réseaux de neurones artificiels - evelyne.lutton.free.frevelyne.lutton.free.fr/slidescours/cours...
TRANSCRIPT

Réseaux de neurones artificiels (formels)
Christian TRELEA AgroParisTech

Plan • L’idée – l’inspiration biologique • Réseaux de neurones formels (artificiels) • Apprentissage supervisé des RN • Capacité de généralisation • RN en classification • Apprentissage non supervisé – autres types de RN
2

L’idée (origine ~1940)
• Les organismes vivants, même assez primitifs (ex. insectes), réalisent des tâches complexes de traitement de l’information – orientation – communication – comportement social – …
• La puissance de traitement de leur système nerveux vient de
l’interconnexion (ex. 1014 connexions chez l’homme) – d’un grand nombre (ex. 1011 chez l’homme) – d’unités de traitement simples et similaires: les neurones
3

L’idée (suite)
• La motivation initiale était de faire du neuro-mimétisme – Toutefois, la vision des années 1940 était assez simpliste; – la réalité biologique c’est avéré plus complexe depuis .
• En revanche, cette idée c’est avérée très féconde en mathématiques et en
ingénierie • Aujourd’hui, les réseaux de neurones artificiels (RN) forment un ensemble
de techniques – matures – efficaces – avec une base théorique solide – largement utilisées dans de nombreux domaines
• Médecine (diagnostic, prothèses, conseils d’urgence) • Prospection minière et pétrolière • Reconnaissance vocale, écriture manuscrite • Télécommunication (compression des données) • Finance (estimation immobilier, détection fausses déclarations, prédiction des cours) • Industrie (mesure, prédiction contrôle) • Transports (pilotage automatique, détection de risques, détection de pannes)
4

Le neuromimétisme
5

Le neuromimétisme • De gros projets
– SyNAPSE (Darpa) – IBM, HP, universités de Columbia, Cornell, … – Human Brain Project (UE, 1 G€) – Ecole polytechnique fédérale de Lausanne + 86 partenaires
• Beaucoup de questions
– Une intelligence peut-elle émerger? Comparable, supérieure à la notre?
– Une conscience? Des émotions? – Un cerveau artificiel aura-t-il besoin de sommeil? Sera-t-il sujet à des
troubles mentaux? – Aidera-t-il à comprendre les maladies mentales? Pourrat-on remplacer
un cerveau endommagé?
6

Plan • L’idée – l’inspiration biologique • Réseaux de neurones formels (artificiels) • Apprentissage supervisé des RN • Capacité de généralisation • RN en classification • Apprentissage non supervisé – autres types de RN
7
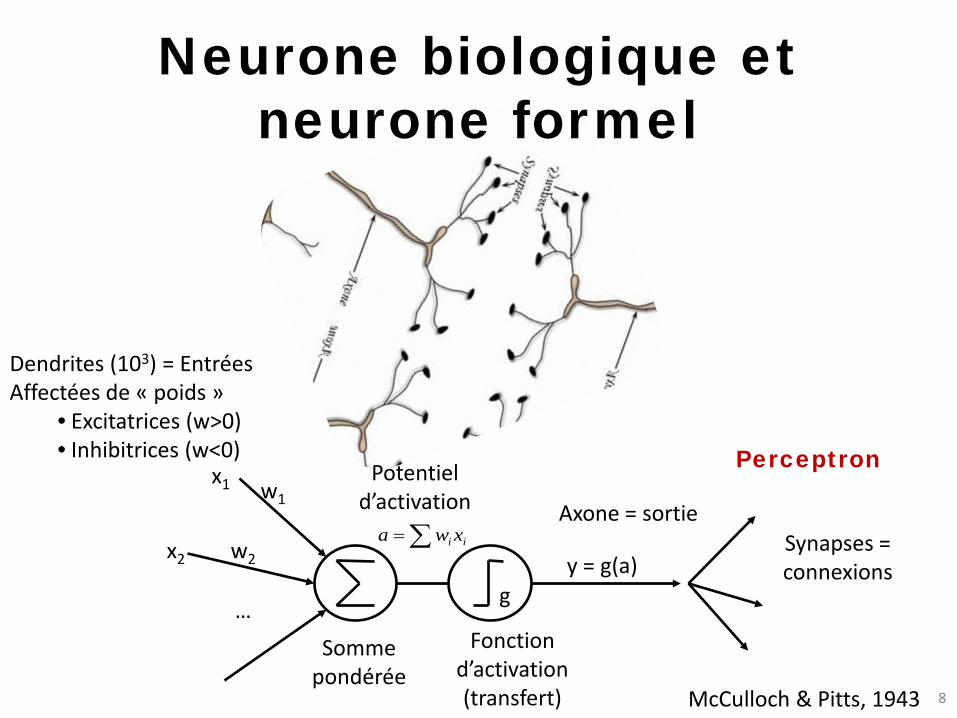
Neurone biologique et neurone formel
Dendrites (103) = Entrées Affectées de « poids »
• Excitatrices (w>0) • Inhibitrices (w<0)
w1
w2
…
x1 Potentiel d’activation
∑= ii xwax2
Somme pondérée
Fonction d’activation (transfert)
Axone = sortie
y = g(a) g
Synapses = connexions
McCulloch & Pitts, 1943
Perceptron
8

Neurone biologique et neurone formel
• L’unité de base est relativement – simple (somme pondérée + seuil) – lente (103 Hz dans le cerveau humain)
• La complexité du traitement, la vitesse et la tolérance aux
pannes sont dues à – Une forte connectivité (103 synapses pour chaque neurone) – Un parallélisme massif (1011 neurones chez l’humain, structurés en
« couches »)
9
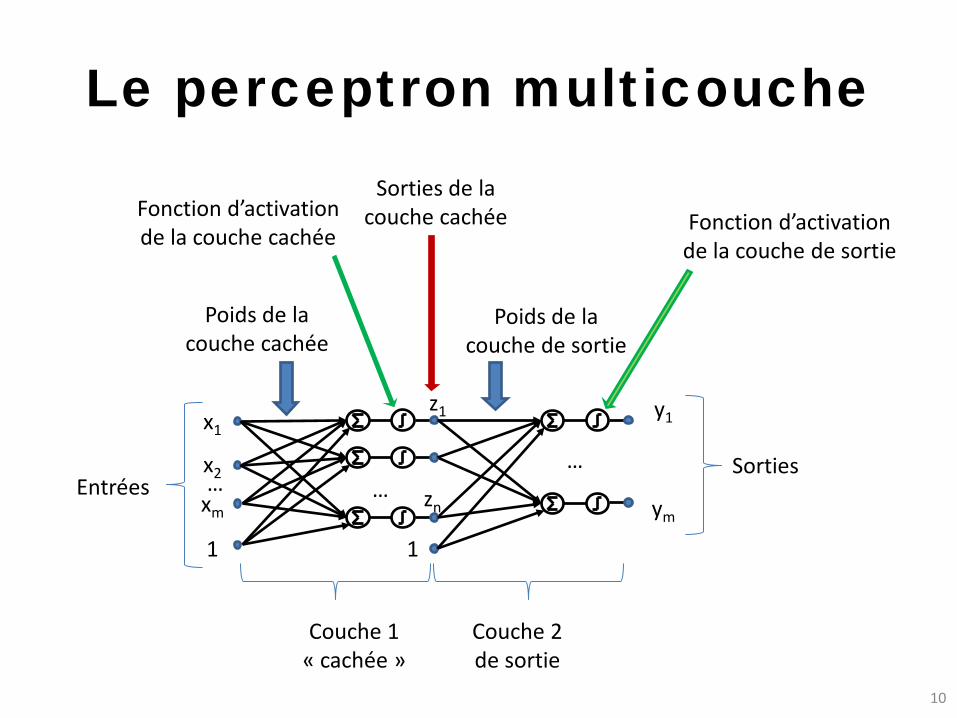
Le perceptron multicouche
1
z1
zn
x1
xm
… x2
1
…
…
y1
ym
Entrées Sorties
Couche 1 « cachée »
Couche 2 de sortie
Poids de la couche cachée
Sorties de la couche cachée
Poids de la couche de sortie
Fonction d’activation de la couche cachée
Fonction d’activation de la couche de sortie
10

Le perceptron multicouche
• La fonction remplie par le RN dépend de – Structure du réseau
• Nombre de couches • Nombre d’entrées • Nombre de sorties • Nombre de neurones dans chaque couche
– Valeur des poids de chaque couche • Potentiel d’activation
– Fonction d’activation de chaque couche • Sortie de chaque neurone
Apprentissage du réseau
Seuil Logistique Tangente
hyperbolique Linéaire Radiale 11

Approximation universelle par RN
• Théorème central – Un perceptron à 2 couches
• Dont la couche cachée a une fonction d’activation sigmoïde (ex. logistique, tanh, etc.)
• Dont la couche de sortie a une fonction d’activation linéaire – Peut approximer
• uniformément • avec une précision arbitraire • sur un domaine fini
– Toute fonction suffisamment régulière
• Remarques – En théorie, il n’y aurait besoin d’aucune autre structure de réseau. Toutefois,
dans les applications, il peut s’avérer plus pratique d’utiliser plusieurs couches, des sorties non linéaires, etc.
– C’est un théorème purement existentiel. Il ne dit pas comment déterminer un nombre approprié de neurones dans la couche cachée et les valeurs des poids pour approximer une fonction donnée avec une précision donnée !
Hornik 1989, 1990, 1991
12

Approximation par RN, comment ça marche ?
-10 -5 0 5 100
0.2
0.4
0.6
0.8
1
1.2
1.4
Entrée (X)
Sort
ie (Y
)
Superposition de sigmoïdes
-10 -5 0 5 100
0.5
1
1.5
2
Entrée (X)
Sort
ie (Y
)
Superposition de sigmoïdes
-10 -5 0 5 100
0.5
1
1.5
2
Entrée (X)
Sort
ie (Y
)
Superposition de sigmoïdes
-10-50510
-100
10
0
0.2
0.4
0.6
0.8
1
1.2
1.4
Entrée (X2)
Superposition de sigmoïdes
Entrée (X1)
Sort
ie (Y
)
-100
10
-100
10
0
0.5
1
1.5
2
2.5
3
Entrée (X1)
Superposition de sigmoïdes
Entrée (X2)
Sort
ie (Y
)
-10
0
10 -10
0
10
0
1
2
3
Entrée (X2)
Superposition de sigmoïdes
Entrée (X1)
Sort
ie (Y
)
13

Autres approximateurs universels
• Il existe de nombreux jeux de « fonctions de base » dont la superposition peut approcher arbitrairement n’importe quelle autre fonction – Polynômes – série de Taylor
• Fonctions de base : 1, x, x2, x3, …
– Fonction trigonométriques – série de Fourrier • Fonctions de base : 1, cos x, sin x, cos 2x, sin 2x, …
– Ondelettes
– Etc.
14

Approximation parcimonieuse nombre de paramètres ajustables (poids) réduit
Barron 1993
Fonctions de base « fixes »
Fonctions de base adaptées au problème en cours
• Si l’approximation dépend des paramètres ajustables (poids) de manière non linéaire, elle est plus parcimonieuse que si elle dépend linéairement des poids – Le nombre de paramètres, pour une précision donnée:
• croît exponentiellement avec le nombre des variables d’entrée pour un approximateur linéaire
• croît linéairement avec le nombre des variables d’entrée pour un approximateur non linéaire
• Exemples – Approximateurs linéaires par rapport aux coefficients ajustables (w)
• Taylor : y = w0 + w1x1 + w2x2 + … • Fourrier : y = w0 + w1cos x + w2sin x + w3cos 2x + w4sin 2x + …
– Approximateur non linéaire par rapport aux coefficients ajustables (w) • RN : y = w1 + w2tanh (w3 + w4x) + w5tanh (w6 + w7x) …
15

Plan • L’idée – l’inspiration biologique • Réseaux de neurones formels (artificiels) • Apprentissage supervisé des RN • Capacité de généralisation • RN en classification • Apprentissage non supervisé – autres types de RN
16

Apprentissage supervisé des RN détermination des poids d’un réseau
• Comme son modèle biologique – un RN « apprend » (= ajuste ses poids) – à partir d’ « exemples » (= couples (X, Y) connus) – en renforçant ou en affaiblissant itérativement ses « synapses » (= poids)
• L’apprentissage est le paradigme central de la résolution d’un problème à l’aide de RN artificiels:
– on ne donne pas de règles, lois, algorithmes ou méthodes, – seulement des « exemples » de valeurs connues (= base de données) – sur lesquels on « entraîne » le réseau (= modifie les poids) – lequel va ensuite travailler « par analogie » (= interpolation)
• Remarques – Une fois mis en service, un RN peut éventuellement continuer d’évoluer (apprendre) au fur et à
mesure que de nouveaux exemples deviennent disponibles – L’apprentissage itératif peut être long, difficile et sans garantie a priori de finir avec un jeu de
poids satisfaisant. C’est le prix à payer pour la parcimonie (non linéarité par rapport aux poids). – (Pour un approximateur linéaire par rapport aux poids, les valeurs des poids se calculent
explicitement par régression linéaire, mais leur nombre devint vite prohibitif si le nombre des entrées et la précision demandée sont élevés)
17

Apprentissage
• Modifier les poids du réseau – dans le sens de la diminution de l’écart – entre la sortie du réseau et les exemples
• Calculer la sensibilité (variation) de l’écart par
rapport à la variation du poids à ajuster
• Modifier le poids en question selon une certaine règle
18
iwE
∂∂
∂∂
+=i
ancieni
nouveaui w
Efww

Apprentissage
19
Soit une base de données de M exemples : ( ) MkYX kk ...1, =
L’écart global est : ( )( )∑=
−=M
kknkpk YwwXXyE
1
21,,1 ...,,...,
Sortie du réseau pour l’exemple k
Sortie connue pour l’exemple k (cible)
Sensibilité de l’écart par rapport au poids wi
( )i
kM
kkk
i wyYy
wE
∂∂
−=∂∂ ∑
=12
Sensibilité de la sortie par rapport au poids wi, pour l’exemple k

Sensibilité de la sortie par rapport aux poids
20
Cas 1 : le poids appartient à la couche de sortie
wi
…
Potentiel d’activation
1)(')(==
agaag
Zi
Fonction d’activation (transfert)
g
y = g(a)
Somme pondérée
kiki
k
i
k Zagwag
wy
,)(')(=
∂∂
=∂∂
Exemples
( ))(1)()('1
1)()(
agagage
alsigag a
−=+
== −
2)(1)('
)tanh()(
agageeeeaag aa
aa
+=+−
== −
−
Activation linéaire Activation logistique Activation tangente hyperbolique
a

Sensibilité de la sortie par rapport aux poids
21
Cas 2 : le poids appartient à la couche cachée
1
Xj
1
…
y
wi Zj a1,j
a2
g1
g2
i
kjjk
i
k
i
k
wZ
wagwag
wy
∂
∂=
∂∂
=∂∂ ,
22,22 )('
)(
wj
kikji
kj
i
kj Xagwag
wZ
,,11,11, )('
)(=
∂
∂=
∂
∂
La règle se généralise pour plusieurs couches : Il faut calculer les dérivées en chaine : Ecart sortie dernière couche cachée …. 1ère couche cachée
« Rétro-propagation du gradient » (du gradient de l’écart par rapport aux poids)

Ajustement des poids
22
010
2030
010
2030
-10
-5
0
5
10
i
ancieni
nouveaui w
Eww∂∂
−= α
Descente selon le gradient
Ecar
t E
Taux d’apprentissage
L’ajustement des poids selon l’opposé du gradient n’a plus qu’une valeur historique
Toutefois, le calcul du gradient de l’écart par rapport aux poids est au cœur d’algorithmes
d’apprentissage beaucoup plus efficaces (Quasi-Newton, Levenberg-Marquardt, …)

Plan • L’idée – l’inspiration biologique • Réseaux de neurones formels (artificiels) • Apprentissage supervisé des RN • Capacité de généralisation • RN en classification • Apprentissage non supervisé – autres types de RN
23

Sur-paramétrage et généralisation • De manière générale, l’ajustement d’un modèle à un jeu de données
(exemples) particulier est d’autant meilleur que le nombre de paramètres ajustables est grand
• Toutefois, un nombre de paramètres excessif peut compromettre la capacité de généralisation (interpolation) du modèle
Exemple: interpolation polynomiale
24
-2 0 2 4 6 8 10-0.5
0
0.5
1
1.5
2
Entrée (X)
Sort
ie (Y
)
Interpolation polynômiale
-2 0 2 4 6 8 10-0.5
0
0.5
1
1.5
2
Entrée (X)
Sort
ie (Y
)
Interpolation polynômiale
-2 0 2 4 6 8 10-0.5
0
0.5
1
1.5
2
Entrée (X)
Sort
ie (Y
)
Interpolation polynômiale
-2 0 2 4 6 8 10-0.5
0
0.5
1
1.5
2
Entrée (X)
Sort
ie (Y
)
Interpolation polynômiale
-2 0 2 4 6 8 10-0.5
0
0.5
1
1.5
2
Entrée (X)
Sort
ie (Y
)
Interpolation polynômiale
-2 0 2 4 6 8 10-0.5
0
0.5
1
1.5
2
Entrée (X)
Sort
ie (Y
)
Interpolation polynômiale
Données disponibles
2 paramètres 4 paramètres
18 paramètres 12 paramètres 8 paramètres

Sur-paramétrage et généralisation
• Les RN sont, par nature, extrêmement sujets au sur-paramétrage
• Ils peuvent apprendre très bien un jeu d’exemples particulier mais proposer des surfaces de réponse très « accidentées » mauvaise généralisation (interpolation) – Le nombre de neurones cachés n’est par connu a priori – Lors de l’apprentissage, les poids sont initialisés par un tirage
aléatoire. La capacité de généralisation peut être très variable d’un tirage à l’autre
• Il peut vite devenir extrêmement fastidieux de chercher aveuglement un nombre de neurones et un tirage initial convenable, surtout si la base de données est grande et l’apprentissage long
• Techniques pour améliorer la capacité de généralisation : – Régularisation
25

0
5
10
05
1015
200
5
10
15
20
25
Entrée 1
Sortie 1
Entrée 2
Sorti
e 1
Exemples : sur-paramétrage d’un RN
26
0 5 10 15 20 250
2
4
6
8
10
12
14
16
18
Entr
Sort
Sortie 1
• Comme d’autres modèles, les RN sur-paramétrés produisent des surfaces de réponse « accidentées », conduisant à une mauvaise interpolation (généralisation)
• Toutefois, grâce aux fonctions d’activation bornées, les variations des sorties prédites restent limitées (comparées aux polynômes par exemple)
15 neurones cachés
25 neurones cachés

Régularisation des RN • Limiter le nombre de paramètres (neurones cachés)
– Difficile de trouver le bon nombre (sous/sur paramétrage)
• Arrêter l’apprentissage avant la convergence – Utiliser une deuxième base d’exemples indépendants : base de
validation – Ajuster les poids sur la base d’apprentissage, mais choisir le
réseau avec l’erreur minimale sur la base de validation : meilleure capacité de généralisation
• Modération des poids – Lors de l’apprentissage, se donner comme objectif
supplémentaire la réduction des valeurs moyenne des poids surface de réponse plus régulière
27

Exemple : régularisation par limitation du nombre des paramètres (poids)
28
0 5 10 15 20 250
5
10
15
20
Entrée
Sorti
e
Sortie 1
0 5 10 15 20 250
2
4
6
8
10
12
14
16
18
Entr
Sort
Sortie 1
2 neurones cachés
15 neurones cachés
02
46
8
0
10
200
5
10
15
20
Entrée 1
Sortie 1
Entrée 2
Sorti
e 1
0
5
10
05
1015
200
5
10
15
20
25
Entrée 1
Sortie 1
Entrée 2
Sorti
e 125 neurones
cachés
3 neurones cachés
Demande des tâtonnements pour trouver le bon nombre de neurones cachés Un nombre trop faible conduit à un mauvais ajustement Un nombre trop élevé conduit à une surface de réponse irrégulière

Exemple : régularisation par arrêt précoce
29
0 5 10 15 20 250
5
10
15
20
Entrée
Sorti
e
Sortie 1
0 5 10 15 20 250
2
4
6
8
10
12
14
16
18
Entr
Sort
Sortie 1
15 neurones cachés
15 neurones cachés
02
46
8
0
10
20-5
0
5
10
15
20
Entrée 1
Sortie 1
Entrée 2
Sorti
e 1
0
5
10
05
1015
200
5
10
15
20
25
Entrée 1
Sortie 1
Entrée 2
Sorti
e 125 neurones
cachés
25 neurones cachés
Si la base de validation contient suffisamment d’exemples représentatifs, le réseau obtenu présente une capacité de généralisation satisfaisante (mais pas forcément une surface de réponse très régulière)
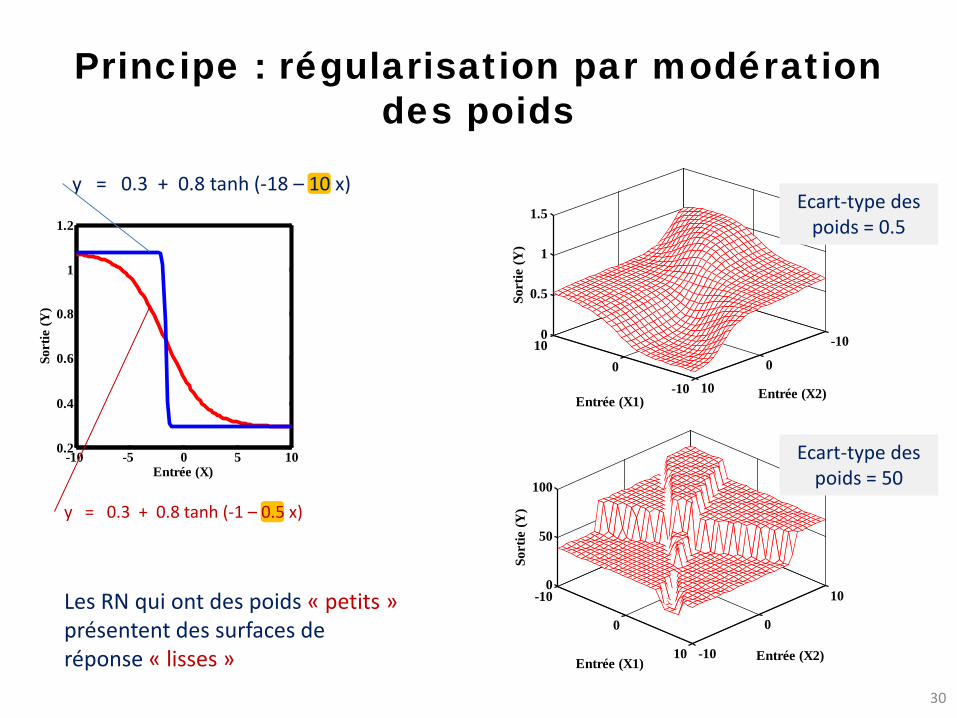
Principe : régularisation par modération des poids
30
-10 -5 0 5 100.2
0.4
0.6
0.8
1
1.2
Entrée (X)
Sort
ie (Y
)
y = 0.3 + 0.8 tanh (-18 – 10 x)
y = 0.3 + 0.8 tanh (-1 – 0.5 x)
-100
10 -10
0
10
0
0.5
1
1.5
Entrée (X2)Entrée (X1)
Sort
ie (Y
)
-10
0
10 -10
0
100
50
100
Entrée (X2)Entrée (X1)
Sort
ie (Y
)
Ecart-type des poids = 0.5
Ecart-type des poids = 50
Les RN qui ont des poids « petits » présentent des surfaces de réponse « lisses »

Principe : régularisation par modération des poids
• Trouver un compromis entre deux critères contradictoires : – Bon ajustement aux exemples de la base
d’apprentissage – Surface de réponse régulière = poids « petits »
31
( ) ∑∑==
+−=N
ii
M
kkk wYyE
1
2
1
2 α

02
46
8
0
10
200
5
10
15
20
Entrée 1
Sortie 1
Entrée 2So
rtie
1
Exemple : régularisation par modération des poids
32
0 5 10 15 20 252
4
6
8
10
12
14
16
18
Entrée
Sort
ie
Sortie 1
0 5 10 15 20 250
2
4
6
8
10
12
14
16
18
Entr
Sort
Sortie 1
15 neurones cachés
Pondération poids = 0.02
15 neurones cachés
Pondération poids = 0
0
5
10
05
1015
200
5
10
15
20
25
Entrée 1
Sortie 1
Entrée 2
Sorti
e 125 neurones
cachés
25 neurones cachés
Demande des tâtonnements pour trouver la bonne pondération Une pondération trop forte des poids conduit à un mauvais ajustement Une pondération trop faible des poids conduit à une surface de réponse irrégulière Les poids « inutiles » ne sont pas forcément mis à zéro Il existe des variantes plus élaborées de cette méthode, qui trouvent automatiquement la bonne pondération et font tendre les poids inutiles vers zéro (idée : se baser sur la précision « attendue » de l’ajustement, ex. précision des mesures) MacKay 1995

Conclusion sur la régularisation des RN
• La régularisation est un point clé pour obtenir de « bons » RN : – Surfaces de réponse lisses – Bonne capacité de généralisation (interpolation)
• Dans la pratique, on combine plusieurs techniques de régularisation :
– Un nombre de neurones cachés « raisonnable » • Selon la complexité de la surface de réponse et le nombre d’exemples disponibles • Nombre de poids réduit, calculs rapides
– Une base de validation formée d’exemples indépendants
• Assurer une bonne représentativité statistique du réseau • Si manque de données : validation croisée
– Une modération des poids pour limiter les effets des paramètres excédentaires
• Paramètre de pondération des poids choisi selon des critères de précision attendue du réseau, par exemple répétabilité des mesures des sorties cible
• Au final, il faut toujours analyser de manière critique le réseau obtenu – Au minimum, tracer les surfaces de réponse
33

Distribution des exemples dans les bases d’apprentissage et de validation
• Pour une bonne généralisation, les exemples utilisés pour mettre au point le réseau (bases d’apprentissage et de validation) doivent être représentatifs de l’utilisation préconisée du réseau
– Couvrir tout l’espace utile des entrées • Etendue dans chaque dimension (pas d’extrapolation) • Pour toutes les combinaisons (pas de trous) : difficile à atteindre si les entrées sont nombreuses
34
-4 -2 0 2 4 6 8 10 121
2
3
4
5
6
7
8
Entrée
Sorti
e
Sortie 1
• Revoir la répartition des exemples • Ne pas utiliser le réseau dans les zones non apprises !
0
5
10
024680
2
4
6
8
10
12
Entrée 1
Sortie 1
Entrée 2
Sorti
e 1

Test final du réseau • Une fois un réseau satisfaisant trouvé
– Structure • Entrées (éliminer entrées peu informatives) • Sorties (un réseau à plusieurs sorties ou plusieurs réseaux) • Nombre de neurones cachés
– Poids • Bon ajustement sur la base d’apprentissage • Bonne généralisation sur la base de validation
• Il est conseillé de tester le réseau sur une base d’exemples
totalement indépendante – Base de test – Qui n’a servi ni à l’ajustement des poids, ni à l’arrêt de l’apprentissage – Dont les exemples sont représentatifs de l’utilisation réelle du réseau
(bonne répartition dans l’espace des entrées)
• En cas de problème revoir la structure du réseau et/ou la répartition des exemples entre les bases (apprentissage, validation, test)
35

Plan • L’idée – l’inspiration biologique • Réseaux de neurones formels (artificiels) • Apprentissage supervisé des RN • Capacité de généralisation • RN en classification • Apprentissage non supervisé – autres types de RN
36
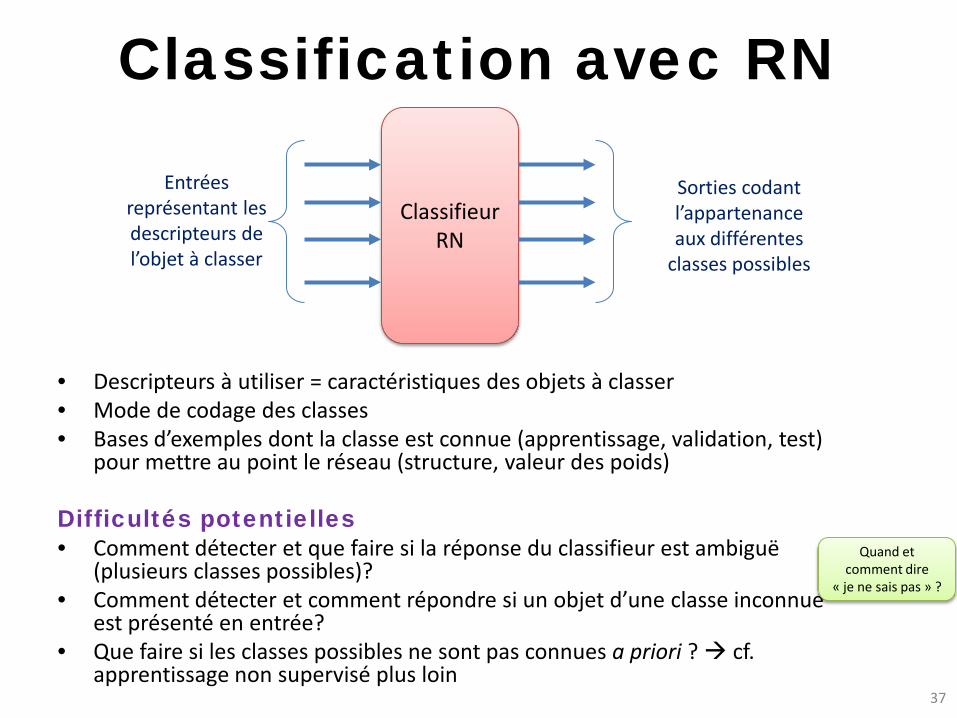
Classification avec RN
37
Classifieur RN
Entrées représentant les descripteurs de l’objet à classer
Sorties codant l’appartenance aux différentes
classes possibles
• Descripteurs à utiliser = caractéristiques des objets à classer • Mode de codage des classes • Bases d’exemples dont la classe est connue (apprentissage, validation, test)
pour mettre au point le réseau (structure, valeur des poids)
Difficultés potentielles • Comment détecter et que faire si la réponse du classifieur est ambiguë
(plusieurs classes possibles)? • Comment détecter et comment répondre si un objet d’une classe inconnue
est présenté en entrée? • Que faire si les classes possibles ne sont pas connues a priori ? cf.
apprentissage non supervisé plus loin
Quand et comment dire
« je ne sais pas » ?

Codage des classes
38
Codage linéaire : Une seule sortie,
dont la valeur indique la classe
Codage « grand-mère » : Autant de sorties que de classes,
dont les valeurs indiquent le degré d’appartenance à chaque classe
RN affinage
Classes ordonnées Classes ordonnées ou non
0 = totalement affiné 1 = affiné 2 = moyennement affiné 3 = peu affiné 4 = frais
Fermeté
Couverture
pH
…
RN affinage
totalement affiné affiné moyennement affiné peu affiné frais
Fermeté
Couverture
pH
…
Une seule sortie vaut 1, les autres 0
Comment interpréter les valeurs intermédiaires des sorties ?

Surface discriminante • La réponse du RN + la règle d’attribution d’un exemple à une classe (ex. degré
d’appartenance maximum) génèrent une partition de l’espace des entrées • Les RN permettent de discriminer des classes non séparables linéairement
39
Entrée 1
Entr
ée 2
« Surface » discriminante Classe 1
Classe 2
exemples
Entrée 1
Entr
ée 2
« Surface » discriminante Classe 1
Classe 2 Classes linéairement séparables
Classes non séparables
linéairement
Entrée 1
Entr
ée 2
Exemple historique de classes non séparables linéairement :
« OU » exclusif (XOR)
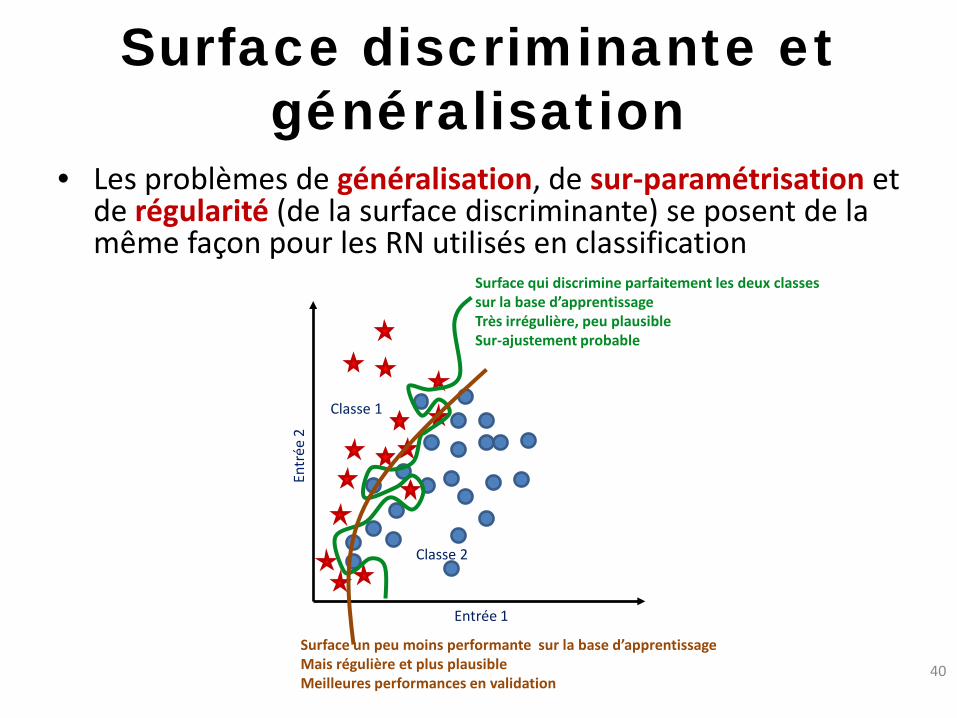
Surface discriminante et généralisation
• Les problèmes de généralisation, de sur-paramétrisation et de régularité (de la surface discriminante) se posent de la même façon pour les RN utilisés en classification
40
Entrée 1
Entr
ée 2
Surface qui discrimine parfaitement les deux classes sur la base d’apprentissage Très irrégulière, peu plausible Sur-ajustement probable
Classe 1
Classe 2
Surface un peu moins performante sur la base d’apprentissage Mais régulière et plus plausible Meilleures performances en validation

Plan • L’idée – l’inspiration biologique • Réseaux de neurones formels (artificiels) • Apprentissage supervisé des RN • Capacité de généralisation • RN en classification • Apprentissage non supervisé – autres types de RN
41

Réseaux à apprentissage non supervisé
• Il n’y a pas de cible (sortie correcte) définie a priori pour chaque exemple
• C’est au réseau de trouver, au cours de l’apprentissage, des similitudes (groupes, régularités) dans les données
• Utilisés comme techniques de réduction, de visualisation et de classification de grandes masses de données multidimensionnelles (~ACP, AFD… mais non linéaire)
42

Carte auto-organisatrice de Kohonen (SOM)
Entr
ées
Poids
Neurones Apprentissage
• Les poids du réseau sont initialisés aléatoirement • Un exemple est choisi aléatoirement dans la base
d’apprentissage – Le neurone dont les poids sont les plus similaires à l’exemple
est choisi comme neurone vainqueur – Les poids du neurone vainqueur et d’autres neurones dans
son voisinage topologique sont modifiés pour se rapprocher de l’exemple
• On recommence un grand nombre de fois, en diminuant progressivement le voisinage topologique
• La carte s’auto-organise pour que les neurones proches topologiquement aient des poids similaires et donc répondent à des exemples similaires

Carte auto-organisatrice de Kohonen (SOM)
Demo Exemple
– Les 3 entrés sont des coordonnées dans l’espace colorimétrique RVB
– La carte s’auto-organise pour que les neurones proches (typologiquement) correspondent à des couleurs proches
– Similitude: les zones où les neurones ont des poids proches sont coloriés en gris clair et inversement

Exemple : carte de la qualité de vie
45
Base de données sur la qualité de vie dans différents pays : santé, nutrition, éducation… Ces indicateurs constituent les entrées du réseau
Après apprentissage, les pays à qualité de vie similaire se retrouvent proches sur la carte Les pays qui n’ont pas servi à l’apprentissage se retrouvent placés de manière cohérente (généralisation)

Conclusion générale • Les RN sont des outils puissants
– Théoriquement « universels »
• A utiliser avec discernement, quand vraiment approprié – Données disponibles
• Nombreuses (outil statistique!) • Représentatives de toutes les situations envisagées (l’extrapolation ne fonctionne pas)
– Relations non linéaires (sinon, un modèle linéaire est plus simple et plus fiable)
– Connaissance a priori insuffisante ou phénomènes trop complexes (sinon, un modèle spécifiquement adapté, construit sur la base de cette connaissance, sera plus simple, plus précis, plus facile à manipuler et à maîtriser, présentera une meilleure extrapolation)
• Un minimum de savoir-faire est nécessaire, sous peine de résultats totalement fantaisistes – Maîtriser les degrés de liberté excédentaires
• Régularisation • Test / validation sur de jeux de données importants et représentatifs de l’utilisation réelle
46