vers une description efï¬cace du contenu visuel pour l
TRANSCRIPT

N˚ d’ordre : 9430
THESE
Pour obtenir le grade dedocteur en science
De l’Universit e d’Orsay, Paris-Sud 11
Specialite : Informatique
par
Nicolas HERVE
Vers une description efficace du contenu visuel
pour l’annotation automatique d’images
Soutenue le 8 juin 2009 devant la Commission d’examen composee de :
Francois YVON President du jury
Patrick GALLINARI Rapporteur
Francoise PRETEUX Rapporteur
Francois FLEURET Examinateur
Michael HOULE Examinateur
Nozha BOUJEMAA Directrice de these
These prepareea l’INRIA-Rocquencourt, Projet IMEDIA
http ://www-rocq.inria.fr/imedia

ii

Resume
Les progres technologiques recents en matiere d’acquisition de donnees multimedia ont
conduit a une croissance exponentielle du nombre de contenus numeriques disponibles. Pour
l’utilisateur de ce type de bases de donnees, la recherche d’informations est tres problematique
car elle suppose que les contenus soient correctement annotes. Face au rythme de croissance de
ces volumes, l’annotation manuelle presente aujourd’hui un cout prohibitif. Dans cette these,
nous nous interessons aux approches produisant des annotations automatiques qui tentent d’ap-
porter une reponsea ce probleme [HB09b]. Nous nous interessons aux bases d’images genera-
listes (agences photo, collections personnelles), c’est-a-dire que nous ne disposons d’aucuna
priori sur leur contenu visuel. Contrairement aux nombreuses basesspecialisees (medicales, sa-
tellitaires, biometriques, . . . ) pour lesquelles il est important de tenir compte de leur specificite
lors de l’elaboration d’algorithmes d’annotation automatique, nous restons dans un cadre gene-
rique pour lequel l’approche choisie est facilement extensible a tout type de contenu.
Pour commencer, nous avons revisite une approche standard basee sur des SVM et examine
chacune desetapes de l’annotation automatique. Nous avonsevalue leur impact sur les perfor-
mances globales et propose plusieurs ameliorations. La description visuelle du contenu et sa
representation sont sans doute lesetapes les plus importantes puisqu’elles conditionnent l’en-
semble du processus. Dans le cadre de la detection de concepts visuels globaux, nous montrons
la qualite des descripteurs de l’equipe Imedia et proposons le nouveau descripteur de formes
LEOH [HB07a]. D’autre part, nous utilisons une representation par sacs de mots visuels pour
decrire localement les images et detecter des concepts plus fins. Nous montrons que, parmi
les differentes strategies existantes de selection de patches, l’utilisation d’unechantillonnage
regulier est plus efficace [HBH09]. Nousetudions differents algorithmes de creation du vocabu-
laire visuel necessairea ce type d’approche et observons les liens existants avec les descripteurs
utilises ainsi que l’impact de l’introduction de connaissancea cetteetape. Dans ce cadre, nous

iv Resume
proposons une nouvelle approche utilisant des paires de mots visuels permettant ainsi la prise en
compte de contraintes geometriques souples qui ontete, par nature, ignorees dans les approches
de type sacs de mots [HB09a]. Nous utilisons une strategie d’apprentissage statistique basee
sur des SVM. Nous montrons que l’utilisation d’un noyau triangulaire offre de tres bonnes per-
formances et permet, de plus, de reduire les temps de calcul lors des phases d’apprentissage et
de prediction par rapport aux noyaux plus largement utilises dans la litterature. La faisabilite
de l’annotation automatique n’est envisageable que s’il existe une base suffisamment annotee
pour l’apprentissage des modeles. Dans le cas contraire, l’utilisation du bouclage de pertinence,
faisant intervenir l’utilisateur, est une approche efficace pour la creation de modeles sur des
concepts visuels inconnus jusque la, ou en vue de l’annotation de masse d’une base. Dans ce
cadre, nous introduisons une nouvelle strategie permettant de mixer les descriptions visuelles
globales et par sac de mots.
Tous ces travaux ontete evalues sur des bases d’images qui correspondent aux conditions
d’utilisation realistes de tels systemes dans le monde professionnel. Nous avons en effet montre
que la plupart des bases d’images utilisees par les academiques de notre domaine sont souvent
trop simples et ne refletent pas la diversite des bases reelles [HB07a]. Ces experimentations ont
mis en avant la pertinence des ameliorations proposees. Certaines d’entre elles ont permisa
notre approche d’obtenir les meilleures performances lorsde la campagne d’evaluation ImagE-
VAL [MF06].

Remerciements
Ce manuscrit est l’aboutissement de pres de trois ans de travaux de recherche. Si j’ai pu
effectuer cette these, c’est principalement en raison du soutien de deux personnes que je sou-
haite tres sincerement remercier. Tout d’abord Sabrina, pour avoir fait ensorte que cette these
se deroule dans une ambiance des plus sereines et pour son soutien permanent dans cette aven-
ture. Ce travail lui est dedie. Ensuite, ma directrice de these, Nozha Boujemaa. Elle m’a ouvert
les portes de l’equipe Imedia, accompagne et conseille tout au long de ma reflexion. J’ai par-
ticulierement apprecie ses points de vue sur notre domaine de recherche ainsi que laliberte
qu’elle m’a laissee sur l’orientation de mes travaux.
Les differents membres de l’equipe Imedia ontegalement contribue a la realisation de ces
travaux, que ce soit au travers de longues discussions scientifiques ou bien gracea l’ambiance
chaleureuse et au tres bonetat d’esprit qu’ils entretiennent. J’ai une pensee particuliere pour
Itheri Yahiaoui qui m’a aide a demarrer mes activites de recherche. Je souhaiteegalement re-
mercier Michel Crucianu, Alexis Joly, Marin Ferecatu et AnneVerroust-Blondet pour leur dis-
ponibilite et lesechanges enrichissant que nous avons eus. Enfin, l’equipe Imedia ne serait pas
tout a fait ce qu’elle est sans Laurence Bourcier que je tiensa saluer.
Je remercie vivement les membres du jury d’avoir pris le temps de se pencher sur mes
travaux. Leur lecture attentive de ce manuscrit et leurs remarques m’ont permis d’ameliorer
cette version finale. J’ai notamment beaucoup apprecie la collaboration avec Michael Houle sur
la comparaison des approches texte et image, ainsi que la visite au NIIa Tokyo qui en a decoule.
J’ai eu l’occasion de croiser de nombreux professionnels dumonde de l’image qui ont pris le
temps de m’expliquer leur travail et de me faire prendre conscience de leurs attentes. Je remercie
ainsi Sam Minelli, Stephanie Roger, Coralie Picault, Christophe Bricot, Denis Teyssoux et Tom
Wuytack, ainsi que les chercheurs de l’INA, Olivier Buissonet Marie-Luce Viaud.

vi Remerciements
De nombreuses personnes ont joue un role important dans le parcours atypique qui m’a
conduit a effectuer une these. Je pense en premier lieua mes parents pour tout ce qu’ils ont
fait et pour avoir su developper mon sens de la curiosite et mon esprit critique. Je les embrasse
chaleureusement. De nombreux enseignants sontegalement intervenus et il serait vain de tenter
de cerner leurs influences respectives. Je salue toutefois Valerie Gouet-Brunet, Michel Scholl et
Marie-Christine Costa du CNAM.
Enfin, toute mon affection pour Come qui lira peut-etre ces lignes un jour.

Table des matieres
Resume iii
Liste des figures x
Liste des tableaux xv
1 Introduction 1
1.1 Positionnement du probleme . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Contexte applicatif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 5
1.2.1 Agences photo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2.2 Collections personnelles . . . . . . . . . . . . . . . . . . . . . . . .. 12
1.2.3 Les moteurs de recherche . . . . . . . . . . . . . . . . . . . . . . . . .13
1.3 Approche generale et principales contributions . . . . . . . . . . . . . . . . . . 15
2 Approche globale 17
2.1 La recherche d’image par le contenu . . . . . . . . . . . . . . . . . .. . . . . 17
2.1.1 Description du contenu visuel . . . . . . . . . . . . . . . . . . . .. . 17
2.1.2 Modalites de requetes visuelles . . . . . . . . . . . . . . . . . . . . . 25

viii TABLE DES MATIERES
2.1.3 Evaluation des performances . . . . . . . . . . . . . . . . . . . . .. . 26
2.1.4 Malediction de la dimension . . . . . . . . . . . . . . . . . . . . . . . 28
2.1.5 Le gap semantique . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.2 Combinaison du texte et de l’image . . . . . . . . . . . . . . . . . . . .. . . 31
2.2.1 Recherche multimodale . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.2.2 Annotation automatique . . . . . . . . . . . . . . . . . . . . . . . . .32
2.3 Strategies d’apprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.3.1 K plus proches voisins . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.3.2 Boosting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.3.3 Machinesa vecteurs supports . . . . . . . . . . . . . . . . . . . . . . 41
2.4 Notre approche pour l’annotation globale . . . . . . . . . . . .. . . . . . . . 47
2.4.1 Etat de l’art . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
2.4.2 Contribution aux descripteurs globaux . . . . . . . . . . . . .. . . . . 50
2.4.3 Description de notre methode fondee sur les “approches SVM” . . . . 55
2.4.4 La campagne d’evaluation ImagEVAL - tache 5 . . . . . . . . . . . . . 57
2.4.5 Etude et discussion sur les differents parametres . . . . . . . . . . . . . 63
2.4.6 Analyse critique des bases d’evaluation existantes . . . . . . . . . . . . 69
2.4.7 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
2.5 Genericite des modeles pour l’annotation globale . . . . . . . . . . . . . . . . 75
3 Annotations locales 81
3.1 Etat de l’art . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
3.2 Analyse de la representation par sac de mots visuels . . . . . . . . . . . . . . . 83
3.2.1 Representation par sac de mots . . . . . . . . . . . . . . . . . . . . . . 84
3.2.2 Vocabulaire visuel . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3.2.3 Algorithmes de partitionnement . . . . . . . . . . . . . . . . . .. . . 86
3.2.4 Qualite des vocabulaires visuels . . . . . . . . . . . . . . . . . . . . . 88
3.2.5 Influence du nombre de patches par image . . . . . . . . . . . . .. . . 95

TABLE DES MATIERES ix
3.2.6 Lien entre dimension des descripteurs et taille du vocabulaire . . . . . 96
3.2.7 Introduction de connaissance pour la creation du vocabulaire . . . . . . 97
3.2.8 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
3.3 Etude comparee des strategies de selection de patches pour le texte et l’image . 98
3.3.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
3.3.2 Cadre generique de representation de documents . . . . . . . . . . . . 101
3.3.3 Evaluation des representations . . . . . . . . . . . . . . . . . . . . . . 102
3.3.4 Degradation du texte . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
3.3.5 Jeux de donnees et resultats de reference . . . . . . . . . . . . . . . . 104
3.3.6 Experimentations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
3.3.7 Resultats et discussions . . . . . . . . . . . . . . . . . . . . . . . . . . 113
3.4 Paires de mots visuels pour la representation des images . . . . . . . . . . . . 118
3.4.1 Motivations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
3.4.2 Extraction des paires . . . . . . . . . . . . . . . . . . . . . . . . . . .119
3.4.3 Experimentations sur Pascal VOC 2007 . . . . . . . . . . . . . . . . . 120
3.4.4 Resultats et discussion . . . . . . . . . . . . . . . . . . . . . . . . . . 121
3.4.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
3.5 Boucles de pertinence avec des representations par sacs de mots . . . . . . . . 127
3.5.1 Motivations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
3.5.2 Fonctionnement du bouclage de pertinence . . . . . . . . . .. . . . . 128
3.5.3 Combinaisons des representations globale et locale . . . . . . . . . . . 132
3.5.4 Methodes d’evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . 132
3.5.5 Resultats sur Pascal VOC 2007 et discussions . . . . . . . . . . . . . .134
3.5.6 Filtrage de la base d’apprentissage avec des boucles de pertinences si-
mulees . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
3.5.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
4 Conclusions 145

x TABLE DES MATIERES
4.1 Resume des contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
4.2 Perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .147
Bibliographie 149
A Annexes 169
A.1 Vocabulaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
A.2 Logiciel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
A.3 Esperance de la precision moyenne . . . . . . . . . . . . . . . . . . . . . . . . 170
A.4 Bouclage de pertinence, details pour quelques concepts visuels . . . . . . . . . 172
A.5 Les 17 principales categories IPTC . . . . . . . . . . . . . . . . . . . . . . . . 173

Table des figures
1.1 AFP - Photo de Rudy Giuliani . . . . . . . . . . . . . . . . . . . . . . . . .. 4
1.2 AFP - Des erreurs sur les mots-cles : ces trois photos sont annotees avecIN-
TERIOR VIEW . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3 Cycle de vie des photos dans une agence . . . . . . . . . . . . . . . . .. . . . 7
2.1 Quantification d’une image . . . . . . . . . . . . . . . . . . . . . . . . .. . . 20
2.2 Histogrammes RGB de deux images . . . . . . . . . . . . . . . . . . . . .. . 21
2.3 Detection des contours avec l’operateur de Canny . . . . . . . . . . . . . . . . 21
2.4 Evolution de la precision et de la precision moyenne en fonction de la propor-
tion de documents pertinents pour un classement aleatoire. . . . . . . . . . . . 28
2.5 Evolution de la precision moyenne en fonction de la proportion de documents
ramenes pour un classement aleatoire. . . . . . . . . . . . . . . . . . . . . . . 29
2.6 Les differents gaps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.7 Annotation automatique : apprentissage des modeles . . . . . . . . . . . . . . 34
2.8 Annotation automatique : prediction des concepts visuels . . . . . . . . . . . . 34
2.9 Le surapprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . 38
2.10 Illustration d’un classifieur k-NN . . . . . . . . . . . . . . . . .. . . . . . . . 40
2.11 Principe de minimisation du risque structurel . . . . . . .. . . . . . . . . . . 42

xii TABLE DES FIGURES
2.12 Quelques hyperplans lineaires separateurs valides . . . . . . . . . . . . . . . . 42
2.13 Hyperplan lineaire separateur ayant la marge maximale . . . . . . . . . . . . . 42
2.14 Quadrillage, jeu d’apprentissage synthetique . . . . . . . . . . . . . . . . . . . 45
2.15 Noyau triangulaire L2,evolution pour0.001 ≤ C ≤ 50 . . . . . . . . . . . . . 46
2.16 Noyau laplace,C = 10, evolution pour0.001 ≤ γ ≤ 10 . . . . . . . . . . . . . 47
2.17 Noyau RBF,C = 10, evolution pour0.001 ≤ γ ≤ 50 . . . . . . . . . . . . . . 48
2.18 Fourier, deux approches pour la partition en disques. Agauche, l’approche de
[Fer05] eta droite notre proposition. . . . . . . . . . . . . . . . . . . . . . . . 51
2.19 Quelques images de la base de textures et leur spectre deFourier . . . . . . . . 51
2.20 Quelques images de la base WonUK GTDB et leur spectre de Fourier . . . . . 52
2.21 Fourier, courbes precision/rappel pour la base Textures . . . . . . . . . . . . . 53
2.22 Fourier, courbes precision/rappel pour la base WonUK GTDB . . . . . . . . . 53
2.23 Fonctionnement du descripteur LEOH . . . . . . . . . . . . . . . .. . . . . . 54
2.24 ImagEVAL-5, liste des concepts . . . . . . . . . . . . . . . . . . . .. . . . . 59
2.25 ImagEVAL-5, autre representation de l’arbre des concepts . . . . . . . . . . . 59
2.26 ImagEVAL-5, quelques exemples de la base d’apprentissage . . . . . . . . . . 61
2.27 ImagEVAL-5, optimisation du noyau triangulaire . . . . .. . . . . . . . . . . 64
2.28 ImagEVAL-5, optimisation du noyau laplace, moyenne sur les 10 concepts . . . 64
2.29 ImagEVAL-5, optimisation du noyau laplace, Art . . . . . .. . . . . . . . . . 64
2.30 ImagEVAL-5, optimisation du noyau laplace, Indoor . . .. . . . . . . . . . . 65
2.31 ImagEVAL-5, optimisation du noyau laplace, Indoor . . .. . . . . . . . . . . 65
2.32 Quelques images de la base Corel2000 . . . . . . . . . . . . . . . . .. . . . . 70
2.33 Quelques images de la base Caltech4 . . . . . . . . . . . . . . . . . .. . . . . 71
2.34 Quelques images de la base Xerox7 . . . . . . . . . . . . . . . . . . .. . . . 72
2.35 Quelques images de la base Caltech101 . . . . . . . . . . . . . . . .. . . . . 74
2.36 ImagEVAL-5, quelques images de la categorie Color . . . . . . . . . . . . . . 76
2.37 Belga100k, quelques images d’information qui sont ignorees . . . . . . . . . . 77
TABLE DES FIGURES xiii
2.38 Belga100k, quelques images de la base . . . . . . . . . . . . . . .. . . . . . . 77
2.39 NRV, quelques images de la base . . . . . . . . . . . . . . . . . . . . .. . . . 78
2.40 Proportions de chaque concept dans les trois bases . . . .. . . . . . . . . . . . 79
2.41 Comparaison des precisions sur trois bases differentes pour le concept visuel
Indoor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
2.42 Comparaison des precisions sur trois bases differentes pour le concept visuel
Outdoor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
2.43 Comparaison des precisions sur trois bases differentes pour le concept visuel
Urban . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
2.44 Comparaison des precisions sur trois bases differentes pour le concept visuel
Natural . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
3.1 Representation par sac de mots visuels . . . . . . . . . . . . . . . . . . . . . .86
3.2 Pascal-VOC-2007, quelques images de la base d’apprentissage . . . . . . . . . 91
3.3 Pascal VOC 2007, descripteurs fou16 et eoh16, couverture et histogramme de
quantification pour des vocabulaires crees par tirage aleatoire . . . . . . . . . . 91
3.4 Pascal VOC 2007, descripteurs fou16 et eoh16, couverture et histogramme de
quantification pour des vocabulaires crees par les K-Moyennes . . . . . . . . . 91
3.5 Pascal VOC 2007, descripteurs fou16 et eoh16, couverture et histogramme de
quantification pour des vocabulaires crees par QT . . . . . . . . . . . . . . . . 92
3.6 Pascal VOC 2007, descripteurs fou16 et eoh16, couverture et histogramme de
quantification pour des vocabulaires crees par QT-10 . . . . . . . . . . . . . . 92
3.7 Pascal VOC 2007, descripteurs fou16 et eoh16, couverture et histogramme de
quantification pour des vocabulaires crees par Dual QT . . . . . . . . . . . . . 93
3.8 Pascal VOC 2007, descripteurs fou16 et eoh16, couverture des vocabulaires de
taille 250 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
3.9 Pascal VOC 2007, descripteurs fou16 et eoh16, quantification des vocabulaires
de taille 250 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
3.10 Pascal VOC 2007, descripteurs fou16 et eoh16, performance selon les algo-
rithmes de partitionnement . . . . . . . . . . . . . . . . . . . . . . . . . . .. 94
3.11 Pascal VOC 2007, descripteur prob64, couverture des vocabulaires de taille 250 94

xiv TABLE DES FIGURES
3.12 Pascal VOC 2007, descripteur prob64, quantification des vocabulaires de taille
250 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
3.13 Pascal VOC 2007, descripteur prob64, performance selon les algorithmes de
partitionnement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
3.14 Pascal VOC 2007,evolution de la MAP pour un vocabulaire de 50 mots en
fonction du nombre de patches extraits par image . . . . . . . . . .. . . . . . 96
3.15 Pascal VOC 2007,evolution de la MAP en fonction de la dimension des des-
cripteurs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
3.16 Pascal VOC 2007,evolution de la MAP pour un vocabulaire generique et pour
des vocabulaires bi-partites specifiquesa chaque concept . . . . . . . . . . . . 97
3.17 Differents types de regions extraites sur une photo . . . . . . . . . . . . . . . . 100
3.18 Reuters RCV1, exemple de fichier XML . . . . . . . . . . . . . . . . . .. . . 105
3.19 Reuters RCV1, distribution de la taille des mots . . . . . . .. . . . . . . . . . 106
3.20 ImagEVAL-4, exemples d’images contenant le drapeau americain . . . . . . . 108
3.21 Reuters RCV1,echantillonnage regulier avec une fenetre de taille 3 . . . . . . 111
3.22 ImagEVAL-4, gain de MAP moyen selon la taille de la fenetre par rapport aux
resultats de reference . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
3.23 ImagEVAL-4, localisation des patches SIFT, Harris et grille fixe . . . . . . . . 117
3.24 Schema illustrant le principe des paires de mots visuels. . . . . .. . . . . . . . 120
3.25 Pascal-VOC-2007, resultats pour les sacs de mots visuels standards . . . . . . . 122
3.26 Pascal-VOC-2007, resultats pour les paires de mots . . . . . . . . . . . . . . . 123
3.27 Pascal-VOC-2007, resultats pour les paires de mots en fonction du nombre de
patches extraits par image . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 125
3.28 Principe du bouclage de pertinence . . . . . . . . . . . . . . . . .. . . . . . . 128
3.29 Boucles de pertinence, exemple 1 . . . . . . . . . . . . . . . . . . .. . . . . . 130
3.30 Boucles de pertinence, exemple 2 . . . . . . . . . . . . . . . . . . .. . . . . . 131
3.31 Nouvelle approche du bouclage de pertinence combinantrepresentations glo-
bale et locale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
3.32 Pascal VOC 2007, bouclage de pertinence, simulation del’utilisateur STO . . . 136
3.33 Pascal VOC 2007, bouclage de pertinence, simulation del’utilisateur EQU . . . 136

TABLE DES FIGURES xv
3.34 Pascal VOC 2007, bouclage de pertinence, simulation del’utilisateur FIX . . . 137
3.35 Pascal VOC 2007, bouclage de pertinence, simulation del’utilisateur GRE2 . . 137
3.36 Pascal VOC 2007, bouclage de pertinence, nombre de clics par iteration en
fonction des strategies utilisateur . . . . . . . . . . . . . . . . . . . . . . . . . 138
3.37 Pascal VOC 2007, approche standard MP, proportion d’images pertinentes four-
nies pour l’apprentissage des SVM . . . . . . . . . . . . . . . . . . . . . .. . 139
3.38 Pascal VOC 2007, bouclage de pertinence, simulation del’utilisateur EQU, per-
formances en fonction du nombre de clics . . . . . . . . . . . . . . . . .. . . 139
3.39 Pascal VOC 2007, bouclage de pertinence, simulation del’utilisateur GRE2,
performances en fonction du nombre de clics . . . . . . . . . . . . . .. . . . 139
3.40 Pascal VOC 2007, comparaison des approches en fonctiondu nombre de clics . 140
3.41 Pascal VOC 2007, comparaison du nombre d’images pertinentes vues selon les
approches, en fonction du nombre de clics . . . . . . . . . . . . . . . .. . . . 141
3.42 Pascal VOC 2007, utilisation du bouclage de pertinencesimule pour filtrer les
images de la base d’apprentissage . . . . . . . . . . . . . . . . . . . . . .. . 141
A.1 Pascal VOC 2007, simulation utilisateur STO, concept visuelavion . . . . . . . 172
A.2 Pascal VOC 2007, simulation utilisateur STO, concept visuelbateau . . . . . . 172
A.3 Pascal VOC 2007, simulation utilisateur STO, concept visuelvache . . . . . . 173
A.4 Les categories IPTC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173

xvi TABLE DES FIGURES

Liste des tableaux
2.1 Quelques noyaux pour SVM . . . . . . . . . . . . . . . . . . . . . . . . . . .45
2.2 ImagEVAL-5, repartition des images de la base d’apprentissage . . . . . . . . 60
2.3 ImagEVAL-5, repartition des images de la base de test . . . . . . . . . . . . . 62
2.4 ImagEVAL-5, options pour la campagne officielle . . . . . . .. . . . . . . . . 62
2.5 ImagEVAL-5, resultats officiels . . . . . . . . . . . . . . . . . . . . . . . . . . 62
2.6 ImagEVAL-5, chaque descripteur seul . . . . . . . . . . . . . . . .. . . . . . 65
2.7 ImagEVAL-5, differentes versions defourier eteoh . . . . . . . . . . . . . . . 66
2.8 ImagEVAL-5, modification des performances par rapporta imd3 en retirant
chaque descripteur separement . . . . . . . . . . . . . . . . . . . . . . . . . . 67
2.9 ImagEVAL-5, test des noyaux triangulaire et laplace . . .. . . . . . . . . . . 68
2.10 ImagEVAL-5, test des noyaux RBF etχ2 . . . . . . . . . . . . . . . . . . . . . 68
2.11 Resultats sur la base Corel2000 . . . . . . . . . . . . . . . . . . . . .. . . . . 70
2.12 Resultats sur la base Caltech4 . . . . . . . . . . . . . . . . . . . . . .. . . . . 71
2.13 Resultats sur la base Xerox7 . . . . . . . . . . . . . . . . . . . . . . .. . . . 73
2.14 Resultats pour la base VOC2005-1 . . . . . . . . . . . . . . . . . . . .. . . . 73
2.15 Resultats pour la base VOC2005-2 . . . . . . . . . . . . . . . . . . . .. . . . 73
2.16 Resultats pour la base Caltech101 . . . . . . . . . . . . . . . . . . .. . . . . 74

xviii LISTE DES TABLEAUX
3.1 Reuters RCV1, nombre de documents contenant les requetes . . . . . . . . . . 106
3.2 Reuters RCV1, precisions moyennes pour le vocabulaireVB . . . . . . . . . . 107
3.3 ImagEVAL-4, nombre d’images et AP pour un tirage aleatoire . . . . . . . . . 109
3.4 ImagEVAL-4, resultats officiels . . . . . . . . . . . . . . . . . . . . . . . . . . 109
3.5 ImagEVAL-4, taille des vocabulaires obtenus avec QT . . .. . . . . . . . . . 110
3.6 Reuters RCV1, taille des vocabulaires pour l’echantillonnage regulier . . . . . 111
3.7 Reuters RCV1, vocabulaires liesa la detection de points d’interet . . . . . . . . 112
3.8 Reuters RCV1, ratio des precisions moyennes pour l’echantillonnage regulier
par rapport aux resultats de reference . . . . . . . . . . . . . . . . . . . . . . . 113
3.9 Reuters RCV1, precisions moyennes pour les points d’interet . . . . . . . . . . 114
3.10 Reuters RCV1, ratio des precisions moyennes pour les vocabulairesV1 etV2 par
rapport aux resultats de reference . . . . . . . . . . . . . . . . . . . . . . . . . 114
3.11 ImagEVAL-4, ratio des precisions moyennes pour les deux strategies par rap-
port aux resultats de reference . . . . . . . . . . . . . . . . . . . . . . . . . . 116
3.12 Pascal-VOC-2007, influence du choix du rayon . . . . . . . . . .. . . . . . . 123
3.13 Pascal-VOC-2007, detail des resultats par classe . . . . . . . . . . . . . . . . . 124
3.14 ImagEVAL-5, utilisation des differentes approches par sacs de mots combinees
aux descripteurs globaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . .126
3.15 Pascal-VOC-2007, detail des resultats d’annotation automatique sur la basetest
en apprenant les modeles sur la basetrainval avec les descripteurs globaux et
locaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
3.16 Pascal-VOC-2007, gain de MAP en utilisant le bouclage depertinence simule
sur 75 iterations pour filter la base d’apprentissage . . . . . . . . . . . . .. . . 142

CHAPITRE 1
Introduction
“La photographie a ouvert des horizons illimitesa la patho-
logie du progres, puisqu’elle nous a incitesa deleguera la
multitude de nos machines de vision le pouvoir exorbitant
de regarder le monde, de le representer, de le controler.”
Paul Virilio, urbaniste et essayiste francais
1.1 Positionnement du probleme
Le pouvoir des images est quelque chose de fantastique. Contrairement aux textes qui
necessitent du temps pouretre lus, nous saisissons et decryptons rapidement le contenu d’une
photo. Cette instantaneite et la confiance que l’on porte generalementa ce que nous voyons
incitent peua la prise de recul eta l’analyse. Les photos ont ainsi la capacite de faire surgir
immediatement toute une palette de sentiments chez ceux qui lesregardent : attrait, compas-
sion, indignation, indifference, desir, nostalgie, . . . Pourtant, une photo ne decrit pas la realite,
mais une realite, telle qu’elle est percue par son auteur. On parle d’ailleurs bien d’auteur et par-
fois d’ecriture photographique. A partir d’un contexte historique, en fonction de codes sociaux,
un photographe va decider de la maniere de restituer unevenement en fonction de sa propre per-
ception ou de l’idee qu’il souhaite vehiculer. Sciemment ou non, un photographe modele donc
la realite en vue de la restituer. De nos jours, les images sont presentes partout. Leur influence
dans nos societes est souvent primordiale. Elles sont utilisees pour temoigner de l’actualite, pour
illustrer les articles de journaux. Deja en 500 av. J.-C., le philosophe chinois Confucius disait

2 Introduction
“une image vaut mille mots”. Ce pouvoir a parfois conduita leur instrumentalisation et il arrive
que l’on assistea de vraies guerres de l’image lors de conflits militaires ou sociaux. Lorsque les
images ont pour but de faire vendre, la manipulation estevidente et souvent pernicieuse. Enfin,
il existe des images qui sont faites pour nous faire rever, qu’on admire simplement pour leur
esthetisme, parce qu’elles font appela notre imaginaire. Dans tous les cas, il est important de
savoir lire une image, de decoder les differents mecanismes. C’est un long apprentissage, mais
il est important.
Les progres technologiques recents en matiere d’acquisition de donnees multimedia ont
conduit a une croissance exponentielle du nombre d’images disponibles. On retrouve main-
tenant des bases d’images dans tous les domaines de la societe. On regroupe sous le terme
generiqueimagetout contenu visuel statique. Outre les photographies classiques, il peut s’agir
de dessins, tableaux, schemas ou encore d’images scientifiques. Leur seul point commun est
d’etre sous format numerique. On distingue deux types de bases d’images [SWS+00]. Les bases
generalistes ont une grande variabilite. On ne possede pas de connaissancesa priori sur leur
contenu. C’est typiquement le cas des agences de presse, des agences photo, des collections de
photo personnelles ou, plus largement, d’Internet. Concernant la volumetrie, l’ordre de grandeur
classique pour ces bases est le million. Sur Internet, on parle de plusieurs dizaines de milliards
d’images. En plus de l’acquisition toujours plus rapide de nouveaux contenus, des fonds d’ar-
chives sous forme argentique sont en cours de numerisation. A cote de ces bases generalistes,
on trouve de tres nombreuses bases specifiques. Elles se cantonnenta un domaine d’application
precis. On peut citer les bases scientifiques (biologie, medecine, botanique, astronomie, . . . ),
satellitaires (cartographie, meteo, agriculture, militaire, . . . ), securitaires (visages, empreintes
digitales, iris, . . . ) ou encore les archives culturelles (oeuvres d’art, numerisation des livres,
. . . ).
Nous nous interessons dans cette these aux bases generalistes. La navigation et la recherche
d’informations dans ces bases est une activite cruciale pour leurs utilisateurs. Traditionnelle-
ment, les images sont annotees et des moteurs de recherche texte classiques sont utilises. Les
approches et les algorithmes utilises dans ce cas sont directement issus du monde du traitement
du langage naturel. C’est par exemple l’approche utilisee par Google et Yahoo ! pour leurs fonc-
tionnalites de recherche d’images. Dans la plupart des cas, on distingue differents types d’an-
notations. Krauze [Kra98] distingue deux niveaux : le “hard indexing” ou “ofness” qui decrit ce
que l’on voit dans l’image et le “soft indexing” ou “aboutness” qui exprime la signification et le
contexte de l’image. Nous considererons les types d’annotations suivantes :
– globales: elles decrivent le type d’image (photo, graphique, croquis, imagede synthese,
. . . ) ou bien caracterisent la scene dans son ensemble (interieur, exterieur, jour, nuit, pay-
sage, ville, portrait, horizontal, vertical, . . . ).
– locales: elles permettent de decrire plus precisement le contenu de l’image et indiquent
la presence d’objets ou de personnes.

1.1 Positionnement du probleme 3
– contextuelles: elles serventa situer l’image. Ce qu’elles decrivent n’apparaıt pas di-
rectement sur l’image mais permet d’indiquer le lieu, la date ou l’auteur et de decrire
l’ evenement qui est pris en photo.
– subjectives: elleevoquent par exemple desemotions que l’image est supposee provoquer
(douceur, tristesse, colere, . . . ).
– techniques: telles que les reglages d’un appareil photo ou les caracteristiques des diffe-
rentselements d’une chaıne de numerisation.
Aujourd’hui les appareils photos sont capables d’ajouter automatiquement un certains nombre
d’annotations. Elles peuvent concerner les reglages techniques de l’appareil (ouverture, vitesse,
caracteristiques de l’objectif, declenchement du flash, balance des blancs, . . . ), le jour et l’heure
de la prise de vue, le nom du photographe. Ces annotations sontgeneralement regroupees dans
le format EXIF. Pour les appareils les plus perfectionnes, il estegalement possible d’avoir le
sens de prise de vue (horizontal ou vertical), une localisation geographique avec un GPS ou
bien l’indication de presence de visages sur la photo. En dehors de ces annotations techniques,
les autres sont generalement ajoutees manuellement. Il peut s’agir simplement de mots-cles ou
bien de phrases completes. Pour le cas particulier des images sur Internet, le texte entourant une
image sur une page web est souvent utilise pour la decrire, avec tous les aleas que cela suppose.
On fait alors facea deux problemes principaux dans la recherche d’images. On a, d’une part,
tous les inconvenients lies aux moteurs de recherche texte et inerantsa la langue (polysemie,
multi-linguisme, synonymes, hypernymes, hyponymes, . . . )et a la formulation des requetes.
Nous n’aborderons pas ces sujets dans le cadre de cette these. Une ontologie textuelle comme
Wordnet [Fel98] est souvent utilisee pour tenter d’y remedier [HSW06, Ven06, HN08].
Le second probleme est directement lie a la nature des images. La subjectivite de l’operateur
humain lors de l’annotation entre en ligne de compte. Deux personnes n’attribueront probable-
ment pas les memes mots-cles ou les memes descriptions pour une image donnee [BDG04,
Ror08]. Selon [Ven06], la probabilite que le meme terme soit choisi par deux individus pour
decrire une entite quelconque est bien inferieurea 20%. Avec l’utilisation d’un thesaurus conte-
nant un vocabulaire contraint, la probabilite ne depasse pas 70%. Au dela de la subjectivite des
iconographes qui annotent les images, il fautegalement tenir compte de la facon dont une meme
image peutetre interpretee dans des contextes ou des cultures differentes. Une autre possibilite
pour tenter de resoudre ce probleme est de faire en sorte que plusieurs personnes annotent une
meme image. C’est par exemple le cas sur Internet avecFlickr 1 ou l’annotation des photos est
ouvertea tout le monde. PourESP Game2 ou Google Image Labeler3, les images sont an-
notees avec un mot-cle uniquement si deux personnes differentes le choisissent en aveugle. Un
autre aspecta considerer est l’exhaustivite des annotations. Comment concevoir l’annotation
d’une image pour faire en sorte qu’elle soit bien retournee comme resultat d’une requete pour
1http ://www.flickr.com2http ://www.espgame.org3http ://images.google.com/imagelabeler/

4 Introduction
laquelle elle est pertinente ? Ce probleme est impossiblea resoudre. Il signifierait que toutes les
interpretations possibles d’une image soient retranscrites dans les annotations et que les utilisa-
tions potentielles soient envisagees. L’annotation manuelle est une operation couteuse en temps
et qui ne garantit pas une satisfaction totale.
A titre d’exemple, on a sur la figure 1.1 une photo de l’AFP avecles annotations qu’elle
comporte. On remarque que les annotations concernent principalement le contexte dans lequel
ObjectName BRITAIN-US-POLITICS-GIULIANICategory POLSuppCategory DiplomacyKeywords VERTICALCaption Former Mayor of New York andRepublican Presidential candidate Rudy Giuliani takesquestions from Celia Sandys, (not seen) granddaughterof former British Prime Minister Winston Churchill,during a visit to London, 19 September 2007. Earlier,Giuliani hailed the ”enduring friendship” between theUnited States and Britain Wednesday, while alsowelcoming new more pro-US leaders in Germany andFrance. Giuliani, speaking after talks with PrimeMinister Gordon Brown in London, noted that therewould always be disagreements like those over the2003 Iraq war, but said these would be overcome.
FIG. 1.1 – AFP - Photo de Rudy Giuliani
cette photo aete prise. Ces informations permettent facilement de retrouver l’image si on sou-
haite illustrer un article concernant la rencontre dont il est question. En revanche, le fait que
cette photo soit prise en interieur, ainsi que la presence des drapeaux americains, ne sont pas
mentionnes. Comment, alors, retrouver cette imagea partir de la requete “Giuliani + indoor +
US flag” ? Dans le corpus normalise de l’AFP, les photos d’interieur doiventetre annotees avec
le mot-cle “Interior view”. En effectuant une recherche sur une base de 100 000 images que cette
agence a misesa notre disposition, on trouve des erreurs. Quelques exemples sont presentes sur
la figure 1.2. On voit de plus qu’il n’y a pas de reelle homogeneite dans l’attribution des mots-
cles. Elles sont tres parcimonieuses pour la photo de Giuliani et tres completes pour la photo
des policiers devant la mosquee. Toutefois, les fusils, qui sont unelement important de la photo,
n’apparaissent pas dans les annotations.
Facea ce constat un nouveau domaine de recherche a fait son apparition : la recherche
d’images par le contenu (Content Based Image Retrieval, CBIR). Le but est de se baser di-
rectement sur le contenu visuel des images et sur leur analyse pour naviguer et effectuer des
recherches dans les bases de donnees d’images. Cette nouvelle modalite a ouvert des possi-
bilit es pour les utilisateurs. La recherche par le contenu visuelpermet de compenser certains
defauts des descriptions textuelles. Elle s’est revelee efficace et tres utile dans de nombreux

1.2 Contexte applicatif 5
HORIZONTAL HORIZONTAL MIDDLE EAST, AFTER THE WAR, POLICE,BORDER STADIUM MOSQUE, RUINS, DAMAGE, RELIGIOUSINTERIOR VIEW RUGBY BUILDING, INTERIOR VIEW, SHIITE,WORKER ILLUSTRATION FLAG, DESTRUCTION, CONFLITCARD GAME GENERAL VIEW INTERCOMMUNAUTAIRE, CONSQUENCES OF WAR,
INTERIOR VIEW VERTICAL
FIG. 1.2 – AFP - Des erreurs sur les mots-cles : ces trois photos sont annotees avecINTERIORVIEW
domaines d’application. Toutefois, cette approche possedeegalement ses propres limitations.
Nous aborderons plus en detail cet aspect dans la section 2.1.2.
Il apparaıt alors que la combinaison des deux sources d’informations, textuelle et visuelle,
est primordiale pour augmenter l’efficacite de l’interrogation des bases d’images [Ino04]. Il
existe deux principales voies de recherche pour cela. On peut d’une part utiliser conjointement
les deux types d’information au moment de la recherche en harmonisant leurs representations
et les paradigmes de requete [FBC05]. D’autre part, l’annotation automatique propose d’ap-
prendre des modeles pour un certain nombre de concepts visuels. Ces modeles sont ensuite
utilises pour predire la presence des concepts sur les images et generer ainsi de nouvelles anno-
tations.
1.2 Contexte applicatif
On trouve quelques travaux qui se penchent sur les besoins des utilisateurs [AE97, Orn97,
MS00, ESL05, TLCCC06, Han06, Pic07], mais ils sont assez rares.Dans [CMM+00] les re-
quetes sur les bases d’images sont classees en trois grandes categories :
1. recherche d’une image specifique: l’utilisateur doit trouver une image specifique dans
la base. C’est la seule qui puisse le satisfaire, l’interrogation de la base ne pourra pas
se terminer avec une autre image, quel que soit son degre de similarite (visuel et/ou
semantique) avec ce que l’utilisateur a en tete. Ce type de requetes arrive par exemple
lors de la recherche d’une photographie historique, d’un portrait de personne celebre ou
d’une photographie d’unevenement particulier. De maniere plus generale, un utilisateur

6 Introduction
peut se rappeler visuellement d’une photographie qu’il a deja vue et souhaite la retrouver.
On doit toutefois avoir la certitude que cette image est bienpresente dans la base.
2. recherche d’une image appartenanta une certaine categorie : l’utilisateur cherche un
certain type d’image, par exemple les photos de chiens, des paysages de montagne ou
encore des matches de basket.
3. navigation libre: l’utilisateur decouvre la base et/ou navigue sans but precis. Typiquement
un utilisateur peut commencer par une recherche particuliere et profiter des differents
resultats pour decouvrir d’autres aspects. Le but de la recherche peut ainsievoluer et
changer plusieurs fois au cours d’une session en fonction des options de recherche qui
sonta sa disposition.
On doit toutefois bien distinguer qu’il existe deux types d’utilisateurs : les producteurs et les
consommateurs de contenu. Dans le cadre de cette these, nous nous interessons aux bases
generalistes. Dans le monde professionnel, les principaux producteurs de contenu sont donc
les agences photo, les agences de presse et les photographesindependants. Leurs clients tra-
ditionnels sont la presse, les institutions et les entreprises. Pour les particuliers, la distinction
entre producteur et consommateur est plus floue.
1.2.1 Agences photo
A travers differents projets de recherche, nous avons pu rencontrer des acteurs profession-
nels etevaluer leurs besoins. Ainsi, dans le cadre d’ImagEVAL, nous avons visite les locaux
de l’agence Hachette Photo (revendue et demantelee depuis). Cela nous a permis de decouvrir
leur metier. Plusieurs personnes interviennent au long du cycle de vie d’une photo au sein d’une
agence :
– photographe : effectue les prises de vue et fournit les premieres annotations
– editeur : selectionne les photos et possede une vue d’ensemble du fonds
– documentaliste : annote completement les photos
– commercial : recueille les besoins du client et effectue les recherches
– client final : a besoin d’une photo particuliere, effectueeventuellement une recherche ou
bien la delegue au commercial
Une agence peut gerer deux types de fonds photographique. Le premier concerne les photos
d’actualite pour lequel le cycle prise de vue/annotation/diffusion/publication est extremement
court. Il n’est pas rare que dans ce cas le travail du documentaliste soit assez restreint. Les
photos sont souvent envoyees directement au client sans qu’il en ait fait la demande. Acharge
pour lui de prendre celles qui l’interessent. Les relations entre une agence photo et ses clients
sont generalement basees sur la confiance. Il n’est donc pas rare que le client ait acces aux
photos. Il ne paye que celles qu’il publie effectivement. Ledeuxieme type de fonds est constitue
des photos d’archive. Nous mettons sous cette denomination toutes les photos qui n’ont pas

1.2 Contexte applicatif 7
trait a un fait d’actualite recent. Il regroupe donc les anciennes photos d’actualite, les photos
d’illustration, les archives historiques, . . . . Dans tous les cas, les photos sont regroupees en
reportage. Un reportage a generalement une unite thematique et temporelle, ainsi qu’un auteur
unique. Le schema 1.3 resume le cheminement classique suivi par un reportage photo.
FIG. 1.3 – Cycle de vie des photos dans une agence
On y retrouve lesetapes suivantes :
1. le photographe propose un reportage sur lequel il a travaill e ou bien qui lui aete com-
mande
2. il fournit egalement une description globale de ce reportage eteventuellement de chaque
photo
3. le documentaliste reprend ces annotations, les verifie et les complete. Des contraintes et
des regles d’annotations plus ou moins fortes peuventetre definies auxquelles les docu-
mentalistes et les photographes doivent se soumettre. Il s’agit generalement de l’utilisa-
tion de vocabulaires predefinis et de formalisme sur les legendes (lieu / date /evenement
/ personnes presentes / . . . )
4. les photos sont ensuites stockees dans le fonds photographique
5. le client final souhaite obtenir une photo pour illustrer un theme particulier. Il effectue
une recherche ou, beaucoup plus frequemment, il decrit ce qu’il souhaite au commercial
qui est charge de la recherche.
6. le commercial doit alors trouver des photos susceptiblesde satisfaire le client. Il doitetre
capable de trouver des photos qui repondenta la demande sur le fond maisegalement sur
la forme (en tenant compte de la politiqueeditoriale, de la charte graphique, . . . ).

8 Introduction
7. le resultat de ces recherches est envoye au client.
Il existe bien sur quelques variantesa ce scenario. Il arrive par exemple souvent que le reportage
soit mis dans le fonds photographique des sa receptiona l’agence. Il peut ensuiteeventuellement
etre visualise par unediteur qui fera un tri pour ne conserver que certaines photos. Seules ces
photos seront annotees par les documentalistes et disponibles pour les clients. Ce cas est typique
lors de la reprise des fonds argentiques. L’etape de numerisationetant longue, seules les photos
ayant un fort potentiel sont conservees. Avec l’avenement des nouvelles technologies web, la
plupart des agences proposent maintenant un acces en lignea leurs clients qui peuvent effectuer
eux-memes les recherches.
On distingue dans le decoupage de ce processus entre les differents intervenants une separa-
tion nette entre les producteurs et les consommateurs de contenu. Cette separation est potentiel-
lement un facteur de difficulte s’il n’y a pas d’echange entre eux. Il est important que chacune
de ces parties connaisse et comprenne le travail de l’autre afin d’adapter son propre travail pour
faciliter et ameliorer l’ensemble.
On peut avoir trois niveaux dans la demande du client :
– La demande peutetre extremement precise et ne porter que sur une photo particuliere. Il
arrive parfois que le client faxe une version de la photo souhaitee ou bien la decrive assez
precisement.
– Le client doit illustrer unevenement ou une thematique et cherche une ou deux photos
percutantes. Dans ce cas, le commercial doit tenir compte dela ligneeditoriale du journal
ou de la charte graphique pour une publicite.
– Le client souhaite un reportage complet sur une thematique transversale qui n’a pas en-
coreete indexee. Le commercial travaille dans ce cas avec unediteur pour constituer une
selection dans le fonds d’archive, ou, parfois, envoyer un photographe sur le terrain.
Dans tous les cas, le commercial utilise le moteur de recherche de l’agence pour trouver les
photos adequates. Nous avons pu remarque que cette recherche s’effectue souvent en deux
etapes. Dans un premier temps, les bons mots-cles pour couvrir la thematique sont devines.
Puis, au bout de quelques essais / erreurs, le commercial a cerne un ensemble de photos qu’il
filtre visuellement en les passant toutes en revue.
Picault [Pic07] a realise uneetude sur le comportement des utilisateurs du moteur de re-
cherche d’images de l’agence Gamma4 (qui faisait partie d’Hachette Photo et qui aete reprise
par Eyedea depuis). Elle distingue deux niveaux chez les personnes qui utilisent cette interface
web : les utilisateurs “novices” et les usagers “assidus”. Selon elle,un individu est dans un pre-
mier temps utilisateur du systeme. Plus il auraa utiliser ce dernier de maniere autonome, plus
il devra mobiliser certaines competences, aussi bien techniques que cognitives. La maıtrise
du dispositif technique lui donnera alors le statut d’usager. Mais l’acquisition des savoirs et
4http ://www.gamma.fr

1.2 Contexte applicatif 9
savoir-faire qu’induit ce dispositif n’est pas immediate nievidente.Son enquete aete realisee
aupres de 760 clients de l’agence (presse : 47%,edition : 22%, publicite : 20%, . . . ). Elle a
consiste en des entretiens, l’observation du comportement des commerciaux et l’analyse des
requetes effectuees sur le site. Une de ses premieres constatations est que si les commerciaux
sont globalement de veritables usagers, les clients finaux rencontrent plus de difficultes avec
la banque d’images sur Internet. Elle note toutefois que certains d’entre eux ont developpe des
methodes et des habitudes de recherche. C’est la un des principaux points de sonetude :de plus
en plus autonomes, comment les clients cherchent-ils les images dont ils ont besoin,a partir des
mots ? Developpent-ils de veritables strategies de recherche ou se limitent-ilsa des requetes
simples ?La grande majorite utilise presque uniquement la fonctionnalite de recherche simple
(86%). Les options de recherche avancee (operateurs booleens, requetes sur les mots-cles, . . . )
sont souvent delaissees. Outre des problemes d’interface, les difficultes liees au langage docu-
mentaire developpe pour l’indexation d’images sont pointees. En dehors des incoherences po-
tentielles au sein du catalogue de cette agence, il faut noter que la plupart des clients consultent
diff erents sites pour trouver des images. Ils ne peuvent donc consulter et apprendre les langages
documentaires de chacun d’entre eux. De plus, Picault expliqueegalement ce delaissement de
la recherche avancee par lesyndrome de l’ere numeriquequ’est la vitesse. La recherche simple
est le moyen le plus rapide pour acceder aux images. Deux pratiques differentes sont alors
identifiees pour trouver l’image souhaitee parmi le nombre important qui est retourne : soit la
navigation, soit le raffinement de la requetea partir des mots-cles suggeres par le moteur.
Interroges sur l’interet d’outils d’annotation automatique dans leur chaıne de traitement des
images, les professionnels d’Hachette nous repondent :
“Nous pensons qu’un certain nombre d’informations techniques et de contexteselementaires
li esa l’image peuvent faire l’objet d’un traitement automatique (Ex : image en hauteur, image
en largeur, image en couleur, image en noir et blanc, virage sepia, . . . ). De meme des contextes
elementaires pourraientetre calcules sur chaque image (Ex : Presence de personnage, image
de jour, image de nuit, . . . ). Les differents flux que nous gerons appartiennenta des sources
identifiees possedant des types de productiona thematique generalement constantes. Afin de
limiter les risques d’annotations inutiles ou fausses nouspourrions imaginer de traiter les flux
selon des grandes thematiques : Actualite internationale, Show-bizz, Illustration voyage, Illus-
tration vie quotidienne, . . . . Dans chaque thematique nous pourrions imaginer des annotations
de types differents. Par exemple il est inutile de cherchera reconnaıtre un personnage de sujet
d’illustration. En revanche nous allonsetre tres attentifs aux dominantes de couleurs pour les
images d’illustration et de voyage. Pour les images d’actualit e, d’archives et de show-bizz nous
aimerions pouvoir utiliser des modules de reconnaissance automatique de personnages. Nous
pourrions imaginer alimenter un trombinoscope de reference pour les personnes recherchees et
un module pourrait tenter de retrouver ces personnes apres analyse de l’image. Nous aimerions
egalement pouvoir utiliser des modules de reconnaissance automatique d’objets et d’acces-

10 Introduction
soires. Comme dans l’exemple precedent nous pourrions imaginer constituer une bibliotheque
de reference des objetsa rechercher eta annoter (Ex : Saca main, chapeau, lunettes de soleil,
. . . ). Pour les images d’illustration nous pourrions envisager d’autres objets de references avec
pour preconisation d’annoter seulement les images possedant ces objets ou des parties d’objets
sur une surface significative des images annotees.”. Ils nous precisentegalement que l’annota-
tion automatique d’images permet de soulager l’utilisateur d’une partie du travail fastidieux. Il
faut toutefois bien gardera l’esprit que le but principal est de permettre une recherche efficace
dans les bases d’images. L’exactitude des annotations generees, leur coherence avec la politique
editoriale et leur utilite sont donc des criteres importants dont il faut tenir compte.
Le marche de la vente d’images est tres competitif et tenda se globaliser. Les detenteurs de
contenu doivent adapter leur processus de travail pour des utilisations sur Internet qui necessitent
une forte reactivite dans la misea disposition du contenu. Pour les images d’actualite, plus le
contenu est en ligne rapidement, plus il a de chance d’etre vendu. Les systemes doivent donc
integrer ces contraintes tout en maintenant leurs objectifs dequalite. Une caricature des biais
induits par la disponibilite sur Internet des photos est observee chez certaines agences photo qui
ont tendancea sur-annoter leurs contenus avec de tres nombreux mots-cles redondants, souvent
sans reel lien avec l’image, en esperant ainsi que les images soient retournees comme resultats
pour differentes requetes. De maniere generale, la tendance actuelle pour l’actualite est d’etre
capable de fournir du contenu tres rapidement. Le contenu est souvent diffuse en n’etant que
tres peu annote dans un premier temps. Aussi les possibilites de post-annotation doiventetre
facilitees (reprise de reportages d’actualite, anticipation d’evenement, creation de collections,
. . . ). Pour les fonds d’archive, les agences doivent fournirdes notices tres detaillees pour pou-
voir vendre leurs photos. De plus en plus, elles constituentmemes des reportages complets,
cle en main, pretsa etre publies. Elles se substituent de plus en plus au travail des journaux et
magazines. Il n’est plus rare aujourd’hui de voir des journalistes de la presseecrite embauches
dans des agences photos pour rediger ces reportages.
Belga5 est une agence de presse belge (equivalent de l’AFP en France). Elle diffuse en
temps reel des depeches et des photos en plusieurs langues. Ces images de pressesont divisees
en deux categories generales. Les imageseditoriales concernent unevenement concret (poli-
tique, economie, personnalites, sport, art, loisir, sante, sciences, environnement, mouvements
sociaux, . . . ). Les images “creatives” ont un contenu plus artistique et intemporel. Elles sont
plus souvent utiliseesa titre d’illustration (nature, idees, travail, style de vie, . . . ). La gestion
de la base d’images est assuree quotidiennement par uneequipe d’iconographes. Leur tache
est d’indexer, d’annoter et de mettre en valeur le flux d’images qui arriventa l’agence de la
part de ses photographes, d’independants ou bien d’agences partenaires. Une autreequipe a
en charge la creation de collections thematiques. De plus certaines personnes doivent en per-
manence retravailler sur les images d’archive. Comme la plupart des agences, Belga cherche
5http ://www.belga.be

1.2 Contexte applicatif 11
a valoriser son fonds numerise (3 millions d’images) en l’enrichissant, maisegalement toutes
les archives qui sont encore sous forme argentique et qui ne sont quasiment pas annotees. Les
problematiques decrites par Belga recoupent celles que nous avons pu observer chez Hachette
ou encorea l’AFP.
Le format des annotations aete standardise dans la pressea travers l’IPTC (Internatio-
nal Press Telecommunications Council) 6. Cette normalisation des metadonnees permet de les
integrer directement dans les fichiers contenant les photos. Onretrouve ainsi des en-tetes IPTC
dans les fichiers JPEG (principal format utilise actuellement). On trouvera en annexe (page
173) les categories standards permettant de classer les grandes thematiques. Des sous-categories
existentegalement. L’EPA (European Photo Agency) edite un guide indiquant comment remplir
les champs IPTC et lesquels sont obligatoires ou optionnels. Certains champs IPTC peuventetre
remplis automatiquement (orientation de l’image, couleur/ noir et blanc, date de prise de vue,
. . . ), mais la majorite necessite une intervention humaine. Selon les cas, ils sont remplis direc-
tement par le photographe ou plus tard par les iconographes.Bien que l’IPTC soit un standard,
chaque agence de presse conserve sa propre politique d’annotation.
Pour des structures plus petites, les problemes sont legerement differents. Il y a quelques
annees nous interrogions Gerard Vandystadt. Il est le fondateur de l’agence photo specialisee
dans le sport qui porte son nom7. Il se declarait tres sceptique sur l’utilite d’outils d’annotation
automatique dans son cas. En effet, malgre les dizaines de milliers de photos qu’il gere, il a une
parfaite connaissance du fonds photographique de son agence et ne voyait pas l’interet d’avoir
d’autres informations que les annotations contextuelles.Concernant la visibilite de ses images
dans des moteurs de recherche, la qualite des photograhies fournies par son agence, lamarque
Vandystadt, suffit amplementa assurer la diffusion.
Christophe Bricot est un photographe independant specialise dans le sportequestre8. Lui
aussi connaıt parfaitement ses images. Ses principaux problemes concernent la diffusion des
photos en temps reel. Il nous explique les dispositifs qui sont actuellementinstalles dans les
salles de presse desevenements sportifs. Chaque photographe amene son ordinateur portable.
Ce dernier est connecte a internet et est de plusequipe d’une connexion wifi. Un boitier wifi
estegalement attache a l’appareil photo. Ainsi, les photographes envoient leursphotos des la
prise de vue sur leur ordinateur portable, alors qu’ils sontencore sur le terrain. La, un logiciel
se charge d’annoter les images avec le minimum d’informations (auteur, lieu, date, nom de
l’ evenement) et les envoie automatiquement aux agences de presse.
6http ://www.iptc.org7http ://www.vandystadt.com8http ://bricot.christophe.free.fr

12 Introduction
1.2.2 Collections personnelles
On distingue deux principales utilisations qui sont faitesdes photos prises par les particu-
liers. De facon classique, dans la droite ligne des habitudes acquises du temps des photos argen-
tiques, les photos numeriques sont stockees sur ordinateur ou cd-rom. Elles sonteventuellement
imprimees pouretre conservees dans un album traditionnel. La consultation des archives reste
dans le cadre familial. Le manque de structuration dans ce type de collection et souventevoque
sous l’appelation de “boıte a chaussures” (shoebox). Rodden [RW03] aetudie la facon dont
les photos personnelles sont organisees. Il conclut que les utilisateurs sont relativement peu
interesses par des fonctionnalites d’annotation de leurs images puisqu’ils connaissent leurs pho-
tos et que l’effort necessaire est trop grand.
En revanche, l’apparition des reseaux sociaux, d’outils comme Picasa9 ou des sites de par-
tages de photos comme Flickr faitemerger de nouveaux besoins. Ces services connaissent un
succes phenomenal. Selon uneetude de comScore10, Flickr aurait actuellement 3.4 milliards
de photos et une croissance de 90 millions par mois. Facebook, dont ce n’est pas la vocation
premiere, est en train de devenir le principal hebergeur de photos sur le net avec 15 milliards
d’images disponibles et une croissance de 850 millions d’ajouts par mois. Les usages sont sen-
siblement differents entre Flickr et Facebook. Le premier est plus facilement utilise par les
photographes professionnels ou semi-professionnels. L’idee maıtresse est le partage des photos
et faire en sorte qu’elles soient vues par le plus grand nombre. La qualite esthetique est sou-
vent mise en avant. L’ensemble des outils qui sont misa la disposition des utilisateurs visenta
favoriser l’annotation et le classement des photos. On trouve quelquesetudes recentes sur les
comportements des utilisateur de Flickr. Zwol [vZ07] analyse la facon dont les internautes y
visualisent les images. Negoescuet al. [NGP08] etudient la facon dont les photos y sont re-
groupees. Sur Facebook en revanche, l’hebergement de photos est principalement tourne vers
l’identification des personnes presentes sur les cliches. La consultation de ces images est plus
restreinte et generalement reservee au cercle des relations proches. Le fait que les collections de
photos personnelles sortent du cadre strictement familialpouretre accessibles via Internet rend
plus que jamais necessaire les outils pour parcourir et chercher dans ces masses de donnees.
Il est probable que les conclusions de Rodden [RW03], vraies il y a quelques annees,evoluent
maintenant. En effet, les collections de photos n’etant plus reserveesa leurs seuls auteurs, leur
connaissance n’est plus assuree pour les personnes qui les consultent. En revanche, l’effort
necessairea l’annotation manuelleetant toujours present, les outils d’annotation automatique
sont promisa un bel avenir sur ce type de sites pour peu qu’ils reussissenta repondrea des
besoins concrets. On peut par exemple citer Riya11 qui permet de reconnaıtre automatiquement
les personnes dans les photos.
9http ://picasa.google.fr10http ://www.pcinpact.com/actu/news/50236-imageshack-facebook-rois-hebergement-photos.htm11http ://www.riya.com

1.2 Contexte applicatif 13
Chorus12(Coordinated approacH to the EurOpean effoRt on aUdio-visualSearch engines)
est une action de coordination qui tente de faire le point surles besoins et les orientations de
la recherche scientifique europeenne. Dans un rapport paru l’an dernier [ODN+08] il est ex-
plique que la distinction entre les utilisateurs professionnelset occasionnels va progressivement
disparaıtre concernant les moteurs de recherche multimedia. On assiste deja a l’erosion de la
barriere entre producteur et consommateur de contenu. Par exemple, on voit de plus en plus
fleurir des agences qui commercialisent sur Internet les photos de bonne qualite faites par des
particuliers (microstock13).
1.2.3 Les moteurs de recherche
On trouve dans [ODN+08] deux reponsesa la question : “quels problemes les moteurs de
recherche tentent-ils de resoudre ?”. La premiere, plutot classique est de dire qu’un moteur de
recherche aide l’utilisateura trouver ce qu’il cherche. Une seconde proposition, moins ortho-
doxe, serait de dire qu’un moteur de recherche essaye de faire de son mieux avec ce qu’il sait
pour fournir a l’utilisateur une information utile bien que ce dernier formule ses requetes de
facon pauvre et generalement inattendue. Cette seconde formulation met en avant plusieurs
points importants. Un moteur de recherche ne peut travailler qu’a partir de l’information dont
il a connaissance, c’est-a-dire l’ensemble des metadonnees qui aurontete fournies ou extraites
des images. Il importe donc de mettre l’accent sur l’extraction de ces metadonnees puisqu’elles
sont d’un interet capital pour la suite. L’utilisateur exprime ses requetes de facon pauvre. Il y
a generalement un gap assez large entre l’intention de l’utilisateur et la maniere dont il l’ex-
prime, c’est-a-dire la maniere dont le systeme le comprend. Reduire ce gap est un des roles
principaux des moteurs de recherche. Ce probleme est potentiellement plus difficile pour les
moteurs multimedia que pour les moteurs texte. Enfin, nous l’avons deja evoque, il n’est pas
possible d’anticiper les requetes. Cet aspect est ce qui distingue un moteur de recherche d’une
simple base de donnees, ce qui oblige l’utilisateura trouver des moyens alternatifs pour obte-
nir l’information qu’il souhaite. La force d’un bon moteur de recherche est de lui fournir toute
l’assistance dont il peut avoir besoin pour cette tache.
Traditionnellement, les moteurs de recherche operent en deuxetapes. Dans un premier
temps, une phase d’enrichissement du contenu et de structuration de la base est executee.
Generalement l’utilisateur n’intervient pasa cetteetape. La seconde phase, interactive, cor-
respond au cycle requete / recherche des images / presentation des resultats. Un bon moteur de
recherche doit trouver l’equilibre entre toutes cesetapes pour maximiser l’efficacite globale du
systeme.
12http ://www.ist-chorus.org13http ://fr.wikipedia.org/wiki/Microstock

14 Introduction
Le volume du contenu numerique disponible augmente, avec un fort biais vers le contenu
non structure. Typiquement, le contenu genere par les utilisateurs est significativement moins
structure que le contenu professionnel. Dans ce cas, la generation automatique de metadonnees
est encore plus importante. De plus, ce volume de donnees est tel que les outils de recherche
vont bientot devenir le seul moyen d’acceder au contenu produit. L’INA (Institut National de
l’Audiovisuel) resume cela en une phrase : “Un fichier inaccessible est un fichier perdu”. Le
succes des moteurs de recherche sur Internet a declenche un phenomene qui se deploie bien
au dela de l’utilisation du web. Les utilisateurs souhaitent avoir des outils ayant le meme cote
intuitif et les memes performances aussi bien dans leur entreprise que chez eux. Ceci explique,
par exemple, la declinaison des moteurs de recherche en version personnelle(Google Desktop,
. . . ). Les moteurs de recherche sont aujourd’hui percus comme une application autonome, mais
ils vont de plus en plus tendrea s’integrer dans les differents environnements applicatifs. Typi-
quement, pour les bases de donnees d’images professionnelles, on se dirige vers une intercon-
nexion beaucoup plus forte entre les moteurs de recherche etles applications d’enrichissement
du contenu.
On a evoque le fait que les moteurs de recherche ne peuvent anticiper toutes les requetes des
utilisateurs. Pour cette raison, l’utilisateur, ainsi quela possibilite d’interagir avec le systeme,
joue un role crucial dans l’efficacite global d’une solution. De ce point de vue, plusieurs criteres
sonta considerer : la simplicite de l’interface, la facilite d’exploitation des resultats pour preparer
la requete suivante, le fait que le systeme soit previsible et que les resultats ne deroutent pas
l’utilisateur (ou,a defaut, que l’utilisateur comprenne pourquoi ces resultats lui sont presentes)
et enfin la capacite du systemea fournir des recommendations automatiques. Toutes ces fonc-
tionnalites sont faites pour faciliter le travail de l’utilisateur mais ne doivent pas le penaliser.
Les temps de reponse doivent donc bienevidemmentetre pris en compte. Plus precisement, il
faut que les gains obtenus par l’utilisateur soient suffisamment pertinents au regard des temps
d’attente qu’il est pret a consentir.
La recherche d’information multimedia basee sur le contenu en est encorea ses debuts,
et ce n’est que tres recemment que les premieres technologies sont sorties des laboratoires de
recherche pouretre accessibles au grand public. En France, la societe Exalead14 a introduit
un service de detection de visages dans son moteur de recherche d’images. Plus recemment,
Google a fait de meme dans le logiciel Picasa. On constate que globalement cestechnologies
commencent tout justea atteindre des niveaux de performance qui les rendent utilisables. Ainsi,
si les techniques de detection de visages fonctionnent bien pour les portraits engros plan, il
n’en est pas de meme pour les visages distants ou non-frontaux. Les prototypes de detection
d’objets fonctionnent sur des petits jeux de donnees mais n’ont pas de bons resultatsa l’echelle
d’Internet.
14http ://www.exalead.fr

1.3 Approche generale et principales contributions 15
1.3 Approche generale et principales contributions
Dans le cadre des bases d’images generiques, nous venons de voir que la distinction entre
les producteurs et les consommateurs de contenus tendaita s’amenuiser. De plus, ces deux
categories d’intervenants dans le cycle de vie des images utilisent quasiment les memes ou-
tils pour effectuer des operations differentes. Les moteurs de recherche sont au coeur de leurs
activites d’annotation et de recherche d’images. Ces moteurs travaillent sur les differentes an-
notations disponibles (voir page 2). Toutefois, il ne nous apparaıt pas opportun de distinguer
les annotations textuelles des autres metadonnees qui sont lieesa l’analyse du contenu visuel.
Toutes ces metadonnees sont des moyens d’acceder au contenu en utilisant le moteur de re-
cherche et les paradigmes de requete adequats.
A ce titre, nous souhaitons introduire la notion de “concept visuel” et la distinguer de la
notion de “mot-cle”. Souvent l’annotation automatique aete presentee comme une technique
permettant de generer des mots-cles pour les images. Nous y voyons deux problemes sous-
jacents. Il est important de bien gardera l’esprit que ce qui peutetre detecte dans une image
doit avoir un aspect visuel. Or de nombreux mots-cles representent des concepts qui ne sont
tout simplement pas visualisables. C’est le cas, par exemple, de toutes les informations contex-
tuelles qui devront toujoursetre ajoutees manuellement. Le deuxieme point sur lequel nous
voulons mettre l’accent est le fait que le systeme d’annotation ne prenne pas de decision bi-
naire sur la presence ou l’absence d’un concept visuel pour une image. Nouspensons qu’il est
preferable de laisser cette decisiona un operateur humain. Ainsi, nous envisageons l’annotation
automatique comme un moyen de generer un score de confiance ou une probabilite concernant
un concept visuel. Cette nouvelle metadonnee va pouvoir s’integrer dans le moteur de recherche
au meme titre que les autres et pourra servira naviguer dans la base,a la filtrer,a la categoriser,
. . . . On pourra voir par exemple les approches de Cioccaet al. [CCS09] ou Magalhaeset al.
[MCR08]. Les mots-cles et les concepts visuels sont de nature differente mais coexistent de
faconetroite. Leur similarite peut bienevidemmentetre exploitee lors de requetes textuelles.
Conserver cette distinction permet en outre une meilleure presentation des resultatsa l’utilisa-
teur qui comprend ainsi mieux le fonctionnement du systeme et est alors capable d’anticiper
son comportement et d’en tirer partie dans la formulation deses requetes. Cette approche est
donc davantage orientee vers l’ordonnancement des images plutot que vers une classification.
C’est pourquoi dans nosevaluations nous privilegierons les mesures de performances axees sur
la recherche d’information plutot que sur le taux de bonne classification.
Parmi les besoins des utilisateurs, la reconnaissance des personnes est tres souvent exprimee
(80% des demandes pour l’agence Gamma selon [Pic07]). Il existe de nombreuses approches
developpees specialement dans ce but que nous n’aborderons pas dans le cadre de cette these.
Nous etudions en detail une approche completement generique qui peut s’adaptera tous les

16 Introduction
concepts visuels. Nous nous interessonsa la production de ces nouvelles metadonnees et lais-
sonsegalement de cote tous les aspects liesa l’interface utilisateur.
Dans la premiere partie de la these, nous revenons sur la recherche d’images par le contenu
(CBIR) et presentons l’extraction de signatures visuellesa l’aide de descripteurs globaux. Nous
introduisons notamment le nouveau descripteur de formes LEOH. Nous introduisons ensuite
notre strategie d’apprentissage basee sur des SVM (Support Vector Machine) et l’appliquons
pour des concepts visuels globaux. Nousetudions en detail l’influence du choix des descrip-
teurs ainsi que les differents parametrages des SVM. Nous montrons que l’utilisation d’un
noyau triangulaire offre de tres bonnes performances et permet, de plus, de reduire les temps de
calcul lors des phases d’apprentissage et de prediction par rapport aux noyaux plus classiques.
Cette approche a obtenu les meilleures performances lors de la campagne d’evaluation ImagE-
VAL. Ces travaux ontete publiesa la conference CIVR en 2007 [HB07a]. Nous terminons par
l’observation de la genericite des modeles enetudiant leurs performances sur differentes bases
d’images.
Dans la deuxieme partie de la these, nous nous interessons aux concepts visuels plus speci-
fiques, comme la presence d’objets particuliers dans les images. Cela necessite une descrip-
tion locale des images. Nous revisitons un approche standard a l’aide de sacs de mots vi-
suels et examinons chacune desetapes du processus, en mesurant leur impact sur les perfor-
mances globales du systeme et en proposant plusieurs ameliorations. Nous montrons que parmi
les differentes strategies existantes de selection de patches, l’utilisation d’unechantillonnage
regulier est preferable. Ces travaux ontete publiesa la conference IST/SPIE Electronic Ima-
ging 2009 [HBH09]. Nousetudions differents algorithmes de creation du vocabulaire visuel
necessairea ce type d’approche et observons les liens existants avec les descripteurs utilises
ainsi que l’impact de l’introduction de connaissancea cetteetape. De plus, nous proposons
une extension de ce modele en utilisant des paires de mots visuels permettant ainsila prise en
compte de contraintes geometriques souples qui sont, par nature, ignorees dans les sacs de mots.
Les travaux sur les paires de mots visuels seront publiesa la conference ICME 2009 [HB09a].
L’utilisation de l’annotation automatique n’est possibleque si une base suffisamment annotee
existe pour l’apprentissage des modeles. Dans le cas contraire, l’utilisation du bouclage de per-
tinence, faisant intervenir l’utilisateur, est une approche possible pour la creation de modeles
sur des concepts visuels inconnus jusque la ou en vue de l’annotation de masse d’une base.
Dans ce cadre, nous introduisons une nouvelle strategie permettant de mixer les descriptions
visuelles globales et par sac de mots.
Un chapitre de livre sur l’annotation automatique sera publie cette annee dans l’Encyclopedia
of Database Systemsde Springer [HB09b].

CHAPITRE 2
Approche globale
“Suggerer, c’est creer. Decrire, c’est detruire.”
Robert Doisneau, photographe francais (1912 - 1994)
2.1 La recherche d’image par le contenu
2.1.1 Description du contenu visuel
Les images les plus classiques sont bien sur les photographies telles que celles que nous pou-
vons prendre avec nos appareils photos. Mais il en existe d’autres, comme les images medicales
(obtenues par rayons X ou par ultrason) ou les images satellites. Elles ont toutes en commun
le fait de representer une certaine realite qui aete obtenuea l’aide d’un capteur en vue de la
presenter, de facon comprehensible,a un humain.
Naıvement, la premiere methodea laquelle on peut penser, pour comparer deux images, est
de comparer leurs pixels una un. Cette methode a plusieurs inconvenients majeurs :
– elle ne resiste pasa la moindre deformation subie par une image
– comment comparer des images de tailles differentes ?
– elle est extremement couteuse en temps de calcul
Le principe de tout systeme de recherche d’images par le contenu est de representer les images
par un ensemble de caracteristiques qui aurontete extraites automatiquement, puis de proposera
l’utilisateur differents paradigmes de requete pour explorer cet ensemble. Ces caracteristiques,
dites de bas-niveau, sont extraites uniquementa partir du signal de l’image. Differents algo-

18 Approche globale
rithmes (appeles ici descripteurs) extraient ces caracteristiques (encore appeleessignatures).
Un descripteur peutetre vu comme une application de projection de l’espace des images vers
l’espace des caracteristiques qui lui est associe. La signature d’une image, qui regroupe ses
caracteristiques, est souvent un vecteur dans un espace de grande dimension. On retrouve prin-
cipalement trois informations qui sont capturees par ces descripteurs : couleurs, formes et tex-
tures. Chaque descripteur definie egalement une mesure de similarite permettant de comparer
les signatures, et par extrapolation d’obtenir une similarite visuelle entre images. On peut clas-
ser les descripteurs selon deux principaux axes :
– global↔ local
– generique↔ specifique
Un descripteur peut caracteriser l’image dans son ensemble ou bien uniquement une partie
de cette image. On parlera de descripteurs globaux ou locauxselon le cas. Dans les bases
specifiques, la connaissancea priori peut etre utilisee pour extraire des caracteristiques plus
appropriees pour decrire la nature particuliere des objets du domaine. Il existe par exemple de
nombreux descripteurs pour la description des visages ou des empreintes digitales.
La description visuelle des images est d’une grande importance puisqu’elle fournit la matiere
brutea partir de laquelle s’enchainent toutes les differentes approches de recherche d’images.
Il n’y a pas de descripteur qui soit universellement bon. Dans les bases generiques, un com-
promis doitetre fait entre l’exhaustivite de la description, la fidelite au contenu, la capacite de
generalisation, differents degres d’invariance, l’espace memoire necessaire au stockage et les
temps de calcul pour l’extraction et la comparaison des signatures. Parmi les invariances qui
sont souvent mises en avant, les conditions techniques d’acquisition des images sont les plus
frequentes. Ainsi les changements d’illumination, les rotations ou les changements d’echelle
sont des transformations qui apparaissent souvent. Idealement, si une meme scene est prise en
photo avec deux appareils ayant des reglages legerement differents, on peut souhaiter que les
caracterisations visuelles soit identiques pour ne pas tenir compte de ces differences. Il faut
toutefois bien voir que cette notion d’invariance est antagoniste avec une description fidele
du contenu. Plus un descripteur est invariant, moins il restitue fidelement le contenu d’une
image. Les choix qui sont faits sur les degres d’invariance souhaitables pour un descripteur sont
generalement guides par des considerations d’ordre semantique. Prenons le cas de deux pho-
tos d’un batiment faitesa des heures differentes de la journee. Seule la lumiere aura change.
Toutefois, en regardant les deux photos obtenues, les differences pourraientegalementetre ex-
pliquees par des reglages differents de l’appareil photo au moment de la prise de vue (ici,
typiquement, l’ouverture du diaphragme et la balance des blancs). Si on choisit d’utiliser un
descripteur couleur invarianta ce type de transformations, on ne sera pas capable par la suite de
faire la distinction entre des photos prises le matin, le midi et le soir. En revanche, pour decrire
la forme du batiment, il est souhaitable d’avoir ce type d’invariance (generalement difficilea
obtenir, notammenta cause de la gestion des ombres). On retrouveegalement des invariances

2.1 La recherche d’image par le contenu 19
plus fortes comme l’invariancea l’occultation, au changement de point de prise de vue ou aux
deformations d’objets. Ce type d’invariances est obtenue avec des descripteurs locaux.
Descripteurs bas-niveau globaux generiques
Il existe de tres nombreux descripteurs visuels globaux dans la literature. On pourra en
trouver un bonetat de l’art dans [SWS+00]. Certains descripteurs ontegalementete integres au
standard MPEG-7 [MSS02].
Quelques descripteurs standard. Gracea leur bonne capacite de generalisation au contenu
dans differentes conditions, les caracteristiques statistiques sont souvent utilisees, generalement
sous forme d’histogrammes. Les histogrammes couleur (ou distributions de couleurs) sont une
des descriptions les plus simples et les plus utilisees pour le contenu des images. Ils ontete
introduit en temps que descripteurs par Swain et Ballard [SB91]. Etant donnee une imagef ,
de tailleM × N pixels, caracterisee pour chaque pixel(i, j) par une couleurc appartenanta
l’espace de couleursC (c’esta direc = f(i, j)), alors l’histogrammeh est defini par
h(c) =1
MN
M−1∑
i=0
N−1∑
j=0
δ(f(i, j) − c), ∀c ∈ C (2.1)
Dans cetteequation,δ represente l’impulsion unitaire de Dirac (δ(0) = 1 et ∀ x 6= 0,
δ(x) = 0). Ainsi, un histogramme contient, pour chaque couleur de l’espace, le nombre de
pixels de l’image qui sont de cette couleur. En divisant par la surface de l’image (MN ), on
obtient la probabilite de chaque couleur d’etre associeea un pixel donne.
Cette representation est toutefois beaucoup trop gourmande en espacememoire. On travaille
en effet sur des images pouvant comporter plusieurs millions de couleurs. Dans ce cas, la taille
de l’histogramme pourraitetre plus grande que la taille de l’image !
Afin de reduire cette taille, on va donc quantifier l’espace de couleurs (c’est-a-dire reduire
le nombre de couleurs) avant de calculer les histogrammes. Il existe plusieurs methodes de
quantification, la plus simple est la quantification uniforme. L’unite de base d’un histogramme
est le bin (qu’on pourrait traduire par case en francais). On quantifie chacune des 3 composantes
de l’espace des couleurs separement. L’espace des couleursetant quantifie independamment des
images, cela nous assure qu’on pourra facilement comparer les histogrammes par la suite. Ainsi,
par exemple, en utilisant 6 bins par composante pour quantifier l’espace, on ramene ce dernier
a 216 couleurs (216 = 63). Les histogrammes de chaque image seront alors calcules sur ces
memes 216 couleurs et on pourra facilement les comparer.

20 Approche globale
Image d’origine 216 bins
27 bins 8 bins
FIG. 2.1 – Quantification sur 216, 27 et 8 bins des couleurs d’une image
A titre d’illustration, nous presentons ici les histogrammes RGB. La premiereetape consiste
a quantifier l’espace RGB. Cela a pour consequence une perte d’informations et donc une
degradation de la qualite des images. La figure 2.1 montre les effets de la quantification sur
une image en fonction de la precision choisie. Une perte de qualite plus ou moins importante
peutetre acceptee en fonction des applications, de la qualite originale des images ou de l’espace
de stockage disponible.
Une fois l’espace quantifie, on peut calculer les histogrammes. Voici par exemple les histo-
grammes de 2 photos (figure 2.2). Pour plus de commodite dans la visualisation, une quantifi-
cation grossiere de l’espace en 27 bins aete effectuee (3 par composante). Deux visualisations
diff erentes sont proposees. Sur la premiere, qui corresponda une visualisation classique d’his-
togrammes, les couleurs ontete indicees de0 a26. Sur la seconde, on a represente pour chaque
triplet (R, G, B) la valeur de l’histogramme par le volume de la sphere.
Pour caracteriser les formes dans une image, Jain et Valaya [JV96] proposent d’utiliser un
histogramme d’orientation des gradients sur les contours (EOH Edge Orientation Histogram).
Une premiere etape de detection des coutours est mise en oeuvrea l’aide de l’operateur de
Canny-Deriche [Can86, Der87]. On peut en voir deux exemples sur la figure 2.3. Pour chaque
pixel appartenanta un contour, on accumule l’orientation de son gradient dansun histogramme.
Les orientations sont quantifies surn bins. Afin de partiellement attenuer les effets de la quan-
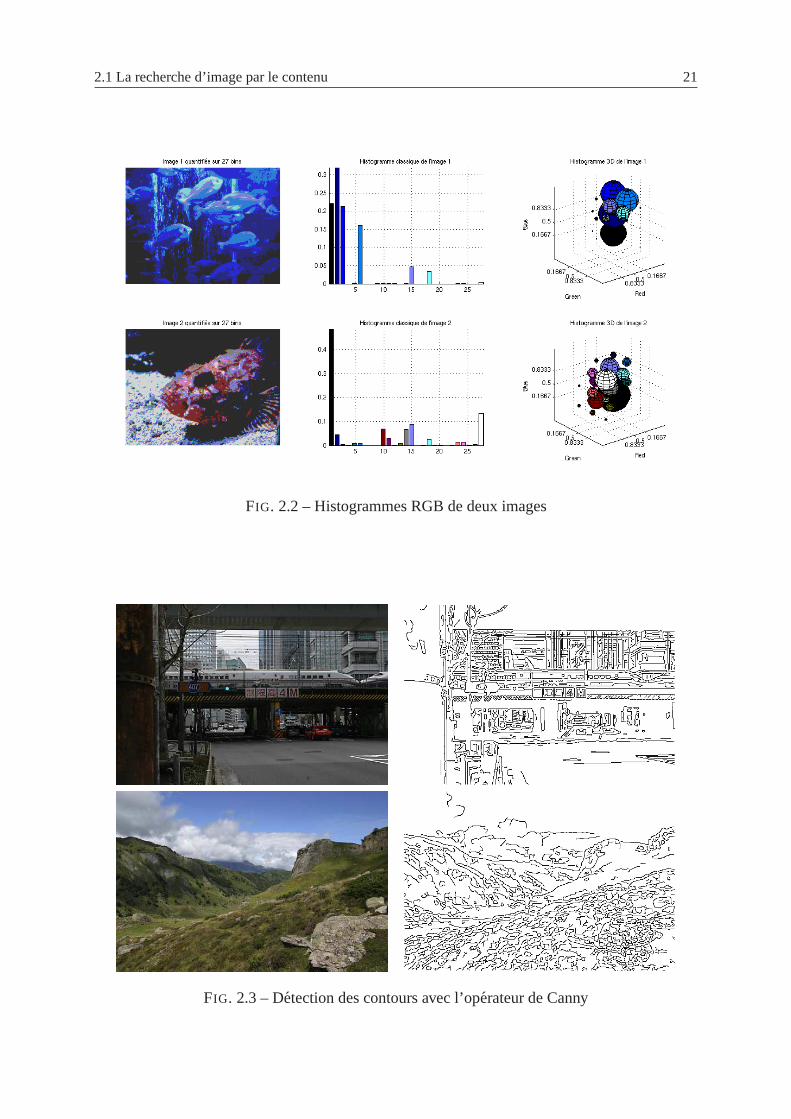
2.1 La recherche d’image par le contenu 21
FIG. 2.2 – Histogrammes RGB de deux images
FIG. 2.3 – Detection des contours avec l’operateur de Canny

22 Approche globale
tification, l’histogramme est lisse. A chaque bin est en fait associee la moyenne de sa valeur
et de celles des deux bins adjacents. Ce descripteur est invariant a la translation, mais, bien
evidemment pasa la rotation.
Les principaux descripteurs Imedia. Les descripteurs que nous decrivons ici sont le resultat
de recherches de plusieurs membres de l’equipe Imedia. Ils sont tous integres au sein du mo-
teur de recherche d’images par le contenu IKONA [BJM+01, Her05]. Ils ontete largement
testes dans des scenarii de recherche par similarite visuelle et d’interaction avec l’utilisateur par
boucles de pertinence. Ils ont l’avantage d’etre structurellement homogenes. En effet, ce sont
tous des histogrammes normalises. Ils peuvent ainsi facilementetre utilises simultanement, avec
la meme distance, les memes fonctions ou les memes noyaux. Cette possibilite de combinaison
des descripteurs est l’un des puissants points sur lesquelsnous reviendrons plus tard. De plus,
les signatures sont rapidesa extraire, et, plus important encore, rapidesa comparer puisque nous
utilisons une distanceL1.
Histogrammes couleur ponderes. Les histogrammes couleur, qui representent une distribu-
tion de premier ordre, presentent plusieurs limitations. Afin d’y pallier des distributions d’ordre
superieur ontete proposees comme les correlogrammes [HKM+97]. Mais le fait que cette ap-
proche soit parametrique et que le cout de calcul soit prohibitif font que Vertan et Boujemaa
[VB00] s’orientent vers une nouvelle approche. Il propose l’utilisation d’histogrammes couleur
ponderes. Le principe est de combiner les informations de couleur et de structure (texture et/ou
forme) dans une meme representation. Il est bien connu que les histogrammes couleur clas-
siques ne conservent aucune information sur la localisation des pixels dans l’image. Mais on
sait egalement que des pixels ayant la meme couleur n’ont pas forcement la meme importance
visuelle en fonction, justement, de leur localisation. Ainsi est arrivee l’idee d’inclure une infor-
mation sur l’activite de la couleur dans le voisinage des pixels, mesurant ainsi l’uniformite ou la
non-uniformite locale de l’information couleur. Dans l’expression classique d’un histogramme,
chaque couleur est ponderee par un facteur exprimant l’activite de la couleur dans le voisinage
de chacun de ses pixels.
h(c) =1
MN
M−1∑
i=0
N−1∑
j=0
ω(i, j)δ(f(i, j) − c), ∀c ∈ C (2.2)
Ainsi ce facteurω pourra caracteriser la texture (en utilisant une mesure probabiliste) oula
forme (en utilisant le Laplacien) attacheea une couleur. Ces travaux seront poursuivis et affines
dans l’equipe [SBV02, Fer05].

2.1 La recherche d’image par le contenu 23
Histogrammes de formes bases sur la transformee de Hough. Dans sa these, Ferecatu
[Fer05] propose un descripteur de formes inspire par la transformee de Hough (permettant de
detecter les lignes dans une image). Ce descripteur travaillesur l’image en niveaux de gris. Pour
chaque pixel, on utilise l’orientation de son gradient ainsi que la taille de la projection du vecteur
pixel sur l’axe tangeant au gradient. Ces deux informations sont captees dans un histogramme
en deux dimensions.
Histogrammes de textures bases sur la transformee de Fourier 2D. Ferecatu [Fer05] pro-
poseegalement un descripteur de texture. Il travaille aussi surl’image en niveaux de gris. Ce
descripteur est base sur la transformee de Fourier 2D de l’image. SoitI(x, y) la valeur du pixel
aux coordonneesx, y d’une image I. Alors sa transformee de Fourier est definie par :
F (u, v) =
∫
R
∫
R
I(x, y)e−j2π(ux+vy) dx dy (2.3)
Apres avoir obtenu la transformee de l’image, deux histogrammes distincts sont calcules sur
l’amplitude deF . Ils representent deux types de distributions de l’energie. Le premier (disks) est
calcule sur une partition en disques concentriques. Les rayons sont calcules de facona avoir un
increment de surface identique entre deux disques successifs. Il permet ainsi d’isoler les basses,
moyennes et hautes frequences. Le second (wedges) decoupe le plan complexe en parts,a la
maniere d’une tarte. Il se focalise donc plutot sur les variations selon differentes orientations.
Ces deux histogrammes sont utilises conjointement et ont le meme poids dans la signature
finale.
Similarit e entre signatures visuelles
Le concept de similarite entre images est sous-jacenta tous les scenarii d’interrogation. Un
systeme qui doit aider l’utilisateur dans cette tache d’exploration de base d’images doit donc
pouvoir modeliser cette notion. Avant meme de parler d’informatisation, comment definir ce
qu’est la similarite (d’un point de vue humain) entre deux images que l’on compare ? Ce pour-
rait etre le theme d’un vaste debat qui serait certainement sans fin tant la perception visuelle est
un domaine de recherche encore actif et loin d’etreepuise faisant intervenir de nombreuses dis-
ciplines (medecine, psychologie, sociologie, philosophie, ...). Au meme titre qu’il doit extraire
des caracteristiques pertinentes, un descripteur doit utiliser une mesure de similarite appropriee
qui fait que deux images proches perceptuellement impliquedeux signatures proches.
Mathematiquement, la notion de distance est clairement definie. NotonsF l’espace des
caracteristiques. Alors la distanced est une application :
d : F × F 7→ R+ (2.4)

24 Approche globale
Pour toutes signaturesI, J etK dansF , la distanced doit satisfaire les proprietes suivantes :
auto-similarite : d(I, I) = d(J,J) (2.5)
minimalite : d(I,J) ≥ d(I, I) (2.6)
symetrie : d(I,J) = d(J, I) (2.7)
inegalite triangulaire : d(I,K) + d(K,J) ≥ d(I,J) (2.8)
On appelle mesure de similarite une application qui satisfait les trois premieres condi-
tions. Une metrique satisfaitegalement trois de ces conditions. Elle ne satisfait pas la symetrie.
[Lew01, page 122] Pour mesurer la similarite entre deux signatures, on a besoin d’une applica-
tion qui satisfait les deux premieres conditions (par abus de langage, on parlera systematique-
ment dans la suite de ce rapport de mesure de similarite). Cela permet d’ordonner les resultats
selon la similarite croissante des signatures (donc des images). Toutefois, il est possible d’utili-
ser des distances (c’est-a-dire d’avoir des contraintes plus fortes) pour mesurer cette similarite.
Dans le cas de l’utilisation de certains index multidimensionnels, c’est meme un pre-requisa la
structuration de l’espace des caracteristiques.
Une famille de distances communes, appelee distances de Minkowski, est souvent em-
ployee. Pour deux signaturesa et b appartenantaRn, on definit la distanceLr par :
Lr(a, b) =
[ n∑
i=1
|ai − bi|r
] 1r
(2.9)
La distanceL1 est egalement appelee distance de Manhattan. La distanceL2 est la distance
euclidienne classique. La distanceL∞ est la fonction max qui retourne le plus grandecart entre
les coordonnees des deux signatures.
Les distances de Minkowski comparent les composantes des signatures unea une. Elles ne
tiennent donc pas compte des similarites qui existent entre les grandeurs representees par les
diff erents bins des histogrammes. Ainsi, par exemple, dans le cas des descripteurs couleur, si
pour deux images on obtient des histogrammes tres piques sur une composante, la distance
entre ces signatures seraequivalente quels que soient les bins preponderants. Or une imagea
tres forte dominante rouge est plus proche d’une imagea forte dominante orange que d’une
imagea forte dominante bleue. C’est en partant de ce constat que la distance quadratique aete
creee. Son utilisation est souventevoquee pour pallier les problemes lies a la quantification.
Elle integre une matrice indiquant les similarites entre tous les bins. Son principal inconvenient
est le temps de calcul quadratique. Une variante est la distance de Mahalanobis qui remplace la
matrice de similarite entre bins par une matrice de covariance. Il existeegalement des distances
permettant de comparer des histogrammes de tailles differentes. C’est par exemple le cas de
la distance EMD (Earth Mover Distance). Son nom est tire de l’analogie avec le probleme du

2.1 La recherche d’image par le contenu 25
transport, classique en recherche operationnelle, consistanta deplacer des quantites d’un point
a un autre et mesurant ainsi l’effort necessaire pour transformer une distribution en une autre.
Le cout en temps de calcul est de l’ordre den3.
Les distances de Minkowski representent un bon compromis entre efficacite et performance.
Pour cette famille de distances, plus le parametrer augmente, plus la distanceLr aura tendancea
favoriser les grandes differences entre coordonnees. La distanceL1 est souvent la plus pertinente
dans le cas de bases d’images heterogenes. On pourra se referer au travail de Tarel et Boughorbel
[TB02] pour uneetude detaillee sur le choix d’une distance de Minkowski.
2.1.2 Modalites de requetes visuelles
L’utilisation de descriptions visuelles des images implique de nouveaux paradigmes de
requete qui repondenta des besoins differents de l’utilisateur. La navigation dans la base cate-
gorisee [LB02, GCB06] permet de decouvrir rapidement la diversite du contenu disponible. La
base est generalement organisee de facon hierarchique par grandes classes d’images similaires.
En plus de la similarite visuelle, on peuteventuellement tenir compte d’autres metadonnees
disponibles, comme la date de prise de vue par exemple. La requete par l’exemple visuel a
longtempsete presentee comme l’equivalent de la recherche par mots cles pour le texte. Une
image est fournie comme requete au systeme qui retourne alors les images de la base triee
par similarite decroissante. Cette approche aete etendue aux signatures visuelles locales pour
fournir de requetes plus precise sur des parties de l’image. Le principal inconvenient de cette
approche est qu’elle necessite de la part de l’utilisateur d’avoira sa disposition une image si-
milaire a celle qu’il cherche. La recherche par croquis a tente de palliera ce probleme. Elle
consistea faire dessiner grossierement par l’utilisateur l’image qu’il cherche. Cette approche
s’est revelee tres decevante pour deux raisons principales. D’une part,a cause de la difficulte
d’avoir des descripteurs visuels capables d’etre suffisament generiques pour capter l’informa-
tion necessaire sur un croquis et dans une photo. D’autre part,a cause des pietres qualites en
dessin de la majorite des utilisateurs. La recherche par croquis est une premiere approche de ce
que l’on appelle la recherche par image mentale [BFG03, WFB08]. L’utilisateur a une image
precise en tete et il utilise les fonctionnalites du systeme pour reussira la retrouver dans la base.
Une version plusevoluee de cette approche consistea utilise un thesaurus de patches visuels.
C’est un dictionnaire regroupant des parties d’image caracteristiques de la base. Par composi-
tion de ces patches, l’utilisateur exprime une requete [FB06, HB07b]. On esta mi-chemin entre
la requete par l’exemple et la requete par croquis. Enfin, il estegalement possible de faire in-
tervenir l’utilisateura travers plusieurs iterations de requetes, appelees boucles de pertinences.
A chaque iteration, ce dernier indique au systeme les images qui sont similairesa celle qu’il
cherche et celles qui en sont tropeloignees [Fer05]. Nous aborderons cette derniere approche
dans la section 3.5.

26 Approche globale
2.1.3 Evaluation des performances
Le jugement qualitatifemis sur les resultats retournes par un systeme de CBIR, effectue
par un operateur humain, ne permet pas d’evaluer globalement le systeme. Il faut en effet pou-
voir faire des testsa plus grandeechelle. Cela suppose une automatisation de ces tests. On
peut ainsi avoir un outil d’evaluation pour comparer des methodes sur des bases communes et
independamment de toute appreciation et de tout jugement humain.
Afin d’ evaluer automatiquement un systeme de CBIR, il faut au prealable connaıtre les
bonnes reponses aux differentes requetes pour pouvoir les comparera celles retournees par le
systeme. C’est ce qu’on appelle la verite terrain (ground truth). Dans le cas de bases specifiques,
bien que cela reste couteux, il est simple d’obtenir cette verite terrain. Par exemple, pour tester
un descripteur qui doit faire de la reconnaissance de visages, on peut facilement annoter chaque
photo de la base par le nom de la personne prise en photo. Ainsi, on pourraevaluer automati-
quement si, pour une photo d’une personne donnee, le systeme retourne bien des photos de la
meme personne.
En revanche, pour les bases generalistes sur lesquelles on doit tester des descripteurs bas-
niveau, cette verite terrain est plus durea obtenir. Il faut, en effet, avoir une reference faisant
foi. Si cette reference est construite par un operateur humain, on retombe dans les travers liesa
l’utilisation des mots cles eta leur subjectivite.
Les mesures deprecisionet derappelsont les plus couramment utilisees pour comparer les
sytemes de CBIR. Soit une base d’imagesD dans laquelle on choisit une image requeteQ. On
noteRTQ l’ensemble desN images que le systeme retourne pour cette requete. On noteV TQ
l’ensemble des images pertinentes que le systeme doit retourner. Il s’agit de la verite terrain. De
facon classique la precision est definie comme la fraction du nombre de documents pertinents
retournes pour une requete par rapport au nombre total de documents retournes.
PQ =|RTQ ∩ V TQ|
|RTQ|(2.10)
Toutefois, la precision seule ne peut suffirea evaluer correctement un systeme. En effet, il suffit
de ne retourner que l’image requete (RTQ = {Q}) pour obtenir une precision maximum de 1a
toutes les requetes. On definit alors le rappelRQ comme la fraction des images pertinentes qui
ont ete retournees.
RQ =|RTQ ∩ V TQ|
|V TQ|
La encore, le rappel seul ne peut suffire puisqu’un systeme qui ramene systematiquement l’en-
semble de la base (RTQ = D) obtiendrait un rappel maximum de 1a toutes les requetes.
La precision et le rappelevoluent donc conjointement et de maniere antagoniste en fonc-
tion des images retournees par le systeme. En prenant toura tour toutes les images de la base

2.1 La recherche d’image par le contenu 27
comme image requete, on obtient les mesures de precision et rappel qui nous permettent de tra-
cer les courbes precision/rappel. On peut en voir des exemples sur les figures 2.21 et 2.22 (page
53). Plus le nombre de resultats retournes augmente, plus la precision decroıt. Les courbes de
precision/rappel sont donc en theorie toujours decroissantes. Un systeme parfait, par rapporta
une certaine base de test, obtient alors une precision de 1 pour un rappelegala 1. On pourra se
referera [BF04] pour plus de details sur l’evaluation des systemes de CBIR.
Ces courbes donnent une bonne vision des performances d’un systeme, mais elles ne sont
pas pratiques pour comparer differents systemes entre eux. Plusieurs approches ontete pro-
posees pour synthetiser les performances en un seul chiffre. On peut par exemple mesurer l’aire
sous la courbe precision/rappel ou encore considerer la precision pour un rappel donne (typi-
quement 0.1, c’est-a-dire la precision quand 10% des documents pertinents ontete retournes).
Une autre approche consistea mesurer la precision moyenne (Average Precision- AP). On
a defini la precision globalePQ pour une requete. Cette precision peutegalementetre mesuree
pour n’importe quel rangr de la reponseRTQ. On introduit pour cela la fonction binairerel qui
mesure la pertinence du document se trouvant au rangr de la reponse.
relQ(r) =
{1 si RTQ(r) ∈ V TQ
0 sinon(2.11)
On a alors :
PQ(r) =
∑r
i=1 relQ(i)
r(2.12)
La precision moyenne est la moyenne des precisions obtenues apres chaque document pertinent
de la reponse.
APQ =
∑N
r=1(PQ(r) relQ(r))
N(2.13)
Alors que la precision et le rappel sont bases sur l’ensemble des documents retournes, la
precision moyenne valorise le fait de ramener le plus tot possible des documents pertinents.
C’est pour cette raison qu’elle est maintenant souvent employee dans les campagnes d’evalua-
tion lieesa la recherche d’information.
Toutes ces mesures sont toutefois dependantes du nombre de documents pertinents dans la
base. Une facon d’avoir une mesure de reference est, par exemple, d’obtenir les performances
pour un systeme qui se contente de classer aleatoirement la base. On a alors, pour une proportion
α de documents pertinents :
E (relα (r)) = α (2.14)
E (Pα (r)) =
∑r
i=1 E (relα (r))
r= α (2.15)
En revanche, si on souhaite connaıtre la precision moyenne pour un rang donne (ce qui est
generalement le cas dans les campagnes d’evaluation ou on ne ramene pas toute la base), le
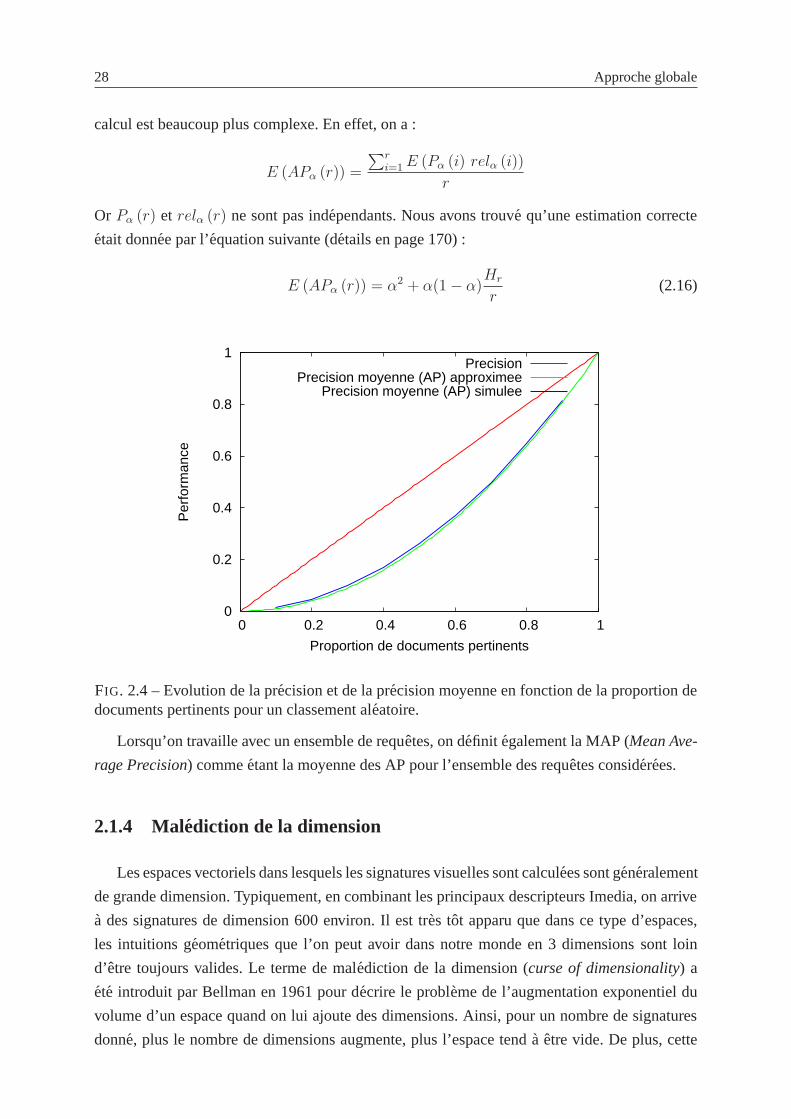
28 Approche globale
calcul est beaucoup plus complexe. En effet, on a :
E (APα (r)) =
∑r
i=1 E (Pα (i) relα (i))
r
Or Pα (r) et relα (r) ne sont pas independants. Nous avons trouve qu’une estimation correcte
etait donnee par l’equation suivante (details en page 170) :
E (APα (r)) = α2 + α(1 − α)Hr
r(2.16)
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Per
form
ance
Proportion de documents pertinents
PrecisionPrecision moyenne (AP) approximee
Precision moyenne (AP) simulee
FIG. 2.4 – Evolution de la precision et de la precision moyenne en fonction de la proportion dedocuments pertinents pour un classement aleatoire.
Lorsqu’on travaille avec un ensemble de requetes, on definit egalement la MAP (Mean Ave-
rage Precision) commeetant la moyenne des AP pour l’ensemble des requetes considerees.
2.1.4 Malediction de la dimension
Les espaces vectoriels dans lesquels les signatures visuelles sont calculees sont generalement
de grande dimension. Typiquement, en combinant les principaux descripteurs Imedia, on arrive
a des signatures de dimension 600 environ. Il est tres tot apparu que dans ce type d’espaces,
les intuitions geometriques que l’on peut avoir dans notre monde en 3 dimensionssont loin
d’etre toujours valides. Le terme de malediction de la dimension (curse of dimensionality) a
ete introduit par Bellman en 1961 pour decrire le probleme de l’augmentation exponentiel du
volume d’un espace quand on lui ajoute des dimensions. Ainsi, pour un nombre de signatures
donne, plus le nombre de dimensions augmente, plus l’espace tenda etre vide. De plus, cette
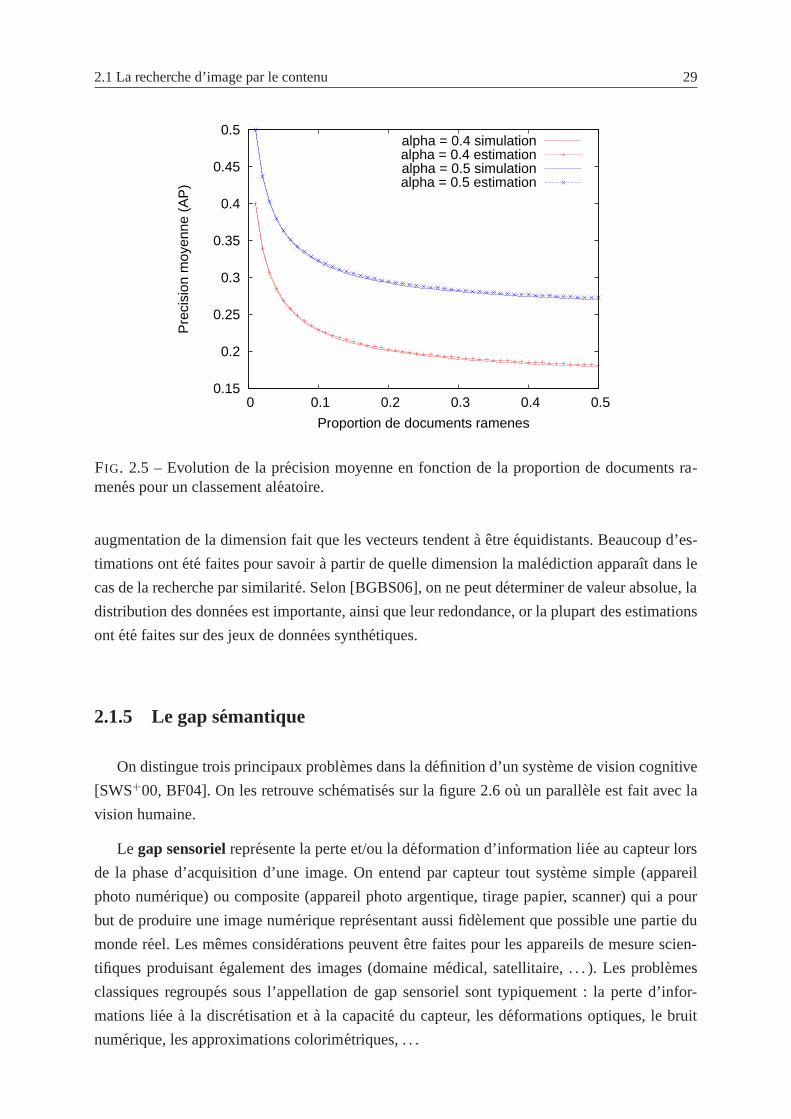
2.1 La recherche d’image par le contenu 29
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0 0.1 0.2 0.3 0.4 0.5
Pre
cisi
on m
oyen
ne (
AP
)
Proportion de documents ramenes
alpha = 0.4 simulationalpha = 0.4 estimationalpha = 0.5 simulationalpha = 0.5 estimation
FIG. 2.5 – Evolution de la precision moyenne en fonction de la proportion de documents ra-menes pour un classement aleatoire.
augmentation de la dimension fait que les vecteurs tendenta etreequidistants. Beaucoup d’es-
timations ontete faites pour savoira partir de quelle dimension la malediction apparaıt dans le
cas de la recherche par similarite. Selon [BGBS06], on ne peut determiner de valeur absolue, la
distribution des donnees est importante, ainsi que leur redondance, or la plupartdes estimations
ont ete faites sur des jeux de donnees synthetiques.
2.1.5 Le gap semantique
On distingue trois principaux problemes dans la definition d’un systeme de vision cognitive
[SWS+00, BF04]. On les retrouve schematises sur la figure 2.6 ou un parallele est fait avec la
vision humaine.
Le gap sensorielrepresente la perte et/ou la deformation d’information liee au capteur lors
de la phase d’acquisition d’une image. On entend par capteurtout systeme simple (appareil
photo numerique) ou composite (appareil photo argentique, tirage papier, scanner) qui a pour
but de produire une image numerique representant aussi fidelement que possible une partie du
monde reel. Les memes considerations peuventetre faites pour les appareils de mesure scien-
tifiques produisantegalement des images (domaine medical, satellitaire, . . . ). Les problemes
classiques regroupes sous l’appellation de gap sensoriel sont typiquement : laperte d’infor-
mations lieea la discretisation eta la capacite du capteur, les deformations optiques, le bruit
numerique, les approximations colorimetriques, . . .
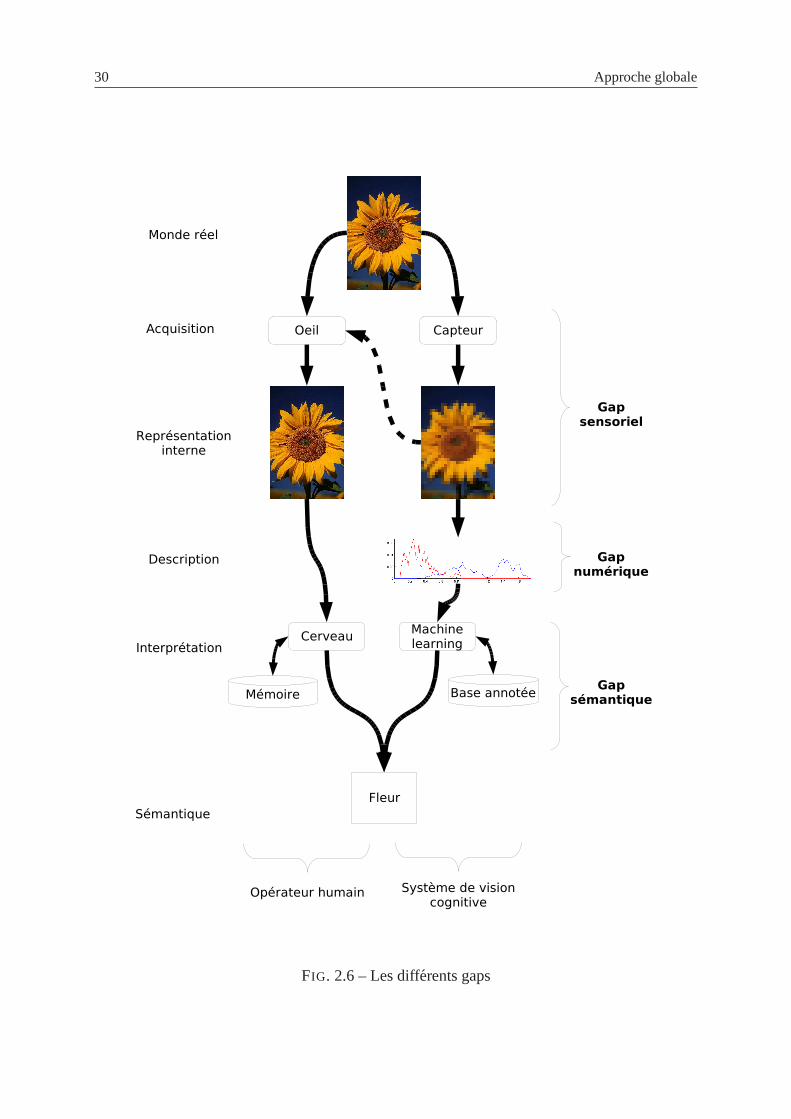
30 Approche globale
FIG. 2.6 – Les differents gaps

2.2 Combinaison du texte et de l’image 31
Le gap numerique represente la sous-capacite d’un descripteura extraire des signatures
visuelles pertinentes pour un systeme de vision cognitive. Ce probleme peutetre lie au choix
meme du descripteur utilise. Par exemple, pour une tache donnee, la caracteristique pertinente
a analyser est la couleur mais on utilise un descripteur de forme, ou bien encore on utilise un
descripteur global alors qu’on ne s’interesse qu’a des petits details de l’image ou un descripteur
local auraitete plus performant. Il peutegalement venir des choix des differents parametres
du descripteur (quantification trop faible, mauvais facteur d’echelle, . . . ). Le gap numerique est
donc l’ecart entre l’information qui est presente visuellement dans une image et celle qu’un des-
cripteur est capable d’extraire et de representer. Il pose le probleme de la fidelite de la signature
par rapporta l’image.
Enfin, le gap semantique represente l’ecart entre la semantique qu’un systeme de vision
cognitive est capable d’extraire pour une image et celle qu’un utilisateur aura pour cette meme
image. Le principal probleme reside dans le fait que toute image est contextuelle. L’ensemble
des informations situant ce contexte (geographique, temporel, culturel, . . . ) ne sont pas presentes
visuellement dans l’image et font appela la memoire de l’utilisateur.
Le but est donc de reduire ces differents gaps. On peut remarquer que le gap sensoriel
n’est, theoriquement, pas forcement un probleme puisqu’un utilisateura qui on presente une
image numerique est presque toujours capable d’en comprendre le sens, indiquant ainsi que
l’information visuelle contenu dans l’image est suffisante. Le gap semantique est souvent mis
en avant commeetant la seule explicationa la difficulte de concevoir un systeme ayant de
bonnes performances. Il ne faut toutefois pas negliger les deux premiers gap. L’adequation
d’eventuels pre-traitement et des descripteurs avec la tachea effectuer est primordiale dans les
performances.
2.2 Combinaison du texte et de l’image
Face aux inconvenients des approches texte et des approches image, il est apparu necessaire
de combiner les deux [Ino04]. Il existe deux principales familles de methodes pour cette com-
binaison. Elles repondenta des besoins differents eta des contextes differents. La recherche
multimodale utilise les paradigmes de requetes classiques en fusionnant les informations vi-
suelles et textuelles. Cette approche offrea l’utilisateur de nouveaux outils pour explorer une
base d’images et y trouver ce qu’il cherche. L’annotation automatique permet de generer de
nouvelles meta-donnees. On peut la considerer comme une indexation multimodale. Ces meta-
donnees ont un contenu semantique plus riche que la simple description visuelle et peuvent,a
leur tour,etre utilisees par les moteurs de recherche.

32 Approche globale
2.2.1 Recherche multimodale
La recherche multimodale combine les caracteristiques semantiques et visuelles. Au meme
titre que le contenu visuel, le contenu semantique (mots-cles, annotations manuelles, metadon-
nees techniques diverses, . . . ) est analyse et est mis sous une representation adequate. On parlera
alors de signature textuelle ou de signature semantique. On doit ensuite fusionner ces deux in-
formations pour fournir les resultatsa une requete. On retrouve les paradigmes classiques pour
l’interrogation de la base (navigation dans la base categorisee, requete par l’exemple, image
mentale, . . . ). On a deja souligne que la notion de similarite entre images est sous-jacentea tous
les modes d’interrogation d’une base. On doit doncetre capable de mesurer une similarite sur
les signatures visuelles, maisegalement sur les signatures textuelles (par exemple [BH01]). La
combinaison des deux sources d’information se fait selon deux approches differentes. Les si-
gnatures peuventetre utilisees dans une representation unique. On parle alors de fusion precoce
(early fusion). Elle consistea trouver une representation et une mesure de similarite commune
pour les deux modalites. Ainsi les informations visuelles et textuelles sont prises en compte
simultanement dans les differents traitements. Cette technique est utilisee par [Fer05] avec
une interrogation de la base par boucle de pertinence. L’ontologie Wordnet [Fel98] est uti-
lisee pour trouver une representation des annotations en se basant sur des concepts pivots. Cette
representation est ensuite agregee aux signatures visuelles. Le second mode de fusion, appele
fusion tardive (late fusion), consistea traiter separement la similarite visuelle et la similarite
textuelle. On obtient ainsi deux listes ordonnees de resultats qu’il convient de fusionner par une
methode adequate avant de les presentera l’utilisateur. On trouve de nombreuses approchesa ce
probleme [FKS03, BBP04, SC03, IAE02, MS05a]. L’appariement d’uneclassification visuelle
et d’une classification textuelle entreegalement dans ce type de fusion. Typiquement, on pense
au rapprochement d’une classification visuelle (non supervisee ou semi-supervisee) et d’une
ontologie textuelle. On trouveraegalement une approche des deux methodes appliqueesa un
probleme de classification sur des images segmentees dans la these de Tollari [Tol06].
2.2.2 Annotation automatique
Bien qu’on puisse retrouver des travaux sur la recherche d’images par le contenu depuis
les debuts du traitement informatique des images, ce sujet a reellement pris son essor depuis
environ une quinzaine d’annees. Plusieurs chercheurs ont tente de faire le point sur l’avancee
des connaissances dans ce domaine et sur les futures pistes de recherche ou sur les problemes
cles non encore resolus. Le papier de Smeulderset al. [SWS+00], datant de 2000, pose les
bases de ce domaine. Depuis, les techniques d’apprentissage ontete massivement adoptes pour
tenter de reduire le gap semantique. Plusieurs publications recentes font le pointa ce sujet
[DLW05, HSC06, HLES06, LSDJ06, DJLW08].

2.2 Combinaison du texte et de l’image 33
[HSC06] fait le constat que la plupart des systemes d’analyse de contenu multimedia ont
ete concus pour des domaines applicatifs trop restreints et sont meme parfois limitesa certains
aspects d’une problematique donnee. Ils sont donc difficilement extensibles. Selon les auteurs,
ceci est du a la trop grande utilisation de connaissances specifiques du domaine pour combler
le gap semantique. Ils pensent que l’on doit donc se focaliser sur des systemes generiques,
aveceventuellement un leger parametrage specifique pour certains domaines, afin d’obtenir
un champs applicatif beaucoup plus large qu’actuellement.Parmi les pistes proposees, l’em-
ploi massif des techniques d’apprentissage non-supervisees est mis en avant. Des techniques
permettant de decouvrir automatiquement les structures etelements du contenu semantique
de documents multimedia, sans suppositions specifiquesa un domaine, permettraient ainsi de
construire des systemes beaucoup plus generiques, allant un peua contre-pied des approches
actuelles (apprentissage supervise, scenario et/ou domaine restreint, probleme de scalabilite,
dependance forte sur les bases d’apprentissage). Une seconde pisteevoquee concerne l’uti-
lisation des metadonnees comme source utile d’information (date et heure de prisede vue,
coordonnees GPS, parametres de prise de vue, . . . ) qui a montre son utilite mais est souvent
delaissee.
Dans [HLES06], une definition du gap semantique est donnee et un apercu des techniques
tentant d’y remedier est aborde. Les deux grandes familles d’approches sontetudiees. Dans
l’approche du gap semantique par le bas, les systemes essayent d’apprendre les relations entre
les signatures visuelles et les labels des objets representes. Les images peuventetre segmentees
en regions (blobs) ou non (dans ce cas, une approche globale est utilisee :scene-oriented). L’ap-
proche de segmentation en regions aete utilisee recemment par differents chercheurs [DBdFF02,
JLM03, LMJ04, MM04]. [MGP03, FML04, JM04] utilisent plutot une segmentation en regions
rectangulaires selon une grille fixe. Oliva et Torralba [OT01, OT02] utilisent une approche glo-
bale. Enfin Hareet al. [HL05, Har06] propose l’utilisation de points d’interet. L’approche du
gap semantique par le haut consistea utiliser des ontologies. Les ontologies sont un des for-
malismes de representation des connaissances. Leur interet croissant est lie aux recherches sur
le web semantique et sur la necessite de rendre comprehensible par un systeme logiciel les
connaissances manipulees par les humains. Une ontologie est une conceptualisation d’un do-
maine, generalement partagee par plusieurs experts, qui consiste en un ensemble de concepts et
de relations les reliant. Les avantages de la representation des connaissances sous cette forme
plus riche sont : les requetes formulees sous formes de concepts et de relations, l’utilisation
de logiciels de raisonnement sur le domaine de connaissances, l’interoperabilite entre systemes
du meme domaine grace a la formalisation des connaissances, une nouvelle approche pour
la navigation dans la base de documents. Les ontologies pourla description de contenu mul-
timedia sont utiliseesa deux niveaux : description du contenu, des objets et de leurs relations,
maisegalement description du support lui-meme (auteur, type, mode de creation, . . . ). A titre

34 Approche globale
d’exemple, on peut se referer aux travaux de Maillot [MTH04, Mai05] oua ce qui aete fait
dans le cadre du projet europeen acemedia [MAA06, PDP+05, SBM+05].
L’annotation automatique a donc pour but de generer de nouvelles metadonnees semantiques
pour les images. La principale approche est de construire des modeles pour les concepts visuels.
Bien que plusieurs formulations aientete proposees, le but principal de la construction de ces
modeles est l’association des concepts visuels avec les regions de l’espace des caracteristiques
visuelles qui les representent le mieux. Ce probleme esta la croisee des chemins de la vision par
ordinateur, de la fouille de donnees et de l’intelligence artificielle. Generalement, les modeles
sont construit gracea un processus d’apprentissage supervise. Un algorithme d’apprentissage
est alimente par un jeu de donnees d’apprentissage, contenanta la fois des images positives
et negatives par rapport au concept visuela apprendre et fournit le modele correspondant. Cet
algorithme doit trouver dans l’espace des caracteristiques visuelles l’information la plus discri-
minante pour representer les concepts. On parlera d’annotation semi-automatique lorsqu’une
intervention humaine est necessaire au cours du processus.
FIG. 2.7 – Annotation automatique : apprentissage des modeles
FIG. 2.8 – Annotation automatique : prediction des concepts visuels
Plusieurs communautes de recherche sont impliquees dans le probleme de l’annotation auto-
matique d’images. En plus de la communaute de vision par ordinateur, de nombreux chercheurs

2.3 Strategies d’apprentissage 35
de l’apprentissage automatique ou du traitement du langagenaturel ont propose de nouvelles ap-
proches. Nous sommes alors confrontesa une multitude de definitions de taches et de strategies
d’evaluation correspondantes. Ainsi, on peut parler de l’enrichissement de contenu, de la clas-
sification d’images, d’auto-annotation, de reconnaissance ou encore de detection d’objets. Pour
ces deux dernieres taches, on distingue la reconnaissance, qui consistea predire la presence d’un
objet dans une image, de la detection qui consistea localiser precisement l’objet dans l’image.
Generalement, les bases d’images annotees dont on se sert pour l’apprentissage ne fournissent
pas d’information sur la localisation de ces annotations. C’est le cas pour la grande majorite des
bases professionnelles et personnelles.
La categorisation de scenes fut une des premieres approches de l’annotation automatique,
avec notamment la distinction classique entre photos d’interieur et d’exterieur. De nombreuses
solutions ontete testees, se concentrant soit sur la description bas niveau des images soit sur les
strategies d’apprentissage. Dans ce dernier cas, la construction de modeles complexes aete trop
souvent presentee comme une facon de combler le gap semantique. Nous voulons insister sur le
fait que l’utilisation de descripteurs qui ne sont pas appropriees pour une tache donnee ou qui
ne sont pas en mesure de capter toutes les informations visuelles des images (y compris des in-
formations sur le contexte) est un probleme qui devraitetre traite avant d’envisager l’utilisation
de nouvelles strategies d’apprentissage. On est typiquement dans le cas du gapnumerique.
Par ailleurs, et paradoxalement, la disponibilite de grandes bases de donnees d’imagesa
des fins de recherche est compromise par l’incertitude qui pese quant aux droits d’auteur. Cela
conduit les chercheursa travailler sur un petit nombre de bases de donnees disponibles. Mal-
heureusement, ces bases de donnees ont d’enormes inconvenients : elles sont tres differents des
bases de donnees reelles et, plus important encore, elles ont tendancea diriger les orientations
de recherche en leseloignant des besoins reels des utilisateurs. Leur utilite etait evidente dans
les premieres annees, nous devons maintenant nous tourner vers l’examen de donnees realistes.
2.3 Strategies d’apprentissage
Le principe de l’apprentissage automatique (machine learning) est de permettre aux ordi-
nateurs d’apprendre des phenomenes du monde reel et d’etre capables de les reproduire. On
considere generalement qu’un ensemble de donnees decrivant l’etat d’un systeme est dispo-
nible. Il faut alors predire l’evolution de ce systeme dans le temps ou bien certaines donnees
manquantes. On se situe dans le cas de l’apprentissage supervise. Les differents algorithmes
se basent sur un corpus de donnees observees pour lesquelles le resultat est deja connu (verite
terrain) et apprennenta modeliser le domaine d’etude,a synthetiser cette connaissance. Partant
de cette connaissance, ils seront ensuite capables de predire les sorties attendues. De maniere
generale, les champs d’application de l’apprentissage automatique sont tres vastes : traitement

36 Approche globale
du langage naturel, robotique, analyse boursiere, diagnostic medical, detection de pannes, mo-
teur de recherche, . . .
En vision par ordinateur, et plus particulierement en ce qui concerne l’annotation automa-
tique, on s’interessea la description du contenu des images. Cette description se presente sous
la forme la plus simple qui soit, c’est-a-dire une liste de mots-cle representant des concepts
visuels presents dans les images. Ainsi,a partir d’une base d’apprentissage constituee d’images
annotees, on va pouvoir construire des modeles capables par la suite de proposer des annotations
pour de nouvelles images. On se situe donc dans une branche del’apprentissage automatique
appelee reconnaissance de formes (pattern recognition) qui visea classer des observations dans
des categories pre-definies. On distingue deux principales familles d’approches :
– generative : des variables cachees du systeme sont modelisees (generalement sous forme
de fonctions de densite de probabilite, mixtures de gaussiennes, reseaux bayesiens, champs
de Markov, . . . ). Dans un premier temps, on definit les principes cles du modele en se ba-
sant sur des hypotheses de travail ou sur des connaissancesa priori. On peut par exemple
supposer que dans l’espace des caracteristiques visuelles, une classe d’objets que l’on
cherchea modeliser est representee par une mixture de gaussienne. La secondeetape va
consistera trouver les parametres du modelea partir des donnees d’apprentissage.
– discriminative : on ne cherche pasa modeliser les distributions sous-jacentes, on se fo-
calise directement sur la liaison entre les entrees et les sorties du systeme (plus proches
voisins, machinesa vecteurs supports, reseaux de neurones, boosting, . . . ). L’idee n’est
donc pas de definir de maniere fine le modele d’un concept mais plutot d’identifier ce
qui le distingue des autres concepts. Bien que plus performantes, les methodes discrimi-
natives ont quelques desavantages. Elles n’ont pas l’elegance des methodes generatives :
incertitude, probabilitesa priori. Ce sont souvent des boıtes noires : les relations entre les
variables ne sont pas explicites et visualisables.
Ces approches peuventegalementetre utilisees conjointement [JH98].
Nous avons choisi d’utiliser l’approche discriminative pour deux raisons principales. D’une
part, elle ne necessite pas de connaissancea priori du domaine d’etude et cela nous a paru plus
judicieux dans le cadre des bases d’images generalistes. Nous cherchonsa definir une approche
qui puisse s’appliquera toute base, sans avoira en modifier deselements cles. D’autre part,
les resultats sur differentes campagnes d’evaluation pour l’annotation automatique tendenta
indiquer que ces approches obtiennent de meilleures performances. Pris individuellement, ces
resultats sont difficilement interpretables puisque chaque approche fait intervenir de nombreux
composants techniques et qu’il est difficile d’isoler les apports de l’un d’entre eux en particulier.
En revanche, consideres globalement, ils nous donnent une bonne tendance que nousavons
choisi de suivre.
Nous detaillons dans la suite quelques algorithmes de cette famille. Nous n’aborderons
pas les differentes versions d’analyse discriminante (discriminant analysis) : lineaire - LDA,

2.3 Strategies d’apprentissage 37
biaisee - BDA, multiple - MDA, Fisher - FDA, . . . . On pourra se referer aux travaux de Yang
[YFyY+05] et Glotin [GTG05] pour en avoir un apercu.
Nous nous placons dans le cas de la classification binaire visanta separer deux classes.
Souvent ces deux classes serventa signifier la presence ou l’absence d’un concept. On dispose
d’une base d’apprentissage qui contientp observations composees d’une part d’unelementx
dans l’espace des caracteristiques (generalement un vecteur dans l’espace multi-dimensionnel
Rd) et d’autre part de la classey a laquelle elles appartiennent (par convention ces classes
portent souvent les labels “+1” et “-1”). Le but de l’apprentissage est de trouver la fonctionf ,
appartenanta une famille de fonctionsF , qui classera au mieux les nouveauxelements deRd
issus du meme phenomene que celui ayant servia constituer la base d’apprentissageTrn. Ce
phenomene est modelise par la distribution de probabiliteP (x, y) = P (x)P (y|x).
L = {+1,−1}
Trn ={(xi, yi) ∈ R
d × L, i ∈ [1, p]} (2.17)
L’approche classique pour trouver le classifieurf est de minimiser le risque,egalement ap-
pele erreur de generalisation. C’est l’erreur moyenne de classification sur l’ensemble de toutes
les donnees possibles. On utilise une fonction de cout l() qui indique la penalite en cas de
mauvaise classification. Generalement on choisit :
l(y, f(x)) =
{1 si y 6= f(x)
0 sinon(2.18)
Le risque est alors defini par :
R(f) =
∫l(y, f(x))dP (x, y) (2.19)
Toutefois, le but de l’apprentissage est de creer un modele permettant de representer au mieux
P (x, y), la distribution sous-jacente de notre phenomene. On ne peut donc se baser sur cette
grandeur qui est inconnue. On approxime alors le risque en mesurant le risque empirique sur la
base d’apprentissageTrn :
Remp(f) =1
p
p∑
i=1
l(yi, f(xi)) (2.20)
Le risque empirique est une bonne approximation du risque pour de grandes bases d’appren-
tissage. En revanche, lorsque le nombre d’exemples est faible, on peut se retrouver confron-
ter au probleme du surapprentissage. Dans ce cas, le classifieur tenda modeliser beaucoup
trop fidelement les donnees d’apprentissage et perd toute capacite de generalisation. Or cette
generalisation est necessaire pour pouvoir s’adaptera la classification de nouveauxelements.
On a schematise un exemple de surapprentissage sur la figure 2.9. On voita droite deux classes

38 Approche globale
FIG. 2.9 – Le surapprentissage
distinctes. Un premier classifieur, represente par la droite, est appris sur ce jeu d’apprentissage.
Il commet une erreur en classant mal un des ronds lors de l’apprentissage. Le second classifieur
est represente par la courbe en pointilles. On voit que cette fonction a une forme qui est plus
proche des contours de la classe des ronds. Sur la figure de gauche, on a represente la distri-
bution reelle des donnees. On se rend alors compte que le premier classifieur est finalement
meilleur et commet moins d’erreurs que le second. On dira donc que ce second classifieur est
en surapprentissage car il est trop proche des donnees d’apprentissage et a du mala generaliser
ce qu’il a appris.
2.3.1 K plus proches voisins
L’algorithme desk plus proches voisins (k-nearest neighbors, k-NN) est un des plus simples
qui existe. Il a beaucoupete utilise dans les premiers travaux lies a l’annotation automatique
pour lesquels l’accentetait surtout mis sur l’amelioration de la description visuelle des images
[SP98, VJZ98, GDO00]. Avec l’utilisation d’approches plussophistiquee, l’approche k-NN a
ete laissee de cote durant les dix dernieres annees. Elle tend maintenanta revenir avec l’utilisa-
tion des structures d’index et l’utilisation de tres grandes bases d’images annotees.
Cet algorithme ne comporte pas de phase d’apprentissagea proprement parle. Pour chaque
nouvelelement, on lui assigne la classe majoritaire parmi lesk observations les plus proches.
Soit Vk (x) le voisinage comportant lesk plus proches voisins de l’elementa classerx. On a
alors :
f (x) = sign
(k∑
j=1
yj
), (xj, yj) ∈ Vk (x) (2.21)
Cette approche est tres facilea mettre en œuvre mais comporte quelques inconvenients. En
cas de jeu d’apprentissage mal balance (une des classes comporte beaucoup plus d’observations
que l’autre), la classe dominante va avoir tendancea biaiser la classification. Pour palliera ce

2.3 Strategies d’apprentissage 39
probleme, outre une modification du jeu d’apprentissage, il est possible de faire intervenir la
distance entre l’elementa classer et les observations. Avecd() une distance sur l’espace des
caracteristiques, on peut par exemple avoir :
f (x) = sign
(k∑
j=1
yj
d(x, xj)
), (xj, yj) ∈ Vk (x) (2.22)
Structures d’index
La classification d’un nouvelelement necessite le calcul de la distance avec tous leselements
de la base, ce qui peut viteetre couteux. Aussi, plusieurs algorithmes ontete proposes pour
accelerer la recherche desk plus proches voisins. Ce sont les structures d’index. Leur principe
est d’eviter un parcours complet des signatures pour retourner lareponse. Pour cela, les signa-
tures ne sont plus simplement stockees de facon sequentielle, mais structureesa l’interieur d’un
index. Generalement ce sont des structures arborescentes. La recherche se fait alors en partant
de la racine de l’arbre, mais toutes les branches ne sont pas visitees,evitant ainsi d’avoira
accedera toutes les signatures de la base. C’est, par exemple, le cas des arbres metriques qui
utilisent les proprietes de l’inegalite triangulaire (par exemple les M-tree [CPZ97]). Un autre
avantage de ces structures d’index est de pouvoir fonctionner sans avoir toutes les signatures
chargees en memoire. Elles utilisent des systemes de pagination sur disque et peuvent donc
gerer des bases beaucoup plus grandes avec un espace memoire limite. Il apparaıt toutefois
que pour des espaces de tres grande dimension, l’utilisation de structures d’index arborescentes
peut parfois s’averer pire qu’un parcours sequentiel. C’est ce qu’on appelle communement la
malediction de la dimensionnalite. Plusieurs hypotheses existent quant au nombre de dimen-
sions ou quanta la distribution des donneesa partir desquelles les performances decroissent.
D’autres approches ont ainsiete proposees. Enfin, certains algorithmes proposentegalement
une recherche approximative des plus proches voisins. Ils sont capables de retourner lesk plus
proches voisins, modulo une erreurǫ, beaucoup plus rapidement que le parcours sequentiel.
Dans cette famille, on peut citer LSH (Locality Sensitive Hashing) [IM98]. Ce domaine de re-
cherche est donc encore tres actif, on peut se referer a [BBK01] pour en avoir un apercu ou
[JB08] pour des resultats plus recents.
Validation croisee
Comme pour toute approche parametrique, se pose le probleme du choix dek. Ce choix
depend des donnees, mais on considere generalement qu’une petite valeur dek va rendre le
modele plus sensible au bruit (les donnees d’apprentissages mal classees ou incoherentes). A
l’inverse, une trop grande valeur dek va rendre la discrimination entre les deux classes plus
delicate. Sur l’exemple de la figure 2.10, les deux nouveauxelementsx1 et x2 sont classes

40 Approche globale
comme des ronds pourk = 1, alors que pourk = 3, x2 est un carre. Le choix de la bonne valeur
FIG. 2.10 – Illustration d’un classifieur k-NN
est souvent obtenu par validation croisee (cross-validation). Cette technique consistea partition-
ner la base d’apprentissage enc sous-ensembles uniformes. Chacun de ces sous-ensembles sert,
a tour de role, de jeu de validation. Pour une valeur dek, on mesure les performances obtenues
sur le jeu de validation en utilisant le reste de la base commeobservations. Le nombre de sous-
ensemblesc est compris entre 2 etp. Plus ce nombre augmente, plus la phase d’optimisation de
parametres prend du temps.
2.3.2 Boosting
L’id ee du boosting vient d’une question posee en 1988 par Kearns[Kea88] : est-il possible de
creer un classifieur performant en combinant plusieurs classifieurs faibles ? On appelle classi-
fieur faible tout classifieur capable de performancesetant, au pire,equivalentesa une prediction
aleatoire. Le boosting est donc un meta-algorithme qui permet d’ameliorer les performances de
classifieurs faibles en les combinant. Historiquement, Adaboost (Adaptive Boosting), propose
par Freund et Schapire [FS97], est le premier algorithme de cette famille capable de s’adapter
a tout type de classifieur faible. Son fonctionnement est assez simple. Le classifieur fort est
construit iterativement en lui ajoutanta chaqueetape un nouveau classifieur faible. Ce dernier
est pondere en fonction de ses performances. De plus,a chaqueetape, les donnees d’appren-
tissage sont ponderees de facona favoriser les exemples qui sont mal classes jusque la. Ainsi,
le prochain classifieur faible aura tendancea se focaliser davantage sur cette partie de la base
d’apprentissage. Ainsi, apresT iterations, on a la fonction de decisionf() definie en fonction
des classifieurs faiblesh() :
f (x) = sign
(T∑
t=1
αtht(x)
)(2.23)

2.3 Strategies d’apprentissage 41
On pourra lire [Sch03] pour un apercu complet d’Adaboost. Il existe d’autres algorithmes de
boosting developpes depuis. On peut citer GentleBoost, RealBoost ou W-boost [HLZZ04].
2.3.3 Machinesa vecteurs supports
Les machinesa vecteurs supports (Support Vector Machine, SVM) lineaires reposent sur
l’id ee de separation des deux classes par un hyperplan qui maximise la marge entre elles
[BGV92]. On les retrouve doncegalement dans la litterature francaise sous l’appelation Sepa-
rateursa Vaste Marge (SVM). Ils sont une implementation de l’approche proposee par Vapnick
de minimisation du risque structurel [Vap95].
Minimisation du risque structurel. L’id ee est que pour reduire les risques de surappren-
tissage il est preferable de reduire la complexite de la famille de fonctionsF dans laquelle on
cherche notre classifieurf . La theorie de Vapnik-Chervonenkis permet d’exprimer la complexite
deF . On l’appelle dimension de VC, elle est generalement noteeh. Elle exprime le nombre de
points que les fonctions deF sont capables de separer. Ainsi, par exemple, dansR2 il est tou-
jours possible de separer 3 points distincts non-alignes, quelles que soit leurs classes respectives,
par une droite. En revanche on peut trouver des configurations de 4 points pour lesquelles cette
separation est impossible. La dimension de VC des classifieurs lineaires dansR2 est doncegale
a 3.
Vapnick [Vap95] a montre qu’il etait possible de borner le risque. Pour toute fonctionf de
F , δ > 0, l’in egalite suivante est vraie avec une probabilite de1 − δ pourp > h :
R(f) < Remp(f) +
√h(log2
2p
h+ 1) − log2
δ4
p(2.24)
Le terme en racine carree represente la capacite. C’est une fonction monotone croissante de
h. Le but est de minimiser la borne definie dans l’inegalite 2.24, c’est-a-dire de minimiser
conjointement le risque empirique et la capacite. Or on sait que le risque empirique decroit
avec l’augmentation de la dimension de VC puisque les fonctions deF sont plusa meme de
representer la complexite des donnees de la base d’apprentissage. On a schematise cela sur
la figure 2.11. Pour une valeur trop faible deh, on est en situation de sous-apprentissage. A
l’inverse, pour de trop grandes valeurs deh, on se retrouve en surapprentissage. Entre les deux
se trouve une valeur optimale deh qui minimisera la borne superieure sur le risque et fournira
le bon classifieur. Le principe de minimisation du risque structurel consistea construire une
famille de fonctions imbriquees ayant une dimension de VC croissante eta voir pour quelle
valeur deh on obtient la plus faible somme du risque empirique et de la capacite.

42 Approche globale
FIG. 2.11 – Principe de minimisation du risque structurel
SVM lin eaire. On voit sur la figure 2.12 qu’il existe une infinite d’hyperplans permettant de
separer les deux classes. En revanche, il existe un unique hyperplan qui maximise la marge
entre les donnees des deux classes. On le voit represente sur la figure 2.13, ainsi que la marge
maximale en lignes pointillees.
FIG. 2.12 – Quelques hyperplans lineairesseparateurs valides
FIG. 2.13 – Hyperplan lineaire separateurayant la marge maximale
Tout hyperplan est defini par l’equation suivante :
w � x + b = 0 (2.25)

2.3 Strategies d’apprentissage 43
Dans cetteequation,w designe le vecteur normala l’hyperplan separateur et� designe le pro-
duit scalaire. On appelled+ la distance des exemples positifs les plus proches de l’hyperplan
separateur, etd− la distance des exemples negatifs les plus proches de cet hyperplan. On peut
definir deux nouveaux hyperplansH− et H+, parallelesa l’hyperplan separateur et situes res-
pectivement aux distancesd− et d+ de celui-ci (voir figure 2.13). Pour un hyperplan donne,
il existe une infinite d’equations. On choisit de normaliserw et b de telle sorte qu’on ait les
equations suivantes :H− : w � x + b = −1
H+ : w � x + b = 1(2.26)
On peut montrer que la marge est alors2‖w‖
. On remarque que, par construction, il ne peut y
avoir d’elements entre les hyperplansH− et H+. On a alors comme contraintes que tous les
elements positifs soient derriereH+ et tous leselements negatifs derriereH−. Ainsi, pour ne
pas avoir d’erreur de classification lors de l’apprentissage, ces contraintes sont exprimees par
l’ equation suivante :
yi(w � xi + b) ≥ 1, (xi, yi) ∈ Trn (2.27)
Dans l’approche de minimisation du risque structurel, on choisit de conserver le risque empi-
riquea 0 grace au respect de ces contraintes. Il faut donc minimiser la capacite dans l’equation
(2.24). Il aete montre que c’etaitequivalenta minimiser :
1
2‖w‖2 (2.28)
Cela peutegalement s’interpreter comme une maximisation de la marge. Il existe plusieurs
algorithmes de resolution de probleme quadratique sous contraintes lineaires. La fonction de
decision issue de cette resolution est alors :
f(x) = sign(
p∑
i=1
αiyi(xi � x) + b) (2.29)
On appelle vecteurs supports tous leselements deTrn pour lesquelsαi est different de zero.
Ils correspondent aux vecteurs appartenant aux hyperplansH− etH+. Ils sont en fait peu nom-
breux, ce qui conduit generalementa une solution comportant peu de vecteurs supports par
rapporta la taille de la base d’apprentissage.
SVM non-lin eaires. L’utilisation de fonctions lineaires pourF est necessairea la formulation
du probleme, mais cela peut vite s’averer insuffisant pour correctement classer des jeux de
donnees complexes. Le seconde idee principale des SVM est alors de projeter les donnees dans
un espace de dimension superieurea celui dans lequel elles existent [Vap98]. Potentiellement,
ce nombre de dimensions peut memeetre infini. On espere alors que dans ce nouvel espace il

44 Approche globale
existe un hyperplan separateur lineaire. On definit Φ la fonction de projection :
Φ : Rd 7→ R
g, g > d
x → Φ(x)(2.30)
On remarque que, dans lesequations de formulation du probleme, les vecteursxi deRd n’ap-
paraissent que dans l’utilisation du produit scalaire. L’idee est donc d’utiliser l’astuce du noyau
(Kernel trick) [Vap98]. Un noyauK est defini par :
K(xi, xj) = (Φ(xi) � Φ(xj)) (2.31)
L’avantage est qu’en utilisant ce type de noyau, il n’est pasnecessaire de definir explicitement la
fonction de projectionΦ. Le calcul du produit scalaire dansRg est en fait possible directement
avec les vecteurs deRd. La fonction de decision devient alors :
f(x) = sign(
p∑
i=1
αiyiK(xi, x) + b) (2.32)
SVM a marge souple. Cependant, meme dans l’espace de plus haute dimensionRg il n’est
pas toujours possible de trouver une separation lineaire des donnees. Cortes et Vapnick [CV95]
proposent l’utilisation d’une marge souple pour la classification. L’idee est de minimiser le
nombre d’erreurs de classificationa l’apprentissage en introduisant des variablesξ (slack va-
riables) permettant de relaxer les contraintes qui s’ecrivent alors :
yi(w � Φ(xi) + b) ≥ 1 − ξi, ξi ≥ 0, (xi, yi) ∈ Trn (2.33)
Dans ce contexte, il faut desormais minimiser
1
2‖w‖2 + C
p∑
i=1
ξi (2.34)
Le parametreC > 0 est la constante de regularisation qui definit le compromis entre l’erreur
empirique et la capacite. Ce parametre est generalement estime par validation croisee lors de la
phase d’apprentissage du SVM.
Quelques noyaux classiques.On distingue deux principaux types de noyaux. Les noyaux pa-
rametriques necessitent l’utilisation d’un ou plusieurs parametres. Generalement un parametre
d’echelleγ est utilise pour s’adaptera l’echelle des donnees. Il existeegalement des noyaux
non-parametriques. Nous presentons ici les noyaux qui seront utilises dans la suite de ce tra-
vail. Un autre noyau populaire est le noyau gaussien. Il est en fait equivalent au noyau RBF en
considerantγ = 12σ2 . On pourra consulter [SS02] ou encore le travail de Boughorbel [Bou05]

2.3 Strategies d’apprentissage 45
Noyau Parametrique
Lineaire k(x, y) =∑
i xiyi
Triangulaire - L1 k(x, y) = −∑
i |xi − yi|
Triangulaire - L2 k(x, y) = −√∑
i(xi − yi)2
Intersection d’histogrammes k(x, y) =∑
i min(|xi|, |yi|)Laplace X k(x, y) = e−γ
P
i |xi−yi|
Radial Basis Function (RBF) X k(x, y) = e−γP
i(xi−yi)2
χ2 X k(x, y) = e−γ
P
i
(xi−yi)2
xi+yi
TAB . 2.1 – Quelques noyaux pour SVM
pour uneetude detaillee des noyaux SVM pour la classification d’images et notamment sur les
conditions necessairesa la definition d’un noyau correct.
SVM et malediction de la dimension. Les SVM sont souvent mis en avant pour leur capacite
a gerer les problemes dans des espaces de haute dimension. En effet, leur fondement theorique
est base sur une projection des donnees dans un espace de dimension potentiellement infinie.
Dans cet espace, les SVM operent une separation lineaire des differentes classes. Toutefois, on
peut quand memeetre confronte a la malediction de la dimension avec des SVM. Si l’espace
de representation des donnees est trop grand devant le nombre d’exemples d’apprentissage, le
SVM sera toujours capable d’optimiser la marge sur le jeu de donnees d’apprentissage, mais les
performances en generalisation seront pauvres.
Apprentissage et optimisation des parametres. Afin de mieux apprehender le comporte-
ment des differents noyaux, on commence par observer leurs resultats sur un jeu de donnees
synthetiques. Nous reprenons l’exemple de l’echiquier de [FS03]. Il s’agit de deux classes de
FIG. 2.14 – Quadrillage, jeu d’apprentissage synthetique
R2, chacune ayant 216 exemples d’apprentissage. Elles sont distribuees selon un quadrillage

46 Approche globale
represente sur la figure 2.14. Nous les avons legerement bruitees par rapporta un quadrillage
parfait. Les donnees sont comprises entre 0 et 24 sur chaque axe. Puisque nous utilisons des
SVM a marge souple, il faut fixer la constante de regularisationC. Dans un premier temps,
nous utilisons le noyau triangulaire (figure 2.15). Avec desvaleurs trop faibles deC, la clas-
FIG. 2.15 – Noyau triangulaire L2,evolution pour0.001 ≤ C ≤ 50
sification est mauvaise et les contours des classes sont tropflous. A partir deC = 0.5 (7eme
image), on constate que la classification n’evolue plus et est correcte.
Outre la constante de regularisation liee aux SVM, certains noyaux ont leurs propres pa-
rametres. C’est le cas deγ pour les noyaux Laplace, RBF etχ2. Il permet une adaptation du
noyaua l’echelle des donnees. Cette adaptation n’est pas necessaire pour le noyau triangulaire
qui y est invariant [FS03]. Nous presentons les resultats pour les noyaux laplace et RBF en
ayant prealablement fixe la valeur deC a 10. La sensibilite de ces deux noyauxa l’echelle des
donnees est tres claire. Siγ est surestime, alors on se retrouve en situation de surapprentissage.
A l’inverse, pourγ trop faible on est en sous-apprentissage.
La determination des parametresC et γ est generalement obtenue par validation croisee.
Nous presenterons des resultats sur cette question pour la base ImagEVAL-5 (section 2.4.5,
page 63).

2.4 Notre approche pour l’annotation globale 47
FIG. 2.16 – Noyau laplace,C = 10, evolution pour0.001 ≤ γ ≤ 10
2.4 Notre approche pour l’annotation globale
2.4.1 Etat de l’art
Nous avons vu que les annotations globales recouvrent deux types de concepts visuels. On
trouve d’une part la nature de l’image qui peutetre une photo, un graphique, un croquis ou
encore une image de synthese. D’autre part, on trouve les concepts qui caracterisent la scene
dans son ensemble (interieur, exterieur, jour, nuit, paysage, ville, portrait, horizontal,vertical,
. . . ). Ce type d’annotation est generalement appele classification de scenesdans la litterature.
Le probleme classique de distinction interieur / exterieur aete etudie au cours des dix dernieres
annees. La classification ville / paysage est aussi un probleme present dans de nombreux articles.
Plusieurs bases de donnees ontete utilisees et un largeeventail d’approches aete explore.
Parmi les premieres tentatives, Szummer et Picard [SP97, SP98] extraient des descripteurs
de couleur et de texture sur les regions rectangulaires obtenues sur une grille fixe des images.
Une approche en deuxetapes aete utilisee pour separer les photos d’interieur et d’exterieur.
Chacun des blocs est ensuite classe, pour chacune des caracteristiques, commeetant indoor
ou outdoor. De simples classifieurs de type k-NN sont utilises. Dans un second temps, une
fusion est effectuee entre les resultats des differents descripteurs et des differents blocs pour

48 Approche globale
FIG. 2.17 – Noyau RBF,C = 10, evolution pour0.001 ≤ γ ≤ 50
obtenir la classification de l’image selon un classifieur de vote majoritaire. Les experiences sont
menees sur une base de 1 300 photos de clients de Kodak (taux de classification≈ 90%). Cette
base n’est pas disponible. [SSL02] utilise une approche similaire, sur la meme base, mais avec
des SVM pour les deux couches de classification. Les resultats sont legerement meilleurs et
sont plus rapides. Dans [SSL04], ce travail est approfondi en ajoutant des indices semantiques
semantic cuestels que l’herbe, le ciel ou les nuages. Ils sont exploites a l’aide d’un reseau
bayesien remplacant la seconde et derniere couche de classification. Le gain sur la methode
precedente reste faible, il est de l’ordre de1%.
[VJZ98] travaillent sur les images entieres pour les discriminer entrecity et landscape. Par
la suite la classification des paysages est raffinee selonforests, moutainset sunset/sunrise. Le
choix de cette classification aete obtenu apres avoir demande a 8 operateurs humains de classer
environ 200 images de facon coherente. Les descripteurs bas-niveaux utilises sont classiques et
leur pouvoir discriminant est observe de maniere empirique sur les histogrammes de distances
inter et intra-classe. Des classifieurs k-NN sont utilises. Les tests sont conduits sur une base
de 2700 photos issues de differentes sources (taux de classification≈ 94%). Ces travaux sont
poursuivis dans [VFJZ99] et [VFJZ01] par l’introduction d’une hierarchie de classes et l’utili-
sation de classifieurs bayesiens binaires. Une methode basee sur la quantification vectorielle et
la selection de representants comme centres de gaussiennes au sein d’une mixture est utilisee

2.4 Notre approche pour l’annotation globale 49
pour estimer les probabilitesa priori des classes (necessaire au formalisme bayesien). Les tests
sont effectues sur une base de 6900 images (taux de classification pourindoor/outdoor≈ 90%).
Une methode d’apprentissage incremental est proposee permettant de s’adaptera l’arrivee de
nouveau contenu. Plusieurs strategies de selection de caracteristiques sontegalement abordees.
Enfin, dans [VZY+02], la methode est encoreetendue et appliqueea la detection automatique
de l’orientation des images. L’utilisation de PCA et LDA est abordee pour reduire la dimension
du vecteur de caracteristiques (600). La methode est ensuite comparee avec d’autres algorithmes
(k-NN, SVM, HDRT et GM). La combinaison de classifieurs est vaguement abordee.
Dans [MR98] lemultiple-instance learningest presente avec son applicationa la classi-
fication de scenes naturelles. La methode repose sur le concept de sac, contenant plusieurs
instances. Seuls les sacs sont annotes et non les instances individuellement. Si un sac est annote
positivement, cela signifie qu’au moins une instance qu’il contient est positive. S’il est annote
negativement, alors toutes les instances sont negatives. Ici chaque image est un sac et les ins-
tances sont des sous-parties de l’image (en l’occurrence des blobsde 2x2 pixels et les 4blobs
voisins). L’algorithmediverse densityest utilise pour l’apprentissage. Les tests sont effectues
sur une partie de la base Corel.
[GDO00] propose d’utiliser la distribution globale des orientations dominantes locales pour
discriminer les scenes naturelles en 4 classes :indoor, urban, open landscapeet closed land-
scape. Les caracteristiques sont calculees dans unscale space. La meilleurechelle est conservee
ensuite et un classifieur k-NN est utilise.
Oliva a presente l’enveloppe spatiale [OT01, OT02] base sur des dimensions perceptuelles
mesurant le naturel, l’ouverture ou l’expansion dans les images. Dans [TO03], les statistiques
des images naturelles sontetudiees.
[ZLZ02] propose d’utiliser un algorithme deboostingpour detecter automatiquement l’orien-
tation des photos. Elles sontegalement classees selon le schemaindoor/outdoor. Les caracte-
ristiques sont calculees sur une grille fixe.Adaboostest utilise. Ne parvenant pasa surpasser
une approche par SVM, les auteurs obtiennent de nouvelles caracteristiques par combinaison
lineaire des caracteristiques existantes et se reposent sur la faculte de l’algorithme deboosting
a faire de la selection de caracteristiques. Les tests sont en partie fait sur la base Corel et sont
comparesa deux approches par SVM.
[MGP03] compareLatent Semantic Analysis(LSA) et Probabilistic LSA(PLSA) avec une
approche plus naıve pour l’auto-annotation sur une partie de la base Corel. Seules 3 regions
predefinies sont extraites des images (centre, haut et bas). Les resultats sont surprenants.
[LZL +05] propose un systeme de classification d’images (indoor/outdoor, city/landscapeet
orientation). En utilisant aussi bien des caracteristiques bas-niveau que les metadonnees EXIF,
LDA est applique pour fournir de nouvelles caracteristiques en entree d’un algorithme deboos-

50 Approche globale
ting. Les signatures visuelles sont extraites selon une grille fixe. L’utilisation des metadonnees
extraites par l’appareil photo sontegalement exploites dans [SJ08, CLH08].
Payne et Singh [PS05a, PS05b] proposent d’etudier la classificationindoor/outdoora l’aide
d’un descripteur caracterisant les principaux contours. Cette approche est compareea d’autres
de l’etat de l’art et doit fournir un benchmark standard dans le domaine. Outre le fait que la base
ne soit finalement qu’a moitie disponible, les mesures effectuees semblent plus que douteuses.
L’utilisation des ontologies visuelles estegalement une approche possible. [SBM+05] pre-
sente une partie de l’approche KAA (Knowledge Assisted Analysis) dans le contexte du projet
europeen aceMedia1. L’accent est mis sur la fusion de plusieurs descripteurs MPEG-7 puis-
qu’une meme distance ne peut pas leuretre appliquee. Cette approche est confrontee au proble-
me de la fusion de descriptions non-homogene des images. Les tests sont menes sur une partie
de la base aceMedia (assez pauvre en diversite). La suite de l’algorithme KAA est presente dans
[MAA06, PDP+05]. Les descripteurs MPEG-7 sontegalement utilises dans [TWS05].
La these de Millet [Mil08] presente ses travaux effectues au CEA sur cette question. Il intro-
duit quelques nouveaux descripteurs, utilise la segmentation en regions, des indices semantiques
et des SVM.
Une comparaison entre ces approches est tres difficile, car les bases de donnees utilisees
sont differentes, et rarement accessibles au public. Reimplementer les algorithmes et les mettre
en oeuvre sur une base commune seraitegalement trop couteux en temps. Parfois, meme les
metriques utilisees sont differentes (taux de classification, avec ou sans conservation des donnees
d’apprentissage, courbes precision/rappel, courbes ROC, . . . ). Generalement, les meilleurs taux
rapportes pour la classification interieur/exterieur sont d’environ 90 %. Les temps de traitement
ne sont presque jamais signales.
2.4.2 Contribution aux descripteurs globaux
Modification du descripteur de texture Fourier
Nous avons voulu connaıtre l’influence du choix effectue par Ferecatu [Fer05] sur le critere
de partitionnement du spectre frequentiel en disques par rapport aux performances du descrip-
teur. Avec cette approche, le rayon des differents disques croit plus lentementa mesure qu’on
s’eloigne de l’origine du plan complexe de Fourier. L’idee est de voir ce qu’apporte une crois-
sance constante de ce rayon. On a represente schematiquement ces deux approches sur la figure
2.18. Le plan de Fourier est partitionne par 4 disques concentriques. On aa gauche un increment
constant de surface eta droite un increment constant de rayon. On voit nettement dans notre
exemple que l’approche de [Fer05] traite la partie centraledu plan complexe, correspondant
1http ://www.acemedia.org

2.4 Notre approche pour l’annotation globale 51
FIG. 2.18 – Fourier, deux approches pour la partition en disques. A gauche, l’approche de[Fer05] eta droite notre proposition.
aux basses frequences, avec un seul disque. Or cette partie contient generalementenormement
d’informations. On peut d’ailleurs en avoir un apercu sur les exemples des deux bases. Il ap-
paraıt donc que ce choix tenda limiter la description de l’information basse frequence. A l’in-
verse, notre approche permettra d’etre plus precise sur les basses frequences mais moins pour
les hautes frequences.
Suivant les protocoles definis par Ferecatu [Fer05], nous avonsevalue ces modifications
sur deux bases d’images pour lesquelles la texture est une composante visuelle importante. La
premiere base contient 792 photos de 88 textures. La taille des images est de 128x128 pixels.
On peut voir quelques exemples sur la figure 2.19. On y aegalement represente l’amplitude
normalisee de la transformee de Fourier enechelle logarithmique. La seconde base,WonUK
FIG. 2.19 – Quelques images de la base de textures et leur spectrede Fourier

52 Approche globale
GTDB 2 est une base de photos aeriennes. Elle aete initiallement constituee par Fauqueuret
al. [FKA05]. Elle contient 1 040 images de taille 64x64 qui ontete manuellement assignees
a 8 categories differentes (bateau, batiment, champs, herbe, riviere, route, arbre et vehicule).
FIG. 2.20 – Quelques images de la base WonUK GTDB et leur spectre de Fourier
Les courbes precision/rappel n’ont pas la meme forme pour les deux bases. Les performances
decroissent plus rapidement pour WonUK GTDB. On remarque parcontre que l’ordre des
courbes et leursecarts sontequivalent dans les deux cas. Prises independemment, on voit que
l’information de direction est clairement moins importante que la frequence. L’utilisation d’un
increment constant de rayon apporte une amelioration significative des performances. Enfin,
logiquement, la combinaison des informationsdiskset wedgesamene les meilleurs resultats.
Le descripteur MPEG-7 HTD (Homogeneous Texture Descriptor) [MSS02] a une approche si-
milaire au descripteur de Fourier. La partition en disques du plan des frequences est effectuee
par octave, accordant ainsi plus d’importancea la partie centrale du plan des frequences. En re-
vanche, le descripteur HTD considere conjointement les partitionsdisksetwedges. Nous avons
experimentee cette approche et elle fournit de moins bonnes performances.
Le descripteur de formes LEOH
Le travail realise par Yahiaouiet al. [YHB06] sur le descripteur DFH (Directional Frag-
ment Histogram) a permis de mettre enevidence ses bonnes performances en termes de per-
tinence et de temps de calcul. Ce descripteur de forme permet de caracteriser un contour. Il
a ete utilise dans le cadre de l’indexation de bases d’images botaniques. Nous avons souhaite
2Disponiblea cette adresse : http ://jfauqueur.free.fr/research/GTDB/
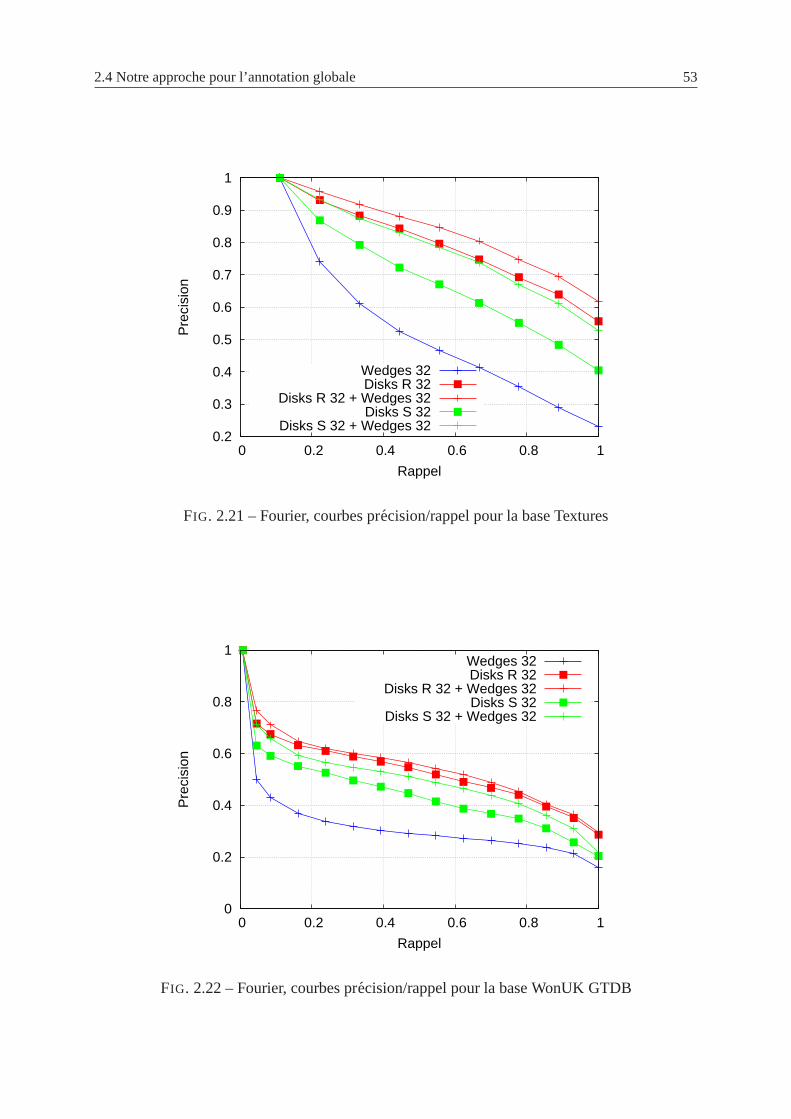
2.4 Notre approche pour l’annotation globale 53
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
Rappel
Wedges 32Disks R 32
Disks R 32 + Wedges 32Disks S 32
Disks S 32 + Wedges 32
FIG. 2.21 – Fourier, courbes precision/rappel pour la base Textures
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
Rappel
Wedges 32Disks R 32
Disks R 32 + Wedges 32Disks S 32
Disks S 32 + Wedges 32
FIG. 2.22 – Fourier, courbes precision/rappel pour la base WonUK GTDB

54 Approche globale
reprendre l’idee principale de ce descripteur et la generalisera tout type de contenu. Suivant
l’id ee exprimee par Qianet al. [QBS00] d’etendre l’utilisation d’histogrammes de blobs aux
orientations locales sur les contours, nous avons developpe le descripteur de formes LEOH (Lo-
cal Edge Orientation Histogram) [HB07a]. La principale raison qui a motive ce travail vient
de la campagne d’evaluation ImagEVAL (voir section 2.4.4, page 57). La distinction entre des
images de paysages et de scenes urbaines est grandement aidee par le fait que les constructions
humaines sont caracterisees par des lignes horizontales et verticales. Partant du meme constat,
Guerin-Dugue et Oliva [GDO00] avaient propose d’utiliser les orientations locales dominantes
dans le spectre des images. Un descripteur standard d’orientation des gradients (voir page 19)
estegalement capable d’encoder ce type d’informations. Mais si un batiment n’occupe qu’une
faible surface de l’image, sa presence sera rapidement noyee dans le bruit environnant. Le des-
cripteur LEOH en revanche a l’avantage d’encodera la fois l’information locale et globale,
permettant ainsi de palliera ce probleme.
Comme pour l’histogramme des gradients standard, on commence par extraire les contours
de l’imagea l’aide de l’operateur de Canny-Deriche. En revanche, au lieu d’accumuler les
orientations des gradients quantifiees enn bins directement dans un histogramme, on va utiliser
une fenetre glissante sur l’image. A chaque position de cette fenetre, on va mesurer la pro-
portion d’orientations des contours pour chaque direction. Les proportions sont elles-memes
quantifiees enp bins. On a donc un histogramme en deux dimensions. La figure 2.23 illustre ce
FIG. 2.23 – Fonctionnement du descripteur LEOH
fonctionnement. Les orientations y sont quantifiees en 8 bins et les proportions en 4 bins. On a
donc au final une signature en 32 dimensions. Pour la positionde la fenetre qui est representee,
on a quelques lignes verticales et une majorite de lignes horizontales. L’histogramme est donc
incremente dans les deux cases correspondantes. Si la fenetre passe sur une zone n’ayant aucun
contour, la position est simplement ignoree. L’histogramme est ensuite normalise pour que la
somme de tous les bins soitegalea un. L’evaluation de ce descripteur sera faite dans la partie
concernant la campagne d’evaluation ImagEVAL-5 (section 2.4.5, page 63).

2.4 Notre approche pour l’annotation globale 55
2.4.3 Description de notre methode fondee sur les “approches SVM”
Nous proposons d’utiliser les descripteurs globaux qui sont a notre disposition dans le cadre
de l’annotation automatique. Leur fidelite au contenu visuel a deja ete largementetudiee dans le
cadre de la recherche d’image par l’exemple, de la recherchepar image mentale, de la compo-
sition de regions et du relevance feedback. Nous pensons que dans un cadre adequat ils peuvent
etre pertinents pour caracteriser des concepts visuels globaux sur les images. Ces descripteurs
sont complementaires et structurellement homogenes. Concretement, ce sont tous des histo-
grammes, et ils peuvent doncetre utilises simultanement, avec la meme distance ou les memes
fonctions noyaux. Cette possibilite de combinaison des descripteurs est l’un des puissants points
sur lesquels nous reviendrons plus tard. Enfin, l’extraction et le calcul des distances sur les si-
gnatures obtenues sont rapides.
Pour la description des couleurs, nous avons utilise un histogramme HSV (hsv, 120 bins).
Nous utilisonsegalement les histogrammes couleur ponderes qui permettent de combiner les
couleurs et la structure des informations dans une representation unique. Forme et couleur sont
fusionnees par ponderation des pixels de couleurs avec le Laplacien (lapl, 216 bins). La texture
et la couleur sont fusionnees en ponderant les couleurs avec une mesure de probabilite (prob,
216 bins). Nous utilisons notre version modifiee du descripteur de texture base sur la trans-
formee de Fourier (four, 64 bins). Les formes sont caracterisees par un histogramme inspire par
la transformation de Hough (hou, 49 bins). Enfin nous utilisons notre nouveau descripteur de
formes (leoh, 32 bins).
Nous avons choisi de fusionner les differents descripteurs avant de les injecter dans un clas-
sifieur SVM a marge souple. Nous n’avons pas d’idee precise sur l’importance de telle ou
telle caracterisitique visuelle pour discriminer les differents concepts (en dehors du descripteur
LEOH pour lequel une vague connaissancea priori a ete utilisee, bien qu’il reste parfaitement
generique). Nous pensons donc qu’il est de la responsabilite de l’algorithme d’apprentissage
de selectionner leselements importants pour les differents concepts. De plus, nous pensons
qu’il est preferable de considerer conjointement les differents types de descripteurs pour que
les eventuelles correlations soient exploitees au mieux. En concatenant les six descripteurs
nous avons une signature de 697 bins par image. Ainsi, en utilisant des descripteurs n’impli-
quant pas d’a priori sur le contenu et une strategie d’apprentissage standard, notre approche est
completement generique et peu s’adaptera tout nouveau contenu et/ou concept.
Generalement on peut organiser les concepts visuels globaux sous forme de hierarchie. La
premiere strategie qui peutetre envisagee pour l’apprentissage des SVM est de considerer cet
arbre de concepts et de mettre en place une hierarchie de SVM. Plusieurs travaux abordent
cet aspect [CDD+04, YKZ04, Jae04, BP05]. Toutefois cette approche est plus adaptee si une
decision de classification doitetre prise. Ici, nous devons plutot obtenir un score de confiance
pour chaque concept. L’avantage d’un arbre de classifieurs est d’eviter de declencher la predic-

56 Approche globale
tion pour les feuilles si une decision dans lesetapes precedentes les a rendues inaccessibles. Or
ici, on a dans tous les cas besoin d’obtenir un score pour tousles concepts. L’arborescence perd
donc de son interet.
L’arbre des concepts peutegalementetre represente comme une partition complete de l’es-
pace. Il peutetre vu comme un aplatissement de l’arbre. Nous avons deux nouvelles strategies
d’apprentissage possibles. Nous pouvons choisir d’apprendre separement chaque concept avec
une approche un-contre-tous. Dans ce cas, nous disposons d’un modele par concept. Enfin, la
troisieme option est de considerer les concepts de l’arbre en extension. Chaque feuille de l’arbre
est alors un concept unique. Ces deux strategies ontete testees, elles fournissent des resultats si-
milaires. Cela est parfaitement comprehensible. Les SVM se concentrent sur les frontieres entre
les concepts dans l’espace des caracteristiques. La seule difference est que dans le premier cas,
les memes frontieres seront apprises plusieurs fois et figureront dans differents modeles. Cela
conduira globalementa des modeles plus lourds (ayant plus de vecteurs support, ce qui implique
un temps de prediction plus long). Mais cette approche est plus souple et l’ajout de nouveaux
concepts y est plus facile.
Comme tous les descripteurs sont des histogrammes, nous garantissons, par construction,
que la somme de tous les bins estegalea un pour chaque signature. Ainsi, initialement, nos
six descripteurs ont la meme importance relative dans le calcul de la fonction noyau.Il est
egalement possible d’appliquer certains pre-traitements sur les vecteurs qui vont casser cette
equite mais vont potentiellement aider les SVMa discriminer les concepts. Nous avons teste
quatre pre-traitements [CHV99, Bou05] :
– aucun : pas de pretraitement
– echelle : chaque bin est misa l’echelle entre 0 et 1 pour l’ensemble de la base d’appren-
tissage
– normalisation : chaque bin est normalise en fonction de sonecart-type sur la base d’ap-
prentissage
– puissance : chaque bin esteleve a une puissance donnee (generalement 0.25)
Une fois que les modeles ontete calcules, ils peuventetre utilises pour predire chaque
concept sur les nouvelles images. Obtenir les previsions de concepts ne suffit pas. Nous avons
egalement besoin de niveaux de confiance afin de classer les resultats. Des recherches ontete
effectuees sur les SVMa sortie probabiliste [Pla99, BGS99]. Cette approche est tres pratique
car elle permet une comparaison entre degres de confiance de differents SVM. Malgre cela,
nous avons choisi une approche plus simple qui consistea assimiler le score de la fonction
de decision du SVMa un niveau de confiance. Nous suivons ainsi l’idee intuitive que plus un
vecteur est loin de la frontiere de decision, moins il est ambigu. Comme tous nos modeles sont
bases sur le meme espace visuel, nous avons trouve que cette approche convenait parfaitement
et permettait de combiner les predictions des differents concepts. Pour une requete impliquant

2.4 Notre approche pour l’annotation globale 57
plusieurs concepts, nous utilisons la fonctionmin sur les scores individuels des concepts afin
de fournir le score global.
2.4.4 La campagne d’evaluation ImagEVAL - t ache 5
Introduction
Dans le domaine de la recherche d’information, il existe unetradition de campagnes d’eva-
luation apparues autour de la recherche de documents texte (TREC, CLEF, . . . ). L’evaluation
est traditionnellement assuree par les publications scientifiques dans des conferences et jour-
naux avec commite de lecture. Toutefois, il n’est pas rare que les conditionsexperimentales
soient trop differentes d’un papiera l’autre pour garantir que les performances des algorithmes
puissentetre comparees de faconequitable. Ainsi, l’objectif d’une campagne d’evaluation est
avant tout de proposer un corpus de donnees unique, une definition de tache claire et une
metrique permettant de mesurer les performances. Etant places dans des conditions experi-
mentales identiques, on peut ainsi plus aisement comparer differentes approches et observer
leurs points forts et leurs faiblesses. Le processus d’evaluation suit generalement un schema
bienetabli. Un corpus d’apprentissage misa disposition. Un corpus et des requetes de test sont
fournis quelques mois en avance pour permettre auxequipes de calibrer leurs algorithmes et
s’assurer que techniquement tout est en place. Les requetes reelles de l’evaluation sont ensuite
envoyees quelques semaines avant la date fixe de remise des resultats. Selon les campagnes,
on distingue deux types de mesures utilisee pourevaluer les algorithmes. Lesevaluations plutot
techniques vont considerees les courbes precision/rappel ou les MAP pour classer les approches.
Desevaluation plus orientees vers l’utilisateur vont tenir compte de facteur tels quela qualite de
l’interface, les temps d’indexation, de reponse ou encore la faculte d’adaptation d’un systemea
un nouveau domaine.
Avec la montee en puissance de la recherche de documents multimedia, on a vu apparaıtre
quelques taches specifiques dans les campagnes deja bienetablies. Mais elles ne sont pas uni-
quement orientees vers la recherche par le contenu et sont plus souvent axees sur la recherche
par le texte de documents multimedia en incluant plus ou moins d’analyse d’image. C’est le cas
de TRECvid et ImageCLEF. En revanche la recherche d’image sansutiliser aucune information
texte n’aete que peu exploree.
ImagEVAL est une nouvelle initiative qui aete lancee en France en 2006 dans le cadre
du programme TechnoVision. ImagEVAL est entierement axee sur la recherche d’images par le
contenu. Un deuxieme aspect interessant qui distingue cette initiative, est que ses caracteristiques
et son organisation ontete etablis conjointement par uneequipe de recherche et des archivistes
professionnels [MF06]. L’objectifetant de combiner uneevaluation technique classique avec
des criteres venant des utilisateurs finaux. La definition des taches aete examinee afin de s’atta-

58 Approche globale
quer aux problemes auxquels font face les agences photo. Les images sur lesquelles l’evaluation
a ete menee sont issue du monde professionnel. Cela a permis d’obtenirun volume de donnees
suffisant pour que l’evaluation soit pertinente d’un point de vue statistique, mais egalement
d’assurer une certaine diversite de qualites et d’usages. Les fournisseurs sont l’agence photo
Hachette, qui regroupe plusieurs fonds photographiques, Renault, la Reunion des Musees Na-
tionaux, le CNRS et le Ministere des Affaires Etrangeres. Les problemes lies aux copyright ont
ete surmontes partiellement et les gros volumes d’images ont ainsiete accessibles aux parti-
cipantsa la campagne d’evaluation. Malheureusement, ces images n’ont pas puetre diffusees
plus largement dans la communaute scientifique pour d’autres tests.
Les images ontete selectionnees et annotees par des professionnels, permettanta la verite
terrain d’etreetablie d’une facon originale. Deux professionnelles de Hachette ont annote ma-
nuellement toutes les images tel qu’elles ont l’habitude dele faire. La subjectivite qui est la leur
dans cetteetape fait partie des contraintes auxquelles nos approchesscientifiques doivent se
plier. Ainsi les bases d’evaluation refletent le quotidien des utilisateurs et non pas la perception
que peuvent en avoir les chercheurs [Pic06]. Nous sommes donc proches de la vie reelle avec
des scenarios et des collections d’images difficiles. Plusieursequipes francaises et europeennes
ont participe a l’evaluation, ainsi que des entreprises privees. ImagEVAL a cinq taches princi-
pales : detection d’images transformees, recherche d’images sur le web, detection de zones de
texte, detection d’objets et extraction d’attributs.
Cette campagne aete l’occasion d’analyser differentes approches de l’annotation automa-
tique. Nous avons ainsietudie l’etat de l’art et confronte les principales methodes sur les jeux de
donnees misa disposition au lancement de la campagne. Nous avons developpe et mis en œuvre
un framework complet d’annotation automatique adosse au moteur de recherche d’images par
le contenu IKONA. Nous avons participe a la tache 4 avec d’autres membres de l’equipe et
mene entierement la participationa la tache 5 qui est decrite dans la section suivante.
Description de la tache 5 - extraction d’attributs.
Le but de cette tache est de permettre la classification des images. Deux types de semantiques
sont cibles : la nature de l’image (representations artistiques, photographies couleur, photo-
graphies noir et blanc, images noir et blanc colorisees) et le contexte de l’image (interieur
/ exterieur, jour / nuit, paysage naturel ou urbain). La figure 2.24 montre l’organisation des
concepts tels qu’ils sont presentes dans la description de la tache. La representation de cet arbre
sous forme applatie est donnee dans la figure 2.25. Cela correspondant plusa notre approche.
Une base de donnees d’apprentissage contenant 5 416 images aete fournie. La taille typique de
ces images est d’environ 1000x700 pixels. La verite terrain aegalementete fournie. La partition
binaire des contextes des photographies n’est pas aussi claire que cela aurait du l’ etre. Il y a des
photos qui sont plus lieesa l’aube ou au crepuscule qu’au jour oua la nuit. La meme ambiguıte
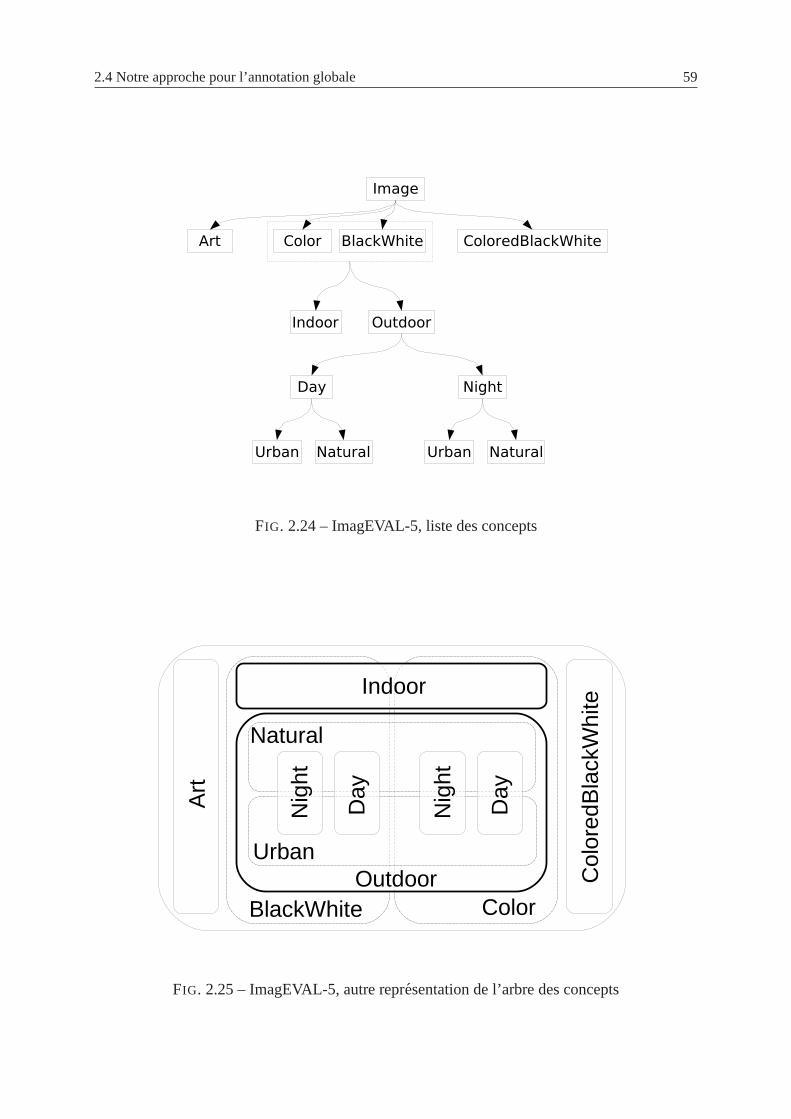
2.4 Notre approche pour l’annotation globale 59
FIG. 2.24 – ImagEVAL-5, liste des concepts
FIG. 2.25 – ImagEVAL-5, autre representation de l’arbre des concepts

60 Approche globale
est apparue pour des photos de scenes urbaines et naturelles, et meme pour la classification
interieur / exterieur. Mais ces ambiguıtes refletent la vie reelle et ces cas doiventetre traites. La
seule contrainte pour les archivistes qui ont annote ces images aete de fournira chaque image
tous les concepts pour atteindre les feuilles de l’arbre. Letableau 2.2 resume la distribution des
Concepts Nb. images
ART 429BlackWhite, Indoor 498BlackWhite, Outdoor, Day, NaturalScene 159BlackWhite, Outdoor, Day, UrbanScene 449BlackWhite, Outdoor, Night, UrbanScene 16Color, Indoor 1 129Color, Outdoor, Day, NaturalScene 946Color, Outdoor, Day, UrbanScene 1 092Color, Outdoor, Night, NaturalScene 3Color, Outdoor, Night, UrbanScene 368ColoredBlackWhite 327
TAB . 2.2 – ImagEVAL-5, repartition des images de la base d’apprentissage
images dans la base d’apprentissage. On peut voir que ces donnees sont tres desequilibrees,
mais cela reflete simplement la repartition naturelle de ces concepts dans les bases de donnees
reelles. La recherche de photographies en noir et blanc prises dans un environnement naturel de
nuit est en fait assez rare. On peut voir quelques exemples decette base dans la figure 2.26. La
base pour l’evaluation finale contient 23 572 images.
Pour l’evaluation, les requetes sont des chemins de l’arbre des concepts (par exemple,Art ou
Color / Indoor). Pour chaque requete, les premieres 5 000 images doiventetre retournees. Etant
une tache de recherche d’images, la mesure utilisee pourevaluer les algorithmes met l’accent
sur la recuperation des documents pertinents au plus tot. La MAP est utilisee. Elle differe de
la mesure utilisee dans les taches de classification (taux de bonne classification par exemple).
Par consequent, la confiance que nous avons dans la prediction d’un concept est importante et
permet de classer les resultats.
Recemment Cutzuet al. [CHL05] ont etudie plusieurs nouveaux descripteurs permettant de
distinguer les tableaux des photos. C’esta notre connaissance le seul travail sur le sujet. On peut
toutefois citer [DJLW06] qui introduit des descripteurs permettant d’etudier l’esthetique dans
les photos qui pourraientetre utilises. D’autres travaux sur l’art sont presentes dans [DNAA06,
VKSH06].
ImagEVAL-5, r esultats officiels
Six equipes ont finalement participe a cette tache (davantageetaient inscrites mais se sont
desistes). Chaqueequipe pouvait soumettre jusqu’a cinq resultats. Lesequipes avaient la pos-

2.4 Notre approche pour l’annotation globale 61
FIG. 2.26 – ImagEVAL-5, quelques exemples de la base d’apprentissage.c©Shah-Jacana/Hoa-Qui, Bassignac-Gamma, Patrimoine Photo, Dufour-Gamma et Faillet-Keystone.
sibilite de fournir des resultats avec des donnees supplementaires pour l’apprentissage mais
aucune ne l’a fait. Il y avait un total de 13 requetes :
1. Art
2. ColoredBlackWhite
3. BlackWhite / Indoor
4. BlackWhite / Outdoor
5. Color / Indoor
6. Color / Outdoor
7. BlackWhite / Outdoor / Night
8. BlackWhite / Outdoor / Day / Urban
9. BlackWhite / Outdoor / Day / Natural
10. Color / Outdoor / Day / Urban
11. Color / Outdoor / Day / Natural
12. Color / Outdoor / Night / Urban
13. Color / Outdoor / Night / Natural
Chaque fichier de resultat devait fournir les 5 000 premieres images de chaque requete (sur un
total de 23 572 images). On presente dans le tableau 2.3 le nombre d’images pour les differents
concepts visuels. Le ratio par rapporta la base d’apprentissage estegalement indique.

62 Approche globale
Concepts Nb. images Ratio
ART 4500 2.41BlackWhite, Indoor 2783 1.28BlackWhite, Outdoor, Day, NaturalScene 225 0.33BlackWhite, Outdoor, Day, UrbanScene 2304 1.18BlackWhite, Outdoor, Night 70 1.01Color, Indoor 4500 0.92Color, Outdoor, Day, NaturalScene 2531 0.61Color, Outdoor, Day, UrbanScene 4500 0.95Color, Outdoor, Night, NaturalScene 70 5.36Color, Outdoor, Night, UrbanScene 1370 0.86ColoredBlackWhite 719 0.51
TAB . 2.3 – ImagEVAL-5, repartition des images de la base de test
Nous avons presente 5 jeux de resultats, correspondant aux differentes options presentees
dans le tableau 2.4.
Run Options
imedia01 Vieille version correspondanta des hypotheses du testa blancimedia02 Noyau GHI, pre-traitement puissance 0.25imedia03 Noyau triangulaire (L1), pre-traitementechelleimedia04 Noyau Laplace, pre-traitementechelleimedia05 Concepts en extension, noyau triangulaire (L1), pre-traitementechelle
TAB . 2.4 – ImagEVAL-5, options pour la campagne officielle
Les resultats complets sont disponibles sur le site dediea la campagne3. Nous fournissons ici
la MAP de tous les jeux de resultats. Il avaitete convenu d’anonymiser tous les resultats apres la
troisiemeequipe. Le meilleur score est obtenu avec le noyau Laplace. Viennent ensuite les trois
MAP MAP
imedia04 0.6784 etis01 0.4912imedia03 0.6556 anonymous 0.4907imedia05 0.6532 anonymous 0.4931imedia02 0.6529 anonymous 0.3676imedia01 0.5979 anonymous 0.3141cea01 0.5771 anonymous 0.1985
TAB . 2.5 – ImagEVAL-5, resultats officiels
jeux utilisant les noyaux non-parametriques. Ils ont des performances strictementequivalentes.
Le surcout lie a l’optimisation d’un parametre supplementaire pour le noyau Laplace amene une
legere amelioration des performances (+3.5%). On remarque que, comme prevu, l’utilisation
des concepts en extension obtient exactement les memes resultats que les concepts en un-contre-
tous. Toutefois, pour le jeu imedia03 on a un temps d’apprentissage de 372 secondes generant
3http ://www.imageval.org

2.4 Notre approche pour l’annotation globale 63
des modeles ayant un total de 11 252 vecteurs support. Le temps de predictionetant alors de
0.1 seconde par image. En revanche, pour le jeu imedia05, le temps d’apprentissage est de
176 secondes, on a 6 595 vecteurs support et la prediction necessite 0.05 seconde par image.
Tous les traitements ontete effectues sur un Pentium 4, 2.8 GHz, 2 Go, Linux. L’extraction
des 6 descripteurs globaux prend en moyenne 6 secondes par photo. On peut remarquer dans
les resultats detailles [MF06] que cette approche est l’une des plus rapides. Si onne tient pas
compte des requetes peu vraissemblables (7 et 13), c’est-a-dire celles pour lesquelles tres peu
d’exemples sont disponibles dans les bases d’apprentissage et de test, alors la MAP est au-
dessus de 0.75. Cela represente des resultats tres satisfaisants. L’approche de l’equipe du CEA
est decrite dans la these de Millet [Mil08] et dans [Moe06]. L’approche d’ETIS est partiellement
decrite dans [PFGC06, GCPF07].
2.4.5 Etude et discussion sur les differents parametres
Une fois la campagne d’evaluation terminee, la verite terrain aete rendue disponible. Nous
en avons profite pour faire davantage de tests pour mesurer l’influence des diff erents parametres
impliques. Nous allons regarder l’impact des differents descripteurs, des noyaux et des pre-
traitements sur les donnees4.
Optimisation des parametres des SVM.
Nous utilisons une validation croisee avec 5 sous-ensembles pour optimiser les parametres.
Nous effectuons un parcours d’une plage de valeurs enechelle logarithmique pour la constante
de regularisationC. Par defaut nous avons :
−15 ≤ log2 C ≤ 15 (2.35)
Nous representons sur la figure 2.27 les scores obtenus en validation croisee pour le noyau
triangulaire, sans pre-traitement, avec les 6 descripteurs. Nous avons calcule les scores moyens
sur les 10 concepts. A titre d’indication, nous avonsegalement represente les scores pour les
conceptsArt et Indoor. Les courbes ont toutes la meme forme. Un croissance tres rapide pour
des valeurs delog2 C autour de−5. Le maximum est generalement atteint pourlog2 C = 1. On
observe ensuite une tres legere decroissance, mais globalement les scores restent stables quand
C augmente.
4Un lecteur attentif notera que les resultats presentes ici different legerement de ceux publies dans [HB07a].Ceci est du a quelques modifications dans l’implementation de l’optimisation des parametres du SVM.
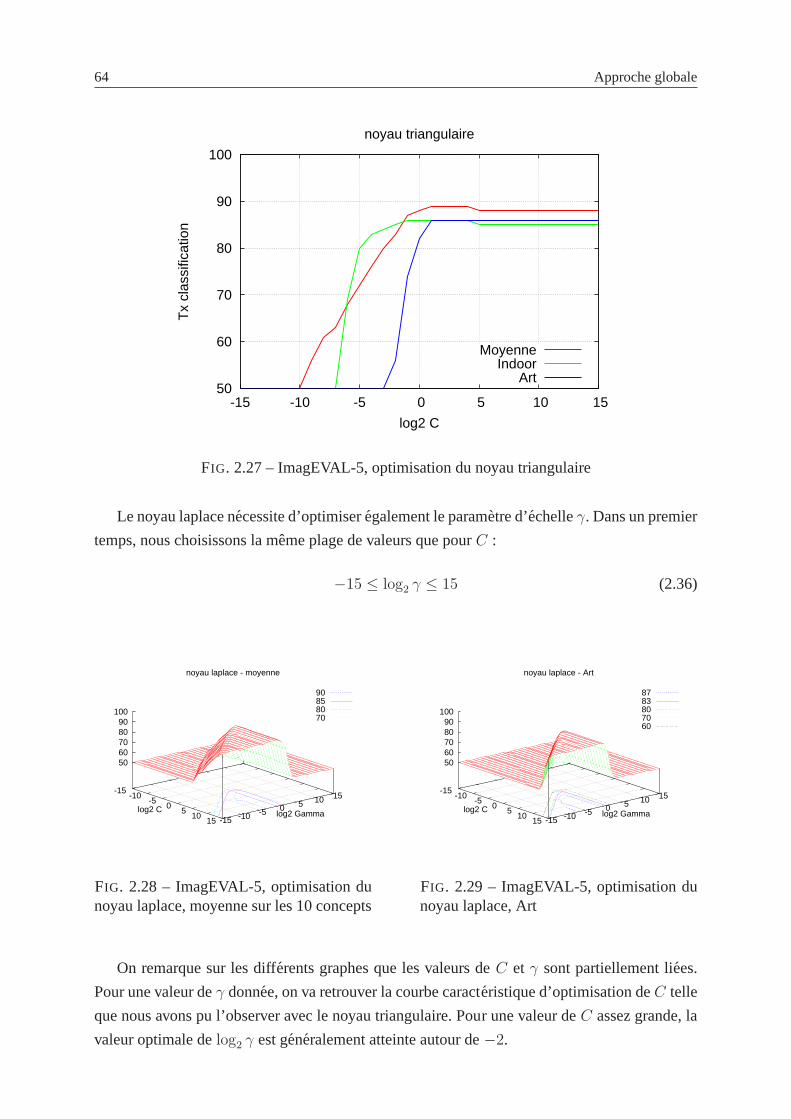
64 Approche globale
50
60
70
80
90
100
-15 -10 -5 0 5 10 15
Tx
clas
sific
atio
n
log2 C
noyau triangulaire
MoyenneIndoor
Art
FIG. 2.27 – ImagEVAL-5, optimisation du noyau triangulaire
Le noyau laplace necessite d’optimiseregalement le parametre d’echelleγ. Dans un premier
temps, nous choisissons la meme plage de valeurs que pourC :
−15 ≤ log2 γ ≤ 15 (2.36)
noyau laplace - moyenne
90 85 80 70
-15-10
-5 0
5 10
15log2 C
-15 -10 -5 0 5 10 15
log2 Gamma
50 60 70 80 90
100
FIG. 2.28 – ImagEVAL-5, optimisation dunoyau laplace, moyenne sur les 10 concepts
noyau laplace - Art
87 83 80 70 60
-15-10
-5 0
5 10
15log2 C
-15 -10 -5 0 5 10 15
log2 Gamma
50 60 70 80 90
100
FIG. 2.29 – ImagEVAL-5, optimisation dunoyau laplace, Art
On remarque sur les differents graphes que les valeurs deC et γ sont partiellement liees.
Pour une valeur deγ donnee, on va retrouver la courbe caracteristique d’optimisation deC telle
que nous avons pu l’observer avec le noyau triangulaire. Pour une valeur deC assez grande, la
valeur optimale delog2 γ est generalement atteinte autour de−2.
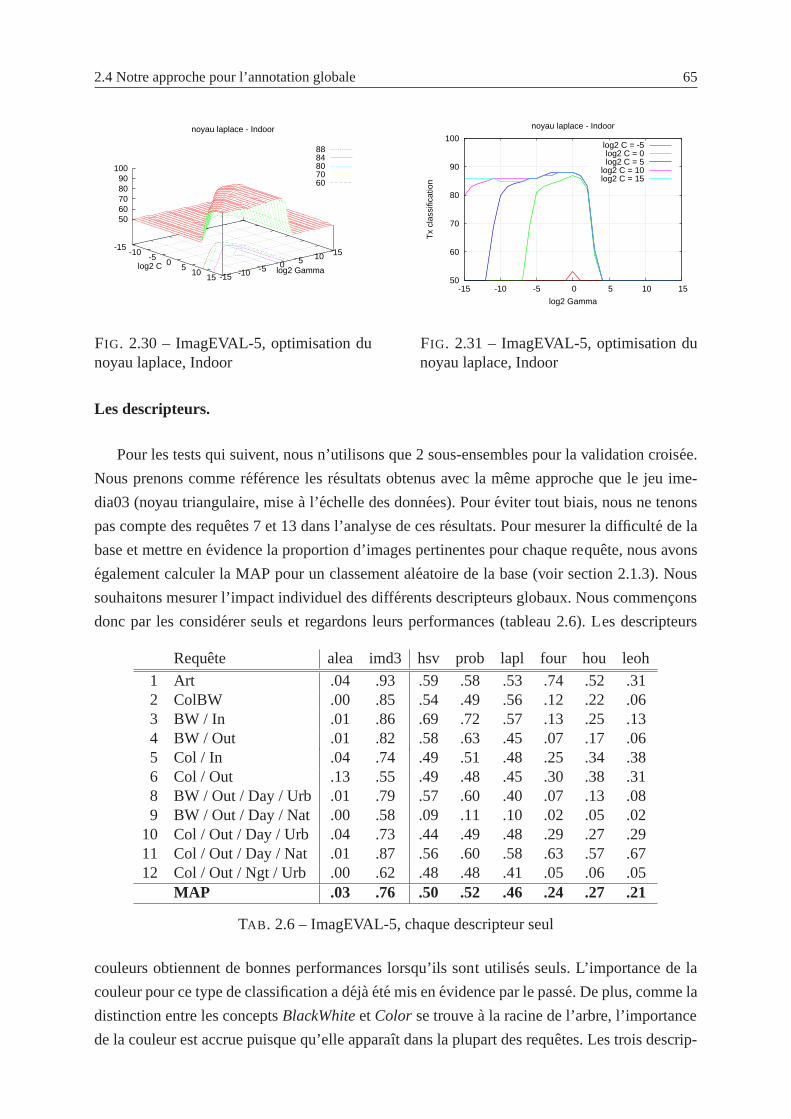
2.4 Notre approche pour l’annotation globale 65
noyau laplace - Indoor
88 84 80 70 60
-15-10
-5 0
5 10
15log2 C
-15 -10 -5 0 5 10 15
log2 Gamma
50 60 70 80 90
100
FIG. 2.30 – ImagEVAL-5, optimisation dunoyau laplace, Indoor
50
60
70
80
90
100
-15 -10 -5 0 5 10 15
Tx
clas
sific
atio
n
log2 Gamma
noyau laplace - Indoor
log2 C = -5log2 C = 0log2 C = 5
log2 C = 10log2 C = 15
FIG. 2.31 – ImagEVAL-5, optimisation dunoyau laplace, Indoor
Les descripteurs.
Pour les tests qui suivent, nous n’utilisons que 2 sous-ensembles pour la validation croisee.
Nous prenons comme reference les resultats obtenus avec la meme approche que le jeu ime-
dia03 (noyau triangulaire, misea l’echelle des donnees). Poureviter tout biais, nous ne tenons
pas compte des requetes 7 et 13 dans l’analyse de ces resultats. Pour mesurer la difficulte de la
base et mettre enevidence la proportion d’images pertinentes pour chaque requete, nous avons
egalement calculer la MAP pour un classement aleatoire de la base (voir section 2.1.3). Nous
souhaitons mesurer l’impact individuel des differents descripteurs globaux. Nous commencons
donc par les considerer seuls et regardons leurs performances (tableau 2.6). Les descripteurs
Requete alea imd3 hsv prob lapl four hou leoh
1 Art .04 .93 .59 .58 .53 .74 .52 .312 ColBW .00 .85 .54 .49 .56 .12 .22 .063 BW / In .01 .86 .69 .72 .57 .13 .25 .134 BW / Out .01 .82 .58 .63 .45 .07 .17 .065 Col / In .04 .74 .49 .51 .48 .25 .34 .386 Col / Out .13 .55 .49 .48 .45 .30 .38 .318 BW / Out / Day / Urb .01 .79 .57 .60 .40 .07 .13 .089 BW / Out / Day / Nat .00 .58 .09 .11 .10 .02 .05 .02
10 Col / Out / Day / Urb .04 .73 .44 .49 .48 .29 .27 .2911 Col / Out / Day / Nat .01 .87 .56 .60 .58 .63 .57 .6712 Col / Out / Ngt / Urb .00 .62 .48 .48 .41 .05 .06 .05
MAP .03 .76 .50 .52 .46 .24 .27 .21
TAB . 2.6 – ImagEVAL-5, chaque descripteur seul
couleurs obtiennent de bonnes performances lorsqu’ils sont utilises seuls. L’importance de la
couleur pour ce type de classification a deja ete mis enevidence par le passe. De plus, comme la
distinction entre les conceptsBlackWhiteetColor se trouvea la racine de l’arbre, l’importance
de la couleur est accrue puisque qu’elle apparaıt dans la plupart des requetes. Les trois descrip-
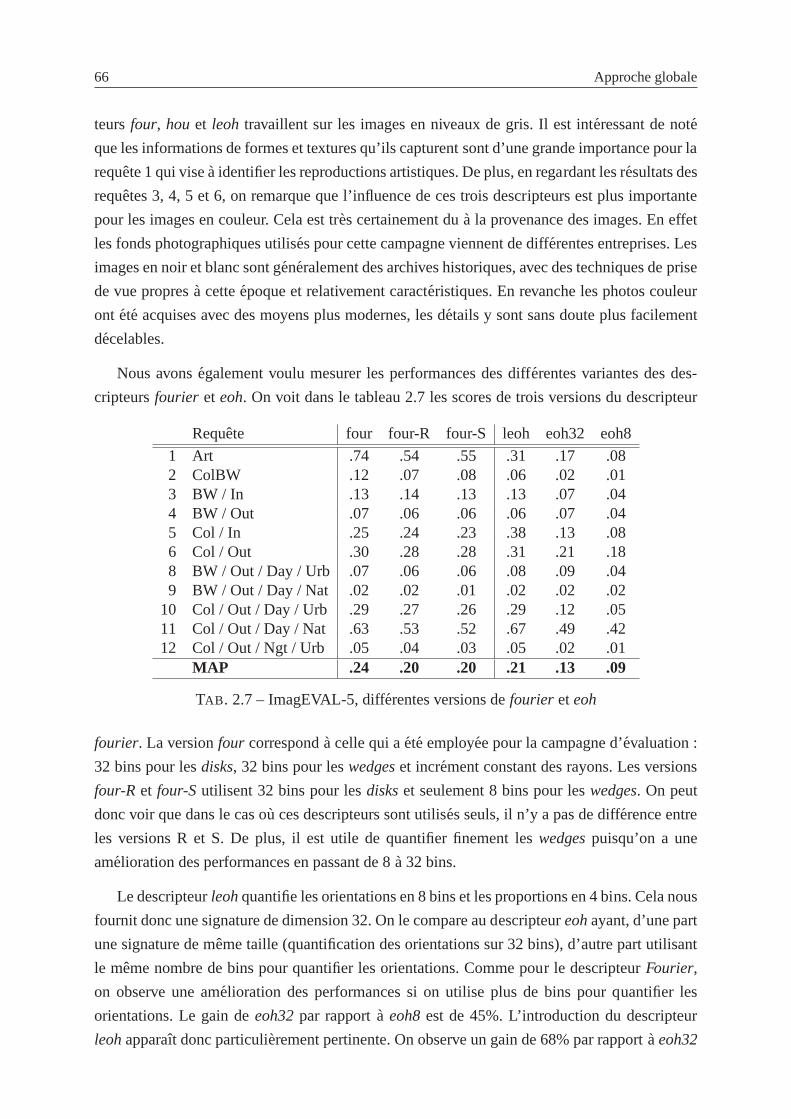
66 Approche globale
teursfour, hou et leoh travaillent sur les images en niveaux de gris. Il est interessant de note
que les informations de formes et textures qu’ils capturentsont d’une grande importance pour la
requete 1 qui visea identifier les reproductions artistiques. De plus, en regardant les resultats des
requetes 3, 4, 5 et 6, on remarque que l’influence de ces trois descripteurs est plus importante
pour les images en couleur. Cela est tres certainement dua la provenance des images. En effet
les fonds photographiques utilises pour cette campagne viennent de differentes entreprises. Les
images en noir et blanc sont generalement des archives historiques, avec des techniques deprise
de vue propresa cetteepoque et relativement caracteristiques. En revanche les photos couleur
ont ete acquises avec des moyens plus modernes, les details y sont sans doute plus facilement
decelables.
Nous avonsegalement voulu mesurer les performances des differentes variantes des des-
cripteursfourier et eoh. On voit dans le tableau 2.7 les scores de trois versions du descripteur
Requete four four-R four-S leoh eoh32 eoh8
1 Art .74 .54 .55 .31 .17 .082 ColBW .12 .07 .08 .06 .02 .013 BW / In .13 .14 .13 .13 .07 .044 BW / Out .07 .06 .06 .06 .07 .045 Col / In .25 .24 .23 .38 .13 .086 Col / Out .30 .28 .28 .31 .21 .188 BW / Out / Day / Urb .07 .06 .06 .08 .09 .049 BW / Out / Day / Nat .02 .02 .01 .02 .02 .02
10 Col / Out / Day / Urb .29 .27 .26 .29 .12 .0511 Col / Out / Day / Nat .63 .53 .52 .67 .49 .4212 Col / Out / Ngt / Urb .05 .04 .03 .05 .02 .01
MAP .24 .20 .20 .21 .13 .09
TAB . 2.7 – ImagEVAL-5, differentes versions defourier eteoh
fourier. La versionfour corresponda celle qui aete employee pour la campagne d’evaluation :
32 bins pour lesdisks, 32 bins pour leswedgeset increment constant des rayons. Les versions
four-R et four-Sutilisent 32 bins pour lesdiskset seulement 8 bins pour leswedges. On peut
donc voir que dans le cas ou ces descripteurs sont utilises seuls, il n’y a pas de difference entre
les versions R et S. De plus, il est utile de quantifier finementles wedgespuisqu’on a une
amelioration des performances en passant de 8a 32 bins.
Le descripteurleohquantifie les orientations en 8 bins et les proportions en 4 bins. Cela nous
fournit donc une signature de dimension 32. On le compare au descripteureohayant, d’une part
une signature de meme taille (quantification des orientations sur 32 bins), d’autre part utilisant
le meme nombre de bins pour quantifier les orientations. Comme pour le descripteurFourier,
on observe une amelioration des performances si on utilise plus de bins pour quantifier les
orientations. Le gain deeoh32par rapporta eoh8est de 45%. L’introduction du descripteur
leohapparaıt donc particulierement pertinente. On observe un gain de 68% par rapportaeoh32
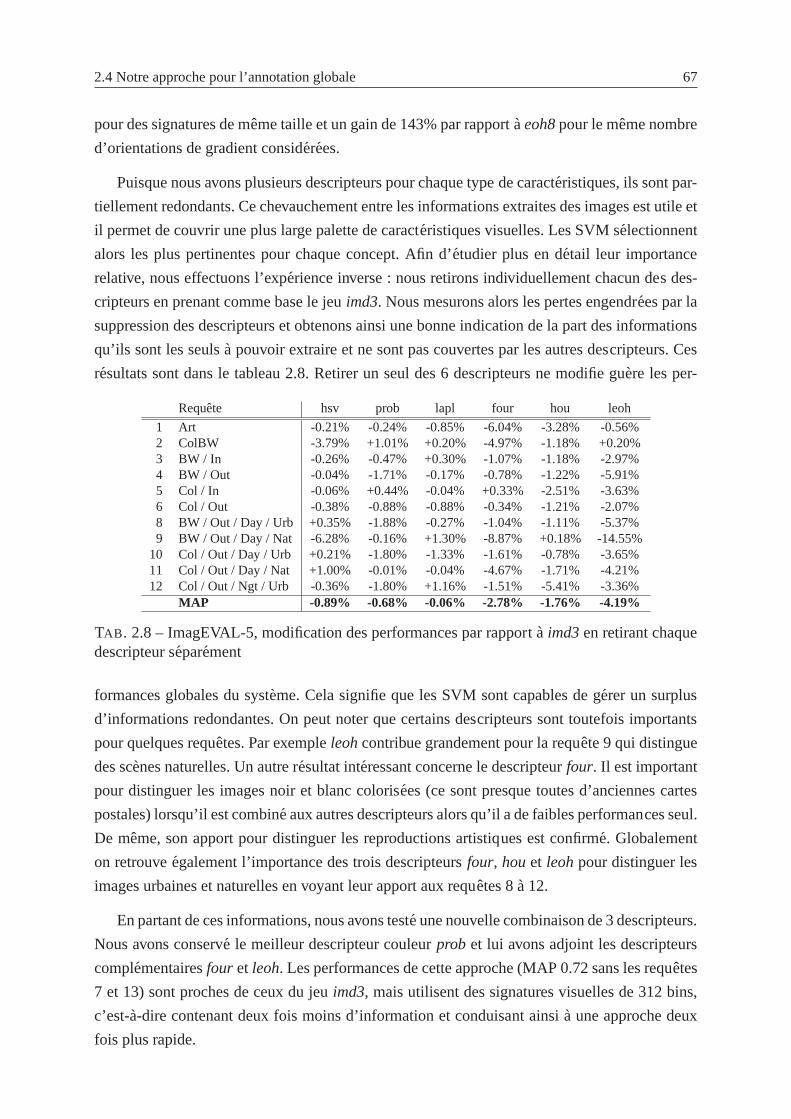
2.4 Notre approche pour l’annotation globale 67
pour des signatures de meme taille et un gain de 143% par rapportaeoh8pour le meme nombre
d’orientations de gradient considerees.
Puisque nous avons plusieurs descripteurs pour chaque typede caracteristiques, ils sont par-
tiellement redondants. Ce chevauchement entre les informations extraites des images est utile et
il permet de couvrir une plus large palette de caracteristiques visuelles. Les SVM selectionnent
alors les plus pertinentes pour chaque concept. Afin d’etudier plus en detail leur importance
relative, nous effectuons l’experience inverse : nous retirons individuellement chacun des des-
cripteurs en prenant comme base le jeuimd3. Nous mesurons alors les pertes engendrees par la
suppression des descripteurs et obtenons ainsi une bonne indication de la part des informations
qu’ils sont les seulsa pouvoir extraire et ne sont pas couvertes par les autres descripteurs. Ces
resultats sont dans le tableau 2.8. Retirer un seul des 6 descripteurs ne modifie guere les per-
Requete hsv prob lapl four hou leoh
1 Art -0.21% -0.24% -0.85% -6.04% -3.28% -0.56%2 ColBW -3.79% +1.01% +0.20% -4.97% -1.18% +0.20%3 BW / In -0.26% -0.47% +0.30% -1.07% -1.18% -2.97%4 BW / Out -0.04% -1.71% -0.17% -0.78% -1.22% -5.91%5 Col / In -0.06% +0.44% -0.04% +0.33% -2.51% -3.63%6 Col / Out -0.38% -0.88% -0.88% -0.34% -1.21% -2.07%8 BW / Out / Day / Urb +0.35% -1.88% -0.27% -1.04% -1.11% -5.37%9 BW / Out / Day / Nat -6.28% -0.16% +1.30% -8.87% +0.18% -14.55%
10 Col / Out / Day / Urb +0.21% -1.80% -1.33% -1.61% -0.78% -3.65%11 Col / Out / Day / Nat +1.00% -0.01% -0.04% -4.67% -1.71% -4.21%12 Col / Out / Ngt / Urb -0.36% -1.80% +1.16% -1.51% -5.41% -3.36%
MAP -0.89% -0.68% -0.06% -2.78% -1.76% -4.19%
TAB . 2.8 – ImagEVAL-5, modification des performances par rapport a imd3en retirant chaquedescripteur separement
formances globales du systeme. Cela signifie que les SVM sont capables de gerer un surplus
d’informations redondantes. On peut noter que certains descripteurs sont toutefois importants
pour quelques requetes. Par exempleleohcontribue grandement pour la requete 9 qui distingue
des scenes naturelles. Un autre resultat interessant concerne le descripteurfour. Il est important
pour distinguer les images noir et blanc colorisees (ce sont presque toutes d’anciennes cartes
postales) lorsqu’il est combine aux autres descripteurs alors qu’il a de faibles performances seul.
De meme, son apport pour distinguer les reproductions artistiques est confirme. Globalement
on retrouveegalement l’importance des trois descripteursfour, houet leohpour distinguer les
images urbaines et naturelles en voyant leur apport aux requetes 8a 12.
En partant de ces informations, nous avons teste une nouvelle combinaison de 3 descripteurs.
Nous avons conserve le meilleur descripteur couleurprob et lui avons adjoint les descripteurs
complementairesfour et leoh. Les performances de cette approche (MAP 0.72 sans les requetes
7 et 13) sont proches de ceux du jeuimd3, mais utilisent des signatures visuelles de 312 bins,
c’est-a-dire contenant deux fois moins d’information et conduisant ainsia une approche deux
fois plus rapide.
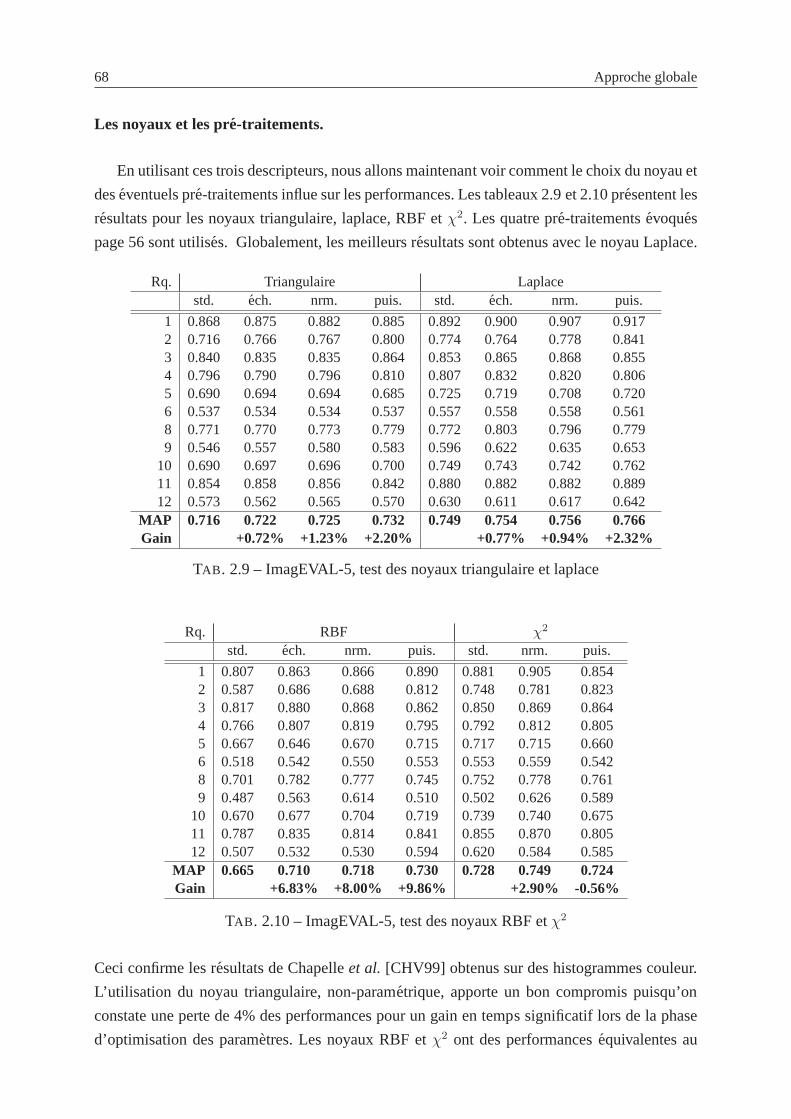
68 Approche globale
Les noyaux et les pre-traitements.
En utilisant ces trois descripteurs, nous allons maintenant voir comment le choix du noyau et
deseventuels pre-traitements influe sur les performances. Les tableaux 2.9et 2.10 presentent les
resultats pour les noyaux triangulaire, laplace, RBF etχ2. Les quatre pre-traitementsevoques
page 56 sont utilises. Globalement, les meilleurs resultats sont obtenus avec le noyau Laplace.
Rq. Triangulaire Laplacestd. ech. nrm. puis. std. ech. nrm. puis.
1 0.868 0.875 0.882 0.885 0.892 0.900 0.907 0.9172 0.716 0.766 0.767 0.800 0.774 0.764 0.778 0.8413 0.840 0.835 0.835 0.864 0.853 0.865 0.868 0.8554 0.796 0.790 0.796 0.810 0.807 0.832 0.820 0.8065 0.690 0.694 0.694 0.685 0.725 0.719 0.708 0.7206 0.537 0.534 0.534 0.537 0.557 0.558 0.558 0.5618 0.771 0.770 0.773 0.779 0.772 0.803 0.796 0.7799 0.546 0.557 0.580 0.583 0.596 0.622 0.635 0.653
10 0.690 0.697 0.696 0.700 0.749 0.743 0.742 0.76211 0.854 0.858 0.856 0.842 0.880 0.882 0.882 0.88912 0.573 0.562 0.565 0.570 0.630 0.611 0.617 0.642
MAP 0.716 0.722 0.725 0.732 0.749 0.754 0.756 0.766Gain +0.72% +1.23% +2.20% +0.77% +0.94% +2.32%
TAB . 2.9 – ImagEVAL-5, test des noyaux triangulaire et laplace
Rq. RBF χ2
std. ech. nrm. puis. std. nrm. puis.
1 0.807 0.863 0.866 0.890 0.881 0.905 0.8542 0.587 0.686 0.688 0.812 0.748 0.781 0.8233 0.817 0.880 0.868 0.862 0.850 0.869 0.8644 0.766 0.807 0.819 0.795 0.792 0.812 0.8055 0.667 0.646 0.670 0.715 0.717 0.715 0.6606 0.518 0.542 0.550 0.553 0.553 0.559 0.5428 0.701 0.782 0.777 0.745 0.752 0.778 0.7619 0.487 0.563 0.614 0.510 0.502 0.626 0.589
10 0.670 0.677 0.704 0.719 0.739 0.740 0.67511 0.787 0.835 0.814 0.841 0.855 0.870 0.80512 0.507 0.532 0.530 0.594 0.620 0.584 0.585
MAP 0.665 0.710 0.718 0.730 0.728 0.749 0.724Gain +6.83% +8.00% +9.86% +2.90% -0.56%
TAB . 2.10 – ImagEVAL-5, test des noyaux RBF etχ2
Ceci confirme les resultats de Chapelleet al. [CHV99] obtenus sur des histogrammes couleur.
L’utilisation du noyau triangulaire, non-parametrique, apporte un bon compromis puisqu’on
constate une perte de 4% des performances pour un gain en temps significatif lors de la phase
d’optimisation des parametres. Les noyaux RBF etχ2 ont des performancesequivalentes au

2.4 Notre approche pour l’annotation globale 69
noyau triangulaire mais comporte un parametre d’echellea optimiser. Parmi les differents pre-
traitements, l’elevationa la puissance 0.25 des bins des histogrammes fournit les meilleurs
resultats. On peut toutefois noter que cette amelioration est surtout flagrante dans le cas du
noyau RBF.
2.4.6 Analyse critique des bases d’evaluation existantes
Quelles informations peut-on obtenir en appliquant la methode decrite precedemmenta une
tache de reconnaissance d’objets ? De facon generale, identifier des objets dans les images
necessite l’utilisation de signatures visuelles plus fines faisant intervenir des descripteurs lo-
caux. Ces signatures sont calculees sur des regions apres segmentation de l’image, autour de
points d’interet ou, plus simplement, selon un decoupage en grille fixe. Quelle que soit l’ap-
proche choisie, elle implique de s’interessera certaine partie de l’image plutot qu’a sa globa-
lit e. Mais l’information contextuelle est importante pour detecter les objets. En effet, il est rare
qu’un objet apparaisse dans un contexte auquel il n’est pas lie. Ceci a par exemple conduit
certains chercheursa travailler sur une integration de l’information contextuelle dans un des-
cripteur local [ASR05]. Nous presenterons notre approche de ce problemea la section 3.4. Nous
ne pretendons donc pas ici resoudre le probleme de la detection d’objets en utilisant uniquement
des descripteurs globaux, mais nous pensons que cette approche permet d’obtenir des informa-
tions importantes sur la difficulte de cette tache pour une base d’images donnees et de juger
ainsi de son utilisabilite. Ce probleme a deja ete souleve dans [PBE+06], nous presentons ici les
resultats obtenus sur des bases standards avec notre approche. Pour toutes les bases de donnees
testees, nous avons utilise les memes configurations experimentales que celles decrites par les
auteurs de cesetudes. Nous avons utilise des SVM avec noyau triangulaire et notre jeu de des-
cripteurs globaux. Lorsque cela s’est avere necessaire, nous avons utilise une version en niveaux
de gris des descripteursprob et lapl afin de de ne pas tenir compte de l’information couleur et
d’etre ainsi en mesure d’effectuer une comparaison avec les autres approches proposees.
Corel2000
La base de donnees Corel est probablement une des plus utilisees en recherche d’images
par le contenu et en categorisation. Des 2002 des papiers expliquant la simplicite de cette base
paraissent [MMMP02, WdV03]. On voit toutefois encore des recherches qui ne se basent que
sur cette collection pour justifier du bien-fonde d’une approche. Certaines experiences utilisent
un sous-ensemble de 2 000 images, divisees en 20 categories. On peut voir quelques exemples
sur la figure 2.32.
Ce jeu est partage aleatoirement en une base d’apprentissage et une base de test aillant
chacune 50 images par categorie. Cette operation est effectuee cinq fois et le ratio de bonne

70 Approche globale
FIG. 2.32 – Quelques images de la base Corel2000
categorisation moyen est reporte. Ces resultats confirment clairement que cette base est beau-
Approche Resultats
Notre approche - 5 desc. 83.7Notre approche -hsvseul 71.6Chen - MILES [CBW06] 68.7Chen - DD-SVM [CW04] 67.5Csurka [CBDF04] 52.3
TAB . 2.11 – Resultats sur la base Corel2000
coup trop simple. Meme en utilisant un histogramme HSV seul, les resultats sont meilleurs que
des approches locales.
Caltech4
Cette base contient quatre classes d’objets. Pour chacune deces categories, des images
d’arriere-plan sontegalement disponibles. L’objectif est de separer les images contenant un
objet des autres.
Il s’agit d’une tache de classification objet/arriere-plan. Nous utilisons les memes ensembles
d’apprentissage et de test que dans [FPZ03]. Nous utilisonsles descripteurslapl, prob en ni-
veaux de gris, ainsi quefour et leoh. Nous avons ainsi des signatures de 84 dimensions par
image. Nous obtenons des resultatsequivalentsa ceux prealablement publies. Des taux de
bonne classification qui atteignent presque les 100% avec une approche globale tendent tou-
tefois clairementa prouver que cette base n’est pas assez difficile pour testerdes algorithmes
de reconnaissance d’objets.

2.4 Notre approche pour l’annotation globale 71
FIG. 2.33 – Quelques images de la base Caltech4
Approche Avion Voiture (vue arriere) Visage Moto
Notre approche 99.2 100 98.6 98.8Chen [CBW06] 98.0 94.5 99.5 96.7Zhang J. [ZMLS05] 98.8 98.3 100 98.5Willamowski [WAC+04] 97.1 98.6 99.3 98.0Fergus [FPZ03] 90.2 90.3 96.4 92.5
TAB . 2.12 – Resultats sur la base Caltech4

72 Approche globale
Xerox7
Cette base contient 1 776 images de 7 classes (visages, velos, voitures, batiments, livres,
telephones et arbres). Comme dans [WAC+04], nous utilisons une classification multi-classes
FIG. 2.34 – Quelques images de la base Xerox7
avec validation croisee sur 10 sous-ensembles. Les performances moyennes sont rapportees.
Nous utilisons les descripteurs en niveaux de gris. La encore, nos resultats sont vraiment proches
des meilleurs publies. La base Xerox7 n’est donc pas adaptee pour la detection d’objets.
Pascal VOC2005
On pourra trouver une description complete de la campagne d’evaluation Pascal VOC 2005
dans [EZW+06]. Deux jeux de donnees sonta notre disposition. On considere quatres classes
d’objets (velos, voitures, motos et personnes). Le premier jeu est considere commeetant plutot

2.4 Notre approche pour l’annotation globale 73
Approche Resultat
Notre approche 92.5Zhang J. [ZMLS05] 94.3Willamowski [WAC+04] 82.0
TAB . 2.13 – Resultats sur la base Xerox7
facile et le second plus difficile. Les performances sont mesurees sur la courbe ROC (Recei-
ver Operating Characteristic) au point pour lequel le taux de faux positifs et de faux negatifs
estegal (Equal Error Rate). On constate effectivement que la premiere base est relativement
Approche Velo Voiture Moto Personne
Notre approche 88.7 92.2 95.8 86.9Meilleur score dans [EZW+06] 93.0 96.1 97.7 91.7
TAB . 2.14 – Resultats pour la base VOC2005-1
Approche Velo Voiture Moto Personne
Notre approche 57.9 66.3 64.8 69.2Zhang J. [ZMLS05] 68.1 74.1 79.7 75.3
TAB . 2.15 – Resultats pour la base VOC2005-2
simple. Notre approche obtient des performances qui sont inferieures de 4% aux meilleures pu-
bliees. En revanche pour la seconde base, les approches localesmontrent quelques benefices.
Notre approche globale est moins bonne de 13%.
La campagne VOC du reseau d’excellence europeen Pascal s’est poursuivie apres cette
premiere initiative. Des resultats sur la base VOC 2007 seront presentes dans le chapitre 3.
Caltech101
Cette base contient 101 classes d’objets, plus une d’arriere-plans qui n’est generalement pas
utilisee [FFFP04]. Les objets sont toujours centres dans les images. On trouve entre 31 et 800
images par categorie, avec de gros problemes sur certaines d’entre elles : il existe deux classes
de visages, une rotation artificielle de45◦ aete effectuee sur certaines classes, . . . . Il existe deux
principaux protocoles d’evaluation, utilisant 15 ou 30 images d’apprentissage par classe. Dans
les deux cas, les approches locales sont nettement meilleures que notre approche globale.
Pour des taches de reconnaissance d’objets, les bases telles que Corel, Caltech4, Xerox7
et Pascal VOC2005-1 doivent clairementetre abandonnees pour tester les approches locales
puisque de simples methodes globales atteignent des performancesequivalentes. On voit bien

74 Approche globale
FIG. 2.35 – Quelques images de la base Caltech101
Approche 30 im./classe 15 im./classe
Notre approche 39.6 32.7Zhang H. [ZBMM06] 66.23 59.08Lazebnick [LSP06] 64.6 56.4
TAB . 2.16 – Resultats pour la base Caltech101
sur les exemples qu’il y a un manque flagrant de diversite dans les images, ce qui explique
les bon scores obtenus avec l’approche globale. La cas de la base Caltech101 est particulier.
L’utilisation d’approches locales y est clairement benefique, mais les images sont loins d’etre
representatives de ce que l’on peut trouver dans les bases reelles. Ainsi, des approches recentes
qui obtiennent de bons resultats sur cette base se focalisent sur une modelisation des formes
et de leur localisation dans l’image [BZM07]. Le fait que toutes les images representent un
objet en gros plan et que, pour certaines categories, toutes les images aientete artificiellement
tournee pour que l’orientation principale de l’objet soit identique, favorisent grandement ce type
d’approches. Toutefois nous doutons fortement qu’elles soient adapteesa des bases realistes.
Ces bases de recherche ont permis des avancees certaines dans le domaine de la vision par
ordinateur, mais elles doivent maintenantetre laissees de cote. L’utilisation de bases realistes
comme celles de la campagne ImagEVAL doitetre privilegiee.

2.5 Genericite des modeles pour l’annotation globale 75
2.4.7 Conclusions
Nous avons mis en place une strategie d’annotation automatique pour les concepts globaux.
Basee sur trois descripteurs visuels et un pool de SVMa noyau triangulaire, cette approche
se revele tres efficace. Nous avonsa cette occasion introduit le nouveau descripteur de formes
LEOH. Cette strategie a obtenu les meilleures performances lors de la campagne d’evaluation
ImagEVAL pour la tache de classification de scenes. Nous avonsetudie les differents parametres
qui interviennent dans la chaıne de traitement et montre qu’il est possible d’ameliorer en-
core legerement les performances de cette approche en utilisant un noyau Laplace et un pre-
traitement des signatures en les passanta la puissance 0.25. L’ajout de trois autres descripteurs
visuels permetegalement d’ameliorer les performances. Toutefois, nous estimons que le choix
que nous faisons offre un bon compromis entre performances et temps de calcul, aussi bien lors
de la phase d’apprentissage que lors de la prediction des concepts. De plus, notre approche est
completement generique et ne fait intervenir aucune connaissance a priori, la rendant facilement
extensiblea tout type de concept visuel global.
Nous pensons que cette technologie est maintenant suffisament mature et doit pouvoiretre
utilisee dans les moteurs d’indexation et de recherche lies aux bases d’images. Par ailleurs, dans
le cadre de l’annotation de concepts locaux, nous savons queles informations contextuelles sont
utiles. L’utilisation d’une approche globale comme la notre n’est pas pertinente pour cela, mais
elle permet de fournir une bonne indication de la difficulte de la tache. Nous avons ainsi pu
mettre en avant le fait que certaines bases d’images issues de laboratoires de recherche n’etaient
plus adaptees pour les approches locales.
2.5 Genericit e des modeles pour l’annotation globale
On vient de voir que l’annotation automatique pour des concepts globaux servanta decrire
la nature ou l’ambiance globale d’une image fonctionne plutot bien sur les bases des campagnes
d’evaluation. Nous pensons que les approches proposees sont suffisamment matures pouretre
misesa disposition d’utilisateurs professionnels. Il reste toutefois encore une question : com-
ment se comporte le modele appris pour un concept visuel sur une base d’images differente ?
Dans les campagnes d’evaluation, une base d’image est constituee, annotee et generalement
partagee aleatoirement en deux sous-ensembles d’apprentissage et de test. Il y a donc une ho-
mogeneite des images entre les deux bases,a la fois en termes de contenu et de qualite tech-
nique. Nous avonsegalementevoque le probleme de la constitution d’une verite terrain fiable
et suffisamment volumineuse pour les algorithmes d’apprentissage. Dans le cadre d’une utili-
sation en situation reelle d’algorithmes d’annotation automatique, on va rapidement constater
une divergence entre les images ayant servia apprendre les modeles et les nouvelles images

76 Approche globale
devantetre annotees. Ces dernieres arrivent au gre de l’actualite pour les agences de presse, et
meme si des thematiques sont recurrentes (conferences de presse, terrains de sport, . . . ) il y a
generalement beaucoup de nouveautes. Pour les agences d’illustration la diversite est encore
plus grande puisque, dans l’optique de pouvoir fournira leurs clients des images sur un nombre
croissant de thematiques, elles produisent des images sur les sujets qui nesont pas encore
presents dans leur fonds photographique. Il existe plusieursapproches pour tenter de resoudre
ce probleme. Elles dependent de l’utilisation qui sera faite des annotations generees automati-
quement par le systeme. Si une validation humaine est necessaire, alors il suffit periodiquement
de reapprendre les modeles en incluant les nouvelles images et leur verite terrain. En revanche,
dans le cas ou les scores de confiance ne sont utilises que pour faire de la recherche, aucune
intervention humaine n’a lieu. Pour s’assurer de la coherence des modeles, on peut alors envi-
sager desetapes regulierement de validation partielle sur unechantillonnage aleatoire de la base.
Il existe egalement des approches tirant partie des donnees non-annotees pour l’apprentissage
[GZ00, ZCJ04, DGL05].
Nous souhaitons quantifier ce phenomene. Pour cela, nous allons predire des concepts vi-
suels appris avec la base ImagEVAL-5 sur deux nouvelles bases. Nous aurons ainsi une idee de
la genericite des modeles.
FIG. 2.36 – ImagEVAL-5, quelques images de la categorie Color
Dans le cadre du projet europeen Vitalas5, une base d’images professionnelles aete collectee
aupres de Belga. Elle comporte 97 773 images [WND+07] qui couvrent tous les types de sujets,
en Belgique eta l’etranger. Les images brutes ontete extraites du systeme Belga. Nous ignorons
donc certaines images particulieres qui sont utilisees pour fournir des informations rapidement
aux clients de l’agence. On peut en voir des exemples sur la figure 2.37. Les images n’etant
5http ://vitalas.ercim.org

2.5 Genericite des modeles pour l’annotation globale 77
FIG. 2.37 – Belga100k, quelques images d’information qui sont ignorees
pas annotees, nous effectuerons une validation manuelle des resultats sur les 1 000 premieres
images retournees pour les conceptsindoor, outdoor, urban et natural. Nous mesurerons la
precision pour ces quatre concepts et les comparerons respectivement avec celles obtenues dans
des conditionsequivalentes sur la base de test d’ImagEVAL-5. Nous utilisons notre jeu reduit
de 3 descripteurs visuels (prob, four et leoh) avec des SVMa noyau triangulaire en utilisant le
pre-traitement de misea l’echelle.
Les deux bases de donnees sont d’origine professionnelle. La qualite technique des photos
est bonne. Pour la base de test ImagEVAL-5, nous ne predisons les concepts que sur les photos
couleur (soit 12 971 images). Les deux bases ayant des tailles differentes, nous mesurons la
precision sur les 133 premieres images de la base ImagEVAL-5 afin de rester dans les memes
proportions (environ 1% de la base). Nous avons appris des modeles differents de ceux de la
section precedente en n’utilisant que les photos couleurs de la base d’apprentissage pouretre
ainsi plus proche des conditions de constitution de la base Belga100k. Concernant le probleme
FIG. 2.38 – Belga100k, quelques images de la base.c©Belga
des images ambigues, nous avons suivi la meme procedure que pour la constitution de la base
ImagEVAL [Pic06]. De maniere generale, le choix de la categoriea laquelle une photo appar-
tient est guide par ce qu’un humain est capable d’en dire. Ainsi, meme si rien visuellement sur

78 Approche globale
l’image ne permet de decider de la categorie mais qu’unelement du contexte nous permet de
le dire, alors on assigne cette categorie. Par exemple, les photos en gros plan des joueurs de
tennis dans un tournoi sont alternativement classees en Indoor ou en Outdoor selon que l’on
capte un detail du decor qui nous fait penser au tournoi de Roland Garros ou au tournoi de Paris
Bercy. En revanche quand nous sommes dans l’impossibilite complete de juger, nous attribuons
l’image a la categorie la plus favorable pour les performances (ce cas est tres rare). Les images
de stadea ciel ouvert sont considerees comme Outdoor / Urban. Pour la categorisation Urban,
nous considerons que tout ce qui se passe en ville ou bien les photos dans lesquelles on dis-
tingue un batiment, une structure de construction humaine.Tout le reste est classe dans Natural
(y compris les scenes dans lesquelles on distingue des vehicules).
De facon similaire nous avons teste les modeles des quatre concepts visuels sur une col-
lection de photos personnelles (appelee NRV). Cette base contient 5 619 photos, de qualite
semi-professionnelle, couvrant des sujets classiques (voyages, reunions familiales) et d’autres
plus varies (portraits en studio, mouvements sociaux,evenements sportifs). La precision est
mesuree sur les 58 premieres images retournees.
FIG. 2.39 – NRV, quelques images de la base
Nous n’avons pas d’idee sur la proportion d’images ayant chacun des concepts dansles bases
Belga100k et NRV. Or nous savons que cette proportion influe sur la mesure de la precision
moyenne. Aussi, nous avons effectue un tirage aleatoire de 1 000 images pour la base Belga100k
et 500 images pour la base NRV afin d’evaluer manuellement ces proportions. Les resultats
sont presentes dans le tableau 2.40. On constate quelques disparites dans ces proportions.
La base NRV possede beaucoup plus de photos prises en exterieur, ceci s’explique par les
thematiques traitees et le fait que nous ne prenions guere de photos au flash. La proportion
interieur/exterieur esta peu pres identique pour ImagEVAL-5 et Belga100k. En revanche, pour
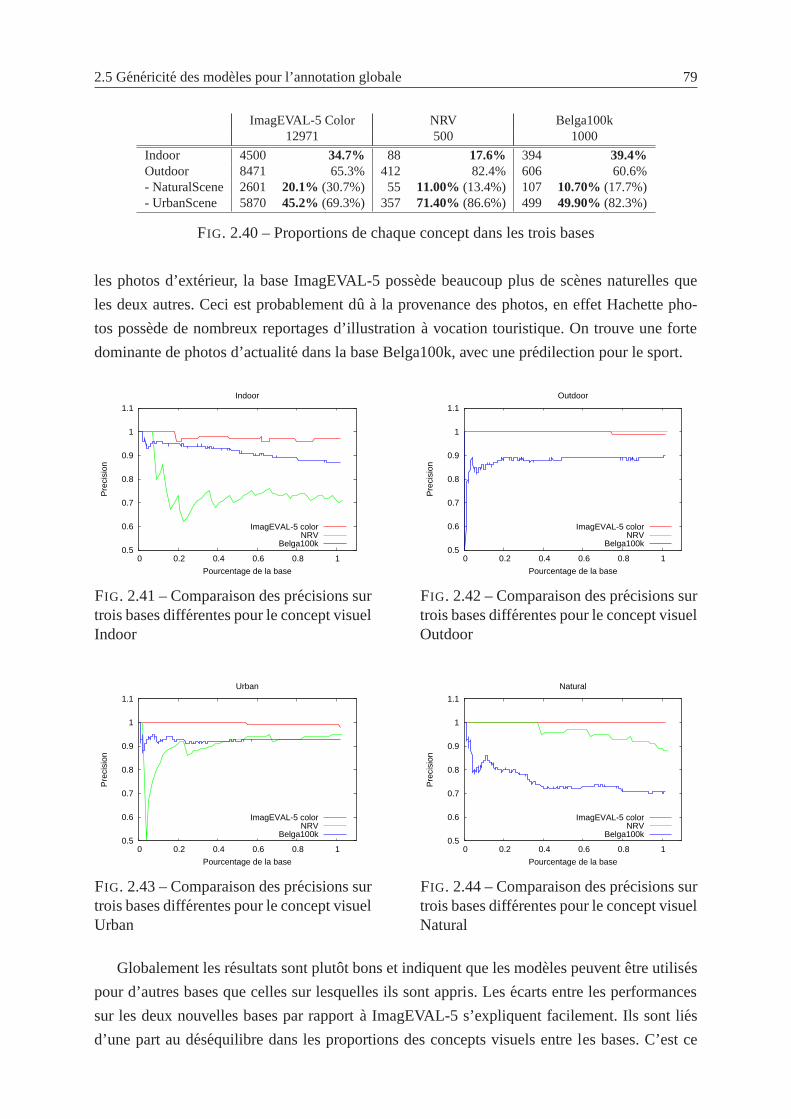
2.5 Genericite des modeles pour l’annotation globale 79
ImagEVAL-5 Color NRV Belga100k12971 500 1000
Indoor 4500 34.7% 88 17.6% 394 39.4%Outdoor 8471 65.3% 412 82.4% 606 60.6%- NaturalScene 2601 20.1% (30.7%) 55 11.00% (13.4%) 107 10.70% (17.7%)- UrbanScene 5870 45.2% (69.3%) 357 71.40% (86.6%) 499 49.90% (82.3%)
FIG. 2.40 – Proportions de chaque concept dans les trois bases
les photos d’exterieur, la base ImagEVAL-5 possede beaucoup plus de scenes naturelles que
les deux autres. Ceci est probablement du a la provenance des photos, en effet Hachette pho-
tos possede de nombreux reportages d’illustrationa vocation touristique. On trouve une forte
dominante de photos d’actualite dans la base Belga100k, avec une predilection pour le sport.
0.5
0.6
0.7
0.8
0.9
1
1.1
0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
Pourcentage de la base
Indoor
ImagEVAL-5 colorNRV
Belga100k
FIG. 2.41 – Comparaison des precisions surtrois bases differentes pour le concept visuelIndoor
0.5
0.6
0.7
0.8
0.9
1
1.1
0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
Pourcentage de la base
Outdoor
ImagEVAL-5 colorNRV
Belga100k
FIG. 2.42 – Comparaison des precisions surtrois bases differentes pour le concept visuelOutdoor
0.5
0.6
0.7
0.8
0.9
1
1.1
0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
Pourcentage de la base
Urban
ImagEVAL-5 colorNRV
Belga100k
FIG. 2.43 – Comparaison des precisions surtrois bases differentes pour le concept visuelUrban
0.5
0.6
0.7
0.8
0.9
1
1.1
0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
Pourcentage de la base
Natural
ImagEVAL-5 colorNRV
Belga100k
FIG. 2.44 – Comparaison des precisions surtrois bases differentes pour le concept visuelNatural
Globalement les resultats sont plutot bons et indiquent que les modeles peuventetre utilises
pour d’autres bases que celles sur lesquelles ils sont appris. Lesecarts entre les performances
sur les deux nouvelles bases par rapporta ImagEVAL-5 s’expliquent facilement. Ils sont lies
d’une part au desequilibre dans les proportions des concepts visuels entre les bases. C’est ce

80 Approche globale
qui explique les plus faibles performances pour le concept Indoor sur la base NRV. La sur-
representation des images naturelles dans ImagEVAL-5 expliqueegalement les performances
moindres de ce concept sur la base Belga100k. D’autre part, nous avons remarque que toutes les
images detecteesa tort comme Indoor par le systeme sont en fait des gros plans. Pour la base
Belga100k, ce sont systematiquement des portraits de sportifs, eneclairage artificiel de type
lumiere du jour (classique dans les stades). Pour la base NRV, on retrouve la des portraits fa-
miliaux pris en exterieur. Il est fort probable que dans la base d’apprentissage ImagEVAL-5 les
photos d’interieur soient principalement des portraits. Le systeme a alors partiellement appris
le concept visuel portrait en meme temps que Indoor.

CHAPITRE 3
Annotations locales
“There is nothing worse than a brilliant image of a
fuzzy concept.”
Ansel Adams, photographe americain (1902 - 1984)
3.1 Etat de l’art
Nous avons deja aborde la possibilite d’utiliser des descriptions locales du contenu visuel
dans le cadre de l’annotation globale (section 2.4.1). Ces representations sont en revanches
inevitables pour les annotations locales. Une des premieres tentative d’annotation d’image est
decrite par [MTO99] qui decoupe l’image selon une grille de regions rectangulaires et applique
un modele de co-occurence entre les mots-cles et les signatures visuelles. Depuis, les chercheurs
ont aborde le probleme selon deux principales voies differentes.
La premiere approche consistea utiliser un algorithme de segmentation pour diviser l’image
en regions irregulieres eta travailler sur ces regionsa l’aide de modeles generatifs. Ainsi
[DBdFF02] cree un vocabulaire discret de clusters de telles regions extraites d’une collection
d’images et applique un modele, inspire du domaine de la traduction automatique, pour faire le
lien entre ces regions et les mots-cles. La segmentation est realisee par l’algorithmenormali-
sed cuts[SM97]. Un modele probabiliste est appris avec EM. Ces travaux seront partiellement
repris avec les travaux de Barnardet al. dans une publication de reference sur les approches
utilisant les modeles generatifs pour l’annotation [BDF+03]. Trois approches differentes y sont
etudiees pour modeliser les distributions jointes entre les mots-cles et les regions segmentees des

82 Annotations locales
images : extension multi-modale du modele cluster/aspect hierarchique de Hofmann [HP98], un
modele de traduction statistique et une extension multi-modale des mixtures d’allocation latente
de Dirichlet [BNJL03].
[JLM03] voit le probleme commeetant lie a la recherche d’informations multilingue. Il
propose l’utilisation deRelevance Modelpour tenir compte de la methode d’expansion de
requete. Cette approche permet de desambiguer les resultats d’une requete en se servant des
premiers resultats pouretendre la requete d’origine. Cela doit permettre de tenir d’avantage
compte des relations entre les regions dans une image. Le modele peutetre utilise pour faire des
requetes et trier les resultats ou pour generer des annotations. Il obtient de meilleurs resultats
que [DBdFF02].
[LMJ04] adapte le modele de [JLM03] pour utiliser des fonctions de densite de probabilite
continues :Continuous Relevance Model. Il espere ainsieviter la perte d’information liee a
la quantification. Sur le meme jeu de donnees, les resultats sont substantiellement meilleurs.
Ces travaux sontegalement proches de [BJ03], mais sans faire de suppositionsur la structure
topologique de la mixture de gaussiennes. Ce modele est adapte a l’annotation automatique
commea la recherche d’informations.
Dans [GT05, TGM05], le systeme DIMATEX est presente. Apres une segmentation en
regions, les descripteurs visuels sont approximes par une approche dichotomique et un seuillage
sur chaque caracteristique. Ensuite un modele bayesien est appris pour la probabilite jointe
descripteurs/mots-cles.
Feng [FML04] utilise un decoupage en regions rectangulaires. Les probabilites des mots
cles sont modelises avec des distributions de Bernoulli et les signatures visuelles continues
par des estimations de densite non parametriquea noyau. Le modele joint (de type modele de
relevance) est appele MBRM. Il est base sur CRM [LMJ04]. Sur la base Corel, les resultats sont
meilleurs que [LMJ04] et [MM04]. Les regions rectangulaires sontegalement utilisees par Jeon
[JM04], appeleesvisterms. Ce choix est argumente par rapporta l’utilisation d’algorithmes de
segmentations. Les relations entre les regions sont utilisees et constituent une part importante
du modele. Les resultats sont meilleurs que pour sa precedente approche [JLM03].
Ferguset al. [FPZ04] modelisent les objets par un ensemble de parties (points, courbes),
de leurs relations, de leurechelle et des probabilites d’occlusion de ces parties par un modele
probabiliste generatif. Il applique ce modele au re-ordonnancement de resultats de recherche de
categories d’objets dans Google Image (supervise et non-supervise). Ces travaux sont poursuivis
dans [FFFPZ05] ou Google Image est utilise pour apprendre automatiquement un modele visuel
d’un concept.
Dans [ZZL+05a], un modele semantique probabiliste est presente. Il est prevu pour exploiter
les synergies pouvant exister entre differentes modalites dans une base d’images. Ce papier se

3.2 Analyse de la representation par sac de mots visuels 83
concentre sur les relations entre des descripteurs visuelset les mots-cles. Le principe est de
modeliser ces relationsa l’aide d’une couche cachee qui represente les concepts semantiques.
Ces concepts semantiques sont appris dans un framework probabilistea l’aide de l’algorithme
EM. Une fois les probabilite conditionnelles de ces concepts caches obtenues, les taches image-
to-text et text-to-image sont aisement effectuees dans un framework bayesien. Cette methode
est compareea MBRM [FML04] sur la base Corel.
Sivic et al. [SRE+05] utilisent la representation par sac de mots avec une approche pLSA,
Perronninet al. [PDCB06] avec une mixture de gaussiennes. L’utilisation de pLSA et des vo-
cabulaires visuels continus est synthetise dans [HLS08].
Plus recemment, l’utilisation de modeles discriminatifs aete mise en avant. On retrouve
principalement les approches par boosting [TMF04, OFPA04,ASR05], par SVM [WAC+04,
ZZL+05b, JT05, NJT06, LSP06, YYH07, GCPF07, Mil08] ou en combinant les deux comme
dans [CDPW06]. D’autres algorithmes d’apprentissage sont parfois envisages [AAR04]. La
representation des images par sacs de mots est devenu un standardpour ces approches. Nous
les detaillerons dans la suite de ce chapitre.
3.2 Analyse de la representation par sac de mots visuels
Initiallement, les signatures visuellesetaient calculees sur l’image dans son ensemble. Cette
approche convient bien pour decrire l’aspect global du contenu mais elle est trop grossiere
pour representer les petits details et les objets. Les signatures doiventetre extraites locale-
ment. Pour cela, des regions supports doiventetre determinees. Une fois leurs localisation,
forme et taille connues, les signatures visuelles sont calculees sur ces portions de l’image.
Ces signatures peuventetre de meme nature que celles extraites au niveau global ou bien
elles peuventetre plus specifiques et tirer partie de la nature des regions supports. Plusieurs
strategies existent pour la selection de ces regions. Les algorithmes de segmentation essayent
de trouver les frontieres entre des regions homogenes de l’image [FB02, BDF+03, PFG06].
Les criteres d’homogeneite peuvent, par exemple,etre bases sur la couleur, la texture ou des
caracteristiques plusevoluees [HB06]. La segmentation est un probleme difficile car il n’est pas
clairement defini. Malheureusement, la tendance generale a toujoursete de se concentrer sur
une segmentation qui detecte les objets, ce qui en soi est deja une tache hautement semantique,
et donc, difficilement realisablea travers un processus completement automatique sans connais-
sancea priori sur les objets. Des approches alternatives consistenta utiliser des fenetres glis-
santes ou des grilles fixes ayant des tailles et espacement diff erents. C’est un moyen classique
d’obtenir unechantillonnage regulier des images. Nous reviendrons sur ce point dans la sec-
tion 3.3. Une autre approche populaire est basee sur la detection de points d’interet. Initiale-
ment ils ontete concus pour le recalage d’images. Ces detecteurs sont generalement attires

84 Annotations locales
dans certaines zones de l’image, commea proximite des angles et des bords des regions. Ils
permettent de selectionner une petite partie des images ayant une forte variabilite dans le si-
gnal visuel [Low99, GMDP00, ZMLS05, MTS+05, MS05b, TM08]. Typiquement, en utilisant
l’ echantillonnage regulier ou les points d’interet, entre quelques centaines et quelques milliers
de regions supports sont extraites de chaque image. Le temps de calcul est alors beaucoup
plus eleve qu’avec les descripteurs globaux. Certaines representations encapsulentegalement
d’autres informations, comme les relations geometriques entre ces regions [ASR05]. Avec les
signatures globales, l’obtention d’une representation de l’image est directe. Cependant, meme
quand des signatures locales sont utilisees, il est parfois necessaire d’avoir une representation
globale pour les images qui englobe toutes les informationsvisuelles locales. La representation
par sac de mots visuels est une des plus populaires pour les images.
3.2.1 Representation par sac de mots
Le succes de l’approche par sac de mots dans la communaute texte a largement inspire
l’utilisation recente de strategies analogues pour obtenir des representations globales d’images
a partir de caracteristiques visuelles locales. L’idee principale est de representer les documents
par des collections non-ordonnees de mots et d’en obtenir une signature globalea l’aide d’un
histogramme comptant les occurences de ces mots. Par analogie, on parle alors de sacs de mots
visuels pour les images. Ces representations sont utilisees dans de nombreuses applications,
dont l’annotation automatique. Elles sont facilesa implementer et fournissent actuellement des
performancesetat-de-l’art dans plusieurs campagnes d’evaluation.
Nous definissons ici le cadre generique permettant de representer tout type de document
compose de patches identifiables. Nous l’utiliserons pour des textes et des images. SoitC une
collection contenantm documents. Chacun de ces documentsDk est compose d’un certain
nombresk de patches.P designe l’espace de tous les patches. Un vocabulaireV est un ensemble
de n mots. Ces mots sont des patches particuliers. La facon dont ces mots ontete obtenus,a
partir des documents deC ou biena partir d’autres documents, n’est pas debattue pour l’instant.
C = {Dk, k ∈ [1,m]} (3.1)
Dk ={P k
j ∈ P, j ∈ [1, sk]}
(3.2)
V = {Wi ∈ P, i ∈ [1, n]} (3.3)
Afin de pouvoir obtenir des representations homogenes des differents documents, il est parfois
necessaire de les quantifier pour travailler dans un espace commun. De maniere generale, on va
associera chaque patch le mot du vocabulaire qui le represente le plus fidelement. On peut pour

3.2 Analyse de la representation par sac de mots visuels 85
cela definir un operateur de quantificationQ.
Q : P 7→ V
Dk → Dk ={wk
j ∈ V} (3.4)
Dans la modelisation par espace vectoriel,a chaque document quantifie Dk est associe un vec-
teur. La taille de ce vecteur correspond au nombre de mots du vocabulaireV . Ainsi, chaque co-
ordonnee du vecteur mesure une grandeur relative au mot correspondant. Il existe plusieurs ap-
proches pour cette modelisation [Sal71]. Dans le modele booleen, le plus simple, on se contente
de consigner la presence ou l’absence d’un mot dans le document.
Bki =
{1 si Wi ∈ Dk
0 sinon(3.5)
Ce modele a ensuiteete etendu. On peut ainsi obtenir un histogramme comptant le nombre
d’occurences de chaque mot dans un document. Generalement on normalise cet histogramme
pour eviter les biais liesa des nombres de patches differents par document. C’est l’approche
que nous utiliserons par la suite. On a alors
Hki =
∣∣∣{
Wi ∈ Dk
}∣∣∣sk
(3.6)
3.2.2 Vocabulaire visuel
Contrairement au texte, ou par nature les patches sont deja sous forme discrete, avec les
images nous utilisons des signatures locales continues. Chaque image est representee par un sac
de signatures locales. Dans notre cas, ce sont des histogrammes de dimensiond :
Dk ={
P kj ∈ [0, 1]d , j ∈ [1, sk]
}(3.7)
Afin de pouvoir quantifier ces signatures, il faut prealablement creer un vocabulaire visuel. C’est
uneetape importante puisque ce vocabulaire doit permettre de representer au mieux l’ensemble
des images de la base. Il existe de nombreuses approches pourobtenir un tel vocabulaire. Elles
sont generalement basees sur des algorithmes de partitionnement. Une base de signatures est di-
visee enn partitions. Chacune de ces partitions est representee par un prototype (generalement
son centre) qui est inclus au vocabulaire. Les principaux parametres ayant un impact sur la qua-
lit e du vocabulaire sont sa taille et l’utilisation ou non de supervision lors de sa constitution
[CBDF04, JT05, WCM05, NJT06, PDCB06]. La basea partir de laquelle le vocabulaire est
cree fait egalement partie des choixa faire. Il peut s’agir de la meme base que celle qui servira
a effectuer l’apprentissage, ou au contraire on peut souhaiter que le vocabulaire soit constitue a

86 Annotations locales
partir d’images qui ne seront plus utilisees par la suite. Nous choisissons d’utiliser la base d’ap-
prentissageTrn pour creer nos vocabulaires. Une fois le partitionnement termine, on dispose de
FIG. 3.1 – Representation par sac de mots visuels. Photoc©AFP.
notre vocabulaire visuelV . Chaque image peut alorsetre quantifieea l’aide de ce vocabulaire
en assignanta chaque signature locale le mot visuel dont elle est le plus proche.
Dk =
{argmin
wkj ∈V
d(wkj , P
kj ), j ∈ [1, sk]
}(3.8)
3.2.3 Algorithmes de partitionnement
Il existe de nombreux algorithmes permettant de faire du partitionnement de donnees. On en
trouvera un apercu dans [JMF99]. Nous nous interessons principalement aux algorithmes non
supervises. En effet, l’utilisation de connaissances lors de la constitution du vocabulaire amene
certes des gains de performance (voir section 3.2.7), mais elle a le defaut de specialiser le
vocabulaire aux concepts visuels qui sont consideres au moment de sa constitution. On perd
alors en genericite et il faut, avec ce type d’approches, creer de nouveaux vocabulaires, et
donc de nouvelles representations des images, pour tout nouveau concept visuel que l’on sou-
haite apprendre. Nous preferons donc nous limiter aux vocabulaires generiques qui ne sont pas
dependants des concepts. Parmi les approches possibles, nous pouvons citer l’algorithme des K-
moyennes [HA79], le partitionnement hierarchique, CA (Competitive Agglomeration) [FK97],
ARC (Adaptive Robust Competition) [LB02] ou encore QT (Quality Threshold) [HKY99]. De
facon beaucoup plus simple, il estegalement possible de choisir aleatoirement les mots du
vocabulaire dans la base, sans vraiment effectuer de partitionnement. Nous allonsetudier le
comportement de certains de ces algorithmes (section 3.2.4).

3.2 Analyse de la representation par sac de mots visuels 87
Algorithme des K-moyennes (Kmeans)
A partir d’un nombre predefini de partitions, l’algorithme construit iterativement les parti-
tions en faisantevoluer leurs centres. L’initialisation de l’algorithme peutetre faite de differentes
manieres. On choisit de creer aleatoirement les partitions. Une condition d’arret doitegalement
etre definie. Il peut s’agir d’un critere de stabilite des partitions entre deux iterations successives
ou, plus simplement, d’un nombre maximum d’iterations. Nous utilisons une combinaison des
deux.
Algorithme 1 K-moyennes
ENTREES: Trn ={
P kj ∈ [0, 1]d , k ∈ [1, p] , j ∈ [1, sk]
}, n, ǫ, T
SORTIES : V ={
Wi ∈ [0, 1]d , i ∈ [1, n]}
initialisation aleatoire :V0 = {W 0i ∈ Trn, i ∈ [1, n]}
t = 0r epeter
Gti = {} ,∀i ∈ [1, n]
pour tout S ∈ Trn fairej = argmin
i
d(S,W ti )
Gtj = Gt
j ∪ {S}fin pourt = t + 1Vt = {}pour i = 1 an faire
W ti = 1
|Gti|
∑S∈Gt
iS
Vt = Vt ∪ {W ti }
fin pourstab =
∑n
i=1 d(W t−1i ,W t
i )jusqu’ a t = T oustab < ǫ
Cet algorithme est probablement le plus utilise pour le partitionnement non-supervise de
donnees. Ceci est du a sa grande simplicite de mise en œuvre eta sa convergence rapide.
Toutefois, il n’est pas garanti que la solution fournie soitoptimale. Elle depend de la phase
d’initialisation.
Algorithme QT
Jurie et Triggs [JT05] constatent que l’approche des K-moyennes conduit souventa un vo-
cabulaire aussi efficace que celui qu’on obtient par tirage aleatoire. Pour y remedier, il pro-
pose une approche similairea celle que nous developpons ici. Initialement l’algorithmeQuality
Thresholdest introduit par Heyeret al. [HKY99] pour l’analyse de donnees sur l’expression
des genes. L’idee principale est de remplir l’espace avec des partitions ayant un rayon fixe

88 Annotations locales
RQT . On commence par la partition ayant le plus grand nombre de signatures. Toutes les signa-
tures appartenanta cette partition sont retirees et on itere jusqu’a ce que la base soit vide. Le
nombre de mots est donc determine par l’algorithme et depend du rayon choisi. QT est facile
Algorithme 2 Quality Threshold - QT
ENTREES: Trn ={
P kj ∈ [0, 1]d , k ∈ [1, p] , j ∈ [1, sk]
}, RQT
SORTIES : V ={
Wi ∈ [0, 1]d , i ∈ [1, n]}
V = {}, i = 0tantque |Trn| > 0 faire
pour tout P kj ∈ Trn faire
Gkj =
{S ∈ Trn|d(S, P k
j ) ≤ RQT
}
fin pourWi = P k
j , argmaxj,k
∣∣Gkj
∣∣
V = V ∪ {Wi}Trn = Trn\Gk
j
i = i + 1fin tantque
a implementer. Le principal inconvenient est son cout de calcul quadratique. On peut toute-
fois choisir une implementation qui optimisera le calcul des distancesa l’aide d’un cache par
exemple. Le principal avantage de QT est qu’il assure une bonne couverture de l’espace vi-
suel de facon deterministe, produisant les memes partitionsa chaque execution. Nous avons la
garantie que chaque signature est quantifiee par un mot visuel se situant dans un rayonRQT .
Evolution de l’algorithme QT
L’algorithme des K-moyennes tient compte de la densite des patches dans l’espace des ca-
racteristiques, mais il arrive parfois qu’il se focalise trop sur cette densite et concentre les centres
des partitions dans un faible rayon. Poureviter ce defaut, nous proposons l’introduction de la
forme duale de l’algorithme QT. Au lieu d’imposer un rayon fixe pour les partitions, on impose
un nombre fixe de signatures par partition, que nous noteronsλ. A chaque iteration, la partition
qui est conservee est celle ayant le plus petit rayon. Comme pour l’algorithme QT, l’ensemble
des points appartenanta la nouvelle partition creee sont retires de la base. On epere ainsieviter
partiellement le defaut des K-moyennes.
3.2.4 Qualite des vocabulaires visuels
Comment juger de la qualite d’un vocabulaire visuel ? Les performances pour l’annota-
tion automatique sont bienevidement le critere final. On cherche toutefoisa savoir s’il existe
des indicateurs de la pertinence d’un vocabulaire pour representer une base d’images. Il existe

3.2 Analyse de la representation par sac de mots visuels 89
Algorithme 3 Dual QT
ENTREES: Trn ={
P kj ∈ [0, 1]d , k ∈ [1, p] , j ∈ [1, sk]
}, λ
SORTIES : V ={
Wi ∈ [0, 1]d , i ∈ [1, n]}
V = {}, i = 0tantque |Trn| > 0 faire
pour tout P kj ∈ Trn faire
Gkj = kP lusProchesV oisins(Trn, λ)
fin pourWi = P k
j , argminj,k
diametre(Gkj )
V = V ∪ {Wi}Trn = Trn\Gk
j
i = i + 1fin tantque
de nombreux criteres qui sont principalement utilises lorsqu’un partitionnement correct des
donnees est disponible. Ces criteres mesurent alors l’adequation du partitionnement obtenu
avec la verite terrain. Cette information n’est pas disponible dans notrecas. Comme precise
dans [HKKR99], la question de la validite d’un partitionnement est de savoir si les hypotheses
sous-jacentesa un algorithme (forme des partitions, nombre de partitions, . . . ) sont satisfaites
pour un jeu de donnees considere. Toutefois, il est impossible de repondrea cette question sans
une certaine connaissance des donnees, typiquement savoir si une structure existe. Or, nous
parlons ici d’un vocabulaire base sur des descripteurs qui peuvent varier.
N’ayant aucuna priori sur l’importance relative des differentes regions de l’espace visuel
dans les performances de reconnaissance d’un concept visuel donne, il faut faire en sorte de n’en
negliger aucune. Les mots du vocabulaire visuel doivent certes representer les regions les plus
denses, maisegalement les regions pour lesquelles on trouve beaucoup moins de signatures.
Nous utiliserons deux mesures pour caracteriser un vocabulaire par rapporta une base. Nous
essaierons de voir s’il existe une correlation entre ces mesures et les performances du vocabu-
laire en annotation automatique.
Nous definissons la couvertureCvg, pour un rayonr, commeetant la proportion de signa-
tures d’une baseB etant couvertes par le vocabulaireV , c’est-a-dire ayant un mot visuela une
distance inferieurea r dans leur voisinage.
B ={
Pj ∈ [0, 1]d , j ∈ [1, z]}
, V ={
Wi ∈ [0, 1]d , i ∈ [1, n]}
Cvgr(B, V ) =1
z|{Pj|∃i ∈ [1, n] , d(Pj,Wi) < r}| (3.9)
Nous pouvons ainsi tracer une courbe indiquant la couverture pour tous les rayons compris entre
0 et la distance maximale.

90 Annotations locales
Nour regardonsegalement l’histogramme global de quantification de l’ensemble de la base
par rapport au vocabulaire. On regarde combien de patches sont quantifies par chaque mot du
vocabulaire. Il nous renseigne sur la quantite d’informations que code chaque mot du vocabu-
laire. Si chaque mot du vocabulaire quantifie le meme nombre de patches, alors ce nombre est
λ = zn. Pour pouvoir facilement effectuer des comparaisons entreles vocabulaires, cet histo-
gramme des quantifications est normalise par rapportaλ. De plus, les mots du vocabulaire sont
ordonnes selon la valeur de l’histogramme. La couverture et l’histogramme de quantification
nous donnent de bonnes indications sur la facon dont les mots du vocabulaire sont distribues
parmi tous les patches.
Les experiences seront menees sur la base Pascal VOC 2007 [EGW+]. Ce jeu de donnees
a l’avantage d’etre assez generique (les images proviennent de Flickr) et d’etre disponible.
20 concepts visuels y ontete manuellement annotes. La collection est divisee en deux sous-
ensembles. La base d’apprentissage et de validation (trainval) contient 5 011 images. La base
de test (test) contient 4 952 images. Nous choisissons dans un premier temps de decrire les
images en extrayant des patches de 16x16 pixels selon une grille fixe. Nous extrayons environs
1 000 patches par image. On obtient une signature pour ces patches en utilisant les descripteurs
Fourier (fou16) et Edge Orientation Histogram(eoh16) avec chacun 16 bins. Dans un second
temps, nous refaisons les memes experimentations avec le descripteur couleurprob64. Nous
pourrons ainsi voir la variabilite dans les comportements des algorithmes de partitionnement
qui est due a la distribution des signatures selon le descripteur utilise. Pour les approches fai-
sant intervenir une part de hasard (K-moyennes et tirage aleatoire), les resultats reportes sont
une moyenne sur 10 executions. Pour l’apprentissage, nous utilisons des SVM avec noyau tri-
angulaire et fixons la constanteC = 1.
Dans la base d’apprentissage, le nombre total de patches visuels est de 4 868 504. Nous
choisissons aleatoirement 50 000 d’entre eux pour lesquels nous appliquerons les differents
algorithmes de partitionnement.
On peut voir les statistiques des vocabulaires crees par un tirage aleatoire sur la figure 3.3.
Sur le graphique indiquant la couverture, on constate que, de maniere logique, plus le nombre de
mots est important, plus le rayon de couverture permettant d’atteindre l’ensemble des patches
avec un mot du vocabulaire diminue. Ainsi, avec 50 mots dans le vocabulaire on couvre 99%
des patches avec un rayon de 0.97. Pour 500 mots, ce rayon tombe a 0.59. Sur l’histogramme
des quantification, on remarque que la forme des courbes est identique pour toutes les tailles de
vocabulaire. Ceci est parfaitement comprehensible. Le tirage aleatoire des mots du vocabulaire
nous assure qu’ils sont choisis conformementa la distribution sous-jacente. En augmentant le
nombre de mots de ce vocabulaire, il n’y a aucune raison pour que l’on devie de cette distri-
bution. Dans tous les cas, les mots du vocabulaire encodent donc une proportionequivalente
d’information. Nous avons trace sur le graphique les lignes correspondanta λ2
et 2λ. On voit
alors que 10% des mots encodent plus de2λ patches et 20% encodent moins deλ2
patches. Les
3.2 Analyse de la representation par sac de mots visuels 91
FIG. 3.2 – Pascal-VOC-2007, quelques images de la base d’apprentissage
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Cou
vert
ure
Rayon de couverture
Couverture
50 mots250 mots500 mots
1000 mots
0.1
1
10
0 0.2 0.4 0.6 0.8 1
Pro
port
ion
de p
atch
es q
uant
ifies
Mots
Quantification
50 mots250 mots500 mots
1000 mots
FIG. 3.3 – Pascal VOC 2007, descripteurs fou16 et eoh16, couverture et histogramme de quan-tification pour des vocabulaires crees par tirage aleatoire
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Cou
vert
ure
Rayon de couverture
Couverture
50 mots250 mots500 mots
1000 mots
0.1
1
10
0 0.2 0.4 0.6 0.8 1
Pro
port
ion
de p
atch
es q
uant
ifies
Mots
Quantification
50 mots250 mots500 mots
1000 mots
FIG. 3.4 – Pascal VOC 2007, descripteurs fou16 et eoh16, couverture et histogramme de quan-tification pour des vocabulaires crees par les K-Moyennes
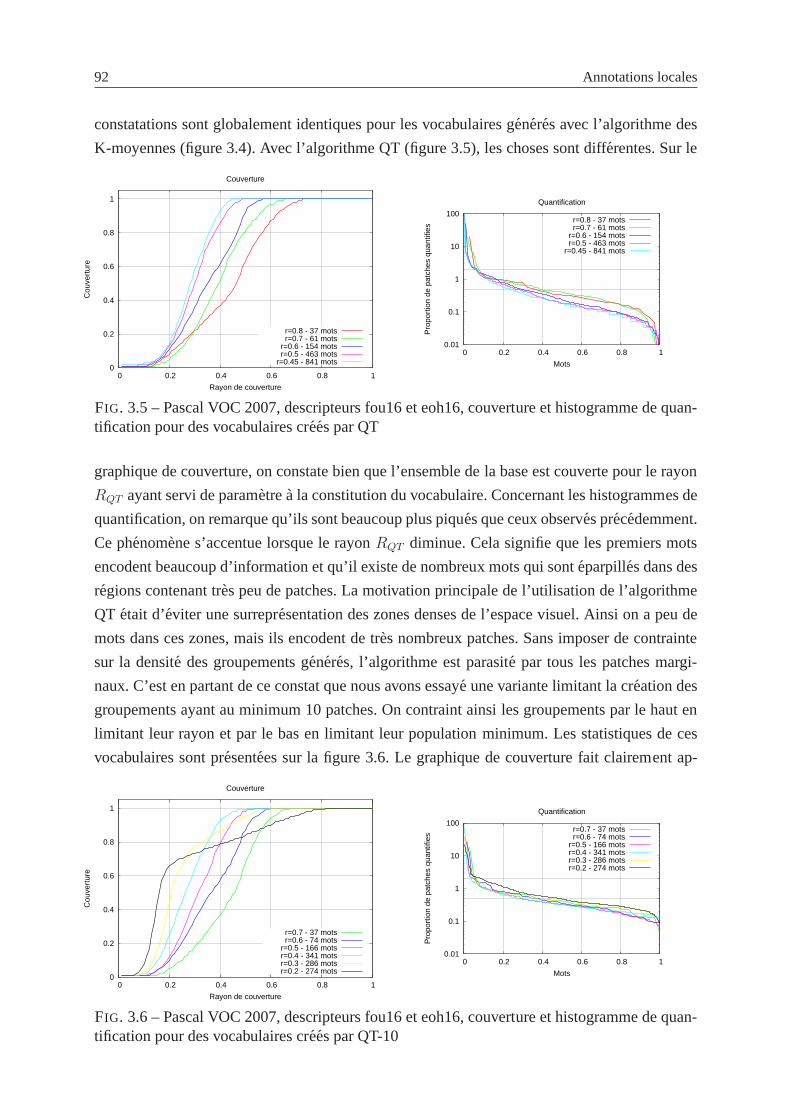
92 Annotations locales
constatations sont globalement identiques pour les vocabulaires generes avec l’algorithme des
K-moyennes (figure 3.4). Avec l’algorithme QT (figure 3.5), les choses sont differentes. Sur le
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Cou
vert
ure
Rayon de couverture
Couverture
r=0.8 - 37 motsr=0.7 - 61 mots
r=0.6 - 154 motsr=0.5 - 463 mots
r=0.45 - 841 mots
0.01
0.1
1
10
100
0 0.2 0.4 0.6 0.8 1
Pro
port
ion
de p
atch
es q
uant
ifies
Mots
Quantification
r=0.8 - 37 motsr=0.7 - 61 mots
r=0.6 - 154 motsr=0.5 - 463 mots
r=0.45 - 841 mots
FIG. 3.5 – Pascal VOC 2007, descripteurs fou16 et eoh16, couverture et histogramme de quan-tification pour des vocabulaires crees par QT
graphique de couverture, on constate bien que l’ensemble dela base est couverte pour le rayon
RQT ayant servi de parametrea la constitution du vocabulaire. Concernant les histogrammes de
quantification, on remarque qu’ils sont beaucoup plus piques que ceux observes precedemment.
Ce phenomene s’accentue lorsque le rayonRQT diminue. Cela signifie que les premiers mots
encodent beaucoup d’information et qu’il existe de nombreux mots qui sonteparpilles dans des
regions contenant tres peu de patches. La motivation principale de l’utilisation de l’algorithme
QT etait d’eviter une surrepresentation des zones denses de l’espace visuel. Ainsi on a peu de
mots dans ces zones, mais ils encodent de tres nombreux patches. Sans imposer de contrainte
sur la densite des groupements generes, l’algorithme est parasite par tous les patches margi-
naux. C’est en partant de ce constat que nous avons essaye une variante limitant la creation des
groupements ayant au minimum 10 patches. On contraint ainsiles groupements par le haut en
limitant leur rayon et par le bas en limitant leur populationminimum. Les statistiques de ces
vocabulaires sont presentees sur la figure 3.6. Le graphique de couverture fait clairement ap-
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Cou
vert
ure
Rayon de couverture
Couverture
r=0.7 - 37 motsr=0.6 - 74 mots
r=0.5 - 166 motsr=0.4 - 341 motsr=0.3 - 286 motsr=0.2 - 274 mots
0.01
0.1
1
10
100
0 0.2 0.4 0.6 0.8 1
Pro
port
ion
de p
atch
es q
uant
ifies
Mots
Quantification
r=0.7 - 37 motsr=0.6 - 74 mots
r=0.5 - 166 motsr=0.4 - 341 motsr=0.3 - 286 motsr=0.2 - 274 mots
FIG. 3.6 – Pascal VOC 2007, descripteurs fou16 et eoh16, couverture et histogramme de quan-tification pour des vocabulaires crees par QT-10
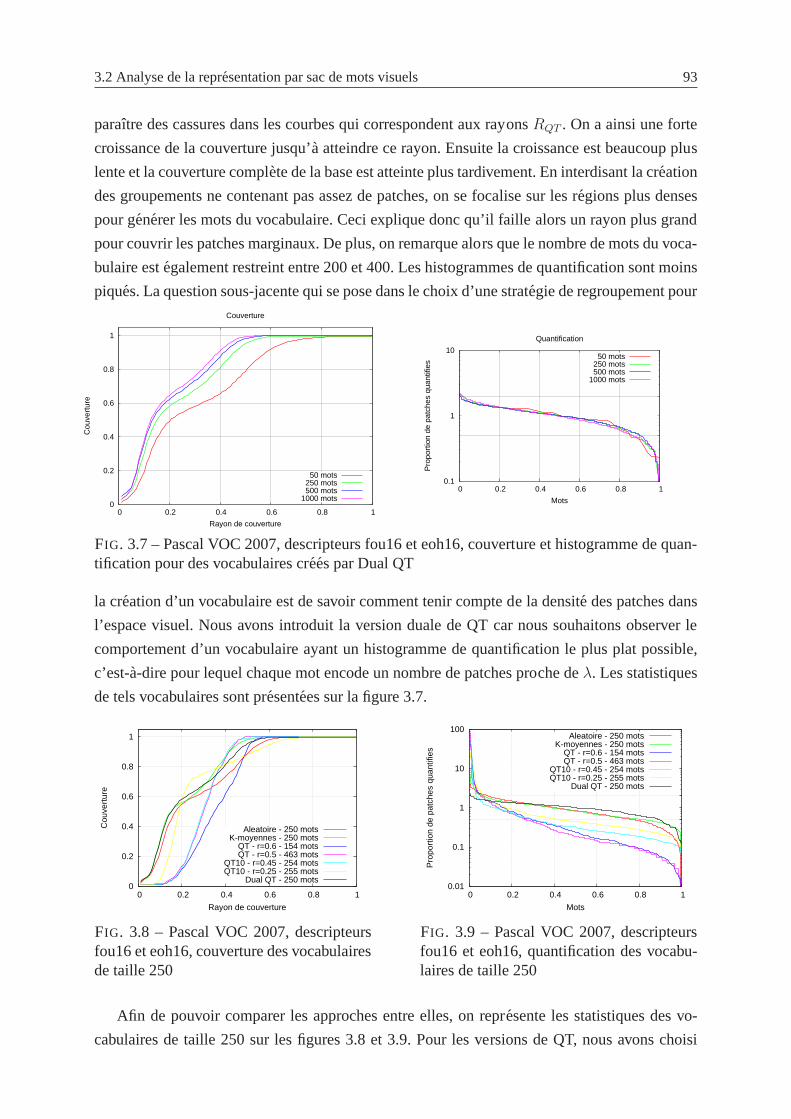
3.2 Analyse de la representation par sac de mots visuels 93
paraıtre des cassures dans les courbes qui correspondent aux rayonsRQT . On a ainsi une forte
croissance de la couverture jusqu’a atteindre ce rayon. Ensuite la croissance est beaucoup plus
lente et la couverture complete de la base est atteinte plus tardivement. En interdisantla creation
des groupements ne contenant pas assez de patches, on se focalise sur les regions plus denses
pour generer les mots du vocabulaire. Ceci explique donc qu’il faillealors un rayon plus grand
pour couvrir les patches marginaux. De plus, on remarque alors que le nombre de mots du voca-
bulaire estegalement restreint entre 200 et 400. Les histogrammes de quantification sont moins
piques. La question sous-jacente qui se pose dans le choix d’une strategie de regroupement pour
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Cou
vert
ure
Rayon de couverture
Couverture
50 mots250 mots500 mots
1000 mots
0.1
1
10
0 0.2 0.4 0.6 0.8 1
Pro
port
ion
de p
atch
es q
uant
ifies
Mots
Quantification
50 mots250 mots500 mots
1000 mots
FIG. 3.7 – Pascal VOC 2007, descripteurs fou16 et eoh16, couverture et histogramme de quan-tification pour des vocabulaires crees par Dual QT
la creation d’un vocabulaire est de savoir comment tenir compte de la densite des patches dans
l’espace visuel. Nous avons introduit la version duale de QTcar nous souhaitons observer le
comportement d’un vocabulaire ayant un histogramme de quantification le plus plat possible,
c’est-a-dire pour lequel chaque mot encode un nombre de patches proche deλ. Les statistiques
de tels vocabulaires sont presentees sur la figure 3.7.
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Cou
vert
ure
Rayon de couverture
Aleatoire - 250 motsK-moyennes - 250 mots
QT - r=0.6 - 154 motsQT - r=0.5 - 463 mots
QT10 - r=0.45 - 254 motsQT10 - r=0.25 - 255 mots
Dual QT - 250 mots
FIG. 3.8 – Pascal VOC 2007, descripteursfou16 et eoh16, couverture des vocabulairesde taille 250
0.01
0.1
1
10
100
0 0.2 0.4 0.6 0.8 1
Pro
port
ion
de p
atch
es q
uant
ifies
Mots
Aleatoire - 250 motsK-moyennes - 250 mots
QT - r=0.6 - 154 motsQT - r=0.5 - 463 mots
QT10 - r=0.45 - 254 motsQT10 - r=0.25 - 255 mots
Dual QT - 250 mots
FIG. 3.9 – Pascal VOC 2007, descripteursfou16 et eoh16, quantification des vocabu-laires de taille 250
Afin de pouvoir comparer les approches entre elles, on represente les statistiques des vo-
cabulaires de taille 250 sur les figures 3.8 et 3.9. Pour les versions de QT, nous avons choisi
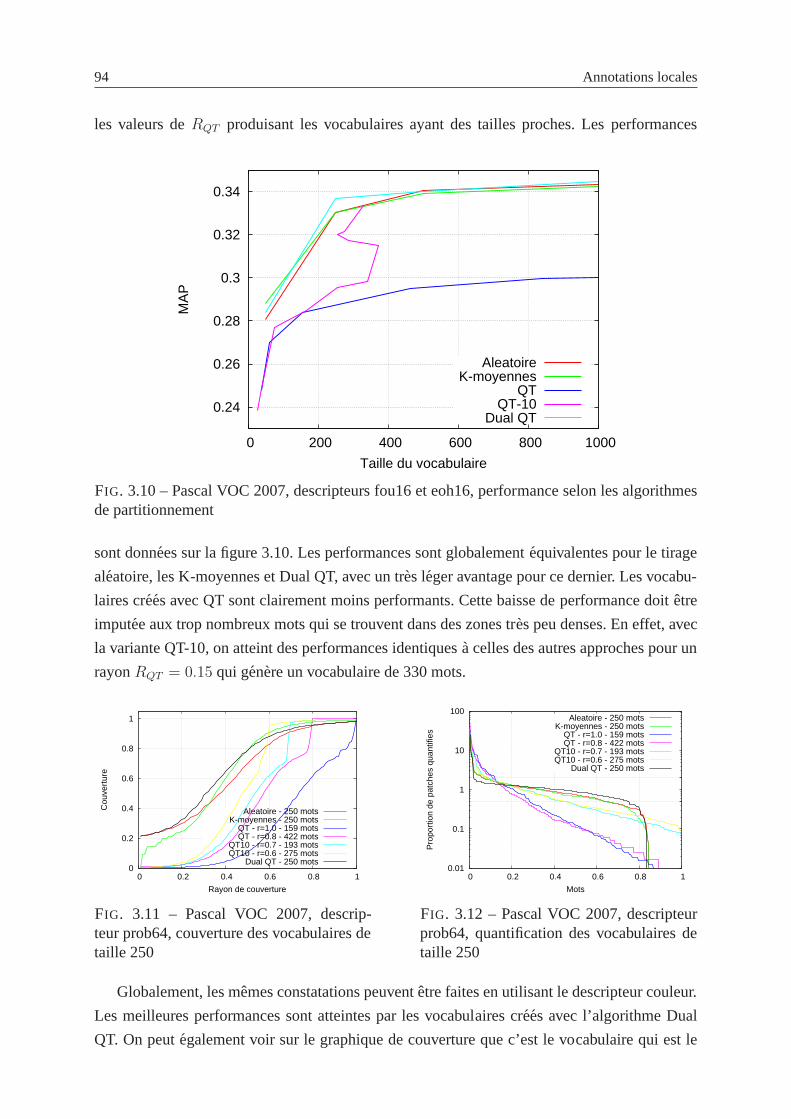
94 Annotations locales
les valeurs deRQT produisant les vocabulaires ayant des tailles proches. Lesperformances
0.24
0.26
0.28
0.3
0.32
0.34
0 200 400 600 800 1000
MA
P
Taille du vocabulaire
AleatoireK-moyennes
QTQT-10
Dual QT
FIG. 3.10 – Pascal VOC 2007, descripteurs fou16 et eoh16, performance selon les algorithmesde partitionnement
sont donnees sur la figure 3.10. Les performances sont globalementequivalentes pour le tirage
aleatoire, les K-moyennes et Dual QT, avec un tres leger avantage pour ce dernier. Les vocabu-
laires crees avec QT sont clairement moins performants. Cette baisse deperformance doitetre
imputee aux trop nombreux mots qui se trouvent dans des zones tres peu denses. En effet, avec
la variante QT-10, on atteint des performances identiquesa celles des autres approches pour un
rayonRQT = 0.15 qui genere un vocabulaire de 330 mots.
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Cou
vert
ure
Rayon de couverture
Aleatoire - 250 motsK-moyennes - 250 mots
QT - r=1.0 - 159 motsQT - r=0.8 - 422 mots
QT10 - r=0.7 - 193 motsQT10 - r=0.6 - 275 mots
Dual QT - 250 mots
FIG. 3.11 – Pascal VOC 2007, descrip-teur prob64, couverture des vocabulaires detaille 250
0.01
0.1
1
10
100
0 0.2 0.4 0.6 0.8 1
Pro
port
ion
de p
atch
es q
uant
ifies
Mots
Aleatoire - 250 motsK-moyennes - 250 mots
QT - r=1.0 - 159 motsQT - r=0.8 - 422 mots
QT10 - r=0.7 - 193 motsQT10 - r=0.6 - 275 mots
Dual QT - 250 mots
FIG. 3.12 – Pascal VOC 2007, descripteurprob64, quantification des vocabulaires detaille 250
Globalement, les memes constatations peuventetre faites en utilisant le descripteur couleur.
Les meilleures performances sont atteintes par les vocabulaires crees avec l’algorithme Dual
QT. On peutegalement voir sur le graphique de couverture que c’est le vocabulaire qui est le
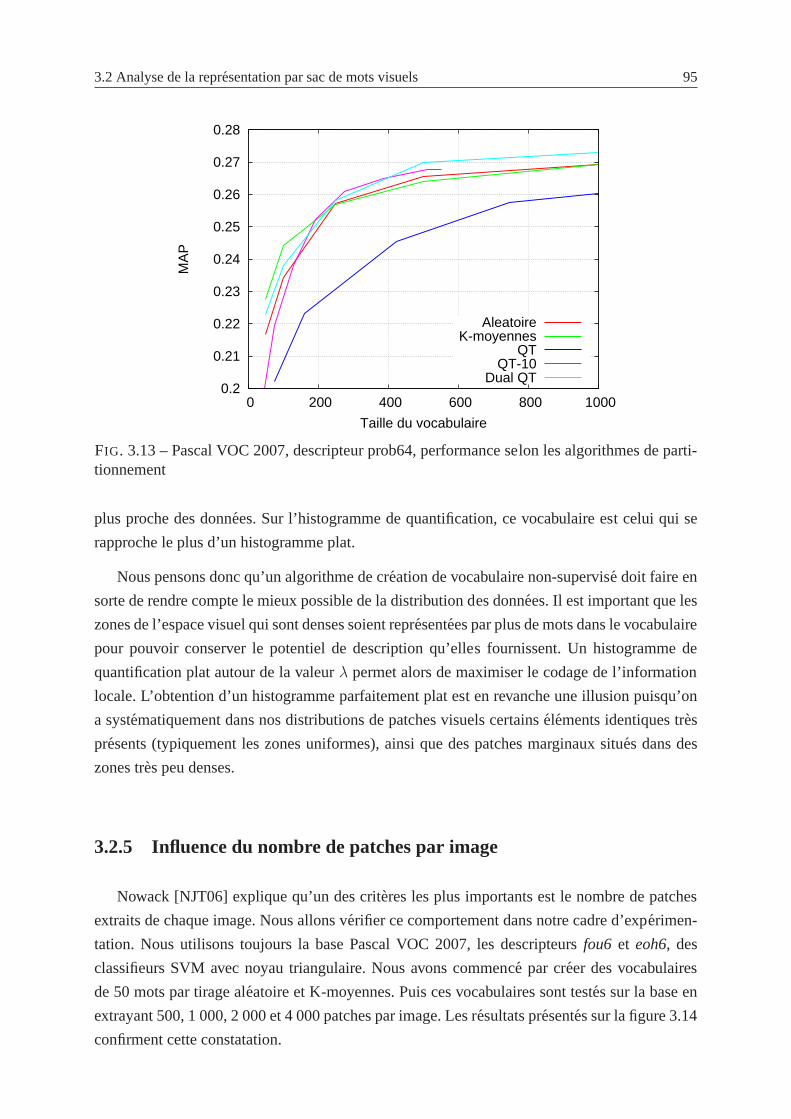
3.2 Analyse de la representation par sac de mots visuels 95
0.2
0.21
0.22
0.23
0.24
0.25
0.26
0.27
0.28
0 200 400 600 800 1000
MA
P
Taille du vocabulaire
AleatoireK-moyennes
QTQT-10
Dual QT
FIG. 3.13 – Pascal VOC 2007, descripteur prob64, performance selon les algorithmes de parti-tionnement
plus proche des donnees. Sur l’histogramme de quantification, ce vocabulaire est celui qui se
rapproche le plus d’un histogramme plat.
Nous pensons donc qu’un algorithme de creation de vocabulaire non-supervise doit faire en
sorte de rendre compte le mieux possible de la distribution des donnees. Il est important que les
zones de l’espace visuel qui sont denses soient representees par plus de mots dans le vocabulaire
pour pouvoir conserver le potentiel de description qu’elles fournissent. Un histogramme de
quantification plat autour de la valeurλ permet alors de maximiser le codage de l’information
locale. L’obtention d’un histogramme parfaitement plat est en revanche une illusion puisqu’on
a systematiquement dans nos distributions de patches visuels certainselements identiques tres
presents (typiquement les zones uniformes), ainsi que des patches marginaux situes dans des
zones tres peu denses.
3.2.5 Influence du nombre de patches par image
Nowack [NJT06] explique qu’un des criteres les plus importants est le nombre de patches
extraits de chaque image. Nous allons verifier ce comportement dans notre cadre d’experimen-
tation. Nous utilisons toujours la base Pascal VOC 2007, lesdescripteursfou6 et eoh6, des
classifieurs SVM avec noyau triangulaire. Nous avons commence par creer des vocabulaires
de 50 mots par tirage aleatoire et K-moyennes. Puis ces vocabulaires sont testes sur la base en
extrayant 500, 1 000, 2 000 et 4 000 patches par image. Les resultats presentes sur la figure 3.14
confirment cette constatation.
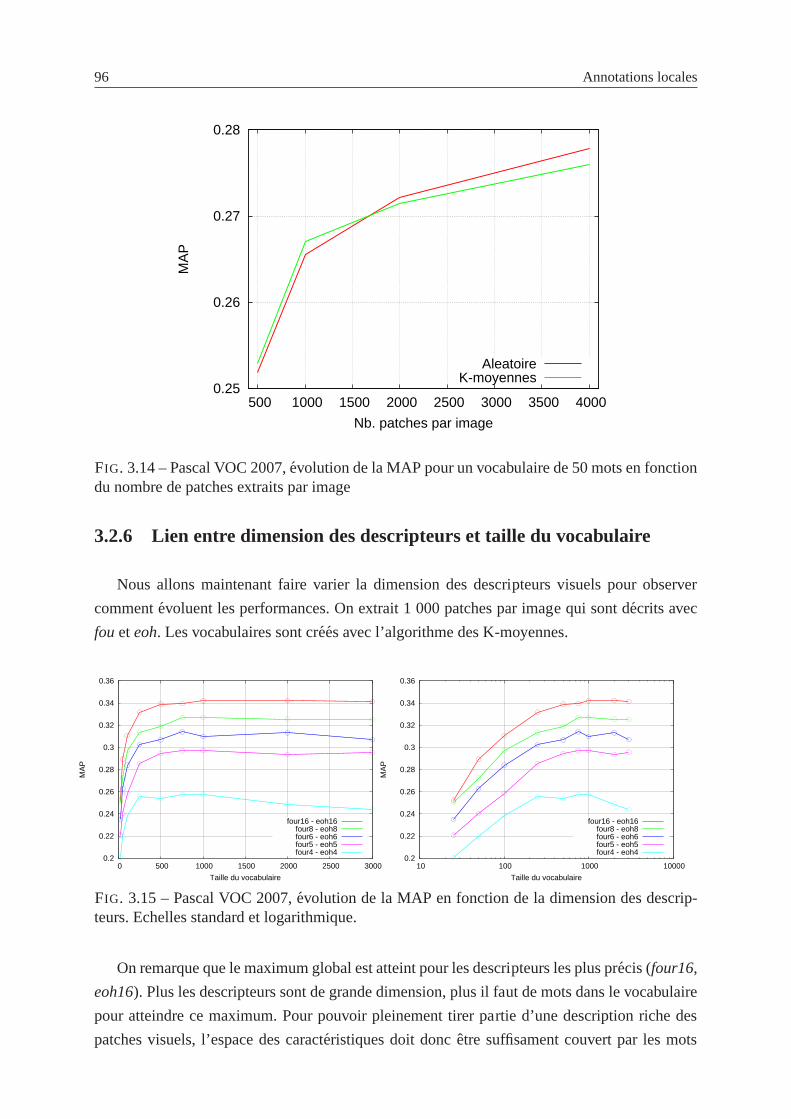
96 Annotations locales
0.25
0.26
0.27
0.28
500 1000 1500 2000 2500 3000 3500 4000
MA
P
Nb. patches par image
AleatoireK-moyennes
FIG. 3.14 – Pascal VOC 2007,evolution de la MAP pour un vocabulaire de 50 mots en fonctiondu nombre de patches extraits par image
3.2.6 Lien entre dimension des descripteurs et taille du vocabulaire
Nous allons maintenant faire varier la dimension des descripteurs visuels pour observer
commentevoluent les performances. On extrait 1 000 patches par image qui sont decrits avec
foueteoh. Les vocabulaires sont crees avec l’algorithme des K-moyennes.
0.2
0.22
0.24
0.26
0.28
0.3
0.32
0.34
0.36
0 500 1000 1500 2000 2500 3000
MA
P
Taille du vocabulaire
four16 - eoh16four8 - eoh8four6 - eoh6four5 - eoh5four4 - eoh4
0.2
0.22
0.24
0.26
0.28
0.3
0.32
0.34
0.36
10 100 1000 10000
MA
P
Taille du vocabulaire
four16 - eoh16four8 - eoh8four6 - eoh6four5 - eoh5four4 - eoh4
FIG. 3.15 – Pascal VOC 2007,evolution de la MAP en fonction de la dimension des descrip-teurs. Echelles standard et logarithmique.
On remarque que le maximum global est atteint pour les descripteurs les plus precis (four16,
eoh16). Plus les descripteurs sont de grande dimension, plus il faut de mots dans le vocabulaire
pour atteindre ce maximum. Pour pouvoir pleinement tirer partie d’une description riche des
patches visuels, l’espace des caracteristiques doit doncetre suffisament couvert par les mots
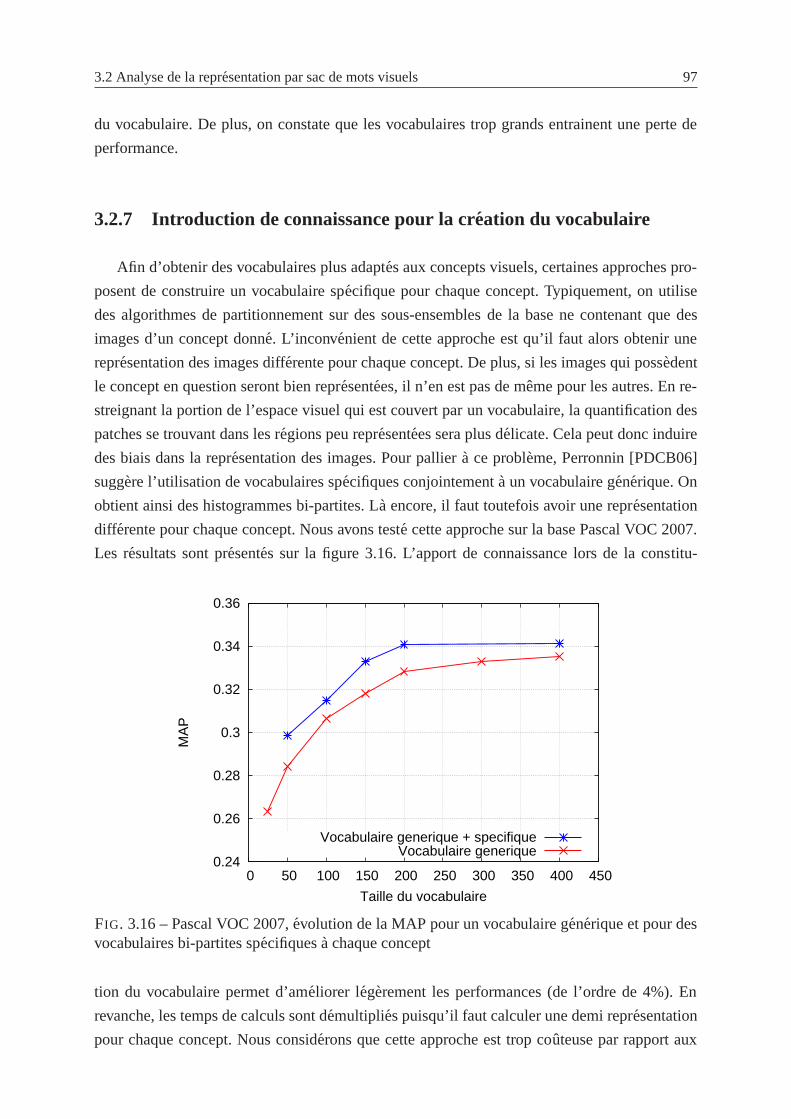
3.2 Analyse de la representation par sac de mots visuels 97
du vocabulaire. De plus, on constate que les vocabulaires trop grands entrainent une perte de
performance.
3.2.7 Introduction de connaissance pour la creation du vocabulaire
Afin d’obtenir des vocabulaires plus adaptes aux concepts visuels, certaines approches pro-
posent de construire un vocabulaire specifique pour chaque concept. Typiquement, on utilise
des algorithmes de partitionnement sur des sous-ensemblesde la base ne contenant que des
images d’un concept donne. L’inconvenient de cette approche est qu’il faut alors obtenir une
representation des images differente pour chaque concept. De plus, si les images qui possedent
le concept en question seront bien representees, il n’en est pas de meme pour les autres. En re-
streignant la portion de l’espace visuel qui est couvert parun vocabulaire, la quantification des
patches se trouvant dans les regions peu representees sera plus delicate. Cela peut donc induire
des biais dans la representation des images. Pour palliera ce probleme, Perronnin [PDCB06]
suggere l’utilisation de vocabulaires specifiques conjointementa un vocabulaire generique. On
obtient ainsi des histogrammes bi-partites. La encore, il faut toutefois avoir une representation
diff erente pour chaque concept. Nous avons teste cette approche sur la base Pascal VOC 2007.
Les resultats sont presentes sur la figure 3.16. L’apport de connaissance lors de la constitu-
0.24
0.26
0.28
0.3
0.32
0.34
0.36
0 50 100 150 200 250 300 350 400 450
MA
P
Taille du vocabulaire
Vocabulaire generique + specifiqueVocabulaire generique
FIG. 3.16 – Pascal VOC 2007,evolution de la MAP pour un vocabulaire generique et pour desvocabulaires bi-partites specifiquesa chaque concept
tion du vocabulaire permet d’ameliorer legerement les performances (de l’ordre de 4%). En
revanche, les temps de calculs sont demultiplies puisqu’il faut calculer une demi representation
pour chaque concept. Nous considerons que cette approche est trop couteuse par rapport aux

98 Annotations locales
gains de performances qu’on peut en attendre. De plus, travailler avec un unique vocabulaire
generique permet d’etendre plus facilement un systemea de nouveaux concepts visuels.
Une alternativea la creation de vocabulaires visuels est presente par Moosmann [MNJ08].
Des arbres aleatoires sont crees en injectant de la connaissance. Ils fournissent une representation
des images qui peut ensuiteetre utilisee par un algorithme d’apprentissage.
3.2.8 Conclusion
La creation d’un vocabulaire visuel est uneetape clee de la representation des images par
sacs de mots visuels. Comme pour notre strategie d’apprentissage, nous souhaitons conserver
une approche completement generique et independante des concepts visuels. Dans ce cadre,
nous avons montre l’importance d’avoir des vocabulaires qui soient le plus representatifs pos-
sibles de la distribution des patches visuels. Afin de conserver le pouvoir informatif de ces
patches, il importe d’adapter la distributions des mots du vocabulairea la densite des patches.
Idealement, il faudrait que chaque mot puisse encoder la meme quantite d’information sur une
base donnee. Pour cela, nous avons mis en avant un nouvel algorithme departitionnement,
appele dual QT. Il permet d’obtenir de meilleures performances que les approches classiques
basees sur les K-moyennes ou le tirage aleatoire. Toutefois, le leger gain observe s’opere au
detriment d’une complexite algorithmique quadratique. Contrairementa ce qui a pu etre ob-
serve par ailleurs [JT05], l’utilisation d’un algorithme de partitionnement qui ignore partielle-
ment la densite des patches, en essayant de representer de faconequitable toutes les zones de
l’espace des caracteristiques visuelles, ne permet pas d’obtenir des resultats satisfaisants. Nous
pensons que ceci est principalement du a la nature eta la distribution des signatures visuelles
qui sont differentes. Par ailleurs, nous confirmons des resultats deja observes indiquant que le
nombre de patches extraits d’une image et le nombre de mots duvocabulaire sont des criteres
importants ayant une grande influence sur les performances globales d’un systeme.
3.3 Etude comparee des strategies de selection de patches
pour le texte et l’image
3.3.1 Motivation
La representation par sac de mots est issue de la communaute texte. Toutefois, il estevident
que la nature des documents texte est differente de celle des images. Ainsi, un certain nombre
de contraintes qu’il a fallu surmonter sont apparues dans l’adaptation de cette representation .
Obtenir une representation sous forme de sac de mots pour un texte est, de facon inherente, plus

3.3Etude comparee des strategies de selection de patches pour le texte et l’image 99
simple que pour une image. En effet, la notion demot est clairement definie. De meme le vo-
cabulaire est connu et generique pour tous les documents. Il s’agit generalement de l’ensemble
des mots pour une langue donnee que l’on retrouve dans un dictionnaire.
Pour les images, la chose est plus complexe. La notion de mot visuel n’est pas un concept
naturel et elle peut recouvrir des realites differentes selon l’approche qui est choisie. On part
du principe qu’un mot visuel est constitue par un ensemble de pixels contigus dans une image.
On peut considerer que les objets presents dans une image definissent les mots visuels, mais
puisque le but meme d’obtenir ces mots est de permettre une reconnaissance des objets dans
l’image, il paraıt illusoire de vouloir baser une approche sur ce prerequis. Nous rappelons que
nous nous situons dans le cadre de bases d’images generiques sansa priori sur leur contenu.
De la meme maniere, l’intervention d’un operateur humain n’est pas souhaiteea cetteetape. Il
faut donc partir du principe qu’il ne peut y avoir de concordance parfaite entre les mots visuels
et les objets representes. Une approche possible pourrait alorsetre de considerer l’ensemble
des mots possibles pour une image. A l’heure actuelle,etant donnees les performances des or-
dinateurs, cela est irrealiste. D’une part, en deux dimensions, ces mots peuvent prendre des
formes geometriques tres diverses et il faudrait toutes les explorer. D’autre part, meme en s’im-
posant un nombre de formes restreint, il faut analyser l’image pour tous les pixels eta toutes les
echelles. Actuellement une image classique contient quelques millions de pixels. On doit donc
s’imposer des restrictions dans le choix des mots visuels. Cette etape n’existe pas pour le texte
et represente donc une difference fondamentale entre les deux approches. De plus, dansle cas
du texte, les mots sont intrinsequement porteurs de sens, ce qui sera beaucoup moins vrai pour
les images.
Il existe donc plusieurs methodes pour selectionner automatiquement certaines regions dans
les images. La plupart de ces methodes existait d’ailleurs bien avant l’application de larepre-
sentation par sac de mots aux images. Parmi les principales,on distingue les approches par
segmentation, le decoupage selon une grille fixe, la selection de points d’interet ou encore un ti-
rage aleatoire des regions. Chacune ayant une multitude de variations selon les caracteristiques
visuelles guidant l’algorithme, selon qu’elle prenne en compte ou non l’echelle, qu’elle per-
mettre ou non le recouvrement entre regions, . . . Sur la figure 3.17, on voit en basa gauche
le resultat d’une segmentation grossiere obtenue selon l’algorithme de Fauqueur et Boujemaa
[FB02]. Les regions obtenues sont representees avec leur couleur moyenne en basa droite. Sur
l’image en hauta droite, trois detecteurs de points d’interet sont utilises : SIFT [Low99] en
rouge, Harris couleur [GMDP00] en vert et grille fixe en bleu.Nous avons deja vu qu’il n’etait
pas pertinent de travailler avec les pixels bruts pour decrire les images, aussi, comme dans le cas
global, les differentes regions seront caracterisees par un descripteur qui fournira une signature
visuelle. Dans la suite, nous appelleronspatchces regions extraites et, par abus de language, les
signatures visuelles qui leur sont rattachees.
Dans l’optique de reduire les temps de calcul lies au traitement d’image, la communaute de

100 Annotations locales
FIG. 3.17 – Differents types de regions extraites sur une photo.c©Bassignac-Gamma.
vision par ordinateur a produit de gros efforts pour le developpement de detecteurs de points
d’interet. Ceci a commence avec les premieres applications liees au recalage d’image. Ces
detecteurs sont generalement attires dans des zones specifiques de l’image qui ont une forte
variation dans le signal visuel, tel que le long des bordureset sur les coins des regions. Une
des plus importantes considerations pour ces detecteurs est le caractere de repetabilite. Ainsi,
la localisation d’un point d’interet selectionne dans des images d’un meme objet, photographie
dans des conditions differentes, sera identique pour toutes les images [Low99]. Lorsequ’il a
ete question de limiter la quantite d’informations traitees pour l’annotation automatique, les
detecteurs de points d’interet se sont trouvesetre une option attractive. En effet, ils permettent
de selectionner une toute petite proportion de patches dans l’image ayant une forte variation
dans le signal. Cette forte variation est souvent consideree commeetant associeea un contenu
semantique riche. Cependant, nous considerons que cette hypothese est loin de toujoursetre jus-
tifi ee puisque dans le cas des bases generiques, des patches n’ayant qu’une faible variation du
signal peuvent tout aussi bienetre porteurs d’une semantique importante pour l’utilisateur. Une
autre justification qui a souventete evoquee pour l’utilisation des detecteurs de point d’interet
est qu’ils vont, de part leur nature, se fixer sur certaines zones des objets photographies et ainsi
fournir une description partiellement independante du contexte dans lequel ils se trouvent. La
description du contexte est aussi importante que la description des objets principaux dans une
image. Nous ne devons pas prejuger de ce qui sera important pour l’utilisateur final. De plus,
les informations contextuelles aident tres largementa la detection des objets.

3.3Etude comparee des strategies de selection de patches pour le texte et l’image 101
3.3.2 Cadre generique de representation de documents
Pour les raisons expliquees precedemment, nous pensons donc que toutes les zones d’une
image doiventetre eligibles pour produire des patches visuels, independemment de la varia-
tion du signal qu’elles comportent. Afin de verifier cette hypothese, nous proposons une ap-
proche originale visanta effectuer des experimentations analogues sur un corpus de textes et
sur une base d’images [HBH09]. Nous souhaitons ainsi revisiter les contraintes existantes pour
les images et, selon une demarche inversea celle couramment pratiquee, les appliquer aux
documents textes. La representation par sacs de mots vient de la communaute travaillant sur
le texte et aete importee et adaptee au monde de l’image. Nous proposons de reintroduire
dans un environnement de recherche purement textuelle d’informations les contraintes lieesa
la nature des images. Pour cela nous allons degrader la qualite d’un corpus de textes et ainsi
reproduire certaines caracteristiques des images. En utilisant une representation similaire des
documents, nous pourronsevaluer le comportement des strategies de selection de patches et
comparer les resultats sur les deux corpus. Nous ne cherchons pas ici une validation formelle
des approchesetudiees pour la selection de patches visuels dans les images, mais plutot une
meilleure comprehension des differents mecanismes impliques.
Nous utilisons le cadre de representation defini a la section 3.2.1 (page 84). On a deja
presente l’histogramme mesurant la frequence d’apparition de chaque mot dans un document.
Cet histogramme normalise est souvent presente dans la litterature sous l’appelationTerm Fre-
quency(TF).
Hki = Tfk
i =
∣∣∣{
wkj ∈ Dk|w
kj = Wi
}∣∣∣sk
(3.10)
Toutefois, tous les mots ne portent pas la meme quantite d’information. Certains sont tres cou-
rants, on peut les trouver dans la majorite des documents. D’autres vontetre plus specifiques
et etre caracteristiques d’un sous-ensemble precis de documents. Enfin on trouvera des mots
extremement rares qui seront presents dans tres peu de documents. Afin de mesurer l’impor-
tance d’un mot, relativementa une collection de documents, on mesure sa frequence d’appari-
tion dans la collection. C’est ce que l’on appelleDocument Frequency(DF).
Dfi =
∣∣∣{
Dk,∃j ∈ [1, sk] |wkj = Wi
}∣∣∣m
(3.11)
On peut combiner ces deux caracteristiques pour obtenir une mesure qui tient comptea la fois de
la frequence d’apparition d’un mot dans un document et de la rarete de ce mot dans la collection.
Ainsi, les mots tres frequents dans la collection vontetre penalises, alors que les mots rares vont
etre favorises dans la description d’un document dans lequel ils apparaissent. On definit alors

102 Annotations locales
l’ Inverse Document Frequency(IDF).
Idfi = log
(1
Dfi
)(3.12)
Et finalement, la mesure TF-IDF mesurant l’importance d’un mot pour un document relative-
menta la collection est definie [Sal71] :
TfIdfki = Tfk
i .Idfi (3.13)
Une mesure de similarite standard pour la representation TF-IDF consistea calculer l’angle
entre les vecteurs de deux documents, ou bien son cosinus. Ainsi, pour les vecteurs representant
Da etDb on a :
dva(Da, Db) = arccos
( ∑n
i=1 aibi√∑n
i=1 a2i
∑n
i=1 b2i
)(3.14)
Un angle approchant zero, ou un cosinus approchant un, indique que les documents sont proches
et ont de nombreux mots en commun.
3.3.3 Evaluation des representations
La qualite des representations et des vocabulaires associes seraevaluee a l’aide du para-
digme de requete par l’exemple pour lequel la performance de requetes par similarite sur un
jeu de documents est mesuree. Ce paradigme de requete est le plus simple qui existe et il per-
met de se detacher au maximum des differents biais qui pourraientetre induits par l’utilisation
d’un cadre d’evaluation plus complexe impliquant l’utilisation de briques technologiques suc-
cessives. On se focalise sur l’evaluation de la representation. De facon generale, on considere
que deux documents similaires d’un point de vue semantique doivent avoir des representations
plus proches que deux documents qui n’ont rien en commun. Le paradigme de requete par
l’exemple est donc particulierement adapte puisqu’on se contente d’evaluer les performances
de la similarite entre les representations. C’est un bon indicateur des performances futures de
ces representations dans des systemes plus complexes.
Pour chaque document de la collection, on connaıt le sous-ensemble de documents perti-
nents qui definit la verite terrain. En dehors de l’identification de ces sous-ensembles et pour les
raisonsevoquees precedemment, nous n’utiliserons pas cette verite terrain pour un apprentis-
sage ou pour la creation des vocabulaires. Ceux-ci seront obtenus de facon generique. Ils seront
fonction du contexte global de la collection de documents mais ne seront pas specifiques aux
diff erents concepts qui interviendront dans l’evaluation.

3.3Etude comparee des strategies de selection de patches pour le texte et l’image 103
La verite terrain est utilisee pourevaluer les performances de la tache de recherche de docu-
ments. On utilise la mesure de la precision moyenne. Puisque le nombre de documents retournes
par le syteme intervient dans le calcul de la performance, il est fixe de facon standard afin de ne
pas biaiser les resultats. Nous avons choisi d’imposer une taille de reponseegalea deux fois la
taille du sous-ensemble de documents pertinents pour chaque requete.
3.3.4 Degradation du texte
Les documents textes ont une structure beaucoup plus simpleque les images. Un texte peut
etre vu comme un flux de symboles de dimension 1 alors que les images sont plus naturelle-
ment vues comme des tableaux de reels en dimension 2. Pour les textes, il n’est pas necessaire
de se soucier avec les variations d’echelle, de point de vue, d’objets deformables, de condi-
tions d’eclairage et d’autres proprietes caracteristiques des images. L’identification des objets
est plus simple et, bien que la polysemie puisse poser des difficultes pour le texte, la semantique
attacheea un mot est plus simplea discerner que celle d’un mot visuel. Ainsi, on peut clai-
rement s’attendrea ce qu’une approche definie pour les images ait de bonnes performances
enetant appliquee pour des textes. Cependant, les differences entre textes et images sont telle-
ment grandes qu’une methode ayant de mauvaises performances pour les images pourrait quand
meme se comporter correctement sur du texte. Pour qu’une comparaison des approches dans les
deux mondes soit profitable, les avantages relatifs du textesur l’image doivent dans un premier
tempsetre neutralises.
Dans un texte, les mots sont tres bien identifies par les espaces et par les signes de ponc-
tuation qui les separent. Afin de partiellementeliminer cet avantage, nous retirons tous ces
caracteres des textes sur lesquels nous travaillons. De meme, nous supprimons les majuscules.
Il nous reste ainsi un jeu de symboles constitue de 36 caracteres (26 lettres et 10 chiffres). Les
mots n’etant plus identifiables, le vocabulaire devientegalement inaccessible. L’approche sac de
mots pour ces textes degrades doit donc, comme pour les images, commencer par construire un
vocabulaire avant de pouvoir obtenir les representations des documents. Dans ce contexte, les
patches extraits du texte degrade seront simplement des sequences de caracteres sans aucune
signification semantique particuliere. Bien que toujours plus simples, ils sont ainsi similaires
aux patches visuels composes par des fenetres extraites autour de points particuliers dans les
images.

104 Annotations locales
3.3.5 Jeux de donnees et resultats de reference
Le corpus texte Reuters RCV1
Le corpus Reuters RCV1 [LYRL04] est un standard dans le domaine de la categorisation de
textes. Il est compose de 806 791 depeches en langue anglaise de l’agence de presse Reuters.
Ces depeches ontete collectees sur une periode d’un an, entre le 20 aout 1996 et le 19 aout 1997.
Elles sont disponibles sont forme de fichiers XML individuels. A titre d’exemple, le fichier brut
correspondanta la depeche 12 799 est represente dans la figure 3.18. En plus du texte de la
depeche, on y retrouve de nombreuses metadonnees. Afin d’eviter de biaiser notreevaluation
basee sur de la recherche par le contenu, toutes ces metadonnees seront ignorees par la suite.
Ainsi, seul le texte compris entre les balises<text> et </text> sera utilise. Les balises
XML sont eliminees et les differents caracteres d’echappement sont remplaces par leur valeur.
Pour ce corpus de base, le vocabulaire contient 435 282 mots.
Afin d’obtenir des resultats de reference pour nos experimentations, nous nous placons dans
un contexte classique pour l’analyse de textes. Nous choisissons de travailler sur le texte en
minuscules uniquement. Tous les caracteres qui ne sont pas alphanumeriques sont transformes
en espaces. De plus, nous supprimons les mots vides (stop words) et effectuons une lematisation
(stemming) selon l’algorithme de Porter [Por80]. Nous conservons lesnombres et les mots
n’ayant qu’un caractere (si ce ne sont pas des mots vides). Apres ce traitement, notre vocabulaire
contient 365 652 mots. Si nous le filtrons pour ne retenir que les mots qui sont presents dans
au moins 50 documents, il reste 34 026 mots. Cette derniereetape n’a pour but que d’accelerer
les calculs lors des experiences. Ce vocabulaire nous servira de reference, on le noteraVB. Pour
information, on peut voir sur la figure 3.19 la distribution de la taille des mots deVB.
Pour les experiences, nous allons considerer 7 requetes composees de mots de tailles dif-
ferentes. Ces requetes sont choisies afin de se concentrer sur un contexte ou unevenement
specifiques et representatifs du corpus. Plusieurs termes ont notammentete choisis en raison de
leur polysemie. Ainsi l’information contextuelle sera necessaire pour retrouver les documents
pertinents dans la base. Enfin, le choix de ces requetes aete legerement guide par l’interet que
nous portonsa ces sujets. Le tableau 3.1 presente les termes choisis ainsi que le nombre de do-
cuments qui les contiennent. En gras nous indiquons les 7 requetes qui seront utilisees pour les
experiences. Deux des requetes sont composees de deux termes. Ainsi, par exemple, la requete
goldman + simpsonse concentre sur unevenement specifique qui a fait couler beaucoup d’encre
dans la presse l’annee ou le corpus aete constitue. Il s’agit du second proces d’O.J. Simpson
et il concernait le meurtre de Ronald Goldman. Le premier proces s’etait deroule en 1995. Les
deux termes de la requete, pris individuellement, sont attachesa de nombreuses significations.
On peut avoir une idee de cette polysemie en voyant la faible proportion de documents qui
contiennent les deux termes conjointement (environ4%) par rapport au nombre de documents

3.3Etude comparee des strategies de selection de patches pour le texte et l’image 105
<?xml version="1.0" encoding="iso-8859-1" ?><newsitem itemid="12799" id="root" date="1996-08-24" xml:lang="en"><title>USA: Judge bans live TV coverage in Simpson civil trial.</title><headline>Judge bans live TV coverage in Simpson civil trial.</headline><byline>Dan Whitcomb</byline><dateline>SANTA MONICA, Calif 1996-08-23</dateline><text><p>The judge in the O.J. Simpson civil trial on Friday ordered a complete blackout of television and radiocoverage, saying he did not want a repeat of the "circus atmosphere" that surrounded the formerfootball hero’s criminal trial on murder charges.</p><p>Judge Hiroshi Fujisaki said the TV camera in Simpson’s first trial had "significantly diverted anddistracted the participants, it appearing that the conduct of witnesses and counsel were unduly influencedby the presence of the electronic media."</p><p>"This conduct was manifested in various ways, such as playing to the camera, gestures, outburstsby counsel and witnesses in the courtroom and thereafter outside of the courthouse, presenting a circusatmosphere to the trial," he said.</p><p>In banning electronic and visual coverage of the civil proceedings, Fujisaki was apparently seeking tocut down on the media frenzy that surrounded Simpson’s criminal trial.</p><p>Simpson was acquitted last October of the 1994 murders of his ex-wife Nicole Brown Simpson and herfriend Ronald Goldman.</p><p>The victims’ families are now suing Simpson for damages in a wrongful-death civil lawsuit, chargingthat he was responsible for the deaths of their loved ones. Trial is set to begin on Sept. 17.</p><p>Live, gavel-to-gavel TV coverage of the first trial kept the nation enthralled for nine months.</p><p>In his ruling on Friday, Fujisaki stated: "The intensity of media activity in this civil trial thusfar strongly supports this court’s belief that history will repeat itself unless the court acts to preventit."</p><p>Fujisaki also ruled that no still photographers or sketch artists would be allowed in the courtroom forthe civil case, saying, "It has been the experience of this court that the presence of a photographerpointing a camera and taking photographs is distracting and detracts from the dignity and decorum of thecourt."</p><p>Fujisaki’s ruling even extends into the Internet. The judge said he would not allow live transcriptstyped by the official court reporter to be transmitted onto the Internet as they were during the criminaltrial.</p><p>He said the transcripts were "rough, unedited or uncorrected notes...which may be incomprehensibleor misleading or otherwise incomplete."</p><p>Fujisaki also left largely intact a wide-ranging gag order prohibiting lawyers, witnesses and anyoneelse connected with the case from talking about it in public.</p><p>He said he would shortly issue an order that any proceedings out of the presence of the jury or atsidebar would be sealed until the end of the trial.</p><p>Paul Hoffman, an attorney representing the American Civil Liberties Union who had earlier urged Fujisakito lift the gag order, said he would appeal the judge’s decision to keep it in place.</p><p>"We believe that the judge is not really on solid ground and we hope that the Court of Appeals willoverturn it (the gag order). From the standpoint of the First Amendment (right to free speech) it’s a sadday," he said.</p><p>Earlier in the day, Fujisaki listened to six lawyers representing the families of Nicole Brown andGoldman, as well as to Hoffman and Sager, arguing why there should be a TV camera in the courtroom.</p><p>Simpson’s attorney, Robert Baker, was the sole dissenting voice, arguing against live televisioncoverage.</p></text><copyright>(c) Reuters Limited 1996</copyright><metadata><codes class="bip:countries:1.0">
<code code="USA"><editdetail attribution="Reuters BIP Coding Group" action="confirmed" date="1996-08-24"/>
</code></codes><codes class="bip:topics:1.0">
<code code="GCAT"><editdetail attribution="Reuters BIP Coding Group" action="confirmed" date="1996-08-24"/>
</code><code code="GCRIM">
<editdetail attribution="Reuters BIP Coding Group" action="confirmed" date="1996-08-24"/></code><code code="GPRO">
<editdetail attribution="Reuters BIP Coding Group" action="confirmed" date="1996-08-24"/></code>
</codes><dc element="dc.date.created" value="1996-08-23"/><dc element="dc.publisher" value="Reuters Holdings Plc"/><dc element="dc.date.published" value="1996-08-24"/><dc element="dc.source" value="Reuters"/><dc element="dc.creator.location" value="SANTA MONICA, Calif"/><dc element="dc.creator.location.country.name" value="USA"/><dc element="dc.source" value="Reuters"/></metadata></newsitem>
FIG. 3.18 – Reuters RCV1, exemple de fichier XML
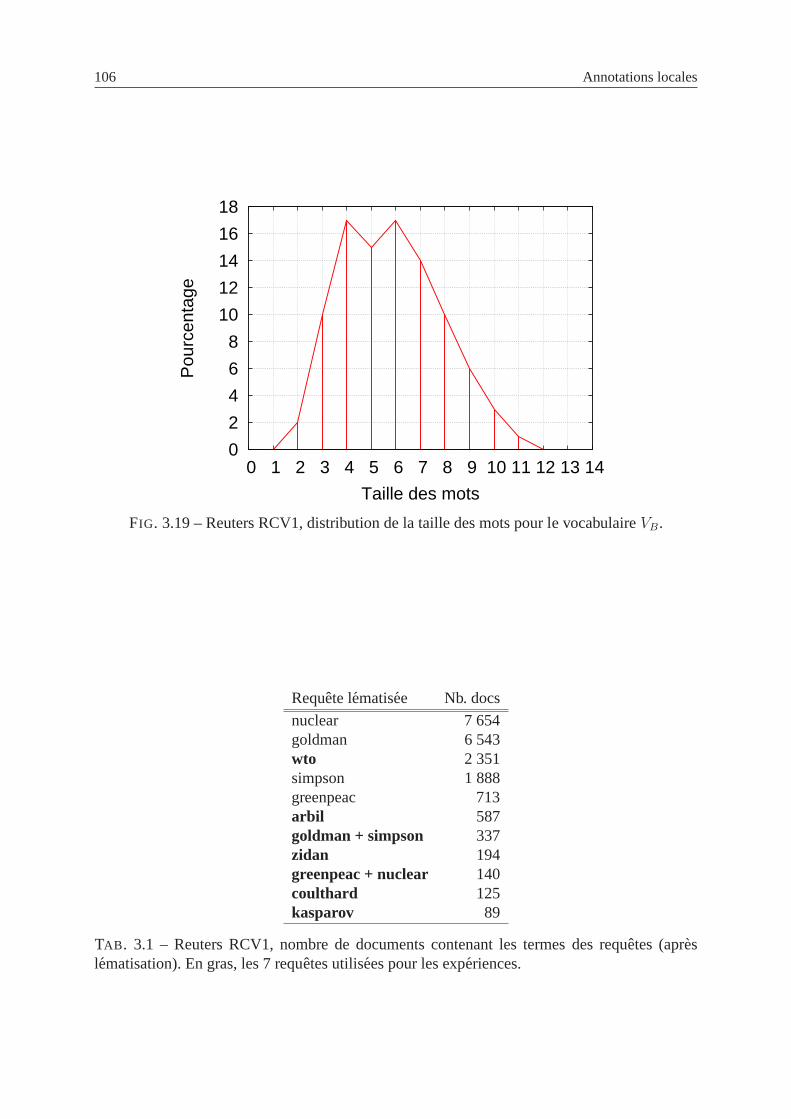
106 Annotations locales
0
2
4
6
8
10
12
14
16
18
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
Pou
rcen
tage
Taille des mots
FIG. 3.19 – Reuters RCV1, distribution de la taille des mots pour le vocabulaireVB.
Requete lematisee Nb. docs
nuclear 7 654goldman 6 543wto 2 351simpson 1 888greenpeac 713arbil 587goldman + simpson 337zidan 194greenpeac + nuclear 140coulthard 125kasparov 89
TAB . 3.1 – Reuters RCV1, nombre de documents contenant les termesdes requetes (apreslematisation). En gras, les 7 requetes utilisees pour les experiences.

3.3Etude comparee des strategies de selection de patches pour le texte et l’image 107
contenant au moins un des deux termes.Goldmanest une partie du nom de Goldman Sachs, une
fameuse banque d’investissement qui apparaıt souvent dans les depeches Reutersa caractere fi-
nancier1. Simpsonest le nom d’un desert en Australie, ainsi que le nom d’un journaliste de Reu-
ters qui apparaıt souvent dans les depeches. Chacune des 7 requetes definit un sous-ensemble du
corpus qui constitue notreverite terrain. Nous avons choisi d’evaluer la representation par sac
de mots selon le paradigme de requete par l’exemple. Pour les 7 sous-ensembles, nous allons
donc effectuer une requete sur l’ensemble du corpusa partir de chacun des documents qu’il
contient et mesurer la precision moyenne. Ainsi, cette mesure nous indiquera la capacite glo-
bale des documents pertinentsa retrouver les membres de leur sous-ensemble. En moyennant
ces scores pour les 7 requetes nous obtiendrons la MAP. En se placant dans les conditions clas-
siques de recherche de documents textes avec le vocabulaireVB, nous obtenons des resultats
etat-de-l’art qui nous serviront de base de reference pour comparer les differentes approches
de selection de patches qui seront developpees par la suite. Les resultats sont presentes dans le
tableau 3.2. Nous rappelons que nous avons choisi d’imposerune taille de reponseegalea deux
Requete lematisee AP
goldman + simpson 0.2389coulthard 0.2045arbil 0.2014kasparov 0.1234wto 0.0897zidan 0.0851greenpeac + nuclear 0.0539MAP 0.1492
TAB . 3.2 – Reuters RCV1, precisions moyennes pour le vocabulaireVB
fois la taille du sous-ensemble de documents pertinents pour chaque requete.
La base d’images ImagEVAL-4
La quatrieme tache de la campagne d’evaluation ImagEVALetait dedieea la detection d’ob-
jets. Dix objets, ou classes d’objets,etait proposee (vehicule blinde, voiture, vache, tour Eiffel,
minaret et mosquee, avion, panneau routier, lunettes de soleil, arbre, drapeau americain). La
base de test contient 14 000 images, couleurs ou noir et blanc. Certaines images coutiennent
des objets de plusieurs classes et 5 000 images ne contiennent aucun objet des 10 classes
considerees. A titre d’exemple, on peut voir sur la figure 3.20 des images contenant le drapeau
americain. Les objets apparaissent avec une grande variete de poses, de tailles et de contextes.
Une base d’apprentissage est fournie. Contrairementa l’usage, cette derniere est composee
uniquement d’images des objets en gros plan. Les arriere plan ontete supprimes. Aucune des
1L’explication est probablement devenue superflue,etant donnee la soudaine notoriete de ces institutions, ycompris de ce cote de l’Atlantique.

108 Annotations locales
FIG. 3.20 – ImagEVAL-4, exemples d’images contenant le drapeauamericain. c©Bassignac-Gamma et Keystone.
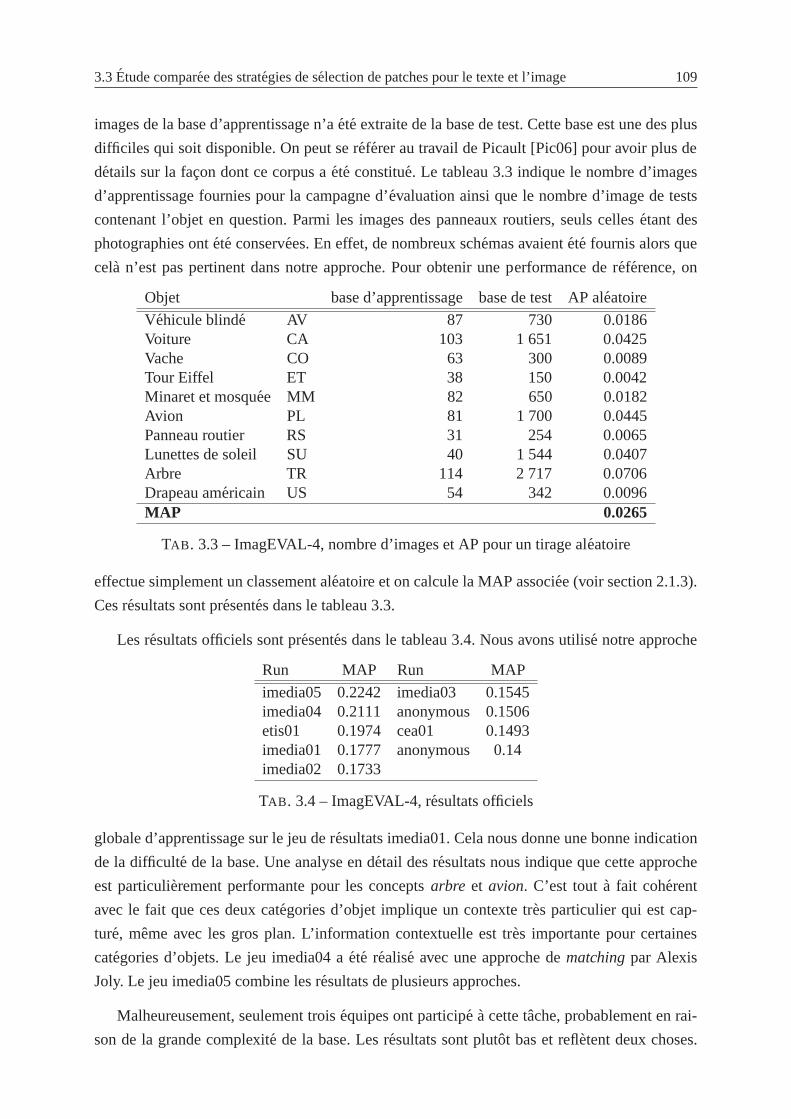
3.3Etude comparee des strategies de selection de patches pour le texte et l’image 109
images de la base d’apprentissage n’aete extraite de la base de test. Cette base est une des plus
difficiles qui soit disponible. On peut se referer au travail de Picault [Pic06] pour avoir plus de
details sur la facon dont ce corpus aete constitue. Le tableau 3.3 indique le nombre d’images
d’apprentissage fournies pour la campagne d’evaluation ainsi que le nombre d’image de tests
contenant l’objet en question. Parmi les images des panneaux routiers, seuls cellesetant des
photographies ontete conservees. En effet, de nombreux schemas avaientete fournis alors que
cela n’est pas pertinent dans notre approche. Pour obtenir une performance de reference, on
Objet base d’apprentissage base de test AP aleatoire
Vehicule blinde AV 87 730 0.0186Voiture CA 103 1 651 0.0425Vache CO 63 300 0.0089Tour Eiffel ET 38 150 0.0042Minaret et mosquee MM 82 650 0.0182Avion PL 81 1 700 0.0445Panneau routier RS 31 254 0.0065Lunettes de soleil SU 40 1 544 0.0407Arbre TR 114 2 717 0.0706Drapeau americain US 54 342 0.0096MAP 0.0265
TAB . 3.3 – ImagEVAL-4, nombre d’images et AP pour un tirage aleatoire
effectue simplement un classement aleatoire et on calcule la MAP associee (voir section 2.1.3).
Ces resultats sont presentes dans le tableau 3.3.
Les resultats officiels sont presentes dans le tableau 3.4. Nous avons utilise notre approche
Run MAP Run MAP
imedia05 0.2242 imedia03 0.1545imedia04 0.2111 anonymous 0.1506etis01 0.1974 cea01 0.1493imedia01 0.1777 anonymous 0.14imedia02 0.1733
TAB . 3.4 – ImagEVAL-4, resultats officiels
globale d’apprentissage sur le jeu de resultats imedia01. Cela nous donne une bonne indication
de la difficulte de la base. Une analyse en detail des resultats nous indique que cette approche
est particulierement performante pour les conceptsarbre et avion. C’est touta fait coherent
avec le fait que ces deux categories d’objet implique un contexte tres particulier qui est cap-
ture, meme avec les gros plan. L’information contextuelle est tres importante pour certaines
categories d’objets. Le jeu imedia04 aete realise avec une approche dematchingpar Alexis
Joly. Le jeu imedia05 combine les resultats de plusieurs approches.
Malheureusement, seulement troisequipes ont participe a cette tache, probablement en rai-
son de la grande complexite de la base. Les resultats sont plutot bas et refletent deux choses.

110 Annotations locales
D’une part, il estevident que des ameliorations qui doivent encoreetre faites pour les approches
locales. D’autre part, le choix d’utiliser uniquement des images en gros plan des objets plutot
que de laisser les objets dans leur contexte contribuea complexifier la tache. Dans le cadre de
l’ evaluation des strategie de selection de patches locaux, une requete par l’exemple est effectuee
pour chaque exemple de la base d’apprentissage.
Signatures bas-niveau. Nous utilisons des signatures visuelles locales tres simples pour cette
evaluation. Il s’agit d’un histogramme couleur pondere par l’activite local de la couleur dans
un petit voisinage de chaque pixel (information de texture)[Fer05]. Nous utilisons 64 bins pour
les encoder et utilisons la distanceL1 pour mesurer leur similarite. Bien qu’incomplete dans
l’absolu, cette description locale est suffisante pour la comparaison des strategies de selection
de patches. De plus, elle peut aisementetre remplacee par d’autres types de signatures dans
le cadre general que nous proposons. Nous utilisons l’algorithme de partitionnement QT pour
creer le vocabulaire visuel. Dans le cadre de cette experimentation, il a fourni des performances
legerement meilleures que les K-moyennes. Uneetude plus poussee dans le cadre de l’annota-
tion automatique a toutefois permis de mettre en avant ses defauts (section 3.2.3). Le tableau
3.5 indiquea titre d’exemple les tailles de vocabulaires obtenues.
w 1.0 0.8 0.7 0.5
Grille 8 115 276 469 1390Points 8 115 260 430 1364Grille 16 106 262 432 1525Points 16 82 197 357 1283Grille 32 112 280 472 1536Points 32 89 224 387 1351Grille 64 116 278 491 1640Points 64 91 229 403 1391
TAB . 3.5 – ImagEVAL-4, taille des vocabulaires visuels obtenusavec QT pour differents rayons
3.3.6 Experimentations
Nousetudions deux strategies de selection de patches locaux : l’echantillonnage regulier et
la detection de points d’interet.
Echantillonnage regulier
Pour les images, unechantillonnage complet (c’est-a-dire pour chaque pixel) serait trop
couteux en temps de calcul. Aussi restreignons-nous cetechantillonnagea une grille fixe.

3.3Etude comparee des strategies de selection de patches pour le texte et l’image 111
De cette facon, nous garantissons que les patches selectionnes sont repartis de maniere uni-
forme sur l’image. Ces patches sont des fenetres carrees de taille fixe centrees sur les positions
determinees par la grille. Les experiences ontete menees avec des taillesw = 8, 16, 32 et64
pixels. Les parametres de la grille sont adaptes automatiquement de facona extraire environ
1 000 patches par image.
Pour le texte, nous appliquons une fenetre glissante de taille fixe sur le texte degrade. Les
tests ontete realises avec des fenetres de taillew = 2, 3, 4 et5 caracteres en considerant
systematiquement toutes les positions possibles. A chaque position, la chaıne de caracteres
apparaissant dans la fenetre est notre patch local. Reprenons l’exemple du document12 799
(page 105). Le debut de cette depeche sous forme degradee est presente sur la figure 3.21 avec
quelques positions de la fenetre glissante et les patches extraits correspondants.
FIG. 3.21 – Reuters RCV1,echantillonnage regulier avec une fenetre de taille 3
Le vocabulaire pour chacun des tests est compose de tous les mots de taille fixe rencontres
lors du parcours de l’ensemble des documents du corpus. Potentiellement, la taille du vocabu-
laire pour une taille de fenetre donnee est doncegalea36w. Toutefois, toutes les combinaisons
de caracteres n’apparaissent pas naturellement. Le tableau 3.6 indique les tailles de ces vocabu-
laires ainsi que la proportion que cela represente par rapport au vocabulaire theorique complet.
w Taille du vocabulaire 10 patches les plus frequents
2 1296 (100%) er, es, re, on, in, at, te, an, nt, ar3 43 700 (93.66%) the, ing, ion, ent, and, ate, ter, for, est, day4 666 418 (39.68%) said, tion, nthe, dthe, ment, atio, onth, ther, inth, rthe5 4 607 713 (7.62%) ation, inthe, ofthe, saidt, llion, aidth,illio, tions,
tiona, idthe
TAB . 3.6 – Reuters RCV1, taille des vocabulaires pour l’echantillonnage regulier
Detection de points d’interet
Parmi les nombreux detecteurs de points d’interet disponibles, nous avons choisi de combi-
ner les detecteurs SIFT [Low99] et Harris couleur [GMDP00]. En effet, ces deux detecteurs ne
s’attachent pas aux memes caracteristiques visuelles saillantes (voir la figure 3.17). On extrait

112 Annotations locales
500 points de chaque type par image. Comme pour les tests sur les grilles fixes, les signatures
visuelles sont calculees sur des fenetres carrees centrees sur les points detectes. Nous ne tenons
pas compte de l’echelle ni de l’orientationeventuellement detectees. Les tests sont effectues
avec les memes tailles de fenetre que precedemment. Le seul parametre qui varie ici est donc la
position des patches extraits.
Afin de pouvoir effectuer une comparaison, la detection de points d’interet doitetre simulee
pour le texte degrade d’une maniere similairea ce qui se passe pour les images. Cela souleve
la question de savoir ce qui constitue une information textuelle utile. Quelle notion peut-on
rapprocher d’une forte variation locale du signal ? Toute strategie de detection doit, comme pour
les images, necessairementetre repetable. Ainsi la sequence de caracteres dans deux documents
diff erents doitetre caracterisee de maniere identique. Les detecteurs de points d’interet visuels
se concentrent sur les zonesa forte variabilite du signal et ignorent les autres. Nous proposons
donc un detecteur pour le texte degrade qui se focaliseegalement sur certains types de patches
et en exclut d’autres. Cela revient en faita considerer qu’un detecteur pour le texte n’est capable
de reperer qu’un sous-ensemble pre-selectionne du vocabulaire. Nous definissons lacouverture
commeetant la proportion de l’ensemble des patches de la base qui se trouventetre presents
dans le vocabulaire, c’est-a-dire qui sont promus au rang de mot. Deux approches ontete testees
dans le cas de la fenetre glissante de taille 2 :
– S1 : en se basant sur la frequence d’apparition des mots dans la collection (DF), nous
creons 5 vocabulaires qui contiennent respectivement les 10,20, 30, 40 et 50 patches les
plus frequents.
– S2 : en se basant sur la frequence d’apparition inverse des mots dans la collection (IDF),
nous conservons le nombre minimum de patches necessaire pour obtenir une couverture
de10% de la collection complete.
S1 simule l’utilisation d’un petit nombre de mots tres frequents alors que S2 utilise un grand
nombre de mots rares. Pour les images, nous avons extrait 1 000 points par image, ce qui cor-
respond environa 1% du nombre de pixels. Les imagesetant en dimension 2, la restriction de
l’information disponiblea 10% pour S2 permet d’etre dans une approche comparable. Nous
resumons les statistiques des vocabulaires ainsi crees dans le tableau 3.7.
Strategie Taille Couverture
Vocabulaire W2 initial 1296 100.00%S1 - 10 10 15.37%S1 - 20 20 25.09%S1 - 30 30 32.48%S1 - 40 40 38.87%S1 - 50 50 44.44%S2 1008 10.00%
TAB . 3.7 – Reuters RCV1, vocabulaires liesa la detection de points d’interet – W2

3.3Etude comparee des strategies de selection de patches pour le texte et l’image 113
3.3.7 Resultats et discussions
Tous les resultats qui sont reportes ici sont exprimes comme un ratio par rapport aux MAP
de reference obtenues precedemment (VB pour Reuters et tirage aleatoire pour ImagEVAL-4).
Le corpus de textes degrades
Les tableaux 3.8 et 3.9 donnent les resultats sur le corpus de texte degrade. Si on regarde
le cas des fenetres de taille 2, on constate que les deux approches S1 et S2 simulant les points
d’interet obtiennent de moins bons scores que l’echantillonnage regulier. Il y a donc bien une
perte d’information ici. Il est interessant de noter que les mots de 2 caracteres les plus informa-
tifs sont aussi les plus rares. En effet, le vocabulaire des 50 mots les plus frequents, couvrant
environ44% de l’information totale, a une performance tres faible (seulement3.95% du score
de reference). A l’inverse, les 1 008 mots les plus rares, qui couvrent 10% de l’information
obtiennent un bien meilleur score, plus proche de celui obtenu par l’echantillonnage regulier.
Ainsi, meme si la simulation de detection de points d’interet obtient un score honorable, la perte
d’information qu’elle induit amene quand meme une degradation des performances par rapport
a l’echantillonnage regulier.
Requete lematisee W2 W3 W4 W5
goldman + simpson 0.5469 0.9361 0.9974 1.0029coulthard 0.1594 0.5845 0.9374 1.0635arbil 0.7333 0.9779 1.1090 1.1288kasparov 0.1729 0.3873 0.7832 1.1042wto 0.1410 0.4168 0.5476 0.6402zidan 0.5739 0.9074 1.0443 1.1417greenpeac + nuclear 0.0701 0.4916 0.8101 1.0106Ratio MAP 0.3425 0.6716 0.8899 1.0131
TAB . 3.8 – Reuters RCV1, ratio des precisions moyennes pour l’echantillonnage regulier parrapport aux resultats de reference
Concernant l’echantillonnage regulier, les resultats pour des tailles plus grandes de fenetre
sont egalement interessants et plutot surprenants. Pour la plupart des requetes on obtient de
meilleurs resultats sur le texte degrade que sur le texte original avec le vocabulaireVB. Ainsi,
pour le vocabulaire W5, en dehors de la requetewto, on observe un gain sur les performances
(+14% pour zidan, +12% pour arbil ou +10% pour kasparovpar exemple). En comparaison
avec le vocabulaire standardVB, une fenetre glissante ne voit qu’une information partielle. La
plupart des positions de cette fenetre vont capturer la structure interne des mots. Si la fenetre
esta cheval sur deux mots consecutifs, on peut considerer qu’elle capture ainsi une information
contextuelle. Enfin, il peut arriver que la fenetre coıncide avec un mot de la meme taille. Ces
trois phenomenes peuventetre observes sur notre exemple precedent (figure 3.21, page 111). La

114 Annotations locales
Requete lematisee S1-10 S1-20 S1-30 S1-40 S1-50 S2
goldman + simpson 0.0012 0.0046 0.0107 0.0179 0.0138 0.5142coulthard 0.0343 0.0400 0.0681 0.0892 0.0954 0.1203arbil 0.0005 0.0088 0.0180 0.0326 0.0575 0.6917kasparov 0.0018 0.0051 0.0161 0.0263 0.0439 0.1777wto 0.0054 0.0129 0.0163 0.0237 0.0264 0.0913zidan 0.0014 0.0056 0.0095 0.0158 0.0207 0.5368greenpeac + nuclear 0.0021 0.0030 0.0135 0.0161 0.0187 0.0202Ratio MAP 0.0067 0.0114 0.0217 0.0316 0.0395 0.3075
TAB . 3.9 – Reuters RCV1, ratio des precisions moyennes pour la simulation de points d’interetpar rapport aux resultats de reference
fenetre de taille 3 va capturer le motthe. Les patchesjud, udg, dgecorrespondenta la structure
interne du motjudge. Le contexte dans lequel le motjudgeapparaıt (c’est-a-dire entre les mots
theet in) est, quanta lui, extrait avec les patcheshtj, eju, gei et ein. Une petite fenetre de taille
2 est deja capable de capturer des informations tres utiles. Bien que seulement2% des mots
de VB soient de taille 2, un tiers des performances de reference peuventetre obtenus avec le
vocabulaire W2. Nous avons extrait un premier sous-ensembleV1 de VB contenant les 1 296
mots apparaissant dans le plus grand nombre de documents. AinsiV1 et W2 ont la meme taille,
et on constate que les performances sont deux fois moins bonnes pourV1. Une premiere hy-
Requete lematisee V1 V2
goldman + simpson 0.3110 0.3958coulthard 0.1284 0.5003arbil 0.2521 0.6577kasparov 0.1967 1.0969wto 0.2102 0.1008zidan 0.1131 0.2306greenpeac + nuclear 0.4500 0.1790Ratio MAP 0.1744 0.4286
TAB . 3.10 – Reuters RCV1, ratio des precisions moyennes pour les vocabulairesV1 et V2 parrapport aux resultats de reference
pothese est que le choix d’une taille fixe de fenetre agit un peu comme un filtre passe-bande se
focalisant sur les mots ayant la meme taille que la fenetre. Il n’est ainsi pas surprenant que les
meilleurs resultats soient obtenus pour W5 puisque, comme on peut le voirsur la figure 3.19, la
taille moyenne des mots deVB est proche de 5. Bien qu’enormement de bruit soit capture (W5
contient environ 12 fois plus de mots queVB), les mots inutiles tendenta etreelimines dans les
representations vectorielles des documents par de faibles poids TF-IDF. L’augmentation de la
taille de la fenetre va aussi contribuera recolter davantage d’information contextuelle qui peut
expliquer les meilleures performances. Ces observations nous ont conduita faire une derniere
experience. Nous construisons un deuxieme sous-ensembleV2 deVB compose de tous les mots
ayant exactement 5 caracteres. Poureviter tout biais, nous avons supprime les deux motsar-

3.3Etude comparee des strategies de selection de patches pour le texte et l’image 115
bil et zidanqui servent de requete.V2 contient 5 274 mots. On constate (tableau 3.10) que les
mots de taille 5 ne contribuent qu’a hauteur de42% dans les performances globales deVB.
Ainsi, le fait que W5 obtienne un scoreequivalenta VB doit plutot etre interprete par l’impor-
tance des informations structurelles et contextuelles capturees par l’echantillonnage regulier.
Ainsi, les resultats de ces experiences nous amenenta conclure que, pour le texte, beneficier
des frontieres exactes des mots n’est pas une information necessaire puisqu’unechantillonnage
regulier des patches est suffisant pour obtenir de bonnes performances. De plus, ces resultats
pour la representation par sacs de mots du texte degrade tendenta conforter l’idee que cette
approche est pertinente pour les images.
La base d’images
Les performances obtenues pour la base ImagEVAL-4 ne peuvent bien evidemment pas
etre comparees avec les resultats publies precedemment. En effet, nous avons choisi ce jeu de
donnees dans le seul but d’avoir un environnement de test controle pour la comparaison des
strategies de selection de patches visuels. Faire une requete par l’exemple est comparablea une
classification par plus proche voisin n’utilisant qu’un seul exemple positif. Les resultats obtenus
par ailleurs mettent en oeuvre des approches d’apprentissage supervise bien plus complexes.
Sur la base ImagEVAL-4, globalement les resultats sont meilleurs avec la selection de patches
utilisant la grille fixe. On observe en moyenne un gain de29% par rapporta l’utilisation des
points d’interet. Pour mieux visualiser l’impact de la taille des fenetres, on represente sur la
figure 3.22 l’evolution du gain de MAP. Pour chaque taille de fenetre, on effectue la moyenne
des valeurs obtenues pour toutes les valeurs deRQT .
Pour quelques cas (comme la classevache), l’utilisation des points d’interet est meilleure
que la grille fixe, quelle que soit la taille de la fenetre. Pour d’autres cas (comme pour la classe
avion), c’est l’inverse. Dans le cas dudrapeau americain, on observe que les resultats sont
meilleurs avec les points d’interet lorsqu’on utilise les petites fenetres (w = 8), mais globa-
lement on obtient d’excellentes performances avec les grilles pour les fenetres de tailles in-
termediaires. On peut se rendre compte sur la figure 3.23 que les points d’interet sont attires
par lesetoiles du drapeau americain et sur les bordures des objets de facon generale. En re-
vanche la grille fixe va permettre d’extraire l’informationli ee aux rayures du drapeau qui a
ete completement ignoree par les points d’interet. La grille permet ici de capturer la struc-
ture interne de l’objet. C’est un point important concernantle drapeau americain, puisqu’etant
generalement present un peu partout il est rarement identifiable grace aux informations contex-
tuelles.
Cet exemple, conjointement aux resultats obtenus precedemment, illustre bien l’avantage de
l’utilisation d’un echantillonnage regulier quand on ne dispose pas d’informationa priori sur
le contenu d’une base d’images. Nous pensons que la perte d’information est moins importante
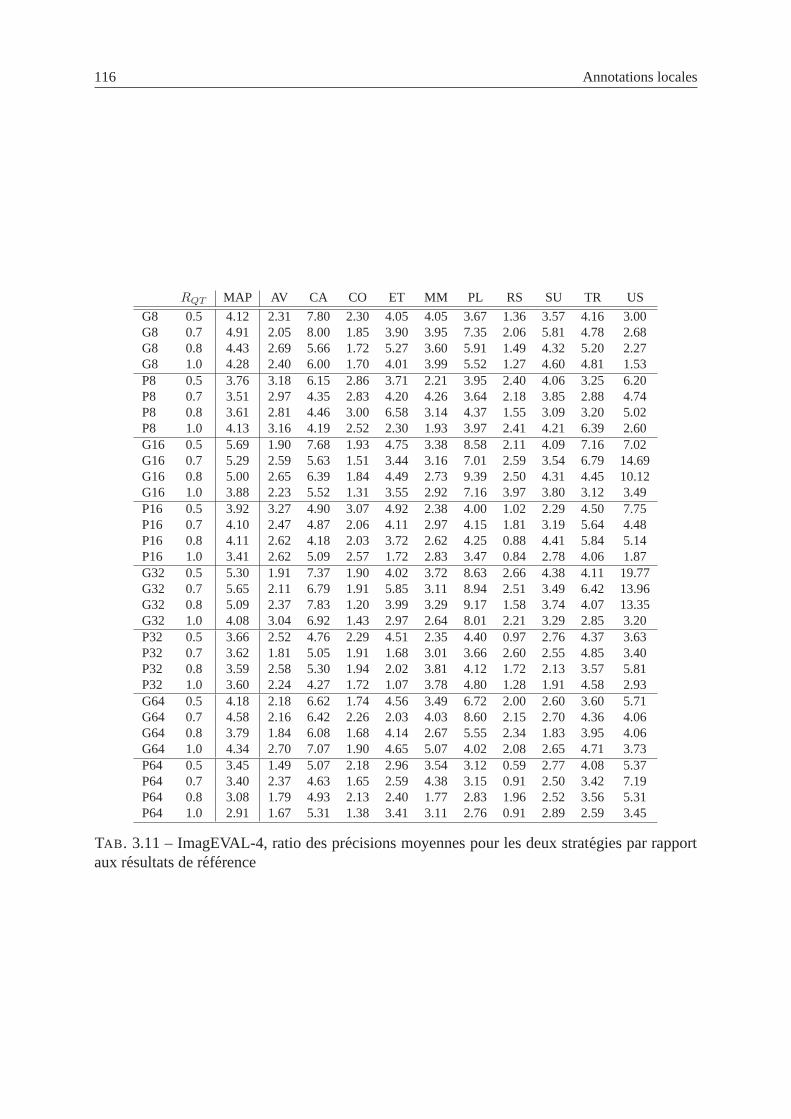
116 Annotations locales
RQT MAP AV CA CO ET MM PL RS SU TR US
G8 0.5 4.12 2.31 7.80 2.30 4.05 4.05 3.67 1.36 3.57 4.16 3.00G8 0.7 4.91 2.05 8.00 1.85 3.90 3.95 7.35 2.06 5.81 4.78 2.68G8 0.8 4.43 2.69 5.66 1.72 5.27 3.60 5.91 1.49 4.32 5.20 2.27G8 1.0 4.28 2.40 6.00 1.70 4.01 3.99 5.52 1.27 4.60 4.81 1.53P8 0.5 3.76 3.18 6.15 2.86 3.71 2.21 3.95 2.40 4.06 3.25 6.20P8 0.7 3.51 2.97 4.35 2.83 4.20 4.26 3.64 2.18 3.85 2.88 4.74P8 0.8 3.61 2.81 4.46 3.00 6.58 3.14 4.37 1.55 3.09 3.20 5.02P8 1.0 4.13 3.16 4.19 2.52 2.30 1.93 3.97 2.41 4.21 6.39 2.60G16 0.5 5.69 1.90 7.68 1.93 4.75 3.38 8.58 2.11 4.09 7.16 7.02G16 0.7 5.29 2.59 5.63 1.51 3.44 3.16 7.01 2.59 3.54 6.79 14.69G16 0.8 5.00 2.65 6.39 1.84 4.49 2.73 9.39 2.50 4.31 4.45 10.12G16 1.0 3.88 2.23 5.52 1.31 3.55 2.92 7.16 3.97 3.80 3.12 3.49P16 0.5 3.92 3.27 4.90 3.07 4.92 2.38 4.00 1.02 2.29 4.50 7.75P16 0.7 4.10 2.47 4.87 2.06 4.11 2.97 4.15 1.81 3.19 5.64 4.48P16 0.8 4.11 2.62 4.18 2.03 3.72 2.62 4.25 0.88 4.41 5.84 5.14P16 1.0 3.41 2.62 5.09 2.57 1.72 2.83 3.47 0.84 2.78 4.06 1.87G32 0.5 5.30 1.91 7.37 1.90 4.02 3.72 8.63 2.66 4.38 4.11 19.77G32 0.7 5.65 2.11 6.79 1.91 5.85 3.11 8.94 2.51 3.49 6.42 13.96G32 0.8 5.09 2.37 7.83 1.20 3.99 3.29 9.17 1.58 3.74 4.07 13.35G32 1.0 4.08 3.04 6.92 1.43 2.97 2.64 8.01 2.21 3.29 2.85 3.20P32 0.5 3.66 2.52 4.76 2.29 4.51 2.35 4.40 0.97 2.76 4.37 3.63P32 0.7 3.62 1.81 5.05 1.91 1.68 3.01 3.66 2.60 2.55 4.85 3.40P32 0.8 3.59 2.58 5.30 1.94 2.02 3.81 4.12 1.72 2.13 3.57 5.81P32 1.0 3.60 2.24 4.27 1.72 1.07 3.78 4.80 1.28 1.91 4.58 2.93G64 0.5 4.18 2.18 6.62 1.74 4.56 3.49 6.72 2.00 2.60 3.60 5.71G64 0.7 4.58 2.16 6.42 2.26 2.03 4.03 8.60 2.15 2.70 4.36 4.06G64 0.8 3.79 1.84 6.08 1.68 4.14 2.67 5.55 2.34 1.83 3.95 4.06G64 1.0 4.34 2.70 7.07 1.90 4.65 5.07 4.02 2.08 2.65 4.71 3.73P64 0.5 3.45 1.49 5.07 2.18 2.96 3.54 3.12 0.59 2.77 4.08 5.37P64 0.7 3.40 2.37 4.63 1.65 2.59 4.38 3.15 0.91 2.50 3.42 7.19P64 0.8 3.08 1.79 4.93 2.13 2.40 1.77 2.83 1.96 2.52 3.56 5.31P64 1.0 2.91 1.67 5.31 1.38 3.41 3.11 2.76 0.91 2.89 2.59 3.45
TAB . 3.11 – ImagEVAL-4, ratio des precisions moyennes pour les deux strategies par rapportaux resultats de reference
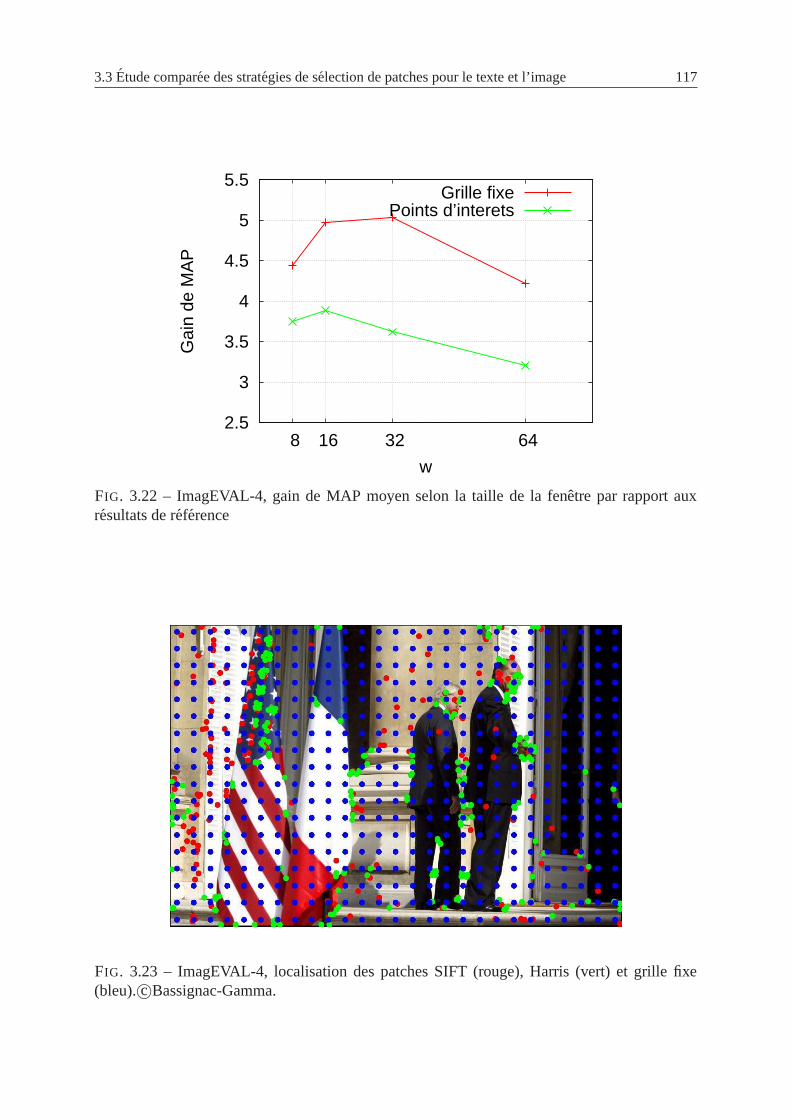
3.3Etude comparee des strategies de selection de patches pour le texte et l’image 117
2.5
3
3.5
4
4.5
5
5.5
8 16 32 64
Gai
n de
MA
P
w
Grille fixePoints d’interets
FIG. 3.22 – ImagEVAL-4, gain de MAP moyen selon la taille de la fenetre par rapport auxresultats de reference
FIG. 3.23 – ImagEVAL-4, localisation des patches SIFT (rouge),Harris (vert) et grille fixe(bleu).c©Bassignac-Gamma.

118 Annotations locales
avec ce type d’extraction de patches et qu’en consequence il doitetre prefere a l’utilisation
de detecteurs de points d’interets. De plus, les informations structurelles et contextuelles sont
mieux preservees, ce qui est important dans le cadre de l’annotation d’images. Ces resultats
confirment les observations d’autres travaux de recherche [JT05, NJT06].
3.4 Paires de mots visuels pour la representation des images
3.4.1 Motivations
La notion de sac de mots visuels est assez parlante. Les images sont representees par des
collections non-ordonnees de mots visuels. Gracea cette representation, il est aise d’obtenir une
signature globale decrivant chaque image et permettant de les comparer entre elles. La nature
non-ordonnee de cette representation est une de ces principales caracteristiques. La position
spatiale des mots dans l’image, qu’elle soit relative ou absolue, n’est pas utilisee. D’un cote
ce choix apporte de la flexibilite et de la robustessea la representation puisque cela la rend
plus aptea gerer les problemes de changement de point de vue ou d’occlusion. En revanche,
les informations spatiales sont parfois importantes et peuvent grandement aidera la reconnais-
sance des objets. La localisation absolue des mots visuels permettra, par exemple, d’identifier
plus facilement le ciel qui est generalement en haut dans une photo ou une pelouse, plus sou-
vent en bas. La localisation relative des mots visuels porteencore plus d’information. Situer
ces mots les uns par rapport aux autres permet de tenir comptedes relations spatiales que les
objets entretiennent entre eux. On pourra ainsi modeliser des informations structurelles (une
voiture est composee d’une carosserie, de vitres et de roues) et des informations contextuelles
(generalement une voiture est sur du bitume). Dans le cadre d’uneapproche generique de l’an-
notation automatique, l’utilisation des relations spatiales doit doncetre envisagee, mais de facon
legere pouretre benefique et ne pas conduirea la construction de modeles trop rigides.
Plusieurs travaux ont deja ete realises sur l’utilisation de l’information geometrique dans
le cadre de l’annotation automatique. Agarwalet al. [AAR04] propose une approche en deux
etapes. Dans un premier temps des parties d’objets sont detectees dans les imagesa l’aide d’un
dictionnaire prealablementetabli. Ensuite, pour les quelques parties qui aurontete detectees,
leurs relations spatiales sont decritesa l’aide d’une quantification de leur orientation et de leurs
distances relatives. La signature finale des images est un vecteur de caracteristiques compose de
deux parties : d’une part les occurrences des parties, d’autre part leurs relations. Amoreset al.
[ASR05] propose de generaliser le descripteurcorrelogrammeen englobanta la fois l’informa-
tion locale et contextuelle. Il montre que l’utilisation simultanee des deux types d’information
est efficace et plus rapide.

3.4 Paires de mots visuels pour la representation des images 119
Dans les images naturelles, les objets sont la plupart du temps presents dans un environ-
nement auquel ils sont lies. Nous avons vu que l’information contextuelle est d’une grande
importance pour detecter la presence de ces objets. La representation globale des images four-
nie par les sacs de mots visuels permet deja d’englober des informations sur les objets et leur
contexte. Nous souhaitons toutefois avoir une descriptionplus precise des relations entre les
mots visuels. Comme precise dans [AAR04], ces relations peuvent encoder la structure interne
d’objets complexes. Nous pensons que ce type d’informationdoit etre incorporee directement
dans la description et traitee au meme niveau que les signatures visuelles. C’est ce qui est fait
dans [ASR05], mais nous trouvons l’encodage spatial trop restrictif et preferons utiliser une
approche moins complexe. Nous choisissons d’utiliser la cooccurrence des mots dans un voi-
sinage predefini de chacun d’entre eux. Ainsi, nous considerons uniquement la distance entre
deux mots, quelle que soit leur orientation relative. La notion de paires de mots visuels est in-
troduite par Sivicet al. [SRE+05] qu’il appelledoublets. Elles encodent les patches localement
cooccurrents. Les paires sont utilisees pour affiner la localisation d’objets dans les images. Les
resultats obtenus tendenta indiquer que cette approche est pertinente et permet de se focaliser
davantage sur les objets. Nous proposons d’utiliser une representation similaire dans le cadre
de l’annotation automatique. Dans [WY08], des paires de patches sontegalement considerees
pour l’annotation semi-automatique, mais il s’agit d’apparier les images deuxa deux et non de
considerer les pairesa l’interieur d’une meme image. Dans [TCG08] un modele n-gram ins-
pire par les approches textes est explique. La cooccurrence de patches est incorporee dans un
algorithme de boosting par Mitaet al. [MKSH08].
3.4.2 Extraction des paires
L’extraction des paires est une nouvelleetape dans le cadre de la representation par sac de
mots visuels. Elle intervient une fois que les patches visuels ont ete extraits, decrits avec des
signatures bas-niveau, le vocabulaire cree et les images quantifiees. A ce stade chaque image
est donc representee par un sac de mots. Nous appeleronsvocabulaire de basece premier voca-
bulaire.
Une methode simple pour representer les paires de mots est de constituer un autre vocabu-
laire contenant l’ensemble de toutes les paires de mots issus du vocabulaire de base [HB09a].
Nous appelleronsvocabulaire de pairesce second vocabulaire. Ainsi pour un vocabulaire de
base ayantn mots, le vocabulaire de paires contiendran(n + 1)/2 elements. La notion de
voisinage doitetre definie. Nous choisissons une approche simple consistanta fixer un rayon
comme parametre de l’algorithme. Ainsi lors du calcul de la signature globale, seules les paires
dont la distance entre les mots est inferieurea ce rayon seront considerees. Les autres seront
simplement ignorees. On peut voir un exemple sur le schema 3.24. Les carres se recouvrant par-
tiellement representent des patches visuels (ici, en l’occurrence, extraits selon une grille fixe).

120 Annotations locales
FIG. 3.24 – Schema illustrant le principe des paires de mots visuels.
Pour un certain rayon, represente par le cercle, les 12 paires contenant le patch central sont
indiquees. Contrairementa [SRE+05], nous conservons tous les mots du vocabulaire de base
pour construire les paires. Les signatures ainsi obtenues sont tres creuses.
3.4.3 Experimentations sur Pascal VOC 2007
Le but de cette experience n’est pas d’obtenir des scores au niveau de l’etat-de-l’art mais
d’illustrer l’apport de l’utilisation des paires de mots dans un contexte standard. Nous preferons
conserver une approche simple n’impliquant qu’un seul choix a chaqueetape de la chaıne de
traitement. L’apport d’une nouvelle brique dans ce processus est ainsi plus facilement mis en
avant. En effet, actuellement les meilleures approches dans les campagnes d’evaluation sont
complexes et combinent souvent plusieurs strategies d’echantillonnage de patches, de descrip-
teurs bas-niveau, de creation de vocabulaire et d’apprentissage. C’est notamment le cas pour la
base PASCAL VOC 2007 [EGW+] sur laquelle nous faisons ce test.
Extraction et description des patches.
La premiere tache consistea extraire des patches visuels de l’image. Comme nous l’avons
vu precedemment, unechantillonnage regulier est preferable. Nous choisissons donc d’extraire
environ 1 000 patches par image selon une grille fixea une seuleechelle. Les patches sont des
carres de 16x16 pixels. Nous decrivons ensuite ces patches avec des signatures de textureet de
forme. Nous laissons de cote l’information couleur pour ce test. Les informations de textures
sont extraites avec un histogramme Fourier de 16 dimensions(version modifiee, voir section

3.4 Paires de mots visuels pour la representation des images 121
2.4.2). Les informations de forme sont quanta elle capturees par un histogramme d’orienta-
tion des gradients classique (EOH) [JV96]. Ces deux descripteurs sont sensiblesa la rotation.
La signature finale est donc un vecteur de 32 dimensions. On utilise la distanceL1 pour les
comparer.
Vocabulaire et sac de mots visuels.
Nous utilisons la base d’apprentissage pour construire notre vocabulaire visuel. Environ
4.8 millions de patches ontete extraits. Nous utilisons K-means pour faire le partitionnement.
Puisque la taille du vocabulaire est un parametre tres important, nous avons fait varier cette
taille et reportons les differents resultats obtenus. Une fois le vocabulaire de base obtenu, nous
l’utilisons pour quantifier les images. Nous utilisons un histogramme normalise comptant les
occurrences de chaque mot dans une image comme signature globale.
Strategie d’apprentissage.
Nous utilisons une SVMa marge souple avec un noyau triangulaire. Nous choisissonsla
configuration un-contre-tous et entrainons donc une SVM parconcept visuel. Le jeu de donnees
etant fortement desequilibre, nous ponderons les donnees d’apprentissage pour faire en sorte
que le poids global des exemples positifs et negatifs soitequivalent. De plus, comme nous
l’avons remarque lors de precedentes experiences, le coefficient de relaxation de la SVM est
pratiquement toujours optimise a la meme valeur, aussi nous choisissons de le fixera 1. Ainsi,
aucune phase d’optimisation n’est necessaire et l’apprentissage est reellement rapide.
3.4.4 Resultats et discussion
Approche standard
Pour chaque concept, le nombre d’images est tres different. Afin d’avoir une premiere idee
de la difficulte de la tache, nous calculons la MAP pour un classement aleatoire de la base.
Nous obtenons 0.0133. Nous avonsegalementevalue les deux descripteurs bas-niveau, cal-
cules globalement sur l’image, en utilisant la meme strategie d’apprentissage. Ceci est un bon
moyen d’avoir des resultats de reference puisque nous aurons ainsi de bonnes indications sur
l’importance de l’information contextuelle et sur la capacite des descripteursa extraire cette
information. Nous obtenons une MAP de 0.2271. Nous reportons sur la figure 3.25 les MAP
obtenues pour la representation par sac de mots visuels standard. Nous voyons unecourbe ayant
une forme classique. Elle croıt rapidement pour les vocabulaires de petite et moyenne taille et
atteint un maximum de 0.3489 pour 3200 mots. Ensuite elle decroıt lentement alors que le vo-
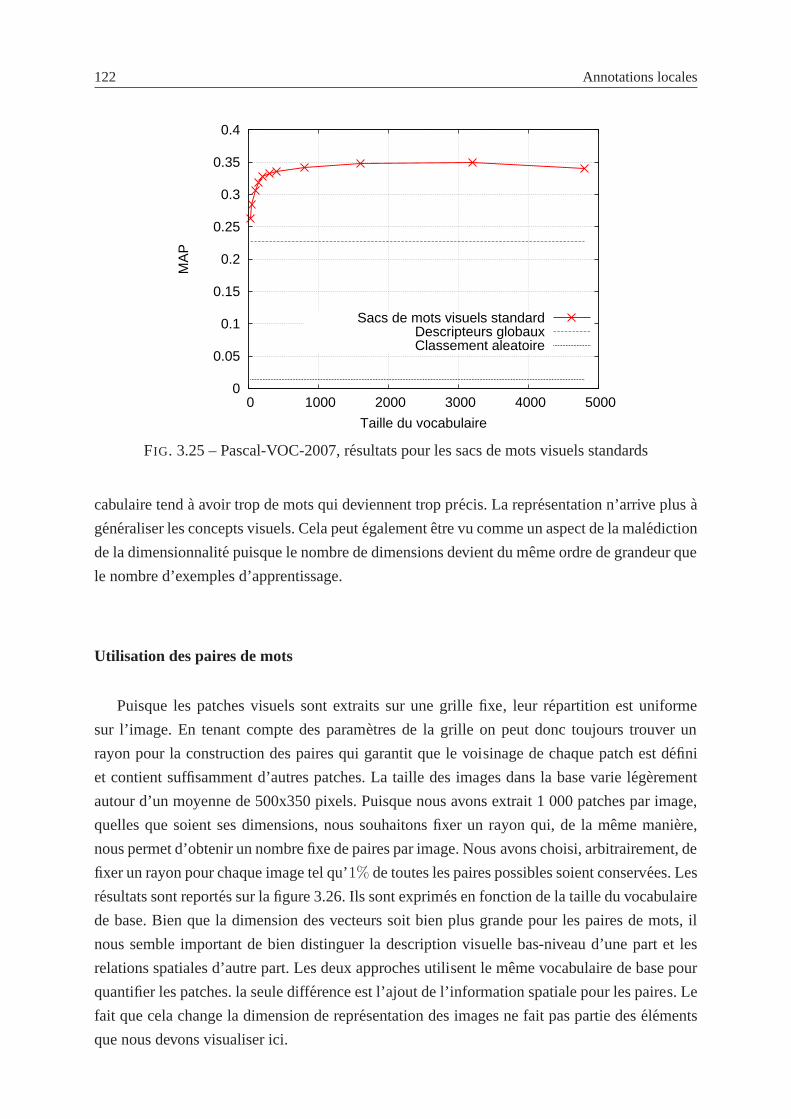
122 Annotations locales
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0 1000 2000 3000 4000 5000
MA
P
Taille du vocabulaire
Sacs de mots visuels standardDescripteurs globauxClassement aleatoire
FIG. 3.25 – Pascal-VOC-2007, resultats pour les sacs de mots visuels standards
cabulaire tenda avoir trop de mots qui deviennent trop precis. La representation n’arrive plusa
generaliser les concepts visuels. Cela peutegalementetre vu comme un aspect de la malediction
de la dimensionnalite puisque le nombre de dimensions devient du meme ordre de grandeur que
le nombre d’exemples d’apprentissage.
Utilisation des paires de mots
Puisque les patches visuels sont extraits sur une grille fixe, leur repartition est uniforme
sur l’image. En tenant compte des parametres de la grille on peut donc toujours trouver un
rayon pour la construction des paires qui garantit que le voisinage de chaque patch est defini
et contient suffisamment d’autres patches. La taille des images dans la base varie legerement
autour d’un moyenne de 500x350 pixels. Puisque nous avons extrait 1 000 patches par image,
quelles que soient ses dimensions, nous souhaitons fixer un rayon qui, de la meme maniere,
nous permet d’obtenir un nombre fixe de paires par image. Nousavons choisi, arbitrairement, de
fixer un rayon pour chaque image tel qu’1% de toutes les paires possibles soient conservees. Les
resultats sont reportes sur la figure 3.26. Ils sont exprimes en fonction de la taille du vocabulaire
de base. Bien que la dimension des vecteurs soit bien plus grande pour les paires de mots, il
nous semble important de bien distinguer la description visuelle bas-niveau d’une part et les
relations spatiales d’autre part. Les deux approches utilisent le meme vocabulaire de base pour
quantifier les patches. la seule difference est l’ajout de l’information spatiale pour les paires. Le
fait que cela change la dimension de representation des images ne fait pas partie deselements
que nous devons visualiser ici.
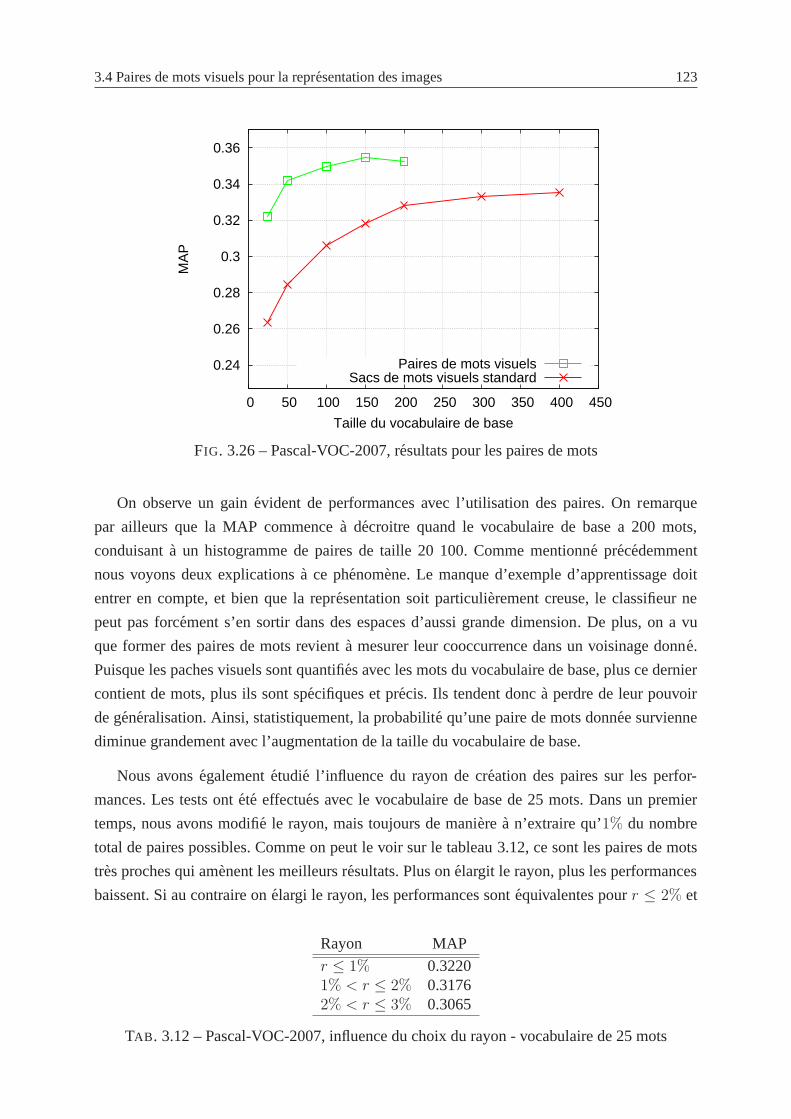
3.4 Paires de mots visuels pour la representation des images 123
0.24
0.26
0.28
0.3
0.32
0.34
0.36
0 50 100 150 200 250 300 350 400 450
MA
P
Taille du vocabulaire de base
Paires de mots visuelsSacs de mots visuels standard
FIG. 3.26 – Pascal-VOC-2007, resultats pour les paires de mots
On observe un gainevident de performances avec l’utilisation des paires. On remarque
par ailleurs que la MAP commencea decroitre quand le vocabulaire de base a 200 mots,
conduisanta un histogramme de paires de taille 20 100. Comme mentionne precedemment
nous voyons deux explicationsa ce phenomene. Le manque d’exemple d’apprentissage doit
entrer en compte, et bien que la representation soit particulierement creuse, le classifieur ne
peut pas forcement s’en sortir dans des espaces d’aussi grande dimension. De plus, on a vu
que former des paires de mots revienta mesurer leur cooccurrence dans un voisinage donne.
Puisque les paches visuels sont quantifies avec les mots du vocabulaire de base, plus ce dernier
contient de mots, plus ils sont specifiques et precis. Ils tendent donca perdre de leur pouvoir
de generalisation. Ainsi, statistiquement, la probabilite qu’une paire de mots donnee survienne
diminue grandement avec l’augmentation de la taille du vocabulaire de base.
Nous avonsegalementetudie l’influence du rayon de creation des paires sur les perfor-
mances. Les tests ontete effectues avec le vocabulaire de base de 25 mots. Dans un premier
temps, nous avons modifie le rayon, mais toujours de manierea n’extraire qu’1% du nombre
total de paires possibles. Comme on peut le voir sur le tableau3.12, ce sont les paires de mots
tres proches qui amenent les meilleurs resultats. Plus onelargit le rayon, plus les performances
baissent. Si au contraire onelargi le rayon, les performances sontequivalentes pourr ≤ 2% et
Rayon MAP
r ≤ 1% 0.32201% < r ≤ 2% 0.31762% < r ≤ 3% 0.3065
TAB . 3.12 – Pascal-VOC-2007, influence du choix du rayon - vocabulaire de 25 mots
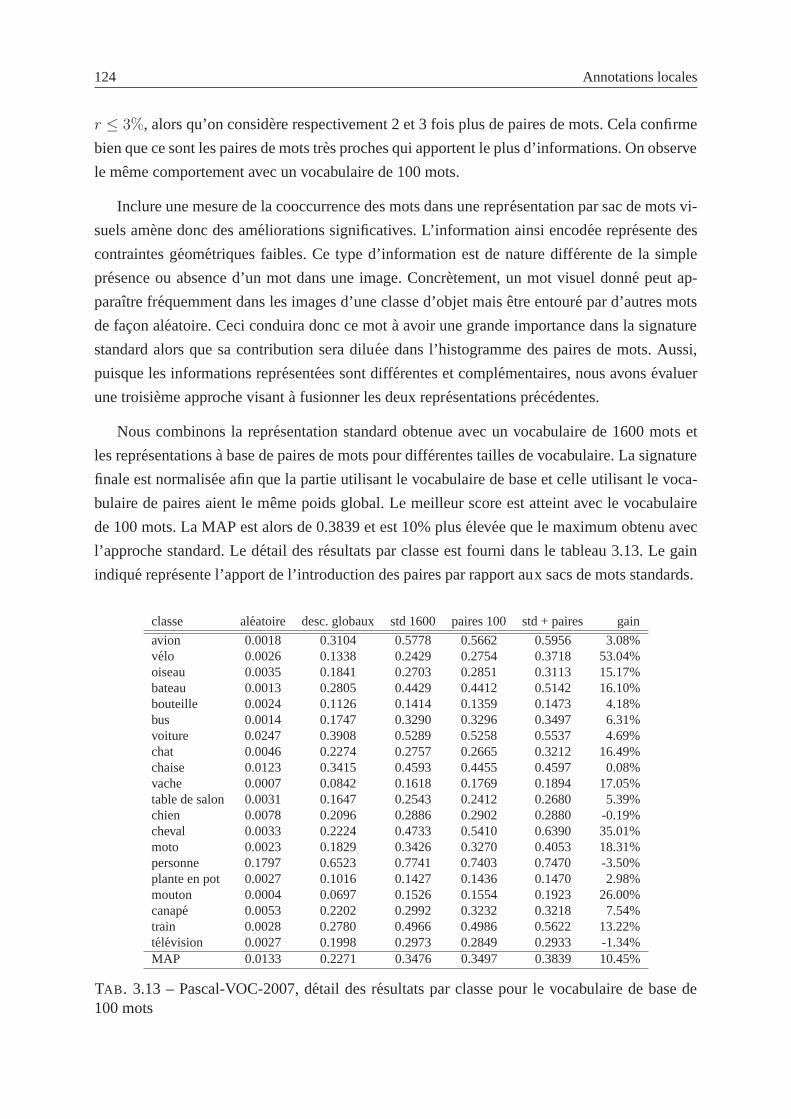
124 Annotations locales
r ≤ 3%, alors qu’on considere respectivement 2 et 3 fois plus de paires de mots. Cela confirme
bien que ce sont les paires de mots tres proches qui apportent le plus d’informations. On observe
le meme comportement avec un vocabulaire de 100 mots.
Inclure une mesure de la cooccurrence des mots dans une representation par sac de mots vi-
suels amene donc des ameliorations significatives. L’information ainsi encodee represente des
contraintes geometriques faibles. Ce type d’information est de nature differente de la simple
presence ou absence d’un mot dans une image. Concretement, un mot visuel donne peut ap-
paraıtre frequemment dans les images d’une classe d’objet maisetre entoure par d’autres mots
de facon aleatoire. Ceci conduira donc ce mota avoir une grande importance dans la signature
standard alors que sa contribution sera diluee dans l’histogramme des paires de mots. Aussi,
puisque les informations representees sont differentes et complementaires, nous avonsevaluer
une troisieme approche visanta fusionner les deux representations precedentes.
Nous combinons la representation standard obtenue avec un vocabulaire de 1600 mots et
les representationsa base de paires de mots pour differentes tailles de vocabulaire. La signature
finale est normalisee afin que la partie utilisant le vocabulaire de base et celleutilisant le voca-
bulaire de paires aient le meme poids global. Le meilleur score est atteint avec le vocabulaire
de 100 mots. La MAP est alors de 0.3839 et est 10% pluselevee que le maximum obtenu avec
l’approche standard. Le detail des resultats par classe est fourni dans le tableau 3.13. Le gain
indique represente l’apport de l’introduction des paires par rapport aux sacs de mots standards.
classe aleatoire desc. globaux std 1600 paires 100 std + paires gain
avion 0.0018 0.3104 0.5778 0.5662 0.5956 3.08%velo 0.0026 0.1338 0.2429 0.2754 0.3718 53.04%oiseau 0.0035 0.1841 0.2703 0.2851 0.3113 15.17%bateau 0.0013 0.2805 0.4429 0.4412 0.5142 16.10%bouteille 0.0024 0.1126 0.1414 0.1359 0.1473 4.18%bus 0.0014 0.1747 0.3290 0.3296 0.3497 6.31%voiture 0.0247 0.3908 0.5289 0.5258 0.5537 4.69%chat 0.0046 0.2274 0.2757 0.2665 0.3212 16.49%chaise 0.0123 0.3415 0.4593 0.4455 0.4597 0.08%vache 0.0007 0.0842 0.1618 0.1769 0.1894 17.05%table de salon 0.0031 0.1647 0.2543 0.2412 0.2680 5.39%chien 0.0078 0.2096 0.2886 0.2902 0.2880 -0.19%cheval 0.0033 0.2224 0.4733 0.5410 0.6390 35.01%moto 0.0023 0.1829 0.3426 0.3270 0.4053 18.31%personne 0.1797 0.6523 0.7741 0.7403 0.7470 -3.50%plante en pot 0.0027 0.1016 0.1427 0.1436 0.1470 2.98%mouton 0.0004 0.0697 0.1526 0.1554 0.1923 26.00%canape 0.0053 0.2202 0.2992 0.3232 0.3218 7.54%train 0.0028 0.2780 0.4966 0.4986 0.5622 13.22%television 0.0027 0.1998 0.2973 0.2849 0.2933 -1.34%MAP 0.0133 0.2271 0.3476 0.3497 0.3839 10.45%
TAB . 3.13 – Pascal-VOC-2007, detail des resultats par classe pour le vocabulaire de base de100 mots
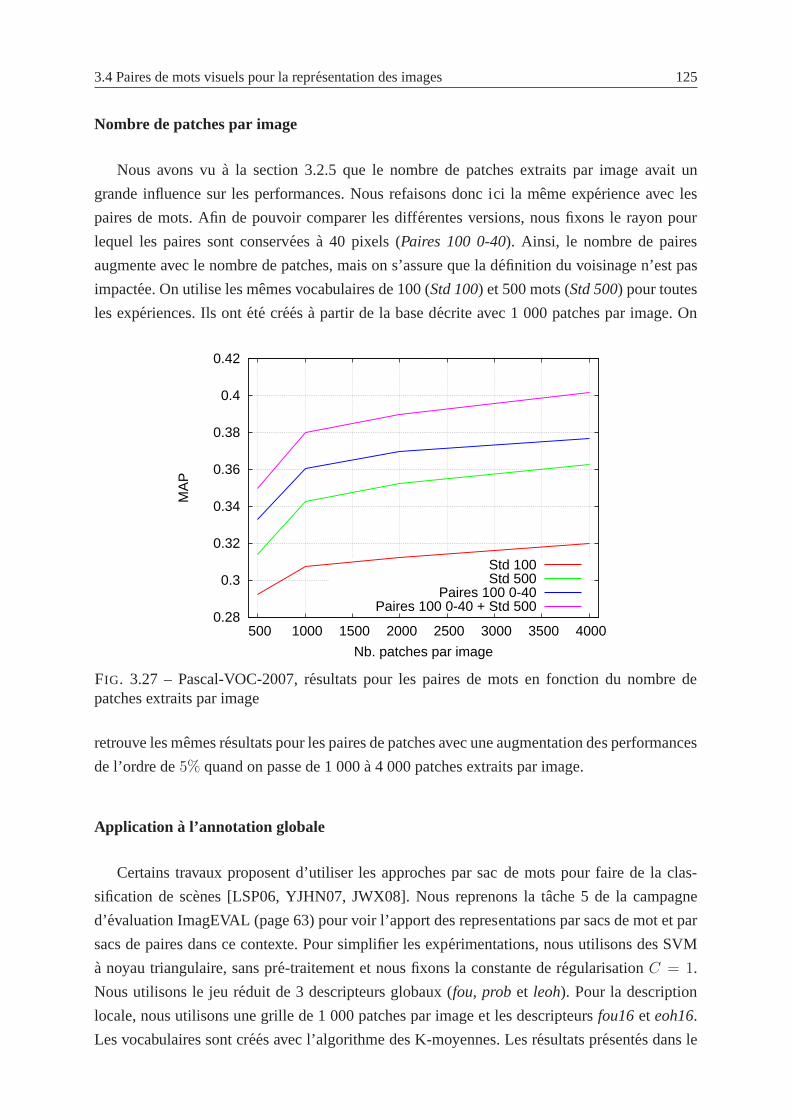
3.4 Paires de mots visuels pour la representation des images 125
Nombre de patches par image
Nous avons vua la section 3.2.5 que le nombre de patches extraits par imageavait un
grande influence sur les performances. Nous refaisons donc ici la meme experience avec les
paires de mots. Afin de pouvoir comparer les differentes versions, nous fixons le rayon pour
lequel les paires sont conserveesa 40 pixels (Paires 100 0-40). Ainsi, le nombre de paires
augmente avec le nombre de patches, mais on s’assure que la definition du voisinage n’est pas
impactee. On utilise les memes vocabulaires de 100 (Std 100) et 500 mots (Std 500) pour toutes
les experiences. Ils ontete creesa partir de la base decrite avec 1 000 patches par image. On
0.28
0.3
0.32
0.34
0.36
0.38
0.4
0.42
500 1000 1500 2000 2500 3000 3500 4000
MA
P
Nb. patches par image
Std 100Std 500
Paires 100 0-40Paires 100 0-40 + Std 500
FIG. 3.27 – Pascal-VOC-2007, resultats pour les paires de mots en fonction du nombre depatches extraits par image
retrouve les memes resultats pour les paires de patches avec une augmentation des performances
de l’ordre de5% quand on passe de 1 000a 4 000 patches extraits par image.
Application a l’annotation globale
Certains travaux proposent d’utiliser les approches par sacde mots pour faire de la clas-
sification de scenes [LSP06, YJHN07, JWX08]. Nous reprenons la tache 5 de la campagne
d’evaluation ImagEVAL (page 63) pour voir l’apport des representations par sacs de mot et par
sacs de paires dans ce contexte. Pour simplifier les experimentations, nous utilisons des SVM
a noyau triangulaire, sans pre-traitement et nous fixons la constante de regularisationC = 1.
Nous utilisons le jeu reduit de 3 descripteurs globaux (fou, prob et leoh). Pour la description
locale, nous utilisons une grille de 1 000 patches par image et les descripteursfou16et eoh16.
Les vocabulaires sont crees avec l’algorithme des K-moyennes. Les resultats presentes dans le
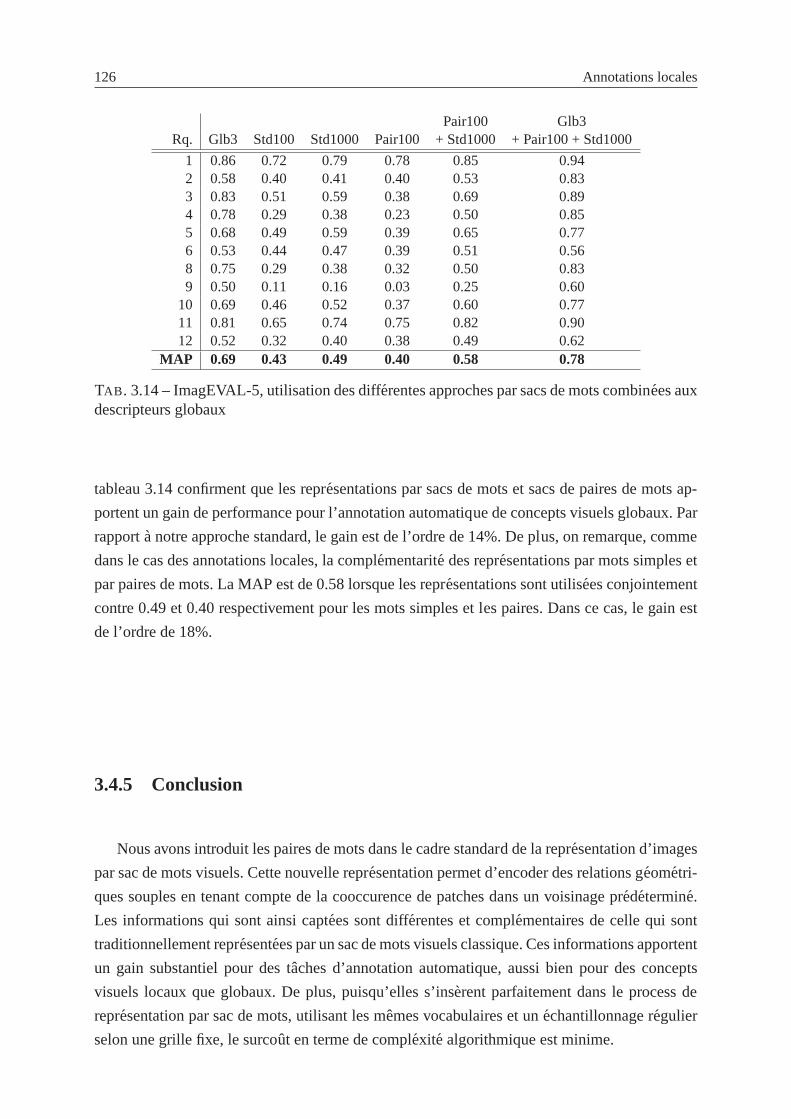
126 Annotations locales
Pair100 Glb3Rq. Glb3 Std100 Std1000 Pair100 + Std1000 + Pair100 + Std1000
1 0.86 0.72 0.79 0.78 0.85 0.942 0.58 0.40 0.41 0.40 0.53 0.833 0.83 0.51 0.59 0.38 0.69 0.894 0.78 0.29 0.38 0.23 0.50 0.855 0.68 0.49 0.59 0.39 0.65 0.776 0.53 0.44 0.47 0.39 0.51 0.568 0.75 0.29 0.38 0.32 0.50 0.839 0.50 0.11 0.16 0.03 0.25 0.60
10 0.69 0.46 0.52 0.37 0.60 0.7711 0.81 0.65 0.74 0.75 0.82 0.9012 0.52 0.32 0.40 0.38 0.49 0.62
MAP 0.69 0.43 0.49 0.40 0.58 0.78
TAB . 3.14 – ImagEVAL-5, utilisation des differentes approches par sacs de mots combinees auxdescripteurs globaux
tableau 3.14 confirment que les representations par sacs de mots et sacs de paires de mots ap-
portent un gain de performance pour l’annotation automatique de concepts visuels globaux. Par
rapporta notre approche standard, le gain est de l’ordre de 14%. De plus, on remarque, comme
dans le cas des annotations locales, la complementarite des representations par mots simples et
par paires de mots. La MAP est de 0.58 lorsque les representations sont utilisees conjointement
contre 0.49 et 0.40 respectivement pour les mots simples et les paires. Dans ce cas, le gain est
de l’ordre de 18%.
3.4.5 Conclusion
Nous avons introduit les paires de mots dans le cadre standard de la representation d’images
par sac de mots visuels. Cette nouvelle representation permet d’encoder des relations geometri-
ques souples en tenant compte de la cooccurence de patches dans un voisinage predetermine.
Les informations qui sont ainsi captees sont differentes et complementaires de celle qui sont
traditionnellement representees par un sac de mots visuels classique. Ces informations apportent
un gain substantiel pour des taches d’annotation automatique, aussi bien pour des concepts
visuels locaux que globaux. De plus, puisqu’elles s’inserent parfaitement dans le process de
representation par sac de mots, utilisant les memes vocabulaires et unechantillonnage regulier
selon une grille fixe, le surcout en terme de complexite algorithmique est minime.

3.5 Boucles de pertinence avec des representations par sacs de mots 127
3.5 Boucles de pertinence avec des representations par sacs
de mots
3.5.1 Motivations
La mise en place d’un processus d’annotation automatique necessite l’apprentissage de
modeles pour les differents concepts visuels, et donc, l’existence d’une base d’apprentissage.
Nous avons vu que la qualite des annotations et leur pertinenceetait souvent sujettesa caution
dans les bases existantes. C’est, par exemple, ce qui a conduit les organisateurs de la campagne
d’evaluation ImagEVALa faire appela des professionnels pour constituer une base correcte-
ment annotee. Ce travail aete fait entierement manuellement et a necessite beaucoup de temps.
Il est cependant possible d’assister l’utilisateur dans cette tache. Les moteurs de recherche
peuvent integrer des modules d’interrogation avec boucles de pertinence [LHZ+00]. Dans ce
cas, la session de recherche d’images est divisee en plusieursetapes successives lors desquelles
l’utilisateur fournit des indications au systeme quanta la pertinence des resultats retournes. Ty-
piquement,a chaqueetape une liste d’images est presenteea l’utilisateur et ce dernier indique
celles qui sont pertinentes par rapport au concept visuel qu’il cherche et celles qui ne le sont pas.
Au fur et a mesure des iterations, le systeme apprend ce que cherche l’utilisateur et le guide vers
les images correspondantes. Nous distinguons trois utilisations potentielles faisant intervenir le
mecanisme de boucles de pertinence.
1. Un utilisateur souhaite retrouver une image particuliere (paradigme de requete par image
mentale), il utilise alors les boucles de pertinence et s’arrete lorsque la cible est affichee
par le systeme.
2. Un iconographe souhaite annoter une base d’images avec unnouveau concept visuel.
Plutot que d’examiner l’ensemble de la base, il utilise le bouclage de pertinence pour
mieux cibler les images pertinentes.
3. En vue de la creation d’un nouveau modele de concept visuel pour l’annotation automa-
tique, un ingenieur selectionne des images pertinentes et non-pertinentes afin d’alimenter
un algorithme d’apprentissage.
Nous nous interessons ici aux deux derniers scenarii. On les regroupe sous l’appellation
d’annotation semi-automatique. Ils peuvent sembler relativement proches puisque l’utilisation
du bouclage de pertinence doit permettre, dans les deux cas,d’accelerer le travail et d’eviter
d’avoir a analyser l’ensemble des images d’une base. Toutefois, lesfinalites ne sont pas iden-
tiques et vont donc conduirea des criteres d’evaluation differents. Le but de l’iconographe est
de trouver l’ensemble des images contenant le concept visuel le plus rapidement possible. Le
but de l’ingenieur est de produire un modele ayant de bonnes performances en annotation auto-
matique.
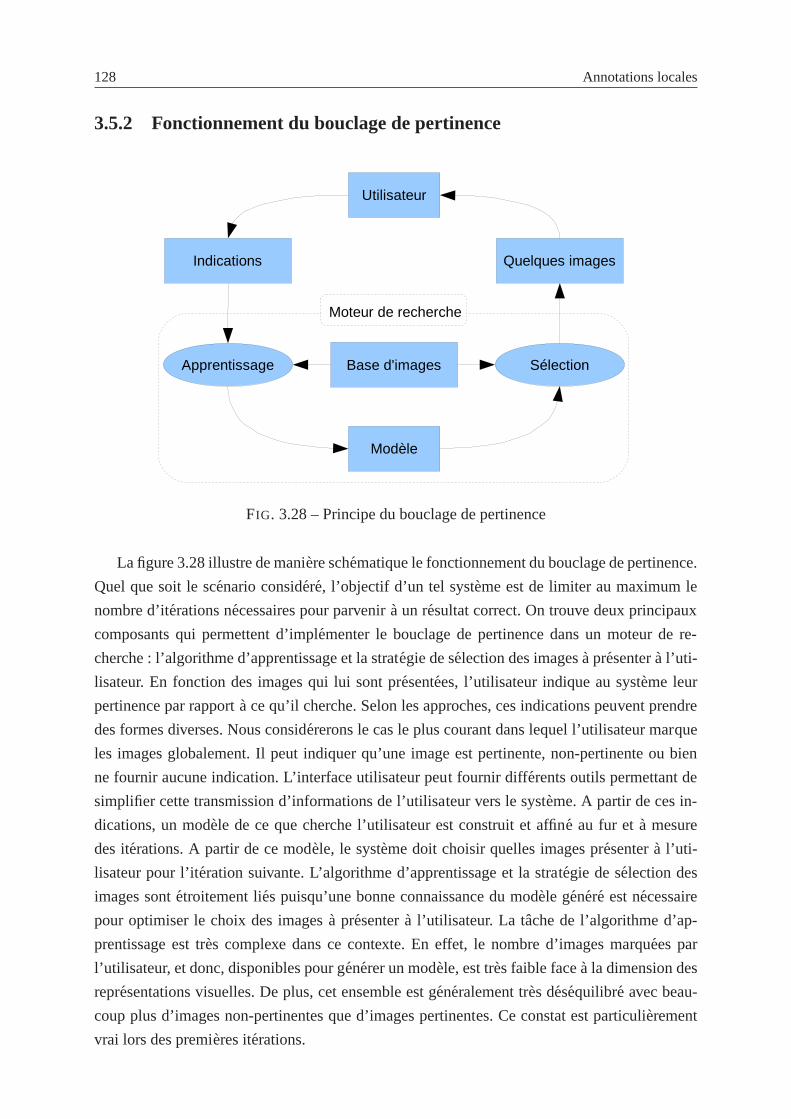
128 Annotations locales
3.5.2 Fonctionnement du bouclage de pertinence
FIG. 3.28 – Principe du bouclage de pertinence
La figure 3.28 illustre de maniere schematique le fonctionnement du bouclage de pertinence.
Quel que soit le scenario considere, l’objectif d’un tel systeme est de limiter au maximum le
nombre d’iterations necessaires pour parvenira un resultat correct. On trouve deux principaux
composants qui permettent d’implementer le bouclage de pertinence dans un moteur de re-
cherche : l’algorithme d’apprentissage et la strategie de selection des imagesa presentera l’uti-
lisateur. En fonction des images qui lui sont presentees, l’utilisateur indique au systeme leur
pertinence par rapporta ce qu’il cherche. Selon les approches, ces indications peuvent prendre
des formes diverses. Nous considererons le cas le plus courant dans lequel l’utilisateur marque
les images globalement. Il peut indiquer qu’une image est pertinente, non-pertinente ou bien
ne fournir aucune indication. L’interface utilisateur peut fournir differents outils permettant de
simplifier cette transmission d’informations de l’utilisateur vers le systeme. A partir de ces in-
dications, un modele de ce que cherche l’utilisateur est construit et affine au fur eta mesure
des iterations. A partir de ce modele, le systeme doit choisir quelles images presentera l’uti-
lisateur pour l’iteration suivante. L’algorithme d’apprentissage et la strategie de selection des
images sontetroitement lies puisqu’une bonne connaissance du modele genere est necessaire
pour optimiser le choix des imagesa presentera l’utilisateur. La tache de l’algorithme d’ap-
prentissage est tres complexe dans ce contexte. En effet, le nombre d’images marquees par
l’utilisateur, et donc, disponibles pour generer un modele, est tres faible facea la dimension des
representations visuelles. De plus, cet ensemble est generalement tres desequilibre avec beau-
coup plus d’images non-pertinentes que d’images pertinentes. Ce constat est particulierement
vrai lors des premieres iterations.

3.5 Boucles de pertinence avec des representations par sacs de mots 129
Dans la continuite de nos travaux sur l’annotation automatique, nousetudions le bouclage
de pertinence base sur des SVM utilisant un noyau triangulaire. De nombreux travaux ont deja
ete menes sur cette approche [HTH00, TC01]. Plus precisement, nous poursuivons les travaux
de Ferecatu [Fer05]. A chaque iteration, un SVM est entraine a partir des images qui ontete
marquees par l’utilisateur. Le modele ainsi genere est utilise sur le reste de la base pour fournir
un score de confiance pour chaque image. Une strategie classique est alors de presentera chaque
iteration les images jugees les plus pertinentes par ce modele. Cette strategie est appelee MP
(most pertinent). Une autre strategie consistea se focaliser sur les images les plus ambigues.
Cette idee est introduite dans [TK00, CCS00] et est souvent referencee sous l’appellation d’ap-
prentissage actif (active learning) [CG08]. Le SVM doit trouver la meilleure frontiere permet-
tant de separer les images pertinentes et non-pertinentes. Pour affiner au mieux cette frontiere,
cette strategie va proposera l’utilisateur les images qui sont les plus proches de la frontiere et
permettre ainsi de lever plus rapidement les ambiguites. Cette strategie est appelee MA (most
ambiguous). Un inconvenient de cette strategie est qu’elle propose souvent des images tres
similairesa l’utilisateur. Cette redondance fait que le systeme ne se concentre que sur une pe-
tite partie de l’espace visuel et ne cherchea optimiser la frontiere qu’a un endroit precis. Il faut
donc plus d’iterations pour optimiser completement le modele. Pour lever ce probleme, Ferecatu
propose l’introduction d’une condition d’orthogonalite sur les images presenteesa l’utilisateur
[FCB04]. La consequence est d’imposer que les images selectionnees, en plus d’etre proches de
la frontiere, soient les pluseloignees les unes des autres. Cette strategie est appelee MAO (most
ambiguous and orthogonal). Ferecatu montreegalement que l’utilisation du noyau triangulaire
est particulierement adaptee dans le cas du bouclage de pertinence puisque ne disposantpas
d’information a priori sur le concept visuel que l’utilisateur cherche, nous ne pouvons fixer au
prealable un quelconque facteur d’echelle.
Le demarrage d’une session peut se fairea l’aide des paradigmes de requete standard (requete
par mot cle, navigation dans la base, requete par l’exemple, . . . ). Nous utilisons des SVM bi-
classes, aussi il est necessaire d’avoir une image pertinente pour amorcer le processus.
A titre d’exemple, nous presentons deux sessions d’interrogation utilisant les boucles de per-
tinence. L’interface graphique est celle du moteur de recherche Ikona developpe dans l’equipe
Imedia. L’implementation des boucles de pertinence est celle de Ferecatu.Nous utilisons tou-
jours le noyau triangulaire, avec la constanteC = 1. Les images utilisees sont celles de la base
Pascal VOC 2007 trainval. Les images sont decrites avec les trois descripteurs globaux utilises
precedemment (prob, four et leoh, voir page 67). La premiere page affiche simplement un tirage
aleatoire sur la base. Dans le premier exemple (figure 3.29), nous souhaitons annoter les images
dans lesquelles une voiture apparaıt. Sur le premierecran, on voit que quatre images corres-
pondenta ce concept. Nous marquons donc ces images comme pertinentes (bordure verte) et
toutes les autres comme non-pertinentes (bordure rouge). La strategie de selection des images
est MP. On voit sur le deuxiemeecran que 9 images sur les 16 contiennent une voiture. Par
130 Annotations locales
FIG. 3.29 – Boucles de pertinence, exemple 1

3.5 Boucles de pertinence avec des representations par sacs de mots 131
ailleurs, on peut remarquer un des effets de la strategie MP qui retourne des images tres proches
de celles deja annotees. Ainsi l’image de la voiture rouge dans la soufflerie (2eme image, 3eme
ligne) est tres proche d’une image vue sur le premierecran. Ces deux images font tres certaine-
ment partie d’une serie. De la meme maniere, la voiture de sport prise en photo de face (1ere
image, 3eme ligne) est la meme que sur le premierecran avec un leger decalage dans la position
de prise de vue. Lesecrans suivants montrent les resultats des iterations 2 et 3.
FIG. 3.30 – Boucles de pertinence, exemple 2. Haut droite : MP. Bas gauche : MA. Bas droite :MAO.
Pour le second exemple (figure 3.30), nous n’effectuons qu’une seule iteration. Les deux
images contenant des avions sont marquees comme pertinentes sur le premierecran. Nous
presentons ensuite les 16 images retournees par le systeme selon les strategies MP, MA et

132 Annotations locales
MAO. Pour la strategie MP, on constate clairement que les imagesa forte dominante bleue sont
retournees. On retrouve ainsi des avions et des bateaux. Pour la strategie MA, bien que le bleu
domine encore, on constate une plus grande diversite du contenu. Enfin, pour la strategie MAO,
on remarque que certaines images retournees par la strategie MA ne sont plus presentes, car
trop similairesa celles deja sur l’ecran. Cela permet d’afficher d’autres images plus diverses
(comme les 3 dernieres).
3.5.3 Combinaisons des representations globale et locale
Nous souhaitons combiner les representations globale et locale dans le cadre du bouclage
de pertinence. L’utilisation d’une representation par sac de mots dans ce contexte n’est pas
nouvelle [JLZ+03]. Les images seront donc decritesa la fois par des descipteurs globaux et
par des descripteurs locaux dans une representation commune. De plus, comme le souligne
Crucianuet al. [CTF08], les classes d’objets dans les bases realistes ont souvent des formes
complexes dans l’espace des caracteristiques et peuventetre multi-modales. Dans ce cas, le
bouclage de pertinence peutetre vu comme un processus lors duquel l’utilisateur guide le
systemea travers l’espace des caracteristiques pour decouvrir les differentes modalites cor-
respondanta un concept visuel particulier. Nous souhaitonsetudier l’influence de chacun des
deux types de representation dans cette decouverte du concept visuel. A l’instar de Yinet al.
[YBCD05], qui suggere de combiner plusieurs strategies de bouclage de pertinence, nous pro-
posons d’isoler dans deux canaux distincts les representations globale et locale. Ainsi l’explo-
ration de l’espace des caracteristiques visuelles pourra se faire alternativement selon chacun des
deux types de representation. La figure 3.31 represente cette nouvelle approche. Nous testerons
la strategie d’orientation la plus simple qui consistea alterner l’apprentissage d’un modele a
base de representations globales ou de representations localesa chaque iteration.
3.5.4 Methodes d’evaluation
La principale difficulte dans l’evaluation d’un systeme de bouclage de pertinence est qu’il
faut des personnes utilisant le systeme. De plus, pour que cesevaluations soient valides d’un
point de vue statistiques, elles doiventetre meneesa grandeechelle. Etant donne le nombre de
parametresa optimiser qui est relativement important, il n’est pas envisageable d’avoir des ses-
sions reelles pour toutes les hypotheses de travail. C’est pourquoi, la plupart du temps, le com-
portement des utilisateurs est simule pour conduire les tests. Ces simulations ne remplacent pas
uneetude realisee avec de vrais utilisateurs, mais elles permettent de degager des grandes orien-
tations. Cette approche est notamment mise en avant dans de recents travaux sur l’evaluation
des algorithmes de bouclage de pertinence [HL08] et justifiee par les problemes potentiels lies
a uneevaluation par des operateurs humains :

3.5 Boucles de pertinence avec des representations par sacs de mots 133
FIG. 3.31 – Nouvelle approche du bouclage de pertinence combinant representations globale etlocale
– le nombre de jugements de pertinence devantetre fournis par chaque utilisateur est pro-
hibitif
– les utilisateurs doiventetre coherents dans leur interpretation d’une tache de recherche au
fil des iterations, et plus encore, independamment des systemesevalues
– les efforts deployes pour uneevaluation ne peuvent pasetre reutilises. A chaque nouvelle
approche, il faut refaire des sessions avec les utilisateurs
– il est difficile de s’assurer que les utilisateurs ne soientpas biaises en fonction de la
methode qui estevaluee. Par exemple, uneevaluation loyale necessite une familiarite
identique avec les differents systemes testes. On sait en effet que la comprehension des
mecanismes internes d’un systeme a une grande influence sur les performances [CMM+00,
Pic07].
Dans [CTF08], 8 strategies differentes sont presentees pour simuler le comportement des
utilisateurs. Ces strategies sont testees sur quatre bases d’images de laboratoire. A partir des
resultats obtenus par Crucianu et en modelisant notre propre comportement dans l’utilisation
des boucles de pertinence, nous utiliserons quatre strategies pour simuler les utilisateurs dans
nos experiences. Par experience, nous pensons que la presentation de 16 images par iteration
est un maximum pour l’utilisateur. Les strategies de simulation d’utilisateur sont :
1. STO : utilisateur stoıque, il marque correctement les 16 images qui lui sont presentees.

134 Annotations locales
2. EQU : utilisateurequitable, il marque correctement les images pertinentes et autant d’ima-
ges non-pertinentes
3. FIX : cet utilisateur marque toujours 4 images par iteration en commencant par les perti-
nentes et en completant, si necessaire, par des images non-pertinentes tirees au sort
4. GRE2 : utilisateur avare, il marque correctement les images pertinentes et une seule
image non-pertinente s’il en existe
Pour ces strategies, les exemples pertinents sont generalement tous marques (sauf pour FIX s’il
y a plus de 4 images pertinentes). En revanche on a une gradation dans le nombre d’images
non-pertinentes retournees au systeme (voir figure 3.37). Dans [CTF08], certaines strategies
utilisateur font intervenir la notion de l’image la moins pertinente au yeux de l’utilisateur. Pour
simuler cette approche, il est necessaire de construire un autre modele base sur l’ensemble
du jeu de donnees. Ce modele est ainsi capable de fournir un score de confiance assimilable
a la pertinence par rapport au concept visuel. Toutefois, cedernier est construita partir des
memes descriptions visuelles et du meme algorithme d’apprentissage. Nous pensons que cela
peut induire un biais et preferons donc l’approche plus simple consistanta choisir aleatoirement
les images non-pertinentes.
Nous utiliserons deux mesures de performances distinctes,correspondanta nos deux scena-
rii d’utilisation des boucles de pertinence. L’iconographe souhaitant annoter toutes les images
de la base possedant un concept visuel, nous mesurerons la proportion d’images pertinentes
vues par l’utilisateur au cours des differentes sessions. L’ingenieur souhaitant construire un
nouveau modele, nous mesurerons les performances en annotation automatique de ce modele
sur une base independante de celle sur laquelle il auraete construit.
Selon les approches, deux criteres peuventetre utilises pour comparer les performances.
On peut considerer que le critere important est le nombre d’images qui ontete presenteesa
l’utilisateur. Cela correspond donc au nombre d’iterations puisqu’on presente le meme nombre
d’imagesa chaque iteration. Une autre approche est de se concentrer sur le transfert d’informa-
tions de l’utilisateur vers le systeme et de considerer le nombre d’images reellement marquees,
encore appelee nombre de clics. Notre approche ignorant les images qui nesont pas marquees
par l’utilisateur, il est possible d’utiliser le nombre de clics comme critere.
3.5.5 Resultats sur Pascal VOC 2007 et discussions
Nous allons effectuer nos experiences sur le jeu de donnees Pascal VOC 2007. La descrip-
tion globale des images est obtenue avec nos trois descripteurs standards (four64, prob216et
leoh32). Pour la description locale, nous extrayons 1 000 patches par image selon une grille
fixe. Ces patches sont decrits avecfour16 et eoh16. Un vocabulaire de 1 000 mots est obtenu
par les K-moyennes, il est utilise pour obtenir la representation par sacs de mots.
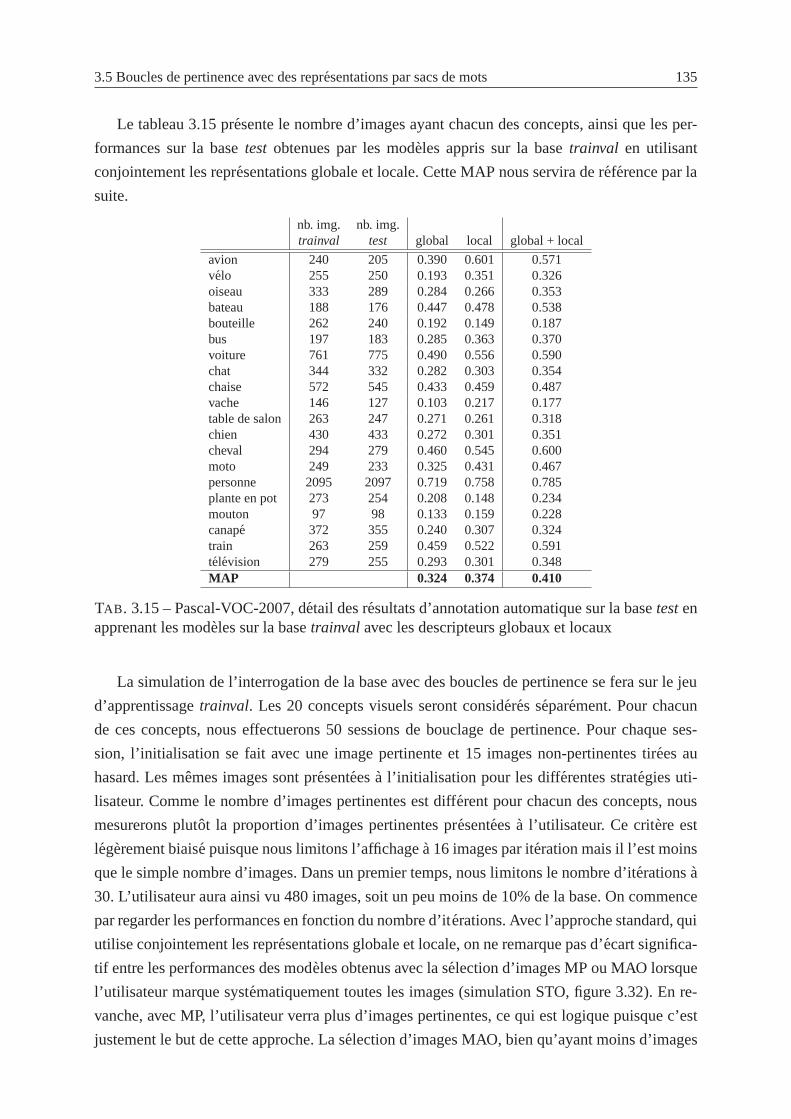
3.5 Boucles de pertinence avec des representations par sacs de mots 135
Le tableau 3.15 presente le nombre d’images ayant chacun des concepts, ainsi que les per-
formances sur la basetest obtenues par les modeles appris sur la basetrainval en utilisant
conjointement les representations globale et locale. Cette MAP nous servira de reference par la
suite.
nb. img. nb. img.trainval test global local global + local
avion 240 205 0.390 0.601 0.571velo 255 250 0.193 0.351 0.326oiseau 333 289 0.284 0.266 0.353bateau 188 176 0.447 0.478 0.538bouteille 262 240 0.192 0.149 0.187bus 197 183 0.285 0.363 0.370voiture 761 775 0.490 0.556 0.590chat 344 332 0.282 0.303 0.354chaise 572 545 0.433 0.459 0.487vache 146 127 0.103 0.217 0.177table de salon 263 247 0.271 0.261 0.318chien 430 433 0.272 0.301 0.351cheval 294 279 0.460 0.545 0.600moto 249 233 0.325 0.431 0.467personne 2095 2097 0.719 0.758 0.785plante en pot 273 254 0.208 0.148 0.234mouton 97 98 0.133 0.159 0.228canape 372 355 0.240 0.307 0.324train 263 259 0.459 0.522 0.591television 279 255 0.293 0.301 0.348MAP 0.324 0.374 0.410
TAB . 3.15 – Pascal-VOC-2007, detail des resultats d’annotation automatique sur la basetestenapprenant les modeles sur la basetrainval avec les descripteurs globaux et locaux
La simulation de l’interrogation de la base avec des bouclesde pertinence se fera sur le jeu
d’apprentissagetrainval. Les 20 concepts visuels seront consideres separement. Pour chacun
de ces concepts, nous effectuerons 50 sessions de bouclage de pertinence. Pour chaque ses-
sion, l’initialisation se fait avec une image pertinente et15 images non-pertinentes tirees au
hasard. Les memes images sont presenteesa l’initialisation pour les differentes strategies uti-
lisateur. Comme le nombre d’images pertinentes est different pour chacun des concepts, nous
mesurerons plutot la proportion d’images pertinentes presenteesa l’utilisateur. Ce critere est
legerement biaise puisque nous limitons l’affichagea 16 images par iteration mais il l’est moins
que le simple nombre d’images. Dans un premier temps, nous limitons le nombre d’iterationsa
30. L’utilisateur aura ainsi vu 480 images, soit un peu moinsde 10% de la base. On commence
par regarder les performances en fonction du nombre d’iterations. Avec l’approche standard, qui
utilise conjointement les representations globale et locale, on ne remarque pas d’ecart significa-
tif entre les performances des modeles obtenus avec la selection d’images MP ou MAO lorsque
l’utilisateur marque systematiquement toutes les images (simulation STO, figure 3.32). En re-
vanche, avec MP, l’utilisateur verra plus d’images pertinentes, ce qui est logique puisque c’est
justement le but de cette approche. La selection d’images MAO, bien qu’ayant moins d’images
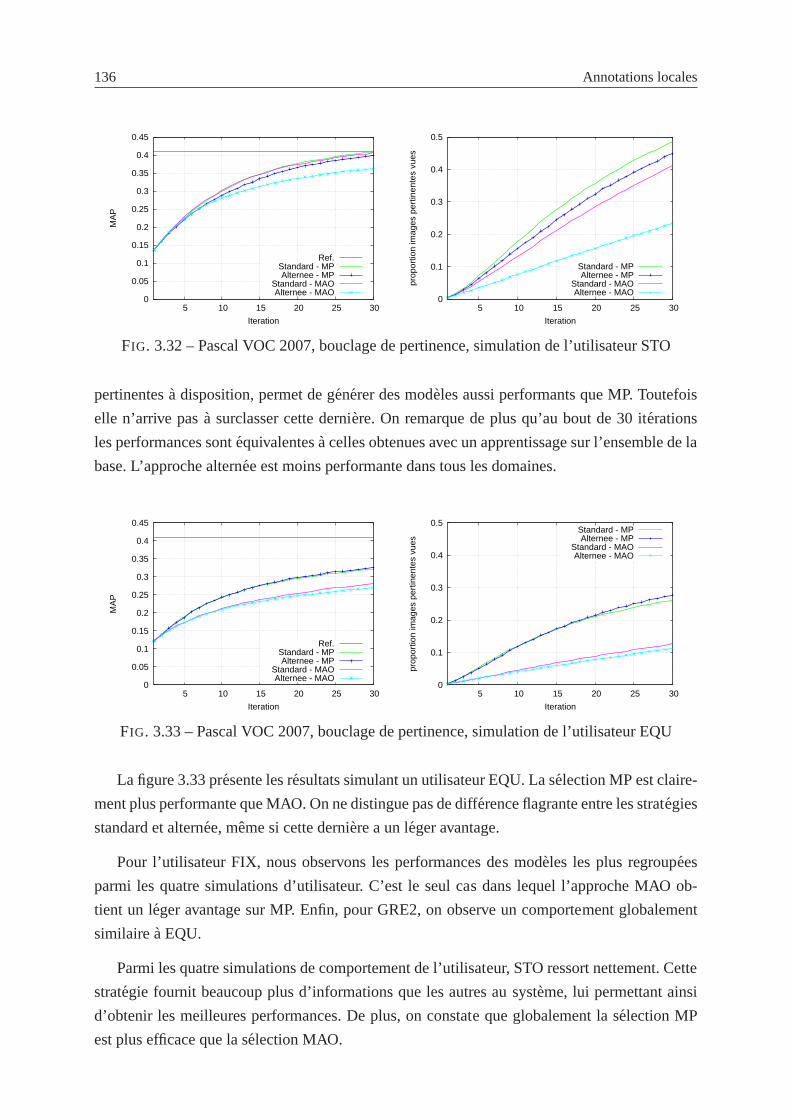
136 Annotations locales
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
5 10 15 20 25 30
MA
P
Iteration
Ref.Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
0
0.1
0.2
0.3
0.4
0.5
5 10 15 20 25 30
prop
ortio
n im
ages
per
tinen
tes
vues
Iteration
Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
FIG. 3.32 – Pascal VOC 2007, bouclage de pertinence, simulationde l’utilisateur STO
pertinentesa disposition, permet de generer des modeles aussi performants que MP. Toutefois
elle n’arrive pasa surclasser cette derniere. On remarque de plus qu’au bout de 30 iterations
les performances sontequivalentesa celles obtenues avec un apprentissage sur l’ensemble de la
base. L’approche alternee est moins performante dans tous les domaines.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
5 10 15 20 25 30
MA
P
Iteration
Ref.Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
0
0.1
0.2
0.3
0.4
0.5
5 10 15 20 25 30
prop
ortio
n im
ages
per
tinen
tes
vues
Iteration
Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
FIG. 3.33 – Pascal VOC 2007, bouclage de pertinence, simulationde l’utilisateur EQU
La figure 3.33 presente les resultats simulant un utilisateur EQU. La selection MP est claire-
ment plus performante que MAO. On ne distingue pas de difference flagrante entre les strategies
standard et alternee, meme si cette derniere a un leger avantage.
Pour l’utilisateur FIX, nous observons les performances des modeles les plus regroupees
parmi les quatre simulations d’utilisateur. C’est le seul cas dans lequel l’approche MAO ob-
tient un leger avantage sur MP. Enfin, pour GRE2, on observe un comportement globalement
similairea EQU.
Parmi les quatre simulations de comportement de l’utilisateur, STO ressort nettement. Cette
strategie fournit beaucoup plus d’informations que les autres ausysteme, lui permettant ainsi
d’obtenir les meilleures performances. De plus, on constate que globalement la selection MP
est plus efficace que la selection MAO.
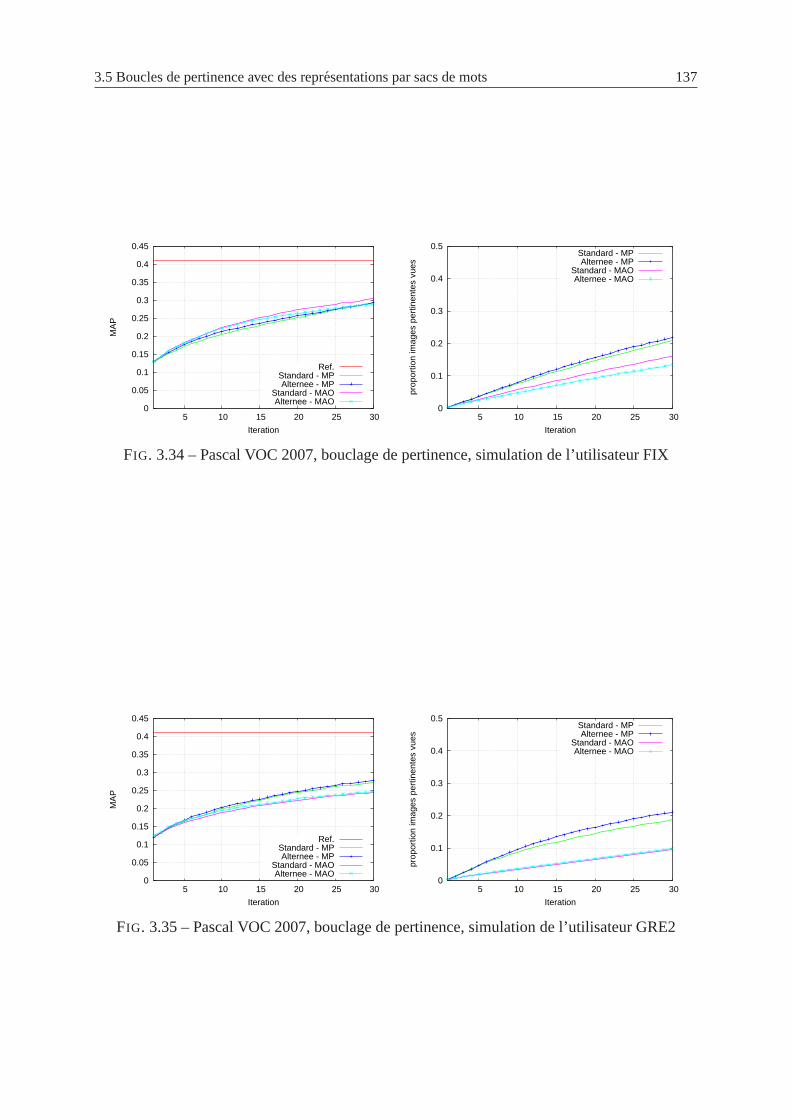
3.5 Boucles de pertinence avec des representations par sacs de mots 137
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
5 10 15 20 25 30
MA
P
Iteration
Ref.Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
0
0.1
0.2
0.3
0.4
0.5
5 10 15 20 25 30pr
opor
tion
imag
es p
ertin
ente
s vu
es
Iteration
Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
FIG. 3.34 – Pascal VOC 2007, bouclage de pertinence, simulationde l’utilisateur FIX
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
5 10 15 20 25 30
MA
P
Iteration
Ref.Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
0
0.1
0.2
0.3
0.4
0.5
5 10 15 20 25 30
prop
ortio
n im
ages
per
tinen
tes
vues
Iteration
Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
FIG. 3.35 – Pascal VOC 2007, bouclage de pertinence, simulationde l’utilisateur GRE2
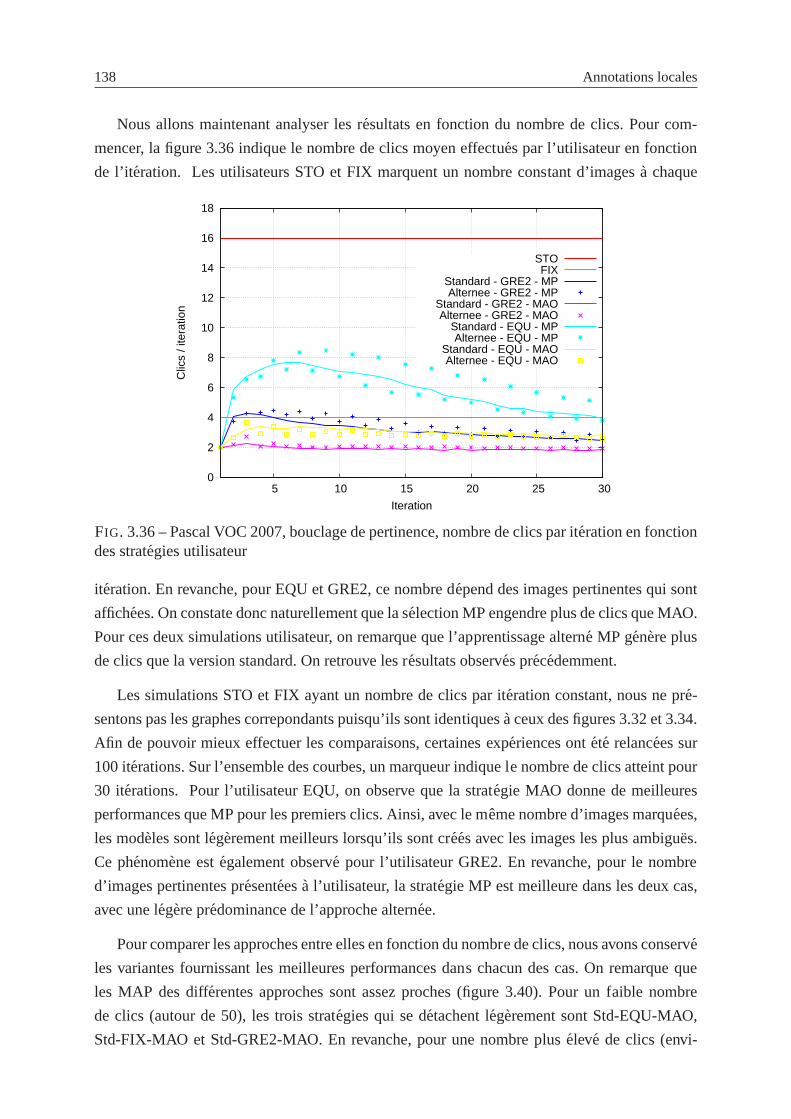
138 Annotations locales
Nous allons maintenant analyser les resultats en fonction du nombre de clics. Pour com-
mencer, la figure 3.36 indique le nombre de clics moyen effectues par l’utilisateur en fonction
de l’iteration. Les utilisateurs STO et FIX marquent un nombre constant d’imagesa chaque
0
2
4
6
8
10
12
14
16
18
5 10 15 20 25 30
Clic
s / i
tera
tion
Iteration
STOFIX
Standard - GRE2 - MPAlternee - GRE2 - MP
Standard - GRE2 - MAOAlternee - GRE2 - MAO
Standard - EQU - MPAlternee - EQU - MP
Standard - EQU - MAOAlternee - EQU - MAO
FIG. 3.36 – Pascal VOC 2007, bouclage de pertinence, nombre de clics par iteration en fonctiondes strategies utilisateur
iteration. En revanche, pour EQU et GRE2, ce nombre depend des images pertinentes qui sont
affichees. On constate donc naturellement que la selection MP engendre plus de clics que MAO.
Pour ces deux simulations utilisateur, on remarque que l’apprentissage alterne MP genere plus
de clics que la version standard. On retrouve les resultats observes precedemment.
Les simulations STO et FIX ayant un nombre de clics par iteration constant, nous ne pre-
sentons pas les graphes correpondants puisqu’ils sont identiquesa ceux des figures 3.32 et 3.34.
Afin de pouvoir mieux effectuer les comparaisons, certainesexperiences ontete relancees sur
100 iterations. Sur l’ensemble des courbes, un marqueur indique le nombre de clics atteint pour
30 iterations. Pour l’utilisateur EQU, on observe que la strategie MAO donne de meilleures
performances que MP pour les premiers clics. Ainsi, avec le meme nombre d’images marquees,
les modeles sont legerement meilleurs lorsqu’ils sont crees avec les images les plus ambigues.
Ce phenomene estegalement observe pour l’utilisateur GRE2. En revanche, pour le nombre
d’images pertinentes presenteesa l’utilisateur, la strategie MP est meilleure dans les deux cas,
avec une legere predominance de l’approche alternee.
Pour comparer les approches entre elles en fonction du nombre de clics, nous avons conserve
les variantes fournissant les meilleures performances dans chacun des cas. On remarque que
les MAP des differentes approches sont assez proches (figure 3.40). Pour un faible nombre
de clics (autour de 50), les trois strategies qui se detachent legerement sont Std-EQU-MAO,
Std-FIX-MAO et Std-GRE2-MAO. En revanche, pour une nombre plus eleve de clics (envi-
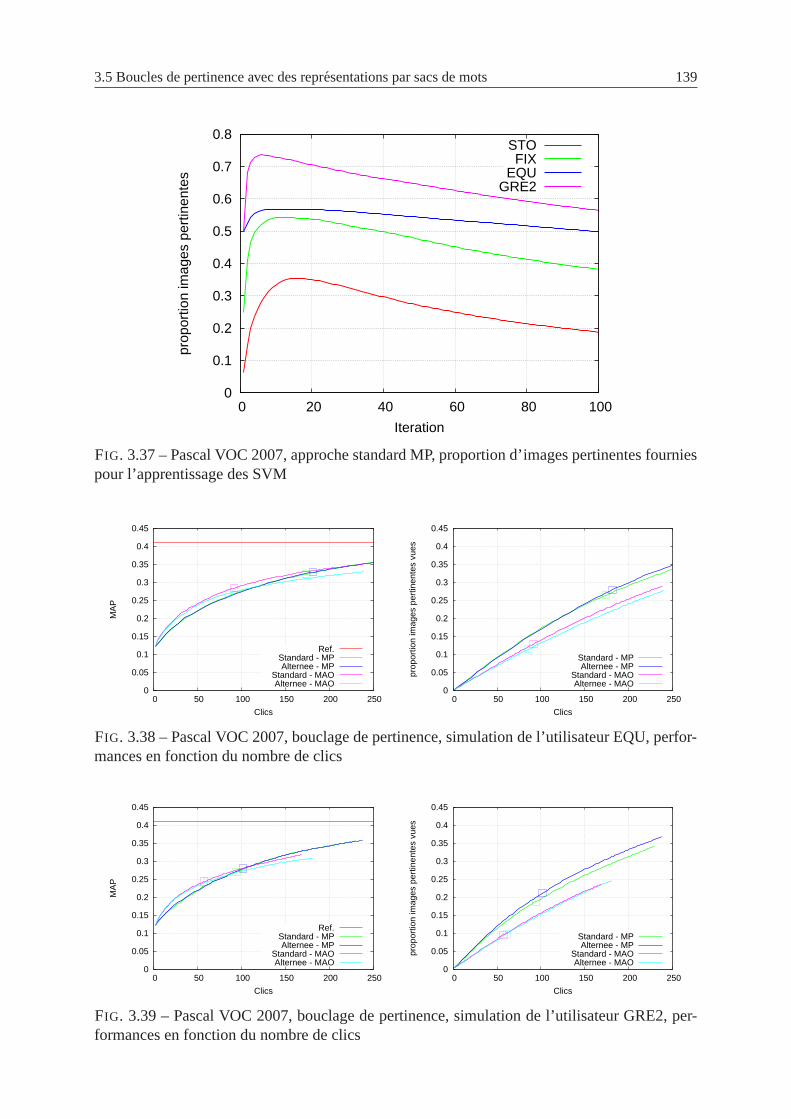
3.5 Boucles de pertinence avec des representations par sacs de mots 139
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 20 40 60 80 100
prop
ortio
n im
ages
per
tinen
tes
Iteration
STOFIX
EQUGRE2
FIG. 3.37 – Pascal VOC 2007, approche standard MP, proportion d’images pertinentes fourniespour l’apprentissage des SVM
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 50 100 150 200 250
MA
P
Clics
Ref.Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 50 100 150 200 250
prop
ortio
n im
ages
per
tinen
tes
vues
Clics
Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
FIG. 3.38 – Pascal VOC 2007, bouclage de pertinence, simulationde l’utilisateur EQU, perfor-mances en fonction du nombre de clics
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 50 100 150 200 250
MA
P
Clics
Ref.Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 50 100 150 200 250
prop
ortio
n im
ages
per
tinen
tes
vues
Clics
Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
FIG. 3.39 – Pascal VOC 2007, bouclage de pertinence, simulationde l’utilisateur GRE2, per-formances en fonction du nombre de clics
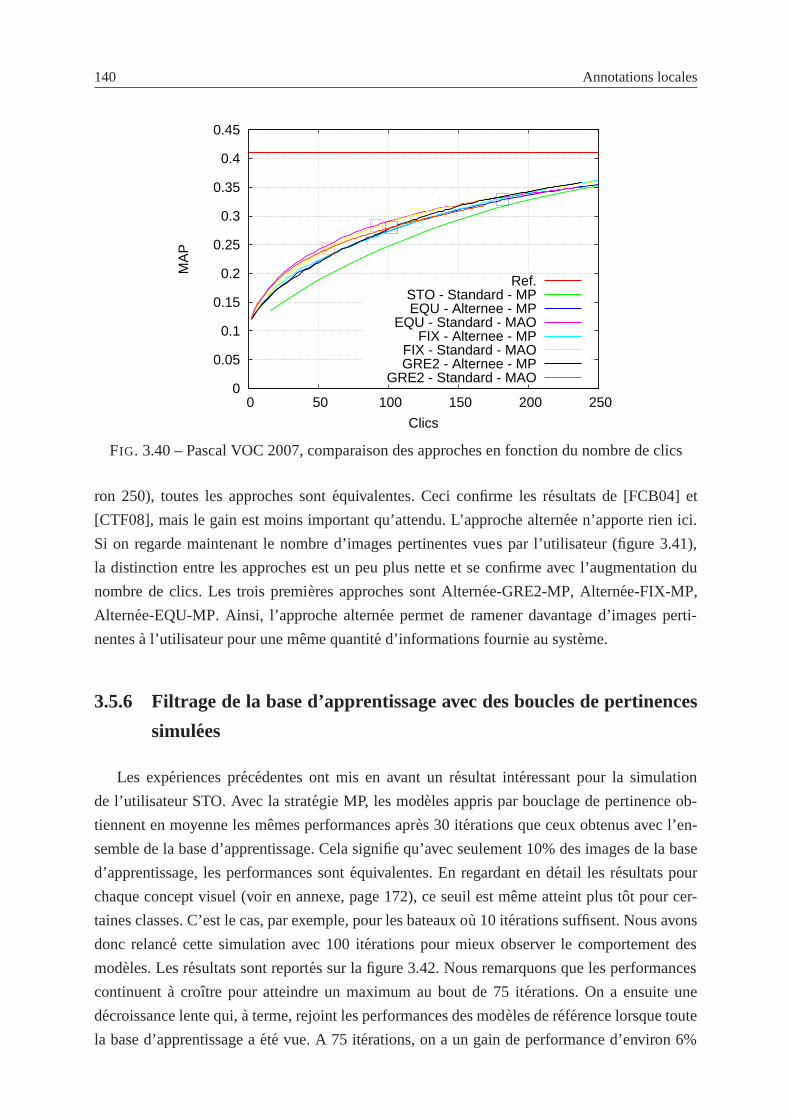
140 Annotations locales
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 50 100 150 200 250
MA
P
Clics
Ref.STO - Standard - MPEQU - Alternee - MP
EQU - Standard - MAOFIX - Alternee - MP
FIX - Standard - MAOGRE2 - Alternee - MP
GRE2 - Standard - MAO
FIG. 3.40 – Pascal VOC 2007, comparaison des approches en fonction du nombre de clics
ron 250), toutes les approches sontequivalentes. Ceci confirme les resultats de [FCB04] et
[CTF08], mais le gain est moins important qu’attendu. L’approche alternee n’apporte rien ici.
Si on regarde maintenant le nombre d’images pertinentes vues par l’utilisateur (figure 3.41),
la distinction entre les approches est un peu plus nette et seconfirme avec l’augmentation du
nombre de clics. Les trois premieres approches sont Alternee-GRE2-MP, Alternee-FIX-MP,
Alternee-EQU-MP. Ainsi, l’approche alternee permet de ramener davantage d’images perti-
nentesa l’utilisateur pour une meme quantite d’informations fournie au systeme.
3.5.6 Filtrage de la base d’apprentissage avec des boucles de pertinences
simulees
Les experiences precedentes ont mis en avant un resultat interessant pour la simulation
de l’utilisateur STO. Avec la strategie MP, les modeles appris par bouclage de pertinence ob-
tiennent en moyenne les memes performances apres 30 iterations que ceux obtenus avec l’en-
semble de la base d’apprentissage. Cela signifie qu’avec seulement 10% des images de la base
d’apprentissage, les performances sontequivalentes. En regardant en detail les resultats pour
chaque concept visuel (voir en annexe, page 172), ce seuil est meme atteint plus tot pour cer-
taines classes. C’est le cas, par exemple, pour les bateaux ou 10 iterations suffisent. Nous avons
donc relance cette simulation avec 100 iterations pour mieux observer le comportement des
modeles. Les resultats sont reportes sur la figure 3.42. Nous remarquons que les performances
continuenta croıtre pour atteindre un maximum au bout de 75 iterations. On a ensuite une
decroissance lente qui,a terme, rejoint les performances des modeles de reference lorsque toute
la base d’apprentissage aete vue. A 75 iterations, on a un gain de performance d’environ 6%
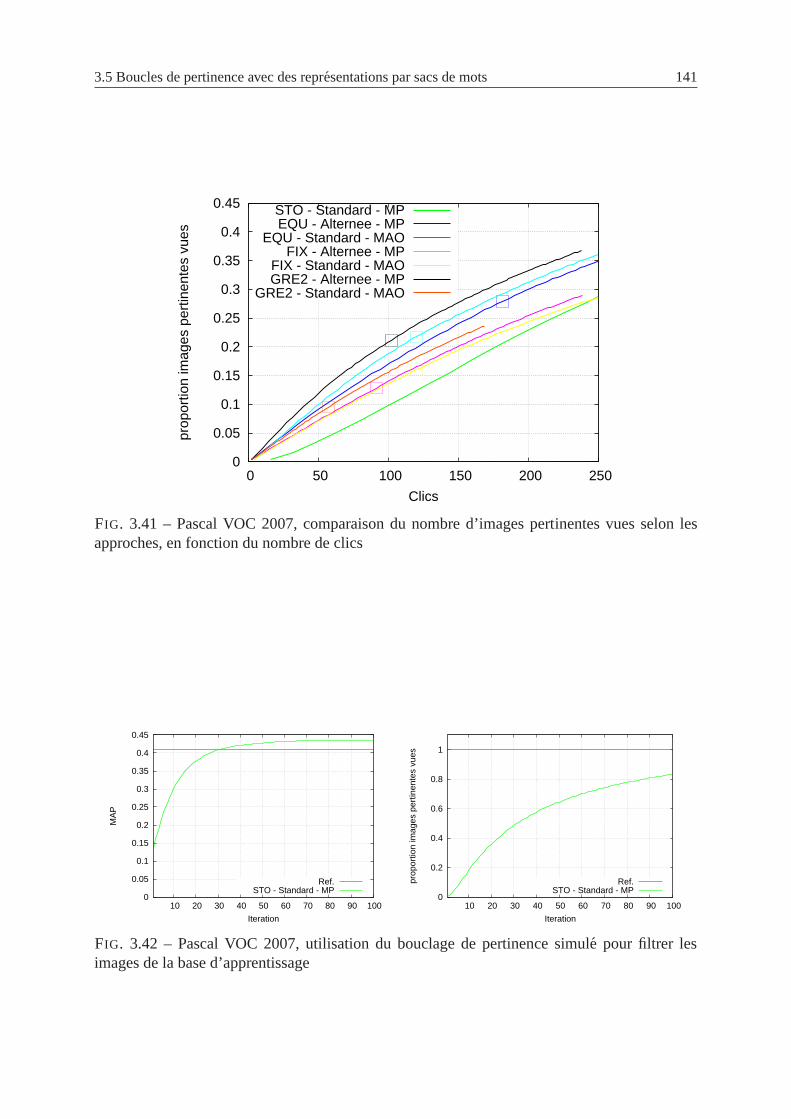
3.5 Boucles de pertinence avec des representations par sacs de mots 141
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 50 100 150 200 250
prop
ortio
n im
ages
per
tinen
tes
vues
Clics
STO - Standard - MPEQU - Alternee - MP
EQU - Standard - MAOFIX - Alternee - MP
FIX - Standard - MAOGRE2 - Alternee - MP
GRE2 - Standard - MAO
FIG. 3.41 – Pascal VOC 2007, comparaison du nombre d’images pertinentes vues selon lesapproches, en fonction du nombre de clics
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
10 20 30 40 50 60 70 80 90 100
MA
P
Iteration
Ref.STO - Standard - MP
0
0.2
0.4
0.6
0.8
1
10 20 30 40 50 60 70 80 90 100
prop
ortio
n im
ages
per
tinen
tes
vues
Iteration
Ref.STO - Standard - MP
FIG. 3.42 – Pascal VOC 2007, utilisation du bouclage de pertinence simule pour filtrer lesimages de la base d’apprentissage
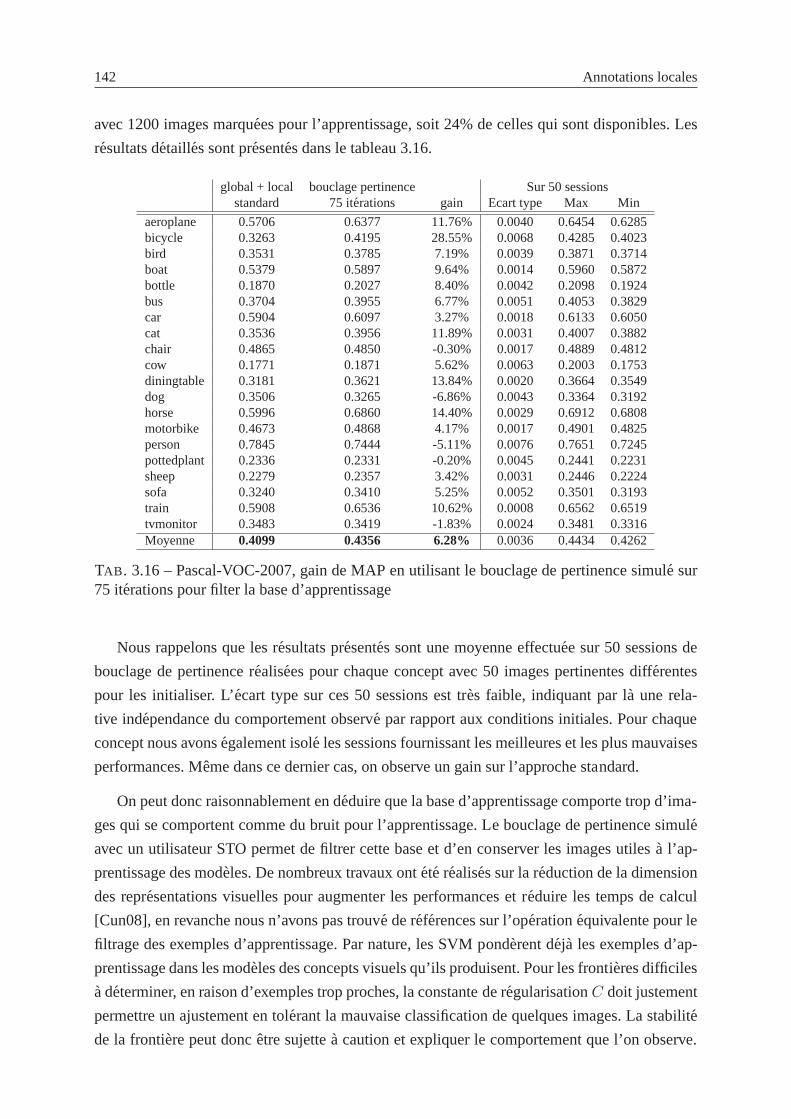
142 Annotations locales
avec 1200 images marquees pour l’apprentissage, soit 24% de celles qui sont disponibles. Les
resultats detailles sont presentes dans le tableau 3.16.
global + local bouclage pertinence Sur 50 sessionsstandard 75 iterations gain Ecart type Max Min
aeroplane 0.5706 0.6377 11.76% 0.0040 0.6454 0.6285bicycle 0.3263 0.4195 28.55% 0.0068 0.4285 0.4023bird 0.3531 0.3785 7.19% 0.0039 0.3871 0.3714boat 0.5379 0.5897 9.64% 0.0014 0.5960 0.5872bottle 0.1870 0.2027 8.40% 0.0042 0.2098 0.1924bus 0.3704 0.3955 6.77% 0.0051 0.4053 0.3829car 0.5904 0.6097 3.27% 0.0018 0.6133 0.6050cat 0.3536 0.3956 11.89% 0.0031 0.4007 0.3882chair 0.4865 0.4850 -0.30% 0.0017 0.4889 0.4812cow 0.1771 0.1871 5.62% 0.0063 0.2003 0.1753diningtable 0.3181 0.3621 13.84% 0.0020 0.3664 0.3549dog 0.3506 0.3265 -6.86% 0.0043 0.3364 0.3192horse 0.5996 0.6860 14.40% 0.0029 0.6912 0.6808motorbike 0.4673 0.4868 4.17% 0.0017 0.4901 0.4825person 0.7845 0.7444 -5.11% 0.0076 0.7651 0.7245pottedplant 0.2336 0.2331 -0.20% 0.0045 0.2441 0.2231sheep 0.2279 0.2357 3.42% 0.0031 0.2446 0.2224sofa 0.3240 0.3410 5.25% 0.0052 0.3501 0.3193train 0.5908 0.6536 10.62% 0.0008 0.6562 0.6519tvmonitor 0.3483 0.3419 -1.83% 0.0024 0.3481 0.3316Moyenne 0.4099 0.4356 6.28% 0.0036 0.4434 0.4262
TAB . 3.16 – Pascal-VOC-2007, gain de MAP en utilisant le bouclagede pertinence simule sur75 iterations pour filter la base d’apprentissage
Nous rappelons que les resultats presentes sont une moyenne effectuee sur 50 sessions de
bouclage de pertinence realisees pour chaque concept avec 50 images pertinentes differentes
pour les initialiser. L’ecart type sur ces 50 sessions est tres faible, indiquant par la une rela-
tive independance du comportement observe par rapport aux conditions initiales. Pour chaque
concept nous avonsegalement isole les sessions fournissant les meilleures et les plus mauvaises
performances. Meme dans ce dernier cas, on observe un gain sur l’approche standard.
On peut donc raisonnablement en deduire que la base d’apprentissage comporte trop d’ima-
ges qui se comportent comme du bruit pour l’apprentissage. Le bouclage de pertinence simule
avec un utilisateur STO permet de filtrer cette base et d’en conserver les images utilesa l’ap-
prentissage des modeles. De nombreux travaux ontete realises sur la reduction de la dimension
des representations visuelles pour augmenter les performances et reduire les temps de calcul
[Cun08], en revanche nous n’avons pas trouve de references sur l’operationequivalente pour le
filtrage des exemples d’apprentissage. Par nature, les SVM ponderent deja les exemples d’ap-
prentissage dans les modeles des concepts visuels qu’ils produisent. Pour les frontieres difficiles
a determiner, en raison d’exemples trop proches, la constantede regularisationC doit justement
permettre un ajustement en tolerant la mauvaise classification de quelques images. La stabilit e
de la frontiere peut doncetre sujettea caution et expliquer le comportement que l’on observe.

3.5 Boucles de pertinence avec des representations par sacs de mots 143
Nous avons initialiement fixe la constanteC = 1 apres avoir observe que cette valeur fournis-
sait generalement les meilleures performances (section 2.4.5). Enutilisant une valeur beaucoup
plus grande (C = 10 000) le meme phenomene est observe, dans les memes proportions.
Nous refaisons cette meme experience en n’utilisant que les trois descripteurs globaux.La
encore, le meme comportement est observe. Les performances de reference (MAP 0.3239) sont
atteintes au bout de 39 iterations et le maximum pour les boucles de pertinence est obtenua 90
iterations (MAP 0.3466), representant alors un gain de 7%.
3.5.7 Conclusion
Globalement la strategie MP est meilleure. Nous ne remarquons pas d’apport significatif de
la strategie MAO. Les seuls cas dans lesquels cette approche permet d’ameliorer legerement
les performances sont en considerant le nombre de clics. Toutefois, en tant qu’utilisateurd’un
tel systeme, nous preferons l’evaluation en fonction du nombre d’iterations. Meme si marquer
les differentes images presentes sur unecran prend du temps, il est facile d’avoir une IHM
permettant de simplifier le marquage des exemples non-pertinents. En dehors de la simulation
STO, les approches standard et alternee fournissent des modelesequivalents, mais l’approche
alternee permet de voir legerement plus d’images pertinentes. Cela signifie que la diversite des
images supplementaires ainsi ramenees ne permet pas d’affiner les modeles. Enfin, parmi les
simulations d’utilisateurs, nous remarquons que l’approche STO est la plus pertinente dans nos
deux scenarii. Nous avons des differences notables dans la mise en œuvre des experimentations
par rapporta [CTF08]. La base utilisee n’est pas la meme et nous utilisons des representations
locales. De plus, nous utilisons une ponderation dynamique des exemples marques pour l’ap-
prentissage des SVM. Ces choix peuvent expliquer les conclusions partiellement differentes que
nous tirons de nos travaux.
Nous avons vu que l’utilisation du bouclage de pertinence simule permettait de filtrer les
images de la base d’apprentissage et d’obtenir ainsi de meilleurs modeles. Ces travaux doivent
etre poursuivis etetendus pour pouvoir fournir une methode fiable en vue d’optimiser les bases
d’apprentissage.

144 Annotations locales

CHAPITRE 4
Conclusions
“A trop vouloir analyser, on tue l’emotion.”
Jean Loup Sieff, photographe francais (1933 - 2000)
4.1 Resume des contributions
Nous avons presente dans ce manuscrit nos travaux sur l’annotation automatique de bases
d’images generalistes. L’etude du contexte applicatif a permis de mettre en avant differents
scenarii d’utilisation de cette technique dans le cadre d’agences photos professionnelles ou de
collections de photos personnelles. Suitea notre travail, il apparaıt clairement que l’annotation
automatique est un outil de generation de nouvelles meta-donnees et d’enrichissement automa-
tique du contenu qui permet d’extraire la connaissance enfouie et de la rendre plus explicite
[HB09b]. Differentes par nature des annotations manuelles, sous forme demots-cles ou de no-
tices completes, ces nouvelles meta-donnees n’en sont toutefois pas treseloignees. Nous pen-
sons que la distinction entre les annotation automatiques et manuelles doit persister tout au long
de la chaıne de traitements et d’exploitation de ces informations, jusque dans l’interface des mo-
teurs de recherche. Il n’est bienevidemment pas exclu que differents paradigmes de requetes
puissent tirer partie de leurs similarites. Toutefois l’utilisateur final d’un systeme proposant l’an-
notation automatique de concepts visuels verra ses possibilit es d’interaction accrues et aura une
meilleure comprehension du comportement de ce dernier s’il peut accedera ces meta-donnees.
Pour mettre au point les techniques d’annotation automatique, nous pensons que l’utilisation
de bases d’images realistes est un pre-requis. Nous avons montre que certaines bases utilisees

146 Conclusions
encore actuellement pourevaluer des travaux de recherche manquent cruellement de diversite
et sont tropeloignees de ce qui existe en dehors des laboratoires. Les approches mises au point
avec ces bases risquent d’une part de ne pas pouvoiretre utilisees dans un contexte different et
d’autre part de ne pas repondre aux bonnes problematiques.
Notre approche est entierement generique et peut s’adaptera tous les concepts visuels. Elle
est basee sur l’utilisation d’un SVM par concept visuel. Nous avonsmontre que l’utilisation
du noyau triangulaire offrait un tres bon compromis en terme de performance par rapport aux
temps de calcul. Conformementa nos preconisations, nous ne fournissons pas de decision bi-
naire sur la presence ou l’absence d’un concept visuel dans une image, maisplutot un score
de confiance. Les principales contributions de cette these resident dans l’amelioration de la
representation et l’extraction de contenu informationnel des images. Nous avonsetudie et pro-
pose plusieursevolutions pour les differentesetapes permettant d’obtenir ces representations.
La qualite des descripteurs est essentielle pour rendre compte de la richesse des contenus vi-
suels. Nous avons ainsi propose le nouveau descripteur global de formes LEOH. Conjointement
a d’autres descripteurs de l’equipe Imedia, il a permisa notre approche d’obtenir les meilleures
performances sur la tache de classification de scenes de la campagne d’evaluation ImagEVAL
[HB07a].
Pour representer plus finement le contenu des images, nous avons adopte l’approche stan-
dard des sacs de mots visuels. Plutot que d’utiliser des detecteurs de points d’interet pour
extraire les patches visuels, nous pensons qu’unechantillonnage regulier est plus approprie,
sans aucun a priori sur l’utilite potentielle de chaque type de patch. Pour mettre enevidence
cette proposition, nous avons introduit un cadre generique de representation de documents, in-
diff eremment texte ou image, permettant d’evaluer differentes strategies de selection de patches
locaux. Nous avons propose que les techniques employees pour les images soient appliqueesa
un corpus de textes degrades pourevaluer leur efficacite [HBH09]. En effet, la representation
par sac de mots vient de la communaute travaillant sur le texte et il nous a semble judicieux
d’observer les effets des hypotheses effectuees sur les images en les appliquant retroactivement
sur des documents texte. Nous avons ainsi montre que les comportements d’unechantillonnage
regulier et par point d’interet etaient similaires sur ces deux types de corpus. L’echantillonnage
regulier conduita une moindre perte d’information et doit doncetre favorise. De plus, l’extrac-
tion des patches necessite alors moins de calculs et est plus rapide. Enfin, nous avons remarque,
lors de nos experiences sur le texte, que la connaissance exacte des frontieres entre les mots
n’etait pas necessaire puisqu’unechantillonnage regulier permettait de capturer les informa-
tions structurelles et contextuelles et d’obtenir ainsi debonnes performances. Nous pensons
que ces proprietes sontegalement valables pour les images et sont un nouvel argument en fa-
veur de l’echantillonnage regulier. Nous utilisons donc l’extraction des patches visuels selon
une grille fixe pour nos representations.

4.2 Perspectives 147
Une fois les patches extraits, il faut constituer un vocabulaire visuel pour obtenir une re-
presentation des images. Nous avonsetudie differentes approches pour le partitionnement de
l’espace visuel et propose l’algorithme dual QT. Nous avons montre l’importance pour un
vocabulaire visuel d’etre le plus representatif possible de la distribution des patches visuels.
Idealement, il faudrait que chaque mot du vocabulaire puisse encoder le meme nombre de
patches sur une base de donnees pour maximiser l’information ainsi encodee. De plus, nous
avons verifie que le nombre de mots du vocabulaire ainsi que le nombre de patches extrait de
chaque imageetaient des parametres influant grandement sur les performances globales d’un
systeme.
Un des inconvenients de la representation par sac de mots est la perte des informations
li eesa la localisation des patches dans les images. Representer les caracteristiques visuelles
sous forme de sacs non-ordonnes permet d’opter pour une labellisation des concepts visuels au
niveau de l’image, ce qui est le cas dans les bases generalistes. On peut toutefois reintroduire
partiellement des informations spatiales dans ce type de representation. Nous avons propose
l’utilisation de paires de mots visuels [HB09a]. Elles permettent d’encoder des relations geome-
triques souples en tenant compte de la cooccurence de patches dans un voisinage predetermine.
Nous avons montre que ces informations apportent un gain substantiel de performance pour des
taches d’annotation automatique, aussi bien pour des concepts visuels locaux que globaux.
Ces differentes contributions permettent d’avoir une representation des images plus fideles
et d’augmenter les performances d’un algorithme d’annotation automatique. Toutefois, lors-
qu’aucune base d’apprentissage n’est disponible pour un concept visuel donne, on ne peut utili-
ser cette approche. On bascule alors vers les approches semi-automatiques pour lesquelles une
interaction avec l’utilisateur est necessaire au cours du processus. Dans ce cadre, nous avons
propose une nouvelle approche pour utiliser conjointement des representations locale et glo-
bale combinee avec du bouclage de pertinence. Si on considere comme critere de comparaison
le nombre de clics effectues par l’utilisateur, cette approche permet de presenter davantage
d’images pertinentes pour le concept en cours d’apprentissage. En revanche, pour l’apprentis-
sage de nouveaux modeles dediesa l’annotation automatique, la strategie standard est la plus
performante. Nous avons par ailleurs montre que l’utilisation du bouclage de pertinence simule
permettait de filtrer efficacement une base d’apprentissagepour ne conserver que les images
reellement utiles et permettre ainsi d’apprendre des modeles plus performants.
4.2 Perspectives
Nous degageons deux principales pistes d’investigations futuresa court terme. Nous pensons
approfondir nos reflexions et experimentations sur les paires de mots visuels. Pour cela, nous
etendrons cette representation pour avoir une version multi-echelles. Actuellement, les patches

148 Conclusions
visuels ne sont extraits que pour uneechelle unique. Le passagea plusieursechelles ouvre plu-
sieurs perspectives pour la definition du voisinage de chaque patch. On peut considerer chaque
echelle independamment des autres, ou, au contraire, les lier entre elles. Nousetudierons donc
plusieurs nouvelles definitions du voisinage pour mesurer la cooccurence de patches dans ce
contexte. Nous avons indique que les paires de patches permettent de capturer des informations
de structure, internes aux objets, et des informations de contexte, situant les objets dans leur
environnement. Nous prevoyons d’analyser plus en details les resultats de l’annotation auto-
matique en typant les paires de patches et en mesurant leur apport respectif aux performances
globales. Nous disposons pour la base Pascal VOC 2007 d’une segmentation grossiere des ob-
jets, nous pourrons ainsi facilement isoler les differents types de paires de patches. De plus,
pour etendre la validation de notre contribution, nous la testerons avec d’autres descripteur vi-
suels. Nous pouvonsegalement envisager des paires de patches construites avecdes descripteurs
diff erents pour mesurer, par exemple, la cooccurence de patchesdecrits avec des signatures cou-
leur et de patches decrits par des signatures de texture. Nous pensonsegalement mettre en place
une heuristique permettant de filtrer les paires de patches,de facon non-supervisee, pour limiter
la dimension de la representation. Enfin, notre approche actuelle commence par quantifier les
patches visuels avant de les associer sous forme de paires. Nous prevoyonsegalement d’effec-
tuer l’operation inverse et de creer un nouveau descripteur. En extrayant les paires avant deles
quantifier, nous serons ainsi proche des dipoles [Jol07] et de SIFT [Low99] tout enetant plus
souples et generiques.
Le deuxieme axe selon lequel nous souhaitons poursuivre nos travauxconcerne la construc-
tion semi-supervisee de modeles par bouclage de pertinence. Nous avons vu que la strategie
consistanta alterner les representations locale et globale pour choisir les imagesa presenter
a l’utilisateur apporte un interet limite a quelques cas d’utilisation tres precis. En revanche, il
pourraitetre interessant de poursuivre dans cette voie en ponderant differemment les represen-
tations et en faisantevoluer ces ponderations selon les actions de l’utilisateur. Enfin, la piste
la plus prometteuse sur le bouclage de pertinence est son utilisation avec un utilisateur simule
pour filtrer les bases d’apprentissage en vue d’ameliorer les modeles des concepts visuels. Nous
prevoyons d’effectuer des tests sur d’autres bases pour confirmer les premiers resultats obtenus.
Nous pensonsegalement ameliorer la prise en compte de la difficutlte des requete lors de la
phase d’evaluation , comme il est suggere par Huiskes et Lew [HL08] pouretre plus proche du
comportement en situation reelle. De plus, nous chercheronsa partir d’une analyse poussee des
images selectionnees si l’on peutetablir des criteres permettant de mettre en œuvre un filtrage
plus rapide et plus efficace encore.
A plus long terme, il serait interessant d’etudier l’impact de l’utilisation des scores de
confiance obtenus par annotation automatique comme signatures permettant d’interroger une
base d’images. En dehors des concepts globaux et de quelquesconcepts locaux, les perfor-
mances des differentes approches de l’etat de l’art sont encore nettement insuffisantes pouretre

4.2 Perspectives 149
utiles en temps que tellesa un utilisateur final. En revanche, leur utilisation conjointe peut avoir
un apport significatif. Actuellement, le manque de capacite de generalisation des representations
visuelles et des strategies d’apprentissage tenda etre compense par l’augmentation du nombre
d’exemples d’apprentissage. On s’oriente ainsi de plus en plus vers des approches dematching
avec comme idee principale en toile de fond : si on dispose d’une collection d’images suffisa-
ment grande, les capacites de generalisation ne sont plus forcement necessaires puisqu’on peut
toujours s’attendrea trouver une image tres proche de celle qu’on souhaite annoter. Les travaux
sur les structures d’index sont alors primordiaux dans ce cadre. Plusieurs travaux recents font
ainsi usage de grandes collections d’images captees sur Internet [QLVG08, WHY+08, JYH08,
TFF08, WZLM08]. Suivant les travaux de Hauptman [NST+06, HYL07], il sera utile de re-
garder l’apport de l’annotation de quelques centaines de concepts sur des scenarii de recherche
d’images.

150 Conclusions

Bibliographie
[AAR04] S. Agarwal, A. Awan, and D. Roth. Learning to detect objects in images via
a sparse, part-based representation.IEEE Transactions on Pattern Analysis and
Machine Intelligence, 26, 2004.
[AE97] L. H. Armitage and P. G. Enser. Analysis of user need inimage archives.Journal
of information science, 23(4) :287–299, 1997.
[ASR05] J. Amores, N. Sebe, and P. Radeva. Efficient object-class recognition by boosting
contextual information. InIbPRIA, 2005.
[BBK01] C. Bohm, S. Berchtold, and D.A. Keim. Searching in high-dimensional spaces -
index structures for improving the performance of multimedia databases.ACM
Computing Survey, 33, 2001.
[BBP04] Stefano Berreti, Alberto Del Bimbo, and Pietro Pala. Merging results for distribu-
ted content based image retrieval.Multimedia Tools and Applications, 24 :215–
232, 2004.
[BDF+03] Kobus Barnard, Pinar Duygulu, David Forsyth, Nando de Freitas, David M. Blei,
and Michael I. Jordan. Matching words and pictures.Journal of Machine Learning
Research, 3 :1107–1135, 2003.
[BDG04] N. Balasubramanian, A.R. Diekema, and A.A. Goodrum. Analysis of user image
descriptions and automatic image indexing vocabularies : An exploratory study. In
International Workshop on Multidisciplinary Image, Video, and Audio Retrieval
and Mining., 2004.
[BF04] N. Boujemaa and M. Ferecatu.Evaluation des systemes de traitement de l’in-
formation, chapter Evaluation des systemes de recherche par le contenu visuel :
pertinence et criteres. Number ISBN 2-7462-0862-8. Hermes Sciences, 2004.

152 BIBLIOGRAPHIE
[BFG03] Nozha Boujemaa, Julien Fauqueur, and Valerie Gouet. What’s beyond query by
example ? Technical report, INRIA, 2003.
[BGBS06] N. Bouteldja, V. Gouet-Brunet, and M. Scholl. Backto the curse of dimensionality
with local image descriptors. Technical report, Cnam - Cedric, 2006.
[BGS99] Djamel Bouchaffra, Venu Govindaraju, and Sargur N.Srihari. A methodology
for mapping scores to probabilities.IEEE Transactions on Pattern Analysis and
Machine Intelligence, 21(9) :923–927, 1999.
[BGV92] Bernhard E. Boser, Isabelle M. Guyon, and Vladimir N. Vapnik. A training algo-
rithm for optimal margin classifiers. InFifth Annual Workshop on Computational
Learning Theory, 1992.
[BH01] Alexander Budanitsky and Graeme Hirst. Semantic distance in wordnet : An expe-
rimental, application-oriented evaluation of five measures. InWorkshop on Word-
Net and Other Lexical Resources, NAACL-2001, 2001.
[BJ03] David M. Blei and Michael I. Jordan. Modeling annotated data. 2003.
[BJM+01] N. Boujemaa, J.Fauqueur, M.Ferecatu, F.Fleuret, V.Gouet, B. Le Saux, and
H.Sahbi. Ikona : interactive specific anf generic image retrieval. In MMCBIR,
2001.
[BNJL03] David M. Blei, Andrew Y. Ng, Michael I. Jordan, and John Lafferty. Latent diri-
chlet allocation. 2003.
[Bou05] Sabri Boughorbel.Kernels for Image Classification with Support Vector Ma-
chines. PhD thesis, Universite Paris 11, Orsay, 2005.
[BP05] R. Brown and B. Pham. Image mining and retrieval usinghierarchical support
vector machines. InInternational Multimedia Modelling Conference, 2005.
[BZM07] Anna Bosch, Andrew Zisserman, and Xavier Munoz. Representing shape with a
spatial pyramid kernel. InCIVR ’07 : Proceedings of the 6th ACM international
conference on Image and video retrieval, pages 401–408, New York, NY, USA,
2007. ACM.
[Can86] John Canny. A computational approach to edge detection. IEEE Transactions on
Pattern Analysis and Machine Intelligence, 8 :679 – 698, 1986.
[CBDF04] G. Csurka, C. Bray, C. Dance, and L. Fan. Visual categorization with bags of
keypoints. InEuropean Conference on Computer Vision - Workshop on Statistical
Learning in Computer Vision, 2004.
[CBW06] Y. Chen, J. Bi, and J. Z. Wang. Miles : Multiple-instancelearning via embedded
instance selection.IEEE Transactions on Pattern Analysis and Machine Intelli-
gence, 2006.
[CCS00] Colin Campbell, Nello Cristianini, and Alexander Smola.Query learning with
large margin classifiers. InInternational Conference on Machine Learning, 2000.

BIBLIOGRAPHIE 153
[CCS09] G. Ciocca, C. Cusano, and R. Schettini. Semantic classification, low level features
and relevance feedback for content-based image retrieval.In Multimedia Content
Access : Algorithms and Systems III, IS&T/SPIE Symposium onElectronic Ima-
ging, 2009.
[CDD+04] Frederic Cao, Julie Delon, Agnes Desolneux, Pablo Muse, and Frederic Sur. An a
contrario approach to hierarchical clustering validity assessment. Technical report,
INRIA, 2004.
[CDPW06] Gabriela Csurka, Christopher R. Dance, Florent Perronnin, and Jutta Willa-
mowski. Toward Category-Level Object Recognition, chapter Generic Visual
Categorization Using Weak Geometry, pages 207–224. Springer-Verlag Lecture
Notes in Computer Science, 2006.
[CG08] Matthieu Cord and Philippe-Henri Gosselin.Machine Learning Techniques for
Multimedia, chapter Online Content-Based Image Retrieval Using ActiveLear-
ning, pages 115 – 138. Springer, 2008.
[CHL05] Florin Cutzu, Riad Hammoud, and Alex Leykin. Distinguishing paintings from
photographs.Computer Vision and Image Understanding, 100 :249–273, 2005.
[CHV99] O. Chapelle, P. Haffner, and V.N. Vapnik. Support vector machines for histogram-
based image classification.IEEE Transactions on Neural Networks, 10(5) :1055–
1064, 1999.
[CL01] Chih-Chung Chang and Chih-Jen Lin.LIBSVM : a library for support vector
machines, 2001. Software available at http ://www.csie.ntu.edu.tw/ cjlin/libsvm.
[CLH08] Liangliang Cao, Jiebo Luo, and Thomas S. Huang. Annotating photo collections
by label propagation according to multiple similarity cues. In MM ’08 : Procee-
ding of the 16th ACM international conference on Multimedia, pages 121–130,
New York, NY, USA, 2008. ACM.
[CMM+00] Ingemar J. Cox, Matt L. Miller, Thomas P. Minka, Thomas V. Papathomas, and
Peter N. Yianilos. The bayesian image retrieval system, pichunter : Theory, im-
plementation, and psychophysical experiments.IEEE Transactions on Image Pro-
cessing, 9, 2000.
[CPZ97] P. Ciaccia, M. Patella, and P. Zezula. Mtree : an efficient access method for simi-
larity search in metric spaces. InIEEE International Conference on Very Large
Data Bases, 1997.
[CTF08] Michel Crucianu, Jean-Philippe Tarel, and Marin Ferecatu. An exploration of
diversified user strategies for image retrieval with relevance feedback. Jour-
nal of Visual Languages and Computing, 19(6) :629–636, December 2008.
http ://perso.lcpc.fr/tarel.jean-philippe/publis/jvlc08.html.

154 BIBLIOGRAPHIE
[Cun08] Padraig Cunningham.Machine Learning Techniques for Multimedia, chapter Di-
mensions Reduction, pages 91 – 114. Springer, 2008.
[CV95] Corinna Cortes and V. Vapnik. Support-vector networks.Machine Learning, 20,
1995.
[CW04] Y. Chen and J. Z. Wang. Image categorization by learning and reasoning with
regions.Journal of Machine Learning Research, 5 :913–939, 2004.
[DBdFF02] Pinar Duygulu, Kobus Barnard, Nando de Freitas, and David Forsyth. Object re-
cognition as machine translation : Learning a lexicon for a fixed image vocabulary.
2002.
[Der87] R. Deriche. Using canny’s criteria to derive an optimal edge detector recursively
implemented.IJCV, 1(2), 1987.
[DGL05] Francois Denisa, Remi Gilleronb, and Fabien Letouzeyb. Learning from positive
and unlabeled examplesstar, open.Theoretical Computer Science, 348(1) :70–83,
2005.
[DJLW06] Ritendra Datta, Dhiraj Joshi, Jia Li, and James Z. Wang. Studying aesthetics in
photographic images using a computational approach. InEuropean Conference
on Computer Vision, 2006.
[DJLW08] Ritendra Datta, Dhiraj Joshi, Jia Li, and James Z. Wang. Image retrieval : Ideas,
influences, and trends of the new age.ACM Computing Surveys, 40(2) :1–60,
2008.
[DLW05] Ritendra Datta, Jia Li, and James Z. Wang. Content-based image retrieval - ap-
proaches and trends of the new age. In7th ACM SIGMM international workshop
on Multimedia information retrieval, 2005.
[DNAA06] Gunilla Derefeldt, Sten Nyberg, Jens Alfredson, and Henrik Allberg. Is woelfflin’s
system for characterizing art possible to validate by methods used in cognitive-
based image-retrieval (cbir) ? InThree-Dimensional Image Capture and Applica-
tions VII, SPIE, 2006.
[EGW+] M. Everingham, L. Van Gool, C. Williams, J. Winn, and A. Zisserman.
The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results.
http ://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html.
[ESL05] Peter G.B. Enser, Christine J. Sandom, and Paul H. Lewis. Automatic annotation
of images from the practitioner perspective. InImage and Video Retrieval : 4th
International Conference, CIVR 2005 Singapore, 2005.
[EZW+06] M. Everingham, A. Zisserman, C. Williams, L. Van Gool, M. Allan, C. Bishop,
O. Chapelle, N. Dalal, T. Deselaers, G. Dorko, S. Duffner, J. Eichhorn, J. Farqu-
har, M. Fritz, C. Garcia, T. Griffiths, F. Jurie, D. Keysers, M.Koskela, J. Laakso-
nen, D. Larlus, B. Leibe, H. Meng, H. Ney, B. Schiele, C. Schmid, E. Seemann,

BIBLIOGRAPHIE 155
J. Shawe-Taylor, A. Storkey, S. Szedmak, B. Triggs, I. Ulusoy, V. Viitaniemi, and
J. Zhang. The 2005 pascal visual object classes challenge. In Selected Proceedings
of the First PASCAL Challenges Workshop, LNAI, Springer-Verlag, 2006.
[FB02] J. Fauqueur and N. Boujemaa. Region-based retrieval: Coarse segmentation
with fine signature. InIEEE International Conference on Image Processing
(ICIP’2002), 2002.
[FB06] J. Fauqueur and N. Boujemaa. Mental image search by boolean composition of
region categories.Multimedia Tools and Applications, 2006.
[FBC05] Marin Ferecatu, Nozha Boujemaa, and Michel Crucianu.Hybrid visual and
conceptual image representation within active relevance feedback context. In
7th ACM SIGMM International Workshop on Multimedia Information Retrieval
(MIR’05), Singapore, 2005.
[FCB04] Marin Ferecatu, Michel Crucianu, and Nozha Boujemaa.Retrieval of difficult
image classes using svm-based relevance feedback. InACM SIGMM International
Workshop on Multimedia Information Retrieval, 2004.
[Fel98] Christiane Fellbaum.WordNet - An Electronic Lexical Database. MIT Press,
1998.
[Fer05] Marin Ferecatu.Image retrieval with active relevance feedback using both vi-
sual and keyword-based descriptors. PhD thesis, University of Versailles Saint-
Quentin-En-Yvelines, 2005.
[FFFP04] L. Fei-Fei, R. Fergus, and P. Perona. Learning generative visual models from
few training examples : an incremental bayesian approach tested on 101 object
categories. InCVPR 2004, Workshop on Generative-Model Based Vision, 2004.
[FFFPZ05] R. Fergus, L. Fei-Fei, P. Perona, and A. Zisserman. Learning object categories
from google’s image search. InInternational Conference on Computer Vision,
2005.
[FK97] H. Frigui and R. Krishnapuram. Clustering by competitive agglomeration.Pattern
Recognition, 30(7), 1997.
[FKA05] Julien Fauqueur, Nick Kingsbury, and Ryan Anderson. Semantic discriminant
mapping for classification and browsing of remote sensing textures and objects.
In IEEE International Conference on Image Processing, 2005.
[FKS03] Ronald Fagin, Ravi Kumar, and D. Sivakumar. Comparing top k lists. InACM-
SIAM Symposium on Discrete Algorithms, 2003.
[FML04] S. L. Feng, R. Manmatha, and V. Lavrenko. Multiple bernoulli relevance models
for image and video annotation. InCVPR, 2004.
[FPZ03] R. Fergus, P. Perona, and A. Zisserman. Object classrecognition by unsupervised
scale-invariant learning. InComputer Vision and Pattern Recognition, 2003.

156 BIBLIOGRAPHIE
[FPZ04] R. Fergus, P. Perona, and A. Zisserman. A visual category filter for google images.
In European Conf. on Computer Vision, ECCV, 2004.
[FS97] Yoav Freund and Robert E. Schapire. A decision-theoretic generalization of on-
line learning and an application to boosting.Journal of Computer and System
Sciences, 55(1) :119–139, 1997.
[FS03] F. Fleuret and H. Sahbi. Scale-invariance of supportvector machines based on the
triangular kernel. InThird International Workshop on Statistical and Computatio-
nal Theories of Vision (part of ICCV2003), 2003.
[GCB06] N. Grira, M. Crucianu, and N. Boujemaa. Fuzzy clustering with pairwise
constraints for knowledge-driven image categorization. In IEE Proceedings - Vi-
sion, Image & Signal Processing, 2006.
[GCPF07] P.-H. Gosselin, M. Cord, and S. Philipp-Foliguet. Kernel on bags for multi-object
database retrieval. InACM International Conference on Image and Video Retrie-
val (CIVR), Amsterdam, The Netherlands, July 2007.
[GDO00] A. Guerin-Dugue and A. Oliva. Classification of scene photographs from local
orientations features.Pattern Recognition Letters, 21 :1135–1140, 2000.
[GMDP00] V. Gouet, P. Montesinos, R. Deriche, and D. Pele. Evaluation de detecteurs de
points d’interet pour la couleur. InReconnaissance des formes et Intelligence
Artificielle (RFIA’2000), volume II, pages 257–266, Paris, France, 2000.
[GT05] Herve Glotin and Sabrina Tollari. Fast image auto-annotation with visual vector
approximation clusters. InWorkshop CBMI, Riga, Latvia, 2005.
[GTG05] Herve Glotin, Sabrina Tollari, and Pascale Giraudet. Approximation of linear
discriminant analysis for word dependent visual features selection. InACIVS2005,
2005.
[GZ00] Sally Goldman and Yan Zhou. Enhancing supervised learning with unlabeled data.
In Proceedings of the 17th International Conference on MachineLearning, 2000.
[HA79] J. Hartigan and M. Wang. A. A k-means clustering algorithm. Applied Statistics,
28 :100–108, 1979.
[Han06] Allan Hanbury. Guide to annotation - v2.12. Technical report, Muscle NoE, 2006.
[Har06] Jonathon S. Hare.Saliency for Image Description and Retrieval. PhD thesis, Uni-
versity of Southampton, Faculty of Engineering, Science and Mathematics School
of Electronics and Computer Science, 2006.
[HB06] H. Houissa and N. Boujemaa. Regions coherence criterion based on points of in-
terest configuration. InInternational Workshop on Image Analysis for Multimedia
Interactive Services, 2006.

BIBLIOGRAPHIE 157
[HB07a] Nicolas Herve and Nozha Boujemaa. Image annotation : which approach for rea-
listic databases ? InACM International Conference on Image and Video Retrieval
(CIVR’07), July 2007.
[HB07b] H. Houissa and N. Boujemaa. A new angle-based spatial modeling for query
by visual thesaurus composition. InIEEE International Conference on Image
Processing, 2007.
[HB09a] Nicolas Herve and Nozha Boujemaa. Visual word pairs for automatic image an-
notation. InIEEE International Conference on Multimedia and Expo (ICME09),
June 2009.
[HB09b] Nicolas Herve and Nozha Boujemaa.Encyclopedia of Database Systems, chapter
Automatic image annotation. Springer, to appear in 2009.
[HBH09] Nicolas Herve, Nozha Boujemaa, and Michael E. Houle. Document description :
what works for images should also work for text ? InIS&T/SPIE Electronic Ima-
ging, Multimedia Processing and Applications, January 2009.
[Her05] Nicolas Herve. Refonte de l’architecture du serveur de cbir maestro. Master’s
thesis, CNAM Paris, 2005.
[HKKR99] Frank Hoppner, Frank Klawonn, Rudolf Kruse, and Thomas Runkler.Fuzzy Clus-
ter Analysis : Methods for Classification, Data Analysis, andImage Recognition.
John Wiley and Sons, 1999.
[HKM +97] Jing Huang, S. Ravi Kumar, Mandar Mitra, Wei-Jing Zhu, and Ramin Zabih.
Image indexing using color correlograms. InComputer Vision and Pattern Re-
cognition, 1997.
[HKY99] Laurie J. Heyer, Semyon Kruglyak, and Shibu Yooseph. Exploring expres-
sion data : Identification and analysis of coexpressed genes. Genome Research,
9 :1106–1115, 1999.
[HL05] Jonathon S. Hare and Paul H. Lewis. Saliency-based models of image content and
their application to auto-annotation by semantic propagation. InSecond European
Semantic Web Conference - ESWC, 2005.
[HL08] Mark J. Huiskes and Michael S. Lew. Performance evaluation of relevance feed-
back methods. InInternational conference on Content-based Image and Video
Retrieval, pages 239–248, New York, NY, USA, 2008. ACM.
[HLES06] Jonathon S. Hare, Paul H. Lewis, Peter G. B. Enser, and Christine J. Sandom.
Mind the gap : Another look at the problem of the semantic gap in image retrieval.
In Multimedia Content Analysis, Management, and Retrieval, SPIE-IS&T, 2006.
[HLS08] Eva Horster, Rainer Lienhart, and Malcolm Slaney. Continuous visual vocabulary
models for plsa-based scene recognition. InCIVR ’08 : Proceedings of the 2008

158 BIBLIOGRAPHIE
international conference on Content-based image and video retrieval, pages 319–
328, New York, NY, USA, 2008. ACM.
[HLZZ04] Jingrui He, Mingjing Li, Hong-Jiang Zhang, and Changshui Zhang. W-boost and
its application to web image classification. InICPR, 2004.
[HN08] Alexander Haubold and Apostol Natsev. Web-based information content and its
application to concept-based video retrieval. InCIVR ’08 : Proceedings of the
2008 international conference on Content-based image and video retrieval, pages
437–446, New York, NY, USA, 2008. ACM.
[HP98] Thomas Hofmann and Jan Puzicha. Statistical models for co-occurrence data.
Technical report, Massachusetts Institute of Technology,1998.
[HSC06] Alan Hanjalic, Nicu Sebe, and Edward Chang. Multimedia content analysis, ma-
nagement and retrieval : Trends and challenges. InMultimedia Content Analysis,
Management, and Retrieval, SPIE-IS&T, 2006.
[HSW06] Laura Hollink, Guus Schreiber, and Bob Wielinga. Query expansion for image
content search, 2006.
[HTH00] Pengyu Hong, Qi Tian, and Thomas S. Huang. Incorporate support vector ma-
chines to content-based image retrieval with relevant feedback. InIEEE Interna-
tional Conference on Image Processing, 2000.
[HYL07] Alexander Hauptmann, Rong Yan, and Wei-Hao Lin. Howmany high-level
concepts will fill the semantic gap in news video retrieval ? In ACM International
Conference on Image and Video Retrieval, 2007.
[IAE02] Ihab F. Ilyas, Walid G. Aref, and Ahmed K. Elmagarmid. Joining ranked inputs
in practice. InVLDB’02,August 20–23, Hong Kong, China, pages 950–961, 2002.
[IM98] P. Indyk and R. Motwani. Approximate nearest neighbors : Towards removing the
curse of dimensionality. InSymposium on Theory of Computing, 1998.
[Ino04] Masashi Inoue. On the need for annotation-based image retrieval. InWorkshop
on Information Retrieval in Context (IRiX) Sheffield, UK, 2004.
[Jae04] Stefan Jaeger. Informational classifier fusion. InICPR, 2004.
[JB08] A. Joly and O. Buisson. A posteriori multi-probe locality sensitive hashing. In
ACM International Conference on Multimedia, 2008.
[JH98] T. Jaakkola and D. Haussler. Exploiting generative models in discriminative clas-
sifiers. Technical report, Dept. of Computer Science, Univ. of California, 1998.
[JLM03] J. Jeon, V. Lavrenko, and R. Manmatha. Automatic image annotation and retrieval
using cross-media relevance models. 2003.
[JLZ+03] Feng Jing, Mingjing Li, Lei Zhang, Hong-Jiang Zhang, andBo Zhang. Learning
in region-based image retrieval. InIEEE International Symposium on Circuits and
Systems, 2003.

BIBLIOGRAPHIE 159
[JM04] J. Jeon and R. Manmatha. Using maximum entropy for automatic image annota-
tion. In International Conference on Image and Video Retrieval (CIVR), 2004.
[JMF99] A. K. Jain, M. N. Murty, and P. J. Flynn. Data clustering : a review.ACM Com-
puting Surveys, 31(3) :264–323, 1999.
[Jol07] Alexis Joly. New local descriptors based on dissociated dipoles. InCIVR ’07 :
Proceedings of the 6th ACM international conference on Imageand video retrie-
val, pages 573–580, New York, NY, USA, 2007. ACM.
[JT05] F. Jurie and B. Triggs. Creating efficient codebooks for visual recognition. In
IEEE International Conference on Computer Vision, 2005.
[JV96] A. Jain and A. Vailaya. Image retrieval using color and shape.Pattern Recogni-
tion, 29(8), 1996.
[JWX08] Aiwen Jiang, Chunheng Wang, and Baihua Xiao. Scene modeling in global-local
view for scene classification. InCIVR ’08 : Proceedings of the 2008 internatio-
nal conference on Content-based image and video retrieval, pages 179–184, New
York, NY, USA, 2008. ACM.
[JYH08] Jimin Jia, Nenghai Yu, and Xian-Sheng Hua. Annotating personal albums via
web mining. InMM ’08 : Proceeding of the 16th ACM international conference
on Multimedia, pages 459–468, New York, NY, USA, 2008. ACM.
[Kea88] M. Kearns. Thoughts on hypothesis boosting. (Unpublished), December 1988.
[Kra98] Michael G Krauze. Intelletual problems of indexingpicture collections.Audiovi-
sual Librarian, 14(4) :73–81, 1998.
[LB02] Bertrand Le Saux and Nozha Boujemaa. Unsupervised robust clustering for image
database categorization. InICPR, 2002.
[Lew01] M. S. Lew. Principles of visual information retrieval. Number ISBN 1-85233-
381-2. Springer, 2001.
[LHZ+00] Ye Lu, Chunhui Hu, Xingquan Zhu, Hong-Jiang Zhang, and Qiang Yang. A uni-
fied framework for semantics and feature based relevance feedback in image re-
trieval systems. InACM International Conference on Multimedia, 2000.
[LMJ04] V. Lavrenko, R. Manmatha, and J. Jeon. A model for learning the semantics of
pictures. 2004.
[Low99] David G. Lowe. Object recognition from local scale-invariant features. InInter-
national Conference on Computer Vision, 1999.
[LSDJ06] Michael S. Lew, Nicu Sebe, Chabane Djeraba, and Ramesh Jain. Content-based
multimedia information retrieval : State of the art and challenges. ACM Tran-
sactions on Multimedia Computing, Communications, and Applications (TOMC-
CAP), 2 :1–19, 2006.

160 BIBLIOGRAPHIE
[LSP06] Svetlana Lazebnik, Cordelia Schmid, and Jean Ponce.Beyond bags of features :
Spatial pyramid matching for recognizing natural scene categories. InCVPR,
2006.
[LYRL04] D. D. Lewis, Y. Yang, T. Rose, and F. Li. Rcv1 : A new benchmark collection for
text categorization research.Journal of Machine Learning Research, 5 :361–397,
2004.
[LZL +05] Xuezheng Liu, Lei Zhang, Mingjing Li, HongJiang Zhang, and Dingxing Wang.
Boosting image classification with lda-based feature combination for digital pho-
tograph management.Pattern Recognition, 38(6) :887–901, 2005.
[MAA06] Ph. Mylonas, Th. Athanasiadis, and Y. Avrithis. Improving image analysis using
a contextual approach. In7th International Workshop on Image Analysis for Mul-
timedia Interactive Services (WIAMIS 2006), Seoul, Korea, 2006.
[Mai05] Nicolas Maillot. Ontology Bases Object Learning and Recognition. PhD thesis,
Universite de Nice Sophia Antipolis, 2005.
[MCR08] Joao Magalhaes, Fabio Ciravegna, and Stefan Ruger. Exploring multimedia in a
keyword space. InMM ’08 : Proceeding of the 16th ACM international conference
on Multimedia, pages 101–110, New York, NY, USA, 2008. ACM.
[MF06] P.-A. Moellic and C. Fluhr. Imageval 2006 official campaign. Technical report,
CEA List, 2006.
[MGP03] Florent Monay and Daniel Gatica-Perez. On image auto-annotation with latent
space models. InACM international conference on Multimedia, 2003.
[Mil08] Christophe Millet. Annotation automatique d’images : annotation coherente et
creation automatique d’une base d’apprentissage. PhD thesis, 2008.
[MKSH08] Takeshi Mita, Toshimitsu Kaneko, Bjorn Stenger, and Osamu Hori. Discriminative
feature co-occurrence selection for object detection.IEEE Transactions on Pattern
Analysis and Machine Intelligence, 30(7), 2008.
[MM04] Donald Metzler and R. Manmatha. An inference networkapproach to image re-
trieval. 2004.
[MMMP02] Henning Muller, Stephane Marchand-Maillet, and Thierry Pun. The truth about
corel - evaluation in image retrieval. InCIVR, 2002.
[MNJ08] Frank Moosmann, Eric Nowak, and Frederic Jurie. Randomized clustering forests
for image classification.IEEE Transactions on Pattern Analysis and Machine
Intelligence, 30(9), 2008.
[Moe06] Pierre-Alain Moellic. A features and svm based images and scenes classification
(imageval task 5). InWorkshop ImagEVAL, 2006.
[MR98] Oded Maron and Aparna Lakshmi Ratan. Multiple-instance learning for natural
scene classification. 1998.

BIBLIOGRAPHIE 161
[MS00] Marjo Markkula and Eero Sormunen. End-user searching challenges indexing
practices inthe digital newspaper photo archive.Information Retrieval, 1 :259–
285, 2000.
[MS05a] Kieran McDonald and Alan F. Smeaton. A comparison ofscore, rank and
probability-based fusion methods for video shot retrieval. In CIVR, 2005.
[MS05b] Krystian Mikolajczyk and Cordelia Schmid. A performance evaluation of lo-
cal descriptors.IEEE Transactions on Pattern Analysis & Machine Intelligence,
27(10) :1615–1630, 2005.
[MSS02] B. S. Manjunath, P. Salembier, and T. Sikora.Introduction to MPEG-7. Multime-
dia content description interface. Number ISBN 0-471-48678-7. 2002.
[MTH04] Nicolas Maillot, Monique Thonnat, and Celine Hudelot. Ontology based object
learning and recognition : Application to image retrieval.In 16th IEEE Interna-
tional Conference on Tools for Artificial Intelligence (ICTAI2004), Boca Raton,
Florida, 2004.
[MTO99] Yasuhide Mori, Hironobu Takahashi, and Ryuichi Oka. Image-to-word transfor-
mation based on dividing and vector quantizing images with words. InInterna-
tional Workshop on Multimedia Intelligent Storage and Retrieval Management,
1999.
[MTS+05] Krystian Mikolajczyk, Tinne Tuytelaars, Cordelia Schmid, Andrew Zisserman,
J. Matas, F. Schaffalitzky, T. Kadir, and L. Van Gool. A comparison of affine
region detectors.International Journal of Computer Vision, 65(1/2) :43–72, 2005.
[NGP08] Radu Andrei Negoescu and Daniel Gatica-Perez. Analyzing flickr groups. In
CIVR ’08 : Proceedings of the 2008 international conference on Content-based
image and video retrieval, pages 417–426, New York, NY, USA, 2008. ACM.
[NJT06] E. Nowak, F. Jurie, and B. Triggs. Sampling strategies for bag-of-features image
classification. InEuropean Conference on Computer Vision, 2006.
[NST+06] M. Naphade, J. R. Smith, J. Tesic, S.-F. Chang, W. Hsu, L. Kennedy, A. Hauptman,
and J. Curtis. Large-scale concept ontology for multimedia.IEEE MultiMedia,
13(3) :86–91, 2006.
[ODN+08] Robert Ortgies, Christoph Dosch, Jan Nesvadba, Adolf Proidl, Henri Gouraud,
Pieter van der Linden, Nozha Boujemaa, Jussi Karlgren, Ramon Compano, Joa-
chim Kohler, Paul King, and David Lowen. Chorus d3.3 - vision document, inter-
mediate, results of the 3rd think-tank, Novembre 2008.
[OFPA04] A. Opelt, M. Fussenegger, A. Pinz, and P. Auer. Weakhypotheses and boosting for
generic object detection and recognition. InEuropean Conference on Computer
Vision, 2004.

162 BIBLIOGRAPHIE
[Orn97] Susanne Ornager. Image retrieval : Theoretical analysis and empirical user studies
on accessing information in images. InProceedings of the ASIS Annual Meeting,
1997.
[OT01] A. Oliva and A. Torralba. Modeling the shape of the scene : a holistic representa-
tion of the spatial envelope.IJCV, 42 :145–175, 2001.
[OT02] A. Oliva and A. Torralba. Scene-centered representation from spatial envelope
descriptors. InBiologically Motivated Computer Vision, 2002.
[PBE+06] J. Ponce, T. L. Berg, M. Everingham, D. A. Forsyth, M. Hebert, S. Lazebnik,
M. Marszalek, C. Schmid, B. C. Russell, A. Torralba, C. K. I. Williams, J. Zhang,
and A. Zisserman.Toward Category-Level Object Recognition, chapter Dataset Is-
sues in Object Recognition. Springer-Verlag Lecture Notesin Computer Science,
2006.
[PDCB06] F. Perronnin, C. Dance, G. Csurka, and M. Bressan. Adapted vocabularies for
generic visual categorization. InEuropean Conference on Computer Vision, 2006.
[PDP+05] Frederic Precioso, Stamatia Dasiopoulou, Kosmas Petridis, Yiannis Kompatsia-
ris, Vaggelis Spyrou, Yannis Avrithis, and Kosmas Petridis. Knowledge-assisted
multimedia analysis module, version 1. Technical report, aceMedia, 2005.
[PFG06] S. Philipp-Foliguet and L. Guigues. Evaluation de la segmentation :etat de l’ar-
ticle, nouveaux indices et comparaison.Traitement du Signal, 23(2) :109–125,
2006.
[PFGC06] Sylvie Philipp-Foliguet, Philippe-Henri Gosselin, and Matthieu Cord. Retin sys-
tem : partial and global feature learning imageval/tasks 4 and 5. In Workshop
ImagEVAL, 2006.
[Pic06] Coralie Picault. Constitution of the imageval database, en end-user oriented ap-
proach. Technical report, Paragraphe Laboratory, Universite Paris 8, 2006.
[Pic07] Coralie Picault. Usages et pratiques de recherche des utilisateurs d’une banque
d’images : l’exemple de l’agence de photographie de presse gamma.Documenta-
liste, 44(6) :374–381, 2007.
[Pla99] John C. Platt. Probabilistic outputs for support vector machines and comparisons
to regularized likelihood methods. InAdvances in Large Margin Classifiers, 1999.
[Por80] M.F. Porter. An algorithm for suffix stripping.Program, 14(3) :130–137, 1980.
[PS05a] Andrew Payne and Sameer Singh. A benchmark for indoor/outdoor scene classi-
fication. InICAPR, 2005.
[PS05b] Andrew Payne and Sameer Singh. Indoor vs. outdoor scene classification in digital
photographs.Pattern Recognition, 38 :1533–1545, 2005.
[QBS00] R.J. Qian, P. Van Beek, and M.I. Sezan. Image retrieval using blob histograms. In
International Conference on Multimedia & Expo, 2000.

BIBLIOGRAPHIE 163
[QLVG08] Till Quack, Bastian Leibe, and Luc Van Gool. World-scale mining of objects
and events from community photo collections. InCIVR ’08 : Proceedings of the
2008 international conference on Content-based image and video retrieval, pages
47–56, New York, NY, USA, 2008. ACM.
[Ror08] Abebe Rorissa. User-generated descriptions of individual images versus labels of
groups of images : A comparison using basic level theory.Information Processing
& Management, 44(5) :1741–1753, 2008.
[RW03] Kerry Rodden and Kenneth R. Wood. How do people manage their digital pho-
tographs ? InACM CHI ’03 : Proceedings of the SIGCHI conference on Human
factors in computing systems, pages 409–416, New York, NY, USA, 2003. ACM.
[Sal71] G. Salton.The SMART Retrieval System—Experiments in Automatic Document
Processing. Prentice-Hall, Inc., Upper Saddle River, NJ, USA, 1971.
[SB91] Michael J. Swain and Dana H. Ballard. Color indexing.International Journal of
Computer Vision, Volume 7 , Issue 1 :11 – 32, 1991.
[SBM+05] Evaggelos Spyrou, Herve Le Borgne, Theofilos Mailis, Eddie Cooke, Yannis Avri-
this, and Noel O’Connor. Fusing mpeg-7 visual descriptors for image classifica-
tion. 2005.
[SBV02] N. Boujemaa S. Boughorbel and C. Vertan. Histogram-based color signatures for
image indexing. InInformation Processing and Management of Uncertainty in
Knowledge-Based Systems, 2002.
[SC03] L. Si and J. Callan. A semi-supervised learning method to merge search engine
results.ACM Transactions on Information Systems, 24 :457–491, 2003.
[Sch03] Robert E. Schapire.Nonlinear Estimation and Classification, chapter The boos-
ting approach to machine learning : An overview. Springer, 2003.
[SJ08] Pinaki Sinha and Ramesh Jain. Classification and annotation of digital photos
using optical context data. InCIVR ’08 : Proceedings of the 2008 internatio-
nal conference on Content-based image and video retrieval, pages 309–318, New
York, NY, USA, 2008. ACM.
[SM97] J. Shi and J. Malik. Normalised cuts and image segmentation. InIEEE Conf. on
Computer Vision and Pattern Recognition, 1997.
[SP97] Martin Szummer and Rosalind W. Picard. Indoor-outdoor image classification.
1997.
[SP98] M. Szummer and R. W. Picard. Indoor-outdoor image classification. InWorkshop
on Content-based Access of Image and Video Databases, 1998.
[SRE+05] J. Sivic, B. Russell, A. Efros, A. Zisserman, and W. Freeman. Discovering objects
and their location in images. InIEEE International Conference on Computer
Vision, 2005.

164 BIBLIOGRAPHIE
[SS02] B. Scholkopf and A. Smola.Learning with Kernels. MIT Press, 2002.
[SSL02] Navid Serrano, Andreas Savakis, and Jiebo Luo. A computationally efficient ap-
proach to indoor/outdoor scene classification. InICPR, 2002.
[SSL04] Navid Serrano, Andreas E. Savakis, and Jiebo Luo. Improved scene classifica-
tion using efficient low-level features and semantic cues.Pattern Recognition,
37(9) :1773–1784, 2004.
[SWS+00] Arnold W.M. Smeulders, Marcel Worring, Simone Santini,Amarnath Gupta, and
Ramesh Jain. Content-based image retrieval at the end of the early years. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 22, 2000.
[TB02] J.P. Tarel and S. Boughorbel. On the choice of similarity measures for image
retrieval by example. InACM Multimedia, 2002.
[TC01] Simon Tong and Edward Chang. Support vector machine active learning for image
retrieval. InACM International Conference on Multimedia, 2001.
[TCG08] Pierre Tirilly, Vincent Claveau, and Patrick Gros. Language modeling for bag-
of-visual words image categorization. InCIVR ’08 : Proceedings of the 2008
international conference on Content-based image and video retrieval, pages 249–
258, New York, NY, USA, 2008. ACM.
[TFF08] Antonio Torralba, Rob Fergus, and William T. Freeman. 80 million tiny images : A
large data set for nonparametric object and scene recognition. IEEE Transactions
on Pattern Analysis and Machine Intelligence, 30(11), 2008.
[TGM05] Sabrina Tollari, Herve Glotin, and Jacques Le Maitre. Enhancement of textual
images classification using segmented visual contents for image search engine.
MTAP, 2005.
[TK00] Simon Tong and Daphne Koller. Support vector machineactive learning with ap-
plications to text classification. InInternational Conference on Machine Learning,
2000.
[TLCCC06] D. Telleen-Lawton, E. Y. Chang, K. Cheng, and C. B. Chang. On usage models
of content-based image search, filtering, and annotation. In Internet Imaging VII,
SPIE, 2006.
[TM08] Tinne Tuytelaars and Krystian Mikolajczyk. Local invariant feature detectors : A
survey.Foundations and Trends in Computer Graphics and Vision, 3(3), 2008.
[TMF04] Antonio Torralba, Kevin P. Murphy, and William T. Freeman. Sharing visual fea-
tures for multiclass and multiview object detection. Technical report, MIT, 2004.
[TO03] A. Torralba and A. Oliva. Statistics of natural imagecategories.Network : Com-
putation in Neural Systems, 14 :391–412, 2003.
[Tol06] Sabrina Tollari. Indexation et recherche d’images par fusion d’informations tex-
tuelles et visuelles. PhD thesis, 2006.

BIBLIOGRAPHIE 165
[TWS05] Vincent S. Tseng, Ming-Hsiang Wang, and Ja-Hwung Su.A new method for
image classification by using multilevel association rules. In International Confe-
rence on Data Engineering, 2005.
[Vap95] Vladimir Vapnik. The Nature of Statistical Learning Theory. Springer-Verlag,
1995.
[Vap98] V. N. Vapnik.Statistical Learning Theory. John Wiley, 1998.
[VB00] C. Vertan and N. Boujemaa. Upgrading color distributions for image retrieval :
can we do better ? InInternational Conference on Visual Information Systems,
2000.
[Ven06] Anthony Ventresque. Une mesure de similarite semantique utilisant des resultats
de psychologie. InCORIA, Session Jeunes Chercheurs, pages 371–376, 2006.
2-9520326-6-1.
[VFJZ99] Aditya Vailaya, Mario Figueiredo, Anil Jain, and Hong Jiang Zhang. Content-
based hierarchical classification of vacation images. 1999.
[VFJZ01] Aditya Vailaya, Mario A. T. Figueiredo, Anil K. Jain, and Hong-Jiang Zhang.
Image classification for content-based indexing.IEEE Transactions on Image
Processing, 10, 2001.
[VJZ98] Aditya Vailaya, Anil Jain, and Hong-Jiang Zhang. Onimage classification : City
images vs. landscapes.Pattern Recognition Journal, 1998.
[VKSH06] E. L. Van Den Broek, T. Kok, T. E. Schouten, and E. Hoenkamp. Multimedia for
art retrieval (m4art). InMultimedia Content Analysis, Management, and Retrieval
- SPIE, 2006.
[vZ07] Roelof van Zwol. Flickr : Who is looking ? InIEEE/WIC/ACM International
Conference on Web Intelligence, 2007.
[VZY +02] Aditya Vailaya, HongJiang Zhang, Changjiang Yang, Feng-I Liu, and Anil K. Jain.
Automatic image orientation detection.Ieee Transactions On Image Processing,
11, 2002.
[WAC+04] Jutta Willamowski, Damian Arregui, Gabriela Csurka, Chris Dance, and Lixin
Fan. Categorizing nine visual classes using local appearance descriptors. InICPR
Workshop Learning for Adaptable Visual Systems Cambridge, 2004.
[WCM05] J. Winn, A. Criminisi, and T. Minka. Object categorization by learned universal
visual dictionary. InIEEE International Conference on Computer Vision, 2005.
[WdV03] Thijs Westerveld and Arjen P. de Vries. Experimentalevaluation of a generative
probabilistic image retrieval model on ’easy’ data. InSIGIR Multimedia Informa-
tion Retrieval Workshop, 2003.

166 BIBLIOGRAPHIE
[WFB08] Simon P. Wilson, Julien Fauqueur, and Nozha Boujemaa. Machine Learning Tech-
niques for Multimedia, chapter Mental Search in Image Databases : Implicit Ver-
sus Explicit Content Query, pages 189 – 204. Springer, 2008.
[WHY+08] Lei Wu, Xian-Sheng Hua, Nenghai Yu, Wei-Ying Ma, and Shipeng Li. Flickr
distance. InMM ’08 : Proceeding of the 16th ACM international conference on
Multimedia, pages 31–40, New York, NY, USA, 2008. ACM.
[WND+07] T. Wuytack, F. Nasr, C. Diou, P. Panagiotopoulos, T. Westerveld, T. Tsikrika,
B. Grilheres, G. Dupont, D. Schneider, ML. Viaud, A. Saulier, O. Buisson, A. Joly,
A. Verroust, P. Altendorf, Inaki Etxaniz, M. Palomino, and Y. Xu. D1.2.1 - spe-
cification of adapted corpora. Technical report, Vitalas project - FP6 - 045389,
2007.
[WY08] Wen Wu and Jie Yang. Semi-supervised learning of object categories from paired
local features. InCIVR ’08 : Proceedings of the 2008 international conference on
Content-based image and video retrieval, pages 231–238, New York, NY, USA,
2008. ACM.
[WZLM08] Xin-Jing Wang, Lei Zhang, Xirong Li, and Wei-Ying Ma. Annotating images by
mining image search results.IEEE Transactions on Pattern Analysis and Machine
Intelligence, 30(11), 2008.
[YBCD05] P.Y. Yin, B. Bhanu, K.C. Chang, and A. Dong. Integrating relevance feedback
techniques for image retrieval using reinforcement learning. IEEE Transactions
on Pattern Analysis and Machine Intelligence, 27 (10) :1536–1551, 2005.
[YFyY+05] Jian Yang, Alejandro F. Frangi, Jing yu Yang, David Zhang, and Zhong Jin. Kpca
plus lda : A complete kernel fisher discriminant framework for feature extraction
and recognition. IEEE Transactions on Pattern Analysis and Machine Intelli-
gence, 27 :230–244, 2005.
[YHB06] Itheri Yahiaoui, Nicolas Herve, and Nozha Boujemaa. Shape-based image retrie-
val in botanical collections. InPCM, 2006.
[YJHN07] Jun Yang, Y-Gang Jiang, Alex Hauptmann, and Chong-Wah Ngo. Evaluating
bag-of-visual-words representations in scene classification. In ACM Multimedia
Information Retrieval Workshop, 2007.
[YKZ04] Xing Yi, Zhongbao Kou, and Changshui Zhang. Classifiercombination based on
active learning. InICPR, 2004.
[YYH07] Jun Yang, Rong Yan, and Alexander G. Hauptmann. Cross-domain video concept
detection using adaptive svms. InACM Multimedia, 2007.
[ZBMM06] Hao Zhang, Alexander C. Berg, Michael Maire, and Jitendra Malik. Svm-knn :
Discriminative nearest neighbor classification for visualcategory recognition. In
CVPR, 2006.

BIBLIOGRAPHIE 167
[ZCJ04] Z.-H. Zhou, K.-J. Chen, and Y. Jiang. Exploiting unlabeled data in content-based
image retrieval. InProceedings of the 15th European Conference on Machine
Learning (ECML’04), Pisa, Italy, 2004.
[ZLZ02] Lei Zhang, Mingjing Li, and Hong-Jiang Zhang. Boosting image orientation de-
tection with indoor vs. outdoor classification. InIEEE Workshop on Applications
of Computer Vision, 2002.
[ZMLS05] Jianguo Zhang, Marcin Marszalek, Svetlana Lazebnik, and Cordelia Schmid. Lo-
cal features and kernels for classifcation of texture and object categories : An
in-depth study. Technical Report RR-5737, INRIA Rhone-Alpes, 665 avenue de
l’Europe, 38330 Montbonnot, France, Nov 2005.
[ZZL+05a] Ruofei Zhang, Zhongfei Zhang, Mingjing Li, Wei-Ying Ma, and HongJiang
Zhang. A probabilistic semantic model for image annotationand multi-modal
image retrieval. InICCV, 2005.
[ZZL+05b] Ruofei Zhang, Zhongfei Zhang, Mingjing Li, Wei-Ying Ma, and HongJiang
Zhang. A probabilistic semantic model for image annotationand multi-modal
image retrieval. InICCV, 2005.

168 BIBLIOGRAPHIE

ANNEXE A
Annexes
A.1 Vocabulaire
La litterature n’est pas homogene concernant les termes techniques relatifs au CBIR. Cette
confusion provient de l’emploi de vocabulaire lie au monde des bases de donnees pour des
operations qui sont differentes. Le melange entre les termes en francais et en anglais a surement
egalement joue un role dans cette confusion.
Un descripteur est une methode permettant de caracteriser une image et de comparer des
images entre elles. Il existe differentes classes de descripteurs que nous detaillerons par la suite.
Une signature est la representation d’une image qui est fournie par un descripteur. Elle
contient les caracteristiques de l’image que le descripteur est capable d’extraire.
Le termeindex sera utilise, comme dans le monde des bases de donnees, pour representer un
moyen d’acces rapidea une information. On parlera de la meme maniere de structure d’index.
On appellerabase d’imagesun ensemble d’images que l’on a souhaite regrouper. C’est
l’entite sur laquelle travaille un systeme de CBIR. On parleraegalement de collection.

170 Annexes
A.2 Logiciel
L’ensemble des experimentations effectuees pour cette these ontete realisees avec des lo-
giciels developpes en C++. Le socle communa tous ces outils est le moteur de recherche
IKONA/Maestro mis au point dans l’equipe Imedia [BJM+01]. La refonte de son architec-
ture a permis d’en faire un framework de developpement efficace pour l’integration et le test
de nouveaux composants [Her05]. Les principaux outils que nous avons concus et developpes
pendant la these sont :
– le descripteur LEOH
– l’extraction de descripteurs locaux avec unechantillonnage regulier
– la gestion complete des concepts semantiques et visuels dans IKONA, pour leur extrac-
tion, leur indexation et leur interrogation
– la strategie d’apprentissage et de predictiona base de SVM1, ainsi que sa version hierar-
chique
– un outil scriptable de creation et d’optimisation de vocabulaires visuels
– la representation generique par sacs de mots, adaptee aux textes et aux images
– adaptation en C++ de l’algorithme de lematisation de Porter
– l’extraction et la representation par sacs de paires de mots
– le mecanisme de bouclage de pertinence et la simulation des comportements des utilisa-
teurs
– un ensemble de scripts systeme permettant de paralleliser les traitements sur un cluster de
calcul
De plus, certains developpements ontegalementete realises pour des experiences qui n’ont
pasete reportees dans ce manuscrit (descripteur global couleur tenant compte d’informations
spatiales, descripteur global PCA2, algorithme d’apprentissage adaboost, outil d’enrichisse-
ment automatique d’annotationsa l’aide d’une ontologie textuelle, une application web de cap-
ture et de gestion d’images et de leur annotations sur les principaux sites d’hebergement de
photos). L’extraction des points d’interet SIFT utilise la librairie Sift++3.
A.3 Esperance de la precision moyenne
Pour un classement aleatoire de la base, on doit trouver une estimation de
E (APα (r)) =
∑r
i=1 E (Pα (i) relα (i))
r
1en utilisant la librairie LibSVM [CL01] que nous avons patchee pour l’ajout de nouveaux noyaux et l’optimi-sation de la selection des parametres
2base sur une implementation de l’ACP par Michel Cruciannu3http ://vision.ucla.edu/ vedaldi/code/siftpp/siftpp.html

A.4 Bouclage de pertinence, details pour quelques concepts visuels 171
Pourr = 1, on a
E (Pα (1) relα (1)) = E
(rel(1)
1rel(1)
)
= 1α + 0(1 − α)
= α
Pourr > 1, on fait l’hypothese reductrice de l’independance derel(r) vis-a-vis derel(i) pour
i < r. On a alors
E (Pα (i) relα (i)) = E
(i∑
j=1
relα (j)
irelα (i)
)
=1
i
(i∑
j=1
E (relα (j) relα (i))
)
=1
i
(i−1∑
j=1
E (relα (j) relα (i)) + E(relα (i))
)
=1
i
(i−1∑
j=1
α2 + α
)
=1
i
((i − 1) α2 + α
)
=α
i(1 + α (i − 1))
On a alors :
E (APα (r)) =
∑r
i=1αi(1 + α (i − 1))
r
=α
r
r∑
i=1
1
i+ α −
α
i
=α
rαr +
α
r(1 − α)
r∑
i=1
1
i
= α2 + α(1 − α)Hr
r
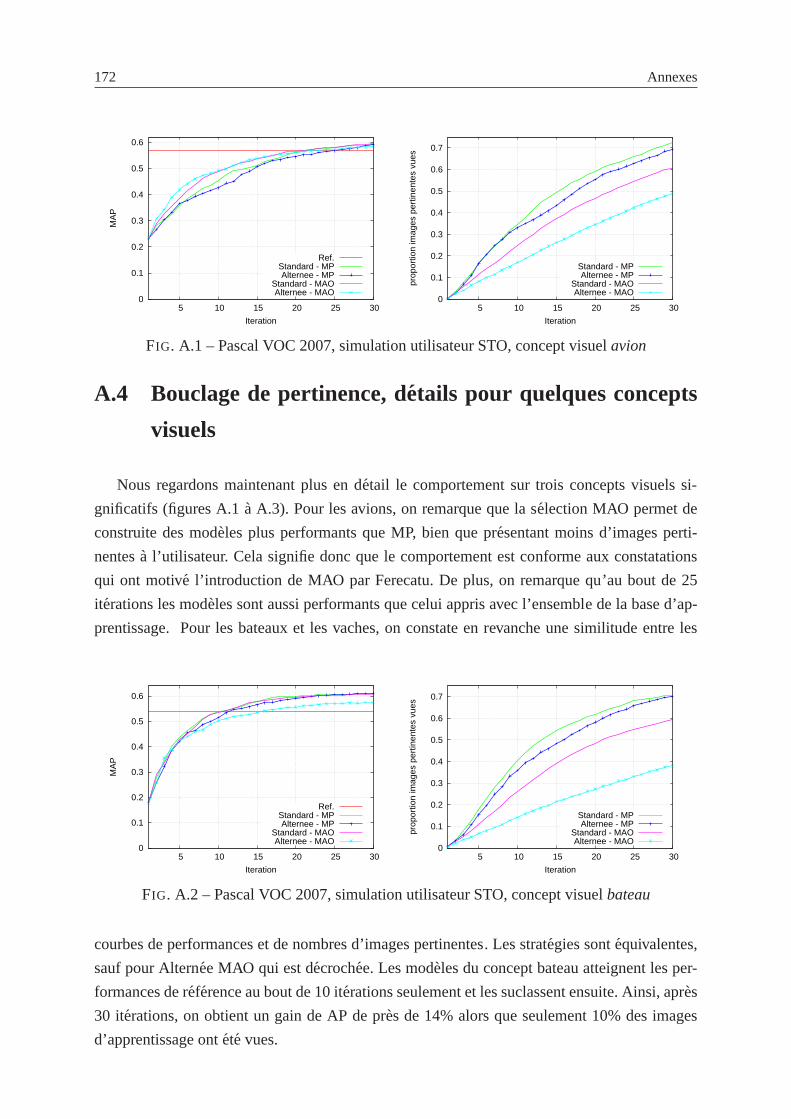
172 Annexes
0
0.1
0.2
0.3
0.4
0.5
0.6
5 10 15 20 25 30
MA
P
Iteration
Ref.Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
5 10 15 20 25 30
prop
ortio
n im
ages
per
tinen
tes
vues
Iteration
Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
FIG. A.1 – Pascal VOC 2007, simulation utilisateur STO, conceptvisuelavion
A.4 Bouclage de pertinence, details pour quelques concepts
visuels
Nous regardons maintenant plus en detail le comportement sur trois concepts visuels si-
gnificatifs (figures A.1a A.3). Pour les avions, on remarque que la selection MAO permet de
construite des modeles plus performants que MP, bien que presentant moins d’images perti-
nentesa l’utilisateur. Cela signifie donc que le comportement est conforme aux constatations
qui ont motive l’introduction de MAO par Ferecatu. De plus, on remarque qu’au bout de 25
iterations les modeles sont aussi performants que celui appris avec l’ensemble de la base d’ap-
prentissage. Pour les bateaux et les vaches, on constate en revanche une similitude entre les
0
0.1
0.2
0.3
0.4
0.5
0.6
5 10 15 20 25 30
MA
P
Iteration
Ref.Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
5 10 15 20 25 30
prop
ortio
n im
ages
per
tinen
tes
vues
Iteration
Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
FIG. A.2 – Pascal VOC 2007, simulation utilisateur STO, conceptvisuelbateau
courbes de performances et de nombres d’images pertinentes. Les strategies sontequivalentes,
sauf pour Alternee MAO qui est decrochee. Les modeles du concept bateau atteignent les per-
formances de reference au bout de 10 iterations seulement et les suclassent ensuite. Ainsi, apres
30 iterations, on obtient un gain de AP de pres de 14% alors que seulement 10% des images
d’apprentissage ontete vues.
A.5 Les 17 principales categories IPTC 173
0
0.05
0.1
0.15
0.2
5 10 15 20 25 30
MA
P
Iteration
Ref.Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
5 10 15 20 25 30
prop
ortio
n im
ages
per
tinen
tes
vues
Iteration
Standard - MPAlternee - MP
Standard - MAOAlternee - MAO
FIG. A.3 – Pascal VOC 2007, simulation utilisateur STO, conceptvisuelvache
A.5 Les 17 principales categories IPTC
ACE arts, culture, entertainmentCLJ crime, law, justiceDIS disasters, accidentsEBF economy, business, financeEDU educationENV environmentHTH healthHUM human interestLAB labour, workLIF lifestyle, leisurePOL politicsREL religionSCI science, technologySOI social issuesSPO sportsWAR unrest, conflicts, warWEA weather
FIG. A.4 – Les categories IPTC