projet d’econometrie - the financial engineer première partie de projet 1. introduction 2....
TRANSCRIPT

2010
M1 IEF
PROJET D’ECONOMETRIE
LE MODELE DE RENTABILITE
A TROIS FACTEURS
DE
FAMA ET FRENCH(1993)
KUNAL TAYLAN

RESUME
De récents travaux ont montré le rôle de variables "fondamentales" (taille, ratio valeur
comptable/valeur de marché ) dans l'explication de la rentabilité des titres.
Fama et French (1993) proposent un modèle à trois facteurs (bêta, HML, SMB) pour expliquer
ces observations.
Dans ce test du modèle de Fama et French (1993) sur le marché américain, l'explication de la
rentabilité des titres dépend négativement du facteur lié à la taille et positivement du ratio
VC/VM. Toutefois, le facteur de marché reste la variable explicative la plus significative.

Sommaire
Première partie de projet
1. INTRODUCTION
2. EXPLICATION DE LA RENTABILITE DES TITRES AVEC UN MODELE MULTIFACTORIEL
2.1. Ratio valeur comptable/valeur de marché et rentabilité des titres, capitalisation boursière
2.1.1. L’effet taille et la rentabilité des titres
2.1.2. L’effet ratio VC/VM et la rentabilité des titres
2.2. Le modèle Fama et French
3. PRESENTATION DES DONNEES ET CONSTRUCTION DES VARIABLES
3.1. Le méthode de calcul des données financières
3.2. Le méthode de calcul des données comptables
3.3. Les variables explicatives: Rm-Rf, SMB et HML
3.4. Les variables expliquées: Six portefeuilles de titres classés par taille et ratioVC/VM
3.5. Le choix de la variable expliquée pour la Partie 1 du projet
4. LE MODELE DE RENTABILITE A TROIS FACTEURS DE FAMA ET FRENCH
5. CONCLUSION

Introduction
Les premiers tests empiriques du Modèle d’Evaluation Des Actifs Financiers (Médaf), au début des
années 70, ont pu laisser croire que le Médaf et l'efficience des marchés financiers au sens de Fama
(1970) fournissaient un cadre théorique capable d'expliquer la rentabilité des titres.
Le Médaf nécessite de construire un portefeuille prenant en compte tous les investissements
possibles sur la planète (actions, obligations, objets d'art, immobilier…).
Les tests du Médaf constituent donc des tests conjoints de l'efficience ex ante du portefeuille retenu
comme portefeuille de marché et du Modèle d'Evaluation Des Actifs Financiers.
L'observation empirique d'anomalies dans les rentabilités des titres contredisant le Médaf représente
une deuxième remise en cause essentielle du modèle qui postule notamment que le coefficient bêta
suffit à décrire les rentabilités espérées en coupe transversale. Ainsi, certaines données fondamentales
liées aux titres présentent un pouvoir explicatif des rentabilités complétant le bêta, en contradiction
avec la théorie du Médaf.
L'objet de cette étude est de tester la capacité explicative du modèle à trois facteurs de Fama et
French (1993) sur le marché américain des actions.

2. EXPLICATION DE LA RENTABILITE DES TITRES AVEC UN MODELE MULTIFACTORIEL
2 .1 Ratio valeur comptable/valeur de marché et rentabilité des titres, capitalisation boursière
2.1.1 L’effet taille et la rentabilité des titres
En 1981, Selon BANZ, la taille de l’entreprise, mesurée par sa capitalisation boursière renforce le Beta
pour expliquer les rentabilités des titres. En effet, par rapport à l’estimation de leur Beta, les rentabilités
moyennes des petites capitalisations sont trop élevées par rapport aux celles des grandes capitalisations qui
sont trop faibles.
Chan et Chen (1988) montrent une très forte corrélation entre la taille moyenne des titres de chaque
portefeuille et les estimations des coefficients de Beta de ces mêmes portefeuilles.
En France, Hamon (1986) observe une rentabilité des titres de faible capitalisation plus importante. Cette
anomalie serait liée à un effet liquidité du marché.
En 1992 Girerd Potin confire une plus forte rentabilité de pf de petites firmes.
La mesure de la taille par la capitalisation boursière repose sur le cours. L’évaluation du cours d’un titre reposant
sur l’actualisation de ces flux futurs et le taux d’actualisation étant lié au risque, il est logique d'observer une plus
grande rentabilité des titres sous-évalués. Berk met en évidence l'une des difficultés des recherches empiriques sur la
rentabilité des titres. La rentabilité des titres dépend directement de leur prix et de son évolution sur une période de
référence : Ri(t-1:t) =
, avec Ri(t-1; t) , rentabilité arithmétique du titre i sur la périodes (t-1,t) et
P it, cours du titre i à l’instant t.
2.1.2 L’effet ratio valeur comptable/valeur de marché et la rentabilité des titres
Fama et French (1991), sur le marché américain identifient le ratio VC/VM comme facteur explicatif
important des rentabilités: Les entreprises avec un ratio VC/VM élevée sont associées des rentabilités
espérées élevées. Ils démontrent que le ratio VC/VM est une variable explicative plus significative que la
variable taille.
Pour Daniel et Titman (1997), la rentabilité attendue d'un titre est déterminée par les caractéristiques de la
firme et non par des primes de risque.
On calcule le ratio VC/VM de la façon suivante:
VM=∑
[ ] Il existe une relation inverse entre rentabilité attendue et valeur de marché.
VM/VC = ∑
[ ] Relation négative entre la rentabilité et le ratio VM/VC.Inversement
une relation positive doit être observée entre le ratio VC/VM, et la rentabilité espérée des titres.

2.2 Le modèle à trois facteurs de Fama et French
Fama et French (1992, 1993), propose un modèle à trois facteurs qui corrige les défaillances du modèle
d’évaluation des actifs financiers Medaf. Le modèle à trois facteurs inclut le risque du marché (le bêta
utilisé dans le MÉDAF), et utilise également le risque relié à la taille et celui attribué au ratio VC / VM
pour mieux expliquer la variabilité des rendements des actions cotée sur le NYSE, l’AMEX et le
NASDAQ.
Selon ces auteurs, on aurait tendance à observer un risque plus élevé dans le cas des petites entreprises et
des entreprises de valeur (ratio VC / VM élevé) comparativement aux grandes entreprises et aux
entreprises de croissance (ratio VC / VM faible), ce qui amènerait les marchés financiers à requérir un
plus fort rendement en compensation.
L’équation du modèle à trois facteurs de Fama et French est la suivante :
( )
: Rendement excédentaire du portefeuille d’entreprise observées par rapport
au rendement sans risque Rft : Un mois de Bon du Trésor des Etats-Unis.
: Rentabilité du portefeuille de marché.
: Rentabilité du portefeuille basé sur la différence entre la rentabilité des titres de petite
capitalisation boursière et la rentabilité des titres de capitalisation boursière importante (SMB,
small minus big).
: Rentabilité du portefeuille basé sur la différence entre la rentabilité des titres avec un
ratio valeur comptable sur valeur de marché élevé et la rentabilité des titres avec un ratio valeur
comptable sur valeur de marché faible (HML, high minus low).
, , : Coefficients des primes de risque , et .

3. Présentation des données et construction des variables
La méthodologie de cette étude est adaptée de Fama et French (1993). Elle repose sur la construction de
portefeuilles de titres tant pour les variables expliquées que pour les variables explicatives fondamentales
(SMB, HML) et de marché (RM - Rf).
3.1 Les données financières
6 portefeuilles formés de taille et Book to market ratio:VC/VM
Rendements mensuels: Juillet 1980-Juin 2010 ( 360 obs)
Les données sont prises sur le site d’internet de Kenneth R. French. Les portefeuilles construits sont
l’intersection de 2 portefeuilles classée par leurs tailles (Small Capi, Big Capi) et 3 portefeuilles classés
par leur ratio de valeur comptable / valeur de marché (High,Neutral,Low).
Les portefeuilles construits de juillet de l’année t à Juin de l’année t+1 inclue tous les titres de NYSE,
d’AMEX et de NASDAQ.
Le placement à taux sans risque utilisé dans le modèle à trois facteurs, Rf, est le placement sur le marché
monétaire à 1 mois. Le taux sans risque retenu dans l'équation est donc le taux moyen mensuel de Bon du
Trésor.
3.2 Les données comptables
La taille de l'entreprise est représentée par sa capitalisation boursière (nombre de titres multiplié par le
cours de bourse). Le classement suivant la taille repose sur la capitalisation boursière des titres en juin t.
La capitalisation boursière de l'entreprise fin décembre t-1 est utilisée pour calculer le ratio valeur
comptable/valeur de marché (VC/VM). Le ratio VC/VM est égal à la valeur comptable des titres en
décembre t-1, divisé par la dernière cotation de décembre t-1. La capitalisation boursière correspond ici,
au nombre de titres multiplié par le dernier cours de décembre t-1.

3.3 Les variables SMB et HML
A la fin du mois de juin de l'année t, les titres de l’échantillon sont répartis en deux groupes (S
pour small et B pour big) suivant que leur valeur de marché en juin t est inférieure ou supérieure
à la valeur de marché médiane de l’échantillon. Indépendamment, les titres sont classés suivant
leur ratio VC/VM en décembre t-1, et répartis en trois groupes correspondant respectivement aux
trois premiers déciles (L pour low,), aux quatre déciles médians (M pour medium) et aux trois
derniers déciles (H pour high). Six portefeuilles (S/L, S/M, S/H, B/L, B/M, B/H) sont constitués
à l'intersection des deux répartitions précédentes. Les rentabilités sont calculées chaque mois de
juillet t à juin t+1.
a) Le portefeuille SMB construit pour reproduire le facteur de risque associé à la taille
correspond à la différence, calculée mensuellement, entre la rentabilité moyenne des trois
portefeuilles de valeur de marché faible (S/L, S/M, S/H) et la rentabilité moyenne des
trois portefeuilles de valeur de marché élevée (B/L, B/M, B/H).
SMB =1/3 (Small Value + Small Neutral + Small Growth) - 1/3 (Big Value + Big Neutral
+ Big Growth).
b) HML correspond à la différence, calculée mensuellement, entre la rentabilité moyenne
des deux portefeuilles de ratio VC/VM élevé (S/H, B/H) et la rentabilité moyenne des
deux portefeuilles de ratio VC/VM faible (S/L, B/L).
HML =1/2 (Small Value + Big Value) - 1/2 (Small Growth + Big Growth).
3.4 Les variables expliquées: Six portefeuilles de titres classés par taille et ratio VC/VM
Six portefeuille sont construits à l’intersection de deux répartitions ( taille et ratio VC/VM )
Nous avons six portefeuilles à expliquer, ce sont : SmallHigh,SmallMedium,SmallLow
BigHigh,BigMedium,BigLow

4. LE MODELE DE RENTABILITE A TROIS FACTEURS DE FAMA ET FRENCH
( )
Nous allons utiliser le modèle de régression multiple pour tester le modèle de rentabilité de Fama
et French (1993).
4.1 Données statistiques des variables explicatives
Tableau 1 :
Données statistiques des rentabilités mensuelles des variables Rm-Rf, SMB et HML de
07/1926 à 01/2009, 991 mois
Commentaire :
Le portefeuille de marché enregistre une rentabilité moyenne annuelle de 59% qui est supérieure
à celle des autres variables explicatives. Le portefeuille SMB a une rentabilité moyenne de 19% ,
qui est inférieure à celle de HML 48%: De plus cette rentabilité moyenne élevé est associée à un
écart type des rentabilités plus élevé.
Rm-Rf SMB HML
Moyenne 0.582 0.182 0.475
Ecart-type 5.45 3.34 3.575
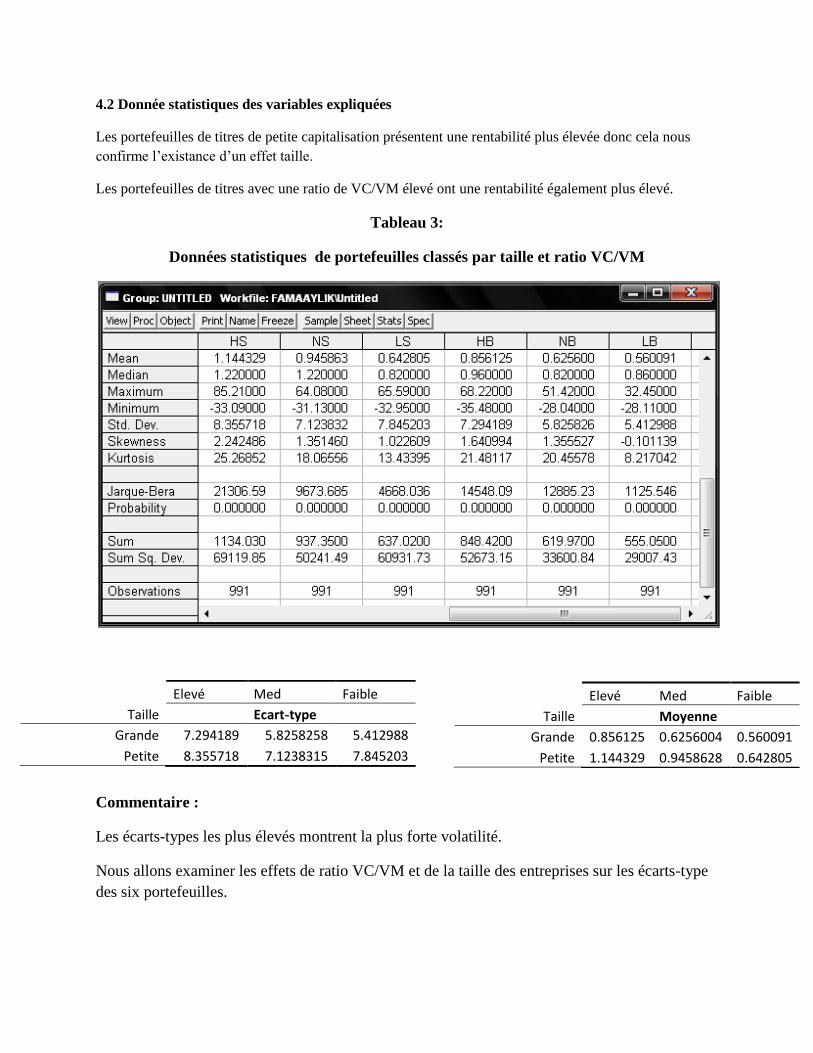
4.2 Donnée statistiques des variables expliquées
Les portefeuilles de titres de petite capitalisation présentent une rentabilité plus élevée donc cela nous
confirme l’existance d’un effet taille.
Les portefeuilles de titres avec une ratio de VC/VM élevé ont une rentabilité également plus élevé.
Tableau 3:
Données statistiques de portefeuilles classés par taille et ratio VC/VM
Commentaire :
Les écarts-types les plus élevés montrent la plus forte volatilité.
Nous allons examiner les effets de ratio VC/VM et de la taille des entreprises sur les écarts-type
des six portefeuilles.
Elevé Med Faible
Taille Ecart-type
Grande 7.294189 5.8258258 5.412988
Petite 8.355718 7.1238315 7.845203
Elevé Med Faible
Taille Moyenne
Grande 0.856125 0.6256004 0.560091
Petite 1.144329 0.9458628 0.642805

Graphique 1:
Projection des portefeuilles dans l’espace espérence de rentabilité mensuelle en excès
(Rm-Rf) /écart type des rentabilité en excès ( Rp-Rf )
Commentaire:
Le portefeuille SMB associe une rentabilité moyenne avec une variabilité faible. Les deux
portefeuilles (SH et SN ) de petits capitalisations ont des rentabilités plus important que les
entreprises avec la grande capitalisation. La ligne bleu signifie “ la Droite de Marché ”, au
dessus de cette droite nous avons des portefeuilles avec fortes rentabilités moyennes et au
dessous il se trouve des portefeuilles avec faible rentabilité moyennes.
Nous pouvons constater un effet lié au ratio VC/VM , les portefeuilles avec un ratio VC/VM
élevé ont également une rentabilités plus élevés et plus ils ont des ratios élevés plus ils sont
risqués.

4.5 Choix de la variable à expliquée pour la partie 1 du projet :
Durant cette partie 1 du projet, Nous allons travailler sur le portefeuille classé des titres de
grande capitalisation et une ratio VC/VM faible pour les raisons suivantes :
Le portefeuille LB se trouve sur la Droite de Marché, les portefeuilles qui sont en dessus
de cette droite ont des rentabilités moyennes plus élevés que les portefeuilles qui se
trouve au dessous de cette droite.
Le portefeuille (LB) a un écart-type moins élevé que les autres, cela signifie qu’il est le
moins volatile.
Le coefficient de détermination du portefeuille LB représente 97,7% . Le modèle de
régression de Fama et French explique 97 ,7% de la rentabilité du portefeuille classé
LB. C’est le portefeuille mieux expliqué entre ces 6 portefeuilles. (Selon la régression
que j’ai faite pour le projet d’économétrie 2009.)
Nous allons travailler pour la suite de projet avec la série désaisonnalisé « LBSA »

4.6 Description de l’allure graphique de la série « LBSA »
4.6.1 Evaluation graphique de la Stationnarité
Commentaire :
Au vue du graphique, on peut conclure qu’il s’agit d’un processus stationnaire, la moyenne et la variance
sont constants au cours du temps.
Le processus ne semble ni un processus DS ni TS , mais un bruit blanc. Dans cette étape on n’a pas
pouvoir de dire qu’il est un bruit blanc car un processus stationnaire n’est pas forcement un bruit blanc.
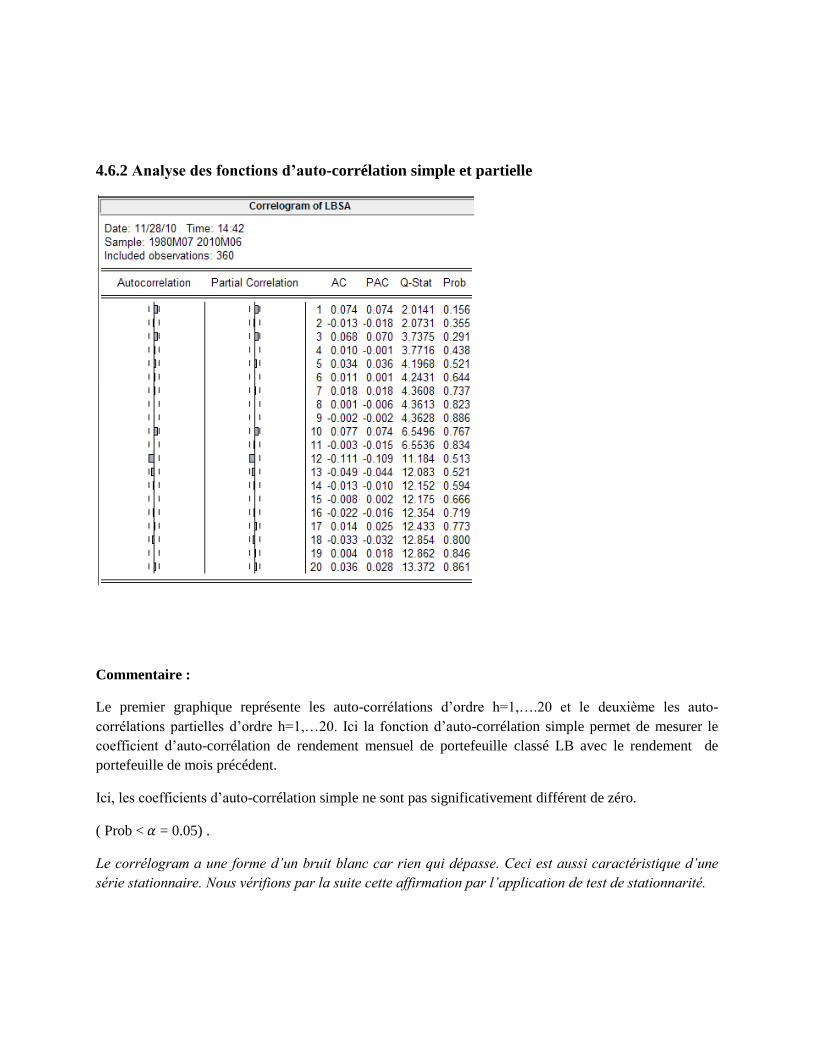
4.6.2 Analyse des fonctions d’auto-corrélation simple et partielle
Commentaire :
Le premier graphique représente les auto-corrélations d’ordre h=1,….20 et le deuxième les auto-
corrélations partielles d’ordre h=1,…20. Ici la fonction d’auto-corrélation simple permet de mesurer le
coefficient d’auto-corrélation de rendement mensuel de portefeuille classé LB avec le rendement de
portefeuille de mois précédent.
Ici, les coefficients d’auto-corrélation simple ne sont pas significativement différent de zéro.
( Prob < = 0.05) .
Le corrélogram a une forme d’un bruit blanc car rien qui dépasse. Ceci est aussi caractéristique d’une
série stationnaire. Nous vérifions par la suite cette affirmation par l’application de test de stationnarité.
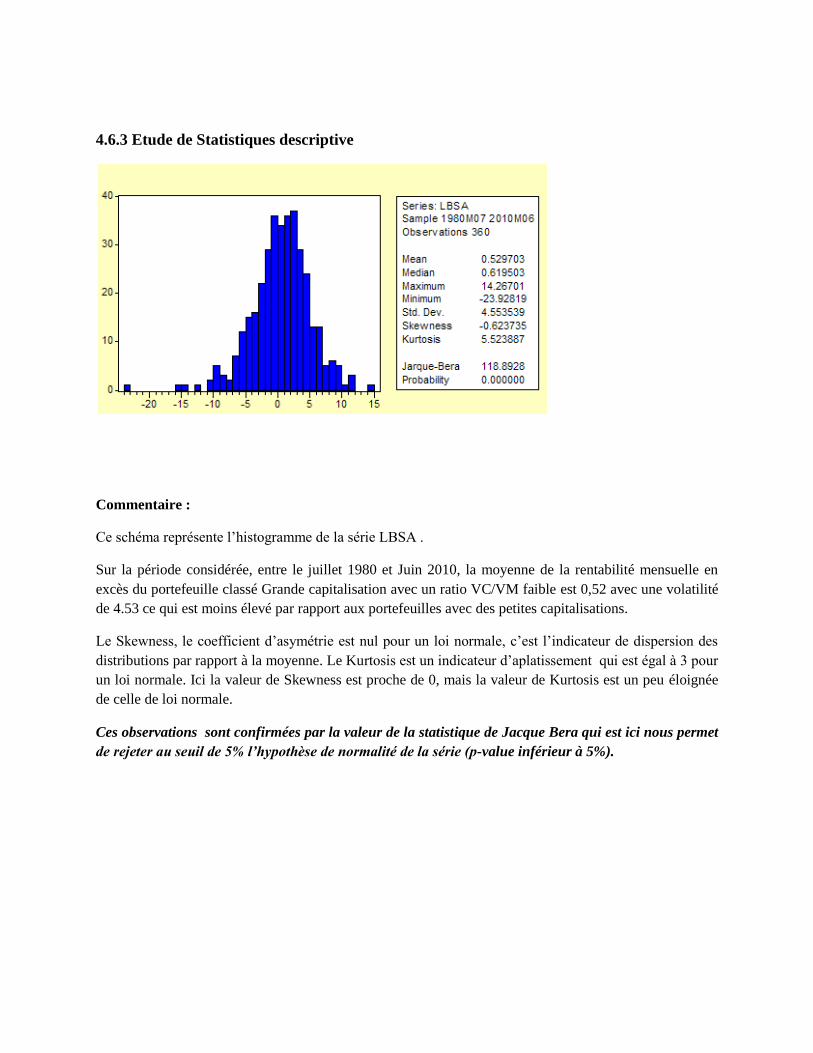
4.6.3 Etude de Statistiques descriptive
Commentaire :
Ce schéma représente l’histogramme de la série LBSA .
Sur la période considérée, entre le juillet 1980 et Juin 2010, la moyenne de la rentabilité mensuelle en
excès du portefeuille classé Grande capitalisation avec un ratio VC/VM faible est 0,52 avec une volatilité
de 4.53 ce qui est moins élevé par rapport aux portefeuilles avec des petites capitalisations.
Le Skewness, le coefficient d’asymétrie est nul pour un loi normale, c’est l’indicateur de dispersion des
distributions par rapport à la moyenne. Le Kurtosis est un indicateur d’aplatissement qui est égal à 3 pour
un loi normale. Ici la valeur de Skewness est proche de 0, mais la valeur de Kurtosis est un peu éloignée
de celle de loi normale.
Ces observations sont confirmées par la valeur de la statistique de Jacque Bera qui est ici nous permet
de rejeter au seuil de 5% l’hypothèse de normalité de la série (p-value inférieur à 5%).

5. Test de Stationnarité
Nous avons mis en évidence la stationnarité de la série par l’étude du corrélogramme. Nous allons utiliser
les tests de DF ( ou DFA) qui nous permet de détecter la non-stationnarité de processus et d’identifier la
nature de cette non stationnarité ( TS, DS ou AR(1) ).
La différence entre DF et DFA reste dans le nombre de retards p retenus. Si le Lag Length est égale à
zéro, alors nous allons faire le test de Dickey Fuller simple. Si p > 0 nous appliquons le test Dickey Fuller
augmenté.
5.1 Le choix du nombre de retards
Pourquoi de choisir un nombre de retard optimal est important ? : Inclusion d’un nombre insuffisant
de retards peut affecter le niveau du test tandis que l’introduction d’un nombre trop-élevé de retards réduit
le nombre de degrés de liberté et donc la puissance du test, c'est-à-dire qu’il y a un Racine unitaires alors
que notre processus est stationnaire.
Nous allons déterminer le nombre de retard p optimal par EViews qui calcule directement le p optimal :
En faisant les tests de racine unitaire par les critères d’Akaike (AIC) et de Schwartz (SIC), Eviews nous
indique p=0.
Nous allons faire le test de Dickey Fuller simple par la suite comme le nombre de retards optimal est zéro.
La procédure de test : On part du modèle le plus général (le modèle 3) (Trend and intercept). On y teste
la racine unitaire puis on vérifie par un test approprié que le modèle retenu est le bon, si on n’est pas dans
le bon modèle, on recommence dans un modèle plus contraint (le modèle 2), puis avec le model 1.

5.2 Test de Racine unitaire :
Etude du Modèle 3 :
On teste les hypothèses suivantes :
| |
Unit Root test sur Eviews :
Commentaire :
Calcul de DF test statistique manuellement :
t-Statistic = -17,552 < VC3 ≈ -3
Règle de décision ;
On rejette l’hypothèse nulle de racine unitaire, il n’existe pas de Racine unitaire donc le série est
stationnaire.
A fin de voir si le modèle 3 est un bon modèle, nous allons faire le test de student sur le paramètre
b du modèle pour voir s’il y a tendance.

Test de Student : Y a-t-il une tendance ?
| | | |
On ne rejette pas l’hypothèse H0 la nullité de b, donc le série n’a pas de tendance. On n’est pas dans le
bon modèle , nous allons continuer de faire le test DF avec le modèle plus contraint (modèle 2)
Etude du Modèle 2 sans tandance :
On teste les hypothèses suivantes :
| |
Unit Root test sur Eviews :

Commentaire :
t-Statistic = -17,5438 < VC2
Règle de décision ;
On rejette l’hypothèse nulle de racine unitaire, il n’existe pas de Racine unitaire donc la série est
stationnaire.
A fin de voir si le modèle 2 est un bon modèle, nous allons faire le test de student sur le paramètre
c du modèle pour voir s’il y a une constante dans mon modèle. ( toujours à droite du stratégie du
test)
Test de Student : Y a-t-il une constante ?
| | | |
On ne rejette pas l’hypothèse H0 la nullité de c, donc mon modèle 2 n’a pas de constante. On
n’est pas dans le bon modèle, nous allons continuer à faire le test DF avec le modèle plus
contraint (modèle 1).

Etude du Modèle 1 ni tendance ni constante :
On teste les hypothèses suivantes :
| |
Unit Root test sur Eviews :
Commentaire :
t-Statistic = -17,37 < VC1
Règle de décision ;
On rejette l’hypothèse nulle de racine unitaire, il n’existe pas de Racine unitaire donc le modèle 1
est stationnaire.
Il s’agit d’un processus stationnaire sans constante.
Nous allons vérifier la stationnarité de la série avec la procédure de test de Phillips-Perron.

5.4 Le test de Phillips Perron
Le test de Phillips et Perron est basé sur une modification non paramétrique des statistiques de
Dickey-Fuller pour prendre en compte l’auto-corrélation des résidus.
Nous allons utiliser les modèles 1 ,2 et 3 avec les mêmes hypothèses sauf les valeurs empiriques du t
Student sont corrigées.
La valeur de l définit le nombre de retards calculé par la règle de Newey West, est environ égale à :
[ (
)
]
Modèle 1, Modèle 2, Modèle 3
Conclusion :
La statistique de Phillips et Perron pour trois modèles est supérieure aux valeurs critiques.
On rejette l’hypothèse nulle de racine unitaire. Il s’agit bien d’un processus stationnaire.

6. Identification du modèle et Estimation des paramètres
Methodologie ( Box et Jenkins 1976)
On choisit le modèle ARMA dont les caractéristiques théoriques se rapprochent le plus des
caractéristiques des caractéristiques de la série observée (LBSA).
Nous allons étudier les corrélogrammes simple et partiel de la série.
Nous allons retenir le modèle qui satisfait ces trois conditions suivantes :
Les coefficients des paramètres sont tous significativement différents de zéro
Les polynômes d’opérateur de la partie AR ne possèdent pas de racine commune et son
module est inferieur à 1.
La probabilité critique de la statistique de Ljung-Box est supérieure à 0,05

6.1. L’Identification du Processus
Le corrélogramme de notre série LBSA est le suivant :
Les probabilités critiques sont tous supérieurs à 5% . On suppose que c’est un processus bruit
blanc non centré. La forme du corrélogramme nous indique également que le processus semble
d’être un bruit blanc comme rien qui dépasse.

Nous allons commencer à effectuer une régression sur ARMA(1,1)
Dependent Variable: LBSA
Method: Least Squares
Date: 11/22/10 Time: 23:39
Sample (adjusted): 1980M08 2010M06
Included observations: 359 after adjustments
Convergence achieved after 11 iterations
Backcast: 1980M07
Variable Coefficient Std. Error t-Statistic Prob.
C 0.477310 0.271150 1.760321 0.0792
AR(1) 0.535793 0.316766 1.691444 0.0916
MA(1) -0.477328 0.331768 -1.438742 0.1511
R-squared 0.007840 Mean dependent var 0.505775
Adjusted R-squared 0.002266 S.D. dependent var 4.537175
S.E. of regression 4.532031 Akaike info criterion 5.868539
Sum squared resid 7311.994 Schwarz criterion 5.900990
Log likelihood -1050.403 F-statistic 1.406511
Durbin-Watson stat 1.970968 Prob(F-statistic) 0.246355
Inverted AR Roots .54
Inverted MA Roots .48
Les coefficients ne sont pas significativement différents de zéro. On ne retient pas ce modèle.
On est amené à enlever la variable MA(1) qui est la moins significative (p-value plus éloigné de 5%) pour
améliorer la significativité globale du modèle.
On estime ce modèle sans constante comme c n’est pas significative :
Variable Coefficient Std. Error t-Statistic Prob.
AR(1) 0.645458 0.242489 2.661809 0.0081
MA(1) -0.577963 0.261246 -2.212335 0.0276
Sans C le modèle ARMA(1,1) est bien significatif.
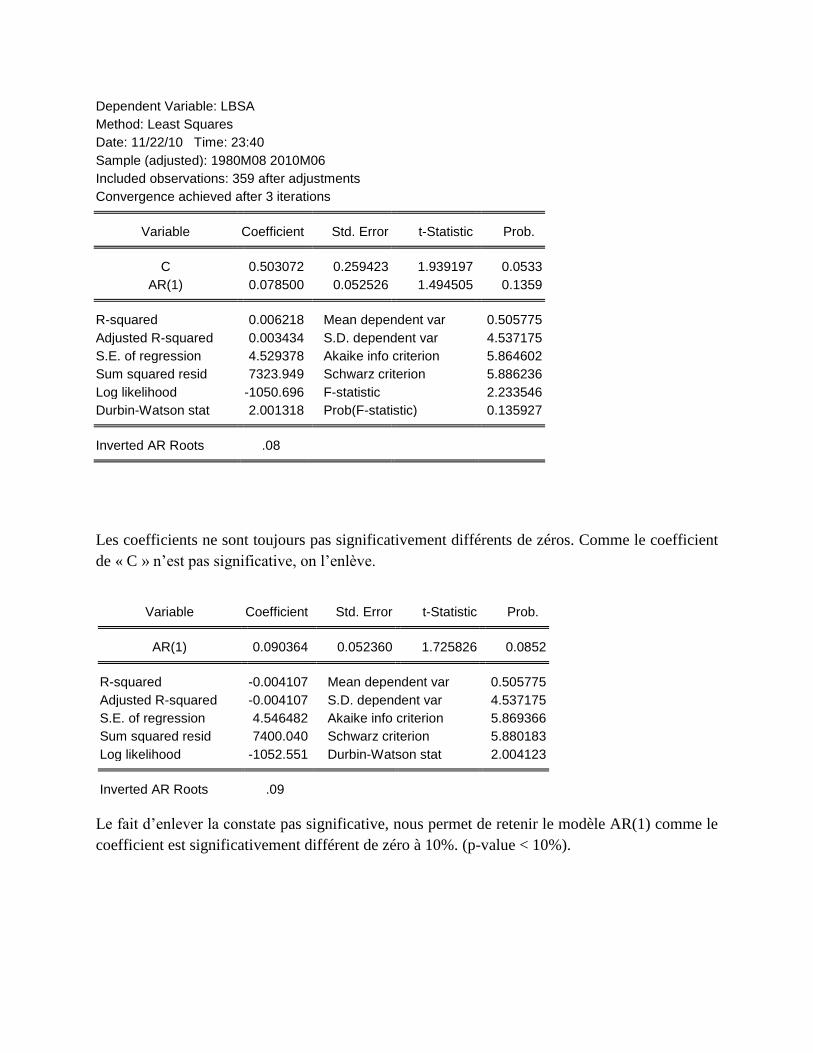
Dependent Variable: LBSA
Method: Least Squares
Date: 11/22/10 Time: 23:40
Sample (adjusted): 1980M08 2010M06
Included observations: 359 after adjustments
Convergence achieved after 3 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 0.503072 0.259423 1.939197 0.0533
AR(1) 0.078500 0.052526 1.494505 0.1359
R-squared 0.006218 Mean dependent var 0.505775
Adjusted R-squared 0.003434 S.D. dependent var 4.537175
S.E. of regression 4.529378 Akaike info criterion 5.864602
Sum squared resid 7323.949 Schwarz criterion 5.886236
Log likelihood -1050.696 F-statistic 2.233546
Durbin-Watson stat 2.001318 Prob(F-statistic) 0.135927
Inverted AR Roots .08
Les coefficients ne sont toujours pas significativement différents de zéros. Comme le coefficient
de « C » n’est pas significative, on l’enlève.
Variable Coefficient Std. Error t-Statistic Prob.
AR(1) 0.090364 0.052360 1.725826 0.0852
R-squared -0.004107 Mean dependent var 0.505775
Adjusted R-squared -0.004107 S.D. dependent var 4.537175
S.E. of regression 4.546482 Akaike info criterion 5.869366
Sum squared resid 7400.040 Schwarz criterion 5.880183
Log likelihood -1052.551 Durbin-Watson stat 2.004123
Inverted AR Roots .09
Le fait d’enlever la constate pas significative, nous permet de retenir le modèle AR(1) comme le
coefficient est significativement différent de zéro à 10%. (p-value < 10%).

Un nouvel examen de corrélogramme des résidus est nécessaire :
Les probabilités critiques sont supérieurs à 5%. Ces deux processus a une tête de bruit blanc. Au
vu de corrélogramme comme rien qui dépasse , cela me confirme qu’il s’agit bien d’un bruit
blanc.
On reconnait ici un processus AR(1) significative à 10% et ARMA(1,1) significative à 5%

6.2.Estimation du processus AR(1) et ARMA(1,1) en enlevant les 3 dernières observations.
Nous allons estimer deux processus AR(1) et ARMA(1,1) sans c car il s’agit des modèles concurrents puis
je vais faire les prévisions avec ses deux modèle pour voir le quel prévoit mieux. ( Pendant le cour on a
dit que si c’est toujours un bruit blanc après les tests on utilise un AR(1) donc nous allons voir quel
modèle est plus fiable pour les prévisions d’une série qui a la tete d’un bruit blanc).
Sample (adjusted): 1980M08 2010M03
Included observations: 356 after adjustments
Convergence achieved after 10 iterations
Backcast: 1980M07
Variable Coefficient Std. Error t-Statistic Prob.
AR(1) 0.689276 0.225214 3.060534 0.0024
MA(1) -0.623102 0.244873 -2.544597 0.0114
R-squared -0.002228 Mean dependent var 0.550556
Adjusted R-squared -0.005059 S.D. dependent var 4.517746
S.E. of regression 4.529160 Akaike info criterion 5.864552
Sum squared resid 7261.704 Schwarz criterion 5.886321
Log likelihood -1041.890 Durbin-Watson stat 1.980545
Inverted AR Roots .69
Inverted MA Roots .62 Lorsqu’on enlève 3 dernières observations, les p-value de modèle ARMA(1,1) sont améliorés en revanche p-value du processus AR(1) a dépassé le seuil de 10%.(0,1015) On va supposer que le modèle AR(1) est significative à 10% en enlevant les 3 dérnières observations.
Dependent Variable: LBSA
Method: Least Squares
Date: 12/04/10 Time: 19:47
Sample: 1980M08 2010M03
Included observations: 356
Convergence achieved after 2 iterations
Variable Coefficient Std. Error t-Statistic Prob.
AR(1) 0.086350 0.052596 1.641738 0.1015
R-squared -0.007246 Mean dependent var 0.550556
Adjusted R-squared -0.007246 S.D. dependent var 4.517746
S.E. of regression 4.534083 Akaike info criterion 5.863928
Sum squared resid 7298.059 Schwarz criterion 5.874813
Log likelihood -1042.779 Durbin-Watson stat 2.004790
Inverted AR Roots .09


6.3. Validation du processus pour un processus AR(1)
6.3.1. L’analyse de Racine AR(1)
Nous allons vérifier la stationnarité de processus AR pour la stabilité du modèle, le module de
racine doit être inférieur à 1.
Un processus étant toujours inversible, il est stationnaire lorsque les racines sont à
l’extérieur du cercle unité du plan.
Inverted AR Roots .09 < 1
La condition sur la racine est bien vérifiée.
6.4. Tests sur les résidus
Nous allons effectuer plusieurs test pour vérifier la pertinence du modèle estimé AR(1).
Test de Ljung Box ou Test de non auto-corrélation des résidus
Analyse du corrélogrammes des résidus, comme on a précédemment fait, la probabilité critique
de la statistique de Ljung-Box est supérieurs à 5%. On ne rejette pas l’hypothèse nul de non
corrélation des résidus. Les termes de auto-corrélation et partial corrélation sont dans l’intervalle
de confiance.
La séries peut être considérée comme un bruit blanc.
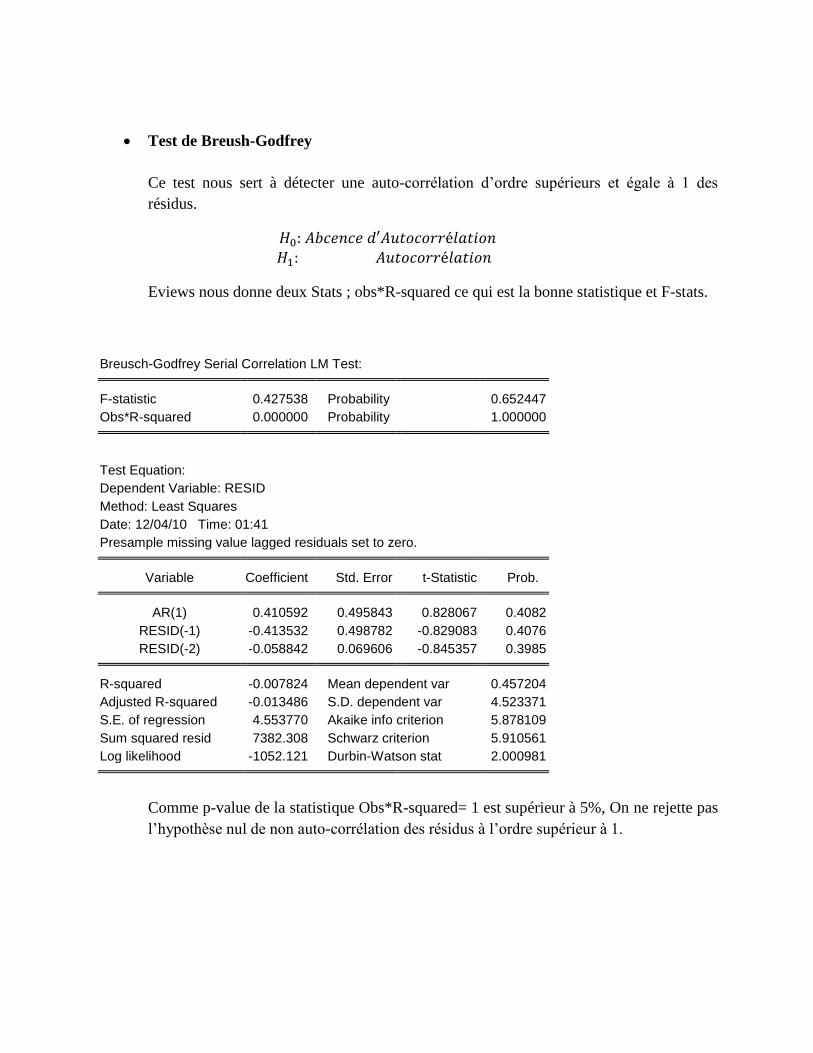
Test de Breush-Godfrey
Ce test nous sert à détecter une auto-corrélation d’ordre supérieurs et égale à 1 des
résidus.
Eviews nous donne deux Stats ; obs*R-squared ce qui est la bonne statistique et F-stats.
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 0.427538 Probability 0.652447
Obs*R-squared 0.000000 Probability 1.000000
Test Equation:
Dependent Variable: RESID
Method: Least Squares
Date: 12/04/10 Time: 01:41
Presample missing value lagged residuals set to zero.
Variable Coefficient Std. Error t-Statistic Prob.
AR(1) 0.410592 0.495843 0.828067 0.4082
RESID(-1) -0.413532 0.498782 -0.829083 0.4076
RESID(-2) -0.058842 0.069606 -0.845357 0.3985
R-squared -0.007824 Mean dependent var 0.457204
Adjusted R-squared -0.013486 S.D. dependent var 4.523371
S.E. of regression 4.553770 Akaike info criterion 5.878109
Sum squared resid 7382.308 Schwarz criterion 5.910561
Log likelihood -1052.121 Durbin-Watson stat 2.000981
Comme p-value de la statistique Obs*R-squared= 1 est supérieur à 5%, On ne rejette pas
l’hypothèse nul de non auto-corrélation des résidus à l’ordre supérieur à 1.

Test d’homoscédasticité
Nous avons déjà conclu que la série est un bruit blanc. Une série de bruit blanc est
homoscédastique.
Test ARCH de Engle (1982)
Résultat du test pour p=1
Résultat du test pour p=2
Résultat du test pour p=3
Le test Arche pour p=1 ;2 ;3 nous permet de conclure à une homoscédasticité comme les p-value des tests
sont tous supérieurs à 5%, On ne rejette pas l’hypothèse nul de homoscédasticité. C’est normale comme
la série est un bruit blanc.
ARCH Test:
F-statistic 0.457623 Probability 0.499176
Obs*R-squared 0.459603 Probability 0.497810
ARCH Test:
F-statistic 0.731336 Probability 0.481991
Obs*R-squared 1.468998 Probability 0.479746
ARCH Test:
F-statistic 0.691185 Probability 0.557924 Obs*R-squared 2.084836 Probability 0.554987
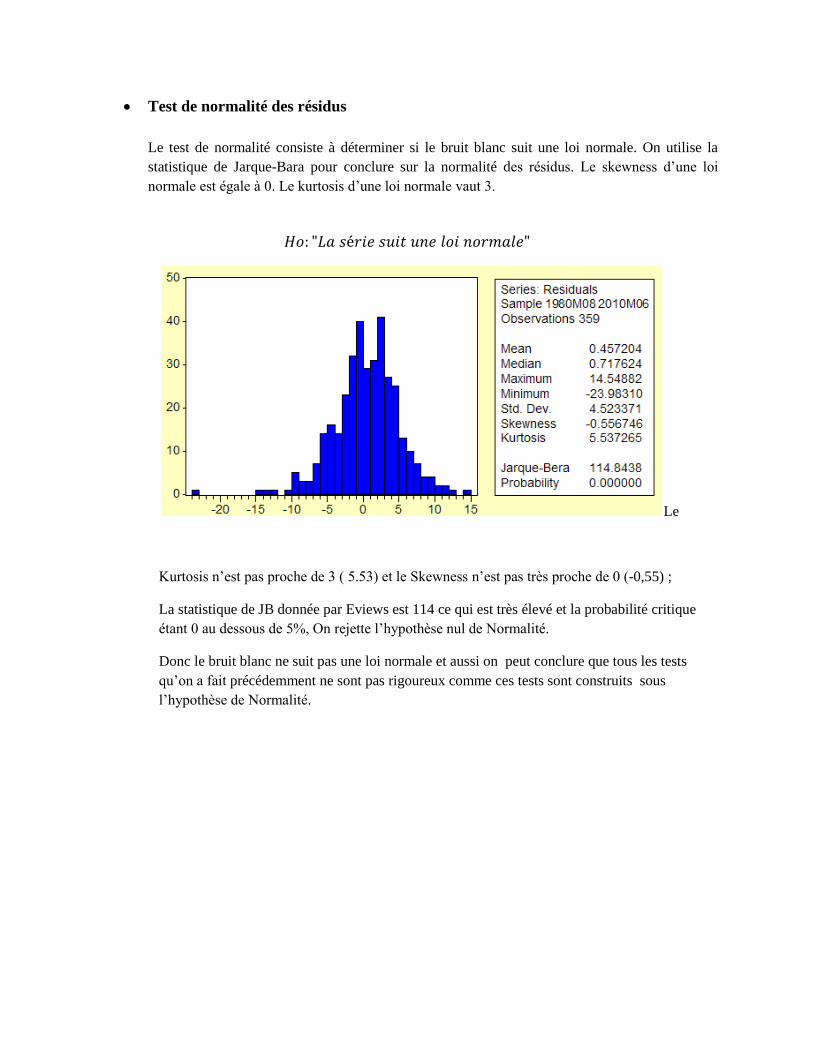
Test de normalité des résidus
Le test de normalité consiste à déterminer si le bruit blanc suit une loi normale. On utilise la
statistique de Jarque-Bara pour conclure sur la normalité des résidus. Le skewness d’une loi
normale est égale à 0. Le kurtosis d’une loi normale vaut 3.
Le
Kurtosis n’est pas proche de 3 ( 5.53) et le Skewness n’est pas très proche de 0 (-0,55) ;
La statistique de JB donnée par Eviews est 114 ce qui est très élevé et la probabilité critique
étant 0 au dessous de 5%, On rejette l’hypothèse nul de Normalité.
Donc le bruit blanc ne suit pas une loi normale et aussi on peut conclure que tous les tests
qu’on a fait précédemment ne sont pas rigoureux comme ces tests sont construits sous
l’hypothèse de Normalité.

6.3.2. L’Analyse de Racine ARMA(1 ,1)
Il est nécessaire de vérifier qu’il n’y ait pas de racines redondantes entre AR et MA. Si tel
était le cas, cela soulèverait des problèmes d’estimation et il faudrait alors éliminer dans la
partie AR ou MA la racine la moins significative. Ici, les racines sont toutes différentes entre
elles.
Un processus AR est toujours inversible. Il est stationnaire losrque les racines sont
à l’extérieur du cercle unité du plan complexe.
Un processus MA est toujours stationnaire. Il est inversible si les racines sont à
l’extérieur du cercle unité du plan complexe.
Les conditions sur les racines sont vérifiées.
Variable Coefficient Std. Error t-Statistic Prob.
AR(1) 0.689276 0.225214 3.060534 0.0024
MA(1) -0.623102 0.244873 -2.544597 0.0114
R-squared -0.002228 Mean dependent var 0.550556
Adjusted R-squared -0.005059 S.D. dependent var 4.517746
S.E. of regression 4.529160 Akaike info criterion 5.864552
Sum squared resid 7261.704 Schwarz criterion 5.886321
Log likelihood -1041.890 Durbin-Watson stat 1.980545
Inverted AR Roots .69
Inverted MA Roots .62
Inverted AR Roots .69 < 1
Inverted MA Roots .62 < 1
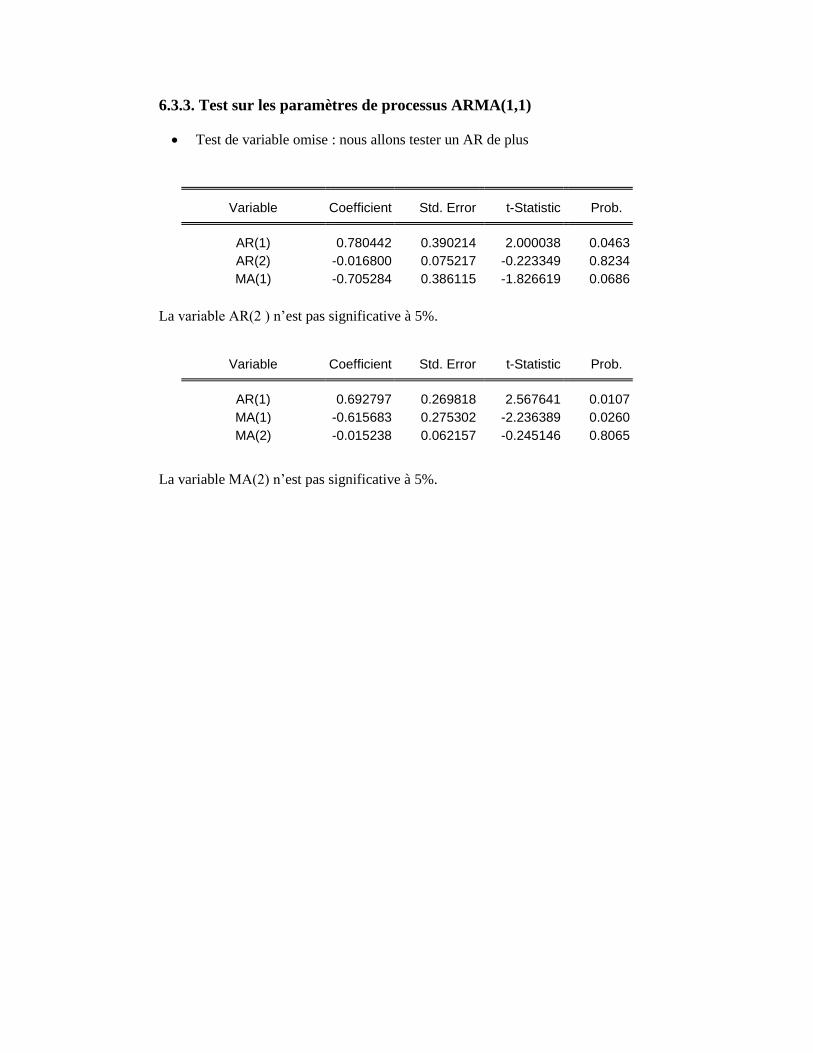
6.3.3. Test sur les paramètres de processus ARMA(1,1)
Test de variable omise : nous allons tester un AR de plus
La variable AR(2 ) n’est pas significative à 5%.
La variable MA(2) n’est pas significative à 5%.
Variable Coefficient Std. Error t-Statistic Prob.
AR(1) 0.780442 0.390214 2.000038 0.0463
AR(2) -0.016800 0.075217 -0.223349 0.8234
MA(1) -0.705284 0.386115 -1.826619 0.0686
Variable Coefficient Std. Error t-Statistic Prob.
AR(1) 0.692797 0.269818 2.567641 0.0107
MA(1) -0.615683 0.275302 -2.236389 0.0260
MA(2) -0.015238 0.062157 -0.245146 0.8065

6.4 Test sur les résidus estimés pour ARMA(1,1)
Test de Ljung Box
La probabilité critique de la statistique de Ljung-Box est supérieurs à 5%. On ne rejette pas
l’hypothèse nul de non corrélation des résidus. Les termes de auto-corrélation et partial
corrélation sont dans l’intervalle de confiance.
La séries peut être considérée comme un bruit blanc.
Test de Breush-Godfrey
Ce test nous sert à détecter une auto-corrélation d’ordre supérieurs et égale à 1 des
résidus.
Comme p-value de la statistique Obs*R-squared= 1 est supérieur à 5%, On ne rejette
pas l’hypothèse nul de non auto-corrélation des résidus à l’ordre supérieur à 1.
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 1.250563 Probability 0.287613
Obs*R-squared 0.000000 Probability 1.000000

Test d’homoscédasticité
Nous avons déjà conclu que la série est un bruit blanc. Une série de bruit blanc est
homoscédastique.
Test ARCH de Engle (1982)
ARCH Test:
F-statistic 1.033793 Probability 0.309966
Obs*R-squared 1.036614 Probability 0.308610
Le test ARCH pour p=1 ;2 nous permet de conclure à une homoscédasticité comme les p-value des tests
sont tous supérieurs à 5%, On ne rejette pas l’hypothèse nul de homoscédasticité.
Les résidus sont bien des bruits blanc.
ARCH Test:
F-statistic 1.341238 Probability 0.262859
Obs*R-squared 2.684885 Probability 0.261207
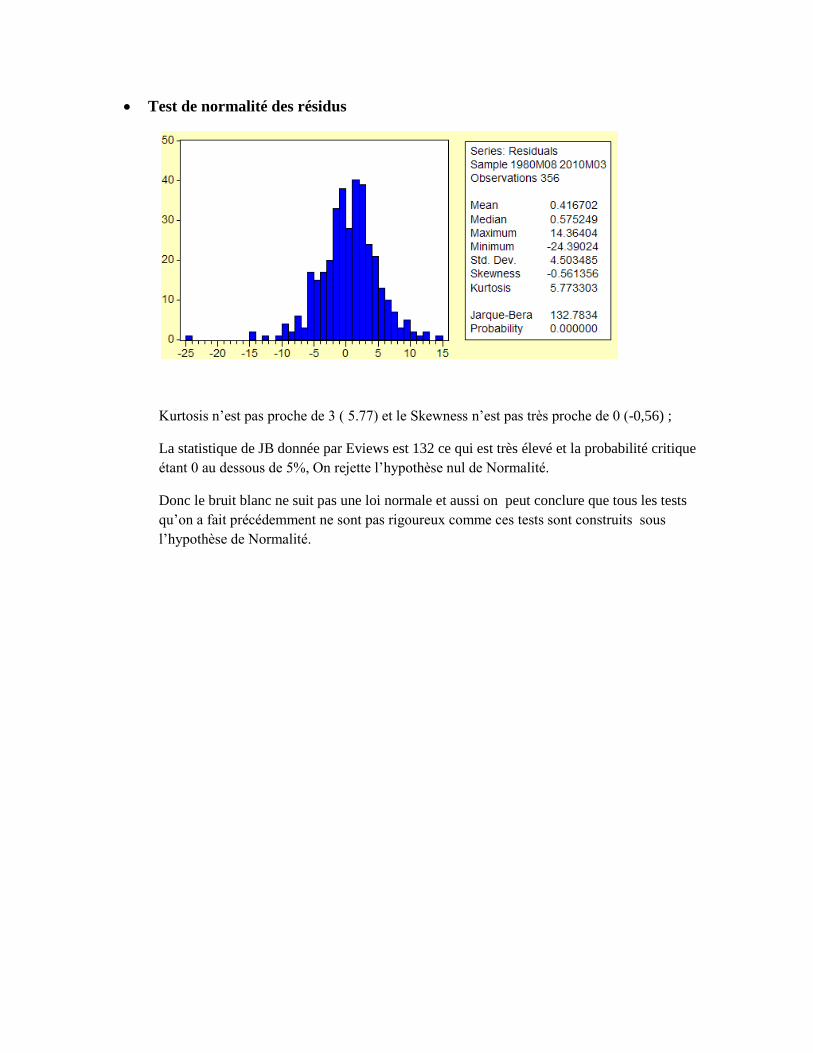
Test de normalité des résidus
Kurtosis n’est pas proche de 3 ( 5.77) et le Skewness n’est pas très proche de 0 (-0,56) ;
La statistique de JB donnée par Eviews est 132 ce qui est très élevé et la probabilité critique
étant 0 au dessous de 5%, On rejette l’hypothèse nul de Normalité.
Donc le bruit blanc ne suit pas une loi normale et aussi on peut conclure que tous les tests
qu’on a fait précédemment ne sont pas rigoureux comme ces tests sont construits sous
l’hypothèse de Normalité.

6.5 Les modèles concurrents et leurs critères de comparaison
Entre ces deux modèles concurrents, on retient le modèle qui minimise les critères de Akaike et
Schwarz.
AR(1) cosidéré significatif à 10% ≈ 0.1015
Critère de Akaike : 5,8639
Critère de Schwarz : 5,8748
ARMA (1,1) sans « c » singificatif à 5%
Critère de Akaike : 5,8645
Critère de Schwarz : 5,8863
Conclusion
Le meilleur modèle selon les critères Akaike et Schwarz, c’est bien le modèle AR(1).
Nous venons de conclure que la série est un bruit blanc donc de continuer à faire des
prévisions avec un processus AR(1) est plus juste.
7. Prévision du processus AR(1) et ARMA(1,1)

Le modèle précédemment retenue est un AR(1) donc la valeur en t dépend de la valeur de la série
au période t-1.
Etapes pour obtenir les prévisions de la série LBSA :
Nous allons faire une prévision de 3 mois de 2010M03 à 2010M06 :
D’abord on fait une estimation du modèle AR(1) en enlevant trois mois d’observation.
Sample Initiale : 1980M08-2010M06 : appelé EstimAR sous Eviews
Sample modifié : 1980M08-2010M03 : appelé EstimfAR sous Eviews
Sur estimfAR nous allons faire les prévisions sur la période enlevé précédemment :
2010M03-2010M06
Proc/Forcast
Forcast Graphique
Lbsafar
Eviews nous calcule des valeurs prévues ; lbsafar pour le modèle AR
lbsafarma pour ARMA
Enfin On regroupe lbsa et lbsafar afin de tracer un graphique de ligne.
Ensuite nous allons comparer les prévisions selon ces deux modèle AR et ARMA pour voir le quel nous
donne la meilleure prévision ;
7.1.1. Comparaison des graphiques de prévision des modèle AR(1) er ARMA(1,1)

Plus les valeurs des measures RMSE, MAPE sont petites, plus le modèle retenu est précis.
Pour une meilleure prévision Root Mean Squared Error doit etre plus petit possible.
RMSE lbsafar : 5,29 vs lbsafarma :5,43
Mean Abs ; Percent Error signifie le risque de ce tromper pour les prévisions.
Lbsafar : 96% vs Lbsafarma : 100%
Nous pouvons conclure que le modèle retenu AR(1) est le bon modèle pour faire nos
prévisions sur 3 mois.
Voici les valeurs de prévisions calculées par Eviews de AR(1) :
LBSA LBSAFAR

Remarque :
On voit bien que les valeurs des prévisions à partir de 2010M03 se rapprochent
plus en plus de zéro.
Voici les valeurs de prévisions calculées par Eviews de ARMA(1,1) :
LBSAFARMA
2010M02 3.945023
2010M03 0.468326
2010M04 0.322806
2010M05 0.222503
2010M06 0.153366
Remarque :
Les prévisions diminuent jusqu’à 0.15 mais cela reste au dessuus des variables
prévues du processus AR(1).
7.1.2 Calcule des prévisions à la main
1. Le modèle final de AR(1) :
2009M06 3.597241 3.597241
2009M07 6.864114 6.864114
2009M08 2.210989 2.210989
2009M09 3.708073 3.708073
2009M10 0.170301 0.170301
2009M11 6.856468 6.856468
2009M12 2.182914 2.182914
2010M01 -0.434030 -0.434030
2010M02 3.945023 3.945023
2010M03 2.304884 0.340651
2010M04 -2.261354 0.029415
2010M05 -9.892835 0.002540
2010M06 -2.270621 0.000219

Calcul des prévisions pour les périodes t=03, 04, 05, 06:
X03= 0.086X02 + ε03
X03=0.086*3.94+E(ε03) E(ε03) =0
X03=0.34
X04=0.086*0.34+E(ε04)
X04=0.029
X05=0.086*0.029
X05=0.002540
X06=0.086*0.00254
X06=0.000219
On retrouve bien les estimations calculées par Eviews et données par le colonne LBSAFAR.
2. Le modèle final de ARMA(1,1) :
X03= 0.689*X02 + ε03-0623*ε02
X03=0.689*3.945+E(ε03) –0.623*E(ε02) E(ε03) =0
X03=2 ,68-0.623*3.61 = 0.469
7.1.3 Intervalle de confiance associé à chacun de ces prévisions de AR(1)
Les intervalles de prévisions , Ce sont les intervalles dans lesquels la valeur XT+h se situe avec
une probabilité 1-α% .

Sous l’hypothèse normalité des résidus
S.E(optional) : fse c’est le nom de l’objet dans lequel seront stockées les écart-type
estimé de l’erreur de prévision.
On met un nom d’objet fse et Eviews stocke dans cet objet l’écart-type estimé de l’erreur
de prévision.
Puis Quick/Show et on met l’équation suivante pour calculer les intervalles de confiance
à 95% pour chaque prévisions : (lbsafar- 2*fse , lbsafar+2*fse)
Voici les écart-type estimé de l’erreur :
Voici les intervalles de previsions:
Ces intervalles de confiance sont représenté par deux lignes rouges de Forcast graph.
8. Représentation de la série prévue et la série observée :
La Série Observée: LBSA
Les Séries Prévues : LBSAFAR et LBSAFARMA
2010M02 NA 2010M03 4.538829 2010M04 4.551026 2010M05 4.551082 2010M06 4.551082
2010M03 -8.737006
2010M04 -9.072637
2010M05 -9.099624
2010M06 -9.101945
9.418309
9.131467
9.104704
9.102384

Notre objectif est de montrer le quel de ces modèles prévoit mieux la série observé :
Conclusion :
La réponse de Pourquoi le modèle AR(1) préfèré si notre série est un bruit blanc ?
1. La série prévues du processus AR(1) étant le plus proche de la série observée. On
constate que même le modèle ARMA(1,1) est globalement plus significatif que AR(1) , il
ne représente pas le meilleur modèle pour cette raison si une série est toujours un bruit
blanc après les tests de validation, c’est mieux de choisir un modèle AR(1) .
2. Les prévisions d’abord sous-estime la série effective puis elle sur-estime. Le point
d’inflexion n’est pas estimé.