xebiconfr 15 - À la découverte des mécanismes internes de cassandra
TRANSCRIPT

Matthieu Nantern
Cassandra internals
#XebiConFr@mNantern
1

#XebiConFr
$ whoami
2

#XebiConFr
1. Je suis présent dans tous les projets informatiques
2. Bien souvent on ne me comprend pas
3. Je limite dès qu'il s'agit de scaler
Qui suis-je ?
3

#XebiConFr4

#XebiConFr
• Se base sur Google BigTable et Amazon Dynamo
• 2008 : libération par Facebook
• 2010 : Top Level Project Apache
• Octobre 2011 : version 1.0
• Septembre 2013 : version 2.0
• Version 3 en bêta
Cassandra
5

#XebiConFr
• Écrire des données
• Lire des données
• Passer à l'échelle
• Survivre
Sommaire
6

#XebiConFr
Écrire des données
7

#XebiConFr
1. Pour écrire vite, écrivons en mémoire !
2. Une table classique avec index
3. Que se passe-t-il si la machine a un problème ?
Memtable
8

#XebiConFr
• Append only file
• Rapide et persistant !
• Permet de rejouer les requêtes en cas de coupure brutale
Commit Log
9

#XebiConFr
• La mémoire c'est bien mais pas pour des To de données
• Il faut parfois écrire sur le disque : Flush !
• Chaque Memtable est écrit en une fois sur le disque et ne bouge plus => Immutable
• Libère la mémoire et supprime le commit log
SSTable
10

#XebiConFr
• Trois structures sont écrites en même
temps que la SSTable :
• Index
• Résumé partition
• BloomFilter
On prépare la lecture
11

#XebiConFr
• Imaginons une table mise à jour fréquemment…
• SSTable
• SSTable everywhere !
• Compaction to the rescue
SSTable everywhere!
12

#XebiConFr
• Il est nécessaire de diminuer régulièrement le nombre de SSTable
• 10 ms pour faire un disk seek !
• Les suppressions
Compaction
13

#XebiConFr
1. Écrire dans le commit log
2. Écrire dans la memtable
3. Flusher sur disque
Write Path
14

#XebiConFr
1. Écrire uniquement de façon séquentielle
2. Ne pas laisser trainer ses affaires
3. Ne pas oublier la lecture
Bilan : écrire vite
15

#XebiConFr
Lire des données
16

#XebiConFr
• Une structure optionnelle en mémoire qui stocke les données lues récemment
• Solution la plus rapide, tout est en mémoire
• La mémoire est limitée, contient peu d'éléments
Row cache
17

#XebiConFr
Read Path
18
1

#XebiConFr
• Structure probabiliste en mémoire
• Permet de dire si une donnée pourrait être dans la SSTable
• Les faux positifs sont possibles pas les faux négatifs
Bloom Filter
19

#XebiConFr
Read Path
20
2

#XebiConFr
• Permet de garder en cache les clés de partitions
• Optionnel
• Si la donnée est dans le cache de clé, on passe directement à l'étape "Compression offset"
Key Cache
21

#XebiConFr
Read Path
22
3
#XebiConFr
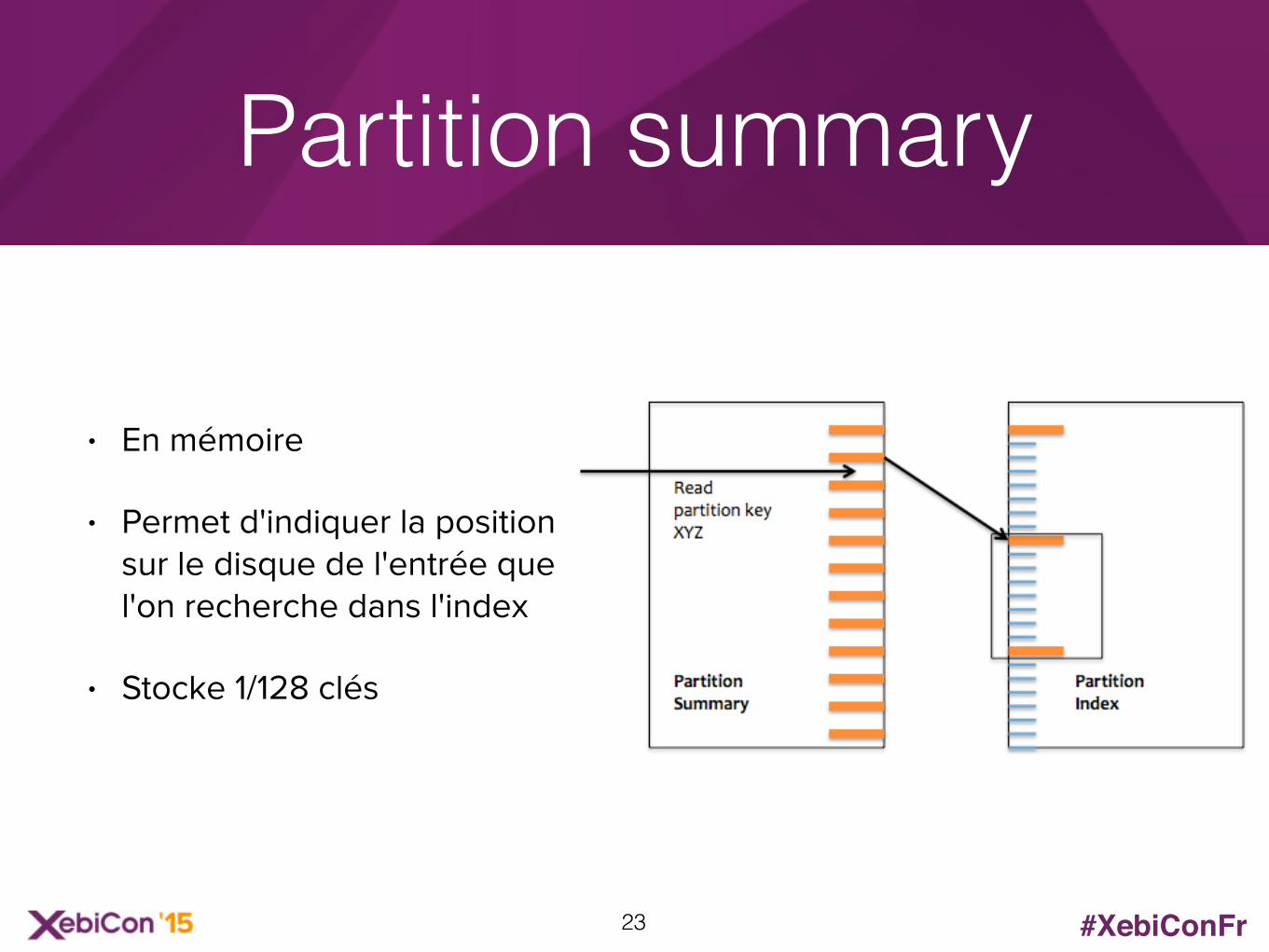
• En mémoire
• Permet d'indiquer la position sur le disque de l'entrée que l'on recherche dans l'index
• Stocke 1/128 clés
Partition summary
23
#XebiConFr
Read Path
24
4

#XebiConFr
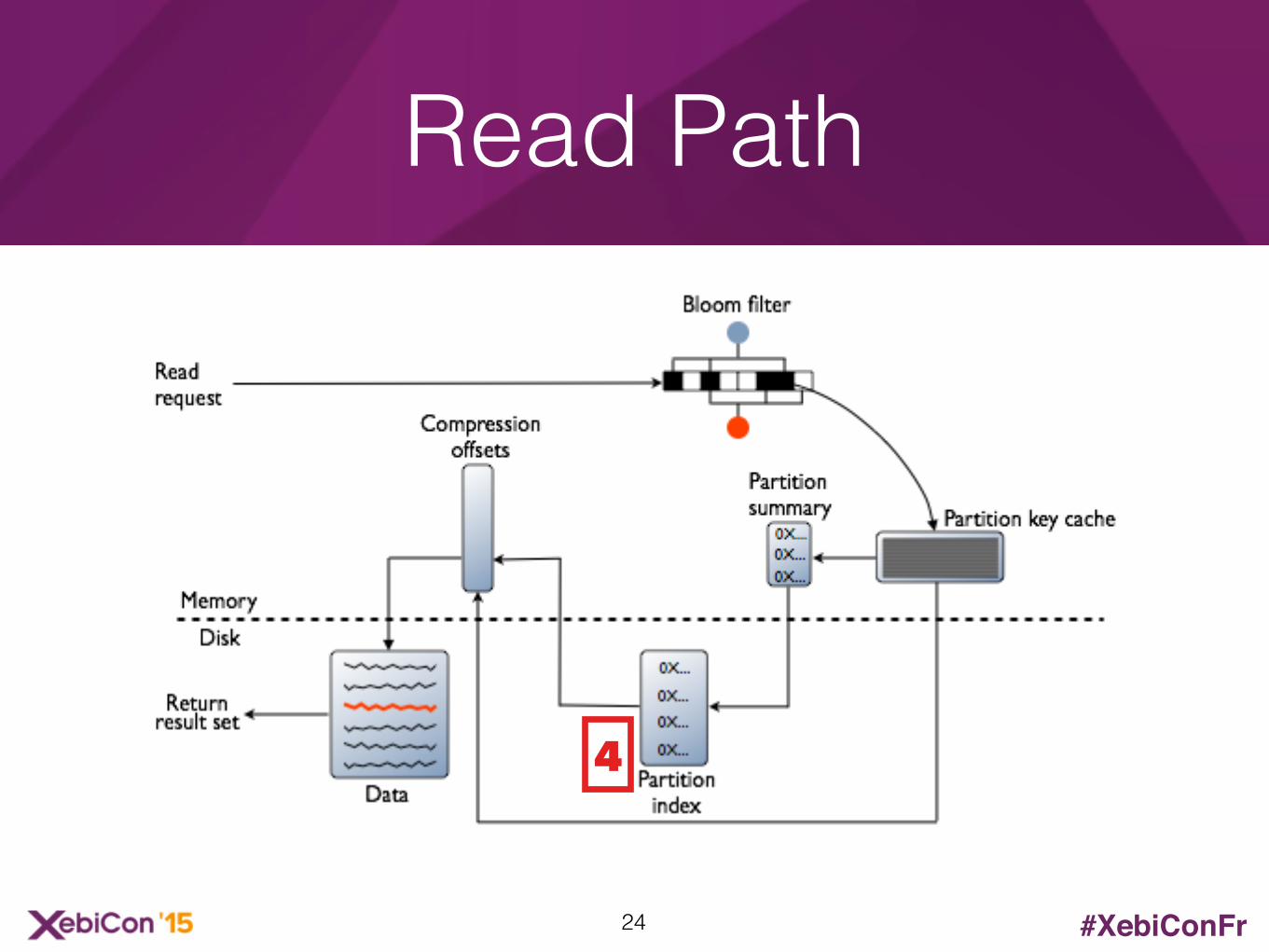
• Premier appel sur le disque
• Permet de retrouver l'emplacement des données de notre clé de partitionnement
• Est ensuite ajouté au "Key Cache"
Partition index
25

#XebiConFr
Read Path
26
5

#XebiConFr
• En mémoire
• Par défaut, toutes les tables sont compressées
• Permet de trouver les blocks contenant les données
Compression offsets Map
27

#XebiConFr
Read Path
28
6

#XebiConFr
• Finalement, on récupère la donnée de la SSTable !
• On combine les données provenant de toutes les SSTables et de la Memtable en prenant la donnée la plus récente
• On a notre donnée finale pour notre machine !
Lecture dans la SSTable
29

#XebiConFr
On résume
30
6
5
4
3 2
1

#XebiConFr
On résume
31

#XebiConFr
1. Minimiser les lectures sur le disque
2. Pour cela garder en mémoire le maximum de choses
3. Faire confiance à l'OS pour les SSTables et les index
Bilan : lire vite
32

#XebiConFr
Passer à l'échelle
33

#XebiConFr
3 mécanismes existent au cours de la vie d'un cluster :
• Seed: configuration
• Gossip: peer to peer, périodique et persisté
• Failure detection: calcul de seuil en fonction de la performance réseau, de la charge et des performances
Trouver ses amis
34

#XebiConFr
• Masterless
• Coordinator
• Cohérence : ALL, QUORUM, ONE
• Attention à la surcharge réseau !
Se partager le travail
35

#XebiConFr
• Partitionnement
• RÉplication des données
• Hinted handoff
Se partager les données
36

#XebiConFr
• Dédié à la lecture
• Si un noeud est trop lent à répondre, la requête est transmise à un autre noeud qui détient la donnée
• Nécessite de répliquer la donnée
Eager retry
37

#XebiConFr
• Le problème
• La solution : LightWeight Transaction
• Comment ? Paxos !
Se mettre d'accord
38
Process 1 Process 2
Lecture
Lecture
=> 0
=> 0Ecriture
Ecriture

#XebiConFr
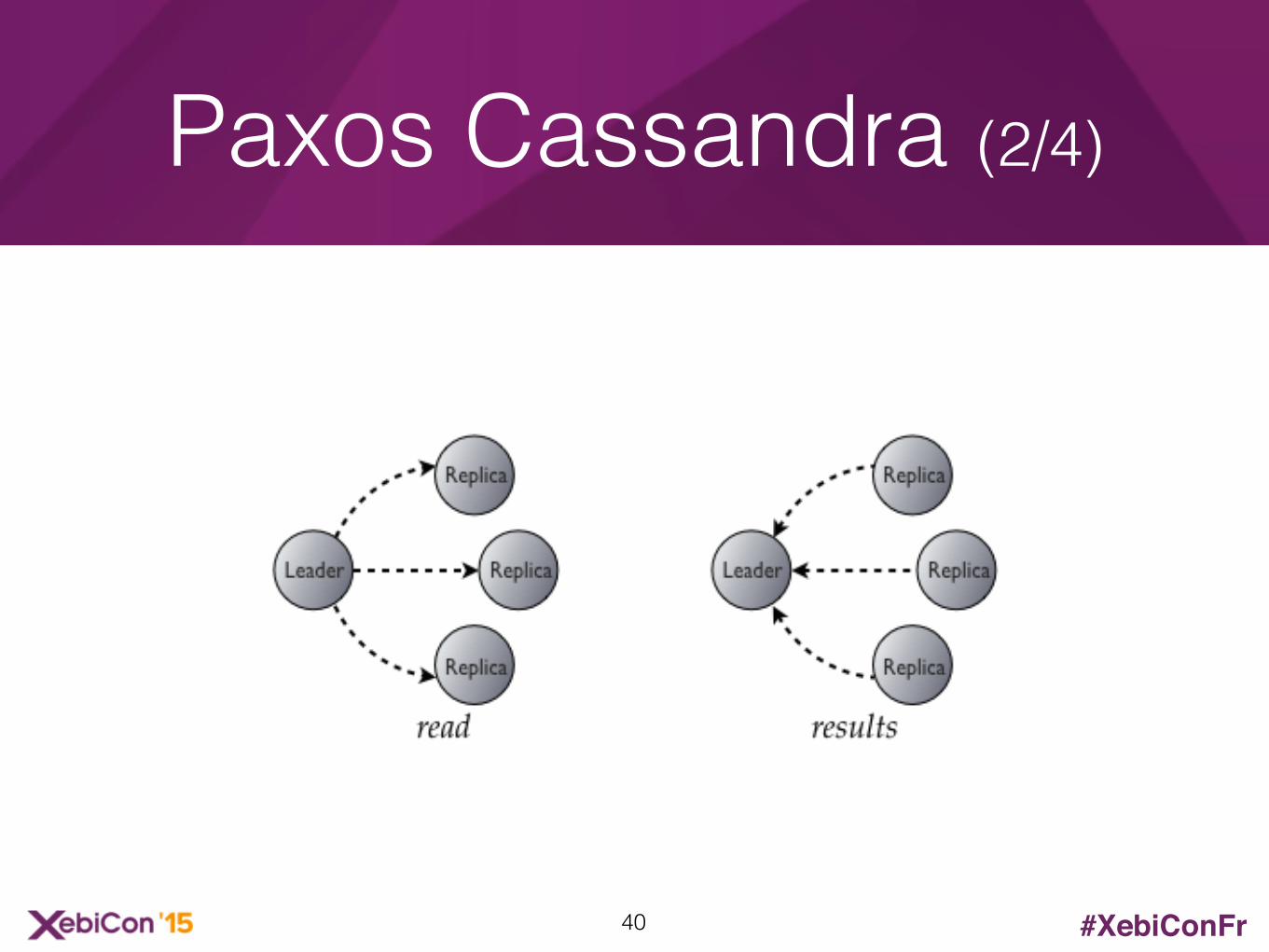
Paxos Cassandra (1/4)
39
#XebiConFr
Paxos Cassandra (2/4)
40

#XebiConFr
Paxos Cassandra (3/4)
41

#XebiConFr
Paxos Cassandra (4/4)
42

#XebiConFr
Démo
43

#XebiConFr
1. Pas de master => Pas de SPOF
2. Répartir la donnée sur certains noeuds
3. Il est possible de se mettre d'accord mais ce n'est pas
gratuit
Bilan : Travailler en équipe
44

#XebiConFr
Survivre
45

#XebiConFr
• La perte d'un serveur est un phénomène normal
• Une seule solution : répliquer la donnée
• Il faut le tester => Chaos Monkey
Perte d'un serveur
46

#XebiConFr
• Se configure simplement dans un fichier texte
• Cassandra s'arrange pour stocker les données dans des racks différents
• Il faut avoir au moins 2 racks !
Perte d'un rack
47

#XebiConFr
• Natif dans Cassandra, à déclarer lors de la création du keyspace :
Perte d'un datacenter
CREATE KEYSPACE "Excalibur" WITH REPLICATION = {'class' : 'NetworkTopologyStrategy',
'dc1' : 3, 'dc2' : 2};
48

#XebiConFr
Démo !
49

#XebiConFr
1. Répliquer ses données sur différents serveurs
2. Dans différents racks
3. Dans différents datacenter
4. Sur différentes planètes
Bilan : Survivre
50

#XebiConFr
Conclusion
51

#XebiConFr
• Des caractéristiques impressionnantes !
• Compliquée à utiliser au quotidien, Paradigm Shift
• Choisir la bonne base pour le bon usage
Silver bullet ?
52

#XebiConFr
Questions ?
53

#XebiConFr
Merci !54