master 1 informatique & miage ce cours est une suite...
TRANSCRIPT

Master 1 Informatique & Miage
Bases de Données Approfondies – 2e partie
Théorie et pratique de NoSQL
Philippe Declercq 2015-2016Bases de Données Approfondies - 2015/2016 Philippe Declercq (2)
Préliminaire
� Ce cours est dispensé dans de le cadre de l’enseignement de Master 1 Informatique & Miage « Bases de Données Approfondies ». Le volume horaire est de 18 heures, réparties en 3 séances de Cours et 3 séances de TD.
� Ce cours est une suite logique et complémentaire à la première partie (dispensée par Serenella Cerrito) qui a abordé les notions suivantes :� Rappel des bases de données relationnelles, objet, relationnelle-objet,� Manipulations XML (Xpath, Xquery, …),� Bases XML.
� Cours et TD associent des parties théoriques, des mises en application sur des cas concrets et des manipulations d’outils.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (3)
Références
[1]: Bases de données documentaires et distribuées (Ph. Rigaux)[2]: Introduction aux systèmes NoSQL (B. Espinasse)[3]: NoSQL, une nouvelle approche du stockage et de la manipulation des données (SMILE)[4]: Blog Xebia : http://blog.xebia.fr/category/nosql/[5]: MongoDB Documentation[6]: NoSQL systems : sharding, replication and consistency[7] : RDBMS to MongoDB Migration Guide
Bases de Données Approfondies - 2015/2016 Philippe Declercq (4)
Plan du cours et des TD
Stockage et manipulation de données avec NoSQL2
Réplication des données3
Partitionnement des données4
Installation et manipulations simples NoSQLTD1
Réplication et partitionnementTD2
Recherche d’information – Moteurs de rechercheTD3
Introduction au NoSQL1
Recherches et calculs en NoSQL5
Et l’avenir ?6

Chapitre 1
Introduction au NoSQL
Théorie et pratique de NoSQL
Philippe Declercq 2015-2016Bases de Données Approfondies - 2015/2016 Philippe Declercq (6)
Introduction - Constats
� Les bases de données relationnelles font la preuve de leur efficacité depuis très longtemps !
� Ces bases sont bien adaptées au stockage et à la manipulation d’informations bien structurées, décomposables en unités simples et représentables sous forme de tableaux.
� Cependant … depuis quelques années, ce modèle est remis en cause … pour des raisons que nous allons (tenter) d’expliquer à partir de deux constats.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (7)
Introduction - Constats
� Constat n°1 : le modèle relationnel présente certaines limites présentées en première partie du cours :
1. On ne peut pas imbriquer les informations.► On multiplie le nombre de tables pour représenter conceptuellement le
même objet.
2. La structure du schéma est très rigide.► une base a un nombre fixé de tables, une table a un nombre fixe
d’attributs, …
Bases de Données Approfondies - 2015/2016 Philippe Declercq (8)
Introduction - Constats
� Exemple : représentation de l’objet « Facture Transport » transmis par les entreprises de Transport de malades à l’Assurance Maladie :
� 11 tables pour stocker un objet facture !
Couverture
Id organisme
Grand rég ime
Code c aisse gestionnaire
Ent ité gest ion
Code nature couverture
Id assuré
Nature pièce justificative ouverture de
droit
Tiers Payant
N° ATMP
Date ATMP
Date de maternité
Contrat
Code cont ra t
Code nature d'assurance
Facture
Date de la facture
Nir individu
Clé nir individu
Nir OD
Clé nir OD
Date de naissance du bénéficaire
Rang
Nom de famille du bénéficaire
Nom d'usage du bénéficaire
Prénom du bénéficaire
Id RPPS exécutant
Code spécialité exécutant
Code organisme destinataire de la facture
N° AM exécutant
Accident causé par un tier
Date d’accident causé par un tiers
N° émetteur
Adresse Email émetteur
N° AM partenaire de santé origine
N° carte CDE/ CDE partenaire de santé origine
Raison sociale partenaire de santé origine
Clause contractuelle
Indicateur clause contractuelle
Information de prescription
N° presc ript ion
Date de prescription
Code type prescription
Id RPPS prescripteur
Code spécialité du prescripteur
N° AM du prescripteur
FINESS prescripteur
Condition d'exercice du prescripteur
Code descriptif du transport
Facture transport
N° facture transporteur
Prestation
Id presta tion
Code nature prestation
Trajet facturé
Date et heure de départ
Complément d'adresse de départ
N° de voie de départ
Complément n° de voie de départ
Type de voie de départ
Nom de voie de départ
Libellé de lieu de départ
Code postal de départ
Ville de départ
Code insee de départ
Date et heure d'arrivée
Complément d'adresse d'arrivée
N° de voie d'arrivée
Complément n° de voie d'arrivée
Type de voie d'arrivée
Nom de voie d'arrivée
Libellé de lieu d'arrivée
Code postal d'arrivée
Ville d'arrivée
Code insee d'arrivée
Distance parcourue GPS
Distance parcourue
Distance facturée
Nbr de malades transportés
N° d'immatriculation du véhicule
Nom du conducteur
Prénom du conducteur
Nom du 2nd membre d'équipage
Prénom du 2nd membre d'équipage
Pourcentage d'abattement
Montant abattement
Code utilisation du distancier
Code niveau certification
Code cadre de transport
Reste à charge de l'assuré
Total montant du trajet
Montant remboursable AMO trajet
Montant part AMC
Condition de remboursement
Taux
Prix unitaire
Montant
Base de calcul
Code justificatif de l'exonération du TM
Elément facturation trajet
Code type facturation
Code élement facturation
Code type majoration
Quantité
Prix unitaire
Montant
Informations complémentaires
Taux de majoration
Table de valeur
Statut de la facture
Code sta tu t fac ture
Libellé statut facture
Type de facturation
Code type fac tura t ion
Libellé type facturation
Elément facturation
Code élément fac tura tion
Libellé élément facturation
Type prescription
Code type presc rip tion
Libellé type prescription
Type majoration
Code type majorat ion
Libellé type majoration
concerne
0,N
1,1
est liée1,1
1,1
Lot de facture
N° de lo t
Date de création du lot
est regroupée0,1
1,N
concerne
1,N1,1
est tarifé
0,N
1,1
est facturé1,1
0,N
liée à
1,1
0,N
Element transport
Indicateur de prise en charge du transport à 100%
Rapport avec L115
Nécessité d'être allongé ou sous surveillance
En lien avec une ALD et défiance ou incapacité
Hospitalisation
En lien avec un AT
contient
0,1
1,1
possède
Date de traitement0,N
1,1
Nature couverture
Code nature c ouv erture
Libellé nature couverture
Nature prestation
Code nature prestat ion
Libellé nature prestation
Niveau certification
Code niv eau c ert if ic a tion
Libellé niveau certification
Utilisation du distancier
Code u tilisat ion du distanc ier
Libellé utilisation du distancier
Total facture
Total montant facturé
Total majoration
Total majoration courte distance
Total des suppléments
Total des suppléments non remboursables
Total montant part AMO
Total montant part AMC
Total reste à charge
est liée0,1
1,1
Cadre de transport
Code c adre de t ransport
Libellé cadre de transport
concerne
1,N
1,1
Référence Archive juridique
Id R éférenc e arch iv eest liée
0,1
1,1
Statut du lot
Code statu t lot
Libellé statut lot
possède
Date de traitement lot
1,1
0,N
create table TT_FACTURE (…) ;
create table TT_CERTIFICAT (…) ;
create table TT_LOT (…) ;
create table TT_COUVERTURE (…) ;
create table TT_CONTRAT (…) ;
create table TT_REMBOURSEMENT (…) ;
create table TT_PRESTATION (…) ;
create table TT_TRAJET (…) ;
create table TT_ELEMENT_TRAJET (…) ;
create table TT_PRESCRIPTION (…) ;
create table TT_TOTAL (…) ;

Bases de Données Approfondies - 2015/2016 Philippe Declercq (9)
Introduction - Constats
� Constat n°2 : croissance exponentielle des données générées par le web.
� Ces masses de données apportent des opportunités d’analyses plus larges et plus fines ainsi que de nouveaux usages de l’information.
� Les données sont devenues le principal actif de certaines entreprises !
� Le phénomène « Big data » !
� Les systèmes de gestion des BD relationnelles n’ont pas été conçus pour gérer de tels volumes de données.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (10)
Introduction - Constats
� Les premiers acteurs à avoir été confrontés à ces deux constats et avoir buté sur les limites des modèles relationnels furent les fournisseurs de services en ligne les plus populaires, tels que Yahoo, Google, ou plus récemment les acteurs du web social comme Facebook, Twitter ou LinkedIn.
� Ces grands acteurs du web ont alors conçu de nouveaux systèmes leur permettant de s’affranchir de ces limites.
� C’est la naissance du phénomène NoSQL !
� NoSQL : No SQL ?
� Faut il jeter le modèle relationnel ?
Bases de Données Approfondies - 2015/2016 Philippe Declercq (11)
Introduction – La réponse NoSQL
� Réponse au constat n°1 : les modèles semi-structurés, plus adaptés à de nombreux cas de collecte et de manipulation des données…
� Pourquoi ?
� XML est un modèle semi-structuré, étudié en première partie du cours.
� Les bases NoSQL manipulent les données à l’aide de modèles semi-structurées : par exemple XML, mais ça n’est pas le seul format de modèles semi-structurés qui existe…
Bases de Données Approfondies - 2015/2016 Philippe Declercq (12)
� Exemple de documents insérés dans la collection « Internaute » d’une base NoSQL :
Introduction – La réponse NoSQL

Bases de Données Approfondies - 2015/2016 Philippe Declercq (13)
Introduction – La réponse NoSQL
� Réponse au constat n°2 : gérer de grands volumes de données nécessite de mettre en place des systèmes distribués ….
� Les capacités de stockage sont démultipliées par la possibilité de répartir les données sur plusieurs nœuds.
� Les systèmes relationnels ne sont pas adaptés aux environnements distribués.
� Pourquoi ?
Bases de Données Approfondies - 2015/2016 Philippe Declercq (14)
Introduction - Résumé
� Les bases NoSQL ne remplacent pas les BD relationnelles mais en sont une alternative, un complément apportant des solutions plus intéressantes dans certains contextes.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (15)
Introduction - Résumé
� Les bases NoSQL adoptent une représentation de données non relationnelle.
� Les bases NoSQL apportent une plus grande performance dans le contexte des applications Web avec des volumétries de données très importantes.
� Les bases NoSQL utilisent une très forte distribution de ces données et des traitements associés sur de nombreux serveurs.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (16)
Introduction - Résumé
� Une proposition de définition de NoSQL :
« Tout système de gestion de donnéessacrifiant des fonctionnalités du relationnelpour faciliter la scalabilité par distribution »
� Ou celle de http://nosql-database.org :
“ Next Generation Databasesmostly addressing some of the points : being non-relational,
distributed, open-source and horizontally scalable.”

Bases de Données Approfondies - 2015/2016 Philippe Declercq (17)
Introduction - Résumé
� La suite de ce cours est dédié à l’étude des systèmes NoSQL et leurs capacités à répondre aux deux constats établis précédemment :
► Le stockage et manipulation de données semi-structurées� chapitre 2 du cours
► La mise en place de solutions distribuées pour gérer de grands volumes de données� chapitres 3 & 4 du cours
► Les mécanismes de recherche et de calcul sur de grands volumes de données, en environnement distribué� chapitre 5 du cours
Chapitre 2
Stockage et manipulation de données avec NoSQL
Théorie et pratique de NoSQL
Philippe Declercq 2015-2016
Bases de Données Approfondies - 2015/2016 Philippe Declercq (19)
Stockage et manipulation de données - JSON
� En introduction de ce cours, nous avons vu que les bases NoSQL manipulent des données déstructurées ou semi-structurées, plus adaptées à de nombreux cas de collecte et de manipulation des données.
� Quels sont les formats de manipulation de données « semi-structurées » ?
► XML, Xquery, XML-Schema : très répandu !► JSON : la valeur qui monte !► Autres : YAML, … : moins répandus
Bases de Données Approfondies - 2015/2016 Philippe Declercq (20)
Stockage et manipulation de données - JSON
� JSON : JavaScript Object Notation. http://www.json.org
� Format de données textuelles dérivé de la notation des objets du langage JavaScript. Permet de représenter de l’information structurée comme le permet XML.
� Dérivé de la représentation littérale d’un objet en Javascript.
� JSON est plus simple que XML, et il est très facile à associer à un langage de programmation.
� JSON est massivement utilisé dans les applications web (AJAX), les web-services (REST), et … les bases de données NoSQL !
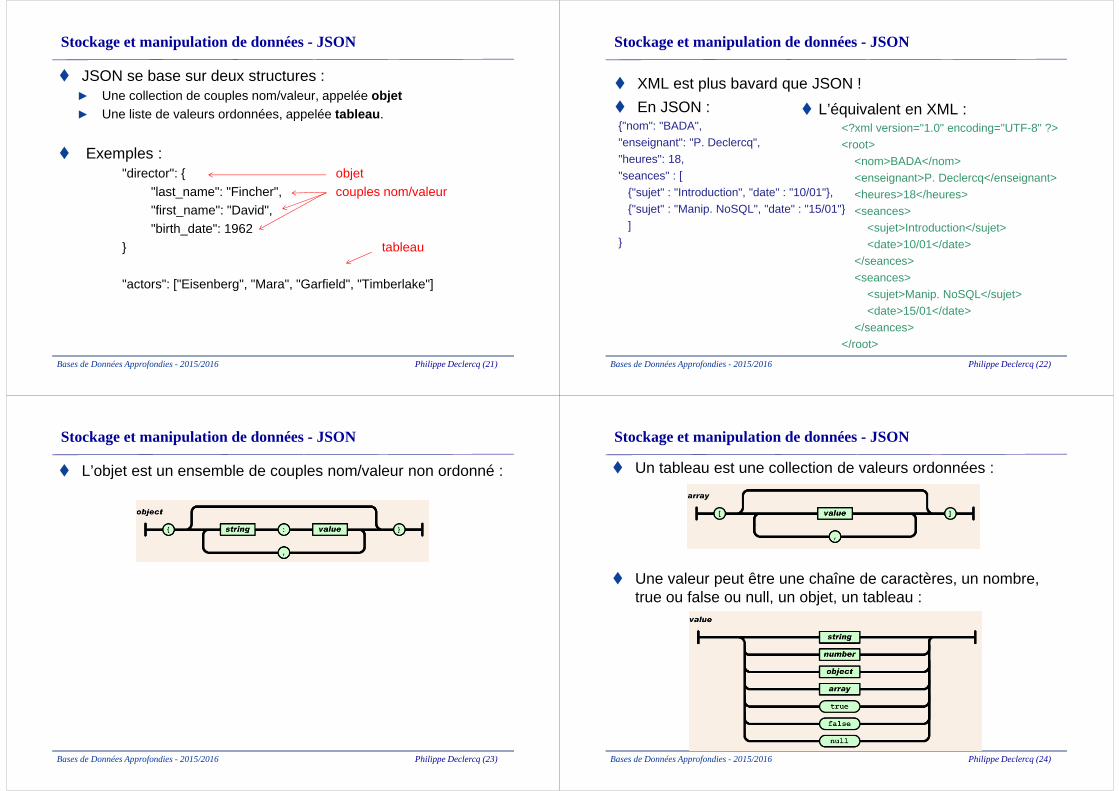
Bases de Données Approfondies - 2015/2016 Philippe Declercq (21)
Stockage et manipulation de données - JSON
� JSON se base sur deux structures :► Une collection de couples nom/valeur, appelée objet► Une liste de valeurs ordonnées, appelée tableau .
� Exemples :"director": { objet
"last_name": "Fincher", couples nom/valeur"first_name": "David","birth_date": 1962
} tableau
"actors": ["Eisenberg", "Mara", "Garfield", "Timberlake"]
Bases de Données Approfondies - 2015/2016 Philippe Declercq (22)
� L’équivalent en XML : <?xml version="1.0" encoding="UTF-8" ?><root>
<nom>BADA</nom><enseignant>P. Declercq</enseignant><heures>18</heures><seances>
<sujet>Introduction</sujet><date>10/01</date>
</seances><seances>
<sujet>Manip. NoSQL</sujet><date>15/01</date>
</seances></root>
Stockage et manipulation de données - JSON
� XML est plus bavard que JSON !
� En JSON :{"nom": "BADA","enseignant": "P. Declercq","heures": 18,"seances" : [
{"sujet" : "Introduction", "date" : "10/01"},{"sujet" : "Manip. NoSQL", "date" : "15/01"}]
}
Bases de Données Approfondies - 2015/2016 Philippe Declercq (23)
� L’objet est un ensemble de couples nom/valeur non ordonné :
Stockage et manipulation de données - JSON
Bases de Données Approfondies - 2015/2016 Philippe Declercq (24)
� Un tableau est une collection de valeurs ordonnées :
� Une valeur peut être une chaîne de caractères, un nombre, true ou false ou null, un objet, un tableau :
Stockage et manipulation de données - JSON

Bases de Données Approfondies - 2015/2016 Philippe Declercq (25)
� Les structures peuvent bien sûr être imbriquées !"MonFilmCulte" {
"title": "The Social network","summary": "On a fall night in 2003, Harvard undergrad and \nprogramming genius Mark Zuckerberg sits down at his \ncomputer and heatedly begins working on a new idea. (...)","year": 2010,"director": { "last_name": "Fincher",
"first_name": "David"},"actors": [
{"first_name": "Jesse", "last_name": "Eisenberg"},{"first_name": "Rooney", "last_name": "Mara"}
]}
Stockage et manipulation de données - JSON
Bases de Données Approfondies - 2015/2016 Philippe Declercq (26)
� JSON est un concurrent plus que sérieux à XML ! ► JSON est plus léger et intuitif que XML,► JSON est facile à parser pour n’importe quel langage de
programmation.
� Extrait de http://www.json.org :Most of the excitement around XML is around a new role as an interchangeable data serialization format. XML provides two enormous advantages as a data representation language : it is text-based, and it is position-independent.
These together encouraged a higher level of application-independence than other data-interchange formats. The fact that XML was already a W3C standard meant that there wasn't much left to fight about (or so it seemed).
Unfortunately, XML is not well suited to data-interchange, much as a wrench is not well-suited to driving nails. It carries a lot of baggage, and it doesn't match the data model of most programming languages. When most programmers saw XML for the first time, they were shocked at how ugly and inefficient it was. It turns out that that first reaction was the correct one. There is another text notation that has all of the advantages of XML, but is much better suited to data-interchange. That notation is JavaScript Object Notation (JSON).
The most informed opinions on XML suggest that XML has big problems as a data-interchange format, but the disadvantages are compensated for by the benefits of interoperability and openness.
JSON promises the same benefits of interoperability and openness, but without the disadvantages.
Stockage et manipulation de données - JSON
Bases de Données Approfondies - 2015/2016 Philippe Declercq (27)
� JSON est plus jeune que XML. Un certain nombre de caractéristiques d’XML ne disposent pas d’équivalent bien établi chez JSON :
► Pas d’équivalent XSD / DTD pour formater ou contrôler un flux• Une initiative JSON-schéma en version draft…
► Pas d’équivalent XQuery / XPath pour la recherche d’informations• JSONiq, the « The JSON Query Language » …
► Pas d’équivalent pour les transformations XSLT• Une initiative isolée JSONT …
Stockage et manipulation de données - JSON
Bases de Données Approfondies - 2015/2016 Philippe Declercq (28)
� XML et JSON sont les deux formats documentaires les plus répandus dans les solutions NoSQL du marché.
� Solutions du marché :► Solutions NoSQL XML : baseX, Berkeley DB XML, eXist, …► Solutions NoSQL JSON : mongoDB, couchDB, …► Solutions multiples : MarkLogic Server, …
Stockage et manipulation de données - JSON

Bases de Données Approfondies - 2015/2016 Philippe Declercq (29)
� Que ce soit en XML ou en JSON, la conception d’une base NoSQL diffère de la conception d’une base relationnelle.
A un modèle de tables unies …va succéder un modèlepar des jointures… imbriqué où l’ensemble
des informations sera accessible sans opération de jointure …
Stockage et manipulation de données – Oubliez vos références !
Bases de Données Approfondies - 2015/2016 Philippe Declercq (30)
� Et dans cet exemple ?
Stockage et manipulation de données – Oubliez vos références !
Bases de Données Approfondies - 2015/2016 Philippe Declercq (31)
� En NoSQL :► Agrégation dans un unique document,► « Pre-joining data »
� Quelques avantages :► Accès aux informations en un seul appel et une seule lecture sur un
serveur,► L’information ainsi regroupée simplifie la répartition des données et la
scalabilité dans le cadre d’un système distribué.
Stockage et manipulation de données – Oubliez vos références !
Bases de Données Approfondies - 2015/2016 Philippe Declercq (32)
� Attention : redondance d’information possible !► le nom de l’auteur !
� Doit on éviter à tout prix la redondance d’informations ? Quels inconvénients cela engendre t il ?
Stockage et manipulation de données – Oubliez vos références !

Bases de Données Approfondies - 2015/2016 Philippe Declercq (33)
� La conception d’une base NoSQL peut paraitre à première vue plus complexe qu’une base relationnelle.
� L’étude des usages est prépondérante.
� Les éléments fondamentaux à prendre en compte pour concevoir une base NoSQL :
► Le ratio des accès en lecture et écriture sur la base,► Le type de requêtes et mises à jour sur la base,► Le cycle de vie des données et le taux de croissance du volume des
données.
� Pour une base relationnelle soumise à de fortes sollicitations, on devrait se poser les mêmes questions…
Stockage et manipulation de données – Oubliez vos références !
Bases de Données Approfondies - 2015/2016 Philippe Declercq (34)
� Contrairement aux bases relationnelles, il n’existe pas (encore) de langage standard pour l’interrogation des bases NoSQL.
� Exemples : ► Cassandra : CQL Cassandra Query Langage, basé sur SQL,► Couchdb : JSON,► eXist, BaseX : Xquery,► Mongodb : langage spécifique,► …
Stockage et manipulation de données – Oubliez vos références !
Bases de Données Approfondies - 2015/2016 Philippe Declercq (35)
� Il existe un très grand nombre de solutions NoSQL :
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (36)
� Les solutions NoSQL peuvent être classées en 4 grandes catégories :1. Bases clé/valeur,2. Bases orientées colonnes,3. Bases orientées documents,4. Bases orientées graphes.
� Le choix d’une catégorie ou d’une autre doit se faire en analysant :
► La structure des données à conserver,► L’usage des données (modes de lectures, mises à jour, …).
Stockage et manipulation de données – Solutions NoSQL

Bases de Données Approfondies - 2015/2016 Philippe Declercq (37)
� Les bases « clé/valeur » :► Il s’agit de la catégorie de base de données la plus basique. Dans ce
modèle chaque objet est identifié par une clé unique qui constitue la seule manière de le requêter.
► La structure de l’objet est libre et le plus souvent laissé au choix du développeur de l’application (XML, JSON, ...), la base ne gérant généralement que des chaînes d’octets.
► Le système de stockage ne connait pas la structure de l'information qu'il manipule.
� Exemples d’implémentation : Voldemort, Redis, Riak
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (38)
� Intérêts : ► L’approche volontairement très limitée de ces systèmes sur le plan
fonctionnel est radicale et leur permet d’afficher des performances exceptionnellement élevées en lecture et en écriture.
► Scalabilité horizontale considérable. Le besoin de scalabilité verticale est fortement réduit au niveau des bases par le caractère très simple des opérations effectuées.
� Limites :► Peu de possibilités de requêtage : uniquement sur les clés.► Le système n'ayant pas d'indice sur la structure de l'information qu'il
stocke, tous les traitements (extraction du contenu, application de filtres…) doivent être effectués en dehors du système par l'utilisateur.
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (39)
� Usages :► dépôt de données avec besoins de requêtage très simples,► système de stockage de cache ou de sessions distribuées,► profils, préférences d'utilisateurs,► données de panier d'achat,► données de capteur,► logs de données.
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (40)
� Les bases NoSQL orientées colonnes :► La représentation orientée colonnes s’oppose à la représentation des
tables dans les bases de données relationnelles. En effet, les SGBDR manipulent les colonnes d’une ligne d’une manière statique. Les bases de données orientées colonnes ont une vision plus flexible permettant d’avoir des colonnes différentes pour chaque ligne et de multiplier de manière conséquente le nombre de colonnes par ligne. Il en résulte une capacité à stocker des listes d’informations pour chaque clé, et à accéder à des intervalles de colonnes.
� Exemples d’implémentation : Hbase, Cassandra, SimpleDB
Stockage et manipulation de données – Solutions NoSQL

Bases de Données Approfondies - 2015/2016 Philippe Declercq (41)
� Exemple :
� Optimisation du stockage par rapport à une solution relationnelle :
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (42)
� Intérêts :► Conçues pour accueillir un grand nombre de colonnes (jusqu’à
plusieurs millions) pour chaque ligne.► Performances et scalabilité
� Limites :► Système de requêtes minimaliste
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (43)
� Usages :► Traitements d’analyse de données et traitements massifs► Listes d’articles pour chaque utilisateur► Liste des actions effectuées par un utilisateur► Chronologie d’évènement maintenue et accédée en temps réel► Commandes en attentes (pour lesquelles le stockage de la liste des
articles sera simple)
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (44)
� Les bases NoSQL orientées documents :► Constituées de collections de documents. Un document est composé
de champs et des valeurs associées, ces dernières pouvant être requêtées.
► Basées sur le modèle « clé-valeur » mais la valeur est un document en format semi-structuré hiérarchique de type JSON ou XML
► Les documents n'ont pas de schéma, mais une structure arborescente : ils contiennent une liste de champs, un champ a une valeur qui peut être une liste de champs, ...
� Exemples d’implémentation : CouchDB, RavenDB, MongoDB
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (45)
� Intérêts :► Capacité à effectuer des requêtes sur le contenu des objets► Modèle de données simple mais puissant► Scalabilité► Pas de maintenance de la BD requise pour ajouter/supprimer des
«colonnes»► Permet de représenter les relations one-to-one et one-to-many. Ainsi
un document pourra être sauvegardé et chargé sans aucun traitement de jointure.
� Limites :► Inadaptée pour les données interconnectées► Lent pour les grandes requêtes
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (46)
� Usages :► Enregistrement d'événements► Systèmes de gestion de contenu► Web analytique ou analytique temps-réel► Catalogue de produits► Systèmes d'exploitation► Stockage de volumes très importants de données pour lesquelles la
modélisation relationnelle aurait entraînée une limitation des possibilités de partitionnement et de réplication
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (47)
� Les bases NoSQL orientées graphes :► Permettent la modélisation, le stockage et la manipulation de données
complexes liées par des relations non-triviales ou variables.► Utilisent un moteur de stockage pour les objets (similaire à une base
documentaire, chaque entité de cette base étant nommée nœud), et un mécanisme de description d'arcs (relations entre les objets), arcs orientés et avec propriétés (nom, date, ...).
� Exemples d’implémentation : Neo4J, OrientDB
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (48)
� Exemple :
Stockage et manipulation de données – Solutions NoSQL

Bases de Données Approfondies - 2015/2016 Philippe Declercq (49)
� Intérêts :► Plus efficaces que les bases relationnelles pour traiter les
problématiques liées aux réseaux (cartographie, relations entre personnes, ...)
► Modèle de données puissant► Performance d’accès pour les données liées, bien plus rapide qu’un
modèle relationnel
� Limites :► Scalabilité moindre : Les mécanismes de synchronisation des écritures
sur des graphes nécessite des opérations complexes. Ces systèmes sont donc fragiles au partitionnement des données sur des supports physiques distincts.
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (50)
� Usages :► Manipulation d'objets complexes organisés en réseaux : cartographie,
réseaux sociaux, ..► Moteurs de recommandations► Semantic Web► Social computing► Données géospatiales► Généalogie► Web of things► Catalogue des produits► Sciences de la Vie et calcul scientifique (bioinformatique, …)► Données liées, données hiérarchiques► Services de routage, d'expédition et de géolocalisation► Services financiers : chaîne de financement, dépendances, gestion
des risques, détection des fraudes, …
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (51)
� Pour choisir une technologie NoSQL, il faut se demander :► Quel type de données sont à manipuler ?► Comment les applications vont au final utiliser ces données ?► Quels sont les fréquences d’écriture, de lecture, de mise à jour ?► Quelle est la complexité des requêtes ?► Quels sont les prévisions d’augmentation du volume de données
gérées ?
Stockage et manipulation de données – Solutions NoSQL
Bases de Données Approfondies - 2015/2016 Philippe Declercq (52)
� Les solutions NoSQL implémentent des solutions de stockage multiples : XML, JSON, …
� JSON est un format d’échange de données de plus en plus utilisé dans les solutions NoSQL.
� Les solutions NoSQL sont en rupture avec les solutions relationnelles, entre autres sur les points suivants :
► la modélisation du stockage des données,► le langage d’accès aux données : pas de langage standard de
manipulation des données.
� De nombreuses solutions NoSQL sont disponibles sur le marché. Ces solutions ont été classifiées en 4 grandes catégories, chacune apportant ses avantages et ses inconvénients et répondant à certains usages privilégiés.
Stockage et manipulation de données – Résumé

Chapitre 3
Réplication des données
Théorie et pratique de NoSQL
Philippe Declercq 2015-2016Bases de Données Approfondies - 2015/2016 Philippe Declercq (54)
Réplication des données
� Scalabilité : aptitude d’un système à maintenir un même niveau de performance face à l’augmentation de charge ou de volumétrie, par augmentation des ressources matérielles et sans impact global sur le système.
� Scalabilité horizontale (ou externe) : possibilité d’ajouter des machines identiques en //.
� Scalabilité verticale (ou interne) : possibilité d’ajouter des ressources supplémentaire à une machine (CPU, RAM, disque…).
� Qu’est ce que la scalabilité pour les bases de données ?
Bases de Données Approfondies - 2015/2016 Philippe Declercq (55)
Réplication des données
� Système distribué :► système logiciel qui permet de coordonner de nombreuses machines► souvent dans un même réseau local (LAN)► communiquant par l‘échange de messages► avec des machines peu spécialisées pouvant être retirées ou ajoutées
� Pour les données distribuées :► un cas particulier de système distribué► accès efficaces avec des volumes de données très importants► accès même en cas d'indisponibilité des machines► possibilités d’extension (infinie !) des capacités de stockage et des
volumétries d’accès
� Les systèmes NoSQL sont des systèmes distribués dédiés à la gestion de grandes masses de données.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (56)
Réplication des données
� En tant que système distribué, un système NoSQL va pouvoir mettre en œuvre la réplication des données qu’il stocke.
� Réplication : processus de partage d'informations pour assurer la cohérence de données entre plusieurs sources de données redondantes, pour améliorer la fiabilité, la tolérance aux pannes, ou la disponibilité. On parle de réplication de données si les mêmes données sont dupliquées sur plusieurs périphériques. (source : wikipedia)
� La réplication repose sur un ensemble de technologies qui permettent de copier et de distribuer des données et des objets de base de données d'une base vers une autre, puis de synchroniser ces bases afin de préserver leur cohérence.

Bases de Données Approfondies - 2015/2016 Philippe Declercq (57)
Réplication des données
� Les systèmes relationnels peuvent aussimettre en œuvre la réplication de données,cependant leurs caractéristiques transactionnelles leur impose le respect des contraintes ACID :
► Atomicity : les mises à jour de la base de données doivent être atomiques (être totalement réalisées ou pas du tout).
► Consistency : les modifications apportées à la base doivent être valides (en accord avec l'ens. de la base et des contraintes d'intégrité).
► Isolation : les transactions lancées au même moment ne doivent jamais interférer entre elles, ni même agir selon le fonctionnement de chacune.
► Durability : toutes les transactions sont lancées de manière définitive.
� Ces contraintes sont difficiles à maintenir dans un système distribué tout en conservant des performances correctes.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (58)
Réplication des données
� Le théorème de CAP (Brewer, 2000) stipule en outre qu’il est impossible, dans un système distribué, d’assurer les 3 propriétés suivantes en même temps :
► C comme Coherence ou Cohérence : tous les nœuds du système voient exactement les mêmes données au même moment.Si j’écris une donnée dans un nœud et que je la lis dans un autre nœud, je dois retrouver ce que j’ai écrit sur le premier.
► A comme Availability ou Disponibilité : la perte de nœuds n'empêche pas les survivants de continuer à fonctionner correctement.Même en cas de panne, mes données restent accessibles.
► P comme Partition tolerance ou Résistance au partiti onnement : aucune panne moins importante qu'une coupure totale du réseau ne doit empêcher le système de répondre correctement.Les données peuvent être partitionnées sans soucis de localisation.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (59)
Réplication des données
� Consistance (Coherence) : Un système S est dit consistant si on peut garantir qu'une fois qu'on y enregistre un état (disons "x = y"), il donnera le même état à chaque opération suivante, jusqu'à ce que cet état soit explicitement changé par quelque chose en dehors de S.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (60)
Réplication des données
� Exemples de consistance :► Exemple 1 : une instance de la BD est automatiquement pleinement
consistante puisqu'il n'y a qu'un seul nœud qui maintient l'état.
► Exemple 2 : si 2 serveurs de BD sont impliqués, et si le système est conçu de telle sorte que toutes les clés de "a" à "m" sont conservées sur le serveur 1, et les clés "n" à "z" sont conservées sur le serveur 2, alors le système peut encore facilement garantir la cohérence.
► Exemple 3 : Supposons 2 BD avec des répliques. Si une des BD fait une opération d'insertion de ligne, cette opération doit être aussi faite (commited) dans la seconde BD avant que l'opération soit considérée comme complète. Pour avoir une cohérence de 100% dans un tel environnement répliqué, les noeuds doivent communiquer, et plus le nb de répliques est grand plus les performances d'un tel système sont mauvaises.

Bases de Données Approfondies - 2015/2016 Philippe Declercq (61)
Réplication des données
� Disponibilité (Availability) : Les BD dans Ex1 ou Ex2 ne sont pas fortement disponibles :
► dans Ex1 : si le nœud tombe en panne, on perd 100% des données► dans Ex2 : si le nœud tombe en panne, on perd 50% des données► dans Ex3 : une simple réplication de la BD sur un autre serveur assure
une disponibilité de 100%.
� Donc :► Augmenter le nb de nœuds avec des copies des données (répliques)
augmente directement la disponibilité du système, en le protégeant contre les défaillances matérielles
► les répliques peuvent aussi aider à équilibrer la charge d'opérations concurrences, notamment en lecture.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (62)
Réplication des données
� Résistance au partitionnement (Partition-tolerance) :► Supposons que soit assuré par réplication « consistance » et «
disponibilité ». Dans le cas Ex3, supposons 2 serveurs de BD dans 2 Data-Centers différents, et que lʼon perde la connexion réseau entre les 2 Data-Centers, faisant que les 2 BD sont incapables de synchroniser leurs états.
► Si vous parvenez à gérer les opérations de lecture/écriture sur ces 2 BD, il peut être prouvé que les 2 serveurs ne seront plus consistants.
► Une application bancaire gardant à tout moment «l'état de votre compte » est l'exemple parfait du problème des enregistrements inconsistants : si un client retire 1000 euros à Marseille, cela doit être immédiatement répercuté à Paris, afin que le système sache exactement combien il peut retirer à tout moment.
► Si les banques décident que la « consistance » est très importante, et désactivent les opérations d'écriture lors de la panne, alors la «disponibilité» du cluster sera perdue puisque tous les comptes bancaires dans les 2 villes seront désormais gelés jusqu'à ce que le réseau soit de nouveau opérationnel.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (63)
Réplication des données
� Pour un système de données distribué, il faut donc choisir et abandonner l’une des trois propriétés … oui mais … laquelle abandonner ? …
Bases de Données Approfondies - 2015/2016 Philippe Declercq (64)
Réplication des données
� Les systèmes relationnels assurent les propriétés C(onsistency) + (A)vailability en vérifiant les propriétés ACID.

Bases de Données Approfondies - 2015/2016 Philippe Declercq (65)
Réplication des données
� L’émergence des nouveaux besoins liés au big data a fait naitre des systèmes de gestion des données conçus de telles sortes qu’ils assurent les propriétés (A)vailability + (P)artitionTolerance, tant pis pour la (C)ohérence ….
� C’est une des caractéristiques des systèmes NoSQL.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (66)
Réplication des données
� Trois niveaux de cohérence peuvent se rencontrer dans les systèmes de gestion des données :1. cohérence forte : toutes les copies sont toujours en phase, le prix à payer étant un délai pour chaque écriture.2. cohérence faible : les copies ne sont pas forcément en phase, et rien ne garantit qu’elles le seront.3. cohérence à terme : c’est le niveau de cohérence typique des systèmes NoSQL : les copies ne sont pas immédiatement en phase, mais le système garantit qu’elles le seront « à terme ».
� Dans la cohérence à terme, il existe donc un risque, faible mais réel, de constater de temps en temps un décalage entre une écriture et une lecture !
Bases de Données Approfondies - 2015/2016 Philippe Declercq (67)
Réplication des données
� Les systèmes NoSQL vont permettre un distribution des données et la mise en œuvre de mécanismes de réplication.
� Réplication : capacité à maintenir à jour une base de données distribuée sur plusieurs machines reliées en réseau, en recopiant à intervalles réguliers des morceaux ou l'intégralité de la base d'une machine à l'autre.
� Il existe 2 types principaux de réplication :► Réplication maitre-esclave (master slave replication),► Réplication multi-nœuds (peer-to-peer replication).
Bases de Données Approfondies - 2015/2016 Philippe Declercq (68)
Réplication des données
� Réplication maitre-esclave (master slave replication) :► Le maître :
• Est responsable des mises à jour des données,• Peut être désigné manuellement ou automatiquement.
► Les esclaves :• Le processus de réplication les synchronise avec le maître,• Lorsque le maître tombe en panne, un esclave peut devenir maître.

Bases de Données Approfondies - 2015/2016 Philippe Declercq (69)
Réplication des données
� Réplication multi-nœuds (peer-to-peer replication) :► Tous les nœuds sont égaux, ils peuvent accepter les écritures,► La scalabilité est meilleure.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (70)
Réplication des données
� La réplication dans les systèmes NoSQL est en général asynchrone :
� Le client reçoit un acquittement alors que la réplication n’est pas complète. Pas de garantie complète de sécurité !
� Le client poursuit son exécution alors que toutes les copies ne sont pas encore mises à jour. Il se peut alors qu’une lecture renvoie une des copies obsolètes.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (71)
Réplication des données
� Mais … répliquer les données, quel(s) intérêt(s) ?
� Réponse : pour assurer la robustesse du système !
� La réplication de données dans les systèmes NoSQL permet d’atteindre les propriétés A et P du théorème de CAP :
► Disponibilité ou Tolérance aux pannes. La réplication permet d’assurer la disponibilité constante du système. En cas de panne d’un serveur, d’un nœud ou d’un disque, la tâche effectuée par le composant défectueux peut être immédiatement prise en charge par un autre.
► Scalabilité (lecture). Si une donnée est disponible sur plusieurs machines, il devient possible de distribuer les requêtes (en lecture) sur ces machines.
► Scalabilité (écriture). On peut penser à distribuer aussi les requêtes en écriture, mais là on se retrouve face à de délicats problèmes potentiels d’écritures concurrentes et de réconciliation.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (72)
Réplication des données – En pratique sous MongoDB
� MongoDB gère la replication avec le concept de replica set : un ensemble d’instances mongoDB qui hébergent les mêmes données.
� Exemple de replica set à 3 nœuds : 1 maître, 2 esclaves :
► Le maître est responsable du stockage de la donnée principale.► Un journal des transactions est maintenu par le maître (une collection
spéciale nommée opLog).► La réplication vers les deux esclaves se fait en mode asynchrone.

Bases de Données Approfondies - 2015/2016 Philippe Declercq (73)
Réplication des données – En pratique sous MongoDB
� 2 niveaux de cohérence sont possibles :► Cohérence forte : imposant au client d’effectuer toujours les lectures
via le maître► Cohérence à terme : les clients peuvent effectuer des lectures sur les
esclaves.
� La robustesse du système est assurée par l’échange de messages de surveillance entre les nœuds, et par la mise en œuvre d’un processus d’élection d’un nouveau maître par la majorité des nœuds survivants en cas de panne.
� Si le nombre de votants est pair, la désignation d’un nouveau maître peut-elle être impossible ?
Bases de Données Approfondies - 2015/2016 Philippe Declercq (74)
Réplication des données – En pratique sous MongoDB
� Sous mongoDB, la création du replica set à 3 nœuds se fait, à partir de l’un des nœuds (« n1 » dans l’exemple), en lançant les commandes :
► rs.initiate()► rs.add(« adresse IP du n2 »)► rs.add(« adresse IP du n3 »)
� mongoDB désigne automatiquement un maître. Pour le connaitre :
► rs.isMaster() ou rs.status()
� mongoDB permet d’autoriser ou d’interdire les lectures sur un esclave :
► rs.slaveOk()
Bases de Données Approfondies - 2015/2016 Philippe Declercq (75)
Réplication des données – En pratique sous MongoDB
� Configuration de mon replica set :
Bases de Données Approfondies - 2015/2016 Philippe Declercq (76)
Réplication des données – En pratique sous MongoDB
� Si l’on simule une panne du maitre, on observe qu’un nouveau maitre a été automatiquement désigné au sein du replica set :

Bases de Données Approfondies - 2015/2016 Philippe Declercq (77)
Réplication des données – En pratique sous MongoDB
� mongoDB offre de nombreuses options de réplication qu’il convient de définir selon le contexte du système (nature des données hébergées, exigences de performance, localisation des différents nœuds…)
� Exemple : writeconcern permet d’indiquer sur combien de nœuds une donnée doit être mise à jour avant d’envoyer un acquittement au client.
► Writeconcern = 1 : la mise à jour sur le maitre suffit à l’envoi de l’ acquittement, les mises à jour sur les autres nœuds sont asynchrones.
► Writeconcern = 2 : mise à jour sur le maitre + un autre nœud avant envoi de l’acquittement
► Writeconcern = "majority" : la mise à jour est effective sur la majorité des nœuds avant envoi de l’acquittement
Bases de Données Approfondies - 2015/2016 Philippe Declercq (78)
Réplication des données – En pratique
� Les solutions NoSQL permettent en général de modifier les options de réplication et de cohérence.
� Exemple sur Cassandra :
Bases de Données Approfondies - 2015/2016 Philippe Declercq (79)
Réplication des données - Résumé
� La réplication est essentiellement destinée à pallier les pannes en dupliquant les données sur plusieurs serveurs et en permettant donc qu’un serveur prenne la relève quand un autre vient à faillir. Le fait de disposer des mêmes données sur plusieurs serveurs par réplication ouvre également la voie à la distribution de la charge et donc à la scalabilité.
� Ce n’est cependant pas une méthode applicable à grande échelle car, sur ce que nous avons vu jusqu’ici, elle implique la copie de toute la collection sur tous les serveurs.
� Nous étudierons au prochain chapitre le mécanisme de partitionnement des données, technique privilégiée pour obtenir une véritable scalabilité.
Chapitre 4
Partitionnement des données
Théorie et pratique de NoSQL
Philippe Declercq 2015-2016

Bases de Données Approfondies - 2015/2016 Philippe Declercq (81)
Partitionnement des données
� Pour augmenter la scalabilité du stockage des données, les systèmes NoSQL offrent des possibilités de partitionnement (sharding) des données sur différent nœuds.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (82)
Partitionnement des données
� Une partition d’un ensemble � est un ensemble {�1, �2, · · · , ��} de parties de �, que nous appellerons fragments, tel que :
► ⋃� �� = �► �� ∩ �� = ∅ pour tout �, �, � ̸= �
� Ou plus simplement : chaque élément de � est contenu dans un et un seul ��.
� Dans notre cas, l’ensemble est une collection, les éléments de l’ensemble sont les documents.
� Les parties sont nommées fragments (shard en anglais).
Bases de Données Approfondies - 2015/2016 Philippe Declercq (83)
Partitionnement des données
� Réplication et partitionnement en topologie Maître-esclave :► Plusieurs maitres, mais chaque donnée a un unique maitre,► 2 possibilités :
• Un nœud peut être maitre pour certaines données et esclave pour d’autres,
• Chaque nœud est dédié pour être maitre ou esclave.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (84)
Partitionnement des données
� Réplication et partitionnement en topologie multi-nœuds :► Chaque partition est présente sur 2 ou 3 nœuds

Bases de Données Approfondies - 2015/2016 Philippe Declercq (85)
Partitionnement des données
� Partitionner les données nécessite de définir une clé de partitionnement.
� Une bonne clé doit permettre le partitionnement en fragments de taille comparable.
� La clé est formée à partir d’un ou plusieurs attributs des documents.
� Idéalement, on choisira comme clé de partitionnement l’identifiant unique des documents.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (86)
Partitionnement des données
� Il existe deux grandes approches pour déterminer une partition en fonction d’une clé : par intervalle et par hachage.
� Par intervalle, on obtient un ensemble d’intervalles disjoints couvrant le domaine de valeurs de la clé.
► A chaque intervalle correspond un fragment,► Exemple : si la clé est une chaîne de caractères, on peut considérer
que les chaînes dont la première lettre est comprise entre A et G verront leur document stocké sur le fragment 1, entre H et P sur le fragment 2, et entre Q et Z sur le fragment 3.
� Par hachage, une fonction appliquée à la clé détermine le fragment d’affectation.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (87)
Partitionnement des données
� Dans un partitionnement par intervalle, le domaine de valeur de la clé de partition est divisé en n intervalles définissant n fragments :
� À chaque intervalle est associé un fragment dans la structure de stockage.
� La structure de routage est constituée de paires (I, a) où I est la description d’un intervalle et a l’adresse du fragment correspondant.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (88)
Partitionnement des données
� Dans un partitionnement par hashage, une fonction de hash est appliquée sur les données de la clé.
� Le résultat de la fonction de hashage sert alors de clé de partitionnement dans les différents fragments.
� Part. par intervalle :
� Part. par hash :

Bases de Données Approfondies - 2015/2016 Philippe Declercq (89)
Partitionnement des données
� Un partitionnement par intervalle donne de meilleurs résultats pour des requêtes basées sur des attributs de la clé. Dans de telles requêtes, le routeur sait facilement envoyer la requête aux partitions concernées.
� Seulement, le partitionnement par intervalle peut entraîner une répartition inégale des données, ce qui peut annuler certains des avantages du partitionnement.
� Le partitionnement par hash, par contre, assure une meilleure distribution des documents.
� Les données sont ainsi réparties de façon aléatoire sur les fragments. Mais cette distribution aléatoire rend plus probable qu’une requête sur les données de partitionnement ne puisse pas cibler quelques fragments mais plus probablement l’ensemble des fragments afin de retourner un résultat.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (90)
Partitionnement des données
� Un système partitionné est construit avec 2 structures :► La structure de routage établit la correspondance entre la valeur d’une
clé et le fragment qui lui est associé (ou, très précisément, l’espace de stockage de ce fragment).
► La structure de stockage est un ensemble d’espaces de stockages séparés, contenant chacun un fragment.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (91)
Partitionnement des données
� Dans un système distribué, cela donne :
Bases de Données Approfondies - 2015/2016 Philippe Declercq (92)
Partitionnement des données – En pratique sous MongoDB
� Sous mongodb, la structure à créer se compose des éléments suivants :
► les routeurs (processus mongos) communiquent avec les applications clientes, se chargent de diriger les requêtes vers les serveurs de stockage concernés, et transmettent les résultats.
► les replica set (processus mongod) servent au stockage des données (avec réplication). Un replica set est en charge d’un ou plusieurs fragments (shards) et gère localement la reprise sur panne par réplication.
► les config servers (processus mongod avec option configsrv) stockent les données de routage et plus généralement la configuration complète du système : liste des replica sets (avec, pour chacun, le maître et les esclaves), liste des fragments et allocation des fragments à chaque replica set.
Bases de Données Approfondies - 2015/2016 Philippe Declercq (93)
Partitionnement des données – En pratique sous MongoDB
� L’insertion en masse dans une collection entraîne alors un partitionnement du stockage des documents :
Bases de Données Approfondies - 2015/2016 Philippe Declercq (94)
Partitionnement des données – En pratique sous MongoDB
� Si l’on décide de partitionner selon une clé correspondant à un ou plusieurs attributs des documents, mongodb partitionne automatiquement les documents sur les shards disponibles :
Bases de Données Approfondies - 2015/2016 Philippe Declercq (95)
Partitionnement des données – Résumé
� Réplication et partitionnement des données assurent la scalabilité du système de stockage des données, et permettent :
► De sécuriser le stockage des données,► De supporter des augmentations de charge sans impacts sur les
performances.
� Toutes les solutions NoSQL implémentent nativement ces mécanismes de réplication et partitionnement. C’est en effet l’une des caractéristiques des bases NoSQL !