etude des arrêtés municipaux et des risques humainstouati/sodas/... · le web a de plus en plus...
TRANSCRIPT

Projet Datamining :
Etude des arrêtés municipaux et des
risques humains
JARRY Flavie
Enseignant : Edwin DIDAY
Master 2 ID Année 2006/2007

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 2
INTRODUCTION
Aujourd’hui, le datamining est perçu par les entreprises comme le moyen d’étudier et
d’analyser un volume important de données afin d’en ressortir des concepts importants. Ce
domaine répond désormais à un nombre important de besoins métiers de l’entreprise.
Mais qu’est ce que le datamining ?
« Le datamining (aussi connu sous le nom « d’exploration de données »), a pour objet
l’extraction d’un savoir ou d’une connaissance à partir de grandes quantités de données, par
des méthodes automatiques ou semi-automatiques, et l’utilisation industrielle ou
opérationnelle de ce savoir ».
L’ensemble des méthodes utilisées lors de ces fouilles de données regroupe à la fois
les mathématiques, les statistiques et l’informatique.
Le web a de plus en plus recours au principe de datamining dû à un nombre important
de données circulant, ainsi qu’à l’augmentation des calculs de grandes envergures liée à
l’évolution des technologies informatiques. Le datamining pourra alors réaliser les actions
suivantes :
Classer les internautes
Définir les profils des visiteurs d’un site
Etablir des liens entre les produits et ses acheteurs (dans le cas d’un site marchand)
Les applications de datamining sont multiples : CRM (Customer Relation Manager),
industrie (optimisation, prévision,…), traitements d’images, outils de collaboration
(classification). On peut résumer les capacités du datamining par les termes suivants:
analyser, prédire, détecter, rechercher et suggérer. Le datamining se « situe à la croisée
des statistiques, de l’intelligence artificielle et des bases de données.»
Le but de ce document consiste à approcher le datamining et à permettre à un lecteur
non expérimenté d’en comprendre les effets à travers un cas concret.
Dans un premier temps, je décrirai quelques concepts fondamentaux de datamining,
ainsi qu’une description des fonctionnalités du logiciel Sodas, puis je poursuivrai cette étude
par une analyse approfondie de la base de données choisie afin de mettre en application les
différentes méthodes d’analyse symbolique proposées par ce logiciel.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 3
TABLE DES MATIERES
INTRODUCTION ................................................................................................................................ 2
I. INTRODUCTION AU DATAMINING ....................................................................................... 4
I.1. QUELQUES CONCEPTS ................................................................................................................. 5 I.1.1. PRINCIPES DU DATAMINING ....................................................................................................... 5 I.1.2. LOGICIELS PRESENTS SUR LE MARCHE ....................................................................................... 6 I.2. INITIATION AU LOGICIEL SODAS ................................................................................................ 8 I.2.1. PRESENTATION DE L’ANALYSE DE DONNEES SYMBOLIQUES ...................................................... 8 I.2.2. PRESENTATION DU LOGICIEL ................................................................................................... 10 I.2.2.1. Interface graphique ............................................................................................................... 10 I.2.2.2. Construction d’une chaîne sous SODAS............................................................................... 11 I.2.2.3. Insertion des méthodes .......................................................................................................... 12
II. ETUDE STATISTIQUE ............................................................................................................ 15
II.1. DESCRIPTION DE LA BASE DE DONNEES .................................................................................. 16 II.1.1. ETUDE DES DONNEES .............................................................................................................. 16 II.1.1.1. Contexte de l’étude menée................................................................................................... 16 II.1.1.2. Schéma de la base de données ............................................................................................. 19 II.1.1.3. Objectifs à atteindre ............................................................................................................. 19 II.2. APPLICATION DU LOGICIEL SODAS......................................................................................... 20 II.2.1. DB2SO ................................................................................................................................... 20 II.2.1.1. Principe ............................................................................................................................... 20 II.2.1.2. Fonctionnement ................................................................................................................... 21 II.2.2. METHODES D’ANALYSE SYMBOLIQUE .................................................................................... 28 II.2.2.1. Rappels des types de données .............................................................................................. 28 II.2.2.2. Méthode VIEW ................................................................................................................... 29 II.2.2.3. Méthode STAT .................................................................................................................... 32 II.2.2.4. Méthode DIV ....................................................................................................................... 36 II.2.2.5. Méthode PYR ...................................................................................................................... 42 II.2.2.6. Méthode SCLUST ............................................................................................................... 45 II.2.2.7. Méthode PCA ...................................................................................................................... 50 II.2.2.8. Méthode TREE .................................................................................................................... 52
CONCLUSION ................................................................................................................................... 54

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 4
I. Introduction au
datamining

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 5
I.1. Quelques concepts
I.1.1. Principes du datamining
Il est important de distinguer le processus d’analyse assimilé au datamining. En effet,
celui-ci se distingue de l’analyse statistique connue de tous.
Comment ces deux approches se distinguent-elles ?
La première idée consiste à différencier le processus de chacune de ces deux analyses.
L’analyse statistique a pour but de confirmer ou contredire une hypothèse de départ à partir
d’un ensemble de données. Au contraire, le datamining montre son évolution en déduisant lui-
même des hypothèses souvent pertinentes (que l’utilisateur n’aurait pas déduit tout seul) grâce
à des données initiales.
De plus, le datamining a pour but principal de rester à la portée d’utilisateurs, non
statisticiens, par sa facilité d’utilisation et de fournir des résultats fiables en des temps corrects
car il est évident que dans le milieu professionnel il n’est pas envisageable de négliger les
temps de calcul.
Quels sont les buts d’une analyse de données ?
Figure 1 : But du traitement des données
La datamining doit suivre quelques règles indispensables à la bonne marche de
l’analyse de données1 :
Utiliser de façon massive et efficace l’information
Rester proche des données sans les déformer
Le modèle doit impérativement suivre les données et surtout pas l’inverse
Suivre un principe d’induction
1 Extrait des cours de « Datamining » de Mr Edwin DIDAY (Année 2006/2007 Master ID)
But du traitement des données
Décrire
Représenter
Visualiser
Classifier Décider

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 6
Le schéma suivant résume le principe de l’analyse de données symboliques :
Figure 2 : Schéma de l’analyse de données symboliques
Le principe de datamining peut être assimilé à un processus. Nous cherchons
maintenant à comprendre comment celui-ci s’organise.
L’extraction des connaissances métiers s’effectue en plusieurs étapes1 :
Formaliser le problème à résoudre en terme de données
Accéder aux données idoines quelles qu’elles soient
Préparer les données en vue des traitements et utilisations futurs
Modéliser les données en leur appliquant des algorithmes d’analyse
Evaluer et valider les connaissances ainsi extraites des analyses
Déployer les analyses dans une entreprise pour une utilisation effective
Le datamining s’appuie sur un ensemble de méthodes descriptives (classification
automatique, analyse factorielle) ou explicatives (analyse canonique, analyse discriminante,
segmentation) afin d’extraire un certain nombre de connaissances.
I.1.2. Logiciels présents sur le marché
Un certain nombre de logiciels sont aujourd’hui présents sur le marché.
En effet, malgré une part encore faible du datamining dans le monde du décisionnel, celui-ci
progresse de plus en plus et pousse les éditeurs à commercialiser des logiciels d’analyse de
données.
Pour en citer un, SAS (logiciel américain) demeure le plus connu sur le marché du
décisionnel. Avec son propre langage de programmation SAS offre de nombreuses
fonctionnalités dans l’analyse de données.
1 Wikipedia, Exploration de données
Tableau de données
multidimensionnelles
Programme informatique
Mise en relief de relations existantes :
entre individus
entre variables
entre individus et variables

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 7
D’autres logiciels sont également présents comme EasyOlap, SPAD, SPSS. Il en
existe également spécialisés dans certains secteurs professionnels comme Tanagra destiné à
l’enseignement et la recherche.
Pour lister l’ensemble des outils présents sur le marché actuellement, je vous propose la
cartographie suivante1 des logiciels de datamining :
Figure 3 : Cartographie des logiciels de datamining
Parmi la liste précédente, certains d’entre eux sont conçus pour étudier de gros
volumes de données et offrent des techniques plus diversifiées d’analyse.
Pour terminer sur les outils utilisés pour le datamining, il est important de savoir
choisir son logiciel en fonctions de ses besoins. Les critères de choix sont les suivants1 :
Variété des algorithmes de datamining, de statistique et de préparation des
données.
Qualité des algorithmes implémentés
Capacité à traiter de grands volumes de données
Types de données gérées
Convivialité du logiciel et facilité à produire des rapports
Prix
Tous les logiciels ne sont pas au même prix, il est donc important et nécessaire de bien
identifier les besoins utilisateurs avant de se lancer dans toutes analyses. Il est évident que
toutes les entreprises ne sont pas en mesure d’investir dans les « gros » outils du marché et les
logiciels libres représentent parfois une alternative avantageuse.
Peut être que dans quelques années, nous pourrons faire figurer le logiciel SODAS
dans la liste des logiciels de datamining utilisés sur le marché. Actuellement, il est en cours de
développement et continue de se perfectionner.
1 http://data.mining.free.fr/cours/Logiciels.pdf, « Logiciels et consultants »

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 8
I.2. Initiation au logiciel Sodas
A présent, je vais vous présenter le logiciel qui a permis de réaliser cette étude :
SODAS, développé au sein de l’université de Dauphine à Paris.
I.2.1. Présentation de l’analyse de données symboliques
Avant la pratique, il est important de définir quelques fondamentaux concernant
l’analyse de données symboliques.
Aujourd’hui la connaissance est devenue accessible à tous. Le développement du Web
est à l’origine de la croissance, ainsi que de l’accessibilité de ces connaissances. Il devient
alors utile d’étudier ces données afin de mieux les appréhender et en extraire ainsi de
nouvelles.
On en arrive alors à énoncer le terme de concepts et de données symboliques.
Le logiciel SODAS est un logiciel prototype public développé dans le cadre de
l’analyse symbolique. Il est issu du projet EUROSTAT, appelé SODAS.
L’idée générale de cet outil est la suivante1 : « A partir d’une base de données,
construire un tableau de données symboliques, parfois muni de règles et de taxonomies, dans
le but de décrire des concepts résumant un vaste ensemble de données, analyser ensuite ce
tableau pour en extraire des connaissances par des méthodes d’analyse de données
symboliques.».
1 www.ceremade.dauphine.fr/~touati/sodas-pagegarde.html, Présentation du projet et du logiciel SODAS

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 9
Le schéma1 suivant illustre les grandes étapes d’exécution du logiciel SODAS.
Figure 4 : Vue d’ensemble du logiciel SODAS
1 http://www.ceremade.dauphine.fr/%7Etouati/imagesodas.htm
« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 10
Nous pouvons résumer le but du projet comme suit :
UNITE STATISTIQUE UNITE CONCEPTUELLE
Le logiciel suit les étapes suivantes lors d’une analyse de données :
Partir d’une base de données relationnelle
Définir les unités statistiques de premier niveau (ex : habitants, ventes, accidents,…),
on parle alors d’individus
Définir les variables décrivant ces individus
Définir les concepts (régions, catégories socioprofessionnelles,…)
Le contexte défini peut être représenté de la façon suivante :
Un tableau de données symboliques peut alors être construit dont les nouvelles unités
statistiques seront désormais les concepts précédemment définis.
I.2.2. Présentation du logiciel
I.2.2.1. Interface graphique
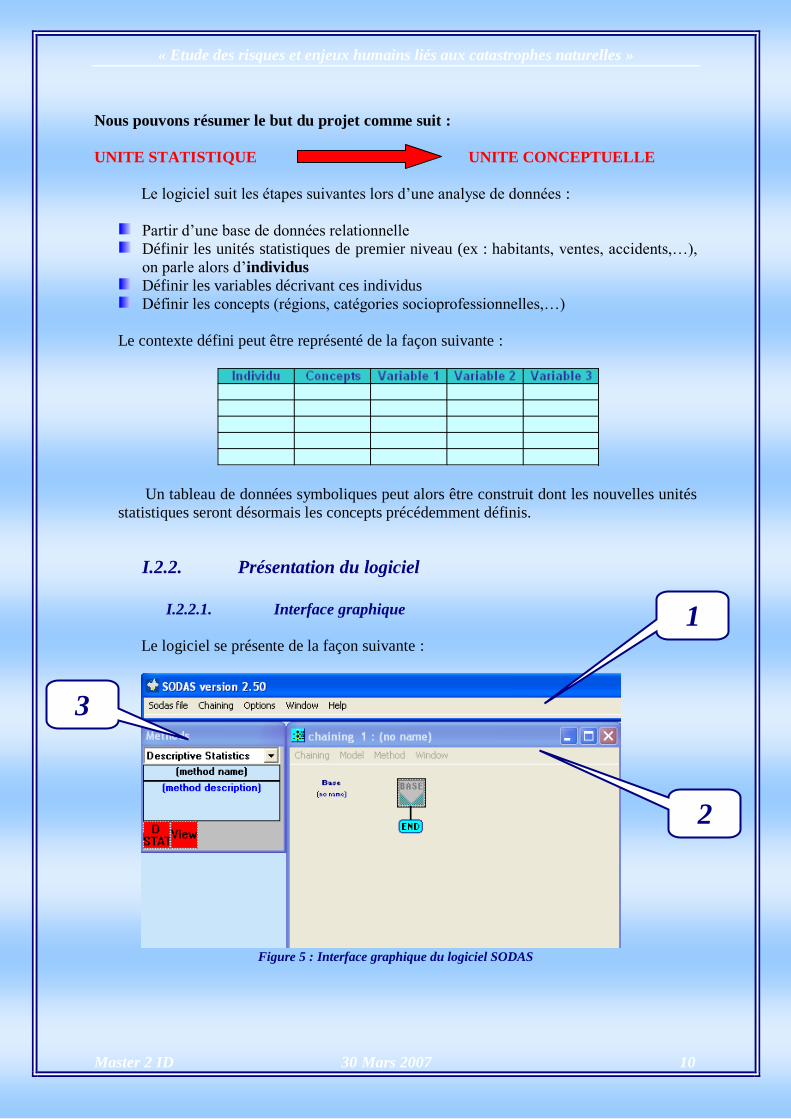
Le logiciel se présente de la façon suivante :
Figure 5 : Interface graphique du logiciel SODAS
1
2
3
« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 11
L’interface graphique se compose de trois zones principales :
Zone 1 : Cette première zone comporte les cinq menus du logiciel.
Zone 2 : Cette seconde zone représente la chaîne construite par l’utilisateur (je
définirai par la suite les caractéristiques d’une chaîne sous SODAS).
Zone 3 : Cette dernière zone regroupe les différentes méthodes proposées par
l’utilisateur. Celles-ci sont organisées par catégories (descriptive statistics,
clustering, factorial,…).
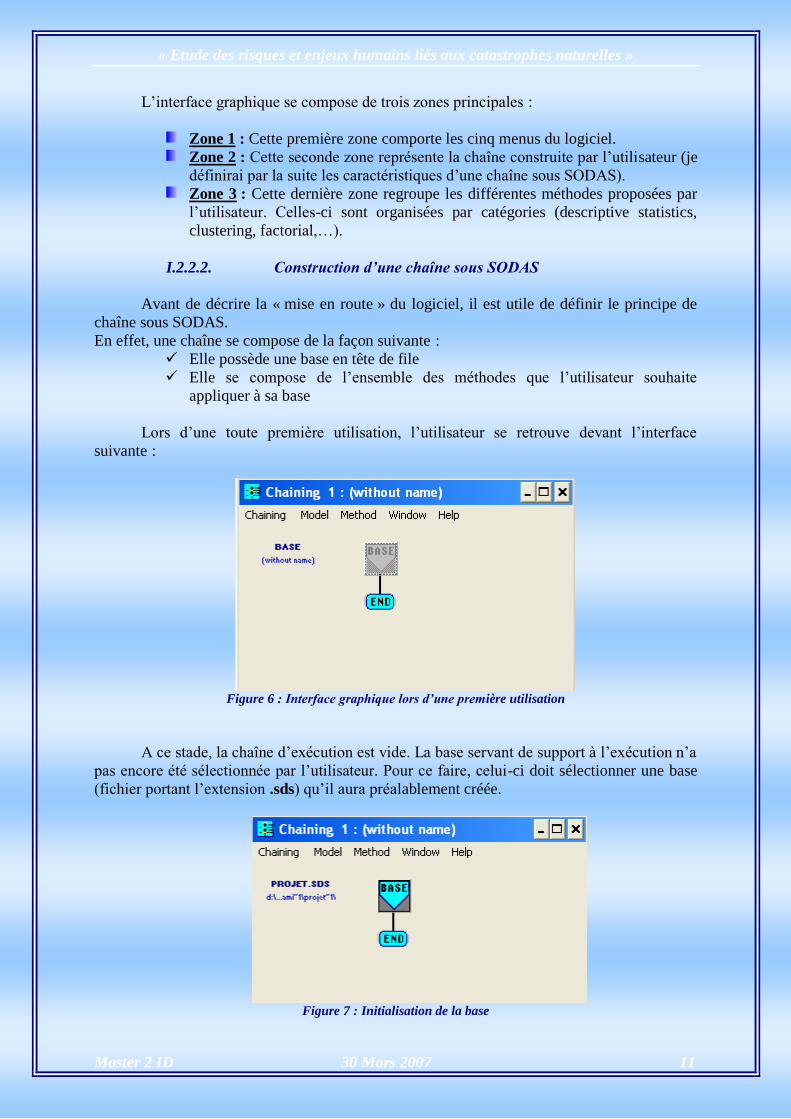
I.2.2.2. Construction d’une chaîne sous SODAS
Avant de décrire la « mise en route » du logiciel, il est utile de définir le principe de
chaîne sous SODAS.
En effet, une chaîne se compose de la façon suivante :
Elle possède une base en tête de file
Elle se compose de l’ensemble des méthodes que l’utilisateur souhaite
appliquer à sa base
Lors d’une toute première utilisation, l’utilisateur se retrouve devant l’interface
suivante :
Figure 6 : Interface graphique lors d’une première utilisation
A ce stade, la chaîne d’exécution est vide. La base servant de support à l’exécution n’a
pas encore été sélectionnée par l’utilisateur. Pour ce faire, celui-ci doit sélectionner une base
(fichier portant l’extension .sds) qu’il aura préalablement créée.
Figure 7 : Initialisation de la base

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 12
Après cette étape franchie, l’utilisateur est alors en mesure d’insérer les méthodes qu’il
souhaite exécuter.
I.2.2.3. Insertion des méthodes
La base actualisée, l’utilisateur est à présent en mesure d’insérer les méthodes de son
choix pour l’analyse de sa base de donnée.
La procédure d’insertion des méthodes est simple pour un utilisateur non expérimenté.
Il doit suivre la commande suivante : cliquer sur la commande « Insert method » du menu
« Method ».
Figure 8 : Procédure d’insertion d’une méthode
Un carré vide apparaît alors, permettant ainsi d’insérer la méthode voulue. Pour cela, il
suffit de faire glisser la méthode (les méthodes sont regroupées par catégories dans le menu
de gauche) dans le carré prévu à cet effet.
Cette étape est à procéder à chaque fois que l’on souhaite insérer une méthode
supplémentaire.
L’insertion terminée, nous obtenons une chaîne (chaining), où chaque méthode est
identifiée par un numéro se trouvant à gauche du carré correspondant.
Un jeu de couleurs permet d’identifier l’état actuel des méthodes :
Méthode grisée :
Cette couleur symbolise que la méthode n’a pas encore été paramétrée ; elle n’est donc
pas active à cet instant.
Par défaut, chaque méthode se trouve grisée après l’insertion.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 13
Figure 9 : Chaîne d’une série de méthodes non paramétrées
Méthode rouge :
Le rouge symbolise que la méthode a été paramétrée par l’utilisateur, celui-ci peut
ainsi l’exécuter.
Figure 10 : Exécution de la méthode VIEW
1 : L’icône jaune représente le listing obtenu, résumant les résultats obtenus par la
méthode (Ex: Méthode VIEW).
2 : L’icône rouge représente le résultat graphique de la méthode.
Le jeu de couleur des boites se trouvant à la gauche des icônes des méthodes permet
également à l’utilisateur de se repérer dans sa procédure d’exécution :
Boite grise : la méthode ne peut pas être exécutée car elle n’a pas encore été
paramétrée.
Boite rouge: la méthode est exécutable
1
2

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 14
Boite verte : la méthode a été désactivée par l’utilisateur, ce qui rend son
exécution impossible.
Avant l’exécution, il est indispensable de sauvegarder la chaîne précédemment créée :
cliquer sur la commande « Save chaining as » du menu principal « Chaining ».
La sauvegarde portera l’extension .fil.
« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 15
II. Etude statistique

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 16
II.1. Description de la base de données
II.1.1. Etude des données
A présent, je vais vous présenter la base de données qui servira de support à la mise en
pratique du logiciel SODAS.
II.1.1.1. Contexte de l’étude menée
Lors de mes recherches sur Internet, j’ai « mis la main » sur une base de données
concernant des catastrophes naturelles, les arrêtés et risques humains liés dans certaines
communes, la base GASPAR.
La base GASPAR1 réunit des informations sur les documents d’information préventive
ou à portée réglementaire :
PPR (Plan de Prévention des Risques) et assimilées
Procédure de type « reconnaissance de l’état de catastrophe naturelle»
Documents d’information préventive (Documents Communaux Synthétiques,
Atlas des Zones Inondable).
La base de données complète est composée de quinze tables. Cependant, j’ai choisi de
m’attacher particulièrement aux risques et enjeux humains dans les différentes communes.
Pour cette étude, seules les tables suivantes seront nécessaires :
Departement
Region
Risque
Commune
Commune_Risque
Commune_PPR
PPR
Enjeux
AZI
Je vais m’attarder sur les tables utilisées et décrire brièvement leur contenu.
Les trois tables suivantes permettent de localiser les catastrophes naturelles à
différentes échelles (régional, départementale, communale).
Region :
Cette tables est composée de deux champs principaux : cod_region et lib_region
1 http://www.prim.net/professionnel/procedures_regl/avancement.html, La base GASPAR

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 17
Departement :
Cette table est constituée de trois colonnes permettant la localisation du département :
cod_departement, lib_departement et cod_region (cet attribut permet d’identifier la région
auquel est rattaché le département).
Commune :
La table commune se trouve être plus complète en terme de données. En effet, elle est
composée de quatre colonnes : cod_commune, cod_departement, lib_departement et
tot_population. L’attribut tot_population pourra s’avérer intéressant lors de l’analyse des
enjeux humains.
Les deux tables suivantes vont servir de support à l’étude des risques à l’échelle
communale.
Risque :
Cette table regroupe les risques recensés à travers toutes les communes. Elle s’articule
autour de quatre colonnes principales : cod_risque, num_risque, lib_risque_long et
lib_risque.
L’attribut lib_risque résume simplement l’attribut lib_risque_long qui peut s’avérer un peu
long en terme de caractères pour être manipulé dans les résultats d’analyses (graphiques,
diagrammes,…).
L’attribut num_risque sera utilisé dans les tables comme clé étrangère pour faire la relation
avec la table Risque au lieu de l’attribut cod_risque.
Commune_Risque :
Cette table permet de faire la liaison entre les catastrophes recensées dans les
communes avec les risques et enjeux qui y sont associés. A l’origine, elle est composée de
trois attributs : cod_commune, cod_enjeu et num_risque. J’ai choisi de rajouter une colonne
num_catastrophe servant de clé primaire.
Pour terminer, j’ai jugé pertinent d’étudier également les tables PPR, Enjeux et AZI.
Commune_PPR :
Cette table permet d’identifier les différents PPR qui ont été mis en place dans les
communes étudiées. Seuls certains champs nous seront utiles : cod_commune et cod_PPR.
PPR :
La table PPR comporte deux colonnes permettant d’identifier le Plan de Prévention
des Risques (PPR) établi : cod_PPR et lib_PPR.
Enjeu :
Comme la précédente, cette dernière table permet d’analyser les enjeux humains à
travers deux attributs : cod_enjeu et lib_enjeu

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 18
.AZI :
Enfin, cette dernière table sera utilisée pour rajouter une variable (Nombre_AZI) dans
le tableau de données symboliques obtenu. J’ai jugé utile de recenser le nombre de code AZI
affecté à une région.
Cette base de données a pour avantage de renseigner de façon très précise les
différentes commune recensées (région, département, population,…) ; ce qui nous permettra
une analyse détaillée.
Deux requêtes supplémentaires ont été programmées : pop_departement et
pop_region. Ces deux tables seront utiles pour la définition de nos concepts. En effet,
initialement, la base de données comptait peu de variables numériques. J’ai jugé utile de
rajouter des variables de ce type afin d’obtenir des variables continues dans la table de
concepts.
Chacune de ces deux tables est de forme identique :
Cod_departement (resp. cod_region)
Population_departement (resp. population_region)
La requête Requete_Concept_Risque fournit le résultat attendu pour l’utilisation du
module DB2SO. J’ai préféré enregistrer cette requête sous la forme d’une table
, celles-ci étant plus faciles à manipuler et permet de contourner les problèmes de clé
étrangère dans la table qui servira de support au module.
Le module DB2SO prendra en entrée la table Concepts.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 19
II.1.1.2. Schéma de la base de données
Le schéma de base de donnée suivant regroupe uniquement les tables que j’ai jugé
pertinent de garder et d’étudier.
Figure 11 : Relations de la base de donnée GASPAR
II.1.1.3. Objectifs à atteindre
Le but de cette étude consiste à étudier les communes de façon indépendante afin
d’évaluer les différents risques et d’en analyser les différentes caractéristiques.
En effet, je juge important de pouvoir identifier les régions « à risque », ainsi que les
enjeux humains associés.
Par exemple, il pourrait être intéressant de pouvoir aboutir à des relations entre les
communes touchées par les catastrophes naturelles et leur localisation, ainsi que son nombre
d’habitants.
Cependant, le nombre et le type de données présents dans la base d’étude poseront
certaines difficultés dans l’exécution des différentes méthodes du logiciel. De plus, l’analyse
sera limitée mais permettra quand même une approche et un premier apprentissage de
SODAS.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 20
II.2. Application du logiciel Sodas
II.2.1. DB2SO
II.2.1.1. Principe
Le principe majeur de DB2SO consiste à créer une série de concepts à partir d’une
base de données initiale. Il est important que celle-ci soit composée d’une série d’individus,
de catégories et de différentes variables permettant de les décrire afin que le module puisse
créer des concepts valables. L’exemple suivant décrit la forme syntaxique que doit posséder la
base d’étude.
L’exemple suivant illustre le principe de DB2SO :
Figure 12 : Illustration du fonctionnement de DB2SO
Individu
s
Catégories Variables
DB2SO
Concepts
« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 21
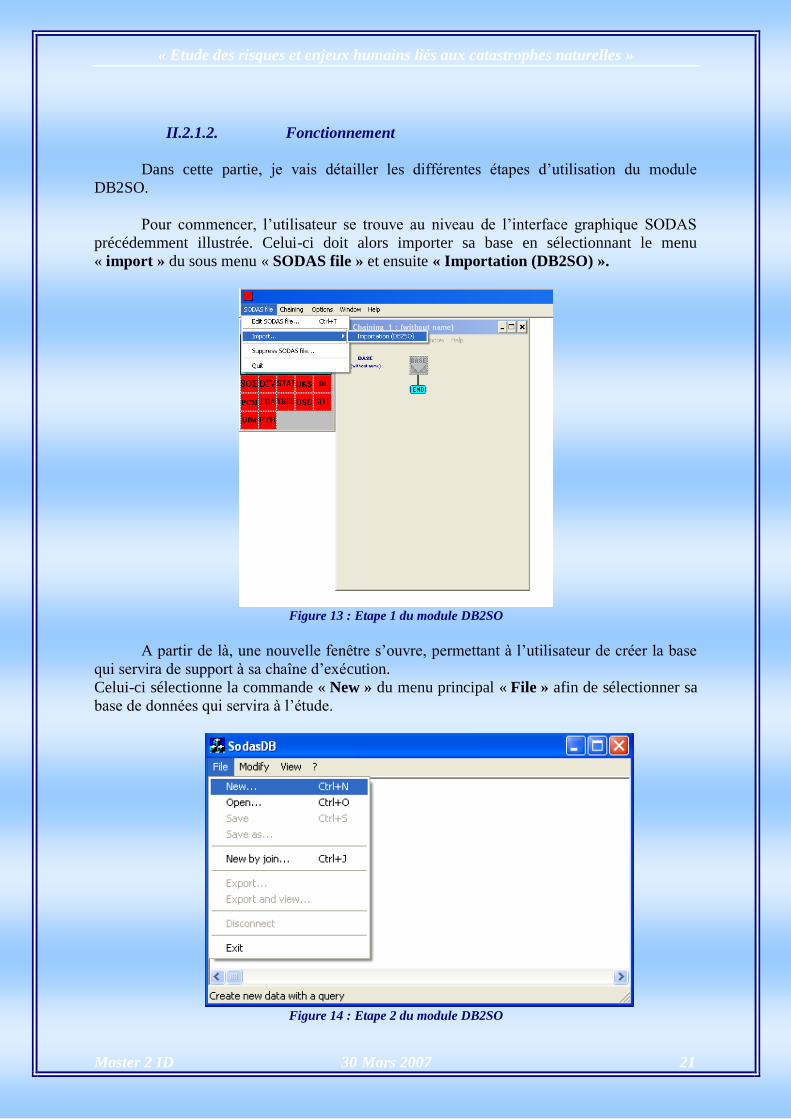
II.2.1.2. Fonctionnement
Dans cette partie, je vais détailler les différentes étapes d’utilisation du module
DB2SO.
Pour commencer, l’utilisateur se trouve au niveau de l’interface graphique SODAS
précédemment illustrée. Celui-ci doit alors importer sa base en sélectionnant le menu
« import » du sous menu « SODAS file » et ensuite « Importation (DB2SO) ».
Figure 13 : Etape 1 du module DB2SO
A partir de là, une nouvelle fenêtre s’ouvre, permettant à l’utilisateur de créer la base
qui servira de support à sa chaîne d’exécution.
Celui-ci sélectionne la commande « New » du menu principal « File » afin de sélectionner sa
base de données qui servira à l’étude.
Figure 14 : Etape 2 du module DB2SO

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 22
L’utilisateur doit maintenant sélectionner sa base de données. Dans notre cas, nous
utiliserons une base de type ACCESS. A partir de l’onglet « Source de données machine »,
l’utilisateur sélectionne le type voulu (MS Access Database) et click sur « OK » afin de
pouvoir la sélectionner dans sa liste de fichiers.
Figure 15 : Etape 3 du module DB2SO
La base choisie, la seconde étape consiste à extraire les individus et les concepts de
façon à obtenir la configuration décrite précédemment (Individus, Concepts, Variables).
Pour ce faire, une requête a été programmée (Requete_Concept_Risque) fournissant les
données nécessaires:
SELECT DISTINCT CR.NUM_CATASTROPHE, Re.LIB_REGION,
Ri.LIB_RISQUE, D.LIB_DEPARTEMENT, C.LIB_COMMUNE,
C.TOT_POPULATION AS POPULATION_COMMUNE, E.LIB_ENJEU,
CP.COD_PPR, PD.POPULATION_DEPARTEMENT, PR.POPULATION_REGION
FROM DEPARTEMENT AS D, REGION AS Re, RISQUE AS Ri, COMMUNE
AS C, PPR AS P, COMMUNE_RISQUE AS CR, ENJEU AS E, COMMUNE_PPR AS
CP, POP_DEPARTEMENT AS PD, POP_REGION AS PR
WHERE CR.COD_COMMUNE=C.COD_COMMUNE AND
C.COD_DEPARTEMENT=D.COD_DEPARTEMENT AND
D.COD_REGION=Re.COD_REGION AND CR.NUM_RISQUE=Ri.NUM_RISQUE
AND CR.COD_ENJEU=E.COD_ENJEU AND
CR.COD_COMMUNE=CP.COD_COMMUNE AND
C.COD_DEPARTEMENT=PD.COD_DEPARTEMENT AND
D.COD_REGION=PR.COD_REGION AND CP.LIB_BASSIN_RISQUE<>'-' AND
CP.LIB_BASSIN_RISQUE<>'';
Le résultat de cette requête est stocké dans la table Concepts.
« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 23
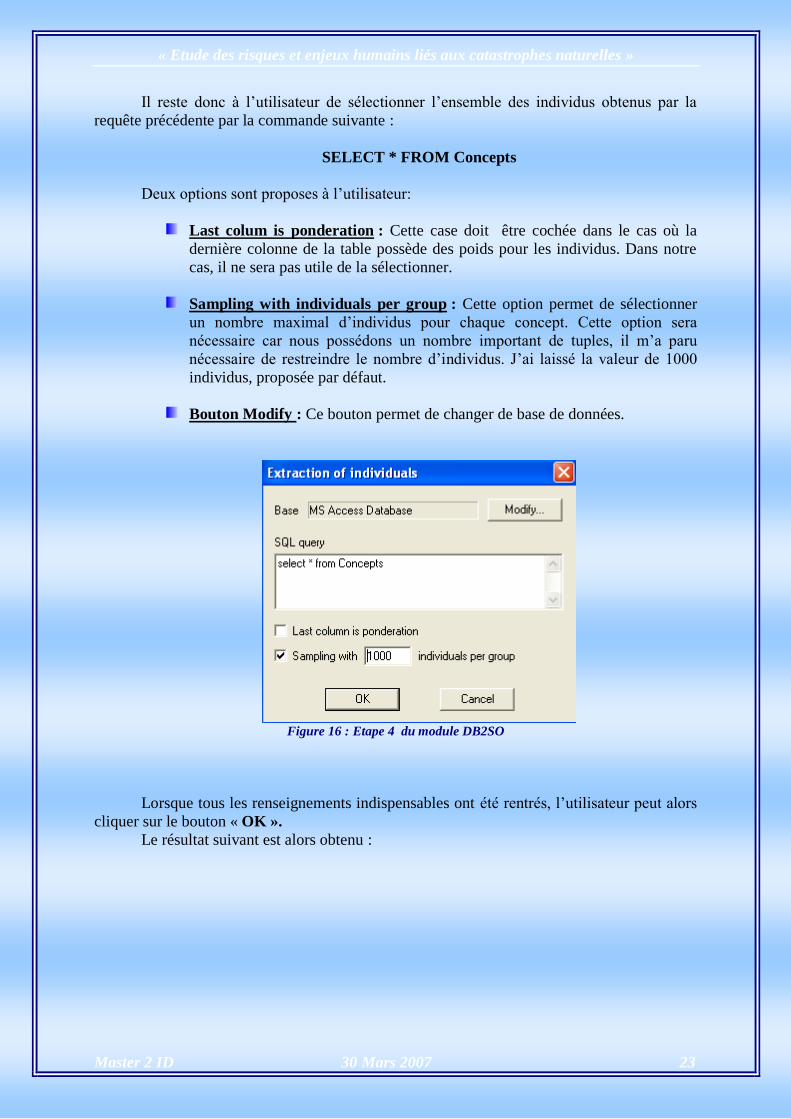
Il reste donc à l’utilisateur de sélectionner l’ensemble des individus obtenus par la
requête précédente par la commande suivante :
SELECT * FROM Concepts
Deux options sont proposes à l’utilisateur:
Last colum is ponderation : Cette case doit être cochée dans le cas où la
dernière colonne de la table possède des poids pour les individus. Dans notre
cas, il ne sera pas utile de la sélectionner.
Sampling with individuals per group : Cette option permet de sélectionner
un nombre maximal d’individus pour chaque concept. Cette option sera
nécessaire car nous possédons un nombre important de tuples, il m’a paru
nécessaire de restreindre le nombre d’individus. J’ai laissé la valeur de 1000
individus, proposée par défaut.
Bouton Modify : Ce bouton permet de changer de base de données.
Figure 16 : Etape 4 du module DB2SO
Lorsque tous les renseignements indispensables ont été rentrés, l’utilisateur peut alors
cliquer sur le bouton « OK ».
Le résultat suivant est alors obtenu :
« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 24
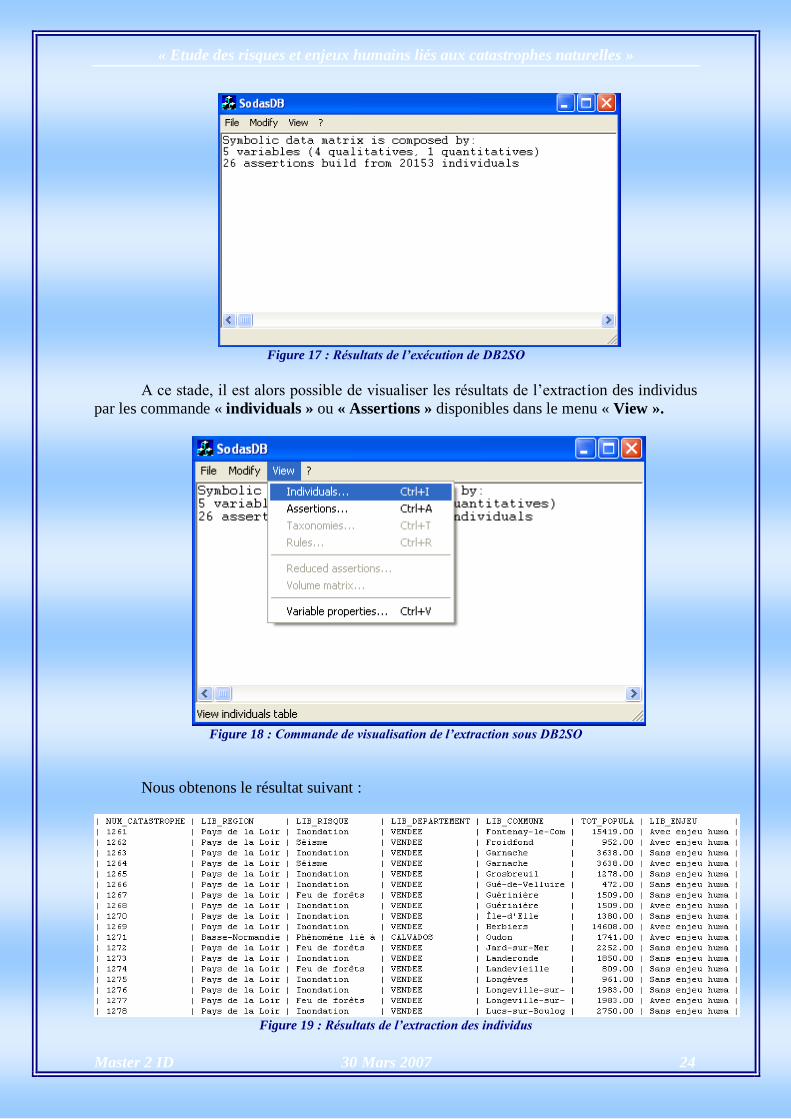
Figure 17 : Résultats de l’exécution de DB2SO
A ce stade, il est alors possible de visualiser les résultats de l’extraction des individus
par les commande « individuals » ou « Assertions » disponibles dans le menu « View ».
Figure 18 : Commande de visualisation de l’extraction sous DB2SO
Nous obtenons le résultat suivant :
Figure 19 : Résultats de l’extraction des individus

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 25
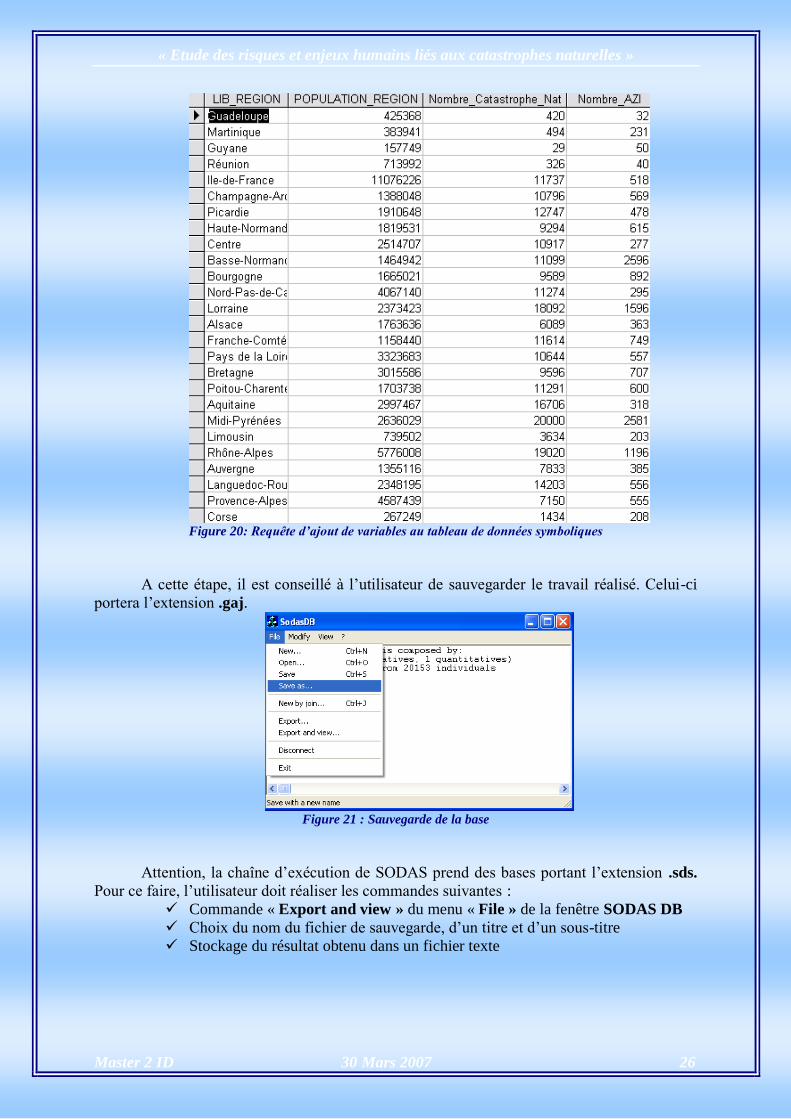
L’extraction des individus réalisée, l’utilisateur a la possibilité de modifier son travail
en ajoutant par exemple des variables permettant de décrire les concepts à partir du menu
« Modify » :
La requête doit renvoyer un résultat suivant une syntaxe bien précise :
1ère
colonne : concept
Colonnes suivantes : variables décrivant les concepts
Dans mon cas, j’ai choisi d’implémenter la requête suivante (Add_single_Var) :
SELECT NC.LIB_REGION, PR.POPULATION_REGION,
NC.Nombre_Catastrophe_Nat, NA.Nombre_AZI
FROM Nombre_Catastrophe AS NC, Nombre_AZI AS NA, POP_REGION AS PR,
REGION AS R
WHERE PR.COD_REGION=R.COD_REGION AND
R.LIB_REGION=NC.LIB_REGION AND R.LIB_REGION=NA.LIB_REGION;
La requête précédente utilise le résultat des requêtes citées ci-dessous, chacune ayant
été programmée pour décrire chaque concept par une variable précise :
Nombre_Catastrophe
Nombre_AZI
Population_Region
La requête précédente renvoie la liste des concepts définis, suivis de trois variables les
décrivant. Pour notre projet, j’ai décrit chaque concept (cod_region) à l’aide de son nombre
d’habitants, du nombre de catastrophes naturelles recensées et du nombre de cod_AZI (Atlas
des Zones Inondables). Le résultat de la requête prend la forme suivante :
« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 26
Figure 20: Requête d’ajout de variables au tableau de données symboliques
A cette étape, il est conseillé à l’utilisateur de sauvegarder le travail réalisé. Celui-ci
portera l’extension .gaj.
Figure 21 : Sauvegarde de la base
Attention, la chaîne d’exécution de SODAS prend des bases portant l’extension .sds.
Pour ce faire, l’utilisateur doit réaliser les commandes suivantes :
Commande « Export and view » du menu « File » de la fenêtre SODAS DB
Choix du nom du fichier de sauvegarde, d’un titre et d’un sous-titre
Stockage du résultat obtenu dans un fichier texte

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 27
Figure 22 : Création d’un fichier .sds

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 28
II.2.2. Méthodes d’analyse symbolique
II.2.2.1. Rappels des types de données
Avant de commencer notre étude statistique, je juge important de rappeler quelques
fondamentaux concernant les types de données et les particularités de certaines méthodes.
Nous distinguons deux types de données : les données classiques et les données
symboliques.
Classique :
Parmi les données classiques, on recense deux types importants :
Données numériques (ou quantitatives):
Exemple : age=15
Données nominales (ou qualitatives):
Exemple : couleur=bleu
Symbolique:
L’analyse symbolique entraîne une transformation au niveau des données, de
nouveaux types apparaissent.
Données intervalles :
Exemple : age= [15 ; 25]
Données multivaluées :
Exemple : couleur= {bleu ; rouge ; vert}
Données modales (fréquence):
Exemple : couleur= (0,7 bleu ; 0,1 rouge ; 0,2 vert)
Certaines méthodes ne traitent que des types de données bien définis. Nous allons
rappeler certaines conditions dans le tableau suivant avant la mise en pratique du logiciel.
Figure 23 : Tableau récapitulatif des méthodes de SODAS

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 29
II.2.2.2. Méthode VIEW
La méthode VIEW permet à l’utilisateur de visualiser ses données et de pouvoir ainsi
les comparer et en tirer certaines conclusions ou hypothèses.
L’interface de cette méthode propose plusieurs types de visualisation de ses résultats :
Modèle en étoile en trois dimensions
Modèle en étoile en deux dimensions
Histogramme
Superposition des concepts
Les différents graphiques sont proposés par les icônes suivants :
Figure 24 : Méthodes de visualisation proposé par le module VIEW
La méthode VIEW exécutée, l’utilisateur visualise un tableau regroupant ses différents
concepts et variables sélectionnés au préalable. Celui-ci est facilement manipulables et permet
à tout moment de modifier les données initiales.
Figure 25 : Tableau proposé par la méthode VIEW
Je vais illustrer les résultats obtenus de la façon suivante: les deux modèles suivants
permettent de comparer les résultats pour la région de Poitou-Charentes et la région de
Rhône-Alpes.
Pour cette première région, nous constatons que les PPR (Plan de prévention des
risques) dominent très nettement par rapport aux autres plans pouvant être mis en place.
Concernant les risques encourus dans cette région, l’utilisateur remarque rapidement
que les inondations sont prédominantes sur les autres catastrophes naturelles envisageables.
Pour la deuxième région, les résultats sont semblables. Cependant, on constate une
part moins importante des PPR dans le Rhône Alpes. En effet, des PSS sont mis en place dans
les communes concernées, mais ne sont cependant pas majoritaires.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 30
REPRESENTATION GRAPHIQUE
Figure 26 : Modèle en étoile pour la région Poitou charente
Figure 27 : Modèle en étoile pour la région Rhône Alpes
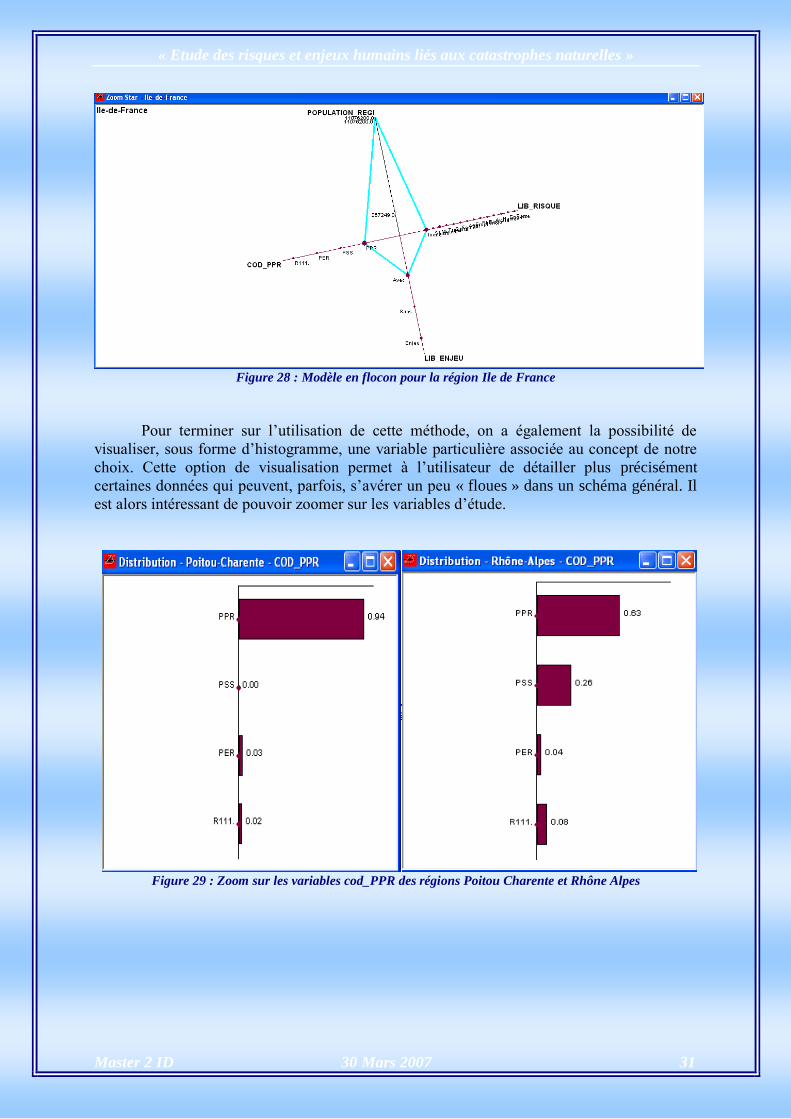
Le modèle en flocon peut être également visualisé en deux dimensions par
l’utilisateur. Le module VIEW s’adapte aux volontés de ses utilisateurs. Le losange tracé en
bleu permet de repérer rapidement les variables symbolisant le mieux chaque concept. Le
module offre une vision claire et précise des résultats, permettant ainsi d’affirmer ou non
certaines hypothèses.
« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 31
Figure 28 : Modèle en flocon pour la région Ile de France
Pour terminer sur l’utilisation de cette méthode, on a également la possibilité de
visualiser, sous forme d’histogramme, une variable particulière associée au concept de notre
choix. Cette option de visualisation permet à l’utilisateur de détailler plus précisément
certaines données qui peuvent, parfois, s’avérer un peu « floues » dans un schéma général. Il
est alors intéressant de pouvoir zoomer sur les variables d’étude.
Figure 29 : Zoom sur les variables cod_PPR des régions Poitou Charente et Rhône Alpes
« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 32
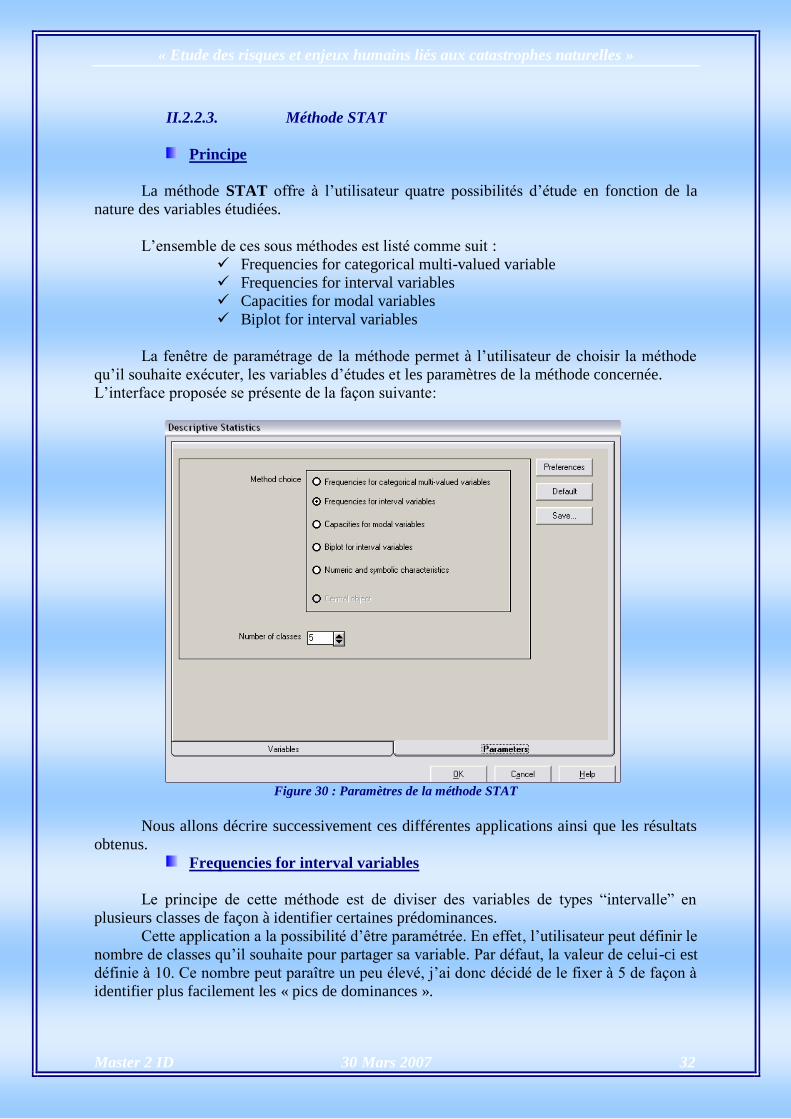
II.2.2.3. Méthode STAT
Principe
La méthode STAT offre à l’utilisateur quatre possibilités d’étude en fonction de la
nature des variables étudiées.
L’ensemble de ces sous méthodes est listé comme suit :
Frequencies for categorical multi-valued variable
Frequencies for interval variables
Capacities for modal variables
Biplot for interval variables
La fenêtre de paramétrage de la méthode permet à l’utilisateur de choisir la méthode
qu’il souhaite exécuter, les variables d’études et les paramètres de la méthode concernée.
L’interface proposée se présente de la façon suivante:
Figure 30 : Paramètres de la méthode STAT
Nous allons décrire successivement ces différentes applications ainsi que les résultats
obtenus.
Frequencies for interval variables
Le principe de cette méthode est de diviser des variables de types “intervalle” en
plusieurs classes de façon à identifier certaines prédominances.
Cette application a la possibilité d’être paramétrée. En effet, l’utilisateur peut définir le
nombre de classes qu’il souhaite pour partager sa variable. Par défaut, la valeur de celui-ci est
définie à 10. Ce nombre peut paraître un peu élevé, j’ai donc décidé de le fixer à 5 de façon à
identifier plus facilement les « pics de dominances ».

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 33
Cette méthode permet d’obtenir le résultat sous deux formes différentes :
Listing
Graphique
LISTING
POPULATION_COMMUNE
limits: 0.0 - 2147860.0 class width: 214786.0
class 1 0.9065
class 2 0.0602
class 3 0.0042
class 4 0.0042
class 5 0.0042
class 6 0.0042
class 7 0.0042
class 8 0.0042
class 9 0.0042
class 10 0.0042
Central tendancy: 159694.6046
Dispersion: 233740.2092
POPULATION_DEPARTEMENT
limits: 78027.0 - 2597360.0 class width: 251933.3
class 1 0.1877
class 2 0.3273
class 3 0.2316
class 4 0.1111
class 5 0.0468
class 6 0.0287
class 7 0.0261
class 8 0.0200
class 9 0.0115
class 10 0.0093
Central tendancy: 689285.5010
Dispersion: 465633.9467

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 34
REPRESENTATION GRAPHIQUE
Nous avons travaillé avec les deux variables suivantes : population_commune et
population_departement.
Figure 31 : Application de la méthode STAT sur des variables intervalles
Il peut être intéressant d’exécuter la méthode en paramétrant un nombre de classe
supérieur.
Par exemple, si nous choisissons la répartition en 10 classes pour la variable
population_departement, nous obtenons les résultats suivants :
Figure 32 : Répartition de la variable population_departement en 10 classes
A partir de ces graphiques, on peut analyser la répartition des départements, en se
concentrant sur les « pointes » du graphique pour en déduire une moyenne du nombre
d’habitants par département. On remarque dominance des départements d’environ 500000
habitants. Autour, ce partage des départements avec plus ou moins 500000 habitants. Les
populations importantes ne sont pas dominantes.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 35
Capacities for modal variables
Après l’étude précédente, il est intéressant d’étudier des variables modales. Deux
visualisations sont possibles, chacune ayant leurs caractéristiques.
Dans un premier temps, je vous propose la comparaison de trois variables modales
(lib_risque, lib_enjeu et cod_ppr). Il est intéressant de comparer les résultats de chacune et
de connaître leurs répartitions.
L’analyse suivante fait ressortir des conclusions pour chaque variable étudiée :
Les quatre risques qui prédominent semblent être les suivants :
inondation, feu, séisme et mouvement de terrain.
Les enjeux sont répartis de façon proportionnelle, on ne distingue pas
d’avantage majeur entre les notions « avec ou sans enjeu humain ».
Les codes PPR et PSS sont majoritaires malgré une part importante de
chacun.
Il semble très utile d’identifier les risques les plus répandus de façon à mettre en place
des politiques de prévention au sein des communes, dont le but premier est de réduire le
nombre de ces catastrophes naturelles.
Le schéma suivant illustre les résultats précédemment énoncés. L’utilisateur a la
possibilité de modifier l’affichage de ces graphiques : modifications des couleurs, ajout de
labels,…. Celui-ci peut obtenir des graphiques clairs et concis pour une analyse simple.
Figure 33 : Application de la méthode STAT sur des variables modales (histogramme)
De plus, une option d’affichage permet d’afficher des histogrammes de capacité des
modalités des variables étudiées (également appelés max/mean/min). En effet, le graphique
obtenu propose l’étendu, ainsi que la moyenne des variables.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 36
Dans notre étude, on constate clairement que la moyenne des inondations est
nettement supérieure aux autres. De plus, précédemment, nous avions des difficultés à
départager les enjeux associés. Avec cette visualisation, on est apte à affirmer que la notion
« d’enjeux humains » prédomine malgré tout. Pour terminer, il semble évident que les PPR
(Rappel : Plan de Prévention des Risques) demeurent les plans les plus régulièrement mis en
place au sein des régions.
Figure 34 : Application de la méthode STAT sur des variables modales (notion de capacité)
II.2.2.4. Méthode DIV
Principe
A présent, nous allons utiliser les fonctionnalités de la méthode DIV.
Cette méthode permet de réaliser une classification hiérarchique des concepts étudiés. Ceci
peut s’avérer particulièrement utile pour analyser certains critères de différenciation des
individus.
La classification effectuée, nous obtenons un tableau résumant pour chaque individu la
classe auquel il appartient. Les classes ainsi obtenues permettent une vision claire, concise et
structurée des données.
Dans notre cas, les concepts étudiés étant des régions, il serait intéressant de connaître
et regrouper celles-ci selon les risques associés aux catastrophes naturelles.
Pour commencer, il est important de signaler que cette méthode peut s’appliquer à la
fois sur des variables qualitatives ou quantitatives. Cependant, il n’est pas possible d’étudier
simultanément des variables de types différents. De plus, la méthode propose à l’utilisateur de
déterminer le nombre de classes voulu pour sa classification.
Cependant, le logiciel étant encore récent du point de vue de son développement, il
n’est pas possible, pour l’instant, de visualiser les résultats sous forme graphiques, seul le
listing est disponible.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 37
L’algorithme de classification hiérarchique peut se traduire de la façon suivante1 :
Partir d’une partition initiale P0 dont les classes sont réduites à un élément
Construire une nouvelle partition en réunissant les deux classes de la partition précédente qui minimise l’indice de dissimilarité entre les individus.
Recommencer le procédé jusqu’à ce que toutes les classes soient réunies en une seule.
Nous allons faire deux études successives sur les variables suivantes :
Variables qualitatives : cod_enjeu, cod_risque et cod_PPR
Variables quantitatives : nombre_catastrophe_regional et nombre_AZI
Application
La première méthode consiste à construire une hiérarchie basée sur les trois grandes
variables qualitatives. Cette analyse peut permettre d’analyser la répartition des régions selon
les risques associés.
Le listing proposé offre à l’utilisateur le résultat d’une répartition en 2, 3, 4 ou 5
clusters.
LISTING
PARTITION IN 2 CLUSTERS :
-------------------------:
Cluster 1 (n=23) :
"Rhône-Alpes" "Picardie" "Languedoc-Roussillon" "Centre" "Provence-Alpes-
Côte d'Azur" "Ile-de-France" "Martinique" "Pays de la Loire" "Poitou-
Charentes" "Limousin"
"Lorraine" "Bourgogne" "Midi-Pyrénées" "Aquitaine" "Haute-Normandie"
"Basse-Normandie" "Alsace" "Franche-Comté" "Auvergne" "Nord-Pas-de-Calais"
"Bretagne" "Champagne-Ardenne" "Corse"
Cluster 2 (n=1) :
"Réunion"
Explicated inertia: 17.270590
PARTITION IN 3 CLUSTERS :
-------------------------:
Cluster 1 (n=14) :
1 Algorithme tiré du cours de Mr DIDAY « Datamining », MASTER 2 ID

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 38
"Rhône-Alpes" "Centre" "Provence-Alpes-Côte d'Azur" "Ile-de-France"
"Martinique" "Limousin" "Bourgogne" "Basse-Normandie" "Alsace" "Franche-
Comté"
"Auvergne" "Bretagne" "Champagne-Ardenne" "Corse"
Cluster 2 (n=1) :
"Réunion"
Cluster 3 (n=9) :
"Picardie" "Languedoc-Roussillon" "Pays de la Loire" "Poitou-Charentes"
"Lorraine" "Midi-Pyrénées" "Aquitaine" "Haute-Normandie" "Nord-Pas-de-
Calais"
Explicated inertia: 28.715449
PARTITION IN 4 CLUSTERS :
-------------------------:
Cluster 1 (n=7) :
"Centre" "Ile-de-France" "Limousin" "Bourgogne" "Franche-Comté" "Bretagne"
"Champagne-Ardenne"
Cluster 2 (n=1) :
"Réunion"
Cluster 3 (n=9) :
"Picardie" "Languedoc-Roussillon" "Pays de la Loire" "Poitou-Charentes"
"Lorraine" "Midi-Pyrénées" "Aquitaine" "Haute-Normandie" "Nord-Pas-de-
Calais"
Cluster 4 (n=7) :
"Rhône-Alpes" "Provence-Alpes-Côte d'Azur" "Martinique" "Basse-Normandie"
"Alsace" "Auvergne" "Corse"
Explicated inertia: 35.364687
PARTITION IN 5 CLUSTERS :
-------------------------:
Cluster 1 (n=7) :
"Centre" "Ile-de-France" "Limousin" "Bourgogne" "Franche-Comté" "Bretagne"
"Champagne-Ardenne"
Cluster 2 (n=1) :
"Réunion"
Cluster 3 (n=9) :

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 39
"Picardie" "Languedoc-Roussillon" "Pays de la Loire" "Poitou-Charentes"
"Lorraine" "Midi-Pyrénées" "Aquitaine" "Haute-Normandie" "Nord-Pas-de-
Calais"
Cluster 4 (n=6) :
"Rhône-Alpes" "Provence-Alpes-Côte d'Azur" "Martinique" "Basse-Normandie"
"Alsace" "Auvergne"
Cluster 5 (n=1) :
"Corse"
Explicated inertia: 41.660774
Nous pouvons constater que « La réunion » se retrouve généralement dans une classe
seule, cette région paraît se distinguer des autres sur les variables sélectionnées.
De plus, on remarque que la région « Corse » se trouve à l’écart lors d’une répartition
en 5 classes.
De manière générale, les régions se regroupent selon les critères choisis. De plus, il est
important de signaler que l’indice d’inertie augmente au fur et à mesure qu’on établit une
classification à plusieurs classes. Cependant, celui-ci reste relativement faible, il ne dépasse
jamais les 50%.
Nous obtenons l’arbre suivant :
THE CLUSTERING TREE:
---------------------
- the number noted at each node indicates
the order of the divisions
- Ng <-> yes and Nd <-> no
+---- Classe 1 (Ng=7)
!
!----3- [LIB_RISQUE <= Inondation]
! !
! ! +---- Classe 4 (Ng=6)
! ! !
! !----4- [LIB_RISQUE <= Mouvement de terrain]
! !
! +---- Classe 5 (Nd=1)
!
!----2- [LIB_ENJEU <= Avec enjeu humain]
! !
! +---- Classe 3 (Nd=9)
!
!----1- [COD_PPR <= PPR]
!
+---- Classe 2 (Nd=1)

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 40
Maintenant, nous allons réitérer cette méthode en l’appliquant à des variables
continues.
LISTING
PARTITION IN 2 CLUSTERS :
-------------------------:
Cluster 1 (n=7) :
"Provence-Alpes-Côte d'Azur" "Martinique" "Limousin" "Alsace" "Réunion"
"Auvergne" "Corse"
Cluster 2 (n=17) :
"Rhône-Alpes" "Picardie" "Languedoc-Roussillon" "Centre" "Ile-de-France"
"Pays de la Loire" "Poitou-Charentes" "Lorraine" "Bourgogne" "Midi-
Pyrénées"
"Aquitaine" "Haute-Normandie" "Basse-Normandie" "Franche-Comté" "Nord-Pas-
de-Calais" "Bretagne" "Champagne-Ardenne"
Explicated inertia : 60.802207
PARTITION IN 3 CLUSTERS :
-------------------------:
Cluster 1 (n=7) :
"Provence-Alpes-Côte d'Azur" "Martinique" "Limousin" "Alsace" "Réunion"
"Auvergne" "Corse"
Cluster 2 (n=13) :
"Picardie" "Languedoc-Roussillon" "Centre" "Ile-de-France" "Pays de la
Loire" "Poitou-Charentes" "Bourgogne" "Haute-Normandie" "Basse-Normandie"
"Franche-Comté"
"Nord-Pas-de-Calais" "Bretagne" "Champagne-Ardenne"
Cluster 3 (n=4) :
"Rhône-Alpes" "Lorraine" "Midi-Pyrénées" "Aquitaine"
Explicated inertia : 85.654636
PARTITION IN 4 CLUSTERS :
-------------------------:
Cluster 1 (n=4) :
"Martinique" "Limousin" "Réunion" "Corse"
Cluster 2 (n=13) :
"Picardie" "Languedoc-Roussillon" "Centre" "Ile-de-France" "Pays de la
Loire" "Poitou-Charentes" "Bourgogne" "Haute-Normandie" "Basse-Normandie"
"Franche-Comté"
"Nord-Pas-de-Calais" "Bretagne" "Champagne-Ardenne"

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 41
Cluster 3 (n=4) :
"Rhône-Alpes" "Lorraine" "Midi-Pyrénées" "Aquitaine"
Cluster 4 (n=3) :
"Provence-Alpes-Côte d'Azur" "Alsace" "Auvergne"
Explicated inertia : 93.621492
PARTITION IN 5 CLUSTERS :
-------------------------:
Cluster 1 (n=4) :
"Martinique" "Limousin" "Réunion" "Corse"
Cluster 2 (n=11) :
"Centre" "Ile-de-France" "Pays de la Loire" "Poitou-Charentes" "Bourgogne"
"Haute-Normandie" "Basse-Normandie" "Franche-Comté" "Nord-Pas-de-Calais"
"Bretagne"
"Champagne-Ardenne"
Cluster 3 (n=4) :
"Rhône-Alpes" "Lorraine" "Midi-Pyrénées" "Aquitaine"
Cluster 4 (n=3) :
"Provence-Alpes-Côte d'Azur" "Alsace" "Auvergne"
Cluster 5 (n=2) :
"Picardie" "Languedoc-Roussillon"
Explicated inertia : 95.577682
THE CLUSTERING TREE :
---------------------
- the number noted at each node indicates
the order of the divisions
- Ng <-> yes and Nd <-> no
+---- Classe 1 (Ng=4)
!
!----3- [Nombre_Catastrophe_Nat <= 4861.500000]
! !
! +---- Classe 4 (Nd=3)
!
!----1- [Nombre_Catastrophe_Nat <= 8563.500000]
!
! +---- Classe 2 (Ng=11)
! !
! !----4- [Nombre_Catastrophe_Nat <= 12242.000000]
! ! !

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 42
! ! +---- Classe 5 (Nd=2)
! !
!----2- [Nombre_Catastrophe_Nat <= 15454.500000]
!
+---- Classe 3 (Nd=4)
En comparaison aux résultats précédents, on constate clairement que les régions sont
partagées de façon égale entre les différentes classes. Aucune région ne se trouve à l’écart.
II.2.2.5. Méthode PYR
Principe
Comme nous l’avons vu précédemment, il existe plusieurs classifications
automatiques dans l’analyse de données symboliques :
Hiérarchie
Arbre
Partition
Classe
Pyramide
Après avoir étudié certaines de ces classifications, il est maintenant intéressant
d’observer une classification pyramidale de nos concepts. Celle-ci s’avère très utilisée pour
des données plus complexes et permet une représentation simple et avantageuse pour
l’analyse.
L’algorithme traduit par SODAS pour réaliser une classification pyramidale est
caractérisé « d’algorithme d’agglomération ». En effet, L’algorithme part des concepts et
agglomère à chaque niveau les classes.
A l’issu de la classification, nous obtenons une série de classes décrivant ces concepts.
Celles-ci sont définies par l’ensemble des éléments de la classe (extension), ainsi que par
l’objet symbolique décrivant les propriétés de celles-ci (intention).
Pour exécuter cette méthode, l’utilisateur a la possibilité de choisir les variables qu’il
souhaite analyser. Cette application possède les avantages de pouvoir étudier tout type de variables (variables quantitatives ou qualitatives). De plus, nous avons le choix de mélanger
des variables de types différents pour notre étude, ce qui n’est pas négligeable.
Dans ce cas, j’ai choisi d’étudier les deux variables liées aux risques et enjeux
humains.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 43
Exécution
Le résultat obtenu est assez impressionnant. En effet, il s’avère que la classification est
partagée en un très grand nombre de classes. De ce fait, il n’est pas possible de vous montrer
l’intégralité de la pyramide obtenu. Ce graphique peut s’expliquer dû au nombre important de
concepts de notre étude.
Le listing résume les différentes classes constituant la pyramide. La définition de
chaque classe y est décrite soigneusement. Je vous propose un aperçu des résultats y figurant :
LISTING
DESCRIPTION-OF-THE-NODES
Where_the_labels_are_of_the_individuals_are:
1.="Rhône-Alpes"
2.="Picardie"
3.="Languedoc-Roussillon"
4.="Centre"
5.="Provence-Alpes-Côte_d'Azur"
6.="Ile-de-France"
7.="Martinique"
8.="Pays_de_la_Loire"
9.="Poitou-Charentes"
10.="Limousin"
11.="Lorraine"
12.="Bourgogne"
13.="Midi-Pyrénées"
14.="Aquitaine"
15.="Haute-Normandie"
16.="Basse-Normandie"
17.="Alsace"
18.="Franche-Comté"
19.="Réunion"
20.="Auvergne"
21.="Nord-Pas-de-Calais"
22.="Bretagne"
23.="Champagne-Ardenne"
24.="Corse"
Where_the_labels_are_of_the_variables_are:
y9.=Nombre_Catastrophe_Nat
y10.=Nombre_AZI
P25=[Nombre_Catastrophe_Nat=(1(0.9688),2(0.0000),3(0.0369),4(0.0000),5(0.00
00),6(0.0691),7(0.0000),8(0.0000),9(0.0000),10(0.0000),11(0.0000),12(0.0000
),13(0.0000),14(0.0000))]^[Nombre_AZI=(1(0.0000),2(0.0000),3(0.0000),4(0.00
00),5(0.0000),6(0.0000),7(0.0000),8(0.0000),9(0.0000),10(0.0000),11(0.0000)
,12(0.0000),13(0.3594),14(0.0000),15(0.0000),16(0.0000),17(0.0000),18(0.000
0),19(0.0000),20(0.0000),21(0.0000),22(0.0000),23(0.0000),24(0.0000),25(0.0
000),26(0.0000),27(0.0000),28(0.0000),29(0.0000),30(0.0000),31(0.0000),32(0
.0000),33(0.0000),34(0.0000),35(0.0000),36(0.0000),37(0.0000),38(0.0000),39
(0.0000),40(0.0000),41(0.0000),42(0.0000),43(0.0000),44(0.0000),45(0.0000),
46(0.0000),47(0.0000),48(0.0000),49(0.0000),50(0.0000),51(0.0000),52(0.0000
),53(0.0000),54(0.0000),55(0.0000),56(0.0000),57(0.0000),58(0.0000),59(0.00
00),60(0.0000),61(0.0553),62(0.0369),63(0.0000),64(0.0000),65(0.0000),66(0.
0000),67(0.0000),68(0.0000),69(0.0000),70(0.0000),71(0.0000),72(0.0000),73(

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 44
0.0000),74(0.0000),75(0.0000),76(0.0000),77(0.1406),78(0.0000),79(0.0000),8
0(0.0000),81(0.0000),82(0.0000),83(0.0000),84(0.0000),85(0.0000),86(0.0000)
,87(0.0000),88(0.0000),89(0.0000),90(0.6452),91(0.0000),92(0.0000),93(0.000
0),94(0.2627),95(0.0000),96(0.0000),97(0.0000),98(0.5000))]
Ext(P25)={"Limousin","Champagne-Ardenne"}
REPRESENTATION GRAPHIQUE
Le graphique suivant symbolise la pyramide (une partie) :
Figure 35 : Exécution de la méthode PYR

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 45
II.2.2.6. Méthode SCLUST
Principe
La méthode SCLUST est un outil de partitionnement utilisé dans le cadre de l’analyse
de données symboliques.
En effet, cet outil possède de nombreux avantages dans le contexte de l’analyse
symbolique :
Nécessite peu de places en mémoire centrale
Traite de grands tableaux de données
Optimise des critères pleinement définis.
Le partitionnement s’appuie sur un modèle de représentation. On parle souvent de
centre de gravité mais il existe d’autres modes comme l’utilisation de droites ou encore de
groupes de points.
Le logiciel SODAS se base sur un algorithme pour réaliser le partitionnement de nos
données. Celui-ci se déroule de la façon suivante :
Trouver une « bonne » partition en deux classes
Deux points A et B sont tirés au hasard et appelés « noyaux »
On associe chaque point au noyau le plus proche
Deux noyaux A et D sont calculés en prenant le point le plus proche du centre
de chaque classe de l’étape précédente
On associe de nouveau chaque point au noyau le plus proche. Les classes naturelles ont donc été détectées par un procédé automatique.
On parle de partitionnement de type nué dynamique.
Dans cet algorithme, on évoque un critère de type :
W(A,P)= D(Ai, Pi ), appelé critère d’inertie
i=1,..,k
Le but de l’algorithme est de réussir à faire décroître ce critère.
A partir des données symboliques que nous possédons, l’application SCLUST
partitionne celles-ci en un certain nombre de classes, chacune d’entre elles représentant un
objet prototype.
Avant l’exécution de la méthode, l’utilisateur peut définir les paramètres de celles-ci. :
Les variables qu’il souhaite étudier.
Le nombre de cluster (représentant les concepts).
Le nombre de run (valeur=5), représentant le nombre de fois où l’on tire les
noyaux.
Le nombre d’itérations (valeur=10), représentant le nombre d’itérations pour
chaque noyau.
Possibilité de sauvegarder les prototypes obtenus, ainsi que la partition.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 46
Figure 36 : Sortie de la méthode SCLUST
En sortie de la méthode, nous avons la possibilité de visualiser le listing (résumant les
différents critères, ainsi que les classes) avec le 1er
icône, le graphique des classes avec le 2ème
icône et la représentation des prototypes pour chaque classe avec le 3ème
icône (on parle de
noyaux symboliques).
Application
J’ai choisi d’exécuter cette méthode sur trois variables modales : cod_risque,
cod_enjeu et cod_PPR. Nous pourrons distinguer ainsi certains critères pour nos concepts.
LISTING
Classe : 4 Cardinal : 15
===============================
( 0) Rhône-Alpes [0.3] ( 1) Picardie
[1.4]
( 2) Languedoc-Roussillon [0.1] ( 3) Centre
[0.6]
( 4) Provence-Alpes-Côte d'Azur [0.5] ( 7) Pays de la Loire
[1.4]
( 9) Limousin [1.6] ( 12) Midi-Pyrénées
[0.0]
( 13) Aquitaine [0.0] ( 16) Alsace
[0.9]
( 19) Auvergne [0.1] ( 20) Nord-Pas-de-Calais
[2.7]
( 21) Bretagne [2.0] ( 22) Champagne-Ardenne
[1.7]
( 23) Corse [1.6]
EDITION PROTOTYPES BY VARIABLES
===============================
Variable ( 6 ) COD-PPR
Set 1 2 3 4 <= Cluster
0.80 0.75 0.91 0.40 0.82 PPR
0.10 0.15 0.08 0.00 0.09 PSS
0.04 0.06 0.01 0.00 0.04 PER
0.06 0.04 0.00 0.60 0.05 R111.3
1er
icône
2ème
icône
3ème
icône

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 47
PROTOTYPE GRAPHICAL REPRESENTATIONS BY VARIABLES
================================================
Variable ( 1 ) LIB_RISQUE , PS files :
D:\Master2\Dataminning\Projet_Final\cluster4x1.ps
D:\Master2\Dataminning\Projet_Final\class4x1.ps
Variable ( 5 ) LIB_ENJEU , PS files :
D:\Master2\Dataminning\Projet_Final\cluster4x5.ps
D:\Master2\Dataminning\Projet_Final\class4x5.ps
Variable ( 6 ) COD_PPR , PS files :
D:\Master2\Dataminning\Projet_Final\cluster4x6.ps
D:\Master2\Dataminning\Projet_Final\class4x6.ps
CRITERION
=========
Run Iteration Class Criterion
1 9 4 3.985283
2 8 3 4.072916
3 8 4 3.424739
4 10 3 3.786898
5 5 3 4.319689
Statistics on criterion distribution :
Minimum 3.424739
Means 3.917905
Maximum 4.319689
Standard deviation 0.300125
------- END OF PROGRAM SCLUST ---------
REPRESENTATION DES PROTOTYPES
Comme je l’ai dit précédemment, le 3ème
icône proposé à l’utilisateur à la suite de son
exécution lui permet de visualiser les différents prototypes obtenus.
Le premier résultat ci-dessous superpose l’ensemble des prototypes issus de
l’exécution. Dans notre cas, 5 prototypes ont été identifiés :
Prototype 1/1
Prototype 1/4
Prototype 2/4
Prototype 3/4
Prototype 4/4
L’utilisateur peut les superposer de façon à comparer les résultats ainsi obtenus.
Lorsque nous avons un nombre trop important de prototypes la superposition n’est pas
toujours idéale, le graphique étant trop complexe pour pouvoir tirer certaines conclusions ou
hypothèses. Il est alors plus utile de visualiser chaque prototype indépendamment de façon à
distinguer les critères de chacun. Les graphiques présentés par la suite nous montre les
résultats de notre exécution.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 48
Figure 37 : Superposition des prototypes issus de l’exécution de la méthode SCLUST
Je tenais à vous présenter également un prototype indépendamment des autre. Le
prototype 4/4 fait ressortir l’importance des codes PPR et R111, ainsi que le risque important
d’inondation. Ces résultats ont déjà pu être établis lors de l’exécution des méthodes
précédentes.
Figure 38 : Présentation de prototype 4/4 de la méthode SCLUST
De plus, il est également possible de « zoomer » sur une variable pour en connaître les
caractéristiques majeures. Effectivement, dû au nombre important de données pour la variable
lib_risque, le graphique général du prototype ne nous permettait pas de déduire beaucoup
d’informations. L’agrandissement de cette variable permet d’identifier les trois risques
majoritaires pour le prototype en question : inondations, mouvements de terrain et les feux.
« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 49
Figure 39 : Zoom sur la variable lib_risque, issu du prototype 4/4
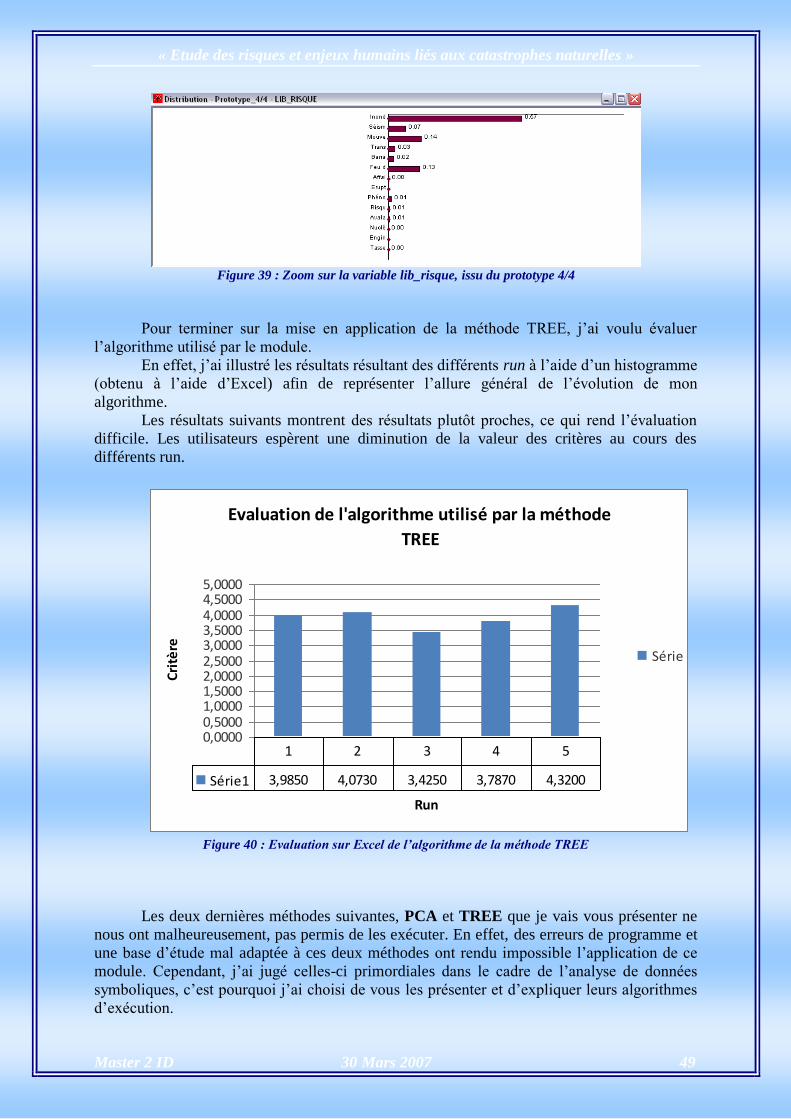
Pour terminer sur la mise en application de la méthode TREE, j’ai voulu évaluer
l’algorithme utilisé par le module.
En effet, j’ai illustré les résultats résultant des différents run à l’aide d’un histogramme
(obtenu à l’aide d’Excel) afin de représenter l’allure général de l’évolution de mon
algorithme.
Les résultats suivants montrent des résultats plutôt proches, ce qui rend l’évaluation
difficile. Les utilisateurs espèrent une diminution de la valeur des critères au cours des
différents run.
Evaluation de l'algorithme utilisé par la méthode
TREE
0,00000,50001,00001,50002,00002,50003,00003,50004,00004,50005,0000
Run
Cri
tère
s
Série1
Série1 3,9850 4,0730 3,4250 3,7870 4,3200
1 2 3 4 5
Figure 40 : Evaluation sur Excel de l’algorithme de la méthode TREE
Les deux dernières méthodes suivantes, PCA et TREE que je vais vous présenter ne
nous ont malheureusement, pas permis de les exécuter. En effet, des erreurs de programme et
une base d’étude mal adaptée à ces deux méthodes ont rendu impossible l’application de ce
module. Cependant, j’ai jugé celles-ci primordiales dans le cadre de l’analyse de données
symboliques, c’est pourquoi j’ai choisi de vous les présenter et d’expliquer leurs algorithmes
d’exécution.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 50
II.2.2.7. Méthode PCA
La méthode PCA permet d’effectuer une analyse factorielle sur les données étudiées.
Les calculs attachés à ce type d’analyse sont souvent longs et fastidieux, l’utilisation de cette
méthode représente une aide non négligeable pour des travaux d’analyse.
Une analyse factorielle repose sur trois grandes étapes :
Calcul des centres de gravité et de centrage
Calcule des axes d’inertie
Représentation dans le nouveau système d’axe
L’algorithme se déroule de la façon suivante :
TROUVER u= u1
u2
UNITAIRE u1 + u2=1
TEL QUE Pi(xti u)
2 SOIT MAXIMUM
L’analyse factorielle peut être défini de la façon suivante1 : « Le nuage de points que
l'on veut décrire ne s'étend pas dans toutes les directions également, mais qu'au contraire
qu'il est déforme (car il y des affinités entre lignes et colonnes). On va donc définir un
nouveau système de repère orthogonal plus "économique" ».
Pour terminer sur la définition de cette méthode, autres que des graphiques, la
méthode PCM permet d’obtenir des informations non négligeables pour les analystes.
De nombreux indicateurs permettent d’établir certaines hypothèses :
Inertie expliquée sur un axe :
Ce taux permet à un utilisateur d’évaluer un point selon un axe (et plus
précisément selon une variable).
Est-ce qu’un point est expliqué par un axe ?
La contribution relative : Inversement, cet indicateur mesure l’allongement sur l’axe.
Est-ce qu’un individu explique l’axe ?
La contribution absolue : Cette contribution concerne la contribution à l’inertie d’un individu par rapport
aux axes individus.
La contribution à l’inertie totale :
Ce calcul peut s’avérer intéressant à étudier pour déduire certains critères de
différenciation des individus.
1 http://www.micheloud.com/FXM/COR/fonctio2.htm, « L’analyse de correspondances »

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 51
Qualité d’un individu dans le plan :
Cet indicateur s’obtient par la somme des contributions relatives.
Avant l’exécution de la méthode, l’utilisateur entre les paramètres de son choix :
Choix des variables
Choix des objets symboliques
Choix des paramètres d’exécution :
Figure 41 : Paramètres de la fonction PCA

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 52
II.2.2.8. Méthode TREE
La méthode TREE proposé par SODAS permet aux utilisateurs d’obtenir l’arbre de
décision à partir des données initiales. La mission première de cette application est d’obtenir
un regroupement des concepts selon les données et le (ou les) critère(s) de segmentation
choisi(s).
Le but principal du datamining est d’aider les analystes à répondre à certaines de ses
interrogations. En effet, il est intéressant de détecter les critères qui ont un impact sur les
champs à étudier.
Les arbres de décision représentent une des méthodes les plus rapides et simples pour
le datamining. La modélisation graphique issue de cette méthode est concise et claire et joue
un rôle non-négligeable dans l’exploration de données. Je clôturerai donc ce travail par la
description de la méthode TREE.
Avant tout, il est important de définir le principe d’arbre de décision 1:
L’arbre se compose de nœuds.
Le nœud gauche est la racine de l’arbre.
Les nœuds droits représentent les feuilles.
Chaque nœud se compose de sous-ensemble de la population (la racine contient tous
les individus).
Avant l’exécution, l’utilisateur paramètre la méthode en choisissant les variables qu’il
souhaite étudier. Le programme favorise les variables intervalles ou histogrammes.
Deux assignations sont permises par SODAS :
Assignation pure (« pure ») : Un individu n’appartient qu’à une seule classe.
Ceci correspond à assigner à gauche avec un poids 1.
Assignation floue (« fuzzy ») : Un individu peut appartenir à plusieurs classes. Ceci correspond à assigner à gauche avec un poids 3/4.
L’exécution de la méthode nous renseigne sur les points suivants :
Liste des variables utilisées
Liste des objets symboliques (différenciation avec les ensembles « training set » et
« set test »
Liste des nœuds et des règles correspondants
Liste des nœuds terminaux
L’algorithme est basé sur un principe de questions binaires, représentant des variables
à expliquer. A chaque étape, le programme cherche la branche la plus intéressante de l’arbre à
développer.
Au final, chaque individu appartient à un nœud terminal. Par contre, concernant les
concepts, ceux-ci peuvent être attachés à plusieurs feuilles.
1 http://www.isoft.fr/html/present_dtree.htm, « Les arbres de décision »

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 53
Le module s’arrête s’il rencontre un des cas suivants :
Une valeur par défaut a été rentrée par l’utilisateur
Le nombre d’objets dans une classe majoritaire est supérieur à 2
Il n’y a pas de nœuds possédant un individu ou moins
Le nombre de nœuds est atteint
L’exécution aurait été très intéressante pour comprendre l’utilité et l’algorithme de
création d’un arbre de décision à partir d’une série de donnée.
Je vous ai présenté les grandes méthodes proposées par SODAS et très favorable à
l’analyse de données symboliques. Bien sûr, il en existe d’autres, possédant des
fonctionnalités différentes. J’ai préféré vous proposer un panel des « types » d’analyse, en
terme mathématique, mis à disposition pour répondre aux attentes du monde professionnel.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 54
CONCLUSION
Le datamining représente un domaine de l’informatique décisionnelle encore peu
approfondi. En effet, les projets propres au datamining sont encore peu nombreux au sein des
entreprises mais tendent à se développer avec l’avancé fulgurante du décisionnel dans le
monde de l’informatique.
L’utilisation et l’apprentissage du logiciel SODAS représentent une approche très
intéressante de l’analyse de données symboliques. Cette application concrète a permis
d’apprécier l’utilité et l’importance de l’étude de données.
Cependant, la base d’étude choisie pour ce travail a limité notre utilisation du logiciel
SODAS. En effet, le type des variables est primordial dans l’application des méthodes
proposées par le logiciel. Ayant préféré garder l’intégralité de ma base de donnée, j’ai été
parfois, freiné dans l’utilisation des différentes fonctionnalités et obligé d’utiliser
régulièrement les mêmes variables.
Pour conclure, j’ajouterais que ce travail fût enrichissant et représentera une première
expérience de datamining pour nos futurs travaux professionnels.

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 55
TABLE DES ILLUSTRATIONS
FIGURE 1 : BUT DU TRAITEMENT DES DONNEES .................................................................................................... 5 FIGURE 2 : SCHEMA DE L’ANALYSE DE DONNEES SYMBOLIQUES ........................................................................... 6 FIGURE 3 : CARTOGRAPHIE DES LOGICIELS DE DATAMINING ................................................................................. 7 FIGURE 4 : VUE D’ENSEMBLE DU LOGICIEL SODAS ............................................................................................. 9 FIGURE 5 : INTERFACE GRAPHIQUE DU LOGICIEL SODAS ................................................................................... 10 FIGURE 6 : INTERFACE GRAPHIQUE LORS D’UNE PREMIERE UTILISATION ............................................................. 11 FIGURE 7 : INITIALISATION DE LA BASE .............................................................................................................. 11 FIGURE 8 : PROCEDURE D’INSERTION D’UNE METHODE ....................................................................................... 12 FIGURE 9 : CHAINE D’UNE SERIE DE METHODES NON PARAMETREES ................................................................... 13 FIGURE 10 : EXECUTION DE LA METHODE VIEW ................................................................................................ 13 FIGURE 11 : RELATIONS DE LA BASE DE DONNEE GASPAR ............................................................................... 19 FIGURE 12 : ILLUSTRATION DU FONCTIONNEMENT DE DB2SO ............................................................................ 20 FIGURE 13 : ETAPE 1 DU MODULE DB2SO.......................................................................................................... 21 FIGURE 14 : ETAPE 2 DU MODULE DB2SO.......................................................................................................... 21 FIGURE 15 : ETAPE 3 DU MODULE DB2SO.......................................................................................................... 22 FIGURE 16 : ETAPE 4 DU MODULE DB2SO ......................................................................................................... 23 FIGURE 17 : RESULTATS DE L’EXECUTION DE DB2SO ........................................................................................ 24 FIGURE 18 : COMMANDE DE VISUALISATION DE L’EXTRACTION SOUS DB2SO .................................................... 24 FIGURE 19 : RESULTATS DE L’EXTRACTION DES INDIVIDUS ................................................................................. 24 FIGURE 20: REQUETE D’AJOUT DE VARIABLES AU TABLEAU DE DONNEES SYMBOLIQUES ..................................... 26 FIGURE 21 : SAUVEGARDE DE LA BASE ............................................................................................................... 26 FIGURE 22 : CREATION D’UN FICHIER .SDS ......................................................................................................... 27 FIGURE 23 : TABLEAU RECAPITULATIF DES METHODES DE SODAS ..................................................................... 28 FIGURE 24 : METHODES DE VISUALISATION PROPOSE PAR LE MODULE VIEW ..................................................... 29 FIGURE 25 : TABLEAU PROPOSE PAR LA METHODE VIEW ................................................................................... 29 FIGURE 26 : MODELE EN ETOILE POUR LA REGION POITOU CHARENTE................................................................. 30 FIGURE 27 : MODELE EN ETOILE POUR LA REGION RHONE ALPES........................................................................ 30 FIGURE 28 : MODELE EN FLOCON POUR LA REGION ILE DE FRANCE ..................................................................... 31 FIGURE 29 : ZOOM SUR LES VARIABLES COD_PPR DES REGIONS POITOU CHARENTE ET RHONE ALPES ................ 31 FIGURE 30 : PARAMETRES DE LA METHODE STAT .............................................................................................. 32 FIGURE 31 : APPLICATION DE LA METHODE STAT SUR DES VARIABLES INTERVALLES ......................................... 34 FIGURE 32 : REPARTITION DE LA VARIABLE POPULATION_DEPARTEMENT EN 10 CLASSES .................................... 34 FIGURE 33 : APPLICATION DE LA METHODE STAT SUR DES VARIABLES MODALES (HISTOGRAMME) .................... 35 FIGURE 34 : APPLICATION DE LA METHODE STAT SUR DES VARIABLES MODALES (NOTION DE CAPACITE) ........... 36 FIGURE 35 : EXECUTION DE LA METHODE PYR .................................................................................................. 44 FIGURE 36 : SORTIE DE LA METHODE SCLUST................................................................................................... 46 FIGURE 37 : SUPERPOSITION DES PROTOTYPES ISSUS DE L’EXECUTION DE LA METHODE SCLUST ....................... 48 FIGURE 38 : PRESENTATION DE PROTOTYPE 4/4 DE LA METHODE SCLUST ......................................................... 48 FIGURE 39 : ZOOM SUR LA VARIABLE LIB_RISQUE, ISSU DU PROTOTYPE 4/4 ........................................................ 49 FIGURE 40 : EVALUATION SUR EXCEL DE L’ALGORITHME DE LA METHODE TREE ............................................... 49 FIGURE 41 : PARAMETRES DE LA FONCTION PCA ............................................................................................... 51

« Etude des risques et enjeux humains liés aux catastrophes naturelles »
Master 2 ID 30 Mars 2007 56
BIBLIOGRAPHIE
Source littéraire :
Extrait des cours de « Datamining » de Mr Edwin DIDAY (Année
2006/2007 Master ID)
Sources Internet :
http://fr.wikipedia.org/, Exploration de données
http://data.mining.free.fr/cours/Logiciels.pdf, « Logiciels et consultants »
www.ceremade.dauphine.fr/~touati/sodas-pagegarde.html, « Présentation
du projet et du logiciel SODAS »
http://www.ceremade.dauphine.fr/%7Etouati/imagesodas.htm
http://www.prim.net/professionnel/procedures_regl/avancement.html,
« La base GASPAR »
http://www.micheloud.com/FXM/COR/fonctio2.htm, « L’analyse de
correspondances »
http://www.isoft.fr/html/present_dtree.htm, « Les arbres de décision »