data exchange platform blue dme - trouver de la donnée pertinente
TRANSCRIPT

© Blue DME SAS | Diffusion interdite sans accord
DEX : Data Exchange Platform
Mathieu DESPRIEE, [email protected]@mdespriee

Qui sommes-nous?
JulienCEO
ESME. Ms IAE Paris
MathieuCTO
ENSEIRB
MohamedData ScientistPhD Math LMV
AurélienSenior
EngineerTelecom Paris
ChristopheData Engineer
INSA
KevinData Engineer
EISTI. Heriot-Watt
AdrianResp. Data
ScienceENSAI
KatiaSenior
EngineerUniversad de
Bilbao
Equipe
Clients
Offre
Blue DME SAS est une startup française (JEI) créée début 2015
#Data Science
Optimiser la performance business en passant au
prédictif
MarketingCommerce
Risques
#Data PlatformSimplifier et fluidifier l’accès aux données
externes
Parcours digitauxCapteurs
Open DataPartenaires
Groupe
#Data Monetization
Valoriser la contribution de vos données à leur
valeur d’usage et développer de nouvelles offres de services pour
vos clients
Enseignement
CedricCSO
Polytech. Sud HEC
© Blue DME SAS | Diffusion interdite sans accord 22

© Blue DME SAS | Diffusion interdite sans accord
BlueDME DEXUne plateforme de recherche de données pour les analystes, les statisticiens et les data scientistsconçue pour monétiser la valeur d’usage et favoriser les transactions entre entités
3

Les usages de la Data
© Blue DME SAS | Diffusion interdite sans accord 4
Modélisation des risques
Acquérir une connaissance plus riche des comportements pour l’amélioration des modèles de risque auprès de tiers de haute
qualité, ex: consommation électrique, entretien véhicule, utilisation des transports en
communs, …
Prédiction des sinistres
Identifier les facteurs leaders, les phénomènes
d’emballement psycho-sociaux et détecter les populations à risques à partir des données
médiatiques, économétriques digitales et comportementales
Lutte contre la fraudeDétecter les situations
suspectes par croisement des données sociales et
comportementales pour les personnes physiques, les
professionnels et les entreprises
Identifier les contextes socio-économiques propices aux différents types de fraude
Pricing comportemental
Construire des modèles de pricing « as you go » basés sur les comportements observés
par des tiers, ex. objets connectés, véhicules
intelligents, opérateurs télécoms, …
PrétargetingEnrichir les prospects et les
entrées en relation de données issues d’entités externes pour
déployer une relation client personnalisée dès le début et améliorer la segmentation des
bases de prospects
Ciblage multi-modalAugmenter la performance des
campagnes de ciblage en limitant l’usure de la base de
données clients par un enrichissement de données comportementales, sociales,
tendancielles et de parcours de forte qualité issus d’entités
externes.
Lutte contre l’attritionDétecter les signaux de churn court terme et moyen terme par acquisition de données
auprès de tiers (comparateurs, distributeurs, auto, …) pour
permettre la mise en place des actions de rétention le plus en
amont possible.
Parcours client omni-canal
Enrichir la vision client 360 des parcours sur des canaux
externes à l’entreprise (médias, distribution, internet, …) et
réduire les coûts de campagne par une meilleure évaluation de
l’appétence aux canaux de relation client
Mieux Vendre Mieux Opérer
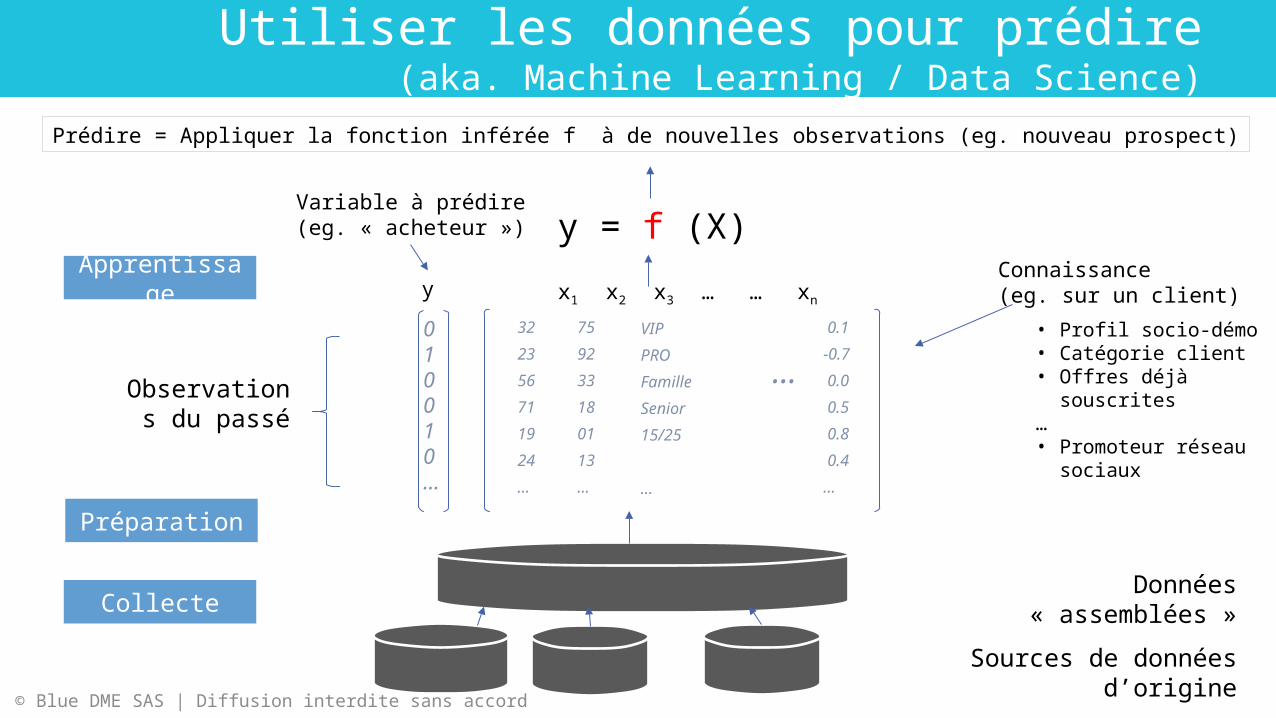
Utiliser les données pour prédire(aka. Machine Learning / Data Science)
© Blue DME SAS | Diffusion interdite sans accord
y = f (X)
Observations du passé
Variable à prédire(eg. « acheteur »)
010010…
Connaissance(eg. sur un client)yx1 x2 x3 … … xn
Prédire = Appliquer la fonction inférée f à de nouvelles observations (eg. nouveau prospect)
322356711924…
• Profil socio-démo • Catégorie client• Offres déjà
souscrites…• Promoteur réseau
sociaux
759233180113…
VIPPROFamilleSenior15/25
…
0.1-0.7 0.0 0.5 0.8 0.4…
…
Données « assemblées »
Sources de données d’origine
Collecte
Préparation
Apprentissage
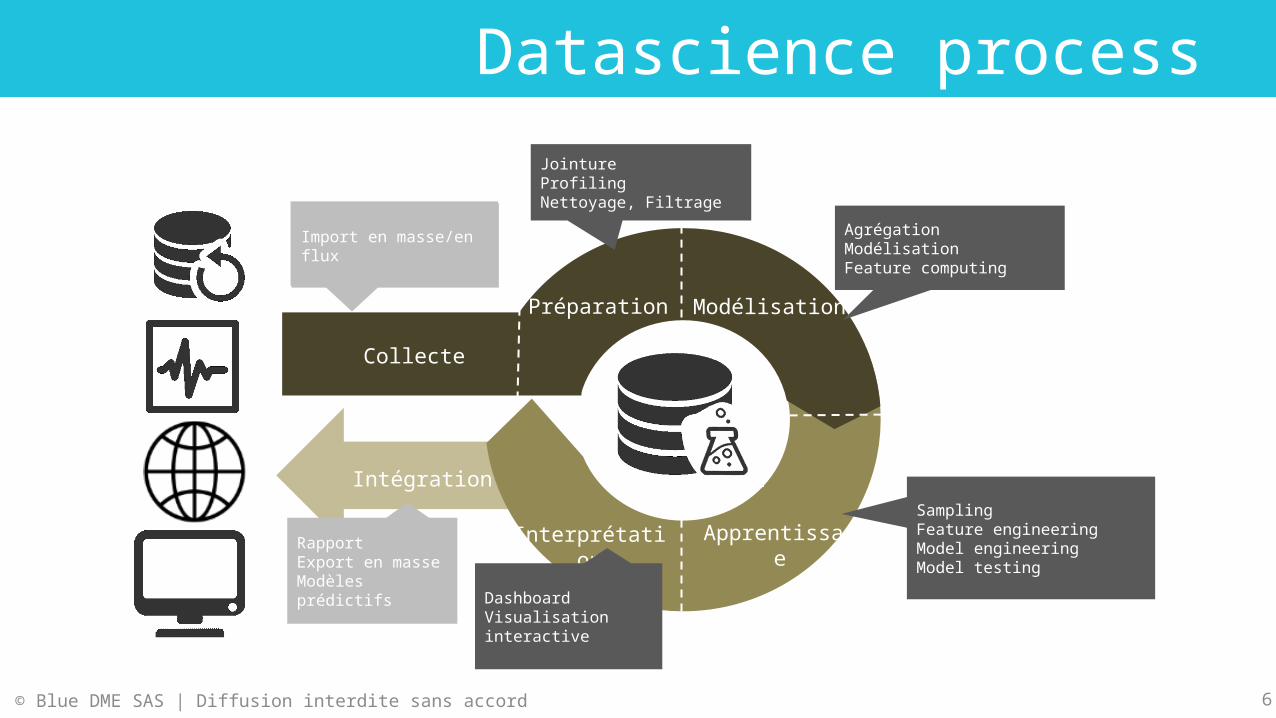
Datascience process
© Blue DME SAS | Diffusion interdite sans accord 6
• Import en masse• Flux• Emission
d’événements
ApprentissageInterprétation
Intégration
Modélisation
Collecte
Préparation
DashboardVisualisation interactive
JointureProfilingNettoyage, Filtrage
Import en masse/en flux
RapportExport en masseModèles prédictifs
SamplingFeature engineeringModel engineeringModel testing
AgrégationModélisationFeature computing
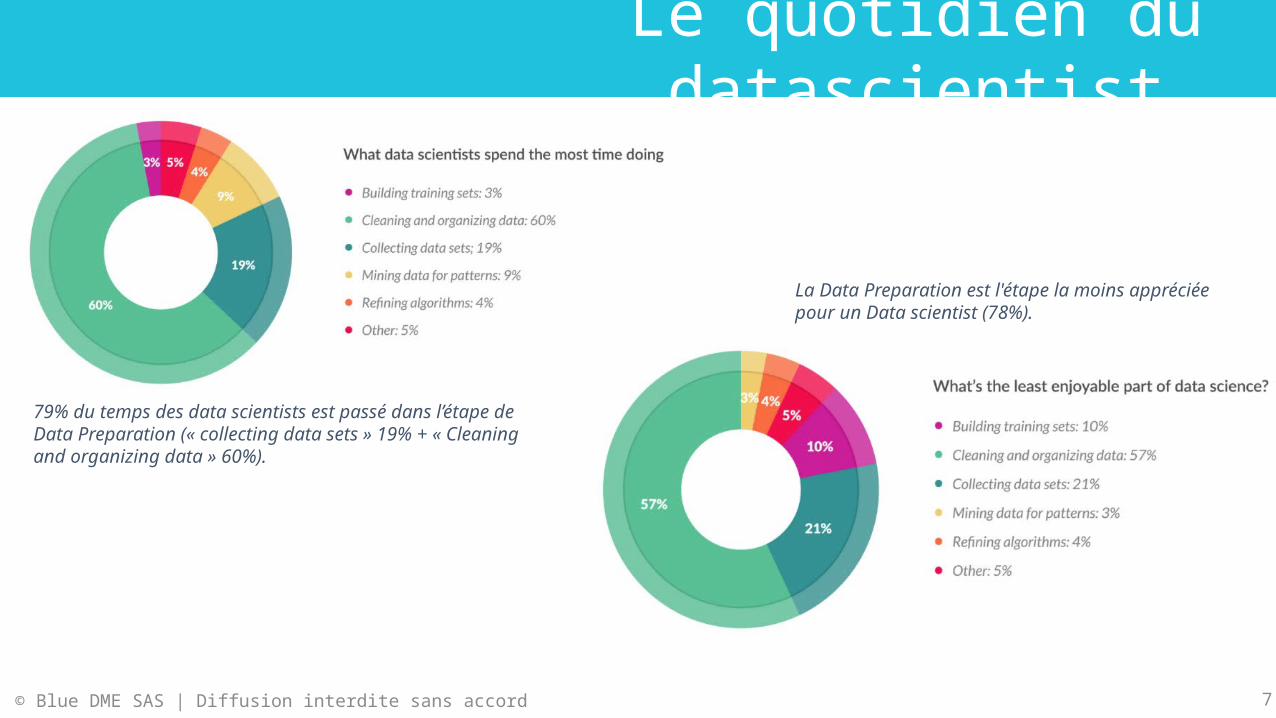
Le quotidien du datascientist…
© Blue DME SAS | Diffusion interdite sans accord 7
79% du temps des data scientists est passé dans l’étape de Data Preparation (« collecting data sets » 19% + « Cleaning and organizing data » 60%).
La Data Preparation est l'étape la moins appréciée pour un Data scientist (78%).
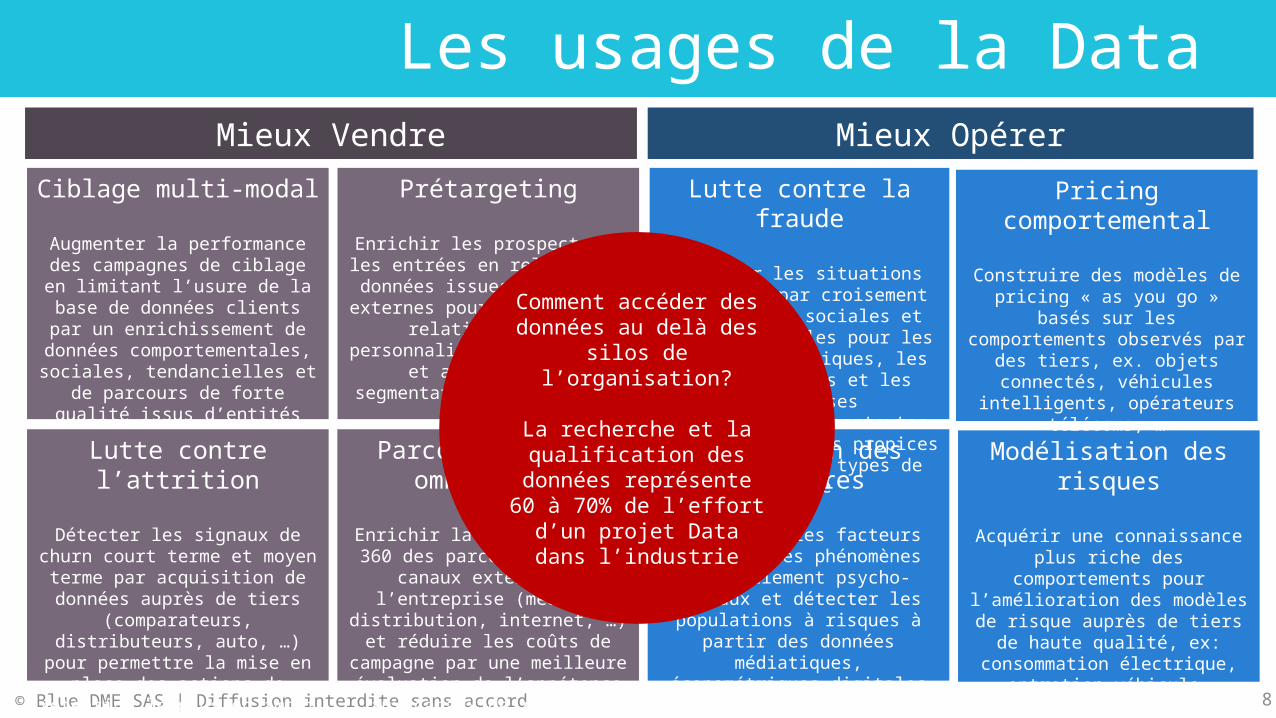
Les usages de la Data
© Blue DME SAS | Diffusion interdite sans accord 8
Modélisation des risques
Acquérir une connaissance plus riche des comportements pour l’amélioration des modèles de risque auprès de tiers de haute
qualité, ex: consommation électrique, entretien véhicule, utilisation des transports en
communs, …
Prédiction des sinistres
Identifier les facteurs leaders, les phénomènes
d’emballement psycho-sociaux et détecter les populations à risques à partir des données
médiatiques, économétriques digitales et comportementales
Lutte contre la fraudeDétecter les situations
suspectes par croisement des données sociales et
comportementales pour les personnes physiques, les
professionnels et les entreprises
Identifier les contextes socio-économiques propices aux différents types de fraude
Pricing comportemental
Construire des modèles de pricing « as you go » basés sur les comportements observés
par des tiers, ex. objets connectés, véhicules
intelligents, opérateurs télécoms, …
PrétargetingEnrichir les prospects et les
entrées en relation de données issues d’entités externes pour
déployer une relation client personnalisée dès le début et améliorer la segmentation des
bases de prospects
Ciblage multi-modalAugmenter la performance des
campagnes de ciblage en limitant l’usure de la base de
données clients par un enrichissement de données comportementales, sociales,
tendancielles et de parcours de forte qualité issus d’entités
externes.
Lutte contre l’attritionDétecter les signaux de churn court terme et moyen terme par acquisition de données
auprès de tiers (comparateurs, distributeurs, auto, …) pour
permettre la mise en place des actions de rétention le plus en
amont possible.
Parcours client omni-canal
Enrichir la vision client 360 des parcours sur des canaux
externes à l’entreprise (médias, distribution, internet, …) et
réduire les coûts de campagne par une meilleure évaluation de
l’appétence aux canaux de relation client
Mieux Vendre Mieux Opérer
Comment accéder des données au delà des
silos de l’organisation?
La recherche et la qualification des
données représente 60 à 70% de l’effort d’un
projet Data dans l’industrie
© Blue DME SAS | Diffusion interdite sans accord 9
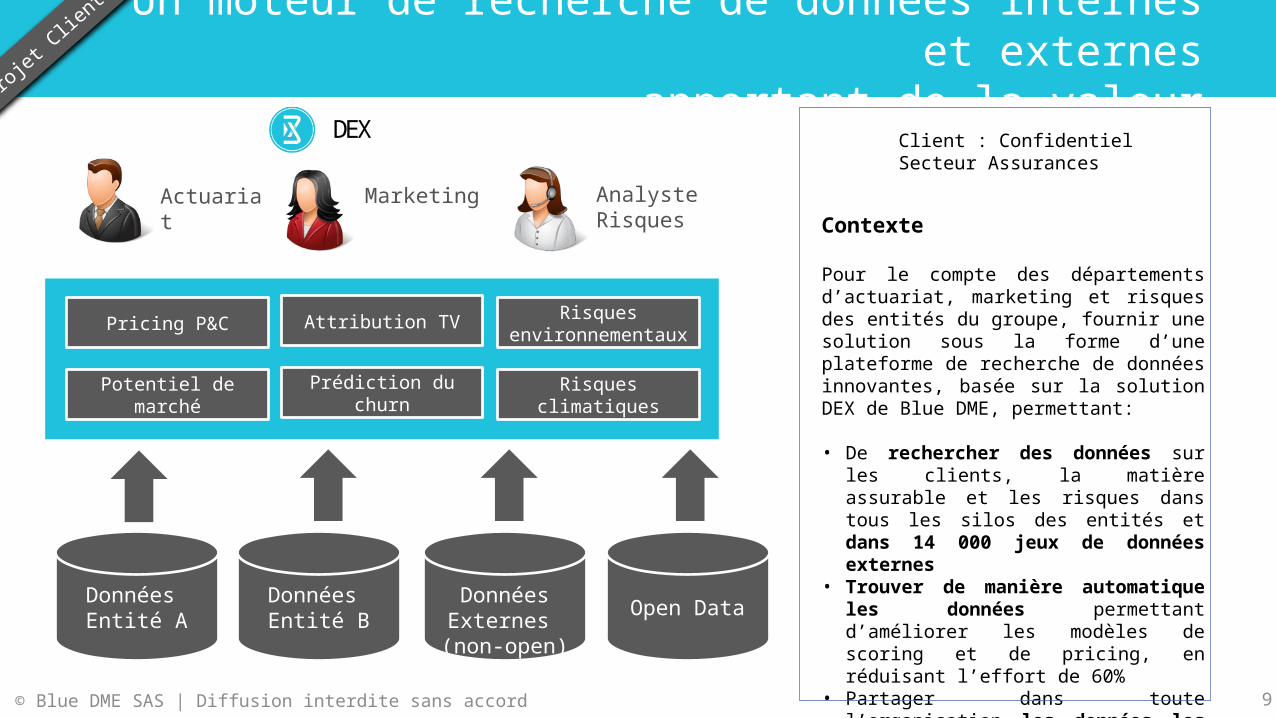
Un moteur de recherche de données internes et externes
apportant de la valeurProjet
Client
Contexte
Pour le compte des départements d’actuariat, marketing et risques des entités du groupe, fournir une solution sous la forme d’une plateforme de recherche de données innovantes, basée sur la solution DEX de Blue DME, permettant:
• De rechercher des données sur les clients, la matière assurable et les risques dans tous les silos des entités et dans 14 000 jeux de données externes
• Trouver de manière automatique les données permettant d’améliorer les modèles de scoring et de pricing, en réduisant l’effort de 60%
• Partager dans toute l’organisation les données les plus utiles et à plus forte valeur ajoutée par des fonctions de collaboration sur la data
DEX
Analyste RisquesActuariat Marketing
Pricing P&C
Potentiel de marché
Attribution TV
Prédiction du churn
Risques environnementaux
Risques climatiques
Données Entité A
Données Entité B
DonnéesExternes
(non-open)Open Data
Client : ConfidentielSecteur Assurances
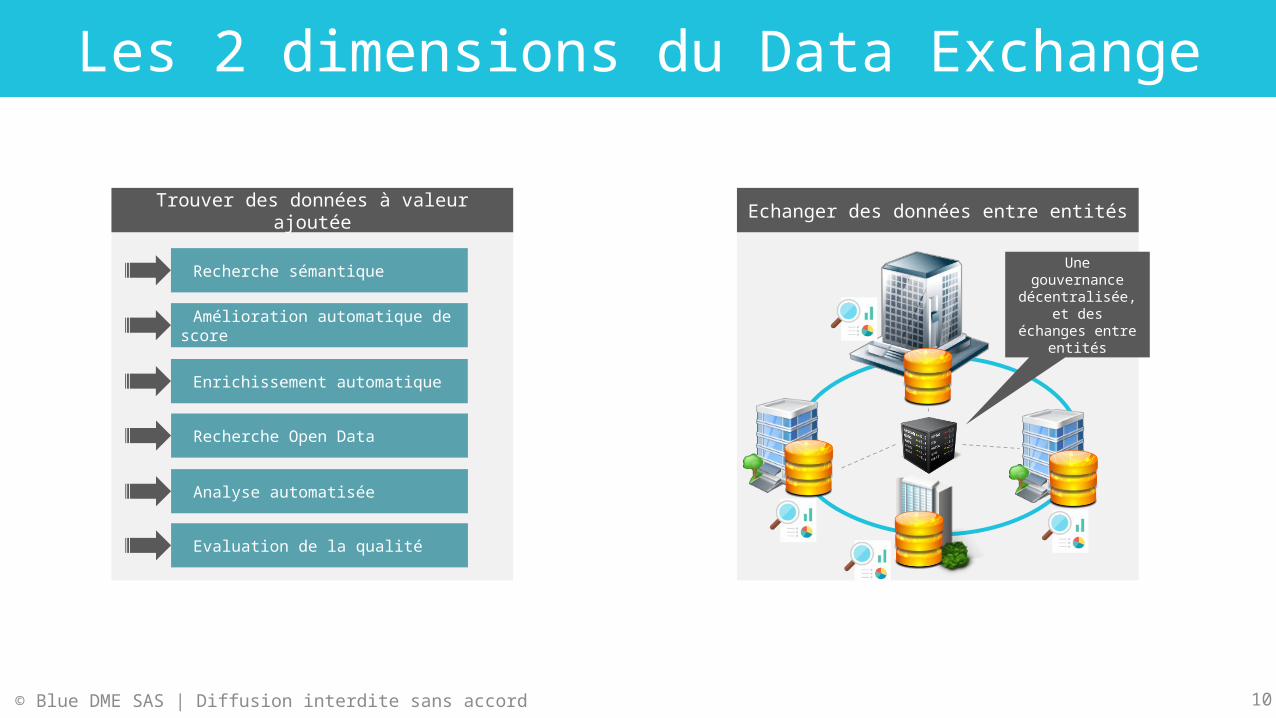
Les 2 dimensions du Data Exchange
© Blue DME SAS | Diffusion interdite sans accord 10
Echanger des données entre entités
Une gouvernance décentralisée, et
des échanges entre entités
Trouver des données à valeur ajoutée
Recherche sémantique
Recherche Open Data
Amélioration automatique de score
Enrichissement automatique
Analyse automatisée
Evaluation de la qualité
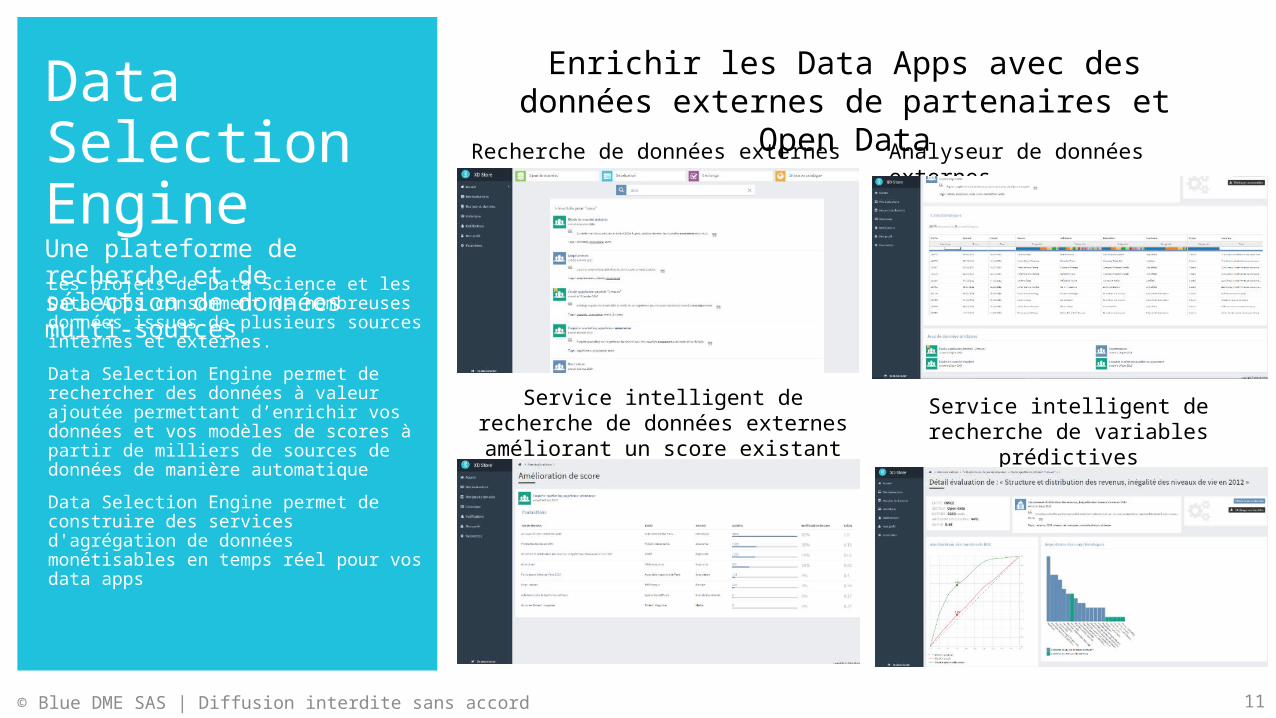
Data Selection EngineUne plateforme de recherche et de sélection de données multi-sourcesLes projets de Data Science et les Data Apps consomment de nombreuses données issues de plusieurs sources internes et externes.Data Selection Engine permet de rechercher des données à valeur ajoutée permettant d’enrichir vos données et vos modèles de scores à partir de milliers de sources de données de manière automatiqueData Selection Engine permet de construire des services d'agrégation de données monétisables en temps réel pour vos data apps
Enrichir les Data Apps avec des données externes de partenaires et Open Data
Recherche de données externes Analyseur de données externes
Service intelligent de recherche de données externes améliorant un
score existantService intelligent de recherche de
variables prédictives
© Blue DME SAS | Diffusion interdite sans accord 11
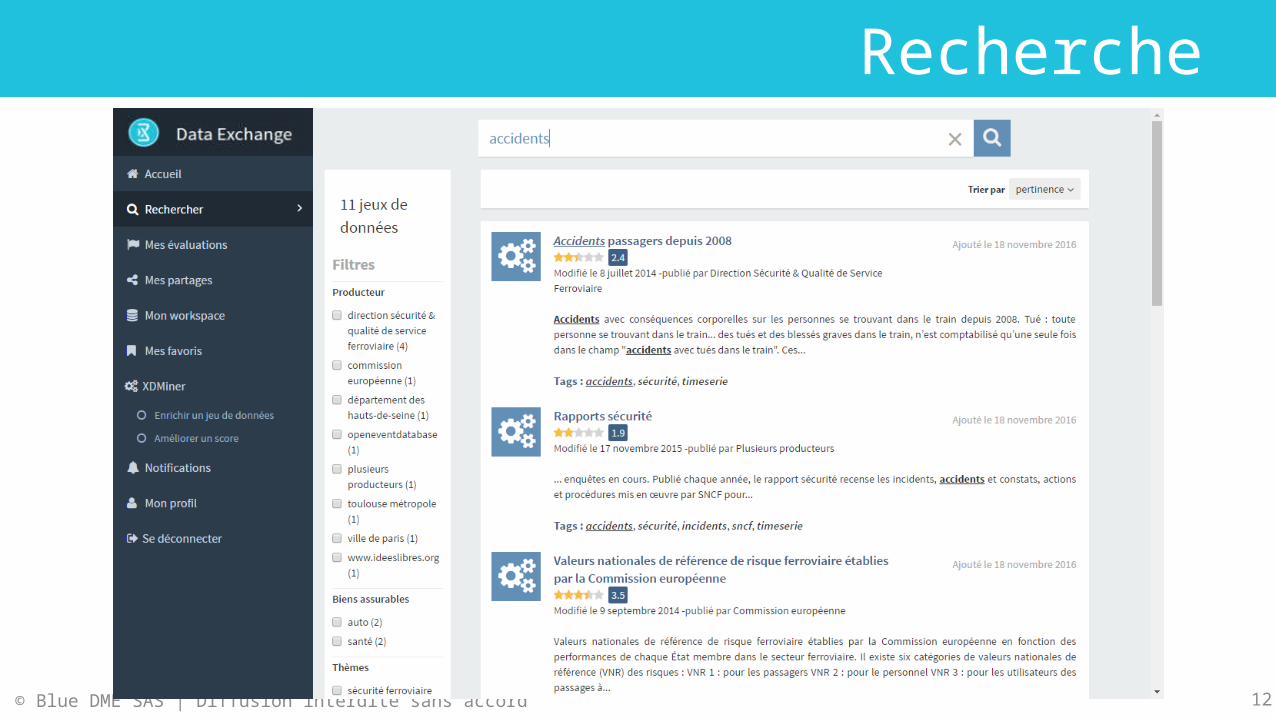
Recherche
© Blue DME SAS | Diffusion interdite sans accord 12
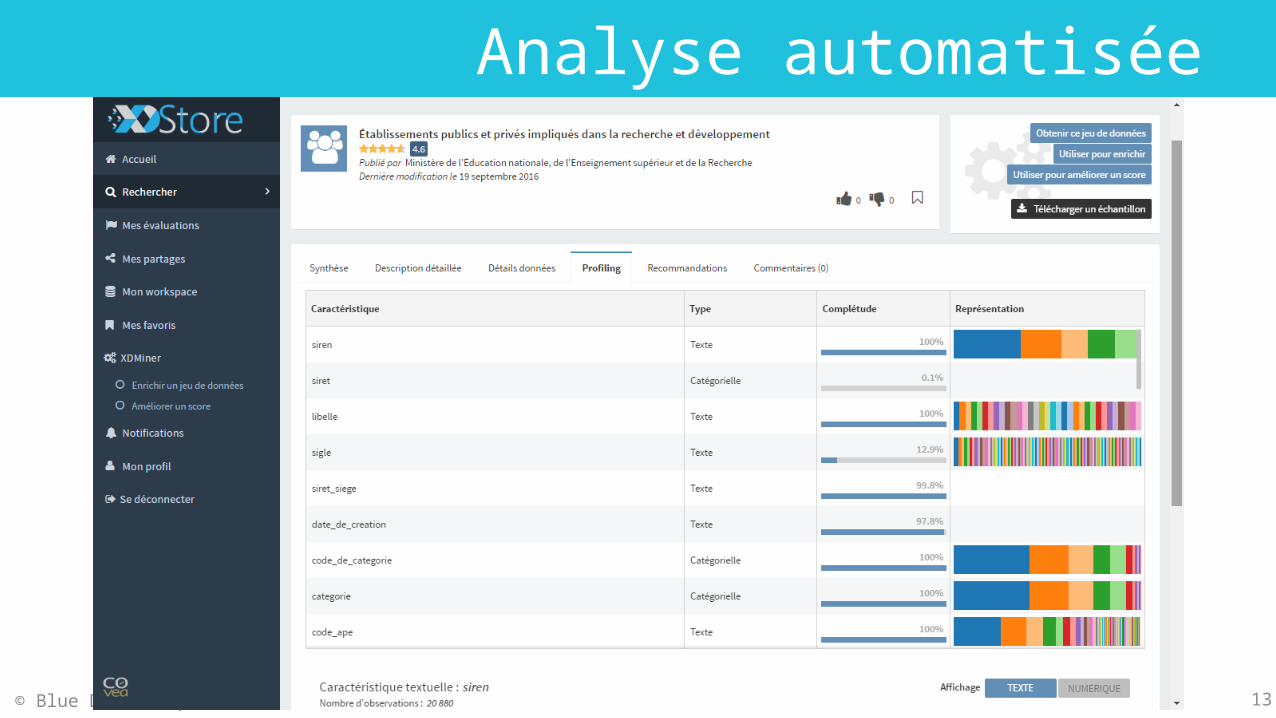
Analyse automatisée
© Blue DME SAS | Diffusion interdite sans accord 13
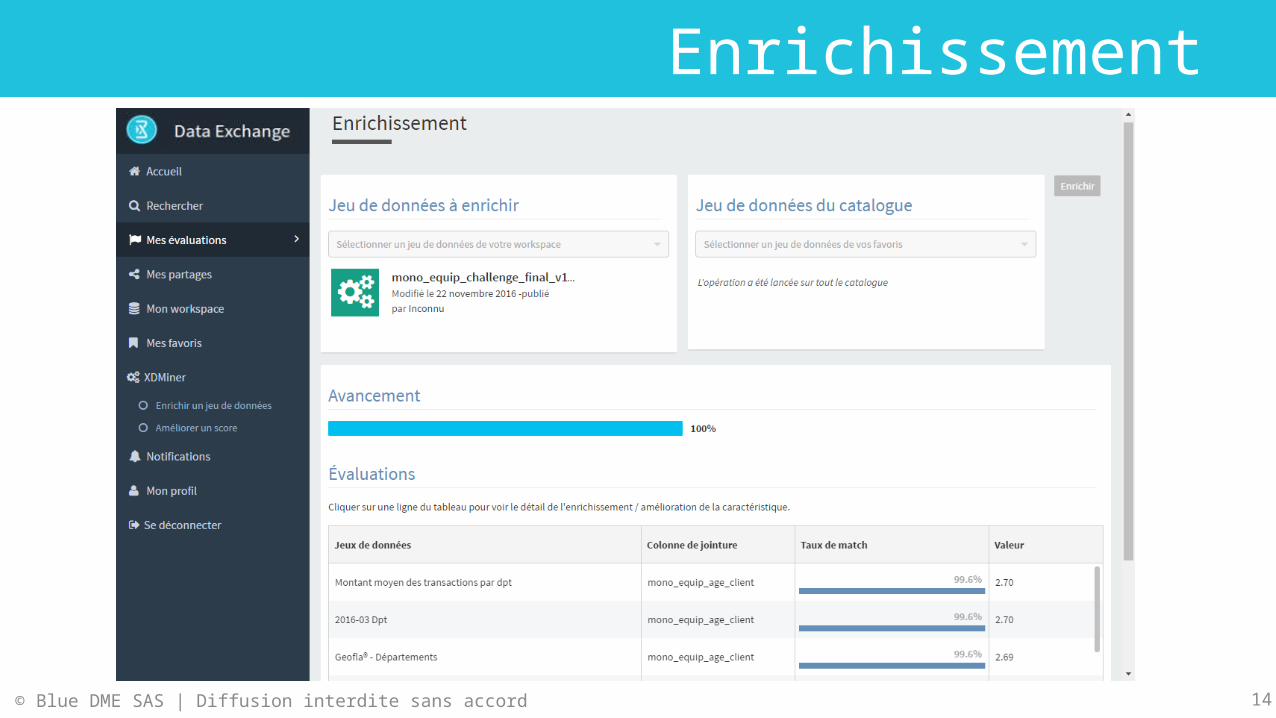
Enrichissement
© Blue DME SAS | Diffusion interdite sans accord 14
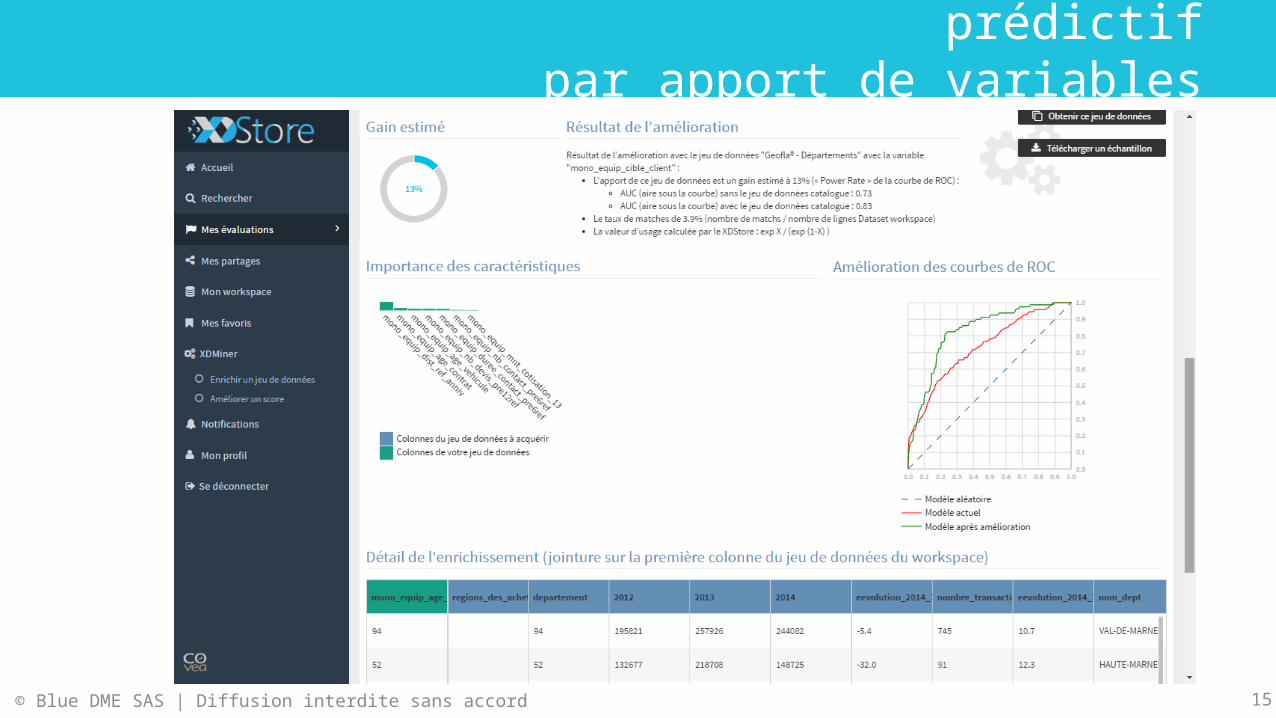
Amélioration automatique de score prédictif par apport de variables supplémentaires
© Blue DME SAS | Diffusion interdite sans accord 15
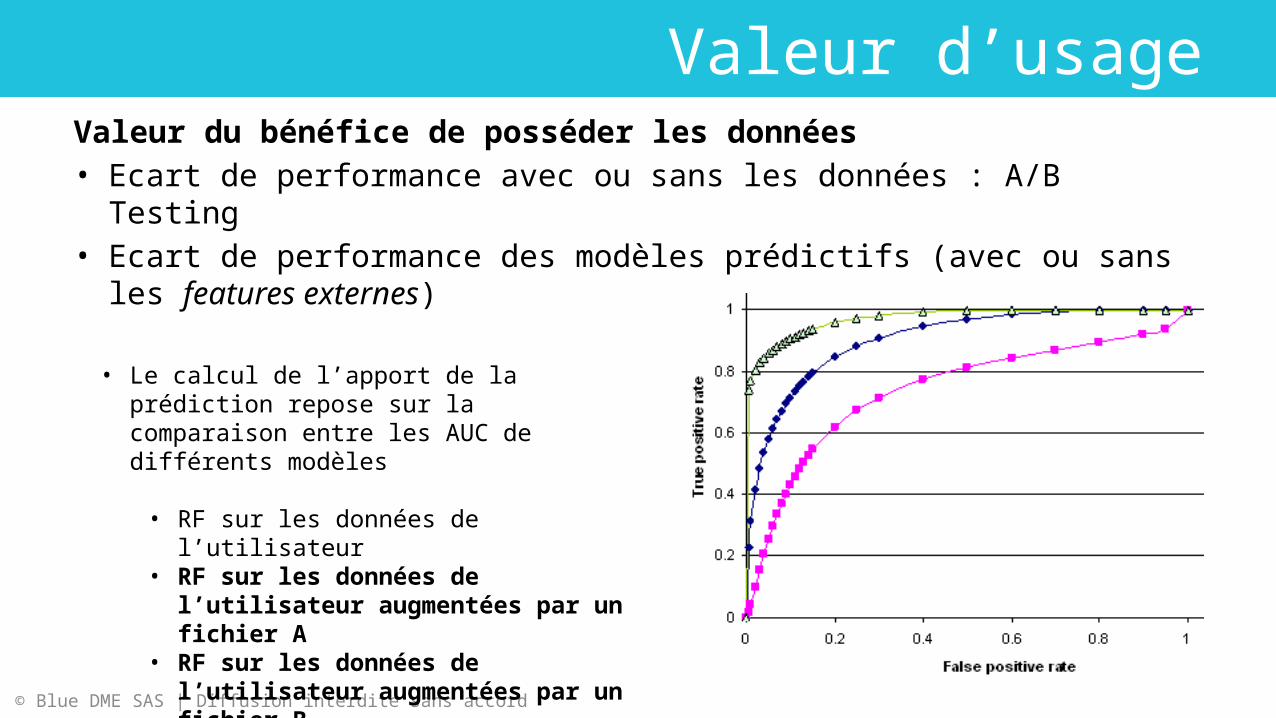
Valeur d’usage
© Blue DME SAS | Diffusion interdite sans accord
Valeur du bénéfice de posséder les données• Ecart de performance avec ou sans les données : A/B Testing• Ecart de performance des modèles prédictifs (avec ou sans les
features externes)
• Le calcul de l’apport de la prédiction repose sur la comparaison entre les AUC de différents modèles
• RF sur les données de l’utilisateur• RF sur les données de l’utilisateur
augmentées par un fichier A• RF sur les données de l’utilisateur
augmentées par un fichier B
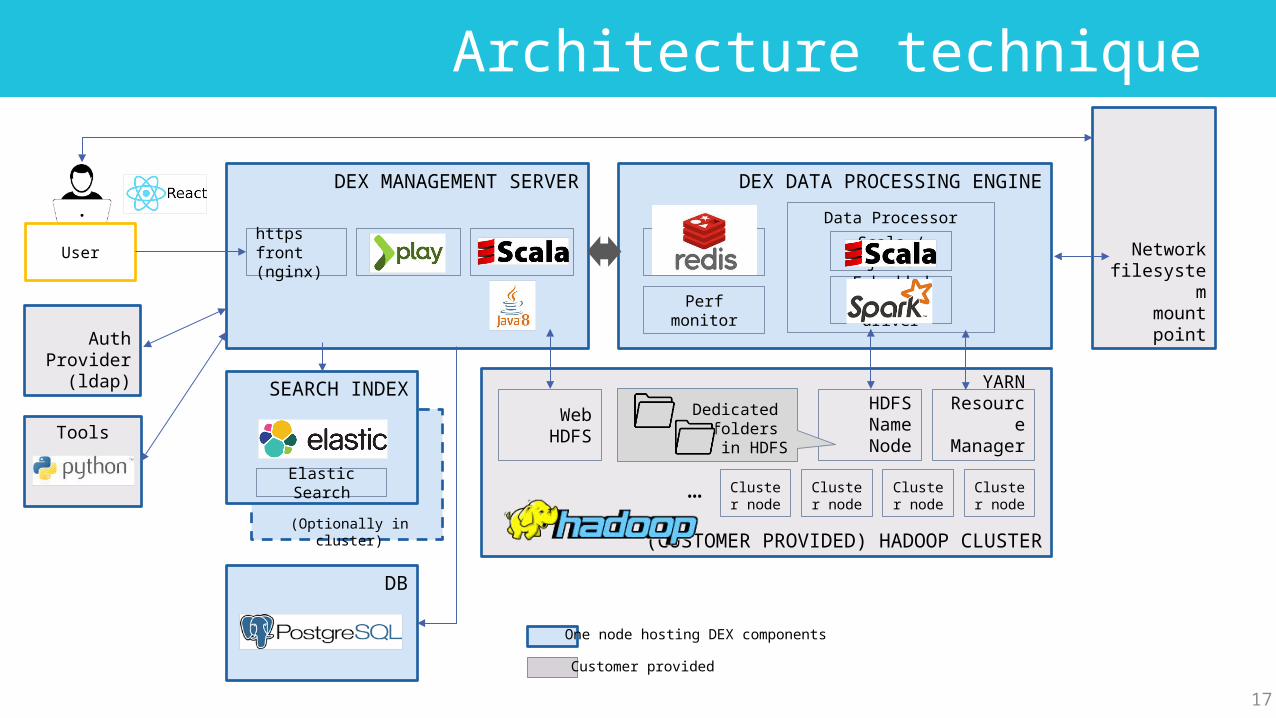
Architecture technique
17
DEX MANAGEMENT SERVER
https front(nginx)
play2
SEARCH INDEX
Elastic Search
(Optionally in cluster)
DB
User
DEX DATA PROCESSING ENGINE
Job Queue
Data Processor
Scala / jre 8
Embedded Spark driver
(CUSTOMER PROVIDED) HADOOP CLUSTER
YARNResource Manager
HDFSNameNode
Cluster node
Cluster node
Cluster node…
Dedicated folders in HDFS
WebHDFS
AuthProvider
(ldap)
Network filesystem
mount point
One node hosting DEX components
Customer provided
Cluster node
Perf monitor
Tools
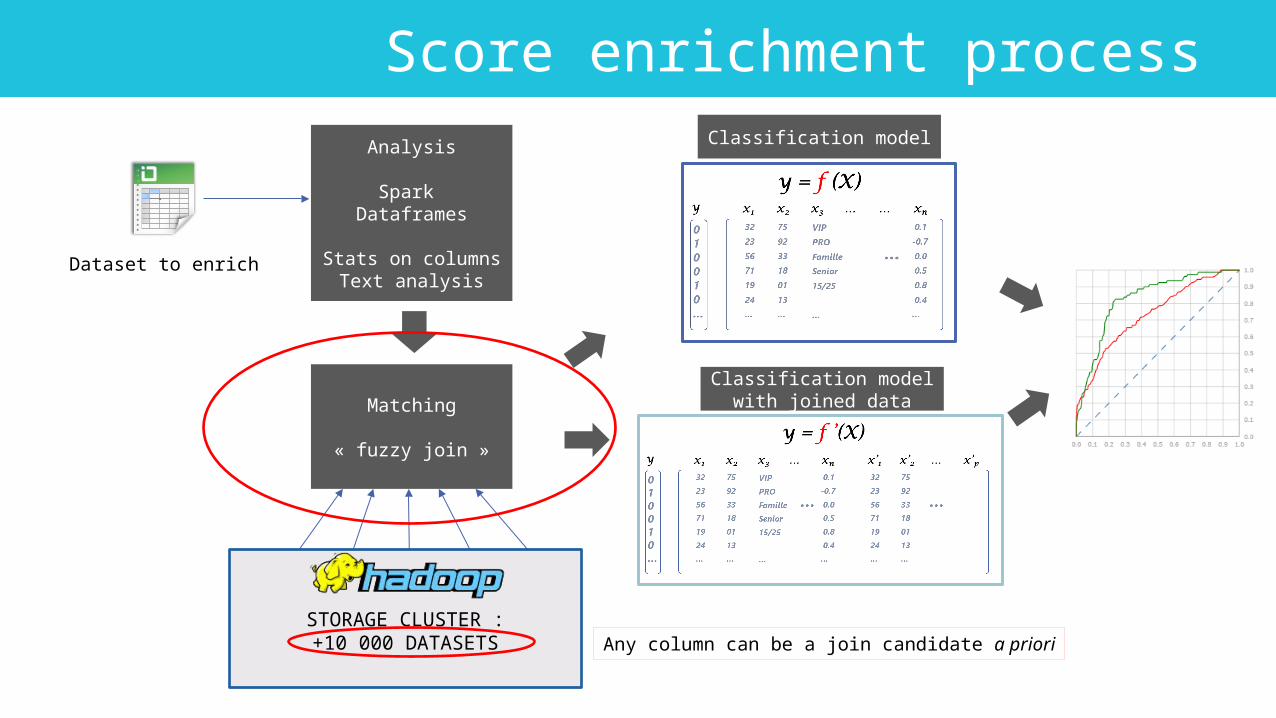
Score enrichment process
Dataset to enrich
Analysis
Spark Dataframes
Stats on columnsText analysis
Matching
« fuzzy join »
STORAGE CLUSTER :+10 000 DATASETS
Classification model
Classification modelwith joined data
Any column can be a join candidate a priori

K min values
© Blue DME SAS | Diffusion interdite sans accord 19
http://people.mpi-inf.mpg.de/~rgemulla/publications/beyer07distinct.pdf
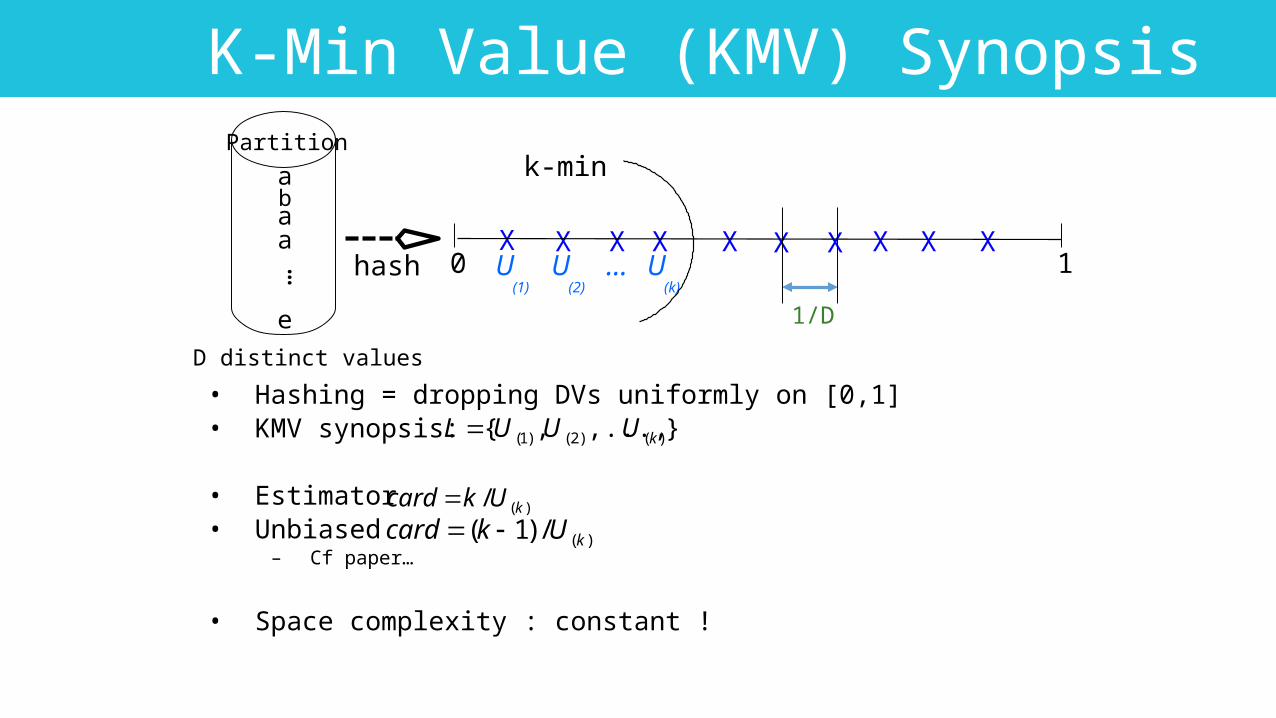
K-Min Value (KMV) Synopsis
• Hashing = dropping DVs uniformly on [0,1]• KMV synopsis:
• Estimator• Unbiased
– Cf paper…
• Space complexity : constant !
)(/ kUkcard
XX X X X X X X
a
e
b
…
D distinct values
hash
aa
Partition
X X
1/D
},...,,{ )()2()1( kUUUL
0 1U(1)U(2)
U(k)
k-min
...
)(/)1( kUkcard
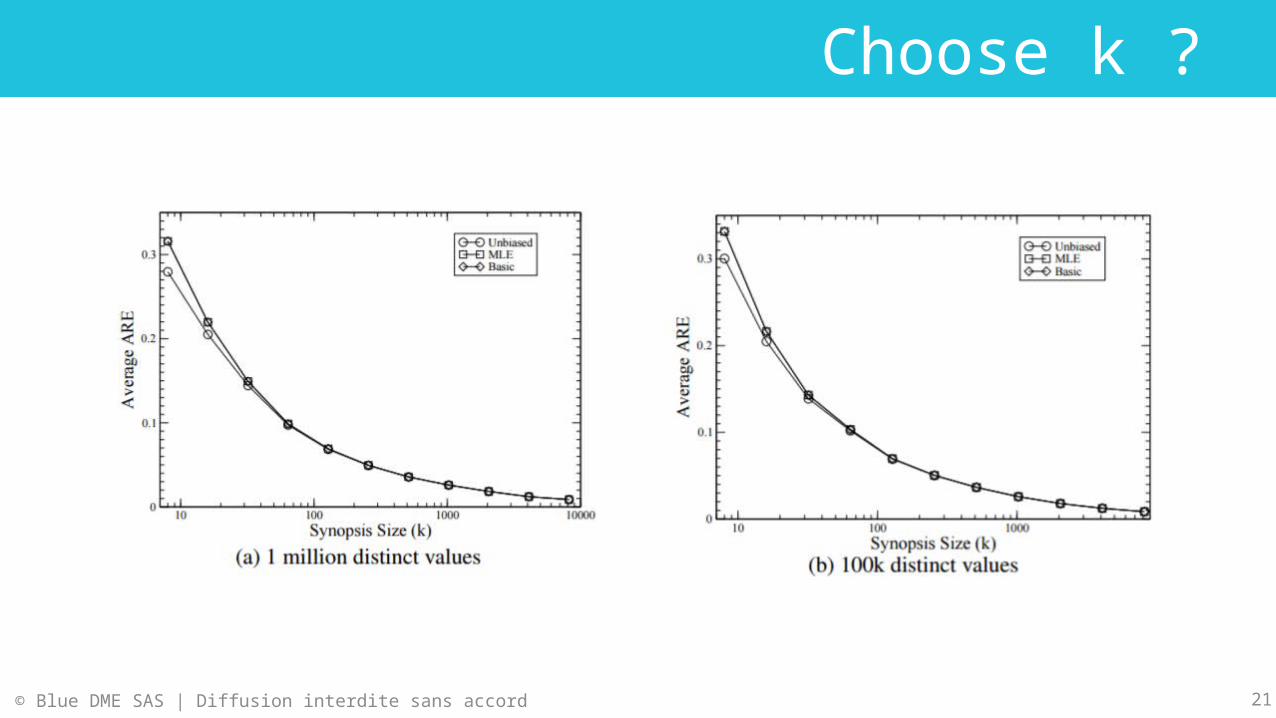
Choose k ?
© Blue DME SAS | Diffusion interdite sans accord 21
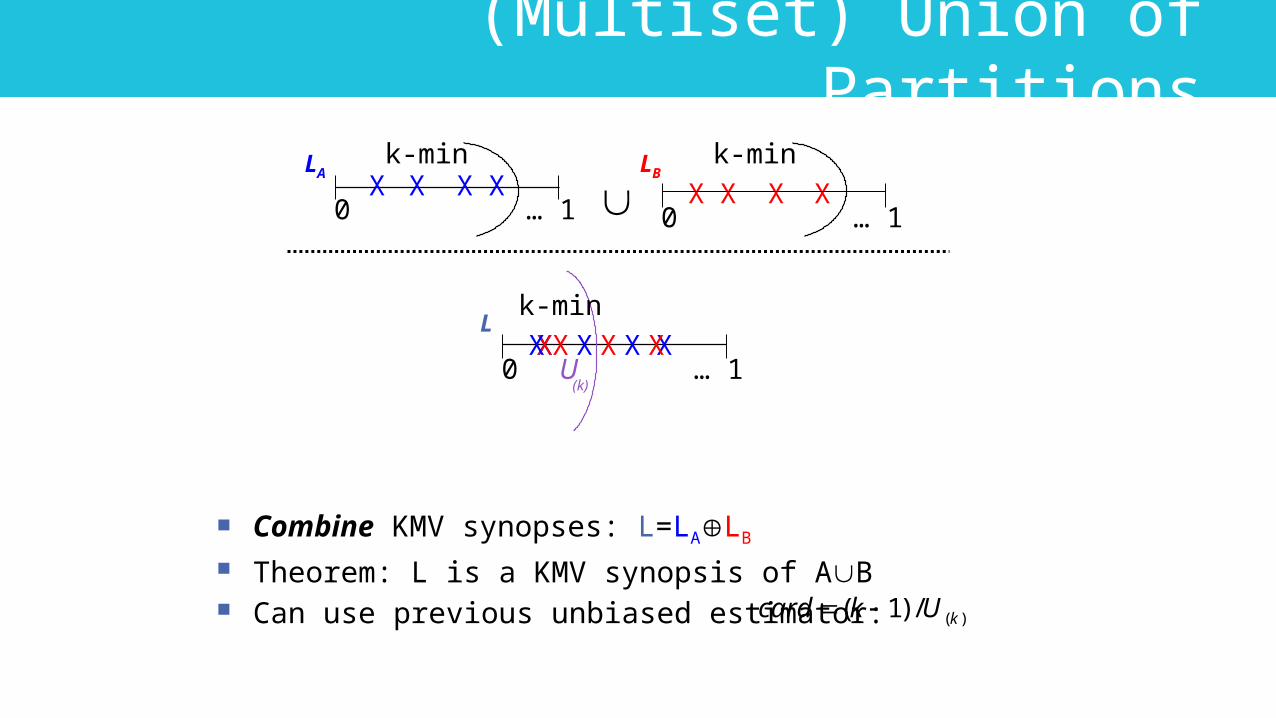
(Multiset) Union of Partitions
0XX X X
k-min
0XX X Xk-min
0XX X X
XX X Xk-min
U(k)
L
LA LB
Combine KMV synopses: L=LALB
Theorem: L is a KMV synopsis of AB Can use previous unbiased estimator:
… 1 … 1
… 1X
)(/)1( kUkcard

L=LALB as with union (contains k elements) Note: L corresponds to a uniform random sample of DVs in AB
K = # values in L that are also in D(AB) Theorem: Can compute from LA and LB alone
K/k estimates Jaccard distance:
estimates
Unbiased estimator of #DVs in the intersection:
See paper for variance of estimator
Can extend to general compound partitions from ordinary set operations
(Multiset) Intersection of Partitions
)(/)1(ˆkUkD )( BADD
)(
1ˆkU
kkKD
)()(BADBAD
DD
SIGMOD 07
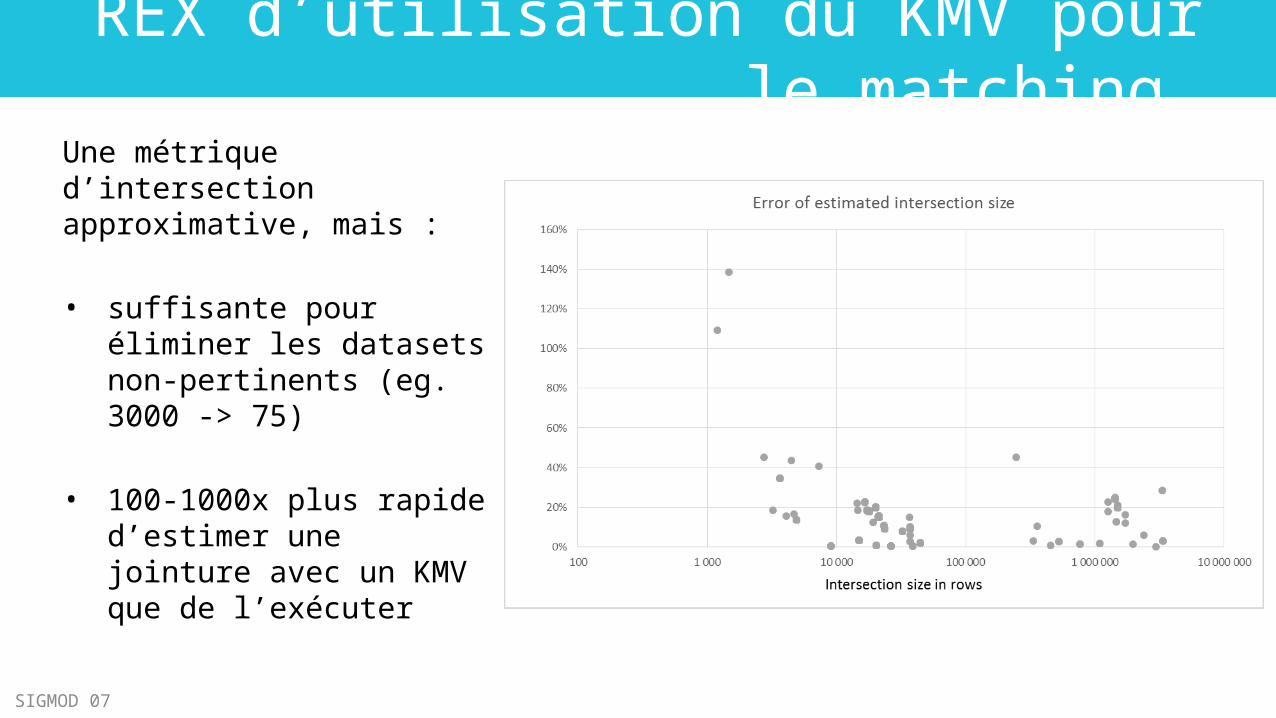
REX d’utilisation du KMV pour le matching
Une métrique d’intersection approximative, mais :
• suffisante pour éliminer les datasets non-pertinents (eg. 3000 -> 75)
• 100-1000x plus rapide d’estimer une jointure avec un KMV que de l’exécuter
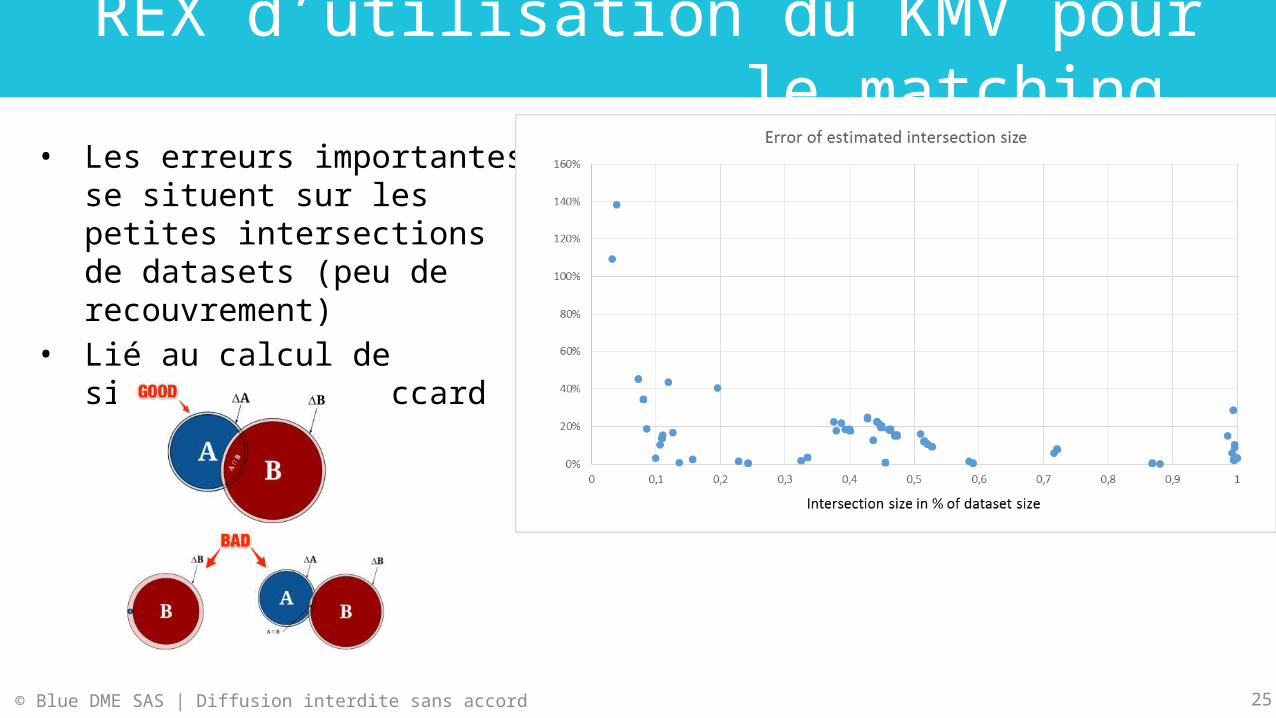
REX d’utilisation du KMV pour le matching
© Blue DME SAS | Diffusion interdite sans accord 25
• Les erreurs importantes se situent sur les petites intersections de datasets (peu de recouvrement)
• Lié au calcul de similarité de Jaccard

Une implémentation simpliste !
© Blue DME SAS | Diffusion interdite sans accord 26
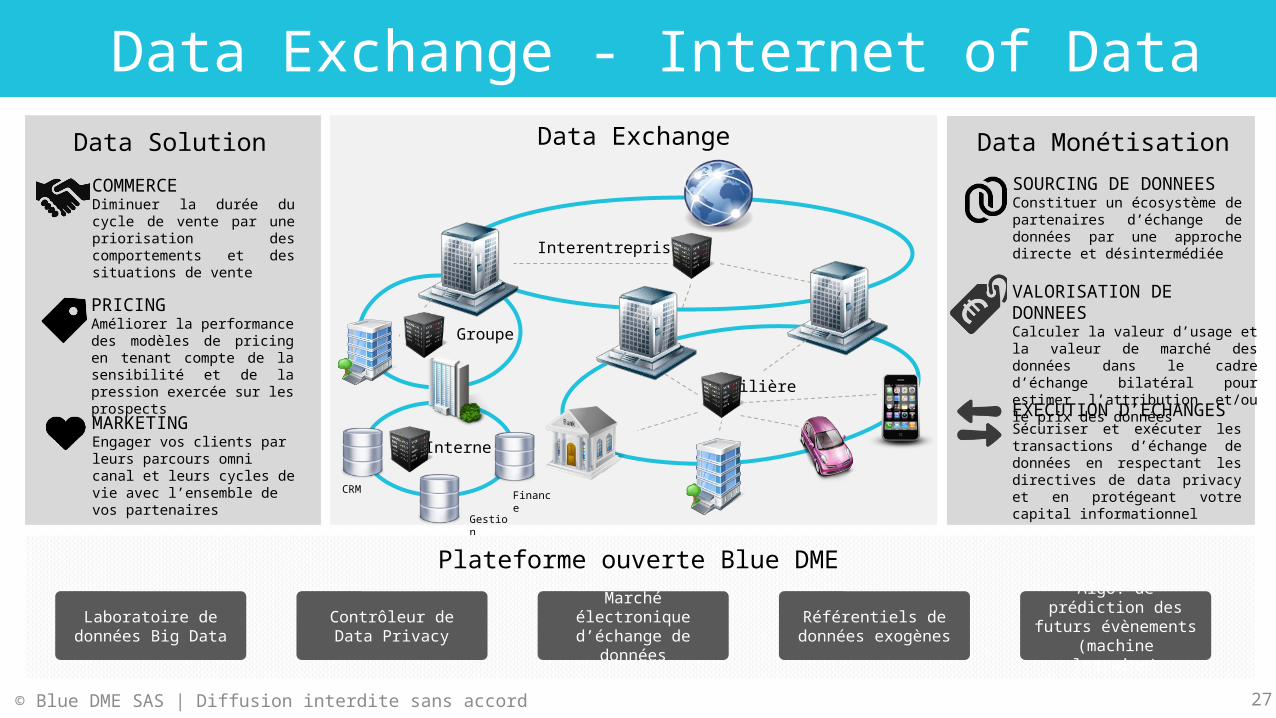
Data Exchange - Internet of Data
© Blue DME SAS | Diffusion interdite sans accord 27
Interentreprises
Filière
Groupe
Interne
CRM
Gestion
Finance
COMMERCEDiminuer la durée du cycle de vente par une priorisation des comportements et des situations de vente
MARKETINGEngager vos clients par leurs parcours omni canal et leurs cycles de vie avec l’ensemble de vos partenaires
Data MonétisationData ExchangeData Solution
PRICINGAméliorer la performance des modèles de pricing en tenant compte de la sensibilité et de la pression exercée sur les prospects
Plateforme ouverte Blue DME
SOURCING DE DONNEESConstituer un écosystème de partenaires d’échange de données par une approche directe et désintermédiée
VALORISATION DE DONNEESCalculer la valeur d’usage et la valeur de marché des données dans le cadre d’échange bilatéral pour estimer l’attribution et/ou le prix des donnéesEXECUTION D’ECHANGESSécuriser et exécuter les transactions d’échange de données en respectant les directives de data privacy et en protégeant votre capital informationnel
Laboratoire de données Big Data
Contrôleur de Data Privacy
Marché électronique d’échange de
donnéesRéférentiels de
données exogènes
Algo. de prédiction des futurs
évènements (machine learning)
