théorique •dagnelie• statistique théorique · exercices et problèmes corrigés cottet-emard...
TRANSCRIPT

La statistique – considérée comme l’ensemble des méthodes qui ont pour but de recueillir et d’analyser des données relatives à des groupes d’individus ou d’objets – joue un rôle essentiel dans de très nombreuses disciplines. Tel est le cas, entre autres, pour les sciences du vivant : biologie, agronomie, écologie, etc.
Les deux tomes de Statistique théorique et appliquée ont précisément pour objectif de permettre aux scientifiques de disciplines très variées, en particulier les sciences du vivant, d’utiliser au mieux les méthodes statistiques classiques, sans en négliger ni les fondements ni les limites.
L’objet du tome 1 est la présentation des notions de base de statistique descriptive (à une et à deux dimensions), de statistique théorique (à une et à deux dimensions également), et d’inférence statistique (distributions d’échantillonnage, problèmes d’estimation et tests d’hypothèses).
Cet ouvrage est conçu de manière à être à la fois un manuel et un livre de référence. À cette fin, il comporte une documentation détaillée, dont plus de 350 références bibliographiques, des tables, et divers index (index bibliographique, index des traductions anglaises, index des matières et index des symboles). Son utilisation comme manuel est facilitée par la définition de différents plans de lecture, clairement indiqués tout au long du texte, et par la présence de nombreux exemples et exercices, accompagnés de leurs solutions. Des informations complémentaires sont présentées dans un site web.
} Pierre DagnelieProfesseur émérite de la Faculté des sciences agronomiques de Gembloux, il a enseigné pendant plus de 30 ans la statistique, théorique et appliquée. Il a exercé des fonctions de professeur visiteur dans plusieurs universités et établissements d’enseignement supérieur de France, de Grande-Bretagne, de Hongrie, de Suisse, d’Algérie, du Maroc et du Brésil. Il a été président de la Société Internationale de Biométrie (International Biometric Society). Il est lauréat du prix du statisticien d’expression française et Honorary Fellow de la Royal Statistical Society de Grande-Bretagne.
STTHAP1
STAT
ISTI
QU
E TH
éORI
QU
E ET
APP
LIQU
éE
•DAGNELIE•
ISBN 978-2-8041-7560-3
STATISTIQUE THéORIQUE
ET APPLIQUéE
•pierre Dagnelie•
1. STATISTIQUE DESCRIPTIvE ET BASES DE L’INFéRENCE STATISTIQUE
3e édition
1
www.deboeck.com
STATISTIQUE THéORIQUE
ET APPLIQUéE
•pierre Dagnelie•
1. STATISTIQUE DESCRIPTIvE ET BASES DE L’INFéRENCE STATISTIQUE
3e édition
STTHAP1-cov.indd 1-3 6/12/12 13:38


STATISTIQUE THÉORIQUE
ET APPLIQUÉETome 1
STTHAP1-PgeLim.indd 1 6/12/12 13:36

Chez le même éditeur
Extrait du catalogue
MathématiquesAslAngul C., Des mathématiques pour les sciences.
Concepts, méthodes et techniques pour la modélisationBogAert P., Probabilités pour scientifiques et ingénieurs.
Introduction au calcul des probabilitésCottet-emArd F., Analyse
Cottet-emArd F., Analyse 2. Calcul différentiel, intégrales multiples, séries de Fourier
Cottet-emArd F., Calcul différentiel et intégral. Exercices et problèmes corrigésCottet-emArd F., Algèbre linéaire et bilinéaire
dAgnelie P., Statistique théorique et appliquée. Tome 2. Inférence statistique à une et à deux dimensionsduPont P., Exercices corrigés de mathématiques.
Tome 1 Algèbre et géométrie. 3e éd.duPont P., Exercices corrigés de mathématiques. Tome 2. Analyse. 3e éd.
etienne d., Exercices corrigés d’algèbre linéaire. Tome 1etienne d., Exercices corrigés d’algèbre linéaire. Tome 2mArChAnd m., Outils mathématiques pour l’informaticien.
Mathématiques discrètes. 2e éd.stewArt J., Analyse, concepts et contextes. Volume 1.
Fonctions d’une variable. 3e éd.stewArt J., Analyse, concepts et contextes. Volume 2.
Fonctions de plusieurs variables. 3e éd.
•pierre DAgnelie•
STTHAP1-PgeLim.indd 2 6/12/12 13:36

STATISTIQUE THÉORIQUE
ET APPLIQUÉE
•pierre DAgnelie•
1. STATISTIQUE DESCRIPTIVE ET BASES DE L’INFÉRENCE STATISTIQUE
3e édition
STTHAP1-PgeLim.indd 3 6/12/12 13:36

Pour toute information sur notre fonds et les nouveautés dans votre domaine de spécialisation, consultez notre site web : www.deboeck.com
© De Boeck Supérieur s.a., 2013 3e édition Rue des Minimes 39, B-1000 Bruxelles Pour la traduction et l’adaptation française
Tous droits réservés pour tous pays. Il est interdit, sauf accord préalable et écrit de l’éditeur, de reproduire (notamment par photo-
copie) partiellement ou totalement le présent ouvrage, de le stocker dans une banque de don-nées ou de le communiquer au public, sous quelque forme et de quelque manière que ce soit.
Imprimé en Belgique
Dépôt légal : Bibliothèque nationale, Paris : janvier 2013 Bibliothèque royale de Belgique, Bruxelles : 2013/0074/047 ISBN 978-2-8041-7560-3
Illustration de couverture : © Eric Marechal - Fotolia.com
STTHAP1-PgeLim.indd 4 6/12/12 13:36

Avant-propos
La statistique peut etre definie comme etant l’ensemble des methodes qui ontpour but de recueillir et d’analyser des donnees, souvent numeriques, relatives ades groupes d’individus ou d’objets. Elle joue un role essentiel dans de tres nom-breuses disciplines. Tel est le cas, entre autres, pour les sciences du vivant : biologie,agronomie (au sens le plus large), ecologie, etc.
Les deux tomes de Statistique theorique et appliquee ont precisement pourobjectif de permettre aux scientifiques de disciplines tres variees, en particulier lessciences du vivant, d’utiliser au mieux les methodes statistiques classiques, sansen negliger ni les fondements ni les limites.
** *
Le tome 1 constitue un expose general, relativement elementaire, de la theoriestatistique. Seules les demonstrations les plus simples y sont donnees, de nom-breuses proprietes etant introduites intuitivement. Quant au tome 2, il presenteun vaste ensemble de methodes statistiques, toujours illustrees par des exemplesnumeriques concrets, issus de situations reelles.
Les deux volumes se terminent par une serie de tables et par divers index (indexbibliographique, index des traductions anglaises, index des matieres et index dessymboles). Ils sont completes par des exercices, accompagnes de leurs solutions, etpar diverses autres informations qui sont disponibles par l’intermediaire d’un siteweb (<www.dagnelie.be>).
Le tome 1 peut ainsi servir en particulier dans le premier cycle de l’enseigne-ment superieur, et le tome 2 dans le deuxieme cycle. Mais par leur ampleur, leurabondante bibliographie et leurs index, les deux volumes sont egalement des ou-vrages de reference, destines non seulement aux universites et aux grandes ecoles,mais aussi aux centres de recherche publics et prives.
L’utilisation des deux volumes tantot comme manuels tantot comme ouvragesde reference est precisee dans un (( mode d’emploi )), qui est presente immediate-ment apres la table des matieres (page 11). Ce (( mode d’emploi )) definit notammentdi↵erents plans de lecture ou niveaux d’etude.

6 AVANT-PROPOS
** *
Ce tome 1 commence par deux chapitres introductifs, relatifs a diverses notionsgenerales et a la collecte des donnees (chapitres 1 et 2). Il part ensuite de la statis-tique descriptive, a une et a deux dimensions (chapitres 3 et 4), pour introduire lesnotions de probabilite mathematique et de distributions theoriques, a une et a deuxdimensions egalement (chapitres 5 a 7). Il se termine par l’expose des principes del’inference statistique : distributions d’echantillonnage, problemes d’estimation ettests d’hypotheses (chapitres 8 a 10).
** *
Les deux tomes de Statistique theorique et appliquee ont remplace en 1998les deux volumes de Theorie et methodes statistiques : applications agronomiques(souvent designes par (( TMS1 )) et (( TMS2 ))), qui avaient ete tres largement dif-fuses anterieurement [Dagnelie, 1969, 1970]. Le recours a un nouveau titre re-sultait a ce moment de l’importance des modifications apportees, tant au texteproprement dit qu’a la structure generale de l’ensemble et a la documentationannexe (plus de 350 references bibliographiques pour ce seul tome 1).
De nouveaux remaniements ont ete realises lors de la publication de la deuxiemeedition en 2006-2007. Il en est de meme pour cette troisieme edition. Il s’agit essen-tiellement d’une actualisation du texte et de la documentation, et de l’introductionde quelques nouveaux developpements 1.
** *
Nous avons deja eu l’occasion de temoigner precedemment notre gratitude auxnombreuses personnes (enseignants, chercheurs, techniciens et etudiants) qui nousont aide dans la preparation des deux volumes de Theorie et methodes statis-tiques, puis de Statistique theorique et appliquee. Nous voudrions mettre encore enevidence les facilites qui nous ont ete accordees au cours des dernieres annees parles autorites de la Faculte des Sciences agronomiques de Gembloux (Belgique) etpar le Professeur Jean-Jacques Claustriaux, en matiere d’acces a la documen-tation bibliographique.
Septembre 2012.
1 Les principales modifications concernent notamment les paragraphes 1.4, 2.4, 3.8, 4.9, 6.10et 10.3.

Table des matieres
Mode d’emploi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
Premiere partie
INTRODUCTION GENERALE
ET COLLECTE DES DONNEES
Chapitre 1Introduction generale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.2 Historique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.3 Cadre general . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231.4 Documentation complementaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
Principaux mots-cles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
Chapitre 2La collecte des donnees . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.2 L’etude par enquete . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.3 L’experimentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.4 La nature, l’enregistrement et le traitement des donnees . . . . . . . . . . . . 44
Principaux mots-cles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Deuxieme partieLA STATISTIQUE DESCRIPTIVE
Chapitre 3La statistique descriptive a une dimension . . . . . . . . . . . . . . . . 533.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 543.2 Les distributions de frequences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54

8 TABLE DES MATIERES
3.3 Les representations graphiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 623.4 La reduction des donnees : generalites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 733.5 Les parametres de position . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 753.6 Les parametres de dispersion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 843.7 Les moments et les parametres de dissymetrie et d’aplatissement . . . 943.8 Le calcul de la moyenne, de la variance et des moments d’ordre
3 et 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 963.9 Quelques informations relatives a l’execution des calculs . . . . . . . . . . . 1013.10 Les nombres-indices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
Principaux mots-cles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
Chapitre 4La statistique descriptive a deux dimensions . . . . . . . . . . . . 1154.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1164.2 Les distributions de frequences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1164.3 Les representations graphiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1214.4 La reduction des donnees : generalites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1234.5 Les moments et la covariance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1254.6 Le coe�cient de correlation et le coe�cient de determination . . . . . . 1284.7 La regression lineaire au sens des moindres carres . . . . . . . . . . . . . . . . . . 1364.8 La regression lineaire au sens des moindres rectangles . . . . . . . . . . . . . . 1504.9 Le calcul de la covariance et des parametres derives . . . . . . . . . . . . . . . 1554.10 La regression curvilineaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1594.11 Quelques notions de statistique descriptive a plusieurs dimensions . 169
Principaux mots-cles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174
Troisieme partie
LA PROBABILITE MATHEMATIQUE
ET LES DISTRIBUTIONS THEORIQUES
Chapitre 5
La probabilite mathematique et les distributionstheoriques : generalites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1795.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1805.2 La notion de probabilite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1805.3 Quelques proprietes de la probabilite mathematique . . . . . . . . . . . . . . . 1835.4 La probabilite conditionnelle et l’independance stochastique . . . . . . . 1885.5 Les notions de variable aleatoire et de distribution theorique . . . . . . . 194

TABLE DES MATIERES 9
5.6 Quelques proprietes des variables aleatoires . . . . . . . . . . . . . . . . . . . . . . . . 2065.7 L’esperance mathematique et ses proprietes . . . . . . . . . . . . . . . . . . . . . . . 2155.8 Les parametres des distributions theoriques a une dimension . . . . . . . 2205.9 Les fonctions generatrices et la fonction caracteristique . . . . . . . . . . . . 235
Principaux mots-cles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 240
Chapitre 6
Les principales distributions theoriquesa une dimension . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2436.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2446.2 Les distributions binomiales et polynomiales . . . . . . . . . . . . . . . . . . . . . . . 2446.3 Les distributions hypergeometriques et hypergeometriques
generalisees . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2526.4 Les distributions de Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2566.5 Quelques autres distributions discontinues . . . . . . . . . . . . . . . . . . . . . . . . . 2616.6 Les distributions normales et log-normales . . . . . . . . . . . . . . . . . . . . . . . . . 2676.7 Les distributions t de Student . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2916.8 Les distributions �2 de Pearson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2926.9 Les distributions F de Fisher-Snedecor . . . . . . . . . . . . . . . . . . . . . . . . . 2976.10 Schema recapitulatif et notions complementaires . . . . . . . . . . . . . . . . . . . 300
Principaux mots-cles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309
Chapitre 7Les distributions theoriques a deux dimensions . . . . . . . . . 3117.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3127.2 Quelques definitions et quelques proprietes relatives aux distribu-
tions theoriques a deux dimensions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3127.3 Les parametres des distributions theoriques a deux dimensions . . . . . 3187.4 Les distributions normales a deux dimensions . . . . . . . . . . . . . . . . . . . . . . 330
Principaux mots-cles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 340Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 340
Quatrieme partie
LES PRINCIPES DE L’INFERENCE STATISTIQUE
Chapitre 8Les distributions d’echantillonnage . . . . . . . . . . . . . . . . . . . . . . . . . 3458.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3468.2 L’echantillonnage : quelques notions complementaires . . . . . . . . . . . . . . 346

10 TABLE DES MATIERES
8.3 Quelques distributions d’echantillonnage . . . . . . . . . . . . . . . . . . . . . . . . . . . 3528.4 Principes generaux relatifs aux distributions d’echantillonnage . . . . . 3708.5 Deux theoremes de convergence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 379
Principaux mots-cles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 381Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 381
Chapitre 9Les problemes d’estimation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3859.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3869.2 L’estimation de la moyenne et de la variance . . . . . . . . . . . . . . . . . . . . . . 3869.3 Principes generaux de l’estimation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3909.4 Les intervalles de confiance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 406
Principaux mots-cles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 418Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 418
Chapitre 10Les tests d’hypotheses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42110.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42210.2 Les di↵erents buts poursuivis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42210.3 Les principes et la realisation des tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42310.4 La fonction de puissance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 444
Principaux mots-cles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 456Exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 457
ANNEXES
Solutions des exercices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 461
Tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473
Index bibliographique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 479
Index des traductions anglaises . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495
Index des matieres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503
Index des symboles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 515

Mode d’emploi
Les deux tomes de Statistique theorique et appliquee sont concus de maniere apouvoir etre utilises a la fois comme manuels, selon di↵erents plans de lecture ouniveaux d’etude, et comme ouvrages de reference.
A court terme, cette solution hybride ne facilite evidemment pas la tache dujeune chercheur ou de l’etudiant qui souhaiterait disposer d’un texte le plus simplepossible. A plus long terme toutefois, cette formule permet d’eviter un obstaclegeneralement di�cile a surmonter, a savoir : passer d’un manuel auquel on s’estprogressivement habitue a un ouvrage de reference, souvent fort di↵erent par sapresentation, son vocabulaire et ses notations.
Utilisation comme manuel
En vue de l’utilisation de ce tome 1 comme manuel, trois niveaux d’etude sontdefinis a l’aide des symboles � , , d et b .
Le premier niveau, relativement elementaire, est constitue des seuls paragra-phes dont le numero est precede du signe � , a l’exclusion, dans ces paragraphes,des alineas et des exemples marques en marge des symboles d et b . Ce niveaud’etude couvre environ 170 pages du texte proprement dit (compte non tenu despages de titre, des exercices, etc.).
Le deuxieme niveau, intermediaire, correspond a l’ensemble du texte, a l’exclu-sion des paragraphes dont le numero est precede du signe et aussi des alineas etdes exemples marques des symboles d et b . Ce niveau ajoute ainsi, par comparaisonavec le premier niveau, pres de 100 pages de texte.
Enfin, le troisieme niveau, plus avance, est constitue de l’ensemble du texte.Il peut eventuellement etre etendu a d’autres documents, auxquels nous faisonsallusion ci-dessous.
Le symbole � indique donc toujours les paragraphes les plus importants (ou lesplus faciles), l’absence de symbole particulier caracterise les paragraphes d’impor-tance (ou de di�culte) intermediaire, tandis que les symboles , d et b signalentles matieres les moins importantes (ou les plus delicates).

12 MODE D’EMPLOI
Pour la facilite du lecteur, le symbole � apparaıt aussi dans les sommaires desdi↵erents chapitres, en regard des paragraphes qui doivent etre pris en considera-tion entierement ou partiellement au premier niveau.
Toujours comme manuel, ce tome 1 comprend de nombreux exemples, qui illus-trent les notions theoriques, des listes de mots-cles, presentees a la fin des differentschapitres, et des exercices, dont les enonces figurent egalement a la fin des cha-pitres et dont les solutions sont donnees immediatement apres l’ensemble du texte(page 461). L’emploi des symboles � , , d et b s’applique comme ci-dessus a cesexercices.
Pour permettre au lecteur de traiter aisement les exemples et les exercices,leurs donnees numeriques eventuelles sont disponibles sur internet a l’adresse<www.dagnelie.be/stdonn.html>.
Enfin, les dernieres pages de ce volume sont consacrees a un index des princi-paux symboles utilises (page 515).
Utilisation comme ouvrage de reference
d Comme ouvrage de reference, ce tome 1 de Statistique theorique et appliqueepeut tout naturellement etre aborde par l’intermediaire de son index des matieres(page 503). Les renvois aux di↵erents elements du texte y sont indiques par lesnumeros des paragraphes et des exemples concernes, ce qui permet une localisationsouvent plus precise que les numeros des pages.
Toujours comme document de reference, l’emploi de cet ouvrage peut etre com-plete par le recours a d’autres travaux, notamment parmi ceux qui sont cites dansl’index bibliographique (page 479). Cet index, qui comporte plus de 350 mentions,comprend a la fois des references tout a fait generales presentees au paragraphe1.4.1, des references plus particulieres citees au debut des di↵erents chapitres,et des references ponctuelles figurant dans le texte, le plus souvent a la fin desdi↵erents paragraphes, immediatement avant les exemples. Diverses indicationsrelatives a la documentation disponible sur internet sont egalement donnees auparagraphe 1.4.2.
Tres souvent, le lecteur aura interet a consulter autant que possible les ouvragesde base mentionnes au paragraphe 1.4.1 et au debut des di↵erents chapitres, voirememe certains autres documents, avant de rechercher les travaux particuliers in-diques dans le texte.
Enfin, la consultation de la litterature de langue anglaise, qui est de loin laplus abondante dans le domaine statistique, est facilitee par la presentation dansle texte des traductions des principaux termes employes et par l’utilisation del’index des traductions anglaises (page 495).b

MODE D’EMPLOI 13
Notations
En ce qui concerne les notations, nous respectons autant que possible les re-commandations de Halperin et al. [1965]. Les lettres minuscules, notamment,designent le plus souvent des valeurs observees ou des fonctions non cumulativesde probabilite (fonctions de densite de probabilite), tandis que les lettres majus-cules designent des variables aleatoires ou des fonctions cumulatives de probabilite(fonctions de repartition). De meme, les lettres grecques sont utilisees en generalpour representer les parametres des populations.
Quant aux caracteres gras, ils sont employes occasionnellement pour designersoit des vecteurs, a l’aide de lettres minuscules, soit des matrices, a l’aide de lettresmajuscules.
Execution des calculs, logiciels et tables
L’etude de ce tome 1 ne necessite le plus souvent que des calculs numeriquesrelativement elementaires, qui peuvent etre realises a l’aide d’une simple calculette,sans aucun recours a l’une ou l’autre procedure de traitement automatique desdonnees. L’emploi de moyens de calcul plus importants peut neanmoins s’avererutile dans certains cas.
d On peut penser notamment a certains logiciels specifiquement statistiques, telsque Minitab (<www.minitab.com>) ou SAS (<www.sas.com>), et aussi le logiciellibre R (<www.r-project.org>) 1 [Cornillon et al., 2008 ; Lafaye de Micheauxet al., 2011].
Une autre possibilite consiste en l’utilisation de l’un ou l’autre tableur, telqu’Excel (<www.microsoft.com>) [Georgin et Gouet, 2005 ; Morineau etChatelin, 2005 ; Vidal, 2004], eventuellement accompagne par exemple de Stat-Box (<www.grimmersoft.com>), UniStat (<unistat.com>), ou XLStat (<www.xlstat.com>). On notera toutefois que la qualite de certains des resultats fournispar les outils statistiques d’Excel est frequemment mise en cause [Keeling etPavur, 2011 ; McCullough et Heiser, 2008 ; Yalta, 2008].b
Nous donnons aussi quelques tables numeriques en fin de volume (page 473),tout en sachant parfaitement bien que la consultation de tels documents peut engeneral etre remplacee par l’utilisation d’algorithmes et de logiciels particuliers.D’autres tables figurent egalement a la fin du tome 2 de cette serie.
1 Les adresses web qui figurent dans le texte et dans l’index bibliographique ont ete controleesen aout 2012.


Premiere partie
Introduction generaleet collecte des donnees
Chapitre 1 Introduction generale
Chapitre 2 La collecte des donnees


Chapitre 1
Introduction generale
Sommaire 1
1.1� Definition1.2� Historique1.3� Cadre general1.4 Documentation complementairePrincipaux mots-cles
1 Nous rappelons que, dans les sommaires des di↵erents chapitres, le signe � indique lesparagraphes qui sont entierement ou partiellement de premiere importance, au sens du (( moded’emploi )) qui suit la table des matieres. Ainsi, les signes � qui apparaissent en marge dans lasuite de ce chapitre montrent que le paragraphe 1.1 doit etre entierement pris en considerationau premier niveau d’etude, que seuls les paragraphes 1.2.3 et 1.2.4 doivent etre consideres a cestade, et que le paragraphe 1.3 doit aussi etre entierement pris en consideration, le paragraphe 1.4pouvant etre neglige (les alineas marques par les symboles d et b devant toujours etre negligesau cours d’une premiere lecture).

18 INTRODUCTION GENERALE 1.2.1
1.1� Definition
Derive du substantif latin status (Etat), le mot statistique possede, en francaiscomme dans d’autres langues, plusieurs significations distinctes.
D’une part, utilise le plus souvent au pluriel, le terme statistiques designe toutensemble coherent de donnees, generalement numeriques, relatives a un grouped’individus ou d’objets. On parle par exemple de la ou des statistiques de laproduction agricole ou industrielle (quantites produites, prix de vente, couts deproduction, etc.), des statistiques demographiques (natalite, mortalite, etc.), desstatistiques du chomage, des statistiques des accidents de la circulation routiere,etc. Il convient toutefois de remarquer que, contrairement a une opinion commu-nement admise, cette acception du terme statistique ne concerne pas seulementdes volumes importants de donnees.
D’autre part, le mot statistique designe l’ensemble des methodes qui permettentde recueillir et d’analyser les donnees dont il vient d’etre question. C’est a cettesignification que nous nous referons dans le present ouvrage.
Enfin, le terme statistique est aussi utilise parfois pour designer l’un ou l’autreparametre, tel qu’une moyenne, calcule a partir d’un ensemble de donnees 2.
Dans la premiere definition que nous avons presentee, le qualificatif (( nume-riques )) doit etre considere dans un sens tres large. Il peut en e↵et concerneraussi bien des donnees quantitatives (resultats de comptages ou de mesures), quedes donnees qualitatives (couleurs, appreciations gustatives, etc.), voire meme destextes, codes sous forme numerique en vue d’un traitement informatique.
Informations complementaires : Bartholomew [1995], Dodge [2004], Dumas [1955],Willcox [1935].
1.2 Historique
1.2.1 Les origines de la statistique
1� Bien que des denombrements de populations humaines et de terres aient eterealises depuis la plus haute antiquite, notamment pour les besoins de la guerreet de l’impot, la statistique n’est pas une discipline fort ancienne. C’est en e↵etau cours du dix-huitieme siecle seulement que l’emploi du terme statistique s’estimpose en Allemagne, dans le sens alors limite de connaissance d’un Etat, a lasuite des travaux de Gottfried Achenwall (1719-1772).
Parallelement a cette tendance, dite aussi d’arithmetique politique, s’est de-veloppe, en France tout d’abord, le calcul des probabilites, dont l’objectif etaitau depart la resolution de problemes relatifs aux jeux de hasard. Les noms de
2 Les traductions anglaises sont d’une part statistics, a la fois pour des ensembles de donneeset pour l’ensemble des methodes, et d’autre part statistic, pour des parametres.

1.2.2 HISTORIQUE 19
Blaise Pascal (1623-1662), Abraham de Moivre (1667-1754), Daniel Bernoulli(1700-1782), Pierre Simon de Laplace (1749-1827), Carl Friedrich Gauss (1777-1855), et Simeon Denis Poisson (1781-1840) peuvent etre associes a cette deuxie-me tendance.
2� La statistique mathematique moderne peut etre consideree comme nee, audix-neuvieme siecle, de la conjonction de ces deux orientations : arithmetique po-litique d’une part et calcul des probabilites de l’autre. Un des principaux artisansde cette union est incontestablement le mathematicien et physicien belge LambertAdolphe Quetelet (1796-1874). Il est notamment l’auteur de nombreux livres etmemoires, le fondateur de plusieurs societes et organismes nationaux et internatio-naux, l’initiateur des recensements decennaux de la population, et l’organisateurdu premier Congres international de Statistique, qui s’est tenu a Bruxelles en 1853.
Parmi les statisticiens de cette epoque, on peut citer egalement, en Grande-Bretagne, Charles Babbage (1792-1871), a qui on doit entre autres choses unepremiere machine a calculer automatique et la fondation en 1834 de la premieresociete de statistique, la Statistical Society of London, ainsi que Francis Gal-ton (1822-1911), auteur de travaux de base relatifs notamment aux notions decorrelation et de regression.
Informations complementaires : Droesbeke et Tassi [1997], Kendall [1972], Lewin[2010], Stigler [1986], Westergaard [1932].
1.2.2 La premiere moitie du vingtieme siecle
1� La premiere moitie du vingtieme siecle est essentiellement marquee, dans ledomaine statistique, par le developpement de methodes de plus en plus nombreuseset par l’utilisation de ces methodes dans des secteurs d’application de plus en plusdiversifies.
Sans essayer d’etre exhaustif, nous voudrions citer ici quelques tendances quinous paraissent preponderantes, en en donnant une certaine chronologie.
2� Apres les premieres applications aux sciences politiques et sociales, realiseesdurant le dix-neuvieme siecle, les annees 1900 voient l’introduction de la statis-tique dans les sciences biologiques et psychologiques, donnant naissance respecti-vement a la biometrie 3 et la psychometrie 4. Les noms de Karl Pearson (1857-1936), Charles Edward Spearman (1863-1945), George Udny Yule (1871-1951),et William Sealy Gosset (1876-1937), qui publia ses travaux sous le pseudonymede Student, peuvent etre associes a ces deux tendances 5.
3 En anglais : biometry, biometrics.4 En anglais : psychometry, psychometrics.5 Durant tout le vingtieme siecle, le mot (( biometrie )) a ete utilise presque exclusivement pour
designer l’utilisation des methodes statistiques et mathematiques dans le domaine de la biologie,au sens large. Plus recemment, la signification du mot (( biometrie )) a ete etendue aux methodesd’identification des personnes en fonction de caracteres biologiques, tels que les empreintes digi-tales, les traits du visage, les caracteristiques de l’iris ou de la retine, etc.

20 INTRODUCTION GENERALE 1.2.3
Les annees 1920 sont ensuite dominees par la forte personnalite du statisti-cien britannique Ronald Aylmer Fisher (1890-1962), auquel on doit notammentle developpement des plans d’experience 6 et l’analyse de la variance et de la co-variance 7, qui occupent une place preponderante dans le domaine agronomiqued’abord, et dans de nombreux autres secteurs ensuite.
Les annees 1930 sont marquees par de nouvelles applications de la statistiqueen economie, donnant naissance a l’econometrie 8, et par l’utilisation de l’outilstatistique dans le domaine industriel, en matiere de maıtrise ou de controle de laqualite 9 des produits manufactures.
Enfin, a partir de 1940, la statistique intervient de facon de plus en plus fre-quente dans certains problemes de gestion, en relation avec le developpement dela recherche operationnelle 10.
Informations complementaires : Droesbeke et Tassi [1997], Kendall [1972].
1.2.3� La deuxieme moitie du vingtieme siecle
1� Durant la deuxieme moitie du vingtieme siecle, l’histoire de la statistiqueest etroitement liee au developpement de l’informatique.
C’est en e↵et vers 1955 que les premiers ordinateurs sont commercialises etintroduits dans les services administratifs et universitaires de statistique. Tresrapidement, ces nouveaux outils y prennent une place considerable, non seulementsur le plan pratique, en ce qui concerne l’emploi des methodes statistiques, maisaussi sur le plan theorique, en matiere de recherche dans le domaine statistique.
2� Schematiquement, on peut considerer que l’ordinateur a presque toujours eteutilise, dans un premier temps, pour e↵ectuer plus rapidement ou plus facilementque par le passe les travaux qui etaient realises anterieurement a l’aide de machinesa calculer de bureau. Dans un deuxieme stade, l’ordinateur a permis l’emploi demethodes statistiques deja anciennes, qui n’avaient pas ete utilisees en pratique ouqui etaient restees sous-employees, en raison precisement de l’importance des cal-culs qu’elles necessitaient. Puis, le developpement de l’informatique a provoque lanaissance de nouvelles methodes statistiques et de nouvelles procedures de calcul.
Parallelement, l’ordinateur a aussi largement influence l’enseignement de la sta-tistique, notamment par les facilites qu’il o↵re en matiere de resolution d’exercices.
Le mouvement ainsi observe d’une maniere generale depuis 1955 s’est conside-rablement accelere a partir de 1975 environ, du fait de l’introduction des micro-ordinateurs ou ordinateurs personnels, de l’augmentation tres rapide de leurs per-formances, et de la mise sur le marche de logiciels de plus en plus conviviaux.
6 En anglais : experimental design.7 En anglais : analysis of variance, analysis of covariance.8 En anglais : econometry, econometrics.9 En anglais : quality control.
10 En anglais : operational research, operations research.

1.2.3 HISTORIQUE 21
3� L’analyse multidimensionnelle ou analyse statistique a plusieurs variables 11,c’est-a-dire l’etude simultanee de plus de deux caracteristiques des di↵erents indi-vidus consideres, constitue un exemple typique de methodes tres largement ante-rieures a la venue de l’ordinateur, mais ayant connu une expansion considerable apartir des annees 1960, du fait des nouveaux moyens de calcul disponibles.
Les methodes du (( jackknife )) et du (( bootstrap )) ou, d’une maniere plus gene-rale, de reechantillonnage 12 se sont par contre entierement developpees en raisonmeme de l’existence de l’ordinateur. Ces methodes sont d’ailleurs parfois qualifieesde methodes faisant un usage intensif de l’ordinateur 13.
On peut citer aussi les multiples possibilites o↵ertes en matiere de conception degraphiques, la tendance francaise de l’analyse des donnees, comparable a l’analysemultidimensionnelle, les methodes de simulation 14, les methodes dites robustes 15,les methodes bayesiennes ou neo-bayesiennes 16, la modelisation 17, et l’utilisationde divers modeles statistiques nouveaux, tels que le modele lineaire ou lineairegeneral 18, le modele lineaire mixte 19 et le modele lineaire generalise 20.
4� Parallelement a ce developpement important des methodes statistiques, ona assiste, au cours de la deuxieme moitie du vingtieme siecle, a une tres largeexpansion du champ d’application de ces methodes.
Le secteur de la recherche pharmaceutique ou medicale est progressivementdevenu un des plus grands utilisateurs des methodes statistiques, donnant nais-sance a ce qui est souvent appele biostatistique 21. Mais a ce secteur et a ceux quenous avons deja mentionnes au paragraphe 1.2.2 (agronomie, biologie, economie,psychologie et controle de la qualite), on peut ajouter la physique et les sciences del’ingenieur, la meteorologie et la climatologie, la geologie et la geographie, l’ecologieet l’environnement, la chimie, la genetique et la biologie moleculaire, la sociologie,les sciences de l’education, et aussi les assurances, l’archeologie, la linguistique, ledroit, etc.
Informations complementaires : en ce qui concerne l’influence de l’informatique sur lastatistique, Jeffers [1995], Murphy [1985], Nelder [1984], Victor [1984a, 1984b] ; ence qui concerne l’evolution de la statistique, Armitage et David [1996], Good [1990],Heyde [1981].
11 En anglais : multivariate analysis.12 En anglais : resampling.13 En anglais : computer-intensive method.14 En anglais : simulation.15 En anglais : robust method.16 En anglais : Bayesian method, neo-Bayesian method.17 En anglais : modelling.18 En anglais : linear model, general linear model.19 En anglais : linear mixed model.20 En anglais : generalized linear model.21 En anglais : biostatistics.

22 INTRODUCTION GENERALE 1.2.4
1.2.4� Quelques tendances recentes et perspectives
1� L’informatique, qui a ete un des principaux moteurs du developpement dela statistique durant la deuxieme moitie du vingtieme siecle, semble devoir gardercette fonction pendant de nombreuses annees encore. L’importance de l’ordina-teur s’est d’ailleurs progressivement accentuee au fil du temps, la simple evolutioninitiale des capacites de memoire et de vitesse de traitement de l’information sedoublant de possibilites d’acquisition automatique de donnees et de liaison entreordinateurs, sous forme de reseaux.
Une consequence de cette evolution est la constitution et la necessite de traiterde grandes bases de donnees 22, dont l’interconnexion permet de former de vastesensembles parfois qualifies d’entrepots de donnees 23. Ces bases et ces entrepots dedonnees sont souvent caracterises, non seulement par leur volume, mais egalementpar des structures relativement complexes et par le caractere tres incomplet desdonnees enregistrees.
2� Quelques tendances recentes, qui se sont developpees aux frontieres de lastatistique traditionnelle et qui sont aussi des perspectives d’avenir, peuvent etrepointees dans ce contexte.
La fouille ou l’extraction des donnees 24, par exemple, a pour but d’identifierautant que possible certaines informations particulieres au sein de vastes ensemblesde donnees. De meme, la methode des reseaux de neurones ou reseaux de neuronesartificiels 25 a pour objet d’etablir ou de modeliser des relations complexes liantde nombreuses variables.
Dans le domaine biologique, on peut citer egalement l’etude du genome ougenomique 26, ou encore bioinformatique 27, dans un sens plus large pouvant inclureen outre l’etude des structures moleculaires.
Enfin, un autre exemple d’evolution recente est donne par la tendance dite (( sixsigma )), dont l’objectif est une gestion optimale de la qualite, par la recherche etl’elimination des defauts, dans des entreprises de toute nature.
Informations complementaires : d’une maniere generale, Hand [2009], Lindsay et al.[2004], Raftery et al. [2002] 28 ; d’une facon plus specifique, Besse et al. [2001], Mont-gomery et Woodall [2008], Sebastiani et al. [2003].
22 En anglais : database.23 En anglais : datawarehouse.24 En anglais : data mining.25 En anglais : neural network, artificial neural network.26 En anglais : genomics.27 En anglais : bioinformatics.28 Cet ouvrage (Statistics in the 21st century) reunit un ensemble de courtes notes qui ont ete
publiees dans les quatre fascicules du Journal of the American Statistical Association de l’annee2000.

1.3.2 CADRE GENERAL 23
1.3 Cadre general
1.3.1� Les di↵erentes etapes de toute etude statistique
1� Toute etude statistique peut etre decomposee en deux phases au moins :le rassemblement ou la collecte des donnees d’une part, et leur analyse ou leurinterpretation d’autre part.
La collecte des donnees peut etre realisee soit par la simple observation desphenomenes auxquels on s’interesse, tels qu’ils se produisent naturellement, soitpar l’experimentation, c’est-a-dire en provoquant volontairement l’apparition decertains phenomenes controles.
Quant a l’analyse statistique, elle peut elle-meme etre decomposee en deuxetapes, l’une deductive ou descriptive, l’autre inductive.
La statistique descriptive a pour but de resumer et de presenter les donneesobservees d’une maniere telle qu’on puisse en prendre connaissance aisement, parexemple sous la forme de tableaux ou de graphiques.
L’inference statistique permet d’etendre ou de generaliser dans certaines condi-tions les conclusions ainsi obtenues. Tres souvent en e↵et, l’observation ou l’ex-perimentation ne concerne qu’une fraction des individus auxquels on s’interessereellement. Les conclusions relatives a cette fraction, appelee echantillon, doiventalors etre etendues autant que possible a l’ensemble des individus, formant la po-pulation. Cette phase inductive comporte evidemment certains risques d’erreur,qui peuvent etre mesures en faisant appel a la theorie des probabilites.
2� Ces di↵erentes etapes de toute etude statistique ne sont cependant pas in-dependantes les unes des autres. Les methodes de l’inference statistique ne sontapplicables en e↵et que dans des conditions particulieres, parfois fort restrictives.Il en resulte notamment que l’observation et l’experimentation doivent etre orga-nisees de maniere a repondre autant que possible a ces conditions.
1.3.2� Plan du tome 1
Au-dela de la presente introduction generale, la premiere partie de ce tome 1est consacree a l’expose, en termes tres simples, de notions de base relatives a lacollecte des donnees (chapitre 2).
Une deuxieme partie traite ensuite de la statistique descriptive, tant a unedimension (chapitre 3) qu’a deux dimensions (chapitre 4).
Apres quoi, une troisieme partie reunit diverses notions relatives au calcul desprobabilites et aux distributions theoriques, d’une part de facon generale (chapi-tre 5), et d’autre part en ce qui concerne plus particulierement les distributionsa une dimension (chapitre 6) et a deux dimensions (chapitre 7). La connaissance

24 INTRODUCTION GENERALE 1.4.1
prealable de notions de statistique descriptive permet, a ce stade, une presentationaussi intuitive que possible des fondements theoriques de la statistique.
Enfin, une quatrieme partie est consacree aux principes de base de l’inferencestatistique : distributions d’echantillonnage (chapitre 8), problemes d’estimation(chapitre 9) et tests d’hypotheses (chapitre 10).
Comme nous l’avons deja signale, cet ensemble de chapitres est suivi, sousforme d’annexes, des solutions des exercices, d’un recueil de tables et d’une seried’index.
1.4 Documentation complementaire
1.4.1 Livres et revues
1� Avant d’entrer dans le vif du sujet, nous voudrions donner quelques indi-cations relatives au choix eventuel d’autres ouvrages a consulter et aux diversessources d’informations auxquelles on peut avantageusement avoir recours dans ledomaine statistique.
Les livres relatifs a la statistique et a ses applications sont extremement nom-breux, tout particulierement en langue anglaise, ce qui rend souvent di�cile lechoix eventuel de l’un ou l’autre d’entre eux. Le cas echeant, un tel choix doit etrebase notamment sur l’objectif poursuivi (etude de la theorie et/ou des applicationsa telle ou telle discipline), et aussi sur le niveau mathematique souhaite.
Nous ne mentionnons ici que les principaux dictionnaires et encyclopedies, ainsique quelques livres generaux rediges en francais, a savoir :les dictionnaires explicatifs et encyclopediques de Dodge [2004] (Statistique : dic-
tionnaire encyclopedique), d’Everitt et Skrondal [2010] (The Cambridgedictionary of statistics), de Rasch et al. [1994] (Elsevier’s dictionary of bio-metry in English, French, Spanish, Dutch, German, Italian and Russian), etd’Upton et Cook [2008] (A dictionary of statistics) ;
les encyclopedies en plusieurs volumes d’Armitage et Colton [2005] (Ency-clopedia of biostatistics) et de Kotz et al. [2006] (Encyclopedia of statisticalsciences) 29 ;
les livres de Dehon et al. [2008] (Elements de statistique), de Saporta [2006](Probabilites, analyse des donnees et statistique), et de Tassi [2004] (Methodesstatistiques).
2� Des recueils de tables peuvent aussi etre utiles. Les plus courants sont ceuxde Fisher et Yates [1982] (Statistical tables for biological, agricultural and med-ical research), et de Pearson et Hartley [1966-1972] (Biometrika tables forstatisticians).
29 Ou les documents anterieurs de Kotz et al., a savoir : Kotz et Johnson [1982-1988, 1989],et Kotz et al. [1997-1999].

1.4.2 DOCUMENTATION BIBLIOGRAPHIQUE 25
D’autres recueils sont dus notamment a Hald [1952], Lindley et Scott[1995], Owen [1962], Zwillinger [2003], et Zwillinger et Kokoska [1999].
3� Quant aux revues, et dans l’optique de ces deux tomes de Statistique theo-rique et appliquee, on peut citer en priorite les titres The American Statistician,Biometrical Journal, Computational Statistics and Data Analysis, Journal of Ap-plied Statistics, et Journal of Statistical Planning and Inference.
Peuvent eventuellement etre ajoutes : Biometrics, Communications in Statis-tics Theory and Methods, Journal de la Societe Francaise de Statistique, StatisticalScience, et Statistics in Medicine, voire encore bien d’autres.
4� On remarquera ainsi, de facon flagrante, que la litterature de langue anglaiseest largement preponderante dans le domaine statistique. Mais la presentationdans tout le texte des traductions des principaux termes utilises et l’index destraductions anglaises qui figure en fin de volume devraient faciliter la consultationdes divers documents.
Informations complementaires : Murphy [1997], Theoharakis et Skordia [2003].
1.4.2 Documentation par internet
1� Le reseau internet o↵re egalement de tres larges possibilites en matiere dedocumentation. Les quelques indications que nous donnons ici sont toutes relativesuniquement a des sites ou des documents qui peuvent etre consultes ou obtenusgratuitement.
On notera cependant que les informations qui concernent les di↵erents sitesweb sont fournies a titre purement indicatif, ces informations pouvant en e↵etdevenir caduques a tout moment, et d’autres sites tout aussi interessants pouvantegalement etre developpes a tout moment.
2� En ce qui concerne les revues, les tables des matieres et les resumes desarticles de la plupart d’entre elles sont integralement disponibles sur internet. Lesadresses des sites web de plusieurs dizaines de revues, essentiellement consacreesa la statistique, sont donnees notamment par <www.stata.com/links/journals4.html>.
En outre, pour certaines revues, les textes complets des articles sont egalementaccessibles. Tel est le cas, entre autres, pour les titres suivants : Electronic Journalof Statistics (<imstat.org/ejs>), Journal de la Societe Francaise de Statistique(<smf4.emath.fr/Publications/JSFdS>), Journal of Statistical Education (<www.amstat.org/publications/jse>), et Revue Modulad (<www.modulad.fr>).
3� D’autre part, de nombreux portails donnent acces a des informations tresdiversifiees (cours, lexiques, logiciels, etc). Tel est la cas, par exemple, pour SMEL(<mistis.inrialpes.fr/software/SMEL/index.html>), StatSci (<www.statsci.org>)et SurfStat (<surfstat.anu.edu.au/surfstat-home/surfstat-main.html>).

26 INTRODUCTION GENERALE
Mais on pourrait citer en outre <www.agro-montpellier.fr/cnam-lr/statnet>,<www.sfds.asso.fr/190-Polys denseignement>, <www.statsoft.com/textbook>,<www.stata.com/links>, etc.
4� Enfin, et d’une maniere tout a fait generale, des recherches peuvent etree↵ectuees a l’aide des moteurs de recherche classiques, tels que Google (<www.google.com>), Yahoo (<search.yahoo.com>), etc., et plus particulierement les ver-sions Books et Scholar de Google, respectivement pour les livres et pour les articlesde revues (<books.google.com/advanced book search> et <scholar.google.com/advanced scholar search>).
On sera cependant toujours tres circonspect lors de la consultation de sitesparticuliers dont les auteurs ne seraient pas bien connus ou bien identifies.
5� Nous tenons a souligner le fait que la bibliographie classique et la documen-tation par internet doivent etre considerees comme complementaires, et non pascomme exclusives l’une de l’autre.
D’une part, les references qui sont citees dans l’index bibliographique du presentouvrage ou eventuellement dans d’autres documents peuvent servir de point dedepart pour des recherches sur internet, notamment a l’aide de la version Scholarde Google. Et d’autre part, comme nous l’avons signale, le reseau internet permetd’avoir largement acces aux revues imprimees traditionnelles.
Informations complementaires : Bringe et Le Guen [2002], Larreamendy-Joers et al.[2005], Shackman [2010].
Principaux mots-cles
Statistique, statistiques.Collecte des donnees, observation, experimentation.Analyse statistique, statistique descriptive, inference statistique.

Chapitre 2
La collecte des donnees
Sommaire
2.1� Introduction2.2� L’etude par enquete2.3� L’experimentation2.4� La nature, l’enregistrement et le traitement des donneesPrincipaux mots-cles

28 COLLECTE DES DONNEES 2.2.1
2.1� Introduction
1� Comme nous l’avons signale anterieurement (§ 1.3.2), nous consacrons cechapitre 2 a la presentation, en termes tres simples, de notions de base relativesa la collecte des donnees, c’est-a-dire a ce qui constitue normalement la premierephase de toute etude statistique.
Nous envisagerons successivement les questions qui concernent les etudes parenquete (§ 2.2), les problemes d’experimentation (§ 2.3), et les questions relatives ala nature, a l’enregistrement et au traitement des donnees (§ 2.4). Nous reviendronsulterieurement de facon plus detaillee sur certains de ces sujets, lorsque nous auronspresente diverses notions de calcul des probabilites et de statistique theorique.
2� L’etude par enquete et l’experimentation doivent normalement etre organi-sees, l’une et l’autre, dans des conditions telles que de nombreux elements (choixdes unites ou des individus observes, a↵ectation aux di↵erentes unites experimen-tales des di↵erents traitements qui sont compares, etc.) soient parfaitement maı-trises. Dans certains cas, et notamment dans certaines enquetes retrospectives, lescirconstances ne permettent pas de maıtriser de tels elements. L’etude est alorsbasee sur une simple accumulation d’observations, sans qu’une structure ou unordre precis puisse etre preetabli.
On parle dans ce cas d’etude par observation 1. Nous ne traitons pas ce sujetdans le present ouvrage.
Informations complementaires : en ce qui concerne l’observation par enquete, Ardilly[2006], Barnett [2002], Dussaix et Grosbras [1993], Thompson [2002], Tille [2001] ;en ce qui concerne l’experimentation, Dagnelie [2012], Fleiss [1999], Goupy et Creigh-ton [2006], Kuehl [2000], Montgomery [2005] ; en ce qui concerne l’etude par obser-vation : Kish [2004], Rosenbaum [2002, 2010], Smith et Sugden [1988].
2.2 L’etude par enquete
2.2.1� Principes generaux
1� Dans le domaine statistique, on appelle enquete ou, parfois, inventaire 2
l’ensemble des operations qui ont pour but de collecter de facon organisee desinformations relatives a un groupe d’individus ou d’elements, observes dans leurmilieu ou dans leur cadre habituel.
Les individus ou les elements en question, egalement appeles unites de base ouunites statistiques 3, peuvent etre aussi bien des personnes humaines que des ani-
1 En anglais : observational study, uncontrolled observational study.2 En anglais : survey.3 En anglais : unit.

2.2.2 ETUDE PAR ENQUETE 29
maux, des plantes, des groupes de personnes (familles, menages, etc.), des groupesd’animaux, des groupes de plantes, ou des elements de toute autre nature (entre-prises industrielles ou commerciales, exploitations agricoles, machines d’un typedonne, etc.). L’ensemble des unites auxquelles on s’interesse est appele populationou univers ou ensemble statistique 4.
2� Quand toutes les unites de la population consideree sont e↵ectivement ob-servees individuellement, l’enquete est dite complete ou exhaustive. Elle est alorsappelee aussi recensement 5.
Quand au contraire, pour reduire l’importance du travail de collecte des don-nees, une partie seulement des individus ou des elements de la population sontreellement observes, l’enquete est dite partielle ou par echantillonnage. Elle estegalement appelee parfois sondage 6.
La partie de la population qui est reellement observee constitue l’echantillon 7,et l’operation de choix de cette fraction de la population est precisement l’operationd’echantillonnage ou de sondage 8. En outre, lorsqu’il est question d’echantillon-nage, la population de depart est souvent qualifiee aussi de population-parent.
3� Les principaux problemes qui se posent dans la preparation ou la planifi-cation 9 de toute enquete, complete ou partielle, sont la definition de l’unite debase et de la population, la definition des observations a realiser, et le choix d’unemethode de collecte des donnees.
Dans le cas des enquetes partielles, a ces di↵erentes questions, s’ajoutent quel-ques problemes supplementaires, tels le choix d’une methode d’echantillonnage etla determination de la taille de l’echantillon.
2.2.2 La definition de l’unite de base et de la population
1� La definition de l’unite de base et de la population, qui constitue ce qu’onappelle aussi la delimitation de l’enquete, est en realite un probleme beaucoup pluscomplexe qu’il n’y paraıt a premiere vue. Nous illustrons ce fait par deux exemples,choisis parmi les plus simples, et a propos de ces exemples, par diverses questions.
2� Le premier exemple concerne la realisation d’un recensement de populationhumaine, normalement base sur l’etude individuelle de chacun des groupes depersonnes qui vivent en commun, dans un meme logement ou (( sous un memetoit )).
4 En anglais : population.5 En anglais : census.6 En anglais : sample survey.7 En anglais : sample.8 En anglais : sampling.9 En anglais : planning.

30 COLLECTE DES DONNEES 2.2.2
Faut-il, dans ce cas, partir de la notion de famille ou de la notion de menage ?Et comment definir exactement ces deux notions ? Qu’est-ce que vivre en communou (( sous un meme toit )), et qu’est-ce qu’un logement ? Comment faut-il considererles communautes, militaires ou religieuses notamment ?
Si le recensement s’etend a un certain territoire administratif, tel qu’un pays,comment faut-il traiter le cas des personnes qui, venues de l’exterieur, se trouventdans le territoire considere au moment de l’enquete, pour une periode plus oumoins longue (travailleurs immigres, agents diplomatiques, membres du personneldes institutions internationales, familles de ces di↵erentes categories de personnes,hommes d’a↵aires, touristes, etc.) ? Inversement, comment faut-il considerer lespersonnes qui, issues du territoire etudie, se trouvent pour une periode plus oumoins longue a l’exterieur de celui-ci ?
Et, a l’interieur du territoire en question, ou faut-il comptabiliser (dans quelleprovince, dans quelle commune) les personnes qui ne vivent pas constamment aumeme endroit (travailleurs saisonniers, etudiants, personnes hospitalisees, occu-pants de (( logements mobiles )), tels que bateaux et caravanes, etc.) ? Commenteviter aussi les doubles comptages ou, inversement, les oublis, qui peuvent etre liesnotamment aux residences secondaires (de fin de semaine, d’ete ou d’hiver) ?
3� D’autre part, au cours d’un recensement agricole, comment definir de faconprecise la notion meme d’exploitation agricole ? En particulier, a partir de quelledimension (en superficie ou en nombre de tetes de betail), faut-il considerer qu’ils’agit reellement d’une (( exploitation )) ? Comment traiter les jardins, les vergerset les petits elevages familiaux, les jardins, les vergers et les elevages des com-munautes (communautes religieuses et pensionnats, par exemple), les terres et lesinstallations experimentales des centres de recherche, etc. ?
4� Nous ne souhaitons nullement tenter de repondre ici a ces di↵erentes inter-rogations, et a toutes les autres questions qui pourraient etre soulevees dans cesdeux cas, ou dans d’autres situations semblables. Nous tenons seulement a insisterdes le depart sur l’absolue necessite de se poser de telles questions et d’y repondrede facon precise avant toute enquete statistique, et aussi sur la necessite de donnerdes indications detaillees a ce sujet dans tout rapport, memoire ou publication.
De meme, le lecteur de tout rapport, memoire ou publication doit toujours exa-miner avec circonspection les resultats dont il serait amene a prendre connaissance,si des reponses circonstanciees a de telles questions ne sont pas donnees.
Pour illustrer ce fait, nous ajoutons simplement, a titre d’indication, que sansaucune anomalie d’aucune sorte, la superficie moyenne des exploitations agricolesrecensees en Belgique etait, en 1987, de 14,6 hectares en considerant toutes les(( exploitations )), quelle que soit leur etendue, et de 17,2 hectares (soit une diffe-rence de plus de 15 %) en limitant conventionnellement l’observation aux seulesexploitations de 1 hectare au moins (tableau 3.2.3).

2.2.3 ETUDE PAR ENQUETE 31
2.2.3 La definition des observations et le choixd’une methode de collecte des donnees
1� Les observations a realiser au cours d’une enquete doivent aussi etre parfai-tement definies dans tous les cas, en fonction notamment du but poursuivi.
S’il s’agit d’observations qualitatives, telles que l’etat civil ou la profession dansun recensement de population ou le type d’exploitation dans un recensement agri-cole, la signification exacte de tous les termes utilises doit etre precisee de manierenon ambigue. De meme, s’il s’agit d’observations quantitatives, telles que le nombrede pieces d’habitation d’un logement ou la superficie sous labour d’une exploita-tion agricole, non seulement les termes utilises doivent etre definis de facon tresprecise, mais en outre, le mode de determination des valeurs numeriques (comp-tage, mesure, estimation visuelle) et les unites de mesure doivent etre clairementspecifies.
Pour illustrer les problemes auxquels on peut etre confronte dans ces quelquescas, il su�t de penser, d’une part, en matiere de professions, aux di�cultes decomptabilisation des travailleurs a temps partiel, des travailleurs aidant un membrede leur famille et des personnes travaillant pour plusieurs employeurs, et d’autrepart, en ce qui concerne les nombres de pieces d’habitation, a la facon de compterpar exemple les cuisines, salles de bain, buanderies, o�ces, debarras, etc.
2� Un autre point important, en matiere de definition des observations, est lafixation de la date a laquelle les observations doivent etre faites, s’il est possiblede les realiser toutes simultanement, ou de la date a laquelle les observations sontsensees avoir ete faites, si la realisation de l’enquete n’est pas instantanee, ou en-core la definition de la periode couverte par l’enquete, si celle-ci concerne, non pasun instant donne, mais bien un certain intervalle de temps.
Il ne faut pas confondre par exemple le nombre de foyers de fievre aphteuse oude peste porcine observes a un moment donne, et le nombre de nouveaux foyersde fievre aphteuse ou de peste porcine observes au cours d’une periode donnee.
3� Quant aux methodes de collecte des observations, les principales possibilitesclassiques sont, d’une part, l’envoi de questionnaires par la poste et leur retourpar la meme filiere, et d’autre part, l’envoi d’enqueteurs, ainsi que des methodesmixtes, telles qu’un envoi de questionnaires prealable au passage d’enqueteurs. Ondoit y ajouter les enquetes, de plus en plus nombreuses, qui sont realisees sousdifferentes formes par telephone et par internet.
Dans tous les cas, une attention particuliere doit etre accordee a la formationeventuelle des enqueteurs, et a la preparation des questionnaires et de tous lesdocuments de travail, que sont par exemple les instructions ecrites donnees auxenqueteurs. Pour eviter des deboires au cours de l’enquete proprement dite, on ad’ailleurs souvent interet a mettre sur pied une pre-enquete ou enquete-pilote 10,
10 En anglais : pilot survey, exploratory survey.

32 COLLECTE DES DONNEES 2.2.4
destinee uniquement a controler sur un petit nombre d’unites la qualite des ques-tionnaires et, le cas echeant, des enqueteurs.
Au moment du depouillement des resultats de l’enquete, on doit egalement etreattentif au probleme des absences de reponses, aussi appelees non-reponses 11, quipeuvent constituer un danger particulierement grand dans le cas des enquetesrealisees par voie postale, par telephone et par internet.
2.2.4 Quelques methodes d’echantillonnage
1� Pour les enquetes par echantillonnage, une premiere facon de constituerl’echantillon consiste a choisir une a une, et independamment les unes des autres,chacune des unites qui seront observees, en donnant a toutes les unites de la po-pulation des chances egales d’etre choisies. Un tel echantillonnage est dit aleatoireet simple ou completement aleatoire 12.
Dans de nombreuses situations, la constitution d’echantillons de ce type peutetre realisee en numerotant de facon continue toutes les unites de la populationet en choisissant (( au hasard )) le nombre voulu de numeros, par l’une ou l’autremethode de tirage au sort. Nous reviendrons ulterieurement, de facon plus precise,sur ce point (§ 8.2).
2� Une autre procedure consiste a choisir comme ci-dessus une premiere unite,et ensuite, a partir de celle-ci, de facon systematique ou reguliere, les autres unitesqui doivent constituer l’echantillon.
Tel peut etre le cas, dans une liste de personnes, en choisissant par exemple unnom au hasard parmi les 20 premiers noms de la liste, et ensuite regulierement, apartir de celui-ci, un nom sur 20 (par exemple le 7eme nom pour commencer, puisle 27eme nom, le 47eme nom, le 67eme nom, etc.).
Tel peut etre le cas egalement, a deux dimensions, en agissant de la meme facondans les deux directions. Par exemple, dans un champ de betteraves, on pourraitchoisir de facon systematique des lignes de betteraves et, dans ces lignes, de faconsystematique ou a intervalle regulier, des betteraves (par exemple la 3eme ligne, la13eme ligne, la 23eme ligne, etc., et dans chacune de ces lignes, la 4eme betterave,la 24eme betterave, la 44eme betterave, etc., ou la premiere betterave se trouvantau-dela du point situe a 2 metres du debut de la ligne, au-dela du point situe a12 metres du debut de la ligne, au-dela du point situe a 22 metres du debut de laligne, etc.).
Un tel echantillonnage est dit systematique 13. En pratique, il est souvent plusfacile a realiser qu’un echantillonnage completement aleatoire, surtout pour desobservations qui doivent etre e↵ectuees en champ, en verger, en foret, etc.
11 En anglais : non-response.12 En anglais : simple random sampling, unrestricted random sampling.13 En anglais : systematic sampling.

2.2.4 ETUDE PAR ENQUETE 33
Pour un meme nombre d’observations, l’echantillonnage systematique possedeaussi l’avantage de donner frequemment des resultats plus precis que l’echantillon-nage completement aleatoire, mais il peut cependant soulever certains problemesparticuliers, que nous evoquerons ulterieurement (§ 8.3.1.3�).
3� Dans certains cas, il peut etre utile de subdiviser la population en plusieursparties, appelees strates 14, avant de proceder au choix des unites qui constituerontl’echantillon. Le choix de ces unites est alors realise independamment dans chacunedes strates, soit de facon completement aleatoire, soit de facon systematique.
Un tel echantillonnage est dit stratifie 15. Son emploi se justifie surtout quandla population-parent est tres heterogene et qu’on souhaite s’assurer que ses dif-ferentes composantes (di↵erentes categories socio-professionnelles, di↵erents typesd’exploitations agricoles, di↵erents types de sols ou de vegetations, par exemple) se-ront toutes bien representees dans l’echantillon. La stratification peut alors appor-ter un gain de precision important, par rapport a l’echantillonnage completementaleatoire, sans modifier le nombre total d’observations a realiser. Pour que ce gainde precision soit maximum, on doit veiller a definir les strates de maniere a cequ’elles soient toutes aussi homogenes que possible [STAT2, § 9.3.4] 16.
4� L’echantillonnage a deux ou plusieurs degres ou niveaux 17, aussi appeleechantillonnage en grappes, est une autre methode couramment utilisee en pra-tique. Son principe est de considerer deux ou plusieurs types d’unites statistiques,correspondant aux deux ou aux di↵erents degres ou niveaux de l’echantillonnage,et de proceder de facon completement aleatoire ou de facon systematique a chacunde ces degres ou niveaux.
Dans une enquete agricole par exemple, on peut choisir de facon completementaleatoire, au premier degre, un certain nombre de communes, puis au second degre,dans les communes ainsi retenues et de facon completement aleatoire egalement, uncertain nombre d’exploitations agricoles. Les communes sont les unites du premierdegre, et les exploitations, dans les communes, les unites du deuxieme degre.
Dans une telle situation, cette facon de proceder permet notamment de limiterles deplacements a un nombre restreint de communes, mais il faut savoir que cettefacilite de realisation ne s’obtient en general qu’au prix d’une certaine perte deprecision. On peut en e↵et montrer que, pour un meme nombre total d’observa-tions, la precision des resultats obtenus par un echantillonnage a deux ou plusieursdegres est en general inferieure a celle d’un echantillonnage completement aleatoire[STAT2, § 9.3.4].
On notera aussi que le principe de l’echantillonnage a deux ou plusieurs degresest utilise tres frequemment dans les processus d’analyse chimique, tels que par
14 En anglais : stratum.15 En anglais : stratified sampling.16 Nous rappelons que les mentions (( [STAT2, . . .] )) renvoient au deuxieme tome de cette serie
Statistique theorique et appliquee.17 En anglais : two-stage sampling, multi-stage sampling.

34 COLLECTE DES DONNEES 2.2.4
exemple, en matiere d’etude de sols ou de fourrages, le prelevement (( au hasard ))
de deux ou plusieurs echantillons de terre ou de fourrage dans une meme parcelleou un meme champ, et la realisation au laboratoire de deux ou plusieurs analysespour chacun des echantillons preleves. Les echantillons de terre ou de fourrage sontici les unites du premier degre, et les analyses les unites du deuxieme degre.
5� La methode des quotas 18, enfin, est une methode largement utilisee dans lessondages d’opinion. Elle consiste a donner a l’echantillon une composition aussisemblable que possible a celle de la population, en fonction de quelques crite-res de classification consideres a priori comme particulierement importants, maissans definir de facon precise la maniere dont les individus devront etre choisis al’interieur de chacune des classes ou categories de la population.
On tient souvent compte du sexe, de l’age et des categories socio-profession-nelles, ou de la repartition geographique des di↵erentes personnes constituant lapopulation. Mais s’il faut choisir, par exemple, 15 ouvrieres agees de 20 a 30 ans,pour assurer proportionnellement une bonne representation de cette categorie dela population, on n’e↵ectue pas ce choix de facon completement aleatoire ou defacon systematique, parmi toutes les personnes qui appartiennent a cette catego-rie, mais on laisse en general la liberte de ce choix aux enqueteurs, moyennanteventuellement certaines directives.
Comme l’echantillonnage stratifie, auquel elle est directement comparable, lamethode des quotas donne, pour un meme nombre d’observations, des resultatsplus precis que l’echantillonnage completement aleatoire. En outre, son utilisationest souvent plus facile ou plus rapide que celle de l’echantillonnage completementaleatoire. Mais l’absence de methode precise de choix des individus a l’interieur desclasses peut conduire a des erreurs importantes, liees notamment au comportementdes enqueteurs.
6� La realisation de tout echantillonnage, quel qu’il soit, ne peut se faire va-lablement que si on possede au depart, pour l’ensemble de la population, un mi-nimum d’informations constituant la base d’echantillonnage ou de sondage 19. Ilpeut s’agir notamment de listes ou de repertoires, de documents cartographiquesou de photographies aeriennes, etc.
Les qualites essentielles de ces documents sont d’etre complets, bien mis a jour,et sans repetitions (c’est-a-dire sans mentions doubles ou multiples des memes uni-tes). Il est evident, en e↵et, que la qualite d’un echantillon, et donc des resultatsqu’on en deduit, est toujours conditionnee dans une large mesure par la qualitedes documents qui ont servi de fondements a l’echantillonnage.
On remarquera aussi que, dans certains cas, la base d’echantillonnage ne doitpas s’etendre en detail a l’ensemble de la population. Par exemple, dans le casde l’enquete agricole dont il a ete question pour illustrer le principe de l’echan-tillonnage a deux degres, il pourrait s’agir d’une liste de toutes les communes et,
18 En anglais : quota.19 En anglais : sampling frame.

2.2.5 ETUDE PAR ENQUETE 35
uniquement pour les communes choisies au premier degre, d’une liste de toutes lesexploitations agricoles.
7� Une caracteristique essentielle de tout echantillonnage est le fait que lesresultats qu’on en deduit sont le plus souvent entaches d’erreurs non negligeables.Il peut s’agir a la fois d’erreurs systematiques 20 et d’erreurs ou de fluctuationsaleatoires 21.
Les premieres conduisent a une surestimation ou une sous-estimation plus oumoins importante des valeurs qu’on souhaite connaıtre (moyennes, pourcentages,etc.), mais elles peuvent etre totalement eliminees dans certaines conditions. Lessecondes, par contre, peuvent se compenser dans une certaine mesure, mais ellesne sont jamais completement eliminees. Nous reviendrons ulterieurement sur cepoint (§ 9.3.1).
Les non-reponses, de meme que les enquetes telephoniques et par internet,peuvent etre des sources importantes d’erreurs systematiques. Diverses methodesd’ajustement ou de redressement 22 permettent toutefois de remedier dans cer-taines limites a ces inconvenients [Bethlehem, 2010].
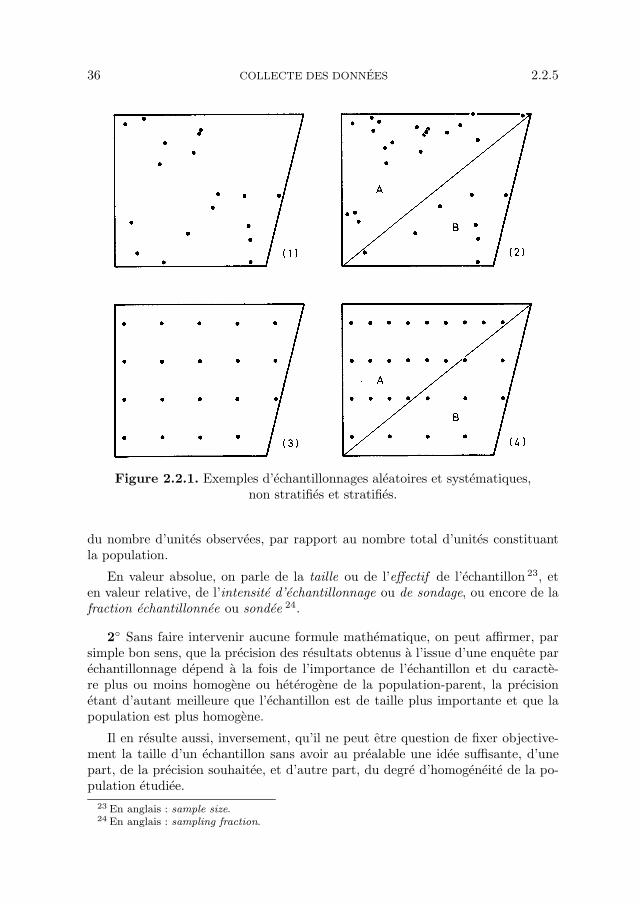
Exemple 2.2.1. Di↵erentes methodes d’echantillonnage.
Les di↵erents croquis de la figure 2.2.1 illustrent quelques-unes des methodesd’echantillonnage qui viennent d’etre citees, dans le cas d’un espace a deux dimen-sions, tel qu’un champ, un verger, une foret, etc. Il s’agit successivement :
1. d’un echantillonnage completement aleatoire (ou aleatoire et simple) de pointsd’observation dans le domaine considere ;
2. d’un echantillonnage aleatoire stratifie, avec une densite de points deux fois plusimportante dans la premiere strate (A), par comparaison avec la deuxiemestrate (B) ;
3. d’un echantillonnage systematique simple ;4. d’un echantillonnage systematique stratifie, avec egalement une densite de points
deux fois plus importante dans la premiere strate (A), par comparaison avecla deuxieme strate (B).
2.2.5 La taille de l’echantillon
1� La derniere question a laquelle nous consacrons quelques lignes, au coursde ce bref expose relatif aux problemes d’enquete, est celle de la taille ou de ladimension des echantillons. Cette taille peut etre fixee en valeur absolue, c’est-a-dire en nombre d’unites observees, ou en valeur relative, c’est-a-dire en proportion
20 En anglais : systematic error.21 En anglais : random error.22 En anglais : adjustment, imputation.
36 COLLECTE DES DONNEES 2.2.5
Figure 2.2.1. Exemples d’echantillonnages aleatoires et systematiques,non stratifies et stratifies.
du nombre d’unites observees, par rapport au nombre total d’unites constituantla population.
En valeur absolue, on parle de la taille ou de l’e↵ectif de l’echantillon 23, eten valeur relative, de l’intensite d’echantillonnage ou de sondage, ou encore de lafraction echantillonnee ou sondee 24.
2� Sans faire intervenir aucune formule mathematique, on peut a�rmer, parsimple bon sens, que la precision des resultats obtenus a l’issue d’une enquete parechantillonnage depend a la fois de l’importance de l’echantillon et du caracte-re plus ou moins homogene ou heterogene de la population-parent, la precisionetant d’autant meilleure que l’echantillon est de taille plus importante et que lapopulation est plus homogene.
Il en resulte aussi, inversement, qu’il ne peut etre question de fixer objective-ment la taille d’un echantillon sans avoir au prealable une idee su�sante, d’unepart, de la precision souhaitee, et d’autre part, du degre d’homogeneite de la po-pulation etudiee.
23 En anglais : sample size.24 En anglais : sampling fraction.

2.2.5 ETUDE PAR ENQUETE 37
On notera egalement que, dans le cas d’un echantillonnage stratifie ou a deuxou plusieurs degres ou niveaux, les tailles des echantillons ou les fractions echantil-lonnees peuvent evidemment etre di↵erentes d’une strate a l’autre ou d’un niveaua l’autre.
Exemple 2.2.2. Inventaire forestier : principes de base.
Pour illustrer les di↵erents elements evoques ci-dessus, nous presentons rapide-ment la methode de travail qui a ete adoptee dans le cadre d’un inventaire forestierrelatif a la partie meridionale de la Belgique [Rondeux et al., 1996].
Le but de cet inventaire est de chi↵rer l’importance de la foret et de la carac-teriser, notament en nombres d’arbres, en dimensions moyennes des arbres et envolumes, pour di↵erents types de peuplements, di↵erentes essences forestieres, etc.Le territoire considere est l’ensemble de la Region wallonne, soit une superficie de16.000 km2 environ, dont pres de 5.000 km2 de forets.
La collecte des donnees se fait a l’aide de photographies aeriennes et de cartestopographiques, en ce qui concerne la localisation des points d’observation, et surle terrain, en ce qui concerne les observations elles-memes.
Les points d’observation sont repartis de facon systematique a raison de deuxpoints par kilometre carre, selon un maillage rectangulaire de 500 m sur 1.000 m(distance entre les points d’observation de 500 m dans la direction nord-sud et de1.000 m dans la direction ouest-est). Le nombre total de points consideres est doncde l’ordre de 10.000 , pour les 5.000 km2 de forets qui sont etudies.
En chacun des points en question, on definit une serie de parcelles circulairesconcentriques. Les arbres de 20 a 69 cm de circonference sont mesures dans uneparcelle de 4,5 m de rayon (soit sur une surface d’environ 64 m2), les arbres de70 a 119 cm de circonference dans un rayon de 9 m (soit environ 2,5 ares), et lesarbres de plus de 119 cm de circonference dans un rayon de 18 m (soit environ10 ares). Des observations complementaires sont egalement realisees pour les semiset les arbres de moins de 20 cm de circonference.
L’intensite d’echantillonnage est en consequence, respectivement pour les troiscategories de grosseur, egale a environ 0,01 %, 0,05 % et 0,2 %. Et au total, pourl’ensemble de l’etendue envisagee, l’observation porte sur pres de 64 ha pour lesbois les plus petits, 2,5 km2 pour la categorie intermediaire, et 10 km2 pour lesbois les plus gros.
Quant aux observations, elles concernent essentiellement, en chaque point, lalocalisation exacte et le type de proprietaire, les caracteristiques du milieu (to-pographie, sol, vegetation, etc.), la description du peuplement (foret constitueed’une seule ou de plusieurs essences, d’arbres de meme age ou d’ages di↵erents,etc.), et les caracteristiques des arbres (circonferences de tous les arbres mesureesa une hauteur de reference de 1,50 m, hauteurs de tous les arbres ou d’un certainnombre d’entre eux seulement, etat sanitaire, etc.).

38 COLLECTE DES DONNEES 2.3.2
2.3 L’experimentation
2.3.1� Principes generaux
1� Contrairement au cas de l’observation par enquete (§ 2.2.1), l’experimenta-tion 25, c’est-a-dire la realisation d’une ou plusieurs experiences ou d’un ou plu-sieurs essais 26, suppose que l’apparition des faits qu’on desire etudier est volon-tairement provoquee, dans des conditions qu’on maıtrise au moins partiellement.
L’experimentation etant souvent plus e�cace que la simple observation parenquete, le chercheur ou l’homme de science doit toujours envisager la possibilited’y recourir, quand cela s’avere realisable, ce qui est frequemment le cas dans ledomaine biologique notamment.
2� Comme toute enquete, par echantillonnage ou non, toute experience doitetre l’objet d’une preparation ou d’une planification 27 minutieuse.
D’une facon generale, les questions qu’il faut examiner en elaborant un pland’experience ou un protocole experimental sont la definition du but et des condi-tions de l’experience, la definition des facteurs qu’on desire etudier, la definitiondes unites experimentales, la definition des observations a realiser, et la definitiondu dispositif experimental. Nous examinerons successivement ces di↵erents points,a l’exclusion toutefois de la question des observations, pour laquelle il n’y a guerede choses a ajouter ici, par rapport a ce qui a ete dit en matiere d’enquete (§ 2.2.3).
A ces principaux elements, on peut eventuellement associer quelques indica-tions preliminaires relatives a l’analyse des resultats.
2.3.2 La definition du but et des conditions de l’experience
1� La definition du but et des conditions de realisation d’une experience cons-titue une operation comparable a la definition de la population-parent dans lecas d’une enquete par echantillonnage (§ 2.2.2). Les conclusions d’une experiencen’auraient en e↵et guere de valeur en general si elles ne s’appliquaient qu’auxquelques individus consideres au cours de l’experience (aux quelques plantes ouaux quelques animaux observes, par exemple). Ces conclusions n’acquierent en faitune reelle valeur que dans la mesure ou elles peuvent s’appliquer a un ensembleplus vaste, tel que, par exemple, l’ensemble des cultures de ble ou l’ensemble desvaches laitieres d’une region donnee.
Il importe donc que cet ensemble plus vaste, ou cette population, soit par-faitement defini, et que les individus choisis pour l’experience en constituent unechantillon bien representatif. On doit notamment etre attentif a ne pas organiserl’experience dans des conditions trop particulieres, sauf si les conclusions qu’on
25 En anglais : experimentation.26 En anglais : experiment, trial, assay.27 En anglais : planning of experiment, experimental planning.

2.3.3 EXPERIMENTATION 39
souhaite en deduire doivent etre appliquees precisement dans de telles conditions(experiences en serres ou en chambres de culture, par exemple).
2� Un point important, qui merite d’etre souligne tout particulierement en cequi concerne la planification des experiences, est leur repetition eventuelle dansl’espace et dans le temps. Dans de nombreux domaines, et notamment en matiereagronomique, le materiel experimental (plantes et animaux, par exemple) presenteen e↵et une variabilite non negligeable d’un endroit a l’autre et d’une annee al’autre, ou d’une saison de culture a l’autre, en relation notamment avec des dif-ferences de milieu et de climat.
En vue d’aboutir a des conclusions su�samment sures pour qu’elles puissentetre transposees dans la pratique, il importe donc que l’experimentation ait ete rea-lisee dans des conditions assez diversifiees, les memes experiences etant repetees enun certain nombre d’endroits, representatifs de l’ensemble du territoire considere,et au cours de plusieurs annees ou de plusieurs saisons de culture.
2.3.3 La definition des facteurs
1� La definition des facteurs 28, dans un plan d’experience, est un elementnouveau par rapport au cas des enquetes. Il s’agit en e↵et, precisement, des ca-racteristiques propres a l’experience, qui sont sous l’entiere dependance de l’expe-rimentateur.
Ces facteurs peuvent etre soit qualitatifs, lorsqu’ils reunissent une serie d’ele-ments qui ne peuvent pas etre classes a priori dans un ordre donne, tels quedes varietes ou des produits phytosanitaires, soit quantitatifs, quand il s’agit aucontraire d’elements qui constituent a priori une suite logique, tels que di↵erentesdoses d’un meme engrais, di↵erentes temperatures, ou di↵erentes pressions.
Les elements individuels qui constituent un facteur (di↵erentes varietes, dif-ferents produits phytosanitaires, di↵erentes doses d’engrais, di↵erentes tempera-tures, di↵erentes pressions, etc.) sont generalement appeles modalites, ou encorevariantes ou niveaux 29, le terme variante correspondant plus particulierement auxfacteurs qualitatifs et le terme niveau aux facteurs quantitatifs.
2� Dans le cas d’un facteur qualitatif, les di↵erentes variantes sont genera-lement definies a priori, en meme temps que le but de l’experience (par exemplequelques varietes donnees de ble). Il peut arriver cependant que les variantes prisesen consideration dans l’experience doivent etre choisies au sein d’un ensemble plusvaste (par exemple quelques lignees de betterave sucriere, choisies parmi les descen-dances resultant d’un grand nombre de croisements). Le choix d’un nombre limitede variantes a mettre en experience peut alors etre realise de facon completementaleatoire.
28 En anglais : factor.29 En anglais : level.

40 COLLECTE DES DONNEES 2.3.4
Dans le cas d’un facteur quantitatif, les di↵erents niveaux sont generalementchoisis de maniere a constituer une progression arithmetique (par exemple 100 ,150 et 200 kg d’azote par hectare), ou une progression geometrique (par exemple1 , 2 , 4 et 8 mg d’une matiere active ou d’une substance de croissance donnee parplante).
Quand deux ou plusieurs facteurs sont etudies simultanement au cours d’unememe experience, on s’e↵orce souvent d’associer chacune des variantes ou chacundes niveaux d’un facteur, a chacune des variantes ou chacun des niveaux du oudes autres facteurs (chacune des varietes associee a chacune des doses d’engrais,par exemple). Une experience organisee de cette maniere est dite factorielle 30.
Chacun des elements individuels consideres, c’est-a-dire aussi bien chacun desniveaux ou des variantes d’une experience a un facteur, que chacune des combi-naisons de niveaux ou de variantes d’une experience a deux ou plusieurs facteurs(une variete associee a une dose d’engrais, par exemple), peut etre appele objet.
Enfin, un probleme connexe, qui doit toujours etre envisage, est celui de l’in-clusion ou la non-inclusion dans l’experience d’un ou plusieurs temoins ou objetsde reference 31, qui ne subissent aucun traitement particulier (parcelles sans en-grais, par exemple), ou qui servent de base de comparaison pour les autres objets(variete bien connue servant de base de comparaison pour un ensemble de varietesnouvelles, par exemple).
2.3.4 La definition des unites experimentales
1� Un autre point important du plan d’experience est la definition de l’uniteexperimentale 32, qui joue un role analogue a celui de l’unite de base en matiered’enquete (§ 2.2.2). Cette unite peut etre soit tout a fait naturelle, tel un arbre ouun animal, soit relativement artificielle, telle une parcelle de terrain plus ou moinsetendue ou un groupe de plantes ou d’animaux. Il y a lieu, dans ce dernier cas, dedeterminer de facon judicieuse la dimension (etendue de la parcelle ou nombre deplantes ou d’animaux, par exemple) et, eventuellement, la forme de l’unite priseen consideration (forme carree ou rectangulaire de la parcelle, par exemple).
2� Le nombre de repetitions 33, c’est-a-dire le nombre d’unites experimentalesqui se voient appliquer un traitement identique ou, d’une facon plus generale, quicorrespondent a un meme objet, doit egalement etre fixe lors de la planificationde l’experience.
Tres souvent, le nombre de repetitions et la dimension des unites experimentalessont deux elements etroitement lies l’un a l’autre, en raison du fait que le materielexperimental total disponible est limite (etendue limitee du terrain disponible,
30 En anglais : factorial experiment.31 En anglais : control.32 En anglais : experimental unit.33 En anglais : replication.

2.3.5 EXPERIMENTATION 41
nombre limite de plantes ou d’animaux, etc.), ce qui contraint l’experimentateura reduire un de ces deux elements quand il veut augmenter l’autre. Dans un telcas, pour obtenir un maximum de precision, il y a generalement interet a augmen-ter le nombre de repetitions, en diminuant autant que possible, dans des limitesraisonnables, la dimension des unites experimentales.
2.3.5 La definition du dispositif experimental
1� Ayant determine de facon precise les di↵erents objets qu’il souhaite etudier,et disposant d’un certain nombre d’unites de base, l’experimentateur doit encoredefinir la maniere dont les objets seront associes aux unites de base, le mode d’as-sociation adopte constituant le dispositif experimental 34.
Une premiere procedure consiste a repartir les objets tout a fait au hasard,parmi les unites experimentales, de telle sorte que chaque unite ait des chancesegales de se voir a↵ecter l’un ou l’autre des di↵erents objets, et de telle sorteaussi que l’a↵ectation d’un objet a une unite experimentale soit independantede l’a↵ectation de l’un ou l’autre objet aux autres unites experimentales. Un teldispositif est dit completement aleatoire 35.
2� Une deuxieme solution consiste a reunir les unites experimentales en groupesaussi homogenes que possible et a repartir les objets au hasard a l’interieur desdi↵erents groupes. Ces groupes d’unites experimentales sont generalement appelesblocs 36 et, dans le cas le plus simple, ou chaque bloc contient autant d’unites ex-perimentales qu’il y a d’objets, l’experience est dite en blocs aleatoires complets 37.Les blocs constituent alors chacun une repetition complete.
Dans une experience en champ, en verger, en foret, etc., chacun des blocs estgeneralement constitue de parcelles voisines, de plantes voisines ou d’arbres voisinsles uns des autres, en couvrant ainsi une certaine etendue de terrain. Au momentou on determine la dimension et la forme des unites experimentales, on doit alorsdefinir aussi la dimension et la forme des blocs.
On notera que la notion de bloc, utilisee en experimentation, est tres semblablea celle de strate, introduite en matiere d’echantillonnage (§ 2.2.4.3�). Dans lesdeux cas en e↵et, l’objectif est de constituer des groupes d’unites de base aussihomogenes que possible, en vue d’obtenir un maximum de precision, en procedantau tirage au hasard a l’interieur de ces groupes, et non dans l’ensemble de toutela population ou dans tout le domaine considere.
d 3� Comme en matiere d’echantillonnage, de nombreux autres dispositifs exis-tent egalement en matiere d’experimentation. Ils portent notamment les noms de
34 En anglais : design of experiment.35 En anglais : completely randomized design.36 En anglais : block.37 En anglais : randomized complete block.

42 COLLECTE DES DONNEES 2.3.5
carre latin 38, de dispositif en blocs incomplets 39, de dispositif en parcelles divi-sees 40, etc., mais nous n’en parlerons pas plus longuement ici.b
Exemple 2.3.1. Experience a deux facteurs sur cereales.
A titre d’illustration, nous presentons de facon relativement sommaire deuxexemples de ce que peuvent etre des experiences agronomiques courantes, d’unepart sur vegetaux et d’autre part sur animaux.
Le premier exemple concerne l’etude de l’influence d’un herbicide, applique adi↵erentes doses, sur les rendements de deux varietes de ble. Nous designerons lesdeux varietes considerees respectivement par A et B , et nous supposerons que lesdoses d’herbicides sont la dose normale conseillee par le producteur (dose 1), unedose double de la normale (dose 2), et l’absence d’herbicide (dose 0).
Les varietes de ble et les doses d’herbicides sont les deux facteurs pris en con-sideration. Le premier est de type qualitatif, et le second de type quantitatif.
Si chacun des trois niveaux du facteur doses est associe a chacune des deuxvarietes, l’experience est de type factoriel et comporte six objets. Ceux-ci peuventetre numerotes de 1 a 6 ou designes par exemple par les symboles :
A0 , A1 , A2 , B0 , B1 , B2 .
Les objets A0 et B0 sont des temoins (non traites).
Les unites experimentales peuvent etre des parcelles rectangulaires, de 6 m sur20 m par exemple, et nous supposerons qu’en fonction des moyens disponibles,le nombre de repetitions a ete fixe a cinq, pour chacun des six objets. L’etenduetotale des 30 parcelles considerees est donc de 36 ares, compte non tenu des cheminsd’acces, sentiers et autres degagements eventuels.
Les observations concerneront essentiellement les rendements en grains parparcelle, exprimes en poids de matiere seche et ramenes conventionnellement a unmeme niveau d’humidite (souvent 16 %).
Comme le montre la figure 2.3.1, dessinee a l’echelle 1/1.000 , l’experience peutetre completement aleatoire ou, au contraire, realisee en blocs aleatoires com-plets. Dans le premier cas, les cinq repetitions de chacun des six objets sont re-parties de facon tout a fait aleatoire dans l’ensemble des 30 parcelles. Dans ledeuxieme cas, par contre, le champ est tout d’abord divise en cinq blocs de sixparcelles, correspondant aux cinq bandes verticales de la figure 2.3.1, et les sixobjets sont ensuite repartis de facon completement aleatoire a l’interieur de chacundes cinq blocs, et cela de maniere independante d’un bloc a l’autre. En pratique,ce deuxieme dispositif est generalement preferable au premier.
38 En anglais : Latin square.39 En anglais : incomplete block.40 En anglais : split-plot.

2.3.5 EXPERIMENTATION 43
Figure 2.3.1. Exemples d’experiences completement aleatoireet en blocs aleatoires complets.
Exemple 2.3.2. Experience a un facteur sur bovins.
Notre deuxieme exemple concerne la comparaison de cinq alimentations dif-ferentes, donnees a de jeunes taurillons. Les cinq alimentations correspondent al’adjonction de cinq complements di↵erents a un meme fourrage, et constituent unfacteur qualitatif.
Le materiel experimental est forme de 60 taurillons d’une meme race et d’unememe categorie d’age. Au cours de l’experience, ceux-ci seront reunis en 20 groupesde trois animaux, a↵ectes a 20 stalles ou loges independantes les unes des autres,les groupes de trois animaux ou les stalles constituant les unites experimentales.
Les observations consisteront essentiellement en des pesees regulieres des ali-ments consommes et des di↵erents animaux. Ces donnees fourniront subsidiaire-ment des caracteristiques derivees, telles que les consommations moyennes jour-nalieres en aliments, les gains moyens journaliers en poids, etc.
Au debut de l’experience, la constitution des 20 groupes de trois animaux peutetre realisee de maniere completement aleatoire, et la repartition des cinq alimen-tations au sein des 20 groupes (quatre groupes de trois animaux pour chacune descinq alimentations) peut egalement etre entierement aleatoire.

44 COLLECTE DES DONNEES 2.4.1
Mais, si on a prevu une periode initiale d’adaptation et d’observation des ani-maux et, au cours de celle-ci, une ou plusieurs pesees prealables des animaux,on peut egalement constituer les groupes en tenant compte de ces donnees pre-liminaires. On peut par exemple former tout d’abord quatre lots de 15 animauxde poids semblables (le premier lot reunissant les 15 taurillons les plus legers, ledeuxieme lot les 15 taurillons de la tranche de poids suivante, le troisieme lot anouveau les 15 taurillons de la tranche de poids suivante, et le quatrieme lot les15 taurillons les plus lourds), puis constituer au hasard cinq groupes de trois tau-rillons au sein de chacun de ces quatre lots, et enfin repartir les cinq alimentationsau hasard et independamment parmi les cinq groupes relatifs a chacun des quatrelots. On assurerait ainsi une meilleure repartition des alimentations, puisque cha-cune d’entre elles serait donnee a trois taurillons de chacune des quatre categoriesde poids.
Les groupes de trois taurillons qui occupent une meme stalle constituant lesunites experimentales, on se trouve, d’une facon comme de l’autre, en presenced’une experience comportant quatre repetitions. Dans le premier cas, l’experienceest completement aleatoire, et dans le deuxieme cas, elle est organisee en blocsaleatoires complets, les blocs correspondant aux quatre lots d’animaux de poidssemblables. Le facteur subsidiaire (( poids initial des animaux )) remplace le facteur(( proximite des parcelles )) de l’exemple 2.3.1.
2.4 La nature, l’enregistrement et le traitementdes donnees
2.4.1� Di↵erents types de donnees
1� Avant d’entreprendre quelque etude statistique que ce soit, il importe d’etrebien conscient de l’existence de di↵erents types de donnees. Le choix de l’uneou l’autre methode d’analyse statistique depend en e↵et de cet element [STAT2,§ 1.2.4].
Nous avons deja signale anterieurement la distinction qui doit etre faite entreles observations qualitatives et les observations quantitatives (§ 2.2.3.1�). Mais ily a lieu d’aller plus loin.
2� En ce qui concerne tout d’abord les donnees quantitatives 41, une nouvelledistinction doit etre introduite entre, d’une part, les denombrements ou comptages,et d’autre part, les mesures ou mensurations.
Les denombrements ou comptages 42 ne soulevent guere de problemes parti-culiers, en ce sens que leurs resultats s’expriment tout simplement en nombresentiers, non negatifs (nombres de fruits par rameau, nombres de tetes de betail
41 En anglais : quantitative data.42 En anglais : enumeration, count.

2.4.1 NATURE, ENREGISTREMENT ET TRAITEMENT DES DONNEES 45
par exploitation agricole, etc.). De telles donnees, et les variables sous-jacentes quiy correspondent, sont fondamentalement de nature discontinue ou discrete 43.
Les mesures ou mensurations 44, par contre, soulevent des problemes de pre-cision et de choix d’unites, auxquels des solutions claires doivent toujours etreapportees. On notera a ce sujet qu’il est souvent inutile, et meme parfois dangereux,de considerer au niveau de la mesure un nombre trop important de chi↵res. Dansle domaine biologique par exemple, il est generalement illusoire d’utiliser plus dedeux ou trois chi↵res pour exprimer des resultats individuels (hauteurs totalesd’arbres exprimees en metres, avec au maximum une decimale, poids de vacheslaitieres exprimes en kilogrammes, sans decimales, etc.).
On notera egalement que, dans le cas des mesures, on e↵ectue en realite desobservations discontinues, en raison de la necessite d’arrondir les donnees a deux,trois ou quelques chi↵res (discontinuites de 1 dm , 1 m , 1 kg , etc.), alors que lesvariables considerees sont fondamentalement de nature continue 45.
3� Quant aux donnees qualitatives 46, elles concernent des caracteres ou desattributs 47, que chacun des individus peut posseder ou ne pas posseder. Souvent,ces donnees sont codees sous forme numerique, comme des variables quantitativesdiscontinues, bien qu’il ne s’agisse pas de telles variables.
Dans les cas les plus simples, qui ne presentent que deux possibilites, telles quela presence ou l’absence d’un caractere donne (pilosite, symptome d’une certainemaladie, etc.), on utilise couramment les valeurs 0 et 1 , en associant la valeur 0 al’absence et la valeur 1 a la presence du caractere considere. Les memes valeurs, oueventuellement les valeurs 1 et 2 , sont aussi employees pour d’autres alternativessimples, telles que vivant ou mort, male ou femelle, etc. De telles variables etde telles donnees, ne pouvant prendre que deux valeurs, sont dites binaires oualternatives ou indicatrices 48.
Quand le caractere considere peut presenter plusieurs niveaux di↵erents, ordon-nes les uns par rapport aux autres (individus sains, individus malades ou faiblementatteints, individus fortement atteints, et individus morts, par exemple), on peutegalement utiliser comme codification une suite de valeurs entieres, telles que leschi↵res de 0 a 3 ou de 1 a 4 , pour l’exemple qui vient d’etre cite. On doit cependantetre extremement prudent dans l’utilisation de telles echelles de valeurs, notam-ment en vue du calcul eventuel de moyennes ou d’autres parametres. Les variableset les donnees resultant d’une telle codification sont qualifiees d’ordinales 49.
Enfin, quand le caractere considere consiste en une serie de modalites ou devariantes qui ne peuvent pas etre ordonnees d’une maniere logique, telles que di-
43 En anglais : discontinuous data, discrete data.44 En anglais : measurement.45 En anglais : continuous data.46 En anglais : qualitative data.47 En anglais : character, attribute.48 En anglais : binary data, indicatory data.49 En anglais : ordinal data.

46 COLLECTE DES DONNEES 2.4.1
verses couleurs de pelage, on peut aussi utiliser une codification basee sur une seriede valeurs numeriques (1 pour un pelage brun, 2 pour un pelage gris, 3 pour unpelage noir, etc.), mais on doit se souvenir du fait que toute operation arithmetiquebasee sur de telles donnees, dites nominales 50, doit etre proscrite.
d Une autre solution applicable a ce dernier cas serait, au contraire, de conside-rer qu’il y a autant de variables di↵erentes que de modalites ou de variantes, enassociant une variable binaire a chacune des modalites ou variantes (une premierevariable pouvant prendre les valeurs 0 et 1 respectivement pour (( non brun )) etbrun, une deuxieme variable pouvant prendre les valeurs 0 et 1 respectivementpour (( non gris )) et gris, etc.).b
4� Independamment des cas les plus classiques, presentes ci-dessus, il faut si-gnaler aussi l’existence de types plus particuliers de donnees, telles que les rangset les donnees directionnelles ou circulaires.
Les rangs 51 sont en fait les numeros d’ordre des di↵erents individus ou desdi↵erents elements observes, classes selon l’ordre croissant de la caracteristiqueconsideree. De telles observations apparaissent notamment dans certains tests sen-soriels, ou lors d’autres examens au cours desquels on ne demande pas aux expertsou aux examinateurs d’attribuer une note a chacun des individus ou des elementsobserves, mais bien de proceder a un classement de ceux-ci.
On remarquera que les observations sont alors egalement, comme pour les de-nombrements ou les comptages, des nombres entiers non negatifs, mais les valeursobtenues ne sont pas independantes les unes des autres. En particulier, pour unensemble de n elements auxquels sont attribues des rangs allant de 1 a n , la sommedes valeurs observees est egale a n (n + 1)/2 , et leur moyenne est toujours egale a(n + 1)/2 .
d 5� Comme leur nom l’indique, les donnees directionnelles ou circulaires 52
concernent principalement des directions, le plus souvent dans un plan ou surune circonference (direction du vent, direction des vols d’oiseaux migrateurs, d’in-sectes, etc.), mais eventuellement aussi sur une sphere ou dans un espace a plus dedeux dimensions. Ces donnees sont generalement de nature continue, mais avec desparticularites telles que, par exemple, pour des observations exprimees en degres,les valeurs 0 et 360 se confondent, la di↵erence entre 350 et 15 est equivalente a ladi↵erence entre 15 et 40 , etc.
De telles donnees peuvent egalement etre considerees dans le temps, en ce quiconcerne par exemple les di↵erentes heures de la journee, les valeurs 0 et 24 etantalors confondues.b
Informations complementaires : Fisher [1995], Fisher et al. [1993], Mardia et Jupp[2000].
50 En anglais : nominal data.51 En anglais : rank.52 En anglais : directional data, circular data.

2.4.2 NATURE, ENREGISTREMENT ET TRAITEMENT DES DONNEES 47
2.4.2 L’enregistrement et le traitement des donnees
1� L’enregistrement ou la saisie des donnees 53 peut tout d’abord etre realisesous forme manuscrite, dans des carnets de notes, sur des feuilles volantes, etc.Quand le volume des donnees le justifie, on peut utilement avoir recours dans cecas a des feuilles de pointage ou des formulaires particuliers, prevoyant la place desdi↵erentes observations qui doivent etre faites, et eventuellement leur codification.En fonction des besoins ulterieurs, de telles donnees peuvent ensuite etre enregis-trees sur ordinateur.
Une deuxieme solution consiste a e↵ectuer egalement un enregistrement ma-nuel des donnees, non plus sur papier, mais directement sur un support infor-matique. Tel est le cas notamment par l’utilisation d’ordinateurs portables oud’autres materiels equivalents. L’emploi eventuel de formulaires cede alors la placea l’utilisation de cadres ou d’ecrans de saisie des donnees.
Enfin, l’enregistrement des donnees peut etre realise automatiquement, les ap-pareils de mesure qui sont utilises englobant l’un ou l’autre systeme informatiqueou etant connectes a de tels systemes. Ces dispositifs peuvent servir a la fois al’enregistrement de donnees quantitatives et a l’enregistrement de donnees quali-tatives, par des processus de reconnaissance de couleurs, de formes, etc.
2� Quelle que soit la methode utilisee, l’enregistrement doit toujours etre l’objetd’une tres grande attention, et cela autant que possible des la planification del’enquete ou de l’experience.
Le cas echeant, la conception des formulaires ou des ecrans de saisie doit etrerealisee avec le plus grand soin, en vue de reduire au maximum les risques d’er-reur. Dans le cas d’un enregistrement sous forme manuscrite, toute transcriptioneventuelle des observations, y compris leur possible encodage sur ordinateur, doitetre l’objet d’une verification tres stricte.
D’une facon generale, un examen critique des donnees, relatif notamment a leurplausibilite, doit etre associe a toute procedure d’enregistrement. Il peut s’agir d’unsimple examen visuel, au cours ou a l’issue d’un enregistrement manuel. Mais ilpeut s’agir aussi, dans le cas d’un enregistrement direct sur support informatique,de la comparaison avec des valeurs minimales et maximales admissibles ou avecune serie de normes ou de codes admissibles, ou de tout autre processus permettantde detecter des erreurs ou des discordances eventuelles.
A cet egard, il faut etre conscient du fait que les procedures automatiquesde collecte des donnees ne sont pas a l’abri de toute defaillance. De plus, cesprocedures peuvent soulever dans certains cas des problemes particuliers, lies auvolume considerable des donnees enregistrees.
Des la fin de la collecte, voire meme progressivement au cours de la collecteelle-meme, il est opportun d’assurer une sauvegarde des donnees, sous forme decopies mises en securite.
53 En anglais : data acquisition, data capture.

48 COLLECTE DES DONNEES 2.4.2
3� Le traitement des donnees doit normalement commencer par un examenpreliminaire, destine notamment a identifier les eventuelles anomalies qui pour-raient encore exister. Cet examen peut etre base sur l’etude de distributions defrequences, la preparation de graphiques, la determination de parametres (moyen-nes, valeurs extremes, etc.), l’application de methodes de detection des valeursanormales, etc. [STAT2, § 2.3 et 3.5].
Le traitement ulterieur des donnees peut alors etre realise soit a l’aide de petitesmachines a calculer, soit par ordinateur.
Le traitement a l’aide de petites machines a calculer (ou calculatrices ou cal-culettes), meme programmables ou dotees de fonctions statistiques (calcul demoyennes, d’ecarts-types, de coe�cients de correlation, etc.), ne se justifie quepour de petits ensembles de donnees, relatifs a la fois a un nombre reduit d’indi-vidus (quelques dizaines d’individus par exemple) et a un nombre tres reduit devariables ou de caracteristiques (generalement une ou deux variables ou caracte-ristiques au maximum).
L’emploi de l’ordinateur s’impose pratiquement dans tous les autres cas. Seposent alors des problemes de choix, non seulement de materiels, mais aussi, et defacon souvent plus aigue, de logiciels. Nous avons deja donne quelques indicationsa ce sujet dans le (( mode d’emploi )) qui suit la table des matieres.
Informations complementaires : Finney [1988], Riley et Ryder [1979].
Exemple 2.4.1. Inventaire forestier : enregistrement des donnees.
Nous pouvons illustrer les questions d’enregistrement des donnees en revenanta l’inventaire forestier dont les principes de base ont ete exposes dans le cadre del’exemple 2.2.2.
La figure 2.4.1 presente le principal formulaire dont l’utilisation avait ete de-cidee au depart, en vue de l’enregistrement, en chacun des points d’observation,de diverses caracteristiques du peuplement forestier (cadre (( Structure ))) et desarbres (Ess = essence, C150 = circonference a 1,50 m de hauteur, Htot = hauteurtotale, etc.) [Rondeux et al., 1996].
Dans un deuxieme temps, l’enregistrement manuel sur des documents papier acede la place a un enregistrement toujours manuel, mais sur des ordinateurs por-tables su�samment robustes pour pouvoir etre utilises en toutes circonstances enforet. Des cadres ou des ecrans de saisie, correspondant par exemple aux di↵erentssous-tableaux de la figure 2.4.1 et pouvant faire intervenir des menus deroulants,pour en faciliter l’utilisation, ont alors remplace les formulaires initiaux [Rondeuxet Cavelier, 2001].
Cette facon de faire a aussi l’avantage de rendre possible la realisation sur leterrain, de maniere automatique, d’un certain nombre de controles, de plausibilitenotamment, qui ne pouvaient intervenir anterieurement qu’a posteriori, au bureau.
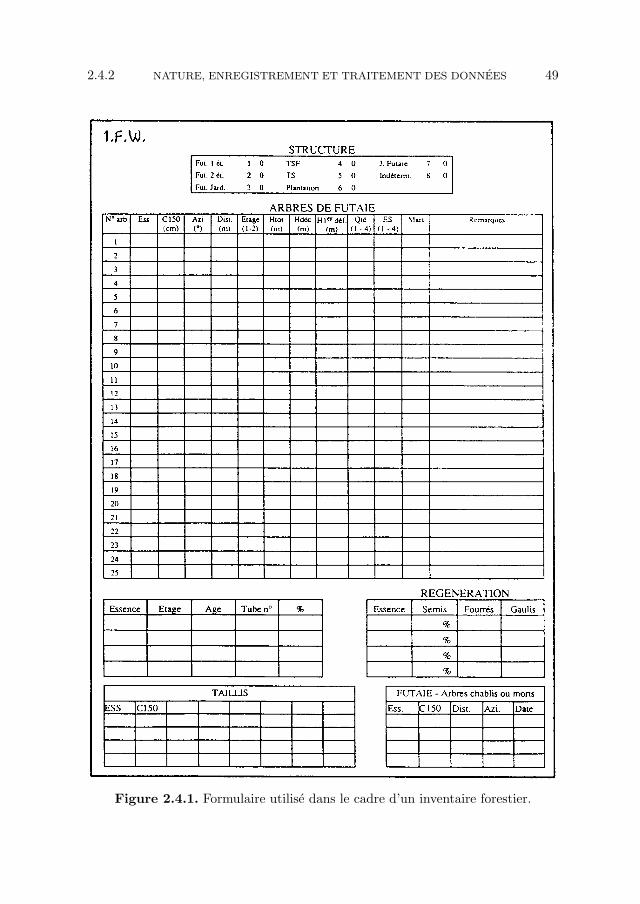
2.4.2 NATURE, ENREGISTREMENT ET TRAITEMENT DES DONNEES 49
Figure 2.4.1. Formulaire utilise dans le cadre d’un inventaire forestier.

50 COLLECTE DES DONNEES
Mais l’enregistrement de certaines donnees peut egalement etre entierementautomatise. Ainsi, la localisation et l’altitude des points d’observation peuventetre relevees a l’aide de certains GPS (global positioning system), et la grosseurdes arbres peut etre mesuree a l’aide de compas enregistreurs. On entend par la dessortes de grands pieds a coulisse, qui sont utilises depuis longtemps pour la mesuredes diametres des arbres, et qui sont completes par des dispositifs d’enregistrementautomatique des mesures [Rotheudt et Verrue, 2002].
Principaux mots-cles
Enquete, experimentation.Population, echantillon, recensement, sondage.Echantillonnage completement aleatoire, systematique, stratifie, a deux ou plu-
sieurs degres, par quotas.Taille ou e↵ectif de l’echantillon, intensite d’echantillonnage ou de sondage.Facteur, modalite, variante, niveau, objet, temoin.Experience factorielle.Experience completement aleatoire, en blocs aleatoires complets.Repetition.Donnees quantitatives, discontinues, continues.Donnees qualitatives, binaires, nominales, ordinales.Rangs.

Deuxieme partie
La statistique descriptive
Chapitre 3 La statistique descriptive a une dimension
Chapitre 4 La statistique descriptive a deux dimensions


Chapitre 3
La statistique descriptivea une dimension
Sommaire
3.1� Introduction3.2� Les distributions de frequences3.3� Les representations graphiques3.4� La reduction des donnees : generalites3.5� Les parametres de position3.6� Les parametres de dispersion3.7 Les moments et les parametres de dissymetrie et d’aplatisse-
ment3.8� Le calcul de la moyenne, de la variance et des moments d’ordre
3 et 43.9� Quelques informations relatives a l’execution des calculs3.10 Les nombres-indicesPrincipaux mots-clesExercices

54 STATISTIQUE DESCRIPTIVE A UNE DIMENSION 3.2.1
3.1� Introduction
1� La statistique descriptive 1 a essentiellement pour but de presenter les don-nees observees sous une forme telle qu’on puisse en prendre connaissance faci-lement. Elle peut concerner une variable ou une caracteristique a la fois, deuxvariables ou deux caracteristiques a la fois, ou encore plus de deux variables ouplus de deux caracteristiques simultanement. Selon les cas, on parle de statistiquedescriptive a une variable ou a une dimension 2, de statistique descriptive a deuxvariables ou a deux dimensions 3, et de statistique descriptive a plusieurs variablesou a plusieurs dimensions 4.
2� A une dimension, le but de simplification de la statistique descriptive peutetre atteint en condensant les observations sous trois formes distinctes.
Des tableaux statistiques permettent de presenter les donnees sous la formenumerique de distributions de frequences (§ 3.2). Di↵erents types de diagrammespermettent de presenter graphiquement ces distributions, ou les donnees initialeselles-memes (§ 3.3). Et enfin, les donnees peuvent egalement etre condensees sousla forme de quelques parametres ou valeurs typiques : le calcul de ces parametresconstitue la reduction des donnees 5 (§ 3.4 et suivants) 6.
La presentation des donnees sous forme de tableaux et de graphiques concerneplus particulierement les cas ou les observations sont assez nombreuses, tandis quela reduction des donnees s’applique indi↵eremment a tous les cas.
Informations complementaires : Alonzo [2006], Hamon et Jegou [2008], Mazerolle[2005].
3.2 Les distributions de frequences
3.2.1� Les series statistiques
La forme la plus elementaire de presentation des donnees statistiques relativesa une seule variable consiste en une simple enumeration des observations :
x1 , x2 , . . . , xi , . . . , xn ,
celles-ci etant eventuellement rangees par ordre croissant, c’est-a-dire de telle sorteque :
x1 x2 . . . xi . . . xn .
1 En anglais : descriptive statistics.2 En anglais : univariate, one-dimensional.3 En anglais : bivariate, two-dimensional.4 En anglais : multivariate, multidimensional.5 En anglais : data reduction.6 L’expression (( reduction des donnees )) est parfois utilisee pour designer l’ensemble de la
statistique descriptive, y compris la preparation de tableaux et de graphiques.

Index des traductionsanglaises
Les numeros renvoient aux paragraphes et aux exemples (ex.).
A
A posteriori power : 10.4.3.7�
A posteriori probability : 5.4.3
A priori power : 10.4.3.7�
A priori probability : 5.4.3
Absolute frequency : 3.2.2.1�
Acceptance region : 10.3.1.2�
Addition theorem : 5.3.1.3�
Adjustment : 2.2.4.7�
Allometry : 4.10.2.4�
Almost certain event : 5.3.1.2�
Almost impossible event : 5.3.2.3�
Alternative hypothesis : 10.3.1.1�
Analysis of covariance : 1.2.2.2�
Analysis of variance : 1.2.2.2�
Arithmetic mean : 3.5.1.1�
Artificial neural network : 1.2.4.2�
Assay : 2.3.1.1�
Association coe�cient : 4.6.3.6�
Assumption : 9.4.3.2�
Asymmetrical distribution : 3.3.3
Asymptotic e�ciency : 10.4.3.3�
Asymptotic normality : 6.6.5.1�
Asymptotically e�cient estimator :9.3.1.5�
Asymptotically minimum variance estima-tor : 9.3.1.5�
Asymptotically normal distribution :6.6.5.1�
Attribute : 2.4.1.3�
Autocatalytic function : 4.10.2.3�
Autoregressive model : 4.10.2.6�
Average : 3.5.1.1�
B
Bahadur’s e�ciency : 10.4.3.4�
Bar diagram : 3.3.1.1�
Bartlett’s adjustment : 10.3.4.1�
Bartlett’s correction : 10.3.4.1�
Base : 3.10.1.2�
Base switching : 3.10.3.2�
Bayes’s theorem : 5.4.3
Bayesian method : 1.2.3.3�
Bell-shaped distribution : 3.3.3
Bernoulli’s distribution : 6.2.1.2�
Bernoulli’s theorem : 8.5.2�
Beta distribution : 6.10.5.5�
Bias : 9.3.1.2�
Bienayme-Tchebychev’s inequality :5.8.4.1�
Bin width : 3.2.3.1�
Binary data : 2.4.1.3�
Binomial distribution : 6.2.1.2�

496 INDEX DES TRADUCTIONS ANGLAISES
Bioinformatics : 1.2.4.2�
Biometrics : 1.2.2.2�
Biometry : 1.2.2.2�
Biostatistics : 1.2.3.4�
Biserial correlation coe�cient : 4.6.3.2�
Bivariate continuous distribution : 5.5.4.1�
Bivariate continuous uniform distribu-tion : ex. 5.5.7
Bivariate discrete distribution : 5.5.3.2�
Bivariate discrete uniform distribution :ex. 5.5.6
Bivariate frequency distribution : 4.2.2.1�
Bivariate frequency table : 4.2.2.1�
Bivariate normal distribution : 7.4.3.1�
Bivariate statistics : 3.1.1�
Block : 2.3.5.2�
Bonferroni’s method : 10.3.5.2�
Bootstrap : 8.4.2.2�
Box-and-whisker plot : 3.3.4.2�
Boxplot : 3.3.4.2�
Bravais’s correlation coe�cient : 4.6.1.1�
C
Calibration : 4.7.6.2�
Censored distribution : 6.10.4.2�
Census : 2.2.1.2�
Centile : 3.6.4.5�
Central limit theorem : 6.6.5.3�
Central moment : 3.7.1.1�
Certain event : 5.3.1.2�
Chain index : 3.10.3.3�
Character : 2.4.1.3�
Characteristic function : 5.9.2.2�
Chi-square distribution : 6.8.1.1�
Circular data : 2.4.1.5�
Circularity : 3.10.3.1�
Class : 3.2.3.1�
Class boundary : 3.2.3.1�
Class frequency : 3.2.3.1�
Class interval : 3.2.3.1�
Class limit : 3.2.3.1�
Class mark : 3.2.3.1�
Class mid-point : 3.2.3.1�
Coe�cient of concentration : 3.6.6.2�
Coe�cient of variation : 3.6.1.2�
Compartment model : 4.10.2.6�
Compartmental model : 4.10.2.6�
Complementary events : 5.3.2.2�
Completely randomized design : 2.3.5.1�
Component analysis : 4.11.2
Composite index : 3.10.1.2�
Compound distribution : 6.5.3.3�
Computer-intensive method : 1.2.3.3�
Concentration curve : 3.6.6.3�
Concentration diagram : 3.6.6.3�
Conditional distribution : 4.2.3.2�
Conditional frequency : 4.2.3.2�
Conditional mean : 4.4.2�
Conditional probability : 5.4.1.2�
Conditional variance : 4.4.2�
Confidence coe�cient : 9.4.1.2�
Confidence interval : 9.4.1.2�
Confidence level : 9.4.1.2�
Confidence limit : 9.4.1.2�
Confidence region : 9.4.1.2�
Conservative test : 10.3.3.8�
Consistent estimator : 9.3.1.7�
Contagious distribution : 6.5.3.1�
Contingency table : 4.6.3.6�
Continuity correction : 6.6.4.3�
Continuous data : 2.4.1.2�
Continuous distribution : 5.5.2.3�
Continuous triangular distribution :ex. 5.6.5
Continuous uniform distribution : ex. 5.5.4
Control : 2.3.3.2�
Convergence in probability : 8.5.1�
Corrected sum of squares : 3.8.1.3�
Correction for grouping : 3.6.1.6�
Correlation coe�cient : 4.6.1.1�
Correlation matrix : 4.11.1.3�
Correlation ratio : 4.6.3.5�
Correspondence analysis : 4.11.2
Count : 2.4.1.2�
Covariance : 4.5.1.2�
Covariance matrix : 4.11.1.2�

INDEX DES TRADUCTIONS ANGLAISES 497
Critical region : 10.3.1.2�
Critical value : 10.3.1.2�
Cubic mean : 3.5.3.3�
Cumulant : 5.9.2.1�
Cumulant generating function : 5.9.2.1�
Cumulative frequency : 3.2.2.4�
Cumulative frequency distribution :3.3.2.3�
Cumulative function : 5.5.1.2�
Cumulative probability distribution :5.5.1.2�
Curvilinear regression : 4.10.1
D
Data acquisition : 2.4.2.1�
Data capture : 2.4.2.1�
Data matrix : 4.11.1.1�
Data mining : 1.2.4.2�
Data reduction : 3.1.2�
Database : 1.2.4.1�
Datawarehouse : 1.2.4.1�
Decile : 3.6.4.5�
Decision theory : 10.3.4.3�
Degree of freedom : 6.7.1�
Dependent variable : 4.7.1
Descriptive statistics : 3.1.1�
Design of experiment : 2.3.5.1�
Determination coe�cient : 4.6.1.5�
Diagonal regression line : 4.8.1.4�
Directional data : 2.4.1.5�
Discontinuous data : 2.4.1.2�
Discrete data : 2.4.1.2�
Discrete probability distribution : 5.5.1.2�
Discrete triangular distribution : ex. 5.6.4
Discrete uniform distribution : ex. 5.5.3
Discriminant analysis : 4.11.2
Dispersion matrix : 4.11.1.2�
Distribution function : 5.5.1.2�
Distribution-free method : 9.3.4.1�
Dotplot : 3.3.4.1�
Double-tailed test : 10.3.3.6�
Doubly non-central F -distribution :6.10.3.2�
E
Eccentricity : 6.10.3.1�
Econometrics : 1.2.2.2�
Econometry : 1.2.2.2�
E�ciency : 9.3.1.4�
E�cient estimator : 9.3.1.4�
Elasticity : 4.10.2.4�
Ellipse of concentration : 7.4.1.3�
Enumeration : 2.4.1.2�
Estimation : 9.3.1.1�
Estimator : 9.3.1.1�
Exclusive events : 5.3.1.3�
Expectation : 5.7.1.1�
Expected value : 4.7.3.1�
Experiment : 2.3.1.1�
Experimental design : 1.2.2.2�
Experimental planning : 2.3.1.2�
Experimental unit : 2.3.4.1�
Experimentation : 2.3.1.1�
Explanatory variable : 4.7.1
Exploratory survey : 2.2.3.3�
Exponential distribution : ex. 5.5.5
Exponential family : 6.10.5.6�
Exponential regression : 4.10.2.2�
Extreme value : 3.2.3.1�
F
Factor : 2.3.3.1�
Factor analysis : 4.11.2
Factorial experiment : 2.3.3.2�
False discovery rate : 10.3.5.5�
False positive : 10.3.5.5�
False positive rate : 10.3.5.5�
F-distribution : 6.9.1.1�
Fiducial limit : 9.4.4.1�
Finite population : 8.2.1.1�
First kind error : 10.3.1.3�
First kind risk : 10.3.1.3�
Fisher’s coe�cient : 3.7.2
Fisher’s logarithmic series : 6.5.1.1�
Fisher-Snedecor’s distribution : 6.9.1.1�
Fitting : 4.10.1

498 INDEX DES TRADUCTIONS ANGLAISES
Fourfold point correlation coe�cient :4.6.3.3�
Fractile : 3.6.4.5�
Frequency : 3.2.2.1�
Frequency distribution : 3.2.2.1�
Frequency function : 5.5.2.1�
Frequency polygon : 3.3.1.1�
Frequentist approach : 9.3.5.3�
G
Gamma distribution : 6.10.5.5�
Gamma function : 6.10.2.1�
General linear model : 1.2.3.3�
Generalized hypergeometric distribution :6.3.2.1�
Generalized linear model : 1.2.3.3�
Genomics : 1.2.4.2�
Geometric mean : 3.5.2.1�
Geometric series : 6.5.2.5�
Gini’s coe�cient : 3.6.6.2�
Gross error : 3.9.1.2�
Gross error sensitivity : 9.3.1.6�
Gumbel’s distribution : 8.3.4.3�
H
Harmonic mean : 3.5.3.1�
Highly significant : 10.3.1.4�
Histogram : 3.3.1.1�
Hochberg’s method : 10.3.5.3�
Holm-Bonferroni’s method : 10.3.5.3�
Holm’s method : 10.3.5.3�
Homoscedasticity : 10.3.3.2�
Hypergeometric distribution : 6.3.1.1�
I
Identification : 4.10.1
Impossible event : 5.3.2.3�
Imputation : 2.2.4.7�
Incomplete block : 2.3.5.3�
Independent variable : 4.7.1
Independently and identically distributedvariables : 5.6.1.3�
Index number : 3.10.1.2�
Indicatory data : 2.4.1.3�
Infinite population : 8.2.1.2�
Influence curve : 9.3.1.6�
Interdependent variables : 4.8.1.1�
Interquartile range : 3.6.4.3�
Interval estimation : 9.4.1.1�
Intraclass correlation coe�cient : 4.6.3.7�
I-shaped distribution : 3.3.3
J
Jackknife : 8.4.2.2�
J-shaped distribution : 3.3.3
K
Kurtosis : 6.6.1.3�
L
Laplace’s theorem : 6.6.4.1�
Laspeyres’s index : 3.10.2.2�
Latin square : 2.3.5.3�
Law of large numbers : 8.5.1�
Least squares method : 4.7.2.1�
Leptokurtic distribution : 6.6.1.3�
Level : 2.3.3.1�
Likelihood function : 9.3.2.2�
Likelihood ratio : 10.3.4.1�
Likelihood ratio test : 10.3.4.1�
Lindeberg-Levy’s theorem : 6.6.5.2�
Linear correlation coe�cient : 4.6.1.1�
Linear mixed model : 1.2.3.3�
Linear model : 1.2.3.3�
Linear regression : 4.7.2.1�
Locally most powerful test : 10.4.3.5�
Logarithmic-normal distribution : 6.6.6.1�
Logistic function : 4.10.2.3�
Logistic regression : 4.10.2.6�
Logit : 4.10.2.6�
Lognormal distribution : 6.6.6.1�
Lorenz’s curve : 3.6.6.3�
Lorenz’s diagram : 3.6.6.3�
Lower critical value : 9.4.3.1�
M
Mann-Whitney’s test : 10.3.3.2�
Marginal distribution : 4.2.3.1�
Marginal frequency : 4.2.3.1�

INDEX DES TRADUCTIONS ANGLAISES 499
Marginal mean : 4.4.2�
Marginal variance : 4.4.2�
Maximum likelihood : 9.3.2.1�
Mean : 3.5.1.1�
Mean deviation : 3.6.2.1�
Mean di↵erence : 3.6.6.1�
Mean vector : 4.11.1.2�
Measure of dispersion : 3.4.1�
Measure of kurtosis : 3.4.1�
Measure of location : 3.4.1�
Measure of skewness : 3.4.1�
Measurement : 2.4.1.2�
Median : 3.5.4.1�
Meta-analysis : 10.3.5.5�
Method of moments : 9.3.3.2�
Mid-range : 9.2.1.4�
Minimum chi-square method : 9.3.3.2�
Minimum variance estimator : 9.3.1.4�
Mitscherlich’s law : 4.10.2.3�
Mixture : 6.10.4.3�
Mode : 3.5.6
Modelling : 1.2.3.3�
Moment : 3.7.1.1�
Moment generating function : 5.9.1.1�
Monte-Carlo method : 8.4.2.1�
Moving average : 4.10.2.6�
Multidimensional statistics : 3.1.1�
Multimodal distribution : 3.5.6
Multinomial distribution : 6.2.3
Multiple comparisons : 10.3.5.5�
Multiple correlation coe�cient : 4.11.2
Multiple endpoints : 10.3.4.5�
Multiple regression : 4.11.2
Multiplication theorem : 5.4.1.2�
Multiplicative congruential method :8.2.3.1�
Multiplicative method : 8.2.3.1�
Multi-stage sampling : 2.2.4.4�
Multivariate analysis : 1.2.3.3�
Multivariate analysis of variance : 4.11.2
Multivariate statistics : 3.1.1�
Mutually exclusive events : 5.3.1.3�
N
Negative binomial distribution : 6.5.2.6�
Neo-Bayesian method : 1.2.3.3�
Neural network : 1.2.4.2�
Neyman’s type A distribution : 6.5.3.2�
Nominal data : 2.4.1.3�
Non-central chi-square distribution :6.10.3.1�
Non-central distribution : 6.10.3.1�
Non-central F -distribution : 6.10.3.2�
Non-central moment : 3.7.1.1�
Non-central t-distribution : 6.10.3.3�
Non-centrality : 6.10.3.1�
Non-linear correlation coe�cient : 4.6.3.5�
Non-linear regression : 4.10.1
Non-null hypothesis : 10.3.1.1�
Non-parametric method : 9.3.4.1�
Non-response : 2.2.3.3�
Normal distribution : 6.6.2.1�
Normal equation : 4.7.2.2�
Null hypothesis : 10.3.1.1�
Numerical classification : 4.11.2
O
Observational study : 2.1.2�
One-dimensional statistics : 3.1.1�
One-sided confidence interval : 9.4.3.6�
One-sided test : 10.3.3.6�
Open-ended class : 3.2.3.2�
Operational research : 1.2.2.2�
Operations research : 1.2.2.2�
Ordinal data : 2.4.1.3�
Organic correlation line : 4.8.1.4�
Orthogonal regression line : 4.8.1.4�
Overdispersed distribution : 6.5.3.4�
Overdispersion : 6.5.3.4�
P
Paasche’s index : 3.10.2.2�
Paired samples t-test : 10.3.3.2�
Parabolic regression : 4.10.2.5�
Pareto’s distribution : 8.3.4.3�
Partial correlation coe�cient : 4.11.2
Pascal’s distribution : 6.5.2.1�

500 INDEX DES TRADUCTIONS ANGLAISES
Pearson’s coe�cient : 3.7.2
Pearson’s correlation coe�cient :4.6.1.1�
Pearson’s distribution : 6.8.1.1�
Pearson’s system : 6.10.5.2�
Percentage point : 5.8.1.4�
Percentage standard deviation : 3.6.1.2�
Percentile : 3.6.4.5�
Permutation test : 10.3.4.2�
Phi-coe�cient : 4.6.3.3�
Piecewise regression : 4.10.2.6�
Pie-chart : 3.3.4.3�
Pilot survey : 2.2.3.3�
Pitman’s e�ciency : 10.4.3.4�
Planning : 2.2.1.3�
Planning of experiment : 2.3.1.2�
Platykurtic distribution : 6.6.1.3�
Point biserial correlation coe�cient :4.6.3.2�
Point estimation : 9.4.1.1�
Poisson-Pascal’s distribution : 6.5.3.3�
Poisson-Poisson’s distribution : 6.5.3.2�
Poisson’s binomial distribution : 6.5.3.3�
Poisson’s distribution : 6.4.1.1�
Poisson’s process : 6.4.1.5�
Polynomial regression : 4.10.2.5�
Population : 2.2.1.1�
Posterior probability : 5.4.3
Power : 10.4.1
Power function : 10.4.1
Price index : 3.10.2.1�
Principal axis : 4.8.1.4�
Principal component analysis : 4.11.2
Prior probability : 5.4.3
Probability : 5.2.1.1�
Probability density function : 5.5.2.1�
Probability distribution : 5.5.1.2�
Probability element : 5.5.2.2�
Probability law : 5.5.1.2�
Probability surface : 7.4.1.2�
Probable error : 3.6.3
Probit : 4.10.2.6�
Product-moment correlation coe�cient :4.6.1.1�
Proportional frequency : 3.2.2.3�
Prospective power : 10.4.3.7�
Pseudo-random number : 8.2.3.1�
Pseudo-value : 9.3.4.3�
Psychometrics : 1.2.2.2�
Psychometry : 1.2.2.2�
P -value : 10.3.2.2�
Q
Quadratic mean : 3.5.3.2�
Quadratic regression : 4.10.3.2�
Qualitative data : 2.4.1.3�
Quality control : 1.2.2.2�
Quantile : 3.6.4.5�
Quantitative data : 2.4.1.2�
Quantity index : 3.10.2.3�
Quartile : 3.6.4.1�
Quartile deviation : 3.6.4.3�
Quota : 2.2.4.5�
R
Random error : 2.2.4.7�
Random event : 5.2.1.1�
Random experiment : 5.2.1.1�
Random number : 8.2.2.2�
Random trial : 5.2.1.1�
Random variable : 5.5.1.1�
Randomization test : 10.3.4.2�
Randomized complete block : 2.3.5.2�
Range : 3.6.5.1�
Rank : 2.4.1.4�
Rectangular distribution : ex. 5.5.4
Reduced residual : 4.7.4.5�
Reduced variable : 5.8.3.1�
Regression coe�cient : 4.7.2.3�
Regression curve : 4.10.1
Regression (straight) line : 4.7.2.1�
Rejection region : 10.3.1.2�
Relative e�ciency : 9.3.1.4�
Relative frequency : 3.2.2.3�
Replication : 2.3.4.2�
Rerandomization test : 10.3.4.2�

INDEX DES TRADUCTIONS ANGLAISES 501
Resampling : 1.2.3.3�
Residual : 4.7.3.1�
Residual standard deviation : 4.7.4.4�
Residual sum of squares of deviates :4.9.1.4�
Residual variance : 4.7.4.1�
Restricted maximum likelihood : 9.3.3.3�
Retrospective power : 10.4.3.7�
Reversibility : 3.10.3.1�
Robust estimator : 9.3.1.6�
Robust method : 1.2.3.3�
Robustness : 9.3.1.6�
Rounding error : 3.9.1.3�
S
Sample : 2.2.1.2�
Sample size : 2.2.5.1�
Sample survey : 2.2.1.2�
Sampling : 2.2.1.2�
Sampling distribution : 8.3.1.2�
Sampling fraction : 2.2.5.1�
Sampling frame : 2.2.4.6�
Scatter diagram : 4.3.1.1�
Scatter plot : 4.3.1.1�
Second kind error : 10.3.1.3�
Second kind risk : 10.3.1.3�
Semi-interquartile range : 3.6.4.3�
Sequential Bonferroni’s method :10.3.5.3�
Sequential estimation : 9.4.4.4�
Sequential test : 10.3.4.4�
Sheppard’s correction : 3.6.1.6�
Shortest confidence interval : 9.4.3.6�
Sigmoid curve : 6.6.1.2�
Significance level : 10.3.1.1�
Significance test : 10.2
Significant : 10.3.1.4�
Significant point : 10.3.1.2�
Simple index : 3.10.1.2�
Simple random sampling : 2.2.4.1�
Simulation : 1.2.3.3�
Simulation method : 8.4.2.1�
Simultaneous tests : 10.3.5.2�
Single-tailed test : 10.3.3.6�
Skew distribution : 3.3.3
Snedecor’s distribution : 6.9.1.1�
Spearman’s rank correlation coe�cient :4.6.3.4�
Spearman’s ⇢ : 4.6.3.4�
Split-plot : 2.3.5.3�
Standard deviation : 3.6.1.2�
Standard error : 8.3.1.2�
Standard error method : 9.4.3.1�
Standardized residual : 4.7.4.5�
Standardized variable : 5.8.3.1�
Statistic : 1.1
Statistical regularity : 5.2.2.1�
Statistics : 1.1
Stem-and-leaf diagram : 3.3.4.1�
Stereogram : 4.3.2.1�
Stochastic convergence : 8.5.1�
Stochastically dependent : 5.4.2.3�
Stochastically independent : 5.4.2.1�
Stratified sampling : 2.2.4.3�
Stratum : 2.2.4.3�
Student’s distribution : 6.7.1�
Student’s t-test : 10.3.2.4�
Su�cient estimator : 9.3.1.7�
Sum of products of deviates : 4.9.1.2�
Sum of squares of deviates : 3.8.1.3�
Survey : 2.2.1.1�
Symmetrical distribution : 3.3.3
System of distributions : 6.10.5.6�
System of frequency curves : 6.10.5.6�
Systematic error : 2.2.4.7�
Systematic sampling : 2.2.4.2�
T
t-distribution : 6.7.1�
Test of bioequivalence : 10.3.3.7�
Test of conformity : 10.2
Test of equality : 10.2
Test of equivalence : 10.3.3.7�
Test of goodness of fit : 10.2
Test of homogeneity : 10.2
Test of hypothesis : 10.2

502 INDEX DES TRADUCTIONS ANGLAISES
Test of independence : 10.2
Test of non-inferiority : 10.3.3.7�
Test of superiority : 10.3.3.7�
Tetrachoric correlation coe�cient :ex. 7.4.4
Three sigma rule : 5.8.4.3�
Time-series : 4.9.1.5�
Trial : 2.3.1.1�
Trimmed mean : 9.2.1.4�
Truncated distribution : 6.10.4.2�
t-test : 10.3.2.4�
Two-dimensional statistics : 3.1.1�
Two-sided test : 10.3.3.6�
Two-stage sampling : 2.2.4.4�
Two-way table : 4.2.2.1�
U
Unbiased estimator : 9.3.1.2�
Unbiased minimum variance estimator :9.3.1.4�
Uncontrolled observational study : 2.1.2�
Underdispersed distribution : 6.5.3.4�
Underdispersion : 6.5.3.4�
Uniformly most powerful test : 10.4.3.5�
Unimodal distribution : 3.5.6
Unit : 2.2.1.1�
Unit bivariate normal distribution :7.4.1.1�
Unit normal distribution : 6.6.1.1�
Univariate statistics : 3.1.1�
Unrestricted random sampling : 2.2.4.1�
Upper critical value : 9.4.3.1�
U-shaped distribution : 3.3.3
V
Validation : 4.10.1
Value index : 3.10.2.4�
Variance : 3.6.1.1�
Variance-covariance matrix : 4.11.1.2�
Variance-ratio distribution : 6.9.1.1�
Variate : 5.5.1.1�
Very highly significant : 10.3.1.4�
W
Weak law of large numbers : 8.5.1�
Weibull’s distribution : 8.3.4.3�
Weight : 3.5.1.3�
Weighted average : 3.5.1.3�
Weighted mean : 3.5.1.3�
Weighted regression : 4.7.6.1�
Welch’s test : 10.3.3.2�
Wilcoxon’s test : 10.3.3.2�
Without replacement : 8.2.2.3�

Index des matieres
Les numeros renvoient aux paragraphes et aux exemples (ex.).
A
A posteriori (probabilite —) : 5.4.3
A posteriori (puissance —) : 10.4.3.7�
A priori (probabilite —) : 5.4.3
A priori (puissance —) : 10.4.3.7�
Absolue (frequence —) : 3.2.2.1�
Acceptation (domaine d’— ou regiond’—) : 10.3.1.2�
Achenwall (Gottfried —) : 1.2.1.1�
Addition de variables aleatoires : voir som-me de variables aleatoires
Additivite (axiome d’— et proprieted’—) : 5.3.1.3�, 5.3.2.1�
Adequation (test d’—) : 10.2
Agregative (distribution —) : 6.5.3
Ajustement (d’une courbe de regression) :4.10.1, 4.10.3
Ajustement (test d’—) : 10.2
Aleatoire (bloc — complet) : 2.3.5.2�
Aleatoire (echantillonnage —) : 2.2.4.1�,8.2.2.1�
Aleatoire (echantillonnage completement—) : 2.2.4.1�, 8.2.2.1�
Aleatoire (erreur —) : 2.2.4.7�, 9.3.1.3�
Aleatoire (evenement —) : 5.2.1.1�
Aleatoire (experience —) : 5.2.1.1�
Aleatoire (experience completement —) :2.3.5.1�
Aleatoire (fluctuation —) : voir aleatoire(erreur —)
Aleatoire (nombre —) : 8.2.2.2�
Aleatoire (variable —) : 5.5.1.1�, 5.5.2.1�,5.5.3.1�
Allometrie (coe�cient d’— et relationd’—) : 4.10.2.4�, ex. 4.10.1
Alternative (hypothese —) : 10.3.1.1�
Alternative (variable — et variable alea-toire —) : voir binaire (variable — etvariable aleatoire —)
Alternative repetee (loi d’—) : voir bino-miale (distribution —, loi — et variable—)
Amplitude : 3.6.5, 3.6.7.1�, 5.8.1.2�, 8.3.5
Amplitude (d’une classe) : voir intervalle(d’une classe)
Analyse a plusieurs variables : 1.2.3.3�,4.11.2
Aplatissement (coe�cient d’— ou parame-tre d’—) : 3.4.1�, 5.8.5, 6.6.1.3�
Approchee (valeur —) : 3.2.4, 3.9.1.4�
Approximation (erreur d’—) : 3.9.1.3�
Arithmetique (moyenne —) : voir moyen-ne arithmetique
Arithmetique (politique) : 1.2.1.1�
Arrondissage (erreur d’—) : 3.9.1.3�
Arret (points d’— multiples) : 10.3.4.5�
Association (coe�cient d’—) : 4.6.3.6�
Association (tableau d’—) : 4.6.3.6�
Asymetrie : voir dissymetrie
Asymptotique (e�cacite —) : 9.3.1,10.4.3.3�

504 INDEX DES MATIERES
Asymptotiquement e�cace : 9.3.1,10.4.3.3�
Asymptotiquement normal : 6.6.5Attendue (valeur —) : voir esperance ma-
thematiqueAttribut : voir qualitative (donnee — ou
observation —)Autocatalytique (fonction —) : voir logis-
tique (fonction —)Autocomparaison (test d’—) : 10.3.4.2�
Autoregressif (modele —) : 4.10.2.6�
Axe majeur : voir moindres rectangles(droite des —)
Axe principal : 4.8.2.3�, 4.11.2Axe principal reduit : voir moindres rec-
tangles (droite des —)
B
Babbage (Charles —) : 1.2.1.2�
Bahadur (e�cacite de —) : 10.4.3.4�
Bartlett (correction de —) : 10.3.4.1�
Base (changement de —) : 3.10.3.2�
Base (d’echantillonnage) : 2.2.4.6�
Base (de donnees) : 1.2.4.1�
Base (periode de —) : 3.10.1.2�
Base (unite de —) : 2.2.1.1�, 2.2.2Batons (diagramme en —) : 3.3.1, 4.3.2.1�
Bayes (theoreme de —) : 5.4.3Bayesienne (methode —) : 1.2.3.3�, 9.3.5,
9.4.4.3�, 10.3.4.3�
Bernoulli (Daniel —) : 1.2.1.1�
Bernoulli (schema de —) : 6.2.1.1�
Bernoulli (theoreme de —) : 8.5.2�
Beta (distribution —) : 6.10.5.5�
Biais : 9.3.1.2�
Biaise : 9.3.1.2�
Biaise (test non —) : 10.4.3.6�
Bibliographie : 1.4.1Bienayme-Tchebychev (inegalite de
—) : 5.8.4Bilateral (test —) : 10.3.3.6�
Binaire (variable —) : 2.4.1.3�
Binaire (variable aleatoire —) : ex. 5.5.2,ex. 5.8.1, 6.10.1.2�
Binomiale (distribution —, loi — et va-riable —) : 6.2.1, 6.2.2, 6.3.1.2�, 6.4.1,6.6.4
Binomiale generalisee (distribution —) :voir polynomiale (distribution — et loi—)
Binomiale negative (distribution —) :6.5.2.6�, 6.5.3.3�, 6.10.2.2�
Bioequivalence (test de —) : 10.3.3.7�
Bioinformatique : 1.2.4.2�
Biometrie : 1.2.2.2�
Biostatistique : 1.2.3.4�
Biserial (coe�cient de correlation —) :4.6.3.2�
Bloc (aleatoire complet) : 2.3.5.2�
Bloc (incomplet) : 2.3.5.3�
Boıte (de dispersion ou — a moustaches) :voir boxplot
Bonferroni (methode de —) : 10.3.5.2�
Bootstrap : 8.4.2.2�, 9.4.4.2�, 10.3.4.2�
Boxplot : 3.3.4.2�, 3.6.4.4�, 4.3.1.2�
Bravais-Pearson (coe�cient de correla-tion de —) : voir correlation (coe�-cient de —)
C
Calcul (numerique) : 3.4.2�, 3.9.1, 3.9.2,3.9.3
Calibrage : 4.7.6.2�
Camembert (diagramme en —) : 3.3.4.3�
Caracteristique (fonction —) : 5.9.2.2�
Carre latin : 2.3.5.3�
Categorie (d’une distribution de frequen-ces) : voir classe (d’une distribution defrequences)
Censuree (distribution —) : 6.10.4.2�
Centile : 3.6.4.5�, 5.8.1.2�
Central (theoreme — limite) : 6.6.5,6.6.6.4�
Centrale (distribution non —) : 6.10.3
Centrale (valeur —) : 3.4.1�
Centre (moment — et non —) : voir mo-ment
Certain (evenement —) : 5.3.1.2�
Chaıne (de rapports et indice en —) :3.10.3.3�
Chronique : voir chronologique (serie —)

INDEX DES MATIERES 505
Chronologique (serie —) : 4.9.1.5�,4.10.2.6�
Circulaire (diagramme —) : 3.3.4.3�
Circulaire (donnee —) : 2.4.1.5�
Circularite (d’un nombre-indice) :3.10.3.1�
Classe (d’une distribution de frequences) :3.2.3.1�, 4.2.2.3�
Classification (numerique) : 4.11.2
Cloche (distribution en —) : 3.3.3
Collecte (des donnees) : 1.3.1.1�, 2.2.3.3�,2.4.2
Combinaison de tests : 10.3.5.4�
Compartiments (modele a —) : 4.10.2.6�
Complementaire (evenement —) : 5.3.2.2�
Complete (enquete —) : 2.2.1.2�
Composantes (analyse des — ou analyseen — principales) : 4.11.2
Compose (indice —) : 3.10.1.2�
Composee (distribution —) : 6.5.3.3�
Comptage : 2.4.1.2�
Concentration (coe�cient de —) : 3.6.6,3.6.7.2�, 5.8.1.2�
Concentration (courbe de — et diagrammede —) : 3.6.6.3�
Concentration (ellipse de —) : 7.4.1.3�
Condition d’application : 9.4.3.2�,10.3.3.2�
Conditionnelle (densite de probabilite—) : 7.2.1.3�
Conditionnelle (distribution —) : 4.2.3.2�,7.2.1
Conditionnelle (frequence —) : 4.2.3.2�,5.4.1.1�
Conditionnelle (moyenne —) : 4.4.2�, 7.3.1
Conditionnelle (probabilite —) : 5.4.1.2�,7.2.1.2�
Conditionnelle (variance —) : 4.4.2�, 7.3.1
Confiance (coe�cient de —, intervalle de— et limite de —) : 9.4.1, 9.4.3,10.3.3.5�
Conformite (test de —) : 10.2
Congruentielle (methode multiplicative—) : 8.2.3.1�
Conservateur (test —) : 10.3.3.8�
Consistant (estimateur — et test —) :9.3.1.7�, 10.4.3.6�
Contagieuse (distribution —) : 6.5.3
Contingence (tableau de —) : 4.6.3.6�
Continue (distribution theorique — et va-riable aleatoire —) : 5.5.2, 5.5.4
Continue (donnee — et variable observee—) : 2.4.1.2�
Continuite (correction de —) : 6.6.4.3�
Contradictoire (evenement —) : 5.3.2.2�
Contraire (evenement —) : 5.3.2.2�
Convergence (stochastique) : 8.5.1�
Convergent (estimateur —) : voir consis-tant (estimateur — et test —)
Correct (estimateur absolument —) : voirbiais
Correctif (terme —) : 3.8.1.3�
Correlation (coe�cient de —) : 4.6.1,4.6.2, 4.6.3, 4.9.1.3�, 7.3.2
Correlation (matrice de —) : 4.11.1.3�
Correlation (rapport de —) : 4.6.3.5�
Correlation non lineaire (coe�cient de—) : 4.6.3.5�
Correlation totale (coe�cient de —) : voircorrelation (coe�cient de —)
Correspondances (analyse des — ou ana-lyse factorielle des —) : 4.11.2
Covariance : 4.5.1.2�, 4.5.2, 4.9.1.3�, 7.3.2
Covariance (analyse de la —) : 1.2.2.2�
Covariance (matrice de —) : 4.11.1.2�
Critique (region — et valeur —) : 10.3.1.2�
Croissance (courbe de —) : 4.10.2
Cubique (moyenne —) : 3.5.3, 3.5.7.2�,5.8.1.1�
Cumulant : 5.9.2.1�
Cumulative (fonction — de frequences) :3.3.2.3�, 4.2.2.4�
Cumulee (frequence —) : 3.2.2.4�, 4.2.2.4�
Curtosis : 6.6.1.3�
Curvilineaire (regression —) : 4.10.1
D
Date (d’observation) : 2.2.3.2�
Decentrage (coe�cient de —) : 6.10.3.1�
Decile : 3.6.4.5�, 5.8.1.2�
Decision (theorie de la —) : 10.3.4.3�

506 INDEX DES MATIERES
Degres (echantillonnage a deux ou plu-sieurs —) : 2.2.4.4�
Degres de liberte (nombre de —) : 6.7.1�,6.8.1.1�, 6.9.1.1�
Delimitation (d’une enquete) : 2.2.2
Denombrement : 2.4.1.2�
Densite de frequence : voir unitaire (fre-quence —)
Densite de probabilite (fonction de —) :5.5.2.1�, 5.5.4.1�
Dependant en probabilite : voir indepen-dance (stochastique)
Dependante (variable —) : 4.7.1
Depenses (indice de —) : 3.10.2.4�
Descriptive (statistique —) : 1.3.1.1�, 3.1,4.1, 4.11
Determination (coe�cient de —) :4.6.1.5�, 4.7.4.3�
Deviation standard : voir ecart-type
Diagonale (droite de regression —) : voirmoindres rectangles (droite des —)
Diagramme : 3.3.1, 3.3.2, 3.3.4, 4.3.1, 4.3.2
Dictionnaires (de statistique) : 1.4.1.1�
Di↵erence de variables aleatoires : 5.7.2.2�,5.8.2.1�, 5.8.3.3�, 7.3.5.3�
Di↵erence moyenne : 3.6.6, 3.6.7.2�,5.8.1.2�
Dimension(s) (statistique a une —, a deux— et a plusieurs —) : 3.1.1�
Directionnelle (donnee —) : 2.4.1.5�
Discontinue (distribution theorique — etvariable aleatoire —) : 5.5.1, 5.5.3
Discontinue (donnee — et variable obser-vee —) : 2.4.1.2�
Discrete : voir discontinue
Discriminante (analyse —) : 4.11.2
Dispersion (boıte de —) : voir boxplot
Dispersion (diagramme de —) : 4.3.1.1�,4.3.2.2�
Dispersion (matrice de —) : 4.11.1.2�
Dispersion (parametre de —) : 3.4.1�,3.7.1.3�, 5.8.1.2�
Dispositif (experimental) : 2.3.5
Dissymetrie (d’une distribution) : 3.3.3,3.7.1.3�, 5.8.5.1�
Dissymetrie (parametre de —) : 3.4.1�,3.7.1.3�, 3.7.2, 5.8.1.3�, 5.8.5
Dissymetrique (distribution —) : 3.3.3,3.7.1.3�, 5.8.5.1�
Distribution (fonction de —) : voir repar-tition (fonction de —)
Distribution (observee) : voir frequences(distribution de —)
Distribution (theorique) : 5.5.1, 5.5.2,5.5.3, 5.5.4, 6.1, 7.1
Divisee (parcelle —) : 2.3.5.3�
Documentation (complementaire) : 1.4.1,1.4.2
Dominante (valeur —) : voir mode
Donnees (analyse des —) : 1.2.3.3�
Donnees (matrice des —) : 4.11.1.1�
Dotplot : 3.3.4.1�
Droite (dissymetrie —) : voir dissymetrie(d’une distribution)
E
Ecarts (somme des carres des —) : 3.8.1.3�
Ecarts (somme des produits des —) :4.9.1.2�
Ecart-type (definition, proprietes, calcul) :3.6.1, 3.6.7.1�, 3.8.1, 5.8.1.2�
Ecart-type (distribution d’echantillonna-ge) : ex. 8.4.1, 8.4.3.2�
Ecart-type (estimation) : 9.2.2
Echantillon : 2.2.1.2�, 8.2.1
Echantillonnage : 2.2.1.2�, 2.2.4, 8.2.2,8.2.3
Echantillonnage (distribution d’—) : 8.4.1,8.4.2, 8.4.3
Echantillonnage (enquete par —) :2.2.1.2�, 2.2.4
Echantillonnee (distribution —) : voirechantillonnage (distribution d’—)
Echantillonnee (fraction —) : 2.2.5.1�
Echelle (d’un diagramme) : 3.3.1.2�,3.3.2.2�, 3.3.4.4�
Econometrie : 1.2.2.2�
E↵ectif : 2.2.5, 3.2.1
E�cace (estimateur —) : 9.3.1.4�
E�cacite : 9.3.1, 10.4.3.3�
Egalite (test d’—) : 10.2
Elaguee (moyenne —) : 9.2.1.4�, 9.3.4.2�

INDEX DES MATIERES 507
Elasticite : 4.10.2.4�
Element de probabilite : 5.5.2.2�, 5.5.4.1�
Elementaire (indice —) : 3.10.1.2�
Empirique (distribution —) : voir frequen-ces (distribution de —)
Encyclopedies (de statistique) : 1.4.1.1�
Enquete : 2.2.1Enqueteur : 2.2.3.3�
Enregistrement (des donnees) : 2.4.2Ensemble (statistique) : voir populationEntrepot (de donnees) : 1.2.4.1�
Equiprobable (ecart —) : voir median(ecart —)
Equivalence (test d’—) : 10.3.3.7�
Erreur (maximum ou marge d’—) :9.4.5.2�
Erreur de deuxieme espece : 10.3.1.3�,10.4.1
Erreur de premiere espece : 10.3.1.3�
Erreur standard : 8.3.1.2�, 8.4.1.1�
Erreur standard (methode de l’—) :9.4.3.1�, 10.3.3.1�
Erreur-type : voir erreur standardEsperance mathematique : 5.7.1, 5.7.2Essai : 2.3.1.1�
Estimateur : 9.3.1.1�
Estimation : 9.1, 9.3.1.1�
Estimee (valeur — par regression) :4.7.3.1�
Etendue : voir amplitudeEvenement (aleatoire) : 5.2.1.1�
Exacte (decimale —) : 3.9.1.4�
Exacte (valeur —) : 3.2.4, 3.9.1.4�
Exactitude : voir biaisExcentricite (coe�cient d’—) : 6.10.3.1�
Exclusifs (evenements —) : 5.3.1.3�
Exhaustif (estimateur —) : 9.3.1.7�
Exhaustive (enquete —) : 2.2.1.2�
Experience : 2.3.1Experience aleatoire : 5.2.1.1�
Experimentale (unite —) : 2.3.4.1�
Experimentation : 2.3.1Explicative (variable —) : 4.7.1Exponentielle (distribution —) : ex. 5.5.5,
ex. 5.6.6, ex. 5.8.4, ex. 5.9.4, 6.4.1.5�,6.8.2.5�, 6.10.5.4�
Exponentielle (distribution — tronquee) :6.10.4.2�
Exponentielle (famille —) : 6.10.5.6�
Exponentielle (regression —) : 4.10.2.2�,4.10.3.1�
Extraction (des donnees) : 1.2.4.2�
Extreme (valeur — d’une classe) : 3.2.3.1�
Extremes (distribution d’echantillonnagedes valeurs —) : 8.3.4
F
F (distribution —) : 6.9.1, 6.9.2, 6.10.1.3�,6.10.2.2�, 6.10.5
F (distribution — non centrale) : 6.10.3.2�
Facteur (d’une experience) : 2.3.3
Factorielle (analyse —) : 4.11.2
Factorielle (experience —) : 2.3.3.2�,ex. 2.3.1
Faux positif : 10.3.5.5�
Fiduciaire (limite —) : 9.4.4.1�
Fisher (coe�cient de —) : 3.7.2, 5.8.1.3�,5.8.5
Fisher (Ronald Aylmer —) : 1.2.2.2�
Fisher (serie logarithmique de —) : 6.5.1,6.5.3.3�
Fisher-Snedecor (distribution F de —) :voir F (distribution —)
Fonction caracteristique : 5.9.2.2�
Fonction de densite de probabilite :5.5.2.1�, 5.5.4.1�
Fonction de distribution : voir fonction derepartition
Fonction de repartition : 5.5.1.2�, 5.5.3.2�
Fonction de variable aleatoire : voir trans-formation (de variable aleatoire)
Fonction generatrice des cumulants :5.9.2.1�
Fonction generatrice des moments : 5.9.1,6.6.2.4�
Fouille (des donnees) : 1.2.4.2�
Fractile : voir quantile
Fraction (echantillonnee) : 2.2.5.1�
Frequences (distribution de —) : 3.2.2,3.2.3, 3.2.4, 4.2.2, 4.2.3
Frequentiste (approche —) : 9.3.5.3�

508 INDEX DES MATIERES
G
Galton (Francis —) : 1.2.1.2�
Gamma (distribution —) : 6.10.5.5�
Gamma (fonction —) : 6.10.2
Gauche (dissymetrie —) : voir dissymetrie(d’une distribution)
Gauss (distribution de —) : voir normale(distribution — a une dimension)
Gauss (Karl Friedrich —) : 1.2.1.1�
Generatrice (fonction — des cumulants) :5.9.2.1�
Generatrice (fonction — des moments) :5.9.1, 6.6.2.4�
Genomique : 1.2.4.2�
Geometrique (moyenne —) : 3.5.2, 3.5.3,3.5.7.2�, 4.10.3.1�, 5.8.1.1�
Geometrique (serie —) : 6.5.2.5�
Gini (coe�cient de —) : voir concentra-tion (coe�cient de —)
Glissante (moyenne —) : 4.10.2.6�
Gosset (William Sealy —) : 1.2.2.2�
Grands nombres (loi des —) : 8.5.1�
Graphique : voir diagramme
Grappes (echantillonnage en —) : 2.2.4.4�
Grossiere (erreur —) : 3.9.1.2�
Groupee (distribution —) : 3.2.3, 3.2.4,4.2.2.3�
Groupee (distribution non —) : 3.2.2,3.2.4, 4.2.2
Gumbel (distribution de —) : 8.3.4.3�
H
Harmonique (moyenne —) : 3.5.3, 5.8.1.1�
Hasard (echantillonnage au —) : 2.2.4.1�
Histogramme : 3.3.1
Histogramme (de frequences cumulees) :3.3.2
Historique : 1.2.1, 1.2.2, 1.2.3, 1.2.4
Hochberg (methode de —) : 10.3.5.5�
Holm (methode de —) : 10.3.5.3�
Holm-Bonferroni (methode de —) :10.3.5.3�
Homogeneite (test d’—) : 10.2
Homoscedasticite : 10.3.3.2�
Hypergeometrique (distribution — et loi—) : 6.3.1, 6.10.1.2�
Hypergeometrique generalisee (distribu-tion — et loi —) : 6.3.2
Hypernormale (distribution —) : 6.6.1.3�
Hyponormale (distribution —) : 6.6.1.3�
Hypothese (test d’—) : 10.2
I
i (distribution en —) : 3.3.3
Identification : 4.10.1, 4.10.2
i.i.d. (variables —) : 5.6.1.3�
Impartial : voir biais
Impossible (evenement —) : 5.3.2.3�
Incomplet (bloc —) : 2.3.5.3�
Independance (stochastique) : 5.4.2, 5.6.1,7.3.2.2�
Independance (test d’—) : 10.2
Independante (variable —) : 4.7.1
Indicatrice (ellipse —) : 7.4.1.3�
Indicatrice (variable — et variable aleatoi-re —) : voir binaire (variable — et va-riable aleatoire —)
Indice (nombre —) : 3.10.1, 3.10.2, 3.10.3
Inexactitude : voir biais
Inference (statistique) : 1.3.1.1�, 9.1, 10.1
Influence (fonction d’— et courbe d’—) :9.3.1.6�
Informatique : 1.2.3, 1.2.4
Initiale (periode —) : 3.10.1.2�
Intensite (d’echantillonnage) : 2.2.5.1�
Interdependantes (variables —) : 4.8.1.1�
Internet (documentation par —) : 1.4.2
Interquartile (ecart —) : 3.6.4.3�, 3.6.7.2�,5.8.1.2�
Intervalle (d’une classe) : 3.2.3.1�, 4.2.2.3�
Intervalle (estimation par —) : 9.4.1.1�
Intervalle de confiance : 9.4.1, 9.4.3,10.3.3.5�
Intraclasse (coe�cient de correlation —) :4.6.3.7�
Inventaire : 2.2.1.1�, ex. 2.2.2
Isometrie : ex. 4.10.1
J
j (distribution en —) : 3.3.3
Jackknife : 8.4.2.2�, 9.4.4.2�, 10.3.4.2�

INDEX DES MATIERES 509
K
Khi-carre (distribution —) : 6.8.1, 6.8.2,6.9.2, 6.10.1, 6.10.2.2�, 6.10.5
Khi-carre (distribution — non centrale) :6.10.3.1�
Khi-carre minimum (methode du —) :9.3.3.3�
L
Laplace (Pierre Simon de —) : 1.2.1.1�
Laplace (theoreme de —) : voir Moivre(theoreme de —)
Laplace-Gauss (distribution de —) : voirnormale (distribution — a une dimen-sion)
Laplace-Liapounov (theoreme de —) :voir central (theoreme — limite)
Laspeyres (indice de —) : 3.10.2
Latin (carre —) : 2.3.5.3�
Leptocurtique (distribution —) : 6.6.1.3�
Liee : voir conditionnelle
Limite (d’une classe) : 3.2.3.1�
Limite (theoreme central —) : 6.6.5,6.6.6.4�
Lindeberg-Levy (theoreme de —) : 6.6.5
Lineaire (modele — general) : 1.2.3.3�
Lineaire (modele — generalise) : 1.2.3.3�
Lineaire (modele — mixte) : 1.2.3.3�
Lineaires (diagramme a echelles non —) :3.3.4.4�
Livres (de statistique) : 1.4.1.1�
Localement le plus puissant (test —) :10.4.3.5�
Logarithmico-normale (distribution —) :6.6.6
Logarithmique (serie — de Fisher) : 6.5.1,6.5.3.3�
Logiciels (statistiques) : (( Mode d’emploi ))
Logistique (fonction —) : 4.10.2.3�,4.10.3.3�
Logistique (regression —) : 4.10.2.6�
Logit : 4.10.2.6�
Log-normale (distribution —) : 6.6.6
Loi (de probabilite) : voir distribution(theorique)
Longueur minimum (intervalle de confian-ce de —) : 9.4.3.6�
Lorenz (courbe de — et diagramme de—) : 3.6.6.3�
M
Mann et Whitney (test de —) : 10.3.3.2�
Marge d’erreur : 9.4.5.2�
Marginale (distribution —) : 4.2.3.1�,5.5.3.3�, 5.5.4.2�, 7.2.1
Marginale (frequence —) : 4.2.3.1�
Marginale (moyenne —) : 4.4.2�, 7.3.1Marginale (variance —) : 4.4.2�, 7.3.1Mediale : 3.5.5, 5.8.1.1�
Median (ecart —) : 3.6.3, 5.8.1.2�
Median (point — d’une classe) : voir pointcentral (d’une classe)
Mediane : 3.5.4, 3.5.7.1�, 5.8.1.1�, 8.3.3Mediane (classe —) : 3.5.4.3�
Melange (de distributions) : 6.10.4.3�
Mensuration : 2.4.1.2�
Mesure : 2.4.1.2�
Meta-analyse : 10.3.5.5�
Mid-range : 9.2.1.4�
Mitscherlich (loi de —) : 4.10.2.3�,4.10.3.3�
Mobile (moyenne —) : 4.10.2.6�
Modale (classe —) : 3.5.6Modalite (d’un facteur) : 2.3.3.1�
Mode : 3.5.6, 3.5.7.1�, 5.8.1.1�
Modelisation : 1.2.3.3�
Module (d’une classe) : voir intervalle(d’une classe)
Moindres carres (droite des —) : voir re-gression (coe�cient de — et droite de—)
Moindres carres (methode des —) : 4.7.2,9.3.3.3�
Moindres rectangles (droite des —) : 4.8.1,4.8.2, 4.9.1.3�
Moivre (Abraham de —) : 1.2.1.1�
Moivre (theoreme de —) : 6.6.4, 6.6.5Moment : 3.7.1, 3.8.1.6�, 4.5.1.1�, 5.8.1.3�,
5.9.1, 7.3.2.1�, 8.4.1.3�
Moments (methode des —) : 9.3.3.2�
Monte-Carlo (methode de —) : 8.4.2.1�
Moustaches (boıte a —) : voir boxplot

510 INDEX DES MATIERES
Moyen (ecart — absolu) : 3.6.2, 3.6.7.1�,5.8.1.2�
Moyenne : voir moyenne arithmetique
Moyenne arithmetique (definition, pro-prietes, calcul) : 3.5.1, 3.5.3, 3.5.7.1�,3.8.1, 5.8.1.1�, 5.8.2, 7.3.5
Moyenne arithmetique (distributiond’echantillonnage) : 8.3.1, 8.3.2,8.4.3.2�
Moyenne arithmetique (estimation) :9.2.1, 9.3.1.2�, ex. 9.3.1, ex. 9.3.5,ex. 9.3.7
Moyenne arithmetique (intervalle de con-fiance) : 9.4.2
Moyenne arithmetique (test d’egalite) :10.3.2, 10.4.2
Moyenne (valeur —) : 3.4.1�, 5.7.1.1�
Moyennes (vecteur de —) : 4.11.1.2�
Multidimensionnelle (analyse —) :1.2.3.3�, 4.11.2
Multiple (coe�cient de correlation —) :4.11.2
Multiple (regression —) : 4.11.2
Multiples (comparaisons —) : 10.3.5.5�
Multiples (tests —) : 10.3.5
Multiplicative (methode — congruen-tielle) : 8.2.3.1�
Multiplicativite (propriete de —) : 5.4.1.2�
Mutuellement exclusifs (evenements —) :5.3.1.3�
N
Neo-bayesienne (methode —) : voirbayesienne (methode —)
Neurones (reseau de —) : 1.2.4.2�
Neyman type A (distribution de —) :6.5.3
Niveau (d’un facteur) : 2.3.3
Niveau de signification : 10.3.1.1�
Niveaux (echantillonnage a deux ou plu-sieurs —) : 2.2.4.4�
Nombre d’observations : 9.4.5, 10.4.4
Nombre-indice : 3.10.1, 3.10.2, 3.10.3
Nominale (variable —) : 2.4.1.3�
Non-centrale (distribution —) : 6.10.3
Non-centralite (coe�cient de —) :6.10.3.1�
Non-inferiorite (test de —) : 10.3.3.7�
Non-reponse : 2.2.3.3�, 2.2.5.7�
Normale (distribution — a deux dimen-sions) : 7.4.1, 7.4.2, 7.4.3
Normale (distribution — a une dimen-sion) : 6.6.1, 6.6.2, 6.6.3, 6.6.4, 6.6.5,6.8.2, 6.9.2.3�, 6.10.1, 6.10.5
Normale (equation —) : 4.7.2.2�, 4.10.3
Normalite asymptotique : 6.6.5
Norme (histogramme —) : 3.3.1.2�
Norme (stereogramme —) : 4.3.2.1�
Nuage (de points) : voir dispersion (dia-gramme de —)
Nulle (hypothese —) : 10.3.1.1�
O
Objet (d’une experience) : 2.3.3.2�
Obliquite (d’une distribution) : voir dissy-metrie (d’une distribution)
Observation : 2.2.3
Observation (etude par —) : 2.1.2�
Observee (distribution —) : voir frequen-ces (distribution de —)
Operationnelle (recherche —) : 1.2.2.2�
Oppose (evenement —) : 5.3.2.2�
Opposee (hypothese —) : 10.3.1.1�
Ordinale (variable —) : 2.4.1.3�
Ordinateur : 1.2.3, 1.2.4, 2.4.2.3�
Organique (droite de correlation —) : voirmoindres rectangles (droite des —)
Origine (regression par l’—) : 4.7.6
Orthogonale (droite de regression —) :voir moindres rectangles (droite des—)
Ouverte (classe —) : 3.2.3.2�
P
Paasche (indice de —) : 3.10.2
Paires (test t par —) : 10.3.3.2�
Parabolique (regression —) : 4.10.2.5�,4.10.3.2�
Parametre : 3.1.2�, 3.4, 4.4, 5.8.1
Parametrique (methode non — et test non—) : 9.3.4.1�, 10.3.3.2�
Parcelle divisee : 2.3.5.3�
Pareto (distribution de —) : 8.3.4.3�

INDEX DES MATIERES 511
Partielle (coe�cient de correlation —) :4.11.2
Partielle (enquete —) : voir echantillonna-ge (enquete par —)
Pascal (Blaise —) : 1.2.1.1�
Pascal (distribution de —) : 6.5.2,6.5.3.3�
Pearson (coe�cient de —) : 3.7.2,5.8.1.3�, 5.8.5
Pearson (distribution �2 de —) : voirkhi-carre (distribution —)
Pearson (Karl —) : 1.2.2.2�
Pearson (systeme de —) : 6.10.5
Percentile : voir centile
Periode (d’observation) : 2.2.3.2�
Permutation (test de —) : 10.3.4.2�
Pilote (enquete —) : 2.2.3.3�
Pitman (e�cacite de —) : 10.4.3.4�
Plan (d’experience) : 2.3.1.2�
Planification (d’une enquete) : 2.2.1.3�
Platycurtique (distribution —) : 6.6.1.3�
Plurimodale (distribution —) : 3.5.6
Poids : 3.5.1.3�, 4.7.6.1�
Point (coe�cient de correlation de —) :4.6.3.3�
Point (estimation de —) : 9.4.1.1�
Point central (d’une classe) : 3.2.3.1�,4.2.2.3�
Poisson (distribution de — et theoremede —) : 6.4.1, 6.4.2, 6.5.2.3�, ex. 6.6.7,6.10.1.2�
Poisson (processus de —) : 6.4.1.5�
Poisson (Simeon Denis —) : 1.2.1.1�
Poisson-binomiale (distribution —) :6.5.3.3�
Poisson-Pascal (distribution —) :6.5.3.3�
Polygone (de frequences) : 3.3.1
Polygone (de frequences cumulees) : 3.3.2
Polynomiale (distribution — et loi —) :6.2.3, 6.3.2.2�, ex. 7.3.3
Polynomiale (regression —) : 4.10.2.5�,4.10.3.2�
Ponctuelle (estimation —) : 9.4.1.1�
Ponderation (coe�cient de —) : 3.5.1.3�,4.7.6.1�
Ponderee (moyenne —) : 3.5.1.3�
Ponderee (regression —) : 4.7.6
Population : 2.2.1.1�, 2.2.2, 2.3.2.1�, 8.2.1
Population-parent : voir population
Position (parametre de —) : 3.4.1�
Precision : 9.3.1.3�
Pre-enquete : 2.2.3.3�
Presque certain (evenement —) : 5.3.1.2�
Presque impossible (evenement —) :5.3.2.3�
Prix (indice de —) : 3.10.2
Probabilite : 5.2.1, 5.2.2
Probabilite (convergence en —) : 8.5.1�
Probabilite (distribution de — et loi de—) : voir distribution (theorique)
Probabilite composee (propriete de la —) :5.4.1.2�
Probabilite totale (axiome de la — et pro-priete de la —) : voir additivite (axio-me d’— et propriete d’—)
Probabilites (calcul des —) : 1.2.1.1�
Probable (ecart —) : voir median (ecart—)
Probit : 4.10.2.6�
Produit de variables aleatoires : 5.7.2.3�,5.8.2.1�, 5.8.3.4�, 7.3.5.1�
Progressif (test —) : 10.3.4.4�
Progressive (estimation —) : 9.4.4.4�
Proportion (distribution d’echantillonnaged’une —) : ex. 8.3.4, ex 8.4.7
Proportion (estimation d’une —) :ex. 9.3.4
Prospective (puissance —) : 10.4.3.7�
Protocole (experimental) : 2.3.1.2�
Pseudo-aleatoire (nombre —) : 8.2.3
Pseudo-valeur : 9.3.4.3�
Psychometrie : 1.2.2.2�
Puissance (d’un test) : 10.4.1, 10.4.3
Puissance (fonction —) : 4.10.2.4�,4.10.3.1�
Puissance (fonction de —) : 10.4.1, 10.4.3
Q
Quadratique (droite de regression enmoyenne —) : voir regression (coe�-cient de — et droite de —)

512 INDEX DES MATIERES
Quadratique (ecart — moyen) : voir ecart-type
Quadratique (moyenne —) : 3.5.3,3.5.7.2�, 5.8.1.1�
Quadratique (regression —) : 4.10.3.2�
Qualitatif (facteur —) : 2.3.3.1�
Qualitative (donnee — ou observation—) : 2.2.3.1�, 2.4.1.3�
Qualite (controle de la —) : 1.2.2.2�
Quantile : 3.6.4.5�, 5.8.1.4�
Quantitatif (facteur —) : 2.3.3.1�
Quantitative (donnee — ou observation—) : 2.2.3.1�, 2.4.1.2�
Quantites (indice de —) : 3.10.2.3�
Quartiers de tarte (diagramme en —) :3.3.4.3�
Quartile : 3.6.4, 5.8.1.2�
Questionnaire : 2.2.3.3�
Quetelet (Lambert Adolphe —) :1.2.1.2�
Quotas (methode des —) : 2.2.4.5�
Quotient de variables aleatoires : 5.7.2.4�,5.8.2.3�, 5.8.3.5�, 7.3.5.2�
R
Rabotee (moyenne —) : 9.2.1.4�, 9.3.4.2�
Randomisation (test de —) : 10.3.4.2�
Rang : 2.4.1.4�
Rang (coe�cient de correlation de —) :4.6.3.4�
Rapports (de moyennes et moyennes de—) : 3.10.1.4�
Recensement : 2.2.1.2�
Rectangulaire (distribution —) : voir uni-forme (distribution — continue a unedimension)
Redressement : 2.2.4.7�
Reduction (des donnees) : 3.1.2�, 3.4, 4.4
Reduit (residu —) : 4.7.4.5�
Reduite (distribution normale — a deuxdimensions) : 7.4.1, 7.4.2
Reduite (distribution normale — a une di-mension) : voir normale (distribution— a une dimension)
Reduite (variable —) : 4.8.2.3�, 5.8.3.1�
Reechantillonnage : 1.2.3.3�, 8.4.2.2�
Reference (periode de —) : 3.10.1.2�
Regression (coe�cient de — et droite de—) : 4.7.2, 4.7.5, 4.9.1.3�, 7.3.4.1�
Regression (courbe de —) : 4.10.1
Regression (diagramme de —) : 4.7.1, 7.3.3
Regression (ligne de —) : 7.3.3.1�
Regularite statistique : 5.2.2.1�, 8.5.2�
Rejet (condition de —) : 10.3.1.4�
Rejet (domaine de — ou region de —) :10.3.1.2�
Relative (e�cacite —) : 9.3.1.4�, 10.4.3.3�
Relative (frequence —) : 3.2.2.3�, 3.2.3.1�,4.2.2.4�
Repartition (fonction de —) : 3.3.2.3�,5.5.1.2�, 5.5.3.2�
Repetition : 2.3.4.2�
Rerandomisation (test de —) : 10.3.4.2�
Residu (de la regression) : 4.7.3, 4.7.4.5�,4.10.4, 7.3.4.2�
Residuel (ecart-type —) : 4.7.4.4�
Residuelle (somme des carres des ecarts—) : 4.9.1.4�
Residuelle (variance —) : 4.7.4, 4.9.1.3�,7.3.4
Retrocumulee (frequence —) : 3.2.2.4�
Retrospective (puissance —) : 10.4.3.7�
Reversibilite (d’un nombre-indice) :3.10.3.1�
Revues (de statistique) : 1.4.1.3�, 1.4.2.2�
Risque de deuxieme espece : 10.3.1.3�,10.4.1
Risque de premiere espece : 10.3.1.3�
Robuste (estimateur — et methode—) : 1.2.3.3�, 9.3.1.6�, 9.3.4, 9.4.4.2�,10.3.4.2�
Robustesse : 9.3.1.6�
Rognee (moyenne —) : 9.2.1.4�, 9.3.4.2�
S
Saisie (des donnees) : 2.4.2.1�
Securite (coe�cient de —, intervalle de —et limite de —) : voir confiance (coef-ficient de —, intervalle de — et limitede —)
Segmentee (regression —) : 4.10.2.6�
Semi-interquartile : 3.6.4.3�, 5.8.1.2�

INDEX DES MATIERES 513
Sensibilite (aux erreurs importantes) :9.3.1.6�
Sequentiel (test —) : 10.3.4.4�
Sequentielle (estimation —) : 9.4.4.4�
Serie (statistique) : 3.2.1, 4.2.1
Sheppard (correction de —) : 3.6.1.6�,3.7.1.4�, 4.5.2.4�
Sigmoıde (courbe —) : 6.6.1.2�
Significatif : 10.3.1.4�
Significatif (chi↵re —) : 3.9.2
Significatif (hautement — et tres haute-ment —) : 10.3.1.4�
Signification (niveau de —) : 10.3.1.1�
Signification (seuil de —) : 10.3.1.2�
Signification (test de —) : 10.2
Simple (echantillonnage —) : 2.2.4.1�,8.2.2.1�
Simple (indice —) : 3.10.1.2�
Simulation : 1.2.3.3�, 8.4.2.1�
Simultanes (tests —) : 10.3.5
Six sigma : 1.2.4.2�
Snedecor (distribution F de —) : voir F(distribution —)
Somme de variables aleatoires : 5.6.3,5.7.2.2�, 5.8.2.1�, 5.8.3.3�, 7.2.2.2�,7.3.5.3�
Sondage : voir echantillonnage
Sondee (fraction —) : 2.2.5.1�
Sous-dispersee (distribution —) : 6.5.3.4�
Sous-dispersion : 6.5.3.4�
Spearman (Charles Edward —) : 1.2.2.2�
Spearman (coe�cient de correlation de—) : 4.6.3.4�
Stabilite des frequences : voir regularitestatistique
Statistique (analyse —) : 1.3.1.1�
Statistique (definition) : 1.1
Statistique (distribution —) : voir fre-quences (distribution de —)
Statistique (unite —) : voir unite (de base)
Stem-and-leaf (diagramme —) : 3.3.4.1�
Stereogramme : 4.3.2.1�
Stochastique (convergence —) : 8.5.1�
Stochastique (independance —) : 5.4.2,5.6.1, 7.3.2.2�
Stochastiquement certain (evenement —) :5.3.1.2�
Stochastiquement dependant : voir inde-pendance (stochastique)
Stochastiquement impossible (evenement—) : 5.3.2.3�
Stochastiquement independant : voir inde-pendance (stochastique)
Strate : 2.2.4.3�
Stratifie (echantillonnage —) : 2.2.4.3�
Student : 1.2.2.2�
Student (distribution t de —) : voir t(distribution —)
Student (test t de —) : 10.3.2.4�
Su�sant (estimateur —) : 9.3.1.7�
Superiorite (test de —) : 10.3.3.7�
Surdispersee (distribution —) : 6.5.3.4�
Surdispersion : 6.5.3.4�
Symetrie : voir dissymetrie
Symetrique (distribution —) : voir dissy-metrique (distribution —)
Synthetique (indice —) : 3.10.1.2�
Systematique (echantillonnage —) :2.2.4.2�
Systematique (erreur —) : 2.2.4.7�,9.3.1.2�
Systeme (de distributions et — de Pear-son) : 6.10.5
T
t (distribution —) : 6.7, 6.8.2.3�, 6.9.2.2�,6.10.1, 6.10.2.2�, 6.10.5
t (distribution — non centrale) : 6.10.3.3�
t (test — de Student) : 10.3.2.4�
t (test — par paires) : 10.3.3.2�
Tableau (a double entree) : 4.2.2.1�
Tables : 1.4.1.2�, 6.1.2�
Taille : voir e↵ectif
Temoin : 2.3.3.2�
Test (d’hypothese ou de signification) :10.2
Tetrachorique (coe�cient de correlation—) : ex. 7.4.4
Tige et feuilles (diagramme en —) :3.3.4.1�
Totale : voir marginale

514 INDEX DES MATIERES
Totalement exclusifs (evenements —) :5.3.2.2�
Traitement (des donnees) : 2.4.2.3�
Transferabilite (d’un nombre-indice) :3.10.3.1�
Transformation (de variable aleatoire) :5.6.2, 5.7.2.1�, 5.8.2, 5.8.3, 7.2.2.1�
Transformation logarithmique : ex. 5.8.6,ex. 5.8.9
Triangulaire (distribution —) : ex. 5.6.5,ex. 5.9.3
Trois sigma (regle des —) : 5.8.4.3�
Tronquee (distribution —) : 6.10.4.2�
Type (de distribution) : 3.3.3, 6.10.5
Typique (valeur —) : voir parametre
U
u (distribution en —) : 3.3.3
Uniforme (carre d’une variable aleatoire —continue a une dimension) : ex. 5.6.2,ex. 5.7.3, ex. 5.8.8
Uniforme (distribution — continue a deuxdimensions) : ex. 5.5.7
Uniforme (distribution — continue aune dimension) : ex. 5.5.4, ex. 5.6.5,ex. 5.7.2, ex. 5.8.3, 6.10.1, 6.10.5.3�
Uniforme (distribution — discontinue adeux dimensions) : ex. 5.5.6
Uniforme (distribution — discontinue aune dimension) : ex. 5.5.3, 6.8.2.4�,6.10.1.2�
Uniformement le plus puissant (test —) :10.4.3.5�
Unilateral (intervalle de confiance —) :9.4.3.6�
Unilateral (test —) : 10.3.3.6�
Unimodale (distribution —) : 3.5.6
Unitaire (frequence —) : 3.2.3.3�, 4.2.2.4�
Unite (de base) : 2.2.1.1�, 2.2.2
Unite (de mesure) : 2.2.3.1�
Unite (experimentale) : 2.3.4.1�
Unite (statistique) : voir unite (de base)
Univers : voir population
Usage intensif (de l’ordinateur) : 1.2.3.3�
V
Valeur P : 10.3.2.2�, 10.3.3.4�
Valeurs (indice de —) : 3.10.2.4�
Validation : 4.10.1, 4.10.4
Variabilite (coe�cient de —) : voir varia-tion (coe�cient de —)
Variable (aleatoire) : 5.5.1.1�, 5.5.2.1�,5.5.3.1�
Variable (intervalle de classe —) : 3.2.3.2�
Variable(s) (statistique a une, a deux et aplusieurs —) : 3.1.1�
Variance (analyse de la —) : 1.2.2.2�
Variance (analyse de la — a plusieurs va-riables) : 4.11.2
Variance (definition, proprietes, calcul) :3.6.1, 3.6.7.1�, 3.8.1, 5.8.1.2�, 5.8.3,5.8.4, 7.3.5.3�
Variance (distribution d’echantillonnage) :8.3.2, 8.4.3.2�
Variance (estimation) : 9.2.2, 9.3.1.2�,ex. 9.3.2, ex. 9.3.5, ex. 9.3.7
Variance minimum (estimateur de —) :9.3.1.4�
Variances (matrice de — et covariances) :4.11.1.2�
Variante (d’un facteur) : 2.3.3
Variation (coe�cient de —) : 3.6.1,3.6.7.1�, 5.8.1.2�, ex. 8.4.2
Vraisemblance (fonction de —) : 9.3.2.2�,10.3.4.1�
Vraisemblance (methode du maximum de—) : 9.3.2
Vraisemblance (methode du maximum de— restreint) : 9.3.3.3�
Vraisemblance (rapport de —) : 10.3.4.1�
W
Weibull (distribution de —) : 8.3.4.3�
Welch (test de —) : 10.3.3.2�
Wilcoxon (test de —) : 10.3.3.2�
Y
Yule (George Udny —) : 1.2.2.2�

Index des symboles
Les principaux symboles utilises dans le texte sont enumeres ici par ordrealphabetique, d’abord pour l’alphabet latin, puis pour l’alphabet grec.
a : ordonnee a l’origine d’une droite de re-gression (valeur observee)
ak : moment par rapport a l’origine (valeurobservee)
AH0 : acceptation d’une hypothese nulle
b , byx : coe�cient de regression (valeur ob-servee)
b1 , b2 : coe�cient de Pearson (valeur ob-servee)
c : coe�cient d’une droite des moindresrectangles (valeur observee)
Cxn : nombre de combinaisons
cov , cov(x, y), cov(X, Y ) : covariance (va-leur observee ou theorique)
cv , cvx : coe�cient de variation (valeurobservee)
Cv , CvX : variable aleatoire correspon-dant au coe�cient de variation d’unechantillon
CV , CVX : coe�cient de variation (valeurtheorique)
d : marge d’erreur
di : residu
d0i : residu reduit
dr : marge d’erreur relative
e : base des logarithmes neperiens
em : ecart moyen absolu (valeur observee)
E(X) : esperance mathematique
exp : exponentielle
F : variable de Fisher-Snedecor
F↵/2 , F1�↵ , F1�↵/2 : valeur theorique(quantile) d’une variable de Fisher-Snedecor
f(x), f1(x), f(x, y) : fonction de densite deprobabilite
F (x), F1(x), F (x, y) : fonction de reparti-tion
f(x | y) : fonction de densite de probabiliteconditionnelle
g : parametre quelconque (valeur obser-vee)
G : variable aleatoire correspondant au pa-rametre g d’un echantillon
g1 , g2 : coe�cient de Fisher (valeur ob-servee)
H : hypothese alternative
H0 : hypothese nulle
k , k1 , k2 : parametre, nombre de degresde liberte

516 INDEX DES SYMBOLES
log : logarithme
loge : logarithme neperien
log10 : logarithme decimal
m , mX : moyenne arithmetique (valeurtheorique)
bm , bmX : moyenne arithmetique (valeur es-timee)
m , mX : mediane (valeur theorique)
mk , mkl : moment centre (valeur obser-vee)
mX|y : moyenne conditionnelle (valeurtheorique)
m11 : covariance (valeur observee)
n , ni , nij : e↵ectif, frequence absolue
N : e↵ectif d’une population finie
n0i , n0ij : frequence relative
n00i , n00ij : frequence unitaire
ni. , n.j : frequence marginale absolue
n0i. , n0.j : frequence marginale relative
n0i|j , n0j|i : frequence conditionnelle rela-tive
N 0(x) : fonction cumulative de frequences
p : nombre de classes, proportion, parame-tre d’une distribution binomiale (va-leur theorique)
bp : proportion, parametre d’une distribu-tion binomiale (valeur estimee)
P(A), P(X = x), P(x), Px , P(x, y) : pro-babilite
P(A |B), P(x | y) : probabilite condition-nelle
q : nombre de classes (ou 1� p)
q1 , q3 : quartile (valeur observee)
r , rxy : coe�cient de correlation (valeurobservee)
r2, r2xy : coe�cient de determination (va-
leur observee)
rS : coe�cient de correlation de rang deSpearman (valeur observee)
RH0 : rejet d’une hypothese nulle
s , sx : ecart-type (valeur observee)
s2, s2x : variance (valeur observee)
S2 : variable aleatoire correspondant a lavariance d’un echantillon
sy.x : ecart-type residuel (valeur observee)
s2y.x : variance residuelle (valeur observee)
sy|i , sy|x : ecart-type conditionnel (valeurobservee)
s2y|i , s2
y|x : variance conditionnelle (valeurobservee)
SCE , SCEx : somme des carres des ecarts
SCEy.x : somme des carres des ecarts resi-duelle
SPE , SPExy : somme des produits desecarts
t : variable de Student
t1�↵ , t1�↵/2 : valeur theorique (quantile)d’une variable de Student
U , Ui : variable aleatoire reduite, variablenormale reduite
uobs : valeur observee de la variable nor-male reduite
u1�↵ , u1�↵/2 : valeur theorique (quantile)de la variable normale reduite
var , var(x), var(X) : variance (valeur ob-servee ou theorique)
w : amplitude (valeur observee)
W : variable aleatoire correspondant al’amplitude d’un echantillon
wi : coe�cient de ponderation, poids
x , xi : valeur observee
X, Xi : variable aleatoire
x : moyenne arithmetique (valeur ob-servee)
X : variable aleatoire correspondant a lamoyenne arithmetique d’un echantillon
x : mediane (valeur observee)
X : variable aleatoire correspondant a lamediane d’un echantillon
xj , xy : moyenne conditionnelle (valeurobservee)

INDEX DES SYMBOLES 517
y : voir x
↵ : ordonnee a l’origine d’une droite de re-gression (valeur theorique), niveau designification, risque de premiere espece
↵k : moment par rapport a l’origine (va-leur theorique)
1� ↵ : degre de confiance
� : risque de deuxieme espece�yx : coe�cient de regression (valeur theo-
rique)�1 , �2 : coe�cient de Pearson (valeur
theorique)1� � : puissance
� : parametre quelconque (valeur theori-que)
b� : parametre quelconque (valeur estimee)�1 , �2 : coe�cient de Fisher (valeur theo-
rique)
� : di↵erence de moyennes�r : di↵erence relative de moyennes�x , �xi : accroissement, intervalle de
classe
"m : ecart moyen absolu (valeur theorique)
µk , µkl : moment centre (valeur theorique)µ11 : covariance (valeur theorique)
⇢ , ⇢XY : coe�cient de correlation (valeurtheorique)
� , �X : ecart-type, erreur standard (valeurtheorique)
b� : ecart-type (valeur estimee)
�2, �2X : variance (valeur theorique)
b�2 : variance (valeur estimee)
�Y.x : ecart-type residuel (valeur theori-que)
�2Y.x : variance residuelle (valeur theori-
que)
�Y |x : ecart-type conditionnel (valeurtheorique)
�2Y |x : variance conditionnelle (valeur theo-
rique)
bXi=a
: symbole de sommation
� : coe�cient de correlation de point (va-leur observee)
�(u), �(u, v) : fonction de densite de pro-babilite d’une distribution normale re-duite
�(u) : fonction de repartition de la distri-bution normale reduite a une dimen-sion
�2 : variable de Pearson
�2obs : valeur observee d’une variable de
Pearson
�2↵/2 , �2
1�↵ , �21�↵/2 : valeur theorique
(quantile) d’une variable de Pearson



La statistique – considérée comme l’ensemble des méthodes qui ont pour but de recueillir et d’analyser des données relatives à des groupes d’individus ou d’objets – joue un rôle essentiel dans de très nombreuses disciplines. Tel est le cas, entre autres, pour les sciences du vivant : biologie, agronomie, écologie, etc.
Les deux tomes de Statistique théorique et appliquée ont précisément pour objectif de permettre aux scientifiques de disciplines très variées, en particulier les sciences du vivant, d’utiliser au mieux les méthodes statistiques classiques, sans en négliger ni les fondements ni les limites.
L’objet du tome 1 est la présentation des notions de base de statistique descriptive (à une et à deux dimensions), de statistique théorique (à une et à deux dimensions également), et d’inférence statistique (distributions d’échantillonnage, problèmes d’estimation et tests d’hypothèses).
Cet ouvrage est conçu de manière à être à la fois un manuel et un livre de référence. À cette fin, il comporte une documentation détaillée, dont plus de 350 références bibliographiques, des tables, et divers index (index bibliographique, index des traductions anglaises, index des matières et index des symboles). Son utilisation comme manuel est facilitée par la définition de différents plans de lecture, clairement indiqués tout au long du texte, et par la présence de nombreux exemples et exercices, accompagnés de leurs solutions. Des informations complémentaires sont présentées dans un site web.
} Pierre DagnelieProfesseur émérite de la Faculté des sciences agronomiques de Gembloux, il a enseigné pendant plus de 30 ans la statistique, théorique et appliquée. Il a exercé des fonctions de professeur visiteur dans plusieurs universités et établissements d’enseignement supérieur de France, de Grande-Bretagne, de Hongrie, de Suisse, d’Algérie, du Maroc et du Brésil. Il a été président de la Société Internationale de Biométrie (International Biometric Society). Il est lauréat du prix du statisticien d’expression française et Honorary Fellow de la Royal Statistical Society de Grande-Bretagne.
STTHAP1
STAT
ISTI
QU
E TH
éORI
QU
E ET
APP
LIQU
éE
•DAGNELIE•
ISBN 978-2-8041-7560-3
STATISTIQUE THéORIQUE
ET APPLIQUéE
•pierre Dagnelie•
1. STATISTIQUE DESCRIPTIvE ET BASES DE L’INFéRENCE STATISTIQUE
3e édition
1
www.deboeck.com
STATISTIQUE THéORIQUE
ET APPLIQUéE
•pierre Dagnelie•
1. STATISTIQUE DESCRIPTIvE ET BASES DE L’INFéRENCE STATISTIQUE
3e édition
STTHAP1-cov.indd 1-3 6/12/12 13:38