rapport technique prÉsentÉ À l’École de … final... · sql : structured query language ti :...
TRANSCRIPT

RAPPORT TECHNIQUE PRÉSENTÉ À L’ÉCOLE DE TECHNOLOGIE SUPÉRIEURE
DANS LE CADRE DU COURS GTI795 / LOG795 - PROJET DE FIN D’ÉTUDES
UBUBI – Conception d’une application web pour le calcul de l’impact environnemental d’un bâtiment
LOUIS WILFRIED MBOG - MBOL09089009 ROMARIC COMLAN - COMR05098501
ADISON BORISUTPECH - BORA08119100 JEAN-PHILIPPE LECLERC - LECJ13069000
DÉPARTEMENT DE GÉNIE LOGICIEL ET DES TI
Professeur : ALAIN APRIL
Superviseur: MATHIEU DUPUIS
MONTRÉAL, 23 AVRIL 2018
HIVER 2018
LW Mbog, C Romaric, A Borisutpech, J-P Leclerc, 2018

1
Cette licence Creative Commons signifie qu’il est permis de diffuser, d’imprimer ou de sauvegarder sur un autre support une partie ou la totalité de cette œuvre à condition de mentionner les auteurs, que ces utilisations soient faites à des fins non commerciales et que le contenu de l’œuvre n’ait pas été modifié.

2
REMERCIEMENTS
Nous tenons à remercier le professeur Alain April ainsi que le promoteur et superviseur technique Mathieu Dupuis pour tous les moyens qu’ils ont déployés sur les plans technique, organisationnel, relationnel afin de nous permettre d’atteindre les objectifs de notre projet de fin d’études.

3
UBUBI
LOUIS WILFRIED MBOG - MBOL09089009 ROMARIC COMLAN - COMR05098501
ADISON BORISUTPECH - BORA08119100 JEAN-PHILIPPE LECLERC - LECJ13069000
RÉSUMÉ
Ce projet de fin d’études du baccalauréat en génie logiciel et des TI a été réalisé en partenariat avec l’École de Technologie Supérieure et l’École Polytechnique de Montréal. Il est la continuité du développement d’un prototype logiciel de recherche nommé UBUBI de l'équipe précédente de l’automne 2017. Le projet a permis d’implémenter une nouvelle interface graphique, un générateur de rapports Excel, une interface pour un plugiciel liant Autodesk Revit à UBUBI, et un graphique dynamique des résultats. Les principales technologies utilisées lors de ce projet sont Angular 2 qui a servi à la refonte de l’interface graphique, Apache POI qui a été utilisé pour la création du générateur de rapports, AmCharts sollicité pour tous les graphiques dynamiques, le cadriciel de développement utilisé avec Revit pour la mise en place de l’interface de liaison avec Autodesk Revit. La difficulté principale a été l’intégration des composants logiciels que nous avons créés au code existant.

4
TABLE DE MATIÈRES
CHAPITRE 1: INTRODUCTION 7
1.1. Contexte et problématique 7
1.2. Objectifs du projet 7
1.3. Méthodologie 8
1.3.1. Formation 8
1.3.2. Organisation du travail 8
1.3.2.1. Rencontre SCRUM hebdomadaire 9
1.3.2.2. Gestion de projet 9
1.4. Composition de l’équipe 10
1.5. Livrables 10
1.6. Risques 11
1.7. Techniques et outils 12
CHAPITRE 2 : CONTRIBUTION DE ADISON BORISUTPECH 13
2.1. Introduction 13
2.1.1. Problématique de la solution existante 13
2.1.2. Objectif général 13
2.2. Conception 14
2.2.1. Conception de la page web 14
2.2.2. L’affichage d’un ensemble de résultats 16
2.2.3. Interaction avec le graphique 21
2.3. Difficultés rencontrées 23
2.4. Conclusion 23
CHAPITRE 3 : CONTRIBUTION DE ROMARIC COMLAN 24
3.1. Introduction 24
3.2. Problématique de la solution existante 24
3.3. Objectif ciblé et démarche 24
3.4. Prérequis et installation de l’environnement de développement 25
3.5. Implémentation des fonctionnalités 25
3.6. Améliorations effectuées 41
3.7. Difficultés rencontrées et démarche de résolution 41
3.8. Conclusion 42
CHAPITRE 4 : CONTRIBUTION DE JEAN-PHILIPPE LECLERC 43

5
4.1. Introduction 43
4.2. Problématiques de l’application cliente courante 43
4.3. Solution: Angular 2 44
4.4. Intégration de la compilation Angular 44
4.5. Refaire l’application de façon statique 44
4.6. Le défi des requêtes au serveur et problèmes de performance 47
4.7. Conclusion 50
CHAPITRE 5 : CONTRIBUTION DE LOUIS WILFRIED MBOG 51
5.1. Introduction 51
5.2. Problématique de la solution existante 51
5.3. Description du processus de résolution de la problématique et présentation des résultats obtenus à la fin de chaque étape du processus 51
5.3.1. Analyse des API pour la génération des rapports Excel 51
5.3.2. Créer le modèle du rapport d’analyse 52
5.3.3. Conception du générateur de rapport 52
5.3.4. Réduction du délai de génération 52
5.4. Les difficultés rencontrées 53
5.5. Conclusion 53
CONCLUSION 54
RÉFÉRENCES / BIBLIOGRAPHIE 55
ANNEXE 56

6
LISTE DES ABRÉVIATIONS, SIGLES ET ACRONYMES
AJAX : Asynchronous JavaScript + XML
Apache POI : Apache Poor Obfuscation Implementation
API : Application Programming Interface
BD : Base de données
HTML : Hypertext Markup Language
IDE : Integrated Development Environment
JPA : Java Persistence API
JSON : JavaScript Object Notation
SQL : Structured Query Language
TI : Technologie de l’Information
UBUBI : Uncertain But Useful Building Information
VM : Machine virtuelle
3D : Trois dimensions

7
CHAPITRE 1: INTRODUCTION
1.1. Contexte et problématique
Depuis plusieurs années, les Québécois sont de plus en plus conscientisés au problème écologique. Ceci se reflète aussi dans le domaine de la construction. Des outils visant à mesurer l’empreinte écologique des bâtiments sont développés afin de répondre aux besoins écologiques. Ces outils produisent des résultats satisfaisants, mais leur utilisation reste complexe et ardue pour obtenir ces résultats ce qui n’encourage pas les entreprises à les utiliser. Il en résulte que l’impact écologique des bâtiments est rarement évalué. Afin d’inciter de plus en plus d’entreprises à évaluer l’impact écologique de leurs bâtiments, le prototype logiciel UBUBI a été développé. UBUBI est un prototype logiciel en logiciel libre qui vise à réduire le temps pour produire une analyse du cycle de vie d’un bâtiment en exploitant les données issues d’un modèle BIM (Building Information Model). UBUBI est un projet de recherche mettant en collaboration l’École de Technologie Supérieure (ÉTS) et l’école Polytechnique de Montréal. Il est encadré par le professeur Alain April et est supervisé par l’étudiant de doctorat Mathieu Dupuis qui est aussi le représentant du client auprès de notre équipe. Actuellement, le prototype logiciel UBUBI n’est pas encore à l’étape d’un premier prototype fonctionnel, car il lui manque encore certaines fonctionnalités avant d’être présenté aux intervenants pour commentaires.
1.2. Objectifs du projet
Le présent projet a pour but de rendre cette version du prototype fonctionnel et prêt pour commentaires par les intervenants. À cette fin, nous avons défini les objectifs suivants:
● Permettre l’exportation des résultats sous Excel; ● Terminer le plugiciel qui fait le lien entre UBUBI et Autodesk Revit; ● Permettre l’exploration des résultats via un graphique; ● Améliorer l’interface graphique de UBUBI.
Les résultats qui sont attendus et qui permettront de déterminer si nos objectifs ont été atteints sont les suivants:
● Un rapport de type Excel est généré à la demande de l’utilisateur. Il est téléchargeable par l’utilisateur et contient les résultats nécessaires pour évaluer l’impact écologique d’un bâtiment;
● Un graphique dynamique affiche des résultats de façon hiérarchique. Les résultats doivent être faciles à lire et à comprendre;
● La connexion interactive entre UBUBI et Autodesk Revit Link est opérationnelle et configurable;
● L’interface utilisateur de UBUBI est implémentée grâce à une technologie moderne.

8
1.3. Méthodologie
Afin d’atteindre les objectifs que nous nous sommes fixés, nous avons d’abord suivi une formation sur le projet UBUBI dans le but d’acquérir des connaissances de base sur le domaine d’affaires ainsi que sur les technologies utilisées par le prototype logiciel. Par la suite, nous avons défini une organisation du travail basée sur la méthode de développement logiciel agile SCRUM.
1.3.1. Formation
Cette activité avait pour but d’obtenir une vue d’ensemble du projet UBUBI, du cadriciel Play! et de l’environnement de développement intégré IntelliJ Idea. La formation a eu lieu en deux étapes:
La présentation de l’application UBUBI : qui consiste à informer les membres de l’équipe sur les buts et les objectifs de l’application UBUBI, présenter l’architecture du logiciel UBUBI, lister les différents composants logiciels constitutifs de UBUBI et les interactions entre ces composants, présenter les cadriciels (c.-à-d. décrire les principaux composants logiciels sur lesquels vont intervenir les membres de l’équipe). La présentation du cadriciel Play 2 et du système de gestion des dépendances : qui consiste à effectuer un travail pratique, d’une durée d’une semaine, et qui consiste à utiliser le cadriciel Amcharts pour afficher, dans une représentation graphique de son choix, des données provenant d’un contrôleur de UBUBI. Chaque membre de l’équipe doit créer un contrôleur qui génère des données aléatoires ainsi que toute la logique nécessaire pour afficher les données générées par le contrôleur dans un graphique Amcharts.
1.3.2. Organisation du travail
Compte tenu de la courte durée du projet de fin d’études (c.-à-d. 12 semaines), l’équipe de conception ne pouvait se permettre de travailler plusieurs semaines sur une fonctionnalité qui ne répond peut-être pas au besoin précis du client. Pour minimiser ce problème de longues périodes de développement sans rétroaction, l’équipe s’est dotée d’un processus de développement agile.

9
1.3.2.1. Rencontre SCRUM hebdomadaire
Une rencontre SCRUM hebdomadaire entre les membres de l’équipe, le professeur Alain April et le superviseur du projet Mathieu Dupuis tous les mercredis, à 17h, au local A-1544 à l'École de Technologie Supérieure de Montréal. Lors de cette rencontre, chaque membre d’équipe énonce les tâches dont il avait la charge pendant la semaine passée, présente le travail qu’il a accompli, indique les portions de travail qu’il reste à réaliser et reçoit de nouvelles tâches. Le représentant du client évalue le travail de chaque membre de l’équipe, souligne les corrections à apporter et identifie les prochaines tâches à assigner à chaque membre de l’équipe. Ce choix est effectué en prenant en compte l’ordre de priorité des tâches (identifiées dans Trello), les compétences de chacun des membres et l’intérêt que chacun de ces membres manifeste pour les tâches proposées. Le représentant du client et l’équipe déterminent les tâches à effectuer au cours de la semaine prochaine. Pour chaque tâche, le représentant du client et les membres de l’équipe conviennent du délai de réalisation.
1.3.2.2. Gestion de projet
Le suivi des tâches réalisé via une application collaborative web, Trello. Trello est utilisée pour conserver l’évolution de chaque tâche. Pour chaque tâche, Trello présente son nom, sa description, son état, sa priorité, le ou les membres assignés à cette tâche. Trello conserve aussi les échanges entre le représentant du client et les membres de l’équipe. Afin de démontrer le progrès du travail, des captures d’écran et des fichiers produits par la fonctionnalité implémentée sont envoyés au représentant du client via Trello. Le représentant du client examine les livrables qui lui ont été envoyés afin de confirmer que les résultats obtenus sont bien ceux qui étaient attendus. En cas d’insatisfaction, il identifie les corrections à apporter. Ses remarques sont transmises aux membres de l’équipe responsable de la fonctionnalité via Trello. Les membres de l’équipe effectuent les modifications nécessaires dans le code source et renvoie de nouveau le produit de son implémentation pour évaluation. Une fois que la fonctionnalité implémentée est jugée satisfaisante, la tâche est marquée dans Trello comme tâche achevée. Pour gérer le contrôle de version du code source du projet, l’équipe utilise GIT. Le dépôt GIT du projet est hébergé en ligne sur un serveur Gitlab à l‘ÉTS. Chaque membre de l’équipe crée une branche GIT qui correspond à la tâche qu’il effectue afin d’isoler ses changements. Une fois la fonctionnalité terminée et validée par le représentant du client, la branche est fusionnée à la branche maîtresse.
10
1.4. Composition de l’équipe
Noms Responsabilités
Adison Borisutpech Implémenter un graphique dynamique des résultats. Améliorer la mise en page des informations dans le graphique dynamique. Implémenter un module d’importation des données.
Jean-Philippe Leclerc Concevoir et implémenter la nouvelle interface utilisateur. Choisir les technologies à utiliser pour implémenter la nouvelle interface utilisateur.
Louis Wilfried Mbog Choisir l’API à utiliser pour implémenter le générateur de rapports Excel. Créer un modèle de rapport de résultats. Implémenter un générateur de rapports Excel de résultats. Optimiser la génération des rapports Excel.
Romaric Comlan Concevoir et implémenter une interface graphique pour la connexion entre UBUBI et Autodesk Revit. Implémenter le processus de connexion entre UBUBI et Autodesk Revit.
Tableau 1.1: Composition de l’équipe
1.5. Livrables
Nom de l'artéfact Description
Code source Code source fonctionnel qui contient les toutes les modifications effectuées dans UBUBI.
Interface de liaison entre UBUBI et Autodesk Revit.
Module de connexion entre UBUBI et Autodesk Revit et son interface graphique associée.
Modèle de rapports de résultats Fichier Excel qui contient les différents onglets, leurs colonnes et la mise en page du
11
rapport d’analyse.
Présentation orale Exposé oral qui donne un aperçu du projet et qui sera effectué le 23 avril 2018.
Proposition de projet Document contenant la proposition initiale du contenu du projet.
Rapport final Document présentant les résultats du projet. Tableau 1.2: Livrables du projet
1.6. Risques
Risque Impact Probabilité Mitigation / atténuation
Manque de connaissances des technologies utilisées
Fort Moyen Assigner un certain nombre de jours pour se familiariser et avoir une base de connaissance initiale afin des tâches de conception/développement
Changements des besoins du client
Fort Moyen Se doter d’une méthodologie Agile pour avoir un retour du représentant du client le plus rapidement possible
Absence de documentations des technologies utilisées
Fort Faible Demander de l’information aux membres expérimentés ou bien contacter directement le support de l’outil en question
Dépassement des délais
Fort Fort Identifier les améliorations prioritaires et ajuster l’envergure du projet.

12
Intégration difficile de Angular avec les outils de build présents dans le projet
Faible Moyen Utiliser la documentation d’intégration de Angular-cli à SBT.
Tableau 1.3: Les risques du projet
1.7. Techniques et outils
Au cours du projet nous avons utilisé ces outils :
● IntelliJ : IDE Java pour travailler sur le projet du côté Web Application. ● Microsoft Visual Studio : IDE permettant de travailler avec C# pour le « plugin »
de Revit. ● Amcharts : Cadriciel web pour générer des graphiques interactifs. ● MySQL : Système de gestion des bases de données. ● Hibernate : Cadriciel de gestion de la persistance d’objets en BD relationnelles. ● JPA : Interface de programmation Java permettant la correspondance entre objets
Java et une base de données relationnelle. ● Autodesk Revit : Logiciel d’architecture permettant la création de modèles de
bâtiment. ● Trello : Outil de gestion et d’assignation des tâches d’un projet. ● GitLab : Logiciel de gestion des projets et des dépôts Git. ● Google Drive : Service Google de partage de fichiers (collaboration). ● Google Hangout : Service Google de messagerie

13
CHAPITRE 2 : CONTRIBUTION DE ADISON BORISUTPECH
2.1. Introduction
Cette section présente les contributions de Adison Borisutpech. Elle décrit le besoin initial du client, la solution implémentée et toutes les étapes de la conception pour ses contributions.
2.1.1. Problématique de la solution existante
Le représentant du client désirait afficher les résultats d’une analyse de cycle de vie de façon simple et intuitive pour le client. Le logiciel avait des résultats réels généré dans la base de données et le représentant du client a fourni un prototype du genre d’affichage qu’il voulait obtenir. Le prototype était une page Web qui affichait un graphique dynamique pour afficher les résultats hiérarchisés. Malheureusement, les résultats présentés dans graphique étaient factices et les éléments du graphique n’étaient pas convenablement disposés.
2.1.2. Objectif général
Pour résoudre le problème, il faut créer un service web qui expose les données réelles disponibles dans la base de données, dans un format JSON permettant à la librairie Amcharts puisse l’utiliser. Le graphe doit être capable d’afficher les données de façon conforme à la demande du client. La demande est que le graphique doit avoir une bande pour chaque catégorie d’impact qui est toujours ramené sur 100% de ses processus enfants avec leurs informations nécessaires comme le nom et sa couleur de la légende, la quantité, leur pourcentage sur le total des processus enfants disponibles et l’incertitude. Il est certain que lorsque le pourcentage est petit, il peut être difficile à observer. C’est pour cela que la bulle d’information est présente pour afficher les détails importants. De plus, il faut assurer que la présentation du graphique est facile au client de lire les données afin d’être capable de réaliser ses analyses.

14
2.2. Conception
La première étape était de faire rétro-ingénierie du code afin de comprendre la structure des fichiers qui sont liés à ma tâche. Si j’avais des incompréhensions, je pouvais poser des questions au représentant du client. Pour le code le plus compliqué du logiciel, j’utilisais le débogueur d’IntelliJ pour connaître la séquence d’exécution des méthodes et les variables manipulées. Un diagramme de la structure des tables de données nécessaires pour réaliser cette tâche a été fourni par le promoteur du projet. La table principale pour créer le graphe est tbl_LCIGraph. Les attributs idNode et idNodeParent sont les deux champs qui permettront la relation Parent-Enfant des résultats. La racine l’arbre de résultats correspond aux résultats qui ont -1 dans le champ idNodeParent. Pour recueillir les enfants d’un enregistrement, il suffit juste de trouver les enregistrements dont le champ IdNodeParent correspond à l’idNode de l’enregistrement courant.
Figure 2.1: Diagramme de tables initiales pour le graphique dynamique
Les autres tables, permet de recueillir les informations additionnelles utiles pour l’affichage tel quel le nom de la catégorie d’impact (tbl_impact_categories) et le nom du processus qui génère cet impact écologique (tbl_processes).
2.2.1. Conception de la page web
Avant de pouvoir afficher le graphique des résultats, je devais créer une page web qui permettait de sélectionner quel ensemble de résultats à afficher. Pour ce faire j’ai créé une fonction AJAX est appelée pour chercher les ensembles de résultats disponibles dans la base de données à l’aide de la fonction getResultSetFromModelId du modèle ResultSets. La requête vers la BD est gérée par l’EntityManager provenant du JPA configurer du projet, voir la figure 2.6.

15
Figure 2.5: Code permettant le rendu de la page des résultats
Figure 2.6: Code pour obtenir les ensembles de résultats disponibles
Pour exposer le service à JavaScript, j’ai ajouté la fonction getResultSetFromModelId dans le contrôleur Router. Ceci permet de créer un objet AJAX préconfiguré du côté JavaScript qui pointe directement vers le service.
Figure 2.7: Ajout des fonctions aux routes de l’application
16
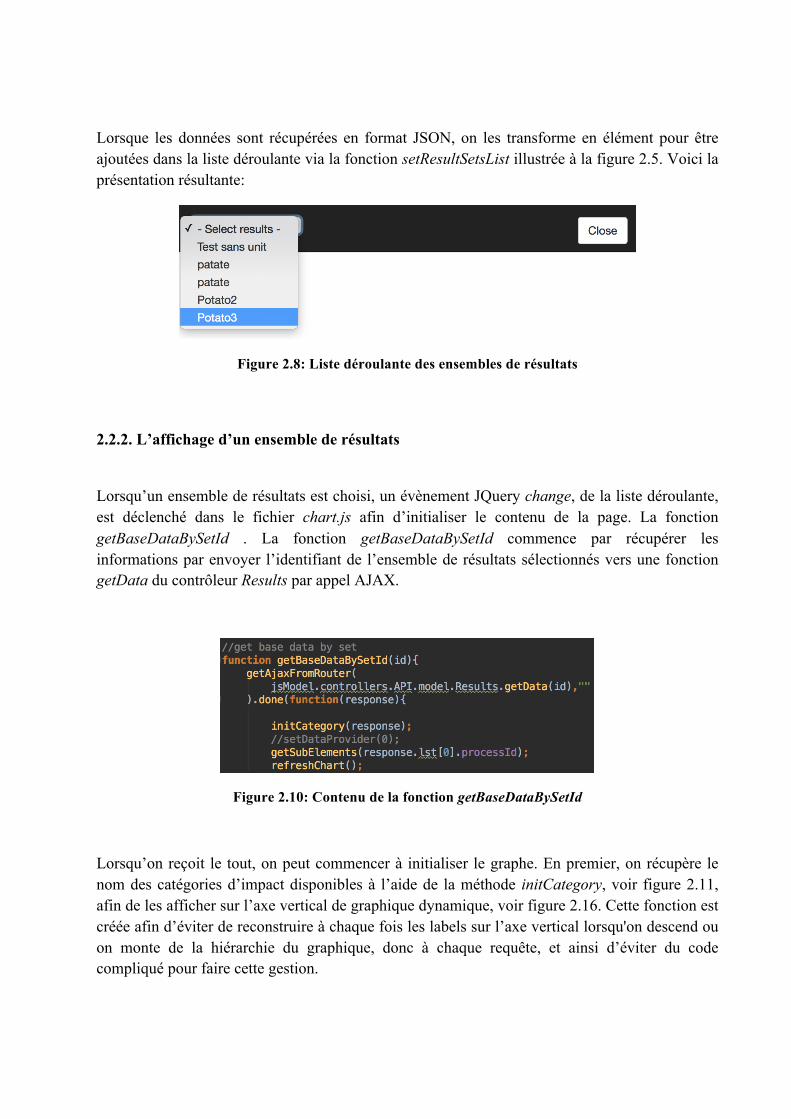
Lorsque les données sont récupérées en format JSON, on les transforme en élément pour être ajoutées dans la liste déroulante via la fonction setResultSetsList illustrée à la figure 2.5. Voici la présentation résultante:
Figure 2.8: Liste déroulante des ensembles de résultats
2.2.2. L’affichage d’un ensemble de résultats
Lorsqu’un ensemble de résultats est choisi, un évènement JQuery change, de la liste déroulante, est déclenché dans le fichier chart.js afin d’initialiser le contenu de la page. La fonction getBaseDataBySetId . La fonction getBaseDataBySetId commence par récupérer les informations par envoyer l’identifiant de l’ensemble de résultats sélectionnés vers une fonction getData du contrôleur Results par appel AJAX.
Figure 2.10: Contenu de la fonction getBaseDataBySetId
Lorsqu’on reçoit le tout, on peut commencer à initialiser le graphe. En premier, on récupère le nom des catégories d’impact disponibles à l’aide de la méthode initCategory, voir figure 2.11, afin de les afficher sur l’axe vertical de graphique dynamique, voir figure 2.16. Cette fonction est créée afin d’éviter de reconstruire à chaque fois les labels sur l’axe vertical lorsqu'on descend ou on monte de la hiérarchie du graphique, donc à chaque requête, et ainsi d’éviter du code compliqué pour faire cette gestion.

17
Figure 2.11: La méthode initCategory
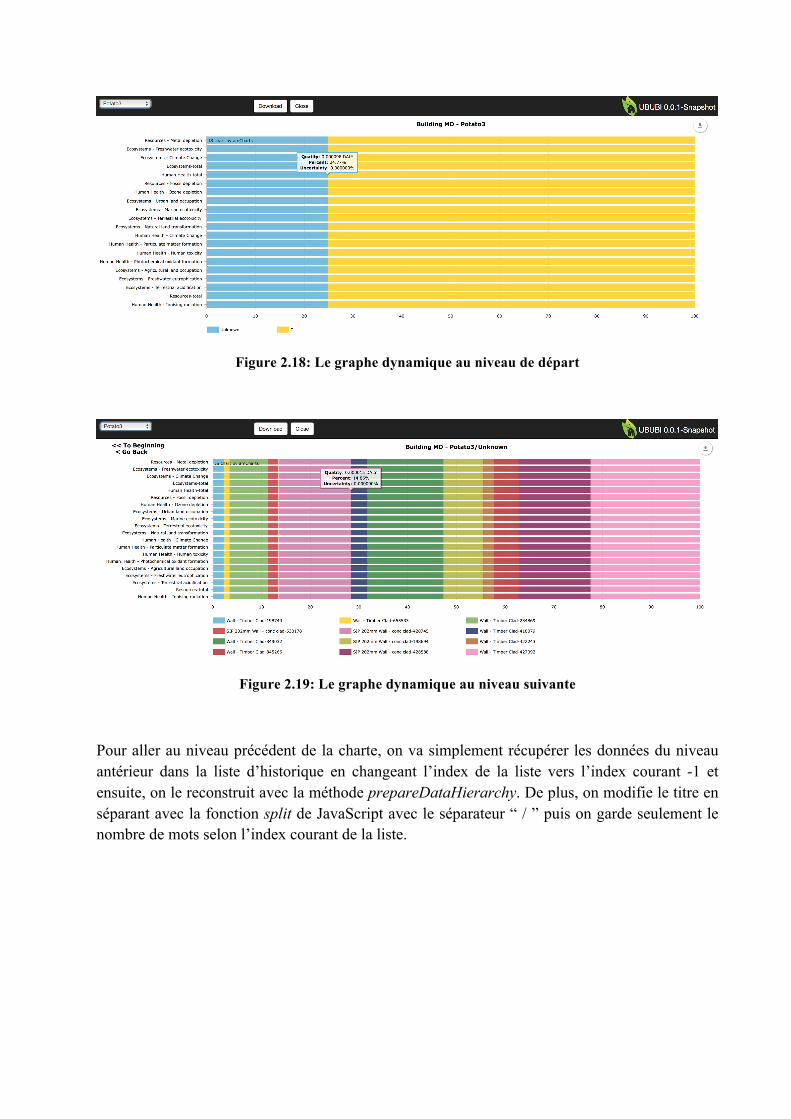
Par la suite, on appelle la fonction getSubElement qui exécute un appel AJAX pour appeler la méthode getDataByNodeId du contrôleur Results avec l’ID du processus racine, donc -1, et l’identifiant de l’ensemble de données en paramètre, pour obtenir ses processus enfants qui le suivent. Ils sont présentés de couleurs différentes dans le graphe, voir figure 2.16 et 2.19. Quand on obtient les processus enfants, ils sont envoyés à la méthode prepareDataHierarchy pour être transmis dans une nouvelle structure qui est adaptée pour Amcharts.

18
Figure 2.12: Contenu de la méthode prepareDataHierarchy
La construction de la structure commence par un objet JavaScript nommé “category” contenant seulement un attribut impactCat qui représente le nom de la catégorie courante à remplir de données et qui va être ajouté à la structure qui est une liste avec la fonction push. En connaissant la taille de la liste des résultats, on le divise selon le nombre de catégories disponibles ce qui donne le nombre de processus existants pour chaque, dataPerElement. À la fin de l’itération des données d’une catégorie, on obtient une structure comme ceci:

19
Figure 2.13: Structure de chaque catégorie
La raison pour que cette structure soit faite de cette façon est que Amcharts n’ait pas capable d’affichage nos données avec sa structure originale qui est statique et qui ressemble un peu à la figure 2.14, mais avec plus d’attributs, donc il n’y avait pas le choix de le construire comme cela pour être le plus compréhensive et facile à apprendre. Non seulement à cause de la structure statique, mais aussi le fait que le nombre de processus par bande peut se varier. Il faut donc que la structure change à chaque fois selon le nombre de processus. En effet, selon le bout de code de prepareDataHierarchy à la figure 2.15, on peut voir comment le graphe va être configuré pour utiliser ces données à chaque changement. Ce code permet seulement de créer une barre du graphique pour chaque catégorie. À chaque nouveau graphe créé, “new AmCharts.AmGraph()”, il représente une bande de couleur pour un processus enfant. Lorsque la nouvelle structure des données et la configuration du graphique sont finies, on sauvegarde les résultats originaux dans une liste d’historique d’ensembles de résultats avec setRequestHistory afin que l’on puisse revenir dessus quand l’utilisateur remontre dans la hiérarchie du graphique dynamique. Le fait de garder les données permet d’éviter de refaire trop des grandes requêtes au serveur. Enfin, on configure la charte avec les données formatées avec la fonction setGraphData, voir figure 2.12, et on la rafraîchit pour afficher les nouvelles données, voir figure 2.16.

20
Figure 2.14: Code représentant la structure statique de la chart
Figure 2.15: Code pour la construction de la barre graphique de chaque catégorie

21
Figure 2.16: Le graphe dynamique au niveau initial
2.2.3. Interaction avec le graphique
Le client demandait d’être capable de se déplacer de niveau dans l’arbre de résultat donc avoir une fonctionnalité Drill-Down et de remonter la hiérarchie des données. Pour réaliser cela, Amcharts nous fournit la possibilité d’ajouter des Listeners sur le graphe. Lorsque l’utilisateur clique sur un impact d’un processus, l’évènement se déclenche et récupère l’identifiant de l’élément sélectionné et est envoyé à la fonction getSubElements ce qui charge les impacts enfants et qui régénère le graphique.
Figure 2.17: Le Listener de la chart
Voici le résultat lorsqu’on clique sur le processus nommé “Unknown” de la catégorie “Human Health-total” qui est la barre bleue.
22
Figure 2.18: Le graphe dynamique au niveau de départ
Figure 2.19: Le graphe dynamique au niveau suivante
Pour aller au niveau précédent de la charte, on va simplement récupérer les données du niveau antérieur dans la liste d’historique en changeant l’index de la liste vers l’index courant -1 et ensuite, on le reconstruit avec la méthode prepareDataHierarchy. De plus, on modifie le titre en séparant avec la fonction split de JavaScript avec le séparateur “ / ” puis on garde seulement le nombre de mots selon l’index courant de la liste.

23
Figure 2.20: Fonction goBack pour remonter dans la hiérarchie
2.3. Difficultés rencontrées
Une des difficultés durant la réalisation de cette tâche est que la documentation de la librairie Amcharts ne spécifie pas comment on peut créer notre graphique personnalisé. Heureusement, il y a beaucoup de supports dans la communauté de Amcharts et ils sont rapides à répondre à nos questions. Cette tâche était ma première expérience avec les cadriciels d’affichage web, ce qui m’a un peu ralenti. Grâce à cette expérience, j’ai découvert les outils de débogage sur les navigateurs. Ces outils marchent extrêmement bien pour obtenir les informations des variables JavaScript lors de l’exécution d’une page. Cela m’a facilité la tâche et permettre d’éviter d’afficher des messages avec la fonction d’alerte de JavaScript pour afficher les valeurs désirées.
2.4. Conclusion
Cette fonctionnalité permet à l’utilisateur de consulter et explorer les résultats de ses analyses d’impact environnemental avec une représentation graphique . Au début, cette fonctionnalité n’était qu’un prototype basé sur des données fictives. Maintenant, on utilise des données réelles venant de la base de données. Il reste encore des améliorations à faire pour cette fonctionnalité. Par exemple, lorsqu’il y a trop d’impacts de processus enfants à afficher, il peut être difficile à lire le graphe, car il y a trop d’éléments afficher en même temps.

24
CHAPITRE 3 : CONTRIBUTION DE ROMARIC COMLAN
3.1. Introduction
J’étais chargé d’implémenter une fonctionnalité qui permet à l’utilisateur de sélectionner un processus dans UBUBI et, par un clic, sélectionner l’objet Revit représenté par le processus. Cela devait être réalisé à l’aide du langage C# et du cadriciel de développement de Revit. Ce chapitre détaillera le mandat confié, la démarche d’implémentation et les difficultés rencontrées.
3.2. Problématique de la solution existante
La solution existante, Revit-Link, comportait des lacunes au niveau de la gestion des jetons (token) du côté d’UBUBI. De plus, la liaison entre Revit et UBUBI n’était pas entièrement fonctionnelle, car l’ouverture de connexion était forcée avec un jeton statique imposé au serveur, ce qui empêchait d’avoir plus d’un client qui utilise ce service. De plus, une fois que Revit était connecté à UBUBI, il gelait et rendait l’application inutilisable jusqu’à tant que l’utilisateur sélectionne un élément dans UBUBI.
3.3. Objectif ciblé et démarche
Pour le projet, je me suis fixé les objectifs suivants :
● Gérer la génération du jeton en respectant le format prescrit par le client, ● implémenter une interface de connexion pour Revit-Link ● implémenter l’échange de messages entre UBUBI et Revit au moyen de sockets, ● résoudre le problème de gel de Revit
Pour atteindre ces objectifs, il a fallu dans un premier temps installer les différents outils nécessaires, comprendre le code existant et implémenter les fonctionnalités attendues.

25
3.4. Prérequis et installation de l’environnement de développement
Pour compiler la partie serveur du projet (UBUBI), il fallait remplir certains prérequis :
Déployer la machine virtuelle UBUBI :
● Installer IntelliJ ● Installer MySQL Workbench et tester la connexion au serveur distant ● Importer le projet UBUBI dans l’environnement de développement ● Installer LOMBOK
Pour la partie gestion du plugin entre UBUBI et le logiciel d’architecture Revit, il fallait :
● Installer Microsoft Visual Studio 2015 ● Installer Autodesk Revit 2017 - Étudiant ● Importer le code de Revit-Link ● Installer le plugin Revit-Link
3.5. Implémentation des fonctionnalités
3.5.1 Gestion des tokens et envoi de message dans UBUBI
En exécutant des tests du projet à l’état existant, j’ai constaté que la fonction de génération des jetons ne retournait pas le format attendu qui est de cinq caractères alphanumériques majuscules. Le projet antérieur avait été implémenté pour que le jeton soit toujours forcé à “1234”.

26
Dans le projet UBUBI, j’ai modifié la fonction de génération des jetons avec le code suivant :
Figure 3.1: Méthode d’envoi de message au serveur UBUBI
Durant les tests, j’ai constaté que le format (nombre de caractères) attendu par le serveur ne correspondait pas à celui envoyé par Revit. J’ai donc modifié la méthode run() du côté serveur pour qu’il y ait conformité du message reçu. La méthode se trouve dans la classe RevitSocket.java dans le dossier \...\UBUBI\app\controllers\API\.

27
Figure 3.2: Validation du jeton attendu par le serveur UBUBI
3.5.2 Revit ne répond pas
Au départ, les utilisateurs ne pouvaient pas travailler sur Revit si Revit-Link était connecté à UBUBI. La source du problème survenait sur la lecture du socket vers UBUBI qui reçoit l’ID de l’élément à sélectionner. Normalement il n’y a pas de problème, car les applications sont multiprocessus, mais pas Revit. Revit est monoprocessus, donc quand Revit-Link bloque le processus principal et unique de Revit, l’application ne répond plus et contraint à sa fermeture. La première solution que j’ai essayée était d’ajouter un temps d’attente (timeout) lors de l’envoi de message au serveur, car je croyais que cela donnerait la main à l’utilisateur pour le choix d’item. Cette solution n’a pas marché, car même si Revit ne gelait plus, la connexion se fermait avant que le message parvienne au serveur. Une deuxième solution essayée était d’ajouter un temps d’attente lors de la réception, car je croyais que cela permettrait de synchroniser le transfert de message et rendrait Revit utilisable. Cette solution n’a pas fonctionné, car avant que le serveur reçoive le message, la connexion se fermait avant. Finalement, j’ai réussi à résoudre le problème en déplaçant la lecture du socket dans l'évènement onIdling de Revit, en plus d’ajouter un délai limite de lecture de 1ms. L’évènement OnIdling s’exécute à chaque fois que Revit est inactif, ce qui veut dire, que l’utilisateur ne travaille pas.

28
Pour commencer, j’avais juste transféré la lecture du socket dans l’évènement OnIdling, mais Revit bloquait encore sur la lecture. Alors j’ai eu l’idée d’ajouter un délai de lecture très court comme cela s’il n’y a pas de message envoyé par UBUBI, la fonction de lecture lance une erreur de type Timeout que j’ai juste à capter pour redonner le contrôle à Revit.
3.5.2. Plugin Revit-Link
Le test du plugin était complexe et prenait beaucoup de temps. Après chaque modification du code, il fallait régénérer la solution, par la suite attacher le processus Revit avant de demander un jeton.
Revit devait être fermé lors de la régénération de la solution. Des fois il fallait régénérer la solution plusieurs fois sans avoir modifié du code avant qu’elle réussisse. Durant mes investigations, j’ai constaté que cela est dû à des fichiers .DLL qui restaient ouverts même si Revit était fermé.
Une fois la solution régénérée, il fallait ouvrir Revit, charger le fichier UbubiRevitWebSocket.dll avant d’attacher le processus.
Figure 3.3: Alerte de sécurité pour le chargement de UbubiRevitWebSocket.dll
Lors de l’attache du processus dans C#, le projet UbubiRevitWebSocket reste gelé jusqu’au moment où le serveur est prêt à recevoir une demande de connexion à partir de Revit.
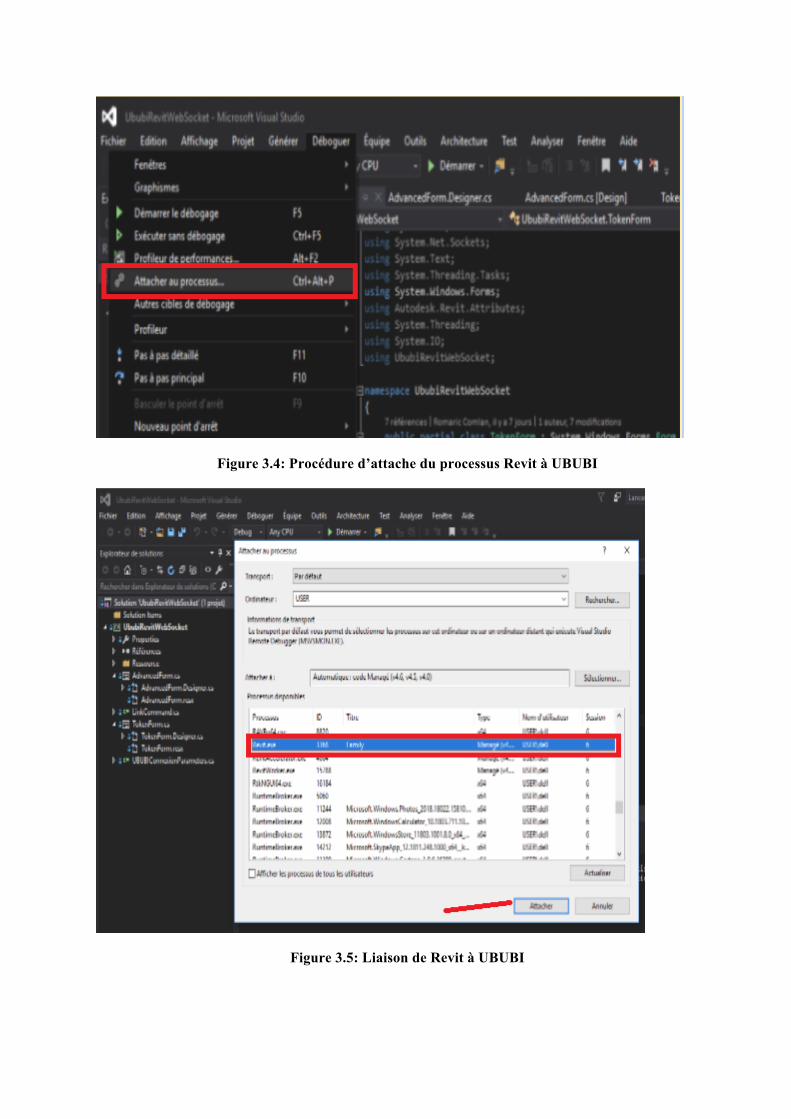
29
Figure 3.4: Procédure d’attache du processus Revit à UBUBI
Figure 3.5: Liaison de Revit à UBUBI
30
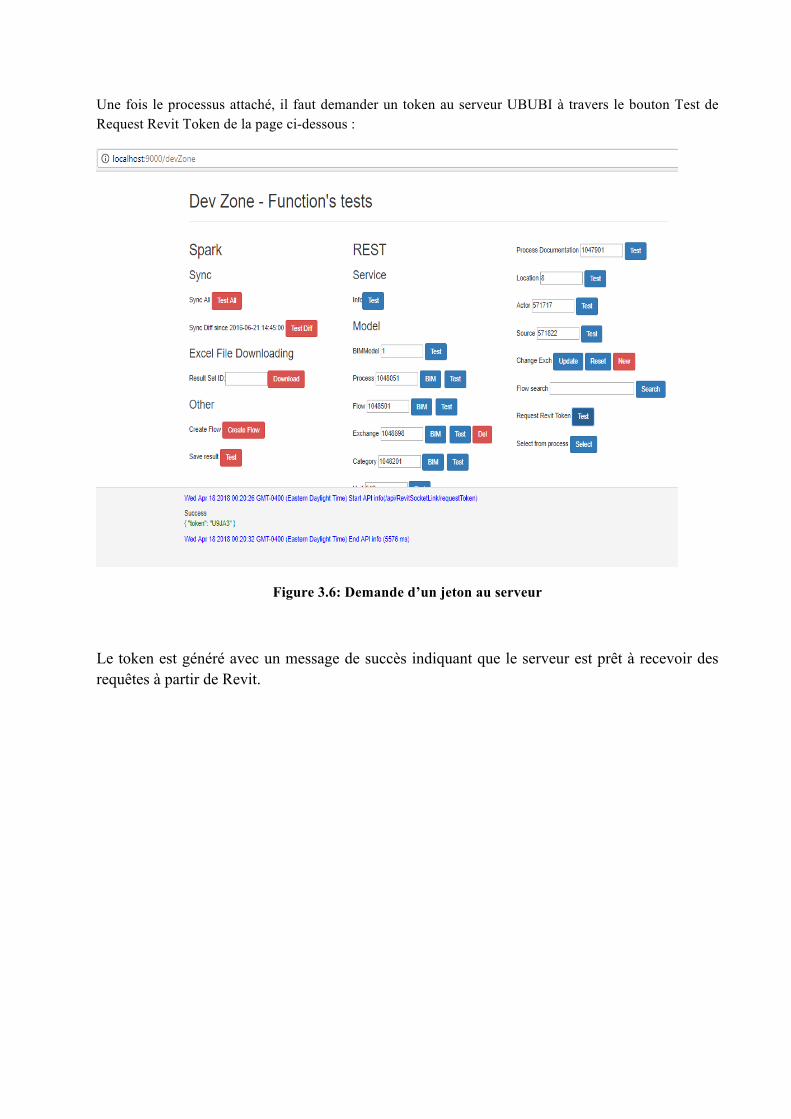
Une fois le processus attaché, il faut demander un token au serveur UBUBI à travers le bouton Test de Request Revit Token de la page ci-dessous :
Figure 3.6: Demande d’un jeton au serveur
Le token est généré avec un message de succès indiquant que le serveur est prêt à recevoir des requêtes à partir de Revit.
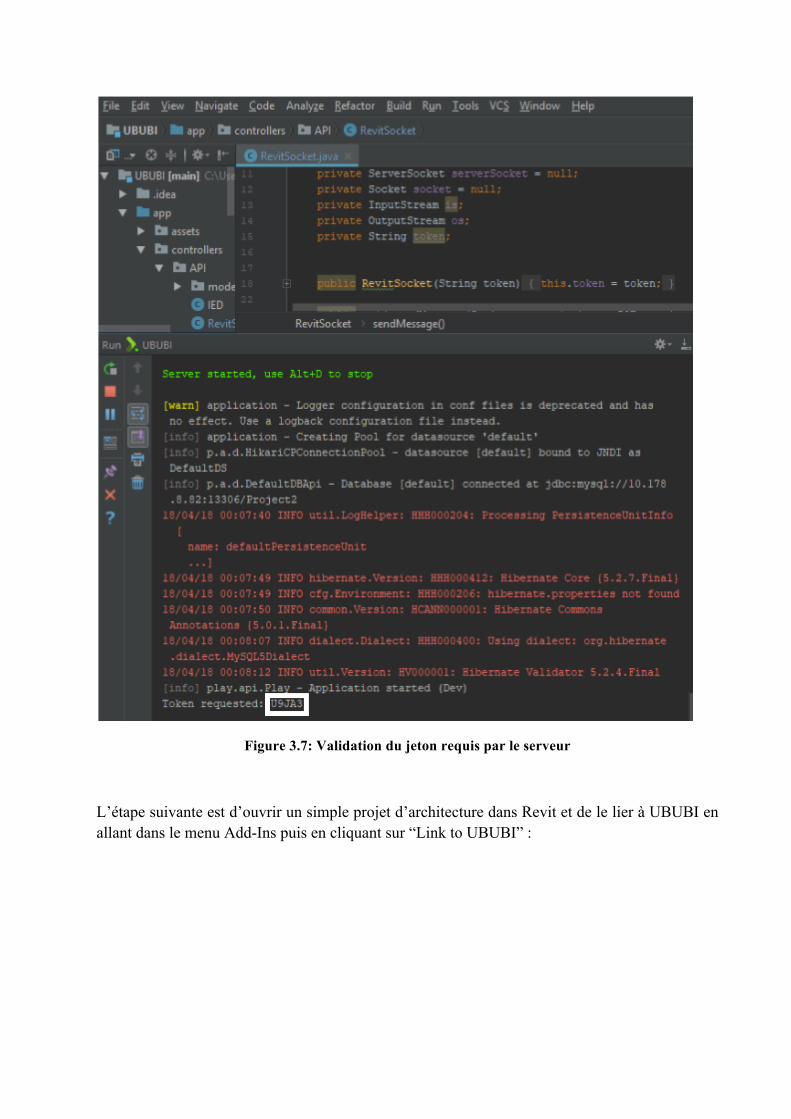
31
Figure 3.7: Validation du jeton requis par le serveur
L’étape suivante est d’ouvrir un simple projet d’architecture dans Revit et de le lier à UBUBI en allant dans le menu Add-Ins puis en cliquant sur “Link to UBUBI” :
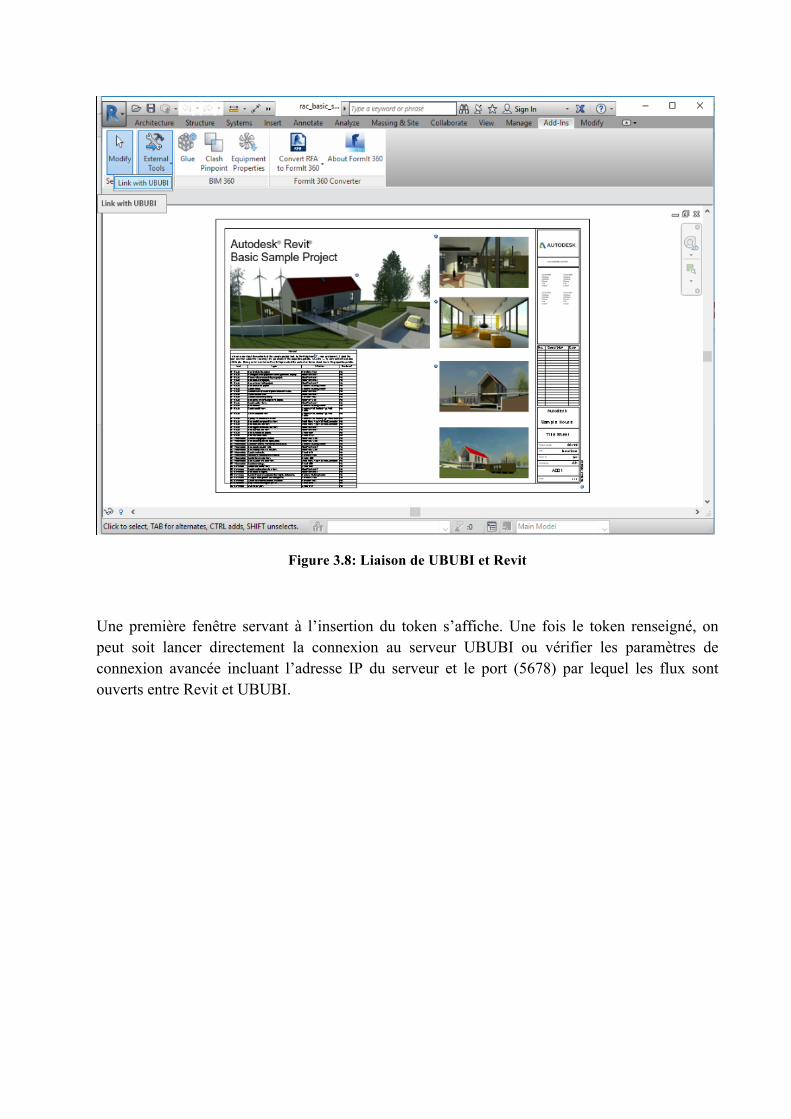
32
Figure 3.8: Liaison de UBUBI et Revit
Une première fenêtre servant à l’insertion du token s’affiche. Une fois le token renseigné, on peut soit lancer directement la connexion au serveur UBUBI ou vérifier les paramètres de connexion avancée incluant l’adresse IP du serveur et le port (5678) par lequel les flux sont ouverts entre Revit et UBUBI.
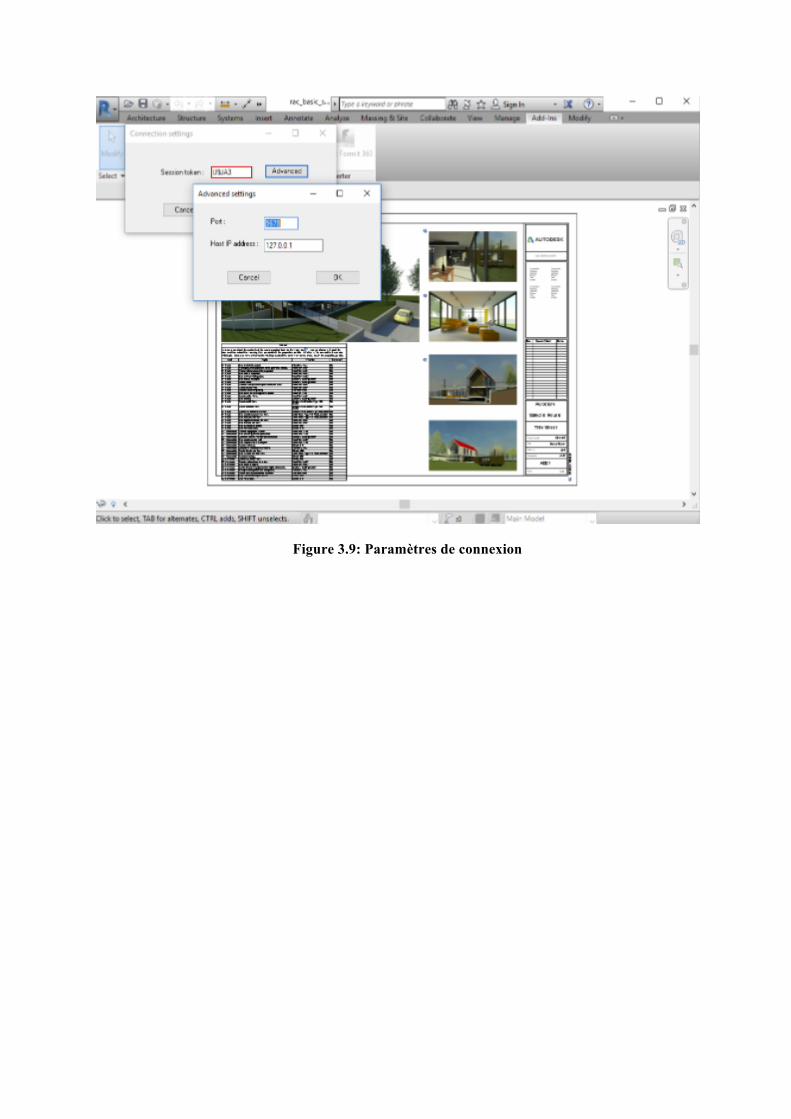
33
Figure 3.9: Paramètres de connexion
34
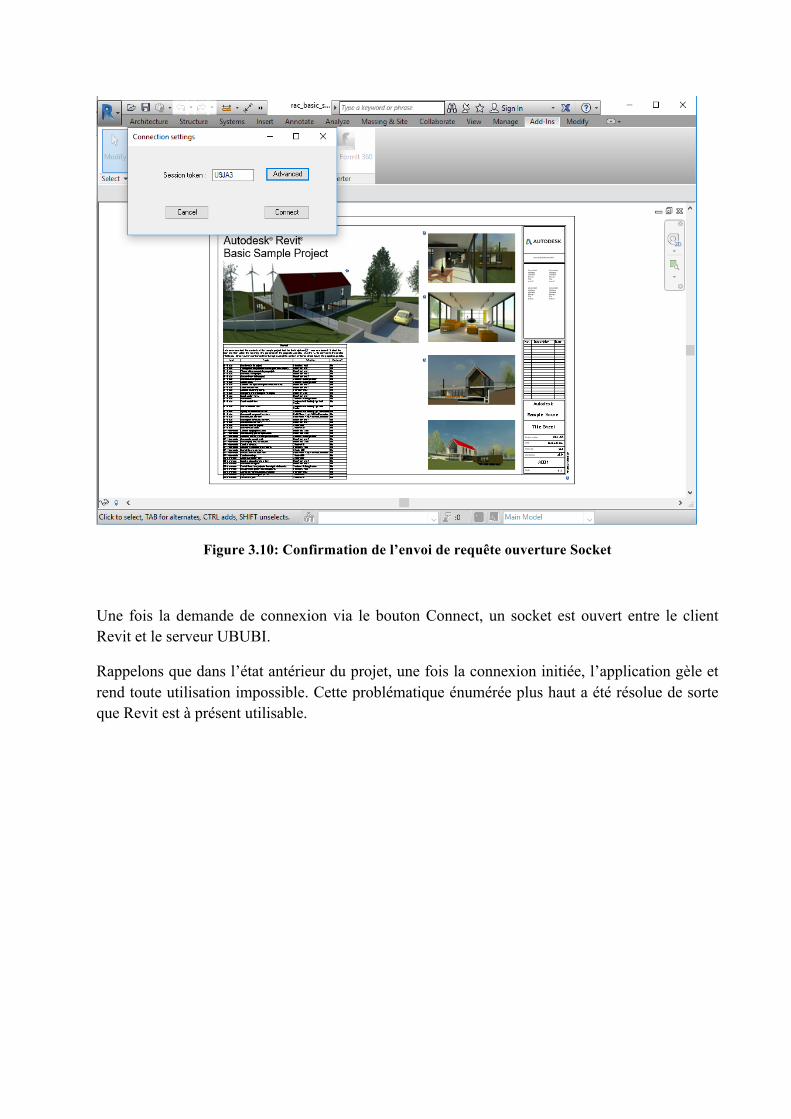
Figure 3.10: Confirmation de l’envoi de requête ouverture Socket
Une fois la demande de connexion via le bouton Connect, un socket est ouvert entre le client Revit et le serveur UBUBI.
Rappelons que dans l’état antérieur du projet, une fois la connexion initiée, l’application gèle et rend toute utilisation impossible. Cette problématique énumérée plus haut a été résolue de sorte que Revit est à présent utilisable.
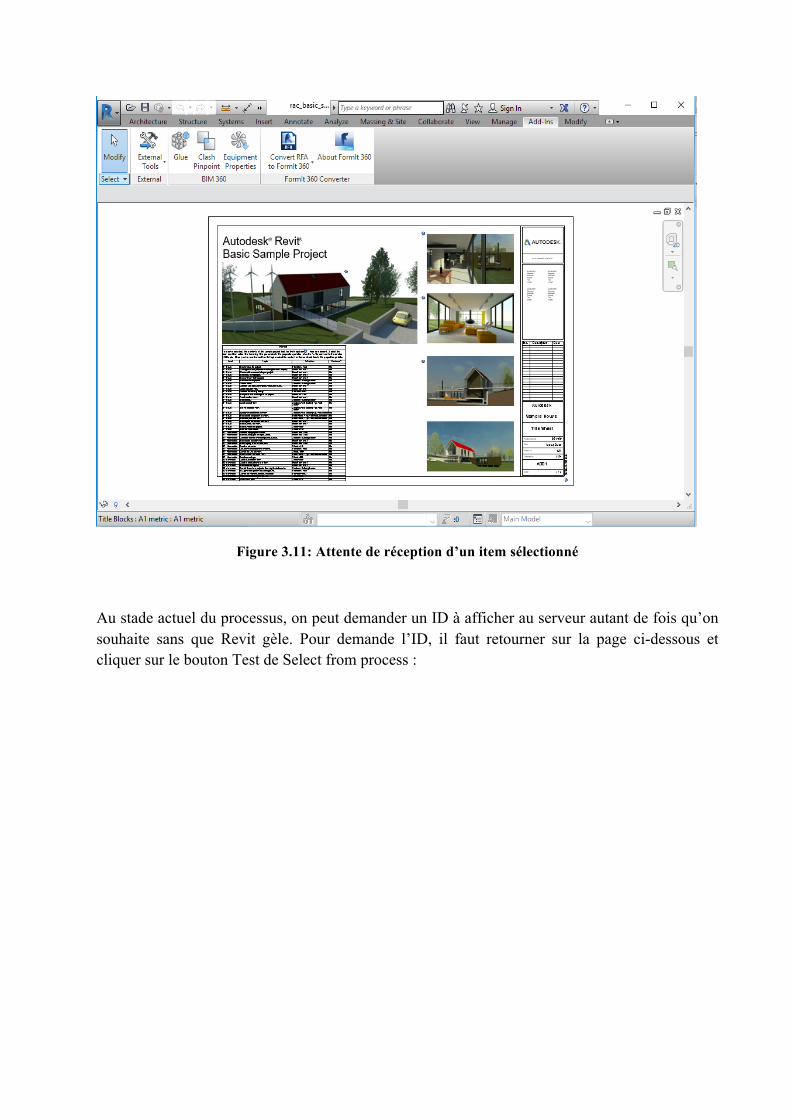
35
Figure 3.11: Attente de réception d’un item sélectionné
Au stade actuel du processus, on peut demander un ID à afficher au serveur autant de fois qu’on souhaite sans que Revit gèle. Pour demande l’ID, il faut retourner sur la page ci-dessous et cliquer sur le bouton Test de Select from process :

36
Figure 3.12: Sélection d’un ID
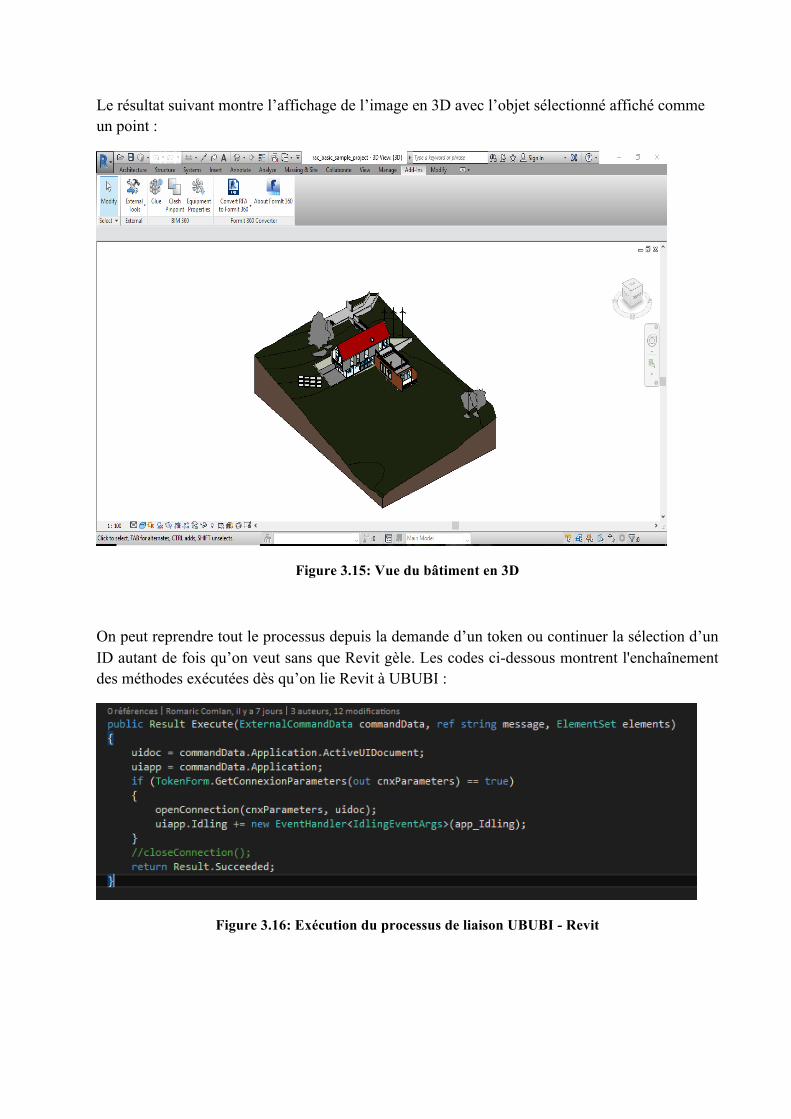
Le statut Succès affiché au bas de la page indique que le serveur a répondu favorablement à la requête puis l’ID a été retourné. Au niveau de Revit, l’ID est récupéré puis qu’on peut afficher l’image en 3D.
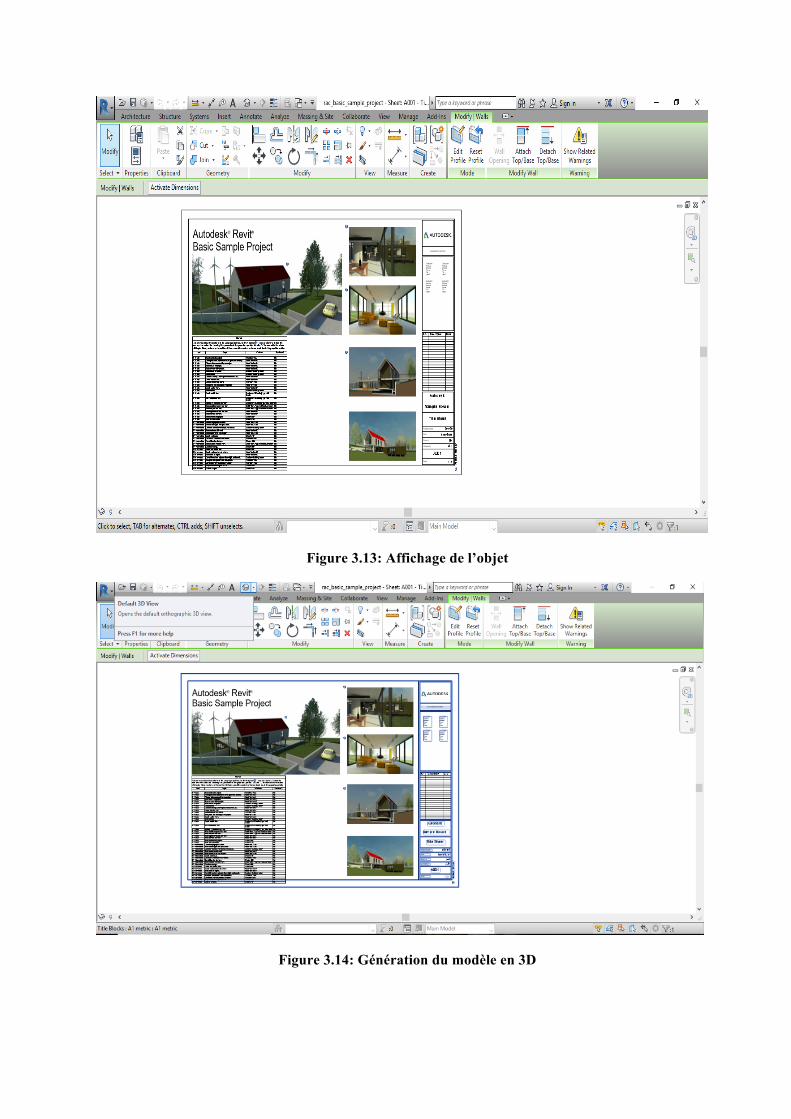
37
Figure 3.13: Affichage de l’objet
Figure 3.14: Génération du modèle en 3D
38
Le résultat suivant montre l’affichage de l’image en 3D avec l’objet sélectionné affiché comme un point :
Figure 3.15: Vue du bâtiment en 3D
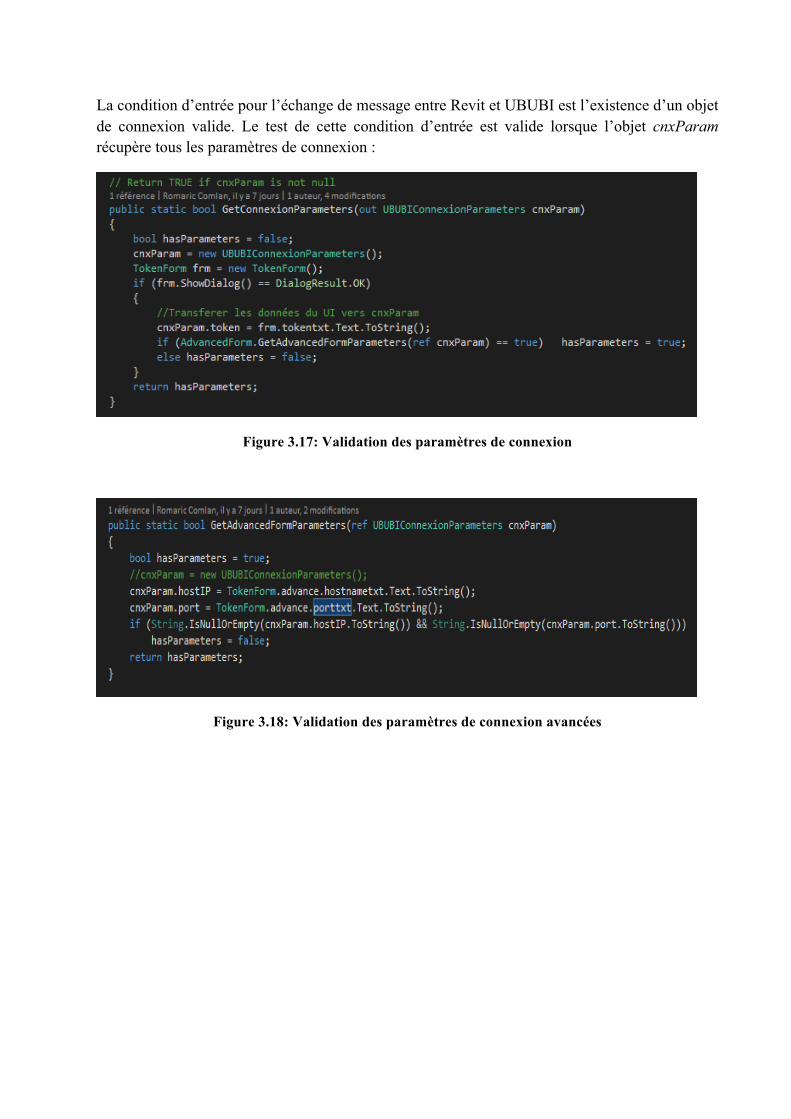
On peut reprendre tout le processus depuis la demande d’un token ou continuer la sélection d’un ID autant de fois qu’on veut sans que Revit gèle. Les codes ci-dessous montrent l'enchaînement des méthodes exécutées dès qu’on lie Revit à UBUBI :
Figure 3.16: Exécution du processus de liaison UBUBI - Revit
39
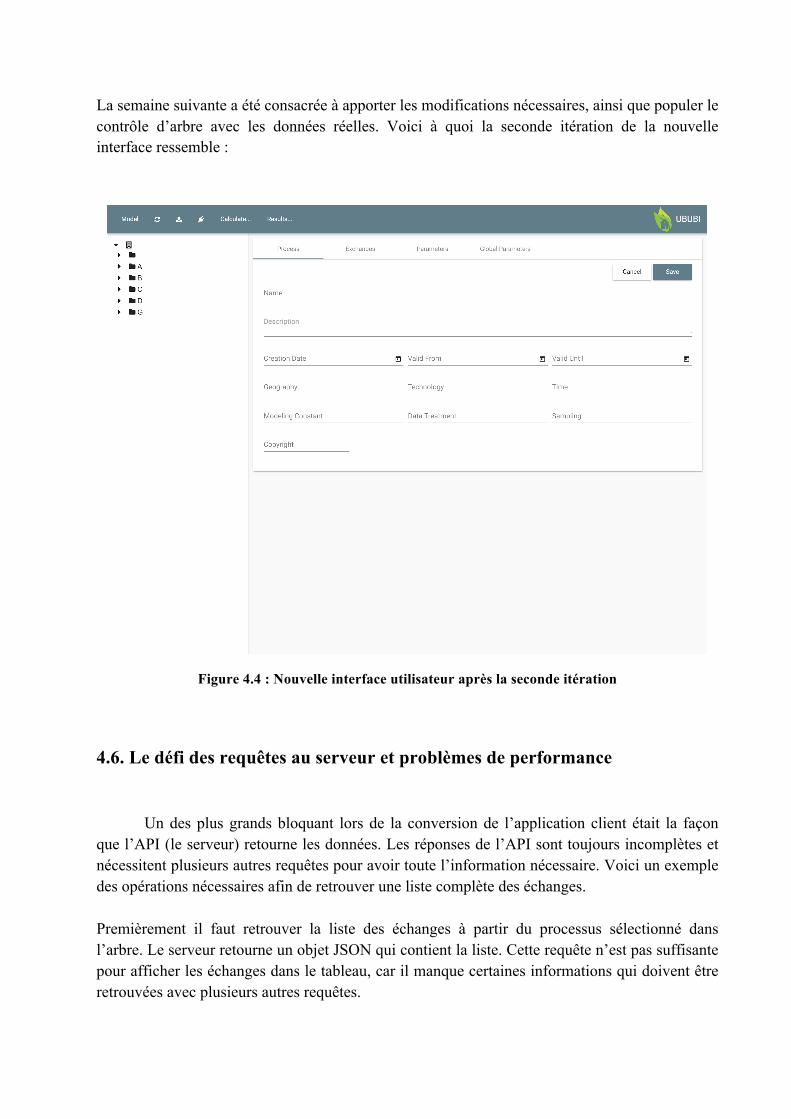
La condition d’entrée pour l’échange de message entre Revit et UBUBI est l’existence d’un objet de connexion valide. Le test de cette condition d’entrée est valide lorsque l’objet cnxParam récupère tous les paramètres de connexion :
Figure 3.17: Validation des paramètres de connexion
Figure 3.18: Validation des paramètres de connexion avancées

40
Figure 3.19: Ouverture d’une connexion Client - Serveur
Figure 3.20: Sélection d’un item via l’évènement Idling
Le gel de Revit a été résolu par l’ajout de l’évènement Idling de Revit. C’est à l’intérieur de cet évènement que la fonction de sélection d’un item a été implémentée. Lors de chaque appel de la fonction de sélection d’un ID, cet évènement s’exécute et empêche le gel.

41
3.6. Améliorations effectuées
Durant le développement de cette partie du projet, j’ai remarqué que certaines valeurs d’entrée étaient codées de manière à permettre de simuler la fonctionnalité. L’objectif étant d’améliorer le projet existant, j’ai validé la partie du code à modifier avec nos superviseurs et donc d’une part, la fonction de génération du jeton a été corrigée puis intégrée au projet. Lors de l’établissement de la liaison UBUBI - Revit, j’ai constaté que les fonctions d’ouverture, de fermeture de connexion au serveur puis l’envoi de message avaient été intégrés dans une seule méthode; ce qui ne facilitait pas la vérification des tests en mode débogage. Les trois fonctions ont donc été séparées de manière à rendre le code plus facile à tester. De plus, il fallait intégrer des temps d’attente lors de la réception de messages entre UBUBI et Revit. Le faible couplage a donc permis, de situer plus facilement quelle partie du code devait être modifiée pour faire fonctionner l’application.
3.7. Difficultés rencontrées et démarche de résolution
Ayant peu d’expérience avec le langage C#, l’adaptation au code existant n’a pas été facile. Bien qu’étant à l’aise avec la programmation orientée objet, la correspondance des syntaxes en C# nécessitait des recherches en ligne; ce qui a développé davantage mon sens de recherche, mon intuitivité. Lors des tests, il fallait reprendre tout le processus pour vérifier le résultat obtenu versus le résultat attendu. Chaque test prenait beaucoup de temps et il fallait modifier le code, le rester autant de fois qu’il fallait jusqu’à ce que les valeurs de sortie soient celles attendues. Au niveau du développement des interfaces, j’avais une approche non recommandée. Sous la direction du superviseur, j’ai remodifié le code afin qu’il y ait une meilleure lisibilité et un faible couplage entre les classes. J’utilisais beaucoup de variables globales lors du passage des données entre les interfaces; ce qui n’est pas une bonne pratique en programmation. Il fallait bien choisir les évènements à utiliser pour chaque interaction avec les interfaces, car un mauvais usage pouvait engendrer des résultats non escomptés. La gestion du gel de Revit n’a pas été sans difficulté. Dans un premier temps, il fallait identifier l’évènement adéquat (implémenté par la compagnie Autodesk) et par la suite développé en son sein, la méthode qu’on voudrait appeler plusieurs fois.

42
Figure 3.20: Évènement Idling
En résumé, l’atteinte de l’objectif n’a pas été sans difficulté. Le respect des échéanciers par rapport aux livrables attendus n’a pas été chose aisée. J’informais continuellement nos encadreurs de l’évolution (même si les résultats n’étaient pas bons) et prenais en compte leurs observations jusqu’à l’atteinte de l’objectif.
3.8. Conclusion
La liaison entre UBUBI et Revit est fonctionnelle. De plus, le gel de Revit lors de la lecture du socket vers UBUBI a été corrigé. Le serveur UBUBI génère un jeton utilisé par Revit pour établir un canal d’échange de messages.

43
CHAPITRE 4 : CONTRIBUTION DE JEAN-PHILIPPE LECLERC
4.1. Introduction
Mon travail consistait à développer à l’aide du cadriciel Angular2 et de la technologie Google Material Design la nouvelle interface utilisateur de UBUBI. Je présente ci-dessous la problématique liée à ma tâche ainsi que le déroulement de la mise en oeuvre de la nouvelle interface utilisateur et les résultats obtenus.
4.2. Problématiques de l’application cliente courante
L’application initiale implémentait Angular 1 mais le cadriciel était mal utilisé ce qui a justifié la réingénierie de l’application client. Le code avait certaines erreurs qui reviennent souvent dans le monde du développement web :
- Les fonctions sont définies dans le « scope » global et ne sont pas compartimentées en classes.
- Les évènements sont appliqués avant que le document soit prêt. - L’application a plusieurs problèmes visuels.
Figure 4.1 : Fonction d’initialisation de la page mal définie

44
4.3. Solution: Angular 2
Angular 2 est un cadriciel développé par Google servant à créer des applications Web en Typescript. Ce cadriciel s’avère être un outil très puissant pour développer des applications performantes et facilement testables. L’utilisation du Typescript rend la base de code plus facile à naviguer avec un IDE moderne et son compilateur peut trouver toutes les erreurs qu’un langage typé trouverait normalement. Un des éléments qui a mis en doute l’intégration d’Angular 2 dans ce projet était le fait que le code client existant ne pouvait être réutilisé, tout le travail des dernières années sur l’interface doit être refait, car les bases de Angular 1 n’ont pas été respectées. En contrepartie, il est plus facile de faire du code plus maintenable avec Angular 2, sans compter qu’avec mon expérience avec ce cadriciel me permettra de produire plus rapidement que d’utiliser un cadriciel compétiteur (ex : React). C’est pour cette raison que l’équipe est allée de l’avant avec l’adoption de cette nouvelle technologie.
4.4. Intégration de la compilation Angular
UBUBI utilise l’outil de compilation ‘SBT’. Afin d’étudier la faisabilité de l’intégration de l’application Angular, il a été important de prototyper l’intégration « d’Angular-cli » avec SBT. Suite à quelque recherche, certaines pistes ont été trouvées, mais la plus intéressante reste un « repository » trouvé sur Github contenant un exemple de projet Playframework avec un côté client développé en Angular. C’est durant cette phase que la configuration du projet « Angular-cli » a été effectuée et que l’intégration à SBT a été prototypée pour en démontrer la faisabilité.
4.5. Refaire l’application de façon statique
La première étape de développement pour la refonte de l’interface graphique était de faire une première ébauche de l’interface utilisateur. Au cours de la rencontre hebdomadaire, il a été décidé qu’une première ébauche de l’interface utilisateur serait la première étape de développement. Cette étape consiste concrètement à reproduire l’interface actuelle de UBUBI avec Angular, mais sans fonctionnalité. Initialement, l’application ressemblait à ceci:

45
Figure 4.2 : Ancienne interface utilisateur de l’application
Afin de faciliter l’implémentation de l’interface, j’ai utilisé la librairie Material2, une librairie créée par Google qui a pour but de simplifier la création d’interfaces utilisateur basée sur Angular 2. Cette librairie comporte plusieurs composantes comme des boutons, des champs pour des formulaires et autres contrôlent les plus importants pour créer une application web.

46
La première ébauche de cette interface était très minimale, mais il a été possible de valider avec le responsable que la direction était bonne :
Figure 4.3 : Première ébauche de l’interface utilisateur
Déjà à la première ébauche, j’ai réussi à intégrer un contrôle d’arbre fonctionnel grâce à la librairie « ng2-tree », mais avec des données fictives. Suite à la présentation de cette interface, les responsables du projet ont porté quelques commentaires pour l’améliorer. Voici les points soulevés durant cette rencontre:
- La couleur bleue est trop éclatante; - Il n’y a pas de boutons, ni une liste déroulante pour la sélection des modèles dans le
menu; - La vue en arbre n’a pas les bonnes icônes; - Il manque le logo de UBUBI.
47
La semaine suivante a été consacrée à apporter les modifications nécessaires, ainsi que populer le contrôle d’arbre avec les données réelles. Voici à quoi la seconde itération de la nouvelle interface ressemble :
Figure 4.4 : Nouvelle interface utilisateur après la seconde itération
4.6. Le défi des requêtes au serveur et problèmes de performance
Un des plus grands bloquant lors de la conversion de l’application client était la façon que l’API (le serveur) retourne les données. Les réponses de l’API sont toujours incomplètes et nécessitent plusieurs autres requêtes pour avoir toute l’information nécessaire. Voici un exemple des opérations nécessaires afin de retrouver une liste complète des échanges.
Premièrement il faut retrouver la liste des échanges à partir du processus sélectionné dans l’arbre. Le serveur retourne un objet JSON qui contient la liste. Cette requête n’est pas suffisante pour afficher les échanges dans le tableau, car il manque certaines informations qui doivent être retrouvées avec plusieurs autres requêtes.
48
Figure 4.5 : Les informations nécessaires pour chaque échange
Pour chaque échange, il faut aller chercher son flow, son provider, et ainsi que son unité. Le nombre de requêtes au serveur nécessaires pour retrouver la liste d'échanges et leurs informations s’exprime donc par la formule suivante: 1 + nombre d'échanges * 3. Par exemple, une liste de 268 échanges va donc se traduire en 805 requêtes et tout le téléchargement peut prendre jusqu'à 30 secondes.
Figure 4.6 : Nombre de requêtes exécutées pour 268 échanges

49
Étant donné la portée limitée du projet, il n’était pas dans les plans de refaire l’application serveur, mais certaines recommandations et améliorations possibles ont été proposées:
1. Ajout d’une fonctionnalité permettant de communiquer au serveur les champs à inclure dans les objets retournés afin d’éviter de faire des requêtes supplémentaires. Par exemple, plutôt que d'appeler l’API à l’URL /api/model/processes/1131548/exchanges, il serait possible d’apposer une querystring avec les champs à inclure dans le résultat. L’URL résultante ressemblerait à ceci: /api/model/processes/1131548/exchanges?fields=flow,prodiver,unit.
2. L’intégration de la technologie GraphQL développée par Facebook. GraphQL est un langage de requête permettant de demander un objet au serveur en définissant seulement les champs nécessaires. La requête retournant tous les “échanges” avec toutes leurs informations serait aussi simple que ceci:
Figure 4.7: Format d’une requête GraphQL

50
4.7. Conclusion
La nouvelle interface utilisateur a pu être implémentée. Elle est plus conviviale et plus intuitive. La connexion de cette nouvelle interface aux fonctionnalités existantes a été assez aisée. L’une des principales difficultés a été l’intégration de l’outil en ligne de commande Angular-cli au SBT de Play framework. J’ai obtenu un gain de performance dans l’affichage des éléments graphiques.Toutefois, les défauts de performances majeurs liés aux fonctionnalités existantes subsistent notamment le nombre de requêtes à effectuer pour obtenir toutes les données d’une « échange ».

51
CHAPITRE 5 : CONTRIBUTION DE LOUIS WILFRIED MBOG
5.1. Introduction
Pour ce projet, j’étais chargé d’implémenter le générateur de rapport d’analyse de l’impact écologique des bâtiments. Je présente dans ce chapitre la problématique qui a conduit à cette implémentation, le processus d’implémentation du générateur ainsi que les difficultés que j’ai rencontrées.
5.2. Problématique de la solution existante
UBUBI utilise l’API Apache Velocity pour générer des rapports. Cependant, Apache Velocity ne permet pas de générer des rapports au format Excel. De plus, les rapports générés ne contiennent aucune donnée, car la base de données a évolué, mais pas le générateur. De plus, les rapports sont présentement dans un format XML qui est par la suite compressé dans un fichier Zip, ce qui oblige l’utilisateur à décompresser le fichier et l’importer dans Excel. Ces étapes n’existeraient pas si les rapports étaient directement générés dans un format Excel. Il importe donc de trouver une API open source capable de générer des rapports au format xlsx, d’utiliser cette API pour implémenter le générateur de rapports et d’insérer les données d’analyse dans les rapports générés.
5.3. Description du processus de résolution de la problématique et présentation des résultats obtenus à la fin de chaque étape du processus
5.3.1. Analyse des API pour la génération des rapports Excel
La première étape était de recenser les différentes « APIS » de génération de rapports afin de comparer leurs avantages et leurs inconvénients des API. J’ai ensuite comparé les API entre elles en me basant sur leurs avantages et leurs inconvénients. Les «API» qui ont suscité mon intérêt sont Apache POI, Aspose et Docx4j.Aspose fournit les fonctionnalités pour exporter des données, formater des feuilles de calcul au niveau le plus granulaire, importer et exporter des images, créer des graphiques et tableaux croisés dynamiques, appliquer et calculer des formules complexes, diffuser des données Excel et enregistrer le résultat dans divers formats. Aspose est l’« API » qui offre le plus de possibilités en terme de traitement. Cependant, Aspose est payante.Docx4j est utilisée Java Architecture Xml Binding(JAXB) pour ouvrir un fichier xlsx

52
existant, créer un nouveau fichier xlsx, manipuler un fichier xlsx, appliquer les transformations au fichier xlsx. Elle propose certaines fonctionnalités absentes de Apache POI, est gratuite et sous licence d’Apache, mais, son support et sa communauté sont moins forts que ceux d’Apache POI. À l’issue de cette comparaison, j’ai retenu l’API Apache POI car elle est très populaire et est soutenue par une grande communauté. De plus, Apache POI affiche de bonnes performances en terme de génération de rapports contenant un nombre conséquent de données et elle est très facile à utiliser.
5.3.2. Créer le modèle du rapport d’analyse
J’ai choisi de générer un modèle de rapport, car cela permettait de ne pas écrire du code source pour créer les onglets, définir pour chaque onglet, les propriétés de chaque colonne et de réduire ainsi de délai de génération du rapport. Avec l’aide du représentant du client, j’ai déterminé les données qui doivent figurer dans le rapport ainsi que la mise en page du rapport. Le modèle du rapport est stocké dans l’application et sera utilisé pour créer le rapport.
5.3.3. Conception du générateur de rapport
J’ai choisi d’utiliser la même hiérarchie que l’ancien générateur, car elle était bien conçue et le processus qu’elle utilisait pour intégrer le générateur était facile à comprendre et comprenait un faible nombre d’étapes. J’ai d'abord répertorié les composants logiciels existants qui me serviront à créer le générateur de rapports. Ces composants sont la classe CalculationApiMappedData qui encapsule les requêtes SQL de récupération des données du rapport d’analyse, la classe controllers.API.Spark qui déclenche la génération de rapports et rend le rapport Excel généré téléchargeable par un utilisateur.Ensuite j’ai créé la classe ExcelApachePoiMappedData qui hérite de CalculationApiMappedData et encapsule les objets Java qui représentent les enregistrements de la base de données ainsi que des métadonnées. J’ai aussi créé la classe ApachePoiXlsxFileCreator qui se charge de créer le rapport xlsx et d’y insérer les données de la base de données en mémoire.
5.3.4. Réduction du délai de génération
Le rapport d’analyse était généré au bout de 7 secondes, ce qui est insatisfaisant.Pour réduire le temps de génération, j’ai utilisé des structures de données natives JAVA nommées HashMap qui ont une complexité d’O(1) pour les opérations d’insertion, de retrait et de lecture des données. Les hashmap ont servi à stocker sous forme d’objets JAVA les enregistrements extraits de la base de données. De plus, le rapport une fois généré une première fois est maintenant conservé pour le retourner la prochaine fois que l’utilisateur désirera télécharger au lieu de régénérer encore une deuxième fois et ainsi éliminer complètement le délai de génération.

53
5.4. Les difficultés rencontrées
En ce qui concerne les problèmes que j’ai rencontrés, je peux mentionner des bogues d’affichage de données du rapport d’analyse. Lorsque certaines données étaient récupérées de la base de données et placées dans une Hashmap, elles affichaient un point d’interrogation contenu dans un losange comme le montre la figure suivante:
Figure 5.8:Bogue d’affichage de caractères
Ce problème est dû à une mauvaise interprétation de caractère de la part du compilateur JAVA. En effet, dans JAVA, tout caractère inconnu transmis via la méthode write() d’un OutputStream est affiché sous la forme d’un point d’interrogation contenu dans un losange. Cela peut dans certains cas être causé par la base de données. La majeure partie des moteurs de bases de données remplacent les représentations numériques non couvertes par un point d’interrogation contenu dans un losange durant les opérations de sauvegarde.
Ce point d’interrogation contenu dans un losange est affiché plus tard lorsque les données sont extraites et présentées à l’utilisateur. Cela peut aussi être dû au fait que ISO-8859 est l’encodage par défaut des « Input/Output streams » alors que l’environnement dans lequel les données sont affichées utile l’encodage UTF-8. Pour résoudre ce problème, j’ai indiqué dans mon code source que l’encodage des caractères utilisé par mes « Input/Output streams » est UTF-8.
5.5. Conclusion
J’ai implémenté le générateur de rapports.Ce générateur produit un fichier Excel qui contient les données liées aux matériaux utilisés pour construire un bâtiment. Le générateur de rapport a été réalisé avec l’API Apache POI qui bénéficie d’un support continu. Le processus d’implémentation du générateur permet d’établir des connexions entre les documents des exigences, de conceptions et les composants logiciels constitutifs du générateur de rapports. Par ailleurs, le générateur a été implémenté de façon à faciliter l’ajout de futures fonctionnalités.

54
CONCLUSION
Nous avons livré une version du logiciel UBUBI dotée d’une nouvelle interface utilisateur, d’un générateur de rapports, d’un plugin Revit pour la liaison avec Autodesk Revit et d’un graphique dynamique de résultats. Cette version est prête pour la séance de présentation du produit au client. Grâce à la méthode SCRUM, nous avons compris que solliciter le client au fur et à mesure que le développement du produit évolue, permet de développer un produit conforme aux attentes du client.Grâce à la méthode SCRUM, nous avons amélioré notre méthode de recherche de solutions aux problèmes de codage et nous avons appris à bien répartir le temps imparti entre les sessions de codage et les sessions de test. Trello a permis de maintenir la traçabilité entre les exigences du produit, le code source du produit et les documents connexes et d’identifier précisément l’origine des défauts. Nous avons aussi compris qu'utiliser un outil collaboratif permet de bénéficier rapidement du soutien technique de la part des autres membres de l’équipe. Identifier les risques avant de se lancer dans le développement permet de prendre les dispositions nécessaires pour éviter certains problèmes futurs qui retarderaient énormément le développement du produit.Nous avons fourni un prototype fonctionnel. Cela permet au projet UBUBI de se rapprocher de plus en plus de sa version finale qui permettra à des entreprises de toute taille de disposer de données pertinentes qui leur permettront d’être mieux outillées pour prendre de judicieuses décisions quant à la construction d’un bâtiment. Le prototype est cependant loin d’être parfait. En effet, le nombre de requêtes nécessaires pour récupérer les informations sur les échanges devrait être réduit, les onglets Contribution Analysis et “LCI by Category” du rapport Excel doivent contenir des données.

55
RÉFÉRENCES / BIBLIOGRAPHIE
● Slides Introduction à UBUBI ● MILETTE, Yves; KANTCHILL, Richard; PAUL-DEGARIE, Maxime; CHAN, Jean-Philippe.
2017. TickSmith : Interface Custom Analytics. “Rapport technique de projets de fin d’études”. Montréal (Qc.): École de technologie supérieure, 133 page
● MySQL Workbench : ○ https://dev.mysql.com/doc/
● Angular 2 : ○ https://angular.io/docs
● Google Material Design : ○ https://material.io/guidelines/#
● Amcharts : ○ https://www.amcharts.com/knowledge-base/
● Les sockets : ○ https://msdn.microsoft.com/en-
us/library/system.net.sockets.socket.sendtimeout(v=vs.110).aspx ○ lien Google : managing sockets
● Idling Event : ○ http://adndevblog.typepad.com/aec/2013/07/tricks-to-force-trigger-idling-event.html
● Apache POI : ○ https://poi.apache.org/spreadsheet/quick-guide.html ○ https://stackoverflow.com/questions/tagged/apache-poi
● Play Framework : ○ https://www.playframework.com/
56
ANNEXE
Figure 6.1 : Trello pour la gestion du projet