atelier n°5 – groupe de travail big data 11h30 – 12h30 · atelier 5: gt big data ... objectifs...
TRANSCRIPT

Atelier n°5 – Groupe de travail Big Data 11h30 – 12h30

ATELIER 5: GT BIG DATA
PRATIQUE DES TECHNIQUES D ’ALGORITHMES PREDICTIFS
A L’OCCASION D’UN CONCOURS KAGGLE:
UNE EXPÉRIENCE DE DATA SCIENTIST

INTERVENANTS Xavier Conort, Actuaire qualifié certifié, champion, avec sa société DataRobot,
de nombreux concours internationaux d'algorithmes Gontran Peubez, Consultant Deloitte Florence Picard, Présidente de la Commission Scientifique
ATELIER 5: GT BIG DATA
Florence Picard

R and Python Packages to Win Kaggle Competitions
Xavier Conort Chief Data Scientist

Previously... … now!

Kaggle: “The social fight club for data geeks”

Why Geeks like to fight?
“My motivation has been
to learn new things.”

Competitions that boosted my R learning curve
The Machine seems much smarter than I am at capturing complexity in the data even for simple datasets!
Humans can help the Machine too! But don’t oversimplify and discard any data.
Don’t be impatient. My best GBM had 24,500 trees with learning rate = 0.01!
SVM and feature selection matter too!

Word n-grams and character n-grams can make a big difference
Parallel processing and big servers can help with complex feature engineering!
Still many awesome tools in R that I don’t know!
Glmnet can do a great job!
Competitions that boosted my R learning curve

Machine Learning works for insurance too!

What I learnt about GLMs
GOOD BAD UGLY Recognized as a standard in the banking and insurance industry Accommodate responses with skewed distributions Simple mathematical formula easy to implement and easy to interpret
Need to pre-process data (missing values, outliers, dimension reduction) GLMs do not automatically capture complexity in the data. It can take weeks or months to go through the GLM iterative modelling process
GLMs are prone to overfitting while used with large amount of features or features with a large number of categories GLMs don’t work with text
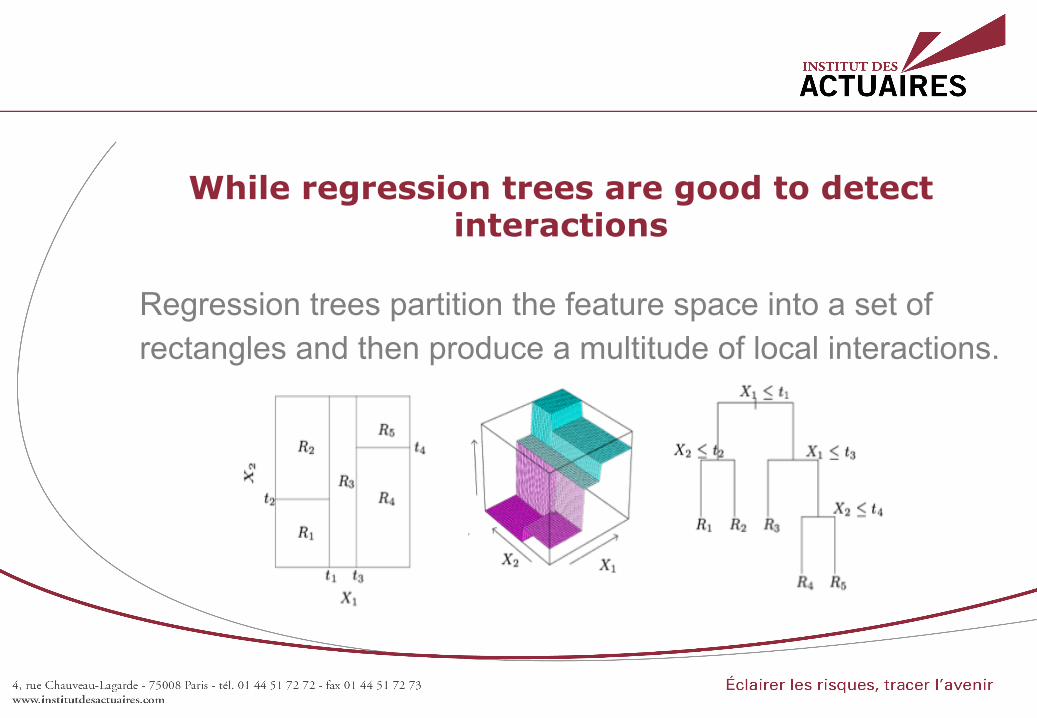
While regression trees are good to detect interactions
Regression trees partition the feature space into a set of rectangles and then produce a multitude of local interactions.

10 R Packages I use very frequently:
Allow the Machine to Capture Complexity 1. gbm 2. randomForest 3. E1071
Take Advantage of High-Cardinality Categorical or Text Data 1. glmnet 2. Tau
Make Your Code More Efficient 1. Matrix 2. SOAR 3. foreach / doMC 4. data.table

Capture Complexity Automatically

1. gbm
Gradient Boosting Machine (Freud & Schapiro) Authors: Greg Ridgeway / Harry Southworth Key Trick: Use gbm.more to write your own early-
stopping procedure

GBMs: key to success for many Kagglers
Gradient Boosting Machines use a mix of GLMs, boosting and decision trees techniques:
• fits a GLM (same loss function and link function) step by step and slowly • uses at each step simple tree to find new simple rules for the GLM • gradually increases emphasis on poorly modeled observations (trees
focus is only on the residuals) • to control overfitting, the contributions of each tree are shrunk by setting
a learning rate very small (and < 1) to give more stable fitted values for the final model and the process uses random subsets of data

2. randomForest
Random Forests (Breiman & Cutler) Authors / Maintainer: Breiman and Cutler / Andy
Liaw
Key Trick: Importance=True for permutation importance Tune the sampsize parameter for faster
computation and handling unbalanced classes

3. e1071
Support Vector Machines Maintainer: David Meyer
Key Tricks: Use kernlab (Karatzoglou, Smola and Hornik) to
get heuristic Write own pattern search

Take Advantage of High-Cardinality Categorical or Text Features

4. glmnet
L1 / Elasticnet / L2 Authors: Friedman, Hastie, Simon, Tibshirani
Key Tricks: - Try interactions of 2 or more categorical variables - Test your code on the Kaggle: “Amazon Employ
Access Challenge”

5. tau
Used for automating text-mining Maintainer: Kurt Hornik
Key Trick: Try character n-grams. They work surprisingly well!

Make Your Code More Efficient

6. Matrix
Authors / Maintainers: Douglas Bates and Martin Maechler
Key Trick: Use sparse.model.matrix for one-hot encoding

7. SOAR Used to store large R objects in the cache and
release memory Author / Maintainer: Bill Venables
Key Trick: Once I found out about it, it made my R
Experience great! (Just remember to empty your cache … )

8. forEach and doMC
Authors: Revolution Analytics
Key Trick: Use for parallel-processing to speed up computation

10. data.table
Authors / Maintainer: M Dowle, T Short and others
Key Trick: Essential for doing fast data aggregation
operations at scale

The Python algos that helped me win 2 insurance competitions
GradientBoostingClassifier RandomForestRegressor ExtraTreesRegressor

Don’t forget ...
● Always consider simple feature engineering such
differences / ratios of features. This can help the Machine a lot!
● Always consider discarding features that are “too good”
They can make the Machine lazy! An example: GE Flight Quest
To use your actuarial intuition to help the machine!

Thank you!

Groupe de travail Big Data Retour d’expérience
concours Kaggle

Introduction et présentation du défi Objectifs et description de la compétition
• Le but de cette compétition était de prédire les options de la police d’assurance que les clients d’une compagnie finiraient par acheter.
• À notre disposition − Une base de train, avec l’historique total (toutes les polices
d’assurances que le client a visitées), dont la dernière ligne contient la police d’assurance (les options de couverture) que le client finit par acheter.
− Une base de test : un historique partiel des polices visitées par le client et sans les options de couverture finalement achetées..
Vecteur à prédire
• Concrètement, il s’agit, pour le fichier train d’un fichier à plat − 500 000 lignes et 25 variables − Des données anonymes − Des variables descriptives plus ou moins interprétables : faible compréhension métier des variables disponibles − Absence totale de compréhension de la problématique (de quel type d’assurance et d’options s’agit-il ?)
• Quelques remarques − Une grande combinatoire : 2 304 possibilités d’option de couverture possibles. − Un benchmark (« algorithme » de référence fourni par Kaggle) difficile à battre − Une prédiction en elle-même complexe, « tout ou rien »

Mode opératoire et enseignements
• Le concours en quelques étapes:
• Quelques enseignements
• Dans le cas de Kaggle, pas de travaux de mise en qualité des données
• Travaux de compréhension « univariée » des données
• Création de nouvelles variables
• Mise en concurrence de plusieurs algorithmes
• Tâtonnements pour l’optimisation de chaque algorithme
1. Un travail d’analyse préalable pour s’approprier le data set
2. Tant dans la préparation des données que dans les optimisations des modélisations, une approche itérative fondée sur l’intuition (autrement appelée « bidouille »)
3. Concernant Kaggle spécifiquement, peu d’effet « connaissance métier » - c’est la limite de l’exercice
4. Pas de « meilleur » modèle, mais DES modèles parfois meilleurs
5. Un travail d’équipe indispensable pour assembler les compétences outil et statistiques
Préparation des données et création de nouvelles variables Modélisations Optimisations Soumissions
Quelques semaines à quelques mois
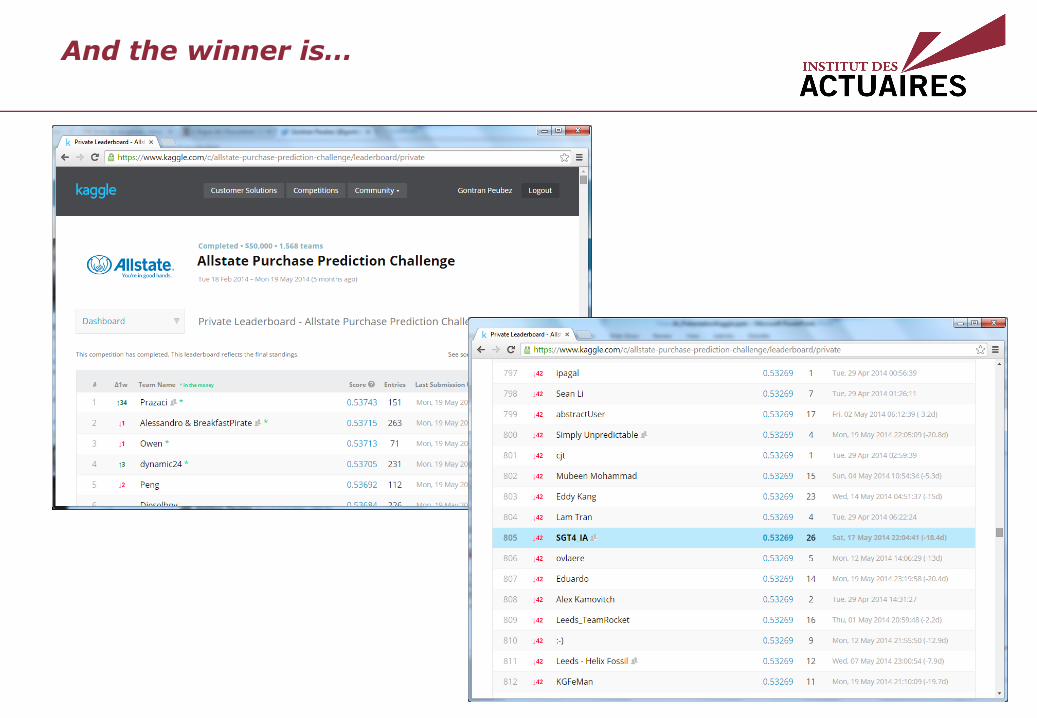
And the winner is…