introduction lÕapprentissage connexionnistebennani/tmpc/apn/an2.pdf · madaline = un ensemble...
TRANSCRIPT

Introduction à
l’Apprentissage Connexionniste
Younès BENNANI
2
Université Paris 13/Younès BennaniApprentissage Connexionniste 2
- Rappels
- limites d’Adaline
- Madaline : Multi-Adaptive Linear Element
- Perceptron
- Théorème de convergence du Perceptron
- Capacités d’un séparateur linéaire
- Limites du Perceptron
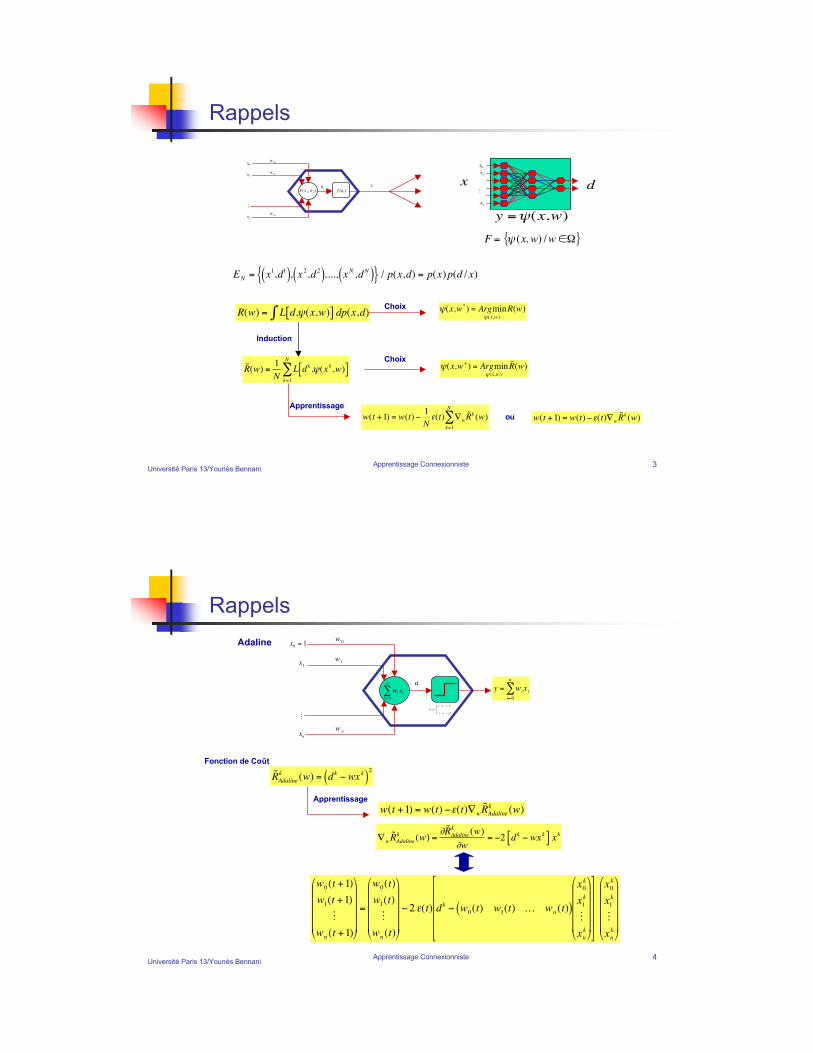
Université Paris 13/Younès BennaniApprentissage Connexionniste 3
x0
wi 0
ai
yi
x1
xn
M
F(x j ,wij) f (ai)
wi 1
win
x0
x1
xn
M
x
!
d
!
y ="(x,w)
!
EN = x1,d1( ), x 2,d2( ),..., xN ,dN( ){ } / p(x,d) = p(x)p(d / x)
F = ! (x, w) /w "#{ }
!
R(w) = L d,"(x,w)[ ] dp(x,d)#
!
"(x,w*) = Argmin
"(x,w )
R(w)
!
˜ R (w) =1
NL d
k,"(x
k,w)[ ]
k=1
N
#
!
w(t +1) = w(t) "1
N#(t) $
w˜ R
k(w)
k=1
N
%
!
w(t +1) = w(t) "#(t)$w
˜ R k(w)
Choix
Choix
Apprentissage
Induction
ou
Rappels
!
"(x,w+) = Argmin
"(x,w )
˜ R (w)
Université Paris 13/Younès BennaniApprentissage Connexionniste 4
Rappels
x0= 1
w0
a
x1
xn
M
wixi
i= 0
n
!
w1
wn !
y = wixii= 0
n
"
f (x) =
1 si x > 0
!1 si x < 0
"
# $
% $
!
˜ R Adaline
k(w) = d
k" wx
k( )2
!
"w
˜ R Adaline
k(w) =
# ˜ R Adaline
k(w)
#w= $2 d
k$ wx
k[ ] xk
!
w(t +1) = w(t) "#(t)$w
˜ R Adaline
k(w)
Adaline
Fonction de Coût
Apprentissage
!
w0(t +1)
w1(t +1)
M
wn(t +1)
"
#
$ $ $ $
%
&
' ' ' '
=
w0(t)
w1(t)
M
wn(t)
"
#
$ $ $ $
%
&
' ' ' '
( 2 )(t) dk ( w0(t) w
1(t) K w
n(t)( )
x0
k
x1
k
M
xn
k
"
#
$ $ $ $
%
&
' ' ' '
*
+
, , , ,
-
.
/ / / /
x0
k
x1
k
M
xn
k
"
#
$ $ $ $
%
&
' ' ' '
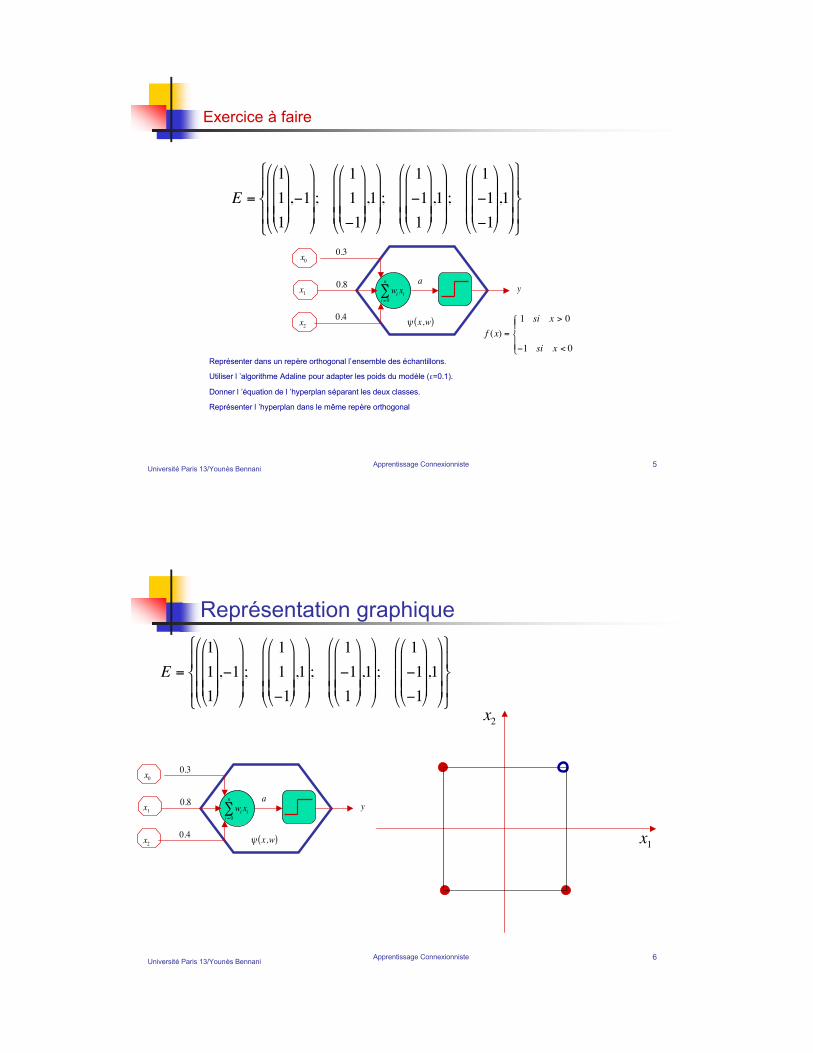
Université Paris 13/Younès BennaniApprentissage Connexionniste 5
Exercice à faire
x0
0.3
a
yx1
x2
wixi
i= 0
n
!0.8
0.4! x,w( )
!
E =
1
1
1
"
#
$ $ $
%
&
' ' ' ,(1
"
#
$ $ $
%
&
' ' ' ;
1
1
(1
"
#
$ $ $
%
&
' ' ' ,1
"
#
$ $ $
%
&
' ' ' ;
1
(1
1
"
#
$ $ $
%
&
' ' ' ,1
"
#
$ $ $
%
&
' ' ' ;
1
(1
(1
"
#
$ $ $
%
&
' ' ' ,1
"
#
$ $ $
%
&
' ' '
)
* +
, +
-
. +
/ +
Représenter dans un repère orthogonal l’ensemble des échantillons.
Utiliser l ’algorithme Adaline pour adapter les poids du modèle (!=0.1).
Donner l ’équation de l ’hyperplan séparant les deux classes.
Représenter l ’hyperplan dans le même repère orthogonal
f (x) =
1 si x > 0
!1 si x < 0
"
# $
% $
Université Paris 13/Younès BennaniApprentissage Connexionniste 6
x0
0.3
a
yx1
x2
wixi
i= 0
n
!0.8
0.4! x,w( )
Représentation graphique
!
E =
1
1
1
"
#
$ $ $
%
&
' ' ' ,(1
"
#
$ $ $
%
&
' ' ' ;
1
1
(1
"
#
$ $ $
%
&
' ' ' ,1
"
#
$ $ $
%
&
' ' ' ;
1
(1
1
"
#
$ $ $
%
&
' ' ' ,1
"
#
$ $ $
%
&
' ' ' ;
1
(1
(1
"
#
$ $ $
%
&
' ' ' ,1
"
#
$ $ $
%
&
' ' '
)
* +
, +
-
. +
/ +
x2
x1
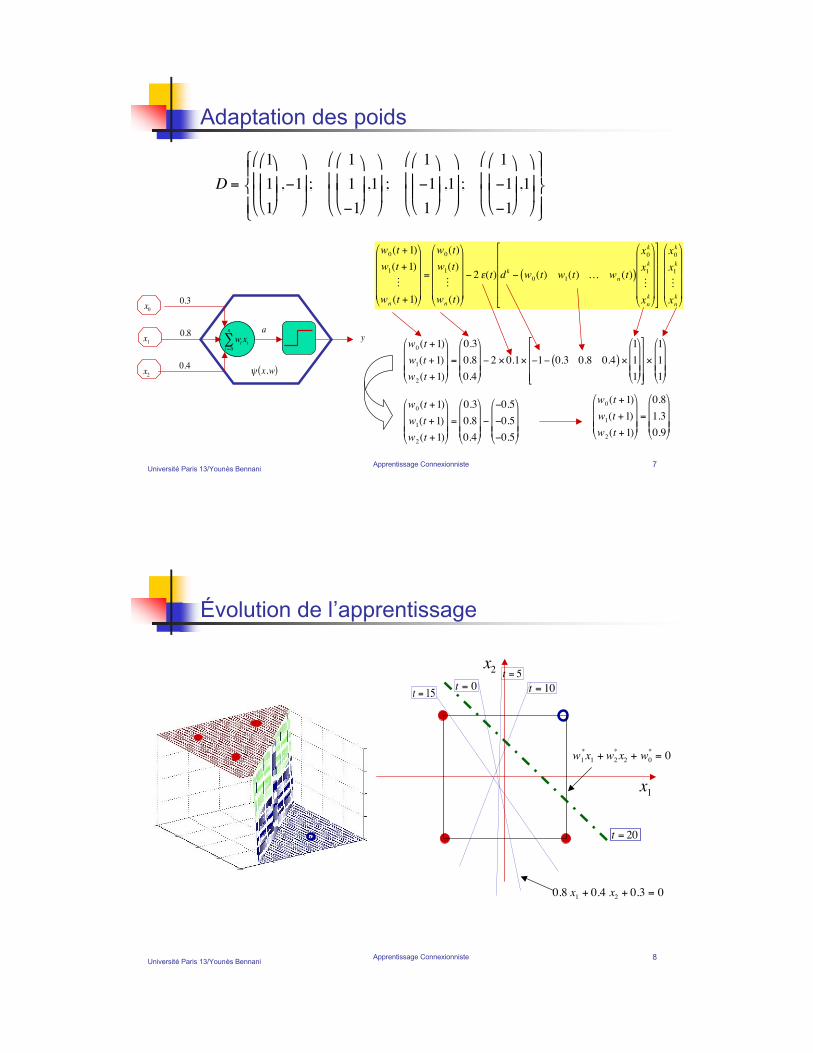
Université Paris 13/Younès BennaniApprentissage Connexionniste 7
Adaptation des poids
!
w0(t +1)
w1(t +1)
w2(t +1)
"
#
$ $ $
%
&
' ' '
=
0.3
0.8
0.4
"
#
$ $ $
%
&
' ' ' ( 2 ) 0.1) (1( 0.3 0.8 0.4( ) )
1
1
1
"
#
$ $ $
%
&
' ' '
*
+
, , ,
-
.
/ / /
)
1
1
1
"
#
$ $ $
%
&
' ' '
D =
1
1
1
!
"
# #
$
%
& & ,'1
!
"
# #
$
%
& & ;
1
1
'1
!
"
# #
$
%
& & ,1
!
"
# #
$
%
& & ;
1
'1
1
!
"
# #
$
%
& & ,1
!
"
# #
$
%
& & ;
1
'1
'1
!
"
# #
$
%
& & ,1
!
"
# #
$
%
& &
(
) *
+ *
,
- *
. *
!
w0(t +1)
w1(t +1)
M
wn(t +1)
"
#
$ $ $ $
%
&
' ' ' '
=
w0(t)
w1(t)
M
wn(t)
"
#
$ $ $ $
%
&
' ' ' '
( 2 )(t) dk ( w0(t) w
1(t) K w
n(t)( )
x0
k
x1
k
M
xn
k
"
#
$ $ $ $
%
&
' ' ' '
*
+
, , , ,
-
.
/ / / /
x0
k
x1
k
M
xn
k
"
#
$ $ $ $
%
&
' ' ' '
!
w0(t +1)
w1(t +1)
w2(t +1)
"
#
$ $ $
%
&
' ' '
=
0.3
0.8
0.4
"
#
$ $ $
%
&
' ' ' (
(0.5
(0.5
(0.5
"
#
$ $ $
%
&
' ' '
!
w0(t +1)
w1(t +1)
w2(t +1)
"
#
$ $ $
%
&
' ' '
=
0.8
1.3
0.9
"
#
$ $ $
%
&
' ' '
x0
0.3
a
yx1
x2
wixi
i= 0
n
!0.8
0.4! x,w( )
Université Paris 13/Younès BennaniApprentissage Connexionniste 8
Évolution de l’apprentissage
x2
x1
t = 10t = 15
w1
*x1+ w
2
*x2+ w
0
*= 0
t = 20
t = 5
t = 0
0.8 x1+ 0.4 x
2+ 0.3 = 0
Université Paris 13/Younès BennaniApprentissage Connexionniste 9
Adaline : limites
! x,w( ) = x1" x
2= XOR(x
1, x2)
x2
x1
1
1
1
-1
-1
1
1
1
-1 1 11
-1 -1 -11
?x0
x1
x2
!
d
x1
x2
x3
x4
Université Paris 13/Younès BennaniApprentissage Connexionniste 10
Séparabilité linéaire
A
B
A
B
Linéairement séparable Non-linéairement séparable
x2
x1
« Deux classes d’objets, décrits dans un espace de dimension n,
sont dits « linéairement séparables » s’ils se trouvent de part et
d’autre d’un hyperplan dans l’espace des descripteurs»
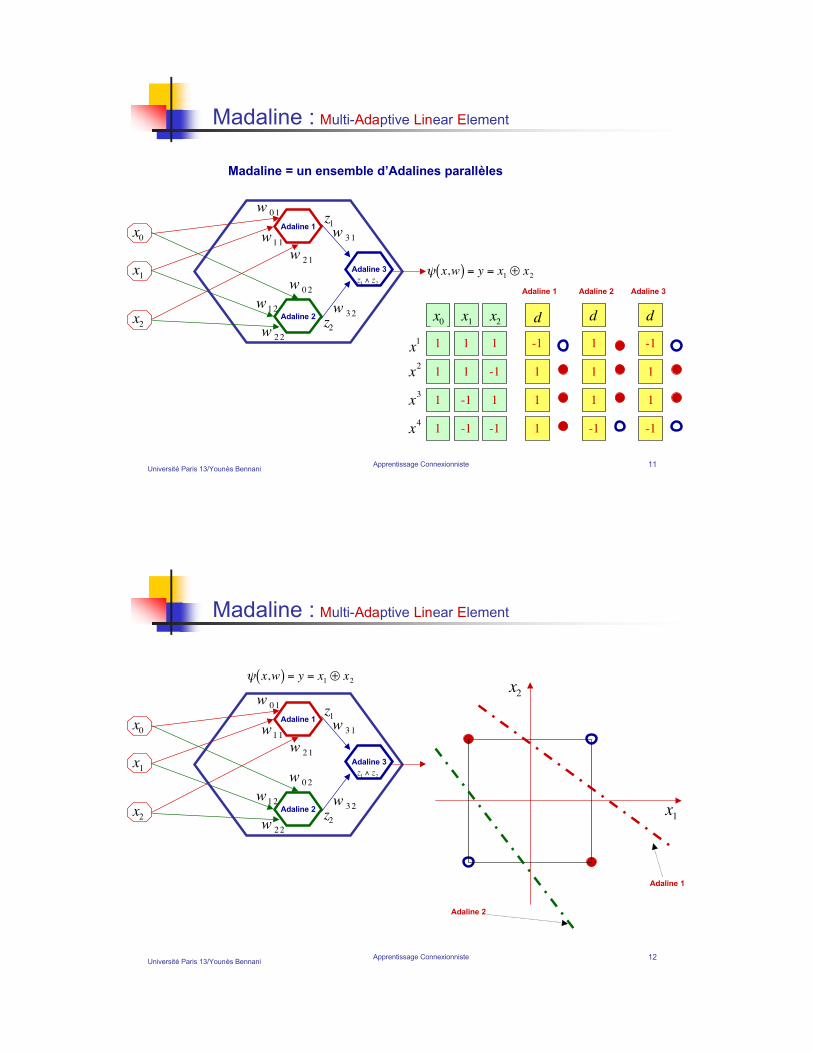
Université Paris 13/Younès BennaniApprentissage Connexionniste 11
Madaline : Multi-Adaptive Linear Element
!
" x,w( ) = y = x1# x
2
Madaline = un ensemble d’Adalines parallèles
Adaline 1
Adaline 2
x0
w01
x1
x2
w11
w21
w02
w12
w22
Adaline 1 Adaline 2
1
1
1
-1
-1
1
1
1
-1 1 11
-1 -1 11
1
1
1
-1
-1
1
1
-1
Adaline 3
w31
w32
z1! z
2
z1
z2
Adaline 3
x0
x1
x2
!
d
!
d
!
d
x1
x2
x3
x4
Université Paris 13/Younès BennaniApprentissage Connexionniste 12
Madaline : Multi-Adaptive Linear Element
x2
x1
Adaline 1
Adaline 2
Adaline 1
Adaline 2
x0
w01
x1
x2
w11
w21
w02
w12
w22
Adaline 3
w31
w32
z1! z
2
z1
z2
!
" x,w( ) = y = x1# x
2
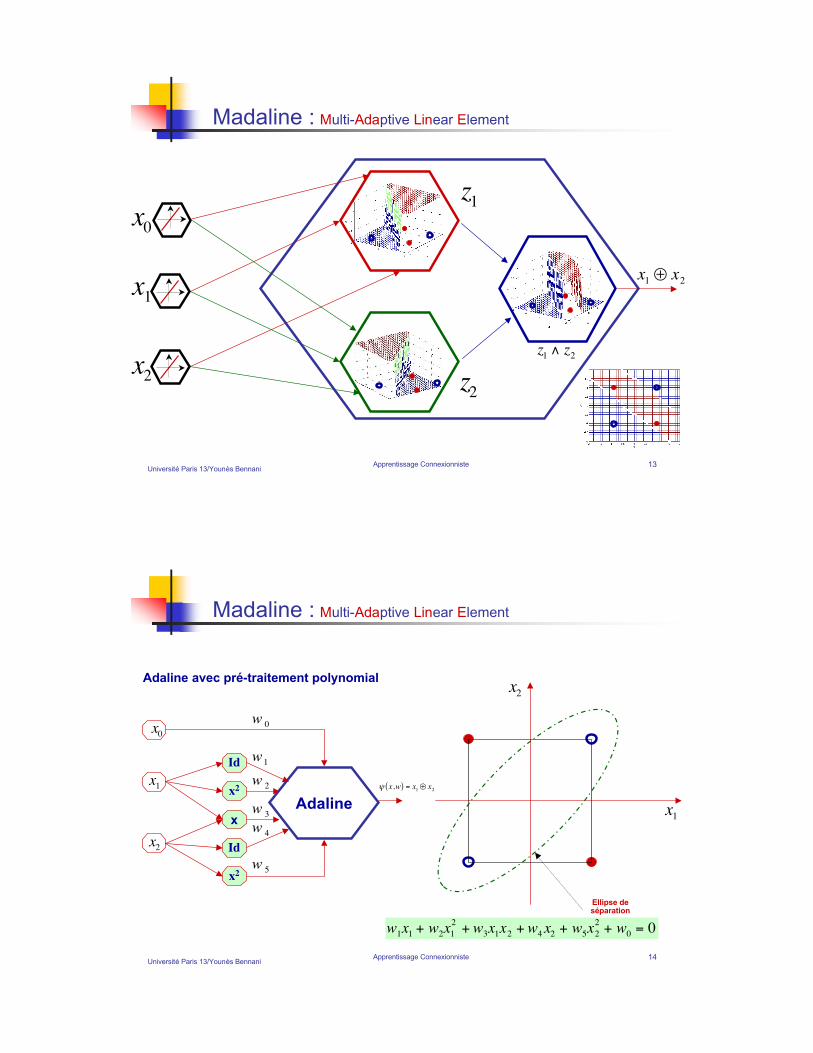
Université Paris 13/Younès BennaniApprentissage Connexionniste 13
Madaline : Multi-Adaptive Linear Element
!
x1" x
2
x0
x1
x2
z1! z
2
z1
z2
Université Paris 13/Younès BennaniApprentissage Connexionniste 14
Madaline : Multi-Adaptive Linear Element
! x,w( ) = x1" x
2
x2
x1
Adaline avec pré-traitement polynomial
x0
x1
x2
Adalinex2
x
Id
x2
Id
w0
w1
w2
w3
w4
w5
w1x1+ w
2x1
2+ w
3x1x2+ w
4x2+ w
5x2
2+ w
0= 0
Ellipse deséparation

Université Paris 13/Younès BennaniApprentissage Connexionniste 15
Perceptron
PerceptronRosenblatt F., 1957, 1962*
* Rosenblatt F. (1957) : « The perceptron: a perceiving and recognizingautomaton », Reports 85-460-1, Cornell Aeronautical Lab., Ithaca, N.Y.* Rosenblatt F. (1962) : « Principles of Neurodynamics: perceptrons andtheory of brain mechanisms », Spartan Books, Washington.
1957, Frank Rosenblatt
Le perceptron ne désigne pas un seul modèlemais regroupe une importante familled ’algorithmes.
Le perceptron = machine adaptative employéepour résoudre des problèmes de classement(discrimination).
X! x,w( )
Université Paris 13/Younès BennaniApprentissage Connexionniste 16
PerceptronRosenblatt F., 1957, 1962
Xwi!i
i= 0
n
" (x)
! x,w( ) = f (wT")
w0
w1
wn
!1
!2
!n
f (x) =
1 si x ! 0
"1 si x < 0
#
$ %
& %
la rétine
qui reçoit les informations
de l'extérieur
la cellule de décisionles cellules d'association
chaque cellule possède une fonction
de transition définie sur la rétine : ! x,w( ) = f w0
+ wi " i(x)i=1
n
#$
% & '
( !ix( ) : R"#
R
wT
= w0,w
1,K, w
n( )
! = 1,!1(x), !
2(x),K, !
n(x)( )
1

Université Paris 13/Younès BennaniApprentissage Connexionniste 17
PerceptronCas de deux classes
xx
x
x
x
x
x
x
x
x
oo
o
o
o
o
o
o
o
o
o
xi
C2
C1
"(x,w)=1"(x,w)= -1
! (x,w) = f w0
+ wi" i (x)i=1
n
#$
% & '
( =
1 si x )C1
*1 si x )C2
+
, -
. -
Un perceptron peut être vu comme un classificateur à 2 classes :
C1= x !R :" (x,w) =1{ }
C2= x !R :" (x,w) = #1{ }
Université Paris 13/Younès BennaniApprentissage Connexionniste 18
PerceptronCas de deux classes
wT!k
> 0 pour xk "C
1
wT! k
< 0 pour xk "C
2
#
$ %
& %
!
" xk, w
T # kdk( ) > 0
w
!
D(w) =1
wmink
wT" k
dk( )
2
3
1
2
3
1
w!
dk
=1 si xk " C
1
dk
= #1 si xk " C
2
$
% &
' &
Transformation
Dmax reflète la difficulté du problème :
Si Dmax grand alors le problème est facile
Si Dmax < 0 alors pas de solution.
Dmax
= maxw
D(w)
! !
!
" w
!
Dmax

Université Paris 13/Younès BennaniApprentissage Connexionniste 19
PerceptronCas de deux classes
Si l ’on appelle la forme prise en compte à l’itération k,
On définit le carré de l’erreur instantanée associée à la forme par :
!
xk,d
k( )
L’erreur quadratique globale ou (MSE) est :
!
xk,d
k( )
!
˜ R Perceptron (w) =1
N˜ R Perceptron
k(w)
k=1
N
" = # wT $ k
dk( )
k : xk
mal classé{ }"
Il existe plusieurs algorithmes d’apprentissage.
!
k= 1,!
1(x
k),!
2(x
k),K,!
n(x
k)( )
!
dk
=1 si xk " C
1
dk
= #1 si xk " C
2
$
% &
' &
wT!k
> 0 pour xk "C
1
wT! k
< 0 pour xk "C
2
#
$ %
& %
!
" xk, w
T # kdk( ) > 0
!
˜ R Perceptron
k(w) = " w
T # kd
k( )
Université Paris 13/Younès BennaniApprentissage Connexionniste 20
PerceptronCas de deux classes
Critère d'arrêt = taux de classement satisfaisant.
Techniques de descente de gradient (la plus grande pente) :
supposons qu ’à l’instant , les poids du Perceptron soient
et qu ’on présente la forme , alors les poids seront
modifiés par :
!
"w˜ R Perceptron
k(w) =
# ˜ R Perceptron
k(w)
#w= $% k
dk
!
w(t +1) = w(t) "#(t)$w˜ R Perceptron
k(w)
t
Le pas du gradientLe gradient instantané
w t( )
!
xk,d
k( )
!
k= 1,!
1(x
k),!
2(x
k),K,!
n(x
k)( )
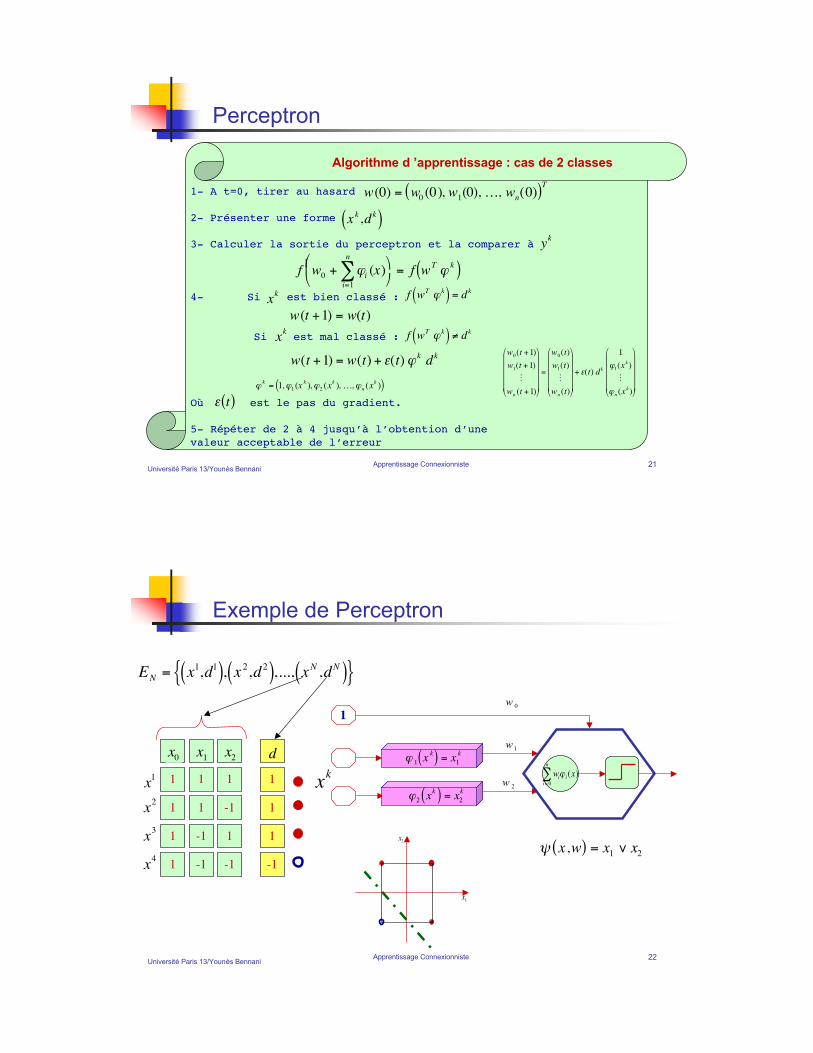
Université Paris 13/Younès BennaniApprentissage Connexionniste 21
Perceptron
1- A t=0, tirer au hasard
2- Présenter une forme
3- Calculer la sortie du perceptron et la comparer à
4- Si est bien classé :
Si est mal classé :
Où est le pas du gradient.
5- Répéter de 2 à 4 jusqu’à l’obtention d’une
valeur acceptable de l’erreur
w(0) = w
0(0), w
1(0),K, w
n(0)( )
T
! t( )
!
xk,d
k( )
f w0
+ !i (x)i=1
n
"#
$ % &
' = f w
T ! k( )
w(t +1) = w(t)
xk
xk
!
w(t +1) = w(t) + "(t)# kdk
Algorithme d ’apprentissage : cas de 2 classes
!
k= 1,!
1(x
k),!
2(x
k),K,!
n(x
k)( )
yk
!
f wT " k( ) = dk
!
f wT " k( ) # dk
!
w0(t +1)
w1(t +1)
M
wn(t +1)
"
#
$ $ $ $
%
&
' ' ' '
=
w0(t)
w1(t)
M
wn(t)
"
#
$ $ $ $
%
&
' ' ' '
+ ((t) dk
1
)1(x
k)
M
)n(x
k)
"
#
$ $ $ $
%
&
' ' ' '
Université Paris 13/Younès BennaniApprentissage Connexionniste 22
Exemple de Perceptron
1
1
1
-1
1
1
1
1
-1 1 11
-1 -1 -11
x0
x1
x2
!
d
x1
x2
x3
x4
!
EN
= x1,d1( ), x 2,d2( ),..., xN ,dN( ){ }
! x,w( ) = x1" x
2
wi!i
i= 0
n
" (x)
w0
w1
w2
!1xk( ) = x1
k
xk
x2
x1
!2xk( ) = x2
k
1
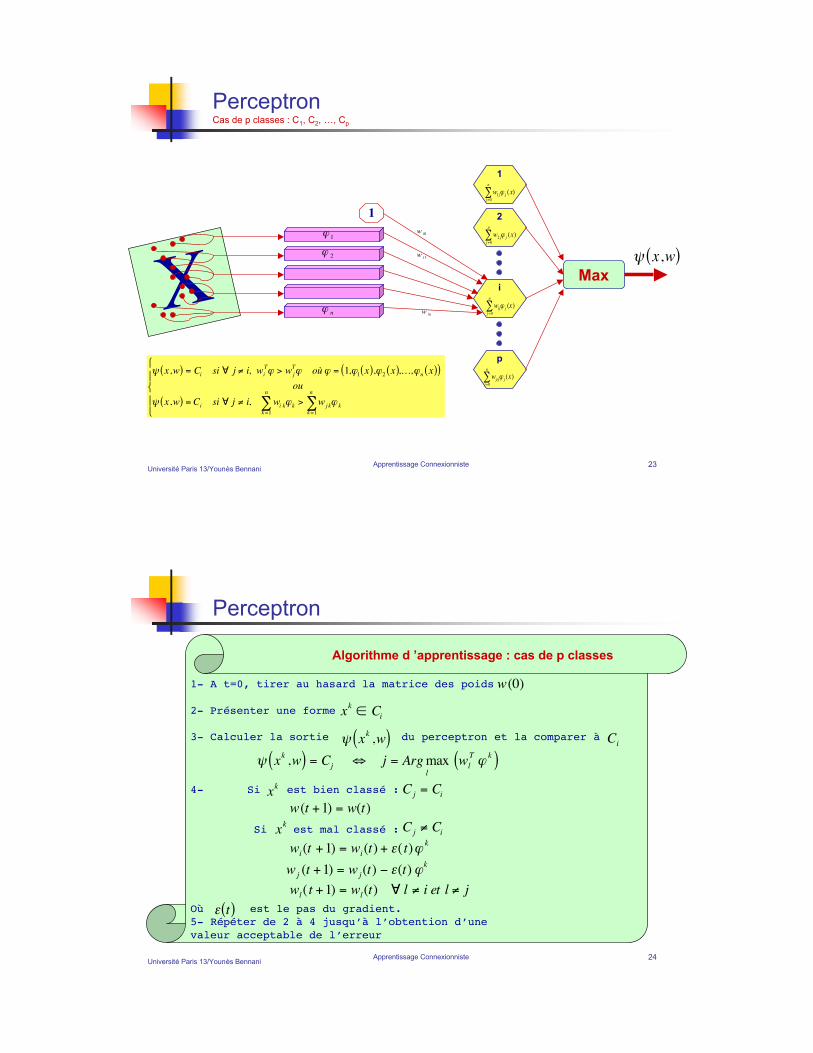
Université Paris 13/Younès BennaniApprentissage Connexionniste 23
p
i
2
PerceptronCas de p classes : C1, C2, …, Cp
X wij! j
j=0
n
" (x)
! x,w( )
wi0
wi1
win
!1
!2
!n
1
Max
wpj! j
j=0
n
" (x)
w2 j! j
j=0
n
" (x)
w1j! j
j=0
n
" (x)
! x,w( ) = Ci si " j # i, wi
T$ > wj
T$ où$ = 1,$1x( ),$
2x( ),K,$n x( )( )
ou
! x,w( ) = Ci si " j # i, wi k$k > wjk$ k
k=1
n
%k=1
n
%
&
' (
) (
1
Université Paris 13/Younès BennaniApprentissage Connexionniste 24
Perceptron
1- A t=0, tirer au hasard la matrice des poids
2- Présenter une forme
3- Calculer la sortie du perceptron et la comparer à
4- Si est bien classé :
Si est mal classé :
Où est le pas du gradient.
5- Répéter de 2 à 4 jusqu’à l’obtention d’une
valeur acceptable de l’erreur
w(0)
! t( )
xk! C
i
! xk,w( ) = Cj " j = Argmax
l
wl
T#
k( )
w(t +1) = w(t)
xk
xk
wi(t +1) = w
i(t) + !( t)"
k
Algorithme d ’apprentissage : cas de p classes
Ci
wj (t +1) = wj(t) ! "(t)#k
! xk,w( )
Cj = Ci
Cj ! Ci
wl( t +1) = wl(t) ! l " i et l " j

Université Paris 13/Younès BennaniApprentissage Connexionniste 25
Perceptron et AdalineCas de 2 classes
Classe A
Classe B
Solution trouvée
Par l ’Adaline
Meilleure séparation robuste
entre les classes.
Solution trouvée
Par le Perceptron
Sépartion qui minimise
Le nombre d ’erreur.
Perc
ep
tro
nA
dalin
e
+
ProfesseurSortie
calculée
Erreur
+
ProfesseurSortie
calculée
Erreur
Université Paris 13/Younès BennaniApprentissage Connexionniste 26
Théorème de convergence du Perceptron
« Si un ensemble de formes est linéairement séparable, alors l’algorithme
d’apprentissage du Perceptron converge vers une solution correcte
en un nombre fini d’itération. »
Arbib M.A. (1987) : « Brains, Machines, and Mathematics »
Berlin, Springer-Verlag.
Rosenblatt F. (1962) : « Principles of Neurodynamics »
N.Y., Spartan.
Block H.D. (1962) : « The Perceptron: A Model for Brain Functioning »
Reviews of Modern Physics 34, 123-135.
Minsky M.L. & Papert S.A. (1969) : « Perceptrons »
Cambridge, MIT Press.
Diederich S. & Opper M. (1987) : « Learning of Correlated Patterns
Spin-Glass Networks by Local Learning Rules »
Physical Review letters 58, 949-952.

Université Paris 13/Younès BennaniApprentissage Connexionniste 27
Théorème de convergence du Perceptron
w*
: une bonne solution
mk: nombre d' adaptation après les présentations de x
k
!
w = " mk# k
k
$ dk
!
w(t +1) = w(t) + "(t)# kdk
!
w.w*
= " mk# k
dk.w
*
k
$
m = mk
k
!
!
w.w* " # m min
k
$ kdk.w
*( ) = # mD w*( ) w*
!
cos(")2 = # =w.w
*( )2
w2. w
*2$1
la règle d ’adaptation est :
Hypothèse :
après ces itérations, devient :mk
w
et
Soit
Soit
Alors
!
D(w) =1
wmink
wT" k
dk( )
Le nombre total d’adaptation
produit scalaire normalisé :
!
w *
!
w
!
"
Université Paris 13/Younès BennaniApprentissage Connexionniste 28
Théorème de convergence du Perceptron
!
w(t +1) 2= w(t)2
+ "2 # k2
dk( )2
+ 2"w(t)# kdk
$ w(t)2
+ "2 # k2
dk( )2
!
" w2
# $2 % k2
dk( )2
# $2n
w2
! m "2
n
1 ! " !mD w
*( )2
n.
!
w.w* " # m min
k
$ kdk.w
*( ) = # mD w*( ) w*
m !n
Dmax
2
!
D(w) =1
wmink
wT" k
dk( )
Dmax
= maxw
D(w)
= n = 1
! 0
Alors
Après itérations on a donc :m
orAlors
Par conséquent :
Cqfd.

Université Paris 13/Younès BennaniApprentissage Connexionniste 29
Capacités d’un séparateur linéaire*
= le nombre maximum de séparations linéaires possibles
en 2 classes dans un ensemble de points en dimension .
C N ,d( )N d
• Si , on peut calculer par récurrence :C N ,d( )
C N ,1( ) = 2 N
C 1, d( ) = 2 d !1( )
* Cover T. (1965) : « Geometrical and statistical properties of linear inequalities with applications
in pattern recognition »
IEEE Transactions on Electronic Computers, 14:326-334.
C N ,d( ) =N !1
k
"
# $ %
& k= 0
N !1
' C 1,d ! k( )
Pour un ensemble de points il y a dichotomies possibles.
- Pour les dichotomies sont linéairement séparables
- Pour seulement sont linéairement séparables.
N 2N
C N ,d( )2N
N ! d +1N > d +1
p
q
!
" # $ % &
p!
(p ' q)! q!
• Si alors N ! d +1 C N ,d( ) = 2N
N > d +1
Université Paris 13/Younès BennaniApprentissage Connexionniste 30
Capacités d’un séparateur linéaire*
= la probabilité qu’une dichotomie aléatoire soit linéairement séparable
dans un ensemble de points en dimension .
F N ,d( )N d
* Cover T. (1965) : « Geometrical and statistical properties of linear inequalities with applications
in pattern recognition »
IEEE Transactions on Electronic Computers, 14:326-334.
F N ,d( ) =
1 si N ! d +1
1
2N "1
N "1
k
#
$ % &
' si N > d +1
k=0
d
(
)
* +
, +
d = 20
d = 1
d = !
N /(d +1)
F(N ,d)
0.0
0.5
1.0
0 1 2 3 4
F(N ,d) = 0.5 pour N = 2(d +1)

Université Paris 13/Younès BennaniApprentissage Connexionniste 31
Limites du Perceptron
Sur les fonctions booléennes à entrées, moins de
sont réalisables par un perceptron (linéairement séparables).
Une limitation importante, qui a justifié à l’époque l ’abandon
des recherches sur les perceptrons.
22d
d
* Lewis P.M. & Coates C.L. (1967) : « Threshold Logic »
N.Y., John Wiley.
** Minsky M.L. & Papert S.A. (1969) : « Perceptrons »
Cambridge, MA : MIT Press.
2d2
d!
*
1969, Minsky Marvin, Papert Seymour**
Un violent coup d’arrêt aux recherches dans le domaine
Université Paris 13/Younès BennaniApprentissage Connexionniste 32
Architecture multi-couches
Le « credit assignment problem »
On se donne un réseau en couches, et un ensemble d ’exemples composés
de paires entrées-sorties.
L ’algorithme de rétro-propagation du gradient apporte une solution d ’une
simplicité déroutante à ce problème.
x0
x1
xn
M
x y
Perceptron
Appliquer l ’algorithme
d ’apprentissage pour
déterminer W2
On ne connaît pas les sorties
Désirées des unités cachées !
On ne peut pas appliquer
l ’algorithme d ’apprentissage
du Perceptron pour
déterminer W1
W1
W2

Université Paris 13/Younès BennaniApprentissage Connexionniste 33
L’après pause connexionniste
Bryson A., Denham W., Dreyfuss S. (1963) : « Optimal Programming Problem With Ineduality Constraints. I: Necessary Conditions for Extremal Solutions »,
AIAA Journal, Vol. 1, pp. 25-44.
LeCun Y. (1986) : « Learning Processes in Asymmetric Threshold Network »
Disordered Systems and Biological Organizations, Les Houches, France, Springer, pp. 223-240.
Rumelhart D., Hinton G.E., Williams R. (1986) : « Learning Internal Representations by Error Propagation »
In Parallel Distributed Processing: exploring the microstructure of cognition, Vol I, Badford Books, Cambridge, MA, pp. 318-362, MIT Press.
Problèmes de contrôle
1963, Bryson A., Denham W., Dreyfuss S.,
“la rétro-propagation du gradient”
Les années 80, la portée exacte de l ’ouvrage de Minsky & Papert
sera correctement perçue.
La “redécouverte” de la “rétro-propagation du gradient”
1986, LeCun Y.
1986, Rumelhart D., Hinton G.E., Williams R.