comment écrire un code de plus de 100 lignes?geuzaine/math0471/cours_1.pdfaller plus loin gmsh...
TRANSCRIPT

Comment écrire un code de plus de 100 lignes?
Université de Liège
MATH0471 - Projet de calcul scientifique multiphysique: développement d'un code de résolution numérique
d'équations aux dérivées partielles
Février 2015

Plan 2
1. Contexte 2. Gmsh 3. Du C à la sauce C++ 4. Compilation d’un projet 5. Trouver les bugs 6. Utiliser un cluster du CECI 7. Divers

Contexte 3
Bref aperçu du projet Le projet consistera à créer, par groupe de 2 étudiants, un code de calcul résolvant des EDP par la méthode des éléments finis (EF). Il vous sera demandé de créer un seul code par groupe. A la fin du projet, le code devra donc pouvoir être compilé une seule fois et utilisé pour générer tous les résultats présentés dans le rapport. Le code devra être rapide (optimisation) et adapté à l’utilisation sur cluster (parallélisme). Ce premier cours consiste à discuter • des bases de programmation requises (rappels C – notions basiques de C++) • des aspects techniques (compilation, gestion du code source, deboguage, etc.) Les exemples choisis pour illustrer ce cours proviennent d’un embryon de programme que l’on vous fournit dès aujourd'hui et qui permet de relire un maillage EF au format gmsh. Ces premières routines constituent la base de votre futur code de calcul.
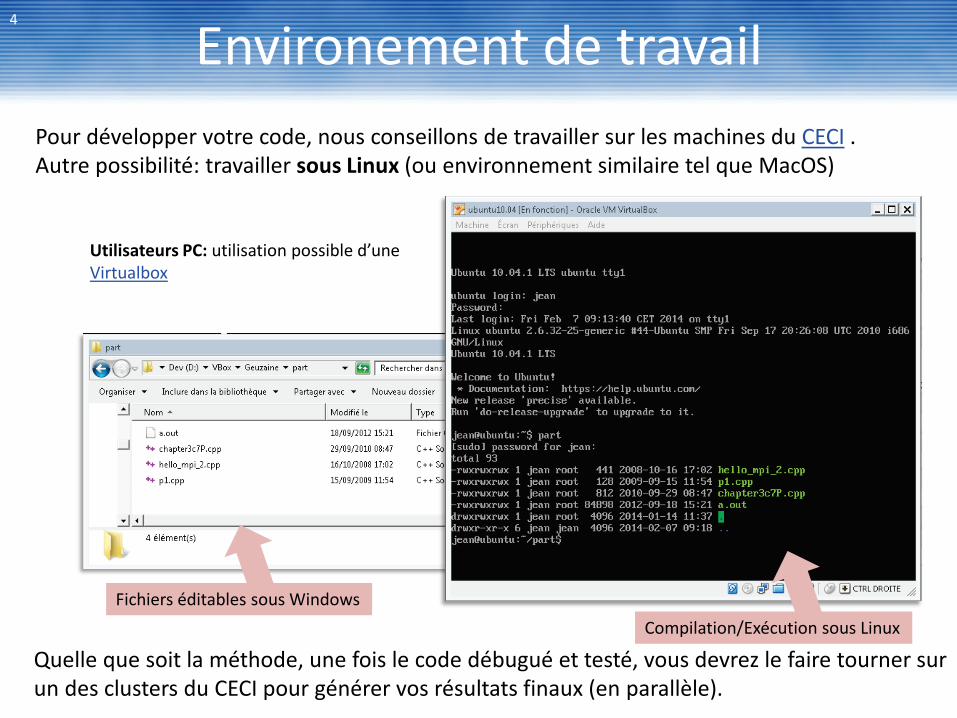
Environement de travail 4
Pour développer votre code, nous conseillons de travailler sur les machines du CECI . Autre possibilité: travailler sous Linux (ou environnement similaire tel que MacOS)
Utilisateurs PC: utilisation possible d’une Virtualbox
Quelle que soit la méthode, une fois le code débugué et testé, vous devrez le faire tourner sur un des clusters du CECI pour générer vos résultats finaux (en parallèle).
Compilation/Exécution sous Linux Fichiers éditables sous Windows

Plan 5
1. Contexte 2. Gmsh 3. Du C à la sauce C++ 4. Compilation d’un projet 5. Trouver les bugs 6. Utiliser un cluster du CECI 7. Divers

Gmsh 6
Création d’un maillage avec gmsh Gmsh est un outil de génération de maillages qui peuvent être utilisés pour effectuer des calculs par la méthode des éléments finis. Exemple: Création d’un cube maillé en hexaèdres
Exemples
Programme
Doc
Longueur côté = 10 10 mailles par arête
Lancez gmsh en ligne de commande avec comme argument : cube.geo
Téléchargement à partir de http://gmsh.info

Gmsh 7
0,0,0 10,0,0
0,10,0 10,10,0
‘q’ pour terminer la création de points
Création de points
Création des 4 sommets de la face inférieure (dans le plan (x,y))
Dans le module « Geometry », sélectionnez « Elementary entities » puis « Add » et enfin « Point ».
Pour plus de précision, spécifiez les coordonnées ici, puis « Add »
Module "Geometry"
Une géométrie dans gmsh est composée de points, de lignes, de surfaces et de volumes. Chaque entité s'appuyant sur les précédentes (BREP).

Gmsh 8
‘q’ pour terminer la création de lignes
Création de lignes droites Sélectionnez
les extrémités de chaque segment
On dessine ensuite les arêtes de la face inférieure du cube en sélectionnant la commande « Straight line » et en sélectionnant à chaque fois les 2 sommets.

Gmsh 9
Un fichier .geo a été créé Ouvrez le avec votre éditeur favori.
gmsh le remplit au fur et a mesure (gardez l'éditeur ouvert et rechargez le fichier régulièrement)
Remarque: à chaque action dans l’interface graphique, le programme ajoute une ligne dans le fichier spécifié lors du lancement du programme (cube.geo). Il a donc jamais besoin de "sauver" cube.geo.
Conséquence: Si vous quittez le programme, vous pouvez continuer votre travail où vous l’avez laissé en utilisant à nouveau la commande: gmsh cube.geo

Gmsh 10
‘e’ puis ‘q’ pour terminer la création de la surface
Création de surfaces
Sélectionner le contour
On crée ensuite une surface en sélectionnant « Plane surface » dans l'arbre de commandes et en sélectionnant le contour dans la vue graphique.

Gmsh 11
‘e’ puis ‘q’ pour terminer la création de la surface
Ligne « transfinie »
Module maillage
On veut mailler la face par « interpolation transfinie » (maillage régulier similaire à un damier). Pour ce faire, il faut définir le nombre d’éléments voulus sur chaque ligne.
11 points = 10 segments
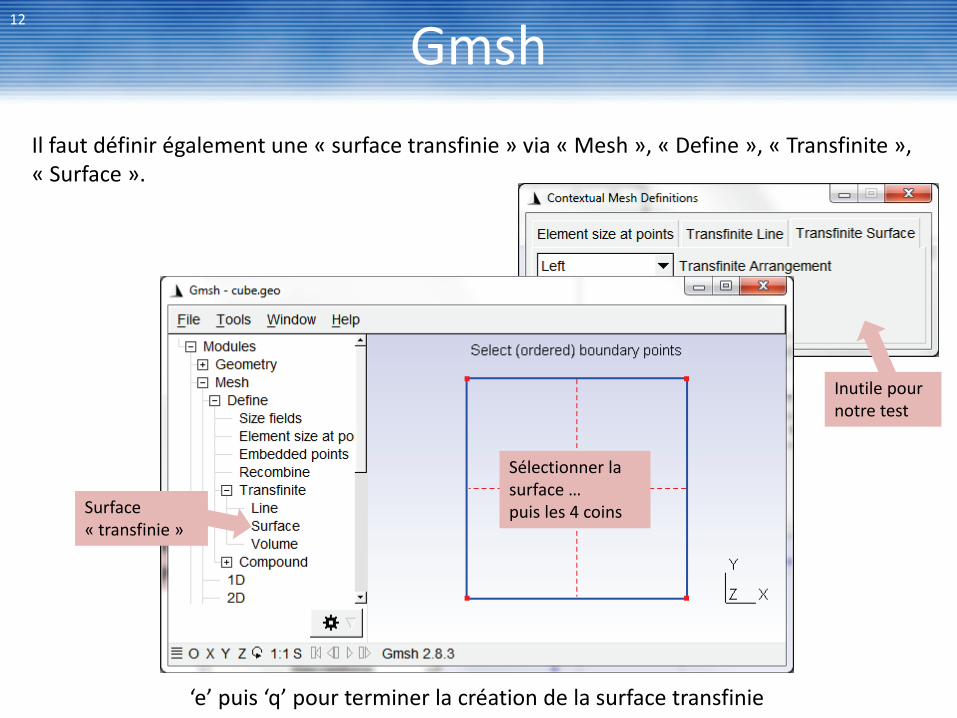
Gmsh 12
‘e’ puis ‘q’ pour terminer la création de la surface transfinie
Surface « transfinie »
Sélectionner la surface … puis les 4 coins
Il faut définir également une « surface transfinie » via « Mesh », « Define », « Transfinite », « Surface ».
Inutile pour notre test

Gmsh 13
‘e’ puis ‘q’ pour terminer la commande
Recombine (conversion triangles vers quadrangles)
Sélection de la surface
Par défaut, le mailleur va générer des triangles. Pour obtenir des quadrangles, il faut « recombiner » les triangles. Cliquez donc sur « Recombine » et choisissez la surface. On spécifie ici des consignes de maillage. Le maillage sera effectué tout à la fin en
respectant ces consignes.

Gmsh 14
Extrusion de la surface
Retour au module géométrie
Changer la longueur d'extrusion
On va maintenant extruder la face inférieure pour obtenir un cube.
L’extrusion est effectuée. Utilisez la souris pour faire pivoter la vue 3D.

Gmsh 15
Si on décidait de lancer l’opération de maillage à ce moment, gmsh génèrerait des tétraèdres et des pyramides... Mais nous voulons des hexaèdres. Editons à la main le fichier cube.geo
Ajoutez ces 2 commandes (sans fermer l’interface graphique de Gmsh) … et sauvez les modifications.
Dans gmsh, rechargez le fichier cube.geo

Gmsh 16
Physical groups
Surface, volume
Créer des groupes (appelés ici « Physical groups ») permettra d’obtenir des ensembles d’éléments (nœuds, arêtes, facettes, …) dans le fichier de maillage. Ce sera très utile par la suite: • Les groupes de nœuds
permettront d’appliquer des chargements ponctuels.
• Les groupes de surfaces serviront à appliquer les conditions aux limites.
• Les groupes de volumes permettront de distinguer différentes parties du maillage possédant par exemple différentes propriétés physiques.
Dans cet exemple, on décide de créer arbitrairement • un groupe lié à une surface. • le groupe lié au volume du cube.

Gmsh 17
Mesh !
Sauvez le maillage dans un fichier cube.msh
On peut enfin mailler notre cube! Utilisez le module « Mesh » puis la commande « 3D »
L'opération de maillage est très rapide
Si le maillage n'apparaît pas sous cette forme, double cliquez sur le fond bleu dans l'interface et adaptez les options de visualisation dans le menu contextuel

Gmsh 18
Utiliser l’interface graphique est pratique au début (création d’un maillage sans connaitre la syntaxe du fichier .geo) mais il devient vite plus simple de modifier le .geo et régénérer le fichier .msh en ligne de commande:
Régénérer le maillage à partir du fichier cube.geo
Aller plus loin gmsh -help Pour obtenir toutes les options de la ligne de commande
"-3" = commande « Mesh, 3D »

Gmsh 19
Paramétrer le fichier .geo
Ajout de paramètres
Nom explicite pour les groupes
Il est très simple et fortement conseillé d’ajouter des paramètres
Erreur fréquente: oubli d’un point-virgule!
Fichier original

Gmsh 20
Le fichier .msh
Format
Nom des groupes
Nombre de nœuds Numéro + coordonnées nœud #1 Numéro + coordonnées nœud #2 …
Chaque ligne = 1 élément (Numéro, type, nbre de tags, liste de tags et liste des numéros de nœuds)
type 3 = quadrangle (groupe « surface droite »)
type 5 = hexaèdre (groupe « Volume »)
Ce fichier sera lu par votre programme lors du démarrage de la simulation numérique
Il est composé de blocs de type:
$Block valeurs $EndBlock

Gmsh 21
Accès aux codes • Exemples de ce cours et lecture de maillages gmsh git clone https://github.com/rboman/gmshio.git
/femcode/geo/cube.geo /femcode/geo/cube.msh
• Exemples suivants … git clone https://github.com/rboman/femcode.git

Plan 22
1. Contexte 2. Gmsh 3. Du C à la sauce C++ 4. Compilation d’un projet 5. Trouver les bugs 6. Utiliser un cluster du CECI 7. Divers

Du C à la sauce C++ 23
Notions supposées connues en C • Types de base (int, double, char) et structures
• Tableaux (int[], double[], char[])
• Boucles (for, while), branchements (if, switch)
• Utilisation de la bibliothèque C standard:
• <math.h> : fonctions mathématiques (sin, cos, sqrt, …) • <stdio.h> : entrées/sorties (FILE, stdin, fopen, printf, scanf, …)
• Allocation de mémoire: double *a = malloc(sizeof(double)*100);
• Fonctions
plus d'infos: cprogramming.com, siteduzero.com

Du C à la sauce C++ 24
Le C++ est une surcouche du C • Types de base (int, double, char) et structures
• structures améliorées • classes /templates • matrices (gmm::dense_vector<>) • nombres complexes (std::complex<>)
• Tableaux (int[], double[], char[]) • std::vector<>, std::map<>, std::string
• Boucles (for, while), branchements (if, switch) • polymorphisme
• Bibliothèque C standard: • bibliothèque standard C++ (STL)
• Allocation de mémoire (malloc/free) • allocation de mémoire (new/delete)
• Fonctions • passage d'arguments par référence
• Autres • définition libre de variables (n'importe où) • exceptions
On choisit, parmi les ajouts du C++, ceux qui vont nous faciliter la vie
On néglige le caractère "orienté objet" du C++ (mis à part pour l'utilisation d'objets préexistants tels que des matrices ou vecteurs)
On peut mélanger du C et du C++ (le compilateur C++ qu'on utilisera peut compiler du C standard)
Le langage mixte résultant est plus simple d'utilisation que le C "pur".
Pour ce projet:

Du C à la sauce C++ 25
Structures Les structures permettent de créer de nouveaux types plus complexes en combinant des types précédemment définis (types de base ou autres structures). Exemple: un noeud = un numéro num (entier) + des coordonnées x, y, z (nbres flottants)
/* version C */ struct Node { int num; double x; double y; double z; }; struct Node n; n.num = 1 n.x = 1.0; n.y = 1.0; n.z = 0.0;
// version C++ (1/2) struct Node { int num; double x; double y; double z; }; Node n; n.num = 1 n.x = 1.0; n.y = 1.0; n.z = 0.0;
le mot struct a disparu en C++
autre style de commentaire
Rappel: on utilise "." pour accéder aux variables composant de la structure

Du C à la sauce C++ 26
// version C++ (2/2) struct Node { int num; double x; double y; double z; Node(int n=0, double px=0.0, double py=0.0, double pz=0.0) { num = n; x = px; y = py; z = pz; } }; Node n1(1, 1.0, 1.0, 0.0); Node n2(2);
Un cran plus loin en C++ : définition d'un constructeur pour la structure.
// version C++ (1/2) struct Node { int num; double x; double y; double z; }; Node n1; n1.num = 1; n1.x = 1.0; n1.y = 1.0; n1.z = 0.0; Node n2; n2.num = 2;
cette fonction définie dans la structure est appelée à la création d'un nouveau noeud! => tous les noeuds seront toujours initialisés!
valeur par défaut
n2.x, n2.y et n2.z valent 0.0 (sécurité)
la définition d'un noeud devient très simple (concision)
n2.x, n2.y et n2.z valent n'importe quoi!

Du C à la sauce C++ 27
// version C++ (2/2) Node *n = new Node(1, 1.0, 1.0, 0.0);
Même chose avec des pointeurs!
// version C++ (1/2) Node *n = new Node; n->num = 1; n->x = 1.0; // ou (*n).x = 1.0; n->y = 1.0; n->z = 0.0;
le "." est remplacé par une flèche "->" quand on manipule Node* et non plus Node
Pour rappel: • le pointeur vers une structure est obtenu à partir de la structure avec l'opérateur "&" • la structure est obtenue à partir du pointeur avec l'opérateur "*"
Node n1; // noeud 1 Node *pn1 = &n1; // crée un pointeur vers n1 nommé pn1 Node *pn2 = new Node; Node n3 = *pn2; // copie le noeud pointé par pn2 dans n3

Du C à la sauce C++ 28
Tableaux (vecteurs)
/* en C */ int taille=20; double *t; t = malloc(sizeof(double)*taille); t [10] = 1.0; printf("taille = %d\n", taille); free(t);
// en C++ #include <vector> int taille=20; std::vector<double> t (taille); t [10] = 1.0; printf("taille = %d\n", t.size()); t.push_back(3.14); // rien
L'objet std::vector<type> peut remplacer avantageusement les tableaux C. Exemple: std::vector<double> ("vecteur" utilisé en calcul matriciel)
même syntaxe qu'en C pour l'utilisation du vecteur
gestion mémoire simplifiée
utilisation avancée (agrandit le tableau et ajoute 3.14 à la fin)
std::vector est défini dans ce fichier
Beaucoup plus puissant pour une même syntaxe d'accès aux éléments!
le tableau C++ contient sa taille!

Du C à la sauce C++ 29
Tableaux (vecteurs de pointeurs)
/* en C */ int i; struct Node *nlist[100]; for(i=0; i<100; ++i) nlist[i] = malloc(sizeof(struct Node)); /* utilisation des noeuds nlist[i] ... */ for(i=0; i<100; ++i) free(nlist[i]);
// en C++ std::vector<Node*> nlist(100); for(int i=0; i<nlist.size(); ++i) nlist[i] = new Node; // utilisation des noeuds nlist[i] ... for(int i=0; i<nlist.size(); ++i) delete nlist[i];
Plus compliqué: un "vecteur de pointeurs vers des noeuds": std::vector<Node*>
Chaque élément de ce vecteur est un pointeur vers un noeud • nlist[i] est de type Node* • nlist[i]->num est le numéro du noeud i

struct Element { int num; int type; int region; std::vector<Node*> nodes; };
Du C à la sauce C++ 30
Exemple d'une structure plus complexe (tiré de la lecture du .msh)
struct Element { int num, type, region; std::vector<Node*> nodes; };
Un élément fini est défini par une structure comportant • son numéro, • son type (quad, hexa=5, quad=3, etc.) - voir doc gmsh. • son numéro de groupe physique (region) • un vecteur de pointeurs vers des noeuds qui le composent
notation compacte
Autre notation tout à fait équivalente:
notation compacte
numérotation interne des noeuds d'un quadrangle = sens trigonométrique (convention gmsh)

Du C à la sauce C++ 31
Exemple d'une structure plus complexe (tiré de la lecture du .msh)
Utiliser des pointeurs permet de ne pas utiliser d'index numérique (source d'erreur et nécessité de passer la liste globale de nœuds à toutes les routines)

Du C à la sauce C++ 32
Dictionnaires (maps)
// definition et remplissage std::map<int, Node*> nodeMap; nodeMap[10] = new Node( 10, 1.0, 1.0, 3.0); nodeMap[200] = new Node(200, 0.0, 3.0, 2.0); nodeMap[412] = new Node(412, 8.0, 1.0, 0.0); // exemple d'utilisation printf("coord x du noeud 412=%e\n", nodeMap[412]->x);
Type avancé C++ utilisé pour lier des clefs à des valeurs Un dictionnaire traductif qui lie un mot dans une langue à sa traduction dans une autre est une map dont les types de clefs et valeurs sont deux chaines de caractères. On écrit : std::map<type_clef, type_valeur> Exemple: dictionnaire (numéro de noeud)=>(pointeur vers noeud)
utiliser un tableau nécessiterait ici un std::vector<int> dont 412-3 = 409 éléments seraient inutilisés (NULL)!
notre map contient 3 nœuds dont la liste des numéros comporte des "trous" ((10, 200 et 412) et non (1, 2, 3))

Du C à la sauce C++ 33
Fonctions Dans un grand programme, il est capital d’utiliser des fonctions pour:
• Éviter les "copier/coller" (source d’erreur et de perte de temps)
• Paramétrer le code
• Réutiliser du code déjà validé
• Clarifier/documenter le code
• Créer des bibliothèques
• Partager le code
Faites un maximum de fonctions!

Du C à la sauce C++ 34
Des structures en argument de fonction
void translateNode(Node nod, double tx) { nod.x += tx; } void printNode(Node nod) { printf("node #%d (%g,%g,%g)\n", nod.num, nod.x, nod.y, nod.z); } int main() { Node n1(1, 0.0, 0.0, 0.0); printNode(n1); translateNode(n1, 1.0); printNode(n1); return 0; }
par défaut, toutes les variables sont passées par valeur : une copie du noeud est passée à la fonction (et une copie de tx)
c'est donc la copie du noeud qui va être modifiée !
moins grave ici puisqu'on ne modifie pas le noeud mais on perd du temps à effectuer une copie en entrée de fonction!
PROBLEME: n1 est toujours en 0,0,0 après appel de la fonction!

Du C à la sauce C++ 35
Des structures en argument de fonction
void translateNode(Node *nod, double tx) { nod->x += tx; } void printNode(Node *nod) { printf("node #%d (%g,%g,%g)\n", nod->num, nod->x, nod->y, nod->z); } int main() { Node n1(1, 0.0, 0.0, 0.0); printNode(&n1); translateNode(&n1, 1.0); printNode(&n1); return 0; }
solution "C": on passe le pointeur. Le pointeur est copié mais pas la structure pointée. On peut la modifier et on gagne du temps (pas de copie)
ici c'est pour éviter une copie inutile
PLUS DE PROBLEME! n1 est bien en en 1,0,0 !
problème: la syntaxe d'accès aux données internes du noeud change partout!

void translateNode(Node &nod, double tx) { nod.x += tx; } void printNode(Node &nod) { printf("node #%d (%g,%g,%g)\n", nod.num, nod.x, nod.y, nod.z); } int main() { Node n1(1, 0.0, 0.0, 0.0); printNode(n1); translateNode(n1, 1.0); printNode(n1); return 0; }
Du C à la sauce C++ 36
Des structures en argument de fonction
solution "C++": on passe la "référence" (opérateur "&")
PLUS DE PROBLEME! n1 est bien en en 1,0,0 !
syntaxe identique à la première version (facilité) ... et impossible de passer un pointeur NULL (sécurité)

void readMSH(const char *fileName, std::vector<Node*> &nodes, std::vector<Element*> &elements) { ... }
Du C à la sauce C++ 37
Exemple tiré de la lecture du .msh
La fonction a besoin d'un nom de fichier (qui ne sera pas modifié), d'un vecteur de pointeurs vers des nœuds et un vecteur de pointeurs vers des éléments. Ces deux vecteurs seront remplis lors de l'exécution et la fonction. Il doivent donc être passés par référence via l'opérateur "&". Dans la fonction, • le nœud i est accédé par nodes[i] • sa composante x par nodes[i]->x
void readMSH(const char *fileName, std::vector<Node*> *nodes, std::vector<Element*> *elements) { ... }
version "pointeurs"... Il faut modifier tout le corps de la fonction. En effet: • le nœud i est accédé par (*nodes)[i] • sa composante x par (*nodes)[i]->x
... et rien n'empêche un appel du type readMSH("cube.msh", NULL, NULL);
La fonction readMSH() remplit une liste de noeuds et d'éléments à partir de la lecture d'un fichier .msh

std::vector<Node*> nodes; std::vector<Element*> elements; readMSH("cube.msh", nodes, elements); for(int i=0; i<nodes.size(); ++i) { // utilisation de nodes[i] }
Du C à la sauce C++ 38
Exemple tiré de la lecture du .msh
Utilisation de la fonction readMSH()
Lecture du fichier cube.msh
Utilisation du vecteur de (pointeurs vers des) noeuds. Le nombre de noeuds est contenu dans le std::vector et peut être récupéré via la fonction size()
Création des 2 vecteurs (vides)

Plan 39
1. Contexte 2. Gmsh 3. Du C à la sauce C++ 4. Compilation d’un projet 5. Trouver les bugs 6. Utiliser un cluster du CECI 7. Divers

Compilation d'un projet 40
Compilation
femcode.cpp #include <stdio.h> struct Node { int num; ... }; void translateNode(Node &nod, double tx) { nod.x += tx; } void printNode(Node &nod) { printf("node #%d (%g,%g,%g)\n", nod.num, nod.x, nod.y, nod.z); } int main() { Node n1(1, 0.0, 0.0, 0.0); printNode(n1); translateNode(n1, 1.0); printNode(n1); return 0; }
g++ -o femcode femcode.cpp ./femcode
On travaille sur le code suivant qui manipule la structure Node précédemment définie On compile avec GCC

Compilation d'un projet 41
Découper son code en plusieurs fichiers
Buts • y voir plus clair dans le code source en rassemblant des fonctions similaires et en
isolant des fonctions trop longues. • accélérer la compilation du code lors de changements dans le source
Méthode Créer un fichier d'entête .h (header) qui regroupe
• toutes les déclarations de structures • tous les prototypes de fonctions
struct Node { int num; ... }; void printNode(Node &nod); void translateNode(Node &nod, double tx);
femcode.h

Compilation d'un projet 42
Découper son code en plusieurs fichiers
#include "femcode.h" int main() { Node n1(1, 0.0, 0.0, 0.0); printNode(n1); translateNode(n1, 1.0); printNode(n1); return 0; }
femcode.cpp
#include "femcode.h" #include <stdio.h> void printNode(Node &nod) { printf("node #%d (%g,%g,%g)\n", nod.num, nod.x, nod.y, nod.z); }
printNode.cpp
#include "femcode.h" void translateNode(Node &nod, double tx) { nod.x += tx; }
translateNode.cpp
• On crée plusieurs fichiers (1 par fonction pour cet exemple - mais on pourrait imaginer rassembler toutes les fonctions agissant sur Node dans un même fichier)
• On inclut (#include) le fichier d'entête dans tous les fichiers

Compilation d'un projet 43
Découper son code en plusieurs fichiers
Compilation: Chaque fichier est compilé séparément dans un fichier "objet" (p. expl. printNode.o) grâce à l'option "-c"
On crée le programme nommé femcode en spécifiant tous les fichiers .o dans une dernière commande (on parle d' "édition des liens" ou "link")
On peut utiliser alors le programme "CMake" pour faciliter le travail!
exécution du programme
Cette procédure devient de plus en plus lourde au fur et à mesure que le programme grossit...

Compilation/exécution 44
Utilisation de CMake CMake permet de générer un fichier Makefile qui sera utilisé par le programme make pour effectuer la compilation. CMake est multiplateforme. Il est par exemple capable de générer de projets "Visual studio" sous Windows ou des projets "XCode" sous MacOS. CMake utilise un fichier CMakeLists.txt dont la syntaxe est très simple.
CMakeLists.txt
Makefile cmake
femcode
make
femcode.sln
femcode.exe
Visual Studio
(exe linux)
(exe windows) http://www.cmake.org/ généré
généré seul fichier à créer!

Compilation/exécution 45
Utilisation de CMake
cmake_minimum_required(VERSION 2.6) project(FEMcode CXX) set(SRCS femcode.cpp translateNode.cpp printNode.cpp) add_executable(femcode ${SRCS})
CMakeLists.txt
Installation dans la Virtualbox : apt-get install cmake
Création du fichier CMakeLists.txt On définit la version minimale de CMake à utiliser (2.6 est OK)
On définit un projet nommé FEMcode. il est codé en C++ (CXX). Un projet peut contenir plusieurs programmes, des bibliothèques, etc..
On crée une variable SRCS qui contient la liste des 3 fichiers (*.cpp) à compiler
On déclare un programme exécutable nommé "femcode" et composé des sources définies par la variable SRCS.

Compilation/exécution 46
Utilisation de CMake Tout est prêt pour la compilation
Je crée un répertoire "build" dans lequel s'effectuera la compilation (le répertoire des sources restera "propre")
Je lance cmake en spécifiant où est mon CMakeLists.txt (ici "..")
J'exécute le code fraîchement compilé
Le Makefile est prêt: je lance la compilation avec make
Voir aussi Tutorial CMake en ligne

Plan 47
1. Contexte 2. Gmsh 3. Du C à la sauce C++ 4. Compilation d’un projet 5. Trouver les bugs 6. Utiliser un cluster du CECI 7. Divers

Trouver les bugs 48
... ou "Comment corriger les problèmes dans mon code sans la commande printf"
#include "femcode.h" void scaleNode(Node &nod, double s) { nod.x /= s; nod.y /= s; nod.z /= s; }
scaleNode.cpp
Notre programme grossit... On définit une fonction scaleNode() qui divise les coordonnées des positions d'un nœud par un scalaire.
Ne pas oublier: • Il faut ajouter le prototype de
cette fonction dans femcode.h • Il faut ajouter le nom de ce
nouveau fichier dans le CMakeLists.txt
Contenu du nouveau fichier:

Trouver les bugs 49
#include "femcode.h" int main() { Node n1(1, 1.0, 1.0, 1.0); printNode(n1); scaleNode(n1, 0.0); printNode(n1); return 0; }
femcode.cpp
On modifie également la routine main()
On va provoquer un problème à l'exécution: On appelle la fonction avec un argument problématique
On recompile le code en faisant uniquement : make # pas besoin de cmake! CMake est relancé automatiquement (la modification de CMakeLists.txt est détectée par le Makefile)

Trouver les bugs 50
Malheureusement le code tourne jusqu'au bout et produit des nombres flottants inf ! (voir norme IEEE 754) Imaginez que votre code source soit très grand et que vous découvriez des inf dans vos résultats de calcul. Vous aimeriez savoir exactement l'opération qui a produit ces inf. Autrement dit: On aimerait que le programme plante dès qu'il génère un inf pour détecter où se situe le problème... et le corriger.
Exécution du code "bugué"
Règle d'or: "Mieux vaut un code qui plante qu'un code qui produit de mauvais résultats" !

Trouver les bugs 51
Cette étape dépend du compilateur. • Pour gcc/g++, on doit ajouter un appel à la feenableexcept() • Pour Visual Studio, on pourrait utiliser la routine _control87()
#include "femcode.h" #include <fenv.h> int main() { feenableexcept(-1); Node n1(1, 1.0, 1.0, 1.0); printNode(n1); scaleNode(n1, 0.0); printNode(n1); return 0; }
femcode.cpp Cet appel de fonction réactive les "Floating Point Exceptions"
Solution (étape 1/2) configurer les routines math pour planter au moindre problème
#include "femcode.h" #ifdef __GNUC__ #include <fenv.h> #endif int main() { #ifdef __GNUC__ feenableexcept(-1); #endif Node n1(1, 1.0, 1.0, 1.0); printNode(n1); scaleNode(n1, 0.0); printNode(n1); return 0; }
je veux pouvoir utiliser aussi d'autres compilateurs
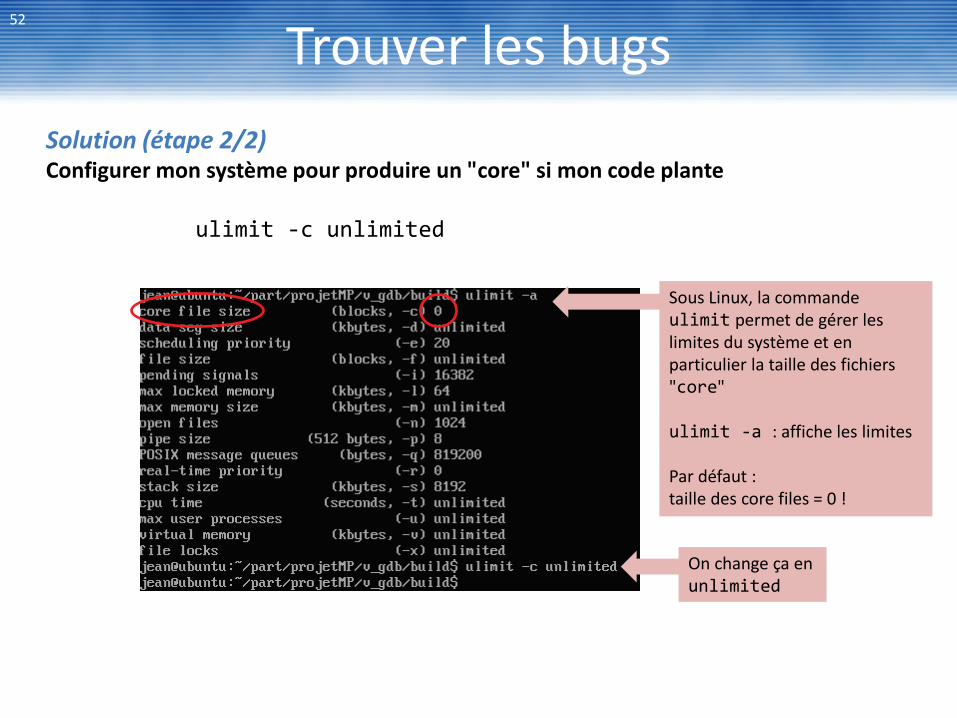
Trouver les bugs 52
Solution (étape 2/2) Configurer mon système pour produire un "core" si mon code plante
Sous Linux, la commande ulimit permet de gérer les limites du système et en particulier la taille des fichiers "core" ulimit -a : affiche les limites Par défaut : taille des core files = 0 !
On change ça en unlimited
ulimit -c unlimited

Trouver les bugs 53
... on exécute le programme modifié dans l'environement modifié
Parfait! Le programme a planté en créant une Floating point exception
Le fichier core est ici
Le fichier core contient l'état de la mémoire quand le programme à planté. Il peut être lu par un débogueur (gdb) pour analyser ce moment en détail.

Trouver les bugs 54
Analyser le core avec gdb
A retenir pour la suite: pas de "debugging symbols" dans notre code...
gdb ./femcode ./core
99% des novices en programmation arrêtent la lecture des infos gdb à cet endroit parce qu'ils ne comprennent rien... Continuez jusqu'au bout!
Partie intéressante
gdb nous apprend qu'il s'agit d'une exception arithmétique dans scaleNode... c'est déjà très précis. ... mais il y a moyen d'apprendre encore plus si on compile "en debug" (avec les "debugging symbols")...
https://www.gnu.org/software/gdb/

Trouver les bugs 55
Compilation "en mode debug" make clean cmake -DCMAKE_BUILD_TYPE=Debug ..
nettoie le dossier "build"
• La version "debug" est une version non optimisée (plus lente) qui peut être exécutée interactivement, ligne par ligne, avec gdb.
• Elle contient également le texte du code source et le nom de toutes nos variables (les "debugging symbols").

Trouver les bugs 56
Les infos sont maintenant complètes: L'erreur se situe à la ligne 4 du fichier scaleNode.cpp où on divise par "s" qui vaut 0!
gdb a chargé les debugging symbols!
gdb ./femcode ./core
Après compilation lancez le code pour produire un core et relancez gdb:
infos supplémentaires

Trouver les bugs 57
toutes les variables (y compris structures) sont affichables au moment où ça a planté!
commande "l": affiche le source au voisinage de l'erreur
commande "p variable": affiche le contenu de la variable
Quelques commandes utiles de gdb dans le contexte de l'inspection d'un core
Cette méthode est d'autant plus utile que le nombre de routines est grand et que l'erreur est perdue profondément dans code.
commande "bt": affiche la pile d'appel (call stack)
(commande "help" pour afficher l'aide intégrée de gdb) quitter gdb avec "q"

Plan 58
1. Contexte 2. Gmsh 3. Du C à la sauce C++ 4. Compilation d’un projet 5. Trouver les bugs 6. Utiliser un cluster du CECI 7. Divers

Utiliser un cluster du CECI 59
Accès aux clusters du CECI
http://www.ceci-hpc.be/ La procédure de connexion aux machines du CECI et de transfert de fichiers est décrite à cette adresse: Se connecter à partir de Windows
Il est strictement interdit de lancer de gros calculs sur le "master node" ! (voir SLURM)

Plan 60
1. Contexte 2. Gmsh 3. Du C à la sauce C++ 4. Compilation d’un projet 5. Trouver les bugs 6. Utiliser un cluster du CECI 7. Divers

Divers 61
Exercices proposés 1. Effectuer les exemples présentés précédemment
2. Construire une géométrie plus complexe qu'un cube avec gmsh et la charger
avec gmshio.cpp
3. A partir du fichier gmshio.cpp • Créer des fonctions • Créer des constructeurs • Découper le fichier en plusieurs fichiers (1 fichier par routine) et un fichier
d’entête contenant les prototypes des fonctions et les structures • Créer un fichier CMakeLists.txt et compiler le code • Compiler le code en mode debug. • Créer un bug et le trouver avec gdb • Lancer le code sur HMEM • Visualiser les résultats

62