système expert pour smartphones - irisa.fr · sur la base de nos recherches de pré-études, nous...
TRANSCRIPT

INSA Rennes – Département INFORMATIQUE
Système Expert pour Smartphones Rapport de Spécification
Romain Boillon;Olivier Corridor;Quentin Decré;Vincent Le Biannic;Germain Lemasson;Nicolas Renaud;Fanny Tollec
2010-2011
Projet sous la direction de Laurence Rozé

1 | P a g e
TABLE DES MATIÈRES
1. INTRODUCTION..................................................................................................... 3
2. PRÉSENTATION GÉNÉRALE .................................................................................... 3
2.1. CONTEXTE ET OBJECTIFS ................................................................................................... 3
2.2. RAPPEL DU PROJET DE L’ANNÉE PRÉCÉDENTE ....................................................................... 4
2.3. EVOLUTION DU PROJET À CETTE ANNÉE ............................................................................... 4
2.3.1. Type de Smartphone ............................................................................................ 5
2.3.2. Réécriture du système expert .............................................................................. 5
2.3.3. Nouveau système de Monitoring ......................................................................... 6
2.3.4. Création d’un module de surveillance des actions de l’utilisateur....................... 6
2.3.5. Nouvelle machine learning pour l’apprentissage ................................................ 6
2.3.6. Interaction avec l’utilisateur ................................................................................ 6
2.4. PLATEFORMES DE DÉVELOPPEMENT ................................................................................... 7
2.4.1. Android ................................................................................................................ 7
2.4.2. iPhone .................................................................................................................. 7
2.4.3. Langages .............................................................................................................. 7
2.4.4. IDE ........................................................................................................................ 8
3. SPÉCIFICATION ...................................................................................................... 9
3.1. FONCTIONNEMENT GÉNÉRAL ............................................................................................ 9
3.1.1. Evolution .............................................................................................................. 9
3.1.2. Exemple de fonctionnement .............................................................................. 10
3.1.3. Format XML des rapports .................................................................................. 11
3.1.4. Format XML des règles ...................................................................................... 12
3.2. PARTIE SERVEUR ........................................................................................................... 14
3.2.1. Apprentissage .................................................................................................... 14
3.2.2. Base de connaissance ........................................................................................ 17
3.2.3. Interface administrateur .................................................................................... 18
3.3. PARTIE EMBARQUÉE (MOBILE) ........................................................................................ 19
3.3.1. Introduction ....................................................................................................... 20
3.3.2. Système de reporting ......................................................................................... 20
3.3.3. Suivi de l’utilisateur ............................................................................................ 22
3.3.4. Système expert................................................................................................... 22

2 | P a g e
4. CONCLUSION ...................................................................................................... 25
5. BIBLIOGRAPHIE ................................................................................................... 27

3 | P a g e
1. Introduction
Manage Yourself est un projet de diagnostic et de surveillance de plateformes
embarquées, inscrit dans une collaboration entre Telelogos et DREAM. Notre but est cette année
de créer, pour iPhone et mobiles Android, une application capable de comprendre, puis
d’anticiper et prévenir les pannes possibles de ces mobiles.
Sur la base de nos recherches de pré-études, nous avons pu définir les objectifs à
atteindre, à savoir créer des rapports d'erreur et de bon fonctionnement du système, améliorer
l'apprentissage du projet de l'an passé et rendre notre application exportable sur divers
systèmes existants. Les outils à notre disposition seront constitués de logiciels de
développement, de simulateurs, de machines mobiles et enfin de serveurs.
Ce rapport présentera dans un premier temps quels sont les objectifs de notre projet : de
quelle manière nous avons décidé de reprendre le projet de l’année précédente, quels sont nos
objectifs précis de modification, d’adaptation sur Android et iOS, et d’amélioration de ce projet.
Puis nous définirons quelles seront les nouvelles fonctionnalités de ce produit,
répondant aux attentes de Télélogos. Notre cahier des charges, ainsi que l’étude de faisabilité
pré requise pour ce projet, nous laissait une marge de décision pour choisir différentes
fonctionnalités les plus pertinentes. Ces choix maintenant décidés vous seront présentés ici.
Nous spécifierons également le fonctionnement de l’ensemble des composants du projet.
2. Présentation Générale
2.1. Contexte et objectifs
ManageYourself est un projet de diagnostic et surveillance de plateformes embarquées, il
s'inscrit dans le cadre d'une collaboration entre Telelogos et DREAM. Telelogos est une
entreprise éditant des logiciels professionnels qui automatisent, administrent et optimisent les
processus d’échanges entre système informatique central et ceux des utilisateurs distants.
DREAM est une équipe de recherche de l'IRISA spécialisée dans l'aide à la surveillance et au
diagnostic de systèmes évoluant dans le temps. Le besoin de développer une telle application
émane de Telelogos, qui cherche à exploiter les possibilités dans le domaine du MBM (Mobile
Device Management).

4 | P a g e
Le but de notre projet cette année est de développer une plateforme de surveillance pour
les Smartphones iPhone et Android, dont la part de marché ne cesse d'augmenter. L'application
sera directement embarquée sur les Smartphones concernés et tournera en tâche de fond. Le but
est de récupérer les éventuelles erreurs de fonctionnement et de générer les rapports
correspondant à ces erreurs potentielles. Ces rapports donnent ensuite un diagnostic de l'erreur
rencontrée. D'autre part, l'application doit également générer des rapports de bon
fonctionnement de l'appareil à intervalles réguliers. Ces rapports permettront par la suite
d'implémenter une liste de règles à appliquer donnant la possibilité d'anticiper les erreurs
éventuelles et de réagir en conséquence. Ils contiendront les spécifications des Smartphones aux
instants durant lesquels ils ont été générer, par exemple la mémoire occupée ou libre, ou encore
le niveau de la batterie.
2.2. Rappel du projet de l’année précédente
Le projet ManageYourself entreprit l’année dernière était un projet de surveillance de
plates-formes embarquées dont le but était de développer une plateforme de surveillance sur
des appareils de type Smartphone ou PDA, fonctionnant sous Windows mobile. L’application
devait être embarquée sur l’appareil et constamment renseignée sur l’état du système afin de
détecter et de remédier { n’importe quel problème du PDA.
Cette application contient un système expert. C’est la partie du logiciel qui gère l’aspect
décisionnel. A partir d’une base de faits et de règles, il doit être capable de déduire des faits et
d’exécuter des actions. Composé d'une base de fait, d'une base de règles et d'un moteur
d'inférence, le système expert se devait d’être léger pour tourner en tâche de fond sur l'appareil.
Le projet était découpé en deux parties : l'une d'entre elles était l'application même sur le
Smartphone. Elle devait suivre les règles acquises pour éviter les plantages potentiels, et générer
des rapports d'erreur lors d'un plantage, et de bon fonctionnement si plantage il n'y avait pas.
L'autre était la partie serveur, s'occupant de l'apprentissage des règles et de les envoyer au
Smartphone.
La communication entre ces deux parties était gérée par MediaContact, logiciel composé
d'une partie serveur, une console d'administration et du logiciel client à déployer sur le mobile.
Cette application était chargée de récupérer les rapports et de gérer l'installation modifiée par
les apprentissages.
2.3. Evolution du projet à cette année

5 | P a g e
Le projet de cette année est découpé de la même manière que celui de l’année dernière, {
savoir :
D’une application mobile tournant en tâche de fond sur le Smartphone
D’une application serveur
Mais le système expert de l'an dernier avait quelques points faibles. On peut entre autres
relever le fait qu'il n'y avait pas de mise à jour des plus anciens attributs de la base de faits,
tandis que les applications sont régulièrement mises à jour. Bien entendu, l'application ne
fonctionnait que sur Windows mobile, donc très restrictif concernant sa portée sur les systèmes
mobiles. C’est pourquoi cette année plusieurs modifications majeures lui seront apportées :
Développement de l’application sur de nouveaux types de Smartphones
Réécriture du système expert
Nouveau système de Monitoring
Création d’un module de surveillance des actions de l’utilisateur
Nouvelles machine learning pour l’apprentissage
Mise en place d’interactions avec l’utilisateur
2.3.1. Type de Smartphone
L’application mobile de l’année dernière a été conçue pour les Smartphones et PDA
tournant sous Windows Mobile. Cette année elle sera implémentée sur les Smartphones équipés
de l’OS Android, ainsi que sur les iPhones.
Ceci implique par exemple que le code constituant l’application mobile soit générique
aux deux différents systèmes d’exploitation. Il s’agira donc bien d’une seule application, mais qui
sera compilée en deux langages différents, afin qu’elle soit utilisable sur iPhone et Androïd.
2.3.2. Réécriture du système expert
Le système expert de cette année reprendra globalement la forme de celui de l’année
précédente, mais il sera adapté aux nouvelles plateformes.

6 | P a g e
2.3.3. Nouveau système de Monitoring
Cette année les informations nécessaires au système expert seront récupérées de
plusieurs manières :
En lisant les informations offertes par les différents OS (état de la batterie, nom et
version de l’OS, état de la mémoire…), similairement au projet précédent.
En récupérant les fichiers de logs des deux OS, comprenant des rapports sur l’état du
système au cours du temps (création de rapports d’erreur et de bon
fonctionnement).
Le système expert bénéficiera alors d’un ensemble de données complet { analyser, ce qui
permettra de traiter un panel de problèmes plus larges sur les différents OS.
2.3.4. Création d’un module de surveillance des actions de
l’utilisateur
Nous étudions par ailleurs la possibilité de capter l’ensemble des actions de l’utilisateur
sur son Smartphone, afin de les intégrer au diagnostic du système expert. En effet suite à des
discussions avec des professionnels, il s’avère qu’assez souvent les plantages des Smartphones
ne sont pas liés { des problèmes matériels ou logiciels mais { des problèmes d’utilisation. Nous
chercherons donc { générer un fichier de log contenant l’ensemble de ces actions, en y joignant
des informations supplémentaires sur l’environnement (coordonnées GPS, qualité du signal…).
Néanmoins cette partie est clairement une voix exploratoire, c’est pourquoi elle constitue un
module à part.
2.3.5. Nouvelle machine learning pour l’apprentissage
Du fait d’une base de données plus importante { analyser, la partie apprentissage sera
elle aussi revue, afin d’intégrer les rapports de bon et mauvais fonctionnement. De plus cette
année nous chercherons { optimiser l’entretien de la base de connaissance, en supprimant par
exemple les anciennes règles devenues inutiles.
2.3.6. Interaction avec l’utilisateur
Le système expert devra par ailleurs envoyer { l’utilisateur des notifications avant de
réaliser chaque action sur son Smartphone. Il aura ainsi la possibilité de les accepter ou de les
refuser. Notre application mobile sera donc plus transparente et adaptée aux besoins de
l’utilisateur.
Ces différentes modifications seront vues plus en détail dans la partie Spécification.

7 | P a g e
2.4. Plateformes de développement
2.4.1. Android
Le projet devra fonctionner sous le système d'exploitation Android.
Ce dernier, open source, est basé sur un noyau Linux et est
principalement destiné aux plateformes mobiles (smartphones, PDA, ...).
Pour exécuter des applications, le système se base sur un principe de machines
virtuelles, appelées machines virtuelles Dalvik, capables de gérer des programmes développés
en Java.
2.4.2. iPhone
Le projet devrai aussi fonctionner sur un iPhone c'est-à-dire sous le système
d’exploitation iOS.
L’iOS est le système d’exploitation des iDevices (iPhone, iPad, iPod touch) développé par
Apple. Nous en sommes actuellement { la version 4. C’est un système désormais multitâche ce
qui nous intéresse dans le cadre de ce projet, de ce fait nous ne nous intéresserons pas aux
précédentes versions.
2.4.3. Langages
Comme dit précédemment, les applications à destination d'un appareil sous Android,
doivent être développées en Java. Il faut cependant noter qu'il est possible d'utiliser du code en
langage C en le compilant en code natif ARM intégrable dans le code à l'aide du kit de
développement dédié (Native Development Kit). Toutefois, cette solution reste complexe à
mettre en place, la librairie C ne respectant pas forcément les normes. Cela est donc en général
seulement utilisé par des librairies ou dans des parties de code nécessitant une forte
optimisation des performances.
Le développement d’application iPhone ne peut se faire qu’en Objective-C, c’est le
langage utilisé par le SDK de l’iOS 4. C’est un langage qui ne ressemble { aucun autre
syntaxiquement. Afin de développer une application pour iPhone, nous allons devoir utiliser
l’API (Application Programming Interface) Cocoa qui est l’infrastructure de base des
applications et qui permet notamment de créer et d’interagir avec les interfaces graphiques
utilisateur.

8 | P a g e
2.4.4. IDE
Pour Android, l'IDE utilisé pour le développement sera le logiciel libre Eclipse.
Environnement de développement gérant de nombreux langages
à l'aide d'un système de plugins, il permet la création d'applications en
Java, langage de base des programmes Android.
XCode est l’outil développement officiel d’Apple pour réaliser des applications pour le
système d’exploitation de l’iPhone (iOS 4). Il permet de développer facilement sous Mac OS X des
applications avec interface graphique pour iPhone.
Pour développer une application multitâche sous iOS 4 nous avons dû installer la
dernière version de Mac OS X (la 10.6), puis XCode (la 3.2.4) qui contient le SDK de l’iOS 4 pour
pouvoir développer des applications multitâches et les tester sur émulateur ou directement dans
un iPhone.

9 | P a g e
3. Spécification
3.1. Fonctionnement général
3.1.1. Evolution
Nous avons choisi de faire évoluer le fonctionnement général du système pour le rendre
plus générique et l’optimiser.
Il faut également noter que cette recherche de généricité et d’optimisation se retrouve
également dans la partie embarquée et la partie serveur. Ces évolutions sont détaillées dans
leurs parties respectives. Nous présenterons dans cette première partie les évolutions des
interactions entre le serveur et les mobiles.
L’évolution passe par un changement des données échangées.
Partie serveur
Partie embarquée
Interface de communication
Rapports binairesNouveau système expert
Remplaçant l’ancien
FIGURE 1 - FONCTIONNEMENT GÉNÉRAL DU PROJET PRÉCÉDENT
Auparavant, le système expert envoyait des rapports binaires qu’il fallait décompresser
puis convertir au format adéquat. Cela présente de nombreux inconvénients, et n’est pas
indispensable pour un projet d’étude, et non destiné { être mit en production. Le format n’est
pas lisible par l’homme, et nécessite un décodage. Ce n’est donc pas pratique { manipuler.
Puis, sur la base de ces rapports intervient alors l’apprentissage puis la définition des
actions par l’administrateur. C’était alors un nouveau système expert qui était compilé sur la
base de ces règles, puis qui était réinstallé sur le mobile. Là encore, ce système présente des
problèmes. Tout d’abord, le système n’est pas générique. En effet, le résultat n’est compatible

10 | P a g e
qu’avec un seul type de smartphone. De plus, dans la mesure où une étape de compilation est
nécessaire, on limite les systèmes possibles pour le serveur. Par exemple, le compilateur C# n’est
pas installé sur les systèmes Mac.
Aujourd’hui, nous souhaitons avoir un serveur d’une part, chargé de l’apprentissage et la
définition des règles, sur la base de rapports communiqués par le mobile, et la partie embarquée
qui récupère un fichier contenant les règles et se charge d’appliquer dynamiquement ces règles,
et envoyer des rapports au serveur.
Partie serveur
Partie embarquée
Interface de communication
Rapports au format XML Règles au format XML
FIGURE 2 - FONCTIONNEMENT GÉNÉRAL PRÉVU
Pour rendre cette communication la plus générique possible, nous avons choisi le format
XML. Ainsi, nous avons établi deux formats de fichiers XML :
Format des rapports
Format des règles
3.1.2. Exemple de fonctionnement
Mais le mieux, pour commencer est de saisir correctement le mécanisme dans son
ensemble. Pour l’illustrer, nous allons suivre un exemple complet.
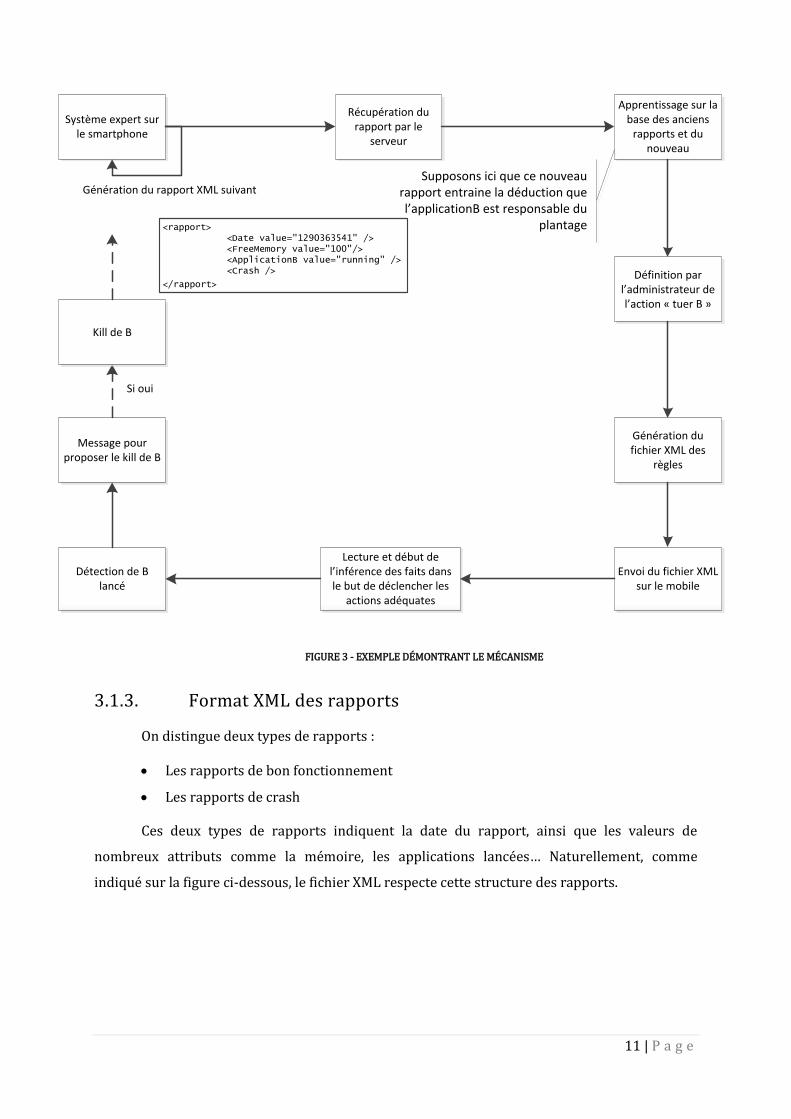
11 | P a g e
Système expert sur le smartphone
Génération du rapport XML suivant
<rapport><Date value="1290363541" /><FreeMemory value="100"/><ApplicationB value="running" /><Crash />
</rapport>
Récupération du rapport par le
serveur
Apprentissage sur la base des anciens
rapports et du nouveau
Définition par l’administrateur de l’action « tuer B »
Génération du fichier XML des
règles
Envoi du fichier XML sur le mobile
Lecture et début de l’inférence des faits dans le but de déclencher les
actions adéquates
Détection de B lancé
Message pour proposer le kill de B
Si oui
Kill de B
Supposons ici que ce nouveau rapport entraine la déduction que l’applicationB est responsable du
plantage
FIGURE 3 - EXEMPLE DÉMONTRANT LE MÉCANISME
3.1.3. Format XML des rapports
On distingue deux types de rapports :
Les rapports de bon fonctionnement
Les rapports de crash
Ces deux types de rapports indiquent la date du rapport, ainsi que les valeurs de
nombreux attributs comme la mémoire, les applications lancées… Naturellement, comme
indiqué sur la figure ci-dessous, le fichier XML respecte cette structure des rapports.

12 | P a g e
Report
Date FreeMemory TotalMemory ApplicationA BatteryLevel ... Crash
Un rapport
Un timestamp (nombre de secondes depuis le 1er
janvier 1970 à minuit UTC)
Il peut y avoir un fils par type d’attributs dont on souhaite
avoir la valeur dans le rapport.
Facultatif: à mettre si un crash a été
détecté
FIGURE 4 - STRUCTURE DU DOCUMENT XML : RAPPORT
Il est { noter que nous avons choisi d’utiliser un timestamp pour la date afin d’éviter tout
problème de référentiel, et de limiter le nombre d’attributs composant la date { un seul.
Exemple de fichier rapport :
<rapport> <Date value="1290363541" /> <FreeMemory value="100"/> ... <ApplicationA value="running" /> <ApplicationB value="running" /> <Crash /> </rapport>
3.1.4. Format XML des règles
Le schéma ci-dessous indique la structure du fichier XML, et l’organisation des balises.
L’objectif final est d’arriver { retrouver une similarité entre le fichier XML et la structure des
classes que nous développerons pour simplifier la lecture du fichier XML, et donc des règles.

13 | P a g e
Rules
Rule Rule Rule
Conditions
Condition ConditionCondition
Actions
Action Action Action
AttributInteger|Strin
g|...
Ensemble de règles.
Les conditions (ET) doivent être vérifiées pour que les
actions soient déclenchées
Plus d’une action peut être déclenchée
Une règles est composée de conditions et d’actions
Il existe différents types de condition (appartenance,
égalité,…).
Toutes les conditions portent sur un
attribut (Mémoire libre, processus fonctionnant…).
En fonction du type, les fils suivant
l’attribut peuvent varier en nombre et
type.
Il y a deux types d’action :
la génération d’un fait (exemple : si MémoireLibre < 10, on peut générer
StatutMémoire = saturée)
L’execution d’une action comme un kill, libérer de la mémoire, afficher une alerte...
FIGURE 5 - STRUCTURE DU DOCUMENT XML : REGLES
Notre fichier de règles est donc tout simplement un ensemble de règles. Une règle est
elle-même un ensemble de conditions devant être vérifiées, qui entraîne l’exécution d’une ou
plusieurs actions. Chaque condition comporte un « type » (appartient, égal, inférieur,…), un
attribut (mémoire libre, nom de fonctionnement), et une valeur ou ensemble. On retrouve la
structure opérande gauche, opérateur, opérande droite. Ce système permet de modéliser toutes
formes de conditions. Voici quelques exemples possibles :
memoireTotale = 250
applicationA = lancee
mémoireLibre < 120
…
On distingue deux types d’actions :
Les actions générant un fait pour alimenter l’inférence (exemple : si MémoireLibre <
10, on peut générer StatutMémoire = saturée).

14 | P a g e
Les actions agissant sur le système. Il est évident que les différentes actions
spécifiées dans les règles doivent être prévues dans le système expert.
On obtient finalement un fichier de règles similaire { l’exemple ci-dessous.
Exemple de fichier de règles :
<rules> <rule id=”42”> <conditions> <condition type="between"> <subject value="FreeMemory" /> <Integer value="0" > <Integer value="100" > </condition> <condition value="equals"> <subject value="applicationABC" /> <String value="running" /> </condition> </conditions> <actions> <action type=”kill” value="applicationABC" /> </actions> </rule> </rules>
3.2. Partie serveur
3.2.1. Apprentissage
L’apprentissage, tout comme l’année dernière, se fera grâce { la librairie weka qui
contient de nombreux algorithmes. Nous utiliserons notamment ceux qui portent sur la
classification. Plusieurs aspects sont à prendre en compte : comment gérer les rapports de bon
et mauvais fonctionnement, l’évolution dans le temps de ces rapports, puis celle des règles
apprise par le système expert et pour finir la dynamique des attributs.
3.2.1.1. Rapport de bon et mauvais fonctionnement
La librairie weka prend en entrée des fichiers de type arff qui ont le format suivant.

15 | P a g e
Il y a séparation entre la définition des attributs et les données. L’année dernière les
rapports de bon et mauvais fonctionnement avaient le même format. Il était donc aisé de trouver
les attributs à utiliser.
Cette année, la pré-étude a montré que les rapports de mauvais fonctionnement
contiennent uniquement les informations en relation avec le crash. Les informations
manquantes se trouvent dans les rapports de bon fonctionnement qui ont un format différent.
Nous allons explorer deux façons de faire.
Une première solution est de compléter les attributs manquants avec les rapports de bon
fonctionnement remontés juste avant et juste après en suivant certaine règle.
Avant Bug Après
AppliA=lancée lancée AppliA=lancée
AppliA=lancée ? AppliA=nonlancée AppliA=nonlancée nonlancée ? AppliA=nonlancée
Le point d’interrogation (?) permet de ne pas choisir la valeur. Le 3eme cas est plus
compliqué à gérer. Est-ce correct de penser que l’application est non lancée ? Imaginons qu’elle
soit la cause du bug, cela induirait en erreur l’apprentissage.
Une deuxième solution possible serait de gérer des tuples d’attribut.
( , … , , , … , , , … , )
Ou serait les attributs des rapports de bon fonctionnement et les les attributs du
rapport de bug. Cette deuxième solution semble plus correct mais implique de doubler voir
tripler le nombre d’attribut.
3.2.1.2. Evolution dans le temps des rapports remontés
Lors de la première utilisation du système expert les rapports générés vont être
aléatoires mais dès que celui-ci aura une base de connaissance non vide ce ne sera plus le cas. En
effet grâce au système expert un certain nombre de rapports d’erreurs ne pourront plus être
générés vu que leurs causes seront évitées. Le simulateur de l’année dernière doit donc évoluer
dans ce sens. Une première solution serait de filtrer les exemples créés en retirant ceux qui
correspondent à des règles déjà présentes dans la base de connaissance. Cela implique de créer
un filtre pour chaque règle, ce qui est bien trop contraignant. Une seconde solution serait de
faire un simulateur incluant les mobiles et le système expert. Ainsi les rapports générés seraient
systématiquement en adéquation avec les règles du système expert.

16 | P a g e
3.2.1.3. Gestion des règles
Premièrement leur création. L’année dernière { l’arrivée d’un nouveau paquet de
rapport, tous les paquets étaient concaténés et l’apprentissage était refait sur ces données. Cette
année notre but est d’automatiser cette procédure. L’apprentissage se fera sous cette forme.
Ensuite les règles inutiles ou devenues obsolètes dans le sens où elles ne sont plus
utilisées. Effectivement des règles peuvent devenir inutiles, par exemple { cause d’une mise à
jour ou de la suppression d’une application. Donc en remontant les rapports, il faut aussi
remonter des informations sur leurs utilisations. Un bilan des règles utilisées est donc créé à
chaque lancement du système expert. La spécification de ces bilans sera vue dans la partie 3.3
Partie Embarquée.
Un cas plus délicat à prendre en compte est l’exécution de règles inutiles ou erronées
mais qui sont quand même exécutées. Dès qu’une règle sera appliquée, l’utilisateur devra
accepter ou non les actions à effectuer. Trois choix lui seront possibles. Appliquer, Ne pas
appliquer, Inefficace. On peut ensuite envisager de traiter ces résultats automatiquement ou
manuellement pour plus de sécurité.
3.2.1.4. La dynamique des attributs
Nous venons de voir que les règles évoluent dans le temps. C’est aussi le cas pour les
attributs et ceci principalement pour les mêmes raisons. Certains attributs comme le niveau de
batterie, la charge de la mémoire, le type de l’OS utilisé, seront toujours présents dans les
rapports. Cependant le nombre d’attributs liés aux applications est amené { varier. Il faudra
détecter à quel moment un attribut devient superflu. Par exemple si un attribut n’apparait plus
Apprentissage
@relation simulateur@attribute memoire NUMERIC@attribute applicationA {lancee,nonLancee}@attribute applicationB {lancee,nonLancee}@attribute applicationC {lancee,nonLancee}...
Règles paquet 1
@relation simulateur@attribute memoire NUMERIC@attribute applicationA {lancee,nonLancee}@attribute applicationB {lancee,nonLancee}@attribute applicationC {lancee,nonLancee}...
Apprentissage Règles paquet 2
FIGURE 6 - APPRENTISSAGE

17 | P a g e
dans aucun rapport et aucune règle utilisée il y a de grande chance de pouvoir le supprimer sans
risque.
En plus de cet aspect temporel des attributs il faut aussi voir leur aspect matériel.
L’année dernière le système expert était utilisé uniquement sur la plateforme Windows mobile.
Les attributs étaient donc uniques pour tous les types de mobile. Or cette année le système
expert sera utilisé pour deux systèmes d’exploitation différents (IOS et Android). Certains
attributs seront probablement spécifiques à l’un d’entre eux. Ils ne devront donc pas être pris en
compte pour l’apprentissage des règles du second.
Arriver à gérer tous cet ensemble de contraintes liées aux attributs sera certainement
une part importante du travail à effectuer dans la partie apprentissage.
3.2.2. Base de connaissance
La base de connaissance contient les données utilisées par le système expert pour
prévenir les problèmes déjà survenus sur le Smartphone. Dans notre cas elle sera constituées
d’un ensemble de règles, dites règles de productions. Les règles sont générées par
l’apprentissage puis converties en XML afin de pouvoir être traitées par l’interface
administrateur.
Nous avons vu précédemment un exemple de fichier de règle en XML :
<rules> <rule> <conditions> <condition type="between"> <subject value="FreeMemory" /> <Integer value="0" > <Integer value="100" > </condition> <condition value="equals"> <subject value="applicationABC" /> <String value="running" /> </condition> </conditions> <actions> <action type=”kill” value="applicationABC" /> </actions> </rule> </rules>
Les règles sont composées d’une ou plusieurs conditions ainsi que d’une ou plusieurs
actions. Elles sont donc de la forme SI condition(s) ALORS action(s). L’opérateur logique utilisé
entre les différentes conditions est donc la conjonction. Ce n’est pas une restriction, car si on
veut utiliser la disjonction « Si condition1 ou condition2 ALORS actions(s) » il suffit alors de
créer deux règles distinctes « Si condition1 ALORS action(s) », « Si condition2 ALORS action(s) ».
Les actions effectuées vont alors empêcher le bug associé à la règle de survenir. Ainsi on ne
cherche pas spécialement { résoudre le bug mais bien { l’éviter.

18 | P a g e
Il existe plusieurs types de conditions. Sur cet exemple le type ‘’between’’ associé au sujet
FreeMemory et aux deux valeurs 0 et 100 signifiera « Si l’espace libre en mémoire est compris
entre 0 et 100 ». En pratique, le type « between » sera traité en deux temps, on utilisera les
opérateurs inférieur (<) et supérieur (>). Notre condition devient alors : « Si l’espace libre en
mémoire est supérieur { 0 et inférieur { 100 alors… ».
Nous devrons donc définir un nombre suffisant de types pour quantifier l’ensemble des
conditions à traiter. Par ailleurs ces conditions sont liées aux différentes informations
récupérées dans les rapports.
Les différentes actions correspondent aux interventions possibles réalisables selon le
système d’exploitation du Smartphone.
La base de connaissances sera gérée par l’interface administrateur { partir des règles
générées par l’apprentissage. Elle sera séparée en plusieurs sous-ensembles qui correspondront
aux différents types de mobiles utilisés. Cet ensemble de règles sera stockée sur le serveur sous
forme de fichiers XML puis transmises { chaque appareil mobile, selon son type. Enfin l’interface
administrateur permettra d’éditer la base de connaissances.
3.2.3. Interface administrateur
Une interface administrateur devra être présente sur le serveur, elle permettra de
visualiser facilement toutes les règles présentes. Elle permettra également de supprimer des
règles ou d’en saisir de nouvelles.

19 | P a g e
FIGURE 7 INTERFACE ADMINISTRATEUR
1) Ensemble des règles déjà présentes dans le système expert.
2) Ensembles des règles apprises, en cliquant sur « étiqueter » on rajoute la règle aux
conditions (3).
3) Ensemble des conditions qui constitueront la nouvelle règle. On peut en ajouter et en
supprimer.
4) Action appliquée si les conditions sont remplies.
En validant les conditions (3) et les actions (4) la nouvelle règle est ajoutée à la base
de connaissance.
Il faut, par ailleurs, que lorsqu’une action est choisie, celle-ci soit implémentée (et donc
possible à exécuter) sur la partie embarquée.
3.3. Partie Embarquée (mobile)
Notre objectif cette année est de pouvoir récupérer puis résoudre les différentes pannes
que peuvent subir un iPhone ou un téléphone sous Android. Nous allons créer un ensemble de
systèmes, embarqués sur le mobile en question, capables de diagnostiquer et d’anticiper les
pannes de celui-ci sans l’aide d’un tiers ordinateur (mais épaulé par un serveur pour
l’apprentissage).

20 | P a g e
3.3.1. Introduction
On distingue deux choses sur le mobile :
Le système de reporting, qui génère des rapports
Le système de suivi utilisateur qui enregistre les actions de l’utilisateur
Le système expert qui { partir des règles et des rapports fait l’inférence pour
exécuter les actions.
3.3.2. Système de reporting
Des méthodes différentes ont été choisies pour la génération des rapports, en
fonction du système visé. Nous allons en premier lieu introduire la méthode choisie pour
Android.
La création des rapports sous Android se fera périodiquement (lors du bon
fonctionnement de l’appareil), et lors de la détection d'un bug.
La détection des bugs sera effectuée { l’aide d’un utilitaire intégré { Android, du nom
de « logcat ». Ce dernier permet de récupérer en temps réel les journaux (logs) créés par le
système et les applications qu’il exécute. Ainsi , en traitant les lignes de log générées, il est
possible de détecter les divers évènements en provenance de l’appareil (ouverture d’une
application, fermeture d’une application, plantage, …). L’appel { des applications externes
étant autorisé depuis le code Java d’un programme, on peut donc exécuter logcat et
récupérer sa sortie dans un buffer qui sera alors traité.
En revanche, dû au système d’exceptions de la machine virtuelle Dalvik, certains
développeurs choisissent de cacher ce genre de problème (par exemple en relançant une
application lors d’un bug sans émettre de ligne de log standard), ce qui pourra peut -être
poser problème et parfois fausser la détection.
La génération des rapports se fera { l’aide d’une application dédiée. Elle sera
chargée de récupérer les diverses informations système, et de les rassembler dans un
fichier XML.
Sous iPhone les rapports de bon fonctionnement et ceux de bug sont générés de
manières différentes. En effet les rapports de bon fonctionnement vont être générés par notre
système expert directement en XML dans le format spécifié précédemment.
Pour ce qui est des rapports de bug, ils vont être générés à partir des crashs log fournis
par le téléphone. En effet lorsqu’une application plante, ou que le téléphone plante { cause d’une
saturation mémoire ou d’une batterie déchargée, le téléphone génère automatiquement un crash

21 | P a g e
log. Pour le cas d’un crash log généré lorsqu’une application a crashé nous pouvons récupérer
dans cet ordre : le modèle du téléphone, le processus qui a planté, la version du processus, la
date et l’heure du crash, la version de l’OS.
Lorsque la mémoire est saturée, le crash log généré nous donne : le modèle du téléphone,
la version de l’OS, l’heure et la date du crash, le nombre de pages mémoires libres, le nombre de
pages mémoires utilisés, le nombre de pages mémoires pouvant être vidés, le processus utilisant
le plus de mémoire et la liste des processus lancés.
Pour le cas de la batterie faible, nous pouvons récupérer la date et l’heure du crash, la
version de l’OS, le temps de veille, le temps d’utilisation, la capacité et le voltage de la batterie.
Ces crashs log ne sont accessibles que lors d’une synchronisation avec iTunes. Ils sont
alors disponibles dans des fichiers .crash { l’adresse suivante :
C:\Users\<user>\AppData\Roaming\Apple Computer\Logs\CrashReporter\MobileDevice\<device>\
C’est donc la partie server qui s’occupera de gérer les crashs log et de générer les
rapports de bug.
En effet ces crashs log ne nous offrent pas assez d’informations pour remplir le fichier
XML précédemment spécifié, nous allons recouper les informations des crashs log avec le
rapport de bon fonctionnement générés juste avant, en comparant les date, comme le montre le
schéma suivant.

22 | P a g e
Crash log généré par
l’iPhone
Dernier rapport de bon
fonctionnement au format
XML
Recoupage
Rapport de bug au format
XML
FIGURE 8 RECOUPAGE DES RAPPORTS
Ainsi nous obtenons un rapport de bug au format XML exploitable pour l’apprentissage.
Pour les deux systèmes, les différents attributs à récupérer pour la génération du rapport
seront par exemple : le nom du système, sa version, la mémoire disponible, l’état de la batterie,
et l’état des différents réseaux (GSM/Wifi/Bluetooth/…).
3.3.3. Suivi de l’utilisateur
Un autre point a été soulevé lors de notre réflexion : la possibilité d’enregistrer les
actions effectuées par un utilisateur sur l’appareil mobile.
Cela est faisable sous Android { l’aide des fichiers de journaux, listant très précisément
les interventions sur l’appareil, ce qui n’est pas le cas sous iPhone, où l’on ne peut récupérer des
fichiers logs qu’en cas de crash, et ne contenant pas les informations souhaitées.
3.3.4. Système expert
Nous avons choisi, pour ce système expert, de reprendre une structure similaire à celle
du projet de l’année précédente. En effet, après étude, le choix d’un chainage avant pour l’aspect
décisionnel semble pertinent, ainsi que celui d’une application légère.

23 | P a g e
Notre système expert embarqué aura donc les caractéristiques suivantes :
Il sera assez léger pour pouvoir fonctionner en tâche de fond, sans nuire à
l’utilisation du mobile.
Il sera capable d’anticiper les pannes de ce mobile de façon autonome, { l’aide de la
base de règle précédemment calculée et fournie par le serveur.
Une interface entre l’utilisateur et l’application contenant le système expert sera
fourni, mais le logiciel tournera principalement en tâche de fond. Le système expert
pourra tourner et diagnostiquer sans aide de l’utilisateur, mais chaque application
d’une règle aura besoin d’une autorisation du propriétaire de ce mobile avant de
s’appliquer. Ce diagnostic pourra se faire en temps réel, grâces aux informations de
bon fonctionnement et de mauvais fonctionnement fournis par le mobile.
Grace { l’utilisation d’un format XML, toute la partie non embarquée, ainsi que les
rapports seront similaires d’un mobile { l’autre. Le système expert, néanmoins, ne pourra pas
l’être.
L’application iPhone sera codée en Objective-C. En effet, peut de langage peuvent
coder une application iPhone (C, JavaScript, Objective-C), et certaines librairies
nécessaires { l’application n’existent que sous Objective-C. Nous avons donc choisit la
langue la plus adapté : Objective-C.
L’application Android, comme expliqué précédemment, sera codé principalement en
Java. Langage le plus intuitif, et le plus utilisé pour des applications Android.
Dues aux caractéristiques propres à chacune de ces machines, le système expert se devra
de fonctionner légèrement différemment d’un mobile { l’autre. La tâche de fond sur iPhone par
exemple consistera en une application réveillée plus ou moins fréquemment par un mécanisme
de géolocalisation, tandis que celle sur Android est gérée de façon plus simple par la machine.
Mais les fonctionnalités principales resteront tout de même presque identiques, au point que
ces différences resteront invisibles { l’utilisateur externe.
Le système expert génère également des bilans sur l’utilisation des règles. Un fichier
bilan consiste { répertorier les règles qui ont été proposés { l’utilisateur. Chaque règle sera
représentée par son identifiant et on lui associera le nombre de fois qu’elle a été appliquée, le
nombre de fois de fois où l’utilisateur a refusé de l’appliquer parce que jugée non efficace, et le
nombre de fois qu’elle n’a pas été appliquée pour d’autres raisons. Ce fichier de bilan sera généré
au format XML par le système expert, comme dans l’exemple suivant :
<rules> <rule id=”42”> <nbapplique value=10 /> <nbnonefficace value=3 />

24 | P a g e
<nbnonapplique value=5 /> </rule> </rules>

25 | P a g e
4. Conclusion
Durant notre phase de spécifications, nous avons joué simultanément sur plusieurs
fronts. Nous avons tenté d’identifier et de formaliser les besoins de la société Télélogos pour ce
projet, afin de faire évoluer le projet de l’année passée. Parallèlement, nous avons continué
l’étude de faisabilité nécessaire pour les applications Android et iPhone. Sur cette dernière,
l’implémentation d’une telle application n’est pas évidente considérant les restrictions de l'iOS,
et nous devions donc nous assurer des possibilités dont nous disposions afin d’y adapter nos
spécifications précises.
Nous avons mis au point le nouveau principe de fonctionnement incluant : le système
expert, le système de reporting, le module de surveillance des actions de l’utilisateur,
l’apprentissage, et la définition de la communication entre ces différents modules.
Sur la partie mobile, les spécifications semblaient très simples, l’outil { développer étant
identique { celui de l’année dernière. Nous avions donc pensé reprendre les spécifications à
l’identique. Mais quatre problèmes sont survenus.
Premièrement, le choix fait l’année passée, de coder et d’envoyer les rapports en binaire
est certainement la bonne chose { faire pour un produit devant être commercialisé. Cela n’est
par contre pas approprié pour un prototype, demande beaucoup de temps de développement, et
rend non lisibles les rapports échangés tant qu’ils ne sont pas décodés. D’où le choix cette année
de passer par un format XML.
Deuxièmement, le fait de fournir les règles sous forme de dll pose le même type de
problème avec en plus la nécessité d’avoir coté serveur les outils de compilation nécessaire,
pour la plateforme cible. D’où le choix de passer cette année par le format XML.
Puis, nous avons rencontré, non pas réellement un problème, mais plutôt un imprévu :
une discussion très récente avec Télélogos leur ont permis de nous faire la demande d’une
fonctionnalité en plus : une option de suivi de l’utilisateur. Nous n’avons alors pas encore eu le
temps de faire la spécification de cette demande.
Enfin, le dernier problème est le plus important. Suite à la pré-étude faite sur Android et
sur iPhone, nous nous sommes aperçus qu’il n’existait pas sur ces systèmes d’équivalent de Dr
Watson sous Windows mobile. L’information sur les plantages ne peut alors n’être remontée
qu’{ partir des fichiers de log. Et dans ces derniers toutes les informations transmises dans le
rapport de bon fonctionnement n’apparaissent pas. Nous en sommes donc arrivés { la
conclusion que cette année les rapports de bons et mauvais fonctionnement auraient une

26 | P a g e
structure différente. Maintenant il nous faut entièrement réfléchir { l’apprentissage en prenant
en compte ces nouvelles données.
Sur la partie apprentissage, les cours n’ayant pas encore eu lieu, le temps passé depuis le
rapport de pré-étude a été en partie consacré à continuer la pré-étude même. Les spécifications
des formats des règles ont été entièrement faites. Celles des rapports de bon et de mauvais
fonctionnement vont dépendre des informations ne nous arriverons à récupérer. Ils
contiendront entre autre la mémoire, la liste des applications ouvertes, etc.
Cette spécification terminée, nous savons quoi faire et comment les différents modules
s’organisent. Notre objectif est maintenant de dresser une planification concrète du projet. Nous
y préciserons les différentes étapes à suivre et l'organisation choisie pour mener à bien les
nombreuses évolutions spécifiées.

27 | P a g e
5. Bibliographie
1. iPuP. Programmez pour iPhone, iPod Touch, iPad avec iOS4. s.l. : Pearson, 2010.
2. Appcelerator, Inc. Appcelerator. [En ligne] [Citation : 21 10 2010.]
http://www.appcelerator.com/.
3. Xsysinfo - Display bar graphs of system load. Linux Software Directory. [En ligne]
[Citation : 27 Septembre 2010.] http://linux.maruhn.com/sec/xsysinfo.html.
4. WITTEN, Ian H. et FRANK, Eibe. Data Mining. s.l. : Morgan Kaufmann, 2005.
5. McEntire, Norman. How to use iPhone with Unix System and Library Calls : A Tutorial
for Software Developers. How to use iPhone with Unix System and Library Calls. [En ligne] 18
Janvier 2009. [Citation : 27 09 2010.] http://www.servin.com/iphone/iPhone-Unix-System-
Calls.html.
6. Guy, Romain. Painless threading. Android Developers. [En ligne] 2009.
http://android-developers.blogspot.com/2009/05/painless-threading.html.
7. Collins, Charlie. Android Application and AsyncTask basics. [En ligne] 2010.
http://www.screaming-penguin.com/node/7746.
8. Apple Inc. iOS Reference Library. [En ligne] 2010.
http://developer.apple.com/library/ios/navigation/.
9. Google. Android SDK. [En ligne] 2010.
http://developer.android.com/sdk/index.html.