recherche bibliographique - méthode de tour de transition
DESCRIPTION
Recherche bibliographique effectuée à l'IRCCyN. Le sujet était les méthodes de validation fonctionnelle et temporelle pour du matériel.Les deux méthodes choisies sont la méthode de Chow et la méthode de Tour de Transition.TRANSCRIPT

1
Ecole Centrale de Nantes - Université de Nantes - Ecole des Mines de Nantes
MASTER AUTOMATIQUE ROBOTIQUE ET INFORMATIQUE APPLIQUEE
SPECIALITE : TEMPS REEL, CONDUITE ET SUPERVISION
Année 2014 / 2015
Rapport Bibliographique
Présenté et soutenu par :
BENBOUIDDA Ossama
Le jeudi 5 février 2015
à L’Institut de Recherche en Communications et Cybernétique de Nantes
TITRE
Validation temporelle d’un modèle de pipeline vis à vis de la cible réelle
Jury : M. Jean-Luc Béchennec
M. Loïg Jezequel M. Mikaël Briday
Laboratoire : L’Institut de Recherche en Communications et Cybernétique de Nantes (IRCCyN)

2
Table des matières :
Table des figures : ......................................................................................................................................4
Introduction : .............................................................................................................................................5
Chapitre 1 : Généralités sur l’architecture des processeurs, sur la modélisation et la vérification.........6
1.1 Architecture des processeurs :.........................................................................................................6
Niveau 0 : Réalisation en logique numérique : ..................................................................................7
Niveau 1 : Micro-architecture : ..........................................................................................................7
Niveau 2 : Architecture de jeu d’instruction (ISA) : ...........................................................................9
1.2 Modélisation ....................................................................................................................................9
Pourquoi faire de la modélisation ? ...................................................................................................9
Exemple : modélisation pour un pipeline donné d’un processeur : ................................................10
Pourquoi la vérification de modèles ? .............................................................................................11
Quelles sont les méthodes de vérification qui existent ? ................................................................11
Quel genre d’erreur on peut détecter ?...........................................................................................11
Chapitre 2 : Eléments sur la théorie des graphes ...................................................................................14
Définition d’un graphe orienté :...........................................................................................................14
Définition du degré d’un sommet : ......................................................................................................14
Définition d’un graphe simple :............................................................................................................15
Définition d’un multigraphe : ...............................................................................................................16
Définition d’un chemin :.......................................................................................................................16
Propriétés d’un chemin : ..................................................................................................................16
Test d’existence d’un chemin :.........................................................................................................17
Définition d’un circuit :.........................................................................................................................17
Définition d’un circuit eulérien et d’un graphe eulérien : ...................................................................17
Définition d’un graphe connexe :.........................................................................................................18
Définition d’un graphe fortement connexe : .......................................................................................18
Définition d’une machine de Mealy : ...................................................................................................19
Propriétés des machines de Mealy : ................................................................................................20
Définition de la k-équivalence :............................................................................................................21
Chapitre 3 : La méthode des séquences caractéristiques .......................................................................22
Principe :...............................................................................................................................................22
Les différentes phases de réalisation de la méthode : ........................................................................22
Réalisation des différentes phases :.....................................................................................................22
Phase 1 : Estimation nombre maximum d’état................................................................................22
Phase 2 : Construction de l’ensemble W ..........................................................................................22

3
Phase 3 : Construction de l’arbre de test de la machine M..............................................................27
Phase 4 : Trouver l’ensemble de couverture de transition, depuis l’arbre de test. ..........................28
Chapitre 4 :...............................................................................................................................................30
La méthode du tour de transition ............................................................................................................30
Le problème du Postier Chinois : .........................................................................................................30
Les grands titres de l’algorithme de la méthode de tour de transition : .............................................30
Conclusion : ..............................................................................................................................................40
Bibliographie : ..........................................................................................................................................41

4
Table des figures : Figure 1 : Une abstraction de machine à 6 niveaux ...................................................................................6
Figure 2 : Modèle de pipeline à 5 étages ...................................................................................................8
Figure 3 : Organisation des niveaux de mémoire cache ............................................................................9
Figure 4 : Pipeline à automate fini ...........................................................................................................10
Figure 5: Modélisation pipeline à deux étages ........................................................................................10
Figure 6: Exemple d'erreur d'opération ...................................................................................................12
Figure 7 : Exemple d'erreur de transfert..................................................................................................12
Figure 8 : Autre type d'erreur ..................................................................................................................13
Figure 9 : Test de conformité ...................................................................................................................13
Figure 10 : Exemple graphe orienté .........................................................................................................14
Figure 11 : Graphe pour calcul de degré ..................................................................................................15
Figure 12: Graphe non simple, problème lien (3,2) .................................................................................15
Figure 13 : Graphe non simple, problème boucle sur 2...........................................................................16
Figure 14 : Exemple multigraphe .............................................................................................................16
Figure 15 : Graphe test pour circuit .........................................................................................................17
Figure 16: Graphe eulérien ......................................................................................................................18
Figure 17 : Graphe non-convexe ..............................................................................................................18
Figure 18 : Graphe convexe......................................................................................................................18
Figure 19 : Exemple d'un graphe fortement connexe .............................................................................19
Figure 20 : Machine de Mealy ..................................................................................................................19
Figure 21 : Deux machines de Mealy équivalentes..................................................................................20
Figure 22 : Deux machines de Mealy qui ne sont pas équivalentes ........................................................20
Figure 23 : Machine de Mealy qui n'est pas minimale ............................................................................21
Figure 24 : Exemple pour trouver l'ensemble W .....................................................................................23
Figure 25 : Machine M sous forme tabulaire ...........................................................................................24
Figure 26 : La table P1 ..............................................................................................................................24
Figure 27 : La table P1, étape intermédiaire ............................................................................................24
Figure 28: La table P2 ...............................................................................................................................25
Figure 29 : La table P3 ..............................................................................................................................25
Figure 30 : La table P4 ..............................................................................................................................26
Figure 31 : Arbre de test de la machine M...............................................................................................27
Figure 32: Spécification test pour méthode W ........................................................................................29
Figure 33 : Figure test avec W ..................................................................................................................29
Figure 34 : Graphe d'exemple pour la méthode de tour de transition ...................................................32
Figure 35 : Contraintes exemple problème de transport ........................................................................33
Figure 36 : Application méthode Nord-Ouest ..........................................................................................34
Figure 37 : Application de la méthode MODI...........................................................................................35
Figure 38: Itération suivante méhtode MODI ..........................................................................................36
Figure 39 : Solution trouvée méthode Nord-Ouest .................................................................................36
Figure 40 : Graphe eulérien après application de la méthode de transport ...........................................37
Figure 41 : Arbre de couverture du graphe eulérien de la figure 39 .......................................................38
Figure 42 : Tableau sommets et arcs prédécesseurs ...............................................................................38
Figure 43 : Séquence de test ....................................................................................................................39

5
Introduction :
Aujourd’hui, les systèmes embarqués, et plus particulièrement, les systèmes temps -réel, touchent de plus en plus de domaines : Automobile, Aéronautique, Téléphonie, Médecine, etc. Les recherches dans ce domaine sont en constante évolution, et ont conduit à un très grand nombre de domaines de sous-recherche : Politiques d’ordonnancement, techniques de programmation temps-réel, modélisation fonctionnelle des systèmes embarqués, modélisation architecturale des systèmes embarqués, validation de modélisation, etc. Sachant que les microcontrôleurs/microprocesseurs constituent l’ossature première de la puiss ance de tout système embarqué, il devient alors évident que plusieurs domaines de recherches se sont penchés là-dessus : Architecture de processeurs, modélisation des architectures, validations de modèles d’architectures, etc. Plusieurs niveaux d’architectures existent, et au sein de ces niveaux,
plusieurs sous-architectures existent. L’une des architectures les plus intéressantes dans le domaine système embarqué, est l’architecture processeur qui prend en compte le pipeline.
La prise en compte de pipeline dans un microprocesseur se fait depuis bien longtemps, et plusieurs
modèles de pipeline ont été développés au fil des années. Maintenant, on arrive à générer des simulateurs de pipeline grâce à des spécifications décrits dans des langages bien spécifiques comme
Harmless [KBBST12]. La vérification de la concordance du comportement de ces simulateurs générés,
avec l’implémentation physique, est ainsi une chose importante pour pouvoir se baser sur ces simulateurs dans des développements futurs Le but de ce séminaire bibliographique est donc de mettre le point sur la validation temporelle des modèles de pipeline. Nous présenterons dans le premier chapitre les différents niveaux d’architectures, leurs particularités, et les différentes architectures qui existent dans chaque niveau. Ensuite, nous étudierons dans le deuxième chapitre plus en détail la microarchitecture processeur en pipeline, et nous allons donc voir quelles sont les approches de modélisation qui avaient été faites
dans ce but, en mettant plus le point sur celles faites avec des machines à états finis [Ura92], [FKA+91], [Con08], [YL95] . On consacrera le troisième chapitre à l’étude de validation temporelle et au genre d’erreurs qui peuvent être évitées avec de telles méthodes. Le quatrième chapitre et le dernier est une mise en pratique de ces techniques de modélisation. En guise d’introduction, nous présenterons dans le premier chapitre des généralités sur l’architecture
des processeurs, sur la modélisation et sur la vérification. Nous enchaînerons juste après avec la
théorie nécessaire pour la réalisation de nos méthodes : La théorie des graphes. Les chapitres 3 et 4 seront consacrés quant à eux à l’introduction de la méthode de Chow et la méthode des tours de transitions, qui sont des méthodes très connues dans la littérature pour la vérification de modèles.

6
Figure 1 : Une abstraction de machine à 6 niveaux
Chapitre 1 : Généralités sur l’architecture des processeurs, sur la modélisation et la vérification
1.1 Architecture des processeurs :
Selon Andrew Tanenbaum, dans son livre « Structured Computer Organization », tout système qui implique une unité de traitement comme un microprocesseur ou un microcontrôleur est organisé
selon les niveaux suivants :
Le niveau qui va nous intéresser le plus

7
D’après cette abstraction, on peut clairement déduire que les niveaux en rapport direct avec l’architecture processeur se situent dans les 3 niveaux les plus bas.
Niveau 0 : Réalisation en logique numérique :
Dans ce niveau, l’information transite de l’état physique à l’état numérique, et ce via des techniques
de codage numérique de l’information, comme l’échantillonnage et la quantification. Ces techniques combinées ont donné naissance à une théorie que l’on appelle la théorie de la logique numérique.
Cette théorie se base sur des fonctions élémentaires pour représenter les unités matérielles équivalentes. Les techniques les plus connue de fabrication de composants électroniques est le CMOS ou Transistor-Transistor Logic.
Niveau 1 : Micro-architecture :
La microarchitecture d’un microcontrôleur ou d’un processeur est une vue logique du processeur. Elle présente :
Le nombre de mémoires caches dont dispose le processeur.
Le nombre de pipelines, ainsi que leurs longueurs.
Les unités de calcul.
La prise en compte du multiprocessing et du multi-threading
La prise en compte de prédiction de branchement.
Intel est le constructeur le plus connu des microarchitectures d’un processeur et a mis au marché un très bon nombre de microarchitectures comme : La famille x86, la famille 186, la famille 286, la
famille Core, etc.
Notions liées à la micro-architecture :
1. Pipeline
Une des manières qui permet d’accroître la vitesse d’exécution des instructions dans un micro-processeur est le pipeline, et ce en parallélisant les étapes d’exécution.
Prenons un modèle d’exécution d’instruction à cinq phases (LI : Lecture d’instruction, DI : Décodage
de l’instruction, EX : Exécution de l’instruction, MEM : Accès mémoire, ER : Ecriture). Un modèle d’exécution en pipeline à 5 étages est alors donné comme exemple dans la figure suivante :

8
Figure 2 : Modèle de pipeline à 5 étages
D’après l’exemple, on remarque bien qu’à partir du 5ème top d’horloge, les 5 instructions sont déjà toutes en exécution. Si on considère que chaque instruction met 5 cycles d’horloge pour s’exécuter, alors 5 instructions mettraient 9 cycles d’horloge pour s’exécuter au lieu de 25. Ceci correspond à un gain très notable en terme vitesse. L’exemple de pipeline à 5 étages est l’exemple le plus répandu, cependant, il existe plusieurs types, pouvant aller jusqu’à 40 étages. Nous allons revenir à cette structure en pipeline dans la partie modélisation, pour voir comment la modéliser. Nous allons aussi voir dans les chapitres 3 et 4, comment valider cette modélisation par rapport à une spécification donnée.
2. Mémoires cache
Les mémoires caches sont un type de mémoire qui servent de buffer au processeur, afin d’y stocker
des informations que le processeur juge pertinentes, coûteuses en terme de temps d’accès et dont il a fréquemment besoin. Le concept de mémoire cache n’est pas exclusif aux microprocesseurs, on en
trouve dans les disques durs, dans les serveurs, dans les mémoires de base de données, etc, cependant, dans les microprocesseurs, ce genre de mémoires a la particularité d’être très rapide (Fait
en général avec des SRAM). Toujours dans les microprocesseurs, on a en général la répartition suivante :
Cache de premier niveau L1 : Le plus petit des 3 niveaux mais le plus rapide.
Cache de second niveau L2 : Moins rapide que le niveau L1.
Cache de niveau L3 : Moins rapide et plus gros que les deux précédents.
La figure 3 illustre bien comment ces niveaux sont organisés autour d’un microprocesseur.

9
Figure 3 : Organisation des niveaux de mémoire cache
L’intérêt est le même que celui des pipelines : L’augmentation de la vitesse d’exécution des programmes, mais cette fois-ci, en réduisant les temps d’accès à la mémoire principale (RAM). Niveau 2 : Architecture de jeu d’instruction (ISA) :
Le jeu d’instruction d’un processeur, est le niveau d’abstraction qui vient juste après le langage
assembleur. C’est l’ensemble d’instructions élémentaires qu’un processeur ou un microcontrôleur peut exécuter ou encore l’ensemble des circuits logiques câblés dans un processeur. Cela peut aller d’opérations très basiques (Comme : And, Or, NOR, XOR) ou encore des opérations plus compliquées comme la division. Comme exemples de famille d’opérations, on trouve :
Les opérations arithmétique et logique (Addition, etc)
Les opérations de transfert de données (Chargement, rangement).
Les opérations de contrôle (Branchement, appel).
Les opérations système.
Les opérations type « Chaines » (Recherche, comparaison, etc).
Il existe sur le marché plusieurs types d’architectures de jeux d’instructions, les principaux sont : x86, PowerPC et ARM (Cette dernière architecture est la plus utilisée dans le domaine des systèmes
embarqués).
1.2 Modélisation Pourquoi faire de la modélisation ?
Aujourd’hui, la modélisation de systèmes complexes est devenue importante plus que jamais. Elle permet sans avoir le matériel nécessaire en place, de prédire le fonctionnement, d’anticiper des anomalies, de faire la correction des erreurs, de faire des simulations et surtout la compréhension d’une telle ou telle approche, avant même de l’installer sur une machine cible. Le but final de la modélisation est de sortir avec un modèle formel, graphique, mathématique ou algorithmique. Ces modèles moyennant quelques propriétés et algorithmes de vérifications nous
permettraient de tirer des conclusions avant de mettre en place le système étudié.

10
Les modèles formels, il en existe beaucoup, et chacun est plus adapté à une situation qu’à une autre. Pour les systèmes d’information, des modèles objet comme UML seraient très adaptés, mais dans notre cadre, le cadre de systèmes embarqués, des modèles à systèmes de transition (Automates, Réseaux de Pétri, etc) ont prouvé leur efficacité tant par leur facilité et tant par les résultats théoriques dont on dispose en utilisant ces modèles. Exemple : modélisation pour un pipeline donné d’un processeur :
Une des manières de modéliser un pipeline qui existent et qui nous intéressent dans le cas de notre
étude, est la modélisation sous forme d’état fini [KBBST12], [BAL95], [MUL93]. Un pipeline à n étages peut être vu comme étant une suite d’états finis. Chaque état du pipeline dans un cycle d’horloge est
modélisé par un état dans un automate fini, la transition correspondante qui permet d’aller à cet é tat sera alors l’instruction (ou les instructions) qui a été faite pour arriver à cet état .Un exemple pour mettre en relief ceci est montré dans la figure 4.
Le pipeline passe d’un état à un autre à chaque cycle d’horloge, et ce, selon la nature des actions
auquel il est soumis :
« Actions d’appel de donnée » qui sont le résultat d’un manque de ressource.
« Actions de dépendance de données » qui sont le résultat de dépendance de données entre
les instructions
Exemple simplifié avec un pipeline à deux étages :
Figure 5: Modélisation pipeline à deux étages
Figure 4 : Pipeline à automate fini

11
Pourquoi la vérification de modèles ?
Les systèmes de transitions ont été utilisés pour modéliser beaucoup de systèmes, et dans beaucoup de domaines. Pour assurer la fiabilité de ces systèmes une fois implémentés, ils doivent passer par des
tests de conformités. En général, on fait la comparaison entre une modélisation sous formes d’automate à état finis, et une implémentation qui est pour nous une « boite noire ». Il faut donc
pouvoir trouver une méthode pour connaître l’état de cette « boite noire » et prendre une séquence de test du modèle pour le vérifier.
Quelles sont les méthodes de vérification qui existent ?
La méthode de Tour de Transition : La méthode la plus simple pour générer une séquence de test est la méthode de Tour de Transition. Les séquences d’entrées sont appliquées au
hasard au modèle, jusqu’à ce que les transitions soient traversées au moins une seule fois. Cette méthode vérifie seulement la sortie des transitions, mais pas les états. Elle peut produire la plus petite séquence de test, mais sa fiabilité de détection d’erreur est moindre par rapport aux autres méthodes. Voir chapitre 4 pour plus de détails. Distinguishing Sequence : Cette méthode d’entrée/Sortie, est capable d’identifier les états du modèle. Cela veut dire que la sortie est différente pour chaque état du modèle pour notre séquence. La méthode de Chow : Cette méthode consiste à créer un ensemble W, d’entrées qui distingue le comportement de deux états distincts. Voir chapitre 3 pour plus de détails. La méthode de séquences probabilistes : Il y’a une nouvelle approche pour attaquer les
problèmes de cas de tests infinis qu’il peut nous arriver de rencontrer parfois, et ce en introduisant les concepts probabilistes dans la génération de notre séquence de test. On ajoute des probabilités aux
transitions, qui dépendent de leur fréquence d’occurrence. Ainsi une séquence de test est générée de manière à ce que la transition qui va sûrement être franchi la première, sera testée en premier lieu.
Cette méthode à un autre nom, la méthode P. Quel genre d’erreur on peut détecter ?
Erreurs d’opération : On dit que l’automate « A » a une erreur d’opération si « A » n’est pas
équivalent à « A’ » (La version correcte) et « A » peut être modifié pour être équivalent à
« A’ » en changeant SEULEMENT les résultats de sortie de l’automate « A ». Ceci veut dire sans ajouter ou supprimer des états. Un exemple est montré dans la figure 6.

12
Figure 6: Exemple d'erreur d'opération
Erreurs de transfert : On dit que l’automate « A » a une erreur de transfert si « A »n’est pas
équivalent à « A’ » (La version correcte) et A peut être modifié pour être équivalent à A’ en
changeant SEULEMENT le prochain état d’un des états de A. Sans donc l’ajout ou la suppression d’états dans « A ». Ce genre d’erreurs est illustré dans la figure 7 :
Figure 7 : Exemple d'erreur de transfert
Autres erreurs : On peut avoir d’autres erreurs, comme les erreurs qu’on appelle « Les erreurs
mixtes » où l’on a les erreurs d’opération et de transfert en même temps. On peut avoir aussi
des erreurs qui proviennent d’un état ajouté de plus à la spécification ou manquant à la spécification. Des exemples sont présentés dans la figure 8.

13
Figure 8 : Autre type d'erreur
En résumé :
Maintenant qu’on a fait le parcours du contexte d’étude, de l’architecture des processeurs, modélisation et vérification. On essayera par la suite de donner l’état de l’art de méthodes, qui nous
permettent de faire ce qu’on appelle un test de conformité, c’est-à-dire, la vérification de la correspondance entre les sorties et les états produit de l’implémentation et la spécification. Sous forme graphique, ce qu’on veut faire est résumé dans la figure suivante :
Figure 9 : Test de conformité

14
Chapitre 2 : Eléments sur la théorie des graphes
Comme nous l’avons évoqué précédemment dans le chapitre 1, nous avons choisi un modèle d’automates à états finis pour la modélisation de nos pipelines. Ainsi, afin de pouvoir appliquer les méthodes qu’on a vues, il faudrait alors commencer par expliciter les bases de la théorie des graphes .
Définition d’un graphe orienté :
En théorie des graphes, un graphe orienté est défini par G(V,E), où V représente l’ensemble des sommets/états, et E représente l’ensemble des arcs du graphe G. Deux sommets quelconques sont reliés par un arc. Et donc, dans le cas où l’on ajoute l’orientation à ces arcs, c’est-à-dire, on fait en sorte que le lien depuis l’arc « u » à l’arc « v » diffère du lien entre l’arc « v » et l’arc « u », on parle alors dans ce cas d'un graphe orienté. Un exemple d’un graphe orienté est montré dans la figure 10.
Figure 10 : Exemple graphe orienté
Ce graphe est constitué de 4 sommets 0, 1, 2 et 3 et de 5 arcs (0,1), (1,0), (2,1), (0,2) et (0,3).
Définition du degré d’un sommet : Considérons un sommet « u » du graphe orienté de la figure précédente. Le degré sortant d’un sommet « u » est le nombre d’arcs ayant pour extrémité initiale le sommet u. Il est noté d+. De façon similaire, le degré entrant d’un sommet u est le nombre d’arcs ayant pour extrémité finale le somme u. Il est noté d-. Le degré d’un sommet « u », noté d est ainsi défini par la somme de son degré sortant et degré entrant. Soit : D = d+ + d- . Faisons des exemples sur le graphe de la figure 11
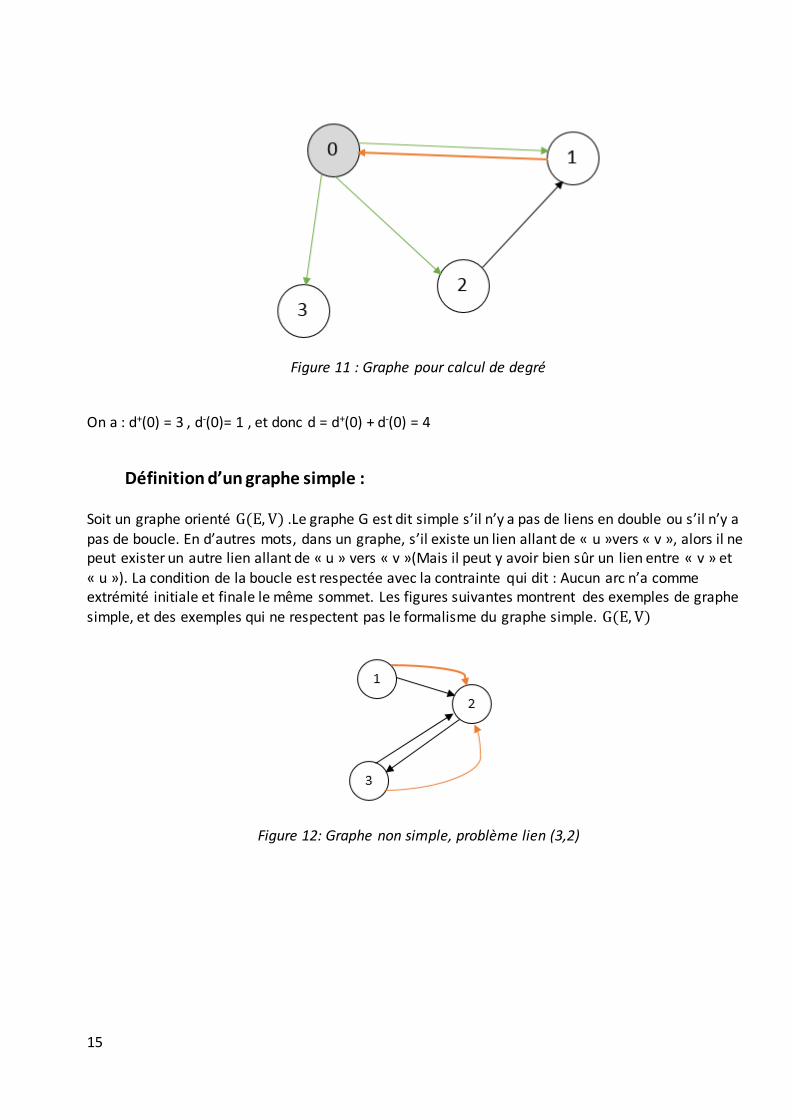
15
Figure 11 : Graphe pour calcul de degré
On a : d+(0) = 3 , d-(0)= 1 , et donc d = d+(0) + d-(0) = 4
Définition d’un graphe simple : Soit un graphe orienté G(E, V) .Le graphe G est dit simple s’il n’y a pas de liens en double ou s’il n’y a
pas de boucle. En d’autres mots, dans un graphe, s’il existe un lien allant de « u »vers « v », alors il ne peut exister un autre lien allant de « u » vers « v »(Mais il peut y avoir bien sûr un lien entre « v » et
« u »). La condition de la boucle est respectée avec la contrainte qui dit : Aucun arc n’a comme extrémité initiale et finale le même sommet. Les figures suivantes montrent des exemples de graphe
simple, et des exemples qui ne respectent pas le formalisme du graphe simple. G(E, V)
Figure 12: Graphe non simple, problème lien (3,2)

16
Figure 13 : Graphe non simple, problème boucle sur 2
Définition d’un multigraphe : Un multigraphe est un graphe orienté qui peut comporter les cas particuliers évoqués dans graphes simples, c’est-à-dire qu’il peut comporter des liens en double (triple, etc), et des boucles. La figure suivante présente un exemple de multigraphe :
Figure 14 : Exemple multigraphe
Définition d’un chemin : Dans un graphe orienté G(E,V), un chemin C est une suite V0,V1…Vn de sommets, tel que deux arcs
consécutifs Vi et Vi+1 sont reliés par un arc. ∀ 𝑖 ∈ [|1, 𝑛|] (𝑉𝑖−1, 𝑉𝑖) ∈ 𝐸
L’origine du chemin C est alors V0 et l’extrémité du chemin C est Vn. Ainsi défini, le chemin C est formé de « n+1 » sommets reliés par « n » arcs. On dira alors que la longueur du chemin C est « n ».
NB : On peut avoir un chemin de longueur nul. C’est le chemin qui se constitue d’un seul sommet. Propriétés d’un chemin :
On dit qu’un chemin est simple s’il ne passe pas deux fois par le même arc.
Un chemin est dit élémentaire s’il ne passe pas deux fois par le même sommet.
Un chemin élémentaire est forcément un chemin simple.
On dit que les sommets a et b sont connectés, s’il existe un chemin les joignant. On note alors :
𝑎 ~ 𝑏

17
Test d’existence d’un chemin :
L’existence d’un chemin entre un sommet et un autre peut être avec un parcours du graphe : Un
parcours en profondeur ou en largeur.
Définition d’un circuit : Un circuit Ci est un chemin de longueur non nulle, dont l’origine et l’extrémité coïncident. On peut
très aisément vérifier les assertions suivantes dans le graphe de la figure 14.
La séquence (0,1,2,3,0) constitue un circuit et un chemin de longueur 4.
L’état (2) constitue un circuit et un chemin de longueur 0.
La séquence (2,1,0) n’est ni un circuit ni un chemin.
Figure 15 : Graphe test pour circuit
Définition d’un circuit eulérien et d’un graphe eulérien :
Soit un graphe G (V,E) et soit un circuit C. Un circuit C est dit circuit eulérien s’il passe par tous les sommets du graphe G, et ce, en ne passant qu’une et une seule fois par chaque arc du graphe. Le
graphe en question peut être un multigraphe.
Dans le cas où le graphe G admet un circuit eulérien, alors le graphe G es t dit graphe eulérien. NB : Un graphe G peut admettre plusieurs circuits eulériens.
18
Figure 18 : Graphe convexe Figure 17 : Graphe non-convexe
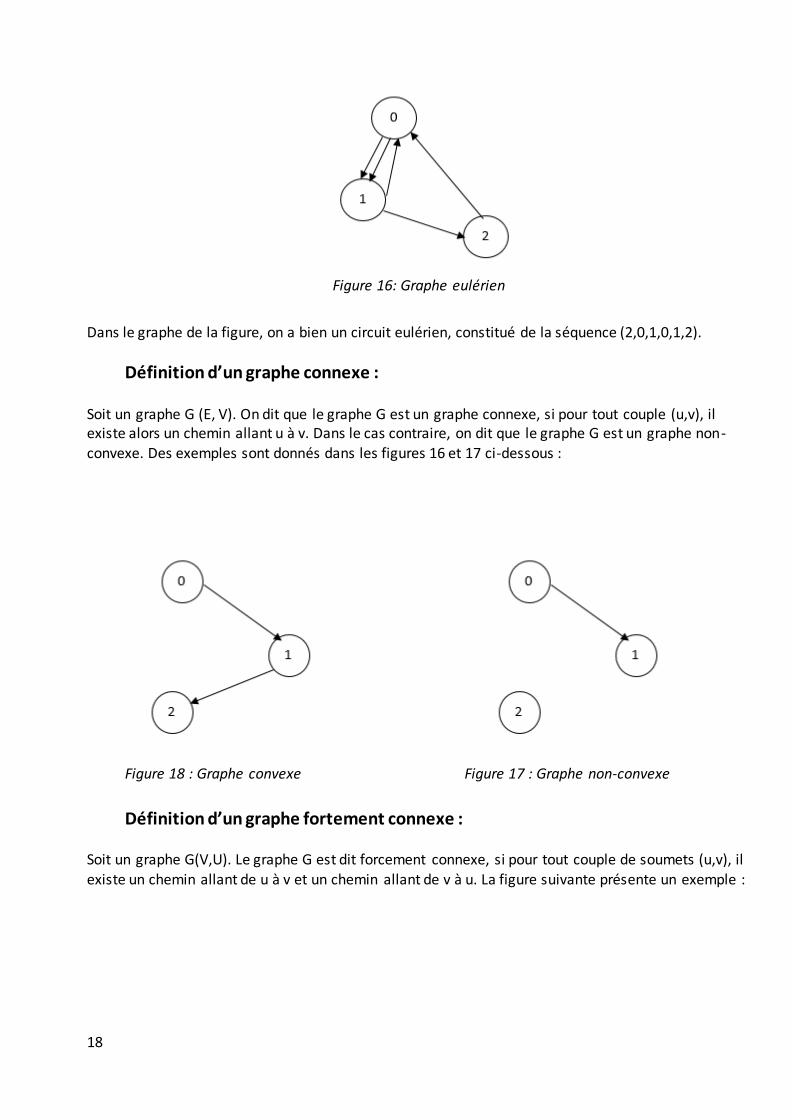
Figure 16: Graphe eulérien
Dans le graphe de la figure, on a bien un circuit eulérien, constitué de la séquence (2,0,1,0,1,2).
Définition d’un graphe connexe : Soit un graphe G (E, V). On dit que le graphe G est un graphe connexe, si pour tout couple (u,v), il existe alors un chemin allant u à v. Dans le cas contraire, on dit que le graphe G est un graphe non-convexe. Des exemples sont donnés dans les figures 16 et 17 ci-dessous :
Définition d’un graphe fortement connexe : Soit un graphe G(V,U). Le graphe G est dit forcement connexe, si pour tout couple de soumets (u,v), il
existe un chemin allant de u à v et un chemin allant de v à u. La figure suivante présente un exemple :

19
Figure 19 : Exemple d'un graphe fortement connexe
Définition d’une machine de Mealy :
On peut définir une machine de Mealy M, par le quintuplé (𝑆, 𝐼, 𝑂, 𝛿, 𝜆) tel que : S est un ensemble d’états finis.
I est un ensemble fini des symboles d’entrée (Le Input).
O est un ensemble fini des symboles de sorties (Le Output).
𝛿: 𝑆 × 𝐼 ⟶ 𝑆 est la fonction de transfert (Qui permet de générer les états).
𝜆:𝑆 × 𝐼 ⟶ 𝑂 est la fonction de sortie (Qui permet en fonction d’un état, et une transition de
générer la sortie).
Intuitivement, supposons qu’on a une machine de Mealy M. Supposons qu’on est dans un état ∈ 𝑆 .
Alors l’application d’une entrée 𝑖 ∈ 𝐼 , avec e’= 𝛿(e,i) , fait passer la machine de l’état « e » à un état « e’ » (Pas forcément différents), et donne une sortie 𝑜 ∈ 𝑂, avec o = 𝜆(𝑜, 𝑖).
Figure 20 : Machine de Mealy
Remarque : Par définition (Par la définition des fonctions de transfert et de sortie), la machine de Mealy est une machine complète et déterministe. C’est-à-dire, ∀𝑠 ∈ 𝑆 et ∀ 𝑖 ∈ 𝐼 , il existe une seule et une seule transition qui a comme état de départ « s » et comme étiquette « i ».
20
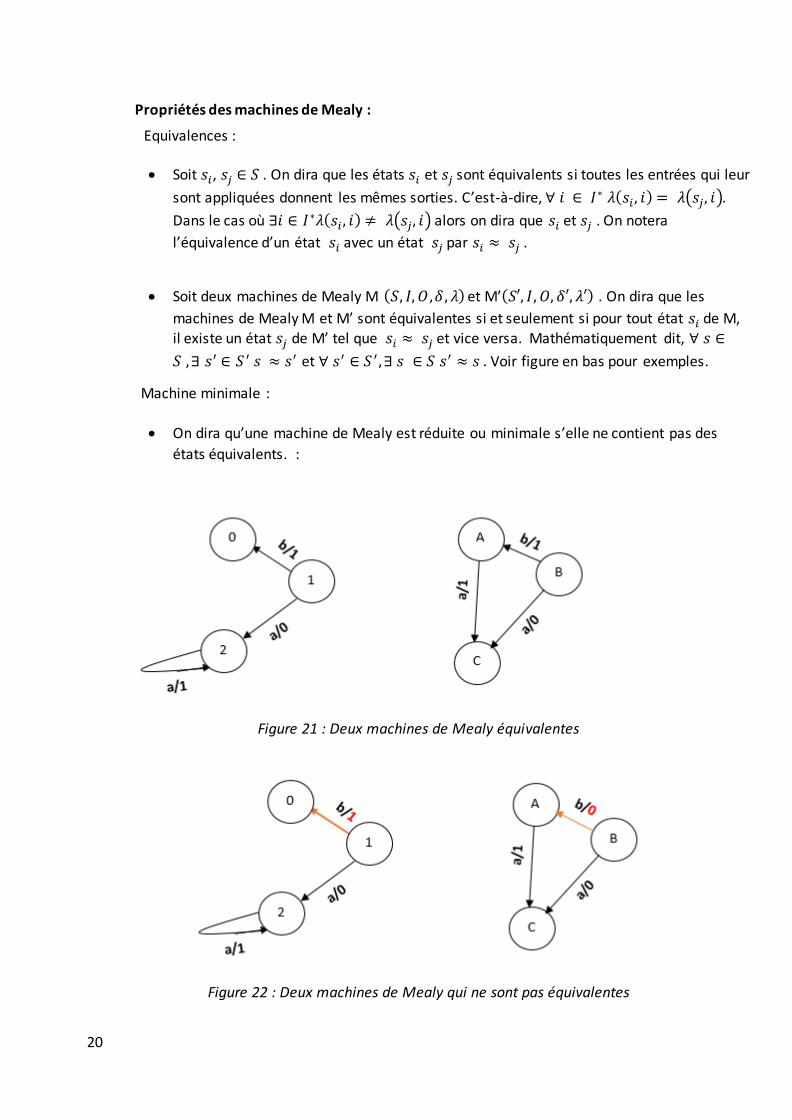
Propriétés des machines de Mealy :
Equivalences :
Soit 𝑠𝑖, 𝑠𝑗 ∈ 𝑆 . On dira que les états 𝑠𝑖 et 𝑠𝑗 sont équivalents si toutes les entrées qui leur
sont appliquées donnent les mêmes sorties. C’est-à-dire, ∀ 𝑖 ∈ 𝐼∗ 𝜆(𝑠𝑖 , 𝑖) = 𝜆(𝑠𝑗, 𝑖).
Dans le cas où ∃𝑖 ∈ 𝐼∗𝜆(𝑠𝑖 , 𝑖) ≠ 𝜆(𝑠𝑗, 𝑖) alors on dira que 𝑠𝑖 et 𝑠𝑗 . On notera
l’équivalence d’un état 𝑠𝑖 avec un état 𝑠𝑗 par 𝑠𝑖 ≈ 𝑠𝑗 .
Soit deux machines de Mealy M (𝑆, 𝐼, 𝑂,𝛿, 𝜆) et M’(𝑆′, 𝐼, 𝑂, 𝛿′, 𝜆′) . On dira que les
machines de Mealy M et M’ sont équivalentes si et seulement si pour tout état 𝑠𝑖 de M, il existe un état 𝑠𝑗 de M’ tel que 𝑠𝑖 ≈ 𝑠𝑗 et vice versa. Mathématiquement dit, ∀ 𝑠 ∈
𝑆 ,∃ 𝑠′ ∈ 𝑆 ′ 𝑠 ≈ 𝑠′ et ∀ 𝑠′ ∈ 𝑆 ′ ,∃ 𝑠 ∈ 𝑆 𝑠′ ≈ 𝑠 . Voir figure en bas pour exemples.
Machine minimale :
On dira qu’une machine de Mealy est réduite ou minimale s’elle ne contient pas des
états équivalents. :
Figure 21 : Deux machines de Mealy équivalentes
Figure 22 : Deux machines de Mealy qui ne sont pas équivalentes

21
Figure 23 : Machine de Mealy qui n'est pas minimale
Définition de la k-équivalence :
Soit « u » et « v » deux états d’une machine de Mealy M. On dira que « u » et « v » sont k-équivalents quand ils ont la même sortie pour n’importe quelle séquence de longueur k.

22
Chapitre 3 :
La méthode des séquences caractéristiques
Principe : La méthode de Chow, la méthode W ou la méthode des séquences caractéristiques [Cho78], est une méthode qui consisté à distinguer deux états d’une machine de Mealy avec une séquence
caractéristique. Le problème, devient alors, un problème ensembliste où il faudrait trouver des séquences caractéristiques de la machine M. Chaque couple d’états de la machine de Mealy M aura ainsi une séquence caractéristique dans l’ensemble qu’on aura trouvé.
De façon formelle : ∀ 𝑠𝑖 , 𝑠𝑗 ∈ 𝑆 ,∃𝐶𝑖𝑗 ∈ 𝐼
∗,𝜆(𝑠𝑖 , 𝑐𝑖𝑗) ≠ 𝜆(𝑠𝑗, 𝑐𝑖𝑗)
NB : La seule condition d’existence de l’ensemble minimale est que la machine de Mealy soit
minimale.
Les différentes phases de réalisation de la méthode : Phase 1 : Estimer le nombre maximum d’états m dans l’implémentation correcte de la machine M
Phase 2 : Construire l’ensemble de caractérisation W de la machine M Phase 3 : Construire l’arbre de test de la machine M
Phase 4 : Générer à partir de l’arbre de test, l’ensemble P : L’ensemble de couverture des transitions. Phase 5 : Construire l’ensemble Z à partir de la donnée de W et de m
Phase 6 : Faire le test T=P.Z (Où le point ici dénote la concaténation).
Réalisation des différentes phases : Phase 1 : Estimation nombre maximum d’état
L’estimation de m est basée sur la connaissance de l’implémentation. En cas d’abence de cette
donnée, on prendra m = Card(S). Phase 2 : Construction de l’ensemble W
Définition de l’ensemble W :
Soit M(𝑆,𝐼, 𝑂, 𝛿, 𝜆) une machine de Mealy minimale et complète. Considérons qu’elle a un état initiale qu’on va noter par q1. L’ensemble de caractérisation W, est un ensemble fini de séquences d’entrée, qui fait distinguer le comportement de toute paire d’états de la machine M (i.e, leurs sorties
via cette séquence). Chaque séquence dans l’ensemble W est de longueur finie.
Formellement, soit 𝑠𝑖 , 𝑠𝑗 ∈ 𝑆 . 𝐴𝑙𝑜𝑟𝑠, ∃𝑠 ∈ 𝑊 𝜆(𝑠𝑖 , 𝑠) ≠ 𝜆(𝑠𝑗, 𝑠) .
Dans la figure 23, on a : 𝑊 = {𝑏𝑎𝑎𝑎,𝑎𝑎, 𝑎𝑎𝑎}. On 𝜆(𝑞1,𝑏𝑎𝑎𝑎) = 1101 𝑒𝑡 𝜆(𝑞2,𝑏𝑎𝑎𝑎) =1100. Donc, la séquence baaa distingue l’état q1 de l’état q2 (puisque 𝜆(𝑞2,𝑏𝑎𝑎𝑎) ≠ 𝜆(𝑞1,𝑏𝑎𝑎𝑎) .

23
Figure 24 : Exemple pour trouver l'ensemble W
Etapes de construction de l’ensemble W :
Etape 1 : Construire des séquences de k-équivalences partitions de l’ensemble Q, qu’on note P1, P2..Pm, avec m>0. Etape 2 : Traverser les partitions de k-équivalence dans l’inverse afin d’avoir les séquences de
distinction pour chaque paire d’état.
Exemple de réalisation des étapes 1 et 2 :
Réalisation de l’étape 1 de la construction de W
Définition : k-équivalence partition d’un ensemble S. Une k-équivalence partition de l’ensemble des états S est un ensemble fini d’ensemble S1, S2..SN, tel que : ⋃ 𝑆𝑖 = 𝑆
𝑛𝑖=1 .
Les états dans un sous ensemble Si, sont dit des états k-équivalents. Si un état u est dans Si, et u dans Sj pour i ≠j, alors « u » et « v » sont k-distinguables. Comment construire une k-équivalence partition ? Etape 1 : On commence par construire une 1-équivalence partition. Et pour ce faire, on commence par représenter d’une manière tabulaire notre machine M. On prend par exemple :

24
Figure 25 : Machine M sous forme tabulaire
Toujours dans l’étape 1, on regroupe les états qui ont les mêmes sorties. Ceci nous donne alors la 1-partition P1 qui consiste dans les ensemble S1={q1,q2,q3} et S2={q4,q5}. Le processus pour faire ceci est décrit dans la figure suivante :
Figure 26 : La table P1
Etape 2 : On réécrit la table P1, et on supprime la colonne des sorties. On remplace chaque état qi
dans la colonne des états suivants, par qij, où j, est l’ensemble dans lequel se trouve l’état qi.
Ceci nous donne alors l’ensemble suivant :
Figure 27 : La table P1, étape intermédiaire

25
Etape 3 : Construction de la 2-équivalence partition. Construction de la table P2. On regroupe toutes lignes qui ont le même deuxième indice pour « b ». Ceci alors nous donne le tableau suivant. Notez bien le changement des indices.
Figure 28: La table P2
Etape 4 : On répète le processus, et on construit la 3ème partition d’équivalence. On le fait toujours
dans avec la colonne « b ». Une fois qu’on aura terminé avec « b », on passe à la colonne « a ». Ceci nous donne le tableau suivant. Notez encore une fois le changement des indices .
Figure 29 : La table P3
Etape 5 : On réitère le processus, jusqu’à avoir un sous -ensemble pour chaque état. Ceci nous donne alors la 5-partition d’équivalence qu’on peut décrire par la table P4 suivante :
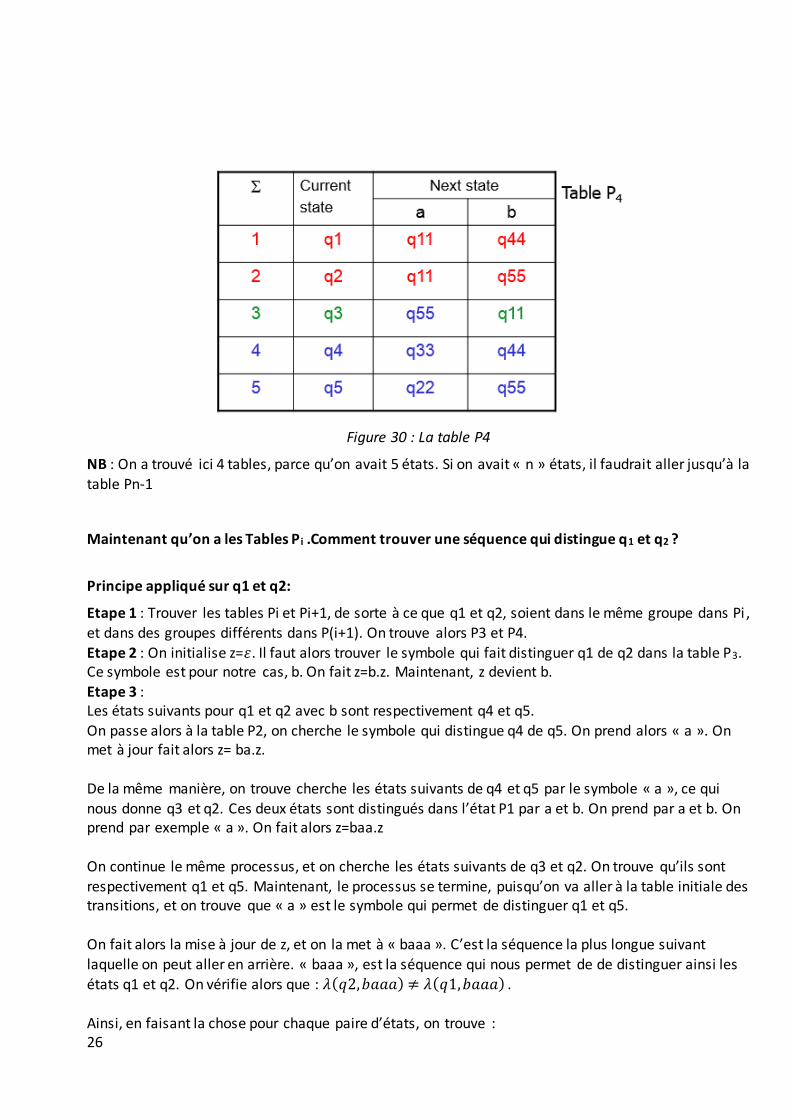
26
Figure 30 : La table P4
NB : On a trouvé ici 4 tables, parce qu’on avait 5 états. Si on avait « n » états, il faudrait aller jusqu’à la
table Pn-1
Maintenant qu’on a les Tables P i .Comment trouver une séquence qui distingue q1 et q2 ?
Principe appliqué sur q1 et q2:
Etape 1 : Trouver les tables Pi et Pi+1, de sorte à ce que q1 et q2, soient dans le même groupe dans Pi , et dans des groupes différents dans P(i+1). On trouve alors P3 et P4.
Etape 2 : On initialise z=휀. Il faut alors trouver le symbole qui fait distinguer q1 de q2 dans la table P3. Ce symbole est pour notre cas, b. On fait z=b.z. Maintenant, z devient b.
Etape 3 : Les états suivants pour q1 et q2 avec b sont respectivement q4 et q5.
On passe alors à la table P2, on cherche le symbole qui distingue q4 de q5. On prend alors « a ». On met à jour fait alors z= ba.z.
De la même manière, on trouve cherche les états suivants de q4 et q5 par le symbole « a », ce qui
nous donne q3 et q2. Ces deux états sont distingués dans l’état P1 par a et b. On prend par a et b. On prend par exemple « a ». On fait alors z=baa.z
On continue le même processus, et on cherche les états suivants de q3 et q2. On trouve qu’ils sont
respectivement q1 et q5. Maintenant, le processus se termine, puisqu’on va aller à la table initiale des transitions, et on trouve que « a » est le symbole qui permet de distinguer q1 et q5. On fait alors la mise à jour de z, et on la met à « baaa ». C’est la séquence la plus longue suivant laquelle on peut aller en arrière. « baaa », est la séquence qui nous permet de de distinguer ainsi les
états q1 et q2. On vérifie alors que : 𝜆(𝑞2,𝑏𝑎𝑎𝑎) ≠ 𝜆(𝑞1,𝑏𝑎𝑎𝑎) .
Ainsi, en faisant la chose pour chaque paire d’états, on trouve :

27
𝑊 = {𝑎, 𝑎𝑎, 𝑎𝑎𝑎, 𝑏𝑎𝑎𝑎 }
Phase 3 : Construction de l’arbre de test de la machine M.
Définition : Un arbre de test d’une machine M, est un arbre qui a comme racine l’état initial. Il contient au moins un chemin de l’état initial au restant des chemins de la machine M. La procédure pour construire l’arbre de test est faite de manière récursive et est décrite ci-dessous : On part de l’état q0, l’état initial et on le met comme racine de notre arbre de test. Supposons alors que l’arbre de test a été construit jusqu’au niveau k. Le (k+1)ème niveau est construit de la manière suivante : On sélectionne un nœud dans le niveau k. Si n apparaît dans un des niveaux de 1 à k, alors ce nœud est un nœud terminal de la branche en question. Quand ce n’est pas le cas, alors on ajoute des branches m de plus au nœud n, avec 𝑚 = 𝛿(𝑛, 𝑖),𝑒𝑡 𝑖 ∈ 𝐼. On fait ceci pour toutes les branches de niveau k, jusqu’à ce que le processus converge.
Exemple de construction :
Figure 31 : Arbre de test de la machine M

28
Phase 4 : Trouver l’ensemble de couverture de transition, depuis l’arbre de test.
Définition : Un ensemble de couverture de transition P, est un ensemble de tous les mots qui représentent tous les sous-chemins, et ce en commençant de la racine de l’arbre de test. Le mot 휀 appartient aussi à P. Pour l’exemple de l’arbre de test qu’on a construit on a :
𝑃 = {휀, 𝑎, 𝑏,𝑏𝑏, 𝑏𝑎, 𝑏𝑎𝑏,𝑏𝑎𝑎, 𝑏𝑎𝑎𝑏, 𝑏𝑎𝑎𝑎,𝑏𝑎𝑎𝑎𝑏, 𝑏𝑎𝑎𝑎 }
Phase 5 : Construction de l’ensemble Z
Supposons que I est l’alphabet d’entrée, et W est notre ensemble de caractérisation, alors on a :
Z = X0.W X1.W ….. Xm-1-n.W Xm-n.W Pour m=n, nous avons :
Z=W Dans notre cas, pour X={a,b}, W={a,aa,aaa,baaa} et m=6, nous avons :
Z = W X1.W ={a, aa, aaa, baaa} {a, b}.{a, aa, aaa, baaa} ={a, aa, aaa, baaa, aa, aaa, aaaa, baaaa, ba,
baa, baaa, bbaaa}.
Phase 6 : Faire le test avec l’ensemble T = P.Z
Faire le test avec l’ensemble T = P.Z, et ce en suivant les sous-étapes suivantes :
Chercher la réponse attendue par chaque élément de T dans la spécification (Sortie et état
final)
Générer ainsi les cas de test pour l’application.
Exécuter l’application avec les séquences de l’ensemble T. Revenir à chaque fois à l’état initial
après chaque test.
Exemple :
On a la spécification suivante :

29
Figure 32: Spécification test pour méthode W
Avec la méthode W, on trouve t1=baaaaaa et t2=baaba des séquences caractéristiques de test. On ainsi
M(t2)= 11011 et M(t1) = 1101001
Avec des modèles qu’on aura fait, on aura testé avec :
Figure 33 : Figure test avec W
Erreur de transfert : état q2 Erreur de transfert : état q2 Et erreur d’opération dans l’état q5
M1(t1)=1101001
Erreur
M2(t2)=11001
Erreur

30
Chapitre 4 : La méthode du tour de transition La méthode du tour de transition [NT81] consiste à faire un parcours de l’intégralité du graphe et générer une suite de tests optimale. Ainsi, le problème du tour de transition devient très simplement
le problème qui est très connu dans la théorie des graphes : Le problème du Postier Chinois [EJ73], [Kwa62].
Le problème du Postier Chinois : En théorie des graphes, le problème du postier chinois consiste à faire le parcours d’un graphe connexe en passant au moins une fois par chaque arc, avec pour condition : Faire le chemin le plus court et revenir au point de départ. Il a été nommé suite au mathématicien chinois Meigu Guan, qui a proposé un algorithme pour minimiser la tournée d’un facteur et ce en passant une fois par chaque région (Formalisé dans notre graphe : Un arc). NB : L’algorithme de résolution du postier chinois ne s’applique que sur des graphes fortement connexes. Dans d’autres cas, des algorithmes comme l’algorithme de Djikstra ou encore du voyageur
de commerce sont plus adaptés.
Les grands titres de l’algorithme de la méthode de tour de transition : Le but de l’algorithme est la résolution du problème du postier chinois. Et pour se faire, l’algorithme essayera de trouver un circuit eulérien, et ce à partir d’un graphe noté « Etiquette, u, v, coût » où Etiquette représente le nom des entrées et sorties de l’arc allant de l’état u à l’état v. Le coût quant à
lui, représente le temps qu’il faut pour implémentation de passer de l’état u à l’état v. Par défaut, on prend la valeur du cout égale à 1. Ainsi pour vérifier tout ceci, nous aurons besoin de faire quelques
définitions au préalable :
Définition : Soit 𝑀(𝑆, 𝐼, 𝑂, 𝛿,𝜆) une machine de Mealy. Soit ∈ 𝑆 . La fonction « différence », notée, est définie par : 𝛿(𝑣) = 𝑑+(𝑣) − 𝑑−(𝑣) .
On dira qu’un sommet v de la machine M est équilibré si et seulement si (𝑣) = 0 , c’est-à-dire, le
nombre d’arcs entrants au sommet est le même que le nombre d’arcs sortants.
Théorème :
Un graphe orienté 𝐺(𝐸, 𝑉) est eulérien si et seulement s’il est fortement connexe et tous ses sommets sont équilibrés.
Reformulation du problème : Puisque le but de l’algorithme est de trouve une séquence optimale, et ce en trouvant un circuit
eulérien, alors le coût total du graphe exploré doit être le plus petit possible. On note 𝐹𝑢𝑣 le nombre de fois qu’on doit ajouter un arc entre u et v.
Par définition, le scalaire 𝐹𝑢𝑣 peut être réécrit sous la forme suivante matricielle suivante :
𝐹𝑢𝑣 = 𝐹[𝑢][𝑣]

31
On note aussi 𝐶𝑢𝑣 (𝐶𝑢𝑣 = 𝐶[𝑢][𝑣]) le coût minimal entre le sommet u et v. Ainsi le but de notre algorithme devient le suivant :
Minimiser la fonction 𝜃 = ∑ 𝐶𝑢𝑣 ×𝐹𝑢𝑣𝑢,𝑣 Si le graphe en question est eulérien, alors c’est fini. Alors 𝜃 = 0, Il faut juste trouver une manière de
faire pour trouver un circuit eulérien dans le graphe et déduire à travers ce parcours la suite de test. Si le graphe n’est pas eulérien, 𝜃 ≠ 0 , donc il y’a des sommets déséquilibrés, alors comme le dit
l’algorithme, le circuit optimal est un circuit eulérien d’un graphe eulérien, et donc, nous devons de ce fait rendre notre graphe eulérien, en ajoutant et en supprimant des arcs. On définit alors deux sous-
ensembles de S qui vont nous aider à faire cela : 𝐷+ = { 𝑣 ∈ 𝑆 𝛿(𝑣) > ⁄ 0 } 𝑒𝑡 𝐷− = { 𝑣 ∈ 𝑆 𝛿(𝑣) < ⁄ 0 } Où les ensembles 𝐷+ et 𝐷− représentent respectivement l’ensemble des sommets en excès d’arcs
sortants (Et d’arcs entrants pour 𝐷−).
Selon le théorème 1, un graphe est eulérien s’il est fortement connexe et si tous ses sommets sont équilibrés. Or, par définition, les sommets appartenant à 𝐷+(respectivement 𝐷−) ne sont pas
équilibrés. Ainsi, chaque sommet 𝑣 ∈ 𝐷+ (respectivement 𝑣 ∈ 𝐷−) a besoin d’arcs entrants (respectivement d’arcs sortants). Ainsi, par définition des ensembles 𝐷+ et 𝐷−, le nombre d’arcs entrants à ajouter à 𝑣 ∈ 𝐷+ (Ou sortant à ajouter à 𝑣 ∈ 𝐷−) est égal à : |𝛿(𝑣)| . Il faudrait exactement n chemins pour équilibrer tous les sommets 𝑣 ∈ 𝐷+ , tel que 𝑛 = ∑ 𝛿(𝑣)𝑣∈ 𝐷+ . De façon analogue, pour tous les chemins 𝑣 ∈ 𝐷− alors, le nombre de chemin n à ajouter est : 𝑛 = −∑ 𝛿(𝑣)𝑣∈ 𝐷− . Mais si on fait, dans notre problème, sortir les arcs des sommets 𝑣 ∈ 𝐷− vers les sommets 𝑢 ∈ 𝐷+, quitte à dupliquer quelque uns, alors ceci nous donne un résultat important, qui est le suivant : Le nombre total d’arcs à ajouter dans notre graphe est n = ∑ 𝛿(𝑣)𝑣∈ 𝐷+ = −∑ 𝛿(𝑣)𝑣∈ 𝐷− . Le problème devient ainsi un simple problème de programmation linéaire, qu’on peut décrire sous la forme suivante : Déterminer à partir du graphe 𝐷+, 𝐷− 𝑒𝑡 𝑐𝑜û𝑡𝑠. Trouver f qui minimise : 𝜃 = ∑ 𝐶𝑢𝑣 ×𝐹𝑢𝑣𝑢,𝑣
{
𝐹𝑢𝑣 ∈ ℕ
∑ 𝐹𝑢𝑣 = −𝛿(𝑢)
𝑣∈ 𝐷+
∑ 𝐹𝑢𝑣 = 𝛿(𝑢)
𝑢∈ 𝐷−
Ainsi présenté, le problème devient le problème de transport [Kle67].
Les différentes phases de réalisation de la méthode du tour de transition [JKG13] :
Phase 1 : Vérifier que le graphe est fortement connexe.
Phase 2 : Identifier les sommets déséquilibrés. Si tous les sommets sont équilibrés, on trouve un circuit eulérien grâce à l’algorithme décrit dans la page.Et l’algorithme s’arrête ici.

32
Phase 3 : Parmi tous les chemins possibles, on détermine les chemins les moins couteux entre chaque sommet déséquilibré. Ceci se fait principalement par la recherche de la solution du problème de transport qu’on va expliciter dans les pages à venir Phase 4 : Construire graphe eulérien avec les solutions trouvées dans la phase 3. Phase 5 : Déterminer un circuit eulérien du graphe. Phase 6 : Trouver la séquence du circuit eulérien. Réalisation des différentes phases de la méthode du tour de transition sur un exemple :
Figure 34 : Graphe d'exemple pour la méthode de tour de transition
Etape 1 : Vérification de la connexité.
Tout état est accessible à partir de n’importe quel autre état. Par conséquent, le graphe est fortement
connexe.
Etape 2 : Identification des sommets déséquilibrés.
Pour l’identification des sommets déséquilibrés, on calcule l’image de la fonction « différence » 𝛿. 𝛿(0) = 𝑑+(0)− 𝑑−(0) = 2 − 2 = 0 ⟹ Sommet équilibré.
𝛿(1) = 𝑑+(1)− 𝑑−(1) = 2 − 3 = −1 ⟹ Sommet déséquilibré. 1 ∈ 𝐷− 𝛿(2) = 𝑑+(2)− 𝑑−(2) = 3 − 2 = +1 ⟹ Sommet déséquilibré. 2 ∈ 𝐷+

33
𝛿(3) = 𝑑+(3)− 𝑑−(3) = 1 − 2 = −1 ⟹ Sommet déséquilibré. 3 ∈ 𝐷− 𝛿(4) = 𝑑+(4)− 𝑑−(4) = 2 − 1 = +1 ⟹ Sommet déséquilibré. 4 ∈ 𝐷+ Le fait qu’il y’ait des sommets déséquilibrés veut dire que le graphe en question n’est pas eulérien. On passera ainsi forcément par l’étape 3.
Ainsi, 𝐷+ = {2,4} et 𝐷− = {1,3}
Etape 3 : Recherche de la solution optimale
Comme évoqué précédemment, on minimise la fonction 𝜃 relative à notre configuration. On a 𝐶12 = 2 , 𝐶14 = 1 , 𝐶32 = 1 et 𝐶34 = 3
Ce qui nous fait : 𝜃 = 2𝑓12 +𝑓14 +𝑓32 +3𝑓34 On minimise la fonction 𝜃 sous les contraintes :
{
𝑓𝑖𝑗 𝑒𝑛𝑡𝑖𝑒𝑟
𝑓12 + 𝑓14 = 1𝑓32 + 𝑓34 = 1
𝑓12 + 𝑓32 = 1
𝑓14 + 𝑓34 = 1
Ce problème est un problème de transport. L’objectif est de déterminer la quantité à envoyer de la source {1,3} à la destination {2,4} tout en minimisant la fonction coût 𝜃. Les contraintes du problème
sont présentées dans le tableau ci-dessous.
Figure 35 : Contraintes exemple problème de transport
L’algorithme du problème de transport se constitue de deux étapes :
Détermination d’une solution initiale.
Détermination de la solution optimale (Pour laquelle la fonction coût 𝜃 est minimale)
Etape 1 de l’algorithme de transport : Recherche de la solution initiale

34
Pour la recherche de la solution initiale, on utilisera une méthode qui s’appelle la méthode du coin Nord-Ouest, qui consisté à faire les étapes suivantes :
Aller au coin-supérieur gauche du tableau représentatif
Allouer le maximum de « coût » possible à la cellule courante et ajuster l’offre à la demande.
Se déplacer vers la droite (Demande nulle) ou le bas (Offre nulle).
Répéter jusqu’à ce que toute l’offre soit allouée.
Cette étape appliquée à notre cas donne :
Figure 36 : Application méthode Nord-Ouest
Ce tableau nous donne ainsi : 𝑓12 = 1 et 𝑓14 = 0 et 𝑓32 = 0 et 𝑓34 = 1
Ce qui donne le coût 𝜃(𝑆𝑜𝑙𝑢𝑡𝑖𝑜𝑛𝐼𝑛𝑖𝑡𝑖𝑎𝑙𝑒) = 2𝑓12 + 𝑓14 + 𝑓32 + 3𝑓34 = 5
Etape 2 de l’algorithme de transport : Recherche de la solution optimale
La méthode utilisée pour la recherche d’une solution optimale est appelée MODI (Modified
Distribution). Cette méthode permet de calculer les indices d’amélioration pour chaque case vide du tableau. Une fois un indice négatif (ou nul) repéré, on trace un seul chemin partant et revenant à la
case de l’indice. Ce chemin nous permet alors de trouver la solution la solution optimale. Et pour ce faire, il faut d’abord calculer les valeurs associées à chaque ligne et à chaque colonne. On adoptera le formalisme suivant : 𝑢𝑖 = valeur affectée à la ligne i 𝑣𝑗 = valeur affectée à la colonne j
𝑐𝑖𝑗 =coût du transport de la source i à la destination j
Il faut suivre après les étapes suivantes :
1. Ecrire toutes les équations possibles sous la forme : 𝑢𝑖 + 𝑣𝑗 = 𝑐𝑖𝑗 . Et cela n’est possible que
pour les cases occupées.
2. On fixe la valeur de 𝑢1à 0.
3. On résout le système d’équation obtenu.

35
4. On calcule l’index d’amélioration entre la source i et la destination j, défini par : 𝐼𝑖𝑗 = 𝑐𝑖𝑗 −
( 𝑢𝑖 + 𝑣𝑗 )
5. On sélectionne le plus grand index d’amélioration négatif ou nul, et on trouve ainsi la nouvelle solution. S’il n’y a aucun index négatif, alors la solution initiale est la solution optimale.
Appliquons cette méthode sur la solution initiale trouvée précédemment : On écrit le système d’équation :
{
𝑢1 = 0 𝑢1 + 𝑣1 = 2 𝑢2 + 𝑣1 = 1𝑢2 + 𝑣2 = 4
Ce qui nous donne :
𝑢1 = 0 , 𝑣1 = 2 , 𝑢2 = −1 et 𝑣2 = 4 On obtient ainsi le tableau suivant :
Figure 37 : Application de la méthode MODI
La seule case inutilisée est la case de la 1ère ligne et la deuxième colonne. On va donc calculer l’indice
d’amélioration de cette case : 𝐼12 = 1 –(4+0) = -3 <0 . Ce qui veut dire que la solution initiale n’est pas la solution optimale, et qu’il faudrait donc chercher encore pour la solution optimale. Pour faire ceci, il faudrait alterner l’ajout et le retrait d’une quantité qu’on appellera 𝜂 , de façon à ne pas avoir une quantité négative. Le tableau suivant résume ce procédé :

36
Figure 38: Itération suivante méhtode MODI
D’après ce tableau, la plus grande valeur que peut prendre 𝜂 sans avoir une valeur négative est de 1.
Ce qui nous donne alors le tableau suivant :
Figure 39 : Solution trouvée méthode Nord-Ouest
Cette nouvelle solution nous a donné : 𝑓12 = 0 , 𝑓14 = 1 , 𝑓32 = 1 et 𝑓34 = 0, qui nous donne comme cout 𝜃 = 2. Et c’est le cout minimal, puisque de toutes façons dans ce cas, on avait que deux
solutions.
Le nouveau graphe eulérien : On avait vu grâce à la méthode du problème de transport qu’il fallait ajouter à un arc du sommet « 1 »
au sommet « 4 », et un autre arc du sommet « 3 » au sommet « 2 ». Ceci nous donne ainsi le graphe eulérien suivant :

37
Figure 40 : Graphe eulérien après application de la méthode de transport
Détermination du circuit eulérien : Pour la détermination du circuit eulérien, on utilise la méthode des arbres de couvertures. Elle est
composée de deux étapes :
1. Extraction d’un arbre de couverture : Il est obtenu par un parcours en profondeur du graphe.
2. Etablissement de liste d’arcs prédécesseurs et de sommets prédécesseurs. Les arcs
appartenant à l’arbre de couverture et les nœuds correspondants sont placés en fin de chaque
liste. A partir du nœud courant du graphe, le premier arc qui n’a pas encore été choisi dans la
liste des arcs prédécesseurs, est choisi et est ajouté à l’ensemble des arcs sélectionnés (arcs
constituant le circuit eulérien) et l’origine de cet arc devient le nœud courant. On arrête
lorsque tous les arcs du graphe ont été sélectionnés et on obtient alors un circuit eulérien du graphe.
Ce procédé ainsi appliqué nous donne les résultats suivants :

38
Figure 41 : Arbre de couverture du graphe eulérien de la figure 39
Figure 42 : Tableau sommets et arcs prédécesseurs
Le graphe eulérien qu’on obtient est ainsi décrit par la séquence : a/1, b/4, c/1, b/4, e/3, f/2, g/3, f/2,
h/0, i/2, j/1, d/0.
Ceci nous donne donc les séquences de tests suivants :

39
Figure 43 : Séquence de test
Ainsi pour le verdict de la figure « 2 », il faut juste savoir que toutes les implémentations produisant
ainsi des sorties différentes que celles représentées sur le tableau seront non conformes à la spécification.

40
Conclusion :
Dans cette revue bibliographique, nous avons abordé la problématique de vérification de modèles. Nous avons commencé par exposé des généralités pour attaquer des algorithmes de vérification vers la fin.
Comme on a vu, tester une spécification par rapport à sa spécification est une chose essentielle. Cela permettrait de créer ou générer même des simulateurs de spécifications dont on est sûrs du comportement. La recherche dans ce domaine est déjà à son plein essor, et beaucoup de méthodes de test existent. Il s’agirait maintenant plus de prendre le pour et le contre de chaque méthode pour un cas donné. Pour l’exemple d’une spécification dont laquelle on ne veut vérifier que les sorties, la très simple méthode de tour de transition serait adéquate. Dans le cas où l’on voudrait même vérifier la bonne présence des états, on doit alors utiliser des méthodes un peu plus développés comme la méthode de Chow.
La complexité algorithmique de ce genre méthodes est à prendre en considération aussi. Elle varie d’algorithmes en 𝑂(𝑛3) (Comme la méthode de Tour de Transition) à des algorithmes dont la complexité est pseudo-polynomiale (Méthode de Chow), jusqu’à exponentielle. N’oublions pas la grandeur de la séquence de tests générés, qui diffère d’une méthode à l’autre, qui est aussi un facteur à prendre en considération.
Il ne faut pas oublier aussi dans ces choix la règle d’or des sciences : Partir de l’existant pour pouvoir construire le futur. D’ailleurs, c’est l’objet même des recherches bibliographiques . Et il ne faut pas oublier que ces méthodes sont faites pour être implémentées sur machine. Il faudrait ainsi voir la possible existence au préalable d’APIs dans des langages spécifiques permettant d’implémenter la méthode, ce qui constituerait un gain de temps et d’effort important.
Ce rapport, bien que simple, se veut être complet pour toute personne voulant s’initier à la théorie des graphes, et à la vérification de modèles. Nous pensons qu’il sera un bon point d’entrée pour tout lecteur voulant s’initier à la méthode de Chow ou encore la méthode de Tour de Transition, pour pouvoir les étudier, en vue peut-être de les optimiser (En prenant en compte par exemple des contraintes probabilistes). Cette exposition de ces méthodes s’est accompagnée par des exemples, remarques et observations tout au long des parties parcourues.

41
Bibliographie :
[YL95] : M. Yannakakis and D. Lee. Testing finite state machines : fault detection. Journal of Computer and System Sciences, 50(2) :209–227, 1995.
[Cho78] : T.S. Chow. Testing software design modeled by finite-state machines. Software Engineering, IEEE Transactions on, (3) :178–187, 1978.
[Con08] : C. Constant. Génération automatique de tests pour des modèles avec variables ou récursivité. PhD thesis, Université Rennes 1, 2008.
[FKA+91] : S. Fujiwara, F. Khendek, M. Amalou, A. Ghedamsi, et al. Test selection based on finite state models. Software Engineering, IEEE Transactions on, 17(6) :591–603, 1991.
[Ura92] : H. Ural. Formal methods for test sequence generation. Computer communications, 15(5) :311–325, 1992.
[NT81] : Sachio Naito and Masahiro Tsunoyama. Fault detection for sequential machines by transition tours. In Proc. FTCS, volume 81, pages 238–243, 1981.
[EJ73] : J. Edmonds and E.L. Johnson. Matching, euler tours and the chinese postman. Mathematical programming, 5(1) : pages 88–124, 1973.
[BAL95] : Bala, V. Efficient instruction scheduling using finite state automata, pages 46 – 56, 1995.
[MUL93] Müller, T. Employing finite automata for resource scheduling, 15(6) pages 12-20, 1993
[KBBST12] Rola Kassem, Mikäel Briday, Jean-Luc Béchennec, Guillaume Savaton, Yvon Trinquet.
Harmless, a Hardware Architecture Description Language Dedicated to Real-Time Embedded System Simulation. Journal of Systems Architecture, Elsevier, 2012, 58 (8), pp.318-337.
[JKG13] Tigori Kabland Toussaint Gautier : Validation d’un modèle matériel : Rapport de stage de
master. IRCCyN. Nantes. Ecole Centrale de Nantes ; 2013, 55 p.