zool2003-1 systèmes de production
TRANSCRIPT

ZOOL2003-1
Systèmes de productionpartim « amélioration génétique en aquaculture »
Frédéric Farnir, Tom Druet

Références
• La référence principale pour ce cours est:
Gjedrem T. Selection and Breeding Programs in Aquaculture. 2005, Springer, Dordrecht, The Netherlands.
• D’autres références seront citées dans le texte.
2

Synopsis
• Introduction
• Eléments de base en génétique
• Dogme central de la génétique
• Caractères mendéliens et polygéniques
• Génétique des populations
• Sélection génétique
• Caractères à améliorer (production, reproduction)
• Parenté et consanguinité
• Héritabilité
• Méthodes et stratégies de sélection
3
Introduction
4
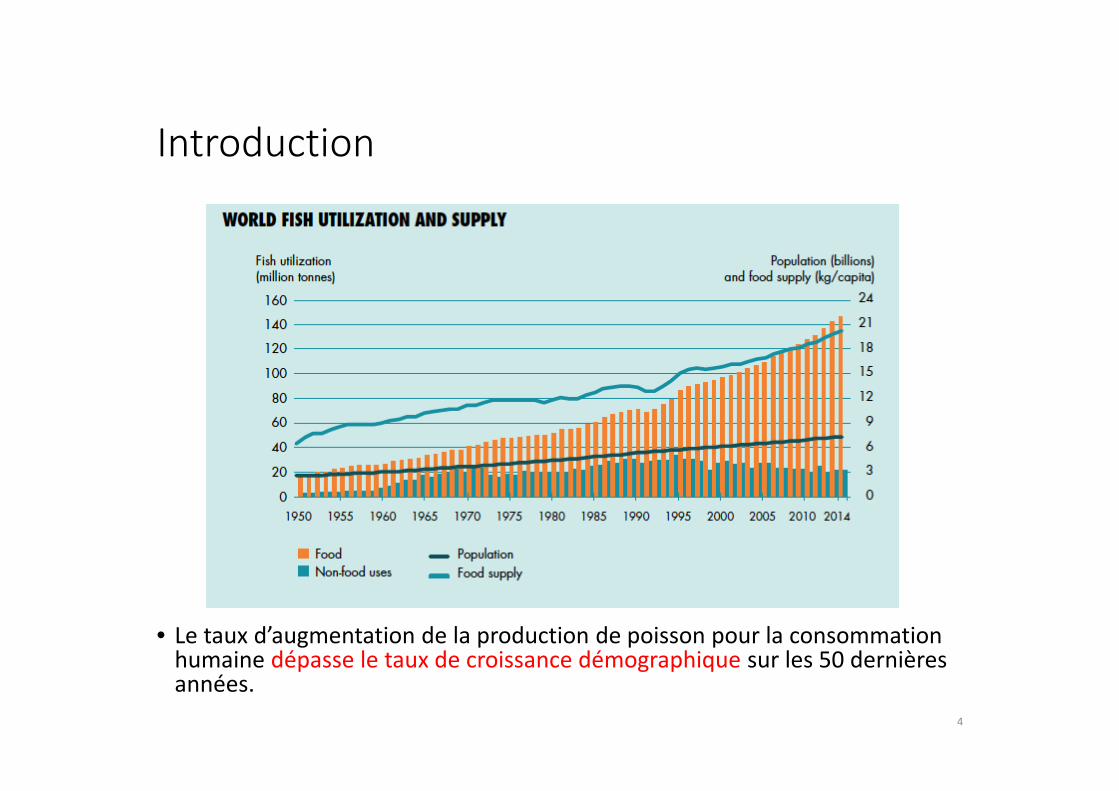
• Le taux d’augmentation de la production de poisson pour la consommation humaine dépasse le taux de croissance démographique sur les 50 dernières années.
Introduction
5
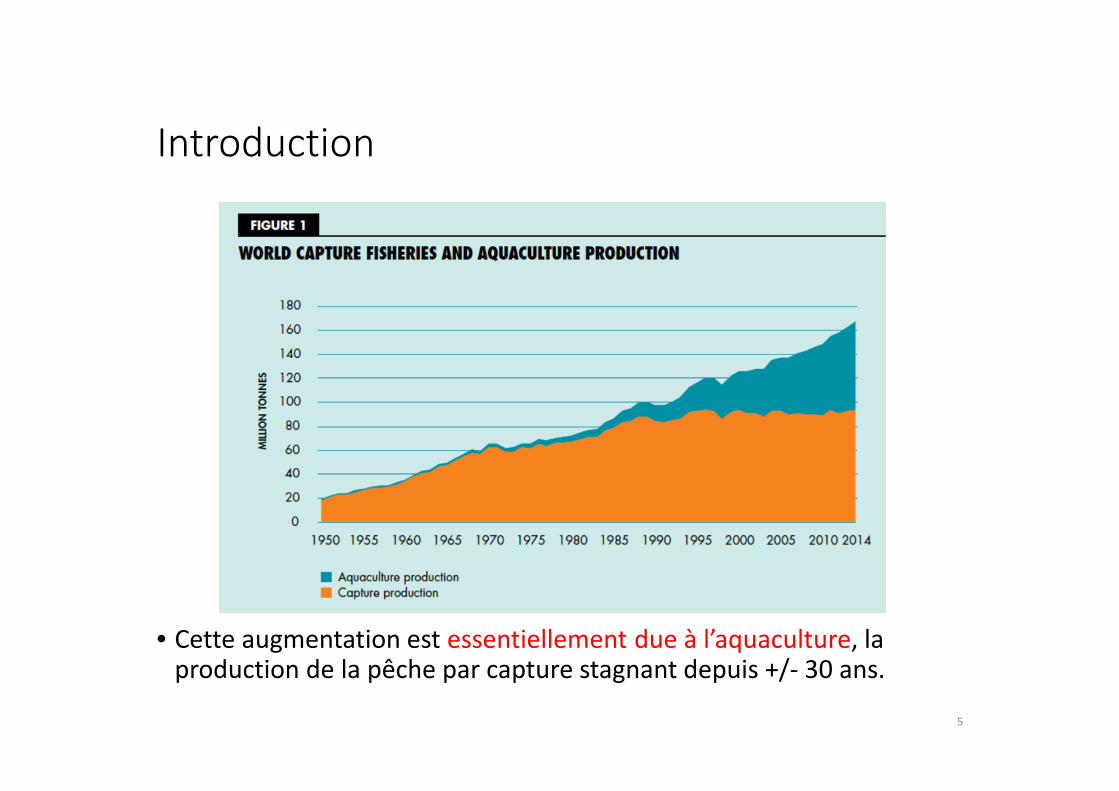
• Cette augmentation est essentiellement due à l’aquaculture, la production de la pêche par capture stagnant depuis +/- 30 ans.

Introduction
• Cette situation souligne le besoin de développer des techniques d’aquaculture efficaces:
• “Efficient breeding programs will be crucial to this development, not only to reach the production goal but also to reduce production cost, improve disease resistance, improve utilisation of feed resources and improving product quality” (Gjedrem, 1997b).
• La maîtrise des techniques de selection génétique donne une partiedes clés pour atteindre ces objectifs.
• Les objectifs de la sélection seront donc:
• d’améliorer la productivité des animaux (poissons et fruits de mer)
• d’améliorer la qualité des produits
• Contrôle de l’environnement, en plus de la sélection génétique
• d’améliorer le bien-être animal
• Animaux domestiqués vs animaux sauvages
6

Introduction
• Effet de la sélection sur la productivité
7

Introduction
• Sélection en aquaculture
• Beaucoup d’espèces cultivées depuis (parfois très) longtemps
• L’éclosion artificielle était déjà pratiquée en Chine en 2000 avant JC, et des descriptions d’étang d’élevage datent de 1200 avant JC !
• Les carpes (depuis plusieurs siècles en Europe), les truites (élevages présents vers 1890), les tilapias (notamment en Asie du Sud-Est, comme en Indonésie depuis 1937), les saumons (depuis les années 60 en Norvège)
• sont élevés parfois en noyaux fermés depuis très longtemps
• montrent des signes de domestication en situation d’élevage
• diminution du cannibalisme, diminution du comportement de proie, diminution de l’énergie consacrée à la nage, à la chasse et à la mise à l’abri.
• Mais relativement peu de programme de sélection...!
• Pourtant, la réponse à la sélection serait plutôt meilleure que dans d’autres espèces
• Causes:
• Reproduction peu maitrisée, identification des parents difficile
• En conséquence, augmentation rapide de la consanguinité dans les expériences de sélection
• Méconnaissance des principes de génétique quantitative...
8
Eléments de base de génétique
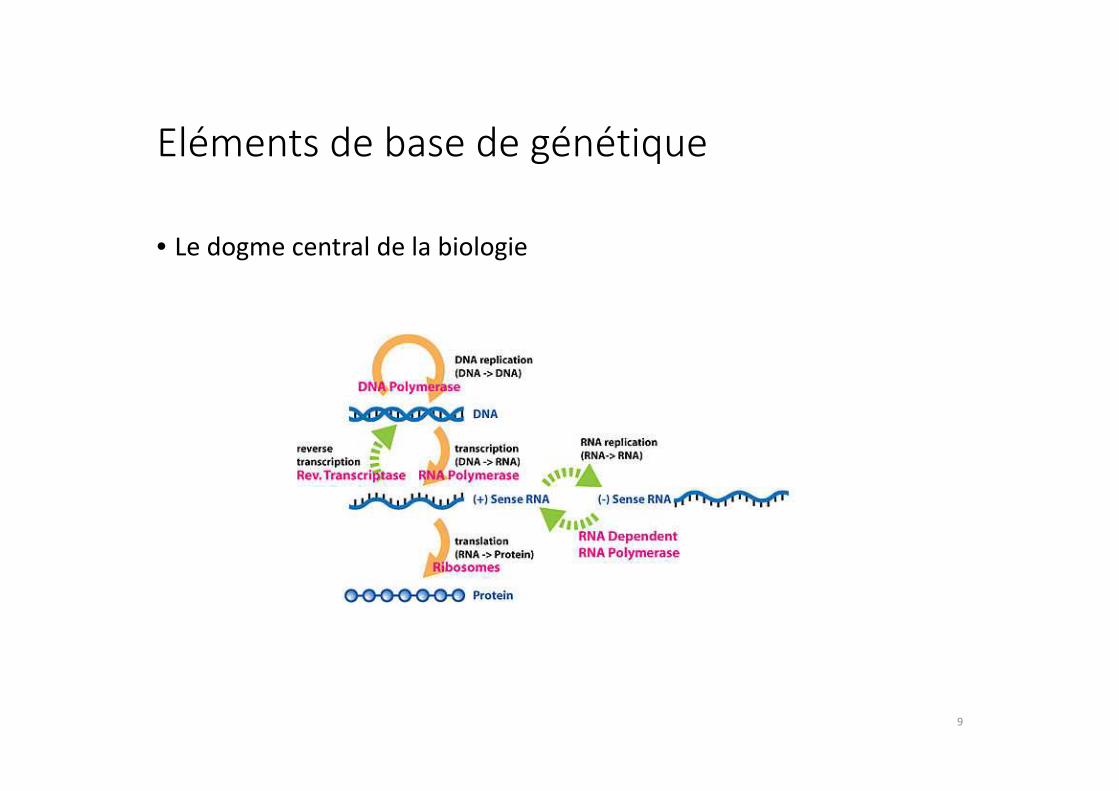
• Le dogme central de la biologie
9

Eléments de base de génétique
• ADN• Chez les eucaryotes (dont les poissons), l’ADN est principalement contenu
dans le noyau (ADN nucléaire)
• Il est aussi présent dans de petites structures (mitochondries) présentes dans le cytoplasme cellulaire (ADN mitochondrial)
• L’ADN est composé d’une série de longues molécules, appelées chromosomes, dont le nombre est spécifique de chaque espèce
10

Eléments de base de génétique
• ADN• Les molécules d’ADN sont formées de 2 brins
antiparallèles enroulés formant une double hélice
• Les brins sont formés d’une succession de nucléotides
• Un nucléotide est formé par une base nucléique (Adénine, Cytosine, Guanine ou Thymine), lié à un sucre (désoxyribose), lui-même lié à un groupe phosphate.
• La succession des bases (appelée « séquence ») contient toute l’information génétique
• Chez l’humain, la séquence mesure +/- 3.2 Gb
• Certaine portions de la séquence (appelées « gènes ») sont transformées en ARN
• Certains ARN (appelés « ARN messagers ») sont transformés en protéine via une structure protéique appelée ribosome.
11
Eléments de base de génétique
• ADN (suite)
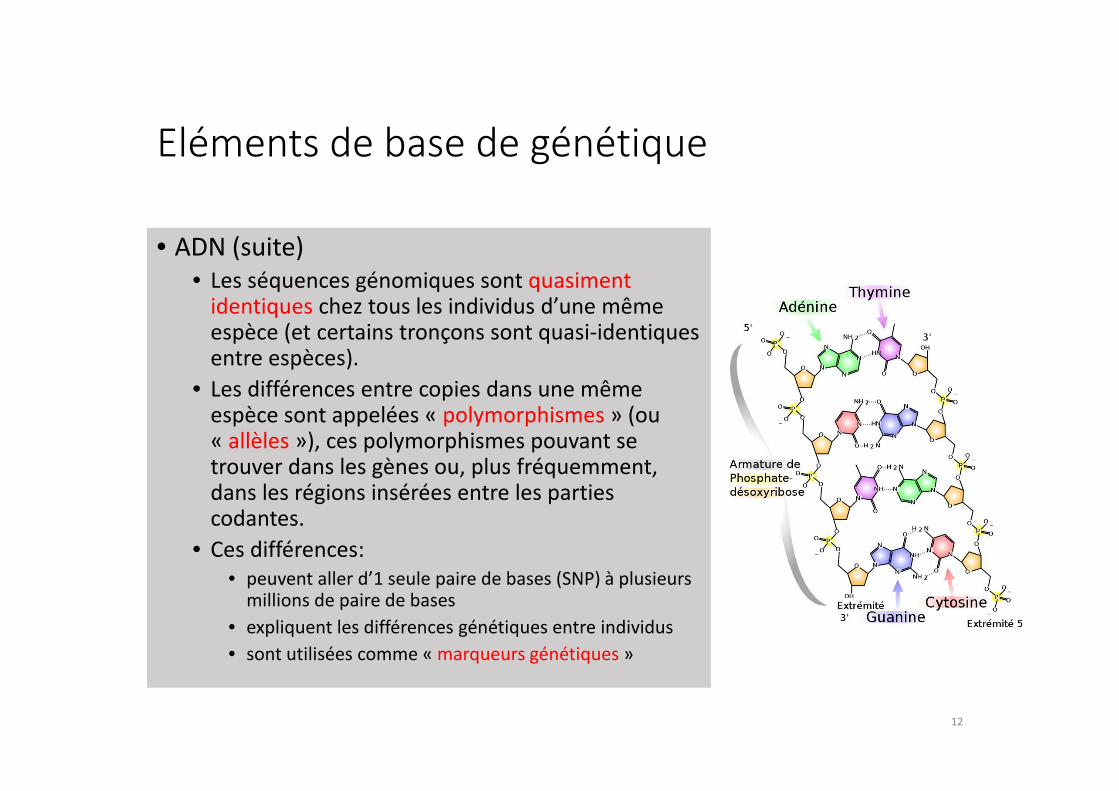
• Les séquences génomiques sont quasiment identiques chez tous les individus d’une même espèce (et certains tronçons sont quasi-identiques entre espèces).
• Les différences entre copies dans une même espèce sont appelées « polymorphismes » (ou « allèles »), ces polymorphismes pouvant se trouver dans les gènes ou, plus fréquemment, dans les régions insérées entre les parties codantes.
• Ces différences:
• peuvent aller d’1 seule paire de bases (SNP) à plusieurs millions de paire de bases
• expliquent les différences génétiques entre individus
• sont utilisées comme « marqueurs génétiques »
12
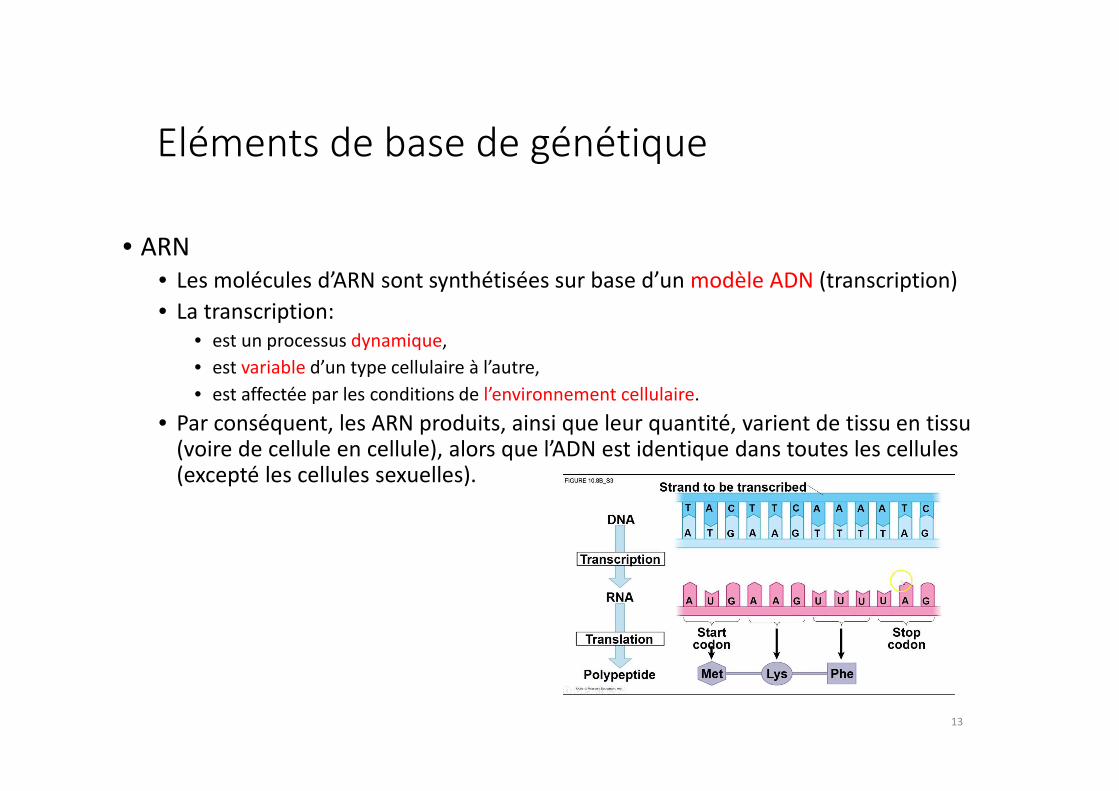
Eléments de base de génétique
• ARN
• Les molécules d’ARN sont synthétisées sur base d’un modèle ADN (transcription)
• La transcription:
• est un processus dynamique,
• est variable d’un type cellulaire à l’autre,
• est affectée par les conditions de l’environnement cellulaire.
• Par conséquent, les ARN produits, ainsi que leur quantité, varient de tissu en tissu (voire de cellule en cellule), alors que l’ADN est identique dans toutes les cellules (excepté les cellules sexuelles).
13

Eléments de base de génétique
• Génétique mendélienne
• Principes de base, découverts par Gregor Mendel (1822-1884), et résumés par deux lois:
• L’héritage des caractères se fait via des unités (aujourd’hui, on sait que ces « unités » sont les « gènes ») qui sont transmises de génération en génération et conservent leur identité (les gènes sont effectivement transmis des parents au descendants tels qu’ils étaient chez les parents*)
• Ces unités sont en double chez chaque individu, qui en transmet une copie aléatoire à chacun de ses descendants. Les copies de deux gènes distincts sont transmises indépendamment l’une de l’autre**
* sauf événement – rare – de recombinaison intra-gène** sauf dans le cas de gènes physiquement proches, la dépendance augmentant avec la proximité
14

Eléments de base de génétique
• Génétique mendélienne: exemple avec 1 seul gène
• Croisement de truites albinos avec des truites normales
15
NN NN aaaa
NN Na Na aa
P
F1
F2
Na Na N>a

Eléments de base de génétique
• Génétique mendélienne: exemple avec 2 gènes
• Ecailles chez la carpe
Ecaille Miroir Linéaire Cuir
SS Ss ss
NN Létal Létal Létal
Nn Linéaire Linéaire Cuir
nn Ecaille Ecaille Miroir
16

Eléments de base de génétique
• Génétique mendélienne: exemple avec 2 gènes
• Exemple: si j’effectue un croisement entre 2 carpes « Cuir » et que je prélève 60 descendants, quels phénotypes, et à quelles fréquences, devrais-je obtenir en moyenne ?
SS Ss ss
NN Létal Létal Létal
Nn Linéaire Linéaire Cuir
nn Ecaille Ecaille Miroir
Ecaille Miroir Linéaire Cuir
0 20 0 40
17

Eléments de base de génétique
• Génétique mendélienne: remarques
• L’exemple des écailles chez la carpe est un cas d’épistasie: l’effet du gène S dépend du génotype au gène S
• Beaucoup de caractères sont le résultat de l’action d’un nombre élevé de gènes, ce qui multiplie les possibilités de génotypes
• Par exemple, pour 200 gènes avec 2 allèles, il y a potentiellement 3200 ~1095 génotypes possibles, soit ~1015 fois plus de génotypes que d’électrons dans l’univers !
• Pour rappel, le génome humain compte plus de 20000 gènes, avec le plus souvent plus de 2 allèles...
SS Ss ss
NN Létal Létal Létal
Nn Linéaire Linéaire Cuir
nn Ecaille Ecaille Miroir
18

Eléments de base de génétique
• Génétique des populations
• Pourquoi ?
• Elevage => Sélection (génétique) => Amélioration globale au niveau de la population
• Amélioration = adaptation
• à l’environnement (sélection naturelle et/ou artificielle)
• aux objectifs des éleveurs (sélection artificielle)
• Comment ?
• On étudie les fréquences alléliques et génotypiques dans une population en fonction des « forces » qui agissent sur ces paramètres
19

Eléments de base de génétique
• Génétique des populations
• Loi d’Hardy-Weinberg (cas d’un locus biallélique)
f(AA) = p f(AB) = 2*q f(BB) = r
dont on déduit:
f(A) = p + q f(B) = q + r
G0
(p+2*q+r = 1)
f(AA) = (p + q)² f(AB) = 2*(p + q)*(q + r) f(BB) = (q + r)²
dont on déduit:
f(A) = p + q f(B) = q + r
G1
f(AA) = (p + q)² f(AB) = 2*(p + q)*(q + r) f(BB) = (q + r)²
dont on déduit:
f(A) = p + q f(B) = q + r
G≥1
20

Eléments de base de génétique
• Génétique des populations
• Loi d’Hardy-Weinberg (cas d’un locus biallélique)
• Sous certaines conditions (voir ci-dessous), les fréquences alléliques et génotypiques se stabilisent en 1 génération, pour atteindre un équilibre dans lequel:
f(AA) = f(A)², f(BB) = f(B)² et f(AB) = 2*f(A)*f(B)
• Les conditions pour atteindre cet équilibre sont ceux d’une « population idéale »:
• population de grande taille (idéalement, infinie),
• pas de recouvrement de générations,
• choix aléatoire des partenaires,
• pas d’immigration (population fermée),
• pas de mutation (changement spontané d’un allèle vers un autre).
• En pratique, en sélection aquacole, avec une population réelle:
• les populations (noyaux de sélection) sont généralement de petite taille,
• les accouplements ne sont pas aléatoires (sélection),
• on importe des individus pour augmenter la variabilité génétique et diminuer la consanguinité – voir plus loin (noyau ouvert),
• des mutations ont lieu (avec une fréquence faible).
21

Eléments de base de génétique
• Génétique des populations
• Loi d’Hardy-Weinberg (cas d’un locus biallélique)
• L’observation d’un déséquilibre conduit à la conclusion qu’une des forces évoquées plus haut agit.
• Exemple: couleur d’une espèce de TilapiaDans cette espèce, 3 couleurs coexistent, codées par 1 seul gène: noir (AA), bronze (AB) et doré (BB). On a recueilli aléatoirement 200 individus, qui se répartissent en 100 noirs, 80 bronzes et 20 dorés. Est-on en équilibre pour ce caractère ?
Un tilapia du Mozambique
(Oreochromis mossambicus)
• Réponse:
• f(A) = (2*100 + 1*80)/(2*200) = 0.7; f(B) = 1 – f(A) = 0.3
• Si H-W, on attend: f(AA) = 0.7² = 0.49, f(BB) = 0.09 et f(AB) = 0.42=> n(AA) = 200*0.49 = 98, n(BB) = 18, n(AB) = 84
• χ² = (100-98)²/98 + (80-84)²/84 + (20-18)²/18 = 0,45
• p[> χ²(1)] = 0,50 => pas d’écart significatif par rapport à H-W
22

Eléments de base de génétique
• Génétique des populations
• Dérive génétique (« genetic drift »)
• Fluctuation aléatoire des fréquence alléliques de génération en génération, due à la taille réduite de la population
• Conséquences:
• Perte éventuelle d’allèles, fixation éventuelle d’autres allèles
• Diminution de la variabilité génétique (et donc, de la possibilité de sélection/adaptation)
• Illustration
• Voir le document excel annexé (et la dia suivante)
0
0,2
0,4
0,6
0,8
1
0 10 20 30 40
Fré
qu
en
ces
Génération
Illustration de la dérive génétique
f(A)
f(B)
23

Eléments de base de génétique
• Génétique des populations
• Dérive génétique (« genetic drift »)
• Illustration
Génération f(A) f(B) Allèles
0 0,5 0,5 A A A A A A A A A A B B B B B B B B B B
1 0,4 0,6 A A A B A B A B A B B B A B B B B B A B
2 0,3 0,7 B A A B B A B B B B B B B A B A B A B B
3 0,25 0,75 A B A B B B B B B B A B B B B B B A B A
4 0,4 0,6 B A B B B A A A B A B B A B A B B B A B
5 0,65 0,35 A A B B B A B A A B A A A A A A A B B A
6 0,6 0,4 A A A B B B B B A A A A A A B A A B A B
7 0,55 0,45 A A A B B A A B B A A A A B B A B B A B
8 0,4 0,6 A B B B B A A B B B A B B B B A A A A B
9 0,15 0,85 B A B A B B B B B B B B B B B A B B B B
10 0,25 0,75 B B B A B B A A B B B B B B B A A B B B
11 0,25 0,75 B B B B B A A B B B B B B A A B B A B B
12 0,2 0,8 B B B A B B A B A A B B B B B B B B B B
13 0,2 0,8 A B B B B B B A B B B B B B B B A A B B
14 0,15 0,85 B B B B B B A B B B A B B A B B B B B B
15 0,05 0,95 B B B B B B B B B B B B B B B B B B B A
16 0 1 B B B B B B B B B B B B B B B B B B B B
24

Eléments de base de génétique
• Génétique des populations
• Dérive génétique (« genetic drift »)
• La consanguinité survient lorsqu’un descendant est produit par deux parents apparentés.
• Cette situation est plus susceptible de se produire quand la population (« efficace ») est petite
• Elle se traduit par une augmentation de l’homozygotie, y compris à des loci portant des allèles délétères
• Les conséquences sont alors une diminution de la variabilité génétique (et de la résilience) et une augmentation de l’occurrence d’effets délétères (maladies, pertes de production, diminution des performances de reproduction => dépression de consanguinité)
• On montre que, dans une population « idéale »:
∆F = 1/(2*Ne)
où Ne est le nombre efficace de reproducteurs. Par exemple, s’il y a Nm mâles et Nf
femelles, on obtient:
Ne = 4*(Nm*Nf)/(Nm+Nf)
25
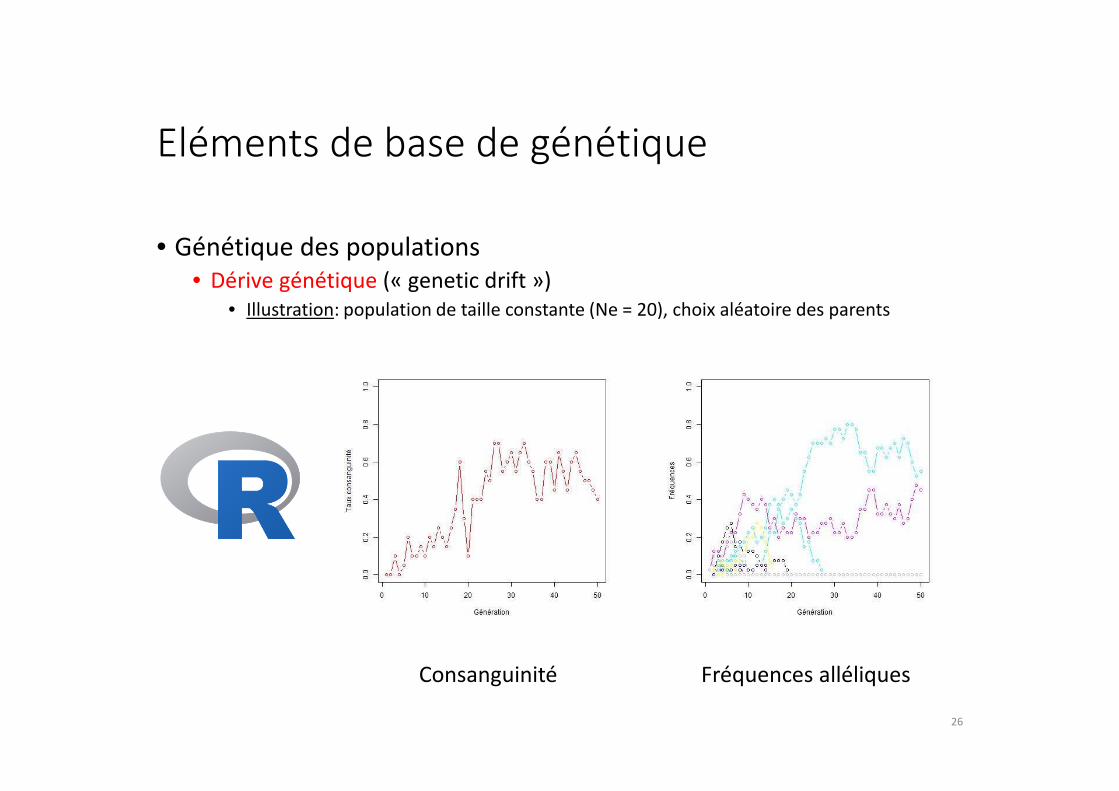
Eléments de base de génétique
• Génétique des populations
• Dérive génétique (« genetic drift »)
• Illustration: population de taille constante (Ne = 20), choix aléatoire des parents
Consanguinité Fréquences alléliques
26

Eléments de base de génétique
• Génétique des populations
• Dérive génétique (« genetic drift »)
• Remarques
• La création d’un noyau à partir d’une grande population initiale aboutit à une sous-population de petite taille, avec un effectif (« efficace ») réduit (« effet fondateur »). Les fréquences alléliques dans cette sous-population seront en général différentes des fréquences dans la population initiale
• Le nombre de descendants est ensuite généralement important, ce qui réduit le phénomène de dérive pour la génération suivante, mais la sélection des reproducteurs dans cette génération va conduire à une nouvelle fluctuation des fréquences alléliques (voir aussi « l’effet de la sélection »)
27

Eléments de base de génétique
• Génétique des populations
• Migration
• Une manière de contrer l’érosion due à la dérive est d’importer des reproducteurs dans la sous-population sélectionnée
• Cette introduction peut être voulue (individus provenant d’une autre souche/exploitation) ou accidentelle (rencontre avec des souches sauvages)
• La fréquence pour un allèle particulier est, après importation d’une proportion p d’individus:
ff = (1 – p)*fi + p*fe = p*(fe – fi) + fi
où ff est la fréquence finale, fi la fréquence avant importation et fe est la fréquence dans la population dont on importe des individus.
• Remarques
• La migration permet éventuellement d’introduire des allèles (d’adaptation) initialement absents dans la population cible (fi = 0).
• Le cas extrême est celui de croisements inter-spécifiques, quand ils sont possibles.
28

Eléments de base de génétique
• Génétique des populations
• Mutation
• La mutation est un phénomène aléatoire, rare, qui peut transformer un allèle en un autre (éventuellement) nouveau
• Le taux peut varier d’un locus à l’autre, et en fonction des conditions « environnementales ».
• Spontanément, le taux (probabilité d’une mutation en un locus donné) est de l’ordre de 10-6.
• La plupart des mutations sont délétères, et seront conservées à une fréquence très faible dans la population en raison d’une sélection « contre » ces mutations; certaines sont favorables et verront leur fréquence s’accroître avec le temps, en raison d’une sélection « pour » ces mutations (voir « l’effet de la sélection »).
• L’effet direct (hors sélection) de la mutation sur la fréquence allélique est faible sur un court nombre de générations mais peut devenir important par accumulation si le nombre de générations augmente
• différentiations inter-espèces
• différentiation des individus intra-espèces
29

Eléments de base de génétique
• Génétique des populations
• Sélection
• La sélection – artificielle ou naturelle - est un phénomène qui se produit quand certains génotypes sont mieux adaptés que d’autres aux conditions d’environnement et/ou aux objectifs de sélection.
• La sous- (ou sur-) utilisation de ces génotypes conduit à une évolution des fréquences de ces génotypes, et par conséquent des allèles sous-jacents.
• Exemple: allèle A dominant, allèle a délétère
Fréq. allèles G0 f(A) = (1 - q) f(a) = q
Fréq. génotype G0 f(AA) = (1-q)² f(Aa) = 2 q (1-q) f(aa) = q²
« Fitness » 1 1 1 - s
Fréq. génotype G1 (1-q)²/(1-q²s) 2q(1-q)/(1-q²s) q²(1-s)/(1-q²s)
Fréq. allèles G1 f(A) = (1-q)/(1-q²s) f(a) = (q-q²s)/(1-q²s)
Variation ∆f(A) = sq²(1-q)/(1-q²s) ∆f(a) = -sq²(1-q)/(1-q²s)
30

Eléments de base de génétique
• Génétique des populations
• Sélection
• Illustration: allèle A dominant, allèle a délétère, s = 0.3, f0(A) = f0(a) = 0.5
31

Eléments de base de génétique
• Caractères polygéniques
• Beaucoup de caractères ont une origine génétique plus complexe que l’effet d’un ou de deux gènes
• On observe des différences corrélées avec l’apparentement => origine génétique
• Il n’est pas évident (ou possible) de lier la variation du caractère aux polymorphismes liés à un nombre restreint de loci => caractère complexe
• La complexité peut avoir différentes origines, dont une importante est la situation où de nombreux gènes contribuent de petits apports à la composante génétique => caractère polygéniqueExemples: poids, taille, et de nombreux autres caractères dits quantitatifs
32
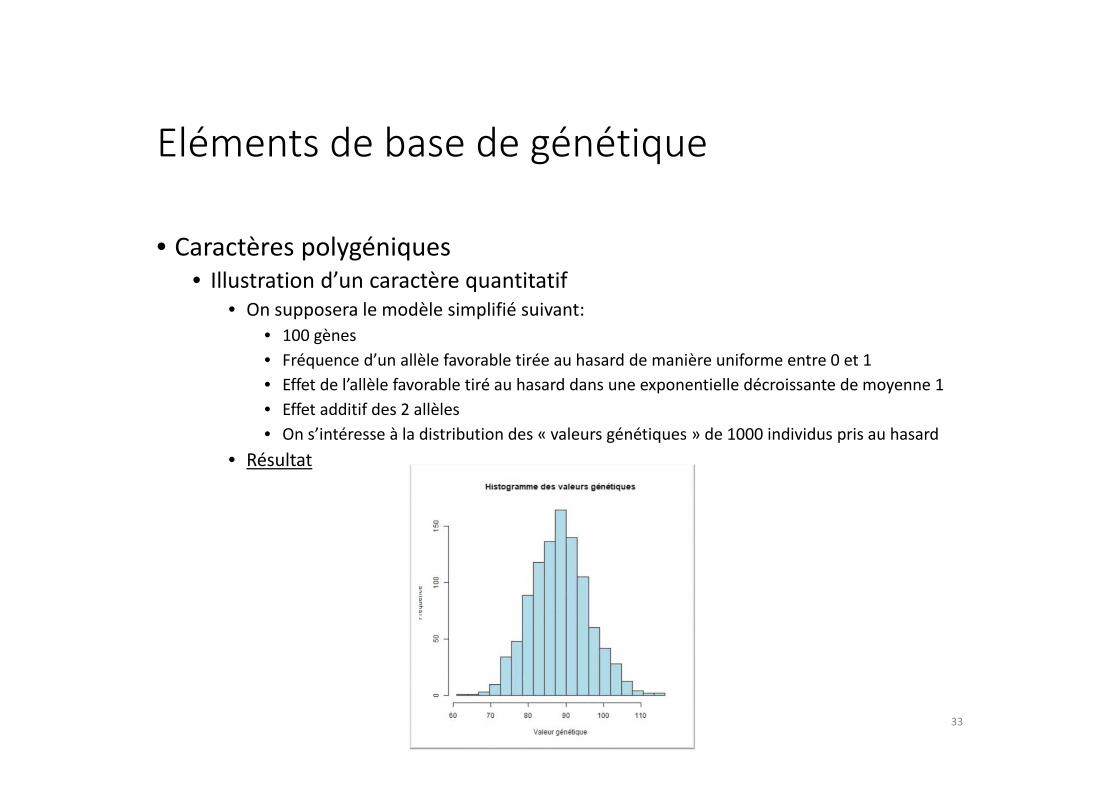
Eléments de base de génétique
• Caractères polygéniques
• Illustration d’un caractère quantitatif
• On supposera le modèle simplifié suivant:
• 100 gènes
• Fréquence d’un allèle favorable tirée au hasard de manière uniforme entre 0 et 1
• Effet de l’allèle favorable tiré au hasard dans une exponentielle décroissante de moyenne 1
• Effet additif des 2 allèles
• On s’intéresse à la distribution des « valeurs génétiques » de 1000 individus pris au hasard
• Résultat
33
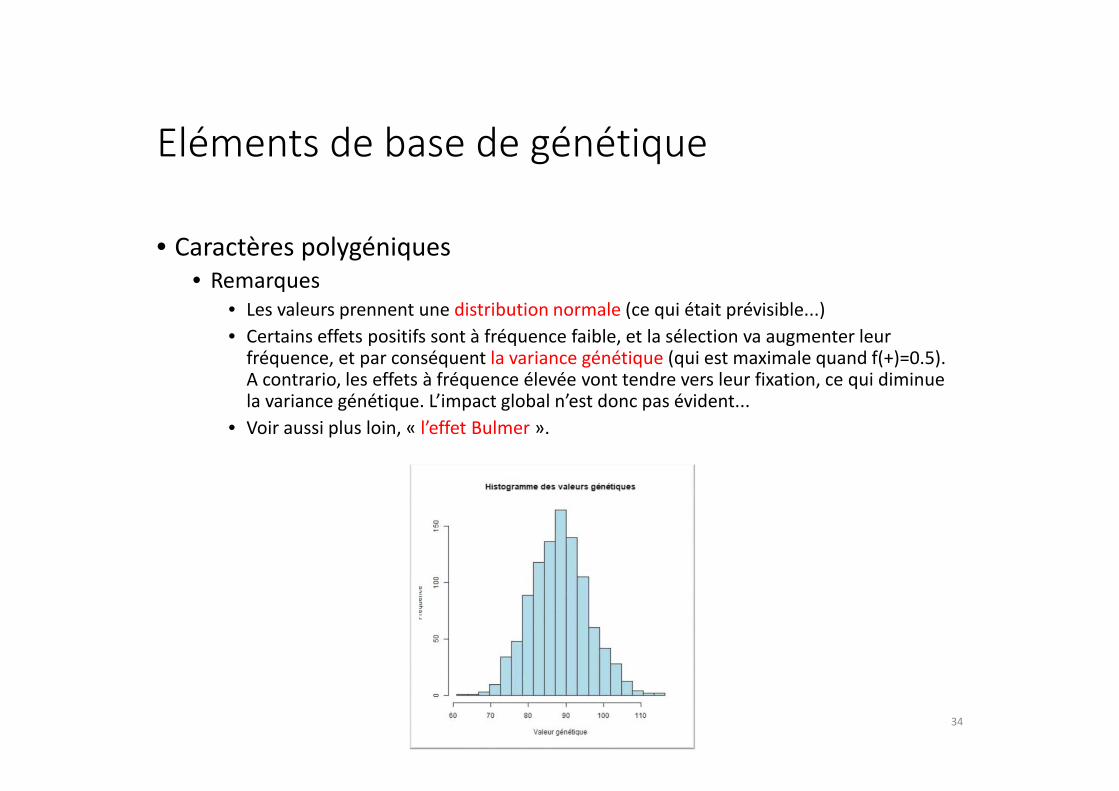
Eléments de base de génétique
• Caractères polygéniques
• Remarques
• Les valeurs prennent une distribution normale (ce qui était prévisible...)
• Certains effets positifs sont à fréquence faible, et la sélection va augmenter leur fréquence, et par conséquent la variance génétique (qui est maximale quand f(+)=0.5). A contrario, les effets à fréquence élevée vont tendre vers leur fixation, ce qui diminue la variance génétique. L’impact global n’est donc pas évident...
• Voir aussi plus loin, « l’effet Bulmer ».
34

Eléments de base de génétique
• Caractères polygéniques
• Le modèle additif
P = G + E
où P est la déviation phénotypique (la grandeur mesurée, comme le poids par exemple), G est la composante génétique et E est l’effet de l’environnement.
• Ce modèle suppose que les effets génétiques et environnementaux s’additionnent.
• L’effet génétique est souvent décomposé en diverses composantes:
G = A + D + I
où A = composante additive (addition des effets alléliques),
D = composante de dominance (interaction entre effets alléliques)I = composante d’interaction (interaction entre loci)
35
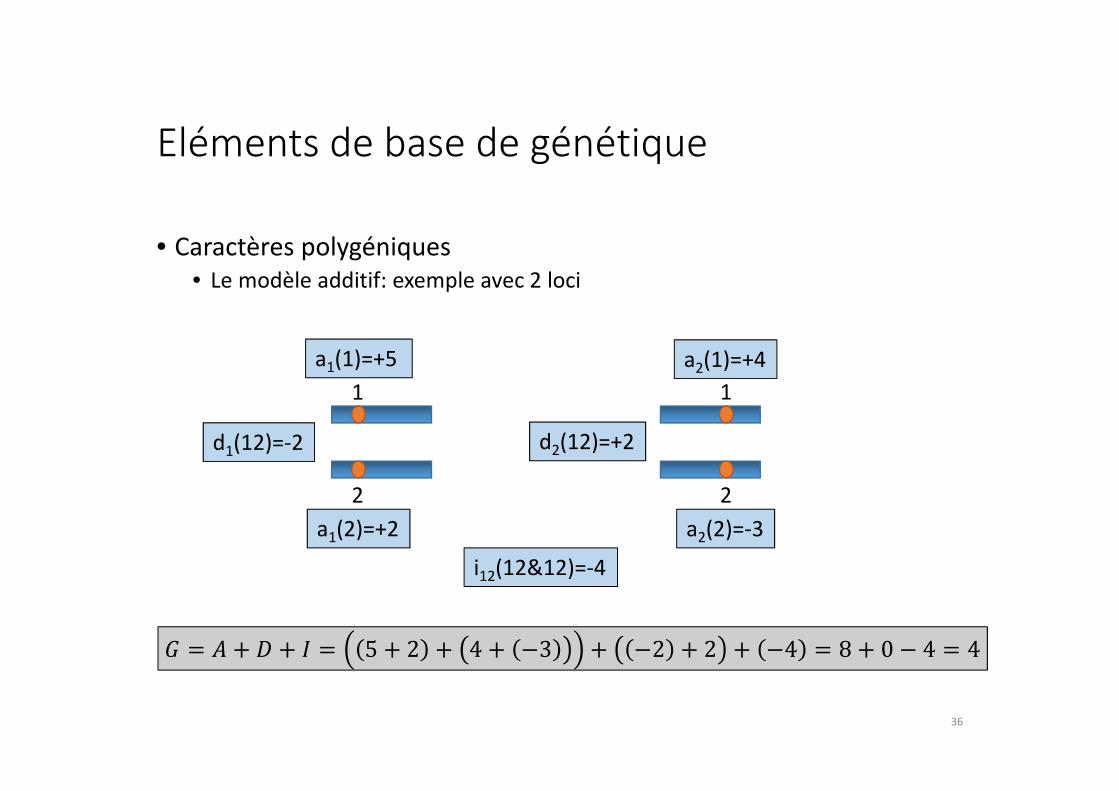
Eléments de base de génétique
• Caractères polygéniques
• Le modèle additif: exemple avec 2 loci
1 1
22
a1(1)=+5 a2(1)=+4
a1(2)=+2 a2(2)=-3
d1(12)=-2 d2(12)=+2
i12(12&12)=-4
� = � + � + � = 5 + 2 + 4 + −3 + −2 + 2 + −4 = 8 + 0 − 4 = 436

Eléments de base de génétique
• Caractères polygéniques• Une question importante: quelle est la part de la variation du phénotype qui
est due à la génétique ?
• La manière classique de décrire cette part est de raisonner sur les variances:
��� = ��� + ��� + 2 ∗ ���• Dans cette expression: ��� est la variance phénotypique,��� est la variance génétique,��� est la variance due à l’environnement,���est la covariance génétique * environnement (voir + loin).
• On peut aussi décomposer la variance génétique en sous-composantes:
��� = ��� + ��� + ���• Dans cette expression: ��� est la variance génétique additive,��� est la variance génétique de dominance,��� est la variance génétique d’interaction,
les covariances entre effets génétiques sont (le plus souvent) supposées nulles.
37
FF1

Diapositive 37
FF1 Fin 18/2/2019
Frederic Farnir; 18-02-19

Eléments de base de génétique
• Caractères polygéniques
• La variation génétique due aux interactions peut aussi se décomposer en:
��� = ���� + ���� + ���� + ����� + ����� + ⋯• Dans cette expression:
• ���� est la variance génétique d’interaction entre effets additifs (l’effet additif à 2 loci pouraitdifférer de la somme des effets additifs à ces 2 loci)
• Idem pour les autres termes...
• En pratique, les termes du membre de droite sont difficiles à évaluer individuellement, et tendent à contribuer de manière plus faible à la covariance entre individus (qui est utilisée pour estimer la variance génétique, cfr plus loin). Par exemple, la covariance génétique entre pleins-frères vaut:
��� = 12 ∗ ��� + 14 ∗ ��� + 14 ∗ ���� + 18 ∗ ���� + 116 ∗ ���� + 18 ∗ ����� + 116 ∗ ����� + ⋯
38

Eléments de base de génétique
• Caractères polygéniques
• La part de la variation du phénotype qui est due à la génétique est alors:
�� = ��� � �!appelée « héritabilité au sens large ».
• En sélection, on s’intéresse principalement à la partie additive de la variation génétique, parce que c’est la seule qui est transmise des parents aux descendants. On utilise alors: ℎ� = �#� � �!
appelée « héritabilité au sens restreint » (ou simplement « héritabilité »).
• Cette notion est importante parce que:
• seuls les caractères héritables peuvent être améliorés par sélection,
• la sélection sera d’autant plus efficace que l’héritabilité sera élevée.
39
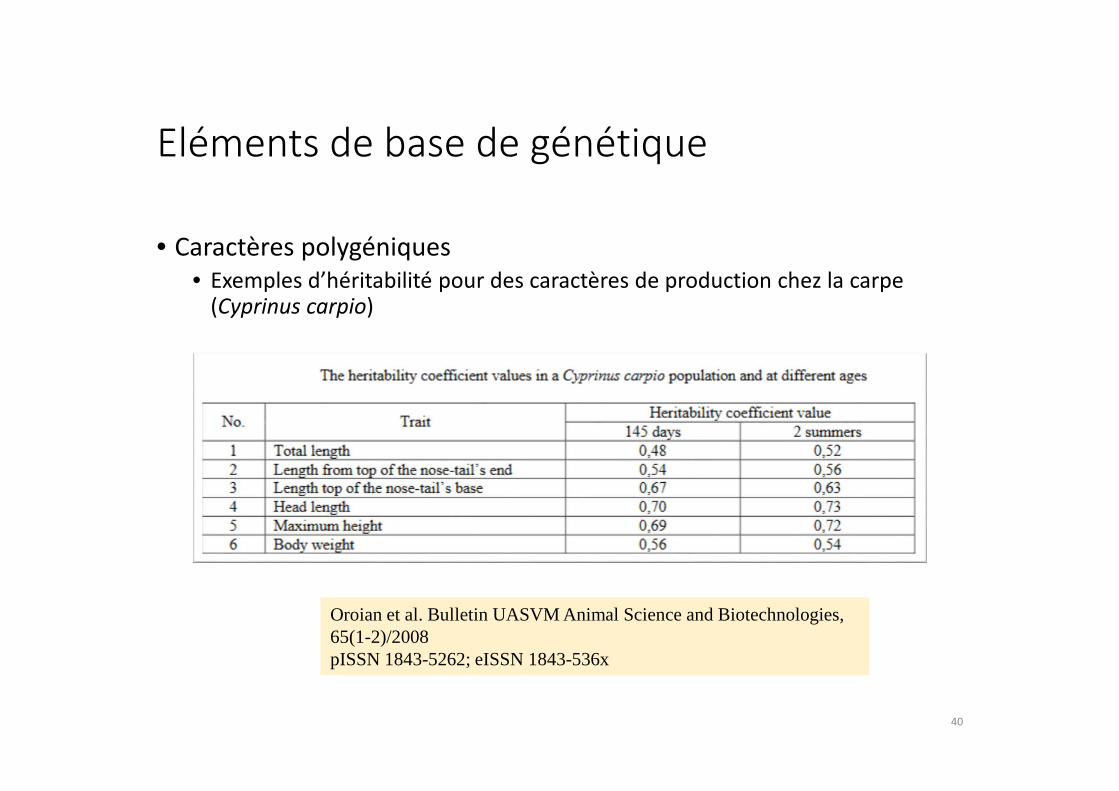
Eléments de base de génétique
• Caractères polygéniques
• Exemples d’héritabilité pour des caractères de production chez la carpe (Cyprinus carpio)
Oroian et al. Bulletin UASVM Animal Science and Biotechnologies, 65(1-2)/2008 pISSN 1843-5262; eISSN 1843-536x
40

Eléments de base de génétique
• Caractères polygéniques
• Exemples d’héritabilité pour des caractères de production chez le tilapia (Oreochromis niloticus)
41

Eléments de base de génétique
• Caractères polygéniques
• Exemples d’héritabilité pour la truite arc-en-ciel
42

Eléments de base de génétique
• Caractères polygéniques
• Un exercice simple, pour illustrer
• Supposons (pour l’exercice) que les valeurs génétiques sont observables. On aurait mesuré les valeurs suivantes sur 5 saumons:
Phénotype
(poids)
P = déviation
phénotypique
A = valeur
génétique
additive
E = déviation
résiduelle
4,4 0,4 0,2 0,2
4,2 0,2 -0,1 0,3
4,05 0,05 0,25 -0,2
3,75 -0,25 -0,05 -0,2
3,6 -0,4 -0,3 -0,1
Moyenne: 0 0 0
Variance: 0,106 0,051 0,055
Dév. standard: 0,326 0,226 0,235 43
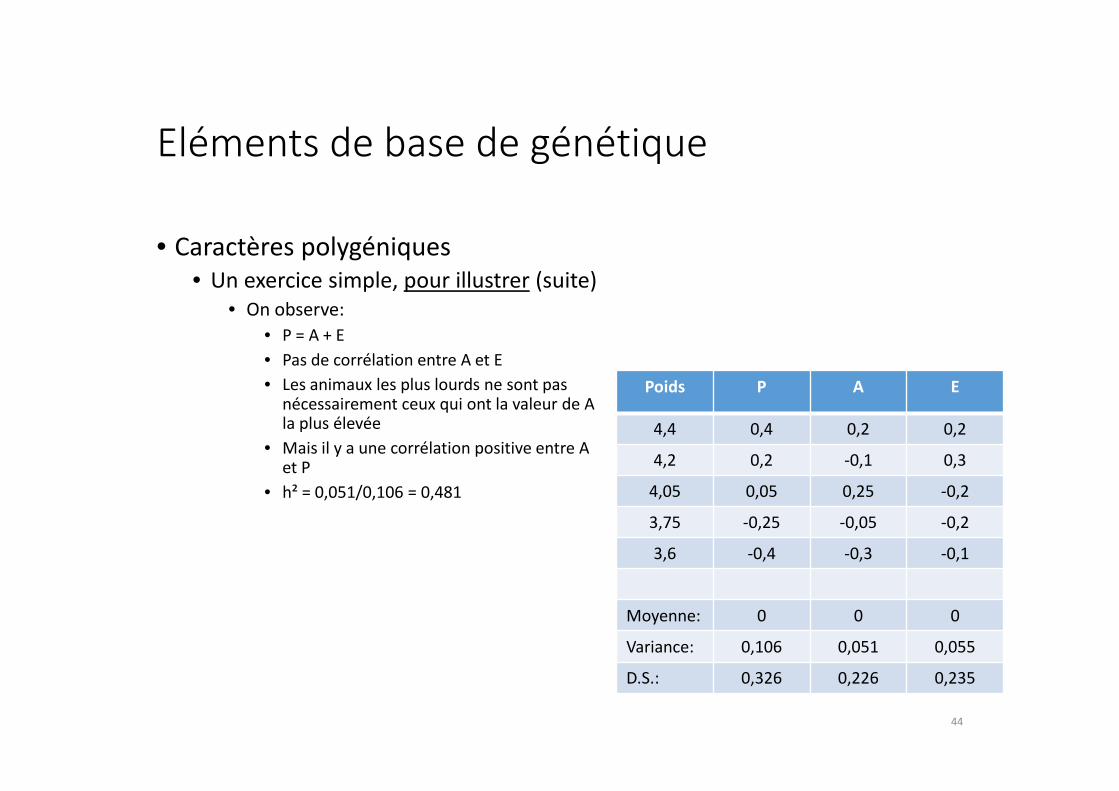
Eléments de base de génétique
• Caractères polygéniques
• Un exercice simple, pour illustrer (suite)
• On observe:
• P = A + E
• Pas de corrélation entre A et E
• Les animaux les plus lourds ne sont pas nécessairement ceux qui ont la valeur de A la plus élevée
• Mais il y a une corrélation positive entre A et P
• h² = 0,051/0,106 = 0,481
Poids P A E
4,4 0,4 0,2 0,2
4,2 0,2 -0,1 0,3
4,05 0,05 0,25 -0,2
3,75 -0,25 -0,05 -0,2
3,6 -0,4 -0,3 -0,1
Moyenne: 0 0 0
Variance: 0,106 0,051 0,055
D.S.: 0,326 0,226 0,235
44

Eléments de base de génétique
• Caractères polygéniques• Covariance génétique * environnement
• Cette composante est souvent supposée nulle, menant à: ��� = ��� + ���• Néanmoins, cette hypothèse est questionnable:
• Les poissons sont très sensibles à l’environnement (température, salinité, qualité de l’eau, manipulation...) et les génotypes favorables dans une situation peuvent différer de ceux qui sont favorables dans une autre
• Si l’environnement est contrôlé, l’interaction éventuelle est moins importante. Mais dans des conditions d’environnement variables, il faut en tenir compte.
• Exemple 1: poids de la carpe = f(génotype, année, type de culture)
45

Eléments de base de génétique
• Caractères polygéniques• Covariance génétique * environnement
• Exemple 2: « démo-génétique » = évolution adaptative des différentes populations d’une même espèce de poissons en fonction des contraintes (sélection) de leur milieu d’accueil
Gauthey, Z., Panserat, S., Elosegi, A., Herman, A., Tentelier, C., Labonne, J. (2016). Experimental evidence ofpopulation differences in reproductive investmentconditional on environmentalstochasticity. Science ofthe Total Environment, 541, 143-148. , DOI : 10.1016/j.scitotenv.2015.09.69
46
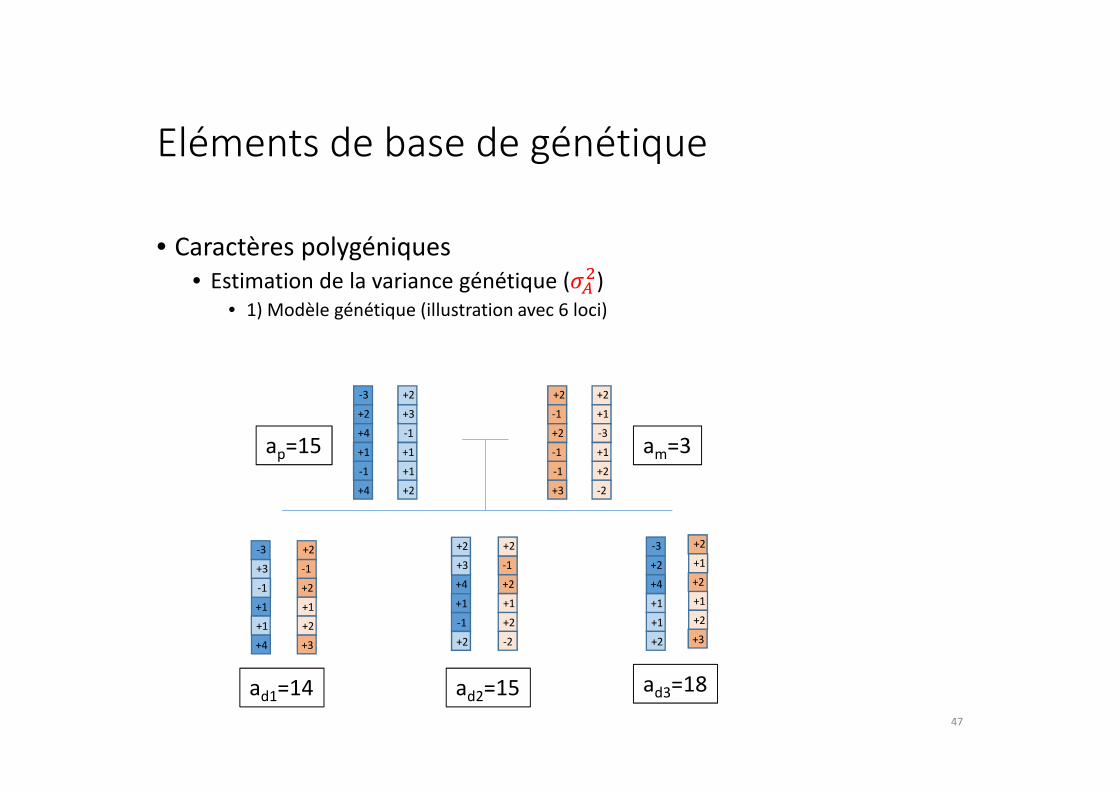
Eléments de base de génétique
• Caractères polygéniques
• Estimation de la variance génétique (���)
• 1) Modèle génétique (illustration avec 6 loci)
-3
+2
+4
+1
-1
+4
+2
+3
-1
+1
+1
+2
+2
-1
+2
-1
-1
+3
+2
+1
-3
+1
+2
-2
ap=15 am=3
-3
+1
+4
+3
-1
+1
+2
-1
+2
+3
+1
+2
+4
+1
-1
+2
+3
+2
-1
+2
+2
+1
+2
-2
-3
+2
+4
+1
+1
+2
+2
+2
+3
+1
+1
+2
ad1=14 ad2=15 ad3=18
47

Eléments de base de génétique
• Caractères polygéniques
• Estimation de la variance génétique (���)
• 1) Modèle mathématique
$% = &� ∗ $' + &
� ∗ $( + $)• Par conséquent: �� $% = &
* ∗ �� $' + &* ∗ �� $( + �� $)
=> 25% de la variance vient des pères, 25% vient des mères et 50% de la ségrégation mendélienne
• Remarque: on a supposé que cov(ap, am) = cov(ap, ar) = cov(am, ar) = 0
48

Eléments de base de génétique
• Caractères polygéniques
• Estimation de la variance génétique (���)
Illustration sur un exemple simple.
• On suppose qu’on a pesé k descendants pris au hasard dans la descendance d’un même père (pour simplifier, on suppose les mères prises au hasard également).
• On souhaite estimer l’héritabilité du caractère et la « valeur génétique additive » du père.
• Le modèle pourrait être le suivant:
+,- = . + /, + 0,-où: +,- est le poids du descendant j (entre 1 et k) du père i (entre 1 et n),. est le poids moyen dans cette population, /, est la valeur génétique additive du père i,0,- est le résidu (partie inexpliquée par le modèle) pour cette mesure.
• On reconnait une ANOVA 1 aléatoire !
49
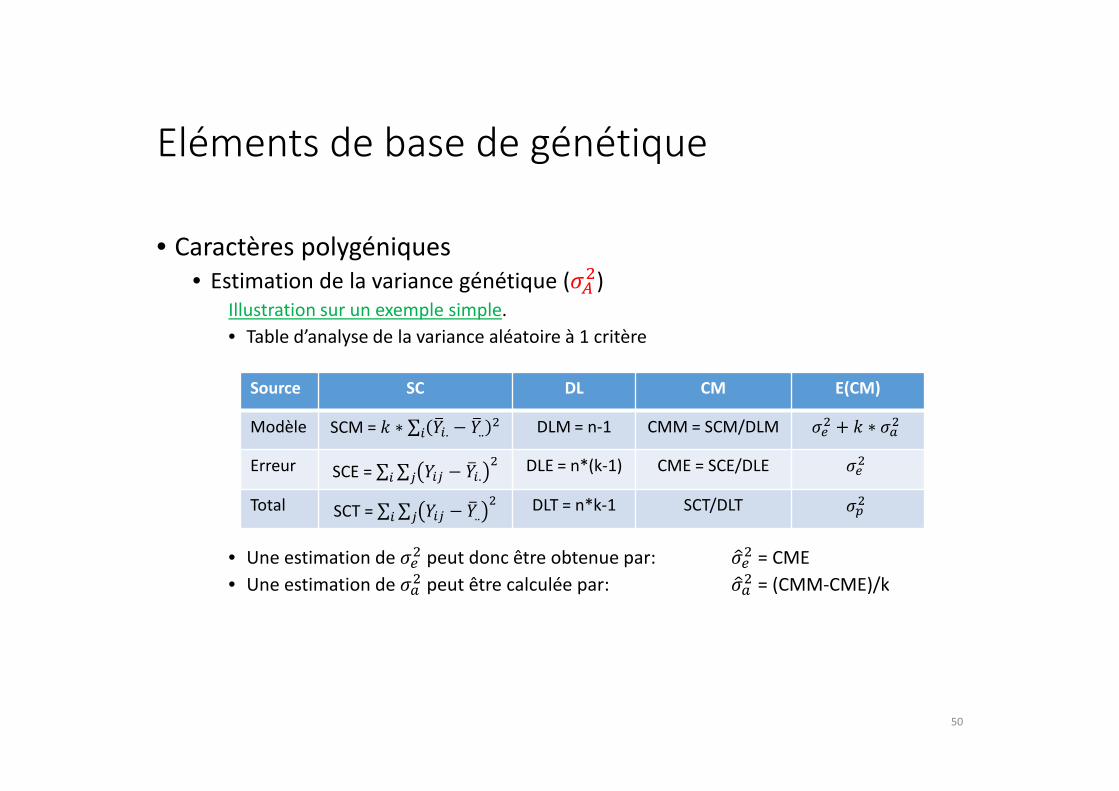
Eléments de base de génétique
• Caractères polygéniques
• Estimation de la variance génétique (���)
Illustration sur un exemple simple.
• Table d’analyse de la variance aléatoire à 1 critère
• Une estimation de �1� peut donc être obtenue par: �21� = CME
• Une estimation de �3� peut être calculée par: �23� = (CMM-CME)/k
Source SC DL CM E(CM)
Modèle SCM = 4 ∗ ∑ 67,. − 67.. �9, DLM = n-1 CMM = SCM/DLM �1� + 4 ∗ �3�Erreur SCE = ∑ ∑ 6,- − 67,. �9-9, DLE = n*(k-1) CME = SCE/DLE �1�Total SCT = ∑ ∑ 6,- − 67.. �9-9, DLT = n*k-1 SCT/DLT �'�
50
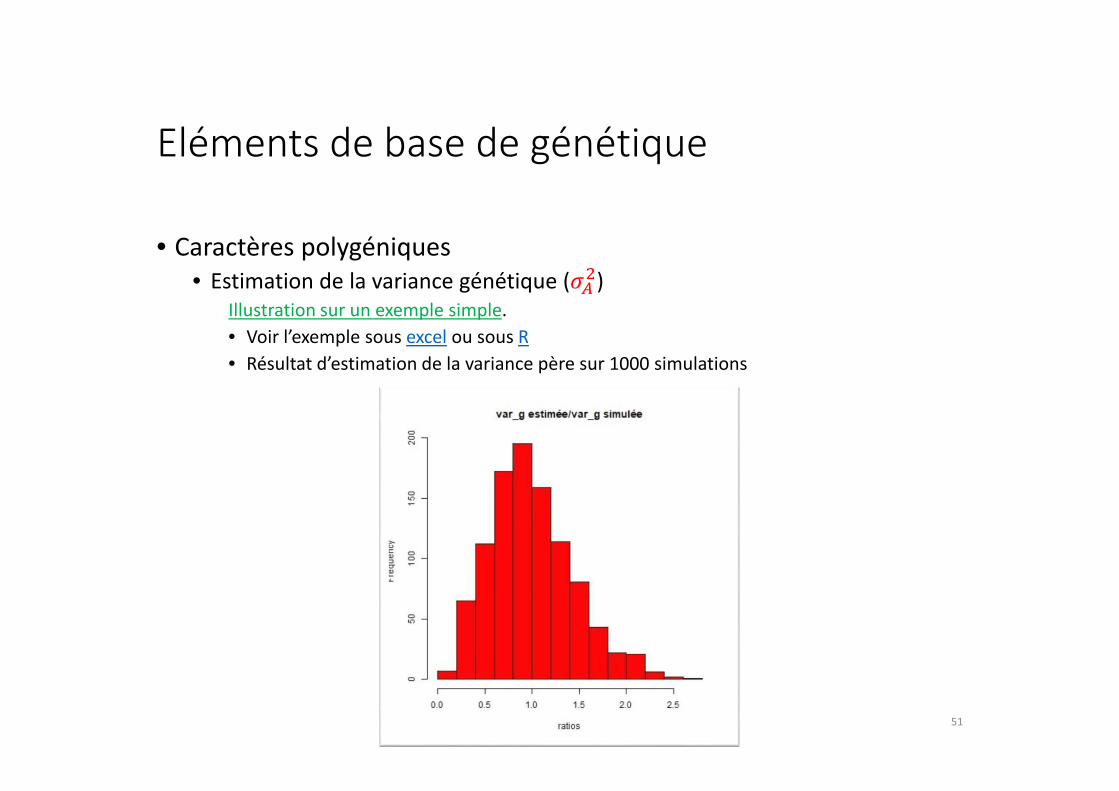
Eléments de base de génétique
• Caractères polygéniques
• Estimation de la variance génétique (���)
Illustration sur un exemple simple.
• Voir l’exemple sous excel ou sous R
• Résultat d’estimation de la variance père sur 1000 simulations
51

Eléments de base de génétique
• Caractères polygéniques• Estimation de la variance génétique (���)
Illustration sur un autre exemple simple.• On suppose qu’on a dispose de mesures sur k couples (parent – descendant)
• On souhaite estimer l’héritabilité du caractère.• Le modèle pourrait être le suivant:
+, = . + /, + 0,+,: = . + &� /, + &� /' + ;,: + 0,:où: +, est la mesure sur le parent i (entre 1 et n) de l’individu i’,+,: est la mesure sur l’individu i’ (entre 1 et n),. est la mesure moyenne dans cette population, /, est la valeur génétique additive du parent i de i’,/' est la valeur génétique additive de l’autre parent de i’,;,: est la valeur génétique provenant de la ségrégation mendélienne
sur l’individu i’ (entre 1 et n),0, =>0,: sont les résidus (parties inexpliquées par le modèle) pour cette mesure.
• Il est facile de voir que:
• ?@A +, , +,: = &� ∗ C$D / = �#�� (si on néglige les interactions => biais vers le haut de ���)
• C$D +, = C$D / + C$D 0 = ��� + ��� = ���• Par conséquent, le coefficient de régression de +,: sur +, vaut: E = FGH IJ,IJKL3) IJ = �#��∗� � = M�
�
52
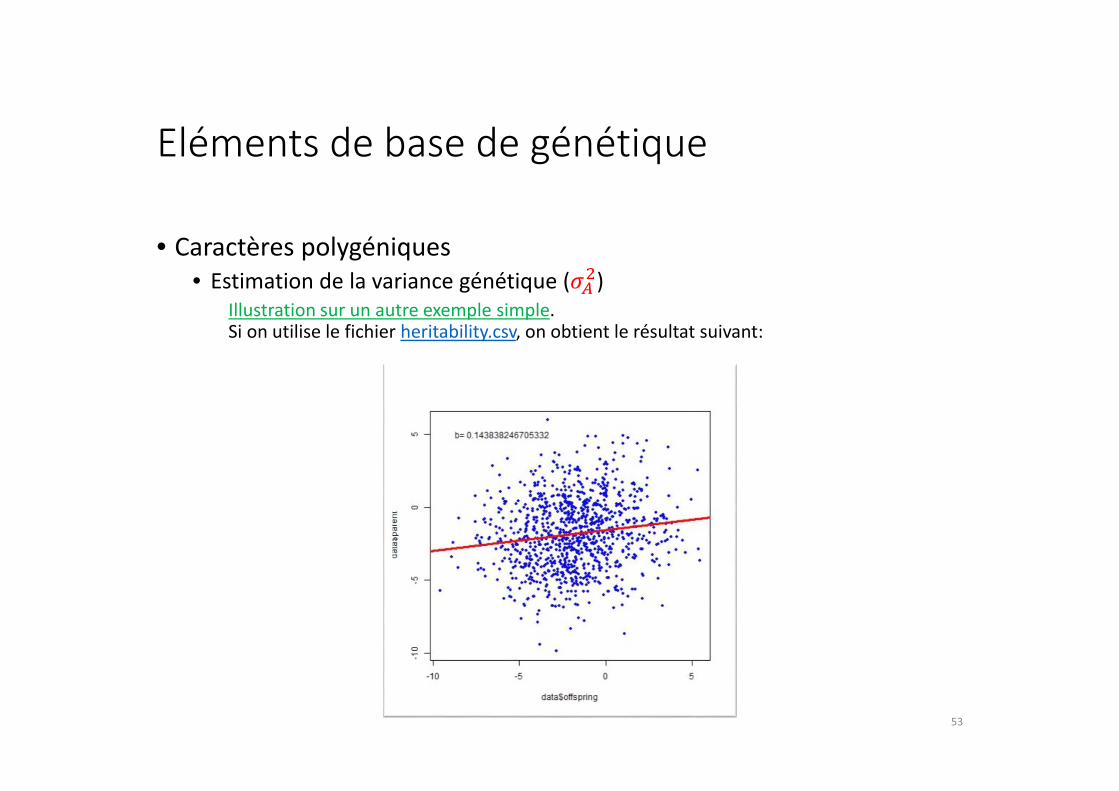
Eléments de base de génétique
• Caractères polygéniques
• Estimation de la variance génétique (���)
Illustration sur un autre exemple simple.Si on utilise le fichier heritability.csv, on obtient le résultat suivant:
53

Eléments de base de génétique
• Caractères polygéniques
• Estimation de la variance génétique (���)
• En général:
• Le design est moins simple
• On désire tenir compte des relations entre individus (voir chapitre suivant)
• On désire tenir compte d’effets d’environnement
• On a parfois plusieurs mesures par individu
• On a parfois plusieurs caractères à estimer
• On souhaite connaitre les valeurs génétiques des mères, des descendants, des apparentés...
• On veut intégrer des corrélations entre génétique et environnement...
• On veut éventuellement tenir compte des interactions
• Conséquence:
• On a recours à des méthodes plus sophistiquées d’estimation des composantes de variance (variances et corrélations)
• La méthode utilisée en pratique est la méthode REML (« REstricted Maximum Likelihood »)
• Il existe des logiciels qui permettent d’implémenter ces méthodes
• exemple: ASREML
54

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2)
• Les modèles décrits plus haut, outre fournir une estimation de la variance génétique additive (entre autres), permettent également d’obtenir une prédiction de la valeur génétique des individus (la vraie valeur, α, n’est pas observable...)
• La qualité de cette prédiction dépendra de l’information disponible ayant mené à cette prédiction:
• Propre(s) performance(s)
• Performances des apparentés (parents, plein- ou demi-frères, ...)
• L’information provenant des individus apparentés proviendra des corrélations existant entre les valeurs génétiques des individus apparentés, créées par le partage d’allèles communs.
• Il est donc important d’étudier les relations de parenté entre individus sous cet angle, ce que nous allons aborder dans la suite.
55

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2)
• Illustration de l’utilisation de la propre performance
• On a vu que: Y = µ + α + E => Y - µ = P = α + E
• Si on essaie de prédire α en partant de P, une régression de α sur P fournit un coefficient de régression qui vaut:b = cov(P, α)/V(P) = cov(α +E, α)/V(P) = V(α)/V(P) = h²
• Par conséquent, l’estimation de la valeur génétique basée sur la propre performance s’obtient simplement en calculant:
/2 = ℎ� ∗ N où P est la déviation du phénotype par rapport à ma moyenne
Poids P α E OP4,4 0,4 0,2 0,2 0,19
4,2 0,2 -0,1 0,3 0,10
4,05 0,05 0,25 -0,2 0,02
3,75 -0,25 -0,05 -0,2 -0,12
3,6 -0,4 -0,3 -0,1 -0,1956

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Illustration de l’utilisation de la propre performance
• Le ranking n’est pas le même sur les valeurs estimées et les valeurs réelles de α, mais...
• La corrélation entre α et /2 (appelée précision (accuracy) et notée rIA) vaut:
Q@D /, /2 = Q@A /, /2 A / ∗ A /29R = ℎ� ∗ Q@A /, N ��� ∗ ℎ* ∗ ���9R = ����� ∗ �� = ℎ• La précision (0.69, ici) sera améliorée si on arrive à inclure dans l’estimation de l’information
provenant des individus apparentés
• L’écart entre α et /2 est appelé « erreur de prédiction »
Poids P A E ST4,4 0,4 0,2 0,2 0,19
4,2 0,2 -0,1 0,3 0,10
4,05 0,05 0,25 -0,2 0,02
3,75 -0,25 -0,05 -0,2 -0,12
3,6 -0,4 -0,3 -0,1 -0,1957

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Utilisation des index de sélection
• Il s’agit d’une technique utilisant une fonction linéaire des observations (ajustées pour les effets non-génétiques) pour prédire les valeurs génétiques
• L’étape I consiste donc à ajuster les observations pour les effets d’environnement non-génétiques
N = µ + � + VW + = ⇒ 6 = N − µ − VW = � + =où µ est la moyenne générale, ET l’ensemble des effets d’environnement (âge, sexe, bassin, ...) et e est le résidu. Y, le caractère ajusté, est donc un déviation par rapport à la moyenne, ajustée pour les effets non génétiques.Remarque: la méthode REML (cfr plus bas) fait cette correction automatiquement
• L’étape II est la construction de l’index sur base du caractère ajuste mesuré sur l’individu et/ou des apparentés:
� = E& ∗ 6& + ⋯ + EY ∗ 6Yoù les 6, sont des mesures de caractères ajustées, et les E, sont des poids inconnus et à obtenir.
58

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Utilisation des index de sélection
• L’étape III consiste à choisir un critère à optimiser pour calculer les E,. Un critère souvent utilisé est de maximiser la corrélation entre I et A (notée rIA). Cette maximisation mène aisément au système suivant:
E& ∗ C$D 6& + ⋯ + EY ∗ ?@A 6&, 6Y =E& ∗ ?@A 6�, 6& + ⋯ + EY ∗ ?@A 6�, 6Y = ?@A �, 6&?@A �, 6�⋮E& ∗ ?@A 6Y, 6& + ⋯ + EY ∗ C$D 6Y = ⋮?@A �, 6Y
• L’étape IV est la résolution de ce système, qui permet d’obtenir les coefficients puis l’index de sélection lui-même.
59

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Propriété des index de sélection
• Démontrées par Wright, Lush and Henderson, nous ne fournirons que les résultats ici.
• La corrélation entre l’index I et la valeur génétique estimée A est appelée « précision de l’estimation » et se calcule par:
D�� = FGH �,�L �
9
• Si on mesure le même caractère sur des individus apparentés, cette formule se réduit à:
D�� = FGH �,�L �
9 = [\∗FGH �,�\ ]⋯][^∗FGH �,�̂L �
9 = E& ∗ $&3 + ⋯ + EY ∗ $Y39
où les $,3 représentent les relations d’apparenté entre les individus a et i (voir plus loin)
• I minimise la somme des écarts des erreurs de prédictions ∑ � − � �99• La variance des erreurs de prédiction vaut: C � − � = 1 − D��� ∗ C �• Le classement sur base de l’index de sélection maximise le gain génétique
60

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Utilisation courante des index de sélection
• Prédiction à partir d’une seule observation par individu (« Propre performance »)
• Nous avons déjà rencontré cette situation
• Index: I = b*Y => b*V(Y) = Cov(A,Y) = V(A)=> b = h²=> I = h²*Y
• Précision: D�� = FGH �,�L �
9=> D�� = M�∗FGH �,�
L �9 = ℎ� ∗ L �
L �9 = ℎ
61

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Utilisation courante des index de sélection
• Prédiction à partir de plusieurs observations par individu (« Propres performances »)
• On utilise 67• Index: I = b*67 => b*V(67) = Cov(A, 67) = V(A)
• La variance de la moyenne de données corrélées vaut:V(67) = C ∗ &](Yb&)cY
où d, la corrélation entre données successives, est appelée répétabilité
• => � = Y∗M�∗�7&] Yb& ∗c
• Précision: D�� = FGH �,�L �
9=> D�� = Y∗M�∗FGH �,�7
&] Yb& ∗c ∗L �9 = Y∗M�
&] Yb& ∗c9
62

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Utilisation courante des index de sélection
• Prédiction à partir de la moyenne des descendants (« Progeny test »)
• On utilise 67• Index: I = b*67 => b*V(67) = Cov(A, 67) = 0,5*V(A)
• La variance de la moyenne de données corrélées vaut:67 = C ∗ &](Yb&)cY
où d, la corrélation entre données de demi-frères vaut h²/4
• => � = e,f∗Y∗M�∗�7&] Yb& ∗e,�f∗M� = �∗Y∗�7gh�] Yb& = �∗Y
gih�h� ]Y ∗ 67 = �∗Y
Y]j ∗ 67 où k = *bM�
M�
• Précision: D�� = FGH �,�L �
9=> D�� = �∗Y∗FGH �,�7
Y]j ∗L �9 = Y
Y]j9
63

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Utilisation courante des index de sélection
• Prédiction d’un descendant futur à partir de la moyenne des descendants actuels
• On utilise 67 pour prédire un A à venir
• Index: I = b*67 => b*V(67) = Cov(A, 67) = 0,25*V(A)
• La variance de la moyenne de données corrélées vaut:67 = C ∗ &](Yb&)cY
où d, la corrélation entre données de demi-frères vaut h²/4
• => � = e,�f∗Y∗M�∗�7&] Yb& ∗e,�f∗M� = Y∗�7gh�] Yb& = Y
gih�h� ]Y ∗ 67 = Y
Y]j ∗ 67 où k = *bM�
M�
• Précision: D�� = FGH �,�L �
9=> D�� = Y∗FGH �,�7
Y]j ∗L �9 = Y
*∗ Y]j9
64

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Utilisation courante des index de sélection
• Prédiction d’un descendant futur à partir des données des parents
• On utilise 6� et 6k pour prédire le A d’un descendant
• Index: � = E� ∗ 6� + Ek ∗ 6k• l E� ∗ C 6� + Ek ∗ ?@A 6� , 6k = ?@A �, 6�Ek ∗ C 6k + E� ∗ ?@A 6� , 6k = ?@A �, 6k• mE� ∗ ��� = 0,5 ∗ ��� ⇒ E� = 0,5 ∗ ℎ�
Ek ∗ ��� = 0,5 ∗ ��� ⇒ Ek = 0,5 ∗ ℎ�• => � = ℎ� ∗ � ]�n�
• Précision: D�� = FGH �,�L �
9 = e,f∗M�∗FGH � ]�n,e,f∗ � ]�nL �9 = M�
�9 = M
�9• La précision est donc inférieure à celle obtenue en utilisant la propre performance
65

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Utilisation courante des index de sélection
• Prédiction à partir de la moyenne de demi-frères (paternels)
• Index: � = E ∗ 67• E ∗ C 67 = ?@A �, 67
• C 67 = &] Yb& ∗cY ∗ ���
• d = FGH e,f∗o ]e,f∗onJ]opJ ,e,f∗o ]e,f∗onq]opq � �R = M�*
• ?@A �, 67 = ?@A 0,5 ∗ /� , 0,5 ∗ /� = �#�*• => � = Y∗e,�f∗M�
&] Yb& ∗e,�f∗M� ∗ 67• Précision: D�� = FGH �,�
L �9 = [∗FGH �,�7
L �9 = [
*9 = Y∗e,er�f∗M�
&] Yb& ∗e,�f∗M�9
66

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Utilisation courante des index de sélection
• Prédiction à partir de la moyenne de plein-frères
• Index: � = E ∗ 67• E ∗ C 67 = ?@A �, 67
• C 67 = &] Yb& ∗cY ∗ ���
• d = FGH e,f∗o ]e,f∗on]opJ ,e,f∗o ]e,f∗on]opq � �R = M��
• ?@A �, 67 = ?@A 0.5 ∗ /� + 0.5 ∗ /k, 0.5 ∗ /� + 0.5 ∗ /k = �#��• => � = Y∗e,f∗M�
&] Yb& ∗(e,f∗M�]s�) ∗ 67• Précision: D�� = FGH �,�
L �9 = [∗FGH �,�7
L �9 = [
�9 = Y∗e,�f∗M�
&] Yb& ∗e,f∗M�9
67

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Utilisation courante des index de sélection
• Prédiction à partir de la moyenne de plein-frères de la même portée
• Index: � = E ∗ 67• E ∗ C 67 = ?@A �, 67
• C 67 = &] Yb& ∗cY ∗ ���
• d = FGH e,f∗o ]e,f∗on]opJ]tn,e,f∗o ]e,f∗on]opq]tn � �R = M�� + Q�
• ?@A �, 67 = ?@A 0.5 ∗ /� + 0.5 ∗ /k, 0.5 ∗ /� + 0.5 ∗ /k = �#��• => � = Y∗e,f∗M�
&] Yb& ∗(e,f∗M�]s�) ∗ 67• Précision: D�� = FGH �,�
L �9 = [∗FGH �,�7
L �9 = [
�9 = Y∗e,�f∗M�
&] Yb& ∗(e,f∗M�]s�)9
Effet maternel
68

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Exercices sur l’utilisation courante des index de sélection
1. Combien faut-il de demi-frères pour obtenir une précision équivalente à celle obtenue grâce à une propre performance ?
2. Et de plein-frères ?
3. Et de descendants ?
• Réponses
• Cfr dias suivantes !
69

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Exercices sur l’utilisation courante des index de sélection
1. Combien faut-il de demi-frères pour obtenir une précision équivalente à celle obtenue grâce à une propre performance ?
• Réponse
• La précision augmente avec le nombre de demi-frères, mais tend vers une limite:
limY→y0.0625 ∗ z ∗ ℎ�
1 + z − 1 ∗ 0.25 ∗ ℎ� = 0.06250.25 = 0.25• Donc, si h² ≥ 0.25, la précision via la moyenne des demi-frères sera toujours inférieure
• Si h² < 0.25, en résolvant ce système, on obtient:
z = &rb*∗M�&b*∗M�
• Par exemple, si h² = 0.1, on obtient n = 26
70

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Exercices sur l’utilisation courante des index de sélection
2. Combien faut-il de plein-frères pour obtenir une précision équivalente à celle obtenue grâce à une propre performance ?
• Réponse
• La précision augmente avec le nombre de plein-frères, et tend aussi vers une limite:
limY→y0. 25 ∗ z ∗ ℎ�
1 + z − 1 ∗ 0.5 ∗ ℎ� = 0.250.50 = 0.50• Donc, si h² ≥ 0.50, la précision via la moyenne des plein-frères sera toujours inférieure
• Si h² < 0.50, en résolvant ce système, on obtient:
z = *b�∗M�&b�∗M�
• Par exemple, si h² = 0.1, on obtient n = 4.75, soit 5
71

Eléments de base de génétique
• Caractères polygéniques
• Prédiction des valeurs génétiques (/2 = EBV)
• Exercices sur l’utilisation courante des index de sélection
3. Combien faut-il de descendants pour obtenir une précision équivalente à celle obtenue grâce à une propre performance ?
• Réponse
• La précision augmente avec le nombre de descendants. On peut écrire:
ℎ� = zz + 4 ⇒ z = ℎ� ∗ 41 − ℎ� = 4 − ℎ�1 − ℎ�
• Par exemple, si h² = 0.3, on obtient n = 5.28, soit 6
72

Eléments de base de génétique
• Caractères polygéniques
• Covariance génétique entre caractères (��{)
• Les valeurs génétiques associées à deux caractères A et B peuvent être corrélées, les gènes sous-jacents ayant potentiellement des effets pléïotropes agissant sur ces deux caractères.
• Suivant le nombre de gènes, et le fait que ces gènes agissent dans le même sens sur les deux caractères ou en sens opposés, la covariance peut être élevée ou faible, et négative, nulle ou positive.
• On calcule la corrélation génétique via: |�{ = �#}�#�∗�}�9
où ��� et �{� sont les variances génétiques pour les caractère A et B, respectivement.
• La connaissance des covariances génétiques entre les caractères d’intérêt est d’importance dans une expérience de sélection, afin d’éviter de sélectionner « contre » un caractère important qui serait négativement corrélé avec un autre caractère important « pour » lequel on sélectionne.
73

Eléments de base de génétique
• Parenté, relation et consanguinité
• Identité par descente (Identity by descent = IBD)
• Deux allèles sont IBD s’ils sont des copies du même allèle provenant d’un ancêtre commun (AC)
AC
I1 I2
Ces deux allèles sont IBD
74

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de parenté ϕ (Kinship coefficient)
• ϕ(A,B) = probabilité qu’un allèle tiré au hasard parmi les deux allèles homologues d’un individu A soit IBD avec un allèle tiré au hasard parmi les deux allèles homologues d’un individu B
~ �, � = 14 ∗ � �' ≡ �' + � �' ≡ �( + � �( ≡ �' + � �( ≡ �(où les indices p et m indiquent l’origine paternelle ou maternelle de l’allèle, respectivement, et le symbole ≡ signifie IBD.
• Exemple:
~ �, � = 14 ∗ � �' ≡ �' + � �' ≡ �( + � �( ≡ �' + � �( ≡ �(= 12 ∗ 1 + � �' ≡ �(
75

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de parenté ϕ (Kinship coefficient)
• Calculs:
76

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de parenté ϕ (Kinship coefficient)
• Exemples:
77

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de parenté ϕ (Kinship coefficient)
• Exemple de calcul: calculer ϕ(3,6).1 2
3 4 5
6
ϕ(3,6) = 0.5*[ϕ(3,4) + ϕ(3,5)]
= 0.5*[0.5*[ϕ(3,1) + ϕ(3,2)] + 0.5*[ϕ(1,5) + ϕ(2,5)]]
= 0.5*[0.5*[0.5*[ϕ(1,1) + ϕ(2,1)] + 0.5*[ϕ(1,2) + ϕ(2,2)]]]
= 0.5*[0.5*[0.5*[0.5 + 0] + 0.5*[0 + 0.5]]]
= 0.5*[0.5*[0.5*0.5 + 0.5*0.5]]
= 0.5*0.5*0.5
= 1/8 78

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de relation A (relationship coefficient)
• Par définition: A(a,b) = 2*ϕ(a,b)
• Remarques:
• comme ϕ peut varier entre 0 et 1 (rappelons que ϕ est une probabilité), A peut varier entre 0 et 2 (et n’est donc pas une probabilité)
• la règle de calcul de ϕ peut évidemment également s ’appliquer pour A, ce qui est utilisé en pratique pour construire « la matrice de relation » A utilisée dans les calculs d’estimation de la valeur génétique (voir plus loin)
1 2
3 4 5
6
S =1.00 0.00 0.500.00 1.00 0.500.50 0.50 1.00
0.50 0.00 0.250.50 0.00 0.250.50 0.00 0.250.50 0.50 0.500.00 0.00 0.000.25 0.25 0.251.00 0.00 0.500.00 1.00 0.500.50 0.50 1.00
79
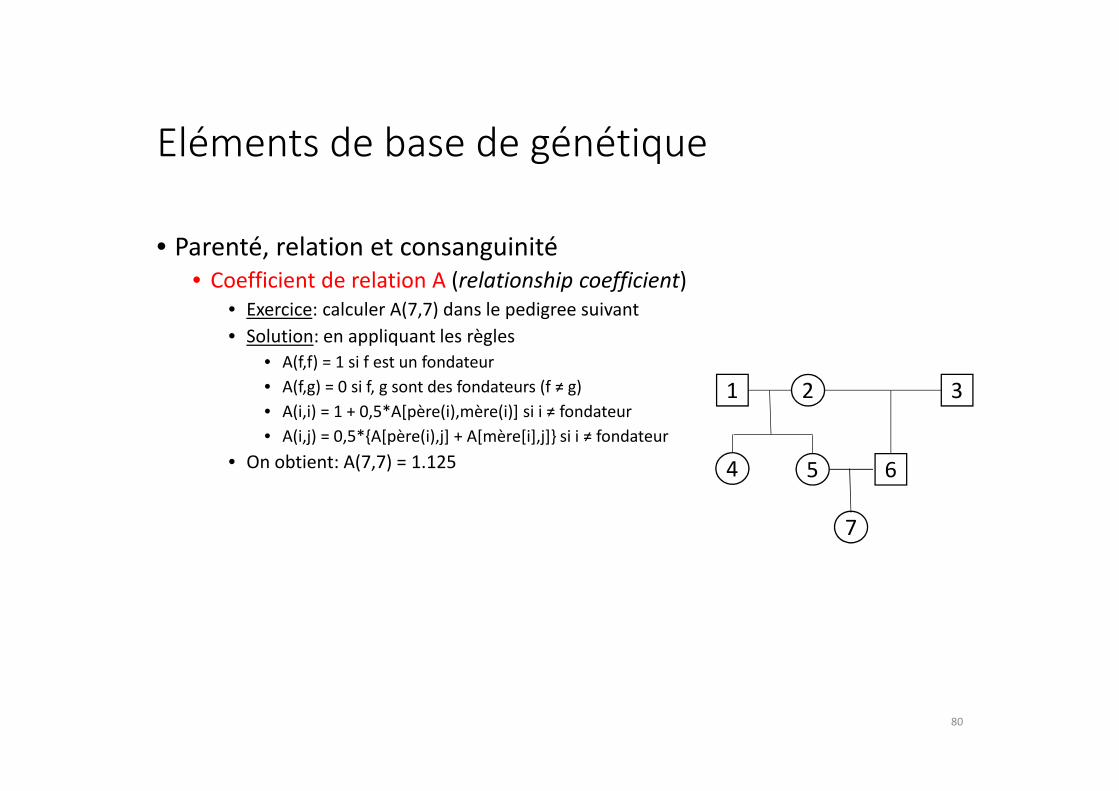
Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de relation A (relationship coefficient)
• Exercice: calculer A(7,7) dans le pedigree suivant
• Solution: en appliquant les règles
• A(f,f) = 1 si f est un fondateur
• A(f,g) = 0 si f, g sont des fondateurs (f ≠ g)
• A(i,i) = 1 + 0,5*A[père(i),mère(i)] si i ≠ fondateur
• A(i,j) = 0,5*{A[père(i),j] + A[mère[i],j]} si i ≠ fondateur
• On obtient: A(7,7) = 1.125
1
6
32
4 5
7
80

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de relation A (relationship coefficient)
• Exercice: calculer A(7,7) dans le pedigree suivant avec R
1
6
32
4 5
7> library(pedigree)> indivs<-1:7> father<-c(0,0,0,1,1,3,6 )> mother<-c(0,0,0,2,2,2,5)> ped<-data.frame(indivs,father,mother)> makeA(ped,which=rep(TRUE,7))[1] TRUE> A<-read.table("A.txt")> A$V3[(A$V1==7) & (A$V2==7)][1] 1.125> # Valeur > 1, indiquant de la consanguinité
81

Eléments de base de génétique
• Parenté, relation et consanguinité
• Matrice de relation A (relationship matrix)
• Cette matrice est utilisée notamment dans la méthode REML évoquée plus haut.
• En effet, on notera que: ?@A /, , /- = � �, � ∗ �3�• où /, , /- sont les valeurs génétiques additives des individus i et j, et �3� est la variance
génétique additive.
• La méthode conduit à un système d’équations (appelées « équations du modèle mixte de Henderson »), qui permet d’estimer simultanément les effets d’environnement et les valeurs génétiques (les paramètres �3� et �1� doivent avoir été estimés au préalable). Ces équations sont proposées le plus souvent sous forme matricielle.
• On modélise en utilisant: y = X b + Z a + eoù b est un vecteur d’effets d’environnement inconnu, et a est un vecteur de valeurs génétiques inconnues (y est un vecteur de productions connues, X et Z sont des matrices connues associant les effets génétiques et d’environnement aux productions correspondantes, et e est un vecteur de résidus inconnus)
• On résout en utilisant : �′�b&� �′�b&��′�b&� �:�b&� + �b& E�/2 = �′�b&+�′�b&+où R = V(e) et G = A*�3�
82

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de consanguinité F (Inbreeding coefficient)
• F(A) = Probabilité que les allèles à un locus neutre aléatoire soient IBD
� � = � �' ≡ �(où les indices p et m indiquent l’origine paternelle ou maternelle de l’allèle, respectivement, et le symbole ≡ signifie IBD.
• Exemple (suite):
� �, � = 12 ∗ 1 + � �' ≡ �(= 12 ∗ 1 + � �
• Par cette définition, il est clair que:
� � = � N � , �(�)
83

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de consanguinité F (Inbreeding coefficient)
• La définition de F montre que la consanguinité est due à la présence de boucles de consanguinité dans le pedigree (sauf « selfing », pas considéré ici)
• Exemple:
84

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de consanguinité F (Inbreeding coefficient)
• Exemples:
• F(5) = f(3,4) = 0.25*[P(3P=A1 & 4P=A1) + P(3P=A2 & 4P=A2) + P(3M=A3 & 4M=A3) + P(3M=A4 & 4M=A4)]= 0.25*[0.5*0.5 + 0.5*0.5 + 0.5*0.5 + 0.5*0.5]= 0.25
• F(10) = 4 * (1/2)6 = 1/16 = 0,0625
• F(15) = 4 * (1/2)8 = 1/64 = 0,015625
85

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de consanguinité F (Inbreeding coefficient)
• Le calcul de la consanguinité fait appel à la structure connue du pedigree, et on considère en général les individus de la première génération comme non-apparentés, ce qui est une hypothèse lourde: dans une population finie, la consanguinité est inévitable
• Exemple: en 20 générations, chaque individu à > 4.000.000 ancêtres...
• Par conséquent, la consanguinité mesurée sur pedigree est souvent sous-estimée.
• Des méthodes utilisant l’homozygotie de l’ADN sont utilisées aujourd’hui pour obtenir une meilleure idée de la consanguinité réelle (« runs of homozygosity »)
86

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de consanguinité F (Inbreeding coefficient)
• Plus important pour la gestion est l’augmentation du coefficient de consanguinité dans la population. Il est mesuré de manière relative par:
△ � = ��]& − ��1 − ��où ��]& est la consanguinité moyenne à la génération (t+1).
• Exemple: un noyau de 30 mâles et 30 femelles (supposés non apparentés) est utilisé pour créer un nouvelle lignée de poissons. Ensuite, 60 descendants (30 mâles et 30 femelles) choisis aléatoirement sont gardés à chaque génération. On peut calculer:
• F1, F2, F3, ...
• △ � pour chaque génération
87
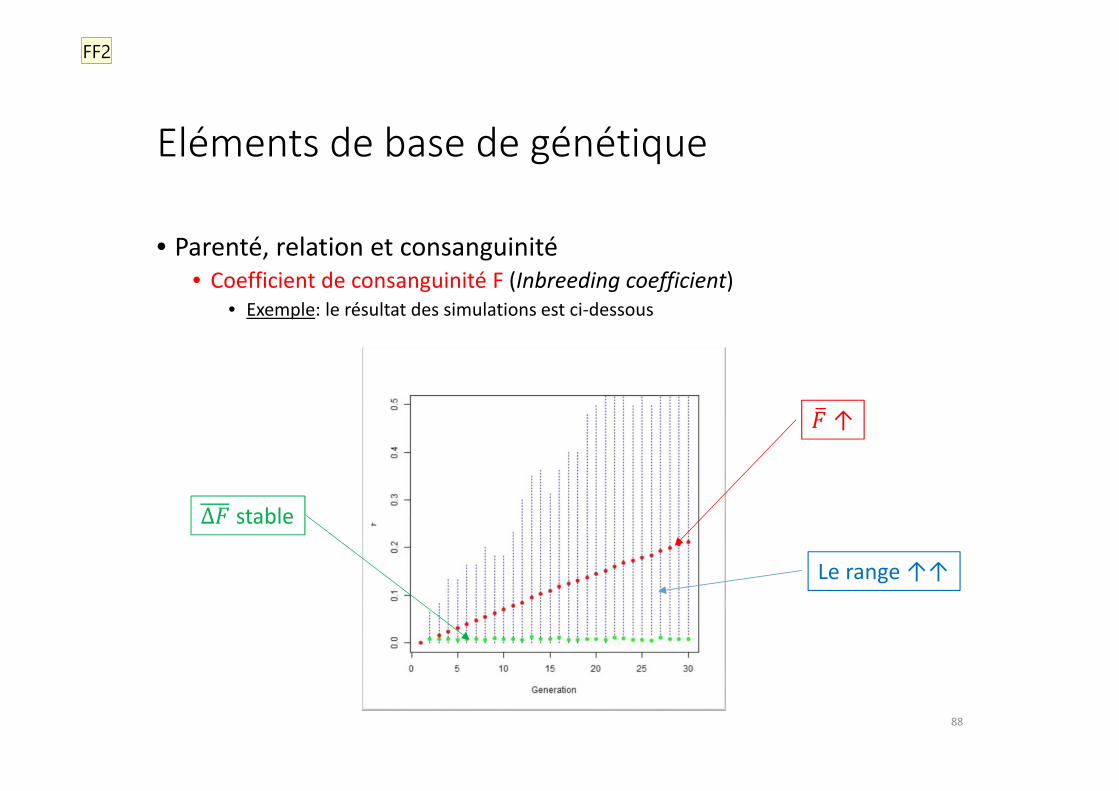
Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de consanguinité F (Inbreeding coefficient)
• Exemple: le résultat des simulations est ci-dessous
�7 ↑
Le range ↑↑
Δ� stable
88
FF2

Diapositive 88
FF2 Fin 25/2/2019
Frederic Farnir; 25-02-19

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de consanguinité F (Inbreeding coefficient)
• Exemple: dans ce type de situations (taille constante, choix aléatoire...), il est facile de montrer qu’en moyenne:
Δ� = &�∗�
où N est le nombre d’individus dans la population de base (« nombre efficace »)
• Ici, N = 60 => Δ� = 1/120 = 0,008333...
• La valeur obtenue après 1000 simulations est Δ� = 0,00820
• Exemple (suite): on recommence le même type d’expérience, mais en gardant cette fois 150 mâles et 150 femelles à chaque génération
89

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de consanguinité F (Inbreeding coefficient)
• Exemple: le résultat des secondes simulations est ci-dessous
�7 ↑ moins vite
Le range moins grand
Δ� stable
90

Eléments de base de génétique
• Parenté, relation et consanguinité
• Coefficient de consanguinité F (Inbreeding coefficient)
• Exemple: dans ce type de situations, il faudrait recalculer l’estimateur attendu, ou l’obtenir par simulations, comme ici. Ici, N = 60 => Δ� = 1/120 = 0,008333...
• La valeur obtenue après 1000 simulations est Δ� = 0,0019 ~ 1/600
• En pratique:
• Il faut tenir compte de l’évolution de la taille du noyau pour évaluer l’augmentation (absolue ou relative) de la consanguinité
• On peut utiliser la formule: Δ� = 1/(2*N), mais en remplaçant le N (= nombre réel d’individus) par Ne (= nombre efficace d’individus) qui dépendra du design
• Ne est donc le nombre d’individus qui conduirait à la même évolution de la consanguinité dans une population idéale (taille fixe, choix aléatoire, ...)
• Le noyau sera sélectionné, ce qui conduira au choix préférentiel de certains reproducteurs, et donc à une diminution de la diversité (c’est-à-dire, de Ne)
91

Eléments de base de génétique
• Hétérosis
• Le croisement d’espèces, quand il est possible, a l’effet inverse de la consanguinité: augmentation de la fréquence d’hétérozygotes, diminution de la fréquence des homozygotes (y inclus ceux donnant des effets délétères)
• Schématiquement: (AA x BB) => AB
• Les intérêts majeurs du croisement:
• Diminution (en première génération) du nombre de récessifs délétères
• Possibilité de combinaisons des caractéristiques favorables des espèces croisées
• Dans certains cas: « avantage à l’hétérozygote »
• Exemples: croisement de deux espèces de tilapias du Nil aux PhilippinesO. aureus x O. spilurus 22% de gain en poidsO. mossambicus x O. niloticus 25% de gain en poids, tolérance à la
salinité améliorée
92

Eléments de base de génétique
• Sélection
• Sélectionner (artificiellement) une population revient à utiliser des animaux jugés supérieurs pour produire les individus de la génération suivante
• La supériorité est basée sur un caractère (ou plusieurs caractères, alors combinés dans un caractère appelé ‘index’) mesurant l’adaptation (fitness) de l’individu à l’objectif de sélection (voir plus loin)
• Exemple: taux de croissance, mesuré par le poids atteint à un âge donné
• L’approche de sélection la plus simple est la « sélection massale (ou individuelle) », qui consiste à choisir les individus sur base de leur propre performance. On procède régulièrement par une sélection par troncature, comme le montre l’exemple sur la dia suivante
93

Eléments de base de génétique
• Sélection par troncature
• Exemple sur la longueur des individus
• Les géniteurs sont choisis parmi les x % supérieurs
• A chaque génération, la longueur moyenne augmente
94
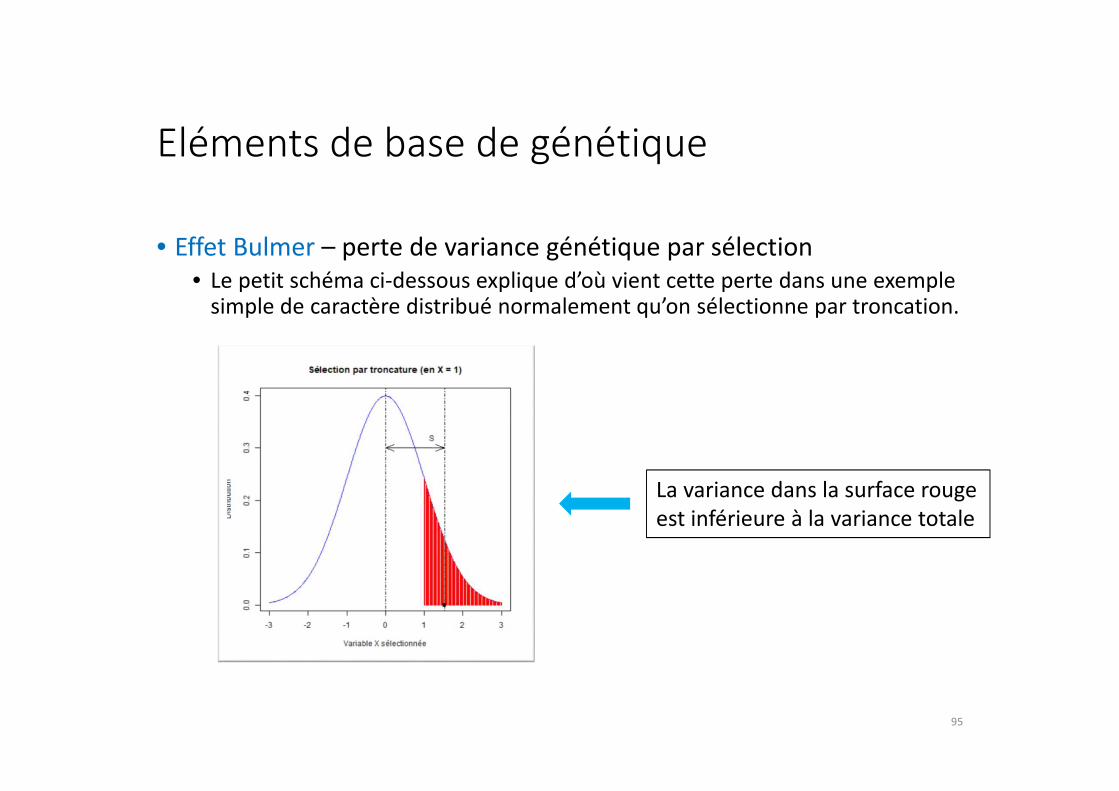
Eléments de base de génétique
• Effet Bulmer – perte de variance génétique par sélection
• Le petit schéma ci-dessous explique d’où vient cette perte dans une exemple simple de caractère distribué normalement qu’on sélectionne par troncation.
La variance dans la surface rouge
est inférieure à la variance totale
95

Eléments de base de génétique
• Effet Bulmer – perte de variance génétique par sélection
• Théoriquement, si on sélectionne de cette manière (variable normale y, sélection « massale » par troncation):
�I∗� = �I� ∗ 1 − � ∗ � − >où �I∗� est la variance après sélection, �I� la variance avant sélection, i est l’intensité de sélection (écart standardisé entre les moyennes avant et après sélection: � = � � ⁄ ) et t est le seuil de troncature (dans l’exemple de la dia précédente, t = 1)
• Pour illustrer, on peut simuler facilement ceci:
1. On échantillonne un grand nombre de valeurs de y ~ N(0,1)
2. On ne conserve que les valeurs > seuil t (par exemple, t = 1)
3. On calcule la moyenne m des valeurs sélectionnées. Ici, m = m – 0 = S = S/1 = i
4. On calcule la variance v des valeurs sélectionnées
5. On pourra vérifier que v ≈ 1² ∗ 1 − � ∗ � − >96

Eléments de base de génétique
• Effet Bulmer – perte de variance génétique par sélection
• Illustration
> # Exemple de troncation en t dans une normale > moyenne<-0> variance<-1> # 1) Génération de valeurs de y> y<-rnorm(1000000,mean=moyenne,sd=sqrt(variance))> # 2) Valeurs supérieures au seuil t (par exemple, t = 1)> t<-1> ys<-y[y>t]> # 3) Moyenne des valeurs sélectionnées> S<-mean(ys)-moyenne> i<-S/sqrt(variance)> # 4) Variance des valeurs sélectionnées> v_empirique<-var(ys)> v_theorique<-variance*(1-i*(i-t))> # 5) Résultats> v_empirique[1] 0.1988824> v_theorique[1] 0.2049292 97

Eléments de base de génétique
• Effet Bulmer – perte de variance génétique par sélection
• D’autres résultats théoriques sont intéressants:
• Effet de la sélection massale sur la variance d’une variable corrélée x (voir dia suivante)
��∗� = ��� ∗ 1 − � ∗ � − > ∗ D�I�• Exemple: cov(y , a) = cov(f+a+e , a) = var(a) = σ²(a)
=> r(y,a) = σ²(a)/[σ(y)*σ(a)] = σ(a)/σ(y) = h => �3∗� = �3� ∗ 1 − � ∗ � − > ∗ ℎ�=> la sélection phénotypique impacte la variance génétique d’autant plus fort
que l’héritabilité du caractère est importante
• Effet de la sélection massale sur la covariance entre deux variables corrélées
���∗ = ��� − � ∗ � − > ∗ ��I ∗ ��I�I�• Effet de la sélection sur la valeur génétique prédite sur la variance génétique
��2∗� = ��2� ∗ 1 − � ∗ � − >
98

Eléments de base de génétique
• Effet Bulmer – perte de variance génétique par sélection
• Illustration sur variable corrélée
> #--------------------------> # Variables corrélées> # X et Y sont non corrélées, U et V sont corrélée s (avec r = rho)> #--------------------------> # 1) Génération de valeurs de U et V> X<-rnorm(10000000)> Y<-rnorm(10000000)> rho<-0.5> U<-sqrt((1+rho)/2)*X+sqrt((1-rho)/2)*Y> V<-sqrt((1+rho)/2)*X-sqrt((1-rho)/2)*Y> # 2) Valeurs supérieures au seuil t (par exemple, t = 1)> t<-1> Us<-U[U>t]> Vs<-V[U>t]> # 3) Moyenne des valeurs sélectionnées> i<-mean(Us)> # 4) Variance des valeurs corrélées sélectionnées> v_empirique<-var(Vs)> v_theorique<-(1-i*(i-t)*rho*rho)> # 5) Résultats> v_empirique[1] 0.7994242> v_theorique[1] 0.7998708 99

Eléments d’un programme d’élevage
• Le design d’un programme d’élevage est constitué par la définition d’une série d’éléments:
• La taille et la structure du noyau de reproducteurs• Nombre de familles de plein- (ou demi-)frères
• Nombre d’individus testés à chaque génération de sélection
• Les schémas d’accouplement (voir plus loin)
• La stratégie de sélection (voir plus loin)
• L’objectif est de maximiser le gain génétique pour l’objectif de sélection (défini plus loin) sur une période de temps donnée en tenant compte des contraintes (typiquement: nombre de familles, nombre de candidats testés, consanguinité tolérée)
• Des questions annexes concernent:• L’établissement de la population de base
• Les méthodes d’identification des individus
• L’établissement de connexions permettant de s’affranchir des effets parasites pour une meilleure estimation des valeurs d’élevage
100

Eléments d’un programme d’élevage
• La construction de tout programme d’élevage nécessite une connaissance préalable des paramètres phénotypiques et génétiques pour les caractères cibles dans l’espèce étudiée
• Des études préalables peuvent être nécessaires
• Sélectionner sur des caractères non héritables est évidemment inutile...
• La sélection d’espèces aquacoles a des caractéristiques propres, avec une série d’avantages et d’inconvénients par rapport aux autres espèces domestiques sélectionnées.
101

Eléments d’un programme d’élevage
• Avantages
• Fertilité très élevée (>> 1000 œufs/femelle vs 1-2 œufs chez les bovins, p.e.)
• Possibilité d’une intensité de sélection élevée
• Fertilisation externe
• Facile de créer des croisements avec des familles de plein-frères et de demi-frères, p.e.
102

Eléments d’un programme d’élevage
• Avantages
• Potentiel élevé d’hybridisation inter-espèces
• Manipulations chromosomiques (relativement) simples
• Création d’individus haploïdes, triploïdes, tétraploïdes
• Production et élevage des animaux peu coûteux par comparaison avec les animaux d’élevage « classiques » (bovins, porcs, moutons, ...)
• Inconvénients
• Difficulté d’identification individuelle des alevins
• Tagging possible à un certaine taille (qq grammes), ce qui nécessite:
• soit un élevage en famille séparées jusqu’à cet âge
• $$$...
• Confusion génétique – environnement
• soit une identification a posteriori via des marqueurs moléculaires (détaillé plus loin)
• Faible valeur individuelle
• La fécondité élevée peut conduire rapidement à une augmentation de la consanguinité, en l’absence de mesures de contrôles
103

Eléments d’un programme d’élevage
• L’objectif de sélection
• A définir en fonction de la demande des producteurs et des consommateurs.
• Potentiellement variable dans l’espace et dans le temps, nécessitant parfois le développement de plusieurs lignées spécialisées.
• Quand plusieurs caractères et plusieurs objectifs sont poursuivis, on peut essayer d’optimiser:� = ∑ �C, + �=C,�,�& ∗ 6, (Olesen, 2000)
• t est le nombre de caractères considérés simultanément
• Yi est la valeur génétique du caractère i
• NVi est le poids « hors marché » associé au caractère i
• Inclut les aspects environnementaux, éthiques, structurels...
• MeVi est le poids économique du caractère i
• Attention: certains caractères dans l’objectif peuvent être négativement corrélés
104

Eléments d’un programme d’élevage
• Les caractères sélectionnés
• Il est nécessaire que ces caractères:
• Aient une impact économique et/ou éthique (sinon, pas d’intérêt)
• Aient une variance génétique non nulle (sinon, pas sélectionnable)
• Soient mesurables à un coût raisonnable
1. Taux de croissance
• Soit les poissons seront plus gros à un âge donné, soit ils atteindront plus vite le poids de commercialisation
2. Efficacité de conversion alimentaire
• Caractère difficile à mesurer => utiliser un « proxy »
3. Résistance aux maladies
• Difficile en général, mais certains challenge tests montrent des différences entre familles pour certaines pathologies spécifiques
105

Eléments d’un programme d’élevage
106

Eléments d’un programme d’élevage
4. Age à la maturité sexuelle
• Une maturité sexuelle précoce est néfaste à la croissance dans certaines espèces (réduction de la croissance, de la qualité de la viande et mortalité plus élevée)
• Dans ces espèces (saumon et tilapia, p.e.), il faut faire en sorte que la maturité sexuelle se produise après avoir atteint le poids commercial
5. Caractères de qualité
• Filet, couleur de la viande, fermeté, goût...
• Caractères difficiles à mesurer, car nécessitent le plus souvent que les animaux soient abattus => mesures sur des collatéraux => sélection familiale
6. Fécondité
• En général, suffisante et ne nécessite pas de sélection en direct
• Mais le taux de fécondation, d’anomalies, de mortalités des œufs et des alevins, et d’autres caractères de qualité des œufs pourraient être affectés de manière négative par la sélection sur d’autres caractères.
7. Comportement
107

Eléments d’un programme d’élevage
• La population de base
• Les critères majeurs pour constituer une population de base sont:
• Utiliser des individus déjà performants !
• S’assurer d’une variabilité additive génétique suffisante, ce qui peut être fait en combinant des animaux d’origines (lignées) diverses
• Exemples:
• Bondari (1983): mélange de reproducteurs de 6 sources de poissons chats (channel catfish)
• Le programme norvégien d’élevage de saumons a été initié au départ de 41 lignées sauvages de saumons de rivières.
• Eknath (1993): croisement de 8 lignées de tilapia
• Farnir (2017): croisement de 30 mâles et 30 femelles pangasius provenant de 3 écloseries différentes
• Pour des populations croisées (crossbreeding), l’idée est de profiter de l’hétérosis (variabilité génétique non additive)
• Il faut que les lignées hybrides dépassent en performances non seulement les lignées parentales, mais également d’autres lignées éventuellement concurrentes
• A utiliser plutôt sur des lignées qui seraient très consanguines, en général.
108

Eléments d’un programme d’élevage
• Identification des individus
• Problématique, à cause du nombre élevé de descendants et de leur petite taille
• Une solution:
• Familles séparées, jusqu’à ce que les alevins atteignent une taille suffisante
• « Pit-tagging » (introduction d’un transpondeur électronique dans une cavité corporelle)
• Problème:
• Confusion entre effet « famille » et effet « environnement commun »
109

Eléments d’un programme d’élevage
• Identification des individus
• Une solution
• Utiliser l’identification par des marqueurs SNP ou microsatellites (voir dia suivante)
• Les prix:
• sont en très nette diminution, et continuent à descendre.
• dépendent de la technologie (SNP, actuellement)
• dépendent du nombre d’individus génotypés (GBS, ...)
• concernent le noyau de reproducteurs, dont la valeur est évidemment supérieure à la valeur individuelle d’un poisson « normal »
110

Eléments d’un programme d’élevage
• Exemple d’identification génomique des parents
Parents
Descendants
P1 P2
D1 D2 D3
4 SNP
P1 ok
P2 ok
P1 ok
P2 ok
P1 ok
P2 ok
111

Eléments d’un programme d’élevage
• Programme d’accouplement (mating design)
• Très souple
• La fertilisation externe est praticable dans de nombreux cas
• la fécondation naturelle peut également être utilisée quand l’approche externe n’est pas praticable (par exemple, remplacer une mère fécondée par une autre dans la cage contenant le mâle pour créer des familles de demi-frères paternels)
• Quelques exemples de designs seront présentés (liste non exhaustive...)
• Frai en masse (mass spawning)
• Paires simples
• Design hiérarchique
• Design factoriel
• ...
112

Eléments d’un programme d’élevage
• Programme d’accouplement (mating design)
• Frai en masse (mass spawning)
• Mâles et femelles matures sont placés dans le même tank pour se reproduire
• Avantages
• Facile à implémenter
• Utile quand la fécondation artificielle est difficile
• Environnement commun, ce qui permet de s’affranchir, lors de la sélection, de différences provenant de la génétique et non de l’environnement
• Inconvénients
• Les contributions respectives des reproducteurs à la génération suivante sont difficiles à contrôler, ce qui peut conduire à une diminution du nombre efficace, et donc de la variance génétique
• Par conséquent, peu recommandé dans un noyau de reproducteurs destiné à l’élevage (mais éventuellement utilisable pour produire des produits terminaux)
113

Eléments d’un programme d’élevage
• Programme d’accouplement (mating design)
• Simples paires
• Avantages
• Facile à implémenter
• Identification du pedigree facile, jusqu’au pit tagging ou au marquage moléculaire
• Inconvénients
• Confusion entre effets d’environnement et génétiques possible
• Seuls des pleins-frères sont générés.
• Les effets génétiques additifs peuvent ne pas être séparés des effets non-additifs et des effets maternels. Il y a donc une potentielle surestimation de la variance génétique, qui peut être importante si les effets non additifs sont grands.
M1
M2
M3
F1
FS1
F2
FS2
F3
FS3
114

Eléments d’un programme d’élevage
• Programme d’accouplement (mating design)
• Plusieurs mères/père (design hiérarchique)
• Avantages
• Mélanges de familles de plein-frères et de demi-frères paternes (ou maternels)
• Identification du pedigree facile, jusqu’au pit tagging ou au marquage moléculaire
• Inconvénients
• Confusion entre effets d’environnement et génétiques possible
• Les effets génétiques additifs peuvent ne pas être séparés des effets non-additifs et des effets maternels dans la variance liée aux femelles (qui vaut ¼ de la variance génétique totale). Il y a donc une potentielle surestimation de la variance génétique, qui peut être importante si les effets non additifs sont grands.
M1
M2
M3
F1
f11
F2
f12
F3
f13
F4
f24
F5
f25
F6
f36
F7
f37
115

Eléments d’un programme d’élevage
• Programme d’accouplement (mating design)
• factoriel (partiel ou complet)
• Avantages
• Mélanges de familles de plein-frères et de demi-frères paternels et maternels
• Identification des effets génétiques additifs et de dominance, ce qui améliore la précision.
• Inconvénients
• Identification du pedigree moins facile, jusqu’au pit tagging ou au marquage moléculaire
• Diminution potentielle du nombre de reproducteurs testables simultanément (le nombre de familles augmente rapidement...)
• Confusion entre effets d’environnement et génétiques possible.
• La confusion entre effets génétique d’interaction et effets maternels demeure.
M1
M2
M3
F1
f11
f21
f31
F2
f12
f22
f32
F3
f13
f23
f33
F4 F5 F6 F7
M4
M5
f44
f54
f45
f55
f46
f56
f47
f57
116

Eléments d’un programme d’élevage
• Sélection
117

Eléments d’un programme d’élevage
• Sélection génomique
118

Eléments de base de génétique
• Bibliographie
119