utilisation de la psychométrie dans les tests … · utilisation de la psychométrie dans les...
TRANSCRIPT

Utilisation de la psychométrie dans les testsd’évaluation dans le domaine de l’éducation
Christophe Lalanne∗
Oct. 2008
Résumé
Cette fiche de synthèse vise à présenter quelques cas d’application dela psychométrie dans le domaine des sciences de l’éducation. L’objec-tif est moins d’approfondir les techniques d’estimation utilisées que defournir un aperçu de la richesse et de la diversité des approches devalidation psychométrique. La présentation des tests SAT et du pro-gramme NAEP repose en grande partie sur les chapitres 33 et 32 duHandbook of Statistics, vol. 26 (Psychometrics), rédigés par M. von Da-vier, S. Sinharay, A. Oranje et A. Beaton, et J. Liu, D.J. Harris et A.Schmidt, respectivement.
1 Les tests LSAT
1.1 Introduction
Historiquement, les évaluations à grande échelle dans les « collèges » amé-ricains ont débuté dès 1926, avec le Scholastic Aptitude Test (SAT). Ce testétait composé à l’origine de 9 sous-tests (définitions, problèmes arithmé-tiques, classification, langage, antonymes, séries de nombres, analogies, infé-rence logique et lecture de courts textes) et a été remplacé désormais par leSAT Reasoning TestTM, censé évaluer essentiellement les aptitudes verbaleset de raisonnement mathématique et administré par le College Board. Versla fin des années 50, un nouveau test, le ACT R© (ACT Inc., www.act.org)a rejoint le panel de tests proposés aux usa. L’idée était d’évaluer à la foisl’aptitude d’un élève à intégrer le collège américain, et les bénéfices qu’ilpourrait tirer des enseignements dispensés en ces lieux. On retiendra que ladifférence fondamentale entre le SAT et le ACT est que le premier s’inté-resse essentiellement aux capacités élaborées de raisonnement tandis que lesecond se focalise beaucoup plus sur la performance. Toutefois la corrélation
∗Ce document est disponible sur www.aliquote.org, au format html (htlatex) et pdf(pdflatex). Pour tout commentaire sur le contenu de ce document, s’adresser à [email protected].
1

entre les deux tests, du point de vue des scores délivrés aux candidats, estrelativement bonne (0.92, n = 103 525, [6]).
L’enjeu primordial est de préserver l’équité des évaluations car les testssont administrés plusieurs fois par an. Pour cela, il est nécessaire d’assurerla qualité des tests (validité et la fidélité), ainsi que la standardisation desscores au travers des différentes sessions de test. Une bonne couverture del’échelle de mesure, et une précision extrême aux points de césure font partieen effet des exigences associées aux tests à fort impact (high-stakes).
Concernant la conception des items, l’organisation générale est assez clas-sique et se retrouve chez de nombreux concepteurs de tests (Figure 1). Nousnous intéresserons plus particulièrement à l’analyse des items et aux étudesde fidélité de mesure.
Figure 1 – Étapes pour la conception des items du CAT.
1.2 Analyse des items
L’analyse d’items consiste à décrire le fonctionnement des items dans untest ou pour un certain groupe d’individus donné. Les principales caractéris-tiques d’un item concernent : sa difficulté relative, sa capacité à discriminerles individus selon leur niveau d’habileté, le comportement des distracteurs(dans le cas d’un item à choix multiple de réponse), le comportement del’item entre différents groupes de répondants, le taux de non-réponses.
Difficulté relative de l’item. La mesure la plus simple de la difficultéd’un item pour un échantillon d’individus donné est l’indice de difficultérelative, encore appelé p-value. Il s’agit simplement de la proportion de can-didats qui ont tenté de répondre à un item et y ont répondu correctement.Dans le cas du programme SAT, les p-values sont converties sur une échellestandardisée appelée delta index, de la manière suivante : δ = 13 + 4× z, où(1− p) est préalablement converti en un score z. Avec cette transformation,
2

les δ et les p sont inversement reliés : plus p est petit, plus δ est grand, etplus l’item est considéré comme difficile.
Il est nécessaire de corriger ces valeurs pour tenir compte de la dépen-dance de ces estimations à l’échantillon de candidats. Pour cela, certainsitems présents dans des versions antérieures de test sont également intégrésau test, ce qui permet de standardiser les indices de difficulté grâce à unesimple procédure de régression linéaire des nouvelles estimations sur les an-ciens paramètres de difficulté.
Enfin, notons que les items trop faciles ou trop difficiles apportent peud’infomation sur les candidats.
Pouvoir discriminant d’un item. Tout item doit permettre de distin-guer entre les candidats de haut niveau et ceux de plus faible niveau, parrapport au concept hypothétique objectivé dans le test. Un item sera consi-déré comme discriminant si un nombre proportionnellement plus grand decandidats de niveau élevé répond correctement à l’item en comparaison descandidats de plus faible niveau. On remarquera que la difficulté d’un itemcontraint d’une certaine manière son pouvoir discriminant, puisqu’un itemtrès facile ne laisse que peu de variation résiduelle possible entre les différentsindividus.
L’indicateur statistique utilisé pour évaluer le pouvoir discriminant d’unitem est le coefficient de corrélation bisériale (rbis), qui mesure la force dela liaison entre la performance à un item et celle observée en considérantl’ensemble des items. Un rbis faible ou négatif indique que l’item ne mesuresans doute pas la même chose que les autres items, tandis qu’une corrélationitem-test très forte (i.e. proche de +1) suggère que l’item est probablementredondant par rapport à l’information apportée par les autres items qui com-posent le test.
L’inspection des corrélations item-test permet souvent de détecter desdysfonctionnements notables, comme par exemple une erreur de clé (labelassocié à la réponse correcte), une ambiguïté dans la formulation de la ques-tion, l’existence de plus d’une réponse correcte, etc.
De plus, à partir du score total, ACT sépare l’effectif en 3 groupes decandidats : faible, intermédiaire et élevé, à partir des 27eet 73epercentiles.Ces valeurs ont été choisies de sorte à maximiser la différence entre les scoresmoyens des groupes supérieur et inférieur, sous l’hypothèse que les erreursde mesure sont identiques entre les deux groupes et que les scores de lapopulation se distribuent selon une gaussienne [10].
Analyse des distracteurs. La qualité d’un item ne s’évalue pas simple-ment au travers du fonctionnement de la clé, mais également à partir de ladistribution des réponses aux distracteurs. Deux méthodes sont alors em-ployées : ACT examine les proportions de réponse dans chacun des deux
3
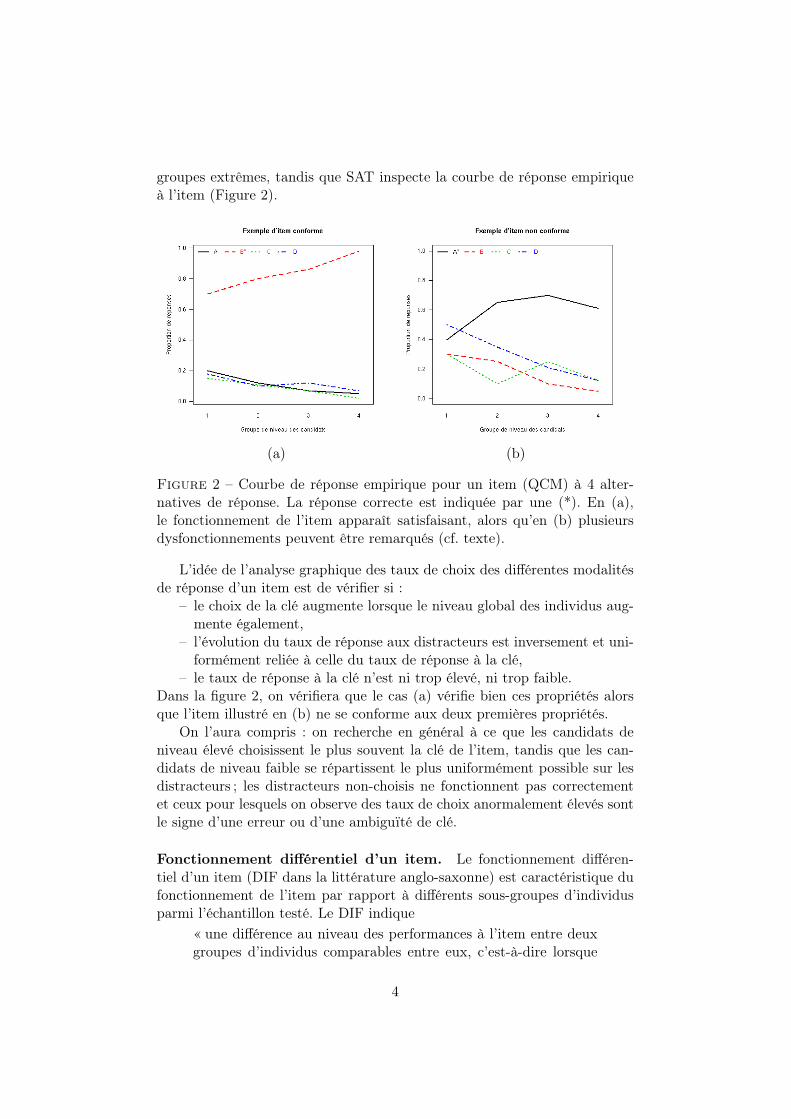
groupes extrêmes, tandis que SAT inspecte la courbe de réponse empiriqueà l’item (Figure 2).
(a) (b)
Figure 2 – Courbe de réponse empirique pour un item (QCM) à 4 alter-natives de réponse. La réponse correcte est indiquée par une (*). En (a),le fonctionnement de l’item apparaît satisfaisant, alors qu’en (b) plusieursdysfonctionnements peuvent être remarqués (cf. texte).
L’idée de l’analyse graphique des taux de choix des différentes modalitésde réponse d’un item est de vérifier si :
– le choix de la clé augmente lorsque le niveau global des individus aug-mente également,
– l’évolution du taux de réponse aux distracteurs est inversement et uni-formément reliée à celle du taux de réponse à la clé,
– le taux de réponse à la clé n’est ni trop élevé, ni trop faible.Dans la figure 2, on vérifiera que le cas (a) vérifie bien ces propriétés alorsque l’item illustré en (b) ne se conforme aux deux premières propriétés.
On l’aura compris : on recherche en général à ce que les candidats deniveau élevé choisissent le plus souvent la clé de l’item, tandis que les can-didats de niveau faible se répartissent le plus uniformément possible sur lesdistracteurs ; les distracteurs non-choisis ne fonctionnent pas correctementet ceux pour lesquels on observe des taux de choix anormalement élevés sontle signe d’une erreur ou d’une ambiguïté de clé.
Fonctionnement différentiel d’un item. Le fonctionnement différen-tiel d’un item (DIF dans la littérature anglo-saxonne) est caractéristique dufonctionnement de l’item par rapport à différents sous-groupes d’individusparmi l’échantillon testé. Le DIF indique
« une différence au niveau des performances à l’item entre deuxgroupes d’individus comparables entre eux, c’est-à-dire lorsque
4

les groupes sont appariés par rapport au concept hypothétiquemesuré par le test. »
Dorans et Holland, 1993, [11], Trad. de l’auteur
Théoriquement, si les candidats de deux groupes différents (e.g. caracté-ristiques socio-démographiques, curricula, etc.) possèdent le même niveaud’habielté, leur probabilité de répondre correctement à l’item devrait être lamême. Les deux groupes considérés sont appelés groupe focal et groupe deréférence, le groupe focal étant le groupe sur lequel se concentre l’analyse. Ilexiste plusieurs manières de caractériser et quantifier le DIF, parmi lesquellesl’approche Mantel-Haenszel [12] et l’approche Standardization [13] utiliséespar ACT et SAT.
La procédure Mantel-Haenszel (MH) est dérivée de la technique de Mantel-Haenszel pour les tableaux 2×2×m, oùm désigne les niveaux d’appariemententre les groupes. Dans le cas présent, il s’agit du score total au test, et onse retrouve avec un tableau de la forme
Groupe Score à l’itemCorrect Incorrect Total
Focal Rfm Wfm Nfm
Référence Rrm Wrm Nrm
Total Rtm Wtm Ntm
L’hypothèse nulle correspondant au test MH est que « l’odds de répondrecorrectement à l’item à un niveau donné de la variable de conditionnementest le même dans le groupe focal et dans le groupe de référence ». Selon cetteapproche, l’odds-ratio commun, noté αMH , se définit comme
αMH =
[∑m
RrmWfm
Ntm
]/
[∑m
RfmWrm
Ntm
], (1)
où m décrit les différents groupes de niveau. Cette valeur est convertie enune différence exprimée sur l’échelle standardisée des δ, i.e.
MH D-DIF = −2.35 ln(αMH). (2)
Des valeurs positives de MH D-DIF sont en faveur du groupe focal, tandisque our des valeurs négatives c’est le contraire.
La procédure Standardization repose sur un principe simiaire, à ceci prèsqu’elle permet d’éviter la contamination causée par un mauvais ajustementdu modèle de mesure. Plus précisément, ACT et SAT utilisent une différencede p-values standardisées, STD P-DIF [14]. Celle-ci est définie comme suit :
STD P-DIF =∑m
[Wm(Pfm − Prm)∑
mWm
]=∑m
[WmDm∑mWm
](3)
5

où Pfm = Rfm
Nfmet Prm = Rrm
Nrmdésignent les proportions de choix correct
dans le groupe focal et le groupe de référence, respectivement, à chaqueniveau m du score total. Dm désigne la différence entre ces deux quantités.L’originalité est d’utiliser un facteur de pondération commun (Wm/
∑mWm)
à la fois pour Pfm et Prm. En pratique, Wm = Nfm de sorte que le poidsle plus important est attribué aux différences entre Pfm et Prm pour lesniveaux du score total les plus fréquemment observés dans le groupe focal.
À ETS, ce type d’analyse se base sur le groupe des candidats de raceblanche (groupe de référence) vs. les candidats afro-américains, hispano-phones, asiatiques et les américains naturalisés (groupes focaux) ; de même,les femmes (groupe focal) sont comparées aux hommes (groupe de référence).À partir de la statistique MH D-DIF, ETS a proposé une classification duDIF en 3 niveaux : négligeable (A), intermédiaire (B) et important (C). Lesitems présentant un biais de fonctionnement de la catégorie C sont systé-matiquement écartés après la phase de prétest (pour être révisé avant d’êtrere-prétesté).
Longueur du test et taux d’omission L’analye des items inclut égale-ment la proportion d’individus ne terminant pas le test. Un taux d’omissionimportant pour certains items peut être une indication que le test est troplong et que « l’échec » à l’item peut être expliqué par un manque de tempsplutôt que par un manque de connaissance. Comme premier indicateur, onpeut considérer la proportion de réponses aux 5 derniers items du test.
La longueur du test est également considérée sous l’angle de l’équité.Les tests SAT reposent sur une mesure différentielle de rapidité pour vérifierqu’un test ne favorise pas une certaine catégorie de la population. Ici, lanotion de DIF renvoit à
existence of differential response rates between focal group mem-bers and matched reference group members to items appearingat the end of a section. (Dorans and Holland, 1993, p. 56)
Cette différence standardisée d’omission s’exprime comme
STD P-DIF (NR) =∑m
Wm (Pfm(NR)− Prm(NR)) /∑m
Wm. (4)
Les mêmes critères STD P-DIF sont utilisés pour construire une classificationen 3 classes. Sur la période 2002–2003 par exemple, les items du SAT-V(verbal) ne présentent pas de biais homme/femme, alors que pour le SAT-M(maths) deux items ont été classés comme présentant un biais intermédiaire.
1.3 Standardisation et normalisation des scores
Les tests ACT et SAT sont des tests « à fort impact » (high-stakes) etsont administrés à plusieurs reprises, sous des formes différentes, durant la
6

période scolaire. Afin que les scores soient comparables entre chaque adminis-tration du test, ce sont des scores standardisés (scaling) qui sont donnés auxcandidats, et non les scores bruts. L’opération de normalisation (equating)vise à exprimer l’ensemble de ces scores sur une échelle de meure commune 1.
Scaling. Les scores standardisés sont définis de manière à conserver uneinterprétation cohérente au travers des différentes versions de test. Un scorede 25 points au test ACT doit signifier la même chose, en termes de capaci-tés, quelle que soit la version de test administrée au candidat. En revanche,les scores bruts peuvent varier d’une version à l’autre, tout en traduisant unmême niveau de compétence : un score de 40 points sur une version peutêtre comparable à un score de 30 points sur une autre version de test sicelle-ci est plus « difficile ». Les standards établis dans le domaine de l’édu-cation (Standards for Educational and Psychological Testing, [16]) précisentque les modalités de calcul des scores et la définition de l’échelle de mesuredoivent être clairement explicitées afin de faciliter l’interprétation des scores(par les candidats et toute personne susceptible de prendre des décisions enconséquence).
Jusqu’à 1995, les scores SAT étaient basés sur une échelle allant de 200à 800 points (moyenne, 500 ± 100), construite à partir d’un échantillon de10000 individus en 1941 2. Le réétalonnage de l’échelle effectué par [17] suitles 7 propriétés suivantes :
1. le score moyen du groupe de référence doit être proche du milieu del’échelle ;
2. la distribution des scores du groupe de référence doit être unimodale ;3. la distribution des scores du groupe de référence doit être symétrique ;4. la forme de la distribution des scores du groupe de référence doit suivre
une distribution connue, e.g. une distribution gaussienne ;5. la gamme des scores observables doit pouvoir dépasser les bornes des
scores reportés afin de permettre de compenser les éventuels glisse-ments du trait latent au niveau de la population ;
6. le nombre de scores calibrés ne doit pas excéder le nombre de scoresbruts ;
7. l’échelle de mesure utilisée pour communiquer les résultats aux candi-dats doit être vue comme une infrastructure ayant besoin d’être conti-nuellement mise à jour.
1. La distinction entre equating et scaling est discutée dans [15], chap. 12. Il existe différentes techniques permettant d’étalonner une échelle de mesure et les les
échelles SAT et ACT n’ont pas été élaborées de la même manière. Notons que l’échelle SATa été révisée (recentrage) en 1995 à cause du changement de la population de candidats, etun intérêt manifeste pour « étoffer » les niveaux élevés de l’échelle. L’échelle ACT, quantà elle, a été révisée en 1989 lorsque l’analyse des scores avant et après cette période a euindiqué des différences notables.
7

L’application de ces critères par [17] a permis de construire une nouvelleéchelle de moyenne 500 et d’écart-type 110, soit une gamme de scores obser-vables de 170 à 830 points environ. De la sorte, les distributions marginalesdes scores aux épreuves verbales et mathématiques étaient identiques.
En ce qui concerne les scores ACT, leur étendue est de 1–36 points,avec une moyenne fixée à 18 points, sur la base de données recueillies surun échantillon national en 1988. Les échelles de mesure ont été établies desorte que l’erreur de mesure vaut environ 2 points pour chaque score compo-site, alors que les erreurs de mesure conditionnelles sont approximativementégales. L’étalonnage des scores ACT est effectué en 3 étapes. Dans un pre-mier temps, les distributions des scores bruts pondérés ont été estimées surun échantillon national et un groupe d’élèves de référence. Ensuite, ces dis-tribution ont été lissées à partir d’un modèle de mélange de lois binomialeet beta [18, 19]. Les scores brutes ajustés ont finalement été utilisés pourcréer des scores calibrés, après arrondis à l’entier le plus proche, tout en pre-nant en compte les contraintes de moyenne ± écart-type, d’absence de sautsdans la progression des scores sur l’échelle et de minimisation des scores àtransformer. Les scores composites ACT ne constituent donc pas une échellede mesure, à proprement parler, mais sont calculés comme la moyenne de 4sous-scores.
L’arrivée d’une nouvelle tâche de production écrite dans les tests ACT aconduit au développement de deux nouvelles échelles. Le sous-score « DirectWriting » repose sur une grille de codage et s’étend de 2 à 12 points. L’échellecombinée « English/Writing » a été créée en standardisant les scores « En-glish » et « Writing » avec des pondérations respectives de 2/3 et 1/3 etune transformation linéaire pour exprimer ces scores sur une échelle de 1–36points. Encore une fois, les scores sont arrondis sous forme entière.
Equating. Une fois que les échelles ont été étalonnées, il reste à standar-diser les scores de manière à ce qu’ils demeurent comparables, en termesd’interprétation, d’une version de test à l’autre (propriété d’interchangabi-lité). Deux types de standardisation sont utilisés pour les scores SAT : laméthode des groupes non-équivalents avec ancrage (NEAT, Nonequivalentgroups anchor test design, Figure ??) et la méthodes des groupes équivalentsou aléatoires (EG, random/equivalent groups design). Lors de l’administra-tion d’une nouvelle version de test, celle-ci est standardisée par rapport àplusieurs versions plus anciennes à l’aide de la méthode NEAT. Lorsquedeux nouvelles versions de test sont administrées en parallèle, les scores dela première version sont standardisés à l’aide de la méthode NEAT tandisque ceux de la seconde version sont standardisés par la méthode EG. Lestechniques de transformation de scores sont diverses et variées et peuventêtre de type linéaire ou non-linéaire ; elles peuvent reposer sur les scoresbruts directement, ou sur des modèles de scores vrais, et la standardisation
8

peut être effectuée en utilisant une post-stratification.
Figure 3 – Dessin d’ancrage par la méthode des groupes non-équivalents(NEAT design).
La procédure de standardisation ACT repose sur un échantillon de candi-dats sélectionnés lors d’une session nationale qui sont soumis à un ensemblede version de tests. L’une des versions administrées est une version ancre in-cluant des items déjà calibrés et permet de la relier à l’échelle de mesure. Lesautres versions de test sont de nouvelles versions. L’utilisation de groupesrandomisés est une caractéristique importante de la procédure de standardi-sation dans la mesure où elle contribue à fournir une certaine « continuité »au niveau des échelles. La méthode utilisée pour la standardisation des scoressur ceux de la version ancrée est la méthode des rangs équipercentiles. Unscore sur la version X et un score sur la version Y sont considérés équivalentss’ils sont au même renag percentile pour un groupe d’individus donné. Lesrésultats de la standardisation sont ensuite lissés à l’aide d’une méthode ana-lytique décrite dans [20] et on conserve des valeurs entières dans les tablesde conversion utilisées pour convertir les scores bruts en scores calibrés.
Des études de stabilité et un suivi régulier ont montré que les dessinsde calibration des tests SAT et ACT fonctionnent de manière satisfaisante[21, 22]. Une façon d’évaluer une procédure de standardisation consiste àvérifier que la fonction de calibrage est invariante à travers différentes sous-populations, définies par exemple par le sexe ou le groupe ethnique des can-didats, comme dans la population générale. En d’autres termes, est-ce quecette fonction de calibrage est la même dans la population générale et dansles différents sous-groupes [23] ? De telles études ont été réalisées pour leSAT-V et le SAT-M, en travaillant sur des sous-groupes définis par le sexe.
1.4 Fidélité de la mesure
La possibilité de commettre des erreurs existe dans toutes les procéduresde mesure des aptitudes cognitives, et il est par conséquent important defournir à l’utilisateur un moyen d’évaluer la confiance que l’on peut avoirdans un score. Le terme d’« erreur » est souvent interprété comme syno-nyme d’inconsistence : dans quelle mesure un candidat obtiendrait un scoreidentique s’il était soumis à un test de manière répétée ? Des scores soumis
9

à des fluctuations aléatoires rendraient en effet les décisions reposant surceux-ci complètement irrationnelles.
Plusieurs facteurs peuvent influencer la consistance des scores ; ceci in-clut : les facteurs liés au test lui-même (e.g. spécifications du test, nombred’items, échelle de mesure), les facteurs liés au candidat (e.g. tendance àdeviner les réponses, niveau de connaissance) et les facteurs situationnels(e.g. le niveau de fatigue d’un candidat, le type d’items administrés). Lesindices de fidélité sont utilisés pour indiquer le degré de consistance espérédes scores d’un test en particulier. Comme il n’est généralement pas possibled’administrer de manière répétée les tests aux mêmes candidats, plusieursindices ont été élaborés pour tenter d’estimer la fidélité de la mesure.
L’un des coefficients de fidélité les plus utilisés est un indicateur de laconsistance interne du test. Ce que l’on appelle la fidélité test–retest est uneestimation de la consistance des scores observés sur un individu à qui l’onadministre le même test plus d’une fois. Comme il est difficile d’obtenir cetype de données en raison de possibles problèmes d’apprentissage ou de biaisliés à l’administration répétée des mêmes items, on estime cette consistanceinterne à l’aide d’un indicateur spécifique calculé sur les données observéeslors d’une seule session de test. Les tests ACT et SAT reposent sur l’indiceKR-20 ; toutefois, comme le SAT utilise un système de notation particulier,l’indice original a été modifié en conséquence [24] :
fidélité =n
n− 1
[1−
∑ni=1 piqi +
∑ni=1 k
2p′iq′i + 2
∑ni=1 kpip
′i
σ2t
], (5)
où pi est la proportion d’individus répondant correctement à l’item i, p′i laproportion d’individus répondant de manière incorrecte, qi = 1 − pi, q′i =1 − p′i, k un facteur de correction pour le calcul des scores (0.250 pour lesitems à 5 modalités de réponse, 0.333 pour ceux à 4 modalités et 0 pour lesréponses construites), n le nombre total d’items dans la sous-échelle du test,et σ2
t la variance des scores totaux pour le type d’item considéré ou la partiede test. Cet indice est similaire au coefficient alpha (Cronbach).
Les estimations de la consistance interne sont faites sur les scores bruts.En revanche, les scores à partir desquelles les décisions sont effectuées sontles scores calibrés, donc il est important d’évaluer également la fidélité desscores calibrés. La fidélité de versions alternées est généralement estimée àpartir de données répétées ou sur une session de test spéciale. Dans les deuxcas, cela présente des désavantages : les candidats passant plusieurs sessionsconsécutives le font par choix personnel et ce sont généralement des candidatsqui n’ont pas obtenus des scores aussi élevés que ce qu’ils auraient escomptélors de la première session.
10

2 Le programme NAEP
2.1 Introduction
Le programme National Assessment of Educational Progress (NAEP),piloté et administré par le National Assessment Governing Board et le Na-tional Center for Education Statistics (NCES), est un programme américaind’évaluation nationale du niveau de connaissances des élèves de grade 4, 8 et12. Les tests sont organisés tous les deux ans auprès d’échantillons représen-tatifs de la population des élèves américains. L’évaluation couvre différentsdomaines comme la lecture, l’expression écrite ou les mathématiques. Desétudes longitudinales sont également réalisées auprès d’un public d’élèvesâgés de 9, 13 et 17 ans. Une description complète de ce programme d’éva-luation est disponible en ligne sur le site de NCES.
En raison de contraintes évidentes de temps, les élèves ne sont évaluésque sur une partie des items assurant la couverture du domaine. De la sorte,on se retrouve dans une situation où seuls certains blocs d’items sont ad-ministrés à des groupes d’élèves, grâce à un plan incomplet équilibré (BIBdans la littérature anglo-saxonne). On a toujours deux blocs d’items appa-riés dans chaque manuel de test, et chaque bloc apparaît un même nombrede fois à chaque position (2 ou 3) dans ce dernier. La conséquence directede cette organisation des items est que les scores des candidats ne sont pascomparables entre eux et il faut recourir à un modèle de réponse à l’item(MRI) permettant d’analyser les patterns de réponse, plutôt que les scoresbruts, et de prendre en considération l’incertitude associée à l’évaluation (er-reur de mesure). Chaque item peut être « relié » aux autres items à l’aide decontraintes d’égalité, grâce aux propriétés des BIB.
Plutôt que de considérer le score individuel, NCES s’intéresse à desgroupes d’individus, de sorte que l’on dispose de suffisamment d’informationpour avoir des estimations fiables du niveau de réussite. Le niveau d’habiletéétant considéré comme un trait latent, la méthode mise en œuvre est unmodèle de régression sur variables latentes incluant une variable prédictricepour le groupe de candidats.
2.2 Le modèle NAEP
Pour chaque individu i, on considère un vecteur d’habileté à p dimen-sions, noté θi = (θi1, θi2, . . . , θip)′. Les différentes composantes de ce vecteurreprésentent les différents sous-tests d’un même domaine ; en mathématique,par exemple, cela peut être l’algèbre, la géométrie, etc. Le vecteur de réponseyi = (yi1, yi2, . . . , yip) de l’individu i apporte de l’information sur θik, et lafonction de vraisemblance (pour un individu quelconque) est de la forme :
f(yi | θi) =p∏q=1
f1(yiq | θiq) ≡ L(θi; yi) (6)
11

Les termes f1(yiq | θiq) suivent un MRI univarié, généralement à 3 paramètresou de type modèle de crédit partiel généralisé (GPCM). Chaque item d’unebatterie de tests NAEP est conçu de manière à n’évaluer qu’un seul concept,de sorte que la multidimensionnalité évoquée ci-dessus demeure entre lesitems. La dépendance de f(yi | θi) envers les paramètres des items peut êtresupprimée, pour faciliter les notations.
Si l’on ajoute à ce modèle décrivant l’habileté des individus un vecteurxi = (xi1, xi2, . . . , xim) décrivantm caractéristiques socio-démographiques etéducatives pour le candidat i, il est possible d’associer les deux types d’infor-mation afin de mieux modéliser les performances des candidats. Condition-nellement à xi, l’habileté d’un candidat θi suit une distribution multivariéenormale, i.e. θi | xi ∼iid N (Γ′xi,Σ). En général, NAEP collecte une centainede variables zi sur chaque candidat, et réalise une analyse en composantesprincipales sur celles-ci ; seules les composantes xi qui expliquent 90 % de lavariance totale au niveau des zi sont retenues pour les analyses subséquentes.
Sous ce modèle, L(Γ,Σ | Y,X), la fonction de vraisemblance (marginale)de (Γ,Σ) basée sur les observations (X,Y ), est donnée par
n∏i=1
∫f1(yi1 | θi1) . . . f1(yip | θip)φ(θi | Γ′xi,Σ)dθi, (7)
où n désigne le nombre d’individus et φ(· | ·, ·) désigne la fonction de densitéd’une loi normale multivariée.
Le modèle NAEP complet, combinant un modèle de réponse à l’item etun modèle de régression latente à deux niveaux, revient à un MRI multi-niveaux ou hiérarchique, dont on trouvera un exemple d’illustration avecR et Stata à la section 4. Outre la complexité de ce modèle, l’aspect leplus intéressant réside dans la possibilité d’estimer une erreur de mesurepropre à l’instrument. En effet, la précision des paramètres de régressioncontribuent à l’erreur qui se reflète au niveau de la distribution latente,puisque l’information sur les groupes est fixée. À partir de là, il est possible deconstruire un modèle d’imputation pour avoir une estimation de l’habileté detous les candidats en dérivant des valeurs probables (plausibles values, PV).La variance de ces PV peut alors être considérée comme une estimation del’erreur de mesure.
2.3 Estimation des paramètres du modèle NAEP
L’estimation du modèle NAEP est réalisée à l’aide de programmes dé-veloppés par ETS (mgroup) et sur lesquels nous ne nous étendrons pas.Globalement, elle se déroule en trois étapes :
1. scaling : on utilise un MRI (3PL ou GPCM) sur l’ensemble des réponsesindividuelles et on estime les paramètres de ce modèle.
12

2. conditionning : dans un premier temps, on suppose les paramètresd’items fixés à leurs valeurs estimées à l’étape (1), et on ajuste unmodèle de régression latente aux données, i.e. les estimés de Γ et Σ.Dans un second temps, les PV (imputations multiples) sont obtenuespour tous les individus ; elles seront utilisées pour estimer les moyennesde groupe.
3. variance estimation : on estime les variances associées aux moyennesdes sous-groupes de l’étape (2), à l’aide d’une procédure d’imputationsmultiples et d’une technique jacknife.
Il a été montré que Γ et Σ, pour des θi inconnus, peuvent être estimésgrâce à l’algorithme EM [4, 5]. L’étape E, qui consiste à estimer à l’étapet + 1 les moyennes E(θi | X,Y,Γt,Σt) et les variances Var(θi | X,Y,Γt,Σt)a posteriori, peut être réalisée par intégration numérique, à l’aide de tech-niques bayésiennes ou par une approximation de Laplace. Les résultats parsous-groupe sont fournis sous la forme de PV, qui reviennent en fait à effec-tuer des imputations multiples en tirant les observations dans la distributionconditionnelle a posteriori des habiletés. L’algorithme est assez relativementsimple :
1. On tire Γ(m) ∼ N (Γ̂, V (Γ̂)), où V (Γ̂) est la variance estimée de l’esti-mateur du maximum de vraisemblance Γ̂ obtenu par l’algorithme EM.
2. Conditionnellement à la valeur générée, Γ(m), et en considérant fixéela variance Σ = Σ̂ (estimée durant la procédure EM), on calcule lamoyenne θ̄i et la variance Σi pour l’estimé a posteriori de chaque in-dividu i dans l’échantillon.
3. On tire un unique θi ∼ N (θ̄i,Σi), indépendemment pour chaque indi-vidu i = 1, 2, . . . , N .
Ces étapes sont répétées M fois, donnant lieu à M ensembles d’imputations(PV) pour chaque individu dans l’échantillon. Les PV sont utilisées commeindicateur de la valeur attendue a posteriori, avec d’autres statistiques telsles rangs percentiles ou les proportions de réussite par rapport à un seuil deréférence.
Ensuite, puisque l’objectif de NAEP est de fournir des estimations duniveau d’habileté pour des sous-groupes spécifiques de candidats, il est né-cessaire de calculer la valeur moyenne d’une certaine fonction de l’habi-leté dans le groupe considéré. Notons cette fonction g(θ). On pourra ainsis’intéresser à estimer (1) g(θ) = θj (moyenne sur une sous-échelle), (2)g(θ) =
∑j ωjθj (moyenne d’un composite, avec pondération des items), ou
(3) g(θ) = I∑jωjθj>K
(proportion d’individus avec un niveau moyen sur uncomposite qui est situé au-dessus d’un certain seuil).
Des alternatives ont été proposées à l’égard de cette technique d’estima-tion ; voir par exemple [2]. Celles-ci visent en particulier à pallier la nature
13

complexe de la « structure » d’analyse et les approximations qui sont faitesà chaque processus d’estimation.
3 Les études PISA
4 Application : étude d’un modèle de réponse àl’item hiérarchique
Il existe plusieurs façons de modéliser un MRI hiérarchique, et plusieurslogiciels disposent des procédures appropriées. Nous nous concentrerons surR et Stata.
4.1 Les enjeux en termes computationnels
4.2 Modélisation avec R
[3]En fait, il existe même un package R, mlirt, qui permet de construire
ce genre de modèle [1]. L’exemple fourni par l’auteur porte justement sur lesdonnées recueillies lors des études PISA 2003.
Les premières étapes visent à construire la matrice de réponse que l’onva utiliser dans le modèle hiérarchique. Pour ne pas biaiser les résultats, onne retient que les individus ayant fourni une réponse à au moins 10 items.
persons <- which(apply(D,1,sum) >= 10)Ys <- matrix(Ypisan[persons,],ncol=K,nrow=Ns)nlls <- rep(0,N)nlls[persons] <- 1nll <- tapply(nlls,school,sum)attributes(nll)$names <- NULLnll[which(nll == 0)]nll <- nll[which(nll != 0)]attributes(nll)$names <- c(1:150)XF <- matrix(c(XF1,XF2,XF3,XF5),ncol=4,nrow=N)XFs <- XF[persons,]group <- unlist(lapply(1:length(nll),function(i,nll) rep(i,nll[i]),nll=nll))W1 <- tapply(XFs[,4],group,mean)J <- 150
La dernière instruction vise à construire la matrice des variables liées auxécoles (n = 150).
Le premier modèle testé est un modèle nul. On l’évaluera de la manièresuivante :
S <- c(1,0,0,0)out1 <- estMLIRT(Ys, S, nll, XG=10000)mlirtout(1000,out1)
14

La fonction mlirtout fournit les valeurs estimées pour les candidats.Le modèle complet peut être évalué à l’aide des instructions suivantes :
S <- c(1,0,4,1)S2[1,1] <- 1out2 <- estmlirt(Ys, S, nll, XG=10000,XF=XFs,W=W1,S2=S2)mlirtout(1000,out2)
4.3 Modélisation avec Stata
Contrairement à R, Stata dispose d’une interface graphique. Il existenéanmoins un macro-language qui permet de faire tourner des scripts conçusà l’aide d’un simple éditeur de texte, et, comme R, on a accès à un en-semble d’extensions disponibles sur le web. Parmi celles-ci, mentionnonsgllamm conçu par S. Rabe-Hesketh et coll. [7, 9, 8] et disponible à l’adressewww.gllamm.org/.
Références
[1] Fox, J.-P. (2007). Multilevel IRT Modeling in Practice withthe Package mlirt. Journal of Statistical Software, 20(5), 1–16.www.jstatsoft.org/v20/i05
[2] M. von Davier and S. Sinharay (2007). An Importance Sampling EM Al-gorithm for Latent Regression Models. Journal of Educational and Be-havioral Statistics, 32(3), 233–251.
[3] Lockwood, J.R., Doran, H. and McCaffrey, D.F. (2003). Using R for Esti-mating Longitudinal Student Achievement Models. R News, 3(3), 17–23.cran.r-project.org/doc/Rnews/Rnews_2003-3.pdf
[4] Mislevy, R. (1984). Estimating latent distributions. Psychometrika,49(3), 359–381.
[5] Mislevy, R. (1985). Estimation of latent group effects. Journal of theAmerican Statistical Association, 80(392), 993–997.
[6] Dorans, N.J. (1999). Correspondences between ACTTM and SAT I R©
scores. College Board Report No. 99-1, ETS Report No. 99-2, CollegeEntrance Examination Board, New York, NY.
[7] Rabe-Hesketh, S., Skrondal, A. and Pickles, A. (2004). Generalized mul-tilevel structural equation modelling. Psychometrika, 69(2), 167–190.
[8] Rabe-Hesketh, S. and Skrondal, A. (2008). Multilevel and LongitudinalModeling using Stata (2nd Edition). College Station, TX : Stata Press.
[9] Zheng, X. and Rabe-Hesketh, S. (2007). Estimating parameters of di-chotomous and ordinal item response models using gllamm. The StataJournal, 7(3), 313–333.
15

[10] Millman, J. and Greene, J. (1989). The specification and developmentof tests of achievement and ability. In : Linn, R.L. (Ed.), EducationalMeasurement, 3rd ed. American Council on Education and Macmillan,New York, pp. 335–366.
[11] Dorans, N.J. and Holland, P.W. (1993). DIF detection and descrip-tion : Mantel-Haenszel and Standardization. In : Holland, P.W., Wainer,H. (Eds.), Differential Item Functioning. Lawrence Erlbaum Associates,Hillsdale, NJ, pp. 35–66.
[12] Holland, P.W. and Thayer, D.T. (1988). Differential item performanceand the Mantel-Haenszel procedure. In : Wainer, H., Braun, H.I. (Eds.),Test Validity. Lawrence Erlbaum Associates, Hillsdale, NJ, pp. 129–145.
[13] Dorans, N.J. and Kulick, E. (1986). Demonstrating the utility of thestandardization approach to assessing unexpected differential item per-formance on the Scolarship Aptitude Test. Journal of Educational Mea-surement, 23, 355–368.
[14] Dorans, N.J. and Kulick, E. (1983). Assessing unexpected differentialitem performance of female candidates on SAT and TSWE forms admi-nistered in December 1977 : An application of the standardization ap-proach. ETS Report 83-9, Educational Testing Service, Princeton, NJ.
[15] Kolen, M.J. and Brennan, R.L. (2004). Test Equating, Scaling, and Lin-king. Methods and Practices. Springer-Verlag.
[16] American Educational Research Association, American PsychologicalAssociation, National Council on Measurement in Education (1999).Standards for Educational and Psychological Testing. AERA, Washing-ton, DC.
[17] Dorans, N.J. (2002). The recentering of SAT scales and its effect onscore distributions and score interpretations. College Board Report No.2002-11, College Entrance Examination Board, New York, NY.
[18] Lord, F.M. (1965). A strong true score theory, with applications. Psy-chometrika, 30, 239–270.
[19] Kolen, M.J. (1991). Smoothing methods for estimating test score distri-butions. Journal of Educational Measurement, 28, 257–282.
[20] Kolen, M.J. (1984). Effectiveness of analytic smoothing in equipercentileequating. Journal of Educational Statistics, 9, 25–44.
[21] McHale, F.J. and Nimmeman, A.M. (1994). The stability of the scorescale for the scholastic aptitude test from 1973 to 1984. ETS StatisticalReport SR-94-24, Educational Testing Service, Princeton NJ.
[22] Hanson, B.A., Harris, D.J. and Kolen, M.J. (1997). A comparisonof single- and multiple linking in equipercentile equating with randomgroups. Paper presented at the Annual Meeting of the American Educa-tional Research Association, Chicago, IL.
16

[23] Dorans, N.J. and Holland, P.W. (2000). Population invariance and theequatability of tests : Basic theory and the linear case. Journal of Edu-cational Measurement, 37(4), 281–306.
[24] Dressel, P.L. (1940). Some remarks on the Kuder-Richardson reliabilitycoefficient. Psychometrika, 5, 305–310.
17