organisation de journée - contexte et définition des …jocelyn.chanussot/teaching/ensimag... ·...
TRANSCRIPT

Organisation de journée
Introduction et principes généraux
- contexte et définition des besoins
- rappels en théorie de l’information
Compression sans pertes
- codage entropique
- codage par plage
- algorithme LZW (zip, GIF)
Compression avec pertes
- quantification scalaire et vectorielle
- codage par transformation linéaire (JPEG)
[- codage hiérarchique et multirésolution, (JPEG 2000)]

Introduction et principes généraux
Contexte et définition des besoins
« monde numérique » ⇒ stockage et transmission d’information
sous forme binaire
- efficacité : optimisation des capacités de stockage et de l’utilisation
de la bande passante
⇒ compression ou codage source :
suppression de la redondance
suppression de l’information « inutile » ou non perceptible
- robustesse aux erreurs de transmission
⇒ codage canal : ajout maîtrisé de redondance
- sécurité / services augmentés :
⇒ codage cryptographique, tatouage…

Introduction et principes généraux
Compression ou codage source
Exemple:
vidéo Haute Définition:
- 1280x720 pixels
- 24 bits / pixel (couleur)
- 100 Hz…
débit source: 2 Gbits / s !!! (sans compter le son haute définition multi-voies…)
- suppression de la redondance : compression sans perte
on peut reconstruire le signal binaire initial exactement.
- suppression de l’information « inutile » ou non (peu) perceptible :
compression avec pertes
on ne peut pas reconstruire exactement le signal initial.

Quelques définitions
Débit : ressource binaire (nombre de bits) utilisée pour coder une seconde de signal (pour les signaux temporels!)
Taux de compression : rapport du débit sans compression et du débit avec compression ou rapport entre la place requise pour le stockage sans et avec compression.
Complexité : degré de sophistication de l’algorithme mesuré par la charge de calcul par unité de temps (MIPS) et par l’occupation des mémoires du système
Contrainte de temps-réel et retard algorithmique
Qualité (pour compression avec pertes) : qualité perçue du signal restitué en regard du signal original⇒ Mesure des distorsions/dégradations ou « bruit de codage »

De la difficulté d’évaluer la qualité…
Difficultés de trouver une mesure de qualité objective
différentes formes de bruit ⇒ différents effets
Recherche d’une mesure objective corrélée au système perceptif (difficile)
Evaluation subjective par tests perceptifs sur signaux codés et originaux (fastidieux et cher)

De la difficulté d’évaluer la qualité: critères numériques classiques
Erreur Absolue Moyenne (EAM, ou MAE pour Mean Absolute Error) :
Erreur Quadratique Moyenne (EQM, ou MSE pour Mean Square Error) :
Rapport Signal à Bruit (RSB, ou SNR pour Signal to Noise Ratio) :
Rapport Signal à Bruit de Crête (RSBC, ou PSNR pour Peak Signal to Noise Ratio) :
( ) ( )∑ ∑= =
−⋅=M
m
N
nnmfnmfNMMAE
1 1,~,1
( ) ( )( )∑ ∑= =
−⋅=M
m
N
nnmfnmfNMMSE
1 1
2,
~,1
( )
( ) ( )( )
−⋅
⋅⋅=
∑ ∑∑ ∑
= =
= =M
m
N
n
M
m
N
n
nmfnmfNM
nmfNMSNR
1 1
21 1
2
,~
,1
,1
log10
( ) ( )( )
−⋅⋅
⋅=∑ ∑
= =
M
m
N
nnmfnmfNM
PSNR
1 1
2
2
,~,1255log10
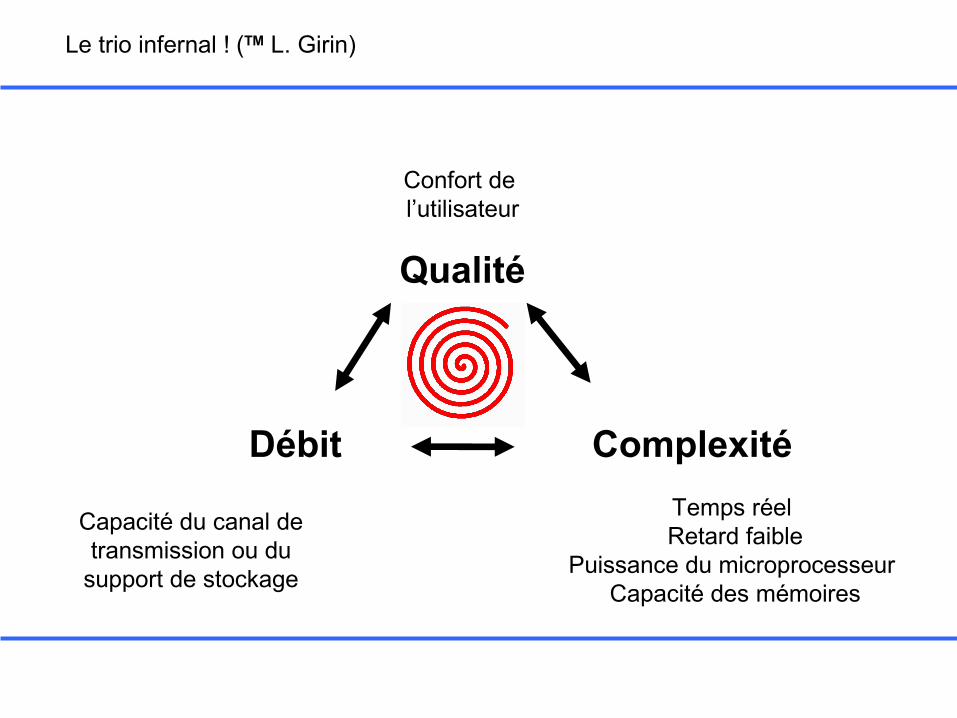
Le trio infernal ! (TM L. Girin)
Débit
Qualité
Complexité
Capacité du canal de transmission ou du
support de stockage
Temps réel Retard faible
Puissance du microprocesseur Capacité des mémoires
Confort de l’utilisateur
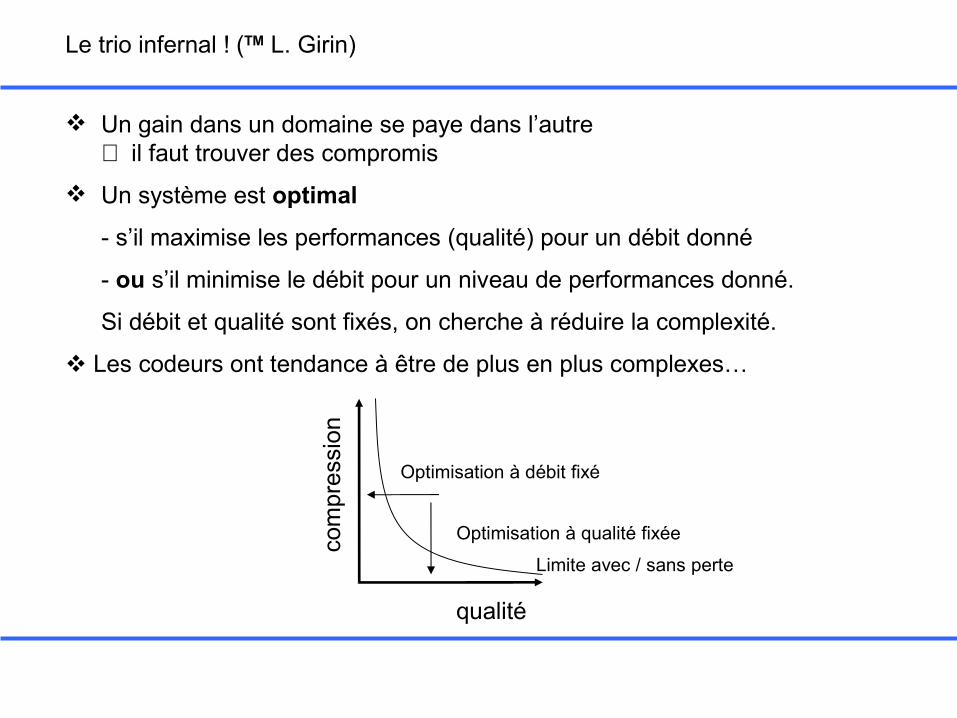
Le trio infernal ! (TM L. Girin)
Un gain dans un domaine se paye dans l’autre ⇒ il faut trouver des compromis
Un système est optimal
- s’il maximise les performances (qualité) pour un débit donné
- ou s’il minimise le débit pour un niveau de performances donné.
Si débit et qualité sont fixés, on cherche à réduire la complexité.
Les codeurs ont tendance à être de plus en plus complexes…
qualité
com
pres
sion
Limite avec / sans perte
Optimisation à qualité fixée
Optimisation à débit fixé

Rappels en théorie de l’information
Définition de l’entropie:
Exemples:
• source binaire p(ix,y=0)=1/2, p(ix,y=1)=1/2, – H(i)=1 bit
• pour une image en niveau de gris quelconque: p(ix,y=0)=p(ix,y=1)= …=p(ix,y=255)=1/256– H(i)=8 bits
⇒ Nombre minimum théorique de bits/pixel nécessaire au codage sans perte …. sans tenir compte de la redondance du signal !
[ ]∑=
−=M,N
y,xy,xy,x )i(plog)i(p)i(H
12

Rappels en théorie de l’information
Théorème du codage sans bruit sans mémoire:
en regroupant N symboles:
Illustration: (H=0.88)0 ➨ 0 et p=0.31 ➨ 1 et p=0.7 lmoy/N=1
0 ➨ 11 et p= 0.4910 ➨ 10 et p= 0.21110 ➨ 01 et p= 0.21111 ➨ 00 et p= 0.09 lmoy/N=0.9
1+≤≤ )i(H)i(l)i(H moy
N)i(HN)i(l
)i(H moy 1+≤≤

Rappels en théorie de l’information
Mais on peut descendre sous l’entropie…
Théorème du codage d’une source sans bruit avec mémoire:
Exemple:S: 0123 3210 0123 3210Si on ne considère que 1 symbole à la fois: p(X=0)=p(X=1)=p(X=2)=p(X=3)=1/4 et H=2Si on considère des mots de codes contenant 4 symboles: p(X=0123)=p(X=3210)=1/2 et H=1Cas limite si on considère des mots de codes contenant 8 symboles:
p(X=01233210)=1 et H=0, le signal est déterministe !
)i(H)i(H smam ≤≤0


Compression sans perte: codage entropique
Principe :
utiliser des codes à longueur variable (VLC) pour coder les symboles les plus fréquents avec peu de bits, au prix d’un nombre plus élevé de bits pour les symboles les moins fréquents.
Décodage
Le décodeur doit savoir séparer les différents symboles.
⇒ synchronisation
⇒ utilisation de codes préfixés: chaque code n’est le début d’aucun autre
Construction du code:
Codage de Shannon Fano, Huffman,…
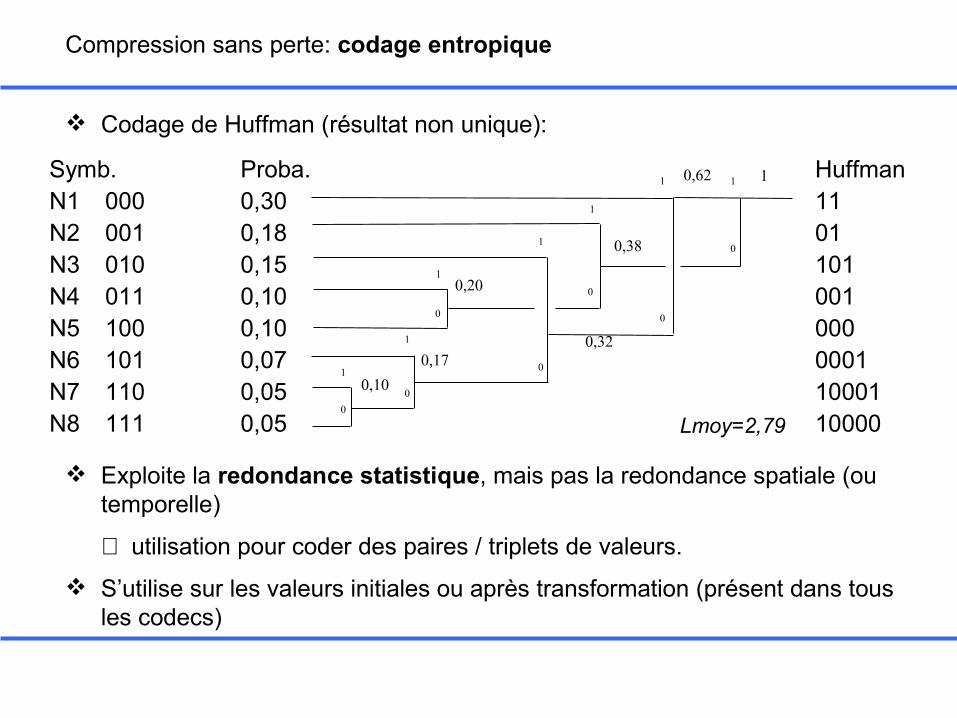
Compression sans perte: codage entropique
Symb. Proba. HuffmanN1 000 0,30 11N2 001 0,18 01N3 010 0,15 101N4 011 0,10 001N5 100 0,10 000N6 101 0,07 0001N7 110 0,05 10001N8 111 0,05 10000
0
1
0
1
1
1
1
1
1
0
0
0
0
0
0,100,17
0,20
0,32
0,38
0,62 1
Codage de Huffman (résultat non unique):
Exploite la redondance statistique, mais pas la redondance spatiale (ou temporelle)
⇒ utilisation pour coder des paires / triplets de valeurs.
S’utilise sur les valeurs initiales ou après transformation (présent dans tous les codecs)
Lmoy=2,79

Compression sans perte: codage par plage
Run Length Encoding (RLE)Principe: coder le nombre de fois ou apparaît un symbole.Exemple: S: 0000000011111 : codage: nombre de répétition sur 3 bits suivi de la valeur codée:
111 0 101 18-0 5-1
- effet néfaste en l’absence de plages uniformes ⇒ intéressant dans le cas binaire (« stack filters »)
- s’applique au signal initial ou après une transformation
- dans le cas bi-dimensionnel: choix du parcours.

Compression sans perte: algo. LZW
Algorithme Lempel Ziv WelchPrincipe: coder des chaînes de caractères qui se répètent.
Les chaînes sont stockées dans une mémoire (table de traduction) et sont codées par l’adresse correspondante.Chaque nouvelle chaîne « apprise » est codée à la première adresse disponibleCodes de longueur constante = + la chaîne est longue, meilleure est la compression
Base des formats .zip, .gif.
Particulièrement efficace pour les images synthétiques (logos, plans, schémas…).Meilleur que JPEG sur ce type d’image : pas de perte et meilleur taux !
Point-clef: apprentissage dynamique des chaînes de caractère qui se répètentapprentissage identique par le codeur et le décodeur.

Compression avec perte: méthodes par quantification
Principe général
• Définition :
conversion de la valeur s du signal prélevé (pouvant prendre éventuellement une infinité de valeurs) en la valeur la plus proche parmi un ensemble fini de N valeurs prototypes si d’un dictionnaire au sens d’une certaine distance (ou distorsion)
• Justification : capacité finie des éléments des systèmes numériques
• Les prototypes sont sensés représenter correctement les valeurs du signal → partition de l’espace de ces valeurs

Compression avec perte: méthodes par quantification
Principe général
• Codage : remplacer une donnée par l’index du prototype associé (rang dans le dictionnaire)
• Décodage : remplacer un index par le prototype associé (dictionnaire préalablement transmis au décodeur)
• Complexité codage >> décodage
Qtrouver le plusproche voisin
s i sq
s1 s2 … sN
Q-1
inspection dansle dictionnaire
s1 s2 … sN

Compression avec perte: méthodes par quantification
Attention !
• La quantification est une opération non-linéaire ! (x+y)q ≠ xq + yq
• La quantification est une opération irréversible ! → codage avec pertes/bruit !
C’est là que l’essentiel du gain est souvent réalisé mais c’est aussi le prix à payer !

Compression avec perte: méthodes par quantification
Quantification scalaire
• Scalaire = échantillon par échantillon• Résolution b = log2N
– si b entier• on peut coder de manière unique (inversible) chaque
prototype par un mot binaire de b bits • b = nombre de bits/échantillon • débit fixe d = bfe (en bits/s)
– si b est non entier, • les codes ont généralement une longueur variable (ceci
peut être vrai aussi si b entier)• débit variable → valeur moyenne
• N ne doit pas être trop grand !

Compression avec perte: méthodes par quantification
Quantification scalaire: Bruit/erreur de quantification
• Définition : q = sq–s• Critère de performance = minimisation de la distorsion moyenne D,
s considéré comme un processus aléatoire
• Cas particulier : d = erreur quadratique, D = puissance moyenne de q
– Avantages : simplicité, résultats analytiques, sens physique– Inconvénients : pas forcément corrélée avec perception mais fondement pour
mesures « perceptives » plus élaborées– En pratique, moyennage sur M échantillons
( ) dsspssD Sqq ∫∞
∞−−== )(22σ
dsspssdD Sq∫∞
∞−= )(),(

Compression avec perte: méthodes par quantification
Rapport signal sur bruit (RSB)
• Définition : rapport des puissances du signal et du bruit de quantification
2
210log10
q
sdBRSB
σσ=

• Définition : cas N très grand + prototypes « bien placés » → distorsion moyenne D faible • Hypothèse utile pour dériver des mesures de performances et guider l’élaboration d’un
quantificateur • Exemples d’approximations utiles sous HR :
– s et q sont non corrélés– la DDP marginale de q est uniforme– le processus q(n) est blanc (séquence non-corrélée)…
• Attention ! hypothèses pas toujours vraies (non-linéarité de la quantification)
Haute résolution
Compression avec perte: méthodes par quantification

• QS la plus simple et très largement employée notamment dans les CAN, en amont de tout traitement numérique (y compris compression)
• Uniforme : les valeurs quantifiées possibles sont équi-réparties sur une échelle linéaire
Quantification scalaire uniforme
Compression avec perte: méthodes par quantification
• Partition de l’intervalle de variation de s en N = 2b cellules• Pas de quantification ∆= 2A/N• Prototypes = centres des cellules indexés de 1 à N
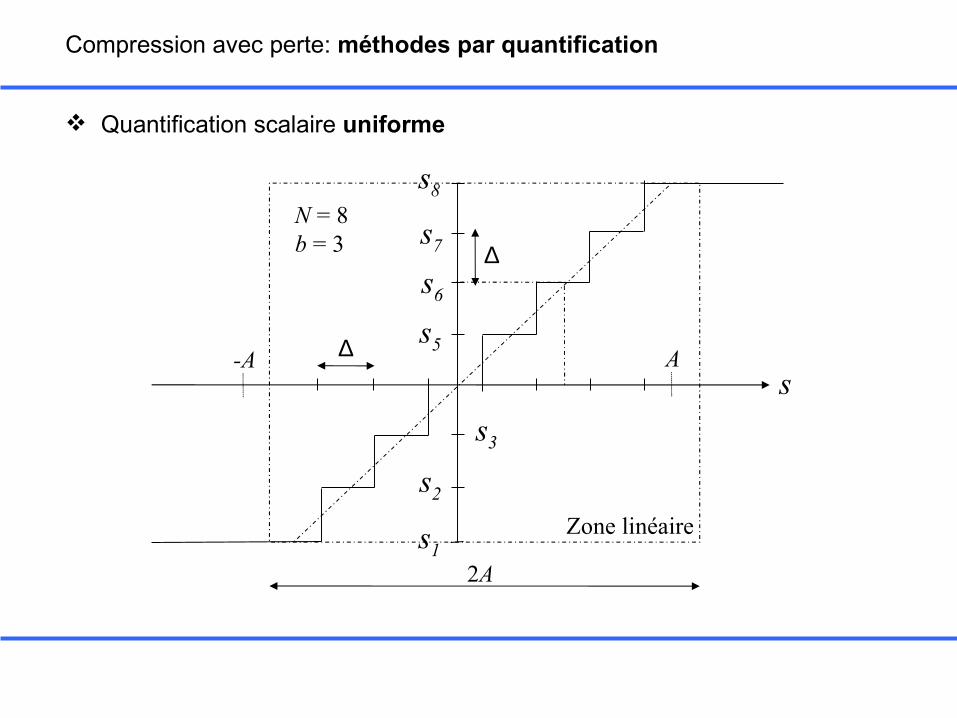
Quantification scalaire uniforme
Compression avec perte: méthodes par quantification
s8
s1
s2
s3
s5
s6
s7
s
Zone linéaire
N = 8b = 3
2A
A-A ∆
∆

Quantification scalaire uniforme: bruits
Compression avec perte: méthodes par quantification
• Bruit de dépassement : bruit occasionné par la troncature du signal si celui-ci sort de la zone linéaire
• Perceptuellement différent et « en compétiton » avec le bruit de quantification granulaire (zone linéaire) lorsque la dynamique de s varie
• Compromis nécessaire = dimensionner A et ∆ en fonction de la DDP de s, ou régler le niveau de s...
• Facteur d’échelle (typiquement entre 2 et 4) :s
Aσ
γ =

Quantification scalaire uniforme: calcul du bruit de quantification
Compression avec perte: méthodes par quantification
• Hypothèses : – haute résolution– pS(s) suffisamment lisse ≈ constante dans chaque cellule– bruit de dépassement négligé
∀ ⇒ q est uniformément réparti entre –∆/2 et + ∆/2.
bq
Adqq 2222/
2/
22 2312
1 −∆
∆−=∆=∫ ∆
=σ

Quantification scalaire uniforme: calcul du RSB
Compression avec perte: méthodes par quantification
• On augmente le RSB de 6dB à chaque fois qu’on rajoute 1 bit pour la quantification. ∀ γ ↓ ⇔ RSB↑ mais attention au bruit de dépassement !• En pratique, il faut tenir compte de la dynamique de s
et garantir une valeur minimale de RSB pour une dynamique faible.• Exemple : données audio sur 16 bits, RSB ≈ 96 dB
γγσ
σ10
22102
210 log2077,402,623log10log10 −+=== bRSB b
q
sdB

Quantification scalaire non uniforme
Compression avec perte: méthodes par quantification
• Premier exemple non immédiat mais encore simple d’application du grand principe de la compression (élimination de la redondance du signal)
• Principe : tenir compte de la répartition statistique des valeurs de s :– pour les signaux utiles réels (parole/musique/images), certaines amplitudes sont plus
fréquentes (probables) que d’autres– pour diminuer D, on alloue plus de précision sur ces amplitudes : le quantificateur doit
être bien adapté à pS(x)
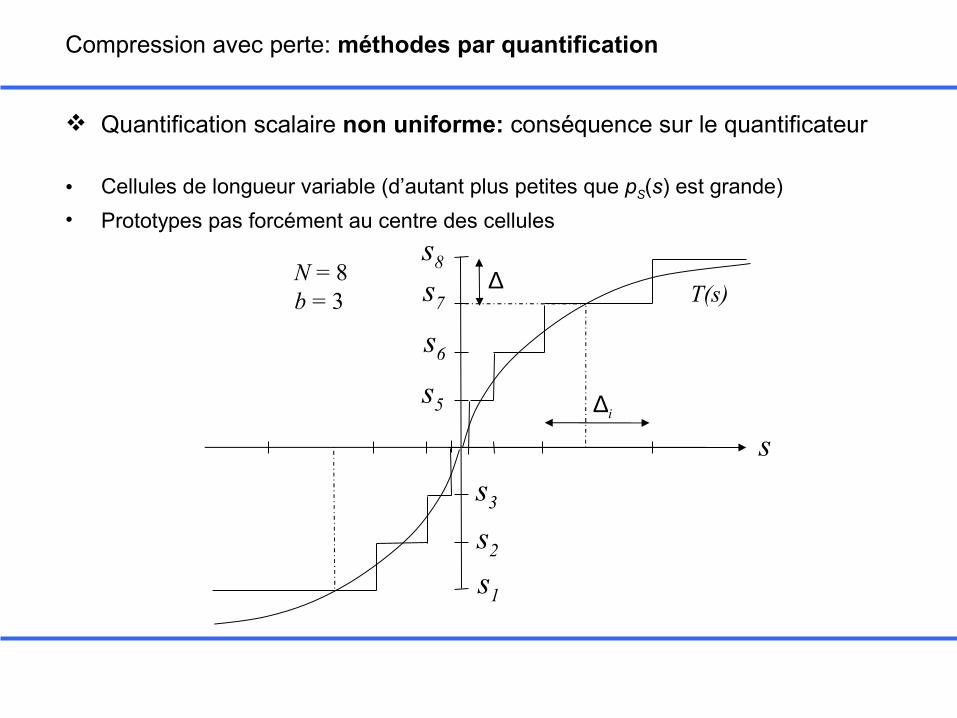
Quantification scalaire non uniforme: conséquence sur le quantificateur
Compression avec perte: méthodes par quantification
• Cellules de longueur variable (d’autant plus petites que pS(s) est grande)• Prototypes pas forcément au centre des cellules
s1
s2
s3
s5
s6
s7
s
N = 8b = 3
∆i
∆s8
T(s)

Quantification scalaire non uniforme: schéma équivalent
Compression avec perte: méthodes par quantification
• T = transformation non-linéaire• Exemple : standard US en téléphonie fixe (G.711)
– Fe = 8 kHz, b = 8 bits, d = 64 kbits/s� µ = 255 réglé pour optimiser le RSB
– T(x) approximée par des segments linéaires
Quantificationuniforme
Qs sq
T T-1
( )( ) Vxx
VxVxT ≤
++
= )(sgn1ln
/1ln)(
µµ

Quantification scalaire non uniforme: calcul du bruit de quantification
Compression avec perte: méthodes par quantification
• Hypothèses : – haute résolution– pS(s) suffisamment lisse ≈ constante dans chaque cellule = pi
– bruit de dépassement négligé
( ) ( )∑ ∫ −=∫ −== ∈
∞
∞−
N
is
Csisqq dsspssdsspss
i1
222 )()(σ
( ) ∑ ∆=∫ −∑≈=∈=
N
iii
si
N
iiq pdsssp
i 1
3
C
2
1
2121σ

Quantification scalaire non uniforme: minimisation du bruit de quantification
Compression avec perte: méthodes par quantification
• si ∆ i = constante, on retrouve • h ne dépend que de pS(s)
– Cas gaussien centré :• Problème majeur : pas de méthode analytique d’élaboration du quantificateur si pS(s)
inconnue !
11
=∑ ∆=
N
iiip 2
qσ constante3 =∆ iipminimale si⇒
bs
bS
sbSq hdxxfdssp 222
33/1
22
33/12 22)(
122)(
121 −−∞
∞−
−∞
∞−=
∫=
∫= σσσ
)()( xpxf sSsS σσ= sSX σ/=DDP de
12/22 ∆=qσ2/3π=h

Quantification scalaire non uniforme: obtention du dictionnaire
Compression avec perte: méthodes par quantification
• Deux conditions nécessaires d’optimalité permettent de déterminer efficacement prototypes et partition (b fixée)
• Idée : séparer encodeur et décodeur :– Pour un décodeur (= {prototypes}) donné, le meilleur encodeur (= partition) donné par la
condition des plus proches voisins :
( ) ( ) { }{ }NjsssssiCellule ji ...1 : 22 ∈−≤−=– Pour un encodeur donné, le meilleur décodeur est donné par la condition des
centroïdes (barycentres) :
[ ]iCelluleSSEdssspdssp
dsssps
iS
i
iCs
CsS
CsS
i )()(
)(∈=== ∫
∫
∫ ∞+
∞−∈
∈
∈

Quantification scalaire non uniforme: obtention du dictionnaire
Compression avec perte: méthodes par quantification
• Pour (1), la connaissance de la partition est inutile (distance + convention pour point équidistant de 2 prototypes)
• (1) et (2) nécessaires mais non suffisantes pour garantir l’optimalité globale du quantificateur
• Démonstrations– (1) triviale– (2) dériver par rapport à si
• Généralisation à d’autres distances : – (1)
– (2) [ ]iCelluleSxSdEsx
i ),(minarg ∈={ }{ }NjssdssdsiCellule ji ...1 ),(),(: ∈≤=

Quantification scalaire non uniforme: obtention du dictionnaire
Algorithme de Lloyd-Max:
Compression avec perte: méthodes par quantification
• Dans la pratique, utilisation d’une large base de données empiriques → itérations successives entre les deux conditions d’optimalité = Algorithme de Lloyd-Max
– (1) affectation des données aux centroïdes plus proches voisins ⇒ nouvelle partition
– (2) calcul des moyennes des échantillons de chaque classe ⇒ nouveaux centroïdes
– (3) calcul de D qui diminue à chaque itération. On arrête quand elle n’évolue plus ou que la diminution relative est inférieure à un seuil faible

Quantification scalaire non uniforme: obtention du dictionnaire
Algorithme de Lloyd-Max:
Compression avec perte: méthodes par quantification
• « Mise en forme » du quantificateur selon pS(s) sans estimation explicite de pS(s) !
• Echantillon de données de taille M>>N pour bien représenter pS(s)
• Attention aux données situées exactement sur la frontière entre deux cellules : il faut changer leur affectation
• Minimum local pour D et pas forcément global→ quantificateur pas forcément optimal mais performant → en pratique : très efficace / nombreuses applications

Techniques adaptatives
• Principe : régler automatiquement le quantificateur en fonction des variations à moyen terme des statistiques de s(t) (localement stationnaire)
• Exemple : adaptation en gain = réglage automatique de A, en fonction du niveau des échantillons passés de s en essayant de garder γ à sa valeur optimale
• Généralisation du principe à tout bloc d’un codeur
Compression avec perte: méthodes par quantification
Compression avec perte: méthodes par quantification
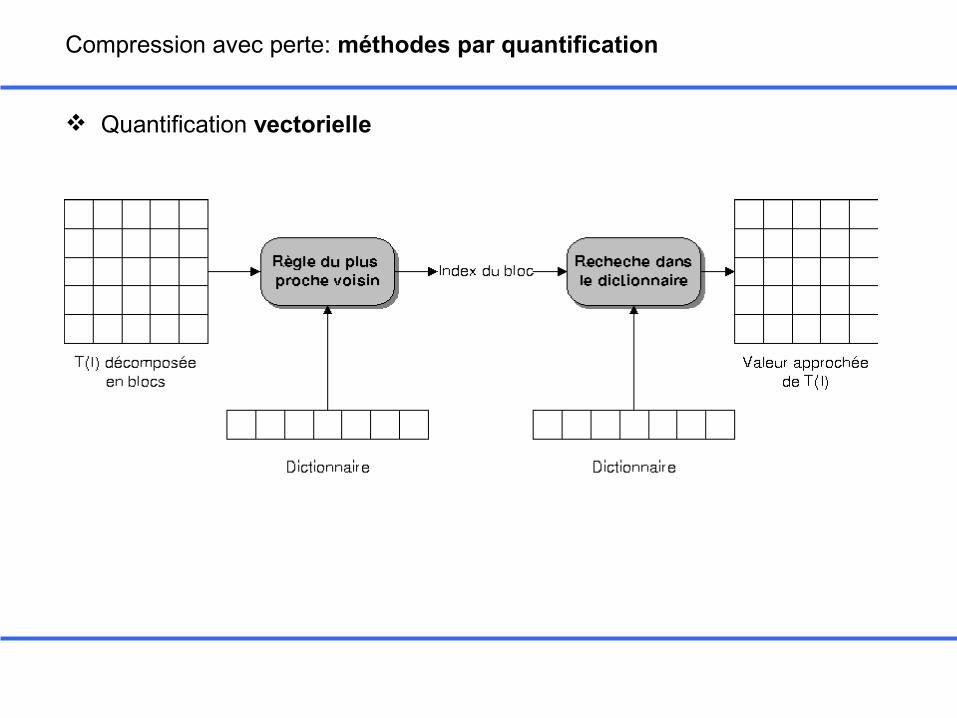
Quantification vectorielle

1. On part d'abord d'un dictionnaire composé d'un seul vecteur V0 qui minimise la distorsion moyenne. C'est le centre de gravité de l'ensemble d'apprentissage.
2. On génère ensuite à partir de V0 deux vecteurs V11 et V21 définis par V11 = V0 + e et V21 = V0 -e
3. En fonction de V11 et V21 on crée deux classes de vecteurs à partir de la base
d'apprentissage en fonction de leur distances vis à vis de V11 et V21. On calcule ensuite les centres de gravité de ces deux classes pour mettre à jour V11 et V21. On itère ce processus tant que la décroissance de la distorsion moyenne reste importante.
4. On partage à nouveau ces 2 vecteurs en 2 et on itère l'étape précédente sur les nouveaux vecteurs.
5. On arrête l'algorithme lorsque l'on a atteint le nombre de vecteurs désiré.
Compression avec perte: méthodes par quantification
Quantification vectorielle: algo de Linde Buzo Gray (LBG)

(1): On part d'abord d'un dictionnaire composé d'un seul vecteur V0 qui minimise la distorsion moyenne. C'est le centre de gravité de l'ensemble d'apprentissage.
V0
Compression avec perte: méthodes par quantification
Quantification vectorielle: algo de Linde Buzo Gray (LBG)
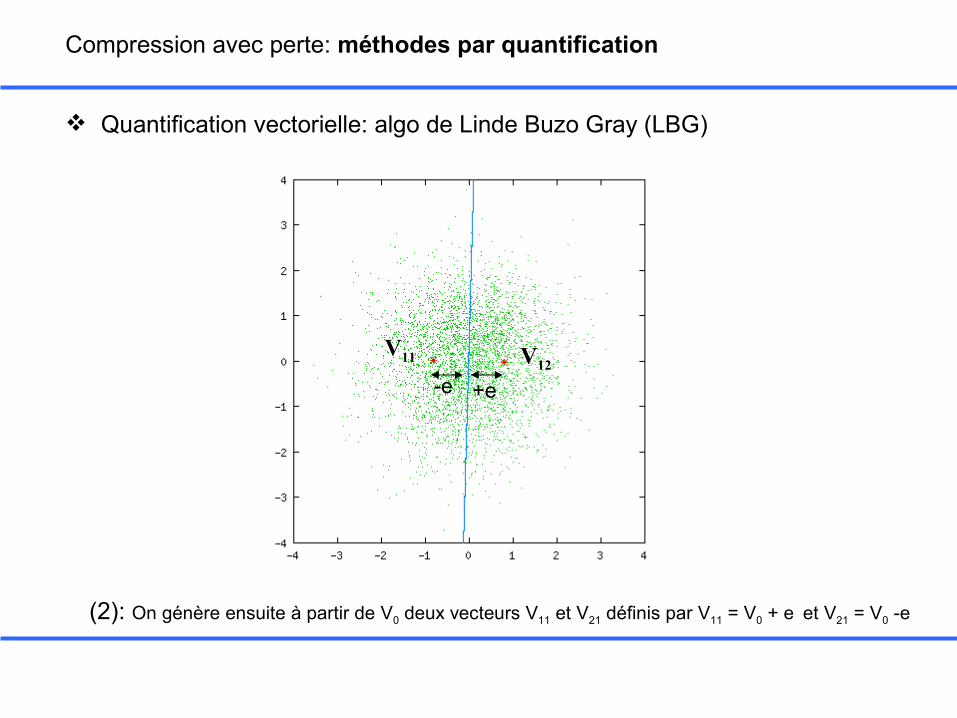
V11 V12-e +e
(2): On génère ensuite à partir de V0 deux vecteurs V11 et V21 définis par V11 = V0 + e et V21 = V0 -e
Compression avec perte: méthodes par quantification
Quantification vectorielle: algo de Linde Buzo Gray (LBG)
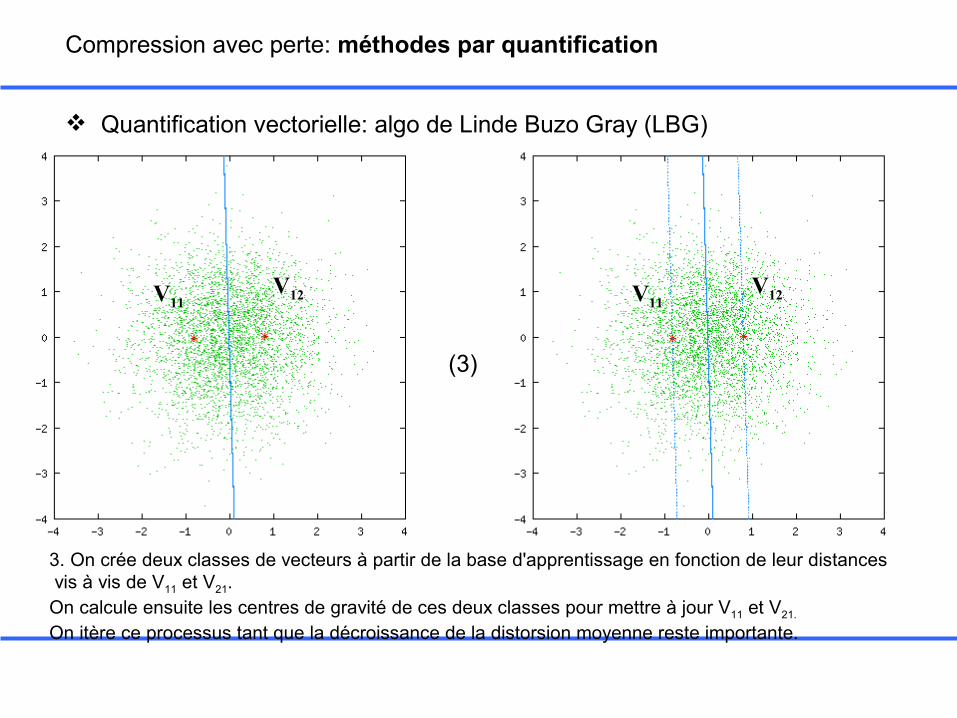
(3)
V11 V12 V11 V12
3. On crée deux classes de vecteurs à partir de la base d'apprentissage en fonction de leur distances vis à vis de V11 et V21.On calcule ensuite les centres de gravité de ces deux classes pour mettre à jour V11 et V21. On itère ce processus tant que la décroissance de la distorsion moyenne reste importante.
Compression avec perte: méthodes par quantification
Quantification vectorielle: algo de Linde Buzo Gray (LBG)
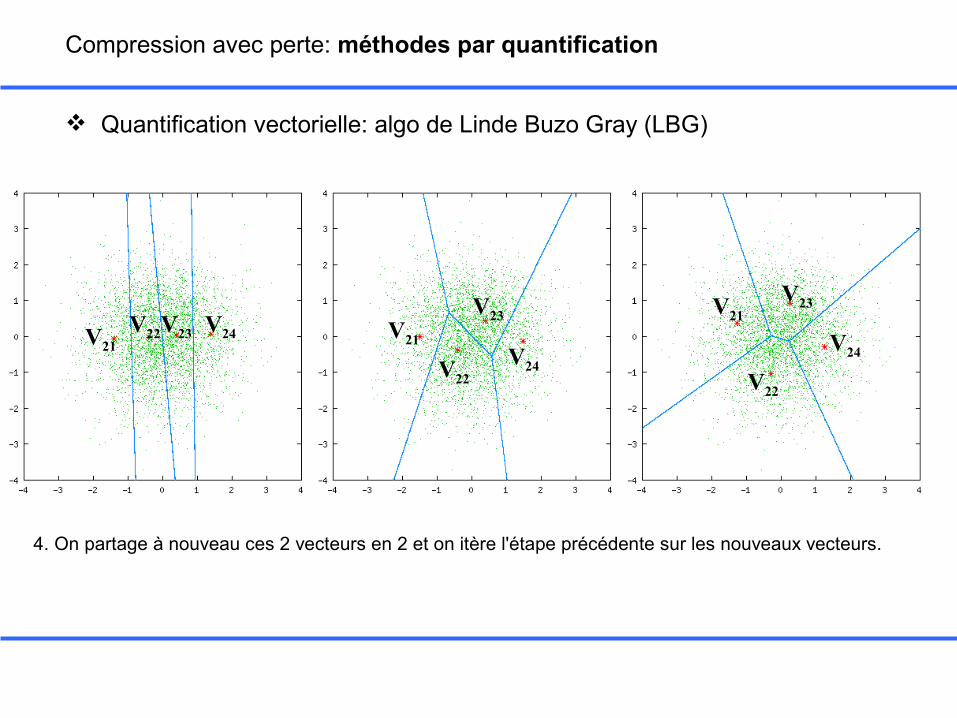
V21V22V23 V24 V21
V22
V23
V24
V21
V22
V23
V24
4. On partage à nouveau ces 2 vecteurs en 2 et on itère l'étape précédente sur les nouveaux vecteurs.
Compression avec perte: méthodes par quantification
Quantification vectorielle: algo de Linde Buzo Gray (LBG)
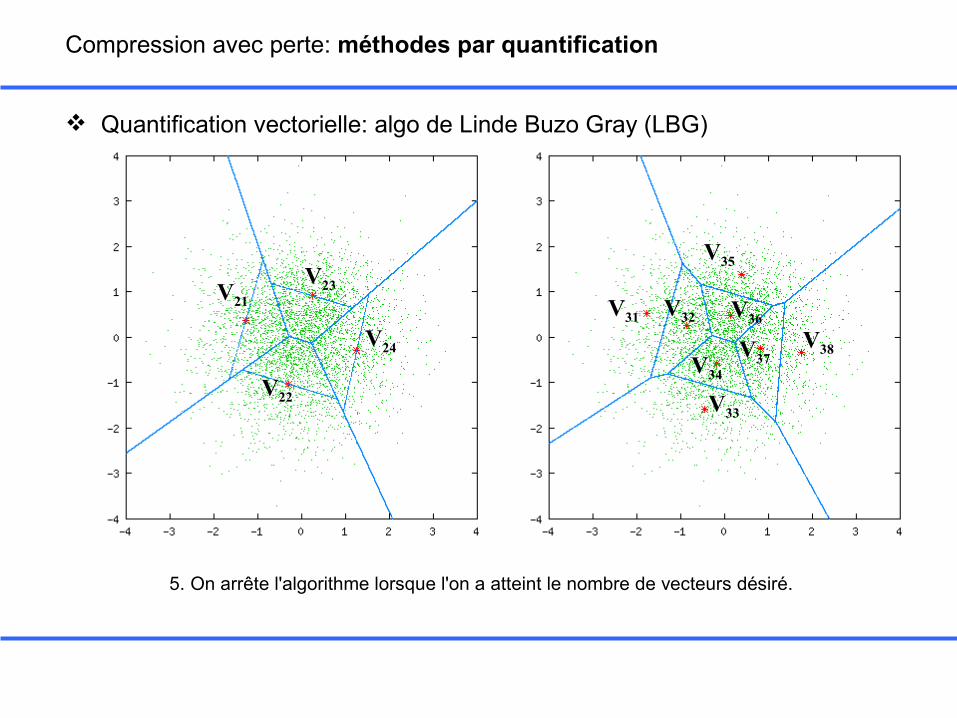
V21
V22
V23
V24V31
V34
V35
V37
V32
V33
V36V38
5. On arrête l'algorithme lorsque l'on a atteint le nombre de vecteurs désiré.
Compression avec perte: méthodes par quantification
Quantification vectorielle: algo de Linde Buzo Gray (LBG)
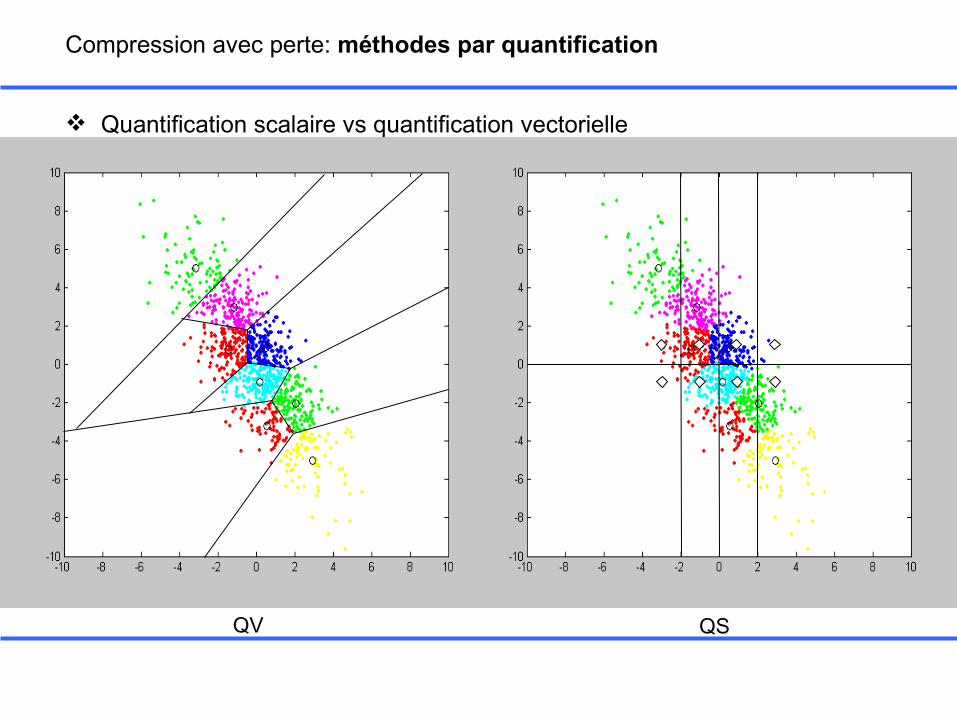
QV QS
Compression avec perte: méthodes par quantification
Quantification scalaire vs quantification vectorielle
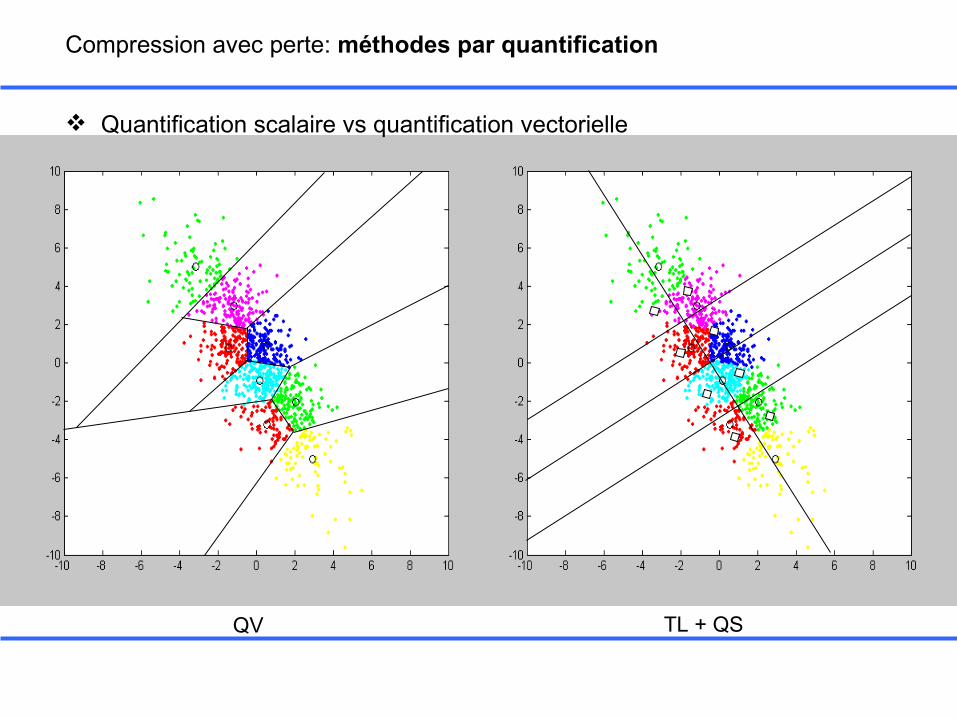
QV TL + QS
Compression avec perte: méthodes par quantification
Quantification scalaire vs quantification vectorielle


Compression avec perte: codage par transformation linéaire (JPEG)
• Principal standard utilisé en compression d’images naturelles
• JPEG= «Joint Photographic Expert Group »: voté comme standard international en 1992
• Permet de compresser les images couleurs ou en niveau de gris dans plusieurs domaines: images naturelles, satellites, médicales
JPEG: généralités

Compression avec perte: codage par transformation linéaire (JPEG)
Création d’un standard
Avantages d ’une norme:– compatibilité– pérennité d’un produit qui s ’appuie sur un standard (argument commercial)
Etapes nécessaires à la création d’un standard:
• Définition des besoins réels:– Définitions des fonctionnalités
• Création d ’un comité ouvert à tous le monde: entreprises, laboratoires• Propositions de solutions (Conditions souvent requises: pas de brevet)• Evaluation des solutions proposées• Sélection de la « meilleure » solution• Description du standard:
– En compression, on ne décrit souvent que la partie décodage du standard• Le codeur n’est pas normalisé: possibilité de créer un codeur plus
performant que les autres (s’il existe des degrés de libertés…)

Compression avec perte: codage par transformation linéaire (JPEG)
Création d’un standard
• Pour JPEG:– 1986: applications aux images fixes couleurs, avec ou sans perte– 1987: Trois techniques proposées: DCT; DPCM, Progressive BTC– 1988: sélection d ’une méthode basée DCT– 1988-90: simulations, testes, documentation– 1991: brouillon de description du Standard– 1992: standard international

Compression avec perte: codage par transformation linéaire (JPEG)
Transformations linéaires
• Définitions:
• Systèmes séparables:
• Illustration: lissage par un masque moyenneur de taille 5x5– H(x,y,u,v) = 1/9 si -3<x-u<3 et -3<y-v<3
= 0 sinon
– H(x,y,u,v)=Hc(x,u) Hv (y,v)– On passe de n2 opérations à 2n
( ) ( ) ( )∑ ∑=
=
=
==
Nx
x
My
yy,x,v,uHy,xI,v,uT
1 1
( ) ( ) ( ) ( )∑ ∑=
=
=
==
Nx
x
My
ylc v,yHx,uHy,xIv,uT
1 1
( ) ( ) ( ) ( )∑ ∑=
=
=
=
=
Nx
xl
My
yc y,vHx,uHy,xIv,uT
1 1

Compression avec perte: codage par transformation linéaire (JPEG)
Transformations linéaires orthogonales
• Formulation matricielle d ’une transformation linéaire:Tdeplié=A.Ideplié
• Transformation orthogonale:
• Propriétés utiles en compression:EQM(T,T’)=EQM(I,I’)
• Intérêt:– si on le code que les N premiers coefficients d’une transformée:
tt AAIdAA =⇔=⋅ − 1
∑=lim
2
lim),(1
eNbejiTNbEQM
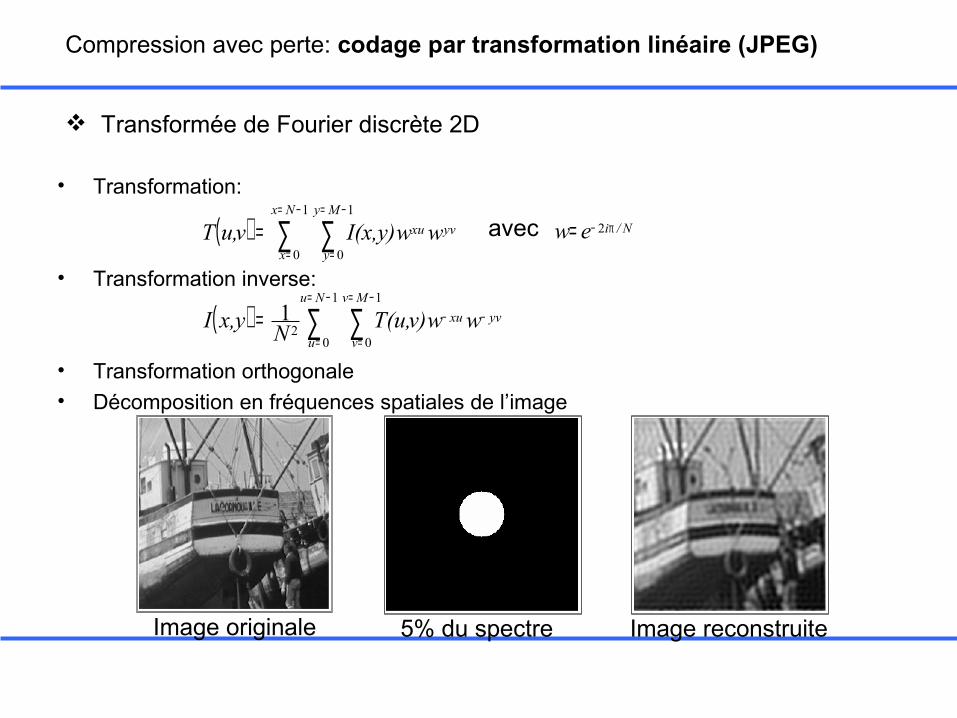
Compression avec perte: codage par transformation linéaire (JPEG)
Transformée de Fourier discrète 2D
• Transformation:
• Transformation inverse:
• Transformation orthogonale• Décomposition en fréquences spatiales de l’image
( ) ∑ ∑−=
=
−=
==
1
0
1
0
Nx
x
My
y
yvxu ww)y,x(Iv,uT avec N/iew π−= 2
( ) ∑ ∑−=
=
−=
=
−−=1
0
1
02
1Nu
u
Mv
v
yvxu ww)v,u(TNy,xI
5% du spectreImage originale Image reconstruite

Compression avec perte: codage par transformation linéaire (JPEG)
Inconvénients de la TF2D
• Coefficients transformés complexes• Création de hautes fréquences artificielles
⇔
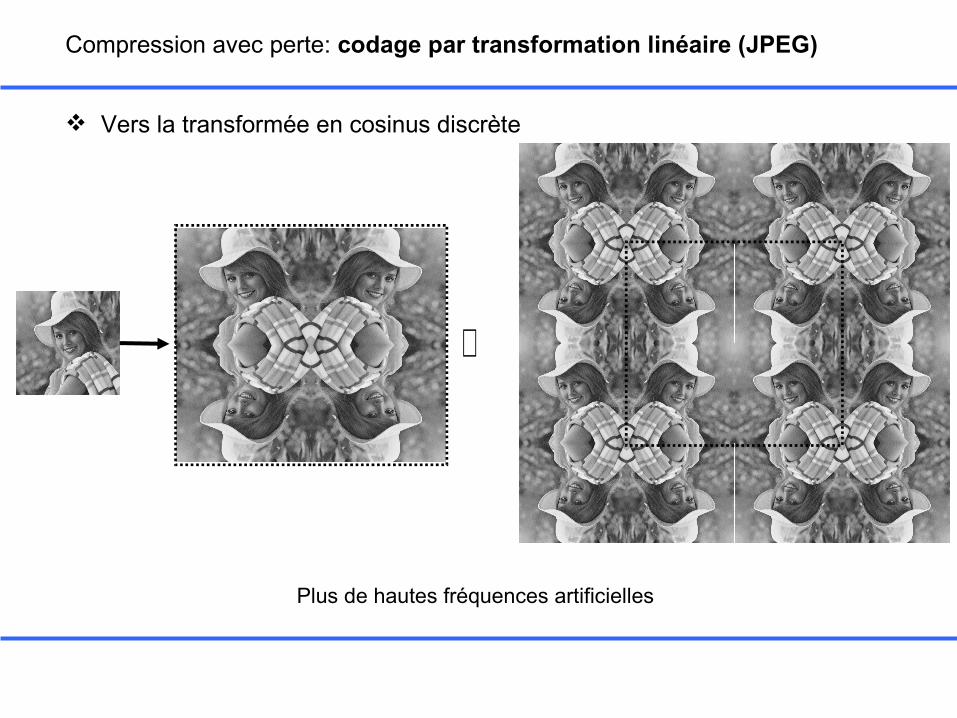
Compression avec perte: codage par transformation linéaire (JPEG)
Vers la transformée en cosinus discrète
⇔
Plus de hautes fréquences artificielles
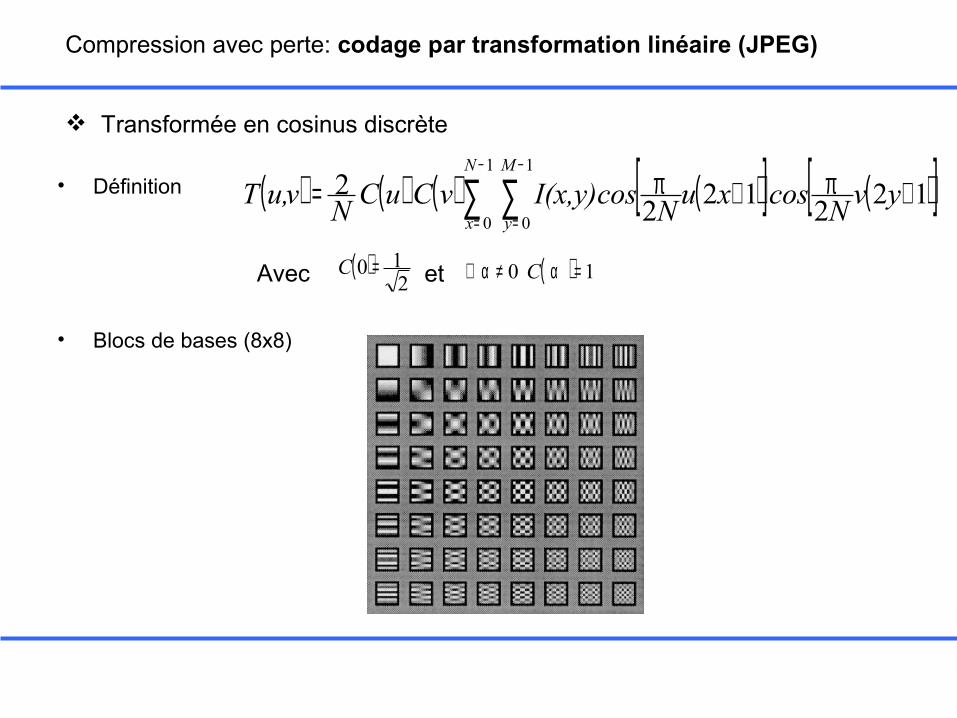
Compression avec perte: codage par transformation linéaire (JPEG)
Transformée en cosinus discrète
• Définition
• Blocs de bases (8x8)
( ) ( ) ( ) ( )[ ] ( )[ ]∑ ∑−
=
−
=+π+π=
1
0
1
0122122
2N
x
M
yyvNcosxuNcos)y,x(IvCuCNv,uT
Avec ( )2
10 =C ( ) 10 =α≠α∀ Cet
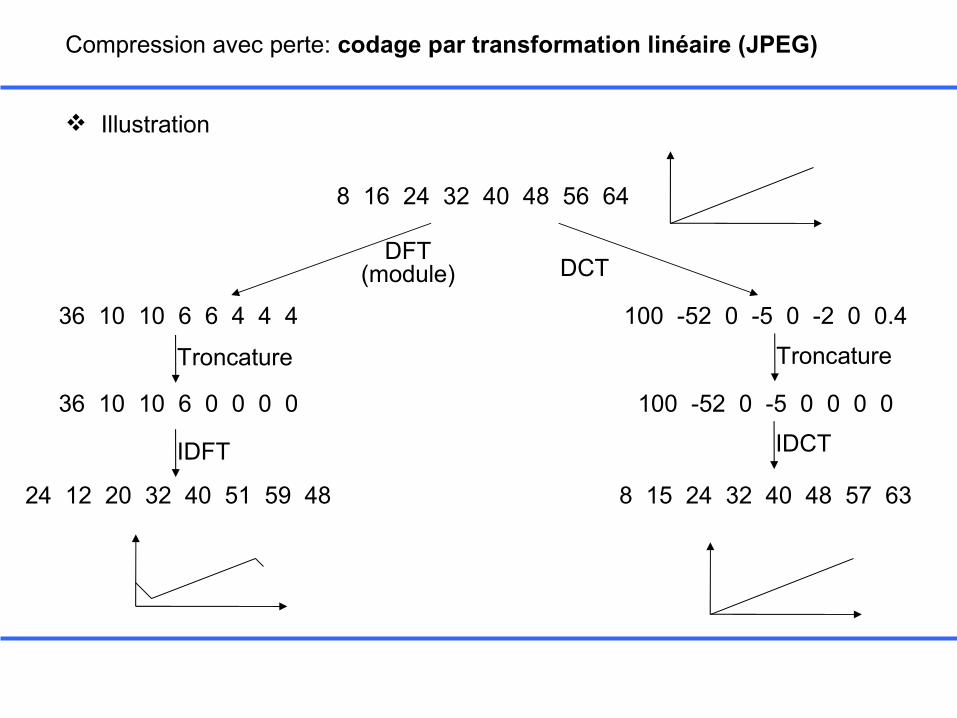
Compression avec perte: codage par transformation linéaire (JPEG)
Illustration
36 10 10 6 6 4 4 4
36 10 10 6 0 0 0 0
24 12 20 32 40 51 59 48
100 -52 0 -5 0 -2 0 0.4
100 -52 0 -5 0 0 0 0
8 15 24 32 40 48 57 63
8 16 24 32 40 48 56 64
DFT(module) DCT
Troncature Troncature
IDFT IDCT
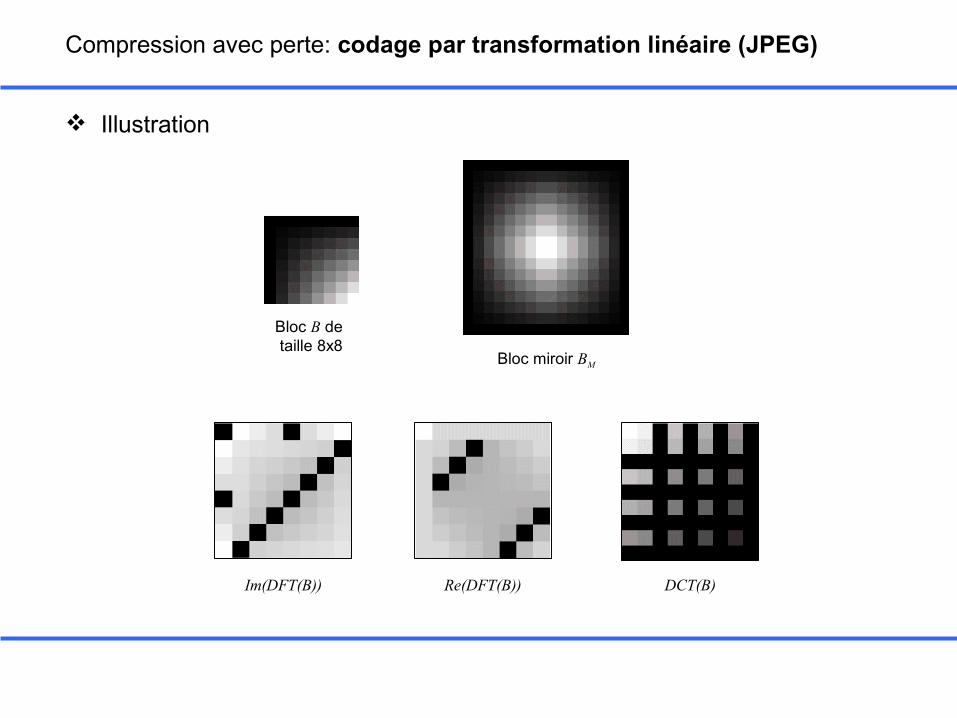
Compression avec perte: codage par transformation linéaire (JPEG)
Illustration
Bloc B de taille 8x8
Bloc miroir BM
Im(DFT(B)) Re(DFT(B)) DCT(B)
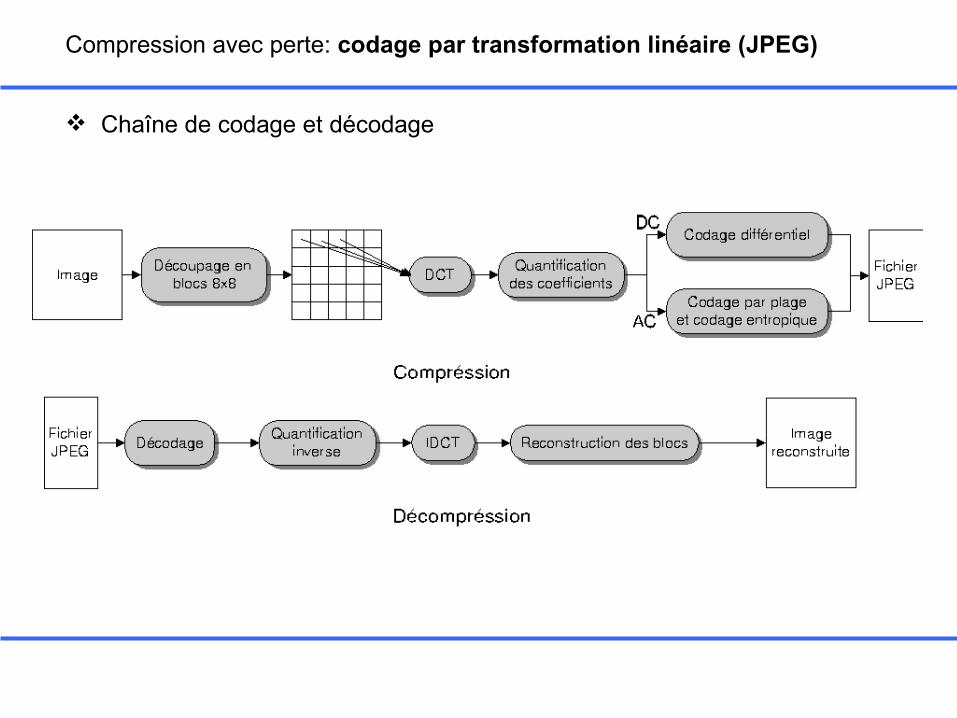
Compression avec perte: codage par transformation linéaire (JPEG)
Chaîne de codage et décodage

Compression avec perte: codage par transformation linéaire (JPEG)
Quantification des coefficients DCT
DCT
Exemple de tablede quantification:
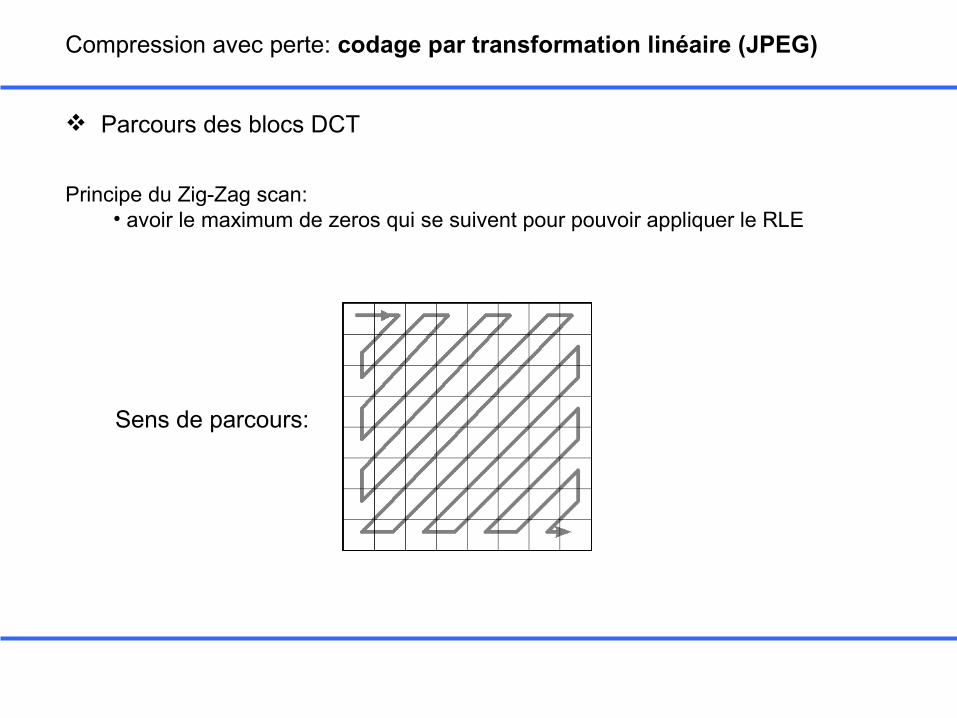
Compression avec perte: codage par transformation linéaire (JPEG)
Parcours des blocs DCT
Principe du Zig-Zag scan: • avoir le maximum de zeros qui se suivent pour pouvoir appliquer le RLE
Sens de parcours:

Compression avec perte: codage par transformation linéaire (JPEG)
Codage des coefficients DC
• Codage différentiel:
– le coefficient DC est égale à la somme des pixels présents dans un blocs 8x8: • il a donc une valeur importante (intensité moyenne)• le coefficient DC d’un bloc est corrélé avec le coefficient DC du bloc
précédent
– On choisit donc de coder Diff=DC(k)-DC(k-1):• « Differential Pulse Code Modulation= DPCM »

Compression avec perte: codage par transformation linéaire (JPEG)
Codage des coefficients DC & AC
• Codage Entropique– des coefficients DC
• codes à longueur variables représentés par le nombre de bits minimums nécessaires pour coder le coeff:
nbmin• 0 ➨ 0• -1,1 ➨ 1• -3,-2,2,3 ➨ 2• -7,-6,-5,-4,4,5,6,7 ➨ 3
• on transmet le code de Huffman de nbmin puis la valeur à coder
– des coefficients AC• on transmet le code de Huffman qui représente la paire (nb de zéros à
passer, taille du coeff AC) puis la valeur à coder
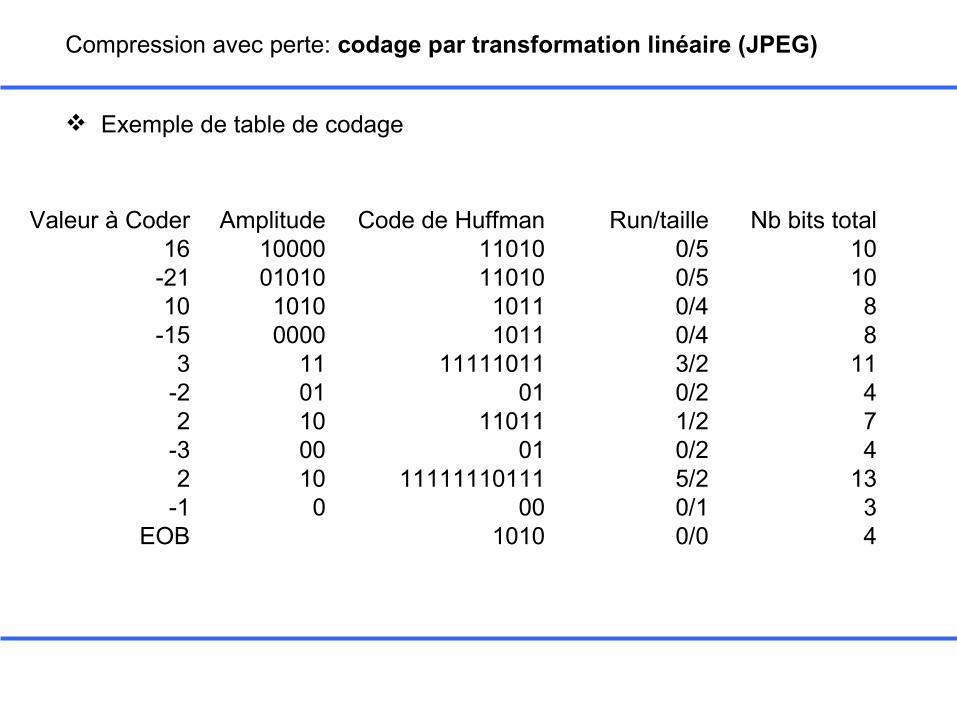
Compression avec perte: codage par transformation linéaire (JPEG)
Exemple de table de codage
Valeur à Coder16
-2110
-153
-22
-32
-1EOB
Run/taille0/50/50/40/43/20/21/20/25/20/10/0
Code de Huffman1101011010
10111011
1111101101
1101101
1111111011100
1010
Amplitude1000001010
10100000
1101100010
0
Nb bits total101088
11474
1334

Compression avec perte: codage par transformation linéaire (JPEG)
Fonctionnement de l’algorithme JPEG
• Deux paramètres de sélections (au choix):1. facteur de qualité:
• compris entre 0% et 100% (valeur standard: 75%)• Agit sur la qualité de l’image reconstruite = matrice de quantification
2. taux de compression ou débits• Agit sur la taille de l ’image compressée
Compression avec perte: codage par transformation linéaire (JPEG)
Autres modes de JPEG
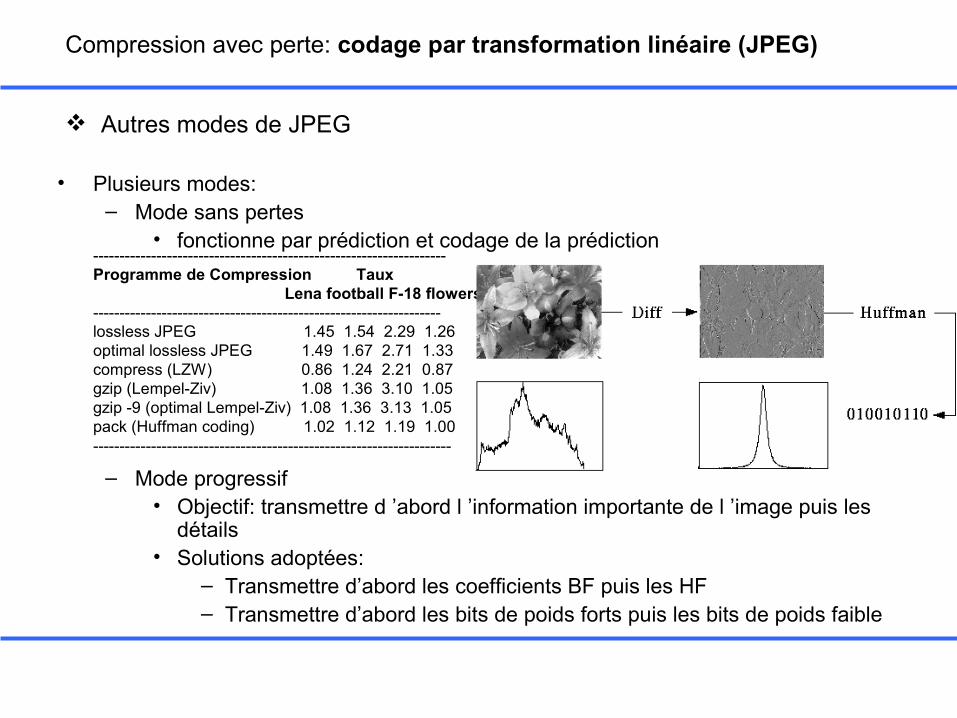
• Plusieurs modes:– Mode sans pertes
• fonctionne par prédiction et codage de la prédiction-------------------------------------------------------------------
Programme de Compression Taux Lena football F-18 flowers ------------------------------------------------------------------
lossless JPEG 1.45 1.54 2.29 1.26 optimal lossless JPEG 1.49 1.67 2.71 1.33compress (LZW) 0.86 1.24 2.21 0.87 gzip (Lempel-Ziv) 1.08 1.36 3.10 1.05 gzip -9 (optimal Lempel-Ziv) 1.08 1.36 3.13 1.05 pack (Huffman coding) 1.02 1.12 1.19 1.00 --------------------------------------------------------------------
– Mode progressif• Objectif: transmettre d ’abord l ’information importante de l ’image puis les
détails• Solutions adoptées:
– Transmettre d’abord les coefficients BF puis les HF– Transmettre d’abord les bits de poids forts puis les bits de poids faible
Compression avec perte: codage par transformation linéaire (JPEG)
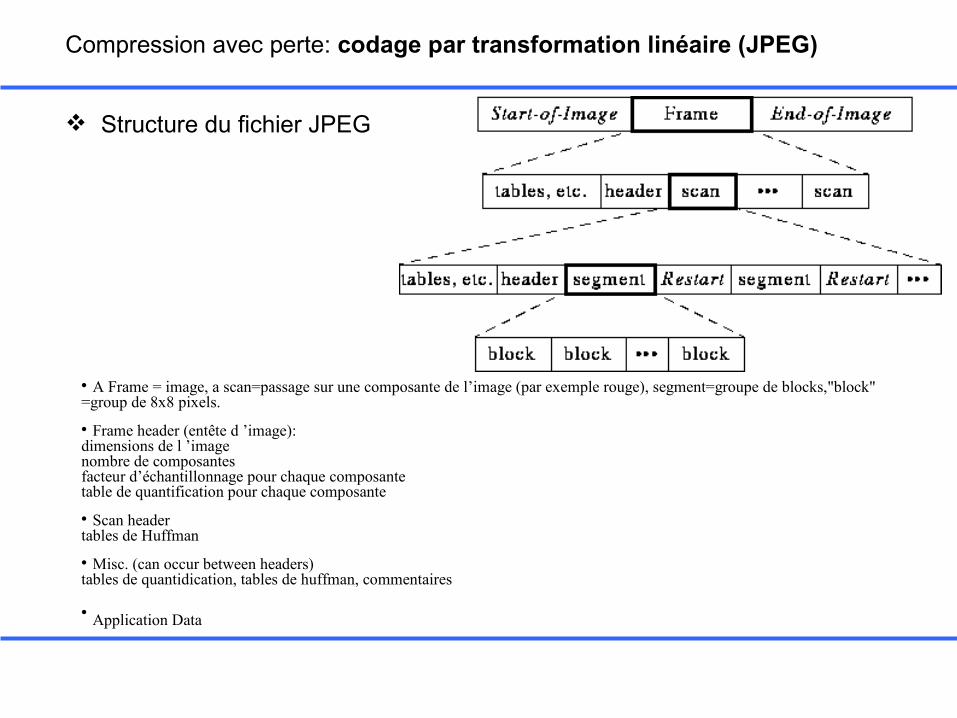
Structure du fichier JPEG
• A Frame = image, a scan=passage sur une composante de l’image (par exemple rouge), segment=groupe de blocks,"block" =group de 8x8 pixels.
• Frame header (entête d ’image): dimensions de l ’image nombre de composantes facteur d’échantillonnage pour chaque composantetable de quantification pour chaque composante
• Scan header tables de Huffman
• Misc. (can occur between headers) tables de quantidication, tables de huffman, commentaires
• Application Data