réseaux de neurones 1 - frostiebek.free.frfrostiebek.free.fr/docs/reseaux de...
TRANSCRIPT

Vincent Boucheny (a.k.a. Mankalas)
Option SCIA
Réseaux de neurones 1
Promo 2007
Ce document reprend les prises de notes e�ectuées durant le cours de Yves-
Jean Daniel et n'est en aucun cas destiné à être di�usé à l'extérieur du cadre
de l'EPITA.

Cours SCIA
Promo 2007
Réseaux de neurones 1
TABLE DES FIGURES
Ing2
EPITA
Table des matières
1 Introduction 1
1.1 Apprentissage numérique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Notion de transparence du système produit . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.3 Apprendre à partir d'exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.4 Di�érents types de réponse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Approximation linéaire 3
2.1 Quelques applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3 Analyse en composantes principales 9
3.1 Détection des linéarités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.2 Algo de recherche des vecteurs et valeurs propres par ordre décroissant des λi . . . . . . . . 153.3 Méthode générique de recherche de vecteurs et valeurs propres . . . . . . . . . . . . . . . . 163.4 Applicatif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4 Perceptron 19
4.1 On suppose le problème linéairement séparable . . . . . . . . . . . . . . . . . . . . . . . . . 194.2 On suppose le cas non-linéairement séparable . . . . . . . . . . . . . . . . . . . . . . . . . . 204.3 Perceptron multi-couches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.3.1 Présentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.3.2 Fonctionnement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.3.3 Fonctionnement du réseau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
A Dérivations usuelles 27
Table des �gures
1 Illustration d'un neurone biologique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 Graphe d'énergie de complexité d'un modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 Exemple de compromis biais / variance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 Prédiction de sin(5) - apprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75 Prédiction de sin(5) - non apprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76 Représentation d'un perceptron multi-couches . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1

Cours SCIA
Promo 2007
Réseaux de neurones 1
1. Introduction
Ing2
EPITA
1 Introduction
1.1 Apprentissage numérique
Entrée : base de données.Sortie : système d'aide à la décision.
Exemple :
Entrée Une base de données de symptômes étiquettés par des pathologies.
Sortie Une liste de symptômes renvoit un diagnostique.
1.2 Notion de transparence du système produit
1. Boîte noire : entrée → sortie sans aucune explication sur le chemin suivi.
2. Boîte transparente : entrée → sortie avec une explication totale du raisonnement suivi pour passerde l'un à l'autre
3. Boîte translucide : entrée → sortie avec un cas intermédiaire.
En général, plus une boîte est transparente, moins les sorties sont de bonne qualité.Un apprentissage est réalisé dans un but. La qualité du système d'apprentissage est uniquement dé�nie parsa capacité à résoudre le but. En général, la qualité doit être donnée par une fonction d'erreur. Celle-ci doitêtre expliquée et doit être validée par le client. Un système doit être toujours fourni avec une procédurede validation� une preuve mathématique� une batterie de tests
Fig. 1 � Illustration d'un neurone biologique
1.3 Apprendre à partir d'exemples
� Choix à partir d'un modèle (un modèle est une famille de fonctions).� Apprendre dans ce modèle = recherche de la fonction de l'ensemble �passant au mieux� par les exemples.�Au mieux� est dé�ni par une fonction d'énergie [erreur].
1. Modèles fonctionnels : entrée x associe de façon déterministe une sortie y.
2. Modèles probabilistes : entrée x associe de façon non nécessairement déterministe une sortie y.
Exemple :
1
Cours SCIA
Promo 2007
Réseaux de neurones 1
1. Introduction
Ing2
EPITA
1. À un poids x on associe la taille moyenne des individus de poids x.
2. À un poids x on associe une taille y telle que P (Y = y\X = x) = P (un individu de poids x ait unetaille y).
Exemple :
Dans la simulation d'un jet de dé à 6 faces, le premier modèle renvoit toujours 3, 5.
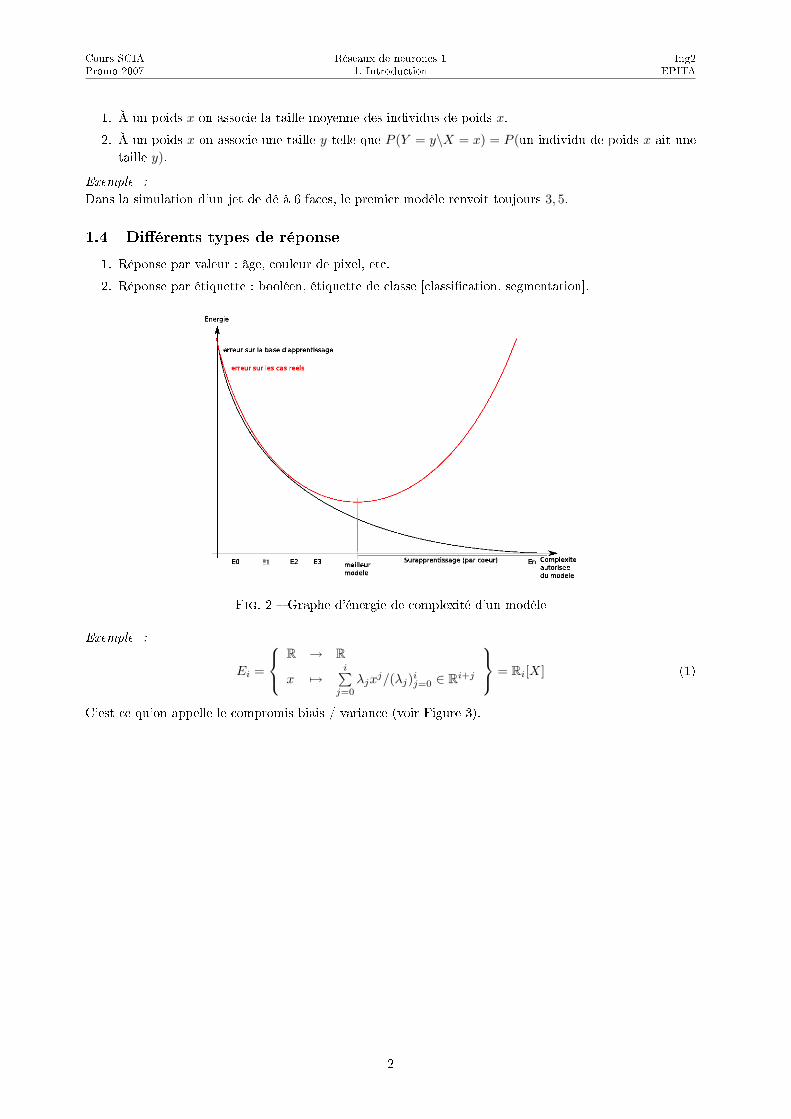
1.4 Di�érents types de réponse
1. Réponse par valeur : âge, couleur de pixel, etc.
2. Réponse par étiquette : booléen, étiquette de classe [classi�cation, segmentation].
Fig. 2 � Graphe d'énergie de complexité d'un modèle
Exemple :
Ei =
R → R
x 7→i∑
j=0
λjxj/(λj)i
j=0 ∈ Ri+j
= Ri[X] (1)
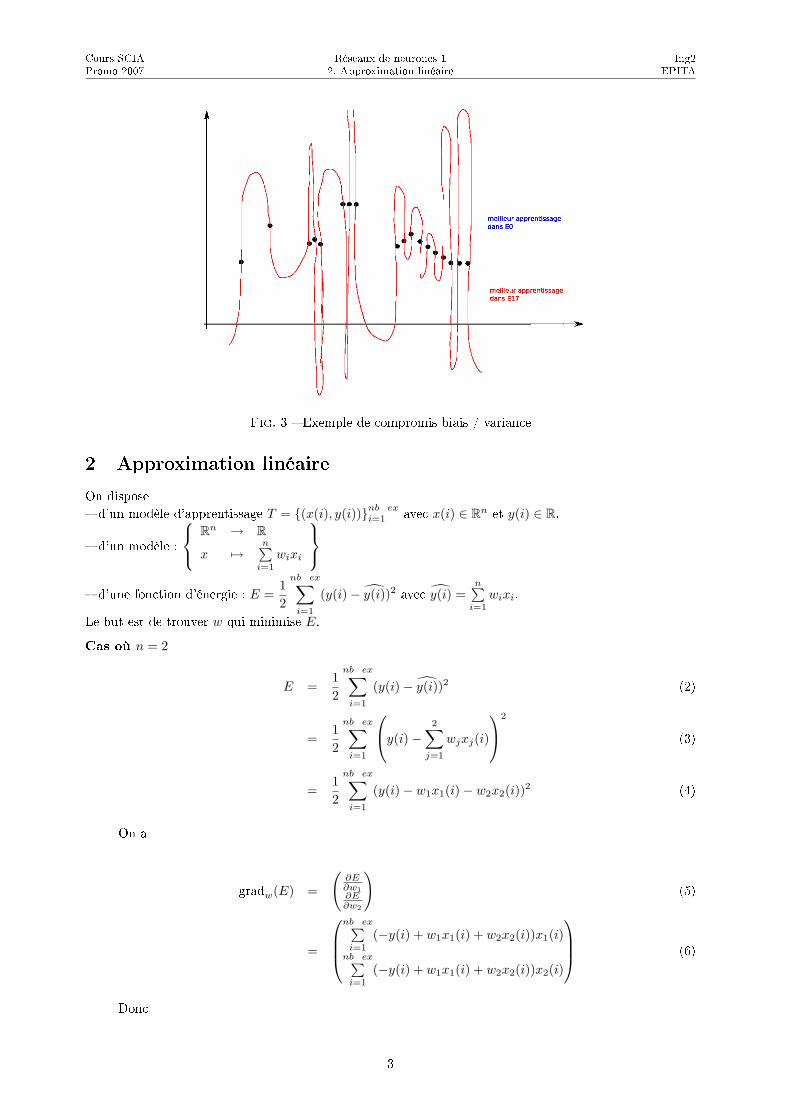
C'est ce qu'on appelle le compromis biais / variance (voir Figure 3).
2
Cours SCIA
Promo 2007
Réseaux de neurones 1
2. Approximation linéaire
Ing2
EPITA
Fig. 3 � Exemple de compromis biais / variance
2 Approximation linéaire
On dispose� d'un modèle d'apprentissage T = {(x(i), y(i))}nb_ex
i=1 avec x(i) ∈ Rn et y(i) ∈ R.
� d'un modèle :
Rn → R
x 7→n∑
i=1
wixi
� d'une fonction d'énergie : E =
12
nb_ex∑i=1
(y(i)− y(i))2 avec y(i) =n∑
i=1
wixi.
Le but est de trouver w qui minimise E.
Cas où n = 2
E =12
nb_ex∑i=1
(y(i)− y(i))2 (2)
=12
nb_ex∑i=1
y(i)−2∑
j=1
wjxj(i)
2
(3)
=12
nb_ex∑i=1
(y(i)− w1x1(i)− w2x2(i))2 (4)
On a
gradw(E) =
(∂E∂w1∂E∂w2
)(5)
=
nb_ex∑
i=1
(−y(i) + w1x1(i) + w2x2(i))x1(i)
nb_ex∑i=1
(−y(i) + w1x1(i) + w2x2(i))x2(i)
(6)
Donc
3

Cours SCIA
Promo 2007
Réseaux de neurones 1
2. Approximation linéaire
Ing2
EPITA
gradw(E) = 0 ⇐⇒
w1
nb_ex∑i=1
x1(i)2 + w2
nb_ex∑i=1
x1(i)x2(i) =nb_ex∑
i=1
y(i)x1(i)
w1
nb_ex∑i=1
x1(i)x2(i) + w2
nb_ex∑i=1
x2(i)2 =nb_ex∑
i=1
y(i)x2(i)
= 0 (7)
C'est un système linéaire de deux équations à deux inconnues : le système est résolu.
Rangement des données :
X =
x1(1) . . . x1(nb_ex)x2(1) . . . x2(nb_ex)...
...xn(1) . . . xn(nb_ex)
; Y =
y(1)...
y(nb_ex)
; W =
w1
...wn
On peut exprimer le cas n = 2 en notation matricielle : XXtW = XY . Si XXt est inversible,W = [(XXt)−1X]Y . On note X+ = (XXt)−1. On l'appelle pseudo-inverse de Penrose. Donc
W = X+Y (8)
Cas général
E =12
nb_ex∑i=1
(y(i)− y(i))2 (9)
=12
nb_ex∑i=1
n∑j=1
wjxj(i)− y(i)
2
(10)
=12
nb_ex∑i=1
((XtW )i − y(i))2 (11)
Pour les dérivées usuelles, voir page 27.
gradW (E) =12
nb_ex∑i=1
2((XtW )i − y(i))gradW ((XtW )i − y(i)) (12)
=nb_ex∑
i=1
((XtW )i − y(i))gradW ((XtW )i) (13)
=nb_ex∑
i=1
((XtW )i − y(i))× Xti,∗︸︷︷︸
ième colonne de X
(14)
=nb_ex∑
i=1
(XtW )iXti,∗ −
nb_ex∑i=1
y(i)Xti,∗ (15)
On a
4

Cours SCIA
Promo 2007
Réseaux de neurones 1
2. Approximation linéaire
Ing2
EPITA
nb_ex∑i=1
y(i)Xti,∗ =
X1,1y(1)X2,1y(1)
...Xn,1y(1)
+ · · ·+
X1,nb_exy(nb_ex)X2,nb_exy(nb_ex)
...Xn,nb_exy(nb_ex)
(16)
=
nb_ex∑k=1
X1,ky(k)
...nb_ex∑k=1
Xn,ky(k)
(17)
De la même façon, on trouve que
nb_ex∑i=1
(XtW )iXti,∗ = X(XtW ) (18)
FinalementgradW (E) = 0 ⇐⇒ XXtW = XY (19)
Si XXt est inversible, alors W = (XXt)−1XY . Mais XXt est-elle inversible ? Si XXt n'est pas inversible,alors il existe une in�nité de points où la dérivée est nulle, il y a donc une in�nité de solutions au problème,donc les points d'entrée sont tous alignés sur un sous-espace vectoriel strict. Or, si on prend assez de points(> n), alors si les points sont su�samment aléatoires, cette situation est de probabilité nulle.Conclusion pratique sur des données réelles, on peut toujours considérer que la matrice est mathématique-ment inversible.On code une inversion de Gauss et on se rend compte que dès que n est élevé, les matrices deviennentnumériquement non-inversibles. Lorsqu'on prend assez de données, celles-ci deviennent de plus en pluscorrélées et on se rapproche donc du cas où les exemples sont sur un sous-espace vectoriel propre : lamatrice est alors numériquement non-inversible.Pour savoir si une matrice est facile à inverser numériquement, on calcule son conditionnement. Lorsqu'elledevient numériquement non-inversible, on utilise l'algorithme de Greville pour résoudre en W l'équationXXtW = XY .
2.1 Quelques applications
1. Un outil sur un tour usine des cyclindres de diamètre 10mm. Au fur et à mesure de l'usinage, il y ausure de l'outil. But : trouver la correction à apporter à la position de l'outil dans le but que la cotenominale soit respectée le plus longtemps possible entre deux changements de l'outil.
Base de donnée :� Série 1 : ∅ pièce 1, ∅ pièce 2, . . .
� Série 2 : ∅ pièce 1, ∅ pièce 2, . . .
� . . .
En utilisant les informations de la première série
X =(
1 1 1 . . . 11 2 3 . . . nb_pieces
); Y =
∅p1, S1
∅p2, S1
...∅pnb_pieces, S1
; W = X+Y =(
w1
w2
)
Donc ∅(pi, S1) = w1 + w2i. Correction à apporter à la position de l'outil avant de présenter lapièce i ≥ 2 :
∆pos(i) = w1 + w2i− 10− (w1 + w2(i− 1)− 10) = w2
Pour i = 1, ∆pos(1) = w1 + w2 − 10.
5

Cours SCIA
Promo 2007
Réseaux de neurones 1
2. Approximation linéaire
Ing2
EPITA
Comment utiliser les autres séries ?
X =(
1 1 . . . 1 1 1 . . . 1 1 . . .
1 1 . . . 1 2 2 . . . 2 3 . . .
); Y =
∅p1, S1
∅p2, S1
...∅pm, S1
∅p1, S2
∅p2, S2
...∅pn, S2
∅p1, S3
...∅pq, Snb_series
2. Prédiction du poids en fonction de la taille, de l'âge, du nombre d'heures passées à réviser les partiels.
X =
1 . . . 1
taille(e1) . . . taille(en)age(e1) . . . age(en)
partiel(e1) . . . partiel(en)
; Y =
poids(e1)...
poids(en)
Donc poids = w0 + w1taille + w2age + w3partiel.
Remarque : Ce modèle peut-il nous donner une indication sur une relation de causalité ? Pourcela, un pré-traitement de normalisation des données est nécessaire. On va passer en coordonnées
centrées-réduites : taille← taille− E(taille)ρtaille
, pareil pour les autres caractéristiques.
Remarque : On ne peut pas retoucher au biais (1, . . . , 1) de X. On n'a pas besoin de centrer,réduire les composantes de Y .
On réalise la recherche de w. Plus |wi| est important, plus on peut supposer qu'il existe un lien decausalité du paramètre wi vers le résultat.
Remarque : Théorème central limite : la somme des quantités aléatoires → loi normale (globale-ment).
La loi normale est symétrique, son intégrale égale 1. Si on obtient une in�nité de résultats, on serapproche de l'espérance.
Si les données sont quasi-linéaires, alors cette exploitation des résultats n'a pas de sens.
3. Auto-régression :
(a) Prédire sin(t) en fonction de sin(t− 1), sin(t− 2), sin(t− 3) sachant que
sin(t) = w0 + w1 sin(t− 1) + w2 sin(t− 2) + w3 sin(t− 3)
X =
1 1 . . . 1
sin(d + 2) sin(d + 3) . . . sin(f − 1)sin(d + 1) sin(d + 2) . . . sin(f − 2)
sin(d) sin(d + 1) . . . sin(f − 3)
; Y =
sin(d + 3)...
sin(f)
(b) Test info : sin(n + sin(n2)). On peut utiliser la prédiction de la façon suivante pour prédire
sin(5).
i. Figure 4 : utilisation correspondant naturellement à l'apprentissage.
ii. Figure 5 : utilisation ne correspondant pas à l'apprentissage.
6

Cours SCIA
Promo 2007
Réseaux de neurones 1
2. Approximation linéaire
Ing2
EPITA
Fig. 4 � Prédiction de sin(5) - apprentissage
Fig. 5 � Prédiction de sin(5) - non apprentissage
Remarque : Si on veut avoir un apprentissage qui corresponde à l'utilisation, on doit, présenterle premier exemple, calculer w, présenter le deuxième exemple, calculer w. Du coup, X n'existepas.
Remarque Autre mise en pratique : on travaille sur une matrice X(t) qui correspond àune fenêtre glissante de largeur déterminée sur les données.
Remarque Hypothèse cognitive : Le comportement actuel est le même que le comportementà un passé proche.
X(act) =
1 . . . 1
sin(act− 10) . . . sin(act− 1)sin(act− 9) . . . sin(act− 2)sin(act− 8) . . . sin(act− 3)
; Y (act) =
sin(act− 9)...
sin(act)
On obtient, après application de la méthode, un vecteur w(actuel).
(c) Prédire le prix de la banane à la date t en fonction du prix de la banane aux dates t− 1 et t− 2sachant que
pb(t) = w0 + w1pb(t− 1) + w2pb(t− 2) + w3pb(t− 1)pb(t− 2) + w4 ln(
pb(t− 1)pb(t− 2)
)
X =
1 . . .
pb(d + 1) . . .
pb(d) . . .
pb(d)pb(d + 1) . . .
ln(
pb(d+1)pb(d)
). . .
; Y =
pb(d + 2)...
pb(f)
Le modèle est linéaire par rapport à ses entrées (en w), mais le modèle n'est pas linéaire parrapport aux données.
Exemple Algorithme de visualisation d'un jeu d'échec :
7

Cours SCIA
Promo 2007
Réseaux de neurones 1
2. Approximation linéaire
Ing2
EPITA
On construit un arbre de positions dont la racine est la position actuelle. L'arc reliant un n÷udà un �ls est étiqueté par le coup qui est joué. On ajoute aux feuilles une étiquette qui est unenote dans R, une note de la position. Plus elle est élevée, plus le premier joueur à jouer estcontent.
On veut construire un modèle de note (position) à partir d'une base de données de partiesétiquetées. On interroge des experts en échec. Question posée : que regardez-vous pour savoirqui est en train de gagner ?
On obtient une liste de critères� le nombre de pièces de chaque joueur.� quelles sont les pièces encore présentes.� le nombre de pièces au centre.� le nombre de pièces proche de la dame.� le nombre de pièces protégées.� ...On en déduit le modèle suivant (par exemple) : note = w0nb_noir+w1nb_blancs+w2nb_noirs_proteges+. . .
8

Cours SCIA
Promo 2007
Réseaux de neurones 1
3. Analyse en composantes principales
Ing2
EPITA
3 Analyse en composantes principales
3.1 Détection des linéarités
On veut trouver un sous-espace a�ne tel qu'en projetant notre ensemble de points sur ce sous-espace, onperde un minimum d'information.On se donne une image en 1024×768, des 256 niveaux de gris. On représente cette image par des blocs de16×16. On a 1024×768
162 blocs.On réécrit chaque bloc dans un vecteur. Pour les représenter (graphiquement), on fait comme si chaquebloc était de dimension 2 (au lieu d'être de dimension 16×16). On note p la projection perpendiculaire surle but. Le but est de minimiser l'espérance des éléments au carré.On va tout d'abord chercher le meilleur axe de projection. On dé�nit cet axe par (A, q) où A est un pointde l'axe et q est un vecteur directeur unitaire.
Soit un point M =
x1
...xn
, déterminer la distance de M à l'axe.
À l'origine,d(M,axe) =
√< M −A|M −A > − < M −A|q >2 (20)
But : trouver l'axe tel quenb_pts∑
i=1
d(M(i), axe)2 soit minimal. On pose
E =nb_pts∑
i=1
< M(i)−A|M(i)−A > − < M(i)−A|q >2 (21)
Recherche de A :
gradA(E) = 0 ⇐⇒nb_pts∑
i=1
2(M(i)−A)− 2 < M(i)−A|q > (−q) = 0 (22)
⇐⇒nb_pts∑
i=1
M(i) =nb_pts∑
i=1
A− q < M(i)−A|q > (23)
⇐⇒nb_pts∑
i=1
M(i) +nb_pts∑
i=1
q < M(i)|q > −q < A|q >= nb_ptsA (24)
On note G = E(M). Donc
G−A = − 1nb_pts
nb_pts∑i=1
q < A|q > −nb_pts∑
i=1
q < M(i)|q >
(25)
= q < A|q > −q < E(M)|q > (26)
= q < A−G|q > (27)
G véri�e évidemment cette équation.Dans toute la suite, on travaille en variables centrées : M(i)← M(i)− E(M). Sur ces variables centrées,l'axe passe par l'origine.En variables centrées
E =nb_pts∑
i=1
< M(i)−G|M(i)−G > − < M(i)−G|q >2 (28)
=nb_pts∑
i=1
< M(i)|M(i) > −nb_pts∑
i=1
< M(i)|q >< M(i)|q > (29)
9

Cours SCIA
Promo 2007
Réseaux de neurones 1
3. Analyse en composantes principales
Ing2
EPITA
But : minimiser E, ce qui revient à maximiser
nb_pts∑i=1
< M |q >< M |q > =nb_pts∑
i=1
qtMM tq (30)
= qt
nb_pts∑i=1
MM t
︸ ︷︷ ︸
On note R
q (31)
But : On recherche q qui maximise
E = qtRq (32)
Losrqu'on a calculé d(M,axe), on a considéré que ‖q‖ = 1.Problème complet : Maximiser q sous la contrainte ‖q‖ = 1. On utilise la méthode du Lagrangien :
L = E− λ(‖q‖ − 1) (33)
= E− λ(qtq − 1) car q est unitaire (34)
gradq(L) = 0 donne 2Rq = −2λq = 0 car R est carrée et symétrique. Donc Rq = λq. q est un vecteurpropre de R associé à la valeur propre λ. On recherche le meilleur vecteur propre, c'est-à-dire celui quimaximise E.
E = qtRq = qtλq = λqtq (35)
= λ (36)
Le vecteur q recherché est le vecteur propre de R associé à la plus grande valeur propre de R.Remarque : R positive ⇒ ∀u, utRu ≥ 0. En e�et,
utRu = ut∑
MM tu (37)
=∑
utMM tu (38)
=∑
< u|M >< M |u > (39)
=∑
< u|M >2 (40)
≥ 0 (41)
Donc toutes les valeurs propres de R sont positives.Maintenent, on recherche le deuxième meilleur axe.On recommence le même travail sur une nouvelle base de données, non plus sur (M(i)) mais sur les M(i)privés de leur composantes sur q1 : M(i)− q1 < M |q1 >.
R2 =∑
(M(i)− q1 < M(i)|q1 >)(M(i)− q1 < M(i)|q1 >)t (42)
=∑
(MM t− < M |q1 > Mqt1− < M |q1 > q1M
t+ < M |q1 >2 q1qt1) (43)
= R +∑
(−M tq1Mqt1 −M tq1q1M
t + (M tq1)2q1qt1) (44)
= R +∑
(−M tq1Mqt1 −M tq1q1M
t) +∑
qt1MM tq1q1q
t1 (45)
= R +∑
(−M tq1Mqt1 −M tq1q1M
t) + qt1Rq1q1q
t1 (46)
= R +∑
(−M tq1Mqt1 −M tq1q1M
t) + qt1λ1q1q1q
t1 (47)
= R +∑
(−M tq1Mqt1 −M tq1q1M
t) + λ1q1qt1 (48)
= R +∑
(−qt1MMqt
1 − q1MtM tq1) + λ1q1q
t1 (49)
10

Cours SCIA
Promo 2007
Réseaux de neurones 1
3. Analyse en composantes principales
Ing2
EPITA
Comme R est symétrique positive, ses vecteurs propres sont orthogonaux 2 à 2.Remarque : Si de plus, on �xe des vecteur propres unitaires, si on choisit
P = Mat(ei),(qi)Id (matrice de passage)
alorsp−1 = pt
On a
R2q1 = Rq1 +∑
(−qt1MM − q1M
tM tq1q1) + λ1q1 (50)
= 2λ1q1 −∑
qt1MM −
∑q1M
tq1Mtq1 (51)
= 2λ1q1 −∑
qt1MM − q1q1
∑MM tq1 (52)
= 2λ1q1 −∑
qt1MM − λ1q1 (53)
= λ1q1 −∑
qt1MM (54)
= λ1q1 −∑
MM tq1 (55)
= λ1q1 − λ1q1 (56)
= 0 (57)
Pour i 6= 1,
R2qi = Rqi −∑
M tq1q1Mtqi (58)
= λiqi −∑
qtiMM tq1q1 (59)
= λiqi − qtiRq1q1 (60)
= λiqi − qtiλ1q1q1 (61)
= 0 (62)
On a montré que les vecteurs propres de R sont vecteurs propres de R2. On montre de même que lesvecteurs propres de R2 sont des vecteurs propres de R, et ceci associés aux mêmes vecteurs propres (saufpour q1).Donc, le 2ème meilleur axe est celui engendré par q2. Par récurrence, le kième meilleur axe est celui associéà la kième plus grande valeur propre de R.On estime tout point x par sa projection sur les k premiers axes
x =k∑
i=1
< x|qi > qi
La quantité perdue sur x est
‖x− x‖2 =
∥∥∥∥∥n∑
i=k+1
< x|qi > qi
∥∥∥∥∥2
(63)
=n∑
i=k+1
< x|qi >2 (64)
L'espérance de la quantité perdue sur la base de données est
11

Cours SCIA
Promo 2007
Réseaux de neurones 1
3. Analyse en composantes principales
Ing2
EPITA
1nb_pts
nb_pts∑i=1
n∑j=k+1
< x|qj >2 =1
nb_pts
n∑j=k+1
nb_pts∑i=1
< x|qj >2 (65)
=1
nb_pts
n∑j=k+1
nb_pts∑i=1
qtjxxtqj (66)
=1
nb_pts
n∑j=k+1
qtj
(∑xxt)
qj (67)
=1
nb_pts
n∑j=k+1
qtjRqj (68)
=1
nb_pts
n∑j=k+1
qtjλjqj (69)
=1
nb_pts
n∑j=k+1
λj (70)
Pourcentage de perte :
qte perdue
qte a perdre=
1nb_pts
n∑j=k+1
λj
1nb_pts
n∑j=1
λj
(71)
=
n∑j=k+1
λj
n∑j=1
λj
(72)
(73)
Supposons que l'on dispose d'un algorithme itératif capable de calculer successivement (λ1, q1)(λ2, q2) . . ..La condition d'arrêt de cet algo est : % perte > tolérance. Réexprimons le pourcentage de perte sans faireappel au futur (mauvaise condition d'arrêt). Rappel : la trace est invariante par changement de base.Pourcentage de perte :
n∑j=k+1
λj
n∑j=1
λj
=
n∑j=k+1
λj
Tr(R)(74)
=Tr(R)−
k∑j=1
λj
Tr(R)(75)
= 1−
k∑j=1
λj
Tr(R)(76)
C'est une bonne condition d'arrêt car on ne fait appel qu'à des quantités déjà calculées.
Résumé implémentation
1. Calculer l'espérance de M : E(M).
2. Centrer les données : ∀M,M ←M − E(M).
12

Cours SCIA
Promo 2007
Réseaux de neurones 1
3. Analyse en composantes principales
Ing2
EPITA
3. Réduction des données. On veut égaliser les di�érents champs. Pour ceci, on norme les composantes :
∀M ∈ [[1..nb_pts]],∀i ∈ [[1..n]],Mi ←Mi
ρiavec ρi =
√√√√ 1nb_pts
nb_pts∑k=1
(M(k)i)2 (77)
4. Calculer la matrice
R =nb_pts∑
i=1
M(i)M(i)t (78)
5. Chercher les vecteurs propres et les valeurs propres de R.
Recherche des vecteurs propres et les valeurs propres de R
1. Recherche globale (tous les vecteurs, toutes les valeurs) : cf. cours de maths.
� Avantage : méthode la plus rapide si on désire tous les vecteurs propres.� Défaut :� En général instable numériquement.� Très lourde si on désire quelques vecteurs propres seulement.� Il faut avoir la matrice R.
2. Recherche incrémentale
(a) En utilisant R. Idée : calcul de Rpu où u est un vecteur propre de Rn. u se décompose dans labase des vecteurs propres :
~u =n∑
i=1
αiqi ⇒ Ru =n∑
i=1
αiRqi =n∑
i=1
αiλiqi (79)
On itère :
R2u =n∑
i=1
αiλiRqi =n∑
i=1
αiλ2i qi (80)
Par récurrence immédiate :
Rpu =n∑
i=1
αiλpi qi (81)
= λp1
n∑i=1
αi
(λi
λ1
)p
qi (82)
∼p→+∞
proba=1
λp1α1q1 (83)
α1 non nul avec une probabilité égale à 1. Donc
Rpu
‖Rpu‖∼
proba=1±q1 (84)
À renommage près, on peut dire que :
Rpu
‖Rpu‖→ q1 (85)
/* Changement de notation du à une rupture de cours : R est renommé en A */
Cette méthode ne fonctionne pas dans la pratique par manque de précision de la part des ordinateurs.
13

Cours SCIA
Promo 2007
Réseaux de neurones 1
3. Analyse en composantes principales
Ing2
EPITA
1ère idée normalisation à chaque itération. On obtient une suite{u0 = u
∀n ∈ N, un+1 = Aun
‖Aun‖(86)
Exprimons un en fonction de n :
u1 =Au
‖Au‖(87)
u2 =A2u
‖Aun‖÷ ‖A
2u‖‖Au‖
=A2u
‖A2u‖(88)
... (89)
up =Apu
‖Apu‖(90)
Doncup →
proba=1±q1 (91)
Mais en machine, des erreurs de calcul se produisent et cette méthode devient assez instable.
2ème idée changer la normalisation.{u0 = u
∀n ∈ N, un+1 = Aun
(Aun)1
(92)
Problème si la première composante est �ennuyeuse� (trop petite ou trop grande valeur). On change doncla méthode en {
u0 = u
∀n ∈ N, αn+1 ← Alea[[1..n]], un+1 = Aun
(Aun)α
(93)
3ième idée pourquoi ne pas étendre ce principe à n'importe quel axe ?{u0 = u
∀n ∈ N, vn+1 ← vecteur aléatoire de dim n, un+1 = Aun
<Aun|vn+1>
(94)
Un problème qui se pose est le coût de calcul de vn. La solution choisie est : vn ← v0 etv0 ← vecteur aléatoire de dim n. On peut exprimer un en fonction de n :
u1 =Au
< Au|v0 >(95)
u2 =A2u
< Au|v0 >÷ 1
< Au|v0 >< A2u|v0 > (96)
... (97)
up =Apu
< Apu|v0 >(98)
On note v0 =∑
βiqi. Donc
up =λp
1
n∑i=1
(λi
λ1
)p
αiqi
λp1
n∑i=1
(λi
λ1
)p
αiβi
(99)
∼proba=1
<u|q1> 6=0∧<v|q1> 6=0
λp1α1q1
λp1α1β1
(100)
14

Cours SCIA
Promo 2007
Réseaux de neurones 1
3. Analyse en composantes principales
Ing2
EPITA
Ceci est la méthode de la dé�ation :
q1 ←up
‖up‖; Aq1 = λq1 ⇒ λ1 ← ‖Aq1‖ (101)
Recherche de q2. Principe :� u← vecteur aléatoire de dim n.� u← u− < u|q1 > q1.
On a Apu = λp2
n∑i=2
(λi
λ2
)p
αiqi. Si on applique la méthode de la dé�ation avec le vecteur u ainsi construit :
up ∼proba=1
λp2α2q2
λp2α2β2
, on code, et on converge vers q1 à cause des erreurs de calcul.
Donc, au lieu de retirer une fois pour toutes la composante q1, on la retire à chaque itération. On au0 ← vecteur aléatoire de dim n
v0 ← vecteur aléatoire de dim n
un = un− < un|q1 > q1
un+1 = Aun
<Aun|v0>
(102)
Compactons ces deux lignes :
un+1 =A(un− < un|q1 > q1)
< A(un− < un|q1 > q1)|v0 >(103)
=Aun− < un|q1 > λ1q1
< Aun− < un|q1 > λ1q1|v0 >(104)
=Aun − λ1q1q
t1un
< Aun − λ1q1qt1un|v0 >
(105)
=(A− λ1q1q
t1)un
< (A− λ1q1qt1)un|v0 >
(106)
On note B = A− λ1q1qt1, on a donc
∀n ∈ N, un+1 =Bun
< Bun|v0 >(107)
Il s'agit exactement du même algorithme que précédemment en remplaçant A par B −A− λ1q1qt1.
3.2 Algo de recherche des vecteurs et valeurs propres par ordre décroissant
des λi
Algorithm 1 Recherche des vecteurs et valeurs propres
Require: Une matrice A symétrique positive à valeurs propres distinctes � le nombre de couples( ~vp, vp) cherchés (noté nbv)for i← 1 à nbv do
u← vecteur aléatoire de dim n
v ← vecteur aléatoire de dim n
repeat
u← Au
< Au|v >until convergence
(q, λ)←(
u
‖u‖,
Au
‖u‖
)Sortir (q, λ)A← A− λqqt
end for
end
15

Cours SCIA
Promo 2007
Réseaux de neurones 1
3. Analyse en composantes principales
Ing2
EPITA
3.3 Méthode générique de recherche de vecteurs et valeurs propres
Algorithmes HA et GHA (Hebbian Algorithm, Generic HA). On revient au problème de départ sous saforme énergétique :
E =12‖x− < x|q > q‖2 (108)
On recherche un algorithme stochastique : on présente et on met à jour exemple par exemple.
Principe de l'algorithme
Algorithm 2 algorithmic il y a des exemples Présenter x q ← q − εgradq(E)
end
Cet algorithme est un outil de base en minimisation.Dans le calcul de E, q est supposé de norme 1. Or cette condition est altérée par q ← q − εgradq(E). Onva forcer la norme de q à valoir 1 en renormant q à chaque itération. Attention, ce n'est plus une descentede gradient en énergie. Donc, si on veut garantir la convergence de l'algorithme vers q1, il faudrait prouverque
1. L'algorithme converge.
2. Il converge vers q1.
On a
E =12(xt− < x|q > qt)(x− < x|q > q) (109)
=12(xtx− 2 < x|q >2 +< x|q >2︸ ︷︷ ︸
u
qtq︸︷︷︸v
) (110)
gradq(E) =12(−4 < x|q > x + < x|q >2︸ ︷︷ ︸
u
2q︸︷︷︸v′
+2 < x|q > x︸ ︷︷ ︸u′
qtq︸︷︷︸v;=1
) (111)
= − < x|q > x + 2 < x|q >2 q (112)
On a q ← q − εgradq(E). Donc
qnew = q + ε < x|q > x− ε < x|q >2 q (113)
‖qnew‖ =
√√√√ n∑i=1
(qi + ε < x|q > xi − ε < x|q >2 qi)2 (114)
=
√√√√ n∑i=1
q2i + 2ε < x|q > xiqi − 2ε < x|q >2 q2
i + ◦(ε2) (115)
=
√√√√( n∑i=1
q2i
)+ 2ε < x|q >
n∑i=1
xiqi − 2ε < x|q >2
n∑i=1
q2i + ◦(ε2) (116)
=√
1 + 2ε < x|q >2 −2ε < x|q >2 + ◦ (ε2) (117)
=√
1 + ◦(ε2) (118)
= 1 + ◦(ε2) (119)
Donc
qnew
‖qnew‖= q + ε < x|q > (x− < x|q > q) (120)
16

Cours SCIA
Promo 2007
Réseaux de neurones 1
3. Analyse en composantes principales
Ing2
EPITA
On note y =< x|q >, on a alors
qnew
‖qnew‖= q + εy(x− yq) (121)
Ce résultat est valide uniquement si ε est très petit. La normalisation par ‖qnew‖ n'a rien changé dans laformule. Dans la situation présente, la descente de gradient réalise automatiquement (par e�et de bord) lanormalisation pour ε assez petit.
Algorithm 3 Apprentissage
repeat
Mélanger la base d'apprentissage x(1), x(2), . . . , x(nb_ex)for i← 1 à nb_ex do
Présenter x
Calculer y = wtx
w ← w + εy(x− yw)end for
Diminuer la valeur de ε
until convergence
end
Remarque fondamentale : On travaille avec une base de données centrée. Si la base de donnée n'estpas centrée, on ajoute une entrée virtuelle x0 valant 1 qui sert de biais, mais ce n'est pas économique.
Conclusion,
w → q1 (122)
GHA Calcul des autres vecteurs propres. On va appliquer la même méthode mais sur les exemples privésde leur composante sur q1. On renomme les wi précédents en w1,i et y en y1. Modi�cation des w2,∗.
w2,∗ ← w2,∗ + εwt2,∗(x− wt
1,∗xw1,∗)(x− wt1,∗xw1,∗ − wt
2,∗(x− wt1,∗xw1,∗)w2,∗) (123)
= w2,∗ + ε(y2 − y1 wt2,∗w1,∗︸ ︷︷ ︸
→0 (abus)
)(x− y1w1,∗ − y2w2,∗ + y1 wt2,∗w1,∗︸ ︷︷ ︸
→0 (abus)
w2,∗) (124)
≈ w2,∗ + εy2(x− y1w1,∗ − y2w2,∗) (125)
≈ w2,∗ + εy2
(x−
2∑i=1
yiwi,∗
)(126)
Par récurrence,
wi,∗ ← wi,∗ + εyi
x−i∑
j=1
yjwj,∗
(127)
Le principe de calcul de w2,∗, w3,∗, . . . est que les wi,∗ sont justes. En réalité, la convergence n'est passuccessive mais simultanée, c'est-à-dire w2,∗, w3,∗, . . . commencent à converger vers q1, q2, . . . avant que leswi,∗ précédents n'aient �ni de converger. Une parallélisation est donc possible.
3.4 Applicatif
Représentation des données Diminuer le nombre de champs pour la représentation des données enlimitant la perte d'information due à la projection.
Compression linéaire On décompose un signal dans une base adaptée et on supprime la partie desdonnées portée sur les axes les moins signi�catifs.
17

Cours SCIA
Promo 2007
Réseaux de neurones 1
3. Analyse en composantes principales
Ing2
EPITA
Construction de base de données simpli�ées à axes orthogonaux Recherche des axes qui rendentles nouveaux champs les plus indépendants possibles ← pré-traitement des données.
Classi�cation On dispose de vignettes de visage. On assimile chaque vignette à un ensemble de vecteurs.On calcule les vecteurs et valeurs propres. On classe les vignettes en fonction des axes et valeurspropres.
Détection d'indépendance des variables Exemple dans une base de données : Individu (age, poids,
taille).
Si la relation suivante existeλage + µpoids + γtaille = 0
alors λ3 ≈ 0.Si on obtient λ2 ≈ 0, alors
(age = µpoids ∨ λage = poids) ∧ (age = γtaille ∨ taille = λage) ∧ . . .
Si uniquement λ + 3 = 0, en oubliant le cas où λ = 0, age = µpoids + γtaille.
Pour rechercher la donnée la plus fortement corrélée, on projette les données sur (q1, q2) et on cherchele champ qui a le moins perdu
18

Cours SCIA
Promo 2007
Réseaux de neurones 1
4. Perceptron
Ing2
EPITA
4 Perceptron
Classi�cation d'un problème binaire. On dispose d'une base d'apprentissage T = {(x(i), d(i))}nb_exi=1 avec
x(i) ∈ Rn et d(i) ∈ {−1, 1}. On cherche un hyperplan H, Hw = {x ∈ Rn/xtw = 0} tel que d'un côté del'hyperplan, il y ait tous les exemples à d = 1 et de l'autre côté, tous les exemples à d = −1.Si le problème est solvable, il admet une in�nité de solutions. Le fait de dé�nir les côtés comme étant largesou stricts ne change pas ce qui est classi�able.L'exemple x(i) est bien placé ssi Si d(i) = 1 alors x(i)tw => 0 ou Si d(i) = −1, alors x(i)tw < 0, ce quirevient à dire que l'exemple x(i) est bien placé ssi d(i)wtx(i) > 0.
4.1 On suppose le problème linéairement séparable
Algorithm 4 Placement des exemples
repeat
Prendre un exemple (x(i), d(i))if d(i)wtx(i) > 0 then
Ne rien faireelse
w ← w + εd(i)x(i)end if
until tous les exemples soient bien placés
end
Preuve de la convergence On renomme x(i)d(i) en y(i). On numérote le temps en nombre d'appelsau �sinon� du code. y(t) est l'exemple x(i)d(i) qui a été utilisé lors du tième appel au �sinon�. On supposeque l'algorithme ne termine pas.On a
w(t) = w0 + εy(1) + εy(2) + · · ·+ εy(t) (128)
= w0 +t∑
i=1
y(i) (129)
Comme le problème est linéairement séparable, ∃u, ∀i, utd(i)x(i) > 0. Comme la base d'exemples est �nie,∃α > 0/∀i, utd(i)x(i) > α. On a
wttpsu = utw0 + ε
tps∑i=1
uty(i) (130)
> utw0 + εαtps (131)
Rappel : inégalité de Cauchy-Schwartz
‖a‖2‖b‖2 ≥< a|b >2 (132)
Preuve :
< λa + b|λa + b >≥ 0 ⇒ λ2‖a‖2 + 2λ < a|b > +‖b‖2 ≥ 0
⇒ ∆ ≤ 0
⇒ 4 < a|b >2 −4‖a‖2‖b‖2 ≤ 0
On a donc
‖wtps‖2‖u‖2 ≥ (wttpsu)2 (133)
19

Cours SCIA
Promo 2007
Réseaux de neurones 1
4. Perceptron
Ing2
EPITA
Si u = 0, alors α = 0, ce qui est IMPOSSIBLE. Donc u 6= 0. Donc
‖wtps‖2 ≥wt
tpsu
‖u‖2(134)
D'autre part,
‖wtps‖2 = ‖wtps−1 + εytps‖2 (135)
≤ ‖wtps−1‖2 + ε2‖ytps‖2 (136)
‖wtps−1‖2 ≤ ‖wtps−2‖2 + ε2‖ytps−1‖2 (137)
‖wtps−2‖2 ≤ ‖wtps−3‖2 + ε2‖ytps−2‖2 (138)... (139)
En sommant ces termes, on obtient
‖wtps‖2 ≤ ‖w0‖2 + ε2
tps∑i=1
‖y(i)‖2 (140)
Comme on a un nombre �ni d'exemples, ∃β > 0,∀i, ‖d(i)x(i)‖2 < β. Donc
‖wtps‖2 ≤ ‖w0‖2 + ε2βtps (141)
Avec (133)
(wttpsu)2 ≤ (‖w0‖2 + ε2βtps)‖u‖2 (142)
Avec (131)
wttpsu > utw0 + εαtps (143)
En combinant ces deux lignes
utw0 + εαtps <√‖wo‖2 + εβtps‖u‖ (144)
⇐⇒ utw0 + εαtps√tps
<
√‖w0‖2tps
+ ε2β‖u‖ (145)
Or, l'algorithme ne termine pas (hypothèse absurde), donc (145) est valide quelque soit le temps. Or lecôté gauche tend vers +∞ quand tps → +∞ et le côté droit a une limite �nie quand tps → +∞. C'estIMPOSSIBLE, donc l'algorithme termine.Remarque : La valeur de ε et de w0 n'interviennent pas dans le fait que l'algorithme converge. Parcontre, elles peuvent in�uencer le temps de convergence.Remarque : Dans les applications pratiques, on n'oubliera pas de rajouter à tous les exemples unecomposante virtuelle à 1. Sinon, on cherche un séparateur qui passe par l'origine, et c'est rarement ce quel'on désire.
4.2 On suppose le cas non-linéairement séparable
Remarque Dé�nition : Une époque est la présentation de tous les exemples de la base de données.On va présenter plusieurs fois la base d'apprentissage et à chaque époque, on va diminuer la valeur de ε.Règles classiques :
�∞∑
epoque=1
εepoque DV .
20

Cours SCIA
Promo 2007
Réseaux de neurones 1
4. Perceptron
Ing2
EPITA
�∞∑
epoque=1
ε2epoque CV .
Exemple :
εepoque =k1
k2epoque + k3
21

Cours SCIA
Promo 2007
Réseaux de neurones 1
4. Perceptron
Ing2
EPITA
4.3 Perceptron multi-couches
4.3.1 Présentation
Fig. 6 � Représentation d'un perceptron multi-couches
Soit n le nombre de couches. Les couches sont numérotées de 0 à n − 1. nbc est le nombre de neuronessur la couche c. Nc,i est le neurone i de la couche c. Les neurones sont numérotés dans une couche de 1 ànbc (sans compter le neurone virtuel). On ajoute à chaque couche un neurone virtuel Nc,0 (il n'a que dessorties, pas d'entrée). On note wc,i,j le poids de la connexion du neurone Nc−1,j vers le neurone Nc,i.On va noter Ac,i l'activation du neurone Nc,i. On note Sc,i la réponse du neurone Nc,i. On note ϕc,i lafonction de tranfert du neurone Nc,i.
4.3.2 Fonctionnement
∀c ∈ [[0..n− 1]], Sc,0 = 1.
∀c ∈ [[1..n− 1]],∀i ∈ [[1..nbc]], Ac,i =nbc−1∑j=0
wc,i,jSc−1,j et Sc,i = ϕc,i(Ac,i).
∀i ∈ [[1..nb0]], S0,i = ième composante de l'exemple courant.
4.3.3 Fonctionnement du réseau
On note X la situation courante.
Algorithm 5 Fonctionnement
for c← 0 à n− 2 do
Sc,0 ← 1 {Initialisation obligatoire des neurones virtuels}end for
{Fonctionnement}for i← 1 à nb0 do
S0,i ← Xi.end for
for c← 1 à n− 1 do
for i← 1 à nbc do
Ac,i ←nbc−1∑j=0
wc,i,jSc−1,j
Sc,i ← ϕc,i(Ac,i)
22

Cours SCIA
Promo 2007
Réseaux de neurones 1
4. Perceptron
Ing2
EPITA
end for
end for
end
La sortie est Sn−1,[[1..nbn−1]]
On dispose d'une base d'apprentissage T = {(x(i), y(i))}nb_exi=1 avec x(i) ∈ Rnb0 et y(i) ∈ Rnbn−1 .
Recherche des wc,i,j permettant de s'adapter au mieux à la base d'apprentissage T .
Algorithme de la rétro-propagation du gradient (back-prop) Soit
E =nb_ex∑
i=1
E(x(i)) avec E(X) =nbn−1∑i=1
(Yi − Sn−1,i)2
On e�ectue ∀c, i, j, wc,i,j ← wc,i,j − ε∂E
∂wc,i,j
1. Calcul de∂E
∂wn−1,i,j:
∂E
∂wn−1,i,j=
∂E
∂Sn−1,i
∂Sn−1,i
∂An−1,i
∂An−1,i
∂wn−1,i,j(146)
On a
∂E
∂Sn−1,i= −2(Yi − Sn−1,i) = 2(Sn−1,i − Yi) (147)
∂Sn−1,i
∂An−1,i= ϕ′n−1,i(An−1,i) (148)
∂An−1,i
∂wn−1,i,j= Sn−2,j (149)
2. Calcul de∂E
∂wc,i,jsous l'hypothèse que l'on a déjà calculé les
∂E
∂wc′,i,javec c′ > c.
On admet que
d
dxf(g1(x), g2(x), . . . , gn(x)) =
⟨(gradg1,...,gn
(f))(g1(x), . . . , gn(x))
∣∣∣∣∣∣∣g′1(x)
...g′n(x)
⟩ (150)
Exemple :
f(x, y) 7→ 2(x2 + y) avec g1(x) : x 7→ ln(x) et g2(x) : x 7→ cos(x)
df(ln(x), cos(x))dx
=⟨(
4 ln(x)2
) ∣∣∣∣( 1x
− sin(x)
)⟩=
2x− 2 sin(x)
Version 1∂E
∂wc,i,j=
∂E
∂Sc,i
∂Sc,i
∂Ac,i
∂Ac,i
∂wc,i,j
On a
∂Sc,i
∂Ac,i= ϕ′c,i(Ac,i)
et
∂Ac,i
∂wc,i,j= Sc−1,j
23

Cours SCIA
Promo 2007
Réseaux de neurones 1
4. Perceptron
Ing2
EPITA
et
∂E
∂Sc,i=
nbc+1∑k=1
∂E
∂Sc+1,k
∂Sc+1,k
∂Sc,i
On calcule
∂Sc+1,k
∂Sc,i=
∂Sc+1,k
∂Ac+1,k
∂Ac+1,k
∂Sc,i
et
∂Sc+1,k
∂Ac+1,k= ϕ′c+1,k(Ac+1,k)
et
∂Ac+1,k
∂Sc,i= wc+1,k,i
Version 2 On recommence cette opération en prenant :
∂E
∂wc,i,j=
∂E
∂Ac,i
∂Ac,i
∂wc,i,j
On a
∂Ac,i
∂wc,i,j= Sc−1,j
et
∂E
∂Ac,i=
nbc+1∑k=1
∂E
∂Ac+1,k
∂Ac+1,k
∂Ac,i
On a
∂Ac+1,k
∂Ac,i=
∂Ac+1,k
∂Sc,i
∂Sc,i
∂Ac,i= wc+1,k,iϕ
′c,i(Ac,i)
3. Algorithme de calcul de∂E
∂wc,i,j
Algorithm 6 Version 1
for i← 1 à nbn−1 do∂E
∂Sn−1,i← 2(Sn−1,i − Yi)
end for
for c← n− 2 à 1 par pas de -1 dofor i← 1 à nbc do
∂E
∂Sc,i←
nbc+1∑k=1
∂E
∂Sc+1,kϕ′c+1,k(Ac+1,k)wc+1,k,i
end for
end for
for c← 1 à n− 1 do
for i← 1 à nbc do
for j ← 0 à nbc−1 do∂E
∂wc,i,j← ∂E
∂Sc,iϕ′c,i(Ac,i)Sc−1,j
24

Cours SCIA
Promo 2007
Réseaux de neurones 1
4. Perceptron
Ing2
EPITA
end for
end for
end for
end
h] Version 2
for i← 1 à nbn−1 do∂E
∂An−1,i← 2(Sn−1,i − Yi)ϕ′n−1,i(An−1,i)
end for
for c← n− 2 à 1 par pas de -1 dofor i← 1 à nbc do
∂E
∂Ac,i← ϕ′c,i(Ac,i)
nbc+1∑k=1
∂E
∂Ac+1,kwc+1,k,i
end for
end for
for c← 1 à n− 1 do
for i← 1 à nbc do
for j ← 0 à nbc−1 do∂E
∂wc,i,j← ∂E
∂Ac,iSc−1,j
end for
end for
end for
end
Conclusion La version 2 est beaucoup plus rapide que la première.
4. h] Calcul de∂E
∂wc,i,j
∂E∂w← 0
for num← 1 à nb_ex do
Faire tourner le réseau avec comme entrée x(num).
Par V2, calculer∂E
∂wsachant que la sortie désirée est Yi.
∂E∂w
+← ∂E
∂w.
end for
end
5. Mise à jour des poids : w ← w − ε∂E∂w
6. Fonctionnement global.
Algorithm 9 Fonctionnement global
Créer la machine et l'initialiserrepeat
Calcul de∂E∂w
Mise à jour de w
until l'apprentissage soit su�sant
end
7. Choix de ϕc,i. On choisit des fonctions de type sigmoïdes (elle doit être strictement croissante, bornée,C∞).
Exemple fonctions sigmoïdes :
25

Cours SCIA
Promo 2007
Réseaux de neurones 1
4. Perceptron
Ing2
EPITA
� ϕ(x) = 11+e−x (mauvaise).
� ϕ(x) = 21+e−x − 1 (bonne).
� ϕ(x) = 2π arctan(x) (longue).
8. Initialisation.
(a) Aléatoire :
� w initialisé en aléatoire uniforme dans [−1, 1].� w initialisé selon une distribution gaussienne centrée en 0 de variance 1.
26

Cours SCIA
Promo 2007
Réseaux de neurones 1
A. Dérivations usuelles
Ing2
EPITA
A Dérivations usuelles
�
gradu(λu) =
λ
λ...λ
�
gradu(utv) = gradu
(n∑
i=1
uivi
)=
v1
v2
...vn
= v
� Soit M une matrice symétrique,gradu(utMu) =???
On a
Mu =
(n∑
k=1
Mi,kuk
)i∈[[1..n]]
⇒ utMu =n∑
i=1
ui
n∑k=1
Mi,kuk =∑
(i,k)∈[[1..n]]2
uiMi,kuk
On a donc
∂utMu
∂ul=
∂
∂ul
∑i6=lk 6=l
uiMi,kuk +∑i=lk 6=l
uiMi,kuk +∑i6=lk=l
uiMi,kuk +∑i=lk=l
uiMi,kuk
=
∂
∂ul
ul
∑k=1k 6=l
Ml,kuk + ul
∑i 6=l
uiMi,l + ulMl,lul
=
∑k 6=l
Ml,kuk +∑i 6=l
Mi,lui + 2Ml,lul
=∑k 6=l
Ml,kuk +∑i 6=l
Ml,iui + 2Ml,lul (M est symétrique)
= 2∑k 6=l
Ml,kuk + 2Ml,lul
= 2∑
k
Ml,kuk
Finalement
gradu(utMu) = 2
∑k
M1,kuk∑k
M2,kuk
...∑k
Mn,kuk
= 2Mu
�gradu(utu) = gradu(utIu) = 2Iu = 2u
27