres dépenses de capital et d’exploitation. Centralisation accrue du routage, de la commutation et de l’acheminement, moindres coûts d’acheminement sur les réseaux optiques
Les réseaux IP permettent la fourniture de services de VoIP moins chers à la place des services de téléphonie sur RTC.
Les réseaux IP permettent la fourniture d’un ensemble élargi de services et le groupage de ces services (offres triples ou quadruples).
Évolution et convergence des Équipements terminaux.
I.4.3. Facteurs sociaux
Demande de services innovants à haut débit (TVHD, VoIP, etc). Demande de contenu plus ciblé ou plus personnalisé (services multimédia, mobilité). Demande d’une plus grande interactivité: possibilité d’interagir avec le service de
façon active, intérêt croissant pour le contenu créé par l’utilisateur Demande de formes évoluées et plus flexible de communication: messagerie
instantanée, vidéoconférence, P2P, etc. Demande des entreprises pour des services intégrés, surtout dans les structures
multinationales avec le besoin de relier différentes branches nationales, de garantir un accès flexible et sûr aux ressources et à l’intelligence centralisée.
I.5. Types de NGN
Il existe trois types de réseau NGN : NGN Class 4, NGN Class 5 et NGN Multimédia.
I.5.1. Les NGN Class 4 et Class 5 [12]
Sont des architectures de réseau offrant uniquement les services de téléphonie. Il s'agit donc de NGN téléphonie. Dans le RTC, un commutateur Class 4 est un centre de transit. Un commutateur Class 5 est un commutateur d'accès aussi appelé centre à autonomie d'acheminement. Le NGN Class 4 (respectivement NGN Class 5) émule donc le réseau téléphonique au niveau transit (respectivement au niveau accès) en transportant la voix sur un mode paquet.
Le Class 4 NGN permet :
Le remplacement des centres de transit téléphoniques (Class 4 Switch). La croissance du trafic téléphonique en transit.
Le Class 5 NGN permet :
Le remplacement des centres téléphoniques d'accès (Class 5 Switch).

Chapitre I Généralité sur NGN
6
La croissance du trafic téléphonique à l'accès. La voix sur DSL/ Voix sur le câble.
I.5.2. Le NGN Multimédia [12]
Est une architecture offrant les services multimédia (messagerie vocale/vidéo, conférence audio/vidéo, Ring-back tone voix/vidéo) puisque l'usager a un terminal IP multimédia. Cette solution est plus intéressante que les précédentes puisqu'elle permet à l'opérateur d'innover en termes de services par rapport à une solution NGN téléphonie qui se cantonne à offrir des services de téléphonie.
Le NGN Multimédia permet d'offrir des services multimédia à des usagers disposant d'un accès large bande tel que xDSL, câble, WiFi/WiMax, EDGE/UMTS, etc.
I.6. Avantages de réseau NGN [21]
La convergence de la voix, vidéo, des données et des réseaux mobiles changent la manière dont les entreprises communiquent et les processus internes en offrant des applications encore inédites.
Dans ce contexte, voici en cinq points les avantages principaux de la convergence NGN :
Plus vite moins cher : le fait que les flux vocaux, vidéo et de données empruntent le même réseau rend inutile la création et la maintenance de réseaux séparés.
Un réseau ultra performant : les réseaux NGN fournissent de meilleures capacités de bandes passantes, beaucoup plus rapides avec un niveau de sécurité plus élevé que les réseaux IP alternatifs. La performance de ces réseaux permet également de réduire les temps de latences.
Une ouverture vers les applications de demain : un des avantages les plus importants de la migration vers un réseau NGN, au-delà de l'amélioration des procès et des couts, est la multitude des applications offertes. La VoIP est la plus connue. Les solutions de vidéo conférence, par exemple, sont des services de plus en plus plébiscités. Les réseaux NGN actuels offrent, pour la première fois, des solutions de vidéo conférence capables de se substituer aux réunions physiques.
Un réseau qui s'adapte en un clic : trop souvent, les communications ont été perçues comme une charge lourde pour l'entreprise. Ajouter des lignes de téléphone et des données supplémentaires à son réseau représentait des couts faramineux et la technologie utilisée était longue et complexe à installer. Avec les réseaux convergés, l'ajout de nouvelles lignes est bien plus facile et beaucoup plus rentable. La flexibilité de la technologie signifie également plus de capacité plus rapidement en fonction des besoins de l'entreprise, et ce quasiment en un clic c'est en particulier le cas des entreprises utilisant l'Ethernet comme technologie d'accès.
Un point de contact unique : un autre effet positif de la convergence est la simplification de la maitrise du fonctionnement et du cout de son réseau. Avec un fournisseur unique, il y a seulement un point de contact pour toute demande concernant le réseau.

Chapitre I Généralité sur NGN
7
I.7. Les limites du NGN [26]
Les limites du NGN peuvent être résumées ci-dessous :
Existence des centraux TDM qui compliquent l'acheminement IP ; Non déploiement complète des équipements d'accès tel les MSAN ; Perte de ligne entrainant les débits faibles sur les boucles locales ; Non interconnexion réelle des NGN HAWEI et ZTE car tout les trafics entre ZTE et
HAWEI passe par les CTN qui sont en TDM ; Existence des équipements NGN qui n'intègrent pas certain services à valeurs ajoutées :
car les MSAN actuels ne sont pas équipés des cartes VOIP ; Existence des régions entières comme l'ADAMAOUA, le NORD , l'EXTREME NORD ,
l'EST le SUD , le SUD OUEST et une grande partie de l'ouest qui sont carrément coupées du NGN et utilisent des systèmes de commutation Siemens EWSD génération 11 ou 15 .
I.8. La convergence et les NGN [44]
La convergence des technologies de réseau, des services et des équipements terminaux est à la base de l’évolution des offres novatrices et des nouveaux modèles économiques dans le secteur des communications. L’utilisation du terme de “convergence” traduit le passage de l’architecture traditionnelle en “compartimentage vertical”, c’est-à-dire d’une situation dans laquelle différents services étaient assurés par des réseaux distincts (réseau mobile, réseau de lignes fixes, télévision par câble, IP) à une situation dans laquelle l’accès et l’utilisation des services de communication se feront de façon intégrée sur différents réseaux, ces services étant dispensés de façon interactive à travers des plates-formes multiples. Dans les années 90 déjà, l’impact éventuel de la numérisation et de la convergence entre les télécommunications et la transmission sans fil était à l’étude et des propositions de modification de la réglementation existante avaient été formulées. Le rôle de plus en plus important de l’Internet dans l’économie et dans la société a renforcé le processus de convergence et a stimulé la vitesse à laquelle celle-ci progresse.

Chapitre I Généralité sur NGN
8
Figure I.2 : La convergence et les NGN [36]
I.9. Modèle d’architecture en couche [1]
Le passage à une architecture de type NGN est notamment caractérisé par la séparation des fonctions de commutation physique et de contrôle d’appel. L’architecture NGN introduit un modèle en couches, qui scinde les fonctions et les équipements responsables du transport du trafic et du contrôle. Il est possible de définir un modèle architectural basé sur cinq couches successives.
I.9.1. La couche d’accès : qui regroupe les fonctions et les équipements permettant de gérer l’accès des équipements utilisateurs au réseau, selon la technologie d’accès (téléphonie commutée, DSL, câble…). Cette couche inclut par exemple les équipements DSLAM (Digital Subscriber Line Access Multiplexeur) fournissant l’accès DSL.
I.9.2. La couche de transport : qui est responsable de l’acheminement du trafic (voix, vidéo ou données) dans le cœur de réseau, selon le protocole utilisé. L’équipement important à ce niveau dans une architecture NGN est le Media Gateway (MGW) responsable de l’adaptation des protocoles de transport aux différents types de réseaux physiques disponibles (RTC, IP, ATM, …).
I.9.3. La couche de contrôle: qui gère l’ensemble des fonctions de contrôle des services en général, et de contrôle d’appel en particulier pour le service voix. L’équipement important à ce niveau est le serveur d’appel, ou « Softswitch », qui fournit, dans le cas de services vocaux, l’équivalent de la fonction de commutation dans un réseau NGN. CSCF (Call Session Control Function).

Chapitre I Généralité sur NGN
9
I.9.4. La couche d’exécution des services : qui regroupe l’ensemble des fonctions permettant la fourniture de services dans un réseau NGN. En termes d’équipements, Cette couche regroupe deux types d’équipement : les serveurs d’application (ou application servers) et les « enablers », qu’ont des fonctionnalités, comme la gestion de l’information de présence de l’utilisateur, susceptibles d’être utilisées par plusieurs applications. Cette couche inclut généralement des serveurs d’application SIP, car SIP (Session Initiation Protocol) est utilisé dans une architecture NGN pour gérer des sessions multimédias en général, et des services de voix sur IP en particulier.
I.9.5. La couche applications : pour les différents services et applications susceptibles d’être offerts dans une architecture NGN. Il peut naturellement s’agir de services IP, mais les opérateurs s’attacheront aussi à supporter les services vocaux existants de réseau intelligent (renvoi d’appel, etc.) dans le cadre d’une migration vers une architecture NGN. Cette couche applications regroupe aussi l’environnement de création de services, qui peut être ouvert à des fournisseurs de services tiers. Le développement d’applications s’appuie sur les serveurs d’application et les « enablers » de la couche d’exécution des services.
La figure suivante représente l’architecture générale d’un réseau NGN :
Figure I.3 : Architecture générale d’un réseau NGN [1]

Chapitre I Généralité sur NGN
10
Ces couches sont indépendantes et communiquent entre elles via des interfaces ouvertes. Cette structure en couches est sensée garantir une meilleure flexibilité et une implémentation de nouveaux services plus efficace. La mise en place d’interfaces ouvertes facilite l’intégration de nouveaux services développés sur un réseau d’opérateur mais peut aussi s’avérer essentielle pour assurer l’interconnexion d’un réseau NGN avec d’autres réseaux qu’ils soient NGN ou traditionnels.
I.10. Typologie des scénarios de migration [38]
La mise en place d’architectures NGN peut se faire avec une plus ou moins grande ampleur, selon que l’utilisation des technologies NGN s’approche ou non au plus près de l’utilisateur final. Le choix de déploiement à retenir conditionne en grande partie les bénéfices à attendre de la mise en place d’un réseau NGN du point de vue de l’économie de coût. Quatre grands scénarios peuvent ainsi être dégagés :
Scénario 1 : Mise en place de solutions NGN en transit ; Scénario 2 : Mise en place de solutions NGN jusqu’au commutateur de classe 4 ; Scénario 3 : Mise en place de solutions NGN jusqu’au classe 5 ; Scénario 4 : Mise en place de solutions tout IP en overlay.
I.11. Principaux équipements d’un réseau NGN
I.11.1. Le Signalling Gateway (SG) [22]
La fonction Signalling Gateway se trouve en bordure du réseau de transport a pour rôle de convertir la signalisation échangée entre le réseau NGN et le réseau externe interconnecté selon un format compréhensible par les équipements chargés de la traiter, mais sans l’interpréter. Notamment, elle assure l’adaptation de la signalisation par rapport au protocole de transport utilisé (exemple : adaptation TDM / IP).Cette fonction est souvent implémentée physiquement dans le même équipement que la Media Gateway, d’où le fait que ce dernier terme est parfois employé abusivement pour recouvrir les deux fonctions MG + SG.
I.11.2. Le Media Gateway Controller (MGC) [22]
Media Gateway Controller aussi appelé Softswitch est le nœud central qui supporte l’intelligence de communication, il n'est autre qu'un serveur informatique, doté d'un logiciel de traitement des appels vocaux permettant de gérer :
L’échange des messages de signalisation transmise de part et d'autre avec les passerelles de signalisation, et l’interprétation de cette signalisation ;
Le choix du MG de sortie selon l'adresse du destinataire, le type d'appel, le charge du réseau, etc ;
La réservation des ressources dans le MG et le contrôle des connexions internes au MG (commande des Media Gateways).

Chapitre I Généralité sur NGN
11
Physiquement, un softswitch peut être implanté sur un serveur dédié ou bien être installé directement sur un équipement différent comme un media gateway ou même un commutateur traditionnel TDM. Dans ce cas, on parlera d’architecture complètement distribuée.
I.11.3. Le Multi Service Access Node (MSAN) [38]
Les MSAN constituent une évolution naturelle des DSLAMs. Un MSAN est un équipement qui constitue, dans la plupart des architectures de type NGN, un point d'entrée unique vers les réseaux d'accès des opérateurs. A la différence d'un DSLAM, dont le châssis ne peut supporter que des cartes permettant de proposer des services de type xDSL, un MSAN peut supporter des cartes RNIS, Ethernet,... De ce fait, au sein d'un seul et même châssis, l'opérateur peut déployer toutes les technologies d'accès envisageables sur son réseau. Le rôle de media Gateway décrit ci-avant peut, dans certains cas, être « embarqué » au sein de ce MSAN, et disparaître en tant que nœud de réseau dédié.
I.12. Le réseau RMS d’ALGERIE TELECOM [29]
Le RMS d’ALGERIE TELECOM est un réseau multiservices de nouvelle génération NGN, de type IP/MPLS et d’envergure nationale. Il offre la possibilité d’utiliser la technologie de transmission par paquet pour construire un réseau commun pour les applications de la voix, vidéo et des données.
Ses principaux objectifs sont :
Répondre aux nouveaux besoins large bande du secteur des télécoms Accroître la performance et la sécurité des réseaux existants.
De part sa capacité de supporter tout types d'interfaces, il permet l'interconnexion et l'interfonctionnement des réseaux existants.
Ce réseau est complètement maillé et comprend quatre nœuds primaires situés dans quatre grandes villes, Oran, Alger, Constantine et Ouargla. Chacun de ces nœuds accueille un couple de routeurs d’une grande capacité qui constitue le noyau (Core) du réseau backbone IP/MPLS. Pour assurer une sécurité maximale, les nœuds primaires sont répartis sur deux sites distincts. Chacun des nœuds secondaires, ainsi que les 4 nœuds primaires, comprennent un couple de routeurs qui constituent la périphérie (Edge) du réseau backbone IP/MPLS.
La supervision du réseau est assurée par un gestionnaire (software) qui assure simultanément les fonctions de gestion d'équipement et de gestion de réseau.

Chapitre I Généralité sur NGN
12
Figure I.4 : Architecture de BACKBONE RMS ALGERIE TELECOM [29]
Conclusion
A travers ce chapitre nous avons défini les réseaux de nouvelle génération en présentant leurs avantages et leurs Modèle d’architecture en couches.
Le déploiement des réseaux convergés de prochaines générations apporte plusieurs défis auxquels il faut faire face. Parmi ces défis, on peut citer l’interopérabilité des différents technologies de transport, la gestion uniformisée des ressources, l’ingénierie de trafic, la garantie d’une meilleure qualité de service de bout-en-bout, etc. Dans notre étude, on s’intéresse à la qualité de service qui sera présenté dans le chapitre suivant.

Chapitre II :Qualité de service

Chapitre II Qualité de Service
14
II. Introduction
Les réseaux convergent d’aujourd’hui, devront permettre le déploiement d’applications multimédia ayant des exigences spécifiques en terme de QoS (Quality of Service). Certains services comme les services vocaux auront besoin d’un faible délai point à point et d’une faible gigue .D’autres, comme les trafics de données, nécessiteront des faibles taux de pertes ou d’erreurs, sans retransmission, avec éventuellement une certaine garantie de bande passante pour les trafics critiques comme les données transactionnelles.
Pour pouvoir garantir la QoS des flux transportés, il va donc falloir suivre des modèles Qos spécifique et utiliser des mécanismes permettant de traiter de manière différenciée les différentes catégories de trafic dans les organes du réseau, ainsi que des protocoles de signalisation de la QoS pour pouvoir allouer des ressources en fonction des besoins des applications. Nous allons, le long de ce chapitre, présenter des généralités sur la qualité de service, en décrivant les deux architectures proposées, IntServ et DiffServ.
II.1. Définition de la qualité de service [10]
II.1.1. Qualité de service vue par l'utilisateur
La qualité de service demandée pour une certaine communication pourra être définie ponctuellement par un ensemble de valeurs affectées aux attributs mentionnés. Par ailleurs, des qualités de service standards pourront être définies qui spécifieront des valeurs pour ces attributs. On parlera alors de classes de service. L'application pourra alors demander une certaine qualité de service en se référant à la classe de service correspondante.
II.1.2. Qualité de service vue par le gestionnaire du réseau
Le gestionnaire du réseau, quant à lui, sera intéressé par la maîtrise de l'attribution des ressources du réseau en fonction de critères qui définiront la politique d'utilisation du réseau : priorité sera donnée par exemple à tel ou tel applicatif ou catégorie d'utilisateurs ou liste de serveurs et ce en fonction de l'heure de la journée et du jour de la semaine. Le réseau dans son ensemble devra permettre de contrôler l'affectation des ressources parmi les utilisateurs, ce contrôle pouvant se conclure par une facturation. L'attribution des ressources pourra être faite à la demande de l'applicatif, sous réserve d'un contrôle de la validité de cette demande eu égard à la politique d'utilisation du réseau définie, ou par les matériels actifs du réseau qui seront alors chargés de discriminer parmi les différentes communications circulant sur le réseau et de leur attribuer des ressources en fonction de la dite politique.
II.1.3. Qualité de service vue par l'exploitant du réseau
L'exploitant du réseau a un autre objectif qui ressort de la qualité de service offerte par celui-ci et qui y concourt. Cet objectif est de veiller à ce que les ressources dont dispose l'infrastructure, commutateurs, routeurs, liaisons, soient constamment utilisées au mieux. Ceci est d'autant plus vrai que ces ressources sont chères et la préoccupation correspondante se fera notamment sentir dans le contexte du réseau à grande distance avec ses liaisons coûteuses et ses routeurs très performants. On parle ici d'ingénierie de réseau.

Chapitre II Qualité de Service
15
III.2. Critères de la qualité de service [3]
La notion de qualité de service est en général traduite en termes de critères quantifiables de performance des transmissions des différents services. Ces critères de QoS (parfois appelés aussi métriques, ou paramètres) s’appuient sur l’analyse des flux individuels dans le réseau et sont généralement évalués de bout en bout, c’est-à-dire entre la source et la destination. Les critères de la QoS sont les suivants :
II.2.1. La bande passante : il s’agit du taux de transfert maximum pouvant être maintenu entre la source et la destination. II.2.2. Le délai de transport (de bout en bout) : se traduit par le temps écoulé entre l'émission du paquet par la source et sa réception à l'arrivée par le destinataire; Il se compose de :
Délai de traitement : c’est le temps qui prend le routeur pour déplacer le paquet de l’interface d'entrée, l’examiné et le mettre dans la file d'attente de l'interface de sortie.
Délai de mise en file d'attente : C'est le temps que le paquet passe dans la file d'attente de sortie du routeur. Il dépend du nombre et de la taille des paquets déjà dans la file et de la bande passante de l'interface, ainsi du mécanisme de file d'attente adopté.
Délai de sérialisation : c’est le temps écoulé pour placer la trame sur le support de transmission.
Délai de propagation : C'est le temps que prend la transmission d'un bit via le média de transmission.
II.2.3. La gigue : la gigue désigne la variation du délai de bout en bout au cours de la transmission. Une trop forte gigue affecte en particulier les flux multimédias temps-réel en détruisant les relations temporelles des trains de données transmis régulièrement par le flux multimédia, entravant ensuite la compréhension du flux par le récepteur. La gigue due généralement à la charge du réseau à un instant donné et la variation des chemins empruntés dans le réseau.
II.2.4. le taux de perte : Ce paramètre représente le pourcentage des unités de données qui ne peuvent pas atteindre leur destination dans un intervalle de temps spécifique. Cette perte de paquets a lieu lorsque le routeur manque d'espace dans le buffer d'une interface, ainsi lorsque la file d'attente de sortie d'une interface particulière est saturée, les nouveaux paquets qui seront dirigés vers cette interface vont être rejetés.
III.3. Exigence des applications en métrique de la QoS [23]
La Qualité de service d’une application est définie comme étant l’ensemble des exigences requises par cette application en termes de bande passante, délai, gigue et taux de perte. Ces exigences sont intrinsèques à la nature des applications .Ces dernières peuvent être classées en deux catégories:

Chapitre II Qualité de Service
16
Les applications temps-réel : Ce type d’applications dites temps-réel ont un besoin strict en terme de délai et de faible variation de délai (gigue). Cependant, elles peuvent tolérer quelques pertes de paquets.
Les applications non-temps-réel : Les applications dites non-temps-réel(ou Best-Effort) sont plus sensibles aux pertes de paquets (par rejet) qu’à des délais élevés. Dans ce cas, la fiabilité de la communication est plus importante que la garantie d’un délai borné.
Le tableau suivant résume les exigences de quelques applications en termes de QoS :
Tableau II.1 : les exigences de quelques applications en termes de QoS [42]
III.4. Qualité de Service et Sécurité [22]
ƒ La sécurité et la mobilité sont exclues de l’offre de service ; ƒ La sécurité et la mobilité peuvent avoir des incidences sur la QoS ; ƒ Impact de la sécurité sur la QoS fausser l’offre de QoS ; ƒ Impact de la mobilité sur la QoS et la sécurité changé les besoins ;
Besoin d’une offre de service globale QoS, Sécurité et Mobilité.
III.5. Les modèles d’implémentation de la qualité du service
L’évolution des diverses applications et ses exigences dans les réseaux convergent a entrainé le développement de trois modèle principaux pour l’implémentation de la qualité de service.
II.5.1. Le modèle best effort [42]
Dans ce modèle, chaque nœud dans le réseau essayera de livrer chaque paquet de donnée à son destinataire dans un délai de temps raisonnable, mais il ne fait absolument aucune garantie et aucune qualité de service. Des paquets peuvent donc être livrés en retard ou pas du tout. L’avantage, c’est qu’il est relativement simple à mettre en œuvre .L’architecture best-effort établi par les réseaux IP ne permet pas de garantir aucune qualité de service, donc il a été nécessaire de définir des nouvelles architectures de réseaux pour répondre à ces nouveaux

Chapitre II Qualité de Service
17
besoins. De cette nécessité sont nées les architectures à intégration de service (modèle IntServ) qui s’appuient sur une réservation préalable des ressources et un multiplexage statistique des trafics, et plus récemment les architectures à différentiation de services (modèle DiffServ) qui effectuent un traitement différencié des trafics, regroupés en quelques classes de services, pour garantir la qualité de service.
II.5.2. Modèle à intégration de service (IntServ)
La première proposition d’architecture capable de prendre en charge la Qualité de service (QoS) a été faite par l’IETF avec le modèle IIS (Internet Integrated Services) ou IntServ. L’idée de base du modèle IntServ est de fournir une QoS individualisée à chaque connexion en utilisant un mécanisme de contrôle d’admission et de réservation de ressources via le protocole RSVP dans les différents éléments du réseau. Ces ressources permettent d'assurer une certaine qualité de service pour les flots identifiés ayant requis cette qualité de service.
II.5.2.1. Fonctionnalités [10]
Le modèle d'implémentation IntServ dans un routeur fait apparaître de nouvelles fonctions pour celui-ci :
Reservation Setup Agent : ce processus, exécuté en tache de fond, consiste à recevoir les messages de réservation de ressources, à contrôler la disponibilité des ressources nécessaires (Admission Control), à accepter ou refuser la demande en conséquence et à tenir à jour la table d'états liés aux flots ("Traffic Control Database").
Classifier : ce processus, inséré dans le chemin de données après le traitement effectué par le contrôleur d'entrée, consiste à détecter les paquets appartenant à des flots requérant une qualité de service particulière et à classer tous ceux-ci par classe de service.
Packet Scheduler : ce processus a pour but de mettre les paquets dans les files d'attente de sortie du routeur en fonction de la classe de service à laquelle ils sont rattachés et de la qualité de service requise.
Figure II.1 : Fonctionnalités dans un routeur IntServ [10]

Chapitre II Qualité de Service
18
II.5.2.2. Les classes de service [24]
Les classes de service définies dans IntServ sont les suivantes :
Guaranteed Service (GS) : s’efforce d’assurer le maximum de QoS en garantissant un débit et un temps de transit étroitement définis. Il n’y a cependant pas de garantie sur la gigue. Le service garanti est donc adapté aux applications temps réel non tolérantes (flots les plus exigeants en termes de délai et de débit).
Controlled-Load (CL) : est une classe de service intermédiaire qui offre un service équivalent au service best-effort dans un réseau peu chargé. Ce service fournit uniquement des garanties de débit moyen. Il est adapté aux applications temps réel tolérantes qui peuvent tolérer un certain taux de perte ou un certain délai sur les paquets (flux audio, visioconférences).
Best-Effort (BE) : Le service dit « au-mieux » ou service normal, ne garantit aucune qualité de service, aucun critère de qualité de service n’est considéré pour acheminer les flots de diverses natures. Ce service adapté aux applications élastiques.
II.5.2.3. Le protocole RSVP (Resource reSerVation Protocol) [10]
Ce protocole est défini par le RFC 2205, "Resource Reservation Protocol V1", et son mode d'utilisation dans le cadre de IntServ par le RFC 2210, "The Use of RSVP with IETF Integrated Services".
RSVP est utilisé par une application pour demander au réseau d'assurer une certaine qualité de service pour un flot donné. Ce même protocole sera utilisé par les routeurs du réseau entre eux pour établir et maintenir les tables d'états liées au flot. RSVP identifie une session par les éléments suivants : adresse de destination, le type de protocole utilisé par la couche transport et le numéro de port de la destination.
Figure II.2 : Processus RSVP [10]
RSVP_session = <dest_address, protocol_transport-layer, dest_port_number>

Chapitre II Qualité de Service
19
Par ailleurs, le protocole de réservation de ressources est basé sur l’utilisation de deux types de messages unidirectionnels :
le message PATH qui permet d’établir un état dans chaque nœud du réseau qu’il traverse et qui trace le chemin à suivre par le second type de message;
le message RESV émis des récepteurs vers les émetteurs et qui consiste à réaliser la réservation proprement dite.
Figure II.3 : Fonctionnement du protocole RSVP [23]
L'émetteur du flot envoie régulièrement des messages de contrôle "path" vers le ou les destinataires. Chaque destinataire répond par un message "RESV" dans lequel il indique les critères de la qualité de service qui lui convient. Les ressources nécessaires, si disponibles, sont réservées par les routeurs sur le chemin destinataire vers l'émetteur. Dans le cas d'un flot multicast, les différentes réservations concourantes sont agrégées. Dans le cas d'absence de message "path" pendant un certain temps, les ressources réservées sont libérées. Les messages "path" et "resv" sont transmis comme des datagrammes ordinaires en "Best-Effort".
II.5.2.4. Difficultés et limitation du modèle IntServ [23]
L’algorithme de RSVP semble être bien complexe puisque chaque routeur doit subir plusieurs opérations ; or les réseaux étant constitués d’un nombre important de nœuds, il est difficile de concevoir l’utilisation de RSVP au sein de réseaux de grande envergure, et à forte charge. La difficulté est notamment due aux communications générées par le protocole entre les équipements, mais aussi au traitement qui est effectué par flots plutôt que par agrégats. Par conséquent, il est incontestable de penser qu’un tel modèle est difficile à déployer à grande échelle et son utilité reste donc restreinte à des niveaux de réseaux locaux de faible étendue.
II.5.3. Modèle à différenciation de service (DiffServ) [36]
Devant les limitation du modèle IntServ un second groupe de l’IETF s’est orienté vers un autre modèle d’implémentation de qualité de service, que l’on peut utiliser pour des réseaux importants en envergure, mais aussi en charge : Le modèle à différenciation de services.
Le principe consiste à rejeter dans les routeurs situés aux frontières du réseau toutes les fonctions de classification de paquets et de mise en forme de trafic, tandis que les routeurs du cœur du réseau n'auront qu'à appliquer des comportements prédéfinis (Per-Hop Behaviour) à des agrégats de flots marqués dans ce but par les routeurs de frontière.

Chapitre II Qualité de Service
20
Figure II.4 : Principe DiffServ [36]
Dans le cœur du réseau, tous les paquets sont marqués, ces marques sont utilisées par des routeurs pour déterminer le comportement qui doit leur être appliqué. Les différents comportements interviennent dans la gestion des files d'attente et dans les algorithmes de sélection de paquets à rejeter en cas de congestion d'une file d'attente. Le choix à faire par le routeur du mode de comportement en fonction de la marque présente dans le paquet est très rapide puisqu'il n'y a plus qu'un seul champ à analyser dans l'en-tête du paquet.
II.5.3.1. Le champ DS [6]
Pour l’identification des classes, DiffServ définit un champ de remplacement dans l’en-tête IP, champ appelé DiffServ (DS) qui remplace les champs déjà existants : Type of Service (TOS) dans l’en-tête IP version 4 ou Traffic Class dans l’en-tête IP version 6. Plus exactement, seulement six bits sur 8 sont utilisés. Les deux autres bits (réservés) sont utilisés pour la notification explicite de la congestion. Les six bits utilisés pour marquer les paquets sont désignés sous le nom DSCP (DiffServ Code Point). Cette valeur DSCP est utilisée par les routeurs cœur pour sélectionner le comportement (PHB) à appliquer au paquet.
Figure II.5 : Le champ DS dans l’en-tête IPv4
II.5.3.2. La notion de comportement (PHB : Per Hop Behavior) :[6]
La RFC 2475 définit le PHB comme le comportement d’acheminement observable de l’extérieur qui s’applique aux données dans un nœud DiffServ. Le système marque les paquets conformément aux codes DSCP et tous les paquets ayant le même code seront agrégés et soumis au même traitement particulier. Un comportement inclut le routage, les politiques de service des paquets (notamment la priorité de passage ou de rejet en cas de congestion) et éventuellement la mise en forme du trafic entrant dans le domaine. Plusieurs PHB standard ont été définis :
a. Le PHB par default : il spécifie que les paquets marqués avec la valeur DSCP «000000 » utilisent le service « traditionnel » Best-Effort dans un nœud DiffServ. De

Chapitre II Qualité de Service
21
plus, si un paquet arrive dans un nœud et son code DSCP ne correspond à aucun PHB, ce paquet recevra le PHB par default.
b. Assured Forwarding (AF) PHB : ce PHB établit une méthode pour laquelle l’agrégation détermine différents niveaux d’assurances sur l’acheminement des paquets avec une haute probabilité sans tenir compte des délais. Quatre classes AF1, AF2, AF3, et AF4 ont été ainsi définies avec des différents niveaux de traitement (rejet) en cas de congestion du réseau. Dans ce cas là, les paquets de basse priorité sont rejetés en premier. La priorité peut être modifiée dans le réseau par les opérateurs en fonction du respect ou non des contrats.
c. Expedited Forwarding (EF) PHB (service premium) a pour but d’offrir un service robuste avec peu de pertes, avec gigue et délai petits et une bande passante garantie .Pour assurer l’efficacité du système, ce service devrait être réservé pour un certain type d’applications (critiques, multimédia, temps réel). La valeur recommandée pour le code DSCP EF PHB est « 101110 ».
II.5.3.3. Architecture du modèle DiffServ et terminologie[6]
L’architecture DiffServ définit les principes suivants :
a. Domaine DiffServ (DS domain) : un domaine un ensemble de nœuds (hôtes et routeurs) administrés de façon homogène et qui possèdent une même définition de service et de PHB. Dans un domaine, on distingue les nœuds internes et les nœuds frontières : les premiers ce sont des équipements centraux du réseau qui appliquent le comportement approprié (PHB) aux paquets IP et assure le service de transit sur le réseau, alors que, les seconds ce sont des équipements de bordure de domaine DiffServ et qui sont connectés à des nœuds frontières d’autres domaines(Figure II.7). Si on considère le sens de communication de la source vers la destination, les nœuds de frontières peuvent être d’entrée (Ingress) dans le domaine ou de sortie (Egress).
b. Région DiffServ (DS région) : c’est un ensemble contigu de domaines DiffServ, qui peuvent offrir la différenciation des services sur des routes empruntant ces domaines. Chaque domaine ne met pas obligatoirement en ouvre la même politique d’approvisionnement ni les même PHB .l’opérateur doit garantir que l’ensemble des domaines DiffServ assurera une QoS de bout en bout.
Figure II.7 : Architecture DiffServ [35]

Chapitre II Qualité de Service
22
II.5.3.4. La notion de SLA (Service Level Agreement) [35]
L’utilisation des services DiffServ implique pour le client la souscription d’un contrat avec le fournisseur des services : ce contrat s’appelle un Service Level Agreement (SLA). Contrairement à ce qui se passe avec RSVP, ce contrat est signé avant toute connexion au réseau. Les spécifications techniques du SLA sont contenues dans le SLS (Service Level Specification).
Le SLA contient les informations suivantes:
le trafic que l’utilisateur peut injecter dans le réseau fournisseur (en termes de volume de données, de débit moyen, d’hôtes source ou destination, …) ;
les actions entreprises par le réseau en cas de dépassement de trafic (rejet, surtaxe, remise en forme du trafic) ;
la QoS que le fournisseur s’engage à offrir au trafic généré ou reçu par l’utilisateur (ou les deux). Celle-ci peut s’exprimer notamment en termes de délai, de bande passante, de fiabilité ou de sécurité.
II.5.3.5. Routeurs de bordure
Les routeurs de bordure sont les portes d’entrées obligatoires pour un flot pénétrant dans le domaine DiffServ. Ils effectuent des traitements classifier, meter et shapper sur les paquets entrant.
II.5.3.6. Routeurs de cœur de réseau
Les routeurs du cœur de réseau réalisent des opérations simples de bufférisassions et de routage des paquets en se basant uniquement sur le marquage effectué par les routeurs situés en bordure de domaine DiffServ. La différenciation de service se fait au niveau des deux mécanismes cruciaux du modèle DiffServ: l’ordonnancement et prévention de congestion.
Chaque sortie du routeur possède un nombre fixe de files logiques où le routeur dépose les paquets arrivant selon leur classe de service. Les files sont servies en accord avec l’algorithme d’ordonnancement.
Les trois fonctions principales de routeur de cœur de réseau sont:Routage, prévention de congestion, Ordonnancement
Généralement, il n’est pas nécessaire pour DiffServ d’associer un régulateur de type Token Bucket à chaque file des routeurs de cœur de réseau. En effet, tous les trafics entrant dans le cœurde réseau ont déjà subi la fonction de police dans les routeurs de bordure.
III.6. La gestion de la QoS
La gestion de la QoS est une subtile combinaison de fonctions appliquées sur les paquets transitant dans les nœuds de réseaux. Ces fonctions opèrent des changements de priorité, bloquent ou laissent passer certains paquets ou encore ordonnancent les paquets en sortie dans un ordre différent que celui d’entrée. On distingue généralement ceux qui opèrent dans le plan de contrôle de ceux du plan de données.

Chapitre II Qualité de Service
23
II.6.1. Plan de données
Les mécanismes du plan de données implémentent les actions que les routeurs doivent entreprendre sur chaque paquet pour offrir différents niveaux de service. On distingue :
Mécanismes de conditionnement : classification, marquage, mesure et contrôle de trafic; Mécanismes d’ordonnancements (gestion de congestion); Mécanismes de préventions de congestion (gestion active de files d’attentes); Mécanismes favorisant l'efficacité des liens.
II.6.1.1. Mécanismes de conditionnement[11]
Figure II.8 : Mécanismes de conditionnement [11]
a. Classification
La classification est effectuée quand les paquets arrivent à un routeur. Elle consiste à identifier les paquets reçus sur un nœud et à les associer à un flux qui peut être un flux individuel (micro-flux), identifié par le quintuple (adresse IP source, adresse IP destination, port source, port destination, protocole de transport) ou un groupe de paquets quelconque (classe), défini par des règles qui portent sur l'application utilisée, la priorité des paquets, sur le réseau de destination ou d'autres critères. A chaque flux ou sont associées des informations de contrôle qui décrivent le traitement à effectuer. Le but principal de la classification est donc de trouver ces informations de contrôle pour chaque paquet reçu .La classification peut être très simple, si très peu de classes sont utilisées ou si la classe est directement indiquée dans chaque paquet. Dans le cas plus général, la classification est effectuée sur la base de plusieurs champs des en-têtes des paquets.
b. Marquage
Le marquage des trafics consiste à appliquer aux trafics une « marque » (par exemple : donner une priorité au paquet ou une valeur au champ DSCP) permettant aux équipements du réseau de les écouler, suivant une politique de gestion spécifique.

Chapitre II Qualité de Service
24
c. Mesure (Meter)
Cette fonctionnalité permet de mesurer le trafic pour vérifier qu’il est conforme au profile déterminé dans le contrat avec l’utilisateur et permet aux autres composants de mettre en œuvre le contrôle de trafic.
d. Contrôle de trafic [30]
Des objectifs de performances ne peuvent être définis pour une classe de paquets que si son trafic reste dans certaines limites. Ces limites sont définies par exemple dans les paramètres d'une réservation qui est établi pour un micro-flux ou dans un SLA (Service Level Agreement) entre un client et un opérateur. Après la classification d'un paquet, un nœud peut effectuer des opérations de contrôle de trafic pour contrôler si le flux respecte le contrat. Les mécanismes de contrôle de trafic vérifient si le trafic est conforme à sa spécification et, le cas échéant, prennent des mesures afin de rendre le trafic conforme. De manière conceptuelle, un mécanisme de contrôle de trafic comprend donc un algorithme de mesure qui classifie les paquets en paquets conformes ou non-conformes.
En fonction de cette classification, une action est effectuée sur les paquets non-conformes :
Shaping : retarder des paquets non conformes, Policing: écarter les paquets non conformes, Reclassification : dégrader la qualité de service des paquets non conformes ou du
flux entier.
Bien que d'autres réalisations de shaping et de policing soient possibles, le plus souvent de ces fonctions sont réalisées à l'aide d'un seau à jetons ou d'un seau percé. Le deux sont souvent confondus, mais ils se distinguent principalement par la contrainte imposée au flux sortant. Le seau percé a comme sortie un trafic avec un débit fixe, tandis que le seau à jetons permet des rafales de trafic dans le flux sortant.
Seau percé (Leaky Bucket)[8]
La figure II.9: Algorithme seau percé. [41]
Seau à jetons (Token Bucket)

Chapitre II Qualité de Service
25
Figure II.10: Principe du Token Bucket [41]
II.6.1.2. Mécanismes d’ordonnancements (Gestion de congestion) [30]
Après la classification et le contrôle de trafic les paquets sont envoyés vers la ou les interfaces de transmission ou ils attentent dans des files d'attente jusqu'à ce qu'ils puissent être transmis. Le mécanisme qui décide l'ordre des paquets à transmettre est appelé scheduler (ordonnanceur). L’ordonnanceur est l'élément clé qui permet le traitement différenciés des différentes classes de trafic. Comme nous avons déjà vus, les architectures de QoS sont basées sur des ordonnanceurs très spécialisés afin de réaliser un service bien précis. Dans la partie suivante on va décrire les principaux mécanismes d’ordonnancement.
e. First In First Out (FIFO)
L’ordonnanceur le plus simple est la discipline FIFO (First-In First Out). Les paquets à transmettre sont mis dans une file d'attente et transmis dans l'ordre d'arrivée. Cette discipline de service ne permet aucune différenciation du service offert aux paquets dans la file d'attente et aucune isolation des flux.
Figure II.11 : L’algorithme FIFO [22]
Ce type de mécanisme est recommandé pour des réseaux à forte bande passante entraînant de faibles délais et présentant une rareté de congestion.
f. Priority Queuing (PQ) [22]
L’ordonnancement par priorité, PQ, utilise un processus de classification pour ordonner les paquets provenant des flux vers différentes files, qualifiées par une priorité. A l’intérieur de ces files à priorité, le traitement est effectué selon l’ordonnancement FIFO. C’est à la sortie que se présente l’ordonnancement par priorité.

Chapitre II Qualité de Service
26
Figure II.12 : Principe du traitement des paquets par priorités (PQ) [38]
g. Fair Queuing (FQ)[40]
L’ordonnancement Fair Queuing a pour principe de permettre à chaque flot d’un réseau de pouvoir accéder aux ressources de ce dernier de manière équitable. Le principe se base tout d’abord sur le classement des flots selon leurs caractéristiques, puis sur l’utilisation de plusieurs files d’attente dédiées à ces flots. L’ordonnancement est effectué sur toutes les files contenant des paquets, de manière séquentielle, selon le mécanisme Round-Robin (Chaque file est servie à tour de rôle).
L’intérêt d’un tel algorithme est que la séparation des flots vers différentes files permet d’avoir des traitements indépendants. Ainsi, si un flot désire obtenir plus de ressources que la part qui lui est attribuée, seul ce flot sera affecté sans engendrer d’impact négatif sur les performances des autres files d’attente.
Figure II.13: L’algorithme FQ [40]
h. Weighted Fair Queuing (WFQ)
Dérivé de l’ordonnancement FQ, le WFQ a été implémenté de manière à déterminer le nombre de paquets qu’il est nécessaire d’ordonnancer à chaque cycle, au niveau de chaque file. Cette quantité est définie par un « poids », d’où la notion de « weighted ». WFQ est implémenté de manière à pouvoir supporter différentes tailles de paquets et ainsi assurer un traitement malgré l’hétérogénéité des flots. Dans sa manière de servir les files d’attente, WFQ se base sur le principe employé par l’algorithme Generalized Processor Sharing (GPS) dont le comportement se résume ainsi : les paquets qui sont placés en tête de file sont servis selon le poids qui leur est attribué, et le traitement des files s’effectue cycliquement et séquentiellement.

Chapitre II Qualité de Service
27
Figure II.14: L’algorithme WFQ[24]
i. Class Based Queuing (CBQ)
L’algorithme CBQ (encore appelé Weighted Round Robin WRR) tente de remédier aux insuffisances des algorithmes Fair Queuing et Priority Queuing. D’une part, CBQ est destiné à traiter des flots avec différents besoins de bande-passante. Ainsi, CBQ attribuera à chaque file un pourcentage de ressources à fournir; d’autre part, CBQ assure qu’il n’y ait pas de famines pour les files de basse priorité, l’algorithme agissant séquentiellement sur toutes les files présentes.
L’ordonnancement CBQ utilise un mécanisme de classification des flots. A chaque classe est attribuée une file d’attente à laquelle est alloué un pourcentage de bande-passante à attribuer. A la sortie des files « par classe », un ordonnanceur général permet de partager la bande-passante du lien de sortie entre les différentes classes, selon le poids qui leur a été attribué, en utilisant le principe séquentiel de Round-Robin. L’estimateur évalue la bande-passante pour chaque classe et effectue un marquage selon le débit d’émission de chaque file. Un ordonnanceur « d’excès » est placé à la sortie de l’estimateur pour pouvoir distribuer un éventuel excès de bande-passante entre les classes. Ce mécanisme permet d’indiquer la (ou les) classe(s) qui est (sont) autorisée(s) à se partager l’excès de ressources, c’est-à-dire celles qui n’ont pas été consommées.
Nous proposons une illustration du ce mécanisme pour mieux comprendre le principe utilisé par l’ordonnancement CBQ.
Figure III.15: L’ordonnancement CBQ[24]
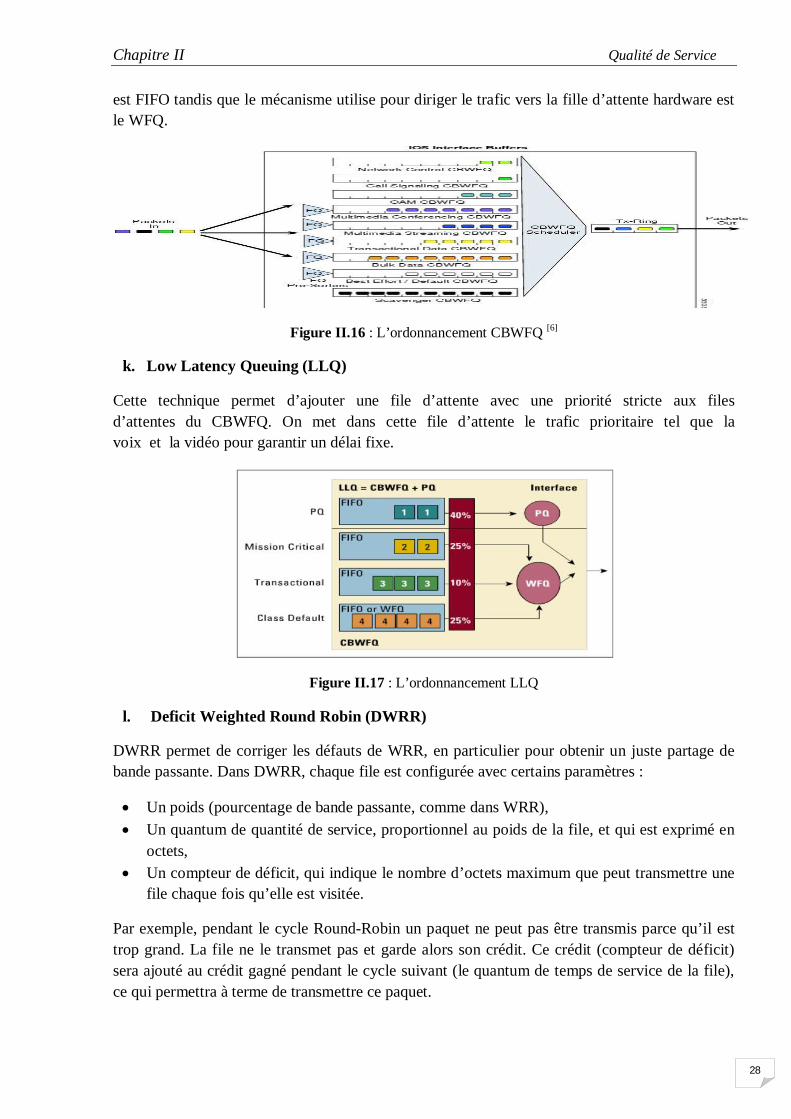
j. Class Based Weighted Fair Queuing (CBWFQ)
Cet algorithme est la combinaison des deux derniers algorithmes (CBQ et WFQ), il permet de créé plusieurs classe de trafic en allouent pour chaque classe certaine proportion de bande passante; le mécanisme d’ordonnancement utilisé pour chaque file d’attente d’une classe
Chapitre II Qualité de Service
28
est FIFO tandis que le mécanisme utilise pour diriger le trafic vers la fille d’attente hardware est le WFQ.
Figure II.16 : L’ordonnancement CBWFQ [6]
k. Low Latency Queuing (LLQ)
Cette technique permet d’ajouter une file d’attente avec une priorité stricte aux files d’attentes du CBWFQ. On met dans cette file d’attente le trafic prioritaire tel que la voix et la vidéo pour garantir un délai fixe.
Figure II.17 : L’ordonnancement LLQ
l. Deficit Weighted Round Robin (DWRR)
DWRR permet de corriger les défauts de WRR, en particulier pour obtenir un juste partage de bande passante. Dans DWRR, chaque file est configurée avec certains paramètres :
Un poids (pourcentage de bande passante, comme dans WRR), Un quantum de quantité de service, proportionnel au poids de la file, et qui est exprimé en
octets, Un compteur de déficit, qui indique le nombre d’octets maximum que peut transmettre une
file chaque fois qu’elle est visitée.
Par exemple, pendant le cycle Round-Robin un paquet ne peut pas être transmis parce qu’il est trop grand. La file ne le transmet pas et garde alors son crédit. Ce crédit (compteur de déficit) sera ajouté au crédit gagné pendant le cycle suivant (le quantum de temps de service de la file), ce qui permettra à terme de transmettre ce paquet.

Chapitre II Qualité de Service
29
II.6.1.3. Mécanismes de préventions de congestion [16]
Par rapport aux mécanismes de gestion de congestion qui décident du paquet à transmettre, le rôle des mécanismes de préventions de congestion est de déterminer les paquets à éliminer au sein d’une même classe en cas de congestion. Le rejet d’un paquet est soit dû à la congestion ou à des techniques de prévention de la congestion.
a. Tail Drop (TD)
Le principe de la politique « Tail Drop » est très élémentaire et souvent utilisée pour sa simplicité d’implémentation dans les routeurs. Cette technique permet d’écouler en priorité les paquets qui arrivent en premier dans la file d’attente. Si cette dernière se trouve saturée, les nouveaux paquets qui arrivent sont automatiquement éliminés. La figure ci-dessous schématise le principe de fonctionnement de cette politique.
Figure II.18 : Tail Drop
Cette politique ne permet en aucun cas de distinguer la priorité des trafics, et par conséquent, tous les paquets, qu’ils soient en besoin de priorité ou non, sont traités de la même manière.
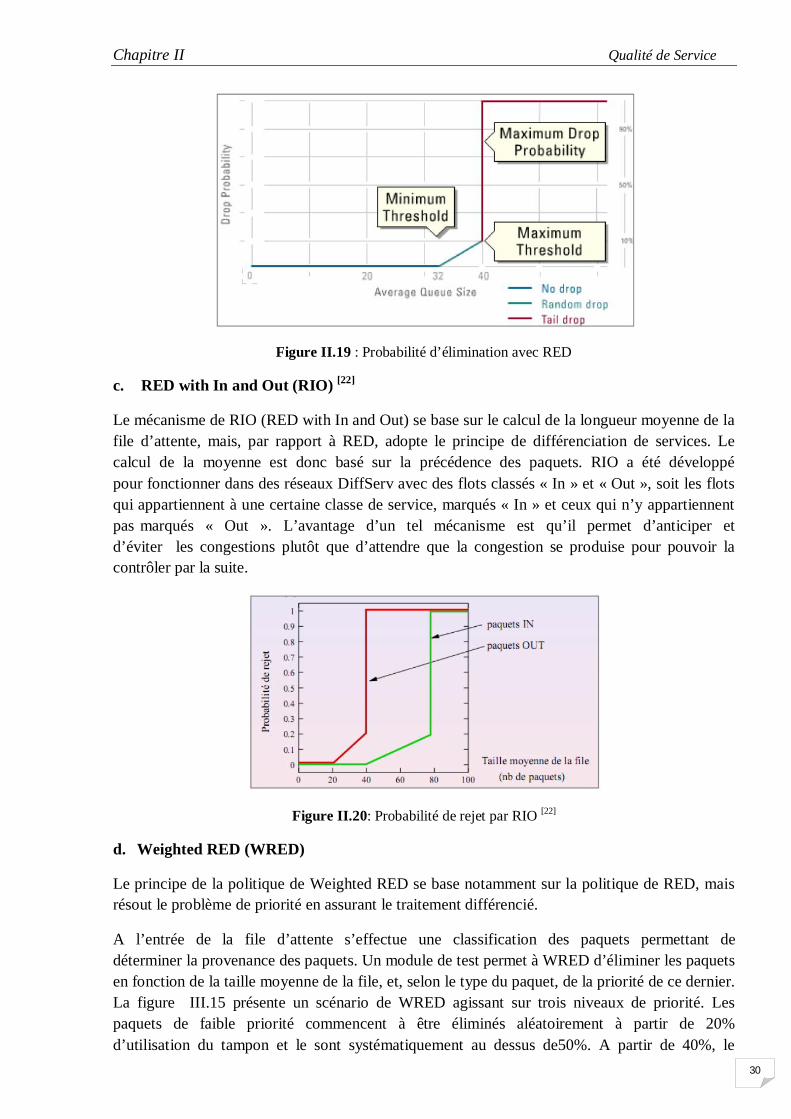
b. Random Early Detection (RED)
La politique Random Early Detection met en jeu le paramètre “threshold” (seuil), un intervalle de seuil dans lequel s’effectue l’élimination des paquets, et est basé sur la taille moyenne (Average) de la file d’attente. RED fonctionne selon le principe suivant : la probabilité d’élimination d’un paquet est basée sur l’intervalle de seuils définis [thresholdmin ; thresholdmax ]. Lorsque la taille de la file dépasse le seuil minimum
(thresholdmin ), l’algorithme RED met en place sa politique d’élimination des paquets. La probabilité d’élimination s’accroît linéairement à mesure que la taille de la file augmente. Au-delà du seuil maximum autorisé, RED élimine systématiquement tous les nouveaux paquets entrants.
Chapitre II Qualité de Service
30
Figure II.19 : Probabilité d’élimination avec RED
c. RED with In and Out (RIO) [22]
Le mécanisme de RIO (RED with In and Out) se base sur le calcul de la longueur moyenne de la file d’attente, mais, par rapport à RED, adopte le principe de différenciation de services. Le calcul de la moyenne est donc basé sur la précédence des paquets. RIO a été développé pour fonctionner dans des réseaux DiffServ avec des flots classés « In » et « Out », soit les flots qui appartiennent à une certaine classe de service, marqués « In » et ceux qui n’y appartiennent pas marqués « Out ». L’avantage d’un tel mécanisme est qu’il permet d’anticiper et d’éviter les congestions plutôt que d’attendre que la congestion se produise pour pouvoir la contrôler par la suite.
Figure II.20: Probabilité de rejet par RIO [22]
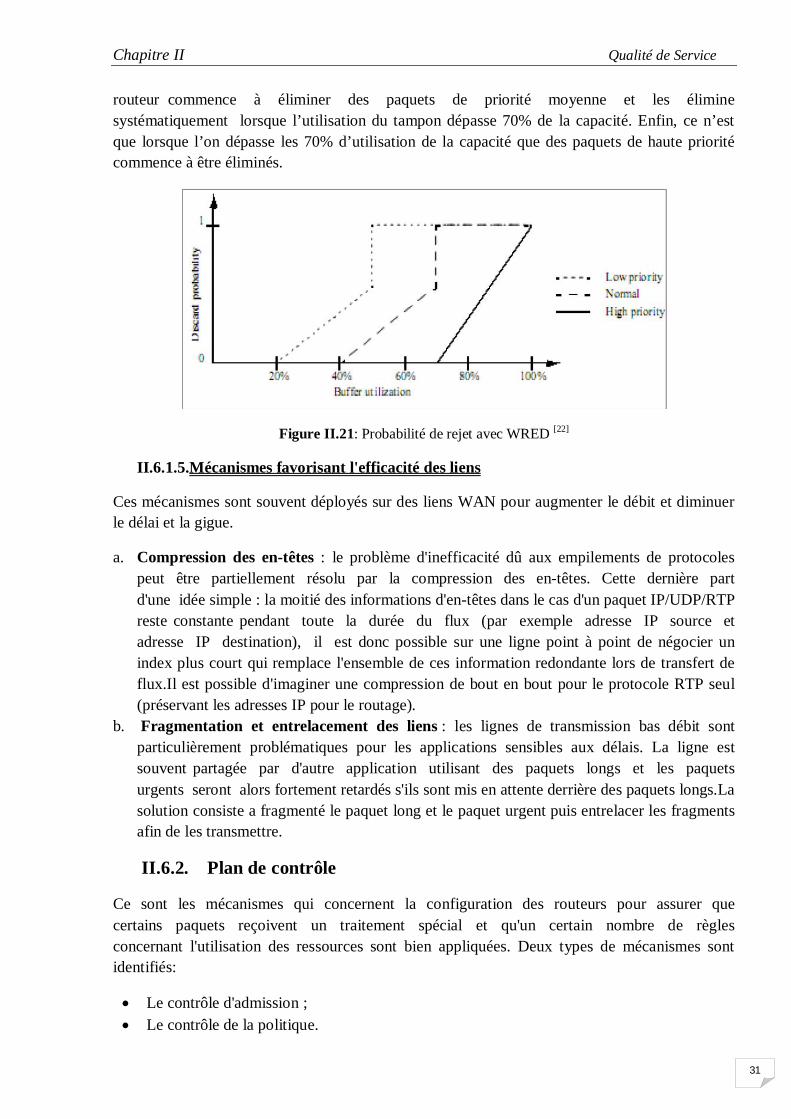
d. Weighted RED (WRED)
Le principe de la politique de Weighted RED se base notamment sur la politique de RED, mais résout le problème de priorité en assurant le traitement différencié.
A l’entrée de la file d’attente s’effectue une classification des paquets permettant de déterminer la provenance des paquets. Un module de test permet à WRED d’éliminer les paquets en fonction de la taille moyenne de la file, et, selon le type du paquet, de la priorité de ce dernier. La figure III.15 présente un scénario de WRED agissant sur trois niveaux de priorité. Les paquets de faible priorité commencent à être éliminés aléatoirement à partir de 20% d’utilisation du tampon et le sont systématiquement au dessus de50%. A partir de 40%, le
Chapitre II Qualité de Service
31
routeur commence à éliminer des paquets de priorité moyenne et les élimine systématiquement lorsque l’utilisation du tampon dépasse 70% de la capacité. Enfin, ce n’est que lorsque l’on dépasse les 70% d’utilisation de la capacité que des paquets de haute priorité commence à être éliminés.
Figure II.21: Probabilité de rejet avec WRED [22]
II.6.1.5.Mécanismes favorisant l'efficacité des liens
Ces mécanismes sont souvent déployés sur des liens WAN pour augmenter le débit et diminuer le délai et la gigue.
a. Compression des en-têtes : le problème d'inefficacité dû aux empilements de protocoles peut être partiellement résolu par la compression des en-têtes. Cette dernière part d'une idée simple : la moitié des informations d'en-têtes dans le cas d'un paquet IP/UDP/RTP reste constante pendant toute la durée du flux (par exemple adresse IP source et adresse IP destination), il est donc possible sur une ligne point à point de négocier un index plus court qui remplace l'ensemble de ces information redondante lors de transfert de flux.Il est possible d'imaginer une compression de bout en bout pour le protocole RTP seul (préservant les adresses IP pour le routage).
b. Fragmentation et entrelacement des liens : les lignes de transmission bas débit sont particulièrement problématiques pour les applications sensibles aux délais. La ligne est souvent partagée par d'autre application utilisant des paquets longs et les paquets urgents seront alors fortement retardés s'ils sont mis en attente derrière des paquets longs.La solution consiste a fragmenté le paquet long et le paquet urgent puis entrelacer les fragments afin de les transmettre.
II.6.2. Plan de contrôle
Ce sont les mécanismes qui concernent la configuration des routeurs pour assurer que certains paquets reçoivent un traitement spécial et qu'un certain nombre de règles concernant l'utilisation des ressources sont bien appliquées. Deux types de mécanismes sont identifiés:
Le contrôle d'admission ; Le contrôle de la politique.

Chapitre II Qualité de Service
32
II.6.2.1. Le contrôle d'admission
La fonction de contrôle d’admission consiste à prendre la décision d’accepter ou de rejeter les nouvelles connexions tout en tenant compte de l’ensemble des requis de ces dernières en termes de QoS. L’admission d’un nouveau trafic ne doit toutefois pas dégrader le service des trafics déjà établis.
II.6.2.2. Le Contrôle de politique [39]
Une politique de qualité de service définit les règles qui déterminent comment, quand et où la QoS doit être appliquée à différents trafic réseaux. L’architecture de base de gestion par politiques se compose des éléments principaux suivants:
Un point de la politique, Le PEP (Policy Enforcement Point) : il constitue le point d’application de la politique (et donc des règles). Il joue le role du policier.
Un point de prise de décision, Le PDP (Policy Decision Point) : il constitue l’organe de décision d’applications des règles, en fonction d’entités les définissant (base de données des politiques, serveur d’authentification, serveurs de règles etc.). il jou le role du juge.
La base de données des politiques, PR (Policy Repository) : elle est en charge du stockage des règles de QoS.
Pour échanger les informations entre ces entités, des protocoles standards sont nécessaires. COPS (Common Open Policy Service) , (RFC2748) permet les échanges entre PDP et PEP. LDAP (Light Weight Access Protocol), permet l'accès aux politiques stockées dans des PIB: Policy Information Base (Base de données des politiques).
Figure II.22: Eléments d’une gestion de politique [39]
Le protocole COPS [39]
COPS (Common Open Policy Service, RFC 2748) est un protocole de communication ayant été proposé par l’IETF. A l’origine prévue pour gérer les règles de QoS associées à RSVP (RFC 2749,2750), ce modèle a été repris pour s’appliquer à l’ensemble des technologies de QoS.

Chapitre II Qualité de Service
33
COPS est un Mode de gestion de réseau IP dans lequel un serveur transmet à des appareils clients, généralement des routeurs, des commutateurs ou des pare-feu, les règles qu'ils sont chargés de mettre en application, afin d'optimiser la transmission des données et d'améliorer la qualité de service. COPS peut s'appuyer également sur le protocole IPSEC pour sécuriser le canal entre le PEP et le PDP.
III.7. QoS IP et MPLS [9]
Le modèle Multi-Protocol Label Switching, MPLS est en cours de définition. Ce modèle est conçu pour permettre la construction de très vastes réseaux IP composés de routeurs et commutateurs de paquets ou cellules.
Le schéma général est similaire à celui de DiffServ, le but étant ici de router les paquets IP à plus grande vitesse. Le principe consiste à rejeter tout le traitement associé au routage des paquets dans les routeurs d'entrée du réseau MPLS et de marquer (par un Label) ces paquets de façon à ce que les routeurs et commutateurs du cœur de réseau n'aient plus qu'à considérer ce label pour retrouver la route à faire suivre au paquet dans une table adéquate dite de commutation (Forwarding Table). Ces tables sont constituées à priori dans tous les éléments du réseau, indépendamment d'un trafic potentiel, et maintenues au fil de l'évolution des tables de routage.
Ce modèle, actuellement accepté comme constituant le futur du cœur des grands réseaux IP, dont l'Internet, est très similaire à celui de DiffServ. Des travaux sont en cours pour évaluer la possibilité d'associer des éléments de qualité de service aux chemins pré-construits par MPLS de façon à ce que des paquets voyageant sur les mêmes routes IP, mais demandant des qualités de service différentes circulent sur des circuits MPLS affectés de qualités de service différentes tout en bénéficiant des hautes performances promises par MPLS.
Conclusion
Dans ce chapitre, nous avons présenté la qualité de service et ses modèles D’implémentation qui sont basés sur plusieurs mécanismes de gestion de la qualité de service.
La mise en œuvre de l’ensemble des mécanismes décrit dans ce chapitre est une tache très lourde. Il est difficile, voire impossible, de configurer manuellement l’ensemble des équipements d’un grand réseau. Pour cette raison, on utilise des solutions software basés sur la gestion par politiques permettant de faciliter l’implémentation de ces mécanismes.
Dans le cadre de notre projet, nous avons effectuer un stage au niveau de RMS OUARGLA qui nous permis d’approfondir notre étude et de consolider nos connaissances théoriques par un savoir faire pratique vis-à-vis de la gestion de la qualité de service .

Chapitre III : MPLS et Qualité de Service

Chapitre III : MPLS et Qualité de Service
35
III. Introduction
Avec l’augmentation du débit des liens de communication et du nombre de routeur dans l’Internet, l’IETF (Internet Engineering Task Force ) a défini le nouveau protocole MPLS (Multi Protocol Label Switching : commutation de label multi-protocole) pour faire face au goulot d’étranglement induit par la complexité de la fonction de routage. Ce protocole a deux objectifs principaux qui sont:
Permettre un acheminement rapide des paquets IP en remplaçant la fonction de routage par une fonction de commutation qui est beaucoup plus rapide, la taille des matrices de commutation devenant très petite .
Faciliter l’ingénierie réseau en fournissant aux opérateurs la maîtrise de l’acheminement des données, qui pouvaient être très complexes avec des protocoles comme OSPF (gestion des métriques).
Dans ce chapitre on va voir les principaux éléments de la technologie MPLS.
III.1. Présentation de MPLS [26]
Le protocole MPLS ou "Multi Protocol Label Switching", est un protocole qui utilise un mécanisme de routage qui lui est propre, basé sur l'attribution d'un " label " à chaque paquet. Cela lui permet de router les paquets en optimisant les passages de la couche 2 à la couche 3 du modèle OSI et d'être indépendant du codage de celles-ci suivant les différentes technologies (ATM, Frame Relay, Ethernet etc).
Le but est d'associer la puissance de la commutation de la couche 2 avec la flexibilité du routage de la couche 3. Schématiquement, on peut le représenter comme étant situé entre la couche 2 (liaison de données) et la couche 3 (réseau).
Figure III.1 : Couche MPLS [33]
MPLS traite la commutation en mode connecté (basé sur les labels), les tables de commutation étant calculées à partir d'informations provenant des protocoles de routage IP.

Chapitre III : MPLS et Qualité de Service
36
III.2. Eléments de domaine MPLS
III.2.1. LSR (Label Switch Router) [2]
Le LSR est un équipement de type routeur, ou commutateur qui appartient au domaine MPLS dont Les fonctions sont :
l’échange d’informations de routage ; l’échange des labels ; l’acheminement des paquets.
III.2.2. LER (Label Edge Router) [2]
LER est un LSR qui fait l'interface entre un domaine MPLS et le monde extérieur. En général, une partie de ses interfaces supportent le protocole MPLS et l'autre un protocole de type IP.
Les deux types de LER qui existent sont :
Ingress LER est un routeur qui gère le trafic qui entre dans un réseau MPLS ; Egress LER est un routeur qui gère le trafic qui sort d'un réseau MPLS.
Figure III.2 : Architecture d’un domaine MPLS [2]
III.2.3. Classe d’Equivalence pour l’Acheminement (FEC)
Une classe d'équivalence de transmission (FEC) représente un groupe de paquets transmis de manière identique sur un réseau MPLS. Ces FEC peuvent par exemple correspondre à des types de services, des types de paquets ou même encore des sous-réseaux. Un label différent est attribué à chacun de ces FEC.

Chapitre III : MPLS et Qualité de Service
37
Ainsi, dès leur entrée dans un réseau MPLS, chaque paquet appartenant à un même groupe reçoit le même label ce qui lui permet d'être acheminé vers la route qui lui a été réservée.
Donc Le routage IP classique distingue les paquets en se basant seulement sur les adresses des réseaux de destination (préfixe d’adresse). Et MPLS constitue les FEC selon de nombreux critères : adresse destination, adresse source, application, QoS, etc.
III.2.4. Le LSP (Label Switch Path)
Il représente le chemin d’une FEC dans un réseau MPLS. Ce chemin est constitué de succession de labels attribués par chaque routeur pour une FEC.
III.3. Architecture MPLS
Le MPLS est constitué de deux plans :
III.3.1. Le plan de contrôle [5]
Contrôle les informations de routages de niveau 3 grâce à des protocoles tels que (OSPF, IS-IS ou BGP) et les labels grâce à des protocoles comme LDP (Label Distribution Protocol), BGP (utilisé par MPLS VPN) ou RSVP (utilisé par MPLS TE) échangés entre les périphériques adjacents ;
III.3.2. Le plan de données [2]
Est indépendant des algorithmes de routages et d'échanges de label. Il utilise une base appelée Label Forwarding Information Base (LFIB) pour acheminer les paquets avec les bons labels, Cette base est remplie par les protocoles d'échange de label.
Figure III.3 : Architecture d’un routeur LSR[5]

Chapitre III : MPLS et Qualité de Service
38
III.4. Structures de données des labels [2]
Les LSR construisent trois bases d’information, la LIB et la LFIB et le FIB :
LIB (Label Information Base): La première table construite par le routeur MPLS est la table LIB. Elle contient pour chaque sous-réseau IP la liste des labels affectés par les LSR voisins. Il est possible de connaître les labels affectés à un sous-réseau par chaque LSR voisin.
LFIB (Label Forwarding Information Base): à partir de la table LIB et de la table de routage IP, le routeur construit une table LFIB qui contient que les labels du meilleur prochain saut qui sera utilisée pour commuter les paquets étiquetés.
FIB (Forwarding Information Base): appartient au plan de donnée, c’est la base de données utilisé pour acheminer les paquets non étiquetés.
Un routeur construit ces structures de données en plusieurs étapes :
1) Les protocoles de routage (OSPF, IS-IS ou EIGRP) construisent les tables de routages ; 2) Chaque LSR alloue indépendamment un label à chaque destination dans sa table
de routage ; 3) Les labels alloués sont enregistrés dans la « LIB » ; 4) Ces labels et leur prochain sauts ont enregistrés dans la table« LFIB »avec
l’action à effectuer ; 5) Le LSR envoie les informations sur sa« LIB »à ces voisins ; 6) Chaque LSR enregistre les informations reçues dans sa« LIB » ; 7) Les informations reçues des prochains sauts sont enregistrées dans la« FIB » ; 8) Chaque LSR construit ses propres structures FIB, LFIB et LIB.
Figure III.4: Structures de données des labels dans une architecture LSR [42]

Chapitre III : MPLS et Qualité de Service
39
III.5. Les labels
III.5.1. Definition [32]
Appelé MPLS Shim, ce label constitue un entête de paquet dont le format dépend essentiellement du réseau sur lequel MPLS est mis en œuvre. Le label MPLS contient un champ label de 20 bits qui permet d’identifier une FEC sur un routeur particulier. En fait, une FEC peut être identifiée par différents labels sur différents routeurs.
Figure III.5: Structure de shim MPLS [17]
LABEL (20 bits) : Contient le label.
EXP (3 bits) : Initialement réservé pour une utilisation expérimentale. Actuellement, la plus part des implémentations utilise ce champ comme indicateur de QoS.
S (1 bit) : Indique s’il ya empilement de labels (Label stack). Le bit S est à 1 lorsque le label se trouve au sommet de la pile, à 0 sinon.
TTL (8 bits) : Même signification que pour IP.
III.5.2. Pile de labels (Label Stack) [2]
Un paquet peut avoir plus qu’un label. Ce concept s’appelle empilement de label. L’empilement de label permet en particulier d’associer plusieurs contrats de service à un flux au cours de son acheminement du réseau MPLS.
Dans le cas de l’empilement de label Le champ STACK permet d’identifier le classement du label dans la pile, s’il est égal à 1 alors il s’agit du dernier label avant l’entête IP.
Figure III.6 : Exemple d’utilisation du champ STACK [2]
III.5.3. Fonctionnement de label [14]
En utilisant une terminologie MPLS, le mécanisme de base de MPLS est le suivant : le paquet IP entre dans le domaine MLPS via le routeur d’entrée (Ingress LSR ou I-LSR). Le I-LSR classe le paquet dans une FEC, selon des critères tels que les adresses source et destination. Le I-

Chapitre III : MPLS et Qualité de Service
40
LSR consulte la table FIB qui indique le routeur suivant et l’opération à réaliser, c'est-à-dire, l’ajout d’une étiquette (Label Push) et sa valeur. L’acheminement dans le domaine MPLS est basé sur l’étiquette (et donc, les LSRs ne regardent pas l’entête IP) en utilisant le paradigme de la commutation d’´etiquettes (label swap/switching) et la table LFIB. Finalement, le paquet étiqueté est reçu par le routeur de sortie du domaine (Egress LSR ou E-LSR) qui enlève l’étiquette (label pop) et procède à un acheminement classique.
Figure III.7: La commutation de label [31]
III.5.4. Distribution des labels [2]
Les LSR se basent sur l’information de label pour commuter les paquets au travers du cœur de réseau MPLS. Chaque routeur, lorsqu’il reçoit un paquet taggué, utilise le label pour déterminer l’interface et le label de sortie. Il est donc nécessaire de propager les informations sur ces labels à tous les LSR. Pour cela, suivant le type d’architecture utilisée, différents protocoles sont employés pour l’échange de labels entre LSR ; en voici quelques exemples :
TDP/LDP (Tag/Label Distribution Protocol) : mapping des adresses IP unicast ; CR-LDP, RSVP-TE : utilisés en Traffic Engineering pour établir des LSP en
fonction de critères de ressources et d’utilisation des liens ; MP-BGP (MultiProtocol Border Gateway Protocol) pour l’échange de routes
VPN.
III.6. Aspects avancés et applications [2]
Les principaux atouts de la technologie MPLS concernent sa capacité à intégrer des solutions de gestion de la qualité de service et d’ingénierie de trafic sur un réseau IP. MPLS est un candidat idéal pour supporter des fonctions évoluées d’ingénierie de trafic et ajouter des fonctionnalités de gestion de la qualité de service dans les cœurs de réseau. De plus, MPLS permet de déployer des fonctions évoluées en reportant la complexité de mise en œuvre aux frontières du réseau et en conservant de bonnes propriétés de résistance au facteur d’échelle.

Chapitre III : MPLS et Qualité de Service
41
III.6.1. Ingénierie de trafic
C’est une des applications les plus immédiates de MPLS. On appelle ingénierie de trafic le fait de répartir la charge sur l’ensemble du réseau en établissant des chemins explicitement routés et en contrôlant la répartition du trafic sur différents chemins. Pour un opérateur, c’est une fonction cruciale qui lui permet de mieux rentabiliser son investissement.
Avec des réseaux IP, les opérateurs ne disposent que de peu d’outils pour :
partager la charge entre plusieurs chemins ; router explicitement le trafic ; router différentes qualités de service sur différents chemins et éventuellement réserver des
ressources.
III.6.2. Qualité de service
MPLS n’étant pas lui-même une solution de qualité de service, il s’intègre dans deux architectures de gestion de la qualité de service proposées à l’IETF : IntServ et DiffServ.
III.6.2.1. MPLS et IntServ
Pour le cas de l’architecture IntServ (Integrated Services), il va de soi que l’on ne considère plus la réservation de bout en bout mais plutôt la réservation de ressources à l’intérieur du cœur de réseau pour un flux de trafic correspondant non pas à des flux applicatifs mais plutôt aux flux d’un réseau client du cœur de réseau. On travaille donc sur des échelles plus importantes et avec des variabilités moins importantes, ce qui permet de réduire le problème de la résistance au facteur d’échelle.
MPLS intervient dans ces architectures comme outil de signalisation et propose deux modes de description des ressources. Le premier mode dans le protocole RSVP-TE est très proche de celui de RSVP et correspond donc parfaitement, non seulement aux implantations existantes de RSVP, mais aussi au modèle IntServ. Le second mode dans le protocole CR-LDP permet de décrire les ressources comme elles le sont dans les réseaux ATM et Frame Relay. De toute manière, quel que soit le mode de description des ressources nécessaires, il est toujours indispensable de traduire les réservations signalées par les protocoles de signalisation en réservations effectives dans les équipements. Pour cela, le modèle de RSVP est sans doute le plus abouti.
III.6.2.2. MPLS et DiffServ[32]
MPLS permet à l’administrateur réseau de spécifier comment les agrégats DiffServ (DiffServ Behavior Aggregates : BAs) sont affectés aux LSPs. En fait, la question est de savoir comment affecter un ensemble de BA au même LSP ou à des LSPs différents. Quand les paquets arrivent à un Ingress-Router du domaine MPLS, le champ DSCP est ajouté à l’entête qui correspond au Behavior Aggregate (BA).

Chapitre III : MPLS et Qualité de Service
42
Figure III.8 : Intégration MPLS avec le modèle DiffServ [32]
A chaque nœud traversé, c’est le DSCP qui va permettre de sélectionner le PHB (Per Hop Behavior), qui définit le Scheduling (classe prioritaire, WFQ etc.) et les probabilités de rejet du paquet. Cette correspondance entre les classes DiffServ et le PHB de MPLS offre de multiples possibilités à un administrateur pour un cœur de réseau DiffServ/MPLS. L’affectation de classes DiffServ à différents LSPs permet aussi d’attribuer des mécanismes de protection différents pour ces différentes classes de service.
Dans ce qui suit, nous décrivons les deux grands types de LSP que sont les E-LSP et les L-LSP. Un réseau MPLS peut combiner et faire cohabiter « à souhait » ces deux types de LSP.
o EXP-Inferred-PSC LSPs (E-LSP) : Un E-LSP peut être constitué de 8 BA (Behavior Aggregate) pour une FEC donnée. Dans tels LSPs, le champ EXP est utilisé pour déterminer le comportement PHB (informations d'ordonnancement et de rejet (dropping).Le routeur LSR peut être configuré pour affecter automatiquement un PHB en fonction du champ EXP. Si cette configuration n’a pas été faite, le routeur prendra une pré-configuration par défaut pour tous les EXP vers le PHB par défaut. L’utilisateur peut aussi spécifier cette correspondance.
Figure III.9 : MPLS et DiffServ (E-LSP) [34]

Chapitre III : MPLS et Qualité de Service
43
o Label-Only-Inferred-PSC LSP (L-LSP) : Dans le cas d’IP avec le champ DSCP on peut définir jusque 64 PHBs .L’inconvénient de E-LSP est qu’il support que 8 PHBs parmi 64. Pour pouvoir en définir plus avec MPLS, il faut créer ce que l’on appelle des L-LSP. C’est à présent le label qui contient la sémantique associée à la qualité de service. Il faut dés lors mettre en place des associations entre labels et classes de service. Avec ce genre de LSP, les informations d'ordonnancement sont transportées implicitement dans le label. Le champ EXP contient les informations de perte uniquement.
Figure III.10 : MPLS et DiffServ (L-LSP) [34]
III.6.2.3. MPLS et COPS [19]
Dans DEN (Directory Enabled Network) toutes les classes de service sont préalablement définies dans un serveur central qui dialogue avec les éléments de réseau pour leur télécharger les configurations de QoS à mettre en œuvre. On aurait pu imaginer que MPLS récupère et intègre cette approche, mais elle fait intervenir un système centralisé, relativement bien accepté par les opérateurs, mais peu apprécié de la communauté Internet.
Dans une autre vision, poussée par Microsoft et qualifiée de « COPS RSVP », le routeur demande à un serveur quelle valeur de DSCP utiliser quand il reçoit d’un serveur applicatif une requête RSVP lui indiquant son nom et lui demandant quel DSCP utiliser. Le serveur applicatif positionnera ensuite dans les datagrammes IP cette valeur de DSCP.
Conclusion
Les principaux atouts de la technologie MPLS concernent sa capacité à intégrer des solutions de gestion de la qualité de service et d’ingénierie de trafic sur un réseau IP. En effet, les opérateurs ont besoin de contrôler leur réseau plus finement que ce que leur permet le routage IP classique, sans pour autant abandonner la souplesse qu’il apporte.
ce chapitre peut se diviser en deux parties principales : Une première sur le mécanise de fonctionnent de l’architecture MPLS, ses éléments les plus importants (LSR, LSP, FEC,..), leurs déférents rôles, et les structure de fonctionnement de la MPLS, et un second sur la relation entre MPLS et QoS avec les deux mécanismes intServ et DéffServ.

Chapitre IV : Application

Chapitre IV Application
45
V. Introduction :
Dans les chapitres précédents, nous avons mis en évidence les différents mécanismes de gestion de
qualité de service; notre application consiste à implémenter et évaluer ces mécanismes.
Pour cela on a élaboré une maquette sur laquelle on a appliqué les techniques décrites
précédemment, donc on a réalisé une émulation comprenant les étapes suivantes:
Réalisation de la maquette
Évaluation de la qualité de service sur la maquette :
Étude du réseau sans qualité de service Qos .
Étude du réseau avec qualité de service Qos.
IV.1. Présentation des logiciels utilisés :
IV.1.1. Logiciels utilisés pour la réalisation de la maquette :
IV.1.1.1. GNS3 [15]
GNS3 est un émulateur graphique de réseaux capable de charger des vraies images de l'IOS de
Cisco permettant ainsi d'émuler entièrement des routeurs ou firewalls Cisco. Pour cela GNS3,
s'appuie principalement sur deux autres programmes: Dynamips (l'émulateur d'IOS) et
Dynagen(interface texte pour Dynamips).
GNS3 est un logiciel libre qui fonctionne sur de multiples plateformes incluant Windows, Linux, et
MacOS X.
IV.1.1.2. VMware Workstation [27]
VMware Workstationest un logiciel permet la création d'une ou plusieurs machines virtuelles au
sein d'un même système d'exploitation (généralement Windows ou Linux), ceux-ci pouvant être
reliés au réseau local avec une adresse IP différente, tout en étant sur la même machine physique
(machine existant réellement). Il est possible de faire fonctionner plusieurs machines virtuelles en
même temps, la limite correspondant aux performances de l'ordinateur hôte.
IV.1.1.3. Elastix [10]
Elastix est une solution logicielle qui intègre les meilleurs outils disponibles pour les PABX basés
sur Asterisk dans une interface simple et facile à utiliser. Elle ajoute aussi ses propres paquets
d'utilitaires et s'autorise par la création de modules tiers, à devenir la meilleure solution logicielle
disponible pour la téléphonie open source .

Chapitre IV Application
46
IV.1.1.4. FileZilla Server [13]
FileZilla est un est un serveur rapide avec une interface facile à utiliser. Le serveur permet le
transfert des données en mode passif.
IV.1.1.5. FileZilla Client [13]
Prend en charge plusieurs types de protocoles de transfert. Il exploite le FTP, le FTPS ou protocole
FTP sécurisé avec et le SFTP SSH et FTP et SSL. Le logiciel supporte également l'Internet Protocol
version 6 ou IPv6.
IV.1.2. Logiciel utilisés pour la supervision de la maquette :
IV.1.2.1. Wireshark [44]
Wireshark est un analyseur de protocole qui examine les données à partir d'un réseau en direct ou à
partir d'une capture de fichier sur disque. Vous pouvez naviguer de façon interactive sur les données
capturées, visionner le résumé et l'information détaillée pour chaque ensemble. Wireshark possède
quelques fonctions puissantes, incluant un affichage de langage filtré et la possibilité de visionner le
flux reconstitué de la session TCP.
IV.1.3. Logiciel utilisé pour générer le trafic:
IV.1.3.1. IxChariot [18]
IxChariot est une véritable solution de génération et d’analyse de trafic qui émule précisément les
flux de données générés par les transactions client/serveur. IxChariot emploie plus de 140 scripts
d’applications préprogrammés pour fournir des flux de trafic réalistes entre les points d’arrivée de
réseau pour les protocoles essentiels (TCP, UDP, RTP, IPX). Elle permet de tester, de modéliser et
d’évaluer l’impact du trafic d’applications, sans exiger l’installation et la gestion de réseaux
clients/serveur complets.
IV.2. Réalisation de la maquette :
IV.2.1. Description de la maquette :
La maquette qui nous avons réalisé représente un réseau IP/MPLS composé de :
Un cœur de réseau composé de trois routeurs P (Provider) de la gamme Cisco 7200 (IOS
c7200-jk9s-mz.124-13b.bin);
Deux routeurs de bordure (Routeur PE: Provider Edge) de la gamme Cisco 3600 (IOS
c3640-jk9s-mz.124-8.bin);
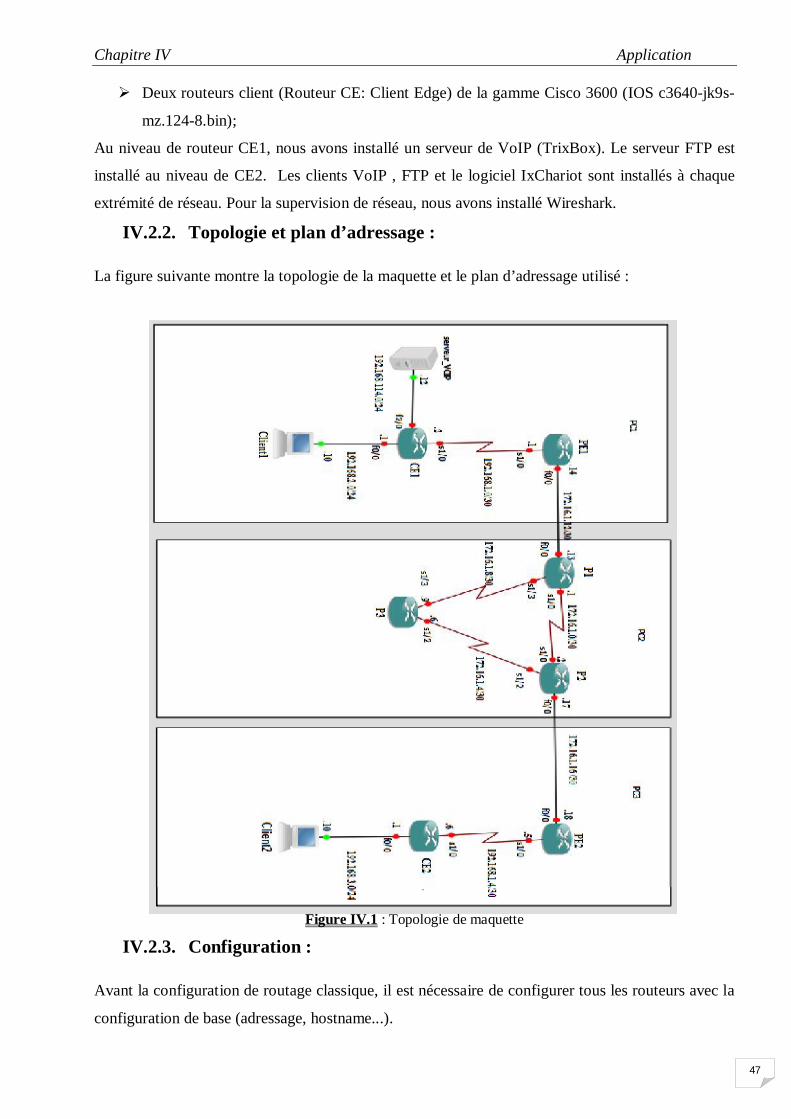
Chapitre IV Application
47
Deux routeurs client (Routeur CE: Client Edge) de la gamme Cisco 3600 (IOS c3640-jk9s-
mz.124-8.bin);
Au niveau de routeur CE1, nous avons installé un serveur de VoIP (TrixBox). Le serveur FTP est
installé au niveau de CE2. Les clients VoIP , FTP et le logiciel IxChariot sont installés à chaque
extrémité de réseau. Pour la supervision de réseau, nous avons installé Wireshark.
IV.2.2. Topologie et plan d’adressage :
La figure suivante montre la topologie de la maquette et le plan d’adressage utilisé :
Figure IV.1 : Topologie de maquette
IV.2.3. Configuration :
Avant la configuration de routage classique, il est nécessaire de configurer tous les routeurs avec la
configuration de base (adressage, hostname...).

Chapitre IV Application
48
IV.2.3.1. Routage :
L’utilisation d’un protocole de routage est nécessaire pour l’échange des routes entre les routeurs.
Nous avons choisi OSPF comme un protocole de routage dans le cœur de réseau (routeurs P et PE).
Ce choix est expliqué par ces raisons :
C’est un protocole de routage à état de lien.
La rapidité de la convergence
Supporte le trafic engineering
Supporte VLSM (Variable Length Subnets Masks)
Il n’envoie les mises à jour que lorsqu’il existe des changements dans le réseau et non
périodiquement. Dans la partie client (PE-CE) nous avons utilisé le protocole EIGRP.
IV.2.3.2. Activation du MPLS :
Après avoir configuré le routage classique, nous avons activé MPLS dans les routeurs P et PE.
La figure suivante montre l’échange de labels entre les routeurs de domaine MPLS.
Figure IV.2: L’échange de labels entre les routeurs de domaine MPLS
IV.2.4. Évaluation de la qualité de service sur la maquette (réseau IP/MPLS) :
L’offre de service et sa garantie sont devenues des soucis majeurs pour les utilisateurs des réseaux.
Ce besoin en qualité de service est argumenté par la croissance de la quantité de données à
transmettre d’une façon exponentielle, la naissance de nouveaux types d’applications qui

Chapitre IV Application
49
demandent beaucoup de bande passante et les applications temps réel. La voix sur IP constitue l’un
des moteurs de cette motivation, c’est un service de plus en plus demandé par les clients puisqu’il
permet une bonne qualité de communication similaire à celle de commutation de circuits mais avec
des coûts beaucoup plus réduits.
Pour cette raison, nous avons focalisé nos mesures et implémentations sur ce type d’application.
Dans un premier scénario, nous évaluons le comportement du réseau traversé par deux flux : le
trafic voix et le trafic FTP. Dans le deuxième scénario, nous appliquons les mécanismes de gestion
de qualité de service sur le réseau et nous réévaluons le comportement des deux flux.
Avant d’entamer cette partie, il indispensable de rappeler les exigences de la VoIP en métrique de la
qualité de service.
Le tableau ci-après présente les seuils de valeurs pour les paramètres critiques et les conséquences
constatées pour le niveau de service de VoIP :
Bon Moyen Mauvais
Délai de transit D<150ms 150ms<D<400ms 400ms<D
Gigue de phase G<20ms 20ms<G<50ms 50ms<G
Perte de données P<1% 1%<P<3% 3%<P
Tableau IV.1: Les exigences de la VoIP en métrique de qualité de service
IV.2.5. Etude du réseau sans qualité de service
IV.2.5.1. Première cas: VoIP seul
A l’aide de logiciel IxChariot, nous avons envoyé un flux «VoIP» seul sur le réseau entre les deux
extrémités.
Les figures suivantes illustrent les variations de délai et de Jitter :
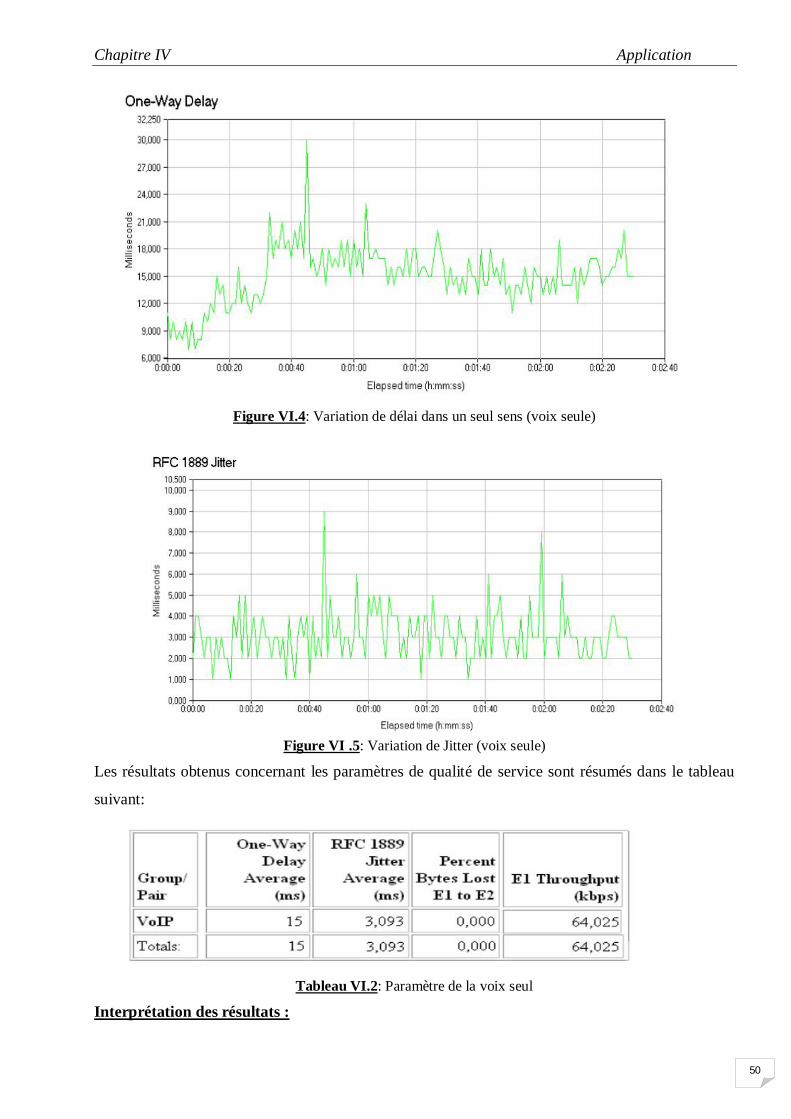
Chapitre IV Application
50
Figure VI.4: Variation de délai dans un seul sens (voix seule)
Figure VI .5: Variation de Jitter (voix seule)
Les résultats obtenus concernant les paramètres de qualité de service sont résumés dans le tableau
suivant:
Tableau VI.2: Paramètre de la voix seul
Interprétation des résultats :
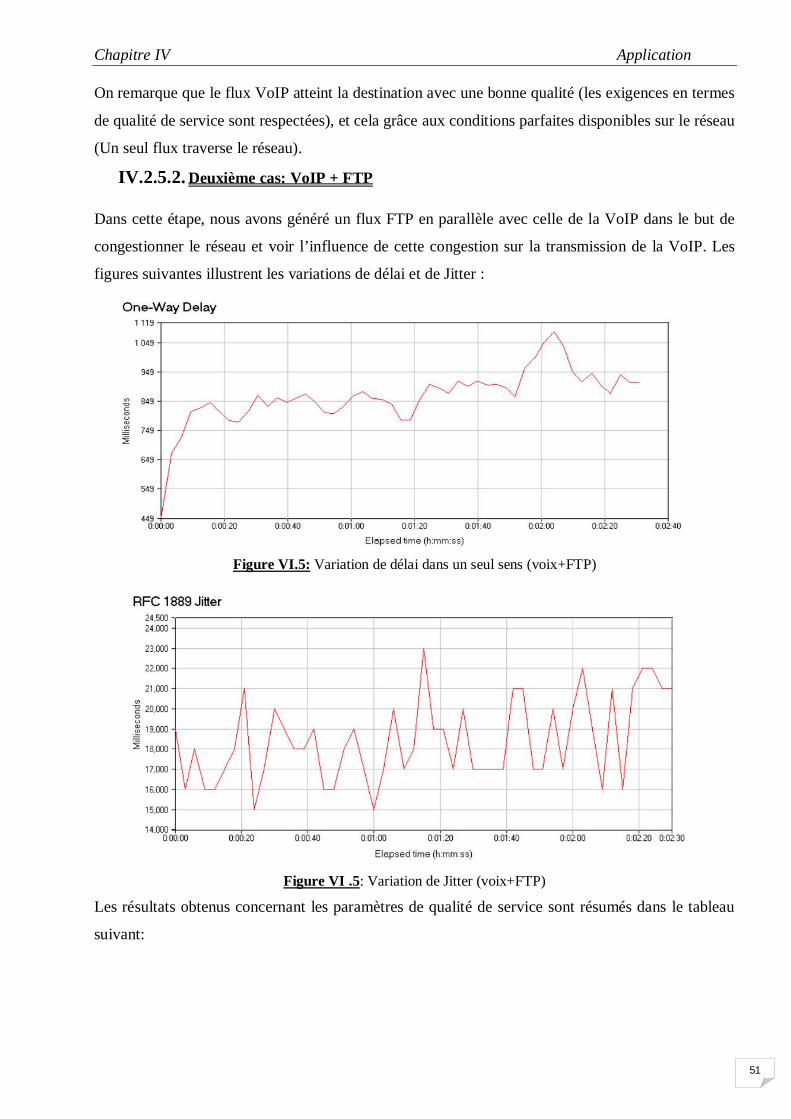
Chapitre IV Application
51
On remarque que le flux VoIP atteint la destination avec une bonne qualité (les exigences en termes
de qualité de service sont respectées), et cela grâce aux conditions parfaites disponibles sur le réseau
(Un seul flux traverse le réseau).
IV.2.5.2. Deuxième cas: VoIP + FTP
Dans cette étape, nous avons généré un flux FTP en parallèle avec celle de la VoIP dans le but de
congestionner le réseau et voir l’influence de cette congestion sur la transmission de la VoIP. Les
figures suivantes illustrent les variations de délai et de Jitter :
Figure VI.5: Variation de délai dans un seul sens (voix+FTP)
Figure VI .5: Variation de Jitter (voix+FTP)
Les résultats obtenus concernant les paramètres de qualité de service sont résumés dans le tableau
suivant:
Chapitre IV Application
52
Tableau VI.6: Paramètres de la voix avec la présence du flux FTP
Interprétation des résultats :
Lors de transfert des deux flux (FTP + VoIP) en parallèle, On remarque que les métriques de qualité
de service augmentent considérablement et le flux VoIP atteint la destination avec une mauvaise
qualité. Cela est expliqué par la congestion due au flux agressive FTP.
IV.2.6. Etude du réseau avec qualité de service
IV.2.6.1. Implémentation de qualité de service :
Appliquons maintenant les mécanismes de QoS. A noter que le traitement de la QoS change suivant
le type de routeurs (PE, P ou CE). Pour le routeur CE, saresponsabilité se limite à la classification
de son trafic jusqu’à son point de liaison avec le Edge IP/MPLS.
a. Application de la classification et le marquage :
Au niveau des routeurs CE, nous avons créé les classes de service suivantes:
Nom de classe Type de trafic PHB DSCP en
binaire
DSCP en
décimal
Voice VoIP EF 101110 46
Data FTP AF13 001110 14
Afin d’assurer la qualité de service requis, nous avons appliqué les mécanismes suivants au niveau
des routeurs PE et P:
Utilisation de mécanisme de gestion de file d’attente LLQ (Low Latency Queuing) qui nous
permet d’allouer une bande passante prioritaire à une file d’attente particulière. Ce mécanisme
est implémenté pour le trafic voix;
Utilisation de mécanisme de prévention de congestion WRED (Weighted Random early
Detection) pour le trafic FTP pour agir avant la congestion en éliminant les paquets
susceptibles de produire la congestion. Il s’agit simplement de fixer un seuil à partir du quel on
commence à éliminer les paquets d’une façon aléatoire ;

Chapitre IV Application
53
Assurer la conversion d’un type de classement à un autre : dans les sites CE, onpeut appliquer
le modèle DiffServ et agir sur les entêtes IP. Mais, au niveau du backbone supportant MPLS le
traitement est limité à la couche 2 donc on doit convertir la classe désignée par le champ
DSCP par celle correspondante dans le champ EXP du label MPLS. Cette tache est réalisée au
niveau des routeurs PE.
Nom de class Type de trafic EXP
Voice VoIP 5
Data FTP 1
NOTE: la configuration de tous les routeurs est jointe dans l’annexe.
Après l’implémentation de ces mécanismes, nous avons généré un flux FTP et un flux VoIP en
même temps, à l’aide de logiciel Wireshark nous avons pu capturer les paquets lors de transfert.
Les Figure suivantes représentent le champ DSCP et le champ EXP :
Figure IV.7: le champ DSCP et EXP dans un paquet FTP
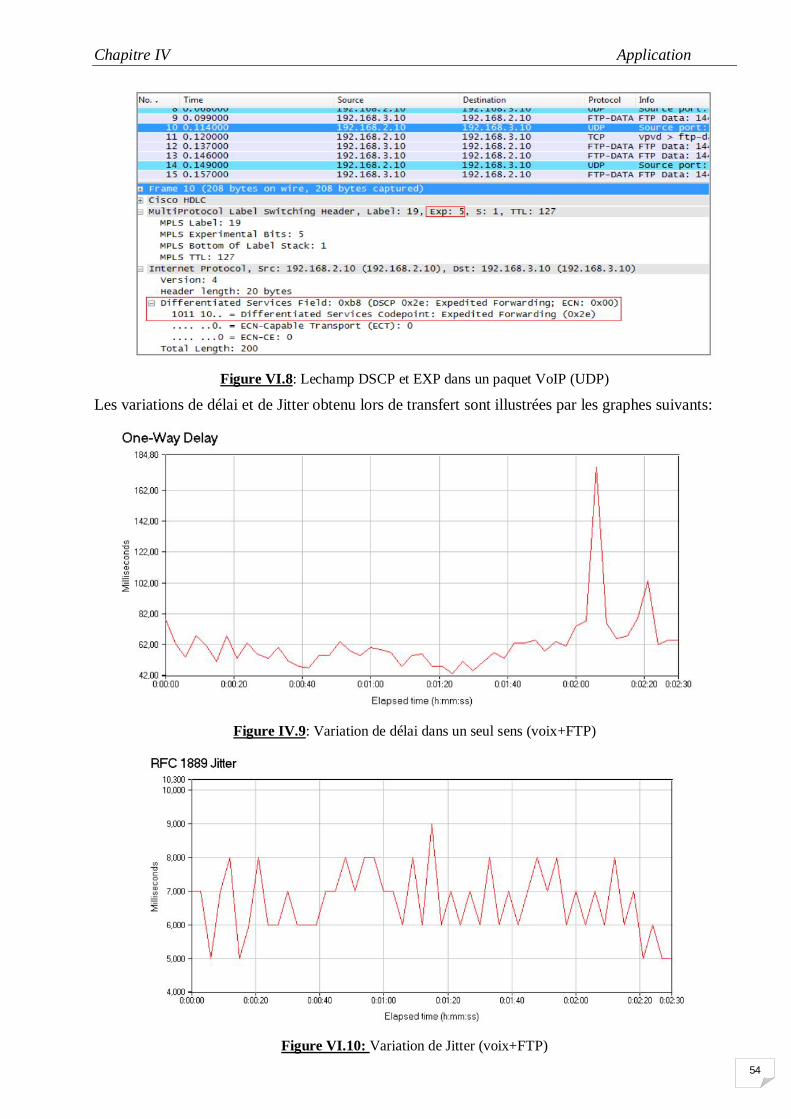
Chapitre IV Application
54
Figure VI.8: Lechamp DSCP et EXP dans un paquet VoIP (UDP)
Les variations de délai et de Jitter obtenu lors de transfert sont illustrées par les graphes suivants:
Figure IV.9: Variation de délai dans un seul sens (voix+FTP)
Figure VI.10: Variation de Jitter (voix+FTP)
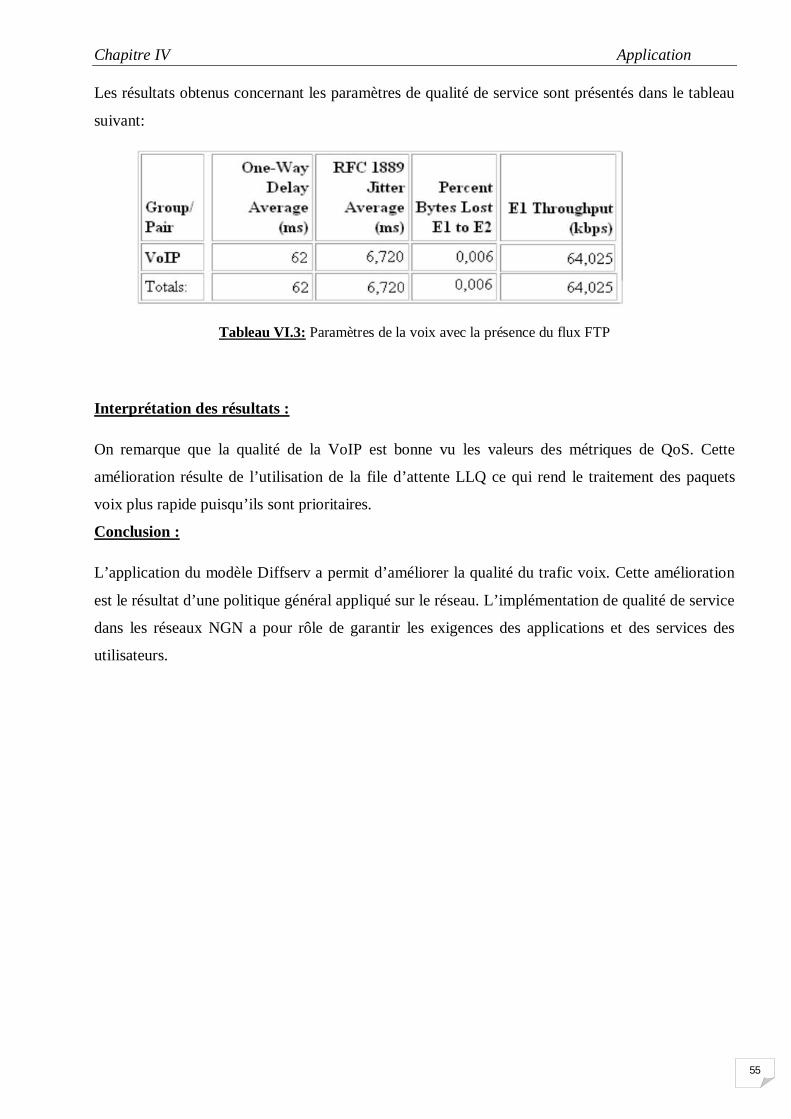
Chapitre IV Application
55
Les résultats obtenus concernant les paramètres de qualité de service sont présentés dans le tableau
suivant:
Tableau VI.3: Paramètres de la voix avec la présence du flux FTP
Interprétation des résultats :
On remarque que la qualité de la VoIP est bonne vu les valeurs des métriques de QoS. Cette
amélioration résulte de l’utilisation de la file d’attente LLQ ce qui rend le traitement des paquets
voix plus rapide puisqu’ils sont prioritaires.
Conclusion :
L’application du modèle Diffserv a permit d’améliorer la qualité du trafic voix. Cette amélioration
est le résultat d’une politique général appliqué sur le réseau. L’implémentation de qualité de service
dans les réseaux NGN a pour rôle de garantir les exigences des applications et des services des
utilisateurs.

Conclusion générale
VII
Conclusion
L’objectif de ce projet est l’étude de la qualité de service (QoS) et des techniques
d’ordonnancement et de gestion des paquets à l’intérieur de réseau NGN.
En effet, à nos jours les pratiques technologiques sont en train d’évoluer, tel que l’Internet
mobile, la téléphonie mobile, le multimédia, etc. Les opérateurs estiment l’émergence des
nouveaux services multimédia qu’il faut fournir indépendamment du temps, du lieu et des
méthodes d’accès à travers des équipements mobiles. Dans ce projet nous avons étudier la
gestion de différents flux de données comme la téléphonie sur IP le FTP et de la vidéo sur IP ;
donc nous sommes dans une convergence des réseaux des télécommunications. Or cette
convergence nécessite un nouveau réseau qui est le NGN. L’utilisation d’un même plan de
transport pour offrir à la fois les services réseaux de données et les services télécoms comme la
vidéo et la voix, nécessite le déploiement d’un réseau de transport commun donnant tous les
types de QoS, ainsi que le développement d’une architecture de service commune et un plan
contrôle.
Dans la première partie de ce travail, nous avons défini les réseaux NGN comme étant des
réseaux transportant des informations de diverses natures. Découle des multiples applications qui
circulent sur l’Internet actuel, à savoir des simples transferts de données (applications FTP par
exemple), des applications multimédia telles que la transmission de voix, vidéo, applications
interactives, etc.
Ensuite , nous avons identifié les paramètres qui définissent la qualité de service d’un réseau, et
sur lesquels il faut agir pour garantir une qualité de service au-dessus d’un réseau. Les métriques
qui nous permettent de définir la qualité de service sont le débit, le délai et par conséquent la
gigue, ainsi que le taux de pertes des données. Ces éléments sont en effet essentiels pour juger de
la qualité de transmission des informations et par conséquent, sont primordiaux pour définir la
qualité de service. Par ailleurs, nous avons évoqué les mécanismes de qualité de service à un
niveau global, en présentant les architectures proposées par les groupes de travail IntServ et
DiffServ. Ces architectures sont basées sur deux approches différentes, mais ont pour point
commun de tenter d’offrir à chaque application le maximum de ressources pour leur assurer une
crédibilité correcte de transmission. La première théorie se base sur le principe de contrôle
d’admission des flots ainsi que de la réservation de ressources au moyen du protocole RSVP.

Conclusion générale
VIII
Cette approche définit trois classes de service : le service « best-effort » pour permettre
d’acheminer les données sans aucune garantie ; le service à charge contrôlée pour offrir une
certaine garantie de débit ; enfin le service garanti qui permet d’attribuer de meilleures garanties
temporelles et en débit que les précédents services. L’approche DiffServ permet, quant à elle,
d’effectuer une différenciation de services en se basant sur les micro-flux : les paquets sont ainsi
marqués au niveau de leur en-tête pour leur attribuer des degrés de priorités selon les
applications auxquelles ils appartiennent et leurs besoins en débit, délai et/ou pertes. Dans cette
architecture, le service « best effort » est destiné aux applications à faible priorité ; le service «
assured forwarding dédié aux applications qui demandent une priorité moyenne, telles la
navigation sur le Web ; enfin, le service à forte priorité, « expedited forwarding » associé aux
applications temps-réel.
Nous avons souligné durant ce travail l’influence de l’approche diffserv en fonction du délai et
de la gigue appliqué au service <<VoIP>> et testé en absence et présence de QoS.
L’implémentation et les tests ont été réalisés au moyen du simulateur GNS3 et ixchariot
respectivement sur différentes topologies de réseaux.
Les résultats obtenus montrent nettement l’importance d’une garantie de la QoS et sa réaction à
la réception de l’information. Ainsi, nous avons pu démontrer qu’en présence d’un certain
nombre d’applications sur un même canal avec de l’application de l’approche Diffserv , il est
possible d’éviter le phénomène de famine des ressources de manière à satisfaire une certaine
qualité de service à chaque application.

Référence bibliographiques
IX
Livres et Articles :
N° le livre ou l’article 1 [A,JELASSI] ,conception et mise en place d’une solution de communication unifiée
chez TUNISIE TELECOM. 2 [A.Amine] , Mise en œuvre d’un cœur de réseau IP/MPLS, Université de Bechar 2011
3 [A.Delley] , Les réseaux IP de prochaine génération arrivent, École d’ingénieurs et d’architectes de Fribourg,2010.
4 [A.Mahul] , Apprentissage de la qualité de service dans les réseaux multiservices , applications au routage optimal sous contraintes, 2012.
6 [B.Nadia] , Contribution à la gestion de qualité de service d’un les réseaux sans fil, univ de Oran , 2013
9 [D.GAUCHARD], Simulation hybride des réseaux IP-DiffServ-MPLS multi-services sur environnement d’exécution.
10 [D.INCERTI] , IP et Qualité de Service, Université Paul Sabatier, 2013
20 [J .A Montagnon & T.H Tran] , MPLS et les reseaux d’entreprise, 2002. 22 [K. Krief] , Qualité de service et sécurité dans les réseaux de nouvelle génération,
Université de Bordeaux LaBRI. 23 [L.Toumi] ,Algorithmes et mécanismes pour la qualité de service dans des réseaux
hétérogènes, Institut National Polytechnique de Grenoble - INPG, Frence,2002. 29 [M.RAOULI], Reseau Multiservices Large Bande De Technologie Ip/Mpls D’algerie
Telecom,2006 30 [M.Abdessalem], Etude et Dimensionnement d’un Réseau de Nouvelle
Génération,Tunisie Télécom. Mémoire d’ingénieurs de l’Ecole Supérieure Des Communications De TUNIS,2005
31 [M.Mostapha] , Analyse de Sécurité et QoS dans les Réseaux à Contraintes Temporelles ,2011.
36 [N. benhamel] , contribution à la gestion de qualité de services dans les réseaux local sans fil, lediplome de magiter , 2013.
38 [O. cabinet], L'évolution du cœur de réseau des opérateurs fixes, le compte de l’Autorité de régulation des Communications électroniques et des Postes, 2006.
43 [R.Freddy],Conception et déploiement de la technologie MPLS dans un réseau métropolitain, diplôme d’ingénieur 2013.
44 [OCDE],Réunion de l’OCDE future économie Internet, Convergence et réseaux de la
prochaine génération.

Référence bibliographiques
X
Les sites web
N° Le site web 5 Architecture MPLS , http://igm.univ-mlv.fr/~dr/XPOSE2006/marot/architecture.html 7 Cisco,
http://www.cisco.com/c/en/us/td/docs/solutions/Enterprise/Video/qoswanvpnaag.html 8 Concepts MPLS, http://www.debuire.net/?p=68 11 Documentation d'Elastix (Version française), www.elastix.org 12 Etude de la solution MSAN, http://www.memoireonline.com/05/12/5835/m_Ingenierie-
des-MSANs-Multi-Service-Access-Node5.html 13 Etude du protocole DiffServ, http://www.guill.net/index.php?cat=3&pro=3&wan=6 14 FileZilla,
http://www.01net.com/telecharger/windows/Internet/serveur_ftp/fiches/27450.html 15 Implémentation Mpls avec Cisco Par Par Christophe Fillot,
http://www.frameip.com/mpls-cisco/ 16 GNS3, Installation gns3 workbench,http://nice.labo-cisco.com/tag/workbench/ 17 Internet nouvelles générations,
www.europainternet.info/mmqos/index.php/Sujet/manel#Condition_du_trafic 18 Introduction à MPLS, http://www.guill.net/index.php?cat=3&pro=3&wan=5 19 Ixchariot, http://www.ixiacom.com/products/ixchariot 21 JDN l’économie demain
,http://www.journaldunet.com/solutions/expert/42870/convergence---5-avantages-promis-par-le-next-generation-networking.shtml ,28/01/2015
24 La qualité de service dans l'Internet, http://christophe.deleuze.free.fr/these/these006.html , 02/02/2015.
25 La qualité de service sur IP : WFQ, RED, Precedence, ECN, Diffserv ,http://mrproof.blogspot.com/2011/01/la-qualite-de-service-sur-ip-wfq-red.html
26 Le NGN,http://www.memoireonline.com/10/13/7591/m_Etude-d-une-offre-technique-innovante-de-telephonie-sur-IP--Camtel-Cameroun29.html,29/12/2015
27 Les protocole réseaux, http://marc.boget.free.fr/stage-html2/Memoire%20de%20stage-6_4_2.html
28 Logiciel de virtualisation VMware , http://mahieus.no-ip.org/articles/print.php?id=64 32 MPLS Concepts , https://www.10gea.org/images/CISCO-MPLS-Concept 33 Mpls par Benbella Benduduh http://www.frameip.com/mpls/ 34 MPLS, .http://igm.univ-mlv.fr/~dr/XPOSE2010/LesVPNMPLS/definition_mpls.html 35 MPLS-QoS J. Kumarasamy, http://fr.slideshare.net/vsurajkumar/mpls-qos-jayk 37 Nouveaux défis de l’interconnexion, http://slideplayer.fr/slide/458990/, 01/01/2015. 39 Pratical IP network QoS, http://web.opalsoft.net/qos/default.php?p=whyqos-2422#. 40 Présentation de COPS,
http://wapiti.telecomlille1.eu/commun/ens/peda/options/st/rio/pub/exposes/exposesrio2004ttnfa05/Malyga-Sokowicz/partie2.htm
41 Qualidade de Serviço em VoIP - Parte I, https://memoria.rnp.br/newsgen/0005/qos_voip1.html
42 Qualité de Service dans l’Internet, http://slideplayer.fr/slide/497181/# . 45 Wireshark, http://media.box.ubiloo.com/-.dls/-.cats/?dfp!ca98116 ,21/04/2015

ANNEXE
XI
La Configuration des routeurs
Après l’entrer des adresses dans touts les routeurs :
1. Dans les routeurs CE (par exemple CE1)
//routage protocole eigrp
Router eigrp 1
network 192.168.1.0
network 192.168.2.0
network 192.168.114.0
no auto-summary
//QoS
class-map match-all Data
match protocol ftp
class-map match-any Voice
match ip rtp 16384 16383
match protocol rtp audio
!
policy-map DSCP
class Voice
set ip dscp ef
class Data
set ip dscp af13
2. Configuration les routeurs PE (par exemple PE1)
//Routage protocols eigrp et ospf
router eigrp 1
redistribute ospf 1 metric 1500 10 255 10 1500 match external 1
network 192.168.1.0
no auto-summary
!
router ospf 1
log-adjacency-changes

ANNEXE
XII
redistribute eigrp 1 metric-type 1 subnets
network 10.10.10.4 0.0.0.0 area 0 //loopback
network 172.16.1.12 0.0.0.3 area 0
//Activation MPLS
Ip cef
Mpls ip
Interface f0/0
Ip cef
Mpls ip
// l’implémentation de ces mécanismes QoS
class-map match-all ftp
match protocol ftp
class-map match-any Voip
match protocol rtp audio
!
policy-map DSCP
class Voip
priority 10000000
//Dans l’interface f0/0
ip nbar protocol-discovery
service-policy input DSCP
//
class-map match-all class-map voip
match mpls experimental topmost 5
class-map match-all class-map voip
match mpls experimental topmost 1
3. Configuration les routeurs P (par exemple P)
//Routage protocols ospf
router ospf 1
network 10.10.10.1 0.0.0.0 area 0
network 172.16.1.0 0.0.0.3 area 0

ANNEXE
XIII
network 172.16.1.8 0.0.0.3 area 0
network 172.16.1.12 0.0.0.3 area 0
//Activation MPLS dans tous les interfaces
Ip cef
Mpls ip
Interface f0/0
Ip cef
Mpls ip
//QoS
class-map match-all ftp
match protocol ftp
class-map match-any Voip
match protocol rtp audio
!
policy-map DSCP
class Voip
priority 10000000
//Dans tous les interfaces
ip nbar protocol-discovery
service-policy input DSCP