introduction à l'analyse de...
TRANSCRIPT

1
Introduction àl’analyse de régression
Jean-François BickelStatistique II – SP08

2
I. Les opérations de la régression
1) Descriptiona) de la relation entre une variable
dépendante (y) et une ou plusieurs variables indépendantes (x) et la forme de cette relation
b) de la force de la relation

3
2. Inférence, sur la base des données d’échantillon,
a) de la présence ou non d’une relation entre une variable dépendante (y) et une ou plusieurs variable(s) indépendante(s) (x) au sein de la population, la forme et la force de cette relation
b) de la valeur de y sur la base de la valeur d’un ou plusieurs x

4
3. Inférence ou généralisation de type causale :déduire de l’existence d’une relation (association) entre x et y, que x est une (des) cause(s) de yOn parle souvent dans ce cas de « l’effet » de x sur y ou que x« explique » (une part de) y

5
II. Principes généraux
1. La régression est une méthode statistique visant à analyser la relation(association) entre une variable dépendante particulière et une ou plusieurs variables indépendantesDans cette relation, la valeur de la variable dépendante (=y) est traitée comme étant fonction de la valeur de la ou des variable(s) indépendante(s) (=x)

6
En langage formel,y = f(xk)pour k=1,2,3… variables indépendantesSupposons que l’on s’intéresse au revenu des personnes ; ce dernier peut être analysé comme étant fonction, par exemple, de l’âge et du niveau d’éducation des individusrevenu=f(âge, éducation)

7
On parle de régression bivariée lorsqu’il y a une seule variable indépendante
par exemple, le revenu comme étant fonction de l’âge uniquement
de régression multiple lorsque sont considérées simultanément deux ou plus variables indépendantes
par exemple, le revenu comme étant fonction à la fois de l’âge et de l’éducation

8
2. La relation entre la variable y et la ou les variable(s) indépendante(s) x est susceptible de prendre des formes très variéesCependant, de manière très générale, elle est traitée comme suivant une forme linéaireD’où l’expression de régression linéaire

9
On parle à ce propos de modèleEn statistique, un modèle est une description (=un résumé) de la relation entre variables dans une population
Un modèle de régression linéaire (ou simplement modèle linéaire) décrit la relation entre la variable y et la ou les variable(s) indépendante(s) x comme ayant la forme d’une équation (linéaire)

10
Dans le modèle linéaire, la relation bivariée entre y et x est décrite (i.e. résumée) par l’équation suivante :y=α + βxSi on reprend notre exemple, on pose donc :revenu= α + β(âge)

11
Selon cette équation, le revenu dépend linéairement de l’âgeI.e. le revenu varie d’un terme constant, représenté par le coefficient β, pour chaque année d’âge supplémentaireAutrement dit, la relation entre x et y est modélisée (=résumée) par une ligne droite dont la pente est β

12
Cette équation permet aussi de calculer un revenu prédit (ou estimé) pour chacun des âges concernésCe revenu prédit (ou estimé) peut être plus ou moins différent du revenu effectivement observé au même âge

13
Supposons que dans notre exemple l’équation ait la forme suivante (chiffres fictifs) :revenu = 20000 + (600 x âge)Cette équation nous dit que le revenu augmente de 600 Frs pour chaque année d’âge additionnelleLe revenu prédit pour une personne âgée de 30 ans est de :20000 + (600 x 30) = 38000 Frs

14
En généralisant aux cas avec plusieurs variables indépendantes, le modèle linéaire décrit (résume) la relation au moyen de l’équation suivantey=α + β1x1 + β2x2 … βkxk

15
Dans cette équationi. y est la variable dépendanteii. x1, x2… xk sont les variables
indépendantesiii. α est un coefficient de valeur constanteiv. β1, β2 … βk sont les coefficients des
variables indépendantes

16
Dans notre exemple,revenu= α + β1(âge) + β2(éducation)Selon cette équation, le revenu dépendlinéairement de l’âge et de l’éducationPour chacun des âges et pour chaque niveau d’éducation, on peut calculer un revenu prédit (ou estimé), qui peut être plus ou moins différent du revenu effectivement observé au même âge ou pour le même niveau d’éducation

17
Le revenu prédit varie d’un terme constant, représenté par le coefficient β1, pour toute année d’âge supplémentaire, indépendamment de la relation existant entre revenu et niveau d’éducation,et, inversement, il varie d’un terme constant, représenté par le coefficient β2,pour tout degré additionnel d’éducation, indépendamment de la relation existant entre revenu et âge

18
Supposons que l’équation ait la forme suivante (chiffres fictifs) :revenu = 18000 + (1000 x éducation)
+ (500 x âge)Cette équation nous dit que le revenu augmente de 500 Frs pour chaque année d’âge additionnelle, et dans le même temps qu’il augmente de 1000 Frs pour chaque niveau d’éducation supplémentaire (par exemple mesuré en nombre d’années d’étude)

19
Ainsi, pour une personne âgée de 40 ans et qui a suivi 12 années d’étude, le revenu prédit est de :
50000 = 18000 + (1000 x 12) + (500 x 40)

20
3. Jusqu’à maintenant, nous avons raisonner sur les paramètres α et βcomme si leurs valeurs étaient directement accessibles et mesurablesOr, les paramètres α et β sont ceux de la population ou univers de référenceLeurs valeurs sont inconnues, et doivent être estimées à partir des données observées (dans l’échantillon)

21
La méthode dite des moindres carrés est la plus couramment utilisée pour estimer les paramètres de l’équation de régression linéaireL’équation des moindres carrés a, dans le cas de la régression bivariée, la formeŷ = a + bxEn généralisant à la régresion multivariée, on aŷ = a + b1x1 + b2x2 +... bkxk

22
Les lettres a et b sont les coefficients de l’équation de régression tels qu’ils sontcalculés à partir des données observées(=de l’échantillon)De manière conventionnelle, on écrit ŷ afind’indiquer qu’il s’agit de la valeur préditede y et non de sa valeur réellementobservée

23
Un peu de terminologie
Ce cours est dans sa plus grande part consacrée à une forme particulière de régression :la régression multiple linéaire des moindres carrés ordinairesmultiple implique que l’on fait intervenir deux ou plus variables indépendanteslinéaire décrit le type d’équation qui est estimée

24
moindres carrés réfère à la méthode utilisée pour estimer les paramètres de l’équation de régressionordinaire se dit de la méthode d’estimation la plus simple basée sur les moindres carrés
ceci pour la distinguer de méthodes d’estimation plus complexes basées sur les moindres carrés

25
III. La régression bivariée
Après avoir posé quelques principes généraux de l’analyse de régression,Entrons plus avant dans sa signification, utilisation et interprétationPour cela, arrêtons-nous au cas le plus simple, celui de la régression bivariée

26
Partons d’un exemple, emprunté à l’ouvrage de Paul Allison, p. 8 (cf. référence complète dans la bibliographie du cours)La base de données est constituée de 35 individus pour lesquels on dispose de deux informations (variables) : le revenu annuel (en dollars) et l’âgeLe fichier de données se présente donc comme suit :
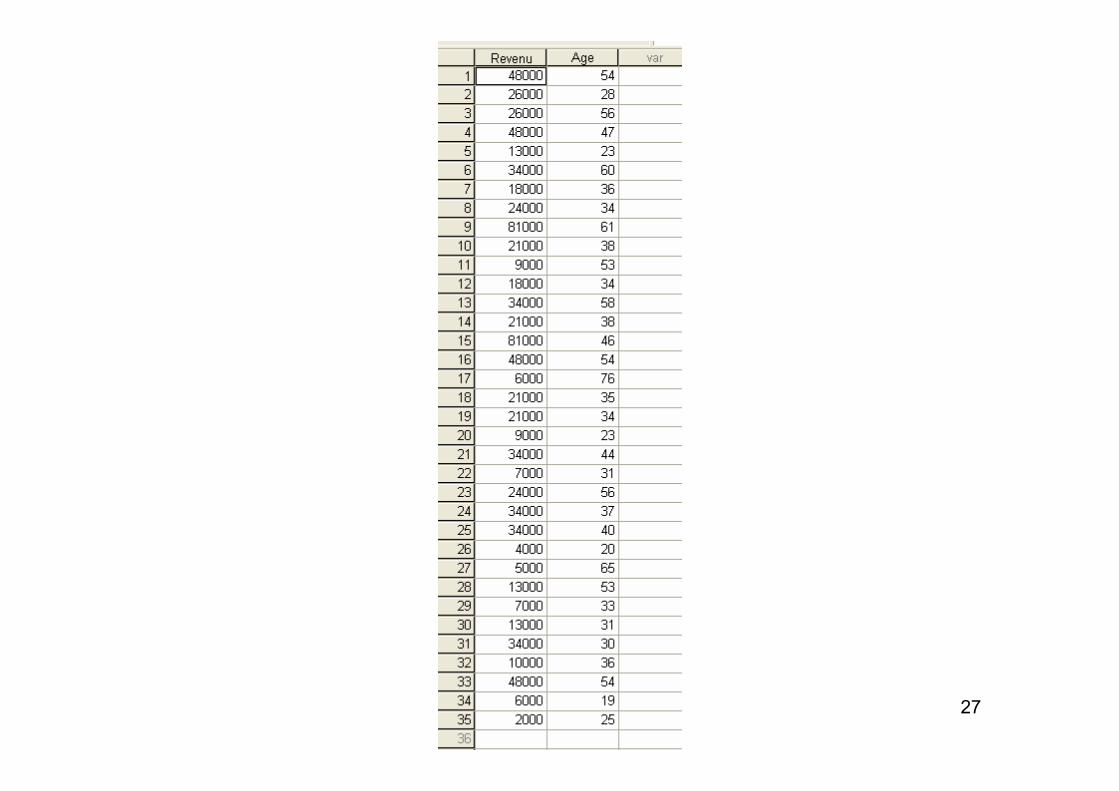
27

28
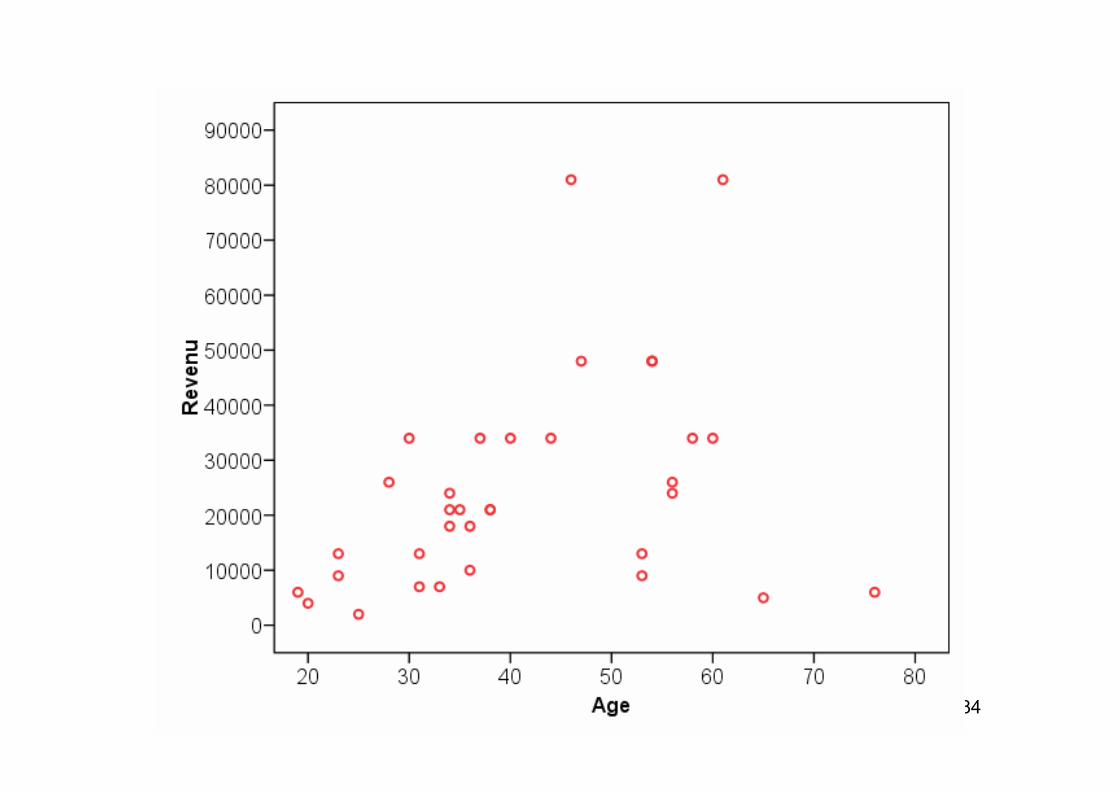
On s’intéresse à déterminer dans quelle mesure le revenu varie en fonction de l’âgePour décrire cette relation, on peut commencer par faire un diagramme de dispersion (scatterplot) où les points représentent les observations (ici des individus) avec l’âge en abscisse et le revenu en ordonnéeUn tel diagramme est utile pour déterminer si la relation entre x et y est au moins approximativement linéaire

29
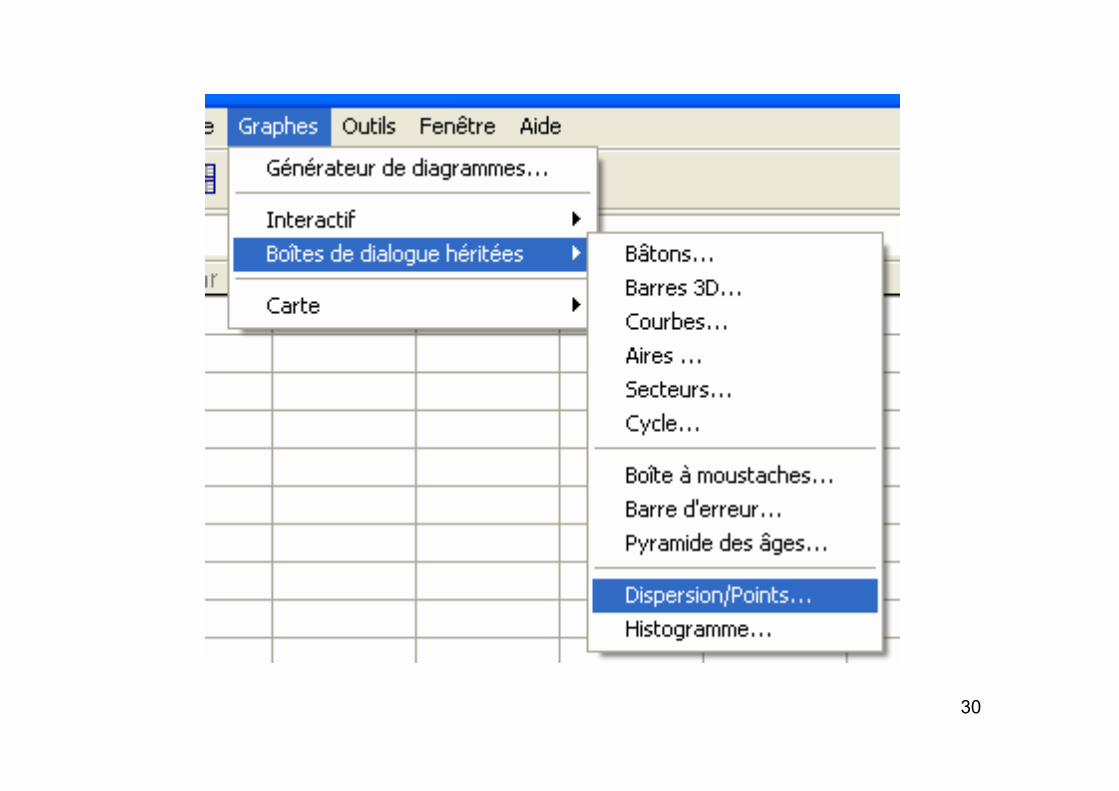
1. Pour cela, aller dans le menuGraphes
Boîtes de dialogue héritéesDispersion/Points (Scatterplot)
30

31
2. Dans la fenêtre qui s’affiche, cliquer sur Dispersion simple, puis sur Définir
3. Puis, dans la fenêtre qui s’affiche, sélectionner les variables Revenu et Age et les faire glisser respectivement sous Axe Y et Axe X
4. Puis cliquer soit sur Ok pour faire exécuter directement l’instruction, soit sur Coller pour l’inscrire dans la fenêtre syntaxe ; dans ce dernier cas, lancer l’exécution depuis la fenêtre syntaxe

32

33
34

35
On observe une tendance à l’augmentation du revenu avec l’âgeCela étant, cette relation est loin d’être parfaiteRemarquons aussi que la variation du revenu en fonction de l’âge augmente avec ce dernier
Sur un plan plus théorique, c’est d’ailleurs là un phénomène qui a été bien documenté par de nombreux travaux

36
Décrire la relation à l’aide d’une droite de régression semble donc adéquatL’équation est de forme ŷ = a + bxOu, en substituant y et x par les variables qui nous intéressent ici :revenu = a + b(âge)

37
L’objectif est de déterminer les coefficients de l’équation pour la droite de régression qui permette la meilleure approximation possible des données observéesPour cela, on peut procéder par essai et erreur en examinant successivement différentes équations pour la droite de régression

38
Ci-après, deux droites de régression sont ainsi représentées dans le même diagramme de dispersion que celui vu ci-dessusLa première droite (ŷ=-12600+840x) est construite de façon à ce qu’une personne encore à l’école obligatoire (âge=15) ait 0$ de revenu, et qu’un individu à l’âge médian (38 ans) dispose d’un revenu équivalent au revenu médian (21000$)

39
La seconde droite (ŷ=-20000+1000x) est construite de façon à avoir une pente plus forte, fixée arbitrairement à 1000, et qu’une personne de 20 ans dispose d’un revenu équivalent au revenu observé à cet âge (4000$)

40
y=-12600 + 840xy=-20000 + 1000x

41
Comme on le voit sur le diagramme, la valeur observée à un âge donné est plus ou moins éloignée de la valeur prédite pour ce même âgePour un même âge, l’écart entre valeur observée et valeur prédite n’a pas la même ampleur selon que l’on considère l’une ou l’autre des droites de régression

42
Sur la base des coefficients de l’équation de régression, on peut calculer la valeur prédite de la variable dépendante (ŷ) pour tous les individus concernésCes valeurs prédites sont généralement différentes des valeurs observées pour cette même variable yOn peut calculer une erreur de prédiction, telle queerreur = valeur observée – valeur préditeet ce pour tous les individus

43
Obs. 31
Obs. 27

44
Ainsi, en référence à la première droite de régression évoquée ci-dessus, on a pour l’observation n° 31 (âge=30) un revenu prédit (« sur la droite ») de 12600 et un revenu observé de 34000, soit une erreur de prédiction de 34000-12600=21400Pour l’observation n° 27 (âge=65), un revenu prédit de 42000 et un revenu observé de 5000, soit une erreur de prédiction de 5000-42000=-37000

45
Il est dès lors possible de calculer la somme des erreurs de prédiction pour l’ensemble des individus (observations)Mais, comme les erreurs de prédiction peuvent être positives (quand la valeur observée est plus grande que la valeur prédite) ou négatives (dans le cas inverse), elles s’annulent

46
Pour tenir compte de ce fait, on élève au carré les erreurs de prédiction (qui dès lors deviennent toutes positives)L’objectif reformulé est dès lors le suivant:
déterminer des valeurs pour les coefficients de l’équation de régression de telle sorte que la somme des carrés des erreurs de prédiction soit la plus petite possible

47
Par la démarche d’essai et erreur esquissé ci-dessus, cela pourrait être long et fastidieux!Mais la méthode d’estimation des moindres carrés permet d’établir directement un tel résultat

48
Plus précisément, la méthode d’estimation des moindres carrés permet d’établir les valeurs pour les coefficients a et b de l’équation de régression qui sont les plus efficientes pour prédire yAutrement dit, c’est avec ces valeurs de coefficient que la somme des carrés des erreurs de prédiction est minimale

49
Les formules sont les suivantes :
∑ (x -⎯x ) (y -⎯y)b = ___________________
∑ (x -⎯x ) 2
a = ⎯y - b⎯x

50
En utilisant ces formules, on peut reprendre notre exemple est calculé les valeurs des coefficients a et bA l’exemple du tableau ci-dessous :

51
.
.
.

52
Pour obtenir b, nous prenons simplement le ratio des deux dernières colonnesb = 3559600 / 6796.17 = 523.76Ce dernier chiffre nous indique qu’à chaque année supplémentaire d’âge est associé un accroissement de 524$

53
Pour obtenir a, on calculea = 25200 – (523.76 * 41.77) = 3323L’équation finale est doncŷ = 3323 + 523.76x

54
Nota Bene
Dans l’argument développé ici, nous avons parlé d’erreurs de prédictionMais on trouve aussi les expressions équivalentes de valeurs résiduelles ou encore de résidus

55
IV. La régression avec SPSS

56

57

58

59

60

61
REGRESSION/MISSING LISTWISE/STATISTICS COEFF OUTS CI R ANOVA/CRITERIA=PIN(.05) POUT(.10)/NOORIGIN/DEPENDENT Revenu/METHOD=ENTER Age .
* alternativement, les statistiques demandées* peuvent s’écrire* /STATISTICS DEFAULTS CI
Sous forme de syntaxe

62
Quelques indications sur l’interprétation des résultats fournis par SPSS
Sans demande additionnelle, SPSS fournit « en standard » trois tableaux de résultats
A. « Récapitulatif du modèle »B. « ANOVA »C. « Coefficients »

63
Donnons quelques éléments d’interprétation à leur propos
N.B. Par souci d’uniformiser le langage de présentation, là où SPSS utilise des majuscules, j’utilise des minuscules
par exemple quand SPSS écrit « R », il faut lire « r »

64
Récapitulatif du modèle
.379a .144 .118 18326.338Modèle1
R R-deux R-deux ajusté
Erreurstandard del'estimation
Valeurs prédites : (constantes), Agea.
Tableaux de résultats dans SPSSA. « Récapitulatif du modèle »

65
A. Dans le premier tableau de résultats nommé « Récapitulatif du modèle », figurent notamment les éléments suivants :
1) Une valeur appelée r : elle est, dans le cas d’une régression bivariée, rien d’autre que le coefficient de corrélation entre x et yr mesure la force de la relation (association)

66
2) Une valeur baptisée « r-deux », qui doit se lire r2 (« r carré »), et que l’on appelle également coefficient de déterminationDans une régression bivariée, c’est aussi une mesure de la force de la relation entre x et yOn l’utilise surtout comme mesure de la qualité du modèle (fit), i.e. le degré auquel celui-ci se rapproche des données observées

67
L’idée de base du r2 est qu’il mesure la différence entre deux grandeurs
i. la somme des carrés des erreurs de prédiction produits par une équation des moindres carrés sans aucune variable indépendante, i.e. avec seulement la constante, qui est alors égale à la moyenne de y (E1)
ii. la somme des carrés des erreurs de prédiction produits par l’équation des moindres carrés sous inspection (E2)

68
Cette différence, exprimée sous forme de proportion, renvoie à l’amélioration de la prédiction due au fait qu’on tient compte de xExprimé en formule, cela donne:
r2 = (E1-E2) / E1

69
Nota Bene
Ces éléments portant sur r et r2 sont repris et développés dans le document « Introduction à l’analyse de régression (2) »

70
ANOVAb
1.86E+009 1 1864395608 5.551 .025a
1.11E+010 33 3358546791.29E+010 34
RégressionRésiduTotal
Modèle1
Sommedes carrés ddl Carré moyen F Signification
Valeurs prédites : (constantes), Agea.
Variable dépendante : Revenub.
Tableaux de résultats dans SPSSB. « ANOVA »

71
B. Dans le tableau intitulé « Anova » figurent notamment
1) Les valeurs pour les sommes des erreurs de prédiction (évoquées ci-dessus)

72
2) Le résultat d’un test (F) selon lequel l’ensemble des coefficients des x sont égales à zéro
I.e. un test de l’absence de toute relation entre x et y, auquel cas le modèle n’est tout simplement pas « meilleur » que celui où ne figure aucun x

73
Nota Bene
Nous revenons plus longuement sur ces éléments, ainsi que les autres informations contenues dans le tableau « ANOVA », dans le document « Introduction à l’analyse de régression (2) »
74
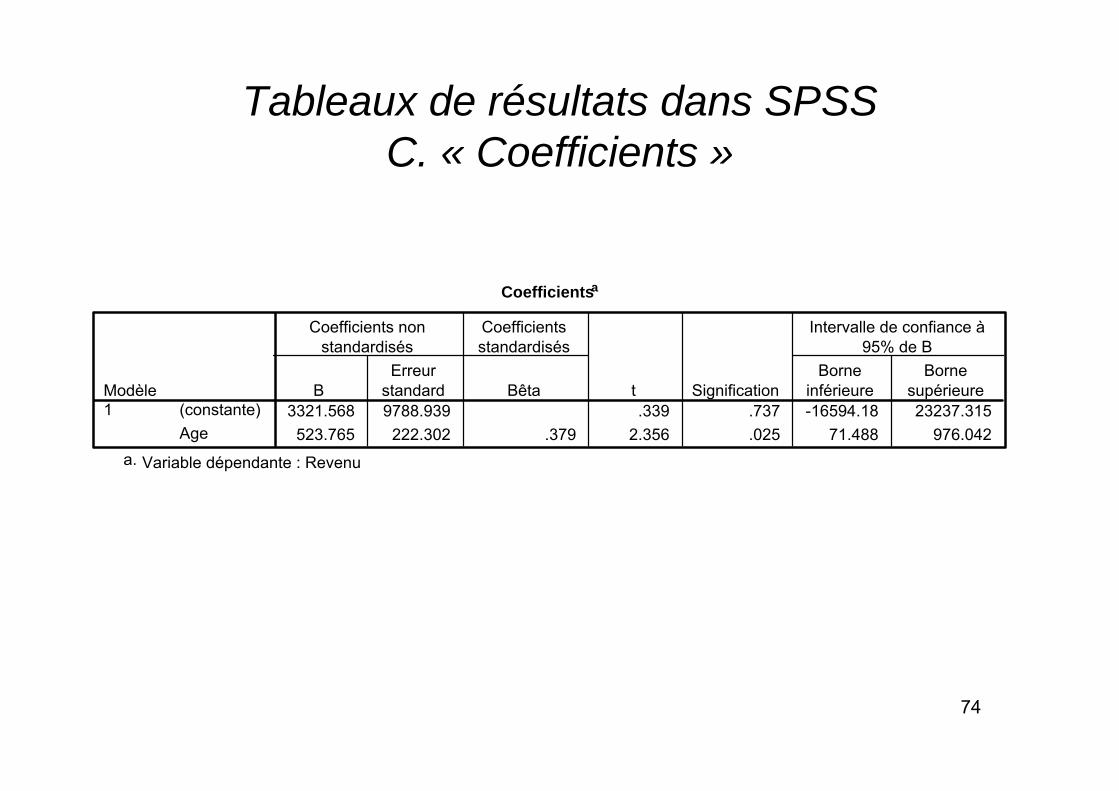
Coefficientsa
3321.568 9788.939 .339 .737 -16594.18 23237.315523.765 222.302 .379 2.356 .025 71.488 976.042
(constante)Age
Modèle1
BErreur
standard
Coefficients nonstandardisés
Bêta
Coefficientsstandardisés
t SignificationBorne
inférieureBorne
supérieure
Intervalle de confiance à95% de B
Variable dépendante : Revenua.
Tableaux de résultats dans SPSSC. « Coefficients »

75
C. Dans le tableau « Coefficients » figurent les éléments suivants :
1) Dans la colonne intitulée « B », la valeur du coefficient b dans l’équation de régression

76
Le signe du coefficient b donne le sens de la relation (ici entre âge et revenu)
si b > 0, la relation est positive : y croît quand x croît
si b < 0, la relation est négative : y décroît quand x croît
si b=0, il y a absence de relation

77
La valeur du coefficient b dépend de l’échelle de mesure de xGénéralement, on ne donc pas déduire de la valeur du coefficient la force de la relation (association)On ne peut comparer entre elles deux valeurs de coefficient que si l’échelle de mesure des variables x est identique

78
2) La valeur sous « Beta » est celle du coefficient b de l’équation de régression lorsqu’on standardise (« score de z »), les valeurs de x et de yla relation entre x et y est dès lors exprimée en termes d’écart type et non plus par rapport aux échelles originellesSe lit « de combien varie y en termes d’écart type lorsque x augmente d’un écart type »

79
Ce coefficient standardisé est une mesure de la force de la relation entre x et yDans le cas d’une régression bivariée, cette valeur est égale au coefficient de corrélation entre x et y, indiquée dans le tableau « Récapitulatif du modèle »

80
3) L’erreur standard (se), qui est une mesure de la variation de la valeur du coefficient b dans la population

81
4) La valeur t, qui est égale au ratio b / seCette valeur renvoie à un test de t (avec un degré de liberté) selon lequel la valeur du coefficient β dans la population est égale à 0
Autrement dit, on teste l’hypothèse d’indépendance selon laquelle il y a une absence de relation entre x et y dans la population

82
5) La valeur p donne le résultat du test de texprimé sous forme de probabilité

83
6) L’intervalle de confiance, indiquant la borne inférieure et la borne supérieure entre lesquelles se trouve, selon toute probabilité (à 95%), la valeur du coefficient β dans la populationAvec les valeurs de l’intervalle de confiance, on peut aussi et du même coup de calculer un éventail de valeurs prédites pour y dans la population

84
Les éléments évoqués sous le point 2) se rapportent à la mesure de la force de la relationCeux évoqués sous les points 3) à 6) se réfèrent à l’inférence statistique, i.e. l’estimation des valeurs dans la population sur la base des valeurs dans l’échantillonCes deux composantes de la régression sont repris et développés dans le document « Introduction à l’analyse de régression (2) »
Nota Bene

85
7) Le coefficient pour la constante (colonne « B »)Souvent, il ne s’interprète pasIl se rapporte en effet à la valeur de yquand x=0

86
Dans notre cas, comme souvent, cela réfère à une situation irréelle ou absurde (ici au revenu des personnes ayant 0 années d’âge!)On doit néanmoins tenir compte de la valeur du coefficient si on souhaite prédire la valeur de y