conception d’une méthode de consolidation de grands...
TRANSCRIPT

Institut National des Sciences Appliquées de Strasbourg
Mémoire de soutenance de Diplôme d’Ingénieur INSA
Spécialité TOPOGRAPHIE
Conception d’une méthode de consolidation degrands réseaux lasergrammétriques
Présenté par : Directeurs de PFE : Correcteur INSA :
Emmanuel Cledat Dr Jean-François Hullo Dr Gilbert Ferhat
Ingénieur-chercheur
Guillaume Thibault
Chercheur Senior
Stage effectué au centre Recherche et Développement de EDF
1 avenue du Général de Gaulle
92 141 ClamartSoutenu le 23 Septembre 2015


Remerciements
Je tiens à adresser des remerciements très chaleureux à Dr. Jean-François HULLO, ingénieurdocteur chez EDF, pour son encadrement continu, régulier et de très bonne qualité tout au longde mon stage (dont ce mémoire fait la synthèse). Sa rigueur, sa culture scientifique, son éruditionmais aussi sa bonne humeur et son sens de l’humour m’ont permis d’approfondir un sujet très richeet intéressant.
Je remercie également Guillaume THIBAULT, qui lui aussi a supervisé mon stage. Ses ques-tions très pertinentes, ses critiques positives et ses corrections approfondies de mes rapports m’ontpermis de remettre en question certains aspects de mon travail.
Je voudrais aussi remercier Hadrien LEROYER, chef du groupe RVVS (Groupe de RéalitéVirtuelle et Visualisation Scientifique) dans lequel j’étais intégré durant ce stage.
De manière générale, je voudrais remercier l’ensemble du groupe RVVS avec qui j’ai beaucoupéchangé, non seulement au sujet des travaux effectués lors de ce stage, mais aussi sur les différentsprojets du groupe, et sur d’autres grandes questions de l’existence.
3


Avant propos : Déroulement du stage, etcadre de travail
0.1 Encadrement du stage
Ce stage a été effectué au sein du groupe RVVS (Groupe de Réalité Virtuelle et VisualisationScientifique, aussi appelé I2C) Appartenant au département SINETICS (Simulation Neutronique,Technologies de l’Information et Calcul Scientifique) de la R&D (Recherche et développement) deEDF.
Une supervision quotidienne a été effectuée par Jean-François Hullo, ingénieur chercheur. Desprésentations résumant l’avancée du travail ont été effectuées tous les mois à Guillaume Thibault,chercheur senior.
Des échanges avec le reste du groupe I2C autour du travail effectué ont été effectués de manièreinformelle tout au long du stage, et de manière formelle lors d’une présentation orale à l’ensembledu groupe au cours d’une réunion qui s’est tenue à mi-stage.
0.2 Rapports avec l’extérieur
Dans le cadre de ce stage, des liens forts se sont créés avec l’HEIG d’Yverdon en Suisse (Ecolede géomatique et de topographie avec laquelle l’INSA est en partenariat). Avant le début du stages’est tenu une réunion à l’HEIG pour présenter les besoins de EDF en terme de relevé 3D Laser-grammétriques, et le cadre du stage. Le groupe SINETICS de EDF était représenté par HadrienLeroyer, Guillaume Thibault, Jean-François Hullo, et Emmanuel Cledat. L’ensemble de l’équipe degéomatique de l’HEIG était présente. Nous avons particulièrement entretenu des liens avec ThomasTouzé, membre de cette équipe, avec qui nous avons correspondu à distance, et qui s’est rendu surle site de Clamart pour échanger autour de plusieurs problématiques rencontrées lors de ce stage.
5

Figure 0.1: Organigramme de la R&D. la description des différentes entités autour de I2C sontrépertoriés dans l’annexe : A.4
Figure 0.2: Le logo de l’HEIG
Nous avons aussi correspondu par courrier électronique avec Bill Triggs et à Richard Hartley,autour de questions à propos de leurs livre TRIGGS et al. [2000] ; et avec Michael Lösler, à proposdu comportement du logiciel Jag 3D dont il est le développeur.
Enfin, nous avons organisé une réunion avec le département de topographie d’EDF, de manièreà permettre une fertilisation croisée autour des thématiques abordées lors de ce stage.
6

0.3 Objectifs et livrables du stageLe fruit de ce stage est une description détaillée des méthodes étudiées, ainsi que leurs fonde-
ments théoriques et leurs démonstrations ; et une implémentation en python de l’ensemble de cestechniques constituant simultanément un POC (proof of concept : démonstration de faisabilité) etune base pour comprendre ces algorithmes.
Ces méthodes de compensations pourront être intégrées à des logiciels spécialisés, comme parexemple TRINET+.
7

Table des matières
0.1 Encadrement du stage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50.2 Rapports avec l’extérieur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50.3 Objectifs et livrables du stage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Table des matières 8
1 Introduction 13
2 Etat de l’art du relevé lasergrammétrique 172.1 La mécanique d’un scanner laser . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.2 Quelques exemples de relevés lasergrammétriques . . . . . . . . . . . . . . . . . . . 182.3 Trois méthodes d’assemblage des nuages . . . . . . . . . . . . . . . . . . . . . . . . 19
2.3.1 Méthode utilisant le nuage de points brut . . . . . . . . . . . . . . . . . . . 192.3.2 Méthode utilisant des primitives géométriques comme cibles de consolidation 192.3.3 Méthode utilisant une primitive géométrique particulière : la sphère . . . . 19
2.4 Les grandes étapes de la construction d’un modèle 3D Tel que construit . . . . . . 202.4.1 Traitement individuel du nuage de points de chaque station . . . . . . . . . 202.4.2 Consolidation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.4.3 Reconstruction 3D . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.5 Difficultés et enjeux dans l’établissement et la résolution de ces conditions pour leréseau lasergrammétrique d’un environnement complexe . . . . . . . . . . . . . . . 222.5.1 Bilan des erreurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.5.2 Propagation d’erreurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.5.3 Principales caractéristiques d’un environnement industriel . . . . . . . . . . 23
3 Appariement des sphères 253.1 État de l’art . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263.2 Algorithmes proposés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2.1 A priori sur la position des stations . . . . . . . . . . . . . . . . . . . . . . . 273.2.2 Algorithme inspiré de l’algorithme de RanSaC . . . . . . . . . . . . . . . . 273.2.3 Adaptation d’une méthode de corrélation d’image . . . . . . . . . . . . . . 30
3.3 Discussion et analyse des méthodes . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4 Compensation 354.1 Différents problèmes posés lors de la compensation : État de l’art et propositions
d’améliorations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.1.1 Formulation paramétrique et formulation de Gauss-Helmert . . . . . . . . . 354.1.2 Différents modèles de verticalité . . . . . . . . . . . . . . . . . . . . . . . . 37
8

4.1.3 Calcul par morceaux ou calcul en bloc . . . . . . . . . . . . . . . . . . . . . 384.1.4 Choix d’une fonction de coût à minimiser . . . . . . . . . . . . . . . . . . . 414.1.5 Méthodes de minimisation de la fonction de coût . . . . . . . . . . . . . . . 44
4.2 Assemblage des différents aspects de la compensation . . . . . . . . . . . . . . . . . 464.3 Tests effectués . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.3.1 Protocole expérimental . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474.3.2 Comparaison des différentes méthodes développées et expérimentées au cours
de ce stage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474.3.3 Comparaison de notre méthode avec Trinet+ et Jag3D . . . . . . . . . . . . 494.3.4 Tests effectués sur l’ensemble du réseau du Bâtiment Réacteur (BR) . . . . 51
5 Algorithme de détection, localisation et suppression de fautes 535.1 Le vecteur de fermetures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 535.2 Vecteur des fermetures normalisées . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.2.1 Le concept de résidu normalisé . . . . . . . . . . . . . . . . . . . . . . . . . 545.2.2 Généralisation du concept de normalisation au vecteur des fermetures . . . 55
5.3 Présentation de trois méthodes de détection de fautes . . . . . . . . . . . . . . . . 565.3.1 Méthode utilisant les anomalies du vecteur des fermetures . . . . . . . . . . 565.3.2 Méthode utilisant le calcul de la position de la sphère . . . . . . . . . . . . 575.3.3 Méthode utilisant les valeurs numériques du vecteur des fermetures . . . . . 58
5.4 Test comparatif des trois méthodes . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
6 Outils d’analyse : estimateurs de qualité 636.1 Analyse topologique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
6.1.1 L’analyse locale d’un graphe et ses limites . . . . . . . . . . . . . . . . . . . 646.1.2 Définition des matrices définissant le graphe . . . . . . . . . . . . . . . . . . 656.1.3 Analyse spectrale du graphe par la méthode du vecteur propre de centralité 666.1.4 Représentation topologique d’un réseau lasergrammétrique, et alternative au
SAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 676.2 Ellipsoïdes d’erreur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 686.3 Fiabilité externe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 696.4 Étude comparative de différents estimateurs. . . . . . . . . . . . . . . . . . . . . . 70
6.4.1 Pseudo-corrélations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 706.4.2 Corrélations logarithmiques . . . . . . . . . . . . . . . . . . . . . . . . . . . 716.4.3 Comparaison quantitative des différents estimateurs de qualité . . . . . . . 716.4.4 Comparaison qualitative des différents estimateurs de qualité . . . . . . . . 72
7 Conclusion 757.1 Synthèse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 757.2 Principales contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 757.3 Perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Table des figures 78
Liste des tableaux 81
A Lexique 83A.1 Définitions issues de LANDES et al. [2011] . . . . . . . . . . . . . . . . . . . . . . . 83A.2 Définitions issues du lexique de l’AFT (Association Française de Topographie) . . 83A.3 Définitions issues de BRABANT et al. [2011] . . . . . . . . . . . . . . . . . . . . . 84
9

A.4 Différentes entités d’EDF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84A.4.1 Les départements de la R&D . . . . . . . . . . . . . . . . . . . . . . . . . . 84A.4.2 Les groupes de SINETICS . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
B Définition de la compensation, et aperçu des différentes méthodes 87B.1 Construction de la fonction de probabilité . . . . . . . . . . . . . . . . . . . . . . . 91
B.1.1 Retournement du problème . . . . . . . . . . . . . . . . . . . . . . . . . . . 91B.1.2 Introduction formelle des résidus . . . . . . . . . . . . . . . . . . . . . . . . 92B.1.3 Création d’un jeu de pseudo-mesures indépendantes . . . . . . . . . . . . . 93B.1.4 Conjonction des pseudo-mesures indépendantes pour exprimer la probabilité 93B.1.5 Construction de la densité de probabilité d’une variable . . . . . . . . . . . 94B.1.6 Ré-assemblage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95B.1.7 Simulation numérique pour visualiser la densité de probabilité . . . . . . . 96
B.2 Recherche du maximum de la fonction de probabilité . . . . . . . . . . . . . . . . . 96B.2.1 Différents exemples de distances . . . . . . . . . . . . . . . . . . . . . . . . 97B.2.2 5 Manières de formaliser le modèle du système . . . . . . . . . . . . . . . . 101B.2.3 Linéarisation des fonctions non linéaires . . . . . . . . . . . . . . . . . . . . 105B.2.4 5 Manières de résoudre la compensation Paramétrique . . . . . . . . . . . . 109B.2.5 Résolution du problème de Gauss-Helmert . . . . . . . . . . . . . . . . . . . 117B.2.6 Fausses pistes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117B.2.7 Utilisation d’un pseudo-inverse de B . . . . . . . . . . . . . . . . . . . . . . 117B.2.8 Résolution du cas général . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
C Notations 121
D Formulaire de compensation 125D.1 Représentation et propagation d’erreur . . . . . . . . . . . . . . . . . . . . . . . . . 125
D.1.1 Propagation de distribution, propagation d’erreur . . . . . . . . . . . . . . . 125D.1.2 Lieu d’erreur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125D.1.3 Visualisation en dimension 2 . . . . . . . . . . . . . . . . . . . . . . . . . . 126D.1.4 Visualisation en dimension 3 . . . . . . . . . . . . . . . . . . . . . . . . . . 127D.1.5 Considération d’une autre loi de probabilité . . . . . . . . . . . . . . . . . . 127
D.2 Formulation du problème de compensation . . . . . . . . . . . . . . . . . . . . . . . 131D.2.1 Entrées du problème . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131D.2.2 Premières définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132D.2.3 Gradient et Laplacien de la fonction de coût . . . . . . . . . . . . . . . . . . 133D.2.4 Résolution du système . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134D.2.5 Ajout de l’incrément du paramètre . . . . . . . . . . . . . . . . . . . . . . . 135
D.3 Outils d’analyse de la précision et de la fiabilité . . . . . . . . . . . . . . . . . . . . 135D.3.1 Matrice des cofacteurs des résidus . . . . . . . . . . . . . . . . . . . . . . . 135D.3.2 Part de redondance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135D.3.3 Résidus standardisés ou résidus normalisés . . . . . . . . . . . . . . . . . . 136D.3.4 Fiabilité externe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
D.4 Spécificité du réseau lasergrammétrique . . . . . . . . . . . . . . . . . . . . . . . . 136D.4.1 Liberté totale de l’orientation des stations . . . . . . . . . . . . . . . . . . . 137D.4.2 Verticalité des station considérée comme une lecture . . . . . . . . . . . . . 139D.4.3 Stations fixées verticalement (2.5D) . . . . . . . . . . . . . . . . . . . . . . 139
E Démonstrations 141E.1 Point de départ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
10

E.2 Calcul du gradient et de la matrice Hessienne des fonctions de coûts . . . . . . . . 141E.2.1 Gradient et matrice Hessienne de la fonctionnelle A et B . . . . . . . . . . . 141E.2.2 Gradient et matrice Hessienne de la fonctionnelle D . . . . . . . . . . . . . 142
E.3 L’approche de la méthode C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143E.3.1 Les deux linéarisations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143E.3.2 Première partie de la résolution . . . . . . . . . . . . . . . . . . . . . . . . . 144E.3.3 Propagation de variances sur les variables en présence . . . . . . . . . . . . 146
E.4 Résolution du système . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146E.4.1 Méthode naïve de résolution du système . . . . . . . . . . . . . . . . . . . . 146E.4.2 Quand N est inversible . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147E.4.3 Quand N est n’est pas inversible . . . . . . . . . . . . . . . . . . . . . . . . 147
F Présentation comparée des réseaux Lasergrammétrique et Photogrammétrique151F.1 Définition des paramètres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151F.2 Utilité de ces paramètres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
F.2.1 Dans le cas du réseau lasergrammétrique . . . . . . . . . . . . . . . . . . . . 151F.2.2 Dans le cas du réseau photogrammétrique . . . . . . . . . . . . . . . . . . . 152
F.3 Observations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152F.3.1 Dans le cas du réseau lasergrammétrique . . . . . . . . . . . . . . . . . . . . 152F.3.2 Dans le cas du réseau photogrammétrique . . . . . . . . . . . . . . . . . . . 154
F.4 Expression des conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156F.4.1 Définition de la matrice antisymétrique induite par le produit vectoriel . . . 156F.4.2 Expression des conditions dans le cas d’un réseau lasergrammétrique . . . . 157F.4.3 Dans le cas du réseau photogrammétrique . . . . . . . . . . . . . . . . . . . 157
F.5 Deux méthodes de calculs de la matrice fondamentale . . . . . . . . . . . . . . . . 159F.5.1 Solution utilisant un calcul par les moindres carrés classique . . . . . . . . . 160F.5.2 Solution utilisant une décomposition en valeurs singulière . . . . . . . . . . 161F.5.3 Optimisation non-linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
G Estimation approximative des paramètres de poses relatives entre deux stations163
H Propriétés admises 167H.1 Une fonction de coût . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167H.2 Une formule de calcul matriciel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167H.3 Calcul des covariances des résidus compensés . . . . . . . . . . . . . . . . . . . . . 168H.4 Liens entre les conditions sur P et les corrélations . . . . . . . . . . . . . . . . . . . 168H.5 Le théorème des parts de redondances . . . . . . . . . . . . . . . . . . . . . . . . . 168H.6 Vecteurs propres d’une matrice d’un produit scalaire . . . . . . . . . . . . . . . . . 168
I Intégration des données dans les logiciels Jag 3D et Trinet+ 169I.1 Intégration des données dans le logiciel Jag 3D . . . . . . . . . . . . . . . . . . . . 169
I.1.1 Intégration des données en tant que relevé de station totale . . . . . . . . . 169I.1.2 Intégration des données en tant que relevé de diverses sessions GNSS . . . . 169
I.2 Intégration des données dans le logiciel Trinet+ . . . . . . . . . . . . . . . . . . . . 170
J Représentation topologique d’un réseau lasergrammétrique, et alternative auSAS 171J.1 L’analyse globale d’un graphe rattaché . . . . . . . . . . . . . . . . . . . . . . . . . 171J.2 Définition du graphe associé à un réseau lasergrammétrique . . . . . . . . . . . . . 172
11

Bibliographie 173
12

Chapitre 1
Introduction
Dans le monde de l’industrie, il est nécessaire d’effectuer des opérations de maintenance et decontrôle, de manière à maintenir une production, et une sécurité au niveau maximal.
Dans le cas d’une centrale nucléaire, ces maintenances nécessitent un arrêt de la productionélectrique qui constitue une perte monétaire pour EDF de l’ordre de 1 000 000 euros par jour. Cescentrales sont des milieux contraignants qui nécessitent la mise en place de nombreux dispositifs desécurité. Enfin, de très nombreux corps de métiers y sont amenés à travailler. Il est donc nécessairede gérer les co-activités. Toute intervention au sein d’une centrale doit donc être minutieusementpréparée, organisée et minutée de manière à garantir sa qualité, sa rapidité et sa sécurité.
Pour accroître la facilité et la fiabilité de la préparation de ces interventions, plusieurs logi-ciels ont été développés au sein du groupe RVVS (Groupe de Réalité Virtuelle et de VisualisationScientifique) appartenant au département SINETICS (Simulation Neutronique, Technologies del’Information et Calcul Scientifique) de la R&D (Recherche et développement) de EDF.
Ces applications ont des fonctions bien particulières. Le logiciel Manutention fine permet deprévoir des déplacements complexes d’objets dans une centrale. Tirs radio permet de préparerles radiographies de tuyaux pour vérifier que ceux-ci ne comportent pas de fissure. VVProPrépa(Visualisation Virtuelle des installations pour jeunes professionnels) permet d’effectuer des visitesimmersives au sein de la centrale. SAAM Colisage permet de gérer les opérations de dépot dematériel...
Si ces logiciels sont différents, ils se basent sur l’utilisation de données géographiques communes :
— Les plans en 2D de chacun des niveaux de la centrale.
— Des photos sphériques consultables en vue bulle à la manière de Google-street View, et desscans laser consultable en vue bulle.
— Un modèle 3D de la centrale Tel que construit, c’est-à-dire, au plus proche de sa sa situationactuelle (cf Lexique : A)
Les vues bulle sont créées à partir de plusieurs clichés effectués par un appareil photographiquemonté sur une plate-forme rotative motorisée. La méthode d’acquisition, les caractéristiques tech-niques de ces images, et une méthode de traitement possible sont présentées dans VU [2014]. Les
13

Figure 1.1: Vue d’un endroit du modèle 3D dans VVProPrepas. Les sphères orange permettentde consulter les photos sphériques
Figure 1.2: Un exemple d’usage du modèle tel que construit à un cas de manutention fine :Simulation 3D puis réalisation en centrale du remplacement du stator de l’alternateur.
14

plans 2D et le modèle 3D Tel que construit sont créés à partir d’un nuage de points : un ensemblede points représentant la surface des objets composant le bâtiment (cf Lexique : A).
Dans le chapitre 2, un état de l’art présentant les méthodes d’acquisition, les traitements né-cessaires à la création de ce nuage de points, et les limites des méthodes actuelles dans le cas desbesoins d’EDF en terme de numérisation seront détaillés. Au cours de ce chapitre seront distinguéeset définies quatre étapes constituant la compensation. Les différents apports seront présentés dansles quatre chapitres : 3, 4, 5, et 6 ; consacrés à chacune des quatre étapes. Respectivement : l’ap-pariement, la compensation, la suppression des fautes et enfin l’analyse des résultats. De manièrecomplémentaire, le chapitre présentera les grandes étapes du stage et le contexte de travail.
Les méthodes trouvées dans la littérature, décrites dans l’état de l’art (chapitre 2), ainsi queles améliorations proposées au cours de ce mémoire ont été implémentés en Python de manière àpouvoir les tester. L’objectif de ce stage est de proposer des méthodes qui pourront être intégréesdans un logiciel métier, de manière à faciliter leurs utilisation. Les programmes codés au cours dece stage pourront simplement être portés dans le langage dans lequel est écrit le logiciel dans lequelon veut les intégrer.
15


Chapitre 2
Etat de l’art du relevé lasergrammétrique
Pour effectuer le relevé en trois dimensions de ses installations, EDF utilise la méthode durelevé lasergrammétrique. Ce chapitre a pour but de présenter cette méthode. Pour plus de détails,le lecteur est invité à se référer à LANDES et al. [2011] et à LANDES et GRUSSENMEYER [2011]qui présentent les notions fondamentales à connaître sur les méthodes lasergrammétriques.
2.1 La mécanique d’un scanner laserUn scanner laser est un appareil effectuant des mesures ponctuelles de l’ensemble des éléments
avec lesquels il y a un contact visuel direct. Pour cela, une partie mobile effectue une rotationautour de l’axe principal de l’appareil (souvent aligné avec la verticale). A l’intérieur de cettepartie mobile, un miroir rotatif permet de diriger un faisceau laser sur 360◦. La combinaison deces deux rotations permet à ce laser de balayer l’ensemble de l’espace entourant le laser scanner.Ce laser permet d’effectuer une mesure de distance entre le centre de rotation du scanner et lepoint visé. Finalement, trois mesures sont effectuées : deux mesures d’angles, et une mesure dedistance. En convertissant ces coordonnées sphériques en coordonnées cartésiennes, on obtient unensemble de points connus dans un repère local centré sur le laser scanner. Cet ensemble de points,appelé nuage de points de la station (cf Lexique : A) décrit une portion ou la totalité de l’espaceou de l’objet que l’on veut modéliser en 3D (l’ensemble des points rouge de la station rouge de lafigure 2.2 par exemple). Les points de ce nuage de points sont représentés par leurs coordonnéesdans le repère de la station. La connaissance des caractéristiques du repère de la station (position
Scanner laser Éclaté d’un scanner laser
Figure 2.1: Scanner laser
17

et attitude) permet de transformer les points du repère de la station vers le repère général. Celapermet d’assembler l’ensemble des nuages de points des différentes stations en un nuage commun,comme sur la figure 2.2.
Figure 2.2: Nuage de point global, union de nuages de points issus de stations différentes
2.2 Quelques exemples de relevés lasergrammétriques
La méthode du relevé lasergrammétrique a de nombreuses applications dans l’industrie, l’archéo-logie, la mise en valeur du patrimoine historique et architectural... LANDES et GRUSSENMEYER[2011] et LANDES et al. [2011] donnent de nombreux exemples de relevés lasergrammétriques,comme par exemple le lycée des Pontonniers à Strasbourg, le mur d’enceinte de Ribeauvillé, lechâteau d’Andleau, la grotte ornée des Fraux, le château du Haut-Koenigsbourg... Plus récem-ment, CADOT [2015] présente une numérisation de grande ampleur du Mont Saint Michel. Ce sitea été numérisé avec plusieurs dizaines de stations de laser scanner faro (ayant une précision de2mm à 25m et une portée maximale de 120m) pendant 3 semaines.
Figure 2.3: Une station de scan sur le Mont Saint Michel (CADOT [2015])
18

Figure 2.4: Détail d’un scan du mont Saint Michel (CADOT [2015])
2.3 Trois méthodes d’assemblage des nuagesTrès souvent, un seul scan ne permet pas de représenter la totalité de l’objet que l’on veut
mesurer. Il faut donc effectuer plusieurs scans, et assembler les nuages de points issus de chacunedes stations. Trois approches sont présentées ici :
2.3.1 Méthode utilisant le nuage de points brut
On peut utiliser le nuage de points brut, un même objet est représenté par plusieurs nuages depoints. L’objet reste le même, mais les points qui le modélisent sont différents. On peut résoudre leproblème en utilisant la technique appelée Iterative Closest Point (ICP). Cette méthode présentetrois défauts majeurs dans notre cas (cf HULLO [2013] page 29) :
— Il y a trop peu de recouvrement entre les nuages de points issus de stations adjacentes,
— Il y a de trop nombreuses surfaces lisses,
— Les temps de calculs sont trop élevés, ceci étant dû au grand nombre de points constituantun nuage, et au nombre de stations.
Ce n’est donc pas la méthode retenue.
2.3.2 Méthode utilisant des primitives géométriques comme cibles deconsolidation
Une autre méthode consiste à reconnaître dans notre nuage de points des formes géométriquesconnues appelées primitives géométriques. Ces primitives peuvent être des plans, des cônes, destores, des sphères... Des éléments issus de nuages de points différents représentant le même objetréel sont dit congruents. La correspondance de primitives congruentes vue de plusieurs stationsdifférentes permet de bloquer des degrés de libertés entre les stations :
2.3.3 Méthode utilisant une primitive géométrique particulière : la sphère
Nous allons utiliser des sphères, qui sont rajoutées lors du relevé par les topographes. Cela aplusieurs avantages : elles sont faciles à détecter dans un nuage de points, la sphère est un objettrès peu présent dans des milieux industriels ou architecturaux, une sphère reste invariante à sonangle de vue...
19

Degrès de liberté contraintsTranslation Rotation
Plan/Plan 1 2Cone/Cône 3 2Tore/Tore 3 2
Sphère/Sphère 3 0
Table 2.1: Degrès de liberté contraints par un couple de primitives géométriques
Figure 2.5: Ensemble de points mesurant une sphère, et sphère qui interpole au mieux ces points
2.4 Les grandes étapes de la construction d’un modèle 3D Telque construit
2.4.1 Traitement individuel du nuage de points de chaque station
La première étape consiste à nettoyer le nuage de points de chaque station individuellementpour supprimer les points aberrants. Puis, on effectue une détection des sphères automatique, demanière à connaître avec précision (sub-millimétrique) le centre de chaque sphère dans le repèrede la station. Cette étape est décrite dans McGLONE [2009] et dans FRANASZEK et al. [2008].
2.4.2 Consolidation
La consolidation est l’étape qui consiste à assembler les nuages de points issus de stations de scandifférentes et à les exprimer dans un repère externe. Ce présent papier apporte des contributionssur cette étape qui se décompose en deux mouvements.
2.4.2.1 Appariement des sphères
Chaque station de scan vise un ensemble de sphères dont on connaît, après extraction, la positiondans le repère de la station. Cependant, ces sphères ne sont ni numérotées, ni répertoriées. On nepossède qu’une information géométrique. Le but de l’appariement est de reconnaître une mêmesphère dans les nuages de points de chaque station qui la vise. Cela permet d’ajouter à l’informationgéométrique, une information sémantique. Une proposition de méthode d’appariement des sphères,basée sur la reconnaissance de triangles semblables, est donnée par FRANASZEK et al. [2008]. Lescontributions relatives à cette étape seront décrites dans le chapitre 3.
2.4.2.2 Compensation et l’analyse du résultat
Une fois l’appariement des sphères effectué, en supposant qu’il n’y a aucune erreur d’apparie-ment, il serait théoriquement possible d’assembler le nuage de points global de la numérisation.Cependant, des erreurs inhérentes au processus de numérisation entachent les mesures. Ce premierassemblage serait imparfait. La solution consiste alors à modéliser le comportement de ces erreurs
20

Figure 2.6: Méthode de cartographie de la France effectuée par triangulation au XV IIIe siècle
de manière à les répartir de la manière la plus probable. C’est ce que l’on appelle : compensation(cf Lexique : Annexe A).
Cette notion de compensation est apparue pour la première fois au 18e siècle lorsque l’on avoulu cartographier le territoire Français. Pour cela, la France a été découpée en triangles (figure2.6) dont les sommets ont été matérialisés par des bornes, et les angles ont été mesurés avec desthéodolites. Quelques lectures de distances ont été effectuées pour mettre à l’échelle le réseau. Dansla mesure où les observations étaient surabondantes, il a été possible de les confronter, d’observerde légères discordances, et de répartir les erreurs.
Si les premières approches de calculs étaient très empiriques, des approches théoriques plusrigoureuses ont été développées au 19e siècle de manière indépendante par Adrien Marie Legendreet Carl Friedrich Gauss (Cf historique donné dans MERMINOD [2011]). Une littérature très richea été écrite sur ce sujet 1, présentant non seulement la répartition de ces erreurs, mais aussi larecherche et la suppression d’erreurs grossières, ou fautes (cf Lexique : Annexe A), et à l’analysedu résultat qu’il est possible de produire à partir ce ces mesures.
Les contributions apportées à ces trois grands aspects de la gestion d’une surdétermination demesure : la répartition des erreurs, la détection des fautes et l’analyse du résultat seront présentésrespectivement dans les chapitres 4, 5 et 6.
1. Nous avons notamment étudié des cours de compensation tels que : MERMINOD [2011] , MIKHAIL etACKERMANN [1976] , GUILLAUME et al. [Version 6.1] , HULLO [2014] , CASPARY [1987] , CATTIN [Version3.3] , COCARD [2009] , CAROSIO [1996] , BAARDA [1968], KIEFER [2007] ; des publications proposant desnouveaux outils telles que : YUANXI [1992] , TRIGGS et al. [2000] , KRARUP [1982] , KRARUP [1981] , VALEROet MORENO [2005], WICKI [2001] ; des approches plus bayésiennes de la compensation : KOCH [1990], KOCH[2007], TSYBAKOV [2006], SAPORTA [1990], ou des manuels de compensation plus spécifiques à un domaineprécis : McGLONE [2009] , VU [2014]... Cette littérature étant hétérogène en terme de notation, nous avons effectuéun tableau comparatif confrontant toutes les notations : (cf Annexe C)
21

2.4.3 Reconstruction 3D
Le nuage de points représentant l’ensemble d’un bâtiment peut en soit être considéré comme unproduit fini. Cependant, si on a besoin d’effectuer des simulations ou des mesures sur un modèle3D, il est souvent nécessaire de posséder un modèle 3D reconstruit en primitives géométriques(formes élémentaires constituant les objets : plans, cylindres, cônes...). Pour cela on effectue unereconstruction par des objets CAO au plus près du nuage de points. C’est ce qui est effectué lorsde la création du modèle 3D des centrales nucléaires de EDF).
2.5 Difficultés et enjeux dans l’établissement et la résolutionde ces conditions pour le réseau lasergrammétrique d’unenvironnement complexe
Le cahier des charges décrivant la qualité de la numérisation à effectuer, défini en fonction desbesoins, impose que chacun des points soient exprimés dans le repère général à ±3cm. Le but decette section est d’effectuer une analyse d’erreur permettant de voir ce qu’implique cette tolérance.
2.5.1 Bilan des erreurs
Il existe trois source d’erreurs :
2.5.1.1 Les erreurs instrumentales
Les données constructeur annoncent une précision millimétrique sur le relevé des points. Cepen-dant, il peut exister certains artefacts (comme des voiles de mariées par exemple) qui constituentdes points faux à supprimer.
2.5.1.2 Les erreurs environnementales
L’environnement industriel dans lequel est effectué la mesure est source de plusieurs erreurs :
— La présence de vibrations peuvent perturber les lectures,
— Des surfaces chaudes peuvent entraîner des réfractions des rayons lasers du scanner,
— Des surfaces réfléchissantes peuvent entraîner la création de points totalement aberrants.
2.5.1.3 Les erreurs de consolidation
Les erreurs de consolidation sont les erreurs sur la connaissance de la position et l’orientationdes scans. Nous verrons que cette source d’erreur est prépondérante par rapport aux autres, puisqueces erreurs sont souvent centimétriques.
2.5.2 Propagation d’erreurs
Formalisons la combinaison de ces erreurs :
Soit −→Ppt la position d’un point pt numérisé par un scanner laser (par exemple un point rouge
de la maison de la figure 2.2). Nous allons effectuer une transmission d’erreur permettant d’évaluerl’erreur commise sur l’estimation de cette position. Si −→
P représente la position de la station ayant
22

mesuré pt, R la matrice de rotation décrivant la rotation du repère de la station par rapport aurepère général et −→
lpt la mesure de la position du point dans le repère de la station, alors −→Ppt se
calcule grâce à la formule :
−→Ppt = −→
P + R−→lpt (2.5.1)
On aimerait effectuer une propagation d’erreurs de manière à estimer : Σ−→P
−→P
la matrice desvariances-covariances de −→
P .Pour cela, il faut connaitre Σ−→
lpt−→lpt
, la matrice des variances-covariances des lectures sur sphères.Généralement, ses valeurs indiquent une précision millimétrique.
Nous avons aussi besoin des variances-covariances de la position −→P de la station : Σ−→
P−→P
, et celledes angles permettant de construire la matrice R. On peut prendre par exemple le triplet d’anglesω, φ, κ dont la matrice des variances-covariances est 2 Σat at.
La formule de propagation de variance s’écrit donc :
Σ−→Ppt
−→Ppt
= Σ−→P
−→P
+ R Σ−→lpt
−→lpt
RT + F Σat at F T (2.5.2)
Où :
F =
à
∂(R−→lpt)
∂ω
����������
∂(R−→lpt)
∂φ
����������
∂(R−→lpt)
∂κ
í
(2.5.3)
Les erreurs instrumentales et environnementales sont représentées par la matrice Σ−→lpt
−→lpt
. Leserreurs de consolidation, prépondérantes sont les incertitudes des paramètres de poses : −→
P et R dela station. Il faudra consacrer un soin particulier à la détermination de ces paramètres, ainsi quevérifier leurs précision.
2.5.3 Principales caractéristiques d’un environnement industriel
Si la section précédente montre à quel point la détermination des paramètres de pose des sta-tions est cruciale, cette section s’attardera sur les difficultés induites par l’univers hostile danslequel la numérisation est effectué.
Les environnements industriels, en particulier les centrales nucléaires sont des lieux labyrin-thiques dans lesquels il est difficile d’avoir du recul pour avoir une vision d’ensemble d’un espace,et les inter-visibilités entre les différents espaces sont rares et difficiles. Ces problématiques sontapprofondies par le besoins impérieux de cartographier toutes les salles. C’est une des raisons quiexplique le grand nombre de stations (de l’ordre du millier) nécessaire pour numériser l’ensembled’un BR (bâtiment réacteur d’une centrale nucléaire).
Ces milieux industriels sont généralement de très grande taille, développés dans les trois dimen-sions. Les réseaux lasergrammétriques des BR seront tri-dimensionnels et fortement multi-étages.
2. Les covariances entre les positions −→P , et les valeurs angulaires ω, φ, κ sont en pratique négligeables.
23

Figure 2.7: Réseau lasergrammétrique permettant de numériser le bâtiment réacteur. Les sphèresvertes représentent les points d’appuis, les sphères rouges les stations, et les traits bleu les viséessur les sphères
Pour géoréférencer le réseau, celui-ci se réfère à des points d’appuis : des points mesurés avecdes méthodes topographiques classiques, ce qui permet de les connaître en coordonnées. Ceux-cisont représentés par les sphères vertes de la figure 6.4 ou de la figure 2.7. Leurs configuration estdéfavorable car ils ne sont pas répartis uniformément dans l’espace.
24
Chapitre 3
Appariement des sphères
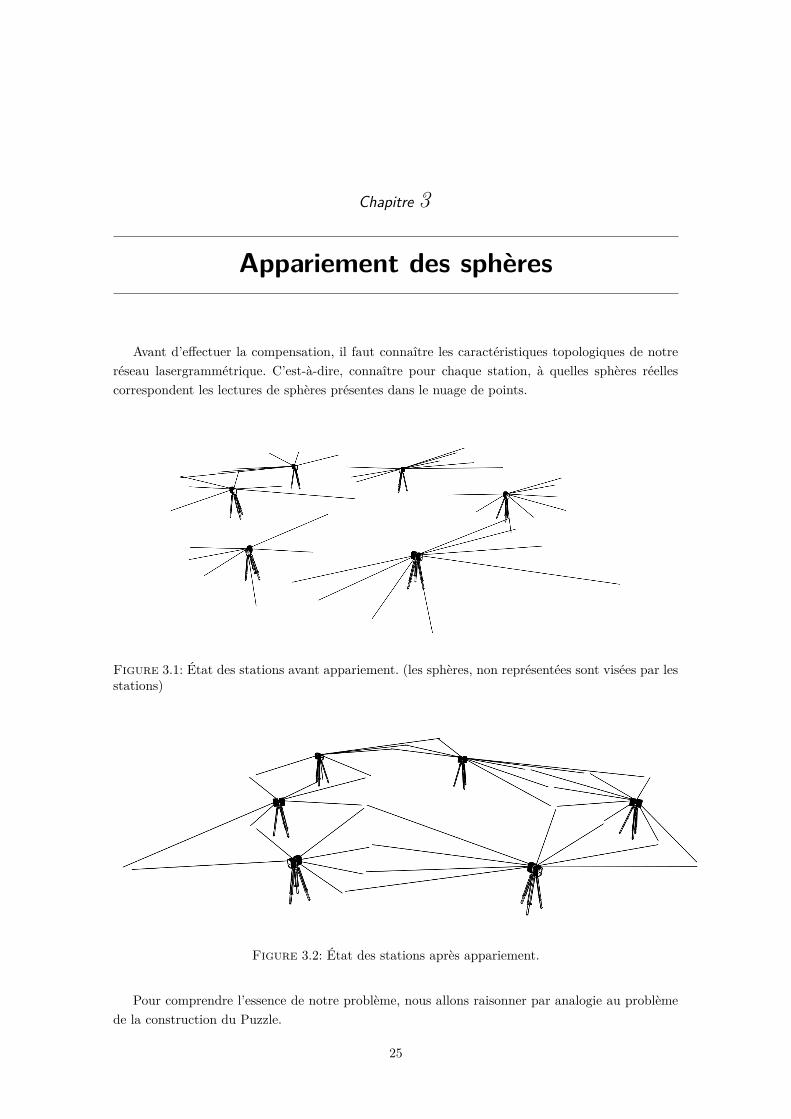
Avant d’effectuer la compensation, il faut connaître les caractéristiques topologiques de notreréseau lasergrammétrique. C’est-à-dire, connaître pour chaque station, à quelles sphères réellescorrespondent les lectures de sphères présentes dans le nuage de points.
Figure 3.1: État des stations avant appariement. (les sphères, non représentées sont visées par lesstations)
Figure 3.2: État des stations après appariement.
Pour comprendre l’essence de notre problème, nous allons raisonner par analogie au problèmede la construction du Puzzle.
25

a) b) c)
On veut ajouter une pièce sur la piècerouge déjà placée. Pour cela, on regardeplusieurs candidats
Pour chaque pièce candidate, on latourne jusqu’à obtenir une orientationconvenable
Si on a choisi la bonne pièce et la bonnerotation, on peut assembler cette pièceavec le reste du puzzle
Figure 3.3: Analogie entre le concept d’appariement et celui de la construction du puzzle
Dans le cas d’un réseau lasergrammétrique, les stations de scans sont représentées par les piècesdu puzzle, et la configuration des sphères selon chacune des stations est représentée par la formedu découpage des pièces du puzzle. Nous allons adapter cette technique d’appariement des piècesdu puzzle à notre problème.
3.1 État de l’artLa méthode de FRANASZEK et al. [2008] nous a servi de référence en terme d’appariement
des sphères. Le principe est le suivant :
— Figure 3.4.1 On cherche deux stations α et β susceptibles de viser un même couple de sphères.La distance entre les deux sphères de ce couple doit être égale dans les nuages de points desstations α et β.
— Figure 3.4.2 On cherche une troisième sphère éloigné de la première sphère (respectivementde la seconde sphère) par la même distance dans chacune des vues des deux stations.
— Figure 3.4.3 Si les trois distances coïncident dans chacune des deux vues par les deux stations,on peut apparier les trois sphères de l’une à l’autre station.
Figure 3.4: Étapes d’appariements de FRANASZEK et al. [2008]
26

3.2 Algorithmes proposés
3.2.1 A priori sur la position des stations
Nous possédons un a priori sur la position des stations avant compensation (les techniques pou-vant être utilisées et la précision que l’on peut obtenir σa priori (de l’ordre de 70cm) sont donnéesdans [HULLO, 2013]). Cependant, on ne connaît pas l’orientation des stations.
Une station vise plusieurs sphères. Si on connaissait parfaitement sa position, on pourraitconstruire une zone annulaire dans laquelle il est possible que des sphères visées par la stationsoient présentes (entre les pointillés rouges). Dans la mesure où la position de la station est connueavec une certaine incertitude, il faut élargir cette zone (à la zone hachurée en vert entre les poin-tillés verts) grâce à une certaine tolérance (les flèches noires). Cette tolérance est donnée par2.57 σa priori.
Figure 3.5: Zone annulaire d’une station, dans laquelle il existe des sphère visées par cette station
3.2.2 Algorithme inspiré de l’algorithme de RanSaC
L’algorithme de RanSaC (Random Sample Consensus) est un algorithme basé sur des choixeffectués à partir de tests sur des tirages aléatoires. C’est un algorithme d’estimation robuste utilisédans des problèmes ayant une lourde combinatoire à casser, comme par exemple la recherche depoints similaires entre deux images en photogrammétrie de manière à estimer la matrice fonda-mentale.
Cette section présente notre version de l’algorithme d’appariement en utilisant les principes del’algorithme de RanSaC, décrit dans HULLO [2013]. L’algorithme sera expliqué en deux dimen-sions. Le passage à la troisième dimension implique peu de concepts nouveaux.
Initialisation:On possède un ensemble de sphères connues en coordonnées:les sphères de référence: liste_ref.C’est ce jeu de sphères que l’on va nourrir au cours de l’algorithme.
27

Tant que: le puzzle n’est pas fini:On choisit une sphère au hasard dans liste_ref que l’on nomme: sph_1
On choisit parmi les stations non déjà placéesune station st possédant la sphère sph_1 dans son anneau.
Station non satisfaisante Station Satisfaisante Station non satisfaisante
Figure 3.6: Utilisation de la zone annulaire pour justifier le choix d’une station
On effectue l’appariement d’une visée au hasard de st vers sph_1.Plus cette visée semble probable, plus elle a de chance d’être choisie.La probabilité d’appariement est une fonction décroissante de la différence en valeurabsolue entre les deux estimations de la distance entre la station et la sphère:l’une d’après la lecture de la station sur la sphère,l’autre donnée par la position de la station a priori et par la position absolue de la sphère.
Figure 3.7: Probabilité d’appariement
On a alors appareillé la sphère sph_1 avec une des mesures de st.Cet appariement doit cependant être confirmé par les vérifications qui vont suivre.
28

On cherche une autre sphère sph_2 de liste_reftelle que la distance entre sph_1 et sph_2 soit la même(à une tolérance centimétrique près)dans liste_ref et dans l’ensemble des lectures vers les sphères de st.
Figure 3.8: Distance entre sph_1 et sph_2 dans liste_ref (en rouge) et dans l’ensemble deslectures de st vers les sphères (en violet). Ici, les distances sont différentes, ce qui permet d’exclurecet appariement
Pour chaque sphère sph_2 satisfaisant cette condition:
On effectue une rotation et une translation grossière en utilisant sph_1 et sph_2.Cela permet de confronter toutes les autres lectures de st aux sphères de liste_ref.
Si plusieurs choix se présententCalculer un score décrivant la vraisemblance de chaque appariement.Plusieurs propositions de score sont effectuées dans HULLO 2013
Choisir la configuration qui maximise ce score.
Figure 3.9: Cas d’un appariement avec la sphère sph_2 ayant un score faible
29

Figure 3.10: Cas d’un appariement avec la sphère sph_2 ayant un score élevé
Si on n’a pas trouvé de sphère sph_2 permettant de faire un appariement,L’appariement de st et de sph_1 était un mauvais choix.
Si on a trouvé une sphère sph_2 permettant de faire un appariement,Effectuer un ajustement de Helmertafin de déterminer les paramètres de position et d’orientation de st.
Calculer par point lancé la position absoluede l’ensemble des sphères visées par st
Ajouter ces nouvelles sphères à liste_ref
3.2.3 Adaptation d’une méthode de corrélation d’image
Les notions de géoréférencement, ou de consolidation sont maîtrisées dans les communautésde topographes, de cartographes, de vision par ordinateurs... Pourtant, ce problème dépasse lessimples applications topographiques. En imagerie médicale, par exemple, lorsque l’on dispose deplusieurs radios du cerveau, il est nécessaire de pouvoir les superposer pour les comparer. Cettesection a pour but d’adapter des méthodes utilisées en imagerie médicale, décrites dans ABRAM[2000], à notre problème.
30

3.2.3.1 Représentation d’une image et d’une configuration de sphères
Figure 3.11: Deux radios d’un cerveau à recaler l’une par rapport à l’autre. Issue de ABRAM[2000]
Le cas décrit par ABRAM [2000] considère une transformation entre les deux images composantune rotation et une translation. La difficulté est de déterminer ces inconnues (deux inconnues detranslations et une inconnue de rotation) alors que celles-ci semblent être de natures différentes,tout en étant liées.
En imagerie, on représente une image par une fonction de deux variables (les coordonnéescartésiennes d’un point de l’image) dont la valeur en un point représente le compte numériqueassocié au niveau de gris (noir correspond au compte numérique 0, blanc à la valeur maximalepossible du compte numérique). On utilise ensuite des outils mathématiques appartenant auxdomaines du traitement du signal et de l’analyse. En particulier, on utilise des transformées deFourier. Dans notre cas, nos fonctions devront modéliser la position de sphères dans l’espace.Ce seront des fonctions d’un vecteur de position 1 −→
P ∈ Rn dans {0, ∞} . Si f représente uneconfiguration de sphères, f sera défini par :
f : Rn → {0, ∞}−→P �→ ∞ Si il y a une sphère en
−→P
−→P �→ 0 Si non
(3.2.1)
On peut décrire cette fonction plus rigoureusement en utilisant la fonction de Dirac : δ :
f(−→P ) =�
sph
δ(−→P − −→P sph) (3.2.2)
L’avantage de cette définition est que la transformée de Fourier 2 de la fonction de Dirac esttrès simple à calculer.
3.2.3.2 Calcul de la corrélation croisée
On considère que la configuration de sphère 1, représentée par la fonction f1 est notre réfé-rence, et que l’on veut connaître la translation −→
T et la rotation R à appliquer à une configuration
1. (n représente la dimension de l’espace dans lequel on travaille, en général 3)2. On définit la transformée de Fourier de la fonction f de Rn dans R comme étant la fonction :
f : Rn → RK �→
�Rn f(−→P ) e−2iπ KT ·−→P d
−→P
(3.2.3)
31

2 représentée par la fonction f2 pour la faire coller à la configuration 1.
Dans le cas de deux radios du cerveau, imprimées sur un film transparent, la méthode manuellepour faire coïncider les deux images est de les superposer l’une à l’autre face à la lumière etde chercher la translation et la rotation qui superpose les zones sombres avec les zones sombres,et les zones transparentes avec les zones transparentes. La quantité de lumière traversant cettesuperposition de radio est :
�
Rn
f1(R−→P + −→
T ) f2(−→P ) d−→P (3.2.4)
Plus cette quantité est élevée, meilleure est la qualité de la superposition des deux images.
Dans un premier temps, on va chercher la translation indépendamment de la rotation. Pourcela, il faut maximiser la fonction (3.2.5).
−→T �→
�
Rn
f1(R−→P + −→
T ) f2(−→P ) d−→P (3.2.5)
Si on pose : ‹f1 : −→P �→ f1(R−→
P ), la fonction à minimiser peut s’écrire avec un produit decorrélation croisée : ∗ :
‹f1 ∗ f2 (3.2.6)
Un théorème très fort de la théorie du traitement du signal est le théorème du produit decorrélation croisée qui stipule que la transformée de Fourier du produit de corrélation croisée dedeux fonctions se traduit par un produit faisant intervenir les transformées de Fourier de chacunede ces fonctions. Si f1 et f2 sont deux fonctions, on note z le complexe conjugué de z et f latransformée de Fourrier d’une fonction f , alors :
÷f1 ∗ f2 = ¯f1 f2 (3.2.7)
La méthode va être la suivante :
— On va calculer la transformée de Fourrier de la fonction (3.2.5), qui n’est autre que le produit
de “‹f1 et de “f2.
— On calcule la transformée de fourrier inverse
— On cherche le maximum.
3.2.3.3 Calcul des transformées de Fourier
Si la fonction f , décrite par (3.2.2) représente une configuration de sphère, sa transformée deFourier est assez simple à calculer :
f(K) =�
Rn
�
sph
δ(−→P − −→P sph) e−2iπ KT ·−→P d
−→P =
�
sph
e−2iπ KT ·−→P sph (3.2.8)
De plus, on ne va pas la calculer pour toutes les valeurs de K possibles, mais seulement cellesqui correspondent à des longueurs d’onde supérieures à une tolérance donnée. Outre le fait quecela permet d’économiser du calcul, cela crée un filtre passe-bas qui permet d’atténuer les valeurstrès dispersées (soit zéro soit l’infini) de f .
32

3.2.3.4 Calcul de le transformée de Fourrier de la première fonction
On peut calculer directement f2 à partir de f2. Le but de ce développement est de calculer ‹f1
alors que l’on ne connait pas la matrice de rotation R. Nous allons montrer que ‹f1 = f1.
On a d’une part, par définition :
f1 : K �→�
Rn
f1(−→P ) e−2iπ KT ·−→P d−→P (3.2.9)
D’autre part, on va calculer ‹f1 :
“‹f1 : K �→�
Rn
f1(R−→P ) e−2iπ KT R
−→P d
−→P (3.2.10)
En effectuant le changement de variable : ‹P = R−→P , sachant que le Jacobien de la transformation
est une matrice de rotation, de déterminant 1 :
“‹f1 : K �→�
Rn
f1(‹P ) e−2iπ KT �P d‹P (3.2.11)
On a donc bien : ‹f1 = f1.
3.2.3.5 Récapitulatif de la méthode
On calcule “f1 et “f2 en utilisant la formule (3.2.8), le vecteur maximal de la transformée inversede “f1 “f2 nous donne le vecteur de translation et on trouve la matrice de rotation par un algorithmede force brute en testant plusieurs combinaisons.
3.3 Discussion et analyse des méthodesLa méthode proposée par FRANASZEK et al. [2008] est très instable. De nombreux faux ap-
pariements sont créés et cette méthode ne peut être utilisée sans une reprise manuelle du résultat.D’autre part, la combinatoire est tellement complexe que le temps de calcul n’est plus acceptabledès que le nombre de stations composant le réseau dépasse la dizaine.
L’adaptation de la méthode de ABRAM [2000] donne pour chaque station un ensemble derésultats contenant la vraie configuration. Il faudrait améliorer cette méthode en prenant en consi-dération l’a priori sur la position, en réglant de manière plus fine les paramètres (en particulier lesdifférentes valeurs de K pour lesquelles on effectue le calcul), et en incluant des étapes de vérifica-tion.
Finalement, la seule méthode réellement opérationnelle est celle basée sur l’algorithme de Ran-SaC. Nous l’avons testée sur un sous ensemble de la numérisation d’un bâtiment réacteur de lacentrale de Cattenom (près du Luxembourg). Les tests ont été effectués sur les 37 scans des étages13, 14 et 15 (les trois étages supérieurs) du BR (bâtiment réacteur). La méthode donne des résul-tats différents à chaque fois que l’on fait l’expérience. Cela est dû au fait que cette méthode estbasée sur des fonctions aléatoires.
33

La méthode donne le bon résultat en moyenne une fois sur trois. En revanche, lorsqu’elle nedonne pas le bon résultat, il n’y a souvent qu’une seule station qui pose problème et ce n’est pasla même d’une fois sur l’autre. Il est donc possible d’améliorer cet algorithme, soit en le lançantplusieurs fois et en confrontant les résultats, soit en effectuant une recherche arborescente, capablede revenir en arrière face à une situation problématique, soit en créant une interface utilisateurpermettant d’effectuer une méthode semi-automatique.
34

Chapitre 4
Compensation
4.1 Différents problèmes posés lors de la compensation : Étatde l’art et propositions d’améliorations
4.1.1 Formulation paramétrique et formulation de Gauss-Helmert
4.1.1.1 Formulation paramétrique
Pour faciliter la lecture, la figure 2.2 est reprise ici. Un réseau lasergrammétrique peut êtredécrit par les paramètres de position et d’orientation de nos stations ainsi que les paramètres depositions des sphères. Considérons la sphère sph de position −−→
Psph et la station α (en rouge) deposition −→
Pα et de matrice d’orientation Rα.
Figure 4.1: Expression des contraintes
La station α vise la sphère sph. Cette lecture est représentée par le vecteur position de la sphère−→lα dans le repère local de la station α. On peut donc écrire :
35

La formulation paramétrique d’un problème de compensation, décrite dans l’annexe : B.2.2.2,exige que l’on puisse calculer nos lectures, dans notre cas, les positions des sphères dans le repèrede nos stations, à partir des paramètres. Pour le cas particulier de la visée de α sur sph :
−→lα = RT
α (−−→Psph − −→
Pα) (4.1.1)
En considérant l’ensemble des stations de notre réseau, et l’ensemble des sphères, on peutconstruire une fonction f prenant en argument x : un vecteur formé par la concaténation desparamètres de position et d’orientation des stations et des paramètres de positions des sphères.Cette fonction permet de simuler les lectures à partir de x.
f
...−→Pα
Rα
...−−→Psph
...
� �� �x
=
. . .
. . .
. . .
. . .
RTα (−−→
Psph − −→Pα)
. . .
. . .
. . .
� �� �l
(4.1.2)
Pour calculer x par la méthode des moindres carrés, on part d’une valeur approchée de x : x,à partir de laquelle on calcule v = f (x) et A, la matrice Jacobienne de f par rapport à x. Si onpose P la matrice des poids des observations l (P est décrite dans l’annexe D.2.4), on retrouve laformule très connue des moindres carrés appelée système d’équations normales.
δx = (AT PA)−1AT P v (4.1.3)
δx est un appoint à ajouter à x pour obtenir un ensemble de paramètres plus vraisemblablesque x. Il faut alors reprendre le calcul en substituant x + δx à x et effectuer autant d’itérationsque nécessaire, jusqu’à ce que les δx soient négligeables. (Ce processus itératif est décrit plus endétail dans l’annexe B).
4.1.1.2 Formulation de Gauss-Helmert
La formulation paramétrique possède un défaut. Elle exige le calcul des positions des sphères.Or, la connaissance de la position de ces sphères dans le repère général n’est pas utile à l’assemblagedes différents nuages de points. Les seuls paramètres qui nous intéressent sont les positions et lesorientations des stations. Le calcul de la position de ces sphères nécessite des calculs inutiles.
C’est pour cela que la méthode de Gauss-Helmert, (présentée dans l’annexe B.2.2.4) est plusadaptée à notre cas. Si la méthode paramétrique nécessite une fonction capable de simuler lesobservations à partir des paramètres, la méthode de Gauss-Helmert n’a besoin que de conditions 1
liant observations et paramètres. Par exemple, la sphère sph induit comme condition entre α et β :
1. Ces conditions sont aussi la base des conditions exprimées en photogrammétrie et en vision par ordinateur.Une comparaison des approches lasergrammétrique et photogrammétrique autour de ces conditions est donnée dansl’annexe : F
36

On peut alors créer une fonction f qui prends en argument les paramètres décrivant le réseauet les observations, et qui renvoie théoriquement 0.
Les lectures l étant entachées d’erreurs, cette fonction évaluée en l est égale à un vecteur defermetures proches de 0. Une description plus détaillée de la construction de cette fonction estdonnée en annexe : D.2 ; et les développements devant être effectués à partir de cette formulationparamétrique sont donnés en annexe : D.4.
4.1.1.3 Formulation plus générale du problème
D’autres méthodes de formulation du problème ont été étudiées, notamment la méthode décritedans l’annexe B.2.2.3 qui permet d’ajouter des conditions entre les paramètres eux-mêmes. Celapermet par exemple d’ajouter une condition imposant une distance fixe entre deux points duréseau. Cette méthode a été souvent utilisée lors de ce stage, par exemple pour fixer la position etl’orientation d’une station.
4.1.2 Différents modèles de verticalité
Toutes les rotations Verticalité décrite Station verticale
sont libres par une lecture
Figure 4.2: Trois modèles de verticalité
Pour représenter la situation d’un objet dans l’espace, par exemple le nuage de points acquispar une station, il faut six paramètres indépendants. On dira que cet objet possède six degrés deliberté. Trois paramètres de positions, ou un vecteur de position à trois composantes : −→
P , et troisparamètres d’orientations : un choix de trois angles d’Euler. Dans ce cas, nous dirons que Toutesles rotations sont libres.
37

Lorsque on utilise un scanner laser, la première étape consiste à le caler, c’est-à-dire que l’onfait coïncider l’axe de rotation principal de l’appareil avec la verticale : l’axe −→eZ du repère général.Cette action contraint deux degrés de libertés : les deux angles décrivant l’inclinaison de l’appareil(et donc du nuage de points correspondant) par rapport à la verticale. Il ne reste donc que quatreparamètres à estimer : les trois paramètres de position et une rotation par rapport à l’axe vertical.Dans ce cas, nous dirons que Les stations sont verticales
Cette dernière méthode possède cependant un défaut. Le calage est une opération qui dépendde la qualité de la mesure de l’angle de l’appareil par rapport à la verticale (effectuée par lecompensateur bi-axial de l’instrument) et de la qualité du travail de l’opérateur. S’il est vrai quel’on impose que la mesure de l’angle d’inclinaison de l’appareil soit nulle, cette mesure est donnéeavec une certaine imprécision 2 σvertical. C’est pour considérer cette imprécision que l’on considèreune dernière méthode pour laquelle toutes les rotations sont possibles, mais la Verticalité est décritepar une lecture égale à 0 ± σvertical. Si la station n’est pas calée (soit à cause d’un oubli, soit parceque la configuration du lieu ne le permettait pas, comme par exemple le cas de la station de lafigure 2.3), on considérera que ces lectures décrivant la verticalité sont fausses.
4.1.3 Calcul par morceaux ou calcul en bloc
Le principe du calcul par morceaux est de ne considérer qu’un sous-ensemble des stations àcompenser et de les compenser entre elles, sans tenir compte des autres stations.
Figure 4.3: Compensation d’un petit réseau de stations (représentées par les triangles) constituantun sous ensemble d’un réseau plus grand
On considérera par la suite que ces stations sont fixées rigidement les unes aux autres. On créeune station fictive fixée solidairement à tout ce sous-ensemble ; et on considère que cette stationvise l’ensemble des sphères visées par ce sous ensemble de stations.
2. En pratique, on considère dans notre cas que σvertical = 2◦
38

Figure 4.4: Station fictive équivalente
On peut alors compenser un réseau composé de plusieurs stations fictives, ou de vraies stations.
Figure 4.5: Compensation d’un réseau de deux stations fictives
On peut effectuer plusieurs compensations, à plusieurs niveaux d’encapsulation. La compen-sation par morceaux exige la programmation de méthodes récursives basées sur des structuresarborescentes.
Figure 4.6: Plusieurs compensations encapsulées
On préférera une représentation arborescente des différents niveaux de compensations.
39

Figure 4.7: Structure arborescente de la compensation
Le principe de la compensation en bloc 3 est de ne considérer qu’un seul niveau de compensation.
Figure 4.8: Compensation en bloc
Lors d’une compensation, l’étape qui nécessite le plus de ressources de calcul est l’inversion dusystème d’équations normales. La complexité de cette étape est cubique en termes de nombre destations. Considérons un réseau de 1000 stations. Si on divise ce réseau de manière à ne compenserque des réseaux de 10 stations, on devra effectuer 100 compensations de réseaux de 10 stations ;puis 10 compensations de réseaux de stations fictives, puis une dernière compensation de ces sta-tions fictives. Le calcul de ces 111 compensations sera relativement rapide puisqu’une compensationd’un réseau de 10 stations est 1 000 000 fois plus rapide qu’une compensation de 1000 stations.Finalement, la compensation par morceaux sera de l’ordre de 10 000 fois plus efficace en termes detemps de calcul qu’une compensation en bloc.
Ce chiffre surestime largement la rapidité des méthodes par morceaux. En effet, la gestion dela structure arborescence des données, la gestion des aspects topologiques du réseau et la créationdes différentes matrices, utilisent des ressources computationnelles qui ne sont plus négligeablesdevant l’inversion du système des équations normales. D’autre part, les moyens actuels de calculsont devenus très efficaces en calcul matriciel, ce qui permet d’effectuer la compensation en blocdans un temps raisonnable.
Si la compensation par morceaux reste plus rapide que la compensation en bloc, elle ne per-mettra jamais de confronter l’ensemble des observations du réseau, mais seulement les observationsappartenant à un même morceau. De ce fait, un calcul par morceaux ne permettra pas d’éliminercertaines fautes.
3. Cf annexe A pour la définition de compensation en bloc
40

4.1.4 Choix d’une fonction de coût à minimiser
Dans le problème de la compensation que nous souhaitons résoudre, nous possédons plus demesures que le strict nécessaire pour déterminer les paramètres qui nous intéressent. Pour confron-ter ces mesures, nous avons besoin d’une part d’un modèle fonctionnel, qui modélise la manièredont les mesures devraient se comporter si elles étaient parfaites et d’autre part d’un modèle sto-chastique, qui décrit la manière dont les mesures réelles diffèrent de leurs valeur idéale. La prise encompte de ce modèle stochastique dans la compensation se traduit par les modèles mathématiquesexposés dans cette section.
4.1.4.1 La fonction de coût des moindres carrés
Soit l une lecture effectuée par un appareil. En raison des erreurs inhérentes au processus demesures, cette lecture ne peut être parfaite. Si on note l la mesure que l’on aurait dû faire, on peutexprimer l’écart ou résidu v entre cette mesure idéale et la mesure effective :
v = l − l (4.1.4)
Généralement, on suppose que ce résidu suit une loi gaussienne. Sa densité de probabilité estreprésentée par la figure 4.9.
Figure 4.9: Histogramme d’une variable aléatoire suivant une distribution normale (en vert) etcourbe gaussienne modélisant ce comportement (en pointillés noirs)
Souvent, on ne possède pas une lecture mais n lectures. On construit alors un vecteur delecture par concaténation de l’ensemble des lectures que l’on a effectuées. On notera Σll la matricedes variances-covariances de ces lectures et P la matrice des poids de ces mesures : une matriceproportionnelle à Σ−1
ll (le coefficient de proportionnalité est choisi de manière à simplifier lescalculs). La densité de probabilité de ce vecteur de résidus, représentée par la figure 4.10 est :
Figure 4.10: Exemple de gaussienne multivariée pour un vecteur aléatoire de dimension 2
p = 1(2π) n
2 |Σll|12
e− 12 vT Σ−1
llv (4.1.5)
41

Ce résultat est démontré dans TSYBAKOV [2006].Le but de la compensation par les moindres carrés est de maximiser cette densité de probabilité.
Cela revient à minimiser la fonctionnelle :
Ω = vT Pv (4.1.6)
C’est cette hypothèse qui mènera à la formule classique : 4.1.3.
Dans le cas où les observations ne sont pas corrélées, cette fonctionnelle devient :
Ω =n�
i=1Pii v2
i (4.1.7)
4.1.4.2 Estimateurs robustes dans le cas particulier d’observations indépen-dantes
La fonctionnelle Ω minimisée par la méthode des moindre carrés est une forme quadratique.Les résidus y interviennent au carré. C’est pourquoi, une faute 4 aura une influence très forte surcette fonctionnelle Ω. Le principe des estimateurs robustes est de remplacer cette fonction carrépar une autre fonction donnant moins de force aux résidus élevés. C’est pour cela que BAARDA[1968], TRACOL [2012], VALERO et MORENO [2005], WICKI [2001], CATTIN [Version 3.3] etCAROSIO [1996] proposent la fonctionnelle :
Ω =n�
i=1Pii N (vi) (4.1.8)
Où N est une fonction paire, croissante sur R+, par exemple la fonction carré dans le cas dela formule 4.1.7. On prend généralement une fonction qui approxime la fonction carré au voisinagede 0, et croît de manière moins marquée que la fonction carrée. Des exemples de telles fonctionssont représentés sur la figure : 4.11.
On peut définir une pseudo-racine carré de cette fonction (par exemple la fonction carré, lafonction valeur absolue et la fonction de Welsch, comme sur la figure 4.12) :
ρ(x) =»
N (x) sign(x) (4.1.9)
Cela permet d’exprimer l’équation 4.1.8 avec une écriture ressemblant à l’équation : 4.1.7 :
Ω =n�
i=1Pii ρ(vi)2 (4.1.10)
(dans le cas particulier des moindres carrés, ρ est la fonction identité)
Cette formule suppose qu’il n’y ait aucune corrélation entre les observations. Cela implique quela matrice des poids P est diagonale. Cette hypothèse n’est pas valable dans notre cas. Il faut donctrouver une généralisation de cette formule prenant en considération les relations existantes entreles lectures.
4. cf Lexique : Annexe A
42

Figure 4.11: Exemple de fonctions de coût
Figure 4.12: Exemples de fonctions ρ associées à des fonctions N
4.1.4.3 Fonctionnelle de TRIGGS et al. [2000]
TRIGGS et al. [2000] propose une autre fonctionnelle. Plutôt que de minimiser vT Pv, il proposede minimiser ρ(vT Pv) où ρ est une fonction d’atténuation qui limite l’influence des fautes (ρ estdéfinie de la même manière que dans le paragraphe précédent, mais il est utilisé différemment).Si cette fonctionnelle possède l’avantage de considérer les corrélations entre les observations, elleprésente un défaut majeur. Le but d’un estimateur robuste est de limiter l’influence de fautesentachant une ou plusieurs observations. C’est ce qui est effectué par la fonctionnelle décrite parla formule 4.1.8. Dans le cas de la fonctionnelle de TRIGGS et al. [2000], l’ensemble des erreursrésiduelles et les fautes sont ajoutées les unes aux autres, et c’est la somme finale qui est atténuée.Cela ne correspond pas à notre besoin.
Face à ce problème, nous avons envoyé un courrier à Bill Triggs et à Richard Hartley, deuxauteurs de TRIGGS et al. [2000]. Ils nous ont tous les deux répondus. Bill Triggs nous conseilled’utiliser la fonctionnelle décrite par la formule 4.1.8 et Richard Hartley nous propose de mélangerla fonctionnelle TRIGGS et al. [2000] et la fonctionnelle décrite par la formule 4.1.8.
43

4.1.4.4 Fonctionnelle de YUANXI [1992]
YUANXI [1992] propose d’utiliser la formule suivante :
Ω =�
i,j∈[|1,n|]Pij ξ(vi, vj) (4.1.11)
ξ est une fonction symétrique de deux variables. (Dans le cas des moindres carrés, ξ(vi, vj) =vi vj).
Dans le cadre de cette étude, nous nous sommes limités à des fonctions du type : ξ(vi, vj) =ρ(vi) ρ(vj) où ρ est toujours la même fonction d’atténuation. La fonctionnelle de YUANXI [1992]peut donc s’écrire :
Ω = ρ(v)T P ρ(v) (4.1.12)
Cette fonctionnelle généralise l’équation : 4.1.8
4.1.4.5 Fonctionnelle déterminée à partir d’une approche Bayésienne
Face à une telle diversité et une absence de justification, il nous paraissait nécessaire de repartirdes fondements statistiques pour construire la fonction de coût à minimiser.
Nous avons adopté une approche Bayésienne et utilisé l’hypothèse de TSYBAKOV [2006] selonlaquelle les lectures réelles corrélées peuvent être déduites d’un jeu de lectures fictives décorréléespar simple relation affine. Ce raisonnement est détaillé dans l’annexe B et aboutit à la fonctionnellesuivante :
Ω =n�
i=1N (
n�
j=1Wijvj) (4.1.13)
La matrice W est donnée par :
W = (V√
Λ)−1 (4.1.14)
où V et Λ sont calculés en décomposant la matrice des variances-covariances des observationsen valeurs propres, vecteurs propres. Λ est la matrice diagonale des valeurs propres, et V est lamatrice des vecteurs propres.
Cette fonctionnelle est encore une généralisation de 4.1.8 pour des matrices W non diagonales.Elle est différente de celle de YUANXI [1992]. Une étude comparative de ces deux fonctionnellesest effectuée dans l’annexe B.
4.1.5 Méthodes de minimisation de la fonction de coût
La fonction de coût Ω est définie. Il faut pouvoir la minimiser.
44

4.1.5.1 Méthode utilisant une pseudo-matrice des poids
Dans le cas des moindres carrés classiques, la fonction f décrivant le modèle fonctionnel de notreproblème décrite dans la section 4.1.1.1 (ou décrite de manière plus générale dans l’annexe B.2.2.2)est linéarisé en effectuant un développement limité à l’ordre 1. La minimisation des moindres carrésse traduit alors une opération algébrique ne faisant intervenir que des fonctions linéaires, ce quise traduit par une simple projection (cf annexe B.2.2.2). Cependant, lors de la linéarisation de f
en série de Taylor, les termes de degrés supérieurs à 1 ont été négligés, ce qui impose de réitérerle processus jusqu’à que ces termes soient négligeables. Une minimisation par les moindres carrésd’une fonction non linéaire est donc un processus itératif (cf Annexe B.2.3).
Si l’on voulait minimiser une autre fonctionnelle Ω, une méthode consisterait à effectuer unelinéarisation de la fonction f comme si on allait effectuer une minimisation par les moindres carrés,puis trouver une méthode pour minimiser la fonctionnelle en travaillant sur la fonction linéarisée.Dans la mesure où Ω n’est plus une fonction bi-linéaire, comme dans le cas des moindres carrés,cette minimisation est plus complexe. Il faut linéariser les fonctions intervenants dans Ω, ce quiimplique que l’on devra effectuer plusieurs itérations.
D’un point de vue mathématique, cela consiste à substituer à la matrice des poids P , unepseudo-matrice des poids P dans la formule des moindres carrés (par exemple, dans la formule4.1.3). C’est ce que proposent YUANXI [1992], VALERO et MORENO [2005], WICKI [2001],CATTIN [Version 3.3] et CAROSIO [1996].
Cette matrice des poids fait intervenir l’inverse des résidus :
Pij = . . .1vi
(4.1.15)
Cette méthode pose trois problèmes majeurs :
— La matrice P n’est pas définie pour des résidus nuls. Sachant que l’on cherche à ce que lesrésidus soient les plus faibles possibles (d’une part en effectuant des mesures de qualité, etd’autre part, en répartissant les erreurs de manière optimale), on aboutira très souvent à desmatrices P mal conditionnées.
— La matrice P n’est pas symétrique, ce qui pose des problèmes lors de la résolution du systèmed’équations normales et de l’étude des erreurs.
— Deux processus itératifs sont mis en jeu. Le premier est dû à la non linéarité de la fonction f
et le second, à la non bi-linéarité de la fonctionnelle Ω. Cependant, ces deux processus sontconsidérés dans la démonstration de manière totalement indépendantes.
4.1.5.2 Méthode utilisant le gradient et la matrice Hessienne de la fonction decoût
Une seconde méthode de minimisation de la fonctionnelle Ω est cependant possible. Nous allonsconsidérer dès le début du raisonnement que la méthode de minimisation devra être itérative. Onpart d’une valeur approchée du vecteur des paramètres x et on lui ajoute un incrément δx pouraboutir à la valeur compensée x (à l’itération suivante, on utilisera ce x comme valeur approchée).On peut donc écrire :
Ω(x) = Ω(x + δx) (4.1.16)
45

La fonctionnelle Ω (exprimée en fonction de x) combine les informations du modèle fonctionnelet celles du modèle stochastique. En linéarisant Ω, on linéarise intrinsèquement toutes les fonctionsnon-linéaires considérées. On aboutit alors à l’équation (cf B.2.33) :
∂2Ω∂x2 δx + ∂Ω
∂x= 0 (4.1.17)
Où ∂Ω∂x et ∂2Ω
∂x2 sont respectivement le gradient et la matrice Hessienne de Ω.
4.2 Assemblage des différents aspects de la compensationLes différents aspects de la compensation, du modèle fonctionnel au modèle stochastique ont
été étudiés séparément. Plusieurs propositions d’amélioration ont été formulées. Le but de cettesection est de combiner le florilège de chacune des faces du problème.
Nous avons choisi de préférer la formulation de Gauss-Helmert généralisée à la méthode pa-ramétrique classique. Nous avons implémenté les trois types de modèles de verticalité et les deuxméthodes de gestion du réseau : par morceaux et par bloc.
Concernant, la fonction de coût et sa méthode de minimisation, toutes les combinaisons defonctions de coût et de méthodes de minimisation n’ont pas été implémentées. Les seules méthodesétudiées et implémentées sont les méthodes A, B, C, D et E du tableau 4.1 (ces appellations réfèrentà l’annexe B et seront utilisées par la suite.)
Table 4.1: Combinaisons des fonctions de cout et des méthodes de minimisation
4.3 Tests effectuésLe but est de comparer trois solutions de compensation des réseaux lasergrammétriques :
— Le programme python basé sur tous les développements théoriques que nous avons développésau cours de ce stage, et que nous présentons dans ce mémoire.
— Le logiciel Jag 3D (cf figure 4.13)
— Le logiciel Trinet+ (cf figure 4.14)
Chacun de ces logiciels propose différentes options que nous allons tester.
46

4.3.1 Protocole expérimental
4.3.1.1 Simulation d’un jeu de données
Nous allons compenser un réseau de 12 (respectivement 37) stations correspondant aux scansdes étages 15 (respectivement 13, 14 et 15 : les trois étages supérieurs d’un bâtiment réacteur). Unepremière compensation permet de connaître la valeur la plus probable de la position des stationset celle des sphères. Cependant, on aimerait comparer les résultats des différentes compensationseffectuées par différents logiciels à des valeurs vraies, ce qui est impossible en pratique. C’est pour-quoi, nous avons conservé les paramètres de positions et d’orientation des stations ainsi que despositions des sphères, puis nous avons simulé des nouvelles lectures à partir de ces paramètres.Nous obtenons alors des mesures parfaites, dont les valeurs vraies des paramètres associés sontles paramètres de positions et d’orientation des stations. Enfin, nous bruitons ces lectures avec unbruit gaussien de 1mm d’écart type auquel nous ajoutons deux faux appariements de sphères. Nousobtenons un jeu de données à compenser très plausible.
Les données peuvent être importées dans Jag3D soit comme si elles avaient été relevées par untachéomètre, soit comme si elles avaient été relevées par plusieurs sessions GNSS. Pour Trinet+,seule la deuxième alternative est possible. Pour plus de détails vis-à-vis de l’importation de donnéesdans ces deux logiciels, se référer à l’annexe : I
4.3.1.2 Estimateurs de la qualité des résultats
Pour chaque valeur de la position des stations, on calcule la distance entre la valeur compenséedonnée par le logiciel et la valeur vraie. On note Δst cet écart.
On observe trois estimateurs d’exactitude :
— La valeur maximale de cet écart sur l’ensemble des stations du jeu de données :
maxst
Δst (4.3.1)
— La moyenne des valeurs absolues de ces deltas ( card{st} est le nombre de stations)
1card{st}
�
st
Δst (4.3.2)
— L’écart type de ces positions compensées
�1
card{st}�
st
Δ2st (4.3.3)
4.3.2 Comparaison des différentes méthodes développées etexpérimentées au cours de ce stage
Nous allons comparer les résultats issus de la compensation utilisant trois méthodes de minimi-sation de la fonction de coût : Ω : A,B et D ; et trois fonctionnelles (trois fonctions N ) : la fonctioncarré (Quadratique, c’est la méthode des moindres carrés), la fonction de Huber et la fonction deWelsch. On sait que toutes les méthodes de minimisation de la fonction de coût : Ω : A,B,C,Det E sont équivalentes quand il s’agit de minimiser les moindres carrés. C’est pour cela que lesrésultats des moindres carrés (en bleu) serviront de référence à laquelle seront comparés tous lesautres calculs. Si les résultats sont meilleurs que les moindres carrés, ils seront en vert, s’ils sontéquivalents, ils seront en jaune et s’ils sont pire, ils seront rouge.
47

Figure 4.13: Représentation des étages 13, 14 et 15 dans le logiciel Jag 3D
Table 4.2: Tableau comparatif des résultats donnés par les différentes méthodes proposées dans cepapier (calcul effectués par rapport à la valeur vraie, unité : m). Bleu : valeur de référence, Vert :résultats meilleurs, Jaune : résultats équivalent, Rouge : résultats plus mauvais
On observe que les résultats des étages 13-14-15 sont meilleurs que ceux de l’étage 15 seul. C’esttout simplement dû au fait que dans le premier cas, il y a 2 faux appariements de sphères pour 12stations, alors que dans le deuxième cas, il y a 2 faux appariement pour 13 stations.
On observe que les meilleurs résultats sont obtenus avec la méthode D utilisant une fonctionnellede Welsch. Ces résultats sont de l’ordre de 3 à 4 fois meilleurs que ceux obtenus avec la méthodedes moindres carrés.
48

Figure 4.14: Représentation des étages 13, 14 et 15 dans le logiciel Trinet+
4.3.3 Comparaison de notre méthode avec Trinet+ et Jag3D
4.3.3.1 Premier jeu de résultats
Les résultats donnés par TRINET+ et par JAG 3D sont moins bons que ceux que me donnentmon implémentation (d’un facteur 10 environ).
Table 4.3: Tableau comparatif des résultats donné par les différents logiciels (unité : m) Bleu :valeur de référence, Vert : résultats meilleurs, Jaune : résultats équivalent, Rouge : résultats plusmauvais
Le problème vient du fait que les stations sont un peu inclinées : non parfaitement verticales.Dans le logiciel Jag3D, ce défaut de verticalité ne peut être considéré.
Le logiciel Trinet+ propose d’intégrer les défauts de verticalité en tant que paramètre inconnusupplémentaire. Cependant, les fonctions faisant intervenir les angles entre la verticale et l’axevertical des stations sont linéarisés. Cette approximation n’est pas viable pour notre réseau danslequel les stations ne sont pas parfaitement verticales (2◦ en moyenne, et cela peut aller jusqu’à4◦). Cette approximation conduit à un échec de la compensation : le processus itératif diverge.
4.3.3.2 Second jeu de résultats, utilisant des stations verticales
Pour obtenir cependant des résultats corrects, j’ai simulé des lectures dans le cas où les stationssont strictement verticales. Ce qui, dans notre cas, ne correspond pas à la réalité.
49

Table 4.4: Tableau comparatif des résultats donnés par les différents logiciels dans le cas destations verticales (unité : m) Bleu : valeur de référence, Vert : résultats meilleurs, Jaune : résultatséquivalent, Rouge : résultats plus mauvais
On obtient des résultats similaires avec chacun des logiciels.
4.3.3.3 Troisième jeu de résultats, simulation avec un bruit gaussien, sansfautes
Nous allons à présent simuler un jeu de données sans aucune faute (sans déplacement de sphères)à partir de stations strictement verticales. Les erreurs qui entachent les mesures sont strictementgaussiennes. Je vais comparer ma solution de compensation avec le logiciel Jag3D et Trinet+.
Contre toute attente, notre programme python avec un estimateur robuste permet d’obtenirdes résultats de meilleure qualité qu’une compensation par les moindres carrés. C’est étonnantdans la mesure où, face à un flou gaussien, d’après les démonstrations se basant sur des fonde-ments statistiques du chapitre B, l’estimateur qui semblerait le plus adapté est la minimisation desmoindres carrés.
Nous allons comparer tous nos résultats à l’estimateur robuste utilisant la fonctionnelle deWelsch calculé via la technique D. On observe que les deux logiciels testés donnent des résultatsd’aussi bonne qualité.
Table 4.5: Tableau comparatif des résultats donné par les différents logiciels dans le cas de sta-tions verticales (unité : m) Bleu : valeur de référence, Vert : résultats meilleurs, Jaune : résultatséquivalent, Rouge : résultats plus mauvais
Il y a un phénomène remarquable : c’est que -avec cette simulation de données- nous obtenonsdes résultats comparables à ceux fournis par les logiciels Jag3D et Trinet+ alors que la méthodeest très différente :Alors que Jag3D et Trinet+ effectuent une compensation par les moindres carrés, au cours de la-quelle certaines observations, plus douteuses que les autres, sont supprimées, ma méthode consisteà n’exclure aucune observation, mais à utiliser une méthode (estimateur robuste) qui minimisel’influence des observations douteuses.
50

Figure 4.15: Les stations appartenant à des îlots morts sont représentés en rouge, les stationsrattachées en bleu, les sphères de références, en vert et les stations dont le fichier de mesures a étéperdu en jaune.
4.3.4 Tests effectués sur l’ensemble du réseau du Bâtiment Réacteur(BR)
Sur les 1057 stations du BR, nous n’avons pu en compenser que 976. Cela est dû au fait queles fichiers de lecture de 35 stations ont mal été importés (très certainement à cause d’erreursde nommage. Ces stations sont représentées par des sphères jaunes sur la figure 4.15). D’autrepart, 81 stations appartenaient à des îlots morts, c’est-à-dire des sous-ensembles du réseau laser-grammétrique non rattachés au reste du réseau ou à des sphères de références. Ces stations sontreprésentées par des sphères rouges sur la figure 4.15. Parmi ces ilots morts, certains sont dus à unmanque d’attention des opérateurs qui n’ont pas placé le nombre minimal de sphères requis pourassembler les stations (3), d’autres sont dus à des contraintes sur le terrains empêchant de placerce minimum requis. Les stations appartenant à des îlots morts représentent moins de 1% de l’en-semble des stations, ce qui permet de dire que les opérateurs ont effectué très consciencieusementle travail de pose des sphères et les vérifications de l’inter-visibilité. Ces stations en îlots mortsnécessiteront d’utiliser des contraintes nuages-nuages pour effectuer la consolidation.
La figure 4.15 permet de constater que de nombreuses stations supposées appartenir à des îlotsmorts (en rouge) sont proches de stations dont on a perdu les fichiers de lectures (en jaune). Ilest donc possible qu’il existe des liaisons entre ces deux types de stations que nous n’avons pas puprendre en compte dans notre calcul, qui explique le fait que certaines stations appartiennent àdes îlots morts.
51

On a pu comparer les résultats donnés par notre programme executé sur l’ensemble des étagesavec les résultats de la compensation effectuée avec le logiciel LTop, rassemblés avec le logicielCovadis. Ces résultats ont été vérifiés en utilisant plusieurs méthodes, notamment que les élémentsprésents dans les nuages de points se superposent bien d’un nuage à l’autre.
L’écart maximal entre ces deux résultats est de 5.7 cm, la moyenne des valeurs absolue desécarts est de 1 cm et l’écart type est de 1.4 cm. Ces calculs ont été effectués avec une méthode parles moindres carrés, sans enlever les fautes. Les résultats peuvent être encore améliorés.
52

Chapitre 5
Algorithme de détection, localisation etsuppression de fautes
Le lexique de l’AFT 1 donne comme définition d’une faute :
Faute (n.f.) Inexactitude souvent grossière provenant de l’inattention ou d’un oubli de l’opérateur.Ne pas confondre faute et erreur.Toutefois la norme AFNOR x 07001 désigne la faute par le terme "erreur parasite", termequ’il est préférable de ne pas utiliser en topographie.
Dans le cas de compensation d’un réseau lasergrammétrique, ces fautes peuvent avoir plusieursorigines. Soit, elles proviennent d’une erreur de lecture sur sphère, soit elles viennent de la sphèreelle-même. Elles peuvent émaner d’une lecture sur sphère si la station de scan a bougé lors du scan,ou que la sphère a mal été extraite du nuage de points. Ces fautes peuvent aussi venir de la sphèreelle-même : il est possible qu’une sphère ait bougée ou que lors de l’appariement des sphères onait considéré que deux sphères proches n’étaient qu’une seule sphère.
Dans tous les cas, on peut toujours se ramener au cas où une sphère a bougé.Le but de cette section est de présenter des algorithmes permettant de déceler des fautes dans
notre jeu de données et dans nos appariements. La difficulté réside dans le fait qu’une faute impactede nombreuses variables. Nous allons présenter ici la détection de faute à partir de la donnée duvecteur des fermetures après compensation.
5.1 Le vecteur de fermeturesSoient deux stations : A (respectivement B) dont la position est −→
PA (respectivement −→PB) et la
matrice d’orientation est RA (respectivement RB) qui visent une même sphère Sphere de position−−−−−→PSphere. On note −→
lA (respectivement −→lB) le vecteur de mesures de la station A (respectivement B)
vers la sphère. La condition donnée est :
−−−−−→PSphere = −→
PA + RA−→lA = −→
PB + RB−→lB (5.1.1)
1. Association Française de Topographie. Cf Annexe A
53

Le vecteur de fermeture associé à cette condition est :
wAB = −→PB + RB
−→lB − −→
PA − RA−→lA (5.1.2)
Généralement, on considère le vecteur de fermetures avant compensation, calculé à partir desparamètres approchés et des lectures : w = f (x, l). C’est ce vecteur qui entre dans le calcul decompensation. Pour détecter les fautes, on utilisera le vecteur de fermetures après compensation,calculé à partir des paramètres compensés et des lectures : w = f(x, l). Le processus de compen-sation étant itératif, ce w n’est autre que le w de l’itération suivante. Par abus de notation, on lenotera dans cette section, simplement w.
On représentera dans les figures de cette section les visées par des flèches bleues et les contraintespar des lignes courbes rouges. Par exemple, ici, les stations A, B et C visent une même sphère.On peut alors former deux conditions qui correspondent à deux fermetures : respectivement wAB
et wBC .
Figure 5.1: Trois mesures sur une sphère permettent de former deux conditions
Dans l’hypothèse qu’une faute impacte la visée de B vers la sphère, les fermetures wAB et wBC
seront élevées. Une méthode naïve consisterait à supprimer toutes les conditions dont les fermeturessont élevées. Cela conduirait à une perte d’information. Dans le cas de notre exemple, les visées deA et de C vers la sphère sont valides, on peut donc construire une condition.
Figure 5.2: Si une mesure est fausse, on peut toujours former une condition
5.2 Vecteur des fermetures normalisées
5.2.1 Le concept de résidu normalisé
Les résidus sont les quantités à retrancher aux lectures brutes pour obtenir les lectures com-pensées. Cependant, toutes les observations n’ont pas le même impact sur la solution.
Le problème est visible sur l’exemple très simple de la régression linéaire. On cherche à ajusterune droite sur un jeu de données. Les observations aux extrémités de la droite ont plus d’influence
54

sur les paramètres définissants la droite que celles au milieu du jeu de données. C’est pourquoi,un résidu élevé aux extrémités de la droite est plus douteux qu’un résidu élevé au centre du jeude données. Pour évaluer ce phénomène de manière quantitative, on utilise la notion de résidusstandardisés : le rapport du résidu (ce que l’on a) par l’estimation de sa variance (ce que l’ons’attend à avoir). Le lecteur est invité à se réferer à MERMINOD [2011] pour plus de détails.
�vi = vi
σvi
(5.2.1)
Figure 5.3: Résidus et résidus standardisés dans le cas d’une régression linéaire
Sur cette figure, on remarque que des résidus qui ont la même valeur (représentés par des traitsverticaux rouges de la même taille) ont des résidus standardisés différents (représentés par l’airedu rectangle rouge). Pour la recherche de faute, on préférera utiliser les résidus standardisés auxrésidus.
5.2.2 Généralisation du concept de normalisation au vecteur desfermetures
Si Qll représente la matrice des cofacteurs des lectures et Qxx représente la matrice des cofac-teurs des paramètres compensés (calculée au cours de la compensation). A et B sont les matricesJacobienne de f par rapport respectivement à x et à l. On a :
Qww = BQllBT − AQxxAT (5.2.2)
On calcule la matrice des Variances-Covariances du vecteur w : Σww en multipliant Qww parσ2
0 . Les écarts moyens quadratiques des fermetures sont les racines carrés des termes diagonaux deΣww.
On peut alors calculer les fermetures standardisées : �w
�wi = wi
σwi
(5.2.3)
Des valeurs anormalement grandes dans ce vecteur de fermetures sont le signe d’une faute pro-bable.
55

5.3 Présentation de trois méthodes de détection de fautesNous avons développé trois méthodes permettant de déceler les fautes :
— La première consiste à distinguer, parmi les contraintes induites par une sphère, celles quisemblent valides (valeur booléenne V rai), et celles qui sont hors tolérance (valeur booléenneFaux). Ensuite, on applique un raisonnement logique sur ces variables booléennes pour nereformer que des contraintes valides.
— La seconde méthode consiste à supprimer momentanément cette sphère pour établir plusfacilement des hypothèses.
— Enfin, la troisième méthode consiste à exploiter, non plus des valeurs booléennes décrivantle vecteur des fermetures : w, mais directement les valeurs numériques de w.
5.3.1 Méthode utilisant les anomalies du vecteur des fermetures
Pour fixer les idées, considérons cinq stations : A, B, C, D et E qui visent une même sphère.Le problème se généralise facilement à n stations.
Figure 5.4: Exemple de cinq stations visant une sphère
Si la fermeture wAB (ou wDE) est anormalement élevée, même après normalisation, il est évidentqu’il y a une faute sur la visée de la station A vers la sphère (respectivement de la station E versla sphère) ou que la sphère a bougé avant ou après cette mesure. Il est alors facile de supprimercette visée.
Cependant, dans la plupart des cas, le problème est plus compliqué. On peut considérer parexemple le cas où les fermetures wAB , wBC et wCD sont douteuses. On peut utiliser le principe deparcimonie pour supposer qu’il n’existe qu’une seule cause à l’origine de cet ensemble de fermeturesélevées. (Si il existe plusieurs fautes, on peut en enlever une première et les autres seront suppriméesen itérant tout le processus). Une explication que l’on peut donner est que la sphère a bougé. Ilfaut alors considérer séparément les mesures qui ont été prises avant (depuis les stations A et C) etaprès (depuis les stations B, D et E) que la sphère ne bouge. Dans le cas général, on peut toujoursséparer les visées vers la sphère avant qu’elle ne bouge et les visées vers la sphère après qu’elle aitbougé, telle que les fermetures hors tolérance soient exactement celles liant les deux positions de lamême sphère.
56
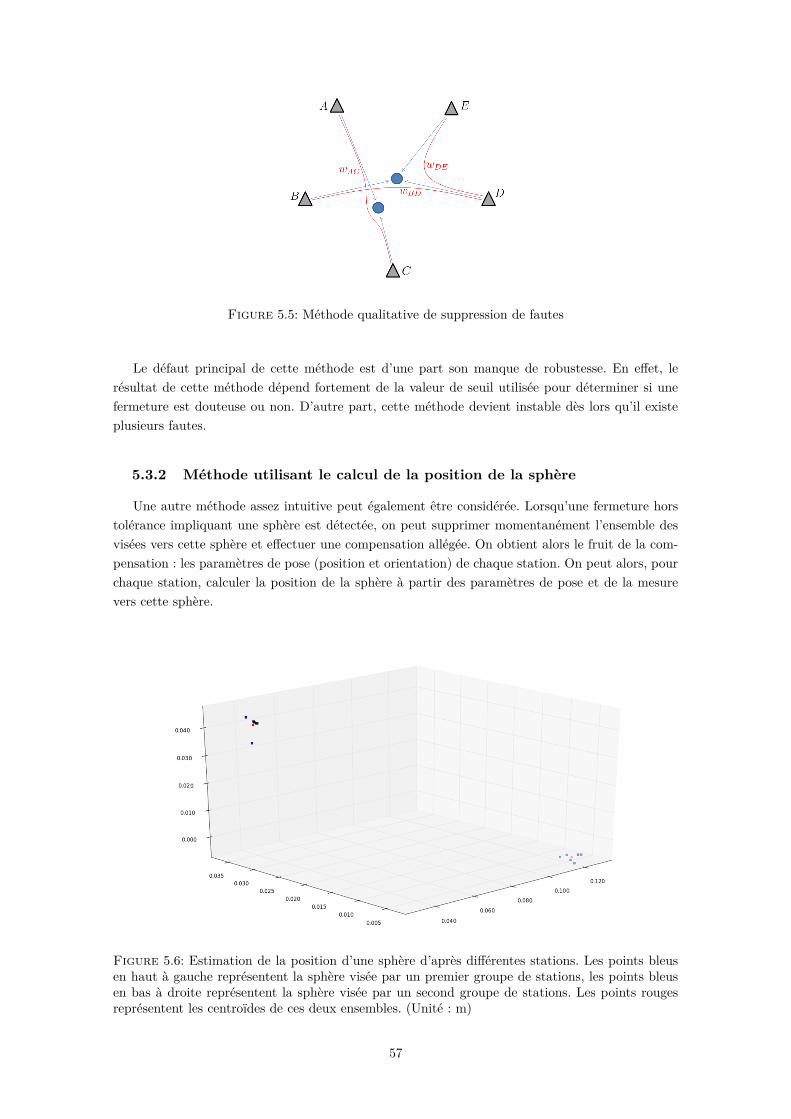
Figure 5.5: Méthode qualitative de suppression de fautes
Le défaut principal de cette méthode est d’une part son manque de robustesse. En effet, lerésultat de cette méthode dépend fortement de la valeur de seuil utilisée pour déterminer si unefermeture est douteuse ou non. D’autre part, cette méthode devient instable dès lors qu’il existeplusieurs fautes.
5.3.2 Méthode utilisant le calcul de la position de la sphère
Une autre méthode assez intuitive peut également être considérée. Lorsqu’une fermeture horstolérance impliquant une sphère est détectée, on peut supprimer momentanément l’ensemble desvisées vers cette sphère et effectuer une compensation allégée. On obtient alors le fruit de la com-pensation : les paramètres de pose (position et orientation) de chaque station. On peut alors, pourchaque station, calculer la position de la sphère à partir des paramètres de pose et de la mesurevers cette sphère.
Figure 5.6: Estimation de la position d’une sphère d’après différentes stations. Les points bleusen haut à gauche représentent la sphère visée par un premier groupe de stations, les points bleusen bas à droite représentent la sphère visée par un second groupe de stations. Les points rougesreprésentent les centroïdes de ces deux ensembles. (Unité : m)
57

On obtient un ensemble de points en 3D, chacun représentant l’estimation de la position de lasphère à partir d’une station qui vise cette sphère. On remarque très souvent que cet ensemble peutse diviser en deux sous-ensembles faiblement dispersés, correspondant chacun à la position de lasphère avant et après son déplacement. On utilise alors l’algorithme des k-means pour scinder cetensemble en deux. La sphère n’est plus une seule sphère, mais deux sphères et on peut reformulerd’autres conditions.
5.3.3 Méthode utilisant les valeurs numériques du vecteur des fermetures
Figure 5.7: Méthode quantitative de suppression de fautes
Pour fixer les idées, considérons cinq stations : A, B, C, D et E qui visent une même sphère.Le problème se généralise facilement à n stations.
En réalité, on soupçonne cette sphère d’avoir bougé. On notera α et β les deux positions decette sphères et
−→T β
α le vecteur de déplacement de cette sphère.
On définit la variable inconnue booléenne �A qui est égale à 0 si A vise la sphère α et 1 si A
vise la sphère β. (On définit de même les variables �B , �C , �D et �E).
On peut considérer sans perte de généralité que la station A vise la sphère α. On a donc �A = 0.
Si on ne considère que les erreurs dues au mouvement de cette sphère, ce qui revient à négligerles erreurs affectant les paramètres compensés et les imprécisions de mesures (qui sont négligeablesdevant la première erreur), la définition des écarts de fermetures permet d’aboutir au système :
wAB = �B
−→T β
α
wBC = (�C − �B)−→T β
α
wCD = (�D − �C)−→T β
α
wDE = (�E − �D)−→T β
α
(5.3.1)
On peut mettre ce système sous forme matricielle :
58

1 0 0 0
−1 1 0 0
0 −1 1 0
0 0 −1 1
� �� �A
�B
�C
�D
�E
−→T β
αT =
wTAB
wTBC
wTCD
wTDE
(5.3.2)
L’équation (5.3.2) possède 4 inconnues dans {0, 1} : les �, et une inconnue dans R3 : le vecteur−→T β
α . On résout ce système en deux étapes.
La première étape consiste à inverser le système en multipliant à gauche par l’inverse de lamatrice A. On peut ajouter l’information : �A = 0. On obtient alors une liste de points en 3dimensions :
0−→T β
α X 0−→T β
α Y 0−→T β
α Z
�B
−→T β
α X �B
−→T β
α Y �B
−→T β
α Z
�C
−→T β
α X �C
−→T β
α Y �C
−→T β
α Z
�D
−→T β
α X �D
−→T β
α Y �D
−→T β
α Z
�E
−→T β
α X �E
−→T β
α Y �E
−→T β
α Z
(5.3.3)
Figure 5.8: Estimation de la position d’une sphère utilisant le vecteur des fermetures après com-pensation. Les points bleus représentent les différentes estimations des sphères et les points rougessont les centroïdes des deux sous-ensembles de sphères (unité : mètre)
Dans cette liste de points, certains points correspondent à la sphère α (au moins le premierpoint), tandis que d’autres correspondent à la sphère β. Pour départager ces deux catégories desphères, on utilise la méthode des k-means, qui donne pour chaque sous ensemble la position ducentroïde. On crée alors deux ensembles de points. Ceux correspondants à la sphère α auquel onassocie des � égal à 0 et ceux correspondant à la sphère β auquel on associe des � égal à 1.
59

Si il n’existe qu’une seule visée vers la sphère α (respectivement vers la sphère β), on supprimecette visée. Si non, on considère non plus une sphère, mais deux sphères et on adapte les conditionsque l’on forme en conséquence.
5.4 Test comparatif des trois méthodesChacune de ces trois méthodes a été implémentée. La seconde méthode est cependant très
coûteuse en terme de temps de calcul puisqu’elle nécessite de re-compenser l’ensemble du réseau àchaque faute détectée.
C’est pour cela que seule les méthodes 1 et 3 ont été testées sur les 100 plus grosses fautes del’ensemble du réseau.
Parmi ces fautes détectées, 6 impactent des conditions imposées par la visée unique d’une sta-tion vers une sphère de rattachement. Ce chiffre est relativement élevé puisque sur l’ensemble desconditions imposées, seules 2% sont les conditions imposées par ces lectures sur les sphères derattachement.
Figure 5.9: Une sphère qui n’induit qu’une condition
Parmi ces 100 fautes détectées, il y avait aussi 12 conditions isolées, c’est à dire que la sphèreutilisée pour établir cette condition n’est pas utilisée pour établir d’autres conditions. Dans cecas-là, il est impossible de déterminer si l’une des deux lectures sur la sphère est fausse (figure5.9.a ou 5.9.b) ou si la sphère a bougé (5.9.c). Quelle que soit la cause de cette faute, le résultatest le même : il faut supprimer cette condition. Les trois méthodes effectuent la même opération.
Finalement, il ne reste que 82 conditions pour lesquelles les différentes méthodes de suppressionde fautes sont susceptibles de donner des résultats différents. Le tableau 5.1 recense le nombre deconditions pour lesquelles les deux méthodes donnent des résultats semblables ou des résultatsdifférents, et ce en fonction de la cause de la faute.
Table 5.1: Tableau comparatif des différentes méthodes de détection de fautes
60

Pour construire ce tableau, une étude manuelle approfondie a été effectuée sur ces 82 fautes.On observe alors que lorsque la cause de la faute n’est pas clairement identifiable, c’est-à-dire queles valeurs étudiées sont très proches du seuil de tolérance utilisé par la méthode 1, dans la mesureoù ce seuil de tolérance est fixé de manière relativement arbitraire, il y a de forte chance que cetteméthode donne un résultat erroné. La méthode 3 à l’inverse effectue une analyse beaucoup plusfine de la situation.
On retiendra alors la méthode 3 et on pourra utiliser l’analyse des résidus standardisés effectuéepar la méthode 1 pour confirmer les résultats donnés par la méthode 3, et la méthode 2 pourobserver avec plus de netteté le déplacement d’une sphère.
61


Chapitre 6
Outils d’analyse : estimateurs de qualité
En science ou en ingénierie, la qualité de tout résultat doit pouvoir être quantifiée. Cette notionde quantification de la précision est particulièrement prégnante dans le domaine de la topographie.Ces estimateurs peuvent être estimés après avoir calculé les résultats, ou alors, avant même avoireffectué une seule opération. Ce dernier cas est très intéressant, puisqu’il consiste, à partir d’unevision approchée de la configuration des mesures à effectuer pour statuer sur la qualité du résultatqu’il est possible de produire. Cela permet de valider ou d’infirmer le choix d’une méthode.
Trois méthodes seront présentées ici. Toutes peuvent être calculées en pré-analyse, avec desvaleurs approchées et un a-priori sur la précision de nos lectures, ou post-consolidation, grâce auxvaleurs compensées et à l’étude des fermetures qui fournissent une estimation de la précision desmesures qui ont été effectuées.
La première approche est une approche utilisant la théorie des graphes, qui n’utilise que lespropriétés topologiques du réseau. La seconde approche est une approche probabiliste, et la troi-sième approche considère la compensation comme un système entrée-sortie et observe l’influencede fautes entachant les données en entrée sur les données en sortie.
6.1 Analyse topologique
Le réseau lasergrammétrique peut-être étudié en utilisant la théorie des graphes. Ce graphe estcréé lors de l’appariement des sphères, décrit au chapitre 3. Il est représenté sur les figures 6.4, 6.5,et 4.15 par l’ensemble des arêtes.
Le problème qui est considéré comme fondateur de la théorie des graphes est celui des Ponts deKonigsberg, résolu par Leonhard Euler en 1736. Le problème consiste à statuer sur l’existence d’unchemin fermé passant par une et une seule fois sur chaque pont. Nous allons utiliser cet exemplehistorique pour introduire des outils de théorie des graphes.
63

Figure 6.1: Plan de la ville de Konigsberg et de ses 7 ponts
Un graphe est par définition un ensemble de noeuds et un ensemble d’arêtes reliant ces noeuds.
Dans le cas de notre exemple de la ville de Konigsberg, les noeuds modélisent des portions deterre ferme, et les arêtes, les ponts.
Figure 6.2: Graphe de la ville de Konigsberg. Les arêtes représentent les ponts (un doublet d’arêtescorrespond à deux ponts)
Le problème que nous allons nous poser est : comment quantifier la qualité du rattachementd’un noeud au sein du graphe ?
6.1.1 L’analyse locale d’un graphe et ses limites
Une approche intuitive consisterait à établir des critères basés sur une observation partielle dugraphe, comme par exemple, combien d’arêtes sont reliés au noeud étudié ? Ou quelle est la distanceentre le noeud étudié et le noeud qui lui est le plus éloigné ? Ou encore, quelle est la somme desdistances entre le noeud considéré et chacun des autre noeuds ? Ces approches constituent la basedes indices de Shimbel, de l’indice de König ou de l’indice de centralité de degrés. Ces méthodessont exposées dans GLEYZE [2001].
Ces indices d’analyse de graphes n’étudient pas le graphe dans son ensemble. Dans notre cas,le graphe représentera un réseau lasergrammétrique très complexe dans lequel la configuration dechaque noeud et chaque arête a une influence sur l’ensemble du graphe. Il faut donc étudier desoutils permettant d’analyser le graphe de manière globale.
64

6.1.2 Définition des matrices définissant le graphe
Pour étudier des graphes, il est possible d’utiliser des outils algébriques. Pour cela, on définitdes matrices qui décrivent le graphe étudié. On utilisera des méthodes issues de l’algèbre pourétudier ces matrices, ce qui nous donnera des informations sur le graphe sous-jacent.
6.1.2.1 Matrice d’incidence
La matrice d’incidence A possède autant de lignes que d’arêtes et autant de colonnes que denoeuds. Aij = −1 si l’arête i part du noeud j, Aij = 1 si l’arête i arrive au noeud j et Aij = 0dans tous les autres cas. Dans le cas de notre exemple :
A =
−1 1 0 0
−1 1 0 0
0 −1 0 1
0 −1 0 1
−1 0 1 0
0 1 −1 0
0 0 1 −1
(6.1.1)
6.1.2.2 Matrice d’adjacence
La matrice d’adjacence ‹N est une matrice carré de coté égal au nombre de noeuds. Elle esttelle que pour tout couple de noeuds (i, j), ‹Nij est le nombre d’arêtes qui relient ces deux noeuds.Dans le cas de notre exemple :
‹N =
0 2 1 0
2 0 1 2
1 1 0 1
0 2 1 0
(6.1.2)
6.1.2.3 La matrice des degrés
La matrice des degrés N est une matrice carré diagonale de côté égal au nombre de noeuds.Elle est telle Nii est le nombre d’arêtes reliées au noeud i. Dans le cas de notre exemple :
N =
3 0 0 0
0 5 0 0
0 0 3 0
0 0 0 3
(6.1.3)
6.1.2.4 La matrice Laplacienne
La matrice Laplacienne N est une combinaison des deux définitions ci-dessus. Elle est définiepar :
N = N − ‹N (6.1.4)
65

On peut construire cette matrice à partir de la matrice d’incidence :
AT A = N (6.1.5)
6.1.3 Analyse spectrale du graphe par la méthode du vecteur propre decentralité
6.1.3.1 Motivation
Un estimateur de qualité de rattachement d’un noeud à l’ensemble du réseau est donné par laméthode du vecteur propre de centralité (EigenVector centrality). Pour expliquer le fonctionnementde cette méthode, nous allons l’illustrer par un exemple.
Supposons que chacun des noeuds possède une information. On note X le vecteur qui quantifiecette information (Xi quantifie la quantité de l’information possédée par le noeud i). Si chacundes noeud envoie son information à tous les autres noeuds auquel il est connecté grâce aux arêtes,l’information reçue par le noeud est donnée par le vecteur : ‹NX. Cela permet de comprendrel’action de la matrice d’adjacence sur un vecteur.
Si on veut que le processus d’échange soit équitable, c’est-à-dire que l’information reçue parles noeuds soit proportionnelle à celle qui a été envoyée, il faut que X soit un vecteur propre de‹N . D’autre part, pour que ce processus d’échange d’information soit le plus rentable possible, ilfaut que ce facteur de proportionnalité entre information émise et information reçue soit maximal.Donc cela correspond au vecteur propre maximal. Plus un noeud joue un rôle important dans cetransfert d’information, plus sa valeur de X est importante.
Cette méthode étant basée sur une décomposition spectrale (décomposition en vecteurs propreset valeurs propres), nous l’avons intitulée SAS : Score d’Analyse Spectrale.
6.1.3.2 Explication de la méthode SAS
La méthode du vecteur propre de centralité consiste donc à décomposer la matrice d’adjacence‹N en valeurs propres et vecteurs propres puis d’étudier le vecteur propre associé à la valeur propremaximale ( cf LOVASZ [2007] et SOH et al. [2010] ).
Sachant que ‹N est symétrique et possède des valeurs positives, le théorème de Perron-Frobeniusstipule que la valeur propre maximale est unique et que les composantes de son vecteur propreassocié sont toutes positives. En utilisant le fait les vecteurs propres sont normés, on déduit queses composantes sont comprises entre 0 et 1.
Dans notre cas, ce vecteur est :�
0.46 0.62 0.42 0.46�T
. Plus la valeur est élevée, meilleureest l’insertion du noeud au sein du réseau. On observe que le noeud 2 est le plus rattaché au restedu réseau, que les noeuds 1 et 4 ont les même degrès de rattachement, et que le noeud 3 est lenoeud le moins rattaché.
66

Pour pouvoir exploiter ces valeurs, on prend l’opposé de son logarithme. On obtient alors unquantificateur de qualité compris entre 0 et l’infini, plus ce quantificateur est grand, moins le noeudest rattaché.
6.1.3.3 Signature spectrale d’un îlot
Cette méthode permet aussi de détecter un îlot mort, c’est-à-dire un ensemble de noeuds telqu’il n’existe aucun chemin permettant de joindre le reste du graphe.
Figure 6.3: Graphe présentant un îlot mort
Dans le cas de cet exemple, le vecteur propre associé à la valeur propre maximale est :�0.46 0.62 0.42 0.46 0 0
�T
. On observe que les noeuds appartenant à l’îlot mort ont unevaleur nulle.
Il existe cependant un autre vecteur propre de ‹N (associée à une valeur propre plus petite) telque le reste du graphe paraît être un îlot et les valeurs associées à l’îlot étudié sont non nulles :�
0 0 0 0 0.71 0.71�T
.
Dans le cas de l’étude d’un réseau lasergrammétrique, il est utile de détecter les îlots morts,puisqu’il est impossible de les compenser.
6.1.3.4 Prise en considération des points de rattachements
Si le graphe représente un réseau lasergrammétrique et si il est rattaché sur un ensemble depoints d’appuis, on peut considérer que cet ensemble de points d’appuis peut être représenté par ununique noeud du graphe. Ce noeud joue le même rôle qu’une masse dans un circuit électronique :il a une place centrale et sert de référence aux autres noeuds.
6.1.4 Représentation topologique d’un réseau lasergrammétrique, etalternative au SAS
Une seconde méthode d’analyse globale d’un graphe rattaché est donné en annexe J.1. Cetteméthode utilise une analogie entre le graphe étudié et un réseau de nivellement, et sera apelléAnalyse de graphe B par la suite.
Des aspects techniques quand à la représentation du réseau lasergrammétrique par un grapheseront soulevés dans l’annexe J.2.
67

6.2 Ellipsoïdes d’erreur
Un ellipsoïde d’erreur permet de visualiser l’incertitude de la position d’un point dans l’espace.C’est une surface fermée telle qu’il est possible d’affirmer que la position réelle de la station a uneprobabilité P de se trouver à l’intérieur de cet ellipsoïde.
Figure 6.4: Visualisation des ellipsoïdes d’erreurs des positions de l’ensemble des stations du BR.Les sphères vertes représentent les points de références, les segments noirs, les liaisons induitespar des sphères et l’échelle de teinte du bleu au rouge indique la qualité de rattachement au senstopologique du terme aux sphères de références. Grossissement par 100 des erreurs.
68

Généralement, on choisit P = 20% 1. C’est par définition un ellipsoïde de confiance dit standard(cf TRACOL [2012]), calculé avec un seuil fixé à un sigma : l’écart-type 2. Ces ellipsoïdes sontcalculés à partir de la matrice des Variances-Covariances des inconnues de notre système (à savoirles positions et les orientations de nos stations). Les détails de ces calculs sont donnés dans lapartie : D.1.2 du formulaire. La figure 6.4 représente les ellipsoïdes de confiance des stations descan utilisés pour relever le BR.
6.3 Fiabilité externe
Dans la section 5, le but était de détecter puis de supprimer les fautes. Cependant, toutes lesméthodes se basent sur la notion de tolérance. Un écart hors tolérance est considéré comme unefaute, un écart inférieur à la tolérance est considéré comme bon. Cette tolérance forme une frontièrequi peut être définie comme la limite de la plus grande faute non détectable, ou de la plus petitefaute détectable.
Le principe de la fiabilité externe est d’étudier l’influence des plus grandes fautes non détec-tables (ou des plus petites fautes détectables) sur la solution. Pour chaque observation, on entachecette observation par sa plus grande faute non détectable et on observe l’influence de cette fautesur la solution. On obtient donc autant de résultats (faux) que de mesures, que l’on peut comparerau résultat sans ajout de fautes (Une description de cette méthode est donnée dans [MERMINOD,2011]).
La fiabilité externe dans le cas de la méthode de Gauss-Helmert (qui considère des conditionsentre lectures et paramètres) est un peu différente. En effet, on ne cherche pas des observationsfausses, mais des conditions (mettant en jeu plusieurs observations) fausses. On considère alorsl’influence des plus grandes fautes non détectables affectant chaque condition.
Pour visualiser la fiabilité externe, nous avons créé une interface interactive, qui à la manièred’un SIG 3, permet de connaître la condition à l’origine d’une influence en cliquant dessus ; ouinversement, l’influence d’une condition sur chacune des stations. Pour obtenir la figure 6.5, on acliqué sur une influence. On est informé (par la fenêtre d’information) de la condition qui en est àl’origine. Celle-ci s’affiche en rouge (en bas à droite de la figure), ainsi que de toutes les influencesde cette condition. Il est surprenant de constater qu’une faute sur une condition à un endroit dugraphe peut avoir des influences sur des stations qui lui sont très éloignées.
1. Cette probabilité est de 68.27% pour un intervalle de confiance, 39% pour une ellipse de confiance, et 20%pour un ellipsoïde de confiance.
2. Formellement, on ne peut pas parler d’écart-type d’un vecteur aléatoire. Cependant, si on définit une droitequelconque passant par le centre de l’ellipse, on peut définir l’écart-type de la projection du vecteur aléatoire surcette droite. La distance entre le centre de l’ellipsoïde et une intersection de cette droite avec l’ellipsoïde est cetécart type.
3. Système d’information Géographique. Cf lexique : A
69

Figure 6.5: Fiabilité externe de quelques stations du BR. Grossissement par 25 des ellipsoïdesd’erreurs et par 100 des influences
6.4 Étude comparative de différents estimateurs.
6.4.1 Pseudo-corrélations
Tous ces estimateurs donnent un indice de qualité compris entre zéro et l’infini. Plus l’indiceest grand, moins bonne est la précision. Le but de cette section est de comparer ces différentsestimateurs. Si x est un vecteur contenant les indices de qualité donnés par un estimateur dequalité (xi est l’indice de qualité de la station i) et y est un vecteur contenant les indices de qualitéd’un second estimateur de qualité, on peut calculer une pseudo-corrélation entre les deux :
xT y
(xT x)(yT y) (6.4.1)
Ces pseudo-corrélations sont comprises entre 0 et 1.
Cette formule n’est pas exactement la formule de la corrélation de deux variables qui auraitimposé que x et y soient centrées (translatées de manière à ce que leurs moyenne soient nulles). Ce-pendant, calculer une corrélation entre des estimateurs compris entre zéro et l’infini et qui suiventune distribution du χ2 n’aurait pas de sens. Le défaut de ce calcul est que les valeurs élevées de x
et de y ont une influence beaucoup plus forte que les valeurs faibles.
70

6.4.2 Corrélations logarithmiques
Pour prendre en compte aussi bien l’influence des valeurs élevées que des valeurs faibles dansle calcul de corrélation, FEENSTRA [2006] propose de calculer la corrélation des logarithmes descomposantes de x et de y.
Il faut donc substituer ln(x) − ln(x) à x (respectivement ln(y) − ln(y) à y) dans le calcul de(6.4.1).
On obtient une corrélation entre -1 et 1.
6.4.3 Comparaison quantitative des différents estimateurs de qualité
Nous allons calculer les coefficient de corrélations et les coefficients de corrélation logarithmiquesdes 4 estimateurs de qualité étudiés dans cette section et des différences entre les positions deréférences considérées comme valeurs vraies :
Différence référence est la différence (en norme euclidienne) entre nos positions compensées etles positions de références, considérées comme valeurs vraies ;
Ellipsoïde d’erreur est la norme de la somme des trois vecteurs directeurs de l’ellipsoïde ;
Fiabilité est la somme des normes de l’ensemble des influences de chacune des contraintes ;
Analyse de graphe A est la méthode d’analyse de graphe par la méthode du vecteur propre decentralité ;
Analyse de graphe B est la méthode d’analyse de graphe par la méthode d’analogie à un réseaude nivellement.
Les valeurs sous la diagonale du tableau sont les pseudo-corrélations, et les valeurs au dessussont les corrélations logarithmiques.
Figure 6.6: Corrélation entre les différents estimateurs
Sans surprise, il y a une forte corrélation entre les deux méthodes d’analyse de graphe. Cela sejustifie par le fait qu’elles se basent toutes deux sur les mêmes données.
Il est important d’étudier la corrélation entre les différences aux références et les estimateursde qualité. On observe que l’analyse de graphe par la méthode du vecteur propre de centralité
71

(Analyse de graphe A) est puissante et nous donne des bons résultats. La figure 6.7 permet de vi-sualiser conjointement les différences aux valeurs de référence et les deux estimateurs qui corrèlentle mieux à celles-ci.
À l’inverse, il y a une corrélation négative entre les fiabilités et les différences de références.Pour expliquer ce chiffre, il faut rappeler que même si les valeurs prises pour références ont étérevérifiées et reprises manuellement, elles se basent sur les mêmes mesures que celles que nous avonsutilisées pour effectuer nos calculs. Pour les parties du réseau dans lesquelles on ne dispose que desobservations minimales permettant de calculer les paramètres, toutes les méthodes de compensa-tion donneront le même résultat puisqu’il est impossible de confronter les observations entre elles.En revanche, la plus petite faute détectable sera infinie (il est impossible de détecter une faute sion ne possède pas de mesures redondantes) et donc la fiabilité, qui est l’influence de ces fautesnon détectable sera infinie. C’est pour cela que la corrélation entre la fiabilité et la différence auxvaleurs de référence est négative.
6.4.4 Comparaison qualitative des différents estimateurs de qualité
Les différents estimateurs étudiés ici mesurent plusieurs facettes de la qualité du résultat. Siles analyses topologiques et les ellipsoïdes d’erreurs se basent sur la configuration du réseau pourstatuer sur la qualité du résultat en utilisant l’hypothèse que les observations possèdent la qualitéattendue ; la fiabilité externe n’utilise pas d’hypothèse sur la qualité d’une observation, mais surla capacité des autres observations de la contrôler. Si les ellipsoïdes d’erreurs sont un indicateurassez objectif quand à la précision atteinte, la fiabilité est beaucoup plus pessimiste.
Nous sommes ici en mesure de présenter une procédure qui permet de produire un résultatfiable et dont la qualité est décrite de manière objective. La première étape est d’effectuer uneanalyse topologique du graphe, de manière à détecter les îlots et les bras morts. Si cette analyserévèle des points faibles, il faut éventuellement envisager un retour sur les différentes étapes derelevé et de traitement (nettoyage du nuage de points, extraction des sphères, appariement dessphères, import des différents fichiers...).
Puis, on peut effectuer la compensation et l’analyse de la fiabilité. Il faut alors vérifier les sta-tions qui ont des vecteurs de fiabilité élevés à partir des nuages de points. On peut aussi vérifierque les mesures responsables de ces valeurs importantes ont été effectuées avec un soin particulier.
Si on n’observe pas de faute particulière, le résultat de la compensation a une précision fidèle-ment décrite par les ellipsoïdes d’erreur.
72

Figure 6.7: Le diamètre de la base des cylindres est le rayon maximal des ellipsoïdes d’erreurs,la hauteur et l’orientation des cylindres sont donnés par les vecteurs de différence entre les valeursde références et les valeurs calculées et l’échelle de teinte du bleu au rouge indique la qualité derattachement au sens topologique du terme aux sphères de références. Grossissement par 100 deserreurs.
73


Chapitre 7
Conclusion
7.1 SynthèseLes différentes étapes de la consolidation, abordées dans les chapitres 3, 4, 5 et 6 permettent
d’assembler les nuages de points partiels issus des scans des stations en un seul nuage de pointsgénéral. Les contributions apportées au cours des différents chapitres permettront, à partir d’unjeu de mesures, de donner un résultat de qualité maximale tout en ayant un regard critique surcelui-ci, et ce de manière la plus automatisée possible.
Si l’ensemble des méthodes présentées ici ont été formalisés dans ce mémoire, elles ont aussiété implémentées en PYTHON de manière à les tester, et à les comparer à d’autres méthodesplus classiques, ou à d’autres logiciels déjà existants. Ce programme PYTHON constitue un POC(Proof Of Concept, ou : démonstration de faisabilité) et plus encore, une base algorithmique pourintégrer ces méthodes dans d’autres logiciels.
7.2 Principales contributionsPour chacune des grandes étapes de la consolidations, des propositions d’améliorations ont été
formulées.
Dans le cadre de l’appariement des sphères, un état de l’art de la littérature très pauvre a étéeffectuée, et une proposition d’algorithme viable dans le cadre d’un réseau de grande taille à étéformulé. Si l’étape d’appariement est celle pour laquelle le contenu de ce rapport est le plus basiqueet que l’on ne dispose pas d’une solution parfaitement opérationnelle, ce mémoire peut constituerune base pour tout travail futur à ce sujet.
La consolidation est l’étape qui a mobilisé le plus de temps. Un état de l’art et une synthèsedes méthodes de compensation et en particulier des méthodes robustes a été effectuée. Cela s’esttraduit par un retour théorique aux axiomes fondateurs de toute la théorie utilisée. Ces estimateursrobustes ont pu être adaptés à notre problème, et combinés à la formulation de Gauss-Helmertpermettant d’optimiser les calculs. De manière parallèle, divers sous problèmes ont été traités,comme par exemple, la prise en compte du fait que les stations de scan sont verticales ou l’étudedes avantages et des inconvénients à effectuer une compensation en bloc plutôt qu’une compensa-tion arborescente.
75

Même l’étape de la détection et de la suppression de fautes, qui semblait élémentaire, a donnélieu à des contributions. En donnant une explication physique à la cause des fautes, une nouvelleapproche a été développée.
Enfin, au cours de tout processus de traitement de données topographiques, l’utilisateur et leclients ont besoin d’outils permettant de quantifier la qualité des résultats calculés, et d’effectuerdes étapes de contrôles. Pour cela il faut quantifier cette qualité, et permettre de la visualiser.C’est ce qui a été fait par exemple pour les ellipsoïdes d’erreurs, qui sont un outil de visualisationclassique, mais dont l’importation dans un logiciel de dessin de manière à les visualiser de manièreergonomique permet de se figurer plus aisément les erreurs. D’autres outils moins répandus, commel’étude de la fiabilité, ont nécessité une adaptation à la formulation de Gauss-Helmert, et la créationd’interface interactive permettant d’ajouter à l’information géométrique visible, une formulationsémantique indispensable. Nous avons aussi construit un quantificateur de qualité complètementnouveau et inédit dans le domaine : le SAS (Score d’Analyse Spectrale) qui permet d’analyser unréseau topographique ou lasergrammétrique non pas de manière géométrique, mais uniquementd’après des considérations topologiques.
Nous sommes alors en mesure de présenter une approche globale de toute la procédure deconsolidation, représentée par la figure 7.1, en combinant le florilège de l’ensemble des fragmentsétudiés jusqu’alors.
7.3 PerspectivesLes résultats présentés dans ce rapport donnent lieu à deux axes de travail futur.
Le premier axe est une continuation du travail de recherche initié lors de ce stage, sur les problé-matiques constituants les points faibles de notre méthode, en particulier sur l’étape d’appariementdes sphères. Des outils mathématiques récents, comme les arbres décisionnels ou les réseaux Bayé-siens pourront être étudiés et adaptés à notre problème.
Le second axe est l’implémentation directe des méthodes développées dans un logiciel métier,plus facile d’utilisation qu’un code Python, plus répandus et plus ergonomique. Cela permettra deles utiliser pour modéliser d’autres centrales nucléaires, ou d’autres types de bâtiments.
76
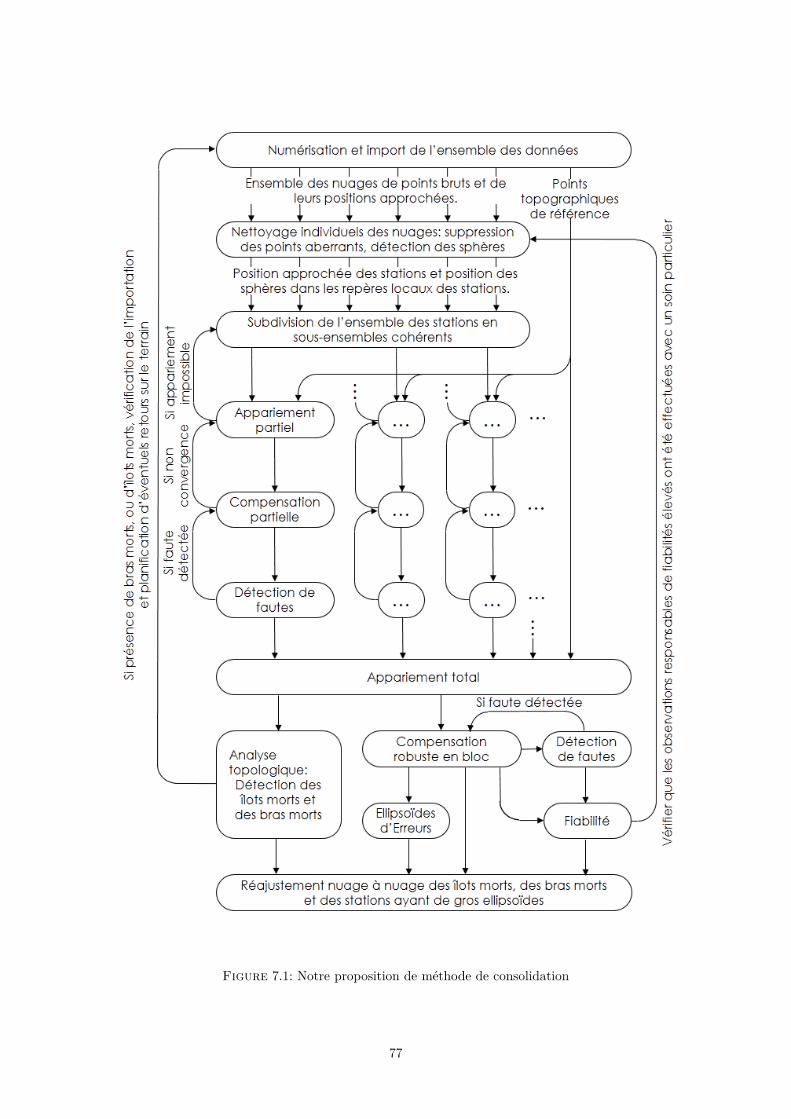
Figure 7.1: Notre proposition de méthode de consolidation
77

Table des figures
0.1 Organigramme de la R&D. la description des différentes entités autour de I2C sontrépertoriés dans l’annexe : A.4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
0.2 Le logo de l’HEIG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.1 Vue d’un endroit du modèle 3D dans VVProPrepas. Les sphères orange permettent deconsulter les photos sphériques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.2 Un exemple d’usage du modèle tel que construit à un cas de manutention fine : Simu-lation 3D puis réalisation en centrale du remplacement du stator de l’alternateur. . . . 14
2.1 Scanner laser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.2 Nuage de point global, union de nuages de points issus de stations différentes . . . . . 182.3 Une station de scan sur le Mont Saint Michel (CADOT [2015]) . . . . . . . . . . . . . 182.4 Détail d’un scan du mont Saint Michel (CADOT [2015]) . . . . . . . . . . . . . . . . . 192.5 Ensemble de points mesurant une sphère, et sphère qui interpole au mieux ces points . 202.6 Méthode de cartographie de la France effectuée par triangulation au XV IIIe siècle . . 212.7 Réseau lasergrammétrique permettant de numériser le bâtiment réacteur. Les sphères
vertes représentent les points d’appuis, les sphères rouges les stations, et les traits bleules visées sur les sphères . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1 État des stations avant appariement. (les sphères, non représentées sont visées par lesstations) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.2 État des stations après appariement. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.3 Analogie entre le concept d’appariement et celui de la construction du puzzle . . . . . 263.4 Étapes d’appariements de FRANASZEK et al. [2008] . . . . . . . . . . . . . . . . . . . 263.5 Zone annulaire d’une station, dans laquelle il existe des sphère visées par cette station 273.6 Utilisation de la zone annulaire pour justifier le choix d’une station . . . . . . . . . . . 283.7 Probabilité d’appariement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.8 Distance entre sph_1 et sph_2 dans liste_ref (en rouge) et dans l’ensemble des lec-
tures de st vers les sphères (en violet). Ici, les distances sont différentes, ce qui permetd’exclure cet appariement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.9 Cas d’un appariement avec la sphère sph_2 ayant un score faible . . . . . . . . . . . 293.10 Cas d’un appariement avec la sphère sph_2 ayant un score élevé . . . . . . . . . . . . 303.11 Deux radios d’un cerveau à recaler l’une par rapport à l’autre. Issue de ABRAM [2000] 31
4.1 Expression des contraintes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.2 Trois modèles de verticalité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.3 Compensation d’un petit réseau de stations (représentées par les triangles) constituant
un sous ensemble d’un réseau plus grand . . . . . . . . . . . . . . . . . . . . . . . . . . 38
78

4.4 Station fictive équivalente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394.5 Compensation d’un réseau de deux stations fictives . . . . . . . . . . . . . . . . . . . . 394.6 Plusieurs compensations encapsulées . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394.7 Structure arborescente de la compensation . . . . . . . . . . . . . . . . . . . . . . . . . 404.8 Compensation en bloc . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404.9 Histogramme d’une variable aléatoire suivant une distribution normale (en vert) et
courbe gaussienne modélisant ce comportement (en pointillés noirs) . . . . . . . . . . 414.10 Exemple de gaussienne multivariée pour un vecteur aléatoire de dimension 2 . . . . . 414.11 Exemple de fonctions de coût . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434.12 Exemples de fonctions ρ associées à des fonctions N . . . . . . . . . . . . . . . . . . . 434.13 Représentation des étages 13, 14 et 15 dans le logiciel Jag 3D . . . . . . . . . . . . . . 484.14 Représentation des étages 13, 14 et 15 dans le logiciel Trinet+ . . . . . . . . . . . . . 494.15 Les stations appartenant à des îlots morts sont représentés en rouge, les stations ratta-
chées en bleu, les sphères de références, en vert et les stations dont le fichier de mesuresa été perdu en jaune. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.1 Trois mesures sur une sphère permettent de former deux conditions . . . . . . . . . . . 545.2 Si une mesure est fausse, on peut toujours former une condition . . . . . . . . . . . . . 545.3 Résidus et résidus standardisés dans le cas d’une régression linéaire . . . . . . . . . . . 555.4 Exemple de cinq stations visant une sphère . . . . . . . . . . . . . . . . . . . . . . . . 565.5 Méthode qualitative de suppression de fautes . . . . . . . . . . . . . . . . . . . . . . . 575.6 Estimation de la position d’une sphère d’après différentes stations. Les points bleus en
haut à gauche représentent la sphère visée par un premier groupe de stations, les pointsbleus en bas à droite représentent la sphère visée par un second groupe de stations. Lespoints rouges représentent les centroïdes de ces deux ensembles. (Unité : m) . . . . . . 57
5.7 Méthode quantitative de suppression de fautes . . . . . . . . . . . . . . . . . . . . . . 585.8 Estimation de la position d’une sphère utilisant le vecteur des fermetures après com-
pensation. Les points bleus représentent les différentes estimations des sphères et lespoints rouges sont les centroïdes des deux sous-ensembles de sphères (unité : mètre) . 59
5.9 Une sphère qui n’induit qu’une condition . . . . . . . . . . . . . . . . . . . . . . . . . 60
6.1 Plan de la ville de Konigsberg et de ses 7 ponts . . . . . . . . . . . . . . . . . . . . . . 646.2 Graphe de la ville de Konigsberg. Les arêtes représentent les ponts (un doublet d’arêtes
correspond à deux ponts) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 646.3 Graphe présentant un îlot mort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 676.4 Visualisation des ellipsoïdes d’erreurs des positions de l’ensemble des stations du BR.
Les sphères vertes représentent les points de références, les segments noirs, les liaisonsinduites par des sphères et l’échelle de teinte du bleu au rouge indique la qualité derattachement au sens topologique du terme aux sphères de références. Grossissementpar 100 des erreurs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
6.5 Fiabilité externe de quelques stations du BR. Grossissement par 25 des ellipsoïdes d’er-reurs et par 100 des influences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
6.6 Corrélation entre les différents estimateurs . . . . . . . . . . . . . . . . . . . . . . . . . 716.7 Le diamètre de la base des cylindres est le rayon maximal des ellipsoïdes d’erreurs, la
hauteur et l’orientation des cylindres sont donnés par les vecteurs de différence entre lesvaleurs de références et les valeurs calculées et l’échelle de teinte du bleu au rouge indiquela qualité de rattachement au sens topologique du terme aux sphères de références.Grossissement par 100 des erreurs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
7.1 Notre proposition de méthode de consolidation . . . . . . . . . . . . . . . . . . . . . . 77
79

B.1 Géométrie du triangle définie par les paramètres α et β ; γ n’est pas nécessaire, α et β
sont suffisants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87B.2 Mesures lα, lβ et lγ des trois angles du triangle α, β et γ . . . . . . . . . . . . . . . . . 88B.3 Le vecteur des mesures : l dans l’espace des mesures . . . . . . . . . . . . . . . . . . . 88B.4 Le triangle ne ferme pas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89B.5 Quatre exemple de points du champ des possibles . . . . . . . . . . . . . . . . . . . . . 89B.6 Le vecteur de mesures l, entaché d’erreur, diffère du modèle théorique . . . . . . . . . 90B.7 Champ de probabilité appliqué au champ des triangles possibles sachant le vecteur de
mesures l . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90B.8 Différents modèles de densité de probabilité pour différents choix de l connaissant l . . 91B.9 Champ de probabilité pour l sachant x . . . . . . . . . . . . . . . . . . . . . . . . . . . 91B.10 Les résidus de nos mesures d’angles sur notre triangle . . . . . . . . . . . . . . . . . . 92B.11 Représentation des résidus dans l’espace des mesures . . . . . . . . . . . . . . . . . . . 93B.12 Histogramme d’une variable aléatoire . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94B.13 Différentes fonctions de densité de probabilités . . . . . . . . . . . . . . . . . . . . . . 95B.14 Différentes fonctions N associées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95B.15 Lancé de 5000 points suivants trois lois multivariées . . . . . . . . . . . . . . . . . . . 96B.16 Distance Euclidienne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97B.17 Représentation de la distance de Mahalanobis dans un espace orthonormé au sens du
produit scalaire canonique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98B.18 Représentation de la distance de Mahalanobis dans la base W . . . . . . . . . . . . . . 99B.19 Deux itinéraires joignant deux points de Manhathan. Données OpenStreetMap . . . . 99B.20 Représentation de la distance de Manhattan . . . . . . . . . . . . . . . . . . . . . . . . 100B.21 Ensemble des points de l’espace des possibles minimisant la distance de Manhattan . . 100B.22 Distribution de Laplace, sachant l représenté sur le champ des possibles . . . . . . . . 100B.23 Le champ des possible est normal à l’ensemble des vecteurs lignes de B . . . . . . . . 101B.24 Le champ des possible est engendré par l’ensemble des vecteurs colonnes de A . . . . . 102B.25 représentation de la condition α = β dans l’espace des mesures . . . . . . . . . . . . . 103B.26 Fusion des inconnues β et γ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104B.27 Récapitulatif des 5 méthodes de formalisation du problème. . . . . . . . . . . . . . . . 105B.28 Ajustement d’une sinusoïde sur un jeu de données . . . . . . . . . . . . . . . . . . . . 105B.29 Ajustement de la phase d’une sinusoïde grâce à trois lectures . . . . . . . . . . . . . . 106B.30 Ajustement de la phase d’une sinusoïde grâce à trois lectures . . . . . . . . . . . . . . 106B.31 Compensation en 4 itérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107B.32 Figure témoin du lancé de 5000 points aléatoires . . . . . . . . . . . . . . . . . . . . . 110B.33 Lancé de 5000 points aléatoires utilisant la matrice donnée par la factorisation de Cholesky111B.34 Lancé de 5000 points aléatoires utilisant la matrice donnée par une décomposition en
vecteurs propres et valeurs propres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111B.35 Différentes fonctions N et leurs fonction ρ associée. . . . . . . . . . . . . . . . . . . . . 112B.36 Quatre boules (courbe iso-distance à 0) . . . . . . . . . . . . . . . . . . . . . . . . . . 114B.37 La fonction de Huber N et ses dérivées . . . . . . . . . . . . . . . . . . . . . . . . . . 116B.38 Aire du rectangle en fonction de x et de y, avec une contrainte isopérimétrique (en rouge)119
D.1 Gaussienne et intervalle de confiance . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126D.2 Lancer de 5000 points, et visualisation de l’ellipsoïde d’erreur . . . . . . . . . . . . . . 126D.3 Section d’une loi normale bi-variée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126D.4 Un ellipsoïde d’erreur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127D.6 Loi de Laplace avec intervalle de confiance . . . . . . . . . . . . . . . . . . . . . . . . . 127D.7 Lancer de 5000 points, et visualisation du parallélogramme d’erreur . . . . . . . . . . 127
80

D.5 Visualisation des ellipsoïdes d’erreurs des positions de l’ensemble des stations du BR.Les sphères vertes représentent les points de références, les segments noirs, les liaisonsinduites par des sphères, et l’échelle de teinte du bleu au rouge indique la qualité derattachement au sens topologique du terme aux sphères de références. Grossissementpar 100 des erreurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
D.8 Section d’une loi de Laplace bi-variée . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128D.9 Octaèdre d’erreur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129D.10 Trois mesures sur une sphère permettent de former deux conditions . . . . . . . . . . . 138
F.1 Nuage de point global, union de deux nuages de points issus de deux stations différentes 152F.2 Vue de deux photos sur un objet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153F.3 Principe de la stéréoscopie, extrait de la Dioptrique de Descartes . . . . . . . . . . . . 153F.4 Projection d’un point sur un plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154F.5 Projection d’un objet sur une sphère . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155F.6 Projection d’un point sur une sphère . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155F.7 Une sphère vue par deux stations A et B . . . . . . . . . . . . . . . . . . . . . . . . . 157F.8 Géométrie épipolaire dans le cas de photos . . . . . . . . . . . . . . . . . . . . . . . . 158F.9 Géométrie épipolaire dans le cas de photos sphériques . . . . . . . . . . . . . . . . . . 158
J.1 Trois méthodes de représentation du graphe d’un réseau lasergrammétrique . . . . . . 172
Liste des tableaux
2.1 Degrès de liberté contraints par un couple de primitives géométriques . . . . . . . . . 20
4.1 Combinaisons des fonctions de cout et des méthodes de minimisation . . . . . . . . . . 464.2 Tableau comparatif des résultats donnés par les différentes méthodes proposées dans
ce papier (calcul effectués par rapport à la valeur vraie, unité : m). Bleu : valeur deréférence, Vert : résultats meilleurs, Jaune : résultats équivalent, Rouge : résultats plusmauvais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.3 Tableau comparatif des résultats donné par les différents logiciels (unité : m) Bleu :valeur de référence, Vert : résultats meilleurs, Jaune : résultats équivalent, Rouge :résultats plus mauvais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.4 Tableau comparatif des résultats donnés par les différents logiciels dans le cas de stationsverticales (unité : m) Bleu : valeur de référence, Vert : résultats meilleurs, Jaune :résultats équivalent, Rouge : résultats plus mauvais . . . . . . . . . . . . . . . . . . . . 50
4.5 Tableau comparatif des résultats donné par les différents logiciels dans le cas de stationsverticales (unité : m) Bleu : valeur de référence, Vert : résultats meilleurs, Jaune :résultats équivalent, Rouge : résultats plus mauvais . . . . . . . . . . . . . . . . . . . . 50
5.1 Tableau comparatif des différentes méthodes de détection de fautes . . . . . . . . . . . 60
81
