sÉlection de modÈles et rÉseaux de … · rÉseaux de neurones julie carreau ird hydrosciences...
TRANSCRIPT

SÉLECTION DE MODÈLES ET RÉSEAUX DE NEURONES
Julie Carreau IRDHydroSciences Montpellier
www.pages-perso-julie-carreau.univ-montp2.fr
samedi 8 mars 2014

Sélection de modèleniveau de complexité - hyperparamètres
samedi 8 mars 2014

Le niveau de complexité ne peut être déterminé sur les données qui sont utilisées pour optimiser les paramètres.
Hyperparamètre Nombre de clusters K
Niveau de complexité (nombre de paramètres) du modèle
• K = 1 : un seul cluster • K = n : autant de clusters que d’exemples et coût nul
K-MEANS
Fonction de coût : la somme des erreurs carrées
E(Y, µ) =n�
i=1
K�
k=1
Yik||Xi − µk||2
Paramètres centres des clusters µk
samedi 8 mars 2014

π ≡ {π1, . . . ,πK} µ ≡ {µ1, . . . , µK}Σ ≡ {Σ1, . . . ,ΣK}
l(π,µ,Σ|X) = −�
n
ln
�K�
k=1
πkf(x;µk,Σk)
�
Nombre de composantes K
Forme de la matrice de variance-covariance Σk = λkDkAkDTk
constante de proportionnalité
matrice de vecteurs propres
matrice diagonale telle que
est une valeur propre
λk
Dk
Akλkak
volume
orientation de la composante
forme de la composante
Les hyper-paramètres contrôlent le nombre de paramètres du modèle
MÉLANGE DE GAUSSIENNES
Fonction de coût : la log-vraisemblance négative
Paramètres
Hyperparamètres
✴ Lorsque le niveau de complexité augmente, la log-vraisemblance tend vers l’infini !samedi 8 mars 2014

Connaissances a priori
On sait qu’il y a K groupes mais on ne connaît pas l’attribution
e.g Old faithful, Seeds
On essaie plusieurs valeurs de K et on cherche à donner une interprétation aux groupes obtenus
e.g. Types de temps : pluie forte, brouillard, sec, pluie moyenne
NOMBRE DE CLUSTERS
samedi 8 mars 2014

Objectif final de la modélisation
Le clustering sert à classer les observations en groupes homogènes et sur chaque groupe on cherchera à conduire une analyse indépendante.
e.g. On veut analyser la croissance des variétés de blés dans différentes conditions.
K-Means sert d’initialisation pour l’estimation de densité par un mélange de Gaussiennes : critère basé sur la log-vraisemblance tel que AIC ou BIC
Critère d’information d’Akaike (AIC)
Critère d’information bayesian (BIC)
vecteur de paramètres du modèle de longueur
NOMBRE DE CLUSTERS
2 lnP (Y |θ)− p ln(n)
2 lnP (Y |θ)− 2p
θ p
samedi 8 mars 2014
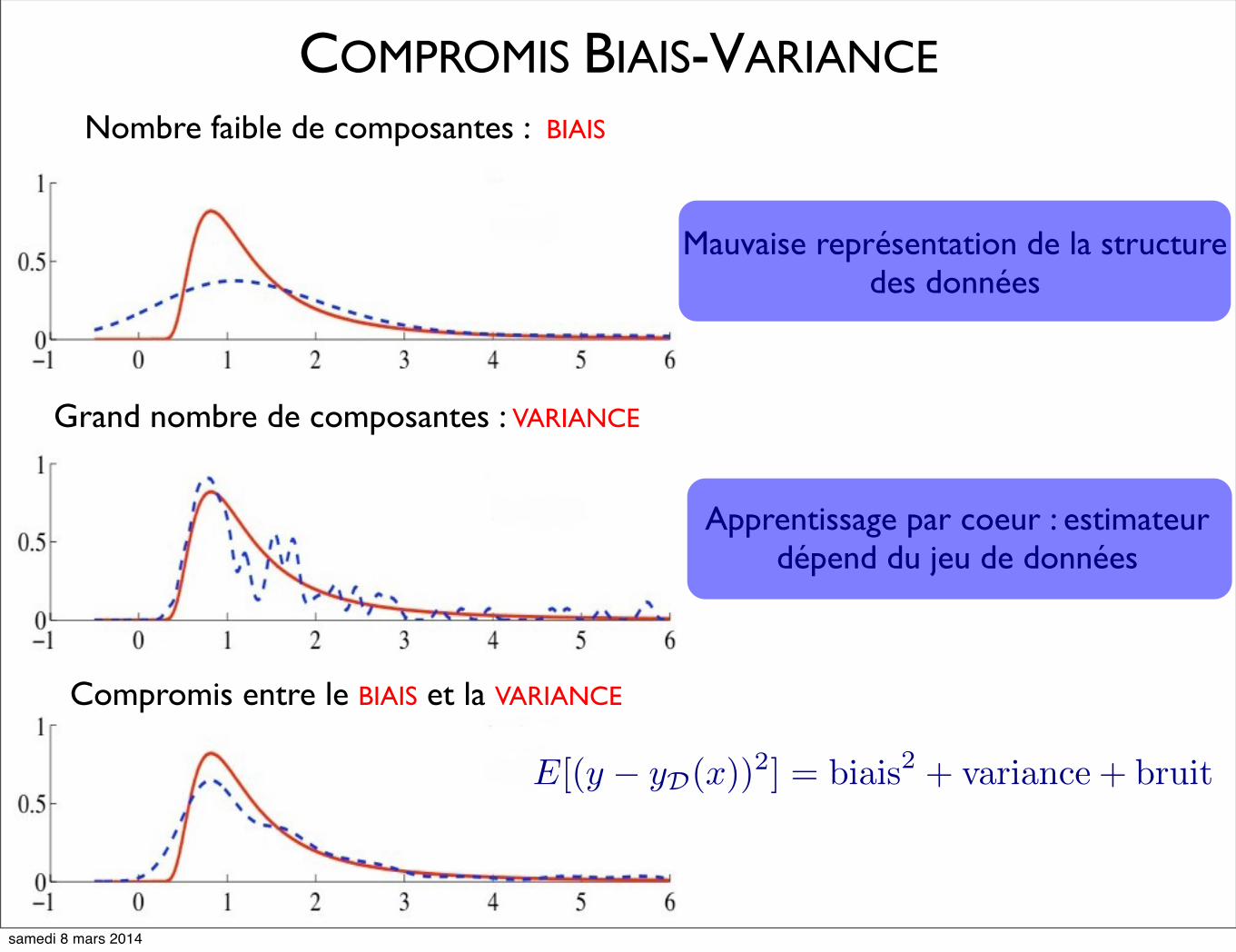
Nombre faible de composantes : BIAIS
COMPROMIS BIAIS-VARIANCE
Mauvaise représentation de la structure des données
Grand nombre de composantes : VARIANCE
Apprentissage par coeur : estimateur dépend du jeu de données
Compromis entre le BIAIS et la VARIANCE
E[(y − yD(x))2] = biais2 + variance + bruit
samedi 8 mars 2014

ENTRAÎNEMENT ET VALIDATION
ENSEMBLE D’ENTRAÎNEMENT : optimisation des paramètres par la minimisation d’une fonction de coût pour différentes valeurs des hyper-paramètres
2/3 ou 80% du jeu de données
ENSEMBLE DE VALIDATION : détermination des hyper-paramètres par la minimisation d’une fonction de coût
ENSEMBLE D’ENTRAÎNEMENT : optimisation des paramètres par la minimisation d’une fonction d’erreur
OBJECTIF : compromis entre le biais et la varianceestimation de l’erreur quadratique espérée
samedi 8 mars 2014

COMPROMIS BIAIS-VARIANCE
niveau de complexité
fonction de coût
erreur d’entraînement
erreur de validation
complexité optimale
sous-apprentissagebiais
sur-apprentissagevariance
Lien avec les critères AIC et BIC : log-vraisemblance + pénalité = biais + variance
bruit
samedi 8 mars 2014
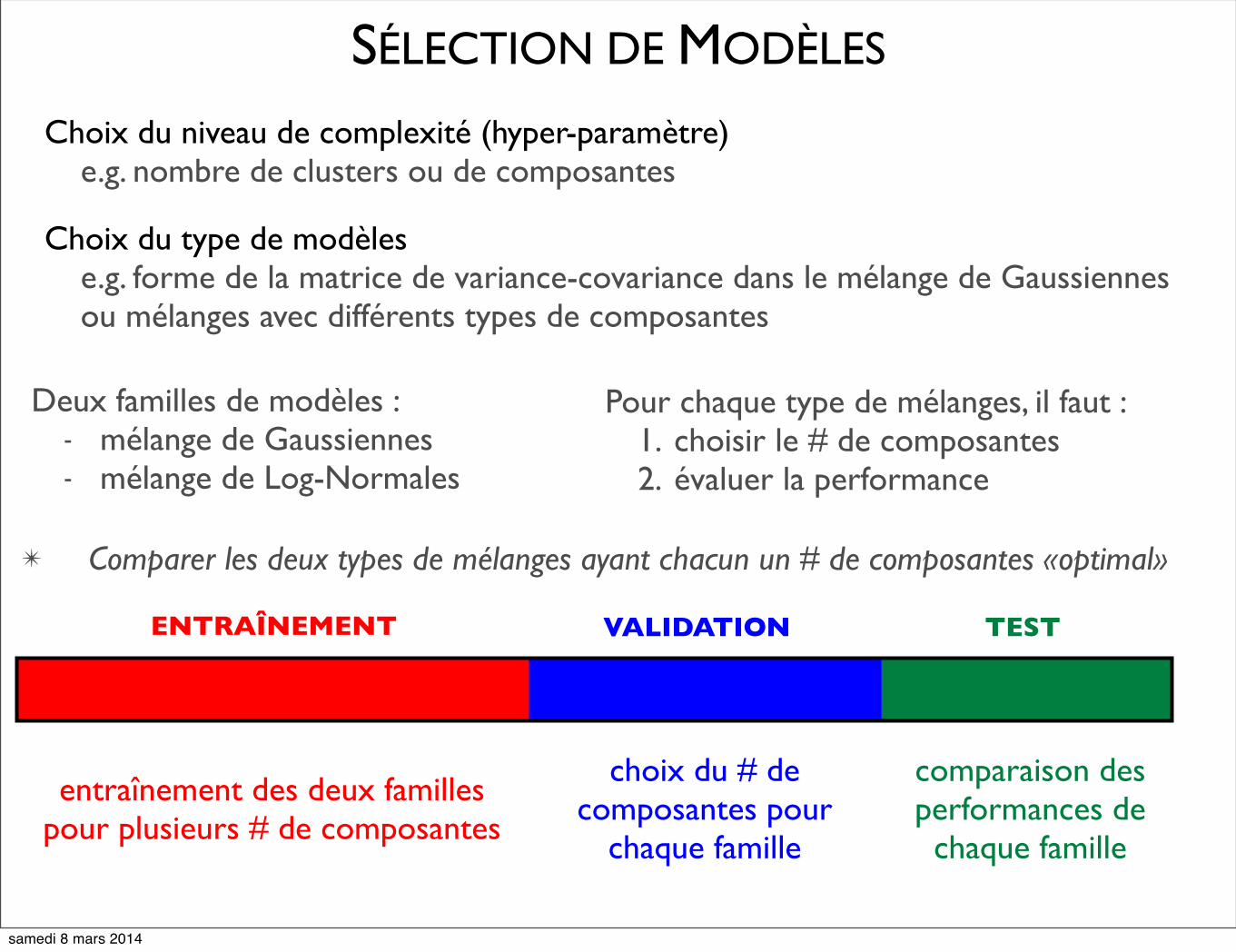
SÉLECTION DE MODÈLES
Choix du niveau de complexité (hyper-paramètre)e.g. nombre de clusters ou de composantes
Choix du type de modèles e.g. forme de la matrice de variance-covariance dans le mélange de Gaussiennesou mélanges avec différents types de composantes
Deux familles de modèles :- mélange de Gaussiennes- mélange de Log-Normales
Pour chaque type de mélanges, il faut :1. choisir le # de composantes2. évaluer la performance
entraînement des deux familles pour plusieurs # de composantes
choix du # de composantes pour
chaque famille
comparaison des performances de
chaque famille
ENTRAÎNEMENT VALIDATION TEST
✴ Comparer les deux types de mélanges ayant chacun un # de composantes «optimal»
samedi 8 mars 2014

VALIDATION CROISÉE✴ Lorsque le jeu de données n’est pas assez grand, on crée plusieurs paires
d’ensembles d’ENTRAÎNEMENT et de VALIDATION de sorte que toutes les données se retrouvent une fois dans un ensemble de validation.
✴ L’erreur de validation est estimée par l’erreur moyenne sur chaque ensemble de validation.
Evalidation =1
n
k�
j=1
Ej
k-fold cross-validation
run 1
E1
run 2
E2
run 3
E3
samedi 8 mars 2014
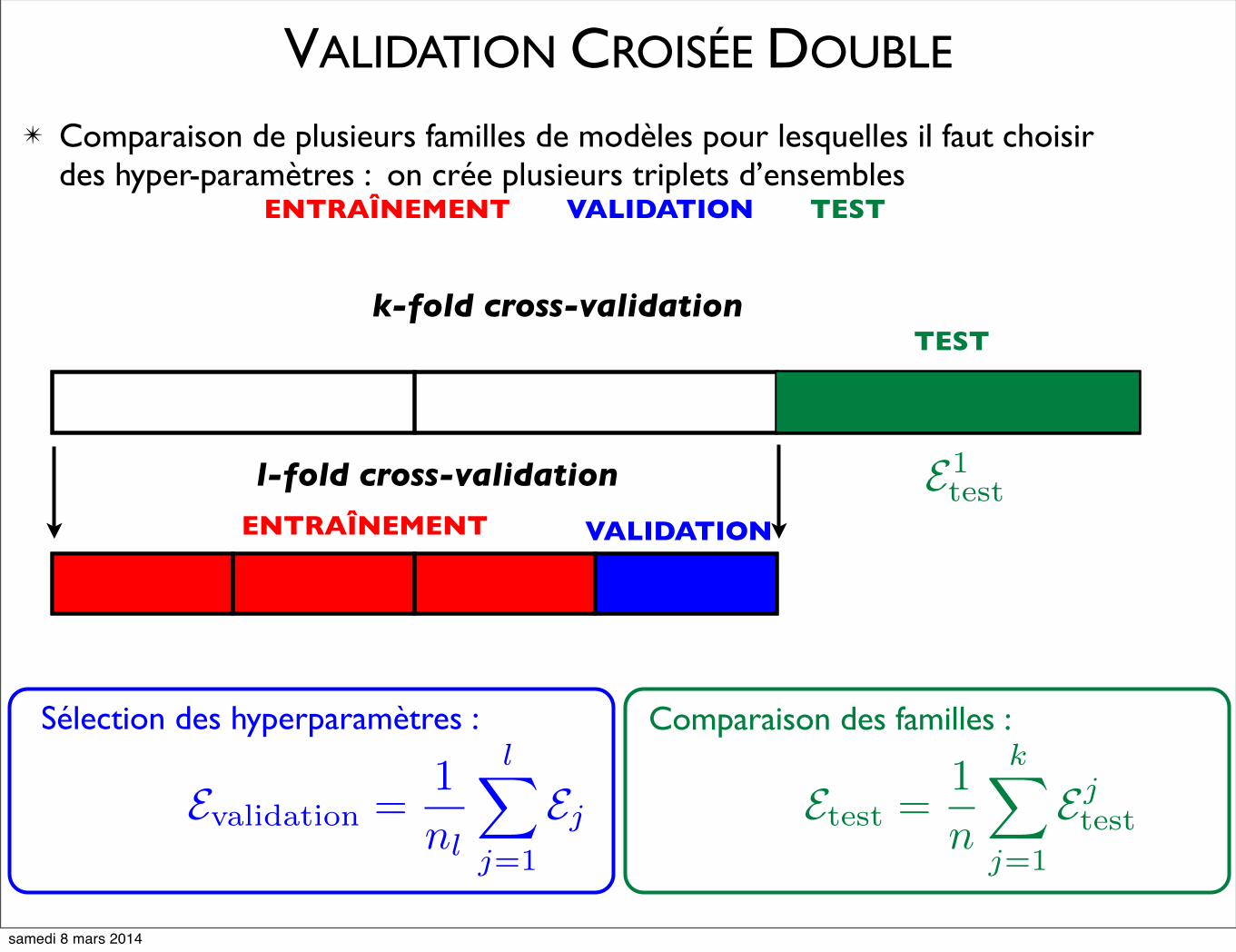
VALIDATION CROISÉE DOUBLE
✴ Comparaison de plusieurs familles de modèles pour lesquelles il faut choisir des hyper-paramètres : on crée plusieurs triplets d’ensembles
ENTRAÎNEMENT VALIDATION TEST
k-fold cross-validation
l-fold cross-validation
ENTRAÎNEMENT VALIDATION
TEST
E1test
Sélection des hyperparamètres :
Evalidation =1
nl
l�
j=1
Ej Etest =1
n
k�
j=1
Ejtest
Comparaison des familles :
samedi 8 mars 2014

• Pour un seul hyper-paramètre, on crée une liste de valeurs de complexité croissante.e.g. Pour le nombre de composantes d’un mélange, on essaie une liste valeurs de croissance logarithmique 1, 2, 4, 8, 16 puis on raffine la recherche.
• Pour deux hyper-paramètres, on crée une grille de valeurs ou de modèles de complexité croissante.e.g. Dans mclust, le choix du nombre de composantes et de la forme de la matrice de variance-covariance se fait sur un tableau
VALIDATION CROISÉE EN PRATIQUE
# de composantes / matrice VCV
1 2 4 8 16
EIIVIIEEIVEIEVIVVIEEEEEVVEVVVV
Limites de la validation croisée • évaluation de nombreuses combinaisons
de valeurs d’hyperparamètres• peut être lourd en temps de calcul• alternative : approche bayesienne
samedi 8 mars 2014

Réseaux de neuronesmodèles de régression non-paramétriques et
non-linéaires
samedi 8 mars 2014

MODÈLES PARAMÉTRIQUES ET NON-PARAMÉTRIQUES
Modèles non-paramétriques : K-Means, mélange de Gaussiennes, réseau de neurones
Modèles paramétriques : régression linéaire ou logistique, la distribution Gaussienne, Log-Normale, Gamma
Modèles non-paramétriques :• nombre variable de paramètres (choisi en fonction des données) qui augmente
avec la taille de l’ensemble d’entraînement et la complexité de la tâche• hypothèses légères sur la continuité• tests sur la capacité prédictive (obtenir une bonne performance sur de nouvelles
données)
Types de tâches : classification (supervisée ou non), régression et l’estimation de densité
Modèles paramétriques : • nombre fixe de paramètres• hypothèses fortes sur le modèle• tests sur l’adéquation du modèle
samedi 8 mars 2014

RÉSEAUX DE NEURONES
Modèles de régression-classification-densité non-paramétrique non-linéaire
Développés dans les années 60 et mise en oeuvre efficace dans les années 80
Inspiration des neurones biologiques mais il n’y a plus de plausibilité biologique
Lorsque bien utilisés, ce sont des modèles flexibles et puissants qui ont la propriété d’approximateur universel
Focus sur une architecture spécifique et la plus répandue : feedforward neural network ou multilayer perceptron (MLP)
➡ Beaucoup d’applications en climat et dans les sciences de la terre
samedi 8 mars 2014
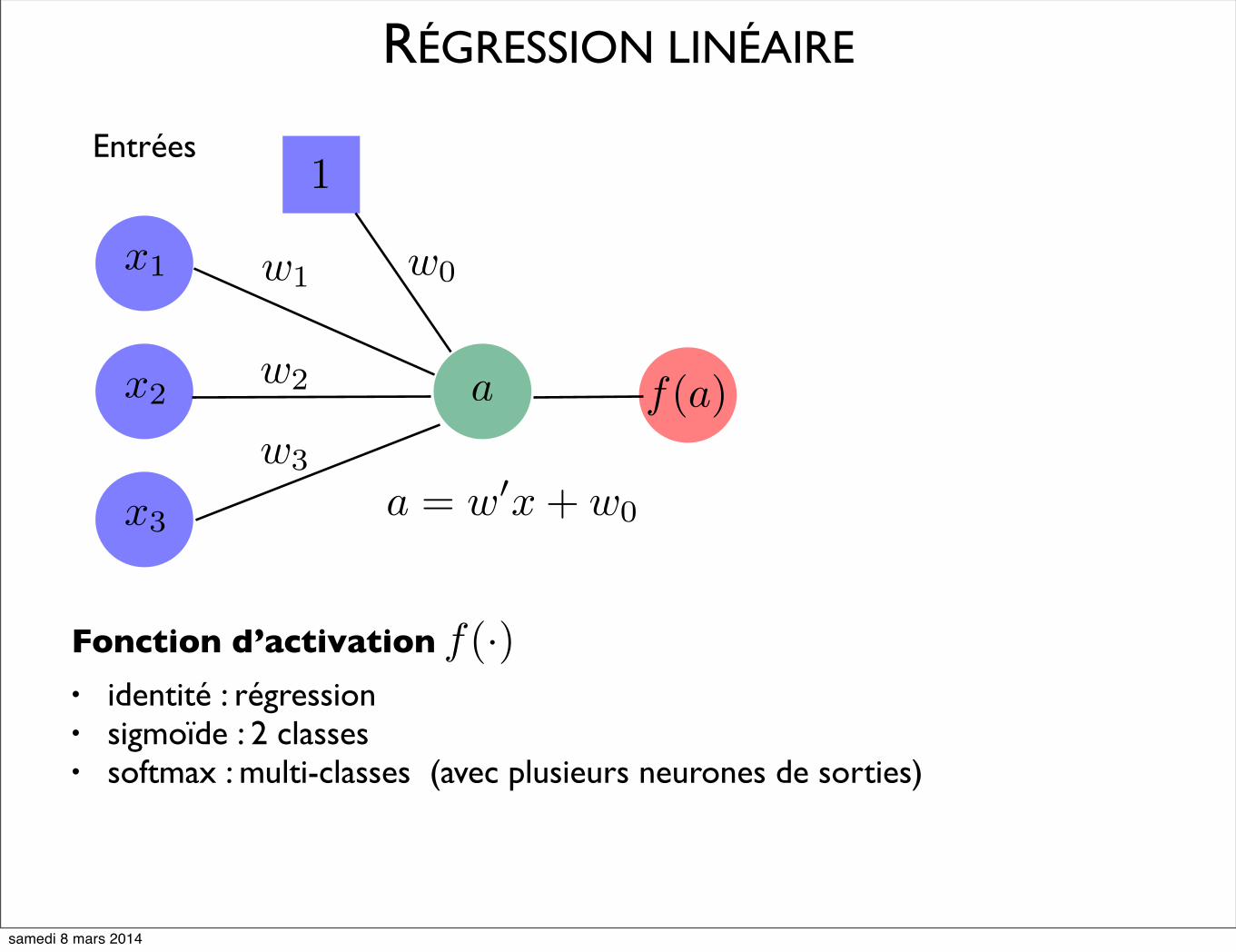
RÉGRESSION LINÉAIRE
x1
x2
x3
Entrées1
w0w1
w2
w3
a
a = w�x+ w0
f(a)
Fonction d’activation
• identité : régression• sigmoïde : 2 classes• softmax : multi-classes (avec plusieurs neurones de sorties)
f(·)
samedi 8 mars 2014
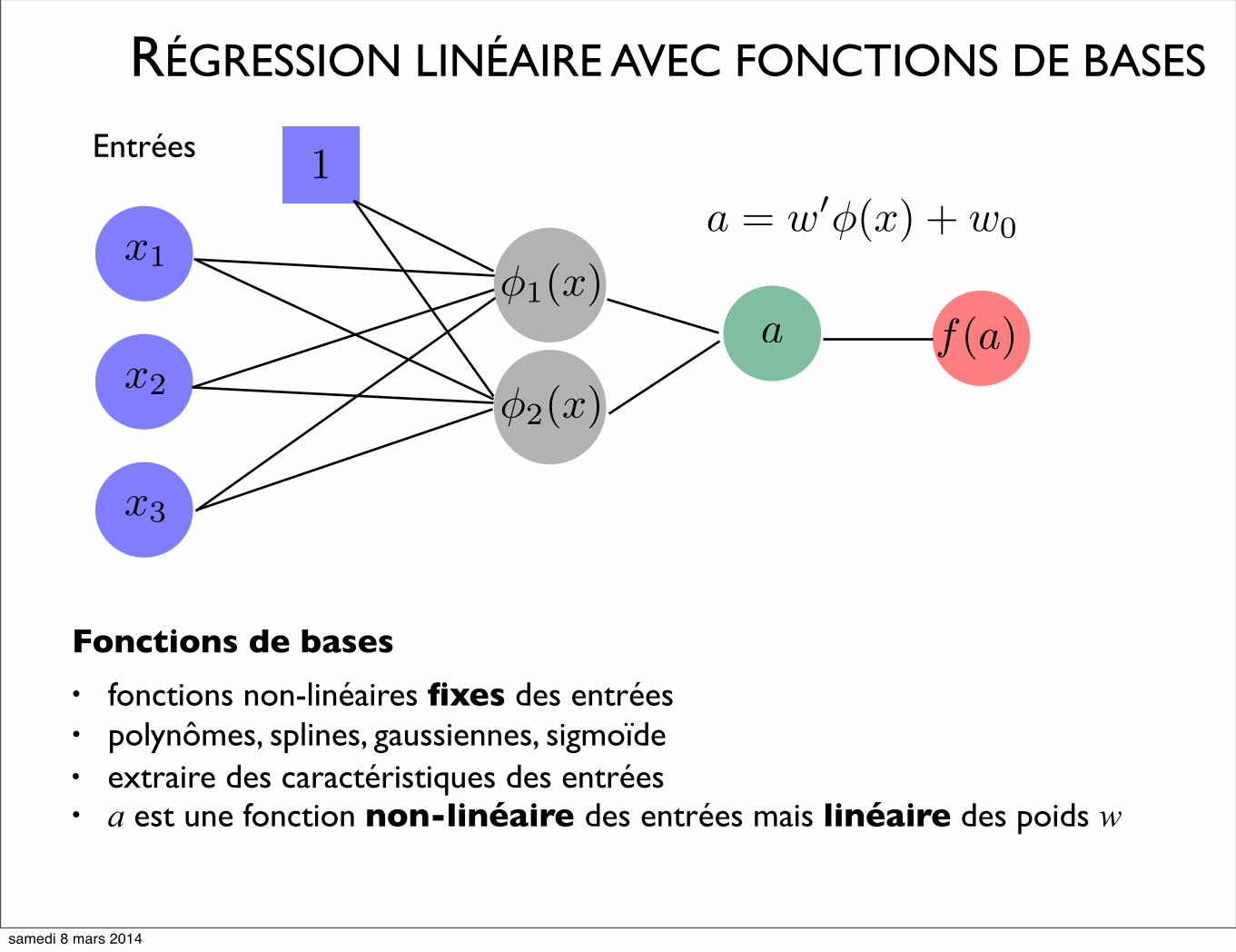
RÉGRESSION LINÉAIRE AVEC FONCTIONS DE BASES
x1
x2
x3
Entrées 1
a f(a)φ1(x)
φ2(x)
a = w�φ(x) + w0
Fonctions de bases
• fonctions non-linéaires fixes des entrées • polynômes, splines, gaussiennes, sigmoïde• extraire des caractéristiques des entrées• a est une fonction non-linéaire des entrées mais linéaire des poids w
samedi 8 mars 2014

FONCTIONS DE BASES POLYNOMIALES
φj(x) = xj
Fonctions globales une variation en x affecte toutes les fonctions de bases
samedi 8 mars 2014

FONCTIONS DE BASES GAUSSIENNES
φj(x) = exp
�− (x− µj)2
2s2
�
Fonctions locales une variation en x affecte seulement les fonctions de bases les plus près et contrôlent la position et la largeur de la fonction de base. µj s
samedi 8 mars 2014
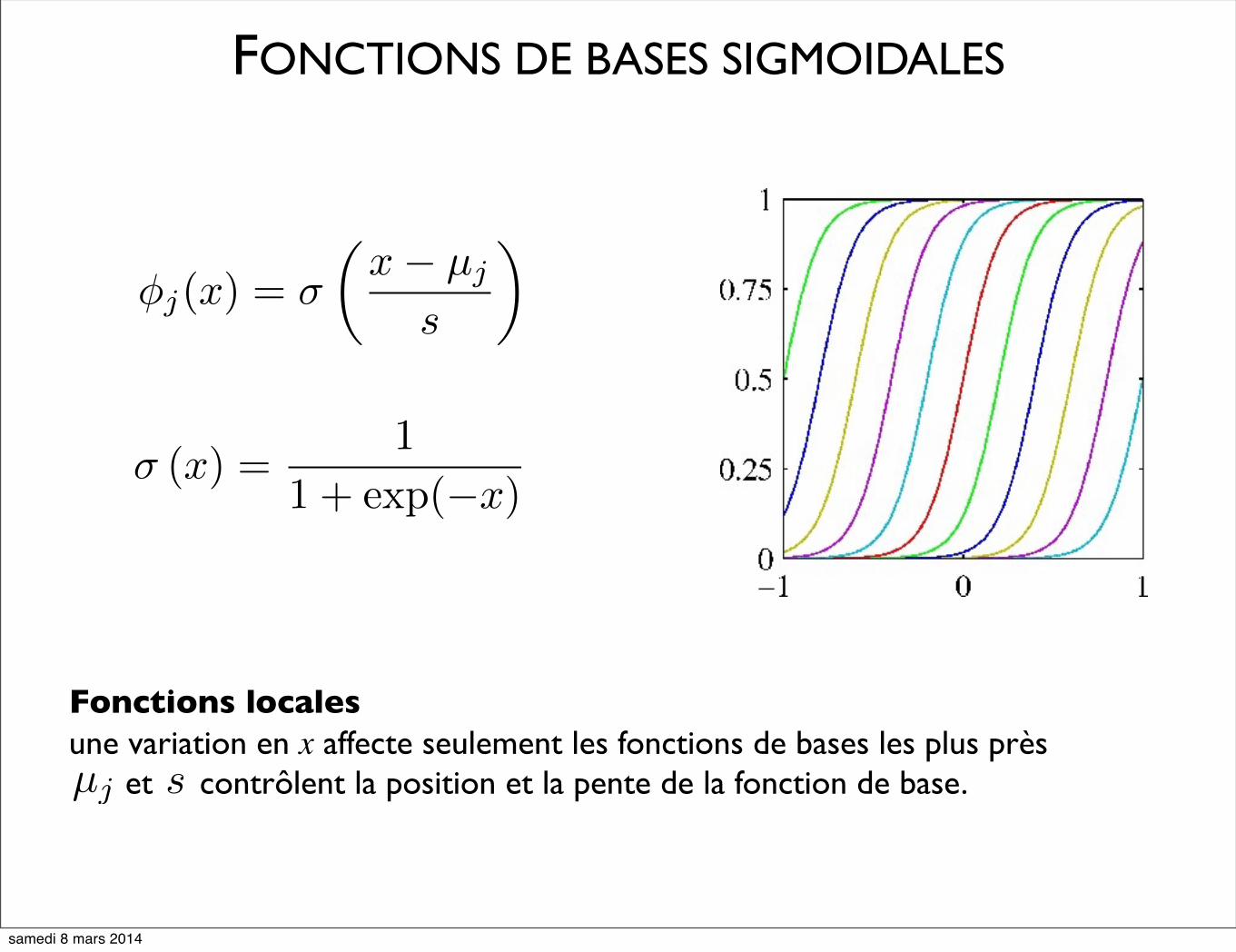
FONCTIONS DE BASES SIGMOIDALES
φj(x) = σ
�x− µj
s
�
σ (x) =1
1 + exp(−x)
Fonctions localesune variation en x affecte seulement les fonctions de bases les plus près et contrôlent la position et la pente de la fonction de base. µj s
samedi 8 mars 2014

DU LINÉAIRE AU NON-LINÉAIRE
y(x,w) = f(a) = f(�
j
wjφj(x) + w0)
Réseau de neurones : fonctions de bases adaptatives, apprises à partir des données.
w = (ΦTΦ)−1ΦTyE(w) =
1
2
n�
i=1
{yi − wtφ(xi)}2Φij = φi(xj)
• limitations : ces fonctions de bases sont fixées indépendamment des données
y(x,w)
• fonctions de bases sont fixes (ne dépendent pas de w)
• correspond à l’extraction de caractéristiques et exige des connaissances a priori (pre-processing)
• est une fonction non-linéaire de x mais linéaire de w dans le cas où f() est l’identité
• pour la régression, il y a une solution analytique pour les w qui minimisent l’erreur carrée :
samedi 8 mars 2014
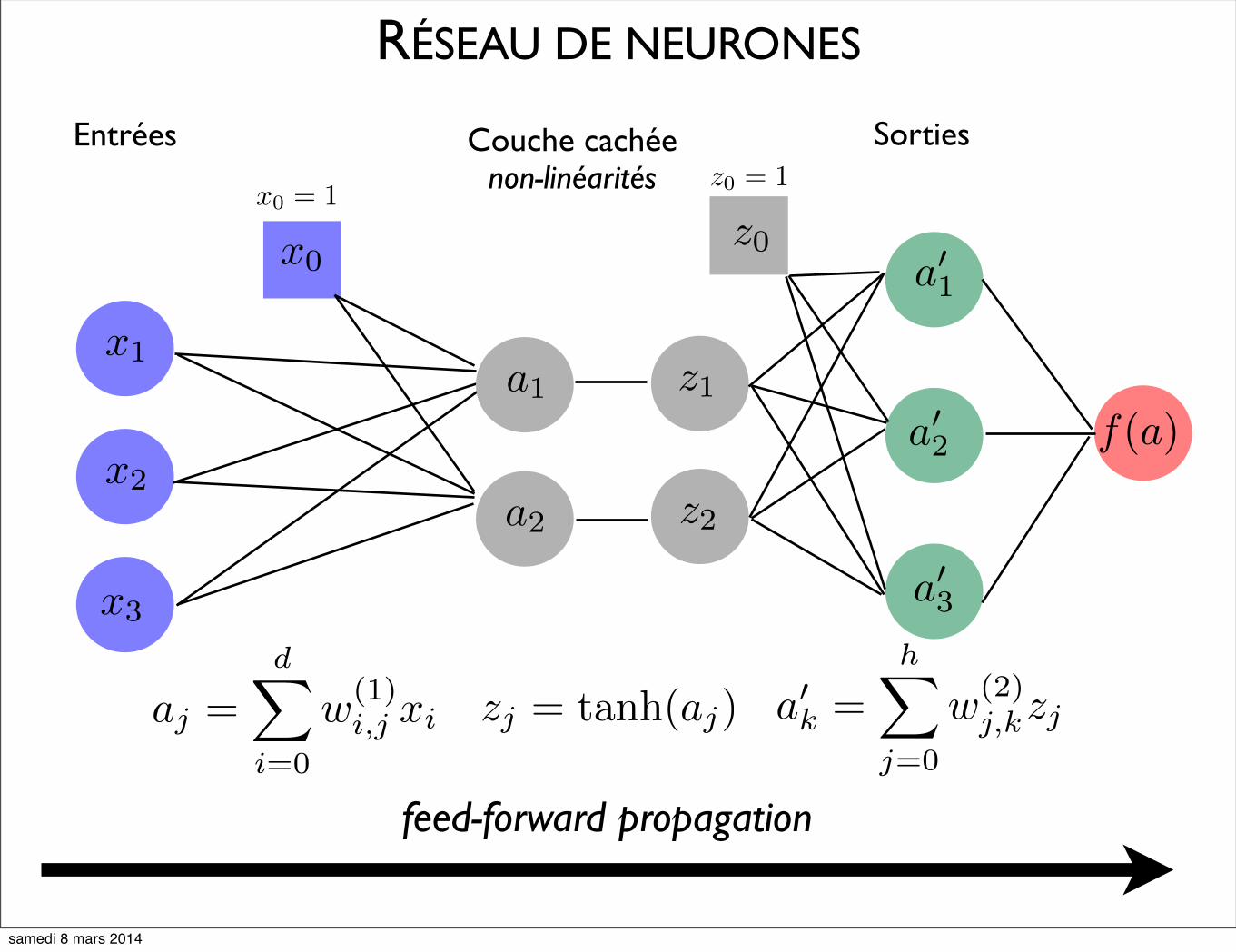
RÉSEAU DE NEURONES
Entrées Couche cachéenon-linéarités
Sorties
x1
x2
f(a)a1
a2
z1
z2
x0z0
a�1
a�2
a�3x3
x0 = 1z0 = 1
feed-forward propagation
zj = tanh(aj) a�k =h�
j=0
w(2)j,kzjaj =
d�
i=0
w(1)i,j xi
samedi 8 mars 2014

Fonctions de bases adaptatives
RÉSEAU DE NEURONES
Réseau de neurones avec h unités cachées
y(x,w) = f
h�
j=1
w(2)1,jφj(x), . . . ,
h�
j=1
w(2)K,jφj(x)
φj(x) = tanh(aj) = tanh�w(1)
i,j xi
�
!! " !!#
!"$%
!"$&
!"$'
!"$(
"
"$(
"$'
"$&
"$%
#
Student Version of MATLAB
Où la non-linéarité est produite par la tangente hyperbolique :
tanh(a) =ea − e−a
ea + e−a
Paramètres
Hyperparamètre Nombre de d’unités cachées h
w = (w(1),w(2))
samedi 8 mars 2014

!! " !!#
!"$%
!"$&
!"$'
!"$(
"
"$(
"$'
"$&
"$%
#
Student Version of MATLAB
Si le nombre d’unités cachées est bien choisi en fonction de l’ensemble d’entraînement (complexité et taille), un réseau de neurones feed-forward à une couche cachée peut approximer toute fonction continue.
RÉSEAU DE NEURONES approximateur universel
10 unités cachées
tangente hyperbolique
samedi 8 mars 2014

Classification : fonction d’activation = sigmoïde ou softmax
y(x,w) = σ(a�(x)) =1
1 + exp(−a�(x)) P (C1|x) P (C2|x) = 1− P (C1|x)
y(x,w) =
�exp (a�1(x))�Kk=1 exp (a
�k(x))
, . . . ,exp (a�K(x))
�Kk=1 exp (a
�k(x))
�
[P (C1|x), . . . , CK |x)]
Minimisation de l’entropie croisée :
E(w) = −n�
i=1
{yi ln y(xi, w) + (1− yi) ln(1− y(xi, w)}
E(w) = −n�
i=1
K�
k=1
yik ln yk(xi, w)
APPRENTISSAGE : RÉSEAU DE NEURONES
deux classes : un seul neurone de sortie
multi-classes : plusieurs neurones de sortie
samedi 8 mars 2014

Régression : fonction d’activation = identité
=
h�
j=1
w(2)1,j tanh
�d�
i=0
w(1)i,j xi
�. . . ,
h�
j=1
w(2)K,j tanh
�d�
i=0
w(1)i,j xi
�
y(x,w) = [a�1(x), . . . , a�K(x)]
Minimisation de l’erreur carrée :
E(w) =1
2
n�
i=1
K�
k=1
{yik − a�k(xi)}2
Pour l’erreur carrée ou l’entropie croisée 2 classes ou multi-classes, même dérivée de la fonction d’erreur en fonction des neurones de sorties :
APPRENTISSAGE : RÉSEAU DE NEURONES
∂E(w)
∂a�k= a�k(xi)− yik
samedi 8 mars 2014

OPTIMISATION DES PARAMÈTRES méthodes numériques basées sur le gradient
• Minimum se produit en un point tel que :
• Mais aussi les points de selle et les maxima
• Le minimum global correspond à la plus petite valeur prise par la fonction d’erreur
• On se contente généralement d’une minimum local qui est bon comparé à d’autres minima locaux
• Pas de solution analytique : minimisation de la fonction d’erreur par descente de gradient
gradient : vecteur des dérivées partiellespointe dans la direction de la plus grande pente
∇E(w)
∇E(w) = 0
w(τ+1) = w(τ) − η∇E(w(τ))
samedi 8 mars 2014

DESCENTE DE GRADIENTBasée sur une approximation locale quadratique
Le gradient est perpendiculaire à la tangente de la courbe de niveau.
Plus l’approximation quadratique est juste, plus rapide la convergence vers l’optimum local.
Le gradient permet une optimization beaucoup plus efficace
Les méthodes dites de quasi-Newton ou du gradient conjugué sont plus robustes que la simple descente du gradient et sont donc à préférer.
Pour trouver un minimum local suffisamment bon, il est recommendé d’exécuter la minimisation plusieurs fois en partant de différents valeurs de poids initiaux.
w(τ+1) = w(τ) − η∇E(w(τ))
samedi 8 mars 2014

RÉTROPROPAGATION calcul du gradientMéthode de rétropropagation permet le calcul efficace de ∇E(w)
Erreur carrée en un seul exemple : En(w) =1
2
K�
k=1
{yi,k − a�k(xn)}2
Application de la règle de la dérivée en chaîne pour calculer :
∂En(w)
∂w(2)k,j
∂En(w)
∂w(1)i,j
poids de la couche cachée (1ère couche)
poids de la couche de sortie (2ème couche)
Objectif : combiner les calculs de la phase forward (avant) et backward (arrière) de façon efficace.
samedi 8 mars 2014

Entrées Couche cachéenon-linéarités
Sorties
x1
x2
f(a)a1
a2
z1
z2
x0z0
a�1
a�2
a�3x3
x0 = 1z0 = 1
feed-forward propagation
backward propagation
w(1)i,j
En(w)
w(2)k,j
samedi 8 mars 2014
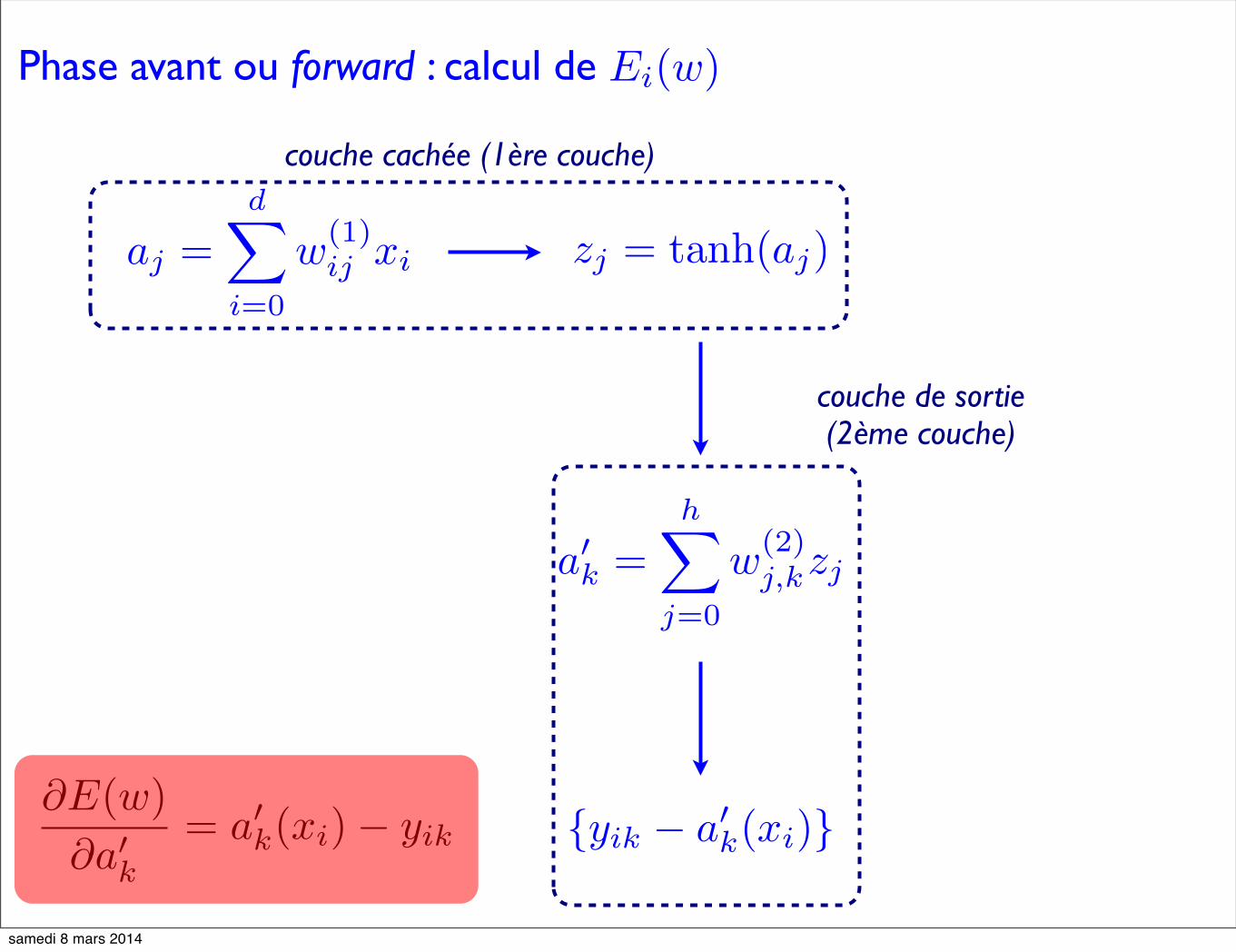
Phase avant ou forward : calcul de Ei(w)
zj = tanh(aj)aj =d�
i=0
w(1)ij xi
couche cachée (1ère couche)
a�k =h�
j=0
w(2)j,kzj
{yik − a�k(xi)}
couche de sortie (2ème couche)
∂E(w)
∂a�k= a�k(xi)− yik
samedi 8 mars 2014
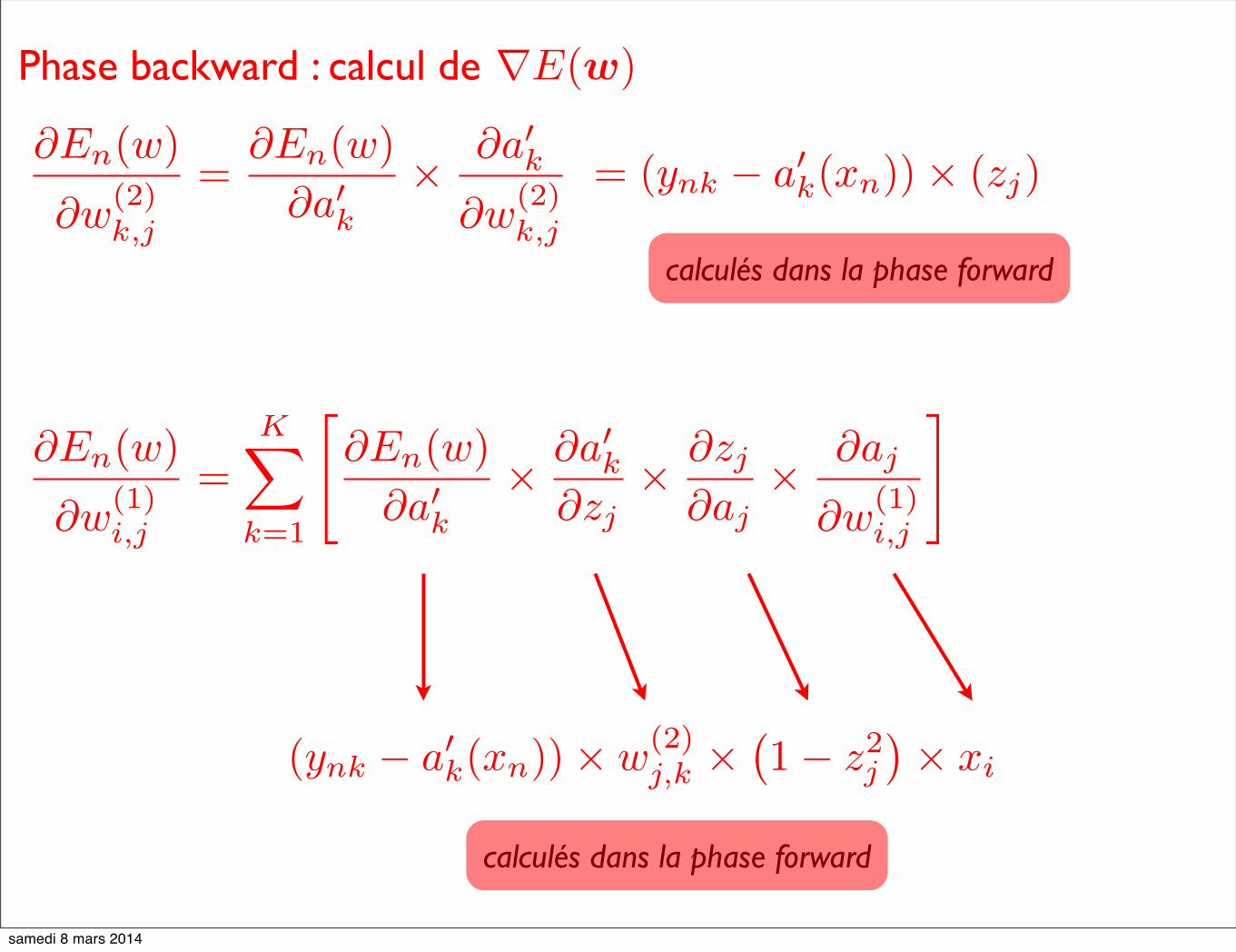
Phase backward : calcul de ∇E(w)
∂En(w)
∂w(2)k,j
=∂En(w)
∂a�k× ∂a�k
∂w(2)k,j
= (ynk − a�k(xn))× (zj)
calculés dans la phase forward
∂En(w)
∂w(1)i,j
=K�
k=1
�∂En(w)
∂a�k× ∂a�k
∂zj× ∂zj
∂aj× ∂aj
∂w(1)i,j
�
(ynk − a�k(xn))× w(2)j,k ×
�1− z2j
�× xi
calculés dans la phase forward
samedi 8 mars 2014

∂Ei(w)
∂w(2)jk
= {yik − a�k}zj
Poids de la deuxième couche cachée
Poids de la première couche cachée
∂Ei(w)
∂w(1)ij
=
�K�
k=1
{yik − a�k}w(2)jk
�(1− z2j )xi
Une modification de la fonction d’erreur requiert la modification du calcul du gradient uniquement de :
∂Ei(w)
∂a�k
RÉTROPROPAGATION calcul du gradient
samedi 8 mars 2014

SYMÉTRIES DANS L’ESPACE DES POIDS
Propriété de la tangente hyperbolique :
Remplaçons les poids associés à une unité cachée par leur inverse additif :
w(1)j ← −w(1)
j
aj =d�
i=0
w(1)i,j xiPuisque aj ← −ajalors
et zj ← −zjzj = tanh(aj)
2h vecteurs de poids équivalents
w(2)j,k ← −w(2)
j,kEn posant
calculées par le réseau de neurones sont inchangés
a�k =h�
j=0
w(2)j,kzjles sorties
tanh(−a) = − tanh(a)
samedi 8 mars 2014

Si on intervertit l’ordre des unités cachées alors les sorties calculées par le réseau de neurones sont également inchangées : h! permutations possibles
h! 2h vecteurs de poids équivalents
Pas d’impacts en pratique si l’on entraîne le réseau de neurones correctement :
• en initialisant les poids de façon raisonnable• en exécutant l’optimisation plusieurs fois à partir de différents poids initiaux• en retenant le minima local le plus petit
SYMÉTRIES DANS L’ESPACE DES POIDS
samedi 8 mars 2014

RÉGULARISATION
• Minimise le risque de sur-apprentissage (over-fitting) en limitant la complexité du modèle
• Weight decay : pénaliser les poids les plus grands
�E(w) = E(w) +λ
2wTw
biais pénalité
Contrôle le compromis entre la minimisation de l’erreur et de la norme des poids : doit être choisi en validation
λ hyper-paramètre
ENTRAÎNEMENT VALIDATION
�E(w) pour différentesvaleurs de λ
E(w) pour évaluer la performance
samedi 8 mars 2014
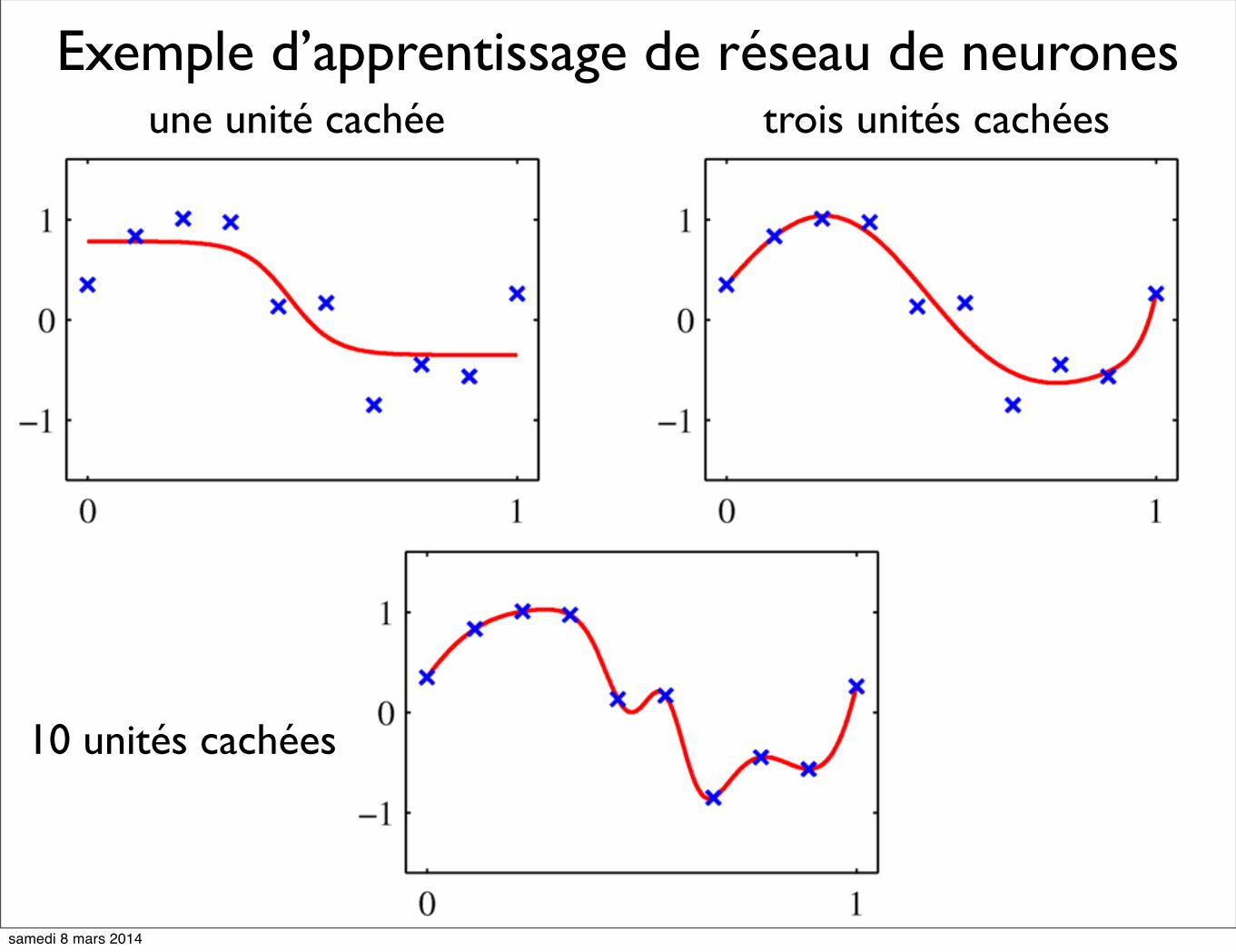
Exemple d’apprentissage de réseau de neuronesune unité cachée trois unités cachées
10 unités cachées
samedi 8 mars 2014

Moyenne et Écart-Type Mobiles
samedi 8 mars 2014

30 jours 100 jours
Moyenne-mobile centrée sur un série de températures
8 jours
samedi 8 mars 2014

Descente d’Échelle ou Downscaling
samedi 8 mars 2014
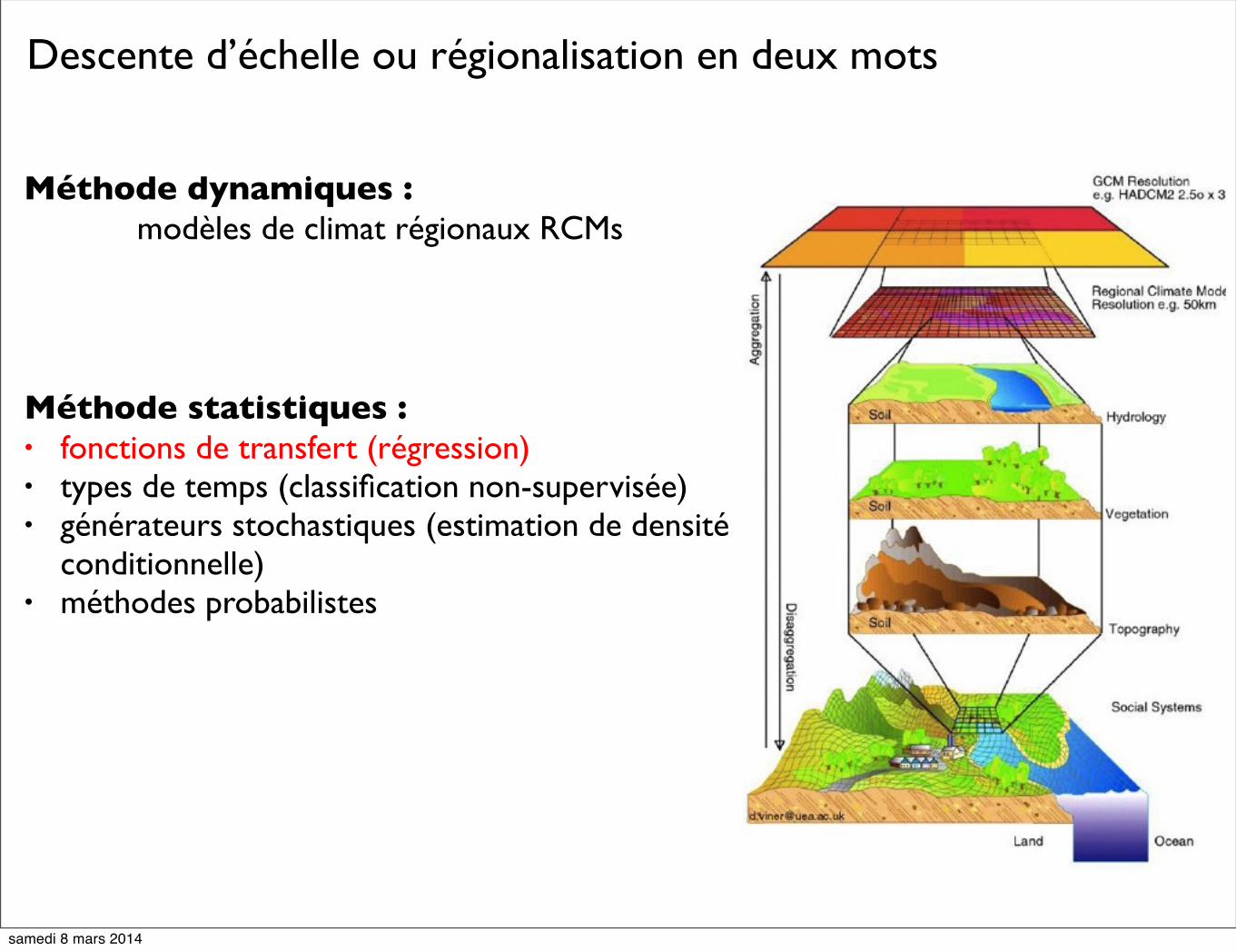
Descente d’échelle ou régionalisation en deux mots
Méthode dynamiques : modèles de climat régionaux RCMs
Méthode statistiques :• fonctions de transfert (régression)• types de temps (classification non-supervisée)• générateurs stochastiques (estimation de densité
conditionnelle)• méthodes probabilistes
samedi 8 mars 2014

Fonctions de transfert
Covariables à grande échelle issues de modèles climatiques (ré-analyses)Maillage à faible résolutionpression au niveau de la mercomposante U et V du venthumidité relativehauteur de géopotentiel
Variable(s) à l’échelle locale (station ou maillage haute résolution) issues des observationstempératureprécipitation (liquide et solide)
Modèle de régression statistique
samedi 8 mars 2014

Étapes
1. Création d’un jeu de covariables parmi les variables à grande échelle
2. Ajustement d’un modèle de régression entre les observations de la variable locale et les covariables issues de ré-analyses
3. Vérification sur les covariables issues de GCM si la relation statistique établie par le modèle de régression est valable pour le GCM
4. Estimation en période future avec les covariables issues du GCM pour différents scénarios de changement climatique.
Période historique
Période future
samedi 8 mars 2014