la projection et la prédiction de la population indienne … · fite pour remercier tous les...
TRANSCRIPT

PROJET DE FIN D’ÉTUDE
À
La Faculté des Sciences et Techniques Guéliz
Université Caddy Ayad à Marrakech
Actuariat, Finance et Calcul Scientifique
Présenté par :
Safouane ABOUTOUFAYL
La Projection et la Prédiction de la PopulationIndienne à l’horizon 2020
Encadrants du projet : Pr. Noureddine BERRAHOU(FSTG)Mr. Karthikeyan SREENIVASAN(Zyme Solutions)
Soutenue le : 08 Septembre 2015
Devant le Jury
JURY
Pr.BERRAHOU Noureddine EncadrantPr.AIT BABRAM Mohamed Chef de la FilièrePr.DAAFI Boubker ExaminateurPr.DOUGE Lahcen Examinateur
Année universitaire : 2015/2016

REMERCIEMENTS
J’aimerais adresser mes sincères remerciements à mes encadrants de stage Mr. Karthi-keyan Sreenivasan, Mr. Sujay Telkar pour leur disponibilité, générosité, encouragementset leur soutien.
C’est avec un réel plaisir que j’ai effectué ce stage de PFE sous leur direction. Je voudraisaussi exprimer tout le plaisir que j’ai éprouvé en travaillant au sein de "Zyme Solutions".Je garde toujours en souvenir ces meilleurs moments de joie, d’aide et de partage . Je pro-fite pour remercier tous les Zymies pour l’entente et l’esprit d’entraide qu’ils ont sans cessemanifesté, et ils sont devenus au fil du temps plus que de véritables amis, des frères.
Mes sincères remerciements s’adressent aussi à mon encadrant Mr. Berrahou Noured-dine pour ses qualités humaines et professionnelles, pour son encadrement, ses directives,ses remarques constructives, et sa disponibilité.
Tous mes camarades, pour leurs encouragements continus et leurs aides précieuses. En-fin, un merci pour toute autre personne qui a contribué de près ou de loin à la réalisation dece projet.
1

DÉDICACES
Je dédie ce travail à toutes les personnes qui me tiennent à coeur et qui m’ont aidé toutle long de mon stage de PFE afin de réussir cette expérience d’expatriation professionnelleau sein de l’entreprise "Zyme Solustions".
Également aussi :
-à ma Mère et mon Père ainsi que mes frères.
-à mes chers camarades, amis ainsi que toute ma famille.
-à tout le corps enseignant de la FSTG Marrakech.
-Au Doyen de La Faculté des Sciences et Techniques Marrakech.
2

RÉSUMÉ
Les projections et prédictions démographiques aident les parties prenantes à planifierl’avenir proche et distant. En effet, si nous savons le nombre de personnes dans un pays ouune région, nous pouvons mieux évaluer le besoin au niveau des nouveaux emplois, ensei-gnants, écoles, médecins, infirmières, logements urbains, nourriture et les besoins à proposdes ressources. Par exemple, Les entreprises sont censées savoir la quantité de productionqu’il faut produire pour mieux répondre aux besoins des populations et générations futures.
Un des prestations fournies par le leader de ce qu’on appel en Anglais "Channel DataManagement" Zyme Solutions est la prédiction des ventes, de la production tout en don-nant aux clients des stratègies clés en main de planification et segmentation des ventes. Laprédiction de cette production future nécessite une projection ou prédiction précise de lapopulation.
C’est dans ce sens que nous avons adopté dans ce document des méthodes avancéesde projection et prédiction de population. Dans un premier temps nous avons fait appel àla technique de projection par groupe d’âge et sexe dite «La méthode des composantes» ;en deuxième lieu et dans le but de prévoir la population nous nous sommes basés sur lesséries chronologiques et les réseaux de neurones qui sont des outils robustes de prédiction ;Et Enfin nous avons présenté une interface dynamique de visualisation des résultats sous lelogiciel Qlick View qui donnera une vue claire des informations de projection et prédiction,et qui aidera l’utilisateur à la prise rapide de décision.
Mot clefs :La Méthode des composantes, Les séries chronologiques, Lissage exponentiel simple,
Lissage exponentiel de Holt Winters, Le Modèle ARIMA, Les réseaux de neurones.
3

ABSTRACT
The demographic projections and forecasts of population help stakeholders plan nearand far future. In fact, if we know how many people are in a country or a region we mayknow better resources needed like job opportunities, teachers, schools, doctors, nurses, hou-sing, food and many other resources. For instance, manufacturers have to know the produc-tion that is needed to be produced in order to satisfy future population.
One of the benefits the leader of "Channel Data Management" Zyme solutions providesis forcasting sales and production by giving a turn key strategies for sales planification andsegmentation. Forcasting future production needs precise population prediction.
In this regard, we have set in this document some of the advanced techniques used toproject and forecast population. First of all we have used the technique called “The com-ponent Method” that projects population per sex and age group ; secondly, based on timesseries and artificial neural networks we were able to forecast the population. Finally, wehave presented a dashboard on Qlik View software for clear data visualization, and quickdecision.
Key words :The cohort Component Method, Time series, Simple exponential smoothing, Holt Win-
ters exponential smoothing, ARIMA Model, Neural Networks.
4

TABLE DES MATIÈRES
Remerciements 1
Dédicaces 2
résumé 3
Abstract 4
Table des figures 9
Introduction 12
I La Projection démographique de la Population Indienne en 2020 14
1 Présentation Générale 151.1 Présentation de l’organisme d’accueil : . . . . . . . . . . . . . . . . . . . . . . . 15
1.1.1 Channel Data Management : . . . . . . . . . . . . . . . . . . . . . . . . 151.1.2 Quelques prestations fournies par Zyme Solutions : . . . . . . . . . . . 16
1.2 Généralités : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201.2.1 Historique : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201.2.2 Différence entre projection et prédiction : . . . . . . . . . . . . . . . . . 201.2.3 Utilité des projections et prévisions démographiques : . . . . . . . . . 20
1.3 Problèmes posés par les projections de la population : . . . . . . . . . . . . . . 211.3.1 Date de départ et durée de la projection : . . . . . . . . . . . . . . . . . 211.3.2 Analyse de la situation : . . . . . . . . . . . . . . . . . . . . . . . . . . . 211.3.3 Nombre de variantes : . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
1.4 Etapes pour faire une projection démographique : . . . . . . . . . . . . . . . . 211.5 Différentes sortes de projections : . . . . . . . . . . . . . . . . . . . . . . . . . . 221.6 Méthodes mathématiques simples des projections démographiques : . . . . . 23
1.6.1 Evolution Linéaire : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231.6.2 Evolution géométrique : . . . . . . . . . . . . . . . . . . . . . . . . . . . 241.6.3 Evolution exponentielle : . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5

TABLE DES MATIÈRES
2 Données nécessaires pour la Projection Démographique 252.1 Introduction : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.2 Population de l’année de base par âge et par sexe : . . . . . . . . . . . . . . . . 25
2.2.1 La définition d’une population : . . . . . . . . . . . . . . . . . . . . . . 252.2.2 La pyramide d’âge : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.3 La Fécondité : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.3.1 Définition : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.3.2 Les Mesures de la Fertilité : . . . . . . . . . . . . . . . . . . . . . . . . . 272.3.3 L’influcence des facteurs sociaux sur L’ISF : . . . . . . . . . . . . . . . . 30
2.4 La Mortalité : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.4.1 Taux brut de mortalité (TBM) (Crude death rate) : . . . . . . . . . . . . 302.4.2 Le Taux de mortalité infantile (TMI) (Infant Mortality Rate) : . . . . . . 312.4.3 L’esperence de vie à la naissance (Life expectancy at birth) : . . . . . . 312.4.4 Les Tables de Mortalité : . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.5 Migration internationale : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.5.1 Les Mesures de la migration : . . . . . . . . . . . . . . . . . . . . . . . . 352.5.2 L’Accroissement d’une population (Population Growth) : . . . . . . . . 36
2.6 Estimation de la croissance de la population : . . . . . . . . . . . . . . . . . . . 362.6.1 La Méthode des composantes de la croissance : . . . . . . . . . . . . . . 362.6.2 La Méthode des composantes de cohorte : . . . . . . . . . . . . . . . . 36
3 La Projection démographique par la Méthode des Composantes(Component Me-thod) 383.1 Introduction : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383.2 Principe de la Méthode des Composantes : . . . . . . . . . . . . . . . . . . . . 39
3.2.1 Le Calcul des naissances : . . . . . . . . . . . . . . . . . . . . . . . . . . 393.2.2 Le Calcul des Décès : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.2.3 La Population de l’année de base : . . . . . . . . . . . . . . . . . . . . . 40
3.3 La Projection de la Fécondité : . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.3.1 Indice synthétique de fécondité : . . . . . . . . . . . . . . . . . . . . . . 413.3.2 Distribution par groupe âge de la fécondité . . . . . . . . . . . . . . . . 42
3.4 La Projection de la Mortalité : . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.4.1 Espérance de vie à la naissance : . . . . . . . . . . . . . . . . . . . . . . 443.4.2 Quotients de Mortalité : . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.5 La Projection de La Migration Internationale : . . . . . . . . . . . . . . . . . . . 493.5.1 Le Nombre net de migrants par sexe et année : . . . . . . . . . . . . . . 493.5.2 La Distribution des migrants par âge pour chaque sexe : . . . . . . . . 50
3.6 Résultats de la projection par la méthode des composantes : . . . . . . . . . . 513.6.1 Analyse de la pyramide d’âge : . . . . . . . . . . . . . . . . . . . . . . . 52
II La Prédiction de la Population Indienne en 2020 54
4 La Théorie des Séries chronologiques 554.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.1.1 Séries chronologiques : vocabulaire . . . . . . . . . . . . . . . . . . . . 554.2 Description schématique de l’étude complète d’une série chronologique : . . 56
TABLE DES MATIÈRES 6

TABLE DES MATIÈRES
4.2.1 Correction des données : . . . . . . . . . . . . . . . . . . . . . . . . . . . 564.2.2 Observation de la série : . . . . . . . . . . . . . . . . . . . . . . . . . . . 574.2.3 Modélisation avec un nombre fini de paramètres : . . . . . . . . . . . . 574.2.4 Analyse de la série à partir de ses composantes : . . . . . . . . . . . . . 584.2.5 Diagnostic du modèle/ajustement du modèle : . . . . . . . . . . . . . . 584.2.6 Prédiction ou Prévision : . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.3 Modélisation déterministe : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 584.3.1 Le Modèle additif : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 584.3.2 le Modèle multiplicatif : . . . . . . . . . . . . . . . . . . . . . . . . . . . 594.3.3 Choix du Modèle : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.4 Analyse de la tendance : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 614.4.1 Ajustement paramétrique : . . . . . . . . . . . . . . . . . . . . . . . . . 614.4.2 Méthode des moindres carrés : . . . . . . . . . . . . . . . . . . . . . . . 614.4.3 Détermination à l’aide d’Excel d’une courbe de tendance : . . . . . . . 624.4.4 Les Moyennes mobiles : Ajustement non paramétrique ou Lissage par
moyennes ou médianes mobiles : . . . . . . . . . . . . . . . . . . . . . . 624.4.5 Estimation de la tendance par les moyennes mobiles : . . . . . . . . . . 634.4.6 Choix pratique de l’ordre d’une moyenne mobile : . . . . . . . . . . . . 64
4.5 Analyse de la saisonnalité : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.5.1 Calcul des données sans tendance : . . . . . . . . . . . . . . . . . . . . . 644.5.2 Calcul des coefficients saisonniers Sj : . . . . . . . . . . . . . . . . . . . 654.5.3 Correction des coefficients saisonniers : . . . . . . . . . . . . . . . . . . 65
4.6 Prévision des valeurs futures : . . . . . . . . . . . . . . . . . . . . . . . . . . . . 674.6.1 Analyse des résidus : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
4.7 Prévision par lissage exponentiel : (exponentiel smoothing) : . . . . . . . . . . 684.7.1 Principe des méthodes de lissage exponentiel : . . . . . . . . . . . . . . 684.7.2 Les différents lissages exponentiels : . . . . . . . . . . . . . . . . . . . . 68
4.8 Le lissage exponentiel simple : . . . . . . . . . . . . . . . . . . . . . . . . . . . . 694.9 La méthode de Holt et Winters : . . . . . . . . . . . . . . . . . . . . . . . . . . . 704.10 La Prévision par un modèle ARIMA(autoregressive integrated moving ave-
rage) : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 704.10.1 Définition : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 714.10.2 Modèle AR (Auto Régressif) : . . . . . . . . . . . . . . . . . . . . . . . . 714.10.3 Modèle MA (Moving Average : Moyenne Mobile) : . . . . . . . . . . . 724.10.4 La Méthode de Box et Jenkins : . . . . . . . . . . . . . . . . . . . . . . . 724.10.5 Validation du modèle et Prévision : . . . . . . . . . . . . . . . . . . . . 74
5 La Prédiction de la population Indienne par un lissage exponentiel et un ModèleARIMA 755.1 La prédiction par un lissage exponentiel de Holt Winters : . . . . . . . . . . . 755.2 Lecture des donnéess sous R : . . . . . . . . . . . . . . . . . . . . . . . . . . . . 755.3 Tracement du graphe de la série chronologique : . . . . . . . . . . . . . . . . . 765.4 Décomposition de la série chronologique : . . . . . . . . . . . . . . . . . . . . . 775.5 La Prévision par un Lissage exponentiel : . . . . . . . . . . . . . . . . . . . . . 79
5.5.1 Lissage exponentiel simple : . . . . . . . . . . . . . . . . . . . . . . . . . 795.5.2 Méthode de Holt : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
TABLE DES MATIÈRES 7

TABLE DES MATIÈRES
5.6 La Prédiction par un modele ARIMA(autoregressive integrated moving ave-rage) : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
5.7 Différenciation de la série chronologique de la population Indienne : . . . . . 885.8 Le choix du modèle ARIMA adéquat : . . . . . . . . . . . . . . . . . . . . . . . 915.9 La Prédiction de la population Indienne à l’horizon 2020 : . . . . . . . . . . . . 93
6 La prédiction de la population Indienne par les réseaux de Neurones 996.1 Définition et Théorie d’un réseau de neurones : . . . . . . . . . . . . . . . . . . 99
6.1.1 Définition d’un neurone : . . . . . . . . . . . . . . . . . . . . . . . . . . 996.1.2 La Théorie d’un réseau de neurones : . . . . . . . . . . . . . . . . . . . 996.1.3 La Fonction d’activation : . . . . . . . . . . . . . . . . . . . . . . . . . . 1006.1.4 Les Types de fonctions d’activation . . . . . . . . . . . . . . . . . . . . 1006.1.5 Architecture d’un réseau de neurone : . . . . . . . . . . . . . . . . . . . 1006.1.6 Réseau de neurone simple : . . . . . . . . . . . . . . . . . . . . . . . . . 1016.1.7 Perceptron Multi-couche : . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.2 La Prédiction par un réseau de neurone autorégressif : . . . . . . . . . . . . . 1026.2.1 Remarque : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
6.3 Prédiction de la population Indienne par un modèle NNAR (p, P, k) : . . . . . 103
III Présentation des Résultats sous Qlik view 108
Conclusion générale 115
Bibliographie 116
Webographie 117
Annexes 118
TABLE DES MATIÈRES 8

TABLE DES FIGURES
1.1 La procédure : Channel Data Management . . . . . . . . . . . . . . . . . . . . 161.2 La Théorie du produit "TrueData" . . . . . . . . . . . . . . . . . . . . . . . . . . 161.3 La Théorie du produit "TrueID" . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.4 ZAP Global :Un exemple de présentation des ventes régionales et mondiales
sous Qlick View . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.5 ZAP Retail :Un exemple de présentation du niveau de vente dans chaque
magasin sous Qlick View . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.6 ZAP Territory :Un exemple de présentation au niveau de chaque pays, ses
commerciaux, ses fournisseurs et ses distributeurs sous Qlick View . . . . . . 19
2.1 Pyramide d’âge, Guinée,2005 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.2 l’ASFR des différents groupes d’âge quinquennaux du Bangladesh en 2004 . 282.3 Les Taux de fécondité par âge au Bangladesh . . . . . . . . . . . . . . . . . . . 282.4 Les Taux de fécondité Urban vs Rural au Bangladesh . . . . . . . . . . . . . . 292.5 La Comparaison de l’ISF des différents pays du Monde . . . . . . . . . . . . . 302.6 Comparaison de IMR dans differents pays du Monde . . . . . . . . . . . . . . 312.7 Probabilités de décès de la table de Mortalité : Table type Ouest féminine de
Coale-Demeny comparées selon le niveau d’espérence de vie . . . . . . . . . . 332.8 Probabilité de décès de la table de Mortalité : Familles de tables types fémi-
nines de Coale-Demeny : Comparaison par famille à e(0)=45 . . . . . . . . . . 332.9 les probabilités des femmes ayant une espérance de vie à la naissance égale à
45 ans pour les cinq familles des Nations Unies . . . . . . . . . . . . . . . . . . 342.10 Les flux migratoires mondiaux . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.11 La Méthode des composantes de la croissance . . . . . . . . . . . . . . . . . . 36
3.1 La Populatione Indienne en 2014 par sexe et groupe d’âge . . . . . . . . . . . 403.2 Les hypothèses formulées de projection de l’ISF . . . . . . . . . . . . . . . . . 423.3 La Projection de l’ISF selon les hypothèses formulées . . . . . . . . . . . . . . 423.4 les distributions de la fécondité par divers ISF pour chacun des quatre modes(Afrique
subsaharienne, nations arabes et Asie) . . . . . . . . . . . . . . . . . . . . . . . 433.5 La Distribution de la fécondité par ISF : Modèle Afrique subsaharienne des
Nations Unies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.6 La Projection de l’ISF de la population Indienne en 2020 . . . . . . . . . . . . . 44
9

TABLE DES FIGURES
3.7 Le Modèle de l’évolution de l’espérence de vie de la Division des nations unies 463.8 Les hypothèses de projection de l’espérence de vie de l’Inde en 2020 . . . . . . 463.9 La Projection de l’espérence de vie selon les scénarii(Centrale, baisse, hausse) 463.10 probabilités de décès pour les 2 sexes en 2014 . . . . . . . . . . . . . . . . . . . 483.11 La Projection des probabilités de décès pour les 2 sexes en 2020 . . . . . . . . 483.12 L’hypothèse de projection du solde migratoire . . . . . . . . . . . . . . . . . . 493.13 La projection du solde migratoire en 2020 . . . . . . . . . . . . . . . . . . . . . 503.14 La Migration en Inde par sexe et âge en 2014 . . . . . . . . . . . . . . . . . . . 503.15 La Migration par sexe et âge en Inde en 2020 . . . . . . . . . . . . . . . . . . . 513.16 Le résultat de la projection de la population Indienne en 2020 par la méthode
des composantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 513.17 La Pyramide d’âge en 2014 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523.18 La Pyramide d’âge en 2020 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.1 Exemple d’une série chronologique avec tendance et saisonnalité . . . . . . . 564.2 Le Modèle additif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 594.3 Le Modèle Multiplicatif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 604.4 Ajustement de la tendance par la méthode de Mayer . . . . . . . . . . . . . . . 614.5 Calcul de moyennes mobiles d’ordre 3 sur une série annuelle . . . . . . . . . . 634.6 Décomposition avec un modèle additif et un ajustement de la tendance(moindres
carrés ou méthode de Mayer) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 674.7 Les différents lissage exponentiels . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.1 Exemple de décomposition d’une série chronologique avec saisonnalité . . . 79
6.1 Un Réseau de neurone simple . . . . . . . . . . . . . . . . . . . . . . . . . . . 1016.2 Un Perceptron Multi couche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1026.3 Page de garde de l’application Qlick View . . . . . . . . . . . . . . . . . . . . 1096.4 Guide d’utilisation de l’application Qlick View . . . . . . . . . . . . . . . . . . 1106.5 Affichage dynamique des résultats de la projection par la méthode de com-
posantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1106.6 Affichage dynamique des résultats de la projection par la méthode de com-
posantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1116.7 L’affcihage dynamique des résultats de prédiction par la méthode de Holt
Winters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1116.8 La communication entre le logiciel R et Qlick View via DCOM . . . . . . . . . 1126.9 Autres résultats de la prédiction par la méthode de Holts Winters sont affichés 1126.10 L’affcihage dynamique des résultats de prédiction par la modèle ARIMA . . . 1136.11 La courbe de prédiction de la population Indienne en 2020 utilisant le modèle
ARIMA(0,1,1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1136.12 L’affcihage dynamique des résultats de prédiction utilisant les Réseaux de
neurones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1146.13 Glossaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1146.14 Exemple de calcul du nombre de femmes en 2017 par la méthode des Com-
posantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1186.15 Exemple de calcul du nombre d’hommes en 2017 par la méthode des Com-
posantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
TABLE DES FIGURES 10

TABLE DES FIGURES
6.16 La projection des taux de Mortalité(hommes)par interpolation linéaire . . . . 1196.17 Exemple du Code VB(Visual Basic) qui permet la communication entre le R
et le Qlick View . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
TABLE DES FIGURES 11

INTRODUCTION
L’augmentation et les variations de la population mondiale, notamment depuis la ré-volution industrielle, ont eu des conséquences importantes voire majeures sur l’évolutiondes sociétés, des économies et des nations dans le monde. L’Inde en particulier, qui compte1,26 milliard d’habitants en 2014, est le deuxième pays le plus peuplé au monde après laChine. L’Inde compte déjà 17,5 % de la population mondiale et devrait devenir le pays leplus peuplé au monde vers 2025 1. L’état Indien, les entreprises et d’autres parties prenantess’intéressent à la projection et la prédiction de la population Indienne future pour mieuxrépondre aux besoins des ses générations futures.
L’objectif principal du présent rapport est de projeter et prévoir la population Indienneen 2020. Afin de mener à bien ce travail nous avons choisi de répartir notre projet en 3parties. La première partie composée de 3 chapitres, sera consacrée à la projection démo-graphique de la population Indienne en 2020 utilisant "La méthode des composantes" diteen Anglais « The Cohort component Method» qui permet de projeter la population partranche d’âge et sexe. Un chapitre préliminaire, assez bref, décrit l’organisme accueillant «Zyme Solutions », ses responsabilités, ses branches et prestations ainsi que des générali-tés sur l’historique, l’utilité, avantages et problèmes posés par les projections et prédictiondémographiques. Le but du deuxième chapitre est d’avoir une idée générale sur les don-nées nécessaires pour les projections démographiques. Le dernier chapitre sera consacré àla théorie de la méthode des composantes avec son application à la population Indienne.
La deuxième partie quant à elle aura pour objectif la prédiction de la population In-dienne en 2020. Elle contient 3 chapitres expliquant en détaille la procédure de prédictionpar différentes méthodes. Le premier chapitre traitera la théorie des séries chronologiquesdans la prédiction démographique. Le deuxième focalisera sur l’application des modèlesde lissage exponentiel comme le lissage exponentiel simple, Holt et HoltWinters dans laprédiction de la population Indienne ; le chapitre exposera aussi l’application du modèleARIMA (autoregressive integrated moving average) dans le but de prévoir la populationIndienne à l’horizon 2020. Le dernier chapitre quant à lui, fera appel aux réseaux de neu-rones qui est une nouvelle technique d’intelligence artificielle permettant la prédiction de lapopulation. Nous allons voir dans ce chapitre la théorie des réseaux de neurones, les types,
1. US Census Bureau, Demographic Internet Staff, " United States Census Bureau - International Data Base(IDB) "
12

TABLE DES FIGURES
l’architecture et l’application de celles-ci à la population Indienne sous le logiciel R. La der-nière partie sera consacrée aux présentations des résultats de projection et de prédiction dela population Indienne en 2020 sous le logiciel Qlick View. Une platorme dynamique re-groupant d’une manière très claire et simple les résultats de la projection et la prédictiondans le but de donner à l’utilisateur l’accès rapide à l’information souhaitée dans un lapsdu temps.
TABLE DES FIGURES 13

Première partie
La Projection démographique de laPopulation Indienne en 2020
14

CHAPITRE 1
PRÉSENTATION GÉNÉRALE
1.1 Présentation de l’organisme d’accueil :
Zyme Solutions est une entreprise qui fournit des solutions intelligentes dans la gestiondes bases de données des différentes entreprises qui pratiquent dans le domaine de la tech-nologie à travers le monde à savoir (DELL, Motorola, Xerox, Logitex...), fondée en 2004, sonsiège sociale est à Redwood shores, Californie, USA. Elle dispose d’un centre d’opérationsà Bangalore en Inde et un bureau au Royaume-Uni.
L’entreprise propose des applications basées sur le cloud Saas(Software as a Service) quiintègrent les systèmes CRM (Customer Relenshenship Management) et ERP (Entreprise Re-source planning) ; et prend en charge la gestion de la chaine de données des clients : Lagestion des ventes, des données des encouragements, les distributeurs, les fournisseurs etrevendeurs, y compris la reconnaissance des revenus, primes de rendement, la gestion duréseau des partenaires, la mise en service des ventes, la planification de la chaîne d’approvi-sionnement, la prédiction, la planification et la segmentation des ventes et de la production.
1.1.1 Channel Data Management :
Le processus par lequel un producteur ou un fournisseur dirige l’activité de marketing,ventes, achats et stock en impliquant et en motivant les parties qui figurent dans sa chainede distribution.
En se basant sur le CDM, Zyme solutions permet aux entreprises de :
– Accélérer les ventes de 5% ou plus par an en identifiant de nouvelles opportunités devente chaque semaine.
– Obtenir des informations précieuses sur la chaine de vente, des partenaires et desincitations, y compris la capacité d’identifier les incitations surpayés jusqu’à 10-15%du chiffre d’affaires.
– Prendre des décisions adéquates avec précision tout en minimisant le temps d’accès àl’information.
15

CHAPITRE 1. PRÉSENTATION GÉNÉRALE
FIGURE 1.1 – La procédure : Channel Data Management
1.1.2 Quelques prestations fournies par Zyme Solutions :
True Data : Channel data that drives decisions that drive dollars to your bottom line :La plupart des entreprises qui exercent dans les industries technologiques vendent leurs
produits par voies indirectes au dernier consommateur via les partenaires (fournisseurs,distributeurs,...), ces données de ventes ainsi que celles du stock sont collectées depuis cespartenaires pour des raisons d’utilisation future. La collecte de ces données est très impor-tante, elle permet à l’entreprise mère d’avoir une traçabilité de toutes informations de vente,et d’en prendre des décisions futures. La difficulté réside dans la crédibilité de ces informa-tions et d’en assurer la qualité.
TrueData offre, aux entreprises technologiques l’information dont ils ont besoin pourprendre des décisions critiques y compris : l’exécution des ventes, la planification de lachaîne d’approvisionnement, la constatation des produits, les incitations, la gestion des par-tenaires, de la maintenance et le service de gestion des contrats.
FIGURE 1.2 – La Théorie du produit "TrueData"
1.1.1 Présentation de l’organisme d’accueil : 16

CHAPITRE 1. PRÉSENTATION GÉNÉRALE
La Théorie du produit "TrueData" est la suivante :
– The Zyme Gateway, alimenté par Informatica 1 accepte les flux de données des par-tenaires de tout format, les transforme et puis les normalise.
– The Zyme Validation est le moteur d’enrichissement, qui valide les données des par-tenaires l’actualise, l’analyse et les compare avec les données de base fournies par levendeur, puis l’enrichit avec des données supplémentaires utiles.
– Zyme Reports, un rapport complet sur toutes les ventes, le stock et d’autres informa-tions est fourni à la société mère.
La procédure de traitement, d’analyse ainsi que la réalisation des rapports est faite enutilisant l’Excel et le logiciel Qlik View.
True Id : Match partners and end-customers on POS (point of Sale) 2 transactions toyour master accounts :
Les entreprises trouvent souvent des problèmes d’identification des différents noms despartenaires ainsi que les clients. Les détails des transactions conclus (Le nom du Client, Lenom du partenaire, Le nom du distributeur...) peuvent être différents des noms qui existentdans les bases de données de la société mère.
Zyme-True ID est une solution innovante qui traite ce problème d’identification despartenaires et du client final. La solution fournit avec plus de 98% de précision les donnéesde transaction avec des noms universellement acceptés, adresses, secteurs de l’industrie etd’autres informations utiles.
FIGURE 1.3 – La Théorie du produit "TrueID"
Upload Channel sales transactions : Cette étape permet de télécharger ou récupérer lestransactions de vente réalisées sur la base de toute la chaine des partenaires, distributeurs
1. Informatica Corporation est un fournisseur indépendant de solutions d’intégration de données2. point de vente (POS) est le moment et le lieu où une transaction de vente est terminée
1.1.1 Présentation de l’organisme d’accueil : 17

CHAPITRE 1. PRÉSENTATION GÉNÉRALE
jusqu’au client final. Ces informations sont transmises sur une base quotidienne, hebdoma-daire ou mensuelle, pour avoir un suivi d’activité des transactions.
Load Partner/ end-Customer master : TrueID télécharge le nom du partenaire pour levalider avec le nom donnée au début par la société mère. Plusieurs clients utilisent TrueIDpour améliorer la qualité de leurs partenaire ou consommateurs finaux.
Identify Partners/ end-Customers : TrueID nettoie et normalise le “Vendu à" nom dupartenaire dans la transaction, et l’enrichit avec des informations manquantes (par exemplel’adresse de la rue, Code Postale...)
Name matching : Un algorithme automatisé correspond à la transaction, permet, de fairele maching de la transaction appropriée c’est-à-dire l’identification du partenaire ou clientfinal.
ZAP Dashboards :Connect decision-makers with the power of channel data :Pour les entreprises l’information sur les ventes et les données du Stock sont extrême-
ment importante car elle permet de gérer significativement le stock ainsi que faire une bonnesegmentation des ventes. Très souvent, ces entreprises ne disposent pas des processus et desoutils pour agréger ces informations de grandes volumes et de les analyser géographique-ment dans un laps du temps.
ZAP Dashboards permettent de résoudre ce problème de temps, avec une flexibilitéd’analyse des données, tout en se basant sur trois solutions particulièrement :
1-ZAP Global :
Conçu pour la gestion et la présentation rapide des ventes régionales et mondiales, ilfournit une vue centrale et unifiée de l’ensemble de la chaine de vente.
FIGURE 1.4 – ZAP Global :Un exemple de présentation des ventes régionales et mondialessous Qlick View
1.1.1 Présentation de l’organisme d’accueil : 18

CHAPITRE 1. PRÉSENTATION GÉNÉRALE
2-ZAP Retail :Pour les retailers, il permet de voir en détaille le niveau de vente dans chaque magasinet ainsi d’avoir une visibilité permettant aux entreprises de contrôler la disponibilité desproduits et de trouver leurs meilleurs partenaires ou endroits idéaux de promotions.
FIGURE 1.5 – ZAP Retail :Un exemple de présentation du niveau de vente dans chaquemagasin sous Qlick View
3-ZAP Territory : Conçu pour les pays, il offre des pistes de réflexion afin de mieux gérerles commerciaux, les fournisseurs et les distributeurs 3...
FIGURE 1.6 – ZAP Territory :Un exemple de présentation au niveau de chaque pays, sescommerciaux, ses fournisseurs et ses distributeurs sous Qlick View
3. http ://www.zyme.com/
1.1.1 Présentation de l’organisme d’accueil : 19

CHAPITRE 1. PRÉSENTATION GÉNÉRALE
1.2 Généralités :
1.2.1 Historique :
Dès le 18ème siècle, les personnes de la recherche sur les populations ont essayé de trou-ver des lois démographiques par analogie avec celles de la physique ou de l’astronomiepour prévoir la population totale d’un pays en partant de l’hypothèse qu’elle suit une loimathématique simple de croissance continue et dans laquelle la notion de la fécondité, lamortalité ou la structure par âge ne sont pas prises en compte(les hypothèses étaient sou-vent faites sur la vitesse de doublement de la population).
Farr en 1873 et Cannan en 1895 avaient utilisé une méthode tenant compte de la structurepar âge de la population, développée par Whelpton en 1928 pour les projections des Etats-Unis. Cette méthode, dite "méthode des composants", est maintenant utilisée par toutes lesprojections démographiques donnant la population par sexe et âge.
1.2.2 Différence entre projection et prédiction :
Une projection de population se définit comme une calculation du nombre de personnesqui seront encore vivante à tel moment dans l’avenir. Elle est fondée sur la formulation deshypothèses sur les naissances, décès et migrations. Les projections de population concernenttoujours un futur “conditionnel” puisque nous ne pouvons jamais être certains sur les hy-pothèses que nous utilisons dans la projection. Par contre la prédiction permet de faire lecalcul du nombre de personnes dans l’avenir sans avoir à formuler des hypothèses sur lafécondité, la mortalité ou la migration.
1.2.3 Utilité des projections et prévisions démographiques :
Les projections démographiques sont utiles pour plusieurs raisons :
– Elles aident les parties prenantes à planifier l’avenir, proche et distant. En effet, si noussavons le nombre de personnes dans un pays ou une région, nous pouvons mieuxévaluer le besoin pour nouveaux emplois, enseignants, écoles, médecins, infirmières,logements urbains, nourriture et les besoins à propos des ressources.
– La projection démographique permet aux gouvernements et le personnel de santé desavoir combien d’enfants seront en vie dans l’avenir pour pouvoir planifier un futurprogramme de vaccinations.
– Les projections de population nous aident à estimer la future taille de la population.Les projections sont également importantes pour sensibiliser les décideurs à telle outelle question. Par exemple, une projection de population peut aider à illustrer l’impor-tance des projets de logements sociaux pour répondre aux besoins d’une populationtoujours plus nombreuse.
1.1.2 Généralités : 20

CHAPITRE 1. PRÉSENTATION GÉNÉRALE
1.3 Problèmes posés par les projections de la population :
1.3.1 Date de départ et durée de la projection :
La date de départ de la projection dépend des données disponibles et correspond habi-tuellement à celle du dernier recensement réalisé dans le pays. La durée de la période deprojection est en fonction de l’utilisation désirée. Il est en effet inutile de projeter la popula-tion totale par sexe et par âge pendant vingt ans si l’on s’intéresse par exemple au nombred’écoles maternelles à créer dans les cinq années à venir. I1 est évident que plus la périodeest courte et plus la projection à des chances d’être proche de la réalité.
1.3.2 Analyse de la situation :
Il faut s’assurer de la qualité des données de base nécessaires pour la projection démo-graphique (population par sexe et âge, mortalité, fécondité, migrations, etc ...). En effet, sicelles-ci sont déficientes, une méthode de calcul, qu’elle soit, même très sophistiquée, nepourra donner que de médiocres résultats. I1 est nécessaire d’effectuer ensuite une analysetrès poussée de la situation présente et passée pour essayer de déterminer les tendances ,et 1’évolution future, ça peut également aider dans le choix des hypothèses car il existe unecertaine inertie démographique.
1.3.3 Nombre de variantes :
En général une projection nécessite au moins deux ou trois variantes relatives à desévolutions différentes des caractéristiques démographiques (Fécondité, Mortalité et Migra-tion...). Dans la pratique, il apparaît que la variante moyenne est celle qui semble la plusprobable, tandis que les variantes haute et basse représenteraient les extrêmes possiblespour la population projetée.
1.4 Etapes pour faire une projection démographique :
Les étapes nécessaires pour faire une projection démographique sont :
1-Choisir la zone géographique :
En Général, les projections démographiques sont réalisées au niveau national. Cepen-dant, elles peuvent également être faites pour d’autres zones géographiques telles que leszones urbaines, les capitales, les provinces, les districts...
2-Déterminer l’année de base et l’horizon de projection :
L’année de base de la projection est souvent choisie en fonction de la disponibilité desdonnées. En général, l’année du recensement le plus récent ou d’une enquête à grandeéchelle peur être prise comme année de base.
L’horizon de la projection est déterminé souvent en fonction du but de l’utilisation dela projection. Par exemple, les projections utilisées des décisions politiques utilisent sou-vent un horizon plus lointain (10-30 ans) alors que pour les activités de planification se
1.1.3 Problèmes posés par les projections de la population : 21

CHAPITRE 1. PRÉSENTATION GÉNÉRALE
concentrent généralement sur des projections à court terme (cinq ans).
3-Collecter des données :
Pour faire la projection démographique, Il faut collecter des données de l’année de basede la population par âge et par sexe, l’ISF(indice synthétique de fécondité) et l’espérance devie à la naissance. La disponibilité des données fiables et adéquates doivent être collectéessoigneusement pour s’assurer de la qualité des projections.
4-Formuler des hypothèses :
Les projections démographiques nécessitent des hypothèses sur les niveaux futurs del’indice synthétique de fécondité (ISF), de l’espérance de vie à la naissance et des migrationsinternationales ainsi que la formulation des hypothèses concernant les tables types de fé-condité et de mortalité les plus appropriées.
Les hypothèses devraient être choisies avec précaution et basées sur des directives desélection raisonnables.
5-Saisir les données :
Une fois les données de l’année de base collectées et les décisions prises sur les hypo-thèses de projection, les données sont saisies dans un programme ou une application quipermet de faire la projection démographique.
6-Examiner les projections :
Après avoir réalisée la projection, il est nécessaire d’examiner les différents indicateursdémographiques produits ainsi que la distribution par âge et par sexe de la population pro-jetée.
7-Réaliser d’autres projections :
Une fois la projection de base réalisée, l’essaie d’autres projections démographiques estnécessaires en modifiant une ou plusieurs des hypothèses de la projection pour l’année debase pour enfin voir clairement l’influence des hypothèses sur l’évolution de la population.
1.5 Différentes sortes de projections :
Généralement, les projections démographiques sont faites sans ou avec la projection dela migration. On trouve aussi :
1-Les projections par sexe et par âge.
2-Les projections globales établies uniquement à l’aide du taux d’accroissement s’appli-quant à l’effectif total de la population.
1.1.5 Différentes sortes de projections : 22

CHAPITRE 1. PRÉSENTATION GÉNÉRALE
3-Les projections de la population urbaine et rurale.
4-Les projections dérivées, déduites de la projection par sexe et âge et qui sont les pro-jections d’effectifs scolaires, de population active (globale ou par branche) et les projectionsde ménages.
Il y a aussi les projections basées sur les hypothèses formulées sur la fécondité et la mor-talité. Souvent quatre cas se présentent selon que l’on associe une fécondité constante ouvariable à une mortalité constante ou variable.
Finalement, la projection démographique peut se faire par année d’âge ou par grouped’âges quinquennaux (5 ans) (dans ce dernier cas, les données annuelles sont estimées parinterpolation).
1.6 Méthodes mathématiques simples des projections démogra-phiques :
Les méthodes mathématiques appelées aussi projections globales consistent à appliquerà l’effectif déterminé à une date plus ou moins récente, un taux d’accroissement hypothé-tique variant en fonction du temps. Il est important de noter que cette projection est faitesur l’effectif total de la population et non sur des groupes de population. On peut estimer letaux d’accroissement sous l’hypothèse d’évolution linéaire, géométrique ou exponentielle.
1.6.1 Evolution Linéaire :
Posons :Pi, l’effectif de la population au 1/1/i.
Pf , l’effectif de la population au 1/1/f.r , le taux d’accroissement moyen annuel
r =Pf − Pi
(f − i) ∗ (Pf−Pi)2
Exemple : Soit un pays où la population s’élevait à 9875 individus au 1/1/1985 et 10863au 1/1/1990.
Le taux calculé correspondra au taux annuel moyen sur l’ensemble de la période, au-trement dit le taux annuel moyen qui, se répétant durant les cinq années de l’observation(1990-1985), donnerait la population finale observée.
Application à l’exemple :
r =10863− 9875
(1990− 1985) ∗ (10863−9875))2
= 0, 0196 = 1, 9%
1.1.6 Méthodes mathématiques simples des projections démographiques : 23

CHAPITRE 1. PRÉSENTATION GÉNÉRALE
1.6.2 Evolution géométrique :
La formule générale du calcul du taux s’établit comme suit :
Pf = Pi ∗ (1 + r)f−i
Soit,
r = (f−i)
√PfPi− 1
Application à l’exemple :
r =(1990−1985)
√10863
9875− 1 = 0, 019254
1.6.3 Evolution exponentielle :
La formule générale du calcul du taux s’établit comme suit :
Pf = Pi ∗ er∗(f−i)
Soit,
r =ln
Pf
Pi
(f − i)Application à l’exemple :
r =ln 10863
9875
5= 0, 01907
Remarque :
Ces méthodes mathématiques présentent des formules faciles à appliquer et donnentdes résultats rapides, toutefois ces formules ne tiennent pas compte des facteurs particulierspouvant influencer l’évolution pendant une période donnée, d’autant plus qu’ils ne peuventpas non plus utiliser lorsque les informations disponibles ou l’expérience acquise montrentque des changements sur le plan économique, politique et social sont possibles. [1]
1.1.6 Méthodes mathématiques simples des projections démographiques : 24

CHAPITRE 2
DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
2.1 Introduction :
Dans ce chapitre nous allons présenter les différents concepts fondamentaux liés auxprojections démographiques à savoir la fécondité, la mortalité et la migration. Nous al-lons traiter les données nécessaires pour faire une projection démographique par sexe etâge dont :
1. Population de l’année de base par âge et par sexe.
2. Fécondité.
3. Mortalité.
4. Migration internationale.
2.2 Population de l’année de base par âge et par sexe :
2.2.1 La définition d’une population :
Une population est le nombre total d’hommes, de femmes, de garçons et de filles d’âgesdifférentes, vivant dans un emplacement défini par exemple, une ville, un district, une ré-gion ou un pays) à tel ou tel moment. En général nous pouvons voir la structure de cettepopulation avec l’aide de ce qu’on appelle la pyramide d’âge.
Toutes les projections démographiques doivent débuter quelque part. Le point de départest la population par âge et par sexe de l’année de base. Pour les hommes et les femmes, lapopulation est divisée en groupes d’âge quinquennaux allant de 0-4 à 75-79. Il existe éga-lement un groupe d’âge final pour les personnes âgées de 80 ans et plus. Ces données sontgénéralement disponible dans :
1. le recensement national qui sera la meilleure source.
2. La Division de la Population des Nations Unies publie une quantité considérable dedonnées démographiques.
25

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
3. l’Annuaire démographique qui contient les données des recensements les plus récentspour la plupart des pays.
4. Le World Population Prospects 1.
5. Le Bureau américain du recensement publie également un ensemble de projectionsdémographiques pour les pays du monde appelé World Population Profile.
Il est important de noter que ces sources peuvent être utilisées quand aucune donnée durecensement fiable n’est disponible.
2.2.2 La pyramide d’âge :
Une pyramide des âges est essentiellement deux graphiques à barres : un qui montre lenombre d’hommes et un qui montre le nombre de femmes dans des groupes d’âges quin-quennaux. En pratique, les hommes sont montrés à gauche et les femmes à droite, et ilspeuvent être mesurés en termes de chiffres bruts ou comme pourcentage de la populationtotale. Elle permet de donner une idée claire sur la structure d’âge ainsi que l’ampleur de lacroissance de la population. Par exemple, Une base qui est large indique un nombre élevéd’enfants c’est-à-dire un taux de natalité élevé mais le rétrécissement rapide vers le hautnous montre que de moins en moins de gens restent en vie au fur et à mesure qu’on avancedans l’âge c’est-à-dire que l’espérance de vie augmente.
Exemple :
FIGURE 2.1 – Pyramide d’âge, Guinée,2005
Dans une projection démographique le changement des hypothèses de la fécondité et lamortalité influencent le changement de la structure de la pyramide d’âge.
1. publié tous les deux ans et qui contient des estimations et projections démographiques pour la plupartdes pays du monde
2.2.2 Population de l’année de base par âge et par sexe : 26

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
2.3 La Fécondité :
2.3.1 Définition :
La fécondité concerne le nombre d’enfants qu’ont les femmes. La fécondité concerneégalement les hommes mais pour les démographes, il est bien plus difficile de mesurer lafécondité chez les hommes et c’est la raison pour laquelle qu’on mesure généralement lafécondité par rapport aux femmes.
Il existe plusieurs mesures différentes de la fécondité. Les données utilisées pour mesu-rer la fécondité et d’autres processus démographiques proviennent de diverses source :
1. Enquêtes nationales sur la fécondité, Enquêtes démographiques et de santé.
2. Enquêtes sur la santé reproductive des Centers for Disease Control and Prevention(CDC).
3. Fiche de données démographiques du Population Reference Bureau et Indicateurs dudéveloppement dans le monde de la Banque Mondiale.
Tout au long de sa vie, une femme peut avoir entre 13 et 17 enfants, en l’absence d’autresfacteurs. Le nombre d’enfants qu’aura une femme dépendra non seulement de sa fertilitémais également de facteurs sociaux qui influencent le début de la procréation. Par exemple,les familles dans les sociétés agricoles ont souvent un plus grand nombre d’enfants que lesfamilles dans les zones industrialisés.
2.3.2 Les Mesures de la Fertilité :
Le Taux brut de natalité (Crude Birth rate) :
Le taux brut de natalité est le nombre de naissances vivantes pour 1000 personnes lorsd’une année donnée. Cette mesure nous indique le nombre d’enfants qui naîtront au seind’une population donnée lors d’une année donnée.
CBR = (Births− in− a− yearMid− year − population
) ∗ 1000
Elle ne nous indique pas combien d’enfants une femme pourrait avoir en général.
Le Taux de fécondité par âge (Age-Specific fertility rate) :
Le TFA est le nombre de naissances enregistrées par an pour 1000 femmes d’un âge spé-cifié. Généralement donné en groupes d’âges quinquennaux.
Il est calculé en divisant le nombre d’enfants nés dans un groupe d’âge donné des mèrespar le nombre total de femmes dans ce groupe d’âge et multiplié par 1000.
Le TFA est plus précis que d’autres mesures mais il demande également plus de don-nées. En effet, cette mesure repose sur les naissances par âge de la mère et la distribution dela population par âge et sexe.
2.2.3 La Fécondité : 27

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
Exemple :
L’exemple ci-dessous nous montre l’ASFR des différents groupes d’âge quinquennauxdu Bangladesh en 2004. A titre d’exemple le plus grand nombre de naissances est dans legroupe d’âge 20 à 24 ans avec 192 naissances, ce qui est tout à fait logique car c’est le grouped’âge où un plus grand nombre de femmes sont mariées.
FIGURE 2.2 – l’ASFR des différents groupes d’âge quinquennaux du Bangladesh en 2004
Remarque : La convention internationale consiste à définir les âges de procréation oul’âge fécond dans la fourchette des 15 à 49 ans.
FIGURE 2.3 – Les Taux de fécondité par âge au Bangladesh
Il est important de noter que ces taux de fécondité par âge varient d’un endroit à l’autredans le pays. En général, on constate une grande divergence entre les zones urbaines et ru-rales.
2.2.3 La Fécondité : 28

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
Exemple :
FIGURE 2.4 – Les Taux de fécondité Urban vs Rural au Bangladesh
La ligne jaune représente la population rurale et la ligne orange représente la populationurbaine.
Indice synthétique de fécondité (ISF) (Total Fertility Rate) :
L’ISF est le nombre de naissances vivantes qu’une femme aurait si elle vivait jusqu’àl’âge de 50 ans et compte tenu les conditions de fécondité par âge du moment. Il s’agitd’une mesure synthétique qui exprime le niveau de fécondité actuel en termes de nombremoyen de naissances vivantes par femme que l’on observerait si les taux de fécondité parâge actuels restaient constants et si toutes les femmes vivaient jusqu’à l’âge de 50 ans.
L’ISF est calculé comme la somme des TFA pour tous les âges, multipliée par 5 et ensuitedivisée par 1000.
La raison pour laquelle on multiplie par 5 car une femme passera 5 ans de sa vie danschaque groupe d’âge quinquennal. On divise en suite par 1000 si les taux de féconditéétaient pour 1000 femmes. Tout ça pour exprimer l’ISF par femme prise individuellement.
Exemple :
Reprenons l’exemple du Bangladesh et calculons l’ISF à partir du taux de la féconditépar âge :
(135 + 192 + 135 + 83 + 41 + 16 + 3) ∗ 51000
= 3
L’ISF pour le Bangladesh est égale à : 3
2.2.3 La Fécondité : 29

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
2.3.3 L’influcence des facteurs sociaux sur L’ISF :
Le tableau ci-dessous nous montre que les facterus sociaux influencent l’ISF :
FIGURE 2.5 – La Comparaison de l’ISF des différents pays du Monde
La Nigerie, Ghinee et le Bangladesh ont une tendance plus agricole ce qui influence l’ISFdu pays, ce qui n’est pas le cas pour les autres pays comme les USA, UK et la Colombie.
Le sex-ratio à la naissance :
Le sex-ratio à la naissance est une autre mesure liée aux naissances. Il est mesuré commele nombre de naissances de sexe masculin pour chaque 100 naissances de sexe féminin.
Dans la plupart des pays, il se situe dans la fourchette des 103–105 : c’est-à-dire que pour100 naissances de filles, on aura entre 103 et 105 naissances de garçons.
2.4 La Mortalité :
A présent, après avoir expliqué les différentes mesures de la Fécondité. Nous allonspasser à la deuxième composante nécessaire pour la projection démographique qui est laMortalité.
Il existe plusieurs manières de parler des décès qui surviennent au sein d’une popula-tion.
2.4.1 Taux brut de mortalité (TBM) (Crude death rate) :
Le Taux brut de mortalité (TBM) pour 1000 personnes est défini comme le nombre depersonnes qui meurt lors d’une année donnée divisé par le nombre de personnes dans lapopulation au milieu de cette même année, multiplié par 1 000.
CDR = (Numberofdeaths
Mid− year − population) ∗ 1000
2.2.4 La Mortalité : 30

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
2.4.2 Le Taux de mortalité infantile (TMI) (Infant Mortality Rate) :
Il est jugé l’une des mesures les plus sensibles de la santé d’une nation.
C’est le nombre de décès chez les enfants de moins d’un an divise par le nombre de nais-sances vivantes lors d’une année particulière, multiplié par 1 000.
IMR = (Number − of − deaths− to− children < 1− yr.old
number − of − live− births) ∗ 1000
Dans les pays moins développés, la probabilité de mourir est plus élevée lors de la pre-mière année d’enfance et continue d’être élevée lors des deux ou trois premières annéesde l’enfance. Les maladies infectieuses, transmissibles et autres maladies liées au manqued’hygiène et à la malnutrition sont des indicateurs d’un taux de mortalité infantile élevé.
L’exemple ci-dessous nous montre que lorsque les pays se développent économique-ment, les taux de mortalité infantile généralement baissent.
FIGURE 2.6 – Comparaison de IMR dans differents pays du Monde
Le Taux de mortalité des moins de cinq ans (Under five Mortality rate) :
Est le nombre de décès chez des enfants de moins de 5 ans pour 1000 naissances vivantespendant la même année.
2.4.3 L’esperence de vie à la naissance (Life expectancy at birth) :
L’espérance de vie à la naissance est le nombre moyen d’années pendant lesquelles onpeut espérer que vivre une nouvelle cohorte de nourrissons en fonction de la situation ac-tuelle de la mortalité.
2.2.4 La Mortalité : 31

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
On peut calculer l’espérance de vie à partir :
– Généralement d’enquête ou de recensement à grande échelle.– Les rapports nationaux préparés en analysant ces enquêtes représentent la meilleure
source d’information sur l’espérance de vie.– Si les estimations nationales ne sont pas disponibles, les estimations sur l’espérance
de vie peuvent être obtenues de différentes sources dont World Population Prospectsou l’Annuaire démographique des Nations Unies, le World Population Profile du Bu-reau américain du recensement, Tableau de données sur la population mondiale duPopulation Reference Bureau. 2.
2.4.4 Les Tables de Mortalité :
L’espérance de vie à la naissance est une donnée de mortalité nécessaire pour indiquerla mortalité générale au sein d’une population mais on a besoin aussi des probabilités demortalité d’un groupe d’âge au prochain groupe d’âge quinquennal pour qu’on puisse réa-liser une projection démographique.
Une table de mortalité nous montre ce qui arriverait à une nouvelle cohorte de nais-sances si les taux de mortalité par âge sur une période donnée restaient constants et s’appli-quaient à la vie entière.
Vu qu’un grand nombre de pays ne possèdent pas de données exactes sur la mortalitépar groupe d’âge, plusieurs pays utilisent des tables types de Mortalité 3.
Tables types de mortalité :
Deux séries de tables types de mortalité sont généralement utilisées :
1. Les tables du modèle de Coale-Demeny (Coale, Demeny et Vaughan, 1983).
2. Les tables des Nations Unies pour les pays en développement depuis la seconde moi-tié du 20e siècle (Nations Unies, 1982).
La différence entre ces deux modèles est l’algorithme qu’ils utilisent pour générer lesschémas de mortalité et aussi les séries de données empiriques à partir desquelles ils sonttirées.
Les tables de Coale-Demeny sont définies comme : Nord, Est, Sud et l’Ouest. Par contre,les tables des Nations Unies désignent des régions très spécifiques : Amérique latine, Amé-rique du Sud, Chili, Asie du Sud, Asie de l’Est, plus Général (générique).
2. voir aussi les Indicateurs du développement dans le monde de la Banque mondiale3. La Division de la Population des Nations unies a publié en 1982 une série de tables types de mortalité
pour tous les pays
2.2.4 La Mortalité : 32
CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
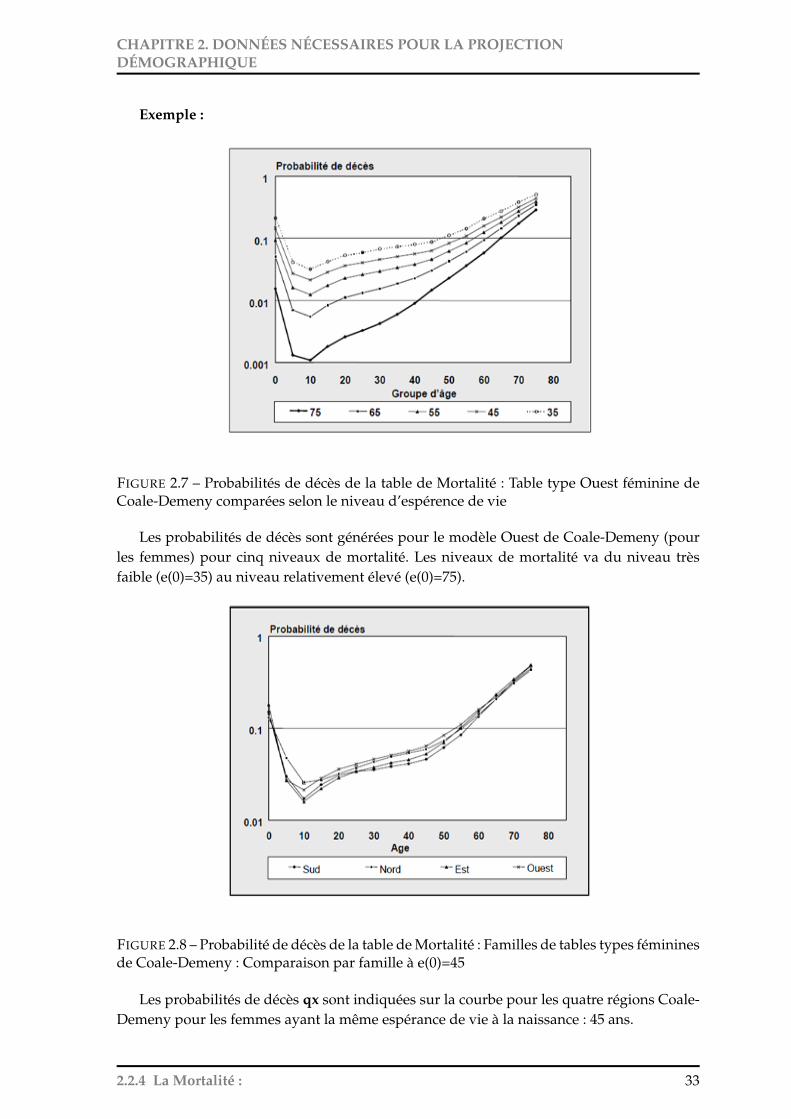
Exemple :
FIGURE 2.7 – Probabilités de décès de la table de Mortalité : Table type Ouest féminine deCoale-Demeny comparées selon le niveau d’espérence de vie
Les probabilités de décès sont générées pour le modèle Ouest de Coale-Demeny (pourles femmes) pour cinq niveaux de mortalité. Les niveaux de mortalité va du niveau trèsfaible (e(0)=35) au niveau relativement élevé (e(0)=75).
FIGURE 2.8 – Probabilité de décès de la table de Mortalité : Familles de tables types fémininesde Coale-Demeny : Comparaison par famille à e(0)=45
Les probabilités de décès qx sont indiquées sur la courbe pour les quatre régions Coale-Demeny pour les femmes ayant la même espérance de vie à la naissance : 45 ans.
2.2.4 La Mortalité : 33

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
Le modèle Nord présente les taux de mortalité les plus élevés pour les nourrissons etles enfants, et l’Ouest a des taux de mortalité élevés pour les personnes âgées de 15 ans etau-delà.
FIGURE 2.9 – les probabilités des femmes ayant une espérance de vie à la naissance égale à45 ans pour les cinq familles des Nations Unies
Dans le Graphique ci-dessus, les probabilités de décès sont indiquées pour les femmesayant une espérance de vie à la naissance égale à 45 ans pour les cinq familles des NationsUnies. On remarque que pour le modèle Asie de l’Est a un niveau de mortalité des adultesélevé par rapports aux autres et un niveau de mortalité des femmes de moins de 10 ansplutôt faible. L’autre extrême est la famille Asie du Sud qui a un modèle de mortalité desadultes nettement faible (entre10 et 50 ans) et un mode de mortalité des enfants relativementélevé.
2.5 Migration internationale :
La taille d’une population est non seulement en fonction des naissances et des décès maiselle subit également l’influence des gens qui quittent un endroit ou qui y viennent s’installer.
Généralement, les flux migratoires sont plus difficiles à mesure que la fécondité et lamortalité en vue de certaines complexités. D’abord, nous devons définir si nous voulonsmesurer la migration nationale ou internationale car les gens se déplacent constamment ausein d’un pays. Certains migrants sont des gens qui reviennent au pays. Non seulement camais aussi de nombreuses personnes qui traversent les frontières à la recherche de camps deréfugiés. C’est pour cela qu’il est difficile de mesurer la migration national ou international.
2.2.5 Migration internationale : 34

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
2.5.1 Les Mesures de la migration :
La Migration nette :
Il s’agit de la différence entre ceux qui rentrent ou qui sortent de la région pour laquelleest préparée la projection de population.
NetMigration = PEOPLEin− PEOPLEout
On parle de la migration internationale si la projection est à l’échelle d’un pays et de lamigration régionale si la projection est à l’échelle d’une région ou d’une ville.
Migration négative nette veut dire qu’un plus grand nombre de personnes partent. Mi-gration positive nette veut dire qu’un plus grand nombre de personnes arrivent. Souvent,il est possible d’ignorer la migration sans que cela ait un effet significatif sur la projectiondémographique.
Exemple :
FIGURE 2.10 – Les flux migratoires mondiaux
Un exemple des flux migratoires mondiaux. La Chine et le Mexique voient un plus grandnombre de gens quitter le pays alors qu’aux Etats-Unis et en Allemagne, un plus grandnombre de personnes arrivent.
La Distribution des migrants par âge pour chaque sexe :
Pour faire une projection démographique par sexe et âge, il est primordial d’obtenir ladistribution des migrants par sexe et âge. Il est difficile de trouver cette information maisles Nations Unies ont conçu une approche pour élaborer des schémas de migration par âge
2.2.5 Migration internationale : 35

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
et par sexe.
2.5.2 L’Accroissement d’une population (Population Growth) :
Le Taux de croissance de la population est le changement en pourcentage dans la tailled’une population en l’espace d’une année. Il est calculé à l’aide de la formule suivante :
population− growth− rate = Population(time2)− Population(time1)Population(time1)
∗ 100
2.6 Estimation de la croissance de la population :
Il existe deux grandes méthodes pour estimer la croissance future de la population :
1. La méthode des composantes de la croissance.
2. La méthode des composantes de cohorte.
2.6.1 La Méthode des composantes de la croissance :
La méthode des composantes de la croissance permet d’estimer la population à n’im-porte quel moment à l’avenir tout en prenant la population au début de la période de temps(Pop1) et ajoutons le nombre projeté de naissances, puis soustrayons le nombre projeté dedécès et ajoutons la migration nette projetée (c’est le nombre de migrants qui arrivent –(moins) le nombre de migrants qui sortent).
FIGURE 2.11 – La Méthode des composantes de la croissance
Le désavantage de cette méthode est quelle ne tient pas compte la structure de la po-pulation par âge et sexe qui est un facteur très important influençant la croissance de lapopulation.
2.6.2 La Méthode des composantes de cohorte :
Cette méthode commence par une distribution de la population par âge et sexe pour uneannée de base et utilise des taux par âge, de l’année de base (fécondité, mortalité, migration
2.2.6 Estimation de la croissance de la population : 36

CHAPITRE 2. DONNÉES NÉCESSAIRES POUR LA PROJECTIONDÉMOGRAPHIQUE
nette), Qui sont généralement disposés en groupes d’âges quinquennaux. Ces taux sont en-suite changés dans les années à venir en fonction des hypothèses choisies. Des hypothèsessont formulées sur l’évolution future de chacune des trois composantes. [2]
Nous allons voir en détailles dans le chapitre qui suit la procédure de l’implémentationde cette méthode pour la projection de la population indienne en 2020.
2.2.6 Estimation de la croissance de la population : 37

CHAPITRE 3
LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
3.1 Introduction :
L’une parmi les méthodes les plus utilisées pour faire une projection démographique estla méthode des composantes. L’expression "méthode des composantes" est la traductionlittérale de la désignation anglaise "component method", qui veut dire en français "projec-tions par sexe et par âge". Cette technique qui diffère des autres méthodes de projection oude prédiction simple, vu qu’elle permet de projeter la population de base par sexe et âge, ils’agit plus particulièrement des groupes d’âges quinquennaux (groupe de 5 ans).
Le Principe de cette méthode consiste en général à projeter la population de l’année debase tout en se basant sur la projection de 3 composantes essentielles : La fertilité, la mor-talité ainsi que la migration sous certaines hypothèses bien choisies. Celles-ci devraient êtreexaminées avec précaution et basées sur des directives de sélection raisonnables.
La projection de la fertilité nécessite la formulation des hypothèses sur l’indice synthé-tique de fécondité (Total Fertility rate). Elle permet de savoir l’évolution du nombre de nais-sances qui auront lieu au cours de l’année. La méthode des composantes procède par lecalcul des décès parmi les générations présentes au début de la période. Cette estimationse fait à l’aide des probabilités de décès appelées encore les quotients de Mortalité par âgeou groupe d’âge. Il ne faut pas oublier que des risques de migration peuvent intervenir àchaque étape de calcul et dans ce cas des hypothèses de migration internationale sont né-cessaires pour la projection.
Dans ce chapitre on va voir dans un premier lieu le principe de base de la méthode descomposantes. Après, on s’intéressera à chaque composantes pour y voir les techniques et lesoutils nécessaires qui vont nous aider à faire la projection démographique par sexe et âge.
L’objectif est de projeter la population Indienne en 2020 dont on dispose de sa base dedonnées par sexe et âge de 2000 jusqu’au 2014, tout en se basant sur la méthode de compo-santes.
38

CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
3.2 Principe de la Méthode des Composantes :
Les projections de la population consistent à estimer, année après année, le nombre desnaissances, des décès et le solde migratoire (les entrées moins sorties du territoire). Le pointde départ c’est la population par sexe et âge de l’année de base n. Cette dernière est pro-bablement disponible dans les rapports du recensement. Souvent, des tableaux donnant lataille de la population par sexe et âge sont disponibles au niveau national ou les niveauxlocaux ou provinciaux.
Au 1er janvier n+1, le nombre d’habitants est égal à la taille de la population au 1er jan-vier de l’année précédente n augmentée des naissances et des entrées nettes de populationsur le territoire qui ont eu lieu au cours de l’année n, et diminuée des décès.
Pop1.1.n+1 = Pop1.1.n + naissancesn − decesn + SoldeMigratoiren
La population totale au 1er janvier de l’année n+1 est la somme des populations calculéepar sexe et âge atteint au 1er janvier de l’année n.
Les hypothèses des projections portent sur les taux de fécondité par âge atteint dansl’année, le solde migratoire réparti par sexe et âge atteint dans l’année et les quotients dedécès par sexe et âge atteint dans l’année.
3.2.1 Le Calcul des naissances :
Le nombre de naissances est en général calculé en appliquant à la population féminined’âges féconds (15-50 ans en âge atteint dans l’année) les taux de fécondité projetés par âge(atteint dans l’année).
Le nombre annuel de naissances est calculé de la façon suivante :
Naissances =50∑
a=15
(Popa−11.1.n,Femmes+(SoldeMigratoirean,Femmes−decesan,Femmes)/2)∗TauxFeconditean
Le nombre de naissances issues de femmes atteignant l’âge a au cours de l’année n estégal la somme du nombre moyen de femmes de cet âge multiplie par le taux de féconditéde ces femmes au cours de l’année. Ce nombre moyen de femmes est estimé par le nombrede femmes présentes au 1er janvier (d’âge a-1 donc au premier janvier) auquel est ajoutée lamoitié des entrées nettes de femmes d’âge a et retirée la moitié des décès de femmes d’âgea.
3.2.2 Le Calcul des Décès :
Au cours de l’année n, Le nombre de décès de personnes de sexe s et d’âge a (atteintdans l’année) est :
Le nombre de décès de femmes (ou d’hommes) d’âge a atteint dans l’année est calculéen appliquant à la population moyenne de l’année les quotients de décès projetés par sexeet âge (atteint dans l’année).
3.3.2 Principe de la Méthode des Composantes : 39

CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
Cette population moyenne est estimée par le nombre de femmes (ou d’hommes) présent(e)sau 1er janvier (d’âge a-1 donc) auquel est ajoutée la moitié des entrées nettes de femmes(d’hommes) d’âge a, pour tenir compte des variations d’effectifs en cours d’année[3].
Decesan,s = (Popa−11,1,n,s + SoldeMigratoirean,s) ∗QuotientMortalitean,s, sia > 0
Le nombre de décès de nouveau-nés est calculé, pour les garçons et les filles de la ma-nière suivante :
Deces0n,s = naissancesn,s ∗QuotientMortalite0n,s
On applique aux naissances de l’année les quotients de mortalité à l’âge 0.
La population au 1er janvier de l’année n+1 par sexe et âge atteint au 1er janvier n+1 sedéduit alors de la population par sexe et âge au 1er janvier n de la façon suivante :
Popa1.1.n+1,s = Popa−11.1.n,s − deces
an,s + SoldeMigratoirean,s
, pour a>0et :
Pop01.1.n+1,s = naissancesn,s − deces0n,s + SoldeMigratoire0n,s
3.2.3 La Population de l’année de base :
Pour les hommes et les femmes, la population de base est divisée en groupes d’âge quin-quennaux allant de 0-4 à 75-79. Il existe également un groupe d’âge final pour les personnesâgées de 80 ans et plus.
FIGURE 3.1 – La Populatione Indienne en 2014 par sexe et groupe d’âge
3.3.2 Principe de la Méthode des Composantes : 40

CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
3.3 La Projection de la Fécondité :
Une projection démographique nécessite une information sur la fécondité obtenue à tra-vers :
1. l’ISF
2. Le Taux de fécondité par groupe d’âge (la distribution par groupe âge de la fécondité).
3.3.1 Indice synthétique de fécondité :
L’ISF est le nombre de naissances vivantes qu’une femme aurait si elle vivait jusqu’àl’âge de 50 ans et compte tenu les conditions de fécondité par âge du moment. Il s’agitd’une mesure synthétique qui résume le niveau de fécondité actuel en termes de nombremoyen de naissances vivantes par femme que l’on observerait si les taux de fécondité parâge actuels restaient constants et si toutes les femmes vivaient jusqu’à l’âge de 50 ans.
Hypothèses quant à l’avenir :
La formulation d’une hypothèse sur le niveau de l’ISF futur est nécessaire pour la plu-part des projections démographiques. Il existe plusieurs options pour déterminer la projec-tion de L’ISF.
1.Objectifs nationaux : De nombreux pays disposent des objectifs démographiques na-tionaux qui incluent souvent l’ISF. Il est préférable d’utiliser ces objectifs comme point dedépart des projections.
2.Projections des Nations Unies : Les projections démographiques préparées par la Di-vision de la population des Nations Unies et indiquées dans World Population Prospectscomprennent trois hypothèses (faible, moyenne et élevée) sur l’évolution future de la fécon-dité dans chaque pays faisant partie du rapport. Seul inconvénient, les Nations Unies ne pré-cisent pas ce qu’elles entendent par "faible","moyenne" et “élevée". La variante "moyenne"est la plus probable.
3.Tendances récentes et expérience internationale : On peut formuler des hypothèsessur l’évolution future d’ISF tout en se basant sur les tendances passées de la fécondité. Mais,il faut noter qu’on n’est pas sûr de voir ces tendances se poursuivent dans le futur.
4.Projections nationales : Plusieurs pays disposent des projections démographiques of-ficielles basées sur une ou plusieurs hypothèses sur l’évolution future de l’ISF.
Ci-dessous la projection de l’indice synthétique de fécondité (Total Fertility Rate) en2020. Les hypothèses de projection sont formulées tout en se basant sur les objectifs dé-mographiques nationaux du pays(Inde) 1 à savoir :
1. http ://articles.economictimes.indiatimes.com/2014-07-11/news/513549501tfr − total − fertility −rate− iucd
3.3.3 La Projection de la Fécondité : 41
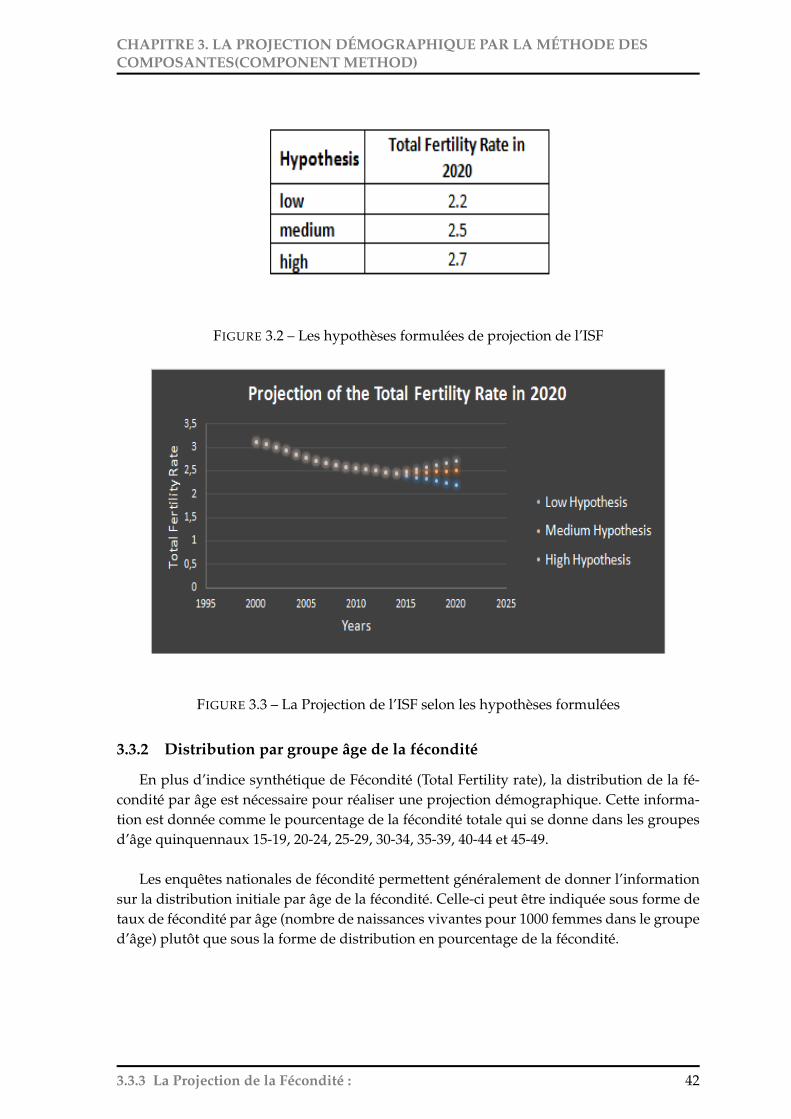
CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
FIGURE 3.2 – Les hypothèses formulées de projection de l’ISF
FIGURE 3.3 – La Projection de l’ISF selon les hypothèses formulées
3.3.2 Distribution par groupe âge de la fécondité
En plus d’indice synthétique de Fécondité (Total Fertility rate), la distribution de la fé-condité par âge est nécessaire pour réaliser une projection démographique. Cette informa-tion est donnée comme le pourcentage de la fécondité totale qui se donne dans les groupesd’âge quinquennaux 15-19, 20-24, 25-29, 30-34, 35-39, 40-44 et 45-49.
Les enquêtes nationales de fécondité permettent généralement de donner l’informationsur la distribution initiale par âge de la fécondité. Celle-ci peut être indiquée sous forme detaux de fécondité par âge (nombre de naissances vivantes pour 1000 femmes dans le grouped’âge) plutôt que sous la forme de distribution en pourcentage de la fécondité.
3.3.3 La Projection de la Fécondité : 42

CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
Les Tables types de fécondité :
La Division de la population des Nations Unies a élaboré des modes régionaux pourdécrire le changement de la fécondité en utilisant des modes désignés par les appellationsAfrique subsaharienne, nations arabes et Asie. Le Tableau ci-dessous indique les distribu-tions de la fécondité par divers indices synthétiques de fécondité pour chacun des quatremodes.
FIGURE 3.4 – les distributions de la fécondité par divers ISF pour chacun des quatremodes(Afrique subsaharienne, nations arabes et Asie)
Exemple :
Ci-dessous, La Distribution de la fécondité par ISF : Modèle Afrique subsaharienne desNations Unies :
FIGURE 3.5 – La Distribution de la fécondité par ISF : Modèle Afrique subsaharienne desNations Unies
3.3.3 La Projection de la Fécondité : 43

CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
Le graphique illustre une distribution relativement plane de la fécondité sur tous lesâges pour des niveaux élevés d’ISF, et une distribution de plus en plus pointue (atteignantun maximum dans le groupe des 20-24 ans) où l’ISF est de 2 ou 3.
Dans notre cas, on dispose de la distribution de la fécondité par âge de l’Inde en 2000 jus-qu’au 2014. Une interpolation linéaire suffit pour projeter cette distribution jusqu’au 2020.La projection est faite sur la base des objectifs sociopolitiques du pays.
FIGURE 3.6 – La Projection de l’ISF de la population Indienne en 2020
On remarque que pour ce pays la distribution de la fécondité se concentre Presque exclu-sivement dans les groupes d’âge féconds 20-24 et 25-29, ce qui signifie que de nombreusesfemmes donnent un nombre assez important de naissances dans ces groupes particuliersd’âge. Cette distribution diminue au fur et à mesure qu’on se déplace aux groupes d’âgeélevés.
3.4 La Projection de la Mortalité :
La mortalité est décrite à travers deux hypothèses : espérance de vie à la naissance parsexe et une table type de mortalité avec des taux de mortalité par âge (quotients de Morta-lité).
Le nombre de décès est projeté chaque année en appliquant à la population survivantedes quotients de décès par sexe et âge atteint dans l’année. Des hypothèses sont formuléessur l’évolution de ces quotients dans les années à venir.
3.4.1 Espérance de vie à la naissance :
L’espérance de vie à la naissance est le nombre moyen d’années que vivrait une cohortede personnes.
3.3.4 La Projection de la Mortalité : 44

CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
Hypothèses futures :
Plusieurs options existent pour déterminer l’hypothèse sur l’espérance de vie qui est né-cessaire pour toutes les projections démographiques :
1-Projections nationales :
Plusieurs pays ont des projections démographiques officielles avec des hypothèses surl’espérance de vie et son évolution, souvent avec plusieurs variantes.
2-Objectifs nationaux :
Un grand nombre de pays ont des objectifs démographiques nationaux qui incluent sou-vent l’espérance de vie. Il est souvent utile d’utiliser ces objectifs comme point de départ desprojections.
3-Projections des Nations Unies et du Bureau américain du recensement :
Les projections démographiques préparées par la Division de la population des NationsUnies et publiées dans World Population Prospects comportent des hypothèses sur les ni-veaux d’espérance de vie pour chaque pays pour lequel des notifications sont faites. Ceshypothèses peuvent être utilisées.
4-Tendances récentes et expérience internationale :
Il peut être utile de formuler une hypothèse future basée sur la poursuite des tendancespassées. Cependant, il convient de noter qu’on ne peut pas s’attendre à voir les tendancespassées se poursuivre pendant très longtemps dans le futur.
5-Tables types des Nations Unies :
En préparant ses projections démographiques tous les deux ans, la division de la po-pulation des Nations Unies utilise un modèle d’évolution de l’espérance de vie. Ce mo-dèle suppose que l’espérance de vie à la naissance, tant pour les hommes que pour lesfemmes, s’accroît de 2,0 à 2,5 années tous les cinq ans lorsque l’espérance de vie est infé-rieure à 60 et ensuite, s’accroît à un rythme plus lent aux niveaux plus élevés. Le Tableauci-dessous indique le modèle de travail utilisé dans les projections démographiques des Na-tions Unies.[4]
Les rapports nationaux représentent la meilleure source d’information sur l’espérancede vie. Pour l’Inde, nous disposons des valeurs passées de l’espérance de vie de 2000 jus-qu’au 2014, Une projection est faite sur la base de 3 hypothèses : Centrale, élevée et faible.
3.3.4 La Projection de la Mortalité : 45

CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
FIGURE 3.7 – Le Modèle de l’évolution de l’espérence de vie de la Division des nations unies
FIGURE 3.8 – Les hypothèses de projection de l’espérence de vie de l’Inde en 2020
Ci-dessous la projection de l’espérance de vie des femmes et des hommes de 2015 jus-qu’au 2020 selon différentes hypothèses.
FIGURE 3.9 – La Projection de l’espérence de vie selon les scénarii(Centrale, baisse, hausse)
3.3.4 La Projection de la Mortalité : 46

CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
3.4.2 Quotients de Mortalité :
L’espérance de vie à la naissance indique la mortalité générale au sein d’une population.Mais, pour calculer le nombre de décès par groupe d’âge il faut connaitre les probabilitésde Mortalité appelées encore les quotients de décès, et donc, on a besoin d’un modèle demortalité (Table de Mortalité) afin de produire des taux de mortalité par groupe d’âge.
Les Tables de Mortalité :
Comme nous avons vu au chapitre précédant l’information sur les probabilités de Mor-talité peuvent être prises des :
1.Tables de Coale-Demeny qui sont définies comme : Nord, Est, Sud et l’Ouest.
2. Les nations unis disposent de tables types de Mortalité qui désignent des régions trèsspécifiques : Amérique latine, Amérique du Sud, Chili, Asie du Sud, Asie de l’Est, plus Gé-néral (générique).
Il est à noter que la meilleure table type de mortalité et celle déterminée par les démo-graphes du pays.
Choix de la table de Mortalité :
Plusieurs approches existent pour déterminer la table de mortalité qui convient le mieuxà un pays ou à une région en termes de niveau et schéma de mortalité :
1- La meilleure table type de mortalité est celle déterminée par les démographes d’un telou tel pays. C’est la meilleure table qui peut être considérée proche à la réalité.
2-L’autre manière est de comparer les données sur la mortalité par âge pour ce pays avecle schéma de mortalité au niveau correspondant d’espérance de vie pour chacune des tablestypes des nations unis.
Dans notre cas, nous disposons des probabilités de décès du pays « Inde » pour les deuxsexes déterminées par ses démographes en 2014 2.
2. Sonjai Kumar,"Mortality Variations in India", Post Graduate Diploma in Actuarial Management, 2005
3.3.4 La Projection de la Mortalité : 47
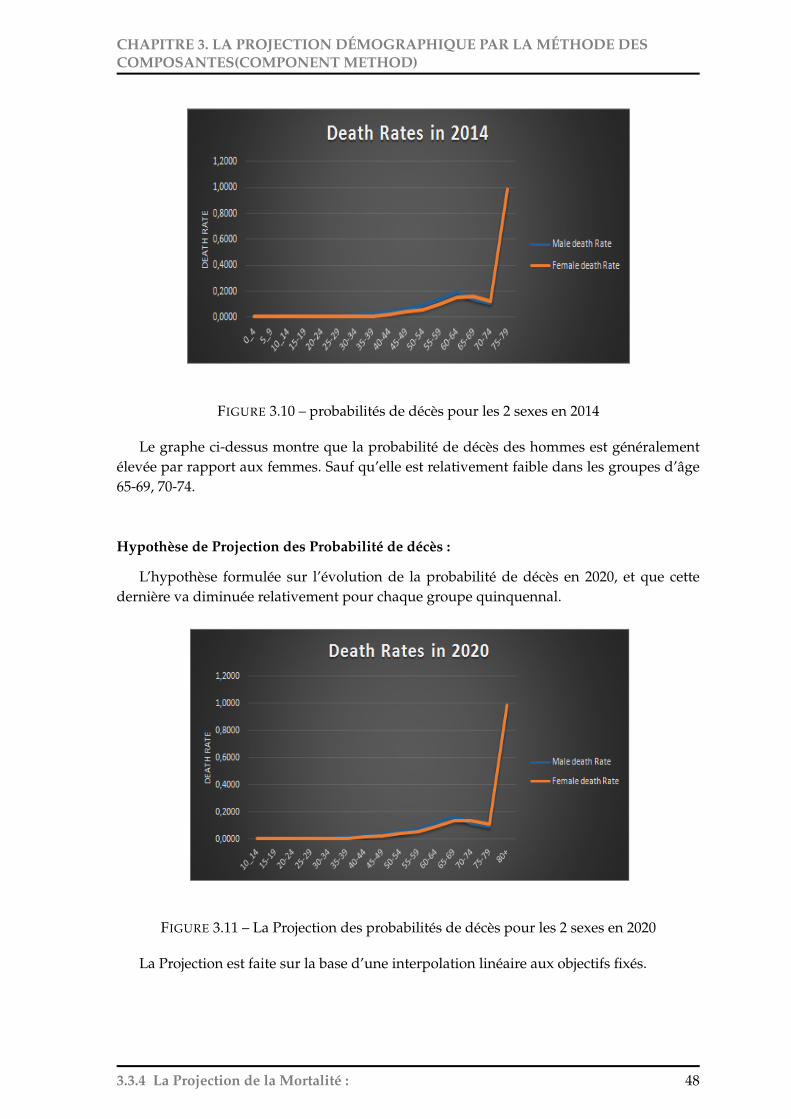
CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
FIGURE 3.10 – probabilités de décès pour les 2 sexes en 2014
Le graphe ci-dessus montre que la probabilité de décès des hommes est généralementélevée par rapport aux femmes. Sauf qu’elle est relativement faible dans les groupes d’âge65-69, 70-74.
Hypothèse de Projection des Probabilité de décès :
L’hypothèse formulée sur l’évolution de la probabilité de décès en 2020, et que cettedernière va diminuée relativement pour chaque groupe quinquennal.
FIGURE 3.11 – La Projection des probabilités de décès pour les 2 sexes en 2020
La Projection est faite sur la base d’une interpolation linéaire aux objectifs fixés.
3.3.4 La Projection de la Mortalité : 48

CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
3.5 La Projection de La Migration Internationale :
La migration internationale concerne le nombre de migrants qui entrent et qui sortentdu pays. La migration internationale est réalisée pour un pays alors que si la projectionconcerne une région ou une ville, alors “migration internationale” se réfère aux personnesqui y entrent et qui sortent.
Généralement, l’information sur la migration proviendra des sources locales, la plupartdes cas d’études basées sur un recensement national.
La migration est présentée à travers deux éléments : le nombre net de migrants par sexeet année et la distribution des migrants par âge pour chaque sexe.
3.5.1 Le Nombre net de migrants par sexe et année :
Le flux net se fait vers l’extérieur, alors la migration nette devrait être un chiffre négatif.Si le flux net se fait vers l’intérieur, alors il devrait être positif.
Hypothèse quant à l’avenir :
L’hypothèse prise pour projeter le solde migratoire net en 2020 pour l’Inde est :
FIGURE 3.12 – L’hypothèse de projection du solde migratoire
Cette hypothèse est basée sur le fait que depuis 2000, L’inde a connu une évolutionnégative du solde migratoire, c’est-à-dire beaucoup de personnes ont quitté le pays. Cetteévolution qui après 2007 connue une augmentation relative jusqu’au 2014. (Voir figure ci-dessous)
3.3.5 La Projection de La Migration Internationale : 49
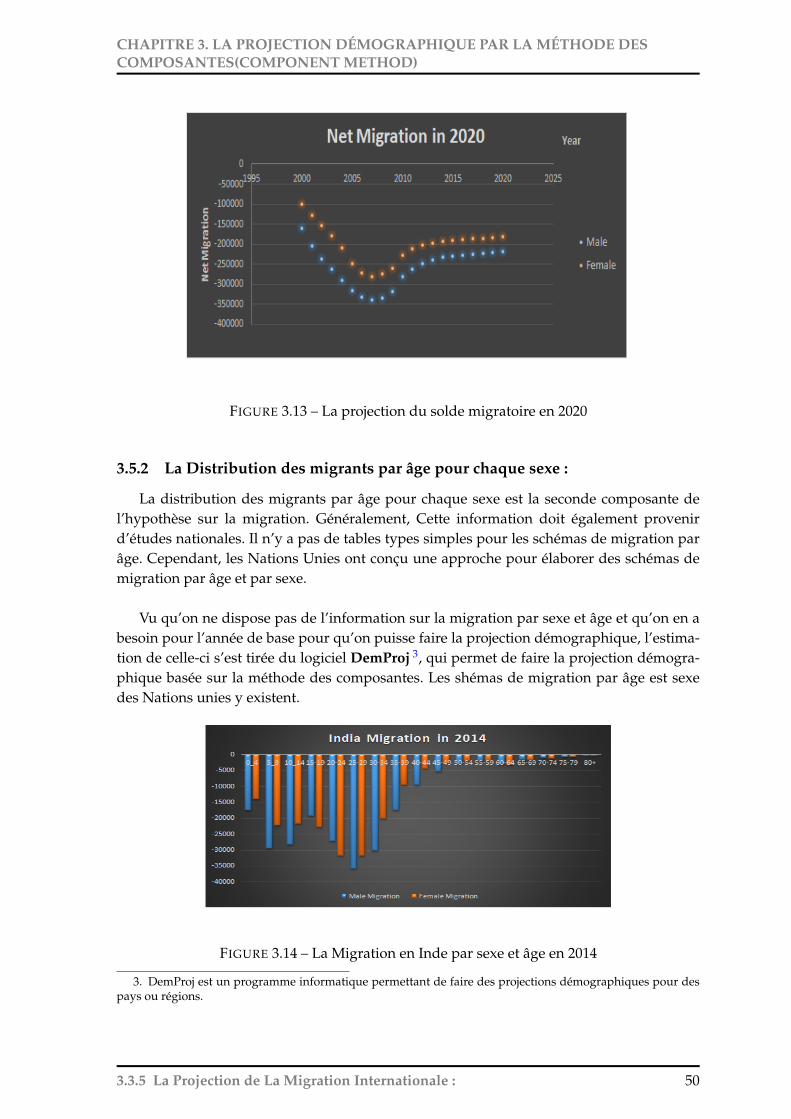
CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
FIGURE 3.13 – La projection du solde migratoire en 2020
3.5.2 La Distribution des migrants par âge pour chaque sexe :
La distribution des migrants par âge pour chaque sexe est la seconde composante del’hypothèse sur la migration. Généralement, Cette information doit également provenird’études nationales. Il n’y a pas de tables types simples pour les schémas de migration parâge. Cependant, les Nations Unies ont conçu une approche pour élaborer des schémas demigration par âge et par sexe.
Vu qu’on ne dispose pas de l’information sur la migration par sexe et âge et qu’on en abesoin pour l’année de base pour qu’on puisse faire la projection démographique, l’estima-tion de celle-ci s’est tirée du logiciel DemProj 3, qui permet de faire la projection démogra-phique basée sur la méthode des composantes. Les shémas de migration par âge est sexedes Nations unies y existent.
FIGURE 3.14 – La Migration en Inde par sexe et âge en 2014
3. DemProj est un programme informatique permettant de faire des projections démographiques pour despays ou régions.
3.3.5 La Projection de La Migration Internationale : 50
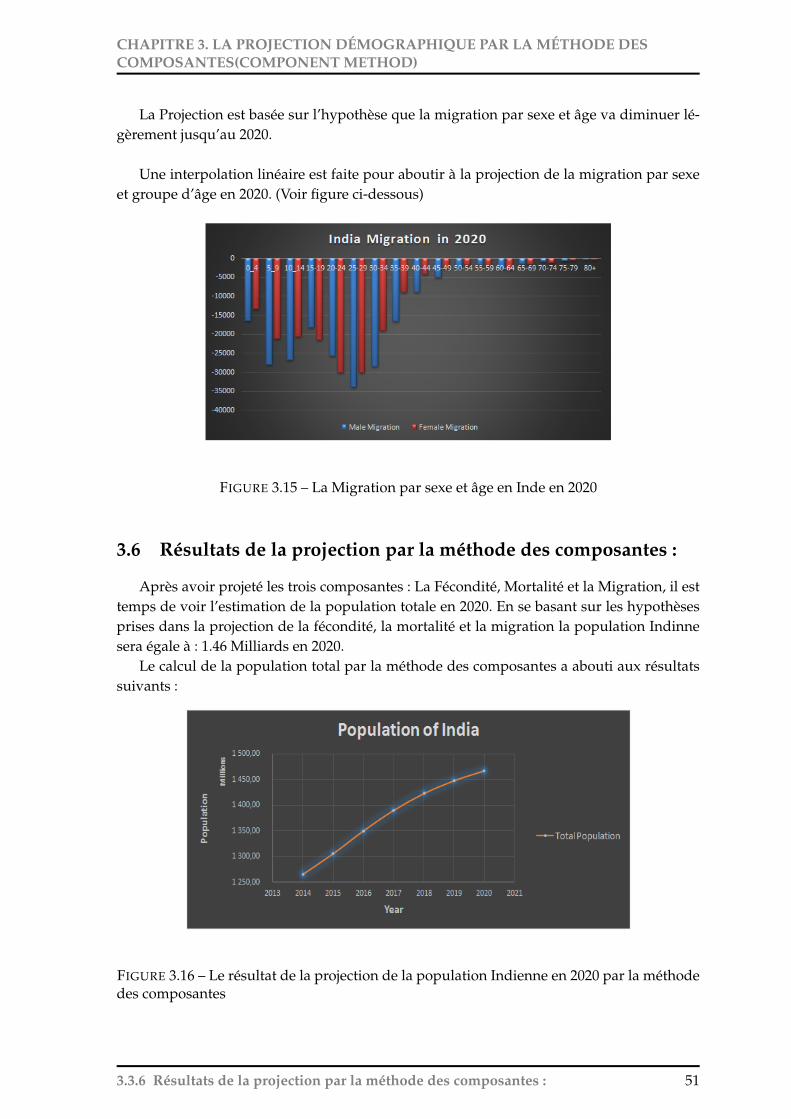
CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
La Projection est basée sur l’hypothèse que la migration par sexe et âge va diminuer lé-gèrement jusqu’au 2020.
Une interpolation linéaire est faite pour aboutir à la projection de la migration par sexeet groupe d’âge en 2020. (Voir figure ci-dessous)
FIGURE 3.15 – La Migration par sexe et âge en Inde en 2020
3.6 Résultats de la projection par la méthode des composantes :
Après avoir projeté les trois composantes : La Fécondité, Mortalité et la Migration, il esttemps de voir l’estimation de la population totale en 2020. En se basant sur les hypothèsesprises dans la projection de la fécondité, la mortalité et la migration la population Indinnesera égale à : 1.46 Milliards en 2020.
Le calcul de la population total par la méthode des composantes a abouti aux résultatssuivants :
FIGURE 3.16 – Le résultat de la projection de la population Indienne en 2020 par la méthodedes composantes
3.3.6 Résultats de la projection par la méthode des composantes : 51
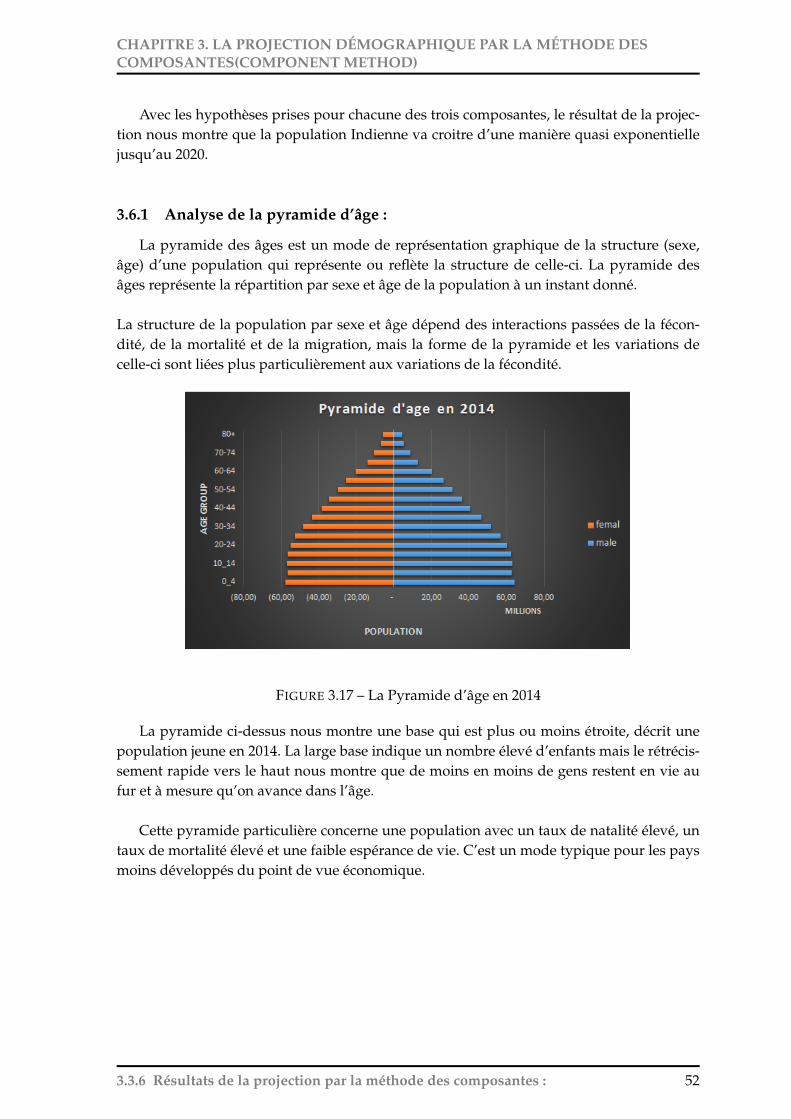
CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
Avec les hypothèses prises pour chacune des trois composantes, le résultat de la projec-tion nous montre que la population Indienne va croitre d’une manière quasi exponentiellejusqu’au 2020.
3.6.1 Analyse de la pyramide d’âge :
La pyramide des âges est un mode de représentation graphique de la structure (sexe,âge) d’une population qui représente ou reflète la structure de celle-ci. La pyramide desâges représente la répartition par sexe et âge de la population à un instant donné.
La structure de la population par sexe et âge dépend des interactions passées de la fécon-dité, de la mortalité et de la migration, mais la forme de la pyramide et les variations decelle-ci sont liées plus particulièrement aux variations de la fécondité.
FIGURE 3.17 – La Pyramide d’âge en 2014
La pyramide ci-dessus nous montre une base qui est plus ou moins étroite, décrit unepopulation jeune en 2014. La large base indique un nombre élevé d’enfants mais le rétrécis-sement rapide vers le haut nous montre que de moins en moins de gens restent en vie aufur et à mesure qu’on avance dans l’âge.
Cette pyramide particulière concerne une population avec un taux de natalité élevé, untaux de mortalité élevé et une faible espérance de vie. C’est un mode typique pour les paysmoins développés du point de vue économique.
3.3.6 Résultats de la projection par la méthode des composantes : 52

CHAPITRE 3. LA PROJECTION DÉMOGRAPHIQUE PAR LA MÉTHODE DESCOMPOSANTES(COMPONENT METHOD)
FIGURE 3.18 – La Pyramide d’âge en 2020
En 2020, La pyramide reflète une base moins large ce qui signifie que le taux de natalitéa commencé à baisser, ce qui décrit l’augmentation de l’espérance de vie. Vous pouvez voirque les quelques bandes au bas de la population en 2020 sont relativement égales. C’est àcause des hypothèses sur les réductions dans le taux de mortalité infantile aussi que dans letaux de fécondité.
3.3.6 Résultats de la projection par la méthode des composantes : 53

Deuxième partie
La Prédiction de la PopulationIndienne en 2020
54

CHAPITRE 4
LA THÉORIE DES SÉRIES CHRONOLOGIQUES
4.1 Introduction
4.1.1 Séries chronologiques : vocabulaire
Définition :
On appelle série chronologique ou chronique une suite (Yt) d’observations chiffrées d’unmême phénomène, ordonnées dans le temps. Généralement, l’objectif est de voir l’évolutionau cours du temps d’un phénomène, dans le but de l’expliquer puis le prévoir dans le futur.
Les dates d’observations sont généralement ordonnées de manière régulière dans letemps. Généralement on manipule des séries :
1. journalières (cours d’une action en bourse).
2. mensuelles (consommation mensuelle d’électricité).
3. trimestrielles (nombre trimestriel de chômeurs).
4. annuelles (chiffre annuel des bénéfices des exportations).
Les Trois composantes d’une série chronologique :
1-La Tendance : Ct :
La tendance correspond à l’évolution à long terme de la série. Elle traduit le comporte-ment de la série.
2-La Composante saisonnière : St :
La saisonnalité correspond à un phénomène qui se répète dans des intervalles de tempsréguliers (périodiques). Par exemple, des fluctuations périodiques à l’intérieur d’une année,et qui se reproduisent de façon plus ou moins permanente d’une année sur l’autre.
3-la Composante résiduelle : (Ou bruit ou résidu) (Qt)
55

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
Les variations accidentelles sont des fluctuations irrégulières et imprévisibles. En géné-ral elles sont de faible intensité mais de nature aléatoire.
FIGURE 4.1 – Exemple d’une série chronologique avec tendance et saisonnalité
4.2 Description schématique de l’étude complète d’une série chro-nologique :
L’un des objectifs principaux de l’étude d’une série chronologique est la prévision deses valeurs futures. Pour cela, nous avons besoin de modéliser le mécanisme de productionde la série chronologique. Principalement, les principales étapes de traitement d’une sériechronologique sont :
4.2.1 Correction des données :
Avant n’importe quelle étude d’une série chronologique, il est parfois nécessaire de mo-difier les données initiales. Par exemple :
– l’évaluation de données manquantes, remplacement de données accidentelles,...– découpage en sous-séries.– standardisation pour se ramener à des intervalles de longueur <U+FB01>xe. Par exemple,
pour des données mensuelles, on se ramène au mois standard en calculant la moyennejournalière sur le mois (total des observations sur le mois divise par le nombre de joursdu mois).
– transformation des données : pour des raisons diverses, on peut être parfois amènesà utiliser des données transformées. Par exemple en économie, on utilise la famille detransformations de Box-Cox :
Yt =1
λ[(Xt)
λ − 1], λ ∈ R∗
4.4.2 Description schématique de l’étude complète d’une série chronologique : 56

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
4.2.2 Observation de la série :
Il est important de commencer par regarder les données avant d’effectuer le moindrecalcul. Ainsi, une fois la série corrigée, le tracement de son graphique, c’est à dire la courbede coordonnées (t, Xt) donne souvent une aide à la modélisation de la série chronologique etpermet de se faire une idée claire sur les différentes composantes de la série chronologique.
4.2.3 Modélisation avec un nombre fini de paramètres :
Un modèle est une image simplifiée de la réalité qui vise à traduire les mécanismes defonctionnement d’un phénomène étudié et permet de mieux les comprendre.
On distingue principalement deux types de modèles :
Les Modèles déterministes :
Ces modèles relèvent de la statistique descriptive. Ils consistent à supposer que l’ob-servation de la série à la date t est une fonction du temps t et d’une variable Qt centréereprésentant l’erreur du modèle :
Xt = f(t, Qt)
On suppose de plus que les Qt sont décorrélées.
Les deux modèles de ce type les plus utilisés sont les suivants :
1. Le Modèle additif :
La variable Xt s’écrit comme le somme des trois termes :
Xt = Zt + St +Qt
où Zt représente la tendance (déterministe), St la saisonnalité (déterministe aussi) et Qtles composantes (erreurs du modèle) aléatoires iid(indépendantes et identiquement distri-buées) 1.
2. Le Modèle multiplicatif :
La variable Xt s’écrit comme le produit de la tendance et d’une composante de saison-nalité :
Xt = Zt ∗ (1 + St)(1 +Qt)
1. sont des variables aléatoires qui ont toutes la même loi de probabilité et sont indépendantes.
4.4.2 Description schématique de l’étude complète d’une série chronologique : 57

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
Les Modèles stochastiques :
Ils sont du même type que les modèles déterministes, la différence est dans le terme dubruit Qt. Elles ne sont pas iid mais possèdent une structure de corrélation non nulle : Qt esten fonction des valeurs passées plus ou mois lointaines) et d’un terme d’erreur ηt
Qt = g(Qt−1, Qt−2, ..., ηt)
4.2.4 Analyse de la série à partir de ses composantes :
Après avoir trouvé le modèle adéquat qui décrit plus ou moins la série chronologique enquestion, l’étape suivante consiste à étudier les composantes du modèle les unes après lesautres. En s’intéressant dans un premier lieu à la tendance et à la saisonnalité éventuelle(s)que l’on isole, modéliser, et les estimer,enfin, les éliminer de la série. Une fois ces compo-santes éliminées, nous obtenons la série aléatoire Qt :
– pour les modelés déterministes, cette série sera considérée comme décorrélée et il n’ya plus rien à faire.
– pour les modèles stochastiques, nous obtenons une série stationnaire (ce qui signifieque les observations successives de la série sont identiquement distribuées mais pasnécessairement indépendantes) qu’il s’agit de modéliser.
4.2.5 Diagnostic du modèle/ajustement du modèle :
Une fois le modèle construit et ses paramètres sont estimés, nous vérifions que le modèleproposé est adéquat :
– En étudiant les résidus, en faisant des tests...
4.2.6 Prédiction ou Prévision :
Finalement, une fois ces différentes étapes sont réalisées, nous sommes en mesure defaire de la prédiction.
4.3 Modélisation déterministe :
4.3.1 Le Modèle additif :
Dans un modèle additif, nous supposons que les 3 composantes : tendance, variationssaisonnières et variations accidentelles sont indépendantes les unes des autres. Nous consi-dèrons que la série Yt s’écrit comme la somme de ces 3 composantes :
Yt = Ct + St + ξt
La tendance Ct exprime un mouvement à moyen terme de la série. La plupart du tempselle est modélisée par une fonction polynomiale du temps.
–La composante saisonnière exprime un phénomène qui se reproduit de manière ana-logue sur chaque intervalle de temps successif.
4.4.3 Modélisation déterministe : 58
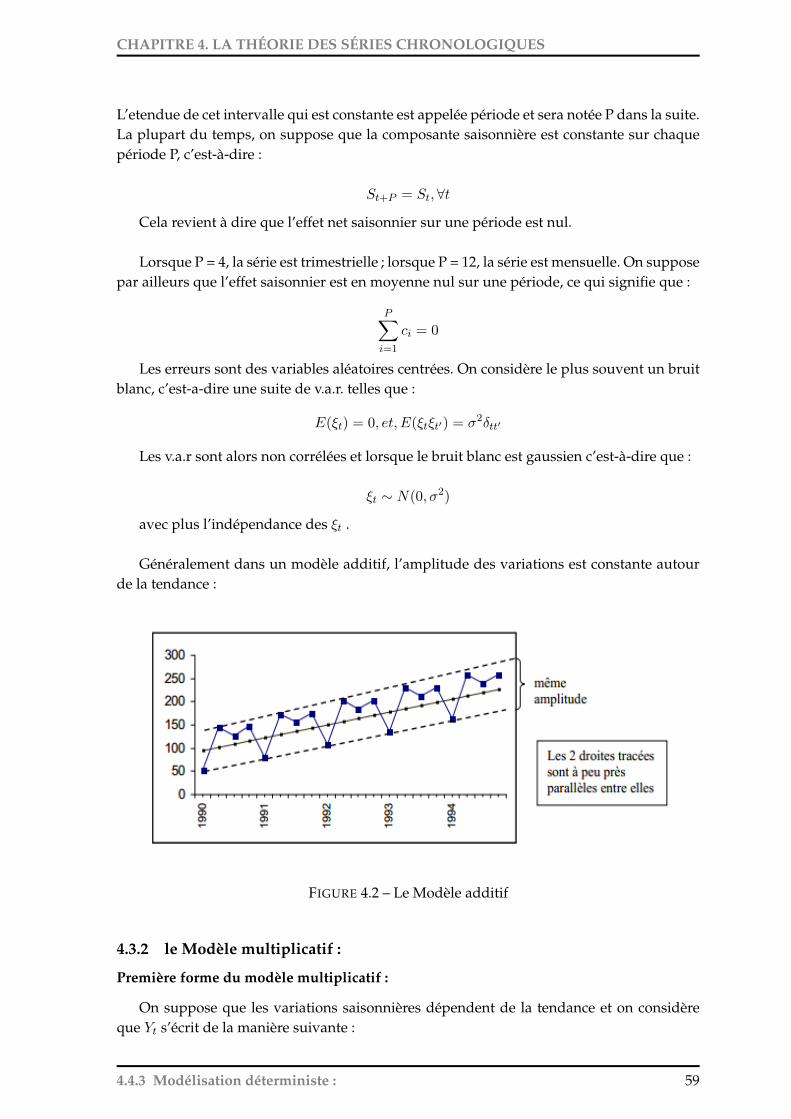
CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
L’etendue de cet intervalle qui est constante est appelée période et sera notée P dans la suite.La plupart du temps, on suppose que la composante saisonnière est constante sur chaquepériode P, c’est-à-dire :
St+P = St,∀t
Cela revient à dire que l’effet net saisonnier sur une période est nul.
Lorsque P = 4, la série est trimestrielle ; lorsque P = 12, la série est mensuelle. On supposepar ailleurs que l’effet saisonnier est en moyenne nul sur une période, ce qui signifie que :
P∑i=1
ci = 0
Les erreurs sont des variables aléatoires centrées. On considère le plus souvent un bruitblanc, c’est-a-dire une suite de v.a.r. telles que :
E(ξt) = 0, et, E(ξtξt′) = σ2δtt′
Les v.a.r sont alors non corrélées et lorsque le bruit blanc est gaussien c’est-à-dire que :
ξt ∼ N(0, σ2)
avec plus l’indépendance des ξt .
Généralement dans un modèle additif, l’amplitude des variations est constante autourde la tendance :
FIGURE 4.2 – Le Modèle additif
4.3.2 le Modèle multiplicatif :
Première forme du modèle multiplicatif :
On suppose que les variations saisonnières dépendent de la tendance et on considèreque Yt s’écrit de la manière suivante :
4.4.3 Modélisation déterministe : 59
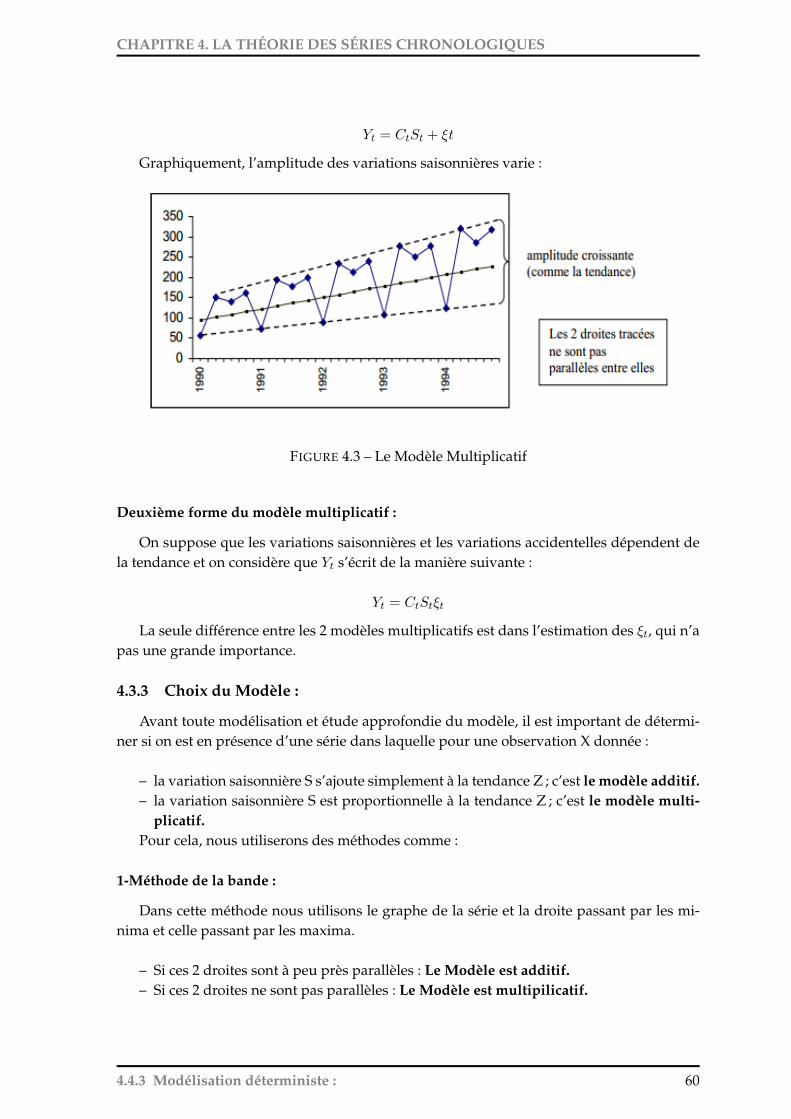
CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
Yt = CtSt + ξt
Graphiquement, l’amplitude des variations saisonnières varie :
FIGURE 4.3 – Le Modèle Multiplicatif
Deuxième forme du modèle multiplicatif :
On suppose que les variations saisonnières et les variations accidentelles dépendent dela tendance et on considère que Yt s’écrit de la manière suivante :
Yt = CtStξt
La seule différence entre les 2 modèles multiplicatifs est dans l’estimation des ξt, qui n’apas une grande importance.
4.3.3 Choix du Modèle :
Avant toute modélisation et étude approfondie du modèle, il est important de détermi-ner si on est en présence d’une série dans laquelle pour une observation X donnée :
– la variation saisonnière S s’ajoute simplement à la tendance Z ; c’est le modèle additif.– la variation saisonnière S est proportionnelle à la tendance Z ; c’est le modèle multi-
plicatif.Pour cela, nous utiliserons des méthodes comme :
1-Méthode de la bande :
Dans cette méthode nous utilisons le graphe de la série et la droite passant par les mi-nima et celle passant par les maxima.
– Si ces 2 droites sont à peu près parallèles : Le Modèle est additif.– Si ces 2 droites ne sont pas parallèles : Le Modèle est multipilicatif.
4.4.3 Modélisation déterministe : 60
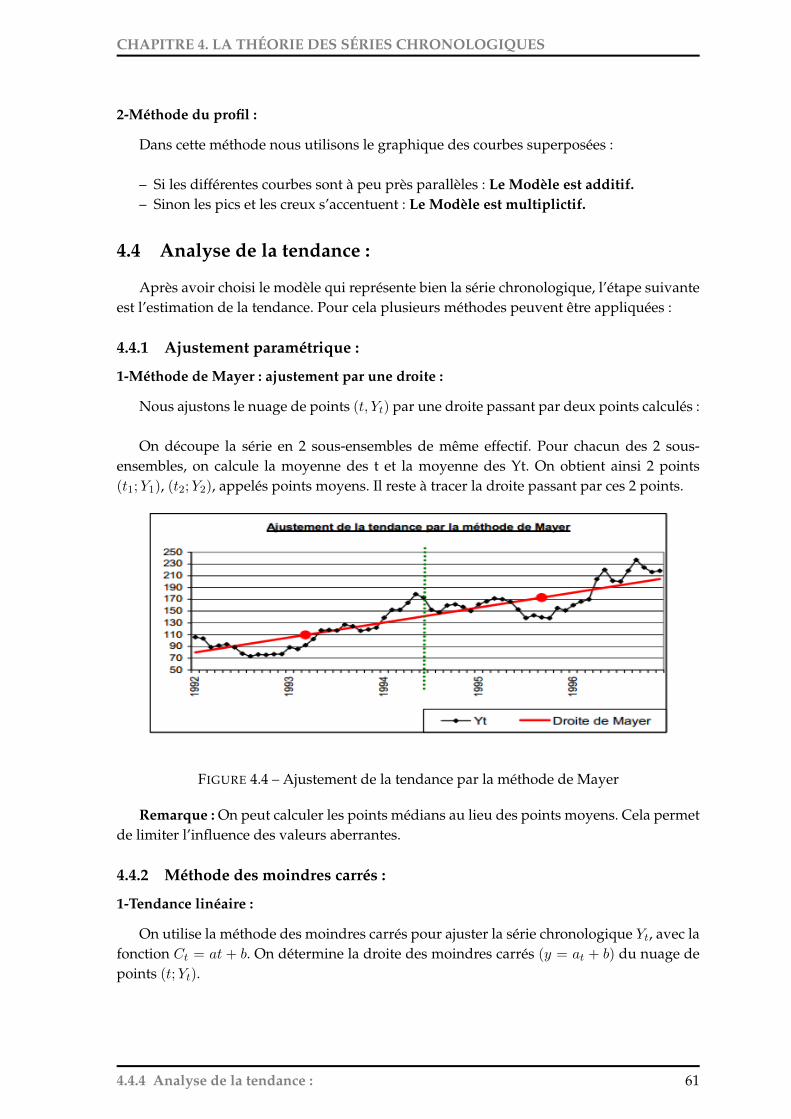
CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
2-Méthode du profil :
Dans cette méthode nous utilisons le graphique des courbes superposées :
– Si les différentes courbes sont à peu près parallèles : Le Modèle est additif.– Sinon les pics et les creux s’accentuent : Le Modèle est multiplictif.
4.4 Analyse de la tendance :
Après avoir choisi le modèle qui représente bien la série chronologique, l’étape suivanteest l’estimation de la tendance. Pour cela plusieurs méthodes peuvent être appliquées :
4.4.1 Ajustement paramétrique :
1-Méthode de Mayer : ajustement par une droite :
Nous ajustons le nuage de points (t, Yt) par une droite passant par deux points calculés :
On découpe la série en 2 sous-ensembles de même effectif. Pour chacun des 2 sous-ensembles, on calcule la moyenne des t et la moyenne des Yt. On obtient ainsi 2 points(t1;Y1), (t2;Y2), appelés points moyens. Il reste à tracer la droite passant par ces 2 points.
FIGURE 4.4 – Ajustement de la tendance par la méthode de Mayer
Remarque : On peut calculer les points médians au lieu des points moyens. Cela permetde limiter l’influence des valeurs aberrantes.
4.4.2 Méthode des moindres carrés :
1-Tendance linéaire :
On utilise la méthode des moindres carrés pour ajuster la série chronologique Yt, avec lafonction Ct = at + b. On détermine la droite des moindres carrés (y = at + b) du nuage depoints (t;Yt).
4.4.4 Analyse de la tendance : 61

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
C’est-à-dire la droite qui minimise la distance :∑((Yt − (a ∗ t+ b))2)
La droite des moindres carrés ajuste au mieux au sens des moindres carrés (c’est cellequi passe le plus près de l’ensemble des points), mais elle ne modélise pas toujours bien latendance, ceci est le cas pour une série possédant une valeur aberrante.
2-Tendance polynomiale :
On peut utiliser la méthode des moindres carrés afin d’ajuster une tendance sous laforme d’un polynôme de degré choisi.
Il faut faire un compromis entre :
– Obtenir des résidus qui fluctuent autour de 0 avec une amplitude la plus faible pos-sible.
– Utiliser un polynôme de degré le plus faible possible.Remarque : On choisit le degré minimum du polynôme qui donne un ajustement cor-
rect : il y a un degré à partir duquel on ne gagne pas beaucoup en continuant à augmenterle degré.
Autre tendance : changement de variable :
Pour d’autres tendances, un changement de variable est nécessaire pour se ramener àune tendance linéaire ou polynomiale.
Exemple :
Si Zt = a ∗ t2 + b, en posant Yt = t2, on se ramène à Zt = aYt + b et on peut faire unajustement linéaire entre Yt et Zt.
4.4.3 Détermination à l’aide d’Excel d’une courbe de tendance :
Excel détermine l’équation d’une courbe de tendance en calculant la courbe des moindrescarrés des points (t;Yt), dans le cas de tendance :
– Linéaire : y = at+ b.– Polynomiale : y = a0 + a1t+ ...+ a6t
6).– Logarithmique : y = aln(t) + b.– Exponentielle : y = c expbt
4.4.4 Les Moyennes mobiles : Ajustement non paramétrique ou Lissage par moyennesou médianes mobiles :
Définition des moyennes mobiles :
Une moyenne mobile en t étant une combinaison linéaire finie des valeurs de la sériecorrespondant à des dates entourant t, elle réalise donc un lissage de la série, une moyenni-
4.4.4 Analyse de la tendance : 62

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
sation.
1-Calcul des moyennes d’ordre p d’une série (Yt) :
Il consiste à :
– considérer les p premières valeurs de la série et en calculer la moyenne.– puis des p valeurs précédentes, on supprime la première valeur et on considère la
valeur qui suit la dernière valeur considérée à l’étape précédente, et on calcule lamoyenne de ces valeurs...
– On répète ceci tant que l’on a p valeurs consécutives.Exemple : Une moyenne mobile d’ordre 3 : Y1+Y2+Y33 , Y2+Y3+Y43 , Y3+Y4+Y53 ,...
2-Affectation des moyennes mobiles à une date :
L’affectation ce fait de la manière suivante :
Yt+1 + Yt+2 + ...+ Yt+pp
est affectée à la date t+ p+12
Exemple :
FIGURE 4.5 – Calcul de moyennes mobiles d’ordre 3 sur une série annuelle
Définition des médianes mobiles :
La définition est analogue à celle des moyennes mobiles : on prend les mêmes valeursde Yt, et on calcule la médiane au lieu de calculer la moyenne.
4.4.5 Estimation de la tendance par les moyennes mobiles :
Si :
4.4.4 Analyse de la tendance : 63

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
– La tendance présente une faible courbure.– Les variations saisonnières sont périodiques de période p et ont une influence nulle
sur l’année.– Les variations accidentelles sont de faible amplitude.Alors la tendance à la date t peut être estimée par une moyenne mobile centrée d’ordre p.
L’ordre p est la périodicité des variations saisonnières, d’où :
– p=4, si la série est trimestrielle.– p=12,si la série est mensuelle.– p=3 ou 5, la série est annuelle.
Les St sont supposées de période p et d’influence nulle sur une année = p mois.
– Les moyennes mobiles d’ordre p Mp (t) effacent les St. Il reste les ξt qui sont supposéesde faible amplitude.
– Les moyennes mobiles permettent de réduire au max le bruit blanc.
4.4.6 Choix pratique de l’ordre d’une moyenne mobile :
Nous rappelons que le but d’un lissage par moyenne mobile est de faire apparaitre l’al-lure de la tendance. Il s’agit donc de faire disparaitre la saisonnalité et de réduire au maxi-mum le bruit blanc. Nous avons vu précédemment que :
– on fait disparaitre une composante saisonnière de période P avec une moyenne mobiled’ordre P.
– on gomme d’autant plus le bruit que l’ordre de la moyenne mobile est grand.– en revanche, on perd les caractéristiques de la tendance avec une moyenne mobile
d’ordre trop élevé. En pratique, on doit donc trouver le meilleur compromis pour lechoix de l’ordre de lissage optimal.
4.5 Analyse de la saisonnalité :
Après avoir estimé la tendance par ajustement ou lissage par une moyenne mobile. Il esttemps d’estimer la composante saisonnale St.
4.5.1 Calcul des données sans tendance :
1.Cas du modèle additif :
Les données sans tendance sont :Yt − Ct
.
4.4.5 Analyse de la saisonnalité : 64

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
2.Cas du modèle multiplicatif :
Les données sans tendance sont :YtCt
.
4.5.2 Calcul des coefficients saisonniers Sj :
Etant donné que l’on a fait l’hypothèse que les variations saisonnières se répètent àl’identique chaque année, on estime un coefficient saisonnier pour chacun des p mois, lavariation saisonnière de tous les mois j sera le coefficient saisonnier du mois j.
On considère les données sans tendance, on les range par année (en ligne) et par mois(en colonne). On calcule la moyenne des données sans tendance concernant le mois j des nannées, ce qui donne une première estimation du coefficient saisonnier Sj , On fait ceci pourchacun des mois j (j = 1, 2, ..., p).
Cas du modèle additif :
Sj =1
n
n∑i=1
(Yij − Cij)
Cas du modèle Multiplicatif :
Sj =1
n
n∑i=1
YijCij
4.5.3 Correction des coefficients saisonniers :
Le principe de conservation des aires consiste à ce que l’influence des variations saison-nières sur une année est nulle, pour conserver ce principe il faut corriger les coefficientssaisonniers. Pour cela on commence par calculer la moyenne des coefficients saisonniers :
S =1
p
p∑i=1
Sj
Cas du Modèle additif :
si la moyenne est non nulle, on calcule les coefficients saisonniers corrigés en soustrayantà chacun des Sj la moyenne :
Sj′ = Sj − S
4.4.5 Analyse de la saisonnalité : 65

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
Cas du Modèle Multiplicatif :
si S est différente de 1, on calcule les coefficients saisonniers corrigés en divisant à cha-cun des Sj la moyenne S :
Sj′ =Sj
S
4.4.5 Analyse de la saisonnalité : 66

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
Exemple :
FIGURE 4.6 – Décomposition avec un modèle additif et un ajustement de la ten-dance(moindres carrés ou méthode de Mayer)
4.6 Prévision des valeurs futures :
Afin de prévoir les valeurs futures de la série, nous utiliserons l’estimation de la ten-dance et celle de la composante saisonnière. Plus précisément, si nous souhaitons prévoirune valeur de la série à l’instant T + h, ou h ≥ 1.
C’est-à-dire à l’horizon h, nous utilisons les estimations de la tendance et de la saisonna-lité et on pose :
XT (h) = QT+h + cj , avec, T + h = j[P ]
4.6.1 Analyse des résidus :
Une fois les composantes du modèle sont estimées,nous pouvons contrôler la pertinencedu modèle par une analyse des résidus. Ceux-ci sont definis par :
ξt = Xt − St −Qt
Si le modèle est bon, il ne doit rester dans les résidus aucune trace de la composantesaisonnale. Pour le vérifier, Nous pouvons tracer le corrélogramme des résidus.
Comme nous le verrons plus loin, le corrélogramme n’est tracé en théorie que dans lecas où la série est stationnaire, ce qui implique en particulier qu’il n’y a dans cette série nitendance ni saisonnalité. En pratique, on s’en sert (dans le cas de l’analyse des résidus pourverifier justement l’absence de la saisonnalité dans les résidus.
– Si c’est le cas et si le modèle est bon, le corrélogramme ne doit présenter que desvaleurs faibles, indiquant une faible corrélation entre les erreurs.
4.4.6 Prévision des valeurs futures : 67

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
– Si au contraire, le corrélogramme 2 présente des pics régulièrement espacés, cela in-dique que le critère saisonnier n’a pas été complètement éliminé et c’est donc le signeque le modèle proposé a échoué. On peut alors réitérer la procédure ci-dessus ou pro-poser un autre modèle.
– Dans le cas où le corrélogramme des résidus n’indique pas la présence d’un mouve-ment saisonnier, on trace le graphe des résidus (t, Qt ) qui sert à repérer d’éventuellesobservations exceptionnelles, un mouvement tendanciel...
– Dans le cas de l’hypothèse d’erreurs gaussiennes, on vérifie celle-ci en traçant l’histo-gramme des résidus, un qq-plot ou encore en effectuant un test de normalité. [5]
4.7 Prévision par lissage exponentiel : (exponentiel smoothing) :
Les méthodes classiques de lissage d’une série chronologique ont un inconvénient ma-jeur qui est celui de la prévision ne tenant pas compte des valeurs les plus récents de la sérieen question, elles ont été éliminées par application de moyenne mobiles. Dans ce qui suit,nous allons présenter des méthodes de lissage exponentiel qui accordent plus ou moinsd’importance aux valeurs passées d’une série temporelle pour faire la prévision à courtterme.
Les méthodes de lissage exponentiel sont des méthodes qui tiennent compte de toutesles observations, mais en diminuant leur importance au fur et à mesure que l’on remontedans le passé.
4.7.1 Principe des méthodes de lissage exponentiel :
Les méthodes de lissage exponentiel sont des méthodes de prévision à court terme :
– Elles supposent que le phénomène étudié ne dépend que de ses valeurs passées.– Ce sont des méthodes d’extrapolation qui donnent un poids prépondérant aux valeurs
récentes : les coefficients de pondération décroissent exponentiellement en remontantdans le temps.
– Chacune des méthodes dépend d’un ou plusieurs paramètres (paramètres de lissage)compris entre et le poids de chacune des valeurs passées se calcule à partir de cesparamètres.
Ces méthodes sont largement diffusées et utilisées. Leur succès est dû à la fois à leursimplicité et à la qualité des prévisions obtenues.
4.7.2 Les différents lissages exponentiels :
1. Le lissage exponentiel simple dépend d’un seul paramètre de lissage.
2. Le lissage de Holt dépend de deux paramètres : l’un relatif au niveau, l’autre à latendance.
2. En analyse des données, un corrélogramme est une représentation graphique mettant en évidence une ouplusieurs corrélations entre des séries de données.
4.4.7 Prévision par lissage exponentiel : (exponentiel smoothing) : 68

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
3. Le lissage de Winters dépend de trois paramètres : l’un relatif au niveau, un autre re-latif à la tendance, et le dernier à la saisonnalité.
FIGURE 4.7 – Les différents lissage exponentiels
4.8 Le lissage exponentiel simple :
Le lissage exponentiel simple (LES) s’applique à des séries chronologiques sans saison-nalité et à tendance plus ou moins constante.
Soit XT (h) la prévision à la date T pour l’horizon h, c’est à dire pour la date T + h. Dansle cas d’un LSE qui s’applique à des séries sans tendance, la prévision faite à la date T estune valeur constante indépendante de l’horizon h :
XT (h) = XT
XT = α.XT + (1− α).XT−1
d’où :
XT = αT−1∑i=0
(1− α)i.XT−i
où α est un paramètre compris entre 0 et 1.
La formule de calcul demande le choix de la valeur initiale. Celle-ci peut être :
– La moynne de la série chronologique.– La première observation x1 de la série chronologique.– Un paramètre proche de 1 donne plus d’importance aux observations récentes, tandis
qu’un paramètre proche de 0 renforce l’importance du passé plus lointain.
Pour les erreurs de prévision eT = XT −XT−1, on peur chercher le paramère α qui mi-nimise la somme des carrés du dernier tiers des erreurs.
4.4.8 Le lissage exponentiel simple : 69

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
4.9 La méthode de Holt et Winters :
Le lissage exponentiel de Holt s’applique aux séries chronologiques sans composantesaisonnière et à tendance localement linéaire.
Cette tendance est donc définie à chaque date par son ordonnée appelée niveau, et lapente qui définit la direction de la droite de prévision.
-Le Niveau :
a1(T ) = λXT + (1− λ)[a1(T − 1) + a2(T − 1)] = λXT + (1− λ)XT−1(1)
-La Pente :
a2(T ) = µ[a1(T )− a1(T − 1)] + (1− µ)a2(T − 1)
où : λ et µ sont des paramètres compris entre 0 et 1.
La prévision à la date T pour l’horizon h, c’est à dire pour la date T+h :
XT (h) = a1(T ) + a1(T ).h
Le choix des valeurs initiales peut être comme suit :
-La pente initiale : XT−X1T−1
-Le niveau initial de la tendance : X1 − 0.5.a0
d’autres valeurs peuvent être envisagées.
En résumé, La méthode de Holt repose sur deux paramètres et suppose la tendance lo-calement linéaire. A chaque date, on remet à jour le niveau et la pente de la tendance.
Le lissage de Winters concerne les séries chronologiques saisonnières, sa compréhensionsupposse une bonne maîtrise du lissage de Holt : établissement d’une fonction localementlinéaire dont la pente et le niveau sont tous les deux estimés à partir des réalisations passéeset de prévisions. On ajoute en effet un coefficient saisonnier, qu’on appelle delta. [6]
4.10 La Prévision par un modèle ARIMA(autoregressive integra-ted moving average) :
En statistique, en particulier dans les séries chronologiques. Le modèle ARIMA(autoregressiveintegrated moving average) est une généralisation du modele ARMA (autoregressive mo-ving average). Les modèles ARMA (modèles autorégressifs et moyenne mobile), ou aussimodèle de Box-Jenkins, sont les principaux modèles des séries temporelles. Elles permettentpour une série temporelle Xt, de prédire, éventuellement, les valeurs futures de cette série.
4.4.9 La méthode de Holt et Winters : 70

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
Le modèle ARMA est composé de deux parties : une partie autorégressive (AR) et unepartie moyenne mobile (MA). Le modèle est généralement noté ARMA (p, q), où p estl’ordre de la partie AR et q l’ordre de la partie MA.
4.10.1 Définition :
Un modèle autorégressif et moyenne mobile d’ordres (p,q) (abrégé en ARMA(p,q)) estun processus temporel discret (Xt, t ∈ N) vérifiant :
Xt = εt +
p∑i=1
ϕiXt−i +
q∑i=1
θiεt−i
où les paramètres ϕi et θi sont constants, et les termes d’erreurs εt sont indépendants duprocessus.
– Un modèle autorégressif AR(p) est un ARMA(p,0).– Un modèle moyenne mobile MA(q) est un ARMA(0,q).Les modèles ARMA sont donc représentatifs d’un processus généré par une combinai-
son des valeurs passées et des erreurs passées.
4.10.2 Modèle AR (Auto Régressif) :
Dans le processus autorégressif d’ordre p, l’observation présente yt est générée par unemoyenne pondérée des observations passées jusqu’à la p-ième période sous la forme sui-vante :
AR(1) : yt = θ1yt−1 + εt
AR(2) : yt = θ1yt−1 + θ2yt−2 + εt
...
AR(p) : yt = θ1yt−1 + θ2yt−2 + ...+ θpyt−p + εt
où θ1, θ2, ..., θp sont des paramètres à estimer positifs ou négatifs, εt est bruit blanc.
Dans l’étude des séries temporelles en statistique :
un processsus εt est qualifié de bruit blanc si :
1. E[εt] = 0.
2. E[ε2t ] = σ2.
3. E[εtετ ] = 0,∀t 6= τ .
4.4.10 La Prévision par un modèle ARIMA(autoregressive integrated moving average) :71

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
4.10.3 Modèle MA (Moving Average : Moyenne Mobile) :
Dans un processus de moyenne mobile d’ordre q, chaque observation yt est générée parune moyenne pondérée d’aléas jusqu’à la q-ième période.
MA(1) : yt = εt − α1εt−1
MA(2) : yt = εt − α1εt−1 − α2εt−2
...
MA(q) : yt = εt − α1εt−1 − α2εt−2 − ...− αqεt−q
où α1, α2, ..., αq sont des paramètres pouvant être positifs ou négatifs et εt est un aléagaussien.
Les termes d’erreur εt sont généralement supposés indépendants et identiquement dis-tribués (iid) selon une loi normale de moyenne nulle : εt ∼ N(0, σ2), où σ2 est la variance.
Conditions d’utilisation :
Les modèles AR, MA, ARMA ne sont représentatifs que dans le cas des séries :
– stationnaires en tendance.– corrigées des variations saisonnières.
L’extension aux processus ARIMA :
Lorsque la série étudiée n’est pas stationnaire. Il convient de la stationnariser par pas-sage aux différences selon l’ordre d’intégration I=d (c’est à dire le nombre de fois qu’il fautdifférencier la série pour la rendre stationnaire). La série différenciée est alors étudiée selonla méthodologie de Box Jenkins qui permet de déterminer les ordres p et q des parties ARet MA. On note ce type de modèle ARIMA (p, d, q).
4.10.4 La Méthode de Box et Jenkins :
La méthodologie de Box Jenkins vise à formuler un modèle permettant de représenterau mieux une série chronologique avec comme objectif de prévoir ses valeurs futures. De cefait, l’objet de cette méthodologie est de modéliser une série temporelle en fonction de sesvaleurs passées et présentes afin de déterminer le processus ARIMA adéquat.
Cette méthodologie suggère une procédure à trois étapes :
1. Identification du modèle.
2. Estimation du modèle.
3. Validation du modèle.
4.4.10 La Prévision par un modèle ARIMA(autoregressive integrated moving average) :72

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
Identification du modèle :
La première étape dans la méthodologie proposée par Box et Jenkins concerne la décom-position retenue de la série chronologique selon les trois types de processus en spécifiantles trois paramètres p, d et q du modèle ARIMA (p,d,q). L’identification des processus au-torégressifs et de moyennes mobiles susceptibles d’expliquer le comportement de la sérietemporelle suppose de vérifier tout d’abord la stationnarité de la série.
Si la série n’est pas stationnaire, c’est à dire que la variabilité de la série est plus élevéesur certaines périodes que sur d’autres ou la moyenne de la série varie sur le court terme,il convient de transformer la série pour obtenir une série stationnaire. Généralement, Latransformation la plus courante est la différenciation de la série, opération où chaque valeurde la série est remplacée par la différence entre cette valeur et celle qui la précède.
Une Transformation logarithmique ou bien racine carrée peuvent être utilisées en situa-tion d’hétéroscédasticité(En statistique, l’on parle d’hétéroscédasticité lorsque les variancesdes variables examinées sont différentes ou la variance de la série n’est pas constante et dé-pend des valeurs prises).
Une fois obtenue la stationnarité de la série, l’étape suivante consiste à analyser le graphede la fonction d’autocorrélation (FAC) et celui de la fonction d’autocorrélation partielle(FAP) afin de déterminer les paramètres (p,d,q) du modèle.
Le paramètre d est fixé par le nombre de différenciations effectuées pour rendre la sériestationnaire, en règle générale une différenciation suffit : d ∈ 2, 1, 0. Une fois ce paramètrefixé, il convient de spécifier l’ordre p du processus autorégressif et q celui de la moyennemobile.
La Fonction d’autocorrélation, ACF, est consitituée par l’ensemble des autocorrélationsρk = corr(yt, yt−k) de la série calculées pour des décalages d’ordre k, k ∈ 1, ...,K.
La Fonction d’autocorrélation partiel, FAP, est constituée par l’ensemble des autocorré-lations partielles musurant la corrélation entre yt et yt−k.
L’interprétation des corrélogrammes pour la spécification des processus AR et MA estgénéralement gouvernée par les règles suivantes :
1-Les processus autorégressifs d’ordre p, AR(p), présentent une fonction d’autocorréla-tion dont les valeurs décroissent exponentiellement avec des alternances possibles de va-leurs positives et négatives ;leur fonction d’autocorrélation partielle présente exactement ppics aux p premières valeurs du corrélogramme d’autocorrélation partielle.
2-Les processus de moyenne mobile d’ordre q, MA(q), présentent exactement q pics auxq premières valeurs du corrélogramme de la fonction d’autocorrélation et des valeurs expo-nentiellement décroissantes de la fonction d’autocorrélation partielle.
4.4.10 La Prévision par un modèle ARIMA(autoregressive integrated moving average) :73

CHAPITRE 4. LA THÉORIE DES SÉRIES CHRONOLOGIQUES
Estimation des paramètres p,d,q :
La procédure ARIMA sous R ou SPSS permet selon un algorithme rapide d’estimationdu maximum de vraisemblance d’estimer les coefficients du modèle que vous avez identifiéau préalable en fournissant les paramètres p, q et d.
4.10.5 Validation du modèle et Prévision :
Les principales vérifications à effectuer portent sur les éléments suivants :
-Les coefficients du modèle doivent être significativement différents de 0 (le test du t deStudent s’applique de manière classique). Si un coefficient n’est pas significativement dif-férent de 0, il convient d’envisager une nouvelle spécification éliminant l’ordre du modèleAR ou MA non valide.
-Les valeurs des fonctions d’autocorrélation et d’autocorrélation partielle de la série desrésidus doivent être toutes nulles. Si les autocorrélations d’ordre 1 ou 2 diffèrent significa-tivement de 0, alors la spécification (p,d,q) du modèle ARIMA est probablement inadaptée.Cependant, une ou deux autocorrélations d’ordre supérieur peuvent par aléas dépasser leslimites de l’intervalle de confiance à 95%.
-Les caractéristiques des résidus doivent correspondre à celle d’un bruit blanc. Une sta-tistique couramment utilisée pour tester un bruit blanc est le Q’ de Box et Ljung.
Lorsque le modèle est validé, la prévision peut alors être calculée à un horizon de quelquespériodes, limitées car la variance de l’erreur de prévision croît très vite avec l’horizon.[7]
4.4.10 La Prévision par un modèle ARIMA(autoregressive integrated moving average) :74

CHAPITRE 5
LA PRÉDICTION DE LA POPULATION INDIENNE PAR UNLISSAGE EXPONENTIEL ET UN MODÈLE ARIMA
5.1 La prédiction par un lissage exponentiel de Holt Winters :
Dans cette Partie, l’objectif principal est de prédire la population Indienne en 2020 enutilisant les séries chronologiques sous le logiciel R. Nous disposons de la base de donnéede la population Indienne de l’année 2000 jusqu’au 2014 que nous allons analyser, voir sonévolution au cours du temps dans le but de l’expliquer puis la prévoir dans le futur proche.
Dans un premier temps, Nous allons observer la série, voir son allure pour avoir uneidée générale sur son évolution. Après, la modéliser c’est à dire trouver le modèle adéquatqui reflète significativement la série. Par la suite, il convient d’analyser ses composantes lesunes après les autres, les ajuster puis les estimer. Finalement, Une fois le modèle construit,ses paramètres sont estimés nous sommes en mesure de faire la prédiction.
5.2 Lecture des donnéess sous R :
La premier des choses qu’il faut mettre en place afin d’analyser la base de donnée de lapopulation indienne est de la lire sous R et voir son allure. La fonction Scan () ou read.csv() permet de lire la série de données puisque nous disposons de celle ci sous format .csv.
> TotalPopulation <-read.csv("D:/PFE/Population.csv",col.names="Population")
> TotalPopulation
Population
1 1.06
2 1.08
3 1.09
4 1.11
5 1.13
6 1.14
7 1.16
8 1.17
75

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
9 1.19
10 1.20
11 1.22
12 1.24
13 1.25
14 1.27
Nous disposons de la population indienne pour les 15 dernières années. Les chiffres sonten milliards.
Après avoir lu la série de donnée, l’étape suivante consiste à stocker celle ci dans un objetde type série chronologique, pour qu’on puisse utiliser toutes les fonctions d’analyse desséries chronologiques sous R. Pour faire ainsi, l’utilisation de la fonction ts () est nécessaire.
> TotalPopulationtimeseries <- ts(TotalPopulation)
> TotalPopulationtimeseries
Time Series:
Start = 1
End = 14
Frequency = 1
Population
[1,] 1.06
[2,] 1.08
[3,] 1.09
[4,] 1.11
[5,] 1.13
[6,] 1.14
[7,] 1.16
[8,] 1.17
[9,] 1.19
[10,] 1.20
[11,] 1.22
[12,] 1.24
[13,] 1.25
[14,] 1.27
La fréquence est égale à 1 puisque il s’agit de données annuelles.
5.3 Tracement du graphe de la série chronologique :
L’étape suivante est de tracer le graphe de la série chronologique pour avoir une idéegénérale sur son évolution. La fonction Plot () sous R permet tracer l’allure :
> plot.ts(TotalPopulationtimeseries,ylab="Population",
+ main="Growth of the Population of India from 2000 to 2014")
5.5.3 Tracement du graphe de la série chronologique : 76

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
Growth of the Population of India from 2000 to 2014
Time
Pop
ulat
ion
2 4 6 8 10 12 14
1.10
1.15
1.20
1.25
Nous pouvons clairement voir que cette série chronologique peut être expliquée par unmodèle additif, puisque, les fluctuations aléatoires sont approximativement constantes entaille dans tout le temps.
La méthode de Bonde permet de valider qu’il s’agit bien d’un modèle additif car géné-ralement dans un tel modèle l’amplitude des variations est constante autour de la tendance.
5.4 Décomposition de la série chronologique :
La décomposition de la série consiste à déterminer ses différentes composantes : Ten-dance, saisonnalité et la composante résiduelle.
Il est clair que notre série de donnée ne représente aucune composante saisonnière. Pourcela, nous allons essayer d’estimer seulement les composantes tendancielle et résiduelle.
Nous avons vu dans la partie théorique qu’un parmi les méthodes utilisées pour estimerla tendance sont les moyennes mobiles.
La fonction SMA () sous R permet d’estimer la tendance en utilisant une moyenne mo-bile simple. Cette fonction est trouvée dans le package TTR.
Après avoir installé le package TTR, nous sommes en mesure d’utiliser la fonction SMA
5.5.4 Décomposition de la série chronologique : 77
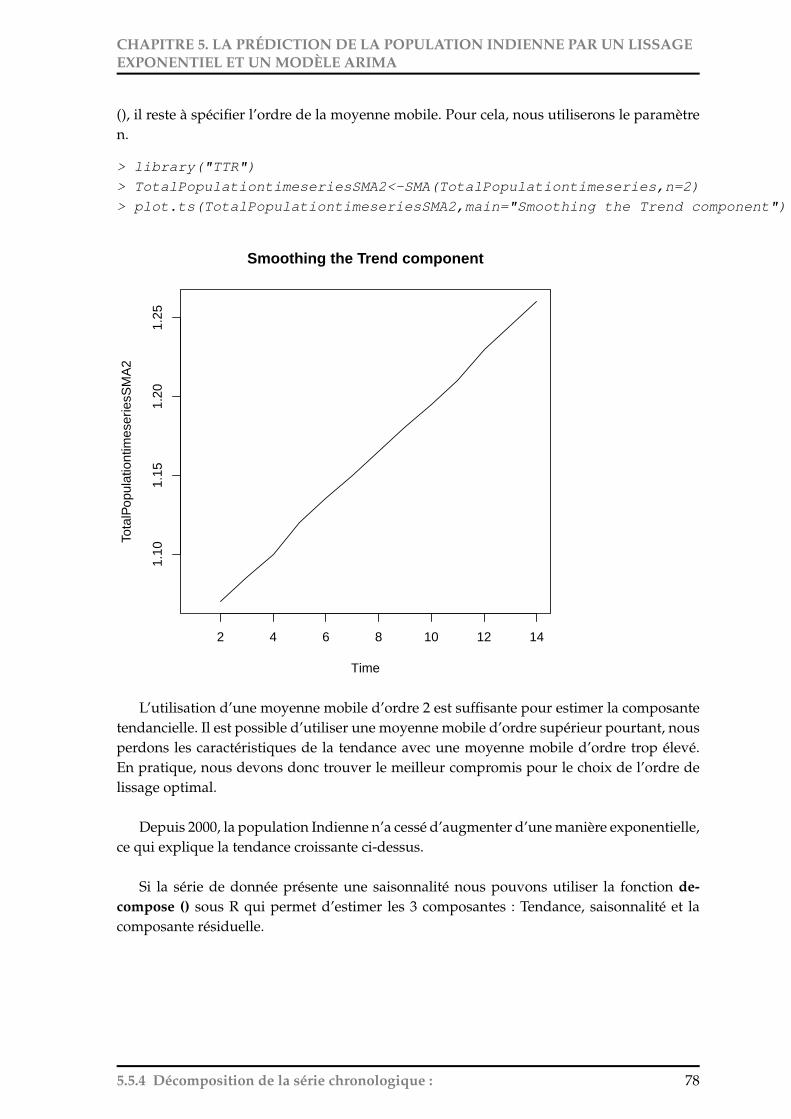
CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
(), il reste à spécifier l’ordre de la moyenne mobile. Pour cela, nous utiliserons le paramètren.
> library("TTR")
> TotalPopulationtimeseriesSMA2<-SMA(TotalPopulationtimeseries,n=2)
> plot.ts(TotalPopulationtimeseriesSMA2,main="Smoothing the Trend component")
Smoothing the Trend component
Time
Tota
lPop
ulat
iont
imes
erie
sSM
A2
2 4 6 8 10 12 14
1.10
1.15
1.20
1.25
L’utilisation d’une moyenne mobile d’ordre 2 est suffisante pour estimer la composantetendancielle. Il est possible d’utiliser une moyenne mobile d’ordre supérieur pourtant, nousperdons les caractéristiques de la tendance avec une moyenne mobile d’ordre trop élevé.En pratique, nous devons donc trouver le meilleur compromis pour le choix de l’ordre delissage optimal.
Depuis 2000, la population Indienne n’a cessé d’augmenter d’une manière exponentielle,ce qui explique la tendance croissante ci-dessus.
Si la série de donnée présente une saisonnalité nous pouvons utiliser la fonction de-compose () sous R qui permet d’estimer les 3 composantes : Tendance, saisonnalité et lacomposante résiduelle.
5.5.4 Décomposition de la série chronologique : 78

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
Exemple :
FIGURE 5.1 – Exemple de décomposition d’une série chronologique avec saisonnalité
Ci dessus un exemple de d’utilisation de la fonction decompose (), nous pouvons consta-ter l’estimation des 3 composantes séparément : Tendance(Trend), Saisonnalité(Seasonal) etla composante résiduelle(Random).
Dans notre cas, la série chronologique de la population Indienne ne présente aucunesaisonnalité donc nous n’aurons pas besoin d’utiliser la fonction decompose (), il suffit d’es-timer les composantes tendancielle et résiduelle. L’utilisation d’une moyenne mobile permetd’estimer la tendance et réduire au max les fluctuations résiduelles.
5.5 La Prévision par un Lissage exponentiel :
5.5.1 Lissage exponentiel simple :
Nous avons vu qu’un parmi les méthodes de prévision par un lissage exponentiel estle lissage exponentiel simple, qui est utilisé dans le cas ou la série chronologique peut êtremodélisée par un modèle additif sans saisonnalité et avec une tendance constante.
Dans notre cas la population indienne peut être modélisée par un modèle additif puisquel’amplitude des variations est constante autour de la tendance d’autant plus que la série neprésente aucune saisonnalité. Cependant, la tendance n’est pas constante, ce qui signifie quel’utilisation d’un lissage exponentiel simple n’est absolument pas approprié.
5.5.5 La Prévision par un Lissage exponentiel : 79
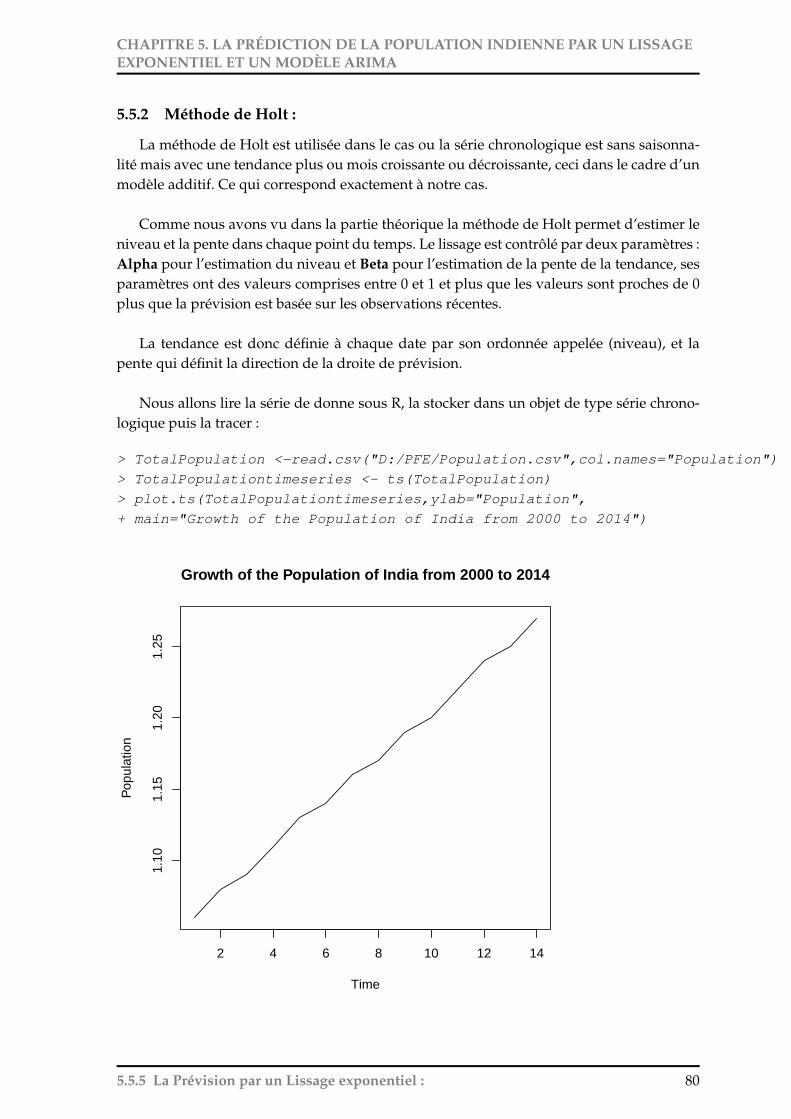
CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
5.5.2 Méthode de Holt :
La méthode de Holt est utilisée dans le cas ou la série chronologique est sans saisonna-lité mais avec une tendance plus ou mois croissante ou décroissante, ceci dans le cadre d’unmodèle additif. Ce qui correspond exactement à notre cas.
Comme nous avons vu dans la partie théorique la méthode de Holt permet d’estimer leniveau et la pente dans chaque point du temps. Le lissage est contrôlé par deux paramètres :Alpha pour l’estimation du niveau et Beta pour l’estimation de la pente de la tendance, sesparamètres ont des valeurs comprises entre 0 et 1 et plus que les valeurs sont proches de 0plus que la prévision est basée sur les observations récentes.
La tendance est donc définie à chaque date par son ordonnée appelée (niveau), et lapente qui définit la direction de la droite de prévision.
Nous allons lire la série de donne sous R, la stocker dans un objet de type série chrono-logique puis la tracer :
> TotalPopulation <-read.csv("D:/PFE/Population.csv",col.names="Population")
> TotalPopulationtimeseries <- ts(TotalPopulation)
> plot.ts(TotalPopulationtimeseries,ylab="Population",
+ main="Growth of the Population of India from 2000 to 2014")
Growth of the Population of India from 2000 to 2014
Time
Pop
ulat
ion
2 4 6 8 10 12 14
1.10
1.15
1.20
1.25
5.5.5 La Prévision par un Lissage exponentiel : 80

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
Pour faire la prévision par la méthode de Holt, nous allons utiliser la fonction Holt Win-ters() sous R. il faut modifier le paramètre gamma= False(le paramètre gamma est utilisédans la méthode Holt Winters exponential smoothing pour estimer la saisonnalité que nousallons voir par la suite).
> TotalPopulationforecasts <- HoltWinters(TotalPopulationtimeseries,
+ gamma=FALSE)
> TotalPopulationforecasts
Holt-Winters exponential smoothing with trend and without seasonal component.
Call:
HoltWinters(x = TotalPopulationtimeseries, gamma = FALSE)
Smoothing parameters:
alpha: 0.3400605
beta : 1
gamma: FALSE
Coefficients:
[,1]
a 1.26927149
b 0.01715626
La valeur estimée de Alpha est égale a 0.34 ce qui signifie que l’estimation du niveau achaque point du temps est basée sur des observations passées. Tendis que, l’estimation deBeta nous indique que l’estimation de la composante tandentielle est plus ou mois basée surles observations récentes de la série chronologique.
Les valeurs prédites par la fonction Holtwinters sont stockées dans la variable TotalPo-pulationforcastsfitted :
> #values predicted by holtwinters for the same period of time
> TotalPopulationforecasts$fitted
Time Series:
Start = 3
End = 14
Frequency = 1
xhat level trend
3 1.100000 1.080000 0.02000000
4 1.113199 1.096599 0.01659940
5 1.127623 1.112111 0.01551161
6 1.144751 1.128431 0.01632007
7 1.157840 1.143135 0.01470439
8 1.174013 1.158574 0.01543897
9 1.186723 1.172649 0.01407417
10 1.203026 1.187837 0.01518862
5.5.5 La Prévision par un Lissage exponentiel : 81
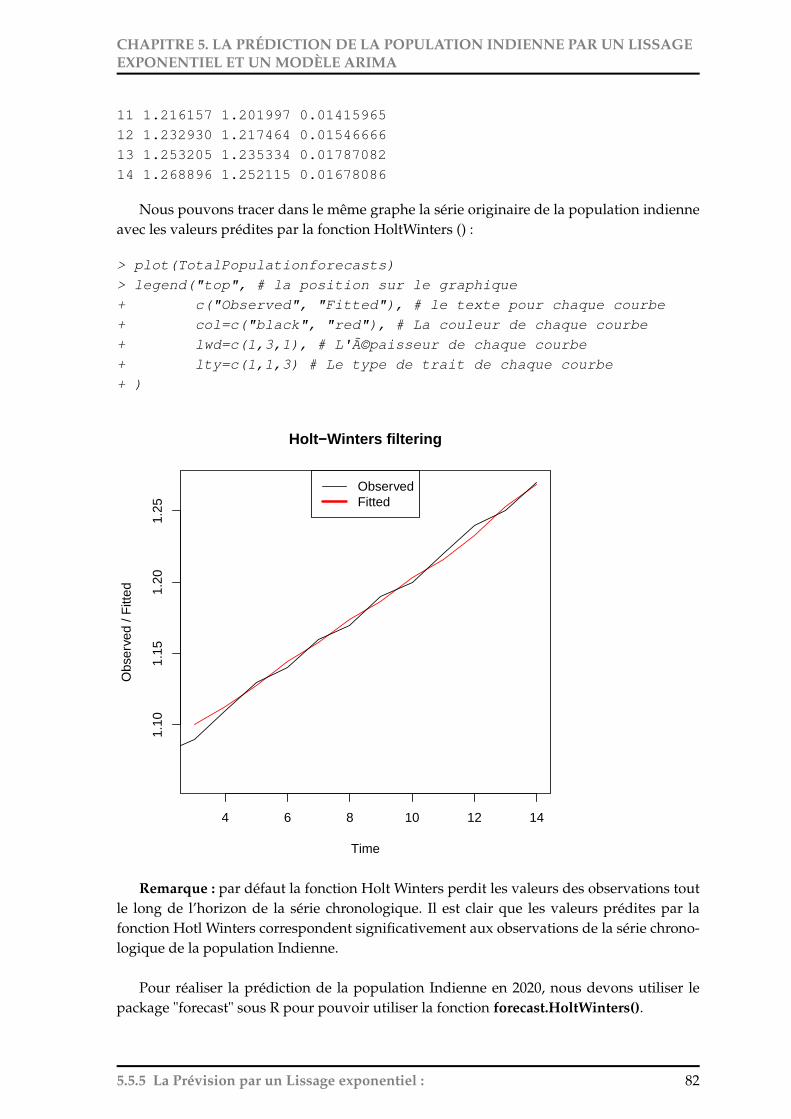
CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
11 1.216157 1.201997 0.01415965
12 1.232930 1.217464 0.01546666
13 1.253205 1.235334 0.01787082
14 1.268896 1.252115 0.01678086
Nous pouvons tracer dans le même graphe la série originaire de la population indienneavec les valeurs prédites par la fonction HoltWinters () :
> plot(TotalPopulationforecasts)
> legend("top", # la position sur le graphique
+ c("Observed", "Fitted"), # le texte pour chaque courbe
+ col=c("black", "red"), # La couleur de chaque courbe
+ lwd=c(1,3,1), # L'épaisseur de chaque courbe
+ lty=c(1,1,3) # Le type de trait de chaque courbe
+ )
Holt−Winters filtering
Time
Obs
erve
d / F
itted
4 6 8 10 12 14
1.10
1.15
1.20
1.25
ObservedFitted
Remarque : par défaut la fonction Holt Winters perdit les valeurs des observations toutle long de l’horizon de la série chronologique. Il est clair que les valeurs prédites par lafonction Hotl Winters correspondent significativement aux observations de la série chrono-logique de la population Indienne.
Pour réaliser la prédiction de la population Indienne en 2020, nous devons utiliser lepackage "forecast" sous R pour pouvoir utiliser la fonction forecast.HoltWinters().
5.5.5 La Prévision par un Lissage exponentiel : 82

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
Après avoir installé le package "forecast", nous pouvons faire appel à :
> library("forecast")
Par la suite nous allons utiliser comme "input" à la fonction forecast.HoltWinters() la sérielissée par la méthode de holtWinters tout en spécifiant le nombre de points h à prédire.
> Populationforecasts2 <-forecast.HoltWinters(TotalPopulationforecasts, h=6)
> Populationforecasts2
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
15 1.286428 1.280324 1.292532 1.277092 1.295763
16 1.303584 1.296202 1.310966 1.292294 1.314874
17 1.320740 1.311083 1.330398 1.305970 1.335510
18 1.337897 1.325160 1.350633 1.318418 1.357375
19 1.355053 1.338623 1.371482 1.329926 1.380179
20 1.372209 1.351593 1.392825 1.340679 1.403739
La fonction Forecast.Holtwinters donne la prédiction de la population avec un inter-valle de confiance de l’ordre de 80% et 95%.
Par exemple, la population Indienne en 2020 sera de 1.372209 milliard avec un intervallede confiance à 95% [1.340679,1.403739].
Nous pouvons tracer le graphe des valeurs prédites :
> #plot forcasts
> plot.forecast(Populationforecasts2,xlab="time",ylab="Population",
+ main="Forcasting of the population of India in 2020")
> legend("top", # la position sur le graphique
+ c("Observed", "Predicted"), # le texte pour chaque courbe
+ col=c("black", "blue"), # La couleur de chaque courbe
+ lwd=c(1,3,1), # L'épaisseur de chaque courbe
+ lty=c(1,1,3) # Le type de trait de chaque courbe
+ )
>
5.5.5 La Prévision par un Lissage exponentiel : 83

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
Forcasting of the population of India in 2020
time
Pop
ulat
ion
5 10 15 20
1.05
1.10
1.15
1.20
1.25
1.30
1.35
1.40 Observed
Predicted
Le graphe ci-dessus illustre la prédiction de la population indienne de 2015 jusqu’au2020 avec les niveaux d’intervalles de confiance à 80% et 95%.
Pour valider le modèle de prédiction de HoltWinters, il faut vérifier certaines conditionssur les erreurs de prédictions (forecast errors) :
1. non corrélation entre 2 erreurs de prédictions successives.
2. Les erreurs de prédiction sont normalement distribuées de moyenne nulle et de va-riance constante.
Pour tester s’il y a une corrélation entre 2 erreurs successives, nous examinerons l’ACFdes erreurs des valeurs prédites.
> acf(Populationforecasts2$residuals, lag.max=20)
5.5.5 La Prévision par un Lissage exponentiel : 84

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
0 2 4 6 8 10
−0.
50.
00.
51.
0
Lag
AC
Fobject$x
Nous pouvons constater que toutes les autocorrélations entre 2 erreurs de prédictionssont significativement faibles et donc l’hypothèse qu’il n’y ait pas de corrélations entre 2erreurs de prédictions successives est validée.
Un autre test pour verifier la non corrélations entre 2 erreurs de prédictions successivesest le test de Ljung-Box.
> Box.test(Populationforecasts2$residuals, lag=10, type="Ljung-Box")
Box-Ljung test
data: Populationforecasts2$residuals
X-squared = 12.1626, df = 10, p-value = 0.2743
Le p value du test de Box Ljung est de 0.2743 supérieur à 0.05, donc nous acceptons l’hy-pothèse de non corrélations entre 2 erreurs successives.
La dernière étape de validation du Modèle de HoltWinters est de verifier que les erreursde prédictions suivent une loi normal avec une moyenne nulle et une variance constante.
Pour cela, nous allons tracer le graphe des résidus des valeurs prédites pour voir si lavariance est constante :
> plot.ts(Populationforecasts2$residuals)
5.5.5 La Prévision par un Lissage exponentiel : 85

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
Time
obje
ct$x
4 6 8 10 12 14
−0.
010
−0.
005
0.00
00.
005
Le graphe ci-dessus nous permet de voir clairement que les résidus des valeurs préditesont approximativement une variance constante dans tout le temps.
Finalement, il reste à vérifier que les résidus des valeurs prédites sont normalementdistribués avec une moyenne constante. Pour cela, nous allons tracer un qqnorm des erreursde prédictions.
> y<-rnorm(1000,0,1)
> qqnorm(Populationforecasts2$residuals)
> qqline(Populationforecasts2$residuals)
5.5.5 La Prévision par un Lissage exponentiel : 86
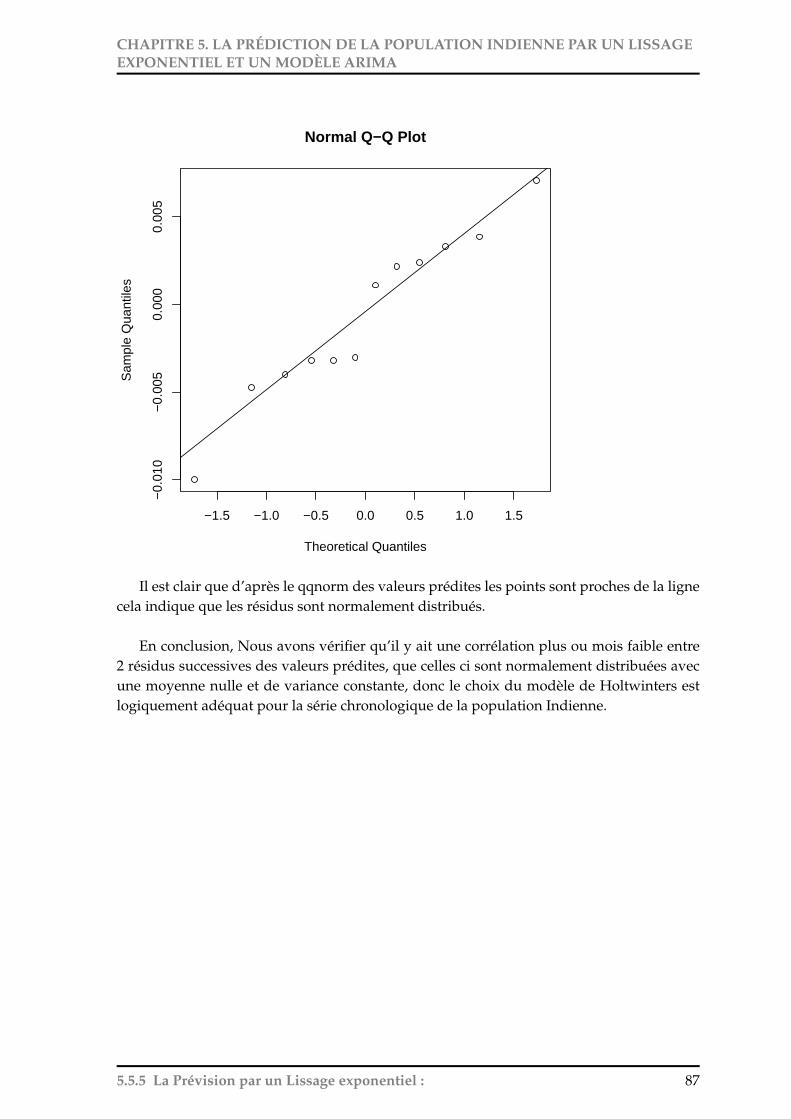
CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5
−0.
010
−0.
005
0.00
00.
005
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Il est clair que d’après le qqnorm des valeurs prédites les points sont proches de la lignecela indique que les résidus sont normalement distribués.
En conclusion, Nous avons vérifier qu’il y ait une corrélation plus ou mois faible entre2 résidus successives des valeurs prédites, que celles ci sont normalement distribuées avecune moyenne nulle et de variance constante, donc le choix du modèle de Holtwinters estlogiquement adéquat pour la série chronologique de la population Indienne.
5.5.5 La Prévision par un Lissage exponentiel : 87

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
5.6 La Prédiction par un modele ARIMA(autoregressive integra-ted moving average) :
Les modèles de lissage exponentiels permettent de faire la prédiction d’une série chro-nologique en ne tenant compte d’aucune corrélation entre 2 observations successives maisrequièrent l’hypothèse que les résidus des valeurs prédites doivent être normalement dis-tribués avec une moyenne nulle et une variance constante.
Le modèle ARIMA prend en considération la corrélation entre 2 observations succes-sives, puisque il inclut la composante irrégulière d’une série chronologique dans la prédic-tion. Cette hypothèse de corrélation permet de prédire au mieux la série chronologique dela population Indienne.
5.7 Différenciation de la série chronologique de la population In-dienne :
Les modèles ARIMA sont définis seulement pour les séries stationnaires. Pour cela, encas de non stationnarité il faut différencier la série d fois si nécessaire pour obtenir finale-ment une série stationnaire. Le Modèle ARIMA sera donc ARIMA (p,d,q) ou d est le nombrede différenciation.
Sous R la fonction qui permet de faire la différentiation est la fonction diff() :
> TotalPopulation <-read.csv("D:/PFE/Population.csv",col.names="Population")
> TotalPopulationtimeseries <- ts(TotalPopulation)
> plot.ts(TotalPopulationtimeseries,ylab="Population",
+ main="Growth of the Population of India from 2000 to 2014")
5.5.6 La Prédiction par un modele ARIMA(autoregressive integrated moving average) :88

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
Growth of the Population of India from 2000 to 2014
Time
Pop
ulat
ion
2 4 6 8 10 12 14
1.10
1.15
1.20
1.25
D’après le graphe ci-dessus, la série présente une non stationnarité illustrée par la pré-sence d’une tendance linéaire croissante.
Avant de faire une telle ou telle différenciation, nous allons mettre en place des tests destationnarité.
Nous allons utiliser dans un premier lieu "KPSS (Kwiatkowski Phillips Schmidt Shin)test". C’est un test utilisé pour tester l’hypothèse nulle "Trend Stationary" ou encore la sérieest caractérisée par une non stationnarité déterministe.
> library(tseries)
> kpss.test(TotalPopulationtimeseries, null="Trend",lshort=TRUE)
KPSS Test for Trend Stationarity
data: TotalPopulationtimeseries
KPSS Trend = 0.0448, Truncation lag parameter = 0, p-value = 0.1
La p value du test est égale à 0.1 supérieur au seuil 0.05 du test donc nous ne rejettonspas l’hypothèse de non stationnarité déterministe.
Pour vérifier la non stationnarité de la série de la population indienne nous allons utiliserle test de "Phillips Perron" pour détecter la non stationnarité. L’hypothèse nulle du test c’estla présence d’une stationnarité déterministe ou encore "non trend stationnary". [8]
5.5.7 Différenciation de la série chronologique de la population Indienne : 89
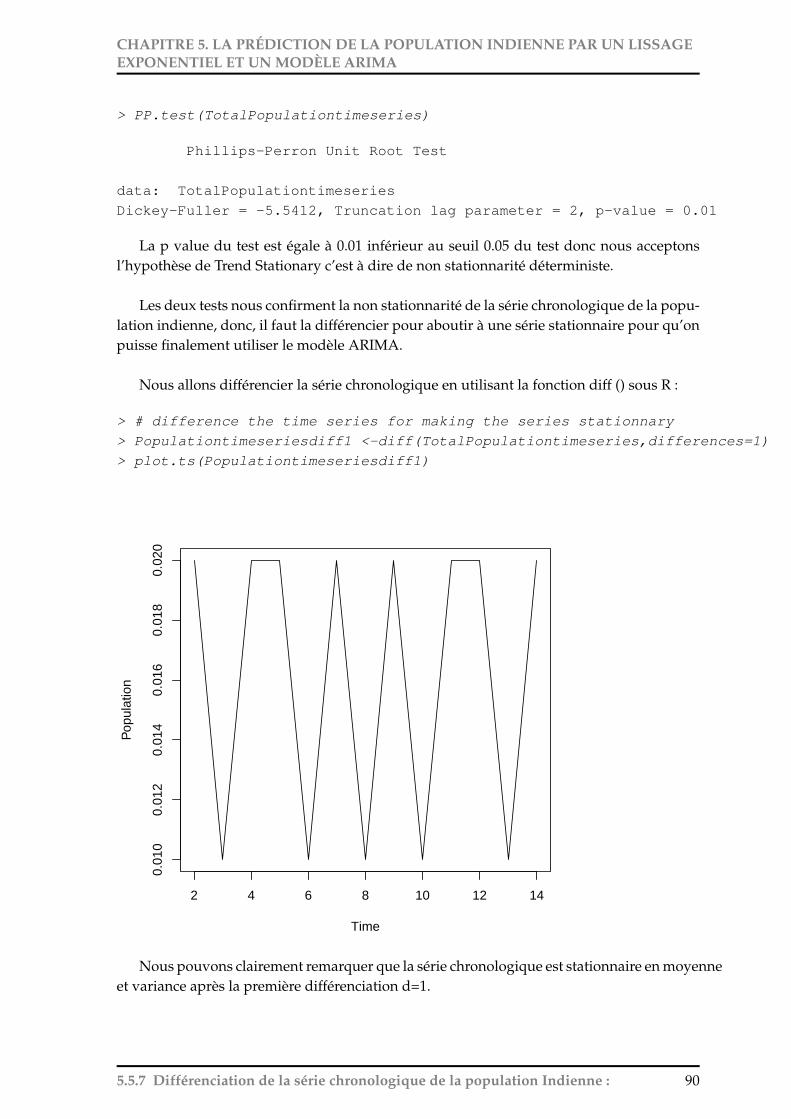
CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
> PP.test(TotalPopulationtimeseries)
Phillips-Perron Unit Root Test
data: TotalPopulationtimeseries
Dickey-Fuller = -5.5412, Truncation lag parameter = 2, p-value = 0.01
La p value du test est égale à 0.01 inférieur au seuil 0.05 du test donc nous acceptonsl’hypothèse de Trend Stationary c’est à dire de non stationnarité déterministe.
Les deux tests nous confirment la non stationnarité de la série chronologique de la popu-lation indienne, donc, il faut la différencier pour aboutir à une série stationnaire pour qu’onpuisse finalement utiliser le modèle ARIMA.
Nous allons différencier la série chronologique en utilisant la fonction diff () sous R :
> # difference the time series for making the series stationnary
> Populationtimeseriesdiff1 <-diff(TotalPopulationtimeseries,differences=1)
> plot.ts(Populationtimeseriesdiff1)
Time
Pop
ulat
ion
2 4 6 8 10 12 14
0.01
00.
012
0.01
40.
016
0.01
80.
020
Nous pouvons clairement remarquer que la série chronologique est stationnaire en moyenneet variance après la première différenciation d=1.
5.5.7 Différenciation de la série chronologique de la population Indienne : 90

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
5.8 Le choix du modèle ARIMA adéquat :
Après avoir stationnarisé la série chronologique, l’étape suivante consiste à choisir lemodèle ARIMA(p, d = 1, q) adéquat, c’est à dire de déterminer les valeurs probables de Pet q. Pour cela, nous allons examiner les correlogrammes acf et pacf de la série.
Sous R nous allons tracer les corrélogrammes en utilisant les fonctions acf() et pacf() :
> #To plot a correlogram and partial correlogram to find
> #the values of most appropriate values
> #of p and q for an ARIMA(p,d,q) model
> acf(Populationtimeseriesdiff1, lag.max=20)
0 2 4 6 8 10 12
−0.
50.
00.
51.
0
Lag
AC
F
Population
Avec 20 lags, nous avons tracé le corrélogramme des autocorrélations entre deux obser-vations successives. Pour obtenir les valeurs de ces autocorrélations nous tapons :
> pacf(Populationtimeseriesdiff1, lag.max=20)
> #pacf(Populationtimeseriesdiff1, lag.max=20, plot=FALSE)
5.5.8 Le choix du modèle ARIMA adéquat : 91
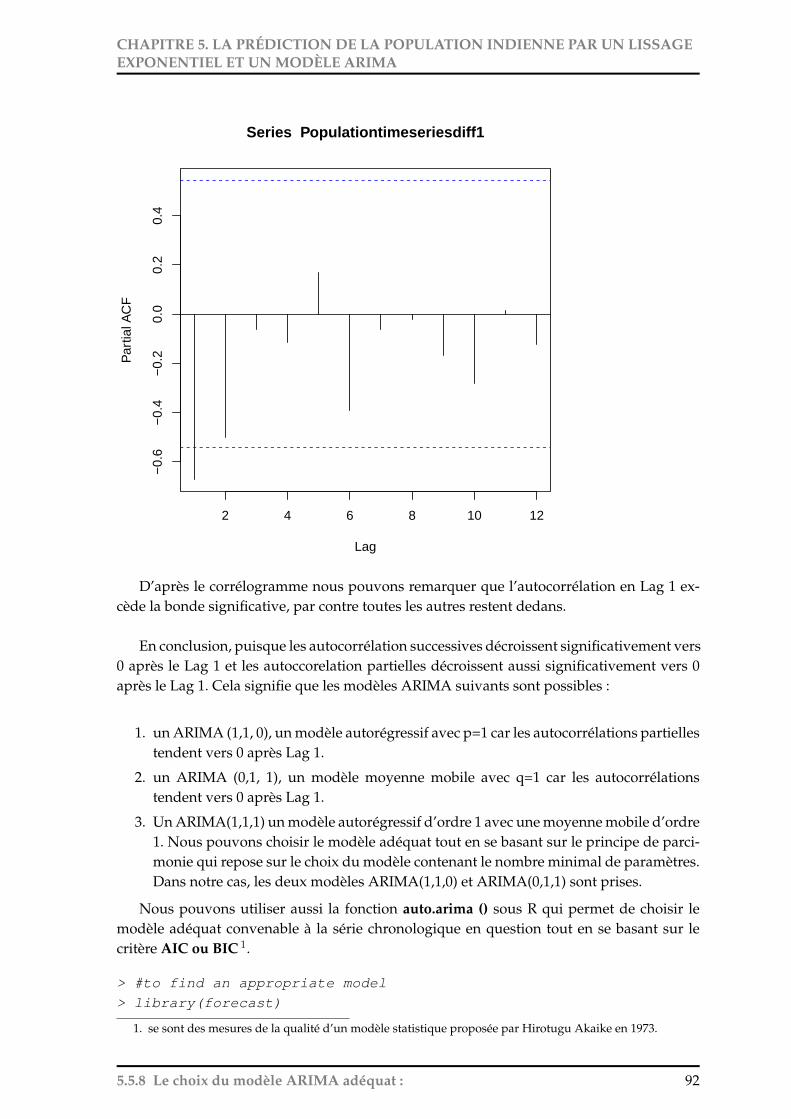
CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
2 4 6 8 10 12
−0.
6−
0.4
−0.
20.
00.
20.
4
Lag
Par
tial A
CF
Series Populationtimeseriesdiff1
D’après le corrélogramme nous pouvons remarquer que l’autocorrélation en Lag 1 ex-cède la bonde significative, par contre toutes les autres restent dedans.
En conclusion, puisque les autocorrélation successives décroissent significativement vers0 après le Lag 1 et les autoccorelation partielles décroissent aussi significativement vers 0après le Lag 1. Cela signifie que les modèles ARIMA suivants sont possibles :
1. un ARIMA (1,1, 0), un modèle autorégressif avec p=1 car les autocorrélations partiellestendent vers 0 après Lag 1.
2. un ARIMA (0,1, 1), un modèle moyenne mobile avec q=1 car les autocorrélationstendent vers 0 après Lag 1.
3. Un ARIMA(1,1,1) un modèle autorégressif d’ordre 1 avec une moyenne mobile d’ordre1. Nous pouvons choisir le modèle adéquat tout en se basant sur le principe de parci-monie qui repose sur le choix du modèle contenant le nombre minimal de paramètres.Dans notre cas, les deux modèles ARIMA(1,1,0) et ARIMA(0,1,1) sont prises.
Nous pouvons utiliser aussi la fonction auto.arima () sous R qui permet de choisir lemodèle adéquat convenable à la série chronologique en question tout en se basant sur lecritère AIC ou BIC 1.
> #to find an appropriate model
> library(forecast)
1. se sont des mesures de la qualité d’un modèle statistique proposée par Hirotugu Akaike en 1973.
5.5.8 Le choix du modèle ARIMA adéquat : 92

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
> auto.arima(TotalPopulation,ic="aic")
Series: TotalPopulation
ARIMA(2,1,0) with drift
Coefficients:
ar1 ar2 drift
-1.0094 -0.4845 0.0160
s.e. 0.2379 0.2552 0.0005
sigma^2 estimated as 9.57e-06: log likelihood=52.26
AIC=-96.52 AICc=-91.52 BIC=-94.26
Le modèle adéquat choisi par la fonction auto.arima () est ARIMA(0, 1, 1) avec drift.
5.9 La Prédiction de la population Indienne à l’horizon 2020 :
Après avoir choisi le modèle ARIMA adéquat pour la série chronologique de la popu-lation Indienne, l’étape prochaine consiste à estimer les paramètres de ce modèle (ARIMA(0,1 ,1)).
La fonction ARIMA () sous R permet d’estimer les paramètres du Modèle :
> # fit an ARIMA(0,1,1) model to the time series of the total population
> TotalPoparima <-arima(TotalPopulationtimeseries,order=c(0,1,1))
> TotalPoparima
Series: TotalPopulationtimeseries
ARIMA(0,1,1)
Coefficients:
ma1
0.6024
s.e. 0.2328
sigma^2 estimated as 0.0001748: log likelihood=37.57
AIC=-71.13 AICc=-69.93 BIC=-70
Un modèle ARIMA(0,1,1) s’écrit sous la forme :
Xt = mu+ Zt − (theta ∗ Z(t−1))
, le paramètre theta est estimé par la fonction ARIMA() : theta = 0.6247.
Maintenant après avoir estimé les paramètres du modèle ARIMA (0,1,1) nous allonsprédire la population Indienne en 2020. Pour cela nous utilisons la fonction forecast.arima()sous R :
5.5.9 La Prédiction de la population Indienne à l’horizon 2020: 93

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
> # use the ARIMA model to make forecasts for future values of the TS
> Populationtimeseriesforecasts <-forecast.Arima(TotalPoparima,h=6)
> Populationtimeseriesforecasts
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
15 1.279987 1.263045 1.296929 1.254077 1.305897
16 1.279987 1.247986 1.311988 1.231046 1.328928
17 1.279987 1.238022 1.321952 1.215807 1.344167
18 1.279987 1.230006 1.329968 1.203548 1.356426
19 1.279987 1.223109 1.336865 1.193000 1.366974
20 1.279987 1.216962 1.343012 1.183599 1.376375
La fonction forcaste.arima() donne la prédiction de la population Indienne pour les 5années suivantes avec un intervalle de confiance à 80% et 95%.
La Population Indienne en 2020 sera approximativement égale à 1.28 milliard avec unintervalle de confiance à 95% [1.183599, 1.376375].
Nous traçons les valeurs prédites avec leurs intervalles de confiance à 80% et 95% :
> plot.forecast(Populationtimeseriesforecasts,xlab="time",ylab="Population",
+ main="Forcasting the population of India in 2020 using ARIMA(0,1,1)")
> legend("top", # la position sur le graphique
+ ,c("Observed", "Predicted"), # le texte pour chaque courbe
+ ,col=c("black", "blue"), # La couleur de chaque courbe
+ ,lwd=c(1,3,1), # L'épaisseur de chaque courbe
+ ,lty=c(1,1,3) # Le type de trait de chaque courbe
+ )
>
5.5.9 La Prédiction de la population Indienne à l’horizon 2020 : 94

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
Forcasting the population of India in 2020 using ARIMA(0,1,1)
time
Pop
ulat
ion
5 10 15 20
1.05
1.10
1.15
1.20
1.25
1.30
1.35
ObservedPredicted
Comme pour les modèles de lissage exponentiel, il est évident de savoir si les erreursdu modèle ARIMA (0,1,1) sont normalement distribuées avec une moyenne nulle et une va-riance constante, ainsi que la vérification de la non autocorrélations entre les observationssuccessives de la série.
Dans un premier temps, nous allons tracer le corrélogramme des erreurs de prédictionsdu modèle ARIMA(0,1,1) ensuite nous pouvons utiliser le test de Box Ljing en tapant sousR :
> acf(Populationtimeseriesforecasts$residuals, lag.max=20)
> Box.test(Populationtimeseriesforecasts$residuals, lag=10, type="Ljung-Box")
Box-Ljung test
data: Populationtimeseriesforecasts$residuals
X-squared = 39.0888, df = 10, p-value = 2.45e-05
5.5.9 La Prédiction de la population Indienne à l’horizon 2020 : 95

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
0 2 4 6 8 10 12
−0.
50.
00.
51.
0
Lag
AC
FSeries Populationtimeseriesforecasts$residuals
D’après l’ACF des erreurs prédites, presque toute les autocorrélations sont faibles.
Le p-value du test de Box Ljung est inférieur à 0.05, donc nous ne rejettons pas l’hypo-thèse de non corrélations entre 2 erreurs successives. Ce qui est clair dans le Lag 1 l’autocor-rélation excède la bonde significative mais toutes les autres autocorrélation y restent dedans.
En conclusion, presque toutes les autocorrélation entre 2 observations successives tendentsignificativement vers 0.
La dernière étape de validation du Modèle ARIMA(0,1,1) est de vérifier si les erreursde prédictions suivent une loi normal avec une moyenne nulle et une variance constante.Nous allons tracer le graphe des résidus des valeurs prédites pour voir si la variance estconstante :
> # make time plot of forecast errors
> plot.ts(Populationtimeseriesforecasts$residuals)
5.5.9 La Prédiction de la population Indienne à l’horizon 2020 : 96

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
Time
Pop
ulat
iont
imes
erie
sfor
ecas
ts$r
esid
uals
2 4 6 8 10 12 14
0.00
00.
005
0.01
00.
015
0.02
0
Il est clair que les résidus des valeurs prédites ont approximativement une varianceconstante dans tout le temps.
Finalement, il reste à verifier si les résidus des valeurs prédites sont normalement distri-bués avec une moyenne constante. Pour cela, nous allons tracer un histogramme des erreursde prédictions :
> # make a histogram
> y<-rnorm(1000,0,1)
> qqnorm(Populationtimeseriesforecasts$residuals)
> qqline(Populationtimeseriesforecasts$residuals)
5.5.9 La Prédiction de la population Indienne à l’horizon 2020 : 97

CHAPITRE 5. LA PRÉDICTION DE LA POPULATION INDIENNE PAR UN LISSAGEEXPONENTIEL ET UN MODÈLE ARIMA
−1 0 1
0.00
00.
005
0.01
00.
015
0.02
0Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Il est clair que d’après le QQplot des résidus des valeurs prédites du modèle ARIMA(0,1,1) les points sont approximativement proche de la droie de la loi normale ainsi les rési-dus sont normalement distribués.
En conclusion, Nous avons verifier qu’il y ait une corrélation plus ou mois faible entre 2résidus successives des valeurs prédites, et que celles ci sont normalement distribuées avecune moyenne nulle et de variance constante, donc le choix du modèle de ARIMA (0,1,1) estlogiquement adéquat pour prédire la série chronologique de la population Indienne.[9]
5.5.9 La Prédiction de la population Indienne à l’horizon 2020 : 98

CHAPITRE 6
LA PRÉDICTION DE LA POPULATION INDIENNE PAR LESRÉSEAUX DE NEURONES
Dans cette partie notre objectif principal est d’utiliser une nouvelle technique robuste deprédiction de la population Indienne, il s’agit d’appliquer les réseaux de neurones.
6.1 Définition et Théorie d’un réseau de neurones :
6.1.1 Définition d’un neurone :
Un neurone est une cellule du système nerveux spécialisée dans la communication et letraitement d’informations.
Un Ensemble de neurones formels interconnectés permettant la résolution de problèmescomplexes tels que la reconnaissance des formes ou le traitement du langage naturel.
Un réseau de neurones est constitué par un certain nombre de neurones interconnectés.Chaque neurone peut recevoir plusieurs signaux des autres neurones, les ajoute en se basantsur une fonction d’entrée et génère, enfin, un signal sortant, basé sur une fonction de sortieappelée fonction d’activation.
Le signal sortant alimentera d’autres neurones suivant la typologie du réseau. La formed’un réseau de neurones est composée de trois types de couches : une couche d’input, unecouche d’output et des couches cachées.
6.1.2 La Théorie d’un réseau de neurones :
Un neurone est comme un dispositif qui reçoit, à partir d’autres neurones ou de l’ex-térieur, des simulations par des entrées (inputs) et les pondère grâce à des valeurs réellesappelées coefficients synaptique.
Un neurone j calcule ainsi, un potentiel Pj par la formule suivante :
99

CHAPITRE 6. LA PRÉDICTION DE LA POPULATION INDIENNE PAR LES RÉSEAUXDE NEURONES
Pj =n∑i=1
(ωijXi) + bj =n∑i=0
(ωijXi)
où :
– ωij : sont les pondération ou les coeficient synaptique.– Xi : les entrées (inputs).– bi : le biais.– n : le nombre d’entrées.
6.1.3 La Fonction d’activation :
En appliquant au potentiel une fonction d’activation phi de manière à ce que la sortie(output) Yj calculée par le neurone est égale :
yj = ϕ(Pj) = ϕ(
n∑i=0
ωijXi)
6.1.4 Les Types de fonctions d’activation
La fonction d’activation (ou fonction de seuillage, ou encore fonction de transfert) sertà introduire une non linéarité dans le fonctionnement du neurone. Des exemples classiquesde fonctions d’activation sont :
1. La fonction logistique : Y = F (X) = 11+exp(−d∗X)
2. La tangente hyperbolique : Y = 2(1+exp(−2∗X))−1
3. La fonction Gaussienne : Y = exp(−(X2)2 )
4. Une fonction à seuil : Y = 0, si,X < 0 et Y = 1, si,X > 0
6.1.5 Architecture d’un réseau de neurone :
Nous pouvons classer les réseaux de neurones selon deux grandes classes :
Les Réseaux Feed Forward :
Appelés aussi réseau de type perceptron, ce sont des réseaux dans lesquels l’informationse propage de couche en couche sans retour en arrière.
Exemple :
– Les Perceptrons monocouche : il se compose d’une seule couche d’entrée et sortie.– Les perceptrons multicouche : il se compose de plusieurs couches entre l’entrée et la
sortie.
6.6.1 Définition et Théorie d’un réseau de neurones : 100

CHAPITRE 6. LA PRÉDICTION DE LA POPULATION INDIENNE PAR LES RÉSEAUXDE NEURONES
Les Réseaux Feed Backward :
Appelés aussi (réseaux récurrents), ce sont des réseaux dans lesquels il y a retour en ar-rière de l’information.
Exemple :
Les cartes de kohonen, ART et les réseaux de Hopeld.
6.1.6 Réseau de neurone simple :
Est historiquement le premier réseau de neurones, c’est le perceptron de Rosenblatt.C’est un réseau simple, puisqu’il ne se compose que d’une couche d’entrée et d’une couchede sortie.
FIGURE 6.1 – Un Réseau de neurone simple
Sa principale limite est qu’il ne peut résoudre que des problèmes linéaire. Il peut êtreutilisé pour faire de la classification.
6.1.7 Perceptron Multi-couche :
Dans un perceptron, plusieurs couches contenant des neurones sont connectées entreelles de l’entrée vers la sortie. Afin d’illustrer un peu ces propos, le dessin suivant représentele schéma type d’un perceptron à trois couches :
Les noeuds d’entrée :
La première couche est appelée couche d’entrée. Elle recevra les données source quel’on veut utiliser pour l’analyse sa taille est donc directement déterminée par le nombre devariables d’entrées.
Les noeuds cachés :
La seconde couche est une couche cachée, en ce sens qu’elle n’a qu’une utilité intrinsèquepour le réseau de neurones, elle n’a pas de contact direct avec l’extérieur. Les fonctions d’ac-
6.6.1 Définition et Théorie d’un réseau de neurones : 101

CHAPITRE 6. LA PRÉDICTION DE LA POPULATION INDIENNE PAR LES RÉSEAUXDE NEURONES
FIGURE 6.2 – Un Perceptron Multi couche
tivations sont en général non linéaires sur cette couche mais il n’y a pas de règle à respecter.Le choix de sa taille n’est pas implicite et doit être ajusté. En général, on peut commencer parune taille moyenne des couches d’entrée et de sortie mais ce n’est pas toujours le meilleurchoix. Il sera souvent préférable pour obtenir de bon résultats, d’essayer le plus de taillespossibles.
Les noeuds de sortie :
La troisième couche est appelée couche de sortie. Elle donne le résultat obtenu aprèscompilation par le réseau des données entrée dans la première couche, sa taille est directe-ment déterminée par le nombre de variables qu’on veut en sortie.
6.2 La Prédiction par un réseau de neurone autorégressif :
Après avoir utilisé les séries chronologiques pour prédire la population Indienne au cha-pitre précèdent utilisant différents modèles : ARIMA, Holts Winters. Nous pouvons aussiutiliser la série chronologique de la population Indienne comme entrée (Inputs) d’un réseaude neurone pour qu’on puisse prédire le output (La population Indienne en 2020).
Dans la suite nous allons utiliser seulement les neurones feed forward avec une seulcouche cachée et nous utiliserons la notation NNAR (p, k) qui signifie un réseau de neu-rones avec p inputs et k nœuds dans la couche cachée.
Par exemple, un NNAR(9, 5) est un réseau de neurones avec les dernières 9 observations(yt−1, yt−2, ..., yt−9) de la série chronologique utilisées comme inputs pour prédire la valeurde yt (output) avec 5 neurones dans la couche cachée.
En général, un model NNAR (p, 0) est équivalent à un ARIMA (p, 0, 0). Avec une sériequi présente une saisonnalité il est préférable d’ajouter les dernières observations de la sai-son comme inputs du réseau de neurones.
6.6.2 La Prédiction par un réseau de neurone autorégressif : 102

CHAPITRE 6. LA PRÉDICTION DE LA POPULATION INDIENNE PAR LES RÉSEAUXDE NEURONES
Par exemple, unNNAR(3, 1, 2)−12 est un modèle contient 12 inputs (yt−1, yt−2, ..., yt−12)
avec 2 neurones dans la couche cachée et une seul composante saisonnière.
Généralement, un NNAR(p, P, k)−m est modèle dont les inputs sont
(yt−1, yt−2, ..., yt−p, yt−m, yt−2m, yt−P∗m)
,avec k neurones dans la couche cachée.
Un modèle NNAR(p, P, 0)m est équivalent à un ARIMA(p, 0, 0)(P, 0, 0)m avec p la di-mension de la partie moyenne mobile et P le nombre des composantes saisonnières.
Sous R la fonction nnetar () permet d’appliquer un modèle NNAR (p, P, k) sur une sériechronologique.[10]
6.2.1 Remarque :
Si les valeurs de p, P ne sont pas spécifiées, elles sont choisies automatiquement par lafonction nnetar.
Pour les séries non saisonnières, la valeur par default est la valeur qui minimise lenombre de lag d’un AR(p) tout en minimisant le caractère AIC.
Pour les séries saisonnières les valeurs par default sont P=1 et p qui est choisie de tellesorte qu’elle minimise le model linéaire qui ajuste la composante saisonnière de la sériechronologique. Le Paramètre k est égale à (p+P+1)
2 .
6.3 Prédiction de la population Indienne par un modèle NNAR (p,P, k) :
Dans cette partie nous allons choisir le modèle adéquat NNAR (p,P,k) à la série chronolo-gique de la population Indienne dont nous disposons de ses observations de 2000 jusqu’au2014 pour en prédire à l’horizon 2020.
La première étape consiste à lire la base de données sous R en utilisant la fonction read.cvqui permet de lire un fichier.csv.
> TotalPopulation <-read.csv("D:/PFE/Population.csv",col.names="Population")
> TotalPopulation
Population
1 1.06
2 1.08
3 1.09
4 1.11
5 1.13
6.6.3 Prédiction de la population Indienne par un modèle NNAR (p, P, k): 103

CHAPITRE 6. LA PRÉDICTION DE LA POPULATION INDIENNE PAR LES RÉSEAUXDE NEURONES
6 1.14
7 1.16
8 1.17
9 1.19
10 1.20
11 1.22
12 1.24
13 1.25
14 1.27
Après avoir lu la série de donnée, l’étape suivante consiste à stocker celle ci dans unobjet de type série chronologique. L’utilisation de la fonction ts () est nécessaire :
> TotalPopulationtimeseries <- ts(TotalPopulation)
> TotalPopulationtimeseries
Time Series:
Start = 1
End = 14
Frequency = 1
Population
[1,] 1.06
[2,] 1.08
[3,] 1.09
[4,] 1.11
[5,] 1.13
[6,] 1.14
[7,] 1.16
[8,] 1.17
[9,] 1.19
[10,] 1.20
[11,] 1.22
[12,] 1.24
[13,] 1.25
[14,] 1.27
Traçant le graphe de la série chronologique en utilisant la fonction plot.ts() :
> #Plot the time series
> plot.ts(TotalPopulationtimeseries, ylab="Population"
+ ,main="Growth of the Population of India from 2000 to 2014")
>
6.6.3 Prédiction de la population Indienne par un modèle NNAR (p, P, k) : 104
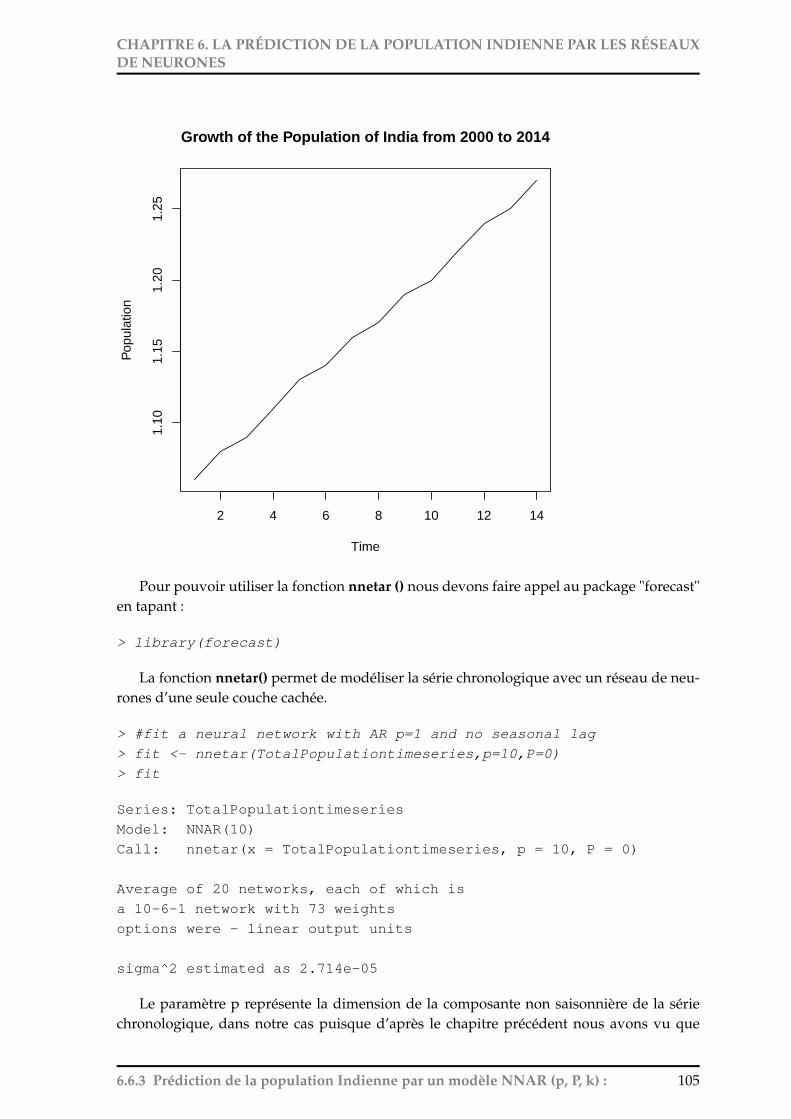
CHAPITRE 6. LA PRÉDICTION DE LA POPULATION INDIENNE PAR LES RÉSEAUXDE NEURONES
Growth of the Population of India from 2000 to 2014
Time
Pop
ulat
ion
2 4 6 8 10 12 14
1.10
1.15
1.20
1.25
Pour pouvoir utiliser la fonction nnetar () nous devons faire appel au package "forecast"en tapant :
> library(forecast)
La fonction nnetar() permet de modéliser la série chronologique avec un réseau de neu-rones d’une seule couche cachée.
> #fit a neural network with AR p=1 and no seasonal lag
> fit <- nnetar(TotalPopulationtimeseries,p=10,P=0)
> fit
Series: TotalPopulationtimeseries
Model: NNAR(10)
Call: nnetar(x = TotalPopulationtimeseries, p = 10, P = 0)
Average of 20 networks, each of which is
a 10-6-1 network with 73 weights
options were - linear output units
sigma^2 estimated as 2.714e-05
Le paramètre p représente la dimension de la composante non saisonnière de la sériechronologique, dans notre cas puisque d’après le chapitre précédent nous avons vu que
6.6.3 Prédiction de la population Indienne par un modèle NNAR (p, P, k) : 105

CHAPITRE 6. LA PRÉDICTION DE LA POPULATION INDIENNE PAR LES RÉSEAUXDE NEURONES
notre série ne présente aucune saisonnalité et donc nous pouvons choisir come input lesobservations de la série chronologique de la population Indienne de 1 à p=10. Le paramètreP est égale à 0 puisque notre série ne présente aucune saisonnalité.
Par défaut la fonction nnetar () permet de tester 20 réseaux de neurones, chacun estformé de 10-6-1 neurones. C’es à dire 10 inputs, 6 noeuds dans la seule couche cachée et uneseul sortie. Chaque neurone est testé avec des poids différents. Lors du calcul des valeursfutures la moyenne de ces poids est prise afin de trouver le bon réseau de neurone qui mo-délise au mieux la série chronologique.
Dans notre cas nous avons utilisé 20 réseaux de neurones avec 73 poids différents.La prédiction de la population Indienne à l’horizon 2020 est :
> pop <-forecast(fit,h=6)
> pop
Point Forecast
15 1.278683
16 1.288814
17 1.298798
18 1.308774
19 1.317681
20 1.326457
> plot(pop)
6.6.3 Prédiction de la population Indienne par un modèle NNAR (p, P, k) : 106

CHAPITRE 6. LA PRÉDICTION DE LA POPULATION INDIENNE PAR LES RÉSEAUXDE NEURONES
Forecasts from NNAR(10)
5 10 15 20
1.05
1.10
1.15
1.20
1.25
1.30
En utilisant ce réseau de neurones la population Indienne sera à un peu près égale à 1.32Milliard en 2020.
Conclusion
Le résutat de la prédiction par les réseaux de neurones est plus ou mois proche au ré-sultat trouvé en utilisant le modèle ARIMA et le lissage exponentiel de Holt vus au chapitreprécédent.
6.6.3 Prédiction de la population Indienne par un modèle NNAR (p, P, k) : 107

Troisième partie
Présentation des Résultats sous Qlikview
108

Dans cette partie nous allons présenter les résultats de la projection de la population In-dienne en 2020 utilisant la méthode des composantes ainsi que la prédiction utilisant à la foisles séries chronologiques et les réseaux de neurones sous le logiciel Qlick View. Le Qlickview est une application de visualisation de données, leader sur le marché. Elle permet lacréation rapide d’applications d’analyses guidées, qui permet aux utilisateurs de créer fa-cilement des visualisations, rapports et tableaux de bord personnalisés et ainsi la prise dedécisions éclairée.
L’objectif général de la plateforme réalisée sous Qlik view est de faciliter l’accès aux ré-sultats obtenus dans un laps du temps ainsi qu’une visualisation plus agréable des résultats.
La page de garde ci-dessous nous permet de commencer la navigation dans les diffé-rentes rubriques des différentes méthodes utilisées dans la projection et la prédiction de lapopulation Indienne en 2020 tout en tapant sur l’icône (get started).
Dans un premier temps nous recommandons d’aller sur l’icône (Learn How to) qui per-met d’avoir une idée générale sur l’utilisation de cette plateforme.
FIGURE 6.3 – Page de garde de l’application Qlick View
En choisissant l’icône (Learn How to), l’interface ci-dessous s’affiche et nous permetde voir et comprendre l’utilisation claire et simple des différentes commandes, buttonset icônes de navigation, sélection, recherche, filtrage de données ainsi que d’autres com-mandes.
109

FIGURE 6.4 – Guide d’utilisation de l’application Qlick View
Si le choix été de choisir (get started) l’interface ci-dessous s’affichera. Elle permet devisualiser les résultats de la projection de la population Indienne en 2020 par groupe d’âgeet sexe en se basant sur la méthode des composantes (Component Method).
FIGURE 6.5 – Affichage dynamique des résultats de la projection par la méthode de compo-santes
A gauche de l’interface l’utilisateur a le choix de filtrer par rapport aux années, sexe etgroupe d’âge. Au milieu :
1. Un graphe en bâtons dynamique de la population Indienne par tranche d’âge et année,en lignes, une pyramide d’âge, un tableau dynamique.
2. Une pyramide d’âge dynamique résumant la structure de la population par sexe etgroupe d’âge.
3. Un tableau dynamique résumant toutes les informations de décès, Mortalité ainsi quemigration par année, groupe d’âge et sexe.
4. Un tableau (gauge chart) indiquant le pourcentage des femmes dans une année pré-cise.
110

FIGURE 6.6 – Affichage dynamique des résultats de la projection par la méthode de compo-santes
5. Un (line chart) illustrant les naissances par tranche d’âge féconde et année.
L’utilisateur peut accéder rapidement à tous ces indicateurs démographiques impor-tantes dans un court temps et avec une très bonne précision.
L’utilisateur peut aller sur la rubrique (HoltWinters) pour accéder aux résultats de laprédiction de la population Indienne par la méthode de Holt Winterns. L’interface suivantes’affichera :
FIGURE 6.7 – L’affcihage dynamique des résultats de prédiction par la méthode de HoltWinters
En cliquant sur le button (Predict) en vert, la fenêtre (Statconn) s’affichera, (DCOM)(Distributed Component Object Model) est une technique propriétaire de Microsoft quipermet la communication entre des composants logiciels distribués au sein d’un réseau in-formatique.
111

Dans notre cas elle permet la communication entre le logiciel R et le Qlick View.
FIGURE 6.8 – La communication entre le logiciel R et Qlick View via DCOM
Un script VB (Visuel Basic) est écrit sous le Qlick View, permet d’exécuter le script (HoltWinters.R) sous le Qlick View, les résultats de la prédiction sont passés du R au Qlick Viewpour les faire présenter dans l’interface Qlick view.
L’utilisateur peut filtrer par rapport aux années et ainsi voir la prédiction de la popula-tion qui est présentée dans un graphe en bâtons.
D’autres résultats peuvent être visualisés en bas de la plateforme :
FIGURE 6.9 – Autres résultats de la prédiction par la méthode de Holts Winters sont affichés
112

De même l’utilisateur peut voir la prédiction réalisée par le modèle ARIMA. Les résul-tats sont obtenus à l’aide de l’interconnexion du logiciel R et Qlick View :
FIGURE 6.10 – L’affcihage dynamique des résultats de prédiction par la modèle ARIMA
Vous pouvez cliquer sur l’icône (show prediction) pour voir la courbe de prédiction dela population Indienne en 2020 utilisant le modèle ARIMA (0, 1, 1) :
FIGURE 6.11 – La courbe de prédiction de la population Indienne en 2020 utilisant le modèleARIMA(0,1,1)
De la même manière l’utilisateur peut choisir de voir la prédiction de la population uti-lisant les réseaux de neurones, il peut encore filtrer par rapport aux années pour connaitrela population correspondante.
113

Les résultats de prédiction sont obtenus de la même manière qu’auparavant c’est-à-direen se basant sur la communication entre le logiciel R et le Qlick View.
FIGURE 6.12 – L’affcihage dynamique des résultats de prédiction utilisant les Réseaux deneurones
L’application contient aussi un glossaire contenant quelques mots clés avec ses défini-tions :
FIGURE 6.13 – Glossaire
114

CONCLUSION GÉNÉRALE
Au terme de cette étude, notre objectif principal été de projeter et prédire la populationIndienne à l’horizon 2020.
Nous avons commencé par projeter la population Indienne utilisant "la méthode descomposantes(Cohort component method)". Cette-ci nous a permis non seulement de pro-jeter la population par sexe et groupe d’âge quinquennaux, mais aussi de projeter le nombrede décès, de naissances ainsi que les migrants.
Par la suite nous avons essayé de prédire la population Indienne en se basant sur les sé-ries chronologiques. Dans un premier temps nous avons fait appel aux méthodes de lissageexponentiel, plus précisement "La méthode de HoltWinters", après nous avons adopté leModèle "ARIMA". Ces deux modèles nous ont permis de prédire la population Indienneavec précision et avec des intervales de confiance à 95%. Les résultats des modèles utili-sés sont acceptables puisqu’ils ont satisfait les tests de validation(normalité des erreurs deprédiction,....). La prédiction par le modèle "ARIMA" nous a donné une population égaleà 1.28 Milliards en 2015, avec 1.26 milliards en 2014, qui va rester constante jusqu’au 2020.ce qui n’est pas tout à fait logique vu la croissance démographique rapide de la populationIndienne. Néanmoins, La méthode de "HoltWinters" nous a indiqué que la population In-dienne sera égale à 1.38 milliards en 2020. Un résultat qui est tout à fait logique avec cettepopulation Indienne désormais la plus forte croissance démographique au monde.
Pour vérifier la prédiction de la population Indienne nous avons fait appel aux "réseauxde neurones", le neurone utilisé a donné une population égale à 1.32 milliards en 2020. c’estun résultat plus ou moins proche de celui du modèle de "HoltWinters" et qui démontre lacroissance exponentiel de la population Indienne.
En conlusion, La méthode des composantes est plus précise, performante et robuste qued’autres méthodes de prédiction ou de projection démographique. Elle permet de projeternon seulement l’effectif total d’une population mais aussi l’effectif par tranche d’âge et sexetout en projectant la mortalité, la natalité et la migration.
Nous tenons à souligner que la problématique de projection démographique peut êtretraitée aussi à l’aide du "modèle de Leslie".
115

BIBLIOGRAPHIE
[1] Berrouyne Mustapha. Les Projections démographiques. 81p, 2013.
[2] The Health Policy Initiative. Introduction to Population Projections. E-learning course,2013.
[3] INSEE. Méthodologie des projections de population. édition, 2001, 77 p.
[4] John Stover. Système Spectrum des Modèles de Politiques. Research Triangle Institute,2005.
[5] Floraence Nicolau. Introduction aux séries chronologiques. Institut universitaire de tech-nologie de Nice Sophia-Antipolis, 2006.
[6] Catherine Pardoux Bernard Goldfarb. Prévision à court terme : Méthodes de lissage expo-nentiel. Université Paris-Dauphine, 2013.
[7] Dominique Desbois. Une introduction à la méthodologie de Box et Jenkins : l’utilisation demodèles ARIMA avec SPSS. Revue Modulad, 2005, 24p.
[8] Heino Bohn Nielsen. Non Stationary Time Series and Unit Root Tests. édition, 2005.
[9] Avril Coghlan. a Little Book of R for Time Series. édition, 2015.
[10] George Athanasopoulos Rob J Hyndman. Forecasting : principles and practice. édition,2013.
116

WEBOGRAPHIE
1. http ://www.actuariesindia.org
2. http ://www.sylbarth.com/nn.php
3. http ://www.qlik.com/
4. http ://www.r-bloggers.com/unit-root-tests/
5. http ://www.jhsph.edu/research/centers-and-institutes/institute-for-international-programs/
6. http ://www.indexmundi.com/g/g.aspx ?c=inv=31
117

ANNEXES
FIGURE 6.14 – Exemple de calcul du nombre de femmes en 2017 par la méthode des Com-posantes
FIGURE 6.15 – Exemple de calcul du nombre d’hommes en 2017 par la méthode des Com-posantes
118

BIBLIOGRAPHIE
FIGURE 6.16 – La projection des taux de Mortalité(hommes)par interpolation linéaire
FIGURE 6.17 – Exemple du Code VB(Visual Basic) qui permet la communication entre le Ret le Qlick View
BIBLIOGRAPHIE 119