réalisé à l’inra de sophia-antipolis . u.m.r. 1112 biologie des populations en intéraction
DESCRIPTION
Concepts de gestion et d' exploitation d'une base de données générique de biologie des populations. Réalisé à l’Inra de Sophia-Antipolis . U.M.R. 1112 Biologie des populations en intéraction U.R.I.H . Unité de recherche intégrée en horticulture. Q’est ce qu’un Data-mart:. - PowerPoint PPT PresentationTRANSCRIPT

24 Aout 2006 R.Boll, N.Mezencev
1
Concepts de gestion et d'exploitation d'une base de
données générique de biologie des populations
Réalisé à l’Inra de Sophia-Antipolis.
U.M.R. 1112 Biologie des populations en intéraction
U.R.I.H. Unité de recherche intégrée en horticulture

24 Aout 2006 R.Boll, N.Mezencev
2
Q’est ce qu’un Data-mart:• Un data-mart est un magasin de données.
• C’ est une base de données décisionnelle structurée et formatée en fonction d'un métier précis ou d'un usage particulier.
• L'information y est préparée pour être « consommée » telle quelle.

24 Aout 2006 R.Boll, N.Mezencev
3
C’est l’ensemble des…
Algorithmes et méthodes Destinées à l’exploration et à l’analyse
De grandes bases de données Sans à priori En vue de détecter dans ces données
Des Règles Des tendances inconnues Des structures particulières
Restituant de façon concise l’essentiel de l’information utile
Pour l’aide à la décisionStéphane Tuffery(2005)
Le data mining :

24 Aout 2006 R.Boll, N.Mezencev
4
• Le Data Mining effectue l’analyse exploratoire des données (On recherche un ordonnancement dans un flot de données collecté avec peu d’à priori).
• et non plus seulement une analyse confirmatoire (Analyse d’un essai planifié avec
l’objectif de prouver un phénomène).
Le data mining (Suite)

24 Aout 2006 R.Boll, N.Mezencev
5
Pourquoi faire du Data Mining ?
• Les volumes de données sont trop importants pour un traitement à l’aide de techniques d’analyses classiques ;
• L’utilisateur final n’est pas, en général statisticien de métier ;

24 Aout 2006 R.Boll, N.Mezencev
6
Objectifs du stage :
Renforcer le schéma conceptuel de la base de donnée BPI existante.
Développer une interface web générique avec cette base répondant aux requêtes usuelles (data mining).

24 Aout 2006 R.Boll, N.Mezencev
7
La base de données BPI :
Base SQL (structured Query Language) hébergée par le serveur UNIX du centre.
Constituée de 42 tables créées au fil des besoins.
Regroupe 97 Mo de données (1,2 millions
d’enregistrements).

24 Aout 2006 R.Boll, N.Mezencev
8
Les choix logiciels : La base de donnée MySQL 4.1.13_max
La gestion administrative du SGBD (Systeme de gestion de bases de données) est réalisée avec phpMyAdmin 2.6.3_pl1
Le requêtage est réalisé en SQL 3
Les langages de programmation choisis sont le PHP 4.0 et le HTML, pour des raisons de généricité

24 Aout 2006 R.Boll, N.Mezencev
9
Le nouveau modèle relationnel :
Dérive relationnelles de la base d’origine :
Analyse des blocages fonctionnels par la méthode
Merise assistée par le logiciel Power AMC.
Nouveau ‘modèle physique de données’ aboutissant à une base BPI2, conservant les
informations contenues dans les tables d’origine.

24 Aout 2006 R.Boll, N.Mezencev
10
Principes pour la reconstitution de la base : 1. Les données doivent occuper le moins de place
possible…mais doivent cependant laisser une liberté de codage et de commentaires suffisante à l’utilisateur.
2. La redondance d’information est interdite.
3. Les mises à jour/suppression de données doivent laisser la base intègre.
4. La recherche d’information doit être sécurisée et rapide.
5. Les tables ne doivent représenter que des données de même nature.

24 Aout 2006 R.Boll, N.Mezencev
11
Le Modèle Conceptuel de Données : Regroupement au sein d’entités homogènes des attributs indispensables pour caractériser:
Un projet Un essai Une collecte Un site Les informations agronomiques correspondant à l’essai réalisé Le matériel végétal travaillé Les variables mesurées Le plan du dispositif. Les événements liés à la temporalité. Les éléments de constitution du masque de saisie. Une table de correspondance entre les méthodes et les variables. La gestion des droits des utilisateurs.

24 Aout 2006 R.Boll, N.Mezencev
12
Le nouveau modèle physique de données
FK_EXPERIMENTER
FK_PARTICIPE
FK_OBS_TEMP
FK_SPATIALISER
FK_CORRESPONDRE
FK_DECRIRE
FK_DECODER
FK_MESURER
FK_COMPLETER
FK_PROVENIR
FK_DETAILLER
FK_IDENTIFIER
FK_SAISIR
FK_COMPOSER FK_IMPOSER
FK_SELECTIONNER
sites
ref_siteprod1prod2prod3prod4propriprenomtelexpltelpexplcontact1contact2telc1telc2lieu_essaiadrexplcp_adr1adr2altmerlatlongiventtyp_lutrem_sitespays
intchar(15)char(15)char(15)char(15)char(30)char(30)char(30)char(30)char(50)char(50)char(30)char(30)char(100)char(200)char(5)char(100)intdecimal(4,1)decimal(8,6)decimal(7,6)char(5)char(20)char(200)char(20)
<pk>
essais
titrerefref_siteorgannée_debutnblignbcolinterColinterLigbiounittrait_statpechantdiryquant_modever_ref_modeprotocole
char(50)intintintintintintdecimal(4,1)decimal(4,1)char(15)char(30)char(15)char(3)char(20)intchar(200)
<pk><fk1><fk2>
projects
orgNomProjetresptelfaxadrmaildesprotocolespecies
intchar(50)char(20)char(20)char(20)char(50)char(30)char(50)char(200)char(50)
<pk>
temporals
tempsrefanneerelrreltemps_abstrait1pro1dose1trait2pro2dose2trait3pro3dose3tsoladvphenopheno_rampheno_flpheno_feupheno_frclim_exceptirrigationfertil isationcommoperateur
intintintdateintintchar(30)char(30)char(30)char(30)char(30)char(30)char(30)char(30)char(30)textchar(15)char(30)char(30)char(30)char(30)char(30)char(30)char(30)char(30)char(200)char(30)
<pk><fk>
spatials
tempsref_varcoorycoorxnatvalrem_spatial
inttextintinttextdecimal(12,2)text
<fk1><fk2>
cultures
refnom_cultgenreespecevarpgrerem_cult
intchar(30)char(30)char(30)char(30)char(30)char(200)
<fk>
agronomie
refsubstrattexture_solproxi_cultant_cultmode_prodsuperserre_hauserre_hau_totser_ouvtuteurser_couvirr_modepaille_typerem_agro
intchar(30)char(30)char(30)char(30)char(30)intdecimal(2,1)decimal(2,1)char(30)decimal(2,1)char(30)char(30)char(30)char(100)
<fk>
variables_exist
ref_varcode_varsignigenre_espstadecom
textchar(11)char(70)char(30)char(30)char(60)
<pk>
methods
ref_varcultunit_obsnotatech
textchar(15)char(15)texttext
<fk>
collects
ref_popref_siteorgref_essaicode_popd_collectcollectorplantfam_plantnindgenre_esph_speciesrem_collects
intintintinttextintchar(30)char(30)char(30)intchar(30)char(30)char(100)
<pk><fk2><fk1>
mspa_orchards
tempsref_varbranche_refram_reffeu_refram_agebourg_refbranche_agepou_agepou_nbfldirtyp_bourgprofhaupou_nbfrpou_longpou_diafru_diaphenoremarquespou_refval
inttextintintintintintintintintchar(2)char(10)char(2)char(1)intintintintchar(30)char(50)intdecimal(12,2)
<fk1><fk2>
masques
nom_masquerefnom_createur
char(15)intchar(30)
<pk><fk>
dispositif
nom_masqueordre_coordcoorxcoory
char(15)intintint
<fk>
variables_masques
nom_masqueref_varnclassesordre
char(15)textintint
<fk1><fk2>
droits
refnompwddroitLdroitWdroitMorgorgLorgWorgM
integerchar(50)char(15)char(1)char(1)char(1)integerchar(1)char(1)char(1)
Power AMC

24 Aout 2006 R.Boll, N.Mezencev
15
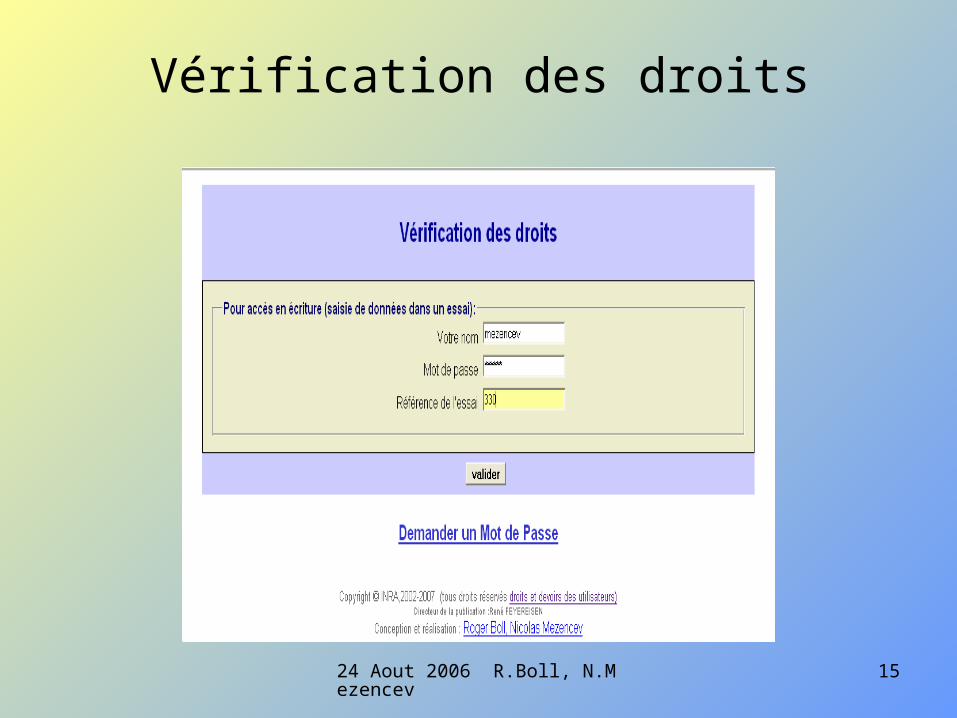
Vérification des droits

24 Aout 2006 R.Boll, N.Mezencev
17
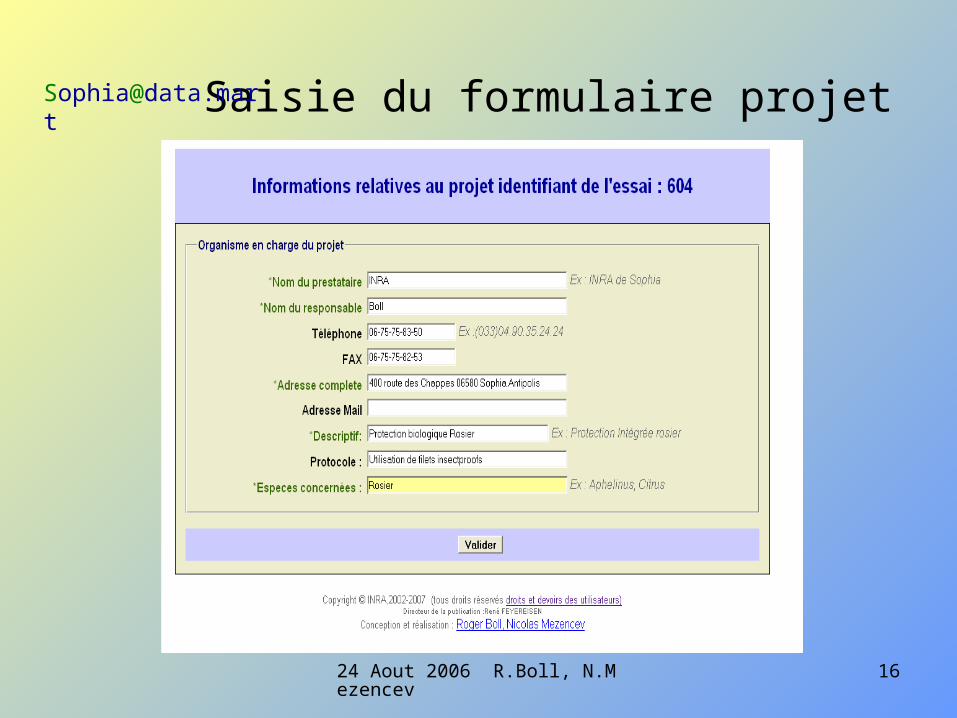
Saisie du formulaire concernant le site d’essai





24 Aout 2006 R.Boll, N.Mezencev
25
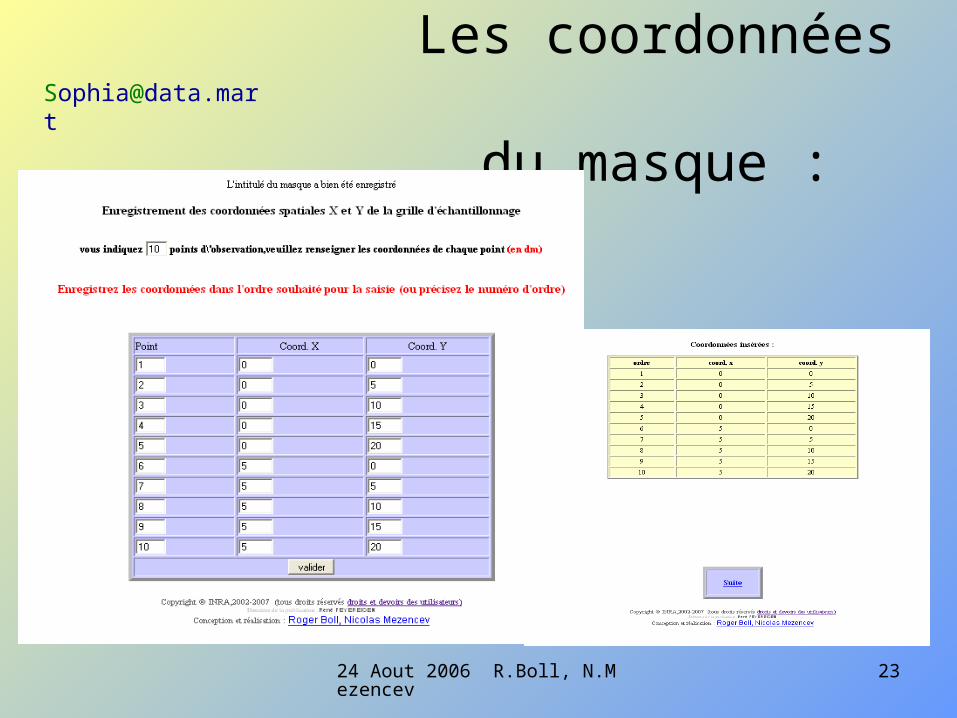
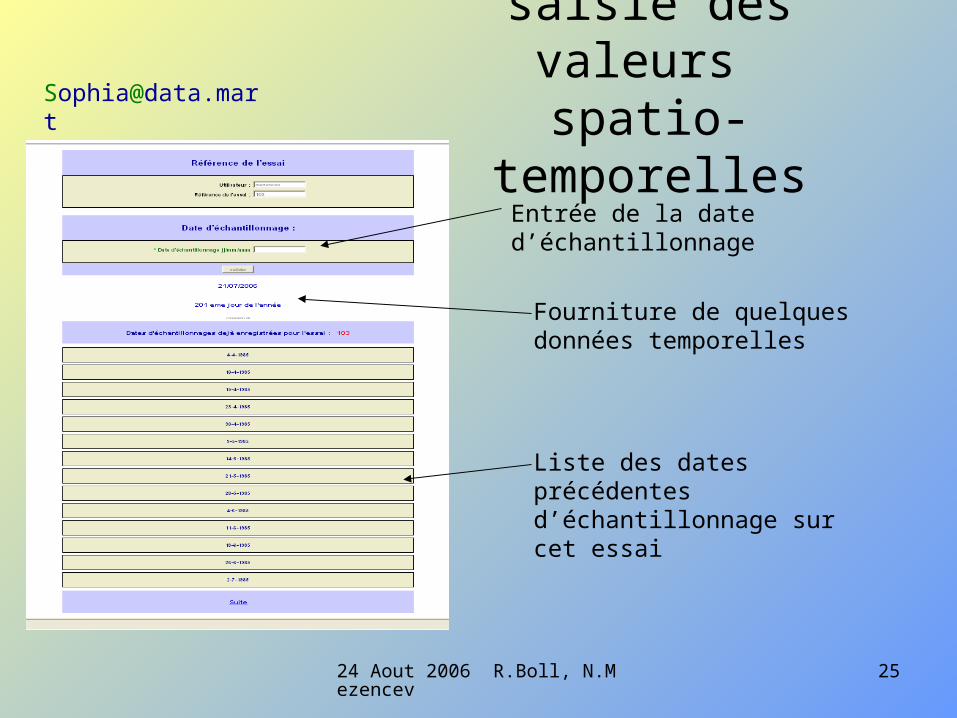
saisie des valeurs spatio-temporelles
Entrée de la date d’échantillonnage
Liste des dates précédentes d’échantillonnage sur cet essai
Fourniture de quelques données temporelles


24 Aout 2006 R.Boll, N.Mezencev
28
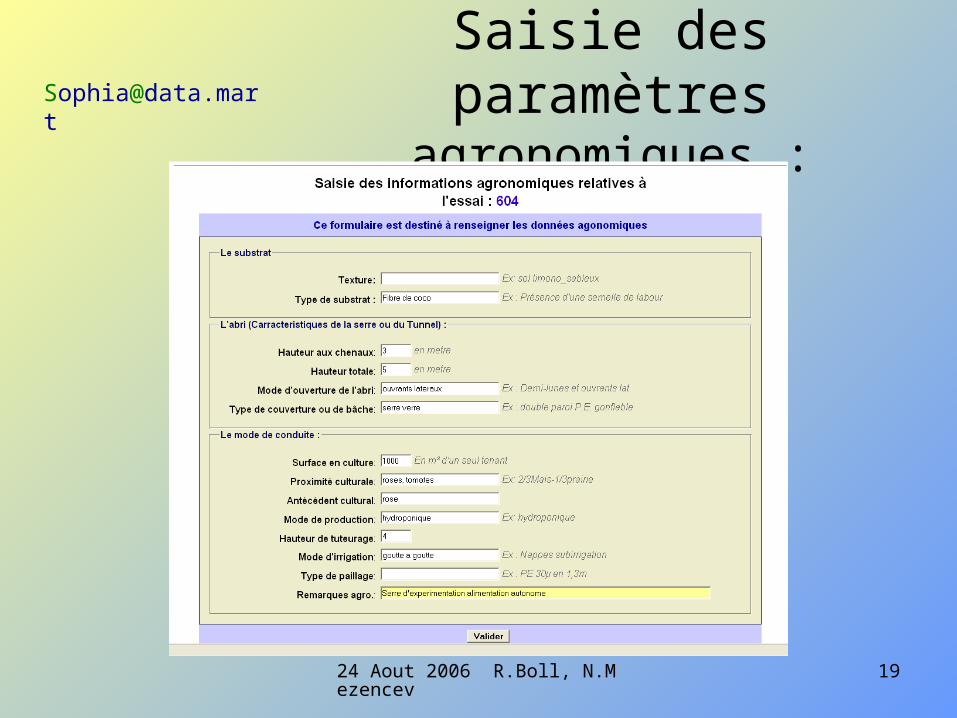
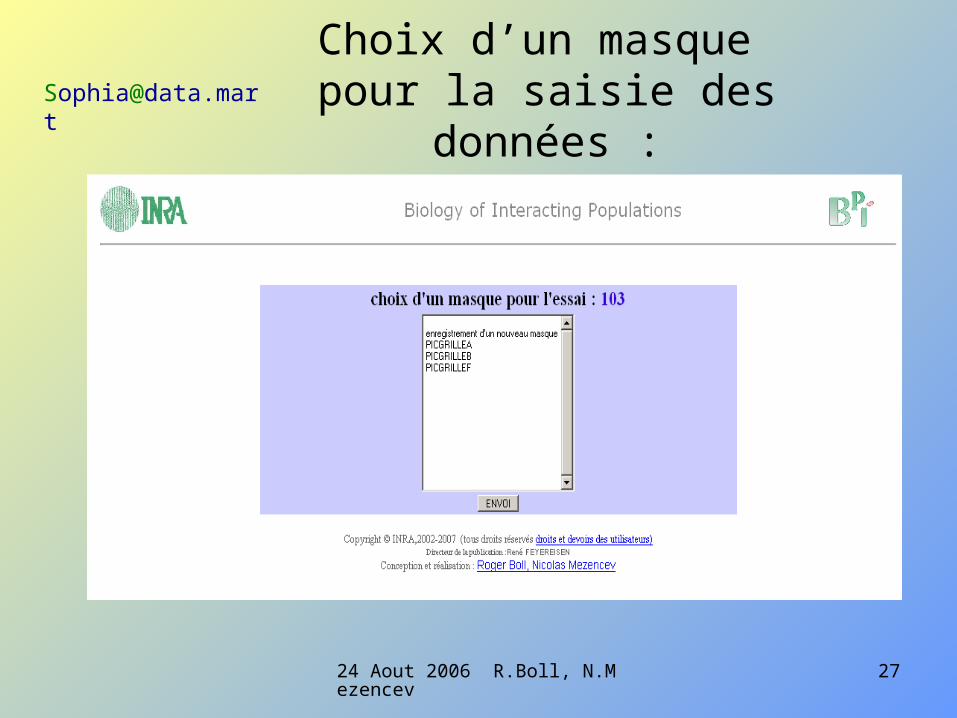
Le masque de saisie :
Ici pour des données en classe
Champs de commentaires

24 Aout 2006 R.Boll, N.Mezencev
29
Menu de visualisation des données de la base :
Date de début et de fin d’extraction


24 Aout 2006 R.Boll, N.Mezencev
31
Les tableaux de données extraites
Triées par variable; par date et par
coordonnées X et Y
Disponibles sous format compatible excel par E_Mail
24 Aout 2006 R.Boll, N.Mezencev
32
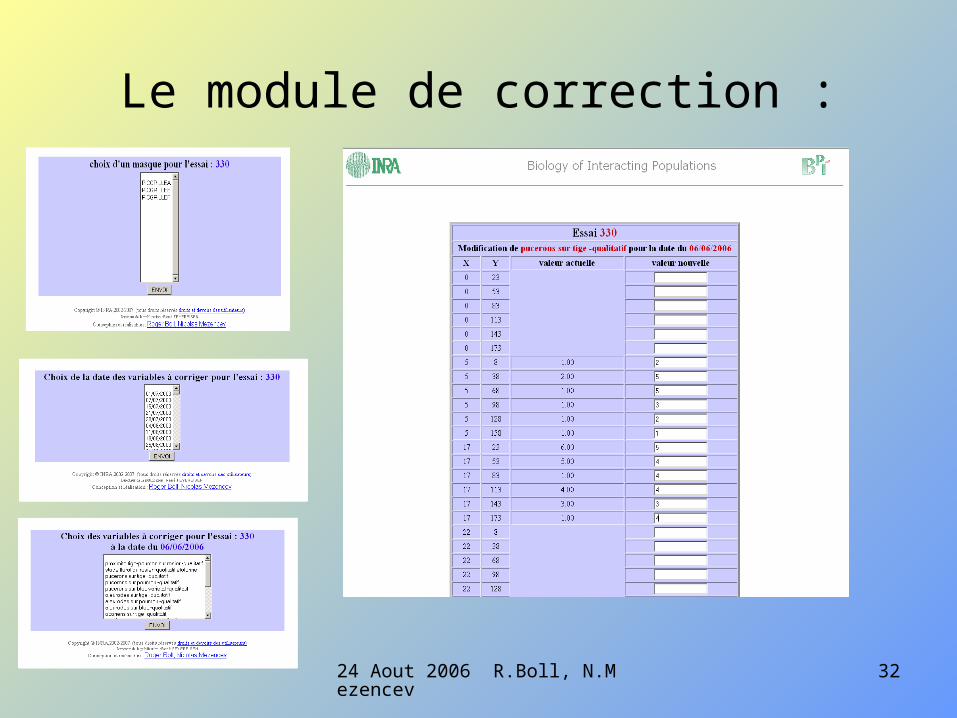
Le module de correction :

24 Aout 2006 R.Boll, N.Mezencev
33
Principales qualités d'un outil de Data Mining :
• Richesses analytiques d'un niveau équivalent aux outils statistiques traditionnels.
• destinés à des utilisateurs "métier" sans compétences statistiques ou informatiques particulières.

24 Aout 2006 R.Boll, N.Mezencev
34
• L'utilisateur doit pouvoir saisir ses propres paramètres.
• Les résultats fournis par l'outil doivent être clairs et compréhensibles (pas trop de termes statistiques par exemple)
• L’accès aux données doit être simple.• Ne doit pas être dédié à un domaine particulier
• Doit pouvoir résoudre des problèmes provenant de contextes différents.
Cahier des charges d'un outil de Data Mining :

24 Aout 2006 R.Boll, N.Mezencev
35
Le couplage data mining/data mart
Développement d’applications statistiques et graphiques :
Un véritable outil de data mining se doit d’etre couplé avec des outils statistiques, ceux-ci peuvent etre réalisés en php ou profiter de possibilités d’interfaçage avec des logiciels statistiques.
Développement d’outils graphiques :PHP offre une classe graphique complete
(jpgraphe) Permettant le tracé de courbes et d’histogrammes…

24 Aout 2006 R.Boll, N.Mezencev
36
Perspectives et discussion :
Extension du data mart sur des données climatiques.
L’affichage spatial ou temporel d’une observation, sous la forme d’un histogramme, d’une courbe ou de toute autre représentation.
Intégration des modèles de dénombrement existants.
Intégration de modèles prédictifs de D.D.P.

24 Aout 2006 R.Boll, N.Mezencev
37
Remerciements :• Je tiens à remercier tout d’abord, Roger Boll pour ses conseils et ses
encouragements.
• Je remercie Christine Poncet directrice de l’unité qui m’a donné l’opportunité de réaliser ce stage.
• Merci à Séverine Doise dont l’aide m’a été précieuse dans l’élaboration de l’INTRANET de l’URIH.
• Merci à Alexandre Bout qui fut notre beta testeur
• Merci à mon épouse qui m’a laissé partir pendant quatre longs mois, et à mes enfants qui cochent scupuleusement les cases du calendrier.
• Merci à tous enfin, dont les encouragements et les conseils m’ont donné envie de poursuivre mes efforts dans le domaine de l’informatique.