projet systèmes embarqués - kadionik.vvv.enseirb … · ainsi dans le cas de notre projet on...
TRANSCRIPT

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 1
MEUNIER Eddy E3
MARTINEZ Johan Option SE
CABRISSEAU Carène
YAKINE Nihale
Projet Systèmes Embarqués Noyaux Linux Temps-Réel embarqués
sur une carte Xilinx Virtex5
avec processeur PowerPC
Professeur encadrant : Patrice Kadionik

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 2
Sommaire
I. Présentation générale
1. Introduction
a. Objectifs
b. Noyau Linux Vanilla
c. Carte Xilinx Virtex5
d. PowerPC 440
2. Communication : PC hôte <-> Carte Xilinx
3. Noyaux patchés Xenomai et preempt-rt a. Concept Temps-Réel
b. Patch Xenomai
c. Patch Preempt-RT
II. Travaux Pratiques
1. TP0: Prise en main de l’environnement
2. TP1: Application “hello world” (TP4)
3. TP3: Portage du noyau Linux Vanilla
4. TP4: Portage du noyau Linux Xenomai
5. TP5: Portage du noyau Linux PREEMPT-RT
III. Conclusion

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 3
I. Présentation Générale
1. Introduction
a. Objectifs
Le but de ce projet était d’étudier et de tester le portage de deux noyaux Linux temps-réel,
Xenomai et Preempt-RT, sur une carte FPGA. Différents outils de test ont été utilisés afin de
comparer les performances de ces noyaux par rapport au noyau standard Vanilla.
Les deux cartes proposées pour le portage des noyaux Linux sont la FPGA Virtex5 PowerPC
440 et l’ARM9. Cependant, sur consigne du professeur encadrant, nous nous sommes focalisés sur
la première carte. S’il le temps le permettait, nous devions réaliser par la suite le même travail sur
la deuxième carte.
Notre groupe de projet a été composé de quatre étudiants : Eddy MEUNIER, Carène
CABRISSEAU, Johan MARTINEZ et Nihale YAKINE. Nous avons travaillé sur ce projet pendant
environ quatre mois dans la salle de TP SE et nous avons amélioré nos compétences en matière
d’électronique, d’informatique et de mesures de performances.
Comme énoncé précédemment, le premier objectif de ce projet a été de porter les noyaux
Vanilla, Xenomai et Preempt-RT sur la carte cible. Ensuite nous devions mesurer les performances
de chaque noyau Linux patché afin de comparer leur efficacité respective. L’utilisation de ces patchs
est nécessaire afin qu’un noyau Linux non temps-réel devienne un noyau Linux temps-réel. Le
troisième objectif de ce projet était de structurer notre rapport sous forme de travaux pratiques
afin que les étudiants de l’année suivante puissent réutiliser notre travail durant les séances de TP.
Ils pourront ainsi, en suivant nos directives et ayant des captures d’écran comme bases, effectuer le
portage des noyaux Linux patchés Xenomai et Preempt-RT en un temps réduit.
b. Noyau Linux Vanilla
Généralement, un système embarqué doit respecter des contraintes temporelles fortes
(hard Real Time) et doit posséder un système d’exploitation Temps Réel.
La question d’utiliser un système d’exploitation Temps Réel ou non se pose plus aujourd’hui
pour des raisons évidentes :
Simplification de l’écriture de l’application embarquée
Portabilité
Evolutivité
Maîtrise des coûts

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 4
Cependant, avant de porter les noyaux Linux patchés Temps Réel, nous nous sommes
intéressés au portage du noyau Linux standard dans la carte. Cette approche permet de mieux
maîtriser notre environnement et ainsi être plus à l’aise lors du portage de Xenomai et Preempt_RT.
Depuis 2001, Linux est en train de conquérir le domaine des systèmes embarqués. En effet,
Linux possède des qualités reconnues dans l’environnement standard du PC grand public :
Open source : gratuit et ouvert
Stable et efficace
Extensible et sécurisé
Aide rapide en cas de problèmes par la communauté Internet des développeurs Linux.
Nombre de plus en plus important des logiciels disponibles
Connectivité IP standard
Linux possède aussi d’autres atouts très importants pour les systèmes embarqués :
Portage sur porcesseurs autres que x86 : PowerPC, ARM, MIPS, 68K, ColdFire, NIOS,
MicroBlaze…
Taille du noyau modeste compatible avec les tailles de mémoires utuilisées dans un système
embarqué (<1 Mo)
Différentes distributions proposées suivant le domaine : routeur IP, PDA, téléphone…
Support du chargement dynamique de modules qui permet d’optimiser l’empreinte
mémoire du noyau
Migration rapide et en douceur pour un spécialiste Linux à Linux embarqué; ce qui réduit
les temps de formation (et les coûts…)
Le noyau Linux Vanilla est un noyau non temps-réel qui a les caractéristique suivante :
Open source : gratuit
Fiable pour les systèmes embarqués
Bonnes performances
Bonne portabilité
Il ne s’agit pas d’un noyau Temps Réel car il possède de longues sections de code où tous les
évènements extérieurs sont masqués (non interruptibles). De plus, le noyau Linux n’est pas
préemptible durant toute l’exécution d’un appel système (structure monolithique) par un
processus et ne le redevient qu’en retour d’appel système (mode user). Il n’est pas non plus
préemptible durant le service d’une interruption ISR (Interrupt Sub Routine).
L’ordonnanceur de Linux essaye d’attribuer de façon équitable le CPU à l’ensemble des
processus (ordonnancement de type “old aging” mise en œuvre pour favoriser l’accès CPU aux
processus récents). C’est une approche égalitaire.
Dans un système, le rôle de l’ordonnanceur est d’assurer aux utilisateurs un temps de
réponse moyen acceptable. Ceci signifie un temps de réponse compris entre deux temps critiques.

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 5
Figure 1. Comparaison TR et non TR
Cependant nous pouvons observer certaines limites en terme d’ordonnancement. Il y a
l’apparition de retard causés par :
Le temps de latence d’une interruption
Le temps de traitement de la routine d’interruption (ISR)
Le temps de latence de l’ordonnanceur
Le temps de traitement de l’ordonnanceur
Figure 2. Gestion du temps (avec retards)
Cependant cette approche égalitaire peut être dangereuse et critique dans certaines
applications de l’embarqué tel que dans l’aérospatiale où il faut que les tâches les plus prioritaires
se déclenchent avant les autres.
Afin d’avoir un noyau Linux Temps Réel, il faut que le temps, entre le moment où une
interruption est détectée et le moment où nous ordonnons une autre tâche, soit compris dans un
intervalle de temps ciblé.
C’est pourquoi des patchs tels que Xenomai ou Premmpt-RT sont utilisés afin qu’un noyau
Linux devienne un noyau Temps Réel. Nous détaillerons ce concept dans la partie 2.

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 6
c. Carte Xilinx Virtex5
La carte sur laquelle nous avons travaillé et porté les différents noyaux Linux est la carte
FPGA PowerPC Virtex5 suivante :
Figure 3. Carte FPGA Xilinx Virtex5
Il s’agit d’une possédant un FPGA Virtex5 de chez Xilinx et un processeur PowerPC 440 de
chez IBM.
La carte ML507 possède les caractéristiques notables suivantes :
FPGA Xilinx Virtex5
1 Mo de mémoire SRAM
32 Mo de mémoire FLASH
Un port Ethernet
Un port RS232
Un port JTAG
Une interface USB maître/esclave
Nous nous sommes servis des trois ports cités ci-dessus afin de communiquer avec la carte

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 7
d. PowerPC 440
Le processeur présent sur la carte, et sur lequel nous avons donc travaillé, est le processeur
PowerPC 440 de chez IBM :
Figure 4. Processeur PowerPC 440
Le processeur possède les caractéristiques notables suivantes :
Processeur Hardcore
32 bits
Fréquence : 400 MHz
Coeur : PPC440
Flexible d’utilisation
Bonnes performances
Faible consommation d’énergie
MMU
Unité de gestion de données et d’instructions

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 8
2. Communication : PC hôte <-> Carte Xilinx ML507
L’environnement de travail de ce projet est constitué d’un PC host et de la carte Xilinx.
Toutes les manipulations et les configurations se font sur le PC hôte, pour ensuite être envoyées à la
carte.
La communication entre ces deux élément est assurée par :
Figure 5 : Schéma de communication
La Liaison Ethernet :
Ethernet est un protocole de réseau local à commutation de paquets, qu’on a utilisé principalement
pour stresser le noyau pour la mesure de performances à travers l’envoi de trams sous forme de
pings ( voir plus loin).
Pour utiliser la liaison Ethernet, il faut commencer par configurer le réseau via la commande:
ifconfig eth0 192.168.168.4.117
Le bus JTAG :
Le bus JTAG est un bus série synchrone composé des 5 signaux de contrôle suivants :
· TMS, (Test Mode Select) Signal d'activation de la communication JTAG,
· TCK, (Test ClocK) Horloge,
· TDI, (Test Data Input) Entrée des données,
· TDO, (Test Data Output) Sortie des données,
· TRST, (Test ReSeT) Réinitialisation. Ce signal optionnel est actif au niveau bas.
Ce bus sert essentiellement à faciliter et automatiser le test des cartes électroniques numériques.
Elle consiste à donner un accès auxiliaire aux broches d'entrée-sortie des composants numériques

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 9
fortement intégrés.
Cependant le JTAG n'est pas limité aux tests de continuité. Il est possible de tester des mémoires en
écrivant puis relisant des valeurs de test. Il est même possible de cette manière de programmer des
mémoires non-volatiles. Ainsi dans le cas de notre projet on utilisait le bus JTAG pour écrire dans la
RAM les données du RAM DISK, Cela se fait par la commande :
[Xilinx EDK] ./goml507
La configuration du noyau se fait sur le PC host pour ensuite être envoyé et finalement exécuté sur
la carte cible, ces manipulations se font grâce au deux logiciels : Uboot et Minicom
Uboot :
U-Boot n'est pas un BIOS (ou firmware) comme ceux que l'on trouve sur les PC, il s'apparente
davantage à un contrôleur. Il est basé sur le projet Open Source nommé U-Boot
(sourceforge.net/projects/u-boot). Il a été grandement amélioré par les frères Frieden et Andrea
Vallinotto avec certainement d'autres personnes de l'équipe AmigaOS 4.
Le rôle de U-Boot est d'initialiser le matériel et de lancer le processus de démarrage du système.
Minicom :
C’est un programme de contrôle de modem et d'émulation de terminal pour les Unix-like. Il peut
être comparé à HyperTerminal dans Windows. Ce programme a été écrit par Miquel van
Smoorenburg d'après le populaire Telix pour MS-DOS. Minicom apporte une émulation totale ANSI
et VT100, un langage de script externe, et d'autres choses encore
Pour ouvrir la fenêtre « mincom » il suffit de taper la commande minicom dans le terminal.
3. Noyaux patchés Xenomai et Preempt-RT
Ce n'est pas que Linux n'est pas rapide ou efficace, mais dans certains cas la rapidité n’est
pas suffisante. Ce qu'il faut plutôt, c'est la capacité de répondre de façon déterministe aux délais
d’ordonnancement avec des tolérances spécifiques. Nous allons voir différentes solutions
permettant d’obtenir un noyaux Linux temps réel et la façon dont ils atteignent le temps-réel en
étudiant les deux patchs qui nous intéressent dans ce projet, à savoir Xenomai et Preemp-RT.

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 10
a. Concept Temps-Rèel
La définition suivante de temps réel prépare le terrain afin de discuter des différentes
architectures temps réel existantes. Cette définition provient de Donald Gillies dans le temps réel
Computing FAQ:
“Un système temps réel est celui dans lequel l'exactitude des calculs dépend non seulement de la
correction logique du calcul, mais aussi sur le moment où le résultat est produit. Si les contraintes
de temps du système ne sont pas remplies, une défaillance du système aurait eu lieu.”
En d'autres termes, le système doit être déterministe pour garantir un comportement de
synchronisation lors d’une phase de variation du système d’exploitation (du cas le moins important
au pire cas). Notons que la définition ci-dessus ne parle pas de la performance, parce que le temps
réel n'est pas une question de vitesse: il s'agit de la prévisibilité.
Par exemple, en utilisant un processeur moderne rapide, Linux peut fournir une réponse
typique d'interruption de 20μs, mais parfois la réponse peut être beaucoup plus longue. C'est le
problème fondamental: ce n'est pas que Linux n'est pas rapide ou efficace, c'est juste qu’il n'est pas
déterministe.
Quelques exemples montreront ce que tout cela signifie. La figure 6 ci-après illustre la
mesure de la latence d'interruption.
Figure 6. Mesure du temps de réponse
Quand une interruption arrive , le CPU est interrompue et commence le traitement des
interruptions. Une certaine quantité de travail est effectué pour déterminer quel événement a eu
lieu et, après un temps de travail, la tâche requise est envoyé pour faire face à l'événement (c’est un
“changement de contexte” ). Le délai entre l'arrivée de l'interruption et l'expédition de la tâche

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 11
requise (en supposant que c'est la tâche la plus prioritaire à l'expédition) est appelé le temps de
réponse. En temps réel, le temps de réponse doit être déterministe et le délai dans le pire cas doit
être connu.
Un exemple utile de ce procédé est l’airbag dans véhicules d'aujourd'hui. Lorsque le capteur
qui fait état d'une collision du véhicule interrompt le CPU, le système d'exploitation doit envoyer
rapidement la tâche qui déploie le coussin gonflable plutôt que de laisser le traitement d’une tâche
en temps non réel intervenir. Un coussin gonflable qui se déploie une seconde plus tard que prévu
est plus acceptable qu’un coussin qui ne se déploie pas du tout.
Le concept de temps-réel peut être divisé en deux approches différentes:
- Un système d'exploitation qui peut supporter les délais voulus des tâches en temps réel est
appelé un système en temps réel dur. Mais ce temps réel dur n'est pas nécessaire dans tous les cas.
- Si un système d'exploitation peut prendre en charge les délais en moyenne, il est appelé un
système temps réel souple.
Les systèmes à temps réel durs sont ceux dans lesquels, manquer une échéance peut avoir
un résultat catastrophique (comme le déploiement d'un coussin gonflable trop tard). Les systèmes
à temps réel souples peuvent manquer des délais sans que l’ensemble du système ne soit perturbé
(comme la perte d'une image de la vidéo par exemple).
Maintenant que nous avons un aperçu des exigences du temps réel, regardons quelques-
unes des architectures temps réel Linux.
b. Patch Xenomai
L'histoire de Xenomai est un peu tumultueuse. L'explication de M. Franke établit une synthèse et un
« arbre généalogique » très clairs auquel le lecteur pourra se reporter.
Xenomai est un système d'exploitation temps réel qui a Linux pour tâche de fond. Linux est
alors préempté comme une simple tâche. Les tâches gérées par Xenomai apportent ainsi une
garantie d'exécution temps réel dur. Qui dit deux systèmes d'exploitation, dit deux ordonnanceurs
et au moins deux problèmes : comment partager le matériel, et comment faire interagir les tâches
Linux et Xenomai entre-elles.
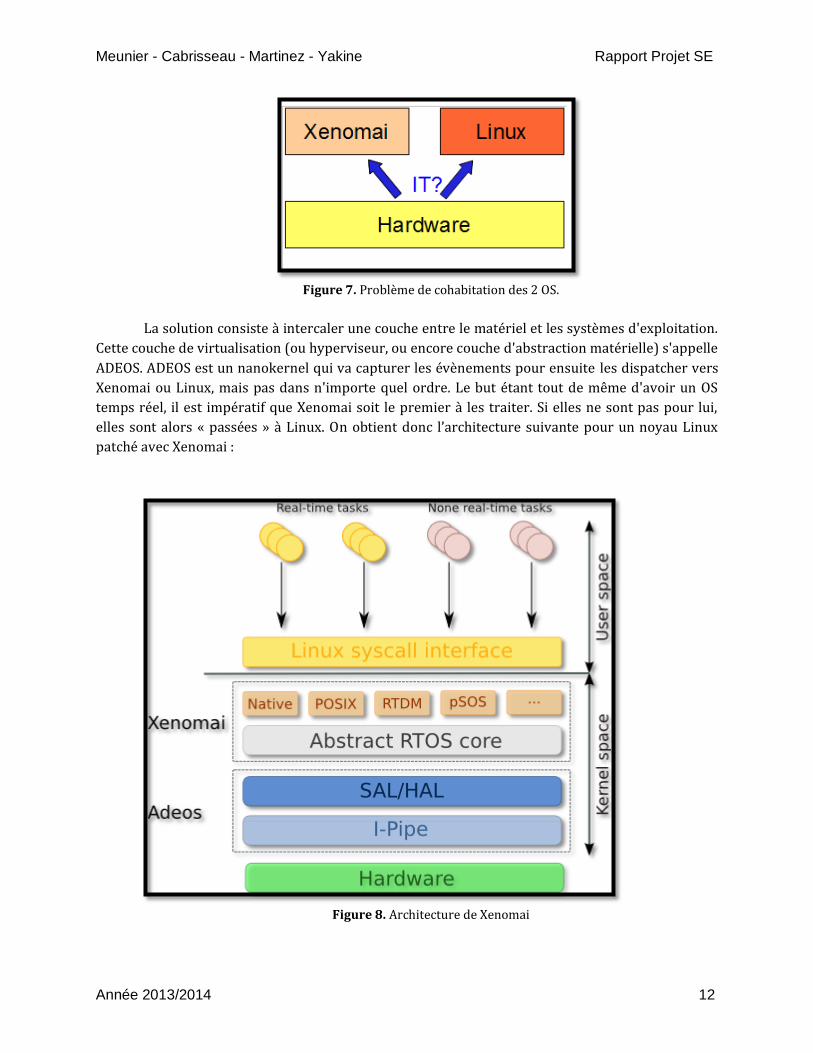
Comment alors faire cohabiter ces deux OS sur le même matériel ? Pour l'accès au CPU et à
la mémoire, il n'y a pas de problème car Linux est une tâche. Mais si une interruption (timer,
carte…) arrive, qui va la traiter ? La figure 7 illustre ce problème :
Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 12
Figure 7. Problème de cohabitation des 2 OS.
La solution consiste à intercaler une couche entre le matériel et les systèmes d'exploitation.
Cette couche de virtualisation (ou hyperviseur, ou encore couche d'abstraction matérielle) s'appelle
ADEOS. ADEOS est un nanokernel qui va capturer les évènements pour ensuite les dispatcher vers
Xenomai ou Linux, mais pas dans n'importe quel ordre. Le but étant tout de même d'avoir un OS
temps réel, il est impératif que Xenomai soit le premier à les traiter. Si elles ne sont pas pour lui,
elles sont alors « passées » à Linux. On obtient donc l’architecture suivante pour un noyau Linux
patché avec Xenomai :
Figure 8. Architecture de Xenomai

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 13
Afin de faire face aux évènements, on utilise aussi le principe de pipeline appelé I-Pipe
(pour Interrupt-Pipe). Chaque événement traité par I-Pipe est traité à l'égard de leur priorité,
sachant que Linux est une tâche de priorité inférieure pour Xenomai.
c. Patch Preempt-RT
Linux-rt (où RT signifie en anglais « Real Time », littéralement « temps réel ») est une
branche du noyau Linux initiée par Ingo Molnar dans le but de répondre aux contraintes d'un
système temps réel. L'application du patch officiel PREEMPT-RT sur le noyau Linux standard lui
confère des fonctionnalités temps réel. Il ne fait que modifier le fonctionnement du noyau standard
sans ajouter un second noyau ou une couche de virtualisation temps réel, pas comme Xenomai.
Son fonctionnement est également très simple. Il rend préemptible la majeure partie du
code du noyau, notamment les sections critiques et les gestionnaires d’interruptions. Grâce à cela,
les tâches se voient attribuer une priorité, et les tâches de haute priorité peuvent prendre la main
sur celle de moindre priorité. Il modifie également certains mécanismes pour réduire les temps de
latences induits par le fonctionnement du système. Ce patch met aussi en place un mécanisme de
protections contre le problème connu sous le nom d'inversion de priorité par l'utilisation de
sémaphore à héritage de priorité.
II. Travaux Pratiques
1. TP0 : Prise en main de l’environnement
But : Mise en œuvre du système d’exploitation Linux embarqué Vanilla sur le processeur PowerPC
440 de la carte ML507.
Nous allons voir comment compiler le noyau Linux embarqué (Vanilla) avec son RAM Disk exécuté
par le PowerPC de la carte cible.
Nous adopterons les conventions suivantes :
Commande Linux PC hôte pour le développement croisé :
host% commande Linux
Commande Linux PC hôte pour le développement Xilinx :
[Xilinx EDK]$

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 14
Commande Linux embarqué sur la carte cible ML507 :
root#
• On démarre le PC sous Linux. Puis on se connecte sous le nom guest, le mot de passe est : guest.
• On se crée un répertoire de travail à son nom et on s’y place :
host% cd
host% mkdir mon_nom
host% cd mon_nom
Etablir le schéma de l’environnement de développement :
- Matériels.
- Liaisons : série, réseau…
- Logiciels et OS utilisés.
On se connecte à la carte cible ML507 en utilisant l’outil minicom en utilisant une autre fenêtre de
terminal. Ce terminal nous permettra d’interagir avec le système Linux embarqué exécuté par le
processeur PowerPC de la carte cible ML507.
Pour sortir du minicom, il suffit de taper la combinaison de touches : CTRL A, Z pour
accéder au menu et taper q pour quitter.
Procédure à suivre:
Dans son répertoire à son nom, recopier le fichier tp-ml507-ppc-linux.tgz sous
présent dans le répertoir de l’enseignant:
host% cp /home/kadionik/tp-ml507-ppc-linux.tgz .
Décompresser et installer le fichier tp-ml507-ppc-linux.tgz. Il faudra au
préalable se connecter comme superutilisateur car la décompression du fichier tpml507-ppc-
linux.tgz crée des points d’entrée de périphériques dans le système de fichiers root (sous /dev) qui
sera ensuite utilisé par le noyau Linux embarqué pour la carte cible ML507 :
host% su
host# tar –xvzf tp-ml507-ppc-linux.tgz
host# exit
host%

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 15
Puis on se place dans le répertoire ml507-ppc-linux/. L’ensemble du travail sera
réalisé à partir de ce répertoire ! Les chemins seront donnés par la suite en relatif
par rapport à ce répertoire...
host% cd ml507-ppc-linux
On compile le noyau Linux pour la carte cible ML507. Que fait le shell script go ?
host% cd linux
host% ./go
On télécharge par le JTAG le fichier de programmation ml507.bit du circuit FPGA
Virtex-5 de la carte cible ML507. Que fait le shell script load-design ?
host% cd ml507-ppc-linux
host% mbsdk
[Xilinx EDK]$ ./load-design ml507
Télécharger par le JTAG le fichier noyau Linux avec son RAM disk dans la RAM de la carte cible
ML507 puis lancer le noyau Linux embarqué. Que fait le shell script goml507 ?
[Xilinx EDK]$ cd ml507-ppc-linux
[Xilinx EDK]$ ./goml507
Réponses aux questions:
Que fait le shell script go ?
On cross-compile (on crée l’exécutable) le noyau Linux pour la carte cible ML507. En effet cette
cross-compilation permet de passer d’une architecture x86 (PC hôte) à l’architecture powerpc pour
la carte ML507.
Que fait le shell script load-design ?
Il charge dans l’environnement Xilinx le fichier de programmation qui configure les périphériques
de la carte Xilinx.
[Xilinx EDK] : développement Xilinx

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 16
Figure 9 : Commande load-design
Que fait le shell script goml507 ?
Il permet de télécharger le fichier compilé du noyau Linux dans la carte cible.
Figure 10 : Commande goml507
Synthèse : On a compilé puis téléchargé dans la carte cible le noyau Linux Vanilla grâce au fichier
de programmation ml507bit.

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 17
2. TP1 : Application « Hello Wordl ! »
Nous allons rajouter une application dans le RAM disk utilisé par le noyau
Linux embarqué exécuté par le processeur PowerPC de la carte cible ML507.
Se placer dans le répertoire ml507-ppc-linux/ :
host% cd ml507-ppc-linux
Se placer ensuite dans le répertoire tst/hello/ et modifier le fichier hello.c afin de
créer le fameux « Hello World! » :
host% cd tst/hello
host% gedit hello.c
Compiler l’application hello pour la carte cible ML507. Que fait le shell script go ?
host% ./go
Installer l’application hello dans le système de fichiers root qui servira de base au RAM
Disk. Que fait le shell script goinstall ?
host% ./goinstall
Se placer dans le répertoire ramdisk/ pour regénérer le RAM disk. Le système de
fichiers root est sous root_fs/ et notre application hello a été précédemment copiée
sous root_fs/bin/ :
host% cd ml507-ppc-linux
host% cd ramdisk
host% ls root_fs/bin
Régénérer le RAM disk. Il faudra le faire en étant superutilisateur pour l’utilisation du
périphérique /dev/loop. Que fait le shell script goramdisk-16M ?
host% su
host# ./goramdisk-16M
host# exit
host%

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 18
Installer le nouveau RAM disk pour qu’il soit utilisé lors de la prochaine compilation du
noyau Linux. Que fait le shell script goinstall ?
host% ./goinstall
Recompiler le noyau Linux pour la carte cible ML507. Que fait le shell script ./go?
host% cd ml507-ppc-linux
host% cd linux
host% ./go
Réponses aux questions
*************************Fichier hello.c***************************
#include <stdio.h> #include <stdlib.h> int main () { printf("Hello World!"); return 0; }
Que fait le shell script ./goinstall ?
Il copie l’application « hello » dans le répertoire root_fs (répertoire de la machine qui regroupe le
systèmes de fichiers root, base pour le RAM disk, qui sont présents dans le noyau Linux).
Figure 11: Commande goinstall

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 19
Que fait le shell script goramdisk-16M ?
On regénère le RAM disk avec la nouvelle application « hello » pour qu’il sache qu’elle est dans le
répertoire root_fs.
Figure 12 : Commande goramdisk-16M
Que fait le shell script goinstall ?
Il installe les applications dans le répertoire RAM disk (dans le répertoire dans lequel on se trouve).

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 20
Figure 13: Commande goinstall
Que fait le shell script ./go?
Le shell script permet de recompiler le noyau Linux afin que le nouveau RAM Disk contenant
l’application soit prise en compte.
Enfin, on télécharge de nouveau le noyau Linux compilé dans la carte cible à l’aide de ./goml507 et
on tape l’application hello : Hello World ! (application que l’on appelle à partir de la carte cible à
l’aide du minicom).
Figure 14 : Commande go
Synthèse : On a donc importé une application « hello » dans le noyau Linux que l’on a téléchargé
dans la carte cible. On a exécuté cette application directement à partir de la carte à l’aide du
minicom.
3. Portage du noyau Linux Vanilla
Le but de ce TP est de réaliser une mesure de performances à l’aide de l’outil cyclictest. Etude

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 21
menée pour un noyau Vanilla non chargé puis chargé.
Le cyclictest permet de mesurer les temps de latence entre deux threads périodique. La valeur
pertinente à étudier est la valeur maximale donnant le temps de latence maximum. on peut alors
juger de l’efficacité du système d’exploitation selon la contrainte.
L’outil stress permet de chargé le noyau en consommant le temps processeur.
Le ping permettra de stresser d’avantage le noyau en générant des interruptions.
Procédure à suivre:
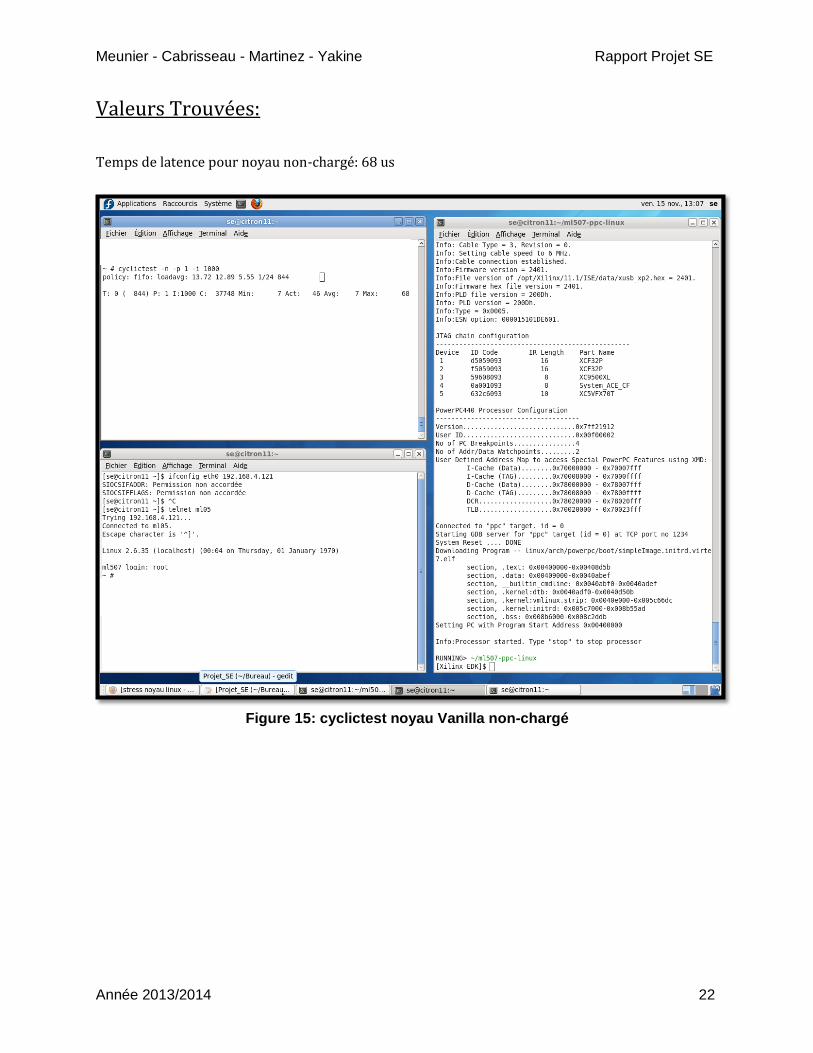
Relever les temps latence entre les threads pour le noyau Vanilla non-chargé:
root # cyclictest -n -p 99 -i 1000
Donner la signification des arguments passés en paramètres.
On va maintenant charger le noyau via un autre terminal en utilisant la commande stress.
Pour se faire on doit se connecter à la carte à partir d’un nouveau terminal (Penser à vérifier
la configuration réseaux avec la commande ifconfig).
host% telnet ml05
ml507 login: root
Charger le noyau et relever la nouvelle valeur donnée par le cyclictest
root # stress -c 20 -i 20
Donner la signification des arguments passés en paramètres.
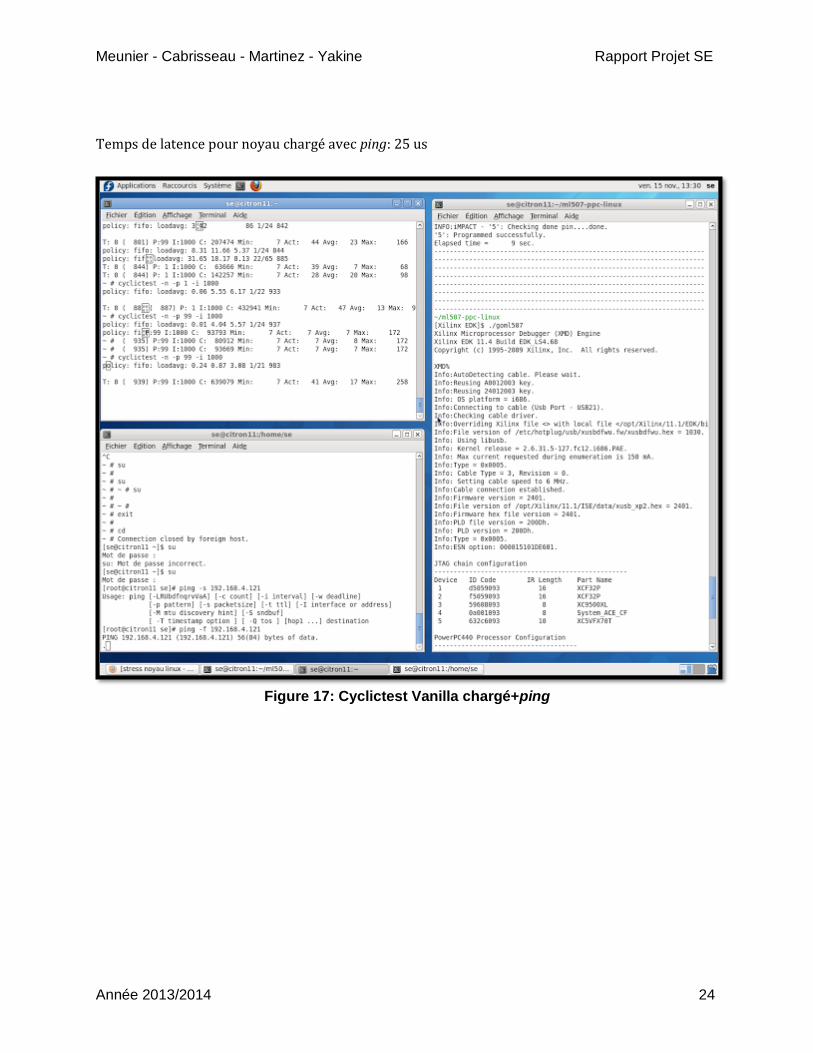
Nous allons utiliser la commande ping afin de stresser d’avantage le noyau.
host% ping -s @IP_carte_cible
Relever la nouvelle valeur du cyclictest.
Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 22
Valeurs Trouvées:
Temps de latence pour noyau non-chargé: 68 us
Figure 15: cyclictest noyau Vanilla non-chargé

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 23
Temps de latence pour noyau chargé: 155us
Figure 16: Cyclictes noyau Vanilla chargé
Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 24
Temps de latence pour noyau chargé avec ping: 25 us
Figure 17: Cyclictest Vanilla chargé+ping

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 25
4. Portage du noyau Linux Xenomai
Dans cette partie nous allons mettre en place un noyau Linux Xenomai. Le patch Xenomai est à
télécharger sur Internet selon la version du noyau Vanilla utilisé.
Si les sources Xenomai ne sont pas dsponibles dans le répertoire du travail, récupérer les sources
Xenomai compatible avec la vesion de vanilla utilisé et eavleec processeur powerPC sur ,le site :
http://download.gna.org/xenomai/stable/
Puis les décompresser par la commande :
host% tar –xvjf fichier.tgz
Maintenant on passe à l’application du patch ADEOS pour powerPC aux sources du noyau Vanilla :
Etablir le lien symbolique pour la bonne version de Xenomai :
host% ln -s linux -2.6.35-xenomai/ linux
Vérifier bien que le fichier “ipipe” se situe dans le fichier “goppc -ipipe-2.6.35”
host% grep -r ipipe kernel
Cross-compilez le « ipipe » :
host% ./goppc-ipipe-2.6.35
Se placer en mode super utilisateur puis copiez le fichier de cross compilation « goinstall » dans le
répertoire « goppc-xenomai »
host% su
host% cp goppc-xenomai goinstall
Exécuter le fichier généré lors de la compilation
host% ./goinstall
Recompilez le noyau Linux afin que le nouveau RAM disk soit utilisé :
host% ./go (dans le répertoire linux de ml507… )
Charger le noyau linux compilé dans la carte cible :

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 26
host% cd ml507-ppc-linux
host% mbsdk
[Xilinx EDK] ./goml507
Dans un terminal accéder à l’outil minicom en tapant et vérifier le chargement du noyau patché.
Vous remarquerez la présence d’un ensemble d’outil de test que nous allons exploiter pour faire les
mesures de performances.
Se placer dans répertoire usr/xenomai/bin puis relever les temps latence entre les threads pour le
noyau Xenomai non-chargé:
host% cd /usr/xenomai/bin
root # cyclictest -n -p 99 -i 1000
Figure 18: Cyclictest Xenomai non-chargé
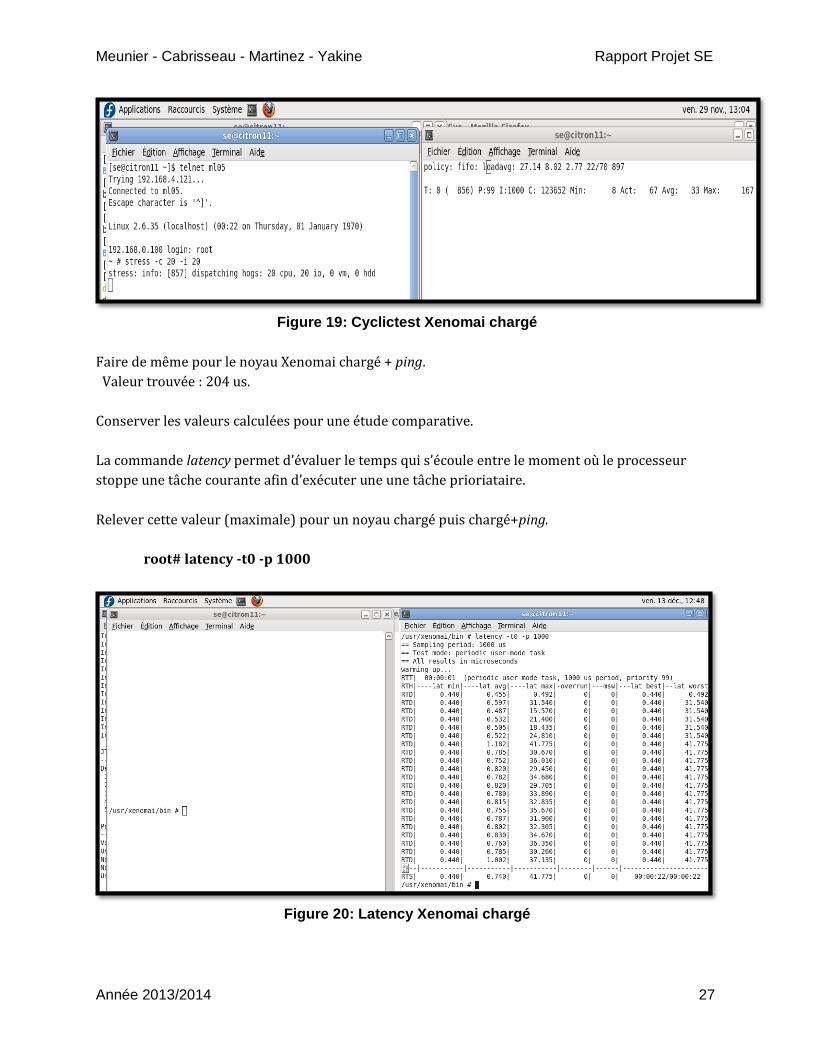
Faire de même pour le noyau Xenomai chargé. Utiliser l’outil stress à partir d’un autre terminal et en
agissant via la liaison Ethernet..
host% telnet ml507
root# stress –c 20 –i 20
Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 27
Figure 19: Cyclictest Xenomai chargé
Faire de même pour le noyau Xenomai chargé + ping.
Valeur trouvée : 204 us.
Conserver les valeurs calculées pour une étude comparative.
La commande latency permet d’évaluer le temps qui s’écoule entre le moment où le processeur
stoppe une tâche courante afin d’exécuter une une tâche prioriataire.
Relever cette valeur (maximale) pour un noyau chargé puis chargé+ping.
root# latency -t0 -p 1000
Figure 20: Latency Xenomai chargé

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 28
Figure 21 : layency Xenomai chargé + ping
Expliquez et commentez les valeurs mesurée.
Synthèse:
Nous avons pu voir la mise en œuvre du noyau Xenomai. L'application du patch Xenomai sur les
sources du noyau Linux Vanilla permet de réaliser du Temps Réel dur et d'avoir des temps de latence
bornés de quelques dizaine de µs même en cas de très forte charge du système.
5. Portage du noyau Linux PREEMPT-RT
Dans cette partie nous allons appliquer le patch PREEMPt-RT aux sources du noyau Vanilla, a fin de
modifier les fichiers sources d'origine pour leur appliquer des corrections et/ou des modification
capables de faire du temps réel mou.
On commence par télécharger la dernière version du patch preempt-rt
« patches - 3.10.24 - rt22.patch.bz2 ».
Créer un répertoire de travail.
host% mkdir Linux+PREEMPT-RT
Récupérer les sources du patch Preempt-RT associé au noyau depuis le site internet.

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 29
host% wget https://www.kernel.org/pub/linux/kernel/projects/rt/3.10/patches/-
3.10.24-rt22.patch.bz2 »
Décompresser le patch.
host% tar -xvjf patches-3.10.24-rt22.patch.bz2
Appliquez le le patch PREEMPT-RT aux sources du noyau
Host% cd linux-3.10.24
Host% patch -p1 < ../patch-3.10.24-rt22.patch
Créer le lien symbolique pour le noyau Preempt-RT.
Modifier les fichiers goconfig et godefconfig afin de cross-compiler pour une architecture
PowerPC 440 Virtex5. Puis lancer l’interface de configuration.
host% cat godefconfig (modifier le code)
Figure 22: fichier modifié godefconfig
host% cat goconfig (modifier le code)
Figure 23 : Fichier modifier goconfig
host% ./godefconfig
host% ./goconfig on lance le menu de configuration
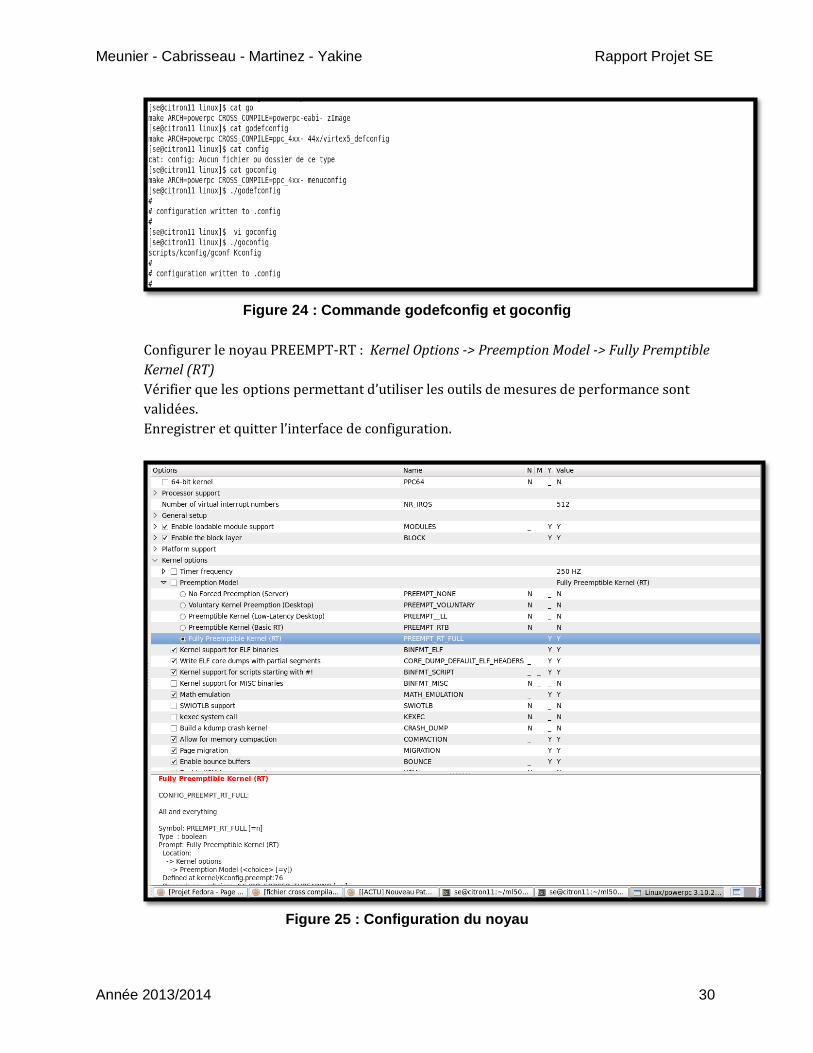
Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 30
Figure 24 : Commande godefconfig et goconfig
Configurer le noyau PREEMPT-RT : Kernel Options -> Preemption Model -> Fully Premptible
Kernel (RT)
Vérifier que les options permettant d’utiliser les outils de mesures de performance sont
validées.
Enregistrer et quitter l’interface de configuration.
Figure 25 : Configuration du noyau

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 31
Compiler alors le noyau PREEMPT-RT.
host% ./go
Figure 26: Commande go
Réaliser le portage de ce nouveau noyau Preempt-RT(Méthodologie vue en amont).
Dans le minicon vérifier le bon chargement du noyau PREEMT-RT et la présence des outils
de test.
Preemp-RT Noyau non-chargé Noyau chargé Noyau chargé + Ping
Cyclictest (us) 25 67 103
Preempt-RT Noyau chargé Noyau chargé+ Ping
Latency min
(us) 8.2 8.3
Latency max
(us) 41.3 105,2
Faire les mesures de latence pour un noyau chargé et chargé + ping. Comparer les résultats
obtenus.
Que déduire du patch PREEMT-RT ?
Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 32
Synthèse:
L'application de ce patch sur les sources du noyau Linux vanilla permet de faire du Temps Réel mou et
d'avoir des temps de latence de l’ordre d’une centaine de us. Le respect des contraintes temporelles
est important dans le cas d'applications spécifiques comme le traitement de flux multimédia et la
musique.
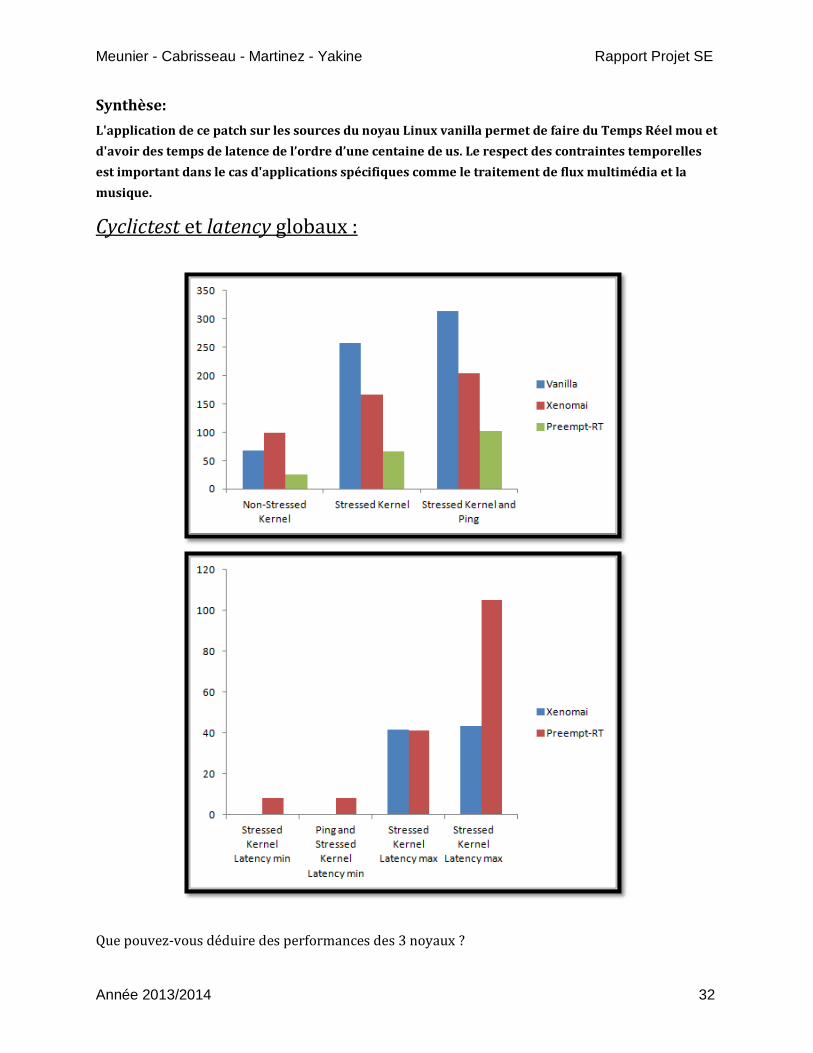
Cyclictest et latency globaux :
Que pouvez-vous déduire des performances des 3 noyaux ?

Meunier - Cabrisseau - Martinez - Yakine Rapport Projet SE
Année 2013/2014 33
III. Conclusion
Ce projet fût l’occasion de réaliser différents portages de systèmes d’exploitation. Nous avons alors
pu apprendre la méthodologie à suivre afin d’embarquer ces systèmes sur le support fourni. Nous
avons de plus eu une réelle approche de ce que nous pouvions retrouver en terme de performances
selon que le noyau soit standard (Vanilla sans traitement Temps-Réel), à Temps-Réel Mou
(PREEMPT-RT) ou dur (XENOMAI).
Nous avons pu observer les vitesses de traitement par le processeur PowerPC 440 selon le système
embarqué. Il nous apparait que celui si met en exergue les spécificités liées aux 2 noyaux « RT »:
- Temps de latence chez Xenomai d’une dizaine de us
- Temps de latence chez Preempt-RT d’une centaine de us
L’ordonnancement veut alors que le noyau Xenomai traite bien plus vite les sollicitations externes
(contraintes dures) dans 100% des cas
Cependant les valeurs faibles de cyclictest dans le cas de l’étude du noyau Preempt-RT indique que
celui-ci optimise le déclenchement des processus (threads) pour le traitement de tâche. Le
caractère préemptible est bien marqué.
Ainsi, à travers la rédaction des TP qui pourront servir de base aux prochains élèves nous avons pu
analyser le comportement du processeur PowerPC en embarquant différents type de système
d’exploitation. Au vue des résultats, nous pouvons conclure que celui-ci est adapté au traitement
temps réel dur comme mou.
D’autres tests auraient sûrement permis d’arriver à ces conclusions (jitter, timer….) et une
progression plus rapide dans le projet nous aurait peut être laissé le temps de réaliser une étude
similaire avec un processeur ARM.