page de garde - univ-setif.dz · mes chers enfants anes et marame ... tels que les défauts de...
TRANSCRIPT

REPUBLIQUE ALGERIENNE DEMOCRATIQUE ET POPULAIRE MINISTERE DE L’ENSEIGNEMENT SUPERIEUR ET DE LA RECHERCHE
SCIENTIFIQUE
UNIVERSITE FERHAT ABBAS – SETIF 1 INSTITUT D’OPTIQUE ET MECANIQUE DE PRECISION
THESE
Présentée à l’Institut d’Optique et Mécanique de Précision en vue de l’obtention du diplôme de
DOCTORAT EN SCIENCES
Option : Optique et Mécanique de Précision
Par
Mr. ZIANI RIDHA
THEME
Contribution à l’analyse et à la classification automatique des défauts mécaniques
Soutenue le : 15/06/2015
Devant le jury composé de :
Président Mr. RECHAK Saïd Professeur ENP. Alger Rapporteur Mr. ZEGADI Rabah Professeur Université de Sétif1
Co-rapporteur Mr. FELKAOUI Ahmed Professeur Université de Sétif1
Examinateur Mr. TOUAT Noureddine Maitre de conférences USTHB. Alger
Examinateur Mr. REBIAI Chérif Maitre de conférences ENST. Alger

Remerciements
En premier lieu, je tiens à exprimer ma gratitude et reconnaissance envers mon
directeur de thèse, Professeur Rabah ZEGADI, pour m’avoir accueilli au sein du laboratoire
LMPA, encadré et soutenu tout au long des années de mon doctorat à l’institut d’optique et
mécanique de Précision. Je le remercie de m’avoir apporté toute son expérience et ses
compétences sans lesquelles ce travail n’aurait pas pu aboutir.
Je ne pourrais jamais remercier suffisamment mon co-directeur de thèse, le
Professeur Ahmed FELKAOUI , pour m’avoir guidé avec perspicacité tout au long de ces
années. Sa disponibilité, son attention et son soutien sont, sans doute, les éléments majeurs
qui m’ont permis de mener à bien cette thèse.
Je voudrais adresser mes sincères remerciements à monsieur Saïd RECHAK,
Professeur à l’École Nationale Polytechniques d’Alger, d’avoir accepté de présider
l’honorable jury de cette thèse.
Je remercie vivement Monsieur Noureddine TOUAT, maître de Conférences à
l'Université des Sciences et de Technologie Houari Boumediene d’Alger, et Monsieur Chérif
REBIAI, maître de Conférences à l’école nationale supérieure de technologie d’Alger, de
m'avoir fait l'honneur d'accepter d'être les Examinateurs de cette thèse.
Mes remerciements s’adressent aussi à tous mes collègues de l’ENST, et plus
particulièrement à : Mr Hamdi AOUICI, Mr Saïd BELAHAMIDI, & Mr Abdelhakim
KECHNIT.
Je remercie tous les membres du LMPA et en particulier Mr semcheddine FEDALA
pour son soutien, son aide, et ses encouragements.
Mes remerciements s’adressent finalement à toute ma famille pour sa patience et son
encouragement infaillible durant toutes les années de mes études

Je dédie ce travail à :
Mes chers Parents Ma chère épouse
Mes chers enfants Anes et Marame À toute la famille

i
Résumé
Contribution à l’analyse et à la classification automatique des défauts mécaniques
L’objectif de cette thèse est la conception d’un système automatique de diagnostic des
défauts mécaniques, tels que les défauts de roulements et d’engrenages. Notre approche est basée
sur l’utilisation des méthodes de Reconnaissance de Formes (RdF). Un vecteur de paramètres
(indicateurs), appelé vecteur forme, est extrait de chacune des mesures effectuées sur la machine.
La règle de décision utilisée, permet de classer les observations, décrites par le vecteur forme, par
rapport aux différents modes de fonctionnement connus avec ou sans défaut. Afin d’avoir un
système de diagnostic performant, il est nécessaire d’employer un processus de sélection des
indicateurs les plus pertinents, permettant d’améliorer les performances de la classification. Dans
ce contexte, nous proposons une nouvelle méthode de sélection d’indicateurs. Cette méthode est
basée sur le couplage d’un algorithme d’Optimisation par Essaim de Particules Binaire (OEPB),
et le Critère de Fisher Régularisé (CFR). L’algorithme ainsi développé a pour acronyme OEPB-
CFR. Dans la phase de classification, les machines à vecteurs supports (Support Vector Machines
(SVM)) ont été retenues. Ce système de diagnostic a été évalué en utilisant des signaux
vibratoires en différents modes de fonctionnement (sain et avec défauts). Les résultats obtenus
montrent l’efficacité de cette approche.
Mots clés : Maintenance conditionnelle, traitement de signal, Machines à Vecteurs Supports
(SVM), optimisation par essaim de particules, analyse discriminante linéaire, sélection des
indicateurs.

ii
Table des matières
Résumé .............................................................................................................................................. i Table des matières ............................................................................................................................. ii Liste des figures ................................................................................................................................ v Liste des tableaux .............................................................................................................................. vii Liste des abréviations et notations .................................................................................................... viii Introduction générale ..................................................................................................................... .1
Chapitre I
État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
I.1 Introduction ................................................................................................................................. .5 I.2 Analyse dans le domaine temporel ............................................................................................. .6 I.2.1 Les indicateurs scalaires ..................................................................................................... .6 I.2.2 Le moyennage temporel synchronisé ................................................................................. .8 I.2.3 Les modèles paramétriques ............................................................................................... .8 I.3 Analyse dans le domaine fréquentiel .......................................................................................... .9 I.3.1 La transformée de Fourrier ................................................................................................ .9 I.3.2 L’analyse d’enveloppe ....................................................................................................... 11 I.3.3 L’analyse cepstrale ............................................................................................................. 12 I.4 Analyse temps-fréquence ............................................................................................................. 14 I.4.1 La Transformée de Fourrier à Fenêtre Glissante (TFFG) ................................................... 14 I.4.2. La distribution Wigner Ville (DWV) ................................................................................ 15I.5 Le Kurtosis spectral et le Kurtogramme ..................................................................................... 16 I.6 Analyse temps-échelle ................................................................................................................ 17 I.6.1.La transformation en ondelettes continues ........................................................................ 18 I.6.2 La transformation en ondelettes discrètes ......................................................................... 19 I.6.3 Les paquets d’ondelettes ................................................................................................... 20 I.7 La décomposition en mode empirique. ........................................................................................ 21 I.8 Analyse de la cyclostationnarité ................................................................................................ 22 I.9 Synthèse ....................................................................................................................................... 23
Chapitre II Les Machines à Vecteurs Supports (SVMs)
II.1Introduction ................................................................................................................................ 25 II.2 Théorie de l’apprentissage statistique ........................................................................................ 26 II.3 Les machines à vecteurs supports (SVMs) ................................................................................ 28 II.3.1 SVMs à marge dure .......................................................................................................... 28 II.3.2 SVMs à marge souple ....................................................................................................... 31 II.3.3.Utilisation des noyaux ..................................................................................................... 33 II.4.Optimisation des SVMs ............................................................................................................. 36 II.4.1 Méthode de chunking ...................................................................................................... 37 II.4.2 Méthode de décomposition successive ............................................................................ 37 II.4.3 Méthode de minimisation séquentielle (SMO) ................................................................ 38 II.5 Implémentation des SVMs ........................................................................................................ 38 II.6 les SVMs multiclasses ............................................................................................................... 38 II.6.1 Approche Un –contre -Reste (1vsR) .............................................................................. 38

iii
II.6.2 Approche Un-contre-un (1vs1) ........................................................................................ 39 II.6.3 Graphe acyclique de décision .................................................................................................. 40 II.7 Conclusion ................................................................................................................................ 40
Chapitre III Sélection d’indicateurs en classification
III.1 Introduction .............................................................................................................................. 42 III.2 Présentation du problème de sélection ...................................................................................... 43 III 2.1 Notions de pertinence et redondance des indicateurs .................................................... 43 III.2.1.1 Pertinence des indicateurs. ............................................................................... 43 III.2.1.2 Redondance des indicateurs .......................................................................... 44 III.2.2 La sélection des indicateurs vue comme un problème d’optimisation combinatoire .... 44 III.2.3 Processus général de la sélection des indicateurs .......................................................... 45 III.2.3.1 Procédure de génération ................................................................................. 46 III.2.3.2 Évaluation ....................................................................................................... 47 III.2.3.3 critère d’arrêt .................................................................................................. 48 III.3 Les approches de sélection des indicateurs .............................................................................. 48 III.3.1 Les approches filtre (filter) .............................................................................................. 48 III.3.2 Les approches enveloppes (wrapper) ............................................................................. 49 III.3.3 Les approches intégrées (embedded) .............................................................................. 50 III.4 Les métaheuristiques pour la sélection d’indicateurs ............................................................... 51 III.4.1 Les métaheuristiques à solution unique ......................................................................... 51 III 4.1.1 Le recuit simulé ................................................................................................. 51 III 4.1.2 La recherche tabou ........................................................................................... 52 III 4.2 Les métaheuristiques à base de population de solutions .................................................. 54 III 4.2.1 Les Algorithmes évolutionnaires ...................................................................... 54 III 4.2.1.1 les algorithmes génétiques ..................................................................... 54 III 4.2.1.2 L’évolution différentielle ....................................................................... 55 III 4.2.2 l’optimisation par essaim de particules ............................................................ 56 III 4.2.3 L’optimisation par colonie de fourmis (Ant colony optimization) .................. 57 III.5 Synthèse sur la sélection des indicateurs ................................................................................... 57 III.6 Contribution à la sélection d’indicateurs pour la classification automatique des défauts ......... 58 III.6.1 Motivation ....................................................................................................................... 58 III.6.2 Approche proposée .......................................................................................................... 59 III.6.2.1 L’optimisation par essaim de particules Binaires (OEPB) ................................ 60 III.6.2.2 L’analyse discriminante linéaire et Critère de Fisher Régularisé (CFR) ........ 61 III.6.3 Conduite des différentes étapes de l’algorithme proposé ................................................ 62 III.7.Conclusion ................................................................................................................................. 67
Chapitre IV Évaluation expérimentale de la méthode proposée : application au diagnostic automatisé des défauts de roulements et d’engrenages
IV.1 Introduction .............................................................................................................................. 67 IV.2 Diagnostic des défauts par OEPB-CFR+SVM ......................................................................... 68 IV.3 Diagnostic automatisé des défauts de roulements ..................................................................... 70 IV.3.1 Système étudié ................................................................................................................ 70 IV.3.2 Analyse des données et extraction des indicateurs ......................................................... 71 IV.3.3 Évaluation des Performances de la méthode de diagnostic proposée ............................. 75 IV.3.3.1 Performances des SVMs sans sélection .................................................................. 75

iv
IV.3.3.2 Performances de l’algorithme BPSO-RFC+SVM (avec sélection) ...................... 79 IV.4 Diagnostic automatisé des défauts d’engrenages ..................................................................... 80 IV.4.1 Système étudié : boite de vitesse CH-46 de l’’hélicoptère « Westland » ....................... 80 IV.4.2 Analyse des données et extraction des indicateurs ......................................................... 87 IV.4.3 Performance des SVMs sans sélection d’indicateurs ...................................................... 88 IV.4.4 Performance de l’algorithme OEPB-CFR+SVM (Avec sélection) ................................. 89 IV .5 conclusion ................................................................................................................................ 91 Conclusion générale ........................................................................................................................ 92 Références Bibliographiques ......................................................................................................... 95 Annexes

Liste des figures
v
Liste des figures Chapitre I
Figure 1.1 Utilisation du cepstre pour la surveillance d’un engrenage. . …………………….. 13
Figure 1.2 Comparaison des représentations temps-fréquence d’un signal vibratoire d’un moteur
Diesel ……………………………………………………………………………...
16
Figure 1.3 Exemple de kurtosis spectral et son Kurtogramme associé………………………. 17
Figure 1.4 Quelques exemples d’ondelettes. …………………………………………………. 18
Figure 1.5 Structure de la décomposition en ondelettes………………………………………. 19
Figure 1.6 Exemples d’ondelettes orthogonales……………………………………………… 20
Figure 1.7 Arbre de décomposition en paquets d’ondelettes pour 3trois niveaux de
décomposition. …………………………………………………………………..
21
Chapitre II
Figure 2.1 Exemple de séparation entre deux classes par les SVMs…………………………. 29
Figure 2.2 Hyperplan séparateur dans le cas de données non-linéairement séparables…….. 32
Figure 2.3 Représentation idéale de la fonction de décision…………………………………. 33
Figure 2.4 Illustration de l'effet du changement d'espace par une fonction noyau………… 34
Figure 2.5 Problème à trois classes : frontières de décision linéaires dans la stratégie Un-
Contre-Reste………………………………………………………………………
39
Figure 2.6 Architecture d’une DAGSVM à quatre catégories ……………………………… . 40
Chapitre III
Figure 3.1 Processus de sélection d’indicateurs………………………………………………. 46
Figure 3.2 Sélection des indicateurs par l’algorithme OEPB-CFR ………………………… 63
Chapitre IV
Figure 4.1 Diagnostic des défauts par OEPB-CFR+SVM…………………………………. ... 69

Liste des figures
vi
Figure 4.2 Banc d'essai de roulements………………………………………………………. 70
Figure 4.3 Signaux temporels acquis sous un couple résistant de 2hp pour des roulements en
état normal et avec défauts de bague intérieure. …………………………… …
72
Figure 4.4 Spectre du signal de roulement avec un défaut de 0.007 Pouces sur la bague
intérieure acquis sous 0HP ……………………………………………..……………
73
Figure 4.5 Arbre de décomposition en paquet d’ondelette au 3ième niveau de décomposition.. 74
Figure 4.6
Convergence de l’algorithme BPSO-RFC vers la meilleure fonction objective
(fitness) en fonction du nombre d’itérations……………………………………….
80
Figure 4.7 Projection 3D des données utilisées dans le cas d’identification de défaut ……… 80
Figure 4.8 Projection 3D des données utilisées dans le cas de l’identification de niveau
défaut de bague intérieure……………………… ………………………………….
81
Figure 4.9 Projection 3D des données utilisées dans le cas de l’identification de niveau
défaut de bague extérieure…………………………………………………………
81
Figure 4.10 Projection 3D des données utilisées dans le cas de l’identification de niveau
défaut de l’élément roulant………………………………………………………...
81
Figure 4.11 Schéma simplifié de la boite de vitesse de l’hélicoptère CH46. Numérotation des
éléments et caractéristiques………………………………………………………..
84
Figure 4.12 Schéma simplifié du système……………………………………………………… 86
Figure 4.13 Différents pignons utilisés…………………………………………………………. 86
Figure 4.14 Signaux temporels du capteur 4, couple 45%, pour différents états du pignon
conique…………………………………………………………………………….
87
Figure 4.15 Projection 3D des données ……………………………………………………….. 90

Liste des tableaux
vii
Liste des tableaux
Chapitre IV
Tableau 4.1 Caractéristiques des défauts de roulements……………………………….. 71
Tableau 4.2 Description des données utilisées dans le cas de l’identification de défaut. 76
Tableau 4.3 Description des données utilisées dans les trois cas de l’identification de niveau de défaut …………………………………………………………..
77
Tableau 4.4 Performance des SVMs dans le cas d’identification de défaut (sans sélection) ................................................ …………………………………..
78
Tableau 4.5
Performance des SVMs dans le cas de l’identification du niveau de défaut (sans sélection) ……………………………………………………………...
78
Tableau 4.6 Performance du BPSO-RFC+SVM dans le cas d’identification de défaut. ...... 82
Tableau 4.7 Performance du BPSO-RFC+SVM dans le cas d’identification du niveau de défaut…………………………………………………………………….
82
Tableau 4.8 Description et position des défauts…………………………………………. 85
Tableau 4.9 Ensemble des données disponibles en fonction du couple et du défaut….. 85
Tableau 4.10 Performance des SVMs sans sélection d’indicateurs………………………. 89
Tableau 4.11 Performance du OEPB-CFR+SVM (avec sélection) ………………………. 90
.

Liste des abréviations et natations
viii
Abréviations et notations
Abréviations
.
RdF
AR
TF
TFFG
DWV
PWVL
TOC
TOD
TPO
VC
VS
OEP
OEPB
ADL
CFR
BA
BT
SVM
RBF
AG
ED
1vs1
1vsR
: Reconnaissance de Formes
: Modèle Autorégressif
: Transformée de Fourrier
: Transformée de Fourrier à Fenêtre glissante
: Distribution de Wigner Ville
: Pseudo Wigner Ville Lissée
: Transformée en ondelettes continue
: Transformée en ondelettes Discrète
: Transformée en paquet d’ondelette
: Dimension de Vapnik-Chernovenkis
: Vecteurs de supports
: Optimisation par Essaim de Particules.
: Optimisation par Essaim de Particules Binaires.
: Analyse Discriminante Linéaire
: Critère de Fisher Régularisé
: Base d’apprentissage.
: Base de Test
: Supports Vector Machines
: Radial Basis Fonction (fonction à base radiale)
: Algorithme Génétique
: Évolution Différentielle
: Un-Contre-Un
: Un-Contre-Reste

Liste des abréviations et natations
ix
Notations
xi : l’ième observation de l’ensemble d’apprentissage
yi : l’ième étiquette (sortie désirée)
R(f) : Risque réel
Remp(f) : Risque empirique
( )f x : Fonction de décision des SVM
iα : Multiplicateurs de Lagrange
C : Paramètre de pénalité d’erreurs
ζi : Variables d’écart
K : La fonction kernel
( i)xΦ : Fonction de transformation
Nc : Nombre de classes
l : Nombre des observations d’apprentissage
m : Nombre des vecteurs supports
P (x, y) : Probabilité d’observation du couple (x, y).
P(C|F) : Probabilité de C connaissant F
ω : Vecteur de poids qui contrôle les effets de la vitesse de la particule
vi,j(t) : La vitesse de la ième particule dans le jème indice de position
xi,j(t) : La position de la particule
c1 et c2 : Coefficients d'accélération de la particule
R1 ,R2 : Nombres aléatoires distribués de façon uniforme dans l'intervalle [0.0, 1.0]
, ( 1)i jx t + : Position de la particule à l’itération t+1
bS : Matrice de dispersion interclasse
wS : Matrice de dispersion intra-classe
W : Matrice de transformation
tr : La trace de la matrice (la somme des éléments de la diagonale)
λ : Paramètre de régularisation

Liste des abréviations et natations
x
E : Essaim de particules (population)
Np : Nombre de particules dans la population
Ni : Nombre d’itérations
M : Nombre d’observations
L : Nombre d’indicateurs
BD : Base de données
DSP : Densité spectrale de puissance
Mbc : Nombre des observations bien classées
FBE : Fréquence caractéristique de défaut de la bague extérieure
FBI : Fréquence caractéristique de défaut de la bague intérieure
FB : Fréquence caractéristique de défaut de l’élément roulant (Bille)
fe : Fréquence d’échantillonnage
fr : Fréquence de rotation
NT : Nombre de point du signal numérique

Introduction générale
‐ 1 ‐
Introduction générale Contexte de travail Le diagnostic des défauts gagne de plus en plus d’importance dans l'industrie en raison
de la demande d’augmenter la disponibilité des moyens de production. En plus, la complexité
des installations actuelles impose le recourt à de nouveaux outils, capables d’évaluer
rapidement l’état de santé d’une machine sans arrêter ou perturber son fonctionnement. Ces
outils doivent permettre aux opérateurs peu qualifiés de prendre des décisions fiables sans
avoir besoin d'un spécialiste pour examiner les données et diagnostiquer les problèmes (Yang
et al., 2005). Par conséquent, il est nécessaire d’intégrer les techniques qui peuvent rendre de
décision sur l'état de santé de la machine d’une façon automatique et fiable. Le choix d’une
méthode de diagnostic automatique dépend essentiellement de la connaissance disponible du
procédé étudié. Parmi les méthodes existantes, les plus appropriées pour le diagnostic des
systèmes complexes sont celles basées sur l’approche par Reconnaissance de Formes (RdF),
car elles ne nécessitent pas de connaissance à priori du système.
Les travaux présentés dans cette thèse s’inscrivent dans le cadre de diagnostic automatique
des défauts mécaniques:
• ·Au niveau de l’application, l’étude est cadrée sur la détection de défauts dans les
machines tournantes tels que les défauts de roulements et d’engranges. Pour ce type de
défauts, l'analyse vibratoire s’est avérée comme outil très apprécié dans l’industrie ces
dernières décennies (Samanta et al., 2001; Jack & Nandi, 2002; Wang & Too, 2002;
Rafiee et al., 2007; Kurek & Osowski, 2010; Konar & Chattopadhyay, 2011).
• Au niveau de la méthodologie de diagnostic, ce travail s’inscrit dans le cadre des
méthodes basées sur l’approche par reconnaissance de formes. La conception d’un tel
système de diagnostic, se déroule en trois phases essentielles: la phase d’analyse, la
phase de classification (décision), et la phase d’exploitations.
Dans la phase d’analyse, un vecteur de paramètres (indicateurs), appelé vecteur forme,
est extrait de chacune des mesures effectuées sur la machine. Dans la deuxième phase,
il s’agit d’établir une règle de décision qui permet de classer les observations, décrites
par le vecteur forme, par rapport aux différentes classes d’appartenance. Mais, avant

Introduction générale
‐ 2 ‐
qu’un modèle de décision ne soit intégré dans un système de reconnaissance de
défauts, il faut avoir procédé auparavant aux deux étapes : l’étape d’apprentissage et
l’étape de test. Dans la phase d’exploitation, le système de diagnostic par RdF peut
être mis en service. Il permet de classer chaque nouvelle observation recueillie sur le
système dans l’une des classes connues, en appliquant la règle de décision élaborée
dans la deuxième phase. La détermination de cette classe permet de connaître le mode
de fonctionnement actuel du système.
Motivation et objectifs
Les méthodes de classification couramment utilisées pour le diagnostic par RdF,
appartiennent à deux grandes catégories, selon la procédure de classification des données
(Worden et al., 2011) : méthodes d'apprentissage supervisé et non supervisé. Les Réseaux de
Neurones Artificiels (RNA), les machines à vecteurs supports (Support Vector Machines
SVMs), les arbres de décision, et les K plus proches voisins (Kppv), sont les méthodes de
classification supervisée les plus connues. Parallèlement, dans les dernières années, un certain
nombre de méthodes, impliquant des procédures d'apprentissage non supervisé ont été
employées pour le diagnostic des défauts. Mais, actuellement la plupart des ces techniques
basées sur l’apprentissage non supervisé nécessitent beaucoup d'expertise pour les mettre en
œuvre avec succès (Gryllias & Antoniadis, 2012). En outre, la plupart de ces méthodes
connait encore des problèmes de stabilité, de convergence, et de la robustesse.
Les Machines à Vecteurs Supports (SVM) introduites par Vapnik (Vapnik, 1998), est
relativement, une nouvelle méthode de classification basée sur la théorie de l’apprentissage
statistique. Contrairement à la plupart des méthodes de classification supervisé, les SVMs ne
nécessitent pas un grand nombre d'échantillons d’apprentissage (Burges, 1998; Gunn, 1998).
De plus de la bonne formulation de sa théorie mathématique, elle peut résoudre le problème
de l'apprentissage même si seulement une petite quantité d’observations est disponible. En
raison du fait qu'il est difficile d'obtenir un nombre suffisant des signatures de défauts dans la
pratique, les SVMs ont été adoptées comme méthode de classification dans ce travail.
Cependant, le choix des SVMs comme méthode de classification n’est pas suffisant
pour élaborer un système de diagnostic rebuse et fiable. En effet, les performances des SVMs
dépendent fortement de la qualité des données de l’apprentissage. Il est fréquent qu’une partie
de celles-ci ne contienne que des indicateurs non pertinents, redondants ou inutiles à la tâche
de classification. Ceux-ci introduisent forcément du bruit et donc une dégradation des
performances. Il est donc nécessaire, d’employer un processus de « sélection d’indicateurs »

Introduction générale
‐ 3 ‐
qui a pour but de filtrer le vecteur forme de manière à en extraire l’information discriminante
et pertinente améliorant la qualité du système de diagnostic.
Dans ce contexte, nous proposons une nouvelle approche pour la sélection
d’indicateurs les plus pertinents. Cette approche est basée sur la mesure de la séparabilité des
classes, comme critère de sélection. Le sous ensemble sélectionné, est celui qui permet de
maximiser la séparabilités des classes de données. Ainsi, une bonne séparabilité des classes
rend la tache de classification plus précise est plus performante. Dans cette approche,
l’exploration de l’espace de recherche est effectuée en utilisant l’Optimisation par Essaim de
Particules Binaires (OEPB) (Kennedy & Eberhart, 1997). Les sous ensembles d’indicateurs
générés par cette méthode, sont évalués en utilisant le critère Fisher régularisé (CFR)
(Friedman, 1989). Ce dernier, se révèle le mieux approprié pour effectuer la mesure de
séparabilité des classes.
La contribution principale de cette thèse, porte sur l’élaboration d’un système de diagnostic
par RdF, basé sur la combinaison de trois méthodes :
1) l’Optimisation par Essaim de Particules Binaire (OEPB) : c’est l’algorithme de
recherche du sous ensemble optimal d’indicateurs, basé sur la génération d’une
population de solutions (particules),
2) le Critère de Fisher Régularisé (CFR): il est utilisé comme fonction objective pour
évaluer la pertinence de chaque sous ensemble généré par les particules de l’OEPB.
3) Les SVMs sont utilisées pour accomplir la tache de classification en affectant chaque
observation (Signal) à l’une des classes connues. En terme de diagnostic, les classes
correspondent aux modes de fonctionnement connus (Normal, avec défaut), et le fait
de classer une nouvelle observation revient donc à identifier l’un de ces modes.
Organisation de la thèse
La thèse est composée, essentiellement, de quatre principaux chapitres :
Dans le premier chapitre, nous présentons un état de l’art des techniques d’analyse
vibratoire et d’extraction d’indicateurs. Cet état de l’art, à pour but d’éclaircir et de visionner
les avantages et les inconvénients de différentes techniques utilisées dans l’analyse vibratoire,
ce qui permet d’avoir une direction de travail assez claire.

Introduction générale
‐ 4 ‐
Le deuxième chapitre est consacré aux machines à vecteurs supports (SVM), qui sont
adoptée comme méthode de classification dans ce travail. Les bases théoriques de cette
méthode, les algorithmes d’implémentation, et les stratégies adoptées dans le cas multiclasses,
sont également évoquées.
Dans le troisième chapitre, nous présentons d’abord le problème de la sélection
d’indicateurs pour situer le travail, et l’intérêt de la thèse. Nous rappelons aussi, les
principales approches qui peuvent être appliquées. Ensuite nous exposons la méthode que
nous proposons pour la sélection d’un sous ensemble optimal d’indicateurs. Notre approche
est basée sur la combinaison de l’optimisation par essaim de particules binaires et le critère de
Fisher régularisé. Il s’agit d’une phase très importante dans un système de diagnostic par RdF.
La sélection permet de réduire la redondance présente dans les données, et de retenir que les
indicateurs pertinents pour la tâche de classification.
Dans le quatrième chapitre, la méthode de sélection proposée est combinée avec les
SVMs dans le but de concevoir un système de diagnostic automatique des défauts. Ce système
est évalué sur deux types de défauts mécaniques, à savoir les défauts de roulement, et
d’engranges. Les expériences ont été menées en utilisant deux jeux de données vibratoires. Le
premier, est issu d’un banc d’essai de roulements. Le deuxième, provient d’une
instrumentation d’une boite de vitesse d’un hélicoptère. La mise en évidence de l’effet de la
sélection par la méthode proposée sur les performances de la classification, est parmi les buts
essentiels de ce chapitre.

Chapitre I
État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
I.1 Introduction ............................................................................................................................................... 5
I.2 Analyse dans le domaine temporel ........................................................................................................... 6
I.2.1 Les indicateurs scalaires .................................................................................................................... 6
I.2.2 Le moyennage temporel synchronisé ............................................................................................... 8
I.2.3 Les modèles paramétriques ............................................................................................................ 8
I.3 Analyse dans le domaine fréquentiel ........................................................................................................ 9
I.3.1 La transformée de Fourrier .............................................................................................................. 9
I.3.2 L’analyse d’enveloppe ..................................................................................................................... 11
I.3.3 L’analyse cepstrale .......................................................................................................................... 12
I.4 Analyse temps-fréquence ........................................................................................................................... 14
I.4.1 La transformée de Fourrier à fenêtre glissante (TFFG) .................................................................... 14
I.4.2. La distribution Wigner Ville (DWV) .............................................................................................. 15
I.5 Le Kurtosis spectral et le Kurtogramme ................................................................................................... 16
I.6 Analyse temps-échelle .............................................................................................................................. 17
I.6.1 La transformation en ondelettes continues ...................................................................................... 18
I.6.2 La transformation en ondelettes discrètes ....................................................................................... 19
I.6.3 Les paquets d’ondelettes ................................................................................................................. 20
I.7 La décomposition en mode empirique. ...................................................................................................... 21
I.8 Analyse de la cyclostationnarité ............................................................................................................... 22
I.9 Synthèse ..................................................................................................................................................... 23

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 5 ‐
Chapitre I : État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
I.1 Introduction
La première phase de la conception d’un système de diagnostic vibratoire automatisé
par RdF, consiste à traiter les signaux vibratoires issus de différents capteurs placés sur les
machines à surveiller. Un vecteur forme composé de plusieurs indicateurs, est extrait de
chacune des mesures effectuées sur la machine. Les indicateurs ainsi calculés doivent être
significatifs de l’évolution du mode de défaillance à anticiper. Pour cela, le choix des
méthodes de traitement de signal a fait l’objet de plusieurs études ces dernières années.
En analyse temporelle, l’étude est basée sur l’évolution des signaux vibratoires dans le
temps. Dans ce type d’analyse, figurent en premier lieu les grandeurs statistiques telles que :
la valeur moyenne, la variance, la valeur efficace …etc. Une autre approche très populaire
dans le domaine temporel est le moyennage temporel synchronisé. Les modèles paramétriques
sont encore utilisées, à l’exemple des modèles autorégressifs AR, et ARMA.
Les approches portant sur le domaine fréquentiel sont basés sur l’analyse par la
transformation de Fourier (TF), d’où ont découlé différentes techniques telles que la Densité
Spectrale de Puissance (DSP), le cepstre, et l’analyse d’enveloppe ou transformée d’
HILBERT.
Les analyses dans le domaine temps-fréquence permettent de représenter dans ces
deux espaces les signaux non stationnaires. Dans cette catégorie, à part la Transformation de
Fourier à Fenêtre Glissante (TFFG), opération à partir de laquelle est déterminé le
spectrogramme, la distribution d’énergie de WIGNER-VILLE constitue une méthode
d’analyse assez utilisée en traitement du signal. Enfin, la décomposition en ondelettes ou
analyse en temps-échelle, figure dans la quatrième catégorie. D’autres approches avancées,
sont encore utilisées à l’exemple de l’analyse cyclostationnaire, et la décomposition en
modes empiriques.
Ce chapitre décrit les principes, et les applications de ces techniques d’analyse dans le
cadre de diagnostic vibratoire automatisé des machines tournantes. Nous nous intéressons, en

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 6 ‐
particulier, à celles que nous allons utiliser dans la partie expérimentale. Notons ici que les
signaux à traiter par ces méthodes, sont des signaux échantillonnés (numériques).
I.2 Analyse dans le domaine temporel
I.2.1 Indicateurs scalaires
Les indicateurs scalaires sont des outils statistiques appliqués à un signal temporel puis
traités afin d’aider à l’analyse des vibrations. Ils permettent de suivre l‘évolution d‘une
grandeur décrivant de la puissance ou de l’amplitude crête du signal. Sa valeur peut ne pas
avoir de signification intrinsèque, c’est son évolution dans le temps qui est significative du
défaut. De nombreux indicateurs existent dans la littérature ont été utilisés dans le domaine
de diagnostic vibratoire automatisé, et certains sont le résultat de la combinaison de plusieurs
d'entre eux. Zhang (Zhang et al., 2013a) a proposé un ensemble d’indicateurs pour le
diagnostic automatisé des défauts de roulements. Il s’agit des indicateurs statistiques
suivants:
La valeur efficace (Root Mean Square) : ∑ (I.1)
L’écart type (Standard déviation) : ∑ (I.2)
La valeur Crète à crête (Peak-Peak) : max min (I.3)
Le Skewness : ∑ (I.4)
Le Kurtosis : ∑ (I.5)
Où xm est la valeur moyenne du signal temporel x(n).
D’autres indicateurs basés sur la combinaison de ces premiers ont été également proposés
dans (Stepanic et al., 2009), tels que:
Le Facteur de crête (Crest factor) : (I.6)
Facteur d’impulsion (Impulse factor) : ∑ | |
(I.7)
Facteur de clairance (Clearance factor) : ∑ | |
(I.8)

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 7 ‐
Facteur de forme (Shape factor) : ∑ | |
(I.9)
Où xmax est la valeur crête du signal temporel x(n), n=1,2,…, N. N est le nombre de points.
Samanta (Samanta et al., 2003) a proposé une autre série d’indicateurs pour le diagnostic
automatisé des défauts de roulements. Elle est composée essentiellement des grandeurs
statistiques suivantes : la moyenne, l’écart type, la variance, le skewness (représente le
troisième moment statistique centré, M3), le kurtosis (quatrième moment statistique centré,
M4), et du cinquième au neuvième moment statistique centré, calculés comme suit :
(I.10)
Où n est le nombre de points du signal numérique, σ est l’écart type, k est l’ordre du moment
statistique.
Parmi les indicateurs cités ci-dessus, Le Kurtosis a une importance particulière. Il a été
largement utilisé comme outil de diagnostic des défauts dans les machines tournantes (Li et
al., 2013a ; Samanta & Nataraj, 2009 ; Zhang et al., 2013a ; Li et al., 2013b). Théoriquement,
le kurtosis représente le taux d’aplatissement de la distribution d’amplitude, il donne une
évaluation de l’importance du pic du sommet de la courbe de densité de probabilité du signal.
Pour la distribution dite « normale » ou « gaussienne », les valeurs mesurées se répartissent en
forme de cloche autour d’une valeur moyenne, et le Kurtosis vaut mathématiquement 3. Un
signal ayant un Kurtosis > 3 se représente par une distribution plus étroite dominée par la
présence d’amplitudes crêtes anormalement élevées comme c’est le cas en présence de défaut
d’engrenage ou de roulement et qui sont généralement caractérisés par des chocs répétés.
La mesure de la Vitesse efficace entre 10 et 1000 Hz : Veff [10-1000Hz] en mm/s
représente un autre indicateur qui est révélateur de phénomènes « basses fréquences » (BF).
Ces phénomènes sont les plus énergétiques donc les plus destructeurs. Une augmentation du
balourd, un défaut d’alignement, se traduiront par une augmentation anormale de cet
indicateur qui est pris comme référence dans la norme ISO 10816. Un extrait de cette norme
est présenté dans l’annexe 1 de cette thèse. Cette norme définit l’emplacement des points de
mesures et des seuils d’alerte et de danger en fonction du type de machine.
1
( ) , 3..9
( 1)
nk
ii
k k
x xM k
n σ=
−= =
−
∑

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 8 ‐
I.2.2 Le moyennage temporel synchronisé
Le moyennage temporel synchronisé (MTS) représente une autre approche très
populaire dans le domaine temporel. L’idée générale de MTS consiste à découper le signal
vibratoire en segments de même longueur et d’effectuer une moyenne d’ensemble sur ces
segments afin d’éliminer ou réduire le bruit, elle est donnée par (Randall, 2011):
1
0
1( ) ( ), 0N
ns t s t nT t T
N
−
=
= + ≤ <∑ (I.11)
Ceci peut être modélisé comme la convolution du signal S(t) avec un train de N fonctions
déplacées par des multiples entiers de la durée de période T. Cette technique a été appliquée
dans plusieurs études pour le suivi vibratoire des machines tournantes (Komgom et al.,
2007 ; Wu & Zhao, 2009 ; Abdul rahman et al., 2011). Rappelons enfin que cette technique
suppose un signal parfaitement stationnaire.
Dans (Vachtsevanos et al., 2006), il a été noté que, généralement, la vitesse de rotation
des machines n’est pas constante même en mode d’opération normal. Dans ce cas là, le
nombre de points par rotation est différent pour une fréquence d’échantillonnage donnée.
Une opération d’interpolation est, donc, nécessaire pour rendre le nombre de point par
révolution le même avant d’exécuter le moyennage temporel synchronisé. Cette interpolation
transforme le signal vibratoire du domaine temporal au domaine angulaire et redéfini la
fréquence d’échantillonnage pour être en fonction de la position angulaire plus que la position
temporelle. Cette méthode nécessite la présence d’un signal top tour ou un signal codeur
optique.
I.2.3 Les Modèles paramétriques
Les modèles paramétriques représentent d’autres approches appliquées dans l’analyse
temporelle des signaux vibratoires, l’idée générale des ces méthodes est de représenter le
signal temporel par un modèle paramétrique et d’extraire des indicateurs basées sur les
paramètres de ce modèle. Indiquons cependant que cette modélisation est une modélisation de
représentation, les paramètres ne sont pas liés à la physique du phénomène (boite noire)
(Felkaoui et al., 1994). Parmi les modèles couramment utilisés on trouve le modèle ARMA
(Autoregressive Moving Average) d’ordre p ,q et noté ARMA(p,q):
1 1 1 1 ,t t p t p t t q t qx a x a x b bε ε ε− − − −= + ⋅⋅⋅+ + − − ⋅⋅⋅− (I.12)

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 9 ‐
Avec xt :le signal temporel,
ai ,bi : les coefficients du modèle ,
p, q : l’ordre du modèle,
ε : un bruit blanc de moyenne nulle.
Le modèle AR et le modèle MA représentent des cas particuliers du modèle ARMA
avec q=0 et p=0 respectivement (Shin & Hammond, 2008). Le problème major lors du calcul
du modèle autorégressif, est la sélection de l’ordre du modèle. Drouiche (Drouiche et al.,
1991) a proposé une méthode basée sur l'analyse de l'erreur de prédiction linéaire d'un modèle
autorégressif. Cette méthode a été proposée pour la détection précoce des défauts
d’engrenages. Le modèle AR utilisé est d'ordre 30. Cet ordre a été retenu car le spectre des
signaux vibratoires exhibe une quinzaine d'harmoniques. La mise en évidence des défauts,
matérialisée par des sauts de l'énergie de l'erreur de prédiction a été possible sur certains
signaux. D’autres critères pour le choix de l’ordre du modèle ont été également proposés dans
(Felkaoui et al., 1994 ; Aparna & Mallikarjun, 2002).
I.3 Analyse dans le domaine fréquentiel
I.3.1 La transformée de Fourier
La transformée de Fourier (TF) est l’une des méthodes les plus utilisées dans le monde
industriel. De part sa facilité de mise en œuvre et d'interprétation, cette représentation permet
de connaître le contenu fréquentiel d'un signal temporel. Pour cette raison la transformée de
Fourier a été largement utilisée dans le domaine de diagnostic des défauts pour localiser les
fréquences caractéristiques de défauts. Dans la pratique, et plus particulièrement pour des
signaux numériques, on utilise la transformée de Fourier discrète rapide (Fast Fourier
Transform, FFT) (Shin & Hammond, 2008), elle est définie par :
1 2
0
1( ) ( )nN j kN
en
X k f x nt eN
π− −
=
Δ = ∑ (I.13)
Où X(kΔf) est la transformée de Fourier rapide,
te est la période d’échantillonnage du signal temporel,
n est le numéro de l’échantillon,
k est le numéro de la ligne fréquentielle,
Δf est l‘intervalle entre deux raies fréquentielles
N est le nombre d‘échantillons prélevés.

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 10 ‐
L’utilisation directe des composantes de la transformée de Fourier comme indicateurs,
d’une manière quantitative, n’est pas pratique en diagnostic des défauts due à la quantité
massive de l’information contenue dans cette représentation et à la résolution fréquentielle
adoptée. Pour cette raison, plusieurs indicateurs ont été proposés dans la littérature.
Dans (Zhao et al., 2013), les auteurs proposent une série d’indicateurs afin de détecter les
défauts d’engrenages d’une boite de vitesse:
La moyenne fréquentelle (Mean frequency) : ∑ (I.14)
Le Centre fréquentiel (Frequency centre) : ∑ .∑ (I.15)
La valeur efficace fréquentielle (RMS frequency) : ∑∑ (I.16)
L’écart type fréquentiel (Standard deviation frequency) : ∑ .∑ (I.17)
L’amplitude des fréquences caractéristiques du 1er et du 2ème étage de la boite de vitesse:
(I.18)
(I.19)
Avec n=-6,-5,…,6 .
Où f c est la fréquence de rotation,
est la valeur de la fréquence de la kième ligne du spectre,
Z est le nombre de dents,
Xk est le spectre, K est la longueur du spectre.
En plus des trois premiers indicateurs, deux autres ont été proposés dans (Zhang et al.,
2013a) pour le diagnostic des roulements à rouleaux:
Pique du spectre de la bague intérieure (Spectrum peak ratio inner) :
∑∑ (I.20)
Pique du spectre de la bague extérieure (Spectrum peak ratio outer)
1 11, 1( )* c
n rf z n f= +
2 21, 2( )* c
n rf z n f= +

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 11 ‐
∑∑ (I.21)
Où S(k) est le spectre calculé pour k=1,2,……..,K. K est le nombre de lignes de spectre;
, sont respectivement les valeurs des pics de la hième harmonique de la fréquence
caractéristiques de défaut de bague extérieure , et de la bague intérieure qui peuvent
être calculés respectivement par les équations suivantes :
1 cos (I.22)
1 cos (I.23)
Où f est la fréquence de rotation, est le nombre d’éléments roulants, est l’angle de
contact, d et D sont le diamètre de bille et le diamètre du roulement respectivement. Pour
plus de détails sur le calcul fréquences caractéristiques des défauts de roulements, on peut se
référer à l’annexe 2.
Dans (Gryllias & Antoniadis 2012), d’autres indicateurs ont été proposés pour le
diagnostic des défauts de roulements tels que l’énergie dans les hautes fréquences, et la
somme des pics des quatre premières harmoniques de la fréquence de rotation. En plus,
d’autres indicateurs ont été extraits du spectre d’enveloppe.
La Densité Spectrale de Puissance (DSP), calculée dans des bandes caractéristiques de
défaut, a été également utilisée comme indicateur pour la détection automatique des défauts
dans plusieurs études (Tyagi, 2008 ; Mollazade et al., 2008; Choudhary et al., 2014). La DSP
est définie comme étant le carré du module de la transformée de Fourier, divisée par le temps
d'intégration T. Ainsi, si x(t) est un signal et X(f) sa transformée de Fourier, la densité
spectrale de puissance vaut :
(I.24)
I.3.2 L’analyse d’enveloppe
L’analyse d’enveloppe est une méthode qui permet de détecter des chocs périodiques à
partir des résonances de structure (carters, paliers, bagues de roulement). En effet, les défauts
de roulement de type choc excitent les hautes fréquences des structures, ainsi un phénomène
de modulation se produit entre la fréquence de défaut (basse fréquence) et la résonance de
structure (haute fréquence). Après avoir démodulé le signal, le spectre d’enveloppe fera donc
2( ) ( )
X fDSP f
T=

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 12 ‐
mieux apparaître les raies d’impulsions dues au défaut. En pratique, pour obtenir le spectre du
signal enveloppe, il faut suivre les étapes suivantes (Li et al., 2012) :
- Déterminer les fréquences de résonance.
- Filtrer, avec un filtre passe bande, le signal temporel autour des fréquences de
résonance.
- Calculer le signal d’enveloppe à l’aide de la transformée d’Hilbert (Voir annexe 3).
- Calculer le spectre d’enveloppe à l’aide de la transformée de Fourier
Un exemple de calcul du spectre d’enveloppe est présenté dans l’annexe 4.
McFadden (McFadden & Smith, 1985) a étudié la façon dont le signal de défaut de
roulement (représenté par un déplacement plutôt que d'une accélération) se manifeste par le
spectre d'enveloppe, et il a développé un modèle de vibration monomode pour expliquer
l'apparition de diverses lignes spectrales relatives aux emplacements différents dans le spectre
d’enveloppe. Ce modèle a été étendu par Su (Su & Lin , 1992) pour caractériser les vibrations
des roulements qui ont été soumis à une variété de charges.
Une autre étude sur les roulements a été menée par Yang (Yang et al., 2007). Dans
cette étude, le signal vibratoire a été décomposé en plusieurs fonctions de mode intrinsèque
(en anglais : Intrinsec Mode Function IMF) en utilisant la décomposition en modes
empirique (Empirical Mode Décomposition EMD), puis le spectre d’enveloppe a été calculé
pour certains IMFs. Les amplitudes des pics autour des fréquences caractéristiques des
défauts, extraits du signal d’enveloppe, ont été utilisées pour construire le vecteur forme
nécessaire à tache de classification.
D’autres application de l’analyse d’enveloppe en diagnostic des défauts de
roulements, peuvent être consultées dans les références (Randall, 2001 ; Stepanic et al., 2009 ;
Li et al., 2012 ; Pan & Tsao, 2013).
I.3.3 L’analyse cepstrale
C’est la représentation de la transformée de Fourier du spectre ; soit deux fois la
transformée de Fourier du signal temporel de base. L’image obtenue est une courbe en
fonction du temps (quéfrence) mesurée en secondes. Mathématiquement, le cepstre d’un
signal x(t) est la transformée de Fourrier inverse du logarithme décimal de sa transformée de
Fourrier directe (El Badaoui et al., 1997) :
Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 13 ‐
(I.25)
Une autre définition est celle du cepstre de puissance :
(I.26)
La variable τ du cepstre a la dimension d'un temps. Elle est appelée « quéfrence »
(anagramme du mot fréquence). Elle représente les périodes d'oscillations des réponses
impulsionnelles de la structure, et les périodes de répétition ou de modulation des forces
d'excitation.
Le cepstre est un outil de diagnostic utilisé pour distinguer des défauts qui donnent des
images spectrales complexes dues à plusieurs modulations d’amplitude concomitantes. Les
engrenages peuvent nécessiter ce type d’analyse. En effet, la fréquence d’engrènement est
souvent modulée par les fréquences de rotation des roues menantes et menées. Le cepstre
permet de séparer et d’identifier, sur une seule image, toutes les fréquences de modulation
(fréquences de rotation des arbres d’entrée, intermédiaire, et de sortie dans un réducteur).
Dans l’analyse spectrale, un phénomène périodique dans le temps n’est représenté que
par un seul pic sur un spectre. De la même façon, un phénomène représenté par un spectre
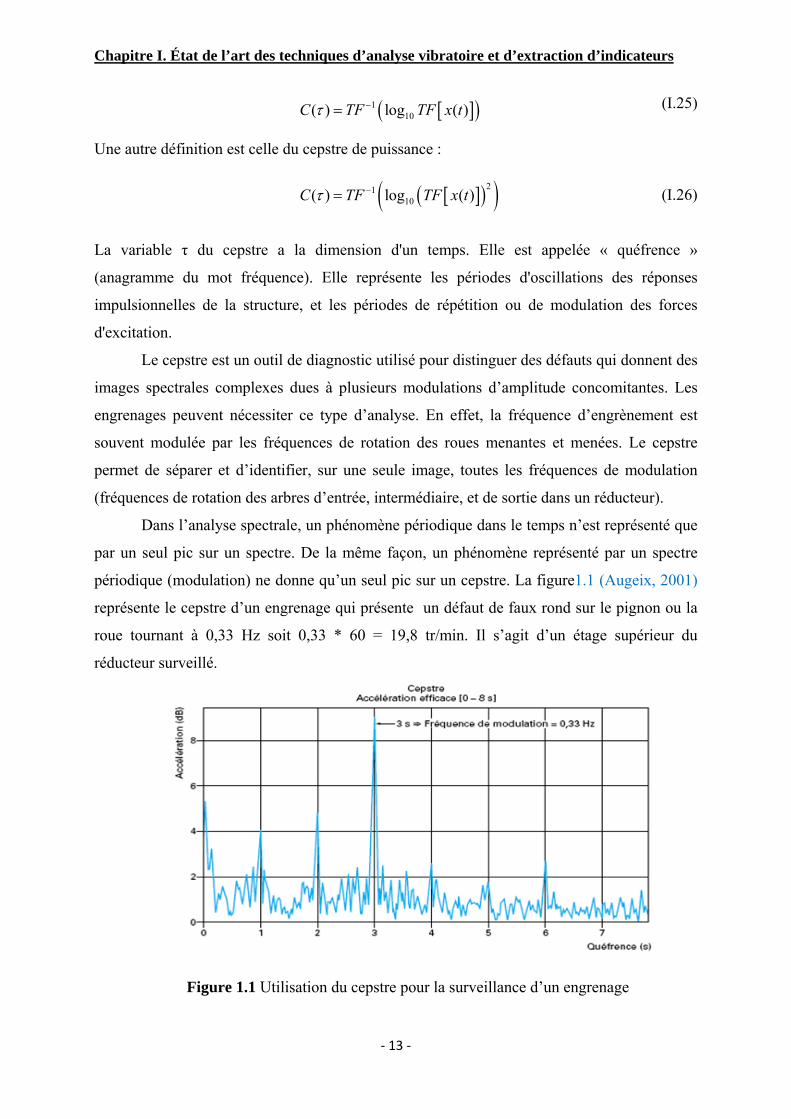
périodique (modulation) ne donne qu’un seul pic sur un cepstre. La figure1.1 (Augeix, 2001)
représente le cepstre d’un engrenage qui présente un défaut de faux rond sur le pignon ou la
roue tournant à 0,33 Hz soit 0,33 * 60 = 19,8 tr/min. Il s’agit d’un étage supérieur du
réducteur surveillé.
Figure 1.1 Utilisation du cepstre pour la surveillance d’un engrenage
[ ]( )( )2110( ) log ( )C TF TF x tτ −=
[ ]( )110( ) log ( )C TF TF x tτ −=

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 14 ‐
Dans (El Badaoui et al., 1997), les auteurs ont utilisés le cepstre de puissance lors de
l’étude d’un réducteur à engrenage. Dans cette étude, les prévisions théoriques concernant la
constance de la somme des premiers pics du cepstre de puissance ont été vérifiées sur deux
expérimentations différentes. Ils ont pu démontrer que cette technique peut constituer un outil
de diagnostic efficace et simple à interpréter. Li (Li et al., 2009) quand à lui, a utilisé le
cepstre pour le diagnostic des défauts d’engrenages. Dans cette étude, l’indicateur utilisé
comme paramètre d’entrée aux Réseaux de Neurones Artificiels (RNA) est l’index
d’impulsion défini par :
(I.27)
Où Cm est le pic du cepstre, est la moyenne du cepstre définie par :
(I.28)
Avec Ci est l’amplitude de l’ième quéfrence, Nc est le nombre de points.
I.4 Analyse temps- fréquence
En utilisant les deux représentations d’un signal vibratoire dans les deux domaines
précédents, plusieurs indicateurs peuvent être obtenus. Mais quand le contenu spectral du
signal change dans le temps, les indicateurs extraits dans un seul domaine (temporel ou
spectral) ne sont pas suffisants pour représenter le signal. Plusieurs méthodes ont été
proposées pour remédier à ce problème. La transformée de Fourrier à fenêtre glissante
(TFFG) ou spectrogramme, et la distribution Wigner–Ville (DWV), sont les distributions
temps -fréquence les plus utilisées. Dans cette catégorie, il convient également de citer une
récente méthode appelée le Kurtogramme.
I.4.1 La transformée de Fourrier à fenêtre glissante (TFFG)
La Transformation de Fourrier à Fenêtre Glissante (TFFG), dite de «Gabor », consiste
à multiplier le signal x(t) par une fenêtre glissante g(τ) centré autour de t = 0, et calculer la
transformée de Fourier du produit x(t)*g(τ). Cette transformée de Fourier fournit une
information fréquentielle du signal au voisinage de t = 0. Dans cette méthode le signal est
supposé quasi stationnaire à l’intérieure de la fenêtre g(τ). La TFFG a pour expression
(Randall, 2011) :
(I.29)
c
mpulse
Cfc
=
1
1 cN
iic
c CN =
= ∑
( , ) ( ). ( ) exp( 2 )gX t f x t g t j ft dtτ π+∞
−∞
= − −∫

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 15 ‐
La densité d’énergie appelée le spectrogramme est défini comme étant le produit de TFFG :
х (I.30)
Le passage d’un axe unique de temps ou de fréquence à un plan temps-fréquence
fournit une meilleure structuration de l’information sur le signal, certes au prix d’une
augmentation de redondance, mais en offrant une possibilité de lecture différente et
complémentaire du signal analysé (Flandrin, 1993). Ainsi, une lecture intelligente de l’image
du plan temps-fréquence (spectrogramme), nous permet de bien comprendre le comportement
du signal et une interprétation directe sur le nombre de composantes et sur leur contenu
temps-fréquence.
Dans (Worden et al., 2011), les auteurs indiquent que la limitation de cette méthode
réside dans la résolution de l’analyse dans le temps et la fréquence. Une bonne résolution dans
le temps (localisation) implique l’utilisation une petite fenêtre temporelle ce qui résulte une
mauvaise résolution fréquentielle et vice versa.
I.4.2 La distribution de Wigner Ville (DWV)
La distribution de Wigner-Ville (DWV) est une extension de la TFFG. Cette
distribution a beaucoup de propriétés utiles pour l’analyse des signaux non stationnaires ou
transitoires elle est définie par :
* 2( , ) ( ) ( ).2 2
j fsW t f x t x t e dπ ττ τ τ
+∞−
−∞
= + −∫ (I.31)
Avec : x(t) signal complexe quelconque.
Cette distribution est bilinéaire, car le signal est multiplié par lui même. On peut interpréter
l’équation (I.31) en utilisant la notion de corrélation. La valeur de la distribution Ws(t, f) est la
mesure de la corrélation du signal avec sa version décalée en fréquence et considérée selon
l’axe du temps inverse.
L’inconvénient principal associé à la distribution de Wigner-Ville est son manque de
lisibilité, conséquence de la présence de termes d’interférence qui n’ont pas de réalité
physique et peuvent masquer les composantes physiquement significatives. L’une des
solutions de ce problème d’interférence consiste à appliquer un lissage dans le plan temps-
fréquence afin de les atténuer. Cette méthode est appelée Pseudo Wigner-Ville lissée (PWVL)
(Baydar, 2001). Elle a la forme suivante :
( , )gX t f*
( , )gX t f

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 16 ‐
(I.32)
Où g(u-t) est une fonction de fenêtrage (Hamming, Hanning...etc). et H(v-f) la fonction de
transfert du filtre passe-bande.
Dans (Baydar & Ball, 2001) a été démontré que la version lissée de la distribution de
Pseudo Wigner-Ville peut servir à la détection des défauts d’engrenage. Pour cela, trois types
de défauts ont été simulés : dent cassée, roue fissurée et arbre usé. Par ailleurs, une
comparaison avec les résultats sur les signaux acoustiques a permis de conclure que cette
méthode peut fournir d’importants éléments de diagnostic.
Une autre solution pour remédier au problème d’interférence de la DWV a été
proposée dans (Liu et al., 2013). Cette méthode consiste à supprimer les interférences par une
fenêtre de traitement appelée (Auto Terms Window ATW). Le but est d’obtenir une meilleure
résolution en temps-fréquence.
La figure 1.2 compare la DWV et la PWVL avec la TFFG pour un signal de vibration d'un
cycle de moteur diesel. Cette figure montre que le lissage donne une résolution simultanée
dans les deux sens qui est meilleure que la TFFG, tout en supprimant les principales
composantes d'interférence.
Figure 1.2 Comparaison des représentations temps-fréquence d’un signal vibratoire d’un moteur Diesel: (a) TFFG;(b) distribution Wigner–Ville; (c) pseudo-Wigner–Ville lissé (Extrait de Randall,
2011) I.5 Le Kurtosis spectral et le Kurtogramme
Le kurtosis spectral (Antoni, 2006) constitue un outil très utile pour caractériser les
signaux non stationnaires, et il a été utilisé pour le diagnostic des défauts dans plusieurs
études (Cong et al., 2012, Belaid et al.,2013, Chen et al., 2014). Cette méthode consiste à
calculer la TFFG comme il a été décrit dans la section précédente, puis calculer le Kurtosis
( , ) ( , ) ( ) ( ) sPW t v W u v g u t H v f du dv+∞
−∞
= × − × −∫
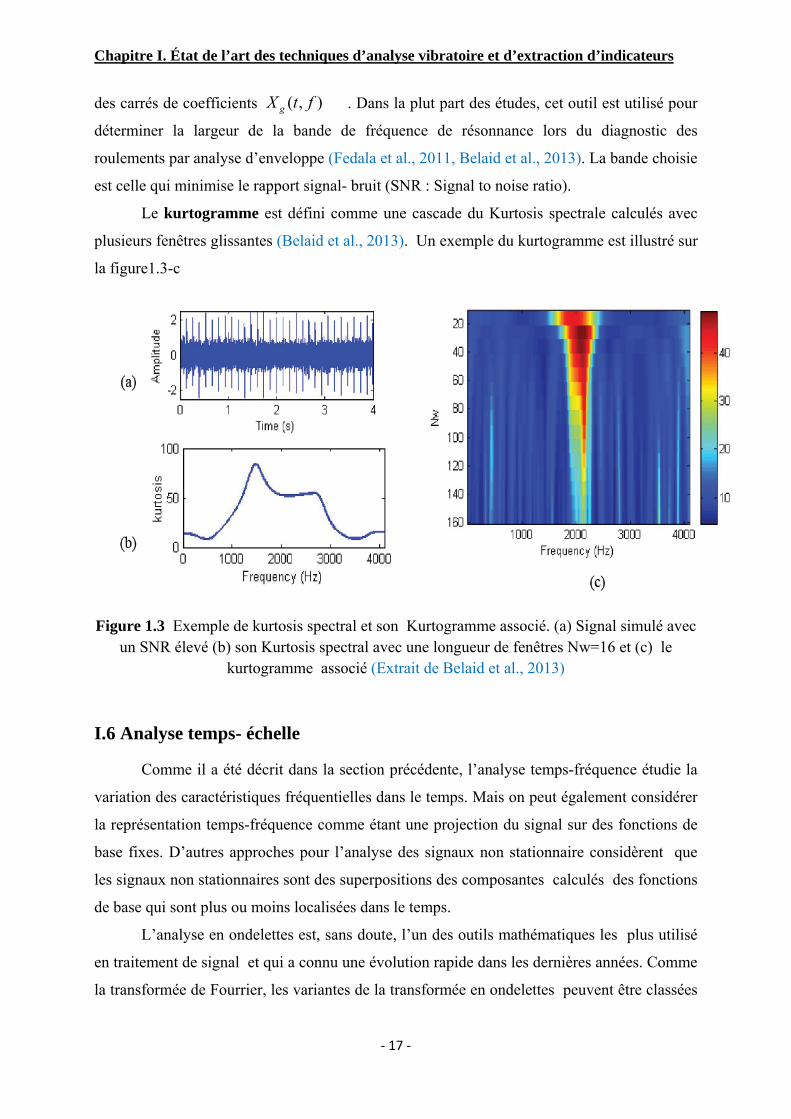
Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 17 ‐
des carrés de coefficients . Dans la plut part des études, cet outil est utilisé pour
déterminer la largeur de la bande de fréquence de résonnance lors du diagnostic des
roulements par analyse d’enveloppe (Fedala et al., 2011, Belaid et al., 2013). La bande choisie
est celle qui minimise le rapport signal- bruit (SNR : Signal to noise ratio).
Le kurtogramme est défini comme une cascade du Kurtosis spectrale calculés avec
plusieurs fenêtres glissantes (Belaid et al., 2013). Un exemple du kurtogramme est illustré sur
la figure1.3-c
Figure 1.3 Exemple de kurtosis spectral et son Kurtogramme associé. (a) Signal simulé avec un SNR élevé (b) son Kurtosis spectral avec une longueur de fenêtres Nw=16 et (c) le
kurtogramme associé (Extrait de Belaid et al., 2013)
I.6 Analyse temps- échelle
Comme il a été décrit dans la section précédente, l’analyse temps-fréquence étudie la
variation des caractéristiques fréquentielles dans le temps. Mais on peut également considérer
la représentation temps-fréquence comme étant une projection du signal sur des fonctions de
base fixes. D’autres approches pour l’analyse des signaux non stationnaire considèrent que
les signaux non stationnaires sont des superpositions des composantes calculés des fonctions
de base qui sont plus ou moins localisées dans le temps.
L’analyse en ondelettes est, sans doute, l’un des outils mathématiques les plus utilisé
en traitement de signal et qui a connu une évolution rapide dans les dernières années. Comme
la transformée de Fourrier, les variantes de la transformée en ondelettes peuvent être classées
( , )gX t f
Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 18 ‐
en continue et discrète. Les ondelettes continues sont mieux adaptées pour l’analyse temps-
fréquence et pour la visualisation, tandis que les ondelettes discrètes sont très utiles en
décomposition, compression et pour l’extraction des indicateurs (Worden et al., 2011).
I.6.1 La transformation en ondelettes continues
Par analogie avec la transformée de Fourrier, la transformée en ondelette est une
transformation linéaire qui décompose un signal x(t) en fonctions élémentaires ψa,b(t) qui sont
obtenus par translation et dilatation de l’ondelette mère (Worden et al., 2011) . Usuellement la
transformée en ondelette continue est définie par:
,√
(I.33)
Où ‘b’ est un paramètre de translation et ‘a’ est un paramètre d’échelle qui mesure la
dilatation ou la contraction de l’ondelette, ψ(t) est l’ondelette mère, l’étoile indique le
conjugué de la fonction. Chaque valeur de la transformée en ondelette w (a,b) est normalisé
par un facteur 1 √⁄ .
Il existe un grand nombre de fonctions réelles et complexe qui peuvent être utilisées
comme ondelettes mère. En générale toutes ces fonctions doivent satisfaire la condition
suivante :
(Énergie finie de l’ondelette) (I.34)
Le choix de l’ondelette mère optimale dépend de l’application envisagée. La figure1.4
montre deux exemples d’ondelettes dont la plus connue est celle de Morlet qui est donnée
par :
21exp( )2
i t tψ σ= −
a) Ondelette de Morlet b) Ondelette de chapeau mexicain
Figure 1.4 Exemples d’ondelettes.
2
( ) dttψ+∞
−∞
< ∞∫

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 19 ‐
I.6.2 La transformation en ondelettes discrètes
Dans l’équation (I.33) de la transformée en ondelettes continue, les paramètres a et b
prennent une infinité de valeurs. Il est possible de limiter le nombre de coefficients sans
perdre d’information sur le signal de départ. On parle alors de transformée en ondelettes
discrète (TOD). Le choix classique de l’échantillonnage des paramètres est une discrétisation
logarithmique pour a, avec b proportionnel à a. Les ondelettes discrètes ont alors la forme :
(I.35)
Où ψm,n(t) est l’ondelette mère ψ translatée et dilatée définie par :
,1 2( ) ( )
22
m
m n mm
t ntψ ψ −=
(I.36)
Dans cette transformation, les termes a et b de la transformation en ondelettes continue sont
remplacés par « 2m » et « 2mn » respectivement
La méthode proposée par Mallat (Mallat,1989) , consiste à utiliser des filtres où le
signal x(t) obtenu après filtrage passe-bas est appelé « approximation », et celui obtenu après
filtrage passe-haut est appelé « détail », le processus de décomposition (Fig. 1.5) est itéré en
décomposant successivement les approximations pour obtenir de basses composantes du
signal.
Figure 1.5 Structure de la décomposition en ondelettes
La transformation en ondelettes discrète est réalisée en utilisant des ondelettes orthogonales.
L’ondelette orthogonale la plus simple est celle de HAAR h(t)qui est égale à 1 dans
*,( ) ( )m
n m nW x t t dtψ+∞
−∞
= ∫
Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 20 ‐
l’intervalle [0,1/2[, et -1 dans [1/2,1[, et 0 à l’extérieur des ces deux intervalles (Fig. 1.6-a).
Le développement important des d’ondelettes orthogonales est, sans doute, la famille
d’ondelettes proposées par Daubchies (Daubchies, 1992). Les ondelettes de Daubchies
(Fig.1.5-b) ne peuvent pas être représentées dans une forme mathématique car elles résultent
des fonctions d’échelles qui correspondent à des réponses des filtres d’impulsions (Worden et
al 2011).
a) ondelette de Haar b) Ondelette de Daubchies 4
Figure 1. 6 Exemples d’ondelettes orthogonales.
On peut imaginer un grand nombre d’applications de la TOD dans le domaine de
diagnostic des défauts. Qiu (Qiu et al., 2006) a utilisé la TOD pour le filtrage des signaux à
travers la reconstruction du signal dont le but est la détection précoce des défauts roulements.
Dans cette étude la décomposition en valeurs singulière a été utilisée pour l’optimisation du
paramètre d’échelle. Dans (Tyagi, 2008), l’auteur a utilisé plusieurs indicateurs statistiques
comme entrées au RNA et SVM pour la détection automatique des défauts de roulements. Ces
indicateurs ont été extraits des coefficients de la TOD au sixième niveau de décomposition.
L’ondelette mère utilisée dans cette étude est celle de Daubchies d’ordre 4 (Db4).
I.6.3 Les paquets d’ondelettes
La décomposition en paquets d’ondelettes (DPO) est similaire à la transformation en
ondelettes discrète. Les deux sont des méthodes d’analyse multi-résolution. La différence
entre les deux méthodes c’est que la DPO décompose simultanément les versions des détails
(Di) et les approximations (Ai) (Fig.1.7), tandis que la TOD décompose uniquement les
approximations. Ajoutant aussi que la DPO a la même largeur de bande fréquentielle dans
chaque résolution, propriété qu’on ne trouve pas en transformée en ondelettes discrète.

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 21 ‐
Figure 1.7 Arbre de décomposition en paquets d’ondelettes pour 3trois niveaux de
décomposition
La décomposition en paquets d’ondelettes a été utilisée par Li (Li et al., 2013b) pour
la détection des défauts multiples d’une boite de vitesse. Dans cette étude, le signal est
décomposé en 2j coefficients (j est le niveau de décomposition). Puis, l’énergie, l’entropie, le
skewness, et le kurtosis de chaque coefficient obtenu par DPO, ont été utilisés comme
indicateurs pour la détection des défauts d’engrenages. Les mêmes indicateurs ont été calculés
dans les IMFs après décomposition en mode empirique. Enfin une méthode de sélection
appelée (locally linear embedding LLE) a été appliquée pour sélectionner les indicateurs les
plus pertinents.
Le choix de niveau de décomposition en paquet d’ondelettes constitue un paramètre
important dans la phase d’extraction d’indicateurs. Dans (Shen et al. 2013), il a été montré
que généralement 3 niveaux de décomposition sont suffisants pour cette tache.
I.7 La décomposition en mode empirique
La décomposition en mode empirique, EMD (Empirical Mode Decomposition) a été
proposée par Huang (Huang et al, 1998) pour l’analyse des signaux non stationnaires.
Contrairement à la représentation temps-fréquence ou aux ondelettes, la base de
décomposition de l’EMD est intrinsèque au signal. L’extraction des composantes oscillantes
appelées modes empiriques est non-linéaire, mais leur recombinaison est linéaire. Cette
méthode est une décomposition adaptée au signal, ne nécessitant pas d’informations a priori
sur ce dernier. Comme l’EMD n’a pas de formulation analytique, elle est définie par un
algorithme et par un processus appelé tamisage (Mahgoune et al., 2011), permettant de
décomposer le signal en modes empiriques ou IMFs (Intrinsic mode functions). La
décomposition est locale, itérative, séquentielle et entièrement pilotée par les données.
Pour calculer les IMFs, la procédure est comme suit :

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 22 ‐
1) Extraire les maxima et minima locaux du signal.
2) Calculer les enveloppes supérieure et inférieure par interpolation,
3) Calculer l’enveloppe moyenne locale m(t) à partir des enveloppes supérieure et
inférieure
4) soustraire l’enveloppe moyenne du signal d’entrée h(t)=x(t)-m(t)
5) Si h(t) est un IMF, le résidu est r(t)=x(t)- h(t) et le nouveau signal sera x(t)=h(t),
6) Si h(t) n’est pas un IMF le nouveau signal sera x(t)=r(t),
La propriété de l’EMD comme étant un filtre passe band, a été exploité par Pan (Pan &
Tsao, 2013) pour déterminer avec précision les IMFs qui contiennent les fréquences de
résonnance avant d’appliquer l’analyse d’enveloppe. Cette méthode a été comparée avec
l’analyse classique de l’enveloppe pour la détection des défauts multiples de roulements.
Dans (Grasso et al.,2014), les auteurs proposent une approche basée sur le couplage
de l’EMD avec l’Analyse en Composante Principale (ACP) pour la maintenance
conditionnelle d’une machine de découpage par jet d’eau. Dans cette étude, le signal de la
haute pression de l’eau a été utilisé comme source d’information. Le signal acquis durant le
processus de découpage est segmenté en plusieurs fenêtres où la largeur de chaque fenêtre
correspond à un cycle de pompage, puis les IMFs de chaque fenêtre sont calculées. La base de
données obtenue est considérée comme base de référence (état de fonctionnement normal). Le
rôle de l’ACP est de contrôler toute déviation par rapport à cet état de référence ce qui
signifie l’apparition d’un défaut.
I.8 Analyse de la cyclostationnarité
L’analyse cyclostationnaire consiste à exploiter l’évolution périodique des paramètres
statistiques d’un signal vibratoire. Les machines tournantes telles que les boites de vitesses
sont des mécanismes à géométrie périodique en rotation, qui par construction évoluent
cycliquement et produisent ainsi des signaux potentiellement cyclostationnaires. D’un point
de vue mathématique, la stationnarité ou la cyclostationnarité d’un signal peut être identifiée à
partir de l’état de son autocorrélation (Breneur, 2002). L’autocorrélation d’un signal
s’exprime de la façon suivante : *( , ) ( / 2). ( / 2)xxR t E x t x tτ τ τ⎡ ⎤= + −⎣ ⎦
(I.37)
Le signal x(t) est stationnaire à l’ordre deux si son autocorrélation est indépendante de t.

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 23 ‐
Le signal x(t) est purement cyclostationnaire si son autocorrélation dépend de t de façon
périodique tel que : Rxx (t, τ)= Rxx (t+T, τ). La fréquence 1/T alors associée est la fréquence de
cyclostationnarité.
Le signal est cyclostationnaire au sens large, si son autocorrélation présente plusieurs
périodicités par rapport à t. Il s’ensuit alors plusieurs fréquences de cyclostationnarité,
introduites notamment par des phénomènes de modulation. C’est le cas des signaux
vibratoires prélevés sur les machines tournantes.
L’autocorrélation étant périodique, le calcul de sa double transformée de Fourier (par rapport
à t et τ) donne une quantité significative, qui est la corrélation spectrale du signal :
[ ] *
,( ) ( , ) ( ). ( )2 2
xx tS f TF R t E x f x fατ
α ατ ⎡ ⎤= = + −⎢ ⎥⎣ ⎦ (I.38)
L’auto corrélation est un outil très intéressant pour l’étude des défauts d’engrenages. La
présence d’un tel défaut entraîne l’apparition de bandes latérales autour des harmoniques
d’engrènement. La corrélation spectrale permet d’étudier le lien existant entre les fréquences
caractéristiques du système telles que la fréquence de rotation et la fréquence d’engrènement
et ces harmoniques (Breneur, 2002). Une étude menée par Bouillaut (Bouillaut & Sidahmed,
2001) montre que l’analyse de cyclostationnarité, comparée au bispectre, présente bien des
intérêts d’un point de vue ‘souplesse’ d’estimation et temps de calcul. Elle fournissait de
meilleurs résultats pour le diagnostic de défauts sur les systèmes d’engrenage, et ce, quelle
que soit la nature du défaut étudié.
Les deux excellentes références (Antoni, 2007) et (Antoni, 2009), donnent des
informations détaillées sur l’estimation et l’interprétation de la corrélation spectrale et
d’autres fonctions d’intérêt dans l’analyse cyclostationnaire
I.9 Synthèse
Nous avons présenté dans ce chapitre des travaux touchant à l’analyse des signaux
vibratoire en vue de diagnostic de défauts dans les machines tournantes.
Les indicateurs statistiques tels que la moyenne, la valeur efficace, le Kurtosis…etc.,
permettent une première appréciation de l’état vibratoire d’une machine ou d’une installation.
Malheureusement, ils trouvent leur limite pour un diagnostic précis identifiant la nature de
défaut et surtout la localisation de l’élément défaillant dans la machine.

Chapitre I. État de l’art des techniques d’analyse vibratoire et d’extraction d’indicateurs
‐ 24 ‐
Les méthodes avancées de diagnostics tels que la transformée de Fourrier, le cepstre
ainsi que l’analyse d’enveloppe, donnent des résultats encourageantes quand il s’agit de
découvrir l’existence de défauts dans les machines tournantes. Il est à noter que l’analyse
d’enveloppe est l’outil le plus approprié à l’analyse des signaux de roulements. Ces signaux
sont caractérisés par de faibles fréquences, et ces derniers sont généralement modulés par les
fréquences de résonnance de la structure. Cependant, ces méthodes offrent peu d’information
sur la localisation tant dans l’espace que dans le temps de ces défauts. Ce problème a été
cerné par le développement des techniques d’analyse du signal dans le domaine temps-
fréquence tels que la distribution de Wigner Ville et la Transformée de Fourrier à fenêtre
glissante, et le kurtosis spectral.
Les trois variantes de la transformées en ondelettes (TOC, TOD, et DPO), ont été
largement utilisées dans le domaine de diagnostic des défauts dans les machines tournantes
grâce à leurs aptitude de traiter des signaux non stationnaire, où beaucoup plus
d’informations aidant au diagnostic apparaissent. Pour cette raison, elles seront appliquées
dans la partie expérimentale de cette thèse.
Cette tache d’analyse des signaux vibratoires et d’extraction des indicateurs constitue
la première phase dans l’élaboration d’un système de diagnostic vibratoire automatisé. La
deuxième phase consiste à choisir une méthode de classification. Cette méthode doit être
entrainée avec l’ensemble d’apprentissage obtenue dans la phase d’analyse afin de pouvoir
prédire l’état de santé de la machine, en affectant toute nouvelle observation (signal) à l’une
des classes de fonctionnement (Normal, avec défaut). Dans le deuxième chapitre nous
présentons les machines à vecteurs supports (SVM) qui sont adoptées comme méthode de
classification dans ce travail.
.

Chapitre II
Les Machines à Vecteurs Supports (SVMs)
II.1Introduction .............................................................................................................................................. 25
II.2 Théorie de l’apprentissage statistique ...................................................................................................... 26
II.3 Les machines à vecteurs supports (SVMs) .............................................................................................. 28
II.3.1 SVMs à marge dure ........................................................................................................................ 28
II.3.2 SVMs à marge souple ..................................................................................................................... 31
II.3.3.Utilisation des noyaux ................................................................................................................... 33
II.4.Optimisation des SVMs ........................................................................................................................... 36
II.4.1 Méthode de Chunking .................................................................................................................... 37
II.4.2 Méthode de décomposition successive .......................................................................................... 37
II.4.3 Méthode de minimisation séquentielle (SMO) .............................................................................. 38
II.5 Implémentation des SVMs ...................................................................................................................... 38
II.6 Les SVMs multiclasses ............................................................................................................................ 38
II.6.1 Approche Un-contre-Reste (1vsR) ................................................................................................ 38
II.6.2 Approche Un-contre-un (1vs1) ...................................................................................................... 39
II.6.3 Graphe acyclique de décision (DAGSVM) ........................................................................................... 40
II.7 Conclusion .............................................................................................................................................. 40

Chapitre II Les machines à vecteurs supports (SVMs)
- 25 -
Chapitre II: Les machines à vecteurs supports (SVMs)
II.1 Introduction
Les machines à vecteurs supports (En anglais : Support Vector Machines (SVMs)) font
partie d’une vaste famille d’algorithmes originalement regroupés dans le domaine de
reconnaissance de formes RdF et de l’intelligence artificielle. Les SVMs ont été initialement
conçus pour trouver un discriminateur optimal entre deux classes de données, et ont été
ensuite étendues pour le cas multi classes. La capacité de généralisation, et l'aspect
stochastique ont favorisé l'utilisation de cette méthode d'apprentissage statistique pour le
diagnostic de défauts. Dans ce cas, le diagnostic est assimilé à un problème de classification
en deux classes (normale, et avec défaut).
Cette méthode découle directement des travaux de Vapnik (Vapnik, 1998 ; Vapnik,
2000) sur la théorie de l’apprentissage statistique. Elle s’est focalisée sur les propriétés de
généralisation (ou prédiction) d’un modèle en contrôlant sa complexité. Le compromis entre
la capacité d’apprentissage et la capacité de généralisation pour ces machines est
respectivement accompli en minimisant l’erreur empirique et dans le même temps, en
essayant de maximiser une marge géométrique. Les SVMs ne dépendent pas de la dimension
de l’espace de représentation des données. Grâce à l’usage d’une fonction noyau, elles
permettent une classification non linéaire comme nous le verrons dans ce chapitre.
Pour deux classes d’exemples donnés, Le principe de base des SVMs consiste de
trouver un hyperplan optimal, qui va séparer les données et maximiser la distance entre ces
deux classes. Deux idées ou astuces permettent d’atteindre cet objectif :
• La première consiste à définir l’hyperplan comme solution d’un problème
d’optimisation sous contraintes dans lequel le nombre de contraintes “actives” ou
vecteurs supports contrôle la complexité du modèle.
• Le passage à la recherche de surfaces séparatrices non linéaires est obtenu par
l’introduction d’une fonction noyau (kernel) dont le produit scalaire induisant
implicitement une transformation non linéaire des données vers un espace

Chapitre II Les machines à vecteurs supports (SVMs)
- 26 -
intermédiaire (feature space) de plus grande dimension. D’où l’appellation
couramment rencontrée de machine à noyau ou kernel machines.
Le présent chapitre introduit les machines à vecteurs supports, leurs origines
théoriques, leurs différentes formes, et leurs méthodes d’optimisation. Pour plus de détails, le
lecteur peut se référer aux références (Vapnik, 1998 ; Burges, 1998 ; Gunn, 1998 ; Duda et al.,
2000).
Le chapitre est organisé comme suit : dans la première section, nous rappelons
quelques éléments essentiels de la théorie de l’apprentissage statistique. Nous introduisons par
la même occasion le principe du risque structurel que minimise les SVMs. Nous verrons
ensuite la forme originale des SVMs : le cas binaire, puis le cas multiclasses. Les algorithmes
d’implémentation sont ensuite présentés. Les stratégies adoptées dans le cas multiclasses sont
présentées dans la dernière section.
II.2 Théorie de l’apprentissage statistique
Effectuer une classification consiste à déterminer une règle de décision capable, à
partir d'observations externes, d'assigner un objet à une classe parmi plusieurs. Le cas le plus
simple consiste à discriminer deux classes. D'une manière plus formelle, la classification bi-
classe revient à estimer une fonction f : x→ {-1, +1} à partir d’un ensemble d’apprentissage
constitué des paires de données étiquetées, tel que :
{ }1 1( , ), .....( , ) 1Ni ix y x y R∈ × ± (II.1)
Où xi représente l’ième observation de l’ensemble d’apprentissage et yi son étiquette.
Le but poursuivi en apprentissage statistique est de parvenir à classer correctement les futures
observations grâce à la connaissance apprise à propos d’un échantillon limité de données. La
meilleure fonction f est celle obtenue en minimisant le risque réel donné par (Burges, 1998) :
1 R( )= ( ) ( , )2
f f x y dP x yα −∫ (II.2)
Dans l’équation (II.2) ne connaissant pas la probabilité de distribution P(x, y), il est difficile d’estimer le risque R(f). Il est possible toutefois de considérer une fonction de risque empirique de la forme :
emp1
1 1 R ( )= ( )2
l
if f x y
l α
=
−∑ (II.3)

Chapitre II Les machines à vecteurs supports (SVMs)
- 27 -
Où l est le nombre des observations d’apprentissage.
Puisque l’ensemble de données d’apprentissage ne représente qu’une simple partie de
tout l’espace d’exemples, la fonction apprise f, qui minimise le risque empirique, peut se
comporter mal avec les nouveaux exemples non vus à l’entrainement. C’est un phénomène
très connu en apprentissage automatique appelé le sur-apprentissage ou apprentissage par
cœur (Scholkopf, 1998). Pour garantir que f, prenne en charge même les exemples non jamais
vus, il faut contrôler sa capacité de généralisation mesurée souvent sur un autre ensemble
d’exemples appelé ensemble de test, réservé uniquement pour tester la fonction apprise. Le
processus de choisir le bon sous-ensemble de fonctions solutions revient à contrôler la
complexité du classificateur en cherchant le meilleur compromis entre une faible erreur
empirique et une complexité moindre.
Une manière de contrôler la complexité d'une classe de fonctions est donnée par la
théorie de Vapnik-Chervonenkis (VC) (Vapnik ,1998) et le principe de minimisation du
risque structurel. Ici, le concept de complexité de la fonction de décision f s'exprime par la
dimension de VC (notée h) de la classe de fonctions F à laquelle appartient la fonction f.
Grossièrement, la dimension de VC mesure combien d'échantillons de l'ensemble
d'apprentissage peuvent être séparés par toutes les classifications possibles. Le risque
structurel constitue une borne supérieure de l’erreur de généralisation, avec la probabilité de
1-η, et qui s’écrit :
2(log ) log( )4 R ( ) ( )emp
lhhf R f
l
η−
≤ + (II.4)
Où h est la dimension VC du modèle de classification, et l la taille de l'échantillon
d'apprentissage. Cette formule n'est valide que lorsque h<l.
Le but recherché ici est de minimiser l'erreur de généralisation R(f) en obtenant un faible
risque empirique Remp (f) tout en gardant la plus petite classe de fonctions possibles.
Trouver la fonction optimale f revient toujours à un problème d’optimisation, ce qui
explique la forte relation entre l’apprentissage et l’optimisation. Avant de rechercher la
fonction f, il faut définir son type puis rechercher ses paramètres. Dans le cas des machines à
vecteur support, la fonction recherchée est de forme linéaire. Les SVMs sont, donc, des
systèmes d’apprentissage qui utilisent un espace d’hypothèses de fonctions linéaires dans un
espace de caractéristique à haute dimension. Cette stratégie d’apprentissage introduite par

Chapitre II Les machines à vecteurs supports (SVMs)
- 28 -
Vapnik (Vapnik, 1998) est une méthode très puissante. Elle a pu, en quelques années depuis
sa proposition, conquérir la plupart des autres systèmes d’apprentissage dans une grande
variété de domaines d’application.
II.3 Les machines à vecteurs supports (SVMs)
La méthode des machines à vecteurs supports est basée sur la construction d’un
hyperplan optimal séparant des données appartenant à deux classes différentes dans deux cas
différents : Le cas des données linéairement séparables (marge dure) et le cas des données non
-linéairement séparables (marge souple).
II.3.1 SVMs à marge dure
Considérons l’ensemble d’apprentissage 1 1 2 2( , ), ( , ).....( , )N Nx y x y x y tells quedx R∈ et { }1, 1y∈ + − , linéairement séparables en deux classes différentes. L’appartenance
de l’observation xi à une classe ou l’autre est matérialisée par la valeur -1 ou +1 de son
étiquette yi.
La classification des données consiste à trouver un hyperplan linéaire : ( . ) H w x b+ qui
sépare les données de deux classes. Les points situés sur cet hyperplan satisfont l’équation
( . ) 0iw x b+ = où [ ]1 2, ,... Nw w w w= est un vecteur perpendiculaire à l’hyperplan, et b est
un scalaire appelé biais. En utilisant le classificateur linéaire définie par la paire (w,b), la
classe de l’observation x est déterminée par :
1 si . 0 ( )
1 si . 0 w x b
f xw x b
+ + ≥⎧= ⎨− + ≤⎩
(II.5)
Nous avons supposé, dans un premier temps, que les données sont linéairement séparables. En
utilisant une mise à l’échelle appropriée de w et b, il est possible de contraindre les
observations de chaque classe à satisfaire les conditions suivantes :
. 1 si 1
. 1 si 1i i
i i
w x b yw x b y −
+ ≥ =⎧⎨ + ≤ − =⎩
(II.6)
Ce qui est équivalent à :
( . ) 1 i iy w x b+ ≥ Pour i=1,…. N (II.7)

Chapitre II Les machines à vecteurs supports (SVMs)
- 29 -
La figure 2.1 donne une représentation visuelle de l'hyperplan optimal séparant les données
appartenant à deux classes différentes dans le cas linéairement séparables.
Figure 2.1 Exemple de séparation entre deux classes par les SVMs.
Les deux hyperplans H1 : ( . ) 1w x b+ = + et H2 : ( . ) 1w x b+ = − , permettent de définir la
marge. H1 et H2 sont parallèles et sont appelés hyperplans canoniques. Grâce à l’équation
(II.6) il n’existe aucun point entre les deux. Les points qui se trouvent sur ces hyperplans
(cercles et rectangles pleins) sont appelés les vecteurs supports (Support Vectors). La
distance qui sépare H1 et H2 est appelée la marge et notée M.
La distance d’un point à l’hyperplan est :
. ( )
w x bd x
w+
= (II.8)
Où w est la norme du vecteur w.
L’hyperplan optimal est celui qui assure une marge maximale, c’est-à-dire qui rend minimale
la quantité w . En effet, il existe plusieurs hyperplans linéaires séparateurs, mais il y en a un
seul qui maximise la marge M. cette marge est la plus petite distance entre l’hyperplan
séparateur et le point positif (respectivement négatif) le plus proche. Elle est donnée par :
yi=-1
yi=+1
{H1 :(w.x)+b=+1}
{H : (w.x)+b=0}
{H2 :(w.x)+b=-1}
Class A
Class B
Marge bw

Chapitre II Les machines à vecteurs supports (SVMs)
- 30 -
/ /
. . m i n m a x
1 1
2
x i y i x i y i
w x b w x bMw w
w w
w
+ += −
−= −
=
(II.9)
Maximiser la marge revient donc à maximiser w2 ce qui est équivalent à minimiser
2
2w
sous la contrainte (II.7). Ceci est un problème de minimisation d'une fonction objective
quadratique avec contraintes linéaires. Ainsi, trouver l’hyperplan optimal revient à résoudre le
problème d’optimisation suivant :
21
2min
( . ) 1i i
w
i y w x b
⎧⎪⎨⎪∀ + ≥⎩
(II.10)
L’introduction des multiplicateurs de Lagrange donne le lagrangien qui s’écrit :
1
1( , , ) [ ( ) 1]2
lT T
i i ii
J w b w w y w x bα α=
= − + −∑ (II.11)
Avec iα : Les multiplicateurs de Lagrange.
Le problème (II.10) doit satisfaire les conditions de KKT (Karush-Kuhn_Tucker) qui consiste
à annuler les dérivées partielles du lagrangien (II.11). Ce dernier doit être minimal par rapport
à w et b et maximal par rapport à α . Le point optimal est celui qui vérifie :
( , , ) 0
( , , ) 0
J w bw
J w bb
α
α
∂=
∂∂
=∂
(II.12)
Résoudre l’équation (II.12) donne :
1
10
l
i i ii
l
i ii
w y x
y
α
α
=
=
=
=
∑
∑ (II.13)

Chapitre II Les machines à vecteurs supports (SVMs)
- 31 -
En substituant ‘w’ par son expression dans l’équation (II.11) on peut écrire le problème dual sous la forme :
1 1 1
1
1m ax ( . )2
0
0
l l l
i i j i j i ji i j
il
i ii
y y x x
i
y
α α α
α
α
= = =
=
⎧ −∑ ∑ ∑⎪⎪⎪∀ ≥⎨⎪
=∑⎪⎪⎩
(II.14)
Ce dernier problème, peut être résolu en utilisant des méthodes standards de programmation
quadratique. Une fois la solution optimale est obtenue, le vecteur poids de la
marge maximale recherchée s’écrit :
i i ii sv
w y xα∈
= ∑ (II.15)
Où sv =i {1 2, . . . , m} : est l’ensemble des indices des Vecteurs Supports (VS) qui se
situent sur la marge, pour les quels les variables αi ≠0.
Comme le paramètre ‘b’ ne figure pas dans le problème dual (II.14), sa valeur optimale peut
être dérivée à partir des contraintes primales, soit donc :
1 1m a x ( . ) m a x ( . )2
y i i y i iw x w xb = − = ++
= − (II.16)
Une fois les paramètres αi et b calculés, la règle de classification d’une nouvelle observation x
basée sur l’hyperplan à marge maximale est donnée par :
( ) s ( ( . ) )i i ii sv
f x ign y x x bα=
= +∑ (II.17)
Si la fonction f(x) est négative alors x appartient à la classe -1, sinon x appartient à la classe +1. +1.
II.3.2 SVMs à marge souple
Dans le cas où les données sont non-linéairement séparables (figure 2.2), l'hyperplan
optimal est celui qui satisfait les conditions suivantes :
-La distance entre les vecteurs bien classés et l'hyperplan optimal doit être maximale.
-la distance entre les vecteurs mal classés et l'hyperplan optimal doit être minimale.
( , ....., )liα α α=

Chapitre II Les machines à vecteurs supports (SVMs)
- 32 -
Pour formaliser tout cela, on introduit des variables de pénalité non-négatives ζi pour
i =1,.. ,l appelées variables d'écart. Ces variables transforment le problème (II.10) comme suit
(Burges, 1998) :
21
2min
( . ) 1
i
ii i
w C
i y w x b
ζ
ζ
⎧ +⎪⎨⎪∀ + ≥ −⎩
∑ (II.18)
Où « C » est un paramètre de pénalité. Il permet de concéder moins d'importance aux
erreurs. Cela mène à un problème dual légèrement différent de celui du cas des données
linéairement séparables. Il revient à maximiser le lagrangien donné par l'équation (II.14) par
rapport à αi sous les contraintes suivantes :
1 1 1
1
1m ax ( . )2
0
0
l l l
i i j i j i ji i j
il
i ii
y y x x
i C
y
α α α
α
α
= = =
=
⎧ −∑ ∑ ∑⎪⎪⎪∀ ≤ ≤⎨⎪
=∑⎪⎪⎩
(II.19)
Le calcul de, iα etb et de la fonction de décision f (x) reste exactement le même que pour le cas des données linéairement séparable.
Figure 2.2 Hyperplans séparateur dans le cas de données non-linéairement séparables
yi=-1
yi=+1
{H1 :(w.x)+b=+1}
{H : (w.x)+b=0}
{H2 :(w.x)+b=-1}
Class A
Class B
ζ
ζ

Chapitre II Les machines à vecteurs supports (SVMs)
- 33 -
La seule différence avec les SVMs à marge dure est que les ne peuvent pas dépasser C, ils
peuvent être dans l’un des trois cas suivants :
(II.20)
Les équations (II.20) reflètent une propriété importante des SVMs, stipulant qu’une
grande proportion des exemples d’apprentissage est située en dehors de la marge et ne sont
pas retenu par le modèle. Par conséquent, leurs multiplicateurs αi sont nuls.
Les conditions de KKT traduisent le fait que seulement les variables αi des points situés sur la
frontière de la marge (0 < αi < C) ou à l’intérieure de celle-ci (αi = C) sont non nulles. Ces
points sont les vecteurs de supports du classificateur (Burges, 1998).
Les SVM produisent alors une solution clairsemée n’utilisant qu’un sous ensemble réduit des
données d’apprentissage. Sans cette propriété, l’entraînement des SVM sur de gros ensembles
de données ainsi que son stockage deviennent extrêmement prohibitifs.
II.3.3 Utilisation des Noyaux
Le fait d’admettre la mal-classification de certains exemples, ne peut pas toujours
donner une bonne généralisation pour un hyperplan même si ce dernier est optimisé (cas des
SVM à marge souple). Plutôt qu’une droite, la représentation idéale de la fonction de décision
serait une représentation qui colle le mieux aux données d’entrainement (figure 2.3).
Figure 2.3 Représentation idéale de la fonction de décision
iα
0 ( ) 1 e t 00 ( ) 1 e t 0 ( ) 1 e t 0
i i i i
i i i i
i i i i
y f xC y f xC y f x
α ζα ζα ζ
= ⇒ ≥ =< < ⇒ = =
= ⇒ ≤ ≥

Chapitre II Les machines à vecteurs supports (SVMs)
- 34 -
La détermination d’une telle fonction non linéaire est très difficile voire impossible. Pour cela
les données sont amenées dans un espace où cette fonction devient linéaire (figure 2.4), Plus
la dimension de l'espace de description est grande, plus la probabilité de pouvoir trouver un
hyperplan séparateur entre les classes est élevée. En transformant l'espace d'entrée en un
espace de redescription de très grande dimension, cette astuce permet de garder les mêmes
modèles de problèmes d’optimisation vus dans les sections précédentes, utilisant les SVMs
basées essentiellement sur le principe de séparation linéaire (Burges, 1998).
Figure 2.4 Illustration de l'effet du changement d'espace par une fonction noyau. Les données non linéairement séparables dans l'espace de départ R² sont à présent séparables dans l’espace
augmenté R3.
Notons Φ, une transformation non linéaire de l'espace d'entrée X en un espace de redescription Φ (X) :
1( , ...., )TdX x x= à 1 , ...( ) ( ( ), ...., ( ) )T
dX x xΦ = Φ Φ (II.21)
Généralement, le vecteur image Φ (x) est de dimension supérieure à la dimension de l’espace
d’origine. Les données sont projetées via la fonction Φ telle que :
( i). ( j)=k ( i, j)x x x xΦ Φ (II.22)
Où k est appelée fonction noyau ou kernel. C'est-à-dire, le produit scalaire dans l'espace des
redescription va être représentable comme un noyau de l'espace d'entrée. Le classificateur est
donc construit sans utiliser explicitement la fonction Φ. Ceci est illustré dans l’exemple
suivant (Gunn, 1998) :
Φ
Espace de redescription: R3 Espace d’entrée : R²

Chapitre II Les machines à vecteurs supports (SVMs)
- 35 -
On a la transformation Φ tel que:
2 3
2 22
:
( , ) ( , , )X u v u uv vΦ
Φ ℜ → ℜ
= →
2 1 2
1 1 2 2
1 1 2 2
1
1 2
2
21
2 22 , 21 1 2
22
2 2 2 21 1 2 2
2
2
2
( , ) ( ). ( )
= ( , )
= ( 2 )
= ( )
= ( , ) ( . )
K u v u v
vu u u u v v
v
u v u v u v u v
u v u v
vu u u v
v
= Φ Φ
⎛ ⎞⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠
+ +
+
⎡ ⎤⎛ ⎞=⎢ ⎥⎜ ⎟
⎝ ⎠⎣ ⎦
Ceci veut dire que le produit interne entre les images des points transformés par la fonction Φ
est équivalent à celui obtenu par un noyau polynomial k (u.v)= (u,v)2 calculé dans l’espace
d’entrée.
Une famille de fonctions qui permet cette représentation, et qui est très appropriée aux
besoins des SVMs, peut être définie comme l'ensemble des fonctions symétriques qui
satisfont la condition de Mercer (Scholkopf, 1998):
Condition de Mercer : Pour être sûr qu'une fonction symétrique K(u,v) est une fonction
kernel, il est nécessaire et suffisant que la condition suivante soit satisfaite :
k ( , ) ( ) ( ) 0u v g u g v dudv ≥∫∫ (II.23)
Pour toute fonction g ≠ 0 avec :
2 ( ) 0g z dz ≥∫ (II.24)
Parmi les noyaux couramment utilisés, on peut citer :
Polynomial : ( , ') ( . ' 1) qK x x x x= + (II.25)
Où q est le degré du polynôme à déterminer par l'utilisateur.
RBF ( Radial Basis Function) : 2
2
'( , ') exp( )
2x x
K x xσ−
= − (II.26)

Chapitre II Les machines à vecteurs supports (SVMs)
- 36 -
Où σ est à déterminer par l’utilisateur.
Sigmoïdal : ( , ') ta n h ( . ' )K x x a x x b= − (II.27)
Avec l’introduction des fonctions noyaux, le lagrangien se transcrit dans ce cas par :
1 1 1
1
2( , )
l l l
D i i j i j i ji i j
L y y K x xα α α=
= = =
−∑ ∑ ∑ (II.28)
Le problème d'optimisation devient donc:
1 1 1
1
1
2m a x ( , )
0
0
l l l
i i j i j i ji i j
il
i ii
y y K x x
i C
y
αα α α
α
α
= = =
=
⎧−⎪
⎪⎪∀ ≤ ≤⎨⎪⎪ =⎪⎩
∑ ∑ ∑
∑
(II.29)
La résolution de ce problème d’optimisation conduit à la fonction de décision suivante :
( ) s ( ( . ) )i i ii sv
f x ign y K x x bα=
= +∑ (II.30)
Où les coefficients iα et b sont obtenus comme précédemment par résolution de l’équation
(II.29). Rappelons ici, que i 1 2, . . . , m. Où m est l’ensemble des Vecteurs Supports (VS)
qui se situent sur la marge, et pour les quels les variables iα vérifiant la condition : 0 i Cα< ≤ .
II.4 Optimisation des SVMs
Afin de trouver les paramètres des SVM, il est nécessaire de résoudre le problème
d’optimisation quadratique convexe donné par l’équation (II.29) dont la formulation
matricielle s’écrit encore :
12
T TDL G Iα α α= − + (II.31)
Où G est une matrice semi-définie positive dont les composantes ( , ) i j i j i jG y y G x x=
, et I est le vecteur unitaire de même taille que α. Comme la fonction objective est convexe,
tout maximum local est aussi un maximum global. Toutefois, il peut y avoir des solutions
optimales différentes en termes de αi donnant lieu à des performances différentes. Il existe une
grande variété de méthodes et de logiciels traitant de la résolution de problèmes quadratiques.
Cependant, quelques méthodes seulement sont capables de traiter un grand nombre
d’exemples. Dans le cas contraire, l’apprentissage d’un SVM de quelques centaines

Chapitre II Les machines à vecteurs supports (SVMs)
- 37 -
d’exemples prendrait énormément de temps de calcul et assez de ressources mémoire.
Seulement, il est possible de dériver des algorithmes qui exploitent la forme particulière de la
fonction objective duale des SVM. Dans cette section, nous allons présenter trois approches
différentes pour la résolution du problème quadratique des SVMs.
II.4.1 Méthode de Chunking
La résolution de la fonction objective duale de l’équation (II.29) avec un très grand
nombre d’exemples donne lieu à un vecteur α creux. Selon les données, plusieurs des
paramètres αi sont soit nuls ou égales à C. S’il y a moyen de savoir a priori les quels αi seront
nuls, il est possible de réduire la taille de la matrice G sans altérer la valeur de la fonction
objective (fonction coût). Aussi, une solution α est valide si et seulement si elle respecte les
conditions de KKT. Vapnik (Vapnik, 1998) était le premier à décrire une méthode qui
exploite cette propriété en prenant en compte seulement les αi non nuls ou ceux violant les
conditions de Karush Kuhn Tucker. La taille de ce sous ensemble dépend du nombre de
vecteurs de support, de la taille des données et de la complexité du problème de classification.
Cette méthode se comporte assez bien sur des problèmes de quelques centaines de vecteurs de
support.
Des tâches plus complexes requièrent un schéma de décomposition de l’objective en
sous problèmes plus facile à résoudre. Cette technique est décrite ci-dessous.
II.4.2 Méthode de décomposition successive
Cette méthode est similaire à celle du «Chunking» dans la mesure où elle considère
aussi une succession de sous problèmes quadratiques à résoudre. La différence est que la taille
des sous problèmes retenus est fixe. Cette méthode est basée sur la constatation qu’une
succession de sous-problèmes quadratiques ayant au moins un exemple qui ne vérifie pas les
conditions de KKT converge toujours vers une solution optimale. Dans (Osuna et al., 1997),
les auteurs suggèrent de conserver la taille du sous-problème fixe et d’ajouter ou d’enlever un
exemple à la fois. Ceci permet d’entraîner de gros ensembles de données. En pratique, cette
stratégie peut converger lentement si diverses heuristiques ne sont pas prises en compte. En
effet, il est possible d’adopter des stratégies sophistiquées afin d’inclure ou d’exclure
quelques exemples de la fonction objective. L’algorithme de SVMlight (Joachim, 1999), est
une implémentation de cette méthode

Chapitre II Les machines à vecteurs supports (SVMs)
- 38 -
II.4.3 Méthode de minimisation séquentielle (SMO)
La méthode d’optimisation par minimisation séquentielle (SMO pour Sequential
Minimal Optimization) proposée par Platt (Platt, 1998) peut être perçue comme le cas extrême
des méthodes de décomposition successive. A chaque itération, elle résout un problème
quadratique de taille égale à deux. La résolution de ce dernier est analytique et donc nul
besoin de recourir à un module d’optimisation quadratique. Encore faut-il choisir le bon
couple de variables (αi, αj) à optimiser durant chaque itération. Les heuristiques que l’auteur
utilise sont basées sur les conditions de KKT. Son implémentation est relativement simple.
pour plus de détails sur cette méthode, voir (Platt,1998).
II.5 Implémentation des SVMs
Ces dernières années, beaucoup d’algorithmes et boites à outils (Toolbox) sont
disponibles sur internet. Ces algorithmes ont été développés pour réduire le temps
d’apprentissage des SVM avec un grand nombre de données. Parmi ces algorithmes on peut
citer : SVMlight (Joachim, 1999), LibSVM (Chang & Lin., 2001), HeroSVM (Dong et al.,
2003) , Cover Vector Machines (CVM), (Tsang et al., 2005 ), SimpleSVM ( Loosli et al.,
2005). Un état de l’art sur ces algorithmes est donné par Bouttou (Bottou & Lin, 2007). Il
existe d’autres boites à outils développées sous Matlab tels que SVM and Kernel Methods
Toolbox (Canu et al.2005 ), Gunn’s Toolbox (Gunn, 1998), et Statistical Pattern Recognition
Toolbox (Stprtool) (Vojtech et al., 2004). Il est à noter que ça reste toujours une liste non-
exhaustive.
II.6 Les SVMs multiclasses
La discussion au sujet des SVM dans les sections précédentes est basée sur le
classificateur bi-classe. Dans des applications pratiques, il est nécessaire que le classificateur
soit construit pour un problème de classification de multiclasses. Là existent plusieurs
méthodes qui ont été proposées pour les SVMs multiclasses. Ces méthodes exploitent
habituellement trois stratégies différentes: Un-contre-Reste, un-contre-un, et DAGSVM.
II.6.1 Approche Un–Contre-Reste (1vsR)
La première stratégie est le prétendu de classificateur Un-Contre-Reste, qui est intuitif
et simple (Yang et al., 2005). Pour un problème de N classes, le classificateur multiclasses
1vsR établit d'abord N classificateurs bi-classe, chacun d’eux est responsable de chaque classe

Chapitre II Les machines à vecteurs supports (SVMs)
- 39 -
respectivement (Figure 2.5). Pour le nième classificateur bi-classe, toutes les données
d’entraînement ont besoin d’être impliqué ; le résultat positif est le point de données dans la
classe N, et le résultat négatif est le point de données dans les autres classes N-1. Chacun des
N classificateurs bi-classes, est formé pour trouver la fonction de décision, et alors toutes les
fonctions de décision sont combinées pour obtenir la fonction finale de décision pour le
problème de classification multiclasses :
∑∈
+=SVi
ni
nii bxxkyxf ),(maxarg)( α (II.32)
Avec : ∑∈
+SVi
ni
nii bxxky ),(α est la fonction de décision du nième classificateur bi-classe.
Figure 2.5 Problème à trois classes : frontières de décision linéaires dans la stratégie
Un-contre-Reste
II.6.2 Approche Un-contre-un (1vs1)
Cette stratégie emploie quelques arrangements et combine des paires de classificateurs
bi-classe pour résoudre le problème de classification multiclasses ; c'est le classificateur un-
contre-un. Dans cette stratégie, un classificateur bi-classe doit être établi pour chaque paire
possible des classes et le nombre total de ces classificateurs bi-classe est égale à N(N-1)/2
(Yang et al., 2005). Chaque classificateur bi-classe inclut seulement les données
d’entraînement des deux classes impliquées. Pendant la phase de test et après la construction
de tous les classificateurs, on utilise la stratégie de vote majoritaire. Si le signe de la fonction

Chapitre II Les machines à vecteurs supports (SVMs)
- 40 -
de décision des deux classes i et j indique que x appartient à la ième classe, le vote pour la ième
classe est incrémenté par +1. Alors que, le vote pour la jème classe est décrémenté de 1. À la
fin, on prédit que x appartient à la classe qui a le vote le plus grand.
II.6.3 Graphe acyclique de décision (DAGSVM)
Une DAGSVM (Directed Acyclic Graph SVM) (Platt et al., 2000) est modèle de
discrimination multiclasses, dont l’architecture est un graphe de décision. Les étiquettes de
ces nœuds sont les SVMs bi-classes formés au niveau de chaque nœud. On associe à chaque
nœud une liste de classes auxquelles l’exemple d’intérêt peut appartenir. La SVM
correspondante effectue une décision entre les deux classes aux extrémités de la liste : les
classes1 et N pour la SVM située à la racine, 2 et N pour la SVM située sur le fils gauche de
la racine ,1 et N-1 pour la SVM située sur le fils droit de la racine et ainsi de suite. Les nœuds
de la gauche d’indice N-1 produisent une décision en séparant les deux seules classes
contenues dans leur liste. La figure 2.6 représente la DAGSVM correspondant au cas où le
nombre de classes est quatre.
Figure 2.6 Architecture d’une DAGSVM à quatre catégories
II.7 Conclusion
Dans ce chapitre nous avons décrit les bases mathématiques de la méthode de
classification par SVM. L’avantage principal de cette méthode réside dans sa capacité de

Chapitre II Les machines à vecteurs supports (SVMs)
- 41 -
généralisation même avec un nombre réduit des exemples d’apprentissage. Ces propriétés
correspondent bien à la problématique de classification des défauts mécaniques, que nous
comptons traiter dans cette thèse. D’après la littérature la méthode SMO proposée pour
résoudre le problème d’optimisation des SVMs semble la plus approprié.
Cependant, les performances des SVMs sont en étroite liaison avec la qualité des données
utilisées pour établir la règle de décision. En effet, la base d’apprentissage peut contenir des
indicateurs qui n’apportent pas une information utile à la classification. Il est donc nécessaire
d’employer un processus de sélection afin de ne garder que les plus pertinents pour
l’application considérée. La classification opère alors dans le sous-espace d’indicateurs
pertinents résultant de cette opération de sélection. Cela fera l’objet du prochain chapitre qui
est consacré à la sélection des indicateurs.

Chapitre III
Sélection d’indicateurs en classification
III.1 Introduction .............................................................................................................................. 42 III.2 Présentation du problème de sélection ...................................................................................... 43 III 2.1 Notions de pertinence et redondance des indicateurs ...................................................... 43 III.2.1.1 Pertinence des indicateurs. ............................................................................... 43 III.2.1.2 Redondance des indicateurs .......................................................................... 44 III.2.2 La sélection des indicateurs vue comme un problème d’optimisation combinatoire .... 44 III.2.3 Processus général de la sélection des indicateurs .......................................................... 45 III.2.3.1 Procédure de génération ................................................................................. 46 III.2.3.2 Évaluation ....................................................................................................... 47 III.2.3.3 Critère d’arrêt ................................................................................................. 48 III.3 Les approches de sélection des indicateurs .............................................................................. 48 III.3.1 Les approches filtres (filter) ............................................................................................ 48 III.3.2 Les approches enveloppes (wrapper) ............................................................................. 49 III.3.3 Les approches intégrées (embedded) .............................................................................. 50 III.4 Les métaheuristiques pour la sélection d’indicateurs ............................................................... 51 III.4.1 Les métaheuristiques à solution unique ......................................................................... 51 III 4.1.1 Le recuit simulé ................................................................................................. 51 III 4.1.2 La recherche tabou ........................................................................................... 52 III 4.2 Les métaheuristiques à base de population de solutions .................................................. 54 III 4.2.1 Les Algorithmes évolutionnaires ...................................................................... 54 III 4.2.1.1 les algorithmes génétiques ..................................................................... 54 III 4.2.1.2 L’évolution différentielle ....................................................................... 55 III 4.2.2 l’optimisation par essaim de particules ............................................................ 56 III 4.2.3 L’optimisation par colonie de Fourmis (Ant colony optimization) ................. 57 III.5 Synthèse sur la sélection des indicateurs ................................................................................... 57 III.6 Contribution à la sélection d’indicateurs pour la classification automatique des défauts ......... 58 III.6.1 Motivation ....................................................................................................................... 58 III.6.2 Approche proposée .......................................................................................................... 59 III.6.2.1 L’optimisation par essaim de particules Binaires (OEPB) ................................ 60 III.6.2.2 L’analyse discriminante linéaire et Critère de Fisher Régularisé (CFR) ........ 61 III.6.3 Conduite des différentes étapes de l’algorithme proposé ................................................ 62 III.7Conclusion .................................................................................................................................. 66

Chapitre III Sélection d’indicateurs en classification
- 42 -
Chapitre III : Sélection d’indicateurs en
classification
III.1 Introduction
La sélection d’indicateurs constitue une étape importante dans le traitement des
données acheminées vers la classification supervisée ou non supervisée. Elle est considérée
comme un processus permettant de choisir un sous-ensemble optimal d’indicateurs pertinents,
à partir d’un ensemble original, selon un certain critère de performance. La sélection des
indicateurs est devenue un sujet de recherche très actif depuis une dizaine d’années, et elle a
été traité dans plusieurs études dans le domaine de l’apprentissage artificiel (Kudo &
Sklansky, 2000 ; Jack & Nandi, 2002; Samanta et al., 2003 ; Sun et al., 2006 ; Lin et al.,
2008 ; Chen et al., 2010; Khushaba et al., 2011), et récemment dans (Zhang et al., 2013 ; He
et al., 2013). La sélection d’indicateurs a pour buts (Kudo & Sklansky, 2000) : (1) réduire le
cout d’extraction d’indicateurs, (2) améliorer la performance de la classification en éliminant
les indicateurs qui sont source de bruit, et (3) améliorer la fiabilité de la classification.
Dans ce chapitre, nous présentons d’abord le problème de la sélection d’indicateurs.
Dans la première partie, nous abordons quelques notions autour desquelles s’articule la
sélection, telles que la notion de pertinence, non-pertinence et redondance. Nous présentons
également, les différents points nécessaires dans un processus de sélection d’indicateurs, ainsi
que les différentes approches utilisées. Dans la deuxième partie, nous présentons notre
contribution en proposant une nouvelle méthode de sélection basée sur l’optimisation par
essaim de particules et le critère de Fisher régularisé.

Chapitre III Sélection d’indicateurs en classification
- 43 -
III.2 Présentation du problème de sélection
La sélection d’indicateurs consiste à choisir parmi un ensemble d’indicateurs de
grande taille un sous-ensemble pertinent pour le problème étudié. Cette problématique peut
concerner différentes tâches d’apprentissage ou de fouille de données (data mining), mais
nous parlerons, seulement ici, de la sélection d’indicateurs réalisée pour la classification
supervisée. Dans ce contexte, les principales motivations de la sélection d’indicateurs sont les
suivantes (Yang & Hanovar, 1997) :
1. Utiliser un sous-ensemble plus petit permet d’améliorer la classification si l’on élimine les
indicateurs qui sont source de bruit. Cela permet aussi une meilleure compréhension des
phénomènes étudiés.
2. Des petits sous-ensembles d’indicateurs permettent une meilleure généralisation des
données en évitant le sur-apprentissage.
3. Une fois que les meilleurs indicateurs sont identifiés, les temps d’apprentissage et
d’exécution sont réduits et en conséquence l’apprentissage est moins coûteux.
III.2.1 Notions de pertinence et redondance des indicateurs
III.2.1.1 Pertinence des indicateurs
Généralement la sélection d’indicateurs peut être formulée comme étant la sélection
d’un sous-ensemble minimal G de l’ensemble initial F tel que P(C|G) est le plus proche
possible de P(C|F). Où P(C|F) or P(C|G) sont les valeurs de distribution de probabilités de la
classe C connaissant les valeurs des indicateurs dans F ou G respectivement (Liu & Motoda,
2007). Le sous ensemble minimal est aussi nommé sous ensemble optimal. Selon Kohavi
(Kohavi et John, 1997), les indicateurs sont classés en trois catégories distinctes ; indicateurs
fortement pertinents, faiblement pertinents, et non pertinents.
Fortement pertinent : Un indicateur Fi est fortement pertinent si :
(III.1)
Où
Faiblement pertinent : Un indicateur Fi est faiblement pertinent si :
(III.2)
' ' ' ( , ) ( , ) tel que ( , ) ( , )i i i i i i i iP C F S P C S et S S P C F S P C S= ∃ ∈ ≠
( , ) ( , ) i i iP C F S P C S≠
i iS F F= −

Chapitre III Sélection d’indicateurs en classification
- 44 -
Non pertinent : Un indicateur Fi est non pertinent si :
(III.3)
Une forte pertinence d’un indicateur indique que celui ci est toujours nécessaire dans le sous
ensemble optimal sélectionné : il n’est pas possible de l’enlever sans baisse dans le pouvoir de
discrimination.
La faible pertinence suggère que l’indicateur n’est pas toujours important, mais il peut devenir
nécessaire pour un sous-ensemble optimal dans certaines conditions.
La non-pertinence d’un indicateur se définit simplement par rapport à III.1 et III.2 et indique
qu’un indicateur n’est pas du tout nécessaire dans un sous-ensemble optimal d’indicateurs.
III.2.2.2 Redondance des indicateurs
La notion de redondance d’indicateurs est généralement définie en terme de
corrélation entre les indicateurs. On peut dire que deux indicateurs sont redondants l’un à
l’autre si leurs valeurs sont complètement corrélées. Selon Liu (Liu & Motoda, 2007), la
redondance d’un indicateur peut être définie comme suit :
Soit G l’ensemble d’indicateurs courant, un indicateur Fi est redondant et par conséquent peut être
enlevé de G ssi il est faiblement pertinent et qu’il possède une couverture de Markov dans G .
La couverture de Markov est définie comme suit :
Soit F l’ensemble total d’indicateurs et C la classe. Soit Fi un indicateur, et Mi un sous-
ensemble d’indicateurs qui ne contient pas Fi, c’est-à-dire :
Mi est une couverture de Markov pour Fi ssi :
(III.4)
III.2.2 La sélection d’indicateurs vue comme un problème d’optimisation combinatoire
La majorité des problèmes de sélection d’indicateurs peuvent s’exprimer comme des
problèmes d’optimisation combinatoire (Jourdan, 2003). Selon Widmer (Widmer, 2001),
l'optimisation combinatoire est le domaine des mathématiques discrètes qui traite de la
résolution du problème suivant :
' ' '( , ) ( , ) ( , ) ( , )i i i i i i iP C F S P C S e t S P C F S P C S= ∀ ⊆ =
e t M i F F i M i⊆ ∉
{ } { }( , , ) ( , )P F M i F i C F i M i P F M i F i C M i− − = − −

Chapitre III Sélection d’indicateurs en classification
- 45 -
Soit X un ensemble de solutions admissibles. Soit f une fonction permettant d'évaluer chaque
solution admissible. Il s'agit de déterminer une solution s* appartenant à X qui minimise
(respectivement maximise) f. L'ensemble X des solutions admissibles est supposé fini et est en
général défini par un ensemble C de contraintes.
Pour ce type de problèmes, la recherche exhaustive dans tout l’ensemble initial nécessite
d’examiner potentiellement 2n−1 sous-ensembles possibles. Ceci est considéré comme un
problème d’optimisation NP-difficile (Garey & Johnson, 1979), et ne pourra pas être donc
résolu de manière exacte dans un temps raisonnable, puisque la capacité de calcul des
machines évolue linéairement, alors que le temps nécessaire à la résolution de ces problèmes
évolue exponentiellement (Jourdan, 2003). Lorsqu’on s’attaque à des problèmes réels, il faut
se résoudre à un compromis entre la qualité des solutions obtenues et le temps de calcul
utilisé.
Compte tenu de ces difficultés, la plupart des spécialistes de l’optimisation
combinatoire ont orienté leur recherche vers le développement de méthodes heuristiques
(Widmer, 2001). Une méthode heuristique est souvent définie comme une procédure
exploitant au mieux la structure du problème considéré, dans le but de trouver une solution de
qualité raisonnable en un temps de calcul aussi faible que possible.
III.2.3 Processus général de sélection d’indicateurs
L’entrée du processus de sélection d’indicateurs nécessite le jeu de données pour
lesquelles les indicateurs pertinents seront identifiés. Le résultat devrait inclure les indicateurs
retenus ainsi que leur niveau de performance. Selon Dash (Dash & Liu, 1997), le processus
de sélection d’indicateurs peut être décortiqué en quatre étapes essentielles (figure 3.1):
1. Procédure de génération : Pour générer les sous-ensembles d’indicateurs qui vont être
évalués.
2. Fonction d’évaluation : Pour mesurer la qualité du sous-ensemble généré ;
3. Critère d’arrêt : Il peut être utilisé ou pas, selon la méthode adoptée, c’est-à-dire si l’on
veut faire une recherche exhaustive, à critères, ou aléatoire ;
4. Procédure de validation : Consiste à utiliser un ensemble de test afin de vérifier si
l’ensemble d’indicateurs est valide.

Chapitre III Sélection d’indicateurs en classification
- 46 -
Figure 3.1 Processus de sélection d’indicateurs
Indépendamment de la nature de l'approche de sélection d’indicateurs, il devrait
prévoir un mécanisme de recherche et une procédure d'évaluation. En d'autres termes, la
première étape de la génération des sous-ensembles produit des sous-ensembles candidats
basés sur une certaine stratégie de recherche. Ensuite, chaque sous-ensemble candidat est
évalué selon certains critères, et par rapport à la meilleure solution trouvée. La génération et
l'évaluation sont répétées jusqu'à ce qu'un critère d'arrêt donné soit satisfait.
III.2.3.1 Procédures de génération
La procédure de génération est une procédure de recherche. Principalement, elle
construit des sous-ensembles d’indicateurs afin qu’ils soient évalués selon un critère bien
déterminé. La procédure de génération peut se faire avec : (i) un ensemble vide d’indicateurs,
(ii) tout l’ensemble d’indicateurs, (iii) un sous-ensemble aléatoire d’indicateurs. Dans les deux
premiers cas, les indicateurs sont ajoutés ou retirés répétitivement au fur et à mesure, alors
que dans le dernier cas, ils sont générés aléatoirement (Dash & Liu, 1997).
Il existe différentes approches pour résoudre ce problème :
1. Génération complète : elle effectue une recherche exhaustive pour trouver l’ensemble
optimal d’indicateurs sur tout l’espace des solutions possibles, qui est de l’ordre (2n).
Ensemble
d’origine
Sous-
ensemble Génération Évaluation
Critère
d’arrêt Validation
Qualité du
Sous-ensemble
OuiNon

Chapitre III Sélection d’indicateurs en classification
- 47 -
2. Génération séquentielle : à chaque itération de cette procédure, on considère à
nouveau tout l’ensemble des indicateurs restants pour l’étape de la sélection. La
génération des sous-ensembles est typiquement incrémentale (diminution/
augmentation) dans un espace de recherche de l’ordre (2n).
3. Génération heuristique : bien que l’espace de recherche est de l’ordre 2n, cette
procédure n’évalue pas toutes les solutions possibles dans cet espace. Un nombre
maximal d’itérations est imposé afin de limiter le temps de calcul. Plusieurs méthodes
basées sur les algorithmes d’optimisation métaheuristique peuvent être utilisées telles
que l’algorithme génétique, évolution différentielle, recherche tabou, recuit simulé,
essaim de particule…etc.
III.2.3.2 Évaluation
L’amélioration des performances d’un système d’apprentissage par une procédure de
sélection d’indicateurs nécessite, dans un premier temps, la définition d’une mesure de
pertinence ou bien un critère d’évaluation. Typiquement, une fonction d’évaluation essaie de
mesurer le pouvoir discriminant d’un indicateur ou d’un ensemble d’indicateurs pour
discerner entre les différentes classes. On peut distinguer deux types d’évaluation :
a) L’évaluation individuelle : cette méthode évalue chaque indicateur indépendamment des
autres et lui assigne une note plus ou moins importante selon sa pertinence (Blansché, 2006).
Les différents indicateurs sont ensuite triés afin de sélectionner les plus discriminants et ainsi
former un sous-ensemble pertinent d’indicateurs. Cependant, l’évaluation individuelle mesure
la pertinence des indicateurs en les appréciant de manière individuelle et ne permet donc pas
d’éliminer les indicateurs redondants, ce qui augmente le risque de ne pas sélectionner le
sous-ensemble le plus discriminant. En revanche, les méthodes d’évaluation de sous-ensemble
évaluent les sous-espaces d’indicateurs de manière globale.
b) L’évaluation d’un sous-ensemble : plusieurs méthodes de sélection sont basées sur
l’évaluation des sous-ensembles pour gérer à la fois la redondance et la pertinence (Liu & Yu,
2005). Chaque sous-ensemble d’indicateurs candidat est évalué par une certaine mesure
d’évaluation et comparé avec le meilleur sous-ensemble d’indicateurs obtenu précédemment
par rapport à cette mesure. Si le sous-ensemble courant est meilleur, il remplace le meilleur
sous-ensemble d’indicateurs mémorisé. Le processus de génération et d’évaluation d’un sous-
ensemble est répété jusqu’à ce qu’un critère d’arrêt soit satisfait.

Chapitre III Sélection d’indicateurs en classification
- 48 -
III.2.3.3 Critère d’arrêt
Les bornes de la recherche sont définies par l’initialisation et le critère d’arrêt. Dans le
cas de méthodes basées sur un critère d’évaluation individuelle la condition d’arrêt peut être
un nombre fixé d’indicateurs à retenir. Dans le cas des méthodes d’évaluation de sous-
ensembles, le critère d’arrêt peut être un temps de calcul fixé, un nombre d’itérations fixé,
l’absence de gain de performance par rapport aux solutions déjà trouvées, ou encore le fait
que les sous-ensembles candidats deviennent trop homogènes (dans le cas d’algorithmes à
base de populations).
III.3 Les approches de sélection d’indicateurs
Les techniques de sélection d’indicateurs sont divisibles en trois catégories, selon la
manière dont elles interagissent avec le classificateur (Tang et al., 2014) :
Les approches filtres
Les approches enveloppes (wrapper)
Les approches intégrées (embbeded )
III.3.1 Les approches filtres ( filter methods)
Les méthodes filtres opèrent directement sur le jeu de données et fournissent une
pondération, un classement, ou un ensemble de variables en sortie. Cette méthode est
considérée, davantage comme une étape de prétraitement (filtrage) avant la phase
d'apprentissage. En d'autres termes, l'évaluation se fait généralement indépendamment d'un
classificateur (Tang et al., 2014). La plupart des approches filtres classent les variables selon
leur pouvoir individuel de prédiction de la classe qui peut être estimé de divers moyens. Ci-
dessous, nous présentons quelques mesures utilisées dans la littérature comme score ou critère
d'évaluation:
L’information mutuelle (Guyon & Elisseeff, 2003) : elle est utilisé pour mesurer la
dépendance entre les indicateurs et les étiquettes et calcule le gain d'informations entre l’ième
indicateur et l’étiquette y de la classe C comme suit :
(III.5)
Où les probabilités P(xi), P(y) et P(xi; y) sont estimées par les fréquences des déférentes
valeurs possibles.
( , )( ) ( , ) lo g( ) ( )
i
ii
x y i
P X x Y yI i P X x Y yP X x P Y y
= == = =
= =∑ ∑

Chapitre III Sélection d’indicateurs en classification
- 49 -
SNR (Signal-to-Noise Ratio coefficient) (Mishra & Sahu, 2011) : C’est un score qui mesure
le pouvoir de discrimination d’un indicateur entre deux classes. Cette méthode classe les
indicateurs en calculant le rapport de la valeur absolue de la différence des moyennes des
classes et de la moyenne des écart-types des classes. La formule de SNR pour un indicateur et
pour un problème a deux classes est calculée par :
(III.6)
où sont les valeurs moyennes des echantillons des classes 1 et 2 respectivement.
sont les ecart types des echantillons dans chaque classe.
Critère de corrélation : les mesures de corrélation ou de dépendance évaluent la capacité de
prédire la valeur d'une variable à partir de la valeur d'une autre variable (Dash & Liu, 2003).
La pertinence d’un indicateur pourrait être mesurée en termes de niveau de la corrélation entre
la classe et un indicateur donné.
Un coefficient de corrélation populaire dans les statistiques, est le coefficient de corrélation
linéaire ou « Bravais-Pearson ». Pour un indicateur xi , ce critère se calcule comme suit :
(III.7)
Où et représentent respectivement les valeurs moyennes de l’ième indicateur et des étiquettes de
l'ensemble d'apprentissage.
III.3.2 Les approches enveloppes (wrapper methods)
Les méthodes enveloppes (wrapper methods) ont été introduites par Kohavi (Kohavi
& John, 1997). Ces méthodes effectuent une recherche dans l’espace des sous-ensembles
d’indicateurs. La fonction objective utilisée pour la sélection d'indicateurs est alors la
performance du modèle de classification sur le sous-ensemble d'indicateurs considérée.
L’appel de l’algorithme de classification est fait plusieurs fois à chaque évaluation (c’est-à
dire à chaque sélection d’un indicateur, on calcule le taux de classification pour juger sa
pertinence). Le principe des wrappers est de générer un sous ensemble bien adaptés à
l’algorithme de classification. Les taux de reconnaissance sont élevés car la sélection prend en
1 2 i ic e t cμ μ
1
1 1
( )( )( )
( )² ( )²
m
i ii
m m
i ii k
x x y yC i
x x y y
=
= =
− −=
− −
∑
∑ ∑
( )1 2
1 2
2( ) i i
i i
c cS N R i
c cμ μ
σ σ× −
=−
1 2 i ic e t cσ σ

Chapitre III Sélection d’indicateurs en classification
- 50 -
compte le biais intrinsèque de l’algorithme de classification. En revanche, un risque de sur-
apprentissage existe. De plus, leur complexité de calcul est donc dépendante de la complexité
du modèle d’apprentissage utilisé.
Les deux méthodes d'optimisation les plus utilisées dans ce domaine sont des
méthodes de recherche locale de type glouton (greedy methods ), qui permettent de pallier au
problème lié à la grande dimension. La première est appelée Sélection ascendante (SFS pour
Sequential Forward Selection). Elle démarre d'une solution ne contenant aucun indicateur et
parcourt l'ensemble des indicateurs en les ajoutant à la solution initiale. Lorsqu'elle les a tous
parcourus, elle garde le meilleur, l'ajoute à la solution optimale, et recommence jusqu'à ce
qu'un critère d'arrêt soit atteint. La deuxième méthode, appelée Élimination descendante (SBS
pour Sequential Backward Selction) fonctionne de la même façon, mais en partant d'une
solution contenant tous les indicateurs et en les retirant tour à tour, pour analement retirer
celui qui obtient les moins bons résultats. Il est à noter que d'autres heuristiques peuvent être
également utilisées.
III.3.3 Les approches intégrées (Embedded methods)
Les méthodes intégrées utilisent l’information interne du modèle de classification
par exemple, le vecteur de poids dans le cas des SVM (support vector machines). Ces
méthodes sont donc proches des méthodes d’enveloppes, du fait qu’elles combinent le
processus d’exploration avec un algorithme d’apprentissage sans étape de validation, pour
maximiser la qualité de l’ajustement et minimiser le nombre d’indicateurs (Guyon &
Elisseeff, 2003).
L’élimination récursive des indicateurs (Recursive Features Elimination (RFE-
SVM)), présentée par Guyon (Guyon & Elisseeff (2003), est Considérée comme l'une des
approches éminentes à la sélection des indicateurs par approche intégrée. Dans cette méthode
l’algorithme RFE supprime à chaque itération l’indicateur le moins pertinent et ré-estime le
résultat du classificateur sur les indicateurs restants. La procédure RFE tente de sélectionnez
n<N indicateurs qui conduisent à plus grande marge dans la séparation de classes. Ce
problème a été résolu par combinaison d’une procédure qui supprime à chaque itération
l’indicateur qui minimise la baisse de la marge entre les limites de l’hyperplan de
classification. La procédure pourrait être accélérée par la suppression de plus d'un indicateur à
chaque itération.

Chapitre III Sélection d’indicateurs en classification
- 51 -
III.4 Les métaheuristiques pour la sélection d’indicateurs
Comme nous avons vu dans la section (III.2.2), pour résoudre un problème
d’optimisation combinatoire tel que le problème de sélection d’un sous ensemble optimal
d’indicateurs, on utilise généralement les méthodes heuristiques, qui sont développées afin de
résoudre un problème particulier d’optimisation combinatoire. Leur principal inconvénient est
qu’elles ne peuvent être appliquées qu’à un problème donnée et que le résultat obtenu ne
pourra pas être appliqué sur une autre classe différente de problèmes Durant ces vingt
dernières années de nouveaux types d’algorithmes, appelés métaheuristiques ont vu le jour et
ne cessent de se développer. Les métaheuristiques désignent un cadre général de résolution de
problèmes NP difficiles. Leur fonctionnement, au contraire des heuristiques, est donc
indépendant du problème traité.
Ces algorithmes, ont été introduits par Glover (Glover, 1986), et jusqu’à une certaine
période, on les appelait les heuristiques modernes. Ils sont généralement utilisés comme des
méthodes génériques pouvant traiter une large gamme de problèmes différents, sans nécessiter
de changements profonds dans l'algorithme employé. Ces méthodes sont souvent inspirées par
des systèmes naturels, qu’ils soient pris en physique (cas de recuit simulé), en biologie de
l’évolution (cas des algorithmes génétiques) ou encore en éthologie (cas des algorithmes de
colonies de fourmis, ou de l’optimisation par essaims particulaires).
Les métaheuristiques sont souvent classées selon deux ensembles : les algorithmes à
base de solution courante unique, et les méthodes à population (Widmer, 2001). Dans le
premier cas, la métaheuristique manipule un point, et décide à chaque itération quel sera le
point suivant. On classe par exemple la recherche avec tabous et le recuit simulé dans cet
ensemble. Dans le second cas, la métaheuristique manipule une population de points, et un
nouveau jeu de points est choisi à chaque itération. Beaucoup d'algorithmes peuvent entrer
dans cet ensemble, comme les algorithmes évolutionnaires ou les algorithmes de colonies de
fourmis.
III.4.1 Les métaheuristiques à solution unique
III.4.1.1 Le recuit simulé
Le recuit simulé est fondé sur une analogie entre un processus physique (le recuit) et
le problème de l'optimisation. Le recuit simulé (Cerny, 1985), en tant que métaheuristique
s'appuie en effet sur des travaux de Metropolis (Metropolis et al., 1953), visant à simuler

Chapitre III Sélection d’indicateurs en classification
- 52 -
l'évolution d'un solide vers son état d'énergie minimale. Dans le cadre d'un problème
d'optimisation, la fonction objective à minimiser est alors assimilée à l'énergie du système. On
introduit également un paramètre fictif T, apparenté à la température, que l'on fait décroître au
fur et à mesure des itérations, afin de simuler le refroidissement. De la valeur de ce paramètre,
va dépendre la probabilité d’acceptation des nouvelles solutions
On démarre alors l'algorithme avec une solution unique x que l'on cherche à
améliorer. On perturbe cette solution afin d'obtenir une nouvelle solution x0 dans le voisinage
de la première. Ensuite, on calcule l'écart des valeurs de la fonction objectif pour ces deux
solutions : Δf = f(x0) - f(x). On se retrouve alors dans deux cas possibles :
Δf ≤0, la nouvelle solution est meilleure que la solution initiale, on la remplace donc : x = x0.
Δf > 0, la nouvelle solution est moins bonne que la solution initiale. Cependant, on a tout de
même la possibilité de la remplacer avec une probabilité d'acceptation :
(III.8)
Où T est la température du système et kB une constante physique connue sous le nom de
constante de Boltzmann.
L’acceptation de la nouvelle solution est décidée en générant de manière aléatoire un nombre
q [0,1]. Si q est inférieur ou égal à prob (Δf,T), alors la nouvelle solution est acceptée.
Autrement la solution actuelle est maintenue. L’utilisation répétée d’une telle règle fait
évoluer le système vers un état d’équilibre thermique. Lorsqu’aucun état nouveau n’est
accepté à une température T donnée, on considère que le système est gelé et on suppose qu’il
a atteint la meilleure solution.
Dans (Lin et al., 2008), les auteurs proposent une approche SA-SVM basé sur le
recuit simulé pour l’optimisation des paramètres des SVMs et pour obtenir le sous ensemble
optimal d’indicateurs. Le sous ensemble sélectionné, est ensuite adopté pour l’entrainement et
le test des SVM, afin d’obtenir un meilleur taux de reconnaissance en classification. Une
comparaison des résultats avec ceux obtenus avec d’autres approches prouvent que
l’approche SA-SVM permet d’améliorer les performances de classification.
III.4.1.2 La recherche tabou
De même que le recuit simulé, la recherche Tabou (Glove, 1989) figure au moins
dans sa version de base, comme une variante de la recherche locale. Dans cette méthode on
débute à partir d’une solution S0 X choisie arbitrairement ou alors obtenue par le biais d’une
méthode constructive. Le passage d’une solution admissible à une autre se fait sur la base
( , ) exp( ).B
fprob f Tk T−Δ
Δ =

Chapitre III Sélection d’indicateurs en classification
- 53 -
d’un ensemble de modifications élémentaires qu’il s’agit de définir de cas en cas. Une
solution s’obtenue à partir de S en appliquant une modification élémentaire. Le voisinage N(s)
d’une solution S X est défini comme l’ensemble des solutions admissibles atteignables
depuis ‘S’, en effectuant une modification élémentaire (Hertz et al., 1995). Supposons que
nous cherchons à minimiser une fonction f(x), les caractéristiques essentielles d’une recherche
Tabou sont résumées comme suit :
Partant d’une solution S à l’itération K, nous définissons un sous voisinage v* dans le
voisinage N(s), en fonction de l’historique déjà mené. Le choix de sous voisinage vise à éviter
une exploration d’une zone trop grande, impraticable ou trop coûteuse en temps. La meilleure
solution s* est calculée dans v*, et devient la nouvelle solution courante. Lorsqu’aucun
mouvement améliorant la solution actuelle n’est pas possible, le risque de créer des cycles
visite de la solution précédente est présent, par exemple un cycle de longueur
2 : s→s’→s→s’..... .Il est donc important d’interdire les mouvements conduisant vers
des solutions récemment visitées ce qui peut se faire en retirant ces solutions de voisinage de
S. Plus généralement, le voisinage de S dépendra de l’itinéraire suivi, ce que nous noterons
N(S, K). L’exclusion de solutions peut se faire grâce à une ou plusieurs listes Tabou qui
tiennent en mémoire les dernières solutions rencontrées ou des caractéristiques communes à
celles ci. En d'autres termes, la méthode Tabou conserve à chaque étape une liste T de
solutions "Taboues", vers lesquelles il est interdit de se déplacer momentanément. L'espace
nécessaire pour enregistrer un ensemble de solutions taboues peut s'avérer important en place
mémoire. Pour cette raison, il est parfois préférable d'interdire uniquement un ensemble de
mouvements qui ramèneraient à une solution déjà visitée. Ces mouvements interdits sont
appelés mouvements tabous.
Dans (Tahir et al., 2007), une méthode basée sur la recherche Tabou (Tabu search), a
été proposée pour la sélection des indicateurs afin d’améliorer les performances de la
classification par les K plus proches voisins (K-PPV). Cette approche utilise à la fois un
vecteur de poids et un vecteur binaire dans le codage de la solution avec la recherche tabou.
Le vecteur de poids se compose de valeurs réelles tandis que le vecteur de sélection
d’indicateurs est un vecteur binaire composé de 0 ou 1. Un classificateur K-PPV est utilisé
pour évaluer chaque sous ensemble d’indicateurs sélectionné par la recherche tabou. En plus
des vecteurs de poids et le vecteur binaire, la valeur de K utilisé dans K –PPV est également
stockées dans la solution de codage du l’algorithme de recherche tabou. Des résultats
prometteurs ont été donnés par l’approche proposée.

Chapitre III Sélection d’indicateurs en classification
- 54 -
Oduntan (Oduntan et al., 2008) a développé un algorithme qui combine la recherche
tabou de niveaux multiples avec une recherche hiérarchique. Les résultats obtenus ont été
comparé avec d’autres algorithmes de sélection tels que la sélection descendante et la
sélection aléatoire.
III.4.2 Les métaheuristiques à base de population de solutions
III.4.2.1 Les Algorithmes évolutionnaires
Les algorithmes évolutionnaires sont inspirés de l'évolution biologique des êtres
vivants, qui décrit comment des espèces s'adaptent à leur environnement. L'analogie avec un
problème d'optimisation a donné lieu à plusieurs approches parmi lesquelles, les algorithmes
génétiques sont, sans doute, l'exemple le plus connu.
III.4.2.1.1 Les algorithmes génétiques
Les algorithmes génétiques (Holland, 1975) manipulent une population d'individus :
un ensemble de points dans l'espace de recherche. Chaque individu est lié à une valeur de la
fonction objectif du problème, dénommée fitness, qui représente son degré d'adaptation. Les
algorithmes génétiques font évoluer cette population d'individus par générations successives,
en utilisant des opérateurs inspirés de la théorie de l'évolution :
La sélection, qui permet aux individus les mieux adaptés de se reproduire le plus souvent ;
Le croisement, qui produit un nouvel individu à partir de deux parents, en recombinant les
caractéristiques de ceux-ci.
La mutation, qui fait varier les caractéristiques d'un seul individu de façon aléatoire.
Beaucoup d'algorithmes évolutionnaires s'appuient également sur la notion de
représentation des individus. Les individus sont ainsi classiquement représentés par des
chromosomes, qui forment une liste d'entiers, un vecteur de nombres réels, . . . etc. Ce sont
ces chromosomes qui sont modifiés par les opérateurs précédents.
En pratique, chaque itération de l'algorithme représente une génération. L'algorithme effectue
ainsi une première phase de sélection, où sont désignés les individus qui vont participer à la
phase suivante de croisement, puis de mutation. La dernière phase évalue la performance des
individus, avant de passer à la prochaine génération.
Les algorithmes évolutionnaires classiques sont implicites. On peut cependant observer que
les opérateurs de croisement et de mutation visent à produire un ensemble de nouveaux points

Chapitre III Sélection d’indicateurs en classification
- 55 -
(diversification) dans les limites de la population précédente (mémoire), points dont on va
ensuite réduire le nombre (intensification), et ainsi de suite.
Les algorithmes génétiques ont été parmi les premiers algorithmes à appliquer dans
le domaine d’optimisation, et plus particulièrement pour la tache de sélection d’indicateurs.
Dans (Samanta et al. 2003), les auteurs proposent un AG pour la sélection d’un sous ensemble
optimal d’indicateurs, dans le cadre de diagnostic automatisé des machines tournantes. Le
sous ensemble sélectionné est utilisé pour entrainer deux classificateurs différents à savoir, les
SVMs et les réseaux de neurones artificiels RNA. Afin de mettre en évidence l’effet de la
sélection sur la performance de la classification, chaque classificateur a été entrainé dans deux
cas différents : avec , et sans sélection d’indicateurs
Dans une étude antérieure (Ziani et al, 2012), nous avons proposé un algorithme
génétique pour la sélection des indicateurs les plus pertinents. Dans cette étude, l’AG a été
combinée avec les réseaux de neurones artificiels pour un problème de classification des
défauts de roulement. La fonction objective, que nous avons utilisé, est le critère de trace de
la matrice de dispersion intra-classe. Ce critère a été utilisé pour évaluer la pertinence de
chaque sous ensemble généré par les chromosomes de l’AG. Des résultats prometteurs, ont
été obtenus avec cette approche.
D’autres applications des AGs pour la sélection des indicateurs ont été également
présentées dans (Jack & Nandi, 2002 ; Samanta et al., 2001 ; Samanta, 2004 ; Avci, 2009 ;
Ziani et al. 2011; Hajnayeb et al. 2011).
III.4.2.1.2 L’évolution différentielle
L’évolution différentielle (ED) ou Différentiel Evolution (Storn & Price, 1997) est
une approche basée sur la population comme les AG, et applique des opérateurs de
reproduction similaires (c’est à dire de croisement et de mutation). La différence principale
est que les AG s’appuient sur le croisement comme un mécanisme d’intensification, tandis
que l’ED utilise un système spécifique de mutation. Cet opérateur principal est basé sur la
différence entre deux solutions aléatoires de la population. L’ED est en mesure d'ajouter la
différence à un troisième membre et, par conséquent, de générer nouvelle solution :
(III.9)
1 2 3*( )i r r rx x f x x= + −

Chapitre III Sélection d’indicateurs en classification
- 56 -
Où xi représente la solution résultante et r1 ≠ r2 ≠r3 trois indices aléatoires distincts des
membres de la population. f est un facteur d'échelle qui contrôle la vitesse à laquelle la
population évolue. Après la génération aléatoire de la population initiale, Le processus itératif
commence par l'opérateur de mutation suivie d’un croisement uniforme entre la solution
actuelle et le résultat de mutation. Une fois la nouvelle solution est évaluée, la descendance
est comparée à celle en cours et la solution la moins apte est remplacée. En outre, toutes les
solutions ont une chance d’être sélectionné sans aucune référence à la fonction d’évaluation
(fitness).
Dans (Khushaba et al., 2011), les auteurs ont proposé une adaptation de l’évolution
différentielle d’origine (initialement destinée pour les problèmes continus) pour le problème
de sélection d’indicateurs par l’utilisation d’une représentation binaire des solutions. Chaque
solution est de taille fixe qui code les indexes des indicateurs. Dans la phase de reproduction
d’une nouvelle population, les auteurs ont introduit un mécanisme similaire à celui de
l’optimisation par essaim de particules. Les résultats obtenus montrent l’efficacité de cette
méthode. Une autre méthode hybride basée sur l’ED et l’optimisation par colonie de fourmis
a été proposée dans (Khushaba et al, 2008).
III.4.2.2 L’algorithme d’optimisation par essaim de particules
Les algorithmes d’optimisation par essaim de particules (en anglais : Particle swarm
optimization PSO) ont été introduits en 1995 par Kennedy (Kennedy & Eberhart, 1995)
comme une alternative aux algorithmes génétiques standards. Ces algorithmes sont inspirés
des essaims d’insectes (ou des bancs de poissons ou des nuées d’oiseaux) et de leurs
mouvements coordonnés. En effet, tout comme ces animaux se déplacent en groupe pour
trouver de la nourriture ou éviter les prédateurs, les algorithmes à essaim de particules
recherchent des solutions pour un problème d’optimisation. Les individus de l’algorithme sont
appelés particules et la population est appelée essaim.
Dans cet algorithme, une particule décide de son prochain mouvement en fonction
de sa propre expérience, qui est dans ce cas la mémoire de la meilleure position qu’elle a
rencontrée, et en fonction de son meilleur voisin. Ce voisinage peut être défini spatialement
en prenant par exemple la distance euclidienne entre les positions de deux particules ou
sociométriquement (position dans l’essaim de l’individu). Les nouvelles vitesses et direction
de la particule seront définies en fonction de trois tendances : la propension à suivre son
propre chemin, sa tendance à revenir vers sa meilleure position atteinte, et sa tendance à aller
vers son meilleur voisin. Les algorithmes à essaim de particules peuvent s’appliquer aussi

Chapitre III Sélection d’indicateurs en classification
- 57 -
bien à des données discrètes qu’à des données continues. Les algorithmes à essaim de
particules ont été utilisés pour réaliser différentes tâches d’extraction de connaissances. III.4.2.3 L’optimisation par colonie de Fourmis (Ant colony optimization)
Comme les algorithmes génétiques, les algorithmes de colonies de fourmi font
évoluer une population d’agents, selon un modèle stochastique. Cet algorithme est encore
inspiré de la nature et de son organisation. Son principe repose sur le comportement
particulier des fourmis lorsqu’elles quittent leur fourmilière pour explorer leur environnement
à la recherche d’une source de nourriture. Ces algorithmes ont été initialement proposés dans
(Dorigo et al. 96) pour résoudre des problèmes d’optimisation combinatoire. L’idée est de
représenter le problème à résoudre sous la forme de la recherche d’un meilleur chemin dans
un graphe, puis d’utiliser des fourmis artificielles pour rechercher de bons chemins dans ce
graphe. Le comportement des fourmis artificielles est inspiré des fourmis réelles : elles
déposent des traces de phéromone sur les composants du graphe et elles choisissent leurs
chemins relativement aux traces de phéromone précédemment déposées ; ces traces sont
évaporées au cours du temps. Intuitivement, cette communication indirecte fournit une
information sur la qualité des chemins empruntés afin d’attirer les fourmis, dans les itérations
futures, vers les zones correspondantes de l’espace de recherche. Ces caractéristiques du
comportement des fourmis artificielles définissent la “métaheuristique d’optimisation par une
colonie de fourmis” ou “Ant Colony Optimization (ACO) metaheuristic” (Dorigo & Di Caro,
1999). Cette métaheuristique a permis de résoudre différents problèmes d’optimisation
combinatoire (Chen et al., 2010 ; Kanan et al., 2007 ; Khushaba et al., 2011).
III.5 Synthèse sur la sélection d’indicateurs
Dans les sections précédentes nous avons montré que le problème de sélection
d’indicateurs peut être modélisé comme un problème d’optimisation NP-difficile et ne pourra
donc être résolu par des méthodes exactes dans un temps raisonnable. Dans le cadre de la
résolution des problèmes combinatoires NP-difficiles, les méthodes métaheuristiques se sont
montrées efficaces dans de nombreuses applications. Les métaheuristiques sont divisées en
deux groupes ; les algorithmes à base de solution courante unique et les méthodes à
population. Dans le premier cas, la métaheuristique manipule un point, et décide à chaque
itération quel sera le point suivant. On classe par exemple la recherche avec tabous et le recuit
simulé dans cet ensemble. Dans le second cas, la métaheuristique manipule une population de
points, et à chaque Itération un nouveau jeu de points est choisi.

Chapitre III Sélection d’indicateurs en classification
- 58 -
Comme notre objectif est de sélectionner un sous ensemble optimal, nécessaire pour
la tache de classification, les métaheuristiques à base de population s’avèrent les mieux
adaptées pour ce type de problème. Dans la suite de ce chapitre nous présentons notre
contribution, en proposant une approche de type filtre pour la sélection d’un sous-ensemble
d’indicateur basée l’optimisation par essaim de particules.
III.6 Contribution à la sélection d’indicateurs pour la classification automatique des
défauts
III.6.1 Motivation
L’Optimisation par Essaim de Particules (OEP) est l’une des méthodes
métaheuristiques à base de population, qui a été employée dans plusieurs études pour la
sélection des indicateurs dans différents domaines. L'un des avantages de l’OEP est que
l'utilisateur n'a pas à indiquer le nombre désiré d’indicateurs, comme il est intégré dans
quelques processus d'optimisation. En plus, contrairement aux algorithmes génétique et
d'autres algorithmes à base de population, l’OEP est facile à mettre en œuvre et n’a pas
beaucoup de paramètres qui ont besoin d'être manipulé correctement pour atteindre une assez
bonne performance (Du et al., 2012 ; Gaitonde & Karnik, 2012).
Dans la littérature, plusieurs études ont été menées sur la sélection d’indicateurs, en
utilisant l’OEP. Nous citons, plus particulièrement, celles réalisées dans le cadre de
diagnostic automatique des défauts mécaniques: (Samanta et Nataraj, 2009 ; Li et al., 2007 ;
Yan & Chu 2007). Les auteurs de ces études, proposent une approche enveloppe (wrapper) où
à chaque itération le classificateur est appelé pour évaluer les sous ensembles générés par les
particules de l’essaim. Cependant, Cette approche se révèle très coûteuse en temps. En plus,
elle n’apporte pas vraiment de justification théorique à la sélection, et elle ne nous permet pas
de comprendre les relations de dépendances conditionnelles qu’il peut y avoir entre les
indicateurs (boite noire). D’autre part, la procédure de sélection est spécifique à un algorithme
de classification particulier et les sous ensembles trouvés ne sont pas forcément valides si
nous changeons de méthode de classification. Cela nous a poussé à proposer une méthode de
sélection par OEP en utilisant une approche filtre. Cette approche se révèle meilleur dans le
domaine de diagnostic des défauts mécaniques, car elle permet à l’utilisateur d’accéder
visuellement aux connaissances implicites représentées par un ensemble d’observations, et de
juger la pertinence des indicateurs. L’inconvénient principal de cette approche réside dans le

Chapitre III Sélection d’indicateurs en classification
- 59 -
fait que la sélection est réalisée indépendamment de la méthode de classification, ce qui influe
par la suite sur les performances de la classification.
Dans le but de limiter les inconvénients des deux approches (filtre, enveloppe), tout
en conservant leurs avantages respectifs, nous proposons une nouvelle méthode de sélection
basée sur l’OEP qui tend à optimiser deux aspects :
- Sélectionner un sous ensemble d’indicateur pertinent, dans un temps raisonnable,
sans nécessité d’employer le classificateur durant le processus de sélection..
- l’évaluation des solutions candidates (sous ensemble générés par les particules de
l’essaim) doit être réalisée en relation avec l’objectif principal qui est
l’amélioration des performances de la classification.
III.6.2 Approche proposée
Du fait que les performances des SVMs sont en étroite liaison avec la distribution des
données d’apprentissages, cela nous a mené à proposer une fonction d’évaluation qui peut
mesurer la séparabilité des classes dans l’ensemble d’apprentissage. L’idée principale est
basée sur le fait que les indicateurs sélectionnés, doivent avoir des valeurs similaires pour les
échantillons de la même classe et des valeurs différentes pour les échantillons de différentes
classes. Ceci, va certainement conduire à une meilleure séparabilité des classes. Par
conséquent, la tache de classification devient plus facile et plus performante. La fonction que
nous avons adoptée est le critère de Fisher régularisé CFR (Friedman, 1989). Ce critère révèle
le mieux approprié pour mesurer la séparabilité des classes. En outre, c’est le seul critère
ayant une relation directe avec l’objectif principal qui est la classification. Une bonne
séparabilité des classes indique que les indicateurs sélectionnés ont une grande sensibilité,
traduite par une variation considérable de leurs valeurs quand on passe d’une classe à une
autre. Cette caractéristique est très importante dans le domaine de diagnostic des défauts
mécaniques ; une grande sensibilité des indicateurs, permet donc une détection précoce et
meilleure de défauts lors de la classification.
La méthode proposée est basée sur une stratégie de recherche utilisant l’Optimisation
par Essaim de Particules Binaires (OEPB) (Kennedy & Eberhart, 1997), qui est la version
discrète de l’OEP. Dans cette méthode, le CFR est utilisée pour évaluer la pertinence des
sous-ensembles candidats générés par les particules de l’OEPB. Notons ici, que ce critère doit
être maximisé durant le processus d’optimisation à la recherche de la meilleure solution. Cette
approche peut être considérée comme un processus séquentiel en deux étapes qui utilise des

Chapitre III Sélection d’indicateurs en classification
- 60 -
techniques complémentaires pour réduire graduellement l’espace de recherche et sélectionner
un sous ensemble pertinent d’indicateurs :
- Étape 1 : Dans cette étape l’algorithme OEPB est utilisé pour générer des sous
ensembles candidats à partir de l’ensemble initial.
- Étape 2 : Cette étape se traduit par l’utilisation du CFR pour évaluer les sous
ensembles générés.
III.6.2.1 L’algorithme d’optimisation par essaim de particules Binaires (OEPB)
Dans la version continue d’OEP (Kennedy & Eberhart, 1995), les individus
(particules) sont composés de cellules appelées positions. L'essaim composé de ces particules
est initialisé aléatoirement, et chaque particule de l'essaim représente une solution possible du
problème. L’OEP converge à un optimum global par une procédure itérative basée sur les
processus de mouvement et de l'intelligence dans un système évolutif. Les meilleures valeurs
obtenues pour chaque particule (meilleure valeur individuelle pbesti, et meilleure valeur
globale gbesti) sont accumulés pour être utilisé dans l'étape suivante pour obtenir la valeur
optimale.
La vitesse et la position de chaque particule sont calculées à l'itération (t + 1) en fonction
des valeurs à l'itération en cours (t) comme suit:
, ,, , 1 1 , 2 2 ,( 1) . ( ) ( ( )) ( ( ))
i j i ji j i j best i j best i jv t v t c R p x t c R g x tω+ = + − + −
(III.10)
, , ,( 1) ( ) ( 1)i j i j i jx t x t v t+ = + + (III.11)
Où : i est l'indice de particule, j est l'indice de position dans la particule, ω est appelée
vecteur de poids qui contrôle les effets de la vitesse précédente de la particule sur sa vitesse
actuelle. vi,j(t) est la vitesse de la ième particule de l’essaim dans le jème indice de position vmin
≤ vk,l(t) ≤ vmax . xi,j(t) est la position. R1 et R2 sont des nombres aléatoires distribués de façon
uniforme dans l'intervalle [0.0, 1.0]. c1 et c2 appelées "coefficients d'accélération" sont des
constantes positives qui ont par défaut une valeur de 2.
Dans la technique d’Optimisation par Essaim de Particule Binaires (OEPB)
(Kennedy & Eberhart, 1997), chaque position des particules est exprimée en tant que vecteur
binaire composé de 0 et de 1.

Chapitre III Sélection d’indicateurs en classification
- 61 -
La vitesse vi,j(t) est utilisée pour calculer la probabilité que le jème bit de la ième position de
particule xi,j(t) prend la valeur 1. La détermination de la position est effectuée en utilisant la
formule suivante:
,,
0 si () ( ( 1))( 1)
1 sinon i j
i j
rand s v tx t
≤ +⎧+ =⎨
⎩ (III.12)
Où rand () est un nombre généré aléatoirement dans l'intervalle fermé [0.0, 1.0]. S (.) est une
fonction sigmoïde utilisée pour transformer le vecteur de vitesse en un vecteur de probabilité
de la manière suivante:
(III.13)
III.6.2.2 L’analyse discriminante linéaire et Critère de Fisher Régularisé (CFR)
Dans la méthode proposée, nous voulons évaluer comment les classes sont ils séparées
dans un espace de D-dimensions en utilisant certains critères tels que celui évoqué ici.
L'analyse discriminante linéaire (ADL) ou analyse de Fisher, est une méthode linéaire de
réduction de dimension. L’ADL est donnée par une matrice de transformation linéaire W
maximisant le critère dite « critère de Fisher » (Duda et al.2000) :
(III.14)
Où et sont la matrice dispersion interclasse, et la matrice de dispersion intra-classe,
respectivement. Ils ont les expressions suivantes:
(III.15)
(III.16)
Où ( )( )Ti i ix Di
S x m x m∈
= − −∑ est la matrice de dispersion intra-classe de la classe i.
1
1 ci ii
m n mn =
= ∑ est le vecteur moyen global, c est le nombre de classes, mi et ni sont le
vecteur moyen et nombre d'échantillons de la classe i respectivement. tr désigne la trace d'une
matrice carrée, soit la somme des éléments diagonaux. W est une matrice de transformation
,, ( 1)1( ( 1))
1 i ji j v ts v te +−
+ =+
Tb
Tw
W S WC F trW S W
⎛ ⎞= ⎜ ⎟
⎝ ⎠
bS wS
1
cw ii
S S=
=∑1
( )( )c Tb i i ii
S n m m m m=
= − −∑

Chapitre III Sélection d’indicateurs en classification
- 62 -
donnée par les vecteurs propres de . Le critère de Fisher est une mesure de la
séparabilité de toutes les classes.
Il est bien connu que l'applicabilité de ce critère pour les tâches de classification de
grande dimension souffre souvent du problème posé par le petit nombre d'échantillons
d’apprentissage disponibles par rapport à la taille ‘d’ de l'échantillon (Sharma & Paliwal,
2012). Dans ce cas la matrice Sw devient singulière, il est donc impossible de calculer le
critère de Fisher de l’équation (III.14). Dans la littérature, plusieurs méthodes ont été
proposées pour résoudre ce problème telles que : ADL basée sur la décomposition généralisée
en valeurs singulières (Generalized singular value decomposition GSVD) proposée dans
(Howland et Park 2004), ADL non corrélée (Uncorrelated linear discriminant analysis
ULDA) (Ye et al., 2004), l’ADL directe (direct LDA method (DLDA)) (Yu & Yang, 2001), et
la méthode de l’ADL régularisée (Regularized LDA method (RLDA)) (Friedman, 1989). Une
étude comparative a été menée par Park (Park & Park, 2007), et d’autres méthodes sont
présentées dans (Ye & Xiong, 2006).
L’Analyse Discriminante Linéaire Régularisée (Regularized Linear Discriminant
Analysis RLDA) proposée par Friedman (Friedman, 1989) est une méthode simple et
compétitive. Dans cette méthode, lorsque Sw est singulière ou mal conditionnés, une matrice
diagonale λI avec λ> 0 est ajoutée à Sw. Tant que Sw est symétrique et positif, Sw + λI est non
singulière avec tout λ> 0.
Où λ est le paramètre de régularisation.
Suivant la même notation, et en remplaçant la matrice Sw par la matrice régularisée Sw + λI
dans (III.14), le critère de Fisher régularisée (CFR) devient:
(III.17)
III.6.3 Conduite des différentes étapes de l’algorithme proposé
La conduite des différentes étapes de l’algorithme de sélection proposé, est illustrée
sur l’organigramme de la figure 3.2. Cet algorithme a pour acronyme : OEPB-CFR.
( )
Tb
Tw
W S WCFR trW S I Wλ⎛ ⎞
= ⎜ ⎟+⎝ ⎠
/b wS S
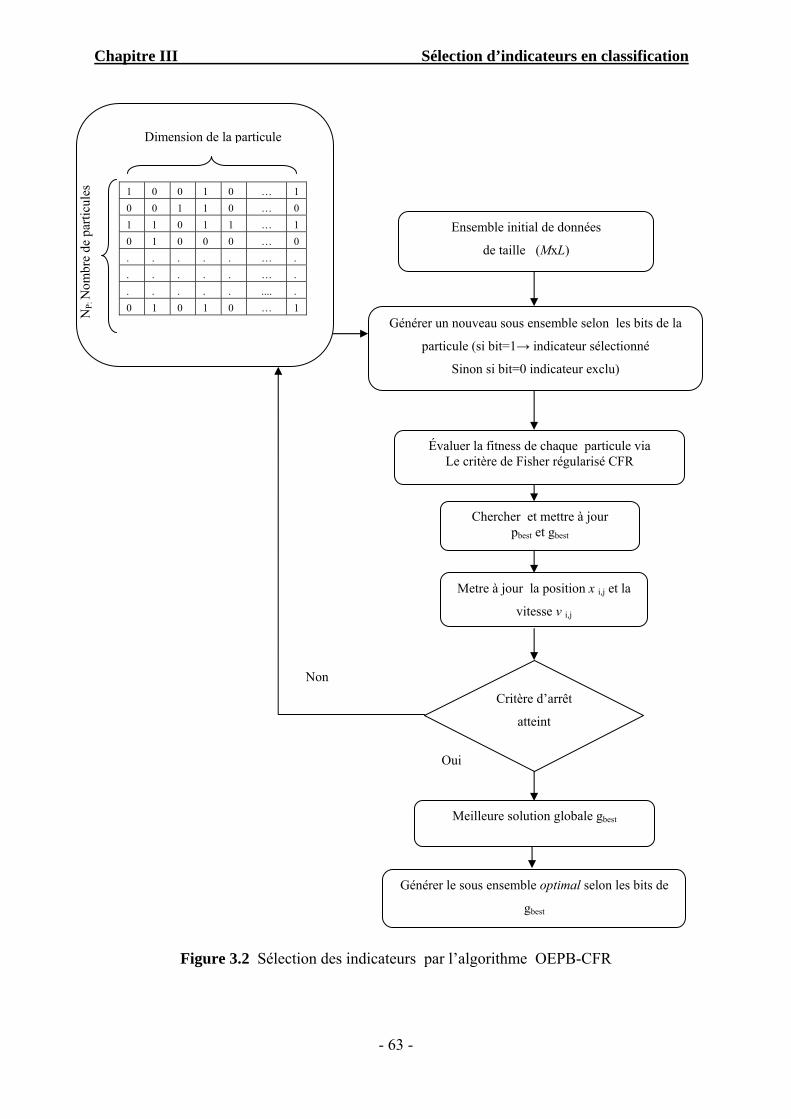
Chapitre III Sélection d’indicateurs en classification
- 63 -
Figure 3.2 Sélection des indicateurs par l’algorithme OEPB-CFR
1 0 0 1 0 … 1 0 0 1 1 0 … 0 1 1 0 1 1 … 1 0 1 0 0 0 … 0 . . . . . … . . . . . . … . . . . . . .... . 0 1 0 1 0 … 1 N
P: N
ombr
e de
par
ticul
es
Dimension de la particule
Non
Oui
Générer le sous ensemble optimal selon les bits de
gbest
Meilleure solution globale gbest
Chercher et mettre à jour pbest et gbest
Metre à jour la position x i,j et la
vitesse v i,j
Critère d’arrêt
atteint
Générer un nouveau sous ensemble selon les bits de la
particule (si bit=1→ indicateur sélectionné
Sinon si bit=0 indicateur exclu)
Ensemble initial de données
de taille (MхL)
Évaluer la fitness de chaque particule via Le critère de Fisher régularisé CFR

Chapitre III Sélection d’indicateurs en classification
- 64 -
Comme le montre la figure 3.2, la première étape nécessite l’ensemble initial de
données (obtenu dans la phase d’analyse), à partir du quel le sous ensemble optimal sera
sélectionnée. Cet ensemble de données est stocké dans une matrice de taille (MхL) de la
forme suivante :
(III.18)
Où M est le nombre des observations (signaux), L est le nombre d’indicateurs.
La sélection nécessite également la connaissance des étiquettes yi des classes de données pour
être utilisée de la manière la plus efficace possible (classification supervisée). Dans le cas des
SVMs, yi prend soit +1 ou -1. On a alors M observation, représentées en lignes et L
indicateurs, représentées en colonnes. Les observations de cette matrice appartiennent à Nc
classes ( Ncwww ,,, 21 ). Chaque classe iw possède m observations.
La sélection d’un sous ensemble optimal est réalisée suivant les étapes suivantes :
1) Génération de l’essaim: l’algorithme commence avec une population de particules
(Essaim) dans laquelle chaque particule représente une solution possible au problème de
séparabilité des classes qui doit être maximisé. La représentation de l’essaim E est :
1 2 ,t
i NpE P P P P⎡ ⎤= ⎣ ⎦
Où iP représente l’iième particule dans l’essaim, et Np représente le nombre de particules.
Les vecteurs de positions xi,j et de vitesse vi,j de l'ensemble des particules de la population,
sont initialisées d’une manière aléatoire, et ont les mêmes dimensions que le nombre
d'indicateurs (L) de la matrice de données considéré. Les positions des particules sont
initialisées aléatoirement avec des valeurs de 0 et des 1. Par exemple x = [0 1 1 0 1.... 0 0 1 1]
est un vecteur de position d'une particule. Le bit 1 lorsqu’il est affecté provoque la sélection
de la colonne de l’indicateur correspondant dans le la matrice de données, et le bit 0
provoque le rejet de l’indicateur correspondant. Cela génère un nouveau sous-ensemble
11 12 1 1
21 22 2 2
1 2
....
..... . . . .. . . . .
....
L
L
M M M L M
x x x Xx x x X
BD
x x x X
⎡ ⎤ ⎡ ⎤⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥= =⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎣ ⎦

Chapitre III Sélection d’indicateurs en classification
- 65 -
correspondant à la particule considérée. Ainsi, pour une population de NP particules, NP
sous-ensembles sont générées. L'objectif de l'algorithme est de trouver la solution optimale
(particule) pour laquelle le sous-ensemble correspondant maximise la séparabilité des classes.
L’étape suivante consiste donc à évaluer chaque sous ensemble généré.
2) Évaluation : La valeur de la fonction objective de chaque particule est évaluée via le CFR
selon l'équation (III.17). Le CFR mesure la distribution de la dispersion inter-classes par
rapport à la dispersion intra-classe. La particule ayant une valeur élevée de la fonction
objective indique que la différence entre les classes est grande car la grandeur de la valeur
CFR détermine le degré de séparation des classes. Pendant le processus d'évolution à la
recherche de plus grande valeur de la fonction objective, la dispersion interclasses est
maximisée et en même temps la dispersion intra-classe est minimisée. Pour le calcul de la
fonction objective, la procédure suivante est exécutée:
1. Supposons qu'il existe un nombre total K des bits ayants des valeurs de 1 dans la
position xij de la particule considérée.
2. Générer un sous-ensemble d’indicateurs à partir de l'ensemble initial avec seulement
les K indicateurs pour les quels le bit 1 a été affecté. Le nouveau sous-ensemble généré
est de taille (MхK). Où K représente le nombre d'indicateurs sélectionnés 1≤K≤L.
3. Calculer les matrices de dispersion Sb et Sw du sous-ensemble généré par cette
particule, en utilisant les équations (III.15) et (III.16) respectivement.
4. Estimer la matrice de transformation W par les vecteurs propres de Sb / (Sw + λI), où λ
est le paramètre de régularisation (λ> 0) déterminée par l’utilisateur, et I est une matrice
d'identité.
5. Lorsque Sb, Sw et W sont obtenus, la valeur du CFR (considérée comme fonction
objective) est calculée selon l'équation (III.17).
3) Mise à jour des meilleures solutions (individuelle, et globale) : à chaque itération de
l'algorithme, la position de chaque particule est comparée avec celle de sa meilleure position
individuelle (Pbest). Si la position actuelle a une meilleure valeur de la fonction objective, elle
est désignée comme la nouvelle Pbest de la particule. Ensuite, les positions actuelles de toutes
les particules sont comparées avec la meilleure position globale de la population (gbest) en
termes de fonction objective. Si la position actuelle de l'une des particules est meilleure que

Chapitre III Sélection d’indicateurs en classification
- 66 -
gbest précédente, alors la position actuelle est désignée comme la nouvelle gbest de la
population.
4) Mise à jours des vitesses et positions : à chaque itération de l’algorithme, les vitesses et
les positions de chaque particule sont mis à jour selon les équations (III.10) et (III.12)
respectivement.
5) vérification du critère d’arrêt : l’Arrêt de l'algorithme est fixé par le nombre d'itérations
Ni qui est initialement fixé. Le nombre d'itérations doit être suffisant pour permettre à
l'algorithme de converger vers la solution optimale.
La solution finale (gbest) retenue par l'algorithme OEPB-CFR, est considérée comme la
solution optimale de l’algorithme. Le sous ensemble optimal d’indicateurs est composé donc
d’indicateurs qui correspondent aux bits portant des valeurs de « 1 » dans le vecteur gbest.
C’est le sous-ensemble avec lequel la séparabilité des classes est maximale. Le nombre des
indicateurs sélectionnés est donc conditionné par le nombre des 1 dans le vecteur gbest..
III.7 Conclusion
Dans ce chapitre, nous avons évoqué d’abord, la forme informelle du problème de
sélection d’indicateurs. Nous avons également décrit les méthodes d’optimisation basées sur
les métaheuristiques en les divisant en deux classes : les méthodes à solution unique et les
méthodes à population de solutions. Nous avons pu constater au fur et à mesure d’un court
état de l’art pour chaque méthode, que leur utilisation en sélection des indicateurs est
relativement répandue. Dans la deuxième partie, nous avons mis en évidence notre
contribution, où nous avons proposé une approche filtre pour tenter de résoudre le problème
de sélection d’un sous-ensemble d’indicateurs. L’algorithme de sélection proposé est basé sur
une stratégie de recherche utilisant l’algorithme d’Optimisation par Essaim de Particules
Binaires OEPB. Afin de guider la recherche d’un sous-ensemble d’indicateur optimal, le
Critère de Fisher Régularisé CFR est utilisé comme fonction d’évaluation.
L’efficacité de cette méthode reste à évaluer en diagnostic automatisé des défauts
mécaniques en combinaison avec les SVMs. Pour cela, nous avons prévu une série de tests et
de résultats que nous exposerons dans le prochain chapitre.

Chapitre IV
Évaluation expérimentale de la méthode proposée : application au diagnostic automatisé des défauts de roulements et d’engrenages
IV.1 Introduction ......................................................................................................................................... 67
IV.2 Diagnostic des défauts par OEPB-CFR+SVM ................................................................................ 68
IV.3 Diagnostic automatisé des défauts de roulements ........................................................................... 70
IV.3.1 Système étudié ........................................................................................................................... 70
IV.3.2 Analyse des données et extraction des indicateurs ............................................................... 71
IV.3.3 Évaluation des Performances de la méthode de diagnostic proposée ................................ 75
IV.3.3.1 Performances des SVMs sans sélection ........................................................................ 75
IV.3.3.2 Performances de l’algorithme BPSO-RFC+SVM (avec sélection) ......................... 79
IV.4 Diagnostic automatisé des défauts d’engrenages ........................................................................... 80
IV.4.1 Système étudié : boite de vitesse CH-46 de l’’hélicoptère « Westland » .......................... 80
IV.4.2 Analyse des données et extraction des indicateurs ............................................................... 87
IV.4.3 Performance des SVMs sans sélection d’indicateurs ........................................................... 88
IV.4.4 Performance de l’algorithme OEPB-CFR+SVM (Avec sélection) ..................................... 89
IV .5 conclusion ............................................................................................................................................ 91

Chapitre IV Évaluation expérimentale de la méthode proposée
- 67 -
Chapitre IV : Évaluation expérimentale de la méthode proposée : application au diagnostic automatisé des défauts de roulements et d’engrenages
IV.1 Introduction
Dans le chapitre précédent, nous avons proposé un algorithme de sélection
d’indicateurs appelé OEPB-CFR. Cet algorithme est basé sur la combinaison de l’algorithme
d’optimisation par essaim de particules binaires et le critère de Fisher régularisé. Dans le
présent chapitre, nous proposons de combiner cet algorithme avec les SVMs dans le but de
concevoir un système automatique de diagnostic des défauts. L’algorithme ainsi développé a
pour acronyme OEPB-CFR+SVM.
Les statistiques concernant les causes de défaillances et la localisation des défauts dans
les machines tournantes, permettent de conclure que les organes les plus sensibles sont les
engrenages et les roulements (voir annexe 5). Pour cette raison, nous nous intéressons, plus
particulièrement, dans ce travail au diagnostic des défauts de ces deux éléments.
Le présent chapitre a pour objectifs d’évaluer les performances de la méthode de
diagnostic proposée (OEPB-CFR+SVM). Pour conduire nos expériences, nous avons utilisé
deux jeux de données vibratoires. Le premier, est issu d’un banc d’essai de roulements. Le
deuxième, provient d’une instrumentation d’une boite de vitesse d’un hélicoptère. La nature
des données vibratoires, acquises sous différents modes de fonctionnement, impose l’emploie
des stratégies adoptés au cas des SVMs multiclasses telles que 1vs1 et 1vsR.

Chapitre IV Évaluation expérimentale de la méthode proposée
- 68 -
IV.2 Diagnostic des défauts par OEPB-CFR+SVM
La procédure de diagnostic des défauts par OEPB-CFR+SVM est résumé sur
l’organigramme de la figure 4.1. Ce système comprend trois phases essentielles: la phase
d’analyse, la phase de classification, et la phase d’exploitation.
Au début de la première phase, les signaux vibratoires sont enregistrés en différents
modes de fonctionnement de la machine. Ensuite, chaque signal est analysé avec différentes
méthodes de traitement de signal afin de construire le vecteur forme. À l’issue de cette étape,
nous obtenons une base de données de taille MxL où M est le nombre d’observations
(signaux) et L est le nombre d’indicateurs. l’étape suivante consiste à normaliser les données
dans l’intervalle [-1,+1]. L’avantage principal de la normalisation est d'éviter que les
indicateurs de plus grandes valeurs suppriment l'influence des plus petits. Un autre avantage
est de rendre l'apprentissage de la machine plus performant lors du calcul. L’algorithme
OEPB-CFR, décrit dans le chapitre précédent, est ensuite employé pour sélectionner un sous
ensemble optimal d’indicateurs à partir de l’ensemble initial. Un exemple détaillé de la
sélection par cet algorithme est fourni dans l’annexe.6.
Dans la phase de classification, la base de données formée avec le sous ensemble
optimal d’indicateur est divisé en deux parties ; une base d’apprentissage (BA) et une base de
test (BT). L’ensemble d’apprentissage est utilisé pour déterminer les paramètres de la fonction
de décision des SVMs tels que le vecteur w et le biais b. L’ensemble de test sert à tester les
performances de la méthode en calculant le taux de classification correcte de l’ensemble de
ses observations. Ce taux est déterminé en divisant le nombre des observations bien classés
sur le nombre d’observations testés :
Le taux de classification Tb(%)
Où Mbc: Nombre des observations bien classées
M : Nombre total d’observations
Cette quantité à beaucoup d'importance. Si le taux d'erreur est proche de 0 %, alors on peut
estimer que non seulement, "en amont", le vecteur forme caractérise convenablement les
données traitées, mais aussi que la règle de décision a une bonne capacité de généralisation
sur des nouvelle observations.
Dans la phase d’exploitation, le système de diagnostic OEPB-CFR+SVM peut être
mis en service. Il permet de classer chaque nouvelle observation recueillie sur le système dans
l’une des classes connues, en appliquant la règle de décision élaborée dans la phase
100bcMM
= ×
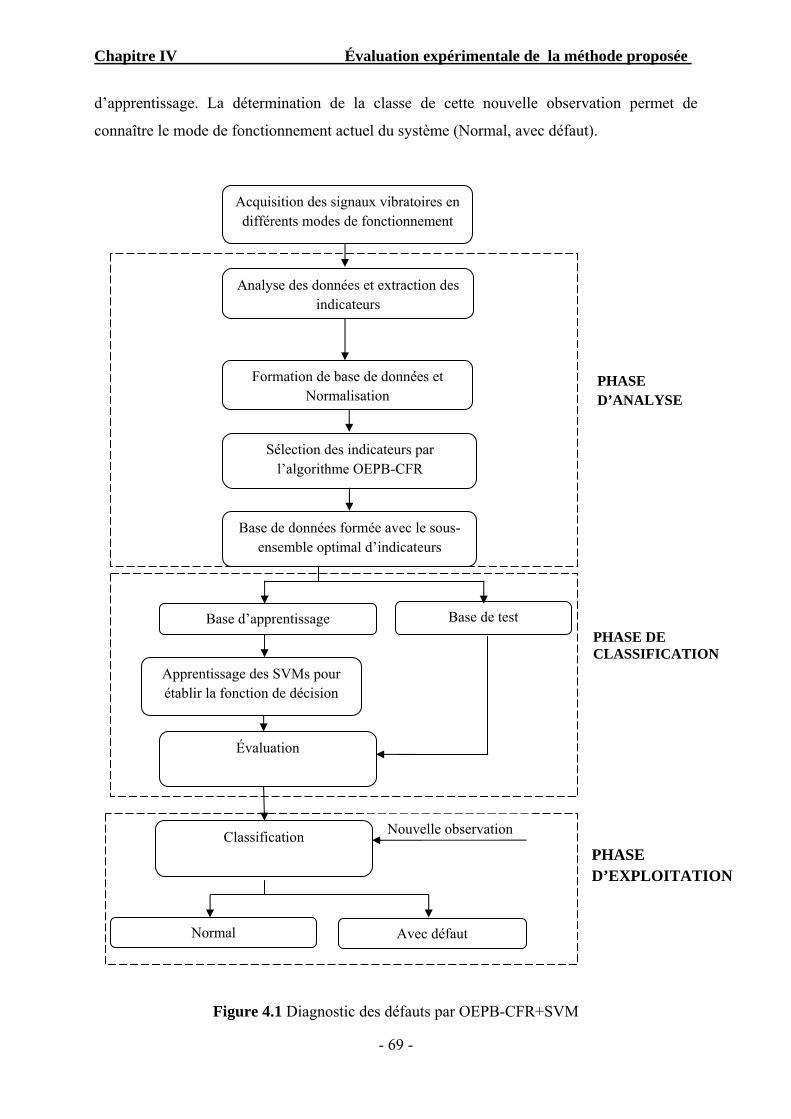
Chapitre IV Évaluation expérimentale de la méthode proposée
- 69 -
d’apprentissage. La détermination de la classe de cette nouvelle observation permet de
connaître le mode de fonctionnement actuel du système (Normal, avec défaut).
Figure 4.1 Diagnostic des défauts par OEPB-CFR+SVM
PHASE D’EXPLOITATION
Nouvelle observation
Analyse des données et extraction des indicateurs
Acquisition des signaux vibratoires en différents modes de fonctionnement
Évaluation
Apprentissage des SVMs pour établir la fonction de décision
Base d’apprentissage Base de test
Sélection des indicateurs par l’algorithme OEPB-CFR
Base de données formée avec le sous-ensemble optimal d’indicateurs
Normal Avec défaut
Formation de base de données et Normalisation
Classification
PHASE D’ANALYSE
PHASE DE CLASSIFICATION

Chapitre IV Évaluation expérimentale de la méthode proposée
- 70 -
IV.3 Diagnostic automatisé des défauts de roulements
Dans cette section, l’aptitude de la méthode proposé à détecter les défauts de
roulements, est évaluée selon les étapes de l’organigramme de la figure 4.1.
Dans le but de mettre en évidence l’effet de la sélection d’indicateurs sur les
performances des SVMs, deux cas sont étudiés ; Dans le premier cas, l’ensemble formé de
tous les indicateurs calculés, participe à l’entraînement (apprentissage) et au test des SVMs.
Dans le deuxième cas, les SVMs sont entrainés et testées en utilisant, seulement, le sous-
ensemble optimal d’indicateurs, sélectionné par l’algorithme OEPB-CFR. Ceci nous permet
de tester l’efficacité de l’algorithme OEPB-CFR proposé, tout en mesurant les performances
des SVMs avec et sans sélection d’indicateurs.
IV.3.1 Système étudié
Les données vibratoires utilisées dans cette partie, proviennent du banc d’essai de
roulements de l’université :" The Case Western Reserve University - Bearing Data Center.
Cleveland, Ohio. USA. " (Loparo, 2013). Le banc d'essai (Fig4.2) se compose principalement
d'un moteur (à gauche), d'un accouplement (centre), d'un dynamomètre (droit) et des circuits
de commande (non montrés). Cette base de données a été utilisée dans plusieurs études pour
valider l’efficacité des nouveaux algorithmes de diagnostic des défauts de roulements
(Gryllias & Antoniadis, 2012; Ziani et al., 2012 ; Zhang et al., 2013a; Shen et al., 2013).
Figure. 4.2 Banc d'essai de roulements (extrait de Loparo, 2013).
Chapitre IV Évaluation expérimentale de la méthode proposée
- 71 -
Des petits défauts sous forme de points de diamètre allant de 0.007 à 0.040 Pouces
(1Pouce=25.4mm), ont été créés sur les roulements du moteur en utilisant l'usinage par
électroérosion. Ces défauts ont été crées séparément sur la bague extérieure, la bague
intérieure, ainsi que l’élément roulant (bille). Ensuite, les roulements défectueux ont été
remontés sur le moteur, et les signaux vibratoires ont été enregistrées sur une gamme de 4
couples résistants (0, 1,2, et 3HP) soit quatre vitesses de rotation différentes (1797, 1772,
1750,1730 rpm) (voir annexe 7). Les signaux sont enregistrés à l'aide des accéléromètres, qui
ont été fixés à la cage du moteur par aimant avec une fréquence d’échantillonnage fe = 12
kHz et un nombre total de points NT= 243938 pts.
Les fréquences caractéristiques des défauts sont des multiples de la vitesse de rotation tels que:
• Fréquence de défaut de la bague intérieure : FBI = 5,415 *fr
• Fréquence de défaut de la bague extérieure : FBE = 3,584 *fr
• Fréquence de défaut de l’élément roulant (Bille) :FB = 4,7135 *fr
Le tableau 4.1 récapitule les fréquences caractéristiques des défauts pour les quatre vitesses de rotation.
Tableau 4. 1 Fréquences caractéristiques des défauts de roulements
Couple résistant (hp)
Vitesse de rotation (rpm)
Fréquence caractéristique de défauts (f)
FBI(Hz) FBE(Hz) FB (Hz) 0 1797 162,18 107.36 141,16
1 1772 159,92 105.87 139,20
2 1750 157,94 104.56 137,47
3 1730 156,13 103.36 135,90
*1rpm=1tr/min
IV.3.2 Analyse des données et extraction des indicateurs
Les signaux vibratoire ont été traités pour extraire le vecteur forme représentatif de
chaque signal. Ce vecteur forme est composé des indicateurs calculé dans trois domaines
différents ; temporel, spectral, temps-échelle.
1) Analyse temporelle : Dans le domaine temporel (Fig. 4.3), les signaux ont été traités pour
extraire les neuf (9) indicateurs suivants : la moyenne, le facteur de crête, le skewness, le
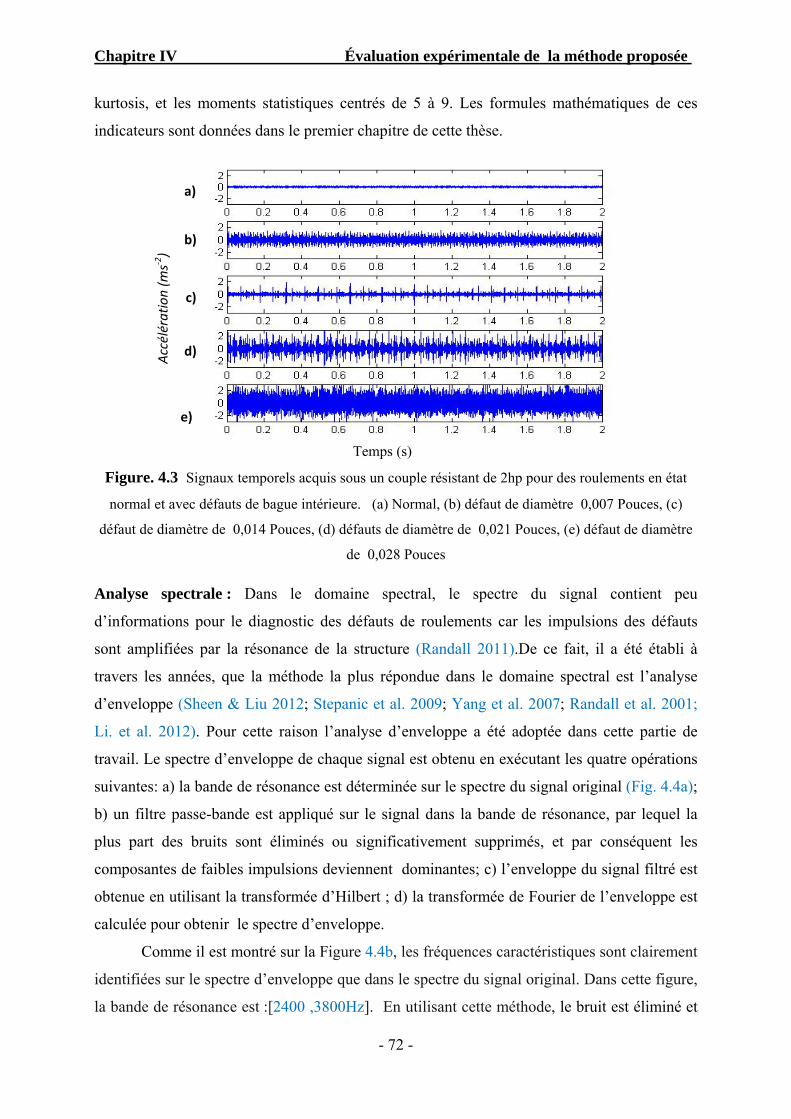
Chapitre IV Évaluation expérimentale de la méthode proposée
- 72 -
kurtosis, et les moments statistiques centrés de 5 à 9. Les formules mathématiques de ces
indicateurs sont données dans le premier chapitre de cette thèse.
Temps (s)
Figure. 4.3 Signaux temporels acquis sous un couple résistant de 2hp pour des roulements en état
normal et avec défauts de bague intérieure. (a) Normal, (b) défaut de diamètre 0,007 Pouces, (c)
défaut de diamètre de 0,014 Pouces, (d) défauts de diamètre de 0,021 Pouces, (e) défaut de diamètre
de 0,028 Pouces
Analyse spectrale : Dans le domaine spectral, le spectre du signal contient peu
d’informations pour le diagnostic des défauts de roulements car les impulsions des défauts
sont amplifiées par la résonance de la structure (Randall 2011).De ce fait, il a été établi à
travers les années, que la méthode la plus répondue dans le domaine spectral est l’analyse
d’enveloppe (Sheen & Liu 2012; Stepanic et al. 2009; Yang et al. 2007; Randall et al. 2001;
Li. et al. 2012). Pour cette raison l’analyse d’enveloppe a été adoptée dans cette partie de
travail. Le spectre d’enveloppe de chaque signal est obtenu en exécutant les quatre opérations
suivantes: a) la bande de résonance est déterminée sur le spectre du signal original (Fig. 4.4a);
b) un filtre passe-bande est appliqué sur le signal dans la bande de résonance, par lequel la
plus part des bruits sont éliminés ou significativement supprimés, et par conséquent les
composantes de faibles impulsions deviennent dominantes; c) l’enveloppe du signal filtré est
obtenue en utilisant la transformée d’Hilbert ; d) la transformée de Fourier de l’enveloppe est
calculée pour obtenir le spectre d’enveloppe.
Comme il est montré sur la Figure 4.4b, les fréquences caractéristiques sont clairement
identifiées sur le spectre d’enveloppe que dans le spectre du signal original. Dans cette figure,
la bande de résonance est :[2400 ,3800Hz]. En utilisant cette méthode, le bruit est éliminé et
Accélération (m
s‐2 )
a)
b)
c)
d)
e)
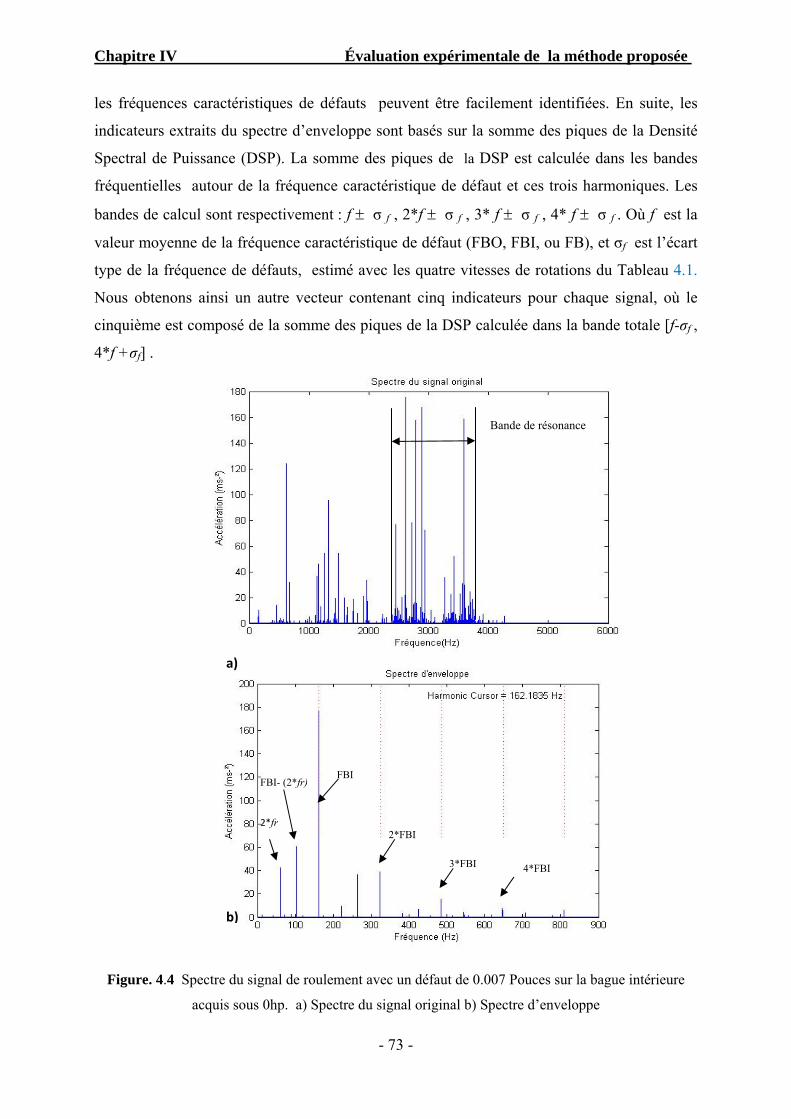
Chapitre IV Évaluation expérimentale de la méthode proposée
- 73 -
les fréquences caractéristiques de défauts peuvent être facilement identifiées. En suite, les
indicateurs extraits du spectre d’enveloppe sont basés sur la somme des piques de la Densité
Spectral de Puissance (DSP). La somme des piques de la DSP est calculée dans les bandes
fréquentielles autour de la fréquence caractéristique de défaut et ces trois harmoniques. Les
bandes de calcul sont respectivement : f ± σ f , 2*f ± σ f , 3* f ± σ f , 4* f ± σ f . Où f est la
valeur moyenne de la fréquence caractéristique de défaut (FBO, FBI, ou FB), et σf est l’écart
type de la fréquence de défauts, estimé avec les quatre vitesses de rotations du Tableau 4.1.
Nous obtenons ainsi un autre vecteur contenant cinq indicateurs pour chaque signal, où le
cinquième est composé de la somme des piques de la DSP calculée dans la bande totale [f-σf ,
4*f +σf] .
Figure. 4.4 Spectre du signal de roulement avec un défaut de 0.007 Pouces sur la bague intérieure
acquis sous 0hp. a) Spectre du signal original b) Spectre d’enveloppe
2*fr
b)
2*FBI
3*FBI 4*FBI
FBIFBI- (2*fr)
a)
Bande de résonance

Chapitre IV Évaluation expérimentale de la méthode proposée
- 74 -
Analyse temps-échelle : Prenons en compte que les signaux vibratoires des
roulements contiennent de nombreuses caractéristiques non stationnaires ou transitoires, la
Décomposition en Paquet d’Ondelettes (DPO) s’avère un outil très utile pour le traitement de
ce type de signaux, et en particulier, pour l’extraction des indicateurs (Li et al., 2013; Zhang
et al. 2013b). La DPO a été développée de l’ondelette discrète, et elle a prouvée ses bonnes
performances d’analyse en basses et hautes fréquences (Mallat, 2003). Cependant, la sélection
de l’ondelette mère peu influencer significativement l’efficacité de la DPO. Rafiee ces co-
auteurs (Rafiee al., 2010) ont pu démontrer que l’ondelette Daubechies 44 est la plus efficace
non seulement pour les defaults d’engrenages mais également pour les défauts de roulements.
Pour cette raison db44 a été adoptée dans cette partie de travail.
la DPO décompose le signal en p coefficients (p= 2q, où q dénotes le niveau de
décomposition). En général, une décomposition au troisième niveau est largement suffisante
pour l’extraction d’indicateurs (Shen et al., 2013). Pour cela, chaque signal est décomposé en
quatorze (14) coefficients à l’aide de la DPO au troisième niveau avec une ondelette mère
Db44. La figure 4 .5 montre l’arbre de décomposition en paquet d’ondelettes en troisième
niveau de décomposition. Afin d’avoir d’autres indicateurs pour l’apprentissage des SVMs, le
kurtosis et l’énergie, sont calculés pour les 14 coefficients obtenus de la DPO. Nous obtenons
ainsi, un autre vecteur contenant 28 indicateurs.
Figure. 4.5 Arbre de décomposition en paquet d’ondelette au 3ième niveau de décomposition

Chapitre IV Évaluation expérimentale de la méthode proposée
- 75 -
La procédure d’extraction des indicateurs dans les trois domaines (temporal, spectral, et
temps- échelle (DPO)) est répétée avec tous les signaux vibratoires. Nous obtenons ainsi un
vecteur forme final contenant 42 indicateurs pour chaque signal. (Voir annexe.8)
IV.3.3 Évaluation des Performances de la méthode de diagnostic proposée
Dans la présente section, la méthode proposée pour le diagnostic des defaults, est évaluées
dans les deux cas suivants :
(I.) Sans sélection : SVM entrainée avec l’ensemble initial (42 indicateurs).
(II.) Avec sélection : SVM entrainée avec le sous ensemble optimal, sélectionné par
l’algorithme OEPB-CFR.
IV.3.3.1 Performances des SVMs sans sélection
Dans les cas réels d'études, il est nécessaire d’estimer la vie utile restante du roulement
avant la défaillance complète de la machine. Il faudra donc non seulement le processus
d'identification de la présence de défaut, mais aussi de quantifier son niveau. Pour cette
raison, nous proposons dans un premier temps d’évaluer les performances des SVMs dans le
cas d'identification de défaut (bague intérieure, bague extérieure, ou élément de roulement).
Dans un deuxième temps, après la détection et l'identification de défaut, les SVMs sont
évaluées dans le cas d'identification de niveau du défaut.
Le tableau 4.2 décrit l'ensemble de données vibratoires utilisées dans le premier cas
(identification de défaut). Cet ensemble couvre une classe normale, et les trois classes
défectueuses du roulement avec la plus petite taille de défaut (0,007 Pouces) dans chacune
d'eux. Ceci, signifie une détection précoce de défaut. Dans le deuxième cas (identification de
niveau de défaut), trois ensembles de données vibratoires ont été utilisés où chacun d’eux,
couvre une classe normale et les classes de tous les niveaux de l'état défectueux. Le tableau
4.3 décrit les trois ensembles de données utilisées dans ce dernier cas.
Afin d'avoir un nombre suffisant d’échantillons d’apprentissage dans tous les cas
considérés, et puisque nous disposons d'enregistrements d'une longueur de 243938 points,
chaque signal a été divisé en quatre échantillons égaux. Les échantillons ainsi obtenus sont
donc, sur-échantillonnés. Nous proposons de les décimer par un facteur de 4 pour que le
théorème de Shannon1 , soit respecté. Ensuite, les 42 indicateurs décrits dans la section
1: la fréquence d’échantillonnage doit être supérieure ou égale à deux fois la fréquence maximale du spectre

Chapitre IV Évaluation expérimentale de la méthode proposée
- 76 -
IV.2.2 sont extraites de chaque échantillon. La procédure d'extraction d’indicateurs a été
répétée avec tous les échantillons des différents cas étudiés. Nous obtenons ainsi, les bases de
données suivantes :
• Dans le cas d'identification de défaut : base de données de taille 64х42.
• Dans le cas d'identification de niveau de défaut, trois bases de données sont
obtenues:
Cas de bague intérieure : 80х42
Cas de bague extérieure : 64х42
Cas de l’élément roulants : 80х42.
Ensuite, les M observations de chaque base de données sont divisés en deux parties de même
taille; la première est utilisée pour l’apprentissage des SVMs, tandis que la seconde est
utilisée pour le test. Les ensembles de données ont été normalisées dans l’intervalle [-1,+1]
pour une meilleure rapidité et succès de l’apprentissage des SVMs. La normalisation est
réalisée en en divisant les composantes de chaque indicateur par la variance et en les centrant
comme suit :
Où σj représente la variance du jième indicateur, et mj sa moyenne.
Tableau 4.2 Description des données utilisées dans le cas de l’identification de défaut
Cas étudié Nombre de classes
Base d’apprentissage
Base de Test
Mode de fonctionnement
Taille de défaut
(Pouces)
Identification
de défaut 4 32х42 32 х42
Normal -
Bague intérieure 0,007
Bague extérieure 0,007
Element Rollant 0,007
,,
i j ji j
j
x mx
σ−
=
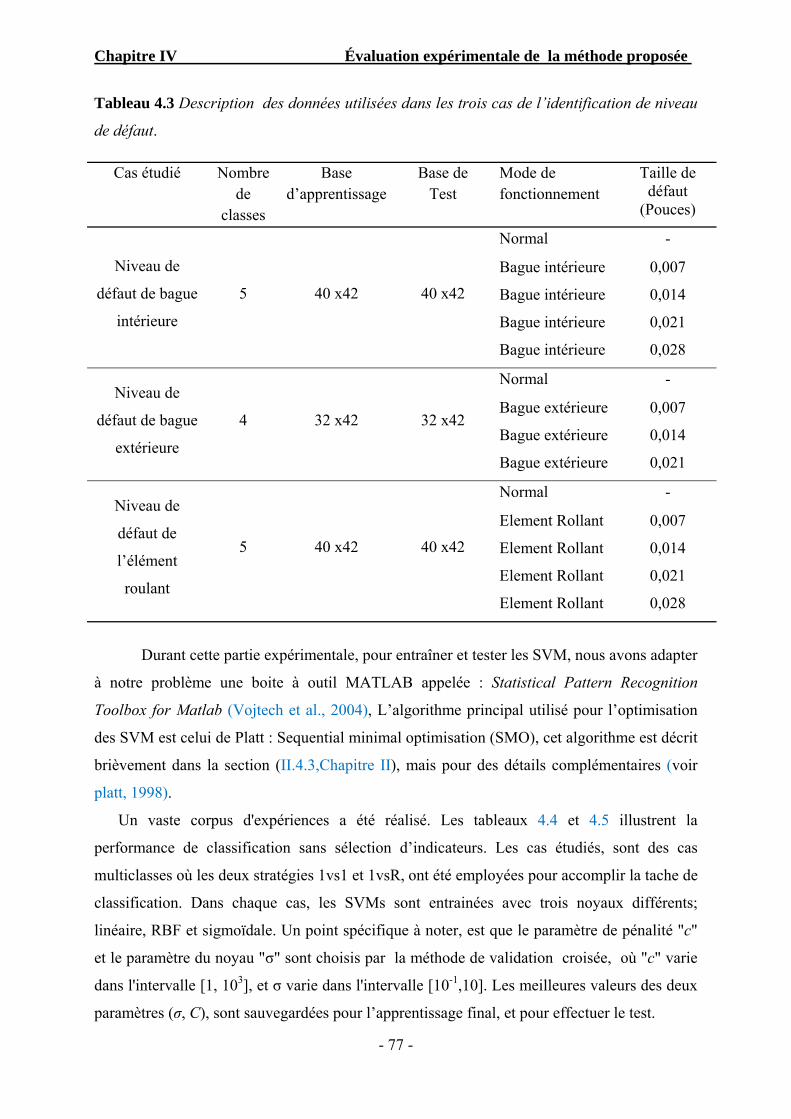
Chapitre IV Évaluation expérimentale de la méthode proposée
- 77 -
Tableau 4.3 Description des données utilisées dans les trois cas de l’identification de niveau
de défaut.
Cas étudié Nombre de
classes
Base d’apprentissage
Base de Test
Mode de fonctionnement
Taille de défaut
(Pouces)
Niveau de
défaut de bague
intérieure
5 40 х42 40 х42
Normal -
Bague intérieure 0,007
Bague intérieure 0,014
Bague intérieure 0,021
Bague intérieure 0,028
Niveau de
défaut de bague
extérieure
4 32 х42 32 х42
Normal -
Bague extérieure 0,007
Bague extérieure 0,014
Bague extérieure 0,021
Niveau de
défaut de
l’élément
roulant
5 40 х42 40 х42
Normal -
Element Rollant 0,007
Element Rollant 0,014
Element Rollant 0,021
Element Rollant 0,028
Durant cette partie expérimentale, pour entraîner et tester les SVM, nous avons adapter
à notre problème une boite à outil MATLAB appelée : Statistical Pattern Recognition
Toolbox for Matlab (Vojtech et al., 2004), L’algorithme principal utilisé pour l’optimisation
des SVM est celui de Platt : Sequential minimal optimisation (SMO), cet algorithme est décrit
brièvement dans la section (II.4.3,Chapitre II), mais pour des détails complémentaires (voir
platt, 1998).
Un vaste corpus d'expériences a été réalisé. Les tableaux 4.4 et 4.5 illustrent la
performance de classification sans sélection d’indicateurs. Les cas étudiés, sont des cas
multiclasses où les deux stratégies 1vs1 et 1vsR, ont été employées pour accomplir la tache de
classification. Dans chaque cas, les SVMs sont entrainées avec trois noyaux différents;
linéaire, RBF et sigmoïdale. Un point spécifique à noter, est que le paramètre de pénalité "c"
et le paramètre du noyau "σ" sont choisis par la méthode de validation croisée, où "c" varie
dans l'intervalle [1, 103], et σ varie dans l'intervalle [10-1,10]. Les meilleures valeurs des deux
paramètres (σ, C), sont sauvegardées pour l’apprentissage final, et pour effectuer le test.
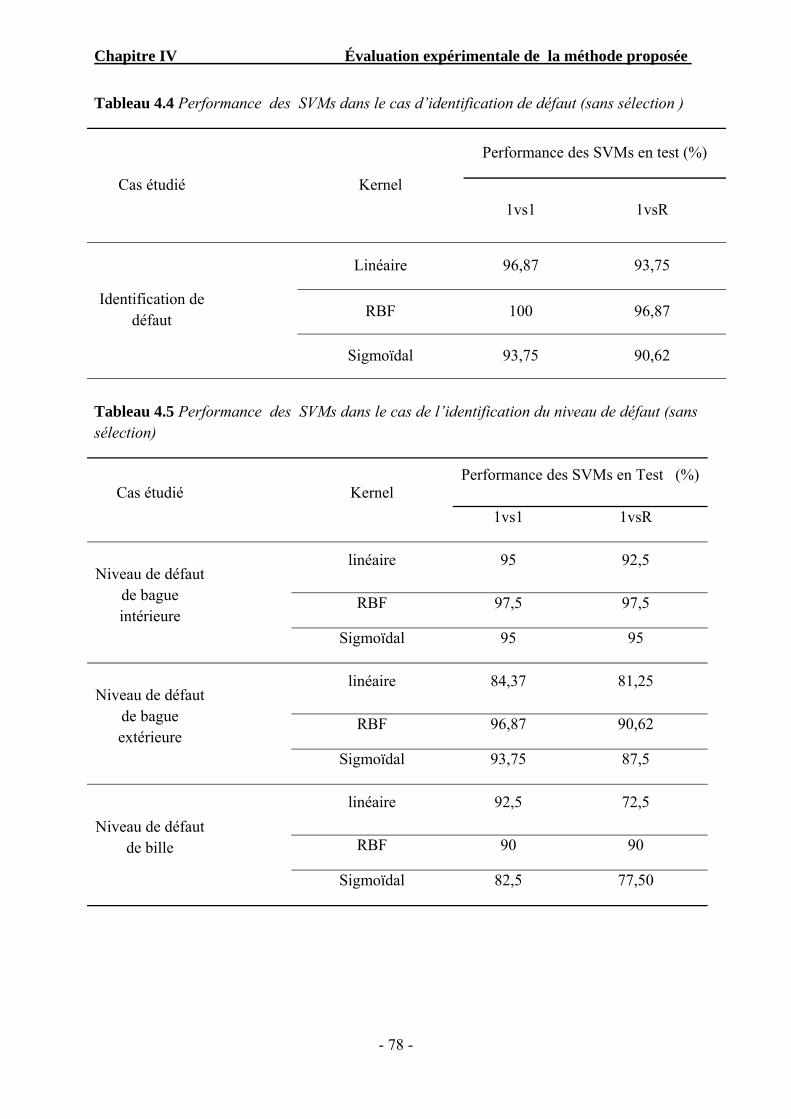
Chapitre IV Évaluation expérimentale de la méthode proposée
- 78 -
Tableau 4.4 Performance des SVMs dans le cas d’identification de défaut (sans sélection )
Cas étudié Kernel
Performance des SVMs en test (%)
1vs1
1vsR
Identification de défaut
Linéaire 96,87 93,75
RBF 100 96,87
Sigmoïdal 93,75 90,62
Tableau 4.5 Performance des SVMs dans le cas de l’identification du niveau de défaut (sans sélection)
Cas étudié Kernel Performance des SVMs en Test (%)
1vs1 1vsR
Niveau de défaut de bague intérieure
linéaire 95 92,5
RBF 97,5 97,5
Sigmoïdal 95 95
Niveau de défaut de bague extérieure
linéaire 84,37 81,25
RBF 96,87 90,62
Sigmoïdal 93,75 87,5
Niveau de défaut de bille
linéaire 92,5 72,5
RBF 90 90
Sigmoïdal 82,5 77,50

Chapitre IV Évaluation expérimentale de la méthode proposée
- 79 -
Les résultats obtenus peuvent être analysés sur trois plans :
(I.) l'utilisation des différents noyaux affecte de manière significative la
performance de classification. De toute évidence, la meilleure performance
pour les deux stratégies des SVM multiclasses, est obtenue en utilisant le
noyau RBF, dans les différents cas étudiés.
(II.) Une analyse plus approfondie de ces résultats montre que la stratégie 1vs1,
réalise une performance de classification plus élevé qu’avec 1vsR, dans tous
les cas considérés.
(III.) En utilisant le noyau RBF et la stratégie 1vs1, la performance des SVMs
atteint :
100% de réussite en cas d'identification de défaut.
Pour l'identification de niveau de défaut, elle atteint 97,5% dans le cas
de bague intérieure, 96,87% , en cas de bague extérieure, et 90% dans
le cas de l’élément roulant.
IV.3.2.2 Performances de l’algorithme OEPB-CFR+SVM (avec sélection)
Afin d'étudier les performances de la classification en utilisant, seulement, le sous-
ensemble optimal d’indicateurs, l’algorithme OEPB-CFR + SVM a été évalué sur les mêmes
cas étudiés dans la section précédente (Tableau 4.2 et Tableau 4.3). L’algorithme de sélection
OEPB-RFC a été implémenté dans l’environnement Matlab, et a été initialisé avec les valeurs
suivantes:
• Taille de l’essaim= 30 particules. (des valeurs entre 20 et 50 sont recommandées par
Samanta (Samanta & Nataraj, 2009))
• Taille de particule=42 (Égale au nombre d’indicateurs extraits)
• ω min=0.1, ωmax=0.6, vmin =-2, vmax=2, c1=2, c2=2, R1 et R2: générés aléatoirement
entre 0 et 1 (Voir section III.6.2.1, Chapitre III).
• λ=0,1
• Nombre d’itérations Ni= 200.
De même que dans le cas sans sélection, les SVM sont entrainées avec les trois noyaux :
Linéaire, RBF, et sigmoïdal. Aussi, les deux stratégies 1vsR, et 1vs1 sont employées pour
accomplir la tache de classification multiclasses. La procédure de diagnostic est exécutée
selon l’organigramme de la figure 4.1.

Chapitre IV Évaluation expérimentale de la méthode proposée
- 80 -
Pour analyser les résultats, on peut commencer par la convergence de l'algorithme
OEPB-CRF, proposé pour la sélection du sous ensemble optimal d’indicateurs. La figure 4.6
montre que l'algorithme OEPB-CRF converge vers la meilleure solution après environ 30
générations. Cela peut confirmer que le nombre d'itérations initialement donné est largement
suffisant. D'autre part, les figures 4.7, 4.8, 4.9, et 4.10 représentent des projections 3D du
nuage de points de données à l'aide de l’Analyse en Composante Principale ACP. Ces figures
illustrent graphiquement l'influence du sous-ensemble sélectionné sur la séparabilité des
classes. Il est très clair que dans tous les cas d'études, les classes sont mieux séparées avec le
sous-ensemble sélectionné qu’avec l’ensemble initial d’indicateurs.
Figure.4.6 Convergence de l’algorithme OEPB-CFR vers la meilleure fonction
objective (fitness) en fonction du nombre d’itérations.
Figure.4.7 Projection 3D des données utilisées dans le cas d’identification de défaut; a) sans
sélection, b) avec sélection (21 indicateurs).
b) a)

Chapitre IV Évaluation expérimentale de la méthode proposée
- 81 -
Fig. 4.8 Projection 3D des données utilisées dans le cas de l’identification de niveau défaut de
bague intérieure ; a) sans sélection, b) avec sélection (28 indicateurs)
Fig. 4.9 Projection 3D des données utilisées dans le cas de l’identification de niveau défaut de
bague extérieure ; a) sans sélection, b) avec sélection (19 indicateurs)
Fig. 4.10 Projection 3D des données utilisées dans le cas de l’identification de niveau défaut de
l’élément roulant ; a) sans sélection, b) avec sélection (13 indicateurs)
b) a)
a) b)
a) b)
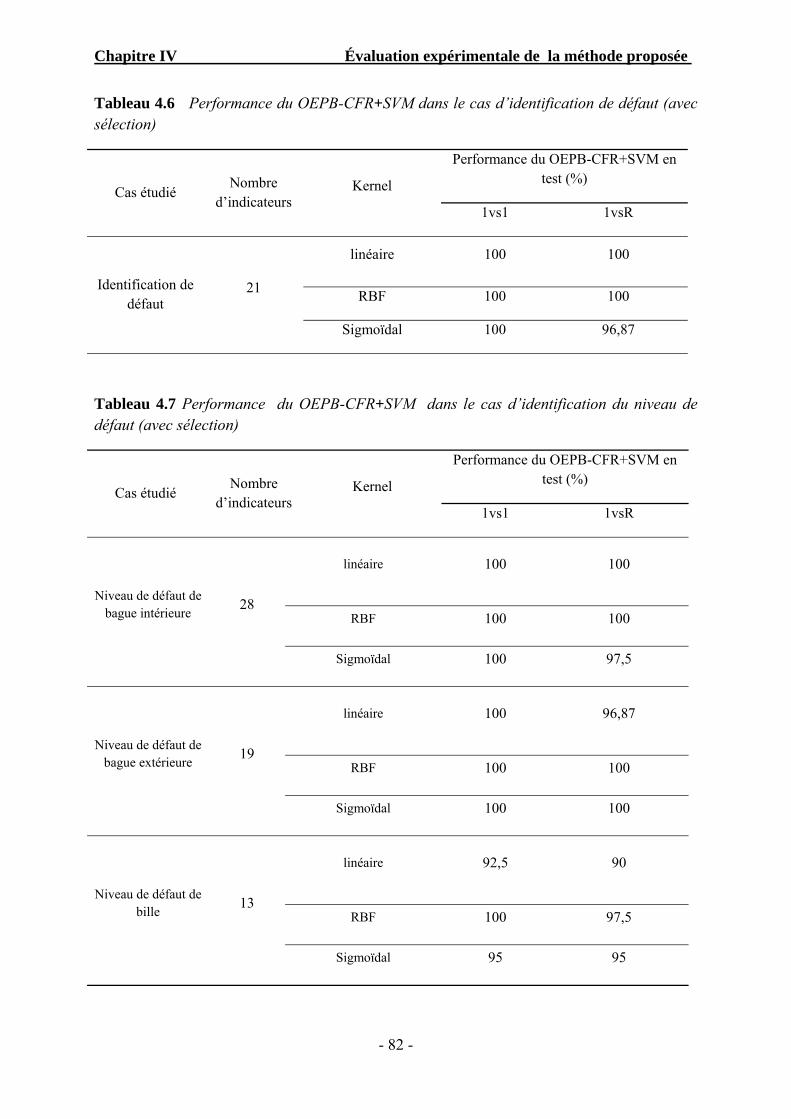
Chapitre IV Évaluation expérimentale de la méthode proposée
- 82 -
Tableau 4.6 Performance du OEPB-CFR+SVM dans le cas d’identification de défaut (avec sélection)
Cas étudié Nombre
d’indicateurs Kernel
Performance du OEPB-CFR+SVM en test (%)
1vs1 1vsR
Identification de défaut
21
linéaire 100 100
RBF 100 100
Sigmoïdal 100 96,87
Tableau 4.7 Performance du OEPB-CFR+SVM dans le cas d’identification du niveau de défaut (avec sélection)
Cas étudié Nombre
d’indicateurs Kernel
Performance du OEPB-CFR+SVM en test (%)
1vs1 1vsR
Niveau de défaut de bague intérieure 28
linéaire 100 100
RBF 100 100
Sigmoïdal 100 97,5
Niveau de défaut de bague extérieure 19
linéaire 100 96,87
RBF 100 100
Sigmoïdal 100 100
Niveau de défaut de bille 13
linéaire 92,5 90
RBF 100 97,5
Sigmoïdal 95 95

Chapitre IV Évaluation expérimentale de la méthode proposée
- 83 -
Les tableaux 4.6 et 4.7 récapitulent respectivement, les performances des SVMs
avec sélection d’indicateurs dans les deux cas : identification de défaut, et identification de
niveau de défaut. Les résultats de classification représentés dans ces deux tableau permettent
de conclure que :
(i) La stratégie 1vs1 a montré, encore une fois, ces avantages en terme de performance (taux
des observations bien classé) par rapport à 1vsR, dans les différents cas étudiés.
(ii) Le taux de réussite des SVM avec le noyau RBF atteint pratiquement 100% dans la
quasi-totalité des cas, sauf dans le cas d’identification de niveau de défaut de l’élément
roulant (bille) avec la stratégie 1vsR. Dans ce cas nous avons obtenus 97,5%.
(iii) En comparant les résultats dans le tableau 4.6 et le tableau 4.7 avec ceux du tableau 4.4 et
du tableau 4.5 respectivement, on peut dire que les performances de la classification par
OEPB-CFR+SVM sont plus élevée que celle des SVM avec l’ensemble initial des indicateurs
(sans sélection). EN effet, OEPB-CFR+SVM avec le noyau de RBF réalise 100% de taux de
réussite dans le cas d'identification de défaut avec seulement 21 indicateurs sur les 42 initiaux,
et 100% dans tous les cas d'identification de niveau de défaut avec un nombre réduit
d’indicateurs : 28 indicateur dans le cas de bague intérieure, 19 indicateurs dans le cas bague
extérieure, et seulement 13 indicateurs dans le cas d'élément roulant (bille).
Ces résultats confirment l'efficacité de l'algorithme OEPB-CFR proposé. Les sous ensemble
sélectionnés par cet algorithme ont conduit à un meilleur taux de classification, dans les
différents cas étudiés.
IV.4 Diagnostic automatisé des défauts d’engrenages
IV.4.1 Système étudié : boite de vitesse CH-46 de l’hélicoptère « Westland »
L’ensemble de signaux étudiés provient de l’instrumentation d’une boite de vitesse
CH-46 d’un hélicoptère Westland de la marine américaine, provenant de l’université d’état de
Pennsylvanie2 USA. Un rapport sur ces données est présenté par Cameron (Cameron, 1993).
De nombreuses études ont été réalisées sur ces signaux, nous citons entre autres : (Williams &
Zalubas, 2000), (Loughlin & Cakrak, 2000) pour l’analyse spectrale, l’analyse temps-
fréquences, et temps-échelle. Les approches cyclostationnaires et bilinéaire ont été utilisées
dans les travaux de Bouillaut (Bouillaut & Sidahmed, 2001). Raad (Raad, 2003) quand elle a
2: http://www/wisdom.qvl. psv.edu/Westland/data

Chapitre IV Évaluation expérimentale de la méthode proposée
- 84 -
appliqué principalement des méthodes cyclostationnaires. Nous trouvons également d’autres
travaux sur la classification et le diagnostic (Chang et al., 2009 ; Nandi et al., 2013), l'analyse
vibro-acoustique dans le but d’établir un diagnostic précoce (Gelman et al., 2000) . L’annexe
9 présente une photo du système étudié ainsi que sa position dans le moteur.
L’objectif de cette partie de travail est d’évaluer les performances de la méthode de
diagnostic proposée pour des défauts d’engrenages. Nous disposons des signaux caractérisant
le système pour sept défauts différents et d’un ensemble provenant du système sain. La figure
4.11 présente un schéma simplifié du système, les numéros de ses éléments, ainsi que leur
nombre de dents et leurs fréquences d’engrènement.
Figure 4.11 Schéma simplifié de la boite de vitesse de l’hélicoptère CH46.
Numérotation des éléments et caractéristiques
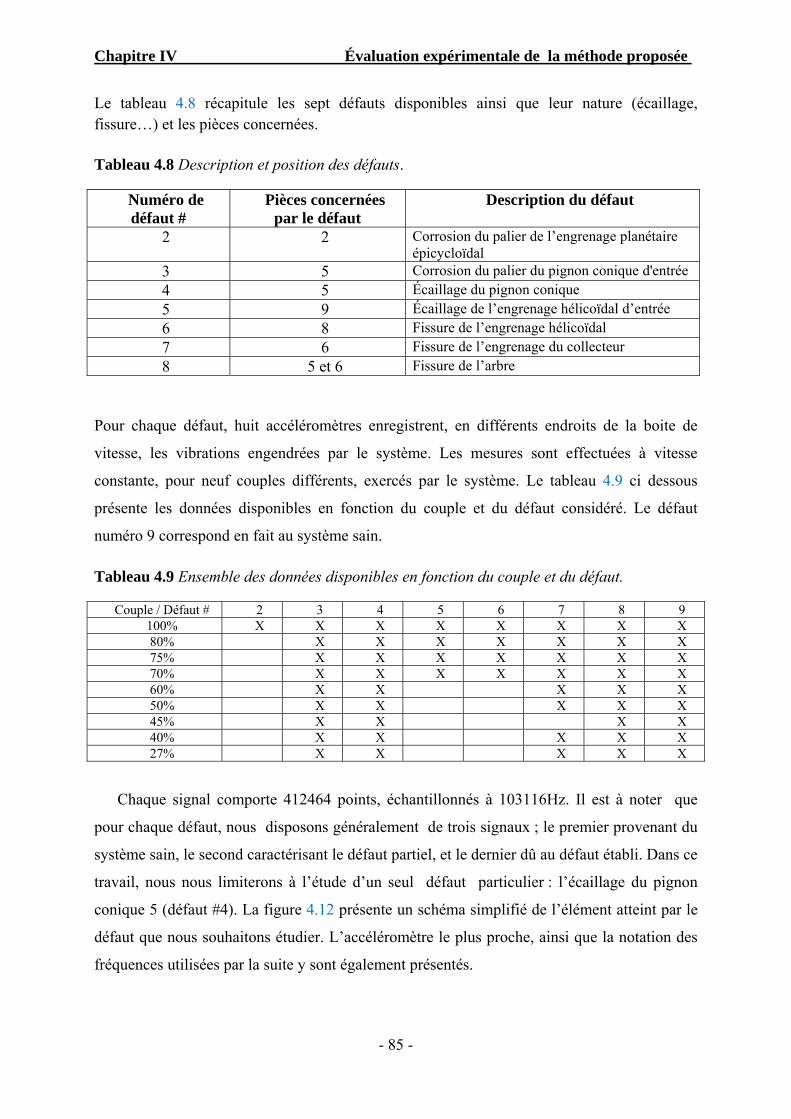
Chapitre IV Évaluation expérimentale de la méthode proposée
- 85 -
Le tableau 4.8 récapitule les sept défauts disponibles ainsi que leur nature (écaillage, fissure…) et les pièces concernées. Tableau 4.8 Description et position des défauts.
Numéro de défaut #
Pièces concernées par le défaut
Description du défaut
2 2 Corrosion du palier de l’engrenage planétaire épicycloïdal
3 5 Corrosion du palier du pignon conique d'entrée 4 5 Écaillage du pignon conique 5 9 Écaillage de l’engrenage hélicoïdal d’entrée 6 8 Fissure de l’engrenage hélicoïdal 7 6 Fissure de l’engrenage du collecteur 8 5 et 6 Fissure de l’arbre
Pour chaque défaut, huit accéléromètres enregistrent, en différents endroits de la boite de
vitesse, les vibrations engendrées par le système. Les mesures sont effectuées à vitesse
constante, pour neuf couples différents, exercés par le système. Le tableau 4.9 ci dessous
présente les données disponibles en fonction du couple et du défaut considéré. Le défaut
numéro 9 correspond en fait au système sain.
Tableau 4.9 Ensemble des données disponibles en fonction du couple et du défaut.
Couple / Défaut # 2 3 4 5 6 7 8 9 100% X X X X X X X X 80% X X X X X X X 75% X X X X X X X 70% X X X X X X X 60% X X X X X 50% X X X X X 45% X X X X 40% X X X X X 27% X X X X X
Chaque signal comporte 412464 points, échantillonnés à 103116Hz. Il est à noter que
pour chaque défaut, nous disposons généralement de trois signaux ; le premier provenant du
système sain, le second caractérisant le défaut partiel, et le dernier dû au défaut établi. Dans ce
travail, nous nous limiterons à l’étude d’un seul défaut particulier : l’écaillage du pignon
conique 5 (défaut #4). La figure 4.12 présente un schéma simplifié de l’élément atteint par le
défaut que nous souhaitons étudier. L’accéléromètre le plus proche, ainsi que la notation des
fréquences utilisées par la suite y sont également présentés.

Chapitre IV Évaluation expérimentale de la méthode proposée
- 86 -
Figure 4.12 Schéma simplifié du système
La figure 4.13 présente des photos du pignon conique 5, avant les tests ainsi que des vues des différents niveaux de défaut mis à notre disposition.
Fig. 4.13. Différents pignons utilisés
Ci-dessous nous présentons les différentes données nécessaires à nos traitements :
• Fréquence d’échantillonnage : Hzfe 103116=
• Nombre de points total est : NT= 412464 points
• Les fréquences d'engrènement : fe1 = 1108.9 Hz . fe2 = 3155.8 Hz
• Nombre de dents du pignon conique 5 : nd1 = 26 dents
• La fréquence de rotation Hznfe
frd
65.4226
9.1108
1
11 ===
Accéléromètre Carter
4
8
2ef
1ef
3rf1rf
2rf
Roue 4
Pignon 5
Roue 6
Pignon 7

Chapitre IV Évaluation expérimentale de la méthode proposée
- 87 -
• Le nombre de points par période Np est : ptsfrfeN p 9671
65.42412464
1
===
• La période T est :
msfe
NTNT pp 87.931** ==Δ=
IV.4.2 Analyse des données et extraction des indicateurs
Pour l’élément étudié (Engrenage conique 5), nous disposons de 24 signaux obtenus en
trois différents modes de fonctionnement :
9 signaux en mode de fonctionnement sain,
6 signaux en mode de fonctionnement avec défaut niveau 1,
9 signaux en mode de fonctionnement avec défaut et défaut niveau 2.
La figure 4.14 représente les signaux temporels recueillis par le capteur 4 pour un couple de 45%.
Figure 4.14 Signaux temporels du capteur 4, couple 45%, pour différents états du pignon conique
Temps

Chapitre IV Évaluation expérimentale de la méthode proposée
- 88 -
Pour avoir suffisamment d’observations pour la classification, chaque signal est décomposé
en 11 échantillons avec un recouvrement de 50%. Par la suite, chaque échantillon a été traité
pour extraire les trois ensembles d’indicateurs suivants :
• Le premier est obtenu dans le domaine temporel et composé des indicateurs
statistiques suivants : la valeur efficace, le facteur de crête, le skewness, le kurtosis, et
les moments statistiques centrés de 5 à 9.
• Le deuxième ensemble est calculé dans le domaine spectral et composé de la somme
des piques de la Densité Spectrale de Puissance (DSP). La DSP est calculée dans
différentes bandes caractéristiques de largeur 426 Hz, soit 10 raies latérales (dix
fréquences de rotation) autour de la fréquence d’engrènement (fe1=1108.9 Hz), autour
de ses trois principales harmoniques (2* fe1=2217.8 Hz, 3*fe1=3326.7 Hz,
4*fe1=4435,6 Hz), ainsi que dans la bande totale. Les bandes de calcul sont
respectivement : [895-1321 Hz], [2004-2430 Hz], [3113-3539 Hz], [4222-4648Hz], et
[895-4648Hz].
• Le troisième ensemble d’indicateurs est obtenu dans le domaine temps –échelle et
composé du kurtosis et de l’énergie calculés dans les 8 derniers coefficients obtenus
par la décomposition en paquets d’ondelettes au troisième niveau de décomposition.
Ces trois ensembles forment une matrice totale de 264 échantillons х30 indicateurs (Voir
annexe10). Ces échantillons (observations) appartiennent aux trois classes suivantes :
• 1ière classe (sans défaut) : composée de 99 échantillons.
• 2ième classe (défaut niveau1) : composée de 66 échantillons.
• 3ième classe (défaut niveau2) : composée de 99 échantillons.
Toutes les données ont été normalisées dans l’intervalle [-1,+1]. Ensuite, La matrice totale est
divisée en deux sous ensembles : Le premier formé de 144 individus (6 tranches de chaque
signal), utilisé pour l’entraînement des SVM, le deuxième composé de 120 (les 5 tranches
restantes de chaque signal), est utilisé pour le test.
IV.4.3 Performance des SVMs sans sélection d’indicateurs
Les SVMs sont entrainés avec l’ensemble initial d’indicateurs (30 indicateurs) en
utilisant trois noyaux (Kernel) différents : linéaire, RBF, et sigmoïdal. Les deux stratégies
1VS1 et 1VSR, ont été employées pour résoudre le problème multi classes des SVMs. De la
même manière que dans le cas des défauts de roulements, les paramètres C et σ sont choisie
par la méthode de validation croisée. Où "C" varie dans l'intervalle [1,103] et «σ » varie dans

Chapitre IV Évaluation expérimentale de la méthode proposée
- 89 -
l'intervalle [10-1,10].
Le tableau 4.10 récapitule les résultats de classification obtenus sans sélection d’indicateurs,
et avec trois fonctions noyaux différentes. Les résultats montrent que les meilleures
performances sont obtenues avec la stratégie 1vs1. En effet, avec cette stratégie, les SVMs
réalisent un taux de classification de 87,5% avec le noyau linéaire, 96,66% avec un noyau
RBF, et 95% avec un noyau sigmoïdal.
Tableau 4.10 Performance des SVMs sans sélection d’indicateurs
IV.4.4 Performance de l’algorithme OEPB-CFR +SVM (Avec s élection)
Dans cette étape L’algorithme OEPB-CFR est utilisé pour sélectionner les
indicateurs les plus pertinents à partir de l’ensemble initial (30 indicateurs). Il a été initialisé
avec les paramètres suivants :
• Taille de l’essaim = 25 particules.
• Taille de particule=30 (égale aux nombre initial des indicateurs (30 indicateurs))
• ω min=0.1, ωmax=0.6, vmin =-2, vmax=2, c1=2, c2=2, R1 et R2: générés aléatoirement
entre 0 et 1 .
• λ=0.2
• Nombre d’itérations Ni= 200.
Le tableau 4.11 représente les performances de la classification par SVMs en utilisant
seulement les indicateurs sélectionnés par l’algorithme OEPB-CFR. Les résultats obtenus
montrent que les performances des SVMs sont nettement améliorées, en comparaison avec les
résultats du tableau 4.10 (sans sélection). En effet, nous avons obtenu un taux de réussite de
Kernel
Performance des SVMs en test (%)
(1vsR)
(1vs1)
linéaire 79.16 87.5
RBF 92.5 96.66
sigmoïdale 83.33 95

Chapitre IV Évaluation expérimentale de la méthode proposée
- 90 -
100% avec un nombre d’indicateurs réduit (10 indicateur) pour les deux stratégies 1vs1 et
1vsR. Ceci est réalisé avec un noyau RBF et sigmoïdal. Cette amélioration de performances
est justifiée par la meilleure séparabilité des données due à la qualité de l’ensemble
d’indicateurs sélectionnés. Ceci est illustré sur la figure 4.15 qui représente la projection 3D
des données avant et après sélection des indicateurs par l’algorithme OEPB-CFR.
Tableau 4.11 Performance du OEPB-CFR+ SVM (avec sélection)
Figure4.15 Projection 3D des données :a) Avec l’ensemble initial (30 indicateurs), b) Avec le sous-ensemble sélectionné par OEPB-CFR (10 indicateurs).
Kernel
Nombre d’indicateurs sélectionnés
Performance des SVM en test (%)
(1vsR) (1vs1)
linéaire
96.66
97.5
RBF 10 100
100
sigmoïdale 98.33 100
b)a)

Chapitre IV Évaluation expérimentale de la méthode proposée
- 91 -
IV.5 Conclusion
Dans ce chapitre nous avons évalué l’efficacité de la méthode de diagnostic proposée
sur des défauts de roulement et d’engrenages. Dans chaque cas, les signaux vibratoires sont
d’abord analysés à l’aide de différentes méthodes de traitement de signal pour former les
matrices d’apprentissage et de test. Ensuite, l’algorithme OEPB-CFR est d’employé pour
sélectionner le sous ensemble optimal d’indicateurs à partir de l’ensemble initial. Les
performances des SVMs sont ensuite évaluées en utilisant l’ensemble de test. Les résultats
obtenus montrent que les performances des SVMs en combinaison avec l’algorithme OEPB-
CFR ont été considérablement améliorées par rapport à celle obtenues en utilisant l’ensemble
initial des indicateurs (sans sélection). Ceci confirme que les performances des SVMs sont en
étroite liaison avec la qualité des indicateurs utilisés pour établir la règle de décision.
L’algorithme OEPB-CFR permet donc de sélectionner que les indicateurs pertinents
améliorant ainsi les performances des SVMs. Nous rappelons ici, que les meilleurs résultats
du système de diagnostic proposé, sont obtenus en utilisant le noyau RBF lors de
l’établissement de la règle de décision. D’autre par la meilleure stratégie pour gérer le cas
multiclasses est, sans doute, la stratégie 1vs1.

Conclusion générale
‐ 92 ‐
Conclusion générale
Les travaux présentés dans cette thèse s’inscrivent dans le cadre de diagnostic des
systèmes complexes à l'aide des méthodes de reconnaissance de formes, et de l'intelligence
artificielle pour une détection et une localisation automatisée et précoce des défauts. Ce
système rassemble des connaissances pluridisciplinaires. L’application concerne en particulier
les défauts des machines tournantes à savoir les défauts de roulements et d’engranges.
L’élaboration d’un tel système de diagnostic se déroule en trois phases essentielles : la phase
d’analyse, La phase de classification (discrimination entre classes), et la phase d’exploitation.
Pour aborder l’étude nous avons présenté, dans le premier chapitre, un état de l’art sur
les différentes techniques utilisées pour l’analyse des signaux vibratoires. Cet état de l’art
nous a permis d’avoir une direction de travail assez claire pour préparer les données
nécessaires à la tache de classification. En plus ce travail préliminaire nous a permis de bien
choisir les méthodes appropriées pour chaque type de défauts dans la partie expérimentale. En
effet, certaines méthodes ne sont pas applicables à certains types de défauts. Cette étape de
d’analyse constitue la première phase dans l’élaboration d’un système de diagnostic par RdF.
À l’issue de cette phase, une base de données composée d’un certain nombre d’indicateurs
est obtenue. Elle définie donc l’espace de représentation des échantillons mesurés sur le
système.
La deuxième phase consiste à définir l’espace de décision, Dans cette phase, nous
avons opté pour les SVMs afin de classer les données en différentes classes correspondantes
aux différents modes de fonctionnements connus. Le deuxième chapitre a été consacré aux
bases théoriques et principe de classification par cette méthode. Le choix des SVM est justifié
par le domaine d’application où il est, généralement, difficile d’obtenir un ensemble suffisant
de données vibratoires, qui peuvent couvrir tous les modes de fonctionnement du système à
surveillé. Les SVMs est l’une des méthode de classification supervisée qui a une bonne
capacité de généralisation même avec un nombre d’échantillons d’apprentissage réduit.

Conclusion générale
‐ 93 ‐
Le système de diagnostic ne peut être exploité qu’après une évaluation de ces
performances. Généralement, la performance de la classification dépond de la qualité des
indicateurs extraits dans la phase d’analyse. Pour cette raison, l’emploie d’un processus de
sélection d’indicateurs s’avère indispensable. Cette étape de sélection permet de sélectionner
que les indicateurs jugés pertinents et représentatifs des signaux vibratoires mesurés. Par
conséquent, elle permet d’améliorer les performances de la méthode de classification, et
d’augmenter sa capacité de généralisation.
Une première contribution de cette thèse porte sur la sélection des indicateurs. Nous
avons proposé un algorithme de sélection afin d’améliorer les performances de la
classification. La méthode proposée est basée sur la combinaison de l’algorithme
d’optimisation par essaim de particules binaires (OEPB) et le critère de Fisher régularisé
(CFR). Une deuxième contribution porte sur la combinaison de cette méthode avec les SVMs
pour concevoir un système automatique de diagnostic de défauts.
L’évaluation expérimentale du système de diagnostic proposé, a été menée en utilisant
deux jeux de données vibratoires ; le premier est issu d’un banc d’essai de roulements. Le
deuxième provient de l’instrumentation d’une boite de vitesse CH-46 d’un hélicoptère
Westland. Deux stratégies des SVMs multiclasses sont utilisées à savoir la stratégie 1vs1 et
1vsR. Les performances des SVMs ont été également évaluées, en utilisant trois noyaux
différents ; linéaire, RBF, et sigmoïdal.
Au début de l’expérience, les signaux vibratoires sont analysés avec différentes
méthodes de traitement de signal afin d’extraire les indicateurs constituant du vecteur forme.
Ensuite, une partie de cette base, appelée « base d’apprentissage », est utilisé pour établir la
règle de décision. Cette dernière permet de classer automatiquement toute mesure ou
observation, c’est à dire de décider automatiquement du mode de fonctionnement que
représente cette mesure. Après l'apprentissage il est nécessaire de tester la règle de décision
établie, sur une partie des données n'ayant pas servi à l'apprentissage. Cette partie de données
est appelé « base de test ». Ainsi, les taux de bonnes ou de mauvaises classifications sont les
éléments qui ont permis d’évaluer les performances du système de diagnostic proposé.
Les résultats obtenus permettent de conclure que :
Au niveau de l’application, le système de OEPB-CFR+SVM peut servir, avec une
grande performance, au diagnostic des deux types de défauts (roulement et

Conclusion générale
‐ 94 ‐
engrenage). En effet, ce système est capable, non seulement, de détecter la présence
des défauts, mais également de quantifier leurs niveaux. Ceci a été prouvé avec le
banc d’essai de roulement où différents niveaux de défauts ont été identifiés.
La comparaison des performances des SVM, dans les deux cas (avec et sans sélection
d’indicateur), a montré que l’algorithme OEPB-CFR proposé, permet de sélectionner
un sous ensemble d’indicateurs pertinents et de taille faible (10 sur les 30 initiaux,
dans le cas des engrenages). Il s’agit d’une représentation parcimonieuse mais
informative, ce qui a conduit a une amélioration des performances de la classification.
L’utilisation de différents noyaux (Kernel), nous a permis de conclure que le noyau
RBF, et le mieux adapté au SVMs. En effet, Les meilleurs résultats ont été obtenus
avec ce noyau dans les différents cas utilisé. D’autres part, la stratégie 1vs1 adopté
pour le cas multiclasses des SVMs, a montré ses avantages par rapport à l’autre
stratégie 1vsR, dans les différents cas étudiés.
Les travaux réalisés dans le cadre de cette thèse pourraient donner lieu à des études
supplémentaires sur plusieurs points :
• Tester l’efficacité des autres méthodes de traitement de signal pour le diagnostic de
défauts, tel que l’EMD (Empirical Mode Decomposition), l’analyse cyclostationnaire
.., etc.
• Il est connu que la vitesse de la machine, même en mode de fonctionnement normale,
n’est pas constante (régime non stationnaire), il est donc préféré de travailler avec des
signaux échantillonnés en fonction de la position (échantillonnage angulaire).
L’application de certaines méthodes nécessite ce type d’échantillonnage, telle que la
méthode de moyennage temporal synchronisé.
• De nombreux problèmes n’ont pas encore été résolus et restent des sujets de recherche
d’actualité. On peut citer les problèmes posés par le mélange des vibrations de
plusieurs organes, le pronostic, et la surveillance en régime variable. Ce dernier
problème est crucial pour ce qui concerne la surveillance des éléments tournants sur
les éoliennes, dans les véhicules automobiles (boîte de vitesse, moteur), en
aéronautique (turboréactteur)… etc.

Références bibliographiques
‐ 95 ‐
Références bibliographiques Abdul Rahman A.G, Chao O.Z, & Ismail. Z (2011). Effectiveness of Impact-Synchronous
Time Averaging in determination of dynamic characteristics of a rotor dynamic system. Measurement. 44,pp 34- 45.
Antoni J. (2006). The spectral kurtosis: a useful tool for characterizing non-stationary signals.
Mechanical Systems and Signal Processing, Vol 20 (2), pp 282-307. Antoni J. (2007). Cyclic spectral analysis in practice. Mechanical Systems and Signal
Processing, Vol 21 (2), pp 597-630. Antoni J. (2009). Cyclostationarity by examples. Mechanical Systems and Signal Processing,
Vol 23 (4), pp 987–1036. Aparna D. & Mallikarjun R. (2002). Pattern Recognition of Acoustic Emission Signals from
PZT ceramics , Journal of Nondestructive Testing Vol. 7 N 09. Avci E. (2009). Selecting of the optimal feature subset and kernel parameters in digital
modulation classification by using hybrid genetic algorithm–support vector machines: HGASVM. Expert Systems with Applications, Vol 36(2), pp1391–1402.
Augeix D. (2001). Analyse vibratoire des machines tournantes -Techniques de l’Ingénieur -
Traité Génie mécanique –. BM 5 145, Vol BD 2, pp1-22. Ayat N. (2004). Sélection de modèle automatique des machines à vecteurs de support:
application à la reconnaissance d’images de chiffres manuscrits, thèse de doctorat, Montréal, 2004.
Baydar N. & Ball A. ( 2001). A comparative study of acoustic signals in detection of gear
failures using Wigner-Ville distribution. Mechanical Systems and Signal Processing., Vol 15, pp 1091-1107.
Belaid K., & Miloudi A. (2013). Detection of gear defects by resonance demodulation
detected by wavelet transform and comparison with the kurtogram. 21ème Congrès Français de Mécanique Bordeaux, 26 au 30 août 2013.
Blansché A. (2006) Classification non supervisée avec pondération d’attributs par des
méthodes évolutionnaires. Thèse de doctorat, Université Louis Pasteur de Strasbourg, Septembre 2006.
Bouillaut L. & Sidahmed M. (2001). Cyclostationary approach and bilinear approach:
comparison, applications to early diagnosis for helicopter gearbox and classification method based on hocs. Mechanical Systems and Signal Processing, 15(5) :pp923-943.

Références bibliographiques
‐ 96 ‐
Bottou L. & Lin C.-J. (2007). Support vector machine solvers. In L_eon Bottou, Olivier Chapelle, Dennis DeCoste, and Jason Weston, eds, Large Scale Kernel Machines, pp 301-320, Cambridge, MA, USA, 2007. MIT Press.
Breneur C. (2002). Eléments de maintenance préventive de machines tournantes dans le cas
de défauts combinés d’engrenages et de roulements. Thèse de doctorat INSA 2002. Burges C. A. (1998). Tutorial on Support Vector Machines for Pattern Recognition. Data
Mining and Knowledge Discovery, 2, pp 955–974. Cameron B.G (1993) Final report on CH-46 Aft transmission seeded fault testing. Westland
Helicopters Ltd, UK, Research Paper RP907. Canu S., Grandvalet Y., Guigue V., & Rakotomamonjy A. (2005). Perception Systemes et
Information. INSA de Rouen; France: 2005. SVM and Kernel Methods MATLAB toolbox.
Cerny V. (1985). Thermodynamical approach to the traveling salesman problem :an efficient
simulation algorithm. Journal of Optimization Theory and Applications, 45(1), pp 41_51.
Chang C.C & Lin C.J (2001). LIBSVM - A Library for Support Vector Machines, software
accessible à http://www.csie.ntu.edu.tw/~cjlin/libsvm/. Chang R.K.Y, Loo C.K, & Rao M.V.C (2009). Enhanced probabilistic neural network with
data imputation capabilities for machine-fault classification, Neural Computing and Applications, Vol 18, (7), pp 791-800.
Chen B., Yan Z.& Chen .W, (2014). Defect Detection for Wheel-bearings with Time-Spectral
Kurtosis and Entropy, Entropy, Vol 16, pp 607-626 Chen Y., Miao D., & Wang R. (2010). A rough set approach to feature selection based on ant
colony optimization. Pattern Recognition Letters, Vol 31,pp 226–233. Choudhary D, Malasri S., Harvey M., & Smith A. (2014) . Time-Frequency Analysis of
Shock and Vibration Measurements Using Wavelet Transforms. International Journal of Advanced Packaging Technology, Vol 2, 1, pp. 60-69,
Cong F., Chen J. & Dong G. (2012). Spectral kurtosis based on AR model for fault diagnosis
and condition monitoring of rolling bearing, Journal of Mechanical Science and Technology , Vol 26 (2),pp 301-306
Daubechies I. (1992), Ten lectures on wavelets, Philadelphia, society for industrial and
applied Mathematics, SIAM, 1992. Dash M. & Liu H. (1997). Feature Selection for Classification. Intelligent Data Analysis.
Vol 1,pp 131–156 Dash M. & Liu H. (2003). Consistency-based search in feature selection. Artificial
Intelligence, Vol 151(1-2) pp155–176.

Références bibliographiques
‐ 97 ‐
Dong J.X, Krzyzak A. & Suen C.Y. (2003)A Fast Parallel Optimization for Training Support
Vector Machine,” Proceedings of 3rd International Conference on Machine Learning and Data Mining, P. Perner and A. Rosenfeld, eds., Springer Lecture Notes in Artificial Intelligence (LNAI 2734), pp. 96-105.
Dorigo M., Maniezzo V., & Colorni A.(1996) .The Ant System : Optimization by a colony of
cooperating agents. IEEE Transactions on Systems, Man, and Cybernetics Part B : Cybernetics, Vol 26(1) pp 29–41,
Dorigo M. , DiCaro G. (1999), The ant colony optimization meta-heuristic. Dans D.Corne, M.
Dorigo, F. Glover (Eds.), New Ideas in Optimization, McGraw-Hill, 1999. Drouiche K., Sidahmed M., Grenier Y.(1991) Analyse des signaux d'accélérométrie pour la
détection de défauts d'engrenage , Colloque GRETSI, Juan les Pins, septembre 1991. Du S., Lv J., & Xi L. (2012). A robust approach for root causes identification in machining
processes using hybrid learning algorithm and engineering knowledge. Journal of Intelligent Manufacturing, Vol 23, pp1833–1847.
Duda R., Hart P., & Stork D. (2000). Pattern Classification, 2nd Edition, John Wiley and
Sons, Ltd. 2000 El Badaoui M., Guillet F., Nejjar N., Martini P. & Danière J. (1997). Diagnostic d'un train
d'engrenages par analyse cepstrale synchrone. Seizième colloque GRETSI — 15-19 septembre 1997 — Grenoble pp 761-764.
Fedala S., Mahgoune H., Felkaoui A., & Zegadi R.(2011). Application du kurtosis spectral
pour la détection des défauts des roulements d’un moteur asynchrone. Journées d’Etudes Nationales de Mécanique, JENM’2011 Ouargla. 07-08 Mars, 2011.
Felkaoui A.,.Fortas B., & Apostoliouk A (1994) Sur la sélection de l’ordre dans l’analyse
spectrale moderne des processus linéaires, ICSS’94 . 1994. Flandrin.P. (1993). Temps-Fréquence, Traité des Nouvelles Technologies, série Traitement du
Signal. Hermès, Paris, 1993. Friedman J. H. (1989). Regularized discriminant analysis. Journal of the American Statistical
Association, Vol 84, pp 165–175. Furey T.S., Cristianini N., Duffy N., Bednarski D.W., Schummer M. & Haussler D. (2000).
Support vector machine classification and validation of cancer tissue samples using microarray expression data. Bioinformatics, Vol 16(10), pp 906-914.
Garey M.R, Johnson D.S. (1979), Computers and intractability: a guide to the theory of NP-
completeness, W.H. Freeman and Company, New York, 1979.

Références bibliographiques
‐ 98 ‐
Gaitonde V.N., & Karnik S.R. (2012). Minimizing burr size in drilling using artificial neural network(ANN)-particle swarm optimization (PSO) approach. Journal of Intelligent Manufacturing, Vol 23,pp 1783–1793.
Gelman L. M., Kripak D.A., Fedorov V.V. & Udovenko L.N. (2000), condition monitoring
diagnosis methods of helicopter units , Mechanical system and signal processing, Vol 14(4) pp 613-624
Glover F. (1989) Tabu search—Part I. ORSA J Comput 1, pp190–206 Grasso M., Pennacchi P., Colosimo B. M. (2014) Empirical mode decomposition of pressure
signal for health condition monitoring in waterjet cutting. The International Journal of Advanced Manufacturing Technology, Vol 72, pp347-364.
Gryllias K.C., & Antoniadis I. A. (2012). A Support Vector Machine approach based on
physical model training for rolling element bearing fault detection in industrial environments. Engineering applications of Artificial Intelligence , Vol 25,pp 326–344.
Gunn S.R. (1998). Support vector machines for classification and regression. Technical
Report, Department of Electrical and Computer Science, University of Southampton. Hajnayeb A., Ghasemloonia A., Khadem S.E, & Moradi M.H.(2011). Application and
comparison of an ANN-based feature selection method and the genetic algorithm in gearbox fault diagnosis. Expert Systems with Applications Vol 38 , pp10205–10209.
He Y., Pan M., Luo F. Chen D. & Hu, X. (2013). Support vector machine and optimized
feature extraction in integrated eddy current instrument. Measurement, Vol 46, pp764–774
Hertz A., Taillard E., De Werra D. (1995). A tutorial on tabu search Proc. of Giornate di
Lavoro AIRO, 1995, pp13-24. Holland J.(1975) . Adaptation in Natural and Artificial Systems. University of Michigan
Press, 1975. Howland P., & Park H. (2004). Generalizing discriminant analysis using the generalized
singular value decomposition. IEEE Trans. Pattern Anal. Mach. Intell, Vol 26 (8),pp 995–1006.
Huang N. E., Shen Z., Long S. R (1998). The empirical mode decomposition and the Hilbert
spectrum for nonlinear and non-stationary time series analysis in: Proceedings of the Royal Society of London Series, Vol 454, pp. 903-995.
Jack L.B., & Nandi A. K. (2002). Fault detection using support vector machines and artificial
neural networks, augmented by genetic algorithms. Mechanical Systems and Signal Processing, Vol 16, pp 373–390.
John G., Kohavi R., & Peger K. (1994). Irrelevant features and the subset selection problème.
Eleventh International Conference on machine Learning, pp. 121-129.

Références bibliographiques
‐ 99 ‐
Joachims T. (1998). Text categorization with support vector machines : learning with many relevant features». 10th European Conference on Machine Learning ECML-98, pp 137–142, 1998.
Joachims T. (1999). Transductive inference for text classification using support vector
machines.In International Conference on Machine Learning, ICML 1999. Jourdan L. (2003). Métaheuristiques pour l’extraction de connaissances : application à la
génomique. Thèse de doctorat, Université des sciences et technologies de Lille 2003. Kanan H.R, Faez K., & Taheri S. M (2007) Feature Selection Using Ant Colony
Optimization (ACO): A New Method and Comparative Study in the Application of Face Recognition System. In Advances in Data Mining. Theoretical aspects and Applications 7th Industrial Conference Proceedings, ICDM 2007, Leipzig, Germany, July 14-18, 2007.
Kennedy J., & Eberhart R. C. (1995). Particle swarm optimization. In Proceedings of IEEE
international conference on neural networks, 4, pp1942–1948. Kennedy J, & Eberhart R. C. (1997). A discrete binary version of the particle swarm
optimisation algorithm, in: Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, pp4104–4108.
Kidar T., Thomas M., Elbadaoui M. & Guilbault R.. (2013). Early detection of gear defects by
cyclostationarity, Surveillance 7, International Conference - October 29-30, 2013 Komgom N,. C., Mureithi N., Aouni L., & Marc, T. (2007). On the use of time synchronous
averaging, independent component analysis and support vector machines for bearing fault diagnosis. In First international conference on industrial risk engineering, 17–19 December, 2007, Montreal pp. 610–624.
Kohavi R., & John G. (1997). Wrappers for feature selection. Artificial Intelligence, Vol
97,pp 273-324. Konar P., & Chattopadhyay P. (2011). Bearing fault detection of induction motor using
wavelet and Support Vector Machines (SVMs). Applied Soft Computing, Vol 11,pp 4203–4211.
Kudo M., & Sklansky J. (2000). Comparison of algorithms that select features for pattern
classifiers. Pattern Recognition, Vol 33(1),pp 25–41. Kurek J., & Stokowski S. (2010). Support vector machine for fault diagnosis of the broken
rotor bars of squirrel-cage induction motor. Neural Computing & Application, Vol 19, pp 557–564.
Khushaba R. N. Al-Ani A., Al-Sukker A., & Al-Jumaily A.(2008). A combined ant colony
and differential evolution feature selection algorithm. In Ant Colony Optimization and Swarm Intelligence, 6th International Conference, (ANTS’08), Brussels, Belgium, pp 1–12.

Références bibliographiques
‐ 100 ‐
Khushaba R. N., Al-Ani A., & Al-Jumaily A. (2011). Feature subset selection using differential evolution and a statistical repair mechanism. Expert Systems with Applications, Vol 38,pp 11515–11526.
Loughlin P. & Cakrak F. ( 2000) . Conditional moments analysis of transients with
application to the helicopter fault data , Mechanical system and signal processing, vol 14, (4), pp515-522.
Li H., Zhang Y. & Zheng H. (2009). Gear fault detection and diagnosis under speed-up
condition based on order cepstrum and radial basis function neural network. Journal of Mechanical Science and Technology, Vol 23,pp 2780-2789
Li H., Lian X., Guo C., & Zhao P. (2013a). Investigation on early fault classification for
rolling element bearing based on the optimal frequency band determination. Journal of Intelligent Manufacturing, doi:10.1007/s10845-013-0772-8
Li Z., Yan X., Tian Z., Yuan C., Peng Z., & Li L. (2013b). Blind vibration component
separation and nonlinear feature extraction applied to the nonstationary vibration signals for the gearbox multi-fault diagnosis. Measurement, Vol 46, pp 259–271.
Li R., Sopon P., & He D. (2012). Fault features extraction for bearing prognostics. Journal of
Intelligent Manufacturing, Vol 23, pp313–321. Li Y., Tong Y., Bai B., & Zhang Y. (2007). An improved particle swarm optimization for
SVM training. In Proceedings of the third international conference on natural computation. Los Alamitos: IEEE Computer Society,pp 611–615.
Lin S. W., Lee Z. J., Chen S. C., & Tseng T.Y. (2008) . Parameter determination of support
vector machine and feature selection using simulated annealing approach. Applied Soft Computing, Vol 8,pp 1505–1512.
Liu H. & Yu L.(2005).Toward integrating feature selection algorithms for classification and
clustering. IEEE Trans. on Knowledge and Data Engineering, Vol 17(4), pp 491–502,
Liu H. & Motoda H.(2007).Computational methods of feature selection. CRC Press, 2007. Liu W, Han J, Lu X. (2013). A new gear fault feature extraction method based on hybrid
time–frequency analysis. Neural Computing & Application. DOI 10.1007/s00521-013-1502-z
Loparo K. A. (2013). Bearings Vibration Data Sets, Case Western Reserve University:
http://csegroups.case.edu/bearingdatacenter/home. Loosli G., Canu S., Vishwanathan S.V.N., Smola A., & Chattopadhyay M., (2005). Une boîte
à outils SVM rapide et simple. Revue d'intelligence artificielle, Vol 19 (4-5), 741-767
Mahgoune H., Bekka R.E., Felkaoui A. (2011). Etude Comparative Entre la Transformée de
Hilbert- Huang et la Transformée en Ondelettes Continue Dans la Détection des

Références bibliographiques
‐ 101 ‐
Défauts de Roulements, Journées d’Etudes Nationales de Mécanique, JENM’2011 Ouargla. 07-08 Mars, 2011.
Mallat S. G.(1989). A Theory of Multiresolution Signal Decomposition: The Wavelet
Representation. IEEE Transactions on Pattern and Machine Intelligence VOL 11(7),pp 674–693.
Mallat S. G. (2003). A wavelet tour of signal processing. The sparse way. 3rd edition. New
York: Academic Press. McFadden P.D. & Smith J.D.(1985). The vibration produced by multiple point defects in a
rolling element bearing. Journal of Sound and Vibration, Vol 98(2):263-273. Metropolis N., Rosenbluth A. R, Rosenbluth. M. N, Teller. A & Teller. E (1953). Equation of
state calculations by fast computing machines. The Journal of Chemical Physics, vol. 21, 6, pp 1087-1092.
Mishra D., Sahu B. (2011). Feature Selection for Cancer Classification: A Signal-to-noise
Ratio Approach . International Journal of Scientific & Engineering Research, Vol 2, Issue 4, pp 1-7
Mollazade K., Ahmadi H., Omid M., & Alimardani R. (2008). An Intelligent Combined
Method Based on Power Spectral Density, Decision Trees and Fuzzy Logic for Hydraulic Pumps Fault Diagnosis, World Academy of Science, Engineering and Technology Vol: 20, pp 08-22
Mortada M. A., Yacout S., & Lakis A. ( 2013). Fault diagnosis in power transformers using
multi-class logical analysis of data. Journal of Intelligent Manufacturing, doi:10.1007/s10845-013-0750-1
Nandi S., Toliyat H. (1999) Condition monitoring and diagnosis of electrical machines- a
review, Proceedings of the IEEE -IAS Annual Meeting Conference, 8 pages, Nandi A.K , Liu.C, & Wong.M.L.D (2013) Intelligent Vibration Signal Processing for
Condition Monitoring, International Conference Surveillance 7, Institute of Technology of Chartres, France, October 29-30, 2013
Oduntan I. O., Toulouse M. & Baumgartner R. (2008). A multi level tabu search algorithm
for the feature selection problem in biomedical data. Computers & Mathematics with Applications, Vol 5, 1019–1033.
Osuna E., Freund R., & Girosi F.(1997) An improved training algorithm for support vector
machines. In Proceedings of the 1997 IEEE Workshop on Neural Networks for Signal Processing, Eds. J. Principe, L. Giles, N. Morgan, E. Wilson, pp 276 – 285, Amelia Island.
Pan M.C., & Tsao.W.C (2013) . Using appropriate IMFs for envelope analysis in multiple
fault diagnosis of ball bearings, International Journal of Mechanical Sciences. Vol 69,pp 114–124.

Références bibliographiques
‐ 102 ‐
Park C. H., & Park H. (2007). A comparison of generalized linear discriminant analysis algorithms. Pattern Recognition. doi: 10.1016/j.patcog.2007.07.022
Platt J.C.(1998). Sequential Minimal Optimization:A Fast Algorithm for Training Support
Vector Machines. Technical Report MSR-TR-98-14 April 21, 1998. Platt J.C., Cristianini N., & Shawe-Taylor J. (2000). Large margin DAGs for multiclass
classi_cation.In NIPS 12, pp 547-553. Qian Y., Xu L., Li X., Lin X., Kraslawski L., & Lubres A. (2008). An expert system
development and implementation for real-time fault diagnosis of a lubricating oil refining process. Expert Systems with Applications, Vol 35(3), pp1251-1266.
Qiu H., Lee J., Lin J., Yu G. (2006). Wavelet filter-based weak signature detection method
and its application on rolling element bearing prognostics, Journal of Sound and Vibration , Vol 289, pp1066–1090.
Raad A. (2003), Contributions aux statistiques cycliques d’ordre supérieur : applications au
diagnostic des défauts d’engrenage, Thèse de doctorat, Université Technologie de Compiègne,2003.
Rafiee J., Arvani F., Harifi A., & Sadeghi M. H. (2007). Intelligent condition monitoring of a
gearbox using artificial neural network. Mechanical Systems and Signal Processing, 21, pp1746–1754
Rafiee J., Rafiee M. A., & Tse P.W. (2010). Application of mother wavelet functions for
automatic gear and bearing fault diagnosis. Expert Systems with Applications, Vol 37, pp 4568–4579.
Randall R. B., Antoni J., & Chobsaard S. (2001). The relationship between spectral
correlation and envelope analysis in the diagnosis of bearing faults and other cyclostationary machine signals. Mechanical Systems and Signal Processing, Vol 15,pp 945-962.
Randall R. B. (2011). Vibration-based condition monitoring : industrial, aerospace and
automotive applications. John Wiley & Sons, Ltd.2011. Samanta B., Al-Balushi K.R, & Al-Araimi S.A. (2001). Use of genetic algorithm and artificial
neural network for gear condition diagnostics. Proceedings of COMADEM, University of Manchester, UK, pp 449–456.
Samanta B., Al-Balushi K. R., & Al-Araimi S. A. (2003). Artificial neural networks and
support vector machines with genetic algorithm for bearing fault detection. Engineering Applications of Artificial Intelligence, Vol 16, pp 657–665
Samanta B. (2004) Gear fault detection using artificial neural networks and support vector
machines with genetic algorithms. Mechanical Systems and Signal Processing, Vol 18 (3),pp 625–644.

Références bibliographiques
‐ 103 ‐
Samanta B., & Nataraj C. (2009). Use of particle swarm optimization for machinery fault detection. Engineering Applications of Artificial Intelligence, Vol 22 , pp 308–316
Sharma A., & Paliwal K. K. (2012). A new perspective to null linear discriminant analysis
method and its fast implementation using random matrix multiplication with scatter matrices. Pattern Recognition, Vol 45, pp 2205–2213.
Scholkopf B. (1998). SVMs-a practical consequence of learning theory. IEEE Intelligent
Systems, Vol 13, pp 18–19. Sheen Y.T., & Liu Y.H. (2012). A quantified index for bearing vibration analysis based on the
resonance modes of mechanical system. Journal of Intelligent Manufacturing, Vol 23, pp 189–203.
Shen C., Wang D., Kong F., & Tse P. W. (2013). Fault diagnosis of rotating machinery based on the statistical parameters of wavelet packet paving and a generic support vector regressive classifier. Measurement, Vol 46, pp 1551–1564.
Shin K & Hammond J.(2008).Fundamentals of Signal Processing for Sound and Vibration
Engineers. John Wiley & Sons Ltd, 2008. Soong T. T. (2004). Fundamentals of probability and statistics for engineers, John Wiley &
Sons, Ltd.2004. Stepanic P., Latinovic I. V., & Djurovic Z. (2009). A new approach to detection of defects in
rolling element bearings based on statistical pattern recognition. International Journal of Advanced Manufacturing Technology, Vol 45, pp 91–100 .
Storn R. & Price K. (1997) . Differential Evolution – a simple and efficient heuristic for
global optimization over continuous spaces. Journal of Global Optimization, Vol 11(4), pp.341–359, 1997.
Su Y.T. &. Lin S.J. (1992). On initial fault detection of a tapered roller bearing:Frequency
domain analysis. Journal of Sound and Vibration, Vol 155(1):75-84. Sun W., Chen J., & Li J. (2006). Decision tree and PCA based fault diagnosis of rotating
machinery. Mechanical Systems and Signal Processing, 21,pp 1300–1317 Tahir M. A, Bouridane A, & Kurugollu F.(2007) Simultaneous feature selection and feature
weighting using Hybrid Tabu Search/K-nearest neighbor classifier. Pattern Recognition Letters, Vol 28. pp. 438–446.
Teti R., Jemielniak K., O’Donnell G., & Dornfeld D. (2010). Advanced monitoring of
machining operations. CIRP Annals - Manufacturing Technology, Vol 59,pp 717–739.
Tsang W., Kwok J. T., & Cheung P.M. (2005). Very large SVM training using core vector
machines. In Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics.2005.

Références bibliographiques
‐ 104 ‐
Tyagi C.S. (2008). A Comparative Study of SVM Classifiers and Artificial Neural Networks Application forRolling Element Bearing Fault Diagnosis using Wavelet Transform Preprocessing. World Academy of Science, Engineering and Technology, Vol 19, pp 309-317.
Vachtsevanos G., lewis F., Roemer M., Hess A., Wu B. (2006). Intelligent fault diagnosis and
prognosis for engineering systems. John Wiley & Sons, Inc.2006. Vapnik V.N. (1998). Statistical Learning Theory. wiley Interscience publication, NewYork,
1998. Vapnik V. N. (2000). The nature of statistical learning theory. 2nd edition. Springer 2000. Vojtech F, Václav H. (2004) Statistical pattern recognition toolbox for Matlab. Center for
Machine Perception, Czech Technical University Prague, Czech. Accessible sur internet à http://cmp.felk.cvut.cz/cmp/software/stprtool/index.html.
Wang C.C, & TOO G.P.J. (2002). Rotating machine fault detection based on HOS and
artificial neural networks. Journal of intelligent manufacturing, Vol 13, 283-293. Williams W. J. & Zalubas E.J.( 2000). Helicopter transmission fault detection via Timefrequency,
scale and spectral methods . Mechanical system and signal processing, Vol 14,(4), pp 545-559.
Widmer M. (2001). Les métaheuristiques : des outils performants pour les problèmes
industriels, 3e Conférence Francophone de MOdélisation et SIMulation “Conception, Analyse et Gestion des Systèmes Industriels” MOSIM’01 – du 25 au 27 avril 2001 - Troyes (France). Pages 9.
Worden K., Staszewski WJ., & Hensman J.J. (2011). Natural computing for
mechanical systems research: A tutorial overview, Mechanical Systems and Signal Processing, Vol 25 (2011), pp 4–111.
Wu J. et Zhao W. (2009). A simple interpolation algorithm for measuring mutli-frequency
signal based on DFT. Measurement., Vol 42, pp. 322-327. Yang J., & Honavar V.(1997). Feature Subset Selection Using a Genetic Algorithm.
Computer Science Technical Reports. Paper 156. Yang B. S., Han T., & Hwang W.W. (2005). Fault Diagnosis of Rotating Machinery Based
on Multi-Class Support Vector Machines. Journal of Mechanical Science and Technology, Vol 19 (3), pp 846-859.
Yang Y., Yu D., & Cheng J. (2007). A fault diagnosis approach for roller bearing based on
IMF envelope spectrum and SVM, Measurement, Vol 40,pp943–950. Yang Z. L., Wang B., Dong X. H., & Liu H. (2012). Expert System of fault Diagnosis for
gear box in wind turbine. Systems Engineering Procedia, pp189-195.

Références bibliographiques
‐ 105 ‐
Ye J., Janardan R., Li Q., & Park H. (2004). Feature extraction via generalized uncorrelated linear discriminant analysis, in: The Proceedings of the International Conference on Machine Learning, pp 895–902
Ye J., & Xiong T. (2006). Computational and Theoretical Analysis of Null Space and
Orthogonal Linear Discriminant Analysis. Journal of Machine Learning Research, Vol 7, pp 1183–1204.
Ypma A. (2001). Learning methods for machine vibration analysis and health monitoring , Thèse de
de doctorat, Université technique de Delft -pays bas, 12 Novembre 2001, pp221. Yu H., & Yang J. (2001). A direct LDA algorithm for high-dimensional data-with application
to face recognition. Pattern Recognition, Vol 34, pp 2067–2070. Yuan S. F., & Chu F.L. (2007). Fault diagnosis based on particle optimization and support
vector machines. Mechanical Systems and Signal Processing, Vol 21(4),pp 1787–1798.
Yusta S. C. (2009). Different metaheuristic strategies to solve the feature selection problem.
Pattern Recognition Letters 30 (2009) 525–534 Zhang Y., Zuo H., & Bai F. (2013a). Classification of fault location and performance
degradation of a roller bearing. Measurement, Vol 46, pp 1178–1189. Zhang Z., Wang Y., & Wang K. (2013b). Fault diagnosis and prognosis using wavelet packet
decomposition, Fourier transform and artificial neural network. Journal of Intelligent Manufacturing, 24, pp 1213–1227.
Zhao X, Zuo M.J., Liu Z., Hoseini M.R. (2013). Diagnosis of artificially created surface
damage levels of planet gear teeth using ordinal ranking, Measurement Vol 46,pp 132–144.
Ziani R. ,Djouada M., felkaoui A., & Zegadi R. (2009). Application de l’intelligence
artificielle a la maintenance conditionnelle des machines tournantes. International Conference on Systems and Information Processing ICSIP'09 May 2-4 , Guelma, Algeria
Ziani R., Zegadi R., Felkaoui A. (2011). Gear fault detection using supports vector machine
(SVM) & genetic algorithms. International Conference Surveillance 6, University of Technology of Compiègne, France October 2011.
Ziani R., Zegadi R., Felkaoui A. (2012). Bearing Fault Diagnosis Using Neural Network and
Genetic Algorithms with the Trace Criterion. In Condition monitoring of machinery in non-stationary operations : proceedings of the Second International Conference "Condition Monitoring of Machinery in Non-Stationnary [i.e. Non-Stationary] Operations" CMMNO'2012 Springer pp 89-96.

Annexes
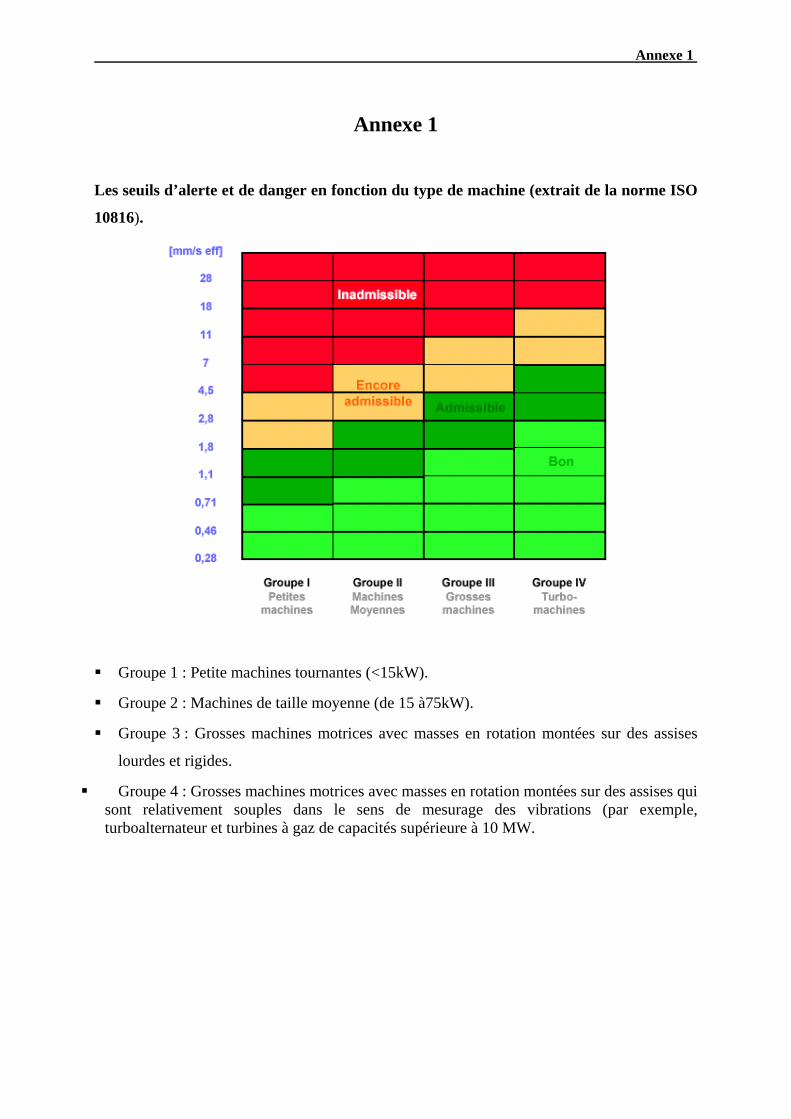
Annexe 1
Annexe 1
Les seuils d’alerte et de danger en fonction du type de machine (extrait de la norme ISO
10816).
Groupe 1 : Petite machines tournantes (<15kW).
Groupe 2 : Machines de taille moyenne (de 15 à75kW).
Groupe 3 : Grosses machines motrices avec masses en rotation montées sur des assises
lourdes et rigides.
Groupe 4 : Grosses machines motrices avec masses en rotation montées sur des assises qui sont relativement souples dans le sens de mesurage des vibrations (par exemple, turboalternateur et turbines à gaz de capacités supérieure à 10 MW.

Annexe 2
A
Annexe 2
Types de défauts sur les roulements
Nous distinguons quatre types de dégradations sur les roulements (Nandi & Toliyat, 1999)
,(Ypma, 2001):
a- Défaut sur la bague intérieure :
Il est caractérisé par la présence d’une raie à la fréquence caractéristique du défaut (fi ).Cette fréquence est modulée par la fréquence de rotation (bandes latérales autour de la raie de défaut).
( )1 cos2
bi s
m
dNf fd
α⎛ ⎞
= +⎜ ⎟⎝ ⎠
(1)
Où fs est la fréquence de rotation de l’arbre, N est le nombre d’éléments roulants, est l’angle de contact, db et dm sont le diamètre de bille et le diamètre du roulement respectivement (voir figure 1.1). b- Défaut sur la bague extérieure :
Ce défaut est caractérisé par la présence d’une raie à la fréquence (fo). Bien que la charge appliquée sur la bague externe soit constante, on peut remarquer une modulation d’amplitude à la fréquence de rotation de l’arbre autour de la fréquence de défaut.
( )1 cos2
bo s
m
dNf fd
α⎛ ⎞
= −⎜ ⎟⎝ ⎠
(2)
c- Défaut sur les éléments roulants :
La première fréquence caractéristique de défaut correspond à la fréquence de rotation de l’élément roulant sur lui-même. De plus, cet élément roulant rencontre une fois la bague interne et une fois la bague externe par tour, il génère donc des chocs à 2 fois cette fréquence.
( )2
1 1 cos2
m bb s
b m
d df fd d
α⎛ ⎞⎛ ⎞⎜ ⎟= − ⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠
(3)
d- Défaut sur la cage : Ce défaut se manifeste par la présence de raies à la fréquence fc et ses harmoniques. A l’instar de la bague interne, on pourra constater des bandes latérales autour de fb (fréquence de défaut d’élément roulants) et 2.fb , ces bandes seront distantes d’une fréquence égale à la fréquence de défaut de la cage fc .
( )1 1 cos2
bc s
m
df fd
α⎛ ⎞
= −⎜ ⎟⎝ ⎠
(4)
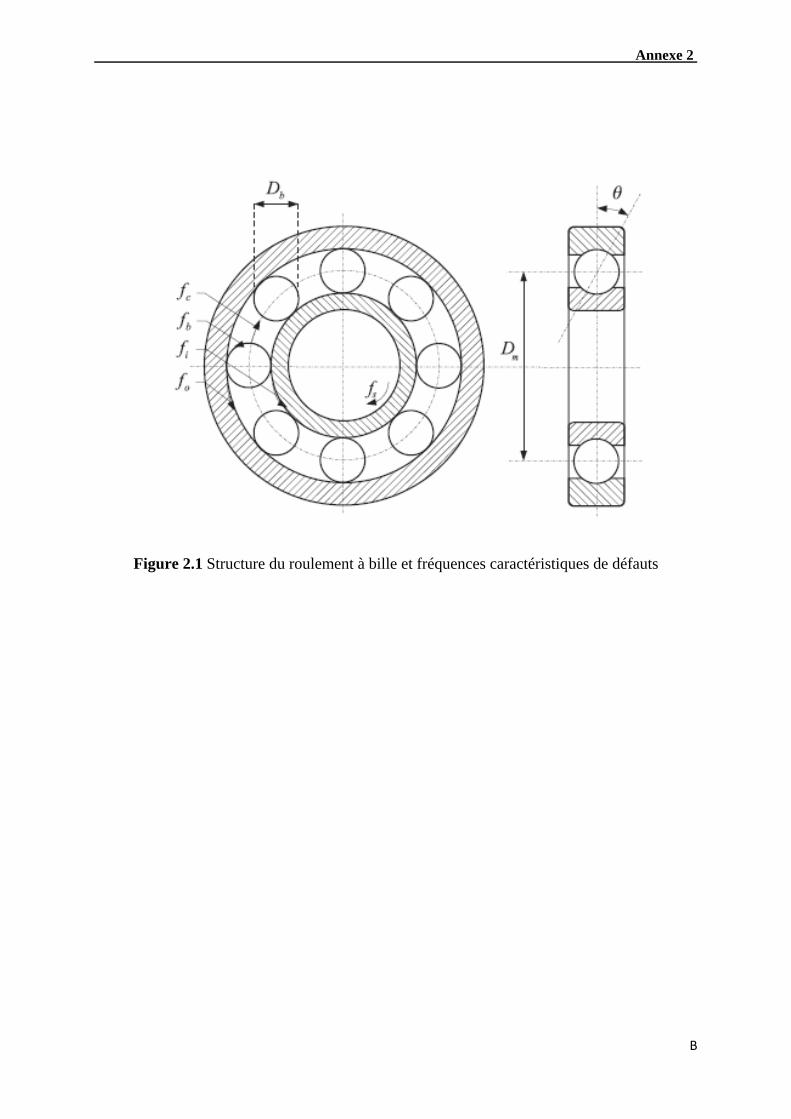
Annexe 2
B
Figure 2.1 Structure du roulement à bille et fréquences caractéristiques de défauts

Annexe 3
Annexe 3
La transformée d’ Hilbert
Soit un signal x(t) dont la transformée de Fourier est X(f). On appelle transformé de
Hilbert de ce signal, le signal défini par la relation suivante (Shin & Hammond, 2008):
{ } 1 ( ) 1ˆ( ) ( ) * ( ) ( )* ( )xH x t x t d x t h t x tt tτ τ
π τ π
+∞
−∞
= = = =−∫
Ceci est considéré comme la convolution du signal x(t) par π
La transformée de fourrier de la transformée d’Hilbert peut être écrite sous la forme suivante :
{ }ˆ ( ) ( )* ( ) ( )* ( )X f TF h t x t H f X f= =
Où H(f) est la transformée de Fourrier de π
:
1 pour 0( ) ( ) avec ( ) 1 pour 0
0 pour 0
fH f jsign f sign f f
f
>⎧⎪= − = − <⎨⎪ =⎩
Il s’agit d’un filtre déphaseur appelé encore filtre en quadrature . Par exemple la transformée
d’Hilbert de cos(wt) est sin (wt), et celle de sin(wt) est –cos(wt).
La transformée d’ Hilbert est généralement utilisée pour construire ce qu’on appel un signal
analytique. Un signal analytique est un signal complexe dont la partie réelle est le signal
original x(t), et la partie imaginaire est la transformée d’Hilbert de x(t). Le signal analytique
ax(t) peut être défini par :
ˆ( ) ( ) ( )xa t x t jx t= +
La partie réelle et imaginaire peuvent être exprimées en cordonnées polaires par
( ) ( )exp( ( ))x xa t A t j tϕ=
Avec 2 2ˆ( ) ( ) ( )A t x t x t= + est l’enveloppe où l’amplitude du signal analytique,
( )x tϕ est la phase du signal analytique.
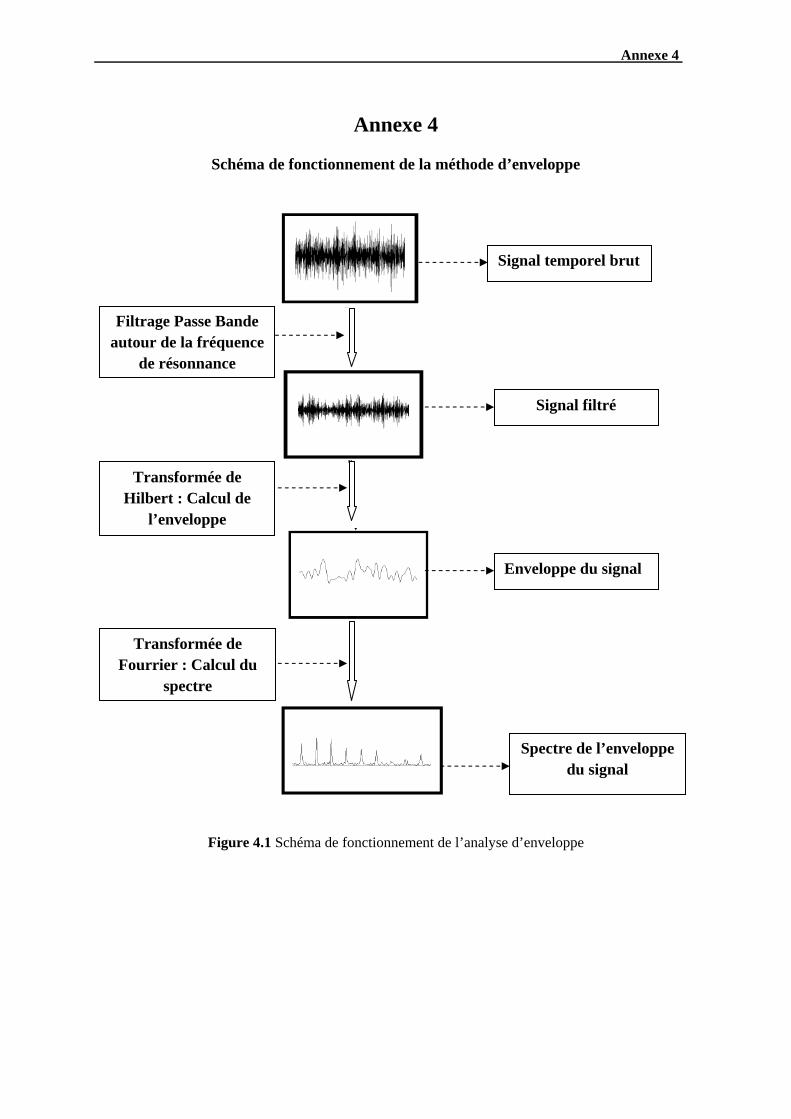
Annexe 4
Annexe 4
Schéma de fonctionnement de la méthode d’enveloppe
Figure 4.1 Schéma de fonctionnement de l’analyse d’enveloppe
Signal temporel brut
Signal filtré
Enveloppe du signal
Spectre de l’enveloppe du signal
Filtrage Passe Bande autour de la fréquence
de résonnance
Transformée de Hilbert : Calcul de
l’enveloppe
Transformée de Fourrier : Calcul du
spectre
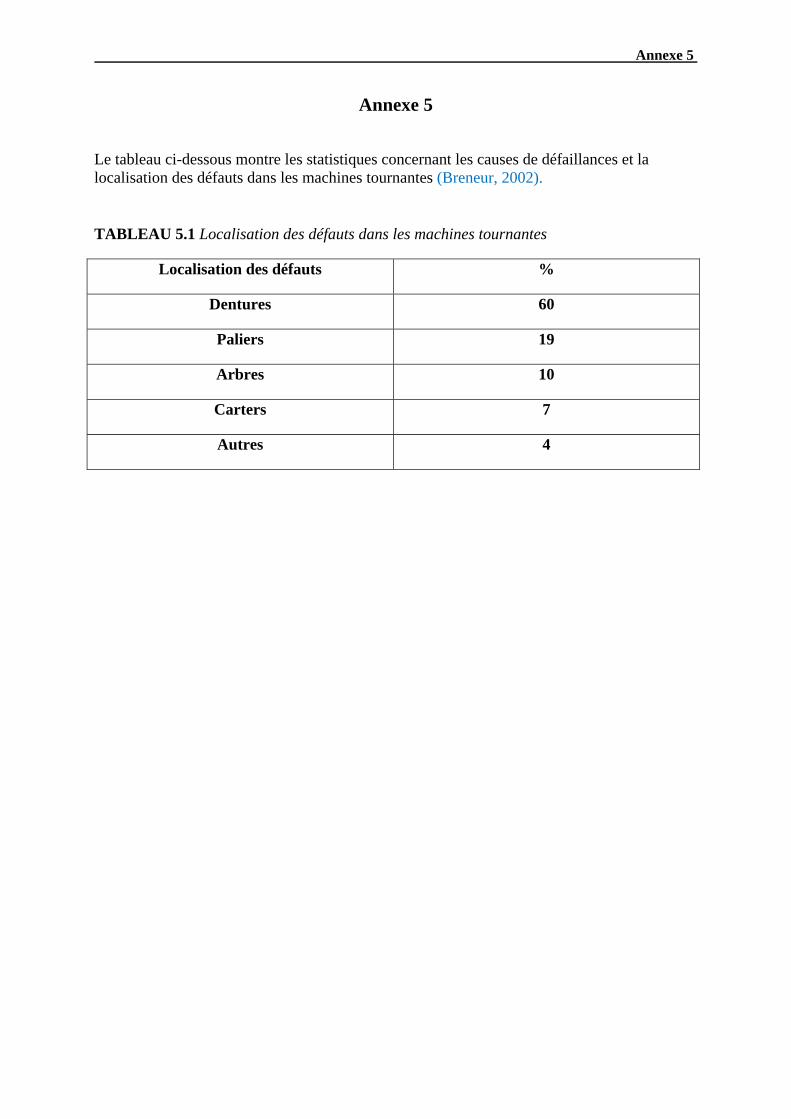
Annexe 5
Annexe 5
Le tableau ci-dessous montre les statistiques concernant les causes de défaillances et la localisation des défauts dans les machines tournantes (Breneur, 2002).
TABLEAU 5.1 Localisation des défauts dans les machines tournantes
Localisation des défauts %
Dentures 60
Paliers 19
Arbres 10
Carters 7
Autres 4
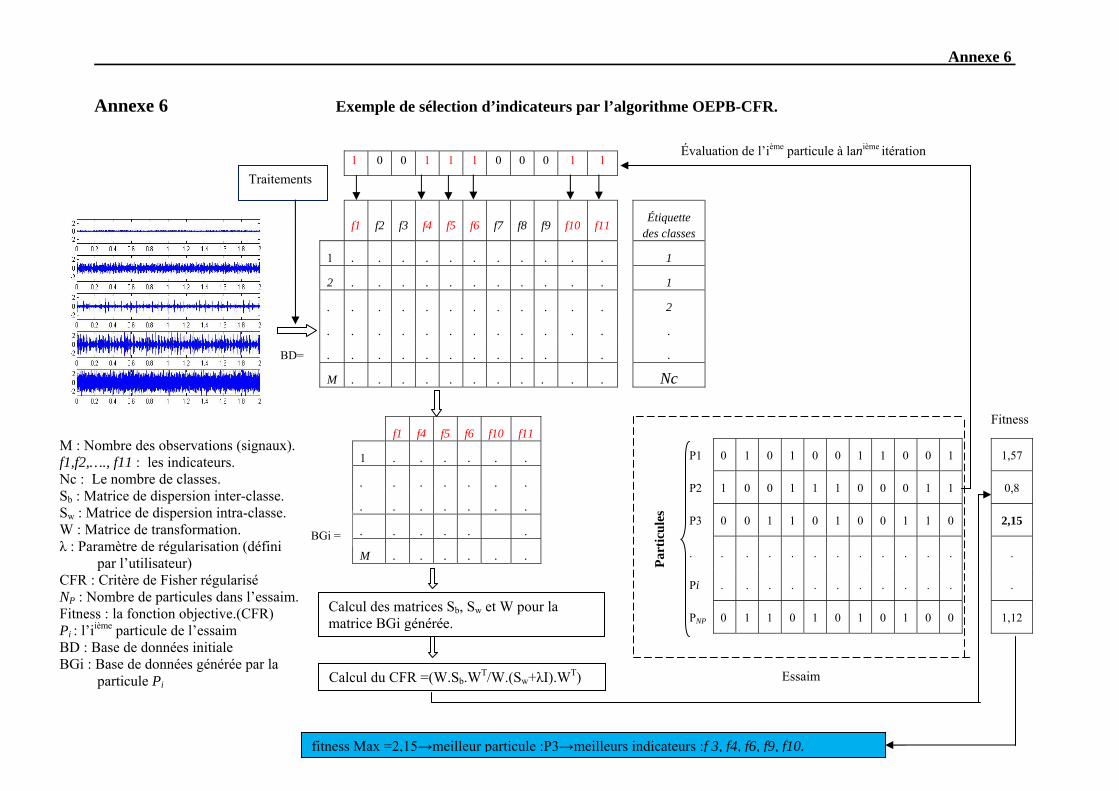
Annexe 6
Annexe 6 Exemple de sélection d’indicateurs par l’algorithme OEPB-CFR.
1 0 0 1 1 1 0 0 0 1 1
f1 f2 f3 f4 f5 f6 f7 f8 f9 f10 f11
Étiquette des classes
1 . . . . . . . . . . . 1
2 . . . . . . . . . . . 1
. . . . . . . . . . . . 2
. . . . . . . . . . . . .
. . . . . . . . . . . .
M . . . . . . . . . . . Nc
f1 f4 f5 f6 f10 f11
1 . . . . . .
. . . . . . .
. . . . . . .
. . . . . .
M . . . . . .
P1 0 1 0 1 0 0 1 1 0 0 1 1,57
P2 1 0 0 1 1 1 0 0 0 1 1 0,8
P3 0 0 1 1 0 1 0 0 1 1 0 2,15
. . . . . . . . . . . . .
Pi . . . . . . . . . . . .
PNP 0 1 1 0 1 0 1 0 1 0 0 1,12
M : Nombre des observations (signaux). f1,f2,…., f11 : les indicateurs. Nc : Le nombre de classes. Sb : Matrice de dispersion inter-classe. Sw : Matrice de dispersion intra-classe. W : Matrice de transformation. λ : Paramètre de régularisation (défini
par l’utilisateur) CFR : Critère de Fisher régularisé NP : Nombre de particules dans l’essaim. Fitness : la fonction objective.(CFR) Pi : l’iième particule de l’essaim BD : Base de données initiale BGi : Base de données générée par la
particule Pi
BGi =
BD=
Calcul des matrices Sb, Sw et W pour la matrice BGi générée.
Calcul du CFR =(W.Sb.WT/W.(Sw+λI).WT)
Traitements
Part
icul
es
Essaim
Fitness
Évaluation de l’ième particule à lanième itération
fitness Max =2,15→meilleur particule :P3→meilleurs indicateurs :f 3, f4, f6, f9, f10.

Annexe 7
Annexe 7
Données vibratoires du banc d’essai de roulement (Loparo, 2013)
Données de roulement sans défaut
Motor Load (HP) Approx. Motor Speed (rpm) Normal Baseline Data
0 1797 Normal_0
1 1772 Normal_1
2 1750 Normal_2
3 1730 Normal_3
Données de Defaults de roulement coté accouplement échantillonnées à 12KH
.Fault Diameter
Motor Load (HP)
Approx. Motor Speed (rpm)
Inner Race
Ball Outer Race
Position Relative to Load Zone (Load Zone Centered at 6:00)
Centered @6:00
Orthogonal@3:00
Opposite @12:00
0.007" 0 1797 IR007_0 B007_0 OR007@6_0 OR007@3_0 OR007@12_0
1 1772 IR007_1 B007_1 OR007@6_1 OR007@3_1 OR007@12_1
2 1750 IR007_2 B007_2 OR007@6_2 OR007@3_2 OR007@12_2
3 1730 IR007_3 B007_3 OR007@6_3 OR007@3_3 OR007@12_3
0.014" 0 1797 IR014_0 B014_0 OR014@6_0 * *
1 1772 IR014_1 B014_1 OR014@6_1 * *
2 1750 IR014_2 B014_2 OR014@6_2 * *
3 1730 IR014_3 B014_3 OR014@6_3 * *
0.021" 0 1797 IR021_0 B021_0 OR021@6_0 OR021@3_0 OR021@12_0
1 1772 IR021_1 B021_1 OR021@6_1 OR021@3_1 OR021@12_1
2 1750 IR021_2 B021_2 OR021@6_2 OR021@3_2 OR021@12_2
3 1730 IR021_3 B021_3 OR021@6_3 OR021@3_3 OR021@12_3
0.028" 0 1797 IR028_0 B028_0 * * *
1 1772 IR028_1 B028_1 * * *
2 1750 IR028_2 B028_2 * * *
3 1730 IR028_3 B028_3 * * *
* = Data not available : données non disponible

Annexe 8
Annexe 8
Tableau 8.1 : Indicateurs calculés pour les signaux de roulements
1 La moyenne 22 Kurtosis du coefficient 3.1 2 Facteur de crête 23 Kurtosis du coefficient 3.2 3 skewness 24 Kurtosis du coefficient 3.3 4 kurtosis 25 Kurtosis du coefficient 3.4 5 moment statistique d’ordre5 26 Kurtosis du coefficient 3.5 6 moment statistique d’ordre6 27 Kurtosis du coefficient 3.6 7 moment statistique d’ordre7 28 Kurtosis du coefficient 3.7 8 moment statistique d’ordre8 29 Énergie du coefficient 1.0 9 moment statistique d’ordre9 30 Énergie du coefficient 1.1 10 DSP de l’enveloppe dans la bande [f-σf, f+σf] 31 Énergie du coefficient 2.0 11 DSP de l’enveloppe dans la bande [2*f-σf, 2*f+σf] 32 Énergie du coefficient 2.1 12 DSP de l’enveloppe dans la bande [3*f-σf, 3*f+σf] 33 Énergie du coefficient 2.2 13 DSP de l’enveloppe dans la bande [4*f-σf, 4*f+σf] 34 Énergie du coefficient 2.3 14 DSP de l’enveloppe dans la bande [f-σf, 4*f+σf] 35 Énergie du coefficient 3.0 15 Kurtosis du coefficient 1.0 36 Énergie du coefficient 3.1 16 Kurtosis du coefficient 1.1 37 Énergie du coefficient 3.2 17 Kurtosis du coefficient 2.0 38 Énergie du coefficient 3.3 18 Kurtosis du coefficient 2.1 39 Énergie du coefficient 3.4 19 Kurtosis du coefficient 2.2 40 Énergie du coefficient 3.5 20 Kurtosis du coefficient 2.3 41 Énergie du coefficient 3.6 21 Kurtosis du coefficient 3.0 42 Énergie du coefficient 3.7 1à 9 : Domaine temporel, 10 à14 : domaine spectrale (spectre d’enveloppe), 15à 42 : temps-échelle (Décomposition en paquets d’ondelettes DPO),
f fréquence caractéristique du défaut.

Annexe 9
A
Annexe 9
Moteur de l’hélicoptère et position de ces différents composants
La photo ci-dessous présente le moteur de l’hélicoptère instrumenté. Elle nous permet de repérer ses différents composantes et notamment le système étudié : la boite de vitesse CH46
Figure 9.1. Moteur de l’hélicoptère et position de ces différents composants

Figure
e 9.2 Photos
Figure
s d’un hélic
9.3. Vue de
optère Wes
e dessus du
stland de la
banc d'essa
marine amé
ai CH-46
A
éricaine
Annexe 9
B
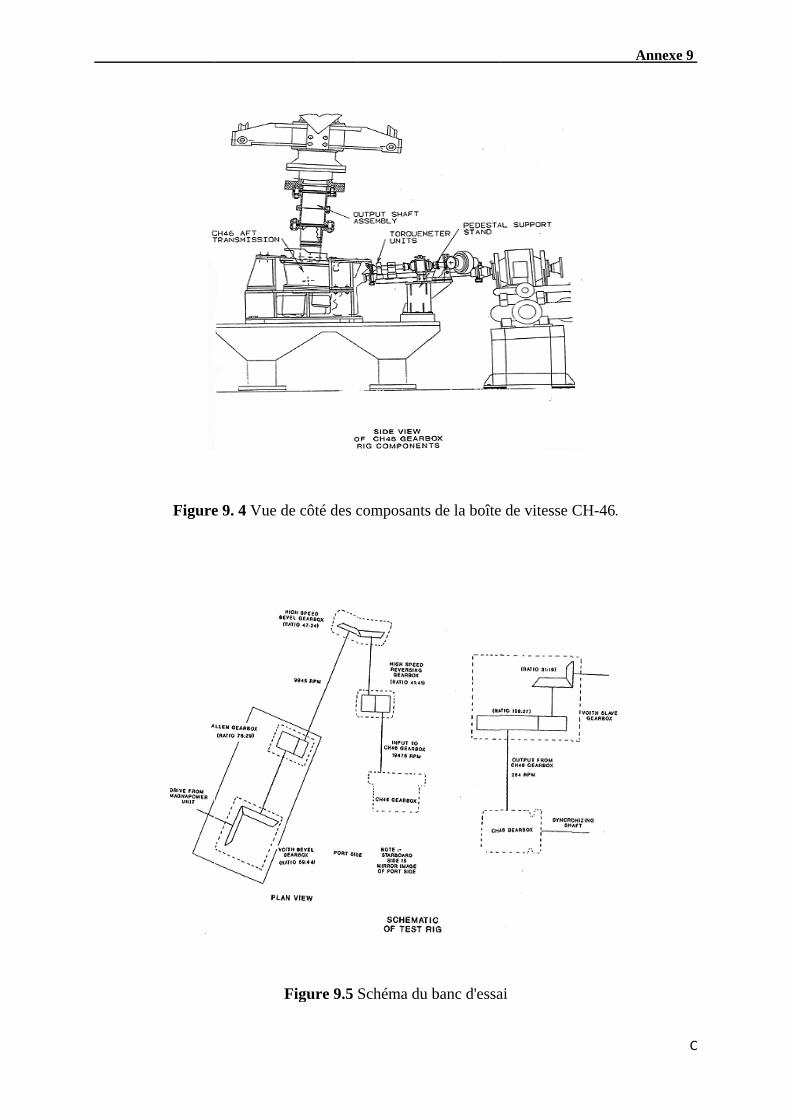
Figure
e 9. 4 Vue d
F
de côté des c
Figure 9.5
composants
Schéma du
s de la boîte
banc d'essa
e de vitesse
ai
A
CH-46.
Annexe 9
C

Annexe 10
Annexe 10
Tableau 10.1 Liste des Indicateurs calculés pour les signaux d’engrenage
1 La valeur efficace 16 Kurtosis du coefficient 3.1 2 Le facteur de crête 17 Kurtosis du coefficient 3.2 3 skewness 18 Kurtosis du coefficient 3.3 4 kurtosis 19 Kurtosis du coefficient 3.4 5 moment statistique d’ordre5 20 Kurtosis du coefficient 3.5 6 moment statistique d’ordre6 21 Kurtosis du coefficient 3.6 7 moment statistique d’ordre7 22 Kurtosis du coefficient 3.7 8 moment statistique d’ordre8 23 Énergie du coefficient 3.0 9 moment statistique d’ordre9 24 Énergie du coefficient 3.1 10 DSP dans la bande [895-1321 Hz] 25 Énergie du coefficient 3.2 11 DSP dans la bande [2004-2430 Hz] 26 Énergie du coefficient 3.3 12 DSP dans la bande [3113-3539 Hz] 27 Énergie du coefficient 3.4 13 DSP dans la bande [4222-4648Hz] 28 Énergie du coefficient 3.5 14 DSP dans la bande [895-4648Hz] 29 Énergie du coefficient 3.6 15 Kurtosis du coefficient 3.0 30 Énergie du coefficient 3.7 1à 9 : Domaine temporel, 10 à14 domaine spectrale (spectre du signal original), 15à 30 temps-échelle (Décomposition en paquets d’ondelettes DPO).

Publications

Liste des publications
Liste des publications réalisées dans le cadre de cette thèse
PUBLICATIONS 1. Ridha Ziani, Ahmed Felkaoui , Rabah Zegadi,(2014) «Bearing fault diagnosis using
multiclass support vector machines with binary particle swarm optimization and regularized Fisher’s criterion». Journal of intelligent manufacturing. DOI 10.1007/s10845-014-0987-3
PROCEEDINGS 1. Ridha Ziani, Rabah Zegadi, Ahmed Felkaoui, and Mohammed Djouada «Bearing fault
diagnosis using neural network and genetic algorithms with the trace criterion». Proceedings of the Second International Conference "Condition Monitoring of Machinery in Non-Stationnary Operations" CMMNO’2012 Springer 2012, pp 89-96.
COMMUNICATIONS INTERNATIONALES
1. Ridha Ziani, Rabah Zegadi, & Ahmed Felkaoui «Utilisation des machines à vecteurs supports et l’essaim de particules pour le diagnostic automatisé des défauts d’engrenages». ICMM14 International Conference on Mechanics and Materials 16-17 Novembre 2014, Sétif, Algéria.
2. Ridha Ziani, Rabah Zegadi, Ahmed Felkaoui «Gear fault detection using supports vector machine (SVM) & genetic algorithms: application to automated vibration diagnosis» International Conference Surveillance 6, University of Technology of Compiègne, France 25-26 October 2011
3. Ziani Ridha , Felkaoui Ahmed, Zegadi Rabah « Application de l’intelligence artificielle a
la maintenance conditionnelle des machines tournantes » International Conference on Systems and Information Processing ICSIP'09 May 2-4, 2009, Guelma, Algeria
4. Djouada Mohamed , Ziani Ridha , felkaoui Ahmed, Zegadi Rabah « Optimisation des paramètres du vecteur forme par algorithmes génétiques et le critère de trace : application au diagnostic vibratoire automatisé » International Conference on Systems and Information Processing ICSIP'09 May 2-4, 2009, Guelma, Algeria
5. Ziani Ridha, Felkaoui Ahmed, Zegadi Rabah « Performances de la classification par les Séparateurs à Vaste Marge (SVM): application au diagnostic vibratoire automatisé » 4th International Conference on Computer Integrated Manufacturing CIP’2007, 03-04 November 2007.Setif, Algeria
6. Mohamed.DJOUADA, Ridha.ZIANI, Ahmed. FELKAOUI, Rabah. ZEGADI «Diagnostic des défauts par un Couplage réseaux de neurones artificiels - algorithmes génétiques » 4th International Conference on Computer. Integrated Manufacturing CIP’2007, 03-04 November 2007.Setif, Algeria

ABSTRACT Contribution to the analysis and the automatic classification of mechanical faults.
The purpose of this thesis is the design of an automated diagnostic system of mechanical defects, such as defects of bearings and gears. Our approach is based on the use of Patterns Recognition methods. A vector of parameters (features), called pattern vector, is extracted from each of the measurements made on the machine. The decision rule is used to classify observations, described by the pattern vector, by comparing them to various known operating conditions. To have an efficient diagnostic system, it is necessary to employ a process of feature selection to improve the classification performance. In this context, we propose a new method for feature subset selection. This method is based on Binary Particle Swarm Optimization (BPSO) and Regularized Fisher’s Criterion (RFC). The developed algorithm has the following acronym BPSO-RFC. In the proposed diagnosis system, Support Vector Machines (SVMs) was chosen as the classification rule. This system was evaluated using vibration signals in different conditions of bearing and gears (healthy and with defects). The results show the effectiveness of this approach. Keywords: Condition monitoring, signal processing, Features selection, Support vector machines (SVMs) · Particle swarm optimization (PSO) · Regularized linear discriminant analysis (RLDA) , ·
:الملخص .للعيوب الميكانيكية اآلليمساهمة في التحليل و التصنيف
ويستند نهجنا على استخدام . المدحرجات والتروسعيوب لهدف من هذه الرسالة هو تصميم نظام للتشخيص اآللي للعيوب الميكانيكية، مثل ا
متجه الشكل ، يستخرج من آل القياسات التي أجريت على ، وتسمى )مؤشرات(متجه من المعلمات . )RdF( أساليب التعرف على األنماطتقوم دالة القرار المستخدمة بتصنيف المالحظات التي وصفها متجه الشكل مقارنة مع أوضاع التشغيل المختلفة مع أو بدون خلل . الجهاز. آثر أهمية لتحسين أداء التصنيفمن أجل أن يكون هناك نظام تشخيص آفء فمن الضروري توظيف عملية اختيار المؤشرات األ. معروف
ويستند هذا األسلوب على اقتران . وفي هذا السياق، فإننا نقترح طريقة جديدة الختيار مجموعة من المؤشرات ذات المستوى األمثلفي . CFR-OEPB :المطورة خوارزمية االختيار سميت. )CFR(ومعيار فيشر النظامي )OEPB(خوارزمية سرب الجسيمات الثنائي
باستخدام إشارات االهتزاز في أوضاع مختلفة تم تقييم نظام التشخيص. )SVM( يف استخدمت أجهزة المتجهات اإلعتماديةمرحلة التصن .أظهرت النتائج فعالية هذا النهج) . عيوبمع الصحية و(
الثنائي، التحليل ، سرب الجسيمات أجهزة المتجهات اإلعتمادية ، اختيار المؤشرات ، اإلشارةالصيانة الشرطية ،تحليل : آلمات مفتاحية
الخطي الفاصل
RÉSUMÉ Contribution à l’analyse et à la classification automatique des défauts mécaniques
L’objectif de cette thèse est la conception d’un système automatique de diagnostic des défauts mécaniques, tels que les défauts de roulements et d’engrenages. Notre approche est basée sur l’utilisation des méthodes de Reconnaissance de Formes (RdF).Un vecteur de paramètres (indicateurs), appelé vecteur forme, est extrait de chacune des mesures effectuées sur la machine. La règle de décision utilisée, permet de classer les observations, décrites par le vecteur forme, par rapport aux différents modes de fonctionnement connus avec ou sans défaut. Afin d’avoir un système de diagnostic performant, il est nécessaire d’employer un processus de sélection des indicateurs les plus pertinents, permettant d’améliorer les performances de la classification. Dans ce contexte, nous proposons une nouvelle méthode de sélection d’indicateurs. Cette méthode est basée sur le couplage d’un algorithme d’Optimisation par Essaim de Particules Binaire (OEPB), et le Critère de Fisher Régularisé (CFR). L’algorithme ainsi développé a pour acronyme OEPB-CFR. Dans la phase de classification, les machines à vecteurs supports (Support Vector Machines (SVM)) ont été retenues. Ce système de diagnostic a été évalué en utilisant des signaux vibratoires en différents modes de fonctionnement (sain et avec défauts). Les résultats obtenus montrent l’efficacité de cette approche.
Mots clés : Maintenance conditionnelle, traitement de signal, Machines à Vecteurs Supports (SVM), optimisation par essaim de particules, analyse discriminante linéaire, sélection des indicateurs.