réalisation d'un logiciel d'étude de la propagation dans...
TRANSCRIPT

Université Libre de Bruxelles Faculté des Sciences Appliquées Ecole Polytechnique
Année académique 2003-2004
Réalisation d'un logiciel d'étude de la propagation dans les réseaux de
télécommunication indoor
Promoteur : Prof. Esteban Zimányi
MÉMOIRE DE FIN D’ÉTUDES PRÉSENTÉ PAR Polet Guillaume EN VUE DE L’OBTENTION DU GRADE D’INGÉNIEUR CIVIL INFORMATICIEN

2
« Entre les savants proprement dits et les directeurs effectifs de travaux
productifs, il commence à se former une classe intermédiaire, celles des ingénieurs, dont la destination spéciale est d’organiser les relations de la théorie et de la pratique. Sans avoir aucunement en vue les progrès des connaissances scientifiques, elle les considère dans leur état présent pour en déduire les applications industrielles dont elles sont suceptibles. »
Auguste Comte (1798-1857)Cours de philosophie positive, deuxième leçon

3
Table des matières Table des matières................................................................................................................................3
Remerciements.................................................................................................................................5 Introduction..........................................................................................................................................6 Chapitre 1.............................................................................................................................................8 Techniques de simulation des réseaux indoor......................................................................................8
1.1. Phénomènes de propagation d’ondes...................................................................................8 1.1.1. Champ direct ................................................................................................................9 1.1.2. Champ transmis..........................................................................................................10 1.1.3. Champ réfléchi...........................................................................................................12 1.1.4. Champ diffracté..........................................................................................................13 1.1.5. Puissance reçue ..........................................................................................................16 1.1.6. Time Delay.................................................................................................................17
1.2. Moteur de calcul.................................................................................................................18 1.2.1. Variables Globales .....................................................................................................19 1.2.2. Structures ...................................................................................................................19 1.2.3. Fonctions à appeler ....................................................................................................20 1.2.4. Eléments Clés.............................................................................................................21
1.3. Interface .............................................................................................................................22 Chapitre 2...........................................................................................................................................23 Analyse Logicielle .............................................................................................................................23
2.1. Exigences (Requirements) .................................................................................................23 2.1.1. Editions de structures tridimensionnelles ..................................................................24 2.1.2. Réalisation des calculs ...............................................................................................24 2.1.3. Affichage des résultats ...............................................................................................25
2.2. Définition des Cas d’utilisation..........................................................................................25 2.2.1. Identification des cas d’utilisation .............................................................................26 2.2.2. Diagramme des cas d’utilisation ................................................................................27 2.2.3. Cas d’utilisation étendus ............................................................................................30

4
2.3. Architecture........................................................................................................................40 2.4. Diagrammes de classes ......................................................................................................40 2.5. Diagrammes de séquences .................................................................................................43 2.6. Possibilités d’extension......................................................................................................46
Chapitre 3...........................................................................................................................................47 Component-Based Software Engineering..........................................................................................47
3.1. Que sont les logiciels basés sur des composants ?.............................................................47 3.1.1. Historique...................................................................................................................48 3.1.2. Définitions..................................................................................................................48 3.1.3. Concepts de base........................................................................................................50 3.1.4. Construction des CBS ................................................................................................52
3.2. Choix d’une plateforme .....................................................................................................54 Chapitre 4...........................................................................................................................................55 Eclipse................................................................................................................................................55
4.1. Etude générale d’Eclipse....................................................................................................55 4.1.1. Approche globale .......................................................................................................55 4.1.2. Concepts de base........................................................................................................56 4.1.3. Architecture d’Eclipse................................................................................................60 4.1.4. Le Workbench............................................................................................................61 4.1.5. Architecture classique d’un plugin Eclipse................................................................64
4.2. Programmation sous Eclipse..............................................................................................65 4.2.1. Patterns les plus courants au travers d’Eclipse ..........................................................65 4.2.2. Règles.........................................................................................................................69
Chapitre 5...........................................................................................................................................72 Design, Implantation et Résultats ......................................................................................................72
5.1. Intégration du moteur de calcul .........................................................................................72 5.1.1. Java Native Interface..................................................................................................73
5.2. Intégration d’un module dans Eclipse – Application à notre module................................75 5.2.1. Extensions ..................................................................................................................75 5.2.2. TreeViewer.................................................................................................................76 5.2.3. Graphical Editing Framework....................................................................................79 5.2.4. Points d’extension ......................................................................................................83
5.3. Résultats .............................................................................................................................85 5.3.1. Moteur de calcul.........................................................................................................85 5.3.2. TreeViewer.................................................................................................................86 5.3.3. Editeur Graphique ......................................................................................................86
Conclusions........................................................................................................................................90 A. Annexes......................................................................................................................................92
A.1.1. Références manuscrites :............................................................................................96 A.1.2. Références Electroniques...........................................................................................97 A.1.3. Interface du moteur de calcul.....................................................................................98 A.1.4. Plugins Eclipse.........................................................................................................114

5
Remerciements Dans la réalisation de ce projet, je tiens à remercier personnellement les personnes qui m’ont aidées. Je remercie Mr. J-M. Dricot, l’assistant qui supervisé et soutenu tout le travail, Mr. E. Zimányi, mon promoteur, Mr. S. Skhiri dit Gabouje, pour ses nombreux et précieux conseils dans Eclipse, Mr. R. Lemaigre, pour ses précieux conseils dans GEF, Melle H. Mahy, pour ses relectures.

6
Introduction Ces dernières années, on a pu observé un véritable essor de l’informatique notamment grâce au support qu’elle fournit à toutes les sciences de l’ingénieur : que ce soit pour le stockage et traitement de données, la puissance de calcul ou bien simplement pour rendre un aspect plus convivial. L’interaction entre informatique et travaux scientifiques n’a jamais été aussi forte qu’aujourd’hui et on voit mal ce qui pourrait changer cette tendance. Dès lors, il m’est apparu très important de réaliser un projet dans lequel l’informatique venait concrétiser un travail reposant sur des théories scientifiques, ce qui est sans doute une des spécialisations dans laquelle l’ingénieur excelle et pour laquelle il est le mieux préparé. Le service Informatique et Réseaux travaille maintenant depuis plusieurs années en étroite collaboration avec le service d’Ondes et Signaux sur des travaux de propagation d’ondes à l’intérieur de bâtiments. Entre autre sur un moteur de calcul de ray-tracing permettant de simuler la propagation d’ondes émises dans le cadre de réseaux sans fil. Ecrit par Ph. De Doncker et retravaillé par J-M. Dricot, il peut être utilisé en collaboration avec un simulateur de réseau : le Network Simulator. Ces différentes parties étant réalisées, il faut maintenant s’atteler à faciliter leur utilisation au moyen notamment d’une interface utilisateur. L’introduction des données ainsi que la création des rendus graphiques pourraient, en effet, être accélérée de façon substantielle. Dans le cadre du travail de fin d’étude, nous nous proposons de réaliser le projet suivant : créer une interface utilisateur du moteur afin d’en simplifier au maximum son utilisation. Ceci inclut l’introduction de la structure d’un bâtiment, les propriétés des éléments constitutifs, le placement des antennes, l’exécution des calculs et les rendus graphiques des résultats obtenus. Nous nous attacherons dans un premier temps à couvrir cette partie du projet. Cependant, nous n’exclurons pas les possibilités d’améliorations et de fonctionnalités supplémentaires par la suite.

7
En effet, les applications à développer sur ce moteur sont nombreuses. Il permet bien sûr de vérifier préalablement à l’installation, la couverture d’un bâtiment, mais on peut également imaginer d’obtenir certaines pièces exemptes d’ondes ou avec un niveau de signal très faible. Nous verrons plus loin un ensemble plus élargi des possibilités d’extension de ce sujet. Séduit par ce projet, j’ai opté pour celui-ci pour plusieurs raisons. La diversité et la richesse de ce travail sont, en effet, impressionnantes et pratiquement illimitées. Les choix à faire sont nombreux et sont loin d’être restrictifs. Les réseaux sans fils ayant littéralement explosés cette année, l’étude de ceux-ci parait tout à fait appropriée. Enfin, l’interopérabilité entre différents systèmes et technologies m’est apparue comme étant aujourd’hui un élément clé en informatique ; il me semblait essentiel qu’il se retrouve au sein de mon travail de fin d’études. Pour parvenir à réaliser un projet correct d’un point de vue informatique, nous allons suivre une démarche similaire au développement d’un programme, mais en abordant plus en profondeur certains aspects théoriques auxquels nous serons confrontés. Nous débuterons par une approche du sujet en étudiant les équations qui régissent les phénomènes de propagation d’ondes et qui sont programmées au sein du moteur de calcul. Ensuite, nous étudierons le moteur de calcul afin d’en découvrir son utilisation et pouvoir créer une interface d’utilisation qui sera reprise lors de l’analyse de notre programme (Chapitre 1). Dans un second temps, nous réaliserons l’analyse complète du problème qui se présentera, dont entre autre les cas d’utilisation ; nous pourrons alors dessiner les premiers diagrammes de classes. L’analyse terminée, nous avons choisi d’approfondir des nouveaux concepts informatiques qui pourraient être adaptés à notre projet (Chapitre 2). L’informatique est en constante évolution, donc il n’est pas rare d’utiliser de nouveaux outils et ce pour deux raisons : ils sont en général plus riches et de meilleures factures et ils ouvrent de nouveaux horizons encore inexploités jusqu’aujourd’hui. Nous avons vu que nous disposions déjà de deux modules, le moteur de calcul ainsi que le simulateur de réseaux. Nous allons nous-mêmes en rajouter un autre, mais nous voudrions pouvoir encore en ajouter par la suite. A cet effet, nous proposons d’aborder les concepts et théories des logiciels basés sur des composants qui semblent aujourd’hui de plus en plus utilisés, et dont la spécificité correspond exactement à notre problème (Chapitre 3). L’approche globale du problème étant terminée, nous allons être confrontés au choix d’une plateforme permettant de mettre en pratique ce que nous aurons étudié jusque là. Le choix de plusieurs outils sera nécessaire, et nous devrons les étudier afin de les utiliser correctement et de bénéficier des avantages qu’ils offrent. Nous serons alors à même de pouvoir réaliser le design de notre programme, d’adapter notre analyse à la plateforme choisie (Chapitre 4). Pour terminer, une fois toutes ces étapes accomplies, on procèdera à l’implantation et tests du logiciel, ce qui implique de coder l’entièreté de l’application. Nous pourrons alors effectuer quelques calculs et opérer des rendus graphiques afin d’en vérifier l’opérationnalité (Chapitre 5).

8
Chapitre 1
Techniques de simulation des réseaux indoor Dans ce chapitre, nous étudierons comment nous pouvons simuler un réseau sans fil au sein d’un bâtiment. Pour ce faire, nous allons d’abord observer d’une part, les phénomènes de propagation d’ondes, nous permettant d’avoir une approche des phénomènes à prendre en ligne de compte, tandis que d’autre part, nous établirons, sur base d’un livre dédié à ce sujet [1], les équations qui permettent de modéliser ces ondes et la façon dont nous pourrons calculer la puissance du signal en un point d’observation. Toutefois, nous n’aborderons pas les aspects de modulation du signal. Nous verrons ensuite comment ceci se retrouve développé au sein du moteur de calcul et comment nous accèderons aux différentes méthodes. Nous effectuerons une analyse du moteur de calcul afin de pouvoir en déduire une interface permettant de réaliser les appels sur celui-ci.
1.1. Phénomènes de propagation d’ondes Nous allons ici étudier les phénomènes physiques que nous voulons par la suite rendre dans notre logiciel. Nous avons une source qui émet un signal à une fréquence donnée. Ce signal est omnidirectionnel afin de couvrir le plus grand espace possible. Si les obstacles vont fortement affaiblir la puissance du signal, ils vont également devenir des sources. En effet, lorsqu’une onde arrive sur une face plane – nous n’entrerons pas dans les calculs de surfaces rugueuses qui posent beaucoup plus de difficultés – celle-ci est partiellement réfléchie. De même, lorsqu’une onde arrive sur une arête, nous savons que l’onde est diffractée, ceci nous obligeant donc à considérer chaque face plane et chaque arête comme une nouvelle source potentielle.
1 Catedra, Manuel F., Cell Planning for Wireless Communications, éd. Artech House, Inc, 1999

9
Lorsque plusieurs ondes électromagnétiques de même fréquence se rencontrent en un même point, il résulte de celles-ci une onde dont l’amplitude peut être plus grande, on parle alors d’ondes constructives, ou bien au contraire dont l’amplitude peut être plus faible, voire nulle, on parle d’ondes destructives. Ce phénomène est simplement dû au fait que deux ondes de fréquences suffisamment proches s’additionnent. Si celles-ci sont en phase, alors il y aura construction et au contraire si celles-ci sont en opposition de phases il y aura destruction. Notre objectif est ici de pouvoir comprendre les principes de base sur la manière dont le moteur de calcul évalue la puissance d’un signal en un point donné, alors qu’une ou plusieurs sources émettent un signal à une fréquence donnée. Nous allons donc nous baser sur un livre qui nous fournira les équations développées pour les calculs : « Cell Planning for Wireless Communications »[1]. On commencera d’abord par évaluer le champ électrique reçu en un point par une antenne réceptrice, et nous montrerons ensuite comment nous pouvons en déduire la puissance reçue. Le calcul du champ électrique en un point sera la somme des champs qui passent en ce point :
∑=
=N
iiT EE
1 directrefractédiffractéréfléchi EEEE +++= ∑∑∑ 1.1
où le membre de gauche est le champ total tandis que les iE représentent les champs électriques résultant de chaque rayon dont le chemin relie le point source au point considéré. On considérera donc le rayon direct, les rayons transmis, les rayons réfléchis ainsi que ceux qui sont diffractés. Cette approche des phénomènes de propagation d’ondes est connue sous le nom de « Théorie géométrique de la diffraction » dans sa version de « la théorie uniforme de la diffraction » [1]. On s’aperçoit rapidement que pour des géométries complexes ce modèle ne peut être maintenu et nous devons le simplifier afin de garder des temps de calculs raisonnables. L’expérience montre que l’on peut se limiter aux rayons doublement réfléchis et aux rayons diffractés une fois, la contribution des autres rayons étant négligeable et n’apportent que peu de précision. Il faut svaoir que la méthode comporte elle-même une certaine imprécision d’environ 3 dBm. Voyons maintenant les quelques équations et techniques de calcul qui permettent d’évaluer les différents champs électriques précités.
1.1.1. Champ direct La contribution du champ direct en un point d’observation O est donnée par :
reEOE
rj
t
β
φθ−
= ),()( 1.2
où
),(2
),( 0 φθπ
ηφθ EGPE r
t = 1.3
avec η, l’impédance du milieu de propagation, Pr , la puissance de l’émetteur, G le gain de l’antenne émettrice et E0(θ,φ) est le patron normalisé de radiation de l’antenne émettrice.

10
1.1.2. Champ transmis Lorsqu’un rayon atteint une interface entre deux milieux différents, une partie de l’énergie est réfléchie tandis qu’une autre partie est transmise, réfractée. Nous allons voir dans la partie juste après (1.1.3) comment le rayon est réfléchi, mais nous allons d’abord nous attacher à déterminer comment le rayon est réfracté. La loi de diffraction de Snell nous donne la direction du rayon réfracté :
ri θβθβ sinsin0 = 1.4où iθ est l’angle d’incidence formé par le vecteur normal à l’interface au point de réfraction et le rayon incident, rθ est l’angle de réfraction formé par le vecteur normal à l’interface au point de réfraction et le rayon réfracté, 0β et β étant les nombres d’ondes, respectivement, dans le premier et second milieu (voir Figure 1.1).
Figure 1.1 : Schéma du phénomène de diffraction
En outre, la loi de Snell spécifie que le rayon incident, la normale à l’interface et le rayon réfracté se trouvent dans un même plan, le plan d’incidence. Prenons maintenant le cas d’un rayon incident sur un mur d’un bâtiment d’épaisseur finie. Comme nous venons de le voir, le rayon sera réfracté 2 fois : une première fois en arrivant sur le mur et une seconde fois en en ressortant (voir Figure 1.2). En entrant dans le mur, le rayon se rapprochera de la normale tandis qu’en sortant il s’en écartera. En supposant que les deux surfaces qui constituent le mur soient planes et parallèles entre elles, et si en plus, le mûr est isotropique et homogène, on peut alors considérer que le rayon n’est pratiquement pas dévié, et qu’il subit uniquement une atténuation. Si ce modèle n’est pas toujours réaliste, l’expérience a montré qu’il donnait d’excellents résultats et que l’erreur commise était acceptable.
β0 β
θi
θr
Milieu 2 Milieu 1

11
Figure 1.2 : Schéma du phénomène de transmission à travers un mur
Nous avons donc :
it ETE = 1.5où le terme de gauche est le champ électrique transmis, tandis que dans le membre de droite on retrouve le champ électrique au point d’incidence à la première interface et la matrice T est définie comme suit [1] :
⎟⎟⎠
⎞⎜⎜⎝
⎛=
h
s
TT
T0
0 1.6
et ( )[ ]
( )( ) ( )22
222
0
20
2
sincoscossinsin2exp
cossinexpcossin4
iriiirir
iiriirs
jd
jdT
θεθθθεθεβ
θθεβθθε
−−−+−−
+−−= 1.7
( )[ ]( )( ) ( )2
22
220
20
2
cossinsincossin2exp
cossinexpcossin4
iiriririr
iiriirrs
jd
jdT
θθεθεθεθεβ
θθεβθθεε
−−−−+−
+−−= 1.8
où d est l’épaisseur du mur, β0 est le nombre d’onde dans l’espace libre, εr est la permittivité relative du mur et β est le nombre d’onde du milieu dont le mur est constitué. Ces deux derniers paramètres sont donnés respectivement par :
0εωσε
εj
r
−= 1.9
et
rελπβ 2
= 1.10
ε et σ dépendent des matériaux du bâtiments, tandis que ω est donné par fπω 2= ; ces trois paramètres sont disponibles dans des tables. Nous notons déjà pour la suite, qu’il peut être intéressant de réaliser une petite bibliothèque de matériaux que l’on rencontre régulièrement dans un bâtiment.
d
β0 β0 β, εr
θi
θr
Mur

12
1.1.3. Champ réfléchi Nous avons établi que certains rayons réfléchis contribuaient à la puissance d’un signal en un point. Mais nous n’avons pas encore expliqué lesquels aboutissent en ce point, et comment les déterminer. Lorsqu’une onde est réfléchie sur une surface plane, nous savons que l’angle d’incidence est équivalent à celui de réflexion. Connaissant la position de la source, la position du récepteur et la position de la face plane, une simple construction géométrique nous permet de déterminer le point de réflexion. En effet, plaçons-nous dans le plan d’incidence, c’est-à-dire le plan passant par la source et le récepteur, et perpendiculaire à la face AB :
Figure 1.3 : Schéma du phénomène de réflexion
soit la face réfléchissante représentée par le segment AB, la source S, l’image S’ de la source S par symétrie orthogonale d’axe AB, le récepteur O, le point d’incidence P et les deux angles qui l’accompagnent θi et θr. Ces deux derniers étant égaux, O, P, S, S’ étant dans le même plan, le plan d’incidence perpendiculaire à AB, il est facile de montrer que O, P et S’ sont alignés. Nous avons le champ incident à la face AB qui est partiellement réfléchi dans la direction PO. Si nous pouvons déterminer le champ réfléchi en P, on pourra donc déduire facilement le champ en O. Commençons par poser des axes : soit un système d’axes cartésien situé en S (l’antenne source), on définit le système d’axes fixes (Xf,Yf,Zf) lié à la facette AB comme suit : Zf est parallèle à la normale du plan AB, Xf parallèle au plan AB et Yf perpendiculaire à ces deux axes. On obtient les axes fixes liés au point image S’ en effectuant une translation des axes (Xf,Yf,Zf) en S’ pour obtenir les axes (Xi,Yi,Zi). Enfin, on peut définir le système de coordonnées sphériques par ses trois vecteurs unitaires : ϕθ 1,1,1r . Le vecteur r1 est
parallèle au rayon d’incidence, tandis que, les vecteurs ϕθ 1,1 sont respectivement, parallèle et perpendiculaire au plan d’incidence, parallèles aux composantes verticales et perpendiculaires du champ, encore appelées composantes hard et soft du champ. Nous pouvons écrire le champ électrique au point O suite à une réflexion de celui-ci sur la facette AB, en considérant une source fictive au point S’. En effet, soient les deux coefficients de Fresnel :
P
S
O
S’
A B
θi θr

13
)²(sin)cos()²(sin)cos(
)(
)²(sin)cos()²(sin)cos(
)(
θεθ
θεθθ
θεθε
θεθεθ
−+
−−=Γ
−+
−−=Γ
r
rs
rr
rrh
1.11
1.12
où θ est l’angle d’incidence du rayon sur la facette AB et εr est la constante diélectrique relative donnée par 1.9. Ces équations étant posées, nous pouvons maintenant calculer le champ réfléchi au point O, en considérant une antenne équivalent au point image S’ avec comme valeur du champ dans le système de coordonnées lié au point image :
IIItIIIII r
rjErE )exp(),(),,( βϕθϕθ −= 1.13
IIIfIsIIIfIhIItI EEE ϕϕθθ ϕθπϕϕθπθϕθ 1),()(1),()(),( −Γ+−Γ= 1.14 et Eθf et Eφf sont les composantes du champ émis par l’antenne émettrice relatives aux axes fixes liés à la facette. Donc, on peut établir que le champ réfléchi est équivalent au champ direct d’une antenne dont le système de coordonnées associé est celui lié au point image, et dont le patron de radiation est donné par 1.13. Ceci revient à dire que pour un problème à double réflexion, la même démarche que celle du problème à simple réflexion, peut être appliquée, mais cette fois en commençant avec l’image de la source comme source. Notons encore que toute cette théorie est limitée par le critère de Raleigh qui détermine si une surface est lisse ou rugueuse, au point de vue du champ électrique. En effet, une surface est considérée comme lisse uniquement si la différence entre la hauteur maximale et minimale de la surface, h, satisfait :
)cos(8 θλ
<h 1.15
Il existe des équations empiriques qui permettent de corriger l’erreur introduite en considérant la surface comme lisse, cependant, nous ne les aborderons pas.
Dans notre cas, cette hypothèse est confirmée car les murs des bâtiments sont généralement lisses, d’un point de vue électromagnétique ; la longueur d’onde est de l’ordre de 15 centimètres.
1.1.4. Champ diffracté Les rayons diffractés proviennent de l’incidence d’un rayon sur une arête. Ce rayon est alors envoyé de façon diffuse dans un infinité de directions. Cette diffusion est essentielle car elle tente à venir lisser le signal spatialement. La puissance du signal étant directement liée avec les flux de données d’un réseau sans fil, ce lissage se retrouve également dans les débits que l’on peut obtenir. Nous allons maintenant voir comment calculer le champ résultant du phénomène de la diffraction en un point d’observation.

14
Commençons par l’expression analytique du champ diffracté :
sjie
ie
ie
ssDQEsE β
ρρ −
+=
)()()( 1.16
où )(QEi
est le champ incident au point de diffraction Q, D est la matrice des coefficients de diffraction, i
eρ est le rayon de courbure de l’onde incidente dans le plan d’incidence, et s est la distance entre le point d’observation et de diffraction. Pour pouvoir appliquer 1.16, le champ incident doit être exprimé dans le système de coordonnées fixes lié à l’arête et au plan d’incidence. Ce dernier est défini par l’arête et le rayon incident. Les vecteurs unitaires de ce système de coordonnées sont calculés comme suit : le vecteur s1 dans la direction du rayon incident, le vecteur ϕ1 perpendiculaire au plan
d’incidence et le vecteur 01β parallèle au plan d’incidence. On en retrouve l’illustration à la Figure 1.4.
Figure 1.4 : Schéma du phénomène de diffraction
Si on considère un vecteur e le long de l’arête, on peut obtenir les deux derniers vecteurs en calculant les expressions :
s
s
e
e
1
11
×
×−=ϕ 1.17
s111 0 ×= ϕβ 1.18
α

15
Les rayons diffractés se propagent dans toutes les directions d1 qui satisfont l’équation :
edes 1111 ⋅=⋅ 1.19L’infinité de rayons qui remplissent cette équation forme un cône appelé « cône de Keller » représenté à la Figure 1.5.
De même que nous avons défini un système de coordonnées pour le champ incident, nous devons définir un système de coordonnées pour le champ diffracté car c’est dans celui-là qu’est exprimé le membre de gauche de 1.16. Rappelons que le plan de diffraction n’est autre que le plan caractérisé par le vecteur e et le vecteur selon le rayon diffracté passant par le point d’observation, sd1 .
Nous avons donc : sd1 , dϕ1 perpendiculaire à ce dernier et au plan de diffraction, et d01β parallèle à ce plan et perpendiculaire aux deux autres vecteurs du système (voir Figure 1.5). Les composantes du champ selon ϕ1 et dϕ1 sont perpendiculaires à l’arête, et sont donc appelées composantes hard du champ. De même, on appelle composantes soft du champ, les composantes selon 01β et d01β . Lorsque l’on résout l’équation du champ dans ses composantes hard et soft, la matrice de diffraction prend la forme suivante :
⎟⎟⎠
⎞⎜⎜⎝
⎛−
−=
h
s
DD
D0
0 1.20
où Ds et Dh sont les coefficients de diffraction soft et hard donnés par : )(),,,,( 43,210, DDDDnLD hsdhs +Γ++=βϕϕ 1.21
où
Figure 1.5 : Illustration du Cône de Keller

16
[ ])(2
)(cot
sin22 00
4/
1 dd
j
LaFnkn
eD ϕϕβϕϕπ
βπ
π
−⎟⎠⎞
⎜⎝⎛ −+−
= +−
1.22
[ ])(2
)(cot
sin22 00
4/
2 dd
j
LaFnkn
eD ϕϕβϕϕπ
βπ
π
−⎟⎠⎞
⎜⎝⎛ −−−
= −−
1.23
[ ])(2
)(cot
sin22 00
4/
3 dd
j
LaFnkn
eD ϕϕβϕϕπ
βπ
π
+⎟⎠⎞
⎜⎝⎛ ++−
= +−
1.24
[ ])(2
)(cot
sin22 00
4/
4 dd
j
LaFnkn
eD ϕϕβϕϕπ
βπ
π
+⎟⎠⎞
⎜⎝⎛ +−−
= −−
1.25
où β0, β0d, φ et φd sont représentés sur la Figure 1.4, β est le nombre d’onde, n est un nombre
lié à l’angle intérieur α (π
απ −=
2n ), F est la fonction de transition de Fresnel, L le
paramètre de distance et a± sont des fonctions que nous n’expliciteront pas ici.
1.1.5. Puissance reçue Maintenant que nous avons passé en revue les différents champs qui arrivent en un point, il faut encore nous occuper du calcul de la puissance reçue aux bornes d’une antenne, en nous basant sur [2]. On retrouve à la Figure 1.6 un schéma de l’antenne.
Figure 1.6 : Courant et densité de courant d’une antenne de transmission
Les courants de volumes, de surface et linéaires sur les antennes sont donnés par :
aJVV IPDPJ )'()'( = 1.26
aJSS IPDPJ )'()'( = 1.27
aJLL IPDPJ )'()'( = 1.28
2 René Meys, A Summary of the Transmitting and Receiving Properties of Antennas, p49-p53, IEEE Antennas and Propagation Magazine, Vol42, n°3, Juin 2000

17
On peut alors calculer la longueur équivalente de l’antenne comme suit :
∫='
' ')'(V
djJVe dVePDL β 1.29
∫='
' ')'(S
djJSe dSePDL β 1.30
∫='
')'(L
djJLe dLePDL β 1.31
Nous allons montrer ci-dessous que la longueur équivalente de l’antenne est directement proportionnelle à la puissance qu’elle consomme. On voit dès lors toute l’importance du courant d’antenne puisqu’il influera directement le niveau du signal, mais au dépend de sa propre consommation.
Pour obtenir la puissance, nous allons utiliser le circuit équivalent de Thévenin d’une antenne réceptrice (voir Figure 1.7).
Figure 1.7 : Circuit équivalent de Thévenin d’une antenne réceptrice
On peut montrer la relation suivante :
)(OELV eoa ⋅−= 1.32
où Le est la longueur équivalente de l’antenne réceptrice qui peut être calculée au moyen d’un intégrale, et E(O) est le champ électrique incident au point d’observation, exprimé dans les coordonnées avec lesquelles a été calculée la longueur équivalente de l’antenne. Dès lors, la puissance maximale que pourra recevoir l’antenne est donnée par :
222
)(8
1)(42
1 OELR
OER
LP e
aa
eRx −== 1.33
où Ra est la résistance d’antenne.
1.1.6. Time Delay Nous avons pu observé dans les paragraphes précédents, que les ondes pouvaient suivre plusieurs chemins pour atteindre un même point, c’est le phénomène de multipath. Cependant, ces chemins n’étant pas tous de la même longueur, le signal émis prendra plus ou moins de temps selon la distance à parcourir, créant ainsi plusieurs échos du signal en ce point.

18
D’après [3], l’expérience a pu montrer que la puissance du signal reçu et de ses échos qui suivent, décroissent avec le temps, ceci est le phénomène de fading. Afin de recevoir correctement les données, et pour ne pas les confondre avec du bruit, le récepteur devra donc attendre un temps suffisant pour le signal suivant ne se confondent pas avec les échos ; ce temps d’attente est le time delay. Ceci revient à dire que l’antenne émettrice ne peut émettre à nouveau tant que le rapport signal sur bruit n’est pas retombé en-dessous d’un certain seuil. L’intérêt de pouvoir connaître ce temps est dès lors capital, puisqu’il limite débit maximal du réseau. Ainsi, si les échos ne diminuent pas suffisamment rapidement, le time delay deviendra très grand, empêchant toute communication car les composants électroniques ne peuvent s’y adapter.
1.2. Moteur de calcul Comme nous l’avons dit dans l’introduction, le moteur de calcul est basé sur un simulateur de réseau : le Network Simulator [18] [19]. Actuellement dans sa seconde version, ce simulateur de réseau offre des ressources importantes pour la simulation du protocole TCP, du routage des paquets et des protocoles multicast, le tout par-dessus un réseau câblé ou non (en local et satellite). Initialement développé par l’université de Columbia, Californie, et par l’université Cornell, il était essentiellement destiné à observer les comportements dynamiques dans les flux de données, les congestions dans le trafic, … Son développement est aujourd’hui assuré par des collaborateurs des universités de Berkeley et du Sud de la Californie, ainsi que Xerox PARC et LBNL. Si au départ, son application principale était l’observation des comportements dynamiques des flots de paquets et les congestions dans le trafic, il est aujourd’hui utilisé dans une multitude de projets, dont le nôtre. Dans ce chapitre nous étudierons le moteur de calcul de ray-tracing et surtout son interface afin de comprendre comment s’en servir. Il n’est pas vraiment utile de connaître le fonctionnement interne du moteur, mais par contre, nous devons comprendre comment passer les paramètres et initialiser le moteur, comment le faire tourner, par le biais de quelles méthodes et enfin, nous devons récupérer les résultats. Nous avons vu au chapitre précédent que nous devions considérer plusieurs phénomènes : la transmission, la diffraction, la réflexion et le champ direct. Pour pouvoir appliquer les trois premiers dans un bâtiment, nous devrons donc en connaître toutes les surfaces planes, pour la transmission et la réflexion, et toutes les arêtes pour la diffraction. Ce qui amène notre modèle du bâtiment à être simplifié à un ensemble de surfaces planes et un ensemble d’arêtes. Nous allons constater que ceci se retrouve implanté dans le moteur de calcul. Le code simplifié du moteur de calcul peut être trouvé en annexe de ce document ; le code complet contenant des secrets de fabrication, il ne peut être diffusé. Nous commençons par constater que le moteur est écrit dans le langage C/C++. Ceci a pour conséquence que le code compilé ne pourra être porté directement d’une plateforme à une autre. Afin de nous aider à structurer un peu le code, nous allons nous servir de Microsoft Visual Studio 6.0 qui nous offrira une vue globale structurée du moteur de calcul, permettant ainsi de repérer les éléments clés que nous recherchons. Nous allons maintenant voir quelques portions de code afin d’en tirer les paramètres à charger, les fonctions à exécuter et trouver les résultats.
3 Simon R. Saunders, Antennas and Propagation for Wireless Communication Systems, pp 206 à 219, John Wiley & Sons Ltd., Sussex, Angleterre, 1999

19
1.2.1. Variables Globales
Facette *facet; Arete *edge; Antenne Tx, Rx; Rayon RayonDirect, RayonSR[NRAY], RayonDR[NRAY], RayonTR[NRAY], RayonSD[NRAY], RayonRD[NRAY]; Trace trace[10000]; ChampCart result; complex < double >voltage; double power; double K=50.26;
Figure 1.8 : Variables globales du moteur de calcul
*facet est un pointeur vers toutes les facettes du bâtiment, de même que *edge est un pointeur vers toutes les arêtes du bâtiment. Tx et Rx représentent l’antenne de transmission et l’antenne de réception, trace est un tableau contenant l’ensemble des rayons qui partent de l’émetteur et aboutissent au récepteur, voltage est la tension (complexe) à l’antenne de réception, tandis que la puissance à la réception est
stockée dans la variable power. K est le nombre d’onde (λπ2 ).
Afin de pouvoir modifier ces variables, nous générerons des fonctions ‘get’ et ‘set’ permettant de connaître ou d’assigner une valeur d’un paramètre et nous les enregistrerons dans une interface (peu importe le langage utilisé).
1.2.2. Structures Nous allons rapidement regarder les quelques structures que nous serons amenés à manipuler par la suite, permettant également ainsi, de voir quels paramètres nous devions fournir au moteur de calcul. Nous nous intéressons, ici, uniquement aux structures non-triviales. Antenne
typedef struct { int type; VecteurCart pos; Axes axe; double Ra; complex < double >Ia; ChampSpher (*Le) (VecteurSpher); } Antenne;
type est un entier qui indique le type prédéfini de l’antenne, pos détermine la position de l’antenne, axe sont les axes qui lui sont attachés, Ra est la résistance d’antenne, Ia est le courant d’antenne (lorsqu’il s’agit d’une antenne émettrice) et *Le est un pointeur vers une fonction qui calcule la longueur équivalente de l’antenne.
VecteurCart est une structure qui contient trois valeurs de type « double » qui indiquent l’extrémité d’un vecteur cartésien.

20
Axe lui contient trois champs de type « VecteurCart » permettant de définir ainsi des axes. Trace
typedef struct { VecteurCart r0 ; VecteurCart r1 ; } CTrace ;
r0 est un vecteur cartésien qui situe l’origine d’un rayon, tandis que r1 en indique son extrémité.
Facet et Edge
Nous allons les voir tout de suite au point suivant.
1.2.3. Fonctions à appeler Un des paramètres du moteur est évidemment la géométrie du bâtiment qui doit être chargée en mémoire. Un rapide parcours des fonctions disponibles nous indique que la fonction LoadGeometry(const char* path1, const char* path2) réalise le chargement du bâtiment. Les deux paramètres ne sont rien d’autres que des noms de fichiers, l’un destiné à contenir les facettes du problème, l’autre, les arêtes. Les données sont simplement une série de nombres réels ou entiers qui se suivent sur chaque ligne. Ainsi, une facette est caractérisée par les différents champs se trouvant dans le code de la Figure 1.9, tandis qu’une arête sera caractérisée par les différents champs de la Figure 1.10.
fscanf (fichier, "%lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %i", &facet[i].pos.x, &facet[i].pos.y, &facet[i].pos.z, &facet[i].axe.x.x, &facet[i].axe.x.y, &facet[i].axe.x.z &facet[i].axe.y.x, &facet[i].axe.y.y, &facet[i].axe.y.z, &facet[i].axe.z.x, &facet[i].axe.z.y, &facet[i].axe.z.z, &facet[i].d.x, &facet[i].d.y, &facet[i].d.z, &epsr, &epsi, &facet[i].pec);
Figure 1.9
facet est un pointeur vers une liste de structs contenant les champs suivants : la position de l’origine du repère lié à la facette (champ ‘pos’), les axes associés à la facette (champ ‘axe’), les dimensions selon les trois directions (champ ‘d’), la partie réelle et imaginaire de la permittivité (champs ‘epsr’ et ‘epsi’) et enfin une valeur booléenne indiquant si la surface est parfaitement conductrice d’un point de vue électrique (champ ‘pec’).

21
fscanf (fichier, "%lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %i %lf %i %i", &edge[i].r0.x, &edge[i].r0.y, &edge[i].r0.z, &edge[i].r1.x, &edge[i].r1.y, &edge[i].r1.z, &edge[i].n, &edge[i].axeo.x.x, &edge[i].axeo.x.y, &edge[i].axeo.x.z, &edge[i].axeo.y.x, &edge[i].axeo.y.y, &edge[i].axeo.y.z, &edge[i].axeo.z.x, &edge[i].axeo.z.y, &edge[i].axeo.z.z, &edge[i].axen.x.x, &edge[i].axen.x.y, &edge[i].axen.x.z, &edge[i].axen.y.x, &edge[i].axen.y.y, &edge[i].axen.y.z, &edge[i].axen.z.x, &edge[i].axen.z.y, &edge[i].axen.z.z, &epsr, &epsi, &edge[i].pec, &edge[i].d, &edge[i].faceo, &edge[i].facen);
Figure 1.10
edge est un pointeur vers une liste de structs contenant les champs suivants : l’origine et l’extrémité d’une facette (champs ‘r0’ et ‘r1’), n est une fonction de l’angle
intérieur α de l’arête (π
απ −=
2n ), les systèmes d’axes de chacune des facettes
composant l’arête en question (champs ‘axeo’ et ‘axen’), la partie réelle et imaginaire de la permittivité du dièdre composé par ces deux facettes (champs ‘epsr’ et ‘epsi’), un booléen indiquant si la surface est parfaitement conductrice d’un point de vue électrique (champ ‘pec’), l’épaisseur du mur (champ ‘d’) et les numéros des facettes composants le dièdre (champ ‘faceo’ et ‘facen’).
Nous avons donc recueilli les éléments clés que devra contenir notre modèle. Voyons maintenant, comment il est possible d’effectuer les calculs. Pour ce faire nous allons simplement essayer de regarder les tâches qu’effectue le main() du programme, ce qui revient à faire un diagramme de séquences avec comme source d’appel le main().
1.2.4. Eléments Clés Avant de réaliser une interface du moteur de calcul, interface qui pourra servir afin de modifier ce moteur par la suite, nous allons établir un petit récapitulatif des éléments que nous devrons retrouver dans notre analyse.
Nous avons vu au paragraphe 1.1 Phénomènes de propagation d’ondes que nous devions prévoir les éléments de réflexion, de transmission ainsi que ceux responsables de la diffraction, c’est-à-dire les faces planes et les coins. Ceux-ci correspondent aux murs et aux arêtes que ceux-ci réalisent à leurs intersections. On devra donc prévoir une interface utilisateur pour introduire la position et la dimension de chaque facette. Cependant, nous avons également constaté que les propriétés d’un mur ne sont pas forcément toutes les mêmes. Nous devrons récolter les propriétés suivantes pour chaque élément faisant partie de la structure du bâtiment au sein duquel on souhaite travailler : • la permittivité • l’angle intérieur pour les arêtes • si le matériau en question est parfaitement conducteur d’un point de vue électrique
En ce qui concerne les antennes, nous devrons connaître leur position, leur résistance ainsi que le courant qui les traverse si il s’agit d’une antenne émettrice.

22
1.3. Interface Nous pouvons donc maintenant établir l’interface que nous appellerons depuis notre projet, le moteur de calcul en réalisera l’implémentation. A priori, nous allons essayer de garder une interface très simple, les boucles, travaux en lot etc… seront quant à eux réalisés au sein de notre programme.
interface IEngine { /* * Chargement des paramètres */ public void setNWave(double K); public void setRX(Antenne rx); public void setTX(Antenne tx); public void loadGeometry(Facette* f, Arete* a); /* * Exécution */ public void executeCalculation(); /* * Récupération des résultats */ public double getPower(); public Trace* getTraces(); public double getVoltage(); }
Figure 1.11 : Interface du moteur de calcul
Le pseudo-code est ici, suffisamment explicite pour ne pas devoir le commenter. La première approche du problème étant réalisée, il va falloir maintenant structurer toutes ces informations afin de pouvoir plus tard obtenir un logiciel. La première phase sera donc l’analyse logicielle à travers laquelle on va établir clairement ce que fera notre programme. Cette phase est cruciale pour la suite du développement ; en effet, une analyse erronée créera pas mal de problèmes et peut même aboutir à l’échec complet du développement.

23
Chapitre 2
Analyse Logicielle Avant de poursuivre la lecture, il faut préciser que cette partie du travail se déroule en plusieurs étapes itératives ; chaque étape permettant de rajouter des éléments, raffiner certaines descriptions, corriger des erreurs, … Il ne m’a pas semblé utile, ni intéressant, de montrer chacune de ces étapes et cela pour plusieurs raisons : entre chaque étape, un grande partie du contenu de l’analyse reste identique, ce qui aurait conduit à une redondance excessive et à une confusion entre ce qui a été modifié et ce qui a finalement été décidé ; ensuite, la limite entre la fin d’une étape et la suivante est loin d’être évidente, d’autant que, travaillant seul, cela ne s’est pas montré nécessaire. Nous avons maintenant en mains, tous les éléments nécessaires à la réalisation de l’analyse et design du logiciel. Dans une optique orientée-objet et donc, dans un premier temps, de façon totalement abstraite, nous allons pouvoir définir successivement les exigences, les cas d’utilisations et l’architecture du projet. En nous servant du langage UML, nous allons établir l’ensemble des spécifications du projet.
2.1. Exigences (Requirements) Ayant réalisé l’étude de tout ce qui était relativement indépendant à la réalisation et la programmation même du logiciel, nous sommes à même d’attaquer l’analyse du projet. Au risque de parfois sembler répétitif, il est essentiel de concentrer ici l’ensemble des caractéristiques de notre logiciel. L’optique de ce chapitre est la suivante : il doit être suffisamment complet et descriptif pour qu’un œil neuf puisse reprendre le projet en lisant ce chapitre. Cependant, nous nous efforcerons de rester relativement abstrait et conceptuel dans la première partie afin d’effectuer une analyse correcte du problème.

24
Un premier examen à réaliser est l’étude du flot des données dans notre programme. On commence par avoir l’utilisateur qui rentre les données relatives à son problème dans notre programme : structures d’un bâtiment, édition de ses propriétés, placements des antennes et des récepteurs. Ensuite toutes ces données sont envoyées au moteur de calcul afin que celui-ci nous renvoie la puissance sur un récepteur. Enfin, ayant obtenu la ou les puissances, nous devons effectuer un rendu graphique. Nous avons donc trois grandes fonctions à réaliser : création et édition de bâtiments, réalisation des calculs, affichage des résultats. Passons maintenant en revue chacune de ces parties, pour les détailler et avoir une vue plus concrète du résultat qu’on souhaite obtenir. Nous allons définir ce que nous voulons faire mais pas encore la façon dont ce sera réalisé, la mise en œuvre de tous ces concepts est réservée à la phase de design.
2.1.1. Editions de structures tridimensionnelles Notre but étant d’avoir un programme assez simple, la manière la plus facile d’introduire une structure 3D est de réaliser son édition dans une vue bidimensionnelle et d’introduire pour chaque élément de la structure un paramètre de hauteur. On aura la possibilité ensuite d’effectuer un rendu tridimensionnel mais ceci n’est pas essentiel dans un premier temps. Nous avons vu dans le chapitre précédent que nous ne pouvions pas considérer la structure d’un bâtiment comme étant uniforme d’un point de vue qualitatif. En effet, les coefficients de permittivité et de perméabilité, entre autres paramètres, varient en fonction du matériel. Nous devrons donc pouvoir éditer une série de propriétés – voir 1.2.4 Eléments Clés – pour chaque élément de la structure. De plus, nous devrons pouvoir positionner une antenne et des récepteurs et, à nouveau, nous devrons pouvoir en définir les propriétés (puissance, hauteur, …). Nous devrons bien sûr assurer la persistance des données et donc une façon de les sauvegarder.
Nous pouvons déjà dire que cette partie est celle qui doit paraître la plus claire pour l’utilisateur car c’est là qu’il doit introduire la majorité des données. Nous devrons donc prévoir d’une part une fenêtre de représentation et d’autre part une fenêtre énumérant chaque élément de la structure afin de pouvoir facilement visualiser le bâtiment mais en même temps observer des éléments qui seraient trop peu visibles sur la première fenêtre.
2.1.2. Réalisation des calculs On pourrait croire que, cette partie étant réalisée, son interfaçage sera relativement aisé, mais on a pu observer au chapitre précédent que le moteur de calcul devra être interfacer une première fois avant que l’interface graphique ne puisse faire ses appels sur la partie contrôle du logiciel. Nous avons ici plusieurs tâches à effectuer. D’une part, il faut instancier le moteur de calcul, ensuite lui envoyer les paramètres nécessaires, effectuer les calculs et récupérer les résultats.
Nous avons vu que le moteur de calcul nous propose de placer une antenne et un récepteur. Or, nous serons souvent amener à considérer plusieurs récepteurs, voire un maillage de tout le bâtiment afin d’avoir une vue globale de la répartition de puissance du champ dans le bâtiment. On peut déjà voir ici que nous devrons offrir plusieurs méthodes de calcul, donc nous devrons également offrir une manière de paramétrer ceux-là.

25
2.1.3. Affichage des résultats Les possibilités d’affichage des résultats sont très nombreuses. Non seulement du point de vue du post-traitement des résultats, qu’au niveau de leur représentation. Cependant nous sommes limités par la puissance des machines actuelles. En effet, le moteur de calcul peut être extrêmement rapide pour des géométries pas trop complexes et pour un calcul ponctuel, mais il en va tout autrement lorsqu’on décide d’analyser la puissance dans tout un bâtiment. Non seulement le temps de calcul croit de façon très importante, mais en plus il faudra réaliser un post-traitement des résultats afin de pouvoir effectuer un rendu visuel.
Dans le cadre de ce travail, nous allons nous limiter aux calculs ponctuels – cependant, nous garderons un concept relativement abstrait lorsqu’on parlera de l’affichage des résultats afin de pouvoir faire entrer n’importe quel rendu graphique dans ce concept – ceci signifie que on demandera toujours au moteur de calculs de les réaliser en un point bien particulier. Cet appel étant assez rapide, on pourrait imaginer que l’utilisateur sélectionne un point dans le bâtiment et notre logiciel afficherait, d’une part, les rayons partant de l’antenne émettrice et arrivant au point choisi, et d’autre part, les valeurs caractéristiques en ce point-là qui sont : la puissance, la tension et le « time delay ».
2.2. Définition des Cas d’utilisation Ce sous-chapitre sera consacré à l’écriture des différentes opérations que réalisera notre logiciel. Ceci reflètera le comportement général de l’application et est sans doute la partie qui « explique » le mieux le programme. Nous procèderons en trois étapes pour définir et représenter chaque cas d’utilisation. Nous allons d’abord nous occuper de tous les relever, ensuite nous les organiserons dans un diagramme et enfin nous finirons par expliciter en détails les plus importants d’entre eux. La majorité des cas d’utilisation est relativement explicite et correspondra à des actions simples que pourra réaliser l’utilisateur. Nous avons vu que le moteur de calcul est codé en C++. Pour pouvoir l’utiliser, nous allons introduire un acteur fictif, un délégué aux calculs. Il offrira une interface simple qui utilisera le moteur pour réaliser ses tâches. Si nous voulons rajouter d’autres fonctionnalités de calcul telle qu’une exécution par lot, nous l’introduirons dans la partie contrôleur de notre programme et non dans le moteur de calcul. Ce choix peut paraître arbitraire mais se fonde sur l’argument suivant : le moteur de calcul étant à la base de notre application, il est dans notre intérêt de le garder le plus « simple » possible. Nous tirons deux avantages principaux de ceci : la stabilité de notre application et plus de facilité pour tester et déboguer notre projet.
26
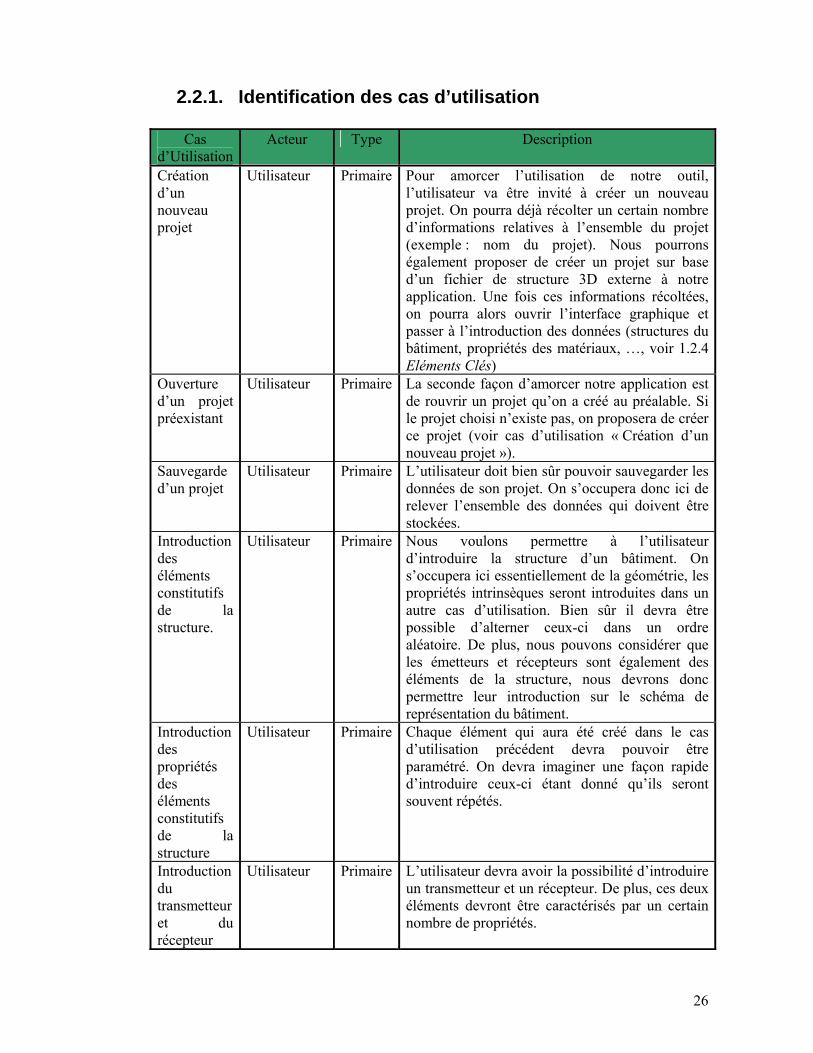
2.2.1. Identification des cas d’utilisation
Cas d’Utilisation
Acteur Type Description
Création d’un nouveau projet
Utilisateur
Primaire Pour amorcer l’utilisation de notre outil, l’utilisateur va être invité à créer un nouveau projet. On pourra déjà récolter un certain nombre d’informations relatives à l’ensemble du projet (exemple : nom du projet). Nous pourrons également proposer de créer un projet sur base d’un fichier de structure 3D externe à notre application. Une fois ces informations récoltées, on pourra alors ouvrir l’interface graphique et passer à l’introduction des données (structures du bâtiment, propriétés des matériaux, …, voir 1.2.4 Eléments Clés)
Ouverture d’un projet préexistant
Utilisateur
Primaire La seconde façon d’amorcer notre application est de rouvrir un projet qu’on a créé au préalable. Si le projet choisi n’existe pas, on proposera de créer ce projet (voir cas d’utilisation « Création d’un nouveau projet »).
Sauvegarde d’un projet
Utilisateur Primaire L’utilisateur doit bien sûr pouvoir sauvegarder les données de son projet. On s’occupera donc ici de relever l’ensemble des données qui doivent être stockées.
Introduction des éléments constitutifs de la structure.
Utilisateur Primaire Nous voulons permettre à l’utilisateur d’introduire la structure d’un bâtiment. On s’occupera ici essentiellement de la géométrie, les propriétés intrinsèques seront introduites dans un autre cas d’utilisation. Bien sûr il devra être possible d’alterner ceux-ci dans un ordre aléatoire. De plus, nous pouvons considérer que les émetteurs et récepteurs sont également des éléments de la structure, nous devrons donc permettre leur introduction sur le schéma de représentation du bâtiment.
Introduction des propriétés des éléments constitutifs de la structure
Utilisateur Primaire Chaque élément qui aura été créé dans le cas d’utilisation précédent devra pouvoir être paramétré. On devra imaginer une façon rapide d’introduire ceux-ci étant donné qu’ils seront souvent répétés.
Introduction du transmetteur et du récepteur
Utilisateur Primaire L’utilisateur devra avoir la possibilité d’introduire un transmetteur et un récepteur. De plus, ces deux éléments devront être caractérisés par un certain nombre de propriétés.
27
Lancement des calculs.
Utilisateur Responsable calcul
Primaire Une fois que notre application aura reçu l’ensemble des données relatives à la structure, nous devrons lancer les calculs. Ceci se déroule en plusieurs étapes : choix et paramétrage de la méthode de calcul (incluant notamment le type de rendu graphique a effectué, une fois les résultats obtenus), instanciation et exécution du moteur de calcul (ceci inclus le passage des paramètres), ensuite on récoltera les résultats libérera les ressources et on offrira un rendu graphique.
Calcul ponctuel
Utilisateur Responsable calcul
Primaire Ce cas d’utilisation est un cas particulier du cas « Lancement des calculs ». En effet, les paramètres à entrer seront les suivants : la structure, une antenne émettrice, un point d’observation. On demandera ensuite au moteur d’effectuer le calcul en ce point avec les paramètres préalablement introduits, et on affichera ensuite dans un cadre les différents résultats que l’on peut faire apparaître. On peut également imaginer de faire apparaître les différents rayons partant du point source et parvenant au point d’observation.
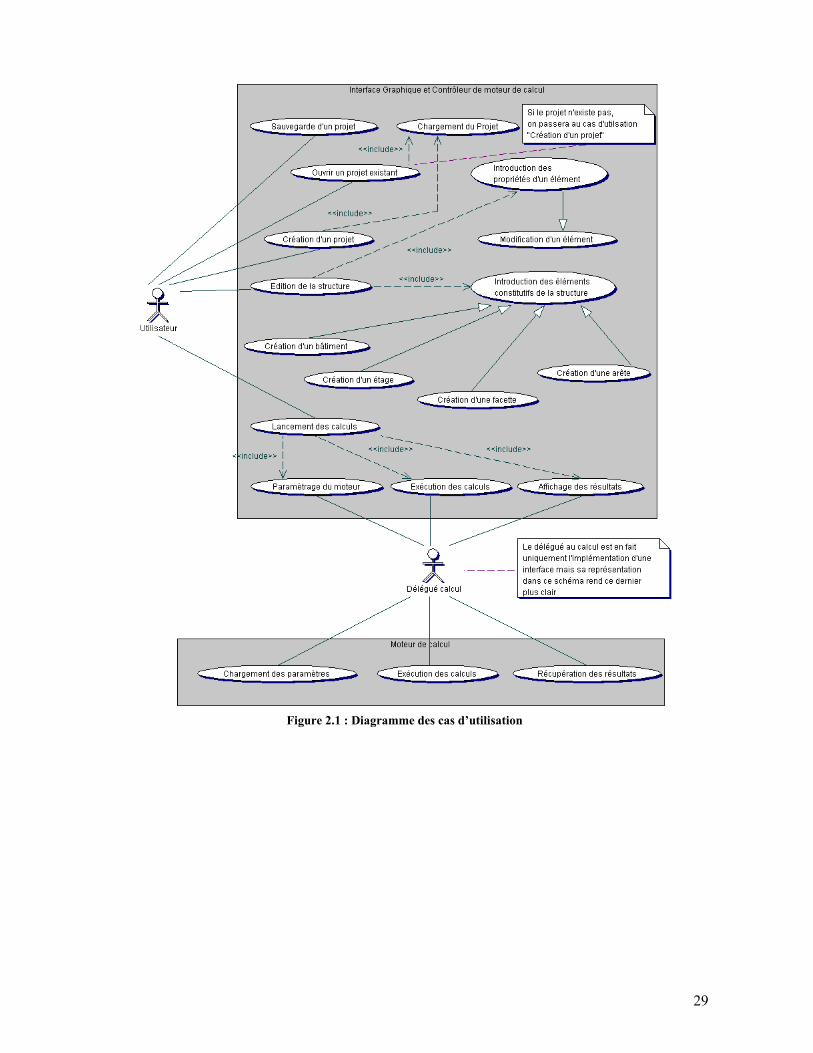
2.2.2. Diagramme des cas d’utilisation Nous allons maintenant nous concentrer sur la réorganisation de ces cas d’utilisation. Ceci nous amènera parfois à en rajouter, à en scinder ou en fusionner. Pour réaliser cela, nous allons nous servir du langage UML qui nous offre la possibilité de créer un diagramme de cas d’utilisation. Cependant, si cet outil est très parlant au niveau du comportement et de l’organisation de notre programme, l’aspect dynamique en est complètement absent. C’est notamment pour palier à ce manque que nous devons détailler chaque cas d’utilisation, afin d’avoir un raffinement de ce que réalise réellement notre application et pour pouvoir répondre à un grand nombre de questions qui sont toujours en suspens.
Le diagramme obtenu se retrouve dans la figure qui suit ce paragraphe. Notre logiciel est divisé en deux parties : une partie interface graphique et contrôleur, et une partie moteur de calcul. On peut, sans perte de généralité, considérer que ces deux parties ne se dérouleront pas au sein d’un même processus. Il va donc falloir établir un protocole de communication entre ces deux entités. Ce choix, dépendant notamment de la plateforme de travail, devra être réalisé au sein de la phase de design.
Passons maintenant en revue les modifications apportées à notre premier modèle, afin de les justifier.
• Création d’un projet : nous considérons qu’en réalité ceci inclus le cas d’utilisation
ouverture d’un projet. • Ouverture d’un projet : on offrira à l’utilisateur la possibilité d’ouvrir un projet
sauvegardé antérieurement. Nous pouvons imaginer qu’il y ait plusieurs façons d’ouvrir un projet (typiquement soit à partir d’une base de données, soit à partir d’un

28
fichier), selon la façon dont on l’a sauvegardé. Il faut donc pouvoir séparer la partie ouverture du projet, de la partie chargement du projet.
• Chargement du projet : c’est ici qu’on lancera l’ensemble de la partie graphique, avec la recréation de tous les objets graphiques sur base du projet ouvert.
• Sauvegarde d’un projet : à tout moment l’utilisateur devra pouvoir sauvegarder son travail, en le mettant soit dans une base de données, soit dans un fichier.
• Edition de la structure : ce cas d’utilisation est bien évidemment fort complexe et rassemble un groupe de cas d’utilisation que l’on va essayer de fusionner et de rendre plus uniformes. Pour y parvenir, le diagramme de Use Case en UML nous sera particulièrement utile.
• Annulation d’une ou plusieurs opérations : on permettra à l’utilisateur d’annuler la ou les dernières opérations d’édition que celui-ci a réalisées. Pour ce faire, on réalisera une pile d’opérations que l’on peut annuler. Lorsqu’on en annulera une ou plusieurs, celles-ci seront empilées dans une pile d’opérations que l’on peut recommencer.
• Recommencement d’une ou plusieurs opérations : lorsqu’une opération a été annulée, celle-ci est placée sur la pile d’opérations que l’on peut recommencer. Lorsque une ou plusieurs sont recommencées, elles repasseront sur la pile des opérations annulables. On notera déjà dès à présent que à chaque fois qu’une nouvelle opération est réalisée, on videra la pile des opérations recommençables.
• Lancement des calculs : ce cas d’utilisation doit être séparé en plusieurs étapes du fait de sa complexité. On commence d’abord par récolter le choix et les paramètres de méthode de calcul, ensuite il faut effectuer les calculs demandés, et enfin il faut effectuer un rendu graphique adapté. Comme expliqué au préalable, nous utilisons un artefact pour utiliser le moteur de calcul : nous lui assignons un délégué qui s’occupera de la communication entre les deux parties de notre application.
• Calcul ponctuel : il reste inchangé par rapport à la description fournit au point 2.2.1. Nous voyons déjà clairement que le programme devra offrir plusieurs « modes » de travail. On en repère déjà deux, dès à présent : le mode « Edition » et le mode « Calcul et Rendu Graphique ». Si les fenêtres resteront sensiblement les mêmes, on devra modifier l’aspect des menus et barres d’outil afin d’empêcher les opérations qui sont réservées exclusivement à un mode (la répartition de celles-ci entre les deux modes est triviale). On pensera également à éliminer les résultats afficher lors du passage du mode « Calcul et Rendu Graphique » vers le mode « Edition ».
29
Figure 2.1 : Diagramme des cas d’utilisation

30
2.2.3. Cas d’utilisation étendus Les cas d’utilisation étendus vont nous permettre une définition plus concrète et plus affinée de ce qui se déroule au sein de notre logiciel. Ceux-ci sont relativement fastidieux à lire, mais ils permettent d’éclaircir pas mal de points obscurs avant de commencer à programmer et permettent à d’autres personnes de pouvoir continuer un tel projet, sans devoir décortiquer en détail le code source. De plus, ils rajoutent un aspect dynamique qui, jusqu’ici, était totalement absent. Avant d’entamer les cas d’utilisation étendus, analysons rapidement ce qu’il ressort du diagramme ci-dessus. On repère trois grande parties : la gestion du projet (création, ouverture, sauvegarde, …), l’introduction de la structure (création de bâtiments, d’étages, de murs (ou facettes), …) et enfin la partie de calculs qui inclus notamment l’affichage des résultats.
Gestion du projet Cas d’utilisation : Création d’un nouveau projet Acteur : Utilisateur Utilité : Permet à l’utilisateur de créer un nouveau projet. Description : L’utilisateur crée un nouveau projet en lui donnant un nom, ainsi que en fournissant quelconque élément nécessaire à l’initialisation d’un projet. Type : primaire
Actions de l’acteur Réponses du système 1. L’utilisateur pourra créer un nouveau projet, au moyen d’une icône ou d’un menu.
2. Une fenêtre s’ouvre dans laquelle l’utilisateur est invité à entrer un nom pour le projet ainsi que l’endroit où le projet sera sauvegardé (en base de donnée ou dans un fichier).
3. L’utilisateur entre un nom de projet et choisit l’emplacement où sauvegarder les données.
4. Le système crée les ressources nécessaires, ensuite, ce projet est ouvert (voir cas d’utilisation « Ouverture d’un projet » au point 8).

31
Cas d’utilisation : Ouverture d’un projet Acteur : Utilisateur Utilité : Permet à l’utilisateur d’ouvrir un projet. Description : L’utilisateur choisit un projet soit en base de données, soit dans un fichier. Type : primaire
Actions de l’acteur Réponses du système
1. L’utilisateur choisi, au moyen d’un menu ou d’un icône, d’ouvrir un projet.
2. Une fenêtre s’ouvre dans laquelle l’utilisateur doit choisir entre un projet en base de donnée soit un projet enregistré dans un fichier. (On peut imaginer que les projets les plus récents soient repris dans une liste).
3. L’utilisateur choisit entre ces 2 modes. 4.a. (Mode « Base de données ») La même
fenêtre affiche cette fois l’ensemble des possibilités en listant tous les projets en mémoire (il faudra éventuellement penser à les classer par date d’utilisation et en afficher que les 5 à 10 premiers). GOTO 5.a.
4.b. (Mode « Fichier ») La même fenêtre affiche le nom du fichier choisi avec un bouton permettant de parcourir le système de fichier. GOTO 5.b.
5.a. Dans la liste des fichiers qui s’affichent, l’utilisateur choisit un projet. Lorsque ceci est fait, l’utilisateur confirme son choix. GOTO 8
5.b. L’utilisateur entre manuellement le nom du fichier ou décide d’utiliser le sélectionneur de fichiers du système (GOTO 6.b., sinon 7b.)
6.b. Un sélectionneur de fichier s’ouvre et permet à l’utilisateur de se déplacer dans tout son système de fichier. On pensera à filtrer les fichiers qui n’ont pas la bonne extension.
7.b. L’utilisateur confirme son choix. Le système empêchera cette confirmation tant que le fichier référencé n’est pas valide.
8. Sur base de la référence, le projet est chargé. On rétablit l’interface graphique dans son état dans laquelle celle-ci était lorsque l’utilisateur a sauvegardé le projet en mémoire pour la dernière fois.

32
Introduction de la structure
Au début de notre analyse, nous avions déjà relevé l’utilité d’offrir deux représentations d’un bâtiment : une vue graphique pour faciliter la visualisation et une vue structurée qui offre une énumération des éléments d’un bâtiment. Dans la première vue, nous avons décidé d’offrir une représentation graphique du bâtiment dans une vue bidimensionnelle. Ceci implique l’on ne peut jamais visionner plus d’un étage à la fois ou bâtiment dans cette vue-là. De ce fait, si cette vue sera éditable, nous relevons que seuls les mûrs et arêtes pourront y être édités. Lors de l’utilisation du logiciel, l’utilisateur sera amené, régulièrement et de façon aléatoire, à passer d’une vue à l’autre (nous pourrons l’observer dans les cas d’utilisations qui suivent). Cependant, lorsque l’utilisateur manipulera la représentation graphique du bâtiment, il s’agira bien sûr toujours d’éléments de type arête ou facette. Notons encore que rien ne nous empêche d’offrir d’autre mode de représentation (et donc aussi d’édition) du bâtiment mais nous allons nous limiter à ces deux-là dans un premier temps.
Enfin on remarquera l’apparition de deux nouveaux cas d’utilisations, qui sont l’annulation et le recommencement d’une ou plusieurs opérations d’édition. Ceci étant une fonctionnalité bien pratique dans un programme d’édition.

33
Cas d’utilisation : Introduction d’un élément Acteur : Utilisateur Utilité : Permet à l’utilisateur d’ajouter un élément à la structure d’un bâtiment. Description : L’utilisateur rentre l’ensemble des données utiles concernant chaque élément (« qui nous intéressent ») du bâtiment. On offrira une certaine souplesse afin de pouvoir facilement paramétrer tous ces éléments (typiquement, un tableau des propriétés de l’élément sélectionné, voir également voir 1.2.4 Eléments Clés). Type : primaire
Actions de l’acteur Réponses du système 1. L’utilisateur choisit le nouvel élément qu’il veut créer : un bâtiment, un étage, une facette ou une arête. Il doit ensuite choisir de créer un élément en le paramétrant (a) ou en le dessinant sur la fenêtre de représentation (b). (b) L’utilisateur dessine alors, au moyen de la souris, sur la fenêtre de représentation, l’élément qu’il souhaite ajouter.
2. (a) Une fenêtre demande l’introduction des paramètres de cet élément. (b) Le système représente l’élément et permet ensuite d’introduire d’autres paramètres ainsi que la correction éventuelle de ceux introduits avec la souris.
3. (a) L’utilisateur donne les paramètres de cet élément. (b) L’utilisateur termine de paramétrer l’élément.
4. (a) Le système représente alors l’élément sur la fenêtre de représentation. (b) Si nécessaire, le système modifie la représentation en fonction des nouvelles données. (a) et (b) Le système vérifie qu’il possède suffisamment de données sur l’élément. Dans le cas contraire, ou au cas où des paramètres seraient incohérents, le système en avertira l’utilisateur et l’invitera à modifier l’élément.
Pré-conditions : Un projet devra être chargé.
34
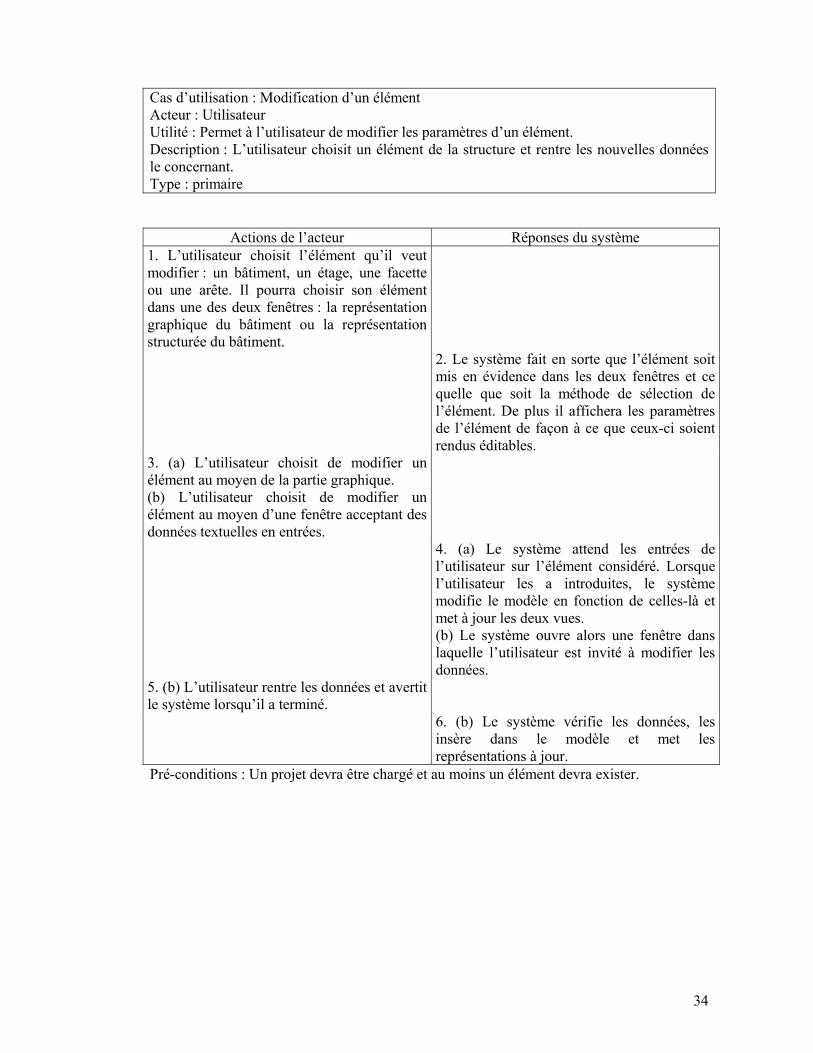
Cas d’utilisation : Modification d’un élément Acteur : Utilisateur Utilité : Permet à l’utilisateur de modifier les paramètres d’un élément. Description : L’utilisateur choisit un élément de la structure et rentre les nouvelles données le concernant. Type : primaire
Actions de l’acteur Réponses du système
1. L’utilisateur choisit l’élément qu’il veut modifier : un bâtiment, un étage, une facette ou une arête. Il pourra choisir son élément dans une des deux fenêtres : la représentation graphique du bâtiment ou la représentation structurée du bâtiment.
2. Le système fait en sorte que l’élément soit mis en évidence dans les deux fenêtres et ce quelle que soit la méthode de sélection de l’élément. De plus il affichera les paramètres de l’élément de façon à ce que ceux-ci soient rendus éditables.
3. (a) L’utilisateur choisit de modifier un élément au moyen de la partie graphique. (b) L’utilisateur choisit de modifier un élément au moyen d’une fenêtre acceptant des données textuelles en entrées.
4. (a) Le système attend les entrées de l’utilisateur sur l’élément considéré. Lorsque l’utilisateur les a introduites, le système modifie le modèle en fonction de celles-là et met à jour les deux vues. (b) Le système ouvre alors une fenêtre dans laquelle l’utilisateur est invité à modifier les données.
5. (b) L’utilisateur rentre les données et avertit le système lorsqu’il a terminé.
6. (b) Le système vérifie les données, les insère dans le modèle et met les représentations à jour.
Pré-conditions : Un projet devra être chargé et au moins un élément devra exister.

35
Cas d’utilisation : Annulation d’une opération Acteur : Utilisateur Utilité : Permet à l’utilisateur d’annuler la ou les dernières opérations qu’il a réalisées. Description : L’utilisateur annule une ou plusieurs opérations d’éditions de structure. Type : primaire
Actions de l’acteur Réponses du système
1. Au moyen d’un menu ou d’un bouton, l’utilisateur choisit d’annuler la dernière opération.
2. Le système annule l’opération en réalisant l’opération inverse. Ceci modifiant alors le modèle et donc forcément les représentations. Il place cette action dans la pile d’actions « recommençables »
Pré-conditions : Un projet devra être chargé et au moins une opération d’édition devra être réalisée.
Cas d’utilisation : Recommencement d’une opération Acteur : Utilisateur Utilité : Permet à l’utilisateur de recommencer la ou les dernières opérations qu’il a annulées. Description : L’utilisateur recommence une ou plusieurs opérations d’éditions de structure. Type : primaire
Actions de l’acteur Réponses du système
1. Au moyen d’un menu ou d’un bouton, l’utilisateur choisit de recommencer la dernière opération qui a été annulée.
2. Le système recommence l’opération en réexécutant l’opération. Ceci modifiant alors le modèle et donc forcément les représentations. Il place cette action dans la pile d’actions « annulables »
Pré-conditions : Un projet devra être chargé et au moins une opération d’édition devra avoir été annulée mais aucune autre ne pourra avoir été réalisée entre temps, auquel cas, la pile des actions « recommençables » sera vide.
36
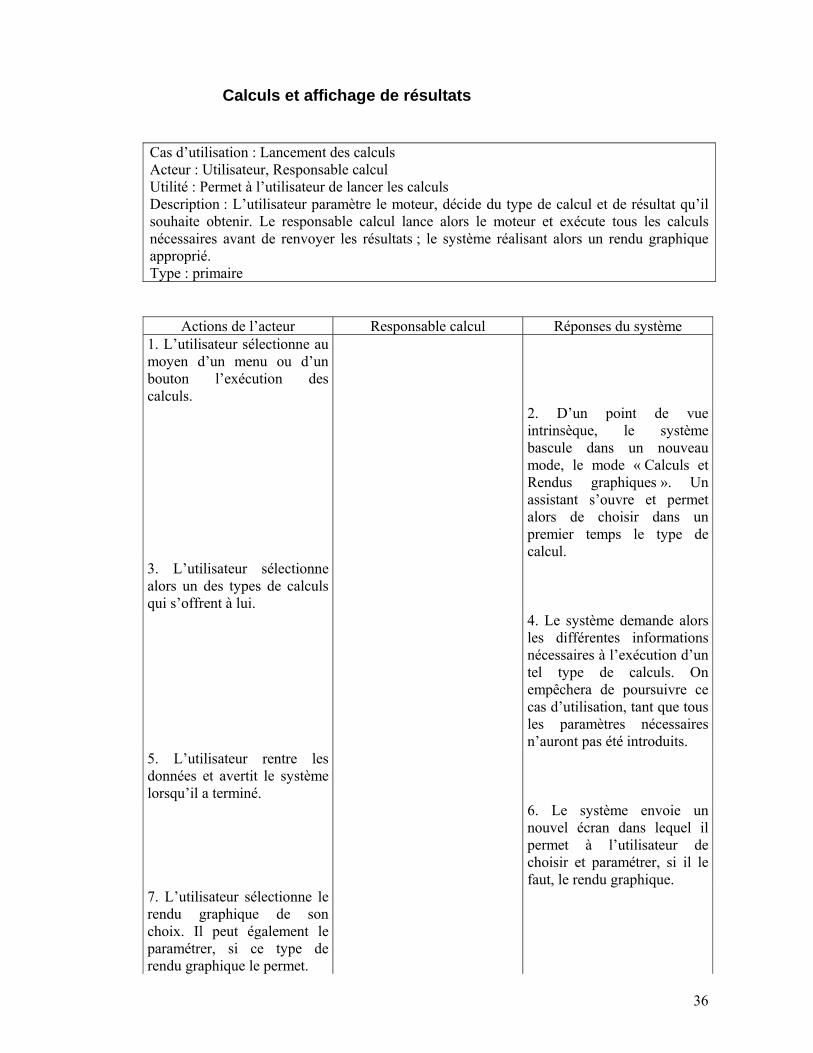
Calculs et affichage de résultats Cas d’utilisation : Lancement des calculs Acteur : Utilisateur, Responsable calcul Utilité : Permet à l’utilisateur de lancer les calculs Description : L’utilisateur paramètre le moteur, décide du type de calcul et de résultat qu’il souhaite obtenir. Le responsable calcul lance alors le moteur et exécute tous les calculs nécessaires avant de renvoyer les résultats ; le système réalisant alors un rendu graphique approprié. Type : primaire
Actions de l’acteur Responsable calcul Réponses du système
1. L’utilisateur sélectionne au moyen d’un menu ou d’un bouton l’exécution des calculs.
2. D’un point de vue intrinsèque, le système bascule dans un nouveau mode, le mode « Calculs et Rendus graphiques ». Un assistant s’ouvre et permet alors de choisir dans un premier temps le type de calcul.
3. L’utilisateur sélectionne alors un des types de calculs qui s’offrent à lui.
4. Le système demande alors les différentes informations nécessaires à l’exécution d’un tel type de calculs. On empêchera de poursuivre ce cas d’utilisation, tant que tous les paramètres nécessaires n’auront pas été introduits.
5. L’utilisateur rentre les données et avertit le système lorsqu’il a terminé.
6. Le système envoie un nouvel écran dans lequel il permet à l’utilisateur de choisir et paramétrer, si il le faut, le rendu graphique.
7. L’utilisateur sélectionne le rendu graphique de son choix. Il peut également le paramétrer, si ce type de rendu graphique le permet.

37
8. Le système vérifie les données, et les envoie au responsable calcul.
9. Le responsable calcul envoie les paramètres au moteur de calcul. Il exécute ensuite le ou les calculs à réaliser au travers de l’interface du moteur de calcul. Enfin, il stocke chaque résultat au fur et à mesure et les renvoie tous lorsque la tâche est terminée.
10. Le système reçoit tous les résultats et effectue le rendu graphique sélectionné par l’utilisateur
Pré-conditions : Un projet devra être chargé. Une structure doit être introduite et paramétrée. Au moins une antenne devra être positionnée. Post-conditions : Lors du retour au mode « Edition », on devra « nettoyer » les rendus graphiques laissés sur la fenêtre.
38
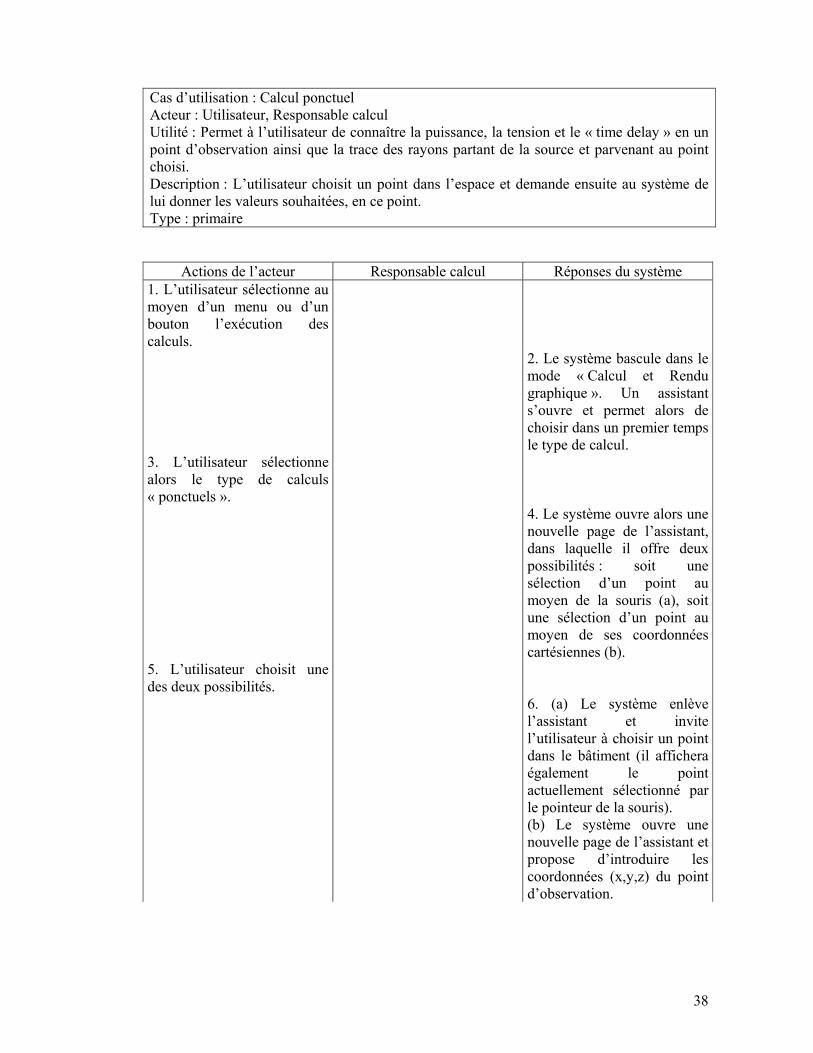
Cas d’utilisation : Calcul ponctuel Acteur : Utilisateur, Responsable calcul Utilité : Permet à l’utilisateur de connaître la puissance, la tension et le « time delay » en un point d’observation ainsi que la trace des rayons partant de la source et parvenant au point choisi. Description : L’utilisateur choisit un point dans l’espace et demande ensuite au système de lui donner les valeurs souhaitées, en ce point. Type : primaire
Actions de l’acteur Responsable calcul Réponses du système
1. L’utilisateur sélectionne au moyen d’un menu ou d’un bouton l’exécution des calculs.
2. Le système bascule dans le mode « Calcul et Rendu graphique ». Un assistant s’ouvre et permet alors de choisir dans un premier temps le type de calcul.
3. L’utilisateur sélectionne alors le type de calculs « ponctuels ».
4. Le système ouvre alors une nouvelle page de l’assistant, dans laquelle il offre deux possibilités : soit une sélection d’un point au moyen de la souris (a), soit une sélection d’un point au moyen de ses coordonnées cartésiennes (b).
5. L’utilisateur choisit une des deux possibilités.
6. (a) Le système enlève l’assistant et invite l’utilisateur à choisir un point dans le bâtiment (il affichera également le point actuellement sélectionné par le pointeur de la souris). (b) Le système ouvre une nouvelle page de l’assistant et propose d’introduire les coordonnées (x,y,z) du point d’observation.
39
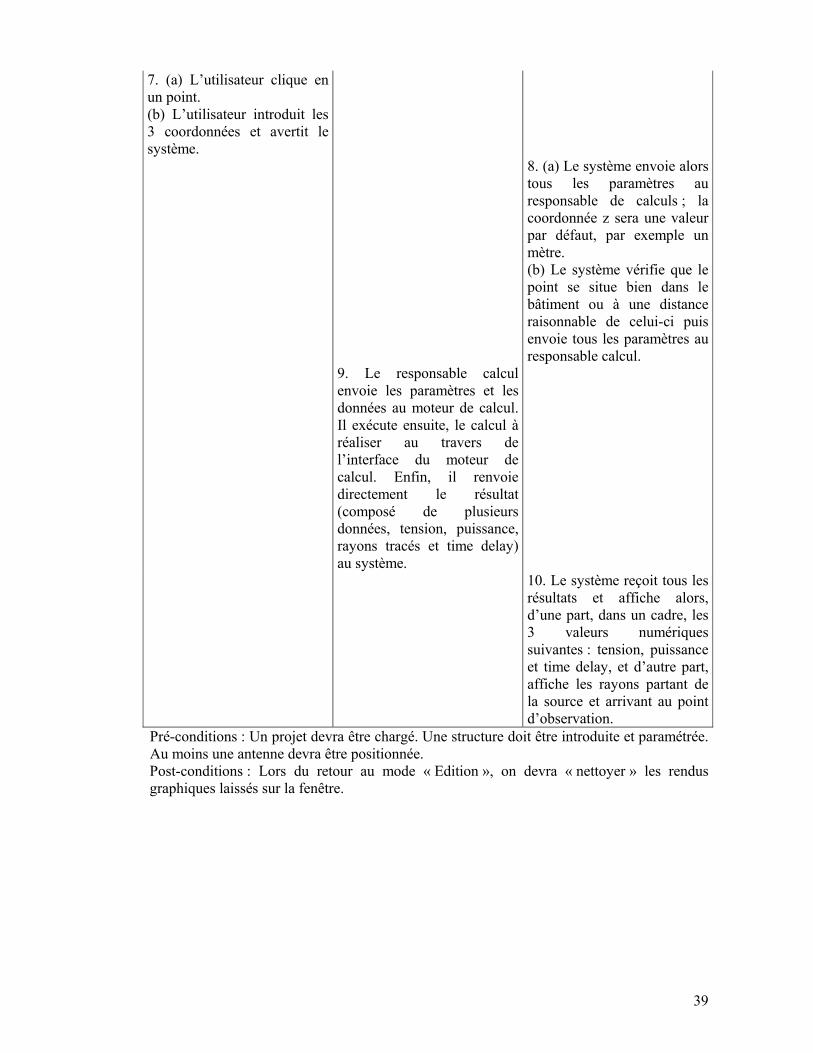
7. (a) L’utilisateur clique en un point. (b) L’utilisateur introduit les 3 coordonnées et avertit le système.
8. (a) Le système envoie alors tous les paramètres au responsable de calculs ; la coordonnée z sera une valeur par défaut, par exemple un mètre. (b) Le système vérifie que le point se situe bien dans le bâtiment ou à une distance raisonnable de celui-ci puis envoie tous les paramètres au responsable calcul.
9. Le responsable calcul envoie les paramètres et les données au moteur de calcul. Il exécute ensuite, le calcul à réaliser au travers de l’interface du moteur de calcul. Enfin, il renvoie directement le résultat (composé de plusieurs données, tension, puissance, rayons tracés et time delay) au système.
10. Le système reçoit tous les résultats et affiche alors, d’une part, dans un cadre, les 3 valeurs numériques suivantes : tension, puissance et time delay, et d’autre part, affiche les rayons partant de la source et arrivant au point d’observation.
Pré-conditions : Un projet devra être chargé. Une structure doit être introduite et paramétrée. Au moins une antenne devra être positionnée. Post-conditions : Lors du retour au mode « Edition », on devra « nettoyer » les rendus graphiques laissés sur la fenêtre.

40
2.3. Architecture Nous avons maintenant analysé le problème d’un point de vue extérieur et donc au niveau de la réponse de notre logiciel vis-à-vis de l’utilisateur. Il faut maintenant s’atteler à voir comment nous allons passer de cette vision externe à une vision interne où nous allons devoir implémenter les fonctionnalités que nous souhaitons offrir. Si certaines parties vont pouvoir être directement passées d’une vision à l’autre, nous allons devoir en décortiquer d’autres afin de réaliser un programme qui puisse être souple et évolutif. Un exemple simple de ce problème est le suivant : pour l’utilisateur, les résultats donnés par le moteur de calcul sont accessibles directement, tandis que pour le programmeur, une fois les résultats obtenus, il faudra encore les retravailler afin de les représenter graphiquement. Ceci peut passer par l’exécution d’algorithmes multiples afin notamment de pouvoir exécuter des interpolations, des rendus graphiques (par exemple : couleur froide pour une faible puissance et couleur chaude pour une forte puissance), … De ce fait, nous allons devoir subtilement découper notre programme en différents aspects qui permettront une souplesse essentielle à la programmation et à l’insertion de nouveaux modules. Au fil de notre analyse, nous avons pu voir surgir naturellement trois parties dans notre projet : l’affichage, le contrôleur de flot de données entre l’interface graphique et le moteur de calcul, et le moteur de calcul et le modèle du bâtiment. Ces trois parties correspondent exactement au patron Modèle-Vue-Contrôleur (MVC) qui est aujourd’hui largement utilisé. On va lui faire correspondre une architecture N-tiers (en trois couches dans notre cas) : les stimuli et données sont envoyés via l’interface graphique au contrôleur, celui-ci réorganise les données et les envoie soit à une base de données, soit à un moteur de calcul ou une quelconque entité qui effectue du traitements de données (requêtes – résultats), et enfin, lorsque les résultats sont obtenus, le modèle averti le contrôleur qui demandera alors un rafraîchissement de l’interface graphique pour afficher les résultats. L’intérêt d’une telle séparation est qu’elle permet de créer des modules pour chaque couche de façons indépendantes et permettant ainsi une grande modularité. Ceci nous permet par exemple de ne pas nous soucier de l’affichage lorsque nous réalisons le contrôleur. En effet nous allons définir une interface claire et propre à travers laquelle devra travailler l’interface graphique. Ainsi, si on décide de faire un affichage tridimensionnel dans une version future, nous devons simplement réaliser une interface graphique en se basant sur les données que renvoie le contrôleur.
2.4. Diagrammes de classes Nous allons maintenant attaquer les prémices de l’architecture du logiciel. Pour réaliser cette partie, nous allons utiliser des outils mis à disposition par le langage UML (Unified Modeling Language), et en particulier d’un outil : les diagrammes de classes. Avec cet outil nous pourrons générer le squelette des classes ainsi que quelques-unes des méthodes qui doivent être appelées à partir d’autres objets. Avant de réaliser le diagramme de classe, essayons de voir quels sont les groupements de classes que l’on peut effectuer. Nous savons que d’une part nous devrons avoir un modèle de la structure du bâtiment, ceci nous incite donc à construire un bâtiment sur base de différents objets (un mur, une arête, un étage, …) que nous allons regrouper dans un premier package : structmodel. Ensuite, nous avons toute une série de classes qui vont s’occuper de gérer le moteur de calcul, de réaliser le chargement des

41
paramètres, la récupération des résultats, etc… Nous allons donc déléguer ce travail à un second package : calculation. Nous avons vu qu’il allait être utile d’avoir la possibilité de visionner le bâtiment par étage. Pour effectuer ce rendu, nous allons projeter sur l’écran une vue de haut d’un étage. Nous voyons clairement la séparation entre le modèle et la vue, et c’est la raison pour laquelle nous attribuerons ce rôle de représentation d’étage à un troisième package : graphicview. Si il est pratique pour un être humain de visualiser un étage sur une vue bidimensionnelle, il n’est, par contre, pas toujours évident de retrouver l’élément que l’on souhaite modifier. Dès lors, nous allons devoir structurer cette visualisation au moyen d’un arbre ; cette partie est affectée au package treeview. Enfin, nous réalisons un cinquième package qui s’occupera essentiellement de gérer le projet, sauvegarder les fichiers, retenir les méta-données, etc…, le package project. Comme il est de coutume, nous ajouterons à tous ces packages, un double préfixe ; dans notre cas, nous avons choisi « tfe.raytracing ». On trouve à la Figure 2.2 une représentation de ces 5 packages contenant chacun les classes de base. Celles-ci seront bien sûr amenées à être modifiées et complétées par la suite mais ceci nous permet déjà d’avoir une idée globale.
project+ProjectManage+ProjectData+Parameters
calculation+Manager+ICalculationManage+IEngine
treeview+TreeViewerUI+TreeAdapter+TreeBuilding+TreeFloor+TreeVertex+TreeFacet+ContentProvider+LabelProvider+TreeVertexGrou+TreeFacetGroup+TreeRoot
structmodel+StructElemen+Building+Floor+VertexGroup+FacetGroup+Facet+Vertex+Root+XYZ
graphicview+Container+View+DisplayProvider+GraphicVertex+GraphicFacet+PaintMouseListene
Figure 2.2 : Packages du projet
On retrouve, sur les deux schémas qui suivent, les diagrammes de classes des packages structmodel à la Figure 2.3, et treeview à la Figure 2.4. Le package graphicview est relativement semblable à treeview au point de vue de la structure des classes.
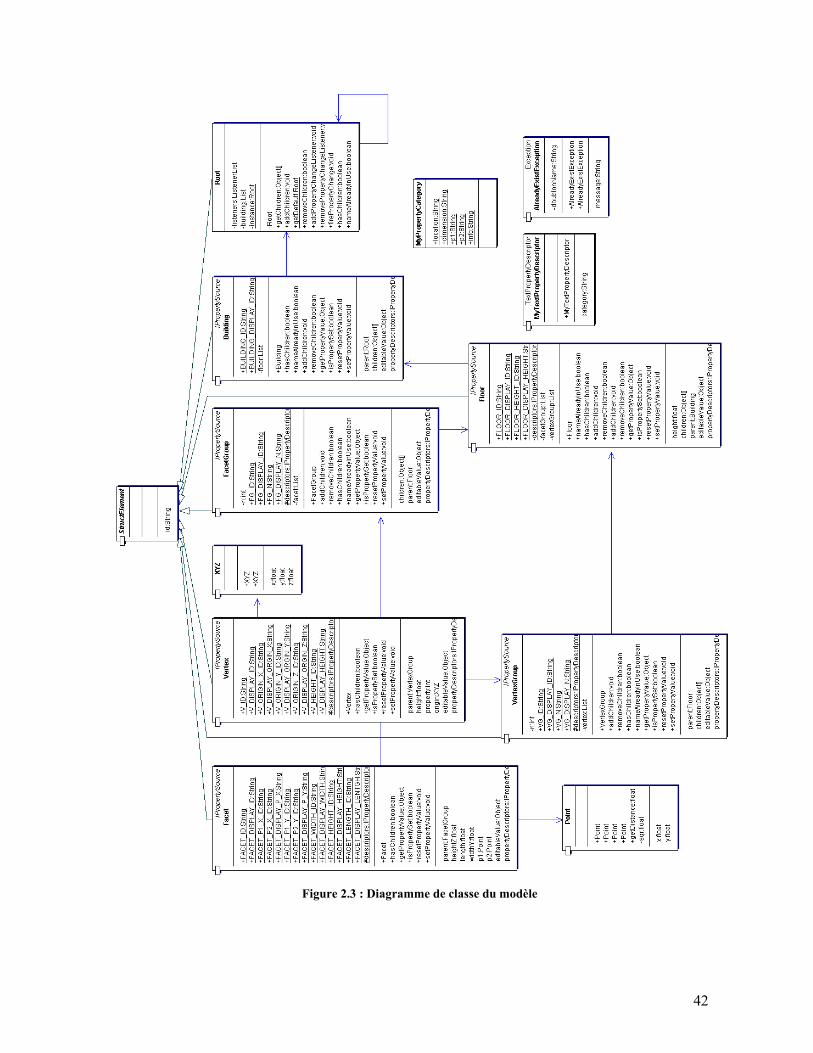
42
Figure 2.3 : Diagramme de classe du modèle

43
ITreeContentProvideIPropertyChangeListene
ContentProvider
-viewer:TreeViewer
+ContentProvider+register:void+getChildren:Object[]+getParent:Object+hasChildren:boolean+dispose:void+inputChanged:void+getElements:Object[]+propertyChange:void
ActionAddAction
-tvui:TreeViewerU+text:String+image:String
+AddAction+run:void
ActionDelAction
-tvui:TreeViewerU-text:String-image:String
+DelAction+run:void
ILabelProviderLabelProvider
+buildingImage:String+floorImage:String+groupImage:String+facetImage:String-imageCache:HashMap
+LabelProvider+getImage:Image+getText:String+addListener:void+dispose:void+isLabelProperty:boolea+removeListener:void
ViewPartISelectionChangedListene
TreeViewerUI
-viewer:MyTreeViewer-iActions:List-menuMgr:MenuManager-contextMenu:Menu-listeners:ListenerList-theTreeViewerUI:TreeViewer+MENU_ID:String
+createPartControl:void+setFocus:void+addListener:void+removeListener:void+selectionChanged:void
contentProvider:ContentProv labelProvider:LabelProviderselection:IStructuredSelectio viewer:TreeViewer
interfaceINewActiveViewListene
+activeViewAdded:void
TreeViewerMyTreeViewer
-vp:ViewPart
+MyTreeViewer#handleDispose:void
Figure 2.4 : Diagramme de classe de la vue en arbre
2.5. Diagrammes de séquences Pour aider à fixer les idées, nous allons maintenant réaliser quelques diagrammes de séquences permettant de voir l’ordre successif des appels aux méthodes, ce qui n’est pas toujours évident lorsqu’on programme en orienté-objet. Nous allons commencer par illustrer l’ajout d’un élément à la structure d’un bâtiment. On retrouve ce diagramme à la Figure 2.5. On peut y observer la séparation MVC, ainsi que l’utilisation d’un CommandStack qui permettra d’annuler ou recommencer cette opération de l’utilisateur.

44
CommandStack
User
Command ParentStructElemenUI UIControl
1.1.3.1: addChild
1: addNewElement
1.1.3.1.1.1: refreshVisuals
1.1.3: execute
1.1.1: new
1.1.2: pushCommand
1.1: addChildren
1.1.3.1.1: firePropertyChange
Figure 2.5 : Diagramme de séquence de l’ajout d’un élément à notre modèle A la Figure 2.6, on retrouve la séquence utilisée lors de l’annulation d’une opération d’édition réalisée par l’utilisateur. On notera que l’appel 1.1.2 undo est à la base de la modification du modèle. La modification du modèle génèrera automatiquement un évènement afin de notifier l’interface graphique.
CommandStack Command
User
UI RedoCommandStacAction
1: actionPerformed
1.1.3: pushCommand
1.1.2: undo
1.1.1: commandPop1.1: run
Figure 2.6 : Diagramme de séquence de l’annulation d’une opération
La séquence de recommencement d’une opération est fort similaire, sauf que les deux piles sont inversées et on fera un appel « redo » sur la commande. La série d’opérations à réaliser pour effectuer l’exécution des calculs est illustrée à la Figure 2.7. L’objet EngineParameterPage est une page d’un assistant permettant à l’utilisateur de configurer tous les paramètres du moteur de calcul. L’assistant empêche d’effectuer le performFinish, tant que les données ne sont pas correctes. Notons encore que la classe RTEngine délègue tous ses appels au moteur de calcul.
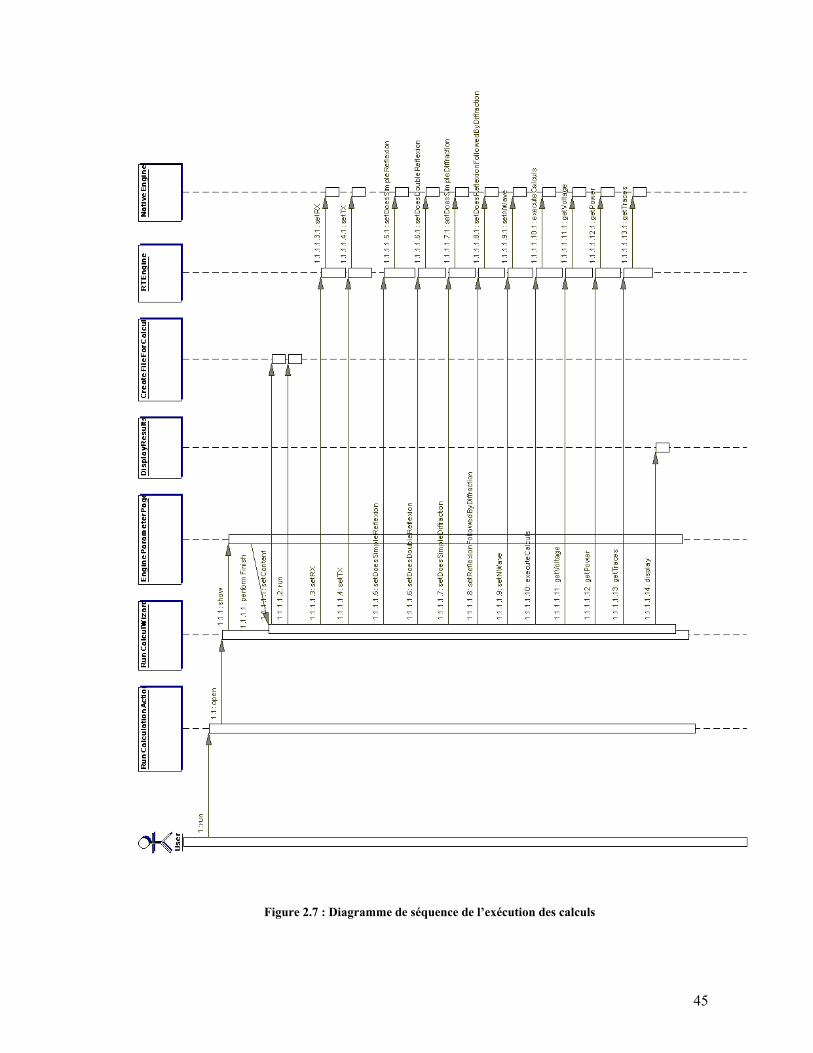
45
Figure 2.7 : Diagramme de séquence de l’exécution des calculs

46
2.6. Possibilités d’extension Les possibilités d’améliorer notre projet sont nombreuses. En effet, tel qu’il est actuellement, le moteur de calcul est déjà utilisé et permet d’effectuer des simulations. Mais le temps de préparation et de création des paramètres est excessivement lent, puisque réalisés manuellement, et en réduit fortement son efficacité. Dans notre programme, beaucoup de tâches sont automatisées ou facilitées afin que l’utilisateur ait un minimum de données à entrer. Mais le nombre de fonctionnalités que l’on peut ajouter est pratiquement infini, et nous allons donc nous limiter à certaines parties du logiciel. Voici les extensions principales que pourrait contenir notre programme dans le futur : un module permettant de visualiser le bâtiment en trois dimensions, la possibilité d’importer des projets venant de fichiers au format DXF (le format utilisé par le logiciel de modélisation 3D AutoCAD), un module permettant d’effectuer des calculs d’interpolation, un fichier d’aide, un algorithme de recherche d’arête au sein d’un bâtiment, utilisation de X3D (VRML 3) pour sauvegarder une structure de bâtiment. On ne peut réaliser une liste exhaustive de toutes les possibilités que devraient contenir notre programme. Cependant, on constate que les limites sont loin d’être atteintes, et dans ce but, il est essentiel de prévoir une architecture dans laquelle il sera simple d’ajouter de nouveaux modules comprenant fonctionnalités. Nous voyons donc que le nombre de fonctionnalités à rajouter est loin d’être négligeable, voir Figure 2.8, et dans cette optique nous allons étudier maintenant les logiciel basé sur des composants.
Figure 2.8 : Schéma des modules de notre application

47
Chapitre 3
Component-Based Software Engineering Dans ce nouveau chapitre, nous essaierons de comprendre et d’observer comment les logiciels basés sur des composants peuvent nous permettre de programmer mieux – on entend par mieux le fait d’avoir une meilleure structure, une meilleure organisation, et donc un programme contenant moins d’erreurs et plus performant. On commencera d’abord par une approche théorique des logiciels basés sur des composants, ensuite nous nous déciderons sur le choix de la plateforme qui permettra de mettre en œuvre tous ces concepts.
3.1. Que sont les logiciels basés sur des composants ? Avant d’entrer dans le vif du sujet, il est nécessaire de poser quelques bases afin de pouvoir comprendre la suite. Grossièrement, on peut considérer qu’il est possible de réaliser un logiciel sur base de composants que l’on considérera, dans un premier temps, comme de gros objets. Ceux-ci sont reliés entre eux par un code de « colle » (« glue » en anglais) qui permet la communication, la hiérarchisation et l’ensemble du fonctionnement de tous ces composants. Pour éviter de refaire inutilement ce code « glue » qui est d’ailleurs souvent source de problème, des frameworks ont été réalisés et permettent l’insertion de composants et la possibilité de redéfinir de nouveau point d’ancrage. Le but de chaque composant est de réaliser un ensemble d’opérations déclarées dans une interface séparée, ceci ayant pour but de pouvoir modifier l’implémentation d’un composant, sans modifier les autres. Nous allons maintenant voir comment les composants sont arrivés et que sont-ils réellement.

48
3.1.1. Historique Les composants (components) ne sont pas arrivés subitement, au contraire, ils sont le fruit d’années d’expériences et de tests sur des concepts souvent proches et qui, pour finir, ont été rassemblés en un seul. En réalité, les composants sont utilisés depuis très longtemps en programmation mais le terme en tant que tel n’était pas encore utilisé. Ce n’est que depuis maintenant quelques années que l’on commence à voir véritablement émerger les composants, ou plutôt leur dénomination. En effet, les besoins informatiques ont petit à petit forcé à créer des entités plus grandes que les objets, la granularité de ces derniers étant beaucoup trop fine. Les exemples sont bien sûrs nombreux : COM, COM+, DCOM, EJB, CORBA … sont tous des composants, du moins en partie, au sens des définitions que nous donnerons plus loin. Avant de voir une définition des composants, il est nécessaire de préciser qu’il n’existe pas de définition concrète des composants, mais bien plutôt un ensemble de concepts et de patterns qui doivent guider notre réflexion lors de la réalisation de l’architecture et du design d’un programme.
3.1.2. Définitions Les CBS sont encore relativement nouveaux et il est bien difficile de pouvoir trouver des avis unanimes sur les questions relatives à ceux-là. La définition qui semble la plus générale et sans doute la moins contestable, est la suivante : « Un composant est une unité de déploiement et de composition réutilisable » [4]. Si cette définition peut être facilement acceptée par tout le monde, elle reste bien trop vague et n’apporte aucune intuition sur ce que devrait être un composant. Il paraît donc intéressant de savoir comment sont définis les composants et quelles caractéristiques font l’objet de discussion entre spécialistes des logiciels basés sur des composants. Dans la vue d’ensemble technique de Microsoft sur les objets COM (Component Object Model), un composant est défini comme : « un morceau de software compilé qui rend un service »[5]. Ici encore, tout le monde acceptera cette définition mais elle est beaucoup trop générale car on peut alors considéré qu’une librairie compilée est un composant, ce qui n’est pas le cas. Les composants amènent un certains nombres de notions supplémentaires telles que les contextes d’utilisation, les pré-conditions et post-conditions d’une opération, … Une série d’informations qui permettent de mieux utiliser du code d’une tierce partie. Voyons maintenant quelques définitions qui sont plus précises et plus explicites, et bien entendu celles-ci sont le centre de bien des débats dans lesquels nous n’entrerons pas. Szyperski [6] définit un composant en énumérant de façon précise les propriétés caractéristiques d’un composant : « Un composant software est une unité de composition, accompagné d’interfaces respectant un contrat, et de dépendances contextuelles uniquement. Un composant software peut être déployé de façon indépendante et peut être implémenté par une tierce partie» [6]. On retrouve ici une notion déjà présente depuis longtemps dans la programmation orienté-objet : l’encapsulation. Par contre, on note ici que l’auteur de cette
4 Building Reliable Component-based Software Systems, Ivica Crnkovic, Magnus Larsson, Artech House Publishers, 2002 5 The Component Object Model Specification, Report Vol. 99, Microsoft Standards, Redmond, WA : Microsoft, 1996. 6 Component Software – beyond Object-Oriented Programming, Szyperski, C., Reading, MA : Addison-Wesley, 1998

49
phrase insiste surtout sur le fait que les opérations doivent être accompagnées d’informations contextuelles et que l’interface doit être clairement séparée de son implémentation. Si bien sûr ces idées étaient sous-jacentes à l’orienté-objet, elles sont ici clairement explicitées, et c’est souvent ce manque de clarté qui est à la base de problèmes surgissant par la suite d’un développement. Théoriquement, cette séparation claire offre les avantages suivants : d’une part, la réutilisation d’un composant à travers différents systèmes est rendue beaucoup plus simple, et d’autre part, l’intégration et le déploiement d’un composant est indépendant du cycle de vie des autres composants. Puisque chaque composant se base sur les interfaces des autres composants présents dans le système, on doit pouvoir changer l’implémentation d’un composant sans devoir réécrire les autres. Comme nous l’avons déjà dit, la seule définition des opérations ne suffit pas à créer un composant, et il est donc essentiel de fournir un ensemble de caractéristiques externes. Parmi celles-ci, on retrouve les interfaces fonctionnelles, les caractéristiques non-fonctionnelles (performance, ressources utilisées, etc…), les cas d’utilisations, les tests, … Malheureusement, les spécifications d’un composant sont loin d’être complètes. Il n’existe pas de méthode à proprement parler qui décrit l’ensemble des caractéristiques que doit définir un composant. En outre, les outils, qui permettent d’expliciter celles-là, sont souvent insuffisants et limitatifs. D’Souza et Wills, quant à eux, voient un composant « comme une partie de software réutilisable qui peut être développée indépendamment et peut être combinée avec d’autres composants afin de construire des entités de plus grande taille » [7]. Dans cette vision, la notion d’interface séparée de son implémentation n’est plus directement présente mais est devenue plutôt un concept sous-entendu. Par contre, on voit ici clairement apparaître le concept de construction de systèmes sur base de composants indépendants pouvant interagir avec d’autres. Les composants sont divisés en deux grandes catégories : les composants généraux et les composants d’implémentation. Les premiers sont, par exemple, les widgets que l’on dépose dans un canvas, les listes de template C++, ou encore les classes frameworks. Les composants d’implémentation reprennent, eux, tout ce qui contient du code exécutable, qui réalise une opération, les spécifications des interfaces ou du code template. Si, comme dans la vision orientée-objet, les composants sont destinés à être réutilisés, l’approche que prend le component-based software engineering pour la réutilisation est différente de celle utilisée traditionnellement. Aoyama explique cette différence comme suit : « d’abord, les composants peuvent être assemblés au moment de l’exécution sans devoir être recompilés, ensuite, un composant offre une interface clairement détachée de son implémentation permettant ainsi l’interopérabilité entre composants sans connaître les détails de son implémentation. » [8] On peut sentir à travers cette phrase que, si l’approche orientée-objet contient beaucoup de bons concepts et de bons principes, le manque d’outils et de technologie de développement plus évoluée a empêché, en partie, l’application d’une telle réutilisation. Nous allons voir maintenant, comment les composants sont plus à même de résoudre ce problème, notamment en inscrivant des contrats sur ceux-ci.
7 D. D’Souza et A.C. Wills, Objects, Components and Frameworks : The catalysis Approach, Reading, MA : Addison-Wesley, 1998 8 M. Aoyama, New Age of Software Development : How Component-Based Software Engineering Changes the Way of Software Development, Proc. 1st Workshop on Component-Based Software Engineering, 1998

50
Comme susmentionné, il n’existe pas de méthodologie complète de description de composants. Cependant, on peut citer un certain nombre de choses qui devraient se retrouver dans la spécification d’un composant, afin de pouvoir l’intégrer et l’utiliser dans un système de manière prévisible. Celui-ci devrait donc contenir : • Un ensemble d’interfaces pourvues pour l’environnement de travail ou requises par
ce dernier. Ces interfaces visent essentiellement à permettre l’interaction avec les autres composants, plus qu’à décrire l’infrastructure de composant.
• Un code exécutable qui peut être couplé au code d’autres composants, via les interfaces.
• Une spécification des caractéristiques non-fonctionnelles qui sont fournies ou requises.
• Un code de validation qui permet de confirmer le bon fonctionnement d’une connexion sur un autre composant.
• Toute information supplémentaire, ceci incluant les documents concernant la spécification des exigences, le design ainsi que les cas d’utilisation.
Avant de voir comment on peut construire des logiciels sur base de composants, il est important de clarifier quelques termes qui reviennent régulièrement et dont la signification peut varier ou peut inclure de nouvelles notions par rapport à leur sens traditionnel.
3.1.3. Concepts de base Interfaces Une interface d’un composant peut être définie comme la spécification de ses points d’accès. Les clients accèdent aux services fournis par ce composant au travers de ces points. De la même façon qu’en orienté-objet, une interface n’offre pas d’implémentation mais bien une énumération des opérations que le composant doit remplir, et des protocoles à utiliser. Ceci a pour conséquence de pouvoir remplacer l’implémentation d’un composant dans le but de l’améliorer, sans devoir refaire l’ensemble du système, et de pouvoir ajouter des interfaces à un composant, ce qui le rend beaucoup plus adaptable. Les interfaces doivent exprimer les propriétés fonctionnelles d’un composant, c’est-à-dire une partie dite de signature, essentiellement les prototypes des méthodes à implémenter (l’IDL, Interface Description Language, permet typiquement ce genre de description) et une autre partie dite de comportement qui exprime la manière dont réagit un composant selon un contexte donné. Cette dernière partie étant souvent omise des interfaces, notamment parce que le terme « interface » ne l’incluait pas par le passé, un autre terme a été assigné à cette partie de comportement : les contrats. Contrats Une spécification plus précise d’un composant peut être atteinte à l’aide de contrats. En effet, comme nous l’avons vu, les interfaces contiennent deux parties ; les contrats s’occupent d’expliciter clairement la partie comportementale d’un composant. De plus, ils englobent les interactions avec les autres composants. Un contrat doit donc surtout contenir 3 types d’informations : • Les invariants : les contraintes globales que le composant va conserver. • Les pré-conditions : les contraintes que doit remplir le client.

51
• Les post-conditions : les contraintes que le composant remplit en retour. En plus de cela, afin d’expliquer et spécifier les interactions avec les autres composants, le contrat contiendra les données suivantes : • L’ensemble des composants qui participent à l’interaction. • Le rôle de chaque composant, ce qui inclut notamment l’envoi de message aux autres
composants. • Les invariants que doivent conserver chaque composant. • La spécification des méthodes qui instancient le contrat. Patterns Au départ, les patrons (« patterns» en anglais) définissaient une solution récurrente à un problème récurrent. Mais on a rapidement affiné cette définition, en spécifiant les caractéristiques et les objectifs d’un pattern. Ceux-ci reprennent des solutions non-triviales, et pas uniquement des principes et stratégies abstraites, d’une façon indirecte. Les solutions doivent prouver qu’elles résolvent bien le problème, plutôt que d’être des spéculations ou des théories. Les patterns décrivent les relations entre les structures et mécanismes approfondis du système. Un composant peut donc être vu comme l’implémentation d’un pattern de design. On classe les patterns en trois catégories : • Patterns architecturaux : ce sont les patterns les plus hauts dans le niveau
d’abstraction. Ils gèrent essentiellement les propriétés globales et l’architecture d’un système formé de composants à grande échelle. Ceux-ci reprennent la structure globale et l’organisation d’un système.
• Patterns de design : déjà plus bas sur l’échelle d’abstraction, ceux-ci s’occupent surtout de la structure et du comportement des sous-systèmes ou des composants du système.
• Idiome : on les retrouve au niveau le plus bas d’abstraction. Ceux-ci dépendent du paradigme choisi et du langage de programmation utilisé.
Les patterns sont donc considérés comme des microarchitectures réutilisables qui contribuent à l’architecture générale du système. Cependant, l’utilisation de ceux-ci n’est pas sans difficulté puisqu’ils contiennent de la connaissance non-structurée dont l’interprétation et la mise en œuvre peuvent souvent être sources d’ambiguïtés. Frameworks Component-based software engineering signifie que l’on construit du software en « mettant des pièces ensembles ». Dans un tel environnement, il est donc essentiel de retrouver un contexte dans lequel peuvent venir se placer les composants : c’est à cet effet que sont prévus les frameworks. Selon le niveau d’abstraction que l’on prend, le terme prend différentes significations. On peut parler d’un environnement de travail qui accepte des composants, aussi bien que d’un design réutilisable de système dans lequel le design est constitué par une représentation de classes abstraites, d’interfaces et des interactions entre les instances de celles-ci. En effet, le framework MVC est une manière d’organiser un logiciel ou des parties de logicielle, mais on peut également considérer que Eclipse est un framework car des composants peuvent venir s’ancrer dans des points d’extension et peuvent également en redéfinir d’autres.

52
Les frameworks sont fortement corrélés aux patterns. Ils définissent un groupe de participants et les relations qui existent entre eux. Ils ne sont pas uniquement définis pour un cas particulier mais peuvent être réutilisés dans n’importe quelle situation isomorphe. On remarque que ce dernier terme n’est pas sans ambiguïté. Relations entre les concepts Il est intéressant de pouvoir comprendre comment sont organisés tous ces concepts et comment ils se positionnent l’un par rapport à l’autre. Dans la vision en composant, on peut représenter ces concepts comme sur la Figure 3.1. Dans ce pattern, un composant implémente une ou plusieurs interfaces. Le composant doit remplir un certain nombre d’obligations spécifiées dans un contrat. Dans un système construit sur des composants, on se base sur des composants qui jouent chacun un rôle spécialisé dans le système et décrit dans une interface. On appelle modèle de composants, l’ensemble des types de composants, leurs interfaces et une spécification des patterns d’interactions entre composants autorisés. Un framework de composant permet leur insertion, assemblage, déploiement, et fournit un ensemble de services au moment de l’exécution.
Figure 3.1 : Relations entre les concepts
3.1.4. Construction des CBS On distingue deux parties dans la construction des CBS : le développement des composants et le développement des systèmes. Le premier s’attache à rendre les composants plus réutilisables, en étant suffisamment généraux, mais en même temps, suffisamment spécifiques pour qu’ils soient réellement utiles. Le second s’occupe de distinguer quelles seront les entités à réaliser, les différents rassemblements de fonctionnalités. Les deux développements interagissent bien sûr l’un avec l’autre.

53
La création des composants est principalement dirigée par les interfaces à travers lesquelles ils communiquent, et par la « réutilisabilité », tandis que la création des systèmes est surtout orientée sur l’identification des entités réutilisables et la sélection des composants qui remplissent les besoins du système. Le développement d’un software pose toujours questions, quant à savoir si on développe soi-même les solutions à son problème, ou si on réutilise des solutions commerciales. La première réponse est bien sûr la plus adaptée à chacun de nos problèmes mais coûte fort cher en temps de développement, tandis que la seconde offre l’avantage d’être prête directement, mais est moins souple.
Développement de systèmes Pour obtenir des composants adaptés et utilisables, ils doivent être spécifiés, de préférence, d’une façon standardisée ; encore que cela ne soit pas toujours possible. La spécification des composants inclura bien sûr la définition précise des interfaces fonctionnelles, tandis que les autres attributs, si présents, seront spécifiés de manière informelle et sans grandes précisions. Malheureusement, les stratégies de développement s’arrêtent souvent là car il n’existe pas de méthode bien définie pour réaliser cette partie. Il existe bien sûr des techniques d’évaluation de la qualité d’un composant, mais elles interviennent beaucoup plus tard dans le développement. Il existe cependant une méthode importante qui permet de réduire le risque de choisir un « mauvais » composant, qui est d’identifier plusieurs candidats, de les étudier et rejeter ceux qui ne répondent pas aux besoins du projet. Ce procédé est connu sous le nom de « requirement-engineering orienté acquisition » (« procurement-oriented requirement-engineering » [9]. Il est souvent plus intéressant d’évaluer un ensemble de composants, plutôt qu’un composant seul. Ceci est d’autant plus vrai lorsque les composants forment une unité fonctionnelle. Le nombre d’assemblages possibles est souvent plus élevé qu’on ne pourrait le croire. Les établir nous permet de comparer les avantages qu’offrent telle ou telle organisation. Si la réalisation de l’architecture d’un système traditionnel découlait toujours de l’analyse, dans le cas des composants, le modèle de composants utilisé et en particulier le framework sélectionné dirigeront la découpe du système. L’architecture de base sera donc le fruit de l’analyse et du choix du modèle de composants. Le modèle influencera surtout la façon dont les composants collaborent entre eux et l’infrastructure nécessaires à leur encadrement, tandis que l’analyse influencera la répartition des fonctionnalités. Le but est d’obtenir la combinaison la plus appropriée et la plus réalisable de composants candidats.
9 COUNCIL (W.T.), HEINEMAN (G.T.), Component-Based Software Engineering, Putting the Pieces Together, Reading, MA: Addison-Wesley, 2001.

54
Développement des composants Le développement des composants est guidé bien sûr par les fonctionnalités qui lui ont été attribuées, mais également par la plateforme qui sera utilisée pour les mettre en œuvre. Notre attention sera particulièrement penchée sur la souplesse de nos composants, le choix entre spécificité et généralité et l’implémentation la plus correcte des contrats établis au préalable. Comme nous venons de le dire, les composants sont fortement influencés par l’environnement qui les encadre. Non seulement, le langage de programmation, mais également les services et librairies qu’offrent la plateforme. Dès lors, nous proposons d’étudier plus en détail, la façon dont on réalise les composants, lors de l’étude de la plateforme que nous aurons choisie.
3.2. Choix d’une plateforme Nous avons maintenant tous les éléments en mains, pour pouvoir choisir la plateforme la plus adéquate à notre problème. Etant donné le nombre de composants que nous souhaitons réaliser, il faudra que la plateforme soit une application de la théorie que nous venons de voir. Notons que le moteur de calcul fonctionne déjà actuellement, mais il ne tire pas encore parti des algorithmes optimisés qui réduisent, de façons drastiques, le degré de complexité ; il faut pouvoir changer le moteur de calculs, sans pour autant devoir retoucher au reste de notre logiciel. En outre, notre logiciel réalisant essentiellement une tâche d’interfaçage graphique, le choix de la plateforme sera surtout guidé par la nécessité d’obtenir quelque chose de simple, de par son utilisation, intuitif et de préférence agréable à regarder. A ce titre-là, nous allons diriger notre choix vers une plateforme naturellement modulaire, un framework de composants. En effet, ceux-ci ont pour caractéristiques d’être facilement extensibles et, donc, de permettre l’ajout de nouveaux modules et de nouvelles fonctionnalités sans risquer de perturber le reste du logiciel. Cette contrainte va déjà réduire notre champ d’investigation, laissant comme choix : Microsoft Visual Studio .NET, la plateforme Eclipse, développée par IBM et la plateforme Java 2 Enterprise Edition (J2EE), développée par Sun. Cette dernière est relativement inutilisable directement puisqu’il s’agit d’une spécification et non de son implémentation. Cependant, il existe plusieurs implémentations de J2EE, mais la plupart de celles certifiées par Sun sont des solutions commerciales. De plus J2EE n’offre pas de framework graphique à l’inverse des deux autres. Ces différents arguments nous amenant à éliminer cette solution, les deux autres proposant des fonctionnalités qui sont beaucoup plus intéressantes de notre point de vue. Le choix entre Eclipse ou .NET se base essentiellement sur les arguments suivant : Eclipse était déjà utilisé par des chercheurs du département d’informatique et réseaux, il est fort détaché des aspects lucratifs, il est un projet open-source, il offre des librairies qui correspondent à nos besoins et il est portable sur différentes plateformes sans modifications. Eclipse étant codé en Java, nous devrons faire appel à la technologie JNI qui permet de réaliser des appels sur du code compilé en langage natif

55
Chapitre 4
Eclipse Comme nous allons le voir, Eclipse constitue un des exemples de plateforme développé selon la théorie exposée ci-dessus. Dans un premier temps, nous allons aborder le monde d’Eclipse en surface et passer en revue les concepts principaux. Ensuite, nous nous attacherons à étudier les fondements de la plateforme Eclipse, comment celle-ci reprend la théorie vue précédemment, ainsi que la façon dont est organisée la plateforme pour la rendre facilement modulaire. Sur base de cela, nous verrons alors les avantages dont nous bénéficierons dans notre développement, et nous pourrons passer à l’étape suivante : le design, et finalement l’implantation de notre logiciel. Nous verrons au Chapitre 5, que l’utilisation d’Eclipse nous conduira à réaliser certaines modifications à notre design initial, et ce, afin de pouvoir rentrer dans le moule des plugins Eclipse. Nous verrons également que Eclipse nous force à effectuer certaines modifications dans la structure même de notre programme, et, bien souvent, cette nouvelle structure sera beaucoup plus claire, beaucoup mieux adaptée. Mais commençons d’abord par voir ce qu’est Eclipse et dans quels contextes il s’utilise.
4.1. Etude générale d’Eclipse Nous étudierons dans un premier temps ce qu’est Eclipse, comment il fonctionne, quels sont les concepts utilisés,… Nous verrons ensuite, comment utiliser et programmer Eclipse.
4.1.1. Approche globale La plateforme Eclipse est un IDE (Integrated Development Environment) pour développer pratiquement tout ce qu’on veut. Si au départ, elle se dirigeait essentiellement vers un outil

56
de développement « développable », dans sa nouvelle version, la 3.0 (achevée en juin 2004), Eclipse est devenu un véritable framework dans lequel pratiquement n’importe quel programme peut s’inscrire. Eclipse fournit une plateforme au sein de laquelle on peut retrouver les éléments graphiques les plus courants : éditeurs de textes, affichage de propriétés, console de communication, vue en arbre, … De plus, un certain nombre de projets sont venus palier à certaines lacunes, permettant ainsi, comme nous allons le voir par la suite, de développer pratiquement n’importe quelle application au sein de ce framework. Eclipse est écrit pratiquement uniquement avec des composants, ce qui permet de pouvoir réutiliser ces composants, mais également rajouter des fonctionnalités à certains ; dans la langue Eclipse, on ne parle pas de composants, mais bien de plugins. Au départ, Eclipse est destiné au développement de code, mais il est bien vite apparu que les possibilités de Eclipse étant telles que bien d’autres applications peuvent très facilement s’y intégrer. Aujourd’hui, on compte par millier les plugins disponibles pour Eclipse, et nombreux sont ceux qui ne sont pas des outils de développement. L’intérêt principal de posséder un environnement de développement auquel on peut ajouter des composants, est la possibilité de pouvoir rajouter ses propres outils et fioritures que l’on souhaite retrouver au sein de notre IDE. De plus, l’architecture en composant permet de ne lancer que ce qui est nécessaire, sans avoir à se soucier de la réaction des autres plugins.
4.1.2. Concepts de base Passons maintenant en revue les concepts essentiels définis dans Eclipse.
Plateforme : La plateforme d’exécution est la plaque de base d’Eclipse, le microkernel de base de l’application. Elle permet la détection à chaque démarrage de tous les plugins, elle vérifie ensuite que les plugins sont valides, enregistre les plugins dans un registre afin de pouvoir y accéder au travers de l’API et finalement lance tous ces composants. Workbench : Le workbench représente l’interface graphique d’Eclipse et c’est donc lui qui offre la structure générale de l’interface utilisateur. C’est dans celui-ci que sont organisés tous les éléments graphiques qui sont tous extensibles. Plugin : C’est le nom attribué aux composants d’Eclipse. En effet, on a pu voir que les composants ne sont rien d’autres que de petites briques, comme des Lego®, qui constituent le système logiciel. En anglais, le terme « plugin » possède une signification bien précise qui est le fait de pouvoir insérer quelque chose ou raccorder deux éléments au moyen d’une prise. Les deux éléments constitutifs d’un plugin sont le manifeste (voir point suivant), et la librairie, sous forme de fichier JAR, lui correspondant. Manifeste : Le manifeste est un fichier XML dans lequel sont repris toute une série d’informations telles que le nom de la librairie du plugin, les autres plugins requis, les points d’extension (voir

57
point suivant) que le plugin étend, et les nouveaux que celui-ci offre … Le manifeste est en fait la pointe de l’iceberg (voir Figure 4.1), pour un plugin. En parcourant ce fichier, la plateforme d’exécution peut effectuer un inventaire de tout ce qui est étendu, et peut donc organiser le démarrage de la plateforme, sans devoir parcourir toutes les classes de chaque plugin.
Figure 4.1 : Schéma de la structure d’un plugin
Points d’extensions : Eclipse fournit un système très simple pour rajouter des fonctionnalités : les points d’extension. Ce sont de véritables points d’ancrage pour les plugins, puisque c’est à travers ceux-là qu’on peut définir les fonctionnalités que l’on souhaite ajouter à Eclipse. Les points d’extension définissent un outil que l’on peut étendre en implémentant une interface. On appellera extension, le code qui implémente l’interface liée à un point d’extension.
Workspace : L’espace de travail est un répertoire rendu accessible aux plugins afin de leur permettre de référencer un autre répertoire dans lequel le plugin souhaite déposer des fichiers et, en général, y organiser les projets. La majorité du temps, on se contentera de créer un répertoire portant le même nom que le projet et se trouvant dans l’espace de travail. Vues : Les vues sont des instances de plugin qui permettent l’affichage d’une interface graphique au sein du workbench de Eclipse. On peut observer une série de vues différentes, encadrées en rouge sur la Figure 4.2.

58
Editeurs : Les éditeurs sont des instances de plugin qui permettent d’ouvrir, afficher, éditer et sauver des objets. Leur cycle de vie est le suivant : ouverture, sauvegarde et fermeture. Eclipse fournit un éditeur standard de texte ; des éditeurs plus spécifiques doivent, quant à eux, être fournis par d’autres plugins. On peut observer un éditeur encadré en bleu à la Figure 4.2. Pour simplifier l’organisation des fenêtres, les éditeurs sont rangés sous une série d’onglets. Perspectives : Lorsqu’on développe de grosses applications, il n’est pas rare d’avoir plusieurs vues et éditeurs à afficher simultanément, l’absence de l’un rendant aberrante la présence d’un autre – on prendra cependant, soin de pouvoir rester stable lorsque cette situation se produit. Il peut donc être intéressant de regrouper ces vues au sein d’un élément plus important : une perspective. La perspective courante à la Figure 4.2 est la perspective Java qui comprend plusieurs vues et un éditeur de code Java.
Projets :
Eclipse inclut déjà une notion de projet dans ses librairies et dans son framework – on peut d’ailleurs facilement s’insérer dans ce concept. Eclipse attribue automatiquement un répertoire pour chaque projet mais laisse la possibilité de modifier cela. En outre, Eclipse fournit un squelette que l’on retrouve au sein de n’importe quel projet, un nom, un répertoire, des paramètres propres, …, il peut donc être intéressant de s’en servir. Contributions :
Dans le monde d’Eclipse, tout ce qu’on rajoute au framework est appelé « contribution ». Il existe une multitudes de contributions : les actions, les menus, les boutons, les barres d’outils, les vues, les éditeurs, les assistants, les pages de préférences, les fichiers d’aide, … Ils sont tous associés à un point d’extension qu’il faut déclarer dans le manifeste, et à une classe qu’il faut étendre pour pouvoir y insérer nos propres fonctionnalités.
59
Figure 4.2 : Workbench d’Eclipse

60
4.1.3. Architecture d’Eclipse Comme nous l’avons vu, pour construire un framework afin d’y accueillir des composants, il est nécessaire de développer un code de « colle » qui va permettre l’organisation des composants, leur activation et rendre un certain nombre de services dont notamment une partie de la persistance. Ce code constitue un petit kernel, que l’on appelle plateforme d’exécution (« Runtime Platform », en anglais), au sein d’Eclipse. Le reste des fonctionnalités d’Eclipse se situe au sein des plugins, codées en Java. Un plugin contient typiquement du code Java, quelques fichiers en lecture seule, notamment le manifeste, et d’autres ressources telles que des images, des librairies en code natif, des pages HTML, … Il arrive que certains plugins ne contiennent aucun code, comme par exemple le plugin qui réalise l’aide sous forme de pages HTML, en se basant notamment sur des Java Server Page qui permettent la génération dynamique des pages. Au démarrage, la plateforme d’exécution va parcourir tous les manifestes des plugins disponibles et constituer un registre de ceux-ci. La plateforme cherche alors à trouver les extensions correspondant aux points d’extension déclarés. Tous les problèmes rencontrés, tels que des fichiers manquants ou des extensions n’ayant pas de points d’extension correspondant, sont enregistrés dans un journal. Une fois la plateforme lancée, il n’est plus possible d’ajouter de plugins. L’atout majeur du manifeste se retrouve dans le fait qu’il permet de ne pas charger tous les plugins. Au contraire, on ne chargera que ce qui est utilisé directement, le code des plugins étant chargé uniquement au moment de son utilisation, permettant ainsi de garder une utilisation des ressources raisonnable, et un temps d’initialisation drastiquement réduit. De plus, un plugin peut s’informer de la présence d’un autre plugin, encore inactivé par exemple, et des fonctionnalités qu’il offre, sans le lancer, le choix des informations disponibles ayant été minutieusement étudié par les développeurs Eclipse. Notons encore que l’interface de programmation d’Eclipse offre la possibilité de lancer des plugins qui seraient restés inactifs jusque là. Par contre, une fois lancé, le plugin reste activé jusqu’à l’arrêt de la plateforme, ceci offrant l’avantage de ne pas devoir recourir à des cycles de vie compliqués qui sont souvent sources de problèmes. En effet, la plateforme donnera toujours les mêmes informations sur les plugins, rendant les contextes beaucoup plus simples, puisque toujours identiques au cours d’une de ses exécutions. Le reste de la plateforme Eclipse comprend 4 parties : le workbench que nous verrons plus en détails par la suite, l’aide, la gestion de projets en équipe et l’espace de travail. L’aide permet d’afficher des pages HTML dans une interface fournie par Eclipse. Chaque plugin a bien sûr la possibilité de s’y intégrer, rendant l’aide unique à travers tous les plugins enregistrés dans la plateforme. La gestion des projets s’occupe de toutes les tâches à effectuer lors de développement en équipe : gestion des différentes versions, configuration de la gestion des fichiers, mise à jour des fichiers dans le répertoire dépositaire, … L’espace de travail est une ressource que Eclipse offre aux différents plugins afin qu’ils puissent gérer un ensemble de ressources faisant partie d’un éventuel projet. On peut retrouver cette organisation à la Figure 4.3.

61
Figure 4.3 : Structure interne du framework Eclipse
4.1.4. Le Workbench Le workbench (plan de travail) est l’interface utilisateur centrale dans Eclipse. Il fournit la structure globale à l’utilisateur, tout en lui offrant la possibilité de l’étendre et de lui ajouter de nouvelles caractéristiques. Comme on peut le voir sur la Figure 4.3, la partie s’occupant du plan de travail se base sur deux boîtes à outils de développement : SWT et JFace. Avant de parler du workbench, il nous a paru pertinent d’expliquer les fondements qu’il utilise, afin de mieux comprendre les mécanismes internes d’Eclipse. Nous allons également étudier comment Eclipse essaie d’améliorer les problèmes rencontrés en Java et comment il facilite la tâche du programmeur.
Notons encore que SWT et JFace peuvent être utilisés dans une application Java traditionnelle de la même façon que les librairies AWT et Swing.
SWT SWT, ou Standard Widget Toolkit, est un ensemble de symboles et de librairies graphiques intégré au système natif de fenêtres, mais offrant une interface de programmation unique à travers les différents systèmes d’exploitation sur lesquels Eclipse peut être exécuté. Le but premier de SWT est de supprimer les deux défauts majeurs que l’on trouve au sein des librairies graphiques traditionnellement utilisées en Java, à savoir AWT (Abstract Window Toolkit) et Swing : d’une part, le peu de ressemblance avec le « look and feel » du système natif de fenêtres, et d’autres part, le ralentissement considérable provoqué par leur utilisation, nuisant très souvent à la réactivité d’une application et l’empêchant de

62
concurrencer sérieusement une application développée pour une plateforme en particulier. De plus, les outils offerts par AWT sont relativement pauvres et sont souvent de bas niveau, car directement basés sur le système d’exploitation : on y retrouve donc le plus petit dénominateur commun entre tous les systèmes de fenêtres existants. Pour palier à ce problème, SWT définit une interface de programmation commune sur les différents systèmes de fenêtres et utilise les symboles graphiques natifs là où c’est possible. Dans le cas où il n’existe pas d’équivalent sur une des plateformes, SWT fournit une émulation appropriée. La majorité des symboles graphiques de bas niveau tels que les listes, les champs de textes, les boutons, … sont implémentés en natif sur toutes les plateformes. Par contre, il arrive que des outils graphiques de plus haut niveau, souvent fort utiles et évitant du code redondant, ne soient pas disponibles à travers tous les systèmes de fenêtres. Un exemple d’une telle situation est la barre d’outils SWT qui est implémentée en natif sur Windows, mais qui est émulée sur le système Motif®. Cette stratégie permet de maintenir un modèle de programmation consistant à travers tous les environnements, laissant en même temps la possibilité au système natif de se refléter dans l’interface utilisateur. Cette collaboration étroite entre SWT et l’interface graphique native n’a pas uniquement pour but de pouvoir ressembler le plus possible à celle-ci, mais permet également d’utiliser des propriétés natives du bureau telles que le glisser-lâcher (« drag and drop » en anglais), ainsi que l’utilisation de composants développés avec les modèles de composants du système d’exploitation. A ce titre, Windows ActiveX® est l’exemple typique, SWT prenant soin d’indiquer, au moyen des noms de package, que ceci est une caractéristique non portable et ne fonctionnant que sous Microsoft Windows®.
JFace JFace est un ensemble d’outils de développement pour les interfaces utilisateurs, permettant de gérer des tâches de programmation courante. Il est bien sûr indépendant des plateformes et est designé pour fonctionner avec SWT. Il inclut les composants graphiques les plus courant, tels que les registres d’images et de polices, les dialogues (question, erreur, information, …), les préférences, les assistants (« wizard » en anglais), et les barres de progression pour les jobs requerrant un temps d’exécution prolongé. JFace définit un mécanisme d’actions indépendant de sa représentation dans l’interface graphique. Une action n’est rien d’autre que du code exécutable déclenché par une commande de l’utilisateur au travers d’un bouton, d’un menu ou encore une unité dans une barre d’outils. L’action est accompagnée d’un certain nombre de caractéristiques, telles qu’un texte, une icône, un conseil d’utilisation, un identificateur, …, toute une série d’informations permettant l’utilisation de la même action au travers des différents déclencheurs graphiques. Les visionneuses (« viewers » en anglais) sont des adaptateurs basés sur des modèles. En effet, celles-ci gèrent le comportement général ainsi que des caractéristiques sémantiques de plus haut niveau que celles fournies par SWT. Pour pouvoir les utiliser, le programmeur est requis de fournir le modèle, les données utiles à la représentation, ainsi qu’un fournisseur de contenu (« Content provider » en anglais) et un fournisseur de label (« Label provider » en anglais). Le premier permet à la visionneuse de parcourir le modèle, tandis que le second s’occupe de la représentation des éléments du modèle.

63
Le fournisseur de contenu va se charger de permettre à la visionneuse de faire correspondre le modèle en entrée, au contenu que l’on souhaite voir apparaître. Il permet également d’exploiter les changements du modèle en mettant à jour la visionneuse. Le fournisseur de label à pour responsabilité de renvoyer les décorations, le texte et/ou l’icône, correspondant à un élément du modèle. On peut également ajouter un fonction de filtre et une fonction de tri, minimisant ainsi la tâche du programmeur et la concentrant essentiellement sur ce qui dépend réellement du client.
Workbench Le workbench n’est pas un outil pour développer l’interface utilisateur, mais contient plutôt la personnalité de l’interface graphique et la structure dans laquelle les outils interagissent avec l’utilisateur. On le considère communément comme l’interface utilisateur de la plateforme Eclipse. Celui-ci est entièrement implémenté à l’aide de JFace et SWT , Java AWT et Swing ne sont jamais utilisé. Le paradigme de l’interface utilisateur de la plateforme Eclipse est entièrement basé sur des éditeurs, des vues et des perspectives. D’un point de vue de l’utilisateur, la fenêtre du workbench consiste en un ensemble de vues et éditeurs, les perspectives se caractérisant par la sélection et l’arrangement de vues et d’éditeurs. « Les outils s’intègrent de façon bien définie dans ce paradigme. Les principaux points d’extension leur permettent d’amender le workbench en : • Ajoutant des nouveaux types d’éditeurs. • Ajoutant des nouveaux types de vues. • Ajoutant de nouvelles perspectives, organisant les anciennes et nouvelles vues pour
s’adapter aux tâches de l’utilisateur. • Ajoutant de nouvelles actions aux menu et barre d’outil d’une vue existante. • Ajoutant de nouvelles actions aux menu et barre d’outil du workbench lorsqu’un
éditeur devient actif. • Ajoutant de nouvelles actions au menu contextuel d’une vu ou d’un éditeur existant. • Ajoutant de nouvelles vues, ensemble d’actions, et raccourcis à une perspective
existante. » [10] La Plateforme s’occupe de tous les aspects de gestion des perspectives et fenêtres du workbench. Les éditeurs et les vues sont instanciés et sont disposés automatiquement au moment souhaité. Les icônes et labels des actions ajoutées par un outil sont listés dans le manifeste du plugin, permettant ainsi au workbench de les afficher dans les menus sans devoir activer le plugin qui les réalisent ; cette tâche étant réalisée au moment où l’utilisateur déclenchera l’action. Il existe bien sûr toute une série d’interfaces permettant à ces outils de communiquer l’un avec l’autre, notamment au moyen de listeners et d’évènements.
10 The Eclipse Project : Eclipse – Technical review, juillet 2001 (mise-à-jour Février 2003)

64
4.1.5. Architecture classique d’un plugin Eclipse La construction d’outils au sein d’Eclipse ne se fait pas exactement de la même façon qu’une application traditionnelle. En effet, on ne part pas de rien pour construire son application mais bien déjà d’un framework comprenant déjà de nombreuses fonctionnalités. La question qu’il faut se poser est « où vais-je étendre Eclipse ? Comment vais-je y contribuer ? ». C’est par la suite que l’on peut commencer à choisir comment organiser son plugin – on peut décider de créer plusieurs plugins afin d’obtenir une bonne séparation entre l’interface utilisateur et le modèle que nous développons. Si on souhaite être informé du cycle de vie du plugin, on peut étendre la classe Plugin. Il est souvent pratique de faire le notamment afin de rassembler des informations partagées dans une même classe. Le ou les plugins étant créés, nous allons rassembler les points d’extension que nous avons choisi d’étendre et les inscrire dans le manifeste – Eclipse fournit une interface graphique pour réaliser cette opération. Chaque point d’extension possède une interface que l’extension doit implémenter. Le plugin qui a déclaré ce point d’extension est responsable de charger toutes les extensions qui lui correspondent. A nouveau, on retrouve ici l’application typique de la notion d’interface clairement séparée qui permet justement de charger de nouveaux composants, sans connaître le réel contenu de celui-ci. Ensuite, nous ajouterons toutes les classes requises par les points d’extensions dans lesquelles nous viendront intégrer nos fonctions et notre modèle. Ici encore, Eclipse offre des classes de bases qui sont beaucoup plus nombreuses, plus riches en fonctionnalités et plus facilement réutilisables. Afin d’illustrer l’architecture d’un plugin Eclipse, nous avons repris à la Figure 4.4 un plugin comprenant une vue et deux actions (auxquelles nous pouvons accéder au moyen de menus et/ou de boutons) – il ne m’a pas paru utile de montrer un plugin d’une taille supérieure. Pour chaque groupement de classes, – les 2 actions (Figure 4.4 (a)) et la vue (Figure 4.4 (c)), la classe de plugin étant un élément plus central (Figure 4.4 (b)) – un point d’extension est défini : « org.eclipse.ui.actionSets », pour les actions, et « org.ui.views pour la vue » ; il n’y a pas de limite quant au nombre de fois que l’on peut étendre un point d’extension.
MyAction2 MyAction1
interfaceIActionDelegate
+run:void+selectionChanged:void
(a)
Plugin
MyPlugin
-instance:MyPlugi
(b)
interfaceIViewPart
WorkbenchPart
+createPartControl:voi
ViewPart
-viewers:Viewer[
+init:void
(c) Figure 4.4 : 2 classes action (a) Classe plugin centrale (b) Classes d’une vue graphique (c)

65
On remarque que Eclipse fournit à chaque fois une classe ou une interface de base qu’il faut étendre, ceci est l’application typique du principe d’interfaces séparées avec des contrats qui l’accompagnent. Dans Eclipse, les contrats sont souvent sous-entendus car les fonctions portent des noms fort explicites, mais on peut toujours en trouver le contenu dans la documentation qui l’accompagne. Avant de passer à l’intégration de notre application dans Eclipse, nous allons voir quelques principes et conseils qui permettront de nous intégrer au mieux dans Eclipse.
4.2. Programmation sous Eclipse Nous allons maintenant voir en détail quelles sont les techniques utilisées, et que nous devrons également appliquer, qui permettent à Eclipse d’être un outil performant et stable.
4.2.1. Patterns les plus courants au travers d’Eclipse On retrouve au sein d’Eclipse un ensemble de patterns qui permettent la bonne gestion des autres composants, leurs interactions, etc… Ceci a permis à Eclipse d’adopter une grande robustesse et stabilité au cours d’une exécution. Il est donc intéressant de pouvoir étudier ces patterns, essentiellement les architecturaux, et dans une moindre mesure ceux de design et les idiomes ; ceci pour trois raisons : nous pourrons mieux comprendre Eclipse, donc plus facilement nous y intégrer, ce qui renforcera également la stabilité de notre outil. Dans ce paragraphe, nous observerons les différentes techniques utilisées dans Eclipse qui permettent à Eclipse d’être un logiciel de qualité. Cette recherche nous fournira un double enseignement : d’une part, une bonne technique globale pour s’intégrer dans Eclipse, et d’autre part, cela nous apprendra également qu’est-ce qui fait que Eclipse est si bien réalisé.
Pattern Modèle-Vue-Contrôleur : Ce pattern est sans doute un des patterns les plus présents au travers d’Eclipse. Ce concept a été éprouvé depuis maintenant plusieurs années et est adopté universellement aujourd’hui. Nous allons procéder en trois parties : la première sera un petit exposé sur le concept de cette séparation, nous verrons ensuite comment il est repris à travers Eclipse et enfin, nous donnerons un petit exemple permettant d’illustrer l’application d’un tel pattern au sein d’un nouveau plugin Eclipse. Comme nous allons maintenant le voir, ce pattern est essentiel dans une architecture en composant. Cette séparation permet de tracer des séparations claires entre les différents rôles d’une application à savoir la (les) vue(s), un modèle et les contrôleurs. Le rôle de la vue est délimité par les responsabilités suivantes : offrir un rendu à l’utilisateur, envoyer aux contrôleurs les actions de l’utilisateur, permettre aux contrôleurs de sélectionner une vue. Le contrôleur doit effectuer les tâches suivantes : définir le comportement d’une application, réagir aux actions de l’utilisateur et pouvoir modifier le modèle en conséquence et sélectionner une vue. Le modèle, quant à lui, est responsable de cacher la structure interne du modèle (encapsulation), répondre aux demandes d’états du

66
modèle. Il contient les fonctionnalités de l’application et informe la (les) vue(s) lorsqu’un changement se produit. On retrouve à la Figure 4.5 un schéma classique de l’architecture Modèle-Vues-Contrôleurs.
Figure 4.5 : Illustration du pattern MVC
Voyons maintenant un exemple illustrant cette architecture au sein d’Eclipse. Nous avons choisi l’exemple d’une vue dont le diagramme de classe est fourni à la Figure 4.6. On peut clairement y voir apparaître les 3 composants : la classe Viewer est évidemment la classe centrale qui relie l’interface utilisateur au modèle, avec l’aide des 2 classes LabelProvider et ContentProvider, elle réalise la partie « Contrôleur ». LabelProvider est la classe qui fournit une représentation pour chaque objet présent dans le modèle, tandis que ContentProvider s’occupe d’extraire les données du modèle. La classe ViewPart est entièrement responsable de l’affichage graphique et fait donc partie de la partie « Vue ». Le modèle, représentant bien évidemment les données qui seront représentées dans la vue, occupe bien sûr la partie « Modèle ».

67
0..*
Viewer
-vp:ViewPart-cp:ContentProvider-lp:LabelProvider-input:Model
+setContentProvider:void+setLabelProvider:void+setInput:void
ViewPart
-viewers:Viewer[]
+init:void
interfaceIViewPart WorkbenchPart
+createPartControl:voi
LabelProvider
ContentProvider
+inputChanged:void
Model
Figure 4.6 : Application du pattern MVC à une des vues d’Eclipse
Pattern de l’observateur Le pattern de l’observateur est également un pattern fort répandu, Eclipse ne faisant pas exception. En effet, cette technique permet d’offrir une solution simple mais excessivement performante aux problèmes de communication entre objets. Lorsque plusieurs classes doivent être averties d’un même évènement, on crée une classe centrale, le sujet, qui se chargera de créer une liste d’inscription pour un ou plusieurs observateurs et d’avertir toutes les objets de la liste lorsqu’un évènement se produit. On retrouve l’illustration de ce schéma à la Figure 4.7, les flèches indiquant les envois de messages.
Il comporte cependant quelques restrictions et ne peut s’appliquer dans chaque cas. Celui-ci est très utile lorsque les communications sont peu corrélées entre elles. En effet, lorsque le nombre d’objets qui doivent être informés d’un évènement est inconnu, que leur classe n’est pas connue d’avance, que l’ordre de réception des messages n’est pas important et que rien ne doit être renvoyé à l’expéditeur du message, on crée alors une interface qui devra être implémentée par chaque classe qui veut être avertie de cet évènement. On retrouve l’application de ceci à travers les quelques lignes de codes suivantes qui se trouvent dans une méthode de la classe sujet :
public void fireEvent(Event e) { for (Iterator all = getListeners().iterator(); all.hasNext();) { IEventListener each= (IEventListener) all.next(); each.eventStarted(e); } }

68
où la fonction getListeners() renvoie la liste des observateurs, Iterator est une classe Java permettant d’effectuer facilement des boucles sur base de vecteurs d’objets tandis que IEventListener est l’interface implémentée par chaque classe qui désire être observateur.
Figure 4.7 : Illustration du pattern de l’observateur
Pattern Proxy
Ce pattern devrait plutôt s’appeler pattern du proxy virtuel, car aucune machine distante n’est utilisée, toutes les opérations restant dans la même application. Ce pattern est utilisé pour éviter de surcharger la mémoire et le temps de chargement pour des grosses classes. Le principe est assez simple, on utilise une classe plus petite, recueillant uniquement les quelques informations nécessaires au démarrage, et qui instanciera la classe dont elle est le proxy au moment nécessaire. On comprend facilement que de grandes parties de code ne sont parfois jamais utilisées et il est dès lors bien plus rapide d’utiliser une classe proxy. Dans Eclipse, les classes proxy sont fort utilisées, notamment au niveau de l’interface graphique. En effet, nous avons vu que chaque contribution était recensée dans les manifestes de chaque plugin. Il serait cependant bien long de lancer tous les plugins pour connaître le nom de tous les menus et boutons qui doivent apparaître dans l’interface graphique. Dès lors, sur base des manifestes, Eclipse utilise des classes proxy génériques dans lesquelles il peut stocker les quelques informations nécessaires pour que le Workbench puisse afficher tous les éléments graphiques. Lorsque l’utilisateur veut accéder à une contribution, la classe proxy charge alors la classe concernée et en exécute le code. Pour fixer les idées, prenons le cas d’une action devant apparaître dans une barre d’outils avec une icône. L’action peut être une grosse classe contenant beaucoup de méthodes et d’attributs nécessitant donc beaucoup de place et de temps pour mettre en mémoire. Or, il se peut que l’utilisateur n’exécute jamais cette action. En plaçant dans le manifeste les 5 données suivantes : l’identifiant de l’action, son label, son icône, son emplacement (dans le workbench) et sa classe, le Workbench peut créer l’affichage graphique de l’action en chargeant une petite classe proxy qui contient ces quelques informations. Nous verrons plus loin que le proxy pattern est en fait une application de la règle du chargement (en mémoire) paresseux.
Sujet
Observateur
Observateur
Observateur
Observateur
IEventListener « implements »

69
Pattern du singleton
Le pattern du singleton est un pattern utilisé depuis longtemps et qui permet de créer une classe qui ne pourra être instanciée qu’une seule fois. L’intérêt de cette technique est qu’elle permet d’avoir des informations partagées entre plusieurs classes mais rassemblées en une seule, évitant ainsi la duplication des données et leur synchronisation. Typiquement, la classe Plugin d’un plugin est construite de la sorte, ainsi, celle-ci n’est instanciée qu’une seule fois, permettant le partage d’informations telles que les préférences, les images et les paramètres sauvegardés.
La réalisation d’un tel artefact se réalise de la façon suivante dans le code : public class SingletonClass { private SingletonClass(){…} private static SingletonClass instance = new SingletonClass() ; public static SingletonClass getInstance(){ return instance ;} … }
Le constructeur étant privé, seule la classe elle-même peut l’appeler. Pour obtenir une référence vers l’instance de la classe, il faut appeler statiquement la fonction getInstance().
4.2.2. Règles
Voici un panaché des règles à appliquer et qui sont appliquées dans Eclipse. Elles sont tirées d’un livre écrit par Erich Gamma et Kent Beck [11]. En effet, elles représentent un ensemble de règles extrêmement simples mais qui éliminent très facilement beaucoup d’erreurs, accélèrent la programmation et structurent mieux le code.
L’application de ces règles sera illustrée au chapitre suivant. Nous verrons alors les modifications qu’elles entraînent et les bénéfices que l’on peut en retirer.
Règle de contribution :
Comme susmentionné, Eclipse fait partie des CBS et donc est composé de plusieurs dizaines de plugins qui se chargent l’un l’autre. Le principe sous-jacent, illustré à la Figure 4.8 sur le schéma de droite, est que chaque partie est la contribution à une autre, excepté la plateforme qui définit les points d’extension de base d’Eclipse ; dans Eclipse, tout est contribution. C’est également ceci qui est à la base de la souplesse et force d’Eclipse par rapport aux autres logiciels.
11 Erich Gamma, Kent Beck, Contributing to Eclipse: Principles, Patterns, and Plug-Ins, MA : Addison-Wesley, 20 Octobre 2003

70
Quelques extensions Eclipse : tout est extension
Figure 4.8 : IDE classique VS Eclipse
Règle du copier-coller :
Sans doute la règle la plus simple mais certainement pas la moins utile. En effet, Eclipse est conçu de façon telle que chaque personne qui souhaite s’y intégrer doit se conformer à la « programmation Eclipse » qui diffère par moment de la programmation C++ ou Java. L’intérêt de cette règle est que, non seulement il ne faut pas retaper du code déjà écrit et corrigé, mais en plus il a sans doute déjà été étudié et la solution offerte est bien souvent la meilleure. On notera surtout que cette règle est très utile lorsque l’on débute dans la programmation Eclipse, en l’appliquant, on appréhende plus vite et mieux les concepts d’Eclipse et sa façon de fonctionner. Règle du chargement (en mémoire) paresseux :
Pour garder des temps de démarrages et des performances intéressantes, Eclipse tente de charger le moins de choses possibles au démarrage. C’est pour pouvoir appliquer cette règle que Eclipse a besoin d’un manifeste. En effet, au démarrage, Eclipse va regarder tous les manifestes, ceux-ci contiennent suffisamment d’information pour construire l’interface utilisateur sans devoir, pour autant, charger toutes les classes de tous les plugins, permettant ainsi de gagner un temps précieux. Nous veillerons donc à faire de même et à n’instancier les classes et les plugins qu’au moment où c’est nécessaire. Règle du partage :
Dans Eclipse, pratiquement tout ce qui peut être étendu utilise cette règle. En effet, elle consiste à faire en sorte que, pour chaque nouvelle fonctionnalité, celle-ci vienne se rajouter aux autres et non en remplacer une. Règle de conformité :
Lorsque l’on étend Eclipse, que l’on y contribue, il faut respecter les interfaces définies et donc les interfaces attendues dans une extension. Cette règle est relativement évidente et il est impossible d’y échapper.

71
Règle d’invitation :
Autant que possible, il faut laisser d’autres contribuer à son projet. On peut le réaliser dans Eclipse au moyen des points d’extension (voir 4.1.2). Lorsqu’on fournit un point d’extension, on est responsable de charger toutes les extensions qui lui correspondent ; ceci est une adaptation du pattern de l’observateur. On observer, ici, l’application de la théorie des logiciel basé sur des composants, puisque pour chaque point d’extension, une interface claire et séparée est requise. Il faut en effet indiquer la- ou les-quelles implémenter, ainsi qu’une documentation suffisante pour connaître les pré-conditions, les post-conditions et les invariants. Règle du Fair-Play :
Tous les clients d’un point d’extension sont à la même enseigne, il n’y a qu’une seule façon pour eux de contribuer à notre projet. La règle de fair-play indique que même celui qui crée un point d’extension, doit passer par ce même point et non pas profiter de certains raccourcis accessibles uniquement au programmeur de celui-là. Règle d’extension explicite :
Eclipse fait une distinction assez nette entre des méthodes publiques et des méthodes publiées. Alors que les méthodes publiées sont prévues pour être utilisées par tous, les méthodes publiques restent en général fort peu accessibles aux autres. Eclipse ré-applique ce concept à travers le manifeste qui regroupe clairement les points d’extension d’un plugin et déclare des points de passages pour les clients, alors que les méthodes publiques sont beaucoup plus masquées et il arrive même que certaines soient interdites à l’utilisation par une tierce partie. Règle de la plateforme sûre :
Eclipse souhaitant pouvoir rester stable à tout instant, lorsque l’on définit un point d’extension, nous sommes priés de nous protéger vis-à-vis des clients qui ne l’utiliseraient pas correctement. Cette règle ayant pour but de pouvoir continuer à travailler dans la même session d’Eclipse, même si un ou plusieurs plugins ne réagissent pas comme il le faudrait, évitant ainsi de détruire éventuellement certains travaux qui n’auraient pas encore été sauvegardés.
Nous avons maintenant acquis suffisamment de connaissances, tant sur les composants que sur Eclipse, pour pouvoir réaliser le design complet de notre application et ensuite la coder. Nous allons donc nous attacher maintenant à modifier et adapter l’analyse que nous avions réalisée précédemment pour qu’elle s’intègre le mieux possible dans le framework d’Eclipse. Pour y parvenir, nous essaierons d’appliquer au maximum les règles et patterns que nous avons vus ci-dessus.

72
Chapitre 5
Design, Implantation et Résultats Ayant choisi Eclipse, nous allons maintenant passer à la mise en place du projet sous Eclipse. Nous devons maintenant déterminer quels sont les points d’extensions que nous allons étendre. Pour ce faire, nous avons eu recours à un livre expliquant la structure d’Eclipse et surtout la manière dont il faut programmer Eclipse : « The Java Developer’s Guide to Eclipse » [12]. Nous allons bien sûr reprendre les diagrammes réalisés préalablement et les adapter légèrement afin qu’ils puissent être utilisés dans Eclipse. Notre tâche ici consistera essentiellement à choisir les bons points d’extension et de profiter un maximum des outils mis à notre disposition. Il faut encore faire une remarque pour Eclipse, si le langage utilisé à travers toute la plateforme est Java, il faut savoir qu’il n’est pas possible de réutiliser les librairies AWT et Swing. Comme nous l’avons vu, Eclipse est entièrement basé sur SWT et JFace pour la réalisation de l’interface graphique, nous devrons donc également nous renseigner sur leur utilisation. Si SWT ressemble très fort aux autres librairies graphiques de Java, JFace, quant à lui, est relativement neuf et contient des outils qui n’existaient pas auparavant. Mais avant de commencer notre travail sous Eclipse, nous devons voir comment nous pouvons nous servir du moteur de calcul, écrit en C/C++, alors qu’Eclipse fonctionne avec le langage Java.
5.1. Intégration du moteur de calcul Comme nous le savons, le moteur de calcul est codé en C/C++, or Eclipse est écrit en Java. Dès lors, nous ne pouvons intégrer directement le moteur à notre programme et nous devons passer par 12 Sherry Shavor, Jim D’Anjou, Scott Fairbrother , Dan Kehn, John Kellerman et Pat McCarthy, The Java Developer’s Guide to Eclipse, 4ème édition, MA : Addison-Wesley, Décembre 2003.

73
une autre méthode pour y parvenir. Ici, deux solutions s’offrent à nous : Java Native Interface ou CORBA. Le premier est destiné à appeler du code compilé en langage natif (c’est à dire compilé pour une machine spécifique), tandis que le second est utilisé pour la distribution d’objets (le langage ne devant pas être le même partout au sein d’une application CORBA. Le premier est destiné directement à notre problème et c’est pour cette solution que nous avons opté. Le second offre un avantage qui pourrait être très intéressant : la distribution. Ce qui signifie qu’un utilisateur pourrait avoir notre logiciel qui tourne sur la plateforme Eclipse, tandis que les calculs pourraient être effectués sur des serveurs dédié, permettant d’accélérer sensiblement le temps d’exécution. La raison qui nous pousse à utiliser Java Native Interface est surtout sa simplicité. En effet, nous verrons par la suite comment passer d’une interface Java à une classe en C++. Pour pouvoir utiliser CORBA, il est nécessaire d’établir pas mal de fonctions et classes avant de pouvoir s’en servir alors que notre but n’est pas d’utiliser des objets distribués au départ. Comme de surcroît, nous ne possédons pas de serveur de calculs, l’intérêt en est réduit à néant.
5.1.1. Java Native Interface
Java Native Interface (JNI) est une technologie développée par Sun Microsystems dans le but de pouvoir utiliser du code natif, en général en C/C++, à partir de code Java. L’atout majeur qu’offre cette technologie repose bien pour sur la vitesse d’exécution du code. En effet, le code étant compilé pour une machine, il ne doit pas être interprété et, en outre, il est optimisé. Nous allons rapidement montrer comment se servir de JNI.
Partie en Java On commence par déclarer une classe qui contient les signatures des fonctions à appeler (voir Figure 5.1). public class RTEngine implements IEngine { public native void setNWave(double K) ; public native void setRX(Antenna rx); public native void setTX(Antenna tx) ; public native void loadGeometry(String facetFile, String vertexFile) ; public native void executeCalculation() ; public native double getPower() ; public native String getTracesFile(); public native double getVoltage() ; static { System.loadLibrary("raytracing"); } }
Figure 5.1 : Classe qui réalise les appels sur la librairie écrite en langage natif

74
On ajoute le chargement statique de la librairie dynamique (.dll ou .so) avec la ligne :
static { System.loadLibrary("raytracing") ;}
où raytracing est le nom de la librairie sans son extension. L’emplacement de celle-ci est indiqué avec l’argument pour la Java Virtual Machine suivant : -Djava.library.path="E:\TFE\eclipse\workspace\tfe.raytracing.structeditor\lib" Ensuite on compile la classe en question avec la commande suivante : $>javac tfe.raytracing.calculation.RTEngine.java A l’aide du générateur d’en-tête fourni avec la JVM, on crée le fichier d’en-tête : $>javah –jni tfe.raytracing.calculation.RTEngine
Partie en natif On prend le fichier d’en-tête généré, et on en écrit son implémentation dans un fichier source. L’accès aux paramètres et le renvoi de valeurs est assisté par le pointeur JNIEnv*. Cette structure offre des fonctions permettant de récupérer des valeurs de champ de classe, d’en exécuter des fonctions, de convertir des types Java en types natifs et vice-versa. Voici quelques lignes de code illustrant l’utilisation de ce pointeur : JNIEXPORT void JNICALL Java_tfe_raytracing_calculation_RTEngine_setTX (JNIEnv *env, jobject object, jobject antenna) { jclass cls=(env)->GetObjectClass(antenna); jfieldID id= (env)->GetFieldID(cls,"x","F"); Tx.pos.x=(env)->GetFloatField(antenna,id); id= (env)->GetFieldID(cls,"y","F"); Tx.pos.y=(env)->GetFloatField(antenna,id); id= (env)->GetFieldID(cls,"z","F"); Tx.pos.z=(env)->GetFloatField(antenna,id); id=(env)->GetFieldID(cls,"resistance","D"); Tx.Ra=(env)->GetDoubleField(antenna,id); }
Figure 5.2 : Obtention des valeurs des champs On observe sur la Figure 5.2, les 3 paramètres en entrée de la fonction : *env, qui permet de manipuler les objets et méthodes Java, object, la classe dans laquelle se trouve la déclaration de cette fonction, et antenna, l’objet de type Antenna passé en paramètre à la fonction (voir Figure 1.11). La récupération des membres de antenna se fait en 3 étapes : d’abord il faut récupérer le type de l’objet antenna (Antenna dans ce cas-ci), ensuite récupérer l’identificateur du champ et enfin récupérer la valeur de ce champ. On retrouve ci-dessous quelques lignes permettant de convertir des string Java en char* JNIEXPORT void JNICALL Java_tfe_raytracing_calculation_RTEngine_loadGeometry (JNIEnv *env, jobject object, jstring facetFilePath, jstring vertexFilePath){ jboolean isCopy; const char* facetPath=(env)->GetStringUTFChars(facetFilePath,&isCopy); const char* vertexPath=(env)->GetStringUTFChars(vertexFilePath,&isCopy); }
Figure 5.3 : Conversion d’un string Java en char* en C

75
Pour la compilation de ce fichier, on ajoutera au compilateur les répertoires à inclure suivant :
Sous Linux : • JDKHome/include • JDKHome/include/linux
Sous Windows : • JDKHome\include • JDKHome\include\win32
5.2. Intégration d’un module dans Eclipse – Application à notre module
Avant toutes choses, rappelons que le modèle établi lors de notre analyse logicielle reste bien sûr valable, et c’est celui que nous utiliserons par la suite dans notre projet. Commençons par déterminer les points d’extension que l’on souhaite étendre. Pour cela, nous allons d’abord voir l’ensemble des vues et actions que l’on désire avoir dans notre logiciel.
5.2.1. Extensions
Lors de l’analyse logicielle, nous avions choisi une vue structurée en arbre, à cet effet donc, nous étendrons le point d’extension suivant : « org.elcipse.ui.views ». La seconde vue que nous souhaitons avoir est une vue graphique. Nous allons donc adopter le même modèle que précédemment, mais cette fois-ci nous allons passer par un projet complémentaire d’Eclipse : GEF, ou le Graphical Editing Framework. Ce projet fournit des classes et des outils qui permettent l’édition de structures graphiques, comme nous avions parlé dans l’analyse logicielle. Nous utiliserons le point d’extension suivant qui est réservé aux éditeurs (quelqu’ils soient) : « org.eclipse.ui.editors ». Nous verrons au point suivant son fonctionnement. Comme nous l’avons vus dans les cas d’utilisation, nous souhaitons pouvoir éditer les propriétés des éléments de la structure. A cet effet, la vue « Properties » semble tout à fait appropriée. Elle ne nécessite pas de point d’extension, elle requiert juste que le modèle implémente l’interface « org.eclipse.ui.views.properties.IPropertySource ». Nous verrons par la suite que cette vue est complémentaire avec la vue en arbre. Pour la création et ouverture de projet, un petit assistant semble approprié, et nous étendrons donc le point suivant : « org.eclipse.ui.newWizards » ; ceci permettra donc d’avoir un assistant qui s’ouvre pour créer un nouveau projet. L’utilisateur aura le choix de créer un projet de ray-tracing parmi les autres projets. Cette intégration dans le framework Eclipse permet de conserver le « look and feel » d’Eclipse, facilitant donc la tâche de l’utilisateur, puisque l’interface est plus intuitive. Enfin nous regrouperons toutes ces vues au sein d’une même perspective qui étend le point « org.eclipse.ui.perpsectives ». Nous avons ici le choix de placer chaque vue dans un nouveau plugin, ou bien, de toutes les rassembler au sein du même plugin. L’intérêt de les

76
séparer en plusieurs plugins est évidemment de pouvoir réutiliser chaque vue séparément. Cependant, dans notre cas, il apparaît que cette séparation est inutile, et que de plus, elle pourrait aboutir sur certaines incohérences. Enfin, nous viendrons ajouter des menus et des boutons dans la barre d’outils pour effectuer les actions suivantes : création, ouverture et sauvegarde de projet, lancement des calculs. Ceci est réalisé en étendant les points suivants : « org.eclipse.ui.actionSets » et « org.eclipse.ui.editorActions ». Nous avons maintenant tous les points d’extensions que nous allons étendre.
5.2.2. TreeViewer Pour étendre le point d’extension des vues, « org.eclipse.ui.views », nous devons étendre la classe org.eclipse.ui.views.ViewPart qui est une classe abstraite contenant quelques fonctions à surécrire afin de pouvoir nous insérer. C’est ici que le livre vient nous épauler, car il nous indique non seulement l’architecture que va prendre notre extension, mais également les outils que JFace fournit pour nous simplifier la tâche. En effet, nous avons directement une architecture à laquelle le pattern MVC a été appliqué que l’on peut retrouver à la Figure 5.5 : la partie modèle est représentée par la classe StructElement, la partie vue est réalisée par la classe ViewPart et sa classe mère, tandis que la partie contrôle est réalisée par le restant des classes. Et, d’autre part, JFace nous fournit une classe, TreeViewer, qui va gérer pour nous tout l’affichage de l’arbre. Notre seul rôle ici sera donc de créer le modèle, fournir un moyen d’accès et de parcours de notre modèle (ContentProvider), et un moyen d’effectuer un rendu graphique des éléments se situant au sein de notre modèle (LabelProvider). Aux moments opportuns, nous devrons rafraîchir l’arbre afin qu’il soit informer des changements au sein du modèle. Pour réaliser cette dernière opération, nous allons appliquer le pattern de l’observateur. Notre modèle va contenir des listes de listeners pour chaque classe de notre modèle. Lorsque le modèle est modifié, nous appellerons la fonction firePropertyChanged. Nous ajoutons également une fonction d’inscription et une de désinscription de listeners. Ces trois fonctions sont regroupées au sein de la classe abstraite tfe.raytracing.structmodel.IPropertyChange que l’on retrouve à la Figure 5.4. public class IPropertyChange { private transient ListenerList listeners=new ListenerList (); public void firePropertyChange(String event, Object[] changes){ Object[] o=listeners.getListeners(); int n=o.length; for (int i=0; i<n;i++) ((IPropertyChangeListener)o[i]).propertyChanged(event, changes); } public void addPropertyChangeListener(IPropertyChangeListener listener){ listeners.add(listener); } public void removePropertyChangeListener(IPropertyChangeListener listener){ listeners.remove(listener);} }

77
Figure 5.4 : Classe IPropertyChange
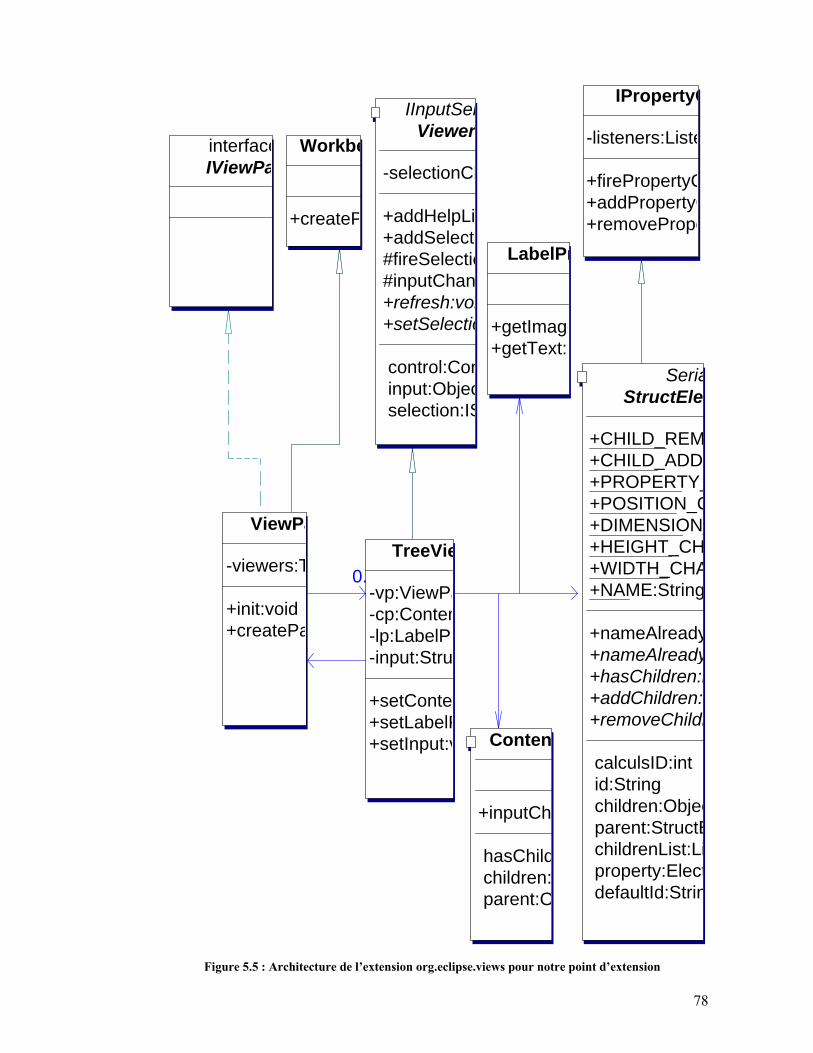
78
Figure 5.5 : Architecture de l’extension org.eclipse.views pour notre point d’extension
0..*
interfaceIViewPa
Workbe
+createP
Conten
+inputCh
hasChildchildren:parent:O
ViewPa
-viewers:T
+init:void+createPa
LabelPr
+getImage+getText:S
SeriaStructEle
+CHILD_REM+CHILD_ADD+PROPERTY_+POSITION_C+DIMENSION_+HEIGHT_CH+WIDTH_CHA+NAME:String
+nameAlready+nameAlready+hasChildren:b+addChildren:+removeChildr
calculsID:int id:String children:Objec parent:StructE childrenList:Li property:Elect defaultId:Strin
IPropertyC
-listeners:Liste
+firePropertyC+addPropertyC+removePrope
TreeVie
-vp:ViewPa-cp:Conten-lp:LabelPr-input:Stru
+setConte+setLabelP+setInput:v
IInputSelViewer
-selectionCh
+addHelpLi+addSelect#fireSelectio#inputChan+refresh:voi+setSelectio
control:Coninput:Objecselection:IS

79
5.2.3. Graphical Editing Framework Le Graphical Editing Framewok (GEF) est un projet qui fournit une série d’outils pour pouvoir réaliser plus facilement de l’édition graphique. Il est réalisé en deux parties : Draw2d et GEF. Draw2d se base sur SWT pour fournir des figures graphiques plus évoluées et pouvant être manipulée par GEF. GEF fournit un véritable framework qui permet d’éditer les graphismes réalisés par Draw2d. Les outils mis à disposition sont nombreux mais manquent souvent de documentation, rendant leur utilisation plus difficile. Nous allons maintenant étudier l’architecture d’un éditeur construit avec GEF.
La première chose à faire est de déclarer l’extension du point d’extension org.eclipse.ui.editors dans le manifeste et d’y indiquer la classe qui étend la classe org.eclipse.ui.part.EditorPart qui est une classe permettant de nous insérer afin de réaliser toutes les tâches d’édition que l’on souhaite réaliser. Dans notre cas, GEF fournit déjà des classes réalisant une grande partie de ces tâches, nous laissant le soin d’insérer juste ce dont on a besoin : l’initialisation, l’insertion du contrôleur d’édition racine (voir plus loin), les tâches de sauvegarde, l’insertion de nos outils d’édition, et un fabrique (« factory » en anglais) de contrôleurs d’édition (« EditPart » en anglais). GEF applique bien sûr le pattern MVC et ceci se reflète fort sur l’architecture des classes que nous devons ajouter. D’une part, nous devons bien sûr fournir un modèle, d’autre part, nous devrons fournir un moyen accéder à notre modèle, les contrôleurs d’édition, et enfin une représentation graphique de notre modèle, les figures.
Les figures
Les figures sont des classes graphiques qui représentent une partie du modèle. GEF fournit un ensemble de figures au travers du plugin Draw2d. Dans notre cas, nous allons utiliser trois figures : RectangleFigure, Polyline et Ellipse. La première est utilisée pour la représentation de pièces rectangulaires, la seconde pour représenter les autres facettes et la dernière pour afficher les arêtes. Nous utiliserons également une couche : FreeFormLayer accompagnée d’un gestionnaire de positionnement des figures avec contraintes. Dans le cas qui nous occupe, nous allons à chaque fois étendre ces classes afin de pouvoir modifier le comportement fournit par défaut à ces figures. On retrouve un schéma des classes que nous utiliserons à la Figure 5.6, cependant, pour ne pas alourdir le diagramme, certaines classes ont été supprimées.
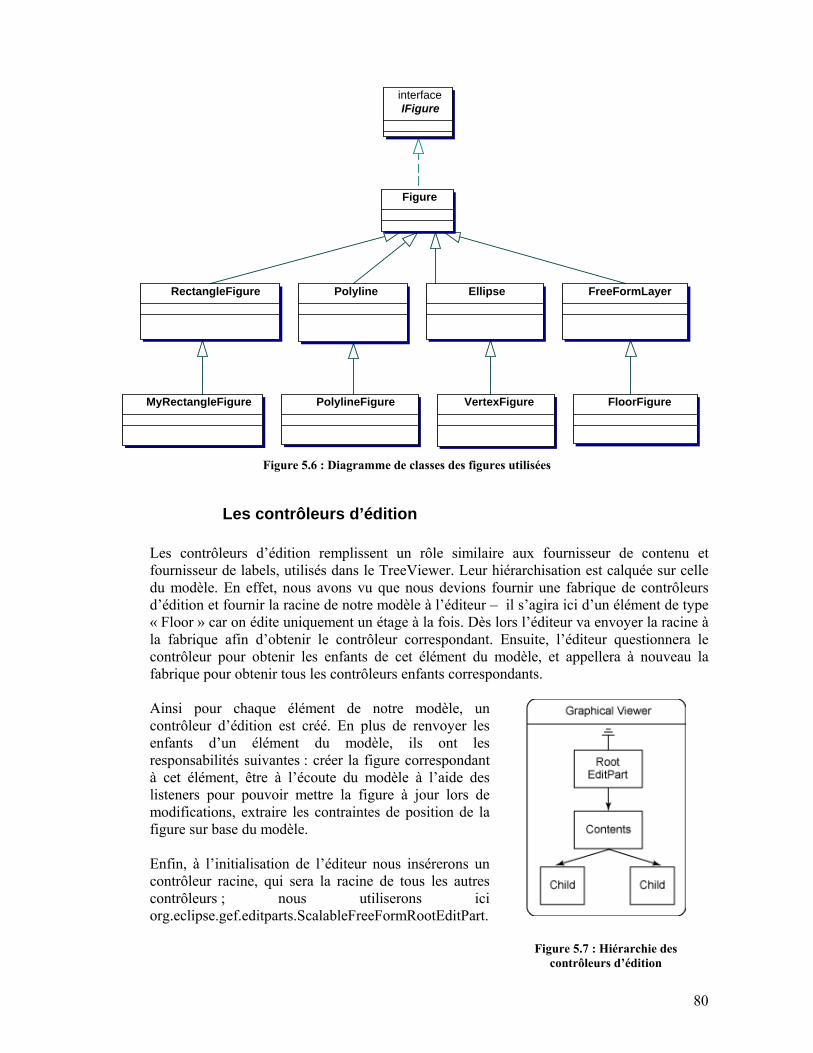
80
RectangleFigure
MyRectangleFigure
Figure
interfaceIFigure
FreeFormLayer
PolylineFigure
Polyline Ellipse
VertexFigure FloorFigure
Figure 5.6 : Diagramme de classes des figures utilisées
Les contrôleurs d’édition Les contrôleurs d’édition remplissent un rôle similaire aux fournisseur de contenu et fournisseur de labels, utilisés dans le TreeViewer. Leur hiérarchisation est calquée sur celle du modèle. En effet, nous avons vu que nous devions fournir une fabrique de contrôleurs d’édition et fournir la racine de notre modèle à l’éditeur – il s’agira ici d’un élément de type « Floor » car on édite uniquement un étage à la fois. Dès lors l’éditeur va envoyer la racine à la fabrique afin d’obtenir le contrôleur correspondant. Ensuite, l’éditeur questionnera le contrôleur pour obtenir les enfants de cet élément du modèle, et appellera à nouveau la fabrique pour obtenir tous les contrôleurs enfants correspondants. Ainsi pour chaque élément de notre modèle, un contrôleur d’édition est créé. En plus de renvoyer les enfants d’un élément du modèle, ils ont les responsabilités suivantes : créer la figure correspondant à cet élément, être à l’écoute du modèle à l’aide des listeners pour pouvoir mettre la figure à jour lors de modifications, extraire les contraintes de position de la figure sur base du modèle.
Enfin, à l’initialisation de l’éditeur nous insérerons un contrôleur racine, qui sera la racine de tous les autres contrôleurs ; nous utiliserons ici org.eclipse.gef.editparts.ScalableFreeFormRootEditPart.
Figure 5.7 : Hiérarchie des contrôleurs d’édition
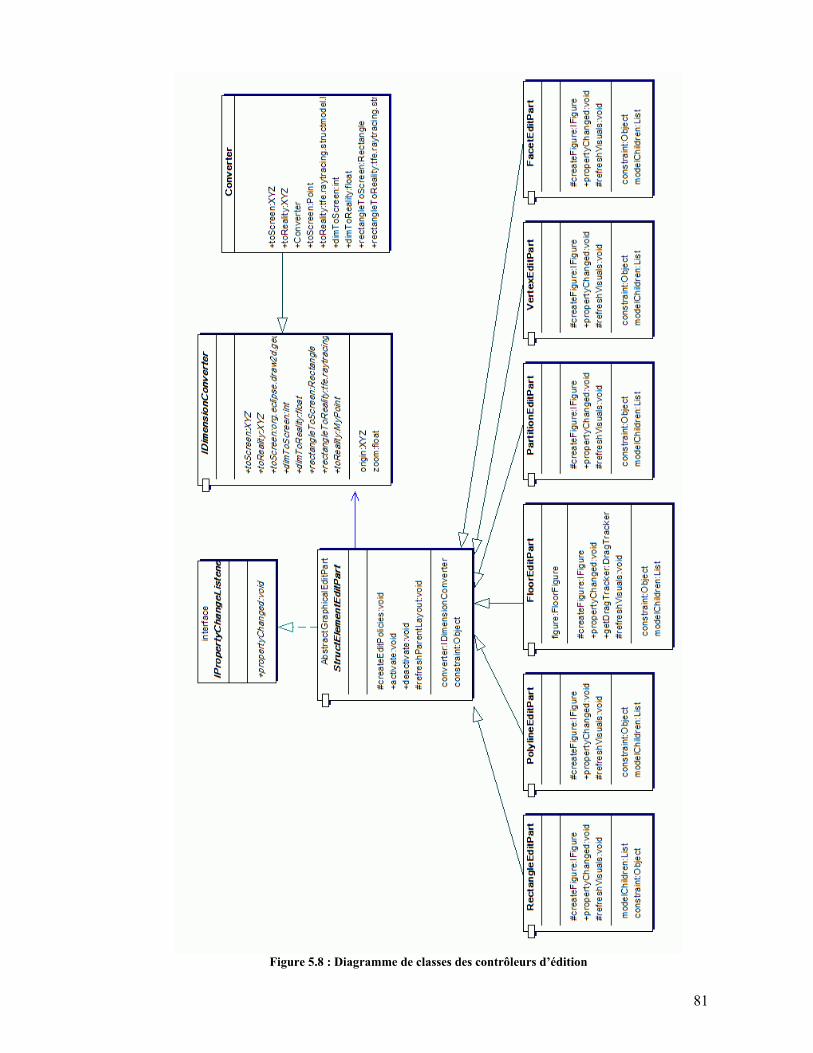
81
Figure 5.8 : Diagramme de classes des contrôleurs d’édition

82
Les éditeurs offrent en général une vue structurée du modèle qu’il représente. A cet effet, nous utiliserons également ce principe, en affichant un arbre représentant l’étage en cours d’édition. Notons qu’ici, nous pourrons réutiliser les classes de la vue en arbre mais en enlevant les parents de l’étage sur la représentation.
Outils d’éditions
GEF fournit également toute une série de classes facilitant l’implémentation d’un éditeur et des ses commandes d’édition. Pour réaliser cette partie, GEF fournit cinq types de classes essentielles que nous allons décrire maintenant.
Outils :
Les outils sont des classes qui permettent d’ajouter un comportement particulier aux inputs de l’utilisateur. Ils reçoivent les entrées de la souris et du clavier et permettent ainsi de contrôler et modifier les figures affichées ou d’en ajouter de nouvelles. Lorsque c’est le cas, l’outil créera alors une requête.
Palette d’outils :
La palette d’outils est un conteneur qui affiche les différents outils disponibles. Cette palette peut être utilisée de plusieurs façons : soit en tant que vue indépendante, soit en tant que conteneur interne à l’éditeur.
Commandes :
Les commandes sont des objets qui représentent une action d’un outil. Elles sont empilées dans la pile de commandes et servent alors à annuler et refaire cette action. Lorsqu’une commande est effectuée, elle est ajoutée sur la pile des commandes et la pile des commandes recommençables est vidée. Lorsqu’une action est annulée, elle est supprimée de la pile de commandes et placée sur la pile des commandes recommençables.
Politiques d’éditions :
Les politiques d’éditions sont associées à chaque contrôleur d’édition. Lorsqu’un outil envoie une requête, ce sont les politiques d’éditions qui renverront la commande appropriée. Elles permettent également de déterminer si une commande est autorisée.
Requêtes : Les requêtes sont des demandes envoyées par les outils aux politiques d’édition liées à une figure. Celles-ci renvoient alors une commande qui est exécutée et placée sur la pile des commandes. Nous avons maintenant exploré tous les aspects pratiques préalables à la programmation. On retrouve à la Figure 5.9, l’illustration de la structure de notre programme. On peut y voir l’ensemble des outils et technologies que nous allons mettre en œuvre par la suite.

83
Figure 5.9 : Structure du projet
Voyons maintenant, si il n’y a pas, au sein de notre plugin, certaines parties qui pourraient être étendues par d’autres. Rappelons que pour chaque point d’extension que nous définissons, la règle du fair-play nous indique de passer, nous aussi, par ce point d’extension.
5.2.4. Points d’extension
Dans cette partie-ci, nous allons essayer de voir quelles parties de notre logiciel nous pouvons découper, et qui pourraient être implémentées par d’autres composants dans le futur. Il parait évident que le moteur de calcul peut être scindé de notre programme afin de pouvoir changer de moteur de calcul. Dès lors, nous allons déclarer le point d’extension « tfe.raytracing.structeditor.rtengine ». Lorsqu’on déclare un point d’extension, il faut également inclure une ou plusieurs interfaces (ou classes abstraites) que l’extension devra implémenter. De notre côté, nous devons charger les extensions qui correspondent à notre point d’extension ainsi que nous protéger d’erreurs éventuelles contenues dans l’extension. Ceci peut être fait au moyen des quelques lignes de codes suivantes :

84
private void gatherEngineExtensions() { IExtensionRegistry registry = Platform.getExtensionRegistry(); IExtensionPoint enginePoint = registry.getExtensionPoint ("tfe.raytracing.structeditor.rtengine"); extensions=enginePoint.getExtensions(); for (int i=0;i<extensions.length;i++){ IConfigurationElement[] elem = extensions[i].getConfigurationElements(); for (int j=0; j<elem.length;j++) { String []s =elem[j].getAttributeNames(); for (int k=0; k<s.length;k++) System.out.println(s[k]+" = "+elem[j].getAttribute(s[k])); } } }
Figure 5.10 : Collecte des extensions correspondants à « tfe.raytracing.structeditor.rtengine » Pour ce point d’extension, nous requerrons 2 classes : une qui implémente tfe.raytracing.calculation.IEngine et une qui implémente tfe.raytracing.calculation.wizards.IEngineParameterPage. La première est l’implémentation du moteur de calcul, tandis que la seconde est une page d’un assistant qui permet au moteur de calcul correspondant de recevoir ses paramètres. Quelques attributs supplémentaires seront déclarés afin d’obtenir quelques décorations (icônes, labels, …) Sur la Figure 5.10, on peut voir successivement, la collecte des extensions, puis le parcours de leurs éléments de configuration et leurs attributs. Dans notre cas, nous recevrons tous les moteurs de calculs présents. Ceux-ci contiennent deux éléments de configuration : « engine » et « parameterpage ». Le premier possède les attributs suivants : la classe qui implémente l’interface et le label du moteur de calcul. Le second contient ces attributs : la classe qui implémente l’interface et une icône qui sera affichée sur la page de paramètres. On pourrait imaginer d’ajouter un point d’extension qui permettrait d’ajouter une vue supplémentaire dans notre logiciel sur base de notre modèle. Cependant, nous préférons offrir une référence vers notre modèle et demander de passer par le point d’extension org.eclipse.ui.views.
Cette référence permet alors à quiconque d’ajouter ou supprimer des objets dans notre modèle . Dès lors, l’ajout des extensions possibles que nous avons évoquées au 2.5 Possibilités d’extension, peut être réalisé via ce point d’entrée. Il ne semble pas utile d’ajouter d’autres points d’extensions, toutefois, ceci peut toujours se faire par la suite, sans grande modification du code.
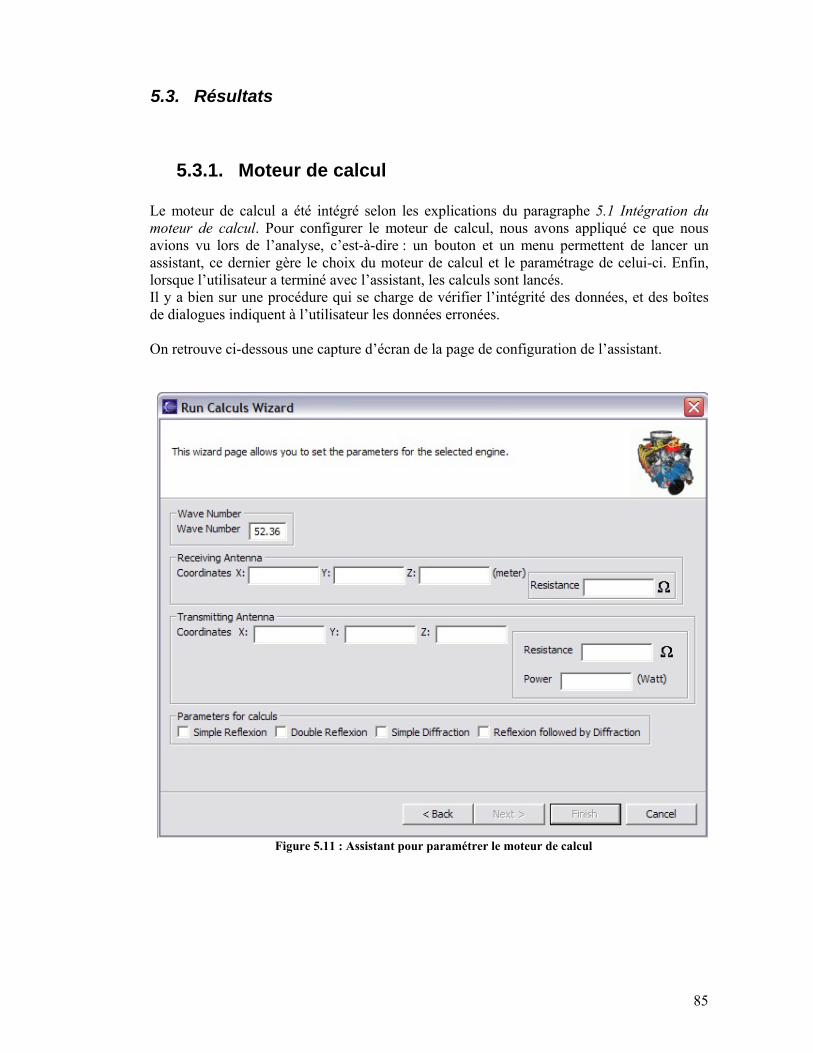
85
5.3. Résultats
5.3.1. Moteur de calcul Le moteur de calcul a été intégré selon les explications du paragraphe 5.1 Intégration du moteur de calcul. Pour configurer le moteur de calcul, nous avons appliqué ce que nous avions vu lors de l’analyse, c’est-à-dire : un bouton et un menu permettent de lancer un assistant, ce dernier gère le choix du moteur de calcul et le paramétrage de celui-ci. Enfin, lorsque l’utilisateur a terminé avec l’assistant, les calculs sont lancés. Il y a bien sur une procédure qui se charge de vérifier l’intégrité des données, et des boîtes de dialogues indiquent à l’utilisateur les données erronées. On retrouve ci-dessous une capture d’écran de la page de configuration de l’assistant.
Figure 5.11 : Assistant pour paramétrer le moteur de calcul
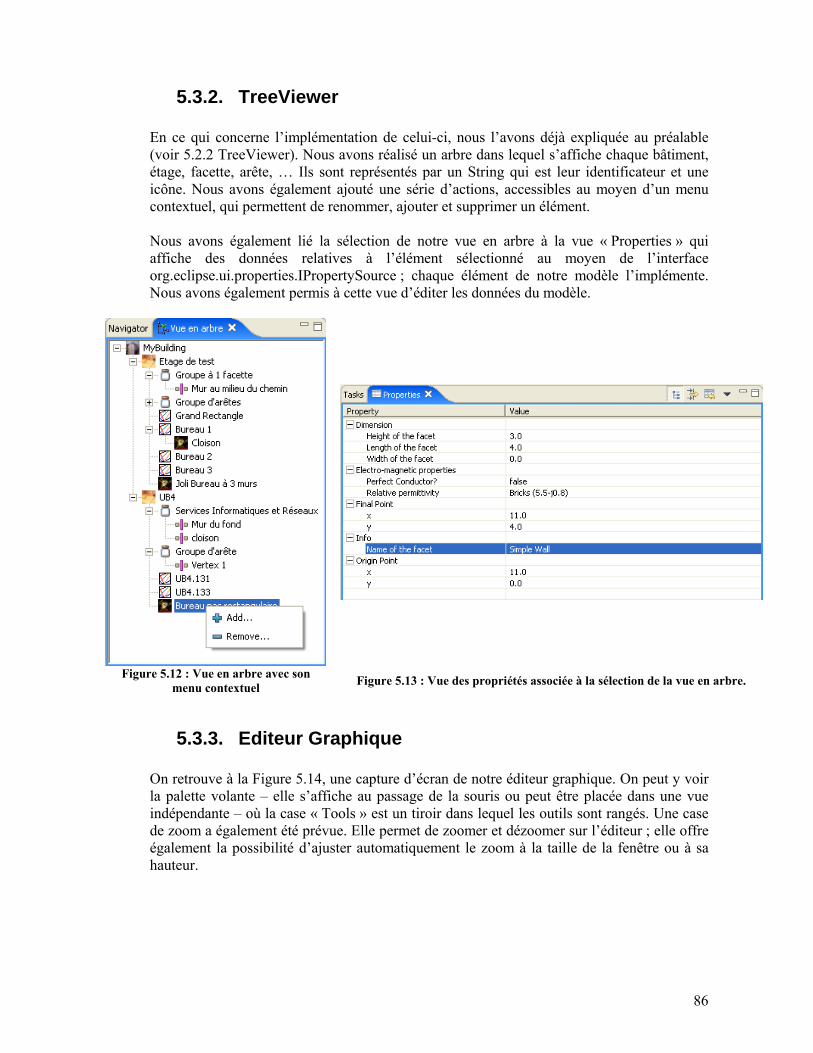
86
5.3.2. TreeViewer En ce qui concerne l’implémentation de celui-ci, nous l’avons déjà expliquée au préalable (voir 5.2.2 TreeViewer). Nous avons réalisé un arbre dans lequel s’affiche chaque bâtiment, étage, facette, arête, … Ils sont représentés par un String qui est leur identificateur et une icône. Nous avons également ajouté une série d’actions, accessibles au moyen d’un menu contextuel, qui permettent de renommer, ajouter et supprimer un élément. Nous avons également lié la sélection de notre vue en arbre à la vue « Properties » qui affiche des données relatives à l’élément sélectionné au moyen de l’interface org.eclipse.ui.properties.IPropertySource ; chaque élément de notre modèle l’implémente. Nous avons également permis à cette vue d’éditer les données du modèle.
Figure 5.12 : Vue en arbre avec son
menu contextuel Figure 5.13 : Vue des propriétés associée à la sélection de la vue en arbre.
5.3.3. Editeur Graphique On retrouve à la Figure 5.14, une capture d’écran de notre éditeur graphique. On peut y voir la palette volante – elle s’affiche au passage de la souris ou peut être placée dans une vue indépendante – où la case « Tools » est un tiroir dans lequel les outils sont rangés. Une case de zoom a également été prévue. Elle permet de zoomer et dézoomer sur l’éditeur ; elle offre également la possibilité d’ajuster automatiquement le zoom à la taille de la fenêtre ou à sa hauteur.
87
Figure 5.14 : Editeur Graphique

88
5.3.4. Traçage des rayons et perspective Pour l’affichage des rayons, il a semblé plus approprié de les tracer sur une image plutôt que dans le même éditeur. A cet effet, nous avons donc rapidement développé un plugin permettant l’affichage d’images (de types GIF, JPG, PNG, BMP et ICO), en nous basant à nouveau sur GEF. En outre, cet éditeur supporte l’ajout de rayons, qu’il tracera le cas échéant, ainsi que d’antennes qu’il affichera également. Nous noterons que cet éditeur ne possède aucune possibilité d’édition et s’apparent donc plus à une vue. Ayant fini ce plugin, nous l’avons inséré dans notre projet, afin qu’il soit lancé directement après l’exécution des calculs. On peut trouver une réalisation de cet éditeur à la Figure 5.15, encadrée en rouge. Nous avons regroupé toutes ces vues et éditeurs au sein d’une même perspective obtenue en étendant le point d’extension : « org.eclipse.ui.perspectives ». Cette perspective comprend les vues suivantes : « Properties » qui permet l’affichage des propriétés de l’élément sélectionné actuellement au sein du workbench, « Navigator » qui permet de naviguer entre les différents projets et fichiers en cours, « Treeview for Ray-Tracing » qui permet l’affichage dans une vue structurée de tous les bâtiments ouverts ainsi que de tous ses descendants dans le modèle, « Outline » qui affiche les éléments en cours d’édition, ainsi que « Palette » qui affiche les outils disponibles pour l’éditeur graphique. La perspective comprend également un ensemble d’actions obtenu en étendant le point d’extension : « org.eclipse.ui.actionSets ». Les éditeurs ne font pas directement partie de la perspective, mais certaines vues permettent d’ouvrir des éditeurs – grâce au mécanisme des extensions de fichiers –, notamment la vue « Navigator ». Pour notre projet, nous avons utilisé l’extension « sf » (pour StructFile). La Figure 5.15 montre la réalisation de cette perspective ; les vues « Navigator » et « TreeView for RayTracing » y sont regroupées en onglets.

89
Figure 5.15 : Perspective de notre projet

90
Conclusions À travers ce travail, nous sommes parvenu, à élaborer un programme qui répond à nos attentes et qui pourra encore évoluer de par le futur. Nous avons étudié comment passer d’une analyse des phénomènes de propagation dans un bâtiment, à l’analyse logicielle qui en découle, à la mise en œuvre de celle-ci. Il est évident que l’informatique supportera toujours les applications des études théoriques ; ce projet en est l’illustration. Le ray-tracing est encore en pleine évolution grâce à l’amélioration des algorithmes, et son utilité devient croissante de nos jours. En effet, l’utilisation de réseaux sans fil dans les bâtiments est de plus en plus importante. Notre logiciel peut venir épauler l’installation d’un tel réseau et ce pour plusieurs aspects : les débits de transmission, la qualité du signal, les temps de parcours, … D’autre part, dans un cadre plus théorique, le projet réalisé peut également être utilisé à des fins didactiques, afin d’illustrer les phénomènes de propagation. On peut facilement exposer l’intérêt du phénomène de diffraction dans les réseaux sans fil, montrer le phénomène de multipath ou encore calculer le time delay. Les logiciels basés sur des composants semblent également en plein essor. En effet, on a pu constater que la réutilisabilité et la stabilité étaient les deux objectifs principaux des composants. La réalisation de ceux-ci est obtenue à travers trois éléments : les interfaces claires et séparées accompagnées de contrats, une granularité meilleure que celles des classes car plus globale facilitant fortement la réutilisation ; enfin la forte réutilisation permet d’obtenir une grande stabilité puisque les composants sont soumis à plus de tests. Eclipse est l’illustration parfaite de cette théorie, tant d’un point de vue de l’application des concepts de la théorie, que au niveau des résultats escomptés. En effet, on a pu remarquer que Eclipse utilisait les interfaces séparées accompagnées de contrats, et que la stabilité qui en découle, était excellente.

91
J’ai, personnellement, fortement apprécié de travailler sous Eclipse. Je me suis retrouvé en constant apprentissage de nouveaux concepts, de nouvelles librairies, de nouveaux aspects de programmation, de nouveaux outils, … J’ai été particulièrement séduit dans ce framework par les possibilités de réutilisation de composants ainsi que d’extensions. Eclipse est devenu aujourd’hui un projet qui s’est très fortement répandu. Nombreuses sont les entreprises qui s’en servent comme environnement de développement, et l’utilisation d’Eclipse comme framework de composants logiciels est également en pleine explosion. Bien que l’apprentissage d’Eclipse ne soit pas évident, la documentation n’étant pas toujours suffisante, le temps d’adaptation est assez long, mais les avantages sont inégalables. Cependant, ce temps est assez vite rattrapé, car le développement de plugin pour Eclipse est fortement assisté : le workbench aide à créer un grand nombre de fichier, les librairies mises à disposition sont très complètes et facilement réutilisables, et Eclipse s’occupe d’une grande partie de la gestion de l’application, nous évitant de recréer ce code qui est souvent source de problèmes. Au vu de la réussite d’Eclipse, la théorie des logiciels basés sur des composants sera amenée à faire partie des nouveaux paradigmes, sans pour autant éliminer le paradigme orienté-objet. En effet, les composants ont montré une meilleure robustesse et une meilleure réutilisation, mais ils ne sont jamais que des agglomérats de classes, donc d’objets. Nous pouvons nous demander si, à terme, Eclipse ne pourrait pas se fondre directement avec les environnements graphiques des systèmes d’exploitation, offrant ainsi une certaine uniformisation de ceux-ci. Après avoir véritablement étudié cet outil aux possibilités innombrables et inouïes, son utilisation me parait indispensable pour ce type de projet. J’espère que cet exemple donnera le goût d’Eclipse à d’autres développeurs.

92
A. Annexes
A.1. Glossaire • Assistant : outil graphique qui assiste l’utilisateur dans la récolte d’informations à travers
différentes étapes. • Canvas : zone dans une fenêtre dans laquelle on peut venir placer des éléments graphiques,
notamment des widgets. • CBS : Component Based Software, logiciel basé sur des composants. • Composant : un composant software est une unité de composition, accompagné d’interfaces
respectant un contrat, et de dépendances contextuelles uniquement. Un composant software peut être déployé de façon indépendante et peut être implémenté par une tierce partie. [14]
• Conductivité : capacité d’un matériau à faire circuler des électrons ; il correspond à l’inverse de
la résistivité. • Contrat : dans les composants, il correspond à la partie descriptive du comportement d’un
composant. • CORBA : Common Object Request Broker Architecture, architecture permettant l’utilisation
d’objets distribués qui ne doivent pas être écrits dans le même langage. • Eclipse : framework développé par IBM dans lequel on peut venir inscrire des composants
nommés plugins.

93
• Editeur : point d’extension dans lequel on peut venir insérer un plugin correspondant à de l’édition de données. Les notions de fichier, projet, sauvegarde, etc… y sont déjà incorporées.
• Encapsulation : fait de cacher (avec l’attribut « private ») la structure interne, les attributs et
méthodes d’une classe pour offrir une interface publique claire, beaucoup plus représentative, d’un objet.
• Extension : partie d’un plugin correspondant à un point d’extension défini dans un autre plugin
ou dans le microkernel. • Fading : phénomène caractérisé par la diminution de puissance des échos d’un signal, lorsque
celui-ci aboutit plusieurs fois au même point en empruntant des chemins différents. • Framework : environnement de base dans lequel viennent s’inscrire les composants. • IDE : Integrated Development Environment, environnement de développement de logiciels et
d’applications dans lequel on peut venir ajouter des outils personnalisés. • Interface : dans les composants, une interface correspond à la déclaration de ses points d’accès. • JFace : librairie graphique d’Eclipse comprenant des objets plus complexes que SWT. • JNI : Java Native Interface, interface à travers laquelle on peut appeler du code compilé pour
une machine spécifique à partir de code Java, ceci ne fonctionne évidemment que sur la machine pour laquelle le code a été compilé.
• Listener : objet de contrôle qui permet d’informer un autre objet lors d’un événement
particulier ; « il est à l’écoute d’un évènement ». • Longueur d’onde : c’est la distance entre deux pics ou deux ventres identiques d’une onde. • Manifeste : fichier XML, dans lequel est repris la partie déclarative du plugin, i.e. ses points
d’extension, ce qu’il étend, les autres plugins requis, la librairie lui correspondant, … • Microkernel : voir Plateforme. • Multipath : en propagation, ce phénomène correspond au fait qu’il existe plusieurs chemins
partant d’un point d’émission et aboutissant en un même point d’observation. • Natif : correspond à du code compilé pour une machine spécifique, offrant l’avantage majeur
d’être optimisé et donc plus rapide. • Nombre d’onde : il équivaut au rapport entre la vitesse angulaire et la vitesse de propagation,
ou encore au rapport donné par l’1.10. • NS2 : Network Simulator 2, simulateur de réseau qui offre des ressources importantes pour la
simulation du protocole TCP, du routage des paquets et des protocoles multicast, le tout par-dessus un réseau câblé ou non (en local et satellite). Initialement développé par l’université de Columbia, Californie, et par l’université Cornell, il était essentiellement destiné à observer les comportements dynamiques dans les flux de données, les congestions dans le trafic, …

94
• Pattern : solution à un problème récurrent. Ils peuvent intervenir à tous les niveaux de la
programmation. • Perméabilité : correspond au rapport entre le champ magnétique et le champ d’induction dans
un milieu donné. • Permittivité : correspond au rapport constant entre le champ électrique et le champ de
déplacement, dans un milieu donné. • Permittivité relative : donnée par l’1.9, elle correspond à un rapport comparatif vis-à-vis de la
permittivité du vide. • Perspective : extension qui regroupe un ensemble cohérent de vues et d’éditeurs. • Plateforme : aussi appelée microkernel, c’est le noyau de base d’Eclipse qui se charge du
lancement de la plateforme. • Plugin : composant utilisé dans Eclipse, composé d’un manifeste contenant la déclaration des
extensions du plugin, et d’une librairie de code compilé. • Point d’extension : point d’ancrage déclaré dans un plugin ou dans le microkernel, pour un
autre composant. • Préférences : ensemble de paramètres déterminés par l’utilisateur. • Ray-Tracing : en propagation, ceci correspond au calcul et à la représentation des ondes qui se
propagent. • SWT : Standard Widget Toolkit, librairie graphique de base d’Eclipse qui fournit un API
indépendant du système d’exploitation, mais en se basant fortement sur des librairies écrites en code natif.
• Template : squelette préformaté d’une classe ou d’un document permettant de les rendre
génériques. • Time Delay : le temps écoulé entre le début de la réception du premier signal d’un paquet de
données et le dernier écho du signal dont la puissance soit suffisante. • UML : Unified Modeling Language, langage de modélisation de logiciel informatique
permettant d’être utilisé indépendamment du langage de programmation. • Vue : point d’extension à travers lequel on peut réaliser un affichage graphique et dans lequel
on peut venir déposer d’autres objets graphiques. • Widget : petits objets graphiques que l’utilisateur peut manipuler afin de contrôler une
application : boutons, menus, listes déroulantes, barres de défilement, … • Workbench : c’est l’interface graphique d’Eclipse, c’est dans celui-là qu’on ajoute les autre
composants graphiques.

95
• Workspace : c’est l’espace de travail dans lequel le plugin est en train de travailler.

96
A.2. Bibliographie
A.1.1. Références manuscrites :
[1] CATEDRA (M.), Cell Planning for Wireless Communications, éd. Artech House, Inc, 1999
[2] MEYS (R.), A Summary of the Transmitting and Receiving Properties of Antennas, dans
IEEE Antennas and Propagation Magazine, Vol 42, n°3, Juin 2000, pp49-53 [3] SAUNDERS (S.), Antennas and Propagation for Wireless Communication Systems,
John Wiley & Sons Ltd., Sussex, Angleterre, 1999, pp 206-219 [4] CRNKOVIC (I.), LARSON (M.), Building Reliable Component-based Software Systems,
Artech House Publishers, 2002 [5] The Component Object Model Specification, Report Vol. 99, Microsoft Standards,
Redmond, WA : Microsoft, 1996 [6] SZYPERSKI (C.), Component Software – beyond Object-Oriented Programming,
Reading, MA : Addison-Wesley, 1998 [7] D’SOUZA (D.) et WILLS (A.C.), Objects, Components and Frameworks : The catalysis
Approach, Reading, MA : Addison-Wesley, 1998 [8] AOYAMA (M.), New Age of Software Development : How Component-Based Software
Engineering Changes the Way of Software Development, Proc. 1st Workshop on Component-Based Software Engineering, 1998
[9] COUNCIL (W.T.), HEINEMAN (G.T.), Component-Based Software Engineering, Putting
the Pieces Together, Reading, MA: Addison-Wesley, 2001 [10] The Eclipse Project : Eclipse – Technical review, juillet 2001 (mise-à-jour février 2003)
[11] BECK (K.), GAMMA (E.), Contributing to Eclipse: Principles, Patterns, and Plug-Ins,
MA : Addison-Wesley, 20 Octobre 2003 [12] D’ANJOU (J.), FAIRBROTHER (S.), KEHN (D.), KELLERMAN (J.), MCCARTHY (P.),
SHAVOR (S.), The Java Developer’s Guide to Eclipse, 4ème édition, MA : Addison-Wesley, Décembre 2003
[14] KO (C-J.), WU (B-C.), YANG (C-F.), A Ray-Tracing Method for Modeling Indoor Wave
Propagation and Penetration, IEEE Transactions On Antennas And propagation, Vol. 46, NO 6, Juin 1998
[15] DAVIS (D.), PAKNYS (R.), SEGAL (B.), TRUEMAN (C.W.), ZHAO (J.), Ray-Tracing
Algorithm for Indoor Propagation, Université de Montreal, 2000

97
[16] CERRI (C.), DE LEO (R.) , MICHELI (D.), RUSSO (P.), Reduction of Electromagnetic Pollution in Mobile Communication Systems by an Optimized Location of Radio Base Stations, Université de Ancona, 2002
[17] DIEZ (M.C), DOMINGO (M.), LOREDO (S.), TORRES (P.), VALLE (L.), CINDOOR:
An Engineering Tool for Planning and Design of Wireless Systems in Enclosed Spaces, IEEE Antennas and Propagation Magazine, Vol. 41, No. 4, Août 1999
A.1.2. Références Electroniques [18] The Network Simulator ns-2 at Boston Univeristy CS Dept.: Frequently Asked Questions,
Université de Boston, http://cs-people.bu.edu/guol/bu_ns/buns-faq.html, 19 Septembre 2002
[19] The Network Simulator - ns-2, Université du Sud de Californie,
http://www.isi.edu/nsnam/ns/, 2002
[20] Eclipse Main Page, IBM, http://www.eclipse.org, 2004 [21] Eclipse Tools - GEF Project, IBM, http://www.eclipse.org/gef/, 2004 [22] JABBER (S.) ([email protected]), Add-In Visual Studio .NET vs Plug-In Eclipse,
http://www.dotnetguru.org/articles/outils/vsdotnet/dossieraddins/VSDotNetAddIn.htm, Janvier 2003
[23] Sun Microsystems, Chapter 5: JNI Technology,
http://java.sun.com/developer/onlineTraining/Programming/JDCBook/jni.html, Sun Microsystems, Inc., 2004
[24] LEMAIGRE (R.) ([email protected]), GefDescription,
http://eclipse-wiki.info/GefDescription, 18 Juillet 2004
[25] LEMAIGRE (R.) ([email protected]), GefDescription2, http://eclipse-wiki.info/GefDescription2, 24 Juillet 2004

98
A.3. Code Source
A.1.3. Interface du moteur de calcul
ray-philippe.h :
#include <complex> #include <stdio.h> #include <stdlib.h> #include <math.h> #define TINY 1.0e-10 #define NRAY 2000 // nombre de rayons de chaque type max #define PI 3.141592 double K=50.26; // nombre d'onde = 2Pi/lambda // k= 37.7 @ 1800MHz // k= 50.26 @ 2,4GHz // k= 104.72 @ 5Ghz // k= 209.44 @ 10 Ghz //k=2*Pi*f/c using namespace std; //--------------------------------------------------------------------------- // Structures utilisées //--------------------------------------------------------------------------- // champ complexe en coordonées cartésiennes typedef struct { complex < double >x; complex < double >y; complex < double >z; } ChampCart; // champ complexe en coordonées sphériques typedef struct { complex < double >r; complex < double >theta; complex < double >phi; } ChampSpher; // vecteur réel en coordonnées cartésiennes typedef struct { double x; double y; double z; } VecteurCart; // vecteur réel en coordonées sphériques typedef struct { double r;

99
double theta; double phi; } VecteurSpher; // système d'axes de coordonnées cartésiennes typedef struct { VecteurCart x; VecteurCart y; VecteurCart z; } Axes; // rayon typedef struct { ChampSpher E; // valeur du champ électrique int e; // est-ce que ce rayon existe ? (1=oui, 0=non) Axes axe; // axes dans lesquels le rayon est défini VecteurCart r0; // origine du rayon VecteurCart r1; // extrémité du rayon double l; // longueur totale du rayon depuis l'émetteur } Rayon; // facette typedef struct { VecteurCart pos; // position de l'origine Axes axe; // axes attachés à la facette (l'axe z étant normal à la facette) VecteurCart d; // dimensions selon les axes attachés à la facette complex < double >eps; // permittivité relative complexe int pec; // la facette est-elle parfaitement conductrice ? (1=oui,0=non) } Facette; // arête (cf McNamara p267) typedef struct { VecteurCart r0; // position de l'origine VecteurCart r1; // position de l'extrémité double n; // n = (2Pi-alpha)/Pi (alpha = angle intérieur) Axes axeo; // Axes attachés à la facette o (to,no,eo) to étant dirigé vers la facette Axes axen; // Axes attachés à la facette n (tn,nn,en) tn étant dirigé vers la facette complex < double >eps; // permittivité du dièdre int pec; // le dièdre est-il parfaitement conducteur ? double d; // épaisseur des côtés int faceo; // numéros de la face o et n formant l'arête int facen; } Arete; // antenne typedef struct { int type; // type d'antenne prédéfini VecteurCart pos; // position Axes axe; // axes attachés à l'antenne double Ra; // résistance d'antenne

100
complex < double >Ia; // courant d'alimentation de l'antenne si émettrice ChampSpher (*Le) (VecteurSpher); // fonction calculant la longueur équivalente en (theta,phi) } Antenne; // trace pour la représentation graphique des rayons typedef struct { VecteurCart r0; // origine de la trace VecteurCart r1; // extrémité de la trace } Trace; //--------------------------------------------------------------------------- // Variables globales //--------------------------------------------------------------------------- Facette *facet; Arete *edge; Antenne Tx, Rx; complex < double >j (0, 1.0); // unité imaginaire int NbFacettes, NbAretes, ComptTrace = 1, // Nombre de facettes et compteur des traces doSR, doSD, doDR, doRD, doTR; Axes AxeAbs; // axes absolus de la géométrie Rayon RayonDirect, RayonSR[NRAY], RayonDR[NRAY], RayonTR[NRAY], RayonSD[NRAY], RayonRD[NRAY]; Trace trace[10000]; ChampCart result; complex < double >voltage; double power; //--------------------------------------------------------------------------- // Fonctions de calcul de base //--------------------------------------------------------------------------- complex < double > expj (double x) { return complex < double >(cos (x), sin (x)); } complex < double > GammaS (Facette facet, double thetai) // Calcul du coefficient de réflexion soft sur la facette facet avec un angle d'incidence thetai // cf Catedra p.25 { } complex < double > GammaH (Facette facet, double thetai) // Calcul du coefficient de réflexion hard sur la facette facet avec un angle d'incidence thetai // cf Catedra p.25 { } complex < double > EdgeGammaS (Arete edge, double thetai)

101
// Calcul du coefficient de réflexion soft sur la facette facet avec un angle d'incidence thetai // cf Catedra p.25 { } complex < double > EdgeGammaH (Arete edge, double thetai) // Calcul du coefficient de réflexion hard sur la facette facet avec un angle d'incidence thetai // cf Catedra p.25 { } complex < double > TH (Facette facet, double thetai) // Calcul du coefficient de transmission hard sur la facette facet avec un angle d'incidence thetai // cf Catedra p.24 { } //--------------------------------------------------------------------------- // Fonctions de base pour le calcul de la diffraction //--------------------------------------------------------------------------- complex < double > FTF (double x) // Fonction de Fresnel (cf Catedra p56) { } double Nplus (double delta, double n) { if (delta >= (n - 1) * PI) return 1.0; else return 0; } double Nmoins (double delta, double n) { if (delta >= PI * (n - 1) + 2 * PI) return 1.0; else if ((delta >= PI * (1 - n)) && (delta < PI * (n - 1) + 2 * PI)) return 0; else return -1; } complex < double > DS (double phi, double phiprim, double beta0, double L, Arete edge) // coefficient de diffraction soft (cf Catedra p19-20) { } complex < double > DH (double phi, double phiprim, double beta0, double L, Arete edge) // coefficient de diffraction hard (cf Catedra p19-20)

102
{ } //--------------------------------------------------------------------------- // Fonctions de Traitement des Champs //--------------------------------------------------------------------------- double AbsField (ChampCart E) // Module du champ E (attention à l'interprétation de ce module !) { return sqrt (norm (E.x) + norm (E.y) + norm (E.z)); } VecteurCart SpherToCart (VecteurSpher VS) // convertit un vecteur sphérique en un vecteur cartésien { VecteurCart VC; VC.x = VS.r * sin (VS.theta) * cos (VS.phi); VC.y = VS.r * sin (VS.theta) * sin (VS.phi); VC.z = VS.r * cos (VS.theta); return VC; } VecteurSpher CartToSpher (VecteurCart VC) // convertit un vecteur cartésien en un vecteur sphérique { VecteurSpher VS; complex < double >c; VS.r = sqrt (VC.x * VC.x + VC.y * VC.y + VC.z * VC.z); if (VS.r > TINY) VS.theta = acos (VC.z / VS.r); else VS.theta = 0; c = complex < double >(VC.x, VC.y); VS.phi = arg (c); return VS; } ChampCart CompCart (ChampSpher CS, VecteurSpher r) // calcule les composantes cartésiennes d'un champ sphérique en r=(r,theta,phi) { ChampCart CC; CC.x = sin (r.theta) * cos (r.phi) * CS.r + cos (r.theta) * cos (r.phi) * CS.theta - sin (r.phi) * CS.phi; CC.y = sin (r.theta) * sin (r.phi) * CS.r + cos (r.theta) * sin (r.phi) * CS.theta + cos (r.phi) * CS.phi; CC.z = cos (r.theta) * CS.r - sin (r.theta) * CS.theta; return CC; }

103
ChampSpher CompSpher (ChampCart CC, VecteurSpher v) // calcule les composantes sphériques d'un champ cartésien en v=(r,theta,phi) { ChampSpher CS; CS.r = sin (v.theta) * cos (v.phi) * CC.x + sin (v.theta) * sin (v.phi) * CC.y + cos (v.theta) * CC.z; CS.theta = cos (v.theta) * cos (v.phi) * CC.x + cos (v.theta) * sin (v.phi) * CC.y - sin (v.theta) * CC.z; CS.phi = -sin (v.phi) * CC.x + cos (v.phi) * CC.y; return CS; } double DotProduct (VecteurCart V1, VecteurCart V2) // calcule le produit scalaire de deux vecteurs cartésiens { return V1.x * V2.x + V1.y * V2.y + V1.z * V2.z; } complex < double > DotProductField (ChampCart V1, ChampCart V2) // calcule le produit scalaire de deux champs cartésiens { return V1.x * V2.x + V1.y * V2.y + V1.z * V2.z; } VecteurCart CrossProduct (VecteurCart v1, VecteurCart v2) // calcule le produit vectoriel de deux vecteurs cartésiens { VecteurCart v; v.x = v1.y * v2.z - v1.z * v2.y; v.y = v1.z * v2.x - v1.x * v2.z; v.z = v1.x * v2.y - v1.y * v2.x; return v; } VecteurCart ConvertVector (VecteurCart V, Axes AxeD, Axes AxeF) // Convertit un vecteur cartésien défini dans les axes AxeD en un vecteur dans les axes AxeF { double a11, a12, a13, a21, a22, a23, a31, a32, a33; VecteurCart Vf; a11 = DotProduct (AxeF.x, AxeD.x); a12 = DotProduct (AxeF.x, AxeD.y); a13 = DotProduct (AxeF.x, AxeD.z); a21 = DotProduct (AxeF.y, AxeD.x); a22 = DotProduct (AxeF.y, AxeD.y); a23 = DotProduct (AxeF.y, AxeD.z); a31 = DotProduct (AxeF.z, AxeD.x); a32 = DotProduct (AxeF.z, AxeD.y); a33 = DotProduct (AxeF.z, AxeD.z);

104
Vf.x = a11 * V.x + a12 * V.y + a13 * V.z; Vf.y = a21 * V.x + a22 * V.y + a23 * V.z; Vf.z = a31 * V.x + a32 * V.y + a33 * V.z; return Vf; } ChampCart ConvertField (ChampCart V, Axes AxeD, Axes AxeF) // Convertit un champ cartésien défini dans les axes AxeD en un champ dans les axes AxeF { double a11, a12, a13, a21, a22, a23, a31, a32, a33; ChampCart Vf; a11 = DotProduct (AxeF.x, AxeD.x); a12 = DotProduct (AxeF.x, AxeD.y); a13 = DotProduct (AxeF.x, AxeD.z); a21 = DotProduct (AxeF.y, AxeD.x); a22 = DotProduct (AxeF.y, AxeD.y); a23 = DotProduct (AxeF.y, AxeD.z); a31 = DotProduct (AxeF.z, AxeD.x); a32 = DotProduct (AxeF.z, AxeD.y); a33 = DotProduct (AxeF.z, AxeD.z); Vf.x = a11 * V.x + a12 * V.y + a13 * V.z; Vf.y = a21 * V.x + a22 * V.y + a23 * V.z; Vf.z = a31 * V.x + a32 * V.y + a33 * V.z; return Vf; } ChampSpher ConvertFieldSpher (ChampSpher V, Axes AxeD, VecteurSpher rD, Axes AxeF, VecteurSpher rF) // Convertit un champ sphérique défini dans les axes AxeD en un champ dans les axes AxeF // dans les axes initiaux, le champ se trouve en rD, et en rF dans les axes finaux { ChampSpher Vf; ChampCart buff; buff = CompCart (V, rD); buff = ConvertField (buff, AxeD, AxeF); Vf = CompSpher (buff, rF); return Vf; } complex < double > ProductFieldVector (ChampCart F, VecteurCart v) // produit scalaire d'un vecteur et d'un champ { complex < double >c; c = F.x * v.x + F.y * v.y + F.z * v.z; return c; } VecteurCart SubstractVector (VecteurCart v1, VecteurCart v2)

105
// soustraction de deux vecteurs { VecteurCart v; v.x = v1.x - v2.x; v.y = v1.y - v2.y; v.z = v1.z - v2.z; return v; } VecteurCart AddVector (VecteurCart v1, VecteurCart v2) // soustraction de deux vecteurs { VecteurCart v; v.x = v1.x + v2.x; v.y = v1.y + v2.y; v.z = v1.z + v2.z; return v; } double dist (VecteurCart v1, VecteurCart v2) // calcul de la distance entre deux points v1 et v2 { VecteurCart r; r = SubstractVector (v2, v1); return sqrt (DotProduct (r, r)); } //--------------------------------------------------------------------------- // Champ de l'antenne émettrice Tx //--------------------------------------------------------------------------- ChampSpher DipoleLe (VecteurSpher r) // Longueur équivalente d'une antenne type dipole électrique // transmet un ChampSpher valant E au point r=(r,theta,phi) dans le système de l'antenne // il manque le terme de propagation -j K Z0/(4 Pi) e^(-jkr)/r pour obtenir le diagramme de rayonnement!! // cf article R. Meys AP-Mag June 2000 { ChampSpher ES; ES.r = complex < double >(0, 0); ES.phi = complex < double >(0, 0); if (r.theta > TINY) ES.theta = -2.0 / K * cos (PI / 2.0 * cos (r.theta)) / sin (r.theta); else ES.theta = complex < double >(0, 0); return ES; } Rayon RayAntenne (Antenne a, VecteurCart r) // calcule le rayon émis par l'antenne a au point r (coordonnées absolues !) // il manque le terme de propagation e^(-jKr)/r !!

106
{ Rayon ray; VecteurCart rcD, rcF; VecteurSpher rsF; rcD = SubstractVector (r, a.pos); // coordonnées relatives du point r par rapport à l'antenne rcF = ConvertVector (rcD, AxeAbs, a.axe); // conversion de ce vecteur dans les axes de l'antenne rsF = CartToSpher (rcF); ray.E = a.Le (rsF); ray.E.theta *= -j * K * 377.0 / (4.0 * PI) * a.Ia; ray.E.phi *= -j * K * 377.0 / (4.0 * PI) * a.Ia; ray.r0 = a.pos; ray.r1 = r; ray.e = 1; ray.axe = a.axe; return ray; } //--------------------------------------------------------------------------- // Calcul du champ associé à un rayon //--------------------------------------------------------------------------- ChampCart FieldValue (Rayon ray) // calcule les composantes dans les axes absolus du champ électrique associé à un rayon // ajoute le terme de propagation e^(-jkr)/r // cf article R. Meys { VecteurSpher rsd, rsf; VecteurCart rcd, rcf; ChampCart Ec; ChampSpher Es; rcf = SubstractVector (ray.r1, ray.r0); rsf = CartToSpher (rcf); rcd = ConvertVector (rcf, AxeAbs, ray.axe); rsd = CartToSpher (rcd); Es = ConvertFieldSpher (ray.E, ray.axe, rsd, AxeAbs, rsf); Es.theta = Es.theta * exp (-j * K * rsf.r) / rsf.r; Es.phi = Es.phi * exp (-j * K * rsf.r) / rsf.r; Ec = CompCart (Es, rsf); return Ec; } ChampCart LengthValue (Rayon ray) // calcule les composantes dans les axes absolus de la longeur équivalente du récepteur dans la direction du rayon { VecteurSpher rsd, rsf; VecteurCart rcd, rcf; ChampCart Lc; ChampSpher L;

107
rcf = SubstractVector (ray.r0, ray.r1); // vecteur joignant le récepteur à l'origine du rayon // dans les axes absolus rsf = CartToSpher (rcf); // en coordonnées sphériques rcd = ConvertVector (rcf, AxeAbs, Rx.axe); // on convertit ce vecteur dans les axes du récepteur rsd = CartToSpher (rcd); // en coordonnées sphériques L = Rx.Le (rsd); L = ConvertFieldSpher (L, Rx.axe, rsd, AxeAbs, rsf); Lc = CompCart (L, rsf); return Lc; } //--------------------------------------------------------------------------- // Coordonnées de l'image d'un point par rapport à une facette //--------------------------------------------------------------------------- VecteurCart PositionImage (VecteurCart a, Facette f) { double num, den, t; VecteurCart image; num = f.axe.x.x * (f.axe.y.y * (a.z - f.pos.z) - f.axe.y.z * (a.y - f.pos.y)); num += -f.axe.y.x * (f.axe.x.y * (a.z - f.pos.z) - f.axe.x.z * (a.y - f.pos.y)); num += (a.x - f.pos.x) * (f.axe.x.y * f.axe.y.z - f.axe.x.z * f.axe.y.y); den = f.axe.x.x * (f.axe.y.y * (-f.axe.z.z) - f.axe.y.z * (-f.axe.z.y)); den += -f.axe.y.x * (f.axe.x.y * (-f.axe.z.z) - f.axe.x.z * (-f.axe.z.y)); den += -f.axe.z.x * (f.axe.x.y * f.axe.y.z - f.axe.x.z * f.axe.y.y); t = num / den; image.x = a.x + 2 * t * f.axe.z.x; image.y = a.y + 2 * t * f.axe.z.y; image.z = a.z + 2 * t * f.axe.z.z; return image; } //--------------------------------------------------------------------------- // Calculs de l'intersection entre un rayon et une facette //--------------------------------------------------------------------------- VecteurCart IntersectRayFacet (Rayon ray, Facette f) // détermine les coordonées du point d'intersection entre un rayon et le plan d'une facette // Catedra p 98 // renvoie une coordonnée x=999 si il n'y a pas d'intersection { } //--------------------------------------------------------------------------- // Calcul de la coordonnée du point de diffraction sur une arête

108
//--------------------------------------------------------------------------- VecteurCart IntersectRayEdge (VecteurCart s, VecteurCart o, Arete e) // détermine les coordonées du point d'intersection entre un rayon et une arête // Catedra p 106-107 // renvoie une coordonnée x=999 si il n'y a pas d'intersection // s est la coordonnée de l'origine du rayon diffracté et o la coordonnée de son extrémité { } //--------------------------------------------------------------------------- // Calcul transmission et rélfexion d'un rayon //--------------------------------------------------------------------------- Rayon Transmission (Rayon ray, Facette f, VecteurCart ip) // ray = rayon incident, f = facette, ip = point d'intersection du rayon et de la facette { } Rayon Reflexion (Rayon ray, Facette f, VecteurCart ip) // ray = rayon incident, f = facette, ip = point d'intersection du rayon et de la facette { } //--------------------------------------------------------------------------- // Calcul du rayon direct //--------------------------------------------------------------------------- void DirectRay (Antenne T, Antenne R) // calcul du rayon direct entre l'émetteur T et le récepteur R { } //--------------------------------------------------------------------------- // Calcul des rayons simplement réfléchis //--------------------------------------------------------------------------- int SReflectedRay (Antenne T, Antenne R) { } //--------------------------------------------------------------------------- // Calcul des rayons doublement réfléchis //--------------------------------------------------------------------------- int DReflectedRay (Antenne T, Antenne R) { } //--------------------------------------------------------------------------- // Calcul des rayons triplement réfléchis

109
//--------------------------------------------------------------------------- int TReflectedRay (Antenne T, Antenne R) { } //--------------------------------------------------------------------------- // Calcul des rayons diffractés //--------------------------------------------------------------------------- Rayon Diffraction (Rayon ray, Arete e, VecteurCart ip, VecteurCart T, VecteurCart R) // ray = rayon incident, e = arête, ip = point d'intersection du rayon et de l'arête // T est la position de l'émetteur du rayon et R la position de réception { } int SDiffractedRay (Antenne T, Antenne R) { } //--------------------------------------------------------------------------- // Calcul des rayons réfléchis-diffractés //--------------------------------------------------------------------------- int ReflectedDiffractedRay (Antenne T, Antenne R) { } //--------------------------------------------------------------------------- // Calcul du champ résultant //--------------------------------------------------------------------------- ChampCart ReceivedField (int nbSR, int nbDR, int nbTR, int nbSD, int nbRefDiff) { return E; } complex < double > ReceivedVoltage (int nbSR, int nbDR, int nbTR, int nbSD, int nbRefDiff) // calcul de la tension induite à circuit ouvert Voa = - Le.E // cf article R. Meys { return -v; } double ReceivedPower (complex < double >v) // calcul de la puissance reçue au niveau de la charge supposée égale à la résistance d'antenne // cf Article R. Meys // P = 1/8 |Voa|^2/Ra { double p; p = pow (abs (v), 2) / (8.0 * Rx.Ra); return p; }

110
//--------------------------------------------------------------------------- // Lecture et Sauvegardes //--------------------------------------------------------------------------- void LoadGeometry (const char *path1, const char *path2) { FILE *fichier; int i; double epsr, epsi; //printf("\nchargement de %s\n",path1); fichier = fopen (path1, "r"); fscanf (fichier, "%i", &NbFacettes); // printf("NbFacettes=%i\n",NbFacettes); if (facet == NULL) { facet = new Facette[NbFacettes + 1]; } else { delete (facet); facet = new Facette[NbFacettes + 1]; } for (i = 1; i <= NbFacettes; i++) { // printf("i is %i\n",i); fscanf (fichier, "%lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %i", &facet[i].pos.x, &facet[i].pos.y, &facet[i].pos.z, &facet[i].axe.x.x, &facet[i].axe.x.y, &facet[i].axe.x.z, &facet[i].axe.y.x, &facet[i].axe.y.y, &facet[i].axe.y.z, &facet[i].axe.z.x, &facet[i].axe.z.y, &facet[i].axe.z.z, &facet[i].d.x, &facet[i].d.y, &facet[i].d.z, &epsr, &epsi, &facet[i].pec); facet[i].eps = complex < double >(epsr, epsi); } fclose (fichier); fichier = fopen (path2, "r"); fscanf (fichier, "%d", &NbAretes); if (edge == NULL) { edge = new Arete[NbAretes + 1]; } else { delete (edge); edge = new Arete[NbAretes + 1]; } for (i = 1; i <= NbAretes; i++) { fscanf (fichier, "%lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %lf %i %lf %i %i", &edge[i].r0.x, &edge[i].r0.y, &edge[i].r0.z, &edge[i].r1.x,

111
&edge[i].r1.y, &edge[i].r1.z, &edge[i].n, &edge[i].axeo.x.x, &edge[i].axeo.x.y, &edge[i].axeo.x.z, &edge[i].axeo.y.x, &edge[i].axeo.y.y, &edge[i].axeo.y.z, &edge[i].axeo.z.x, &edge[i].axeo.z.y, &edge[i].axeo.z.z, &edge[i].axen.x.x, &edge[i].axen.x.y, &edge[i].axen.x.z, &edge[i].axen.y.x, &edge[i].axen.y.y, &edge[i].axen.y.z, &edge[i].axen.z.x, &edge[i].axen.z.y, &edge[i].axen.z.z, &epsr, &epsi, &edge[i].pec, &edge[i].d, &edge[i].faceo, &edge[i].facen); edge[i].eps = complex < double >(epsr, epsi); } fclose (fichier); // printf("fin de fonction LoadGeometry\n"); } /* void SaveField(int n) { FILE *fichier; int i; fichier = fopen("fieldz.data","w"); for(i=1;i<=n;i++) fprintf(fichier,"%g \n",abs(result[i].z)); fclose(fichier); fichier = fopen("fieldy.data","w"); for(i=1;i<=n;i++) fprintf(fichier,"%g \n",abs(result[i].y)); fclose(fichier); fichier = fopen("fieldx.data","w"); for(i=1;i<=n;i++) fprintf(fichier,"%g \n",abs(result[i].x)); fclose(fichier); } void SaveVoltage(int n) { FILE *fichier; int i; fichier = fopen("voltage.data","w"); for(i=1;i<=n;i++) fprintf(fichier,"%g \n",abs(voltage[i])); fclose(fichier); } void SavePower(int n) { FILE *fichier; int i; fichier = fopen("power.data","w"); for(i=1;i<=n;i++) fprintf(fichier,"%g \n",power[i]); fclose(fichier); } */ void SaveTrace () { FILE *fichier; int i; fichier = fopen ("/tmp/trace.data", "w"); for (i = 1; i <= ComptTrace; i++) fprintf (fichier, "%g %g %g %g %g %g\n", trace[i].r0.x, trace[i].r0.y,

112
trace[i].r0.z, trace[i].r1.x, trace[i].r1.y, trace[i].r1.z); fclose (fichier); } jim.c : #include "string.h" #include "ray_philippe.h" //#include "stdio.h" double Friis(double Pt, double Gt, double Gr, double lambda, double L, double d) { /* * Friis free space equation: * * Pt * Gt * Gr * (lambda^2) * P = -------------------------- * (4 * pi * d)^2 * L */ double M = lambda / (4 * PI * d); return (Pt * Gt * Gr * (M * M)) / L; } void shadowing(double Xt, double Yt, double Zt, double Xr, double Yr, double Zr) { double L = 0.9; // system loss double pathlossExp_=3.0; double dist0_=1.0; double dX = Xr - Xt; double dY = Yr - Yt; double dZ = Zr - Zt; double d = sqrt(dX * dX + dY * dY + dZ * dZ); // get antenna gain double Gt = 0.8; double Gr = 0.8; // calculate receiving power at distance double Pr0 = Friis(0.01, Gt, Gr, K, L, d); // calculate average power loss predicted by path loss model double avg_db = -10.0 * pathlossExp_ * log10(d/dist0_); // get power loss by adding a log-normal random variable (shadowing) // the power loss is relative to that at reference distance dist0_ double powerLoss_db = avg_db; // calculate the receiving power at dist power = Pr0 * pow(10.0, powerLoss_db/10.0); } void solve(double _Tx, double _Ty, double _Tz, double _Rx, double _Ry, double _Rz) { double nTotal; Rayon rayon; ChampCart E; int nbSR=0,nbSD=0,nbDR=0,nbTR=0, nbRefDiff=0;

113
// InitVar(); // FIXME: l'utilisateur devrait poser le type d'emeteur et de Rx avant ! // EMITTER Tx.Le = DipoleLe; Tx.Ra = 50.0; Tx.Ia = complex<double>(.5*sqrt(0.01/50.0),0.0); Tx.axe.x.x=1; Tx.axe.x.y=0; Tx.axe.x.z=0; Tx.axe.y.x=0; Tx.axe.y.y=1; Tx.axe.y.z=0; Tx.axe.z.x=0; Tx.axe.z.y=0; Tx.axe.z.z=1; //RECEIVER Rx.Le = DipoleLe; Rx.Ra = 50.0; Rx.Ia = complex<double>(0.0,0.0); Rx.axe.x.x=1; Rx.axe.x.y=0; Rx.axe.x.z=0; Rx.axe.y.x=0; Rx.axe.y.y=1; Rx.axe.y.z=0; Rx.axe.z.x=0; Rx.axe.z.y=0; Rx.axe.z.z=1; AxeAbs.x.x = 1.0; AxeAbs.x.y = 0; AxeAbs.x.z = 0; AxeAbs.y.x = 0; AxeAbs.y.y = 1.0; AxeAbs.y.z = 0; AxeAbs.z.x = 0; AxeAbs.z.y = 0; AxeAbs.z.z = 1.4; Tx.pos.x = _Tx; Tx.pos.y = _Ty; Tx.pos.z = 0.1; Rx.pos.x = _Rx; Rx.pos.y = _Ry; Rx.pos.z = 1.5; ComptTrace = 1; // parametres simulation doSR=1; doDR=1; doTR=0; doSD=1; doRD=1; DirectRay(Tx,Rx); if (doSR) nbSR = SReflectedRay(Tx,Rx); if (doDR) nbDR = DReflectedRay(Tx,Rx); if (doTR) nbTR = TReflectedRay(Tx,Rx); if (doSD) nbSD = SDiffractedRay(Tx,Rx); if (doRD) nbRefDiff = ReflectedDiffractedRay(Tx,Rx); result = ReceivedField(nbSR,nbDR,nbTR,nbSD,nbRefDiff); voltage = ReceivedVoltage(nbSR,nbDR,nbTR,nbSD,nbRefDiff); power = ReceivedPower(voltage); } void loopme() { int i,j; double step,posx,posy; double dbm; FILE* file=fopen("res24_shadowing.txt","w+"); //lambda=16.7 cm -> lambda/2 comme dist. carac. step=0.08; //parcours 1 posx=10.0-step; posy=0; while (posx<=40) { posx+=step; posy=step;

114
while(posy<=20) { //comparaison ray/shadowing.... solve(25.0,2.0,1.5,posx,posy,1.6); shadowing(25.0,2.0,1.5,posx,posy,1.6); dbm=30+10*log10(power); printf("power is %.2f\n",dbm); fprintf(file," %.2f %.2f %.2f\n",posx,posy,dbm); posy+=step; } } fclose(file); } double getPower() { return power; } void load() { printf("Loading geometries..."); LoadGeometry("/u/jdricot/tests/test2bis.facets.rayml","/u/jdricot/tests/test2bis.edges.rayml"); printf("loaded\n"); } int main(int argc, char**ee) { //load(); loopme(); return 0; }
A.1.4. Plugins Eclipse
Le code source est disponible dans le CD-ROM en annexe, ainsi qu’au Service d’Informatique et Réseaux de la faculté des sciences appliquées.
A.4. JavaDoc
La JavaDoc est disponible sur le CD-ROM en annexe, ainsi qu’au Service d’Informatique et Réseaux de la faculté des sciences appliquées.