notes de cours de mathématiques en tsi 1 - olivier …olivier-lader.fr/tsi1.pdf · tsi1...
TRANSCRIPT

TSI 1 Lycée Heinrich-Nessel 2016/2017
Notes de cours de Mathématiques enTSI 1O. Lader
1

TSI 1 Lycée Heinrich-Nessel 2016/2017
2

Table des matières
1 Calculs et rappels 111.1 Les nombres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.2 Calcul algébrique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.3 Puissances . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.4 Le logarithme Népérien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.5 La racine carrée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.6 Fonction inverse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.7 Équations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.8 Polynômes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.8.1 Forme canonique d’un polynôme du second degré . . . . . . . . . . . . . . . . . . . 211.8.2 Équation du second degré . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221.8.3 Polynôme de degré 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
1.9 Inégalités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241.10 Valeur absolue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281.11 Partie entière, partie décimale et approximation . . . . . . . . . . . . . . . . . . . . . . . . 30
2 Logique et raisonnements 332.1 Un peu de logique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.2 Éléments de logique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.3 Techniques élémentaires de raisonnement . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.3.1 Démonstration par disjonction des cas . . . . . . . . . . . . . . . . . . . . . . . . . 382.3.2 Démonstration par l’absurde . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.3.3 Démonstration par contraposée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 392.3.4 Démonstration par analyse-synthèse . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.4 Entiers naturels et raisonnement par récurrence . . . . . . . . . . . . . . . . . . . . . . . . 402.4.1 Entiers naturels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 402.4.2 Raisonnement par récurrence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3 Nombres complexes 433.1 Définition, rappels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.2 Le plan complexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.3 Module, argument . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473.4 Forme trigonométrique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503.5 Rappels : Les formules de trigonométrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523.6 Équation trigonométrique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 543.7 Écriture exponentielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 553.8 Exponentielle complexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 563.9 Nombres complexes de module 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 573.10 Géométrie, le plan complexe (annexe) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3

TSI 1 Lycée Heinrich-Nessel 2016/2017
3.10.1 Angles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 583.10.2 Alignement. Orthogonalité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.10.3 Translations et symétries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 603.10.4 Rotations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.11 Linéarisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 623.12 Équations polynomiales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.12.1 Équation du second degré à coefficients réels . . . . . . . . . . . . . . . . . . . . . 643.12.2 Racine carrée d’un complexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 653.12.3 Trinômes à coefficients complexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 663.12.4 Racines ne de l’unité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4 Ensembles et manipulation algébrique 694.1 Les ensembles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.1.1 Intervalles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 724.1.2 Sous-ensemble . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 734.1.3 Union . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 744.1.4 Intersection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 754.1.5 Complémentaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 754.1.6 Produit cartésien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 764.1.7 Ensemble des sous-ensembles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 774.1.8 Majoration et minoration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.2 Manipulation algébrique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 804.2.1 Variables muettes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 804.2.2 Le symbole de sommation Σ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 804.2.3 Somme sur un ensemble fini arbitraire . . . . . . . . . . . . . . . . . . . . . . . . . 834.2.4 Somme télescopique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 844.2.5 Symbole de multiplication Π . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 844.2.6 Somme multiple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 854.2.7 Coefficients binomiaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
5 Fonctions, dérivation, logarithme et exponentielle 895.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
5.1.1 Représentation graphique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 915.2 Parité et périodicité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 935.3 Opérations sur les fonctions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 955.4 Variations de fonction, tableau de signes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.4.1 Fonction croissante, fonction décroissante . . . . . . . . . . . . . . . . . . . . . . . 965.5 Bijections . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
5.5.1 Signe d’une fonction et comparaison de fonctions . . . . . . . . . . . . . . . . . . . 995.5.2 Majoration, minoration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 995.5.3 Résolution graphique d’une inéquation . . . . . . . . . . . . . . . . . . . . . . . . . 100
5.6 Limites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1015.7 Dérivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
5.7.1 Nombre dérivé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1045.7.2 Notation de Leibniz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1085.7.3 Dérivées successives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1085.7.4 Fonction dérivée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1085.7.5 Variations des fonctions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
4

TSI 1 Lycée Heinrich-Nessel 2016/2017
5.7.6 Extremum d’une fonction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1125.7.7 Extremum local . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
5.8 Fonctions de référence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1145.8.1 Fonction logarithme Népérien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1145.8.2 Fonction exponentielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1155.8.3 Résolution d’une équation du type xn = k . . . . . . . . . . . . . . . . . . . . . . . 1165.8.4 Fonction puissance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1175.8.5 Croissances comparées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
6 Géométrie dans le plan 1216.1 Repère du plan Euclidien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
6.1.1 Vecteurs colinéaires du plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1236.1.2 Les vecteurs en dimension n . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1246.1.3 Bases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
6.2 Angles et coordonnées polaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1286.2.1 Mesure d’un angle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1286.2.2 Cosinus et sinus d’un angle orienté . . . . . . . . . . . . . . . . . . . . . . . . . . . 1316.2.3 Coordonnées polaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1316.2.4 Lien entre les deux modes de repérage . . . . . . . . . . . . . . . . . . . . . . . . . 132
6.3 Produit scalaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1336.3.1 Orthogonalité de deux vecteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1336.3.2 Propriétés du produit scalaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1336.3.3 Deux autres définitions du produit scalaire . . . . . . . . . . . . . . . . . . . . . . 1346.3.4 Carré scalaire et norme d’un vecteur . . . . . . . . . . . . . . . . . . . . . . . . . . 1356.3.5 Deux applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
6.4 Déterminant dans une base orthonormée directe . . . . . . . . . . . . . . . . . . . . . . . 1386.5 Droites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
6.5.1 Intersections . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1426.5.2 Médiatrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1426.5.3 Projeté orthogonal et distance à une droite . . . . . . . . . . . . . . . . . . . . . . 142
6.6 Cercles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1446.7 Transformations affines du plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
6.7.1 Translations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1456.7.2 Homothéties . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1456.7.3 Symétrie centrale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1466.7.4 Réflexions du plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1476.7.5 Rotations du plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
7 Fonctions circulaires, complexes et intégration 1517.1 Fonctions circulaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1517.2 Les fonctions circulaires réciproques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1537.3 Fonctions à valeurs dans C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1567.4 Intégration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
7.4.1 Intégrale d’une fonction positive . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1587.4.2 Propriétés de l’intégrale de fonctions continues quelconques . . . . . . . . . . . . . 1607.4.3 Primitives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
8 Géométrie dans l’espace 165
5

TSI 1 Lycée Heinrich-Nessel 2016/2017
8.1 Les solides usuels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1668.2 Repère de l’espace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1678.3 Les vecteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168
8.3.1 Bases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1708.4 Droites, plans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
8.4.1 Milieu de deux points . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1718.4.2 Droites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1718.4.3 Plans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1748.4.4 Intersections . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176
8.5 Produit scalaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1778.5.1 Distance entre points, droites, plans . . . . . . . . . . . . . . . . . . . . . . . . . . 1808.5.2 Vecteur normal et orthogonal (annexe) . . . . . . . . . . . . . . . . . . . . . . . . . 181
8.6 Produit vectoriel dans l’espace orienté . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1828.6.1 Produit mixte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1848.6.2 Applications au calcul de distances . . . . . . . . . . . . . . . . . . . . . . . . . . . 186
8.7 Sphères . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
9 Dénombrement 1899.1 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
9.1.1 Injectivité. Surjectivité. Bijectivité . . . . . . . . . . . . . . . . . . . . . . . . . . . 1909.1.2 Composition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1939.1.3 Restrictions d’applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
9.2 Cardinal d’un ensemble fini . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1949.2.1 Opérations sur les ensembles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1959.2.2 Application entre deux ensembles . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1969.2.3 Produit cartésien, p-uplets et combinaisons . . . . . . . . . . . . . . . . . . . . . . 197
10 Équations différentielles linéaires 20310.1 Compléments sur l’intégration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20310.2 Quelques généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20410.3 Équation différentielle linéaire d’ordre 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20610.4 Équation différentielle linéaire d’ordre 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
11 Systèmes linéaires 21511.1 Systèmes linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215
11.1.1 Systèmes et opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21711.2 Matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
11.2.1 Opération sur les matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21911.2.2 Inverse d’une matrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
11.3 Retour aux systèmes linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22211.3.1 Matrices échelonnées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22411.3.2 Algorithme du pivot de Gauss-Jordan . . . . . . . . . . . . . . . . . . . . . . . . . 22511.3.3 Rang . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 226
11.4 Familles de vecteurs de Rn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22711.5 Annexe : Les matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
11.5.1 Opérations élémentaires et produit de matrices . . . . . . . . . . . . . . . . . . . . 23011.5.2 Recherche de l’inverse d’une matrice . . . . . . . . . . . . . . . . . . . . . . . . . . 231
12 Nombres réels et suites numériques 233
6

TSI 1 Lycée Heinrich-Nessel 2016/2017
12.1 Entiers naturels et raisonnement par récurrence . . . . . . . . . . . . . . . . . . . . . . . . 23412.1.1 Raisonnement par récurrence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234
12.2 Ensemble ordonné des nombres réels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23412.2.1 Inégalités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23512.2.2 Valeur absolue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23612.2.3 Borne inférieure, supérieure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 237
12.3 Suites numériques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23812.4 Opérations sur les suites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 240
12.4.1 Suites et variations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24112.4.2 Majoration. Minoration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242
12.5 Convergence d’une suite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24312.5.1 Convergence vers une limite finie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24312.5.2 Divergence vers l’infini . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 248
12.6 Suites adjacentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24912.7 Notation de Landau et équivalence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25012.8 Suites arithmétiques et géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25312.9 Suites arithmético-géométriques (annexe) . . . . . . . . . . . . . . . . . . . . . . . . . . . 25512.10 Suites extraites (annexe) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256
13 Polynômes 25713.1 Généralités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25713.2 Fonction polynômiale associée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26113.3 Arithmétique dans K[X] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26313.4 Racines d’un polynôme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26513.5 Polynômes dérivés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 268
14 Limites et continuité 27514.1 Limites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 275
14.1.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27514.1.2 Opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27814.1.3 Comparaisons des fonctions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 279
14.2 Notation de Landau et équivalence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28014.3 Continuité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284
14.3.1 Opérations sur les fonctions continues . . . . . . . . . . . . . . . . . . . . . . . . . 28614.3.2 Deux théorèmes fondamentaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28614.3.3 Bijectivité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 288
14.4 Application aux suites numériques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 289
15 Calcul matriciel 29115.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29215.2 Opérations sur les matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29315.3 Inverse d’une matrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29715.4 Opérations élémentaires, matrices échelonnées . . . . . . . . . . . . . . . . . . . . . . . . . 29815.5 Recherche de l’inverse d’une matrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30015.6 Applications linéaires de Kn dans Km . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 301
16 Dérivation 30516.1 Nombre dérivé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30516.2 Fonction dérivée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 308
7

TSI 1 Lycée Heinrich-Nessel 2016/2017
16.3 Théorème de Rolle et des accroissements finis . . . . . . . . . . . . . . . . . . . . . . . . . 30916.4 Fonctions de classe Ck . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31216.5 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314
16.5.1 Suite réelle définie par récurrence . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31416.5.2 Développement limité d’ordre 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31416.5.3 Résolution d’équation : Méthode de Newton . . . . . . . . . . . . . . . . . . . . . . 315
17 Espaces vectoriels 31717.1 Corps (annexe) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31817.2 Espace et sous-espace vectoriel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31917.3 Familles de vecteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324
17.3.1 Famille génératrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32417.3.2 Indépendance linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324
17.4 Espaces vectoriels en dimension finie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32617.4.1 Bases et dimensions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32617.4.2 Sous-espaces vectoriels en dimension finie . . . . . . . . . . . . . . . . . . . . . . . 328
18 Probabilités sur un univers fini 33118.1 Rappels sur le dénombrement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 331
18.1.1 Cardinal d’un ensemble fini . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33118.1.2 Opérations sur les ensembles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33218.1.3 Application entre deux ensembles . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33218.1.4 Produit cartésien, p-uplets et combinaisons . . . . . . . . . . . . . . . . . . . . . . 333
18.2 Probabilités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33518.3 Probabilité conditionnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33818.4 Indépendance de deux événements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343
19 Développements limités 34519.1 Développements limités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34619.2 Développement limité des fonctions de classe Cn . . . . . . . . . . . . . . . . . . . . . . . 34819.3 Développements limités des fonctions de référence . . . . . . . . . . . . . . . . . . . . . . . 35019.4 Développements limités et opérations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35219.5 Formules de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35419.6 Asymptotes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35619.7 Formulaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 357
20 Applications linéaires 35920.1 Rappels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36020.2 Applications linéaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36120.3 Application linéaire et sous-espace vectoriel . . . . . . . . . . . . . . . . . . . . . . . . . . 365
20.3.1 Application linéaire entre espaces vectoriels de dimension finie . . . . . . . . . . . 36920.4 Changement de bases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373
20.4.1 Matrice d’une application linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37320.4.2 Changement de bases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 376
20.5 Les différentes définitions du rang . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 378
21 Variables aléatoires 38321.1 Variable aléatoire et loi de probabilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38321.2 Fonction de répartition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 385
8

TSI 1 Lycée Heinrich-Nessel 2016/2017
21.3 Espérance et variance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38621.4 Loi de Bernoulli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38921.5 Loi binomiale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39021.6 La planche de Galton (1894) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39421.7 Échantillonnage (annexe) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 396
22 Integration 40122.1 Intégrale d’une fonction continue positive . . . . . . . . . . . . . . . . . . . . . . . . . . . 40222.2 Intégrale d’une fonction continue quelconque . . . . . . . . . . . . . . . . . . . . . . . . . 40322.3 Sommes de Riemann et méthode des rectangles . . . . . . . . . . . . . . . . . . . . . . . . 40622.4 Approximation de l’intégrale avec Numpy . . . . . . . . . . . . . . . . . . . . . . . . . . . 40922.5 Primitives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41022.6 Intégration par parties et Changement de variables . . . . . . . . . . . . . . . . . . . . . . 41322.7 Formule de Taylor avec reste intégral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414
9

TSI 1 Lycée Heinrich-Nessel 2016/2017
10

Chapitre 1
Calculs et rappels
Programme• Les ensembles de nombres : N, Z, D, Q, R et C
• L’addition, la multiplication et propriétés• Fractions• identités remarquables• développer, factoriser• racine carrée, propriétés• fonction inverse• puissances, fonction exponentielle, fonction logarithme• Égalité, opérations, R est intègre...• Polynôme de degré deux : Racines, discriminant, signe• Polynôme de degré trois. Racine évidente, division Euclidienne par x− α• factoriser un polynôme de degré inférieur ou égal à trois dont une racine est connue• Inégalités larges strictes. Opérations (compatibilité).L’objectif est une maitrise de la manipulation élémentaire des inégalités
• Fonction monotone• inégalité et signe de la différence• signe d’un trinôme du second degré• valeur absolue, propriétés• Interpréter sur la droite réelle des inégalités du type |x− a| ≤ b.• distance entre deux réels, inégalité triangulaire• partie entière, propriétés• valeur approchée
1.1 Les nombres
Définition 1.1.1) L’ensemble des nombres entiers naturels est noté N :
N = 0, 1, 2, 3, 4, 5, . . .
2) L’ensemble des nombres entiers relatifs est noté Z :
Z = . . . ,−3,−2,−1, 0, 1, 2, 3, 4, 5, . . .
3) L’ensemble des nombres entiers décimaux est noté D. C’est l’ensemble des nombres qui peuvent
11

TSI 1 Lycée Heinrich-Nessel 2016/2017
s’écrire avec un nombre fini de chiffres après la virgule. Par exemple, 0.33 est un nombre décimalmais 1
3 n’en est pas un.4) L’ensemble des nombres rationnels est noté Q. C’est l’ensemble des nombres qui peuvent s’écrire
sous la forme ab avec a un entier relatif et b un entier relatif non nul.
5) L’ensemble des nombres réels est noté R. Cet ensemble complète d’une certaine manière l’en-semble des rationnels Q, on y a ajouté les racines carrés et encore beaucoup d’autres nombres.
0 1 2 3 4 5 6 7 . . .N
-1-2-3-4-5-6-7. . .Z
D-7.9 -6.342 -3.876 3.21 5.24231
227
−133
−167
5011Q
π√
2−eR
Figure 1.1 – Les ensembles de nombres
Définition 1.2. Pour décrire un ensemble fini, on utilise des accolades de la manière suivante
x1, . . . , xn.
Avec cette notation, on désigne un ensemble à n éléments dont les éléments sont notés xi pour i allantde 1 à n.
Exemples.• L’ensemble des 5 premiers entiers naturels : 0, 1, 2, 3, 4.• L’ensemble des nombres premiers inférieurs ou égaux à 30 : 2, 3, 5, 7, 11, 13, 17, 19, 23, 29.
Les intervalles de R : Soient a ≤ b deux nombres réels, alors [a; b] = x ∈ R; a ≤ x ≤ b est l’ensembledes nombres réels compris entre a et b avec a et b inclus. Si on ouvre le crochet d’un côté ou de l’autre,on retire la borne en question. Par exemple, ]a; b] représente l’intervalle précédent mais avec a exclu.Enfin, [a; +∞[ désigne l’ensemble des nombres supérieurs ou égaux à a et ] −∞; b[ désigne l’ensembledes nombres inférieurs strictement à b.
1.2 Calcul algébrique
Définition 1.3 (propriété). L’ensemble des nombres réels est muni de deux opérations :• L’addition de deux éléments : a+ b ;
12

TSI 1 Lycée Heinrich-Nessel 2016/2017
• La multiplication de deux éléments : a× b.Ces opérations vérifient les propriétés suivantes : Quels que soient a, b et c trois nombres réels :
1) 0 est l’élément neutre pour l’addition : a+ 0 = 0 + a = a ;2) Tout élément admet un opposé −a tel que (−a) + a = a+ (−a) = a− a = 0 ;3) 1 est l’élément neutre pour la multiplication : 1× a = a× 1 = a ;4) Tout élément non nul a admet un inverse, noté 1
a ou a−1 : a× 1a = 1
a × a = 1 ;5) a+ (b+ c) = (a+ b) + c ; (associativité de l’addition)6) a× (b× c) = (a× b)× c ; (associativité de la multiplication)7) a+ b = b+ a ; (commutativité de l’addition)8) a× b = b× a ; (commutativité de la multiplication)9) a(b+ c) = ab+ ac ; (distributivité)10) 0× a = 0 ; (0 est absorbant pour la multiplication)
Notation. La seule et unique situation où l’on n’écrit pas un symbole d’opération sur les nombres estlors de la multiplication à droite par une variable ! Par exemple, 2x signifie 2× x.
Remarque.
• On évitera soigneusement de dire dans la situation suivante x(x2+x+1)x(1+x+
√x) = x2+x+1
1+x+√x
que les « xs’annulent » mais plus justement qu’on simplifie les x ! Cette précaution facilitera la distinctionentre les nombres 0 et 1.
• L’ordre dans lequel on multiplie deux nombres ne compte pas. Par exemple, on a la simplificationsuivante
2x× 3 = 2× x× 3 = 6x
• Soit a un nombre réel, alors a1 = a.
• Soit b un nombre réel non nul, alors 0b = 0 par contre a
0 n’existe pas !• L’opposé d’un quotient a
b est −ab = −ab = a
−b .
Définition 1.4. Les calculs à effectuer en premier sont ceux qui sont écrits entre parenthèses encommençant par celle qui sont le plus à l’intérieure. En l’absence ou à l’intérieur des parenthèses, lesopérations doivent être effectués dans l’ordre suivant :• d’abord les puissances et les racines ;• ensuite les multiplications et les divisions ;• enfin les additions et les soustractions.
Exercice 1.1.1) Compléter le schéma et déterminer l’expression en fonction de x à laquel il correspond.
x x 3
2carré
opposé
somme
produit
somme
13

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) Mettre les expressions suivantes sous forme de schéma de calcul :a) (3x+ 2)2 + 2(x+ 11) + (x− 5)
√x+ 5 ;
b) 1x + π(3(
√x+1−2)2+x2)+
√x−1
3x−5 .
Certaines fois les parenthèses sont inutiles par exemple :• (a+ b) + (c+ d) = a+ b+ c+ d ;• (ab) (cd) = a b c d.
Plus généralement, dans une expression :• on peut supprimer les parenthèses lorsqu’elles sont précédées du signe plus +.• on ne peut pas supprimer les parenthèses lorsqu’elles sont précédées du signe moins -. Dans ce cas,
pour enlever les parenthèses, il faut développer, en changeant le signe de chaque terme de la sommealgébrique. Par exemple : 3x− (5x2 − 2x+ 3) = 3x − 5x2 + 2x − 3 .
Remarque. Une situation où les parenthèses sont nécessaires : lors de la substitution dans une expressiond’un terme par une autre expression. Par exemple, si dans l’égalité 2x+4y = 7, on substitue y par 3x+5,alors il faudra écrire à chaque fois cette nouvelle expression introduite entre parenthèses :
2x+ 4(3x+ 5) = 7
Ensuite, seulement, on simplifie l’expression !
Définition 1.5.Développer : c’est transformer un produit de facteurs en une somme de termes.Factoriser : c’est transformer une somme de termes ayant un facteur commun en un produit de facteurs.
Formellement, le fait de développer peut être représenté de la manière suivante :
a (b+ c) = a b+ a c (?)
le fait de factoriser peut être représenté de la manière suivante :
a b+ a c = a (b+ c)
On remarque que pour développer, on lit l’identité (?) de la gauche vers la droite et pour factoriser, onlit l’identité (?) dans l’autre sens de la droite vers la gauche. En quelque sorte, les actions de développeret de factoriser sont réciproque l’une de l’autre.
Remarque. À l’aide des schémas de calculs présentés dans l’exercice précédent, on note qu’une expressionest dite « factorisée » si la dernière opération en bas du schéma est la multiplication. Ou, en revenantaux priorités des opérations, une expression est dite « factorisée » si la dernière opération à effectuer estune multiplication.
Exemples.1) x(2 + x+ x2) = 2x+ x2 + x3.2) 12x3 + 8x = 4x(3x2 + 2).3) (a+ b)(a− b) = (a+ b)a− (a+ b)b = a2 + ab− ab− b2 = a2 − b2.
Une conséquence de la distributivité :
Proposition 1.6 (double distributivité). Soient a, b, c et d quatre nombres, on a
(a+ b)(c+ d) = ac+ ad+ bc+ bd
Exemples.1) (2x+ 4)(x+ y) = 2x2 + 2xy + 4x+ 4y,2) (3x− 2)(x− 4) = 3x2 − 12x− 2x+ 8 = 3x2 − 14x+ 8,3) x2 − 5x+ 6 = (x− 2)(x− 3).
14

TSI 1 Lycée Heinrich-Nessel 2016/2017
Propriétés 1.7 (identités remarquables). Soient a et b deux nombres,
(a+ b)2 = a2 + 2ab+ b2,
(a− b)2 = a2 − 2ab+ b2,
(a+ b)(a− b) = a2 − b2.
Remarque. Effectivement, en général (a+ b)2 6= a2 + b2. Par exemple, si a = 1 et b = 3 alors (1+3)2 = 16qui est différent de 12 + 32 = 10.
Exemples.1) (x+ 3)2 = x2 + 6x+ 9,2) (x− 1)2 = x2 − 2x+ 1,3) x2 + 4x+ 4 = (x+ 2)2,4)
(a+ b+ c)2 = (a+ b)2 + 2(a+ b)c+ c2
= a2 + 2ab+ b2 + 2ac+ 2bc+ c2
(a+ b+ c)2 = a2 + b2 + c2 + 2 (ab + ac + bc)
En d’autres termes, une somme de trois nombres au carrée est égale à la somme des carrés plusdeux fois la somme des produits des trois couples possibles entre les nombres.
5)
(a+ b)3 = (a+ b)(a+ b)2
= (a+ b)(a2 + 2ab+ b2)= a3 + 2a2b+ ab2 + a2b+ 2ab2 + b3
(a+ b)3 = a3 + 3a2 b + 3ab2 + b3
Comme application, on déduit que (x+ 1)3 = x3 + 3x2 + 3x+ 1.
Exercice 1.2. Développer (a− b)3.
Vocabulaire. Soit a un nombre réel et b un nombre réel non nul, alors l’expressiona
b= a× 1
b
est appelée une fraction et a le numérateur et b le dénominateur de cette fraction.
Définition 1.8.1) Deux fractions sont dites « réduite au même dénominateur » si elles ont le même dénominateur.2) Soit a
c et bc deux fractions réduites au même dénominateur c, alors
a
c+ b
c= a+ b
c
Proposition 1.9 (addition de deux fractions). Pour tous nombres a, b, c et d avec b 6= 0 et d 6= 0, ona :
a
b+ c
d= ad+ bc
bd
Exemples.1) 5
6 + 34 = 5×4+3×6
6×4 = 3824 = 19
12 . Avec, un peu d’astuce, on aurait pu remarquer que le plus petitcommun multiple (ppcm) des dénominateurs 6 et 4 est 12, ainsi : 5
6 + 34 = 5×2+3×3
12 = 1912 .
2) Soit x un nombre différent de 1 et -1,
7x− 1 + x
x+ 1 = 7(x+ 1) + x(x− 1)(x− 1)(x+ 1) = x2 + 6x+ 7
x2 − 1
15

TSI 1 Lycée Heinrich-Nessel 2016/2017
Par contre, le produit de deux fractions est plus simple à calculer :
a
b× c
d= a× cb× d
Proposition 1.10. Soit a, b, c et d quatre nombres non nuls.1) L’inverse d’une fraction non nulle s’obtient en échangeant son numérateur et son dénominateur :(a
b
)−1= 1
ab
= b
a
2) Diviser par une fraction revient à multiplier par son inverse :abcd
= a
b× d
c
Proposition 1.11 (égalité entre deux fractions).
a
b= c
dsi et seulement si, a× d = b× c.
Proposition 1.12.1) Un produit est nul si et seulement si l’un au moins de ses facteurs est nul.
a× b = 0 si et seulement si, a = 0 ou b = 0
2) Un quotient est nul si et seulement si son numérateur est nul :
ab = 0 si et seulement si a = 0.
1.3 Puissances
Définition 1.13. Soit n un entier naturel non nul, on note :
an = a× . . .× a︸ ︷︷ ︸n fois
Lorsque de plus, a est non nul, on note
a0 = 1 et a−n = 1an
L’expression an se lit « a puissance n » et n est appelé l’ exposant.
À l’aide des fonctions logarithme et exponentielle, on peut étendre la définition des puissances :
Proposition 1.14. Soit a un nombre réel strictement positif et x un nombre réel quelconque, alorsa puissance x est définie ainsi :
ax = ex ln(a)
De plus, lorsque x est un entier relatif, la définition de la puissance coïncide avec la précédentedéfinition.
16

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 1.15. Quels que soient a > 0, α et β des nombres réels,
1) 1α = 1 ;2) aα × aβ = aα+β ;3) 1
aα = a−α ;
4) aα
aβ= aα−β ;
5) (aα)β = aα×β ;6)√aα = a
α2 .
Proposition 1.16. Soit a > 0. On admet que la fonction x 7→ ax, définie sur R, est :• strictement décroissante lorsque 0 < a < 1 ;• constante lorsque a = 1 ;• strictement croissante lorsque a > 1.
x
y
0 < a < 1
x
y
a > 1
Exemple.• La fonction x 7→ 0.9x est strictement décroissante sur R car 0 < 0.9 < 1 ;• La fonction x 7→ 2.4x est strictement croissante sur R car 1 < 2.4.
Une conséquence,
Proposition 1.17. Si a 6= 1, alors pour tous nombres réels α et β, on a :
aα = aβ si et seulement si α = β
1.4 Le logarithme Népérien
Proposition 1.18.1) Pour tout y > 0 et x ∈ R, on a y = ex si et seulement si x = ln(y) ;2) Pour tout x ∈ R : ln(ex) = x.
Proposition 1.19. Soit a et b deux nombres de l’intervalle ]0; +∞[. Alors,1) ln(a) = ln(b) si et seulement si a = b ;2) ln(a) < ln(b) si et seulement si a < b.
En particulier :• ln(a) = 0 équivaut à a = 1• ln(a) < 0 équivaut à 0 < a < 1• ln(a) > 0 équivaut à a > 1
17

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 1.20. Pour tout a, b > 0 et x ∈ R, on a
1) ln(ab) = ln(a) + ln(b) ; (le logarithme du produit est la somme des logarithmes)2) ln( 1
a ) = − ln(a) ;3) ln(ab ) = ln(a)− ln(b) ;4) ln(ax) = x× ln(a).
Applications : équations et inéquationsSoit a et b des nombres réels strictement positifs tels que a 6= 1.
Proposition 1.21. L’équation ax = b, d’inconnue x, a une unique solution dans R : le nombre ln(b)ln(a) .
x
y
0 < a < 1
ln(b)ln(a)
b
y = ax
x
y
a > 1
ln(b)ln(a)
b
y = ax
Proposition 1.22. L’ensemble des solutions de l’inéquation ax < b est :• dans le cas 0 < a < 1, l’intervalle ] ln(b)
ln(a) ; +∞[ ;
• dans le cas 1 < a, l’intervalle ]−∞; ln(b)ln(a) [ ;
Proposition 1.23. L’ensemble des solutions de l’inéquation ax > b est :• dans le cas 0 < a < 1, l’intervalle ]−∞; ln(b)
ln(a) [ ;
• dans le cas 1 < a, l’intervalle ] ln(b)ln(a) ; +∞[ ;
1.5 La racine carrée
x 7→√x
Proposition 1.24.• La fonction racine carrée x 7→
√x est définie sur l’intervalle [0; +∞[.
• Pour tout x ≥ 0 :√x est le nombre tel que si on l’élève au carré on obtient x :
x = (√x)2
18

TSI 1 Lycée Heinrich-Nessel 2016/2017
• Pour tout x1 ≥ 0 et x2 ≥ 0, on a √x1 x2 =
√x1√x2
et √x1
x2=√x1√x2
• La fonction racine carrée est strictement croissante sur [0; +∞[.
1.6 Fonction inverse
x 7→ 1x
Le graphe de la fonction inverse est une hyperbole.
Proposition 1.25.• La fonction inverse f(x) = 1
x est définie sur ]−∞; 0[ et sur ]0; +∞[.• Le fonction inverse est strictement décroissante sur ]−∞; 0[ et est strictement décroissante sur
]0; +∞[.
1.7 Équations
Dans cette section, par équation, nous entendrons toutes égalités entre deux expressions mathématiquesfaisant intervenir des nombres, des paramètres (nombres fixés arbitraires, notés à l’aide de lettres, engénéral a, b, c, A, B, M , α, β, . . . ) et des inconnues (notés à l’aide de lettres, en général : x, y, z, t)prenant leurs valeurs dans un ensemble donné (par exemple, un intervalle, R ou C).Le choix du nom des paramètres et des variables est totalement arbitraire et souvent guidé par des raisonspratiques. On pourrait par exemple nommer la variable « tartempion », mais ce serait assez fastidieux àrecopier plusieurs fois dans une expression... Par contre, en informatique, pour gagner en lisibilité dansun code, il est préférable de nommer les variables avec des noms en toutes lettres (par exemple, somme,total, compteur, message, . . . ).
Exemples. Quelques exemples d’équations :1) 5
2x+ 413 = 0 d’inconnue x dans R.
2) (x+ 1)(x− 5) = 0 d’inconnue x dans R.3) 12y + 1.2 = −3 d’inconnue y dans R.4) x+ 1 = 3x+4
5 d’inconnue x dans R.5) x+ a = 3x+4
5 d’inconnue x et paramètre a dans R.6) ax+ b = 0 d’inconnue x et de paramètres a et b dans R.7) ax2 + bx+ c = 0 d’inconnue x et de paramètres a, b et c dans C.
Vocabulaire. L’ensemble des solutions d’une équation est l’ensemble de toutes les valeurs que peuventprendre les inconnues de telle sorte qu’après substitution l’égalité soit effectivement vérifiée.
19

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemple. L’ensemble des solutions de l’équation x + 1 = 0 est −1 et l’ensemble des solutions del’équation x2 + x− 2 = 0 est 1; −2.
Définition 1.26. On dit que deux équations (ou des inéquations) sont équivalentes lorsqu’elles ontle même ensemble de solutions.
Résoudre une équation revient à déterminer l’ensemble solution de l’équation. Quelques outils pour ré-soudre une équation :
Proposition 1.27.1) Lorsqu’on ajoute ou retranche un même nombre de part et d’autre d’une équation, on obtient
une équation équivalente.2) Lorsqu’on multiplie ou divise par un même nombre non nul de part et d’autre d’une équation,
on obtient une équation équivalente.
Exercice 1.3. Soit m un nombre réel, considérons l’équation
mx
2 + (m− 1)x3 = 1
d’inconnue x.1) Déterminer m pour que x = 6 soit solution de l’équation.2) Déterminer m pour que l’équation n’admette pas de solution.
Proposition 1.28. Soit A(x, . . .) et B(x, . . .) deux expressions mathématiques dépendant de para-mètres et d’inconnues, alors de la proposition 1.12, on déduit que
A(x, . . .)×B(x, . . .) = 0 implique A(x, . . .) = 0 ou B(x, . . .) = 0
Exemple.
5x2 + 4x = 0 on factorise xx(5x+ 4) = 0 on applique la propositionx = 0 ou 5x+ 4 = 0
x = 0 ou x = −45
Ainsi l’équation du seconde degré 5x2 + 4x = 0 admet deux solutions −45 et 0.
Si on applique la méthode usuelle (avec le calcul du discriminant) de résolution des équations du seconddegré, bien évidemment qu’on retrouve les mêmes solutions. Néanmoins, pour une équation du seconddegré sans coefficient constant (i.e : c = 0), il est préférable d’utiliser la méthode précédente. On n’utiliseaucune formule !
1.8 Polynômes
Définition 1.29. Une fonction polynôme de degré deux (ou un trinôme du second degré) est unefonction f : R→ R définie par :
f(x) = ax2 + bx+ c
où a, b et c sont des nombres réels donnés tel que a 6= 0.Les trois réels a, b et c sont appelés les coefficients de la fonction f et plus précisément a est appeléle coefficient dominant.
Remarque. Par abus de langage, on se permet d’identifier la fonction f avec l’expression algébriqueax2 + bx+ c.
20

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemples. Quelques exemples de fonctions polynômes du second degré :• f(x) = 1043x2 + 12564x− 1954,• f(x) = (x− 1)(x+ 2),• f(x) = (x+ 1)2.
Les fonctions suivantes ne sont pas des fonctions polynômes du second degré :• f(x) = 1
x2 + x+ 1,• f(x) = x3 + x+ 1,• f(x) = (x+ 1)2 − x2.
On peut définir la notion de fonction polynôme de degré n ainsi f : R→ R définie par
f(x) = anxn + an−1x
n−1 + . . .+ a1x+ a0
Par exemple, x 7→ x + 12 est une fonction polynôme de degré un et x 7→ x4 − x3 + x2 − x + 1 est unefonction polynôme de degré 4.
Proposition 1.30 (admis). Deux fonctions polynômes sont égales si et seulement si les coefficientsdevant les différents monômes sont deux à deux égaux :
(Pour tout x ∈ R : anxn + an−1x
n−1 + . . .+ a0 = bnxn + bn−1x
n−1 + . . .+ b0
)⇐⇒
an = bn
an−1 = bn−1... =
...a0 = b0
1.8.1 Forme canonique d’un polynôme du second degré
Propriété-Définition 1.31. Soit f : R→ R, f(x) = ax2 + bx+ c une fonction polynôme du seconddegré (a 6= 0). Il existe de nombre réels α et β tels que pour tout nombre réels x, on a
ax2 + bx+ c = a(x− α)2 + β
L’écriture a(x− α)2 + β est la forme canonique du trinôme ax2 + bx+ c.
Démonstration. Soit x un nombre réel, comme a est non nul, on a
ax2 + bx+ c = a(x2 + 2 b
2ax) + c
Posons, α = −b2a , alors
ax2 + bx+ c = a(x2 − 2αx) + c
Dans la parenthèse, à l’ajout de α2 près, on voit apparaître une identité remarquable :
ax2 + bx+ c = a(x2 − 2αx+ α2) + c− aα2
Posons β = c− aα2, alors
ax2 + bx+ c = a(x2 − α)2 + β
Remarque. Il peut être intéressant de retenir le principe de la démonstration au lieu de la propriété. Unexemple d’application :
x2 + x+ 1 =(x2 − 2
(−12
)x+
(−12
)2)
+ 1−(−1
2
)2 = (x+ 1
2)2 + 34
Avec cette écriture, comme (x+ 12 )2 ≥ 0, on note que f(x) = x2 +x+ 1 ≥ 3
4 quel que soit le nombre réelx et on a égalité lorsque x = −1
2 (f(−12 ) = 3
4 ).
21

TSI 1 Lycée Heinrich-Nessel 2016/2017
1.8.2 Équation du second degré
Rappelons que :• Pour tout nombre réel x, x2 > 0. Ainsi l’équation x2 = a n’a pas de solution si a est strictementnégatif.
• D’autre part, le seul nombre dont le carré est 0 est 0 lui-même : x2 = 0 implique que x = 0.• Pour tout nombre réel x, (−x)2 = x2. Ainsi, si x est un nombre tel que x2 = a alors (−x)2 = aaussi.
Plus précisément :
Proposition 1.32. Soit a un nombre réel. Distinguons trois cas :1) Si a > 0, alors l’équation x2 = a admet deux solutions x =
√a et x = −
√a.
2) Si a = 0, alors l’équation x2 = 0 admet une unique solution x = 0.3) Si a < 0, alors l’équation x2 = a n’admet pas de solution.
Exemples.1) x2 = 9 admet deux solutions x =
√9 = 3 et x = −3.
2) x2 = 7 admet deux solutions x =√
7 et x−√
7.3) x2 = 0 admet une unique solution x = 0.4) x2 = −9 n’admet pas de solution, car un nombre au carré est toujours positif.
Définition 1.33. Une équation du second degré, d’inconnue x, est une équation qui peut s’écrire sousla forme ax2 + bx+ c = 0, où a, b et c sont des nombres réels tels que a soit non nul.
Dans une équation du second degré, les nombres a, b et c sont des paramètres, c’est-à-dire qu’ils sontdéterminés à l’avance et l’objet de la résolution est de déterminer les valeurs que x peut prendre.
Définition 1.34. Une solution de l’équation du second degré ax2 + bx+ c = 0 est appelée une racinedu trinôme ax2 + bx+ c.
Soit ax2 + bx+ c = 0 une équation du second degré, si l’on pose α = −b2a et β = c− b2
4a , on a ax2 + bx+ c =a(x− α)2 + β. Ainsi, le nombre réel x est solution de l’équation du second degré si et seulement si
a(x− α)2 + β = 0 ⇐⇒ a(x− α)2 = −β ⇐⇒ 4a2(x− α)2 = b2 − 4ac ⇐⇒ (2ax− 2aα)2 = b2 − 4ac
D’autre part, le nombre b2 − 4ac admet une racine carrée si et seulement s’il est positif.Distinguons deux cas :• Si b2 − 4ac < 0, l’équation du second degré n’admet pas de solution.• Si b2 − 4ac ≥ 0, alors les solutions X2 = b2 − 4ac sont X = ±
√b2 − 4ac. Ainsi, x est solutions de
l’équation du second degré si et seulement si
2ax− 2aα = ±√b2 − 4ac ⇐⇒ x = −b+±
√b2 − 4ac
2aEn résumé, on vient de voir la propriété suivante :
Propriété-Définition 1.35. Soit ax2 +bx+c = 0 une équation du second degré. Le nombre b2−4acest appelé le discriminant de l’équation et est noté ∆. De plus, on a• Si ∆ > 0, l’équation du second degré ax2 + bx+ c = 0 admet deux solutions :
x1 = −b −√
∆2a et x2 = −b +
√∆
2a
• Si ∆ = 0, l’équation du second degré ax2 + bx+ c = 0 admet une unique solution x0 = −b2a .
Dans ce cas, on dit que x0 est une racine double.
22

TSI 1 Lycée Heinrich-Nessel 2016/2017
• Si ∆ < 0, l’équation du second degré ax2 + bx+ c = 0 n’admet pas de solution dans R mais dansC elle admet deux solutions :
x1 = −b − i√−∆
2a et x2 = −b + i√−∆
2a
Propriété 1.36 (Factorisation du trinôme). Soit ax2 + bx+ c = 0 une équation du second degré.• Supposons que le discriminant ∆ est non nul et notons x1 et x2 les deux racines, alors
ax2 + bx+ c = a(x− x1)(x− x2)
• Supposons que ∆ = 0, alors x0 = −b2a est l’unique racine et
ax2 + bx+ c = a(x− x0)2
1.8.3 Polynôme de degré 3
Définition 1.37. Une fonction polynôme de degré trois est une fonction f : R→ R définie par :
f(x) = ax3 + bx2 + cx+ d
où a, b, c et d sont des nombres réels donnés tel que a 6= 0.Les quatre réels a, b et c sont les coefficients de la fonction f et a est appelé le coefficient dominant.
On peut aussi chercher à résoudre l’équation de degré 3 associée :
ax3 + bx2 + cx+ d = 0
et les solutions sont aussi appelées des racines.
Remarque. Il existe encore une méthode pour résoudre de telles équations, la méthode de Cardan, maisnous ne la verrons pas dans le cours.
Exemple. Considérons la fonction polynôme de degré trois f : R→ R définie par f(x) = x3 +x2−10x+8pour tout nombre réel x.L’équation x3 +x2− 10x+ 8 = 0 admet une solution évidente x = 1. Effectuons une division Euclidienne(similaire à celle avec les nombres) :
x3 + x2 − 10x+ 8 x− 1−( x3 − x2) x2 + 2x− 8
2x2 − 10x+ 8−( 2x2 − 2x )−8x+ 8−( −8x+ 8)
0
Ainsi, on en déduit que x3 + x2 − 10x+ 8 = (x− 1)(x2 + 2x− 8) et
x3 + x2 − 10x+ 8 = 0x− 1 = 0 ou x2 + 2x− 8 = 0
La seconde équation est une équation du second degré qui admet deux racines x1 = 2 et x2 = −4.Conclusion, l’équation x3 + x2 − 10x+ 8 = 0 admet trois solutions −4, 1 et 2.
23

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 1.4.1) Effectuer la division Euclidienne de x2 + 3x− 1 par x− 2.2) Effectuer la division Euclidienne de x3 + 2x2 + 4x + 8 par x + 2 et en déduire les racines de
x3 + 2x+ 4x+ 8.3) Résoudre x4 − 4x3 − x+ 4 = 0.
Méthode. Pour résoudre une équation de degré trois
ax3 + bx2 + cx+ d = 0
On peut chercher une racine évidente α et ensuite effectuer la division Euclidienne de ax3+bx2+cx+d =0 par x− α. Pour aboutir à ax3 + bx2 + cx+ d = (x− α)(ax2 + b′x+ c′) = 0 et déterminer toutes lessolutions en résolvant l’équation du second degré ax2 + b′x+ c′ = 0.
1.9 Inégalités
Définition 1.38. Une inégalité est une formule mathématiques, indiquant dans quel ordre sont rangésdeux expressions. Les différents symboles d’inégalités :• ≤ se dit « inférieur (ou égal) » (inégalité large)• ≥ se dit « supérieur (ou égal) » (inégalité large)• < se dit « inférieur strictement » (inégalité stricte)• > se dit « supérieur strictement » (inégalité stricte)
Remarque. Soit a et b deux nombres, alors
a ≤ b si et seulement si b ≥ a
eta < b si et seulement si b > a
Vocabulaire. On dit qu’une inégalité change de sens lorsqu’on passe du symbole ≤ au ≥ et récipro-quement (mais en gardant les expressions déduites dans le même ordre). De même, avec les inégalitésstrictes.
Exemples.• 1 < 3 et −1 > −3.• si x < 2 alors −x > −2.
Définition 1.39. Encadrer un nombre x, c’est donner deux nombres a et b tels que a ≤ x ≤ b. Ondit alors que x est compris entre a et b.
Lorsqu’un nombre est inférieur à un second qui est inférieur au troisième, bien sûr que le premier estaussi inférieur au troisième nombre :
Proposition 1.40. Soit a, b et c trois nombres réels, alors• a ≤ a et a ≥ a (réflexivité)• Si a ≤ b et b ≤ c alors a ≤ c (transitivité)
Si a ≥ b et b ≥ c alors a ≥ c
Par contre, on n’a pas a < a ni a > a !
24

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 1.41 (inégalité et opérations).• Une inégalité est conservée lorsqu’on ajoute ou retranche un même nombre de part et d’autrede l’inégalité.
• Une inégalité est conservée lorsqu’on multiplie ou divise par un même nombre strictement positifde part et d’autre de l’inégalité.
• Par contre, l’inégalité change de sens lorsqu’on multiplie ou divise par un même nombre stric-tement négatif de part et d’autre de l’inégalité.
Corollaire 1.42. Soit a, b, c et d quatre nombres réels.1) Si a ≤ b et c ≤ d alors a+ c ≤ b+ d ;2) Si a ≤ b et c ≥ d alors a− c ≤ b− d ;
Supposons de plus que les nombres a, b, c et d sont strictement positifs.3) Si a ≤ b et c ≤ d alors a× c ≤ b× d ;4) Si a ≤ b et c ≥ d alors a
c ≤bd .
En revenant à la définition d’une fonction monotone (croissante, décroissante), on a
Proposition 1.43. Soit f une fonction définie sur un intervalle I et a , b deux nombres réels.1) Si f est croissante alors a ≤ b implique f(a) ≤ f(b) ; l’inégalité est conservée2) Si f est décroissante alors a ≤ b implique f(a) ≥ f(b) ; l’inégalité change de sens3) Si f est strictement croissante alors a < b implique f(a) < f(b) ;4) Si f est strictement décroissante alors a < b implique f(a) > f(b).
Conséquence :
Corollaire 1.44. Soit a et b deux nombres réels.1) Si 0 ≤ a < b alors a2 < b2 ; conservée2) Si a < b ≤ 0 alors a2 > b2 ; change3) Si 0 ≤ a < b alors
√a <√b ; conservée
4) Si a < b alors a3 < b3 ; conservée5) Si 0 < a < b alors 1
a >1b ; change
6) Si a < b < 0 alors 1a >
1b ; change
Exercice 1.5. Démontrer le corollaire précédent en appliquant les règles sur les opérations et inégalitésde la proposition 12.9.
Vocabulaire.• Un nombre a est dit positif si a ≥ 0 ;• Un nombre a est dit négatif si a ≤ 0.
On note R+ l’ensemble des nombres positifs, R− l’ensemble des nombres négatifs et R∗ l’ensemble desnombres non nuls.
R0
nombres positifs : R+nombres négatifs : R−
Remarque. Le seul nombre à la fois positif et négatif est zéro.
Proposition 1.45. Si ab ≥ 0, alors(a ≥ 0 et b ≥ 0
)ou(a ≤ 0 et b ≤ 0
). C’est-à-dire, les nombres
a et b sont de même signe.
25
TSI 1 Lycée Heinrich-Nessel 2016/2017
Méthode. Chercher le signe d’une quantité A revient à déterminer si A ≥ 0 ou A ≤ 0.
Comparer deux nombres, c’est déterminer s’ils sont égaux ou lequel est le plus grand. On cherche finale-ment à établir une inégalité. La proposition suivante sera utile pour comparer deux fonctions :
Proposition 1.46. Quels que soient les nombres réels a et b, on a1) a ≥ b si et seulement si a− b est positif ;2) a ≤ b si et seulement si a− b est négatif ;3) a = b si et seulement si a− b est nulle ;
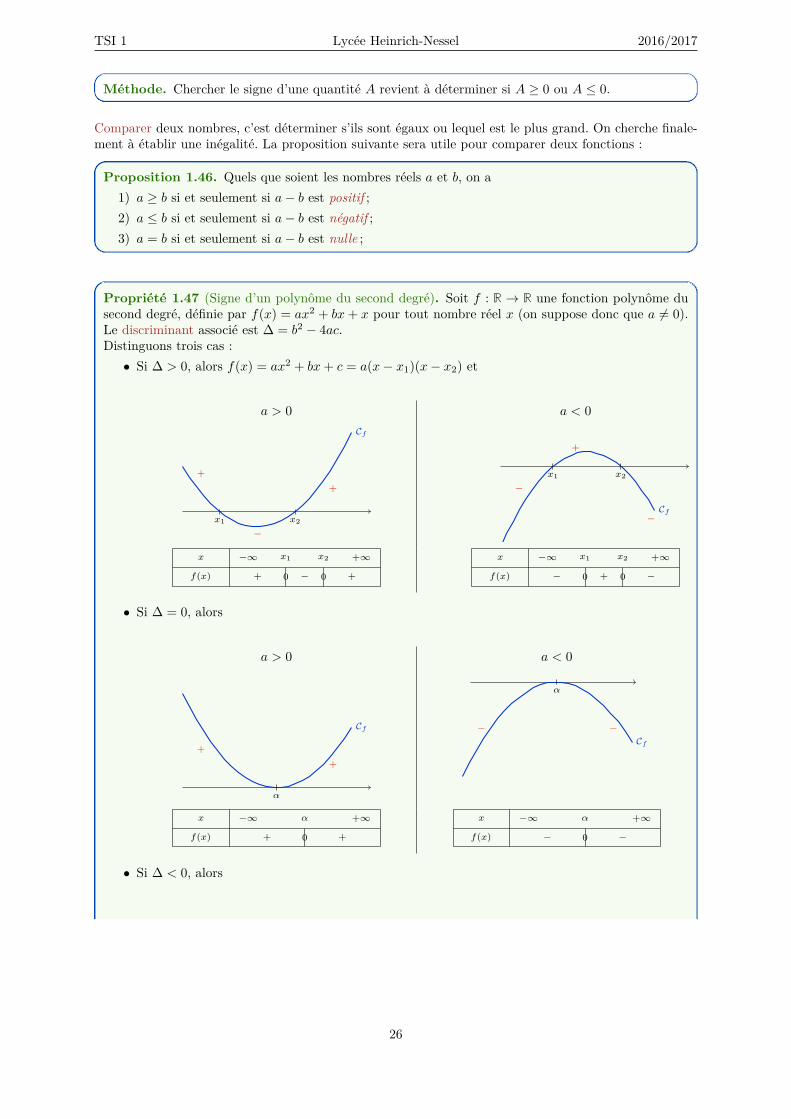
Propriété 1.47 (Signe d’un polynôme du second degré). Soit f : R → R une fonction polynôme dusecond degré, définie par f(x) = ax2 + bx+ x pour tout nombre réel x (on suppose donc que a 6= 0).Le discriminant associé est ∆ = b2 − 4ac.Distinguons trois cas :• Si ∆ > 0, alors f(x) = ax2 + bx+ c = a(x− x1)(x− x2) et
a > 0 a < 0Cf
−
++
x1 x2Cf
+
−
−
x1 x2
x −∞ x1 x2 +∞
f(x) + 0 − 0 +
x −∞ x1 x2 +∞
f(x) − 0 + 0 −
• Si ∆ = 0, alors
a > 0 a < 0
Cf
++
α
Cf− −
α
x −∞ α +∞
f(x) + 0 +
x −∞ α +∞
f(x) − 0 −
• Si ∆ < 0, alors
26

TSI 1 Lycée Heinrich-Nessel 2016/2017
a > 0 a < 0
Cf
++
α
Cf
−−
α
x −∞ +∞
f(x) +
x −∞ +∞
f(x) −
Exemple. Étudions le signe des expressions suivantes :a) 3x+ 1 ;b) −4x+ 6 ;c) (3x+ 1)(−4x+ 6) ;d) (x+ 5)2 + 1 ;e) x2 + x+ 1 ;f) x2 − 3x− 10 ;g) 3x+1
x−5 .On a
a) b) c)
x −∞ −13
32 +∞
3x+ 1 − + +0
−4x+ 6 + + −0
(3x+ 1)(−4x+ 6) − + −0 0
d) Comme un nombre au carré est positif, on en déduit que (x + 5)2 + 1 ≥ 1 > 0 pour tout nombreréel x ;
e) Le discriminant du polynôme x2 + x + 1 est ∆ = b2 − 4ac = 12 − 4 × 1 × 1 = −3 est négatif, lepolynôme est du signe de son coefficient dominant a = 1. C’est-à-dire x2 + x + 1 est positif pournombre réel x.
f) Notons que x2 − 3x − 10 = (x + 2)(x − 5) et le polynôme du second degré x2 − 3x − 10 admetdeux racines x1 = −2 et x2 = 5. Comme le coefficient dominant a = 1 est positif, le polynômex2 − 3x− 10 est négatif sur l’intervalle [−2; 5] et positif sinon.
g) Pour déterminer le signe de 3x+1x−5 , nous allons refaire un tableau de signes :
x −∞ −13 5 +∞
3x+ 1 − + +0
x− 5 − − +0
3x+1x−5 + − +0
Exemple (Étude d’une fonction). Considérons la fonction f définie sur D = R − −1; 1 par f(x) =x2−x+1x2−1 . Pour tout x dans D, la dérivée de f est définie par
f ′(x) = (2x− 1)(x2 − 1)− (x2 − x+ 1)(2x)(x2 − 1)2
= 2x3 − 2x− x2 + 1− 2x3 + 2x2 − 2x(x2 − 1)2
= x2 − 4x+ 1(x2 − 1)2
27
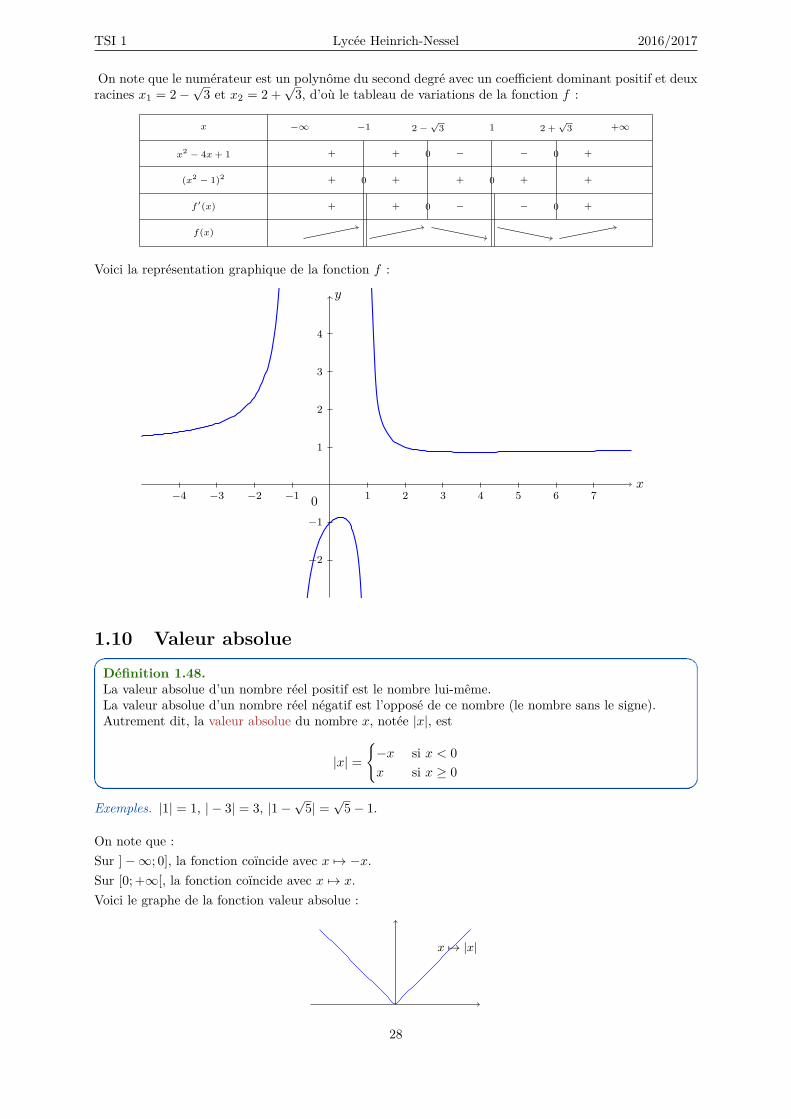
TSI 1 Lycée Heinrich-Nessel 2016/2017
On note que le numérateur est un polynôme du second degré avec un coefficient dominant positif et deuxracines x1 = 2−
√3 et x2 = 2 +
√3, d’où le tableau de variations de la fonction f :
x −∞ −1 2−√
3 1 2 +√
3 +∞
x2 − 4x+ 1 + + − − +0 0
(x2 − 1)2 + + + + +0 0
f ′(x) + + − − +0 0
f(x)
Voici la représentation graphique de la fonction f :
−4 −3 −2 −1 1 2 3 4 5 6 7
−2
−1
1
2
3
4
0x
y
1.10 Valeur absolue
Définition 1.48.La valeur absolue d’un nombre réel positif est le nombre lui-même.La valeur absolue d’un nombre réel négatif est l’opposé de ce nombre (le nombre sans le signe).Autrement dit, la valeur absolue du nombre x, notée |x|, est
|x| =−x si x < 0x si x ≥ 0
Exemples. |1| = 1, | − 3| = 3, |1−√
5| =√
5− 1.
On note que :Sur ]−∞; 0], la fonction coïncide avec x 7→ −x.Sur [0; +∞[, la fonction coïncide avec x 7→ x.Voici le graphe de la fonction valeur absolue :
x 7→ |x|
28

TSI 1 Lycée Heinrich-Nessel 2016/2017
Le graphe est symétrique par rapport à l’axe des ordonnées car pour tout nombre réel x, | − x| = |x|.
Proposition 1.49. 1) La valeur absolue d’un nombre est toujours positive. Autrement dit, pourtout réel x, |x| ≥ 0.
2) |x| = 0 si et seulement si x = 03) Pour tout réel x, on a : | − x| = |x|.4) Pour tous réels x, y, on a : |xy| = |x| × |y|.
5) Pour tous réels x, y 6= 0, on a :∣∣∣xy ∣∣∣ = |x|
|y| .
6) Pour tout réel x, on a :√x2 = |x|.
Proposition 1.50. Soit a ∈ R. L’équation |x| = a admet :• deux solutions x = a et x = −a si a > 0• une solution x = 0 si a = 0• aucune solution si a < 0.
Exemple. Soit x un nombre réel tel que |x− 3| ≤ 1. Distinguons deux cas :
• Si x− 3 est positif, c’est-à-dire x ≥ 3, alors
|x− 3| ≤ 1x− 3 ≤ 13 ≤ x ≤ 3 + 1
• Si x − 3 est négatif, c’est-à-dire x ≤ 3, alors|x− 3| = −(x− 3) et
|x− 3| ≤ 1−(x− 3) ≤ 1
x− 3 ≥ −13 ≥ x ≥ 3− 1
On en déduit que |x− 3| ≤ 1 si et seulement si 2 ≤ x ≤ 4.
Proposition 1.51. Soit a un nombre réel et M > 0. Pour tout nombre réel x, on a
|x− a| ≤M ⇐⇒ a−M ≤ x ≤ a+M
Raa−M a+M
−M +M
C’est-à-dire, si et seulement si x appartient à l’intervalle [a−M ; a+M ].
Méthode. Étant donné a et M , pour montrer que |x − a| ≤ M , en général, on montre qu’on a lesdeux inégalites : a−M ≤ x et x ≤ a+M .
En considérant le cas a = 0 et en remarquant que |x| > M est la négation de |x| ≤M , on déduit :
Corollaire 1.52. Si M est un nombre positif, alors1) |x| ≤M si et seulement si −M ≤ x ≤M ;2) |x| > M si et seulement si x < −M ou M < x.
Remarque. Le premier point du corollaire peut être reformuler ainsi : |x| ≤M si et seulement si −x ≤Met x ≤M .
29

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 1.53. La distance entre deux réels a et b est la distance entre les pointsM etN d’abscissesa et b sur la droite réelle munie d’un repère (O,−→i ). On la note d(a, b).
RM
a
N
b
d(a, b) = MN
Proposition 1.54.1) Pour tout réel x, d(x, 0) = |x|.2) Pour tous réels a et b,
d(a, b) = |b− a| = |a− b|
Proposition 1.55 (inégalité triangulaire). Pour tous réels x et y, on a
|x+ y| ≤ |x|+ |y|
Proposition 1.56 (seconde inégalité triangulaire). Soit x et y deux nombres réels. Alors,
||x| − |y|| ≤ |x− y|
En particulier, |x| − |y| ≤ |x− y| et |x| − |y| ≤ |x+ y|.
1.11 Partie entière, partie décimale et approximation
Proposition 1.57. Soit x ∈ R. Alors il existe un unique entier relatif n ∈ Z tel que n ≤ x < n+ 1.
R−1 20 1
. . .x
n n+ 1
Définition 1.58. Soit x ∈ R. La partie entière de x est l’unique entier n tel que n ≤ x < n + 1. Onle note bxc.
Définition 1.59. Soit x ∈ R. La partie décimale de x est le nombre x− bxc ∈ [0; 1[.
Exercice 1.6. Donner la partie entière et la partie décimale des nombres suivants :
0, 3, −2, 3.14, −3.14, 12 ,
75 , −
134
Voici la courbe représentative de la fonction partie entière b·c : R→ R :
30
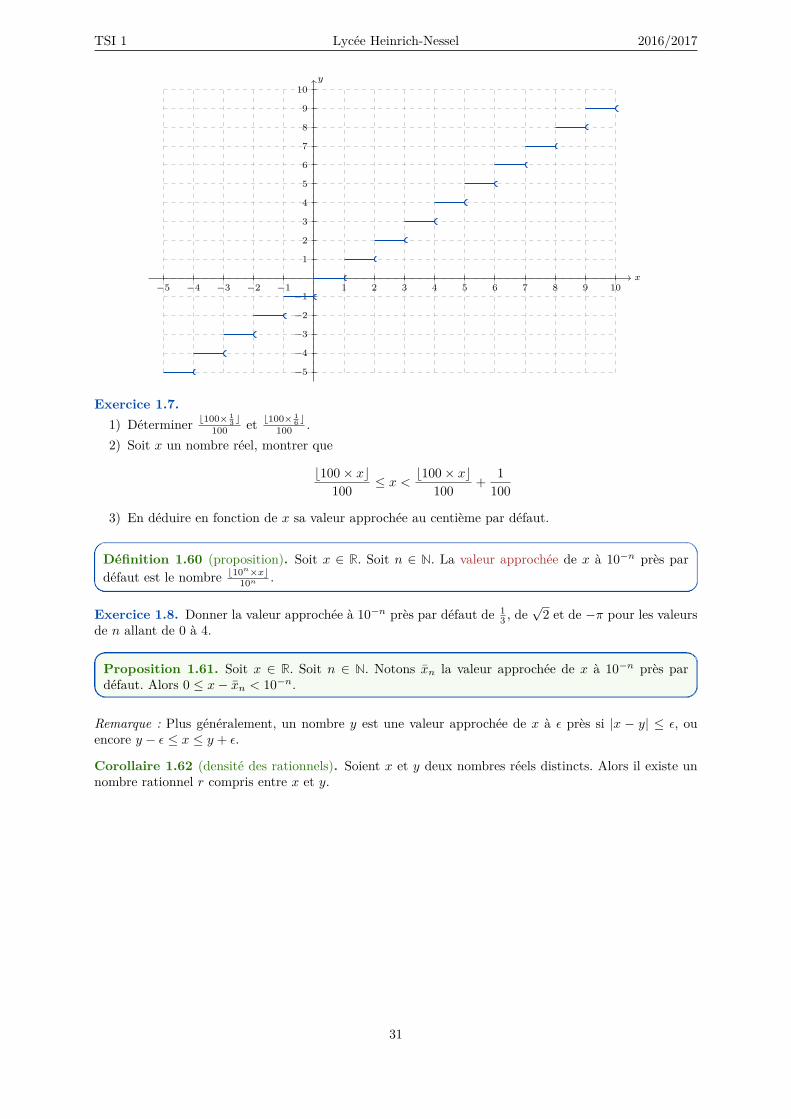
TSI 1 Lycée Heinrich-Nessel 2016/2017
x
y
−5 −4 −3 −2 −1 1 2 3 4 5 6 7 8 9 10
−5
−4
−3
−2
−1
1
2
3
4
5
6
7
8
9
10
Exercice 1.7.1) Déterminer b100× 1
3 c100 et b100× 1
6 c100 .
2) Soit x un nombre réel, montrer que
b100× xc100 ≤ x < b100× xc
100 + 1100
3) En déduire en fonction de x sa valeur approchée au centième par défaut.
Définition 1.60 (proposition). Soit x ∈ R. Soit n ∈ N. La valeur approchée de x à 10−n près pardéfaut est le nombre b10n×xc
10n .
Exercice 1.8. Donner la valeur approchée à 10−n près par défaut de 13 , de
√2 et de −π pour les valeurs
de n allant de 0 à 4.
Proposition 1.61. Soit x ∈ R. Soit n ∈ N. Notons xn la valeur approchée de x à 10−n près pardéfaut. Alors 0 ≤ x− xn < 10−n.
Remarque : Plus généralement, un nombre y est une valeur approchée de x à ε près si |x − y| ≤ ε, ouencore y − ε ≤ x ≤ y + ε.
Corollaire 1.62 (densité des rationnels). Soient x et y deux nombres réels distincts. Alors il existe unnombre rationnel r compris entre x et y.
31

TSI 1 Lycée Heinrich-Nessel 2016/2017
32

Chapitre 2
Logique et raisonnements
Programme• Connecteurs logiques : disjonction (ou), conjonction (et), implication, équivalence.• Quantificateurs :Passer du langage naturel au langage formalisé en utilisant les quantificateurs.
• Formuler une négation• L’emploi des quantificateurs en guise d’abréviations est exclu.• Raisonnement par contraposition, par l’absurde.• Principe d’analyse/synthèse.• Distinguer condition nécessaire et condition suffisante.• Propriétés de l’ensemble N.• Toute partie non vide de N a un plus petit élément. Application au principe de récurrence.• Mener un raisonnement par récurrence simple ou avec prédécesseurs.
2.1 Un peu de logique
Les lois de la pensée (1854) - G. Boole (1815-1864) « Le but de ce traité est d’étudier les loisfondamentales des opérations de l’esprit par lesquelles s’effectue le raisonnement ; de les exprimer dansle langage symbolique d’un calcul, puis, sur un tel fondement, d’établir la science de la logique et deconstituer sa méthode[. . . ] »« De fait, dans sa forme ancienne et scolastique, la logique se rattache presque exclusivement au grandnom d’Aristote. C’est sous l’aspect où elle fut exposée à la Grèce antique par la démarche, en partietechnique et en partie métaphysique de l’Organon, qu’elle a continué, presque sans aucun changementessentiel, de se présenter jusqu’à nos jours. Le mouvement de recherche original s’est plutôt dirigé versdes questions de philosophie générale qui, quoiqu’issues de controverses entre logiciens, ont débordé deleur lieu d’origine pour conférer aux âges successifs de la pensée leur tour et leur caractère particuliers. »« [. . . ] la science a pour rôle de dégager des lois [. . . ] »« On examinera dans la Proposition suivante, l’analyse et la classification des signes dans lesquels sontmenées les opérations du raisonnement.Proposition 2.1. Toutes les opérations du langage en tant qu’instrument du raisonnement se peuventconduire dans un système de signes composé des éléments suivants
1) Des symboles littéraux tels que x, y, etc. représentent les choses en tant qu’objets de nos conceptions.2) Des signes d’opération tels que +, −, ×, qui traduisent les opérations de l’esprit par lesquelles les
conceptions des choses sont combinées ou séparées de manière à former de nouvelles conceptionscomprenant les mêmes éléments.
3) Le signe d’identité =.Et ces symboles logiques voient leur usage soumis à des lois déterminées, qui en partie s’accordent et enpartie ne s’accordent pas avec les lois des symboles correspondants dans la science de l’algèbre. »
33

TSI 1 Lycée Heinrich-Nessel 2016/2017
2.2 Éléments de logique
En mathématique, on s’attache à établir la vérité ou la fausseté d’assertions (énoncés, propositions,. . . )sur la base de règles de bon sens (plus techniquement des axiomes). Nous allons approfondir sur le langagemathématique, c’est-à-dire un langage formel construit à partir de connecteurs logiques, de quantificateurset de symboles introduits au gré des théories, pour proposer progressivement une approche plus rigoureusedes mathématiques que vous pratiquez depuis votre enfance.
Pour nous, un énoncé mathématique sera toujours supposé soit vrai (V) soit faux (F).Comme en informatique, il y a trois connecteurs logiques « élémentaires » que nous utilisons fréquemmenten mathématiques : NON, ET, OU.
Définition 2.2. Le connecteur de négation NON permet d’écrire le contraire d’une phrase. Ainsi,si P est une assertion, NON P est son contraire. Ainsi, si P est vraie, alors NON P est fausse etréciproquement. On peut résumer cela dans une table de vérité :
P NON PV FF V
La double négation : NON ( NON P) est la même chose que P.
Définition 2.3. Le connecteur de conjonction ET : L’assertion P ET Q est vraie uniquement dansle cas où à la fois P et Q sont vraies. Sa table de vérité est :
P Q P ET QV V VV F FF V FF F F
Définition 2.4. Le connecteur de disjonction OU : L’assertion P OU Q est vraie dès que P ou Q(ou les deux) est vraie. Sa table de vérité est :
P Q P OU QV V VV F VF V VF F F
Remarque.• Symétrie : Notons que l’assertion P ET Q est la même chose que l’assertion Q ET P. De même,l’assertion P OU Q est la même chose que l’assertion Q OU P.
• Pour montrer que l’assertion P ET Q est fausse, il suffit de montrer que l’une des deux assertionsest fausse.
• Pour montrer que l’affirmation P OU Q est vraie, il suffit de montrer qu’au moins une des deuxaffirmation est vraie.
Proposition 2.5 (lois de Morgan). Soit P et Q deux affirmations.
34

TSI 1 Lycée Heinrich-Nessel 2016/2017
• NON (P ET Q) est la même chose que ( NON P) OU ( NON Q)• NON (P OU Q) est la même chose que ( NON P) ET ( NON Q)
Une assertion peut dépendre d’une autre. Par exemple, pour résoudre une équation du second degrédonné, considérons l’assertion P = « Le discriminant ∆ du polynôme est positif » et Q = « le polynômeadmet au moins une racine ». Il est bien connu maintenant que P implique Q. L’implication traduit laphrase « Si P est vraie, alors Qi est vraie ».L’affirmation P implique Q signifie que si P est vraie alors nécessairement Q est vraie mais on ne ditrien si P est fausse !Plus formellement,
Définition 2.6. L’implication, notée P ⇒ Q, correspond par définition à l’assertion ( NON P) OU Q.Sa table de vérité est :
P Q P ⇒ QV V VV F FF V VF F V
Exemple. Soit f une fonction dérivable sur [0; +∞[, considérons les trois assertions suivantes :• P = « f(0) ≥ 0 » ;• Q = « f est croissante » ;• R = « f est positive ».
On note alors que R ⇒ P par contre P n’implique pas Q ni R. À l’aide des deux premières assertions,on a
( P ET Q )⇒ R
Exercice 2.1. Pendant le repas, un mathématicien dit à son fils :- Si tu ne manges pas tes légumes, tu n’auras pas de crème glacée.Le fils mange donc ses légumes, et son père ne lui donne pas de crème glacée.Est-ce que le père a tenu sa parole ? Oui
Proposition 2.7. Pour montrer que P ⇒ Q est fausse, il suffit de montrer que P est vraie et Q estfausse.
En général, pour contredire une implication, on suppose l’hypothèse P est on démontre que la conclusionQ est fausse.La réciproque de l’implication P ⇒ Q est par définition l’implication Q ⇒ P. Bien entendu, il se peut quel’implication P ⇒ Q soit vraie mais que la réciproque soit fausse. Par exemple, l’implication (concernantla variable réelle x) x = 1⇒ x2 = 1 est vraie mais sa réciproque x2 = 1⇒ x = 1 est fausse.
Définition 2.8. On dit qu’une proposition P est équivalente à une proposition Q, et on note P ⇐⇒Q, si on a P ⇒ Q ET Q ⇒ P.
L’équivalence est vraie lorsque les deux propositions P et Q sont simultanément vraies ou simultanémentfausses. On la lit aussi « P si et seulement si Q ».
Vocabulaire.• Une proposition P est une condition suffisante pour une proposition Q si l’implication P ⇒ Q est
vraie.Il suffit que P soit vraie pour que Q soit vraie.
35

TSI 1 Lycée Heinrich-Nessel 2016/2017
• Une proposition Q est une condition nécessaire pour une proposition P si l’implication P ⇒ Q estvraie.Pour que P soit vraie, il faut nécessairement que Q soit vraie.
• Une proposition P est une condition nécessaire et suffisante pour une proposition Q si l’équivalenceP ⇐⇒ Q est vraie.
Les implications jouent un rôle prépondérant dans les démonstrations mathématiques en vertu du principede déduction (ou syllogisme) suivant :
Si P est vraie et si P ⇒ Q est vraie, alors Q est vraie.
Proposition 2.9. La négation d’une implication NON (P ⇒ Q) correspond à P ET ( NON Q).
Définition 2.10. La contraposée de l’implication P ⇒ Q est l’implication ( NON Q)⇒ ( NON P).
Exercice 2.2. Compléter la table suivante :
P Q NON (P) NON (Q) P ⇒ Q NON (Q)⇒ NON (P)V V F F V VV F F V F FF V V F V VF F V V V V
Ainsi, une implication et sa contraposée ont même valeur de vérité : si l’une est vraie alors l’autre aussi.
Remarque. Il ne faut pas confondre la contraposée avec la négation.Il est important lorsqu’on écrit une phrase mathématique complexe d’utiliser des parenthèses pour levertoute ambiguïté. Ainsi, il ne faut pas écrire quelque chose du genre P ET Q OU R mais selon le cas(P ET Q) OU R ou P ET (Q OU R). Ces deux propositions étant différentes.
Pour la clarté de la rédaction, il est impératif d’utiliser le symbole d’implication à bon escient : en aucuncas il ne peut être utilisé comme abréviation de « j’en déduis ». Ainsi, la phrase 2x+ 3 = 5⇒ x = 1 estvraie mais ne dit pas que x = 1. Elle dit « s’il est vrai que 2x+ 3 = 5, alors il est vrai que x = 1 ».
Logique modale du premier ordre Les mathématiques s’attachent à démontrer les résultats les plusgénéraux possibles. C’est pour cela que l’on utilise souvent les expressions « pour tout » et « il existe ».On les appelle des quantificateurs. Quelques notations :
Vocabulaire.• L’expression « pour tout » s’appelle le quantificateur universel et se note ∀. Ainsi, l’expression∀ x ∈ R se lit « pour tout réel x » ou encore « quelque soit le réel x » ou encore « pour un réel xquelconque » ou encore « pour n’importe quel réel x ». . .
• L’expression « il existe » s’appelle le quantificateur existentiel et se note ∃. Ainsi, l’expression ∃x ∈ Rse lit « il existe un réel x » ou encore « on peut trouver un réel x » ou encore « pour un certain réelx ». . .
On trouve parfois le raccourci ∃! pour signifier « il existe un unique ». D’ailleurs le symbole ∃ seul signifietoujours qu’il existe au moins un (mais qu’il peut en exister plusieurs).
Exercice 2.3.1) ∀ x ∈ R, x2 ≥ 0 signifie : pour tout nombre réel x, on a x2 ≥ 0 ;2) ∃ x ∈ R, x3 < 0 signifie : il existe un nombre réel x tel que x3 < 0.3) Écrire la phrase suivante sous forme symbolique : Pour tout a > 0, il existe un unique nombre réel
x > 0 tel que x2 = a.∀ a > 0 ∃! x > 0 : x2 = a
36

TSI 1 Lycée Heinrich-Nessel 2016/2017
4) Écrire la négation des trois assertions précédentes.
Remarque. Il arrivera souvent par la suite qu’on utilise plusieurs quantificateurs à la suite. L’ordre esttrès important et ne doit JAMAIS être changé ! Pour s’en convaincre, que peut-on dire de l’affirmation
∃x > 0 ∀ a > 0 : x2 = a
par rapport à l’affirmation précédente ∀ a > 0 ∃x > 0 : x2 = a. Laquelle est vraie ?
Proposition 2.11 (Négation et quantificateurs). Soit P(x) une affirmation qui dépend d’une variablex.• La négation de l’affirmation ∀ x ∈ E, P(x) est ∃ x ∈ E, NON P(x).• La négation de l’affirmation ∃ x ∈ E, P(x) est ∀ x ∈ E, NON P(x)
En d’autres termes, pour montrer que quelque chose n’est pas vraie pour tout x, il suffit de trouver uncontre-exemple (c’est-à-dire qu’il existe x contredisant l’affirmation).
Exercice 2.4.1) Montrer que l’affirmation :
∀x ∈ R : x2 + x ≥ 0
est fausse.2) Déterminer la négation de l’affirmation :
∃x ∈ [0; 1] : x(1− x) > 2
et déterminer si l’affirmation ou sa négation est vraie.
2.3 Techniques élémentaires de raisonnement
Raisonnements et démonstrations élémentaires Pour démontrer une proposition mathématique,on doit isoler les objets donnés au départ, les hypothèses, de la propriété à démontrer, le but. Il n’y a pasde recette miracle pour trouver une démonstration. Toutefois le bon emploi de quelques règles simplesrend souvent de très grands services. En voici quelques unes :
• Pour démontrer une conjonction P ET Q, il faut montrer P et montrer Q. On doit donc faire deuxdémonstrations.
• Pour démontrer une disjonction P OU Q, il faut montrer P ou montrer Q. Cela se fait souvent pardisjonction des cas (voir ci-dessous)
• Pour montrer une négation, on pourra commencer par appliquer les règles de logiques pour trans-former la négation en une proposition où les négations portent sur les formules élémentaires (on ditaussi atomiques).
• Pour démontrer une implication P ⇒ Q, on suppose que P est vraie et on démontre Q. Autrementdit, on ajoute P aux hypothèses pour montrer Q.
• Pour démontrer une équivalence P ⇐⇒ Q, il faut montrer les deux implications P ⇒ Q et Q ⇒ P.On dit qu’on raisonne par double implication.
• Pour démontrer une propriété universelle ∀ x ∈ E, P(x), on se donne un élément x quelconque deE et on montre que P(x) est vraie. La démonstration commencera donc par une phrase de la forme« Soit x ∈ E. Montrons que P(x). »
• Pour démontrer une propriété existentielle ∃ x ∈ E, P(x), on cherche à construire un élément x deE qui vérifie P(x). On pourra être amené à raisonner par analyse-synthèse (voir ci-dessous).
Obtenir une démonstration nécessite aussi de bien analyser les hypothèses, de savoir les traduire de façonutile. Voici quelques exemples :
37

TSI 1 Lycée Heinrich-Nessel 2016/2017
2.3.1 Démonstration par disjonction des cas
Exemple. Considérons l’affirmation (proposition)
∀ n ∈ N,n(n+ 1)
2 ∈ N
Exprimer en langage courant cette proposition : Pour tout entier naturel n, la fraction n(n+1)2 est aussi
un entier naturel.
On peut observer que si n est pair alors n2 est un entier et donc n(n+1)
2 = n2 (n+ 1) est aussi entier. Ainsi,
il est naturel ici, de considérer l’autre situation, c’est-à-dire lorsque n est impair. Voici, la démonstrationcomplète :
Démonstration. Soit n ∈ N.• Premier cas : Supposons que n soit pair. Alors il existe un entier k tel que n = 2k. Donc, on a
n(n+ 1)2 = 2k(n+ 1)
2 = k(n+ 1) ∈ N
On a bien établi dans ce cas que n(n+1)2 ∈ N.
• Deuxième cas : Supposons que n ne soit pas pair, autrement dit que n soit impair. Alors il existeun entier k tel que n = 2k + 1 et donc tel que n+ 1 = 2k + 1 + 1 = 2k + 2 = 2(k + 1). Donc, on a
n(n+ 1)2 = n(2(k + 1))
2 = n(k + 1) ∈ N
On a bien établi dans ce cas que n(n+1)2 ∈ N.
Ainsi, dans tous les cas, on a n(n+1)2 ∈ N.
On utilise un raisonnement par disjonction de cas de façon (quasiment) systématique lorsqu’il s’agitde démontrer un OU ou d’utiliser un OU . Ainsi pour montrer que P OU Q est vraie on raisonne pardisjonction des cas :• Premier cas : On suppose que P est vraie. Alors P OU Q est vraie. Il n’y a rien à démontrer.• Deuxième cas : On suppose que P est fausse. Alors on doit montrer que Q est vraie.
Dans l’exemple précédente, on a posé P = « n est pair », Q = « n est impair » et R = « n(n+1)2 est un
entier ». Pour montrer que P OU Q ⇒ R, on a bien montré que P ⇒ R (le premier cas) et Q ⇒ R (lesecond cas). On notera aussi qu’ici, on avait NON (P) = Q.
2.3.2 Démonstration par l’absurde
Nous allons voir deux exemples.1) Considérons la proposition :
« Il n’existe pas d’entier naturel plus grand que tous les autres ».
On peut démontrer cette proposition par l’absurde : on suppose le contraire (la négation) et onmontre que cela aboutit à une contradiction.
Démonstration. Montrons qu’il n’existe pas d’entier naturel plus grand que tous les autres parl’absurde. Supposons ainsi qu’il existe un entier naturel plus grand que tous les autres. Notons Nun tel entier plus grand que tous les autres. Or, N + 1 est aussi 1 un entier. On devrait donc avoirN + 1 ≤ N , ce qui est absurde. On en déduit que l’affirmation est vraie.
2)
1. C’est en fait un axiome (hypothèse) fait sur la construction des entiers naturels (Axiomes de Peano, 1889), voirsection 2.4.1 ci-dessous.
38

TSI 1 Lycée Heinrich-Nessel 2016/2017
Montrons que√
2 est irrationnel.
1
√2
1
Démonstration. Supposons par l’absurde que√
2 est rationnel, c’est-à-dire qu’il existe un entierrelatif p et un entier naturel non nul q tels que p et q soient premiers entre eux et
√2 = p
q . Alors√
22 =(pq
)22 = p2
q2
2q2 = p2
D’où p2 est pair et comme on le verra dans l’exemple suivant, ce fait implique que p est aussi pair.Il existe donc un entier relatif k tel que p = 2k et en revenant aux identités précédentes, on a
2q2 = (2k)2
2q2 = (2k)2
2q2 = 4k2
q2 = 2k2
De même, on déduit que q est pair. En résumé, les entiers p et q sont pairs tous les deux. Or, nousavions choisi p et q premiers entre eux. D’où une contradiction. Ainsi,
√2 est irrationnel.
Remarque. Une approximation à 10−4 près de√
2 était déjà connue des Babyloniens (la tablette YBC7289) au premier tiers du second millénaire avant notre ère (l’algorithme de Héron). Ensuite, les mathé-maticiens de la Grèce antique (sans doute avant le Ve siècle avant notre ère) ont découvert et démontréque√
2 est irrationnel. Plus précisément, ils ont démontré que la longueur de la diagonale d’un carré estincommensurable, c’est-à-dire qu’on ne peut pas trouver de segment unité, aussi petit soit-il avec lequelmesurer de façon exacte (un entier naturel de fois l’unité) ces deux longueurs.
2.3.3 Démonstration par contraposée
Soit n un entier naturel, considérons la proposition
n2 pair ⇒ n pair
On peut démontrer cette implication directement mais il peut être plus simple de démontrer sa contra-posée, à savoir
n impair ⇒ n2 impair
Démonstration. Montrons que n2 pair ⇒ n pair par contraposée. Il faut donc montrer que n impair ⇒n2 impair. Supposons ainsi que n soit impair. Alors il existe un entier k tel que n = 2k+ 1. On en déduitque
n2 = (2k + 1)2 = 4k2 + 4k + 1 = 2(2k2 + 2k) + 1Ainsi, n2 est également impair.
Méthode. Pour montrer que P ⇒ Q, on peut montrer sa contraposée NON (Q)⇒ NON (P).
2.3.4 Démonstration par analyse-synthèse
La technique de l’analyse-synthèse consiste à procéder en deux temps. On commence par supposer quel’on dispose d’une solution à notre problème et on cherche à obtenir le plus de propriétés possibles decette solution. Puis on vérifie que tout objet ayant les propriétés voulues est solution du problème. Cettestratégie est souvent mise en oeuvre pour trouver un (ou plusieurs) objets satisfaisant à une série deconditions. Elle donc souvent utilisée pour montrer une propriété existentielle.A titre d’exemple, montrons que
∃ f : R→ R, ∀ x ∈ R, ∀ y ∈ R, f(x)f(y) = f(xy) + x+ y
39

TSI 1 Lycée Heinrich-Nessel 2016/2017
• Analyse : Supposons que f soit une application de R dans R telle que
∀ x ∈ R, ∀ y ∈ R, f(x)f(y) = f(xy) + x+ y
Alors, si on choisit x = 0 et y = 0, on doit avoir f(0)f(0) = f(0). On en déduit que f(0) = 0 ouf(0) = 1. Supposons pour commencer que f(0) = 0. Alors en choisissant x = 0 et y = 1, on doitavoir f(0)f(1) = f(0) + 0 + 1, autrement dit 0 = 1. Ceci est absurde. Ainsi, il est impossible quef(0) = 0. Il faut donc nécessairement que f(0) = 1. Choisissons alors y = 0 et x quelconque. Ondoit avoir f(x)f(0) = f(0)+x+0, autrement dit f(x) = x+1. En conclusion, si f est une solution,alors nécessairement f est l’application x 7→ x+ 1.
• Synthèse : L’application f : x 7→ x + 1 est solution du problème car f(x)f(y) = (x + 1)(y + 1) =xy + x+ y + 1 = f(xy) + x+ y.
2.4 Entiers naturels et raisonnement par récurrence
2.4.1 Entiers naturels
On définit (caractérise) l’ensemble des entiers naturels N par le système d’axiomes (d’hypothèses) dePeano :L’ensemble des entiers naturels, noté N, vérifie les axiomes suivants (Peano 1858-1932) :• N possède l’élément zéro, noté 0 ;• Tout entier naturel n a un unique successeur, noté s(n) ;• 0 n’est le successeur d’aucun entier naturel ;• Si deux entiers naturels ont le même successeur alors ils sont égaux• Si un sous-ensemble d’entiers naturels contient 0 et contient le successeur de chacun de ses éléments,
alors cet ensemble est égal à N. (principe de récurrence)Uniquement à l’aide de ses axiomes, on peut définir rigoureusement, l’addition et la relation d’ordre ≤sur l’ensemble des entiers naturels.
2.4.2 Raisonnement par récurrence
Exercice 2.5.1) Montrer qu’un carré 4× 4 privé d’un carreau peut être découpé en « angles » de trois carreaux.
2) Proposer une démonstration du fait que la même chose est vraie pour tout carré 2n × 2n.
Théorème 2.12. Toute partie non vide de N admet un plus petit élément.
Théorème 2.13 (Récurrence). Soit P(n) une proposition dépendant d’un entier naturel n et soitn0 ∈ N un entier. Supposons que• P(n0) est vraie. (initialisation)• Pour tout entier n ≥ n0, l’implication P(n)⇒ P(n+ 1) est vraie. (hérédité)
Alors la proposition P(n) est vraie quel que soit l’entier n ≥ n0.
40

TSI 1 Lycée Heinrich-Nessel 2016/2017
Corollaire 2.14 (Récurrence forte). Soit P(n) une proposition dépendant d’une variable n ∈ N. Soitn0 ∈ N un entier. Supposons que :• P(n0) est vraie.• Pour tout entier n ≥ n0,(
P(n0) ET P(n0 + 1) ET . . . ET P(n))⇒ P(n+ 1)
est vraie.Alors la proposition P(n) est vraie pour tout entier n ≥ n0.
Exemple. Montrons par récurrence sur n ∈ N \ 0 que 1 + 2 + · · ·+ n = n(n+1)2 .
Démonstration. Notons P(n) la propriété 1 + 2 + · · ·+ n = n(n+1)2 .
• Initialisation : La propriété P(1) est vraie car elle s’écrit 1 = 1×22 .
• Hérédité : Soit n ∈ N. Supposons que la propriété P(n) soit vraie. Montrons que la propriété P(n+ 1) estvraie également. On calcule :
1 + 2 + · · ·+ n+ (n+ 1) = n(n+ 1)2 + (n+ 1) car P(n) est vraie
= (n+ 1)(n
2 + 1)
= (n+ 1)(n+ 2
2
)= (n+ 1)((n+ 1) + 1)
2
Donc P(n+ 1) est aussi vraie. Ainsi, par récurrence, l’identité P(n) est vraie pour tout entier naturel n.
Exemple. Montrons par récurrence forte sur n ∈ N \ 0 qu’il existe deux entiers p et q tels que n =2p(2q + 1).
Démonstration. Notons P(n) la propriété : « il existe deux entiers p et q tels que n = 2p(2q + 1) ».• Initialisation : La propriété P(1) est vraie car 1 = 20 (2× 0 + 1) (on peut donc choisir p = 0 et q = 0).• Hérédité : Soit n ∈ N. On suppose que P(1), P(2), . . . , P(n) sont vraies. Montrons que P(n+ 1) est vraie.
Raisonnons par disjonction des cas :— Si n + 1 est impair, il existe un entier k tel que n + 1 = 2k + 1 = 20(2k + 1). On peut donc choisir
p = 0 et q = k.— Sinon, si n + 1 est pair, il existe un entier k tel que n + 1 = 2k. Comme k ≤ n, on peut utiliser la
propriété P(k), qui est supposée vraie. Ainsi, il existe deux entiers p′ et q′ tels que k = 2p′(2q′ + 1).
Donc, n+ 1 = 2p′+1(2q′ + 1) et on pose p = p′ + 1 et q = q′.
On a bien déduit par disjonction des cas que la propriété P(n+ 1) est vraie.Ainsi, par récurrence forte, la propriété P(n) est démontrée pour tout entier naturel n.
41

TSI 1 Lycée Heinrich-Nessel 2016/2017
42

Chapitre 3
Nombres complexes
Programme• La construction de C n’est pas exigible.• Parties réelle et imaginaire, forme algébrique• Opérations sur les nombres complexes• Conjugaison, compatibilité avec les opérations• Plan complexe : affixe d’un point, d’un vecteur (on identifie C au plan usuel muni d’un repèreorthonormal direct)
• Module d’un nombre complexe (interprétation géométrique), produit, quotient. Relation |z|2 = z z
• inégalité triangulaire, cas d’égalité.• argument d’un nombre complexe non nul (interprétation géométrique), produit, quotient, coordon-nées polaires.
• ρeiθ avec ρ > 0 et θ ∈ R : forme polaire• Interprétation géométrique |z − a|• Utiliser le cercle trigonométrique pour résoudre des équations et inéquations trigonométriques.• Formules exigibles : cos(a+ b), sin(a+ b), cos(2x) et sin(2x).• Exprimer cos(a− b) et sin(a− b).• Factoriser des expressions du type cos(p) + cos(q).• Définition de eiθ
• formule d’Euler, eiaeib = ei(a+b), formule de Moivre.• Définition de l’exponentielle d’un nombre complexe exp(z) = ez = ea+ib = ea eib
• ez+z′ = ez ez′
• Résoudre une équation du type : ez = ez′
• Ensemble U des nombres complexes de module 1. Description.• Factoriser 1± eiθ
• Linéariser et factoriser les expressions trigonométriques. Retrouver cos(nt) et sin(nt) en fonction decos(t) et sin(t) pour de petites valeurs de n.Il s’agit de consolider une pratique de calcul, en évitant tout excès de technicité.
• transformer a cos(t) + b sin(t) en A cos(t− φ)• Déterminer les racines carrées d’un nombre complexe sous forme algébrique ou trigonométrique• Équation du second degré dans C
• Racines de l’unité : définition, description, propriétés (représenter géométriquement les racines del’unité). Notation Un.
• Description des racines n-ème d’un nombre complexe. Résoudre zn = λ.
43

TSI 1 Lycée Heinrich-Nessel 2016/2017
3.1 Définition, rappels
Théorème 3.1 (admis). L’ensemble des nombres de la forme a+ bi où a et b sont des nombres réelset i désigne le nombre imaginaire
√−1 muni des opérations :
• (a+ bi) + (a′ + b′i) = (a+ a′) + (b+ b′)i ;• (a+ bi)× (a′ + b′i) = (aa′ − bb′) + (ab′ + ba′)i ;
pour tous a+ bi et a′ + b′i définie un corps (un ensemble muni d’une somme et d’une multiplicationvérifiant quelques propriétés) est appelé l’ensemble des nombres complexes, noté C.De plus, on a• C contient l’ensemble R des nombres réels ;• C est muni d’une addition et d’une multiplication prolongeant celles de R ;• dans C, i2 = −1 ;• tout nombre complexe z s’écrit de façon unique sous la forme z = a + bi, où a et b sont des
nombres réels. Cette écriture est appelée écriture algébrique.
Remarque. En utilisant la double distributivité et le fait que i2 = −1, la définition du produit correspondà l’intuition :
(a+ bi)× (a′ + b′i) = aa′ + ab′i+ bi a′ + bi b′i= aa′ + ab′i+ ba′i+ bb′i2
= (aa′ − bb′) + (ab′ + ba′)i
Exemples.1)
(3 + i)× (1− i) = 3 − 3 i+ i− i2 = 3 − 2 i− (−1 ) = 4 − 2 i
2)
5− 7i1 + 2i = (5 − 7 i)(1 − 2 i)
(1 + 2 i)(1 − 2 i) = 5 − 10 i− 7 i+ 14 i2
1 − (2 i)2
= 5 − 17 i− 141 − 2 2 × i2
= −9 − 17 i1 + 4
= −95 − 17
5 i
3)
1 + i− (5−√
2 i) = 1 + i− 5 +√
2 i = −4 + (1 +√
2 ) i
Un cas particulier : Si λ est un nombre réel, alors λ(a+ bi) = λa+ λbi.
Définition 3.2. Soit z = a+ bi un nombre complexe.• Le nombre réel a est appelé partie réelle de z et on écrit : Re(z) = a.• Le nombre réel b est appelé partie imaginaire de z et on écrit : Im(z) = b.
Quant a est nul, le nombre complexe z s’écrit z = bi et on dit que z est un imaginaire pur.
Remarque. On notera que la partie réelle et la partie imaginaire d’un nombre complexe z, Re(Z) et Im(z)sont des nombres réels !
Proposition 3.3. Soit z = a+ bi et z′ = a′ + b′i deux nombres complexes,1) Nombre complexe nul :
a+ bi = 0 ⇐⇒ a = 0 et b = 0
44

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) Égalité :a+ bi = a′ + b′i ⇐⇒ a = a′ et b = b′
Deux nombres complexes sont égaux s’ils ont la même partie réelle et la même partie imaginaire.3) Caractérisation d’un nombre réel :
z ∈ R ⇐⇒ Im(z) = 0
Un nombre complexe est en particulier un nombre réel si et seulement s’il n’a pas de partieimaginaire.
4) Caractérisation d’un nombre imaginaire pur :
z ∈ Ri ⇐⇒ Re(z) = 0
Un nombre complexe est imaginaire pur si et seulement s’il n’a pas de partie réelle.
Définition 3.4. Soit z = a+bi un nombre complexe, le nombre complexe a−bi est appelé le conjuguéde z et on note
z = a− bi
La notation z se lit « z barre ».
Rappelons que grâce aux identités remarquables, on a, par exemple :
111 + 4i = 11− 4i
(11 + 4i)(11− 4i) = 11 + 4i112 − 42 i2
= 11 + 4i137 = 11
137 + 4137i
Ainsi, l’inverse du nombre 11 + 4i est le nombre complexe 11137 + 4
137 i. Généralisons :
Proposition 3.5. Soit z = a+ bi un nombre complexe non nul (c’est-à-dire, tel que a 6= 0 ou b 6= 0),alors z est admet un inverse et
1z
= a− bia2 + b2
= z
z z
Remarque. En particulier, 1i = i
i2 = −i.
Proposition 3.6. Soit z = a+ bi un nombre complexe, alors1) z + z = 2a = 2 Re(z)2) z − z = 2b i = 2i Im(z)3) z est un réel si et seulement si z = z ;4) z est un imaginaire pur si et seulement si z = −z.
Remarque. Les deux premiers points implique en particulier que
Re(z) = z + z
2 et Im(z) = z + z
2i
Proposition 3.7. Soit z, z′ deux nombres complexes. Alors,1) z + z′ = z + z′ ; Le conjugué de la somme est la somme des conjugués2) z × z′ = z × z′ ; Le conjugué du produit est le produit des conjugués
3) Si z 6= 0,(
1z
)= 1
z et(z′
z
)= z′
z . Le conjugué du quotient est le quotient des conjugués
4) Pour tout entier n, zn = zn.
45

TSI 1 Lycée Heinrich-Nessel 2016/2017
3.2 Le plan complexe
Définition 3.8. On se place dans le plan P muni d’un repère orthonormé direct. Nous allons définirune correspondance entre les points du plan et les nombres complexes :• À tout nombre complexe z = a + bi (avec a et b réels), on associe le point M de coordonnées
(a; b) dans ce repère.On dit que M(a; b) est le point image de z.
• Inversement, à tout point M(a; b) du plan, on associe le nombre complexe z = a+ bi.On dit que z est l’affixe du point M .
C oo // Plan
z = a+ bi oo // M(a; b)
affixe point image
Le point d’affixe z sera parfois noté M(z).
De même, à un nombre complexe z = a+ bi, on associe le vecteur −→u(a
b
)et on dit que z est l’affixe du
vecteur −→u .
R
Axe des réels
Ri Axe des imaginaires purs
z = a+ bi
a
b
1
i
O
−→u
Soit A(a; b) et B(a′; b′) deux points du plan complexe d’affixes zA = a + bi et zB = a′ + b′i. Alors, onnote que :
1)zB − zA = (a′ + b′i)− (a+ bi) = (a′ − a) + (b′ − b)i
est l’affixe du vecteur −−→AB(a′ − ab′ − b
).
2)zA + zB
2 = 12(a+ bi+ a′ + b′i) = a+ a′
2 + b+ b′
2 i
est l’affixe du milieu I(a+a′2 ; b+b′
2 ) du segment [AB].
Proposition 3.9. Soit A et B deux points du plan complexe d’affixes zA et zB respectivement. Alors :1) Le vecteur −−→AB est d’affixe zB − zA ;2) Le milieu I du segment [AB] est d’affixe zA+zB
2 .3) Le symétrique de A par la symétrie de centre O est d’affixe −zA.4) Le symétrique de A par rapport à l’axe des réels est le point d’affixe zA.
46

TSI 1 Lycée Heinrich-Nessel 2016/2017
R
Ri
1
i
O
zA
−zA
zB
zA+zB2
zA
−−→AB
Proposition 3.10. Soit −→u et −→v deux vecteurs du plan complexe d’affixes z et z′ respectivement etλ un nombre réel (un scalaire), alors
1) −→u +−→v est d’affixe z + z′.2) L’opposé −−→u du vecteur −→u est d’affixe −z.3) λ−→u est d’affixe λz.
Une application :
Proposition 3.11. Soit A, B, C et D quatre points du plan complexe d’affixes zA, zB , zC et zDrespectivement.Le quadrilatère ABCD est un parallélogramme si et seulement si
zB − zA = zC − zD
3.3 Module, argument
Définition 3.12. Soit θ et θ′ deux mesures d’angles. On dit que θ est congru à θ modulo (2π) et onnote
θ ≡ θ′ [2π] ou θ ≡ modulo (2π)
s’il existe un entier relatif k tel queθ = θ′ + 2 k π
Remarque. Lorsque θ ≡ θ′ [2π], alors θ et θ′ mesurent le même angle.
On note (O,−→u ,−→v ) le repère orthonormé direct du plan complexe. Soit M un point du plan complexed’affixe z non nul :
47
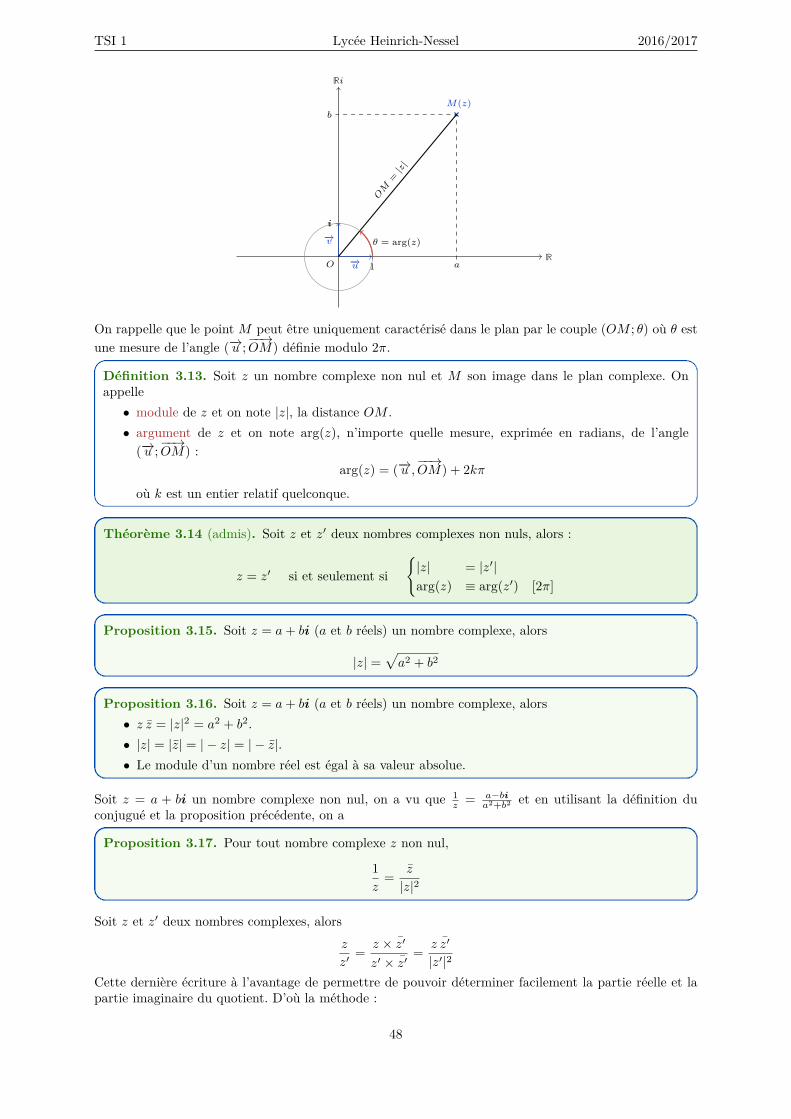
TSI 1 Lycée Heinrich-Nessel 2016/2017
R
Ri
M(z)
a
b
1
i
−→u
−→v
O
OM
=|z|
θ = arg(z)
On rappelle que le point M peut être uniquement caractérisé dans le plan par le couple (OM ; θ) où θ estune mesure de l’angle (−→u ;−−→OM) définie modulo 2π.
Définition 3.13. Soit z un nombre complexe non nul et M son image dans le plan complexe. Onappelle• module de z et on note |z|, la distance OM .• argument de z et on note arg(z), n’importe quelle mesure, exprimée en radians, de l’angle
(−→u ;−−→OM) :arg(z) = (−→u ,−−→OM) + 2kπ
où k est un entier relatif quelconque.
Théorème 3.14 (admis). Soit z et z′ deux nombres complexes non nuls, alors :
z = z′ si et seulement si|z| = |z′|arg(z) ≡ arg(z′) [2π]
Proposition 3.15. Soit z = a+ bi (a et b réels) un nombre complexe, alors
|z| =√a2 + b2
Proposition 3.16. Soit z = a+ bi (a et b réels) un nombre complexe, alors• z z = |z|2 = a2 + b2.• |z| = |z| = | − z| = | − z|.• Le module d’un nombre réel est égal à sa valeur absolue.
Soit z = a + bi un nombre complexe non nul, on a vu que 1z = a−bi
a2+b2 et en utilisant la définition duconjugué et la proposition précédente, on a
Proposition 3.17. Pour tout nombre complexe z non nul,
1z
= z
|z|2
Soit z et z′ deux nombres complexes, alorsz
z′= z × z′
z′ × z′= z z′
|z′|2
Cette dernière écriture à l’avantage de permettre de pouvoir déterminer facilement la partie réelle et lapartie imaginaire du quotient. D’où la méthode :
48

TSI 1 Lycée Heinrich-Nessel 2016/2017
Méthode. Pour exprimer sous forme algébrique un quotient de deux complexes zz′ , on multiplie le
numérateur et le dénominateur par la conjugué du dénominateur.
Proposition 3.18. Pour tous nombres complexes z et z′, on a :1) |zz′| = |z| × |z′| ; (Le module d’un produit est le produit des modules)2) |zn| = |z|n pour tout entier naturel n ;3) si z 6= 0,
∣∣ 1z
∣∣ = 1|z| ;
4) si z 6= 0,∣∣∣ z′z ∣∣∣ = |z′|
|z| ;
5) |z| = 0 si et seulement si z = 0 ;
En revenant à la figure ci-dessus, on note que Oa = |Re(z)| et Ob = | Im(z)|. De plus, dans un trianglerectangle, le plus long des côtés est l’hypoténuse. D’où
Lemme 3.19. Soit z un nombre complexe, alors1) |Re(z)| ≤ |z|;2) | Im(z)| ≤ |z|;3) Si |Re(z)| = |z| alors z ∈ R ;4) Si | Im(z)| = |z| alors z ∈ iR.
Proposition 3.20 (inégalité triangulaire). Soit z et z′ deux nombres complexes, alors :
|z + z′| ≤ |z|+ |z′|
R
Ri
O
Mz
Mz′
Mz+z′
|z|
|z′||z + z′|
De plus, il y a égalité |z+z′| = |z|+ |z′| si et seulement s’il existe un nombre réel λ ≥ 0 tel que z = λz′
ou z′ = λz.
Démonstration. Soit z et z′ deux nombres complexes, on a
|z + z′| ≤ |z|+ |z′|⇐⇒ |z + z′|2 ≤ (|z|+ |z′|)2
⇐⇒ (z + z′) ¯(z + z′) ≤ (|z|+ |z′|)2
⇐⇒ |z|2 + zz′ + z z′ + |z′|2 ≤ |z|2 + 2|zz′|+ |z′|2
⇐⇒ zz′ + ¯zz′ ≤ 2|z z′|
⇐⇒ Re(zz′) ≤ |zz′|
Or, d’après la précédente proposition, cette dernière égalité est bien vérifiée d’où la première partie de la propo-sition.Si z′ = 0, alors l’égalité est toujours vérifiée et z′ = λz avec λ = 0. Supposons maintenant qu’il y a égalité et deplus que z′ soit non nul, alors
Re(zz′) = |zz′| = |z||z′| ≥ 0
49
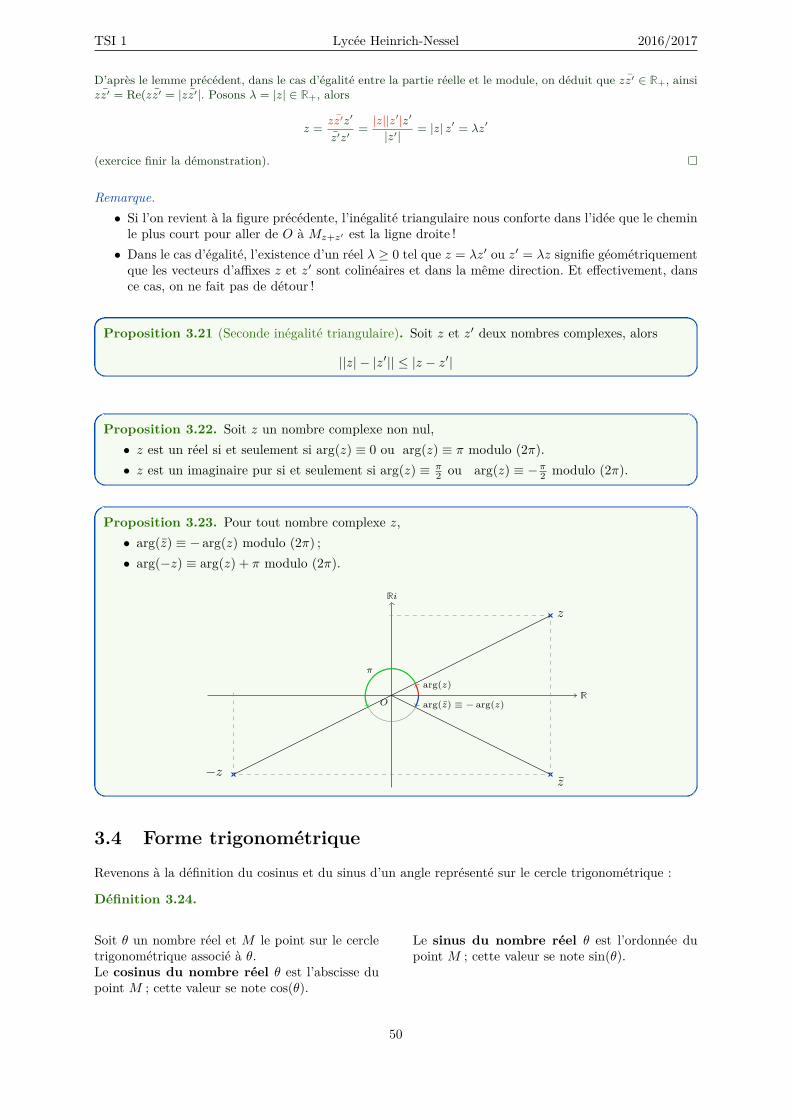
TSI 1 Lycée Heinrich-Nessel 2016/2017
D’après le lemme précédent, dans le cas d’égalité entre la partie réelle et le module, on déduit que zz′ ∈ R+, ainsizz′ = Re(zz′ = |zz′|. Posons λ = |z| ∈ R+, alors
z = zz′z′
z′z′= |z||z
′|z′
|z′| = |z| z′ = λz′
(exercice finir la démonstration).
Remarque.• Si l’on revient à la figure précédente, l’inégalité triangulaire nous conforte dans l’idée que le cheminle plus court pour aller de O à Mz+z′ est la ligne droite !
• Dans le cas d’égalité, l’existence d’un réel λ ≥ 0 tel que z = λz′ ou z′ = λz signifie géométriquementque les vecteurs d’affixes z et z′ sont colinéaires et dans la même direction. Et effectivement, dansce cas, on ne fait pas de détour !
Proposition 3.21 (Seconde inégalité triangulaire). Soit z et z′ deux nombres complexes, alors
||z| − |z′|| ≤ |z − z′|
Proposition 3.22. Soit z un nombre complexe non nul,• z est un réel si et seulement si arg(z) ≡ 0 ou arg(z) ≡ π modulo (2π).• z est un imaginaire pur si et seulement si arg(z) ≡ π
2 ou arg(z) ≡ −π2 modulo (2π).
Proposition 3.23. Pour tout nombre complexe z,• arg(z) ≡ − arg(z) modulo (2π) ;• arg(−z) ≡ arg(z) + π modulo (2π).
R
Ri
O
arg(z)
arg(z) ≡ − arg(z)
π
z
−zz
3.4 Forme trigonométrique
Revenons à la définition du cosinus et du sinus d’un angle représenté sur le cercle trigonométrique :
Définition 3.24.
Soit θ un nombre réel et M le point sur le cercletrigonométrique associé à θ.Le cosinus du nombre réel θ est l’abscisse dupoint M ; cette valeur se note cos(θ).
Le sinus du nombre réel θ est l’ordonnée dupoint M ; cette valeur se note sin(θ).
50

TSI 1 Lycée Heinrich-Nessel 2016/2017
x
y
O−1 1
−1
1
cos(θ)
θsin(θ)
1
Soit z = a + bi un nombre complexe non nul, notons r = |z| son module et θ = arg(z) (une mesure de)son argument. On note M le point d’affixe z et N le point sur le cercle trigonométrique correspondant àl’angle θ. Alors, par définition, le point N est de coordonnées (cos(θ); sin(θ)).Supposons de plus que a > 0 et b > 0 (M se trouve dans le premier quart de plan) :
R
Ri
O 1
i
a
bM(z)
N
r
θsin(θ)
cos(θ)
Ainsi, en appliquant le théorème de Thalès dansle triangle bleu, on a
1r
= cos(θ)a
= sin(θ)b
D’où a = r cos(θ)b = r sin(θ)
et z = r cos(θ) + ri sin(θ) = r(cos(θ) + i sin(θ)).
Ce fait reste vrai quelle que soit la position du point M(z) dans le plan :
Proposition 3.25. Soit z un nombre complexe non nul, notons θ son argument et r son module,alors
z = r ( cos(θ) + i sin(θ) )
Cette écriture est appelée forme trigonométrique de z.Réciproquement si z = r(cos(θ) + sin(θ)) avec r > 0 et θ ∈ R quelconque, alors |z| = r et arg(z) = θ
modulo (2π).
Proposition 3.26 (définition). Soit M un point d’affixe z non nul, alors il existe un unique couple(r; θ) ∈ R∗+ × [0; 2π[ tel que z soit de module r et d’affixe θ.On dit alors que les coordonnées polaires de M sont (r; θ).
Remarque. Comme les coordonnées cartésiennes (x; y) d’un point, les coordonnées polaires (r; θ) per-mettent de localiser précisément un point du plan.Par contre, pour l’orginie du repère, les coordonnées polaires ne sont pas définies. En effet, lorsque r = 0,on ne peut plus mesurer l’angle entre −→u et le vecteur nul −−→OM !
Proposition 3.27. Pour tous nombres complexes z et z′ et tout entier relatif n, on a :1) arg(zz′) ≡ arg(z) + arg(z′) [2π] ; (L’argument du produit est congru à la somme des arguments)2) arg(zn) ≡ n arg(z) [2π] ;3) si z 6= 0, arg( 1
z ) ≡ − arg(z) [2π] ;
51

TSI 1 Lycée Heinrich-Nessel 2016/2017
cos(α)
sin(α)
O0
π6
π3
π4
π2
2π3
3π4
5π6
π
−π6
−π3
−π4
−π2
−2π3
−3π4
−5π6
12
−12
12
¯12
√2
2−√
22
√2
2
¯√
22
√3
2−√
32
√3
2
¯√
32
Figure 3.1 – Valeurs particulières
4) si z 6= 0, arg( z′
z ) ≡ arg(z′)− arg(z) [2π] ;
Remarque. On notera que la première identité implique que l’argument suit une propriété similaire à lafonction exponentielle.
Proposition 3.28. Soit a, b, r et θ des nombres réels tels que r > 0 et a ou b non nul, on a
a+ bi = r(cos(θ) + sin(θ)) ⇐⇒
r =√a2 + b2
cos(θ) = ar et sin(θ) = b
r
⇐⇒
a = r cos(θ)b = r sin(θ)
3.5 Rappels : Les formules de trigonométrie
Propriété 3.29 (Valeurs particulières).
α 0 π6
π4
π3
π2
cos(α) 1√
32
√2
212 0
sin(α) 0 12
√2
2
√3
2 1
Proposition 3.30. Soit α un nombre réel alors :1) cos2(α) + sin2(α) = 1 ;2) Pour tout entier relatif k, cos(α+ 2kπ) = cos(α) et sin(α+ 2kπ) = sin(α).
Soit α ∈ [0; π2 ]. Dans la figure ci-dessous, on a représenté l’angle α sur le cercle trigonométrique ainsi
que son cosinus, son sinus et les angles −α, α + π2 , α + π. Il n’est pas bien difficile de vérifier que les
triangles 1, 2, 3 et 4 en bleu sont rectangles et ont les mêmes dimensions (en particulier l’hypoténuse
52

TSI 1 Lycée Heinrich-Nessel 2016/2017
vaut 1). Ainsi, en revenant à la définition du cosinus et du sinus, l’abscisse et l’ordonnée du point sur lecercle trigonométrique et en comparant les triangles entre eux, on note les relations suivantes :
• des triangles 1 et 2 : cos(−α) = cos(α) etsin(−α) = − sin(α).
• des triangles 1 et 3 : cos(α+ π2 ) = − sin(α)
et sin(α+ π2 ) = cos(α).
• des triangles 1 et 4 : cos(α + π) = − cos(α)et sin(α+ π) = − sin(α).
x
y
O−1 1
−1
1
cos(α)
αsin(α)
α+ π2
α+ π −α
1
2
3
4
Ces relations restent vraies quel que soit α.
Propriété 3.31. Pour tout réel α, on a1) cos(−α) = cos(α) et sin(−α) = − sin(α) ; (le cosinus est pair et le sinus impair)2) cos(π + α) = − cos(α) et sin(π + α) = − sin(α) ;3) cos(π − α) = − cos(α) et sin(π − α) = sin(α) ;4) cos(π2 + α) = − sin(α) et sin(π2 + α) = cos(α) ;5) cos(π2 − α) = sin(α) et sin(π2 − α) = cos(α).
Démonstration. Les relations 1, 2 et 4. ont été vu avant pour des cas particulier (exercice : traiter les autres cas).Soit α un nombre réel,3. Si on applique les relations 2. et 1. avec le nombre réel −α, on a
cos(π − α) = cos(π + (−α)) 2.= − cos(−α) 1.= − cos(α)
De même, on montre la seconde identité.5. Nous allons appliquer les identités 4. et 1.,
cos(π2 − α) = cos(π2 + (−α)) 4.= − sin(−α) 1.= sin(α)
et de même, on déduit le seconde identité.
Propriété 3.32 (Formules d’addition et de duplication). Quels que soient les réels a et b, on a1) cos(a− b) = cos(a) cos(b) + sin(a) sin(b) ;2) cos(a+ b) = cos(a) cos(b)− sin(a) sin(b) ;3) sin(a− b) = sin(a) cos(b)− cos(a) sin(b) ;4) sin(a+ b) = sin(a) cos(b) + cos(a) sin(b) ;
Démonstration. Soit a et b deux nombres réels,1) Cette relation est admise pour le moment. Nous en verrons une démonstration dans le chapitre sur le produit
scalaire.2) À l’aide de la propriété précédente et du point précédent, on a :
cos(a+ b) = cos(a− (−b)) 1.= cos(a) cos(−b) + sin(a) sin(−b) prop 3.31.1.= cos(a) cos(b)− sin(a) sin(b)
53

TSI 1 Lycée Heinrich-Nessel 2016/2017
3) De même,
sin(a− b) prop 3.31.5.= cos(π2 − (a− b))
= cos( (π2 − a) + b)2.= cos(π2 − a) cos(b)− sin(π2 − a) sin(b)
prop 3.31.5.= sin(a) cos(b)− cos(a) sin(b)
4) et
sin(a+ b) = sin(a− (−b))3.= sin(a) cos(−b)− cos(a) sin(−b)
prop 3.31.1.= sin(a) cos(b) + cos(a) sin(b)
Propriété 3.33 (Formules de duplication). Quel que soit le réel a, on a1) cos(2a) = cos2(a)− sin2(a) = 2 cos2(a)− 1 = 1− 2 sin2(a) ;2) sin(2a) = 2 sin(a) cos(a).
Démonstration. (Exercice : Démontrer ces formules à l’aide des propriétés précédentes).
3.6 Équation trigonométrique
Propriété 3.34. Soit a un nombre réel.1) Les solutions de l’équation cos(x) = cos(a) sont de la forme
x = a+ 2 kπ ou x = −a+ 2 kπ
où k est un entier relatif. L’ensemble solution est donc :
S = a+ 2 k π; k ∈ Z ∪ −a+ 2 k π; k ∈ Z
2) Les solutions de l’équation sin(x) = sin(a) sont de la forme
x = a+ 2 kπ ou x = π − a+ 2 kπ
où k est un entier relatif. L’ensemble solution est donc :
S = a+ 2 k π; k ∈ Z ∪ π − a+ 2 k π; k ∈ Z
Exemples.
1) On considère l’équation cos(x) = 12 .
On note que cos(π3 ) = 12 , ainsi d’après la pro-
priété précédente, les solutions de l’équationsont de la forme :
12
π3
−π3
x = π
3 + 2 kπ ou x = −π3 + 2 kπ
où k est un entier relatif.2)
54

TSI 1 Lycée Heinrich-Nessel 2016/2017
On considère l’équation sin(x) = 12 .
On note que sin(π6 ) = 12 , ainsi d’après la pro-
priété précédente, les solutions de l’équationsont de la forme :
12
5π6
π6
x = π
6 + 2 kπ ou x = π − π
6 + 2 kπ = 5π6 + 2 kπ
où k est un entier relatif.3) On considère l’équation :
cos(5x+ π
3 ) =√
22
On note que cos(π4 ) =√
22 , ainsi, si x est solution de la précédente équation, alors il existe un entier
relatif k tel que
5x+ π
3 = π
4 + 2 kπ ou 5x+ π
3 = −π4 + 2 kπ
⇐⇒ 5x = π
4 −π
3 + 2 kπ ou 5x = −π4 −π
3 + 2 kπ
⇐⇒ 5x = −π12 + 2 kπ ou 5x = −7π12 + 2 kπ
⇐⇒ x =−π12 + 2 kπ
5 ou x =− 7π
12 + 2 kπ5
⇐⇒ x = −π60 + 2 kπ5 ou x = −7π
60 + 2 kπ5
En résumé, les solutions de l’équation trigonométrique cos(5x + π3 ) =
√2
2 sont de la forme x =−π60 + 2 kπ
5 ou x = − 7π60 + 2 kπ
5 , où k est un entier relatif.
Exercice 3.1. Résoudre l’équation sin(α) = cos( 5π3 ).
3.7 Écriture exponentielle
Définition 3.35. La notation eiθ désigne le nombre complexe de module 1 et d’argument θ :
eiθ = cos(θ) + i sin(θ)
Proposition 3.36. Soit θ ∈ R, alors le conjugué : (eiθ) = e−iθ.
Exemples. Revenons au cercle trigonométrique, mais vu dans le plan complexe. Si on identifie les pointsavec leurs affixes, on a :
R
iR
01 = ei0
eiπ6
eiπ3
eiπ4
i = eiπ2
ei 2π3
ei 3π4
ei 5π6
−1 = eiπ
e−iπ6
e−iπ3
e−iπ4
−i = e−iπ2e−i 2π
3
e−i 3π4
e−i 5π6
55

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 3.37. Soit z un nombre complexe non nul, r = |z| et θ = arg(z) alors
z = r eiθ
Cette écriture est appelée forme exponentielle.
Théorème 3.38 (Euler). Soit t un nombre réel. Alors :
cos(t) = eit + e−it
2 et sin(t) = eit − e−it
2 i
Un des intérêts de cette écriture :
Proposition 3.39. Soit a et b deux nombres réels alors1) eia × eib = ei(a+b) ;
2) eia
eib= ei(a−b).
Remarque. Cette proposition donne lieu à une méthode pour retrouver les formules de trigonométrie. Parexemple :
ei(a+b) = eia × eib
cos(a+ b) + isin(a+ b) = (cos(a) + i sin(a))× (cos(b) + i sin(b))= (cos(a) cos(b)− sin(a) sin(b)) + i(cos(a) sin(b) + sin(a) cos(b))
D’où par identification des parties réelles et imaginaires :cos(a+ b) = cos(a) cos(b)− sin(a) sin(b)sin(a+ b) = cos(a) sin(b) + sin(a) cos(b)
Proposition 3.40. Soit z1 = r1eiθ1 et z2 = r2 e
iθ2 deux nombres complexes non nuls, alors1) z1 × z2 = r1r2 e
i(θ1+θ2) ;2) 1
z1= 1
r1e−iθ1 ;
3) z1z2
= r1r2ei(θ1−θ2).
Méthode.• Pour passer de l’écriture algébrique de z = a+bi à son écriture trigonométrique ou exponentielle,on doit :1) Calculer son module R = |z|.2) Chercher un argument θ de z
R . Le nombre θ est alors solution des deux équations
cos(θ) = a
|z|et sin(θ) = b
|z|
3) Écrire la forme trigonométrique ou exponentielle correspondante.• Pour passer de la forme exponentielle ou trigonométrique à la forme algébrique, il suffit decalculer cos(θ) et sin(θ) puis de multiplier le complexe cos(θ) + sin(θ)i par le module qui est enfacteur.
3.8 Exponentielle complexe
56

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 3.41. Soit z = a + ib un nombre complexe (sous forme algébrique), l’exponentielle de zest le nombre complexe :
ea eib
noté exp(z) ou ez.
Exercice 3.2. Soit t ∈ R. Écrire sous forme algébrique le nombre et(1+i).
Exercice 3.3. Soit z = a+ bi et z′ = a′ + b′i deux nombres complexes sous formes algébriques.1) Calculer |ez|. Que peut-on en déduire ? Donner un argument de ez.2) Comparer ez et ez.
Proposition 3.42. Soit z et z′ deux nombres complexes.1) ez ∈ C∗, l’ensemble des nombres complexes non nuls ;2) |ez| = eRe(z) ;3) arg(ez) ≡ Im(z) modulo [2π] ;4) ez = ez ;5) ez+z′ = ez ez
′ ;6) e−z = 1
ez ;
7) ez−z′ = ez
ez′;
8) ∀n ∈ N : (ez)n = enz.
À l’aide du théorème 3.14 et de la proposition précédente, on déduit :
Lemme 3.43. Soit z un nombre complexe, alors
ez = 1 si et seulement s’il existe k ∈ Z : z = 2 i k π
Plus généralement :
Théorème 3.44. Soit z′ un nombre complexe fixé, l’ensemble des solutions de l’équation
ez = ez′
sur C estz′ + 2 i k π; k ∈ Z
Exercice 3.4. Résoudre l’équation ez = 1 + i dans C.
3.9 Nombres complexes de module 1
Définition 3.45. On note U l’ensemble des nombres complexes de module 1.
Proposition 3.46.1) L’ensemble U correspond au cercle trigonométrique dans le plan complexe.2) Soit z = a + bi. Le nombre z appartient à U si et seulement si a2 + b2 = 1 si et seulement s’il
existe un nombre réel θ tel que z = ei θ.
Exercice 3.5. Soit z et z′ deux nombres complexes de module 1.1) Montrer que zz′ est aussi dans U.2) Supposons que z 6= −z′, montrer que 1+zz′
z+z′ est un réel.
57

TSI 1 Lycée Heinrich-Nessel 2016/2017
3.10 Géométrie, le plan complexe (annexe)
Proposition 3.47.1) Soit A et B deux points du plan complexe, alors
AB = |zB − zA| = |zA − zB |
2) Soit −→v un vecteur d’affixe z, alors ‖−→v ‖ = |z|.
Proposition 3.48. Soit A un point d’affixe zA. Soit R un nombre réel positif. Alors le pointM d’affixe zest sur le cercle de centre A et de rayon R si et seulement si |z−zA| = R si et seulement si |z−zA|2 = R2.
Corollaire 3.49. Le point M d’affixe z est sur le cercle trigonométrique si et seulement si |z|2 = 1.
Le produit scalaire : Rappelons que −→u(x
y
)· −→v
(x′
y′
)= xx′ + yy′ et que (x + yi) × (x′ + y′i) =
(xx′ − yy′) + (xy′ + yx′)i, d’où
Proposition 3.50. Soit −→u et −→v deux vecteurs d’affixes respectives z et z′, alors
−→u · −→v = Re(z z ′) = 12(z z ′ + z z ′
)Exercice 3.6. Soit −→u et −→v deux vecteurs d’affixes respectives z et z′. Supposons que −→v est non nul.Montrer que −→u · −→v = 0 si et seulement si Re( zz′ ) = 0.
Proposition 3.51. Soit A, B, C trois points deux à deux distincts du plan d’affixes zA, zB et zC .1) Les trois points A, B et C sont alignés si et seulement si zC−zAzB−zA est un réel pur.
2) Les vecteurs −−→AB et −→AC sont orthogonaux si et seulement si zC−zAzB−zA est un imaginaire pur.
3.10.1 Angles
Dans toute cette partie, (O; (~u;~v)) désigne un repère orthonormé du plan.
Proposition 3.52. Soit M un point d’affixe z. Alors (~u; ~OM) ≡ arg(z).
Proposition 3.53. Soit ~w un vecteur d’affixe z. Alors (~u; ~w) ≡ arg(z).
Proposition 3.54. Soient A, B et C trois points d’affixes zA, zB et zC . Alors :1) (~u; ~AB) ≡ arg(zB − zA)
2) ( ~AB; ~AC) ≡ arg(
zC−zAzB−zA
)
Proposition 3.55. Soient ~w et ~w′ deux vecteurs d’affixes z et z′. Alors (~w; ~w′) ≡ arg(
z′z
).
Théorème 3.56 (de l’angle inscrit). Soit A et B deux points distincts d’un cercle de centre O.
1) Pour tout point M de C distinct de A et B, (−→OA,−−→OB) = 2(−−→MA,−−→MB) modulo (2π).
2) Soit T la tangente à C en A et (T,AB) une mesure (modulo π) de l’angle orienté entre la tangente
58

TSI 1 Lycée Heinrich-Nessel 2016/2017
et la droite (AB). Alors (−→OA,−−→OB) = 2(T,AB) modulo (2π).
O
B
M
A
T
Démonstration. 1) On note que AOB et AMB sont isocèles, d’où2(−−→MA,
−−→MO) + (−−→OM,
−→OA) = π modulo (2π)
2(−−→MO,−−→MB) + (−−→OB,−−→OM) = π modulo (2π)
En effectuant le somme de ces deux identités et en appliquant la relation de Chasles, on déduit le premierpoint.
2) Soit D la médiatrice du segment[AB]. Les droites (OA) et T d’une part, (AB) et D d’autre part, sontperpendiculaires. Ainsi, (T,AB) = (OA,D) modulo (π). Le triangle OAB étant isocèle, la médiatrice D estaussi une bissectrice des demi-droites [OA) et [OB). D’où 2(OA,D) = (−→OA,−−→OB) modulo (2π).
La réciproque est vraie :
Théorème 3.57. Soit A, B deux points distincts du plan et a un nombre réel. Posons
E = M ∈ P \ A;B : 2(−−→MA,−−→MB) = a modulo (2π)
1) si a ≡ 0 modulo (2π) alors E est la droite (AB) privé des deux points A et B.2) sinon, E est le cercle passant par A et B, privé des points A et B, tel qu’une mesure de l’angle
entre la tangente T au cercle en A et la droite (AB) soit congrue à a2 modulo (π).
Remarque. On peut aussi décrire l’ensemble E ainsi M ∈ P \ A;B : (−−→MA,−−→MB) = a
2 modulo (π).
Corollaire 3.58. Soit A et B deux points distincts du plan. Le pointM appartient au cercle de diamètre[AB] si et seulement si ABM est rectangle en M .
3.10.2 Alignement. Orthogonalité
Théorème 3.59. Soient A, B et C trois points du plan d’affixes zA, zB et zC . Les points A, B et Csont alignés si et seulement si arg
(zC−zAzB−zA
)≡ 0 [π] si et seulement si zC−zAzB−zA est un nombre réel.
Corollaire 3.60. Soient A et B deux points du plan d’affixes zA et zB . La condition arg(z−zBz−zA
)= 0 [π]
caractérise la droite (AB) privée des deux points A et B.
59

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 3.61. Soient ~w et ~w′ deux vecteurs d’affixes z et z′. Alors ~w et ~w′ sont colinéaires si etseulement si arg
(z′
z
)= 0 [π] si et seulement si z
′
z est un nombre réel.
Théorème 3.62. Soient A, B et C trois points du plan d’affixes zA, zB et zC . Les droites (AB) et(AC) sont orthogonales si et seulement si arg
(zC−zAzB−zA
)= π
2 [π] si et seulement si zC−zAzB−zA est un nombrecomplexe imaginaire pur.
Corollaire 3.63. Soient A et B deux points du plan d’affixes zA et zB . La condition arg(z−zBz−zA
)=
0[π2]caractérise le cercle de diamètre [AB] privé des deux points A et B.
Théorème 3.64. Soient ~w et ~w′ deux vecteurs d’affixes z et z′. Alors ~w et ~w′ sont orthogonaux si etseulement si arg
(z′
z
)= π
2 [π] si et seulement si z′
z est un nombre complexe imaginaire pur.
3.10.3 Translations et symétries
Proposition 3.65. Soit ~w un vecteur d’affixe w. La translation de vecteur ~w envoie le point Md’affixe z sur le point M ′ d’affixe z′ définie par z′ = z + w.
Proposition 3.66. Soit A un point d’affixe zA. La symétrie de centre A envoie le point M d’affixe zsur le point M ′ d’affixe z′ définie par z′ = 2zA − z.
Corollaire 3.67. La symétrie de centre O envoie le point M d’affixe z sur le point M ′ d’affixe z′ définiepar z′ = −z.
Proposition 3.68. L’application qui envoie le point M d’affixe z sur le point M ′ d’affixe z′ = z estla symétrie orthogonale par rapport à l’axe des abscisses.
3.10.4 Rotations
Dans le plan complexe muni du repère orthonormé direct (O;−→u ;−→v ), soit M un point d’affixe z = reiθ
non nul et α un réel. Alors, on az × eiα = rei(θ+α)
Notons M ′ le point d’affixe z′ = z × eiα. L’argument (l’angle avec −→u ) de z′ est augmenté de α. Géomé-triquement, le point M ′ est l’image de M par la rotation de centre O et d’angle α.
R
Ri
α
M(reiθ)M ′(rei(θ+α))
O
Plus généralement, le vecteur −−→OM est d’affixe zM − zO et le vecteur OM ′ est d’affixe zM ′ − zO. Ainsi, siM ′ est l’image de M par la rotation de centre O et d’angle α alors
α ≡ (−−→OM,−−−→OM ′) ≡ arg(zM
′ − zOzM − zO
) modulo (2π)
On en déduit que zM ′ − zO = (zM − zO)eiα.
60

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 3.69. Soit O un point d’affixe zO. Soit α un nombre réel. L’application qui à un point Md’affixe z associe le point M ′ d’affixe z′ définie par
z′ = eiα(z − zO) + zO
est la rotation de centre O et d’angle α.
Corollaire 3.70. La rotation de centre O et d’angle π2 est donnée par la transformation complexe z 7→ iz.
61

TSI 1 Lycée Heinrich-Nessel 2016/2017
3.11 Linéarisation
En revenant au fait que ei(a+b) = eia×eib, nous allons déduire des relations entre les puissances de cosinuset sinus. Une première conséquence qui se déduit par récurrence :
Théorème 3.71 (Moivre). Soient t un nombre réel et n un entier relatif. Alors :(cos(t) + sin(t)i
)n= cos(nt) + sin(nt)i
Méthode. Soit n ∈ N et l ∈ R.1) En exploitant les formules d’Euler, on en déduit que cosn(t) ou sinn(t) peut s’exprimer comme
une somme de λk cos(kl) ou une somme de λk sin(kl) avec k ∈ J0; nK et λ0, . . . , λn des réels. Unetelle transformation d’écriture s’appelle une linéarisation d’expression trigonométrique.
2) En exploitant la formule de Moivre, on en déduit que cos(nl) ou sin(nl) peut s’exprimer commeune somme de λk cosk(t) ou une somme de λk sink(t) avec k ∈ J0; nK et λ0, . . . , λn des réels. Unetelle transformation d’écriture s’appelle une factorisation d’expression trigonométrique.
Un premier retour sur les formules d’Euler : Soit θ un nombre réel, alors 1±eiθ = ei θ2(e−i θ2 ±ei θ2
). Ainsi,
en revenant aux formules d’Euler, on déduit que :
Lemme 3.72. Soit θ un nombre réel, alors1) 1 + eiθ = 2 cos( θ2 ) ei θ2 ;
2) 1− eiθ = −2i sin( θ2 ) ei θ2 .
Plus généralement, on a
Proposition 3.73. Soient a et b deux nombres réels. Alors :
1) eia + eib = 2 cos(a−b
2)
ei( a+b2 )
2) eia − eib = 2 i sin(a−b
2)
ei( a+b2 )
3) −eia = ei(a+π)
Par identification des parties réelles et imaginaires dans le premier point de la proposition, on déduit :
Corollaire 3.74. Soient a et b deux nombres réels, alors
1) cos(a) + cos(b) = 2 cos( a−b2 ) cos( a+b
2 ) ;
2) sin(a) + sin(b) = 2 cos( a−b2 ) sin( a+b
2 ) ;
Exercice 3.7. Déduire de la démonstration, des formules similaires pour cos(a)−cos(b) et sin(a)−sin(b)et les démontrer.
62

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemple (Linéarisation).
sin(t)3 =(eit − e−it
2i
)3
d’après le théorème d’Euler
=(eit − e−it
)3(2i)3
=(eit − e−it
)3−8i
= − 18i((eit)3 − 3(eit)2e−it + 3eit(e−it)2 − (e−it)3)
= − 18i(ei3t − 3eit + 3e−it − e−i3t)
= −14 ×
12i((ei3t − e−i3t)− 3(eit − e−it)
)= −1
4 ×(ei3t − e−i3t
2i − 3eit − e−it
2i
)= −1
4 × (sin(3t)− 3 sin(t))
= 34 sin(t)− 1
4 sin(3t)
Remarque. On peut trouver davantage d’exemples de linéaristion sur la page suivante : http://villemin.gerard.free.fr/aMaths/Trigonom/aaaBases/Linearis.htm
Méthode. Pour linéariser une expression de la forme sink(t) cosl(t), on utilise la formule d’Euler,pour obtenir ( e
it−e−it
2 )k( eit+e−it
2 )l et on développe (via la formule du binôme de Newton) puis onrassemble les termes eiα et e−iα afin de faire apparaître une somme de cosinus et sinus.
Exemple (Factorisation). On peut aussi être amené à faire le travail inverse, c’est-à-dire à transformerune fonction de la forme cos(mt) ou sin(mt) en puissances de cos et sin. Pour cela, on utilise la formulede Moivre, dont on prend, selon le cas, la partie réelle ou imaginaire. A titre d’exemple, opérons cettetransformation sur cos(3t) :
cos(3t) = Re(cos(3t) + i sin(3t))= Re
((cos(t) + sin(t)i)3) Formule de Moivre
= Re(cos(t)3 + 3 cos(t)2 × (sin(t)i) + 3 cos(t)× (sin(t)i)2 + (sin(t)i)3)
= Re(cos(t)3 + 3 cos(t)2 sin(t)i− 3 cos(t) sin(t)2 − 3 sin(t)3i
)= cos(t)3 − 3 cos(t) sin(t)2
= cos(t)3 − 3 cos(t)(1− cos(t)2)
= 4 cos(t)3 − 3 cos(t)= cos(t)(4 cos(t)2 − 3)
Exercice 3.8. Linéariser cos2(t) pour t ∈ R et en déduire l’intégrale∫ π
0 cos2(t) dt.
Il est aussi possible de factoriser une somme d’un cosinus et d’un sinus à l’aide des formules de trigono-métrie. Considérons l’identité :
A cos(t− φ) = A cos(φ) cos(t) +A sin(φ) sin(t)
et posons a = A cos(φ) et b = A sin(φ) alors
A cos(t− φ) = a cos(t) + b sin(t)
Réciproquement, nous avons vu que pour tout nombre complexe a+ ib, il existe A ≥ 0 et φ ∈ R tels quea+ ib = Aeiφ. C’est-à-dire tels que : a = A cos(φ) et b = A sin(φ). D’où
63

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 3.75. Soit a, b deux nombres réels, alors il existe A ≥ 0 et φ ∈ R tels que :
∀ t ∈ R : a cos(t) + b sin(t) = A cos(t− φ)
Exercice 3.9. Résoudre cos(t) +√
3 sin(t) = 0.
Exercice 3.10 (Amplitude et phase). On appelle oscillateur harmonique tout système dont l’évolu-tion est décrite par une grandeur x fonction du temps t et de la forme :
x(t) = a cos(ω t) + b sin(ω t)
où a, b sont des nombres réels et ω > 0. Cette grandeur peut s’écrire A cos(ωt + φ), A est appelél’amplitude de x et φ la phase à l’origine.Déterminer l’amplitude et la phase à l’origine sachant que x(0) = 1 et x′(0) = −ω et φ ∈ [0; π
2 ].On a
x(0) = a = 1x′(0) = bω = −ω
⇒ a+ ib = 1− i =√
2 e−iπ4
D’où A =√
2, φ = π4 et pour tout t ≥ 0 :
x(t) =√
2 cos(ωt+ π
4 )
3.12 Équations polynomiales
3.12.1 Équation du second degré à coefficients réels
Soit λ > 0 un nombre réel, alors (i√λ)2 = i2 × (
√λ)2 = −λ. D’où :
Proposition 3.76. Soit λ un nombre réel, alors dans C l’équation
x2 = λ
admet toujours au moins une solution. Plus précisément :• Si λ > 0, deux solutions : x1 =
√λ et x2 = −
√λ ;
• Si λ = 0, une solution : x1 = 0 ;• Si λ < 0, deux solutions : x1 = i
√|λ| et x2 = −i
√|λ|.
Théorème 3.77. Soit, dans C, l’équation du second degré
az2 + bz + c = 0
où a 6= 0, b et c sont des nombres réels. On pose ∆ = b2 − 4ac et on note S l’ensemble des solutionsde l’équation. Alors :
• Si ∆ > 0, S =−b−
√∆
2a ; −b+√
∆2a
;
• Si ∆ = 0, S =−b
2a;
• Si ∆ < 0, S =−b−i
√−∆
2a ; −b+i√−∆
2a
.
Remarque. On vient de voir que tout polynôme du second degré à coefficients réels admet une racinedans l’ensemble des nombres complexes. Plus généralement, le théorème de D’Alembert-Gauss affirmeque « tout polynôme de degré n à coefficients complexes admet n racines distinctes ou confondues dansC lui-même. » On dit que le corps des nombres complexes C est algébriquement clos. Nous reviendronssur ce théorème au second semestre.
64

TSI 1 Lycée Heinrich-Nessel 2016/2017
Propriété 3.78 (Factorisation du trinôme). Soit ax2 + bx+ c = 0 une équation du second degré.• Supposons que le discriminant ∆ est non nul et notons x1 et x2 les deux racines, alors
ax2 + bx+ c = a(x− x1)(x− x2)
• Supposons que ∆ = 0, alors x0 = −b2a est l’unique racine et
ax2 + bx+ c = a(x− x0)2
3.12.2 Racine carrée d’un complexe
Définition 3.79. Soit z un nombre complexe. Une racine carrée de z est un nombre complexe w tel quew2 = z.
Rappelons que pour tout réel θ, (eiθ)2 = e2iθ, d’où, pour tout réel t :(ei t
2
)2= eit
On pourrait aussi vouloir chercher une racine carrée à l’aide des expressions des nombres complexes sousforme algébrique. Si w = α+iβ est une racine carrée de z = a+ib, alors w2 = z et aussi |w|2 = |w2| = |z|,d’où
α2 + 2αβi− β2 = a+ ib
α2 + β2 = |z|α2 − β2 = a
2αβ = b
α2 + β2 = |z|α2 = |z|+a
2β2 = |z|−a
2αβ = b
2
Ensuite, a priori, nous avons quatre choix différents : α = ±√|z|+a
2 et β = ±√|z|−a
2 . Or, d’après latroisième équation, le produit αβ est du même signe que b. Ainsi, le signe de α détermine celui de β.D’où, le troisième point du théorème ci-dessous.
Théorème 3.80. Soit z un nombre complexe non nul. Alors :1) Il existe deux racines carrées z1 et z2 de z. De plus, z2 = −z1 .2) Si z = Reit est une écriture exponentielle de z, alors
z1 =√
R ei t2 et z2 = −
√R ei t
2 =√
R ei( t2 +π)
sont les deux racines carrées de z.3) Si z = Re(z) + i Im(z) est sous forme algébrique, alors le nombre complexe z1 tel que
Re(z1) =√|z|+ Re(z)
2 et Im(z1) = sgn(Im(z))√|z| − Re(z)
2
est une racine carrée de z.
Remarque. Pour la troisième propriété, il est préférable de retenir la démonstration (méthode) au lieu dela formule.
Exercice 3.11.1) Déterminer les racines carrées de 5 e7iπ.2) Écrire 3 + 3i sous forme exponentielle et en déduire les racines carrées de 3 + 3i.
65

TSI 1 Lycée Heinrich-Nessel 2016/2017
3) Déterminer les racines carrées de 5− 12i. 5− 12i = (3− 2i)2
Méthode. Pour trouver la racine d’un nombre complexe z non nul, on peut :• Ecrire z sous forme exponentielle. On cherche alors une racine w sous forme exponentielle éga-
lement. On écrit la relation w2 = z sous forme exponentielle puis on identifie les modules et lesarguments (modulo 2π).
• Ecrire z sous forme algébrique. On cherche alors une racine w sous forme algébrique également.On développe la relation w2 = z puis on identifie partie réelle et partie imaginaire. Pour faciliterla résolution, on peut aussi ajouter la relation |w|2 = |z|.
3.12.3 Trinômes à coefficients complexes
Théorème 3.81. Soient a, b et c trois nombres complexes. On suppose que a est non nul. Soit δune racine carrée de ∆. Alors le trinôme az2 + bz + c admet deux racines complexes (éventuellementconfondues) :
z1 = −b − δ2a et z2 = −b + δ
2aDe plus, on a az2 + bz + c = a(z − z1 )(z − z2 ).
Corollaire 3.82. Soit az2 + bz + c un trinôme à coefficients complexes (avec a 6= 0). Soient z1 et z2 sesdeux racines. Alors
z1 + z2 = − ba et z1 × z2 = c
a
Le corollaire permet de déduire la seconde racine de la première : z2 = −ba − z1 par exemple.
3.12.4 Racines ne de l’unité
Définition 3.83. Soit z un nombre complexe non nul. Soit n un entier strictement positif. Une racinene de z est un nombre complexe w tel que wn = z. Lorsque z = 1, on parle de racine ne de l’unité.
Théorème 3.84. Il existe exactement n racines ne de l’unité distinctes :
ei 2kπn , k ∈ 0 , 1 , . . . ,n − 1
Exemple. L’ensemble des racines 6e de l’unité est
ei 2kπ6 ; 0 ≤ k ≤ 5 = ei kπ3 ; 0 ≤ k ≤ 5 = 1; eiπ3 ; ei 2π
3 ; −1; ei 4π3 ; ei 5π
3
Dans le plan complexe :
R
iR
1
eiπ3e
2iπ3
−1 = eiπ
e4iπ3 e
5iπ3
π3
π3
π3
π3
π3
π3
66

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 3.85. Soit z un nombre complexe non nul. Il existe n racines ne de z (éventuellementconfondues). Si de plus w est une racine ne de z, alors les racines ne de z sont les nombres complexes :
w × ei 2kπn , k ∈ 0 , 1 , . . . ,n − 1
Corollaire 3.86. Soit z un nombre complexe non nul. Notons w1, . . . , wn ses n racines ne distinctes.Alors
n∑k=1
wk = 0 etn∏k=1
wk = (−1 )n−1
C’est-à-dire la somme des racines ne est nulle et leur produit vaut ±1 en fonction de la parité de n.
Démonstration. Rappelons que Xn − 1 = (X − 1)(1 +X + . . .+Xn−1). Soit ω = ei 2πn , alors
0 = ωn − 1 = (ω − 1)(1 + ω + . . .+ ωn−1)
D’où l’on déduit le premier point. Le second se déduit de :
n−1∏k=0
ωk = exp(in−1∑k=0
2kπn
) = eiπ(n−1) = (−1)n−1
Exercice 3.12. On pose ω = e2iπ7 , résoudre dans C l’équation
∑6i=0 ω
ixi = 0.
Théorème 3.87. Soit z un nombre complexe non nul. Soit z = Reit une écriture exponentielle de z.Alors une racine ne de z est donnée par
z1 = n√R ei t
n = R 1n ei t
n
67

TSI 1 Lycée Heinrich-Nessel 2016/2017
68

Chapitre 4
Ensembles et manipulationalgébrique
Programme• Les ensembles : On se limite à une approche naïveappartenance, inclusion Démontrer une égalité, une inclusion de deux ensembles
• Intervalles• Sous-ensembles, Ensemble vide• union, intersection, complémentaire, Maîtriser le lien entre connecteurs logiques et opérations en-semblistes
• produit cartésien de deux ensembles, d’un nombre fini d’ensembles.• Ensemble des parties d’un ensemble.• Cardinal d’un ensemble fini• Majoration, minoration, encadrement de sommes, de produits et de quotients.• Manipulations algébriques : somme
∑, produit
∏.
• Notations et règles de calcul sur des exemples de difficulté raisonnable.• Effectuer un changement d’indice (de variable)• sommes et produits télescopiques
•n∑k=0
k etn∑k=0
qk
• Factorielle : n!• coefficient binomial
(nk
)lu « k parmi n ». Aucun lien avec le dénombrement à ce stade.
• Triangle de Pascal, Formule du binôme de Newton• Développer (a± b)n et factoriser an − bn.
4.1 Les ensembles
Le mathématicien allemand R. Dedekind (1831-1916) cherche à fonder l’analyse sur des bases solides.Pour cela, il se propose de donner une construction des nombres réels par coupures. A la suite de sesrecherches, il décide d’étudier plus en profondeur la construction de tous les types de nombres, ce qui leconduit à une première ébauche de théorie des ensembles.Dedekind commence alors une correspondance avec le mathématicien allemand G. Cantor (1845-1918),qui se passionne pour cette étude des ensembles. Il poussera plus loin les idées de Dedekind et mettra surpied la première théorie des ensembles, et notamment des ensembles transfinis.Mais, la théorie de Cantor souffre de certaines lacunes qui conduisent à divers paradoxes découverts parles logiciens, et notamment B. Russel (1872-1970). Pour pallier ces inconvénient, les mathématiciens E.Zermelo (1871-1953) et A. Fraenkel (1891-1965) proposent une définition axiomatique des ensembles.
69

TSI 1 Lycée Heinrich-Nessel 2016/2017
Le paradoxe du barbier : Un barbier se propose de raser tous les hommes qui ne se rasent pas eux-mêmes,et seulement ceux-là. Le barbier doit-il se raser lui-même ? L’étude des deux possibilités conduit à unecontradiction. Pour ne pas avoir de paradoxe, un tel barbier ne peut pas exister.On ne donnera aucune définition précise du mot « ensemble » dans ce chapitre. En référence à Cantor,« par ensemble, nous entendons toute collection E d’objets x de notre intuition ou de notre pensée, définiset distincts, ces objets étant appelés les éléments de E ».
On peut décrire un ensemble de deux manières :1) En extension : Il s’agit de faire la liste exhaustive de tous les éléments de l’ensemble.2) En compréhension : On regroupe tous les éléments qui satisfont certaines contraintes ou
propriétés.L’ensemble qui n’a aucun élément, c’est l’ensemble vide, noté ø ou parfois .Pour signifier qu’un élément appartient à un ensemble, on utilise le symbole ∈.
Remarque. Un ensemble qui ne contient qu’un seul élément s’appelle un singleton. Notez bien que øest un exemple de singleton : c’est un ensemble qui contient un seul élément, l’ensemble vide.. !
Exemples. 1) En extension : l’ensemble J de tous les jours de la semaine est décrit en extension par
lundi, mardi, mercredi, jeudi, vendredi, samedi, dimanche
l’ensembleM des mois de l’année par
janvier, février, mars, avril, mai, juin, juillet, août, septembre,
octobre, novembre, décembre
l’ensemble C des chiffres par0; 1; 2; 3; 4; 5; 6; 7; 8; 9
Par exemple, lundi ∈ J , mars ∈M et 7 ∈ C. Par contre, 10 6∈ C et vendredi 6∈ M.2) En compréhension : Considérons
mois ∈M, mois a 31 jours
qui est la même chose que l’ensemble
janvier, mars, mai, juillet, août, octobre, décembre
ou encorec ∈ C, c est pair
qui est la même chose que l’ensemble0; 2; 4; 6; 8
On peut aussi imposer des conditions plus compliquées comme
mois ∈M, mois a 31 jours et mois contient la lettre ’r’
qui est la même chose que l’ensemble
janvier, mars, octobre, décembre
ouc ∈ C, c est pair ou divisible par 3
qui est la même chose que l’ensemble
0; 2; 3; 4; 6; 8; 9
Notons qu’en mathématiques, le « ou » est toujours « inclusif ». C’est l’un ou l’autre ou les deux.
70

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 4.1. Un ensemble fini est un ensemble E ayant un nombre fini d’éléments. Dans ce cas,on note card(E) ou ]E le nombre d’éléments de E, qu’on appelle le cardinal de E.
Notations. Quelques ensembles de nombres :• L’ensemble des entiers naturels est noté N = 0; 1; 2; 3; . . .• L’ensemble des entiers relatifs est noté Z = . . . ,−2;−1; 0; 1; 2; . . .• L’ensemble des nombres rationnels est noté Q =
ab , a ∈ Z et b ∈ N et b 6= 0
• L’ensemble des nombres réels est noté R
• L’ensemble des nombres complexes est noté C
0 1 2 3 4 5 6 7 . . .N
-1-2-3-4-5-6-7. . .Z
D-7.9 -6.342 -3.876 3.21 5.24231
227
−133
−167
5011Q
π√
2−eR
Figure 4.1 – Les ensembles de nombres
Notation. On désignera par K l’ensemble des nombres réels R ou l’ensemble des nombres complexes C.
Pour définir formellement un sous-ensemble d’un ensemble E en compréhension, il y a essentiellementdeux façons différentes :
1)e ∈ E : conditions
qui se lit : « l’ensemble des éléments e de E tels que [conditions] ».2)
f(e) : e ∈ E
qui se lit : « l’ensemble des éléments de la forme f(e) où e appartient à E ».
Exemples.• L’ensemble des entiers pairs : n ∈ N : ∃ k ∈ N, n = 2k = 2k, k ∈ N ;• L’intervalle [0; 1] : x ∈ R : 0 ≤ x et x ≤ 1 ;• L’intervalle ]0; 1] : x ∈ R : 0 < x et x ≤ 1 ;• L’intervalle ]0; +∞[ : x ∈ R : 0 < x, c’est l’ensemble des nombres strictement positif ;
71

TSI 1 Lycée Heinrich-Nessel 2016/2017
• k2 : k ∈ N et k ≤ 10, l’ensemble des carrés d’entiers naturels inférieurs à 10, autrement dit0; 1; 4; 9; 16; 25; 36; 49; 64; 81; 100 (en extension). On peut aussi définir cet ensemble ainsi : n ∈N : ∃ k ∈ N, n = k2 et k ≤ 10.
• 2n : n ∈ J0; 10K est l’ensemble des 11 premières puissances de 2, soit en extension 1 ;2 ;4 ;8 ;16 ;32 ;64 ;128 ;256 ;512 ;1024 .
• a2 + b2 : a ∈ N et b ∈ N = x ∈ N : ∃ a ∈ N et ∃ b ∈ N, x = a2 + b2 (une autre description decet ensemble est donné par un théorème de Fermat).
Définition 4.2. Soit a ≤ b deux entiers relatifs, on pose
Ja; bK = m ∈ Z : a ≤ m ≤ b
Exemple. J−1; 10K = −1; 0; 1; 2; 3; 4; 5; 6; 7; 9; 10.
Définition 4.3. Deux ensembles sont dit égaux lorsqu’ils ont exactement les mêmes éléments.
Remarque. On a 1, 2, 3 = 3, 2, 1 6= a, b, c. Lorsqu’on décrit un ensemble, l’ordre des éléments necompte pas.
4.1.1 Intervalles
Soient a et b deux nombres réels tels que a < b. On pose :
[a; b] = x ∈ R, a ≤ x ≤ b
Ra b
[a; b[= x ∈ R, a ≤ x < b
Ra b
]a; b] = x ∈ R, a < x ≤ b
]a; b[= x ∈ R, a < x < b
[a; +∞[= x ∈ R, a ≤ x
]a; +∞[= x ∈ R, a < x
]−∞; b] = x ∈ R, x ≤ b
]−∞; b[= x ∈ R, x < b
]−∞; +∞[= R
Vocabulaire. Soit a, b des nombres réels ou éventuellement égaux à ±∞. On dit que l’intervalle [a; b]est fermé, l’intervalle ]a; b[ est ouvert et l’intervalle [a; b[ est fermé en a et ouvert en b.
Lorsque un intervalle est ouvert (resp. fermé) en l’une de ses bornes c’est tout simplement qu’il ne contientpas (resp. contient) cette borne.
72

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 4.4. Un intervalle I de R est une partie de R telle que
∀ a ∈ I, ∀ b ∈ I, [a; b] ⊂ I
C’est-à-dire que quels que soient les réels a ≤ b, si a et b sont dans l’ensemble I, alors I contient aussitout l’intervalle [a; b] (tous les nombres compris entre a et b).
Géométriquement, un intervalle se représente sur l’axe des réels sans lever le crayon (il n’y a pas de trou).
Exemple. L’ensemble [1; 2] est un intervalle, par contre 1; 2; 3 ni [1; 2[∪]2; 3] sont des intervalles.
Théorème 4.5. Un intervalle I de R est toujours d’une des neuf formes ci-dessus.
4.1.2 Sous-ensemble
Définition 4.6. Soient A et B deux ensembles.On dit que A est un sous-ensemble de B (ou unepartie de B ou que B contient A) si tous les élé-ments de A appartiennent aussi à B. On notealors A ⊂ B. Ainsi,
A ⊂ B signifie ∀ x ∈ A, x ∈ B
Dans ce cas, on dit aussi que A est inclus dans Bet le symbole ⊂ est appelé symbole d’inclusion.
B
A
Remarque. D’après la définition précédente, B est un sous-ensemble de lui-même !Parfois la notation A ⊆ B est utilisé pour insister sur le fait qu’ éventuellement le sous-ensemble A peutêtre égal à B lui-même. Pour signifier une inclusion stricte, on utilise la notation suivante : A ( B.
Exemples.• B ⊂ B• ø ⊂ B• 2k, k ∈ N ⊂ N
• x ∈ R, 0 ≤ x et x ≤ 1 ⊂ R
• N ⊂ Z ⊂ Q ⊂ R ⊂ C
Méthode. Pour montrer que A ⊂ B, il faut montrer que quel que soit l’élément x dans A, il appartientaussi à B. Plus précisément, on choisit un élément quelconque de A et on montre qu’il appartient àB. La rédaction ressemble à :« Soit x ∈ A. Montrons que x ∈ B :[. . .]Donc, A est inclus dans B. »
Exemple. Prenons A = 4k, k ∈ N et B = 2l, l ∈ N. Montrons que A ⊂ B.
Démonstration. Soit x ∈ A. Montrons que x ∈ B.Par définition, x est de la forme 4k, où k ∈ N. Donc, x = 4k = 2× (2k). Comme k ∈ N, 2k ∈ N. Donc x est de laforme 2l où l = 2k ∈ N. Ainsi x ∈ B.Donc, A ⊂ B.
Le relation d’inclusion est transitive : un sous-ensemble d’un sous-ensemble est un sous-ensemble.
73

TSI 1 Lycée Heinrich-Nessel 2016/2017
Propriété 4.7. Quels que soient les ensembles A, B et C, on a :1) A ⊂ A ;2) Si A ⊂ B et B ⊂ C alors A ⊂ C ; (transitivité)3) Si A ⊂ B et B ⊂ A alors A = B. (double inclusion)
Du troisième point, on déduit la méthode suivante :
Méthode. Pour montrer que A = B, on montre d’une part que A ⊂ B et d’autre part que B ⊂ A(double inclusion).
Définition 4.8. Soit A un sous-ensemble d’un ensemble B, alors on note B \A (ou BA, ou A et selit « B privé de A ») le sous-ensemble des éléments de B mais qui ne sont pas dans A.L’ensemble B \A est le complémentaire de A dans B.
Remarque. Si A n’est pas un sous-ensemble de B, on utilise le symbole 6⊂. On a
A 6⊂ B = NON (∀ x ∈ A, x ∈ B) = ∃ x ∈ A, x 6∈ B
Par exemple, −1; 0; 1 6⊂ N car −1 6∈ N. Pour montrer que A 6= B, il suffit de montrer que A 6⊂ B ouque B 6⊂ A.
Méthode.• Pour montrer que A 6⊂ B, il suffit de trouver un élément de A qui n’appartient pas à B.• Pour montrer que A 6= B, il suffit d’éxiber un élément appartenant à un des sous-ensembles maispas à l’autre.
4.1.3 Union
Définition 4.9. Soient A et B deux ensembles.L’union de A et B est l’ensemble
A ∪B = x : x ∈ A ou x ∈ B
Un élément est dans A ∪ B s’il appartient à aumoins un des deux ensembles A ou B.
A BA ∪B
Exemple. Posons −N = −x, x ∈ N. Alors Z = (−N) ∪ N. Remarquons aussi que N = 0 ∪ 1 ∪ · · ·Un ensemble est toujours l’union de tous les singletons qu’il contient.
Remarque. En mathématique, contrairement au langage usuel, la conjonction de coordination "ou" estutilisé au sens large ("ou inclusif"). C’est-à-dire, un élément qui est dans A∪B peut être dans A, dans Bou être dans les deux à la fois. Par exemple 0 appartient à [−1; 0] ∪ 0, tout comme −0.5.Cette différence de sens commun donne lieu à la blague suivante :Une mathématicienne a eu un bébé. On lui demande si c’est un garçon ou une fille. Que répond-elle ?Oui.
Méthode. Pour montrer que x ∈ A ∪B, on montre que x ∈ A ou que x ∈ B. On peut raisonner pardisjonction des cas : ou bien x ∈ A (et il n’y a rien à montrer) ou bien x 6∈ A et il faut montrer quenécessairement x ∈ B.
Proposition 4.10. Soient A, B et C trois ensembles. Alors :1) A ∪B = B ∪A (commutativité)2) A ∪ø = A (neutre)
74

TSI 1 Lycée Heinrich-Nessel 2016/2017
3) A ∪A = A
4) A ∪ (B ∪ C) = (A ∪B) ∪ C (associativité)5) Si A ⊂ B alors A ∪B = B
6) A ⊂ A ∪B et B ⊂ A ∪B
Exercice 4.1. Soient A et B deux ensembles tels que B = A ∪B. Montrer que A ⊂ B.
4.1.4 Intersection
Définition 4.11. Soient A et B deux en-sembles. L’intersection de A et B est l’ensemble
A ∩B = x; x ∈ A et x ∈ B
Un élément appartient A∩B si et seulement s’ilappartient à A et B simultanément.
A B
A ∩B
Exercice 4.2. Une classe de 28 élèves de TSI2 obtient les résultats suivants au concours : 22 élèvessont admissibles au concours CCP et 10 sont admissibles au concours CCS. Malheureusement 2 ne sontadmissibles à aucun concours. Combien d’étudiants sont admissibles à un seul concours ?
Exemple. Posons −N = −x, x ∈ N. Alors 0 = (−N) ∩ N. Remarquons aussi que l’intersection desingletons différents est toujours vide.
Définition 4.12. Deux ensembles A et B sont disjoints si A ∩B = ø.
Méthode. Pour montrer que x appartient à l’intersection de A et B (x ∈ A ∩ B), on montre que xappartient à A et que x appartient à B.
Proposition 4.13. Soient A, B et C trois ensembles. Alors :1) A ∩B = B ∩A (commutativité)2) A ∩ø = ø3) A ∩A = A
4) A ∩ (B ∩ C) = (A ∩B) ∩ C (associativité)5) Si A ⊂ B alors A ∩B = A
6) A ∩B ⊂ A et A ∩B ⊂ B
Exercice 4.3.1) Soient A et B deux ensembles tels que A = A ∩B. Montrer que A ⊂ B.2) Soient A et B deux ensembles tels que A ∪B = A ∩B. Montrer que A = B.
Comme pour l’addition et la multiplication des nombres, avec l’union et l’intersection nous avons aussides formules de distributivité.
Proposition 4.14 (Distributivité). Soient A, B et C trois ensembles. Alors :1) A ∩ (B ∪ C) = (A ∩B) ∪ (A ∩ C)2) A ∪ (B ∩ C) = (A ∪B) ∩ (A ∪ C)
4.1.5 Complémentaire
75

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 4.15. Soit A et B deux sous-ensemble d’un ensemble E. Le complémentairede A dans B est l’ensemble
B \A = x ∈ E : x ∈ B et x 6∈ AL’ensemble des éléments de B qui ne sont pasdans A.
A B
B \A
Notation. Durant l’année, nous utiliserons fréquemment les ensembles R\0 et N\0, qui sont parfoisnotés R∗ et N∗.
Méthode. Pour montrer que x ∈ B \A, il faut montrer que x ∈ B et que x 6∈ A.
Proposition 4.16. Soit A un sous-ensemble de l’ensemble E. Alors :1) E \ (E \A) = A : le complémentaire du complémentaire c’est l’ensemble lui-même.2) E \ E = ø le complémentaire du "tout" c’est le vide3) E \ø = E le complémentaire du vide est le "tout"
Proposition 4.17 (Morgan). Soient A et B deux sous-ensembles de l’ensemble E. Alors :1) E \ (A ∩B) = (E \A) ∪ (E \ B)2) E \ (A ∪B) = (E \A) ∩ (E \ B)
On notera une analogie avec en logique les identités suivantes (lois de Morgan) :NON (P ET Q) = ( NON P) OU ( NON Q) et NON (P OU Q) = ( NON P) ET ( NON Q).En effet, étant donné un ensemble E non vide et x un élément de E, on peut définir une l’application :
A; A ⊂ E // Vrai; FauxA // x ∈ A
A ∪B // x ∈ A ∪B équivaut à (x ∈ A) OU (x ∈ B)
A ∩B // x ∈ A ∩B équivaut à (x ∈ A) ET (x ∈ B)
EA // x ∈ EA équivant à NON (x ∈ A)
Une telle application est appelée un morphisme car elle préserve les identités entre les opérateurs (lastructure) de l’univers des sous-ensembles dans l’univers des assertions. Quel est l’antécédent de l’assertion« x ∈ A⇒ x ∈ B » ? EA ∪B.
Digression. De telles considérations permettent d’aboutir à une démonstration élégante (mais technique)du théorème de représentation de Stone (1937) qui a pour conséquence l’existence des compactifiés deStone-Cech en topologie ([Paul R. Halmos, Lectures on Boolean Algebras. Van nostrand mathematicalstudies, 1967]).
Exercice 4.4. Soit E un ensemble. Soient A et B deux sous-ensembles de E. Résoudre l’équationX∪A =B, d’inconnue X sous-ensemble de E. Résoudre de même X ∩A = B.
4.1.6 Produit cartésien
Définition 4.18. Soient A et B deux ensembles. Le produit cartésien de A et B est l’ensemble
A×B = (x, y) : x ∈ A et y ∈ B
76

TSI 1 Lycée Heinrich-Nessel 2016/2017
L’ensemble des couples (x, y) où x ∈ A et y ∈ B.
Exercice 4.5. Décrire en expansion l’ensemble 1, 2, 3 × a, b.
Proposition 4.19. Soient E et F deux ensembles. Soient A et B des sous-ensembles respectivementde E et F . Alors A×B ⊂ E × F .
Notation. On note A2 au lieu de A×A, A3 au lieu de A×A×A, etc. Par exemple, on a
R2 = (x; y), x ∈ R et y ∈ R
etR3 = (x; y; z), x ∈ R et y ∈ R et z ∈ R
Exemple. Soit f : R+ → R définie par f(x) =√x, alors l’ensemble
Γf = (x; y) ∈ R2 : x ∈ R+ et y = f(x)
est un sous-ensemble de R2. C’est en fait le graphe de la fonction f .
4.1.7 Ensemble des sous-ensembles
Définition 4.20. Soit E un ensemble. On note P(E) l’ensemble des parties de E :
P(E) = A : A ⊂ E
Remarque. On a toujours ø ∈ P(E) et E ∈ P(E).Se donner un sous-ensemble de E équivaut à se donner un élément de l’ensemble P(E). Mais, on feraattention à ne jamais écrire A ∈ E mais A ⊂ E ou A ∈ P(E).
Exercice 4.6. On considère les deux ensembles E = 0; 1 et F = 0; 1; 2. Décrire P(E) et P(F ).
Proposition 4.21. Soient A et B deux ensembles tels que A ⊂ B. Alors P(A) ⊂ P(B).
4.1.8 Majoration et minoration
Définition 4.22. Soit A une partie non vide de R. On dit que A est majorée si
∃M ∈ R, ∀ x ∈ A, x ≤M
Tout nombre M satisfaisant à cette propriété est appelé un majorant.
Définition 4.23. Soit A une partie non vide de R. On dit que A est minorée si
∃m ∈ R, ∀ x ∈ A, x ≥ m
Tout nombre m satisfaisant à cette propriété est appelé un minorant.
Définition 4.24. Soit A une partie non vide de R. On dit que A est bornée si A est majorée etminorée.
Exemples.1) L’intervalle [10; 102] est majoré par 1 000 000 mais aussi par 102. Il est minoré par −10100 mais
aussi par 10.
77

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) L’ensemble sin(n), n ∈ N est majoré par1 et minoré par -1.3) L’ensemble (−1)n n, n ∈ N n’est ni majoré ni minoré.4) L’ensemble A = n
n+1 , n ∈ N est majoré par 1 et minoré par 0. Dans cet exemple, on note que lemajorant 1 n’est pas atteint (il n’appartient pas à l’ensemble A). En effet, si on cherche cet entier ntel que n
n+1 = 1 alors n = n+ 1 et donc 0 = 1 ce qui est absurde ! Par contre, si on choisit M ′ < 1,éventuellement très proche de 1, est-ce encore un majorant de A ?En fait, non ! Montrons le. Soit M ′ < 1, alors 1−M ′ > 0 et
n
n+ 1 ≤M′
n ≤M ′(n+ 1)(1−M ′)n ≤M ′
n ≤ M ′
1−M ′ l’inégalité est conservée car 1−M ′ > 0
En considérant la contraposée, si n0 >M′
1−M′ alorsn0n0+1 n’est pas plus petit que M ′ et donc M ′ n’est pas
un majorant (de tous les éléments) de A.
5) L’ensemble A = r ∈ Q; r2 ≤ 2 est majoré par√
2 qui n’appartient pas à A car (comme nousl’avons vu dans le chapitre 1)
√2 est irrationnel.
Exercice 4.7. Quels sont les intervalles majorés ? minorés ? bornés ?
Remarque. Si M est un majorant de A, tout nombre réel M ′ ≥M est aussi un majorant de A. De même,si m est un minorant de A, tout nombre réel m′ ≤ m est aussi un minorant de A.
Définition 4.25. Soit A une partie non vide de R, alors1) A admet un maximum s’il existe un nombre, noté max(A), élement de A tel que pour tout x
dans A, on a x ≤ max(A) ;2) A admet un minimum s’il existe un nombre, noté min(A) élement de A tel que pour tout x
dans A, on a x ≥ min(A) ;
Digression. Un maximum ou minimum n’existe pas toujours. En effet, on a vu dans les exemples précé-dents qu’un nombre M ′ < 1 ne peut être un majorant de l’ensemble A = n
n+1 , n ∈ N et le nombre1 n’est pas dans A. Ainsi, aucun n
n+1 < 1 ne peut majorer les autres ! On aurait aussi pu le voir plussimplement en obeservant que la suite (un)n∈N définie un = n
n+1 est strictement croissante et donc aucunélément ne peut majorer les autres comme les suivants sont plus grand ! Néanmoins, il existe un pluspetit majorant, le nombre 1 est le plus petit majorant de A, car nous avons montré précédemment que siM ′ < 1 alors M ′ n’est plus un majorant de A.
Théorème 4.26 (définition). Soit A une partie non vide de R.1) Si A est majorée, alors il existe un plus petit majorant, appelée borne supérieure de A (ou
supremum) et on le note sup(A).2) Si A est minorée, alors il existe un plus grand minorant, appelée borne inférieure de A (ou
infimum) et on le note inf(A).
Remarque. Si A n’est pas majorée, on pose sup(A) = +∞ et si A n’est pas minorée, on pose inf(A) = −∞.
Exemples. Si l’on revient aux exemples précédents :1) L’intervalle I = [10; 102] : sup(I) = 102 et inf(I) = 10.2) L’ensemble A = sin(n), n ∈ N, on admettra que sup(A) = 1 et inf(A) = −1.3) L’ensemble A = (−1)n n, n ∈ N : sup(A) = +∞ et inf(A) = −∞.4) L’ensemble A = n
n+1 , n ∈ N : sup(A) = 1 et inf(A) = 0.
5) L’ensemble A = r ∈ Q; r2 ≤ 2 : sup(A) =√
2 et inf(A) = −√
2.
78

TSI 1 Lycée Heinrich-Nessel 2016/2017
Digression. Le dernier exemple montre que le précédent théorème n’est pas vrai pour une partie nonvide de Q, l’ensemble des nombres rationnels. C’est une nouvelle propriété propre aux nombres réels quiaboutie entre autre à la richesse des théorèmes sur les fonctions et suites numériques. Par exemple, onverra au second semestre que toute suite croissante majorée admet une limite finie lorsque n tend versl’infini.
Méthode. Pour savoir si une partie de R est majorée, minorée, bornée, on sera amené à travailler surdes inéquations.Pour montre qu’une partie n’est pas majorée (resp. minorée) par un élément λ, il suffit de trouver unélement de la partie plus grand (resp. plus petit) que λ.
Digression.• Voici une caractérisation de la borne supérieure : Soit A une partie de R non vide et majorée. Laborne supérieure de A est l’unique nombre réel sup(A) tel que :1) si x ∈ A alors x ≤ sup(A) (sup(A) est un majorant) ;2) pour tout T < sup(A), il existe x ∈ A tel que T < x
Si T est strictement plus petit que sup(A) alors T ne peut pas être un majorant de A.)
• De même, voici une caractérisation de la borne inférieure : Soit A une partie de R non vide etmajorée. La borne inférieure de A est l’unique nombre réel inf(A) tel que :1) si x ∈ A alors x ≥ inf(A) (inf(A) est un minorant) ;2) pour tout T > inf(A), il existe x ∈ A tel que x < T
Si T est strictement plus grand que inf(A) alors T ne peut pas être un minorant de A.)
79

TSI 1 Lycée Heinrich-Nessel 2016/2017
4.2 Manipulation algébrique
4.2.1 Variables muettes
Un des objectifs d’une rédaction mathématique est d’être la plus rigoureuse possible. A cet effet, certainsformes d’abréviations sont techniquement à proscrire et doivent ainsi être remplacées par une formalisationclaire et non ambiguë.A titre d’exemple, l’ensemble des chiffres s’écrit en extension par la formule
C = 0; 1; 2; 3; 4; 5; 6; 7; 8; 9
que l’on a tendance à abréger 0; 1; . . . ; 9. Afin d’éviter la lourdeur de l’écriture en extension et l’ambi-guité potentielle d’une écriture utilisant « . . . », on a recours à l’écriture en compréhension :
x ∈ N, 0 ≤ x ≤ 9
Dans cette écriture, apparaît une variable x. Toutefois, le nom choisi ici est tout-à-fait arbitraire et peutêtre remplacé par n’importe quel autre symbole. On peut donc décrire le même ensemble par la formule♠ ∈ N, 0 ≤ ♠ ≤ 9, ou tout autre choix de variable qu’il vous plaira ! On dit que la variable est muette.Si on doit travailler avec cet ensemble et en choisir un élément quelconque, on pourra à nouveau fixerun nouveau nom. Ainsi, je peux écrire « Soit n ∈ C » pour signifier que je choisis un élément quelconquedans C. A partir de ce moment là, je dois bien entendu continuer ma démonstration avec le symbole quej’ai choisi (c’est-à-dire ici n). On ne peut plus changer de lettre au milieu de la démonstration !Nous avons déjà rencontré d’autres situations faisant intervenir une variable muette. Ainsi, l’utilisationdu quantificateur universel introduit lui aussi une telle variable. Dans la phrase ∀x ∈ R, ∃n ∈ N, n ≤ x, lesymbole x est muet. D’ailleurs si on doit démontrer cette phrase, on commencera par choisir un élémentquelconque dans R en disant « Soit t ∈ R. Montrons qu’il existe n ∈ N tel que n ≤ t ». À nouveau, unefois que j’ai choisi un nom, je dois m’y tenir !Le cas du quantificateur existentiel est un peu différent dans la mesure où il fixe plus ou moins déjàun nom pour l’objet spécial dont on affirme l’existence. Cela est particulièrement important lorsqu’ily a plusieurs quantificateurs existentiels (ou plusieurs phrases avec un quantificateur existentiel). Parexemple, imaginons la situation suivante : on dispose d’une fonction f : [0, 1] → [0; 1] et on sait que∃ x ∈ [0; 1], f(x) = 0 et aussi que ∃ y ∈ [0; 1], f(y) = y. Ici les deux variables x et y n’ont aucuneraison d’être la même ! Il est donc essentiel d’avoir deux noms différents. Si la fonction f est définie parf(t) = 1 − t, alors x = 1 et y = 1
2 sont les seuls choix possibles pour x et y, et se sont bien des valeursdistinctes. En résumé, on est libre de fixer le nom qu’il nous plaît pour chaque variable à condition de nejamais choisir deux fois le même nom.Autre exemple important de variable muette, celle utilisée pour définir une application (ou une fonction).Ainsi, je vais écrire que l’application identité de R dans R est l’application x 7→ x, mais on pourrait toutaussi bien écrire t 7→ t ou ♣ 7→ ♣. Là encore, on peut remplacer la variable par toute expression de notrechoix. On rencontre d’ailleurs souvent des constructions sur les fonctions telles que f(x + y) ou encoref(2x),. . .
4.2.2 Le symbole de sommation Σ
Dans cette section, nous allons considérer le somme des plusieurs nombres, par exemple 1 + 2 + 3 + 4 +5+6+7+8. L’écriture de tous les éléments étant assez fastidieuse, on peut la réduire ainsi 1+2+ · · ·+8.Voici, une autre somme 1 + 2 + 4 + 8 + 16 + 32 + 64, on ne peut pas la réduire comme précédemment1 + 2 + . . .+ 64. Il y a une certaine ambiguïté avec l’utilisation des . . ..Pour palier au problème, on va décrire la suite des termes qu’on souhaite additionner et utiliser le symbolede sommation :
• Pour 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9, on fait la somme des entiers k allant de 1 à 9 :9∑k=1
k
• Pour 1 + 2 + 4 + 8 + 16 + 32 + 64 = 20 + 21 + 22 + 23 + 24 + 25 + 26, on fait la somme des puissances
de deux 2k pour k allant de 0 à 6 :6∑k=0
2k.
80

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 4.27. Soit f : N→ K une application et a ≤ b deux entiers relatifs, alors
b∑k=a
f(k) = f(a) + f(a+ 1) + f(a+ 2) + . . .+ f(b− 1) + f(b)
représente la somme des images f(k) pour k allant de a à b.
Remarque. Il est souvent plus commode d’utiliser une notation relative aux suites et non aux fonctions.Une somme peut être notée :
b∑k=a
uk
Exercice 4.8. Décrire ce que font les sommes suivantes :
10∑j=1
j2,
8∑l=3
3l + 1,5∑
m=−2
2mm+ 3 ,
6∑n=1
cos(nπ
6
)Exercice 4.9.
1) Calculer les sommes∑4k=1 1 et
∑4k=0 1.
2) Soit n un entier naturel, exprimer∑nk=1 1 et
∑nk=0 1 en fonction de n.
On peut parfois être amené à effectuer un « changement de variables » dans une somme. Voici un exemple.
On part de la somme9∑k=0
k et on effectue le changement de variables k = l − 1, alors l = k + 1 et
k 1 2 3 4 5 6 7 8 9l = k + 1 2 3 4 5 6 7 8 9 10
Ainsi, la nouvelle variable l va de 1 + 1 = 2 à 9 + 1 = 10. D’où9∑k=1
k =10∑l=2
l − 1
On notera qu’on peut ensuite remplacer la variable muette l par n’importe quelle lettre, en l’occurence
k, d’où9∑k=1
k =10∑k=2
k − 1.
Exercice 4.10. Compléter l’identité :9∑k=1
k =8∑
m=0m+ 1
Exercice 4.11. Notons S =9∑k=1
k.
1) Dans la somme S effectuer le changement de variable m = 10 − k. Écrire explicitement tous lestermes de la somme à partir de l’expression utilisant m.
2) À l’aide de la somme précédente, montrer que
29∑k=1
k =9∑k=1
10
3) En déduire S.
Exercice 4.12. Dans chacun des cas suivants, effectuer le changement de variable demandé dans lasomme S :
81
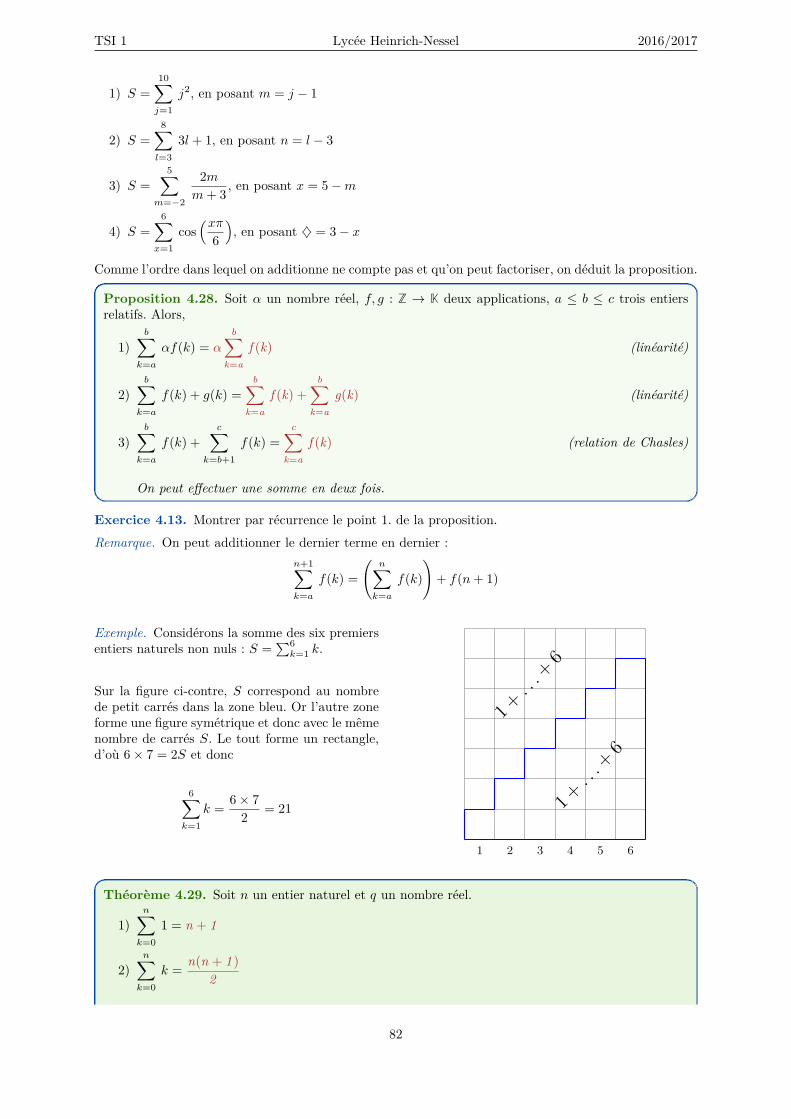
TSI 1 Lycée Heinrich-Nessel 2016/2017
1) S =10∑j=1
j2, en posant m = j − 1
2) S =8∑l=3
3l + 1, en posant n = l − 3
3) S =5∑
m=−2
2mm+ 3 , en posant x = 5−m
4) S =6∑
x=1cos(xπ
6
), en posant ♦ = 3− x
Comme l’ordre dans lequel on additionne ne compte pas et qu’on peut factoriser, on déduit la proposition.
Proposition 4.28. Soit α un nombre réel, f, g : Z → K deux applications, a ≤ b ≤ c trois entiersrelatifs. Alors,
1)b∑
k=aαf(k) = α
b∑k=a
f (k) (linéarité)
2)b∑
k=af(k) + g(k) =
b∑k=a
f (k) +b∑
k=ag(k) (linéarité)
3)b∑
k=af(k) +
c∑k=b+1
f(k) =c∑
k=af (k) (relation de Chasles)
On peut effectuer une somme en deux fois.
Exercice 4.13. Montrer par récurrence le point 1. de la proposition.Remarque. On peut additionner le dernier terme en dernier :
n+1∑k=a
f(k) =(
n∑k=a
f(k))
+ f(n+ 1)
Exemple. Considérons la somme des six premiersentiers naturels non nuls : S =
∑6k=1 k.
Sur la figure ci-contre, S correspond au nombrede petit carrés dans la zone bleu. Or l’autre zoneforme une figure symétrique et donc avec le mêmenombre de carrés S. Le tout forme un rectangle,d’où 6× 7 = 2S et donc
6∑k=1
k = 6× 72 = 21
1 2 3 4 5 6
1 + .. .
+ 6
1 + .. .
+ 6
Théorème 4.29. Soit n un entier naturel et q un nombre réel.
1)n∑k=0
1 = n + 1
2)n∑k=0
k = n(n + 1 )2
82

TSI 1 Lycée Heinrich-Nessel 2016/2017
3) Si q 6= 1 alorsn∑k=0
qk = 1 − qn+1
1 − q
Corollaire 4.30.
1)n∑
k=m1 = n −m + 1
2)n∑
k=mk = (m + n)× (n −m + 1 )
2
3) Si q 6= 1 alorsn∑
k=mqk = qm 1 − qn−m+1
1 − q
4.2.3 Somme sur un ensemble fini arbitraire
Il arrive parfois que l’on ajoute sous la somme une condition supplémentaire, en voici quelques exemples :
10∑k=0, k pair
k,
10∑k=0, k 6=5
1k − 5
Dans certain cas, il facile de se ramener à une somme « standard » par un changement de variables. Ainsi,on a
10∑k=0, k pair
k =5∑l=0
2l, car un nombre pair est de la forme 2l
Plus généralement, on peut trouver une expression de la forme∑k∈I
f(k). Dans ce cas, I est un ensemble
fini de valeurs que va prendre k successivement. Ainsi, la situation standardn∑k=1
f(k) correspond à un
ensemble I = k ∈ N, 1 ≤ k ≤ n. On peut donc décrire la même somme par les deux expressionssuivantes : ∑
k∈x∈N, 1≤x≤n
f(k) ou∑
1≤k≤nf(k)
Par convention, on pose∑k∈ø
f(k) = 0.
À l’aide de cette notation, il est possible de donner une formule pour le changement de variable.
Proposition 4.31. Soit E, F deux ensembles finis, f : E → K une application et φ : E → F unebijection. Si on pose l = φ(k), on a ∑
k∈E
f(φ(k)) =∑l∈F
f(l)
Néanmoins, dans la pratique, on n’utilisera pas cette formule pour effectuer un changement de variable.On utilisera le bon sens !
La relation de Chasles se généralise :
Proposition 4.32 (Chasles - sommation par regroupement des termes). Soit I un ensemble fini. Onsuppose que I peut se décomposer en l’union de deux sous-ensembles I1 et I2 disjoints, alors on a :∑
k∈I
f(k) =∑k∈I1
f (k) +∑k∈I2
f (k)
83

TSI 1 Lycée Heinrich-Nessel 2016/2017
4.2.4 Somme télescopique
Considérons la somme
S =5∑k=1
( k7 − (k + 1)7 )
D’après la linéarité de la somme, on a
S =5∑k=1
k7 −5∑k=1
(k + 1)7
= 1 + 27 + 37 + 47 + 57 + 67 − (27 + 37 + 47 + 57 + 67)
= 1 +@@27 +@@37 +@@47 +@@57 +@@67 −@@27 −@@37 −@@47 −@@57 − 67
= 1− 67
Les simplifications successives donnent l’impression que la somme se télescope.
Définition 4.33. Une somme télescopique est une somme de la formeb∑
k=af(k + 1)− f(k).
Proposition 4.34. Soitb∑
k=af(k + 1)− f(k) une somme télescopique. Alors
b∑k=a
f(k + 1)− f(k) = f (b + 1 )− f (a)
4.2.5 Symbole de multiplication Π
Comme pour la somme, il y a un symbole pour écrire un produit de plusieurs termes, comme
cos(x)× cos(2x)× cos(3x)× cos(4x)× cos(5x)
Il s’agit du symbole∏
(c’est la lettre grecque π majuscule), que l’on utilise ainsi :5∏k=1
cos(kx)
À nouveau la variable utilisée est muette et on peut effectuer un changement de variables de la mêmefaçon que pour la somme.
Proposition 4.35.
1)b∏
k=af(k)g(k) =
b∏k=a
f (k)×b∏
k=ag(k)
2)b∏
k=aαf(k) = αb−a+1 ×
b∏k=a
f (k)
On a aussi une notion de produit télescopique :n∏
k=m
uk+1
uk=
um+1
um×
um+2
um+1× . . .× un
un−1× un+1
un= un+1
um
Ainsi qu’une notation plus générale pour un produit indexé par un ensemble fini :∏k∈I
f(k). Par convention,
on pose∏k∈ø
f(k) = 1.
84

TSI 1 Lycée Heinrich-Nessel 2016/2017
Remarque. On trouve aussi un symbole analogue pour l’union et pour l’intersection. Par exemple :
9⋃k=−10
[k; k + 1] = [−10; 10] et20⋂k=1
[−k; k] = [−1; 1]
4.2.6 Somme multiple
En revenant, à la notion de somme sur un ensemble fini arbitraire, on peut considérer comme ensemble,un ensemble produit. Par exemple, E = J1; 4K× J1; 3K et la somme∑
(i,j)∈E
f(i, j)
Il faudrait donc faire la somme des termes f(1, 1), f(1, 2), f(1, 3), f(2, 1), f(2, 2), f(2, 3), . . . , f(4, 2) etf(4, 3) :
j
i
1
1
f(1, 1)
2
f(1, 2)
3
f(1, 3)
2
1
f(2, 1)
2
f(2, 2)
3
f(2, 3)
3
1
f(3, 1)
2
f(3, 2)
3
f(3, 3)
4
1
f(4, 1)
2
f(4, 2)
3
f(4, 3)
Les élements f(i, j) ont été placé de tel sorte qu’un f(i, j) se trouve sur la ie ligne et je colonne. Ainsi,en effectuant la somme par colonne ou par ligne, on déduit que
∑(i,j)∈E
f(i, j) =3∑j=1
( 4∑i=1
f(i, j))
=4∑i=1
( 3∑j=1
f(i, j))
On dit dans ce cas qu’on somme sur un rectangle.
Exercice 4.14.1) Représenter comme précédemment dans un repère les éléments qu’on somme dans le somme sui-
vante :5∑j=1
j∑i=1
f(i, j)
Dans ce cas, on dit que le somme est faite sur un triangle.2) Compléter l’identité :
5∑j=1
j∑i=1
f(i, j) =5∑
i=1
5∑j=i
f(i, j)
Proposition 4.36 (somme sur un rectangle). Soit a ≤ b et c ≤ d des entiers relatifs,
d∑j=c
b∑i=a
f(i, j) =b∑
i=a
d∑j=c
f (i, j)
La proposition suivante est facultative, il est plus simple comme dans l’exemple précédent de faire unefigure pour retrouver le résultat que de retenir ce genre de formules.
85

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 4.37 (somme sur un triangle). Soit a ≤ b deux entiers relatifs,
1)b∑
j=a
j∑i=a
f(i, j) =b∑
i=a
b∑j=i
f (i, j)
2)b∑
j=a
b∑i=j
f(i, j) =b∑
i=a
i∑j=a
f (i, j)
4.2.7 Coefficients binomiaux
Définition 4.38. Soit n un entier naturel, le nombre factorielle n est définie par
n! =n∏k=1
k = 1 × 2 × . . .× (n − 1 )× n
C’est le produit des entiers naturels non nuls inférieurs ou égaux à n.
Remarques.• Par convention, 0! = 1.• Bien qu’on note le symbole ! à droite : n!, on ne dit pas « n factorielle » mais bien « factorielle n ».• Considérons l’application φ : N → N définie par φ(n) = n! pour tout entier n. On note alors que
pour tout entier n :
φ(n+ 1) = (n+ 1)! = (n+ 1)× n× (n− 1)× . . .× 2× 1 = (n+ 1)× n! = (n+ 1)φ(n)
L’application factorielle peut aussi être définie par récurrence :0! = 1(n+ 1)! = (n+ 1)× n! pour tout entier n
Exemples.
n 0 1 2 3 4 5 6n! 1 1 2 6 24 120 720
Définition 4.39 (Formule de Fermat). Soit n un entier naturel. Soit k un entier naturel tel que0 ≤ k ≤ n. Le nombre appelé k parmi n est(
n
k
)= n!k!× (n− k)!
Remarque. Lorsque k > n, on pose(nk
)= 0.
Proposition 4.40. Soit n un entier naturel. Alors1)(n0)
= 1 =(n
n)
2)(n1)
= n =( n
n−1)
3) Pour tout entier naturel k tel que 0 ≤ k ≤ n, on a(nk
)=( n
n−k)
4) Pour tout entier naturel k tel que 1 ≤ k ≤ n, on a k(nk
)= n
(n−1k−1
)
86

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 4.41 (Relation de Pascal). Soit n un entier naturel et 1 ≤ k ≤ n− 1, alors(n− 1k − 1
)+(n− 1k
)=(
nk
)
Définition 4.42. Le triangle de Pascal :
0
0
1
1
1
1 1
2
2
1 2 1
3
3
1 3 3 1
4
4
1 4 6 4 1
5
5
1 5 10 10 5 1
6
6
1 6 15 20 15 6 1
7
7
1 7 21 35 35 21 7 1
k − 1 k
n− 1
n
......
(nk
)
+=
+=
(n−1k−1
) (n−1k
)(nk
)Exercice 4.15. A l’aide d’un raisonnement par récurrence et du triangle de Pascal, justifier que pourtout n ∈ N et pour tout k ∈ 0; . . . ;n,
(nk
)∈ N.
Proposition 4.43 (Formules du binôme de Newton).
1) (a+ b)n =n∑k=0
(n
k
)akbn−k
2) (a− b)n =n∑k=0
(n
k
)(−1)n−kakbn−k
3) an − bn = (a− b)n−1∑k=0
akbn−k−1
Remarque. La troisième identité avec a = 1 et b = q devient l’identité bien connue :
1− qn = (1− q)n−1∑k=0
qn−k−1 = (1− q)(1 + q + . . .+ qn−1)
Exercice 4.16. À l’aide de la formule du binôme de Newton, compléter les identités suivantes :1) (a+ b)2 = a2 + 2ab + b2 ;2) (a− b)2 = a2 − 2ab + b2 ;3) (a+ b)3 = a3 + 3a2 b + 3ab2 + b3 ;4) (a− b)3 = a3 − 3a2 b + 3ab2 − b3 ;
87

TSI 1 Lycée Heinrich-Nessel 2016/2017
5) a3 − b3 = (a − b)(b2 + ab + a2 ) ;6) (a+ b)4 = a4 + 4 a3 b + 6 a2 b2 + 4 a b3 + b4 .
Corollaire 4.44. Soit n un entier naturel, alors
1)n∑k=0
(n
k
)= 2 n ;
2)n∑k=0
(−1)k(n
k
)= 0 .
88

Chapitre 5
Fonctions, dérivation, logarithme etexponentielle
Programme• Fonctions : Définition, identifier la variable et éventuellement l’ensemble de définition.• Image, antécédent• Courbe représentative• Représenter graphiquement x 7→ f(x) + a, x 7→ f(x + a), x 7→ f(ax) et x 7→ af(x) à partir du
graphe de f .• Interpréter graphiquement une équation du type f(x) ≤ λ• Fonctions paires, impaires, périodiques. Interpréter géométriquement ces propriétés.• Somme, produit, composée.• Monotonie• Fonction majorée, minorée, bornée. Interprétation géométrique.• Une fonction f est bornée si et seulement si |f | est majorée.• Extremum (local).• Calcul de limites en un point ou à l’infini. Aucune étude théorique de la limite n’est abordée à cestade. On s’appuiera sur les connaissances des limites acquises au lycée.
• Limite d’une somme, d’un produit, d’un quotient, d’un inverse.• Exemples de formes indéterminées : ∞−∞, 0×∞, 0
0 ,∞∞
• Calculer une limite par encadrement ou par comparaison.
• Limite d’une fonction composée.• Dérivée des fonctions usuelles, x 7→ xn avec n ∈ Z, exp, ln (Aucune étude théorique de la dérivationn’est abordée à ce stade).
• Équation de la tangente en un point (Interpréter géométriquement la dérivée d’une fonction en unpoint).
• Application : Lever, sur des exemples simples, certaines formes indéterminées à l’aide de limites detaux d’accroissement :
limx→0
sin(x)x
= 1; limx→0
ln(1 + x)x
= 1; limx→0
ex − 1x
= 1; limx→0
cos(x)− 1x2 = −1
2
• Opérations : somme, produit, quotient.• Dériver une fonction composée.• Application à l’étude des variations d’une fonction. Dresser le tableau de variation d’une fonction.• À ce stade, un tableau de variation clairement présenté, accompagné de la détermination du signede la dérivée et des valeurs ou limites aux bornes, vaut justification de bijectivité
89

TSI 1 Lycée Heinrich-Nessel 2016/2017
• Fonction réciproque : tracer la graphe d’une fonction réciproque, calculer la dérivée d’une fonc-tion réciproque (obtenue géométriquement à l’aide de la symétrie des tangentes. La formule seradémontrée ultérieurement).
• Dérivée de l’inverse d’une fonction bijective.• Plan d’étude d’une fonction : Déterminer les variations, limites, extremums (locaux) éventuels.Les asymptotes ainsi que la position des tangentes par rapport à la courbe seront traitées ultérieu-rement comme des applications des développements limités.
• Fonction logarithme, fonctions exponentielles, puissances• Forme indéterminée : 1∞.• Croissances comparées• Les fonctions hyperboliques sont hors programme
90

TSI 1 Lycée Heinrich-Nessel 2016/2017
5.1 Définition
Définition 5.1. Soit D un sous-ensemble de l’ensemble des nombres réels R. Une fonction f : D → Rest une application 1 qui à un nombre réel quelconque x dans D associe un nombre réel, noté f(x).L’ensemble D est appelé le domaine de définition de f .
1. Dictionnaire Hachette : "application n. f. 5. MATH Correspondance qui, à chaque élément d’un ensemble, associeun élément, et un seul, d’un autre ensemble."
Remarque. Lorsque le domaine de définition d’une fonction f n’est pas donné et qu’il faut le déterminer,on cherchera toujours la plus grande (au sens de l’inclusion) partie D sur laquelle l’application peut êtredéfinie.On peut aussi définir une application à valeurs dans l’ensemble C des nombres complexes.
Exemples.1) La fonction valeur absolue est la fonction dont le domaine de définition est R et qui à x ∈ R associe|x| ∈ R.
2) La fonction partie entière est la fonction dont le domaine de définition est R et qui à x ∈ R associebxc ∈ R.
3) La fonction identité est la fonction dont le domaine de définition est R et qui à x ∈ R associe x ∈ R.On la note parfois id.
4) La fonction carrée est la fonction dont le domaine de définition est R et qui à x ∈ R associe x2 ∈ R.5) La fonction inverse est la fonction dont le domaine de définition est R \ 0 et qui à x ∈ R associe
1x ∈ R.
6) La fonction racine carrée est la fonction dont le domaine de définition est [0; +∞[ et qui à x ∈ Rassocie
√x ∈ R.
Exercice 5.1. Soit f une fonction définie par f(x) = x2 + x− 1, compléter le tableau suivant :
x −2 1 54 A x− 1
2 ax+ b
f(x)
Remarque. Lorsqu’une fonction f est définie par une expression de la forme f(x) égal une expressiondépendant de x, pour calculer l’image par f d’une expression donné, on remplace toutes les occurrencesde x dans la définition par l’expression donné.Encore une fois, si on est amené à remplacer x par une expression longue (avec des opérations : somme,soustraction, multiplication, . . . ), on ajoutera à chaque fois des parenthèses autour de l’expression !
5.1.1 Représentation graphique
Définition 5.2. Soit f une fonction et un nombre x appartenant au domaine de définition de f .• L’ image de x par la fonction f est le nombre f(x).• Le nombre x est un antécédent du nombre f(x).
Exemple. Considérons la fonction f : R→ R défi-nie par f(x) = x2 + 3. Le nombre 28 est l’imagede 5 par f car f(5) = 52 + 3 = 28. De plus, 5 estun antécédent de 28 par f .
f : D R
-1
1
un antécédent de b
x
5
4
b
f(x) image de x
28
91

TSI 1 Lycée Heinrich-Nessel 2016/2017
On se place dans le plan muni d’un repère orthonormé (O, I, J).
Définition 5.3. Soit f : D → R une fonc-tion. Dans le plan muni d’un repère (O; I; J),le lieu géométrique des points M(x; f(x)) où xparcourt l’ensemble D est appelé courbe repré-sentative de f , notée Cf .
C’est-à-dire : ∀(x; y) ∈ R2 :
M(x; y) ∈ Cf ⇐⇒ x ∈ D et y = f(x)
O I
J
Cf
M(x; f(x))
x
f(x)
Exercice 5.2. Soit a un nombre réel et f : R→ R la fonction carrée définie par f(x) = x2 pour tout x.Posons
ga : R // R
x // ga(x) = f(x) + a
et ha : R // R
x // ha(x) = f(x+ a)
1) Tracer les courbes représentatives des fonctions f et ga pour a allant de −2 à 5 avec un pas de 1dans un même repère. Que remarque-t-on ?
2) Tracer les courbes représentatives des fonctions f et ha pour a allant de −2 à 5 avec un pas de 1dans un même repère. Que remarque-t-on ?
On se place dans le plan muni d’un repère (O;−→ı ;−→ ). Soit x un nombre réel.3) Déterminer les coordonnées du point N image du point M(x; f(x)) par la translation de vecteur
a−→ . Que peut-on dire des points M et N par rapport aux courbes représentatives des fonctions ?4) a) Déterminer les coordonnées du point P image du point M(x; f(x)) par la translation de
vecteur −a−→ı .b) Calculer ga(x− a).c) Sur quelle courbe représentative se trouve le point P ?
Pour une illustration des deux propositions suivantes voir la figure 5.1 ci-dessous.
Proposition 5.4 (translation verticale). Soit a un nombre réel et f : D → R une fonction. Posonsg : D → R définie par g(x) = f(x) + a pour tout x dans D. Alors, g est bien définie et sa courbereprésentative est l’image de la courbe représentative de f par la translation de vecteur a−→ .
Proposition 5.5 (translation horizontale). Soit a un nombre réel et f : D → R une fonction. Posons
D−a = x : x+ a ∈ D
et g : D−a → R définie par g(x) = f(x+a) pour tout x dans D−a. Alors g est bien définie et sa courbereprésentative est l’image de la courbe représentative de f par la translation de vecteur −a−→ı .
Exercice 5.3. Simplifier cos(x+ π2 ) et interpréter cette propriété graphiquement.
Proposition 5.6. Soit a ∈ R∗ et f une fonction.1) La courbe représentative de x 7→ af(x) est Cf dans le repère (O;−→ı ; 1
a−→ ), ce qui équivaut à
multiplier les valeurs en ordonnées par a.2) La courbe représentative de x 7→ f(ax) est Cf dans le repère (O; a−→ı ;−→ ), ce qui équivaut à
multiplier les valeurs en abscisse par 1a .
92

TSI 1 Lycée Heinrich-Nessel 2016/2017
−→ı
−→O xx− a
f(x) + a
f(x) = g(x− a)
Cf
DD−a
translation : −a−→ı
tran
slat
ion
:a−→
Figure 5.1 – Translation horizontale et verticale d’une courbe
Exercice 5.4 (Décharge d’un condensateur).1) On considère la fonction f : t 7→ e−t définie sur R+ dont on note C la courbe représentative.
a) Tracer C puis donner des valeurs approchées des images par f de 1 et 2 à 10−2 près.b) Résoudre l’inéquation f(t) ≤ 1
100 .2) La tension aux bornes d’un condensateur est, sous certaines conditions, donnée par u(t) = Ue−
tRC
où U , R et C sont des constantes positives. Dans quel repère la courbe de u est-elle C ? Interpréterles résultats de la question 1.
5.2 Parité et périodicité
Définition 5.7. Un sous-ensemble D de R est dit symétrique par rapport à l’origine si elle contient0 et si pour tout x dans D, −x est aussi dans D.
Exercice 5.5. Quels sont les intervalles symétriques par rapport à l’origine ?
Définition 5.8. Soit f : D → R une fonction et supposons que D est symétrique par rapport àl’origine. On dit que :
1) f est paire si ∀x ∈ D : f(−x) = f(x).2) f est impaire si ∀x ∈ D : f(−x) = −f(x).
Exemple. La fonction carrée x 7→ x2 est paire sur R et la fonction cube x 7→ x3 est impaire.
Exercice 5.6. Soit M(x; y) un point du plan muni d’un repère.1) Déterminer les coordonnées de N le symétrique de M par rapport à l’axe des ordonnées.2) Déterminer les coordonnées de P le symétrique de M par rapport à l’origine.
93

TSI 1 Lycée Heinrich-Nessel 2016/2017
3) Soit f : D → R une fonction paire, quelle propriété géométrique possède sa courbe représentative ?4) Soit f : D → R une fonction impaire, quelle propriété géométrique possède sa courbe représentative ?
Proposition 5.9. Soit f : D → R une fonction et a ∈ D. La courbe représentative de la fonction fest symétrique par rapport à la droite verticale d’équation x = a si et seulement si
∀x ∈ R : a− x ∈ D ⇒ a+ x ∈ D et f(a− x) = f(a+ x)
Lorsque a = 0, on retrouve la définition d’une fonction paire.
Exercice 5.7.1) Soit f : x 7→ x2
x4−x2+3 . Montrer que f est paire.2) Soit f : x 7→ x3 − x. Montrer que f est impaire.3) Soit f : x 7→ x2 + 2x+ 2. Tracer sa courbe représentative. Démontrer que la courbe représentative
de f admet un axe de symétrie et le déterminer.4) Étudier la parité de f : x 7→ ln(1 + ex)− ln(1 + e−x).
Digression. Pour montrer que la courbe représentative de la fonction f : D → R est symétrique parrapport au point I(a; b), il suffit de montrer que pour tout x, I est le milieu des pointsM(a−x; f(a−x))et N(a + x; f(a + x)) (en d’autres termes, les coordonnées du milieu de M et N sont indépendantes dex !).
Exercice 5.8. Soit f : R→ R une fonction. Posons g : x 7→ f(x)+f(−x)2 et h : x 7→ f(x)−f(−x)
2 .1) Montrer que g est paire et h est impaire.2) Calculer g + h.
Conséquence :
Proposition 5.10. Soit f : D → R une fonction et supposons que D est symétrique par rapport àl’origine. Alors il existe deux fonctions g et h définies sur D telles que
g est paire, h est impaire et f = g + h
De plus, un tel couple (g, h) est unique.
Définition 5.11. Soit T > 0. Soit D un sous-ensemble de R. On dit que D est T - périodique si pourtout x dans D, x+ T est aussi dans D.
Définition 5.12. Soit T > 0. Soit f : D → R une fonction définie sur un sous-ensemble T -périodiqueD. On dit que f est T -périodique si
∀ x ∈ D : f(x+ T ) = f(x)
Exemple. Les fonctions cosinus et sinus sont 2π-périodiques.
Exercice 5.9. Soit f une fonction T -périodique. Montrer qu’on a aussi f(x−T ) = f(x), f(x+2T ) = f(x)
Proposition 5.13. Soit f : D → R une fonction T -périodique et k un entier relatif. Alors pour toutx ∈ D, f(x+ kT ) = f(x).
Définition 5.14. Une fonction f définie sur A est périodique s’il existe un nombre T > 0 tel que Asoit T -périodique et f soit T -périodique. Le plus petit T > 0 possible s’appelle la période de f .
Exercice 5.10. Rappeler la période de la fonction x 7→ cos(x) et résoudre cos(x) = 12 .
94

TSI 1 Lycée Heinrich-Nessel 2016/2017
Remarque. Une fonction f : R → R T -périodique est entièrement déterminée par sa restriction f |[0; T ](ou f |[−T2 ; T
2 ]). Ainsi, pour résoudre l’équation :
f(x) = y0
avec f T -périodique, il suffit de chercher les solutions x1, . . . , xn dans l’intervalle [0; T ] (on un autreintervalle de longueur la période). On en déduit alors l’ensemble des solutions :
S =n⋃i=1xi + kT ; k ∈ Z
Exercice 5.11. Soit ω > 0 et φ ∈ R. Démontrer que t 7→ cos(ωt+ φ) est périodique.
5.3 Opérations sur les fonctions
Définition 5.15. Soit f, g : D → R deux fonctions et λ et µ deux nombres réels.1) La fonction λf + µg est la fonction définie sur D par
(λf + µg)(x) = λf(x) + µg(x)
2) La fonction f × g est la fonction définie sur A ∩B par
(f × g)(x) = f(x)× g(x)
Les propriétés entre l’addition et la multiplication des nombres se retrouvent avec les fonctions :
Proposition 5.16. Soient f , g et h trois fonctions.1) 0× f = 0 et 1× f = f
2) f + g = g + f (commutativité)3) f × g = g× f (commutativité)4) (f + g) + h = f + (g + h) (associativité)5) (f × g)× h = f × (g× h) (associativité)6) (f + g)× h = f × h + g× h (distributivité)
Comme une fonction est une application en particulier, on rappelle la définition de la composition defonctions.
Définition 5.17. Soit f : A→ B et g : B → R deux fonctions. La composée de g par f est la fonctiong f définie sur x ∈ A, f(x) ∈ B par
(g f)(x) = g(f(x)
)
Proposition 5.18. Soient f , g et h trois fonctions.1) g id = g et id f = f
2) h (g f) = (h g) f (associativité)
Remarque. De plus, on a :• (h+ g) f = h f + h f (distributivité à droite)• (h× g) f = h f × g f (distributivité à droite)
Par contre, la composition n’est pas commutative : f g 6= g f en général. Elle n’est pas non plusdistributive à gauche : h (f + g) 6= h f + h g.
Exemple. Soit f : x 7→ x2 et g : x 7→√x.
95

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) Déterminer le domaine de définition de g f et calculer g f(x) en fonction de x dans le domainede définition.
2) Déterminer le domaine de définition de f g et calculer f g(x) en fonction de x dans le domainede définition.
5.4 Variations de fonction, tableau de signes
5.4.1 Fonction croissante, fonction décroissante
fonction croissante
x1 x2<
>
f(x1)
f(x2)
fonction décroissante
x1 x2
f(x1)
f(x2)
<
>
Intuitivement, dire qu’une fonction f : I → R est croissante (resp. décroissante) sur l’ensemble D, c’estdire que quand la variable x augmente dans D, son image f(x) augmente aussi (resp. diminue).
Définition 5.19. Soit f : D → R une fonction et E une partie de D. On dit que f est1) croissante sur E si
∀ (x1, x2) ∈ E2 : x1 ≤ x2 ⇒ f(x1) ≤ f(x2)
2) strictement croissante sur E si
∀ (x1, x2) ∈ E2 : x1 < x2 ⇒ f(x1) < f(x2)
3) décroissante sur E si
∀ (x1, x2) ∈ E2 : x1 ≤ x2 ⇒ f(x1) ≥ f(x2)
4) strictement décroissante sur E si
∀ (x1, x2) ∈ E2 : x1 < x2 ⇒ f(x1) > f(x2)
Remarque. Une fonction croissante conserve l’ordre et une fonction décroissante renverse l’ordre entre x1et x2 et leurs images respectives.
Vocabulaire. On dit qu’une fonction f : D → R est (strictement) monotone si elle est (strictement)croissante ou (strictement) décroissante sur tout le domaine de définition D.
Proposition 5.20. Soient f et g deux fonctions monotones. Alors :1) Si f et g ont même sens de variations, f + g est monotone, de même sens de variations.2) Si λ ≥ 0, alors λf est monotone de même sens de variations que f .3) Si λ ≤ 0, alors λf est monotone de sens de variations contraire de celui de f .4) Si f et g ont même sens de variations, g f est croissante.5) Si f et g sont de sens de variations contraire, g f est décroissante.
96

TSI 1 Lycée Heinrich-Nessel 2016/2017
Remarque. Il n’existe pas de règle générale simple pour le produit de fonctions monotones ni pour lasomme d’une fonction croissante et d’une fonction décroissante.
Vocabulaire. Étudier les variations d’une fonction f , c’est dire sur quel(s) sous-ensemble(s) elle estcroissante et sur quel(s) sous-ensemble(s) elle est décroissante. On peut résumer les informations sur lesvariations d’une fonction dans un tableau de variations.
Proposition 5.21. Soit f : R→ R une fonction, 0 ≤ a < b deux nombres réels,1) Si f est paire et f est croissante (resp. décroissante) sur [a; b], alors f est décroissante (resp.
croissante) sur [−b; −a].2) Si f est impaire et f est croissante (resp. décroissante) sur [a; b], alors f est croissante (resp.
décroissante) sur [−b; −a].
Remarque. Ainsi, si f est paire ou impaire, il suffit de l’étudier sur R+.
5.5 Bijections
Définition 5.22. Soit f une application d’un ensemble E dans un ensemble F .1) On dit que f est injective si
∀ a ∈ E, ∀ b ∈ E, f(a) = f(b) ⇒ a = b
Si deux éléments ont la même image par f alors ils sont égaux.2) On dit que f est surjective si
∀ y ∈ F ∃ x ∈ E : f(x) = y
C’est-à-dire, si tout élément y de F admet au moins un antécédent par f dans E.3) On dit que f est bijective si elle est injective et surjective.
Proposition 5.23. Soit f : E → F une application. Alors f est bijective si et seulement si toutélément de F admet exactement un antécédent par f :
∀ y ∈ F ∃!x ∈ E : f(x) = y
Remarque. Géométriquement, cela signifie que toute droite horizontale passant par un point d’ordonnéedans B coupe exactement une fois la courbe représentative de f .
Proposition 5.24. Une fonction f est une bijection de A sur B si et seulement si il existe une fonctiong définie sur B telle que g f = id et f g = id. On note alors g = f−1.
Proposition 5.25. Toute fonction strictement monotone est injective. En particulier, elle est bijectivesur son image.
Exemple. Considérons la fonction logarithme Népérien ln :]0; +∞[→ R caractérisée par la propriété :
∀(a, b) ∈]0; +∞[2: ln(ab) = ln(a) + ln(b)
Sa dérivée est définie par ln′(x) = 1x > 0 pour tout x > 0. Ainsi, le logarithme est strictement croissant
et commelimx→0+
ln(x) = −∞ et limx→+∞
ln(x) = +∞
97
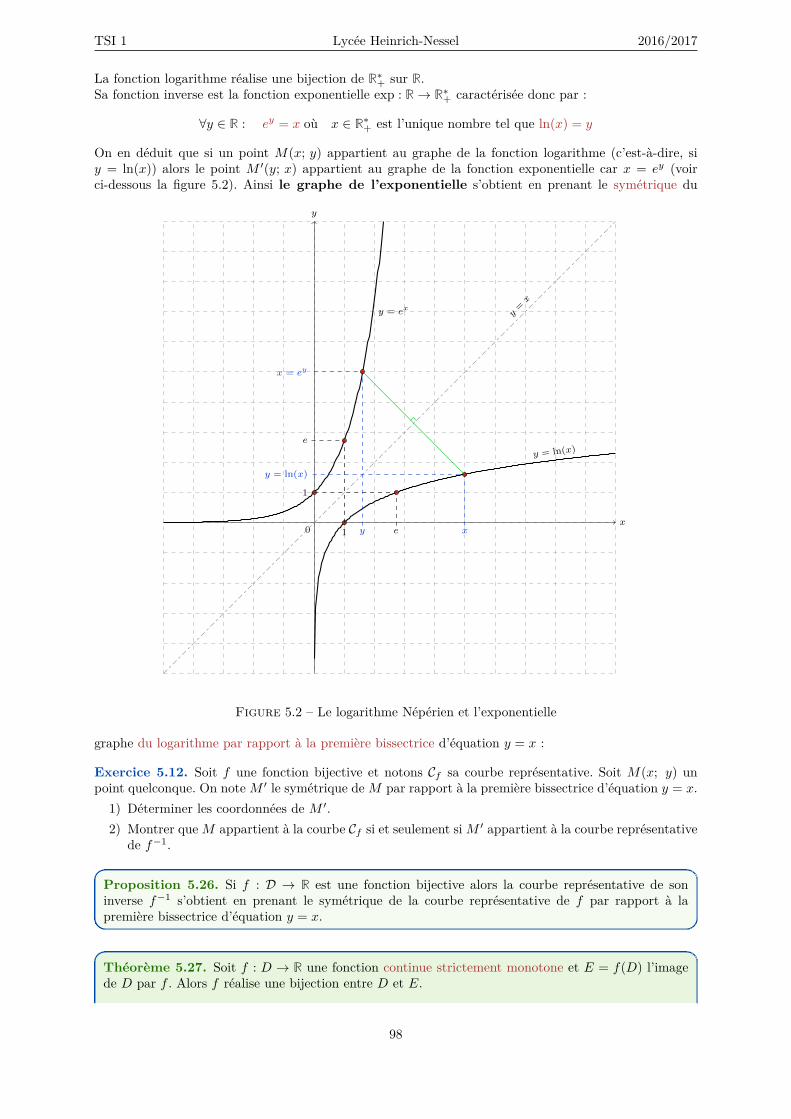
TSI 1 Lycée Heinrich-Nessel 2016/2017
La fonction logarithme réalise une bijection de R∗+ sur R.Sa fonction inverse est la fonction exponentielle exp : R→ R∗+ caractérisée donc par :
∀y ∈ R : ey = x où x ∈ R∗+ est l’unique nombre tel que ln(x) = y
On en déduit que si un point M(x; y) appartient au graphe de la fonction logarithme (c’est-à-dire, siy = ln(x)) alors le point M ′(y; x) appartient au graphe de la fonction exponentielle car x = ey (voirci-dessous la figure 5.2). Ainsi le graphe de l’exponentielle s’obtient en prenant le symétrique du
x
y
y = ln(x)
1
1
0 e
e
y = ex y=x
y
x = ey
x
y = ln(x)
Figure 5.2 – Le logarithme Népérien et l’exponentielle
graphe du logarithme par rapport à la première bissectrice d’équation y = x :
Exercice 5.12. Soit f une fonction bijective et notons Cf sa courbe représentative. Soit M(x; y) unpoint quelconque. On noteM ′ le symétrique deM par rapport à la première bissectrice d’équation y = x.
1) Déterminer les coordonnées de M ′.2) Montrer queM appartient à la courbe Cf si et seulement siM ′ appartient à la courbe représentative
de f−1.
Proposition 5.26. Si f : D → R est une fonction bijective alors la courbe représentative de soninverse f−1 s’obtient en prenant le symétrique de la courbe représentative de f par rapport à lapremière bissectrice d’équation y = x.
Théorème 5.27. Soit f : D → R une fonction continue strictement monotone et E = f(D) l’imagede D par f . Alors f réalise une bijection entre D et E.
98

TSI 1 Lycée Heinrich-Nessel 2016/2017
De plus, f−1 : E → D est aussi monotone et de même sens de variations que f .
Exercice 5.13. Soit f définie sur [1; 5] par f(x) = x2 − 2x− 4.1) Dresser le tableau de variations de f .2) Déterminer f([1; 5]) et montrer que f réalise une bijection sur cet ensemble.3) Déterminer f−1.
5.5.1 Signe d’une fonction et comparaison de fonctions
Définition 5.28. Soit f : D → R une fonction et E un sous-ensemble de D.1) On dit que f est positive sur E si pour tout x dans E, f(x) ≥ 0.2) On dit que f est négative sur E si pour tout x dans E, f(x) ≤ 0.
Vocabulaire. On dit que f : D → R est positive (resp. négative) et on note f ≥ 0 (resp. f ≤ 0) si ellepositive (resp. négative) sur tout son ensemble de définition D.Si on considère des inégalités strictes, alors on dira que f est strictement positive ou strictement négative.
Vocabulaire. Étudier le signe d’une fonction f , c’est dire sur quel(s) sous-ensemble(s) elle est positiveet sur quel(s) sous-ensemble(s) elle est négative. On peut résumer les informations sur les changementsde signe d’une fonction dans un tableau de signes.
Définition 5.29. Soit f, g : D → R deux fonctions et E un sous-ensemble de D.1) On dit que f est inférieure à g sur E si pour tout x dans E, f(x) ≤ g(x).2) On dit que f est supérieure à g sur E si pour tout x dans E, f(x) ≥ g(x).
Notation. De même, on donne sens aux notations f ≤ g, f ≥ g, f < g, f > g.
Exercice 5.14.1) Écrire les définitions associées aux notations précédentes.2) Donner un exemple de fonctions telles que f < g.3) Donner un exemple de fonctions telles qu’on ait pas f < g.
Vocabulaire. Soit f, g : D → R deux fonctions et notons Cf et Cg leurs courbes représentatives respec-tives. Étudier le position relative des courbes Cf et Cg, c’est dire sur quel(s) sous-ensembles(s) f ≤ g etsur quel(s) sous-ensemble(s) f ≥ g.
Soit a et b deux nombres, rappelons que
a ≤ b ⇐⇒ a− b ≤ 0
Méthode. Pour étudier la position relative d’une courbe représentative par rapport à une autre, onpeut étudier le signe de la différence des fonctions associées.
Exercice 5.15. Étudier la position relative des courbes représentatives des fonctions x 7→ x2 et x 7→2x+ 5 sur R.
5.5.2 Majoration, minoration
Définition 5.30. Soit f : D → R une fonction. On dit que• f est majorée s’il existe un nombre réel M tel que pour tout x dans D f(x) ≤M .,• f est minorée s’il existe un nombre réel m tel que pour tout x dans D f(x) ≥ m.,• f est bornée si elle est majorée et minorée.
99

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 5.31. Une fonction f est bornée si et seulement si |f | est majorée.
Définition 5.32. Soit f : D → R une fonction.1) Dire que f atteint son maximum en a sur D signifie que pour tout x de D, f(x) ≤ f(a). Le
maximum de f sur D est f(a).2) Dire que f atteint son minimum en a sur D signifie que pour tout x de D, f(x) ≥ f(a). Le
minimum de f sur D est f(a).
Remarque. Si f atteint son maximum (respectivement son minimum) en a alors M = f(a) (resp. m =f(a)) est la borne supérieure (resp. borne inférieure) de l’ensemble de images f(D) de f .
Digression. Soit f : [a; b]→ R une fonction continue sur un intervalle fermé, alors f atteint ses bornes.Si l’intervalle n’est pas fermé, ce n’est pas toujours le cas, par exemple la fonction inverse sur ]0; +∞[n’atteint pas ses bornes.
Exemple. Considérons une fonction f : I → R telle que sont graphe soit de la forme suivante :
x
y
x1 x2 x3 x4
x5
Cf
Le tableau de variation de f :
x
f(x)
a x1 x2 x3 x4 x5 b
f(a)
f(x1)
f(x2)
f(x3)
f(x4)f(x5)
f(b)
La fonction f atteint son maximum en x4 et son minimum en x1. On note aussi qu’en x2, x3 la fonctionadmet aussi un extremum mais localement (au voisinage des points correspondants sur la courbe).
Définition 5.33. Soit f : D → R une fonction. On dit que :1) f admet un maximum local en a si pour tout x proche de a, on a f(x) ≤ f(a).2) f admet un minimum local en a si pour tout x proche de a, on a f(x) ≥ f(a).
5.5.3 Résolution graphique d’une inéquation
Vocabulaire. Soit k un nombre réel et f : D → R une fonction.• Résoudre l’inéquation f(x) < k consiste à trouver l’ensemble de tous les antécédents x de D telsque leurs images f(x) par f soient inférieurs strictement au nombre k.
• Résoudre l’inéquation f(x) > k consiste à trouver l’ensemble de tous les antécédents x de D telsque leurs images f(x) par f soient supérieurs strictement au nombre k.
Exemples.
100
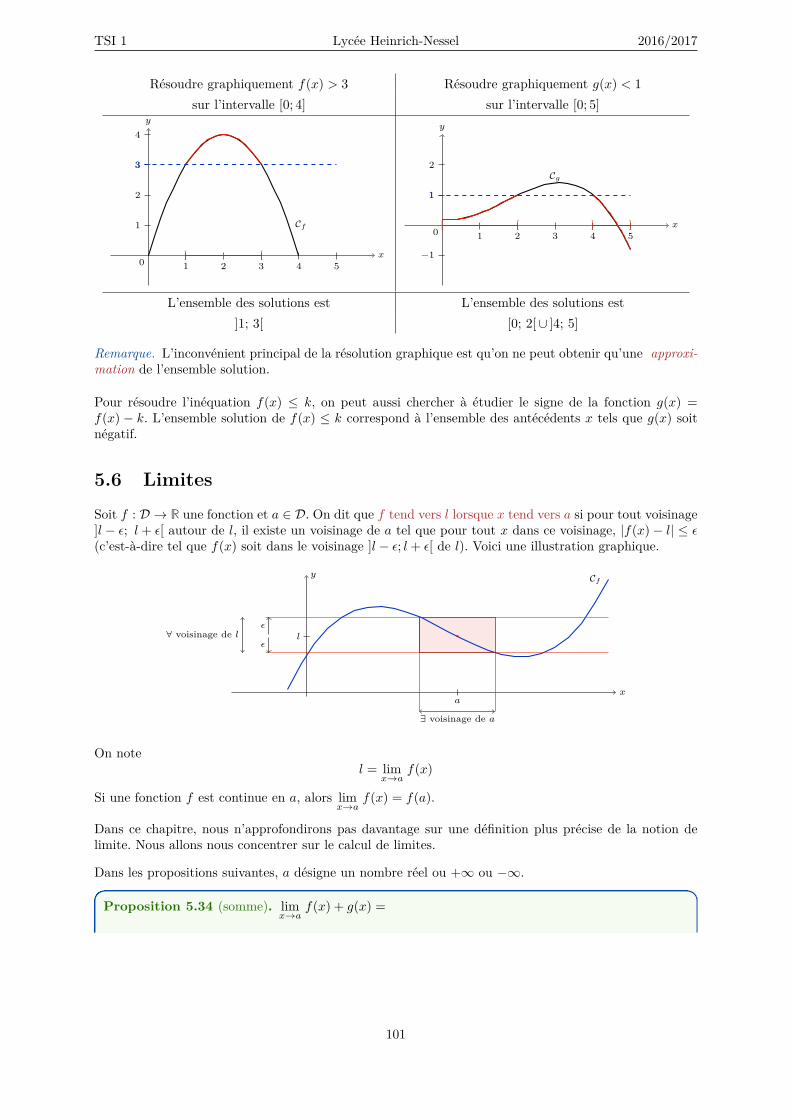
TSI 1 Lycée Heinrich-Nessel 2016/2017
Résoudre graphiquement f(x) > 3 Résoudre graphiquement g(x) < 1sur l’intervalle [0; 4] sur l’intervalle [0; 5]
x
y
1 2 3 4 5
1
2
3
4
0
3
] [
Cf x
y
1 2 3 4 5
−1
1
2
0
1
[ [ ] ]
Cg
L’ensemble des solutions est L’ensemble des solutions est]1; 3[ [0; 2[∪ ]4; 5]
Remarque. L’inconvénient principal de la résolution graphique est qu’on ne peut obtenir qu’une approxi-mation de l’ensemble solution.
Pour résoudre l’inéquation f(x) ≤ k, on peut aussi chercher à étudier le signe de la fonction g(x) =f(x) − k. L’ensemble solution de f(x) ≤ k correspond à l’ensemble des antécédents x tels que g(x) soitnégatif.
5.6 Limites
Soit f : D → R une fonction et a ∈ D. On dit que f tend vers l lorsque x tend vers a si pour tout voisinage]l − ε; l + ε[ autour de l, il existe un voisinage de a tel que pour tout x dans ce voisinage, |f(x)− l| ≤ ε(c’est-à-dire tel que f(x) soit dans le voisinage ]l − ε; l + ε[ de l). Voici une illustration graphique.
x
y Cf
ε
ε∀ voisinage de l
a
l
∃ voisinage de a
On notel = lim
x→af(x)
Si une fonction f est continue en a, alors limx→a
f(x) = f(a).
Dans ce chapitre, nous n’approfondirons pas davantage sur une définition plus précise de la notion delimite. Nous allons nous concentrer sur le calcul de limites.
Dans les propositions suivantes, a désigne un nombre réel ou +∞ ou −∞.
Proposition 5.34 (somme). limx→a
f(x) + g(x) =
101
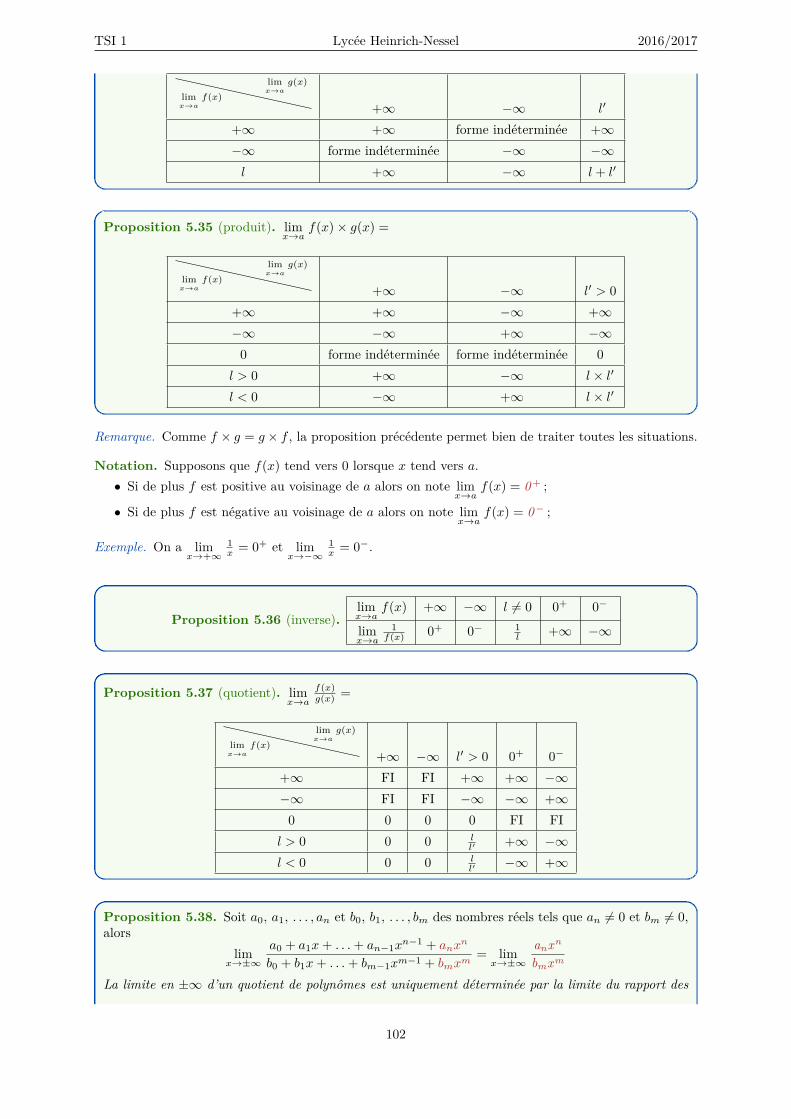
TSI 1 Lycée Heinrich-Nessel 2016/2017
limx→a
f(x)limx→a
g(x)
+∞ −∞ l′
+∞ +∞ forme indéterminée +∞−∞ forme indéterminée −∞ −∞l +∞ −∞ l + l′
Proposition 5.35 (produit). limx→a
f(x)× g(x) =
limx→a
f(x)limx→a
g(x)
+∞ −∞ l′ > 0+∞ +∞ −∞ +∞−∞ −∞ +∞ −∞
0 forme indéterminée forme indéterminée 0l > 0 +∞ −∞ l × l′
l < 0 −∞ +∞ l × l′
Remarque. Comme f × g = g × f , la proposition précédente permet bien de traiter toutes les situations.
Notation. Supposons que f(x) tend vers 0 lorsque x tend vers a.• Si de plus f est positive au voisinage de a alors on note lim
x→af(x) = 0 + ;
• Si de plus f est négative au voisinage de a alors on note limx→a
f(x) = 0− ;
Exemple. On a limx→+∞
1x = 0+ et lim
x→−∞1x = 0−.
Proposition 5.36 (inverse).limx→a
f(x) +∞ −∞ l 6= 0 0+ 0−
limx→a
1f(x) 0+ 0− 1
l +∞ −∞
Proposition 5.37 (quotient). limx→a
f(x)g(x) =
limx→a
f(x)limx→a
g(x)
+∞ −∞ l′ > 0 0+ 0−
+∞ FI FI +∞ +∞ −∞−∞ FI FI −∞ −∞ +∞
0 0 0 0 FI FIl > 0 0 0 l
l′ +∞ −∞l < 0 0 0 l
l′ −∞ +∞
Proposition 5.38. Soit a0, a1, . . . , an et b0, b1, . . . , bm des nombres réels tels que an 6= 0 et bm 6= 0,alors
limx→±∞
a0 + a1x+ . . .+ an−1xn−1 + anx
n
b0 + b1x+ . . .+ bm−1xm−1 + bmxm= limx→±∞
anxn
bmxm
La limite en ±∞ d’un quotient de polynômes est uniquement déterminée par la limite du rapport des
102

TSI 1 Lycée Heinrich-Nessel 2016/2017
monômes de plus au degré.
Proposition 5.39. Soit f, g : D → R deux fonctions et a dans D ou +∞ ou −∞. Alors :
f ≤ g ⇒ limx→a
f(x) ≤ limx→a
g(x)
Corollaire 5.40. Soit f, g : D → R deux fonctions et a dans D ou +∞ ou −∞. Supposons que f ≤ g.1) Si lim
x→af(x) = +∞ alors lim
x→ag(x) = +∞ ;
2) Si limx→a
g(x) = −∞ alors limx→a
f(x) = −∞.
Théorème 5.41 (de l’encadrement). Soit f, g, h : D → R trois fonctions telles que f ≤ g ≤ h. Si
l = limx→a
f(x) = limx→a
h(x)
alors la fonction encadrée g converge aussi vers la limite commune l lorsque x tend vers a.
Exemple. Considérons f : x 7→ −1x , g : x 7→ sin(x)
x et h : x 7→ 1x définies sur R∗+. Alors, on a bien f ≤ g ≤ h
et limx→+∞
f(x) = limx→+∞
h(x) = 0. Ainsi, la fontion g converge aussi en +∞ et limx→+∞
sin(x)x = 0.
x
y
Corollaire. Soit f, g : D → R deux fonctions. Supposons que1) |f | ≤ g2) lim
x→ag(x) = 0.
Alors limx→a
f(x) = 0.
Proposition 5.42 (composée). Soit D f // Eg // R deux fonctions, posons l = lim
x→af(x) et
supposons que g est définie au voisinage de la limite l. Alors :
limx→a f(x) = l
limx→l
g(x) = l′
⇒ limx→a g( f(x) ) = l′
Exercice 5.16. Déterminer la limite de1) e−x2+x+1 lorsque x tend vers +∞.2) x cos( 1
x ) lorsque x tend vers +∞.
Méthode. Soit f une fonction. Pour calculer la limite de f(x) lorsque x tend vers a 1, on peut chercher
103

TSI 1 Lycée Heinrich-Nessel 2016/2017
à déterminer u une bijection, poser x = u(t) et b = u−1(a), de telle sorte que
limx→a f(x) = lim
t→bf u( t )
Si, on choisit bien u, la seconde limite est plus simple à déterminer.
1. Le cas a = ±∞ peut aussi être considérer en posant b = limx→a
f−1(x).
Quelques cas particuliers : Si on pose :• t = −x, alors lim
x→−∞f(x) = lim
t→+∞f(−t)
• t = 12x, alors lim
x→+∞f(x) = lim
t→+∞f(2t)
• t = 1x , alors lim
x→0±f(x) = lim
t→±∞f( 1
t )
• t = ex, alors limx→−∞
f(ex) = limt→0+
f(t)
5.7 Dérivation
5.7.1 Nombre dérivé
Définition 5.43. Soient A(xA; yA) et B(xB ; yB) deux points d’abscisses distinctes du plan. On appelletaux d’accroissement de A vers B le nombre
yB − yAxB − xA
Proposition 5.44. Soient D la droite d’équation y = mx + p, A et B deux points distincts de ladroite. Le taux d’accroissement de A vers B est égal à m, le coefficient directeur de la droite D.
Exemple.1) Soit A(2, 4) et d la droite de coefficient directeur 4 passant par A. Connaissant, le coefficient direc-
teur, on sait que l’équation réduite de la droite d est de la forme :
y = 4x+ p
D’autre part, A appartient à d, doù
4 = 4× 2 + p ⇒ p = 4− 8 = −4
Ainsi, d est d’équation y = 4x− 4.2) Soit a un nombre réel, soit M(a, a2). Détmerinons l’équation de la droite d passant par M est de
coefficient directeur 2a. Alors, on a à nouveau
y = 2ax+ p
et comme M appartient à d, on déduit que
a2 = 2a× a+ p ⇒ p = a2 − 2a2 = −a2
Ainsi, d est d’équation y = 2ax− a2.
Définition 5.45. Soit f : D → R une fonction et a ∈ D. On dit que f est dérivable en a, lorsque htend vers 0, le taux de variation de f de a vers a+ h
f(a+ h)− f(a)h
tend vers un réel l, ce qu’on note limh→0
f(a+h)−f(a)h = l.
104

TSI 1 Lycée Heinrich-Nessel 2016/2017
Dans ce cas, le nombre l est appelé le nombre dérivé de f en a et on le note f ′(a).
Remarque. Si, on pose x = a+ h, alors
limx→a
f(x)− f(a)x− a
= limh→0
f(a+ h)− f(a)h
= f ′(a)
Digression. Soit f : D → R dérivable en a. Pour tout x très proche de a, on a
f(x)− f(a)x− a
' f ′(a) ⇐⇒ f(x) ' f(a) + (x− a)f ′(a)
Dans cette dernière expression, le terme de droite correspond à une fonction affine en x (plus précisément,elle décrit la tangente en a à f). On remarque donc qu’au voisinage de a, la tangente approxime la fonctionf .Posons ε : x 7→ f(x)−f(a)
x−a − f ′(a) si x 6= a au voisinage de a et ε(a) = 0. Alors, pour tout x proche de a,on a
f(x) = f(a) + (x− a)f ′(a) + (x− a)ε(x) et limx→a
ε(x) = 0
Réciproquement, s’il existe une fonction ε définie au voisinage de a telle que :1) Pour tout x proche de a : f(x) = f(a) + (x− a)f ′(a) + (x− a)ε(x) ;2) ε(x) tend vers 0 lorsque x tend vers a.
Alors f est dérivable en a.
Exemple. Soit f la fonction carrée, c’est-à-dire f(x) = x2 pour tout nombre réel x.Nous allons calculer le nombre dérivé de la fonction carré en 5 :Commençons par calculer f(5), f(5 + h) :
f(5) = 52, f(5 + h) = (5 + h)2 = 25 + 10h+ h2
D’où, le taux de variation est
f(5 + h)− f(5)h
= 25 + 10h+ h2 − 25h
= 10h+ h× hh
= h(10 + h)h
= 10 + h
Ainsi, lorsque h tend vers 0, le taux de variation tend vers 10 :
limh→0
f(5 + h)− f(5)h
= limh→0
10 + h = 10
Moralement, dans l’expression 10 +h si on prend h de plus en plus petit, on se rapproche d’autant qu’onveut de 10, d’où à la limite lorsque h est très proche de 0, le nombre 10 + h s’identifie avec le nombre 10lui même.
Exercice 5.17.1) Soit f la fonction carrée sur R : f(x) = x2. Soit a un nombre réel.
a) Soit h un nombre réel non nul, montrer que f(a+h)−f(a)h = 2a+ h.
f(a+ h)− f(a)h
= (a+ h)2 − a2
h= a2 + 2ah+ h2 − a2
h= h(2a+ h)
h= 2a+ h
b) En déduire f ′(a). En faisant tendre h vers 0 dans l’expression précédente, on déduit que pour toutréel a,
f ′(a) = limh→0
f(a+ h)− f(a)h
= limh→0
2a+ h = 2a
2) Soit f la fonction cube sur R : f(x) = x3. Soit a un nombre réel.
105

TSI 1 Lycée Heinrich-Nessel 2016/2017
a) Soit h un nombre réel non nul, montrer que f(a+h)−f(a)h = 3a2 + 3ah+ h2.
f(a+ h)− f(a)h
= (a+ h)3 − a3
h
= (a+ h)(a+ h)2 − a3
h
= (a+ h)(a2 + 2ah+ h2)− a3
h
= a3 + 3a2 h+ 3a h2 + h3 − a3
h
= h(3a2 + 3a h+ h2)h
= 3a2 + 3ah+ h2
b) En déduire f ′(a). En faisant tendre h vers 0 dans l’expression précédente, on déduit que pour toutréel a,
f ′(a) = limh→0
f(a+ h)− f(a)h
= limh→0
3a2 + 3ah+ h2 = 3a2
3) Soit f la fonction racine carrée sur l’intervalle ]0; +∞[ : f(x) =√x. Soit a > 0 un nombre réel.
a) Soit h un nombre réel non nul, montrer que f(a+h)−f(a)h = 1√
a+h+√a.
f(a+ h)− f(a)h
=√a+ h−
√a
h
= (√a+ h−
√a)(√a+ h+
√a)
h(√a+ h+
√a)
= a+ h− ah(√a+ h+
√a)
= h
h(√a+ h+
√a)
= 1√a+ h+
√a
b) En déduire f ′(a). En faisant tendre h vers 0 dans l’expression précédente, on déduit que pour toutréel a strictement posifif,
f ′(a) = limh→0
f(a+ h)− f(a)h
= limh→0
1√a+ h+
√a
= 12√a
c) Calculer le limite de f ′(a) lorsque a tend vers 0+. La dérivée tend vers +∞ en 0+.4) Soit f la fonction inverse sur l’ensemble ] −∞; 0[∪]0; +∞[ : f(x) = 1
x . Soit a un nombre réel nonnul,a) Soit h un nombre réel non nul, montrer que f(a+h)−f(a)
h = −1(a+h)a .
f(a+ h)− f(a)h
=1
a+h −1a
h
=(a+ h)a× ( 1
a+h −1a
)(a+ h)a× h
= a− (a+ h
(a+ h) a h
= −1(a+ h)a
106

TSI 1 Lycée Heinrich-Nessel 2016/2017
b) En déduire f ′(a). En faisant tendre h vers 0 dans l’expression précédente, on déduit que pour toutréel a non nul,
f ′(a) = limh→0
f(a+ h)− f(a)h
= limh→0
−1(a+ h)a = −1
a2
Définition 5.46. Soit f : D → R une fonction dérivable en un point a de D, la tangente à la courbeCf au point d’abscisse a, notée Ta(f), est la droite passant par le point A et dont le coefficient directeurest f ′(a).
Proposition 5.47. Soit f : D → R une fonction dérivable en un point a de D, alors l’équation de latangente à la courbe Cf au point d’abscisse a est :
y = f ′(a)(x− a) + f(a)
Graphiquement :
0
A
1
f ′(a)
a
f(a)
Ta(f) : y = f ′(a)(x− a) + f(a)
Cf
Définition 5.48. Soit f : D → R une fonction, on dit que f est dérivable sur D si elle est dérivableen tout réel a de D.
Vocabulaire. Lorsqu’on se donne une fonction f , on appelle domaine de dérivabilité le plus grand sous-ensemble de R sur lequel la fonction f est dérivable.
Exercice 5.18 (Tangente à l’origine lors de la décharge d’un condensateur). On considère la fonction t 7→U e−
tRC . Déterminer une équation de la tangente en t = 0 et interpréter cette propriété graphiquement.
La fonction représente la tension aux bornes du condensateur Uc(t).L’équation de la tangente en t = 0 et u = −U
RCt + U = U(1 − t
RC) et on note qu’elle coupe l’axe des abscisses en
t = RC (le produit de la capacité et de la résitance), noté aussi τ et est appelé constante de temps.
Une application directe de la définition et des connaissances sur les dérivées des fonctions de référence :
Proposition 5.49.
limx→0
sin(x)x
= 1; limx→0
ln(1 + x)x
= 1; limx→0
ex − 1x
= 1
Exercice 5.19. Démontrer que pour tout x 6= 0, cos(x)−1x2 = −1
2
(sin( x2 )x2
)2et en déduire que
limx→0
cos(x)− 1x2 = −1
2
107

TSI 1 Lycée Heinrich-Nessel 2016/2017
5.7.2 Notation de Leibniz
Étant donné une fonction f : D → R dérivable en a ∈ D, il arrive qu’on note le taux d’accroissement dupoint d’abscisse a au point d’abscisse x de la courbe ainsi :
∆y∆x = f(x)− f(a)
x− a
On fait le rapport des variations en y sur le rapport des variations en x. D’autre part, le nombre dérivéen a :
f ′(a) = limx→a
f(x)− f(a)x− a
par passage à la limite est le rapport des variations « infinitésimales » en y sur les variations « infinitési-males » en x. Un tel passage à la limite sur les variations est aussi noté :
f ′(a) = lim∆x→0
∆y∆x = dy
dx
Si l’on considère plusieurs fonctions et surtout pour plus de rigueur, on préfèrera la notation :
Notation. Soit f une fonction dérivable, sa dérivée est notée ainsi :
f ′ = dfdx = d
dxf
Cette dernière notation est appelée notation de Leibniz en mémoire de Leibniz 1646-1716, qui est l’undes premiers à avoir commencé à étudier le calcul dit infinitésimal avec Newton 1643-1727.
Exemples.• d
dx (ax2 + bx+ c) = 2ax + b ;
• ddt
(−12 gt
2 + z0
)= −gt ;
• ddθ ( cos(ωθ + φ) ) = −ω sin(ωθ + φ).
On aura remarqué que la notation de Leibniz est très utile lorsqu’on étudie des expressions (fonctions)dépendantes de paramètres.
5.7.3 Dérivées successives
Définition 5.50. Soit f : D → R une fonction dérivable. Supposons que f ′ est aussi dérivable sur D,on dit alors que f est deux fois dérivable et sa dérivée seconde, notée f ′′, est la dérivée de f ′.On peut continuer le processus par récurrence, et définir la dérivée troisième, quatrième, . . . , d’ordren, . . . qu’on note f (3), f (4), . . . , f (n), . . . .
Notation. Avec les notations de Leibniz, la dérivée seconde en a est notée
f ′′(a) = d2
dx2 f(a)
et f (n)(a) = dndxn f(a) pour tout entier naturel n.
Exercice 5.20. Calculer la dérivée seconde des fonctions : x 7→ x3, x 7→ x2, x 7→ x, x 7→ ex, x 7→ ln(x)et x 7→ xn pour un entier relatif quelconque.
5.7.4 Fonction dérivée
Proposition 5.51. Soit n un entier relatif
108

TSI 1 Lycée Heinrich-Nessel 2016/2017
f est dérivable sur : f(x) = f ′(x) =c (constante) 0
R x 1x2 2xx3 3x2
R ou R∗ si n < 0 xn nxn−1
R∗ 1x
−1x2
]0; +∞[√x 1
2√x
R cos(x) − sin(x)R sin(x) cos(x)R ex ex
]0; +∞[ ln(x) 1x
Remarque. Pour un peu plus de rigueur, on notera un abus de notation dans (xn)′ = nxn−1 lorsquen = 0. En effet, lorsque n = 0, (xn)′ = (1)′ = 0 tout simplement et non pas 0x−1 qui suggère que ladérivée n’est pas définie en 0 !
Proposition 5.52.
u et v des fonctions Si f(x) s’écrit alors f est dérivable sur I etdéfinies et dérivables sur I. f ′(x) est égale à
Somme u+ v f(x) = u(x) + v(x) f ′(x) = u′(x) + v′(x)Différence u− v f(x) = u(x)− v(x) f ′(x) = u′(x)− v′(x)
Produit de u par un f(x) = c u(x) f ′(x) = c u′(x)une constante c c u
La dérivée de la somme (ou de la différence) de deux deux fonctions dérivables est tout simplementégale à la somme (resp. la différence) des dérivées. De même, la dérivée d’une fonction multipliée parune constante c est égale à la constante fois la dérivée de la fonction. Formellement, on a
(u+ v)′ = u′ + v′
(u− v)′ = u′ − v′
(c u)′ = c u′
Exemples.• f(x) = x2 + 2x+ 3 : f ′(x) = 2x+ 2.• f(x) = −4x3 + 123x2 + 678678x : f ′(x) = −12x2 + 246x+ 678678.• f(x) = 3
x +√
4x : On note au préalable que√
4x =√
4√x = 2
√x, d’où f ′(x) = −3
x2 + 1√x.
Proposition 5.53 (Produit, inverse et quotient). Soient u, v : D → R deux fonctions dérivables surD alors,
1) la fonction f : D → R définie par f(x) = u(x)× v(x) est dérivable et on a
f ′(x) = u′(x)× v(x) + u(x)× v′(x)
2) Si de plus la fonction v ne s’annule pas sur D, alors
109

TSI 1 Lycée Heinrich-Nessel 2016/2017
a) la fonction f : D → R définie par f(x) = 1v(x) est dérivable et on a
f ′(x) = −v′(x)
[v(x)]2
b) la fonction f : D → R définie par f(x) = u(x)v(x) est dérivable et on a
f ′(x) = u′(x)× v(x)− u(x)× v′(x)[v(x)]2
Remarque. Formellement, à nouveau, les identités précédentes sur les dérivées peuvent être écrites de lamanière suivante :
(uv)′ = u′v + uv′(1v
)′= −v′
v2(u
v
)′= u′v − uv′
v2
On note que la troisième formule se déduit des deux précédentes :(u
v
)′=(u× 1
v
)′= u′ × 1
v+ u× −v
′
v2 = u′v − uv′
v2
Il est préférable de retenir cette démonstration pour ne pas oublier qu’on met le signe moins devant v′car dans la dérivée de 1
v , il y a un signe moins qui apparait !
Proposition 5.54 (composée). Soit u : D → R et f : E → R deux fonctions dérivables, supposonsque l’image u(D) est incluse dans le domaine E, alors la composée f u est dérivable sur D et pourtout x dans D, on a
(f u)′(x) = u′(x)× f ′(u(x) )
Formellement, on a : (g f)′ = f ′× (g′ f). Cette fois-ci la notation formelle est plus technique à mettreen oeuvre. On se concentrera uniquement sur la formule de la proposition dans un premier temps.
Exercice 5.21. Soit u une fonction dérivable et n un entier relatif. Compléter les identités et préciser sibesoin les hypothèses supplémentaires sur la fonction u.
•(un)′
(x) = n u′(x) un−1 (x) si n 6= 0 ;
•(√
u(x))′
= u′(x)2√
u(x)si u > 0 ;
•(
ln (u(x)))′
= u′(x)u(x) si u > 0 ;
•(eu(x)
)′= u′(x) eu(x) ;
•(
sin(u(x) ))′
= u′(x) cos( u(x) ) ;
•(
cos(u(x) ))′
= −u′(x) sin( u(x) ).
Exercice 5.22. ? Soit u : D → E et f : E → R deux fonctions dérivables en a et u(a) respectivement.1) À l’aide de la remarque 5.7.1,
a) justifier qu’il existe une fonction ε1 telle que u(x) = u(a) + (x − a)u′(a) + (x − a)ε1(x) auvoisinage de a et qui converge vers 0 lorsque x tend vers a.
b) justifier qu’il existe une fonction ε2 telle que f(y) = f(u(a))+(y−u(a))f ′(u(a))+(y−u(a))ε2(y)au voisinage de u(a) et qui converge vers 0 lorsque y tend vers u(a).
2) En considérant y = u(x) avec x au voisinage de a dans la question précédente, montrer que f uest dérivable en a.
Exercice 5.23. On se place dans le plan muni d’un repère. Soit A(xA; yA) et B(xB ; yB) deux pointstels que leurs abscisses et leurs ordonnées soient distinctes. On note A′ et B′ les symétriques de A et Bpar rapport à la première bissectrice respectivement.
110

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) Rappeler les coordonnées de A′ et B′.2) Soit τ = ∆y
∆x le taux d’accroissement de A à B. Exprimer en fonction de τ le taux d’accroissementde A′ à B′.
3) Soit f une fonction bijective et supposons que yA = f(xA). On rappelle que f ′(xA) = lim∆x→0
∆y∆x .
a) On suppose que f ′(xA) 6= 0. En déduire une expression de (f−1)′(yA), le nombre dérivé del’inverse f−1 en yA, en fonction de f ′(xA).
b) Quelle est la relation entre la tangente à Cf en xA et la tangente à Cf−1 en yA ?c) On suppose que f ′(xA) = 0. Justifier que la tangente à la courbe représentative de f−1 au
point d’abscisse yA est verticale. Peut-on déterminer (f−1)′(yA) dans ce cas ?
Proposition 5.55 (inverse). Soit f une fonction bijective et dérivable sur D. Si f ′ ne s’annule passur D, alors son inverse f−1 est aussi dérivable et pour tout x dans D, on a
(f−1)′(x) = 1f ′( f−1(x) )
Exercice 5.24. Soit f : [0; +∞[→ [0; +∞[ la fonction carrée.1) Justifier que f est une bijection.2) Rappeler la dérivée de f .3) On rappelle que la fonction racine carrée
√· : [0; +∞[→ [0; +∞[ est la fonction inverse de f ,
la fonction carrée, sur [0; +∞[. À l’aide de la proposition précédente, retrouver le domaine dedérivabilité ainsi que la dérivée de la fonction racine carrée.
5.7.5 Variations des fonctions
En revenant à la définition de la tangente, on voit que si la tangente en un point A d’abscisse a estcroissante (resp. décroissante), il en va de même pour f au voisinage de a.
f(a)
a
Cf
Tf,af(a)
a
Cf
Tf,a
Or le coefficient directeur de la tangente Ta(f) de Cf en A est le nombre dérivé f ′(a). Ainsi, la droitetangente est croissante (resp. décroissante) si et seulement si f ′(a) > 0 (resp. f ′(a) < 0).
Proposition 5.56 (admis). Soit f : I → R une fonction dérivable sur l’intervalle I,1) f est constante sur I, si et seulement si, la dérivée f ′ est nulle sur I.2) f est strictement croissante sur I, si et seulement si, la dérivée f ′ est strictement positive sur I
(éventuellement nulle en des points isolés).3) f est strictement décroissante sur I, si et seulement si, la dérivée f ′ est strictement négative
sur I (éventuellement nulle en des points isolés).
En terme de tableaux de variations les trois propriétés précédentes se présentent de la manière suivante :
111
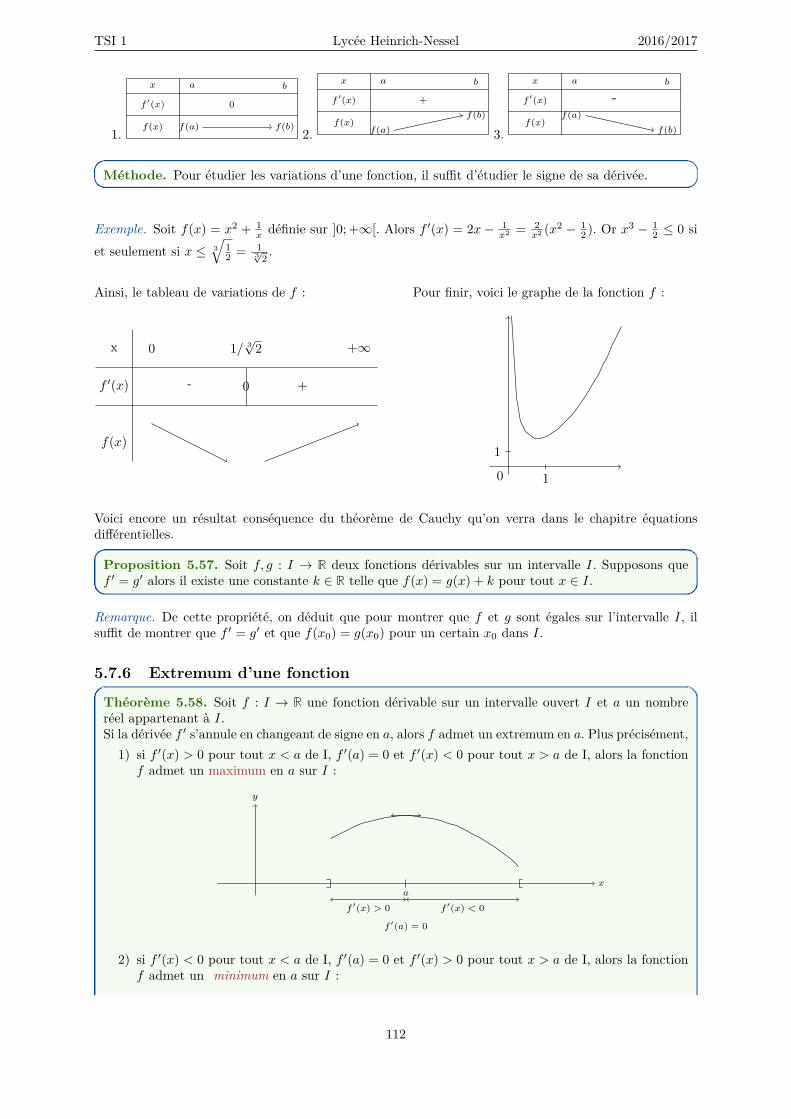
TSI 1 Lycée Heinrich-Nessel 2016/2017
1.
x a b
f ′(x)
f(x) f(a) f(b)
0
2.
x a b
f ′(x)
f(x)f(a)
f(b)+
3.
x a b
f ′(x)
f(x)f(a)
f(b)
-
Méthode. Pour étudier les variations d’une fonction, il suffit d’étudier le signe de sa dérivée.
Exemple. Soit f(x) = x2 + 1x définie sur ]0; +∞[. Alors f ′(x) = 2x− 1
x2 = 2x2 (x2 − 1
2 ). Or x3 − 12 ≤ 0 si
et seulement si x ≤ 3√
12 = 1
3√2 .
Ainsi, le tableau de variations de f :
x
f ′(x)
f(x)
0 1/ 3√
2
0
+∞
- +
Pour finir, voici le graphe de la fonction f :
1
1
0
Voici encore un résultat conséquence du théorème de Cauchy qu’on verra dans le chapitre équationsdifférentielles.
Proposition 5.57. Soit f, g : I → R deux fonctions dérivables sur un intervalle I. Supposons quef ′ = g′ alors il existe une constante k ∈ R telle que f(x) = g(x) + k pour tout x ∈ I.
Remarque. De cette propriété, on déduit que pour montrer que f et g sont égales sur l’intervalle I, ilsuffit de montrer que f ′ = g′ et que f(x0) = g(x0) pour un certain x0 dans I.
5.7.6 Extremum d’une fonction
Théorème 5.58. Soit f : I → R une fonction dérivable sur un intervalle ouvert I et a un nombreréel appartenant à I.Si la dérivée f ′ s’annule en changeant de signe en a, alors f admet un extremum en a. Plus précisément,
1) si f ′(x) > 0 pour tout x < a de I, f ′(a) = 0 et f ′(x) < 0 pour tout x > a de I, alors la fonctionf admet un maximum en a sur I :
x
y
a
f ′(x) > 0 f ′(x) < 0
f ′(a) = 0
2) si f ′(x) < 0 pour tout x < a de I, f ′(a) = 0 et f ′(x) > 0 pour tout x > a de I, alors la fonctionf admet un minimum en a sur I :
112

TSI 1 Lycée Heinrich-Nessel 2016/2017
x
y
a
f ′(x) < 0 f ′(x) > 0f ′(a) = 0
Remarque. L’hypothèse du changement de signe est nécessaire : la fonction x 7→ x3 n’admet pas d’extre-mum sur R, pourtant la dérivée f ′(x) = 3x2 s’annule en x = 0, mais cette dérivée ne change pas de signe(elle est toujours positive).
5.7.7 Extremum local
Définition 5.59. Soit f : I → R une fonction et a ∈ I.1) On dit que f admet un maximum local en a si pour tout x dans un voisinage de a, on a
f(x) ≤ f(a).
avoisinage de a
2) On dit que f admet un minimum local en a si pour tout x dans un voisinage de a, on af(x) ≥ f(a).
avoisinage de a
Proposition 5.60. Soit f : I → R une fonction dérivable et a un nombre dans l’intervalle I. Si fadmet un extremum local en a, alors f ′(a) = 0.
Méthode. Pour étudier une fonction, on doit :1) Déterminer le domaine de définition (parfois donné dans l’énoncé).2) Déterminer les restrictions possibles du domaine d’étude par parité ou périodicité.3) Justifier que f est dérivable sur le domaine d’étude.4) Calculer la fonction f ′ sur le domaine d’étude.5) Étudier le signe de f ′(x)
(parfois cela nécessite d’étudier la dérivée seconde f ′′).6) Calculer les limites de la fonction f aux bords de son domaine d’étude.7) Déterminer les asymptotes éventuelles.
113

TSI 1 Lycée Heinrich-Nessel 2016/2017
8) Dresser le tableau de variations de f , en faisant figurer les limites ainsi que les extrema éventuels.
Méthode.• Pour déterminer le maximum ou le minimum d’une fonction, on peut en faire l’étude détailléeci-dessus.
• Pour déterminer le signe d’une fonction, on peut également en faire l’étude.• Pour démontrer une inégalité de la forme f(x) ≤ g(x) on peut étudier le signe de f − g.
5.8 Fonctions de référence
5.8.1 Fonction logarithme Népérien
Théorème 5.61 (définition). Il existe une unique fonction dérivable ln :]0; +∞[→ R, appelée fonctionlogarithme Népérien, telle que
1) pour tout x > 0, ln′(x) = 1x ;
2) ln(1) = 0.De plus,
∀(a, b) ∈]0; +∞[2: ln(ab) = ln(a) + ln(b)
Remarques.1) Le logarithme a été découvert par John Napier (1550-1617) et, de façon indépendante, par le Suisse
Jost Bürgi (1552–1632). Elle remplace le calcul des multiplications, des divisions et des extractionsde racine par celui d’additions, de soustractions et de division par deux, ce qui a permis d’accélérerles calculs sur des nombres qui ont de nombreux chiffres. C’est dans ce cadre d’ailleurs que Napierutilise son système d’écriture pour les nombres fractionnaires, qui lui a permis de dresser la premièretable de logarithmes avec cinq décimales exactes. L’Anglais Henry Briggs (1561–1630) complète cetravail en publiant une table donnant la valeur avec quatorze décimales exactes des logarithmesdes entiers entre 1 et 20000. On observe dans le travail de Napier un mélange entre des idéesgéométriques (Napier considère des points se mouvant sur une droite) et des calculs arithmétiques(usage des nombres décimaux).
2) Le logarithme Népérien est aussi appelé logarithme de base e. Pour tout a > 0, le logarithme debase a, noté loga, est la fonction croissante telle que loga(x y) = loga(x)+loga(y) pour tout x, y > 0et loga(a) = 1.Parmi les logarithmes de base a, le logarithme de base 10 est noté log. En particulier, pour toutentier relatif n, log(10n) = n, l’ordre de grandeur de 10n. Et pour tout x > 0, log(x) = ln(x)
ln(10) .
Proposition 5.62. La fonction logarithme ln est continue et strictement croissante sur ]0; +∞[.
x
y
y = ln(x)
1 2 3 4 5 6 7 8 9 10
−2
−1
0
1
2
e
114

TSI 1 Lycée Heinrich-Nessel 2016/2017
De plus,1) Si 0 < x < 1, alors ln(x) < 0 ;2) Si x > 1 alors ln(x) > 0.3) lim
x→0+ln(x) = −∞ et lim
x→+∞ln(x) = +∞.
Proposition 5.63. Pour tout a, b > 0 et n ∈ Z, on a
1) ln(ab) = ln(a) + ln(b) ; (le logarithme du produit est la somme des logarithmes)2) ln( 1
a ) = − ln(a) ;3) ln(ab ) = ln(a)− ln(b) ;4) ln(an) = n× ln(a).
Soit (un) une suite géométrique de raison q. Posons pour tout entier naturel n, vn = ln(un).Soit n un entier naturel, appliquons le logarithme népérien à la relation de récurrence qui caractérise(un) :
un+1 = qun
ln(un+1) = ln(q un)ln(un+1) = ln(un) + ln(q)
vn+1 = vn + ln(q) par définition de la suite (vn)
Ainsi, la suite (vn) est une suite arithmétique de raison r = ln(q).
Proposition 5.64. Si la suite (un) est une suite géométrique alors la suite (vn), définie par vn =ln(un) pour tout entier n, est arithmétique.
5.8.2 Fonction exponentielle
La fonction ln étant continue strictement croissante réalise une bijection d’après le théorème 5.27. Onnote exp : R→]0; +∞[ la fonction inverse, appelée fonction exponentielle (de base e). Alors, comme ln eststrictement croissante, son inverse exp est aussi strictement croissante (voir figure 5.2). De plus, d’aprèsla proposition 5.55, pour tout x ∈ R,
exp′(x) = 1ln′(exp(x))
= 11
exp(x)= exp(x)
En résumé,
Théorème 5.65 (définition). On note exp : R →]0; +∞[ la fonction inverse du logarithme qu’onappelle fonction exponentielle et qu’on note exp ou x 7→ ex. De plus, la fonction exponentielle estl’unique fonction dérivable telle que
1) ∀x ∈ R : exp′(x) = exp(x) ;2) exp(0) = 1.
Proposition 5.66.1) Pour tout y > 0 et x ∈ R, on a y = ex ⇐⇒ x = ln(y) ;2) Pour tout x ∈ R : ln(ex) = x.
Proposition 5.67. La fonction exponentielle exp est strictement croissante sur R.
115

TSI 1 Lycée Heinrich-Nessel 2016/2017
x
y
y=ex
1
1
0
e
De plus,1) e ' 2.71828 ;2) exp > 0 ;3) lim
x→−∞ex = 0 et lim
x→+∞ex = +∞.
Proposition 5.68. Pour tous a, b dans R et tout entier relatif n, on a1) ea+b = ea eb ;2) e−a = 1
ea ;3) ea−b = ea
eb;
4) e a2 =√ea ;
5) ena = (ea)n.
5.8.3 Résolution d’une équation du type xn = k
Soit k un nombre réel strictement positif et n un entier naturel.Supposons qu’il existe x > 0 vérifiant la condition xn = k et appliquons le logarithme à cette équation :
xn = k
ln(xn) = ln(k) on applique le logarithmen ln(x) = ln(k) logarithme d’une puissance
ln(x) = ln(k)n
eln(x) = eln(k)n on applique l’exponentielle
x = eln(k)n
Donc si x > 0 est solution de xn = k, alors nécessairement x = eln(k)n .
Proposition. Si k est un réel strictement positif et si n est un entier naturel non nul alors l’équation
xn = k
116

TSI 1 Lycée Heinrich-Nessel 2016/2017
admet une unique solution x dans ]0; +∞[ :
S = eln(k)n
5.8.4 Fonction puissance
On observe que pour tout entier relatif n et x > 0, on a
en ln(x) = xn
Or l’expression de gauche est aussi définie si n est un nombre réel quelconque :
Définition 5.69. Soit a un nombre réel, pour tout nombre réel x > 0, on appelle x puissance a lenombre ea ln(x), noté xa.
Proposition 5.70. Soit x > 0, a, b ∈ R :1) 1a = 1 ;2) xa+b = xa xb ;3) x−a = 1
xa ;4) xa−b = xa
xb;
5) xab = (xa)b.
Exercice 5.25. Soit q > 0 et f : x 7→ qx définie sur R.1) À l’aide de la formule de dérivation d’une composée, déterminer la dérivée de f .2) Suivant le paramètre q, déterminer le signe de f ′.3) Suivant le paramètre q, déterminer les limites de f en ±∞.
Proposition. On admet que la fonction x 7→ qx, définie sur R, est :• strictement positive• strictement décroissante lorsque 0 < q < 1 ;• constante lorsque q = 1 ;• strictement croissante lorsque q > 1.
x
y
0 < q < 1
x
y
q > 1
Exemple.• La fonction x 7→ 0.9x est strictement décroissante sur R car 0 < 0.9 < 1 ;• La fonction x 7→ 2.4x est strictement croissante sur R car 1 < 2.4.
Une conséquence,
117

TSI 1 Lycée Heinrich-Nessel 2016/2017
Propriété 5.71. Si q 6= 1 strictement positif, alors pour tous nombres réels a et b, on a :
qa = qb si et seulement si a = b
Exercice 5.26. Soit a un nombre réel et f : x 7→ xa définie que R∗+.1) À l’aide de la formule de dérivation d’une composée, déterminer la dérivée de f .2) Que retrouve-t-on lorsque a = 1
2 , 2, 3, n un entier relatif ?3) Suivant le paramètre a, déterminer le signe de f ′.4) Suivant le paramètre a, déterminer les limites de f en ±∞.
Proposition 5.72. Soit a un nombre réel, la dérivée de f : x 7→ xa, la fonction puissance a, estdéfinie par
x 7→ a xa−1
sur ]0; +∞[.
Exercice 5.27. ?
1) Soit f : x 7→ (1 + 1x )x, à l’aide du changement de variable t = 1
x déterminer la limite limx→+∞
f(x).
limx→+∞
ex ln(1+ 1x
) = limt→0+
eln(1+t)
t = e
2) En déduire, la limite limx→+∞
(1 + 1x )x2 .
limx→+∞
ex2 ln(1+ 1
x) = lim
x→+∞ex×x ln(1+ 1
x) = lim
x→+∞ex = +∞
3) Déterminer la limite limx→+∞
(1− 1x )x2 .
limx→+∞
ex2 ln(1− 1
x) = lim
t→0+e
1−t
ln(1−t)−t = lim
t→0+e
1−t = 0
4) Les trois limites précédentes sont de la forme limx→+∞
u(x)v(x). Dans chacun des cas, déterminer versquoi convergent les fonctions u et v. À chaque fois, lim
x→+∞u(x) = 1 et lim
x→+∞v(x) = +∞, par contre la
limite de u(x)v(x) change !
5) En déduire une nouvelle forme indéterminée. 1+∞
Proposition 5.73. Soit v : E → R une fonction et u : D → R une fonction positive strictement, alors
limx→a
u(x)v(x) limx→a
v(x)
−∞ l′ < 0 0 0 < l′ +∞0 +∞ +∞ FI 0 0
0 < l < 1 +∞ ll′ 1 ll
′ 0limx→a
u(x) 1 FI 1 1 1 FI
1 < l 0 ll′ 1 ll
′ +∞+∞ 0 0 FI +∞ +∞
5.8.5 Croissances comparées
Exercice 5.28.
118

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) Préciser l’ensemble de définition de f : x 7→ ln(x)− 2√x et étudier ses variations.
2) Démontrer que pour tout x ≥ 1, 0 ≤ ln(x)x ≤ 2√
x.
3) En déduire limx→+∞
ln(x)x .
Théorème 5.74. Quel que soit α ∈ R,
limx→+∞
ex − αx = +∞
Si on pose t = ex, alors (proposition 14.18), pour tout α > 0 :
limt→+∞
t− α ln(t) = limx→+∞
ex − αx = +∞
De la même manière, on déduit :
Corollaire 5.75 (Croissances Comparées). On a :
∀ α ∈ R, limx→+∞
ex
xα= +∞
∀ α > 0, limx→+∞
xα
ln(x) = +∞
∀ n ∈ Z, limx→−∞
xn ex = 0
∀ α > 0, limx→0+
xα ln(x) = 0
Démonstration. Nous allons effectuer quelques changement de variables (proposition 14.18) :
limx→+∞
ln( ex
xα) = lim
x→+∞x− α ln(x) = +∞
limx→+∞
ex
xα= limx→+∞
exp(ln( ex
xα)) = lim
y→+∞ey = +∞ où y = ln( e
x
xα)
limx→+∞
xα
ln(x) = limy→+∞
(ey)α
ln(ey) où y = ln(x)
= limy→+∞
eαy
y
= limt→+∞
αet
toù t = αy
= +∞ car α > 0
limx→−∞
xnex = limt→+∞
(−1)n tn
etoù t = −x
= limt→+∞
(−1)n 1et
tn
= 0
limx→0+
xα ln(x) = limt→+∞
− ln(t)tα
où t = 1x
= limt→+∞
− 1tα
ln(t)
= 0
119

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 5.29. Déterminer les limites :
1) ∀α ∈ R, limx→+∞
xα
ex
2) ∀α > 0, limx→+∞
ln(x)xα
3) ∀n ∈ N ∀ a ∈ R, limx→+∞
ex − axn
4) ∀n ∈ N ∀ a ∈ R, limx→+∞
axn − ln(x)
Exercice 5.30. Soit n ≥ 1, (a0, a1, . . . , an) ∈ Rn tel que an 6= 0 et P : x 7→ anxn+an−1x
n−1+. . . a1x+a0la fonction polynôme associée. Montrer que
limx→+∞
ex − P (x) = +∞ et limx→+∞
P (x)− ln(x) = limx→+∞
P (x)
Méthode. On retiendra qu’en +∞, l’exponentielle l’emporte sur les polynômes qui l’emportent surle logarithme.
120

Chapitre 6
Géométrie dans le plan
Programme• Maîtriser le lien entre la géométrie pure et la géométrie repérée.• Repère orthonormal (orthonormé)• coordonnées cartésiennes, coordonnées polaires (passer de l’une à l’autre)• Produit scalaire : définition géométrique avec le cosinus de l’angle entre les vecteurs. Propriétés.• Déterminer une mesure d’un angle non orienté.• Déterminant dans une base orthonormée directe• La notion d’orientation du plan est admise, ainsi que celle de base orthonormée directe• Définition géométrique avec le sinus de l’angle entre les vecteurs• Bilinéarité, antisymétrie• Caractériser la colinéarité entre deux vecteurs• Démonstrations non exigibles• Droites : définition, vecteur directeur, normal• équation cartésienne, système d’équations paramétriques (passer de l’une à l’autre)• intersection de deux droites• Déterminer le projeté orthogonal d’un point sur une droite• Cercles : définition• équation cartésienne : reconnaitre une équation cartésienne, la déterminer à partir du centre et durayon (et réciproquement), la déterminer à partir des extrémités d’un diamètre.
• représentation paramétrique• Exemples de transformations affines du plan• translation, rotation, homothétie, réflexion• utiliser divers modes de représentation de ces transformations : point de vue géométrique et pointde vue analytique.
6.1 Repère du plan Euclidien
Définition 6.1. Se donner un repère du plan revient à se donner trois points non alignés O, I, J eton note le repère de la manière suivante : (O, I, J).
Un repère (O, I, J) est dit orthogonale si la droite (OI) est perpendiculaire à la droite (OJ).
Un repère (0, I, J) orthogonale est dit orthonormé si de plus OI = OJ = 1.
121

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 6.2 (définition). Soit (O, I, J) un repère quelconque du plan etM un point du plan. Onconstruit le parallélogramme OPMQ tel que le point P appartient à l’axe des abscisses (OI) de co-ordonnée x sur cet axe et le point Q appartient à l’axe des ordonnées (OJ) de coordonnée y sur cet axe.
Le couple (x, y) ∈ R2 est uniquement déterminé par les conditions précédentes et on les appelle lescoordonnées Cartésiennes du point M dans le repère (O, I, J). La coordonnée x est appelée l’abscissedu point M et la coordonnée y est appelée l’ordonnée du point M .
O
P
Q
M(x; y)
x
y
I
J
Une application du théorème de Thalès :
Proposition 6.3. Soient A(xA, yA) et B(xB , yB) deux points dans un repère (O, I, J) du plan. Lemilieu K du segment [AB] a pour coordonnées (xA+xB
2 ; yA+yB2 ). En d’autres termes, les coordonnées
du milieu du segment [AB] sont obtenues en prenant la moyenne des coordonnées.
Une application du théorème de Pythagore :
Proposition 6.4. Soient A(xA, yA) et B(xB , yB) deux points dans un repère orthonormé (O, I, J)du plan. La distance AB est égale à :
AB =√
(xB − xA)2 + (yB − yA)2
La distance entre deux points s’obtient en prenant la racine carrée de la somme des différences descoordonnées des points au carré.
Définition 6.5. Soient A et A′ deux points du plan. On appelle translation de A vers A′ l’uniquetransformation τ du plan qui envoie tout point M sur un point, noté M ′, tel que AMM ′A′ soit unparallélogramme (éventuellement aplati).
A
A′
M
M ′
−→u
On associe un vecteur : −→u =−−→AA′ =
−−−→MM ′ caractérisant cette transformation et on dit que τ est la
translation de vecteur −→u .
Le vecteur−−→AA′ représente le déplacement de A vers A′. D’autre part, quelque soit les points A et B du
plan, il existe une translation de A vers B à laquelle on associe le vecteur −−→AB.
Propriété-Définition 6.6. Soient A,B,C et D quatre points du plan. Dire que −−→AB = −−→CD signifieque D est l’image de C par la translation qui envoie A sur B. Par conséquent, −−→AB = −−→CD si et
122

TSI 1 Lycée Heinrich-Nessel 2016/2017
seulement si le quadrilatère ABDC est un parallélogramme.
Schématiquement, deux vecteurs sont égaux si et seulement si ils ont même direction, même sens, mêmelongueur.
Définition 6.7. Soit (O, I, J) un repère. Les coordonnées d’un vecteur −→u sont les coordonnées dupoint M tel que −−→OM = −→u .
O −→ı
−→
M
Proposition 6.8 (Relation de Chasles). Pour tous points A,B et C, on a−→AC = −−→AB +−−→BC
Proposition 6.9. Dans le plan muni d’un repère, si A(xA; yA) et B(xB ; yB) sont deux points, levecteur −−→AB a pour coordonnées (xB − xA, yB − yA).
Étant donné un repère, comme les coordonnées d’un point sont uniquement déterminées, les coordonnéesd’un vecteur sont uniquement déterminées. Ainsi, l’application coordonnées :
Plan // R2
−→u // (x; y)
réalise une bijection. Au choix d’un repère près, on peut identifier le plan avec R2.
Naturellement, un triplet (x, y, z) ∈ R3 peut être considéré comme représentant un vecteur de l’espace(muni d’un repère).
6.1.1 Vecteurs colinéaires du plan
Définition 6.10. Deux vecteurs sont colinéaires si et seulement si l’un est le produit de l’autre parun réel.
Remarque. • En d’autres termes, le vecteur −→u est colinéaire à −→v s’il existe un nombre réel (unscalaire) λ tel que −→u = λ−→v ou −→v = λ−→u .
• Tout vecteur du plan est colinéaire avec le vecteur nul.
Exercice 6.1 (théorème des milieux). Soit ABC un triangle non aplati et I, J les milieux de [AB] et[AC] respectivement. Démontrer que −→IJ et −−→BC sont colinéaires.
Proposition 6.11. Dans un repère du plan, les vecteurs −→u (x, y) et −→v (x′, y′) sont colinéaires si etseulement si leurs coordonnées sont proportionnelles si et seulement si xy′ − x′y = 0.
Remarque. Le nombre xy′−x′y est appelé le déterminant des vecteurs −→u et −→v . La propriété se reformuleainsi : les vecteurs −→u et −→v sont colinéaires si et seulement si leur déterminant est nul.
Exercice 6.2. Démontrer la proposition précédente dans les trois cas suivants :1) x′ 6= 0 ;
123

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) y′ 6= 0 ;3) −→v = −→0 .
Conclure.
Démonstration. La première équivalence est évidente par définition (voir (P ) ci-dessous).Si −→u et −→v sont colinéaires, alors il existe λ tel que −→u = λ−→v ou −→v = λu. Quitte à intervertir les rôles de −→u et−→v , supposons que −→u = λ−→v : (
x
y
)= λ
(x′
y′
)=
(λx′
λy′
)⇐⇒
x = λx′
y = λy′(P)
D’où xy′ − x′y = λx′ y′ − λx′y′ = 0.Réciproquement, si xy′ − x′y = 0. Si −→u = −→0 , alors on a déjà vu que −→v est colinéaire avec −→u . Supposons doncque −→u est non nul. Distinguons deux cas :• Si x 6= 0, alors
xy′ = x′y ⇐⇒ y′ = x′
xy ⇐⇒
x′ = x′
xx
y′ = x′
xy
et donc −→u = λ−→v avec λ = x′
x∈ R. C’est-à-dire −→u et −→v sont colinéaires.
• Sinon, alors y 6= 0 et
xy′ = x′y ⇐⇒ x′ = y′
yx ⇐⇒
x′ = y′
yx
y′ = y′
yy
et donc −→u = λ−→v avec λ = y′
y∈ R. C’est-à-dire −→u et −→v sont colinéaires.
Deux applications à la géométrie :
Proposition 6.12. Deux droites (AB) et (CD) sont parallèles si et seulement si les vecteurs −−→AB et−−→CD sont colinéaires.
Proposition 6.13. Trois points A,B,C distincts sont alignés si et seulement si les vecteurs −−→AB et−→AC sont colinéaires.
Le triplet (0; I; J) définit donc un repère du plan si et seulement si −→OI et −→OJ ne sont pas colinéaires.D’où
Corollaire 6.14 (définition). Se donner un repère du plan revient à se donner un point O et deuxvecteurs −→ı et −→ non colinéaires et on note le repère (0;−→ı ;−→ ).
6.1.2 Les vecteurs en dimension n
Définition 6.15. Soit n un entier naturel non nul. Les éléments (x1, . . . , xn) de Rn sont appelés desn-uplets.
Nous verrons un n-uplet comme un vecteur dans l’espace de dimension n : −→v = (x1, . . . , xn). L’ensembledes vecteurs Rn est muni de deux opérations : ∀ (x1, . . . , xn) ∈ Rn ∀ (x′1, . . . , x′n) ∈ Rn ∀λ ∈ R :• (x1, . . . , xn) + (x′1, . . . , x′n) = (x1 + x ′1 , . . . , xn + x ′n) ; (addition)• λ (x1, . . . , xn) = (λ x1 , . . . , λ xn). (multiplication par un scalaire)
L’addition et la multiplication se font termes à termes.
Exercice 6.3. Calculer les sommes suivantes :
1) 2(
2−1
)+ 1
2
(1220
);
124

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) 37
(1 2 −1
)+ 6
7
(4 −5 3
)+(
0 12
23
);
3)
123
− 2
456
+
789
.
Vocabulaire. Soit −→v1, . . . ,−→vk des vecteurs et λ1, . . . , λk des scalaires, alors le vecteur
λ1−→v1 + . . .+ λk
−→vk =k∑i=1
λi−→vi
est appelée combinaison linéaire des vecteurs −→v1, . . .−→vk.
La définition de la colinéarité entre deux vecteurs se généralise facilement en dimension n :
Définition 6.16. Les vecteurs −→u et −→v sont colinéaires s’il existe un nombre réel (un scalaire) λ telque −→u = λ−→v ou −→v = λ−→u .
Remarque. Le vecteur nul est colinéaire à tous les autres vecteurs.
Proposition 6.17. Les vecteurs −→u et −→v sont colinéaires si et seulement s’il existe λ, µ deux nombresréels non tous nuls tels que
λ−→u + µ−→v = −→0
Exemples.
• Les vecteurs −→u =(
2−1
)et −→v =
(3−1.5
)sont colinéaires : −→v = 3
2−→u ou encore 2−→v − 3−→u = −→0 .
• Les vecteurs −→i et −→j ne sont pas colinéaires.
• Les vecteurs −→u =
101
et −→v =
303
sont colinéaires : −→v = 3−→u ou encore −→v − 3−→u = −→0 .
Définition 6.18. Trois vecteurs −→u , −→v et −→w sont linéairement dépendants (ou liés) si on peut trouvertrois scalaires λ, µ et ν non tous les trois nuls tels que
λ−→u + µ−→v + ν−→w = −→0
Exercice 6.4. ? Montrer que si −→u et −→v sont colinéaires, alors −→u , −→v et −→w sont liés quelque soit letroisième vecteur −→w choisi.En effet, par hypothèse, il existe deux scalaires λ et µ non tous les deux nuls tels que λ−→u + µ−→v = −→0 . Donc,λ−→u + µ−→v + 0×−→w = −→0 .
Exemples.
• Les vecteurs −→u =
123
, −→v =
−21−4
et −→w =
052
sont liés car −→w = 2−→u + −→v ou encore
2−→u +−→v −−→w = −→0 .• Les vecteurs −→i , −→j et
−→k ne sont pas liés.
On peut continuer à généraliser cette notion en parlant d’une famille de 4, 5, 6, etc, vecteurs liés : On ditdonc qu’une famille de vecteurs (−→v1, . . .
−→vk) est liées si et seulement s’il existe des scalaires λ1, . . . , λk telsque λ1
−→v1 + . . .+ λk−→vk = −→0 .
125

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 6.19. Les vecteurs −→u , −→v ,. . . sont indépendants (ou libres) s’ils ne sont pas liés.
En particulier, nous avons déjà vu que −→u =(x
y
)et −→v =
(x′
y′
)sont liées si et seulement si on a la
relation xy′ − x ′y = 0 .
Définition 6.20. Soient −→u =(x
y
)et −→v =
(x′
y′
)deux vecteurs du plan. Le déterminant de (−→u ;−→v )
dans la base canonique est le nombre réel
det(−→u ;−→v ) =
∣∣∣∣∣ x x′
y y′
∣∣∣∣∣ = xy′ − x′y
Proposition 6.21 (règle de Sarrus). Soient −→u =
x
y
z
, −→v =
x′
y′
z′
et −→w =
x′′
y′′
z′′
trois vecteurs de
l’espace. Alors la famille (−→u ;−→v ;−→w ) est liée si et seulement si on a la relation :
x(y′z′′ − y′′z′)− y(x′z′′ − x′′z′) + z(x′y′′ − x′′y′) = 0
Définition 6.22. Soient −→u =
x
y
z
, −→v =
x′
y′
z′
et −→w =
x′′
y′′
z′′
trois vecteurs de l’espace. Le
déterminant de (−→u ;−→v ;−→w ) dans la base canonique est le nombre réel
det(−→u ;−→v ;−→w ) =
∣∣∣∣∣∣∣∣x x′ x′′
y y′ y′′
z z′ z′′
∣∣∣∣∣∣∣∣ = x(y′z′′ − y′′z′)− y(x′z′′ − x′′z′) + z(x′y′′ − x′′y′)
Remarque. On peut retenir la formule du déterminant de la manière suivante :
det(−→u ;−→v ;−→w ) = x
∣∣∣∣∣ y′ y′′
z′ z′′
∣∣∣∣∣− y∣∣∣∣∣ x′ x′′
z′ z′′
∣∣∣∣∣+ z
∣∣∣∣∣ x′ x′′
y′ y′′
∣∣∣∣∣Méthode. Pour montrer que deux (ou trois) vecteurs sont colinéaires (ou liés), on peut :• Exhiber une combinaison linéaire entre les deux vecteurs (éventuellement en utilisant judicieu-sement la relation de Chasles).
• Montrer que le déterminant associé est nul.Pour montrer que deux (ou trois) vecteurs sont indépendants, on peut :• Supposer qu’il existe une relation de liaison entre ces vecteurs et montrer que nécessairementtous les scalaires sont nuls.
• Montrer que le déterminant associé est non nul.
6.1.3 Bases
126

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 6.23. Une famille (−→u1;−→u2; . . . ;−→un) de vecteurs du plan ou de l’espace est génératrice sitout vecteur −→v est une combinaison linéaire des vecteurs −→uk :
∃ λ1 ∈ R, . . . ,∃ λn ∈ R, −→v = λ1−→u1 + · · ·+ λn
−→un
Définition 6.24. Une famille de vecteurs qui est génératrice et libre est une base.
Exemples. Les vecteurs
• e1 =(
10
)et e2 =
(01
)forment une base (e1, e2) du plan R2.
• e1 =
100
, e2 =
010
et e3 =
001
forment une base (e1, e2, e3) du plan R3.
Ces bases sont appelées base canonique.
Les résultats suivant sont admis pour le moment et seront démontrés en fin de semestre.
Théorème 6.25. Toute base du plan contient exactement deux vecteurs. Toute base de l’espacecontient exactement trois vecteurs.
Méthode (proposition). Pour montrer qu’une famille est une base, on peut montrer qu’elle est librepuis vérifier qu’elle contient le « bon » nombre d’éléments (2 pour le plan ; 3 pour l’espace).
Proposition 6.26 (definition). Soit (−→u ;−→v ) une base du plan. Alors pour tout vecteur −→w , on peuttrouver un unique couple de scalaires λ et µ tels que −→w = λ−→u + µ−→v . Le couple (λ, µ) s’appelle lescoordonnées de −→w dans la base (−→u ;−→v ).
Proposition 6.27 (définition). Soit (−→u ;−→v ;−→w ) une base de l’espace. Alors pour tout vecteur −→a , onpeut trouver un unique triplet de scalaires λ, µ et ν tels que −→a = λ−→u +µ−→v + ν−→w . Le triplet (λ, µ, ν)s’appelle les coordonnées de −→a dans la base (−→u ;−→v ;−→w ).
Exercice 6.5.
1) Montrer que la famille B =((
12
);(
21
))est une base de R2. Son déterminant vaut −3 et elle
contient exactement 2 vecteurs, donc B est une base de R2.
2) Exprimer le vecteur(
35
)dans la base B.
On cherche deux scalaires λ et µ tels que(35
)= λ
(12
)+ µ
(21
)On doit donc avoir l’égalité de vecteurs (
35
)=
(λ+ 2µ2λ+ µ
),
ce qui aboutit au système 3 = λ+ 2µ5 = 2λ+ µ
127

TSI 1 Lycée Heinrich-Nessel 2016/2017
La résolution de ce système donne λ = 73 et µ = 1
3 . Les coordonnées du vecteur
(35
)dans la base((
12
);
(21
))sont donc le couple
(73 ; 1
3
).
Exemple. Soient −→u (2, 1) et −→v (1, 3) deux vecteurs. On note qu’ils ne sont pas colinéaires. Soient −→w (x, y)un vecteur arbitraire du plan et λ, µ deux nombres réels. Alors, −→w = λ−→u +µ−→v si et seulement si les deuxvecteurs ont les mêmes coordonnées. C’est-à-dire, l’abscisse x (resp. l’ordonnée y) de −→w doit être égale à2λ+ µ (resp. λ+ 3µ) l’abscisse (resp. ordonnée) de λ−→u + µ−→v . Formellement, on a le système suivant :
x = 2λ+ µ
y = λ+ 3µ
Résolvons ce système :
⇐⇒
x− 2y = −5µy = λ+ 3µ
⇐⇒
µ = 2y−x
5λ = y + 3
5 (x− 2y) = 15 (3x− y)
En résumé, on vient de voir que quel que soit −→w de coordonnées (x, y), on a
−→w = 3x− y5−→u + 2y − x
5−→v
Ainsi ( 3x−y5 ; 2y−x
5 ) sont les coordonnées de −→w dans le repère (−→u ;−→v ).
Méthode. Pour exprimer les coordonnées d’un vecteur dans une base donnée, on résoudra un systèmed’équations.
6.2 Angles et coordonnées polaires
6.2.1 Mesure d’un angle
Cette section comporte essentiellement des rappels sur la mesure, en radians, des angles orientés entredeux vecteurs.
Définition 6.28. On appelle radian (symbole :rad) la mesure d’un angle qui intercepte un arcdont la longueur est égale à son rayon R.
1 rad
O A
B
R
R
Proposition 6.29. La définition du radian nedépend pas du rayon de l’arc. Plus précisément,le rapport de la longueur de l’arc par le rayoncorrespondant est constant.
l1
r2
r1
l2
l1r1
= l2r2
128

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 6.30. La longueur l d’un arc de cercle intercepté par un angle α, exprimé en radians,est donnée par :
l = Rα
Ainsi, en particulier, la mesure en radians d’un angle plein (tour complet) est de 2π radians.
Exemples.
1) Le périmètre du cercle de rayon 1 est 2πainsi la longueur de l’arc correspondant àun tour complet est 2π. C’est-à-dire que lamesure en radian d’un tour complet est 2π.
2) L’angle correspondant à un demi-tour me-sure π radians.
3) L’angle correspondant à un tiers d’un demi-tour mesure π
3 radians.
π3
2π3
π3
π
Valeurs remarquables :
degrés 0 30 45 60 90 180radians 0 π
6π4
π3
π2 π
Définition 6.31. Le plan est dit orienté lorsqu’on a choisi un sens positif de rotation.
Dans le plan, par convention, on définit le sens positif comme l’inverse de celui des aiguilles d’une montre.
Il est appelé sens trigonométrique :
Dorénavant, pour mesurer un angle, on tient compte du fait qu’on le mesure en tournant dans le sensdirect ou dans le sens inverse. Si on « tourne » dans le sens inverse alors on ajoute un signe − devant lamesure. Par exemple, dans le plan orienté par le sens trigonométrique :
π3
2π3
π3−π3
π
Définition 6.32. Le cercle trigonométrique est un cercle de rayon 1 centré en l’origine dans le planmuni d’un repère orthonormé.
En enroulant la droite verticale d’équation x = 1, voir la figure ci-dessous, on définit une application qui ànombre réel α, représenté par un point N d’ordonnée α, associe un point M sur le cercle trigonométriquetel que la longueur de l’arc du point I au point M soit de α radians (voir la figure ci-contre).On remarque que si on ajoute 2π à α, le point N1 d’ordonnée α+ 2π se retrouve aussi en M sur le cercletrigonométrique. En effet, le périmètre du cercle trigonométrique est de 2π, ainsi en enroulant "cettelongueur de fil", on fait exactement un tour complet.On peut réitérer le processus est ajouter 2k π avec k un entier relatif.
Proposition 6.33. Si un point de la droite d d’ordonnée a se trouve en M après enroulement sur lecercle trigonométrique C, alors les points d’ordonnées...,a− 4π, a− 2π, a, a+ 2π, a+ 4π, a+ 6π, ...,a+ 2kπ,... se retrouvent également en M après enroulement sur C, où k est un entier relatif.
129

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 6.34. Tout pointM sur le cercle trigonométrique correspond à un unique angle admettantune unique mesure α appartenant à l’intervalle ]− π; π], appelée mesure principale.Réciproquement, si les mesures α et β correspondent à un même angle et donc au même point sur lecercle trigonométrique alors il existe un unique entier relatif k tel que β = α + 2 k π et on note dansce cas :
β ≡ α modulo (2π)
x
y
I
J
O
M(α)
β ≡ α modulo (2π)
Définition 6.35. Soit −→u et −→v deux vecteurs de longueur 1.Une mesure de l’angle orienté (−→u ,−→v ) est égale à la longueur de l’arc permettant d’aller de M1 à M2munie d’un signe. Le signe est positif lorsqu’on tourne dans le sens direct pour aller de −→u à −→v etnégatif sinon.
(−→u , −→v )
−→u
−→v
(−→u , −→v )
−→u
−→v
Proposition 6.36. Si α est une mesure de l’angle orienté (−→u , −→v ), les autres mesures de (−→u , −→v )sont égales à α+ 2kπ avec k entier relatif quelconque :
(−→u , −→v ) ≡ α modulo (2π)
Proposition 6.37. Soit −→u et −→v deux vecteur de longueur 1.On a la relation suivante :
(−→u , −→v ) ≡ −(−→v , −→u ) modulo (2π)
On peut aussi mesurer l’angle orienté entre deux vecteurs qui ne sont pas nécessairement de longueur unde la manière suivante.
Définition 6.38. Soit −→u et −→v deux vecteurs non nuls quelconques. On pose u1 = 1||−→u ||−→u et v1 =
1||−→v ||−→v (c’est deux vecteurs (les vecteurs u1 et v1 sont de longueurs un).
Une mesure de l’angle orienté (−→u , −→v ) est égale à une mesure de l’angle orienté (−→u 1,−→v 1)
Définition 6.39. Parmi toutes les mesures d’un angle orienté, celle qui se situe dans l’intervalle]− π; π] est appelée mesure principale.
Proposition 6.40 (Relation de Chasles). Soit O, M , N et P quatre point du plan tels que O soitdistincts des trois M , N et P .
130

TSI 1 Lycée Heinrich-Nessel 2016/2017
On a alors la relation suivante :
(−−→OM,−−→OP ) + (−−→OP, −−→ON) ≡ (−−→OM,
−−→ON) modulo (2π)
Une conséquence :
Proposition 6.41. Soit −→u et −→v deux vecteurs non nuls. Alors
(−→u ; −−→v ) ≡ (−→u ; −→v ) + π modulo (2π)
En effet, on a (−→u ; −−→v ) ≡ (−→u ; −→v ) + (−→v ; −→−v) ≡ (−→u ; −→v ) + π modulo (2π).
Définition 6.42. Soit (O;−→ı ;−→ ) une base orthonormé. On dit que la base est directe si (−→ı ,−→ ) ≡ π2
modulo (2π).
Remarque. Si (O;−→ı ;−→ ) est une base orthonormé directe alors (−→ ,−→ı ) ≡ −π2 modulo (2π).
6.2.2 Cosinus et sinus d’un angle orienté
Définition 6.43.
Soit α un nombre réel etM le point sur le cercletrigonométrique associé à α.Le cosinus du nombre réel α est l’abscisse dupoint M ; cette valeur se note cos(α).Le sinus du nombre réel α est l’ordonnée dupoint M ; cette valeur se note sin(α). x
y
O−1 1
−1
1
cos(α)
αsin(α)
1
En d’autres termes, les coordonnées du point M sur le cercle trigonométrique correspondant à l’angle αsont (cos(α); sin(α)).
Définition 6.44. Soit −→u et −→v deux vecteurs non nuls et α une mesure de l’angle (−→u , −→v ).Le cosinus de l’angle orienté (−→u , −→v ) est cos(α), cette valeur se note cos(−→u , −→v ).Le sinus de l’angle orienté (−→u , −→v ) est sin(α), cette valeur se note sin(−→u , −→v ).
6.2.3 Coordonnées polaires
Définition 6.45 (proposition). Soit (0,−→ı ,−→ ) un repère orthonormé du plan orienté. Tout point Mdu plan différent de l’origine est uniquement caractérisé par le couple (ρ : θ) ∈ R∗+×] − π; π] oùρ = OM et θ est la mesure principale de l’angle (−→ı ;−−→OM).Le couple (ρ : θ) est appelé coordonnées polaires de M .
Remarque. • Il arrive qu’on autorise θ a être un nombre réel quelconque (une mesure quelconque del’angle (−→ı ;−−→OM) mais dans ce cas, θ est seulement déterminé modulo (2π).
• L’origine peut être considérer comme le point de coordonnées (0 : θ) avec θ arbitraire.• Comme pour les coordonnées cartésiennes, les coordonnées polaires d’un vecteur −→v non nul sontpar définition les coordonnées polaires du point M tel que −−→OM = −→v .
131

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 6.6. Soit −→u de coordonnées polaires (2 : π6 ).1) Donner les coordonnées polaires du vecteur −→e1 unitaire (de longueur un) de même direction que −→u .2) Donner les coordonnées polaires du vecteur −→e2 tel que (−→e1 ,
−→e2) soit une base orthonormée directe.
6.2.4 Lien entre les deux modes de repérage
Nous avons (re)vu que pour tout point M sur le cercle trigonométrique, on peut déterminer ses coordon-nées cartésiennes M(cos(θ); sin(θ)), à l’aide de θ = (−→OI, −−→OM) une mesure de l’angle orienté entre −→OI et−−→OM .Généralisation : Soit A un point quelconque du plan. Pour simplifier, supposons que A se trouve dans
le premier quart du plan (i.e. ses coordonnées sont positives) :
x
y
O−1 1
−1
1
cos(θ)
θsin(θ)
1
OA
xA
yA
A
xA
yA
Dans les deux triangles en bleu, si on applique lethéorème de Thalès, on a les relations suivantes :
cos(θ)xA
= 1OA = sin(θ)
yA
De la première identité, on déduit que :
xA = OA cos(θ)
et de la seconde :
yA = OA sin(θ).
Il est facile de reproduire la précédente démonstration pour les 3 autres cas où le point A se trouve dansles différents quarts de plan. Ainsi, on a :
Proposition 6.46. Dans le repère orthonormé (O;−→ı ,−→ ), si A est un point distinct de l’origine Otel qu’une mesure en radians de l’angle (−→i ,−→OA) soit égale à θ, alors les coordonnées cartésiennes deA sont
(OA× cos(θ); OA× sin(θ))
Corollaire 6.47. Dans le repère orthonormé (O;−→ı ,−→ ), soit A un point distinct de l’origine. Notons(x; y) ∈ R2 ses coordonnées cartésiennes et (ρ : θ) ∈ R∗+×]− π; π] ses coordonnées polaires, alors :
x = ρ cos(θ)y = ρ sin(θ)
⇐⇒
ρ =
√x2 + y2
cos(θ) = x√x2+y2
sin(θ) = y√x2+y2
Exercice 6.7. Dans le plan muni d’un repère orthonormé direct (O;−→ı ;−→ ).1) SoitA,B, C, etD quatre points de coordonnées cartésiennes respectives : (2; 2), (−
√3; 1), (−8;−8
√3)
et (−6;−1). Déterminer les coordonnées polaires de ces points.2) Soit E et F deux points de coordonnées polaires respectives (
√2 : 3π
4 ) et (16 : −5π6 ). Déterminer
les coordonnées cartésiennes de ces points.
Exercice 6.8 (rotation d’un quart de tour). Dans le plan muni d’un repère orthonormé direct (O;−→ı ;−→ ),on note r la rotation de centre O et d’angle π
2 . Soit M un point du plan et M ′ son image par la rotationr. Notons (ρ : θ) les coordonnées polaires de M et (x; y) les coordonnées cartésiennes de M .
1) Déterminer les coordonnées polaires de M ′.
132

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) Déduire de la question précédente les coordonnées cartésiennes de M ′ en fonction de x et y.3) Compléter la description de l’application r :
r : R2 // R2
(x; y) // (−y; x)
4) Déterminer r r(x; y) en fonction de (x; y). À quelle transformation du plan correspond r r ?
6.3 Produit scalaire
On se place dans un plan muni d’un repère (O,−→i ,−→j ) orthonormé direct.
6.3.1 Orthogonalité de deux vecteurs
Définition 6.48. Deux vecteurs −−→AB et −−→CD sont orthogonaux si et seulement si soit l’un des deuxvecteurs est nul, soit les droites (AB) et (CD) sont perpendiculaires.
Exercice.1) Soit A(3; 4) et B(−1; 1). Le triangle OAB est-il rectangle en O ?2) Une condition générale :
Soit M(x; y) et N(x; y) deux point distincts de O.a) Donner une condition nécessaire et suffisante sur OM2 + ON2 −MN2 pour que OMN soit
rectangle en O.b) Exprimer OM2 +ON2 −MN2 en fonction de x, y, x′ et y′.c) En déduire une condition nécessaire et suffisante sur les coordonnées des vecteurs −−→OM et −−→ON
pour que −−→OM soit orthogonal à −−→ON .
Proposition 6.49. Soit −−→OM(x
y
)et −−→ON
(x′
y′
)deux vecteurs. Alors, −−→OM est orthogonal à −−→ON si et
seulement si le nombre 12(OM 2 + ON 2 −MN 2 ) = xx ′ + yy′ est nul.
Définition 6.50. Soit −→u(x
y
)et −→v
(x′
y′
)deux vecteurs. Le produit scalaire de −→u et −→v , noté −→u ·−→v ,
est le nombre réel défini par−→u · −→v = xx′ + yy′
Théorème 6.51. Les vecteurs −→u et −→v sont orthogonaux si et seulement si −→u · −→v = 0.
6.3.2 Propriétés du produit scalaire
Proposition 6.52. Soit −→u ,−→v ,−→w trois vecteurs du plan. Soit λ un nombre réel, alors,• −→u · −→v = −→v · −→u ; (symétrie)• −→u · (−→v +−→w ) = −→u · −→v +−→u · −→w ; (distributivité)• (λ−→u ) · −→v = λ(−→u · −→v ) = −→u · (λ−→v ). (linéarité)• −→u · −→u ≥ 0 (positivité)• −→u · −→u = 0 si et seulement si −→u = −→0 .
133

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 6.53. Soit −→u un vecteur. Le nombre −→u ·−→u est appelé carré scalaire de −→u et est noté −→u 2.
Comme conséquence de la propriété précédente, on déduit des identités analogues aux identités remar-quables :
Proposition 6.54. Pour tous vecteurs −→u et −→v du plan, on a• (−→u +−→v )2 = −→u 2 + 2−→u · −→v +−→v 2 ;• (−→u −−→v )2 = −→u 2 − 2−→u · −→v +−→v 2 ;• (−→u +−→v ) · (−→u −−→v ) = −→u 2 −−→v 2 .
6.3.3 Deux autres définitions du produit scalaire
Définition 6.55. Soit A, B et C trois points du plan deux à deux distincts. Le projeté orthogonalH de C sur la droite (AB) est le pied de la hauteur issue de C dans le triangle ABC. En d’autrestermes, le point H est l’unique point sur la droite (AB) tel que (CH) soit perpendiculaire à (AB).
A
B
H
C
Remarque. Lorsque C est confondu avec A (respectivement B) le projeté orthogonal H est aussi définiet égal au point A (respectivement B).D’ailleurs, on note que le projeté orthogonal H de C coïncide avec le point C lui-même si et seulementsi C appartient à la droite (AB).
Proposition 6.56. Si A, B et C sont trois points du plan deux à deux distincts. Si H est le projetéorthogonal de C sur la droite (AB), alors• Si H appartient à la demi-droite [AB) :
−−→AB ·
−→AC = −−→AB · −−→AH = AB ×AH
A BH
C
• Si H n’appartient pas à la demi-droite [AB) :−−→AB ·
−→AC = −−→AB · −−→AH = −AB ×AH
A BH
C
134

TSI 1 Lycée Heinrich-Nessel 2016/2017
Supposons que H appartienne à la demi-droite [AB) et AC 6= 0. Alors, dans le triangle AHC rectangleen H, on a
cos(−→AB,−→AC) = cos(−−→AH,−→AC) = AH
AC
AC × cos(−→AB,−→AC) = AH−→AB ·
−→AC = AB ×AH
−→AB ·
−→AC = AB ×AC × cos(−→AB, −→AC)
Exercice 6.9. On suppose que H n’appartient pas à la demi-droite [AB) et AC 6= 0. Montrer quel’identité précédente est encore vraie.
Théorème 6.57. Soit −→u et −→v deux vecteurs du plan.Le produit scalaire de −→u et −→v est égal à :
−→u · −→v =
0 si −→u = −→0 ou −→v = −→0 ;||−→u || × ||−→v || × cos(−→u ,−→v ) sinon.
Proposition 6.58. Soit −→u et −→v deux vecteurs non nuls, alors l’angle entre les deux vecteurs est
(−→u ,−→v ) ≡ ± arccos( −→u · −→v||−→u || ||−→v ||
)modulo (2π)
Exercice 6.10. Déterminer une valeur approchée en radians d’une mesure de l’angle (−→u ,−→v ), les vecteurs−→u et −→v ayant pour coordonnées (1; 4) et (5;−3) dans un repère orthonormé direct.
6.3.4 Carré scalaire et norme d’un vecteur
Définition 6.59. Soit −→u(x
y
)un vecteur dans le plan muni d’un repère orthonormé. On note la
longueur du vecteur ||−→u || et on l’appelle norme du vecteur −→u .
Une application immédiate du théorème de Pythagore :
Proposition 6.60. Soit −→u(x
y
)un vecteur. Alors,
||−→u || =√ −→u 2 =
√x2 + y2
Remarque. La précédente identité est équivalente à : ||−→u ||2 = −→u 2.
Proposition 6.61 (inégalité de Cauchy-Schwarz). Soit −→u et −→v deux vecteurs, alors
|−→u · −→v | ≤ ||−→u || ||−→v ||
De plus, il y a égalité si et seulement si −→u et −→v sont colinéaires.
Démonstration. Si −→v est nul la proposition est évidente. Supposons que −→v est non nul. Considérons la fonctionP : R→ R définie par P (t) = ||−→u + t−→v ||2. Elle est positive et de plus
∀ t ∈ R : P (t) = ||−→u ||2 + 2−→u · −→v t+ ||−→v ||2 t2
135

TSI 1 Lycée Heinrich-Nessel 2016/2017
On en déduit que P (t) est un polynôme du second degré prenant toujours des valeurs positives. Il ne peut doncavoir deux racines distincts et son discriminant est négatif :
4(−→u · −→v )2 − 4||−→u ||2 ||−→u ||2 ≤ 0(−→u · −→v )2 ≤ ||−→u ||2 ||−→u ||2
|−→u · −→v | ≤ ||−→u || ||−→u ||
Enfin, s’il y a égalité, on déduit que le discriminant est nul et donc il existe 1 un réel t tel que ||−→u + t−→v ||2 = 0.C’est-à-dire −→u = −t−→v et les vecteurs sont colinéaires. Réciproquement, l’identité est immédiate si les vecteurssont colinéaires.
Proposition 6.62. Soit −→u et −→v deux vecteurs du plan et λ un nombre réel.1) ||−→u || = 0 si et seulement si −→u = −→0 .
2) ||λ−→u || = |λ| ||−→u || ;
3) ||−→u +−→v || ≤ ||−→u ||+ ||−→v || (inégalité triangulaire)
4) ||−→u +−→v ||2 + ||−→u −−→v ||2 = 2 (||−→u ||2 + ||−→v ||2 ) (identité du parallélogramme)
5) −→u · −→v = 12(||−→u +−→v ||2 − ||−→u ||2 − ||−→v ||2
). (identité de polarisation)
6) ||−→u +−→v ||2 = ||−→u ||2+||−→v ||2 si et seulement si −→u et −→v sont orthogonaux (théorème de Pythagore).
Remarque. Comme conséquence de l’inégalité triangulaire, on retrouve un fait assez intuitif :
AC ≤ AB +BC
Le chemin le plus court pour relier deux points est la ligne droite.
Théorème (théorème de la médiane). Soit A et B deux points du plan et I le milieu de [AB].Pour tout point M du plan, on a
MA2 +MB2 = 2MI2 + AB2
2
A
B
I
M
||
||
Exemple. On considère un segment [AB] de lon-gueur 4.Déterminons le lieu géométrique des pointsM telsque MA2 +MB2 = 20. A B
IM
Soit M un point du plan tel que MA2 +MB2 = 20. D’après le théorème de la médiane, si l’on note I le
1. On utilise encore une fois le fait que −→v est non nul.
136

TSI 1 Lycée Heinrich-Nessel 2016/2017
milieu du segment [AB], alorsMA2 +MB2 = 20
2MI2 + AB2
2 = 20
2MI2 = 20− 42
2 = 12
MI2 = 6MI =
√6
Ainsi, le point vérifie l’équation MA2 + MB2 = 20 si et seulement si MI =√
6. On en déduit que lelieu géométrique des points M tels que MA2 +MB2 = 20 est le cercle de rayon
√6 centré au milieu du
segment [AB].
Exemple. On considère les points A(2; 3) etB(−1;−2) dans le plan muni d’un repère ortho-normé. Déterminons les coordonnées des pointsd’intersection de la droite (AB) avec le cercle Cde centre A et de rayon 4.
A
B
x11
y
C
1) Commençons par les équations de (AB) et du cercle C : Soit ax+ by+ c = 0 l’équation de la droite
(AB). Le vecteur −−→AB(−3−5
)est un vecteur directeur de la droite (AB), ainsi b = 3 et a = −5 et
donc l’équation est de la forme −5x + 3y + c = 0. Le point A appartient à la droite (AB), d’où−5× 2 + 3× 3 + c = 0, c’est-à-dire c = 1. En résumé, l’équation −5x+ 3y+ 1 = 0 est une équationde la droite (AB) et son équation réduite est :
y = 5x− 13 = 5
3x−13 .
D’après la propriété 6.88, le cercle de centre A et de rayon 4 est d’équation :
(x− 2)2 + (y − 3)2 = 16.
2) Soit M(x; y) le point d’intersection de la droite (AB) et du cercle centré en A. Comme y = 53x−
13 ,
on en déduit que
(x− 2)2 + (53x−
13 − 3)2 = 16
(x− 2)2 + (53x−
103 )2 − 16 = 0
x2 − 2× 2× x+ 22 + 259 x
2 − 2× 53 ×
103 x+ 100
9 − 16 = 0
349 x
2 − 1369 x− 8
9 = 0
34x2 − 136x− 8 = 017x2 − 68x− 4 = 0
Le discriminant de cette équation du second degré est ∆ = b2 − 4ac = (−68)2 − 4 × 17 × (−4) =4896 > 0. Ainsi, il y a deux solutions :
x1 = −b−√
∆2a = 68−
√4896
34 ' −0.06y1 = 5
3x1 − 13 ' −0.43
etx2 = −b+
√∆
2a = 68+√
489634 ' 4.06
y2 = 53x2 − 1
3 ' 6.43
6.3.5 Deux applications
Soit A et B deux points sur le cercle trigonométrique et posons a, b une mesure des angles (−→OI,−→OA) et(−→OI,−−→OB). En calculant de deux manières différentes le produit scalaire −→OA · −−→OB, on déduit la formulede trigonométrie suivante.
137

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 6.63. Soit a et b deux nombres réels, alors
cos(a− b) = cos(a) cos(b) + sin(a) sin(b)
Une autre application à une généralisation du théorème de Pythagore :
Théorème 6.64 (théorème d’Al-Kashi). Pour tout triangle ABC, on a
a2 = b2 + c2 − 2 b c cos(A)
A B
C
c
ab
A B
C
De même, comme le choix du sommet est arbitraire, on a
b2 = a2 + c2 − 2a c cos(B) et c2 = a2 + b2 − 2a b cos(C)
Démonstration. On utilise le fait que −−→BC = −−→BA+−→AC et on développe l’expression : a2 = −−→BC2.(exercice : finir la démonstration).
Exercice 6.11.1) Soit ABC un triangle direct tel que AB = 4, AC = 1 et BC =
√13. Calculer de deux façons −−→BC2
et en déduire une mesure θ de (−−→AB,−→AC).
2) Existe-t-il un autre triangle ABC tel que AB = 4 et (−−→AB,−→AC) ≡ θ (2π) et BC =√
13 ? Si oui, quevaut alors AC ?
Exercice 6.12. ? Avec les notations du théorème, on suppose que le triangle ABC n’est pas aplati.1) Montrer que |b− c| < a < b+ c.2) Montrer que b2 − a2 = a(b cos(C)− c cos(B)).3) Montrer que b = c si et seulement si cos(B) = cos(C). Énoncer une proposition exprimant cette
propriété.
6.4 Déterminant dans une base orthonormée directe
Nous avons déjà vu la notion de déterminant dans la base canonique de R2. Dans cette section, nousallons donner une autre définition dans une base orthonormée directe et montrer qu’elle coïncide dans R2
muni de la base canonique.
Définition 6.65. On appelle déterminant dans une base orthonormée directe de −→u et −→v le réel définipar
[−→u ,−→v ] =
0 si −→u = −→0 ou −→v = −→0 ,||−→u || ||−→v || sin(−→u ,−→v ) sinon.
Proposition 6.66. Les vecteurs −→u et −→v sont colinéaires (liées) si et seulement si le déterminant[−→u ,−→v ] est nul.
Remarque. Le produit scalaire mesure l’orthogonalité et le déterminant la colinéarité.
Exercice 6.13.
138
TSI 1 Lycée Heinrich-Nessel 2016/2017
On considère le parallélogramme ABCD dans leplan muni d’un repère orthonormé direct suivant :
A B
CD
H H′
On suppose que la mesure principale de (−−→AB,−−→AD)est positive et que le parallélogramme n’est pasaplati.
1) Exprimer DH en fonction de AD et(−−→AB,−−→AD).
2) En déduire l’aire de HH ′CD en fonction deAD, AB et (−−→AB,−−→AD).
3) Montrer que l’aire de ABCD est égale à[−−→AB,−−→AD].
Proposition 6.67. Le déterminant [−→u ,−→v ] est l’aire orienté du parallélogramme formé par −→u et −→v .
Corollaire 6.68. Soient A, B et C trois points non alignés. L’aire du triangle ABC vaut
12
∣∣∣det(−−→AB,−→AC)∣∣∣
Remarque. Si la mesure principale de (−→u ,−→v ) est négative, alors le sinus de l’angle est aussi négatif ainsi[−→u ,−→v ] est négatif. Mais, ça valeur absolue représente bien l’aire du parallélogramme associé. D’autrepart, pour que l’angle soit de mesure principale positive, il suffit de changer l’orientation du plan, d’oùla notion d’aire orienté.
Encore une conséquence du corollaire précédent :
Proposition. Pour tout triangle ABC nonplat, on a
a
sin(A)= b
sin(B)= c
sin(C)= abc
2S
où S désigne l’aire du triangle.A B
C
c
ab
A B
C
Exercice 6.14. Dans un triangle ABC, on connaît a = 41.25, B = 2π9 radians et C = 5π
12 radians.Donner une valeur approchée de A, b et c.
Exercice 6.15.1) Démontrer que pour tous −→u , −→v , on a [−→u ,−→v ] = −[−→v ,−→u ].2) On note −→u ′ l’image de −→u par la rotation d’angle π
2 . Démontrer que [−→u ,−→v ] = −→u ′ · −→v et en déduireque [·, ·] est bilinéaire (voir proposition ci-dessous).
3) À l’aide de l’exercice 6.8, exprimer [−→u ,−→v ] en fonction des coordonnes cartésiennes (x; y) et (x′; y′)des vecteurs −→u et −→v .
Proposition 6.69. Soit −→u , −→v , −→w trois vecteurs et λ un nombre réel, alors1) [−→u ,−→v ] = −[−→v ,−→u ] (anti-symétrie)2) [−→u , λ−→v ] = [λ−→u ,−→v ] = λ[−→u ,−→v ]
[−→u ,−→v +−→w ] = [−→u ,−→v ] + [−→u ,−→w ][−→u +−→v ,−→w ] = [−→u ,−→w ] + [−→v ,−→w ] (bilinéarité)
Proposition 6.70. Soit −→u (x; y), −→v (x′; y′) deux vecteurs dont les coordonnées cartésiennes sont ex-primées dans une base orthonormée directe, alors :
[−→u ,−→v ] = xy′ − yx ′
139

TSI 1 Lycée Heinrich-Nessel 2016/2017
Notation. Le déterminant précédent est noté∣∣∣∣∣x x′
y y′
∣∣∣∣∣ := xy′ − yx′
Exercice 6.16. Dans le plan complexe (le repère (0, 1, i) induit une base orthonormé direct), soit −→v ,−→v ′ d’affixes z et z′, montrer que [−→v ,−→v ′] = Im(z z′).
6.5 Droites
Théorème-définition 6.71. Soit A, B deux points distincts. Il existe une unique droite qui passepar A et B et on la note (AB).De plus la droite (AB) est le lieu géométrique des points M alignés avec A et B.
Soit A(xA, yA) et B(xB , yB) deux points distincts dans le plan muni d’un repère. Alors, un pointM(x; y)
appartient à la droite (AB) si et seulement si−−→AM(x− xAy − yA
)est colinéaire à−−→AB
(xB − xAyB − yA
). C’est-à-dire,
les coordonnées (x; y) sont solutions de l’équation :
(x− xA)(yB − yA)− (xB − xA)(y − yA) = 0⇐⇒ (yB − yA)x+ (xB − xA)y +−xA(yB − yA) + yA(xB − xA) = 0⇐⇒ a x+ b y + c = 0
où les expressions en couleur désignent des nombres constants. Donc la droite (AB) est le lieu géométriquedes points M(x; y) tels que ax+ by + c = 0.
Propriété-Définition 6.72. Toute droite D dans un plan repéré admet une équation de la forme
ax+ by + c = 0
où a, b et c sont des nombres réels fixés tels que a 6= 0 ou b 6= 0. On appelle cette équation, l’équationcartésienne de D.Réciproquement, toute équation cartésienne avec a 6= 0 ou b 6= 0 décrit une droite dans le plan repéré.
Exercice 6.17. Donner le négation de l’affirmation « a 6= 0 ou b 6= 0 ».
En revenant aux opérations sur les équations, on note que quel que soit le nombre réel k non nul, leséquations k(ax+ by+ c) = 0 (c’est-à-dire, ka x+ kb y+ kc = 0) et ax+ by+ c = 0 sont équivalentes (ellespartagent les mêmes solutions).
Définition 6.73. Soit D une droite du plan. Quels que soient A et B deux points distincts de ladroite D, on appelle −→u = −−→AB un vecteur directeur de D.
Proposition 6.74. Deux droites sont parallèles si et seulement si leurs vecteurs directeurs sont coli-néaires.
En d’autres termes, le vecteur directeur donne la direction d’une droite.
Lemme 6.75. Soient −→v un vecteur directeur d’une droite D et A un point de D. Un point Mappartient à la droite D si et seulement si −−→AM est colinéaire à −→v .
Si A ∈ D et −→v est un vecteur directeur de D, la droite D est l’ensemble des points M tel qu’il existe λun nombre réel : −−→AM = λ−→v . On part de A dans la direction −→v pour parcourir la droite D.
Exercice 6.18. Dans le plan muni d’un repère, soit A(1, 2) et B(5, 3).
140

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) Déterminer une équation cartésienne de la droite (AB).2) Soit M(x; y) un point tel que :
x = 1 + 4ty = 2 + t
pour un certain réel t. Montrer que M appartient à la droite (AB).
Proposition 6.76. Toute droite D du plan P peut être décrit ainsi
M ∈ P; ∃ t ∈ R−−→AM = t−→v
où A est un point et −→v un vecteur directeur de la droite D.
Notation. Si on note A(xA; yA),M(x; y) et −→v (xv; yv) les coordonnées cartésiennes dans un repère duplan, alors la description précédente de la droite précédente peut aussi se faire sous la forme suivante :
D :x = xA + t xv
y = yA + t yv
appelé système d’équations paramétriques de D.
Remarque. Si D est d’équation y = mx + p,une telle équation est appelée équation réduite.Le nombre m est appelé coefficient directeur etle nombre p est appelé ordonnée à l’origine dela droite (fonction affine). Les points A(0; p) etB(1;m + p) appartiennent à la droite D, ainsi levecteur −→v = −−→AB = (1;m) est un vecteur direc-teur de D.
D
A
B
1m
−→v
L’équation réduite y = mx+ p peut être mise sous la forme d’une équation cartésienne :
m︸︷︷︸a
x+ (−1)︸︷︷︸b
y + p︸︷︷︸c
= 0
et −→v est alors de coordonnées (−b; a).
Proposition 6.77. Soit D la droite d’équation ax + by + c = 0 dans un plan repéré. Le vecteur−→u
(−ba
)est un vecteur directeur de D.
Application :
Proposition 6.78. Les droites d’équations ax+ by + c = 0 et a′x+ b′y + c′ = 0 sont parallèles si et
seulement si le déterminant
∣∣∣∣∣a a′
b b′
∣∣∣∣∣ = ab′ − a′b est nul.
Méthode.• Pour trouver les équations paramétriques d’une droite, on utilise directement la définition de ladroite en termes de vecteurs colinéaires.
• Pour trouver une équation cartésienne d’une droite, on traduit la colinéarité de la définition à
141

TSI 1 Lycée Heinrich-Nessel 2016/2017
l’aide du déterminant.
Exercice 6.19.1) Soit D la droite d’équation cartésienne 2x+ 5y − 4 = 0. Déterminer un système d’équations para-
métriques de la droite D.2) Soit D′ la droite de système d’équations paramétriques :
x = 1 + 3ty = 5− 4t
; t ∈ R.
Déterminer une équation cartésienne de la droite D′.
Remarque. Soit D d’équation cartésienne ax + by + c = 0 et A(xA; yA) un point de la droite, alors Dadmet comme système d’équations paramétriques :
x = xA − bty = xB + at
; t ∈ R
et on peut retrouver c ainsi :c = −(axA + bya)
On déduit ainsi une méthode général pour passer d’un mode de représentation d’une droite donnée àl’autre.
6.5.1 Intersections
Proposition 6.79. Soient D et D′ deux droites du plan. Alors exactement une des propositionssuivantes est vraie :• soit D = D′ et alors D ∩D′ = D (les deux droites sont confondues)• soit D ∩D′ est réduit à un point (les deux droites sont sécantes)• soit D ∩D′ = ø (les deux droites sont parallèles)
Exercice 6.20. Déterminer l’intersection des deux droites de l’exercice précédent (exercice 6.19).
6.5.2 Médiatrice
Définition 6.80. Soit A, B deux points distincts du plan. La médiatrice du segment [AB] est le lieugéométrique des points du plan équidistants de A et B.
Proposition 6.81. Soit A et B deux points distincts du plan. La médiatrice du segment [AB] est ladroite passant par le milieu du segment [AB] et perpendiculaire à la droite (AB).
Exercice 6.21. Soit A(xA; yA) et B(xB ; yB) deux points distincts du plan muni d’un repère orthonormé.Déterminer une équation cartésienne de la médiatrice du segment [AB].
6.5.3 Projeté orthogonal et distance à une droite
Définition 6.82. Un vecteur est dit normal à une droite s’il est orthogonal à un vecteur directeur dela droite.
Soit ax + by + c = 0 une équation d’une droite D, on rappelle que le vecteur −→u(−ba
)est un vecteur
directeur de la droite D.
142

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 6.83. Dans le plan muni d’un repère orthonormé direct.• Soit a, b et c trois réels avec a ou b non nul. La droite d’équation ax+ by+ c = 0 a pour vecteur
normal−→n(a
b
).
• Réciproquement, soit a, b deux nombres réels non tous deux nuls, toute droite de vecteur normal−→n
(a
b
)admet une équation de la forme ax+ by + c = 0 où c est un nombre réel fixé.
Exercice 6.22. Soit A, B et C trois points deux à deux distincts. Notons H le projeté orthogonal de Asur la droite (BC). Montrer que pour tout point M de la droite (BC), on a AM ≥ AH (la distance deA à M est supérieure de celle à H).
Définition 6.84. Soit D une droite et A un point du plan. La distance entre A et D est le nombre
d(A,D) = infAM ; M ∈ D
Remarque. La définition précédente se généralise à un lieu géométrique E autre qu’une droite :
d(A, E) = infAM ; M ∈ E
Proposition 6.85. Soit H le projeté orthogonal de A sur la droite D, alors d(A,D) = AH.
H
A
D
d(A,D) = AH
Exercice 6.23. Calculer la distance du point M(1; 2) à la droite passant par B(−1;−3) et C(5; 0).
Théorème 6.86. Dans le plan muni d’un repère orthonormé direct, soit D une droite d’équationcartésienne ax+ by + c = 0 et A(xA; yA) un point du plan, alors
d(A,D) = |axA + byA + c|√a2 + b2
Démonstration. Soit M(x; y) un point de la droite et −→n
(a
b
)normal à la droite D. Notons que ax + by = −c,
d’où
|−−→AM · −→n | = |a(x− xA) + b(y − yA)| = | − c− axA − byA| = |axA + byA + c|
D’autre part, par hypothèse sur H, le triangle AMH est rectangle en H et ainsi le point H est aussi le projetéorthogonal de M sur la droite passant par A et de vecteur directeur −→n , d’où :
|−−→AM · −→n | = AH × ||−→n || = AH ×
√a2 + b2
D’où, l’on déduit qued(A,D) = AH = |axA + byA + c|√
a2 + b2
143

TSI 1 Lycée Heinrich-Nessel 2016/2017
Méthode. Pour calculer la distance d’un point A à une droite D, il faut :1) Déterminer un vecteur directeur −→u de D
2) Chercher les coordonnées d’un point M ∈ D tel que −−→AM · −→u = 0
3) Calculer d(A;M) = ‖−−→AM‖.ou bien utiliser la formule précédente.
6.6 Cercles
Définition 6.87. Soit A un point du plan et r > 0 un nombre. Le cercle de centre A et de rayon rest le lieu géométrique des points M à distance r de A (c’est-à-dire tels que AM = r).
Proposition 6.88. Soit C le cercle de centre A(a; b) et de rayon r.Un point M(x; y) appartient au cercle C si et seulement si
(x− a)2 + (y − b)2 = r2
On dit que (x− a)2 + (y − b)2 = r2 est une équation cartésienne du cercle C.
Exercice 6.24. 1) Déterminer une équation cartésienne du cercle centré en A(4, 2) et de rayon 3.2) Montrer que l’équation suivant décrit un cercle dont on déterminera le centre et le rayon : x2 +y2−
2x− 3y + 8 = 0.3) Que peut-on dire du lieu géométrique des points M(x; y) tel que x2 + y2 − 2x− 3y + 10 = 0 ?
Remarque. Si on développe les carrées dans l’équation cartésienne d’un cercle, l’équation se réécrit sousla forme suivante :
x2 + y2 + αx+ βy + γ = 0
Par contre, comme on vient de le voir dans l’exercice précédent, une telle équation ne décrit pas néces-sairement un cercle.
Proposition 6.89. Soit [AB] un diamètre d’un cercle C. Un point M appartient au cercle C si etseulement si AMB est rectangle en M .
Proposition 6.90. Un pointM appartient au cercle de diamètre [AB] si et seulement si−−→MA·−−→MB = 0.
Exercice 6.25. Soit A(−1; 5) et B(4; 1). Déterminer une équation cartésienne du cercle de diamètre[AB].
Proposition 6.91 (représentation paramétrique). Un point M(x; y) appartient au cercle de centreA(a; b) et de rayon r si et seulement si :
x = a+ r cos(t)y = b+ r sin(t)
6.7 Transformations affines du plan
Définition 6.92. Une transformation du plan est une application qui à tout point du plan associeun point du plan.
144

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemple. L’application identité, notée id, est une transformation géométrique qui associe à tout point cemême point.
Définition 6.93. On dit qu’un point M est un point fixe d’une application τ si le point M et sonimage M ′ sont confondu (i.e : τ(M) = M).
6.7.1 Translations
Revenons sur les translations. Soient A et A′ deux points du plan. On rappelle que la translation de Avers A′ est l’unique transformation τ du plan qui envoie tout point M sur un point, noté M ′, tel queAMM ′A′ soit un parallélogramme (éventuellement aplati). À l’aide de la notion de vecteur, on peutreformuler la définition ainsi :
Définition 6.94. Soit −→u un vecteur. La translation de vecteur −→u est l’application qui à tout pointM associe le point M ′ tel que
−−−→MM ′ = −→u .
Remarque. Si −→u = −→0 , alors la translation de vecteur −→u est l’application identité.
M
M ′
−→u
Proposition 6.95. Soit −→u =(ux
uy
)un vecteur du plan. Alors la translation de vecteur −→u associe
au point M(x; y) le point M ′(x + ux ; y + uy).
Proposition 6.96. Soit −→u un vecteur non nul. Alors la translation de vecteur −→u n’admet aucunpoint fixe.
Proposition 6.97. Soient −→u et −→v deux vecteurs. Alors la composition de la translation de vecteur−→u et de la translation de vecteur −→v est la translation de vecteur −→u +−→v .
Corollaire 6.98. Soit −→u un vecteur. Alors la composition de la translation de vecteur −→u et de latranslation de vecteur −−→u est l’identité.
Corollaire 6.99. Soit −→u un vecteur. La translation de vecteur −→u est une bijection de réciproque latranslation de vecteur −−→u .
Exercice 6.26. Soient A et B deux points. Soit −→u un vecteur. On note A′ l’image de A par la translationde vecteur −→u et B′ l’image de B par la translation de vecteur −→u . Montrer que −−→AB =
−−−→A′B′.
En déduire que si C un troisième point et si C ′ est l’image de C par la translation de vecteur −→u , alors−−→AB ·
−→AC =
−−−→A′B′ ·
−−→A′C ′, (−−→AB;−→AC) = (
−−−→A′B′;
−−→A′C ′) et ‖−−→AB‖ = ‖
−−−→A′B′‖.
Remarque. Cette dernière identité, nous dit que la distance entre deux point est conservée par unetranslation. Une telle application qui vérifie AB = A′B′ pour tout les couples de point est appelée uneisométrie.
6.7.2 Homothéties
145

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 6.100. Soit k ∈ R. Soit A un point. L’homothétie de centre A et de rapport k est latransformation qui à tout point M associe le point M ′ tel que
−−→AM ′ = k
−−→AM .
Remarque. Une homothétie de rapport 1 est l’application identité.
A M M ′
N
N ′
Proposition 6.101. Soit k ∈ R. Soit A(a; b) un point du plan. L’homothétie de centre A et de rapportk associe au point M(x; y) le point M ′(a + k(x − a); b + k(y − b)).
Proposition 6.102. Soit k ∈ R différent de 1. Soit A un point. Alors l’homothétie de centre A et derapport k a exactement un point fixe, son centre A.
Proposition 6.103. Soient k et k′ deux nombres réels. Soit A un point. Alors la composition d’unehomothétie de centre A et de rapport k et d’une homothétie de centre A et de rapport k′ est unehomothétie de centre A et de rapport kk′.
Corollaire 6.104. Soit k un nombre réel non nul. Soit A un point. Alors la composition de l’homothétiede centre A et de rapport k et de l’homothétie de centre A et de rapport 1
k est l’application identité.
Corollaire 6.105. Soit k un nombre réel non nul. Soit A un point. Alors l’homothétie de centre A et derapport k est une bijection de réciproque l’homothétie de centre A et de rapport 1
k
Exercice 6.27. Soit k un nombre réel non nul. Soit A un point. Notons hA;k l’homothétie de centre Aet de rapport k. Soient B, C et D trois points. On pose B′ = hA;k(B), C ′ = hA;k(C) et D′ = hA;k(D).Exprimer
−−−→B′C ′ en fonction de −−→BC. A-t-on ‖−−→BC‖ = ‖
−−−→B′C ′‖ ? −−→BC · −−→BD =
−−−→B′C ′ ·
−−−→B′D′ ? (−−→BC;−−→BD) =
(−−−→B′C ′;
−−−→B′D′) ?
6.7.3 Symétrie centrale
Définition 6.106. Soit A un point. La symétrie de centre A est l’homothétie de centre A et derapport −1 : elle associe au point M le point M ′ tel que
−−→AM ′ = −−−→AM .
Remarque. Si M ′ est l’image de M par la symétrie de centre A, alors A est le milieu de [MM ′].
A MM ′
N
N ′
Proposition 6.107. Soit A(a; b) un point du plan. Alors la symétrie de centre A associe au pointM(x; y) le point M ′(2a − x; 2b − y).
146

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 6.108. Soit A un point. Alors la symétrie de centre A possède exactement un pointfixe, son centre A.
Proposition 6.109. Soit A un point. Alors la composition de la symétrie de centre A avec elle-mêmeest l’application identité.
Corollaire 6.110. Soit A un point. Alors la symétrie de centre A est une bijection et est sa propreréciproque.
Exercice 6.28. SoitA un point. Notons sA la symétrie de centreA. SoientB, C etD trois points. On poseB′ = sA(B), C ′ = sA(C) et D′ = sA(D). Exprimer
−−−→B′C ′ en fonction de −−→BC. A-t-on ‖−−→BC‖ = ‖
−−−→B′C ′‖ ?
−−→BC ·
−−→BD =
−−−→B′C ′ ·
−−−→B′D′ ? (−−→BC;−−→BD) = (
−−−→B′C ′;
−−−→B′D′) ?
6.7.4 Réflexions du plan
Définition 6.111. Soit D une droite du plan. La réflexion par rapport à la droite D est la transfor-mation du plan qui à tout point M associe le point M ′, symétrique (orthogonale) de M par rapportà la droite D.
Remarque. Si M ′ est l’image de M par la réflexion d’axe D et si H est le projeté orthogonal de M surD, alors H est le milieu de [MM ′].
D
M ′
M
Proposition 6.112.1) Soit D la droite d’équation y = 0. Alors la réflexion d’axe D associe àM(x; y) le point M ′(x;−y).2) Soit D la droite d’équation x = 0. Alors la réflexion d’axe D associe àM(x; y) le point M ′(−x; y).
Proposition 6.113. Soit D une droite du plan. Alors tout point de D est un point fixe pour laréflexion d’axe D.
Proposition 6.114. Soit D une droite du plan. Alors la composition de la réflexion d’axe D avecelle-même est l’application identité.
Corollaire 6.115. Soit D une droite du plan. Alors la réflexion d’axe D est une bijection et est sapropre réciproque.
Exercice 6.29. Soit D une droite. Notons r la réflexion d’axe D. Soient B, C et D trois points. On poseB′ = r(B), C ′ = r(C) et D′ = r(D). Exprimer
−−−→B′C ′ à l’aide des points B, C et des projetés orthogonaux
de B et C sur D. A-t-on ‖−−→BC‖ = ‖−−−→B′C ′‖ ? −−→BC · −−→BD =
−−−→B′C ′ ·
−−−→B′D′ ? (−−→BC;−−→BD) = (
−−−→B′C ′;
−−−→B′D′) ?
Remarque. Une réflexion est une isométrie.
147

TSI 1 Lycée Heinrich-Nessel 2016/2017
6.7.5 Rotations du plan
Définition 6.116. Soit A un point du plan.Soit θ ∈ R. La rotation de centre A et d’angleθ est la transformation du plan qui à tout pointM associe le point M ′ tel que AM = AM ′ et(−−→AM ;
−−→AM ′) ≡ θ modulo (2π).
M
M ′
θ
A
Remarque. La rotation de centre A et d’angle 0 est l’application identité.
On se donne (O;−→ı ;−→ ) un repère orthonormé direct du plan P et on considère la rotation de centreA(a; b) et d’angle θ. Soit M(x; y) un point du plan P et M ′(x′; y′) son image par la rotation. Notons φune mesure de l’angle (−→ı ;−−→AM), ainsi les coordonnées de −−→AM sont(
x− ay − b
)=(AM cos(φ)AM sin(φ)
)
D’après la relation de Chasles sur les angles :
(−→ı ;−−→AM ′) ≡ (−→ı ;−−→AM) + (−−→AM ;
−−→AM ′) ≡ φ+ θ [2π]
D’où, les coordonnées du vecteur−−→AM ′ sont(
AM ′ cos(φ+ θ)AM ′ sin(φ+ θ)
)=
(AM(cos(φ) cos(θ)− sin(φ) sin(θ))AM(cos(φ) sin(θ) + sin(φ) cos(θ))
)=
((AM cos(φ)) cos(θ)− (AM sin(φ)) sin(θ)(AM cos(φ)) sin(θ) + (AM sin(φ)) cos(θ)
)
=
((x− a) cos(θ)− (y − b) sin(θ)(x− a) sin(θ) + (y − b) cos(θ)
)
De la relation de Chasles, on déduit que les coordonnées de−−−→OM ′ = −→OA+
−−→AM ′ sont(
a
b
)+(
(x− a) cos(θ)− (y − b) sin(θ)(x− a) sin(θ) + (y − b) cos(θ)
)=(a+ (x− a) cos(θ)− (y − b) sin(θ)b+ (x− a) sin(θ) + (y − b) cos(θ)
)
et les coordonnées de M ′ dans le repère (O;−→ı ;−→ ) sont par définition égales à celles de−−−→OM ′ dans la base
(−→ı ;−→ ), d’où :
Proposition 6.117. Soit A(a; b) un point du plan muni d’un repère orthonormé direct. Soit θ ∈ R.Alors la rotation de centre A et d’angle θ associe à M(x; y) le point
M ′(a + (x − a) cos(θ)− (y − b) sin(θ); b + (x − a) sin(θ) + (y − b) cos(θ))
Proposition 6.118. Soit A un point du plan. Soit θ ∈ R. On suppose θ 6≡ 0 modulo [2π]. Alors larotation de centre A et d’angle θ admet exactement un point fixe, son centre A.
Proposition 6.119. Soit A un point du plan. Soient θ et φ deux nombres réels. Alors la compositionde la rotation de centre A et d’angle θ et de la rotation de centre A et d’angle φ est la rotation decentre A et d’angle θ + φ.
Corollaire 6.120. Soit A un point du plan. Soit θ ∈ R. Alors la composition de la rotation de centre Aet d’angle θ et de la rotation de centre A et d’angle −θ est l’application identité.
Corollaire 6.121. Soit A un point du plan. Soit θ ∈ R. Alors la rotation de centre A et d’angle θ estune bijection et sa réciproque est la rotation de centre A et d’angle −θ.
148

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 6.30. Soit A un point du plan. Soit θ ∈ R. Notons R la rotation de centre A et d’angle θ.Soient B, C et D trois points. Notons B′ = R(B), C ′ = R(C) et D′ = R(D). A-t-on ‖−−→BC‖ = ‖
−−−→B′C ′‖ ?
−−→BC ·
−−→BD =
−−−→B′C ′ ·
−−−→B′D′ ? (−−→BC;−−→BD) = (
−−−→B′C ′;
−−−→B′D′) ?
Remarque. Une rotation est une isométrie.
149

TSI 1 Lycée Heinrich-Nessel 2016/2017
150

Chapitre 7
Fonctions circulaires, complexes etintégration
Programme
• Étude des fonctions circulaires directes et réciproques : sin, cos, tan, arcsin, arccos, arctan.• Dérivée et variations, graphes de ses fonctions• Dérivation de t 7→ exp(φ(t)) avec φ à valeurs dans C.• Primitive sur un intervalle• Reconnaître des expressions du type u′
u , u′ un, u′
un , u′ (v′ u)
7.1 Fonctions circulaires
Soit α un nombre réel et M le point sur le cercletrigonométrique associé à α.Le cosinus du nombre réel α est l’abscisse dupoint M ; cette valeur se note cos(α).Le sinus du nombre réel α est l’ordonnée dupoint M ; cette valeur se note sin(α). x
y
O−1 1
−1
1
cos(α)
αsin(α)
1
On associe les fonctions cos : x 7→ cos(x) et sin : x 7→ sin(x) définies sur R.
Pour tout nombre réel x, on a1) cos2(x) + sin2(x) = 1 ;2) −1 ≤ cos(x) ≤ 1 et −1 ≤ sin(x) ≤ 1.3) cos(−x) = cos(x) et sin(−x) = − sin(x).4) cos(x+ 2kπ) = cos(x) et sin(x+ 2kπ) = sin(x)
Théorème 7.1.1) La fonction cosinus est paire, 2π-périodique, bornée.2) La fonction sinus est impaire, 2π-périodique, bornée.
151
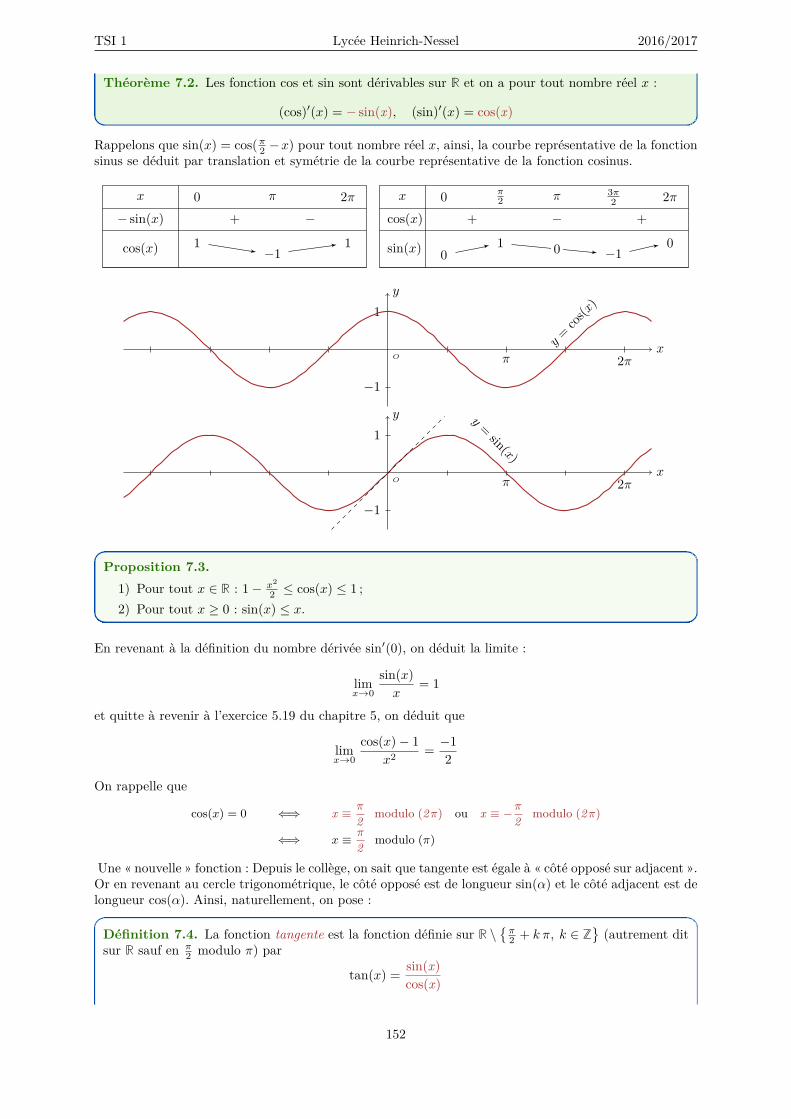
TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 7.2. Les fonction cos et sin sont dérivables sur R et on a pour tout nombre réel x :
(cos)′(x) = − sin(x), (sin)′(x) = cos(x)
Rappelons que sin(x) = cos(π2 −x) pour tout nombre réel x, ainsi, la courbe représentative de la fonctionsinus se déduit par translation et symétrie de la courbe représentative de la fonction cosinus.
x
− sin(x)
cos(x)
0 π 2π+ −
11−1−1
11
x
cos(x)
sin(x)
0 π2 π 3π
2 2π+ − +
0011
−1−1000
x
y
O
y=
cos(x)
π 2π
−1
1
x
y
O
y =sin(x)
π 2π
−1
1
Proposition 7.3.1) Pour tout x ∈ R : 1− x2
2 ≤ cos(x) ≤ 1 ;2) Pour tout x ≥ 0 : sin(x) ≤ x.
En revenant à la définition du nombre dérivée sin′(0), on déduit la limite :
limx→0
sin(x)x
= 1
et quitte à revenir à l’exercice 5.19 du chapitre 5, on déduit que
limx→0
cos(x)− 1x2 = −1
2
On rappelle que
cos(x) = 0 ⇐⇒ x ≡ π
2 modulo (2π) ou x ≡ −π2 modulo (2π)
⇐⇒ x ≡ π
2 modulo (π)
Une « nouvelle » fonction : Depuis le collège, on sait que tangente est égale à « côté opposé sur adjacent ».Or en revenant au cercle trigonométrique, le côté opposé est de longueur sin(α) et le côté adjacent est delongueur cos(α). Ainsi, naturellement, on pose :
Définition 7.4. La fonction tangente est la fonction définie sur R \π2 + k π, k ∈ Z
(autrement dit
sur R sauf en π2 modulo π) par
tan(x) = sin(x)cos(x)
152

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 7.1. Déterminer la dérivée de la fonction tangente et dresser son tableau de variations.
Proposition 7.5. La fonction tangente :1) est π-périodique.2) admet une famille d’asymptotes verticales x = (2k + 1)π2 , où k ∈ Z.3) est dérivable et pour tout x 6≡ π
2 modulo (2π) :
tan′(x) = 1 + tan(x)2 = 1cos(x)2
4) est strictement croissante sur chaque intervalle](2k − 1)π2 ; (2k + 1)π2
[, où k ∈ Z.
5) s’annule en tous les points d’abscisses kπ, où k ∈ Z.
x
1 + tan2(x)
tan(x)
−π2 0 π2
+
−∞−∞+∞+∞0
O−π2
π2
π
Proposition 7.6. Pour tout 0 ≤ x < π2 ,
x ≤ tan(x)
7.2 Les fonctions circulaires réciproques
Théorème 7.7.1) La fonction cosinus réalise une bijection de [0;π] sur [−1; 1].2) La fonction sinus réalise une bijection de
[−π2 ; π2
]sur [−1; 1].
3) La fonction tangente réalise une bijection de]−π2 ; π2
[sur R.
Définition 7.8. On appelle :1) arccos la fonction réciproque de cos : [0;π]→ [−1; 1]. Ainsi,
arccos : [−1; 1]→ [0;π]
153

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) arcsin la fonction réciproque de sin :[−π2 ; π2
]→ [−1; 1]. Ainsi,
arcsin : [−1; 1]→[−π2 ; π2
]3) arctan la fonction réciproque de tan :
]−π2 ; π2
[→ R. Ainsi,
arctan : R→]−π2 ; π2
[
Proposition 7.9 (admis).
limx→−∞
arctan(x) = −π2 et limx→+∞
arctan(x) = π
2
Exercice 7.2. Montrer que pour tout x ∈ [−1; 1], sin(arccos(x)) = cos(arcsin(x)) =√
1− x2.Exercice 7.3. À l’aide des propositions 5.26 et 5.55 sur les fonctions inverses, tracer les courbes repré-sentatives des fonctions arc cosinus, arc sinus et arc tangente ainsi que leurs dérivées.
Proposition 7.10.1) Les fonctions circulaires réciproques arccos et arcsin sont dérivables sur ]− 1; 1[ et on a
arccos′(x) = − 1√1 − x2
et arcsin′(x) = 1√1 − x2
2) La fonction arctan est dérivable sur R et on a
arctan′(x) = 11 + x2
Exercice 7.4.
1) Calculer I =∫ 1
2
0
dx√1− x2
.
2) Calculer la dérivée de x 7→ x√
1− x2 et en déduire J =∫ 1
2
0
√1− x2 dx.
Une primitive de x 7→√
1− x2 est x 7→ 12
(x√
1− x2 + arcsin(x)). Ainsi,J = π
12 +√
38 .
3) De même, calculer K =∫ 1
2
0
x2 dx√1− x2
.
Une primitive de x 7→ x2√1−x2
est 12
(− x√
1− x2 + arcsin(x))et K = π
12 −√
38 .
Remarque. Comme nous l’avions déjà évoqué dans le chapitre 5 sur l’étude de fonctions, d’après lethéorème de Cauchy qu’on verra dans le chapitre équations différentielles. On a le résultat suivant :
Proposition 7.11. Soit I un intervalle, f, g : I → R deux fonctions dérivables sur I. Si f ′ = g′ sur Iet il existe x0 ∈ I tel que f(x0) = g(x0) alors f = g.
Proposition 7.12.1) Pour tout x ∈ [−1; 1], on a arccos(x) + arcsin(x) = π
2
2) Pour tout x > 0, on a arctan(x) + arctan( 1x
)= π
2 .3) Pour tout x < 0, on a arctan(x) + arctan
( 1x
)= −π2 .
Exercice 7.5. Démontrer que f : x 7→ arccos(
1−x2
1+x2
)est définie sur R puis que pour tout x ≥ 0,
f(x) = 2 arctan(x). Que dire pour x < 0 ?
La fonction arctan est très utile pour déterminer un argument d’un nombre complexe non nul :
154

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 7.13. Soit z = x+ iy un nombre complexe non nul. Alors :
arg(z) =
arctan
(yx
)si x > 0
π + arctan(yx
)si x < 0
π2 si x = 0 et y > 0−π2 si x = 0 et y < 0
Remarque. Pour calculer cos (arctan(x)) et sin (arctan(x)), on utilise les deux équations suivantes :
cos (arctan(x))2 + sin (arctan(x))2 = 1 et sin (arctan(x))cos (arctan(x)) = x
Puis on résout ce système à deux inconnues.
Fonction arccosinus : x 7→ arccos(x).Domaine de définition [−1; 1].Dérivée sur ]− 1; 1[ x 7→ − 1√
1−x2 .Primitive x 7→ x arccos(x)−
√1− x2.
x−1√1−x2
arccos(x)
−1 0 1−
ππ00
π2
O
π2
π
−1 1
Tangente en x = 0 : y = −x+ π2 .
Fonction arcsinus : x 7→ arcsin(x).Domaine de définition [−1; 1].Dérivée sur ]− 1; 1[ x 7→ 1√
1−x2 .Primitive x 7→ x arcsin(x) +
√1− x2.
x1√
1−x2
arcsin(x)
−1 0 1+
−π2−π2
π2π20
O
−π2
π2
−1 1
Tangente en x = 0 : y = x.
Fonction arctangente : x 7→ arctan(x).Domaine de définition R.Impaire.Dérivée x 7→ 1
1+x2 . Primitive x 7→ x arctan(x) −ln(√
1 + x2).
x
11+x2
arctan(x)
−∞ 0 ∞
+
−π2−π2
π2π20
155

TSI 1 Lycée Heinrich-Nessel 2016/2017
O
−π2
π2
−1 1
Tangente en x = 0 : y = x.Inégalité de convexité : arctan(x) ≤ x pour x ≥ 0.
7.3 Fonctions à valeurs dans C
L’ensemble des nombres complexes C étant une extension de l’ensemble des nombres réels R possédant lesmêmes propriétés sur les opérations entre les nombres. Il est naturel de considérer des fonctions f : D → Cà valeurs dans C.
Définition 7.14. Une fonction complexe d’une variable réelle est une application d’une partie nonvide de R à valeurs dans C.
Exemples. 1) f1 : x 7→ ix définie sur R.2) f3 : x 7→ (1 + i)x définie sur R.3) f2 : x 7→ x+ ix2 définie sur R.4) f4 : t 7→ ei t définie sur R.5)
f5(t) =
t si 0 ≤ t ≤ 11 + (t− 1)i si 1 ≤ t ≤ 2(3− t) + i si 2 ≤ t ≤ 3(4− t)i si 3 ≤ t ≤ 4
définie sur [0; 4].
Exercice 7.6. Pour chacune des fonctions précédentes, décrire l’ensemble image des points M d’affixefi(x) où x parcourt l’ensemble de définition de fi.
Proposition 7.15. Se donner une fonction f : D → C équivaut à se donner deux fonctions réellesa, b : D → R en posant f(x) = a(x) + b(x) i pour tout x ∈ D.De plus les fonctions a = Re(f) et b = Im(f) sont uniquement déterminées.
Définition 7.16. On dit que f : I → C est dérivable (resp. intégrable) sur I si et seulement sia = Re(f) et b = Im(f) le sont sur I et alors :
∀t ∈ I : f ′(t) = a′(t) + b′(t)i et∫I
f(t) dt =∫I
a(t) dt+ i∫I
b(t) dt
Remarque. L’étude d’une fonction à valeurs complexes revient essentiellement à l’étude de deux fonctionsréelles.
Exercice 7.7.1) Soit f : t 7→ 1
t−i . Préciser le domaine de définition de f et déterminer sa dérivée.2) Même question pour g : t 7→ at où a ∈ C.
156

TSI 1 Lycée Heinrich-Nessel 2016/2017
On a utilisé la notation algébrique des nombres complexes, on peut aussi définir une fonction complexeà l’aide de la notation exponentielle : Soit φ : D → R et r : D → R, on associe f : D → C définie par
f(t) = r(t) eiφ(t)
pour tout t ∈ D.
Exercice 7.8. Soit f : t 7→ eit définie sur R.1) Déterminer sa fonction partie réelle et partie imginaire à l’aide de fonctions de références.2) En déduire f ′(t) en fonction de eit pour tout t ∈ R.3) Dans le plan complexe, représenter l’ensemble image de f .4) Soit M le point d’affixe e iπ
3 et −→v le vecteur d’affixe f ′(π3 ). Placer le point M et représenter en Mle vecteur −→v .
5) Déterminer une mesure de l’angle (−−→OM, −→v ) et |−→v |.6) Interpréter la figure.
Exercice 7.9. ?
Soit f, g : I → C deux fonctions dérivables sur I. Montrer que f × g : t 7→ f(t) g(t) est une fonctioncomplexe dérivable sur I et (f × g)′ = f ′ × g + f × g′.Si f = a+ ib et g = α+ iβ alors
f × g = (aα− bβ) + i(aβ + bα)est une fonction dérivable car le produit de fonctions réelles dérivables est dérivable. De plus,
(f × g)′ = (aα′ + a′α− b′β − bβ′) + i(a′β + aβ′ + b′α+ bα′)f ′ × g + f × g′ = (a′ + ib′)(α+ iβ) + (a+ ib)(α′ + iβ′)
= (f × g)′
Soit θ : I → R une fonction dérivable sur I, posons f : t 7→ eiθ(t) pour tout t ∈ I. Montrer que
∀t ∈ I : f ′(t) = θ′(t) i eiθ(t)
Soit t ∈ I, alors f(t) = cos(θ(t) + i sin(θ(t)). Comme les fonctions circulaires sont dérivables sur R et θ sur I, ondéduit que f est dérivable sur I. De plus, pour tout t ∈ I, on a
f ′(t) = −θ′(t) sin(θ(t)) + iθ′(t) cos(θ(t)) = iθ′(t)(i sin(θ(t)) + cos(θ(t))
= iθ′(t)eiθ(t)
Proposition 7.17. Soit φ : I → C une fonction complexe dérivable sur I, posons f : t 7→ eφ(t) pourtout t ∈ I. Alors,
∀t ∈ I : f ′(t) = φ′(t) eφ(t)
Démonstration. Posons a = Re(φ) et b = Im(φ), alors pour tout t ∈ I, on a
φ(t) = a(t) + ib(t) et f(t) = ea(t)+ib(t) = ea(t) × eib(t)
Ainsi, d’après l’exercice précédent, on déduit que f est dérivable sur I et que pour tout t ∈ I, on a
f ′(t) = (ea(t))′ × eib(t) + ea(t) × (eib(t))′
= a′(t)ea(t)+ib(t) + ea(t)ib′(t)eib(t)
= (a′(t) + ib′(t))ea(t)+ib(t)
= φ′(t)eiφ(t)
157

TSI 1 Lycée Heinrich-Nessel 2016/2017
Remarque. On admettra que les règles de dérivations et d’intégrations vues pour les fonctions réellesrestent vraies pour les fonctions complexes.Par contre, comme on ne peut pas comparer deux complexes, la comparaison f ≤ g n’a non plus pas desens pour des fonctions complexes. En particulier, on ne fera pas de tableau de variations de fonctionscomplexes.
Exercice 7.10.1) Soit a ∈ C∗. Déterminer la dérivée et une primitive de t 7→ eat.2) Soit f : t 7→ cos(t)et.
a) Démontrer que f est la partie réelle de eat où a est un nombre complexe à déterminer.b) En déduire une primitive de f .
3) Calculer les deux intégrales ci-dessous :
A =∫ π
0cos(2t)et dt et B =
∫ 2π
0
sin(t)et
dt.
7.4 Intégration
7.4.1 Intégrale d’une fonction positive
On dit qu’une fonction f est positive sur un intervalle si, pour tout x de l’intervalle f(x) est positif :f(x) ≥ 0.
Définition 7.18. Soit f une fonction définie sur l’intervalle [a; b], continue et positive sur [a; b].
On appelle intégrale de la fonction f sur [a; b] la mesure de l’aire du domaine du plan délimitépar la courbe représentative C de f , l’axe des abscisses et les droites verticales d’équation x = a etx = b.
Ce nombre est noté∫ baf(x) dx.
x
y
I
J
Oa b
Cf
Aire =∫ baf(x) dx
L’aire du domaine en rouge s’appelle aussi « aire sous la courbe ».
Remarque.• Le domaine en rouge qui permet de définir l’intégrale peut aussi être définie comme étant le lieugéométrique des points M(x; y) tels que
a ≤ x ≤ b et 0 ≤ y ≤ f(x)
• Le nombre∫ baf(x) dx se lit « intégrale de a à b de f(x) dx ».
• Les réels a et b sont appelés les bornes de l’intégrale.• Dans l’expression d’une intégrale, le terme x est appelé variable muette.
On peut aussi remplacer x par d’autres expressions, par exemple∫ bax2 dx =
∫ bat2 dt.
L’aire d’un rectangle étant simple à calculer, on a la propriété suivante :
158

TSI 1 Lycée Heinrich-Nessel 2016/2017
Propriété 7.19 (Intégrale d’une fonction constante). Soit k ≥ 0 et f : [a; b]→ R la fonction constantedéfinie par f(x) = k pour tout x dans l’intervalle [a; b]. Alors∫ b
a
f(x) dx =∫ b
a
k dx = (b− a)× k
x
y
I
J
O a b
kAire =
∫ bak dx = (b− a)× k
Si l’on juxtapose plusieurs rectangles, on peut réussir à approximer l’aire sous une courbe. Par exemple,soit f : R → R, la fonction carrée, définie par f(x) = x2 et cherchons à approximer l’intégrale de f surl’intervalle [1; 2] :
I =∫ 2
1x2 dx
On fixe ε = 0.1 et on découpe l’intervalle [1; 2] en intervalles réguliers de longueur ε et on trace lesrectangles de hauteur maximale partant de l’axe des abscisses jusqu’à la courbe représentative de lafonction f comme sur la figure ci-dessous.
Cf
x
y
O 0.5 1 1.5 2
0.5
1
1.5
2
2.5
3
3.5
4
1.01.1
1.21.3
1.41.5
1.6
1.7
1.8
1.9
ε
On observe que la somme S des aires des rectangles en bleu est inférieure ou égale à l’intégrale I =∫ 21 x
2 dx. De plus, comme l’aire de la partie en rouge, qui fait défaut, est petit, la précédente somme Sconstitue une approximation de I.Dans le tableau suivant, on calcul la somme des aires des rectangles en bleu.
159

TSI 1 Lycée Heinrich-Nessel 2016/2017
rectangle N x 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 Totalhauteur = x2 1.0 1.21 1.44 1.69 1.96 2.25 2.56 2.89 3.24 3.61
aire = hauteur ×ε 0.1 0.121 0.144 0.169 0.196 0.225 0.256 0.289 0.324 0.361 2.185
D’où,∫ 2
1 x2 dx ' 2.185.
On notera que plus on veut une approximation précise de l’intégrale∫ baf(x) dx, plus on doit choisir un
découpage en intervalles de taille ε avec ε d’autant plus petit.
Remarque. Le procédé qu’on vient d’évoquer dans l’exemple précédent a été utilisé par Bernard Riemanndans « über die Darstellbarkeit einer Funktion durch eine trigonometrische Reihe » en 1854 pour définirrigoureusement l’intégrale d’une fonction continue sur un intervalle. D’ailleurs, en sa mémoire, on parleaussi d’intégrale de Riemann pour la notion d’intégrale que nous étudions dans ce chapitre.
Nous n’allons pas approfondir d’avantage sur la notion d’intégrale (ce sera l’objet d’un chapitre au secondsemestre) et dans les sections suivantes, nous allons nous concentrer sur les propriétés et les techniquesde calcul des intégrales.
7.4.2 Propriétés de l’intégrale de fonctions continues quelconques
Propriété 7.20 (positivité de l’intégrale). Soit f : [a; b] → R une fonction continue et positive sur[a; b], alors l’intégrale
∫ baf(x) dx est aussi positive.
Lorsque la courbe représentative d’une fonction f est en dessous d’une courbe représentative d’une autrefonction g sur un intervalle [a; b] alors l’intégrale de f est inférieure à l’intégrale de g sur [a; b].
Cf
Cg
x
y
O a b
∫ baf(x) dx ≤
∫ bag(x) dx
Propriété 7.21. Soit f et g deux fonctions définies sur un intervalle [a; b] continues et positives tellesque f ≤ g (c’est-à-dire telles que f(x) ≤ g(x) pour tout x dans l’intervalle [a; b]), alors :∫ b
a
f(x) dx ≤∫ b
a
g(x) dx.
Remarque. Formellement, on a : f ≤ g ⇒∫f(x) dx ≤
∫g(x) dx.
Propriété 7.22 (relation de Chasles). Soit f : [a; b] → R continue et positive. Soit c un nombre del’inervalle [a; b], alors
160

TSI 1 Lycée Heinrich-Nessel 2016/2017
Cf
x
y
O a c b
∫ caf(x) dx
∫ bcf(x) dx
∫ baf(x) dx
∫ c
a
f(x) dx+∫ b
c
f(x) dx =∫ b
a
f(x) dx
Théorème 7.23. Soit f : [a; b] → R une fonction continue et positive. On associe la fonction F :[a; b]→ R définie par
F (x) =∫ x
a
f(t) dt.
La fonction F est dérivable sur l’intervalle [a; b] et sa fonction dérivée est la fonction f :
F ′(x) = f(x)
pour tout x ∈ [a; b].
Remarque.• On notera que dans l’écriture F (x) =
∫ xaf(t) dt, la variable t est une variable muette, utile unique-
ment pour le calcul de l’intégrale.• F (a) = 0.
En fait, d’après le théorème de Cauchy-Lipschitz 1, la fonction F est l’unique primitive de la fonctionf telle que F (a) = 0.
• Le théorème nous dit entre autre que toute fonction continue f admet une primitive F .• Néanmoins, toutes le primitives ne peuvent pas être exprimées à partir des fonctions usuelles. Parexemple, la fonction de Gauss f(x) = e−x
2 n’admet pas de primitive en terme de fonctions usuelles.
Définition 7.24. Soit f : I → R une fonction continue. On dit qu’une fonction F est une primitivede la fonction f si la dérivée de la fonction F est égale à la fonction f sur I :
F ′ = f
Comme conséquence du théorème, on a la propriété suivante.
Propriété 7.25. Soit f : I → R une fonction continue positive et a < b deux nombres de l’intervalleI.Soit F : I → R une primitive de la fonction f , alors∫ b
a
f(t) dt = F (b)− F (a)
Nous pouvons maintenant généraliser le définition de l’intégrale aux fonctions de signe quelconque (plusnécessairement positives).
1. Augustin Louis Cauchy (1789-1857) et Rudolf Lipschitz (1832-1903)
161

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 7.26. Soit f : I → R une fonction continue (quelconque), a, b deux nombres réels dansl’intervalle I et F une primitive de la fonction f .On appelle intégrale de a à b de la fonction f le nombre∫ b
a
f(t) dt = F (b)− F (a).
Remarque. D’après la propriété précédente, lorsque a < b et f > 0, la définition de l’intégrale coïncideavec celle donnée en terme d’aire sous la courbe en début de chapitre.
Notation : Pour faciliter les calculs dans la pratique, on utilise la notation suivante :
[F (t) ]ba = F (b)− F (a)
Propriété 7.27. Soit f, g : I → R, a, b deux nombres dans I et α, β des nombres réels quelconques.Alors
1)∫ abf(t) dt = −
∫ baf(t) dt ; (l’ordre des bornes compte !)
2)∫ ba
(αf(t) + βg(t)) dt = α∫ baf(t) dt+ β
∫ bag(t) dt ; (linéarité de l’intégrale)
3)∫ aaf(t) dt = 0 ;
4)∫ caf(x) dx+
∫ bcf(x) dx =
∫ baf(x) dx ; (relation de Chasles)
Si a ≤ b,
5) si f ≥ 0 alors∫ baf(t) dt ≥ 0 ; (positivité de l’intégrale)
6) si f ≤ g alors∫ baf(t) dt ≤
∫ bag(t) dt.
De même,
Définition 7.28. La valeur moyenne d’une fonction f définie sur l’intervalle [a; b] avec a 6= b,continue sur [a; b], est égale au nombre
µ = 1b− a
∫ b
a
f(t) dt
Propriété 7.29. Soit f : [a; b] → R continue avec a 6= b. Soit m un minorant et M un majorant dela fonction f , c’est-à-dire deux nombres tels que pour tout x dans l’intervalle [a; b], m ≤ f(x) ≤ M .Alors la valeur moyenne de la fonction f est comprise entre m et M :
m ≤ 1b− a
∫ b
a
f(x) dx ≤M
7.4.3 Primitives
Soit f : I → R une fonction continue. On rappelle qu’une fonction F est une primitive de la fonction fsi la dérivée de la fonction F est égale à la fonction f sur I :
F ′ = f
162

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemple. Soit f : R → R la fonction carrée, définie par f(x) = x2 pour tout réel x. Soit k un nombreréel, posons F : R→ R définie par F (x) = 1
3x3 + k pour tout réel x. Alors,
F ′(x) = 13 × 3x2 + 0 = x2 = f(x)
Ainsi, F est une primitive de la fonction carrée f et ceci quel que soit le nombre réel k !
Propriété 7.30. Soit f : I → R une fonction continue et soit F et G deux de ses primitives. Alors lafonction F −G est une fonction constante, de plus il existe un nombre réel k tel que G = F + k.
Remarque. Deux primitives d’une fonction f sur un intervalle I ne diffèrent que d’une constante k.
Donnons les primitives des fonctions de référence :
Propriété 7.31. Soit n un entier naturel. Soit k un nombre réel quelconque.
Intervalle de définition I Fonction : f(x) = Primitive F (x) =R 0 k
R 1 x+ k
R x 12 x
2 + k
R x2 13 x
3 + k
R xn 1n+1 x
n+1 + k
]0; +∞[ 1√x
2√x+ k
]−∞; 0[ ou ]0; +∞[ 1x ln(x) + k
]−∞; 0[ ou ]0; +∞[ 1x2 − 1
x + k
]−∞; 0[ ou ]0; +∞[ 1xn avec n ≥ 2 1
−n+1x−n+1 + k
R ex ex + k
R cos(x) sin(x) + k
R sin(x) − cos(x) + k
]− 1; 1[ −1√1−x2 arccos(x) + k
]− 1; 1[ 1√1−x2 arcsin(x) + k
R 11+x2 arctan(x) + k
Remarque. Le fait de « déterminer une primitive » est l’opération inverse de « dériver une fonction ».Ainsi, dans le tableau précédent, le passage de la troisième colonne à la seconde se fait en dérivant.
Exercice 7.11.1) Déterminer une primitive de x 7→
√x sur R∗+.
2) Dériver la fonction x 7→ x ln(x) et en déduire une primitive de la fonction logarithme népérien.
Propriété 7.32. Soit f, g, u, v : I → R quatre fonctions continues, α, β, k des nombres réels etn ∈ N∗. On note F , G une primitive de f et g respectivement. Alors :
163

TSI 1 Lycée Heinrich-Nessel 2016/2017
Fonction définie sur I Primitive sur If + g F +G+ k
αf αF + k
αf + βg αF + βG+ k
u′ un 1n+1u
n+1 + k
Si u ne s’annule pas, u′
u2−1u + k
Si u ne s’annule pas, u′
un1
(1−n)un−1 + k
u′ eu eu + k
Si u > 0, u′
u ln(u) + k
Proposition 7.33. Soit u : D → R et f : E → R deux fonctions dérivables et supposons que pourtout x ∈ D, u(x) ∈ E . Alors les primitives de u′. (f ′ u) sont de la forme f u+ k où k ∈ R.
Exemple. Considérons la fonction f : x 7→ cos(x)1+sin2(x) , en remarquant que cos(x) = sin′(x) et arctan′(x) =
11+x2 , on a
cos(x)1 + sin2(x)
= sin′(x)× arctan′(sin(x))
D’où, les primitives de f sont de la forme x 7→ arctan(sin(x)) + k où k ∈ R.
164

Chapitre 8
Géométrie dans l’espace
Programme• Maîtriser le lien entre la géométrie pure et la géométrie repérée.• Repère orthonormal (orthonormé) de l’espace• déterminant de trois vecteurs de R3
• Coordonnées cartésiennes• Produit scalaire : définition géométrique. Propriétés (bilinéarité, symétrie).• Produit vectoriel dans l’espace orienté :
−→u ∧ −→v =−→0 si −→u et −→v sont colinéaires;‖−→u ‖‖−→v ‖ sin(−→u ,−→v )−→n sinon.
où −→n est le vecteur unitaire orthogonal à −→u et −→v tel que (−→u ,−→v ,−→n ) est une base directe de l’espace.• Exprimer le produit vectoriel dans une base orthonormée directe.• Déterminer si deux vecteurs sont colinéaires.• Produit mixte de trois vecteurs dans l’espace orienté :
[−→u , −→v , −→w ] = (−→u ∧ −→v ) · −→w
• Déterminer si trois vecteurs sont coplanaires.• |[−→u , −→v , −→w ]| est le volume du parallélépipède engendré par les trois vecteurs.• Trilinéarité, antisymétrie• Exprimer le produit mixte dans une base orthonormée directe• Plans : équation cartésienne, système d’équations paramétriques• Passer d’une représentation à l’autre• Différents modes de définition d’un plan :
— par un point et deux vecteurs non colinéaires— un point et un vecteur normal— trois points non alignés
• Droites : système d’équations cartésiennes, système d’équations paramétriques• Passer d’une représentation à l’autre• Différents mode de définition d’une droite• Distance d’un point à un plan, d’un point à une droite• Déterminer le projeté orthogonal d’un point sur une droite, sur un plan• Sphères : Équation cartésienne dans un repère orthonormé• Reconnaître une équation cartésienne de sphère (ainsi que le centre et le rayon), déterminer uneéquation cartésienne d’une sphère à partir du centre et de son rayon
• Déterminer l’intersection d’une sphère et d’un plan.
165

TSI 1 Lycée Heinrich-Nessel 2016/2017
8.1 Les solides usuels
Définition 8.1. Un solide est un objet en trois dimensions. Par exemple un cube, un pavé, unepyramide, un cylindre...
Une représentation en perspective cavalière du cube :
angle de fuite
arête non visible
arête visible
face arrière
face frontale
deux droites parallèles dans la réalité sontreprésentées par des parallèles en perspective cavalière
Remarques.
• Un patron permet de fabriquer le solide par pliage.
• La perspective cavalière permet de représenter le solide sur une feuille papier en donnant l’impressionde la 3D.
Propriété 8.2 (Perspective cavalière). Une perspective cavalière est une convention mathématiquede représentation des solides dans un plan vérifiant les propriétés suivantes :
1) Si deux droites sont parallèles dans la réalité, alors elles le sont aussi dans la représentation enperspective cavalière.
2) Si des points sont alignés dans la réalité, alors ils le sont aussi en perspective cavalière.3) La perspective cavalière conserve les proportions.
Quelques exemples :
Parallélépipède rectangle Le patron est composé de rectangles.V = largeur× hauteur× profondeur L’aire d’un rectangle est : A = Longueur× largeur
longueur
hauteur
largeur
Pyramides Le patron est composé d’un polygone et de tri-angles.
V = (Aire de la base× hauteur)÷ 3 L’aire d’un triangle est : A = (base× hauteur)÷ 2
hauteu
r
166

TSI 1 Lycée Heinrich-Nessel 2016/2017
Cylindre de révolution Le patron est composé d’un rectangle et de deuxV = Aire de la base× hauteur disques. L’aire d’un disque est : A = π × rayon2
rayon
−
hauteur rayon
circonférencede
labase
hauteur
Cône de révolution Le patron est composé d’un disque et d’une portionde
V = 13 ×Aire de la base× hauteur disque avec α = rayon÷ génératrice× 360˚
rayon
génératrice hauteu
r
rayongénératrice
α
Sphère et boule V = 43π × rayon3 A = 4× π × rayon2
rayon La sphère n’a pas de patron.
8.2 Repère de l’espace
Si l’on identifie l’espace avec R3 = (x, y, z); x, y, z ∈ R. L’espace est naturellement muni du repère(O,−→ı ,−→ ,
−→k ) représenté ainsi :
−→ı
−→−→k
x
z
y
M(x; y; z)
Le triplet (x, y, z) est appelé coordonnées cartésiennes de M dans le repère (O;−→ı ;−→ ;−→k ). Le point N est
appelé le projeté orthogonale deM sur le plan (0;−→ı ;−→ ). De plus, si dans le plan (O;−→ı ;−→ ), on considèreles coordonnées polaires de N :
167

TSI 1 Lycée Heinrich-Nessel 2016/2017
−→−→ı
−→k
x
z
Ny
ρ
M(x; y; z)
θ
Si M est distinct de O, le triplet (ρ, θ, z) ∈ R∗+ × [0; 2π[×R est appelé coordonnées cylindriques du pointM dans le repère (O;−→ı ;−→ ;
−→k ). De plus, si on note φ la mesure principale de l’angle (
−→k ;−−→OM), le triplet
(ρ, θ, φ) ∈ R∗+ × [0; 2π[×[0; π] est appelé coordonnées sphériques du point M .
Étant donné un plan P et un vecteur −→n orthogonal à ce plan, on dit que le vecteur −→n oriente le planP en indiquant l’orientation pour la mesure des angles dans le plan : il s’agit du sens trigonométriquelorsqu’on regarde de le plan P « par dessus » le vecteur −→n :
P
−→n
+
Digression. On note qu’il n’y a pas de raison de privilégier −→n à son opposé −−→n . Plus précisément, il n’estpas possible étant donné un plan quelconque d’associer à vecteur −→n orthogonal à ce plan permettantd’une privilégier une orientation du plan à une autre. Ce fait à pour conséquence, qu’à chaque fois qu’onparlera de la mesure d’un angle entre deux vecteurs dans l’espace, il sera non orienté et sa mesure seradonc toujours positive.
8.3 Les vecteurs
Définition 8.3. Soit n un entier naturel non nul. Les éléments (x1, . . . , xn) de Rn sont appelés desn-uplets.
Nous verrons un n-uplet comme un vecteur dans l’espace de dimension n : −→v = (x1, . . . , xn). L’ensembledes vecteurs Rn est muni de deux opérations : ∀ (x1, . . . , xn) ∈ Rn ∀ (x′1, . . . , x′n) ∈ Rn ∀λ ∈ R :• (x1, . . . , xn) + (x′1, . . . , x′n) = (x1 + x ′1 , . . . , xn + x ′n) ; (addition)• λ (x1, . . . , xn) = (λ x1 , . . . , λ xn). (multiplication par un scalaire)
L’addition et la multiplication se font termes à termes.
Vocabulaire. Soit −→v1, . . . ,−→vk des vecteurs et λ1, . . . , λk des scalaires, alors le vecteur
λ1−→v1 + . . .+ λk
−→vk =k∑i=1
λi−→vi
est appelée combinaison linéaire des vecteurs −→v1, . . .−→vk.
Exercice 8.1. Dans R3, exprimer :
1) −→v =
12− 2
3
4
comme combinaison linéaire des vecteurs −→v1 =
101
, −→v2 =
011
et −→v3 =
001
.
−→v = 12−→v1 − 23−→v2 − 22
3−→v3
168

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) −→v =
1−14
comme combinaison linéaire des vecteurs −→v1 =
101
, −→v2 =
011
et −→v3 =
110
.
−→v = 3−→v1 +−→v2 − 2−→v3
3) pour tout θ ∈ R, le vecteur −→v =
cos(2θ)sin(2θ)cos(θ)
comme combinaison linéaire des vecteurs −→v1 =
cos(θ)sin(θ)
0
, −→v2 =
− sin(θ)cos(θ)
0
et −→v3 =
001
. −→v = cos(θ)−→v1 + sin(θ)−→v2 + cos(θ)−→v3
Définition 8.4. Les vecteurs −→u et −→v sont colinéaires s’il existe un nombre réel (un scalaire) λ telque −→u = λ−→v ou −→v = λ−→u .
Remarque. Le vecteur nul est colinéaire à tous les autres vecteurs.
Proposition 8.5. Les vecteurs −→u et −→v sont colinéaires si et seulement s’il existe λ, µ deux nombresréels non nuls tels que
λ−→u + µ−→v = −→0
Définition 8.6. Trois vecteurs −→u , −→v et −→w sont linéairement dépendants (ou liés) si on peut trouvertrois scalaires λ, µ et ν non tous les trois nuls tels que
λ−→u + µ−→v + ν−→w = −→0
Exercice 8.2. Montrer que si −→u et −→v sont colinéaires, alors −→u , −→v et −→w sont liés quelque soit le troisièmevecteur −→w choisi.En effet, par hypothèse, il existe deux scalaires λ et µ non tous les deux nuls tels que λ−→u + µ−→v = −→0 . Donc,λ−→u + µ−→v + 0×−→w = −→0 .
On peut continuer à généraliser cette notion en parlant d’une famille de 4, 5, 6, etc, vecteurs liés : On ditdonc qu’une famille de vecteurs (−→v1, . . .
−→vk) est liées si et seulement s’il existe des scalaires λ1, . . . , λk telsque λ1
−→v1 + . . .+ λk−→vk = −→0 .
Définition 8.7. Les vecteurs −→u , −→v ,. . . sont indépendants (ou libres) s’ils ne sont pas liés.
Proposition 8.8 (règle de Sarrus). Soient −→u =
x
y
z
, −→v =
x′
y′
z′
et −→w =
x′′
y′′
z′′
trois vecteurs de
l’espace. Alors la famille (−→u ;−→v ;−→w ) est liée si et seulement si on a la relation :
x(y′z′′ − y′′z′)− y(x′z′′ − x′′z′) + z(x′y′′ − x′′y′) = 0
Définition 8.9. Soient −→u =
x
y
z
, −→v =
x′
y′
z′
et −→w =
x′′
y′′
z′′
trois vecteurs de l’espace. Le détermi-
169

TSI 1 Lycée Heinrich-Nessel 2016/2017
nant de (−→u ;−→v ;−→w ) dans la base canonique est le nombre réel
det(−→u ;−→v ;−→w ) =
∣∣∣∣∣∣∣∣x x′ x′′
y y′ y′′
z z′ z′′
∣∣∣∣∣∣∣∣ = x(y′z′′ − y′′z′)−y(x′z′′ − x′′z′) + z(x′y′′ − x′′y′)
Remarque. On peut retenir la formule du déterminant de la manière suivante :
det(−→u ;−→v ;−→w ) = x
∣∣∣∣∣ y′ y′′
z′ z′′
∣∣∣∣∣−y∣∣∣∣∣ x′ x′′
z′ z′′
∣∣∣∣∣+ z
∣∣∣∣∣ x′ x′′
y′ y′′
∣∣∣∣∣Vu ainsi, on dit qu’on développe le déterminant par rapport à la première colonne.
Exercice 8.3. Montrer qu’on peut développer par rapport à la 3e colonne :
det(−→u ;−→v ;−→w ) = x′′
∣∣∣∣∣ y y′
z z′
∣∣∣∣∣− y′′∣∣∣∣∣ x x′
z z′
∣∣∣∣∣+ z′′
∣∣∣∣∣ x x′
y y′
∣∣∣∣∣Méthode. Pour montrer que deux (ou trois) vecteurs sont colinéaires (ou liés), on peut :• Exhiber une combinaison linéaire entre les deux vecteurs (éventuellement en utilisant judicieu-sement la relation de Chasles).
• Montrer que le déterminant associé est nul.Pour montrer que deux (ou trois) vecteurs sont indépendants, on peut :• Supposer qu’il existe une relation de liaison entre ces vecteurs et montrer que nécessairementtous les scalaires sont nuls.
• Montrer que le déterminant associé est non nul.
8.3.1 Bases
Définition 8.10. Une famille (−→u1;−→u2; . . . ;−→un) de vecteurs du plan ou de l’espace est génératrice sitout vecteur −→v est une combinaison linéaire des vecteurs −→uk :
∃ λ1 ∈ R, . . . ,∃ λn ∈ R, −→v = λ1−→u1 + · · ·+ λn
−→un
Définition 8.11. Une famille de vecteurs qui est génératrice et libre est une base.
Exemples. Les vecteurs
• e1 =(
10
)et e2 =
(01
)forment une base (e1, e2) du plan R2.
• e1 =
100
, e2 =
010
et e3 =
001
forment une base (e1, e2, e3) du plan R3.
Ces bases sont appelées base canonique.
Les résultats suivant sont admis pour le moment et seront démontrés en fin de semestre.
Théorème 8.12. Toute base du plan contient exactement deux vecteurs. Toute base de l’espacecontient exactement trois vecteurs.
170

TSI 1 Lycée Heinrich-Nessel 2016/2017
Méthode (proposition). Pour montrer qu’une famille est une base, on peut montrer qu’elle est librepuis vérifier qu’elle contient le « bon » nombre d’éléments (2 pour le plan ; 3 pour l’espace).
Proposition 8.13 (definition). Soit (−→u ;−→v ;−→w ) une base de l’espace. Alors pour tout vecteur −→a , onpeut trouver un unique triplet de scalaires λ, µ et ν tels que −→a = λ−→u +µ−→v + ν−→w . Le triplet (λ, µ, ν)s’appelle les coordonnées de −→a dans la base (−→u ;−→v ;−→w ).
Exercice 8.4. Soit
−→v =
x
y
z
, −→v1 =
210
, −→v2 =
102
et −→v3 =
021
quatre vecteurs de R3. Démontrer qu’il existe un unique triplet (a, b, c) ∈ R3 tel que
−→v = a−→v1 + b−→v2 + c−→v3
En déduire que (−→v1,−→v2 ,−→v3) est une base de R3 et les coordonnées de −→v dans la base (−→v1 ,
−→v2,−→v3). On note
que−→v = a−→v1 + b−→v2 + c−→v3
⇐⇒
a = 1
9 (4x+ y − 2z)b = 1
9 (x− 2y + 4z)c = 1
9 (−2 + 4y + z)
Méthode. Pour exprimer les coordonnées d’un vecteur dans une base donnée, on résoudra un systèmed’équations.
Théorème 8.14. Trois vecteurs de l’espace R3 forment une base de R3 si et seulement si leur déter-minant est non nul.
8.4 Droites, plans
On se place dans l’espace E muni d’un repère (O;−→ı ;−→ ;−→k ).
8.4.1 Milieu de deux points
Définition 8.15. Soient A et B deux points distincts de l’espace. Le milieu de [AB] est le point I telque −→AI = 1
2−−→AB.
Proposition 8.16. Soient A et B deux points distincts de l’espace. Soit I le milieu de [AB]. Alors :
1) −→AI = −→IB2) Si A(xA; yA; zA) et B(xB ; yB ; zB) alors I
( xA+xB2 ; yA+yB
2 ; zA+zB2)
8.4.2 Droites
Théorème-définition 8.17. Soit A, B deux points distincts de l’espace E . Il existe une unique droitequi passe par A et B et on la note (AB).De plus la droite (AB) est le lieu géométrique des points M alignés avec A et B.
171

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 8.18. Soient A et B deux points distincts de l’espace E . On dit qu’un point C est entre Aet B s’il existe λ ∈ [0; 1] tel que −→AC = λ
−−→AB. L’ensemble de tous les points entre A et B est le segment
[AB] :[AB] =
C ∈ E , ∃ λ ∈ [0; 1],−→AC = λ
−−→AB
Proposition 8.19. Soient A et B deux points distincts de l’espace. Alors :1) [AB] = [BA]2) [AB] ⊂ (AB)
Exercice 8.5. La figure 8.1 ci-dessous représente un cube ABCDEFGH en perspective cavalière. Lespoints I,J,K sont des points des arêtes respectives [AE], [BF ], [CG] tels que :• BJ = 1
5 GF ;• CK = 1
3 CG ;• I milieu de [AE].• L est le point d’intersection du plan (IJK) avec la droite (DH).
On considère le repère R = (D;−−→DA;−−→DC;−−→DH).
A B
C
GH
EF
D
I
K
J
N
M
L
Figure 8.1 – Section d’un cube
1) Déterminer les coordonnées des différents points : A, B, C, D, E, F , G, H, I, J , K.2) Déterminer un vecteur directeur de la droite (IJ) et un vecteur directeur de la droite (KL).3) Montrer que M(x, y, z) ∈ R3 appartient à la droite (IJ) si et seulement si il existe λ ∈ R tel que
x = 1y = λ
z = 12 −
310λ
Une telle caractérisation s’appelle équations paramétriques de la droite.4) En déduire les équations paramétriques de (KL).5) Déterminer les équations paramétriques de (JK) et (IL).
172

TSI 1 Lycée Heinrich-Nessel 2016/2017
6) Montrer que M(x, y, z) appartient à la droite (KL) si et seulement six = 0310y + z = 19
30
Une telle caractérisation s’appelle équations cartésiennes de la droite.7) Déterminer les équations cartésiennes de la droite (IL).8) En déduire les coordonnées du point L.9) La droite (LJ) :
a) Déterminer les équations paramétriques de la droite (LJ).b) En déduire les équations cartésiennes de (LJ).
Définition 8.20. Soit D une droite et −→u un vecteur non nul de l’espace E .1) On dit que −→u est un vecteur directeur de D s’il existe deux points A et B appartenant à la
droite D tels que −→u = −−→AB.2) On dit que la droite D est vectorielle si elle passe par l’origine O.
Proposition 8.21. Soit A un point et −→u un vecteur non nul de l’espace E .1) La droite vectorielle dirigée par −→u (on dit aussi engendrée par −→u ) est l’ensemble
D−→u = V ect(−→u ) =M ∈ E , ∃ λ ∈ R,
−−→OM = λ−→u
2) La droite affine passant par A et dirigée par −→u (on dit aussi engendrée par −→u ) est l’ensemble
D−→u ;A =M ∈ E , ∃ λ ∈ R,
−−→AM = λ−→u
SoitD la droite passant parA(xA, yA, zA) et de vecteur directeur−→u
xu
yu
zu
. Un pointM(x, y, z) appartient
à la droite D si et seulement si
∃λ ∈ R :
x− xA = λxu
y − yA = λyu
z − zA = λzu
⇐⇒ ∃λ ∈ R :
x = xA + λxu
y = yA + λyu
z = zA + λzu
De plus,
∃λ ∈ R :x− xA = λxu
y − yA = λyu⇒
(x− xAy − yA
)et
(xu
yu
)sont colinéaires ⇒ (x− xA)yu = (y − yA)xu
∃λ ∈ R :y − yA = λyu
z − zA = λzu⇒
(y − yAz − zA
)et
(yu
zu
)sont colinéaires ⇒ (y − yA)zu = (z − zA)yu
∃λ ∈ R :x− xA = λxu
z − zA = λzu⇒
(x− xAz − zA
)et
(xu
zu
)sont colinéaires ⇒ (x− xA)zu = (z − zA)xu
Donc, le triplet (x, y, z) est solution du système :yux− xuy = yuxA − xuyAzuy − yuz = zuyA − yuzAzux− xuz = zuxA − xuzA
(∆)
173

TSI 1 Lycée Heinrich-Nessel 2016/2017
Comme le vecteur directeur −→u est non nul, au moins une de ses coordonnées est non nulle. Supposonsque yu 6= 0, alors les deux premières équations impliquent la troisième (car L3 = zu
yuL1 + xu
yuL2). Ainsi, le
système est équivalent à ax+ by + cz = d
a′x+ b′y + c′z = d′(C)
où a, b, c, d, a′, b′, c′, d′ sont des nombres réels fixés (dépendant uniquement des coordonnées de A et −→u ).De même, on montre que si xu ou zu est non nul, on peut se ramener à un système de la forme (C).
Proposition 8.22. Soit A = (xA; yA; zA) un point et −→u =
xu
yu
zu
un vecteur non nul de l’espace E .
On note D la droite passant par A et de vecteur directeur −→u .1) Équations paramétriques de D :
D = M(x, y, z) ∈ E : ∃λ ∈ R,
x = xA + λux
y = yA + λuy
z = zA + λuz
2) Équations cartésiennes de D : Il existe a, b, c, d, a′, b′, c′, d′ des nombres réels fixés tels que
D = M(x, y, z) ∈ E :ax+ by + cz = d
a′x+ b′y + c′z = d′
Méthode.• Pour trouver les équations paramétriques d’une droite, on utilise directement la définition de ladroite en termes de vecteurs colinéaires.
• Pour trouver une équation cartésienne d’une droite, on traduit la colinéarité de la définition àl’aide du déterminant (voir page précédente le système (∆)).
8.4.3 Plans
Proposition 8.23. Soit A, B et C trois points de l’espace distincts et non alignés, alors les vecteurs−−→AB et −→AC sont linéairement indépendants.
Définition 8.24. Soit A, B, C trois points del’espace distincts et non alignés. Le plan noté(ABC) est constitué par les points des droitespassant par A et parallèles ou sécantes à la droite(BC).
A
B
C++
+
Remarques.• La donnée de 3 points non alignés ou de 2 droites sécantes ou 2 droites parallèles (non confondues)suffit à déterminer un plan
• Dans chaque plan de l’espace, on peut appliquer tous les théorèmes de géométrie plane.
Proposition 8.25. Soit A, B, C trois points de l’espace distincts et non alignés et M un point, alors
M ∈ (ABC) ⇐⇒ ∃! (x, y) ∈ R2 : −−→AM = x−−→AB + y
−→AC
174

TSI 1 Lycée Heinrich-Nessel 2016/2017
Le couple (x, y) est appelé coordonnées de M dans le repère (A;−−→AB;−→AC) du plan (ABC).
Vocabulaire. Si le plan P passe par l’origine du repère de l’espace E , on dit que le plan est un planvectoriel. Un plan quelconque de l’espace est appelé plan affine.
Définition 8.26. Soit P un plan de l’espace E . On dit qu’un vecteur −→u appartient au plan P s’ilexiste deux points A et B du plan P tels que −→u = −−→AB.
Proposition 8.27. Soit P un plan de l’espace E et O un point du plan P. Alors, il existe −→u et −→vdeux vecteurs non colinéaires du plan P tels que
P =M ∈ E , (−−→OM ;−→u ;−→v ) sont liés
De plus, (O;−→u ;−→v ) définie un repère du plan P.
Vocabulaire. Avec les notations, hypothèses, de la proposition, (−→u ,−→v ) est appelé un couple de vecteursdirecteurs de plan P.
Avec les notations, hypothèses, de la proposition précédente et en notant les coordonnées de A ainsi(Ax, Ay, Az) dans le repère de l’espace E . et de manière analogue pour les vecteurs −→u et −→v , on a
(−−→AM ;−→u ;−→v ) sont liés
⇐⇒
∣∣∣∣∣∣∣x−Ax ux vx
y −Ay uy vy
z −Az uz vz
∣∣∣∣∣∣∣ = 0 (P)
⇐⇒ (x−Ax)(uxvz − vyuz)− (y −Ay)(uzvx − uxvz) + (z −Az)(uxvy − vxuy) = 0⇐⇒ (uxvz − vyuz)x− (uzvx − uxvz)y + (uxvy − vxuy)z
= Ax(uxvz − vyuz)−Ay(uzvx − uxvz) +Az(uxvy − vxuy)⇐⇒ ax+ by + cz = d
où a, b, c, d sont des nombres réels fixés. Ainsi, comme pour les droites, on peut représenter un plan dedeux manières par des équations :
Proposition 8.28. Soit P un plan affine de l’espace E passant par un point A et dirigé par le couplede vecteurs (−→u ;−→v ) libre. Alors :
1) Équations paramétriques du plan P :
P = M(x, y, z) ∈ E :
x = Ax + λux + µvx
y = Ay + λuy + µvy
z = Az + λuz + µvz
2) Équation cartésienne du plan P : Il existe a, b, c, d quatre nombres réels fixés tels que :
P = M(x, y, z) ∈ E : ax+ by + cz = d
Méthode.• Pour trouver un système d’équations paramétriques d’un plan, on traduit la définition en termesde vecteurs liés.
• Pour trouver une équation cartésienne d’un plan, on peut éliminer les deux paramètres λ et µd’un système d’équations paramétriques ou on utilise le déterminant de trois vecteurs (équation(P ) ci-dessus).
175
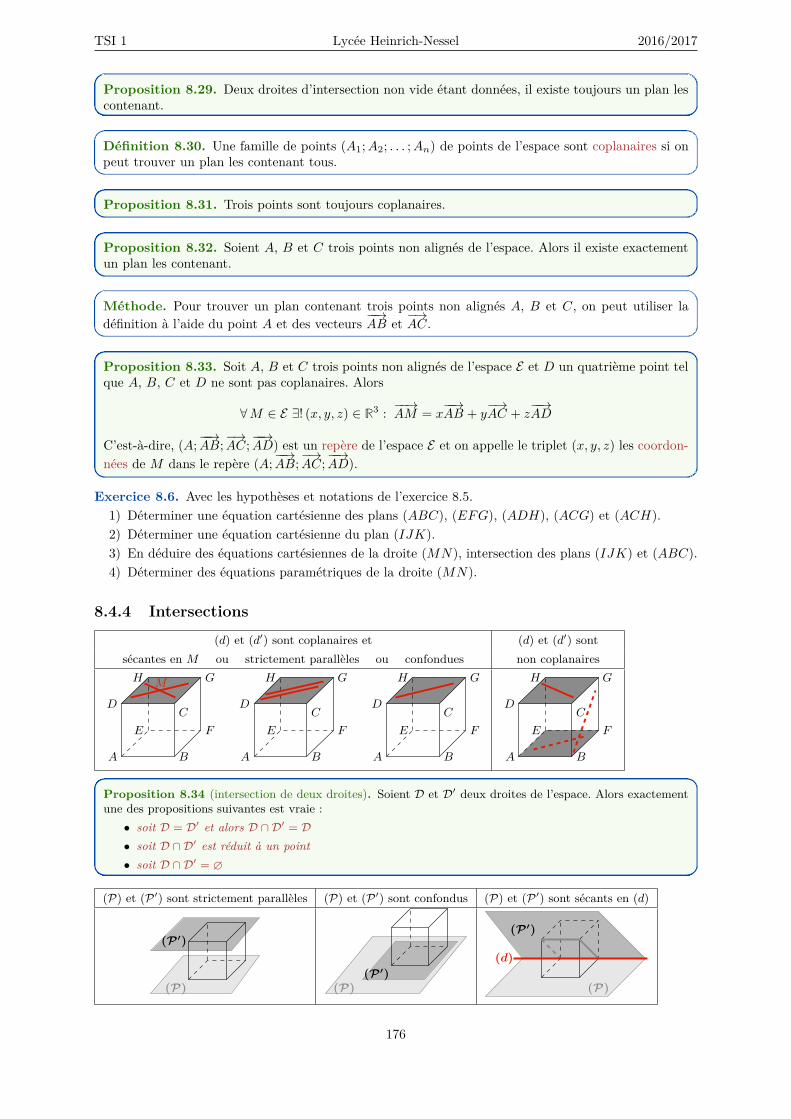
TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 8.29. Deux droites d’intersection non vide étant données, il existe toujours un plan lescontenant.
Définition 8.30. Une famille de points (A1;A2; . . . ;An) de points de l’espace sont coplanaires si onpeut trouver un plan les contenant tous.
Proposition 8.31. Trois points sont toujours coplanaires.
Proposition 8.32. Soient A, B et C trois points non alignés de l’espace. Alors il existe exactementun plan les contenant.
Méthode. Pour trouver un plan contenant trois points non alignés A, B et C, on peut utiliser ladéfinition à l’aide du point A et des vecteurs −−→AB et −→AC.
Proposition 8.33. Soit A, B et C trois points non alignés de l’espace E et D un quatrième point telque A, B, C et D ne sont pas coplanaires. Alors
∀M ∈ E ∃! (x, y, z) ∈ R3 : −−→AM = x−−→AB + y
−→AC + z
−−→AD
C’est-à-dire, (A;−−→AB;−→AC;−−→AD) est un repère de l’espace E et on appelle le triplet (x, y, z) les coordon-nées de M dans le repère (A;−−→AB;−→AC;−−→AD).
Exercice 8.6. Avec les hypothèses et notations de l’exercice 8.5.1) Déterminer une équation cartésienne des plans (ABC), (EFG), (ADH), (ACG) et (ACH).2) Déterminer une équation cartésienne du plan (IJK).3) En déduire des équations cartésiennes de la droite (MN), intersection des plans (IJK) et (ABC).4) Déterminer des équations paramétriques de la droite (MN).
8.4.4 Intersections
(d) et (d′) sont coplanaires et (d) et (d′) sontsécantes en M ou strictement parallèles ou confondues non coplanaires
A B
CD
E F
GH M
A B
CD
E F
GH
A B
CD
E F
GH
A B
CD
E F
GH
Proposition 8.34 (intersection de deux droites). Soient D et D′ deux droites de l’espace. Alors exactementune des propositions suivantes est vraie :• soit D = D′ et alors D ∩D′ = D• soit D ∩D′ est réduit à un point• soit D ∩D′ = ø
(P) et (P ′) sont strictement parallèles (P) et (P ′) sont confondus (P) et (P ′) sont sécants en (d)
(P ′)
(P) (P)(P ′)
(P)
(P ′)
(d)
176

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 8.35 (intersection de deux plans). Soient P et P ′ deux plans de l’espace. Alors exactement unedes propositions suivantes est vraie :• soit P = P ′ et alors P ∩ P ′ = P (on dit que les deux plans sont confondus)• soit P ∩ P ′ est une droite (on dit que les deux plans sont sécants)• soit P ∩ P ′ = ø (on dit alors que les deux plans sont parallèles)
Remarques.• Deux plans confondus sont considérés comme parallèles.• Un plan coupe deux plans parallèles en deux droites parallèles.• Deux plans sont parallèles si et seulement s’il existe deux droites sécantes de l’un qui sont respectivement
parallèles à deux droites sécantes de l’autre.
(d) est strictement parallèle à (ABF ) (d) est incluse dans (HDC) (d) est sécante à (ABC)
A B
CD
E F
GH
A B
CD
E F
GH
A B
CD
E F
GH−
−
Proposition 8.36. Soient D une droite de l’espace et P un plan de l’espace. Alors exactement une despropositions suivantes est vraie :• soit D ⊂ P et alors D ∩ P = D• soit D ∩ P est réduit à un point• soit D ∩ P = ø (on dit alors que la droite est parallèle au plan)
Remarques.• Une droite est parallèle à un plan si et seulement si elle est parallèle à une droite du plan.• Deux droites de l’espace sont dites parallèles si leur intersection est vide et qu’elles appartiennent à un
même plan.
8.5 Produit scalaireRappelons que dans R2, il y a trois façons différentes de calculer le produit scalaire −→u · −→v :• xx′ + yy′, à partir des coordonnées dans la base canonique ;•−→AB ·
−→AC = ±AH ×AC où H est le projeté orthogonal de B sur la droite (AC).
• ||−→u || × ||−→v || × cos(−→u ,−→v )Par analogie, nous allons définir le produit scalaire dans l’espace R3 à partir de la première méthode de calcul :
Définition 8.37. Soient −→u et −→v deux vecteurs de l’espace, dont les coordonnées sont données dans la base
(−→i ;−→j ;−→k ) par −→u =
xyz
et −→v =
x′
y′
z′
. Le produit scalaire (canonique) de −→u et −→v est le nombre
−→u · −→v = xx′ + yy′ + zz′
On retrouve les mêmes propriétés :
Proposition 8.38. Soient −→u , −→v et −→w trois vecteurs. Soient λ et µ deux scalaires.1) −→u · −→v = −→v · −→u symétrie2) −→u · (λ−→v + µ−→w ) = λ−→u · −→v + µ−→u · −→w linéarité3) −→u · −→u ≥ 0 positivité
177

TSI 1 Lycée Heinrich-Nessel 2016/2017
4) −→u · −→u = 0 si et seulement si −→u = −→0
Définition 8.39.• Deux vecteurs −→u et −→v sont orthogonaux si −→u · −→v = 0.• Le carré scalaire du vecteur −→u est le nombre −→u 2 = −→u · −→u .• La norme d’un vecteur −→u est le nombre ‖−→u ‖ =
√−→u 2.• Si ‖−→u ‖ = 1, on dit que le vecteur −→u est unitaire.
Proposition 8.40. Soit A(xA; yA; zA) et B(xB ; yB ; zB) deux points de l’espace R3 muni du repère canonique(O;−→ı ;−→ ;
−→k ). Alors la distance entre A et B est
AB =√
(xB − xA)2 + (yB − yA)2 + (zB − zA)2 =√−→AB2
Remarque. D’après la proposition précédente, la norme d’un vecteur −→u correspond bien à sa longueur.
Proposition 8.41. Pour tous vecteurs −→u et −→v du plan, on a• (−→u +−→v )2 = −→u 2 + 2−→u · −→v +−→v 2 ;• (−→u −−→v )2 = −→u 2 − 2−→u · −→v +−→v 2 ;• (−→u +−→v ) · (−→u −−→v ) = −→u 2 −−→v 2 .
Proposition 8.42. Soient −→u et −→v deux vecteurs. Soit λ un scalaire.1) ‖−→u ‖ = 0 si et seulement si −→u = −→0 .2) ‖λ−→u ‖ = |λ|‖−→u ‖3) ‖−→u +−→v ‖ ≤ ‖−→u ‖+ ‖−→v ‖ Inégalité triangulaire4) |−→u · −→v | ≤ ‖−→u ‖‖−→v ‖ Inégalité de Cauchy-Schwarz5) ‖−→u +−→v ‖2 + ‖−→u −−→v ‖2 = 2
(‖u‖2 + ‖v‖2
)Identité du parallélogramme
6) −→u · −→v = 12
(‖−→u +−→v ‖2 − ‖−→u ‖2 − ‖−→v ‖2
)Identité de polarisation
7) ‖−→u +−→v ‖2 = ‖−→u ‖2 + ‖−→v ‖2 si et seulement si −→u et −→v sont orthogonaux Pythagore
Étant donné que trois points A, B et C deux à deux distincts de l’espace, ils déterminent un plan dans lequel onpeut se placer. On déduit, de la même manière que dans le chapitre 6, les deux « autres façons » de calculer leproduit scalaire de deux vecteurs :
Définition 8.43. Soit A, B et C trois points de l’espace deux à deux distincts. Le projeté orthogonal H deC sur la droite (AB) est le pied de la hauteur issue de C dans le triangle ABC. En d’autres termes, le pointH est l’unique point sur la droite (AB) tel que (CH) soit perpendiculaire à (AB).
A
B
H
C
Remarque. Lorsque C est confondu avec A (respectivement B) le projeté orthogonal H est aussi défini et égal aupoint A (respectivement B).D’ailleurs, on note que le projeté orthogonal H de C coïncide avec le point C lui-même si et seulement si Cappartient à la droite (AB).
178

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 8.44. Si A, B et C sont trois points de l’espace deux à deux distincts. Si H est le projetéorthogonal de C sur la droite (AB), alors
• Si H appartient à la demi-droite [AB) :−→AB ·
−→AC = −→AB · −−→AH = AB ×AH
A BH
C
• Si H n’appartient pas à la demi-droite [AB) :−→AB ·
−→AC = −→AB · −−→AH = −AB ×AH
A BH
C
Théorème 8.45. Soit −→u et −→v deux vecteurs du plan.Le produit scalaire de −→u et −→v est égal à :
−→u · −→v =
0 si −→u = −→0 ou −→v = −→0 ;||−→u || × ||−→v || × cos(−→u ,−→v ) sinon.
Proposition 8.46. Soit −→u et −→v deux vecteurs non nuls, alors l’angle entre les deux vecteurs est
(−→u ,−→v ) ≡ ± arccos( −→u · −→v||−→u || ||−→v ||
)modulo (2π)
Définition 8.47. Une famille de vecteurs est orthogonale si ses vecteurs sont deux à deux orthogonaux. Unefamille de vecteurs est orthonormée si elle est orthogonale et si ses vecteurs sont tous normés.
Exemple. La base canonique (−→ı ,−→ ,−→k ) est orthonormé.
Proposition 8.48. Une famille de vecteurs orthogonale qui ne contient pas le vecteur −→0 est nécessairementlibre.
Corollaire 8.49.1) Deux vecteurs non nuls orthogonaux du plan forment toujours une base du plan.2) Trois vecteurs non nuls deux à deux orthogonaux de l’espace forment toujours une base de l’espace.
Définition 8.50. Un repère orthonormé est la donnée d’un point et d’une base orthonormée.
Soit (−→e 1;−→e 2;−→e 3) une base orhtonormé de l’espace E . Si −→u = x−→e1 + y−→e2 + z−→e3 et −→v = x′−→e1 + y′−→e2 + z′−→e3 sontdeux vecteurs quelconque de l’espace, alors
−→u · −→v = (x−→e1 + y−→e2 + z−→e3) · (x′−→e1 + y′−→e2 + z′−→e3)= xx′−→e1 · −→e1 + xy′−→e1 · −→e2 + . . .+ zz′−→e3 · −→e3
= xx′ × 1 + xy′ × 0 + . . .+ zz′ × 1 par hypothèse sur les −→ei= xx′ + yy′ + zz′
Proposition 8.51. Soit−→u
xyz
et−→v
x′
y′
z′
deux vecteurs dont les coordonnées sont données dans un repère
orthonormé de l’espace E , alors−→u · −→v = xx′ + yy′ + zz′
179

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 8.7.
1) Compléter le point Ω(1; 2) et le vecteur −→u =
(3545
)en un repère orthonormé du plan.
2) Compléter le point Ω(1; 2; 3) et le vecteur −→u =
232313
en un repère orthonormé de l’espace.
Définition 8.52. Un vecteur −→n est normal à unplan P s’il est orthogonal à un couple de vecteursdirecteurs de P.
P
−→n
Proposition 8.53. Si un vecteur est normal à un plan, alors il est orthogonal à tous les vecteurs du plan.
Soit P un plan d’équation cartésienne ax+ by+ cz = d et A(xA, yA, zA), B(xB , yB , zB) et C(xC , yC , zC) formantun repère de P. On a
axA + byA + czA = d
axB + byB + czB = d
axC + byC + czC = d
⇒a(xB − xA) + b(yB − yA) + c(zB − zA) = 0a(xC − xA) + b(yC − yA) + c(zC − zA) = 0
L2 ← L2 − L1 et L3 ← L3 − L1
⇒
abc
·xB − xAyB − yAzB − zA
= 0 et
abc
·xC − xAyC − yAzC − zA
= 0
C’est-à-dire
Proposition 8.54. Soit P un plan d’équation cartésienne ax + by + cz = d, alors le vecteur −→n
abc
est
normal au plan P.
Exercice 8.8. Trouver une équation du plan passant par A(1; 2;−1) et de vecteur normal −→n =
−32−1
.
Définition 8.55.• Un vecteur −→v est orthogonal à une droite D s’il est orthogonal à un vecteur directeur de D.• Deux droites sont orthogonales si leurs vecteurs directeurs sont orthogonaux.• Une droite et un plan sont orthogonaux si un vecteur directeur de la droite est normal au plan.• Deux plans sont orthogonaux s’il existe une base (−→u ;−→v ) de l’un et (−→u ;−→w ) de l’autre avec −→v et −→w
orthogonaux.
8.5.1 Distance entre points, droites, plans
Définition 8.56. Soient A et B deux points. La distance de A à B est le nombre d(A;B) = ‖−→AB‖. On lanote aussi AB.
180

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 8.57. Soient A et B deux points.1) d(A;B) = d(B;A) ou AB = BA
2) d(A;C) ≤ d(A;B) + d(B;C) ou AC ≤ AB +BC inégalité triangulaire
Définition 8.58. Soit E une partie non vide de l’espace. Soit A un point. La distance de A à E est le nombred(A; E) = infAB,B ∈ E.
Définition 8.59. Soit D une droite. Soit A un point. Un projeté orthogonal de A sur D est tout point Mappartenant à D tel que −−→AM est orthogonal à D.
Remarque. Pour que le point M de D soit le projeté orthogonal de A sur D, il suffit que −−→AM · −→u = 0 pour unvecteur directeur −→u de D.
Proposition 8.60. Soit D une droite. Soit A un point. Alors il existe un et un seul projeté orthogonal H deA sur D. De plus, d(A;D) = AH.
Définition 8.61. Soit P un plan. Soit A un point. Un projeté orthogonal de A sur P est tout point Mappartenant à P tel que −−→AM est orthogonal à P.
Remarque. Pour que le point H de P soit le projeté orthogonal de A sur P, il suffit que −−→AH soit orthogonal àune base de P.
Proposition 8.62. Soit P un plan. Soit A un point. Alors il existe un et un seul projeté orthogonal H de Asur P. De plus, d(A;P) = AH.
Méthode. Pour calculer la distance d’un point A à une droite D, il faut :1) Déterminer un vecteur directeur −→u de D
2) Chercher les coordonnées d’un point M ∈ D tel que −−→AM · −→u = 0
3) Calculer d(A;M) = ‖−−→AM‖.
Pour calculer la distance d’un point A à un plan P, il faut :1) Déterminer une base (−→u ;−→v ) de P
2) Chercher les coordonnées d’un point M ∈ P tel que −−→AM · −→u = 0 et −−→AM · −→v = 0
3) Calculer d(A;M) = ‖−−→AM‖.
Exercice 8.9.1) Calculer la distance du point A(1; 2) à la droite D passant par O et B(1; 1).2) Calculer la distance du point A(1; 2; 1) à la droite D passant par O et C(1; 1; 2).3) Calculer la distance du point A(1; 2; 1) au plan P passant par O, B(1; 1; 1) et C(−1; 3; 2).
8.5.2 Vecteur normal et orthogonal (annexe)
Définition 8.63. Soit E une partie non vide de l’espace. L’orthogonal de E , noté E⊥, est l’ensemble de tousles vecteurs orthogonaux à tous les vecteurs de E . Un élément de E⊥ s’appelle un vecteur normal à E .
Exemple. L’orthogonal de la droite vectorielle D dirigée par −→u =(
1 1)
est la droite vectorielle dirigée par−→v =
(1 −1
). Le vecteur −→v est un exemple de vecteur normal à D.
181
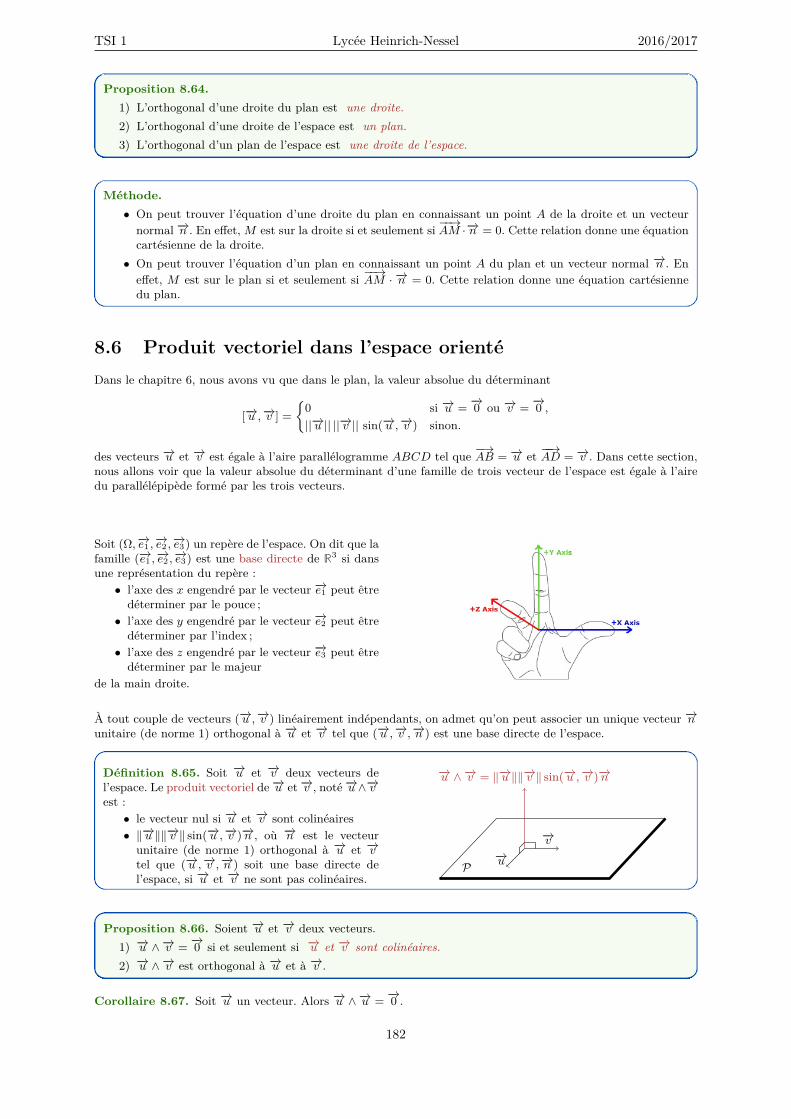
TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 8.64.1) L’orthogonal d’une droite du plan est une droite.2) L’orthogonal d’une droite de l’espace est un plan.3) L’orthogonal d’un plan de l’espace est une droite de l’espace.
Méthode.• On peut trouver l’équation d’une droite du plan en connaissant un point A de la droite et un vecteur
normal −→n . En effet,M est sur la droite si et seulement si −−→AM ·−→n = 0. Cette relation donne une équationcartésienne de la droite.
• On peut trouver l’équation d’un plan en connaissant un point A du plan et un vecteur normal −→n . Eneffet, M est sur le plan si et seulement si −−→AM · −→n = 0. Cette relation donne une équation cartésiennedu plan.
8.6 Produit vectoriel dans l’espace orientéDans le chapitre 6, nous avons vu que dans le plan, la valeur absolue du déterminant
[−→u ,−→v ] =
0 si −→u = −→0 ou −→v = −→0 ,||−→u || ||−→v || sin(−→u ,−→v ) sinon.
des vecteurs −→u et −→v est égale à l’aire parallélogramme ABCD tel que −→AB = −→u et −−→AD = −→v . Dans cette section,nous allons voir que la valeur absolue du déterminant d’une famille de trois vecteur de l’espace est égale à l’airedu parallélépipède formé par les trois vecteurs.
Soit (Ω,−→e1 ,−→e2 ,−→e3) un repère de l’espace. On dit que la
famille (−→e1 ,−→e2 ,−→e3) est une base directe de R3 si dans
une représentation du repère :• l’axe des x engendré par le vecteur −→e1 peut être
déterminer par le pouce ;• l’axe des y engendré par le vecteur −→e2 peut être
déterminer par l’index ;• l’axe des z engendré par le vecteur −→e3 peut être
déterminer par le majeurde la main droite.
À tout couple de vecteurs (−→u ,−→v ) linéairement indépendants, on admet qu’on peut associer un unique vecteur −→nunitaire (de norme 1) orthogonal à −→u et −→v tel que (−→u ,−→v ,−→n ) est une base directe de l’espace.
Définition 8.65. Soit −→u et −→v deux vecteurs del’espace. Le produit vectoriel de −→u et −→v , noté −→u ∧−→vest :• le vecteur nul si −→u et −→v sont colinéaires• ‖−→u ‖‖−→v ‖ sin(−→u ,−→v )−→n , où −→n est le vecteur
unitaire (de norme 1) orthogonal à −→u et −→vtel que (−→u ,−→v ,−→n ) soit une base directe del’espace, si −→u et −→v ne sont pas colinéaires.
P
−→u ∧ −→v = ‖−→u ‖‖−→v ‖ sin(−→u ,−→v )−→n
−→v−→u
Proposition 8.66. Soient −→u et −→v deux vecteurs.1) −→u ∧ −→v = −→0 si et seulement si −→u et −→v sont colinéaires.2) −→u ∧ −→v est orthogonal à −→u et à −→v .
Corollaire 8.67. Soit −→u un vecteur. Alors −→u ∧ −→u = −→0 .
182

TSI 1 Lycée Heinrich-Nessel 2016/2017
Corollaire 8.68. Les points A, B, C de l’espace sont alignés si et seulement si le produit vectoriel −→AB ∧−→AC estnul.
Proposition 8.69. Soient −→u , −→v et −→w trois vecteurs. Soient λ et µ deux scalaires.1) −→v ∧ −→u = −−→u ∧ −→v (anti-symétrie)2) −→u ∧ (λ−→v + µ−→w ) = λ−→u ∧ −→v + µ−→u ∧ −→w (linéarité)
Hors programme. 1) Comme la fonction sinus est impaire, on déduit le premier point.2) On fixe −→u et on va montrer que l’application −→v 7→ −→u ∧ −→v est linéaire (i.e : vérifie bien le point 2),
la propriété de linéarité). Nous étudierons particulièrement les applications linéaires au second semestre.Admettons pour le moment que la composée d’applications linéaires 1 est encore linéaire (ou vous pouvez ledémontrer en exercice). Notons P le plan vectoriel tel que −→u soit normal à −→u . On munit P de l’orientationinduit par le vecteur −→u (voir début de chapitre). On note r : P → P la rotation d’angle π
2 . Cette applicationest linéaire d’après l’exercice ci-dessous. Au vecteur −→v , on associe le vecteur p(−→v ) le projeté orthogonalede −→v sur le plan P, qui est aussi linéaire (exercice, on notera que c’est une conséquence de la linéarité duproduit scalaire).Enfin, si on note −→v1 = p(−→v ) et −→v2 = r(−→v1). Comme dans la figure ci-dessous, supposons que −→v est nonnul et se trouve dans le quart supérieur du plan engendré (−→u ,−→v1). Alors, en ce plaçant dans le trianglerectangle « engendré » par les vecteurs −→v et −→v1 , on a
‖−→v1‖‖−→v ‖
= cos(−→v ,−→v1) = cos(π2 − (−→u ,−→v )) = sin(−→u ,−→v )
D’où, on déduit que ‖−→v2‖ = ‖−→v1‖ = ‖−→v ‖ sin(−→u ,−→v ) (sans hypthèse sur la position de −→v ). D’où −→u ∧ −→v =‖−→u ‖r p(−→v ). La composée de la projection p, avec la rotation r et avec l’homothétie de centre O et derapport le scalaire ‖−→u ‖ est linéaire. D’où le second point.
P
−→u
−→v−→v1
−→v2
Exercice 8.10. On considère la rotation r : R2 → R2 de centre O(0, 0) et d’angle θ ∈ R.
1) Soit −→v
(x
y
)un vecteur de R2. Notons (r;α) ∈ R+ × [0; 2π[ les coordonnées polaires de −→v .
a) Déterminer les coordonnées polaires de r(−→v ).
b) En déduire r(−→v ) =
(cos(θ)x− sin(θ)ysin(θ)x+ cos(θ)y
).
2) Montrer que r est linéaire : pour tout −→u , −→v et tout λ, µ ∈ R on a r(λ−→u + µ−→v ) = λr(−→u ) + µr(−→v ).
Remarque. En combinant les deux points de la proposition, on déduit qu’on a aussi
(λ−→v + µ−→w ) ∧ u = λ−→v ∧ −→u + µ−→w ∧ −→u
la linéarité en la première variable.
1. Une application f de l’espace dans lui-même est dite linéaire si pour tout −→u , −→v et tout λ, µ ∈ R on a f(λ−→u +µ−→v ) =λf(−→u ) + µf(−→v ).
183

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 8.11. ? Dans R3, on note −→ı =
100
, −→ =
010
et−→k =
001
tels que (−→ı ,−→ ,−→k ) soit la base
canonique de R3.1) Calculer tous les produits vectoriels −→u ∧ −→v où −→u et −→v sont l’un des trois vecteurs de la base canonique.
2) Soit −→u =
abc
et −→v =
a′
b′
c′
deux vecteurs de R3.
a) Exprimer −→u et −→v comme combinaison linéaire des vecteurs de la base (−→ı ,−→ ,−→k ).
b) À l’aide de la proposition précédente, en déduire −→u ∧ −→v en fonction des coordonnées de −→u et −→v .
Proposition 8.70. Soient −→u =
abc
et −→v =
a′
b′
c′
deux vecteurs. Le produit vectoriel de −→u et −→v est le
vecteur
−→u ∧ −→v
bc′ − b′cca′ − c′aab′ − a′b
Soit −→u
abc
et −→v
a′
b′
c′
. En revenant au déterminant, on note que pour tout −→w
xyz
,
det(−→u , −→v , −→w ) =
∣∣∣∣∣∣∣a a′ x
b b′ y
c c′ z
∣∣∣∣∣∣∣ =
∣∣∣∣∣b b′
c c′
∣∣∣∣∣x−∣∣∣∣∣a a′
c c′
∣∣∣∣∣ y +
∣∣∣∣∣a a′
b b′
∣∣∣∣∣ z =
bc′ − cb′
ca′ − ac′
ab′ − ba′
·xyz
= (−→u ∧ −→v ) · −→w
Ainsi, calculer le déterminant des trois vecteur revient à calculer le produit scalaire entre le produit vectoriel−→u ∧ −→v et le vecteur −→w .
Proposition 8.71. Soit −→u et −→v deux vecteurs de l’espace E , alors
∀−→w ∈ E : det(−→u , −→v , −→w ) = (−→u ∧ −→v ) · −→w
Supposons que −→v et −→w sont linéairement indépendants, alors −→w appartient au plan vectoriel P dirigé par le couple(−→u ,−→v ) (i.e : det(−→v ,−→v ,−→w ) = 0) si et seulement si −→w est orthogonal au vecteur −→u ∧ −→v (i.e : (−→u ∧ −→v ) · −→w = 0).On retrouve que −→u ∧ −→v est normal au plan vectoriel P.
Méthode. Pour montrer que deux vecteurs de l’espace sont colinéaires, on peut montrer que leur produitvectoriel est nul.
Méthode. Pour compléter deux vecteurs orthogonaux en une base orthogonale, il suffit de lui adjoindre leurproduit vectoriel.
8.6.1 Produit mixte
Définition 8.72. Soient −→u , −→v et −→w trois vecteurs. Le produit mixte de −→u , −→v et −→w est le nombre
[−→u ,−→v ,−→w ] = (−→u ∧ −→v ) · −→w
Remarque. D’après la proposition précédente, on a que [−→u ,−→v ,−→w ] = det(−→u ,−→v ,−→w ).
Soit −→u , −→v et −→w trois vecteurs comme représentés ci-dessous
184

TSI 1 Lycée Heinrich-Nessel 2016/2017
−→u
−→v
−→w
−→u ∧ −→v
hθ
L’aire du parallélogramme engendré par −→u et −→v est ‖−→u ‖‖−→v ‖| sin(−→u ,−→v )| = ‖−→u ∧ −→v ‖ par définition du produitvectoriel. La hauteur du parallélépipède est
h = ‖−→w ‖ cos(θ) = ‖−→w ‖| cos(−→u ∧ −→v ,−→w )|
De plus, le volume V du parallélépipède engendré par les trois vecteurs s’obtient en faisant l’aire de la base foisla hauteur :
V = ‖−→u ∧ −→v ‖ × h = ‖−→u ∧ −→v ‖‖−→w ‖| cos(−→u ∧ −→v ,−→w )| = |(−→u ∧ −→v ) · −→w | = |[−→u ,−→v ,−→w ]|
Généralisation :
Théorème 8.73. Soit −→u , −→v et −→w trois vecteurs. Le volume du parallélépipède formé par les trois vecteursest égale à la valeur absolue du produit mixte des trois vecteurs.
Définition 8.74 (formelle). Une base (−→u ,−→v ,−→w ) de l’espace est directe si [−→u ,−→v ,−→w ] > 0.
Exemples.• La base canonique est directe.• Soient −→u et −→v deux vecteurs non nuls et orthogonaux. Alors (−→u ,−→v ,−→u ∧ −→v ) est une base orthogonale
directe.
Proposition 8.75. Soient −→u , −→v , −→w et−→u′ quatre vecteurs. Soient λ et µ deux scalaires. Alors
1) [−→u ,−→v ,−→w ] = −[−→v ,−→u ,−→w ] = −[−→u ,−→w ,−→v ]
2) [λ−→u + µ−→u′ ,−→v ,−→w ] = λ[−→u ,−→v ,−→w ] + µ[
−→u′ ,−→v ,−→w ]
Exercice 8.12.1) Exprimer [−→w ,−→u ,−→v ], [−→v ,−→w ,−→u ] et [−→w ,−→v ,−→u ] en fonction de [−→u ,−→v ,−→w ].2) On suppose que (−→u ,−→v ,−→w ) est une base directe. Pour chacune des permutations des trois vecteurs déter-
miner si la base induite est directe.
Remarques.• Le premier point dit que si on permute deux vecteurs, le produit mixte change de signe. On notera la
cohérence avec la définition précédente d’une base directe. En effet, si dans une base directe (−→u ,−→v ,−→w ) onpermute les deux premiers vecteurs, elle n’est plus directe (le critère des trois doigts de la main droite n’estplus vérifié).
• Encore une fois, à l’aide du premier point, on déduit du second point que le produit mixte est aussi linéaireen la seconde et en la troisième variable :
[−→v , λ−→u + µ−→u′ ,−→w ] = λ[−→v ,−→u ,−→w ] + µ[−→v ,
−→u′ ,−→w ]
[−→v ,−→w , λ−→u + µ−→u′ ] = λ[−→v ,−→w ,−→u ] + µ[−→v ,−→w ,
−→u′ ]
Proposition 8.76. Soient −→u , −→v et −→w trois vecteurs. Alors −→u , −→v et −→w sont coplanaires si et seulement si[−→u ,−→v ,−→w ] = 0.
185

TSI 1 Lycée Heinrich-Nessel 2016/2017
Méthode. Pour déterminer l’équation d’un plan, on peut utiliser le produit mixte au lieu du déterminant.
8.6.2 Applications au calcul de distances
Proposition 8.77 (distance entre un point et une droite). Soit M un point et D une droite dirigée par −→u etpassant par A de l’espace. Alors
d(M ;D) = ‖−−→AM ∧ −→u ‖‖−→u ‖
Démonstration. Soit H le projeté orthogonal de M sur la droite D. Le triangle AMH est rectangle en H, d’où
d(M ;D) = MH = AM × | sin(−→u ,−−→AM)| = ‖−−→AM‖‖−→u ‖| sin(−→u ,−−→AM)|‖−→n ‖
‖−→u ‖= ‖−−→AM ∧ −→u ‖‖−→u ‖
où −→n est le vecteur normal unitaire qui par définition permet de déterminer le produit mixte −−→AM ∧ −→u .
Remarque. On peut aussi utiliser cette formule dans le plan, en plongeant les objets dans l’espace en ajoutantune troisième coordonnée nulle.
Proposition 8.78 (distance entre un point et un plan). La distance du point A(xA; yA; zA) au plan Pd’équation cartésienne ax+ by + cz + d = 0 est donnée par la formule
d(A,P) = |axA + byA + czA + d|√a2 + b2 + c2
Exercice 8.13. Reprendre la démonstration de la formule donnant la distance entre un point et une droite dansle chapitre 6 Géométrie dans le plan pour démontrer la proposition précédente.
Démonstration. Soit H(xH ; yH ; zH) le projeté orthogonal de A sur le plan et −→n (a; b; c), vecteur normal au plan.Alors axH + byH + czH = −d et les vecteurs −−→AH et −→n sont colinéaires. On en déduit que la distance entre le pointet le plan est
AH = |−−→AH · −→n |‖−→n ‖
= |(xA − xH)a+ (yA − yH)b+ (zA − zH)c|‖−→n ‖
= |axA + byA + czA + d|√a2 + b2 + c2
Une dernière application facultative :
Proposition (distance entre deux droites). Soit D (resp. D′) la droite passant par A (resp. A′) de vecteurdirecteur −→v (resp. −→v ′). Supposons que D et D ne sont pas parallèles, alors la distance entre les deux droitesest
d(D,D′) = |(−→v ∧
−→v′ ) ·
−−→AA′|
‖−→v ∧−→v′‖
= |[−→v ,−→v′ ,−−→AA′]|
‖−→v ∧−→v′‖
D
D′
A′−→v′
A−→v
−→v ∧−→v′
186

TSI 1 Lycée Heinrich-Nessel 2016/2017
Démonstration. Comme D et D′ ne sont pas parallèles, les vecteurs −→v et−→v′ ne sont pas colinéaires et la famille
de vecteurs (−→v ,−→v′ ,−→v ∧
−→v′ ) détermine une base de l’espace. Montrons qu’il existe H ∈ D et H ′ ∈ D′ tel que
−−→HH ′
soit orthogonal aux deux droites simultanément.
D’après ce qu’on a remarqué, il existe un unique triplet (x, y, z) ∈ R3 tel que−−→AA′ = x−→v + y
−→v′ + z−→v ∧
−→v′ (ce sont
les coordonnées du vecteur−−→AA′ dans la base (−→v ,
−→v′ ,−→v ∧
−→v′ )). Soit H le point de la droite D tel que −−→AH = x−→v
et H ′ le point de la droite D′ tel que−−−→A′H ′ = −y
−→v′ , alors, d’après la relation de Chasles, on a
−−→HH ′ = −−→HA+
−−→AA′ +
−−−→A′H ′
= −x−→v + x−→v + y−→v′ + z−→v ∧
−→v′ − y
−→v′
= z−→v ∧−→v′
C’est-à-dire, le vecteur−−→HH ′ est colinéaire au produit vectoriel −→v ∧
−→v′ qui par construction est orthogonal aux
des vecteurs directeurs −→v et −→v ′. Ainsi, on a bien trouvé les deux points H et H ′ tels que−−→HH ′ soit orthogonal
aux deux droites.Soit M ∈ D et M ′ ∈ D′, alors
−−−→MM ′2 = (−−→MH +
−−→HH ′ +
−−−→H ′M ′)2
=−−→HH ′2 +−−→MH2 +
−−−→H ′M ′2 + 2−−→MH ·
−−−→H ′M ′
−−→HH ′est orthogonal à −−→MH et
−−−→H ′M ′
≥−−→HH ′2 +−−→MH2 +
−−−→H ′M ′2 − 2|−−→MH ·
−−−→H ′M ′|
≥−−→HH ′2 +−−→MH2 +
−−−→H ′M ′2 − 2‖−−→MH‖ ‖
−−−→H ′M ′‖ d’après l’inégalité de Cauchy-Schwarz
=−−→HH ′2 + (‖−−→MH‖ − ‖
−−−→H ′M ′‖)2
≥−−→HH ′2
D’où ∀M ∈ D ∀M ′ ∈ D′ : MM ′ ≥ HH ′. On en déduit que d(D,D′) = HH ′. Distinguons deux cas : Si H etH ′ sont confondus alors les droites D et D′ se coupent en H et la distance entre elle est nulle. De plus, les deuxdroites sont incluse dans un même plan P (d’après la proposition 8.29). Ainsi les trois vecteurs −→v ,
−→v′ et
−−→AA′ sont
dans P. Donc [−→v ,−→v′ ,−−→AA′] = 0 et on a bient les égalités annoncées dans la proposition dans ce cas. Sinon, si H et
H ′ ne sont pas confondus (les droites ne se coupent pas) et HH ′ 6= 0. D’autre part,−−→AA′ ·
−−→HH ′ = (−−→AH +
−−→HH ′ +
−−→HA′) ·
−−→HH ′ =
−−→HH ′ ·
−−→HH ′ = (HH ′)2
|−−→AA′ ·
−−→HH ′|
‖−−→HH ′‖
= HH ′
Or,−−→HH ′ = z−→v ∧
−→v′ , d’où ‖
−−→HH ′‖ = |z|‖−→v ∧
−→v′‖ et
d(D,D′) = |−−→AA′ ·
−−→HH ′|
‖−−→HH ′‖
= |−−→AA′ · (z−→v ∧
−→v′ )|
|z| × ‖−→v ∧−→v′‖
= |z| × |−−→AA′ · (−→v ∧
−→v′ )|
|z| × ‖−→v ∧−→v′‖
= |−−→AA′ · (−→v ∧
−→v′ )|
‖−→v ∧−→v′‖
8.7 Sphères
Définition 8.79. Soit A un point de l’espace. Soit R ≥ 0. La sphère de centre A et de rayon R est l’ensemble
SA;R = M ∈ R3, AM = R
La boule de centre A et de rayon R est l’ensemble
BA;R = M ∈ R3, AM ≤ R
Deux points A et B tels que AB = 2R forment un diamètre de la sphère. L’aire de la sphère de rayon R vaut4πR2 ; le volume de la boule de rayon R vaut 4πR3
3 .
187

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 8.80. Soit A(xA; yA; zA) un point de l’espace. Soit R ≥ 0. Le point M(x; y; z) est sur la sphèrede centre A et de rayon R si et seulement si
(x− xA)2 + (y − yA)2 + (z − zA)2 = R2
On appelle cette équation une équation cartésienne de la sphère.
Proposition 8.81. Soient A et B deux points. Le point M appartient à la sphère de diamètre [AB] si etseulement si −−→AM · −−→BM = 0.
Remarque. Cela signifie que si M est sur le cercle (ou la sphère) de diamètre [AB] alors le triangle ABM estrectangle en M .
Méthode.• Pour déterminer l’équation d’un cercle ou d’une sphère, on peut utiliser la définition si on connaît le
centre et le rayon ou la propriété du diamètre si on en connaît un.• Pour savoir si une équation donnée représente un cercle ou une sphère, on essaie de la mettre sous forme
canonique.
Exercice 8.14.1) Déterminer l’équation de la sphère de centre O(1, 3, 2) et de rayon 5.2) Déterminer le centre et le rayon de la sphère d’équation x2 +y2 +z2−6x+2y+10z = 44. Centre (3,−1,−5)
et rayon 3
Exercice 8.15. Déterminer la nature de l’intersection d’une droite et d’un cercle ; d’un plan vectoriel et d’unesphère de centre O.
Définition 8.82. Des points sont dits cocycliques s’ils sont sur un même cercle ou une même sphère.
Proposition. Soient A, B, C et D quatre points de l’espace. Alors• Ou les points sont A, B, C et D coplanaires• Ou les points sont A, B, C et D cocycliques
188

Chapitre 9
Dénombrement
Programme• Applications : ! le point de vue est intuitif, Manipuler le langage élémentaire des applications. Faire le lien
avec la notion de graphe.• Application identité• image (directe), antécédent
• image réciproque : ! On évitera tout développement technique sur la notion d’image réciproque introduiteprincipalement en vue des probabilitésnotation : f#(A).
• composition : reconnaître une fonction composée• Restriction, notation f |I .• injection, surjection, bijection, réciproque d’une bijection• Applications et ensembles finis• Dénombrement• ! On adopte un point de vue intuitif. L’utilisation systématique de bijections dans les problèmes de dénom-
brement n’est pas un attendu du programme• Cardinal d’un ensemble fini, d’une partie d’un ensemble fini. Cas d’égalité.• Une application entre deux ensembles finis de même cardinal est bijective si et seulement si elle est injective
si et seulement si elle est surjective.• Opérations sur les ensembles et cardinaux : union (disjointe), complémentaire, produit cartésien
• ! La formule du crible est hors programme• Cardinal de l’ensemble des parties d’un ensemble fini• Nombre de p-uplets (ou p-listes).• Nombre de permutations d’un ensemble à n éléments.• ! On n’utilise pas la notation Apn.• Nombres de parties à p éléments d’un ensemble à n éléments : notation
(np
)• Donner une interprétation combinatoire des propriétés suivantes :(
n
p
)=(
n
n− p
) n∑p=0
(n
p
)= 2n
(n− 1p− 1
)+(n− 1p
)=(n
p
)
9.1 ApplicationsDans cette section, les fonctions au sens habituel vont être nommé application. La différence entre fonction etapplication réside essentiellement dans la précision ou non du domaine de définition.
Définition 9.1. Soient E et F deux ensembles. Une application de E dans F est une correspondance quiassocie à tout élément de E un seul élément de F .On note une application f de E dans F ainsi f : E → F .Soit x un élément de E. L’élément de F associé à x par f est appelé l’image de x par f et se note f(x).
189

TSI 1 Lycée Heinrich-Nessel 2016/2017
La correspondance f qui à x associe son image f(x) se note x 7→ f(x).
Exemples. • L’application f : N→ N définie par f(n) = 2n pour tout entier naturel.• L’application identité de E est l’application, notée idE , de E dans E qui associe x à x :
idE : E → E
x 7→ x
• Si E et F sont deux ensembles, on dispose de deux applications « naturelles », les projections
prE : E × F → E
(x; y) 7→ x
et
prF : E × F → F
(x; y) 7→ y
Définition 9.2. Soit f une application d’un ensemble E dans un ensemble F . L’image de f est le sous-ensemblede F
Im(f) = f(E) = y ∈ F, ∃ x ∈ E, y = f(x) = f(x), x ∈ EC’est le sous-ensemble des images des éléments de E par l’application f dans F .
Remarque. Si f est une application constante, alors l’image Im(f) est un singleton.
Définition 9.3. Soit f une application d’un ensemble E dans un ensemble F . Soit A une partie de E. L’imagedirecte de A par f est la partie de F :
f(A) = f(x), x ∈ A = y ∈ F, ∃ x ∈ A, y = f(x)
C’est le sous-ensemble des images des éléments de la partie A par l’application f dans F .
Définition 9.4. Soit f une application d’un ensemble E dans un ensemble F . Soit y un élément de F . Unantécédent de y par f est tout élément x de E tel que f(x) = y.
Remarque. Il peut arriver que certains éléments de F n’aient aucun antécédent ou que d’autres en aient plusieurs.
Définition 9.5. Soit f une application d’un ensemble E dans un ensemble F . Soit B une partie de F . L’imageréciproque de B est la partie de E :
f#(B) = x ∈ E, f(x) ∈ B
Remarque.• En particulier, l’ensemble des antécédents d’un élément y est f#(y) = x ∈ E, f(x) = y.• Dans certains livres, on note l’image réciproque de B ainsi f−1(B). On évite cette notation afin d’éviter
toute confusion avec la notion de fonction inverse.
Définition 9.6. Soit f une application d’un ensemble E dans un ensemble F . Le graphe de f est la partie Gde E × F définie par
G = (x; f(x)), x ∈ E = (x, y) ∈ E × F : y = f(x) ⊂ E × F
Remarque. La notion de graphe permet de donner une autre définition des applications : une application f d’unensemble E dans un ensemble F est la donnée d’une partie G de E ×F telle que pour tout x ∈ E, G∩ (x × F )est un singleton. La deuxième composante de ce singleton est par définition notée f(x).
9.1.1 Injectivité. Surjectivité. Bijectivité
190

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 9.7. Soit f une application d’un ensemble E dans un ensemble F . On dit que f est injective si
∀ a ∈ E, ∀ b ∈ E, f(a) = f(b) ⇒ a = b
C’est-à-dire, si deux éléments ont la même image par f alors ils sont égaux.
De la définition (on considérant la contraposée), on déduit que si f : E → F est injective alors pour tous a, bdans E, on a a 6= b implique f (a) 6= f (b).
Exemples.1) L’application suivante est injective.
E Ff
×××××
×××××××
Moralement, l’application f permet d’ "injecter" l’ensemble E dans l’ensemble F . Il parait assez naturelavec une telle application de vouloir identifier E avec son image dans F ...
2) L’application f : N→ N, définie par f(n) = 5n pour tout entier naturel n, est injective.3) L’application f : R → R, définie par f(x) = x2 pour tout nombre réel x, n’est pas injective. Car, f(−1) =
f(1) et −1 6= 1.4) L’application g : [0; +∞[→ R, définie par g(x) = x2 pour tout x ≥ 0, est injective.5) L’application φ : R → C définie par φ(a) = a+0i = a pour tout nombre réel a est une injection des nombres
réels R dans l’ensemble des nombres complexes C.
Proposition 9.8. Une application f est injective si et seulement si tout élément de F admet au plus unantécédent par f .
Méthode. Pour montrer qu’une application f : E → F est injective, on peut :• Considérer deux éléments x et y de E tels que f(x) = f(y) et montrer que x = y.• Montrer que l’équation f(x) = z a au plus une solution x quelque soit le choix de z dans F .• Montrer que si x et y sont deux éléments distincts de E, alors f(x) et f(y) sont deux éléments distincts
de F .
Remarque. Pour montrer qu’une application n’est pas injective, il suffit de trouver deux éléments x et y différentstels que f(x) = f(y).
Définition 9.9. Soit f une application d’un ensemble E dans un ensemble F . On dit que f est surjective si
∀ y ∈ F ∃ x ∈ E : f(x) = y
C’est-à-dire, si tout élément y de F admet au moins un antécédent par f dans E.
Remarque. Les propriétés suivantes sont équivalentes :• f est surjective ;• ∀y ∈ F f#(y) 6= ø ;• ∀y ∈ F card( f#(y) ) > 0 ;• f(E) = F
Exemple. L’application suivante est surjective.
191

TSI 1 Lycée Heinrich-Nessel 2016/2017
E Ff
×××××
×××××××
Méthode. Pour montrer qu’une application f : E → F est surjective, on se donne un y dans F arbitraire eton montre que l’équation f(x) = y admet au moins une solution x.En général, on sera amené à résoudre explicitement cette équation.
Exemple. L’application g : N→ N définie par
g(n) =n2 si n est pairn−1
2 si n est impair
est surjective. En effet, si m ∈ N, l’équation g(n) = m admet au moins une solution car g(2m) = 2m2 = m.
Remarquons qu’on a aussi g(2m+ 1) = 2m+1−12 = m. Ainsi, l’application n’est pas injective.
Remarque. Pour montrer qu’une application n’est pas surjective, il suffit de trouver un élément y de F qui n’aaucun antécédent par f .
Exemple. L’application f : R→ R définie par f(x) = x2 n’est pas surjective. Car il n’existe pas de nombre réel xtel que f(x) = −1. On peut vérifier que Im(f) = [0; +∞[.
Définition 9.10. Soit f une application d’un ensemble E dans un ensemble F . On dit que f est bijective sielle est injective et surjective.
Proposition 9.11. Soit f : E → F une application. Alors f est bijective si et seulement si tout élément deF admet exactement un antécédent par f :
∀ y ∈ F ∃!x ∈ E : f(x) = y
À l’aide de la notion d’image réciproque, une application f est bijective si et seulement si pour tout y dans F , ona card(f#(y)) = 1.
Méthode. Pour montrer qu’une application f : E → F est bijective, on peut :• Montrer que f est injective et que f est surjective.• Montrer que l’équation f(x) = z a exactement une solution x quelque soit le choix de z dans F .• Utiliser la composition (voir ci-dessous).
Exemple. L’application f : [0; +∞[→ [0; +∞[ définie par f(x) = x2 est bijective et sa réciproque est la fonction√·. En effet, pour tout y ∈ [0; +∞[ l’équation f(x) = y a une unique solution, x = √y.
Proposition-Définition 9.12. Soit f une application bijective d’un ensemble E sur un ensemble F . L’ap-plication qui a tout y ∈ F , associe l’unique x ∈ E tel que f(x) = y est appelée réciproque de f et est notéef−1 : F → E.
Proposition 9.13. Soit f : E → F une bijection, alors :1) ∀(x, y) ∈ E × F : f(x) = y ⇐⇒ f−1(y) = x ;2) ∀y ∈ F , f(f−1(y)) = y ;
192

TSI 1 Lycée Heinrich-Nessel 2016/2017
3) ∀x ∈ E, f−1(f(x)) = x.
Remarque. Les deux derniers points de la proposition peuvent être réécrit ainsi :
f f−1 = idF et f−1 f = idE
Proposition 9.14. Soit f une application bijective d’un ensemble E dans un ensemble F . Alors sa réciproquef−1 est aussi bijective et
(f−1)−1 = f .
Exemple. Considérons l’application f : J1; 5K→ A,B,C,D,E définie ainsi :
J1; 5K A,B,C,D,Ef
1 A2 B3 C4 D5 E
A,B,C,D,E J1; 5Kf−1
1A2B3C4D5E
On observe que f est une bijection et son application réciproque f−1 est représenté ci-dessus (visuellement, onretourne les flèches dans l’autre sens pour obtenir la réciproque).
9.1.2 CompositionConsidérons deux applications f : E → F et g : F → G. Si à x, on associe l’image par g de l’image par f de x,on obtient une nouvelle application :
g f : Ef // F
g // G
x // f(x) // g( f(x) )
Définition 9.15. Soit f une application d’un ensemble E dans un ensemble F . Soit g une application de Fdans un ensemble G. La composée g f est l’application :
g f : E → G
x 7→ g (f(x))
Remarque. On portera attention à l’ordre des applications dans la notation g f . Bien qu’on considère en premierl’image par f puis celle de g, on ne note pas f g (de gauche à droite) !
Proposition 9.16. Soit f une application d’un ensemble E dans un ensemble F . Soit g une application deF dans un ensemble G. Soit h une application de G dans un ensemble H. Alors :
1) f idE = f2) idF f = f3) h (g f) = (h g) f (associativité)
Proposition 9.17. Soit f une application d’un ensemble E dans un ensemble F . Soit g une application deF dans un ensemble G. Alors :
1) Si f est injective et si g est injective, alors g f est injective.2) Si f est surjective et si g est surjective, alors g f est surjective.3) Si f est bijective et si g est bijective, alors g f est bijective.
De plus,(g f)−1 = f−1 g−1
193

TSI 1 Lycée Heinrich-Nessel 2016/2017
E
f
,,
gf
&&F
g
,,
f−1
ll G
g−1
ll
(gf)−1
ff
Théorème 9.18. Soit f une application d’un ensemble E dans un ensemble F . Alors, f est bijective si etseulement s’il existe une application g de F dans E telle que g f = idE et f g = idF .Dans ce cas, l’application g est unique et on a g = f−1
Méthode. Pour montrer que l’application f : E → F est bijective, on peut chercher une application g : F → Etelle que g f = idE et f g = idF .
Méthode. Pour trouver la réciproque d’une application f : E → F bijective, on peut :• Si on a trouvé une application g : F → E telle que g f = idE et f g = idF , alors on a f−1 = g.• Si on trouvé explicitement l’unique solution de l’équation f(x) = z d’inconnue x, la solution dépend dez et est l’expression explicite de la réciproque de f .
Exemple. Montrons que l’application f : R → R définie par f(x) = 3x − 7 est bijective. Soit z ∈ R. On résoutl’équation f(x) = z d’inconnue z, autrement dit l’équation 3x− 7 = z. Elle admet une unique solution : x = z+7
3 .Ainsi, f est bijective et sa réciproque est f−1(z) = z+7
3 .
Proposition. Soit f une application d’un ensemble E dans un ensemble F . Alors :1) f est injective si et seulement s’il existe une application g de F dans E telle g f = idE
2) f est surjective si et seulement s’il existe une application g de F dans E telle f g = idF
Proposition. Soit f : E → F et g : F → G deux applications, alors1) si g f est injective alors f est injective.2) si g f est surjective alors g est surjective.
9.1.3 Restrictions d’applications
Définition 9.19. Soit f une application d’un ensemble E dans un ensemble F . Soit A une partie de E. Larestriction de f à A est l’application de A dans F définie par
f |A: A→ F
x 7→ f(x)
Proposition 9.20. Soit f une application d’un ensemble E dans un ensemble F . Soit A une partie de E.Alors :
1) Si f est injective, alors f |A est injective.2) Si f |A est surjective, alors f est surjective.
Remarque. Il existe une autre sorte de restriction. En effet, l’application f envoie E sur Im(f). Donc à l’arrivéeon n’utilise que les éléments de F qui sont dans Im(f). Autrement dit, on peut toujours supposer que f est uneapplication de E dans Im(f). Dans ce cas, f est automatiquement surjective !
9.2 Cardinal d’un ensemble fini
194

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 9.21. Un ensemble fini est un ensemble E ayant un nombre fini d’éléments. Dans ce cas, on notecard(E) ou ]E ou |E| ce nombre, qu’on appelle le cardinal de E.Dans le cas contraitre, on dit que l’ensemble est infini.
Exemple. Soit n un entier naturel, les ensembles
E = 1; . . . ;n = k ∈ N; 1 ≤ k ≤ n = J1;nKF = 0; 1; . . . ;n = k ∈ N; 0 ≤ k ≤ n = J0;nK
sont finis et on a card(E) = n et card(F ) = n + 1 .
Notation. Par convention, l’ensemble vide est fini et on pose card(ø) = 0 .
Dénombrer les éléments d’un ensemble fini E = x1, . . . , xn à n éléments revient à construire une application
J1;nK // E
i // xi
bijective !
Théorème 9.22. Soit n un entier naturel. Le cardinal d’un ensemble E est égal à n si et seulement s’il existeune bijection avec J1;nK.
Exercice 9.1. Soit A et B deux ensembles finis. Démontrer que card(A) = card(B) si et seulement si A et Bsont en bijection 1 (i.e : il existe une bijection de A sur B).
Proposition 9.23. Soit E un ensemble fini. Alors toute partie A de E est un ensemble fini et
card(A) ≤ card(E)
De plus, card(A) = card(E) si et seulement si A = E .
Méthode. Pour montrer que deux ensembles finis E et F sont égaux, on peut montrer une inclusion (parexemple E ⊂ F ) puis montrer l’égalité des cardinaux (i.e. card(E) = card(F )).
Remarque. En particulier, on a aussi si A,B sont deux sous-ensembles d’un ensemble fini, alors A ⊂ B impliquecard(A) ≤ card(B).
9.2.1 Opérations sur les ensemblesOn rappelle qu’on dit que deux parties A et B d’un ensemble E sont disjointes si A ∩B = ∅.
Théorème 9.24 (admis). Soit A et B deux parties finies et disjointes d’un ensemble E, alors
card(A ∪B) = card(A) + card(B).
Proposition 9.25. Soit E un ensemble. Soit A, B deux sous-ensembles finis de E. Alors1) B \A et A ∩B sont finis et card (B \A) = card(B)− card(A ∩ B) ;2) card(A ∪B) = card(A) + card(B)− card(A ∩ B).
Exercice 9.2. Soit A un sous-ensemble de E fini. Exprimer card(EA) en fonction des cardinaux de A et E.
Exercice 9.3 (Formule du crible ou de Poincaré pour n = 3).
1. Cette caractérisation permet d’étendre la notion de cardinal aux ensembles infinis. Il existe des bijections entre N,Z et Q. Par contre, par le procédé de la diagonale de Cantor (1845-1918), on peut démontrer que N et R ne sont pas enbijection.
195

TSI 1 Lycée Heinrich-Nessel 2016/2017
Soit A, B, C trois sous-ensembles finis d’un ensembleE. Exprimer card(A ∪ B ∪ C) en fonction des cardi-naux de A, B, C, A∩B, A∩C, B ∩C et A∩B ∩C.
A
B
C
9.2.2 Application entre deux ensemblesExercice 9.4 (autour du principe des tiroirs). ? Soit A et B deux ensembles finis et f : A→ B une application.
1) On suppose que f est injective.a) On associe φ : A→ Im(f) définie par φ(x) = f(x) pour tout x dans A. Que peut-on dire de φ ?b) En déduire que card(A) ≤ card(B) (si f est injective). Étudier le cas d’égalité.c) Démontrer que dans une classe de 29 élèves, au moins deux élèves ont un prénom commençant par la
même initiale.2) On suppose que f est surjective.
a) Justifier que⋃b∈B
f#(b) est une union disjointe d’ensembles non vides.
b) En déduire que card(A) ≥ card(B) (si f est surjective). Étudier le cas d’égalité.
Théorème 9.26. Soit f : A→ B une application entre deux ensembles finis.1) si f est injective alors card(A) ≤ card(B) ;2) si f est surjective alors card(A) ≥ card(B).
Remarque. Le théorème précédent est connu aussi sous le nom de principe des tiroirs : Si 5 dossiers sont rangésdans quatre tiroirs, deux dossiers au moins sont dans le même tiroir.
Corollaire 9.27. Soit f : A → B une application entre deux ensembles finis. Si f est une bijection alorscard(A) = card(B).
Exercice 9.5. Montrer que dans un village de 700 habitants, deux d’entre eux au moins ont les mêmes initiales.
Théorème 9.28. Soit f : E → E une application d’un ensemble fini E dans lui-même. Alors f est bijectivesi et seulement si f est injective si et seulement si f est surjective.
Démonstration. Soit f : E → E une application d’un ensemble fini E dans lui-même. Par définition de labijectivité, on a
f injective ⇐ f bijectivie ⇒ f surjectiveMontrons les réciproques.• Supposons que f est injective. Posons g : E → f(E) définie par g(x) = f(x) pour tout x ∈ E. L’applicationg est injective car f l’est. Par définition de l’ensemble f(E), on déduit que g est surjective donc bijective.Ainsi, d’après le corollaire précédent, card(E) = card(f(E)) et d’après la proposition 9.23, on a f(E) = E.C’est-à-dire, f est surjective et donc bijective.
• Supposons que f est surjective. Supposons par l’absurde que f n’est pas injective. Il existe donc (a, b) ∈ E2
tel que f(a) = f(b). Posons A = E \ b et g = f |A : A → F , alors l’élément f(b) ∈ F admet encore unantécédent par g. On en déduit que g est aussi surjective. Ainsi, d’après le théorème précédent,
card(A) ≥ card(g(A))card(E)− 1 ≥ card(E)
Ce qui est absurde. D’où f est injective et donc bijective.
Corollaire 9.29. Soit f : E → F une application entre deux ensembles finis. Supposons que card(E) = card(F ),alors f est bijective si et seulement si f est injective si et seulement si f est surjective.
196

TSI 1 Lycée Heinrich-Nessel 2016/2017
Méthode. Pour montrer qu’une application est bijective, on peut vérifier si E et F sont deux ensembles finisde même cardinal puis montrer que f est injective (ou surjective).
9.2.3 Produit cartésien, p-uplets et combinaisons
Théorème 9.30 (admis). Soient E et F deux ensembles finis. Alors E × F est fini et
card(E × F ) = card(E)× card(F)
Exercice 9.6.1) Combien il y a-t-il de résultats différents, en tenant compte de l’ordre, lorsqu’on lance deux dés ?2) Dans la situation précédente, de combien de façons différentes peut-on obtenir une somme égale à 7 ? à 8 ?3) Combien il y a-t-il de résultats différents, en tenant compte de l’ordre, lorsqu’on lance trois dés ?4) Soit n un entier naturel non nul. Combien il y a-t-il de résultats différents, en tenant compte de l’ordre,
lorsqu’on lance n dés ?
Proposition 9.31. Si A1, . . . , An est une famille d’ensembles finis alors
card (A1 ×A2 × . . .×An) =n∏i=1
card(Ai)
Démonstration. Pour n = 1, on a bien card(A1) =∏1i=1 card(Ai) quel que soit l’ensemble fini A1. Soit n ≥ 1
un entier quelconque fixé, supposons par récurrence que pour toute famille A1, . . . , An d’ensembles finis on a larelation card (A1 ×A2 × . . .×An) =
∏n
i=1 card(Ai). Soit A1, . . . , An, An+1, une famille quelconque d’ensemblesfinis. Notons que l’application
(A1 × . . .×An)×An+1 oo // A1 × . . .×An ×An+1
((x1, . . . , xn), xn+1) oo // (x1, . . . , xn, xn+1)
réalise une bijection. Du théorème 9.26, on déduit que
card (A1 × . . .×An ×An+1) = card ((A1 × . . .×An)×An+1)
De plus, d’après la proposition précédente,
card (A1 × . . .×An ×An+1) = card (A1 × . . .×An)× card(An+1)
Enfin, par hypothèse de récurrence,
card (A1 × . . .×An ×An+1) = card(A1)× . . .× card(An)× card(An+1)
Ainsi, la relation est encore vraie avec n+ 1 ensembles finis et par récurrence, on a la proposition.
Définition 9.32.• Soit E un ensemble, pour tout entier naturel non nul n, on pose
En = E × . . .× E︸ ︷︷ ︸n fois
=n∏i=1
E
• On note F(A,B) l’ensemble des applications de A dans B.• On note P(E) l’ensemble des parties de E :
P(E) = A : A ⊂ E
Une conséquence de la proposition précédente,
197

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 9.33. Si E est un ensemble fini, alors pour tout entier n,
card(En) = card(E)n
Définition 9.34. On appelle n-uplet (ou n-liste) de E tout élément (x1, . . . , xn) de En.
Proposition 9.35. Soit E un ensemble fini, le nombre de n-uplets de E est card(E)n.
Remarque. Soit I un ensemble fini et E un ensemble. Une famille d’éléments de E indexés par I est la donnéed’une application f de I dans E. On note par un indice l’image de i ∈ I : xi = f(i). La famille se note alors(xi)i∈I .Un n-uplets (x1, . . . , xn) de E une famille d’éléments de E indéxées par I = 1; . . . ;n. Ainsi, (x1; . . . ;xn)s’identifie avec (xi)i∈I .
Exercice 9.7 (Nombre d’applications de E dans F ). ? Soit E = x1, . . . , xn et F deux ensembles finis decardinaux n et p respectivement.
1) a) Quel est le cardinal de Fn ?b) Que peut-on dire de l’application :
F(E,F ) // Fn
f // (f(x1), . . . , f(xn))
c) En déduire que card(F(E,F )) = pn.2) Pour tout A ⊂ E, on associe l’application 1B : A→ 0, 1 définie par
∀x ∈ E 1B(x) =
1 si x ∈ A0 sinon
a) Démontrer que Φ : A 7→ 1A qui envoie donc le sous-ensemble A sur l’application indicatrice 1A réaliseune bijection entre deux ensembles qu’on précisera.
b) En déduire que card(P(E)) = 2n.
Théorème 9.36. Soit E un ensemble fini. Alors l’ensemble P(E) des parties de E est fini et
card (P(E)) = 2 card(E)
Démonstration. Notons n le cardinal de E et x1, x2, . . . , xn les élements de E. L’application
φ : 0, 1n // P(E)
(b1, . . . , bn) // xi ∈ E; i ∈ J1;nK et bi = 1
associe à tout n-uplet (b1, . . . , bn) d’élements de 0, 1 la partie consistué des éléments xi tels que bi = 0. Réci-proquement, on pose
ψ : P(E) // 0, 1n
A // (b1, . . . , bn)
où pour tout i ∈ J1;nK, bi est égal à 1 si xi ∈ A et 0 sinon. On vérifie alors que ψ φ = id et φ ψ = id, d’où φest bijective. D’après le théorème 9.28 et la proposition 9.33, on a
card(P(E)) = card(ψ(P(E))) = card(0, 1n) = card(0, 1)n = 2n
Exercice 9.8. Un acier est un alliage de fer et de carbone auquel on ajoute ajoute fréquemment des élémentschimiques afin d’améliorer certaines propriétés de cet acier. Ces éléments sont par exemple la manganèse, lechrome, le nickel, le molybdène, l’aluminium.
1) Combien d’aciers peut-on obtenir avec tout ou partie de ces éléments chimiques (sans tenir compte desproportions utilisées) ?
2) Combien d’aciers peut-on obtenir avec aucun ou un seul élément chimique (sans tenir compte des proportionsutilisées) ?
198

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 9.37. Soit p ∈ N. Un p-uplet (x1, . . . , xp) de E est appelé un arrangement de p éléments de E side plus les éléments sont deux à deux distincts : ∀ i 6= j : xi 6= xj .
Définition 9.38 (rappel). Soit n un entier naturel, le nombre
n! =n∏k=1
k = n× (n− 1)× . . .× 1
est appelé factorielle de n.
Proposition 9.39. Soit E un ensemble de cardinal n et p ≤ n un entier. Le nombre de p-uplets de E quisont des arrangements est
n× (n− 1)× . . .× (n− p+ 1) = n!(n− p)!
Remarque.• Si p > n, alors il n’existe pas d’arrangement de p éléments de E.• Pour choisir un arrangement de taille n de E, on peut le faire par étape en commençant par choisir x1. On
a n choix, puis pour chacun de ces choix, pour x2 on a n− 1 choix et ainsi de suite. D’où, effectivement lenombre d’arrangements de E est n× (n− 1)× (n− 2)× . . .× 2× 1 = n!.
Démonstration. Si p = 1, un 1-uplet est simplement la donné d’un élément de E d’où le nombre de 1-uplets estn = card(E). Soit p ∈ J1;n − 1K quelconque. Supposons par récurrence que pour tout entier n et tout ensembleE de cardinal n, le nombre d’arrangements de taille p de E est n!
(n−p)! . Soit E = e1, . . . , en un ensemble fini.Posons
A = (x1, x2, . . . , xp+1) ∈ Ep+1 : (x1, x2, . . . , xp+1) est un arrangement∀ i ∈ J1 : nK Ai = (ei, x2, . . . , xp+1) ∈ Ep+1 : (ei, x2, . . . , xp+1) est un arrangement
Soit i ∈ J1;nK. Un élément de Ai est un arrangement de p + 1 éléments de E mais commençant par ei. D’où,A = ∪ni=1Ai et c’est une union disjointe. De plus, choisir un élément (ei, x2, . . . , xp+1) ∈ Ai revient à choisir(x2, . . . , xp+1) un arrangement de p éléments de E \ ei. Ainsi, par hypothèse de récurrence,
card(Ai) = (n− 1)!(n− 1− p)!
En résumé,
card(A) =n∑i=1
card(Ai) =n∑i=1
(n− 1)!(n− 1− p)! = n× (n− 1)!
(n− 1− p)! = n!(n− (p+ 1))!
C’est-à-dire la relation avec des arrangements de taille p+ 1. D’où, par récurrence, la proposition.
Exercice 9.9. On choisit successivement et sans remise 5 cartes dans un jeu de 32 cartes. En tenant compte del’ordre de tirage,
1) de combien de façons différentes peut-on le faire ?2) Combien de tirages commencent par deux carreaux ?3) ? Combien ne finissent pas par un trèfle ?4) ? Combien de tirages contiennent au moins un as ?5) ? Combien de tirages contiennent exactement un as ?
Définition 9.40. Une permutation de E est une application bijective de E dans lui-même. On note S(E)l’ensemble des permutations de E.
Exercice 9.10. Écrire toutes les permutations possibles de E = 1, 2 et de F = 1; 2, 3.
D’après le théorème 9.28, on déduit :
199

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 9.41. Soit E un ensemble de cardinal n. Se donner une permutation de E équivaut à se donnerun arrangement (x1, . . . , xn) de taille n de E.
Théorème 9.42. Soit E un ensemble de cardinal n, alors l’ensemble S(E) des permutations de E est fini etson cardinal vaut n! (factorielle de n).
Démonstration. Soit p = n, d’après la proposition précédente, le cardinal de S(E) est égal au nombre de p-upletsqui sont des arrangements de E et donc égal à n!
(n−p)! = n!0! = n!.
Exercice 9.11. On considère les nombres de dix chiffres où chacun des chiffres apparait une et une seule foisdans l’écriture du nombre. Combien existe-t-il de tels nombres ? Combien sont pairs ? impaires ?
Définition 9.43. Soit E un ensemble. On appelle combinaison de p éléments de E toute partie de A decardinal p.
Exercice 9.12.1) Décrire tous les arrangements de 3 éléments de 1, 2, 3, 4.2) Que peut-on dire des ensembles 1, 2, 3, 1, 3, 2 et 3, 1, 2 ?3) Décrire toutes les combinaisons de 3 éléments de 1, 2, 3, 4.4) Comparer les deux listes.
Remarque. On notera que :• Pour un arrangement de p éléments de E, on tient compte de l’ordre ;• Pour une combinaison de p éléments de E, on ne tient pas compte de l’ordre.
Définition 9.44 (rappel). Soit n un entier naturel. Soit k un entier naturel tel que 0 ≤ k ≤ n. On pose(n
k
)= n!k!× (n− k)! = n× (n− 1)× . . .× (n− k + 1)
k!
Exercice 9.13. Calculer(10
2
),(10
3
),(50
5
),(50
45
),(n2
)en fonction de n un entier naturel supérieur à deux.
La quantité(nk
)se lit « k parmi n », en voici la raison :
Théorème 9.45. Posons n = card(E). Soit p un entier naturel tel que 0 ≤ p ≤ n. Alors, le nombre decombinaisons de p éléments de E est
card A ∈ P(E)| card(A) = p =(
np
)
Remarque.• Se donner une combinaison de p éléments de E revient à se donner un arrangement sans tenir compte de
l’ordre. Or il y a p! façons différentes de permutter (d’ordonner) p éléments, d’où
card A ∈ P(E)| card(A) = p =n!
(n−p)!
p! = n!p!(n− p)! =
(n
p
)• Choisir une partie avec p éléments dans E de cardinal n revient à choisir « p éléments deux à deux distinctsparmi n éléments » (sans tenir compte de l’ordre dans lequel on les choisit).
Démonstration (hors programme). Soit n ∈ N∗, sans perte de généralité, supposons que E = J1;nK. Soit 1 ≤ p ≤n, posons
Ap = A ∈ P(E)| card(A) = pOp = (x1, . . . , xp) ∈ Ep| (x1, . . . , xp) est un arrangement
200

TSI 1 Lycée Heinrich-Nessel 2016/2017
Se donner un élément de Ap revient à se donner x1, . . . , xp des nombres dans E deux à deux distincts et rangésdans l’ordre croissant. Il n’y qu’une seule façon de caractériser ainsi une partie de E. Donc l’application
φ : Ap ×S(J1; pK) // Op
(x1, . . . , xp, σ) // (xσ(1), . . . , xσ(p))
où les xi sont choisis dans l’ordre croissant pour décrire un élément de Ap, est bien définie. On note que σ estune permutation des indices de 1 à p ainsi l’élément (xσ(1), . . . , xσ(p)) est une permutation des éléments x1 à xp.Réciproquement, si on se donne un arrangement (y1, . . . , yp), il est possible de les ordonner yσ(1) < . . . < yσ(p) oùσ est une permutation des indices J1; pK. De plus, cette permutation est uniquement déterminée par les yi (il n’ya qu’une seule façon d’ordonner p nombres deux à deux distincts). Ainsi, l’application
φ : Op // Ap ×S(J1; pK)
(y1, . . . , yp) // (yσ(1), . . . , yσ(p), σ)
est bien définie. On peut vérifier que ψ φ = id et φ ψ = id. D’où φ réalise une bijection et
card(Ap ×S(J1; pK)) = card(φ (Ap ×S(J1; pK)))card(Ap)× card(S(J1; pK)) = card(Op)
card(Ap)× p! = n!(n− p)!
card(Ap) = n!p!(n− p)!
Exercice 9.14. Un étudiant affamé veut se préparer un sandwich en choisissant 4 ingrédients dans la listesuivante : jambon, poulet, boeuf, canard, tomate, cornichon, salade, céleri, mayonnaise, ketchup, moutarde, sauceblanche.
1) Combien de sandwichs peut-il concevoir ?2) Cet étudiant, soucieux de sa santé, décide de préparer son sandwich en choisissant une viande, deux légumes
et une sauce. Combien de sandwichs peut-il concevoir ?
Exercice 9.15. Soit n un entier naturel et p ≤ n un entier naturel, on place n boules numérotés de 1 à ndans une urne. Combien y a-t’il de façons différentes de tirer
1) p boules successivement avec remise ? Il y a n choix à chaque tirage, d’où
n× n× . . .× n︸ ︷︷ ︸p fois
= np
Correspond au nombre p-uplets de J1;nK.2) p boules successivement sans remise ? Après chaque tirage, il y a une boule en moins :
n× (n− 1)× . . .× (n− p+ 1)︸ ︷︷ ︸pour les p tirages
Correspond au nombre d’arrangements de p éléments de J1;nK.3) p boules simultanément ? Par rapport à la situation précédente, on ne tient pas compte de l’ordre, d’où
n× (n− 1)× . . .× (n− p+ 1)p! =
(n
p
)Correspond au nombre de combinaisons de p éléments de J1;nK.
Proposition 9.46 (rappel). Soit n un entier naturel et k ∈ N.1)(n0
)= 1 =
(nn
)2)(n1
)= n =
( nn−1
)3) Si 0 ≤ k ≤ n, on a
(nk
)=( n
n−k
)4) Si 1 ≤ k ≤ n− 1, on a
(n−1k−1
)+(n−1k
)=(n
k
)(Relation de Pascal)
201

TSI 1 Lycée Heinrich-Nessel 2016/2017
5)∑n
k=0
(nk
)= 2n.
Proposition (Formule président-comité). Soit n ∈ N, pour tout entier k tel que 1 ≤ k ≤ n, on a
k
(n
k
)= n
(n− 1k − 1
)
Remarque. On l’appelle ainsi car d’après la démonstration : il y a autant de façons différentes de choisir le présidentpuis le reste du comité ou le comité qui élit ensuite un président.
Une généralisation de la formule Président-comité, la formule du selectionneur (on choisit une équipe avec destitulaires et des remplaçants) :
Exercice 9.16. Montrer que pour tout 0 ≤ k ≤ p ≤ n, on a(n
p
)(p
k
)=(n
k
)(n− kp− k
)
202

Chapitre 10
Équations différentielles linéaires
Programme• Intégration par parties.• Changement de variables. Tout excès de technicité est exclu.• Équation différentielle linéaire d’ordre 1 :
y′(x) + a(x)y(x) = b(x)
où a, b sont des fonctions à valeurs réelles ou complexes, définies et continues sur un intervalle de R.• Écrire et résoudre l’équation homogène associée• Utiliser le principe de superposition ou la méthode de variation de la constante pour trouver une solution
particulière.• Déterminer la solution générale• Équation différentielle linéaire d’ordre 2 :
y′′(x) + ay′(x) + by(x) = f(x)
où a, b ∈ R et f est une application continue à valeurs réelles ou complexes.• Écrire et résoudre l’équation homogène associée.• Déterminer une solution particulière dans le cas d’un second membre de la forme x 7→ Aeωx où (A,ω) ∈ C2.• Utiliser le principe de superposition• Exprimer la solution générale à l’aide d’une solution particulière et des solutions de l’équation homogène
associée.• ! Aucune technique n’est exigible pour toute autre forme de second membre• Déterminer une solution vérifiant une condition initiale.• Existence et unicité de la solution d’un problème de Cauchy.
10.1 Compléments sur l’intégrationOn rappelle qu’on désigne par K le corps des nombres réels R ou complexes C. Une fonction complexe f = a+ bi :D → C est continue (resp. dérivable, intégrable) si et seulement si ses fonctions partie réelle a et partie imaginaireb sont continues (resp. dérivables, intégrables).Soit I un intervalle et f : I → K une fonction continue sur I. On dit qu’une F : I → K dérivable sur I est uneprimitive de f si F ′ = f sur I.
Théorème 10.1 (admis). Soit I un intervalle et f : I → K une fonction continue sur I. Alors f admet aumoins une primitive F : I → K dérivable sur I. De plus, si F,G : I → K sont deux primitives alors il existeλ ∈ K tel que G = F + λ.
Corollaire 10.2. Soit I un intervalle et f : I → K une fonction continue sur un intervalle I et F une primitivede f sur I. Alors l’ensemble des primitives de f sur I est
F + λ; λ ∈ K
203

TSI 1 Lycée Heinrich-Nessel 2016/2017
Corollaire 10.3. Soit I un intervalle et f : I → K une fonction continue sur un intervalle I. Pour tout (x0, y0) ∈I × K, il existe une unique primitive F : I → K de f telle que f(x0) = y0.
En d’autres termes, pour toute fonction f : I → K continue sur l’intervalle I, l’ensemble des solutions de l’équationdifférentielle
y′ = f
est F + λ; λ ∈ K où F est une primitive de f sur I.
Exercice 10.1. ? Soit f, g : I → R deux fonctions.1) On suppose que f et g sont dérivables sur I et que f ′ et g′ sont continues sur I. Soit x0 ∈ I. Montrer que
(∀x ∈ I : f(x) = g(x)) ⇐⇒∀x ∈ I : f ′(x) = g′(x)f(x0) = g(x0)
2) On suppose que f et g sont deux fois dérivable sur I et que les dérivées secondes f ′′ et g′′ sont continuessur I. Soit x0 ∈ I. Montrer que
(∀x ∈ I : f(x) = g(x)) ⇐⇒
∀x ∈ I : f ′′(x) = g′′(x)f(x0) = g(x0)f ′(x0) = g′(x0)
Théorème 10.4 (Intégration par parties). Soit f, g : [a; b] → R deux fonctions dérivables telles que f ′ et g′soient continues. Alors ∫ b
a
f(t)g′(t) dt = [f(t)g(t)]ba −∫ b
a
f ′(t)g(t) dt
Théorème 10.5 (Changement de variables). Soit I un intervalle, f : I → R une fonction continue et φ :[α; β]→ I une fonction dérivable telle que sa dérivée φ′ soit continue. Alors∫ β
α
f(φ(x))φ′(x) dx =∫ φ(β)
φ(α)f(t) dt
On dit qu’on a effectué le changement de variables t = φ(x).
Remarque. En revenant à la notation de Leibniz : dtdx = φ′(x), on induit le moyen mnémotechnique suivant :
t = φ(x) ⇒
dt = φ′(x) dxx = α ⇒ t = φ(α)x = β ⇒ t = φ(β)
D’où la formule du théorème de changement de variables :∫ φ(β)φ(α) f(t)dt =
∫ βαf(φ(x))φ′(x) dx.
Méthode. Soit f : [a; b]→ K une fonction continue, alors l’application F : [a; b]→ K définie par
F (x) =∫ x
a
f(t) dt
pour tout x ∈ [a; b], est la primitive de f telle que F (a) = 0.
10.2 Quelques généralités
Définition 10.6.• Une équation différentielle d’ordre 1 est une équation de la forme
F (t, y(t), y′(t)) = 0
où F est une fonction de 3 variables à valeurs dans R.
204

TSI 1 Lycée Heinrich-Nessel 2016/2017
• Une équation différentielle d’ordre 2 est une équation de la forme
F (t, y(t), y′(t), y′′(t)) = 0
où F est une fonction de 4 variables à valeurs dans R.
Exemples :1) La recherche de primitives d’une fonction f se traduit par une équation différentielle : y′(t) = f(t) ou encore
y′(t)− f(t) = 0. La fonction F est alors la fonction F (t, x, y) = y − f (t).2) La fonction exponentielle satisfait une équation différentielle très simple : y′(t) = y(t) ou encore y′(t)−y(t) =
0. La fonction F est ainsi la fonction F (t, x, y) = y − x.3) Dans un circuit RL soumis à une tension U constante, l’intensité vérifie l’équation différentielle Li′(t) +
Ri(t) = U ou encore Li′(t) +Ri(t)− U = 0. La fonction F est dans ce cas F (t, x, y) = Ly + Rx −U .4) L’équation y(t) = ty′(t) + f(y′(t)) s’appelle une équation de Clairaut (indroduite en 1734). La fonction F
qui lui correspond est F (t, x, y) = ty + f (y)− x.5) Dans un circuit RLC série soumis à une tension E constante, la tension aux bornes du condensateur
satisfait l’équation différentielle LCu′′(t) +RCu′(t) +u(t)−E = 0. La fonction F associée à cette équationest F (t, x, y, z) = LCz + RCy + x − E .
6) Un oscillateur de van der Pol satisfait l’équation y′′(t) − µ(1 − t2)y′(t) + y(t) = 0. La fonction F est iciF (t, x, y, z) = z − µ(1 − t2 )y + x.
Définition 10.7. Soit F (t, y(t), y′(t)) = 0 une équation différentielle d’ordre 1. Une solution de cette équationest un couple (I, f) où f est une fonction définie sur l’intervalle I, dérivable et satisfaisant F (t, f(t), f ′(t)) = 0pour tout t ∈ I. On dit aussi que le graphe de f est une courbe intégrale pour l’équation différentielle.
Définition 10.8. Soit F (t, y(t), y′(t), y′′(t)) = 0 une équation différentielle d’ordre 2. Une solution de cetteéquation est un couple (I, f) où f est une fonction définie sur l’intervalle I, deux fois dérivable et satisfaisantF (t, f(t), f ′(t), f ′′(t)) = 0. On dit aussi que le graphe de f est une courbe intégrale pour l’équation différentielle.
Exemples1) Les fonctions constantes sont les solutions de l’équation différentielle y′(t) = 0.2) La fonction x 7→ ex est solution de l’équation différentielle y′(x) = y(x). La fonction x 7→ 2ex est solution
de la même équation différentielle.3) La fonction t 7→ U
R
(1− exp
(−Rt
L
))est solution de l’équation différentielle du circuit RL.
4) Dans un circuit LC, la fonction t 7→ E cos(
t√LC
)+ E est une solution.
Définition 10.9.• La forme résolue d’une équation différentielle d’ordre 1 est une équation de la forme y′(t) = φ(t, y(t))
où φ est une fonction de deux variables à valeurs dans R.• La forme résolue d’une équation différentielle d’ordre 2 est une équation de la forme y′′(t) = φ(t, y(t), y′(t))
où φ est une fonction de trois variables à valeurs dans R.
Définition 10.10. Soit F (t, y(t), y′(t)) = 0 une équation différentielle d’ordre 1.• On appelle problème de Cauchy pour l’équation différentielle la donnée d’une condition initiale de la
forme y(t0) = y0 : F (t, y(t), y′(t)) = 0y(t0) = y0
• Une solution du problème Cauchy ci-dessus est un couple (I, f) où f est une fonction définie sur unintervalle I contenant t0, dérivable et telle que F (t, f(t), f ′(t)) = 0 pour tout t ∈ I et f(t0) = y0.
Définition 10.11. Soit F (t, y(t), y′(t), y′′(t)) = 0 une équation différentielle d’ordre 2.• On appelle problème de Cauchy pour l’équation différentielle la donnée de conditions initiales de la
205

TSI 1 Lycée Heinrich-Nessel 2016/2017
forme y(t0) = y0 et y′(t0) = v0 : F (t, y(t), y′(t), y′′(t)) = 0y(t0) = y0
y′(t0) = v0
• Une solution du problème Cauchy ci-dessus est un couple (I, f) où f est une fonction définie sur unintervalle I contenant t0, deux fois dérivable et telle que F (t, f(t), f ′(t), f ′′(t)) = 0 pour tout t ∈ I,f(t0) = y0 et f ′(t0) = v0.
Remarque. D’un point de vue cinématique, une équation différentielle d’ordre 1 est une équation qui relie laposition et la vitesse en fonction du temps. Un problème de Cauchy associé est la donnée d’une position initiale.De même, une équation différentielle d’ordre 2 est une équation qui relie la position, la vitesse et l’accélération enfonction du temps. Un problème de Cauchy associé est la donnée d’une position initiale et d’une vitesse initiale.
Notation. Lorsqu’il n’y pas d’ambiguïté, nous ferons les abus de notations suivants :• On note l’équation différentielle d’ordre de 2 (ou 1), ainsi : F (t, y, y′, y′′) = 0 où l’on identifie y(t), y′(t) ety′′(t) avec y, y′ et y′′ respectivement.
• De même F (t, y, dydt ,
d2ydt2 ) = 0 ;
• et F (t, y, y, y) = 0.
Exemple. Considérons l’équation différentielle d’ordre 1 :
y′ + ty = t (E)
Posons f : R2 → R l’application définie par f(t, y) = t− ty, alors (E) équivaut à
∀ t ∈ R : y′(t) = f(t, y(t))
Soit y : R → R une solution de (E), alors pour déterminer le coefficient directeur y′(x) du point M(x; y) surla courbe représentative de y, il suffit de calculer f(x, y). Dans la figure suivante, nous avons représenté pourdifférents points M(x; y) un segment de droite de pente f(x; y), le champs de directions :
x
y
0 1
1
Les trois courbes représentent des solutions du problème de Cauchy avec comme condition initiale y(0) = 0,y(0) = 2 et y(0) = 3.
Nous verrons dans la section suivante que les solutions de (E) sont de la forme y : R→ R définie par
y(x) = 1 + λe−x22
10.3 Équation différentielle linéaire d’ordre 1
206

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 10.12. Soient a et b deux fonctions réelles ou complexes définies sur un même intervalle J .1) On appelle équation différentielle linéaire d’ordre 1 (EDL1) une équation différentielle d’ordre 1 de la
formey′(t) + a(t)y(t) = b(t) (EDL1)
2) Lorsque b est la fonction nulle, on parle d’EDL1 homogène.
y′(t) + a(t)y(t) = 0 (H)
3) Une solution de l’EDL1 est la donnée d’un intervalle I inclus dans J et d’une fonction f : I → R dérivabletelle que pour tout t ∈ I, f ′(t) + a(t)f(t) = b(t).
4) Un problème de Cauchy pour l’EDL1 est la donnée d’une condition initiale :y′(t) + a(t)y(t) = b(t)y(t0) = y0
où t0 ∈ J et y0 ∈ R.
Remarque. ,• Lorsque a est une fonction constante (et donc l’EDL1 est y′(t)+ay(t) = b(t)), on parle d’EDL1 à coefficient
constant.• Il est fréquent d’étudier des équations différentielles d’ordre 1 de la forme α(t)y′(t) +β(t)y(t) = γ(t). On se
ramène à une EDL1 en divisant par α(t) sur des intervalles où α ne s’annule pas pour résoudre la nouvelleéquation. La résolution de l’équation de départ nécessite alors d’étudier les recollements de solutions (voirTD).
• En physique, afin de bien faire apparaître l’homogénéité des différents termes, on exprime une équationdifférentielle d’ordre 1 sous la forme canonique :
dydt (t) + 1
τy(t) = 1
τb(t)
où τ a la même dimension que t.
Dans le suite de la section, on se donne a, b : J → R deux fonctions et une EDL1
y′(t) + a(t) y(t) = b(t) (EDL1)
et l’équation homogène associée :y′(t) + a(t) y(t) = 0 (H)
Proposition 10.13 (Linéarité). Soient f et g deux solutions l’EDL1 homogène (H) et λ, µ deux nombresréels, alors λ f + µ g est aussi solution de l’EDL1 homogène (H).
Proposition 10.14. Soient f et g deux solutions de l’EDL1, alors f − g est solution de l’ EDL1 homogèneassociée.
Soit f : I → R une solution l’EDL1 et h : I → R une solution de l’EDL1 homogène (H), alors
(f + h)′(t) + a(t)(f + h)(t) =(f ′(t) + a(t)f ′(t)
)+(h′(t) + a(t)h(t)
)= b(t)
D’où
Proposition 10.15. Soit f une solution de l’EDL1. Soit h une solution de l’EDL1 homogène associée. Alorsf + h est une solution de l’EDL1 y′(t) + a(t)y(t) = b(t)
Digression. Supposons qu’il existe f0 : I → R une solution de l’EDL1, alors on vient de voir que
h : I → R solution de (H) // f : I → R solution de (EDL1)
h // f0 + h
f − f0 foo
est une bijection. Ainsi, après avoir trouvé une solution particulière de (EDL1), il suffit de déterminer les solutionsde (H) pour déterminer l’ensemble de toutes les solutions de (EDL1).
207

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 10.16. Soit a une fonction définie sur un intervalle J et admettant une primitive A. Les solutionsde l’EDL1 homogène
y′(t) + a(t)y(t) = 0 (H)définies sur J sont les fonctions de la forme
t 7→ C exp (−A(t))
où C ∈ K est une constante.
Exercice 10.2. Considérons l’EDL1y′(t)− y(t) = t (E)
et son équation homogène associéey′(t)− y(t) = 0 (H)
1) Résoudre sur R l’équation homogène (H).2) On suppose qu’il existe une solution de (E) de la forme
f : t 7→ C(t)et
où C : R→ R est une fonction dérivable (on suppose que la « constante varie » en fonction de t).a) Simplifier f ′(t)− f(t) pour tout t ∈ R.b) Déterminer une primitive de t 7→ te−t.c) En déduire une solution de (E).
3) Déterminer toutes les solutions de (E).
Le procédé mis en oeuvre dans l’exercice précédent s’appelle méthode de la variation de la constante, il permetde déterminer dans certains cas une solution particulière d’une EDL1.
Théorème 10.17 (Variation de la constante). Soit a, b : J → K deux fonctions définies sur un intervalle J .Supposons que a admet une primitive A : J → K et qu’il existe une fonction dérivable C : J → K telle
∀ t ∈ J : C′(t) = b(t) exp (A(t))
Alors, la fonction f : J → K définie par
f(t) = C (t) exp (−A(t))
pour tout t ∈ J est une solution de l’EDL1 : y′(t) + a(t)y(t) = b(t).
Démonstration. Soit a, b : J → K deux fonctions définies sur un intervalle J . Supposons que a admet une primitiveA : J → K et qu’il existe une fonction dérivable C : J → K telle
∀ t ∈ J : C′(t) = b(t) exp (A(t))
Soit t ∈ J ,
f ′(t) =(C′(t)−A′(t)C(t)
)exp(−A(t))
= (b(t) exp(A(t))− a(t)C(t)) exp(−A(t))= b(t)− a(t)C(t) exp(−A(t))
f ′(t) + a(t)f(t) = b(t)− a(t)C(t) exp(−A(t)) + a(t)C(t) exp(−A(t))= b(t)
D’où le théorème.
Remarque. Du théorème, on déduit que pour déterminer une solution particulière de l’EDL1, il suffit de trouverune primitive C de t 7→ b(t) exp(A(t)) et de poser f : t 7→ C(t) exp(−A(t)).Mais, il est préférable de reprendre la méthode mise en place dans la démonstration. C’est-à-dire, « faire varierla constante », en considérant une solution de la forme t 7→ C(t) exp(−A(t)). Ainsi, en travaillant les données, defaire apparaître le fait que C est une primitive d’une certaine fonction déterminée à l’aide des données a, A, et b.
208

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 10.18 (Principe de superposition). Soit f une solution de l’EDL1
y′(t) + a(t)y(t) = b1(t) (E1)
Soit g une solution de l’EDL1y′(t) + a(t)y(t) = b2(t) (E2)
Alors f + g est une solution de l’EDL1 y′(t) + a(t)y(t) = b1(t) + b2(t).
Exercice 10.3.1) Soit f : I → C une fonction complexe dérivable sur I. Montrer que son conjugué f : I → C, définie par
f(t) = f(t) pour tout t ∈ I, est aussi dérivable sur I et de plus
∀ t ∈ I : f ′(t) = f ′ (t)
2) Soit a : I → R une fonction réelle et b : I → C une fonction complexe. Soit y0 : I → C une solution del’EDL1 : y′(t) + a(t)y(t) = b(t). Montrer quea) la partie réelle Re(y0) : I → R de y0 est une solution de l’EDL1 : y′(t) + a(t)y(t) = Re(b(t)).b) la partie imaginaire Im(y0) : I → R de y0 est une solution de l’EDL1 : y′(t) + a(t)y(t) = Im(b(t)).
Théorème 10.19 (Cauchy-Lipschitz). Soit a, b : J → K deux fonctions continues sur un intervalle J . Alorsl’EDL1 y′(t) + a(t)y(t) = b(t) admet au moins une solution f définie sur J .De plus, tout problème de Cauchy
y′(t) + a(t)y(t) = b(t)y(t0) = y0
où t0 ∈ J et y0 ∈ K, admet une unique solution définie sur J .
Démonstration. Avec les hypothèses du théorème, comme a est continue, elle admet une primitive A : J → K. Demême, la fonction t 7→ b(t) exp(A(t)) admet aussi une primitive C0 : J → K. Ainsi, d’après le théorème variationde la constante, l’EDL1 admet au moins une solution définie sur J .Soit f : J → K une solution, posons C : J → K définie par C(t) = f(t) exp(A(t)) pour tout t ∈ J . Soit t ∈ J , enutilisant les propriétés de l’exponentielle, on déduit que f(t) = C(t) exp(−A(t)). De plus,
f ′(t) =(C′(t)−A′(t)C(t)
)exp(−A(t))
=(C′(t)− a(t)C(t)
)exp(−A(t))
b(t) = f ′(t) + a(t)f(t)
=(C′(t)− a(t)C(t)
)exp(−A(t)) + a(t)C(t) exp(−A(t))
= C′(t) exp(−A(t))
D’où C′(t) = b(t) exp(A(t)). Or, la fonction t 7→ b(t) exp(A(t)) est continue sur I, ainsi d’après le théorème 22.19,il existe une unique constante λ ∈ K telle que C = C0 + λ. On en déduit que
∀ t ∈ J : f(t) = (C0(t) + λ) exp(−A(t))
En particulier, si f est solution du problème de Cauchy, alors
y0 = f(t0) = (C0(t0) + λ) exp(−A(t0)) ⇐⇒ λ = y0 exp(A(t0))− C0(t0)
C’est-à-dire λ, et donc la solution f , est uniquement déterminé par la condition initiale y(t0) = y0.
Corollaire 10.20. Soit a, b : J → K deux fonctions continues sur un intervalle J et f0 : J → K une solution del’EDL1 y′(t) + a(t)y(t) = b(t). Notons A : J → K une primitive de a, alors l’ensemble des solutions de l’EDL1 est
t 7→ f0(t) + C exp(−A(t)) sur J ; C ∈ K
Méthode. Pour résoudre une équation différentielle linéaire d’ordre 1 de la forme y′(t) + a(t)y(t) = b(t), ondoit :
1) Déterminer le (ou les) intervalle(s) sur le(s)quel(s) on étudie l’équation.2) Résoudre l’équation homogène associée y′(t) + a(t)y(t) = 0.3) Résoudre l’équation générale y′(t) + a(t)y(t) = b(t) par la méthode de variation de la constante.
Si de plus un problème de Cauchy est posé, on terminera l’étude en cherchant la valeur de la constante pour
209

TSI 1 Lycée Heinrich-Nessel 2016/2017
laquelle la condition initiale est vérifiée.
Exercice 10.4. Résoudre le problème Cauchy suivant :u′ − u = 1− t− sin(t)− cos(t)u(0) = 2
10.4 Équation différentielle linéaire d’ordre 2
Définition 10.21. Soient a, b et c trois fonctions réelles ou complexes définies sur un même intervalle J .1) On appelle équation différentielle linéaire d’ordre 2 (EDL2) une équation différentielle d’ordre 2 de la
formey′′(t) + a(t)y′(t) + b(t)y(t) = c(t)
2) Lorsque c est la fonction nulle (et donc l’EDL2 est y′′(t) + a(t)y′(t) + b(t)y(t) = 0), on parle d’EDL2homogène.
3) Lorsque a et b sont deux fonctions constantes :
y′′(t) + ay′(t) + by(t) = c(t) (EDL2)
on parle d’EDL2 à coefficients constants.4) Une solution de l’EDL2 y′′(t)+a(t)y′(t)+b(t)y(t) = c(t) est une fonction f définie et deux fois dérivable
sur un intervalle inclus dans J et qui vérifie f ′′(t) + a(t)f ′(t) + b(t)f(t) = c(t).5) Un problème de Cauchy pour l’EDL2 est la donnée d’une EDL2 et de conditions initiales :
y′′(t) + a(t)y′(t) + b(t)y(t) = c(t)y(t0) = y0
y′(t0) = y1
où t0 ∈ J , y0 ∈ K et y1 ∈ K.
Proposition 10.22 (Linéarité). Soient f et g deux solutions de l’EDL2 homogène
y′′(t) + a(t)y′(t) + b(t)y(t) = 0 (H)
et λ, µ deux nombres réels, alors λ f + µ g est aussi solution de cette EDL2.
Proposition 10.23. Soient f et g deux solutions de l’EDL2 y′′(t) + a(t)y′(t) + b(t)y(t) = c(t). Alors f − gest solution de l’EDL2 homogène associée y′′(t) + a(t)y′(t) + b(t)y(t) = 0.
Proposition 10.24. Soit f une solution de l’EDL2 y′′(t) + a(t)y′(t) + b(t)y(t) = c(t). Soit h une solutionde l’EDL2 homogène associée y′′(t) + a(t)y′(t) + b(t)y(t) = 0. Alors f + h est aussi solution de l’EDL2y′′(t) + a(t)y′(t) + b(t)y(t) = c(t).
Digression. Encore une fois, supposons qu’il existe f0 : I → R une solution de l’EDL2, alors on vient de voir que
h : I → R solution de (H) // f : I → R solution de (EDL2)
h // f0 + h
f − f0 foo
est une bijection. Ainsi, après avoir trouvé une solution particulière de (EDL2), il suffit de déterminer les solutionsde (H) pour déterminer l’ensemble de toutes les solutions de (EDL2).
Proposition 10.25 (Principe de superposition). Soit f une solution de l’EDL2
y′′(t) + a(t)y′(t) + b(t)y(t) = c1(t) (E1)
210

TSI 1 Lycée Heinrich-Nessel 2016/2017
Soit g une solution de l’EDL2y′′(t) + a(t)y′(t) + b(t)y(t) = c2(t) (E2)
Alors f + g est solution de l’EDL2 y′′(t) + a(t)y′(t) + b(t)y(t) = c1(t) + c2(t).
Remarque. En physique, afin de bien faire apparaître l’homogénéité des différents termes, on exprime une équationdifférentielle d’ordre 2 à coefficients constants sous la forme canonique :
d2y
dt2 (t) + 2αω0dydt (t) + ω2
0y(t) = ω20c(t)
où ω0 a la même dimension que 1tet où α est sans dimension.
Définition 10.26. Soit y′′(t) + ay′(t) + by(t) = 0 une EDL2 homogène à coefficients constants. L’équationcaractéristique de l’EDL2 est l’équation d’inconnue r :
r2 + ar + b = 0 (C)
Exercice 10.5. Soit y′′(t) + ay′(t) + by(t) = 0 une EDL2 homogène à coefficients constants. Supposons quel’équation caractéristique de l’EDL2
1) admet deux racines réelles distincts r1 et r2. Vérifier que yi : R → R, définie par yi(t) = erit pour toutt ∈ R, est une solution de l’EDL2 pour i = 1 et i = 2.
2) admet une racine réelle r0 (le discriminant est nul). Exprimer a et b en fonction de r0. Vérifier que y1 : R→ Rdéfinie par y(t) = er0t pour tout t ∈ R et y2 : R → R définie par y(t) = ter0t pour tout t ∈ R sont deuxsolutions de l’EDL2.
3) admet deux racines complexes r1 et r2. Justifier que r1 et r2 sont conjugués et qu’il existe un unique couple(r0, ω) ∈ R2 tel que r1 = r0 + iω et r1 = r0 − iω. En déduire que y1 : R→ R définie par y(t) = cos(ωt)er0tpour tout t ∈ R et y2 : R→ R définie par y(t) = sin(ωt)er0t pour tout t ∈ R sont deux solutions (réelles) del’EDL2.
Théorème 10.27. Soit a, b deux nombres réels et
y′′(t) + ay′(t) + by(t) = 0 (H)
une EDL2 homogène à coefficients constants.1) Si l’équation caractéristique de l’EDL2 a deux solutions réelles r1 et r2, alors les solutions de l’EDL2
sont les fonctions de la formet 7→ λer1 t + µer2 t
où λ et µ sont deux constantes arbitraires.2) Si l’équation caractéristique de l’EDL2 a une racine double r0, alors les solutions de l’EDL2 sont les
fonctions de la formet 7→ (λt + µ)er0 t
où λ et µ sont deux constantes arbitraires.3) Si l’équation caractéristique de l’EDL2 a deux solutions complexes conjuguées r1 = α+iω et r2 = α−iω,
alors les solutions de l’EDL2 sont les fonctions de la forme
t 7→ (λ cos(ωt) + µ sin(ωt)) eαt
où λ et µ sont deux constantes arbitraires.
Démonstration. D’après l’exercice précédent, l’équation (H) admet au moins une solution définie sur R. Soity : R→ R une solution réelle quelconque.On note r1 et r2 deux nombres réels tels que r1, r2 soit l’ensemble 1 des racines de l’équation caractéristique de(H). En revenant à la relation (r − r1)(r − r2) = r2 + ar + b, on déduit que r1 + r2 = −a.On pose C : R→ R définie par C(t) = y(t)e−r1t pour tout t ∈ R. La fonction C est alors deux fois dérivable. Soitt ∈ R, alors
y(t) = C(t)er1t
y′(t) = (C′(t) + r1C(t))er1t
y′′(t) =(C′′(t) + 2r1C
′(t) + r21C(t)
)er1t
1. Ainsi, s’il n’y a qu’une racine r0 alors r1 = r2 = r0.
211

TSI 1 Lycée Heinrich-Nessel 2016/2017
Par hypothèse sur y, on a
0 = y′′(t) + ay′(t) + by(t)
0 = er1t(C′′(t) + 2r1C
′(t) + r21C(t) + aC′(t) + ar1C(t) + bC(t)
)0 = C′′(t) + 2r1C
′(t) + aC′(t) + (r21 + ar1 + b)C(t)
0 = C′′(t) + (2r1 + a)C′(t) (1)
Distinguons trois cas :1) Si l’équation caractéristique admet deux racines réelles distinctes r1 et r2. D’après le théorème 10.16 (solu-
tions d’une EDL1 homogène), il existe µ0 ∈ R tel que C′(t) = µ0e−(2r1+a)t pour tout t ∈ R. D’autre part,
on ar1 + r2 = −a ⇒ r1 + a = −r2 ⇒ 2r1 + a = r1 − r2 6= 0
Ainsi, il existe λ ∈ R tel que
∀ t ∈ R : C(t) = µ0
r1 − r2e(r2−r1)t + λ
Si, on pose µ = µ0r1−r2
, alors C(t) = µe(r2−r1)t + λ pour tout t ∈ R. En résumé,
∀ t ∈ R : y(t) =(µe(r2−r1)t + λ
)er1t = λer1t + µer2t
D’où le premier point du théorème.2) Si l’équation caractéristique admet une racine simple r0. Avec les notations précédentes, on a r0 = r1 = r2
et donc 2r0 = −a. D’après (1), on déduit que C′′ = 0, ainsi en intégrant deux fois, on déduit qu’il existe(λ, µ) ∈ R2 tel que C(t) = λ+ µt. En résumé,
∀ t ∈ R : y(t) = λer0t + µter0t
3) Si l’équation caractéristique admet deux racines complexes distinctes r1 et r2. Comme l’équation caracté-ristique est à coefficient réelles, les racines sont conjugués : r1 = r2 et er1t = er2t. Soit α la partie réelle der1 et ω la partie imaginaire r1 alors r1 = α+ iω et r2 = α− iω. De plus, comme r1 ∈ C \ R, ω 6= 0.En reprenant la démonstration du premier cas, on déduit qu’il existe (z1, z2) ∈ C tels que pour tout t ∈ R,z1e
r1t + z2er2t. D’autre part, y : R→ R est une solution réelle. Ainsi,
∀ t ∈ R : y(t) = y(t)⇒ ∀ t ∈ R : z1e
r1t + z2er2t = z1e
r2t + z2er1t
⇒ ∀ t ∈ R : (z1 − z2)er1t = (z2 − z1)er2t
⇒ ∀ t ∈ R : (z1 − z2)e(r1−r2)t = z2 − z1
⇒ ∀ t ∈ R : (z1 − z2)e2ωt = z1 − z2
⇒ ∀ t ∈ R : ze2ωt = z où z = z1 − z2
⇒z = z
ze2ω = zen particulier, avec t = 0 et t = 1
⇒z = λ ∈ R
λ(e2ω − 1) = 0
⇒ λ = z = 0 car ω 6= 0
Donc z1 − z2 = 0. Soit (λ, µ) ∈ R2 tel que z1 = λ2 + iµ2 . Soit t ∈ R, alors
y(t) = z1er1t + z1e
r2t
=(
(λ2 + iµ
2 )eiωt + (λ2 − iµ
2 )e−iωt)eαt
=(λeiωt + e−iωt
2 − µeiωt − e−iωt
2i
)eαt
= λ cos(ωt)eαt − µ sin(ωt)eαt
Corollaire 10.28. Les solutions de l’EDL2
y′′(t) + ω2y(t) = 0
sont les fonctions de la forme t 7→ λ cos(ωt) + µ sin(ωt), où λ et µ sont deux constantes arbitraires.
212

TSI 1 Lycée Heinrich-Nessel 2016/2017
Remarque. Dans le troisième cas, en factorisant, on peut aussi exprimer les solutions sous la forme λ cos(ωt+φ)er0t,où λ et φ sont deux constantes arbitraires, ou encore sous la forme λ sin(ωt+φ)er0t, où λ et φ sont deux constantesarbitraires.
Théorème 10.29. Soit y′′(t) + ay′(t) + by(t) = Aeωt une EDL2 à coefficients constants, où A ∈ R et ω ∈ C.1) Si ω n’est pas solution de l’équation caractéristique, alors il existe une solution particulière de l’EDL2
de la forme t 7→ Ceωt.2) Si ω est racine simple de l’équation caractéristique, alors il existe une solution particulière de l’EDL2 de
la forme t 7→ Cteωt.3) Si ω est racine double de l’équation caractéristique, alors il existe une solution particulière de l’EDL2
de la forme t 7→ Ct2eωt.
Remarque. Grâce au principe de superposition et à la formule d’Euler, on peut aussi trouver une solution parti-culière dans le cas où la fonction t 7→ c(t) est une fonction trigonométrique de type cosinus ou sinus.
Remarque. En mettant ensemble les théorèmes 10.27 et 10.29 et la proposition 10.24, on peut entièrement résoudreles équations du type y′′(t) + ay′(t) + by(t) = c(t) lorsque c(t) = keαt, etc.
Théorème 10.30 (Cauchy-Lipschitz). Soient a, b et c trois fonctions définies sur un intervalle J et admettantune primitive. Alors l’EDL2 y′′(t) + a(t)y′(t) + b(t)y(t) = c(t) admet au moins une solution f définie sur J .De plus, tout problème de Cauchy
y′′(t) + a(t)y′(t) + b(t)y(t) = c(t)y(t0) = y0
y′(t0) = y1
où t0 ∈ J , y0 ∈ R et y1 ∈ R, admet exactement une solution définie sur J .
Méthode. Pour résoudre une équation différentielle linéaire d’ordre 2 à coefficients constants de la formey′′(t) + ay′(t) + by(t) = c(t), on doit :
1) Déterminer le (ou les) intervalle(s) sur le(s)quel(s) on étudie l’équation.2) Résoudre l’équation homogène associée y′′(t) + ay′(t) + by(t) = 0 en cherchant les racines de l’équation
caractéristique.3) Chercher une solution particulière de y′′(t) + ay′(t) + by(t) = c(t) à l’aide des théorèmes ci-dessus.
On pourra aussi utiliser le principe de superposition pour découper c(t) en fonctions élémentaires,polynomiales ou exponentielles.
4) On conclut en ajoutant la solution particulière à la solution générale de l’équation homogène.Si de plus un problème de Cauchy est posé, on terminera l’étude en cherchant la valeur des constantes pourlesquelles les conditions initiales sont vérifiées.
Théorème. Soit y′′(t) + ay′(t) + by(t) = p(t) une EDL2 à coefficients constants, où p est une fonctionpolynomiale.
1) Si 0 n’est pas racine du polynôme caractéristique, alors il existe une solution particulière polynomialede même degré que p.
2) Si 0 est racine simple du polynôme caractéristique, alors il existe une solution particulière polynomialede degré un de plus que p.
3) Si 0 est racine double du polynôme caractéristique, alors il existe une solution particulière polynomialede degré deux de plus que p.
213

TSI 1 Lycée Heinrich-Nessel 2016/2017
214

Chapitre 11
Systèmes linéaires
Programme• Définition d’un système linéaire de n équations à p inconnues, système homogène• Matrice A d’un système linéaire, matrice augmentée (A|B) où b est la colonne des seconds membres.• Calculer le produit d’une matrice par une colonne. Écrire un système sous la forme matricielle AX = B.• Opérations élémentaires sur les lignes : Pour tout i 6= j :
— Li ↔ Lj , (permutation)— Li ← Li + aLj , (transvection)— Li ← λLi avec λ 6= 0. (dilatation)
• Deux systèmes (matrices) sont dit(e)s équivalent(e)s si on passe de l’un à l’autre par une suite finied’opérations élémentaires sur les lignes. Pour les matrices, notations A ∼
LB.
• Deux systèmes équivalents ont le même ensemble de solutions, lien avec l’équivalence des matrices• Échelonner une matrice, algorithme du pivot de Gauss-Jordan• Matrice échelonnée (réduites) en lignes (lorsque tous les pivots sont égaux à 1 et sont les seuls éléments non
nuls de leur colonne).• Un schéma en escalier illustre la notion de matrice échelonnée.• Toute matrice non nulle est équivalente en lignes à une unique matrice échelonnée réduite en lignes• Résolution de systèmes, inconnues principales, secondaires.• Rang (nombre de pivots) d’un système linéaire• Système incompatible (compatible) s’il n’admet pas de solution.• Structure de l’ensemble des solutions d’un système compatible• Familles de vecteurs de Rn
• Combinaison linéaire d’une famille finie F de vecteurs, famille libre, famille liée• Sous espace engendré : Vect(F).• (u1, . . . , up) est libre si et seulement si AX = 0 admet une unique solution si et seulement si le nombre de
pivots est égal à p• famille génératrice de Rn.• (u1, . . . , up) est génératrice si et seulement si pour toute matrice colonne B, l’équation AX = B admet au
moins une solution si et seulement si le nombre de pivots est égal à n.• Interprétation géométrique dans le cas n = 2, 3.• L’équivalence de ces trois propriétés dans un cadre général et formel n’est pas un attendu du programme. En
revanche la mise en oeuvre sur des exemples permet d’illustrer le changement entre les registres suivants :familles de vecteurs, matrices, systèmes.
11.1 Systèmes linéairesNotation. Dans ce chapitre K désigne R ou C.
215

TSI 1 Lycée Heinrich-Nessel 2016/2017
Deux exemples de systèmes linéaires à deux équations et deux variables :x+ 3y = 43x+ y = 6
et 2a+ 3b = 13a− b = −4
Nous allons donner une définition générale des systèmes linéaires et donner précisément les opérations qu’on peuteffectuer afin de les résoudre. Ensuite, on introduira la notion de matrice qui nous sera très utile dans un premiertemps pour la résolution de systèmes.
Un exemple de système à trois équations et trois inconnus :x− y + 3z = 0x+ y + 3z = 0y + z = 0
Un système linéaire à trois équations et trois inconnus est de la forme suivante :a11 x+ a12 y + a13 z = b1
a21 x+ a22 y + a23 z = b2
a31 x+ a32 y + a33 z = b3
où les aij et les bi sont des nombres dans K fixés. Plus généralement,
Définition 11.1.1) Un système linéaire de m équations à n inconnues x1, . . . , xn est la donnée de m équations linéaires en
les mêmes n inconnues :
a11 x1 + a12 x2 + . . .+ a1n xn = b1
a21 x1 + a22 x2 + . . .+ a2n xn = b2
a31 x1 + a32 x2 + . . .+ a3n xn = b3... =
...am1 x1 + am2 x2 + . . .+ amn xn = bm
(S)
2) Si tous les termes b1, b2, . . . , bm sont nuls,
a11 x1 + a12 x2 + . . .+ a1n xn = 0a21 x1 + a22 x2 + . . .+ a2n xn = 0a31 x1 + a32 x2 + . . .+ a3n xn = 0
... =...
am1 x1 + am2 x2 + . . .+ amn xn = 0
(H)
On dit que le système est homogène.
Vocabulaire. On appelle solution du système linéaire tout n-uplet (x1, . . . , xn) ∈ Kn de nombres qui sontsimultanément solutions des m équations et on note
S = (x1, . . . , xn) ∈ Kn solution de (S)
l’ensemble des solutions de (S).
Dans la définition précédente, on dit que (H) est le système homogène associé au système (S).
Exemple. Lorsqu’on étudie l’intersection de deux droites dans le plan, on est amené à résoudre un système àdeux équations et deux inconnues. Déterminer l’intersection de trois plans revient à résoudre un système à troiséquations et trois inconnues
Proposition 11.2. Soit (H) un système linéaire homogène de m équations à n inconnues. Alors,1) le n-uplet nul (0; 0; . . . ; 0) ∈ Kn est solution de (H) ;
216

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) Si deux n-uplets sont solutions de (H), alors toute combinaison linéaire de ces n-uplets aussi.
Remarque. Une conséquence de cette proposition : si un système linéaire homogène a une solution non nulle, alorsil admet une infinité de solutions.
Proposition 11.3. Soit (S) un système linéaire. Soit (H) le système homogène associé.1) Si (a1, . . . , an) est solution de (S) et (h1, . . . , hn) est solution de (H), alors (a1 + h1, . . . , an + hn) est
aussi solution de (S).2) Si (a1, . . . , an) et (b1, . . . , bn) sont deux solutions de (S), alors (a1 − b1, . . . , an − bn) est solution de
(H).
Exercice 11.1 (Droite et equation homogène). Dans le plan muni d’un repère, soit D une droite d’équation
cartésienne ax+by = c. Montrer que −→v
(x
y
)est un vecteur directeur de D si et seulement si x et y sont solutions
de l’équation homogène ax+ by = 0.
Digression. Supposons qu’il existe (a1, . . . , an) une solution de (S), alors on obtient ici aussi une bijection entreles solutions de (S) et de (H) :
(h1, . . . , hn) ∈ Kn solution de (H) // (x1, . . . , xn) ∈ Kn solution de (E)
(h1, . . . , hn) // (a1, . . . , an) + (h1, . . . , hn)
(x1, . . . , xn)− (a1, . . . , an) (x1, . . . , xn)oo
Contrairement aux équations différentielles linéaires du premier et du second ordre, ici, il n’y a pas de théorèmedonnant l’existence d’une solution à (S). Au contraire, il est facile de trouver un système n’ayant pas de solution.Par exemple, le système
2x− 6y = 1 (11.1)−x+ 3y = 1 (11.2)
où (11.1) correspond à une droite D1 et (11.2) correspond à une droite D2. Comme les droites sont parallèles nonconfondues dans le plan, elles ne se coupent pas et le système n’admet pas de solution. Mais, le système homogèneassocié :
2x− 6y = 0−x+ 3y = 0
⇐⇒−1
2 (2x− 6y) = −12 × 0
−x+ 3y = 1
⇐⇒−x+ 3y = 0−x+ 3y = 0
⇐⇒ x = 3y
On en déduit que (x; y) est solution de (H) si et seulement si x = 3y si et seulement si la famille de R2 est de laforme (3y; y) pour un certain y ∈ R. Ainsi,
S(H) = (3y; y); y ∈ R = λ(3; 1); λ ∈ R n’est pas en bijection avec S(S) = ∅
Du point de vu géométrique, les deux droites D1 et D2 sont parallèles et donc partagent les mêmes vecteurs
directeurs. D’où S(H) est infini et correspond à l’ensemble des vecteurs colinéaires au vecteur directeur −→v
(31
).
Dans la section suivante, nous allons préciser les opérations élémentaires permettant de résoudre un systèmelinéaire.
11.1.1 Systèmes et opérationsDans un système linéaire (S) à m équations et n inconnues, on note L1, . . . , Lm les m lignes du système.
217

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 11.4. Soit (S) un système linéaire. On dit qu’un système (S′) est obtenu par opération élémentaireà partir de (S) s’il est obtenu d’une des trois façons suivantes :• Li ↔ Lj : en échangeant deux lignes de (S) ; (permutation)• Li ← aLi : en multipliant une ligne de (S) par un nombre a 6= 0. (dilatation)• Li ← Li +λLj : en remplaçant une ligne de (S) par la somme de cette ligne avec λ fois une autre, λ ∈ K
quelconque. (transvection)où Li et Lj désignent deux lignes distinctes (i 6= j).
Définition 11.5. Deux systèmes linéaires (S) et (S′) sont équivalents si on peut obtenir (S′) à partir de (S)par une succession finie d’opérations élémentaires.
Remarque. Par récurrence, on note qu’on peut ajouter à Li la combinaison linéaire∑
k 6=i λkLk des autres lignes :Li ← Li +
∑k 6=i λkLk. Cette opération est bien une succession d’opérations élémentaires.
Théorème 11.6. Soient (S) et (S′) deux systèmes linéaires équivalents (par opérations élémentaires) alorselles admettent le même ensemble de solutions : S = S ′.
Définition 11.7. On dit qu’un système d’équations linéaires est compatible s’il admet au moins une solution,sinon on dit qu’il est incompatible.
Exercice 11.2. Soit m ∈ R un nombre fixé. Pour quels valeurs de m le systèmex+my = 1−x+ y = 2
est compatible.
11.2 MatricesDéfinition 11.8. Une matrice de dimension m×n est un tableau d’éléments de K à m lignes et n colonnes :
M =
a11 a12 a13 . . . a1j . . . a1n
a21 a22 a23 . . . . . . a2n
a31 a32 a33 . . . . . . a3n...
...
ai1 aij...
......
am1 am2 am3 . . . . . . amn
= (aij)
On notera que le coefficient aij se trouve sur la i-ème ligne et la j-ème colonne 1.L’ensemble des matrices de dimension m× n est notéMm,n(K).
1. Pour se souvenir qu’on prend d’abord en compte les lignes et ensuite les colonnes, on peut utiliser comme moyenmnémotechnique le terme "Lycos", qui dans la mythologie grecque est un fils de Poseidon.
Définition 11.9. • Une matrice avec une seule ligne est une matrice ligne.• Une matrice avec une seule colonne est une matrice colonne.• Lorsque m = n, donc que le tableau est carré, on dit que la matrice est une matrice carrée de taille n.
Remarque. Une matrice colonne de taille n× 1 s’identifie à un vecteur de Kn. Une matrice ligne s’identifie aussià un vecteur de Kn.
Notation. On noteMn(K) l’ensemble des matrices carrées de taille n.
Exemples.
218

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) M =
(−1 3 10111.3 3 −5
);
2) A =
(1 24 −1
);
3) B =
−1 10 5053 534 2340 −1 1001
;
4) Y =
(1−1
);
5) A =
(a1,1 a1,2
a2,1 a2,2
);
6) A =
a1,1 a1,2 a1,3
a2,1 a2,2 a2,3
a3,1 a3,2 a3,3
.
Définition 11.10. Dire que deux matrices A = (aij) et B = (bij) sont égales signifie qu’elles ont le mêmeformat n×m et les nombres qui occupent la même position sont deux à deux égaux :
∀ k ∈ 1, . . . , n, ∀ l ∈ 1, . . . ,m, ak,l = bk,l
Définition 11.11.• La matrice de taille m× n dont tous les coefficients sont nuls s’appelle la matrice nulle, et se note 0n,m
ou tout simplement 0.• La matrice de taille n×n dont tous les coefficients diagonaux (c’est-à-dire sur la ke ligne et ke colonne)
valent 1 et tous les autres 0 s’appelle matrice identité de taille n et se note In.
Exemple. La matrice identité de taille 4 :
I4 =
1 0 0 00 1 0 00 0 1 00 0 0 1
Définition 11.12. Une matrice de taillem×n est diagonale si ses seuls coefficients non nuls sont les coefficientssur la première diagonale (c’est-à-dire ceux en position (k, k)).
Définition 11.13. Une matrice A de taille m× n est• triangulaire supérieure si ses seuls coefficients non nuls sont les Ak,l avec k ≤ l. Elle est dite triangulaire
supérieure stricte si de plus ses coefficients diagonaux sont nuls.• triangulaire inférieure si ses seuls coefficients non nuls sont les Ak,l avec k ≥ l. Elle est dite triangulaire
inférieure stricte si de plus ses coefficients diagonaux sont nuls.
Exemple. La matrice T =
1 2 −10 5 120 0 8
est triangu-
laire supérieure,
La matrice U =
0 0 0−1 0 012 5 0
est triangulaire infé-
rieure stricte.
11.2.1 Opération sur les matrices
Définition 11.14. Soit A = (aij) et B = (bij) deux matrices de même taillem×n. La somme (resp. différence)de A et B la matrice, notée A+B (resp. A−B), obtenue en additionnant (resp. en soustrayant) deux à deuxchaque coefficient qui occupent la même position :
A+B = (aij + bij)
219

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemple. Soit A =
(1 23 4
)et B =
(5 67 8
). Alors
A+B =
(1 23 4
)+
(5 67 9
)=
(1 + 5 2 + 63 + 7 4 + 9
)=
(6 810 13
)et
A−B =
(1 23 4
)−
(5 67 9
)=
(1− 5 2− 63− 7 4− 9
)=
(−4 −4−4 −5
)
Définition 11.15. Soit A = (aij) une matrice de taille m × n et λ un nombre réel. La matrice λA est lamatrice obtenue en multipliant chaque coefficient de A par le nombre λ :
λA = (λaij)
Définition 11.16. On appelle matrice scalaire toute matrice carrée de la forme λIn, où λ ∈ K.
Exemple : La matrice
3 0 0 00 3 0 00 0 3 00 0 0 3
est une matrice scalaire.
Proposition 11.17. Soit A ∈Mm,n(K). Soient λ ∈ K et µ ∈ K. Alors :1) 0×A = 0n,m2) 1×A = A
3) λ× (µ×A) = (λµ)×A = µ× (λ×A)
Proposition 11.18. Soient A ∈Mm,n(K) et B ∈Mm,n(K). Soient λ ∈ K et µ ∈ K. Alors :1) A+ 0 = A = 0 +A
2) A+B = B +A (commutativité)3) (A+B) + C = A+ (B + C) (associativité)4) λ(A+B) = λA+ λB (distributivité)5) (λ+ µ)A = λA+ µA
Remarque. On a 0 = 0×A = (1 + (−1))A = 1×A+ (−1)×A = A+ (−1)A. On note alors −A au lieu de (−1)A.On définit alors la soustraction de deux matrices de même taille par A−B = A+ (−B).
L’opération la plus subtile sur les matrices est le produit. Quelques exemples et cas particuliers de produits dematrices :
1)
(3 17 9
)×
(23
)=
(3× 2 + 1× 37× 2 + 9× 3
)=
(941
); 2)
(a b
c d
)×
(x
y
)=
(a× x+ b× yc× x+ d× y
);
3)
(a b
c d
)×
(x z
y t
)=
(a× x+ b× y a× z + b× tc× x+ d× y c× z + d× t
);
4)
1 2 34 5 67 8 9
×abc
=
a+ 2b+ 3c4a+ 5b+ 6c7a+ 8b+ 9c
220

TSI 1 Lycée Heinrich-Nessel 2016/2017
5)
1 2 34 5 67 8 9
×10 12 14−1 −2 −344 47 33
=
1× 10 + 2× (−1) + 3× 44 1× 12 + 2× (−2) + 3× 47 1× 14 + 2× (−3) + 3× 334× 10 + 5× (−1) + 6× 44 4× 12 + 5× (−2) + 6× 47 4× 14 + 5× (−3) + 6× 337× 10 + 8× (−1) + 9× 44 7× 12 + 8× (−2) + 9× 47 7× 14 + 8× (−3) + 9× 33
=
140 149 107299 320 239458 491 371
.
Définition 11.19 (Multiplication). Soit A = (aij) ∈Mn,m(K) et B = (bij) ∈Mm,p(K). Le produit de A parB est 1 la matrice A×B = (pij) dansMn,p(K) par
∀ 1 ≤ k ≤ n ∀ 1 ≤ l ≤ p : pk,l =m∑j=1
ak,jbj,l
1. On notera que pour calculer le produit A×B, il faut que le nombre de colonnes de A soit égal au nombre de lignesde B.
Proposition 11.20. Soit A ∈ Mn,m(K). Soit B ∈ Mm,p(K). Soit B′ ∈ Mm,p(K). Soit C ∈ Mp,q(K). Soitλ ∈ K. Alors :
1) A× 0 = 0×A = 02) A× Im = A = In ×A3) (AB)C = A(BC) (associativité)4) (λA)B = A(λB) = λ(AB)5) A(B +B′) = AB +AB′ et (B +B′)C = BC +B′C (distributivité)
Remarque. En particulier, on a λA = λI ×A = (λI)×A
Définition 11.21. Soit A ∈Mn(K). On définit les puissances de A par récurrence par :A0 = In;Ak+1 = A×Ak pour tout k ∈ N.
Proposition 11.22. Soit A ∈Mn(K), k et l deux entiers, alors AkAl = AlAk = Ak+l.
Remarque. Attention ! Considérons la matrice A =
(1 10 1
)et B =
(0 00 1
).On note que
A×B =
(0 10 1
)et B ×A =
(0 00 1
)Ainsi, avec les matrices, A×B 6= B ×A en général.
11.2.2 Inverse d’une matriceDéfinition 11.23. Soit A ∈Mn,m(K). On dit que :• A est inversible à gauche s’il existe B ∈ Mm,n(K) telle que BA = Im. La matrice B s’appelle inverse à
gauche de A.• A est inversible à droite s’il existe C ∈ Mm,n(K) telle que AC = In. La matrice C s’appelle inverse à
droite de A.• A est inversible si A est inversible à gauche, à droite et que ses deux inverses sont les mêmes.
221

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 11.3. 1) Calculer le produit
(a 00 b
)×
(c 00 d
).
2) Déterminer une condition nécessaire et suffisante pour que
(a 00 b
)soit inversible et déterminer l’inverse.
3) Déterminer les coefficients a, b, c et d tels que
(a b
c d
)×
(1 −12 1
)= I2.
4) Avec les coefficients précédents, calculer
(1 −12 1
)×
(a b
c d
).
Exemple. 1) La matrice identité est inversible et est son propre inverse.
2) Une matrice carrée diagonale est inversible si et seulement si ses éléments diagonaux sont tous non nuls.
3) La matrice nulle n’est inversible ni à gauche ni à droite.
4) La matrice
A =
1000
est inversible à gauche, mais pas à droite.
Théorème 11.24 (admis). Soit A ∈ Mn(K), une matrice carrée de taille n. Alors A est inversible à gauchesi et seulement si A est inversible à droite. De plus les inverses à droite et à gauche sont automatiquement lesmêmes.
Notation. Lorsque A ∈Mn(K) est inversible, on note A−1 son inverse. On note GLn(K) ou GL(n,K) l’ensembledes matrices dansMn(K) qui sont inversibles.
Proposition 11.25. Soient A ∈ GL(n,K) et B ∈ GL(nK). Soit λ ∈ K \ 0. Alors AB ∈ GL(n,K) et(λA) ∈ GL(n,K). De plus, on a (AB)−1 = B−1A−1 et (λA)−1 = 1
λA−1.
Proposition 11.26. Soit A ∈ GL(n,K). Alors A−1 ∈ GL(n,K) et(A−1)−1 = A.
11.3 Retour aux systèmes linéairesFaisons maintenant le lien avec les systèmes linéaires.
Exemple. Considérons la matrice A =
(2 34 7
), X =
(x
y
)et B =
(818
).
Notons que,
A×X =
(2x+ 3y4x+ 7y
)Ainsi, l’égalité matricielle A×X = B équivaut au système linéaire :
2x+ 3y = 84x+ 7y = 18
222

TSI 1 Lycée Heinrich-Nessel 2016/2017
Pour la résolution des systèmes, on associera une matrice augmentée :
(A|B) =
(2 3 84 7 18
)
⇐⇒
(2 3 80 1 2
)L2 ← L2 − 2L1
⇐⇒
(2 0 20 1 2
)L1 ← L1 − 3L2
⇐⇒
(1 0 10 1 2
)L1 ←
12 × L1
D’où, 2x+ 3y = 84x+ 7y = 18
⇐⇒x = 1y = 2
On note que l’utilisation des matrices augmentée nous évite d’avoir à recopier les inconnues x et y et nous permetde nous concentrer sur les paramètres et les opérations élémentaires.
Définition 11.27. Avec les notations de la définition 11.1, au système linéaire (S) on associe la matriceA = (aij) ∈Mm,n(K), B = (bi) ∈ Km et la matrice augmentée :
(A|B) =
a11 . . . a1n b1...
......
am1 . . . amn bm
Proposition 11.28. Avec les notations de la définition 11.1 et de la définition précédente, la famille (x1, . . . , xn)
est solution du système (S) si et seulement si la matrice colonne X =
x1...xn
est solution de l’équation matri-
cielle :AX = B
Vocabulaire. L’écriture AX = B de la proposition s’appelle écriture matricielle du système (S).
Proposition 11.29. Soit (S) un système linéaire écrit sous forme matricielle AX = B. Si A est une matricecarrée inversible, alors (S) admet une unique solution X = A−1B.
Sur les matrices, comme pour les systèmes linéaires, on s’autorise les différentes opérations élémentaires :
Définition 11.30. Soit A une matrice (augmentée). On dit qu’une matrice (augmentée) A′ est obtenu paropération élémentaire à partir de A s’il est obtenu d’une des trois façons suivantes :• Li ↔ Lj : en échangeant deux lignes de (S) ; (permutation)• Li ← aLi : en multipliant une ligne de (S) par un nombre a 6= 0. (dilatation)• Li ← Li +λLj : en remplaçant une ligne de (S) par la somme de cette ligne avec λ fois une autre, λ ∈ K
quelconque. (transvection)où Li et Lj désignent deux lignes distinctes (i 6= j).
Définition 11.31. Deux matrices (augmentées) A et A′ sont équivalentes en lignes si on peut obtenir A′ àpartir de A par une succession finie d’opérations élémentaires et on note
A ∼LA′
223

TSI 1 Lycée Heinrich-Nessel 2016/2017
Si on passe d’un système linéaire (S) à un autre système (S′) par une suite finie d’opérations élémentaires sur leslignes, la matrice augmentée de (S′) s’obtient en effectuant la même suite d’opérations élémentaires sur la matriceaugmentée de (S).
Exercice 11.4. Démontrer que les matrices ci-dessous sont telles que A ∼LA′ et B ∼
LB′ et interpréter le résultat.
A =
3 0 −3 6 6−2 0 4 −1 8−3 0 5 −3 6
A′ =
1 0 −1 2 20 0 2 3 120 0 0 0 0
B =
1 2 −11 2 −12 −1 21 0 0
B′ =
1 2 −10 5 −40 0 10 0 0
Proposition 11.32. Soit A, A′ la matrice augmentée des systèmes (S) et (S′) respectivement. Le système(S) est équivalent au système (S′) si et seulement si A est équivalent en lignes à A′.
Afin de pouvoir résoudre un système, nous allons chercher à transformer la matrice augmentée en une matriceéquivalente d’une certaine forme dite échelonnée :
11.3.1 Matrices échelonnéesDéfinition 11.33. Une matrice A est échelonnée en lignes si elle vérifie les conditions suivantes :• Si une ligne de A est nulle, alors toutes les lignes suivantes aussi.• à partir de la deuxième ligne, dans chaque ligne non entièrement nulle, le premier coefficient non nul à
partir de la gauche est situé à droite de premier coefficient non nul de la ligne précédente.Le premier coefficient non nul de chaque ligne non nulle s’appelle un pivot.
Remarque. D’après le deuxième point de la définition, les pivots ne peuvent être sur une même colonne ! Ils sonttoujours sur une espèce d’escalier avec que des zéros à gauche et en dessous de chacun d’eux.
Définition 11.34. Une matrice A est échelonnée réduite en lignes si elle est échelonnée en lignes et si le pivotde chaque ligne non nul vaut 1 et est le seul coefficient non nul de sa colonne.
Définition 11.35. Une matrice augmentée (A|B) est dite échelonnée (réduite) en lignes si A est échelonnée(réduite) en lignes.
Exemples :
• La matrice suivante est échelonnée :
0 −4 ∗ ∗ ∗ ∗0 0 22
7 ∗ ∗ ∗0 0 0 0 π ∗0 0 0 0 0 00 0 0 0 0 00 0 0 0 0 0
• La matrice suivante est échelonnée réduite :
0 1 0 ∗ 0 ∗0 0 1 ∗ 0 ∗0 0 0 0 1 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 0
• La matrice nulle est échelonnée (réduite)• La matrice identité est échelonnée (réduite)
Exercice 11.5. Considérons les systèmes linéaires suivants
(a)
a+ 2b− c = 3a+ 3b+ c = 02a+ 5c+ d = 1
(b)
u+ 2v − w + x = 2u+ w + 3x = 02u+ 2v + w + 2x = 1
Échelonner les matrices augmentées associées aux systèmes.
224

TSI 1 Lycée Heinrich-Nessel 2016/2017
11.3.2 Algorithme du pivot de Gauss-JordanAlgorithme de Gauss-Jordan : Si A = (aij) ∈Mn,p(R) est non nulle :
1) On place les lignes nulles en dernier.2) Soit j le plus petit indice tel que la colonne j soit non nul.3) Soit i le plus petit indice tel que aij 6= 0.4) Effectuer Li ← 1
aijLi de telle sorte que le pivot a′ij en (i, j) soit égal à 1.
5) Annuler tous les coefficients sous le pivot et au dessus :Pour k de 1 à n, si k 6= i faire : Lk ← Lk − akjLi.
6) Permuter les lignes L1 et Li.7) Réitérer le procédé avec la sous-matrice obtenue en ne considérant que les coefficients d’indices de ligne
strictement supérieurs à ceux du pivot tant que cette matrice existe.
Exemple. Voir https://youtu.be/6EAxrPVL-Hg
Théorème 11.36. Toute matrice non nulle est équivalente en lignes à une unique matrice échelonnée réduiteen lignes.
Définition 11.37. Avec les notations de la définition 11.1, on appelle inconnue principale (et sinon secondaireou paramètre) tout inconnue xk telle qu’il existe un pivot d’indice de colonne k sur la matrice échelonnéeréduite.
Proposition 11.38. Soit un système linéaire de m équations à n inconnues telle que m < n. Alors il y a aumoins n−m inconnues secondaires.
Exemple. On considère un système linéaire homogène (S) de cinq équations à 6 inconnues, de forme matricielleAX = B et on suppose que sa matrice échelonnée réduite est :
A′ =
0 1 0 −1 0 50 0 1 3 0 −30 0 0 0 1 80 0 0 0 0 00 0 0 0 0 0
et B′ =
12300
Les lignes principales sont les lignes L1, L2 et L3. Les inconnues principales sont x2, x3, x5 et les inconnuessecondaires (paramètres) sont x1, x4 et x6.De plus, l’équation AX = 0 est équivalent à
x2 − x4 + 5x6 = 1x3 + 3x4 − 3x6 = 2x5 + 8x6 = 3
⇐⇒
x2 = 1 + x4 − 5x6
x3 = 2− 3x4 + 3x6
x5 = 3− 8x6
D’où l’ensemble des solutions de (S) est :
S =
x1
1 + x4−5x6
2−3x4 + 3x6
x4
3−8x6
x6
; x1, x4, x6 ∈ R
=
012030
+ x1
100000
+ x4
01−3100
+ x6
0−530−81
; x1, x4, x6 ∈ R
sous-ensemble de R6.
Exercice 11.6. Résoudre par la méthode de Gauss les systèmes suivants :
225

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) x− 2y + t = 2x− y − z + 4t = 2x− 3y + z − 2t = 2
(infinité de solutions, deux pa-ramètres z et t)
2) x+ 5y − z = 73x+ 16y + 4z = 22x+ 9y + z = 3
(solution unique (−6; 2;−3))
3) y + z = 2x+ y + z = 2x+ z = 1x+ y − z = 1
(pas de solutions)
11.3.3 Rang
Définition 11.39. Soit A une matrice deMm,n(K) et A′ la matrice échelonnée réduite associée à A. Le rangde A est le nombre de pivot de A′. On le note rg(A).Le rang d’un système linéaire est égal au rang de la matrice associée A.
Remarque.
• Le rang est inférieur ou égal au nombre de ligne de la matrice A (respectivement d’équations du système).
• Le rang d’un système linéaire est égal à son nombre d’inconnues principales.
Exemples.
1) La matrice nulle est de rang 0.
2) Une matrice de rang 0 est forcément nulle.
3) La matrice identité In est de rang n.
4) Les matrices de transvections sont toutes de rang n.
5) Les matrices de dilatation (avec a 6= 0) sont toutes de rang n.
Théorème 11.40. Avec les notations de la définition 11.1, on considère un système linéaire (S) à m équationset n inconnues. On associe la matrice augmentée échelonnée réduite de rang r :
a′1,j1 . . . a′1,n b′1
0 a′2,j2 . . . a′1,n b′2
a′r,jr . . . a′r,n b′r
0 . . . 0 b′r+1...
...0 0 b′m
où a′1,j1 , a
′2,j2 , . . . , a
′r,jr sont les pivots (égaux à un). Alors le système (S) est compatible si et seulement si
b′r+1, . . . , b′m sont nuls. Dans ce cas :
• (S) possède une solution unique si et seulement si r = n ;• (S) possède une infinité de solutions si et seulement si r < n.
Dans la situation où b′r+1, . . . , b′m sont nuls et que le rang r est inférieur strictement au nombre d’inconnues n, alors
l’ensemble des solutions est en bijection avec Kn−r, l’ensemble K à la puissance le nombre d’inconnues secondaires(de paramètres).
Corollaire 11.41. Tout système de m équations linéaires à n inconnues possède
• ou bien une infinité de solutions ;
• ou bien aucune solution ;
• ou bien une unique solution.
226

TSI 1 Lycée Heinrich-Nessel 2016/2017
11.4 Familles de vecteurs de Rn
Un système linéaire peut être vu comme une équation sur des vecteurs, par exemple :x− y + 3z = 0x+ y + 3z = 0y + z = 0
⇐⇒ x
110
+ y
−111
+ z
331
=
000
Dans cette section, nous allons faire un lien entre des propriétés sur des familles de vecteurs et l’ensemble dessolutions de systèmes.
Définition 11.42. Une famille de n vecteurs de Rm est la donnée de (vk)1≤k≤n = (v1, . . . , vn) éléments deRm.
Définition 11.43. Soit m un entier naturel, soit v1, . . . , vn des vecteurs de Rm. On appelle combinaisonlinéaire de la famille (vk)1≤k≤n toute somme de la forme
v =n∑k=1
λkvk
où les λk ∈ R qu’on appelle dans ce cas des scalaires.
Définition 11.44. Soitn∑k=1
λkvk une combinaison linéaire de la famille (vk). On dit que
• la combinaison linéaire est triviale si tous les scalaires λk sont nuls ;• la combinaison linéaire est nulle si la somme est égale au vecteur nul.
Exemple. La combinaison linéaire
(2−4
)− 2
(1−2
)=
(00
)n’est pas triviale mais nulle.
Définition 11.45. Soit F = (v1, . . . , vn) ∈ Rm une famille de vecteurs, on appelle espace vectoriel engendrépar F et on note VectF , le sous-ensemble de Rn formé des combinaisons linéaires des vecteurs de la famille Fà coefficients réels :
Vect(F) = n∑k=1
λkvk; avec λ1, . . . , λn ∈ Rm
Exercice 11.7. Considérons la famille F = (
1−10
,
10−1
) et les vecteurs :
v1 =
2−1−1
; v2 =
1−10
; v3 =
14−5
et v4 =
5312
1) Quels vecteurs appartiennent à Vect(F) ?2) Montrer que les vecteurs v1 + v3 et 1
2v2 + 47v3 appartiennent à Vect(F).
Proposition 11.46. Soit F une famille de vecteurs de Rm, u, v deux vecteurs de Vect(F), le sous-espacevectoriel engendré par la famille F , et λ, µ deux nombres réels. Alors la combinaison linéaire λu+µv appartientaussi à Vect(F).
227

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 11.47. On dit qu’une famille F = (v1, . . . , vn) de Rm est génératrice si Vect(F) = Rm, c’est-à-diresi
∀u ∈ Rm ∃ (λ1, . . . , λn) ∈ Rn : u = λ1v1 + . . .+ λnvn
Remarque. Une famille (v1, . . . , vn) est génératrice si et seulement si tout vecteur peut s’écrire comme combinaisonlinéaire des vecteurs v1, . . . , vn.
Exemple. La famille (
(10
),
(−11
),
(01
)) est une famille génératrice de R2. On note aussi que
(10
)+
(−11
)−
(01
)=
(00
)= λ
(10
)+ λ
(−11
)− λ
(01
)pour tout λ ∈ R. Il y a une infinité de façons différentes d’obtenir le vecteur nul à partir de cette famille.
Théorème 11.48. Soit (v1, . . . , vn) une famille de vecteurs de Rm. On lui associe la matrice A ∈ Mm×n(R)dont les colonnes sont les coordonnées des n vecteurs v1, . . . , vn. Les propriétés suivantes sont équivalentes :
1) la famille (v1, . . . , vn) est génératrice ;2) pour tout matrice colonne B ∈ Mm,1(R), le système linéaire AX = B associé admet au moins une
solution ;3) le rang de A est égal à m.
Définition 11.49. On dit qu’une famille F = (v1, . . . , vn) de Rm est libre si
∀(λ1, . . . , λn) ∈ Rn : λ1v1 + . . .+ λnvn = −→0 ⇒ λ1 = . . . = λn = 0
Remarques.• La famille de vecteurs (v1, . . . , vn) est libre si et seulement si la seule combinaison linéaire nulle est la
combinaison linéaire triviale.• La famille vide (ne comportant aucun vecteur) est libre.
Proposition 11.50.1) Toute famille ne comportant qu’un seul vecteur non nul est libre.2) Une famille contenant le vecteur nul ou bien deux fois le même vecteur est toujours liée.
Théorème 11.51. Soit (v1, . . . , vn) une famille de vecteurs de Rm. On lui associe la matrice A ∈ Mm×n(R)dont les colonnes sont les coordonnées des n vecteurs v1, . . . , vn. Les propriétés suivantes sont équivalentes :
1) la famille (v1, . . . , vn) est libre ;2) le système linéaire (homogène) AX = 0 associé a pour seule solution la solution triviale (0, . . . , 0) ;3) le rang de A est égal à n.
Proposition 11.52. Soit F et F ′ deux familles de vecteurs de Rm telles que F soit incluse dans F ′.• Si F ′ est libre, alors F est libre.• Si F est génératrice alors F ′ est génératrice.
Définition 11.53. Une famille F de vecteurs de Rm est une base si elle est libre et génératrice.
Exercice 11.8. À l’aide des deux théorèmes précédents, donner deux propositions équivalentes au fait qu’unefamille F de n vecteurs soit une base de Rm. En déduire une justification du vocabulaire « base ».
228

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 11.54. Une famille de n vecteurs de Rn est une base si et seulement si elle est libre si et seulementsi elle est génératrice.
229

TSI 1 Lycée Heinrich-Nessel 2016/2017
11.5 Annexe : Les matrices
11.5.1 Opérations élémentaires et produit de matrices
Définition 11.55. Soit n ∈ N un entier non nul. Soit m ∈ N un entier non nul. Soit k un entier entre 1 et n.Soit l un entier entre 1 et m. La matrice élémentaire Ek,l deMn,m(K) est la matrice de taille n×m dont tousles coefficients sont nuls sauf le coefficient de la ke ligne et le colonne qui vaut 1.
Exemple : La matrice élémentaire E2,3 deM3(K) est la matrice
E2,3 =
0 0 00 0 10 0 0
Proposition 11.56. Soit A = (ai,j) ∈Mn,m(K). Alors
A =n∑i=1
m∑j=1
ai,jEi,j
Définition 11.57. Soit a ∈ K\0. Soit n ∈ N un entier non nul. Soit k ∈ 1, . . . , n. La matrice de dilatationDk(a) est la matrice définie par
Dk(a) =n∑
i=1, i6=k
Ei,i + aEk,k
Exemple : La matrice de dilatation D2(a) deM3(R) est
D2(a) =
1 0 00 a 00 0 1
Proposition 11.58. Soit a ∈ K \ 0. Soit n ∈ N un entier non nul. Soit k ∈ 1, . . . , n. La matrice Dk(a)est inversible et a pour inverse Dk(a)−1 = Dk
(1a
).
Proposition 11.59 (Lk ← aLk). Soit a ∈ K \ 0. Soit n ∈ N un entier non nul. Soit k ∈ 1, . . . , n. SoitA ∈Mn(K). Le produit Dk(a)×A est obtenue à partir de A en remplaçant la ke ligne par la ke ligne multipliéepar a.
Proposition 11.60. Soit a ∈ K \ 0. Soit n ∈ N un entier non nul. Soit k ∈ 1, . . . , n. Soit A ∈Mn(K). Lamatrice ADk(a) est obtenue à partir de A en remplaçant la ke colonne par la ke colonne multipliée par a. Onnote Ck ← aCk cette opération.
Définition 11.61. Soit n ∈ N non nul. Soit k ∈ 1, . . . , n. Soit l ∈ 1, . . . , n avec l 6= k. Soit λ ∈ K. Lamatrice de transvection Tk,l(λ) est la matrice définie par
Tk,l(λ) = In + λEk,l
Exemple. La matrice de transvection T1,3(λ) deM3(R) est
T1,3(λ) =
1 0 λ
0 1 00 0 1
230

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 11.62. Soit n ∈ N non nul. Soit k ∈ 1, . . . , n. Soit l ∈ 1, . . . , n avec l 6= k. Soit λ ∈ K. Lamatrice Tk,l(λ) est inversible et a pour inverse Tk,l(λ)−1 = Tk,l(−λ).
Proposition 11.63 (Lk ← Lk + λLl). Soit n ∈ N non nul. Soit k ∈ 1, . . . , n. Soit l ∈ 1, . . . , n avec l 6= k.Soit λ ∈ K. Soit A ∈Mn(K). Le produit Tk,l(λ)×A est obtenue à partir de A en remplaçant la ke ligne de Apar la ke ligne additionnée à la le ligne préalablement multipliée par λ.
Proposition 11.64. Soit n ∈ N non nul. Soit k ∈ 1, . . . , n. Soit l ∈ 1, . . . , n avec l 6= k. Soit λ ∈ K. SoitA ∈Mn(K). La matrice ATk,l(λ) est obtenue à partir de A en remplaçant la ke colonne de A par la ke colonneadditionnée à la le colonne préalablement multipliée par λ. On note Ck ← Ck + λCl cette opération.
À l’aide des matrices de dilatations et de transvections, il est possible de représenter par un produit de matrice àgauche, l’opération de permutation des lignes.
Proposition 11.65 (Lk ↔ Ll). Soit n ∈ N non nul. Soit k ∈ 1, . . . , n. Soit l ∈ 1, . . . , n avec l 6= k. SoitA ∈Mn(K). Le produit Dk(−1)Tl,k(1)Tk,l(−1)Tl,k(1)×A est obtenue à partir de A en échangeant la ke ligneet la le ligne.
Proposition 11.66. Soit n ∈ N non nul. Soit k ∈ 1, . . . , n. Soit l ∈ 1, . . . , n avec l 6= k. Soit A ∈Mn(K).La matrice ADk(−1)Tl,k(1)Tk,l(−1)Tl,k(1) est obtenue à partir de A en échangeant la ke colonne et la lecolonne. On note Ck ↔ Cl cette opération.
On peut alors reformuler le théorème 11.36 sur l’échelonnement des matrices ainsi :
Théorème 11.67. Soit A ∈ Mn,m(K) non nulle. Alors il existe une matrice carrée P produit de matricesde dilatation et/ou de transvection telle que PA est échelonnée réduite. La forme échelonnée réduite ainsiobtenue est unique.
Remarque. La matrice P , produit de matrices inversibles, est inversible.
11.5.2 Recherche de l’inverse d’une matrice
Exemple. Considérons la
A =
1 1 12 −1 1−1 2 −1
231

TSI 1 Lycée Heinrich-Nessel 2016/2017
Nous allons échelonner la matrice augmentée (A|I3) :
(A | I3) =
1 1 1 1 0 02 −1 1 0 1 0−1 2 −1 0 0 1
∼L
1 1 1 1 0 00 −3 −1 −2 1 00 3 0 1 0 1
∼L
1 1 1 1 0 00 1 1
323 − 1
3 00 0 −1 −1 1 1
∼L
1 1 1 1 0 00 1 1
323 − 1
3 00 0 1 1 −1 −1
∼L
1 1 0 0 1 10 1 0 1
3 0 13
0 0 1 1 −1 −1
∼L
1 0 0 − 13 1 2
3
0 1 0 13 0 1
3
0 0 1 1 −1 −1
= (PA | P )
D’où PA = I3, c’est à dire, d’après un théorème précédent, la matrice A est inversible et
A−1 = P =
− 13 1 2
313 0 1
3
1 −1 −1
Proposition 11.68. Une matrice A carrée de taille n est inversible si et seulement si la matrice échelonnéeréduite de la matrice augmentée (A|In) est de la forme (In|P ). De plus, dans ce cas, A−1 = P .
Méthode. Pour déterminer si une matrice A est inversible et déterminer son inverse, on peut échelonner lamatrice augmentée (A|In).
Corollaire 11.69. Une matrice carrée A ∈Mn(K) est inversible si et seulement si son rang est n.
Corollaire 11.70. Une matrice carrée A est inversible si et seulement si le système AX = 0 admet une uniquesolution, à savoir X = 0.
232

Chapitre 12
Nombres réels et suites numériques
Programme• Nombres réels :• Les ensembles de nombres : N, Z, D, Q, R et C. La construction de ces ensembles est hors programme.• Une partie I de R est un intervalle si et seulement si, pour tout (a, b) ∈ I2 avec a < b, [a; b] ⊂ I.• valeur absolue, propriétés. Interpréter sur la droite réelle des inégalités du type |x− a| ≤ b.• distance entre deux réels, inégalité triangulaire• La relation d’ordre ≤ dans R : majorant, maximum, minorant, minimum.• Borne supérieure (resp. inférieure) d’une partie non vide majorée (resp. minorée) de R. Aucun développement
n’est attendu.• Suites réelles : Mode de définition d’une suite, opérations.• Suites monotones, strictement monotones, minorées, majorées, bornées.• Suite extraite.• Suite arithmétiques et suites géométriques.• Limite d’une suite réelle : Les définitions sont données avec des inégalités larges.• Limite finie ou infinie d’une suite, unicité de la limite. Suite convergente, suite divergente.• Pour une suite (un) donnée, prouver l’existence d’une limite l en majorant |un − l|, notamment lorsque la
suite vérifie une inégalité du type : |un+1 − l| ≤ k|un − l| avec 0 < k < 1.• Toute suite réelle convergente est bornée.• Si une possède une limite (finie ou infinie) alors toutes ses suites extraites possèdent la même limite.• Prouver la divergence d’une suite à l’aide de suite(s) extraite(s).• Opérations sur les limites : somme, multiplication par un scalaire, produit, inverse. Lever une indétermina-
tion.• Cas des suites géométriques, arithmétiques.• Passage à la limite dans une inégalité.• Théorème de l’encadrement. Divergence par comparaison, théorème de la limite monotone.• Théorème des suites adjacentes.• Comparaison de suites• Relations de comparaison : domination un = O(vn), négligeabilité un = o(vn), équivalence un ∼ vn.• On définit ces relations à partir du quotient un
vnen supposant que (vn) ne s’annule pas à partir d’un certain
rang.• Croissance comparées des suites usuelles : lnβ(n), nα et eγn à l’aide de o.• Lien entre les différentes relations de comparaison : un ∼ vn si et seulement si un − vn = o(vn).• Compatibilité de l’équivalence avec le produit, le quotient, les puissances.• Propriétés conservées par équivalence : signe, limite.
233

TSI 1 Lycée Heinrich-Nessel 2016/2017
12.1 Entiers naturels et raisonnement par récurrenceOn définit (caractérise) l’ensemble des entiers naturels N par le système d’axiomes (d’hypothèses) de Peano :L’ensemble des entiers naturels, noté N, vérifie les axiomes suivants (Peano 1858-1932) :• N possède l’élément zéro, noté 0 ;• Tout entier naturel n a un unique successeur, noté s(n) ;• 0 n’est le successeur d’aucun entier naturel ;• Si deux entiers naturels ont le même successeur alors ils sont égaux• Si un sous-ensemble d’entiers naturels contient 0 et contient le successeur de chacun de ses éléments, alors
cet ensemble est égal à N. (principe de récurrence)Uniquement à l’aide de ses axiomes, on peut définir rigoureusement, l’addition et la relation d’ordre ≤ surl’ensemble des entiers naturels.
12.1.1 Raisonnement par récurrence
Théorème 12.1. Toute partie non vide de N admet un plus petit élément.
Théorème 12.2 (Récurrence). Soit P(n) une proposition dépendant d’un entier naturel n et soit n0 ∈ N unentier. Supposons que• P(n0) est vraie. (initialisation)• Pour tout entier n ≥ n0, l’implication P(n)⇒ P(n+ 1) est vraie. (hérédité)
Alors la proposition P(n) est vraie quel que soit l’entier n ≥ n0.
Corollaire 12.3 (Récurrence forte). Soit P(n) une proposition dépendant d’une variable n ∈ N. Soit n0 ∈ N unentier. Supposons que :• P(n0) est vraie.• Pour tout entier n ≥ n0, (
P(n0) ET P(n0 + 1) ET . . . ET P(n))⇒ P(n+ 1)
est vraie.Alors la proposition P(n) est vraie pour tout entier n ≥ n0.
12.2 Ensemble ordonné des nombres réelsSoient a et b deux nombres réels tels que a ≤ b. On rappelle qu’on pose :
[a; b] = x ∈ R, a ≤ x ≤ b[a; b[ = x ∈ R, a ≤ x < b]a; b] = x ∈ R, a < x ≤ b]a; b[ = x ∈ R, a < x < b
[a; +∞[ = x ∈ R, a ≤ x]a; +∞[ = x ∈ R, a < x
]−∞; b] = x ∈ R, x ≤ b]−∞; b[ = x ∈ R, x < b
]−∞; +∞[ = R
Vocabulaire. Soit a, b des nombres réels ou éventuellement égaux à ±∞. On dit que l’intervalle [a; b] est fermé,l’intervalle ]a; b[ est ouvert et l’intervalle [a; b[ est fermé en a et ouvert en b.
Lorsque un intervalle est ouvert (resp. fermé) en l’une de ses bornes c’est tout simplement qu’il ne contient pas(resp. contient) cette borne.
234

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 12.4. Un intervalle I de R est une partie de R telle que
∀ a ∈ I, ∀ b ∈ I, [a; b] ⊂ I
C’est-à-dire que quels que soient les réels a ≤ b, si a et b sont dans l’ensemble I, alors I contient aussi toutl’intervalle [a; b] (tous les nombres compris entre a et b).
Théorème 12.5. Un intervalle I de R est toujours d’une des neuf formes ci-dessus.
12.2.1 Inégalités
Définition 12.6. Une inégalité est une formule mathématiques, indiquant dans quel ordre sont rangés deuxexpressions. Les différents symboles d’inégalités :• ≤ se dit « inférieur (ou égal) » (inégalité large)• ≥ se dit « supérieur (ou égal) » (inégalité large)• < se dit « inférieur strictement » (inégalité stricte)• > se dit « supérieur strictement » (inégalité stricte)
Remarque. Soit a et b deux nombres, alors
a ≤ b si et seulement si b ≥ a
eta < b si et seulement si b > a
Vocabulaire. On dit qu’une inégalité change de sens lorsqu’on passe du symbole ≤ au ≥ et réciproquement(mais en gardant les expressions déduites dans le même ordre). De même, avec les inégalités strictes.
Définition 12.7. Encadrer un nombre x, c’est donner deux nombres a et b tels que a ≤ x ≤ b. On dit alorsque x est compris entre a et b.
Lorsqu’un nombre est inférieur à un second qui est inférieur au troisième, bien sûr que le premier est aussi inférieurau troisième nombre :
Proposition 12.8. Soit a, b et c trois nombres réels, alors• a ≤ a et a ≥ a (réflexivité)• Si a ≤ b et b ≤ c alors a ≤ c (transitivité)
Si a ≥ b et b ≥ c alors a ≥ c
Par contre, on n’a pas a < a ni a > a !
Proposition 12.9 (inégalité et opérations).• Une inégalité est conservée lorsqu’on ajoute ou retranche un même nombre de part et d’autre de l’in-
égalité.• Une inégalité est conservée lorsqu’on multiplie ou divise par un même nombre strictement positif de part
et d’autre de l’inégalité.• Par contre, l’inégalité change de sens lorsqu’on multiplie ou divise par un même nombre strictement
négatif de part et d’autre de l’inégalité.
Corollaire 12.10. Soit a, b, c et d quatre nombres réels.1) Si a ≤ b et c ≤ d alors a+ c ≤ b+ d ;2) Si a ≤ b et c ≥ d alors a− c ≤ b− d ;
Supposons de plus que les nombres a, b, c et d sont strictement positifs.3) Si a ≤ b et c ≤ d alors a× c ≤ b× d ;
235
TSI 1 Lycée Heinrich-Nessel 2016/2017
4) Si a ≤ b et c ≥ d alors ac≤ b
d.
Vocabulaire.• Un nombre a est dit positif si a ≥ 0 ;• Un nombre a est dit négatif si a ≤ 0.
On note R+ l’ensemble des nombres positifs, R− l’ensemble des nombres négatifs et R∗ l’ensemble des nombresnon nuls.
R0
nombres positifs : R+nombres négatifs : R−
Remarque. Le seul nombre à la fois positif et négatif est zéro.
12.2.2 Valeur absolue
Définition 12.11. Soit x ∈ R, la valeur absolue dunombre x, notée |x|, est
|x| =−x si x < 0x si x ≥ 0
x 7→ |x|
Proposition 12.12.1) La valeur absolue d’un nombre est toujours positive. Autrement dit, pour tout réel x, |x| ≥ 0.2) |x| = 0 si et seulement si x = 03) Pour tout réel x, on a : | − x| = |x|.4) Pour tous réels x, y, on a : |xy| = |x| × |y|.5) Pour tous réels x, y 6= 0, on a :
∣∣xy
∣∣ = |x||y| .
6) Pour tout réel x, on a :√x2 = |x|.
Proposition 12.13. Soit a un nombre réel et M > 0. Pour tout nombre réel x, on a
|x− a| ≤M ⇐⇒ a−M ≤ x ≤ a+M
Raa−M a+M
−M +M
C’est-à-dire, si et seulement si x appartient à l’intervalle [a−M ; a+M ].
Méthode. Étant donné a et M , pour montrer que |x − a| ≤ M , en général, on montre qu’on a les deuxinégalites : a−M ≤ x et x ≤ a+M .
En considérant le cas a = 0 et en remarquant que |x| > M est la négation de |x| ≤M , on déduit :
Corollaire 12.14. Si M est un nombre positif, alors1) |x| ≤M si et seulement si −M ≤ x ≤M ;2) |x| > M si et seulement si x < −M ou M < x.
Remarque. Le premier point du corollaire peut être reformuler ainsi : |x| ≤ M si et seulement si −x ≤ M etx ≤M .
236

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 12.15. La distance entre deux réels a et b est la distance entre les points M et N d’abscisses a etb sur la droite réelle munie d’un repère (O,−→i ). On la note d(a, b).
RM
a
N
b
d(a, b) = MN
Proposition 12.16.1) Pour tout réel x, d(x, 0) = |x|.2) Pour tous réels a et b,
d(a, b) = |b− a| = |a− b|
Proposition 12.17 (inégalité triangulaire). Pour tous réels x et y, on a
|x+ y| ≤ |x|+ |y|
Proposition 12.18 (seconde inégalité triangulaire). Soit x et y deux nombres réels. Alors,
||x| − |y|| ≤ |x− y|
En particulier, |x| − |y| ≤ |x− y| et |x| − |y| ≤ |x+ y|.
12.2.3 Borne inférieure, supérieure
Définition 12.19. Soit A une partie non vide de R. On dit que A est majorée si
∃M ∈ R, ∀ x ∈ A, x ≤M
Tout nombre M satisfaisant à cette propriété est appelé un majorant.
Définition 12.20. Soit A une partie non vide de R. On dit que A est minorée si
∃m ∈ R, ∀ x ∈ A, x ≥ m
Tout nombre m satisfaisant à cette propriété est appelé un minorant.
Définition 12.21. Soit A une partie non vide de R. On dit que A est bornée si A est majorée et minorée.
Définition 12.22. Soit A une partie non vide de R et α un nombre réel. On dit que• α est la borne supérieure de A et on note α = sup(A) si α est le plus petit majorant de A.• α est la borne inférieure de A et on note α = inf(A) si α est le plus grand minorant de A.
Exercice 12.1. Déterminer la borne inférieure et la borne supérieure de la partie A = 2nn+1 ; n ∈ N de R.
Théorème 12.23 (R possède la propriété de la borne supérieure).1) Toute partie non vide et majorée de R admet une borne supérieure.2) Toute partie non vide et minorée de R admet une borne inférieure.
Exercice 12.2.1) Soit A une partie non vide et minorée de R. Que peut-on dire de l’ensemble A′ = −x; x ∈ A ?2) Montrer que dans le théorème précédent, le point 2. est une conséquence du point 1.
Remarque. Si A n’est pas majorée, on pose sup(A) = +∞ et si A n’est pas minorée, on pose inf(A) = −∞.
237

TSI 1 Lycée Heinrich-Nessel 2016/2017
Méthode. Pour savoir si une partie de R est majorée, minorée, bornée, on sera amené à travailler sur desinéquations. Pour montre qu’une partie n’est pas majorée (resp. minorée) par un élément λ, il suffit de trouverun élement de la partie plus grand (resp. plus petit) que λ.
Digression.• Voici une caractérisation de la borne supérieure : Soit A une partie de R non vide et majorée. La borne
supérieure de A est l’unique nombre réel sup(A) tel que :1) si x ∈ A alors x ≤ sup(A) (sup(A) est un majorant) ;2) pour tout T < sup(A), il existe x ∈ A tel que T < x
Si T est strictement plus petit que sup(A) alors T ne peut pas être un majorant de A.)• De même, voici une caractérisation de la borne inférieure : Soit A une partie de R non vide et majorée. La
borne inférieure de A est l’unique nombre réel inf(A) tel que :1) si x ∈ A alors x ≥ inf(A) (inf(A) est un minorant) ;2) pour tout T > inf(A), il existe x ∈ A tel que x < T
Si T est strictement plus grand que inf(A) alors T ne peut pas être un minorant de A.)
12.3 Suites numériquesNotation. Pour tout entier n, on rappelle que :
Jn; +∞[= [n; +∞[∩N = k ∈ N, k ≥ n = n;n+ 1;n+ 2; . . .
Définition 12.24. Une suite réelle u est une application définie sur Jp; +∞[, à valeurs dans R.
u : Jp; +∞[ // R
n // un := u(n)
• Le domaine de définition Jp; +∞[ de la suite s’appelle le support de u.• La suite u peut aussi être notée ainsi : (un)n≥p ou (un).• Le nombre un est appelé n-ème terme de la suite (un)n≥p.
En d’autres termes, une suite de nombres réels (un)n≥p est la donnée pour tout entier naturel n ≥ p d’un nombreréel noté un.
Exemples.• (un) = (0, 1, 2, 3, 4, . . .), c’est-à-dire pour tout n : un = n.• (un) = (0, 2, 4, 6, 8, . . .), c’est-à-dire pour tout n : un = 2n.• (un) = (0, 1, 4, 9, 16, 25, 36, . . .), c’est-à-dire pour tout n : un = n2.• (un) = (1, 5, 25, 125, . . .), c’est-à-dire pour tout n : un = 5n.
Notation. L’ensemble des suites (un)n∈N, dont le support est N, est noté RN.
Une conséquence du principe de récurrence :
Proposition 12.25. Soit p ∈ N, I un intervalle de R, f une fonction de I dans I et a ∈ I. Il existe une uniquesuite (un)n≥p telle que
up = a
un+1 = f(un) pour tout entier n ≥ p
Vocabulaire. Dans la proposition précédente, la seconde relation est appelée relation de récurrence et on dit quela suite (un)n≥p est définie par récurrence.
Exemple. Soit (un) la suite définie par récurrence ainsi :u0 = 1un+1 = 5un − 2
L’algorithme suivant permet d’obtenir le terme d’un rang donné de la suite (un) :
238

TSI 1 Lycée Heinrich-Nessel 2016/2017
1: Variables : n, U et i sont des nombres2: Saisir n3: U prend la valeur 14: Pour i allant de 1 à n faire5: U prend la valeur 5× U − 26: Fin Pour7: Afficher U
Méthode. Il est important de bien vérifier les conditions du théorème avant de manipuler une suite définiepar récurrence. Autrement dit, il faut s’assurer que le premier terme appartient à un intervalle I stable par f ,c’est-à-dire tel que ∀ x ∈ I, f(x) ∈ IOn procédera souvent à une étude préalable de la fonction f pour déterminer un tel intervalle I.
Exemples. 1) Les suites arithmétiques et géométriques sont généralement définies par récurrence (voir plusloin)
2) La suite de Fibonacci est définie par une récurrence double : un+2 = un+1 + un, et u0 = u1 = 1.
3) La suite de Syracuse est définie par récurrence par
un+1 =
un/2 si n est pair3un + 1 sinon
4) Une suite homographique est une suite définie par une relation de récurrence de la forme un+1 = aun+bcun+d
Représentation graphique
Définition 12.26. Soit (un) une suite réelle. On se place dans le plan muni d’un repère, on peut alors associerà la suite l’ensemble des points A(n; un), où n parcourant l’ensemble des entiers naturels. Cet ensemble depoints est appelé le nuage de points associé à la suite (un).
Exemple. Soit (un) la suite définie par un = 13n
3 − 10n2 + 75n+ 30 pour tout entier naturel n. Voici le nuage depoints associé à la suite (un) :
n
A0
0
A1
1
A2
2
A3
3
A4
4
A5
5
A6
6
A7
7
A8
8
A9
9
A10
10
A11
11
A12
12
A13
13
A14
14
A15
15
A16
16
A17
17
A18
18
A19
19
A20
20
50
100
150
200
Pour une suite définie par récurrence, donc de la forme un+1 = f(un) et u0 = a, on trace la fonction f ET ladroite y = x. On place en abscisse le point u0 = a, puis
• on trace un segment verticale depuis ce point jusqu’à la courbe, pour obtenir le point de la courbe decoordonnées (u0, f(u0)) ;
• on trace un segment horizontale depuis ce point jusqu’à la première bissectrice (d’équation y = x), ce pointà pour abscisse u1.
Puis, on recommence indéfiniment pour déterminer les termes suivants de la suite (voir l’illustration ci-dessous).
239

TSI 1 Lycée Heinrich-Nessel 2016/2017
Cf
y=x
0 u0 u1 u2 u3 u4
Cf
y=x
0 u0 u1u2 u3u4 u5
Dans les deux exemples précédents, la suite semble converger vers un nombre l, abscisse le point d’intersection dela courbe représentative et la droite d’équation y = x. C’est-à-dire, la limite est telle que f(l) = l.
Exemple. Considérons la suite (un)n∈N définie par un = (−1)n pour tout entier n alors
un =
1 si n est pair−1 si n est impair
On peut associer la suite (vn)n∈N définie par vn = u2n pour tout entier n. On note que vn = 1 pour tout entiern et
(vn) = (1,−1, 1,−1, 1,−1, . . .) et (un) = (1, 1, 1, . . .)On dit que la suite (vn) est une suite extraite de la suite (un).
Définition 12.27. Soit (un)n≥p et (vn)n≥q deux suites. On dit que (vn)n≥q est une suite extraite de (un)n≥ps’il existe une application φ de Jq; +∞[ dans Jp; +∞[ strictement croissante telle que
∀ n ∈ Jq; +∞[, vn = uφ(n)
Notation. Il arrive qu’on note la suite extraite (vn)n≥q ainsi (unk )k≥q avec nk = φ(k) pour tout k ≥ q. Cettenotation met en valeur la suite de départ (un) utilisée pour extraire la sous-suite.
Exemples.1) La suite (vn) définie par vn = u2n est une suite extraite de u, celle des termes d’indices pairs.2) La suite (vn) définie par vn = u2n+1 est une suite extraite de u, celle des termes d’indices impairs.3) La suite (vn) définie par vn = un+p est une suite extraite de u qui consiste à « oublier » les premiers termes
de u.4) Plus généralement, la suite (vn) définie par vn = ukn+p est une suite extraite de u.
12.4 Opérations sur les suites
Définition 12.28. Soient (un) et (vn) deux suites de même support [[p; +∞[. La somme de (un) et de (vn)est la suite (un) + (vn) définie par
∀ n ∈ [[p; +∞[, (u+ v)n = un + vn
Définition 12.29. Soit (un) une suite de support [[p; +∞[. Soit λ ∈ R. Le produit de (un) par le scalaire λest la suite λ(un) définie par
∀ n ∈ [[p; +∞[, (λu)n = λun
Proposition 12.30. Soient u, v et w trois suites de même support [[p; +∞[. Soient λ et µ deux scalaires.Alors :
1) u+ v = v + u
2) u+ (v + w) = (u+ v) + w
240

TSI 1 Lycée Heinrich-Nessel 2016/2017
3) 0× u = 0 et 1× u = u
4) λ(u+ v) = λu+ λv
5) (λ+ µ)u = λu+ µu
6) λ(µu) = (λµ)u
Notation. On note −u au lieu de −1× u.
Définition 12.31. Soient u et v deux suites de même support [[p; +∞[. Le produit de u par v est la suite uvdéfinie par
∀ n ∈ [[p; +∞[, (uv)n = un × vn
Définition 12.32. Soient u et v deux suites de même support [[p; +∞[. On suppose que v ne s’annule jamais.Le quotient de u par v est la suite u
vdéfinie par
∀ n ∈ [[p; +∞[,(u
v
)n
= unvn
Proposition 12.33. Soient u, v et w trois suites de même support [[p; +∞[. Soient λ et µ deux scalaires.Alors :
1) uv = vu
2) u(vw) = (uv)w3) λ(uv) = (λu)v = u(λv)
12.4.1 Suites et variationsDéfinition 12.34. Une suite (un)n≥p est dite• croissante si pour tout entier n ≥ p, on a un ≤ un+1.• strictement croissante si pour tout entier n ≥ p, on a un < un+1.• décroissante si pour tout entier n ≥ p, on a un ≥ un+1.• strictement décroissante si pour tout entier n ≥ p, on a un > un+1.• constante si pour tout entier n ≥ p, on a un = un+1.
Vocabulaire. Une suite est dite monotone si elle est soit croissante, soit décroissante, soit constante.
Proposition 12.35. Soit (un)n≥p une suite.• Si (un) est croissante, alors pour tous entiers m,n ∈ Jp; +∞[, on a m ≤ n implique un ≤ um.• Si (un) est décroissante, alors pour tous entiers m,n ∈ Jp; +∞[, on a m ≤ n implique un ≥ um.
Définition 12.36. Soit (un)n≥p une suite. On dit que (un) est stationnaire si
∃N ∈ Jp; +∞[ ∀n ≥ N : un = uN
En d’autres termes, il existe un rang N à partir duquel la suite (un) est constante.
Méthode. Pour savoir si une suite (un) est croissante ou décroissante, il suffit d’étudier le signe de un+1−unpour tout n ∈ Jp; +∞[.
Exercice 12.3. Montrer que les suites suivantes sont croissantes ou décroissantes :
un = 2n+ 3, vn = −5n+ 7, wn = n2 − 1, xn+1 = xn + x2n, yn = 2n, zn = ln(n)
241

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 12.37. Soit (un) une suite de support [[p; +∞[ dont tous les termes sont strictement positifs.Alors :
1) (un) est croissante si et seulement si ∀ n ∈ [[p; +∞[, un+1un≥ 1
2) (un) est strictement croissante si et seulement si ∀ n ∈ [[p; +∞[, un+1un
> 1
3) (un) est décroissante si et seulement si ∀ n ∈ [[p; +∞[, un+1un≤ 1
4) (un) est strictement décroissante si et seulement si ∀ n ∈ [[p; +∞[, un+1un
< 1
Méthode. Pour savoir si une suite strictement positive (un) est croissante ou décroissante, on peut chercherà comparer un+1
unà 1.
Exercice 12.4. Montrer que les suites suivantes sont croissantes ou décroissantes :
un = 2n+ 3, vn = 2n, wn = n2
Proposition 12.38. Soit (un) une suite monotone. Alors toute suite extraite de (un) est monotone, de mêmesens de variations.
Proposition 12.39. Soit f une fonction définie sur un intervalle contenant [p; +∞[ à valeurs dans R. Soit(un) la suite définie par un = f(n), pour n ∈ [[p; +∞[. Alors
1) si f est croissante, (un) est croissante2) si f est décroissante, (un) est décroissante
Exercice 12.5. Interpréter les exemples précédents (lorsque cela est possible à l’aide de la proposition ci-dessus.
Proposition 12.40. Soit f : I → I une fonction et a ∈ I. Soit (un) la suite définie par récurrence :u0 = a
un+1 = f(un)
Supposons que f est croissante.1) Si a ≤ f(a) alors (un) est croissante ;2) si a ≥ f(a) alors (un) est décroissante.
Exercice 12.6. Soit f : I → I une fonction et a ∈ I. Soit (un) la suite définie par récurrence :u0 = a
un+1 = f(un)
Supposons que f est décroissante.1) Si a ≤ f(a) alors la suite extraite (u2n) est croissante et la suite extraite (u2n+1) est décroissante ;2) Si a ≥ f(a) alors la suite extraite (u2n) est décroissante et la suite extraite (u2n+1) est croissante ;
Exercice 12.7. Étudier la monotonie de la suite définie par un+1 = un(un + 1) avec u0 = 1.
12.4.2 Majoration. MinorationEn identifiant une suite (un) avec l’ensemble de ses termes un; n ∈ Jp; +∞[ , on peut naturellement définir lesnotions de suites minorées, majorées, bornées, de majorants, de minorants.
Définition 12.41. Soit (un) une suite de support [[p; +∞[. On dit que (un) est• majorée si
∃M ∈ R, ∀ n ∈ [[p; +∞[, un ≤M
• minorée si∃m ∈ R, ∀ n ∈ [[p; +∞[, un ≥ m
242

TSI 1 Lycée Heinrich-Nessel 2016/2017
• bornée si (un) est majorée et minorée.
Exercice 12.8. Les suites suivantes sont-elles majorées ? minorées ?
un = (−1)n, vn = 2n, wn+1 = sin(wn), xn = sin(n)− 3 cos(n2 − 5n),
yn+1 = 1yn
et y0 = 10
Proposition 12.42. Une suite (un) est bornée si et seulement si la suite des valeurs absolues ( |un| ) estmajorée.
Définition 12.43. Soit (un) une suite de support [[p; +∞[.1) Si (un) est majorée, on appelle majorant de (un) tout nombre réel M tel que
∀ n ∈ [[p; +∞[, un ≤M
2) Si (un) est minorée, on appelle minorant de (un) tout nombre réel m tel que
∀ n ∈ [[p; +∞[, un ≥ m
Définition 12.44. Soit (un) une suite de support [[p; +∞[. Si (un) est majorée, le supremum de (un) estle plus petit majorant de (un). On le note sup(u). Si (un) est minorée, l’infimum de (un) est le plus grandminorant. On le note inf(u).
Remarque. Si (un) n’est pas majorée, on pose sup(u) = +∞. Si (un) n’est pas minorée, on pose inf(u) = −∞.
12.5 Convergence d’une suite
12.5.1 Convergence vers une limite finieRappel : Soit x un nombre réel quelconque, la valeur absolue du nombre x, notée |x|, est le nombre
|x| =−x si x < 0x si x ≥ 0
Soit a et b deux nombres réels, alors |b− a| est égale à la distance entre a et b sur la droite des nombres réels.
Ra b
|b− a|
Définition 12.45. Une suite réelle (un)n≥p a pour limite le nombre ` quand n tend vers l’infini, si quelle quesoit la distance ε qu’on se fixe, il existe un rang N à partir du quel tous les termes un de la suite sont à unedistance inférieure ou égale à ε du nombre ` :
∀ ε > 0 ∃N ∈ Jp; +∞[ ∀n ∈ Jp; +∞[ n ≥ N ⇒ |un − `| ≤ ε
On note alorslim
n→+∞un = ` ou un → `
243
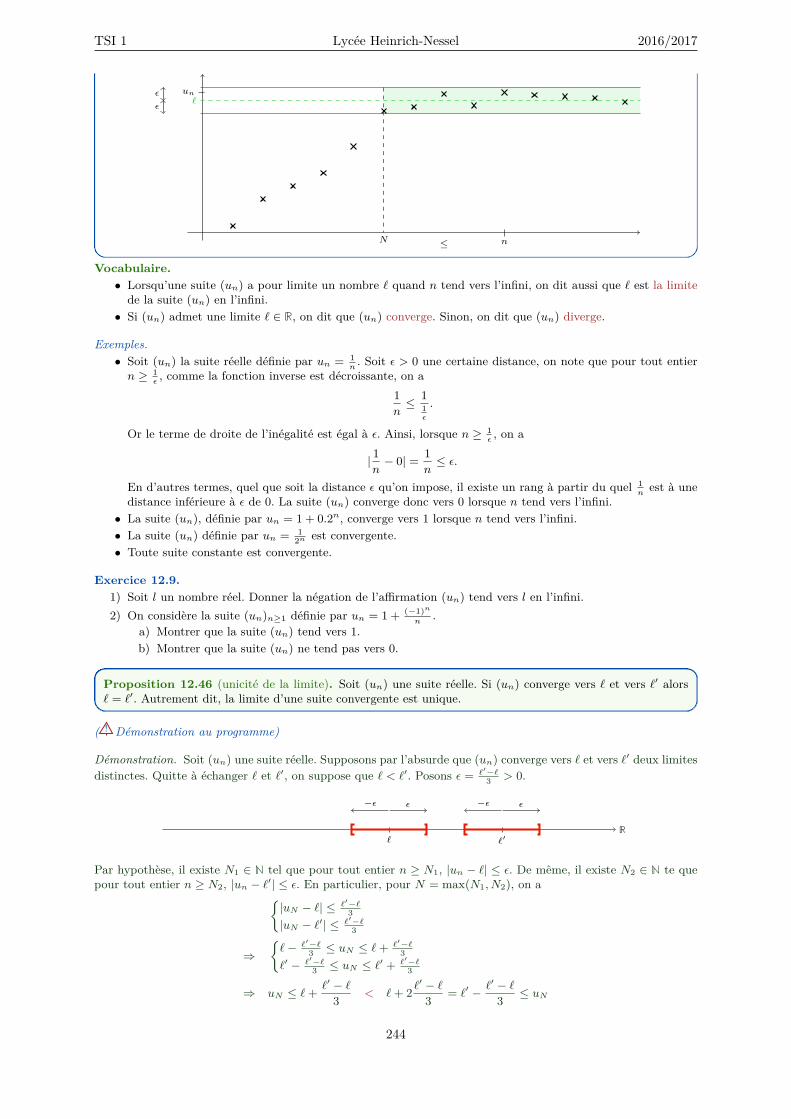
TSI 1 Lycée Heinrich-Nessel 2016/2017
`ε
ε
N n≤
un
Vocabulaire.• Lorsqu’une suite (un) a pour limite un nombre ` quand n tend vers l’infini, on dit aussi que ` est la limite
de la suite (un) en l’infini.• Si (un) admet une limite ` ∈ R, on dit que (un) converge. Sinon, on dit que (un) diverge.
Exemples.• Soit (un) la suite réelle définie par un = 1
n. Soit ε > 0 une certaine distance, on note que pour tout entier
n ≥ 1ε, comme la fonction inverse est décroissante, on a
1n≤ 1
1ε
.
Or le terme de droite de l’inégalité est égal à ε. Ainsi, lorsque n ≥ 1ε, on a
| 1n− 0| = 1
n≤ ε.
En d’autres termes, quel que soit la distance ε qu’on impose, il existe un rang à partir du quel 1nest à une
distance inférieure à ε de 0. La suite (un) converge donc vers 0 lorsque n tend vers l’infini.• La suite (un), définie par un = 1 + 0.2n, converge vers 1 lorsque n tend vers l’infini.• La suite (un) définie par un = 1
2n est convergente.• Toute suite constante est convergente.
Exercice 12.9.1) Soit l un nombre réel. Donner la négation de l’affirmation (un) tend vers l en l’infini.2) On considère la suite (un)n≥1 définie par un = 1 + (−1)n
n.
a) Montrer que la suite (un) tend vers 1.b) Montrer que la suite (un) ne tend pas vers 0.
Proposition 12.46 (unicité de la limite). Soit (un) une suite réelle. Si (un) converge vers ` et vers `′ alors` = `′. Autrement dit, la limite d’une suite convergente est unique.
( ! Démonstration au programme)
Démonstration. Soit (un) une suite réelle. Supposons par l’absurde que (un) converge vers ` et vers `′ deux limitesdistinctes. Quitte à échanger ` et `′, on suppose que ` < `′. Posons ε = `′−`
3 > 0.
R` `′
−ε ε −ε ε
Par hypothèse, il existe N1 ∈ N tel que pour tout entier n ≥ N1, |un − `| ≤ ε. De même, il existe N2 ∈ N te quepour tout entier n ≥ N2, |un − `′| ≤ ε. En particulier, pour N = max(N1, N2), on a
|uN − `| ≤ `′−`3
|uN − `′| ≤ `′−`3
⇒`− `′−`
3 ≤ uN ≤ `+ `′−`3
`′ − `′−`3 ≤ uN ≤ `′ + `′−`
3
⇒ uN ≤ `+ `′ − `3 < `+ 2 `
′ − `3 = `′ − `′ − `
3 ≤ uN
244

TSI 1 Lycée Heinrich-Nessel 2016/2017
Ce qui est absurde. D’où ` = `′.
Proposition 12.47. Soit (un) une suite. Si (un) converge vers `, alors toute suite extraite de (un) convergevers `.
Démonstration. Quitte à réindexer les éléments de la suite (un), on suppose que le support de la suite est N. Soit(vn) une suite extraite de (un) alors il existe φ : N→ N une application strictement croissante telle que vn = uφ(n)pour tout entier n. Notons que, pour tout entier n, on a
φ(n) > φ(n− 1)φ(n) ≥ φ(n− 1) + 1 > φ(n− 2) + 1φ(n) ≥ φ(n− 2) + 2φ(n) ≥ φ(0) + n par récurrenceφ(n) ≥ n (?)
Soit ε > 0, par hypothèse (un) converge vers `. Ainsi, il existe N ∈ N tel que pour tout entier n ≥ N , on ait|un − `| ≤ ε. Soit n ∈ N, d’après (?) on a :
n ≥ N ⇒ φ(n) ≥ φ(N) ≥ N ⇒ |uφ(n) − `| ≤ ε
Donc, la suite extraire (uφ(n)) converge aussi vers `.
Méthode. On peut montrer qu’une suite n’est pas convergente par l’absurde, en exhibant deux suites extraitesconvergentes vers des limites différentes.
Exemple (important !). La suite (un) définie par un = (−1)n n’est pas convergente.
Proposition 12.48. Soit (un) une suite convergente. Alors (un) est bornée.
Démonstration. Notons ` la limite de la suite (un). Soit ε = 1, alors il existe N ∈ N tel que pour tout entiern ≥ N , on ait `− 1 ≤ un ≤ `+ 1. Posons
A = un; n ∈ Jp;N − 1K ∪ `− 1; `+ 1
C’est un ensemble fini, ainsi M = max(A) et m = min(A) sont bien définies. On vérifie par disjonction de cas quepour tout n ∈ Jp; +∞[, m ≤ un ≤M . D’où (un) est bornée.
Lemme 12.49 (limite d’une somme). Soient (un) et (vn) deux suites. Si (un) converge vers ` et (vn) convergevers `′ alors la somme (un + vn) converge vers `+ `′.
( ! Démonstration au programme)
Démonstration. Avec les hypothèses et notations du lemme, soit ε > 0. Par hypothèse, il existe deux entiers N1et N2 tels que pour tout entier n :
n ≥ N1 ⇒ |un − `| ≤ ε2
n ≥ N2 ⇒ |vn − `′| ≤ ε2
Posons N = max(N1, N2), alors pour tout entier n ≥ N , on a
|un + vn − (`+ `′)| = |un − ` + vn − `′ |≤ |un − `|+ |vn − `′| d’après l’inégalité triangulaire
≤ ε
2 + ε
2≤ ε
Pour un ε > 0 arbitraire, on a donc trouvé N ∈ N tel que pour tout n ≥ N , |un + vn − (` + `′)| ≤ ε. Ainsi, pardéfinition, la suite somme (un + vn) converge vers la somme des limites `+ `′.
245

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 12.50 (Linéarité). Soient (un) et (vn) deux suites. Soient λ et µ deux scalaires. Si (un) convergevers ` et (vn) converge vers `′ alors la combinaison linéaire (λun + µvn) converge vers λ`+ µ`′.
Démonstration. Si λ = 0, alors la suite (λun) est identiquement nulle et converge donc vers 0 = λ`. Supposonsque λ 6= 0. Soit ε > 0, alors par hypothèse, il existe N ∈ N tel que pour tout entier n ≥ N , on ait
|un − `| ≤ε
|λ||λ| |un − `| ≤ ε car |λ| ≥ 0|λun − λ`| ≤ ε
Ainsi (λun) converge vers λ`. De même, on montre que (µvn) converge vers µ`′. Ainsi, d’après le lemme précédent,on déduit que (λun + µvn) converge vers λ`+ µ`′.
Proposition 12.51. Soient (un) et (vn) deux suites. Si (un) converge vers ` et (vn) converge vers `′ alors uvconverge vers `× `′.
Démonstration. Comme (un) est convergente, elle est bornée (proposition 12.48). Notons M > 0 un majorant des|un| et de |`′|.Soit ε > 0. Par hypothèse, il existe N ∈ N tel que pour tout entier n ≥ N , on ait
|un − `| ≤ ε2M
|vn − `′| ≤ ε2M
D’où
|unvn − ``′| = |unvn − un`′ + un`′ − ``′|
≤ |un| |vn − `′|+ |un − `||`′| d’après l’inégalité triangulaire
≤M(|vn − `′|+ |un − `|
)≤M
(ε
2M + ε
2M
)≤ ε
Donc (unvn) converge vers ``′.
Proposition 12.52. Soient (un) et (vn) deux suites. On suppose que (vn) ne s’annule jamais. Si (un) convergevers ` et (vn) converge vers `′ 6= 0 alors la suite des quotients
(unvn
)converge vers le quotient des limites `
`′ .
Démonstration. D’après la proposition précédente, il suffit de montrer que 1vn
converge vers 1`′ poue en déduire
que le produit (un × 1vn
) converge vers ``′ .
Quitte à remplacer (vn) par (−vn), on peut supposer que (vn) converge vers `′ > 0. Par hypothèse sur la suite(vn), il existe N1 ∈ N tel que pour tout n ≥ N, on ait
n ≥ N1 ⇒ |vn − `′| ≤`′
2 ⇒ 0 < `′ − `′
2 ≤ vn ⇒ 1|vn|
≤ 2`′
Soit ε > 0, encore une fois par hypothèse sur (vn), il existe N2 ∈ N tel que pour tout entier n, on ait
n ≥ N2 → |vn − `′| ≤ε `′2
2Posons N = max(N1, N2), alors pour tout entier n ≥ N , on a∣∣∣ 1
vn− 1`′
∣∣∣ =∣∣∣∣ `′ − vn`′vn
∣∣∣∣ = |vn − `′|
`′|vn|= 1`′× 1|vn|× |vn − `′| ≤
2`′2|vn − `′| ≤
2`′2
ε `′2
2 = ε
Donc ( 1vn
) converge vers 1`′ .
246

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 12.53 (Limite monotone). Toute suite monotone et bornée est convergente. Toute suite monotoneet convergente est bornée.
Démonstration. Supposons que (un) est croissante bornée et posons A = un; n ∈ Jp; +∞[ . Alors A est unepartie non vide et majorée de R, ainsi, d’après le théorème de la borne supérieure, il existe un réel ` tel quesup(A) = `.Soit ε > 0. Comme ` est le plus petit des majorants de A, ` − ε < ` n’est plus un majorant de A. On en déduitqu’il existe un entier N ∈ N tel que uN ≥ `− ε. Ainsi, comme (un) est croissante, pour tout entier n ∈ N, on a
n ≥ N ⇒ `− ε ≤ uN ≤ un ≤ ` ≤ `+ ε ⇒ |un − `| ≤ ε
Donc (un) converge vers `. Le cas, (un) décroissante est laissé en exercice.
Remarque. Si (un) est croissante et majorée, alors limn→+∞
un = sup(un). Si (un) est décroissante et minorée, alors
limn→+∞
un = inf(un).
Exercice 12.10 (méthode de Héron). Considérons la suite (un)n∈N définie paru0 = 2un+1 = 1
2 (un + 2un
) pour tout n ∈ N
1) Déterminer u1, u2, u3 et u4.2) Montrer que pour tout entier naturel n, on a
√2 ≤ un ≤ 2.
3) Montrer que la suite (un)n∈N est décroissante.4) En déduire que la suite (un)n∈N converge et déterminer sa limite.5) Généralisation : Soit a un nombre réel positif. Déterminer une suite qui converge vers
√a.
Proposition 12.54 (Comparaison). Soient (un) et (vn) deux suites. On suppose que (un) converge vers ` etque (vn) converge vers `′. On suppose aussi que un ≤ vn à partir d’un certain rang. Alors ` ≤ `′.
Démonstration. En reprenant la même idée que dans la preuve de l’unicité de la limite (théorème 12.46). Sup-posons par l’absurde que `′ < `. Posons ε = `−`′
3 , alors il existe un entier N ∈ N, tel que pour tout entiern ≥ N ,
vn ≤ `′ + ε < `− ε ≤ unOr, par hypothèse, à partir d’un certain rang, un ≤ vn. Ce qui est contradictoire. Donc ` ≤ `′.
Théorème 12.55 (Encadrement). Soient (un), (vn) et (wn) trois suites. On suppose que
un ≤ vn ≤ wn
à partir d’un rang. On suppose que (un) et (wn) sont convergentes et ont même limite `. Alors (vn) estconvergente et a pour limite `.
Démonstration. Soit ε > 0, par hypothèse sur (un) et (wn), il existe N ∈ N tel que pour tout n ∈ N, on ait
n ≥ N ⇒`− ε ≤ un ≤ `+ ε
`− ε ≤ wn ≤ `+ ε⇒ l − ε≤un ≤ vn ≤ wn≤ `+ ε ⇒ |vn − `| ≤ ε
Ainsi, par définition, (vn) converge vers `.
Méthode. Pour montrer qu’une suite (un) converge, on peut :• Montrer qu’elle est croissante et majorée.• Montrer qu’elle est décroissante et minorée.• Encadrer la suite (un) par deux suites convergentes de même limite.• Trouver un nombre k ∈ [0; 1[ tel que |un+1 − `| ≤ k|un − `| pour tout n.
247
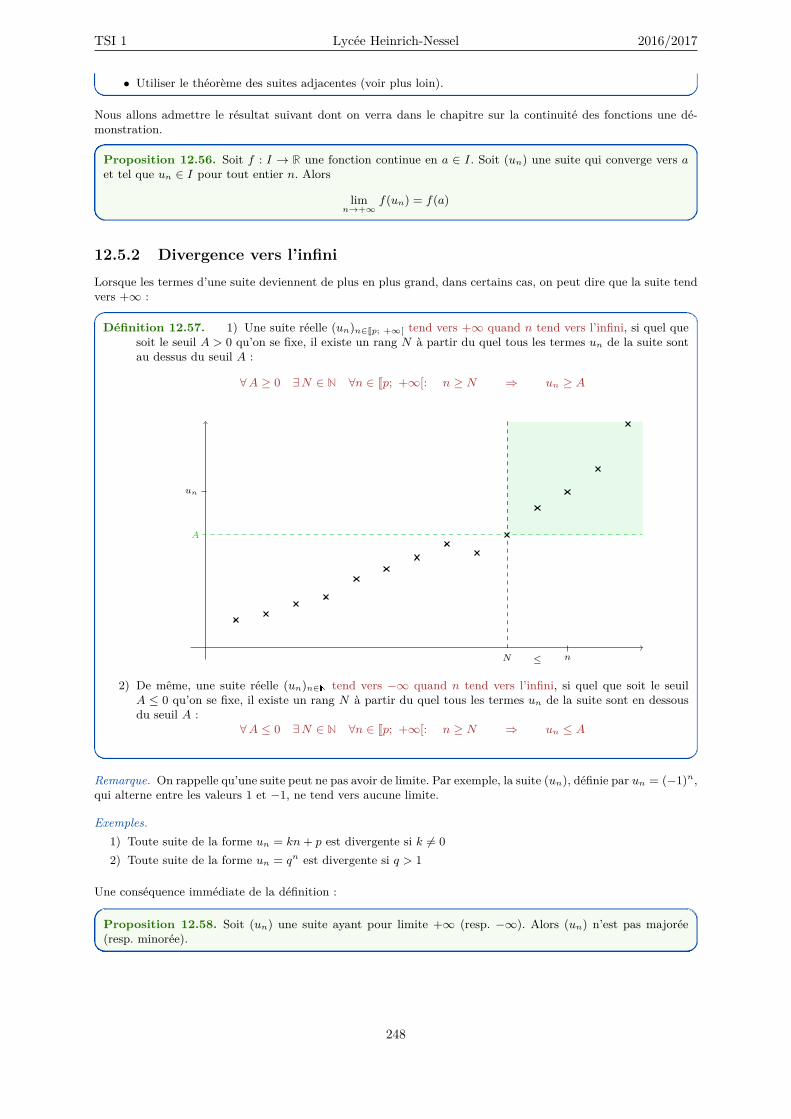
TSI 1 Lycée Heinrich-Nessel 2016/2017
• Utiliser le théorème des suites adjacentes (voir plus loin).
Nous allons admettre le résultat suivant dont on verra dans le chapitre sur la continuité des fonctions une dé-monstration.
Proposition 12.56. Soit f : I → R une fonction continue en a ∈ I. Soit (un) une suite qui converge vers aet tel que un ∈ I pour tout entier n. Alors
limn→+∞
f(un) = f(a)
12.5.2 Divergence vers l’infiniLorsque les termes d’une suite deviennent de plus en plus grand, dans certains cas, on peut dire que la suite tendvers +∞ :
Définition 12.57. 1) Une suite réelle (un)n∈Jp; +∞[ tend vers +∞ quand n tend vers l’infini, si quel quesoit le seuil A > 0 qu’on se fixe, il existe un rang N à partir du quel tous les termes un de la suite sontau dessus du seuil A :
∀A ≥ 0 ∃N ∈ N ∀n ∈ Jp; +∞[: n ≥ N ⇒ un ≥ A
A
N n≤
un
2) De même, une suite réelle (un)n∈N tend vers −∞ quand n tend vers l’infini, si quel que soit le seuilA ≤ 0 qu’on se fixe, il existe un rang N à partir du quel tous les termes un de la suite sont en dessousdu seuil A :
∀A ≤ 0 ∃N ∈ N ∀n ∈ Jp; +∞[: n ≥ N ⇒ un ≤ A
Remarque. On rappelle qu’une suite peut ne pas avoir de limite. Par exemple, la suite (un), définie par un = (−1)n,qui alterne entre les valeurs 1 et −1, ne tend vers aucune limite.
Exemples.1) Toute suite de la forme un = kn+ p est divergente si k 6= 02) Toute suite de la forme un = qn est divergente si q > 1
Une conséquence immédiate de la définition :
Proposition 12.58. Soit (un) une suite ayant pour limite +∞ (resp. −∞). Alors (un) n’est pas majorée(resp. minorée).
248

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 12.59. Soit (un) une suite ayant pour limite +∞ (resp. −∞). Alors toute suite extraite de (un)a aussi pour limite +∞ (resp. −∞).
Proposition 12.60. Soit (un) une suite croissante (resp. décroissante). Si (un) n’est pas majorée (resp.minorée), alors (un) diverge vers +∞ (resp. −∞).
Démonstration. Soit (un) une suite croissante qui n’est pas majorée. Soit A ≥ 0, comme (un) n’est pas majorée,elle n’est pas majorée par A en particulier, ainsi il existe un rang N tel que uN ≥ A. De plus, (un) est croissante,ainsi pour tout entier n ∈ N, on a
n ≥ N ⇒ un ≥ uN ≥ ADonc, par définition, limun = +∞ (l’autre cas se démontre de la même manière).
Méthode. Limites et opérations : Les règles sur les limites sont les mêmes que celles énoncées dans lechapitre sur les fonctions. Les méthodes pour lever les F.I. aussi !
Proposition 12.61 (Comparaison). Soient (un) et (vn) deux suites de même support [[p; +∞[. On supposeque (un) a pour limite +∞. On suppose aussi que un ≤ vn à partir d’un rang. Alors (vn) a pour limite +∞.
Exercice 12.11. Écrire la démonstration de la proposition précédente.
Méthode. Pour montrer qu’une suite (un) diverge, on peut :• Considérer deux suites extraites de (un) qui convergent vers des limites distinctes.• Montrer que (un) n’est pas bornée.• Montrer que (un) est plus grande qu’une suite qui diverge vers +∞.• Montrer que (un) est plus petite qu’une suite qui diverge vers −∞.
12.6 Suites adjacentes
Définition 12.62. Deux suites (un) et (vn) sont adjacentes si• Une des deux suites est croissante• L’autre suite est décroissante• la suite u− v converge vers 0
Exercice 12.12. Soit f : [0; 2]→ R la fonction définie par f(x) = −x3 + 3x2 − 1.1) Étudier les variations de la fonction f .2) Justifier que f(x) = 0 admet une unique solution, qu’on notera α.3) On considère l’algorithme de dichotomie appliqué à cette fonction :
1: Variables : n est un entier et an, bn sont des nombres indexés par n2: Initialisation :3: n prend la valeur 04: an prend la valeur 05: bn prend la valeur 26: Traitement :7: Tant que Vraie faire8: Si f(an+bn
2 )× f(an) ≤ 0 alors9: bn+1 prend la valeur an+bn
210: an+1 prend la valeur an11: Sinon12: an+1 prend la valeur an+bn
213: bn+1 prend la valeur bn.14: Fin Si15: n prend la valeur n+ 1
249

TSI 1 Lycée Heinrich-Nessel 2016/2017
16: Fin Tant que17: Sorties : Afficher an et bn
a) Calculer les trois premières itérations de cet algorithme pour en déduire a0, a1, a2, a3 et b0, b1, b2, b3.Illustrer les calculs à l’aide de la courbe représentative de la fonction f .
b) Est-ce que l’algorithme ainsi défini s’arrête ? Quelle modification faut-il apporter pour qu’il s’arrête ?c) On suppose qu’on remplace dans la ligne 7, la condition Vraie par la condition bn − an > 10−5.
Implémenter cet algorithme et donner le résultat retourné en sortie.
Pour l’étude théorique des séquences (an) et (bn), nous allons accepter le fait que l’algorithme ne s’arrêtejamais et permet donc de déterminer deux suites numériques.d) Montrer que la suite (an) est croissante et que la suite (bn) est décroissante.e) Montrer que la suite (an) tend vers une limite l, la suite (bn) tend vers une limite l′ et on a l ≤ α ≤ l′.f) Déterminer la limite de la suite (bn − an). Que peut-on dire des suites (an) et (bn) ?g) En déduire que
limn→+∞
an = limn→+∞
bn = α
Exemple. Le principe de dichotomie conduit à la construction de deux suites adjacentes.
Théorème 12.63 (convergence des suites adjacentes). Soient (un) et (vn) deux suites adjacentes. Alors (un)et (vn) convergent vers la même limite ` :
limn→+∞
un = l = limn→+∞
vn
De plus, si (un) est croissante et (vn) décroissante, on a pour tout n dans le support de (un) et (vn), un ≤ ` ≤ vn
Conséquence : Lorsque l’on a deux suites adjacentes, on peut encadrer la limite simplement grâce aux termesdes deux suites.
Exercice 12.13. Montrer que les deux suites (un) et (vn) ci-dessous sont adjacentes :un+1 = un + 1
(n+1)! pour tout n ≥ 0u0 = 1
vn = un + 1
n×n! pour tout n ≥ 1v0 = 3
Déterminer une valeur approchée de la limite à 10−4 près. Pouvez-vous deviner la valeur exacte de la limite ?
12.7 Notation de Landau et équivalence
Définition 12.64. Soit (un)n∈N et (vn)n∈N deux suites de nombres réels telles les termes vn sont non nuls àpartir d’un certain rang n0. On dit alors que la suite (un) est :• dominée par (vn) (au voisinage de l’infini), si la suite (un/vn)n≥n0 est bornée.• négligeable devant (vn) (au voisinage de l’infini), si la suite (un/vn)n≥n0 converge vers 0.• équivalente à (vn) (au voisinage de l’infini), si la suite (un/vn)n≥n0 converge vers 1 et on note
un ∼ vn
Exercice 12.14. Soit (an), (bn), (cn) et (dn) quatre suites numériques définies par
an = n2, bn = (−1)n(n2 − 2n+ 1), cn = ln(n) et dn = n2 − 52n+
√3
pour tout entier n ≥ 1. Montrer que :1) (bn) est dominée par (an) ;2) (cn) est négligeable devant (an) ;3) (dn) est équivalente à (an).
250

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 12.65. Soit (un)n≥n0 et (vn)n≥n0 deux suites de nombres réels.1) Si (un) est dominée par (vn) alors il existe un réel M ≥ 0 tel que
∀n ≥ n0 : |un| ≤M |vn|
2) Si (un) est négligeable devant (vn) alors il existe une suite (εn)n≥n0 telle que
∀n ≥ n0 : un = εn × vn et limn→+∞
εn = 0
3) Si (un) est équivalente à (vn) alors il existe une suite (εn)n≥n0 telle que
∀n ≥ n0 : un = (1 + εn)× vn et limn→+∞
εn = 0
Notation (de Landau, 1924). Soit (un)n∈N et (vn)n∈N deux suites de nombres réels.• Si (un) est dominée par (vn), on note un = O(vn) et on dit que « un est un grand o de vn au voisinage de
l’infini ».• Si (un) est négligeable devant (vn), on note un = o(vn) et on dit que « un est un petit o de vn au voisinage
de l’infini ».
Remarque. D’après la proposition précédente, cette notation est intuitive. Le grand o pour un majorant et le petito pour une suite (εn) qui tend vers 0.
Digression. Si on utilise la proposition précédente pour définir les trois notions : dominée, négligeable et équivalent,alors l’hypothèse vn non nul à partir d’un certain rang n’est plus nécessaire et le lemme ci-dessous n’est plus vrai.
Proposition 12.66. Soit (un)n∈N et (vn)n∈N deux suites de nombres réels, alors
un ∼ vn ⇐⇒ un − vn = o(vn)
Remarque. On peut reformuler la propriété ainsi : un = vn + o(vn) si et seulement si un ∼ vn.
Lemme 12.67. Soit (un)n∈N et (vn)n∈N deux suites de nombres réels, supposons que un ∼ vn alors un aussi estnon nul à partir d’un certain rang.
Exercice 12.15. Soit (un) et (vn) deux suites numériques.1) Supposons que un = o(1), déterminer la limite de la suite (un).2) Supposons que la suite (un) tend vers +∞, que (vn) est positive et que (un) est dominée par (vn). Déterminer
la limite de la suite (vn).3) Supposons que (un) tend vers un nombre réel ` et un ∼ vn. Déterminer la limite de la suite (vn).
Théorème 12.68. Soit (un)n∈N et (vn)n∈N deux suites de nombres réels telles que un ∼ vn, alors
∀ l ∈ R ∪ ±∞ : limn→+∞
un = l ⇐⇒ limn→+∞
vn = l
Proposition 12.69. Soit (un)n∈N et (vn)n∈N deux suites de nombres réels telles que un ∼ vn, alors un et vnsont de même signe pour n assez grand.
Comme on a étudié les opérations sur les limites, nous allons voir les opérations sur les équivalents :
Proposition 12.70. Soit (un), (vn), (u′n) et (v′n) des suites réelles telles que
un ∼ u′n et vn ∼ v′n
Alors1) un × vn ∼ u′n × v′n ;
251

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) Si (vn) et (v′n) sont non nulles à partir d’un certain rang, alors unvn∼ u′n
v′n;
3) Si vn > 0 à partir d’un certain rang, alors vαn ∼ (v′n)α pour tout α ∈ R.
Remarque. D’après le lemme précédent, l’hypothèse (vn) et (v′n) sont non nulles à partir d’un certain rang esttoujours vérifiée. Donc, il n’est pas nécessaire de la préciser, mais il est important de garder en mémoire de nepas diviser par zéro !
( ! Démonstration au programme)
Démonstration. D’après le lemme précédent, les quatre suites sont non nulles à partir d’un certain rang N . Enpassant à la limite sur des produits et des quotients, on déduit
1)lim un × vn
u′n × v′n= lim un
u′n× lim vn
v′n= 1
Donc un × vn ∼ u′n × v′n.2) et
limunvn
u′nv′n
= lim unvn× v′nu′n
= lim unu′n× lim v′n
vn= 1
Donc la seconde équivalence.3) Enfin, d’après la proposition précédente, pour n assez grand, v′n est aussi (strictement) positif. Par continuité
de la fonction puissance x 7→ xα sur ]0; +∞[, on déduit que
lim vαn(v′n)α = lim
(vnv′n
)α= 1α = 1
D’où la troisième équivalence.
Proposition 12.71. Soit (un), (vn) et (wn) trois suites numériques et α, β deux réels tels que
α+ β 6= 0, un ∼ αwn, et vn ∼ βwn
alorsun + vn ∼ (α+ β)wn
Remarque. Il faut faire très attention avec l’addition. En général, les équivalents ne s’additionnent pas. Parexemple,• un = 1
n+ 1
n3 ∼ 1n
• vn = −1n
+ 1n2 ∼ −1
n
• or (un + vn) n’est pas équivalente à la suite identiquement nulle.
Quelques conséquences de la croissance comparée des fonctions puissances, exponentielle et logarithme :
Proposition 12.72. Soit α > 0, β > 0 et γ > 1, alors1) ( ln(n) )α = o(nβ)2) nβ = o(γn)3) γn = o(n!)
Exercice 12.16. Soit f : R∗+ → R définie par f(x) = (1 + x)α.1) Calculer la dérivée de f2) En déduire lim
x→0
(1+x)α−1x
.
3) Soit (un) une suite réelle qui tend vers 0, conjecturer
limn→+∞
(1 + un)α − 1αun
252

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 12.73. Soit (un) ∈ RN, α ∈ R. Supposons que limn→+∞
un = 0, alors
1) sin(un) ∼ un2) 1− cos(un) ∼ u2
n2
3) tan(un) ∼ un4) ln(1 + un) ∼ un
5) eun − 1 ∼ un6) (1 + un)α − 1 ∼ αun
12.8 Suites arithmétiques et géométriques
Définition 12.74. Une suite arithmétique de terme initial a et de raison r est la suite définie de la manièresuivante :
up = a
un+1 = un + r pour tout entier n ≥ p
Proposition 12.75. Soit (un) une suite arithmétique de terme initial up = a et de raison r. Alors :1) un = a+ (n− p)r pour tout entier n ≥ p2) Soit n ≥ k ≥ p et S la somme uk + uk+1 + . . .+ up des termes consécutifs de la suite (un) de uk à up,
alors :
S = uk + uk+1 + . . .+ up
= (nombre de termes de S) (premier terme de S) + (dernier terme de S)2
= (p− k + 1)uk + up2
3) En particulier,u1 + . . .+ un︸ ︷︷ ︸
n termes
= nu1 + un
2
Exemple. Soit (un) la suite définie par un = n. Cette suite est arithmétique de raison 1 et d’après la propriétéprécédente, on a
1 + 2 + . . .+ n = u0 + . . .+ un = (n+ 1)n2
Proposition 12.76. Soit (un) une suite arithmétique de raison r et de terme initial up. Notons que pour toutentier n ≥ p, un+1 − un est égale à la raison r.
1) Si r > 0, alors pour tout n ≥ p : un < un+1 et la suite est strictement croissante.2) Si r = 0, alors pour tout n ≥ p : un = un+1 = un+2 = . . . et la suite est constante.3) Si r < 0, alors pour tout n ≥ p : un > un+1 et la suite est strictement décroissante.
Exercice 12.17. Soit (un) une suite arithmétique de raison r. Déterminer la limite de la suite en fonction de laraison r.
Définition 12.77. Une suite géométrique de terme initial a et de raison q est la suite définie de la manièresuivante :
up = a
un+1 = qun pour tout entier n ≥ p
Exercice 12.18. Soit (un)n≥p une suite géométrique de raison q. Supposons que (un) est strictement positive.1) Donner une condition nécessaire et suffisante sur up et q pour la suite (un)n≥p soit effectivement strictement
positive.2) Posons, pour tout entier n ≥ p, vn = ln(un). Déterminer la nature de la suite (un)n≥p.
253

TSI 1 Lycée Heinrich-Nessel 2016/2017
Rappelons que pour tout nombre réel q 6= 1, on a
1 + q + q2 + . . .+ qn = 1− qn+1
1− q
Soit (un) une suite géométrique de raison q 6= 1, on a rappelé que un = u0 qn pour tout entier n. Ainsi :
u0 + u1 + u2 + . . .+ un = u0 + u0 q + u0 q2 + . . .+ u0 q
n
= u0(1 + q + q2 + . . .+ qn
)(on a factorisé par u0)
= u01− qn+1
1− q
Proposition 12.78. Soit (un) une suite géométrique de terme initial up = a et de raison q. Alors :1) un = a qn−p pour tout entier n ≥ p.2) Si p = 0, alors pour tout entier naturel n :
u0 + u1 + . . .+ un = u01− qn+1
1− q
3) Soit n ≥ k ≥ p etS = uk + uk+1 + . . .+ un︸ ︷︷ ︸
n−k+1 termes
la somme de termes consécutifs de la suite géométrique, alors
S = 1er terme× 1− qnombre de termes
1− q = uk ×1− qn−k+1
1− q
Exemple. Soit (un) la suite géométrique de raison q = 1.2 et de terme initial u0 = 1000. Posons S = u3 + u4 +. . .+ u10.Le terme initial de la somme est u3 = u0 q
3 = 1000× 1.23 = 1728.La somme S comporte 10− 3 + 1 = 8 termes.D’où
S = 1728× 1− 1.28
1− 1.2 ' 28 510.42
Exercice 12.19. Soit (un) une suite géométrique de raison q et de terme initial up = a. En fonction desparamètres q et a déterminer :
1) les variations de la suite géométrique (un).2) la limite de la suite géométrique (un).
Proposition 12.79. Soit (un) une suite géométrique de raison q, alors• Si −1 < q < 1, alors
limn→+∞
(u0 + u1 + . . .+ un) = u0
1− q• Si 1 ≤ q, alors
limn→+∞
(u0 + u1 + . . .+ un) =
+∞ si u0 > 0−∞ si u0 < 0
Exercice 12.20. Étudier le comportement à l’infini de la suite géométrique (un) de terme initial u0 = 1 et deraison q = −2.
254

TSI 1 Lycée Heinrich-Nessel 2016/2017
12.9 Suites arithmético-géométriques (annexe)
Définition 12.80. Une suite (un) définie par un terme initial et une relation de récurrence de la forme :
un+1 = aun + b
où a et b sont des nombres réels, est appelée suite arithmético-géométrique.
Remarque. Quelques cas particuliers :• si a = 0, alors la relation de récurrence est de la forme un+1 = b et la suite est constante égale à b.• si a = 1, alors la relation de récurrence est de la forme un+1 = un+ b. La suite (un) est alors, en particulier,
une suite arithmétique de raison r = b.• si b = 0, alors la relation de récurrence est de la forme un+1 = aun. La suite (un) est alors, en particulier,
une suite géométrique de raison q = a.
Exemple. La suite (un) définie par u0 = 1000un+1 = 1.1un + 20
est une suite arithmético-géométrique.u1 = 1.1u0 + 20 = 1.1× 1000 + 20 = 1120 ;u2 = 1.1u1 + 20 = 1.1× 1120 + 20 = 1252 ;u3 = 1.1u2 + 20 = 1.1× 1252 + 20 = 1397.2.
Méthode. Soit (un) une suite arithmético-géométrique définie par la donnée de u0 (ou d’un autre terme) etpar la relation de récurrence un+1 = aun + b.On suppose de plus que a 6= 0, a 6= 1 et b 6= 0.
• On définit une suite auxiliaire (vn) parvn = un − α
où α nous a été donné 1 de telle manière que la suite (vn) soit géométrique.• On démontre qu’effectivement la suite (vn) est bien géométrique en prouvant que vn+1 = q vn pour tout
entier naturel n.• On exprime le terme vn en fonction de n.• On en déduit l’expression de un en fonction de n.
Si le premier terme de la suite (un) est u0 et que la suite (vn) est de raison q, alors un = α+ v0qn pour tout
entier naturel n. L’intérêt d’une telle écriture est en premier de pouvoir calculer par exemple u10 sans avoir àcalculer les termes précédents et une seconde application est l’étude de la limite de la suite (un).
1. Pour les plus courageux, on peut retenir que α solution de l’équation α = aα+ b convient.
Exemple. Soit (un) la suite arithmético-géométrique définie paru0 = 1000un+1 = 1.1un + 20 pour tout entier naturel n
Posons vn = un + 200 pour tout entier naturel n.• Montrons que la suite (vn) est géométrique. Soit n un entier naturel, alors
vn+1 = un+1 + 200 on applique la relation précédente avec n+ 1.= 1.1un + 20 + 200 d’après le relation de récurrence sur (un).= 1.1un + 220
= 1.1(un + 2201.1 )
= 1.1(un + 200)= 1.1vn
Ainsi, on déduit que la (vn) est géométrique de raison q = 1.1 et de terme initial v0 = u0 + 200 = 1200.
255

TSI 1 Lycée Heinrich-Nessel 2016/2017
• D’après le cours, quel que soit l’entier naturel n, vn = 1200× 1.1n. D’où :
vn = un + 2001200× 1.1n = un + 200
un = 1200× 1.1n − 200
pour tout entier naturel n.
Proposition 12.81. Soit (un) une suite arithmético-géométrique de formule de récurrence un+1 = qun + ravec r 6= 0 et q 6= 1. Alors il existe un unique nombre réel h tel que la suite (vn) définie par vn = un + h soitgéométrique. De plus, la raison de (vn) est q.
Corollaire 12.82. Soit (un) une suite arithmético-géométrique de formule de récurrence un+1 = qun + r avecr 6= 0 et q 6= 1. Alors
un = qn(u0 + r
1− q
)+ r
1− q
12.10 Suites extraites (annexe)Lemme 12.83 (lemme des pics). Toute suite bornée admet une sous-suite monotone.
Démonstration. Soit (un) une suite bornée. On pose
E = n ∈ N| ∀ p > n : un > upO = n ∈ N| ∃ p > n : un ≤ up
On note que N est l’union disjointe de E et de O. Distinguons deux cas :• Si E est infini, dans ce cas, la suite extraite (un)n∈E est décroissante.• Sinon, E est fini. Notons N le maximum de l’ensemble fini E, alors φ(1) = N + 1 ∈ O. Par définition, deO, il existe φ(2) ∈ N tel que uφ(1) ≤ uφ(2). Comme φ(2) > φ(1) > N , on déduit que φ(2) ∈ O et l’existencede φ(3) ∈ O tel que uφ(2) ≤ uφ(3). On continie ainsi par récurrence pour obtenir une application φ : N→ Otelle que la suite extraite (uφ(k))k∈N soit croissante.
Remarque. Il est possible d’interpréter autrement la démonstration. Pour ce faire, voyons les entiers n comme desindividus situés à une hauteur un, alignés les uns derrières les autres d’ouest en est et éclairés par le soleil levant.On dit que n est « éclairé » si, quel que soit p > n, un > up (i.e. n ∈ E) et n est « dans l’ombre » s’il existe p > n,up ≥ un (i.e. n ∈ O). Le premier cas, correspond à la situation où il y a une infinité d’individus éclairés. Dans,le second cas, il y a une infinité d’individus dans l’ombre. De plus, un individu est dans l’ombre à cause de laprésence d’un individus plus haut et plus à l’est que lui. On commence par choisir un individus dans l’ombre et àl’est des individus éclairés. Puis on choisit l’individus qui lui fait de l’ombre mais comme cette individus est aussidans l’ombre, on peut continuer à considérer l’individus suivant faisant de l’ombre. Ainsi de suite, on selectionneune infinité d’individus telle que chacun fasse de l’ombre à son prédécesseur.
Théorème 12.84 (Bolzano-Weiertstrass, 1817). Toute suite bornée admet une sous-suite convergente.
Démonstration. Soit (un) une suite bornée. D’après le lemme des pics, il existe une suite extraite (vk) monotone.De plus, (vk) est bornée, ainsi, d’après le théorème de la limite monotone, la suite extraite (vk) converge.
256

Chapitre 13
Polynômes
Programme• Ensemble K[X] des polynômes à une indéterminée :• Le programme se limite au cas où les coefficients sont réels ou complexes.• Opérations : somme, produit et composée.• Degré d’un polynôme, coefficient dominant, polynôme unitaire.• Degré d’une somme et d’un produit.• Fonction polynomiale associée à un polynôme. On pourra confondre polynômes et fonctions polynômiales.• Base de l’arithmétique dans K[X]• Divisibilité dans K[X], diviseurs et multiples, division Euclidienne.• Dérivation :• Polynôme dérivé, linéarité, dérivée d’un produit.• Dérivées d’ordre supérieure. Formule de Leibniz.• Formule de Taylor.• Racines :• Récine (ou zéro) d’un polynôme. Multiplicité d’une racine.• Caractérisation par les valeurs des dérivées successives en a de l’ordre de multiplicité de la racine a.• Un polynôme de degré n admet au plus n racines distinctes.• Un polynôme P est scindé sur K s’il admet exactement deg(P ) racines dans K comptées avec leur multiplicité.• Expression de la somme et du produit des racines d’un polynôme en fonction de ses coefficients. Les autres
fonctions symétriques élémentaires sont hors programme.• Cas des polynômes de degré deux.• Décomposition en facteur irréductibles :• Théorème de D’Alembert-Gauss• Polynômes irréductibles, description des polynômes irréductibles sur C et sur R.• Décomposition d’un polynôme en facteurs irréductibles sur C et sur R.
13.1 GénéralitésConsidérons les trois polynômes suivants :
P (X) = X2 − 3X + 12 , Q(X) = X5 + 1
4X4 + 1
3X3 + 1
2X2 +X, R(X) = 1 +X + . . .+Xd
mais non pas comme des fonctions mais comme des expressions formelles. Alors, se donner un polynôme revientà essentiellement à se donner sa liste de coefficients (c0, . . . , cn) et quitte à ajouter des 0, les coefficients formentune suite (ck)k∈N presque tous nuls (sauf un nombre fini). Ainsi, la suite (cn)n∈N des coefficients définissant lepolynôme
257

TSI 1 Lycée Heinrich-Nessel 2016/2017
• P (X) est
cn =
12 si n = 0−3 si n = 11 si n = 20 si n > 2
• Q(X) est
cn =
1n
si 1 ≤ n ≤ 41 si n = 50 sinon
• R(X) est
cn =
1 si 0 ≤ n ≤ d0 sinon
Cette approche permet d’utiliser la notion de suites numériques pour définir rigoureusement l’addition. Enfin, lanotation standard avec P (X) = c0 + c1X + . . . cdX
d permet d’ajouter une notion de produit entre les polynômes(bien connue déjà).
Remarque. On rappelle que K désigne le corps des nombres réels R ou celui des nombres complexes C.
Définition 13.1. Un polynôme à coefficients dans K est une suite (cn) ∈ KN telle qu’il existe un entier naturelN vérifiant cn = 0 pour tout entier naturel n > N .En particulier, le polynôme (cn) définie par cn = 0 pour tout entier naturel n, est appelé polynôme nul.
Définition 13.2. Soit P = (cn) et Q = (c′n) deux polynômes. On dit que P et Q sont égaux si cn = c′n pourtout entier naturel n.
Définition 13.3. Soit P = (cn) un polynôme à coefficients dans K. Le degré du polynôme P est
deg(P ) =−∞ si P est nulmaxn ∈ N : cn 6= 0 sinon
Exemple. Si on revient aux trois polynômes P , Q et R donnée en début de chapitre, alors deg(P ) = 2, deg(Q) = 5et deg(R) = n.
Notation.• Le polynôme nul est noté 0.• Soit P = (cn) un polynôme à coefficients dans K non nul et soit X une variable indéterminée. Posons d son
degré, alors on associe à P la notation
P (X) = c0X0 + c1X + . . .+ cdX
d =d∑k=0
ckXk
• où par convention X0 = 1.• On note K[X] l’ensemble des polynômes à coefficient dans K (d’indéterminée X).
Dans la suite, on identifiera le polynôme P avec l’expression P (X).
Remarque.• Dire que P (X) = cnX
n + . . .+ c1X + c0 est un polynôme de degré n implique que cn est non nul.• Un polynôme P à coefficients dans K est non nul si et seulement si deg(P ) ≥ 0.• Il peut arriver qu’on préfère une autre indéterminée que X. Par exemple, P (T ) = −T 4 + 4T 3 − 1 ∈ K[T ]
ou P (λ) = −λ4 + 4λ3 − 1 ∈ K[λ].• Tout scalaire λ de K est en particulier un polynôme P (X) = λ. Un tel polynôme de degré zéro est appelé
polynôme constant.
258

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 13.4. Soit un polynôme P (X) = cnXn + . . .+ c1X + c0 ∈ K[X] de degré n.
• pour tout entier k, le scalaire ck est appelé le coefficient de degré k de P (X).• le scalaire cn est appelé le coefficient dominant de P (X)• le scalaire c0 est appelé le coefficient constant de P .• Lorsque le coefficient dominant vaut 1, on dit que le polynôme est unitaire (ou normalisé).
Proposition 13.5. Deux polynômes P et Q sont égaux si et seulement s’ils ont même degré et mêmescoefficients degré par degré.
Notation. Soit n un entier naturel, on note• Rn[X] l’ensemble des polynômes à coefficients réels de degré au plus n• Cn[X] l’ensemble des polynômes à coefficients complexes de degré au plus n.
Avant de donner la définition de la somme et produit de polynôme, une première approche intuitive :
Exercice 13.1. Soit P (X) =m∑k=0
akXk de degré m et Q(X) =
n∑k=0
bkXk de degré n deux polynômes non nuls à
coefficients dans K.1) Soit l un entier, développer XlP (X).2) On pose
Q(X) =
(m∑k=0
akXk
)×
(n∑l=0
blXl
)et R(X) =
m+n∑k=0
(k∑i=0
aibk−i
)Xk
a) On suppose que m = 2 et n = 3. Développer Q(X) et comparer avec R(X).b) Montrer que Q(X) = R(X).
3) On prolonge le m + 1-uplet (a0, a1, . . . , an) en suite de nombres réels (a0, a1, . . . , an, 0, 0, . . .) et de mêmepour le n+ 1-uplet (b0, b1, . . . , bn). Pour tout entier naturel k, on pose :
ck =k∑i=0
aibk−i
Montrer que ck = 0 pour tout k > n+m.
Définition 13.6. Soit P (X) et Q(X) deux polynômes à coefficients dans K dont on note (ak) (respectivement(bk)) la suite des coefficients de P (X) (respectivement de Q(X)). Soit λ ∈ K et n un entier. Alors
1) La somme P (X) +Q(X) est le polynôme dont la suite des coefficients est (ak + bk) :
P (X) +Q(X) =N∑k=0
(ak + bk)Xk
où N = max(deg(P ),deg(Q)).2) Le produit par un scalaire λP (X) est le polynôme dont la suite des coefficients est (λak) :
λP (X) =deg(P )∑k=0
λakXk
3) Le produit P (X)×Q(X) est le polynôme dont la suite des coefficients est (ck) définie par ck =k∑i=0
aibk−i
pour tout entier k :
P (X)×Q(X) =N∑k=0
ckXk
où N = deg(P ) + deg(Q).
259

TSI 1 Lycée Heinrich-Nessel 2016/2017
4) La puissance n-ème de P (X) est définie par récurrence :
P (X)n =
1 si n = 0P (X)× P (X)n−1 si n > 0
Remarque. D’après l’exercice précédent, la somme définissant le produit est fini car les ck sont tous nuls à partird’un certain rang.
Ces opérations sur les polynômes respectent les mêmes propriétés que l’addition et la multiplication des entiersrelatifs :
Proposition 13.7. Soit P (X), Q(X), R(X) ∈ K[X], alors1) P (X) +Q(X) = Q(X) + P (X) (commutativité de l’addition)2) P (X) + 0 = 0 + P (X) = P (X) (polynôme nul : élément neutre pour l’addition)3) P (X)− P (X) = 04) P (X)×Q(X) = Q(X)× P (X) (commutativité du produit)5) P (X)× 1 = 1× P (X) = P (X) (le scalaire 1 : élément neutre pour le produit)6) P (X)(Q(X) +R(X) ) = P (X)Q(X) + P (X)R(X) (distributivité)
Exercice 13.2 (identités remarquables). Soit P (X), Q(X) ∈ K[X], développer les expressions (P (X) +Q(X))2,(P (X)−Q(X))2 et (P (X) + (Q(X))(P (X) +Q(X)).
Proposition 13.8 (Formules du binôme de Newton). Soit P , Q deux polynômes à coefficients dans K, alors
1) (P +Q)n =n∑k=0
(n
k
)P kQn−k
2) (P −Q)n =n∑k=0
(n
k
)(−1)n−kP kQn−k
3) Pn −Qn = (P −Q)n−1∑k=0
P kQn−k−1
Si on se donne un polynôme Q(X) ∈ K[X], on peut maintenant substituer chaque occurrence de l’indéterminé Xpar un polynôme P (X) donné :
Définition 13.9. Soit P (X) = amXm + · · ·+ a1X + a0 et Q(X) = bnX
n + · · ·+ b1X + b0. La composée deP (X) par Q(X) est définie par
Q P (X) = bnP (X)n + · · ·+ b1P (X) + b0
Proposition 13.10. Soit P et Q deux polynômes, alors Q P est aussi un polynôme.
Théorème 13.11 (Opérations et degré). Soit P et Q deux polynômes non nuls. Alors1) deg(PQ) = deg(P ) + deg(Q) ;2) deg(P k) = k × deg(P ) pour tout entier naturel k ;3) deg(λP ) = deg(P ) pour tout λ ∈ R \ 0 ;4) deg(P +Q) ≤ max(deg(P ); deg(Q)).
De plus, il y a égalité deg(P +Q) = max(deg(P ); deg(Q)) si deg(P ) 6= deg(Q).
5) deg(Q P ) = deg(Q)× deg(P ) ;
( ! Démonstration au programme)
Démonstration. Soit P (X) =∑m
k=0 akXk de degré m et Q(X) =
∑n
k=0 bkXk de degré n deux polynômes non
nuls. En particulier, am 6= 0 et bn 6= 0. On pose ak = 0 pour tout k > m et bk = 0 pour tout k > n.
260

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) Posons R(X) = P (X)Q(X) =∑+∞
i=0 ciXi où
ci =i∑
j=0
aibi−j
Alors,
cm+n =m+n∑i=0
aibm+n−i =m−1∑i=0
ai bn+(m−i)︸ ︷︷ ︸=0
+ambn +m+n∑i=m+1
ai︸︷︷︸=0
bm+n−i = ambn 6= 0
et de même, on montre que pour tout i > m+ n, ci = 0. Ainsi, on déduit que deg(PQ) = n+m.2) Pour k = 0, on a deg(P 0) = deg(1) = 0×deg(P ). Supposons par récurrence que pour un entier k quelconque,
on ait deg(P k) = k × deg(P ). Alors, d’après le point précédent,
deg(P k+1) = deg(P k × P ) = deg(P k) + deg(P ) = k deg(P ) + deg(P ) = (k + 1) deg(P )
D’où la relation est vraie pour tout k ∈ N.3) Le scalaire λ est un polynôme constant de degré 0, ainsi d’après le premier point, on déduit que deg(λP ) =
0 + deg(P ) = deg(P ).4) Si k ≥ max(m,n), alors ak + bk = 0, ainsi, deg(P +Q) ≤ max(m,n). De plus si m 6= n, quitte à échanger
P et Q on peut supposer que m < n, alors an + bn = bn 6= 0 et le polynôme P +Q est de degré m+ n.5) Si P (X) = λ ∈ K est un polynôme constant, alors deg(P ) = 0 et Q P (X) = bnλ
n + . . . + b0 ∈ K est unpolynôme constant. Donc deg(Q P ) = 0 = deg(P )× deg(Q). Supposons que P (X) est non constant, ainsim le degré de P (X) est strictement positif. D’après les points 1) et 2), on déduit que pour tout k ∈ N, sibk 6= 0, alors deg(bkP (X)k) = km. Comme m > 0, les degrés de termes non nuls bkP (X)k sont deux à deuxdistincts et deg(bmP (X)m) = nm. Ainsi, d’après le point précédent, on déduit que
deg(Q P ) = max(deg(bkP k); k ∈ J0;nK) = nm = deg(Q)× deg(P )
Remarque. De la démonstration du premier point, on déduit que le coefficient dominant du produit PQ est égalau produit des coefficients dominants de P et de Q.
Proposition 13.12 (K[X] est intègre). Soit P, Q ∈ K[X] deux polynômes, alors
P Q = 0 ⇒ P = 0 ou Q = 0
Démonstration. Montrons la contraposé : Soit P , Q deux polynômes non nuls alors d’après la proposition précé-dente deg(PQ) = deg(P ) + deg(Q) ≥ 0. Ainsi, PQ est non nul 1.
Corollaire 13.13. Soit P un polynôme non nul, Q et R sont deux polynômes quelconques, on a
PQ = PR ⇒ Q = R
Démonstration. D’après la proposition précédente :
PQ = PR ⇐⇒ PQ− PR = 0 ⇐⇒ P (Q−R) = 0 ⇒ P = 0 ou Q−R = 0
Si P 6= 0, on déduit que Q−R = 0, c’est-à-dire Q = R.
13.2 Fonction polynômiale associéeLorsqu’on substitue l’indéterminé X par un élément (concret) x de K, on dit qu’on évalue le polynôme en x :
1. On a ici un exemple d’utilisation un peu subtil de la convention deg(0) = −∞. On on aurait aussi pu remarquer quele coefficient dominant de PQ est égal au produit des coefficients dominants de P et Q qui par hypothèse sont non nuls.
261

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 13.14. Soit P (X) =n∑k=0
akXk un polynôme à coefficients dans K et α ∈ R. L’évaluation de P en
α est le nombre
evα(P ) = P (α) =n∑k=0
akαk ∈ K
Ainsi, on associe la fonction polynômiale :
P = ev(P ) : K // K
x // P (x) = evx(P )
Nous avons ainsi une application :
ev : K[X] // f : K→ K fonction
P (X) // (x 7→ P (x))
qui à un polynôme formel associe une fonction polynômiale.
Théorème 13.15. Soit f, g : K→ K deux fonctions polynômiales définie par
f(x) = amxm + . . .+ a1x+ a0 et g(x) = bnx
n + . . .+ b1x+ b0
pour tout x ∈ K. Supposons que∀x ∈ K : f(x) = g(x)
alors :• m = n
• ak = bk pour tout 0 ≤ k ≤ n
Démonstration. La réciproque est évidente. Pour le sens direct : Supposons que pour tout x ∈ K : f(x) = g(x)et montrons que 2 le polynôme (f − g)(X) est nul. Quitte à échanger f et g, on peut supposer que m ≤ n. Soitx0, x1, . . . , xn n + 1 nombres dans K deux à deux distincts. Notons aj les coefficients de la fonction polynômialef − g. Par hypothèse, on a
⇐⇒ ∀ 0 ≤ i ≤ n : (f − g)(xi) = 0
⇐⇒ ∀ 0 ≤ i ≤ n :n∑j=0
ajxji = 0
⇐⇒
a0 + a1x0 + a2x20 + a3x
30 + . . .+ anx
n0 = 0
a0 + a1x1 + a2x21 + a3x
31 + . . .+ anx
n1 = 0
a0 + a1x2 + a2x22 + a3x
32 + . . .+ anx
n2 = 0
... =...
a0 + a1xn + a2x2n + a3x
3n + . . .+ anx
nn = 0
⇐⇒
1 x0 x2
0 x30 . . . xn0
1 x1 x21 x3
1 . . . xn1
1 x2 x22 x3
2 . . . xn2...
...1 xn x2
n x3n . . . xnn
a0
a1
a2...an
=
000...0
(?)
Notons A la matrice carrée de taille n+ 1 ci-dessus 3. Comme les xj sont deux à deux distincts, on admet 4 quela matrice carrée A est de rang n+ 1, égal à sa taille. Ainsi, la seule solution de (?) est la matrice colonne nulle,c’est-à-dire a0 = a1 = . . . = an = 0. D’où le polynôme (f − g)(X) est nul et on a bien le théorème.
2. Nous verrons une preuve plus élémentaire de ce fait (corollaire 13.27).3. Cette matrice est appelée matrice de Vandermonde.4. Exercice? : Démontrer ce fait par récurrence.
262

TSI 1 Lycée Heinrich-Nessel 2016/2017
Remarque. En d’autre termes, si f = g en tant que fonction polynomiale alors les polynômes f(X) et g(X) sontégaux (de même degré et les mêmes coefficients degré par degré).
Corollaire 13.16. L’application qui à tout polynôme P (X) ∈ R[X] associe sa fonction polynomiale associée estune bijection.
Conséquence : On peut (et on va) confondre polynôme et fonction polynomiale associée.
Exercice 13.3. Trouver un polynôme P (X) ∈ R[X] tel que
P (−1) = 1, P (0) = 3 et P (2) = 0
Exercice 13.4 (Interpolation de Lagrange). ? Soit (x1, . . . , xn) ∈ Rn et (y1, . . . , yn) ∈ Rn tels que les xi sontdeux à deux distincts.
1) On pose P1(X) =∏i 6=1
X − xix1 − xi
.
a) Quel est le degré du polynôme P1(X) ?b) Calculer P1(xi) pour tout 1 ≤ i ≤ n.
2) En déduire un polynôme P (X) de degré au plus n tel que
∀ i ∈ J1; nK : P (xi) = yi
13.3 Arithmétique dans K[X]Dans l’ensemble des polynômes K[X], si on se donne un polynôme P (X) quelconque, il n’existe pas en généralun inverse Q(X) du polynôme P (X), c’est-à-dire telle que P (X)Q(X) = 1. Par contre, comme pour les entiersrelatifs, nous allons voir qu’il est possible d’effectuer des divisions Euclidiennes. Rappelons que
Proposition 13.17 (division Euclidienne dans Z). Soit a un entier relatif et b un entier naturel . Il existe ununique couple (q, r) ∈ Z2 tel que
a = bq + r et 0 ≤ r < b
Vocabulaire. Dans l’écriture a = bq + r d’une division Euclidienne de a par b, on dit que• q est le quotient ;• r est le reste ;• b est le diviseur ;• a est le dividende.
Définition 13.18. Soit A et B deux polynômes. On dit que B divise A (ou que A est divisible par B, ou queA est un multiple de B) s’il existe un polynôme Q tel que A = BQ. On note B|A.
Proposition 13.19. Soit A et B deux polynômes. Si A est non nul et B divise A alors deg(B) ≤ deg(A).
Démonstration. Supposons donc qu’il existe Q ∈ K[X] tel que A = BQ. Comme A est non nul, on déduit que Bet Q sont non nuls. Ainsi, deg(B) ≤ deg(B) + deg(Q) = deg(A).
Exercice 13.5. Soit A,B,C trois polynômes à coefficients réels tels que C divise B et B divise A.1) Montrer que C divise A.2) Montrer que pour tout λ ∈ K non nul, λB divise A.3) Est-ce que l’ensemble des diviseurs de A est fini ?4) Donner la liste de tous les polynômes unitaires qui divisent le polynôme A(X) = (2X + 1)(X + 1)2.
Exercice 13.6. Soit A, B deux polynômes non nuls tels que A|B et B|A. Montrer qu’il existe λ ∈ K∗ tel queA = λB.
Exemples.1) Le polynôme nul est divisible par n’importe quel polynôme.
263

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) Le polynôme nul est le seul polynôme divisible par le polynôme nul.3) Les polynômes constants non nuls divisent n’importe quel polynôme.4) Un polynôme est toujours divisible par lui-même et par tout multiple scalaire de lui-même.
Définition 13.20. Un polynôme P est irréductible si son degré est au moins 1 et les seuls diviseurs de P sontles polynômes constants et les polynômes de la forme λP où λ ∈ K \ 0.
Exemples. Un polynôme de degré 1 est toujours irréductible. Le polynôme P = (X − 1)2 n’est pas irréductible.Le polynôme Q = X2 − 1 n’est pas irréductible. Le polynôme R = X2 + 1 est irréductible sur R mais pas sur C.Le polynôme X4 + 3X2 + 2 n’est pas irréductible.
L’algorithme d’Euclide : Soit A(X), B(X) deux polynômes non nuls de degrés m et n respectivement.1) Si deg(A) < deg(B), alors on pose Q = 0 et R = A.2) Sinon, si deg(A) ≥ deg(B). Notons a0 (resp. b 6= 0) le coefficient dominant de A (resp. B). Posons Q0(X) =
a0bXm−n et A1(X) = A(X)−B(X)×Q0(X). Alors deg(A1) < deg(A).
a) Si deg(A1) < deg(B), alors on pose Q = Q0 et R = A1.b) Sinon, on recommence : On note a1 le coefficient dominant de A1 et on pose Q1(X) = a1
bXdeg(A1)−n
et A2(X) = A1(X)−B(X)×Q1(X). Alors deg(A2) < deg(A1) < deg(A).
On continue ainsi de suite à définir les polynômes Ar etQr tant que deg(Ar) ≥ deg(B). On sera effectivementamené à s’arrêter car
deg(Ar) < deg(Ar−1 < . . . < deg(A2) < deg(A1) < deg(A)
ainsi, nécessairement pour un certain r on aura deg(Ar) < deg(B).Enfin, une fois cette dernière condition remplie, on pose
R(X) = Ar(X) et Q(X) =r∑i=0
Qr(X)
A(X)−B(X)Q0(X)
A1(X). . .
R(X) = Ar(X)
B(X)Q(X) =
∑r
i=0 Qr(X)
Théorème 13.21 (Division Euclidienne). Soit A et B deux polynômes tels que B 6= 0. Il existe un uniquecouple (Q,R) ∈ K[X]2 tels que
A = BQ+R et deg(R) < deg(B)
Démonstration. L’existence résulte de l’algorithme d’Euclide qui permet toujours de déterminer Q et R quiconviennent. Montrons l’unicité : Soient Q,Q′, R,R′ quatre polynômes tels que A = BQ + R = BQ′ + R′,deg(R) < deg(B) et deg(R′) < deg(B). Alors,
BQ+R− (BQ′ +R′) = 0 ⇐⇒ B(Q−Q′) = R′ −R (?)
etdeg(R′ −R) ≤ max
(deg(R), deg(R′)
)< deg(B)
Supposons que Q 6= Q′, alors Q−Q′ est non nul et donc
deg(B) > deg(R′ −R) = deg(B(Q−Q′)) = deg(B) + deg(Q−Q′) ≥ deg(B)
ce est absurde. Ainsi Q = Q′ et de (?), on déduit que R = R′.
264

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 13.22. Soit A et B deux polynômes tels que B 6= 0. Soit (Q,R) l’unique couple donné par ladivision euclidienne de A par B. On appelle Q le quotient de (la division Euclidienne de) A par B et R le restede A par B.
Une remarque :
Corollaire 13.23. Soit A et B deux polynômes tels que B 6= 0. Alors A est divisible par B si et seulement lereste de la division Euclidienne de A par B est nul.
Exercice 13.7. Soit P (X) ∈ R[X]. Déterminer une primitive de x 7→ P (x)ax+b .
Exercice 13.8. Démontrer que pour tout n ∈ N et tout θ ∈ R :
X2 − 2 cos(θ)X + 1 divise cos((n− 1)θ)Xn+1 − cos(nθ)Xn − cos(θ)X + 1
13.4 Racines d’un polynôme
Définition 13.24. Soit a ∈ K et P (X) ∈ K[X]. On dit que a est une racine de P (X) si P (a) = 0.
Exercice 13.9. Soit P (X) ∈ K[X] et a ∈ K un scalaire. Exprimer le reste de la division Euclidienne de P (X)par X − a en fonction de P (X) et a.
Théorème 13.25. Soit a ∈ K et P (X) ∈ K[X]. Les propositions suivantes sont équivalentes :1) a est racine de P (X) ;2) le reste de la division Euclidienne de P (X) par (X − a) est nul ;3) Il existe un polynôme Q(X) ∈ K[X] tel que P (X) = (X − a)Q(X).
( ! Démonstration au programme)
Démonstration.• 1) ⇒ 2) : Supposons que a est une racine de P (X). Soit Q(X) le quotient et R(X) le reste de la division
Euclidienne de P (X) par (X − a) alors
P (X) = (X − a)Q(X) +R(X) (?)
et deg(R(X)) < deg(X − a) = 1. Donc R(X) = λ est un polynôme constant. De plus, en évaluant en a larelation (?), on a
0 = P (a) = Q(a)(a− a) + λ = λ = R(X)Donc, le reste de la division Euclidienne est bien nul.
• 2) ⇒ 3) : Supposons que le reste de la division Euclidienne de P (X) par X − a est nul. Soit Q(X) lequotient, alors P (X) = (X − a)Q(X).
• 3) ⇒ 1) : Supposons qu’il existe un polynôme Q(X) ∈ K[X] tel que P (X) = (X − a)Q(X). Alors, P (a) =(a− a)Q(a) = 0, c’est-à-dire a est une racine de P (X).
On en déduit que 1) ⇐⇒ 2) ⇐⇒ 3).
Remarque. Le reste de la division Euclidienne de P (X) par X − a est le polynôme constant P (a).
Soit P (X) ∈ K[X] non nul. Supposons que P (X) admet m racines a1, . . . , am ∈ K deux à deux distincts. D’aprèsle théorème, il existe Q(X) ∈ K[X] tel que P (X) = (X − a1)Q(X). Ainsi, 0 = P (a2) = (a2 − a1)Q(a2), ora2 − a1 6= 0 par hypothèse, d’où a2 est une racine du quotient Q(X). On en déduit qu’il existe Q2(X) ∈ K[X] telQ(X) = (X − a2)Q2(X) et donc P (X) = (X − a1)(X − a2)Q2(X).Par récurrence sur l’entier m, on déduit qu’il existe un polynôme Q(X) non nul tel que
P (X) = Q(X)m∏i=1
(X − ai)
De plus, deg(Q(X)) = deg(P (X))−m ≥ 0 :
Corollaire 13.26. Soit P (X) ∈ K[X]. Si P (X) est non nul, alors P (X) admet au plus deg(P ) racines différentes.
265

TSI 1 Lycée Heinrich-Nessel 2016/2017
Nous avions vu (théorème 13.15) que si deux fonctions polynômiales f et g étaient telles que f(x) = g(x) pourtout x ∈ K alors les polynômes f(X) et g(X) sont égaux. Voici, un second corollaire où l’on affaiblit l’hypothèsef(x) = g(x) pour une infinité de valeurs prisent par x.
Corollaire 13.27. Soit P (X) ∈ Kn[X] et Q(X) ∈ Kn[X]. Si P (X) et Q(X) coïncident sur au moins n+1 valeursdistincts, alors P (X) = Q(X).
Démonstration. Supposons que P (X) et Q(X) sont de degré inférieur ou égal à n et coïncident sur n+ 1 valeursx1, . . . , xn+1 (deux à deux distincts). Alors le polynôme P (X)−Q(X) de degré inférieur ou égal à n admet n+ 1racines x1, . . . , xn+1. Ainsi, d’après le corollaire précédent (sa contraposée), on déduit que P (X)−Q(X) est nul.C’est-à-dire P (X) = Q(X).
Définition 13.28. Soit a ∈ K, P (X) ∈ K[X] un polynôme non nul et m ∈ N \ 0.• On dit que a est racine de P (X) de multiplicité m si
(X − a)m divise P (X) et (X − a)m+1 ne divise pas P (X)
• Lorsque m = 1, on parle de racines simples.• Lorsque m = 2, on parle de racines doubles, etc.
Remarque. • En particulier, l’ordre de multiplicité ne peut pas être supérieur au degré du polynôme.• Notons que (X − a)0 = 1 divise n’importe quel polynôme donné. On peut redéfinir la multiplicité d’une
racine a d’un polynôme P (X) comme étant le plus grand entier m tel que (X − a)m divise P (X).
En reprenant le raisonnement précédent (pour le corollaire 13.26), on montre de la même manière que si lepolynôme P admet m racines ai de multiplicité αi, on déduit qu’il existe un polynôme Q tel que
P (X) = Q(X)m∏i=1
(X − ai)αi
D’où, par comparaison des degrés, on déduit
Corollaire 13.29. Soit P (X) ∈ K[X] non nul, alors P (X) admet au plus deg(P ) racines comptées avec leurmultiplicité.
Définition 13.30. Un polynôme P (X) ∈ K[X] de degré au moins 1 est dit scindé sur K s’il admet exactementdeg(P ) racines comptées avec leur multiplicité.
Remarque. Un polynôme P (X) ∈ K[X] est scindé si et seulement si
∃ r ∈ N ∃ (a1, . . . , ar) ∈ Kr ∃ (m1, . . . ,mr) ∈ Nr ∃λ ∈ K : P (X) = λ
r∏i=1
(X − ai)mi
Exemples.1) Tout polynôme de degré 1 est scindé.2) Un polynôme de degré 2 est scindé sur R si son discriminant est positif ou nul.3) Tout polynôme de degré 2 est scindé sur C.
Le théorème fondamental suivant est admis.
Théorème 13.31 (D’Alembert-Gauss 1). Tout polynôme de degré au moins 1 est scindé sur l’ensemble desnombres complexes C.
1. Jean le Rond D’Alembert (1717 - 1783) et Johann Carl Friedrich Gauss (1777 - 1855)
En reprenant encore une fois le raisonnement pour le corollaire 13.26, on déduit du théorème de D’Alembert-Gauss :
266

TSI 1 Lycée Heinrich-Nessel 2016/2017
Corollaire 13.32. Soit P (X) ∈ C[X] un polynôme de degré n ≥ 1 et de coefficient dominant a. Il existe(a1, . . . , ar) ∈ Cr des nombres complexes deux à deux distincts et (m1; . . . ;mr) ∈ Nr des nombres entiers tousnon nuls tels que
P (X) = a
r∏k=1
(X − ak)mk
De plus,r∑k=1
mk = n.
Soit P (X) ∈ C[X] un polynôme irréductible, d’après le théorème de D’Alembert-Gauss, il existe a ∈ C tel queX − a divise P (X). Or P (X) est irréductible, ainsi par définition, il existe λ ∈ C tel que P (X) = λ(X − a) :
Corollaire 13.33. Les polynômes irréductibles sur C sont les polynômes de degré 1.
Proposition 13.34. Soit P (X) un polynôme à coefficients réels vu comme élément de C[X]. Si z ∈ C est uneracine de P (X), alors son conjugué z est aussi une racine de P (X).
Démonstration. Soit P (x) = anXn + . . .+ a1X + a0 ∈ R[X], supposons que z ∈ C est une racine de P , alors en
utilisant les propriétés du conjugué, on déduit que
0 = anzn + . . .+ a1z + a0 = anzn + . . .+ a1z + a0 = anz
n + . . .+ a1z + a0 = P (z)
Donc z est une racine de P .
Exercice 13.10. Soit z ∈ C, montrer que P (X) = (X − z)(X − z) appartient à R[X].
Corollaire 13.35. Les polynômes irréductibles sur R sont les polynômes de degré 1 et les polynômes de degré 2de discriminant strictement négatif.
Théorème 13.36 (Factorisation). Soit P ∈ K[X] un polynôme de degré au moins 1 et de coefficient dominantλ. Alors il existe des polynômes P1,. . . ,Pm irréductibles et unitaires tels que P = λP1 × · · · × Pm
Digression. Le théorème nous dit que tout polynôme P (X) se décompose en produit de facteur irréductibles(i.e : P = λPm1
1 × . . . × Pmrr , où les Pi sont irréductibles). C’est encore une propriété partagée avec l’ensembledes entiers relatifs. En effet, le théorème fondamentale de l’arithmétique nous dit que tout nombre relatif n sedécompose en produit de facteurs premiers (i.e : n = ±1pm1
1 × . . .× pmrr où les pi sont premiers).
Exercice 13.11. Soit P (X) = c2X2+c1X+c0 ∈ C2[X], notons α1 et α2 les racines (non nécessairement distincts)
tels queP (X) = c2(X − α1)(X − α2)
Exprimer les coefficients du polynôme P en fonction des racines α1 et α2.
Proposition 13.37. Soit P (X) = aX2 + bX+ c un polynôme de degré 2. Soit α et β ses deux racines complexes,alors
α+ β = − ba
et αβ = c
a
Plus généralement, si P (X) est scindé alors
P (X) =n∑k=0
akXk = an
n∏k=1
(X − αk)
anXn + an−1X
n−1 + . . .+ a0 = an(X − α1)(X − α2)(X − α3) . . . (X − αn−1)(X − αn)= an(Xn + (−α1 − α2 − . . .− αn−1 − αn)Xn−1 + . . .+ (−α1)(−α2) . . . (−αn))
= anXn−an
∑αkX
n−1 + . . .+ (−1)n∏
αk
Par identification des coefficients :
Théorème 13.38 (Relations de Viète 1). Soit P (X) ∈ K[X] scindé. On note 2
P (X) =n∑k=0
akXk = an
n∏k=1
(X − αk)
267

TSI 1 Lycée Heinrich-Nessel 2016/2017
Alors
1)n∑k=1
αk = −an−1
an
2)n∏k=1
αk = (−1)n a0
an
1. François Viète (1540 - 1603)2. Les αk ne sont pas nécessairement distincts.
13.5 Polynômes dérivés
Rappelons que pour tout entier naturel n, la dérivée de la fonction polynomiale x 7→ xn est x 7→ nxn−1. Formel-lement, la dérivée du monôme Xn est nXn−1 :
Définition 13.39. Soit P (X) =n∑k=0
akXk ∈ K[X]. Le polynôme dérivé de P (X) est le polynôme
P ′(X) =n∑k=1
kakXk−1.
La dérivation induit une application :
K[X] // K[X]
P // P ′
Remarque. Le polynôme dérivé de P (X) ∈ R[X] correspond à la dérivée de la fonction polynômiale x 7→ P (x) surR. On retrouve donc toutes les règles usuelles de dérivation :
Proposition 13.40 (Linéarité). Soit P et Q deux polynômes. Soit λ et µ deux scalaires, alors
(λP + µQ)′ = λP ′ + µQ′
Proposition 13.41. Soit P (X) ∈ K[X] non constant. Notons n le degré de P (X) et c son coefficient dominant,alors le polynôme dérivé P ′(X) est un polynôme de degré n− 1, de coefficient dominant n c.
Corollaire 13.42. Soit P (X) ∈ K[X], alors : P ′ = 0 si et seulement si P est un polynôme constant.
Proposition 13.43 (dérivée du produit). Soit P et Q deux polynômes, alors
(PQ)′ = P ′Q+ PQ′
Démonstration. Soit P (X) =∑m
k=0 akXk et Q(X) =
∑n
k=0 bkXk deux polynômes de degré m et n respective-
268

TSI 1 Lycée Heinrich-Nessel 2016/2017
ment. Alors
PQ(x) =m+n∑k=0
(k∑i=0
aibk−i
)Xk =
m+n∑k=0
(k∑i=0
aiXibk−iX
k−i
)
(PQ)′(X) =m+n∑k=1
(k∑i=0
kaibk−i
)Xk−1
=m+n∑k=1
(k∑i=0
(i+(k − i))aibk−i
)Xk−1
=m+n∑k=1
(k∑i=1
iaibk−i
)Xk−1+
m+n∑k=1
(k−1∑i=0
(k − i)aibk−i
)Xk−1
=m+n∑k=1
(k∑i=1
iaiXi−1bk−iX
k−i
)+m+n∑k=1
(k−1∑i=0
(k − i)aiXibk−iXk−i−1
)Xk−1
= P ′(X)Q(X) + P (X)Q′(X)
Exercice 13.12. ? Soit P , Q deux polynômes, montrer que (Q P )′ = P ′ ×Q′ P .
Définition 13.44 (dérivées successives). Soit P (X) ∈ K[X]. On définit par récurrence le polynôme dérivéd’ordre m de P par
P (0) = P
P (m+1) =(P (m))′ pour tout m ≥ 0
Exercice 13.13. Soit n un entier naturel, posons P (X) = Xn ∈ K[X]. Exprimer P (m), la dérivée d’ordre m deP , en fonction de m et n.
Exercice 13.14 (linéarité de la dérivée d’ordre m). Soit P , Q deux polynômes, λ, µ deux scalaires et m un entiernaturel. Montrer que
(λP + µQ)(m) = λP (m) + µQ(m)
Lemme 13.45. Soit a ∈ K, n ∈ N et P (X) = (X − a)n ∈ K[X]. Pour tout entier 0 ≤ k ≤ n, on a
P (k)(X) = n!(n− k)! (X − a)n−k
Démonstration. Pour k = 0, on note que P (0)(X) = P (X) = n!(n−0)! (X − a)n−0. Soit 0 ≤ k < n, supposons par
récurrence que P (k)(X) = n!(n−k)! (X − a)n−k. Alors
P (k+1)(X) =(P (k)(X)
)′=(
n!(n− k)! (X − a)n−k
)′par hypothèse de récurrence
= n!(n− k)× (n− k − 1)! (n− k)× 1× (X − a)n−k−1 dérivée d’une composée
= n!(n− (k + 1))! (X − a)n−(k+1)
D’où le lemme.
Proposition 13.46. Soit P (X) ∈ K[X] non nul et m ∈ N, alors
m > deg(P ) ⇐⇒ P (m) = 0
Démonstration. De la proposition 13.41, on déduit, par récurrence, que pour tout m ≤ deg(P ), deg(P (m)) =deg(P ) − m. Donc si n = deg(P ), alors deg(P (n)) = 0, c’est-à-dire P (n) est constant. D’où pour tout m > n,P (m) = (P (n+1))(m−n−1) = 0(m−n−1) = 0.
269

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 13.47 (Leibniz 1). Soit P (X) et Q(X) deux polynômes. Soit m ∈ N \ 0, alors
(PQ)(m) =m∑k=0
(m
k
)P (k)Q(m−k)
1. Gottfried Wilhelm Leibniz (1646 - 1716)
Démonstration. Pour m = 1, on a bien
(PQ)′ = P ′Q+ PQ′ =(
10
)PQ′ +
(11
)P ′Q =
1∑k=0
(1k
)P (k)Q(1−k)
Soit m ∈ N∗, supposons par récurrence que
(PQ)(m) =m∑k=0
(m
k
)P (k)Q(m−k)
alors
(PQ)(m+1) =((PQ)(m))′
=
(m∑k=0
(m
k
)P (k)Q(m−k)
)′par hypothèse de récurrence
=m∑k=0
(m
k
)(P (k) ×Q(m−k))′ par linéarité
=m∑k=0
(m
k
)(P (k))′ ×Q(m−k) + P (k) × (Q(m−k))′ dérivée d’un produit
=m∑k=0
(m
k
)P (k+1) ×Q(m−k) + P (k) ×Q(m−k+1)
=m∑k=0
(m
k
)P (k+1) ×Q(m−k) +
m∑k=0
(m
k
)P (k) ×Q(m−k+1)
=m+1∑i=1
(m
i− 1
)P (i) ×Q(m+1−i) +
m∑k=0
(m
k
)P (k) ×Q(m−k+1) en posant i = k + 1
=(m
m
)P (m+1)Q(0) +
m∑k=1
(m
k − 1
)P (k) ×Q(m+1−k)
+m∑k=1
(m
k
)P (k) ×Q(m+1−k) +
(m
0
)P (0)Q(m+1)
= P (m+1)Q(0) +m∑k=1
((m
k − 1
)+(m
k
))P (k) ×Q(m+1−k)
+ P (0)Q(m+1)
=(m+ 1m+ 1
)P (m+1)Q(0) +
m∑k=1
(m+ 1k
)P (k) ×Q(m+1−k) d’après la relation de Pascal
+(m+ 1
0
)P (0)Q(m+1)
=m+1∑k=0
(m+ 1k
)P (k) ×Q(m+1−k)
270

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 13.15 (polynômes de Legendre). Pour tout n ∈ N, on considère les polynômes
Rn(X) = (X2 − 1)n et Ln(X) = R(n)n (X)
1) Développer Rn(X) et en déduire que le coefficient de Xn dans Ln est égal à (2n)!n! .
2) a) Développer le coefficient de Xn dans Ln(X) par une autre méthode. Appliquer la formule de Leibnizà ((X − 1)n × (X + 1)n)(n)
b) En déduire enfin une expression den∑k=0
(n
k
)2
. La somme est (2n)!(n!)2
Théorème 13.48 (Formule de Taylor 1). Soit P (X) ∈ K[X] un polynôme de degré n et a ∈ K, alors
P (X) =n∑k=0
P (k)(a)k! (X − a)k
En particulier,
P (X) =n∑k=0
P (k)(0)k! Xk
1. Frederick Winslow Taylor (1856 - 1915)
Démonstration. Soit a ∈ K. Démontrer le théorème revient à montrer que la propriété :
∀P (X) ∈ K[X] : deg(P ) ≤ n ⇒ P (X) =n∑k=0
P (k)(a)k! (X − a)k (Pn)
est vraie pour tout n ∈ N. Pour n = 0, si deg(P ) ≤ 0, alors le polynôme P est constant, égal à λ ∈ K. Ainsi,
P (X) = λ = P (a) = P (0)(a)0! (X − a)0 =
0∑k=0
P (0)(a)k! (X − a)k
c’est-à-dire (P0) est vraie. Soit n ∈ N un entier quelconque. Supposons par récurrence que (Pn) est vraie. SoitP (X) =
∑n+1k=0 akX
k ∈ K[X] un polynôme de degré (inférieur ou égal à) n+ 1. Posons
Q(X) = P (X)− an+1(X − a)n+1
=n+1∑k=0
akXk − an+1
n+1∑k=0
(n+ 1k
)(−a)n+1−kXk d’après la formule du binôme
= an+1Xn+1 +
n∑k=0
akXk − an+1
(Xn+1 +
n∑k=0
(n+ 1k
)(−a)n+1−kXk
)
=n∑k=0
akXk −
n∑k=0
(n+ 1k
)(−a)n+1−kXk
=n∑k=0
(ak −
(n+ 1k
)(−a)n+1−k
)Xk
Donc, Q est un polynôme de degré inférieur ou égal à n. Par hypothèse de récurrence (on applique la propriété(Pn) à Q), on a
P (X)− an+1(X − a)n+1 = Q(X) =n∑k=0
Q(k)(a)k! (X − a)k
P (X) = an+1(X − a)n+1 +n∑k=0
Q(k)(a)k! (X − a)k (?)
271

TSI 1 Lycée Heinrich-Nessel 2016/2017
Soit 0 ≤ k ≤ n, alors
Q(k)(X) =(P (X)− an+1(X − a)n+1)(k)
= (P (X))(k) − an+1((X − a)n+1)(k) par linéarité
= P (k)(X)− an+1(n+ 1)!
(n+ 1− k)! (X − a)n+1−k d’après le lemme précédent
= P (k)(X)− an+1(n+ 1)!
(n+ 1− k)! (X − a)n+1−k︸ ︷︷ ︸6=1
car k ≤ n < n+ 1
⇒ Q(k)(a) = P (k)(a)− an+1(n+ 1)!
(n+ 1− k)! (a− a)n+1−k
= P (k)(a)
et
P (n+1)(X) =n+1∑k=0
ak(Xk)(n+1) par linéarité de la dérivée
= an+1(Xn+1)(n+1) d’après la proposition 13.46= an+1 × (n+ 1)! d’après le lemme précédent (avec a = 0)
⇒ P (n+1)(a)(n+ 1)! = an+1
En revenant à l’identité (?), on a
P (X) = P (n+1)(a)(n+ 1)! (X − a)n+1 +
n∑k=0
P (k)(a)k! (X − a)k =
n+1∑k=0
P (k)(a)k! (X − a)k
D’où la propriété (Pn+1) est encore vraie.
Théorème 13.49. Soit P (X) ∈ K[X] et a ∈ K. Alors a est racine de P (X) de multiplicité m si et seulementsi
∀ k ∈ 0; 1; . . . ;m− 1, P (k)(a) = 0 et P (m)(a) 6= 0
( ! Démonstration au programme)
Démonstration. Le sens direct : Supposons que a est une racine de multiplicité m, alors il existe un polynômeQ(X) ∈ K[X] tel que
P (X) = (X − a)mQ(X)Q(a) 6= 0
En appliquant la formule de Leibniz et le lemme précédent, on a
P (k)(X) =k∑i=0
(k
i
)((X − a)m)(k−i)Q(i)(X)
= m!(m− k) (X − a)m−kQ(X) + (X − a)
k∑i=1
(k
i
)m!
(m− i)! (X − a)k−i−1Q(k−i)(X)
⇒ P (k)(a) =
0 si 0 ≤ k ≤ m− 1Q(a) 6= 0 si k = m
Réciproquement, supposons que pour tout k ∈ J0;m − 1K, on ait P (k)(a) = 0 et P (m)(a) 6= 0. Alors d’après la
272

TSI 1 Lycée Heinrich-Nessel 2016/2017
formule de Taylor, si m ≤ n :
P (X) =n∑k=0
P (k)(a)k! (X − a)k
=m−1∑k=0
P (k)(a)k!︸ ︷︷ ︸=0
(X − a)k +n∑
k=m
P (k)(a)k! (X − a)k
= (X − a)mn∑
k=m
P (k)(a)k! (X − a)k−m = (X − a)Q(X)
et
Q(a) =n∑
k=m
P (k)(a)k! (a− a)k−m = P (m)(a)
m! 6= 0
Donc a est une racine de multiplicité m. Supposons par l’absurde que m > n, de la Formule de Taylor, on déduitque P = 0, ainsi P (m)(a) = 0 ce qui est contradictoire avec les hypothèses.
Remarque.• En particulier, un nombre a est une racine simple d’un polynôme P si et seulement si P (a) = 0 et P ′(a) 6= 0.• Un nombre a ∈ K est une racine de multiplicité m de P (X) ∈ K[X] si et seulement si
∃Q(X) ∈ K[X] :P (X) = (X − a)mQ(X)Q(a) 6= 0
273

TSI 1 Lycée Heinrich-Nessel 2016/2017
274

Chapitre 14
Limites et continuité
Programme• Limite finie ou infinie d’une fonction f en a, lorsque f est définie sur I \ a. Maîtriser le formalisme
mathématique de la définition de la limite et le mettre en relation avec l’intuition géométrique. Les définitionssont énoncées avec des inégalités larges.
• Notations : f(x) −→x→a
` ou limx→a
f(x) = `.
• Unicité de la limite.• Limite à droite, à gauche.• Notations : lim
x→a, x>af(x) ou lim
x→a+f(x).
• Si f admet une limite fini en a alors f est bornée au voisinage de a.• Opérations sur les fonctions admettant une limite finie ou infinie en a.• Image d’une suite de limite a par une fonction admettant une limite en a.• Passage à la limite dans une inégalité. Théorème de l’encadrement. Théorème de la limite monotone.• Relations de domination, de négligeabilité (notation de Landau).• Un premier développement limité :
11− x = 1 + x+ . . .+ xn + o(xn)
• Relation d’équivalence. Notation : f(x) ∼ag(x).
• Propriété : Relation d’équivalence, produit, quotient et puissance.• Continuité en un point• Continuité de f en un point a de I. Continuité à droite, à gauche.• Prolongement par continuité en un point.• Opérations sur les fonctions continues : somme, produit, quotient, composition.• Continuité sur un intervalle. On note C(I,R) l’ensemble des fonctions continues sur I.• Théorème des valeurs intermédiaires. Appliquer le procédé de dichotomie à l’approximation d’un zéro d’une
fonction continue.• Image d’un intervalle par une fonction continue.• Théorème des bornes atteintes : Une fonction continue sur un segment est bornée et atteint ses bornes.
Démonstration hors programme.• Toute fonction f continue et strictement monotone sur un intervalle I réalise une bijection de I sur l’in-
tervalle f(I). De plus sa réciproque est continue et strictement monotone sur f(I). Démonstration horsprogramme.
14.1 Limites
14.1.1 DéfinitionsNotation. Soit I un intervalle de R. On note R = R ∪ +∞ ∪ −∞. Plus généralement, on note I la versionobtenue à partir de I en ajoutant ses bornes. Par exemple, ]a; b[ = [a; b], [a; +∞[ = [a; +∞[∪+∞, etc.
275

TSI 1 Lycée Heinrich-Nessel 2016/2017
Dans toute cette section, on se donne f : I → R une fonction définie sur un intervalle noté I.
Vocabulaire. Soit a ∈ R. Un voisinage de a est un intervalle ouvert U telle que a ∈ U .
Définition 14.1. Soit a ∈ I. On dit que f admet une limite ` lorsque x tend vers a par la droite (ou parvaleurs supérieures) si
∀ ε > 0, ∃ δ > 0, ∀ x ∈ I, a < x ≤ a+ δ ⇒ |f(x)− `| ≤ ε
On note alors limx→a+
f(x) = ` ou limx→a, x>a
f(x) = `.
x
y Cf
+ε
−ε∀ voisinage de l
a
l
∃ δ
Exercice 14.1.1) Montrer que lim
x→0+x2 = 0 ;
2) À l’aide d’une inégalité de référence, montrer que limx→0+
sin(x) = 0 ;
3) Montrer que la fonction x 7→ sin( 1x
) n’admet pas de limite lorsque x tend vers 0 par la droite.
Définition 14.2. Soit a ∈ I. On dit que f tend vers +∞ lorsque x tend vers a par la droite (ou par valeurssupérieures) si
∀M ∈ R, ∃ δ > 0, ∀ x ∈ I, a < x ≤ a+ δ ⇒ f(x) ≥MOn note alors lim
x→a+f(x) = +∞
x
y
M
a a+ δ
Cf
Définition 14.3. Soit a ∈ I. On dit que f tend vers −∞ lorsque x tend vers a par la droite (ou par valeurssupérieures) si
∀m ∈ R, ∃ δ > 0, ∀ x ∈ I, a < x ≤ a+ δ ⇒ f(x) ≤ m
276
TSI 1 Lycée Heinrich-Nessel 2016/2017
On note alors limx→a+
f(x) = −∞
Définition 14.4. Soit a ∈ I. On dit que f admet une limite ` lorsque x tend vers a par la gauche (ou parvaleurs inférieures) si
∀ ε > 0, ∃ δ > 0, ∀ x ∈ I, a− δ ≤ x < a ⇒ |f(x)− `| ≤ ε
On note alors limx→a−
f(x) = ` ou limx→a, x<a
f(x) = `.
Définition 14.5. Soit a ∈ I. On dit que f tend vers +∞ lorsque x tend vers a par la gauche (ou par valeursinférieures) si
∀M ∈ R, ∃ δ > 0, ∀ x ∈ I, a− δ ≤ x < a ⇒ f(x) ≥MOn note alors lim
x→a−f(x) = +∞
Définition 14.6. Soit a ∈ I. On dit que f tend vers −∞ lorsque x tend vers a par la gauche (ou par valeursinférieures) si
∀m ∈ R, ∃ δ > 0, ∀ x ∈ I, a− δ ≤ x < a ⇒ f(x) ≤ mOn note alors lim
x→a−f(x) = −∞
Définition 14.7. Soit a ∈ I. On dit que f admet une limite ` lorsque x tend vers a si f admet une limite parla gauche et une limite par la droite en a et si lim
x→a−f(x) = ` = lim
x→a+f(x) On note alors lim
x→af(x) = `
Proposition 14.8. Soit a ∈ I. La fonction f admet une limite ` lorsque x tend vers a si et seulement si
∀ ε > 0, ∃ δ > 0, ∀ x ∈ I \ a, |x− a| ≤ δ ⇒ |f(x)− `| ≤ ε
x
y Cf
+ε
−ε∀ voisinage de l
a
l
+δ−δ
∃ voisinage de a
Remarque. La fonction f : I → R admet pour limite l lorsque x tend vers a si quel que soit le voisinage V de ldans R, l’ensemble d’arrivée de f , on peut trouver un voisinage U de a dans I, l’ensemble de départ, tel que tousles éléments du voisinage U sont envoyés par f dans V (c’est-à-dire : f(U) ⊂ V).
Définition 14.9. On suppose que +∞ ∈ I. On dit que f admet une limite ` lorsque x tend vers +∞ si
∀ ε > 0, ∃M ∈ R, ∀x ∈ I, x ≥M ⇒ |f(x)− `| ≤ ε
On note alors limx→+∞
f(x) = `
Définition 14.10. On suppose que +∞ ∈ I. On dit que f tend vers +∞ lorsque x tend vers +∞ si
∀M ∈ R, ∃M ′ ∈ R, ∀x ∈ I, x ≥M ′ ⇒ f(x) ≥M
277

TSI 1 Lycée Heinrich-Nessel 2016/2017
On note alors limx→+∞
f(x) = +∞
Définition 14.11. On suppose que +∞ ∈ I. On dit que f tend vers −∞ lorsque x tend vers +∞ si
∀m ∈ R, ∃M ∈ R, ∀x ∈ I, x ≥M ⇒ f(x) ≤ m
On note alors limx→+∞
f(x) = −∞
Définition 14.12. On suppose que −∞ ∈ I. On dit que f admet une limite ` lorsque x tend vers −∞ si
∀ ε > 0, ∃m ∈ R, ∀x ∈ I, x ≤ m ⇒ |f(x)− `| ≤ ε
On note alors limx→−∞
f(x) = `
Définition 14.13. On suppose que −∞ ∈ I. On dit que f tend vers +∞ lorsque x tend vers −∞ si
∀M ∈ R, ∃m ∈ R, ∀x ∈ I, x ≤ m ⇒ f(x) ≥M
On note alors limx→−∞
f(x) = +∞
Définition 14.14. On suppose que −∞ ∈ I. On dit que f tend vers −∞ lorsque x tend vers −∞ si
∀m ∈ R, ∃m′ ∈ R, ∀x ∈ I, x ≤ m′ ⇒ f(x) ≤ m
On note alors limx→−∞
f(x) = −∞
Exercice 14.2.1) Trouver la limite de la fonction identité en tout point de R.2) Trouver la limite de la fonction valeur absolue en tout point de R.3) Trouver la limite de la fonction partie entière en tout point de R.
Proposition 14.15 (Unicité). Soit f une fonction définie sur I. Si f admet une limite ` et une limite `′ en a(ou a+ ou a− ou +∞ ou −∞), alors ` = `′.
Proposition. Soit f une fonction définie sur I. Soit a ∈ I. Si f admet une limite finie en a, alors il existe unvoisinage de a sur lequel f est bornée.
Rappelons que d’après le théorème de la borne supérieure : Toute partie non vide et majorée (resp. minorée) deR admet une borne supérieure (resp. inférieure). Ainsi, comme pour les suites numériques, on déduit le théorèmesuivant :
Théorème 14.16 (Limite monotone). Soit f une fonction définie sur I. Soit a ∈ I. On suppose que f estmonotone. Alors f admet une limite en a si et seulement si elle est bornée au voisinage de a.
14.1.2 OpérationsExercice 14.3. Soit f, g : I → R et a ∈ I. Posons
` = limx→a
f(x) et `′ = limx→a
g(x)
Supposons que les deux limites sont finies, c’est-à-dire ` ∈ R et `′ ∈ R. Montrer que
limx→a
f(x) + g(x) = `+ `′
De même, toutes les opérations sur les limites vues au chapitre Fonctions au premier semestre sont démontrablesà partir des définitions ci-dessus.
278

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 14.17. Soit a0, a1, . . . , an et b0, b1, . . . , bm des nombres réels tels que an 6= 0 et bm 6= 0, alors
limx→±∞
a0 + a1x+ . . .+ an−1xn−1 + anx
n
b0 + b1x+ . . .+ bm−1xm−1 + bmxm= limx→±∞
anxn
bmxm
La limite en ±∞ d’un quotient de polynômes est uniquement déterminée par la limite du rapport des monômesde plus au degré.
Proposition 14.18 (composée). Soit Df // E
g // R deux fonctions, posons l = limx→a
f(x) et supposons
que g est définie au voisinage de la limite l. Alors :
limx→a f(x) = l
limx→l
g(x) = l′
⇒ limx→a g( f(x) ) = l′
14.1.3 Comparaisons des fonctions
Proposition 14.19. Soit f, g : I → R deux fonctions et a dans I. Si f et g admettent une limite en a, alors :
f ≤ g ⇒ limx→a
f(x) ≤ limx→a
g(x)
( ! Démonstration au programme)
Démonstration. Supposons dans un premier temps que a ∈ R et que f(x) et g(x) convergent vers une limite finielorsque x tend vers a. Posons ` = lim
x→af(x) et `′ = lim
x→ag(x). Supposons par l’absurde que ` > `′. Soit ε = `−`′
3 ,notons que `′ + 3ε = `, d’où
`′ + 2ε = `− ε
D’autre part, par définition de la convergence, il existe δ > 0, tel que
∀x ∈ I \ a : |x− a| ≤ δ ⇒|f(x)− `| ≤ ε|g(x)− `′| ≤ ε
⇒`− ε ≤ f(x) ≤ `+ ε
`′ − ε ≤ g(x) ≤ `′ + ε
Soit x ∈ I \ a tel que |x− a| ≤ δ, alors :
g(x) ≤ `′ + ε < `′ + 2ε = `− ε ≤ f(x)
ce qui est en contradiction avec l’hypothèse f ≤ g sur I. Les autres cas sont laissés en exercice. D’où la proposition.
Corollaire 14.20. Soit f, g : I → R deux fonctions et a dans I. Supposons que f ≤ g :1) Si lim
x→af(x) = +∞ alors lim
x→ag(x) = +∞ ;
2) Si limx→a
g(x) = −∞ alors limx→a
f(x) = −∞.
Théorème 14.21 (de l’encadrement). Soit f, g, h : I → R trois fonctions telles qu’on ait l’encadrement :
f ≤ g ≤ h
sur I. Soit a ∈ I, sil = lim
x→af(x) = lim
x→ah(x)
alors la fonction encadrée g converge aussi vers la limite commune l lorsque x tend vers a.
Exemple. Considérons f : x 7→ −1x, g : x 7→ sin(x)
xet h : x 7→ 1
xdéfinies sur R∗+. Alors, on a bien f ≤ g ≤ h et
limx→+∞
f(x) = limx→+∞
h(x) = 0. Ainsi, la fontion g converge aussi en +∞ et limx→+∞
sin(x)x
= 0.
279

TSI 1 Lycée Heinrich-Nessel 2016/2017
x
y
Corollaire. Soit f, g : I → R deux fonctions et a ∈ I, alors
|f | ≤ glimx→a
g(x) = 0
⇒ lim
x→af(x) = 0
Démonstration. Si |f | ≤ g alors on a l’encadrement −g ≤ f ≤ g. Comme limx→a
g(x) = 0, on a aussi limx→a
−g(x) = 0.Ainsi, on applique le théorème de l’encadrement pour déduire que f(x) admet une limite en a et cette limite estégale à 0.
14.2 Notation de Landau et équivalenceDans cette section, on se donne f, g : I → R deux fonctions définies sur intervalle I et a ∈ I (a peut être égal à±∞).
Définition 14.22. On suppose que f et g ne s’annulent pas au voisinage de a. On dit alors que la fonction fest :• dominée par g au voisinage de a, si f(x)/g(x) est bornée au voisinage de a.• négligeable devant g au voisinage de a, si f(x)/g(x) converge vers 0 lorsque x tend vers a.• équivalente à g au voisinage de a, si la suite f(x)/g(x) converge vers 1 lorsque x tend vers a et on note
f(x) ∼ag(x)
Proposition 14.23.1) Si f est dominée par g au voisinage de a alors
∃M ≥ 0 ∃ δ ≥ 0 ∀x ∈ I : |x− a| ≤ δ ⇒ |f(x)| ≤M |g(x)|
2) Si f est négligeable devant g au voisinage de a alors il existe une fonction ε : I → R telle que
∀x ∈ I : f(x) = ε(x)× g(x) et limx→a
ε(x) = 0
3) Si f est équivalente à g au voisinage de a alors il existe ε : I → R telle que
∀x ∈ I : f(x) = (1 + ε(x))× g(x) et limx→a
ε(x) = 0
Notation (de Landau, 1924). Soit f, g : I → R deux fonctions et a ∈ I.• Si f est dominée par g au voisinage de a, on note f(x) =
aO(g(x)) et on dit que « f(x) est un grand o de
g(x) au voisinage de a ».• Si f est négligeable devant g au voisinage de a , on note f(x) =
ao(g(x)) et on dit que « f(x) est un petit
o de g(x) au voisinage de a ».
Remarque. On retiendra donc qu’on utilise le grand o pour un majorant et le petit o pour un terme ε(x) qui tendvers 0 en a.
Exercice 14.4. Justifier que :
280

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) x2 =+∞
o(ex) ;
2) xln(x) =+∞
o(ex).
Soit n un entier naturel et x ∈ R \ 1, on rappelle que
1 + x+ . . .+ xn = 1− xn+1
1− x
1 + x+ . . .+ xn = 11− x −
xn+1
1− x1
1− x = 1 + x+ . . .+ xn + xn × x
1− x1
1− x = 1 + x+ . . .+ xn + xn × ε(x) avec limx→0
ε(x) = 0
11− x =
01 + x+ . . .+ xn + o(xn) d’après la proposition précédente.
Proposition 14.24 (Développements limités). Soit n ∈ N, au voisinage de 0, on a
1) 11− x = 1 + x+ x2 + . . .+ xn + o(xn) ;
2) 11 + x
= 1− x+ x2 − x3 + . . .+ (−1)nxn + o(xn) ;
Ces identités sont appelées des développements limités à l’ordre n de 11−x et 1
1+x respectivement.
Exercice 14.5. Soit α ∈ N un entier. À l’aide de la formule du binôme de Newton,1) montrer qu’au voisinage de 0, on a (1 + x)α = 1 + αx+ o(x) ;2) montrer qu’au voisinage de 0, on a
(1 + x)α = 1 + αx+ α(α− 1)2! x2 + α(α− 1)(α− 2)
3! x3 + o(x3);
3) montrer qu’au voisinage de 0, pour tout n ≤ α, on a
(1 + x)α = 1 + αx+ α(α− 1)2! x2 + α(α− 1)(α− 2)
3! x3 + . . .+ α(α− 1) . . . (α− n+ 1)n! xn + o(xn)
Cette identité est appelée développement limité à l’ordre n de (1 + x)α.
Proposition 14.25. On a
f(x) ∼ag(x) ⇐⇒ f(x)− g(x) =
ao(g(x))
Remarque. On peut reformuler la propriété ainsi : f(x) =ag(x) + o(g(x)) si et seulement si f(x) ∼
ag(x).
Comme pour les suites réelles, on a retrouve les mêmes propriétés sur les équivalents et petit « o » :
Exercice 14.6.1) Supposons que f(x) = o(1) au voisinage de a, déterminer la limite de f(x) lorsque x tend vers a.2) Supposons que f(x) tend vers +∞, que g est positive et f est dominée par g au voisinage de +∞. Déterminer
la limite de g(x) lorsque x tend vers +∞.3) Supposons que f(x) tend vers un nombre réel ` lorsque x tend vers a et f(x) ∼
ag(x). Déterminer la limite
de g(x) lorsque x tend vers a.
Théorème 14.26. Supposons que f(x) ∼ag(x), alors
∀ ` ∈ R ∪ ±∞ : limx→a
f(x) = ` ⇐⇒ limx→a
g(x) = `
281

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 14.27. Si f(x) ∼ag(x), alors f(x) et g(x) sont de même signe pour tout x dans un voisinage
de a.
Comme on a étudié les opérations sur les limites, nous allons voir les opérations sur les équivalents :
Proposition 14.28. Soit f1, f2, g1 et g2 des fonctions définies sur I telles que
f1(x) ∼af2(x) et g1(x) ∼
ag2(x)
Alors1) f1(x)× g1(x) ∼
af2(x)× g2(x) ;
Si g1 et g2 sont non nulles au voisinage de a,
2) f1(x)g1(x) ∼a
f2(x)g2(x) ;
3) (f1(x))α ∼a
(f2(x))α pour tout α ∈ R.
Proposition 14.29. Soit h : J → I, f, g : I → R trois fonctions et α ∈ J . On a
limx→α
h(x) = a
f(x) ∼ag(x)
⇒ f h(x) ∼αg h(x)
Exemple.limx→0+
1x
= +∞
x2 + 512x− 1 ∼+∞
x2
⇒ 1x2 + 512
x− 1 ∼
0+
1x2
En revenant à la définition du nombre dérivé d’une fonction :
f ′(a) = limx→a
f(x)− f(a)x− a = lim
h→0
f(a+ h)− f(a)h
On déduit
Proposition 14.30. Si f : I → R est dérivable en a ∈ I et f ′(a) 6= 0 alors
f(x)− f(a) ∼af ′(a)(x− a)
Corollaire 14.31. Soit f ∈ RN, α ∈ R. Au voisinage de 0, on a
1) sin(x) ∼0x
2) 1− cos(x) ∼0
x2
2
3) tan(x) ∼0x
4) ln(1 + x) ∼0x
5) ex − 1 ∼0x
6) (1 + x)α − 1 ∼0αx
Remarque. Le second point du corollaire précédent n’est pas une conséquence de la proposition précédente.
Exercice 14.7.1) Le premier équivalent du corollaire précédent peut être reformulé ainsi : sin(x) = x+ o(x), au voisinage de
0. Reformuler de même les autres équivalents du corollaire.
2) Démonstration de l’équivalent 1− cos(x) ∼0x2
2 .
282

TSI 1 Lycée Heinrich-Nessel 2016/2017
a) Montrer que pour tout x ∈ R, on a
1− x2
2 ≤ cos(x) ≤ 1− x2
2 + x4
4!
b) En déduire que cos(x) = 1− x2
2 + o(x2) et l’équivalent recherché.
Quelques conséquences de la croissance comparée des fonctions puissances, exponentielle et logarithme :
Proposition 14.32. Soit β > α > 0 et γ > 1. On a
1) au voisinage de 0 : | ln(x)|γ =0o(1/xα) et xβ =
0o(xα).
2) au voisinage de +∞ : ( ln(x) )γ =+∞
o(xα), xα =+∞
o(xβ) et xα =+∞
o(γx).
Exercice 14.8. Calculer limx→0+
x+√x
x+ln(x) et limx→+∞
x+√x
x+ln(x) .
Proposition 14.33 (Équivalents de polynôme). Soit P : R→ R une fonction polynômiale définie par
∀x ∈ R : P (x) = anxn + . . .+ ad+1x
d+1 + adxd =
n∑k=d
akxk
avec ad et an non nuls. Alors :1) Au voisinage de 0, P (x) ∼
0adx
d ;
2) Au voisinage de +∞, P (x) ∼+∞
anxn.
( ! Démonstration au programme)
Démonstration. Au voisinage de 0. Soit x ∈ R∗, on a
P (x)adxd
= 1adxd
n∑k=d
akxk
= adxd
adxd+
n∑k=d+1
akadxk−d
= 1 +n∑
k=d+1
akadxk−d
Soit k ∈ Jd+ 1;nK, comme k > d on a k − d > 0, ainsi limx→0
xk−d = 0 et
limx→0
P (x)adxd
= 1
Donc, par définition, P (x) ∼0adx
d.
Au voisinage de +∞ : Soit x ∈ R, on a
P (x)anxn
= 1anxn
n∑k=d
akxk
=n−1∑k=d
akanxk−d + anx
n
anxn
=n−1∑k=d
akanxk−n + 1
Soit k ∈ Jd;n− 1K, comme k < n on a k − n < 0, ainsi limx→+∞
xk−d = 0 et
limx→+∞
P (x)anxn
= 1
Donc, par définition, P (x) ∼+∞
anxn.
283
TSI 1 Lycée Heinrich-Nessel 2016/2017
Remarque. Au voisinage de 0, une fonction polynômiale est équivalente à son monôme de plus petit degré et auvoisinage de l’infini, elle est équivalente à son monôme de plus haut degré.
Exercice 14.9. Déterminer un équivalent le plus simple possible au voisinage de +∞ des fonctions ci-dessous eten déduire leur limite en +∞ :
1) f1(x) = x5−x2+3x12x5+x4+1 ;
2) f2(x) = ln(1 + 1x
) ;
3) f3(x) = ln(1− 1x
)
21+x+ 1x;
4) f4(x) =3√1+x3
ln(x−x2) .
14.3 ContinuitéDéfinition 14.34. Soit f une fonction définie sur I. Soit a ∈ I. On dit que• f est continue à gauche en a si f admet une limite à gauche en a et f(a) = lim
x→a−f(x).
• f est continue à droite en a si f admet une limite à gauche en a et f(a) = limx→a+
f(x).
• f est continue en a si f admet une limite en a et si limx→a
f(x) = f(a). Autrement dit, f est continue ena si
∀ ε > 0, ∃ δ > 0, ∀ x ∈ I, |x− a| ≤ δ ⇒ |f(x)− f(a)| ≤ ε
Lemme 14.35. Soit a ∈ I un intervalle ouvert et f : I → R une fonction. La fonction f est continue en a si etseulement si
f(a) = limx→a−
f(x) et f(a) = limx→a+
f(x)
Exemples.
1)
a b
2)
a bc
3)
a b
4)
a b
Parmi les différents graphes de fonction représentés, les graphes 1), 3) et 4) correspondent à une fonction continue.
Exercice 14.10. Montrer que la fonction partie entière x 7→ bxc définie sur R est continue 12 mais n’est pas
continue en 1.
Définition 14.36. Soit f une fonction définie sur I. On dit que f est continue sur I si f est continue en toutpoint a ∈ I.
Notation. On note C(I; R) l’ensemble des fonctions continues de I dans R.
Exemples.1) Toute fonction constante est continue sur R.2) La fonction identité est continue sur R.3) La fonction valeur absolue est continue sur R.4) La fonction inverse est continue sur R \ 0.5) Les fonctions exp et ln sont continues sur leur domaine de définition, tout comme les fonctions trigonomé-
triques et leurs réciproques.6) La fonction partie entière n’est pas continue sur R. En revanche, elle est continue à droite sur R. Elle est
également continue sur [0; 1[ par exemple.
Remarque. La fonction partie entière est un exemple de fonction continue par morceaux.
284

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 14.37. Excepté la fonction partie entière, les fonctions de référence sont continues sur leursensembles de définition.
Théorème (Caractérisation séquentielle). (admis)Soit I un intervalle, a ∈ I et f une fonction définie sur I. Alors f est continue en a si et seulement si pourtoute suite (un) qui converge vers a la suite f(un) converge vers f(a).
Remarque. Le sens direct du théorème peut être reformuler ainsi : Si (un) converge vers a et f est continue en aon peut alors permuter f et le passage à la limite :
limn→+∞
f(un ) = f
(lim
n→+∞un
)
Nous avions déjà l’habitude d’utiliser ce fait, par exemple dans la situation suivante :
limn→+∞
e3+ 1n = e3
La justification provient bien du théorème précédent avec la fonction exponentielle f : x 7→ ex continue en 3 et lasuite (un) définie par un = 3 + 1
npour tout n ∈ N∗.
Démonstration. Nous allons uniquement démontrer le sens direct. Supposons que f est continue en a, alors
∀ ε > 0, ∃ δ > 0, ∀ x ∈ I, |x− a| ≤ δ ⇒ |f(x)− f(a)| ≤ ε (1)
Soit (un) une suite qui converge vers a lorsque n tend vers l’infini, alors
∀ ε > 0 ∃N ∈ N ∀n ∈ N n ≥ N ⇒ |un − `| ≤ ε (2)
Montrons que limn→+∞
f(un) = f(a) : Soit ε > 0, d’après (1), il existe δ > 0 tel que pour tout x ∈ I si |x− a| ≤ δ
alors |f(x)− f(a)| ≤ ε. Ensuite, d’après (2), il existe N ∈ N, tel que pour tout n ≥ N , on ait |un − a| ≤ δ.Soit n ∈ N, on a donc
n ≥ N ⇒ |un − a| ≤ δ ⇒ |f(un)− f(a)| ≤ ε
On vient de voir que pour tout ε > 0, il existe N ∈ N tel que pour tout entier n ≥ N , on ait |f(un)− f(a)| ≤ ε.C’est-à-dire, la suite f(un) converge vers f(a).
Définition 14.38. Soit I un intervalle, a ∈ I et f une fonction définie sur I\a. On dit que f est prolongeablepar continuité en a s’il existe une fonction g définie et continue sur I telle que ∀ x ∈ I \ a, g(x) = f(x)
Proposition 14.39 (Prolongement par continuité). Soit I un intervalle. Soit a ∈ I. Soit f une fonctiondéfinie sur I \ a. Si f admet une limite à gauche en a et une limite à droite en a, alors f est prolongeablepar continuité en a si et seulement lim
x→a−f(x) = lim
x→a+f(x). De plus le prolongement est unique et donné par
la fonction
g : x ∈ I 7→
f(x) si x 6= a
limx→a±
f(x) si x = a
Remarque. Un prolongement par continuité d’une fonction continue f : D → R ne peut être envisagé qu’auxbornes de son domaine de définition D. Par exemple, si• D =]a; b], on peut uniquement envisager un prolongement par continuité en a. Prolongement possible si et
seulement si la limite de f(x) lorsque x tend vers a par la droite est finie.• D = [a; c[∪]c; +∞[, on peut uniquement envisager un prolongement par continuité en c. Prolongement
possible si et seulement si les limites de f(x) lorsque x tend vers a par la droite et par la gauche existentet sont égales.
Exercice 14.11. Montrer que la fonction f : R∗ → R définie par f(x) = sin(x)x
est prolongeable par continuité.
285

TSI 1 Lycée Heinrich-Nessel 2016/2017
14.3.1 Opérations sur les fonctions continuesExercice 14.12. Soit f : I → R une fonction et a ∈ I. Supposons que f est continue en a et que f(a) 6= 0.Montrer qu’il existe un voisinage V de a tel que f ne s’annule pas sur V.
D’après les règles d’opérations sur les limites, on déduit que si f et g sont deux fonctions continues en a, alors
(f + g)(a) = f(a) + g(a) = limx→a
f(x) + limx→a
g(x) = limx→a
(f + g)(x)
D’où f + g est continue en a. Le même raisonnement pour le produit, quotient et inverse permet de déduire laproposition suivante :
Proposition 14.40. Soient f et g deux fonctions définies sur I et continues en a. Soient λ et µ deux réels.Alors,
1) la fonction combinaison linéaire λf + µg est continue en a.2) la fonction produit f × g est continue en a.3) si g ne s’annule pas, la fonction inverse 1
gest continue en a.
4) si g ne s’annule pas, la fonction quotient fgest continue en a.
Remarque. Dans le proposition précédente, on peut remarquer que les affirmations restent vraies si on remplace« continue en a » par « continue sur I ».
Corollaire 14.41. Toute fonction polynomiale est continue sur R.
Proposition 14.42. Soit f une fonction définie sur I et continue en a. Soit g une fonction définie sur f(I)et continue en f(a). Alors g f est continue en a.
14.3.2 Deux théorèmes fondamentauxPour rechercher la solution de l’équation f(x) = 0, on peut par exemple mettre en oeuvre l’algorithme dedichotomie.1: Variables : a, b, ε sont des nombres2: Entrées : Saisir a, b, ε3: Traitement :4: Si a > b alors5: c prend la valeur b6: b prend la valeur a7: a prend la valeur c8: Fin Si9: Si f(b)× f(a) ≤ 0 alors10: Tant que b− a > ε faire11: Si f(a+b
2 )× f(a) ≤ 0 alors12: b prend la valeur a+b
213: Sinon14: a prend la valeur a+b
215: Fin Si16: Fin Tant que17: Fin Si18: Sorties : Afficher a et b
Si f est continue et strictement monotone sur [a, b], cet algorithme permet de trouver une approximation deprécision arbitraire de la solution de f(x) = 0. Le nombre a retourné est une valeur approchée par défaut de lasolution à ε près. Le nombre b retourné est une valeur approchée par excès de la solution à ε près.
Exercice 14.13. Soit f : [a, b]→ R une fonction continue et strictement monotone. Soit k un nombre réel comprisentre a et b. Écrire un algorithme qui permet de trouver la solution de l’équation f(x) = k.
Théorème 14.43 (des valeurs intermédiaires). Soit f : [a; b]→ R, avec a < b, une fonction continue [a, b] etk un nombre réel compris entre f(a) et f(b) alors l’équation
f(x) = k
286
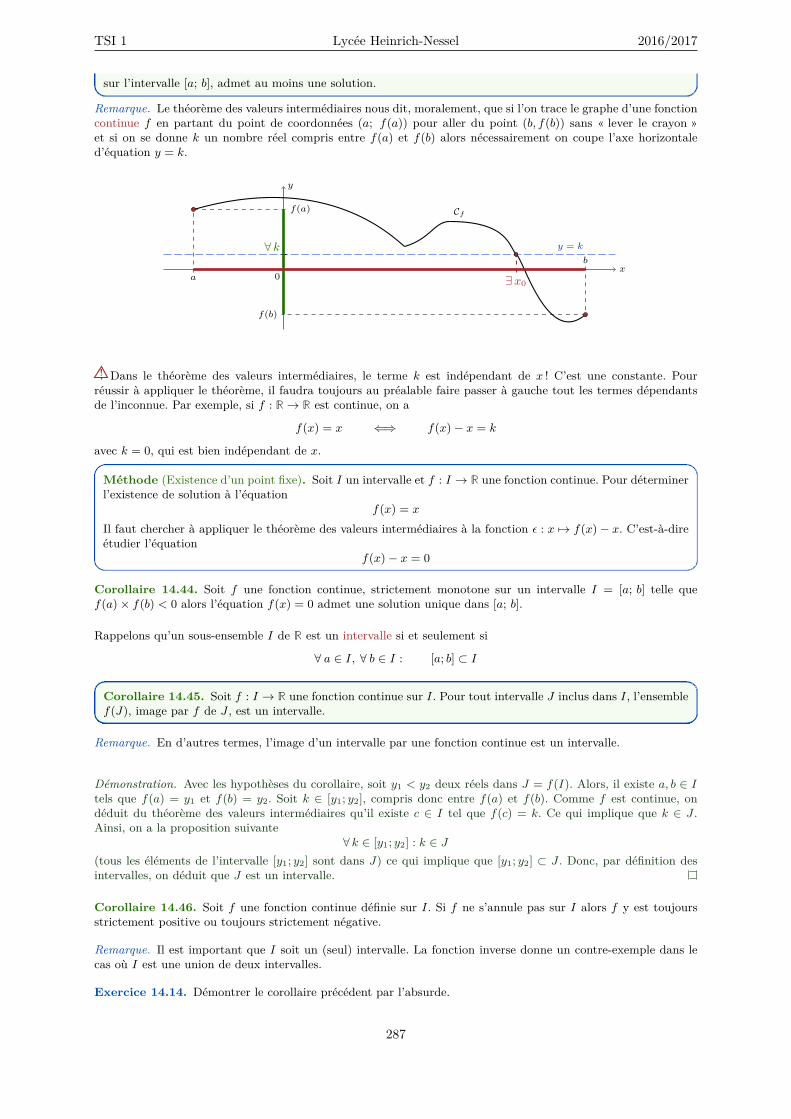
TSI 1 Lycée Heinrich-Nessel 2016/2017
sur l’intervalle [a; b], admet au moins une solution.
Remarque. Le théorème des valeurs intermédiaires nous dit, moralement, que si l’on trace le graphe d’une fonctioncontinue f en partant du point de coordonnées (a; f(a)) pour aller du point (b, f(b)) sans « lever le crayon »et si on se donne k un nombre réel compris entre f(a) et f(b) alors nécessairement on coupe l’axe horizontaled’équation y = k.
x
y
0a
f(a)
b
f(b)
Cf
y = k∀ k
∃x0
! Dans le théorème des valeurs intermédiaires, le terme k est indépendant de x ! C’est une constante. Pourréussir à appliquer le théorème, il faudra toujours au préalable faire passer à gauche tout les termes dépendantsde l’inconnue. Par exemple, si f : R→ R est continue, on a
f(x) = x ⇐⇒ f(x)− x = k
avec k = 0, qui est bien indépendant de x.
Méthode (Existence d’un point fixe). Soit I un intervalle et f : I → R une fonction continue. Pour déterminerl’existence de solution à l’équation
f(x) = x
Il faut chercher à appliquer le théorème des valeurs intermédiaires à la fonction ε : x 7→ f(x)− x. C’est-à-direétudier l’équation
f(x)− x = 0
Corollaire 14.44. Soit f une fonction continue, strictement monotone sur un intervalle I = [a; b] telle quef(a)× f(b) < 0 alors l’équation f(x) = 0 admet une solution unique dans [a; b].
Rappelons qu’un sous-ensemble I de R est un intervalle si et seulement si
∀ a ∈ I, ∀ b ∈ I : [a; b] ⊂ I
Corollaire 14.45. Soit f : I → R une fonction continue sur I. Pour tout intervalle J inclus dans I, l’ensemblef(J), image par f de J , est un intervalle.
Remarque. En d’autres termes, l’image d’un intervalle par une fonction continue est un intervalle.
Démonstration. Avec les hypothèses du corollaire, soit y1 < y2 deux réels dans J = f(I). Alors, il existe a, b ∈ Itels que f(a) = y1 et f(b) = y2. Soit k ∈ [y1; y2], compris donc entre f(a) et f(b). Comme f est continue, ondéduit du théorème des valeurs intermédiaires qu’il existe c ∈ I tel que f(c) = k. Ce qui implique que k ∈ J .Ainsi, on a la proposition suivante
∀ k ∈ [y1; y2] : k ∈ J(tous les éléments de l’intervalle [y1; y2] sont dans J) ce qui implique que [y1; y2] ⊂ J . Donc, par définition desintervalles, on déduit que J est un intervalle.
Corollaire 14.46. Soit f une fonction continue définie sur I. Si f ne s’annule pas sur I alors f y est toujoursstrictement positive ou toujours strictement négative.
Remarque. Il est important que I soit un (seul) intervalle. La fonction inverse donne un contre-exemple dans lecas où I est une union de deux intervalles.
Exercice 14.14. Démontrer le corollaire précédent par l’absurde.
287

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 14.47 (des bornes atteintes, Bolzano 1830 et Weierstrass 1860). (admis)Soit f une fonction continue sur [a; b]. Alors f est bornée et atteint ses bornes.
Démonstration (hors programme). Notons ` la borne supérieure de f([a, b]), éventuellement égale à +∞, alorspour tout n ∈ N, il existe xn ∈ [a, b] telle que 1 |f(xn) − `| ≤ 1
n. Alors, par construction, la suite (f(xn))n∈N∗
converge vers ` lorsque n tend vers l’infini. D’autre part, la suite (xn) ainsi définie est bornée, ainsi d’après lethéorème de Bolzano-Weierstrass (en annexe du chapitre 12 sur les suites), il existe une sous-suite (xφ(n)) quiconverge vers une limite finie c ∈ [a; b]. Par hypothèse, f est continue sur [a, b], d’où
sup f([a, b]) = limn→+∞
f(xφ(n)) = f( limn→+∞
xφ(n)) = f(c)
Donc, pour tout x ∈ [a, b], f(x) ≤ f(c). C’est-à-dire, f est majorée et atteint son majorant. De même, on montreque f est minorée et atteint son minorant.
14.3.3 BijectivitéExercice 14.15. Soit f : I → R, supposons que f n’est pas strictement monotone. Montrer qu’il existe a < b < ctrois nombres réels dans I tels que f(a) ≤ f(b) ≥ f(c) ou f(a) ≥ f(b) ≤ f(c).
Encore un corollaire du théorème des valeurs intermédiaires :
Proposition 14.48. Soit f : I → R une fonction continue sur un intervalle I. Si f est injective alors f eststrictement monotone.
Théorème 14.49. Soit f une fonction continue et strictement monotone sur I, alors f réalise une bijectionde I sur f(I). De plus, sa réciproque est strictement monotone et de même monotonie que f .
Proposition 14.50. Soit f : I → J une fonction continue et bijective sur I alors sa fonction réciproquef−1 : J → I est continue sur J .
Démonstration. D’après la proposition précédente, on déduit que f est strictement monotone. Pour simplifier,supposons que J = [a; b] et f est strictement croissante sur I, alors d’après le théorème précédent, f−1 est aussistrictement croissante. Soit y0 ∈]a; b[, soit ε > 0 quelconque. Posons x0 = f−1(y0), puisque y0 est différent desbornes de l’intervalle J , on déduit que x0 est aussi différent des bornes de l’intervalle I et donc il existe 0 < ε′ < εtel que ]x0 − ε′;x0 + ε′[⊂ I. Comme f est strictement croissante, on déduit que f(x0 − ε′) < y0 < f(x0 + ε′).Encore une fois, les inégalités sont strictes, d’où il existe δ > 0 tel que
f(x0 − ε′) < y0 − δ < y0 < y0 + δ < f(x0 + ε′)
Comme f−1 est strictement croissante, on déduit que pour tout y ∈ J , on a
|y − y0| ≤ δ⇐⇒ y0 − δ ≤ y ≤ y0 + δ
⇒ f−1 f(x0 − ε′) < f−1(y0 − δ) ≤ f−1(y) ≤ f−1(y0 + δ) < f−1 f(x0 + ε′)⇒ x0 − ε′ ≤ f−1(y) ≤ x0 + ε′
⇒ f−1(y0)− ε ≤ f−1(y) ≤ f−1(y0) + ε car ε′ < ε
⇒ |f−1(y)− f−1(y0)| ≤ ε
Ainsi, par définition, f−1 est continue en y0. Les cas y0 = a et y0 = b sont laissés en exercice.
Remarque. Rappelons que le graphe de la réciproque d’une fonction bijective est obtenu en prenant le symétriquedu graphe de f par rapport à la première bissectrice (la droite d’équation y = x)
1. Si ` = +∞, l’inéquation correspondante est f(x) ≥ n.
288
TSI 1 Lycée Heinrich-Nessel 2016/2017
14.4 Application aux suites numériquesExercice 14.16. Soit f une fonction définie sur [p; +∞[. Soit (un) la suite définie par un = f(n) pour n ∈ [[p; +∞[.Montrer que
limn→+∞
un = limx→+∞
f(x)
Proposition 14.51. Soit f une fonction définie sur un intervalle I et (un) une suite à valeurs dans I quiconverge vers ` ∈ I. Si f(x) admet une limite lorsque x tend vers ` alors
limn→+∞
f(un) = limx→`
f(x)
Méthode. Pour montrer qu’une fonction n’a pas de limite en a, on peut construire deux suites (un) et (vn)qui tendent vers a et telles que f(un) et f(vn) n’ont pas la même limite.
Théorème 14.52. Soit f : I → I une fonction continue et (un) une suite définie paru0 ∈ Iun+1 = f(un) pour tout n ∈ N
On suppose que (un) admet une limite `. Alors, ` est un point fixe de f , autrement dit
f(`) = `
Remarque. Attention, ce théorème NE dit PAS que (un) admet pour limite ` ! ! ! ! Mais, qui si elle admet unelimite, alors la limite est une des solutions de l’équation f(x) = x.
Exercice 14.17. Étudier les limites possibles pour la suite (un) définie par u0 ∈ [0; 1] et un+1 = sin(un).
289

TSI 1 Lycée Heinrich-Nessel 2016/2017
290

Chapitre 15
Calcul matriciel
Programme• Matrices : Ensemble des matrices à n lignes et p colonnes à coefficients dans K notéMn,p(K).• Matrices carrées, matrices triangulaires, matrices diagonales.• Somme, différence de deux matrices, multiplication par un scalaire d’une matrice.• Produit de deux matrices :
Si A = (ai,j) ∈Mn,m(K) et B = (bi,j) ∈Mm,p(K) alors AB ∈Mn,p(K) et AB =( m∑k=1
ai,kbk,j
)• Interpréter la i-ème ligne du produit AB comme le produit de la i-ème ligne de A par B.• Deux matrices A, B carrées de taille n commutent si AB = BA.• Formule du binôme.• Si A,B dansMn(K) commutent, alors Ap+1 −Bp+1 = (A−B)
∑p
k=0 AkBp−k.
• Matrices inversibles : Matrice carrée inversible, inverse.• L’ensemble des matrices carrées de taille n inversible est noté GLn(K) et est appelé groupe linéaire.• Inverse du produit de matrices inversibles• Opérations élémentaires sur les lignes : Pour tout i 6= j :
— Li ↔ Lj , (permutation)— Li ← Li + aLj , (transvection)— Li ← λLi avec λ 6= 0. (dilatation)
• Deux systèmes (matrices) sont dit(e)s équivalent(e)s si on passe de l’un à l’autre par une suite finied’opérations élémentaires sur les lignes. Pour les matrices, notations A ∼
LB.
• Deux systèmes équivalents ont le même ensemble de solutions, lien avec l’équivalence des matrices.• Échelonner une matrice : algorithme du pivot de Gauss-Jordan• Matrice échelonnée (réduites) en lignes (lorsque tous les pivots sont égaux à 1 et sont les seuls éléments non
nuls de leur colonne).• Toute matrice non nulle est équivalente en lignes à une unique matrice échelonnée réduite en lignes• Résolution de systèmes, inconnues principales, secondaires• Rang (nombre de pivots) d’un système linéaire, d’une matrice• Système incompatible (compatible) s’il n’admet pas de solution.• Structure de l’ensemble des solutions d’un système compatible• Soit A ∈Mn(K), alors les propositions suivantes sont équivalentes :
1) la matrice A est inversible.2) la matrice A est produit de matrices de dilatation et/ou de transvection.3) le rang de la matrice A est n.4) il existe une matrice B ∈Mn(K) telle que AB = In.5) il existe une matrice C ∈Mn(K) telle que CA = In.6) le système AX = 0 admet une unique solution, à savoir X = 0.
291

TSI 1 Lycée Heinrich-Nessel 2016/2017
7) Pour tout B ∈Mn,1(K) matrice colonne, le système AX = B admet une unique solution.
• Applications linéaires de Kn dans Km
• Application X 7→ AX. Linéarité.• Si f : Kn → Kn est linéaire, déterminer la matrice A telle que f(X) = AX pour tout X ∈ Kn.• L’image de AX est combinaison linéaire des colonnes de A.• Noyau d’une application linéaire f , noté ker(f).• Image d’une application linéaire f , noté Im(f).• Déterminer le noyau et l’image d’une application linéaire f : Kn → Km en échelonnant un système linéaire.
15.1 DéfinitionsDéfinition 15.1. Une matrice de dimension m×n est un tableau d’éléments de K à m lignes et n colonnes :
M =
a11 a12 a13 . . . a1j . . . a1na21 a22 a23 . . . . . . a2na31 a32 a33 . . . . . . a3n...
...
ai1 aij...
......
am1 am2 am3 . . . . . . amn
= (aij)
On notera que le coefficient aij se trouve sur la i-ème ligne et la j-ème colonne 1.L’ensemble des matrices de dimension m× n est notéMm,n(K).
1. Pour se souvenir qu’on prend d’abord en compte les lignes et ensuite les colonnes, on peut utiliser comme moyenmnémotechnique le terme "Lycos", qui dans la mythologie grecque est un fils de Poseidon.
Définition 15.2.Une matrice avec une seule ligne est une matrice ligne.Une matrice avec une seule colonne est une matrice colonne.Lorsque m = n, on dit que la matrice est une matrice carrée de taille n.
Remarque. Une matrice colonne de taille n× 1 s’identifie à un vecteur de Kn. Une matrice ligne s’identifie aussià un vecteur de Kn.
Notation. On noteMn(K) l’ensemble des matrices carrées de taille n.
Exemples.
1) A =(a1,1 a1,2a2,1 a2,2
); 2) A =
(a1,1 a1,2 a1,3a2,1 a2,2 a2,3a3,1 a3,2 a3,3
).
Définition 15.3. Dire que deux matrices A = (aij) et B = (bij) sont égales signifie qu’elles ont les mêmesdimensions n×m et les nombres qui occupent la même position sont deux à deux égaux :
∀ k ∈ 1, . . . , n, ∀ l ∈ 1, . . . ,m, ak,l = bk,l
Définition 15.4.• La matrice de taille m× n dont tous les coefficients sont nuls s’appelle la matrice nulle, et se note 0n,m
ou tout simplement 0.• La matrice de taille n×n dont tous les coefficients diagonaux (c’est-à-dire sur la ke ligne et ke colonne)
valent 1 et tous les autres 0 s’appelle matrice identité de taille n et se note In.
292

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemple. La matrice identité de taille 4 :
I4 =
1 0 0 00 1 0 00 0 1 00 0 0 1
Définition 15.5. Une matrice de taillem×n est diagonale si ses seuls coefficients non nuls sont les coefficientsdiagonaux (c’est-à-dire ceux en position (k, k)).
Définition 15.6. Une matrice A de taille m× n est• triangulaire supérieure si ses seuls coefficients non nuls sont les Ak,l avec k ≤ l. Elle est dite triangulaire
supérieure stricte si de plus ses coefficients diagonaux sont nuls.• triangulaire inférieure si ses seuls coefficients non nuls sont les Ak,l avec k ≥ l. Elle est dite triangulaire
inférieure stricte si de plus ses coefficients diagonaux sont nuls.
15.2 Opérations sur les matrices
Définition 15.7. Soit A = (aij) et B = (bij) deux matrices de même taille m×n. La somme (resp. différence)de A et B la matrice, notée A+B (resp. A−B), obtenue en additionnant (resp. en soustrayant) deux à deuxchaque coefficient qui occupent la même position :
A+B = (aij + bij)
Définition 15.8. Soit A = (aij) une matrice de taille m×n et λ un nombre réel. La matrice λA est la matriceobtenue en multipliant chaque coefficient de A par le nombre λ :
λA = (λaij)
Définition 15.9. On appelle matrice scalaire toute matrice carrée de la forme λIn, où λ ∈ K.
Proposition 15.10. Soit A ∈Mm,n(K), λ ∈ K et µ ∈ K. Alors :1) 0×A = 0n,m et 1×A = A
2) λ× (µ×A) = (λµ)×A = µ× (λ×A)
Proposition 15.11. Soit A ∈Mm,n(K), B ∈Mm,n(K), λ ∈ K et µ ∈ K. Alors :1) A+ 0 = A = 0 +A
2) A+B = B +A (commutativité)3) (A+B) + C = A+ (B + C) (associativité)4) λ(A+B) = λA+ λB (distributivité)5) (λ+ µ)A = λA+ µA
Définition 15.12. Soit k ≥ 2 un entier. Une combinaison linéaire des matrices A1, A2, . . . , Ak deMn,p(K)est une matrice deMn,p(K) de la forme
λ1A1 + . . .+ λkAk =k∑i=1
λiAi
où λ1, λ2, . . . , λk sont des éléments de K (des scalaires).
293

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 15.13 (Multiplication). Soit A = (aij) ∈ Mn,m(K) et B = (bij) ∈ Mm,p(K). Le produit de A parB est 1 la matrice A×B = (pij) dansMn,p(K) par
∀ 1 ≤ k ≤ n ∀ 1 ≤ l ≤ p : pk,l =m∑j=1
ak,j bj,l
1. On notera que pour calculer le produit A×B, il faut que le nombre de colonnes de A soit égal au nombre de lignesde B.
Exercice 15.1. Vérifier qu’on a
AX =
(a1,1 a1,2 a1,3 a1,4a2,1 a2,2 a2,3 a2,4a3,1 a3,2 a3,3 a3,4
)x1x2x3x4
= x1
(a1,1a2,1a3,1
)+ x2
(a1,2a2,2a3,2
)+ x3
(a1,3a2,3a3,3
)+ x4
(a1,4a2,4a3,4
)
Le produit de la matrice A par la matrice colonne X est une combinaison linéaire des colonnes de la matrice A.
Proposition 15.14. Soit A = (ai,j) ∈ Mn,p(K) et X = (xj)1≤j≤p ∈ Mp,1(K) une matrice colonne. NotonsC1, C2, . . . , Cp les p matrices colonnes formées par les colonnes de A :
∀ k ∈ J1; pK : Ck = (ai,k)1≤i≤n
Le produit A×X est alors une combinaison linéaire des colonnes de A :
A×X =p∑k=0
xk Ck
Démonstration. En effet,
p∑k=0
xk Ck =p∑k=0
xk
a1,ka2,k...
an,k
=p∑k=0
xk a1,kxk a2,k
...xk an,k
=
∑p
k=0 a1,k xk∑p
k=0 a2,k xk...∑p
k=0 an,k xk
A ·X =
a1,1 a1,2 . . . a1,pa2,1 a2,2 . . . a2,p...
...an,1 an,2 . . . an,p
·x1x2. . .xp
=
a1,1x1 + a1,2x2 + . . .+ a1,pxpa2,1x2 + a2,2x2 + . . .+ a2,pxp
...an,1xn + an,2x2 + . . .+ an,pxp
D’où l’identité de la proposition.
Proposition 15.15. Soit A ∈ Mn,m(K). Soit B ∈ Mm,p(K). Soit B′ ∈ Mm,p(K). Soit C ∈ Mp,q(K). Soitλ ∈ K. Alors :
1) A× 0 = 0×A = 02) A× Im = A = In ×A (élément neutre)3) (AB)C = A(BC) (associativité)4) (λA)B = A(λB) = λ(AB) (associativité)5) A(B +B′) = AB +AB′ et (B +B′)C = BC +B′C (distributivité)
Remarque. En particulier, on a λA = λI ×A = (λI)×A
Exercice 15.2. Posons A =(1 0
0 2
). Trouver deux matrices B et C appartenant àM2(R) telles que l’ensemble
des matrices M ∈M2(R) vérifiant MA = AM est l’ensemble des combinaisons linéaires de B et C.
294

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 15.16. Soit A ∈Mn(K). On définit les puissances de A par récurrence par :A0 = In;Ak+1 = A×Ak pour tout k ∈ N.
Proposition 15.17. Soit A ∈Mn(K), k et l deux entiers, alors AkAl = AlAk = Ak+l.
Proposition 15.18 (Puissance d’une matrice diagonale). Soit D ∈ Mn(K) une matrice diagonale. Soit(d1, . . . , dn) ∈ Kn ses coefficients diagonaux. NotonsD = Diag(d1, . . . , dn), alors pour tout entier k, la puissancek-ième de D est la matrice diagonale :
Dk = Diag(dk1 , . . . , dkn)
Remarque. Attention ! Considérons la matrice A =(1 1
0 1
)et B =
(0 00 1
).On note que
A×B =(0 1
0 1
)et B ×A =
(0 00 1
)Ainsi, avec les matrices, A×B 6= B ×A en général.
Exercice 15.3.
1) Considérons les matrices A et B précédentes, a-t-on (A+B)2 = A2 + 2AB +B2 ?
2) Justifier que pour toutes matrices A, B carrées de taille n, on a
(A+B)2 = A2 +AB +BA+B2
Définition 15.19. Soit A et B deux matrices carrées de taille n, on dit qu’elles commutent si AB = BA.
Théorème 15.20 (Formule du binôme). Soit A et B deux matrices carrées de taille n. On suppose qu’ellescommutent : AB = BA, alors
∀ k ∈ N, (A+B)k =k∑j=0
(k
j
)AjBk−j
( ! Démonstration au programme)
Démonstration. Supposons que AB = BA et raisonnons par récurrence :Initialisation : Si k = 0, on a
(A+B)0 = In0∑j=0
(0j
)AjB0−j =
(00
)A0B0 = In
D’où l’identité lorsque k = 0.Hérédité : Soit k ∈ N, un entier quelconque, supposons que
(A+B)k =k∑j=0
(k
j
)AjBk−j (H)
295

TSI 1 Lycée Heinrich-Nessel 2016/2017
alors,
(A+B)k+1 = (A+B)(A+B
)k= (A+B)
(k∑j=0
(k
j
)AjBk−j
)par hypothèse de récurrence
=k∑j=0
(k
j
)Aj+1Bk−j +
k∑j=0
(k
j
)BAjBk−j par distributivité
=k∑j=0
(k
j
)Aj+1Bk−j +
k∑j=0
(k
j
)AjBk+1−j car AB = BA
=k+1∑i=1
(k
i− 1
)Ai ×Bk+1−i +
k∑j=0
(k
j
)Aj ×Bk+1−j en posant i = j + 1
=(k
k
)Ak+1B0 +
k∑j=1
(k
j − 1
)Aj ×Bk+1−j +
k∑j=1
(k
j
)Aj ×Bk+1−j +
(k
0
)A0Bk+1
= Ak+1B0 +k∑j=1
((k
j − 1
)+(k
j
))Aj ×Bk+1−j +A0Bk+1
=(k + 1k + 1
)Ak+1B0 +
k∑j=1
(k + 1j
)Aj ×Bk+1−j +
(k + 1
0
)A0Bk+1 d’après la relation de Pascal
=k+1∑j=0
(k + 1j
)Aj ×Bk+1−j
D’où, par récurrence, la relation est vraie pour tout k ∈ N.
Proposition 15.21. Soit A etB deux matrices carrées de taille n. On suppose qu’elles commutent : AB = BA,alors
∀ k ∈ N, Ak+1 −Bk+1 = (A−B)×k∑i=0
Ai ×Bk−i
Démonstration. Avec les hypothèses de la proposition, soit k ∈ N, on a
(A−B)×k∑i=0
Ai ×Bk−i
= A
k∑i=0
Ai ×Bk−i −Bk∑i=0
Ai ×Bk−i
=k∑i=0
Ai+1 ×Bk−i −k∑i=0
B×Ai ×Bk−i+1
=k∑i=0
Ai+1 ×Bk−i −k∑i=0
Ai ×Bk−i+1 car A et B commutent
=k+1∑j=1
Aj ×Bk+1−j −k∑i=0
Ai ×Bk+1−i avec j = i+ 1
= Ak+1 ×B0 +k∑j=1
Aj ×Bk+1−j −A0 ×Bk+1 −k∑i=1
Ai ×Bk+1−i
= Ak+1 −Bk+1
296

TSI 1 Lycée Heinrich-Nessel 2016/2017
15.3 Inverse d’une matriceDéfinition 15.22. Soit A ∈Mn,m(K). On dit que :• A est inversible à gauche s’il existe B ∈ Mm,n(K) telle que BA = Im. La matrice B s’appelle inverse à
gauche de A.• A est inversible à droite s’il existe C ∈ Mm,n(K) telle que AC = In. La matrice C s’appelle inverse à
droite de A.• A est inversible si A est inversible à gauche, à droite et que ses deux inverses sont les mêmes. C’est-à-dire :
∃B ∈Mn(K) : AB = BA = In
Lemme 15.23. Soit A une matrice inversible de Mn(K). Il existe une unique matrice B ∈ Mn(K) telle queAB = BA = In. Cette matrice s’appelle l’inverse de A et se note A−1.
( ! Démonstration au programme)
Démonstration. Soit A ∈Mn(K) supposons qu’il existe B et C dansMn(K) telles que
AB = BA = In et AC = CA = In
alorsB = InB = (C A)B = C (AB) = C In = C
D’où, l’unicité.
Exemple.1) La matrice identité est inversible et est son propre inverse.2) Une matrice carrée diagonale est inversible si et seulement si ses éléments diagonaux sont tous non nuls.3) La matrice nulle n’est inversible ni à gauche ni à droite.4) La matrice
A =
(200
)est inversible à gauche, mais pas à droite.
Proposition 15.24. Soit B,C ∈Mn,p(K).1) Si A est une matrice inversible deMn(K) et si AB = AC alors B = C.2) Si A est une matrice inversible deMp(K) et si BA = CA alors B = C.
Démonstration. Si A est une matrice inversible, alors :1) AB = AC ⇒ A−1AB = A−1AC ⇒ B = C ;2) BA = CA ⇒ BAA−1 = CAA−1 ⇒ B = C.
Proposition 15.25. Soit A une matrice inversible de Mn(K). Pour tout B ∈ Mn,1(K) matrice colonne, lesystème AX = B admet une unique solution X = A−1B.
Démonstration. Si A est inversible, alors
AX = B ⇒ A−1AX = A−1B ⇒ X = A−1B
Notation. On note GLn(K) ou GL(n,K) l’ensemble des matrices dansMn(K) qui sont inversibles.
297

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 15.26. Soit A ∈ GLn(K), B ∈ GLn(K) et λ ∈ K \ 0, alors :1) AB ∈ GLn(K) et de plus 1 (AB)−1 = B−1A−1 ;2) (λA) ∈ GLn(K) et de plus (λA)−1 = 1
λA−1 ;
3) A−1 ∈ GLn(K) et de plus(A−1)−1 = A.
1. On portera une attention particulière au fait qu’en passant à l’inverse, on échange les deux matrices !
Démonstration. On a1) (AB)× (B−1A−1) = A(BB−1)A−1 = AInA
−1 = AA−1 = In et de même, (B−1A¯1)× (AB) = In, d’où ABest inversible d’inverse (AB)−1 = B−1A−1.
2) (λA)× ( 1λA−1) =
(λ 1λ
)AA−1 = 1× In = In et de même, ( 1
λA−1)× (λA) = In, d’où λA est inversible (si
λ 6= 0) et (λA)−1 = 1λA−1.
3) A−1A = A−1A = In, d’où A−1 est inversible d’inverse (A−1)−1 = A.
15.4 Opérations élémentaires, matrices échelonnées
Définition 15.27. Soit n et m deux entiers non nuls, k et l deux entiers tels que 1 ≤ k ≤ n et 1 ≤ l ≤. Lamatrice élémentaire Ek,l deMn,m(K) est la matrice de taille n×m dont tous les coefficients sont nuls sauf lecoefficient de la ke ligne et le colonne qui vaut 1.
Exemple. La matrice élémentaire E2,3 deM3(K) est la matrice(0 0 00 0 10 0 0
)
Exercice 15.4. Vérifier que A = (ai,j) dansM2,3(R), on a A =∑2
i=1
∑3j=1 ai,jEi,j .
Proposition 15.28. Soit A = (ai,j) ∈Mn,m(K), alors
A =n∑i=1
m∑j=1
ai,jEi,j
où les Ei,j sont les matrices élémentaires deMn,m(K).
Définition 15.29. Soit a ∈ K\0, n ∈ N un entier non nul et k ∈ 1, . . . , n. La matrice de dilatation Dk(a)est la matrice définie par
Dk(a) =n∑
i=1, i6=k
Ei,i + aEk,k
Exemple. La matrice de dilatation D2(a) deM3(R) est
D2(a) =
(1 0 00 a 00 0 1
)
Proposition 15.30. Soit a ∈ K \ 0, n ∈ N un entier non nul et k ∈ 1, . . . , n. La matrice Dk(a) estinversible et a pour inverse Dk
(1a
).
298

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 15.31 (Lk ← aLk). Soit a ∈ K\0, n ∈ N un entier non nul et k ∈ 1, . . . , n. Soit A ∈Mn(K).Le produit Dk(a)×A est obtenue à partir de A en remplaçant la ke ligne par la ke ligne multipliée par a.
Définition 15.32. Soit n ∈ N non nul, k ∈ 1, . . . , n et l ∈ 1, . . . , n avec l 6= k. Soit λ ∈ K. La matrice detransvection Tk,l(λ) est la matrice définie par
Tk,l(λ) = In + λEk,l
Exemple. La matrice de transvection T1,3(λ) deM3(R) est
T1,3(λ) =
(1 0 λ0 1 00 0 1
)
Proposition 15.33. Soit n ∈ N non nul, k ∈ 1, . . . , n, l ∈ 1, . . . , n avec l 6= k et λ ∈ K. La matrice Tk,l(λ)est inversible et a pour inverse Tk,l(−λ).
Proposition 15.34 (Lk ← Lk + λLl). Soit n ∈ N non nul, k ∈ 1, . . . , n, l ∈ 1, . . . , n avec l 6= k et λ ∈ K.Soit A ∈ Mn(K). Le produit Tk,l(λ) × A est obtenue à partir de A en remplaçant la ke ligne de A par la keligne additionnée à la le ligne préalablement multipliée par λ.
À l’aide des matrices de dilatations et de transvections, il est possible de représenter par un produit de matrice àgauche, l’opération de permutation des lignes.
Proposition 15.35 (Lk ↔ Ll). Soit n ∈ N non nul, k ∈ 1, . . . , n, l ∈ 1, . . . , n avec l 6= k et A ∈ Mn(K).Le produit Dk(−1)Tl,k(1)Tk,l(−1)Tl,k(1)×A est obtenue à partir de A en échangeant la ke ligne et la le ligne.
On note qu’on peut reformuler la définition de l’ équivalences en lignes des matrices :
Définition 15.36. Deux matrices A et A′ sont équivalentes en lignes si on peut obtenir A′ à partir de A parune succession finie de multiplications à gauche par une matrice de dilatation et/ou de transvection et on noteA ∼
LA′.
Remarque. Plus formellement, A ∼LA′ s’il existe E1, . . . , Ek des matrices de dilatation et/ou de transvection telles
que A′ = E1 × . . .× Ek ×A.
De même en multipliant à droite, on représente les opérations sur les colonnes à l’aide de produit par les matricesde dilatation et/ou de transvection :
Proposition 15.37. Soit a ∈ K\0, n ∈ N un entier non nul et k ∈ 1, . . . , n. Soit A ∈Mn(K). La matriceA×Dk(a) est obtenue à partir de A en remplaçant la ke colonne par la ke colonne multipliée par a. On noteCk ← aCk cette opération.
Proposition 15.38. Soit n ∈ N non nul, k ∈ 1, . . . , n, l ∈ 1, . . . , n avec l 6= k et λ ∈ K. Soit A ∈Mn(K).La matrice ATk,l(λ) est obtenue à partir de A en remplaçant la ke colonne de A par la ke colonne additionnéeà la le colonne préalablement multipliée par λ. On note Ck ← Ck + λCl cette opération.
Proposition 15.39. Soit n ∈ N non nul, k ∈ 1, . . . , n et l ∈ 1, . . . , n avec l 6= k. Soit A ∈ Mn(K). Lamatrice Dk(−1)Tl,k(1)Tk,l(−1)Tl,k(1)A est obtenue à partir de A en échangeant la ke colonne et la le colonne.On note Ck ↔ Cl cette opération.
299

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 15.40. Deux matrices A et A′ sont équivalentes en colonnes si on peut obtenir A′ à partir de Apar une succession finie de multiplications à droite par une matrice de dilatation et/ou de transvection et onnote A ∼
CA′.
Dans le chapitre systèmes linéaires, nous avions déduit de l’étude de l’algorithme de Gauss-Jordan le théorèmesuivant :
Théorème 15.41. Toute matrice non nulle est équivalente en lignes à une unique matrice échelonnée réduiteen lignes.
Qu’on peut reformuler ainsi :
Corollaire 15.42. Soit A ∈ Mn,m(K) non nulle. Alors il existe une matrice carrée P produit de matrices dedilatation et/ou de transvection telle que PA est échelonnée réduite. La forme échelonnée réduite ainsi obtenueest unique.
Remarque. La matrice P , produit de matrices inversibles, est inversible.
Définition 15.43. Soit A une matrice deMm,n(K) et A′ la matrice échelonnée réduite associée à A. Le rangde A est le nombre de pivots de A′. On le note rg(A).
Remarque. Le rang est inférieur ou égal au nombre de lignes de la matrice A (respectivement d’équations dusystème).
Proposition 15.44. Supposons que A est une matrice carrée en échelons. Alors A est triangulaire supérieure.De plus, si la dernière ligne n’est pas nulle, les coefficients diagonaux de A sont tous non nuls.
Proposition 15.45. Soit T une matrice triangulaire supérieure de Mn(K). Si les coefficients diagonaux deT sont tous égaux à 1, alors T est produit de matrices de dilatation et/ou de transvection. De plus, T estinversible.
Théorème 15.46. Soit A ∈Mn(K) une matrice carrée, les propriétés suivantes sont équivalentes :1) la matrice A est produit de matrices de dilatation et/ou de transvection.2) le rang de la matrice A est n.3) la matrice A est inversible.4) il existe une matrice B ∈Mn(K) telle que AB = In.5) il existe une matrice C ∈Mn(K) telle que CA = In.
Démonstration (hors programme). Algèbre 1er année, Liret Martinais, p. 67.
15.5 Recherche de l’inverse d’une matriceExemple. Considérons la
A =
(1 1 12 −1 1−1 2 −1
)
300

TSI 1 Lycée Heinrich-Nessel 2016/2017
Nous allons échelonner la matrice augmentée (A|I3) :
(A|I3) =
(1 1 1 | 1 0 02 −1 1 | 0 1 0−1 2 −1 | 0 0 1
)
∼L
(1 1 1 | 1 0 00 −3 −1 | −2 1 00 3 0 | 1 0 1
)=[T2,1(−2)T3,1(1)A | T2,1(−2)T3,1(1) I3
]∼L
(1 1 1 | 1 0 00 1 1
3 | 23 − 1
3 00 0 −1 | −1 1 1
)=[. . .A|. . .
]∼L
(1 1 1 | 1 0 00 1 1
3 | 23 − 1
3 00 0 1 | 1 −1 −1
)= . . .
∼L
(1 1 0 | 0 1 10 1 0 | 1
3 0 13
0 0 1 | 1 −1 −1
)= . . .
∼L
(1 0 0 | − 1
3 1 23
0 1 0 | 13 0 1
30 0 1 | 1 −1 −1
)=[PA | P
]D’où PA = I3, c’est à dire, d’après un théorème précédent, la matrice A est inversible et
A−1 = P =
(− 1
3 1 231
3 0 13
1 −1 −1
)
Proposition 15.47. Une matrice A carrée de taille n est inversible si et seulement si la matrice échelonnéeréduite de la matrice augmentée (A|In) est de la forme (In|P ). De plus, dans ce cas, A−1 = P .
Méthode. Pour déterminer si une matrice A est inversible et déterminer son inverse, on peut échelonner lamatrice augmentée (A|In).
Corollaire 15.48. Soit A ∈Mn(K) une matrice carrée. Les propositions suivantes sont équivalentes :1) la matrice A est inversible.2) le système AX = 0 admet une unique solution, à savoir X = 0.3) Pour tout B ∈Mn,1(K) matrice colonne, le système AX = B admet une unique solution.
15.6 Applications linéaires de Kn dans Km
Dans cette section, pour tout entier n, on identifie les matrices colonnes de Mn,1(K) avec les vecteurs colonnesde Kn.
Définition 15.49. Soit (m,n) ∈ (N∗)2 et f : Kn → Km une application. On dit que f est une applicationlinéaire si :
∀u, v ∈ Kn ∀λ, µ ∈ K : f(λu+ µv) = λf(u) + µf(v)
Remarque. Une application f est linéaire, si l’image d’une combinaison linéaire est égale à la combinaison linéairedes images.
Exercice 15.5. Soit f : R3 → R2 définie par
∀(x1, x2, x3) ∈ R3 : f
(x1x2x3
)=
(x1 + x2
3x1 − x27 + 2x3
x2 + 6x3
)1) Montrer que f est linéaire.2) Montrer qu’il existe une matrice A ∈M2,3(R) telle que pour tout X ∈ R3, f(X) = AX.
301

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 15.50. Soit A ∈Mm,n(K), l’application associée :
f : Kn // Km
X // AX
est une application linéaire.
Démonstration. Soit X1 et X2 deux vecteurs de Kn et λ1, λ2 ∈ K deux scalaires, alors
f(λ1X1 + λ2X2) = A(λ1X1 + λ2X2)= λ1AX1 + λ2AX2 par distributivité du produit des matrices= λ1f(X1) + λ2f(X2)
D’où f est linéaire.
Exercice 15.6. Soit f : R2 → R2 une application linéaire et (e1, e2) la base canonique de R2.1) Calculer f(e1), f(e2).2) Pour tout (x, y) ∈ R2, exprimier f(xe1 + ye2) en fonction de f(e1) et f(e2).3) En déduire qu’il existe une matrice A ∈M2,3(R) telle que pour tout X ∈ R2, f(X) = AX.
Proposition 15.51. Soit f : Kn → Km une application linéaire, alors il existe une matrice A ∈Mm,n(R) telleque pour tout X ∈ Rn, f(X) = AX.
Démonstration. Pour tout j ∈ J1;nK, posons ej = (0, . . . , 0, 1, . . . , 0) ∈ Kn le vecteur avec un 1 sur la j-ème ligneet des 0 partout ailleurs, ainsi la famille (e1, . . . , en) est appelé base canonique de Kn. Pour tout j ∈ J1;nK, notonsle vecteur
a1,ja2,j...
am,j
les coordonnées du vecteur f(ej). Soit X ∈ Kn, notons (x1, . . . , xn) ses coordonnées (dans la base canonique), ona
f(X) = f
(n∑j=1
xjej
)=
n∑j=1
xjf(ej) par linéarité de f
=n∑j=1
xj
a1,ja2,j...
am,j
=
a1,1 a1,2 . . . a1,na2,1 a2,2 . . . a2,n...
...am,1 am,2 . . . am,n
·x1x2. . .xn
d’après la proposition 15.14
= AX
où
A =
a1,1 a1,2 . . . a1,na2,1 a2,2 . . . a2,n...
...am,1 am,2 . . . am,n
∈Mm,n(K)
Remarque. Les colonnes de la matrice A dans la proposition précédente sont les coordonnées des vecteurs imagesf(ej) où (e1, . . . , ej , . . . , en) est la base canonique de Kn.
Méthode. Pour montrer qu’une application f : Kn → Km est linéaire, il suffit de montrer qu’elle est de laforme f : X 7→ AX où A ∈Mm,n(K).
302

TSI 1 Lycée Heinrich-Nessel 2016/2017
Lemme 15.52. Soit f : Kn → Km une application linéaire. Soit a, b deux vecteurs de Kn alors
f(a) = f(b) ⇐⇒ f(a− b) = O
de plus f(O) = O.
Démonstration. Avec les hypothèses du lemme, soit a, b deux vecteurs de Kn, alors
f(a) = f(b) ⇐⇒ f(a)− f(b) = O
⇐⇒ f(a− b) = O car f est linéaire
De plus, f(O) = f(0 · O) = 0 · f(O) = O.
Ainsi, déterminer si une application linéaire est injective revient à comprendre l’ensemble des antécédents duvecteur 0 par f . Cet ensemble mérite donc une attention particulière :
Définition 15.53. Soit f : Kn → Km une application linéaire. On appelle noyau 1 de f l’ensemble
ker(f) = x ∈ Kn| f(x) = O
1. Pour faire le lien avec la notation : en anglais, kernel signifie noyau.
Notation. Pour toute matrice A ∈Mm,n(K), on note ker(A) le noyau de l’application linéaire associée :
ker(A) = X ∈ Kn| AX = O
D’après le lemme précédent, quelle que soit l’application linéaire f , on a
O ⊂ ker(f)
Proposition 15.54. Soit f : Kn → Km une application linéaire. L’application f est injective si et seulementsi ker(f) = O.
Démonstration. Soit f : Kn → Km une application linéaire, alors
f est injectivie⇐⇒ ∀ a, b ∈ Kn : f(a) = f(b) ⇒ a = b
⇐⇒ ∀ a, b ∈ Kn : f(a− b) = O ⇒ a− b = O par linéarité de f⇐⇒ ∀x ∈ Kn : f(x) = O ⇒ x = O
⇐⇒ ker(f) = O car O ⊂ ker(f)
Définition 15.55. Soit f : Kn → Km une application linéaire. On rappelle que l’image de f est l’ensemble
Im(f) = y ∈ Km| ∃x ∈ Kn : y = f(x)
Notation. Pour toute matrice A ∈Mm,n(K), on note Im(A) l’image de l’application linéaire associée :
Im(A) = Y ∈ Km| ∃X ∈ Kn : Y = AX
Lemme 15.56 (stabilité par combinaison linéaire). Soit f : Kn → Km une application linéaire, alors 0 ∈ Im(f)et
∀ y1, y2 ∈ Im(f) ∀λ1, λ2 ∈ K : λ1y1 + λ2y2 ∈ Im(f)
Démonstration. Soit y1, y2 ∈ Im(f) et λ1, λ2 ∈ K. Par définition de l’image de f , il existe x1, x2 dans Kn tels queyi = f(xi) pour i = 1, 2. Ainsi, par linéarité de f , la combinairon linéaire des images
λ1y1 + λ2y2 = λ1f(x1) + λ2f(x2) = f (λ1x1 + λx2)
appartient aussi à l’image Im(f).
303

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 15.57. Soit f : Kn → Km une application linéaire. L’application f est surjective si et seulementsi Im(f) = Km.
Exercice 15.7. On considère l’application
f : K2 // K3
(x, y) // (2x+ y; y − x; 5x+ 7y)
1) Déterminer la matrice A de l’application f .2) Déterminer le noyau de f .3) Soit (a, b, c) ∈ R3. Donner une condition nécessaire et suffisante pour que (a, b, c) ∈ Im(f).4) En déduire une description de Im(f).
Exercice 15.8. Soit f : Kn → Km une application linéaire et (e1, . . . , en) la base canonique de Kn. Montrer quey appartient à l’image Im(f) si et seulement si y est une combinaison linéaire des vecteurs f(e1), . . . , f(en).
304

Chapitre 16
Dérivation
Programme• Nombre dérivé, fonction dérivée. Étudier la dérivabilité d’une fonction en un point particulier, à partir de
la définition. Notation f ′(a).• Équivalence avec l’existence d’un développement limité à l’ordre 1.• Tangente : y = f(a) + f ′(a)(x− a).• Dérivabilité à droite et à gauche en a. Dérivabilité d’une fonction sur un intervalle.• Opérations sur les fonctions dérivables : Si f , g sont dérivables en a, dérivabilité et dérivé de f + g, fg ena et, si g′(a) 6= 0, de f
g.
• Dérivabilité et dérivée en a de g f lorsque f est dérivable en a et g dérivable en f(a).• Si f est une fonction bijective dérivable, condition nécessaire et suffisante de dérivabilité de la fonction
réciproque f−1 en f(a) et, calcul de la dérivée en ce point.• Propriétés des fonctions dérivables• Notion d’extremum local. Condition nécessaire d’extremum local en un point intérieur.• Théorème de Rolle. Théorème (égalité) des accroissements finis. Inégalité des accroissements finis.• Interprétation géométrique de l’égalité des accroissements finis.• Caractérisation des fonctions constantes, croissantes parmi les fonctions dérivables.• Théorème de la limite de la dérivée.• Fonctions de classe Ck. Fonctions de classe Ck sur un intervalle I, où k ∈ N ∪ ∞.• Opérations : combinaison linéaire, produit (formule de Leibniz), quotient, composée, réciproque.• Maitriser le calcul de fonctions dérivées.• Application :• Étude d’une suite définie par récurrence• Développements limités à l’ordre 2 des fonctions de référence• Méthode de Newton
16.1 Nombre dérivéQuelques rappels sur les fonctions affines : Soient A(xA; yA) et B(xB ; yB) deux points d’abscisses distinctes duplan. On appelle taux d’accroissement de A vers B le nombre
yB − yAxB − xA
Soit D la droite d’équation y = mx+ p, A et B deux points distincts de la droite. Le taux d’accroissement de Avers B est égal à m, le coefficient directeur de la droite D.
Définition 16.1. Soit f : I → R une fonction et a ∈ I. On dit que f est dérivable en a, si le taux de variationde f de a vers a+ h
f(a+ h)− f(a)h
305

TSI 1 Lycée Heinrich-Nessel 2016/2017
converge lorsque h tend vers 0. Dans ce cas, on note
f ′(a) = limh→0
f(a+ h)− f(a)h
et ce nombre est appelé le nombre dérivé de f en a.
Remarque. Si, on pose x = a+ h, alors
limx→a
f(x)− f(a)x− a = lim
h→0
f(a+ h)− f(a)h
= f ′(a)
Définition 16.2. Soit f : D → R une fonction dérivable en un point a de D. La tangente à la courbe Cf aupoint d’abscisse a est la droite d’équation :
y = f ′(a)(x− a) + f(a)
Notons Cf la courbe représentative de la fonction f et A(a, f(a)) le point de la courbe d’abscisse A.• La tangente à la courbe Cf au point d’abscisse a, est la droite passant par le point A et dont le coefficient
directeur est f ′(a), le nombre dérivé de f en a.• Par définition du nombre dérivée, on note que la tangente est la droite limite des droites sécantes (AM),
où M est le point de Cf d’abscisse a+ h, lorsque h tend vers 0.Graphiquement :
0
A
1
f ′(a)
a
f(a)
Ta(f) : y = f ′(a)(x− a) + f(a)
Cf
Définition 16.3. Soit f : I → R et a ∈ I. On dit que f est dérivable à droite (resp. à gauche) en a si letaux d’accroissement f(x)−f(a)
x−a admet une limite finie à droite (resp. à gauche) en a. Cette limite se note f ′d(a)(resp. f ′g(a)).
Proposition 16.4. Soit f : I → R et a ∈ I. La fonction f est dérivable en a si et seulement si elle est dérivableà gauche et dérivable à droite en a et f ′d(a) = f ′g(a).
Exercice 16.1. Montrer que la fonction valeur absolue est dérivable à droite et à gauche en 0 mais n’est pasdérivable en 0.
Exercice 16.2.1) Rappeler les limites (de référence) de sin(h)
het cos(h)−1
hlorsque h tend vers 0.
2) En déduire que les fonctions sinus et cosinus sont dérivables en un réel à déterminer.
306

TSI 1 Lycée Heinrich-Nessel 2016/2017
3) Soit a un réel quelconque, à l’aide des formules de trigonométrie, déduire que les fonctions sinus et cosinussont dérivables en a.
Soit f : I → R dérivable en a. Pour tout x très proche de a, on a
f(x)− f(a)x− a ' f ′(a) ⇐⇒ f(x) ' f(a) + (x− a)f ′(a)
Dans cette dernière expression, le terme de droite correspond à la tangente à f en a. On remarque donc qu’auvoisinage de a, la fonction affine déterminée par la tangente approxime la fonction f . Plus précisément, posonsε : h 7→ f(a+h)−f(a)
h− f ′(a) si h 6= 0 et ε(0) = 0. Alors, pour tout x ∈ I, on a
f(x) = f(a) + (x− a)f ′(a) + (x− a)ε(x− a) et limh→0
ε(h) = 0
Avec les notations de Landau, on a f(x) =0f(a) + (x− a)f ′(a) + o(x− a).
Proposition 16.5. Soit f : D → R. Les deux propositions suivantes sont équivalentes :1) la fonction f est dérivable en a.2) Il existe λ ∈ R telle que
∀x ∈ I : f(x) =0f(a) + (x− a)λ+ o(x− a)
De plus, si f est dérivable en a, alors λ = f ′(a).
Rappelons
Vocabulaire. Si f : I → R est dérivable en a ∈ I, alors l’identité
f(x) = f(a) + (x− a)f ′(a) + o(x− a)
est appelée développement limité à l’ordre 1 de f en a.
Remarque. Si on pose h = x− a, alors on peut réécrire le développement limité à l’ordre 1 de f en a ainsi :
f(a+ h) = f(a) + hf ′(a) + o(h)
Démonstration. Le sens direct a été traité avant la proposition. Réciproquement, s’il existe λ ∈ R et une fonctionε telle que :
1) Pour tout x ∈ I : f(x) = f(a) + (x− a)λ+ (x− a)ε(x− a) ;2) ε(h) tend vers 0 lorsque h tend vers 0.
Alors, pour tout x ∈ I \ a, on a
f(x)− f(a) = (x− a)λ+ (x− a)ε(x− a)f(x)− f(a)
x− a = λ+ ε(x− a) −→x→a
λ
C’est-à-dire f est dérivable en a.
Corollaire 16.6. Si une fonction est dérivable en a, elle est continue en a.
Démonstration. Si f : I → R est dérivable en a ∈ I, alors, d’après la proposition précédente :
limx→a−
f(x) = limx→a−
f(a) + (x− a)f ′(a) + o(x− a) = f(a)
limx→a+
f(x) = limx→a+
f(a) + (x− a)f ′(a) + o(x− a) = f(a)
Donc f est continue en a.
Exercice 16.3. Soit α ∈ R. Compléter les développements limités à l’ordre 1 en 0 des fonctions de référence :
307

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) ex = 1 + x+ o(x)
2) ln(1 + x) = x+ o(x)
3) ln(1− x) = −x+ o(x)
4) 11−x = 1 + x+ o(x)
5) cos(x) = 1 + o(x)
6) sin(x) = x+ o(x)
7) tan(x) = x+ o(x)
8) (1 + x)α = 1 + αx+ o(x)
9) arccos(x) = π2 − x+ o(x)
10) arcsin(x) = x+ o(x)
11) arctan(x) = x+ o(x)
Définition 16.7. Soit f : I → R une fonction, on dit que f est dérivable sur I si elle est dérivable en toutréel a de I.
Vocabulaire. Lorsqu’on se donne une fonction f , on appelle domaine de dérivabilité le plus grand (pour l’inclu-sion) sous-ensemble de R sur lequel la fonction f est dérivable.
16.2 Fonction dérivée
Proposition 16.8 (linéarité de la dérivée). Soit u, v : I → R dérivables en a ∈ I et (λ, µ) ∈ R2 alors lafonction combinaison linéaire λu+ µv est dérivable en a. De plus,
(λu+ µv)′(a) = λu′(a) + µv′(a)
Remarque. La proposition précédente reste encore vraie si on remplace « en a » par « sur I ».
Proposition 16.9 (Produit, inverse et quotient). Soient u, v : I → R deux fonctions dérivables sur I alors,1) la fonction produit u v : I → R est dérivable sur I et on a
(uv)′(x) = u′(x)× v(x) + u(x)× v′(x)
pour tout x ∈ I.2) Si de plus la fonction v ne s’annule pas sur I, alors
a) la fonction inverse 1v
: I → R est dérivable sur I et on a(1v
)′(x) = −v
′(x)[v(x)]2
pour tout x ∈ I.b) la fonction quotient u
v: I → R est dérivable sur I et on a(
u
v
)′(x) = u′(x)× v(x)− u(x)× v′(x)
[v(x)]2
pour tout x ∈ I.
Proposition 16.10 (composée). Soit u : D → R et f : E → R deux fonctions dérivables, supposons quel’image u(D) est incluse dans le domaine E, alors la composée f u est dérivable sur D et pour tout x dansD, on a
(f u)′(x) = u′(x)× f ′(u(x) )
Remarque. Formellement, on a : (f u)′ = u′ × (f ′ u).
Démonstration. Soit a ∈ D, x ∈ D et y ∈ E, par hypothèse sur u et f , on a deux développements limités à l’ordre1 :
u(x) = u(a) + (x− a)u′(a) + o(x− a) ⇐⇒ u(x)− u(a) = (x− a)u′(a) + o(x− a)f(y) = f(u(a)) + (y − u(a))f ′(u(a)) + o(y − u(a))
308

TSI 1 Lycée Heinrich-Nessel 2016/2017
En particulier, si y = u(x), alors
f(u(x)) = f(u(a)) + (u(x)− u(a))f ′(u(a)) + o(u(x)− u(a))
f u(x) = f u(a) +((x− a)u′(a) + o(x− a)
)f ′(u(a)) + o(u(x)− u(a))
= f u(a) + (x− a)u′(a)f ′(u(a)) + f ′(u(a))o(x− a) + o(u(x)− u(a))= f u(a) + (x− a)u′(a)f ′(u(a)) + (x− a)ε(x− a)
où
ε(x− a) = 1x−a (f ′(u(a))o(x− a) + o(u(x)− u(a))) si x 6= a
0 sinonDe plus,
limh→0, h6=0
ε(h) = limh→0, h6=0
1h
(f ′(u(a))o(h) + o(u(a+ h)− u(a)))
= limh→0, h6=0
f ′(u(a))o(h)h
+ o(u(a+ h)− u(a))h
= limh→0, h6=0
f ′(u(a))× o(1) + u(a+ h)− u(a)h
× o(u(a+ h)− u(a))u(a+ h)− u(a)
= f ′(u(a))× 0 + u′(a)× limh→0
o(h)h
= 0
Donc, f u(x) = f u(a) + (x− a)u′(a)f ′(u(a)) + o(x− a). D’après la proposition 16.5, f u est dérivable en aet (f u)′(a) = u′(a)f ′(u(a)).
Proposition 16.11 (réciproque). Soit f : I → J une fonction bijective et dérivable sur I. Si f ′ ne s’annulepas sur I, alors sa fonction réciproque f−1 est aussi dérivable et pour tout x dans J , on a
(f−1)′(x) = 1f ′( f−1(x) )
Démonstration. Supposons que f est bijective dérivable sur I et que f ′ ne s’annule pas sur I. Comme f estcontinue, on déduit que J = f(I) est aussi un intervalle. Soit (a, x) ∈ I2 et (b, y) ∈ J2 tels que y = f(x), b = f(a)et y 6= b. Soit ε la fonction telle que
f(x) = f(a) + (x− a)f ′(a) + (x− a)ε(x− a)limh→0
ε(h) = 0
Alors,
f−1(y)− f−1(b)y − b = x− a
f(x)− f(a)
= x− a(x− a) (f ′(a) + (x− a)ε(x− a))
= 1f ′(f−1(b)) + (f−1(y)− f−1(b)) ε (f−1(y)− f−1(b))
Or, on a vu dans le chapitre sur les fonctions continues que f−1 est continue. D’où
limy→b
f−1(y)− f−1(b) = 0
et donc, on déduit que
limy→b
f−1(y)− f−1(b)y − b = 1
f ′(f−1(b))Ainsi, f−1 est dérivable en b et l’expression précédente détermine (f−1)′(b).
16.3 Théorème de Rolle et des accroissements finisDans cette section, si on se donne un intervalle [a; b], on supposera toujours que a < b.
309
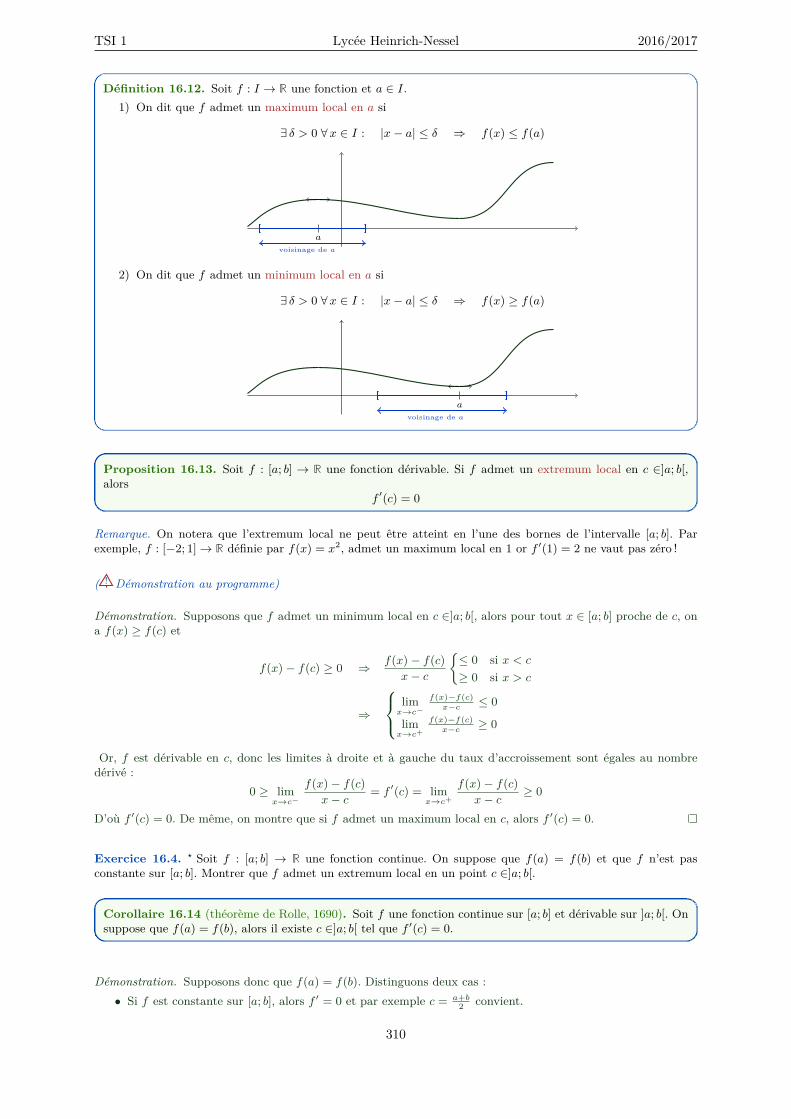
TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 16.12. Soit f : I → R une fonction et a ∈ I.1) On dit que f admet un maximum local en a si
∃ δ > 0 ∀x ∈ I : |x− a| ≤ δ ⇒ f(x) ≤ f(a)
a
voisinage de a
2) On dit que f admet un minimum local en a si
∃ δ > 0 ∀x ∈ I : |x− a| ≤ δ ⇒ f(x) ≥ f(a)
a
voisinage de a
Proposition 16.13. Soit f : [a; b] → R une fonction dérivable. Si f admet un extremum local en c ∈]a; b[,alors
f ′(c) = 0
Remarque. On notera que l’extremum local ne peut être atteint en l’une des bornes de l’intervalle [a; b]. Parexemple, f : [−2; 1]→ R définie par f(x) = x2, admet un maximum local en 1 or f ′(1) = 2 ne vaut pas zéro !
( ! Démonstration au programme)
Démonstration. Supposons que f admet un minimum local en c ∈]a; b[, alors pour tout x ∈ [a; b] proche de c, ona f(x) ≥ f(c) et
f(x)− f(c) ≥ 0 ⇒ f(x)− f(c)x− c
≤ 0 si x < c
≥ 0 si x > c
⇒
limx→c−
f(x)−f(c)x−c ≤ 0
limx→c+
f(x)−f(c)x−c ≥ 0
Or, f est dérivable en c, donc les limites à droite et à gauche du taux d’accroissement sont égales au nombredérivé :
0 ≥ limx→c−
f(x)− f(c)x− c = f ′(c) = lim
x→c+
f(x)− f(c)x− c ≥ 0
D’où f ′(c) = 0. De même, on montre que si f admet un maximum local en c, alors f ′(c) = 0.
Exercice 16.4. ? Soit f : [a; b] → R une fonction continue. On suppose que f(a) = f(b) et que f n’est pasconstante sur [a; b]. Montrer que f admet un extremum local en un point c ∈]a; b[.
Corollaire 16.14 (théorème de Rolle, 1690). Soit f une fonction continue sur [a; b] et dérivable sur ]a; b[. Onsuppose que f(a) = f(b), alors il existe c ∈]a; b[ tel que f ′(c) = 0.
Démonstration. Supposons donc que f(a) = f(b). Distinguons deux cas :• Si f est constante sur [a; b], alors f ′ = 0 et par exemple c = a+b
2 convient.
310

TSI 1 Lycée Heinrich-Nessel 2016/2017
• Si f n’est pas constante sur [a; b], comme f(a) = f(b), on déduit qu’il existe c ∈]a; b[ tel que f(c) 6= f(a).Quitte à considérer −f au lieu de f , on suppose que f(c) < f(a). D’autre part, comme f est continue sur[a; b], on déduit du théorème des bornes atteintes que f admet un minimum et l’atteint : c’est-à-dire qu’ilexiste m ∈ [a; b] tel que
∀x ∈ [a; b] : f(x) ≥ f(m)En particulier f(m) ≤ f(c) < f(a) et de même f(m) < f(b), d’où m ∈]a; b[. Enfin, d’après la propositionprécédente, f ′(m) = 0.
D’où le corollaire.
Exercice 16.5. ? Soit a < b et f une fonction continue sur [a; b] et dérivable sur ]a; b[. On considère la fonctiong : [a; b]→ R définie par
g(x) = f(x)− x− ab− a (f(b)− f(a))
1) Calculer g(a) et g(b).2) Peut-on appliquer le théorème de Rolle à la fonction g ? Qu’en déduit-on ?
Théorème 16.15 (Accroissements Finis). Soit f une fonction continue sur [a; b] et dérivable sur ]a; b[. Alorsil existe c ∈]a; b[ tel que
f(b) = f(a) + (b− a)f ′(c)
( ! Démonstration au programme)
Démonstration. Par hypothèse a < b, d’où posons τ = f(b)−f(a)b−a et g : [a; b]→ R définie par
g(x) = f(x)− (x− a)τ
pour tout x ∈ [a; b]. Alors, par opérations élémentaires sur des fonctions dérivables (respectivement continues), lafonction g est dérivable sur ]a; b[ et continue sur [a; b]. De plus,
g(a) = f(a)− (a− a)τ = f(a) et g(b) = f(b)− (b− a)f(b)− f(a)b− a = f(a)
Ainsi, d’après le théorème de Rolle, il existe c ∈]a; b[ tel que g′(c) = 0. D’autre part, pour tout x ∈]a, b[, on ag′(x) = f ′(x)− τ . D’où,
f ′(c) = τ = f(b)− f(a)b− a ⇒ f(b)− f(a) = (b− a)f ′(c)
Corollaire 16.16 (Inégalité des Accroissements Finis). Soit f une fonction continue sur [a; b] et dérivable sur]a; b[. On suppose qu’il existe M ≥ 0 tel que ∀ x ∈]a; b[, |f ′(x)| ≤M . Alors
|f(b)− f(a)| ≤M(b− a)
Corollaire 16.17. Soit f : [a; b]→ R une fonction continue sur [a; b] et dérivable sur ]a; b[.1) Si f ′(x) = 0 pour tout x ∈]a; b[, alors f est constante sur [a; b].2) Si f ′(x) ≥ 0 pour tout x ∈]a; b[, alors f est croissante sur [a; b].3) Si f ′(x) > 0 pour tout x ∈]a; b[, alors f est strictement croissante sur [a; b].
Exercice 16.6.1) Montrer que les réciproques des points 1) et 2) du corollaire précédent sont vraies.2) Donner un contre-exemple à la réciproque du point 3) du corollaire.
Théorème 16.18 (de la limite de la dérivée). Soit f : I → R une fonction définie sur un intervalle I et a ∈ I.On suppose que :• f est continue sur I ;• f est dérivable sur I \ a ;• f ′ admet une limite ` (fini ou infini) en a.
Alors,limx→a
f(x)− f(a)x− a = `
311

TSI 1 Lycée Heinrich-Nessel 2016/2017
De plus, si ` est un nombre réel, alors f est dérivable en a, f ′(a) = ` et f ′ est continue en a.
Démonstration. Supposons que ` est fini : Soit ε > 0, comme f ′(x) converge vers ` lorsque x tend vers a, il existeδ > 0 tel que
∀x ∈ I : |x− a| ≤ δ ⇒ |f ′(x)− `| ≤ εSoit x ∈ I \ a tel que |x − a| ≤ δ. D’après le théorème des accroissements finis, appliqué à f sur [x; a] (resp.[a;x]), il existe c ∈]x; a[ (resp. ]a;x[) tel que f(x)−f(a)
x−a = f ′(c). Or le nombre c vérifie |c− a| ≤ |x− a| ≤ δ, ainsi
|f(x)− f(a)x− a − `| = |f ′(c)− `| ≤ ε
On vient ainsi d’établir que
∀ ε > 0 ∃ δ > 0 ∀x ∈ I \ a : |x− a| ≤ δ ⇒ |f(x)− f(a)x− a − `| ≤ ε
C’est-à-dire :limx→a
f(x)− f(a)x− a = `
Ainsi, f est dérivable en a. De plus, par hypothèse, limx→a±
f ′(x) = ` = f ′(a), d’où f ′ est aussi continue en a. Lescas ` = ±∞ sont laissés en exercice.
16.4 Fonctions de classe Ck
Définition 16.19. Une fonction f définie sur I est de classe C1 si f est continue et dérivable sur I et si f ′est continue sur I. On note
C1(I; R)l’ensemble des fonctions de classe C1 sur I.
Proposition 16.20. Toute combinaison linéaire, tout produit, tout quotient (si possible) et toute composition(si possible) de fonctions de classe C1 est encore de classe C1.
Exemple. Toute fonction polynomiale et tout quotient de fonctions polynomiales est de classe C1 sur son domainede définition.
Définition 16.21. Soit I et J deux intervalles, une fonction f : I → J est un C1-difféomorphisme de I sur Jsi f est de classe C1, réalise une bijection de I sur J et si f−1 est C1.
Soit f une fonction de classe C1 sur un intervalle I et posons J = f(I). Supposons que f ′ ne s’annule pas surI, comme f ′ est continue I, on déduit du théorème des valeurs intermédiaires de f ′ est de signe constant. D’oùf est strictement monotone, continue sur I et induit une bijection de I sur J . De plus, d’après la proposition16.11, la réciproque f−1 est dérivable sur J et sa dérivée (f−1)′ = 1
f ′f−1 est continue sur J , car obtenue à partird’opérations élémentaires sur des fonctions continues. C’est-à-dire f est C1-difféomorphisme. D’où, la réciproquede la proposition suivante :
Proposition 16.22. Soit f une fonction de classe C1 sur un intervalle I. Alors f est un C1-difféomorphismede I sur f(I) si et seulement si f ′ ne s’annule pas sur I.
Démonstration. Il nous reste à montrer le sens direct. Supposons que f : I → J est un C1-difféomorphisme.Comme f−1 f = idI , on déduit, par dérivation d’une composée, que pour tout x ∈ I,
f ′(x)×(f−1)′(f(x)) = 1 6= 0 ⇒ f ′(x) 6= 0
C’est-à-dire, f ′ ne s’annule pas sur I.
Exemples. • La fonction exp est un C1-difféomorphisme de R sur ]0; +∞[, d’inverse la fonction logarithme ln.•
312

TSI 1 Lycée Heinrich-Nessel 2016/2017
La fonction cube f : x 7→ x3 est un C1-difféomorphisme de ]0; +∞[ sur ]0; +∞[ mais n’enn’est par un de R sur R. En effet, f ′(0) = 3×02 = 0et donc f ne vérifie pas la condition nécessaire etsuffisante de la proposition précédente sur R.
O
D’autre part, on peut remarquer que la fonction (réciproque de f) racine cubique f−1 : x → x−1/3 n’estpas dérivable en 0, car :
limx→0+
f−1(x)− f−1(0)x− 0 = lim
x→0+
x1/3
x
= limx→0+
x−2/3 = +∞
Définition 16.23. Soit f : I → R une fonction. Soit n ∈ N∗.• On dit que f est n fois dérivable sur I si f ′ est n− 1 fois dérivable sur I.• Si f est n fois dérivable sur I, on pose par récurrence :
f (0) = f
f (k) = (f (k−1))′ pour tout 1 ≤ k ≤ n
et la dérivée f (k) est appelée la dérivée k-ème de f .
Remarque. Une fonction f est n fois dérivable si et seulement si elle est n−1 fois dérivable et f (n−1) est dérivable.
Définition 16.24. Soit I un intervalle et k ∈ N.• On dit qu’une fonction f : I → R est de classe Ck si f est k fois dérivable sur I et f (k) est continue surI.
• On dit que f est de classe C∞ si elle est de classe Ck pour tout k ∈ N.
Notation. Pour tout k ∈ N ∪ ∞ et tout intervalle I, on note Ck(I,R) l’ensemble des fonctions f : I → R declasse Ck sur I.
Remarque. L’ensemble C0(I; R) est l’ensemble des fonctions réelles continues sur I.
Digression. Soit I un intervalle, on peut aussi définir l’ensemble des fonctions de classe Ck par récurrence :C1(I) = f : I → R| f dérivable sur I et f ′ continue sur ICk(I) = f : I → R| f ∈ C1 et f ′ ∈ Ck−1 pour tout k ≥ 1
Proposition 16.25. Soit k ∈ N ∪ ∞. Toute combinaison linéaire, tout produit, tout quotient (si possible)et toute composition (si possible) de fonctions de classe Ck est encore de classe Ck.
Exemple. Toute fonction polynomiale et tout quotient de fonctions polynomiales est de classe C∞ sur son domainede définition. Les fonctions exp et ln aussi, tout comme les fonctions trigonométriques.
Proposition 16.26 (Leibniz). Soient f et g deux fonctions définies sur I de classe Cn. Alors la fonctionproduit fg est de classe Cn et
(fg)(n) =n∑k=0
(n
k
)f (k)g(n−k)
313

TSI 1 Lycée Heinrich-Nessel 2016/2017
16.5 Applications
16.5.1 Suite réelle définie par récurrence
Proposition 16.27. Soit f ∈ C(I; I). On suppose que f est dérivable et que |f ′| est majorée par M ∈ [0; 1[.Toute suite définie par récurrence par
u0 ∈ Iun+1 = f(un) pour tout n ∈ N
tend vers un réel ` dans I lorsque n tend vers en +∞. De plus f(`) = `.
Remarque. L’hypothèse f ∈ C(I, I), donc f(I) ⊂ I garantie que la suite (un) est bien définie : Quelque soit lavaleur de u0 dans I, on peut calculer u1 = f(u0) ∈ I et réitérer u2 = f(u1) ∈ I ainsi de suite.
16.5.2 Développement limité d’ordre 2
Théorème 16.28 (développement limité d’ordre 2). Soit I un intervalle ouvert et f : I → R une fonction declasse C2. Soit a ∈ I, alors au voisinage de a, on a
f(x) = f(a) + f ′(a)(x− a) + f ′′(a)2 (x− a)2 + o
((x− a)2
)
Démonstration. Comme f ′ est dérivable en a, on a d’après la proposition 16.5,
f ′(x) = f ′(a) + f ′′(a)(x− a) + o(x− a)
Posons R : I → R définie par
R(x) = f(x)− f(a)− f ′(a)(x− a)− f ′′(a)2 (x− a)2
le reste dans le développement limité de la proposition. La fonction R est dérivable sur I et pour tout x ∈ I, on a
R′(x) = f ′(x)− f ′(a)− f ′′(a)(x− a) = o(x− a)
Soit ε > 0, par définition de la notation de Landau, il existe δ > 0 tel que
∀x ∈ I : |x− a| ≤ δ ⇒ |R′(x)| ≤ ε(x− a)
Ainsi, d’après l’inégalité des accroissements finis,
∀x ∈ I : |x− a| ≤ δ ⇒ |R(x)| ≤ ε(x− a)2 (?)
Donc pour tout ε > 0, il existe δ > 0, telle qu’on ait la propriété (?). C’est-à-dire, le reste R(x) = o(x− a)2 (estun petit « o » de (x− a)2) et on a la relation annoncée dans la proposition.
Exercice 16.7. Soit α ∈ R. Compléter les développements limités à l’ordre 2 en 0 des fonctions de référence :
1) ex = 1 + x+ x2
2 + o(x2)
2) ln(1− x) = −x− x2
2 + o(x2)
3) 11−x = 1 + x+ x2 + o(x2)
4) cos(x) = 1− x2
2 + o(x2)
5) sin(x) = x+ o(x2)
6) tan(x) = x+ o(x2)
7) (1 + x)α = 1 + αx+ α(α−1)2 x2 + o(x2)
8) arccos(x) = π2 − x+ o(x2)
9) arcsin(x) = x+ o(x2)
10) arctan(x) = x+ o(x2)
Exercice 16.8. Supposons qu’au voisinage de 0, on ait f(x) =0o(x2), déterminer la limite
limx→0
f(x)x2
En déduire les relationso(x2) =
0x o(x) et o(x2) =
0x2 o(1)
Exercice 16.9. Calculer les limites314

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) limx→0
sin(x)− ln(1 + x)x2 ; 2) lim
x→0
tan(x)− ex + 1√1 + x2 − 1
.
16.5.3 Résolution d’équation : Méthode de NewtonSoit f : [a; b] → R une fonction de classe C2, strictement croissante. On suppose que f(a) < 0 < f(b) et f ′ nes’annule pas sur [a; b]. D’après le théorème des valeurs intermédiaires, il existe un unique réel c ∈]a; b[ tel quef(c) = 0.On pose x0 = b, puis x1 l’abscisse du point M l’intersection de la tangente à la courbe Cf au point d’abscisse x0et l’axe des abscisses (voir l’illustration ci-dessous). Comme M est d’ordonnée nul, on déduit que
0 = f ′(x0)(x1 − x0) + f(x0)
x1 − x0 = − f(x0)f ′(x0) car, par hypothèse, f ′ ne s’annule pas
x1 = x0 −f(x0)f ′(x0)
Maintenant, si x1 ∈ [a, b], on peut recommencer x2 = x1 − f(x1)f ′(x1) . On souhaiterait poursuivre :
x0 = b
xn+1 = xn − f(xn)f ′(xn) pour tout n ∈ N
afin d’obtenir une suite (un)n∈N. Donnons une condition suffisante pour que la suite (un)n∈N soit définie.
x
y
x0x1
Cf
x2
c
Proposition 16.29. Soit f : [a; b]→ R une fonction de classe C2 telle que f ′ et f ′′ sont strictement positivessur [a; b] et f(a) < 0 < f(b). Alors, la suite (un)n∈N :
x0 = b
xn+1 = xn − f(xn)f ′(xn) pour tout n ∈ N
est :1) bien définie ;2) décroissante ;3) converge vers l’unique solution c ∈ [a; b] de l’équation f(x) = 0.
De plus, il existe M ∈ R+ tel que pour tout entier n ∈ N :
|un+1 − c| ≤M |un − c|2
Remarque. Le dernier point, nous indique que la convergence de la suite est quadratique. Lorsque n est tel que|un − c| < 1, à chaque étape supplémentaire, on réduit, à une constante près, la distance du terme un+1 avec lalimite c du carré de la distance de un avec c.
315

TSI 1 Lycée Heinrich-Nessel 2016/2017
Démonstration. Des hypothèses, on déduit que f est strictement croissante, continue sur [a; b] et f(a) < 0 < f(b).Ainsi, d’après le corollaire du théorème des valeurs intermédiaires, il existe un unique réel c ∈ [a; b] tel quef(c) = 0.Posons F : x 7→ x− f(x)
f ′(x) définie sur [a; b] car f ′ > 0. Soit x ∈ [a; b], alors
F (x) = x− f(x)f ′(x)︸ ︷︷ ︸≥0
≤ x ≤ b
D’après la formule de Taylor-Lagrange 1, il existe θ ∈ [c; b] tel que
f(c) = f(x) + (c− x)f ′(x) + f ′′(θ)2 (x− c)2
0 = f(x)f ′(x) + c− x+ f ′′(θ)
2f ′(x) (x− c)2
x− f(x)f ′(x) − c = f ′′(θ)
2f ′(x) (x− c)2
F (x)− c = f ′′(θ)2f ′(x) (x− c)2 (?)
F (x)− c ≥ 0 car f ′ > 0 et f ′′ > 0F (x) ≥ c
Donc,∀x ∈ [c; b] : c ≤ F (x) ≤ x (??)
Rappelons que u0 = b ∈ [c; b]. Soit n ∈ N quelconque, supposons que un ∈ [c; b]. D’après (??) on déduit quec ≤ un+1 = F (un) ≤ un ≤ b. Ainsi, par récurrence, on déduit que
∀n ∈ N : c ≤ un+1 ≤ un ≤ b
C’est-à-dire, la suite (un) est bien définie, décroissante et minorée par c. Donc, d’après le théorème de la limitemonotone, (un) converge vers une limite `. En passant à la limite sur la relation de récurrence définissant (un) etcomme f et f ′ sont continues, on a que ` vérifie :
` = `− f(`)f ′(`) ⇐⇒ f(`)
f ′(`) = 0 ⇐⇒ f(`) = 0
car f ′ > 0. D’où, par unicité de la solution à f(x) = 0, on a que ` = c.Il nous reste à prouver le dernier point. Soit n ∈ N, d’après (?), il existe θ ∈ [a; b] tel que
un+1 − c = f ′′(θ)2f ′(un) (un − c)2
Comme f ′ est continue sur l’intervalle [a; b], fermé borné, d’après le théorème des bornes atteintes, f ′ atteint sonminimum et comme f ′ > 0, on déduit que inf(f ′) > 0. Posons M = sup(f ′′)
2 inf(f ′) . Alors d’après l’identité précédente,on a
|un+1 − c| ≤M |un − c|2
1. Admis pour le moment. On verra ce résultat dans la chapitre 19 sur les développements limités.
316

Chapitre 17
Espaces vectoriels
Programme• Espaces vectoriels : Définition d’un K-espace vectoriel où K = R ou C.• Espaces vectoriels de référence : Kn, K[X], KΩ etMn,p(K), où n, p ∈ N∗ et Ω est un ensemble non vide. Cas
particulier KN, les suites.• Produit d’une famille de K-espaces vectoriels.• Sous-espace d’un K-espace vectoriel : définition et caractérisation. Droites et plans vectoriels. Identifier un
ensemble comme un sous-espace vectoriel d’un espace vectoriel connu.• L’ensemble des solutions d’un système linéaire homogène est un sous-espace vectoriel.• L’ensemble des solutions sur un intervalle I d’une équation différentielle linéaire homogène est un sous-
espace vectorielde KI .• Combinaisons linéaires d’un nombre fini de vecteurs.• Sous-espace engendré par une famille finie de vecteurs : Notation Vect(u1, . . . , up).• Intersection de sous-espaces vectoriels, somme de deux sous-espaces vectoriels : notation F + G. Somme
direct F ⊕G.• Sous-esapces supplémentaires : E = F ⊕ G. Déterminer l’unique décomposition d’un vecteur donné dans
une somme directe.• Familles finies de vecteurs :• Vecteurs colinéaires. Famille libre, famille liée. Déterminer si une famille donnée est libre ou liée.• Famille génératrice d’un sous-espace vectoriel. Déterminer si une famille est génératrice.• Toute famille de polynômes non nuls à coefficients dans K et de degrés échelonnées est libre.• Bases. Exemples usuels : bases canoniques des espaces vectoriels Kn, Kn[X],Mn,p(K).• Coordonnées dans une base.• Base adaptée à une somme directe : Si (e1, . . . , ek, ek+1, . . . , en) est une famille libre d’un K-espace vectorielE alors Vect(e1, . . . , ek) et Vect(ek+1, . . . , en) sont en somme directe. Proposition 17.43.
• Espaces vectoriels de dimension finie : Un espace vectoriel est dit de dimension finie s’il admet une famillegénératrice finie.
• Théorèmes de la base extraite et de la base incomplète.• Dans un espace engendré par n vecteurs, toute famille de n+ 1 vecteurs est liée.• Dimension : Dimensions de Kn, Kn[X],Mn,p(K).• Si E est de dimension n et F est une famille de n vecteurs de E, alors les conditions suivantes sont
équivalentes :— F est une base de E.— F est libre.— F est une famille génératrice de E.— La matrice carrée A de taille n associée à F est de rang n.— La matrice carrée A de taille n associée à F est inversible.
• Si F est un sous-espace vectoriel de E, alors : E = F ⇐⇒ dim(F ) = dim(E).• Supplémentaire d’un sous-espace vectoriel. Existence. Dimension du supplémentaire.• Formule de Grassmann.
317

TSI 1 Lycée Heinrich-Nessel 2016/2017
17.1 Corps (annexe)Dans les chapitres précédents, nous avons déjà vu différentes « opérations » sur des ensembles. Par exemple,l’addition (la multiplication) de nombres, polynômes, matrices. Dans cette section, nous allons mettre en avantcertaines propriétés fondamentales partagées par ses « opérations » (lois internes).
Définition 17.1. Soit G un ensemble muni d’une loi interne
∗ : G×G // G
(x, y) // x ∗ y
On dit que (G, ∗) est un groupe si1) La loi * est associative : ∀x, y, z ∈ G : x ∗ (y ∗ z) = (x ∗ y) ∗ z,2) La loi * admet un élément neutre : ∃e ∈ G ∀x ∈ G : x ∗ e = e ∗ x = x,3) Tout élément admet un inverse : ∀x ∈ G ∃y ∈ G : x ∗ y = y ∗ x = e.
La première propriété nous dit que l’ordre dans lequel on calcul un produit de trois éléments ne compte pas, d’oùla notation :
x ∗ y ∗ z := x ∗ (y ∗ z) = (x ∗ y) ∗ z
Exemples.1) (Z,+), (Q,+), (R[X],+),Mn(R),+).2) (R∗,×)3) (GL2(R),×)
Proposition 17.2. Soit (G, ∗) un groupe, alors1) L’élément neutre e est unique.2) Soit x ∈ G, son inverse est unique et on la note x−1.
Définition 17.3. Soit (G, ∗) un groupe. On dit que G est commutatif (ou abélien 1) s’il vérifie en plus lapropriété suivante :
∀ (x, y) ∈ G2 : x ∗ y = y ∗ x
1. Niels Henrik Abel (1802 - 1829)
Remarque. Une convention :• (G, ∗) groupe quelconque, élément neutre noté e ou 1, inverse noté x−1.• (G,+) groupe commutatif, élément neutre noté 0, symétrique noté −x.
Définition 17.4. Soit A un ensemble muni de deux lois internes
A×A // A A×A // A
(x, y) // x+ y (x, y) // x× y = xy
On dit que (A,+,×) est un anneau si1) (A,+) est un groupe commutatif.2) La loi de composition × de A est associative, commutative et admet un élément neutre 1.3) Les deux lois somme + et produit × sont compatibles :∀(x, y, z) ∈ A3 : x(y + z) = xy + xz et (x+ y)z = xz + yz (distributivité)
Remarque. L’axiome de commutativité de l’addition peut être déduit des autres. En effet, soit (x, y) ∈ A2, alors
(1 + x)(1 + y) = (1 + x) + (1 + x)y = 1 + x+ y + xy
= (1 + y) + x(1 + y) = 1 + y + x+ xy
D’où x+ y = y + x.
Exemples.
318

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) (Z,+,×), (Q,+,×) ; 2) (Mn(R),+,×) ; 3) (R[X],+,×).
Exercice 17.1. Soit n un nombre. on note Z/nZ l’ensemble 0, 1, . . . , n− 1 des entiers compris entre 0 et n− 1muni de l’addition et de la multiplication suivantes : Pour tout a, b ∈ Z/nZ,• a+ b est le reste de la division Euclidienne du nombre a+ b par n.• a× b est le reste de la division Euclidienne du nombre a× b par n.
1) On suppose que n = 3. Compléter les tables des deux lois internes de Z/3Z :+ 0 1 20 012 1
× 0 1 2012
2) De même, pour n = 4, dresser les tables des deux lois internes de Z/4Z.3) Démontrer que (Z/nZ,+,×) est un anneau.
Définition 17.5. Soit K un anneau. On dit que K est un corps si de plus1) ∀x ∈ K \ 0 ∃x−1 ∈ K : xx−1 = x−1x = 1 (existence d’un inverse)2) 1 6= 0.
Exemples.• (Q,+,×), (R,+,×), (C,+,×) sont des corps.• L’ensemble Z/2Z des entiers modulo 2 avec l’addition et la multiplication induites est un corps.• Par contre, Z n’est pas un corps, car par exemple 2 n’admet pas d’inverse pour la multiplication.
Exercice 17.2. Posons K = Q + Qi ⊂ C l’ensemble des nombres complexes de la forme a + bi, où a, b sontrationnelles, muni de l’addition et de la multiplication induite par celle des nombres complexes. Montrer que Kest un corps.D’ailleurs, on peut faire la même construction avec
√2 au lieu de i et vérifier qu’on obtient encore un corps.
Proposition 17.6. Soit p un nombre premier, alors Z/pZ est un corps.
Exercice 17.3. Démontrer que la réciproque est vraie.
Proposition 17.7. Soit K un corps, alors, on a les propriétés suivantes :1) ∀x ∈ K : 0x = x0 = 0.2) ∀x ∈ K : (−1)x = −x.3) ∀x, y ∈ K : x(−y) = −xy.4) ∀x, y, z ∈ K : (x− y)z = xz − yz et x(y − z) = xy − xz.5) ∀n ∈ N∗ ∀ (x1, . . . , xn) ∈ Kn : x(x1 + . . .+ xn) = xx1 + . . .+ xxn
6) ∀n ∈ N ∀x ∈ K : nx = x+ . . .+ x
7) (formule du binôme de Newton) ∀x, y ∈ K ∀n ∈ N : (x+ y)n =∑n
k=0
(nk
)xkyn−k.
17.2 Espace et sous-espace vectorielOn rappelle que K désigne R ou C.
Définition 17.8. Soit E un ensemble muni d’une loi de composition interne, l’addition (noté +) et d’une loide composition externe, la multiplication par un scalaire (noté .), c’est-à-dire deux applications :
E × E // E K× E // E
(u, v) // u+ v (λ, v) // λ.v
On dit que E = (E,+, .) est un K-espace vectoriel si,1) a) ∃OE ∈ E ∀v ∈ E : v +OE = OE + v = v. (vecteur nul)
319

TSI 1 Lycée Heinrich-Nessel 2016/2017
b) ∀u, v, w ∈ E : u+ (v + w) = (u+ v) + w (associativité)c) ∀ v ∈ E ∃ − v ∈ E : v − v = (−v) + v = OE (existence d’un opposé)d) ∀u, v ∈ E : u+ v = v + u (commutativité)
2) a) ∀λ, µ ∈ K, ∀ v ∈ E : λ.(µ.v) = (λµ).v (associativité)b) ∀ v ∈ E : 1.v = v où 1 est l’élément neutre de K.
3) a) ∀λ, µ ∈ K, ∀ v ∈ E : (λ+ µ).v = λ.v + µ.v
b) ∀λ ∈ K, ∀u, v ∈ E : λ.(u+ v) = λ.u+ λ.v (distributivité)
Exercice. ? Dans un espace vectoriel E, montrer que pour tout vecteur v, l’opposé −v est unique. Montrer quele vecteur nul OE est unique.
Propriétés 17.9. Pour tous λ, µ ∈ K et tous u, v, w ∈ E un K-espace vectoriel :1) u+ w = v + w ⇒ u = v (lemme de simplification)2) 0.u = OE et λ.OE = OE
3) (λ− µ).u = λ.u− µ.u4) λ.(u− v) = λ.u− λ.v5) λ.v = OE ⇒ λ = 0 ou v = OE
Démonstration.1) u+ w = v + w ⇒ u+ w − w = v + w − w ⇒ u = v ;2) 0.u = (0.u+ 0.u) = 0.u+ 0.u ⇒ OE = 0.u− 0.u = 0.u ;3) Au préalable, OE = 0.u = (1 − 1).u = u + (−1).u, d’où (−1).u = −u. D’où (λ − µ).u = (λ + (−µ)).u =
λ.u+ (−µ).u = λ.u− µ.u ;4) Idem ;5) Si λ.v = OE , supposons que λ 6= 0, alors OE = 1
λ.(λ.v) = ( 1
λλ).v = 1.v = v.
Exemples.1) (Kn,+, .) est un K-espace vectoriel.2) (Mn,p(K),+, .) est un K-espace vectoriel.3) Soit Ω un ensemble. On pose KΩ = f : Ω→ K l’ensemble des applications de Ω dans K muni de l’addition
des applications et du produit par un scalaire :• ∀ f ∈ KΩ ∀ g ∈ KΩ : f + g : Ω→ K définie par (f + g)(x) = f(x) + g(x) pour tout x ∈ Ω.• ∀ f ∈ KΩ ∀ λ ∈ K : λ.f : Ω→ K définie par (λf)(x) = λf(x) pour tout x ∈ Ω.
Alors KΩ est K-espaces vectoriels.4) En particulier KN l’ensemble des suites à valeurs dans K est un K-espace vectoriel.5) K[X] (resp. Kn[X]) l’anneau des polynômes à coefficients dans K (resp. les polynômes de degré inférieur ou
égal à n) est un K-espace vectoriel.6) Soit k ∈ N ∪ ∞ et I un intervalle ouvert. L’espace des fonctions f : I → K de classe Ck est un K-espace
vectoriel.7) R = R1 est un R-espace vectoriel.8) C est un R-espace vectoriel.
À partir de maintenant, on se donne E un K-espace vectoriel.
Définition 17.10. Soitm un entier naturel, soit v1, . . . , vn des vecteurs de E un K-espace vectoriel. On appellecombinaison linéaire de la famille (vk)1≤k≤n toute somme de la forme
v =n∑k=1
λkvk
où les λk ∈ K sont des scalaires.
320

TSI 1 Lycée Heinrich-Nessel 2016/2017
Vocabulaire. Soitn∑k=1
λkvk une combinaison linéaire de la famille (vk). On dit que
• la combinaison linéaire est triviale si tous les scalaires λk sont nuls ;• la combinaison linéaire est nulle si la somme est égale au vecteur nul.
Définition 17.11. Soit F une partie de E un K-espace vectoriel. On dit que F est un sous-espace vectorielde E si• le vecteur nul de E appartient à F ;• ∀ (u, v) ∈ F ∀ λ ∈ K : λ.u+ v ∈ F . (stabilité)
Exemples.1) Soit I un intervalle de R alors l’espace des fonctions continues (ou dérivables) de I dans R est un sous-espace
vectoriel de RI .2) Soit Ω un ensemble alors K(Ω) le sous-ensemble des applications de Ω dans K non nulles uniquement pour
un nombre fini d’éléments de Ω est un sous-espace vectoriel de KΩ.3) L’ensemble des solutions d’une équation différentielle linéaire homogène d’ordre 2 à coefficients réels constants
est un sous-espace vectoriel de RR.
Exercice 17.4. Dites si les ensembles E suivants sont des sous-espaces vectoriels.1) K = R, E = (x, y) ∈ R2, x2 ≥ 0.2) K = R, E = (x, y) ∈ R2, x2 > 0.3) K = R et E est l’ensemble des fonctions de [0; 1] dans R continues bornées.4) E = GLn(K), l’ensemble des matrices inversibles de taille n× n.5) E = Sn(R) = M ∈Mn(R), tM = M l’ensemble des matrices symétriques de tailles n× n.6) K = R et E est l’ensemble des suites arithmétiques réelles.7) K = R et E est l’ensemble des fonctions périodiques de R dans R de période T fixé.8) E = Kn[X] l’ensemble des polynômes sur K de degré inférieur ou égal à n, où n est un entier naturel fixé.
Lemme 17.12. Soit E un K-espace vectoriel.1) Le sous-ensemble OE est un sous-espace vectoriel de E.2) Tout sous-espace vectoriel de E est en particulier un K-espace vectoriel.
Exercice 17.5.1) Montrer que F = (x, y, z) ∈ R3 : x− 3y + 5z = 0 est un sous-espace vectoriel de R3.2) Montrer que f ∈ C(R,R); f(π) = 0 est un R-espace vectoriel.
Méthode. Pour montrer qu’un ensemble E est un K-espace vectoriel, on peut montrer que E est un sous-espace vectoriel d’un espace vectoriel connu. Il suffit alors de montrer que E est non vide (ou contient OE) etest stable par combinaisons linéaires.
Proposition 17.13.1) Pour tout A ∈Mn,p(K) le sous-ensemble
K = v ∈ Kp; Av = 0
est un sous-espace vectoriel de Kp.2) Pour tous n > 2 et a1, . . . , an ∈ K, le sous-ensemble
F = (x1, . . . , xn) ∈ Kn : a1x1 + . . .+ anxn = 0
est un sous-espace vectoriel de Kn.
Démonstration. 1) Comme A0 = 0, le vecteur nul 0 appartient à K. Soit λ ∈ K, u, v dans K, alors
A(λu+ v) = λAu+Av = 0 ⇒ λu+ v ∈ K
D’où, K contient le vecteur nul et est stable par combinaisons linéaires.
321

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) Posons A = (a1 a2 . . . an) ∈M1,n(K), alors
F = X ∈ Kn : AX = 0
Ainsi, d’après le point précédent, F est un sous-espace vectoriel.
Proposition 17.14 (Stabilité par combinaisons linéaires). Si F est sous-espace vectoriel de E alors
∀n ∈ N ∀ (λ1, . . . , λn) ∈ Kn ∀ (v1, . . . , vn) ∈ Fn : λ1.v1 + . . . λn.vn ∈ F
Démonstration. Pour n = 1, par définition, pour tout v1 ∈ F et tout λ1 ∈ F , on a λ1v1 = λ1v1 + OE ∈ F (parstabilité). Montrons la stabilité pour n = 2 : Soit λ1, λ2 ∈ K et v1, v2 deux vecteurs de F , alors, en appliquanttrois fois la propriété de stabilité donnée dans la définition d’un sous-espace vectoriel, on déduit que
(λ1 − 1)v1 + v2 ∈ F(λ2 − 1)v2 + v1 ∈ F
⇒ 1
((λ1 − 1)v1 + v2
)+(v1 + (λ2 − 1)v2
)= λ1v1 + λ2v2 ∈ F
D’où, le cas n = 2. On termine la démonstration par récurrence à l’aide du cas n = 2 (exercice).
Proposition-Définition 17.15 (Produit cartésien). Soit E1 et E2 deux K-espaces vectoriels, alors l’ensembleE1 × E2 muni de l’addition et de la multiplication par un scalaire :
(E1 × E2)× (E1 × E2) // E1 × E2 K× (E1 × E2) // E1 × E2
((u1, v1), (u2, v2) // (u1 + u2, v1 + v2) (λ, (v1, v2)) // (λ.v1, λ.v2)
est un espace vectoriel sur K et il est appelé espace vectoriel produit de E1 et E2.
Remarque.• Le vecteur nul de E1 × E2 est (OE1 , OE2).• Dans un espace vectoriel produit les opérations se font coordonnée par coordonnée.• Généralisation : On définit par analogie le produit d’un nombre fini d’espaces vectoriels : E1 × . . .× En.• Conséquence : On retrouve que Rn, Cn ou En = E × . . .× E sont des espaces vectoriels.
Proposition 17.16 (Intersection). Soit F et G deux sous-espaces vectoriels de E, alors l’intersection F ∩Gest encore un sous-espace vectoriel.
Remarque. L’intersection de deux sous-espaces vectoriels n’est jamais vide ! Etant donnée qu’un sous-espace vec-toriel contient toujours le vecteur nul !
( ! Démonstration au programme)
Démonstration. Le vecteur nul OE appartient à F et G car ce sont des sous-espaces vectoriels, donc OE appartientà F ∩G.Soit λ ∈ K, u et v deux vecteurs de F ∩G, comme :• F est un sous-espace vectoriel, λu+ v ∈ F• G est un sous-espace vectoriel, λu+ v ∈ G
D’où λu + v ∈ F ∩ G. Ainsi, le sous-ensemble F ∩ G contient le vecteur nul et il est stable par combinaisonslinéaires, d’où F ∩G est un sous-espace vectoriel.
Exercice 17.6.1) Montrer que le sous-ensemble (x, y) ∈ R2; xy = 0 du plan R2 est l’union de deux sous-espaces vectoriels
mais qu’il n’est pas un sous-espace vectoriel.2) Soit F et G deux sous-espaces vectoriels de E. Montrer que F ∪ G est un sous-espace vectoriel de E si et
seulement si F ⊂ G ou G ⊂ F .
La proposition suivante caractérise le plus petit sous-espace vectoriel contenant l’union.
322

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition-Définition 17.17 (Somme). Soit F, G deux sous-espaces vectoriels de E, on pose
F +G := u+ v | u ∈ F et v ∈ G
l’ensemble des sommes des éléments de F et de G. Alors F +G est un sous-espace vectoriel de E. On l’appellela somme de F et G.
Démonstration. Notons que OE = f + g avec f = OE ∈ F et g = OE ∈ G, d’où OE ∈ F + G. Soit λ ∈ K etui = fi + gi ∈ F +G avec (fi, gi) ∈ F ×G pour i = 1, 2, alors
λu1 + u2 = λf1 + λg1 + f2 + g2 = λf1 + f2︸ ︷︷ ︸∈F
+λg1 + g2︸ ︷︷ ︸∈G
∈ F +G
car F et G sont des sous-espaces vectoriels. Ainsi, F + G contient le vecteur nul et est stable par combinaisonslinéaires, c’est-à-dire un sous-espace vectoriel de E.
Proposition 17.18. Soit F,G deux sous-espaces vectoriels de E, alors1) F +G est, pour l’inclusion, le plus petit sous-espace vectoriel contenant F et G :
F +G =⋂
H sev: F⊆H et G⊆H
H
2) E = F +G si et seulement si pour tout w ∈ E il existe u ∈ F et v ∈ G tels que w = u+ v.
Exercice 17.7. Soit F , G deux sous-espaces vectoriels de E. Montrer que F+G = G+F , F+F = F , F+0 = Fet F + E = E.
Exercice 17.8. Décrire F +G lorsque :1) F = (x, y) ∈ R2; y = 0 et G = (0, y); y ∈ R dans R2.2) F = f : [0; 1]→ R; f(0) = f(1) et G = f : [0; 1]→ R; f(0) = 0 dans R[0;1].
Définition 17.19. Soit F et G deux sous-espaces vectoriels de E. On dit que F et G sont supplémentaires,ou que G est un supplémentaire de F , ou que E est la somme directe de F et G, si tout vecteur de E s’écritde manière unique comme somme d’un vecteur de F et d’un vecteur de G :
∀ w ∈ E ∃! u ∈ F ∃! v ∈ G : w = u+ v.
Dans ce cas, on note :E = F ⊕G
Proposition 17.20. Soit F, G deux sous-espaces vectoriels de E, les deux propriétés suivantes sont équiva-lentes :
1) E = F ⊕G ;2) E = F +G et F ∩G = 0.
Démonstration. 1)⇒ 2) : Supposons que E = F ⊕G, alors de l’existence dans la proposition
∀ w ∈ E ∃! u ∈ F ∃! v ∈ G : w = u+ v. (?)
on déduit que E = F +G. Soit u ∈ F ∩G, alors
u = u︸︷︷︸∈F
+ 0︸︷︷︸∈G
= 0︸︷︷︸∈F
+ u︸︷︷︸∈G
De l’unicité dans (?), on déduit que u = 0 nécessairement. Donc F ∩G = 0.2)⇒ 1) : Comme E = F +G, on a bien l’existence dans (?), il nous reste à montrer l’unicité de la décompositionen somme. Soit u = fi + gi ∈ E avec (fi, gi) ∈ F ×G pour i = 1, 2, alors
u = f1 + g1 = f2 + g2 ⇒ f1 − f2︸ ︷︷ ︸∈F
= g2 − g1︸ ︷︷ ︸∈G
∈ F ∩G
323

TSI 1 Lycée Heinrich-Nessel 2016/2017
Or, par hypothèse, F ∩G = 0, donc
f1 − f2 = g2 − g1 = 0 ⇒f1 = f2
g1 = g2
C’est-à-dire, la décomposition de u en somme de deux éléments de F et G est unique. On en déduit que E =F ⊕G.
Enfin, par récurrence, on définit la somme de n sous-espaces vectoriels F1,. . . ,Fn de E :
F1 + . . .+ Fn = (F1 + . . .+ Fn−1) + Fn
17.3 Familles de vecteurs
17.3.1 Famille génératrice
Définition 17.21. Soit (v1, . . . , vn) une famille de vecteurs de E. On dit qu’un vecteur u de E est combinaisonlinéaire des v1, . . . , vn s’il existe (λ1, . . . , λn) ∈ Kn tels que u = λ1.v1 + . . .+ λn.vn.
Proposition-Définition 17.22. Soit v1, . . . , vn ∈ E des vecteurs fixés. L’ensemble des combinaisons linéairesdes v1, . . . , vn :
Vect(v1, . . . , vn) := λ1v1 + . . .+ λnvn| λ1, . . . , λn ∈ K est un sous-espace vectoriel. On l’appelle le sous-espace vectoriel engendré par les vecteurs v1, . . . , vn.
Remarque. On peut étendre la définition précédente à une famille quelconque de vecteurs : Soit F un sous-ensemble de E. L’espace vectoriel engendré par F est le plus petit sous-espace vectoriel de E pour l’inclusion, quicontient F et on le note Vect(F). Par convention, Vect(∅) = 0.
Vocabulaire. Soit E un K-espace vectoriel, F un sous-espace vectoriel de E et (v1, . . . , vn) une famille de vecteursde E. On dit que F est engendré par la famille (v1, . . . , vn) si F = Vect(v1, . . . , vn).
Proposition 17.23. Soit F, G deux sous-espaces vectoriels de E. Si F est engendré par v1, . . . , vn et G estengendré par u1, . . . , um alors F +G est engendré par v1, . . . , vn, u1, . . . , um. En d’autres termes :
Vect(v1, . . . , vn) + Vect(u1, . . . , um) = Vect(v1, . . . , vn, u1, . . . , um)
Définition 17.24. On dit qu’une famille F = (v1, . . . , vn) de E est génératrice de E si Vect(F) = E, c’est-à-dire si
∀u ∈ E ∃ (λ1, . . . , λn) ∈ Kn : u = λ1v1 + . . .+ λnvn
Remarque. Une famille (v1, . . . , vn) est génératrice si et seulement si tout vecteur peut s’écrire comme combinaisonlinéaire des vecteurs v1, . . . , vn.
Exemples.
1) La famille de vecteurs (
(10−1
),
(011
),
(001
)) est une famille génératrice de R3.
2) La famille (1, X, . . . ,Xn) est une famille génératrice de Kn[X].
Exercice 17.9. ? Soit n ∈ N. Montrer que la famille de vecteurs ((X − 1)k)0≤k≤n est une famille génératrice deRn[X].
17.3.2 Indépendance linéaire
Définition 17.25. Soit n un entier naturel non nul et v1, . . . , vn des vecteurs de E. Les vecteurs v1, . . . , vnsont dit linéairement indépendants si pour tous λ1, . . . , λn ∈ K, on a l’implication :
λ1v1 + . . .+ λnvn = OE ⇒ λ1 = . . . = λn = 0
Dans ce cas, on dit aussi que la famille de vecteurs (v1, . . . , vn) est libre.
324

TSI 1 Lycée Heinrich-Nessel 2016/2017
Si une famille de vecteurs n’est pas libre, on dit qu’elle est liée.
Remarques.• « La famille de vecteurs (v1, . . . , vn) est libre si et seulement si la seule combinaison linéaire nulle est la
combinaison linéaire triviale. »• La famille réduit à un vecteur (v) est libre si et seulement si v est non nul.• La famille vide (ne comportant aucun vecteur) est libre.
Exemples. Les vecteurs (1, 0, 1) et (0, 1, 0) de R3 sont linéairement indépendants. Par contre (1, 1, 1), (1, 0, 1) et(0, 1, 0) ne le sont pas.
Méthode.• Pour montrer qu’une famille (v1, . . . , vn) de vecteurs de E est libre, on commence par se donner des
scalaires λ1, . . . , λn dans K tels que λ1v1 + . . .+ λnvn = OE . Puis on résout l’équation (le plus souventle système) en les inconnues λ1, . . . , λn.
• Pour montrer qu’une famille (v1, . . . , vn) de vecteurs de E est liée, il suffit de trouver des scalairesλ1, . . . , λn dans K non tous nuls tels que λ1v1 + . . .+ λnvn = OE .
Proposition 17.26. Soit v1, . . . , vn des vecteurs de E linéairement indépendants et v ∈ E un vecteur tel qu’ilexiste λ1, . . . , λn ∈ K tels que v = λ1v1 + . . . λnvn, alors les λi sont uniquement déterminés.
Démonstration. Soit (λ1, . . . , λn) ∈ Kn et (µ1, . . . , µn) ∈ Kn tels que
v = λ1v1 + . . . λnvn = µ1v1 + . . . µvn
⇒ (λ1 − µ1)v1 + . . .+ (λn − µn)vn = 0
Or les vecteurs v1, . . . , vn sont linéairement indépendants, donc
λ1 − µ1 = . . . = λn − µn = 0 ⇒
λ1 = µ1...λn = µn
C’est-à-dire, les λi sont uniquement déterminés.
Proposition 17.27. Soit (v1, . . . , vn) une famille libre de E.1) Les vecteurs vi sont non nuls.2) Les vecteurs vi sont deux à deux distincts.3) Quel que soit 1 ≤ p ≤ n, les vecteurs v1, . . . , vp sont aussi linéairement indépendants.
Ainsi, une famille contenant le vecteur nul ou bien deux fois le même vecteur est toujours liée.
Démonstration.1) Sans perte de généralité (quitte à réordonner les vecteurs), supposons par l’absurde que v1 = 0, alors
1v1 + 0v2 + . . .+ 0vn est une combinaison linéaire non triviale mais nulle, ce qui est en contradiction avecle fait que (v1, . . . , vn) est libre.
2) Sans perte de généralité, supposons par l’absurde que v1 = v2, alors 1v1 − 1v2 + 0v2 + . . . + 0vn est unecombinaison linéaire non triviale mais nulle, ce qui est en contradiction avec le fait que (v1, . . . , vn) est libre.
3) Supposons par l’absurde que (v1, . . . , vp) est liée, alors il existe λ1, . . . , λp ∈ K non tous nuls tels queλ1v1 + . . .+ λpvp = 0. D’où
λ1v1 + . . .+ λpvp + 0vp+1 + . . .+ 0vn = 0
est une combinaison linéaire non triviale mais nulle, ce qui est en contradiction avec le fait que (v1, . . . , vn)est libre.
325

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 17.28. Soit v1, . . . , vn des vecteurs de E linéairement indépendants et v un vecteur quelconquede E. Alors v est combinaison linéaire de v1, . . . , vn si et seulement si v1, . . . , vn, v ne sont pas linéairementindépendants.Formellement :
v ∈ Vect(v1, . . . , vn) ⇐⇒ (v1, . . . , vn, v) est liée
( ! Démonstration au programme)
Démonstration. Le sens direct : Si v ∈ Vect(v1, . . . , vn), alors il existe λ1, . . . , λn dans K tels que
v = λ1v1 + . . .+ λnvn ⇒ 1︸︷︷︸6=0
×v − λ1v1 − . . .− λnvn = OE
Ainsi, il existe une combinaison linéaire non triviale des vecteurs v, v1, . . . , vn qui est nulle. C’est-à-dire la famille(v, v1, . . . , vn) est liée.Réciproquement : Si la famille (v, v1, . . . , vn) est liée, alors il existe λ0, λ1, . . . , λn dans K non tous nuls tels queλ0v + λ1v1 + . . .+ λnvn = OE . Supposons par l’absurde que λ0 = 0, alors nécessairement les scalaires λ1, . . . , λnsont non tous nuls et
0E = 0v + λ1v1 + . . .+ λnvn = λ1v1 + . . .+ λnvn
D’où, la famille (v1, . . . , vn) est liée. Or, on a supposé que les vecteurs v1,. . . ,vn sont linéairement indépendants,ce qui est contradictoire. Donc λ0 6= 0 et
0E = λ0v + λ1v1 + . . .+ λnvn
−λ0v = λ1v1 + . . .+ λnvn
v = −λ1
λ0v1 + . . .+ −λn
λ0vn
C’est-à-dire v est une combinaison linéaire des vecteurs v1, . . . ,vn et v ∈ Vect(v1, . . . , vn).
Un cas particulier E = K[X]. Rappelons que le polynôme nul est de degré −∞.
Proposition. Soit (P1(X), . . . , Pn(X)) une famille de K[X] telle que
0 ≤ deg(P1) < deg(P2) < . . . < deg(Pn−1) < deg(Pn)
alors la famille (P1(X), . . . , Pn(X)) est libre.
17.4 Espaces vectoriels en dimension finie
17.4.1 Bases et dimensionsDéfinition 17.29. On dit qu’une famille (e1, . . . , en) de vecteurs de E est une base de E si elle est libre etgénératrice de E.
Proposition-Définition 17.30. Une famille (e1, . . . , en) de vecteurs de E est une base si est seulement si
∀ v ∈ E ∃!(x1, . . . , xn) ∈ Kn : v = x1e1 + . . .+ xnen
Dans ce cas, le n-uplet de scalaires (x1, . . . , xn) est appelé coordonnées de v dans la base (e1, . . . , en).
Lemme 17.31 (coordonnées de la somme et du produit par un scalaire). Soit (x1, . . . , xn) ∈ Kn et (y1, . . . , yn) ∈Kn les coordonnées dans la base B = (e1, . . . , en) de v et w respectivement. Alors les coordonnées de v + w sont(x1 + y1, . . . , xn + yn) et les coordonnées de λv sont (λx1, . . . , λxn) dans la base B.
Exemples.
1) ((1
0
),(0
1
)) est une base de R2.
326

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) Soit n ≥ 1, on pose
e1 := (1, 0, 0, . . . , 0)e2 := (0, 1, 0, . . . , 0)e3 := (0, 0, 1, . . . , 0)
...en := (0, . . . , 0, 1)
Alors (e1, . . . , en) est une base de Kn et on l’ap-pelle la base canonique de Kn.
3) (1, X, . . . ,Xn) est la base canonique de Kn[X].4) Pour tout 1 ≤ i ≤ n et tout 0 ≤ j ≤ p, on pose
Ei,j :=
(0 0
10 0
)la matrice élémentaire avec 1 sur la i-ème ligneet la j-ème colonne et des zéros partout ailleurs.La famille des matrices élémentaires (Ei,j) estune base deMn,p(K).
Théorème 17.32 (de la base incomplète). Soit f1, . . . , fp des vecteurs de E linéairement indépendants etg1, . . . , gq des vecteurs qui engendrent E. Alors, il existe un entier n ≥ p et une base (e1, . . . , en) de E telleque :
1) ei = fi pour tout i ≤ p.2) ei est l’un des gj pour tout i > p
Remarque.• En particulier, on notera qu’on a nécessairement p ≤ q et plus précisément, la base (e1, . . . , en) est de la
forme suivante :(f1, f2, . . . , fp, gi1 , . . . , gin−p)
• On peut reformuler ainsi la proposition : Si E est un espace vectoriel engendré par une famille fini devecteurs, alors toutes familles libres de E peut être complété en base de E (par adjonction, si nécessaire,de certains des vecteurs de la famille génératrice).
Démonstration. La preuve est un simple algorithme où l’on utilise la proposition 20.3.
Si l’on ne se donne pas de famille libre (i.e : p = 0) mais uniquement une famille génératrice le raisonnement dela preuve est encore valide, d’où
Corollaire 17.33 (théorème de la base extraite). Tout K-espace vectoriel engendré par un nombre fini devecteurs admet au moins une base.
Digression. Dans le cadre de la théorie des ensembles, on peut ajouter (ou pas) un axiome : l’axiome du choix duà Ernest Zermelo (1871-1953) en 1904. Il dit la chose suivante : « Pour toute collection Ω d’ensembles non vides,il existe une fonction définie sur Ω, appelée fonction de choix, qui à chaque ensemble A appartenant à Ω associeun élément de cet ensemble A ». Il a été montré que (dans le cadre de la théorie des ensembles) cet axiome estéquivalent au lemme de Zorn 1 en 1935 : si une collection non vide d’ensembles A est telle que l’union de toutechaine non vide d’inclusions de A est encore un élément de A alors A possède un élément maximal pour l’inclusion(une sorte de théorème de la borne atteinte pour l’inclusion des ensembles).Donc, si on accepte l’axiome du choix, on peut appliquer le lemme de Zorn à l’ensemble des familles libres d’unespace vectoriel E quelconque. On en déduit ainsi tout espace vectoriel admet au moins une base.Par exemple, R[X] admet comme base la suite des polynômes (1, X,X2, . . .). On déduit aussi que R en tant queQ-espace vectoriel admet une base.
Rappelons un résultat vu au premier semestre :
Lemme 17.34. Soit A ∈Mn,p(K), si n < p alors le système AX = 0 admet au moins une solution non nulle.
À propos de la preuve. Le système admet comme solution évidente X = 0, il n’est donc pas incompatible. Onéchelonne la matrice A. Sur chaque ligne se trouve au plus un pivot, donc le rang de la matrice est inférieurstrictement à p. On en déduit qu’il existe au moins une inconnue secondaire (un paramètre) et donc une infinitéde solution. En particulier, une solution non nulle.
Lemme 17.35. Supposons que E possède une base formée de n vecteurs. Si p est un entier tel que p > nalors p vecteurs de E sont linéairement dépendants.
D’où1. Max Zorn (1906-1993) et Kazimierz Kuratowski (1896-1980)
327

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème-définition 17.36. Si E est engendré par un nombre fini de vecteurs alors toutes les bases de Eont le même nombre de vecteurs. Ce nombre de vecteurs est appelé dimension de E et on le note dimK(E).
Par convention, la dimension de l’espace vectoriel trivial O est 0.
Vocabulaire. Dans la suite, on ne dira plus qu’un espace vectoriel es qu’un espace vectoriel est engendré par unnombre fini de vecteurs mais tout simplement de dimension finie.
Exemples.• Kn est de dimension n.• Mn,p(K) est de dimension np.• Kn[X] est de dimension n+ 1.• dimC(C2) = 2 et dimR(C2) = 4.
Exercice 17.10. Déterminer la dimension des espaces vectoriels suivants :1) Mn(K) ;2) (x, y, z) ∈ R3; x+ y − 4z = 0 ;3) (x, y, z) ∈ R3; x+ y − 4z = 0 et x+ z = 0 ;4) Cn[X] en tant que R-espace vectoriel.
Définition 17.37. Un espace vectoriel de dimension• 1 est appelé droite vectorielle ;• 2 est appelé plan vectoriel.
Proposition 17.38. Si F, G sont des K-espaces vectoriels de dimension finie, alors l’espace vectoriel F ×Gest de dimension finie et
dimK(F ×G) = dimK(F ) + dimK(G)
Donnons la contraposée du lemme 17.35 et des conséquences du théorème de la base incomplète :
Théorème 17.39. Supposons que E est de dimension n.• Si p vecteur de E sont linéairement indépendants alors p ≤ n.• Si n vecteurs de E sont linéairement indépendants alors ils forment une base de E.• Si E est engendré par q vecteurs alors q ≥ n.• Si n vecteurs de E engendrent E alors ils en forment une base.
Corollaire 17.40. Supposons E de dimension n ≥ 1. Soit (e1, . . . , en) une base de E et f1, . . . , fn des vecteursde E. Notons A ∈Mn(K) la matrice dont les coefficients de la j-ème colonne sont les coordonnées du vecteurfj dans la base (e1, . . . , en). Les propositions suivantes sont équivalentes :
1) (f1, . . . , fn) est une base de E ;2) (f1, . . . , fn) est libre dans E ;3) (f1, . . . , fn) est génératrice dans E ;4) la matrice A est de rang n ;5) la matrice A est inversible.
17.4.2 Sous-espaces vectoriels en dimension finie
Théorème 17.41. Supposons que E est de dimension finie. Si F est un sous-espace vectoriel de E alors Fest de dimension finie et sa dimension est inférieure où égale à celle de E.De plus, si dimK(F ) = dimK(E) alors F = E.
328

TSI 1 Lycée Heinrich-Nessel 2016/2017
Méthode. Pour montrer que F un sous-espace vectoriel de E est égal à E, il suffit de montrer que dimK(F ) =dimK(E).
Proposition 17.42. Si E est de dimension finie et si F est un sous-espace vectoriel de E de dimension p ≥ 1,alors il existe une base de E dont les p premiers vecteurs appartiennent à F .
Proposition 17.43. Supposons E de dimension finie. Soit F et G deux sous-espaces vectoriels de E etdifférents de 0. Si (e1, . . . , ep) est une base de F et si (ep+1, . . . , ep+q) est une base de G alors, F et G sontsupplémentaires (i.e : E = F ⊕G) si et seulement si (e1, . . . , ep+q) est une base de E.
Corollaire 17.44. Si E = F ⊕G de dimension finie alors dimE = dimF + dimG.
Encore une application du théorème de la base incomplète :
Corollaire 17.45. Si E est de dimension finie alors tout sous-espace vectoriel de E admet un supplémentaire.
Théorème 17.46 (formule de Grassmann). Soit F, G deux sous-espaces vectoriels d’un espace vectoriel Ede dimension finie. Alors,
dim(F +G) = dimF + dimG− dim(F ∩G)
Démonstration. D’après la proposition précédente, dans l’espace vectoriel G, il existe S un sous-espace vectorieltel que (F ∩G )⊕ S = G. Montrons que F +G = F + S par double inclusion :• Soit v ∈ F + S, alors il existe (f, s) ∈ F × S tel que v = f + s. Or S ⊂ G, d’où
v = f︸︷︷︸∈F
+ s︸︷︷︸∈G
∈ F +G
et donc F + S ⊂ F +G.• Soit v ∈ F + G, alors il existe (f, g) ∈ F × G tel que v = f + g. De plus, il existe un unique couple
(i, s) ∈ (F ∩G)× S tel que g = i+ s. D’où
v = f + (i+ s) = f + i︸︷︷︸∈F
+ s︸︷︷︸∈S
∈ F + S
et donc F +G ⊂ F + S.On a donc F +G = F + S. Soit v ∈ F ∩ S, comme S ⊂ G, on a v ∈ G. D’où v ∈ F ∩G ∩ S, or par constructiondu supplémentaire S, (F ∩ G) ∩ S = OE et v = OE . On en déduit que F ∩ S = OE et donc F et S sontsupplémentaire dans F +G :
F +G = F ⊕ SEn appliquant deux fois l’avant dernier corollaire, on déduit que
dim(G) = dim ((F ∩G)⊕ S) = dim(F ∩G) + dim(S) ⇒ dim(S) = dim(G)− dim(F ∩G)dim(F +G) = dim(F ⊕ S) = dim(F ) + dim(S)
D’oùdim(F +G) = dim(F ) + dim(G)− dim(F ∩G)
329

TSI 1 Lycée Heinrich-Nessel 2016/2017
330

Chapitre 18
Probabilités sur un univers fini
Programme• Espace probabilisé fini : Expérience aléatoire. Modéliser des situations aléatoires.• L’ensemble des issues d’une expérience aléatoire est appelé univers. On se limite au cas où l’univers est fini.• Événements, événements élémentaires (singleton), événement certain, événement impossible, événements
incompatibles, événement contraire (notation A).• Opérations sur les événements.• Définition d’une probabilité P : P(Ω)→ R sur un univers Ω.• Un espace probabilisé fini est un couple (Ω,P) où Ω est un univers fini et P une probabilité sur Ω.• Probabilités et opérations élémentaires sur les événements.• Si Ω = ω1, . . . , ωn et p1, . . . , pn sont des réels positifs de somme 1 alors il existe une unique probabilité P
sur Ω telle que P(ωi) = pi pour tout 1 ≤ i ≤ n.• Équiprobabilité (ou probabilité uniforme).• Conditionnement• définition de la probabilité conditionnelle de A sachant B noté P(A |B) (ou PB(A)).• L’application probabilité conditionnelle sachant B, PB : P(B)→ R est une probabilité sur l’univers B.• Version 1 :
— Formule des probabilités composées : P(A ∩B) = P(A)× P(B|A) ;— Formule des probabilités totales : P(A) = P(A ∩B) + P(A ∩ B) ;— Formule de Bayes : P(A |B) = P(B |A)P(A)
P(B) .• Système complet d’événements (Ai)i=1,...,n.• Version 2 avec (Ai)i=1,...,n :
— Formule des probabilités composées : P(A1 ∩ . . . ∩An) = P(A1)× P(A2|A1)× P(A3|A1 ∩A2)× · · · ×P(An|A1 ∩ . . . ∩An−1) ;
— Formule des probabilités totales : P(B) =∑n
i=1 P(B|Ai)P(Ai) ;
— Formule de Bayes : P(Ak|B) = P(B|Ak)P(Ak)∑i
P(B|Ai)P(Ai).
• Illustrer une expérience aléatoire à l’aide d’arbres de probabilités• Indépendance• Indépendance de deux événements A et B. Si P(B) 6= 0, alors l’indépendance équivaut à P(A |B) = P(A).• Indépendance mutuelle d’une famille finie d’événements. L’indépendance deux à deux n’entraine pas l’in-
dépendance mutuelle.
18.1 Rappels sur le dénombrement
18.1.1 Cardinal d’un ensemble fini
331

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 18.1. Un ensemble fini est un ensemble E ayant un nombre fini d’éléments. Dans ce cas, on notecard(E) ou ]E ou |E| ce nombre, qu’on appelle le cardinal de E.Dans le cas contraitre, on dit que l’ensemble est infini.
Exemple. Soit n un entier naturel, les ensembles
E = 1; . . . ;n = k ∈ N; 1 ≤ k ≤ n = J1;nKF = 0; 1; . . . ;n = k ∈ N; 0 ≤ k ≤ n = J0;nK
sont finis et on a card(E) = n et card(F ) = n+ 1.
Notation. Par convention, l’ensemble vide est fini et on pose card(ø) = 0.
Dénombrer les éléments d’un ensemble fini E = x1, . . . , xn à n éléments revient à construire une application
J1;nK // E
i // xi
bijective !
Théorème 18.2. Soit n un entier naturel. Le cardinal d’un ensemble E est égal à n si et seulement s’il existeune bijection avec J1;nK.
Proposition 18.3. Soit E un ensemble fini. Alors toute partie A de E est un ensemble fini et
card(A) ≤ card(E)
De plus, card(A) = card(E) si et seulement si A = E.
Remarque. En particulier, si A,B sont deux sous-ensembles d’un ensemble fini, alors A ⊂ B implique card(A) ≤card(B).
18.1.2 Opérations sur les ensemblesOn rappelle qu’on dit que deux parties A et B d’un ensemble E sont disjointes si A ∩B = ∅.
Théorème 18.4 (admis). Soit A et B deux parties finies et disjointes d’un ensemble E, alors
card(A ∪B) = card(A) + card(B).
Proposition 18.5. Soit E un ensemble. Soit A, B deux sous-ensembles finis de E. Alors1) B \A et A ∩B sont finis et card (B \A) = card(B)− card(A ∩B) ;2) card(A ∪B) = card(A) + card(B)− card(A ∩B).
Exercice 18.1. Soit A un sous-ensemble de E fini. Exprimer card(EA) en fonction des cardinaux de A et E.
Exercice 18.2 (Formule du crible ou de Poincarépour n = 3). Soit A, B, C trois sous-ensembles fi-nis d’un ensemble E. Exprimer card(A ∪ B ∪ C) enfonction des cardinaux de A, B, C, A ∩ B, A ∩ C,B ∩ C et A ∩B ∩ C. A
B
C
18.1.3 Application entre deux ensembles
332

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 18.6. Soit f : A→ B une application entre deux ensembles finis.1) si f est injective alors card(A) ≤ card(B) ;2) si f est surjective alors card(A) ≥ card(B).
Remarque. Le théorème précédent est connu aussi sous le nom de principe des tiroirs : Si 5 dossiers sont rangésdans quatre tiroirs, deux dossiers au moins sont dans le même tiroir.
Corollaire 18.7. Soit f : A → B une application entre deux ensembles finis. Si f est une bijection alorscard(A) = card(B).
Théorème 18.8. Soit f : E → E une application d’un ensemble fini E dans lui-même. Alors f est bijectivesi et seulement si f est injective si et seulement si f est surjective.
Corollaire 18.9. Soit f : E → F une application entre deux ensembles finis. Supposons que card(E) = card(F ),alors f est bijective si et seulement si f est injective si et seulement si f est surjective.
18.1.4 Produit cartésien, p-uplets et combinaisons
Théorème 18.10 (admis). Soit E et F deux ensembles finis. Alors E × F est fini et
card(E × F ) = card(E)× card(F )
Proposition 18.11. Si A1, . . . , An est une famille d’ensembles finis alors
card (A1 ×A2 × . . .×An) =n∏i=1
card(Ai)
Définition 18.12.• Soit E un ensemble, pour tout entier naturel non nul n, on pose
En = E × . . .× E︸ ︷︷ ︸n fois
=n∏i=1
E
• On note F(A,B) l’ensemble des applications de A dans B.• On note P(E) l’ensemble des parties de E : P(E) = A : A ⊂ E.
Une conséquence de la proposition précédente,
Proposition 18.13. Si E est un ensemble fini, alors pour tout entier n,
card(En) = card(E)n
Définition 18.14. On appelle n-uplet (ou n-liste) de E tout élément (x1, . . . , xn) de En.
Proposition 18.15. Soit E un ensemble fini, le nombre de n-uplets de E est card(E)n.
Remarque. Soit I un ensemble fini et E un ensemble. Une famille d’éléments de E indexés par I est la donnéed’une application f de I dans E. On note par un indice l’image de i ∈ I : xi = f(i). La famille se note alors(xi)i∈I .Un n-uplets (x1, . . . , xn) de E une famille d’éléments de E indéxées par I = 1; . . . ;n. Ainsi, (x1; . . . ;xn)s’identifie avec (xi)i∈I .
333

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 18.16. Soit E un ensemble fini. Alors l’ensemble P(E) des parties de E est fini et
card (P(E)) = 2card(E)
Définition 18.17. Soit p ∈ N. Un p-uplet (x1, . . . , xp) de E est appelé un arrangement de p éléments de E side plus les éléments sont deux à deux distincts : ∀ i 6= j : xi 6= xj .
Définition 18.18. Soit n un entier naturel, le nombre
n! =n∏k=1
k = n× (n− 1)× . . .× 1
est appelé factorielle de n.
Proposition 18.19. Soit E un ensemble de cardinal n et p ≤ n un entier. Le nombre de p-uplets de E quisont des arrangements est
n× (n− 1)× . . .× (n− p+ 1) = n!(n− p)!
Remarque.• Si p > n, alors il n’existe pas d’arrangement de p éléments de E.• Pour choisir un arrangement de taille n de E, on peut le faire par étape en commençant par choisir x1. On
a n choix, puis pour chacun de ces choix, pour x2 on a n− 1 choix et ainsi de suite. D’où, effectivement lenombre d’arrangements de E est n× (n− 1)× (n− 2)× . . .× 2× 1 = n!.
Définition 18.20. Une permutation de E est une application bijective de E dans lui-même. On note S(E)l’ensemble des permutations de E.
D’après le théorème 18.8, on déduit :
Proposition 18.21. Soit E un ensemble de cardinal n. Se donner une permutation de E équivaut à se donnerun arrangement (x1, . . . , xn) de taille n de E.
Théorème 18.22. Soit E un ensemble de cardinal n, alors l’ensemble S(E) des permutations de E est finiet son cardinal vaut n! (factorielle de n).
Définition 18.23. Soit E un ensemble. On appelle combinaison de p éléments de E toute partie de A decardinal p.
Remarque. On notera que :• Pour un arrangement de p éléments de E, on tient compte de l’ordre ;• Pour une combinaison de p éléments de E, on ne tient pas compte de l’ordre.
Définition 18.24. Soit n un entier naturel. Soit k un entier naturel tel que 0 ≤ k ≤ n. On pose(n
k
)= n!k!× (n− k)! = n× (n− 1)× . . .× (n− k + 1)
k!
La quantité(nk
)se lit « k parmi n ».
334

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 18.25. Posons n = card(E). Soit p un entier naturel tel que 0 ≤ p ≤ n. Alors, le nombre decombinaisons de p éléments de E est
card A ∈ P(E)| card(A) = p =(n
p
)
Remarque.• Se donner une combinaison de p éléments de E revient à se donner un arrangement sans tenir compte de
l’ordre. Or il y a p! façons différentes de permutter (d’ordonner) p éléments, d’où
card A ∈ P(E)| card(A) = p =n!
(n−p)!
p! = n!p!(n− p)! =
(n
p
)• Choisir une partie avec p éléments dans E de cardinal n revient à choisir « p éléments deux à deux distinctsparmi n éléments » (sans tenir compte de l’ordre dans lequel on les choisit).
Exercice 18.3. Soit n un entier naturel et p ≤ n un entier naturel, on place n boules numérotés de 1 à ndans une urne. Combien y a-t’il de façons différentes de tirer
1) p boules successivement avec remise ? Il y a n choix à chaque tirage, d’où
n× n× . . .× n︸ ︷︷ ︸p fois
= np
Correspond au nombre p-uplets de J1;nK.2) p boules successivement sans remise ? Après chaque tirage, il y a une boule en moins :
n× (n− 1)× . . .× (n− p+ 1)︸ ︷︷ ︸pour les p tirages
Correspond au nombre d’arrangements de p éléments de J1;nK.3) p boules simultanément 1 ? Par rapport à la situation précédente, on ne tient pas compte de l’ordre, d’où
n× (n− 1)× . . .× (n− p+ 1)p! =
(n
p
)Correspond au nombre de combinaisons de p éléments de J1;nK.
1. Sans tenir compte de l’ordre et sans remise.
Proposition 18.26 (rappel). Soit n un entier naturel et k ∈ N.1)(n0
)= 1 =
(nn
)2)(n1
)= n =
(nn−1
)3) Si 0 ≤ k ≤ n, on a
(nk
)=(n
n−k
)4) Si 1 ≤ k ≤ n− 1, on a
(n−1k−1
)+(n−1k
)=(nk
)(Relation de Pascal)
5)∑n
k=0
(nk
)= 2n
18.2 ProbabilitésDéfinition 18.27. Une expérience aléatoire est une expérience vérifiant les deux conditions suivantes :• elle comporte plusieurs issues envisageables.• on ne peut prévoir l’issue lorsqu’on réalise l’expérience.
L’univers (noté Ω) de l’expérience aléatoire est l’ensemble des issues de cette expérience.Lorsque le nombre d’issues est fini, on dit que l’univers est fini.Un événement est un ensemble d’issues de l’expérience aléatoire.
335

TSI 1 Lycée Heinrich-Nessel 2016/2017
Les événements élémentaires sont les événements réduits à une unique issue de l’expérience.
Exemple. Le jet d’un dé, tirage d’une carte dans un jeu de carte, tirage d’une boule dans une urne.
Définition 18.28. On appelle événement contraire d’un événement A, l’événement noté A qui contient l’en-semble des issues n’appartenant pas à A.Formellement, A = Ω \A.
Définition 18.29. Soit A et B deux événements d’une expérience aléatoire donnée.• L’intersection des deux événements A et B est l’événement constitué des issues qui sont dans A et dansB, notée A ∩B.
• L’union des deux événements A et B est l’événement constitué des issues de A ou de B (au sens large),notée A ∪B.
• On dit que A est inclus dans B, noté A ⊂ B si toutes les issues de A sont aussi des issues de B.
L’événement A ∩B se réalise lorsque les deux événements à la fois se réalisent.L’événement A ∪B se réalise lorsqu’au moins un des deux événements se réalise.
A BA ∪B
A B
A ∩B
Définition 18.30. Dans une expérience aléatoire, deux événements E et E′ sont dit incompatibles s’ils nepartagent pas d’issue commune (i.e : leur intersection est vide).
Dans la suite Ω désigne un univers fini.
Définition 18.31. Une probabilité sur (Ω,P(Ω)) est une application P : P(Ω)→ R telle que :1) Pour tout événement E ∈ P(Ω) : 0 ≤ P(E) ≤ 1,2) P(Ω) = 1,3) Pour tout couple (A, B) d’événements incompatibles de Ω, on a P(A ∪B) = P(A) + P(B).
Remarque. L’hypothèse P(Ω) = 1, peut être interprétée par le fait qu’on considère que dans une expériencealéatoire, il se passe certainement quelque chose.Étant donné un événement E, le nombre P(E) donne (mesure) les chances de réussite de E. Plus P(E) est prochede 1, plus il est probable que l’événement E se réalisera.
Théorème 18.32 (loi des grands nombres). Lors d’une expérience répétée n fois, les fréquences obtenuesd’un événement E de l’expérience se rapprochent du nombre théorique P(E), la probabilité de l’événement E.
Étant donné un univers Ω, on peut associer différentes probabilités. Par exemple, lorsqu’on jette un dé, l’universest Ω = 1, 2, 3, 4, 5, 6, mais suivant que le dé soit trucqué ou non les probabilités changent. D’où la définitionsuivante :
Définition 18.33. Un espace probabilisé (fini) est un triplet (Ω,P(Ω),P) où Ω est un ensemble fini et P estune probabilité sur (Ω,P(Ω)).
Proposition 18.34. Soit (Ω,P(Ω),P) un espace probabilisé. Soit A,B deux événements de Ω, alors :1) P(∅) = 0 ;2) P( A ) = 1− P(A) ;3) Si A ⊂ B alors P(A) ≤ P(B) ; (Croissance d’une probabilité)
336

TSI 1 Lycée Heinrich-Nessel 2016/2017
4) P(A) = P(A ∩B) + P(A ∩ B) ; (Formule des probabilités totales, version 1)5) P(A ∪B) = P(A) + P(B)− P(A ∩B) ; (Formule de Poincaré)
Remarque. Moralement, la propriété 3) nous dit que plus un événement contient d’issues plus il est probable.
( ! Démonstration au programme)
Démonstration. À l’aide des trois propriétés vérifiées par une probabilité (définition 18.31), on déduit :1) Comme Ω ∩ ∅ = ∅, les deux événements Ω et ∅ sont incompatibles. De plus Ω = Ω ∪ ∅, donc
1 1)= P(Ω) = P(Ω ∪ ∅) 3)= P(Ω) + P(∅)⇒ 1 = 1 + P(∅)⇒ 0 = P(∅)
2) Par définition du complémentaire, A et A sont incompatibles, ainsi
1 1)= P(Ω) = P(A ∪ A) 3)= P(A) + P(A)⇒ 1− P(A) = P(A)
3) Si A ∪B alors B = A ∪ (B \A), c’est une union disjointe d’où
P(B) = P(A ∪ (B \A)) 3)= P(A) + P(B \A)︸ ︷︷ ︸≥0 d’après 2)
⇒ P(B) ≥ P(A)
4) On a
A = A ∩ Ω = A ∩ (B ∪ B) = (A ∩B) ∪ (A ∩ B) union disjointe
⇒ P(A) = P(
(A ∩B) ∪ (A ∩ B))
3)= P(A ∩B) + P(A ∩ B)
5) et
A ∪B = (A ∩B) ∪ (A ∩ B) ∪ (A ∩B) union disjointe
⇒ P(A ∪B) 3)= P(A ∩B) + P(A ∩ B) + P(A ∩B)⇒ P(A ∪B) = P(A ∩B) + P(A)− P(A ∩B) + P(B)− P(A ∩B) d’après le point précédent⇒ P(A ∪B) = P(A) + P(B)− P(A ∩B)
Lemme. Soit (Ω,P(Ω),P) un espace probabilisé et A1, . . . , An une famille d’événements deux à deux incompa-tibles de Ω, alors
P( n⋃i=1
Ai
)=
n∑i=1
P(Ai)
Proposition 18.35. Soit (Ω,P(Ω),P) un espace probabilisé. Notons Ω = ω1, . . . , ωn et pi = P(ωi) laprobabilité que l’issue ωi se réalise, pour tout 1 ≤ i ≤ n. Alors,
p1 + . . .+ pn = 1
Autrement dit, la somme des probabilités des issues élémentaires d’une expérience aléatoire vaut toujours un :∑ω∈Ω
P(ω) = 1
Ce fait, peut être utilisé comme un premier test de vraisemblance d’une théorie de probabilité proposée pourmodéliser une expérience aléatoire !
Réciproquement :
337

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 18.36. Soit Ω = ω1, . . . , ωN un univers fini, (p1, . . . , pN ) ∈ [0; 1]N des nombres réels tels que
p1 + · · ·+ pN = 1.
Alors, il existe une unique probabilité sur Ω telle que :
∀ 1 ≤ i ≤ N : P(ωi) = pi
Définition 18.37. Deux événements qui ont la même probabilité de se réaliser sont dit équiprobables.
Exemple. Dans un lancé d’un dé équilibré, d’une pièce équilibrée les issues élémentaires sont équiprobables.
Proposition 18.38. Soit (Ω,P(Ω),P), notons n le cardinal de Ω. Supposons que les n issues élémentairessont équiprobables, alors :• La probabilité de chaque événement élémentaire est 1
n:
• La probabilité d’un événement A est
P(A) = card(A)card(Ω) = nombre d’issues favorables à A
nombre d’issues élémentaires
Exercice 18.4. On lance deux dés. Décrire l’univers correspondant. On s’intéresse à la somme S des deux dés.Décrire l’univers correspondant. Calculer les probabilités suivantes :
P(S = 1), P(S = 2), P(S = 12), P(S = 6).
Exercice 18.5. On considère un jeu de 52 cartes.1) On tire au hasard deux cartes.
a) Combien y a-t-il de façons de tirer 2 cœurs ? Un roi et un As ? Un cœur et un roi ?b) Calculer la probabilité de chacun de ces tirages.
2) On distribue aléatoirement les 52 cartes à 4 joueurs. Chaque joueur a une main de 13 cartes.a) Combien y a-t-il de mains possibles ?b) Quelle est la probabilité d’avoir une main ayant les 4 As ?
18.3 Probabilité conditionnelleExemple.
Une usine possède deux unités de production A et B.On prélève un échantillon de 100 pièces et on observe :
Unité A (A) Unité (B) Totalpossède un dé-faut (D)
5 5 30
sans défaut (D) 40 50 70Total 45 55 100
On choisit au hasard une pièce de l’échantillon.
La probabilité que la pièce sorte de l’unité A estP(A) = 45
100 = 920 .
La probabilité que la pièce sorte de l’unité A et a undéfaut est P(A ∩D) = 5
100 = 120 .
Sachant que la pièce provient de l’unité A, la proba-bilité qu’elle ait un défaut est
PA(D) = 545 =
510045100
= P(D ∩A)P(A)
Définition 18.39. Soit (Ω,P(Ω),P) un espace probabilisé, A, B deux événements de Ω tels que P(A) 6= 0.La probabilité conditionnelle de B sachant A est le nombre
PA(B) = P(B |A) = P(A ∩B)P(A)
338

TSI 1 Lycée Heinrich-Nessel 2016/2017
Remarque. On retiendra qu’on divise par la probabilité de l’événément par lequel on conditionne. Il y a une sorted’analogie avec une situation d’équiprobabilité où l’on divise par le cardinal de l’univers.Le fait de diviser par P(A) sachant que A s’est réalisé est une façon de prendre en compte la « plausibilité » queA se soit effectivement réalisé.
Proposition 18.40. Soit (Ω,P(Ω),P) un espace probabilisé, A, B deux événements de Ω tels que P(A) 6= 0.Alors :
1) P(A ∩B) = P(A) P(B |A) ;2) P(∅ |A) = 0 et P(A |A) = 1 ;3) 0 ≤ P(B |A) ≤ 1 ;4) P(B |A) + P(B |A) = 1.
Démonstration. 1) Par définition de la probabilité conditionnelle, on a
P(B |A) = P(A ∩B)P(A) ⇒ P(A ∩B) = P(A) P(B |A)
2) et
P(∅ |A) = P(∅ ∩A)P(A) = P(∅)
P(A) = 0
P(A |A) = P(A ∩A)P(A) = P(A)
P(A) = 1
3) et
0 ≤ P(B ∩A) ≤ P(A)
⇒ 0 ≤ P(B ∩A)P(A) ≤ P(A)
P(A) car P(A) > 0
⇒ 0 ≤ P(B |A) ≤ 1
4) Enfin, d’après la formule des probabilités totales, on a
P(A) = P(A ∩B) + P(A ∩ B)
⇒ P(A)P(A) = P(A ∩B)
P(A) + P(A ∩ B)P(A) car P(A) 6= 0
⇒ 1 = P(B |A) + P(B |A)
Corollaire 18.41. Soit (Ω,P(Ω),P) un espace probabilisé, A un événement de Ω de probabilité non nulle.L’application probabilité conditionnelle P( · |A) : P(A)→ R est une probabilité sur (Ω,P(Ω)).
Démonstration. Vérifions que P(· |A) : P(A)→ R est une probabilité (définition 18.31), c’est-à-dire que :1) Pour tout événement E de P(A), 0 ≤ P(E |A) ≤ 1 ;2) P(A |A) = 1 ;3) Pour tout couple (B1, B2) d’événements incompatibles de A, on a P(B1 ∪B2 |A) = P(B1 |A) + P(B2 |A).
Les deux premiers points ont été démontré dans la proposition précédente. Soit B1 et B2 deux événementsincompatibles de A, on a
P(B1 ∪B2 |A)
= 1P(A)P
((B1 ∪B2) ∩A
)= 1
P(A)P(
(B1 ∩A) ∪ (B2 ∩A))
= 1P(A)
(P(B1 ∩A) + P(B2 ∩A)
)car B1 ∩A et B2 ∩A sont incompatibles et P est une probabilité
= P(B1 |A) + P(B2 |A)
339

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 18.42. Dans une situation d’équiprobabilité, on a
P(B |A) = nombre d’issues de A ∩Bnombre d’issues de A
Démonstration. Comme les issues sont équiprobables, de la proposition 18.38, on déduit que
P(B |A) = P(A ∩B)P(A) =
#(A∩B)#(Ω)#(A)#(Ω)
= #(A ∩B)#(A) = nombre d’issues de A ∩B
nombre d’issues de A
Lemme 18.43. Soit A un événement de probabilité non nulle. Pour tout événement B, si A ⊂ B alors B estaussi de probabilité non nulle.
Démonstration. Des deux hypothèses, on déduit que 0 < P(A) ≤ P(B). Donc P(B) 6= 0.
Théorème 18.44 (Formule des probabilités composées).1) Soit A et B deux événements avec P(A ∩B) 6= 0. Alors
P(A ∩B) = P(A)× P(B|A)
2) Soit A1, . . . , An des événements tels que P(A1 ∩ . . . ∩An) 6= 0. Alors
P(A1 ∩ . . . ∩An) = P(A1)× P(A2|A1)× P(A3|A1 ∩A2)× · · · × P(An|A1 ∩ . . . ∩An−1)
Démonstration. Le premier point a déjà été vu dans la proposition 18.40. Soit n ≥ 2, supposons par récurrenceque pour tout famille d’événements A1, . . . , An telle que P(A1 ∩ . . . ∩An) 6= 0, on a
P(A1 ∩ . . . ∩An) = P(A1)× P(A2|A1)× P(A3|A1 ∩A2)× · · · × P(An|A1 ∩ . . . ∩An−1)
Soit B1, . . . , Bn, Bn+1 une famille d’événements telle que P(B1∩ . . .∩Bn+1) 6= 0, alors d’après le lemme précédentP(B1 ∩ . . . ∩Bn) est aussi non nulle. Ainsi, d’après le point précédent et de l’hypothèse de récurrence, on déduitque
P(B1 ∩ . . . ∩Bn ∩Bn+1) = P(B1 ∩ . . . ∩Bn) P(Bn+1 |B1 ∩ . . . ∩Bn)= P(B1)× P(B2|B1)× P(B3|B1 ∩B2)× · · · × P(Bn|B1 ∩ . . . ∩Bn−1) P(Bn+1 |B1 ∩ . . . ∩Bn)
D’où, par récurrence sur n le nombre d’événements, on déduit que le second point de la proposition est vraie.
Théorème 18.45 (Formule de Bayes 1, version 1). Soit A et B deux événements de probabilité non nulle,alors
P(A |B) = P(B |A) P(A)P(B)
1. Thomas Bayes (1702 - 1761)
( ! Démonstration au programme)
Démonstration. Par définition de la probabilité conditionnelle, on a
P(A |B) = P(A ∩B)P(B)
=P(A∩B)P(A) P(A)
P(B) car P(A) 6= 0
= P(B |A)P(A)P(B)
340

TSI 1 Lycée Heinrich-Nessel 2016/2017
En appliquant la formule de Poincaré à P(B), au dénominateur, on a
Corollaire 18.46. Soit A et B deux événements de probabilité non nulle tels que P(A) 6= 0, alors
P(A |B) = P(B |A) P(A)P(B |A)P(A) + P(B | A)P(A)
Exercice 18.6. Dans une population, environ deux millièmes de la population souffre d’une pathologie. Unlaboratoire pharmaceutique met au point un test sanguin. En principe, celui-ci est positif si le patient est malade,mais le test n’est pas fiable à 100%. Plus précisément, si le patient est malade alors le test est positif 99.9 fois sur100, mais 4 fois sur 1 000, il est positif sur une personne non malade.Quelle est la probabilité qu’une personne soit malade sachant que le test est positif ?
Remarque. Dans le contexte de l’exercice précédent, notons M l’évènement un individus est malade et T le testpositif. La connaissance de :• P(T |M), la probabilité que le test soit positif sachant qu’une personne est malade,• P(T | M), la probabilité que le test soit positif sachant qu’une personne est non malade,• P(M) la probabilité qu’une personne soit malade,
permet, grâce à la formule de Bayes, de déduire P(M |T ), la probabilité d’être malade sachant que le test estpositif.Si le test était infaillible, l’évènementM (être malade) impliquerait T (le test est positif). DoncM peut être appeléla cause et T la conséquence et la formule de Bayes permet de déterminer la probabilité que la « réciproque » soitvraie.C’est pour cela que la formule de Bayes a longtemps été appelée formule de probabilité des causes.
Considérons maintenant n événements A1, A2, . . . , An de probabilité non nulle, formant une partition de Ω.C’est-à-dire que les événements Ai sont deux à deux incompatibles et leur union est l’univers entier. Soit B unévénement, on a B =
⋃n
i=1 B ∩Ai et l’union est disjointe. D’où
P(B) =n∑i=1
P(B ∩Ai)
B
Ω
. . .
A1
A2
A3
A5
An−1
A4
An
En d’autres termes, une partition A1, A2, . . . , An est une manière de classer les issues possibles de l’expérienceen n catégories d’événements notées A1 à An. La probabilité d’un événement B s’obtient en additionnant lesprobabilités des événements des B ∩Ai, c’est-à-dire, en distinguant les différents cas.
Définition 18.47. Un système complet (ou exhaustif) d’événements est une famille (Ai)i∈I d’événementsdeux à deux incompatibles telle que
⋃i∈I
Ai = Ω.
De la remarque précédente, on déduit
Théorème 18.48 (Formule des probabilités totales, version 2). Soit n un entier et (Ai)i∈J1;nK un système
341

TSI 1 Lycée Heinrich-Nessel 2016/2017
complet d’événements de probabilités toutes non nulles. Pour tout événement B, on a
P(B) =n∑i=1
P(B|Ai)P(Ai)
( ! Démonstration au programme)
Démonstration. Par hypothèse Ω est égale à l’union disjointe des An, ainsi
B = B ∩ Ω = B ∩( n⋃i=1
Ai
)=
n⋃i=1
(B ∩Ai
)union disjointe
⇒ P(B) =n∑i=1
P(B ∩Ai) par additivité d’une probabilité
⇒ P(B) =n∑i=1
P(B ∩Ai)P(Ai)P(Ai)
car pour tout i, P(Ai) 6= 0
⇒ P(B) =n∑i=1
P(B |Ai)P(Ai)
Théorème 18.49 (Bayes, version 2). Soit n un entier et (Ai)i∈J1;nK un système complet d’événements deprobabilités toutes non nulles. Pour tout événement B et tout indice k ∈ J1;nK, on a
P(Ak|B) = P(B|Ak)P(Ak)∑i
P(B|Ai)P(Ai)
( ! Démonstration au programme)
Démonstration. Par définition de la probabilité conditionnelle, on a
P(Ak |B) = P(Ak ∩B)P(B)
=P(Ak∩B)P(Ak) P(Ak)
P(B) car P(Ak) 6= 0
= P(B |Ak)P(Ak)P(B)
= P(B|Ak)P(Ak)∑i
P(B|Ai)P(Ai)d’après la formule des probabilités totales
On peut aussi retrouver la formule des probabilités totales à l’aide des arbres pondérés : Sur un arbre pondéréde probabilités (réalisé ci-dessous pour n = 4 dans la figure 18.1), une branche est représentée par un segment(portant une probabilité), un noeud est la jonction de deux ou plusieurs branches, et un chemin est une successionde branches allant du noeud initial de l’arbre à l’une de ses extrémités.Chaque chemin correspond à l’évènement intersection des événements figurant sur ce chemin (par exemple A2∩Bpour le 3e chemin de la figure 18.1).
À partir de là, pour les calculs, on utilise les règles suivantes :1) La somme des probabilités portées sur les branches issues d’un même noeud est égale à 1.2) La probabilité de l’événement correspondant à un chemin est le produit des probabilité portées sur ses
branches.
342

TSI 1 Lycée Heinrich-Nessel 2016/2017
A1
P(A
1)
BPA1(B)
BPA1 (B)
A4
P(A4 )
BPA4(B)
BPA4 (B)
Arbre Événement Probabilité
A2P(A2)
BPA2(B)
BPA2 (B)
A2 ∩B P(A2 ∩B) = P(A2)× P(B |A2)
A3
P(A3 )
BPA3(B)
BPA3 (B) A3 ∩ B P(A3 ∩ B) = P(A3)× P(B |A3)
Figure 18.1 – Système complet de 4 événements
3) La probabilité d’un événement est la somme des probabilités des événements correspondant aux cheminsqui y aboutissent.
Le premier point est une conséquence de la proposition 18.40, le second point de la formule des probabilitéscomposées et le troisième point de la formule des probabilités totales.Avec n = 4, on retrouve :
P(B) = P(A1)× P(B |A1) + P(A2)× P(B |A2) + P(A3)× P(B |A3) + P(A4)× P(B |A4)
La figure 18.2 représente un second exemple lorsque n = 2.
AP(A
)
BpA(B)
BpA (B)
A ∩B P(A ∩B) = P(A)× P(B |A)
A
P(A)BpA
(B)
BpA (B)
A ∩B P(A ∩B) = P(A)× P(B | A)
B = (A ∩B) ∪ (A ∩B) P(B) = P(A ∩B) + P(A ∩B)
Figure 18.2 – Formule des probabilités totales (version 1)
18.4 Indépendance de deux événementsExemple. Considérons une urne qui contient 5 boules rouges et 7 boules bleues et les boules sont numérotés de1 à 12. On tire une boule, ensuite on remet la boule et on retire encore une fois une boule. L’univers de cetteexpérience aléatoire est
Ω = 1, 2, . . . , 122
de cardinal 122 = 144. Considérons les événements :• A : "Lors du premier tirage, on tire une boule rouge"• B : "Lors du second tirage, on tire une boule bleue"
343

TSI 1 Lycée Heinrich-Nessel 2016/2017
Comme il y a remise, les deux tirages de boules sont indépendants (le résultat du premier tirage n’a aucuneinfluence sur le second). Ainsi, les événements A et B sont en quelque sorte indépendants.L’événement A∩B est le suivant : "on tire en premier une boule rouge et en second une boule bleue". Le cardinalde A ∩B est 5× 7 = 35. Les issues élémentaires sont équiprobables, donc on a
P(A ∩B) = 35144 = 5× 7
12× 12 = 512 ×
712 = P(A)× P(B)
Cette propriété suggère la définition suivante.
Définition 18.50. Dans l’univers Ω d’une expérience aléatoire, on considère des événements A et B. On ditque A et B sont des événements indépendants lorsque
P(A ∩B) = P(A)× P(B)
On dit que deux événements sont dépendants lorsqu’ils ne sont pas indépendants.
En supposant que P(B) 6= 0, l’égalité dans la définition précédente équivaut P(A∩B)P(B) = P(A), c’est-à-dire :
Proposition 18.51. Lorsque l’événement B est de probabilité non nulle (P(B) 6= 0), les événements A et Bsont indépendants si et seulement si P(A |B) = P(A).
En d’autres termes, A et B sont indépendants si et seulement si la probabilité de A sachant B dépend uniquementde l’événement A.
Définition 18.52. Soit A1, . . . , An des événements d’une expérience aléatoire d’univers Ω. On dit que lesévénements A1, . . . , An sont mutuellement indépendants si pour tout k ∈ 1, . . . n, et pour tout sous-ensemblede k indices deux à deux distincts i1, . . . , ik ⊂ 1, . . . , n, on a
P(Ai1 ∩ . . . ∩Aik ) = P(Ai1)× · · · × P(Aik )
Exercice 18.7.1) Soit A1, A2, A3 trois événements, lister toutes les conditions qu’ils doivent vérifier pour être mutuellement
indépendants.2) On jette un dé équilibré deux fois, on note :
• A1 l’événement « on obtient un 1 au premier lancer » ;• A2 l’événement « on obtient un 1 au second lancer » ;• A3 l’événement « on obtient le même résultat aux deux lancers ».
a) Montrer que les couples (Ai, Aj) sont indépendants pour tout i 6= j. On dit que A1, A2, A3 sont deuxà deux indépendants.
b) Est-ce que A1, A2, A3 sont mutuellement indépendants ?
Remarque. Si les événements (Ai) sont mutuellement indépendants, alors ils sont deux à deux indépendants.MAIS la réciproque est fausse ! ! !
344

Chapitre 19
Développements limités
Programme• Développement limité d’ordre n d’une fonction f au voisinage d’un point a :
∃P (X) =n∑k=0
akXk ∈ Rn[X] ∀x ∈ I : f(x) = a0 + a1(x− a) + . . .+ an(x− a)n + o((x− a)n)
où o((x− a)n) = (x− a)nε(x− a) avec ε une fonction telle que limh→0
ε(h) = 0.
• Interpréter un développement limité comme une approximation polynômiale d’une fonction.• Ramener un développement limité en 0 par translation. Adaptation au cas où f est définie sur I \ a.• Unicité, troncature. Développement limité en 0 d’une fonction paire ou impaire.• Forme normalisée d’un développement limité :
f(a+ h) = hp(ap + ap+1h+ . . .+ aqh
q + o(hq))
avec a0 6= 0.• Étudier le signe d’une fonction au voisinage d’un point à l’aide d’un DL. Équivalence f(a+ h) ∼
0aph
p.
• Formule de Taylor-Young : Calculer le développement limité d’une fonction de classe Cn à partir de sesdérivées successives.
• Opérations sur les DL : combinaison linéaire, produit, composition. Application au quotient.• Déterminer sur des exemples simples le développement limité d’une fonction composée. Aucun résultat
général sur ce point n’est exigible.• La division selon les puissances croissantes est hors programme.• Intégration terme à terme d’un développement limité.• Exploiter la forme normalisée pour prévoir l’ordre d’un développement limité.• Développements limités usuels. À connaître :
1) 11−x = 1 + x+ x2 + x3 + · · ·+ xn + o(xn) =
n∑k=0
xk + o(xn)
2) ln(1− x) = −x− x2
2 −x3
3 − · · · −xn
n+ o(xn) = −
n∑k=1
xk
k+ o(xn)
3) ex = 1 + x+ x2
2 + x3
3! + · · ·+ xn
n! + o(xn) =n∑k=0
xk
k! + o(xn)
4) cos(x) = 1− x2
2 + · · ·+ (−1)n x2n
(2n)! + o(x2n+1) =n∑k=0
(−1)k x2k
(2k)! + o(x2n+1)
5) sin(x) = x− x3
3! + · · ·+ (−1)n x2n+1
(2n+1)! + o(x2n+2) =n∑k=0
(−1)k x2k+1
(2k + 1)! + o(x2n+2)
6) (1 + x)α = 1 + αx+ α(α−1)2! x2 + . . .+
(αn
)xn + o(xn) =
n∑k=0
(α
k
)xk + o(xn) pour tout α ∈ R.
345

TSI 1 Lycée Heinrich-Nessel 2016/2017
7) arctan(x) = x− x3
3 + · · ·+ (−1)n x2n+1
2n+1 + o(x2n+2) =n∑k=0
(−1)k x2k+1
2k + 1 + o(x2n+2)
8) tan(x) = x+ x3
3 + o(x4)• Exploiter les DL usuels dans le cadre de calculs de DL simples. Exploiter des outils logiciels pour des
développements limités plus complexes.
19.1 Développements limités
Définition 19.1. Soit I un intervalle contenant 0, f : I \ 0 → R une fonction continue et n un entier. Ondit que f possède un développement limité à l’ordre n au point 0 s’il existe un polynôme P (X) ∈ Rn[X] telque
limx→0
f(x)− P (x)xn
= 0
Notation (de Landau au voisinage de 0). Pour tout entier n, on note
o(xn) = xn ε(x)
où limx→0
ε(x) = 0.
Si f possède un développement limité à l’ordre n en 0 si :
∃P (X) =n∑k=0
akXk ∈ Rn[X] ∀x ∈ I : f(x) = a0 + a1x+ . . .+ anx
n + o(xn)
Ainsi, un développement limité est une approximation de la fonction f par une fonction polynômiale P qui estd’autant plus précise qu’on se rapproche de 0.
Proposition 19.2 (troncature d’un développement limité). Si f admet un développement limité d’ordre nen 0 :
f(x) = a0 + a1x+ . . .+ apxp + . . .+ anx
n + o(xn)alors f admet un développement limité d’ordre p en 0 :
f(x) = a0 + a1x+ . . .+ apxp + o(xp)
pour tout entier p ≤ n.
Démonstration. Soit p ≤ n un entier. Pour tout x ∈ I, on a
f(x) = a0 + a1x+ . . .+ apxp + . . .+ anx
n + xnε(x) avec ε(x) −→x→0
0
= a0 + a1x+ . . .+ apxp + xp(ap+1x+ . . .+ anx
n−p + xn−pε(x))= a0 + a1x+ . . .+ apx
p + xpε′(x) avec ε′(x) −→x→0
0
Définition 19.3. Soit I un intervalle, a ∈ I, f : I \a → R une fonction et n un entier. On dit que f possèdeun développement limité à l’ordre n au point a si la fonction x 7→ f(x+ a) possède un développement limitéà l’ordre n au point 0, c’est-à-dire :
∃P (X) =n∑k=0
akXk ∈ Rn[X] ∀x ∈ I : f(x) = a0 + a1(x− a) + . . .+ an(x− a)n + o((x− a)n)
où o((x− a)n) = (x− a)nε(x− a) avec ε une fonction telle que limh→0
ε(h) = 0.
Si on pose h = x− a, la relation précédente devient :
f(a+ h) = a0 + a1h+ . . .+ anhn + o(hn)
346

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 19.4 (forme normalisée). Soit I un intervalle, a ∈ I et f : I \a → R une fonction. La fonctionf admet un développement limité d’ordre n en a si et seulement si il existe (p, q) ∈ N2, (a0, . . . , an) ∈ Rn+1
tels que p+ q = n etf(a+ h) = hp
(a0 + a1h+ . . .+ aqh
q + o(hq))
avec a0 6= 0.
Remarque. Pour tous p, q entiers, on a hp o(hq) = o(hp+q).
Corollaire 19.5. Avec les notations et hypothèses de la proposition précédente, on a :1) l’équivalence
f(a+ h) ∼h→0
a0 hp
lorsque h est au voisinage de 0 ;2) l’image f(x) est du signe de a0(x− a)p au voisinage de a.
Une conséquence de la formule de Taylor vue dans le chapitre 13 Polynômes :
Proposition 19.6. Soit f : R→ R une fonction polynomiale de degré d. Quel que soit l’entier n et quel quesoit le réel a, f admet un développement limité à l’ordre n en un point a.
Théorème 19.7 (d’unicité). Si la fonction f possède un développement limité à l’ordre n au point a, alorsce développement est unique.
Démonstration. Quitte à remplacer f par g : x 7→ f(x + a), on suppose que a = 0. Soit P (X) ∈ Rn[X] etQ(x) ∈ Rn[X] tels que
∀x ∈ I : f(x) = P (x) + o(xn) = Q(x) = o(xn)⇒ ∀x ∈ I : P (x)−Q(x) = xnε(x) avec ε(x) −→
x→00
Supposons par l’absurde que R(X) = P (X)−Q(X) est non nul. Alors, R(X) est de la forme
apXp + ap+1X
p+1 + . . .+ anXn ∈ Rn[X]
avec ap 6= 0. Or, pour tout x ∈ I \ 0
apxp + ap+1x
p+1 + . . .+ anxn = xnε(x)
⇒ xp(ap + ap+1x+ . . .+ anx
n−p) = xpxn−pε(x)
⇒ ap + ap+1x+ . . .+ anxn−p = xn−pε(x)
En faisant tendre x vers 0 dans l’identité précédente, on déduit que
ap = 0
ce qui est absurde. D’où P (X) = Q(X).
Corollaire 19.8. Soit f : I → R, supposons que f admet un développement limité à l’ordre n en 0 : f(x) =P (x) + o(xn).
1) Si f est une fonction paire, le polynôme P est pair.2) Si f est une fonction impaire, le polynôme P est impair.
Démonstration. Nous allons uniquement démontrer le premier cas. Supposons que f est paire, alors quel que soitx ∈ I,
f(x) = f(−x) = P (−x) + o((−x)n) = P (−x) + (−1)nxnε(−x)
où ε est une fonction qui tend vers 0 au voisinage de 0. Posons ε′(x) = (−1)nε(−x), alors ε′(x) tend aussi vers 0lorsque x tend vers 0 et est telle que
f(x) = P (−x) + xnε′(x)
347

TSI 1 Lycée Heinrich-Nessel 2016/2017
Or P (−X) est aussi un polynôme de degré inférieur ou égal à n. Ainsi, l’identité précédente définie un dé-veloppement limité à l’ordre n de f en 0. Par unicité du polynôme dans un développement limité, on déduitque
P (X) = P (−X)
C’est-à-dire le polynôme P est pair.
Proposition 19.9. Soit I un intervalle ouvert, f : I → R une fonction et a ∈ I. La fonction f est dérivable en asi et seulement si f possède un développement limité à l’ordre 1 au point a. Dans ce cas, le développement limitéest
f(x) = f(a) + (x− a)f ′(a) + o(x− a)
19.2 Développement limité des fonctions de classe Cn
Lemme 19.10. Soit a < b deux réels et f : [a, b] → R une fonction continue, alors il existe un nombre c ∈ [a; b]tel que ∫ b
a
f(t) dt = (b− a)f(c)
Démonstration. Comme f est continue sur l’intervalle fermé borné [a; b], on déduit du théorème des bornesatteintes qu’il existe (m,M) ∈ [a; b]2 tel que :
∀ t ∈ [a; b] : f(m) ≤ f(t) ≤ f(M)
⇒∫ b
a
f(m)︸ ︷︷ ︸constante
dt ≤∫ b
a
f(t) dt ≤∫ b
a
f(M)︸ ︷︷ ︸constante
dt
⇒ (b− a)f(m) ≤∫ b
a
f(t) dt ≤ (b− a)f(M)
⇒ f(m) ≤ 1b− a
∫ b
a
f(t) dt ≤ f(M) car b− a > 0
On applique ensuite le théorème des valeurs intermédiaires à la fonction continue f et la constante k =1b−a
∫ baf(t) dt comprise entre f(m) et f(M), pour déduire qu’il existe c ∈ [a; b] tel que f(c) = 1
b−a
∫ baf(t) dt.
D’où le lemme.
Proposition 19.11 (intégration d’un développement limité). Soit f : I → R une fonction continue et soit Fune primitive de f . Supposons qu’au point a ∈ I, la fonction f admet comme développement limité à l’ordren :
f(x) = a0 + a1(x− a) + a2(x− a)2 + . . .+ an(x− a)n + o((x− a)n)Alors la primitive F de f admet un développement limité à l’ordre n+ 1 au point a et de plus, on a
F (x) = F (a) + a0(x− a) + a1(x− a)2
2 + a2(x− a)3
3 + . . .+ an(x− a)n+1
n+ 1 + o((x− a)n+1)
Démonstration. Rappelons que o((x− a)n) = (x− a)nε(x− a) avec limh→0
ε(h) = 0. Comme F est un primitive def , on déduit que :
F (x)− F (a) =∫ x
a
f(t) dt
=∫ x
a
a0 + a1(t− a) + a2(t− a)2 + . . .+ an(t− a)n + (t− a)nε(t− a) dt
=[a0(t− a) + a1
(t− a)2
2 + a2(t− a)3
3 + . . .+ an(t− a)n+1
n+ 1
]xa
+∫ x
a
(t− a)nε(t− a) dt
= a0(x− a) + a1(x− a)2
2 + a2(x− a)3
3 + . . .+ an(x− a)n+1
n+ 1 +∫ x
a
(t− a)nε(t− a) dt
348

TSI 1 Lycée Heinrich-Nessel 2016/2017
On pose
ε′(h) =
1
hn+1
∫ a+ha
(t− a)nε(t− a) dt si h 6= 0 et a+ h ∈ I0 si h = 0
définie au voisinage de 0. Alors,
F (x)− F (a) = a0(x− a) + a1(x− a)2
2 + a2(x− a)3
3 + . . .+ an(x− a)n+1
n+ 1 + (x− a)n+1ε′(x− a) (?)
Soit h 6= 0 (tel que a+ h ∈ I), d’après le lemme précédent, il existe c compris entre a et a+ h tel que∫ a+h
a
(t− a)nε(t− a) dt = h(c− a)nε(c− a)
⇒ ε′(h) = h(c− a)n
hn+1 ε(c− a)
Comme c est compris entre a et a+ h, on déduit que |c− a| ≤ |h| et donc
|ε′(h)| =∣∣∣ hhnhn+1 ε(c− a)
∣∣∣ ≤ |ε(c− a)|
et de plus lorsque h tend vers 0, le nombre c− a tend vers 0. Du théorème de l’encadrement, on déduit que
limh→0
ε′(h) = 0
Ainsi, de (?) on déduit le développement limité à l’ordre n+ 1 de F donné dans le théorème.
Théorème 19.12 (Formule de Taylor-Young). Soit f : I → R une fonction de classe Cn sur un intervalleouvert I et a ∈ I. La fonction f a pour développement limité à l’ordre n au point a :
f(x) = f(a) + f ′(a)1! (x− a) + f ′′(a)
2! (x− a)2 + . . .+ f (n)(a)n! (x− a)n + o((x− a)n)
Démonstration. Pour n = 0 : Supposons que f est de classe C0, c’est-à-dire continue. Posons ε(h) = f(a+h)−f(a),alors pour tout x ∈ I,
f(x) = f(a) + ε(x)et limiteax→ af(x) = f(a). Avec les notations de Landau, on a bien dans ce cas : f(x) = f(a) + o(1).Soit n ∈ N quelconque, supposons que le théorème est vraie pour toute fonction de classe Cn+1. Soit f : I → Rune fonction de classe Cn+1, remarquons que pour tout entier 0 ≤ k ≤ n, on a (f ′)(k) = f (k+1). D’où, la fonctiondérivée f ′ est de classe Cn et on peut lui appliquer l’hypothèse de récurrence :
f ′(x) = f ′(a) + (f ′)′(a)1! (x− a) + (f ′)′′(a)
2! (x− a)2 + . . .+ (f ′)(n)(a)n! (x− a)n + o((x− a)n)
= f ′(a) + f (2)(a)1! (x− a) + f (3)(a)
2! (x− a)2 + . . .+ f (n+1)(a)n! (x− a)n + o((x− a)n)
Comme f est une primitive de f ′, on déduit de la proposition précédente que f admet un développement limitéà l’ordre n+ 1 et
f(x) = f(a) + f ′(a)(x− a) + f (2)(a)1!
(x− a)2
2 + f (3)(a)2!
(x− a)3
3 + . . .+ f (n+1)(a)n!
(x− a)n+1
n+ 1 + o((x− a)n+1)
= f(a) + f ′(a)(x− a) + f (2)(a)2! (x− a)2 + f (3)(a)
3! (x− a)3 + . . .+ f (n+1)(a)(n+ 1)! (x− a)n+1 + o((x− a)n+1)
D’où le théorème par récurrence sur l’entier n.
Exercice 19.1. Pour tout entier n, déterminer le développement limité à l’ordre n de la fonction exponentielleen 0.Exercice 19.2. Soit f : R → R une fonction de classe C2 telle que f(0) = 0. Calculer la limite de f(x)+f(−x)
x2
quand x tend vers 0.Exemple (développement limité nul). On considère la fonction suivante :
f : R −→ R
x 7−→
exp(−1x
)si x > 0
0 si x ≤ 0
On rappelle que f est de classe C∞ et que pour tout entier k, f (k)(0) = 0. Ainsi, pour tout entier n, le dé-veloppement limité à l’ordre n de f en 0 est f(x) = o(xn). Or la fonction f n’est la pas la fonction nulle surR.
349

TSI 1 Lycée Heinrich-Nessel 2016/2017
19.3 Développements limités des fonctions de référence
Exercice 19.3. Pour chacune des fonctions fi ci-dessous, calculer f (k)i (0) en fonction de l’entier k.
1) f1 : x 7→ 11−x ;
2) f2 : x 7→ cos(x) ;3) f3 : x 7→ sin(x) ;4) f4 : x 7→ (1 + x)α où α ∈ R ;5) f5 : x 7→ arctan(x), pour k compris entre 0 et 3.
Notation. Pour tout α ∈ R et tout k ∈ N, on pose :(α
k
)= α(α− 1) . . . (α− k + 1)
k! =k∏i=1
α− i+ 1i
Proposition 19.13 (Les développements limités de référence). Voici quelques développements limités aupoint 0 :
1) 11−x = 1 + x+ x2 + x3 + · · ·+ xn + o(xn) =
n∑k=0
xk + o(xn)
2) ln(1− x) = −x− x2
2 −x3
3 − · · · −xn
n+ o(xn) = −
n∑k=1
xk
k+ o(xn)
3) ex = 1 + x+ x2
2 + x3
3! + · · ·+ xn
n! + o(xn) =n∑k=0
xk
k! + o(xn)
4) cos(x) = 1− x2
2 + · · ·+ (−1)n x2n
(2n)! + o(x2n+1) =n∑k=0
(−1)k x2k
(2k)! + o(x2n+1)
5) sin(x) = x− x3
3! + · · ·+ (−1)n x2n+1
(2n+1)! + o(x2n+2) =n∑k=0
(−1)k x2k+1
(2k + 1)! + o(x2n+2)
6) (1 + x)α = 1 + αx+ α(α−1)2! x2 + . . .+
(αn
)xn + o(xn) =
n∑k=0
(α
k
)xk + o(xn) pour tout α ∈ R.
7) arctan(x) = x− x3
3 + · · ·+ (−1)n x2n+1
2n+1 + o(x2n+2) =n∑k=0
(−1)k x2k+1
2k + 1 + o(x2n+2)
8) tan(x) = x+ x3
3 + o(x4)
Remarque. ! Attention ! Pour pouvoir utiliser le développement limité de (1 + x)α, il faut que le nombre α soitune constante indépendante de x.
Démonstration. Certains points de la démonstration dépendent des résultats de la section suivante.On pourra yrevenir dans une seconde lecture.
1) On a vu dans l’exercice précédent que si f(x) = 11−x alors f est de classe C∞ sur son domaine de définition
et pour tout entier k, on a f (k)(x) = k!(1 − x)−k−1. Ainsi, en appliquant la formule de Taylor-Young à fen a, on a bien 1
11− x = 1 + x+ x2 + x3 + · · ·+ xn + o(xn)
2) En remarquant que d(ln(1−x))dx = −1
1−x , on pourrait déduire les dérivées de tout ordre de x 7→ ln(1 − x) etretrouver le développement limité à l’aide de la formule de Taylor-Young. Nous allons procédé autrementen intégrant un développement limité (proposition 19.19). Du point précédent, on déduit le développementà l’ordre n− 1 suivant
f(x) = −11− x = −1− x− x2 − . . .− xn−1 + o(xn−1) = P (x) + o(xn−1)
1. Avec un peu de mémoire, on se souviendra que nous avons déjà vu ce développement limité dans le chapitre continuité.Nous l’avions démontré avec une autre méthode.
350

TSI 1 Lycée Heinrich-Nessel 2016/2017
Soit F définie par F (x) = ln(1−x), alors F est une primitive de f et d’après la proposition 19.19, F admetun développement limité à l’ordre n :
F (x) = F (0) +∫ x
0P (t) dt+ o(xn)
= 0− x− x2
2 −x3
3 − . . .−xn
n+ o(xn)
ln(1− x) = −x− x2
2 −x3
3 − . . .−xn
n+ o(xn)
3) Notons que pour tout entier k, dk exdxk = ex, d’où le développement limité annoncé en appliquant la formule
de Taylor-Young à la fonction exponentielle (qui est de classe C∞).4) On a vu dans l’exercice précédent que pour tout entier n, on a
cos(n)(x) =
cos(x) si n = 4k− sin(x) si n = 4k + 1− cos(x) si n = 4k + 2sin(x) si n = 4k + 2
pour un certain k ∈ N
D’où, on déduit que pour tout entier k,
cos(2k)(0) = (−1)k et cos(2k+1)(0) = 0
Enfin, on applique encore une fois la formule de Taylor-Young à la fonction cosinus.5) On procède de même que dans le point précédent, en établissant que pour tout entier k,
sin(2k)(0) = 0 et sin(2k+1)(0) = (−1)k
6) Posons f(x) = (1 +x)α, on a vu dans l’exercice précédent que f est de classe C∞ sur ]−1; +∞[ et que pourtout entier k,
f (k)(x) = α(α− 1) . . . (α− k + 1)(1 + x)α−k+1
f (k)(0)k! = α(α− 1) . . . (α− k + 1)(1 + x)α−k+1
k! =(α
k
)f(x) =
n∑k=0
f (k)(0)k! xk + o(xn) =
n∑k=0
(α
k
)xk + o(xn)
d’après la formule de Taylor-Young appliquée à f .7) Posons f(x) = arctan(x), la fonction f est de classe C∞ sur R et pour tout x ∈ R, f ′(x) = 1
1+x2 . Rappelonsle premier point
11− y = 1 + y + y2 + . . .+ yn + yn × ε(y) avec lim
y→0ε(y) = 0
11 + x2 = 1− x2 + (−x2)2 + . . .+ (−x2)n + (−x2)nε(−x2) en posant y = −x2
= 1− x2 + x4 + . . .+ (−1)nx2n + x2n × ε′(x)
où
ε′(x) = (−1)nε(−x2) −→x→0
0
Ainsi, on déduit que
f ′(x) = 1− x2 + x4 + . . .+ (−1)nx2n + o(x2n)
f(x) = f(0) + x− x3
3 + x5
5 + . . .+ (−1)n x2n+1
2n+ 1 + o(x2n+1)
en intégrant le développement limité de f ′ (proposition 19.19).8) Notons que
tan(x) = sin(x)cos(x) = sin(x)× 1
1 + g(x)
351

TSI 1 Lycée Heinrich-Nessel 2016/2017
avec g(x) = cos(x)− 1 vérifiant g(0) = 0. De plus, en 0 :
11 + y
= 1− y + y2 − y3 + y4 + o(y4) = A(y) + o(y4)
g(x) = cos(x)− 1 = −x2
2 + x4
24 + o(x4) = x2(−12 + x2
24 ) + o(x4) = B(x) + o(x4)
En composant les développements limités (proposition 19.18), on a
1cos(x) = 1
1 + g(x) = A(B(x)) + o(x4)
= 1− (x2(−12 + x2
24 )) +(x2(−1
2 + x2
24 ))2
−(x2(−1
2 + x2
24 ))3
+(x2(−1
2 + x2
24 ))4
+ o(x4)
= 1 + x2
2 −x2
24 + x4(−12 )2 + o(x4)
= 1 + x2
2 + 524x
4 + o(x4)
Ainsi, en effectuant un produit de développements limités (proposition 19.17), on déduit que
tan(x) = sin(x)× 1cos(x)
=(x− x3
6 + o(x4))×(
1 + x2
2 + 524x
4 + o(x4))
= x+ 12x
3 − 16x
3 + o(x4)
= x+ 13x
3 + o(x4)
Corollaire 19.14. Au voisinage de 0, on a les développements limités suivants :
1) 11+x = 1− x+ x2 − x3 + · · ·+ (−1)nxn + o(xn) =
n∑k=0
(−1)kxk + o(xn) ;
2) ln(1 + x) = x− x2
2 + x3
3 + · · ·+ (−1)n−1 xnn
+ o(xn) =n∑k=1
(−1)k−1xk
k+ o(xn).
Démonstration.1) De la première formule donnée dans la proposition précédente, on déduit que :
11 + x
= 11− (−x)
= 1 + (−x) + (−x)2 + (−x)3 + . . .+ (−x)n + o((−x)n)= 1− x+ x2 − x3 + . . .+ (−1)nxn + o(xn)
2) De même, en revenant au second développement limité, on a
ln(1 + x) = ln(1− (−x))
= −(−x)− (−x)2
2 − (−x)3
3 − . . .− (−x)n
n+ o((−x)n)
= x− x2
2 + x3
3 + . . .+ (−1)n−1 xn
n+ o(xn)
Exercice 19.4. Montrer qu’au voisinage de 0, on a les développements limités suivants :1) arcsin(x) = x+ x3
6 + o(x4) ;
2) arccos(x) = π2 − x−
x3
6 + o(x4).
19.4 Développements limités et opérations
352

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 19.15 (combinaison linéaire). Soit f, g : I → R deux fonctions, on suppose que f et g admettentun développement limité à l’ordre n en 0 :
f(x) = An(x) + o(xn) et g(x) = Bn(x) + o(xn)
où An(X), Bn(X) appartiennent à Rn[X]. Pour tout (λ, µ) ∈ R2, la fonction λf + µg : I → R admet undéveloppement limité d’ordre n au voisinage de 0 et on a :
(λf + µg)(x) = (λAn + µBn)(x) + o(xn)
Rappelons que si A(X) =∑n
k=0 akXk et B(X) =
∑n
k=0 bkXk sont deux polynômes de degré inférieur ou égal à
n, alors le polynôme produit est
P (X) =deg(A)+deg(B)∑
k=0
ckXk
où, pour tout 0 ≤ k ≤ deg(A) + deg(B) :
ck =k∑i=0
aibk−i
Définition 19.16. Soit P (X) =∑d
k=0 akXk un polynôme de degré d, pour tout entier n ≤ d, le polynôme
P (X) tronqué à l’ordre n est le polynôme :
R(X) =n∑k=0
akXk
Remarque. Le polynôme tronqué à l’ordre n d’un polynôme P (X) est le reste de la division Euclidienne de P (X)par Xn+1.
Avant de passer au produit, notons que
∀m ∈ N ∀n ∈ N : m > n ⇒ xm = o(xn)
Proposition 19.17 (produit). Soit f, g : I → R deux fonctions, on suppose que f et g admettent un déve-loppement limité à l’ordre n en 0 :
f(x) = An(x) + (xn) et g(x) = Bn(x) + o(xn)
où An(X), Bn(X) appartiennent à Rn[X]. La fonction produit f × g : I → R admet un développement limitéd’ordre n au voisinage de 0 et on a :
(f × g)(x) = Rn(x) + o(xn)
où Rn est le polynôme An ×Bn tronqué à l’ordre n.
Exercice 19.5. Déterminer le développement limité à l’ordre 4 de x 7→ sin(x) ln(1− x) en 0.
Proposition 19.18 (composition). Soit f : I → R une fonction définie sur un intervalle ouvert I contenant0. Soit g : J → I une fonction définie sur un intervalle ouvert J contenant 0 telle que g(0) = 0. On supposeque f et g admettent un développement limité à l’ordre n en 0 :
f(x) = An(x) + (xn) et g(x) = Bn(x) + o(xn)
où An(X), Bn(X) appartiennent à Rn[X]. Alors, f g : J → R admet un développement limité d’ordre n auvoisinage de 0 et on a :
(f g)(x) = Rn(x) + o(xn)où Rn est le polynôme An Bn tronqué à l’ordre n.
Exercice 19.6.1) Déterminer le développement limité à l’ordre 3 de x 7→ cos(ex − 1) en 0.
353

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) Déterminer le développement limité à l’ordre 4 de x 7→ 1cos(x) en 0.
Remarque (développement limité de l’inverse). Soit f : I → R une fonction définie sur un intervalle ouvert I. Soita ∈ I,• Si f(a) = 1, on pose g : I → R définie par g(x) = f(x) − 1, alors g(0) = 0. Ainsi établir un DL de 1
f(x)revient à établir un DL de la composée 1
1+g(x) .
• Si f(a) ∈ R \ 1, 0, on pose g : I → R définie par g(x) = f(x)−f(a)f(a) , alors g(0) = 0 et
1f(x) = 1
f(a) + (f(x)− f(a)) = 1f(a) ×
11 + f(x)−f(a)
f(a)
= 1f(a) ×
11 + g(x)
Ainsi établir un DL de 1f(x) revient à établir un DL de la composée 1
1+g(x) et de multiplier ensuite par laconstante 1
f(a) .• Si f(a) = 0, il faut établir en premier un DL de f(x) et factoriser le DL par la plus grand puissance de
(x− a) afin de se ramener à une expression de la forme :
1f(x) = 1
α(x− a)k1
1 + P (x− a) + o((x− a)l) = 1α(x− a)k
11 + g(x)
où P (X) ∈ R[X] sans coefficient constant.
Proposition 19.19 (intégration). Soit f : I → R continue sur un ouvert I contenant 0 admettant undéveloppement limité à l’ordre n en 0 : f(x) = Pn(x) + o(xn). Soit F : I → R une primitive de f sur I, alors
F (x) = F (0) +∫ x
0Pn(t) dt+ o(xn+1)
Proposition 19.20 (dérivation). Soit f : I → R dérivable sur un ouvert I contenant 0 admettant un déve-loppement limité à l’ordre n en 0 : f(x) = Pn(x) + o(xn). Supposons que f ′ admette un développement limitéd’ordre n− 1 en 0, alors
f ′(x) = P ′n(x) + o(xn−1)
Remarque. Dans la proposition précédente, si f est de classe Cn, alors f ′ est de classe Cn−1 et admet un dévelop-pement limité à l’ordre n− 1 (en tout point de l’intervalle) et la proposition s’applique.
19.5 Formules de TaylorOn se donne f : I → R une fonction de classe Cn sur un intervalle ouvert I et a ∈ I. Nous allons donner, dans descas particuliers, deux expressions différentes du reste o((x − a)n) dans le développement limité (lorsqu’il existe)de f au point a :
f(x) = f(a) + f ′(a)1! (x− a) + f ′′(a)
2! (x− a)2 + . . .+ f (n)(a)n! (x− a)n + o((x− a)n) (DL)
Supposons que f : I → R est de classe C2 sur l’ouvert I. Soit b ∈ I, en intégrant par parties, on a∫ b
a
(b− t)f ′′(t) dt =[(b− t)f ′(t)
]ba−∫ b
a
(−1)f ′(t) dt
= −(b− a)f ′(a) + f(b)− f(a)
D’où
f(b) = f(a) + (b− a)f ′(a) +∫ b
a
(b− a)f ′′(t) dt
et le reste du (DL) avec n = 1 est o(x− a) =∫ xa
(x− a)f ′′(t) dt. Par récurrence, on déduit :
Théorème 19.21 (Formule de Taylor-Cauchy, avec reste intégrale). Soit f : I → R une fonction de classe
354

TSI 1 Lycée Heinrich-Nessel 2016/2017
Cn+1 sur un intervalle ouvert I. Pour tous nombres a et b dans I, on a
f(b) = f(a) + f ′(a)1! (b− a) + f ′′(a)
2! (b− a)2 + . . .+ f (n)(a)n! (b− a)n +
∫ b
a
(b− t)n
n! f (n+1)(t) dt
Démonstration. Pour n = 0, si f est de classe C1, alors on a bien la relation suivante :
f(b) = f(a) +∫ b
a
f ′(t) dt
Soit n un entier quelconque. Supposons que la relation est vraie pour tout fonction de classe Cn+1. Soit f unefonction de classe Cn+2, alors par intégration par parties, on déduit que∫ b
a
(b− t)n+1
(n+ 1)!︸ ︷︷ ︸u(t)
× f (n+2)(t)︸ ︷︷ ︸v′(t)
dt
=[
(b− t)n+1
(n+ 1)! × f(n+1)(t)
]ba
−∫ b
a
(n+ 1)(−1) (b− t)n
(n+ 1)! × f(n+1)(t) dt
= − (b− a)n+1
(n+ 1)! f (n+1)(a) +∫ b
a
(b− t)n
n! f (n+1)(t) dt
= − (b− a)n+1
(n+ 1)! f (n+1)(a) + f(b)−(f(a) + f ′(a)
1! (b− a) + f ′′(a)2! (b− a)2 + . . .+ f (n)(a)
n! (b− a)n)
D’où
f(b) = f(a) + f ′(a)1! (b− a) + . . .+ f (n)(a)
n! (b− a)n + (b− a)n+1
(n+ 1)! f (n+1)(a) +∫ b
a
(b− t)n+1
(n+ 1)! f (n+2)(t) dt
par hypothèse de récurrence appliquée à f . D’où la relation du théorème avec n+ 2 et on en déduit le théorèmepar récurrence sur l’entier n.
Corollaire 19.22. Soit f : I → R une fonction de classe Cn+1 sur un intervalle ouvert I et a ∈ I. Pour toutb ∈ I, le reste o((b− a)n) dans le développement limité (DL) d’ordre n de f en a est
o((b− a)n) =∫ b
a
(b− t)n
n! f (n+1)(t) dt
Théorème 19.23 (Formule de Taylor-Lagrange, avec reste en f (n+1)(θ)). Soit f : I → R une fonction declasse Cn+1 sur un ouvert I. Supposons que a et b sont deux réels distincts de I, alors il existe θ compris entrea et b tels que
f(b) = f(a) + f ′(a)1! (b− a) + f ′′(a)
2! (b− a)2 + . . .+ f (n)(a)n! (b− a)n + (b− a)n+1
(n+ 1)! f (n+1)(θ)
Remarque. ! Attention ! Le nombre θ dépend de a, b et n. Cette formule donne une expression moins explicitepour le reste o((x− a)n) du (DL) à l’ordre n. Néanmoins elle donne la possibilité de majorer le reste du (DL).
Corollaire 19.24 (Inégalité de Taylor-Lagrange). Avec les hypothèses du théorème, si de plus, il existe M ∈ Rtel que pour tout t ∈ [a; b], |f (n+1)(t)| ≤M , alors∣∣∣∣f(b)−
(f(a) + f ′(a)
1! (b− a) + f ′′(a)2! (b− a)2 + . . .+ f (n)(a)
n! (b− a)n)∣∣∣∣ ≤M |b− a|n+1
(n+ 1)!
Exercice 19.7.1) Montrer que pour tout x ∈ R :
| cos(x)− 1 + x2
2 | ≤x4
242) En déduire une valeur approchée de cos(0.1) à 10−5 près (sans utiliser la calculatrice).
Exercice 19.8. Montrer que pour tout réel x > 0, on a32√x+ 3
8√x+ 1
≤ (x+ 1)3/2 − x3/2 ≤ 32√x+ 3
8√x
355

TSI 1 Lycée Heinrich-Nessel 2016/2017
19.6 Asymptotes
Définition 19.25. Soit f une fonction définie sur un intervalle I sauf en un point a. On dit que la droitex = a est asymptote verticale à la courbe de f si les limites de f à droite et à gauche en a sont infinies (peuimporte leur signe).
Définition 19.26. Soit f une fonction définie sur un intervalle de la forme ]a; +∞[. On dit que f admet uneasymptote horizontale en +∞ si f a une limite finie ` en +∞. L’équation de l’asymptote est alors y = `.
Définition 19.27. Soit f une fonction définie sur un intervalle de la forme ]−∞; b[. On dit que f admet uneasymptote horizontale en −∞ si f a une limite finie ` en −∞. L’équation de l’asymptote est alors y = `.
Définition 19.28. Soit f une fonction définie sur un intervalle de la forme ]a; +∞[. On dit que f admet uneasymptote oblique en +∞ d’équation y = mx+ p en +∞ si lim
x→+∞f(x)−mx− p = 0.
Définition 19.29. Soit f une fonction définie sur un intervalle de la forme ]−∞; b[. On dit que f admet uneasymptote oblique en −∞ d’équation y = mx+ p en −∞ si lim
x→−∞f(x)−mx− p = 0.
Remarque. Si m = 0, l’asymptote est horizontale d’équation y = p et les définitions 19.28 et 19.29 coïncident avecles définitions 19.26 et 19.27.
Méthode. Pour déterminer une droite asymptote à la courbe de f en ±∞, on va :1) Calculer lim
x→±∞f(x)
2) a) Si limx→±∞
f(x) n’existe pas, alors il n’y a pas d’asymptote oblique
b) Si limx→±∞
f(x) = `, alors il y a une asymptote horizontale d’équation y = `
c) Si limx→±∞
f(x) = ±∞, alors on calcule limx→±∞
f(x)x
i. Si limx→±∞
f(x)x
= ±∞ ou si limx→±∞
f(x)x
n’existe pas, alors il n’y a pas d’asymptote oblique
ii. Si limx→±∞
f(x)x
= m, on calcule limx→±∞
f(x)−mx
A. Si limx→±∞
f(x)−mx = ±∞ ou si limx→±∞
f(x)−mx n’existe pas, alors il n’y a pas d’asymptoteoblique
B. Si limx→±∞
f(x)−mx = p, alors il y a une asymptote oblique d’équation y = mx+ p
356

TSI 1 Lycée Heinrich-Nessel 2016/2017
19.7 FormulaireLes développements limités ci-dessous sont donnés en 0 :
11− x = 1 + x+ x2 + x3 + · · ·+ xn + o(xn) =
n∑k=0
xk + o(xn)
ln(1− x) = −x− x2
2 −x3
3 − · · · −xn
n+ o(xn) = −
n∑k=1
xk
k+ o(xn)
ex = 1 + x+ x2
2 + x3
3! + · · ·+ xn
n! + o(xn) =n∑k=0
xk
k! + o(xn)
cos(x) = 1− x2
2 + · · ·+ (−1)n x2n
(2n)! + o(x2n+1) =n∑k=0
(−1)k x2k
(2k)! + o(x2n+1)
sin(x) = x− x3
3! + · · ·+ (−1)n x2n+1
(2n+1)! + o(x2n+2) =n∑k=0
(−1)k x2k+1
(2k + 1)! + o(x2n+2)
(1 + x)α = 1 + αx+ α(α−1)2! x2 + . . .+
(αn
)xn + o(xn) =
n∑k=0
(α
k
)xk + o(xn)
arctan(x) = x− x3
3 + · · ·+ (−1)n x2n+1
2n+1 + o(x2n+2) =n∑k=0
(−1)k x2k+1
2k + 1 + o(x2n+2)
tan(x) = x+ x3
3 + o(x4)
11 + x
= 1− x+ x2 − x3 + · · ·+ (−1)nxn + o(xn) =n∑k=0
(−1)kxk + o(xn)
ln(1 + x) = x− x2
2 + x3
3 + · · ·+ (−1)n−1 xnn
+ o(xn) =n∑k=1
(−1)k−1xk
k+ o(xn)
arcsin(x) = x+ x3
6 + o(x4)
arccos(x) = π2 − x−
x3
6 + o(x4)
357

TSI 1 Lycée Heinrich-Nessel 2016/2017
358

Chapitre 20
Applications linéaires
Programme• Applications linéaires : (notation L(E,F ))• Endomorphismes de E (notation L(E) ou End(E)). Identité (notation idE), Homothéties.• Opérations sur les applications linéaires : combinaisons linéaires et composées.• Images directe, image réciproque d’un sous-espace vectoriel.• Image Im(f), Noyau ker(f). Savoir les déterminer. Propriétés.• L’image d’une application linéaire f d’une famille génératrice de E est génératrice de Im(f).• Isomorphismes, automorphismes (notation GL(E) : groupe linéaire). Composéee d’isomorphismes• Une application linéaire de E dans F est un isomorphisme si et seulement si elle transforme une (toute)
base de E en une base de F .• Espaces isomorphes, caractérisation par la dimension.• Si E et F sont de même dimension (finie) alors une application linéaire de E dans F est bijective si et
seulement si elle est injective ou surjective.• Une application linéaire est entièrement déterminée par l’image d’une base.• Une application linéaire définie sur E = E1 ⊕ E2 est déterminée par ses restrictions à E1, E2.• Projecteurs et symétries associés à deux sous-espaces supplémentaires. Propriétés : p est un projecteur si
et seulement si p p = p et s est une symétrie si et seulement si s s = idE .• Rang d’une application linéaire. Pour le calcul à la main, on se limite à des cas simples.• Théorème du rang : Si E est de dimension finie et f : E → F linéaire, alors f est de rang fini et dim(E) =
dim(ker(f)) + rg(f).• Équations linéaires : Structure des solutions, condition de compatibilité, lien avec ker(f) et Im(u).• Représentation matricielle en dimension finie• Matrice d’une application linéaire f dans un couple de bases (notation : MatB,C(f) où B est une base de
l’espace de départ et C est une base de l’espace d’arrivé.• Matrice d’une composée. Lien entre matrice inversible et isomorphisme.• Matrice de passage d’une base à une autre autre.• Effet de changement de bases sur la matrice d’une vecteur, d’une application linéaire, d’un endomorphisme.
Choisir une base adaptée à un problème donné.• Matrice semblables.• ! L’objectif est de donner une première approche de notions qui seront approfondies en seconde année. La
diagonalisation des endomorphismes est hors programme.• Rang d’une matrice. Lien entre divers aspects de la notion de rang.• Rang d’une composée : rg(g f) ≤ min(rg(f), rg(g)). Invariance du rang par composition à droite ou à
gauche par un isomorphisme.• Le rang d’une matrice A ∈Mn,m(K) est égal au rang du système AX = 0.• Le rang d’une matrice A est égal au rang de l’application linéaire canoniquement associée Km → Kn définie
par X 7→ AX.• Le rang d’une famille de vecteurs est égal au rang de sa matrice dans une base.• Le rang d’une application linéaire est égal au rang de sa matrice dans un couple de bases.
359

TSI 1 Lycée Heinrich-Nessel 2016/2017
• Calculer le rang d’une famille de vecteurs, d’une application linéaire par la méthode du pivot.• Conservation du rang par multiplication à droite ou à gauche par une matrice inversible.
Dans ce chapitre K désigne R ou C.
20.1 Rappels
Définition 20.1. Soit n un entier naturel non nul et v1, . . . , vn des vecteurs de E un K-espace vectoriel. Lesvecteurs v1, . . . , vn sont dit linéairement indépendants si pour tous λ1, . . . , λn ∈ K, on a l’implication :
λ1v1 + . . .+ λnvn = OE ⇒ λ1 = . . . = λn = 0
Dans ce cas, on dit aussi que la famille de vecteurs (v1, . . . , vn) est libre.Si une famille de vecteurs n’est pas libre, on dit qu’elle est liée.
Méthode.• Pour montrer qu’une famille (v1, . . . , vn) de vecteurs de E est libre, on commence par se donner des
scalaires λ1, . . . , λn dans K tels que λ1v1 + . . .+ λnvn = OE . Puis on résout l’équation (le plus souventle système) en les inconnues λ1, . . . , λn.
• Pour montrer qu’une famille (v1, . . . , vn) de vecteurs de E est liée, il suffit de trouver des scalairesλ1, . . . , λn dans K non tous nuls tels que λ1v1 + . . .+ λnvn = OE .
Proposition 20.2. Soit (v1, . . . , vn) une famille libre de E.1) Les vecteurs vi sont non nuls.2) Les vecteurs vi sont deux à deux distincts.3) Quel que soit 1 ≤ p ≤ n, les vecteurs v1, . . . , vp sont aussi linéairement indépendants.
Proposition 20.3. Soit v1, . . . , vn des vecteurs de E linéairement indépendants et v un vecteur quelconquede E. Alors v est combinaison linéaire de v1, . . . , vn si et seulement si v1, . . . , vn, v ne sont pas linéairementindépendants.Formellement :
v ∈ Vect(v1, . . . , vn) ⇐⇒ (v1, . . . , vn, v) est liée
Définition 20.4. On dit qu’une famille F = (v1, . . . , vn) de E est génératrice si Vect(F) = E, c’est-à-dire si
∀u ∈ E ∃ (λ1, . . . , λn) ∈ Kn : u = λ1v1 + . . .+ λnvn
Remarque. Une famille (v1, . . . , vn) est génératrice si et seulement si tout vecteur peut s’écrire comme combinaisonlinéaire des vecteurs v1, . . . , vn.
Définition 20.5. On dit qu’une famille (e1, . . . , en) de vecteurs de E est une base de E si elle est libre etgénératrice.
Proposition-Définition 20.6. Une famille (e1, . . . , en) de vecteurs de E est une base si est seulement si
∀ v ∈ E ∃!(x1, . . . , xn) ∈ Kn : v = x1e1 + . . .+ xnen
Dans ce cas, le n-uplet de scalaires (x1, . . . , xn) est appelé coordonnées de v dans la base (e1, . . . , en).
Lemme 20.7 (coordonnées de la somme et du produit par un scalaire). Soit (x1, . . . , xn) ∈ Kn et (y1, . . . , yn) ∈ Kn
les coordonnées dans la base B = (e1, . . . , en) de v et w respectivement. Alors les coordonnées de v + w sont(x1 + y1, . . . , xn + yn) et les coordonnées de λv sont (λx1, . . . , λxn) dans la base B.
360

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 20.8 (de la base incomplète). Soit f1, . . . , fp des vecteurs de E linéairement indépendants etg1, . . . , gq des vecteurs qui engendrent E. Alors, il existe un entier n ≥ p et une base (e1, . . . , en) de E telleque :
1) ei = fi pour tout i ≤ p.2) ei est l’un des gj pour tout i > p
Théorème 20.9. Supposons que E est de dimension n.• Si p vecteur de E sont linéairement indépendants alors p ≤ n.• Si n vecteurs de E sont linéairement indépendants alors ils forment une base de E.• Si E est engendré par q vecteurs alors q ≥ n.• Si n vecteurs de E engendrent E alors ils en forment une base.
Corollaire 20.10. Supposons E de dimension n ≥ 1. Soit (e1, . . . , en) une base de E et f1, . . . , fn des vecteursde E. Notons A ∈Mn(K) la matrice dont les coefficients de la j-ème colonne sont les coordonnées du vecteurfj dans la base (e1, . . . , en). Les propositions suivantes sont équivalentes :
1) (f1, . . . , fn) est une base de E ;2) (f1, . . . , fn) est libre dans E ;3) (f1, . . . , fn) est génératrice dans E ;4) la matrice A est de rang n ;5) la matrice A est inversible.
Théorème 20.11. Supposons que E est de dimension finie. Si F est un sous-espace vectoriel de E alors Fest de dimension finie et sa dimension est inférieure où égale à celle de E.De plus, si dimK(F ) = dimK(E) alors F = E.
Méthode. Pour montrer que F un sous-espace vectoriel de E est égal à E, il suffit de montrer que dimK(F ) =dimK(E).
Proposition 20.12. Si E est de dimension finie et si F est un sous-espace vectoriel de E de dimension p ≥ 1,alors il existe une base de E dont les p premiers vecteurs appartiennent à F .
Proposition 20.13. Supposons E de dimension finie. Soit F et G deux sous-espaces vectoriels de E etdifférents de 0. Si (e1, . . . , ep) est une base de F et si (ep+1, . . . , ep+q) est une base de G alors, F et G sontsupplémentaires (i.e : E = F ⊕G) si et seulement si (e1, . . . , ep+q) est une base de E.
Corollaire 20.14. Si E = F ⊕G de dimension finie alors dimE = dimF + dimG.
Encore une application du théorème de la base incomplète :
Corollaire 20.15. Si E est de dimension finie alors tout sous-espace vectoriel de E admet un supplémentaire.
Théorème 20.16 (formule de Grassmann). Soit F, G deux sous-espaces vectoriels d’un espace vectoriel Ede dimension finie. Alors,
dim(F +G) = dimF + dimG− dim(F ∩G)
20.2 Applications linéairesConsidérons les applications suivantes entre espaces vectoriels :
361

TSI 1 Lycée Heinrich-Nessel 2016/2017
1)f : R2 // R2
(x, y) // x(1
0
)+ y(1
1
)2) Soit v1, . . . , vn des vecteurs d’un espace vectoriel E,
f : Kn // E
(x1, . . . , xn) // x1v1 + . . .+ xnvn
3) Soit C1(R,R) l’espace vectoriel des fonctions de classe C1,
f : C1(R,R) // C(R,R)
φ // φ′
4)f : C(R,R) // C1(R,R)
φ //
(x 7→
∫ x0 φ(t) dt
)On peut vérifier que toutes ces applications "courantes" f : E → F vérifient les deux propriétés suivantes :
∀u, v ∈ E : f(u+ v) = f(u) + f(v)∀λ ∈ K ∀ v ∈ E : f(λv) = λf(v)
En d’autres termes, l’image de la somme de deux vecteurs est la somme des images et l’image d’un vecteurmultiplié par un scalaire est l’image du vecteur multipliée par le scalaire 1.
Définition 20.17. Soit E,F deux espaces vectoriels. Une application linéaire (ou homomorphisme 1 d’espacesvectoriels) f de E dans F est une application f : E → F telle que
1) ∀u, v ∈ E : f(u+ v) = f(u) + f(v)2) ∀λ ∈ K ∀ v ∈ E : f(λv) = λf(v)
1. Application entre deux ensembles munis d’une même espèce de structure, qui respecte cette structure.
Lemme 20.18. Soit f : E → F une applications entre deux espaces vectoriels. Alors f est linéaire si et seulementsi
∀u, v ∈ E ∀λ ∈ K : f(u+ λv) = f(u) + λf(v)
Une application linéaire de E dans F est une application qui respecte les structures d’espace vectoriel de E et deF .
Définition 20.19 (Rappel). Soit f, g : E −→ F deux applications,• On dit que f est égale à g si pour tout v ∈ E : f(v) = g(v).• L’application f est différente de g si seulement s’il existe un vecteur v ∈ E tel que f(v) 6= g(v).
Définition 20.20. Soit f : E → F une application linéaire, si y = f(x) pour un certain x ∈ E, on dit que yest l’image de x par f .
Définition 20.21. Une application linéaire d’un espace vectoriel dans K est appelée une forme linéaire.
Exemple. L’application f : R3 → R définie par f(x, y, z) = x+ y − z est une forme linéaire.
Proposition 20.22 (Combinaisons linéaires). Soit f : E → F une application linéaire, alors1) f(0) = 02) Pour tous λ1, . . . , λn ∈ K et tous v1, . . . , vn ∈ E, on a
f(λ1v1 + . . .+ λnvn) = λ1f(v1) + . . .+ λnf(vn)
1. L’accord du participe passé multiplié donne un sens à la seconde partie de la phrase...
362

TSI 1 Lycée Heinrich-Nessel 2016/2017
L’image d’une combinaison linéaire par une application linéaire est la combinaison linéaire des images.
Exemples. Les applications suivantes sont linéaires.1) Soit v un vecteur d’un espace vectoriel E et f : K→ E l’application définie par f(λ) = λv pour tout λ ∈ K.2) Soit
idE : E // Ev // v
l’application identité.3) Soit
O : E // E
v // OE
l’application nulle.4) Soit λ ∈ K et
λ idE : E // E
v // λv
l’homothétie de rapport λ.
Proposition-Définition 20.23.1) Soit f1, f2 : E → F deux applications linéaires, on définit la somme
f1 + f2 : E // F
v // f1(v) + f2(v)
2) Soit f : E → F une application linéaire et λ ∈ K, on définit la multiplication par un scalaire
λf : E // F
v // λf(v)
3) Soit f : E → F et g : F → G deux applications linéaires, on définit la composée
g f : E // G
v // g(f(v))
Ces applications sont linéaires.
Proposition-Définition 20.24. Soit E,F deux K-espaces vectoriels.1) On note L(E,F ) le K-espace vectoriel des applications linéaires de E dans F .2) On dit qu’une application linéaire de E dans E est un endomorphisme de E. On note End(E) l’espace
vectoriel des endomorphismes de E.
Proposition 20.25. Pour tous f, g, h endomorphismes de E, on a1) f − f = 02) f + (g + h) = (f + g) + h
3) f + 0 = f
4) idE f = f idE = f
5) f (g h) = (f g) h6) f (g + h) = f g + f h7) (f + g) h = f h+ g h
Remarque. On dit que (End(E),+, ) est muni d’une structure d’anneau. Attention ! En générale, on n’a pasf g = g f . En effet, par exemple avec f, g : R2 −→ R2 définies par f
(xy
)=(x0
)et g
(xy
)=(yx
), on a
f g(1
0
)=(1
0
)6= g f
(10
)=(0
0
)
363
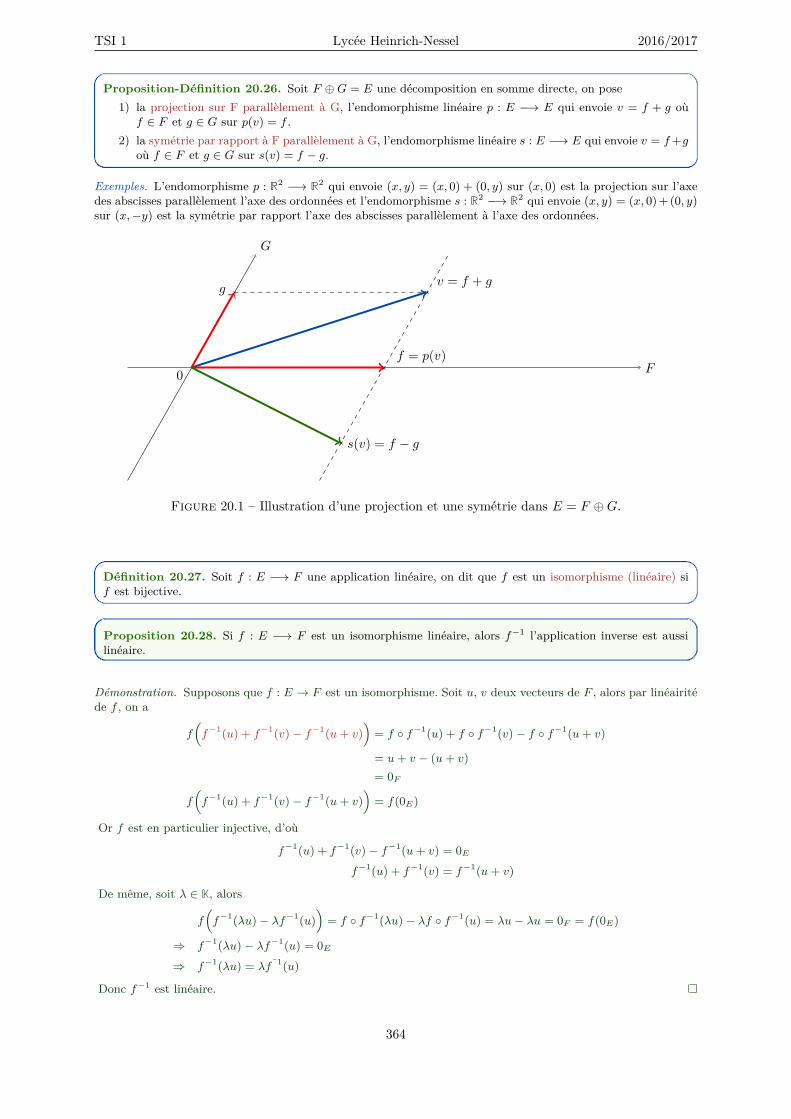
TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition-Définition 20.26. Soit F ⊕G = E une décomposition en somme directe, on pose1) la projection sur F parallèlement à G, l’endomorphisme linéaire p : E −→ E qui envoie v = f + g où
f ∈ F et g ∈ G sur p(v) = f .2) la symétrie par rapport à F parallèlement à G, l’endomorphisme linéaire s : E −→ E qui envoie v = f+g
où f ∈ F et g ∈ G sur s(v) = f − g.
Exemples. L’endomorphisme p : R2 −→ R2 qui envoie (x, y) = (x, 0) + (0, y) sur (x, 0) est la projection sur l’axedes abscisses parallèlement l’axe des ordonnées et l’endomorphisme s : R2 −→ R2 qui envoie (x, y) = (x, 0) + (0, y)sur (x,−y) est la symétrie par rapport l’axe des abscisses parallèlement à l’axe des ordonnées.
0
v = f + gg
f = p(v)
s(v) = f − g
G
F
Figure 20.1 – Illustration d’une projection et une symétrie dans E = F ⊕G.
Définition 20.27. Soit f : E −→ F une application linéaire, on dit que f est un isomorphisme (linéaire) sif est bijective.
Proposition 20.28. Si f : E −→ F est un isomorphisme linéaire, alors f−1 l’application inverse est aussilinéaire.
Démonstration. Supposons que f : E → F est un isomorphisme. Soit u, v deux vecteurs de F , alors par linéairitéde f , on a
f(f−1(u) + f−1(v)− f−1(u+ v)
)= f f−1(u) + f f−1(v)− f f−1(u+ v)
= u+ v − (u+ v)= 0F
f(f−1(u) + f−1(v)− f−1(u+ v)
)= f(0E)
Or f est en particulier injective, d’où
f−1(u) + f−1(v)− f−1(u+ v) = 0Ef−1(u) + f−1(v) = f−1(u+ v)
De même, soit λ ∈ K, alors
f(f−1(λu)− λf−1(u)
)= f f−1(λu)− λf f−1(u) = λu− λu = 0F = f(0E)
⇒ f−1(λu)− λf−1(u) = 0E⇒ f−1(λu) = λf¯1(u)
Donc f−1 est linéaire.
364

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 20.29. Soit E un espace vectoriel, l’ensemble des isomorphismes linéaires de E est noté GL(E)et est appelé groupe linéaire.
Exercice 20.1. Justifier que le groupe linéaire GL(E) vérifie les trois propriétés suivantes :1) ∀ f, g, h ∈ GL(E) : h (g f) = (h g) f (associativité de )2) ∀ f ∈ GL(E) : f idE = idE f = f (existence d’un élément neutre pour )3) ∀ f ∈ GL(E) ∃g ∈ GL(E) : f g = g f = idE (existence d’un symétrique par rapport à )
Définition 20.30. On dit que deux espaces E et F sont isomorphes s’il existe un isomorphisme de E sur F .
Proposition 20.31 (Homothétie). Soit λ ∈ K.1) Si λ = 0, alors λ idE = 0.2) Si λ 6= 0, alors l’homothétide λ idE de rapport λ est un isomorphisme et (λ idE)−1 = 1
λidE .
De plus, dans tous les cas, l’homothétie λ idE commute à n’importe quel autre endomorphisme g de E, c’est-à-dire :
∀ g ∈ L(E), (λ idE) g = g (λ idE) = λg
20.3 Application linéaire et sous-espace vectorielSoit f : E −→ F une application linéaire où E,F sont deux K-espaces vectoriels.
Définition 20.32.1) Soit y ∈ F et x ∈ E tels que f(x) = y, on dit que x est un antécédent de y (par f).2) Soit S une partie de E et T une partie de F , on pose
• f(S) = f(x) ; x ∈ S l’image de S par f .• f#(T ) = x ∈ E ; f(x) ∈ T l’image réciproque (ou préimage) de T par f .
Proposition 20.33. Si G est un sous-espace vectoriel de E et H un sous-espace vectoriel de F . Alors f(G)l’image de G par f et f#(H) la préimage de H par f sont des sous-espaces vectoriels.
Définition 20.34. On appelle image de f le sous-espace vectoriel f(E) de F et on le note Im(f).
Remarque. L’application linéaire f : E −→ F est surjective si et seulement si l’image de f est égale à F lui-même.
Définition 20.35. On appelle noyau de f le sous-espace vectoriel
f#(0) = x ∈ E; f(x) = 0
et on le note 1 ker(f).
1. L’abréviation ker vient du mot kernel qui signifie noyau en anglais.
Remarque. Le vecteur nul 0 appartient toujours au noyau !
Rappels. Soit f : E −→ F une application quelconque. Alors f est• injective si et seulement si
∀x, x′ ∈ E : f(x) = f(x′)⇒ x = x′
⇐⇒ ∀ y ∈ F : #(f#(y)) ≤ 1
si et seulement si tout élément de F admet au plus un antécédent par f .
365

TSI 1 Lycée Heinrich-Nessel 2016/2017
• surjective si et seulement si
∀ y ∈ F ∃x ∈ E : f(x) = y
⇐⇒ ∀ y ∈ F : #(f#(y)) ≥ 1
si et seulement si tout élément de F admet au moins un antécédent par f .• bijective si et seulement si elle est injective et surjective, si et seulement si
∀ y ∈ F ∃!x ∈ E : f(x) = y
⇐⇒ ∀ y ∈ F : #(f#(y)) = 1
si et seulement si tout élément de F admet exactement un antécédent par f .
Proposition 20.36. Une application linéaire f est injective si et seulement si ker(f) = OE.
Vocabulaire. Lorsque ker(f) = OE, on dit que le noyau de f est trivial.
Proposition 20.37. Soit (e1, . . . , en) une famille libre de E. Si f : E → F est injective alors la famille devecteurs (f(e1), . . . , f(en)) est aussi libre.
Remarque. La réciproque est fausse.
Proposition 20.38. Si G est le sous-espace vectoriel engendré par les vecteurs v1, . . . , vn de E, alors f(G)l’image de G par f est le sous-espace vectoriel engendré par f(v1), . . . , f(vn). C’est-à-dire :
f( Vect(v1, . . . , vn) ) = Vect( f(v1), . . . , f(vn) )
C’est-à-dire, l’image d’un sous-espace vectoriel engendré par une famille de vecteurs est égale au sous-espacevectoriel engendré par les images des vecteurs de la famille.
Corollaire 20.39. Soit (e1, . . . , en) une famille génératrice de E et f : E → F une application linéaire. L’appli-cation f est surjective si et seulement si (f(e1), . . . , f(en)) est une famille génératrice de F .
Méthode. Lorsque E et F sont de dimension fini. Pour trouver une base de Im(f), on pourra choisir unebase (e1, . . . , en) de E puis extraire une base de Im(f) de (f(e1), . . . , f(en)).
Théorème 20.40. Soit f : E → F une application linéaire. L’application f est un isomorphisme si etseulement si elle transforme une (toute) base (e1, . . . , en) de E en (f(e1), . . . , f(en)) une base de F .
Corollaire 20.41. Soit E, F deux K-espaces vectoriels de dimension fini et f : E → F une application linéaire.Alors :
1) Si f est injective, alors dim(E) ≤ dim(F ) ;2) Si f est surjective, alors dim(E) ≥ dim(F ) ;3) Si f est un isomorphisme, alors dim(E) = dim(F ).
Exercice 20.2. Soit F et G deux sous-espaces vectoriels d’un espace vectoriel E. On pose f : F ×G→ E définiepar
∀ (u, v) ∈ F ×G : f(u+ v) = u+ v.
Montrer que f est un isomorphisme si et seulement si E = F ⊕G.
Proposition 20.42 (caractérisation des projections). Soit p : E → E un endomorphisme. L’application p estune projection si et seulement si
p2 = p
De plus, dans ce cas, on a1) Im(p) = ker(idE −p) = x ∈ E; p(x) = x.2) E = ker(p)⊕ Im(p).
366

TSI 1 Lycée Heinrich-Nessel 2016/2017
3) p est la projection sur Im(p) parallèlement à ker(p).
Démonstration. Le sens direct : Supposons que p est la projection sur F parallèlement à G (avec E = F ⊕ G).Soit v ∈ E, alors il existe un unique couple (f, g) ∈ F ×G tel que v = f + g. Notons que la décomposition de fdans E = F ⊕G est f = f +OE . D’où
p p(v) = p(p(f + g)) = p(f) = p(f +OE) = f = p(v)
C’est-à-dire p p = p.Réciproquement : Supposons que p = p p. Posons
F = Im(p) et G = ker(p)
Montrons que ces deux sous-espaces sont en somme directe : Soit v ∈ F ∩ G, comme v ∈ Im(p), il existe u ∈ Etel que v = p(u). Or
v ∈ ker(f) ⇒ p(v) = 0E⇒ p(p(u)) = 0E car v = p(u)⇒ p(u) = 0E car p = p p⇒ v = 0E
Ainsi, F ∩G = 0E. Soit v ∈ E, posons f = p(v), c’est un élément de Im(F ), et posons g = v − p(v). Alors
v = p(v) + (v − p(v)) = f + g
et
p(g) = p(v − p(v))= p(v)− p p(v) car p est linéaire= p(v)− p(v) car p = p p= 0E
Donc g ∈ ker(p) et on vient de démontrer que
∀ v ∈ E ∃ (f, g) ∈ F ×G : v = f + g
Ainsi E = F +G et comme F ∩G = 0E, on déduit que E = F ⊕G.De plus, pour tout v ∈ E, si on se donne (f, g) ∈ Im(p)× ker(p), alors il existe f ′ ∈ E tel que f = p(f ′) et on a
p(v) = p(f + g) = p(f) + 0E = p(p(f ′)) = p(f ′) = f.
Par définition, p est donc la projection sur Im(p) parallèlement à ker(f).Il nous reste à établir la relation Im(p) = ker(idE −p). Soit v ∈ Im(p), alors il existe u ∈ E tel que v = p(u) et
(idE −p)(v) = v − p(v) = p(u)− p(p(u)) = p(u)− p(u) = 0E ⇒ v ∈ ker(idE − Im(p))
D’où Im(p) ⊂ ker(idE −p). L’inclusion inverse : Soit v ∈ ker(idE −p), alors
(idE −p)(v) = 0E⇒ v − p(v) = 0E⇒ v = p(v)⇒ v ∈ Im(p)
D’où ker(idE −p) est inclus dans Im(p) et par double inclusion, les deux sous-espaces sont égaux.
Proposition 20.43 (caractérisation des symétries). Soit s : E −→ E un endomorphisme. L’application s estune symétrie si et seulement si
s2 = idE
De plus, dans ce cas, on a1) s est un isomorphisme et s−1 = s ;2) E = ker(s− idE) ⊕ ker(s+ idE) ;3) s est la symétrie par rapport à ker(s− idE) parallèlement à ker(s+ idE).
367

TSI 1 Lycée Heinrich-Nessel 2016/2017
Démonstration. Le sens direct : Supposons que s est la symétrie par rapport à F et parallèlement à G (avecE = F ⊕ G). Soit v ∈ E, alors il existe un unique couple (f, g) ∈ F × G tel que v = f + g (la décomposition def − g dans E = F ⊕G est f − g = f + (−g)) et
s s(v) = s(s(f + g)) = s(f − g) = f + g = v = idE(v)
C’est-à-dire s2 = idE .Réciproquement : Supposons que s2 = idE . Posons
F = ker(s− idE) et G = ker(s+ idE)
Soit v ∈ F ∩G, alors
(s− idE)(v) = OE
(s+ idE)(v) = OE
⇒
s(v) = v
s(v) = −v
⇒ v = −v ⇒ v = 0E
Donc F ∩G = 0E. Soit v ∈ E, posons
f = 12(v + s(v)) et g = 1
2(v − s(v))
En développant (proposition 20.25), on déduit que
(s− idE) (s+ idE) = s2 + s− s− idE = s2 − idE
D’où,
(s− idE)(f) = (s− idE)(1
2(s+ idE)(v))
= 12(s− idE) (s+ idE)(v) car s− idE est linéaire
= 12(s2 − idE)(v)
= 12(v − v) car s2 = idE
= 0E
et f ∈ ker(s− idE). De même, (s+ idE) (s− idE) = s2 − idE et
(s+ idE)(g) = (s+ idE)(1
2(s− idE)(v))
= 12(s+ idE) (s− idE)(v) car s+ idE est linéaire
= 12(s2 − idE)(v)
= 12(v − v) car s2 = idE
= 0E
et g ∈ ker(s + idE). On en déduit que E = ker(s − idE) + ker(s + idE). Or ker(s − idE) ∩ ker(s + idE) = 0E,d’où E = ker(s− idE)⊕ ker(s+ idE).D’autre part, avec les notations précédentes, on a
s(v) = s(f + g)
= s(1
2(v + s(v)) + 12(v − s(v))
)= 1
2(s(v) + s2(v)) + 12(s(v)− s2(v)) car s est linéaire
= 12(s(v) + v) + 1
2(s(v)− v) car s2 = idE
= 12(v + s(v))− 1
2(v − s(v))
= f − g
Ainsi, s est la symétrie par rapport à ker(s− idE) parallèlement à ker(s+ idE).Enfin, comme s s = idE , on déduit que s est une bijection (donc un isomorphisme) et s−1 = s.
368

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 20.3. Soit M la matrice à coefficients dans R donnée par M =
(2 3 0−1 −2 0−1 −3 1
)et soit s : R3 → R3
l’application linéaire associée (i.e. ∀X ∈ R3, s (X) = MX).
1) Calculer M2 et en déduire que s est une symétrie vectorielle.
2) Déterminer une base B1 de ker (s− id) et une base B2 de ker (s+ id).
3) Retrouver par le calcul que ker (s− id)⊕ ker (s+ id) = R3.
4) Déterminer l’image de chacun des vecteurs de la base B = B1 ∪ B2 par s.
Exercice 20.4. ? Soit s un endomorphisme de E. Montrer que s est une symétrie si et seulement si 12 (idE +s)
est une projection si et seulement si 12 (idE −s) est une projection.
20.3.1 Application linéaire entre espaces vectoriels de dimension finie
Dans cette section, on suppose que E et F sont des espaces vectoriels de dimension finie. On rappelle que dansce cas, les espaces vectoriels E et F admettent tous les deux une base (finie).
Définition 20.44. Soitf : E // Kn
x // (f1(x), . . . , fn(x))
On appelle f1, . . . , fn les composantes de f .
Proposition 20.45. Une application f de E dans Kn est linéaire si et seulement si toutes ses composantesfi sont des formes linéaires.
Exemple. Soit E un espace vectoriel de dimension n et (e1, . . . , en) une base de E. Soit f : E −→ Kn qui àun vecteur v de E associe (x1, . . . , xn) les coordonnées de v dans la base (e1, . . . , en). Alors, l’application f estlinéaire et la i-ème composante fi est la forme linéaire qui à une vecteur associe sa i-ème coordonées dans la base(e1, . . . , en).
Théorème 20.46. Soit E un espace vectoriel de dimension n ≥ 1, (e1, . . . , en) une base de E et (v1, . . . , vn)une famille arbitraire de vecteurs d’un espace vectoriel F . Soit f : E −→ F l’application définie de la manièresuivante :
∀x1, . . . , xn ∈ K : f(x1e1 + . . .+ xnen) = x1v1 + . . .+ xnvn
L’application f est linéaire. De plus, f est l’unique application linéaire vérifiant la propriété :
∀ i ∈ J1;nK : f(ei) = vi
Remarque.
• En d’autres termes, une application linéaire définie sur un espace vectoriel de dimension finie est uniquementdéterminée par l’image d’une base.
• L’application f est bien définie car la famille (e1, . . . , en) est une base de E, ainsi les coordonnées (x1, . . . , xn)sont uniquement déterminées :
∀ v ∈ E ∃! (x1, . . . , xn) ∈ Kn : v =n∑i=1
xiei et f(v) =n∑i=1
xivi
( ! Démonstration au programme)
Démonstration. Avec les notations et hypothèses du théorème, montrons que l’application f est linéaire. Soit uet v dans E, notons (x1, . . . , xn) ∈ Kn et (y1, . . . , yn) ∈ Kn les coordonnées de u et v dans la base B = (e1, . . . , en)
369

TSI 1 Lycée Heinrich-Nessel 2016/2017
respectivement. Alors, les coordonnées de u+ v sont (x1 + y1, . . . , xn + yn) et
f(u+ v) = f
(n∑i=1
(xi + yi)ei
)
=n∑i=1
(xi + yi)vi
=n∑i=1
xivi +n∑i=1
yivi
= f(u) + f(v)
de même, pour tout λ ∈ K, les coordonnées λu dans la base B sont (λx1, . . . , λxn) et
f(λu) = f
(n∑i=1
λxi
)=
n∑i=1
λxivi = λ
n∑i=1
xivi = λf(u)
Donc f est linéaire.
Soit g : E → F une application linéaire telle que pour tout i ∈ J1;nK, g(ei) = vi. Soit v ∈ E quelconque, notons(x1, . . . , xn) les coordonnées de v dans la base B, alors
g(v) = g
(n∑i=1
xiei
)
=n∑i=1
xig(ei) car g est linéaire
=n∑i=1
xivi par hypothèse sur g
= f(v) par définition de f
D’où g = f et l’unicité.
Exercice 20.5. Justifier qu’il existe une unique application linéaire f : Rn[X]→ Rn[X] telle que f(Xk) = Xn−k
pour tout k ∈ 0, . . . , n. Est-elle bijective ? Décrire f(P ) pour P (X) ∈ Rn[X] quelconque.
Corollaire 20.47. Soit E de dimension n, (e1, . . . , en) une base de E et f, g : E −→ F deux applications linéaires.Alors,
f = g ⇐⇒(∀i ∈ J1;nK : f(ei) = g(ei)
)C’est-à-dire : deux applications linéaires sont égales si et seulement si elles coïncident sur une base de E.
Démonstration. Le sens direct est immédiat. Réciproquement, posons vi = f(ei) pour tout i ∈ J1;nK, alorsg(ei) = vi pour tout i ∈ J1;nK. Ainsi, de l’unicité dans le théorème précédent, on déduit que f = g.
Corollaire 20.48. L’application f : Kn −→ K est linéaire si et seulement s’il existe a1, . . . , an ∈ K tels que
∀ (x1, . . . , xn) ∈ Kn : f(x1, . . . , xn) = x1a1 + . . .+ xnan
Démonstration. Notons C = (e1, . . . , en) la base canonique de Kn.Le sens direct : Si f est linéaire, posons ai = f(ei) pour tout 1 ≤ i ≤ n. Alors, pour tout (x1, . . . , xn) ∈ Kn, on a
f(x1, . . . , xn) = f
(n∑i=1
xiei
)=
n∑i=1
xif(ei) =n∑i=1
xiai
Réciproquement, soit (a1, . . . , an) ∈ Kn. Pososn vi = ai dans F = K pour tout 1 ≤ i ≤ n. D’après le théorèmeprécédent avec C comme base de E = Kn, la condition
∀ (x1, . . . , xn) ∈ Kn : f(x1, . . . , xn) = x1a1 + . . .+ xnan
définie une unique application linéaire.
À l’aide du théorème 20.40, on déduit encore un troisième corollaire.
370

TSI 1 Lycée Heinrich-Nessel 2016/2017
Corollaire 20.49. Soit E et F deux espaces vectoriels de dimension finie, alors E et F sont isomorphes si etseulement s’ils sont de même dimension.
Démonstration. Le sens direct : Supposons que E et F sont isomorphes, soit f : E → F un isomorphisme et(e1, . . . , en) une base de E. D’après le théorème 20.40, la famille image (f(e1), . . . , f(en)) est une base de F . D’oùdim(F ) = n = dim(E).Réciproquement, supposons que E et F sont de même dimension. Soit (e1, . . . , en) une base de E et (f1, . . . , fn)une base de F . D’après le théorème précédent, il existe une application linéaire φ : E → F et une applicationlinéaire ψ : F → E telles que
∀ i ∈ J1;nK : φ(ei) = fi et ψ(fi) = ei
Ainsi,
∀ i ∈ J1;nK :
ψ(φ(ei)
)= ψ(fi) = ei = idE(ei)
φ(ψ(fi)
)= φ(ei) = fi = idE(fi)
Comme les applications coïncident sur une base (corollaire 20.47), elles sont égales :
ψ φ = idE et φ ψ = idF
D’où, ψ : E → F est une bijection linéaire et les espaces vectoriels E et F sont isomorphes.
Digression. L’isomorphisme dont l’existence est établie dans la preuve du corollaire précédent est dit non cano-nique car il dépend d’un choix d’une base de E et d’une base de F .
Définition 20.50. On appelle rang de f la dimension de l’espace vectoriel Im(f) et on le note rg(f).
Exemples.1) Le rang de l’application nulle est 0.2) Si rg(f) = 0 alors f = 0.3) Si E est de dimension finie, alors rg(idE) = dim(E).4) Si E et F sont de dimension finie, et si f est un isomorphisme, alors rg(f) = dim(F ) = dim(E).
Rappelons que si G est un sous-espace vectoriel de F alors G = F si et seulement si dim(G) = dim(F ).
Proposition 20.51. Les propriétés suivantes sont équivalentes :1) L’application linéaire f : E → F est surjective.2) Im(f) = F .3) rg(f) = dim(F ).
Théorème 20.52 (théorème du rang). Soit E est un espace vectoriel de dimension finie et f : E → F uneapplication linéaire. Alors f est de rang fini et
dim(E) = dim(
ker(f))
+ rg(f)
Remarque. On se souviendra que dans le théorème du rang, E correspond à l’espace vectoriel de départ de f .
Démonstration (hors programme). Un cas particulier : Supposons que E est de dimension finie. Nous avons vudans le chapitre sur les espaces vectoriels que d’après un corollaire du théorème de la base incomplète, il existe Sun supplémentaire de ker(f) dans E : E = ker(f)⊕ S. Posons φ : S → Im(f) définie par
∀ v ∈ S : φ(v) = f(v).
371

TSI 1 Lycée Heinrich-Nessel 2016/2017
C’est une application linéaire. Soit v ∈ ker(φ), alors
φ(v) = 0E⇒ f(v) = 0E⇒ v ∈ ker(f) et v ∈ S⇒ v ∈ ker(f) ∩ S⇒ v = 0E car ker(f) ∩ S = 0E
Donc φ est injective (proposition 20.36). D’autre part, soit y ∈ Im(f), alors il existe x ∈ E tel que y = f(x).D’autre part, il existe un unique couple (k, s) ∈ ker(f)× S tel que x = k + s. Ainsi,
y = f(x) = f(k + s) = f(k) + f(s) = f(s) = φ(s) avec s ∈ S
D’où φ : S → Im(f) est surjective et réalise un isomorphisme. D’après le corollaire précédent, on a dim(Im(f)) =dim(S) et donc
dim(E) = dim(ker(f)⊕ S) = dim(ker(f)) + dim(S) = dim(ker(f)) + dim(Im(f)) = dim(ker(f)) + rg(f).
Exercice 20.6. Trouver le rang de f dans les cas suivants :1) f : R2 → R2 définie par f(x; y) = (2x− y; 3x+ 4y) ;2) f : R2 → R3 définie par f(x; y) = (2x− y; 3x+ 4y;−x+ 2y) ;3) f : C3 → C2 définie par f(z1; z2; z3) = (z1 + iz2 + z3; (1 + i)z1) ;4) f : R2 → R définie par f(x; y) = ax+ by où (a, b) ∈ R2 ;5) f : R→ C1(R,R) définie par f(x) est la fonction φ telle que φ′(t) = aφ(t) et φ(0) = x.
Corollaire 20.53. Supposons E et F de même dimension. Si f est injective ou surjective alors f est unisomorphisme.
Démonstration. Si E et F sont de même dimension, alors
f est injective⇐⇒ ker(f) = 0E⇐⇒ dim(ker(f)) = 0⇐⇒ dim(E) = rg(f) d’après le théorème du rang⇐⇒ dim(F ) = rg(f) car dim(E) = dim(F )⇐⇒ f est surjective
D’où si f est injective ou surjective alors elle est nécessairement injective et surjective, et donc un isomorphisme.
Corollaire 20.54. Soit (a1, . . . , an) ∈ Kn non nul, alors le sous-espace vectoriel de Kn des solutions de l’équation
a1x1 + . . .+ anxn = 0
est de dimension n− 1.
Démonstration. Soit (a1, . . . , an) ∈ Kn non nul, alors il existe un indice i0 tel que ai0 6= 0. Notons (e1, . . . , en) labase canonique de Kn. Posons f : Kn → K définie par
∀ (x1, . . . , xn) ∈ Kn : f(x1, . . . , xn) = x1a1 + . . .+ xnan
Alors f est linéaire (corollaire 20.48) et
ker(f) = (x1, . . . , xn) ∈ Kn : a1x1 + . . . anxn = 0
De plus,0 6= f(ei0) = ai0 ∈ Im(f) ⇒ Im(f) 6= 0 ⇒ rg(f) > 0
Or Im(f) ⊂ K, donc 0 ≤ rg(f) ≤ dim(K). On en déduit que rg(f) = 1 et d’après le théorème du rang :
dim(ker(f)) = dim(Kn)− rg(f) = n− 1
D’où le corollaire.
372

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exercice 20.7. Soit f, g ∈ L(E,K) deux formes linéaires.1) Que peut-on dire de rg(f) ? Et de dim(ker(f)) ?2) On suppose que ker(f) = ker(g). Montrer que f et g sont proportionnelles.
20.4 Changement de basesSoit f : E −→ F une application linéaire, on suppose que E et F sont de dimension finie.
20.4.1 Matrice d’une application linéaire
Définition 20.55. Soit B = (b1, . . . , bm) base de E et C = (e1, . . . , en) une base de F . La matrice de l’appli-cation linéaire f dans les bases B et C, notée MatB,C(f), est la matrice dont les coefficients de la j-ème colonnesont les coordonnées de f(bj) dans la base C.Si E = F et B = C, alors on note la matrice de l’endomorphisme f dans la base B de la manière suivante :MatB(f).
Exercice 20.8.1) Donner la matrice de idE dans les bases (B;B).2) Donner dans les bases canoniques la matrice de
f : (x, y) ∈ R2 7→ (2x+ 3y,−x+ 5y) ∈ R2
3) Donner dans les bases canoniques la matrice de
p : (x1, . . . , xn) ∈ Rn 7→ (x1, . . . , xn−1) ∈ Rn−1
4) Donner dans les bases canoniques la matrice de
g : (x1, . . . , xn) ∈ Rn 7→ (x2, . . . , xn, 0) ∈ Rn
Exercice 20.9. On pose e1 = (1, 2), e2 = (−1, 0), f1 = (−1, 0) et f2 = (1, 1) et
f : (x, y) ∈ R2 7→ (2x+ 3y,−x+ 5y) ∈ R2
1) Montrer que B = (e1, e2) et C = (f1, f2) sont des bases de R2.2) Calculer f(e1) et exprimer les coordonnées de f(e1) dans la base C. De même pour f(e2).3) En déduire la matrice M = MatB,C(f) de l’application f dans les bases B et C.
4) Soit(xy
)∈ R2, on pose
(ab
)= M
(xy
).
a) Vérifier que f(xe1 + ye2) = af1 + bf2.b) Que représente le couple (a, b) pour le vecteur v de coordonnées (x, y) dans la base B ?
En revenant à la définition, schématiquement, on a
MatB,C(f) =
(f(b1), . . . , f(bm)
)C
Plus précisément, soit aij ∈ K tels que pour tout 1 ≤ j ≤ m :
f(bj) =n∑i=1
aijei
c’est-à-dire f(bj) est de coordonnées (a1j , . . . , anj) dans la base C. Alors, MatB,C(f) = [aij ].De plus
MatB,C(f)
0...
1j...0
=
a1j...ajj...enj
373

TSI 1 Lycée Heinrich-Nessel 2016/2017
Soit x ∈ E, notons (x1, . . . , xm) ∈ Km les coordonnées de x dans la base B et posons y = f(x). Alors,
y = f
(m∑j=1
xjbj
)=
m∑j=1
xjf(bj) =m∑j=1
xj
(n∑i=1
aijei
)=
n∑i=1
(m∑j=1
xjaij
)ei
d’où les coordonnées de y, image de x par f , sont
∑m
j=1 xja1j
...∑m
j=1 xjajj...∑m
j=1 xjanj
=m∑j=1
xj
a1j...ajj...enj
D’autre part, nous avons vu dans le chapitre sur le calcul matriciel que multiplier une matriceM par une matricecolonne revient à faire une combinaison linéaire des colonnes de M , d’où
MatB,C(f)
x1...xj...xm
=m∑j=1
xj
a1j...ajj...enj
D’où la proposition suivante :
Proposition 20.56 (image d’un vecteur). Soit f : E −→ F une application linéaire, B = (b1, . . . , bm) unebase de E et C = (e1, . . . , en) une base de F . Soit A = MatB,C(f) la matrice de f dans les bases B et C. Soitx ∈ E et y = f(x), on se donne (x1, . . . , xm) (resp. (y1, . . . , yn)) les coordonnées de x (resp. y) dans la base B(resp. C). Alors, y1
...yn
= A
x1...xm
Remarque. Pour calculer les coordonnées de f(x) dans la base de l’espace d’arrivé, il suffit de multiplier lescoordonnées de x dans la base de l’espace de départ par la matrice de l’application f dans les deux précédentesbases.
Proposition 20.57 (combinaison linéaire). Soit f, g : E −→ F deux applications linéaires et λ ∈ K. SoitB = (b1, . . . , bm) une base de E et C = (e1, . . . , en) une base de F , alors
MatB,C(f + λg) = MatB,C(f) + λMatB,C(g)
Remarque. La matrice d’une combinaison linéaire d’applications linéaires dans les bases B et C est la combinaisonlinéaire des matrices des ces dernières applications.
Théorème 20.58. Soit B = (e1, . . . , en) une base de E et B′ = (e′1, . . . , e′n) une base de F . L’applicationΦ : L(E,F ) → Mm,n(K), qui à une application linéaire f de E dans F associe sa matrice MatB,B′(f) dans lesbases B et B′, est un isomorphismes d’espaces vectoriels.
Corollaire 20.59. L’espace vectoriel L(E,F ) des applications linéaires de E dans F est de dimension finie etdim(L(E,F )) = dim(E)× dim(F ).
20.4.2 Changement de bases
Proposition 20.60 (composée). Soit f : E −→ F et g : F −→ G deux applications linéaires, alors
MatB,D(g f) = MatC,D(g)×MatB,C(f)
où B, C et D sont des bases de E,F et G respectivement.
Remarque. On notera une forme de similarité avec les relations de Chasles.
374

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 20.61. Soit f un endomorphisme de E, un espace vectoriel de dimension finie et B une base deE.
1) Pour tout entier n, MatB(fn) = MatB(f)n.2) Si f est un isomorphisme alors MatB(f−1) = MatB(f)−1.
Lorsqu’un endomorphisme est inversible, la matrice de son inverse dans une base donnée est égale à l’inverse desa matrice dans la même base.
Nous allons maintenant voir comment la matrice d’une application donnée change lorsqu’on change de bases.
Définition 20.62. Soit B = (b1, . . . , bn) et B′ = (b′1, . . . , b′n) deux bases de E. On pose
P = MatB′,B(id)
la matrice où la j-ème colonne est constituée des coordonnées de b′j dans la base B. On appelle P la matricede passage de B vers la base B′ et on la note :
PB′B ou MatB(B′)
Pour retrouver les coordonnées d’un vecteur dans la base B, il suffit de multiplier les coordonnées dans la base B′par la matrice de passe PB
′B (à gauche) :
Proposition 20.63. Soit v un vecteur de E. On se donne (x1, . . . , xn) (resp. (x′1, . . . , x′n)) les coordonnées dev dans la base B (resp. B′) et PB
′B la matrice de passage de B vers B′. Alors, on a la relation suivante :x1
...xn
= PB′B
x′1...x′n
Lemme 20.64. Soit B et B′ deux bases de E. Soit P la matrice de passage de B vers B′, alors la matrice P estinversible et P−1 est la matrice de passage de B′ vers B.
Remarque. En général, B′ est une nouvelle base qui est déterminée à l’aide des coordonnées de ses éléments dansl’ancienne base B. Ainsi, déterminer la matrice P de passage de B vers B′ est simple (voir l’exemple ci-dessous).Le lemme nous dit que pour revenir en arrière, passer de B′ à B, il suffit d’inverser la matrice P .
Théorème 20.65 (formule de changement de base). Soit B, B′ deux bases de E et f un endomorphisme deE. Soit P la matrice de passage de B vers B′, alors
MatB′(f) = P−1 ×MatB(f)× P
( ! Démonstration au programme)
Démonstration. C’est une conséquence de la proposition 20.60 sur la matrice d’une composée et du lemme pré-cédent :
P−1 ×MatB(f)× P = MatB,B′(idE)×(
MatB,B(f)×MatB′,B(idE))
= MatB,B′(idE)×MatB′,B(f idE)= MatB,B′(idE)×MatB′,B(f)= MatB′,B′(idE f)= MatB′(f)
375

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemple. Soit B = (e1, e2, e3) la base canonique de R3, f(x, y, z) = (−x+ y + z,−2x+ y + z,−6x+ 2y + 4z). Onse donne v1 = (1, 0, 2), v2 = (1, 1, 2) et v3 = (2, 1, 5), les trois vecteurs forment une base B′ de R3. La matrice depassage de B vers B′ est :
P =
(1 1 20 1 12 2 5
)et
MatB(f) =
(−1 1 1−2 1 1−6 2 4
), MatB′(f) = P−1 MatB′(f)P =
(1 1 00 1 00 0 2
)
Exercice 20.10. Soit B, B′ deux bases de E, C et C′ deux bases de F et f : E → F une application linéaire. SoitP la matrice de passage de B vers B′ et Q la matrice de passage de C vers C′. Montrer que
MatB′,C′(f) = Q−1 MatB,C(f)P
Définition 20.66. Soit A,B ∈ Mn(K), on dit que A et B sont semblables s’il existe une matrice inversibleP ∈ GLn(K) telle que
A = P−1 B P
Proposition 20.67. Soit f : E → E un endomorphisme, B et C deux bases de E alors les matrices
A = MatB(f) et B = MatC(f)
sont semblables.
Exercice 20.11. Soit F et G deux sous-espaces vectoriels supplémentaires de E. On se donne (b1, . . . , bn) unebase de F et (bn+1, . . . , bn+m) une base de G. On pose B = (b1, . . . , bn+m), base de E.
1) Soit p : E → E la projection sur F parallèlement à G. Déterminer la matrice de p dans la base B.2) Soit s : E → E la symétrie par rapport à F parallèlement à G. Déterminer la matrice de s dans la base B.
20.5 Les différentes définitions du rang
Proposition 20.68. Soit f : E → F et g : F → G deux applications linéaires, alors
rg(g f) ≤ min(
rg(f), rg(g))
Démonstration. On a
Im(g f) = g(Im(f))Im(f) ⊂ F ⇒ g(Im(f)) ⊂ g(F )
Im(g) = g(F )
⇒ Im(g f) ⊂ Im(g)
D’où rg(g f) ≤ rg(g). Soit (v1, . . . , vr) une base du sous-espace vectoriel Im(f), ainsi rg(f) = r. D’après laproposition 20.38, on a
Im(g f) = g(Im(f)) = g(Vect(v1, . . . , vr)) = Vect(g(v1), . . . , g(vr))
et dim(Vect(g(v1), . . . , g(vr))) ≤ r, d’où
rg(g f) = dim(Im(g f)) ≤ r = rg(f)
En résumé, à l’aide des deux inégalités, on déduit que
rg(g f) ≤ min(
rg(f), rg(g))
Corollaire 20.69. Soit f : E → F une application linéaire.1) Pour tout isomorphisme g de F , on a rg(g f) = rg(f).2) Pour tout isomorphisme h de E, on a rg(f h) = rg(f).
376

TSI 1 Lycée Heinrich-Nessel 2016/2017
Démonstration. Nous allons uniquement démontrer le premier point, le second est laissé en exercice. De la pro-position, on déduit que
rg(g f) ≤ rg(f)
rg(g−1 (g f)︸ ︷︷ ︸
=f
)≤ rg(g f)
⇒ rg(g f) = rg(f)
Théorème 20.70. Soit f : E → F une application linéaire entre deux espaces vectoriels de dimensions m etn respectivement. Soit r un entier naturel. Les deux propositions suivantes sont équivalentes :
1) L’application f est de rang r.2) Il existe une base B = (b1, . . . , bm) de E et une base de C = (c1, . . . , cn) de F telles que la matrice de f
dans ses bases soit de la forme suivante :
MatB,C(f) =
r colonnes︷ ︸︸ ︷1 0 . . . 0
m− r colonnes︷ ︸︸ ︷0 1 0...
. . . 0 00 . . . 0 1
0 0
et le nombre de 1 sur la diagonale de la précédente matrice est égal à r.
Démonstration. Le sens direct : Notons r le rang de f , alors d’après le théorème du rang, on a
dim(ker(f)) = dim(E)− rg(f) = m− r
Soit S un supplémentaire de ker(f) dans E et B = (b1, . . . , br, br+1, . . . , bm) une base adaptée à la décompositionE = S ⊕ ker(f). Comme les vecteurs br+1, . . . , bm sont dans le noyau de f , on a
∀ i ∈ Jr + 1;mK : f(bi) = 0F (1)
et en revenant à la démonstration du théorème du rang, on déduit que si on pose
∀ i ∈ J1; rK : ci = f(bi) (2)
alors (c1, . . . , cr) est une base de Im(f), sous-espace vectoriel de F . Du théorème de la base incomplète, oncomplète la précédente famille libre de vecteurs en C = (c1, . . . , cn) base de F . Des deux propriétés (1) et (2), ondéduit que la matrice de f dans les bases B et C est de la forme annoncée dans la proposition. La réciproque estimmédiate : Supposons que le point 2. est vérifié, alors d’après l’allure de la matrice de f dans les bases B et C,on déduit que
Im(f) = Vect(f(b1), . . . , f(bm)) = Vect(c1, . . . , cr, 0E , . . . , 0E) = Vect(c1, . . . , cr)
Or la sous-famille (c1, . . . , cr) est libre (car extraite de la famille libre C), d’où
rg(f) = r.
Soit M = (aij) ∈ Mn,m(K) une matrice quelconque. On rappelle qu’on peut lui associer une application linéairef : Km → Kn qui est définie par
∀X ∈ Kn : f(X) = MX
Notons B = (b1, . . . , bm) la base canonique de Km et C = (c1, . . . , cn) la base canonique de Kn, alors
∀ j ∈ J1;mK : f(bj) = M
0...
1j...0
=
a1j...ajj...anj
=n∑i=1
aijci
le vecteur issue de la j-ème colonne de la matrice M . Ainsi, les coordonnées de f(bj) sont (a1j , . . . , anj) dans labase C. On en déduit que M = MatB,C(f).
On rappelle que
377

TSI 1 Lycée Heinrich-Nessel 2016/2017
Définition 20.71 (rang d’une matrice). SoitM une matrice deMn,m(K) etM ′ la matrice échelonnée réduiteéquivalente en lignes à M . Le rang de M est le nombre de pivots de M ′ et on le note rg(M).
Théorème 20.72. Soit M une matrice deMn,m(K) et f : X 7→MX de Rm dans Rn, alors
rg(M) = rg(f)
À l’aide du corollaire 20.69, on déduit
Corollaire 20.73. Si M ∈Mn(K) et si P ∈ GLn(K), alors rg(PMP−1) = rg(M).
et
Corollaire 20.74. Pour tous M ∈Mn,m(K), P ∈ GLm(K), Q ∈ GLn(K), on a rg(Q−1MP ) = rg(M).
Or, nous avions vu dans le chapitre sur le calcul matriciel que de faire une opération élémentaire• sur les lignes de M revient à multiplier M par une matrice inversible Q à gauche : Q×M .• sur les colonnes de M revient à multiplier M par une matrice inversible P à droite : M × P .
Corollaire 20.75. Le rang d’une matrice M ne change pas si on effectue l’une des opérations suivantes :1) sur les lignes :
• Li ↔ Lj : en échangeant deux lignes de M ; (permutation)• Li ← aLi : en multipliant une ligne de M par un nombre a 6= 0. (dilatation)• Li ← Li + λLj : en remplaçant une ligne de M par la somme de cette ligne avec λ fois une autre,λ ∈ K quelconque. (transvection)
où Li et Lj désignent deux lignes distinctes (i 6= j).2) sur les colonnes :
• Ci ↔ Cj : en échangeant deux colonnes de M ; (permutation)• Ci ← aCi : en multipliant une colonne de M par un nombre a 6= 0. (dilatation)• Ci ← Ci + λCj : en remplaçant une colonne de M par la somme de cette colonne avec λ fois une
autre, λ ∈ K quelconque. (transvection)où Ci et Cj désignent deux colonnes distinctes (i 6= j).
Remarque. Pour déterminer le rang d’une matrice M , on peut procéder de l’une des manières suivantes :1) étudier le rang de l’application linéaire associée X 7→MX ;2) échelonner la matrice M par colonnes ;3) échelonner la matrice M par lignes.
Méthode. Soit M une matrice deMn,m(K) et f : X 7→MX de Rm dans Rn l’application linéaire associée.• Pour étudier le noyau de f , on échelonnera par lignes la matrice M afin de pouvoir extraire facilement
une base de ker(f).• Pour étudier l’image de f , on échelonnera par colonnes la matrice M . Ensuite les vecteurs colonnes non
nulles de la matrice échelonnée déterminent une base de Im(f).
Digression. Soit m et n deux entiers naturels. On dit que deux matrices M et N deMn,m(K) sont équivalentess’il existe P ∈ GLm(K) et Q ∈ GLn(K) telle que N = Q−1MP .Des deux propositions précédentes, on déduit que toute matrice M ∈ Mn,m(K) est équivalente à une matrice dela forme donnée dans le théorème 20.70. Or ce dernier type de matrice dépend uniquement du rang de M , ainsion déduit la proposition suivante :Quelles que soient M , N ∈Mn,m(K), les matrices M et N sont équivalentes si et seulement si elles sont de mêmerang.
378

Chapitre 21
Variables aléatoires
Programme• Une variable aléatoire est une application définie sur l’univers Ω fini à valeurs dans un ensemble E. LorsqueE ⊂ R, la variable aléatoire est dite réelle.
• Modéliser des situations données en langage naturel à l’aide de variables aléatoires.• Pour tout x ∈ E, (X = x) = X−1(x) et tout A ⊂ E : (X ∈ A) = X−1(A). Si X est réelle, pour toutx ∈ R, (X ≤ x) = X−1(]−∞;x]),. . .
• Loi de probabilité PX : et fonction de répartition. Déterminer la loi d’une variable aléatoire à partir de safonction de répartition.
• La connaissance des propriétés générales des fonctions de répartition n’est pas exigible.• Espérance d’une variable aléatoire réelle :
E(X) =∑ω∈Ω
X(ω) P(ω) =∑
x∈X(Ω)
xP(X = x)
Interpréter l’espérance en terme de moyenne pondérée.• Variable aléatoire centrée.• Théorème de transfert : E(φ(X)) =
∑x∈X(Ω) φ(x)P(X = x).
• E(aX + b) = aE(X) + b.• Variance et écart type d’une variable aléatoire réelle. Variable réduite.• Interpréter la variance comme indicateur de dispersion.
• ! Les moments d’ordre supérieur ne sont pas au programme.• Formule de Koenig-Huygens : V(X) = E(X2)− E(X)2
• V(aX + b) = a2V(X)• Inégalité de Bienaymé-Tchebychev. L’inégalité de Markov n’est pas au programme.• Lois usuelles• Loi certaine, loi uniforme.• Loi de Bernouilli de paramètre p ∈ [0; 1]. Notation B(p).• Loi binomiale de paramètres n ∈ N∗ et p ∈ [0; 1]. Notation B(n, p).• Reconnaître des situations modélisables par une des précédentes lois.• Espérance et variance associées à ces différentes lois.
21.1 Variable aléatoire et loi de probabilité
Définition 21.1. Soit une expérience aléatoire dont l’univers est l’ensemble Ω et E un ensemble.Une variable aléatoire est une fonction X définie sur Ω et à valeurs dans E. Lorsque E ⊂ R, on dit que lavariable aléatoire est réelle.
Une variable aléatoire est une application qui à toute issue de l’expérience associe un élément de E.
379

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemple. Considérons l’expérience aléatoire qui consiste à lancer deux dés. L’univers Ω est
(1, 1), (1, 2), . . . , (6, 5), (6, 6),
l’ensemble de tous les couples de nombres de un à six. On définit la variable aléatoire X qui est égale à la sommedes résultats des deux dés :
X : Ω // R
(a, b) // a+ b
Par exemple, si après avoir jeter les deux dés, on obtient un 2 et un 3, la variable aléatoire X vaut alors 2 + 3 = 5.On note que les valeurs que X peut prendre sont comprise dans 1, 2, 3, . . . , 12 ⊂ R.La probabilité que la somme X soit égale à 12 est égale à la probabilité d’avoir deux 6, ainsi, formellement on a
P(X = 12) = P(“obtenir deux six") = 136
Pour obtenir la probabilité que la somme X soit égale à 4, on peut énumérer toutes la façons d’obtenir 4 :
4 = 1 + 3 = 2 + 2 = 3 + 1
d’où P(X = 4) = 336 = 1
12 . De même, on déduit
xi 2 3 4 5 6 7 8 9 10 11 12P(X = xi) 1
36118
112
19
536
16
536
19
112
118
136
Remarque. Soit X : Ω → R une variable aléatoire et f : R → R une fonction, alors Y = f X : Ω → R est aussiune variable aléatoire (par abus de notation, on note Y = f(X)).
Définition 21.2. Soit X une variable aléatoire de Ω dans E. Soit A ⊂ E une partie. L’événement imageréciproque de A est le sous-ensemble de Ω défini par
(X ∈ A) = X−1(A) = ω ∈ Ω |X(ω) ∈ A
Lorsque A = a est un singleton, on note (X = a) au lieu de (X ∈ A).De plus, si E ⊂ R,• lorsque A =]−∞;x], on note (X ≤ x) ;• on note (X < x) au lieu de (X ∈]−∞;x[) ;• on note (X > x) au lieu de (X ∈]x; +∞[) ;• on note (X ≥ x) au lieu de (X ∈ [x; +∞[).
Proposition-Définition 21.3. Soit X une variable aléatoire définie sur un univers fini Ω d’une expériencealéatoire. L’application
PX : X(Ω) // [0; 1]
x // P(X = x)
est une probabilité sur X(Ω), appelée loi de probabilité de X.
Proposition 21.4. SoitX : Ω→ R une variable aléatoire sur un univers Ω fini, notons x1, . . . , xn l’ensembledes valeurs prises par X et pi = P(X = xi) pour tout 1 ≤ i ≤ n, alors
1) 0 ≤ pi ≤ 1 pour tout 1 ≤ i ≤ n ;2) p1 + p2 + . . .+ pn = 1.
Remarque. La famille de sous-ensembles (X = xi)i∈J1;nK constitue un système complet d’événements de Ω.
Définition 21.5. Soit X une variable aléatoire définie sur un univers Ω fini dans E. On dit que X suit la loicertaine s’il existe a ∈ E tel que P(X = a) = 1.
380

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition-Définition 21.6. SoitX une variable aléatoire définie sur un univers Ω fini dans E = x1, . . . , xn.On dit que X suit une loi uniforme sur E si ,
∀ (i, j) ∈ J1;nK2 : P(X = xi) = P(X = xj)
Dans ce cas, on a∀ i ∈ J1;nK : P(X = xi) = 1
n
Comme pour les applications à valeurs dans R, on peut définir la notion de variable aléatoire positive :
Définition 21.7. Soit X : Ω→ R une variable aléatoire réelle, si pour toute issue ω ∈ Ω, on a X(ω) ≥ 0, ondit alors que X est positive et on note : X ≥ 0.
Exercice 21.1. Soit X une variable aléatoire réelle définie sur un univers fini Ω. Supposons que pour toutx ∈ X(Ω), on a P(X = x) > 0. Montrer que X ≥ 0 si et seulement si 1 P(X < 0) = 0.
21.2 Fonction de répartition
Définition 21.8. Soit X une variable aléatoire réelle, l’application F : R→ R définie par
∀x ∈ R : F (x) = P(X ≤ x)
est appelée fonction de répartition de X.
Soit X une variable aléatoire réelle définie sur un univers fini. Posons x1, . . . , xn l’ensemble des valeurs prisespar X. Soit x ∈ [xi;xi+1[, comme X ne prend que les valeurs x1, . . . , xn, on déduit que
F (x) = P(X ≤ x) = P(X ≤ xi) = F (xi)
Ainsi, la fonction de répartition est constante égale à F (xi) sur l’intervalle [xi;xi+1[. De plus, si x < x1, alorsF (x) = 0 et si x ≥ xn, alors F (x) = F (xn) = P(X = x1) + . . . + P(X = xn) = 1. D’où, la courbe représentativede la fonction de répartition :
x
p1
p1 + p2
p1 + p2 + p3
+ p3
. . .
p1 + . . .+ pn−2
p1 + . . .+ pn−1
1
0x1 x2 x3 x4 xn−2 xn−1 xn
De plus, pour tout i ∈ J2;nK, on a
limx→x−
i
F (x) = F (xi−1) et limx→x+
i
F (x) = F (xi)
1. On pourrait aussi définir la notion de variable aléatoire positive ainsi : si P(X < 0) = 0. On notera néanmoins quecette définition n’est pas équivalente à celle donnée dans la définition 21.7.
381

TSI 1 Lycée Heinrich-Nessel 2016/2017
et donc
limx→x+
i
F (x)− limx→x−
i
F (x) = F (xi)− F (xi−1)
= P(X ≤ xi)− P(X ≤ xi−1)
= P(
(X ≤ xi) ∩ (X ≤ xi−1))
car (X ≤ xi−1) ⊂ (X ≤ xi)
= P(
(X ≤ xi) ∩ (X > xi−1))
= P(xi−1 < X ≤ xi)= P(X = xi)
De même, on déduit que pour tout x ∈ R :
P(X = x) = P(X ≤ x)− P(X < x) = F (x)− limt→x−
F (t)
Proposition 21.9. Soit X une variable aléatoire réelle et F : R→ R sa fonction de répartition, alors :1) F est croissante ;2) F est continue à droite ;3) lim
x→−∞F (x) = 0 ;
4) limx→+∞
F (x) = 1.
Exercice 21.2. Soit X une variable aléatoire réelle, déterminer et représenter la fonction de répartition de Xlorsque :
1) X suit une loi certaine ;2) X suit la loi uniforme sur J1;nK.
21.3 Espérance et varianceDans toute cette section, X désigne une variable aléatoire sur un espace probabilisé (Ω,P(Ω),P) fini. On noteX(Ω) = x1, . . . , xn l’image de X et PX la loi de X correspondante.
Définition 21.11. L’espérance mathématique de X est le nombre réel défini par :
E(X) =n∑k=1
xk P(X = xk) =∑
x∈X(Ω)
xP(X = x)
Lorsque E(X) = 0, on dit que X est centrée.
Remarque. Cette définition doit être comparée à celle de la moyenne en statistique : la valeur de E(X) s’interprètealors comme la valeur moyenne prise par X :
valeurs : k x1 x2 . . . xn « Moyenne » : Espérance« fréquences » : P(X = k) p1 p2 . . . pn p1x1 + . . .+ pnxn
Proposition 21.12. Supposons que X suit une loi uniforme sur x1, . . . , xn, alors E(X) = 1n
n∑k=1
xk.
Exercice 21.3. Soit n ∈ N∗, on suppose que X suit une loi uniforme sur J1;nK. Exprimer l’espérance de X enfonction de n.
Exercice 21.4. Calculer E(X) lorsque X est la variable aléatoire qui correspond à la somme obtenue après le jetde deux dés.
Lemme 21.13. On aE(X) =
∑ω∈Ω
X(ω) P(ω)
382

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 21.14 (de transfert). SoitX une variable aléatoire réelle définie sur un espace probabilisé (Ω,P(Ω),P).Soit f une fonction définie sur X(Ω) = x1, . . . , xn, l’image de X. Alors
E(f(X)) =n∑k=1
f(xk)P(X = xk)
Corollaire 21.15. Pour tous nombres réels a et b, on a
E(aX + b) = aE(X) + b
Corollaire 21.16. Soit X, Y deux variables aléatoires sur (Ω,P(Ω),P), alors :• Pour tout (λ, µ) ∈ R2, E(λX + µY ) = λE(X) + µE(Y ) ; linéarité• Si X ≥ 0 alors E(X) ≥ 0 ; positivité• Si X ≤ Y alors E(X) ≤ E(Y ). croissance
Proposition 21.17 (somme). Soit n ∈ N∗, X1, . . . , Xn une famille de variables aléatoires sur (Ω,P(Ω),P),alors
E(X1 + . . .+Xn) = E(X1) + . . .+ E(Xn)
Définition 21.18.1) La variance de X est donnée par :
V(X) = E((X − E(X))2) =
n∑k=1
(xk − E(X)
)2P(X = xk)
2) L’écart type de X est la racine carrée de la variance σ(X) =√
V(X).3) Lorsque V(X) = 1, on dit que X est réduite.
Remarque. Pour tout k ∈ J1, nK, le nombre(xk − E(X)
)2=∣∣∣xk − E(X)
∣∣∣2correspond à la distance au carré entre xk et l’espérance de X. Ainsi, la variance mesure l’écart quadratiquemoyen de X autour de l’espérance (la moyenne) de X.Plus la variance est petite, plus l’écart quadratique moyen est petit et donc plus la variable aléatoire X prend (trèsprobablement) des valeurs proche de son espérance. Nous établirons ce fait plus précisément dans la propositioninégalité de Bienaymé-Tchebychev.
Exercice 21.5. Soit X une variable aléatoire réelle. Déterminer l’espérance, la variance et l’écart type de Xlorsque :
1) X suit une loi certaine ;2) X suit la loi uniforme sur J1;nK.
Exercice 21.6. Soit X une variable aléatoire réelle à valeurs dans x1, . . . , xn ⊂ R. Montrer que si la variancede X est nulle alors il existe une constante λ ∈ R telle que P(X = λ) = 1. Quelle est la loi suivie par X dans cecas ?
Proposition 21.19 (Formule de Koenig-Huygens). Soit X une variable aléatoire, alors
V(X) = E(X2)− E(X)2
La relation précédente peut être reformuler ainsi : « la variance de X est égale à l’espérance de son carré moinsle carré de son espérance ».
( ! Démonstration au programme)
383

TSI 1 Lycée Heinrich-Nessel 2016/2017
Démonstration. Notons x1, . . . , xn l’ensemble des valeurs prises par X et pi = P(X = xi) pour tout i ∈ J1;nK,alors
V(X) =n∑i=1
pi(xi − E(X))2
=n∑i=1
pi
(x2i − 2E(X)xi + E(X)2
)=
n∑i=1
pix2i − 2E(X)
n∑i=1
pixi + E(X)2n∑i=1
pi
=n∑i=1
pix2i − 2E(X)E(X) + E(X)2 × 1
=n∑i=1
pix2i − E(X)2
= E(X2)− E(X)2 d’après le théorème de transfert
Proposition 21.20. Soit a et b deux nombres réels, alors :1) V(aX + b) = a2V(X) ;2) σ(aX + b) = |a|σ(X).
( ! Démonstration au programme)
Démonstration. Soit a et b deux nombres réels, d’après la formule de Koenig-Huygens, on a
V(aX + b) = E((aX + b)2)− (E(aX + b))2
= E(a2X2 + 2abX + b2
)− (E(aX + b))2
= a2E(X2) + 2abE(X) + b2 − (aE(X) + b)2 par linéarité de l’espérance
= a2E(X2) + 2abE(X) + b2 −(a2E(X)2 + 2abE(X) + b2
)= a2(E(X2)− E(X)2)= a2V(X) d’après la formule de Koenig-Huygens
et donc
σ(aX + b) =√
V(aX + b)
=√a2V(X)
=√a2 σ(X)
= |a|σ(X)
Exercice 21.7. Soit X une variable aléatoire d’écart type non nul. On pose N = X−E(X)σ(X) . Montrer que N est
centrée réduite.
Proposition (Inégalité de Markov). (hors programme)Soit X une variable aléatoire réelle d’image positive, alors
∀a > 0, P(X ≥ a) ≤ E(X)a
Démonstration (hors programme). Soit a > 0, rappelons que
E(X) =∑
x∈X(Ω)
xP(X = x)
384

TSI 1 Lycée Heinrich-Nessel 2016/2017
et
aP(X ≥ a) = aP
⋃x∈X(Ω):x≥a
X = x
=
∑x∈X(Ω):x≥a
aP(X = x)
≤∑
x∈X(Ω):x≥a
xP(X = x) car P(X = x) ≥ 0
≤∑
x∈X(Ω):x<a
xP(X = x)︸ ︷︷ ︸≥0
+∑
x∈X(Ω):x≥a
xP(X = x) car X est positive
=∑
x∈X(Ω)
xP(X = x)
= E(X)
Donc
aP(X ≥ a) ≤ E(X) ⇒ P(X ≥ a) ≤ E(X)a
car a > 0.
Proposition 21.21 (Inégalité de Bienaymé-Tchebychev). Soit X une variable aléatoire réelle, alors
∀λ > 0, P(|X − E(X)| > λ
)≤ V(X)
λ2
Démonstration (hors programme). Soit λ > 0, alors
|X − E(X)| > λ ⇐⇒ (X − E(X))2 > λ2
D’où
P(|X − E(X)| > λ
)= P(
(X − E(X))2 > λ2)
On applique l’inégalité de Markov à la variable aléatoire positive Z = (X − E(X))2 et avec a = λ2 > 0 :
P(Z > λ2) ≤ E(Z)
λ2
P(|X − E(X)| > λ
)≤
E(
(X − E(X))2)
λ2
P(|X − E(X)| > λ
)≤ V(X)
λ2
21.4 Loi de BernoulliDéfinition 21.22. Soit p ∈ [0; 1] et X une variable aléatoire sur un espace probabilisé (Ω,P(Ω),P). On ditque X suit une loi de Bernoulli de paramètre p et on note X ∼ B(p), si :• X(Ω) = 0; 1 ;• P(X = 1) = p et P(X = 0) = 1− p.
Voici la loi de X présentée sous forme de tableau :
k 0 1P(X = k) 1− p p
385

TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemples.
1) Lors du jet d’une pièce, X la variable aléatoire, qui vaut 1 lorsqu’on obtient pile et 0 sinon, suit une loi deBernoulli de paramètre p = P(”pile”).
2) On tire au hasard une boule dans une urne avec a boules rouges et b boules bleues. On considère la variablealéatoire Y qui vaut 1 lorsqu’on tire une boule rouge et 0 sinon. Alors Y suit aussi une loi de Bernoulli deparamètre p = a
a+b .
Proposition 21.23. Si X suit une loi de Bernoulli de paramètre p, alors X est :• d’espérance E(X) = p ;• de variance V(X) = p(1− p) ;• d’écart type σ(X) =
√p(1− p).
21.5 Loi binomiale
Définition 21.24. Soit p ∈ [0; 1], n ∈ N∗ et X une variable aléatoire sur un espace probabilisé (Ω,P(Ω),P).On dit que X suit une loi binomiale de paramètre n et p et on note X ∼ B(n, p), si :• X(Ω) = J0;nK ;• Pour tout entier 0 ≤ k ≤ n :
P(X = k) =(n
k
)pk (1− p)n−k
Exercice 21.8. Soit n un entier non nul. Démontrer que
1) Pour tout entier k ∈ J1;nK, k(nk
)= n(n−1k−1
).
2) Pour tout entier k ∈ J2;nK, k(k − 1)(nk
)= n(n− 1)
(n−2k−2
).
Proposition 21.25. Si X est une variable aléatoire qui suit une loi binomiale de paramètres n et p, alors• son espérance est E(X) = np ;• sa variance est V(X) = np(1− p) ;• son écart type est σ(X) =
√np(1− p).
( ! Démonstration au programme)
Démonstration. Soit k ∈ J1;nK, nous avons revu dans l’exercice précédent que
k
(n
k
)= n
(n− 1k − 1
)386

TSI 1 Lycée Heinrich-Nessel 2016/2017
D’où,
E(X) =n∑k=0
k P(X = k)
=n∑k=0
k
(n
k
)pk(1− p)n−k
=n∑k=1
k
(n
k
)pk(1− p)n−k
=n∑k=1
n
(n− 1k − 1
)pk(1− p)n−k
= np
n∑k=1
(n− 1k − 1
)pk−1(1− p)n−1−(k−1)
= np
n−1∑i=0
(n− 1i
)pi(1− p)n−1−i avec i = k − 1
= np (p+ (1− p))n−1 d’après la formule du binôme= np
Si n = 1, X ∼ B(p) et nous avons déjà vu que E(X) = p(1− p) = np(1− p) dans ce cas. Supposons que n > 1.De même, rappelons que pour tout k ∈ J2;nK, on a
k(k − 1)(n
k
)= n(n− 1)
(n− 2k − 2
)D’où,
E(X(X − 1)) =n∑k=0
k(k − 1)P(X = k)
=n∑k=0
k(k − 1)(n
k
)pk(1− p)n−k
=n∑k=2
k(k − 1)(n
k
)pk(1− p)n−k
=n∑k=2
n(n− 1)(n− 2k − 2
)pk(1− p)n−k
= n(n− 1)p2n∑k=2
(n− 2k − 2
)pk−2(1− p)n−2−(k−2)
= n(n− 1)p2n−2∑i=0
(n− 2i
)pi(1− p)n−2−i avec i = k − 2
E(X(X − 1)) = n(n− 1)p2 (p+ (1− p))n−2 d’après la formule du binômeE(X2 −X) = n(n− 1)p2
E(X2)− E(X) = n(n− 1)p2 par linéarité de l’espéranceE(X2) = E(X) + n(n− 1)p2 = np+ n(n− 1)p2
Ainsi, d’après la formule de Koenig-Huygens, on a
V(X) = E(X2)− E(X)2
= np+ n(n− 1)p2 − (np)2
= np+ n2p2 − np2 − n2p2
= n(p− p2)= np(1− p)
et σ(X) =√
V(X) =√np(1− p).
387
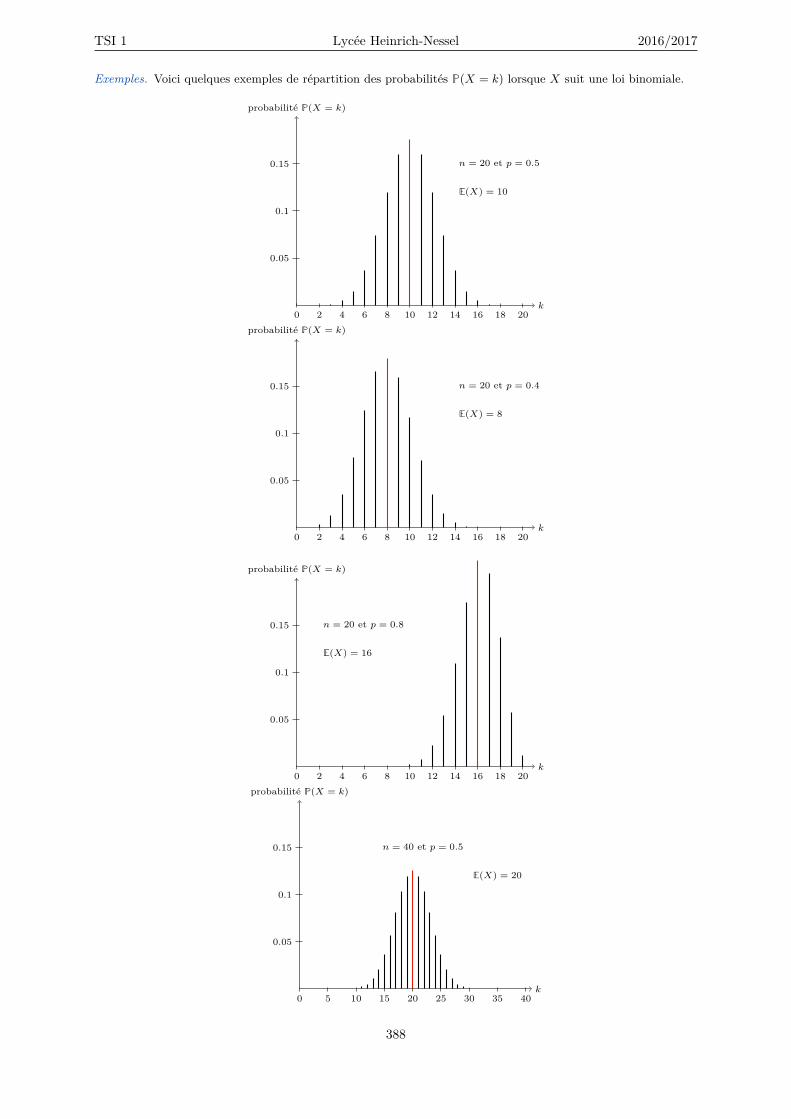
TSI 1 Lycée Heinrich-Nessel 2016/2017
Exemples. Voici quelques exemples de répartition des probabilités P(X = k) lorsque X suit une loi binomiale.
k
probabilité P(X = k)
0 2 4 6 8 10 12 14 16 18 20
0.05
0.1
0.15 n = 20 et p = 0.5
E(X) = 10
k
probabilité P(X = k)
0 2 4 6 8 10 12 14 16 18 20
0.05
0.1
0.15 n = 20 et p = 0.4
E(X) = 8
k
probabilité P(X = k)
0 2 4 6 8 10 12 14 16 18 20
0.05
0.1
0.15 n = 20 et p = 0.8
E(X) = 16
k
probabilité P(X = k)
0 5 10 15 20 25 30 35 40
0.05
0.1
0.15 n = 40 et p = 0.5
E(X) = 20
388

TSI 1 Lycée Heinrich-Nessel 2016/2017
Remarque. Si p ∈]0; 1[, alors la probabilité P(X = k) est maximale lorsque k = b(n+ 1)pc. Ce nombre est appeléle mode de la loi binomiale. En particulier, si l’espérance np est un entier, alors le mode est égal à np.
Théorème 21.26. Soit p ∈ [0; 1], n ∈ N∗ et X1, . . . , Xn des variables aléatoires sur un espace probabilisé(Ω,P(Ω),P). Supposons que• Pour tout k ∈ J0; 1K, Xk ∼ B(p) (suit une loi de Bernoulli de paramètre p).• Les événements (Xk = ε)1≤k≤n, ε∈0,1 sont mutuellement indépendants.
Alors la variable aléatoire somme S = X1 + . . .+Xn suit une loi binomiale de paramètres n et p :
S ∼ B(n, p).
Démonstration. Soit k ∈ J0;nK, on pose
Ek = (r1, . . . , rn) ∈ 0, 1n : r1 + . . .+ rn = k
Choisir un n-uplet (r1, . . . , rn) de Ek revient à choisir k coordonnées ri qui valent un 1 parmi les n coordonnées(les autres vaudront 0). De plus, le nombre de façons de placer k 1 parmi les n-coordonnées du n-uplet (r1, . . . , rn)est égal à
(nk
). D’où le cardinale de Ek est
card(Ek) =(n
k
)Supposons que S = k et posons ri = Xi pour tout 1 ≤ i ≤ n, alors (r1, . . . , rn) ∈ Ek et réciproquement. On endéduit l’égalité entre les événements :
(S = k) =⋃
(r1,...,rn)∈Ek
((X1 = r1) ∩ . . . ∩ (Xn = rn)
)Comme, les événements dans l’union sont incompatibles, on a
P(S = k) =∑
(r1,...,rn)∈Ek
P((X1 = r1) ∩ . . . ∩ (Xn = rn))
Les événements (Xi = ri) sont mutuellement indépendants, d’où
P(S = k) =∑
(r1,...,rn)∈Ek
P(X1 = r1)× . . .× P(Xn = rn)
Ensuite, les Xi suivent tous la même loi :
P(Xi = ri) =p si ri = 11− p si ri = 0
et nous avons vu que si (r1, . . . , rn) ∈ Ek alors il y en a k qui valent 1 et n− k qui valent 0, d’où
P(S = k) =∑
(r1,...,rn)∈Ek
pk(1− p)n−k
= pk(1− p)n−k
∑(r1,...,rn)∈Ek
1
= pk(1− p)n−k card(Ek)
=(n
k
)pk(1− p)n−k
On en déduit que S ∼ B(n, p).
Exemple. Pour n = 3, dans le théorème précédent, on peut représenter les résultats obtenus avec X1, X2 puis X3dans un arbre de probabilités :
389

TSI 1 Lycée Heinrich-Nessel 2016/2017
X1 X2 X3
1
0
1
0
1
0
1
0
1
0
1
0
1
0
p
1− p
p
1− p
p
1− p
p
1− p
p
1− p
p
1− p
p
1− p
P(X1 +X2 +X3 = 1) =(
31
)p(1− p)2 = 3p(1− p)2
21.6 La planche de Galton (1894)
Une planche de Galton est une planche verticale surlaquelle on a disposé des clous en quinconce.Plusieurs billes sont jetées au-dessus du clou A ettombent avec une probabilité de 1
2 sur le clou B oule clou C. Si la bille se trouve au-dessus de B, elleaura de même une chance sur 2 de tomber sur D etune chance sur 2 de tomber sur E. À chaque étage,elle tombera ainsi soit à gauche soit à droite avec uneprobabilité de 1
2 , jusqu’à atteindre un des cinq bacssitués en dessous.
n1 n2 n3 n4 n5
G H I J
D E F
B C
A
Exercice 21.9.1) Quelle est la probabilité pour qu’une bille partant de A arrive sur chacun des clous D, E et F ?2) Quelle est la probabilité pour qu’une bille partant de A arrive sur chacun des clous G, H, I et J ?3) On note X la variable aléatoire égale au numéro du bac dans lequel tombe la bille (lâché à la verticale au
dessus du premier clou A). Déterminer la loi de X.4) Généralisation : Soit n un entier naturel non nul, on suppose qu’on dispose de n − 1 rangés de clous en
quinconce et qu’on a donc n bacs en dessous. On note à nouveau X la variable aléatoire égale au numérodu bac dans lequel tombe la bille. Déterminer la loi de X.
390

TSI 1 Lycée Heinrich-Nessel 2016/2017
loic
ertaine
loiu
niform
eloid
eBerno
ulli
loib
inom
iale
Paramètres
a∈
RE
=x
1,...,xn
p∈
[0;1
]n∈
Netp∈
[0;1
]
Notation:X∼
aU
(E)
B(p
)B
(n,p
)
Image:X
(Ω)
a
E0
;1
J0;n
K
loid
eX
:P
(X=a)=
1∀x∈E
P(X
=x
)=1 n
P(X
=1)
=p
P(X
=0)
=1−p
∀0≤k≤n
:
P(X
=k)=
( n k) pk(1−p)n−k
espé
rance:E
(X)
ax
=x
1+...+xn
np
np
varia
nce:V
(X)
01 n
n ∑ i=1
(xi−x
)2p(1−p)
np(1−p)
écarttype
:σ(X
)0
√ V(X
)√ p(1
−p)
√ np(1−p)
391

TSI 1 Lycée Heinrich-Nessel 2016/2017
21.7 Échantillonnage (annexe)
Définition 21.27. Un échantillon de taille n est obtenu en prélevant au hasard, successivement et avecremise, n éléments d’une population.
Lors d’un sondage . La propriété de "remise" signifie qu’on s’autorise à interroger plusieurs fois la même personne.Ce fait permet de garantir l’indépendance entre les résultats des différents « prélèvements ». Ainsi, la loi de lavariable aléatoire correspondant à l’effectif des éléments ayant le caractère suit une loi bien connue :
Proposition 21.28. Soit une population dont une proportion p des éléments admet un caractère donné.Dans un échantillon de taille n prélevé dans cette population, l’effectif des éléments qui présentent ce caractèreest une variable aléatoire qui suit la loi binomiale de paramètres n et p.
Définition 21.29. Soit X la loi binomiale qui correspond à la réalisation d’un échantillon de taille n dansune population ayant une proportion p d’éléments avec un caractère donné.L’intervalle de fluctuation au seuil 95% de la fréquence observée est l’intervalle[
an
; bn
]où a est le plus entier tel que P (X ≤ a) > 0.025 et b est le plus petit entier tel que P (X ≤ b) ≥ 0.975.
Exemple. Lorsqu’on prélève un échantillon de taille n, il y a 95% de chance que la fréquence observée f = Xn
appartienne à l’intervalle de fluctuation [ an
; bn
] :
xa b0 n
P (X < a) ' 2.5% P (a ≤ X ≤ b) ' 95% P (b < X) ' 2.5%
Proposition 21.30. Pour un échantillon de grande taille, c’est-à-dire n ≥ 30, ayant une proportion ducaractère p comprise entre 0.2 et 0.8, l’intervalle :[
p− 1√n
; p+ 1√n
]est une bonne approximation de l’intervalle de fluctuation au seuil de 95% de la fréquence observée f ducaractère.
Définition 21.31 (test stastistique). On considère une population dans laquelle on suppose que la proportiond’un caractère est p.On observe f la fréquence de ce caractère dans un échantillon de taille n.Soit l’hypothèse : “la proportion de ce caractère dans la population est p". et on note I un intervalle defluctuation de la fréquence à 95% dans les échantillons de taille n, alors l’algorithme de décision (teststatistique) est le suivant :• Si la fréquence observée f de l’échantillon est l’intervalle de fluctuation I alors on accepte l’hypothèse
que p soit la fréquence de ce caractère dans la population entière, avec un risque d’erreur de 5%.• Si la fréquence observée f de l’échantillon n’est pas l’intervalle de fluctuation I alors on rejette l’hy-
pothèse, p n’est pas la fréquence de ce caractère dans la population entière, avec un risque d’erreur de5%.
Remarque. On retiendra qu’on ne peut pas rejeter de manière définitive l’hypothèse en considérant un échantillon,la probabilité de se tromper est de 5% (ou que le hasard à fait que la fréquence observée ne soit finalement pasdans l’intervalle de fluctuation).Il est d’usage de considérer qu’un événement qui a une probabilité inférieure à 5% est « rare » (voir impossible). . .
Exercice 21.10. Un graphologue prétend être capable de déterminer le sexe d’une personne d’après son écrituredans 90% des cas.Lisa, qui en doute, lui soumet 20 exemples d’écriture. Elle reconnaîtra sa compétence s’il réussit au moins 90%des identifications du sexe, soit au moins 18 sur les 20. Dans le cas contraire, elle le considérera comme menteur.
392

TSI 1 Lycée Heinrich-Nessel 2016/2017
1) Quelle est la probabilité :
a) que Lisa accepte l’affirmation du graphologue alors qu’il s’est prononcé 20 fois au hasard ?
b) que Lisa rejette l’affirmation alors qu’elle est totalement fondée ? Quel inconvénient présente le testde Lisa ?
2) Sur quel nombre N (minimal) d’identifications réussies Lisa aurait-elle pu se fixer pour être en mesure derejeter l’affirmation du graphologue avec un risque de se tromper inférieur à 4%? Quel conseil pouvez-vousdonner à Lisa pour que son test prenne en compte le hasard ?
Corrigé de l’exercice 21.10. Un graphologue prétend être capable de déterminer le sexe d’une personned’après son écriture dans 90% des cas.Lisa, qui en doute, lui soumet 20 exemples d’écriture. Elle reconnaîtra sa compétence s’il réussit au moins 90%des identifications du sexe, soit au moins 18 sur les 20. Dans le cas contraire, elle le considérera comme menteur.
1) a) Supposons que le graphologue réponde au hasard et indépendamment pour chacun des 20 textes. No-tons X le nombre réponses justes. Alors par hypothèse, la variable aléatoire X suit une loi binomiale deparamètres n = 20 et p = 0.5. Lisa accepte l’affirmation du graphologue lorsqu’il répond correctementau moins 18 fois, c’est-à-dire lorsque l’événement X ≥ 18 se réalise. Or,
P(X ≥ 18) = P(X = 18) + P(X = 19) + P(X = 20)
P(X ≥ 18) = P(X = 18) + P(X = 19) + P(X = 20)
=(
2018
)(12 )18(1
2 )2 +(
2019
)(12 )19(1
2 ) +(
2020
)(12 )20
=((
2018
)+(
2019
)+ 1)
1220
= 190 + 20 + 1220
= 2111 048 576
' 2× 10−4
D’où, la probabilité que Lisa accepte l’affirmation du graphologue est de 0,02%.Remarque : On aurait aussi pu calculer P(X ≥ 18) = 1− P(X < 18) = 1− P(X ≤ 17) en utilisant lacommande Binomial Cumulative Distribution de la calculatrice.
b) On suppose maintenant que le graphologue dit vrai. On note Y la variable aléatoire correspondant aunombre de réponses justes. Encore une fois, Y suit une loi binomiale de paramètres n = 20 et p = 0.9.Lisa rejette l’affirmation lorsque l’événement Y < 18 se produit et P(Y < 18) = P(Y ≤ 17) '0.32 = 32% à l’aide la calculatrice. Ainsi, si le graphologue dit vrai, la probabilité que Lisa rejette sonaffirmation après l’expertise des 20 exemples d’écriture est de 32%. Cette probabilité est conséquente !Il y a presque une chance sur trois de rejette l’hypothèse qui est vraie.L’inconvénient de la méthode de Lisa est de ne pas assez prendre en compte la fluctuation du nombrede bonnes réponses.
393
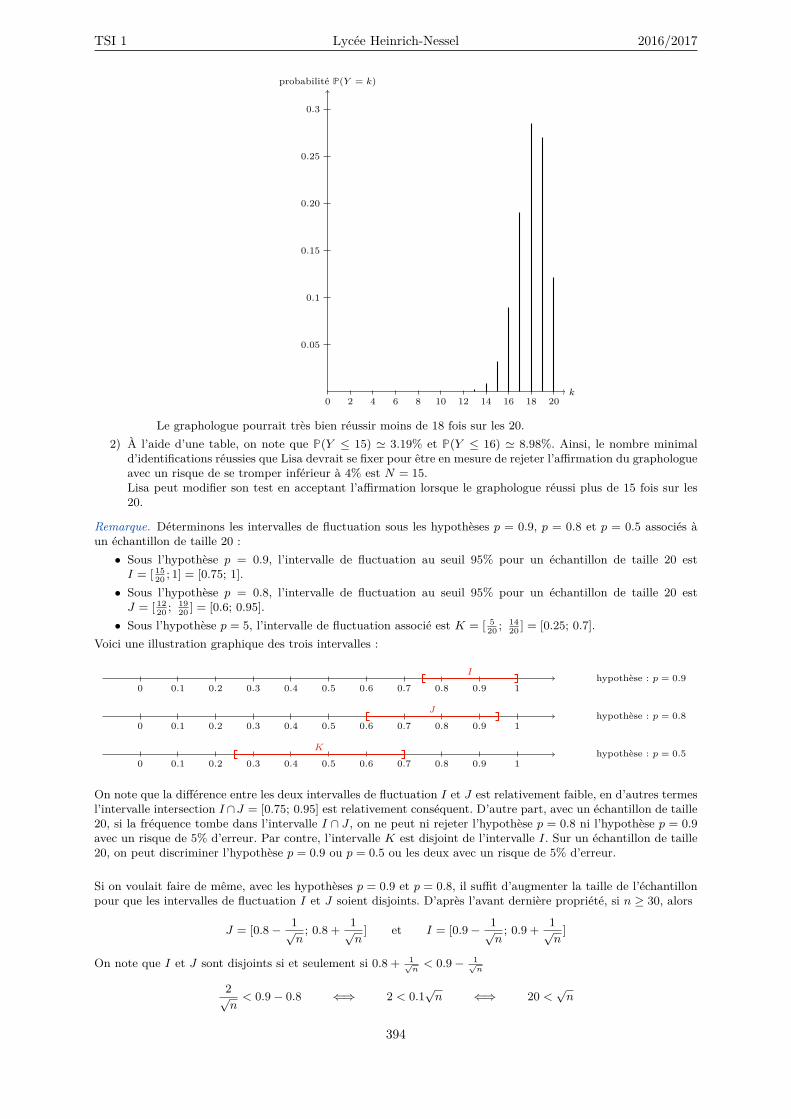
TSI 1 Lycée Heinrich-Nessel 2016/2017
k
probabilité P(Y = k)
0 2 4 6 8 10 12 14 16 18 20
0.05
0.1
0.15
0.20
0.25
0.3
Le graphologue pourrait très bien réussir moins de 18 fois sur les 20.2) À l’aide d’une table, on note que P(Y ≤ 15) ' 3.19% et P(Y ≤ 16) ' 8.98%. Ainsi, le nombre minimal
d’identifications réussies que Lisa devrait se fixer pour être en mesure de rejeter l’affirmation du graphologueavec un risque de se tromper inférieur à 4% est N = 15.Lisa peut modifier son test en acceptant l’affirmation lorsque le graphologue réussi plus de 15 fois sur les20.
Remarque. Déterminons les intervalles de fluctuation sous les hypothèses p = 0.9, p = 0.8 et p = 0.5 associés àun échantillon de taille 20 :• Sous l’hypothèse p = 0.9, l’intervalle de fluctuation au seuil 95% pour un échantillon de taille 20 estI = [ 15
20 ; 1] = [0.75; 1].• Sous l’hypothèse p = 0.8, l’intervalle de fluctuation au seuil 95% pour un échantillon de taille 20 estJ = [ 12
20 ; 1920 ] = [0.6; 0.95].
• Sous l’hypothèse p = 5, l’intervalle de fluctuation associé est K = [ 520 ; 14
20 ] = [0.25; 0.7].Voici une illustration graphique des trois intervalles :
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
I hypothèse : p = 0.9
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
J hypothèse : p = 0.8
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
K hypothèse : p = 0.5
On note que la différence entre les deux intervalles de fluctuation I et J est relativement faible, en d’autres termesl’intervalle intersection I ∩J = [0.75; 0.95] est relativement conséquent. D’autre part, avec un échantillon de taille20, si la fréquence tombe dans l’intervalle I ∩ J , on ne peut ni rejeter l’hypothèse p = 0.8 ni l’hypothèse p = 0.9avec un risque de 5% d’erreur. Par contre, l’intervalle K est disjoint de l’intervalle I. Sur un échantillon de taille20, on peut discriminer l’hypothèse p = 0.9 ou p = 0.5 ou les deux avec un risque de 5% d’erreur.
Si on voulait faire de même, avec les hypothèses p = 0.9 et p = 0.8, il suffit d’augmenter la taille de l’échantillonpour que les intervalles de fluctuation I et J soient disjoints. D’après l’avant dernière propriété, si n ≥ 30, alors
J = [0.8− 1√n
; 0.8 + 1√n
] et I = [0.9− 1√n
; 0.9 + 1√n
]
On note que I et J sont disjoints si et seulement si 0.8 + 1√n< 0.9− 1√
n
2√n< 0.9− 0.8 ⇐⇒ 2 < 0.1
√n ⇐⇒ 20 <
√n
394

TSI 1 Lycée Heinrich-Nessel 2016/2017
C’est-à-dire, en élevant au carré, comme n est positif, 202 = 400 < n.Donc, pour discriminer au moins une des deux hypothèses p = 0.9 ou p = 0.8 avec un risque de 5% d’erreurenviron, il faut considérer un échantillon de taille supérieure à 400.
395

TSI 1 Lycée Heinrich-Nessel 2016/2017
396

Chapitre 22
Integration
Dans ce chapitre, nous allons voir comment calculer l’aire d’une figure délimitée entre autre par la courbe repré-sentative d’une fonction.
Le plan est muni d’un repère orthogonal (O, I, J) ; l’unité d’aire qui sera utilisée pour mesurer les aires est l’airedu rectangle formé à partir des trois points O, I et J .
Programme• La présentation de l’intégrale d’une fonction positive sur un segment s’appuie sur la notion d’aire, maistout développement théorique sur ce sujet est hors programme.
• Intégrale∫
[a;b] f d’une fonction f continue sur un segment [a; b]. Interpréter géométrique l’intégrale d’unefonction positive (aire sous la courbe).
• Modéliser une situation physique par une intégration.• Linéarité, positivité et croissance de l’intégrale.• Valeur moyenne.
• Inégalité de Jensen∣∣∣ ∫[a;b] f
∣∣∣ ≤ ∫[a;b] |f |. Majorer et minorer une intégrale.
• Une fonction continue et positive sur [a; b] (où a < b) est nulle si et seulement si son intégrale est nulle.• Sommes de Riemann et méthode des rectangles. Interpréter géométriquement cette propriété. Démonstra-
tion dans la cas d’une fonction de classe C1.• Approximer une intégrale par la méthode des rectangles ou la méthode des trapèzes.• Si f est une fonction continue sur I et si x0 ∈ I, alors la fonction
x 7→∫ x
x0
f(t) dt
est l’unique primitive de f sur I s’annulant en x0.• En particulier, toute fonction continue sur I admet des primitives sur I. Deux primitives d’une fonction
continue sur l’intervalle I, diffèrent d’une constante.• Calcul d’une intégrale au moyen d’une primitive. Pour f de classe C1 :∫ b
a
f ′(t) dt = f(b)− f(a)
• Intégration par parties.• Changement de variable : Si φ : [a; b]→ I est de classe C1 et f : I → R continue, alors∫ φ(b)
φ(a)f(x) dx =
∫ b
a
f(φ(t))φ′(t) dt
Tout excès de technicité est exclu.• Primitives des fonctions usuelles. Savoir reconnaître des primitives usuelles.• Pour les fonctions rationnelles, on se limite à des cas simples : aucune théorie de la décomposition en
éléments simples n’est au programme.• Formule de Taylor avec reste intégral.
397

TSI 1 Lycée Heinrich-Nessel 2016/2017
22.1 Intégrale d’une fonction continue positiveOn rappelle qu’une fonction f est dite positive sur un intervalle I si, pour tout x ∈ I, f(x) est positif (f(x) ≥ 0).
Définition 22.1. Soit f une fonction définie sur l’intervalle [a; b], continue et positive sur [a; b].
On appelle intégrale de a à b de f la mesure de l’aire du domaine du plan délimité par la courbe représentativeC de f , l’axe des abscisses et les droites verticales d’équation x = a et x = b.
Ce nombre est noté∫ baf(x) dx.
x
y
I
J
Oa b
Cf
Aire =∫ baf(x) dx
L’aire du domaine en rouge s’appelle aussi « aire sous la courbe » Cf entre a et b.
Remarque. Le domaine en rouge qui permet de définir l’intégrale peut aussi être définie comme étant le lieugéométrique des points M(x; y) tels que
a ≤ x ≤ b et 0 ≤ y ≤ f(x)
Vocabulaire.• L’expression
∫ baf(x) dx se lit « intégrale de a à b de f(x) dx ».
• Les réels a et b sont appelés les bornes de l’intégrale.• Dans l’expression d’une intégrale, le terme x est appelé variable muette.
On peut aussi remplacer x par d’autres expressions, par exemple∫ bax2 dx =
∫ bat2 dt.
L’aire d’un rectangle étant simple à calculer, on a la propriété suivante :
Proposition 22.2 (Intégrale d’une fonction constante). Soit k ≥ 0 et f : [a; b] → R la fonction constantedéfinie par f(x) = k pour tout x dans l’intervalle [a; b]. Alors∫ b
a
f(x) dx =∫ b
a
k dx = (b− a)× k
x
y
I
J
O a b
kAire =
∫ bak dx = (b− a)× k
L’aire d’un rectangle de largeur nulle étant nulle :
Proposition 22.3. Soit f : [a; b]→ R une fonction continue et positive sur [a; b]. Pour tout réel c de l’intervalle[a; b] : ∫ c
c
f(x) dx = 0
398

TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 22.4. Soit f : [a; b]→ R une fonction continue et positive sur [a; b], alors∫ b
a
f(x) dx = 0 ⇐⇒ f = 0
Démonstration. La réciproque : Si f = 0 alors f est en particulier constante et∫ b
a
f(x) dx = (b− a)× 0 = 0
Le sens direct : Raisonnons par l’absurde, supposons que∫ baf(x) dx = 0 et que f n’est pas identiquement nulle.
Alors, il existe x0 ∈ [a; b] tel que f(x0) 6= 0. Pour simplifier, on suppose que a < x0 < b (les cas x0 = a et x0 = b
sont laissés en exercices). Or f est positive, donc f(x0) > 0. Soit ε = f(x0)2 > 0, comme f est continue, il existe
δ > 0 tel que [x0 − δ;x0 + δ] est inclus dans [a; b] et
∀x ∈ [x0 − δ;x0 + δ] : |f(x)− f(x0)| ≤ ε
Ainsi, pour tout x ∈ [x0 − δ;x0 + δ], on a
f(x) ≥ f(x0)− ε = f(x0)− f(x0)2 = f(x0)
2 > 0
Graphiquement :
x
y
x0 − δ x0 + δ
f(x0)2
f(x0) Aire = 2δ × f(x0)2
a bx0
Le rectangle de largeur 2δ et de hauteur f(x0)2 est inclus dans le domaine permettant de calculer l’intégrale de a
à b de f . Ainsi, ∫ b
a
f(x) dx ≥ 2δ︸︷︷︸>0
× f(x0)2︸ ︷︷ ︸>0
> 0
Ce qui est contradictoire. Donc, si∫ baf(x) dx = 0, on a bien f = 0.
22.2 Intégrale d’une fonction continue quelconque
Définition 22.5 (généralisation). Soit a < b deux réels et f : [a; b] → R une fonction continue (quelconque)sur [a; b]. On appelle intégrale de a à b de f , et on note
∫ baf(x) dx (ou
∫ baf), l’aire algébrique de la portion du
plan délimitée d’une part par le graphe de f et l’axe des abscisses, par les droites d’équations x = a et x = bd’autre part.Ainsi, l’aire est comptée positivement lorsque le graphe est au-dessus de l’axe des abscisses et négativementdans le cas contraire (lorsque f est négative).
x
y
I
J
Oa b
Cf
Aire algébrique =∫ baf(x) dx
−
+
399
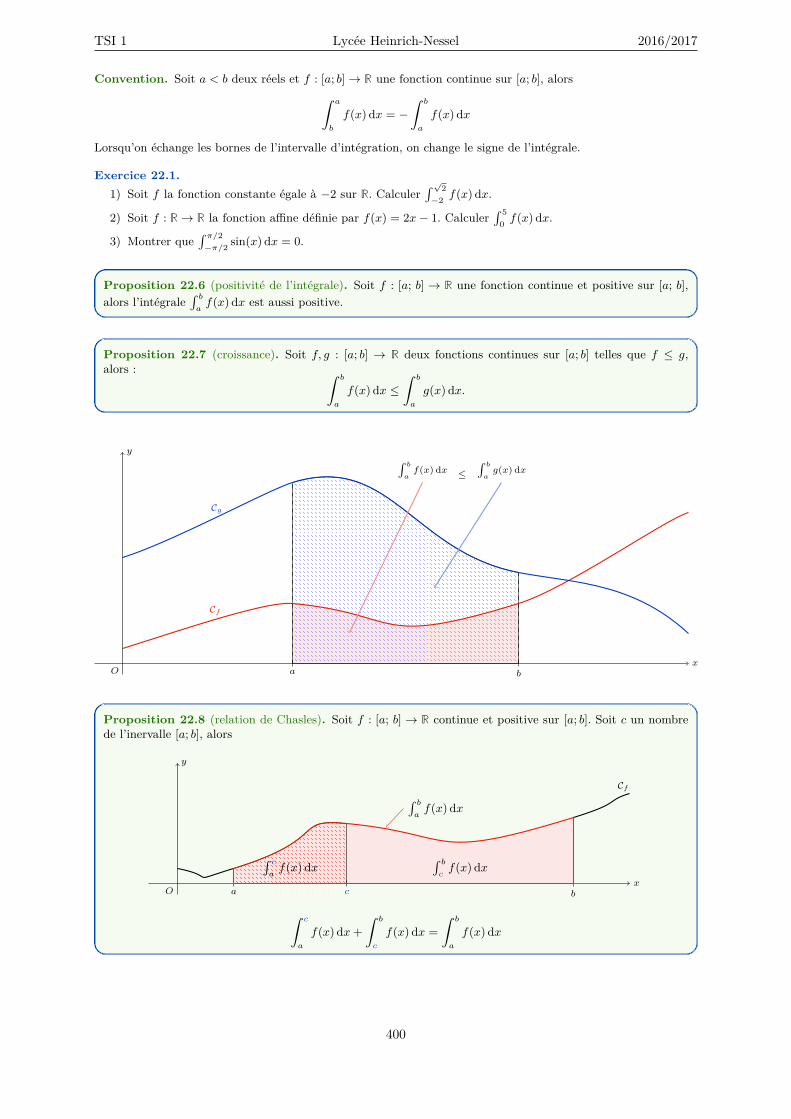
TSI 1 Lycée Heinrich-Nessel 2016/2017
Convention. Soit a < b deux réels et f : [a; b]→ R une fonction continue sur [a; b], alors∫ a
b
f(x) dx = −∫ b
a
f(x) dx
Lorsqu’on échange les bornes de l’intervalle d’intégration, on change le signe de l’intégrale.
Exercice 22.1.1) Soit f la fonction constante égale à −2 sur R. Calculer
∫ √2−2 f(x) dx.
2) Soit f : R→ R la fonction affine définie par f(x) = 2x− 1. Calculer∫ 5
0 f(x) dx.
3) Montrer que∫ π/2−π/2 sin(x) dx = 0.
Proposition 22.6 (positivité de l’intégrale). Soit f : [a; b] → R une fonction continue et positive sur [a; b],alors l’intégrale
∫ baf(x) dx est aussi positive.
Proposition 22.7 (croissance). Soit f, g : [a; b] → R deux fonctions continues sur [a; b] telles que f ≤ g,alors : ∫ b
a
f(x) dx ≤∫ b
a
g(x) dx.
Cf
Cg
x
y
O a b
∫ baf(x) dx ≤
∫ bag(x) dx
Proposition 22.8 (relation de Chasles). Soit f : [a; b] → R continue et positive sur [a; b]. Soit c un nombrede l’inervalle [a; b], alors
Cf
x
y
O a c b
∫ caf(x) dx
∫ bcf(x) dx
∫ baf(x) dx
∫ c
a
f(x) dx+∫ b
c
f(x) dx =∫ b
a
f(x) dx
400
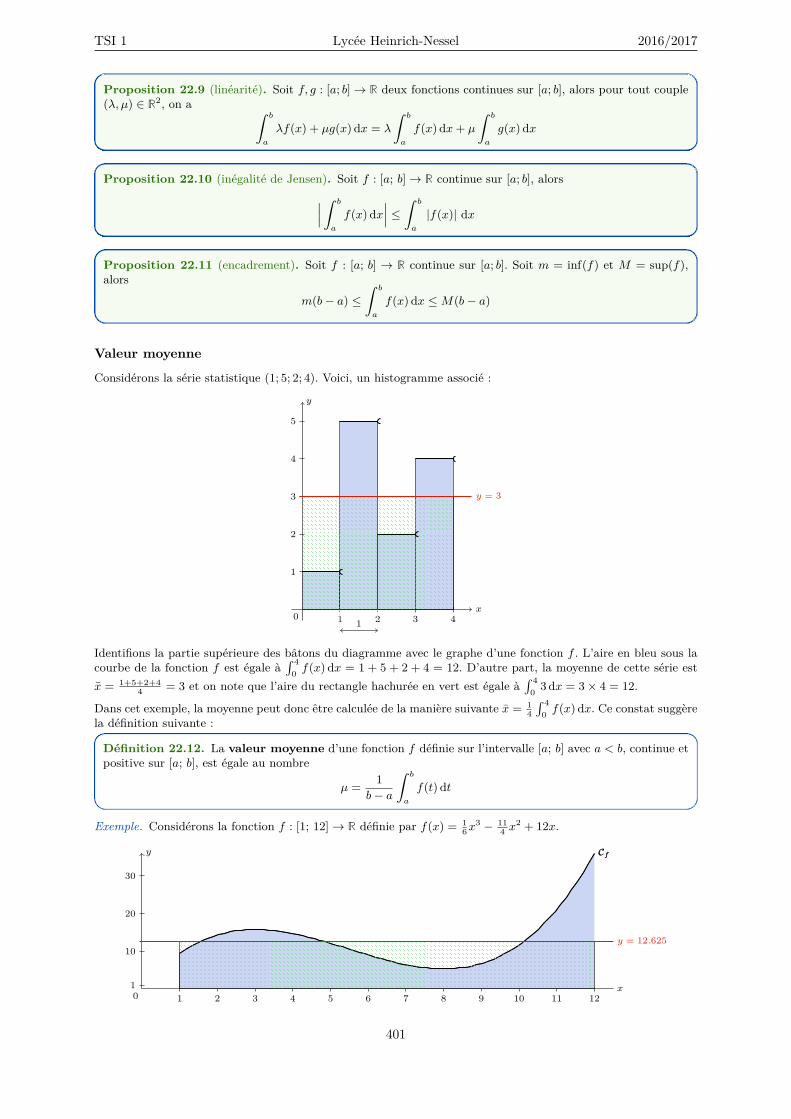
TSI 1 Lycée Heinrich-Nessel 2016/2017
Proposition 22.9 (linéarité). Soit f, g : [a; b]→ R deux fonctions continues sur [a; b], alors pour tout couple(λ, µ) ∈ R2, on a ∫ b
a
λf(x) + µg(x) dx = λ
∫ b
a
f(x) dx+ µ
∫ b
a
g(x) dx
Proposition 22.10 (inégalité de Jensen). Soit f : [a; b]→ R continue sur [a; b], alors∣∣∣ ∫ b
a
f(x) dx∣∣∣ ≤ ∫ b
a
|f(x)| dx
Proposition 22.11 (encadrement). Soit f : [a; b] → R continue sur [a; b]. Soit m = inf(f) et M = sup(f),alors
m(b− a) ≤∫ b
a
f(x) dx ≤M(b− a)
Valeur moyenne
Considérons la série statistique (1; 5; 2; 4). Voici, un histogramme associé :
x
y
0 1 2 3 4
1
2
3
4
5
1
y = 3
Identifions la partie supérieure des bâtons du diagramme avec le graphe d’une fonction f . L’aire en bleu sous lacourbe de la fonction f est égale à
∫ 40 f(x) dx = 1 + 5 + 2 + 4 = 12. D’autre part, la moyenne de cette série est
x = 1+5+2+44 = 3 et on note que l’aire du rectangle hachurée en vert est égale à
∫ 40 3 dx = 3× 4 = 12.
Dans cet exemple, la moyenne peut donc être calculée de la manière suivante x = 14
∫ 40 f(x) dx. Ce constat suggère
la définition suivante :
Définition 22.12. La valeur moyenne d’une fonction f définie sur l’intervalle [a; b] avec a < b, continue etpositive sur [a; b], est égale au nombre
µ = 1b− a
∫ b
a
f(t) dt
Exemple. Considérons la fonction f : [1; 12]→ R définie par f(x) = 16x
3 − 114 x
2 + 12x.
x
y
0 1 2 3 4 5 6 7 8 9 10 11 121
10
20
30
CfCf
y = 12.625
401
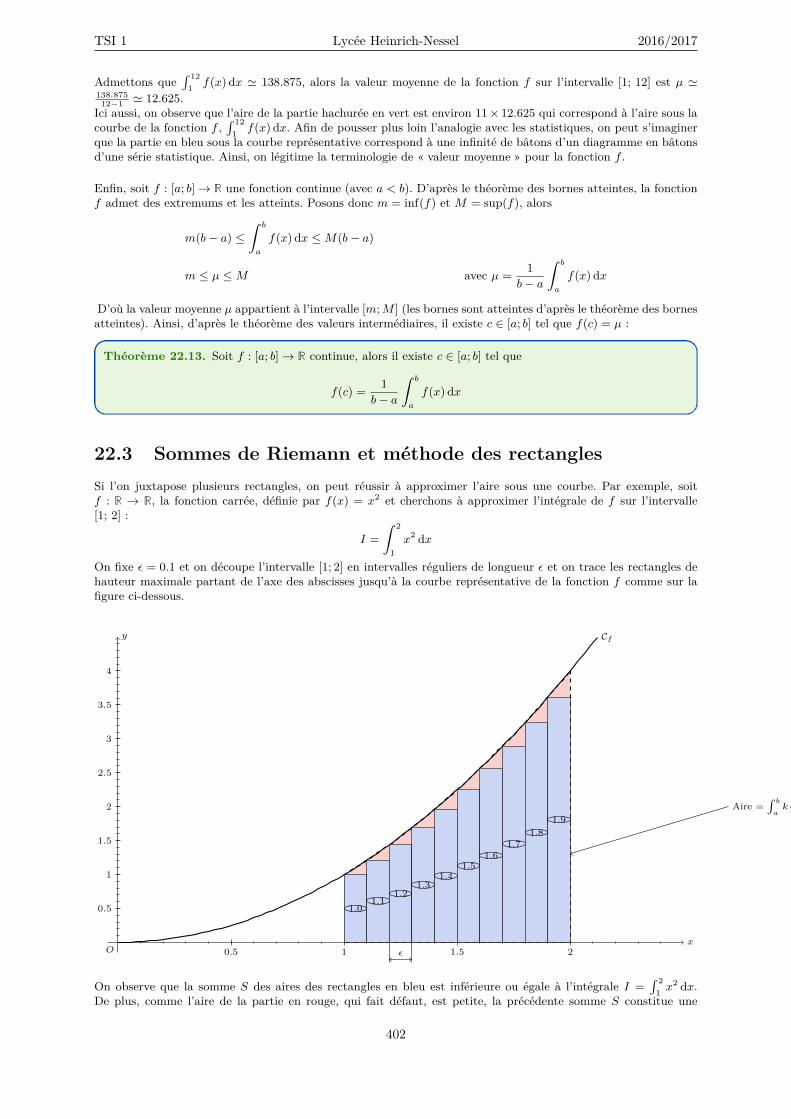
TSI 1 Lycée Heinrich-Nessel 2016/2017
Admettons que∫ 12
1 f(x) dx ' 138.875, alors la valeur moyenne de la fonction f sur l’intervalle [1; 12] est µ '138.87512−1 ' 12.625.
Ici aussi, on observe que l’aire de la partie hachurée en vert est environ 11× 12.625 qui correspond à l’aire sous lacourbe de la fonction f ,
∫ 121 f(x) dx. Afin de pousser plus loin l’analogie avec les statistiques, on peut s’imaginer
que la partie en bleu sous la courbe représentative correspond à une infinité de bâtons d’un diagramme en bâtonsd’une série statistique. Ainsi, on légitime la terminologie de « valeur moyenne » pour la fonction f .
Enfin, soit f : [a; b]→ R une fonction continue (avec a < b). D’après le théorème des bornes atteintes, la fonctionf admet des extremums et les atteints. Posons donc m = inf(f) et M = sup(f), alors
m(b− a) ≤∫ b
a
f(x) dx ≤M(b− a)
m ≤ µ ≤M avec µ = 1b− a
∫ b
a
f(x) dx
D’où la valeur moyenne µ appartient à l’intervalle [m;M ] (les bornes sont atteintes d’après le théorème des bornesatteintes). Ainsi, d’après le théorème des valeurs intermédiaires, il existe c ∈ [a; b] tel que f(c) = µ :
Théorème 22.13. Soit f : [a; b]→ R continue, alors il existe c ∈ [a; b] tel que
f(c) = 1b− a
∫ b
a
f(x) dx
22.3 Sommes de Riemann et méthode des rectanglesSi l’on juxtapose plusieurs rectangles, on peut réussir à approximer l’aire sous une courbe. Par exemple, soitf : R → R, la fonction carrée, définie par f(x) = x2 et cherchons à approximer l’intégrale de f sur l’intervalle[1; 2] :
I =∫ 2
1x2 dx
On fixe ε = 0.1 et on découpe l’intervalle [1; 2] en intervalles réguliers de longueur ε et on trace les rectangles dehauteur maximale partant de l’axe des abscisses jusqu’à la courbe représentative de la fonction f comme sur lafigure ci-dessous.
Cf
x
y
O 0.5 1 1.5 2
0.5
1
1.5
2
2.5
3
3.5
4
Aire =∫ bak dx = (b− a)× k
1.01.1
1.21.3
1.41.5
1.61.7
1.81.9
ε
On observe que la somme S des aires des rectangles en bleu est inférieure ou égale à l’intégrale I =∫ 2
1 x2 dx.
De plus, comme l’aire de la partie en rouge, qui fait défaut, est petite, la précédente somme S constitue une
402

TSI 1 Lycée Heinrich-Nessel 2016/2017
approximation de I.Dans le tableau suivant, on calcul la somme des aires des rectangles en bleu.
rectangle N x 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 Totalhauteur = x2 1.0 1.21 1.44 1.69 1.96 2.25 2.56 2.89 3.24 3.61
aire = hauteur ×ε 0.1 0.121 0.144 0.169 0.196 0.225 0.256 0.289 0.324 0.361 2.185
D’où,∫ 2
1 x2 dx ' 2.185.
Exercice 22.2. Soit f : [1; 2]→ R définie par f(x) = x2. Pour tout entier n, on pose
In =n−1∑k=0
1nf(1 + k
n)
1) Calculer I10.2) Justifier que pour tout entier n, In ≤
∫ 21 x
2 dx.
3) On admet (rappelle) que pour tout entier n, on a∑n
k=1 k2 = n(n+1)(2n+1)
6 . Exprimer In en fonction de n.
In =n−1∑k=0
1nf(1 + k
n)
=n−1∑k=0
1n
(1 + k
n)2
=n−1∑k=0
1n
(1 + 2kn
+ k2
n2 )
= 1 + 2n2
n−1∑k=1
k + 1n3
n−1∑k=1
k2
= 1 + 2n2
(n− 1)(n− 1 + 1)2 + 1
n3(n− 1)n(2n− 1)
6
= 1 + n2 − nn2 + (n2 − n)(2n− 1)
6n3
= 1 + n2 − nn2 + 2n3 − 3n2 + n
6n3
4) En déduire la limite de In lorsque n tend vers l’infini.
limn→+∞
In = 1 + 1 + 26 = 7
3
5) À l’aide des méthodes de calcul vu au premier semestre, déterminer∫ 2
1 f(x) dx. Que remarque-t-on ?
Remarque. On notera que plus on veut une approximation précise de l’intégrale∫ baf(x) dx, plus on doit choisir
un découpage en intervalles de taille ε avec ε d’autant plus petit.
Théorème 22.14 (Sommes de Riemann). Soit f : [a; b]→ R une fonction continue sur [a; b], alors
limn→+∞
b− an
n−1∑k=0
f(a+ k
b− an
)=∫ b
a
f(x) dx
Remarque. Ce théorème est encore vrai pour une fonction à valeurs complexes.
Démonstration. On se restreint au cas où f est de classe C1 sur [a; b]. Soit n un entier non nul, pour tout k ∈ J0;nK,on pose, à l’aide du théorème des bornes atteintes (appliqué à la fonction continue f) :• ak = a+ k b−a
n;
• ck ∈ [ak; ak+1] tel que f(ck) = inf(f(x); x ∈ [ak; ak+1] (si k < n) ;• dk ∈ [ak; ak+1] tel que f(dk) = sup(f(x); x ∈ [ak; ak+1] (si k < n).
403

TSI 1 Lycée Heinrich-Nessel 2016/2017
Alors, a0 = 0, an = b, ak+1 − ak = b−an
pour tout entier 0 ≤ k < n. Les nombres ak constituent un découpage del’intervalle [a; b] en intervalles tous de longueurs b−a
n. Plus n est grand plus les intervalles sont de longueur petite.
En revenant à la fonction f , on a
b− an
n−1∑k=0
f (ck) ≤ b− an
n−1∑k=0
f (ak) ≤ b− an
n−1∑k=0
f (dk)
et pour tout x ∈ [ak; ak+1], on a f(ck) ≤ f(x) ≤ f(dk). D’où
b− an
n−1∑k=0
f(ck) ≤∫ b
a
f(x) dx ≤ b− an
n−1∑k=0
f(dk)
et donc pour tout entier n,∣∣∣ b− an
n−1∑k=0
f (ak)−∫ b
a
f(x) dx∣∣∣ ≤ b− a
n
n−1∑k=0
f(dk)− b− an
n−1∑k=0
f(ck)
∣∣∣ b− an
n−1∑k=0
f (ak)−∫ b
a
f(x) dx∣∣∣ ≤ b− a
n
n−1∑k=0
f(dk)− f(ck) (?)
Par hypothèse, f est de classe C1, ainsi, sa dérivée f ′ est continue et d’après le théorème des bornes atteintes, ilexiste D ≥ 0 tel que |f ′(x)| ≤ D pour tout x ∈ [a; b].Ensuite, en appliquant l’inégalité des accroissements finis, on déduit que pour tout k ∈ J0;n− 1K, on a
|f(dk)− f(ck)| = f(dk)− f(ck) ≤ |dk − ck| ×D≤ |ak+1 − ak| ×D
f(dk)− f(ck) ≤ b− an
D
De l’inégalité (?), on déduit que∣∣∣ b− an
n−1∑k=0
f (ak)−∫ b
a
f(x) dx∣∣∣ ≤ b− a
n
n−1∑k=0
b− an
D
≤ (b− a)2
n2 D
n−1∑k=0
1
≤ (b− a)2
n2 D × n
≤ (b− a)2 D
n
Ainsi, d’après le théorème de l’encadrement, on déduit que la distance entre la somme b−an
∑n−1k=0 f(ak) et
l’intégrale de a à b de f tend vers 0. D’où, le théorème.
Remarque. Ce procédé a été utilisé par Bernard Riemann dans « über die Darstellbarkeit einer Funktion durcheine trigonometrische Reihe » en 1854 pour définir plus rigoureusement l’intégrale d’une fonction continue sur unintervalle. D’ailleurs, en sa mémoire, on parle aussi d’intégrale de Riemann pour la notion d’intégrale que nousétudions dans ce chapitre.
En reprenant la démonstration, on montre de même que :
Corollaire 22.15. Soit f : [a; b]→ R une fonction continue sur [a; b], alors
limn→+∞
b− an
n∑k=1
f(a+ k
b− an
)=∫ b
a
f(x) dx
En effectuant la demi-somme des deux suites précédente, on déduit immédiatement :
Corollaire 22.16 (méthode des trapèzes). Soit f : [a; b] → R une fonction continue sur [a; b]. Pour tout0 ≤ k ≤ n, posons
ak = a+ kb− an
404
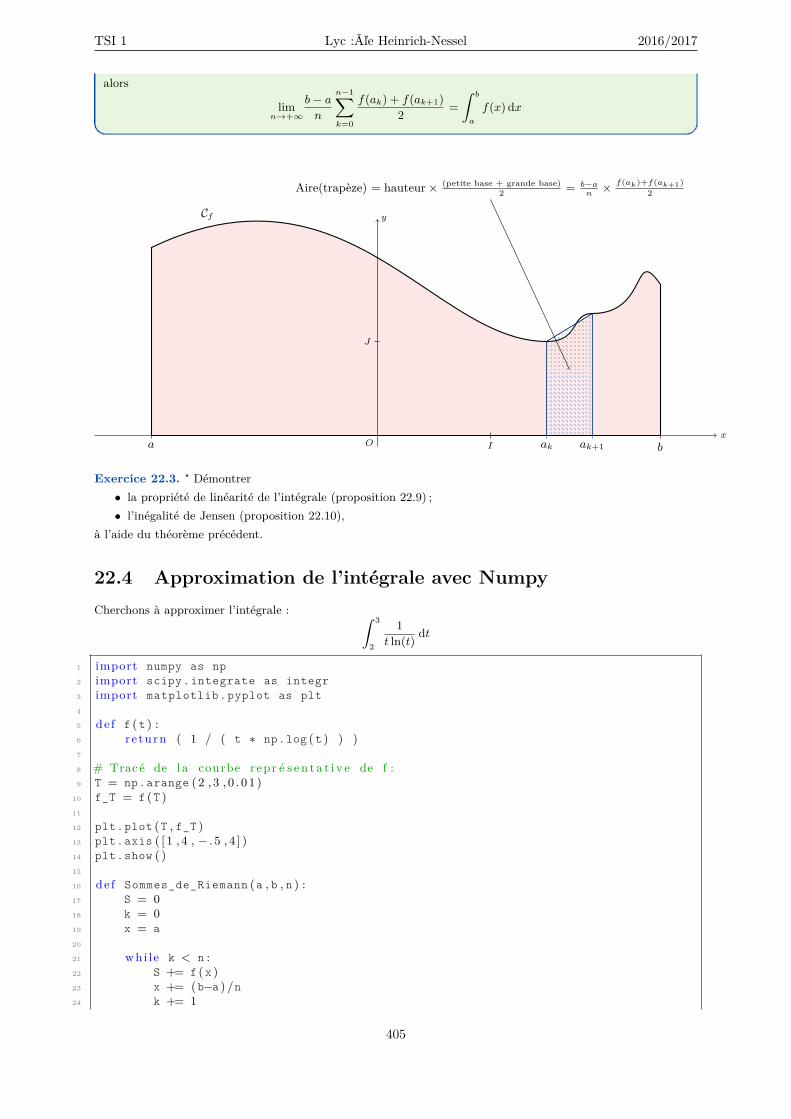
TSI 1 Lyc :Ãľe Heinrich-Nessel 2016/2017
alors
limn→+∞
b− an
n−1∑k=0
f(ak) + f(ak+1)2 =
∫ b
a
f(x) dx
x
y
I
J
Oa b
Cf
ak ak+1
Aire(trapèze) = hauteur× (petite base + grande base)2 = b−a
n× f(ak)+f(ak+1)
2
Exercice 22.3. ? Démontrer• la propriété de linéarité de l’intégrale (proposition 22.9) ;• l’inégalité de Jensen (proposition 22.10),
à l’aide du théorème précédent.
22.4 Approximation de l’intégrale avec NumpyCherchons à approximer l’intégrale : ∫ 3
2
1t ln(t) dt
1 import numpy as np2 import scipy . integrate as integr3 import matplotlib . pyplot as plt4
5 de f f (t ) :6 re turn ( 1 / ( t ∗ np . log (t ) ) )7
8 # Trac é de l a courbe repr é s en t a t i v e de f :9 T = np . arange ( 2 , 3 , 0 . 0 1 )
10 f_T = f (T )11
12 plt . plot (T , f_T )13 plt . axis ( [ 1 , 4 , − . 5 , 4 ] )14 plt . show ( )15
16 de f Sommes_de_Riemann (a , b , n ) :17 S = 018 k = 019 x = a20
21 whi le k < n :22 S += f (x )23 x += (b−a ) /n24 k += 1
405

TSI 1 Lycée Heinrich-Nessel 2016/2017
25
26 S ∗= (b−a ) /n27 re turn S28
29 # Approximation de l ’ i n t é g r a l e avec une commande du package s c ipy :30 pr in t ( " Calcu l avec s c ipy : " , integr . quad (f , 2 , 3 ) )31
32 # Approximation à l ’ a ide des sommes de Riemann :33 pr in t ( "Sommes de Riemann : " , Sommes_de_Riemann (2 ,3 ,10∗∗6) )34
35 # Ré su l t a t obtenu avec un c a l c u l de l ’ i n t é g r a l e :36 pr in t ( " Calcu l th é or ique : " , np . log ( np . log (3 ) ) − np . log ( np . log (2 ) ) )
Le résultat affiché :Calcul avec scipy: (0.4605607481983634, 5.113251468884121e-15)Sommes de Riemann: 0.460560957144Calcul théorique: 0.460560748198
On observe que la commande de Scipy s’exécute très rapidement avec une précision à 15 chiffres (comme indiquépar le second terme entre parenthèses). Par contre, la fonction Somme_de_Riemann met beaucoup de temps pours’exécuter et ne donne qu’une approximation à 10−7 près.
En revenant à la démonstration du théorème Sommes de Riemann, posons m = 10n, alors
∣∣∣ b− am
m−1∑k=0
f (ak)−∫ b
a
f(x) dx∣∣∣ ≤ 1
10n × (b− a)2 max(|f ′(x)|; x ∈ [a; b])
Ainsi, si on multiplie m par 10 alors on augmente d’un ordre de grandeur (n augment de 1) la précision del’approximation de l’intégrale par la somme de Riemann. En d’autre terme, pour augmenter la précision d’unordre de grandeur, il faut multiplier le temps de calcul par 10.
22.5 Primitives
On rappelle qu’on désigne par K le corps des nombres réels R ou complexes C. Une fonction complexe f = a+ bi :D → C est continue (resp. dérivable, intégrable) si et seulement si ses fonctions partie réelle a et partie imaginaireb sont continues (resp. dérivables, intégrables).
Définition 22.17. Soit f : I → K une fonction continue. On dit qu’une fonction F est une primitive de lafonction f si la dérivée de la fonction F est égale à la fonction f sur I :
F ′ = f
Théorème 22.18. Soit f : I → R une fonction continue sur un intervalle I et x0 ∈ I, alors la fonctionF : I → R définie par
F (x) =∫ x
x0
f(t) dt
est l’unique primitive de f sur I s’annulant en x0.
406

TSI 1 Lycée Heinrich-Nessel 2016/2017
Démonstration. Montrons que F est dérivable et que sa dérivée est f : Soit a ∈ I, pour tout x ∈ I \ a,
F (x)− F (a)x− a − f(a) = 1
x− a
(∫ x
x0
f(t) dt−∫ a
x0
f(t) dt)− f(a)
= 1x− a
∫ x
a
f(t) dt− f(a) d’après la relation de Chasles
= 1x− a
∫ x
a
f(t) dt− 1x− a
∫ x
a
f(a) dt
= 1x− a
∫ x
a
f(t)− f(a) dt∣∣∣ F (x)− F (a)x− a − f(a)
∣∣∣ =∣∣∣ 1x− a
∫ x
a
f(t)− f(a) dt∣∣∣
≤ 1x− a
∫ x
a
| f(t)− f(a) | dt d’après l’inégalité de Jensen
Soit ε > 0, comme f est continue en a, il existe δ > 0 tel que pour tout t ∈ I, on ait :
|t− a| ≤ δ ⇒ |f(t)− f(a)| ≤ ε
Soit x ∈ I tel que |x− a| ≤ δ, alors∣∣∣ F (x)− F (a)x− a − f(a)
∣∣∣ ≤ 1x− a
∫ x
a
|f(t)− f(a)|︸ ︷︷ ︸≤ε
dt
≤ 1x− a
∫ x
a
εdt
≤ 1x− a × (x− a)ε
≤ ε
Donc, pour tout ε > 0, il existe δ > 0 tel que
∀ x ∈ I \ a : |x− a| ≤ δ ⇒∣∣∣F (x)− F (a)
x− a − f(a)∣∣∣ ≤ ε
Ainsi, par définition, F est dérivable en a et de plus F ′(a) = f(a). Ensuite, notons que
F (x0) =∫ x0
x0
f(t) dt = 0
Il nous reste à montrer que F est unique. Soit G : I → R une primitive de f telle que F (x0) = 0. Alors, pour toutx ∈ I, (F −G)′(x) = f(x)− f(x) = 0 et (F −G)(x0) = 0. La fonction F −G s’annule en x0 et sa dérivée est nullesur l’intervalle I, ainsi d’un corollaire du théorème des accroissements finis, on déduit que F −G est nulle sur I.Donc F = G, c’est-à-dire l’unicité.
Corollaire 22.19. Soit I un intervalle et f : I → K une fonction continue sur I. Alors f admet au moins uneprimitive F : I → K dérivable sur I. De plus, si F,G : I → K sont deux primitives alors il existe λ ∈ K tel queG = F + λ.
Remarque. Deux primitives d’une fonction f sur un intervalle I ne diffèrent que d’une constante k.
Corollaire 22.20. Soit I un intervalle et f : I → K une fonction continue sur un intervalle I et F une primitivede f sur I. Alors l’ensemble des primitives de f sur I est
F + λ; λ ∈ K
Exercice 22.4. ? Soit f, g : I → R deux fonctions.1) On suppose que f et g sont dérivables sur I et que f ′ et g′ sont continues sur I. Soit x0 ∈ I. Montrer que
(∀x ∈ I : f(x) = g(x)) ⇐⇒∀x ∈ I : f ′(x) = g′(x)f(x0) = g(x0)
407

TSI 1 Lycée Heinrich-Nessel 2016/2017
2) On suppose que f et g sont deux fois dérivable sur I et que les dérivées secondes f ′′ et g′′ sont continuessur I. Soit x0 ∈ I. Montrer que
(∀x ∈ I : f(x) = g(x)) ⇐⇒
∀x ∈ I : f ′′(x) = g′′(x)f(x0) = g(x0)f ′(x0) = g′(x0)
Corollaire 22.21. Soit f : [a; b]→ R une fonction de classe C1, alors∫ b
a
f ′(t) dt = f(b)− f(a)
Notation. Pour faciliter les calculs dans la pratique, on utilise la notation suivante :
[F (t) ]ba = F (b)− F (a)
Rappelons les primitives des fonctions de référence :
Proposition 22.22. Soit n un entier naturel. Soit k un nombre réel quelconque.
Intervalle de définition I Fonction : f(x) = Primitive F (x) =R f(x) = 0 F (x) = k
R f(x) = 1 F (x) = x+ k
R f(x) = x F (x) = 12 x
2 + k
R f(x) = x2 F (x) = 13 x
3 + k
R f(x) = xn F (x) = 1n+1 x
n+1 + k
]0; +∞[ f(x) = 1√x
F (x) = 2√x+ k
]−∞; 0[ ou ]0; +∞[ f(x) = 1x
F (x) = ln(|x|) + k
]−∞; 0[ ou ]0; +∞[ f(x) = 1x2 F (x) = − 1
x+ k
]−∞; 0[ ou ]0; +∞[ f(x) = 1xn
avec n ≥ 2 F (x) = 1−n+1x
−n+1 + k
R f(x) = ex F (x) = ex + k
Remarque. Le fait de « déterminer une primitive » est l’opération inverse de « dériver une fonction ». Ainsi, dansle tableau précédent, le passage de la troisième colonne à la seconde se fait en dérivant.
Proposition 22.23. Soit f, g, u, v : I → R quatre fonctions continues et α, β, k des nombres réels. On noteF , G une primitive de f et g respectivement. Alors :
Fonction définie sur I Primitive sur If + g F +G+ k
αf αF + k
αf + βg αF + βG+ k
u′ u 12u
2 + k
Si u ne s’annule pas, u′
u2−1u
+ k
u′ eu eu + k
Si u > 0, u′
uln(u) + k
22.6 Intégration par parties et Changement de variablesDeux conséquences du corollaire 22.21 :
Théorème 22.24 (Intégration par parties). Soit f, g : [a; b]→ R deux fonctions de classe C1, alors∫ b
a
f ′(t)g(t) dt = [f(t)g(t)]ba −∫ b
a
f(t)g′(t) dt
408

TSI 1 Lycée Heinrich-Nessel 2016/2017
Démonstration. Rappelons que (fg)′ = f ′g + fg′, ainsi, d’après le corollaire 22.21, on a∫ b
a
f ′(t)g(t) + f(t)g′(t) dt =∫ b
a
(fg)′(t) dt =[f(t)g(t)
]ba∫ b
a
f ′(t)g(t) dt =[f(t)g(t)
]ba−∫ b
a
f(t)g′(t) dt
Théorème 22.25 (Changement de variables). Soit I un intervalle, φ : [α; β] → I une fonction de classe C1
et f : I → R une fonction continue, alors∫ β
α
f(φ(x))φ′(x) dx =∫ φ(β)
φ(α)f(t) dt
On dit qu’on a effectué le changement de variables t = φ(x).
Remarque. En revenant à la notation de Leibniz : dtdx = φ′(x), on induit le moyen mnémotechnique suivant :
t = φ(x) ⇒
dt = φ′(x) dxx = α ⇒ t = φ(α)x = β ⇒ t = φ(β)
D’où la formule du théorème de changement de variables :∫ φ(β)φ(α) f(t)dt =
∫ βαf(φ(x))φ′(x) dx.
Démonstration. Soit F : I → R une primitive de f alors la fonction F φ est dérivable sur [α;β] et pour toutx ∈ [α;β], on a (F φ)′(t) = f(φ(t))φ′(t). On en déduit que F φ est de classe C1, ainsi d’après le corollaire 22.21,on a ∫ β
α
(F φ)′(t) dt = F φ(β)− F φ(α)∫ β
α
f(φ(t))φ′(t) dt =[F (x)
]φ(β)
φ(α)=∫ φ(β)
φ(α)f(x) dx
Exercice 22.5. Soit f : [−a; a]→ R une fonction continue.1) Supposons que f est impaire. À l’aide d’un changement de variable, montrer que
∫ a−a f(t) dt = 0.
2) Supposons que f est paire. De même, montrer que∫ a−a f(t) dt = 2
∫ a0 f(t) dt.
Exercice 22.6. Soit f : R→ R une fonction T -périodique et a ∈ R. Montrer que pour tout entier relatif k,∫ a+(k+1)T
a+kTf(t) dt =
∫ a+T
a
f(t) dt
22.7 Formule de Taylor avec reste intégralOn se donne f : I → R une fonction de classe Cn sur un intervalle ouvert I et a ∈ I. Nous allons donner, dans descas particuliers, deux expressions différentes du reste o((x − a)n) dans le développement limité (lorsqu’il existe)de f au point a :
f(x) = f(a) + f ′(a)1! (x− a) + f ′′(a)
2! (x− a)2 + . . .+ f (n)(a)n! (x− a)n + o((x− a)n) (DL)
Supposons que f : I → R est de classe C2 sur l’ouvert I. Soit b ∈ I, en intégrant par parties, on a∫ b
a
(b− t)f ′′(t) dt =[(b− t)f ′(t)
]ba−∫ b
a
(−1)f ′(t) dt
= −(b− a)f ′(a) + f(b)− f(a)
D’où
f(b) = f(a) + (b− a)f ′(a) +∫ b
a
(b− a)f ′′(t) dt
et le reste du (DL) avec n = 1 est o(x− a) =∫ xa
(x− a)f ′′(t) dt. Par récurrence, on déduit :
409

TSI 1 Lycée Heinrich-Nessel 2016/2017
Théorème 22.26 (Formule de Taylor-Cauchy, avec reste intégrale). Soit f : I → R une fonction de classeCn+1 sur un intervalle ouvert I. Pour tous nombres a et b dans I, on a
f(b) = f(a) + f ′(a)1! (b− a) + f ′′(a)
2! (b− a)2 + . . .+ f (n)(a)n! (b− a)n +
∫ b
a
(b− t)n
n! f (n+1)(t) dt
Démonstration (voir chapitre 19, développements limités). Pour n = 0, si f est de classe C1, alors on a bien larelation suivante :
f(b) = f(a) +∫ b
a
f ′(t) dt
Soit n un entier quelconque. Supposons que la relation est vraie pour tout fonction de classe Cn+1. Soit f unefonction de classe Cn+2, alors par intégration par parties, on déduit que∫ b
a
(b− t)n+1
(n+ 1)!︸ ︷︷ ︸u(t)
× f (n+2)(t)︸ ︷︷ ︸v′(t)
dt
=[
(b− t)n+1
(n+ 1)! × f(n+1)(t)
]ba
−∫ b
a
(n+ 1)(−1) (b− t)n
(n+ 1)! × f(n+1)(t) dt
= − (b− a)n+1
(n+ 1)! f (n+1)(a) +∫ b
a
(b− t)n
n! f (n+1)(t) dt
= − (b− a)n+1
(n+ 1)! f (n+1)(a) + f(b)−(f(a) + f ′(a)
1! (b− a) + f ′′(a)2! (b− a)2 + . . .+ f (n)(a)
n! (b− a)n)
D’où
f(b) = f(a) + f ′(a)1! (b− a) + . . .+ f (n)(a)
n! (b− a)n + (b− a)n+1
(n+ 1)! f (n+1)(a) +∫ b
a
(b− t)n+1
(n+ 1)! f (n+2)(t) dt
par hypothèse de récurrence appliquée à f . D’où la relation du théorème avec n+ 2 et on en déduit le théorèmepar récurrence sur l’entier n.
Corollaire 22.27. Soit f : I → R une fonction de classe Cn+1 sur un intervalle ouvert I et a ∈ I. Pour toutb ∈ I, le reste o((b− a)n) dans le développement limité (DL) d’ordre n de f en a est
o((b− a)n) =∫ b
a
(b− t)n
n! f (n+1)(t) dt
410

TSI 1 Lycée Heinrich-Nessel 2016/2017
Références :
1) Le programme au BO : http://cache.media.enseignementsup-recherche.gouv.fr/file/special_3_ESR/44/5/programme-TSI_252445.pdf.
2) Maths TSI 1re année, Nicolas Nguyen, Walter Damin, Mathieu Fontes, Christophe Jan, Layla Pharamond,Prépas Sciences, édition Ellipses, 2014.
3) Mathématiques TSI1, Stéphane Passerat, http://www.tsi.lycee-louis-vincent.fr/wp-content/uploads/2015/09/M1_Maths_1516.pdf, 2015.
4) Prépas au Lycée Al Khawarizmi, Safi, Maroc, http://www.tsimaths.com/drupal/node/7.5) Le simulateur de Khôlles de Maths en MPSI, Guillaume Connan, Jean-Philippe Rouquès, édition Ellipses,
2001.6) Notes de cours en TSI 1, Guillaume Tomasini, lycée Heinrich-Nessel, 2015.7) SujetCCP, filière TSI : http://ccp.scei-concours.fr/sccp.php?page=cpge/sujet/sujet_accueil_cpge.
html#
8) Sujet Centrale-Supélec https://www.concours-centrale-supelec.fr/CentraleSupelec/
9) Prépas Dupuy de Lôme http://mp.cpgedupuydelome.fr/
10) Quelques problèmes mathématiques, Valentin Vinoles, http://valentin.vinoles.free.fr/index.php?page=divers
11) Notes de cours en prépa ATS : http://www.yann-angeli.fr/enseignement/ats/ats-2013-2014/
12) Géométrie, Michèle Audin, EDP Sciences, 2006.13) Algèbre 1re année, François Liret et Dominique Martinais, 2e édition, Dunod, 2003.14) Analyse 1re année, François Liret et Dominique Martinais, 2e édition, Dunod, 2003.
411