e structuras de d atos o rientadas a o...
TRANSCRIPT

UNIVERSIDAD CENROCCIDENTAL " LISANDRO ALVARADO "
ESCUELA DE CIENCIAS
Estructuras de Datos Orientadas a Objeto
en Turbo Pascal
Lucía Bujanda de Boscán
Barquisimeto, Septiembre de 1992

Indice de Contenido
CAPITULO 1 PROGRAMACION ORIENADA A OBJEtOS EN
TURBO PASCAL
Propiedades 4
Objetos y Métodos 4
Encapsulamiento 8
Herencia 9
Métodos Estáticos y Virtuales 16
Métodos Estáticos 16
Métodos Virtuales 20
Tabla de Métodos Virtuales 21
Declaración de Métodos Virtuales 21
Reglas Para la Construcción de
Métodos Virtuales 22
Métodos Constructores 22
Observando Internamente las VMT 22
Polimorfismo 24
Objetos Dinámicos 30
Asignación Dinámica de Objetos 30
Liberación Dinámica de Objetos 32
Métodos Destructores 33
Cláusula PRIVATE 36
Ejercicios Propuestos 40
CAPITULO 2 ESTRUCTURA DE DATOS Y SU METODOLOGIA
DE DISEÑO
Datos 41
Estructura de Datos 42
Características 42
Diseño Descendente 43
Ocultamiento de la Información 43
Abstracción de Datos 44
Encapsulamiento de Datos 44
Niveles de los Datos 44

Tipos de Implementación 45
Clasificación de las Estructuras de
Datos 45
CAPITULO 3 ESTRUCTURA DE DATOS PILA o STACK
Nivel de Abstracción 46
Definición 46
Operaciones 47
Nivel de Implementación 51
Nivel de Aplicación 58
Ejercicios Propuestos 87
CAPITULO 4 ESTRUCTURA DE DATOS COLA o QUEUE
Nivel de Abstracción 69
Definición 69
Operaciones 70
Nivel de Implementación 73
Otros Diseños de Colas 79
Segundo Enfoque 79
Tercer Enfoque 80
Nivel Aplicación 88
Ejercicios Propuestos 97
CAPITULO 5 ESTRUCTURA DE DATOS LISTAS o LIST
Nivel de Abstracción 98
Definición 98
Visión Abstracta de una Lista
Enlazada 101
Paquete Lista 102
Nivel de Implementación 111
Nivel de Aplicación 126
Desventajas de Utilización de Memoria
Estática 139
Memoria Dinámica 139
Listas Lineales Doblemente
Encadenadas 149

Paquete Lista 150
Nivel de Aplicaciones 165
Ejercicios Propuestos 166
CAPITULO 6 ESTRUCTURA DE DATOS ARBOL o TREE
Nivel de Abstracción 168
Definición 168
Visión Abstracta de un Arbol
Binario 170
Recorrido de un Arbol Binario 172
Paquete Arbol Binario 174
Nivel de Implementación 186
Nivel de Aplicación 202
Representación de una Expresión
Aritmética en un Arbol Binario 202
Construcción de un Indice de
Palabras para un Texto 214
Ejercicios Propuestos 226

Página 1
Prólogo
Es mas que evidente, que la tendencia del mundo de la computación hoy
en día, finales de la década de los 90's, es hacia las tecnologías orientadas a
objetos. Se habla de Programación Orientada a Objetos, Bases de Datos
Orientadas a Objetos, Diseño de Sistemas Orientados a Objetos, etc.
La acogida que las tecnologías orientadas a objetos han tenido, tanto en
el mundo académico como en la práctica profesional, se debe por una parte a
que permiten resolver, en una forma más eficiente, problemas típicos que han
venido siendo discutidos reiteradamente en la literatura; y por otra, a la
orientación de esas técnicas hacia la reusabilidad, hacia lo "abierto", lo que
parece ser la tendencia en muchos aspectos de la computación, y que va a
separar en un futuro muy próximo la Ingeniería del Software como una disciplina
propia.
En nuestro medio, tal como en el resto del mundo, la programación
orientada a objetos ha sido acogida con gran entusiasmo. Sin embargo su
difusión y utilización fuera del mundo académico ha sido relativamente escasa.
Las razones de esto son diversas, casi todas relativas a la crisis del país. Tal
vez la razón mas importante sea la carencia de material sobre el tema. Si bien
existen una variedad de textos y revistas que lo abordan, la mayoría tratan el
tema de manera superficial, sin mostrar en detalle las técnicas y su aplicación,
lo que los hace de escasa utilidad desde el punto de vista práctico.
Este trabajo es fundamentalmente un texto de estructuras de datos
basado en tecnologías orientadas a objeto. El tratamiento del tema es
radicalmente diferente al que se hace en los textos tradicionales. El trabajo,
además de realizar una discusión detallada sobre las tecnologías orientadas a
objeto, expone los tópicos básicos de las estructuras de datos, realizando el
análisis e implementación de las mismas con esas tecnologías. El trabajo
expone detalladamente las abstracciones y métodos de las estructuras de datos
básicas, así como ejemplos de utilización de esas abstracciones.

Página 2
Se escogió Turbo Pascal como lenguaje para realizar las
implementaciones, debido a su difusión en nuestro medio y a lo relativamente
económico de su adquisición.

Página 3
CAPITULO 1
PROGRAMACION ORIENTADA A OBJETOS en
TURBO PASCAL
- INTRODUCCION
La Programación Orientada a Objetos es la tecnología de moda dentro
del mercado de software.
La Programación Orientada a Objeto tiene sus orígenes en el Unix, y
dado que Unix va a ser uno de los sistemas operativos mas utilizados en los
próximos diez años, serán muchos y por mucho tiempo los seguidores de esta
nueva tecnología.
La justificación del uso de esta tecnología en la implementación de las
Estructuras de Datos, se debe a la necesidad imperiosa de lograr una
abstracción completa de los datos en el uso posterior por parte del usuario de
dicha implementación. Adicionalmente, Programación Orientada a Objetos
(OOP), da mayor relevancia al diseño de Estructuras de Datos en comparación
a la importancia que le da a la codificación en sí, lo que la hace totalmente
diferente a la Programación Estructurada.
Programación Orientada a Objetos (OOP), es un nuevo enfoque de
programación, ya que rompe con la tradicional separación del código y los
datos. Es decir la definición de Tipos de Datos y sus correspondientes
Procedimientos o Funciones que lo manipulan se combinan dentro de Objetos.

Página 4
Programación Orientada a Objetos (OOP), es más modular, abstracta y
estructurada que cualquiera de los intentos hechos por medio de la
programación estructurada y de la abstracción de datos.
Borland ofrece Programación Orientada a Objetos para Turbo Pascal, a
partir de la versión 5.5, manteniendo el sueño de su creador Niklaus Wirth
cuando reproduce su famosa ecuación que lleva como título su obra, en la
ecuación básica para OOP:
Código + Datos = Objeto
- PROPIEDADES Tres principales propiedades caracterizan un lenguaje de Programación
Orientado a Objetos:
-Encapsulamiento: Es la combinación de un registro con los procedi–
mientos y funciones que definen y manipulan el nuevo tipo de dato,
formando así un Objeto. -Herencia: La que recibe un Objeto que es descendiente jerarquica–
mente de otro Objeto, tanto a código como a dato se refiere.
-Polimorfismo: Se presenta cuando una acción dada de un Objeto es
compartida por algún Objeto descendiente jerarquicamente, imple–
mentando la acción de forma apropiada para su uso.
- OBJETOS Y METODOS Un Objeto contiene las características de una entidad (datos) y su
comportamiento (procedimientos y funciones). La combinación de ambas son
necesarias para capturar la esencia de la entidad, el Objeto, y por medio de esa
combinación logramos una simulación del Objeto. Este proceso de
combinación se le denomina Encapsulamiento.

Página 5
Ejemplo_1: Las características físicas de un avión, se pueden
representar por medio de un registro, de la siguiente manera:
TYPE
Avión = RECORD
Velocidad : WORD;
Altitud : WORD;
Señales : (Arriba,Abajo)
END;
Las funciones, conductas, operaciones o mensajes a través de
procedimientos:
PROCEDURE Inicialización;
BEGIN
{ ..... }
END;
PROCEDURE Aceleración;
BEGIN
{ ..... }
END;
PROCEDURE Desaceleración;
BEGIN
{ ..... }
END;
PROCEDURE SeñalArriba;
BEGIN
{ ..... }
END;
PROCEDURE SeñalAbajo;
BEGIN
{ ..... }
END;
{ ...... }

Página 6
Esa sería la forma tradicional de programar dicha entidad, pero en OOP,
características y conducta o funciones son combinados en una sola entidad
llamada Objeto, de la siguiente manera:
TYPE
Avión = OBJECT
Velocidad : WORD;
Altitud : WORD;
Señales : (Arriba,Abajo);
PROCEDURE Inicialización;
PROCEDURE Aceleración;
PROCEDURE Desaceleración;
PROCEDURE Aterrizaje;
PROCEDURE Despegue;
PROCEDURE SeñalArriba;
PROCEDURE SeñalAbajo;
END;
PROCEDURE Avión.Inicialización;
BEGIN
Señales := Abajo;
Velocidad := 0;
Altitud := 0;
END;
PROCEDURE Avión.SeñalArriba;
BEGIN
Señales := Arriba
END;
{ ............... }
La palabra clave OBJETO, sustituye la palabra clave RECORD.

Página 7
Note que dentro de los Objetos se definen solo los encabezados de los
procedimientos y funciones, la codificación de los mismos se especifica
separadamente.
Las funciones y procedimientos, que aparecen en la definición de los
datos se conocen como Métodos.
Un Mensaje representa lo que se le desea hacer a un objeto. Un
Método representa como el mensaje es realizado.
En el momento de codificar cada uno de los Métodos por separado, hay
que especificar a cual objeto pertenece dicho método por medio de Nombres
Calificados. Por ejemplo, el método que inicializa a el objeto Avión, se definió
colocando Avión.Inicialización, tal como se debe hacer referencia a un campo
definido dentro de un registro.
Dentro de los métodos, los campos de datos (Señales) se utilizan sin
especificar el nombre del objeto. La especificación de Avión en la declaración
del procedimiento actúa como un With en el cuerpo del procedimiento.
Una vez que se ha definido un objeto, se pueden declarar variables
utilizando el nombre del objeto:
VAR
A : Avión;
En el programa que utiliza esta implementación, es posible escribir
instrucciones como las siguientes:

Página 8
WITH A DO
BEGIN
Inicializar;
SeñalesArriba;
Acelerar;
Ascender;
END;
- ENCAPSULAMIENTO Esta manera de utilizar objetos en Turbo Pascal es bastante conveniente
y clara. Sin embargo Turbo Pascal permite que los programadores accesen
directamente los contenidos de los Objetos, lo que es contrario a los principios
de OOP. Por ejemplo, es legal escribir:
A.Señales := Arriba;
Una manera de resolver este problema, es definiendo la implementación
como una Unidad y definiendo Privados los campos del objeto. Definición de
objetos en unidades y privatización de campos se discutirá más adelante.
En resumen en OOP, Encapsulamiento es la creación de objetos que
funcionan como unidades completas, ya que nunca un programador debe
accesar campos de datos definidos dentro de objetos, sino a través de los
métodos definidos dentro de los mismos. Para ello deben ser declarados
suficientes métodos de manera que realicen todo tipo de manipulación de sus
datos. Esto puede significar que sus programas sean mas largos y mas lentos,
pero obteniendo una gran ventaja, la de claridad en la codificación y fácil
mantenimiento.

Página 9
- HERENCIA En la construcción de nuevos tipos de datos, se presentan muchos casos
donde la mejor forma de definirlos es a través de un Arbol Familiar; es decir,
que existiendo entre ellos una relación "categorías y subcategorías" o "clases y
subclases" puedan ser representados en forma jerárquica.
De la misma manera, nosotros podemos definir Objetos Descendientes de otros objetos, dada que las características de su Ascendiente forman parte
en su totalidad, como subconjunto de las nuevas características del Objeto
Descendiente.
También un Objeto Descendiente puede utilizar algunos de los métodos
de su Ascendiente.
Así como los objetos contienen datos y métodos de su propiedad,
Objetos Descendientes pueden heredar tanto datos como métodos de sus
ascendientes, siendo ésta quizás, la propiedad más importante de OOP, la de
la Herencia.
Ejemplo_2: En un ambiente de Gráficos, las coordenadas X y Y
representan una localización en la pantalla, y un punto no es más que una
localización visible o invisible en la pantalla. En la forma tradicional de
programar, representaríamos ambas definiciones por medio de registros
anidados, de la siguiente manera:
TYPE
Localización = RECORD
X,Y : INTEGER
END;
Punto = RECORD
Posición : Localización;
Visible : BOOLEAN
END;

Página 10
Programando en OOP, primero definimos el Objeto Ascendiente
llamado Localización y luego un Objeto Descendiente de éste llamado Punto,
el cual va a heredar las características del primero, colocando el nombre del
ascendiente entre paréntesis, contiguo a la palabra clave OBJETO.
En algunos lenguajes como C++, definen a el objeto ascendiente en el
árbol de jerarquía como Superclase, a los descendientes inmediatos, Subclase.
En Turbo Pascal pocas veces se utiliza estos conceptos, aunque pueden ser
aplicados de la misma manera, como en el siguiente ejemplo:
TYPE
Localización = OBJECT
X,Y : INTEGER
END;
Punto = OBJECT(Localización)
Visible : BOOLEAN
END;
Note que los campos X y Y características del Objeto Localización
(SuperClase) no quedaron explícitos en la definición del Objeto Punto
(SubClase), ya que él lo hereda en forma virtual.
Ejemplo_3: Dado el siguiente ejemplo, utilizando programación tradicional:
TYPE
Movimiento = RECORD
Dirección : 0..360; (* Grados de un circulo*)
Velocidad : 0..400; (* Km por hora *)
Aceleración : -10..10 (* Km/Hora/seg *)
END;

Página 11
StatusAereo = RECORD
Mvmt : Movimiento;
Altitud :0..35000 (* Pies *)
CambioDeAltitud : -100..100 (* Pies/seg *)
END;
El registro Movimiento contiene campos utilizados en la determinación
de la velocidad y dirección. El segundo registro, StatusAereo, declara a Mvmt
que contiene los campos existentes en el record Movimiento. Este tipo de
anidación permite la definición de tipos de datos cada vez más complejos.
En OOP, el concepto de herencia reemplaza la necesidad de anidar
registros y simplifica el proceso de incrementar la complejidad. El mismo
ejemplo anterior, pero aplicando este concepto:
TYPE
Movimiento = OBJECT
Dirección : 0..360; (* Grados de un circulo*)
Velocidad : 0..400; (* Km por hora *)
Aceleración : -10..10; (* Km/Hora/seg *)
PROCEDURE Inicializar;
END;
StatusAereo = OBJECT(Movimiento)
Altitud :0..35000; (* Pies *)
CambioDeAltitud : -100..100; (* Pies/seg *)
PROCEDURE Inicializar;
END;
A diferencia de las declaraciones de registros, las declaraciones de
objetos incluyen declaraciones de métodos. Note como la declaración de
StatusAereo incluye una referencia a Movimiento:

Página 12
StatusAereo = OBJECT(Movimiento)
A través de esta declaración, StatusAereo hereda todo lo que contiene
Movimiento, no solo sus datos, sino también sus métodos. En terminología de
OOP, Movimiento es un tipo ascendiente (padre) y StatusAereo es un tipo
descendiente (hijo). En el ejemplo anterior, Movimiento es el ascendiente
inmediato de StatusAereo y StatusAereo el descendiente inmediato de
Movimiento. La línea de ascendientes y descendientes de un objeto, se
denomina Jerarquía de Objetos.
Se puede también notar que tanto Movimiento como StatusAereo
contienen un método llamado Inicializar. Cuando un método en un objeto
descendiente, se le da un nombre similar al de un método de un objeto
ascendiente, el método del objeto descendiente tiene precedencia. Por
consiguiente, si se quiere llamar al método Inicializar de Movimiento dentro de
un procedimiento del Objeto StatusAereo se debe especificar
Movimiento.Inicializar.
Es necesario puntualizar que los nombres de los métodos pueden ser
similares en objetos de una misma jerarquía; sin embargo, los nombre de
los datos no pueden ser idénticos. Una vez que se asigna un nombre a un
dato de un objeto, este nombre no puede aparecer en los objetos
descendientes.
Ejemplo_4: Una determinada universidad, desea mantener datos generales de
los tres tipos de personal que en ella labora.

Página 13
En programación tradicional, utilizando registros de tamaño fijo, se
tendría que declarar tres registros:
TYPE
Cad15 = STRING[15];
Cad30 = STRING[30];
Cad50 = STRING[50];
Obrero = RECORD
Nombre : Cad30;
Dirección : Cad50;
Sexo : CHAR;
Año_Ingreso : WORD;
Escuela : Cad15;
Cargo : Cad15;
Salario : REAL;
Lugar_Pago : Cad15
END;
Empleado = RECORD
Nombre : Cad30;
Dirección : Cad50;
Sexo : CHAR;
Año_Ingreso : WORD;
Escuela : Cad15;
Cargo : Cad15;
Sueldo : REAL;
Banco : Cad15
END;

Página 14
Docente = RECORD
Nombre : Cad30;
Dirección : Cad50;
Sexo : CHAR;
Año_Ingreso : WORD;
Escuela : Cad15;
Categoría : Cad15;
Dedicación : Cad15;
Sueldo : REAL;
Banco : Cad15
END;
Observe que los registros tienen campos comunes, por lo que es posible
englobar en un registro variable las declaraciones de los tres registros. Sin
embargo es necesario declarar un campo extra que mantenga el tipo TipoPer.
TYPE
Cad15 = STRING[15];
Cad30 = STRING[30];
Cad80 = STRING[80];
TipoPer = (Obrero,Empleado,Docente);
Personal = RECORD
Nombre : Cad30;
Dirección : Cad80;
Sexo : CHAR;
Año_Ingreso : WORD;
Escuela : Cad15
END;

Página 15
CASE Clase : TipoPer OF
Obrero : (Cargo : Cad15;
Salario : REAL;
Lugar_Pago : Cad15);
Empleado : (Cargo : Cad15;
Sueldo : REAL;
Banco : Cad15);
Docente : (Categoría : Cad15;
Dedicación : Cad15;
Sueldo : REAL;
Banco : Cad15)
END;
Utilizando OOP, podemos declarar Personal como un objeto y Obrero,
Empleado y Administrativo como objetos descendientes de Personal, heredando
todas sus características:
TYPE
Cad15 = STRING[15];
Cad30 = STRING[30];
Cad80 = STRING[80];
Personal = OBJECT
Nombre : Cad30;
Dirección : Cad80;
Sexo : CHAR;
Año_Ingreso : WORD;
Escuela : Cad15
END;
Obrero = OBJECT (Personal)
Cargo : Cad15;
Salario : REAL;
Lugar_Pago : Cad15
END;

Página 16
Empleado = OBJECT (Personal)
Cargo : Cad15;
Sueldo : REAL;
Banco : Cad15
END;
Docente : OBJECT (Personal)
Categoría : Cad15;
Dedicación : Cad15;
Sueldo : REAL;
Banco : Cad15
END;
- Métodos Estáticos y Métodos Virtuales
OOP permite dos tipos de métodos: Estáticos y Virtuales.
Los Métodos Estáticos son menos complicados, requieren menos
memoria y se ejecutan mas rapidamente, pero no nos brindan todas las ventajas
que nos ofrece OOP. Por el contrario Métodos Virtuales nos brindan mayor flexibilidad en el
uso de objetos.
- Métodos Estáticos.
En los ejemplos mencionados hasta ahora, solo se han usado métodos
Estáticos por su sencillez. Pero una de las ventajas de OOP, es la de que
objetos diferentes puedan compartir métodos con el mismo nombre.
A continuación ilustraremos esta ventaja a través de un ejemplo:
PROGRAM Estático;
USES Crt;

Página 17
(***********************************************)
(* OBJECT : Localización *)
(***********************************************)
TYPE
Localización = OBJECT
X, Y : BYTE;
PROCEDURE Inicialización;
PROCEDURE Posición(NuevoX, NuevoY, : BYTE);
END;
PROCEDURE Localización.Inicialización;
BEGIN
X := 1;
Y := 1
END;
PROCEDURE Localización.Posición(NuevoX,NuevoY : BYTE);
BEGIN
X := NuevoX;
Y := NuevoY
END;
(***********************************************)
(* OBJECT : Ch *)
(***********************************************)
TYPE
Ch = OBJECT(Localización)
C : CHAR;
PROCEDURE Inicialización;
PROCEDURE Mostrar;
PROCEDURE ActualiceC(NuevoC : CHAR);
PROCEDURE MuevaA(NuevoX, NuevoY : BYTE);
END;

Página 18
PROCEDURE Ch.Inicialización;
BEGIN
Localización.Inicialización;
C := 'A'
END;
PROCEDURE Ch.Mostrar;
BEGIN
WRITE(C)
END;
PROCEDURE Ch.ActualiceC(NuevoC : CHAR);
BEGIN
C := NuevoC
END;
PROCEDURE Ch.MuevaA(NuevoX, NuevoY : BYTE)
BEGIN
X := NuevoX;
Y := NuevoY;
GotoXY(X,Y)
Mostrar;
END;
(***********************************************)
(* OBJECT : St *)
(***********************************************)
TYPE
St = OBJECT(Ch)
S : STRING;
PROCEDURE Inicialización;
PROCEDURE Mostrar;
PROCEDURE ActualiceS(NuevoS : STRING);
END;

Página 19
PROCEDURE St.Inicialización;
BEGIN
Ch.Inicialización;
S := ' '
END;
PROCEDURE St.Mostrar;
BEGIN
Write(S)
END;
PROCEDURE St.ActualiceS(NuevoS : STRING);
BEGIN
S := NuevoS
END;
VAR
S : St;
BEGIN
ClrScr;
WITH S DO
BEGIN
Inicialización;
ActualiceS('ESTE ES UN STRING');
MuevaA(10,10)
END;
READLN
END.
Este programa contiene tres objetos: Localización, Ch, y St. Tanto Ch
como St contienen un método llamado Mostrar, el cual es invocado desde el
método MuevaA localizado en Ch.

Página 20
La versión de MuevaA en el Objeto St muestra un STRING, mientras la
versión en Ch muestra un CHAR.
En el programa principal se declara y se actualiza una variable tipo
String, y luego se ejecuta el Método MuevaA. En vez de mostrar un String el
programa muestra un caracter del Objeto Ch. En otras palabras, el programa
ejecuta la versión equivocada de Mostrar.
Esto sucede ya que al ejecutarse MuevaA, hace que Turbo Pascal
busque hacia atrás desde St a Ch Objetos y luego localiza el Método. Cuando
el Método MuevaA se ejecuta, este encuentra una llamada a Mostrar, sin otro
tipo de información, entonces Turbo Pascal ejecuta la versión más cercana de
Mostrar que es la que aparece en la definición del Objeto Ch, por lo tanto se
muestra un Caracter en vez de un String.
Esto es un ejemplo de Enlace Temprano. Cuando el programa es
compilado, Turbo Pascal resuelve la llamada a Mostrar apuntando a el
procedimiento localizado en Ch. Este enlace es denominado Temprano ya que
lo realiza en tiempo de compilación.
Una solución a este problema sería la de redefinir el método Mostrar dentro del Objeto St( String ), pero esto va en contra de la filosofía de OOP, que
consiste en reducir código redundante.
La solución correcta es usar Métodos Virtuales, los cuales realizan los
enlaces en tiempo de ejecución. - Métodos Virtuales.
Por medio de Métodos Virtuales los pase se realiza por medio de un
Enlace Tardío, en tiempo de ejecución, por medio de una Tabla de Método
Virtual (VMT), la cual Turbo Pascal la actualiza para cada tipo de Objeto que
contiene o hereda Métodos Virtuales.

Página 21
- Tabla de Método Virtual.
Una VMT es un tabla de direcciones que apunta a procedimientos y
funciones. Manteniendo una tabla de direcciones para cada tipo de objeto,
Turbo Pascal puede determinar un pase de ejecución que sería imposible
determinar en tiempo de compilación.
La estructura de una VMT comienza con dos palabras, la primera
conteniendo el tamaño de el objeto que la usa, la segunda conteniendo el valor
negativo de la primera palabra, y es usada para demostrar que dicha tabla ha
sido apropiadamente inicializada.
- Declaración de Métodos Virtuales.
Para declarar métodos virtuales, simplemente agregan la palabra
reservada Virtual en la declaración del método, de la siguiente manera:
TYPE
Ch = OBJECT(Localización)
C : CHAR;
CONSTRUCTOR Inicialización;
PROCEDURE Mostrar; VIRTUAL;
PROCEDURE ActualiceC(NuevoC : CHAR);
PROCEDURE MuevaA(NuevoX, NuevoY : BYTE);
END;
St = OBJECT(Ch)
S : STRING;
CONSTRUCTOR Inicialización;
PROCEDURE Mostrar; VIRTUAL;
PROCEDURE ActualiceS(NuevoS : STRING);
END;

Página 22
- Reglas para la construcción de Métodos Virtuales
1-) Una vez declarado un Método Virtual en una definición de Objeto,
métodos con el mismo nombre definidos en otros objetos descendien–
tes deben ser también declarados Virtuales.
2-) Una vez declarado un Método Virtual, su encabezado debe ser el
mismo para cualquier subsecuente definiciones en objetos descen–
dientes, incluyendo lista de parámetros etc.
3-) En cualquier objeto que se defina un Método Virtual, deben tam–
bién definir Método Constructor (Constructor) antes de la definición
del Virtual.
- Métodos Constructores.
Este tipo de Métodos juegan un papel muy importante en Enlaces Tardíos, y se declaran solo sustituyendo la palabra Constructor en vez de
Procedure en los métodos que permiten inicializar el objeto. Ellos deben ser
invocados antes de cualquier ejecución de un Método Virtual, ya que los métodos Constructores son los que inicializan la tabla VMT. Cualquier
método Constructor puede ser heredado por otros objetos descendientes al que
lo define.
- Observando internamente las VMT.
Todas las variables definidas del mismo tipo de Objeto apuntan a la
misma VMT, la cual es invisible al programador. En le ejemplo anterior el
Objeto Localización no tiene métodos virtuales por lo que no se le asigna tabla
VMT. Pero a el Objeto Ch si posee método virtual, por lo que se le asigna una
VMT a continuación de sus datos. Sin embargo, el objeto St, a pesar de poseer
métodos virtuales, no se le asigna tabla VMT, ya que el hereda la misma que se
le asignó al Objeto Ch junto con sus datos, como se observa en el siguiente
gráfico.

Página 23
Si al ejemplo anterior se le declarara Virtual el método ActualizarC en el
Objeto Ch, como se muestra a continuación,
TYPE
Ch = OBJECT(Localización)
C : CHAR;
CONSTRUCTOR Inicialización;
PROCEDURE Mostrar; VIRTUAL;
PROCEDURE ActualiceC(NuevoC : CHAR); VIRTUAL;
PROCEDURE MuevaA(NuevoX, NuevoY : BYTE);
END;
St = OBJECT(Ch)
S : STRING;
CONSTRUCTOR Inicialización;
PROCEDURE Mostrar; VIRTUAL;
PROCEDURE ActualiceS(NuevoS : STRING);
END;
la tabla VMT mostraría las siguientes direcciones, tanto en los datos de Ch
como en los datos de St:

Página 24
Note que en la tabla mostrada en St, incluye herencia del procedimiento
ActualizarC, observando la misma dirección que en la tabla mostrada en Ch.
Sin embargo, el Método Mostrar presenta diferentes direcciones en Ch y St,
esto es debido a que el Objeto St lo redeclaró ya que su contenido era diferente.
En otras palabras el método usa el pointer localizado en VMT, y es la Tabla
VMT la que dice cual de los dos métodos debe ejecutar.
- Métodos Estáticos Vs Virtuales.
• Usar métodos estáticos solo cuando se desee optimizar la eficiencia
en cuanto velocidad y memoria.
• Utilizar método virtual si existe la posibilidad de que algún futuro
descendiente del objeto siendo definido, requiera reescribir dicho
método.
- POLIMORFISMO
Las variables tipo Objeto siguen reglas algo diferente a las variables
comunes en Turbo Pascal. La principal diferencia es que un Tipo Ascendiente
es compatible con cualquier Tipo Descendiente, pero a la inversa no funciona.

Página 25
Ejemplo:
VAR
C : Ch;
S : St;
BEGIN
C := S; { es Válido }
S := C; { no es Válido }
La razón es que por herencia, S contiene todo lo que está en C, pero C
no tiene por que contener todo lo que está en S. En la primera asignación, solo
los valores de los campos que son comunes en S con respecto a C, son
asignados. En la segunda asignación, campos en S quedarían sin ser
actualizados en su contenido.
La flexibilidad que nos ofrece la compatibilidad de tipos de objetos, hasta
ahora pareciera que carece de importancia, sin embargo esta hace posible otras
de las características de OOP, la de Polimorfismo. Dada la siguiente declaración:
PROCEDURE CambiarValor(VAR C : Ch);
BEGIN
{ .... }
END;
desde el programa podría ser invocado de ambas maneras:
CambiarValor(C); { un caracter }
CambiarValor(S); { un string }

Página 26
Polimorfismo es una manera de decirle o enviarle mensajes al
procedimiento de que debe permitir ser accesado por un amplio rango de tipos
de objetos, aún cuando esto lo desconoce en tiempo de compilación, siempre y
cuando los parámetros actuales son descendientes del tipo de objeto definido
como parámetro formal.
Polimorfismo tiene otra importante implicación, ya que como los
procedimientos que aceptan variables polimorfas, solo pueden obtener
información acerca de sus variables en tiempo de ejecución.
Usted está en capacidad de definir nuevos objetos compatibles a los
anteriormente definidos, sin recompilar la unidad que contiene el procedimiento.
Usted define todos los objetos y métodos como una unidad de implementación
UNIT, lo compila, distribuye la unidad compilada sin el código fuente a sus
posibles usuarios, y ellos podrán crear nuevos objetos y ser manipulados por
los métodos compilados.
UNIT Unidades;
INTERFACE
USES Crt;
TYPE
(***********************************************)
(* OBJECT : Localización *)
(***********************************************)
Localización = OBJECT
X, Y : BYTE;
PROCEDURE Inicialización;
PROCEDURE Posición(NuevoX, NuevoY, : BYTE);
END;

Página 27
(**********************************************)
(* OBJECT : Ch *)
(**********************************************)
Ch = OBJECT(Localización)
C : CHAR;
CONSTRUCTOR Inicialización;
PROCEDURE Mostrar; VIRTUAL;
PROCEDURE ActualiceC(NuevoC : CHAR); VIRTUAL;
PROCEDURE MuevaA(NuevoX, NuevoY : BYTE);
END;
(*********************************************)
(* OBJECT : St *)
(*********************************************)
St = OBJECT(Ch)
S : STRING;
CONSTRUCTOR Inicialización;
PROCEDURE Mostrar; VIRTUAL;
PROCEDURE ActualiceS(NuevoS : STRING);
END;
IMPLEMENTATION
(*********************************************)
(* Métodos de Localización *)
(*********************************************)
PROCEDURE Localización.Inicialización;
BEGIN
X := 1;
Y := 1
END;

Página 28
PROCEDURE Localización.Posición(NuevoX,NuevoY : BYTE);
BEGIN
X := NuevoX;
Y := NuevoY
END;
(**********************************************)
(* Métodos de Ch *)
(*********************************************)
CONSTRUCTOR Ch.Inicialización;
BEGIN
Localización.Inicialización;
C := 'A'
END;
PROCEDURE Ch.Mostrar;
BEGIN
Write(C)
END;
PROCEDURE Ch.ActualiceC(NuevoC : CHAR);
BEGIN
C := NuevoC
END;
PROCEDURE Ch.MuevaA(NuevoX, NuevoY : BYTE);
BEGIN
X := NuevoX;
Y := NuevoY;
GotoXY(X,Y);
Mostrar
END;

Página 29
(*********************************************)
(* Métodos de St *)
(*********************************************)
CONSTRUCTOR St.Inicialización;
BEGIN
Ch.Inicialización;
S := ' '
END;
PROCEDURE St.Mostrar;
BEGIN
Write(S)
END;
PROCEDURE St.ActualiceS(NuevoS : STRING);
BEGIN
S := NuevoS
END;
{ no existe sección de inicialización }
END.
PROGRAM caracteres;
USES Crt, Unidades;
VAR S : St;
BEGIN
ClrScr;
WITH S DO
BEGIN
Inicialización;
ActualiceS('ESTE ES UN STRING');
MuevaA(10,10)
END;
READLN;
END.

Página 30
Polimorfismo no puede ser alcanzado sin la utilización de Métodos
Virtuales. Métodos Virtuales garantiza que el mensaje enviado a las variables
objeto sean apropiadamente interpretado. Esto ocurre, por que los problemas
ocasionados por la anidación de los métodos, son resueltos en tiempo de
ejecución y no en tiempo de compilación.
- OBJETOS DINAMICOS. Objetos pueden ser localizados en un Heap en la memoria y ser
manipulados por apuntadores. Turbo Pascal 5.5, incluye algunas extensiones
de las instrucciones correspondientes a memoria dinámica muy poderosas, que
hacen la asignación y liberación dinámica de objetos más fácil y eficiente.
- Asignación Dinámica de Objetos.
Si se desea crear un objeto dinamicamente, así como el objeto St del
ejemplo anterior, se debe declarar una variable tipo apuntador a ese objeto,
mediante el procedimiento NEW:
VAR
PtrSt : ^ St;
NEW(PtrSt);
El procedimiento NEW asigna suficiente espacio sobre el Heap para
contener una ocurrencia de St, retornando la dirección de ese espacio en la
variable apuntadora PtrSt.
Si el objeto contiene métodos virtuales, el objeto debe ser inicializado con
una llamada al procedimiento Constructor, antes de realizar cualquier llamada
a los otros métodos definidos para ese objeto:

Página 31
PtrSt^.Inicialización;
Las llamadas a los métodos pueden ser realizadas normalmente, usando
el nombre de la variable de tipo apuntador, seguida por el caracter ^ en lugar
del nombre de la variable definida de el tipo del objeto, tal como se realizó en
forma estática:
PtrSt^.ActualiceS('Este es un String');
Como se dijo anteriormente, Turbo Pascal 5.5 agregó extensiones a la
sintaxis de la instrucción New, permitiendo así un significado más compacto y
conveniente de la localización de espacio de memoria para un objeto sobre el
Heap e inicializando el objeto con una operación. La instrucción New ahora
puede ser invocada con dos parámetros; el nombre de la variable tipo
apuntador como primer parámetro, y la invocación al método constructor como
segundo parámetro:
New(PtrSt,Inicialización('Este es un String));
Usando esta extensión de la instrucción New, el constructor Inicialización
desarrolla la asignación dinámica, usando un código de entrada generado como
parte de una compilación del constructor. El compilador identifica la llamada al
correspondiente método de inicialización a través del tipo de apuntador pasado
como primer parámetro.
New también ha sido extendida como función en vez de procedimiento,
retornando un valor apuntador. En este caso, el parámetro pasado a el New es
el tipo del apuntador a el objeto, en vez de la variable tipo apuntador:
TYPE
PtrSt=^St;
VAR
PSt : PtrSt;
PSt := NEW(PtrSt);

Página 32
quedando la sintaxis extendida para este caso de la siguiente manera:
PSt := NEW(PtrSt,Inicialización('Este es un String));
La sintaxis ampliada de la instrucción New, genera código más corto y
eficiente, por lo que es más recomendable su uso.
- Liberación Dinámica de Objetos.
Los objetos asignados sobre el Heap pueden ser liberados con la
instrucción DISPOSE cuando ellos no sean más requeridos:
DISPOSE(PtrSt);
Un objeto puede contener apuntadores a estructuras u objetos dinámicos
que necesitan ser liberados o limpiados en un orden particular, especialmente
cuando estructuras de datos complejas asignadas dinamicamente están
envueltas en el problema (ver Listas Encadenadas). Esto debe ser realizado
mediante un simple método, de manera de ser resuelto con una sola llamada a
un método destructor que contenga todas las instrucciones Dispose necesarias.
Es legal y a menudo útil definir múltiples métodos de limpieza para un tipo dado
de objeto. Objetos complejos pueden requerir diferentes maneras de limpieza
dependiendo como ellos fueron asignados o dependiendo sobre que estado el
objeto se encuentra cuando se desee realizar la limpieza del mismo.

Página 33
- Métodos Destructores.
Turbo Pascal 5.5 proporciona un tipo especial de método llamado
destructor, denominado así porque limpia y dispone del espacio de memoria
asignado dinamicamente a objetos. Como cualquier otro método, se pueden
definir destructores para un solo tipo de objeto. Un destructor se define con
todos los restantes métodos del objeto en la definición del mismo. Los
destructores pueden ser heredados y estáticos o virtuales, aunque es
recomendable que sean virtuales de modo que en cada caso el destructor
correcto se ejecutará para su correspondiente tipo objeto.
Un ejemplo de uso de métodos Destructores estáticos sería:
TYPE
Ch = OBJECT(Localización)
C : CHAR;
CONSTRUCTOR Inicialización;
DESTRUCTOR Terminación; VIRTUAL;
PROCEDURE Mostrar; VIRTUAL;
PROCEDURE ActualiceC(NuevoC : CHAR);
PROCEDURE MuevaA(NuevoX, NuevoY : BYTE);
END;
St = OBJECT(Ch)
S : STRING;
CONSTRUCTOR Inicialización;
DESTRUCTOR Terminación; VIRTUAL;
PROCEDURE Mostrar; VIRTUAL;
PROCEDURE ActualiceS(NuevoS : STRING);
END;

Página 34
Es buena idea siempre declarar el Destructor Virtual, de manera de que
en cada caso el correspondiente Destructor sea ejecutado por su tipo de objeto.
La verdadera función que realiza un destructor se puede observar sobre
objetos asignados dinamicamente. Un método destructor combina la tarea de
liberar el espacio desde el Heap con cualquier otra tarea requerida para la
limpieza o finalización del objeto en cuestión, garantizando que el número
correcto de Bytes de memoria del Heap sea liberado.
No existe regla que prohiba el uso de destructores cuando los objetos
sean asignados estaticamente; de hecho, por no dar a un tipo de objeto un
destructor, usted le está impidiendo a ese tipo de darle el beneficio completo de
la administración de memoria dinámica que Turbo Pascal ofrece.
Otra situación en donde se observa un gran beneficio al utilizar
Destructores, es cuando objetos polimórficos deben ser limpiados y su
ocupación en el Heap liberada. Las reglas observadas en la asignación entre
variables de objetos polimórficos también se observan en la asignación entre
apuntadores a objetos polimórficos, dado que esos apuntadores pasan a ser
polimórficos en la misma medida.
El término polimórfico es apropiado porque el código utilizado por el
objeto no conoce en tiempo de compilación, que tipo de objeto se está
utilizando, solo conoce que el objeto es uno de los tantos objetos que
jerarquicamente es descendiente desde tipo específico de objeto.
En cuanto al tamaño del objeto polimórfico se desconoce también en
tiempo de compilación. Entonces cómo sabe el procedimiento DISPOSE el
número de bytes que debe liberar desde el Heap?. El Destructor resuelve
este problema referenciando el lugar donde esa información se encuentra
almacenada: en la ocurrencia que ocupa esa variable en la tabla VMT.

Página 35
Por cada tabla VMT correspondiente a un tipo de objeto, se encuentra
almacenado el número de Bytes requerido por ese tipo de Objeto. La tabla VMT
para cada tipo de objeto es disponible a través de un parámetro invisible
SELF, que es pasado a la invocación de cualquier método definido para ese
tipo. Uno de estos métodos es el Destructor, el cual recibe una copia del
correspondiente parámetro SELF cuando el objeto lo invoque.
De manera que un objeto pudiendo ser polimórfico en tiempo de
compilación, nunca lo es en tiempo de ejecución, gracias al enlace tardío. Para
la realización de la liberación de memoria en enlace tardío, el Destructor debe
invocar al procedimiento Dispose en su sintaxis extendida:
Dispose( PtrSt,Terminación);
Invocando al Destructor fuera de la llamada al procedimiento Dispose,
no realiza la liberación completa, ya que el Destructor es el que observa el
tamaño del objeto en la tala VMT, lo cual es requerido para que el correcto
numero de Bytes de espacio ocupado por el objeto en el HEAP sea liberado.
El método Destructor puede no contener ninguna instrucción dentro del
cuerpo del procedimiento y sin embargo realizar ese servicio:
DESTRUCTOR St.Terminación;
BEGIN
END;
La tarea fundamental que desarrolla este Destructor no se debe al cuerpo
del método en sí, sino al código generado por el compilador en respuesta a la
palabra reservada DESTRUCTOR.

Página 36
- Métodos Constructores y Destructores.
• Los constructores se utilizan para inicializar objetos. Típicamente
la inicialización se basa en valores pasados como parámetros al
constructor.
• Los destructores son opuestos a los constructores y se utilizan para
limpiar objetos desde la tabla VMT asociada después de su uso.
• Los constructores son vitales para la utilización de métodos virtua–
les y los destructores son cruciales para el uso de la asignación di–
námica.
- Clausula PRIVATE Turbo Pascal versión 6.0 introduce la palabra clave PRIVATE, para
restringir el acceso directo a los campos de datos definidos en el objetos, así
como el pase de mensaje a través de los métodos definidos para el manejo de
los mismos.
La regla general es hacer todos los campos privados y en algunos casos
ofrecer métodos especiales también privados para accesarlos.
La sintaxis utilizada para declarar métodos y campos de datos privados
en la siguiente:
<Nombre del Objeto> = OBJECT(<Nombre del Objeto ascendente>)
<Lista de campos de datos Públicos>
<Encabezados de los métodos Públicos>
PRIVATE
<Lista de campos de datos Privados>
<Encabezados de los métodos Privados>
END;

Página 37
Las reglas para el uso de la clausula PRIVATE son las siguientes:
1.- La palabra clave PRIVATE no ejecuta ninguna acción sobre campos
de datos o métodos definidos dentro de un programa.
PROGRAM Publico;
TYPE
TPublico = OBJECT
X : WORD;
PRIVATE
Y : WORD;
END;
TPublico2 = OBJECT(TPublico)
Z : WORD;
PRIVATE
W : WORD;
END;
VAR
P : TPublico2;
BEGIN
P.X := 1;
P.Y := 2;
P.Z := 10;
P.W := 20;
WRITELN('P = ',P.X,',',P.Y,',',P.Z,',',P.W);
END.
El ejemplo anterior muestra una jerarquía de objetos con campos
de datos privados en cada objeto. La variable P declarada de tipo
TPublico2, puede accesar los campos privados tanto de TPublico2
como también de TPublico. Si métodos fueran insertado en la
sección privada, la variable objeto P también puede invocarlos.

Página 38
2-. Los campos de datos y métodos declarados privados en una unidad,
pueden ser accesados también por variables objetos y métodos de
objetos aunque sean descendientes a él, si son definidos en la mis– ma
unidad.
UNIT UPublico;
INTERFACE
TYPE
TPublico = OBJECT
X : REAL;
PROCEDURE TONTO;
PRIVATE
Y : REAL;
END;
IMPLEMENTATION
VAR
P : TPublico;
PROCEDURE TPUBLICO.TONTO;
BEGIN
END;
BEGIN
P.X := 1.0;
P.Y := 2.0;
WRITELN('P = ',P.X:2:0,' + ',P.Y:2:0);
END.

Página 39
3-. Los campos de datos y métodos declarados en una unidad de librería
no son accesibles por las siguientes entidades declaradas en otras
unidades de librerías o programas:
• Variables objetos definidas por el tipo de objeto exportado.
• Tipos de objetos descendientes.
• Variables objetos definidas por tipos de objetos descendien–
tes.

Página 40
EJERCICIO PROPUESTO_____________________
1-) Una compañía de seguros ofrece tres tipos de pólizas: vida, automóvil y
casa. Un número de póliza identifica cada póliza de seguros de cualquier tipo.
Para los tres tipos de seguros es necesario el tener seguros de cualquier tipo.
Para los tres tipos de seguros es necesario tener el nombre del asegurado,
dirección, la cantidad asegurada y el pago de la póliza mensual. Para las
pólizas de automóvil y casa es necesario además hacer una deducción de una
cierta cantidad. Para una póliza de seguro de vida se requiere el dato sobre la
fecha de nacimiento del asegurado y del beneficiario. Para la póliza de seguro
del carro, se requiere el número de la licencia, el estado modelo y el año. Para
la póliza del propietario de la casa, se requiere antigüedad de la casa y
seguridades o alarmas existentes. Escribir las declaraciones que permitan
mantener esta información utilizando OOP en Pascal.

Página 41
CAPITULO 2
ESTRUCTURA DE DATOS y su
METODOLOGIA DE DISEÑO - DATOS Los datos en el mundo de la programación , representan los objetos que
son manipulados o procesados en una computadora por medio de un programa.
En cierto sentido, esa información es simplemente un conjunto de bits en
estados On u Off. La propia computadora necesita tener los datos de esta
forma. Sin embargo, los humanos tendemos a pensar en la información en
unidades algo mayores, de forma que tenga sentido para nosotros. Para
separar la visión de los datos en la computadora con respecto a la nuestra,
crearemos una nueva visión llamada "Abstracción de Datos".
Un entero puede representarse fisicamente en forma diferente, sobre
diferentes computadoras. En la memoria del computador puede ser un decimal
codificado en binario o puede ser un binario con signo o un complemento a uno
o un complemento a dos. Ejemplo:
Binario Sin Signo Decimal en Binario Compl. a Uno Comp a Dos
10011001 153 99 -102 -103
El hecho de que no se tenga conocimiento de esos términos, no
imposibilita el trabajar con enteros, ello solo dependerá de como esté siendo
representado internamente en la máquina. Sin embargo, como programadores
en Pascal, no tenemos por que referirnos a ese nivel "Físico", solo usamos los
enteros como un tipo de datos que nos ofrece un cierto lenguaje. Solo nos
interesa saber como declarar una variable entera y las operaciones permitidas
sobre ellas, en otras palabras, el nivel de Abstracción de Datos o nivel Lógico.

Página 42
Pascal, como la mayoría de lenguajes de alto nivel, empaqueta o
encapsula el tipo de datos Integer, y nos da justo la información necesaria para
crear y manipular variables de este tipo. La ventaja de utilizar una abstracción
de datos, es que se puede pensar en los datos y en las operaciones en un
sentido lógico, considerando su uso sin tener que preocuparse de los detalles
de implementación. Los niveles inferiores o físicos están allí, solo que ocultos
al usuario de la misma.
Cuando un programa requiere de un conjunto de datos, tendremos que
considerar una Estructura de Datos adecuada.
- ESTRUCTURA DE DATOS
Es una colección elementos de datos relacionados y organizados, cuya
representación en memoria principal, caracteriza y facilita las operaciones de
acceso usadas para almacenar y recuperar los elementos en forma individual.
- Características
Las Estructuras de Datos cumplen con una serie de características:
- Pueden ser descompuestas.
- La colocación de sus elementos en la colección es una caracterís–
tica propia de la estructura, la cual afectará la forma de accesar
cada elemento en particular.
- El orden de colocación de los elementos y la forma de acceso a
ellos deben permitir el agrupamiento en una sola unidad conocida
como implementación de la Estructura de Datos.

Página 43
- DISEÑO DESCENDENTE
El Diseño Descendente, también llamado refinamiento sucesivo, toma el
enfoque de Divide y Vencerás. El problema se divide en grandes tareas, éstas
a su vez en subtareas, y así sucesivamente. La característica importante es la
de retrasar los detalles tanto como sea posible, conforme se va de una solución
general a una específica.
Este enfoque de diseño exige diferenciar lo que implementación de una
Estructura de Datos se refiere de la aplicación de un problema que usa esa
implementación.
- Ocultamiento de la Información
Una característica principal del diseño descendente, es que los detalles
que se especifican en los niveles inferiores están ocultos a los niveles
superiores. El Ocultamiento de la Información previene a los niveles más altos
del diseño de ser dependiente de los detalles de diseño de bajo nivel o
implementación que pueden ser cambiados con más probabilidad. El
programador o usuario de la aplicación debe solo conocer los detalles que son
relevantes a un nivel particular del diseño que se denomina abstracción.
- Abstracción de Datos

Página 44
Abstracción de Datos consiste en separar las propiedades lógicas de las
Estructura de Datos o funciones de su implementación. El objetivo de ella es la
de manipular datos dentro de un programa desde el punto de vista lógico, en
vez de la forma como se va a almacenar fisicamente. La Abstracción de Datos
se logrará realizando la implementación de las Estructuras de Datos en
unidades.
- Encapsulamiento de Datos
Encapsulamiento de Datos consiste en agrupar todo aquello requerido
para la representación interna de la Estructura de Datos así como las
operaciones que permitan manipularla. Es aquí que juega un papel muy
importante la Programación orientada a Objetos. De hecho, el concepto de
Encapsulamiento de Datos fué definido detalladamente en el capítulo anterior
como característica principal de OOP.
- Niveles de los Datos
En los próximos capítulos, se hará el diseño de Estructuras de Datos no
incorporadas en Turbo Pascal, tales como Pila (Stack), Cola (Queue), Arboles
(Tree) etc., considerándolas desde tres perspectivas o niveles diferentes de
datos:
1.- Nivel de Aplicación (o del usuario de la implementación).
2.- Nivel de Abstracción ( o lógico).
3.- Nivel de Implementación ( o físico).

Página 45
- TIPOS DE IMPLEMENTACION
Existen dos formas de implementación:
- Hardware: Donde los circuitos necesarios para desarrollar opera–
ciones requeridas son diseñadas y construidas como parte del com–
putador.
- Software: En la que mediante un programa escrito en un lenguaje
de alto nivel es utilizado para interpretar un nuevo tipo de datos y
para desarrollar las operaciones requeridas para ese nuevo tipo de
datos.
- CLASIFICACION DE LAS ESTRUCTURAS DE DATOS
- Según su Implementación:
Primitivas: Implementadas a nivel de Hardware. Ej: Varia–
bles, Arreglos, Strings, etc.
No_Primitivas: Implementadas a nivel de Software, utilizan–
do Estructuras de Datos Primitivas. Ej: Stacks, Colas, Listas,
Arboles, etc.
- Según el tipo de almacenamiento:
Estáticas: Implementadas en localizaciones secuenciales de
memoria. Ej: Variables, Arreglos, Strings, Stacks, Colas, etc.
Dinámicas: Implementadas utilizando memoria Dinámica. Ej:
Listas, Arboles, Grafos, etc.

Página 46
CAPITULO 3
ESTRUCTURA DE DATOS
PILA o STACK Los principios básicos de la metodología de diseño discutida en el
capítulo anterior, los utilizaremos en la construcción de nuevas Estructuras de
Datos. Estas estructuras no están incorporadas a nivel de Hardware en la
mayoría de los lenguajes de programación, por lo que han de ser
implementadas antes de su utilización en alguna aplicación.
- NIVEL DE ABSTRACCION
- Definición
Una Pila o Stack es un grupo ordenado de elementos homogéneos. La
característica principal del Stack, es la de que el insertar o eliminar elementos
del conjunto, sólo puede llevarse a cabo por la cabeza (Tope) de la Pila.
Ejemplo: Una Pila de libros.
Si el libro que deseo leer es el número 3, sólo podría tomarlo sin
derrumbar dicha pila, eliminando el libro número 5, luego el número 4,
quedando así el número 3 en el tope de la pila de libros.

Página 47
Luego el libro numero 3 puede ser eliminado del montón, y devueltos en
el orden inverso los libros 4 y 5.
Se dice que las Pilas son conjunto ordenados de elementos, ya que su
orden es de tipo cronológico, es decir de acuerdo al momento en que fueron
insertados dichos elementos en la estructura. Debido a que los elementos se
añaden y giran solo por la cabeza de la Pila, el último elemento en ser insertado
es el primero en ser eliminado, con respecto a los que están por debajo de él en
el montón. Por lo tanto el comportamiento de la Pila es LIFO ( Ultimo que Entra,
Primero que Sale).
- Operaciones
Las operaciones para insertar un elemento en la Pila se denominará en
lo sucesivo Meter (PUSH), y la operación de eliminación se denominará Sacar
(POP). Antes de comenzar a utilizar cualquier estructura, debe estar vacía, por
lo que es necesario definir una operación que inicialice la Pila en Vacía la cual
denominaremos Inicializar.
Antes de definir las operaciones más elementales, que permitan al
usuario la manipulación de los elementos dentro de la Pila, observemos como
funciona paso a paso una Pila con capacidad máxima de tres elementos, en el
siguiente ejemplo:

Página 48
Paso1.- Inicializar Paso 6.- Meter el valor 9
Paso 2.- Meter el valor 5 Paso 7.- Meter el valor 10
Condición: "PILA OVERFLOW"
Paso 3.- Meter el valor 7 Paso 8.- Sacar un elemento
Paso 4.- Meter el valor 3 Paso 9.- Sacar un elemento
Paso 5.- Sacar un elemento Paso 10.- Sacar un elemento

Página 49
Paso 11.- Sacar un elemento
Condición : "PILA UNDERFLOW"
Note que en el paso 7, al desear realizar una operación de inserción del
valor 10, no pudo llevarse a cabo, ya que la Pila se encuentra en su máxima
capacidad, por lo que se determina una condición de Pila Overflow (por encima
de su capacidad). El caso opuesto sucede en el paso 11, donde se trata de
eliminar un elemento de la Pila, encontrándose la misma vacía, por lo que se
determina una condición de Pila Underflow (Por debajo de su capacidad).
Esto nos demuestra que son sumamente necesarias dos nuevas
operaciones. Una que me permita determinar si la Pila se encuentra Vacía, y
otra que me permita chequear si la Pila se encuentra llena.
Para poder hacer uso de esta estructura dentro de una aplicación, el
usuario debe tener conocimiento de las especificaciones del paquete, para
tener una interfase con la implementación. El segmento de la aplicación que
haga uso de una Pila, no tiene que hacer referencia de cómo fué implementada
la misma. Las operaciones como Meter, Sacar, etc, son las ventanas del
encapsulamiento de la Pila, por la cual pasan los datos a la o desde la
aplicación.

Página 50
PPaaqquueettee PPiillaa
Los elementos se insertan y eliminan por la
cabeza o tope de la Pila.
Inicializar
Función : Inicializar la Pila.
Entrada : Ninguna.
Salida : Pila Inicializada.
Vacío
Función : Chequear si la Pila está vacía.
Entrada : Ninguna.
Salida : Boolean.
Lleno
Función : Chequear si la Pila está llena.
Entrada : Ninguna.
Salida : Boolean.
Meter(Elemento, SIZEOF(Elemento))
Función : Insertar un nuevo elemento en el tope de la Pila.
Entrada : El nuevo elemento y el tamaño(# de Bytes) del e–
lemento.
Salida : Pila actualizada.
Sacar(Elemento, SIZEOF(Elemento))
Función : Eliminar el elemento del tope de la Pila.
Entrada : El Tamaño(# de Bytes) del elemento.
Salida : Pila actualizada y el elemento eliminado.

Página 51
- NIVEL DE IMPLEMENTACION
Debido a que los elementos de una Pila son homogéneos, es decir del
mismo tipo de dato, un arreglo unidimensional parece ser una estructura
razonable para representar una Pila; en otras palabras, utilizaremos
almacenamiento secuencial. Podemos colocar el primer elemento de la Pila en
la primera posición, el segundo elemento en la segunda posición, y así
sucesivamente.
. . . . . . . . . . . . .
1 2 3 4 MaxElem
Para obtener algo similar al Polimorfismo, pero en cuanto a la
información que pueda ser almacenada dentro de la Pila, cada elemento del
arreglo consistirá de un conjunto de Bytes, definidos fuera del Objeto Pila
como un Tipo de Dato que se denominará Información. El tipo información
consistirá de un arreglo unidimensional de Bytes, con un máximo número en
nuestro ejemplo de 300 Bytes. De esta manera, la información será
almacenada Byte por Byte, permitiendo así enteros, reales, string, records o
cualquier otro tipo de dato que el usuario de la implementación desee
almacenar en la estructura.
CONST
MaxElem = 100;
MaxByte = 299;
TYPE
LongInfo = 0..MaxByte;
Información = ARRAY[LongInfo] OF BYTE;
Este enfoque permite almacenar datos cuyos tipos se desconocen en
tiempo de compilación.

Página 52
Para llevar la pista de la posición ocupada por el elemento que
corresponde al actual tope de la Pila, es necesario utilizar una variable externa
a la estructura física la cual llamamos Tope, definida como parte del objeto Pila.
Dicha variable se le asignará valor cero, para el caso inicial en donde la Pila
debe estar vacía; se incrementará en uno, cuando se realice una operación de
Meter un nuevo valor, para apuntar a la nueva posición dentro de la Pila y se
reducirá en uno, cuando se realice una operación de Sacar el elemento del
tope de la Pila, quedando Tope apuntando a la posición previa a la operación.
Pila = OBJECT
.
. (* Métodos *)
PRIVATE
Elemento : ARRAY[1..MaxElem] OF Informacion;
Tope : 0..MaxElem;
END;
Observe que las variables Elemento y Tope están privatizadas, esto
con el fin de que el usuario de esta implementación no pueda accesarlos
directamente desde la aplicación. Los métodos por los cuales el usuario manda
mensajes al objeto, no deben ser privatizados, ya que de serlo y por estar
definida su implementación en una unidad, no podrían cumplir con su función
específica.
Entre las operaciones definidas para la Estructura Pila tenemos la de
Inicializar, la cual realiza la inicialización de la variable Tope en un valor cero.
Tope := 0;

Página 53
La operación Vacío, la cual chequea si la variable Tope es igual a cero,
en cuyo caso retorna TRUE como valor Booleano indicando que la Pila está
vacía. Esto nos permite hacer ese chequeo, antes de realizar una operación de
Sacar un elemento de la misma; pues de lo contrario, se podría dar la
Condición de " Pila Underflow ".
Vacio := Tope = 0;
La operación Lleno, la cual averigua por el contrario si la Pila ha llegado
a su máxima capacidad, permite hacer el chequeo de la misma antes de realizar
una operación de Meter un elemento, ya que de lo contrario ocurriría la
Condición de " Pila Overflow ".
Lleno := Tope = MaxElem;
En el encabezado de las operaciones Meter y Sacar, el primer
parámetro, el que recibe la información a ser incluida en la Pila o el que envía
la información del elemento eliminado respectivamente, debe ser declarado sin
tipo, por lo que se requiere definir en la parte VAR del cuerpo del método una
variable de tipo arreglo de BYTEs, la cual es ABSOLUTE a la dirección de
memoria que ocupa dicho parámetro en la aplicación.
PROCEDURE Pila.Meter(VAR Valor; Longitud : WORD);
VAR
I : WORD;
DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor;
Todo parámetro sin tipo requiere ser definido en el encabezado del
procedimiento o función de parámetro VAR, aún cuando en realidad se
comporte como parámetro de referencia.

Página 54
Esto permite dentro de la implementación referenciar la misma variable
de la aplicación (Valor), asignándole la misma dirección de memoria a la
variable DirValor, con la diferencia de que el dato dentro de DirValor es
referenciado Byte por Byte.
El referenciar la información de la forma antes descrita y el hecho de
programar la implementación de la Pila como una Unidad de librería, nos
permite lograr un total Polimorfismo, ya que el hecho de declarar el parámetro
que contiene la información de entrada o salida dependiendo del caso, sin tipo,
nos brinda la oportunidad de utilizar la misma implementación de Pila, en
aplicaciones donde la información es de tipo CHAR, INTEGER, REAL, Registro
e inclusive Direcciones de Memoria.
Dado que la información debe ser manipulada dentro de la Pila como un
conjunto de Bytes, es necesario agregarle un parámetro de referencia a las
operaciones Meter y Sacar, el cual contenga la longitud en Bytes de la
información a ser almacenada o recuperada de la Pila. El valor correspondiente
a este parámetro, lo asigna el usuario de la implementación, utilizando la
función incorporada SIZEOF(Información) como segundo parámetro de dichas
operaciones, la cual evalúa el número de bytes que ocupa la información en la
aplicación dependiendo del tipo de dato y retorna esa cantidad como un valor
de tipo WORD.
Meter(Valor,SIZEOF(Valor));
En ningún momento se debe utilizar la función de SIZEOF dentro de la
implementación, dado que el número de Bytes que retorna en ese caso se pudo
comprobar que no era el correcto.
A continuación se presenta la implementación completa de la Estructura
de Datos Pila o Stack.

Página 55
UNIT Stack;
INTERFACE
CONST
MaxElem = 100;
MaxByte = 299;
TYPE
LongInfo = 0..MaxByte;
Informacion = ARRAY[LongInfo] OF BYTE;
(****************************************************) (* DEFINICION DEL OBJETO PILA *) (****************************************************)
Pila = OBJECT
PROCEDURE Inicializar;
FUNCTION Vacio : BOOLEAN;
FUNCTION Lleno : BOOLEAN;
PROCEDURE Meter(VAR Valor; Longitud : WORD);
PROCEDURE Sacar(VAR Valor; Longitud : WORD);
PRIVATE
Elemento : ARRAY[1..MaxElem] OF Informacion;
Tope : 0..MaxElem;
END;

Página 56
(**************************************************)
(* IMPLEMENTACION DE LOS METODOS *)
(**************************************************)
IMPLEMENTATION
PROCEDURE Pila.Inicializar;
BEGIN
Tope := 0
END;
FUNCTION Pila.Vacio : BOOLEAN;
BEGIN
Vacio := Tope = 0
END;
FUNCTION Pila.Lleno : BOOLEAN;
BEGIN
Lleno := Tope = MaxElem
END;
PROCEDURE Pila.Meter(VAR Valor; Longitud:WORD);
VAR
I : WORD;
DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor;
BEGIN
IF NOT Lleno
THEN BEGIN
INC(Tope);
FOR I := 0 TO Longitud-1 DO
Elemento[Tope,I] := DirValor[I]
END
ELSE WRITELN( 'Pila Overflow')
END;

Página 57
PROCEDURE Pila.Sacar(VAR Valor; Longitud:WORD);
VAR
I : WORD;
DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor;
BEGIN
IF NOT Vacio
THEN BEGIN
FOR I := 0 TO Longitud-1 DO
DirValor[I] := Elemento[Tope,I];
DEC(Tope)
END
ELSE WRITELN('Pila Underflow')
END;
END.
Observe que en los métodos correspondientes a Meter y Sacar, la
información a insertar o eliminar respectivamente, no se almacena o se copia en
o desde el parámetro Valor, sino que se referencia por medio de la variable
Dirvalor.
Observe también que en la implementación de las operaciones Meter y
Sacar no se hace el chequeo de las condiciones de Overflow y Underflow
respectivamente a través de un parámetro Booleano como en la mayoría de los
textos de Estructuras de Datos. Considero que son innecesarias, dado que
existen para ello implementadas las operaciones Lleno y Vacío, las cuales
siendo invocadas previa llamada a las operaciones de Meter y Sacar, resultan
ser más efectivas en detectar dichas situaciones.

Página 58
- NIVEL DE APLICACION
Pila es una estructura de datos adecuada en los casos en que deba
guardarse la información y luego recuperarse la misma en el orden inverso.
Una situación que requiera volver atrás a una posición anterior, puede ser
idónea el utilizar una Pila, como el caso del problema del laberinto. Muchos
sistemas utilizan una pila para llevar las direcciones de vuelta, valores de los
parámetros y otro tipo de información requerida por los subprogramas.
Las Pilas también se utilizan extensivamente en la evaluación de las
expresiones aritméticas, tanto en el proceso de conversión a su equivalente
en Posfix, así como en su evaluación final. Utilizaremos como ejemplo de
aplicación el proceso de conversión de una expresión de la forma Infix a la
forma Posfix. Se asume que el lector tiene conocimientos previo de este
proceso, ya que el mismo aparece en la mayoría de los textos de Estructuras de
Datos.
Muchas de las expresiones aritméticas, hacen uso de paréntesis para
alterar el orden natural de prioridad de los operadores. Subexpresiones que
contienen anidación de paréntesis, requieren que los operandos que se
encuentran entre los paréntesis más internos, es decir los que corresponden al
último paréntesis que se abre, deben ser los primeros en ser convertidos en
Posfix, para luego considerar aquellos que se encuentran entre paréntesis más
externos. Este comportamiento del último que entra primero que sale, nos
sugiere inmediatamente el uso de una pila.
El programa que a continuación se muestra, en su cuerpo principal,
obtiene por lectura la expresión en Infix, como una cadena de caracteres.
Asumimos que la expresión previamente ha sido validada; es decir, que el
número de paréntesis que abren corresponden a los que cierran. Luego el
procedimiento Convertir es invocado para que convierta dicha expresión a la
forma Posfix, como una cadena de caracteres para luego imprimirla.
El procedimiento Convertir, recibe como parámetro la cadena de
caracteres correspondiente al Infix, como parámetro de entrada o referencia y

Página 59
tiene como segundo segundo parámetro el Posfix, el cual es considerado como
parámetro de salida o de Valor. Dentro de éste procedimiento se hace llamada
a otros dos procedimientos.
El procedimiento Operador, comprueba si el caracter que se envía como
parámetro, es un operador.
El procedimiento Prioridad, recibe dos parámetros de entrada. El
primero corresponde al operador que se encontraba en el tope del Stack y el
segundo al operador que se está evaluando. En el se considera todos los
casos posibles de prioridad, inclusive la de los paréntesis, retornando el valor
booleano TRUE en caso de que se deba colocar el operador del Stack en el
Posfix, y FALSE, en caso de que se deba devolver el operador previamente
obtenido del tope del Stack, para su consideración además del operador siendo
considerado.
PROGRAM Conversion; (* Unidad que contiene la Implementación de Pila *) USES Stack; CONST Max = 30; TYPE Cad30 = String[30]; VAR Infix,Posfix : Cad30; PosIn,PosOut : WORD; Continuar : BOOLEAN; (* Funcion que chequea si el caracter es un operador *) FUNCTION Operador(Caracter : CHAR) : BOOLEAN; BEGIN Operador := Caracter IN ['+','-','*','/','$','(',')'] END; (* Funcion que chequea si el caracter tiene prioridad sobre *) (* proximo *) FUNCTION Prioridad(Caracter,Proximo : CHAR) : BOOLEAN;

Página 60
VAR Prio : BOOLEAN; PrioPro,PrioCar : WORD; BEGIN (* Chequeo de parentesis *) IF Proximo = '(' THEN Prio := FALSE ELSE IF Caracter = '(' THEN Prio := FALSE ELSE IF Proximo = ')' THEN IF Caracter = '(' THEN Prio := FALSE ELSE Prio := TRUE ElSE BEGIN (* Chequeo de operadores *) IF Caracter IN ['+','-'] THEN PrioCar := 1 ELSE IF Caracter IN ['*','/'] THEN PrioCar := 2 ELSE PrioCar := 3; IF Proximo IN ['+','-'] THEN PrioPro := 1 ELSE IF Proximo IN ['*','/'] THEN PrioPro := 2 ELSE PrioPro := 3; IF PrioPro > PrioCar THEN Prio := FALSE ELSE IF PrioPro < PrioCar THEN Prio := TRUE ELSE IF Proximo = '$' THEN Prio := FALSE ELSE Prio := TRUE; END; Prioridad := Prio END;

Página 61
(*************************************************) (* Proceso de Conversion del Infix al Posfix *) (*************************************************) PROCEDURE Convertir(Infix : Cad30; VAR Posfix : Cad30); VAR PosIn,PosOut : WORD; Proximo,Caracter : CHAR; (* Declaracion de la Pila de Operadores *) PilaOpera : Pila; BEGIN PilaOpera.Inicializar; PosIn := 1; PosOut := 0; Proximo := Infix[PosIn]; (* Obtiene el primer caracter del Infix *) WHILE Proximo <> ' ' DO BEGIN IF NOT Operador(Proximo) (* Chequea si el caracter no es *) (* operador *) THEN BEGIN PosOut := PosOut + 1; PosFix[PosOut] := Proximo
(* Insercion del caracter en *) (* Posfix *)
END ELSE BEGIN (* Proceso en caso del caracter *) (* sea un operador *) Continuar := TRUE; IF NOT PilaOpera.Vacio THEN BEGIN (* Proceso que Saca de la Pila y coloca en el Posfix *) (* todos los caracteres que sean de menor priori- *) (* dad que el Proximo *)

Página 62
PilaOpera.Sacar(Caracter,SIZEOF(Caracter)); WHILE Prioridad(Caracter,Proximo) AND Continuar DO BEGIN PosOut := PosOut + 1; PosFix[PosOut] := Caracter; IF NOT PilaOpera.Vacio THEN PilaOpera.Sacar(Caracter,SIZEOF(Caracter)) ELSE Continuar := FALSE END; IF NOT Continuar (* Coloca el Proximo en la Pila *) THEN PilaOpera.Meter(Proximo,SIZEOF(Proximo)) ELSE IF Proximo <> ')' (* Devolver el caracter a la Pila y meter el *) (* Proximo *) THEN BEGIN PilaOpera.Meter(Caracter,SIZEOF(Caracter)); PilaOpera.Meter(Proximo,SIZEOF(Proximo)) END END (* Caso de Pila vacia *) ELSE PilaOpera.Meter(Proximo,SIZEOF(Proximo)) END; (* Proceso de Busqueda del Proximo caracter *) IF PosIn < Length(Infix) THEN BEGIN PosIn := PosIn + 1; Proximo := Infix[PosIn] END ELSE Proximo := ' ' END;

Página 63
(* Guarda en Posfix Operadores restantes en la Pila *) WHILE NOT PilaOpera.Vacio DO BEGIN PilaOpera.Sacar(Caracter,SIZEOF(Caracter)); PosOut := PosOut + 1; PosFix[PosOut] := Caracter END; (* Colocar blanco en las posiciones restantes del Posfix *) WHILE PosOut <= Max DO BEGIN PosOut := PosOut + 1; Posfix[PosOut] := ' ' END END; BEGIN Infix := ''; (* Inicializa el Infix en nulo *) WRITE('** Introducir la expresion en Infix : '); READLN(Infix); (* Llamada al procedimiento que convierte el Infix en Posfix *) Convertir(Infix,Posfix); (* Impresion del Posfix resultante *) WRITE('** La Expresion en Posfix es : '); PosOut := 1; WHILE PosFix[PosOut] <> ' ' DO BEGIN WRITE(Posfix[PosOut]); PosOut := PosOut + 1; END; WRITELN;
END.

Página 64
- Otra Aplicación
A continuación se presenta un ejemplo muy sencillo de utilización de la
implementación de Pila, el cual define internamente un objeto que permite el
manejo de diferentes campos de información dentro de la Pila, así como un
método que realiza la actualización de dichos campos de manera que puedan
ser enviados a la estructura Pila como un solo campo de información.
PROGRAM Monton; (* Unidad que contiene la implementacion de Pila *) USES Stack; TYPE Cadena10 = String[10]; Cadena20 = String[20]; (* Declaracion de un nuevo tipo de Objeto Nuevo *) Nuevo = OBJECT Cedula : Cadena10; Nombre : Cadena20; PROCEDURE ActualiceInfo(NuevaCedula:Cadena10; NuevoNombre:Cadena20); END; (* Codificacion del Metodo que permite actualizar los valores *) (* del Objeto *) PROCEDURE Nuevo.ActualiceInfo(NuevaCedula:Cadena10; NuevoNombre:Cadena20); BEGIN Cedula := NuevaCedula; Nombre := NuevoNombre END;

Página 65
VAR S : Pila; Variable : Nuevo; NuevaCedula : Cadena10; NuevoNombre : Cadena20; BEGIN S.Inicializar; (* Inicializacion de la Pila *) (* Proceso que obtiene por lectura los campos de *) (* informacion y los introduce dentro la Pila *) WHILE NOT EOF DO BEGIN READLN(NuevoNombre); READLN(NuevaCedula); Variable.ActualiceInfo(NuevaCedula,NuevoNombre); S.Meter(Variable,SIZEOF(Variable)) END; (* Proceso que Saca de la Pila los valores de los campos *) (* y los imprime, mientras la Pila no se vacie *) WHILE NOT S.Vacio DO BEGIN S.Sacar(Variable,SIZEOF(Variable)); WRITELN(Variable.Cedula); WRITELN(Variable.Nombre) END; READLN END. Observe que en las operaciones Meter y Sacar de la implementación Pila, se envía o recibe como parámetro respectivamente, la variable Variable, la cual por definición es un nuevo objeto que contiene dos campos, Cédula y Nombre. Observe también que como segundo parámetro en ambos casos se envía la longitud en bytes de ambos campos.

Página 66
Podría haberse definido una operación similar a la de ActualiceInfo, la cual
retornara en las variables simples NuevaCedula y NuevoNombre los valores
obtenidos en los campos del objeto Cedula y Nombre a través de la operación
Sacar de la implementación de la Pila. Se deja como tarea al lector, agregar
esa operación a este ejemplo.

Página 67
EJERCICIOS PROPUESTOS___________________
1- Escribir la implementación de una Pila en OOP de Pascal, que utilice un
arreglo de [0..100] posiciones, donde la posición [0] es utilizada para contener
el índice del elemento superior de la Pila, es decir realice las veces del tope de
la Pila, y donde el resto de las posiciones [1..100] se utiliza para almacenar los
elementos de la misma.
2-) Considere que el lenguaje no posee arreglos como estructura de datos
primitiva, pero sí cuenta con la implementación presentada en este capítulo de
Pila, escribir la implementación que me permita trabajar con arreglos de una
dimensión, utilizando para ello dos Pilas.
3-) Escribir en Pascal un procedimiento que permita imprimir el contenido de
una Pila, utilizando para ello la implementación presentada en este capítulo.
4-) Agréguele a la aplicación tratada en este capítulo un procedimiento que
permita evaluar la expresión en Posfix obtenida por el procedimiento convertir,
dado por lectura los valores correspondientes a las variables de la expresión.
La implementación de Pila a utilizar en este procedimiento debe ser la misma
utilizada en el procedimiento convertir.
5-) Escribir segmentos de programa en Pascal que ejecute cada una de las
siguientes operaciones, utilizando al implementación de Pila.
a. Insertar un elemento en la primera posición de la Pila, quedando el
resto de los elementos una posición más arriba.
b. Eliminar todos los elementos de la Pila cuyo valor sea igual a cero, sin
modificar el resto de los elementos dentro de la Pila.
c. Invertir los elementos de la Pila, quedando como tal almacenados
dentro de la misma.
d. Realizar un swap entre el segundo elemento de la Pila con el penúl– timo
elemento de la Pila.
6-) Agregar a la implementación de la Pila, una operación que retorne el
contenido del elemento en el tope de la Pila sin eliminarlo.

Página 68

Página 69
CAPITULO 4
ESTRUCTURA DE DATOS
COLA o QUEUE Muchas colecciones de datos funcionan, en cuanto al acceso a sus
elementos, en forma inversa, siendo este el caso de las Colas.
- NIVEL DE ABSTRACCION
- Definición
Una Cola es un grupo ordenado de elementos homogéneos en el que
nuevos elementos se insertan por un extremo, por el final de la Cola, y donde
los elementos solo pueden ser eliminados por el otro extremo, el frente de la
Cola. Esta Estructura tiene un comportamiento FIFO; es decir, Primero que
Entra, Primero que Sale.
Como ejemplo, observemos una línea de estudiantes en la cafetería de la
universidad, esperando cancelar en la caja su consumo correspondiente al
almuerzo. En teoría, y se desearía que también en la práctica, cada nuevo
estudiante que ingresa a la Cola debe hacerlo por el final de la misma. Cuando
la cajera esté preparada para atender a un nuevo estudiante, el consumo del
estudiante que está al principio de la Cola o frente de la misma, será el que
registre.

Página 70
Recuerde que los elementos presentes en el medio de una Cola no son
accesibles desde el punto de vista lógico, aunque si utilizamos representación
secuencial, el acceso podría ser realizado en forma directa. Es por ello que es
imprescindible la abstracción de datos, ya que solo mediante las operaciones
implementadas para esa estructura, se debe permitir manipular los elementos
de acuerdo a las características de acceso.
- Operaciones
Las operaciones para insertar un elemento en la Cola se denominará en
lo sucesivo Insertar (Insert), y la operación de eliminación se denominará
Eliminar (Remove). Antes de comenzar a utilizar cualquier estructura, debe
estar vacía, por lo que es necesario definir una operación que incialice la Cola
en Vacía la cual denominaremos Inicializar. Otra operación útil sobre una Cola,
es la que me permite observar si se encuentra vacía, la cual denominaremos
Vacío. Todos sabemos que por lo general una cola no tiene un tamaño
limitado. Sin embargo, sabemos por nuestra experiencia con las pilas, que si se
utiliza implementación secuencial, se debe inspeccionar si la estructura está
llena antes de añadir otro elemento, porque de lo contrario se daría la condición
de Underflow. Para ello será implementada una operación que denominaremos Lleno.
Antes de definir las operaciones más elementales, que permitan al
usuario la manipulación de los elementos dentro de la Cola, observemos como
funciona paso a paso una Cola con capacidad máxima de tres elementos,
observando la misma secuencia de instrucciones utilizadas en la discusión de
las Pilas:
Paso1.- Inicializar Paso 6.- Insertar el valor 9
Condición: "COLA OVERFLOW"

Página 71
Paso 2.- Insertar el valor 5 Paso 7.- Insertar el valor 10
Condición: "COLA OVERFLOW"
Paso 3.- Insertar el valor 7 Paso 8.- Eliminar un elemento
Paso 4.- Insertar el valor 3 Paso 9.- Eliminar un elemento
Paso 5.- Eliminar un elemento Paso 10.- Eliminar un elemento
Condición:"COLA UNDERFLOW"
Paso 11.- Eliminar un elemento
Condición : "COLA UNDERFLOW"
Note que en el paso 6, al desear realizar una operación de inserción del
valor 10, no pudo llevarse a cabo, ya que la Cola se encuentra en su máxima
capacidad por lo que se determina una condición de Cola Overflow (por encima
de su capacidad). Esto es desde el punto de vista físico, ya que a diferencia de
las colas desde el punto de vista real, una vez realizada una operación de
eliminación, no se mueven los elementos una posición al frente. El caso
opuesto sucede en el paso 10, donde se trata de eliminar un elemento de la
Cola, encontrándose la misma vacía, por lo que se determina una condición de
Cola Underflow (por debajo de su capacidad).

Página 72
Para poder hacer uso de esta estructura dentro de una aplicación, el
usuario debe tener conocimiento de las especificaciones del paquete, para
tener una interfase con la implementación. Recuerde que las operaciones
definidas al nivel de abstracción, son las ventanas del encapsulamiento de la
Cola, por la cual pasan los datos a la o desde la aplicación.
PPaaqquueettee CCoollaa
Los elementos se insertan al final y eliminan por el
frente de la Cola.
Inicializar
Función : Inicializar la Cola.
Entrada : Ninguna.
Salida : Cola Inicializada.
Vacío
Función : Chequear si la Cola está vacía.
Entrada : Ninguna.
Salida : Boolean.
Lleno
Función : Chequear si la Cola está llena.
Entrada : Ninguna.
Salida : Boolean.
Insertar(Elemento, SIZEOF(Elemento))
Función : Insertar un nuevo elemento al final de la Cola.
Entrada : El nuevo elemento y el tamaño(# de Bytes) del e–
lemento.
Salida : Cola actualizada.
Eliminar(Elemento, SIZEOF(Elemento))

Página 73
Función : Eliminar el elemento del frente de la Cola.
Entrada : El Tamaño(# de Bytes) del elemento.
Salida : Cola actualizada y el elemento eliminado.
- NIVEL DE IMPLEMENTACION
Similar a la implementación de la Pila, utilizaremos almacenamiento
secuencial. Podemos colocar el primer elemento de la Cola en la primera
posición, el segundo elemento en la segunda posición, y así sucesivamente.
. . . . . . . . . . . . . . .
1 2 3 4 MaxElem
Para obtener un total Polimorfismo, es decir que la Cola pueda contener
cualquier tipo de información, cada elemento del arreglo consistirá de un
conjunto de Bytes, definidos fuera del Objeto Cola como un Tipo de Dato que
se denominará Información, el cual consistirá de un arreglo unidimensional de
Bytes, con un máximo número en nuestro ejemplo de 300 Bytes.
CONST
MaxElem = 100;
MaxByte = 299;
TYPE
LongInfo = 0..MaxByte;
Informacion = ARRAY[LongInfo] OF BYTE;
Cola = OBJECT
.
. (* Encabezados de los Métodos *)
.
PRIVATE
Elemento : ARRAY[1..MaxElem] OF Informacion;
Frente,Final : 0..MaxElem;

Página 74
END;
Para llevar la pista de la posición ocupada por el elemento que
corresponde al frente y final de la Cola, es necesario utilizar dos variables
externas a la estructura física las cuales llamaremos Frente y Final
respectivamente, definidas como parte del objeto Cola. Dichas variables se les
dará un valor inicial , Frente igual a uno y Final igual a cero, dada que la Cola
debe estar vacía al comienzo de su utilización; Final se incrementará en uno.
Cuando se realice una operación de Insertar un nuevo valor, y Frente
se reducirá en uno, cuando se realice una operación de Eliminar el elemento
del Frente de la Cola, quedando Frente apuntando a la posición
correspondiente al actual frente de la Cola.
Entre las operaciones definidas para la Estructura Cola tenemos la de
Inicializar, la cual realiza la inicialización de las variables Frente y Final de la
siguiente manera:
Final := 0;
Frente := 1;
Mientras existan elementos en la Cola, la variable Frente debe apuntar a
una posición igual o menor que la apuntada por Final. El caso contrario sucede
cuanto la Cola esté vacía. La operación Vacío chequea si el contenido de la
variable frente es mayor que el contenido de la variable Final, en cuyo caso
retorna TRUE como valor Booleano indicando que la Cola está vacía. Esto nos
permite hacer ese chequeo antes de realizar una operación de Eliminar un
elemento de la misma; pues de lo contrario, se podría dar la Condición de "
Pila Underflow ". Observe que esta misma desigualdad es la que se detecta
una vez realizada la inicialización de la Cola.
IF Frente > Final THEN Vacio := TRUE
ELSE Vacio := FALSE;

Página 75
La operación Lleno, la cual averigua por el contrario si la Cola ha llegado
a su máxima capacidad, permite hacer el chequeo de la misma antes de realizar
una operación de Insertar un elemento, ya que de lo contrario ocurriría la
Condición de " Cola Overflow ".
Lleno := Final = MaxElem;
Similar al caso de la Pila, en el encabezado de las operaciones Insertar y
Eliminar, el primer parámetro, el que recibe la información a ser incluida en la
Cola o el que envía la información del elemento eliminado respectivamente,
debe ser declarado sin tipo, para lograr un Polimorfismo total.
PROCEDURE Cola.Insertar(VAR Valor; Longitud : WORD);
VAR
I : WORD;
DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor;
Recuerde que el referenciar la información de la forma antes descrita, y
el hecho de programar la implementación de la Cola como una Unidad de
Librería, nos permite lograr un total Polimorfismo, ya que el hecho de declarar
el parámetro que contiene la información de entrada o salida dependiendo del
caso, sin tipo, nos brinda la oportunidad de utilizar la misma Implementación de
Pila en aplicaciones donde la información es de tipo CHAR, INTEGER, REAL,
Registro e inclusive Direcciones de Memoria.
También en esta implementación es necesario agregarle un parámetro
de referencia a las operaciones de insertar y eliminar, el cual contenga la
longitud en Bytes de la información a ser almacenada o recuperada de la Cola.
A continuación se presenta la implementación completa de la Estructura
de Datos Cola o Queue.

Página 76
UNIT Queue;
INTERFACE
CONST
MaxElem = 100; (* Maximo Numero de Elementos *)
MaxByte = 299; (* Maximo Numero de Bytes por Elemento *)
TYPE
LongInfo = 0..MaxByte;
Informacion = ARRAY[LongInfo] OF BYTE;
(**************************************************)
(* D E F I N I C I O N D E L O B J E T O C O L A *)
(**************************************************)
Cola = OBJECT
PROCEDURE Inicializar;
FUNCTION Vacio : BOOLEAN;
FUNCTION Lleno : BOOLEAN;
PROCEDURE Insertar(VAR Valor; Longitud : WORD);
PROCEDURE Remover(VAR Valor; Longitud : WORD);
PRIVATE
Elemento : ARRAY[1..MaxElem] OF Informacion;
Frente,Final : 0..MaxElem;
END;

Página 77
(**************************************************)
(* I M P L E M E N T A C I O N D E L O S M E T O D O S *)
(**************************************************)
IMPLEMENTATION
PROCEDURE Cola.Inicializar;
BEGIN
Final := 0;
Frente := 1
END;
FUNCTION Cola.Vacio : BOOLEAN;
BEGIN
IF Frente > Final
THEN Vacio := TRUE
ELSE Vacio := FALSE
END;
FUNCTION Cola.Lleno : BOOLEAN;
BEGIN
Lleno := Final = MaxElem
END;
PROCEDURE Cola.Insertar(VAR Valor; Longitud : WORD);
VAR
I : WORD;
DirValor:ARRAY[LongInfo] OF BYTE ABSOLUTE Valor;

Página 78
BEGIN
IF NOT Lleno
THEN BEGIN
INC(Final);
FOR I := 0 TO Longitud-1 DO
Elemento[Final,I] := DirValor[I]
END
ELSE WRITELN( 'Cola Overflow')
END;
PROCEDURE Cola.Remover(VAR Valor; Longitud : WORD);
VAR
I : WORD;
DirValor:ARRAY[LongInfo] OF BYTE ABSOLUTE Valor;
BEGIN
IF NOT Vacio
THEN BEGIN
FOR I := 0 TO Longitud-1 DO
DirValor[I] := Elemento[Frente,I];
INC(Frente)
END
ELSE WRITELN('Cola Underflow')
END;
END.
Observe que en los métodos correspondientes a Insertar y Eliminar, la
información no se almacena o se copia en o desde el parámetro Valor, sino que
se referencia por medio de la variable Dirvalor.

Página 79
Observe también que en la implementación de dichas operaciones no se
realiza el chequeo de las condiciones de Overflow y Underflow
respectivamente a través de un parámetro Booleano, como en la mayoría de los
textos de Estructuras de Datos. De nuevo considero que son innecesarias,
dado que existen para ello implementadas las operaciones Lleno y Vacío, las
cuales siendo invocadas previa llamada a las operaciones de Insertar y
Eliminar, resultan ser más efectivas en detectar dichas situaciones.
Evaluemos este diseño de Cola. Su gran ventaja es la simplicidad, sin
embargo no se asemeja completamente a las Colas del mundo real, ya que
estas mueven una posición al frente, una vez realizada la eliminación del
elemento del frente de la misma. Su gran desventaja, es la de que la Cola
puede alcanzar el final desde el punto físico, y darse la condición de Overflow,
aún cuando existan espacios disponibles y por lo tanto la cola no haya
alcanzado su total lleno. Esto nos dice que aquellas aplicaciones donde el
número de inserciones y el de eliminaciones son equivalentes, no es
conveniente utilizar este enfoque sencillo de Cola.
- Otros diseños de Colas.
- Segundo Enfoque
Para emular las colas del mundo real, y eliminar la gran desventaja
presentada en el enfoque anterior, permitamos que el frente de la misma
permanezca fijo en la primera posición. Cuando se realiza una eliminación,
queda la primera posición desde el punto de vista lógico, vacía; luego todos los
elementos presentes en la cola, deben ser movidos una posición al frente.

Página 80
El dejar el frente de la Cola fijo en la primera posición, hace
innecesario el utilizar la variable Frente como apuntador externo. Esto implica
también que las operaciones de Inicializar la Cola, Vacío y Lleno sean más
sencillas y parecidas a las operaciones implementadas para la Pila. Sin
embargo, la operación de Eliminar se hace más complicada, ya que no solo
debe contemplar la eliminación del frente, sino que también debe realizar el
desplazamiento de todos los elementos presentes desde el punto de vista lógico
en la Cola.
La implementación de este enfoque de la Cola, queda como tarea del
lector por su simplicidad.
Existen múltiples formas funcionalmente correctas de implementar una
cola, el saber escoger la más apropiada, dependerá de la aplicación.
En el último enfoque estudiado, se mantiene la simplicidad observada en
el primer enfoque. Sin embargo el tiempo de ejecución de la operación Eliminar
se ha incrementado en un factor N, donde N se considera el número de
elementos presentes en la Cola. Si la Cola se va a utilizar para almacenar
grandes cantidades de elementos de una vez o si los elementos de la Cola
son muy grandes, como en el caso de que registros de muchos campos, el
tiempo que se requeriría para mover todos los elementos restantes en la cola,
sería alarmante, por lo que encontraría este enfoque sumamente ineficiente.
Por lo tanto repito que la escogencia del enfoque de diseño, depende
exclusivamente de las especificaciones de la aplicación que requiere de una
implementación de Cola.
- Tercer Enfoque
Volviendo a nuestro primer enfoque, recuerde que su gran desventaja era
la que era posible que el final de la cola alcance el final físico aún cuando
cuando desde el punto de vista físico, no estuviese lleno.

Página 81
Debido a que puede haber aún espacio disponible en el comienzo del
arreglo, la solución obvia es unir los dos extremos del arreglo. En otras
palabras el arreglo puede ser tratado como una estructura circular en la que la
última posición va seguida de la primera.
Para apuntar al siguiente espacio al final de la Cola hay que utilizar las
siguientes instrucciones:
IF Final = MaxElem
THEN Final := 1
ELSE INC(Final);

Página 82
El mismo tratamiento sería necesario cada vez que se desee
incrementar la variable Frente.
Esta situación nos conduce a un nuevo problema. Cómo determinar
cuando una cola está llena o vacía?. Observe los siguientes casos:
Primer caso:
Segundo caso:
En el primer caso existe un solo elemento en la Cola, siendo frente igual
a final. Una vez eliminado dicho elemento, observe los valores con que quedan
frente y final. En el segundo caso, añadimos un elemento a la última posición
libre de a cola, dejando la cola llena. En este caso, en donde se da la condición
de que la Cola está llena, los valores de frente y final son idénticos a los del
primer caso, los cuales corresponden a una situación de Cola vacía.
Una solución sería la de añadir otra variable externa además de
Frente y Final, que haría la función de un contador de los elementos de la
Cola. Cuando el contador tenga un valor cero, la Cola estará vacía; cuando el
contador sea igual al máximo número de elementos, indicará que la Cola está
llena.
Observe que el llevar este contador añade más instrucciones a las
operaciones de Insertar y Eliminar. Si el usuario de la Cola, necesita conocer

Página 83
frecuentemente el número de elementos en la Cola, esta solución podría ser
muy eficiente. Dejamos al lector el desarrollo de esta implementación.
Otra forma más discutida en los textos de Estructura de Datos, consiste
en sacrificar un elemento del arreglo utilizado en la implementación, de
manera que el Frente apunte al elemento que precede al Frente real de la
Cola, en vez del propio elemento del frente. Si Final apunta al mismo elemento,
esto indica que la Cola está vacía. Este chequeo debe realizarse antes de
invocar la operación de Eliminar.
Sin embargo para insertar un elemento, debemos primero incrementar
en forma ficticia la variable Final, para que contenga la posición del siguiente
elemento del arreglo. Si se da la condición de que Frente igual a Final a través
de la operación Lleno, entonces significa que la Cola está en su máxima
capacidad, por lo que no se debe realizar la operación de inserción.

Página 84
Se dijo que la variable se incrementa en forma ficticia, ya que de no
realizarse la inserción del nuevo elemento, por considerarse que la Cola está
llena, la aplicación puede continuar con su ejecución sin que se vea alterada la
condición de la Cola.
El incremento en forma ficticia de la variable Final y el posterior chequeo
de igualdad de las dos variables, deben ser realizados en la operación que
chequea si la Cola está llena y no dentro de la operación de Insertar.
IF Final = MaxElem THEN Senal := 1 ELSE Senal := Final + 1; Lleno := Senal = Frente
Usando este enfoque, cómo debemos inicializar la Cola, para que esté
en condición de Vacía?. Recuerde que deseamos que la variable Frente apunte
al elemento que precede al verdadero frente de la Cola, por lo que cuando
insertamos por primera vez, el frente real de la Cola debe estar en la primera
posición del arreglo. Entonces cuál es la posición que precede a la primera
posición en una Cola Circular?, por lo que hemos acordado, la posición que
precede a la primera en una Cola Circular es la última posición; en nuestra
implementación, MaxElem. Dado que al comienzo la Cola debe ser inicializada
en Vacía, y ya que llegamos a la conclusión de que la condición de vacío en la
Cola se da cuando Frente es igual a Final, entonces Final debe ser inicializada
en MexElem también.
PROCEDURE Cola.Inicializar;
BEGIN
Final := MaxElem;
Frente := MaxElem
END;

Página 85
El paquete de especificaciones para el usuario de la implementación
permanece igual al del enfoque anterior. Recuerde que la forma como fué
implementada la estructura debe ser trasparente al usuario de la misma.
A continuación se presenta la implementación completa de una Cola
Circular. Los nombres del objeto y de las operaciones permanecen iguales a la
implementación del primer enfoque de Cola.
UNIT Circular;
INTERFACE
CONST
MaxElem = 100;
MaxByte = 299;
TYPE
LongInfo = 1..MaxBYte;
Informacion = ARRAY[LongInfo] OF BYTE;
(***************************************************)
(*D E F I N I C I O N D E L O B J E T O C O L A C I R C U L A R*)
(***************************************************)
Cola = OBJECT
PROCEDURE Inicializar;
FUNCTION Vacio : BOOLEAN;
FUNCTION Lleno : BOOLEAN;
PROCEDURE Insertar(VAR Valor; Longitud : WORD);
PROCEDURE Remover(VAR Valor; Longitud : WORD);
PRIVATE
Elemento : ARRAY[1..MaxElem] OF Informacion;
Frente,Final : 1..MaxElem;
END;
(***************************************************)

Página 86
(* I M P L E M E N T A C I O N D E L O S M E T O D O S *)
(***************************************************)
IMPLEMENTATION
PROCEDURE Cola.Inicializar;
BEGIN
Final := MaxElem;
Frente := MaxElem
END;
FUNCTION ColaCircular.Vacio : BOOLEAN;
BEGIN
Vacio := Frente = Final
END;
FUNCTION ColaCircular.Lleno : BOOLEAN;
VAR
Senal : 1 .. MaxElem;
BEGIN
IF Final = MaxElem
THEN Senal := 1
ELSE Senal := Final + 1;
Lleno := Senal = Frente
END;

Página 87
PROCEDURE ColaCircular.Insertar(VAR Valor; Longitud : WORD);
VAR
I : WORD;
DirValor:ARRAY[LongInfo] OF BYTE ABSOLUTE Valor;
BEGIN
IF Final = MaxElem
THEN Final := 1
ELSE INC(Final);
FOR I := 0 TO Longitud-1 DO
Elemento[Final,I] := DirValor[I]
END;
PROCEDURE ColaCircular.Remover(VAR Valor; Longitud : WORD);
VAR
I : WORD;
DirValor:ARRAY[LongInfo] OF BYTE ABSOLUTE Valor;
BEGIN
IF Frente = MaxElem
THEN Frente := 1
ELSE INC(Frente);
FOR I := 0 TO Longitud-1 DO
DirValor[I] := Elemento[Frente,I];
END;
END.

Página 88
- NIVEL DE APLICACION
Una aplicación en la que las colas figuran como una estructura de datos
prominente, es la simulación por computadora de situaciones del mundo real.
Las colas también se utilizan de muchas maneras en los sistemas operativos,
para planificar el uso de los distintos recursos de la computadora. Uno de estos
recursos es el propio CPU ( Unidad Central de Procesamiento). Si se está
trabajando en un sistema multiusuario, cuando se ordena la ejecución de un
programa en particular, el sistema operativo añade esa petición a la cola de
trabajo. Cuando esa petición se encuentre al frente de la cola, el programa
solicitado pasa a ser ejecutado. De igual manera, las colas se utilizan para
asignar tiempo a los distintos usuarios de los dispositivos de entrada/salida.
En este capítulo se han discutido tres enfoques de implementación de la
cola. Las especificaciones de la aplicación, determinará cual de ellas es la
más eficiente para ese caso particular. Sin embargo todas las
implementaciones definen el objeto cola con el mismo nombre, al igual que
todas sus operaciones, de manera que el usuario de las mismas solo tenga que
preocuparse por recordar el nombre de la unidad que la representa.
Antes de que los astronautas fueran al espacio, fué necesario utilizar
muchas horas en diseñar un simulador espacial, que permitiera reproducir en
otro objeto todas las cosas que les sucedería en el espacio.
Este simulador de vuelo espacial es un modelo físico de otro objeto. La
técnica que utilizaron se llama simulación. En informática se utiliza la misma
técnica para construir modelos computacionales de objetos y sucesos en vez de
modelos físicos.

Página 89
En una simulación por computadora, cada objeto del sistema del mundo
real se representa normalmente como un objeto de datos. Las acciones del
mundo real se representan como operaciones sobre los objetos de datos. Las
reglas que describen el comportamiento determinan las acciones que deben
realizarse.
La mayoría de las simulaciones por computadora utilizan colas como
estructura de datos básica. De hecho, el sistema del mundo real se llama un
sistema de cola. Un sistema de cola está formado por servidores y colas de
objetos a servir. El comportamiento que observamos usualmente es el tiempo
de espera.
Para hacer una simulación por computadora de un sistema de cola, hay
cuatro cosas que necesitamos saber:
• El número de sucesos y cómo afectan al sistema.
• El número de servidores.
• La distribución de los tiempos de llegada.
• El tiempo de servicio esperado.
El programa utiliza estos parámetros para predecir el tiempo medio de
espera.
Por ejemplo, consideremos el caso de un autocine. Supongamos que
existe un cajero en el autocine y la transacción media necesita 5 mimutos. Cuál
es el tiempo medio de espera de un carro?. Si el negocio va bien, los carros
llegan con más frecuencia; entonces, qué efecto tiene esto en el tiempo medio
de espera?. Cuándo será necesario abrir una segunda ventanilla?.

Página 90
Este problema es claramente un problema de colas. Tenemos un
servidor, el cajero y objetos a ser servidos, el cliente o el carro y estamos
interesados en observar el tiempo medio de espera.
Los sucesos son las llegadas y salidas de los clientes o carros.
Debido a que los carros son los que entran y salen, serán considerados como
los objetos. El número de servidores es uno, representando la ventanilla del
cajero. Los tiempos de llegada se cuantificarán utilizando probabilidades.
Estos tiempos de llegada se observarán en minutos, dado que el tiempo de
servicio esperado que es el tiempo de transacción, es expresado en minutos,
para ser exactos en 5 minutos.
Los problemas de simulación en computación, pueden resolverse de dos
maneras. Una, en la que se utiliza un contador para representar un reloj y
donde cada iteración corresponde a una unidad de tiempo. La segunda, se
realiza mediante el uso de listas de eventos, la cual es una lista donde se
almacena cada evento, la cual se mantiene ordenada ascendentemente de
acuerdo al tiempo de realización del suceso. En este caso utilizaremos un reloj.
En cada minuto que pase, es decir que se incremente el reloj, pueden ocurrir
diferente sucesos.

Página 91
Los sucesos que pueden ocurrir así como las acciones que deben
realizarse son:
• Si llega un carro, colocarlo en la cola de espera.
• Si el cajero está libre, avanza un carro a la ventanilla. El tiempo
de servicio se le coloca en 5 minutos.
• Si hay un cliente en la ventanilla, el tiempo que le queda a ese
cliente para estar servido debe reducirse en uno ( 1 minuto).
• Si hay carros en la cola de espera, debe registrarse el hecho de
que van a permanecer en la cola un minuto más.
Debido a que cada incremento del reloj representa 1 minuto, podemos
simular la llegada de un cliente usando un generador de números aleatorios.
Pascal ofrece una función incorporada que devuelve un número aleatorio entre
0.0 y 1.0, y obteniendo como entrada la probabilidad de llegada, podemos
simular la llegada de un carro de la siguiente manera:
• Si el número aleatorio es menor o igual a la probabilidad de llega–
da, entonces ha llegado un carro.
• Si el número aleatorio es mayor que la probabilidad de llegada,
entonces se considera que no ha llegado carro alguno.
FUNCTION LlegaCarro : BOOLEAN; BEGIN LlegaCarro := RANDOM <= ProbLlegada END;
Para mover un carro a la ventanilla, simplemente quitamos el primer
carro de la cola e inicializamos e tiempo que le queda en 5 minutos, tiempo de
servicio determinado.
Si el cliente está en la ventanilla y el tiempo que le queda para terminar
es diferente de 0, lo decrementamos en 1. Una vez realizada esta acción y si
el tiempo de servicio le queda en 0, se considerará que el cajero está libre en el
siguiente intervalo de minuto, es decir en la siguiente iteración.

Página 92
Ahora que se han descrito las acciones, consideremos los objetos.
Podemos representar el cajero o ventanilla como una variable, la cual se le
asigna un valor de 5, cuando se mueve un carro hacia la caja y se decrementa
en 1 cada minuto que el carro permanece allí.
Cada carro puede representarse por una variable entera. Esta variable
que funciona como un contador se le asigna un valor 0 cuando entra un carro
en la cola y se incrementa por cada minuto que permanece allí. Esto es
necesario para poder calcular el tiempo de espera en cola de cada carro,
acumularlo una vez que han sido servidos en el tiempo total de espera de todos
los carros.
Para incrementar el tiempo de espera en la cola para cada carro,
debemos accesar cada elemento de la cola. La propia cola debe quedar sin
cambiar. Esto se puede realizar, removiendo el carro al frente de la cola,
incrementándole el tiempo e insertándolo al final de la cola. Para poder
determinar cuando volvemos a obtener el carro que en un comienzo estaba el
frente de la cola, utilizaremos un indicador. Cuando eliminemos de la cola este
elemento indicador, habremos accesado todos los elementos de la cola. Debido
a que nuestros elementos son enteros positivos, podemos utilizar un valor de -1
como indicador.
Indicador := -1; ColaCarros.Insertar(Indicador,SIZEOF(Indicador)); ColaCarros.Remover(Carro,SIZEOF(Carro)); WHILE Carro <> Indicador DO BEGIN Carro := Carro + 1; ColaCarros.Insertar(Carro,SIZEOF(Carro)); ColaCarros.Remover(Carro,SIZEOF(Carro)) END

Página 93
PROGRAM Autocine; (**************************************************) (* Llamada a la unidad que contiene la implementacion Queue *) (**************************************************) USES Queue; VAR ColaCarros : Cola; (* Declaracion de la Cola *) Cero : INTEGER; DatosOK : BOOLEAN; SumaTiempos,NumCarros : INTEGER; Reloj,Cajero : INTEGER; CajeroLibre : BOOLEAN; TiempoLimite,TiempoServicio : INTEGER; ProbLlegada,Semilla,Media : REAL; longitud : WORD; PROCEDURE Inicializar; BEGIN SumaTiempos := 0; NumCarros := 0; Reloj := 0; Cajero := 0; ColaCarros.Inicializar; (* Llamada al metodo de Inicializacion de la *) (*Cola *) CajeroLibre := TRUE END; PROCEDURE ObtenerParametros(VAR ProbLlegada:REAL; VAR TiempoServicio:INTEGER; VAR DatosOK : BOOLEAN); VAR Respuesta : CHAR;

Página 94
BEGIN DatosOK := FALSE; WHILE NOT DatosOK DO BEGIN WRITE('** Probabilidad de Llegada :'); READLN(ProbLlegada); WRITE('** Tiempo de Servicio: '); READLN(TiempoServicio); WRITE('** Datos Correctos? : S/N '); READLN(Respuesta); DatosOK := Respuesta IN ['s','S']; WRITELN END END; PROCEDURE CarroACaja(VAR ColaCarros : Cola; VAR NumCarros,SumaTiempos,Cajero : INTEGER); VAR Carro : INTEGER; BEGIN IF NOT ColaCarros.Vacio THEN BEGIN ColaCarros.Remover(Carro,SIZEOF(Carro)); NumCarros := NumCarros + 1; WRITELN('** Tiempo de Espera del Carro ',NumCarros, ' es de : ',carro,' minutos'); SumaTiempos := SumaTiempos + Carro; WRITELN('** Suma Acumulada de Tiempo de Espera: ' ,Sumatiempos); Cajero := TiempoServicio; END END; PROCEDURE Incrementar(VAR ColaCarros : Cola; VAR Cajero,Reloj : INTEGER); VAR Carro,Indicador : INTEGER;

Página 95
BEGIN Indicador := -1; Reloj := Reloj + 1; IF Cajero <> 0 THEN Cajero := Cajero - 1;
ColaCarros.Insertar(Indicador,SIZEOF(Indicador)); ColaCarros.Remover(Carro,SIZEOF(Carro));
(* Proceso de Incrementar todas los tiempos de espera *) (*hasta conseguir un valor igual al Indicador *) WHILE Carro <> Indicador DO BEGIN Carro := Carro + 1; ColaCarros.Insertar(Carro,SIZEOF(Carro)); ColaCarros.Remover(Carro,SIZEOF(Carro)) END END; FUNCTION LlegaCarro : BOOLEAN; BEGIN LlegaCarro := RANDOM <= ProbLlegada END; BEGIN Cero := 0; Semilla := 4.0; WRITE( '** Introduzca el Tiempo Limite de Simulacion: '); READLN(TiempoLimite); WRITELN( '** La Simulacion se realizara durante ',TiempoLimite:4, ' minutos'); WHILE NOT EOF DO BEGIN ObtenerParametros(ProbLlegada,TiempoServicio,DatosOK); IF DatosOK THEN BEGIN Inicializar; WHILE Reloj < TiempoLimite DO BEGIN

Página 96
(* Insertar Carro con Tiempo de Espera Cero *) IF LlegaCarro THEN ColaCarros.Insertar(Cero, SIZEOF(Cero)); IF CajeroLibre THEN CarroACaja(ColaCarros,NumCarros, SumaTiempos,Cajero); Incrementar(ColaCarros,Cajero,Reloj); CajeroLibre := Cajero = Cero END; WRITELN; WRITELN; Media := SumaTiempos / NumCarros; WRITELN(' El Tiempo de Espera Media fue de ', Media,' Minutos.') END END
END.

Página 97
EJERCICIOS PROPUESTOS___________________ 1-) Implementar utilizando Programación Orientada a Objetos en Pascal, la cola
discutida en el segundo enfoque que emula las colas del mundo real.
2-) Dada como solución inicial al problema presentado cuando observamos por
primera vez la cola circular, la que consistía en añadir otra variable externa
(contador) además de Frente y Final, modificar la implementación de la cola
circular presentada anteriormente, de manera que quede reflejada dicha
solución.
3-) Escribir un procedimiento en Pascal para una aplicación dada, el cual
imprima el contenido de una cola. Recuerde que solo puede utilizar las
operaciones que le ofrece la implementación de Cola para cualquiera de los
enfoques.
4-) Escribir un procedimiento en Pascal, que permita determinar el número de
elementos que contiene en un momento dado una Cola. Recuerde de nuevo
que solo puede utilizar las operaciones que le ofrece la implementación de
Cola.
5-) Dado un nuevo enfoque de Cola, que consiste en agregarle las posiciones [-
1] y [0] al vector que se utiliza para mantener los elementos de la misma, donde
la posición [-1] hace las veces de la variable Frente y la posición [0] hace las
veces de la variable Final, implementarlo utilizando OOP de Pascal.

Página 1
CAPITULO 5
ESTRUCTURA DE DATOS
LISTAS o LIST Todos sabemos intuitivamente lo que es una lista. En nuestra vida diaria
utilizamos las listas constantemente: listas de compras, lista de tareas ha realizar,
lista de direcciones o de teléfonos, lista de invitados a una fiesta. De todas las
estructuras de datos, listas es la más conocida y utilizada en el mundo de la
informática.
- NIVEL DE ABSTRACCION
- Definición
Una lista es una colección de elementos homogéneos, con una relación
lineal entre los elementos. Esto significa que cada elemento de la lista excepto el
primero, tiene un predecesor y cada elemento excepto el último, tiene un único
sucesor en la lista. El orden de los elementos en la lista afecta a su función de
acceso; por ejemplo, si la lista está ordenada de menor a mayor el sucesor de
cualquier elemento de la lista será mayor o igual a ese elemento.
Comunmente se utiliza la terminología de lista al hacer referencia a un
arreglo de una dimensión. La semejanza está dada en cuanto a la relación lineal
de sus elementos. A la primera se le conoce como Lista Secuencial, ya que la
colocación física de sus elementos coincide con su orden lógico.

Página 2
Por el contrario, en una Lista Enlazada, el orden lógico de sus elementos
no es necesariamente equivalente a su colocación física. En el caso de una lista
de personas, como en el ejemplo anterior, puede que fisicamente se encuentre la
información almacenada en el orden en que fueron introducidos los elementos,
cuando en realidad el orden que se observa al imprimir la lista enlazada ordenada
ascendentemente es el siguiente:
1. Beatriz
2. Carmen
3. Erys
4. Lucía
5. Virgilio
Ahora suponga que al ejemplo anterior se le desea agregar un nuevo
elemento cuyo nombre es Zurama. En este caso la inserción es muy sencilla,
dado que la inserción se haría al final de la Lista manteniéndose el orden lógico
establecido. Pero supónganse que se desea agregar el nombre Florinda; en
caso de que la Lista fuese Secuencial, no nos quedaría otro camino que la de
colocarlo al final de la misma, lo que traería como consecuencia el que la Lista
quede desordenada.

Página 3
Lo mismo sucedería en el caso de que se eliminase el nombre Lucía, ya
que quedaría ese espacio en blanco en caso de que se estuviese utilizando Listas
Secuenciales.
Todo las operaciones anteriormente descritas pueden ser posibles
realizarlas utilizando Listas Encadenadas, por las bondades que nos ofrece el uso
de un apuntador que contiene la dirección de el elemento vecino desde el punto
de vista lógico.
Para observar esta diferencia en forma más determinante, tomemos el
punto de vista de un director de una escuela determinada. Este usuario de listas
de estudiantes, necesita poder mantener lo que parece a nivel lógico, una lista de
elementos de información; en otras palabras, una lista de estudiantes que
cumplan ciertas características, por ejemplo la que se exige para pertenecer a la
lista de honor. El director conoce los campos que observará en dicha lista: cédula
del estudiante, nombre y apellido del mismo y la nota o índice obtenido al final del
año escolar. Adicionalmente el orden en que obtendrá dicha lista, por ejemplo
ordenado alfabeticamente por nombre y apellido. El director no necesita tener
conocimientos de cómo ha de representarse la lista en la memoria principal, ni
como se mantiene el orden lógico internamente. Esta información solo la conoce
quien implementó lista como estructura de datos abstracta.

Página 4
- Visión Abstracta de una Lista Enlazada
Una Lista Enlazada consiste de una colección de elementos o nodos los
cuales contienen un campo de información (el cual puede contener uno o
muchos campos de información), dependiendo de lo que envíe el usuario de la
implementación, y un campo de enlace o apuntador al siguiente nodo de la lista.
Los elementos de una lista no pueden ser accesados directamente. Para
llegar a un elemento determinado, debemos comenzar por el primer elemento de
la lista, a través de una variable externa que contenga su dirección; luego
podemos accesar el segundo elemento, cuya dirección se encuentra en el campo
del enlace del primer elemento y así sucesivamente hasta llegar al último
elemento de la lista, que por no tener sucesor, su campo de enlace contendrá el
valor Nulo.
Representando graficamente el ejemplo anterior, obtendremos:
Por supuesto quien utilice Lista Encadenada, como estructura de datos
abstracta, debe tener alguna forma de llegar a los elementos de la misma. Las
ventanas de la implementación de la lista se suministran mediante el paquete de
operaciones de la lista. Existen diferentes operaciones de inserción e eliminación
de elementos que podemos implementar para una Lista, debido a que el acceso
a sus elementos no está restringida en forma alguna. En el paquete de lista
que ofrecemos a continuación, aparecen solo las operaciones básicas.
PPaaqquueettee LLiissttaa

Página 5
Los elementos de Información se insertan y eliminan
en cualquier lugar de la Lista.
Inicializar(Lista)
Función : Inicializar la Lista en Vacío.
Entrada : Apuntador externo de la Lista.
Salida : Lista Inicializada.
Vacío(Lista) : BOOLEAN
Función : Chequear si la Lista está Vacía.
Entrada : Apuntador externo de la Lista.
Salida : Boolean.
Lleno : BOOLEAN
Función : Chequear si la Lista está Llena.
Entrada : Ninguna.
Salida : Boolean.
InsComienzo(Lista, Elemento, SIZEOF(Elemento))
Función : Insertar un nuevo elemento al comienzo de la Lista.
Entrada : Apuntador externo de la Lista, Nuevo Elemento de Infor–
mación, el tamaño(# de Bytes) del elemento.
Salida : Lista Actualizada, Elemento de Información Insertado al
comienzo.
EliComienzo(Lista, Elemento, SIZEOF(Elemento))
Función : Eliminar el elemento que se encuentra al comienzo de la
Lista.

Página 6
Entrada : Apuntador externo de la Lista, el Tamaño(# de Bytes) del
elemento.
Salida : Lista Actualizada, Elemento de Información Eliminado al
comienzo.
InsFinal(Frente, Final, Elemento, SIZEOF(Elemento))
Función : Insertar un nuevo elemento al final de la Lista.
Entrada : Apuntadores externos de la Lista al Frente y al Final,
Nuevo Elemento de Información,el Tamaño(# de Bytes) del
elemento.
Salida : Lista Actualizada, Elemento de Información Insertado al
final .
InsDespues(Apuntador, Elemento, SIZEOF(Elemento))
Función : Insertar un Nuevo Elemento de Información después del
elemento cuya dirección está en Apuntador.
Entrada : Apuntador que contiene dirección del elemento de refe–
rencia, Nuevo Elemento de Información, el Tamaño (# de
Bytes) del nuevo elemento.
Salida : Lista Actualizada, Elemento de Información Insertado
después del elemento de referencia.
EliDespues(Apuntador, Elemento, SIZEOF(Elemento))
Función : Eliminar Elemento de Información que se encuentra
después del elemento cuya dirección está en Apuntador.
Entrada : Apuntador que contiene dirección del elemento de refe–
rencia, el Tamaño(# de Bytes) elemento a eliminar.
Salida : Lista Actualizada, Elemento de Información Eliminado
después del elemento de referencia.
Visualizar(Apuntador, Elemento, SIZEOF(Elemento))
Función : Mostrar el Elemento de Información que se encuentra en
la dirección de Apuntador, retornando la dirección del
siguiente elemento.

Página 7
Entrada : Apuntador que contiene la dirección del elemento a
mostrar, el Tamaño(# de Bytes) del elemento.
Salida : Información del Elemento, Apuntador con la dirección del
próximo elemento.
Liberar(Lista)
Función : Liberar todo el espacio asignado a la lista de informa–
ción.
Entrada : El apuntador externo a la Lista de Información.
Salida : Espacio ocupado por lista totalmente liberado, el apunta–
dor externo a la Lista de Información en Nulo.
Es necesario destacar, que las operaciones definidas en el Paquete de
Operaciones, engloban en la misma implementación las operaciones primitivas
InsDespués, EliDespués; así como las necesarias para Listas con restricción de
Pila, InsComienzo, EliComienzo; y las de Listas con restricción de Cola,
EliComienzo, que en realidad es la misma que se define para el caso de
restricción Pila y la de InsFinal.
Esto se debe a que no se justifica el crear diferentes implementaciones,
una para cada caso, por varias razones. Para comenzar, existen operaciones
como la de EliComienzo, la cual se requiere tanto para la de restricción de Pila
así como para la de restricción de Cola. Otra razón y quizás la más
fundamentada, es la de que en la mayoría de las aplicaciones, se pueden estar
manipulando Listas Encadenadas, cuyos nodos tienen la misma estructura, pero
que por razones de la aplicación en un momento dado deben ser tratadas con o
sin restricción. Esto lo podrán observar en la aplicación que será tratada en este
capítulo.
Antes de comenzar a definir más exactamente cada una de las operaciones
dentro del paquete Lista, quiero hacer algunas observaciones con respecto a la
forma tan particular con que se ha de tratar esta nueva estructura.
Hasta ahora, en las anteriores implementaciones, no tuvimos que definir
variables externas al objeto que representa la estructura. En este caso sí, ya

Página 8
que se pueden representar varias Listas utilizando la misma representación que
me brinda la implementación de Lista, así como también, como veremos más
adelante en el caso de las Colas, que se requieren dos apuntadores externos.
La primera operación Inicializar, es la que permite inicializar la Lista en
vacío. Por lo tanto es necesario enviarle como parámetro de entrada/salida el
apuntador externo. Así como también es necesario pasar el mismo parámetro
externo a la operación Vacío, dado que como se dijo antes, puedo estar
representando varias listas y debo referirme sobre cual de ellas debo realizar la
operación.
La operación Lleno, no requiere que se le defina a cual lista se refiere,
dado que dicha condición se da cuando no existe más espacio disponible para
realizar inserción alguna de elemento.
Se definieron dos operaciones que involucran el acceso al comienzo de la
estructura, tal como funcionaría una lista con restricción de una Pila. Ellas son
la de InsComienzo y la de EliComienzo cuyos comportamientos serán ilustrados
mediante el siguiente ejemplo.

Página 9
Supónganse que ya tenemos una lista con información desordenada,
y por alguna razón deseo insertar al comienzo un elemento cuyo campo de
información contenga el valor numérico 6,
InsComienzo(Lista,6,SIZEOF(6));
los cambios que se deben realizar son de tipo de enlace y no de información,
luego la lista quedaría desde el punto lógico de la siguiente manera.
En caso de que la lista de información estuviese vacía para el momento en
que se realizara la operación,
los cambios de enlaces serían los siguientes:
Si lo que se desea es eliminar el elemento al comienzo de la Lista, donde
la variable Valor al final de la operación deba presentar el contenido del campo de
información del elemento eliminado al comienzo de la Lista,
EliComienzo(Lista,Valor,SIZEOF(Valor));
los cambios que se realizan son los siguientes,

Página 10
En caso de que el elemento a eliminar sea el único en la Lista, el
apuntador externo a la Lista debe quedar con una dirección Nula.
De igual manera el cambio a realizar es de tipo de enlace. Una vez
efectuada la operación la lista queda tal como estaba incialmente.
Donde se obtienen o se depositan los nodos restantes?, eso es
transparente al usuario de la implementación.
Otra operación muy útil para el caso en que la Lista deba ser tratada
como una Cola, es decir con restricción de acceso, es la de Inserción al Final, ya
que la Eliminación al comienzo fué descrita anteriormente mediante la operación
EliComienzo. En el caso de utilizar esta operación como la equivalente a
eliminar por el frente de la Cola, la aplicación tendrá que asegurarse, de que en
caso de que la cola quede vacía, asignarle al nuevo apuntador Final un valor
Nulo.
InsFinal requiere de los apuntadores externos Frente y Final, que como
sus nombres lo indican, contienen la dirección del nodo al frente y del nodo al
final de la Lista respectivamente. El apuntador Frente hace el mismo papel que el
apuntador externo Lista, ya que su función es mantener la dirección del primer
elemento o nodo de la Lista. Es necesario el pasar como parámetros los dos
apuntadores, ya que para el caso inicial de inserción del primer elemento, ambos
apuntadores deben ser actualizados
InsFinal(Lista,Final,'6',SIZEOF('6'));

Página 11
En el caso de que la Lista con restricción de Cola esté vacía, la operación
debe realizar las siguientes acciones:
Las operaciones InsDespues y EliDespues permiten realizar inserciones y
eliminaciones después de cualquier nodo diferente al primero y último de la lista,
como sucede en el caso de una Pila. Como sus nombres lo indican, las acciones
se realizan después de un cierto nodo de referencia, cuya dirección se envía
como primer parámetro. Observemos como funcionan ambas operaciones, por
medio de un ejemplo.
Se desea insertar el nombre FELIPE a la Lista ordenada de nombres
descrita anteriormente, por supuesto conociendo la dirección del elemento que lo
debe preceder en la lista, y enviándole dicha dirección como parámetro de
referencia en la variable P. La llamada a la operación que permita realizar dicha
actualización debe ser como sigue:
InsDespues(P,'FELIPE',SIZEOF('FELIPE'));
De alguna manera se obtiene el nodo conteniendo en su campo de
información el nombre FELIPE,
luego deben realizarse los siguientes cambios de enlaces,

Página 12
También esta operación es utilizada en el caso de que la inserción se
deba realizar al final, y no se disponga de una apuntador externo que contenga la
dirección del último elemento.
InsDespues(P,'Zurama',SIZEOF('Zurama'));
Si por el contrario se desea eliminar un elemento diferente al primer
elemento de la lista, la operación a utilizar debe ser la de EliDespues, enviando
como parámetro la dirección del elemento que precede al elemento que se ha de
eliminar.
EliDespues(P,Valor,SIZEOF(Valor));
La dirección del nodo a eliminar nunca puede ser utilizada directamente
como referencia; ya que de ser así, al tratar de realizar el cambio de
direcciones, no se pueda efectuar el cambio de enlace del nodo que precede
al eliminado.
La operación Visualizar, como su nombre lo indica, permite observar
desde la aplicación, el contenido del campo de información de un elemento cuya

Página 13
dirección se envía como primer parámetro. Este primer parámetro a su vez
retorna la dirección del siguiente nodo o elemento en la Lista.
La información no puede ser observada desde la implementación, ya que
dentro de ella los campos de información son tratados como conjuntos de
bytes.
Esta operación es muy útil para los casos en que como por ejemplo, se
desee imprimir el contenido de los elementos de la lista ya sea total o
parcialmente desde la aplicación. Ejemplo que imprime el contenido del campo
Info de todos los elementos de una lista, donde cada campo Info contiene un solo
dato:

Página 14
PROCEDURE Imprimir(Lista:Apuntador);
VAR
P : Apuntador;
BEGIN
P := Lista;
WHILE P <> Nulo DO
BEGIN
L.Visualizar(P,Informacion,SIZEOF(Informacion));
WRITE(Informacion,' ')
END
END;
Por último, la operación Liberar, la cual libera todo el espacio asignado
hasta el momento a una lista de información en particular, retornando el
apuntador externo con un valor nulo, para que más adelante en la aplicación sea
posible determinar que dicha Lista ya no existe o en otras palabras, esté vacía.
Liberar (Lista);
- NIVEL DE IMPLEMENTACION
Puesto que la Lista es simplemente una colección de nodos,
inmediatamente se piensa en un arreglo de nodos, donde cada nodo contiene al
menos dos campos. Un campo de información, el cual denominaremos Info, y un
apuntador a su sucesor desde el punto de vista lógico el cual denominaremos
Prox.
Similar a las implementaciones anteriores, la información debe ser
almacenada como conjuntos de bytes para lograr un polimorfismo total.

Página 15
El arreglo unidimensinal que me permitirá representar los nodos de la
lista, debe ser definido Privado, de esta manera se garantiza que usuario alguno
tenga acceso directo a los elementos de la lista. Noten que en la definición del
nodo, TipoNodo, no se utilizó la palabra PRIVATE. En este caso no es
necesario, ya que al definir Privado el arreglo Nodo, con el que se implementa la
lista, se hace referencia al objeto TipoNodo convirtiéndolo en privado; y la otra
razón, es por que no existe método alguno que manipule exclusivamente este
objeto.
CONST MaxElem = 300; MaxByte = 299; Nulo = 0; TYPE Apuntador = 0 .. MaxElem; LongInfo = 0 .. MaxByte; Informacion = ARRAY[LongInfo] OF BYTE; TipoNodo = OBJECT Info : Informacion; Prox : Apuntador; END; Lista = OBJECT(TipoNodo) . . . PRIVATE Nodo : ARRAY[1..MaxElem] OF TipoNodo;
El valor Nulo que se le asigna en algunos casos a las variables
apuntadoras, se declara como una constante cero (0), dado que en el caso de
utilización de memoria estática, el contenido de las variables apuntadoras
corresponde a las posiciones relativas del arreglo.
La razón por la que no se define dentro del tipo lista el (los)
apuntador(es) externo(s), se debe a que la estructura debe permitir representar

Página 16
en un mismo arreglo varias Listas encadenadas. Los Nodos corresondientes a
cada lista de información se encuentra dispersos al azar a través del arreglo. La
manera de conocer en que nodo comienza cada Lista, es a través de un
apuntador externo a la lista, el cual debe ser declarados en la aplicación, por
desconocerse en la implementación la cantidad de Listas de información a utilizar.
Inicialmente todos los nodos están sin uso, puesto que no se ha formado
aún ninguna lista con información. Por lo tanto, todos pueden ser enlazados
formando así una lista de nodos disponibles, por lo que es necesario utilizar una
variable global Disponible, para que apunte al primer nodo de la Lista de Nodos
Disponibles.
Lista = OBJECT(TipoNodo) . . (* Métodos Públicos *) PRIVATE Nodo : ARRAY[1..MaxElem] OF TipoNodo; Disponible : Apuntador;
Dentro de las operaciones a implementar se encuentra la de Inicializar,
que permite enlazar el total de nodos en su orden natural, haciendo que el
apuntador externo Disponible apunte al primer nodo, además de inicializar un
único apuntador externo a alguna Lista de Información en Nulo.
BEGIN Lista := Nulo; FOR I := 1 TO MaxElem - 1 DO Nodo[I].Prox := I+1; Nodo[MaxElem].Prox := 0; Disponible := 1; END;
La operación Vacío, la cual obtiene como parámetro de entrada el
apuntador a la lista de información, permite determinar si dicha lista se encuentra
vacía.

Página 17
FUNCTION Lista.Vacio(Lista : Apuntador) : BOOLEAN; BEGIN Vacio := Lista = Nulo END;
La operación Lleno, se encarga de chequear si el apuntador externo
Disponible es igual a Nulo, indicando en tal situación que la o las Listas de
Información se encuentran en Condición de Overflow, por no haber
disponibilidad de espacio. La operación Lleno no requiere parámetro de entrada,
pues solo existe una sola Lista de Disponible, aún cuando se estén
representando más de una Lista de Información.
FUNCTION Lista.Lleno : BOOLEAN; BEGIN Lleno := Disponible = Nulo END;
Cuando se requiere un nodo para la inserción de un nuevo nodo en una
lista particular, éste se obtiene desde la Lista de Disponibles. Igualmente cuando
ya no se necesita un nodo, como en el caso de un eliminación, éste debe ser
regresado a la lista de disponibles. Estas dos operaciones ObtenerNodo y
DevolverNodo respectivamente, relizan ambas acciones necesarias, eliminando
o insertando los nodos al comienzo de la Lista de Disponibles; en otras palabras,
restringiendo el acceso a la Lista de Disponibles como una Pila. Ambas
operaciones ObtenerNodo y DevolverNodo, no fueron definidas en el paquete de
Operaciones, ya que por sus funciones solo deben ser utilizadas por otras
operaciones de listas, tal como las de insertar o eliminar un elemento en la Lista
de Información; por lo tanto, ellas deben ser transparentes al usuario de la
implementación y definidas como Privadas.
PRIVATE Nodo : ARRAY[1..MaxElem] OF TipoNodo; Disponible : Apuntador; PROCEDURE ObtenerNodo(VAR Nuevo : Apuntador); PROCEDURE DevolverNodo(Viejo : Apuntador);

Página 18
PROCEDURE Lista.ObtenerNodo(VAR Nuevo : Apuntador); BEGIN IF NOT Lleno THEN BEGIN Nuevo := Disponible; Disponible := Nodo[Disponible].Prox END ELSE WRITELN('LISTA OVERFLOW') END;
En el caso de ObtenerNodo, la primera acción es la de determinar la
existencia de nodos disponible por medio de la función Lleno. En el caso de
disponibilidad, se obtiene el primer nodo de la Lista de Disponible y se retorna la
dirección que el ocupa.
El caso de DevolverNodo es más sencillo, ya que solo se necesita obtener
como parámetro de entrada la dirección del nodo a ser devuelto a la Lista de
Disponible, para luego insertarlo al comienzo de la misma.
PROCEDURE Lista.DevolverNodo(Viejo : Apuntador); BEGIN Nodo[Viejo].Prox := Disponible; Disponible := Viejo END;
El resto de operaciones primitivas a Listas, fueron claramente descritas
desde el punto de vista gráfico, en la sección de nivel de abstracción. Sin
embargo se aclarará ciertos puntos en algunas de ellas.
La operación de InsComienzo, se asegura de que no está dada la
condición de Overflow para invocar a la operación de ObtenerNodo. Una vez
teniendo un nodo vacío, se le asigna byte por byte al campo Info la información
que obtuvo por parámetro de entrada en la variable Valor. Luego el campo Prox
del nodo a ser insertado, se le asigna la dirección del primer nodo en la Lista de
Información si existe, la cual se encuentra en la variable externa Lista. Por último,
la variable Lista se le asigna el valor de ese nodo recién insertado.

Página 19
PROCEDURE Lista.InsComienzo(VAR Lista : Apuntador; VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador; I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF NOT Lleno THEN BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nodo[Nuevo].Info[I] := DirValor[I]; Nodo[Nuevo].Prox := Lista; Lista := Nuevo END ELSE WRITELN( 'LISTA OVERFLOW') END;
La operación EliComienzo, consiste en detectar si la Lista de Información
no se encuentra vacía, en cuyo caso se copia la información contenida en el nodo
apuntado por Lista, se le asigna a un apuntador local Viejo la dirección del nodo a
ser eliminado, y se le asigna a Lista la dirección del próximo nodo. Por último se
invoca a la operación DevolveNodo, enviándole la dirección del elemento
eliminado contenida en la variable Viejo, para que sea devuelto a la Lista de
Disponible.
PROCEDURE Lista.EliComienzo(VAR Lista : Apuntador; VAR Valor; Longitud : WORD); VAR VIEJO : Apuntador; I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF NOT Vacio(Lista) THEN BEGIN FOR I := 0 TO Longitud-1 DO DirValor[I] := Nodo[Lista].Info[I]; Viejo := Lista; Lista := Nodo[Lista].Prox;

Página 20
DevolverNodo(Viejo) END ELSE WRITELN('LISTA UNDERFLOW') END;
La operación InsFinal realiza al comienzo las acciones de cualquier
operación de inserción de elemento en una Lista, obteniendo un nuevo nodo por
medio de la operación ObtenerNodo, cuya dirección la recibe la variable
apuntadora Nuevo, se le asigna a su campo Info la información contenida en la
variable Valor, byte por byte; y a su campo Prox se le asigna Nulo dado que
cualquiera que sea el caso, el nuevo nodo se insertará al final de la Lista.
Para los cambios de enlaces, primero debe diferenciar los dos casos
posibles. En caso de que la Lista esté vacía, llamando a la función vacío con el
apuntador Frente que hace las veces del apuntador Lista, Frente debe apuntar al
nuevo nodo. De lo contrario el nodo al final de la Lista en su campo Prox, debe
asignarsele la dirección del nuevo nodo. Por último cualquiera que sea el caso, la
variable apuntadora Final debe apuntar al nuevo nodo. PROCEDURE Lista.InsFinal(VAR Frente,Final : Apuntador; VAR Valor; Longitud:WORD); VAR Nuevo : Apuntador; I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nodo[Nuevo].Info[I] := DirValor[I]; Nodo[Nuevo].Prox := Nulo; IF Vacio(Frente) THEN FRENTE := Nuevo ELSE Nodo[Final].Prox := Nuevo; Final := Nuevo END;

Página 21
Las siguientes dos operaciones InsDespués y EliDespués, reciben como
parámetro de entrada la dirección del nodo de referencia después del cual se
deben realizar ya sea la inserción o eliminación. En cualquiera de las dos
operaciones, lo primero que se debe asegurar es de que dicha dirección de
referencia exista, y los cambios de enlaces se realizan entre el nodo de referencia
así como el nodo que le sucede antes de la realización de cualquiera de estas
operaciones. PROCEDURE Lista.InsDespues(P : Apuntador; VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador; I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF P <> Nulo THEN BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nodo[Nuevo].Info[I] := DirValor[I]; Nodo[Nuevo].Prox := Nodo[P].Prox; Nodo[P].Prox := Nuevo END; END;
PROCEDURE Lista.EliDespues(P : Apuntador; VAR Valor; Longitud : WORD); VAR VIEJO : Apuntador; I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF P <> Nulo THEN IF Nodo[P].Prox <> Nulo THEN BEGIN Viejo := Nodo[P].Prox; FOR I := 0 TO Longitud-1 DO DirValor[I] := Nodo[Viejo].Info[I]; Nodo[P].Prox := Nodo[Viejo].Prox; DevolverNodo(Viejo) END ELSE WRITELN('NODO NO EXISTE') END;

Página 22
La operación Visualizar como se dijo anteriormente, permite visualizar la
información contenida en un nodo cuya dirección se recibe como parámetro de
entrada en la variable Próximo. Se copia la información contenida en el nodo en
la variable Valor, y se retorna en la variable Próximo la dirección del siguiente
nodo, permitiéndo así desde la aplicación recorrer la lista. PROCEDURE Lista.Visualizar(VAR Proximo : Apuntador; VAR Valor; Longitud : WORD); VAR I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF Proximo <> Nulo THEN BEGIN FOR I := 0 TO Longitud-1 DO DirValor[I] := Nodo[Proximo].Info[I]; Proximo := Nodo[Proximo].Prox END END;
Por último, la operación Liberar consiste en ir recorriendo la lista de
información, nodo a nodo, permitiendo la liberación de cada uno de ellos para
insertarlo en la lista de disponibles; hasta que Lista, como apuntador externo,
obtenga el valor Nulo.
PROCEDURE Lista.Liberar(VAR Lista : Apuntador); VAR P : Apuntador; BEGIN WHILE Lista <> Nulo DO BEGIN P := Lista; DevolverNodo(Lista); Lista := Nodo[P].Prox END END;
A continuación, se ofrece la Unidad List, con la implementación completa
de la estructura Lista Encadenada antes discutida.

Página 23
UNIT List; INTERFACE CONST MaxElem = 100; (* Maximo Numero de Elementos *) MaxByte = 300; (* Maximo Numero de Bytes por Elemento *) Nulo = 0; TYPE Apuntador = 0 .. MaxElem; LongInfo = 0..MaxByte; Informacion = ARRAY[LongInfo] OF BYTE;

Página 24
(***************************************************) (* DEFINICION DEL OBJETO L I S T A L I N E A L *) (***************************************************) TipoNodo = OBJECT Info : Informacion; Prox : Apuntador; END; Lista = OBJECT(TipoNodo) PROCEDURE Inicializar(VAR Lista : Apuntador); FUNCTION Vacio(Lista : Apuntador) : BOOLEAN; FUNCTION Lleno : BOOLEAN; PROCEDURE InsComienzo(VAR Lista : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE EliComienzo(VAR Lista : Apuntador; VAR Valor ; Longitud : WORD); PROCEDURE InsFinal(VAR Frente,Final : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE InsDespues(P : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE EliDespues(P : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE Visualizar(VAR Proximo : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE Liberar(VAR Lista : Apuntador); PRIVATE Nodo : ARRAY[1..MaxElem] OF TipoNodo; Disponible : Apuntador; PROCEDURE ObtenerNodo(VAR Nuevo : Apuntador); PROCEDURE DevolverNodo(Viejo : Apuntador); END;

Página 25
(**************************************************) (* I M P L E M E N T A C I O N D E L O S M E T O D O S *) (**************************************************) IMPLEMENTATION PROCEDURE Lista.Inicializar(VAR Lista : Apuntador); VAR I : Apuntador; BEGIN Lista := Nulo; FOR I := 1 TO MaxElem - 1 DO Nodo[I].Prox := I+1; Nodo[MaxElem].Prox := 0; Disponible := 1; END; FUNCTION Lista.Vacio(Lista : Apuntador) : BOOLEAN; BEGIN Vacio := Lista = Nulo END; FUNCTION Lista.Lleno : BOOLEAN; BEGIN Lleno := Disponible = Nulo END; PROCEDURE Lista.ObtenerNodo(VAR Nuevo : Apuntador); BEGIN IF NOT Lleno THEN BEGIN Nuevo := Disponible; Disponible := Nodo[Disponible].Prox END ELSE WRITELN('LISTA OVERFLOW') END;

Página 26
PROCEDURE Lista.DevolverNodo(Viejo : Apuntador); BEGIN Nodo[Viejo].Prox := Disponible; Disponible := Viejo END; PROCEDURE Lista.InsComienzo(VAR Lista : Apuntador; VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador; I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF NOT Lleno THEN BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nodo[Nuevo].Info[I] := DirValor[I]; Nodo[Nuevo].Prox := Lista; Lista := Nuevo END ELSE WRITELN( 'LISTA OVERFLOW') END; PROCEDURE Lista.EliComienzo(VAR Lista : Apuntador; VAR Valor; Longitud : WORD); VAR VIEJO : Apuntador; I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF NOT Vacio(Lista) THEN BEGIN FOR I := 0 TO Longitud-1 DO DirValor[I] := Nodo[Lista].Info[I]; Viejo := Lista; Lista := Nodo[Lista].Prox; DevolverNodo(Viejo) END ELSE WRITELN('LISTA UNDERFLOW') END;

Página 27
PROCEDURE Lista.InsFinal(VAR Frente,Final : Apuntador; VAR Valor; Longitud:WORD); VAR Nuevo : Apuntador; I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nodo[Nuevo].Info[I] := DirValor[I]; Nodo[Nuevo].Prox := Nulo; IF Vacio(Frente) THEN FRENTE := Nuevo ELSE Nodo[Final].Prox := Nuevo; Final := Nuevo END; PROCEDURE Lista.InsDespues(P : Apuntador; VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador; I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF P <> Nulo THEN BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nodo[Nuevo].Info[I] := DirValor[I]; Nodo[Nuevo].Prox := Nodo[P].Prox; Nodo[P].Prox := Nuevo END; END;

Página 28
PROCEDURE Lista.EliDespues(P : Apuntador; VAR Valor; Longitud : WORD); VAR VIEJO : Apuntador; I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF P <> Nulo THEN IF Nodo[P].Prox <> Nulo THEN BEGIN Viejo := Nodo[P].Prox; FOR I := 0 TO Longitud-1 DO DirValor[I] := Nodo[Viejo].Info[I]; Nodo[P].Prox := Nodo[Viejo].Prox; DevolverNodo(Viejo) END ELSE WRITELN('NODO NO EXISTE') END; PROCEDURE Lista.Visualizar(VAR Proximo : Apuntador; VAR Valor; Longitud : WORD); VAR I : WORD; DirValor :ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF Proximo <> Nulo THEN BEGIN FOR I := 0 TO Longitud-1 DO DirValor[I] := Nodo[Proximo].Info[I]; Proximo := Nodo[Proximo].Prox END END;

Página 29
PROCEDURE Lista.Liberar(VAR Lista : Apuntador); VAR P : Apuntador; BEGIN WHILE Lista <> Nulo DO BEGIN P := Lista; DevolverNodo(Lista); Lista := Nodo[P].Prox END END
END.
- NIVEL DE APLICACION
La implementación de Lista, sobre todo si se considera con restricción de
Cola, es muy utilizada en problemas de simulación. En el capítulo anterior,
pudimos observar que existen dos formas de modelar situaciones del mundo real.
Una mediante la simulación de un Reloj, estudiada en la aplicación para la
implementación de Cola, y otra es mediante el uso de Lista de Eventos.
En la aplicación a discutir en este capítulo, utilizaremos simulación por
Lista de Eventos, y consistirá en la simulación del servicio que presta un banco
tomado del texto de Estructura de Datos en Pascal de Tenenbaum y Augenstein.

Página 30
BBAANNCCOO
Considere un banco con cuatro ventanillas. Un cliente entra al banco en
una unidad de tiempo específica T1 y desea realizar un transacción, con una
duración T2 en cualquier ventanilla. Si una de las ventanillas se encuentra libre,
ésta puede procesar la transacción del cliente inmediatamente y el cliente sale del
banco al tiempo T1 + T2. El tiempo que permanece el cliente en el banco es de
T2, es decir el tiempo que transcurrió mientras realizaba la transacción.
Sin embargo, es posible que ninguna de las ventanillas esté desocupada.
En este caso debe incorporarse a alguna cola de espera existente en cada una de
las ventanillas. El cliente, tal como sucede en el mundo real, se incorporará a
aquella cola de espera de menor longitud y tendrá que esperar que todos
aquellos clientes, que estén a su frente en la cola, hayan sido atendidos para
poder realizar su transacción. En este caso el cliente sale del banco en un tiempo
T2 más el tiempo que duró en la cola de espera.

Página 31
Por lo general los problemas de simulación esperan conseguir el tiempo
promedio de duración del cliente en el banco. Se tiene como dato de entrada el
tiempo de llegada de un cliente, expresado en minutos desde que abrió sus
puertas el banco, así como la duración de su transacción. Cada línea de entrada
representa un cliente, y deben sucederse en forma ordenada ascendentemente
con respecto al tiempo de llegada.
Las cuatro líneas de espera se representarán mediante cuatro Listas con
restricción de Cola. Cada nodo en esta lista de cola representa un cliente
esperando a ser atendido, y el primer nodo de la misma representará al cliente
siendo atendido en la ventanilla.
Supongamos que en algún instante del tiempo las cuatro líneas contienen
cada una un número específico de clientes. Qué puede suceder?. Los sucesos
son las llegadas y salidas de los clientes, lo que nos indica que en un momento
dado pueden suceder 5 acciones, una llegada, y a lo sumo la salida de los
clientes de las cuatro ventanillas. Estos sucesos se mantendrán en un Lista de
Eventos, la cual puede contener como máximo cinco nodos. Cada nodo
contenido en la lista representa la llegada o salida de algún cliente de alguna de
las ventanillas, por lo que de alguna manera tenemos que identificar a cuál
ventanilla corresponde la salida. Dado que los eventos de hecho se suceden en
orden cronológico, esta lista debe mantenerse ordenada ascendentemente por
el tiempo en que debe sucederse el evento.
Debido a que los clientes son los que entran y salen, serán considerados
como los objetos. El número de servidores es cuatro, representando los
cajeros. Los tiempos de llegada se obtendrán por lectura. Estos tiempos de
llegada se observarán en minutos, al igual que los tiempos de las
transacciones.

Página 32
Los sucesos que pueden ocurrir así como las acciones que deben
realizarse son los siguientes:
• Si llega un cliente, colocarlo en la Lista de Eventos.
• Si la Lista de Eventos no está vacía, eliminar el siguiente evento a
realizarse.
• Si el evento es de tipo de llegada, se coloca un nodo en la cola de espera
de menor longitud.
• Si el cliente recién colocado en la cola de espera es el único en la misma,
se inserta un nodo en la Lista de Eventos, registrando su salida y se lee la
próxima línea de entrada.
• Si el evento es de tipo de salida, el nodo al frente de la cola
correspondiente se elimina, ya que él representa el nodo a ser eliminado.
En este caso el tiempo que el cliente de salida ha permanecido en el
banco, es calculado y agregado al total acumulado para el promedio.
• Si existe un cliente en la Cola de Espera de donde fue eliminado el
cliente que sale, pasa a ser atendido por el cajero correspondiente; y se
agrega un nodo a la Lista de Eventos, previo cálculo del tiempo de su
salida.
Observe que la Lista de Eventos en sí misma no representa ninguna parte
de la situación del mundo real. Es utilizada unicamente como parte del programa
para controlar el proceso en forma global. Una simulación de este tipo, es decir,
que funciona al cambiar la situación en respuesta a la ocurrencia de uno de los
varios eventos, se le denomina Simulación de Cambio por Evento.
Ahora observemos las estructuras de datos que se utilizarán. Para mayor
sencillez se utilizará un solo tipo de nodo, tanto en la Lista de Eventos así como la
que representa un cliente en la Cola de Espera.

Página 33
Campos = Record Tiempo : INTEGER; Duracion : INTEGER; NTipo : 0..4 END;
Para el caso de un cliente en la Cola de Espera, Tiempo es el tiempo de
llegada del cliente y Duración es la duración de la transacción. NTipo no tendrá
utilización para este caso.
En la Lista de Eventos, Tiempo se utiliza para almacenar el tiempo en que
debe ocurrir el evento sea llegada o salida. Duración, se utiliza para mantener la
duración del evento, aún cuando en un evento de salida no tenga mucha
importancia. El contenido del campo NTipo indicará, en caso de ser 0, que el
evento es de llegada; si contiene un valor entre 1 y 4, la salida de un cliente y el
número permitirá identificar en cual cajero se está llevando a cabo la salida.
La Lista de Eventos al igual que las cuatro colas serán representadas
sobre el mismo arreglo que se utiliza en la implementación de la Lista,
L : Lista;
por lo que es necesario declarar un objeto que encierre lo necesario para
representar una cola, como son los dos apuntadores externos Frente y Final, así
como una variable que me permita mantener el número de clientes en la misma
que denominaremos Num.

Página 34
TYPE Indice = 1..4; Cola = OBJECT Frente : Apuntador; Final : Apuntador; Num : INTEGER; PROCEDURE Inicializar; END; VAR C : ARRAY[Indice] OF Cola;
Definiremos un procedimiento inicializar, que me permita inicializar las
cuatro colas. En este caso no es necesario definir el método de tipo virtual, a
pesar de que llevan el mismo nombre, dado que Cola no es objeto
descendiente del objeto Lista. De haberlo definido como objeto descendiente
de Lista, hubiese utilizado un arreglo para cada implementación de Cola, hecho
que ocurriría por herencia.
PROCEDURE Cola.Inicializar; BEGIN Frente := Nulo; Final := Nulo; Num := 0 END;
También es necesario definir una variable apuntadora a la Lista de Eventos
que llamaremos EvenLista.
EvenLista : Apuntador;

Página 35
El cuerpo principal consiste en considerar los sucesos en la Lista de
Eventos, ejecutando las acciones correspondientes hasta que la Lista de Eventos
quede vacía. Dentro de los sucesos a considerar, está el de la llegada de un
cliente, lo que involucra una inserción en la Lista de Eventos de un nodo de NTipo
= 0. Dado que en la Lista de Eventos, la información debe mantenerse ordenada
ascendentemente por el tiempo de ejecución del suceso, se llama al
procedimiento Insertar, el cual realiza una búsqueda para determinar el lugar en
que corresponda insertar el nuevo elemento. Para observar en cada nodo el
contenido del campo tiempo y posicionarse en el siguiente, utiliza la operación
Visualizar y dependiendo del lugar en que se deba realizar la inserción se
llamará a la operación InsDespues o a la de InsComienzo.
El programa principal realiza también llamadas a los procedimientos
Llegada y Salida, los cuales realizan cambios en la Lista de Eventos y en
algunas de las Colas, dependiendo si el suceso es de tipo de llegada o salida.
El procedimiento Llegada refleja la llegada de un cliente en el tiempo
ATiempo con una duración de la transacción en minutos indicada en Dur. Inserta
en la Lista de Eventos un nodo de llegada correspondiente al nuevo cliente, en la
parte posterior de la cola de menor longitud. Este procedimiento a su vez
incrementa el campo Num de la cola correspondiente.
Si el cliente que está siendo asignado a la cola es el único en la misma, se
agreaga un nodo en la Lista de Espera representando su salida. Luego se lee la
siguiente línea de entrada, si existiese alguna, colocándo un nodo de llegada en
la Lista de Eventos. Si no existe más entradas, el procedimiento retorna sin
agregar el nuevo nodo de llegada y el programa continua procesando los nodos
de salida que restan en la Lista de Eventos.

Página 36
Salida por su parte refleja la salida del cliente que se encuentre al
comienzo de la cola indicada por QIndice en el tiempo DTiempo. El cliente es
retirado de la cola indicada por QIndice, actualizando el apuntador Final en caso
de que la cola haya quedado vacía; luego, se disminuye en 1 el campo Num de la
cola correspondiente. Se totaliza el tiempo de espera del cliente que recién
acaba de ser servido, además de contabilizarlo. Luego el siguiente nodo en la
cola pasa a ser servido, por lo que se le calcula su tiempo de salida para
insertarlo en la Lista de Eventos, por medio de un nodo de salida.
En la aplicación no es necesario llamar la operación Liberar, ya que
tanto en la Lista de Eventos así como en las Colas que utilizan la implementación
de Listas Encadenadas, durante la ejecución de la aplicación y a través de las
operaciones de eliminación, son liberados todos los nodos que las conforman.
A continuación se presenta la codificación total de la aplicación, pero sin
antes hacer énfasis al lector de la importancia de comprender esta aplicación, ya
que la mayoría de los programas de simulación utilizan en una alta proporción las
estructuras de Listas unidas al concepto de Cola.
PROGRAM Banco; USES List; TYPE Cola = OBJECT Frente : Apuntador; Final : Apuntador; Num : INTEGER; PROCEDURE Inicializar; END; Indice = 1..4;

Página 37
Campos = Record Tiempo : INTEGER; Duracion : INTEGER; NTipo : 0..4 END; VAR AuxInfo : Campos; C : ARRAY[Indice] OF Cola; (* Definicion de las 4 *) (* Colas *) L : Lista; (* Definicion del Objeto Lista*) EvenLista : Apuntador; (* Apuntador a la Lista de Eventos *) TotTiempo : INTEGER; ATiempo,DTiempo : INTEGER; Cont,Dur : INTEGER; QIndice : Indice; P,Q : Apuntador; (* Implementacion de la operacion Inicializar del Objeto Cola *) PROCEDURE Cola.Inicializar; BEGIN Frente := Nulo; Final := Nulo; Num := 0 END; (* Procedimiento que inserta en la Lista de Eventos *) (* el nuevo evento manteniendo el orden creciente por *) (* el tiempo en que deba ejecutarse *) PROCEDURE Insertar(VAR EvenLista:Apuntador;Valor:Campos); VAR P,Q,R : Apuntador; Encontrado : BOOLEAN; BEGIN R := Nulo; Q := Nulo; Encontrado := FALSE; P := EvenLista;

Página 38
WHILE (NOT Vacio(P)) AND (NOT Encontrado) DO BEGIN Q := P; L.Visualizar(P,AuxInfo,SIZEOF(AuxInfo)); IF AuxInfo.Tiempo < Valor.Tiempo THEN R := Q ELSE Encontrado := TRUE END; IF Q = Nulo THEN L.InsComienzo(EvenLista,Valor,SIZEOF(Valor)) ELSE IF R = Nulo THEN IF AuxInfo.Tiempo > Valor.Tiempo THEN L.InsComienzo(EvenLista,Valor,SIZEOF(Valor)) ELSE L.InsDespues(Q,Valor,SIZEOF(Valor)) ELSE L.InsDespues(R,Valor,SIZEOF(Valor)) END; (* Procedimiento que realiza las acciones en caso de *) (* determinar que el siguiente evento corresponde a *) (* la llegada de un cliente al banco *) PROCEDURE Llegada(ATiempo,Dur : INTEGER); VAR Pequeno : INTEGER; Q,P : Apuntador; QIndice,Posicion : Indice; BEGIN Posicion := 1; Pequeno := C[1].Num; FOR QIndice := 2 TO 4 DO IF C[QIndice].Num < Pequeno THEN BEGIN Pequeno := C[QIndice].Num; Posicion := QIndice END; WITH AuxInfo DO BEGIN Tiempo := ATiempo; Duracion := Dur; NTipo := Posicion END; L.InsFinal(C[Posicion].Frente,C[Posicion].Final,AuxInfo, SIZEOF(AuxInfo)); C[Posicion].Num := C[Posicion].Num + 1;

Página 39
IF C[Posicion].Num = 1 THEN BEGIN AuxInfo.Tiempo := ATiempo + Dur; Insertar(EvenLista,AuxInfo); (* Impresion del contenido de la Lista de Eventos *) P := EvenLista; WHILE NOT Vacio(P) DO BEGIN L.Visualizar(P,AuxInfo,SIZEOF(AuxInfo)); WITH AuxInfo DO WRITELN(Tiempo,' ',Duracion,' ',NTipo) END END; IF NOT EOF THEN BEGIN WITH AuxInfo DO BEGIN WRITE('* Introduzca Tiempo de Llegada : '); READLN(Tiempo); WRITE('* Introduzca Duracion de la Transaccion : '); READLN(Duracion); NTipo := 0 END; Insertar(EvenLista,AuxInfo); (* Impresion del contenido de la Lista de Eventos *) P := EvenLista; WRITELN('TIEMPO ','DURACION ','TIPO'); WHILE NOT Vacio(P) DO BEGIN L.Visualizar(P,AuxInfo,SIZEOF(AuxInfo)); WITH AuxInfo DO WRITELN(Tiempo,' ',Duracion,' ',NTipo) END END END; PROCEDURE Salida(QIndice:Indice;DTiempo:INTEGER); VAR AuxInfo : Campos; P,Q : Apuntador; BEGIN L.EliComienzo(C[QIndice].Frente,AuxInfo,SIZEOF(AuxInfo));

Página 40
IF C[QIndice].Frente = Nulo THEN C[QIndice].Final := Nulo; C[QIndice].Num := C[QIndice].Num - 1; TotTiempo := TotTiempo + (DTiempo - AuxInfo.Tiempo); Cont := Cont + 1; IF C[Qindice].Num > 0 THEN BEGIN P := C[QIndice].Frente; WITH AuxInfo DO BEGIN L.Visualizar(P,AuxInfo,SIZEOF(AuxInfo)); Tiempo := DTiempo + AuxInfo.Duracion; NTipo := QIndice END; Insertar(EvenLista,AuxInfo); (* Impresion del contenido de la Lista de Eventos *) P := EvenLista; WHILE NOT Vacio(P) DO BEGIN L.Visualizar(P,AuxInfo,SIZEOF(AuxInfo)); WITH AuxInfo DO WRITELN(Tiempo,' ',Duracion,' ',NTipo) END END END; BEGIN L.Inicializar(EvenLista); FOR QIndice := 1 TO 4 DO C[QIndice].Inicializar; Cont := 0; TotTiempo := 0;

Página 41
WITH AuxInfo DO BEGIN WRITE('* Introduzca Tiempo de Llegada : '); READLN(Tiempo); WRITE('* Introduzca Duracion de la Transaccion : '); READLN(Duracion); NTipo := 0 END; Insertar(EvenLista,AuxInfo); (* Impresion del contenido de la Lista de Eventos *) P := EvenLista; WRITELN('TIEMPO ','DURACION ','TIPO'); WHILE NOT Vacio(P) DO BEGIN L.Visualizar(P,AuxInfo,SIZEOF(AuxInfo)); WITH AuxInfo DO WRITELN(Tiempo,' ',Duracion,' ',NTipo) END; WHILE NOT Vacio(EvenLista) DO BEGIN L.EliComienzo(EvenLista,AuxInfo,SIZEOF(AuxInfo)); IF AuxInfo.NTipo = 0 THEN BEGIN ATiempo := AuxInfo.Tiempo; Dur := AuxInfo.Duracion; Llegada(Atiempo,Dur) END ELSE BEGIN QIndice := AuxInfo.NTipo; DTiempo := AuxInfo.Tiempo; Salida(QIndice,Dtiempo) END END; WRITELN('** TIEMPO TOTAL ACUMULADO : ',TotTiempo); WRITELn('** CANTIDAD DE CLIENTES ATENDIDOS : ',Cont); WRITELN('** TIEMPO PROMEDIO DE ESPERA : ',TotTiempo/Cont)
END.

Página 42
-Desventajas de Utilización de Memoria Estática
La mayor desventaja de utilizar Memoria Estática, es la de que mientras
las listas siendo implementadas no utilicen la mayoría de los nodos disponibles,
ese espacio de memoria está siendo inutilizado; aún devolviéndose a la Lista de
Disponibles, por lo que se puede hablar de una ineficiencia en el uso de espacio
de memoria. Si por el contrario, el estimado fué demasiado pequeño, el programa
fallará en tiempo de ejecución.
Pero cómo conocer con anterioridad el espacio necesario?. Bajo nuestro
enfoque, en el que el implementador de la estructura puede ser una persona
diferente al que la utiliza en alguna aplicación, no existiría manera alguna de
resolver el problema, aún más cuando el hecho de utilizar un arreglo en la
implementación, donde cada elemento a su vez es una arreglo de bytes requiere
de mayor espacio de memoria.
Pascal al igual que otros lenguajes de alto nivel, nos proporciona la
posibilidad de asignar o liberar espacios de memoria en tiempo de ejecución.
Esto es posible mediante el uso de Memoria Dinámica.
Es importante enfatizar, que implementaciones tal como hasta ahora
hemos desarrollado, son válidas para aplicaciones que requieren estructuras de
no gran tamaño o en caso de que la implementación se codifique en algún
lenguaje que no soporte Memoria Dinámica.
- MEMORIA DINAMICA
En lo que a nuestra materia respecta, la definición del Tipo de Nodo se
realizará en Tiempo de Compilación; pero la asignación de espacio al mismo, lo
controlará el usuario de la implementación durante la ejecución de la aplicación.
Para utilizar la asignación dinámica en Pascal, es preciso declarar un
nuevo tipo de variable especial de tipo apuntadora. Estas variables podrán
contener solo direcciones reales de memoria. El tipo pointer en Pascal se define

Página 43
mediante el uso del caracter †, seguido del nombre del tipo de la estructura de
datos a que la variable apuntadora accesará. En aquellos equipos de
computadora, en cuyos teclados no incluyan dicho símbolo, se utilizará el simbolo
^ (sombrerito). Para mayor información, regresar al capítulo 1.
Apuntador = ^TipoNodo;
TipoNodo = RECORD
PRIVATE
Info : TipoInfo;
Prox : Apuntador
END;
VAR
Lista,P : Apuntador;
En este caso cualquier variable declarada de tipo Apuntador, solo podrá
contener direcciones reales de memoria, y no podrán ser actualizadas mediante
operación alguna de lectura o escritura.
La definición del arreglo como parte útil en la implementación del objeto
Lista, no es necesaria, ya que los espacios de tipo TipoNodo serán creados
dinámicamente durante la ejecución del programa. Es por esta razón que
TipoNodo debe ser definido como Privado. Como pueden observar en la previa
implementación de lista, al hacerse privado el arreglo Nodo, automaticamente
privatizaba los campos de cada nodo.
Observe también TipoNodo ha sido utilizado en la definición de
Apuntador, antes de ser definido. Esta es una excepción a la regla general de
Pascal, que dice que los tipos deben ser definidos antes de ser usado en
cualquier otra definición.
Las variables de tipo apuntador podrán ser utilizadas en una operación de
asignación, sólo si son apuntadoras al mismo tipo de variable.
P := Lista

Página 44
La diferencia entre Lista y Lista^, es que Lista es una variable de tipo
Pointer y Lista^ se refiere al contenido del espacio apuntado por Lista.
MEMORIA PRINCIPAL
Para hacer referencia al campo Info o al campo Prox de un nodo
apuntado por la variable P, nos referimos a cada campo en particular de la
siguiente manera:
P^.Info := Elemento;
P^.Prox := Lista;
Para asignarle al último nodo de la lista un valor Nulo, se usa la palabra
reservada en Pascal NIL, la cual es una constante que representa una dirección
absurda a una variable de tipo apuntadora. En nuestro caso, podemos inicializar
la lista en vacío, mediante la siguiente instrucción
Lista := NIL;
Normalmente Pascal implementa el valor Nil como una dirección 0 (cero),
pero 0 (cero) como valor entero nunca podrá ser asignado a variable alguna de
tipo apuntadora, pues causaría un error en tiempo de compilación.
Pascal además nos suministra dos muevos procedimientos incorporados
los cuales realizan una labor similar al de las operaciones ObtenerNodo y
DevolverNodo definidas en la implementación anterior.

Página 45
Uno de ellos es New, mediante el cual solicitamos al sistema nos asigne
espacio de memoria del tipo al cual apunta la variable que se envía como
parámetro de salida, y la cual recibe la dirección que ocupa dicho espacio.
NEW(P);
El otro procedimiento incorporado es el de DISPOSE, el cual permite
liberar el espacio de memoria cuya dirección se envía como parámetro de
entrada.
DISPOSE(P);
La operación Lleno, descrita en las anteriores implementaciones, requiere
ser definida en forma distinta en implementaciones que utilicen Memoria
Dinámica, ya que dicha condición solo podría ocurrir en caso de que el usuario
agotara totalmente el espacio de memoria RAM de su computadora. Ver capítulo
uno para más detalle.
Turbo Pascal divide la memoria de su computadora en cuatro partes: el
segmento de código, el segmento de datos, el segmento de Pila (Stack) y el
segmento Montículo o de Almacenamiento Dinámico (HEAP). Las variables
locales de los procedimientos y funciones se almacenan en la Pila (Stack),
mientras que las variables globales o estáticas se almacenan en el segmento de
datos y las variables Dinámicas se asignan al Montículo.
La Pila y el Montículo ocupan la zona alta de memoria para su posible
crecimiento durante la ejecución de la aplicación. La Pila crece hacia abajo
mientras el montículo crece hacia arriba, dado que comparten la misma zona, y
ese crecimiento en sentido contrario permite el que ellos nunca lleguen a
solaparse.
El conocimiento de cuánta memoria está realmente disponible para
variables Dinámicas en un momento dado, puede ser determinado por medio de

Página 46
la función MemAvail, la cual devuelve un entero largo indicando en bytes la
cantidad de memoria disponible para variables Dinámicas.
La función MemAvail, puede ser utilizada en la función Lleno, para
determinar si la cantidad de espacio disponible en Bytes en el Montículo es
suficiente como para asignarlo a una variable de tipo TipoInfo.
FUNCTION Lista.Lleno : BOOLEAN; BEGIN Lleno := MemAvail < SIZEOF(TipoNodo) END;
A continuación podrán observar la implementación completa de Lista
Encadenada utilizando Memoria Dinámica. El paquete de operaciones no difiere
en nada al señalado en la anterior implementación. Si el objeto está
completamente encapsulado, un cambio en el tipo de representación no debe
alterar el uso del mismo. La interfase permanece siendo la misma, permitiendo al
usuario de la implementación pierda la atención en los detalles de la
implementación, por lo tanto la aplicación discutida anteriormente puede ser
ejecutada con esta implementación, modificando solo el nombre de la
unidad.

Página 47
Aún cuando existe una manera directa de asignar o liberar espacio de
memoria en tiempo de ejecución, mediante el uso de los procedimientos NEW y
DISPOSE, se definieron las operaciones de ObtenerNodo y DevolverNodo,
las cuales hacen las llamadas a esos procedimientos respectivamente. Existen
dos lugares en donde pueden ser definidos ambos procedimientos como privados.
Uno en la definición del TipoNodo, con la diferencia que en la implementación, el
encabezado debe aparecer la palabra TipoNodo calificando el nombre del
procedimiento en vez de Lista como fué descrito en la anterior definición.
El otro caso, en el que la definición aparece en el mismo lugar que en la
implementación anterior, es decir al final de las definiciones de los encabezados
de los métodos correspondiente al objeto Lista. Este caso será el que utilice, para
mantener las diferentes implementaciones de la misma estructura lo más
parecidas posibles.
Sea cualquiera de los casos, la implementación funciona exitosamente, así
como igual de exitosa es su utilización en una aplicación determinada.
UNIT ListDina; INTERFACE CONST MaxByte = 300; (* Maximo Numero de Bytes De Informacion *) Nulo = Nil; TYPE LongInfo = 0..MaxByte; Informacion = ARRAY[LongInfo] OF BYTE; Apuntador = ^TipoNodo;

Página 48
(**************************************************) (* DEFINICION DEL OBJETO L I S T A L I N E A L *) (**************************************************) TipoNodo = OBJECT PRIVATE Info : Informacion; Prox : Apuntador; END; Lista = OBJECT(TipoNodo) PROCEDURE Inicializar(VAR Lista : Apuntador); FUNCTION Vacio (Lista : Apuntador) : BOOLEAN; FUNCTION Lleno : BOOLEAN; PROCEDURE InsComienzo(VAR Lista : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE EliComienzo(VAR Lista : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE InsFinal(VAR Frente,Final : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE InsDespues(P : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE EliDespues(P : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE Visualizar(VAR Proximo : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE Liberar(VAR Lista : Apuntador); PRIVATE PROCEDURE ObtenerNodo(VAR Nuevo : Apuntador); PROCEDURE DevolverNodo(Viejo : Apuntador); END; (**************************************************) (* I M P L E M E N T A C I O N D E L O S M E T O D O S *) (**************************************************) IMPLEMENTATION PROCEDURE Lista.Inicializar(VAR Lista : Apuntador); BEGIN Lista := Nulo END; FUNCTION Lista.Vacio(Lista : Apuntador) : BOOLEAN; BEGIN Vacio := Lista = Nulo

Página 49
END; FUNCTION Lista.Lleno : BOOLEAN; BEGIN Lleno := MemAvail < SIZEOF(TipoNodo) END; PROCEDURE Lista.ObtenerNodo(VAR Nuevo : Apuntador); BEGIN NEW(Nuevo) END; PROCEDURE Lista.DevolverNodo(Viejo : Apuntador); BEGIN DISPOSE(Viejo) END; PROCEDURE Lista.InsComienzo(VAR Lista : Apuntador; VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador; I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nuevo^.Info[I] := DirValor[I]; Nuevo^.Prox := Lista; Lista := Nuevo END;

Página 50
PROCEDURE Lista.EliComienzo(VAR Lista : Apuntador; VAR Valor; Longitud : WORD); VAR VIEJO : Apuntador; I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF NOT Vacio(Lista) THEN BEGIN FOR I := 0 TO Longitud-1 DO DirValor[I] := Lista^.Info[I]; Viejo := Lista; Lista := Lista^.Prox; DevolverNodo(Viejo) END ELSE WRITELN('LISTA UNDERFLOW') END; PROCEDURE Lista.InsFinal(VAR Frente,Final : Apuntador; VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador; I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nuevo^.Info[I] := DirValor[I]; Nuevo^.Prox := Nulo; IF Final = Nulo THEN FRENTE := Nuevo ELSE Final^.Prox := Nuevo; Final := Nuevo END;

Página 51
PROCEDURE Lista.InsDespues(P : Apuntador;VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador; I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF P <> Nulo THEN BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nuevo^.Info[I] := DirValor[I]; Nuevo^.Prox := P^.Prox; P^.Prox := Nuevo END; END; PROCEDURE Lista.EliDespues(P : Apuntador; VAR Valor; Longitud : WORD); VAR VIEJO : Apuntador; I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF P <> Nulo THEN IF P^.Prox <> Nulo THEN BEGIN Viejo := P^.Prox; FOR I := 0 TO Longitud-1 DO DirValor[I] := Viejo^.Info[I]; P^.Prox := Viejo^.Prox; DevolverNodo(Viejo) END ELSE WRITELN('NODO NO EXISTE') ELSE WRITELN('NODO DE REFERENCIA NO EXISTE') END;

Página 52
PROCEDURE Lista.Visualizar(VAR Proximo : Apuntador; VAR Valor; Longitud : WORD); VAR I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF Proximo <> Nulo THEN BEGIN FOR I := 0 TO Longitud-1 DO DirValor[I] := Proximo^.Info[I]; Proximo := Proximo^.Prox END END;
PROCEDURE Lista.Liberar(VAR Lista : Apuntador); VAR P : Apuntador; BEGIN WHILE Lista <> Nulo DO BEGIN P := Lista; DevolverNodo(Lista); Lista := P ^.Prox END END;
END.
- LISTAS LINEALES DOBLEMENTE ENCADENADAS
Algunas de las limitaciones de las Listas Simplemente Encadenadas, son
las de que dado un nodo en particular no se pueda eliminar directamente, así
como la de accesar el predecesor a partir de un nodo en particular. En estos
casos puede ser útil utilizar una Lista Doblemente Encadenada.
En una Lista Doblemente Encadenada, los nodos se enlazan en ambas
direcciones. Por lo tanto cada nodo debe contener al menos tres campos:

Página 53
Este tipo de enlace, conduce a que el primer nodo de la lista en su campo
IZQ contenga Nil, ya que no existe predecesor al mismo, situación similar al caso
del último nodo en la lista en su campo DER.
PPaaqquueettee LLiissttaa
Los elementos de Información se insertan y eliminan
en cualquier lugar de la Lista.
Inicializar(Lista)
Función : Inicializar la Lista en Vacío.
Entrada : Apuntador externo de la Lista.
Salida : Lista Inicializada.
Vacío(Lista):BOOLEAN
Función : Chequear si la Lista está Vacía.
Entrada : Apuntador externo de la Lista.
Salida : Boolean.
Lleno:BOOLEAN
Función : Chequear si hay disponibilidad de espacio en el Heap.
Entrada : Ninguna.
Salida : Boolean.
InsDerecha(Apuntador, Elemento, SIZEOF(Elemento))

Página 54
Función : Insertar un Nuevo Elemento de Información a la derecha
del elemento de referencia cuya dirección está en Apun–
tador.
Entrada : Apuntador externo de la Lista con la dirección del ele–
mento de referencia, Nuevo Elemento de Información, el
tamaño(# de Bytes) del elemento.
Salida : Lista Actualizada, Elemento de Información Insertado a
la derecha del elemento de referencia.
InsIzquierda(Lista, Elemento, SIZEOF(Elemento))
Función : Insertar un Nuevo Elemento de Información a la izquierda
del elemento de referencia cuya dirección está en Apun–
tador.
Entrada : Apuntador externo de la Lista con la dirección del ele–
mento de referencia, Nuevo Elemento de Información, el
tamaño(# de Bytes) del elemento.
Salida : Lista Actualizada, Elemento de Información Insertado a
la izquierda del elemento de referencia.
InsFinal(Frente, Final, Elemento, SIZEOF(Elemento))
Función : Insertar un nuevo elemento al final de la Lista.
Entrada : Apuntadores externos de la Lista al Frente Final, Nuevo
Elemento de Información, el Tamaño (# de Bytes) del
elemento.
Salida : Lista Actualizada, Elemento de Información Insertado al
final de la Lista.

Página 55
Eliminar(Apuntador, Elemento, SIZEOF(Elemento))
Función : Eliminar Elemento de Información cuya dirección está en
Apuntador.
Entrada : Apuntador que contiene dirección del elemento a ser
eliminado, el Tamaño(# de Bytes) de la información a ser
eliminada.
Salida : Lista Actualizada, Elemento de Información Eliminado,
Elemento conteniendo la información del elemento elimi–
nado, la dirección del elemento a la derecha del elimi–
nado.
Visualizar(Apuntador, Elemento, SIZEOF(Elemento))
Función : Mostrar el Elemento de Información que se encuentra en
la dirección indicada en el Apuntador.
Entrada : Apuntador que contiene la dirección del elemento a mos–
trar, el Tamaño (# de Bytes) del campo de información
del elemento.
Salida : Información del Elemento.
VisualizarIzq(Apuntador, Elemento, SIZEOF(Elemento))
Función : Mostrar el Elemento de Información que se encuentra en
la dirección indicada en el Apuntador, retornando la di–
rección del elemento a su izquierda.
Entrada : Apuntador que contiene la dirección del elemento a mos–
trar, el Tamaño (# de Bytes) del campo de información
del elemento.
Salida : Información del Elemento, Apuntador con la dirección del
elemento a su izqierda.

Página 56
VisualizarDer(Apuntador, Elemento, SIZEOF(Elemento))
Función : Mostrar el Elemento de Información que se encuentra en
la dirección indicada en el Apuntador, retornando la di–
rección del elemento a su derecha.
Entrada : Apuntador que contiene la dirección del elemento a mos–
trar, el Tamaño (# de Bytes) del campo de información
del elemento.
Salida : Información del Elemento, Apuntador con la dirección del
elemento a su derecha.
Liberar(Lista)
Función : Liberar todo el espacio correspondiente al Heap asignado
a la Lista de Información.
Entrada : El apuntador externo a la Lista.
Salida : Espacio ocupado por lista totalmente liberado, el apunta–
dor externo a la Lista de Información en Nulo.
Las primeras operaciones Inicializar, Vacío y Lleno son idénticas a las de
la implementación anterior.
Se definieron dos operaciones inserción, dada la dirección de un
elemento de referencia. Esto se debe a la posibilidad de insertar por la derecha o
izquierda de un nodo en particular.
La operación InsertarDer, como su nombre lo indica, permite la inserción
de un nuevo elemento a la derecha del que sirve de referencia.
InsertarDer(P,Lucia,SIZEOF(Lucia));

Página 57
Por razones muy obvias, las operaciones en Listas Doblemente
Encadenadas son algo más complejas, ya que requieren mayor número de
cambios de apuntadores que las anteriores Listas Simplemente Encadenadas.
Observe los cambios que hay que realizar para esta operación la cual es
equivalente a la de InsDespués de la implementación anterior.
Esta a su vez contempla el caso de la primera inserción en la Lista de
Información, por lo que en algún momento el parámetro de entrada con la
dirección de algún nodo o elemento de referencia, pueda contener un valor Nulo.
InsertarDer(Lista,Beatriz,SIZEOF(Beatriz));
Esta operación contempla también el caso de insertar al final de la lista.
InsertarDer(P,Zurama,SIZEOF(Zurama));

Página 58
La operación de InsertarIzq es la inversa de la operación antes descrita.
La diferencia reside, en el hecho de que la primera no contempla casos de
inserción al comienzo.
InsertarIzq(Lista,Lucia,SIZEOF(Lucia));
Otra operación muy útil para el caso en que la Lista deba ser tratada
como una Cola, es decir con restricción de acceso, es la de Inserción al Final
directamente, ya que la Eliminación al comienzo puede ser realizada mediante la
operación Eliminar que detallaremos mas adelante. En el caso de utilizar esta
operación como la equivalente a eliminar por el frente de la Cola, la aplicación
tendrá que asegurarse, de que en caso de que la cola quede vacía, asignarle al
nuevo apuntador Final un valor Nulo.
InsFinal requiere de los apuntadores externos Frente y Final, que como
sus nombres lo indican, contienen la dirección del nodo al frente y del nodo al
final de la Lista respectivamente. El apuntador Frente hace el mismo papel que el
apuntador externo Lista, ya que su función es mantener la dirección del primer
elemento o nodo de la Lista. Es necesario pasar como parámetros los dos
apuntadores, ya que para el caso inicial de inserción del primer elemento, ambos
apuntadores deben ser actualizados.
Esta operación es equivalente a que si se invocara la operación
InsertarDer enviando la dirección del último nodo. Su diferencia estriva en que
no se envía el apuntador externo Final, lo que no invalida esta nueva operación,
ya que debe recorrer toda la lista hasta alcanzar el último nodo. Si los accesos
son frecuentes al final de la lista, es más eficiente definir un apuntador externo,
que por conveniencia debe ser llamado Final manteniendo siempre así la
dirección del último nodo.

Página 59
InsFinal(Lista,Final,'9',SIZEOF('9'));
En el caso de que la Lista con restricción de Cola esté vacía, la operación
debe realizar las siguientes acciones:
InsFinal(Lista,Final,'6',SIZEOF('6'));
La operación Eliminar, permite la eliminación de un nodo cuya dirección se
envía como parámetro de entrada, así como también de entrada se envía el
tamaño en bytes del tipo de dato que se ha de eliminar. El segundo parámetro
retorna el valor del elemento eliminado.
Eliminar(P,Valor,SIZEOF(Valor));

Página 60
Otro caso que contempla la operación, Eliminar es la de que el nodo a ser
eliminado sea el último de la Lista, por lo que los cambios a realizar varían un
tanto.
La operación Eliminar también contempla la eliminación del único nodo en
la Lista.
Eliminar(Lista,Valor,SIZEOF(Valor));
La operación Visualizar, como su nombre lo indica, permite observar
desde la aplicación, el contenido del campo de información de un elemento cuya
dirección se envía como primer parámetro.
La información no puede ser observada desde la implementación, ya que
dentro de ella los campos de información son tratados como conjuntos de
bytes.
Adisional a la operación anterior, se implementaron dos nuevas
operaciones de Visualizar. VisualizarDer, la cual además de visualizar la
información contenida en el nodo apuntado por P retorna la dirección del nodo a
la derecha de P y VisualizarIzq que realiza la misma función con la diferencia de

Página 61
que retorna la dirección del nodo a la derecha de P. Estas operaciones son muy
útiles para los casos que requieran recorrer la lista, en sentido normal o a la
inversa.

Página 62
Ejemplo que imprime el contenido de una lista.
PROCEDURE Imprimir(Lista:Apuntador);
VAR
P : Apuntador;
BEGIN
P := Lista;
WHILE P <> Nulo DO
BEGIN
L.VisualizarDer(P,Informacion,SIZEOF(Informacion));
WRITE(Informacion,' ')
END
END;
Por último, la operación Liberar, la cual libera todo el espacio asignado
hasta el momento a una lista de información en particular, retornando el
apuntador externo con un valor nulo, para que más adelante en la aplicación sea
posible determinar que dicha Lista ya no existe, es decir que está vacía.
Liberar (Lista);
A continuación se ofrece la unidad LisDobDi que contiene la
implementación de una Lista Lineal Doblemente Encadenada utilizando como
representación, memoria dinámica.
UNIT LisDobDi; INTERFACE CONST MaxByte = 300; (* Maximo Numero de Bytes de Informacion *) Nulo = Nil;

Página 63
TYPE LongInfo = 0..MaxByte; Informacion = ARRAY[LongInfo] OF BYTE; Apuntador = ^TipoNodo; (**************************************************) (* DEFINICION DEL OBJETO L I S T A L I N E A L *) (**************************************************) TipoNodo = OBJECT Izq : Apuntador; Info : Informacion; Der : Apuntador; END; Lista = OBJECT(TipoNodo) CONSTRUCTOR Inicializar(VAR Lista : Apuntador); FUNCTION Vacio (Lista : Apuntador) : BOOLEAN; FUNCTION Lleno : BOOLEAN; PROCEDURE ObtenerNodo(VAR Nuevo : Apuntador); PROCEDURE DevolverNodo(Viejo : Apuntador); PROCEDURE InsDerecha(VAR P : Apuntador;VAR Valor; Longitud : WORD); PROCEDURE InsIzquierda(VAR P : Apuntador;VAR Valor; Longitud : WORD); PROCEDURE InsFinal(VAR Frente,Final:Apuntador;VAR Valor; Longitud:WORD); PROCEDURE Eliminar(VAR P : Apuntador;VAR Valor; Longitud : WORD); PROCEDURE Visualizar(Proximo:Apuntador;VAR Valor; Longitud:WORD); PROCEDURE VisualizarDer(VAR Proximo:Apuntador;VAR Valor; Longitud:WORD); PROCEDURE VisualizarIzq(VAR Proximo:Apuntador;VAR Valor; Longitud:WORD); DESTRUCTOR Liberar(VAR Lista: Apuntador);VIRTUAL; END;

Página 64
(**************************************************) (* I M P L E M E N T A C I O N D E L O S M E T O D O S *) (**************************************************) IMPLEMENTATION CONSTRUCTOR Lista.Inicializar(VAR Lista: Apuntador); BEGIN Lista := Nulo END; FUNCTION Lista.Vacio(Lista : Apuntador) : BOOLEAN; BEGIN Vacio := Lista = Nulo END; FUNCTION Lista.Lleno : BOOLEAN; BEGIN Lleno := MemAvail < SIZEOF(TipoNodo) END; PROCEDURE Lista.ObtenerNodo(VAR Nuevo : Apuntador); BEGIN NEW(Nuevo) END; PROCEDURE Lista.DevolverNodo(Viejo : Apuntador); BEGIN DISPOSE(Viejo) END; PROCEDURE Lista.InsDerecha(VAR P : Apuntador; VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador; I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor;

Página 65
BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nuevo^.Info[I] := DirValor[I]; IF P = Nulo THEN BEGIN Nuevo^.Der := Nulo; Nuevo^.Izq := Nulo; P := Nuevo END ELSE BEGIN Nuevo^.Der := P ^.Der; Nuevo^.Izq := P; IF P^.Der <> Nulo THEN P^.Der^.Izq := Nuevo; P^.Der := Nuevo END END; PROCEDURE Lista.InsIzquierda(VAR P : Apuntador; VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador; I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF P <> Nulo THEN BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nuevo^.Info[I] := DirValor[I]; Nuevo^.Der := P; Nuevo^.Izq := P^.Izq; IF P^.Izq <> Nulo THEN P^.Izq^.Der := Nuevo; P^.Izq := Nuevo; IF Nuevo^.Izq = Nulo THEN P := Nuevo END ELSE WRITELN('NODO NO EXISTE') END; PROCEDURE Lista.InsFinal(VAR Frente,Final : Apuntador; VAR Valor; Longitud:WORD); VAR Nuevo : Apuntador;

Página 66
I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nuevo^.Info[I] := DirValor[I]; Nuevo^.Der := Nulo; Nuevo^.Izq := Final; IF Final = Nulo THEN Frente := Nuevo ELSE Final^.Der := Nuevo; Final := Nuevo END; PROCEDURE Lista.Eliminar(VAR P : Apuntador; VAR Valor; Longitud : WORD); VAR Viejo : Apuntador; I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF P <> Nulo THEN BEGIN Viejo := P; FOR I := 0 TO Longitud-1 DO DirValor[I] := Viejo^.Info[I]; IF P^.Der <> Nulo THEN P^.Der^.Izq := P^.Izq; IF P^.Izq <> Nulo THEN P^.Izq^.Der := P^.Der ELSE P := P^.Der; DevolverNodo(Viejo) END; END; PROCEDURE Lista.Visualizar(Proximo : Apuntador; VAR Valor; Longitud : WORD); VAR I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF Proximo <> Nulo

Página 67
THEN BEGIN FOR I := 0 TO Longitud-1 DO DirValor[I] := Proximo^.Info[I] END END; PROCEDURE Lista.VisualizarIzq(VAR Proximo : Apuntador; VAR Valor; Longitud : WORD); VAR I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN IF Proximo <> Nulo THEN BEGIN FOR I := 0 TO Longitud-1 DO DirValor[I] := Proximo^.Info[I]; Proximo := Proximo^.Izq END END; PROCEDURE Lista.VisualizarDer(VAR Proximo : Apuntador; VAR Valor; Longitud : WORD); VAR I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor;

Página 68
BEGIN IF Proximo <> Nulo THEN BEGIN FOR I := 0 TO Longitud-1 DO DirValor[I] := Proximo^.Info[I]; Proximo := Proximo^.Der END END; DESTRUCTOR Lista.Liberar(VAR Lista : Apuntador); VAR P : Apuntador; BEGIN WHILE Lista <> Nulo DO BEGIN P := Lista; DevolverNodo(Lista); Lista := P ^.Der END END;
END.
- NIVEL DE APLICACION Dado que la Lista Lineal Doblemente Encadenada se utiliza como
representación interna para la implementación de otras estructuras de datos,
como en Arbol Binario que desarrollaremos en el siguiente capítulo y en Matrices
Esparcidas entre otras, no se privatizó campo de dato o método alguno; ya que
de otra manera y de acuerdo a las reglas de uso de la cláusula PRIVATE
descritas en el primer capítulo, no permitiría implementar nuevos métodos que
requieran accesar directamente los campos de datos de un nodo en particular.
Por lo tanto, dejaremos su nivel de aplicación como el de representación de otras
estructuras.

Página 69
EJERCICIOS PROPUESTOS______________________ 1-) Implementar, utilizando Programación Orientada a Objetos en Pascal, tanto
con memoria estática como con memoria dinámica, la estructura de Lista Circular
Simplemente Encadenada a la que hacen referencia la mayoría de los textos de
Estructuras de Datos, donde el paquete de operaciones debe contener:
• Inicializar
• Vacío
• Lleno
• InsDespués
• EliDespués
• Visualizar
• Liberar.
2-) Implementar similarmente al ejercicio anterior, Listas Circulares Doblemente
Encadenadas, donde el paquete de operaciones debe contener las mismas
operaciones descritas para Listas Lineales Doblemente Encadenadas.
3-) Escriba una operación que elimine, dado un valor determinado del campo
clave de información, en una Lista Lineal Simplemente Encadenada, ordenada
ascendentemente. Esta operación es similar a la utilizada para insertar un nuevo
nodo en la Lista de Eventos, de la aplicación de simulación de un banco.
4-) Agregar a cada implementación de Lista descritas en este capítulo, las
siguientes operaciones:
• Concatenar dos listas.
• Invertir los nodos de una lista, es decir el último nodo debe ser el
primero, el penúltimo el segundo y así sucesivamente. Solo se
permiten cambios de enlaces sobre la misma lista.
5-) Escribir las siguientes operaciones para cualquier tipo de Lista, como parte de
alguna aplicación; es decir, sólo pueden hacer uso de las operaciones descritas
en cada implementación.
• Intercalar dos listas ordenadas en una tercera lista ordenada.

Página 70
• Formar una tercera lista que represente la unión de dos listas.
Eliminar los campos repetidos en la lista resultante.
• Formar una tercera lista que represente la intersección de dos
listas.
• Ordenar los elementos de la lista en orden creciente respecto a
uno de los campos de información.
• Imprimir la lista.
6-) Sustituir en la aplicación correspondiente a la Simulación de Banco, los
segmentos correspondientes a la impresión del contenido de la Lista de Eventos,
por la llamada a un procedimiento dentro de la misma aplicación que realice dicha
tarea.

Página 71
CAPITULO 6
ESTRUCTURA DE DATOS
ARBOL o TREE
El usar lista encadenadas nos da grandes ventajas en cuanto poder
mantener infomación almacenada con un cierto orden. Sin embargo, la búsqueda
de cierta información, sigue siendo proporcional al tamaño de la misma. En este
capítulo se hará énfasis en una nueva estructura llamada Arbol Binario, ya que
retiene la flexibilidad de una lista enlazada, permitiendo además un acceso más
rápido a cualquiera de sus nodos, como en el caso específico de Arbol Binario
de Búsqueda.
- NIVEL DE ABSTRACCION
- Definición
Un Arbol Binario consiste en una colección finita de elementos
homogéneos, el cual puede estar vacío o contener un elemento denominado Raíz
o más de un elemento con una relación jerárquica entre ellos. Esto significa que
cada elemento en el árbol, y de allí su calificativo de binario, puede tener un hijo
izquierdo y un hijo derecho, cada uno de los cuales son de por sí un árbol binario.
Estos dos subconjuntos son denominados Subárbol Izquierdo y Subárbol
Derecho del árbol original.
Lo único en que difiere un Arbol Binario con respecto a una Lista Lineal
Doblemente Encadenada, es el que en el primer caso, un nodo en particular solo
puede ser direccionado por un nodo llamado nodo padre, cuando en una Lista
Lineal Doblemente Encadenada, un nodo es direccionado tanto por el que lo
precede como por el que le sucede.

Página 72
Es por esa razón, que la realción que se plantea entre nodos en un Arbol
Binario es la de Padre e Hijo y la de Hermanos.
Pero antes de entrar en detalle sobre esta relación, recordaremos algunos
de los conceptos asociados a Arboles Binario.
Como podemos observar en la figura del árbol anterior, existe un nodo que
se denomina raíz, en nuestro ejemplo es el nodo con contenido igual a (A), el cual
desde el punto de vista lógico, se considera el primer nodo del árbol. Un
apuntador externo es utilizado para contener la dirección de ese primer nodo raíz.
La raíz puede apuntar a su vez a lo sumo dos nodos. El de su izquierda (B), el
cual se denomina hijo izquierdo de la raíz y uno a su derecha (C), denominado
hijo derecho de la raíz. La relación entre ambos hijos es la de hermanos y la raíz
pasa a ser el padre o ancestro de ambos hijos.
Estos tipos de relaciones es aplicable a todo el árbol en forma recursiva, ya
que tanto el hijo izquierdo de la raíz así como el hijo derecho representan
subárboles de la raíz y son raíces del Subárbol Izquierdo y Subárbol Derecho
respectivamente. En otras palabras, todo subárbol es a su vez un árbol.
Dado que un nodo puede tener 0,1 o 2 nodos hijos, podemos definir
aquellos nodos con 0 hijos, nodos hojas o nodos terminales.

Página 73
- Visión Abstracta de un Arbol Binario
Los nodos o elementos de un árbol, similar a las listas encadenadas,
constan de varias partes. Un campo Info y dos apuntadores, uno para su hijo
izquierdo y otro para su hijo derecho.
Similar a las listas encadenadas, los elementos de árbol no pueden ser
accesados directamente. Para llegar a un elemento determinado, debemos
comenzar por el primer elemento del árbol, a través de una variable externa que
contenga su dirección, luego podemos accesar sus hijos izquierdo y derechos ,
cuyas direcciones se encuentran en sus campos de enlace Izq y Der
respectivamente, aplicando el mismo procedimiento a través de los subárboles,
hasta llegar a algún nodo hoja, que por no tener hijos, sus campos de enlace
contendrán el valor Nulo.
Representando graficamente el ejemplo anterior, obtendremos:

Página 74
Un caso especial de Arbol Binario es el de Arbol Binario de Búsqueda, el
cual tiene la siguiente restricción: El nodo a la izquierda contiene un valor más
pequeño que el nodo que le apunta y el nodo a la derecha contiene un valor
más grande.
La definición de Arbol Binario de Búsqueda asume que todos los valores
de sus nodos son distintos. Por lo general, el contenido de los nodos en este tipo
de árbol se refieren a claves únicas.
La eficiencia en la utilización de Arboles Binarios de Búsqueda, es en
cuanto a que las búsquedas son proporcionales a la profundidad del árbol. Un
ejemplo de ello se ilustra en el siguiente gráfico, sombreado el camino por el que
se realiza la búsqueda del elemento con valor 7.
Si esta información se hubiese almacenado en una Lista Encadenada, aún
cuando la lista se mantuviera ordenada ascendentemente, la búsqueda hubiese
requerido 7 comparaciones; en el Arbol Binario de Búsqueda, solo requirió de 4
comparaciones.

Página 75
Para almacenar información con el simple propósito de búsqueda, como en
el caso de un índice, es recomendable utilizar Arbol Binario de Búsqueda si
las inserciones o eliminaciones de los elementos en el índice no son
frecuentes; de lo contrario, utilizar Listas Encadenadas ordenadas por el
campo clave.
- Recorridos de un Arbol Binario
Es muy frecuente en las aplicaciones, el recorrer un Arbol Binario, ya sea
para la impresión de su contenido o cualquier otra acción realizable en la visita de
cada nodo en el árbol. Similar a las Listas Encadenadas, para recorrer un Arbol
Binario, comenzamos por el nodo raíz, cuya dirección es la única conocida a
través del puntero externo. Pero por cual seguimos, por el hijo derecho o el
izquierdo?. Es por ello que existen fundamentalmente tres tipos de recorridos en
un Arbol Binario. Recorrido InOrden, PreOrden y PosOrden.

Página 76
El recorrido InOrden, muy utilizado en Arboles Binarios de Búsqueda,
consiste en recorrer todo el Subárbol Izquierdo para poder visitar la Raíz, y luego
recorrer todo el Subárbol Derecho. Dado que cada subárbol es de por sí un Arbol
Binario, se aplica el mismo procedimiento en forma recursiva.
En programación tradicional, el recorrido en InOrden para imprimir el
contenido de los nodos del árbol sería como sigue:
PROCEDURE InOrden (Arbol : Apuntador);
BEGIN
IF Arbol <> Nil
THEN BEGIN
InOrden(Arbol^.Izq); (*Recorre todo el Subarbol Izquierdo *)
WRITE(Arbol^.Info); (* Imprime el contenido Info de la raiz *)
InOrden(Arbol^.Der) (* Recorre todo el Subarbol Derecho *)
END
END
Como puede observar, en la operación anterior se hace referencia directa
a campos definidos dentro de la estructura, así como el tratar de visualizar la
información almacenada en los nodos. Si este tipo de recorrido va a ser utilizado
por el usuario de la implementación, como se aclaró para el caso de Lista, lo debe
hacer por medio de las operaciones de VisualizarIzq y VisualizarDer. Un ejemplo
de este uso por parte del diseñador de la aplicación, lo veremos en un
procedimiento que imprime el contenido de un Arbol Binario, en el primer ejemplo
de aplicación que se discutirá más adelante.

Página 77
Ahora bien, ustedes se preguntarán, por qué la operación de imprimir un
árbol, al igual que en las listas, debe ser escrita dentro de la aplicación, cuando
siempre se ha hablado de que es una de las operaciones básicas de las
estructuras Listas y Arboles?. Como siempre, la respuesta es que en la
implementación, la información almacenada en los nodos no tiene forma alguna,
recuerden que no son más que un conjuntos de Bytes.
Diferente es el caso de la utilización de recorridos en la implementación,
como observaremos en la operación de Liberar, que detallaremos en el nivel de
implementación.
Por supuesto, quien utilice Arboles Binarios como estructura de datos
abstracta, debe tener alguna forma de llegar a los elementos de la misma. Las
ventanas a la implementación de Arbol Binario y las de Arbol Binario de Búsqueda
se suministran mediante el paquete de operaciones.
Como podrán observar, existen diferentes operaciones de inserción e
eliminación de elementos que podemos implementar para un Arbol Binario,
debido a que el acceso a los elementos para el caso de Arbol Binario de
Búsqueda son diferentes, por estar restringidas por la regla antriormente
expuesta.
PPaaqquueettee AArrbbooll BBiinnaarriioo iinncclluuyyeennddoo eell ccaassoo ddee BBúússqquueeddaa
Los elementos de Información se insertan y eliminan
en cualquier lugar del Arbol Binario.
En caso de utilizar Arbol Binario de Búsqueda, el acce–
so a sus nodos debe seguir la siguiente regla: El valor
de la clave, la cual debe estar como primer campo del
registro, debe ser mayor que el valor de la clave de
cualquier elemento en su Subárbol Izquierdo, y menor
que el valor de la clave de cualquier elemento en su
Subárbol Derecho.

Página 78
Inicializar(Arbol)
Función : Inicializar el Arbol Binario en Vacío.
Entrada : Apuntador externo del árbol.
Salida : Arbol Inicializado.
Vacío(Arbol):BOOLEAN
Función : Chequear si el Arbol Binario está Vacío.
Entrada : Apuntador externo del árbol.
Salida : Boolean.
Lleno:BOOLEAN
Función : Chequear si hay disponibilidad de espacio en el Heap.
Entrada : Ninguna.
Salida : Boolean.
CrearArbol(Elemento, SIZEOF(Elemento)) : Apuntador
Función : Crear un nodo como raíz de un Arbol Binario, con la infor–
mación contenida en Elemento, donde su hijo derecho e
izquierdo están vacíos y retorna la dirección del nodo
raíz.
Entrada : Nuevo Elemento de Información y el tamaño(# de Bytes)
del elemento.
Salida : Arbol Binario creado con un elemento raíz y la dirección
del nodo raíz.

Página 79
InsHijoDer(Apuntador, Elemento, SIZEOF(Elemento))
Función : Insertar en el Arbol Binario un Nuevo Elemento de Infor–
mación como hijo derecho del elemento de referencia cu–
ya dirección está en Apuntador.
Entrada : Apuntador externo del árbol con la dirección del elemento
de referencia, Nuevo Elemento de Información, el tamaño
(# de Bytes) del elemento.
Salida : Arbol Actualizado, Elemento de Información Insertado
como Hijo Derecho del elemento de referencia.
InsHijoIzq(Apuntador, Elemento, SIZEOF(Elemento))
Función : Insertar en el Arbol Binario un Nuevo Elemento de Infor–
mación como hijo Izquierdo del elemento de referencia
cuya dirección está en Apuntador.
Entrada : Apuntador externo del árbol con la dirección del elemento
de referencia, Nuevo Elemento de Información, el tamaño
(# de Bytes) del elemento.
Salida : Arbol Actualizado, Elemento de Información Insertado
como Hijo Izquierdo del elemento de referencia.
Combinar(Arbol1,Arbol2 :Apuntador, Elemento, SIZEOF(Elemento))
: Apuntador
Función : Combinar el Arbol1 y el Arbol2 en un solo Arbol Binario,
creando un nodo raíz con la información contenida en
Elemento, donde sus hijos Izquierdo y Derecho apuntarían
a Arbol1 y Arbol2 respectivamente y retornando la di–
rección del nuevo nodo raíz en Apuntador .
Entrada : Apuntadores externos a los árboles binarios Arbol1 y
Arbol2, Nuevo Elemento de Información, el Tamaño( # de
Bytes) del elemento.
Salida : Nuevo Arbol Binario resultante de la combinación del
Arbol1 y Arbol2, cuyo nodo raíz contine la información
recibida en Elemento, la dirección del nuevo nodo raíz .
Buscar(Arbol,Elemento,SIZEOF(Elemento),Clave,SIZEOF(Clave),

Página 80
Boolean)
Función : Buscar en Arbol Binario de Búsqueda un nodo cuya clave
sea igual a Clave, retornando la información completa del
registro en caso de ser exitosa la búsqueda, así como un
indicador de éxito o no de la misma.
Entrada : Arbol como apuntador a la raíz del árbol, el tamaño(# de
Bytes) del registro completo, Clave, el Tamaño(# de By–
tes) de la clave.
Salida : Elemento conteniendo la información del registro con
clave igual a Clave, en caso de ser exitosa la búsqueda;
indicador del exito o no de la búsqueda de tipo Booleano.
Insertar(Arbol, Elemento, SIZEOF(Elemento),SIZEOF(Clave))
Función : Construir nodo conteniendo la información en Elemento e
insertarlo en el lugar correspondiente en el Arbol de Bús–
queda Binaria.
Entrada : Arbol como apuntador a la raíz del árbol, Nuevo Elemento
de Información, el Tamaño (# de Bytes) del elemento, el
tamaño (# de Bytes) de la Clave.
Salida : Arbol Actualizado, Elemento de Información Insertado
en el lugar correspondiente.
Eliminar(Arbol,Elemento,SIZEOF(Elemento),Clave,SIZEOF(Clave))
Función : Eliminar Elemento de Información de un Arbol Binario de
Búsqueda cuya clave sea igual a Clave.
Entrada : Apuntador externo al árbol con la dirección del nodo raíz,
el Tamaño (# de Bytes) del elemento, la Clave del ele–
mento a ser eliminado, el Tamaño(# de Bytes) de la clave.
Salida : Arbol actualizado, Elemento conteniendo la información
del elemento eliminado.
Visualizar(Apuntador, Elemento, SIZEOF(Elemento))

Página 81
Función : Mostrar el Elemento de Información que se encuentra en
la dirección indicada en el Apuntador.
Entrada : Apuntador que contiene la dirección del elemento a
mostrar, el Tamaño(# de Bytes) del campo de información
del elemento.
Salida : Información del Elemento.
VisualizarIzq(Apuntador, Elemento, SIZEOF(Elemento))
Función : Mostrar el Elemento de Información que se encuentra en
la dirección indicada en el Apuntador, retornando la di–
rección del elemento a su Izquierda.
Entrada : Apuntador que contiene la dirección del elemento a mos–
trar, el Tamaño(# de Bytes) del campo de información del
elemento.
Salida : Información del Elemento, Apuntador con la dirección del
elemento a su Izqierda.
VisualizarDer(Apuntador, Elemento, SIZEOF(Elemento))
Función : Mostrar el Elemento de Información que se encuentra en
la dirección indicada en el Apuntador, retornando la di–
rección del elemento a su Derecha.
Entrada : Apuntador que contiene la dirección del elemento a mos–
trar, el Tamaño(# de Bytes) del campo de información del
elemento.
Salida : Información del Elemento, Apuntador con la dirección del
elemento a su Derecha.
Liberar(Lista)
Función : Liberar todo el espacio correspondiente al Heap asignado
al Arbol Binario.

Página 82
Entrada : El apuntador externo al Arbol Binario.
Salida : Espacio ocupado por el árbol totalmente liberado, el a–
puntador externo al la Arbol en Nulo.
Estas operaciones en su mayoría son idénticas a aquellas que provee el
paquete de Lista Doblemente Encadenada, como son la de Inicializar, Vacío,
Lleno, Visualizar, VisualizarDer, VisualizarIzq. De hecho, estas operaciones
son heredadas del paquete de operaciones LisDobDi, la cual debe ser definida
en la cláusula de USES, dado que Arbol Binario se Implementará como un objeto
descendiente de Listas Doblemente Encadenadas.
A continuación nos dedicaremos a detallar solo aquellos métodos
específicos de Arbol Binario.
La operación CrearArbol, me permite crear un árbol con un solo nodo, el
de la raíz de la siguiente manera:
Arbol := CrearArbol(5,SIZEOF(5));
La operación InsHijoDer, la que permite la inserción de un nodo como hijo
derecho de un nodo en particular, puede ser invocada de la siguiente manera:
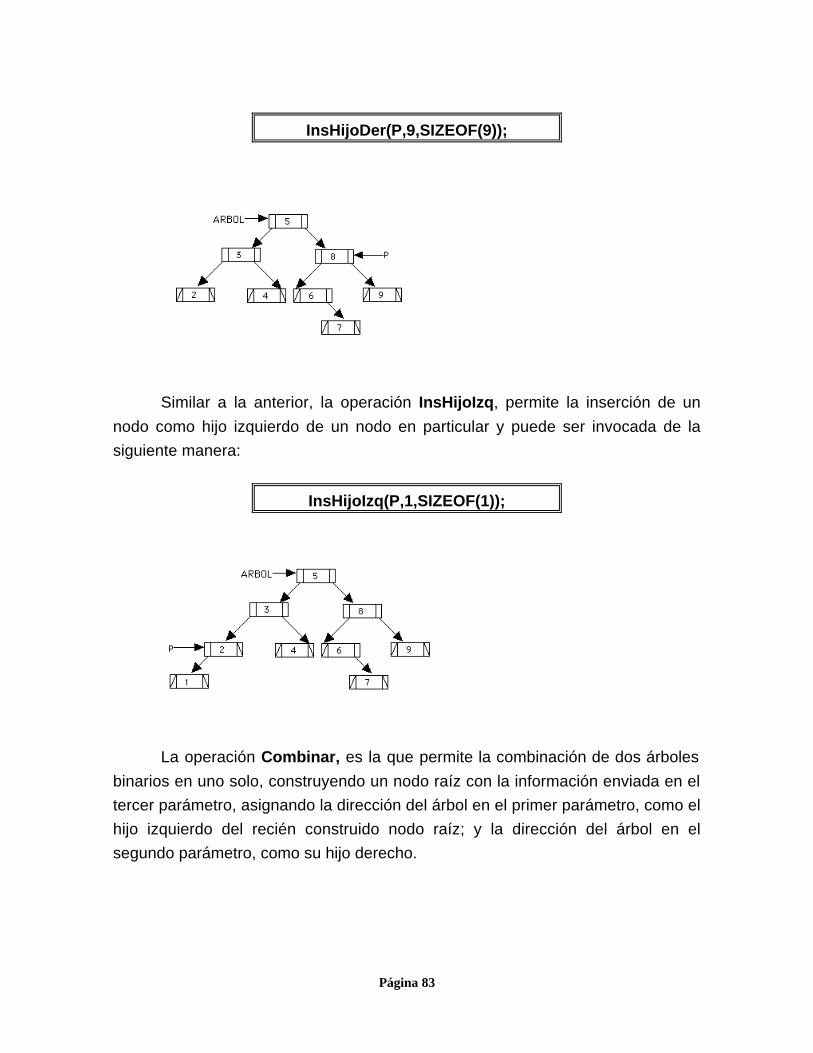
Página 83
InsHijoDer(P,9,SIZEOF(9));
Similar a la anterior, la operación InsHijoIzq, permite la inserción de un
nodo como hijo izquierdo de un nodo en particular y puede ser invocada de la
siguiente manera:
InsHijoIzq(P,1,SIZEOF(1));
La operación Combinar, es la que permite la combinación de dos árboles
binarios en uno solo, construyendo un nodo raíz con la información enviada en el
tercer parámetro, asignando la dirección del árbol en el primer parámetro, como el
hijo izquierdo del recién construido nodo raíz; y la dirección del árbol en el
segundo parámetro, como su hijo derecho.

Página 84
Arbol := Combinar(Arbol1,Arbol2,5,SIZEOF(5))

Página 85
Cómo recorrer el árbol para posicionarse sobre un nodo específico
distinto al nodo raíz?. El usuario de la implementación puede construir un
procedimiento de búsqueda distinto al especificado en el paquete de operaciones,
ya que el implementado solo permite búsqueda en Arboles Binarios de Búsqueda,
y puede relizarlo por medio de las operaciones VisualizarIzq o VisualizarDer, tal
como se hizo en los capítulos anteriores en el que se construyeron
procedimientos desde las aplicaciones que permitían imprimir o recorrer una Lista
Encadenada.
Las operaciones de Buscar, Insertar y Eliminar corresponden
especificamente a Arboles Binarios de Búsqueda.
La operacion de Búsqueda en un Arbol Binario de Búsqueda, consiste
en dada una Clave, recorrer el árbol hasta que en caso de conseguir algún
elemento en ella con clave igual a la buscada, retornando el contenido completo
del elemento, así como un indicador en el último parámetro con valor TRUE
señalando el éxito de la búsqueda. De lo contrario, el contenido del parámetro
que debería contener el registro, tendría un valor incierto; y el indicador en
FALSE, señalando que la búsqueda no fué exitosa.
La operación de Insertar un elemento en el Arbol Binario de Búsqueda,
contempla los casos de inserción del primer nodo, en caso de que el árbol se
encuentre vacío; así como la inserción del resto de los casos. Para ello,
inicialmente realiza una búsqueda en el árbol hasta que consiga un nodo hoja, a
partir del cual insertará el nuevo valor ya sea como hijo izquierdo o derecho
dependiendo del caso.
A continuación se describe graficamente la creación de un Arbol Binario de
Búsqueda en base a llamadas consecutivas al procedimiento de Insertar, dados
los siguientes valores:
40,60,50,33,55,11

Página 86
Arbol Vacío Insertar(Arbol,40,SIZEOF(40),SIZEOF(40))
Insertar(Arbol,60,SIZEOF(60),SIZEOF(60)) Insertar(Arbol,50,SIZEOF(50),SIZEOF(50))
Insertar(Arbol,33,SIZEOF(33),SIZEOF(33)) Insertar(Arbol,55,SIZEOF(55),SIZEOF(55))
Insertar(Arbol,11,SIZEOF(11),SIZEOF(11))
La operación de Eliminar contempla tres casos de eliminaciones, ya que el
nodo ha eliminar en el Arbol Binario de Búsqueda puede tener 0 hijos, es decir
es un nodo hoja; un hijo ya sea izquierdo o derecho; o el caso de tener dos hijos,
incluyendo el caso especial en donde el nodo a eliminar sea el de la raíz. Estos
tres casos se consideran por separado, ya que los cambios ha relizar son
sustancialmente distintos.
A continuación, podemos observar mediante un gráfico los tres casos de
eliminación.

Página 87
El Arbol Binario de Búsqueda antes de las eliminaciones
1-) Eliminación de un nodo hoja
Eliminar(Arbol,Elemento,SIZEOF(Elemento),'J',SIZEOF('J'))

Página 88
2-) Eliminación de un nodo con un hijo
Eliminar(Arbol,Elemento,SIZEOF(Elemento),'C',SIZEOF('C'))
3-) Eliminación de un nodo con dos hijos
Este es el único caso donde cambia el contenido del nodo a eliminar por el
valor inmediato menor que exista entre sus descendientes, de manera que el
árbol resultante después de la eliminación permanezca siendo Arbol Binario de
Búsqueda. La razón por la que se realiza cambio de contenido, es la de que sería
muy complicado el realizar los cambios por enlace.
La aplicación de esta regla se visualiza mejor en el siguiente ejemplo, en el
cual el nodo a eliminar corresponde al de la Raíz del Arbol, el cual tiene dos hijos.
En este caso, se posiciona sobre el hijo izquierdo luego se recorre tantos nodos a
la derecha mientras existan.
Eliminar(Arbol,Elemento,SIZEOF(Elemento),'L',SIZEOF('L'))
Otro ejemplo:

Página 89
Eliminar(Arbol,Elemento,SIZEOF(Elemento),'A',SIZEOF('A'))
Por último la operación de Liberar, consiste en liberar todos los nodos del
Arbol Binario, y le asigna valor Nulo al apuntador externo del mismo, indicando
que el árbol está en condición vacío.
- NIVEL DE IMPLEMENTACION Como se dijo anteriormente, la implementación de Listas Lineales
Doblemente Encadenada discutida en el capítulo anterior, va a ser utilizada como
representación interna de Arbol Binario.
En otras palabras, Arbol Binario incluyendo Arbol Binario de Búsqueda
serán declarados como objetos descendientes de Listas Lineales Doblemente
Encadenadas.
Arbol = OBJECT(Lista)
Arbol Binario hereda todas las características y los métodos definidos en
la implementación de su ascendiente, utilizando los métodos Vacío, Inicializar,
Lleno, Visualizar, VisualizarDer, VisualizarIzq. Solo el método Liberar va a ser
definido de nuevo como Virtual, como observaremos mas adelante.
Lo único que contiene la definición de Arbol Binario, son los encabezados
de los nuevos métodos. Los cuatro primeros y el último se requieren para

Página 90
manipular un Arbol Binario o un Arbol Binario de Búsqueda, y los cuatro
siguientes, son utilizados específicamente por Arbol Binario de Búsqueda.
Dado que para la estructura Arbol Binario de Búsqueda se requiere trabajar
con claves dentro de la implementación, se definió la longitud de la misma con la
misma cantidad de bytes que el campo de información, ya que como ocurre en
algunos casos, la información es de por sí un solo campo conviriéndose el mismo
en clave.
TYPE LongInfo = 0..MaxByte; LongClave = 0..MaxByte;
La operación CrearArbol, es una función que consiste en crear un nodo,
asignándolo como la raíz de un Arbol Binario con subárboles derecho e izquierdo
vacíos, retornando la dirección del nodo raíz.

Página 91
ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nuevo^.Info[I] := DirValor[I]; Nuevo^.Der := Nulo; Nuevo^.Izq := Nulo; CrearArbol := Nuevo
La operación InsHijoIzq, crea un nodo como raíz, y lo inserta como hijo
izquierdo del nodo cuya dirección se envía como referencia, recibiéndolo el
parámetro actual P.
Nuevo := CrearArbol(Valor,Longitud); P^.Izq := Nuevo
La operación InsHijoDer, es similar a la anterior, solo que el hijo se inserta
como hijo derecho del nodo P.
Nuevo := CrearArbol(Valor,Longitud); P^.Der := Nuevo
La operación Combinar, consiste en combinar dos árboles binarios Tree1
y Tree2 en uno, creando un nodo raíz con la información enviada y asignándoles
como hijo izquierdo la dirección del árbol Tree1 y como hijo derecho la dirección
del árbol Tree2.
Nuevo := CrearArbol(Valor,Longitud); Nuevo^.Izq := Tree1; Nuevo^.Der := Tree2;

Página 92
La operación Buscar, consta de dos pasos. El primer paso consiste en
encontrar el nodo que contenga la clave deseada dentro del árbol. En la
implementación este proceso primero requiere como parámetro de entrada la
Clave (sin tipo), la cual se direcciona a través de la variable DirClave así como
su longitud LonClave, similar a como se ha manejado la información hasta el
momento dentro de la implementación.
PROCEDURE Arbol.Buscar(Arbol : Apuntador; VAR Valor; Longitud : WORD; VAR Clave; LonClave : WORD; VAR Exitosa : BOOLEAN); VAR DirClave : ARRAY[LongClave] OF BYTE ABSOLUTE Clave;
Las comparaciones se realizarán byte por byte de la clave en DirClave, con
respecto al contenido de las primeras posiciones de la información del nodo
dentro del árbol.
I := 0; WHILE (I <= LonClave-1) AND (DirClave[I] = Ptr^.Info[I]) DO I := I + 1;
Es bueno mantener siempre en mente, que una de las pocas limitaciones de esta
implementación es la siguiente:
Toda Clave debe encontrarse como primer campo en la esructura de la
información del nodo.
El proceso de búsqueda se realizará mientras la Clave no sea encontrada
o mientras exista nodos por comparar en el ramal determinado. Al comienzo Ptr
se hará igual a la dirección de la raíz del árbol. Se comienza por comparar la
Clave con el valor clave contenido en el nodo apuntado por Ptr. Si al comparar
todos los bytes (LonClave) resultan ser iguales, lo cual se determina comparando
I > LonClave-1, se dice que la clave fué encontrada, y se para el proceso de
búsqueda asignando el valor TRUE a la variable booleana Exitosa.
Ptr := Arbol; WHILE (Ptr <> Nulo) AND (NOT Exitosa) DO BEGIN

Página 93
I := 0; WHILE (I <= LonClave-1) AND (DirClave[I] = Ptr^.Info[I]) DO I := I + 1; IF I > LonClave-1 THEN Exitosa := TRUE
En caso contrario, el proceso de comparación de bytes se suspende en el
momento en que alguno de los bytes sean desiguales. Entonces la búsqueda
debe continuar, obteniendo el siguiente nodo dentro del árbol, mediante la
aplicación de la regla por la cual fué construido: Si la clave buscada es menor que
la contenida en el nodo, moverse al Hijo Izquierdo; de lo contrario, moverse al Hijo
Derecho.
ELSE IF Ptr^.Info[I] > DirClave[I] THEN Ptr := Ptr^.Izq ELSE Ptr := Ptr^.Izq
El último paso de este proceso consiste que en caso de que la búsqueda
sea exitosa, devolver la información completa contenida en el nodo.
IF Exitosa THEN FOR I := 0 to Longitud-1 DO DirValor[I] := Ptr^.Info[I] END;
Dado de que existe una regla para la construcción del Arbol Binario de
Búsqueda, se justifica la implementación de nuevas operaciones para la inserción
o eliminación de nodos desde el mismo; las cuales, como vimos anteriormente,
requieren sean contemplado múltiples casos.

Página 94
La operación Insertar consta de dos pasos. El primero consiste en
conseguir el lugar adecuado de la inserción del nuevo nodo, proceso que es muy
similar al de la operación Buscar previamente discutida. En este caso fué
necesario casi reescribir el proceso, ya que se requiere mantener la dirección del
padre (Anterior) al nodo siendo estudiado, como se puede observar en los
gráficos correspondientes a esta operación en el nivel de Abstracción. Ptr := Arbol; Anterior := Nulo; WHILE Ptr <> Nulo DO BEGIN Anterior := Ptr; I := 0; WHILE (I <= LonClave-1) AND (DirValor[I] = Ptr^.Info[I]) DO I := I + 1; IF DirValor[I] < Ptr^.Info[I] THEN Ptr := Ptr^.Izq ELSE Ptr := Ptr^.Der END;
El segundo paso consiste en crear el nodo con la información completa e
insertarlo dependiendo del caso. Si Anterior es igual a Nulo, significa que el Arbol
está vacío, por lo que se debe llamar a la operación CrearArbol. En caso
contrario y dependiendo como es la nueva clave respecto a la clave contenida en
el nodo que pasa a ser su nodo padre (Anterior^), se invocarán las operaciones
InsHijoIzq o InsHijoDer respectivamente.
IF Anterior = Nulo THEN Arbol := CrearArbol(Valor,Longitud) ELSE IF Anterior^.Info[I] > DirValor[I] THEN InsHijoIzq(Anterior,Valor,Longitud) ELSE InsHijoDer(Anterior,Valor,Longitud) END;
Similar a la operación de Insertar, la operación de Eliminar un nodo desde
un Arbol de Búsqueda Binaria consiste en dos pasos. El primero requiere de
encontrar el nodo contentivo de la Clave, y el segundo consiste en eliminarlo para
luego retornar la información completa del nodo. Dada la complejidad de esta

Página 95
operación, el segundo paso es implementado en un método llamado ElimNodo, el
cual no fué descrito en el paquete de operaciones, ya que el usuario de la
implementación no debe invocarla.
Como se dijo en el nivel de abstracción, al eliminar un nodo en un Arbol
Binario de Búsqueda pueden suceder tres casos, dependiendo del número de
hijos que posea el nodo a ser eliminado. Estos casos serán contemplados en la
operación ElimNodo.
El proceso de búsqueda en esta operación es similar al de Insertar, solo
que acá debe existir la clave en alguno de los nodos del Arbol. Para asegurarse,
siempre se debe invocar a la operación de Buscar antes de realizar una
eliminación de un nodo.
Ptr := Arbol; Anterior := Nulo; I := 0; WHILE (I <= LonClave-1) AND (DirClave[I] = Ptr^.Info[I]) DO I := I + 1; WHILE I <= LonClave-1 DO BEGIN Anterior := Ptr; IF Ptr^.Info[I] > DirClave[I] THEN Ptr := Ptr^.Izq ELSE Ptr := Ptr^.Der; I := 0; WHILE (I <= LonClave-1) AND (DirClave[I] = Ptr^.Info[I]) DO I := I + 1; END;
Observe que el proceso de búsqueda se suspende en el momento que I >
LonClave-1, momeno en que Ptr queda apuntando al elemento a eliminar y
Anterior a su nodo Padre. Luego se guarda en DirValor la información completa
del nodo siendo apuntado por Ptr, y se invoca a la operación ElimNodo, ya sea

Página 96
para eliminar el nodo Raiz (Arbol), o el hijo izquierdo o derecho de Anterior
respectivamente.
FOR I := 0 To Longitud-1 DO DirValor[I] := Ptr^.Info[I]; IF Ptr = Arbol THEN ElimNodo(Arbol) ELSE IF Anterior^.Izq = Ptr THEN ElimNodo(Anterior^.Izq) ElSE ElimNodo(Anterior^.Der) END;
Es importante hacer notar que dado que la operación ElimNodo, es
invocada enviándosele la dirección del nodo a eliminar, pero referenciando esa
dirección desde el padre como en el caso de Anterior^.Izq, lo cual permite que al
regresar al procedimiento de eliminar, automáticamente se modifique dicha
dirección sin tener que volver a chequear la dirección del padre; ya que sería
imposible hacerlo, pues el elemento para ese momento ya ha sido eliminado.
Los tres casos de eliminación bien diferenciados en el nivel de abstracción,
van a ser contemplados en la operación en la siguiente secuencia:
- Eliminar Nodo con un hijo: Consistiría en devolver la dirección de
su hijo izquierdo o derecho dependiendo del caso, el cual será en lo
adelante direccionado por el que anteriormente era su abuelo.
IF Ptr^.Der = Nulo
THEN Ptr := Ptr^.Izq ELSE IF Ptr^.Izq = Nulo
THEN Ptr := Ptr^.Der
- Eliminar Nodo Hoja: Sería contemplado en la primera de las pre–
guntas del caso anterior, ya que como el único cambio a realizar es
retornar Nulo al Nodo padre, esto es llevado a cabo en el momento que
trata de direccionar al hijo izquierdo que no posee, por lo que Ptr se le
asigna el valor Nulo.

Página 97
- Eliminar Nodo con dos Hijos: Ptr se mantiene apuntando al nodo
que supuestamente se va a eliminar, ya que para este caso realmente se
modificaría su valor por aquel descendiente más a la derecha de su hijo
izquierdo,ya que el contendrá la información inmediata menor de la que
contiene el nodo apuntado por Ptr. Para ello se utilizarán dos apuntadores
auxiliares Temp y Anterior, los cuales permitirán buscar el valor de
reemplazamiento y como apuntador local al padre del nodo apuntado por
Temp, respectivamente.
ELSE BEGIN Temp := Ptr^.Izq; Anterior := Ptr; WHILE Temp^.Der <> Nulo DO BEGIN Anterior := Temp; Temp := Temp^.Der END;
Cuando el nodo (el apuntado por Temp) que contiene el valor de
reemplazamieno es encontrado, su campo Info se copiará en el Nodo
apuntado por Ptr; luego se actualiza el apuntador local Anterior, ya que el
representa el padre del nodo que permitió el reemplazamiento, por el hijo
Izquierdo de Temp si existiese.
Ptr^.Info := Temp^.Info; IF Anterior = Ptr THEN Anterior^.Izq := Temp^.Izq ELSE Anterior^.Der := Temp^.Izq
Por último, y para cualquiera de los casos se invocaría a DevolverNodo
( recuerden que este método es heredado desde la implementación
LisDobDi) para liberar el nodo apuntado por Temp, quedando la opera–
ción ElimNodo de la siguiente manera:
Temp := Ptr; IF Ptr^.Der = Nulo THEN Ptr := Ptr^.Izq ELSE IF Ptr^.Izq = Nulo

Página 98
THEN Ptr := Ptr^.Der ELSE BEGIN Temp := Ptr^.Izq; Anterior := Ptr; WHILE Temp^.Der <> Nulo DO BEGIN Anterior := Temp; Temp := Temp^.Der END; Ptr^.Info := Temp^.Info; IF Anterior = Ptr THEN Anterior^.Izq := Temp^.Izq ELSE Anterior^.Der := Temp^.Izq END; DevolverNodo(Temp) END;
Por último la operación Liberar consiste en recorrer el árbol e ir liberando
el espacio de cada nodo. Por ello utilizaremos el recorrido InOrden discutido
anteriormente, liberando en ese orden los espacios ocupados por cada nodo del
Arbol. Ya que al invocar esta operación se hace a través del apuntador externo
del árbol, y que el parámetro que recibe dicha dirección no es de tipo VAR,
posteriormente debe inicializarse el apuntador externo, mediante la invocación a
la operación de Inicializar, la cual es heredada de la implementación de Lista.

Página 99
IF Tree <> Nulo THEN BEGIN Liberar(Tree^.Izq); DevolverNodo(Tree); Liberar(Tree^.Der)
END
A continuación se presenta la codificación completa de la unidad
correspondiente a la implementación de esta estructura.
UNIT ArbolBin; INTERFACE USES LisDobDi; CONST MaxByte = 290; (* Maximo Numero de Bytes De Informacion *) Nulo = Nil; TYPE LongInfo = 0..MaxByte; LongClave = 0..MaxByte; (***************************************************) (* DEFINICION DEL OBJETO A R B O L B I N A R I O *) (***************************************************) Arbol = OBJECT(Lista) FUNCTION CrearArbol(VAR Valor; Longitud : WORD) : Apuntador; PROCEDURE InsHijoDer(P : Apuntador; VAR Valor; Longitud : WORD); PROCEDURE InsHijoIzq(P : Apuntador; VAR Valor; Longitud : WORD); FUNCTION Combinar(Tree1, Tree2 : Apuntador; VAR Valor; Longitud : WORD) : Apuntador; PROCEDURE Buscar(Arbol : Apuntador; VAR Valor; Longitud : WORD; VAR Clave; LonClave:WORD; VAR Exitosa:BOOLEAN); PROCEDURE Insertar(VAR Arbol : Apuntador; VAR Valor; Longitud:WORD; LonClave:WORD); PROCEDURE ElimNodo(VAR Ptr : Apuntador); PROCEDURE Eliminar(VAR Arbol : Apuntador; VAR Valor; Longitud : WORD; VAR Clave; LonClave : WORD);

Página 100
DESTRUCTOR Liberar(VAR Tree : Apuntador); VIRTUAL; END; (***************************************************) (* I M P L E M E N T A C I O N D E L O S M E T O D O S *) (***************************************************) IMPLEMENTATION FUNCTION Arbol.CrearArbol(VAR Valor; Longitud : WORD):Apuntador; VAR I : WORD; Nuevo : Apuntador; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; BEGIN ObtenerNodo(Nuevo); FOR I := 0 TO Longitud-1 DO Nuevo^.Info[I] := DirValor[I]; Nuevo^.Der := Nulo; Nuevo^.Izq := Nulo; CrearArbol := Nuevo END; PROCEDURE Arbol.InsHijoDer(P : Apuntador; VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador; BEGIN IF P <> Nulo THEN BEGIN Nuevo := CrearArbol(Valor,Longitud); P^.Der := Nuevo END ELSE WRITELN('NODO DE REFERENCIA NO EXISTE') END; PROCEDURE Arbol.InsHijoIzq(P : Apuntador; VAR Valor; Longitud : WORD); VAR Nuevo : Apuntador;

Página 101
BEGIN IF P <> Nulo THEN BEGIN Nuevo := CrearArbol(Valor,Longitud); P^.Izq := Nuevo END ELSE WRITELN('NODO DE REFERENCIA NO EXISTE') END; FUNCTION Arbol.Combinar(Tree1,Tree2 : Apuntador; VAR Valor; Longitud : WORD) : Apuntador; VAR Nuevo : Apuntador; BEGIN Nuevo := CrearArbol(Valor,Longitud); Nuevo^.Izq := Tree1; Nuevo^.Der := Tree2; Combinar := Nuevo END; PROCEDURE Arbol.Buscar(Arbol : Apuntador; VAR Valor; Longitud : WORD; VAR Clave; LonClave : WORD; VAR Exitosa : BOOLEAN); VAR Ptr : Apuntador; I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; DirClave : ARRAY[LongClave] OF BYTE ABSOLUTE Clave; BEGIN Ptr := Arbol; Exitosa := FALSE; WHILE (Ptr <> Nulo) AND (NOT Exitosa) DO BEGIN I := 0; WHILE (I <= LonClave-1) AND (DirClave[I] = Ptr^.Info[I]) DO I := I + 1; IF I > LonClave-1 THEN Exitosa := TRUE ELSE IF Ptr^.Info[I] > DirClave[I] THEN Ptr := Ptr^.Izq ELSE Ptr := Ptr^.Der END; IF Exitosa

Página 102
THEN FOR I := 0 to Longitud-1 DO DirValor[I] := Ptr^.Info[I] END; PROCEDURE Arbol.Insertar(VAR Arbol : Apuntador; VAR Valor; Longitud : WORD; LonClave : WORD); VAR Nuevo : Apuntador; I : WORD; DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; Ptr : Apuntador; Anterior : Apuntador; BEGIN Ptr := Arbol; Anterior := Nulo; WHILE Ptr <> Nulo DO BEGIN Anterior := Ptr; I := 0; WHILE (I <= LonClave-1) AND (DirValor[I] = Ptr^.Info[I]) DO I := I + 1; IF DirValor[I] < Ptr^.Info[I] THEN Ptr := Ptr^.Izq ELSE Ptr := Ptr^.Der END; IF Anterior = Nulo THEN Arbol := CrearArbol(Valor,Longitud) ELSE IF Anterior^.Info[I] > DirValor[I] THEN InsHijoIzq(Anterior,Valor,Longitud) ELSE InsHijoDer(Anterior,Valor,Longitud) END; PROCEDURE Arbol.ElimNodo(VAR Ptr : Apuntador); VAR Anterior,Temp : Apuntador;

Página 103
BEGIN Temp := Ptr; IF Ptr^.Der = Nulo THEN Ptr := Ptr^.Izq ELSE IF Ptr^.Izq = Nulo THEN Ptr := Ptr^.Der ELSE BEGIN Temp := Ptr^.Izq; Anterior := Ptr; WHILE Temp^.Der <> Nulo DO BEGIN Anterior := Temp; Temp := Temp^.Der END; Ptr^.Info := Temp^.Info; IF Anterior = Ptr THEN Anterior^.Izq := Temp^.Izq ELSE Anterior^.Der := Temp^.Izq END; DevolverNodo(Temp) END; PROCEDURE Arbol.Eliminar(VAR Arbol : Apuntador; VAR Valor; Longitud : WORD; VAR Clave; LonClave : WORD); VAR DirValor : ARRAY[LongInfo] OF BYTE ABSOLUTE Valor; DirClave : ARRAY[LongClave] OF BYTE ABSOLUTE Clave; I : WORD; Ptr : Apuntador; Anterior : Apuntador; BEGIN Ptr := Arbol; Anterior := Nulo; I := 0; WHILE (I <= LonClave-1) AND (DirClave[I] = Ptr^.Info[I]) DO I := I + 1;

Página 104
WHILE I <= LonClave-1 DO BEGIN Anterior := Ptr; IF Ptr^.Info[I] > DirClave[I] THEN Ptr := Ptr^.Izq ELSE Ptr := Ptr^.Der; I := 0; WHILE (I <= LonClave-1) AND (DirClave[I] = Ptr^.Info[I]) DO I := I + 1; END; FOR I := 0 To Longitud-1 DO DirValor[I] := Ptr^.Info[I]; IF Ptr = Arbol THEN ElimNodo(Arbol) ELSE IF Anterior^.Izq = Ptr THEN ElimNodo(Anterior^.Izq) ElSE ElimNodo(Anterior^.Der) END; DESTRUCTOR Arbol.Liberar(VAR Tree : Apuntador); BEGIN IF Tree <> Nulo THEN BEGIN Liberar(Tree^.Izq); DevolverNodo(Tree); Liberar(Tree^.Der) END END; END.

Página 105
- NIVEL DE APLICACION Dado que en este capítulo se han implementado, podríamos decir, dos
estructuras de datos independientes en una sola unidad, por razones que ya
discutimos anteriormente, analizaremos dos aplicaciones, una para cada
estructura. La primera en presentar utilizará la implementación de Arbol Binario,
ya que consistirá en representar una expresión arimética en el mismo. La otra,
utilizará la implementación de Arbol Binario de Búsqueda para mantener palabras
que deben ser constantemente observadas para la obtención de un índice
correspondiente a un texto de un libro. _ Representación de una Expresión Aritmética en un Arbol Binario
Es muy común asociar Expresión Arimética con Arbol Binario, en el sentido
de que en una operación aritmética binaria existe un operador y dos operandos.
La relación puede plantearse así: el nodo raíz contiene el operador y los hijos
izquierdo y derecho del nodo raíz contienen los operandos izquierdo y derecho de
la expresión respectivamente.
A continuación observamos 2 ejemplos sencillos de operaciones
aritméticas y su represenación en un Arbol Binario.
5 - 3 7 * 9
Ahora el problema se presenta en como representar los paréntesis?. La
respuesta es que ellos no son partes del arbol, ya que una vez construido el Arbol
Binario con la expresión, los niveles de los nodos en los que se encuentran
representadas las operaciones elementales, dictaminarán el orden de
precedencia en que deben ser consideradas. Por lo tanto esto me revela el
hecho de que para la construcción del arbol, es más sencillo si observamos la
expresión en forma Posfix.

Página 106
En la mayoría de los textos de Estructura de Datos, contienen
fundamentalmene el mismo procedimiento, para la evaluación de las expresiones
aritméticas, teniendo como entrada una variable de tipo String, conteniendo la
expresión arimética en forma Posfix.
En escencia, este mismo procedimiento será utilizado para la construcción
del Arbol Binario que represente la expresión arimética obtenida en forma Posfix.
Para ello, requerirá un Stack o Pila cuyo contenido sea direcciones absolutas de
memoria. Pero no se preocupe, el hecho de utilizar Programación Orientada a
Objetos y la de almacenar la información en bytes, nos brinda esa posibilidad de
no preocuparnos por detalles pequeños. Inclusive, dentro del programa se
requerirá de otro Stack, para la conversión de la expresión a Posfix (ver
aplicación del capítulo de Pila), con contenido totalmente diferente ( solo
caracteres). De haber usado la forma tradicional de programar las
implementaciones de estructuras, tendría que haber codificado
implementaciones por separada para cada uno de los dos Stack.
La regla a seguir consiste en que si el caracter es un operando, la acción a
tomar debe ser la de construir un nodo por separado, tal como un nodo raíz con
contenido igual al operando, guardando en el Stack la dirección del nodo recién
construido. En caso de ser un operador, la acción a tomar debe ser la de eliminar
los dos elementos al tope del Stack, los cuales corresponderán a las direcciones
de los nodos conteniendo los operandos de la operación. Luego se llama a la
operación Combinar, de manera de crear un nodo con el operador, y tomar como
hijos izquierdo y derecho a los nodos conteniendo los operandos, en el orden
siguiente: el primero que se obtenga del Stack, corresponderá al operando de la
derecha; y el segundo, al operando de la izquierda.
Para hacer la explicación más sencilla, utilizaremos un ejemplo, el cual lo
desarrollaremos paso a paso, tal como lo hará el procedimiento que construirá el
Arbol Binario.
Dada la expresión ' ( A + ( B - C ) ) * D ' , el primer paso consiste en
convertir la expresión en la forma Posfix. Este paso fué discutido en el capítulo
correspondiente al de Pila, y el procedimiento que realiza la conversión será el

Página 107
mismo utilizado en la aplicación discutida en ese capítulo, por lo que no
entraremos en detalle de la misma.
Una vez que se tenga la expresión en Posfix validada ' A B C - + D * ',
recorreremos la expresión caracter por caracter, aplicando las acciones descrita
anteriormente.
Caracter Oper1 Oper2 Operación Invocada y resultados Stack
Arbol.Incializar(Tree); Tree := Nulo
Stack.Inicializar;
'A' DirA := Arbol.CrearArbol('A',SIZEOF('A'));
'B' DirB := Arbol.CrearArbol('B',SIZEOF('B'));
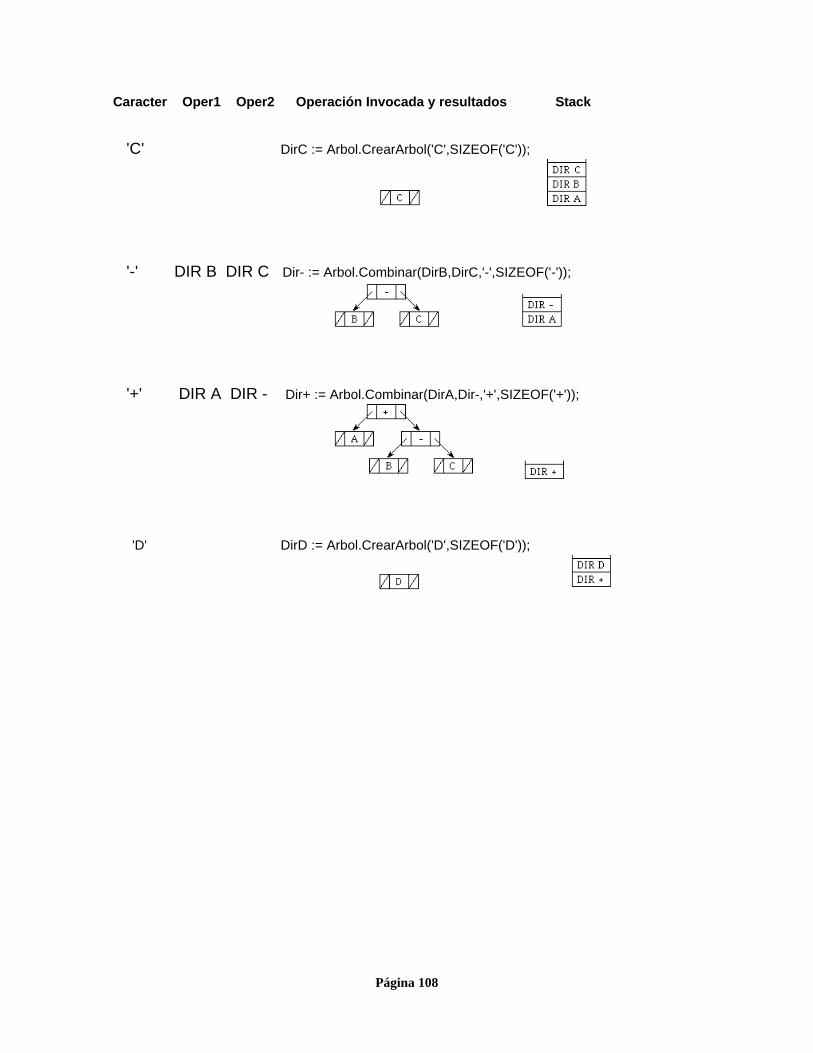
Página 108
Caracter Oper1 Oper2 Operación Invocada y resultados Stack
'C' DirC := Arbol.CrearArbol('C',SIZEOF('C'));
'-' DIR B DIR C Dir- := Arbol.Combinar(DirB,DirC,'-',SIZEOF('-'));
'+' DIR A DIR - Dir+ := Arbol.Combinar(DirA,Dir-,'+',SIZEOF('+'));
'D' DirD := Arbol.CrearArbol('D',SIZEOF('D'));

Página 109
Caracter Oper1 Oper2 Operación Invocada y resultados Stack
'*' DIR + DIR D Dir* := Arbol.Combinar(Dir+,DirD,'*',SIZEOF('*'));
Como pueden observar, en el caso de un operando solo se tiene que
invocar a la operación de Arbol Binario CrearArbol, y Meter en el Stack la
dirección retornante.
IF NOT Operador(Simbolo) THEN BEGIN Tree := ArbolExpre.CrearArbol(Simbolo,SIZEOF(Simbolo)); PilaApunta.Meter(Tree,SIZEOF(Tree)); END
En caso contrario, Sacar la dirección del Operando de la Derecha desde el
Stack, e inmediatamente Sacar la siguiente dirección correspondiente al
Operando de la Izquierda. Posteriormente se invoca a la operación de Arbol
Binario Combinar, enviándole las direcciones recién obtenidas del Stack y el
operador, que le corresponde como valor al nodo Raíz, resultante de la
combinación. Luego, la dirección que retorna la operación combinar
correspondiente al nuevo nodo raíz, debe Meterse en el Stack. ELSE BEGIN PilaApunta.Sacar(Opnd2,SIZEOF(Opnd2)); PilaApunta.Sacar(Opnd1,SIZEOF(Opnd1)); Tree := ArbolExpre.Combinar(Opnd1,Opnd2,Simbolo, SIZEOF(Simbolo)); PilaApunta.Meter(Tree,SIZEOF(Tree)); END;
Una vez que no existan más caracteres del String por considerar, se Saca
del Stack el único elemento que debe contener para ese momento
correspondiente a la raíz del Arbol resultante.

Página 110
PilaApunta.Sacar(Tree,SIZEOF(Tree));
Todo este proceso se realiza en un procedimiento llamado ArbExpArit, al
cual solo se le envía como parámetro de entrada, la expresión en forma Posfix,
retornando la dirección del nodo raíz del Arbol Binario.
ArbolExpre.Inicializar(Tree); (* Metodo heredado desde LisDobDi *) Tree := ArbExpArit(Posfix);
Posterior a la llamada de este procedimiento, se invoca a un procedimiento
llamado InOrden, el cual permite imprimir el contenido del Arbol en forma
InOrden.
PROCEDURE InOrden(Tree : Apuntador); VAR Simbolo : CHAR; P : Apuntador; BEGIN IF Tree <> Nulo THEN BEGIN P := Tree; ArbolExpre.VisualizarIzq(P,Simbolo,SIZEOF(Simbolo)); (* Metodo heredado desde LisDobDi *) InOrden(P); WRITELN(Simbolo); ArbolExpre.VisualizarDer(Tree,Simbolo,SIZEOF(Simbolo)); (* Metodo heredado desde LisDobDi *) InOrden(Tree) END END;
Por último, se invoca a los métodos de Liberar e Inicializar el Arbol.
Estas dos últimas invocaciones se hicieron a manera ilustrativa y para hacer
énfasis, en que posterior a la operación de liberar Arbol, debe siempre
Inicializarse el Arbol para garantizar la asignación del valor Nulo a su apuntador
externo.

Página 111
A continuación se presenta el programa completo, el cual define en la parte
USES el uso de las unidades Stack, LisDobDi y ArbolBin. Es necesario definir
la unidad LisDobDi, aún cuando ella es definida en ArbolBin, por descendencia.
De lo contrario daría error.
PROGRAM ExpreArb; (* Invocacion a las unidades que contienen lasimplementacio- *) (* nes de Pila, Listas Doblemente Encadenadas y Arbol Binario *) USES Stack,LisDobDi,ArbolBin; CONST Max = 30; TYPE Cad30 = String[30]; C30 = ARRAY[1..Max] OF CHAR; VAR (* Declaracion de la Pila de Operadores *) ArbolExpre : Arbol; Simbolo : CHAR; Infix : Cad30; Posfix : C30; PosIn : WORD; PosOut : WORD; Tree : Apuntador; FUNCTION Operador(Caracter : CHAR) : BOOLEAN; BEGIN Operador := Caracter IN ['+','-','*','/','$','(',')'] END; FUNCTION Prioridad(Caracter,Proximo : CHAR) : BOOLEAN; VAR Prio : BOOLEAN; PrioPro : WORD; PrioCar : WORD; BEGIN IF Proximo = '(' THEN Prio := FALSE ELSE IF Caracter = '(' THEN Prio := FALSE

Página 112
ELSE IF Proximo = ')' THEN IF Caracter = '(' THEN Prio := FALSE ELSE Prio := TRUE ElSE BEGIN IF Caracter IN ['+','-'] THEN PrioCar := 1 ELSE IF Caracter IN ['*','/'] THEN PrioCar := 2 ELSE PrioCar := 3; IF Proximo IN ['+','-'] THEN PrioPro := 1 ELSE IF Proximo IN ['*','/'] THEN PrioPro := 2 ELSE PrioPro := 3; IF PrioPro > PrioCar THEN Prio := FALSE ELSE IF PrioPro < PrioCar THEN Prio := TRUE ELSE IF Proximo = '$' THEN Prio := FALSE ELSE Prio := TRUE; END; Prioridad := Prio END; (*********************************************) (* Proceso de Conversion del Infix al Posfix *) (*********************************************) PROCEDURE Convertir(Infix : Cad30; VAR Posfix : C30); VAR PosIn,PosOut : WORD; Proximo,Caracter : CHAR; Continuar : BOOLEAN; PilaOpera : Pila;

Página 113
BEGIN PilaOpera.Inicializar; PosIn := 1; PosOut := 0; Proximo := Infix[PosIn]; (* Obtiene el primer caracter del Infix *) WHILE Proximo <> ' ' DO BEGIN IF NOT Operador(Proximo) (* Chequea si el caracter no es operador *) THEN BEGIN PosOut := PosOut + 1; PosFix[PosOut] := Proximo (* Insercion del caracter en el Posfix*) END ELSE BEGIN (* Chequeo en caso del caracter sea un operador *) Continuar := TRUE; IF NOT PilaOpera.Vacio THEN BEGIN PilaOpera.Sacar(Caracter,SIZEOF(Caracter)); (* Proceso que Saca de la Pila y coloca en el Posfix *) (* todos los caracteres que sean de menor prioridad *) (* que el Proximo *) WHILE Prioridad(Caracter,Proximo) AND Continuar DO BEGIN PosOut := PosOut + 1; PosFix[PosOut] := Caracter; IF NOT PilaOpera.Vacio THEN PilaOpera.Sacar(Caracter,SIZEOF(Caracter)) ELSE Continuar := FALSE END; IF NOT Continuar (* Coloca el Proximo en la Pila *) THEN PilaOpera.Meter(Proximo,SIZEOF(Proximo)) ELSE IF Proximo <> ')' THEN BEGIN (* Devolver el caracter a la Pila y meter el Proximo *) PilaOpera.Meter(Caracter,SIZEOF(Caracter)); PilaOpera.Meter(Proximo,SIZEOF(Proximo)) END END (* Pila vacia *) ELSE PilaOpera.Meter(Proximo,SIZEOF(Proximo)) END;

Página 114
IF PosIn < Length(Infix)(* Proceso de Busqueda del Proximo *) (* caracter *) THEN BEGIN PosIn := PosIn + 1; Proximo := Infix[PosIn] END ELSE Proximo := ' ' END; WHILE NOT PilaOpera.Vacio DO (* Guarda en Posfix Operadores *) (* restantes en la Pila *) BEGIN PilaOpera.Sacar(Caracter,SIZEOF(Caracter)); PosOut := PosOut + 1; PosFix[PosOut] := Caracter END; WHILE PosOut <= Max DO BEGIN PosOut := PosOut + 1; Posfix[PosOut] := ' ' END END; (**************************************************) (* Proceso de creacion del arbol desde el Posfix *) (**************************************************) FUNCTION ArbExpArit(Posfix : C30) : Apuntador; VAR PilaApunta : Pila; Opnd1 : Apuntador; Simbolo : CHAR; Opnd2 : Apuntador; PosOut : WORD; Tree : Apuntador;

Página 115
BEGIN PilaApunta.Inicializar; PosOut := 1; Simbolo := Posfix[PosOut]; WHILE Simbolo <> ' ' DO BEGIN IF NOT Operador(Simbolo) THEN BEGIN Tree := ArbolExpre.CrearArbol(Simbolo,SIZEOF(Simbolo)); PilaApunta.Meter(Tree,SIZEOF(Tree)); END ELSE BEGIN PilaApunta.Sacar(Opnd2,SIZEOF(Opnd2)); PilaApunta.Sacar(Opnd1,SIZEOF(Opnd1)); Tree := ArbolExpre.Combinar(Opnd1,Opnd2,Simbolo, SIZEOF(Simbolo)); PilaApunta.Meter(Tree,SIZEOF(Tree)); END; IF PosOut < LENGTH(Posfix) THEN BEGIN PosOut := PosOut + 1; Simbolo := Posfix[PosOut] END ELSE Simbolo := ' ' END; PilaApunta.Sacar(Tree,SIZEOF(Tree)); ArbExpArit := Tree END; (*************************************************) (* Proceso que recorre el arbol en forma InOrden *) (* imprimiendo c/nodo *) (*************************************************) PROCEDURE InOrden(Tree : Apuntador); VAR Simbolo : CHAR; P : Apuntador; BEGIN IF Tree <> Nulo THEN BEGIN

Página 116
P := Tree; ArbolExpre.VisualizarIzq(P,Simbolo,SIZEOF(Simbolo)); (* Metodo heredado desde LisDobDi *) InOrden(P); WRITELN(Simbolo); ArbolExpre.VisualizarDer(Tree,Simbolo,SIZEOF(Simbolo)); (* Metodo heredado desde LisDobDi *) InOrden(Tree) END END; (*********************************************) (* Programa Principal *) (*********************************************) BEGIN Infix := ''; WRITE('** Introducir la expresion en Infix : '); Readln(Infix); Convertir(Infix,Posfix); WRITE('** La Expresion en Posfix es : '); PosOut := 1; WHILE PosFix[PosOut] <> ' ' DO BEGIN WRITE(Posfix[PosOut]); PosOut := PosOut + 1; END; WRITELN; ArbolExpre.Inicializar(Tree); (* Metodo heredado desde LisDobDi *) Tree := ArbExpArit(Posfix); InOrden(Tree); WRITELN; ArbolExpre.Liberar(Tree);(* Invoca el metodo implementado en arbol *) ArbolExpre.Inicializar(Tree); (* Metodo heredado desde LisDobDi *)
END.
- Construcción de un Indice de Palabras para un Texto
Un Arbol Binario Búsqueda, como estructura de ramificación, es la más
adecuada para almacenar información ordenada, ya que permite reducir

Página 117
sustancialmente el tiempo de búsqueda de algún elemento en particular. Pero si
la mayor parte de la aplicación requiere procesos secuenciales antes que directo
de los elementos, sería preferible la utilización de Lista Simplemente
Encadenada, ya que un Arbol requeriría de un puntero adicional, y sus
operaciones son mucho más complicadas.
El Libro de "Pascal y Estructura de Datos" de Dale and Lilly en su
segunda edición, desarrolla como aplicación para este caso, la Construcción de
un Indice de Palabras desde un Texto. Esta aplicación será la misma que se
describa a continuación, ya que con esto se quiere demostrar la gran diferencia
que existe al incluir la codificación de las implementaciones como parte de la
programación de la aplicación, lo que favorese las modificaciones de las
implementaciones, haciéndolas completamente particulares a la aplicación.
En la explicación solo se hará mayor énfasis en las diferencias que existen
entre ambas versiones de las aplicaciones, ya que la definición y desarrollo del
problema, está suficientemente explicado en el Libro de donde se obtuvo la
aplicación.

Página 118
Las estructuras de datos requeridas son las de Arbol Binario de
Búsqueda y Colas Circulares. Recuerden que aún cuando no se declaren
directamente variables de tipo de Listas Doblemente Encadenadas, es necesario
definirla como unidad, por ser objeto Ascendiente de Arbol Binario. De no
definirla, ocasionaría errores de Compilación.
El único problema con las implementaciones que requiere solución, por
capacidad del Stack interno, es el número de elementos de la Cola Circular, así
como el número de Bytes de información para cada elemento de la misma. Es por
ello que fué modificada la unidad Circular, quedando el máximo número de
elementos en 6, que es lo que exige la aplicación, y el número de Bytes de
información en 10.
INTERFACE
CONST
MaxElem = 6;
MaxByte = 10;
En la aplicación se definieron dos árboles, uno para mantener las palabras
correspondientes al Indice, y otro para las palabras del Diccionario,
ArbolIndice : Arbol; ArbolDiccionario : Arbol;
donde cada nodo contiene los siguientes campos de información:
TipoPalabraInfo = RECORD CampoPalabra : TipoCadena; ColaPagina : ColaCircular;

Página 119
Ya que constantemente es necesario conocer para una palabra dentro del
árbol Indice, la última página donde fué referenciada dicha palabra, se codificó en
la aplicación un procedimiento ObservarFinal, el cual retorna el contenido del
último elemento de la Cola de Paginas, sin modificar la cola, de tal manera de que
si es igual a la página actual, no debe ser añadida a la misma como nueva
referencia.
PROCEDURE ObservarFinal(ColaPagina : ColaCircular; VAR Pagina : TipoPagina); BEGIN WHILE NOT ColaPagina.Vacio DO ColaPagina.Remover(Pagina,SIZEOF(Pagina)); END;
Observe que para obtener el último elemento de la Cola, no se puede
accesar directamente el elemento al final de la misma. Solo se puede observar
dicho elemento, en base a las operaciones implementadas para la estructura.
Además no fué necesario el regresar los elementos eliminados de la Cola, ya que
la estructura regresa al lugar donde fué invocada, intacta por no ser de tipo VAR.
En la codificación original de la aplicación, fué adaptada la operación de
Insertar correspondiente a Arbol Binario de Búsqueda, de manera que actualizara
internamente la cola de páginas correspondiente a la palabra a ser insertada en
el Arbol Indice; en donde la actualización llega a ser mayor, dado que debe ser
insertada la Página Acual en la Cola de Páginas.
Ya que en todo momento se ha hecho énfasis en la utilización de las
operaciones implementadas para cada estructura en particular, la solución a ello,
es la de actualizar la Cola de Página en la variable InfoArbol, la cual siendo del
mismo tipo que el campo de infomación de los nodos de cada uno de los árboles,
pueda ser insertarda en el árbol correspondiente, pero ya con la Cola de Página
actualizada.
InfoArbol.CampoPalabra := Palabra; InfoArbol.ColaPagina.Inicializar;

Página 120
InfoArbol.ColaPagina.Insertar(PaginaActual, SIZEOF(PaginaActual)); ArbolIndice.Insertar(Indice,InfoArbol,
SIZEOF(InfoArbol),SIZEOF(Palabra))
Inclusive, en el caso de actualizar la Cola de Páginas correspondiente a
una palabra ya incluida en el árbol Indice, previamente se debe eliminar el nodo
desde el árbol Indice, que contenga la Palabra referencida, manteniendolo su
información en la variable InfoArbol. Desde ella podremos observar la última
página existente en la Cola, mediante el procedimiento discutido anteriormente.
También para el caso en que la cola, alcance su máxima capacidad, lo que
implicaría inicializarla e insertarla en el árbol Diccionario. De lo contrario, debe
insertarse de nuevo en el Arbol Indice ya sea por inserción de la Página Actual o
por regresarla sin ninguna actualización.
ArbolIndice.Eliminar(Indice,InfoArbol,SIZEOF(InfoArbol), Palabra,SIZEOF(Palabra)); ObservarFinal(InfoArbol.ColaPagina,Pagina); IF Pagina <> PaginaActual THEN BEGIN InfoArbol.ColaPagina.Insertar(PaginaActual, SIZEOF(PaginaActual)); IF InfoArbol.ColaPagina.Lleno THEN BEGIN (* Se guarda la información en el Archivo Depuración y se *) (* inserta en el Arbol Diccionario *) ImpNodo(InfoArbol); ArbolDiccionario.Insertar(Diccionario,InfoArbol, SIZEOF(InfoArbol),SIZEOF(Palabra)) END ELSE ArbolIndice.Insertar(Indice,InfoArbol,SIZEOF(InfoArbol), SIZEOF(Palabra));(* regresa actualizada *) END ELSE ArbolIndice.Insertar(Indice,InfoArbol,SIZEOF(InfoArbol), SIZEOF(Palabra)); (*regresa sin actualización *) END;

Página 121
De nuevo observamos dos procedimientos recursivos, Imprimir e ImpTest
los cuales aplicando recorrido InOrden, permiten realizar acciones sobre cada
nodo en particular. Pero lo importante en la actual aplicación, es que para no
accesar directamente los campos de información de los nodos, tal como lo hace la
versión original del problema, se hacen referencias a las operaciones de
Visualizar ya sea por la Derecha o Izquierda, definidas en la implementación de
Listas Doblemente Encadenadas LisDobDI.
PROCEDURE Imprimir(Ptr : Apuntador); VAR EntradaIndice : TipoPalabraInfo; P : Apuntador; BEGIN IF Ptr <> Nulo THEN BEGIN P := Ptr; ArbolIndice.VisualizarIzq(P,EntradaIndice,SIZEOF(EntradaIndice)); Imprimir(P); ImpNodo(EntradaIndice); ArbolIndice.VisualizarDer(Ptr,EntradaIndice,SIZEOF(EntradaIndice)); Imprimir(Ptr) END END;
A continuación se presenta la codificación completa de la aplicación, de
manera que se pueda hacer una comparación global de ambas codificaciones, y
observar las ventajas de tener implementadas las estructuras de datos en
unidades utilizando el concepo de Programación Orientada a Objetos.
PROGRAM ConstruirIndice(Libro,PalabrasTriviales,IndiceLibro,ArchivoDepuracion); USES Circular, LisDobDi, ArbolBin; CONST MaxCadena = 15; MinLongitud = 3; MaxPaginas = 999; Blancos = ' '; FinDePagina = '# '; Depurar = TRUE;

Página 122
TYPE Rangoindice = 0..MaxCadena; TipoCadena = PACKED ARRAY[1..MaxCadena] OF CHAR; ConjuntoDePunto = SET OF CHAR; TipoPagina = 1..MaxPaginas; TipoElemento = TipoPagina; TipoPalabraInfo = RECORD CampoPalabra : TipoCadena; ColaPagina : ColaCircular; END; VAR ArbolIndice : Arbol; ArbolDiccionario : Arbol; Indice : Apuntador; Diccionario : Apuntador; InfoArbol : TipoPalabraInfo; Libro : TEXT; LibroIndice : TEXT; PalabraTriviales : TEXT; ArchivoDepuracion : TEXT; Palabra : TipoCadena; PaginaActual : TipoPagina; Puntuacion : ConjuntoDePunto; Exito : BOOLEAN; PROCEDURE ObservarFinal(ColaPagina : ColaCircular; VAR Pagina : TipoPagina); BEGIN WHILE NOT ColaPagina.Vacio DO ColaPagina.Remover(Pagina,SIZEOF(Pagina)); END; FUNCTION LongitudOK(Palabra : TipoCadena) : BOOLEAN; BEGIN LongitudOK := Palabra[MinLongitud] <> ' ' END; PROCEDURE ConjuntoPuntuacion(VAR Puntuacion : ConjuntoDePunto); BEGIN Puntuacion := [',', '.', '!', '?', ':', ';', ' '] END; FUNCTION Mayuscula(Caracter : CHAR) : CHAR;

Página 123
VAR Diferencia : INTEGER; BEGIN Diferencia := ORD('a') - ORD('A'); IF (Caracter >= 'a') AND (Caracter <= 'z') THEN Mayuscula := CHR(ORD(Caracter) - Diferencia) ELSE Mayuscula := Caracter END; PROCEDURE LeerPalabra ( VAR ArchivoDatos : TEXT; VAR Palabra : TipoCadena); VAR Caracter : CHAR; Contador : INTEGER; BEGIN Palabra := Blancos; Contador := 0; REPEAT READ(ArchivoDatos, Caracter) UNTIL NOT(Caracter IN Puntuacion) OR EOF(ArchivoDatos); WHILE NOT(Caracter IN Puntuacion) AND (Contador < MaxCadena) DO BEGIN Contador := Contador + 1; Palabra[Contador] := Mayuscula(Caracter); READ(ArchivoDatos, Caracter) END; WHILE NOT (Caracter IN Puntuacion) DO READ(ArchivoDatos, Caracter); IF Depurar THEN WRITELN(ArchivoDepuracion, 'Despues de leer Palabra = ', Palabra) END; PROCEDURE ImpNodo(VAR EntradaIndice : TipoPalabraInfo); VAR NumeroPagina : TipoPagina; BEGIN WRITE(LibroIndice,EntradaIndice.CampoPalabra : 16); WHILE NOT EntradaIndice.ColaPagina.Vacio DO BEGIN EntradaIndice.ColaPagina.Remover(NumeroPagina, SIZEOF(NumeroPagina)); WRITE(LibroIndice,NumeroPagina : 4) END; WRITELN(LibroIndice); EntradaIndice.ColaPagina.Inicializar;

Página 124
END; PROCEDURE ActualizarListaPagina(Palabra : TipoCadena; VAR Indice : Apuntador; VAR Diccionario : Apuntador); VAR Pagina : TipoPagina; InfoArbol : TipoPalabraInfo; BEGIN IF Depurar THEN WRITELN(ArchivoDepuracion, 'Actualizando ', Palabra, ' para pagina ', PaginaActual); ArbolIndice.Eliminar(Indice,InfoArbol,SIZEOF(InfoArbol), Palabra,SIZEOF(Palabra)); ObservarFinal(InfoArbol.ColaPagina,Pagina); IF Pagina <> PaginaActual THEN BEGIN InfoArbol.ColaPagina.Insertar(PaginaActual, SIZEOF(PaginaActual)); IF InfoArbol.ColaPagina.Lleno THEN BEGIN ImpNodo(InfoArbol); ArbolDiccionario.Insertar(Diccionario,InfoArbol, SIZEOF(InfoArbol),SIZEOF(Palabra)) END

Página 125
ELSE ArbolIndice.Insertar(Indice,InfoArbol,SIZEOF(InfoArbol), SIZEOF(Palabra)); END ELSE ArbolIndice.Insertar(Indice,InfoArbol,SIZEOF(InfoArbol), SIZEOF(Palabra)); END; PROCEDURE Imprimir(Ptr : Apuntador); VAR EntradaIndice : TipoPalabraInfo; P : Apuntador; BEGIN IF Ptr <> Nulo THEN BEGIN P := Ptr; ArbolIndice.VisualizarIzq(P,EntradaIndice,SIZEOF(EntradaIndice)); Imprimir(P); ImpNodo(EntradaIndice); ArbolIndice.VisualizarDer(Ptr,EntradaIndice,SIZEOF(EntradaIndice)); Imprimir(Ptr) END END; PROCEDURE ImpTest(Ptr : Apuntador); VAR InfoArbol : TipoPalabraInfo; P : Apuntador; BEGIN IF Ptr <> Nulo THEN BEGIN P := Ptr; ArbolDiccionario.VisualizarIzq(P,InfoArbol,SIZEOF(InfoArbol)); ImpTest(P); WRITELN(ArchivoDepuracion,InfoArbol.CampoPalabra); ArbolDiccionario.VisualizarDer(Ptr,InfoArbol,SIZEOF(InfoArbol)); ImpTest(Ptr) END END;

Página 126
PROCEDURE ProcesarPalabra(Palabra : TipoCadena; VAR Indice : Apuntador; VAR Diccionario : Apuntador); VAR InfoArbol : TipoPalabraInfo; BEGIN ArbolDiccionario.Buscar(Diccionario,InfoArbol, SIZEOF(InfoArbol),Palabra,SIZEOF(Palabra),Exito); IF NOT Exito THEN BEGIN ArbolIndice.Buscar(Indice,InfoArbol,SIZEOF(InfoArbol), Palabra,SIZEOF(Palabra),Exito); IF Exito THEN ActualizarListaPagina(Palabra,Indice,Diccionario) ELSE BEGIN InfoArbol.CampoPalabra := Palabra; InfoArbol.ColaPagina.Inicializar; InfoArbol.ColaPagina.Insertar(PaginaActual, SIZEOF(PaginaActual)); ArbolIndice.Insertar(Indice,InfoArbol, SIZEOF(InfoArbol),SIZEOF(Palabra)) END END END; PROCEDURE ObtenerPalabra(VAR Palabra : TipoCadena; VAR ArchivoDatos : TEXT); BEGIN REPEAT LeerPalabra(ArchivoDatos,Palabra); IF Palabra = FinDePagina THEN PaginaActual := PaginaActual + 1 UNTIL LongitudOK(Palabra) OR EOF(ArchivoDatos) END; PROCEDURE ObtenerDiccionario(VAR Diccionario : Apuntador; VAR PalabraTriviales : TEXT); VAR Palabra : TipoCadena;

Página 127
BEGIN WHILE NOT EOF(PalabraTriviales) DO BEGIN ObtenerPalabra(Palabra,PalabraTriviales); IF NOT EOF(PalabraTriviales) THEN BEGIN InfoArbol.CampoPalabra := Palabra; InfoArbol.ColaPagina.Inicializar; ArbolDiccionario.Insertar(Diccionario,InfoArbol, SIZEOF(InfoArbol),SIZEOF(InfoArbol.CampoPalabra)) END END; IF Depurar THEN BEGIN WRITELN(ArchivoDepuracion, 'Las Palabras del diccionario son : '); ImpTest(Diccionario); END END; PROCEDURE Inicializar; BEGIN ArbolIndice.Inicializar(Indice); ArbolDiccionario.Inicializar(Diccionario); ASSIGN(Libro,'Libro.txt'); ASSIGN(PalabraTriviales,'Palabrat.txt'); ASSIGN(LibroIndice,'Indice.txt'); ASSIGN(ArchivoDepuracion,'Depuracion.txt'); RESET(Libro); RESET(PalabraTriviales); REWRITE(LibroIndice); IF Depurar THEN REWRITE(ArchivoDepuracion); PaginaActual := 1; ConjuntoPuntuacion(Puntuacion) END; BEGIN Inicializar; ObtenerDiccionario(Diccionario,PalabraTriviales); WHILE NOT EOF(Libro) DO BEGIN ObtenerPalabra(Palabra,Libro);

Página 128
IF NOT EOF(Libro) THEN ProcesarPalabra(Palabra,Indice,Diccionario) END; Imprimir(Indice); CLOSE(ArchivoDepuracion); CLOSE(LibroIndice);
END.

Página 129
EJERCICIOS PROPUESTOS______________________ 1-) Escribir un procedimiento recursivo que mediante las operaciones de
Visualizar de la implementación de Arbol, imprima el contenido de un Arbol
Binario en PreOrden.
2-) Similar al ejercicio anterior, pero en PosOrden.
3-) Escribir el procedimiento que construye un Arbol Binario pero a partir de una
expresión aritmética en forma Prefix.
4-) Escribir una nueva versión de la segunda aplicación, donde la Cola de
Páginas sea representada mediante una Lista Lineal Simplemente Encadenada
Dinámica.
5-) Modificar la implementación de Arbol Binario de manera que el procedimiento
ElimNodo, sea definido como un método privado y ejecute de nuevo la segunda
aplicación.

BIBLIOGRAFIA
AHO, A./HOPCROFT, J./ULLMAN, J., "Estructuras de Datos y Algoritmos ", Addison-
Wesley, 1990.
BORLAND INTERNATIONAL, Inc., "Object-Oriented Programming Guide ", Turbo
Pascal 5.5, 1988.
BULMAN, D., "Refining Candidate Objects ", Computer Language, Volumen 8,
Número 1, Pág. 30-39, Enero 1991.
CONSTANTINE, L.,"Objects, Functions, and Program Extensibility ", Computer
Language, Volumen 7, Número 1, Pág. 34-54, Enero de 1990.
DICKERSON, R., "Object-Oriented Borland ", Entrevista, DBMS, Volumen 4, Número
5, Pág. 45, 46, 49, 73, Mayo de 1991.
DALE, N./LILLY,S., "Pascal y Estructuras de Datos ", McGraw-Hill/Interamericana de
España, 1989.
JOYANES L., "Programación en TURBO PASCAL Versiones 4.0, 5.0 y 5.5 ",
McGraw-Hill/Interamericana de España, 1990.
KRUSE, R., "Estructura de Datos y Diseño de Programas ", Prentice-Hall
Hispanoamericana, 1988.
KRUSE, R., "Programming With Data Structures ", Prentice-Hall International, 1989.
O'BRIEN, S., "Turbo Pascal 5.5, The Complete Reference ", Borland-
Osborne/McGraw-Hill, 1989.
SHAMMAS, C., "Turbo Pascal 6 Object-Oriented Programming ", Sams, 1991.
SPICER, S., " Object-Oriented C That Goes VROOMM ", BYTE, Volumen 15, Número
10, Octubre de 1990.

TENENBAUM, A./AUGENSTEIN, M., "Estructura de Datos en Pascal ", Dossat, S.
A., 1983.
TREMBLAY, J./SORENSON P., "An Introduction to Data Structures With
Applications " , International Sudent Edition, 1985.
WIRTH, N., "Algoritmos y Estructuras de Datos ", Prentice-Hall International, 1987.
BORLAND, " Turbo Pascal for Windows User’s Guide ", Turbo Pascal 7, 1991.

AAGGRRAADDEECCIIMMIIEENNTTOOSS
AA llooss PPrrooffeessoorreess WWiilllliiaamm AAccoossttaa yy RRooddoollffoo CCaanneellóónn,,
qquuiieenneess mmee bbrriinnddaarroonn iiddeeaass ddee ggrraann aayyuuddaa eenn llaa
ccoonncceeppcciióónn ddee eessttee ttrraabbaajjoo..
AA mmiiss ddooss NNeessttoorrss ppoorr ssuu ccoollaabboorraacciióónn eenn llooss ddiisseeññooss
ggrrááffiiccooss yy ddiiaaggrraammaacciióónn..