rapport de stage les modèles spatiaux prédictifs de ... · master 2 ecologie evolution biométrie...
TRANSCRIPT

Maxime Passerault Master 2 Ecologie Evolution Biométrie Université Lyon 1, année 2008-2009
Rapport de stage Les modèles spatiaux prédictifs de distribution
en écologie
[Analyse critiques de la Littérature]
Les modèles de distribution en écologie : les contraintes et les limites
[Travail de recherche]
Développement d’une démarche aboutissant à un modèle spatial prédictif d’abondance du Milan noir,
Milvus migrans
Soutenue le 12/06/2009
Sous la direction de Vincent Bretagnolle, directeur de recherche Et de David Pinaud, ingénieur de recherche Centre d’Etude Biologiques de Chizé, UPR CNRS 1934

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 2
REMERCIEMENTS
Je tiens tout particulièrement à remercier :
David Pinaud pour son accueil lors de mon arrivée au laboratoire, et pour m’avoir bien intégré
parmi le personnel.
Thomas et David pour l’ambiance de travail agréable dans le bureau des deux-sévriens. Leur
aide et leur expérience m’ont été très précieuses tout au long de mon stage, me permettant
d’avancer dans la réflexion et de sortir de certaines impasses.
Vincent Bretagnolle qui a su guider ma réflexion et apporter un regard critique orientant mon
questionnement.
Angèle pour sa patience, son soutien et ses encouragements dans les moments difficiles.
Lucas, sans qui ce rapport ne serait peut-être jamais arrivé sur papier.
Je suis également reconnaissant à :
Toute l’équipe de stagiaires en particulier aux deux Vincent, Marion, Arzhela, Marine, Kelly,
Sébastien, Adrien et Hélène, ainsi que Pamela pour les encouragements mutuels, les bons
moments de vie en communauté et de rigolade.
Tous les personnes que j’ai rencontrées au laboratoire et avec qui j’ai partagé des
connaissances, découvert des choses enrichissantes. En particulier Mich’, Max’ et Hervé,
les thésards herpéto qui m’ont fait découvrir énormément de choses et ont sut répondre à
ma curiosité.
Toutes les personnes présentes sur le CEBC pour l’ambiance conviviale qui règne ici en plein
cœur de la forêt de Chizé.
Christophe le cuisinier pour avoir préparé de bons petits plats.
Tous les joueurs de baby-foot pour les parties enflammées indispensables pour décompresser.

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 3
SOMMAIRE
Analyse critiques de la Littérature : Les modèles de distribution en écologie : les contraintes et les
limites
p
5
Introduction p 6 I. Autocorrélation spatiale p 7 1) Origines p 7 2) Problèmes p 8 3) Solutions p 8 II. Contraintes de l’étude p 9 1) Contraintes liées au but de l’étude p 9 2) Contraintes liées à la nature des variables p 9 3) Contraintes liées au type de variables p 10 4) Modélisation des communautés p 10 III. Hypothèses biologiques et mathématiques p 10 1) La stationnarité et l’isotropie p 10 2) La forme de la courbe de réponse p 11 3) La tranférabilité p 12 4) Les changements d’échelle p 13 Conclusion p 13

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 4
Travail de recherche
Développement d’une démarche aboutissant à un modèle spatial prédictif d’abondance du Milan noir, Milvus migrans
p
15
Introduction p 16 Matériel et méthodes p 20 Zone d’étude p 20 Les données p 21 Les variables environnementales p 21 Les analyses p 22 Logiciels p 22 L’exploration des données p 23 La démarche adoptée p 23 Le modèle logistique p 25 Le seuil de présence p 26 Le modèle d’abondance p 27 La validation croisée p 28 Résultats p 29 Les probabilités de présence p 29 Le seuil de discrimination entre présence et absence p 30 Le modèle d’abondance p 32 L’évaluation des prédictions p 33 Discussion p 34 Le modèle logistique des présences/absences p 35 Détermination du seuil p 35 Le modèle d’abondance p 36 Intérêts et limites de la méthode employée p 37 Conclusion p 39 Références p 40 Annexe 1 : Résultats des simulations de la validation croisée p 44 Annexe 2 : Tableau de classification des variables d’occupation du sol p 45 Annexe 3 : Matrice des corrélation des variables du GAM logistique p 46

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 5
[Analyse critiques de la Littérature]
Les modèles de distribution en écologie : les contraintes et les limites

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 6
INTRODUCTION
Au sein d’un environnement, les espèces ne se répartissent pas aléatoirement mais suivant
leurs besoins et leurs capacités à répondre aux conditions du milieu. On parle de sélection
d’habitat. On ne retrouve les espèces que dans les milieux où les conditions leur sont
favorables et permettent de maximiser leur fitness. En écologie, l’étude de ces relations entre
les espèces et leur environnement a toujours été une question centrale pour expliquer et
comprendre les déterminants écologiques et évolutifs des patterns de répartition observés
(Keitt et al. 2002; Guisan & Zimmermann 2000) (Scott et al. 2002).
Avec le développement concomitant des ordinateurs et de l’écologie quantitative au milieu du
20ème siècle, des méthodes de plus en plus complexes voient le jour pour étudier les relations
entre les espèces et leur milieu. Durant cette période, il n’y a que peu de considération pour la
validité des méthodes statistiques employées (Scott et al. 2002). Des congrès, comme celui de
1984 « Wildlife 2000 : Modeling Habitat Relationships of Terrestrial Vertebrates » dont la
problématique est le développement et l’application des modèles prédictifs, s’organisent. Une
attention de plus en plus grande est portée sur les hypothèses à ne pas violer, les conditions
d’application des méthodes, les limites et le caractère adapté du jeu de données. Cependant,
récemment encore, certains auteurs dénoncent le fait que la théorie écologique en relation
avec les modèles soit négligée (Guisan & Thuiller 2005; Guisan et al. 2006). C’est un facteur
limitant dans l’application des modèles (Austin 2002). Aujourd’hui, les modèles de
distribution d’espèces sont de plus en plus utilisés pour répondre aux problématiques
majeures que sont la prédiction et la compréhension des facteurs qui déterminent cette
distribution (Graham et al. 2008). Ils représentent donc un outil valable pour la gestion et la
conservation de l’environnement (Barbosa, Real & Vargas 2009; Guisan & Zimmermann
2000).
Il existe une multitude de méthodes pour modéliser la distribution des espèces. Elles varient
suivant le type de réponse qu’elles prennent en compte, la manière d’ajuster le modèle, par la
capacité à pondérer les observations, à incorporer des interactions, et par la manière de prédire
(Elith et al. 2006). Une seule méthode ne peut révéler toutes les caractéristiques importantes
des données spatialisées (Dale et al. 2002). Le choix d’une méthode adaptée n’est pas aisé et
dépend de nombreux facteurs.
Ce présent rapport se propose d’analyser l’ensemble des limites d’application des modèles de
distribution en écologie et des contraintes qui permettent d’orienter le choix de la méthode
utilisée. Dans un premier temps, nous aborderons les contraintes inhérentes aux données

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 7
spatialisées qui ne sont pas indépendantes (Bustamante 1997). Dans un second temps, nous
poserons le problème des contraintes amenées par la question sous-jacente à l’étude, c'est-à-
dire par le but de l’étude et le type de données associées. En effet, le jeu de données récolté
dépend énormément de cette question et va beaucoup influencer les choix méthodologiques
(Dale et al. 2002). Enfin, nous verrons les hypothèses mathématiques et biologiques fortes qui
limitent l’utilisation des modèles et qu’il est rarement possible de contourner. En effet, les
modèles doivent être en adéquation avec les processus biologiques qu’ils représentent et le
choix ne doit donc pas seulement reposer sur des considérations statistiques mais également
sur les théories écologiques (Guisan & Zimmermann 2000).
I. AUTOCORELATION SPATIALE
1) Origines
Dans la nature, les variables physiques et biologiques observées présentent généralement des
patterns spatiaux (Perry et al. 2002). Les données échantillonnées à des localisations proches
ne sont pas indépendantes les unes des autres (Dormann et al. 2007; Dormann 2007; Carl &
Kuhn 2008) et sont donc sujettes à l’autocorrélation spatiale positive si elles ont tendance à
être plus similaires, et négative si elles ont tendances à être différentes (Dale et al. 2002). Les
processus responsables de l’autocorrélation sont multiples. Legendre et al. (2002) classe ces
facteurs suivant deux origines liées aux patterns observés dans la variable réponse. La
première, la dépendance spatiale, intervient dans le cas où les variables explicatives sont
elles-mêmes structurées. On peut citer les relations fonctionnelles espèce ↔ environnement
mal spécifiées (Dormann et al. 2007) ou le cas d’une variable environnementale structurée
spatialement, non prise en compte dans le modèle (Guisan & Thuiller 2005; Dormann et al.
2007; Keitt et al. 2002). La seconde, l’autocorrélation spatiale vraie correspond à des
processus dynamiques dans la variable réponse elle-même. Elle correspond aux facteurs
externes historiques (événements volcaniques, de glaciation) et environnementaux (barrières
géographiques) qui limitent la dispersion (Dormann et al. 2007; Bustamante & Seoane 2004)
et leurs processus biologiques associés (spéciation, extinction) ainsi que d’autres processus
biologiques intrinsèques comme les interactions entre espèces ou le comportement (Guisan &
Thuiller 2005; Dormann et al. 2007; Maggini et al. 2006; Keitt et al. 2002). Mais, il reste
souvent une part de dépendance résiduelle dans les données due à des variables

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 8
environnementales ou des processus biologiques non mesurables (Dormann 2007; Miller,
Franklin & Aspinall 2007).
Pour attester de la présence de l’autocorrélation spatiale, il existe différentes méthodes : les
corrélogrammes de Moran ou de Geary ou bien encore des variogrammes qui mesurent la
similarité ou la dissimilarité en fonction de la distance. Les corrélogrammes constituent la
représentation la plus commune en écologie (Dormann et al. 2007).
2) Problèmes
Dans les méthodes standards, lorsque l’autocorrélation spatiale est ignorée, un modèle peut
conduire à une estimation biaisée des paramètres (Dormann 2007) et à une augmentation du
taux d’erreur de type 1 (Bahn, O'Connor & Krohn 2006; Dormann et al. 2007), c'est-à-dire au
rejet de l’hypothèse nulle (H0) de non effet alors que les données sont conformes à cette
dernière, ce qui amène à des conclusions incorrectes (Maggini et al. 2006; Keitt et al. 2002;
Kuhn 2007; Schabenberge & Gotway 2005). Si une structure spatiale de la variable reste
présente dans les résidus d’un modèle, une des hypothèses clés est violée, à savoir que les
résidus sont indépendants et identiquement distribués (iid) (Bahn et al. 2006). Ce phénomène
est équivalent à de la pseudo-réplication, ce qui diminue le nombre de degrés de liberté
(Guisan & Zimmermann 2000). L’incorporation de termes prenant en compte
l’autocorrélation spatiale produit donc de meilleurs modèles (Maggini et al. 2006; Dormann
2007; Bustamante & Seoane 2004).
3) Solutions
L’autocorrélation peut être vue comme un problème mais aussi comme une source
d’information pour étudier les processus responsables des patterns observés (Dormann et al.
2007; Dormann 2007; Liebhold & Gurevitch 2002; Schabenberge & Gotway 2005). L’intérêt
pour quantifier et inclure cette structure dans la compréhension du phénomène étudié, n’a eu
de cesse d’augmenter (Dale et al. 2002; Liebhold & Gurevitch 2002). Ainsi une multitude de
méthodes ont été développées récemment pour prendre en compte et corriger les effets de
l’autocorrélation spatiale (Maggini et al. 2006).
Parfois il est possible d’adapter l’échantillonnage pour avoir des points assez éloignés pour
être indépendants (Guisan & Zimmermann 2000), mais quand la distance est trop grande, ceci
n’est pas réalisable (Guisan & Zimmermann 2000). D’autres chercheurs considèrent que
l’autocorrélation spatiale agit à toutes les échelles (Keitt et al. 2002), et qu’il est donc
impossible de la neutraliser par l’échantillonnage. Il est alors nécessaire de la prendre en
compte explicitement dans les analyses statistiques. Pour les études de corrélations simples

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 9
entre 2 variables, il est possible d’utiliser des tests de comparaison modifiés, comme le test t
de Dutilleul (Legendre et al. 2002). Pour les analyses de régressions ou de classifications, il
existe une multitude de méthodes qui permettent l’ajout de matrices de corrélations ou de
distances, de paramètres tirés des corrélogrammes, ou encore des surfaces de tendances, dans
le modèle pour caractériser cette autocorrélation spatiale.
II) CONTRAINTES DE L’ETUDE
1) Contraintes liées au but de l’étude
Parmi les études de distribution spatiale certaines sont plus orientées vers des statistiques
descriptives, d’autres sont plus exploratoires et permettent de construire des hypothèses ou de
mettre en évidence les caractéristiques de la structure spatiale (Dale et al. 2002). En fonction
de la question amenée par l’étude, les méthodes d’échantillonnage varient et les variables
d’intérêts sont de différente nature. Il est possible d’échantillonner des aires ou des points,
avec des attributs (x, y, z) ou non (x, y), et ces données peuvent être spatialement explicites
ou non (Perry et al. 2002).
2) Contraintes liées à la nature des variables
Dans la littérature, les études sont presque exclusivement traitées à partir de données de
‘présences seules’ d’espèces/d’individus ou bien de données de ‘présences absences’. Les
données de ‘présences seules’, les plus courantes et les plus accessibles, sont analysées avec
des méthodes comme l’ENFA (Hirzel et al. 2002; Engler, Guisan & Rechsteiner 2004). Il
existe d’autres méthodes utilisables qui génèrent des pseudo-absences, comme les GLM.
Mais, dans certains cas, il est préférable de modéliser la sélection d’habitat avec les données
de ‘présences-absences’ car les absences représentent une grande source d’information en
particulier pour modéliser les espèces généralistes (Brotons et al. 2004). Quels que soient le
type de données ou méthodes utilisées, les espèces avec des niches écologiques plus
restreintes seront toujours modélisées de manière plus juste que les espèces généralistes
(Brotons et al. 2004). Très peu d’études s’appuient sur des données quantitatives alors que ce
sont les seules qui permettent de détecter les phénomènes d’interactions entre espèces (Austin
2002) et que pour les questions de conservation des espèces face aux changements globaux,
des prédictions quantitatives sont indispensables (Austin 2007).

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 10
3) Contraintes liées au type de variables
Une partie des modèles prédictifs s’appuient sur les variables de l’environnement. Ces
variables se répartissent en 3 types de gradients (Austin 2002; Guisan & Zimmermann 2000) :
indirects, dont la variable n’a pas d’effet sur la physiologie mais dont la localisation affecte
d’autres variables (ex : altitude) ; directs, dont la variable a un effet direct sur la physiologie
(ex : température) ; et ressources, dont la variable cette fois est consommée (ex : proies). Il
existe des facteurs qui impactent directement la physiologie (prédicteurs proximaux) et des
facteurs non-causaux (distaux) qui agissent sur la physiologie par une cascade de processus
(Austin 2002). L’utilisation dans la modélisation des facteurs proximaux et directs produit des
modèles plus robustes et plus généralisables (Guisan & Zimmermann 2000). Cependant, ces
variables sont difficilement accessibles et parfois impossibles à mesurer (Austin 2002).
L’utilisation des facteurs distaux et indirects est donc souvent privilégiée. Le modèle est alors
faiblement généralisable géographiquement (Guisan & Zimmermann 2000).
4) Modélisation des communautés
S’intéresser à la communauté ou à des groupes d’espèces, a pour but d’obtenir des cartes
prédictives, de détecter des variations dans la composition en espèces, ou de mettre en
évidence des interactions interspécifiques. Il existe trois stratégies (Ferrier & Guisan 2006) :
prédire dans un premier temps les espèces séparément puis rassembler ces prédictions par des
méthodes de classification ou d’ordination ; la stratégie inverse ; ou alors effectuer la
classification et l’ordination en même temps que la modélisation. Pour les deux premières
stratégies, il est possible d’utiliser des méthodes comme les GLM ou GAM avec des Arbres
de Classification ou de Régression. Pour la dernière, il est nécessaire d’utiliser des méthodes
plus spécifiques comme ‘Vector GLM’ ou ‘Vector GAM’ ou encore MARS (Ferrier &
Guisan 2006). C’est également un outil utile pour prédire la distribution d’une espèce rare. La
prédiction à l’aide d’informations apportées par d’autres espèces associées augmente la
puissance des analyses (Ferrier & Guisan 2006). Cependant, la modélisation à l’échelle de la
communauté est discutée du fait que les espèces modernes n’ont pas une longue histoire
commune et qu’il est probable que ces assemblages ne soient pas stables et réagissent de
manière différente face aux changements climatiques (Guisan & Zimmermann 2000).

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 11
III) HYPOTHESES BIOLOGIQUES ET MATHEMATIQUES
1) La stationnarité et l’isotropie
L’échantillonnage se fait généralement sur un espace ou un temps limité. Les modèles
construits alors à partir de ces données ne reflètent qu’une vue restreinte de la relation qui
existe entre l’espèce et l’environnement (Guisan & Thuiller 2005). Les modèles classiques
sont statiques et présument que ces relations (moyenne, variance, autocorrélation) sont
constantes sur toute la zone d’étude et dans le temps, ainsi que dans toutes les directions
(Schabenberge & Gotway 2005; Guisan & Zimmermann 2000). C’est le principe de la
stationnarité et de l’isotropie. Ceci est plus ou moins discutable suivant l’étendue de la zone
d’étude (Dormann et al. 2007). Plus la zone d’étude est grande, plus augmente la probabilité
que les mécanismes de structuration spatiale varient. La non stationnarité est même plus
réaliste en écologie, mais alors la complexité des modèles pour la prendre en compte rend
cette hypothèse indispensable (Guisan & Zimmermann 2000). Cette hypothèse ne constitue
pas une contrainte forte pour les espèces persistantes ou celles qui réagissent très lentement.
Mais dans le cas où l’espèce est en expansion ou qu’il existe de fortes perturbations ou des
dynamiques successionelles rapides, cette hypothèse rend la modélisation difficile (Guisan &
Zimmermann 2000; Guisan, Edwards & Hastie 2002). Ainsi, des modèles comme les GLM
sont biaisés dans le cas d’études sur des espèces en expansion. Des méthodes comme l’ENFA
sont plus résistantes, mais lorsque l’espèce est surabondante, travailler avec un GLM utilisant
les absences est plus adapté (Hirzel, Helfer & Metral 2001).
L’isotropie stipule que les caractéristiques du pattern et les structures de dépendances sont les
mêmes dans toutes les directions (Schabenberge & Gotway 2005), c'est-à-dire que les
processus causant l’autocorrélation spatiale agissent de la même manière dans toutes les
directions. Les facteurs courants causant l’anisotropie sont le vent, les courants d’eau, les
mouvements dirigés (ex : migration). Des méthodes récemment développées peuvent prendre
en compte cette anisotropie (Dormann et al. 2007).
2) La forme de la courbe de réponse
Dans le choix de la méthode, la forme de la réponse attendue d’une espèce est une hypothèse
centrale (Austin 2002). Les premières méthodes dites paramétriques émettent l’hypothèse
d’une réponse linéaire. Cependant, il est de plus en plus admis que les courbes unimodales
symétriques sont rares (Austin 2002; Guisan et al. 2006). Les courbes de réponses à un
gradient indirect peuvent prendre toutes sortes de formes (Austin 2002; Austin 2007). Les

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 12
courbes unimodales non symétriques sont donc mieux représentées par des méthodes semi-
paramétriques type GAM (Guisan et al. 2006).
3) La transférabilité
Par transférabilité, on parle d’application des modèles prédictifs de distribution dans une autre
zone géographique que celle de l’étude. Cette extrapolation peut être problématique (Barbosa
et al. 2009) selon l’environnement (différences entre régions) et les conditions biotiques
(différences d’interactions entre l’espèce considérée et les autres associées) (Randin et al.
2006). En effet, derrière les modèles se cachent des hypothèses (interactions biotiques, effets
stochastiques négatifs…) et il est important de savoir si ces hypothèses sont transférables
(Guisan et al. 2002). La transférabilité dépend alors de la généralité des prédicteurs choisis
(Randin et al. 2006). L’utilisation de paramètres indirects, qui sont la combinaison de
plusieurs facteurs directs, limite l’application à une autre région (Guisan & Zimmermann
2000) car la combinaison risque de changer. L’utilisation des facteurs directs / ressources rend
le modèle plus généralisable et transférable. Les GLM semblent plus transférables qu’un
GAM car les modèles non linéaires peuvent être sur ajustés aux données et donc moins
généralisables (Randin et al. 2006). De même, si l’Autocorrélation Spatiale représente une
structure de l’environnement (variable d’habitat) plutôt qu’une structure biologique, le
modèle est difficilement applicable à une autre région (Guisan & Thuiller 2005). Dans
l’exemple de Barbosa et al. (2009) (Fig. 1) un GLM modélisant la distribution du desman est
développé sur des données au Portugal, un autre sur les données en Espagne et un troisième
sur le total. Les cartes prédictives des 3 modèles appliqués sur toutes les zones montrent que
les prédictions spatiales sont très différentes. Transférer un modèle dans l’espace peut donc
s’avérer problématique.
Figure 1 : Prédiction de 3 glm de la qualité de l’habitat pour le desman des Pyrénées, appliqués à la Péninsule
Ibérienne. Ils sont respectivement ajustés à l’aide des données (1) du Portugal (2) de l’Espagne (3) de l’ensemble. Les degrés de qualités vont de 0 (blanc) à 1 (noir).(Barbosa et al. 2009)

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 13
4) Les changements d’échelle
Les relations espèces-environnements observées et détectées peuvent différer si l’échelle
d’étude des processus change. Les résultats peuvent varier en termes de moyenne, variance,
pattern d’Autocorrélation Spatiale…(Dungan et al. 2002). Les variables environnementales
qui influencent statistiquement la répartition des êtres vivants sont différentes suivant le grain
et l’étendue de l’étude, ce qui influence les conclusions (Sanchez-Zapata & Calvo 1999).
Ainsi, on différencie deux types d’étude : les statistiques spatiales locales qui ont pour but de
quantifier le pattern à des localisations relativement voisines, et les statistiques spatiales
globales qui résument les caractéristiques du pattern sur la zone d’étude entière. (Dale et al.
2002). Ainsi, suivant la question posée, l’échelle de l’échantillonnage et de l’analyse va
varier.
CONCLUSION
Le développement des problématiques de gestion de milieux parallèlement aux
problématiques d’étude de répartition des espèces et de prédiction des effets des changements
globaux ont amené la nécessité de développer des modèles statistiques de prédiction de
distribution (Austin 2007). Cependant, les méthodes classiques peuvent difficilement être
utilisées sur ces jeux de données spatialisées. En effet, ils impliquent une multitude de
contraintes dont la première est la dépendance spatiale des données. Si cette dernière n’est pas
prise en compte, il peut y avoir des conséquences fortes sur les conclusions de l’analyse (Keitt
et al. 2002; Dormann et al. 2007). Des méthodes spatialisées ont donc été développées et se
développent encore aujourd’hui. Mais ces méthodes doivent répondre à beaucoup d’autres
contraintes, ce qu’elles réussissent plus ou moins bien. Il est en particulier indispensable de
vérifier la stationnarité et l’isotropie et de tester le caractère unimodal symétrique ou non de la
courbe de réponse. Il est important de rester vigilant quant à la possibilité de transférer le
modèle prédictif sur une autre zone géographique ou à une autre échelle. Souvent ces
extrapolations sont biaisées et conduisent à des conclusions fausses (Randin et al. 2006;
Dungan et al. 2002).
Parmi la multitude de nouvelles méthodes qui voient le jour, un débat s’est lancé pour tester
quelle serait ‘LA’ meilleure méthode. De nombreuses publications comparent des méthodes
d’analyses sur un ou plusieurs jeux de données, sur une ou plusieurs espèces (Brotons et al.
2004; Guisan, Weiss & Weiss 1999; Segurado & Araujo 2004) et les avis sont parfois
différents. D’autres appuient leurs comparaisons sur des jeux de données artificiels (Hirzel et
al. 2001). L’utilisation de données artificielles est discutée, mais elle s’avère utile pour voir ce

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 14
qui ‘ne marche pas’ (Austin 2007) et pour tester la réponse des méthodes aux scénarii
évolutifs (Hirzel et al. 2001). D’après Austin (2007), deux paradigmes de Kuhn opèrent. Il
prend pour preuve deux revues proches dans le temps qui n’ont aucune citation en commun.
Dans la littérature, il existe deux visions différentes sur le rôle de la modélisation entre les
modèles explicatifs et prédictifs (Guisan et al. 2002). Ainsi, le choix de ‘LA’ meilleure
méthode serait un faux débat par l’absence de réponse unique. Dans les études de
comparaison, il y a énormément d’effets confondants et les performances d’un modèle
dépendent du type de distribution géographique ou environnementale de l’espèce considérée
(Segurado & Araujo 2004), ce qui appuie l’idée qu’un modèle n’est valable que pour une
espèce (Austin 2007). La véritable question est donc : quelles méthodes pour quelles données
et pour quels objectifs (Austin 2007). En effet, la sélection des méthodes doit se faire en
fonction des contraintes et hypothèses qu’elles portent. De plus, négliger les connaissances en
écologie est un facteur limitant dans l’utilisation des modèles prédictifs de distribution
(Austin 2002). Il faut donc avoir une approche type ‘Coût-Bénéfice’ dans la sélection des
méthodes. Il y a d’abord un choix entre optimiser la justesse ou la généralité du modèle en
sélectionnant les covariables à incorporer dans le modèle (Guisan & Zimmermann 2000), un
choix à faire entre les différentes hypothèses acceptables ou non, les limites et contraintes
d’applications des méthodes… C’est la meilleure procédure pour choisir le modèle adapté à la
question et aux données.

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 15
[Travail de recherche]
Développement d’une démarche aboutissant à un modèle spatial prédictif d’abondance du Milan noir,
Milvus migrans

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 16
Introduction
Dans un contexte de changements globaux provoqués directement ou indirectement par
l’activité humaine, la conservation de la biodiversité est devenue un enjeu majeur. Les
changements climatiques entraînent des modifications dans la phénologie de reproduction de
certaines espèces, déséquilibrant les écosystèmes. Les changements d’habitats, comme
l’urbanisation ou l’évolution des pratiques agricoles, entraînent des bouleversements
paysagers par la fragmentation des habitats (Palomino & Carrascal 2007), ce qui a un effet
néfaste pour beaucoup d’espèces comme les oiseaux (Sanchez-Zapata & Calvo 1999). Les
activités humaines affectent donc les espèces en réduisant l’étendue de leurs distributions et
diminuant leurs effectifs (Osborne, Alonso & Bryant 2001). Un déclin général de la
biodiversité est constaté. Ce phénomène inquiétant préoccupe et intéresse les naturalistes et
les écologues. Une multitude de programmes, généralement des atlas, sont lancés pour faire
un état des lieux de la biodiversité, voir comment elle réagit face à ces changements et
cartographier la distribution des espèces (Brotons et al. 2004). Généralement les informations
récoltées ne renseignent que sur la présence des espèces (Bustamante & Seoane 2004). Plus
rarement, elles renseignent sur la ‘présence/absence’ et exceptionnellement sur l’abondance
(Nielsen et al. 2005).
Ces études nécessitant de gros investissements en moyens humains et financiers, elles font
souvent appel à des réseaux de volontaires et leurs protocoles sont alors flexibles et peu
contraignants, ce qui pose des problèmes au moment de l’analyse. L’effort d’échantillonnage
est rarement quantifié, l’étendue de la zone d’étude est souvent faible et échantillonnée de
manière hétérogène, étant irréaliste de vouloir échantillonner l’étendue de la zone en continu.
Plus la pression d’échantillonnage est forte, plus les prédictions seront bonnes. En revanche si
on augmente l’étendue de l’étude, la pression va diminuer et il est alors difficile d’avoir des
prédictions correctes en s’appuyant seulement sur les informations échantillonnées. Ces
études permettent la production de cartes de distribution parfois lissées à l’aide de méthodes
simples d’interpolation s’appuyant sur l’autocorrélation spatiale, qui renvoie au fait que des
données proches dans l’espace ont tendance à être similaires (Dale et al. 2002; Dormann
2007). Mais aujourd’hui ces études se destinent à des applications qui vont au delà de la
simple cartographie et ont donc tendance à standardiser de plus en plus leurs protocoles. Les
programmes de récolte de données pour les atlas, malgré leurs efforts, souffrent par ailleurs
d’un manque d’exploitation scientifique des données. Ce manque est causé par la complexité
de ces données et des méthodes pour les analyser. Les méthodes classiques ne sont pas

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 17
adaptées pour analyser des données de présence, de présence/absence ou de comptage avec
une hétérogénéité spatiale, ceci violant entre autre des hypothèses d’ordre statistique.
Etant donnée l’importance des connaissances de la distribution des espèces et pour répondre à
l’augmentation du nombre d’études et à leurs objectifs, il est nécessaire de développer des
méthodes qui permettent d’analyser les données de ‘présence stricte’, de ‘présence/absence’
ou d’abondance à différentes échelles spatiales (Austin 2007). Ces méthodes doivent prendre
en compte le fait que ces données sont spatialisées et autocorrélées, elles doivent répondre au
problème de l’hétérogénéité de prospection et pouvoir prédire dans les zones faiblement
échantillonnées. La présente étude constitue un travail de réflexion sur la manière de gérer ces
données en prenant en considération l’autocorrélation spatiale, et un travail exploratoire de
développement d’une démarche pour analyser des données récoltées lors d’atlas réalisés à
grande échelle.
Lors de l’analyse, il est possible d’utiliser des variables externes qui permettent d’appuyer les
prédictions. Les variables de l’environnement peuvent être utilisées pour construire des cartes
plus précises qui à l’aide de quelques points échantillonnés dans la zone permettent de prédire
la présence d’une espèce de manière continue avec un effort d’échantillonnage limité
(Bustamante & Seoane 2004). En effet, les espèces ne se répartissent pas aléatoirement en
fonction des variables de l’environnement éco-géographique (Hirzel et al. 2002), mais
seulement dans une zone plus ou moins étroite de conditions environnementales (Hirzel & Le
Lay 2008). Ainsi, la distribution des espèces étant, au moins en partie, déterminée par les
variables de l’environnement (Austin 2007), il est possible d’étudier les corrélations spatiales
entre l’environnement et leur abondance (Bustamante & Seoane 2004). Les modèles basés sur
ce principe de sélection d’habitat par les espèces sont des modèles de prédiction de
distribution, aussi appelés ‘fonctions de sélection de ressources’ ou ‘modèle d’habitat
convenable’ (Hirzel et al. 2006). Des études précédentes ont montré que les variables
climatiques ou d’usage des sols étaient très utiles pour prédire la distribution de beaucoup
d’espèces de plantes (Leathwick, Whitehead & McLeod 1996), de poissons (Maxwell et al.
2008), de mammifères (Jaberg & Guisan 2001) ou d’oiseaux (Lennon, Greenwood & Turner
2000; Manel et al. 1999), et parmi ces derniers, les rapaces (Austin et al. 1996; Balbontin et
al. 2008; Bustamante & Seoane 2004; Sanchez-Zapata & Calvo 1999). Le développement
récent des techniques statistiques, des outils d’analyse, combinés à la disponibilité toujours
plus grande des données environnementales à large échelle, offre une opportunité pour tester
et utiliser des méthodes pour des cartographies qualitatives et quantitatives de la distribution

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 18
des espèces à grande échelle (Brotons et al. 2004). Le développement de méthodes
statistiques s’appuyant sur l’habitat est donc nécessaire pour des suivis à grande échelle
(Osborne et al. 2001) et aujourd’hui des méthodes se développent permettant donc de faire
des prédictions spatiales de l’abondance et de donner un sens écologique aux facteurs
déterminant cette distribution (Suarez-Seoane, Osborne & Alonso 2002).
Les données issues d’enquêtes comme les atlas sont les plus couramment utilisées pour faire
des cartes de distributions (Austin 2002; Guisan & Zimmermann 2000). Des méthodes ont été
développées et permettent de travailler sur ces données de ‘présence stricte’ (Elith et al. 2006;
Engler et al. 2004) et de ‘présence absence’ qui apportent plus d’information (Brotons et al.
2004; Hirzel et al. 2006). On note d’ailleurs que la majorité des études utilisent des données
de présence ou de ‘présence/absence’ (Balbontin 2005). En revanche, les données
d’abondance, pourtant essentielles, sont très peu utilisées (Austin 2007; Hirzel et al. 2006),
car elles représentent un coût supplémentaire en terme d’effort et nécessitent un protocole
plus standardisé (Brotons et al. 2004; Nielsen et al. 2005). Peu de méthodes sont développées
pour prendre en compte les données d’abondances. Pourtant, ces méthodes statistiques de
prédictions quantitatives sont centrales pour des questions appliquées et théoriques (Austin
2007; Barry & Welsh 2002). Mais ces données de comptage ne peuvent pas être analysées par
des méthodes gaussiennes classiques, suivant généralement une distribution de Poisson, et, en
écologie, les données de comptage récoltées sont souvent plus dispersées qu’attendu sous une
distribution de Poisson (Welsh et al. 1996; Barry & Welsh 2002). La variance est alors
supérieure à la moyenne, ce qui peut entraîner des erreurs dans les conclusions d’une analyse
(Barry & Welsh 2002). Ce problème peut être contourné par différents moyens. Il est possible
par exemple, de transformer les données, avec le logarithme ou la racine carrée, pour se
rapprocher d’une distribution normale (Bustamante 1997). Mais ceci pose des problèmes de
validité des hypothèses de linéarité et d’homocédasticité des variances (Welsh et al. 1996).
Un autre moyen est d’utiliser des distributions comme la Binomiale Négative ou bien la
Poisson Généralisée qui permettent la modélisation indépendante de la moyenne et de la
variance par l’ajout d’un paramètre supplémentaire (Gschlossl & Czado 2008). Cependant, le
plus souvent, le phénomène de surdispersion est causé par un nombre excessif de zéros,
généralement dû à la présence de deux processus qui agissent à différentes échelles spatiales.
L’hypothèse de stationnarité est alors non respectée, il est donc nécessaire d’utiliser des
modèles ‘Zéro-enflés’. Les modèles les plus adaptés sont les modèles de mélange qui
modélisent les données par la combinaison de deux lois : une première distribution uniforme

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 19
qui modélise une certaine proportion de zéros qui sont causé par les processus à grande
échelle, et une seconde, qui correspond aux données de comptage et qui se focalise sur les
processus plus locaux (Nielsen et al. 2005). La seconde peut être une distribution de Poisson,
Poisson Généralisée ou Binomiale Négative. Cependant, ces méthodes ne prennent pas en
compte le caractère spatial des données. Une alternative serait d’utiliser les modèles ‘Zéro-
enflés’ spatialisés dans un contexte Bayésien en ajoutant un effet spatial aléatoire. Ces
méthodes partent d’une distribution a priori des paramètres pour faire une nouvelle estimation
par ‘Markov Chain Monte Carlo’ (MCMC) de la distribution complexe a posteriori des
paramètres (Gschlossl & Czado 2008). Cette méthode qui semble être la plus adaptée est
complexe et malheureusement longue à implémenter.
Les données récoltées ne sont pas indépendantes, mais assujetties à l’autocorrélation spatiale
(Bustamante 1997; Carl & Kuhn 2008). Si cette structure spatiale n’est pas prise en compte,
les conclusions d’une étude peuvent être largement biaisées (Keitt et al. 2002; Maggini et al.
2006; Bahn et al. 2006). Il existe également des problèmes liés à l’isotropie et à la
stationnarité : les processus à modéliser doivent être respectivement les mêmes dans toutes les
directions et constants en tout point de la zone d’étude (Guisan & Zimmermann 2000), ou
bien les méthodes doivent prendre en compte explicitement ces problèmes (Dormann et al.
2007). De plus, la forme de la réponse d’une espèce à une variable environnementale est une
hypothèse centrale (Austin 2002), mais modéliser ces relations de manière linéaire n’est
souvent pas adapté (Guisan et al. 2002). Il est donc préférable d’utiliser des modèles non
linéaires pour se libérer de cette hypothèse de linéarité (Suarez-Seoane et al. 2002). Très peu
d’études prennent toutes ces caractéristiques en compte.
Le présent travail a donc pour but de développer une démarche produisant un modèle spatial
d’abondance à grande échelle, prenant tous ces biais en considération. L’objectif de ce modèle
sera de prédire de manière précise la distribution de l’abondance d’une espèce mais également
d’utiliser des variables externes comme l’habitat pour obtenir des estimations plus robustes
dans le cas d’un échantillonnage spatial hétérogène. Il pourra devenir ainsi un outil potentiel
pour la création d’estimations à grande échelle d’abondance.
Pour ce faire, les données de comptage utilisées sont issues d’une enquête nationale réalisée
récemment dont l’objectif était de déterminer l’abondance et la distribution des rapaces
nicheurs de France’ (Thiollay & Bretagnolle 2004). Ce jeu de données a déjà fait l’objet
d’analyses statistiques spatialisées, mais aucun modèle prédictif incorporant des données

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 20
d’habitat n’a vu le jour. C’est précisément l’un des objectifs de ce travail. Ainsi, à l’aide de
variables d’habitats et de variables climatiques, un modèle spatial prédictif de l’abondance des
rapaces en France sera développé. En effet, des études ont montré que les rapaces ont des
préférences de milieux de vie, que leur distribution et leur abondance diffèrent suivant des
variables climatiques (Lennon et al. 2000) et entre les habitats (Sanchez-Zapata et al. 2003).
De plus, ce sont des prédateurs supérieurs dont la présence et la richesse indiquent la qualité
de l’écosystème (Sanchez-Zapata et al. 2003), ils peuvent donc être utilisés comme
indicateurs biologiques sensibles aux changements globaux (Palomino & Carrascal 2007).
Cette étude constitue donc un travail exploratoire de développement d’un modèle prédictif
d’abondance spatiale dans l’optique de développer par la suite de manière plus rigoureuse un
modèle ‘Zéro enflé’ par la méthode MCMC. Cependant, la démarche en deux étapes qui va
être utilisée ici prendra en compte la non stationnarité des données par la modélisation des
deux processus séparément. La démarche est inspirée de la méthode de Welsh et al. (1996).
Elle va également prendre en compte les améliorations proposées par Barry & Welsh (2002)
qui conseillent d’utiliser des modèles non linéaires. Ainsi l’utilisation de modèles de
régression permettra également d’incorporer l’autocorrélation spatiale. Cette démarche
consiste en une modélisation de la ‘présence-absence’ par un modèle logistique suivi de la
modélisation de l’abondance conditionnellement à la présence définie par le modèle
logistique. Les facteurs d’habitats déterminant la distribution des espèces sont nichés au sein
de variations à plus large échelle géographique, dans des conditions climatiques adéquates
(Anderson et al. 2009). Ainsi, comme l’a suggéré Seoane et al. (2003), les variables
climatiques vont être utilisées pour prédire la ‘présence-absence’ et les variables d’habitat
pour prédire l’abondance. Pour finir, la capacité de la démarche à prédire dans une zone sous
échantillonnée est testée par validation croisée par bloc.
Matériel et Méthodes
Zone d’étude
L’étude s’est déroulée sur toute la France continentale et la Corse (c.550 000 km2).
L’échantillonnage systématique est basé sur la couverture nationale des cartes IGN (Institut
Géographique National) au 1/25 000e. Un quadrat de 5x5 km (‘carré central’) est disposé au
centre de chaque carte IGN. La superficie des carrés est un compromis entre le temps de
prospection nécessaire et la dimension des domaines vitaux de la plupart des espèces
(Thiollay & Bretagnolle 2004). Les carrés qui sont recouverts en majeure partie par la mer ou

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 21
dans un pays frontalier ont été supprimés de l’échantillonnage. Ainsi sur les 2210 carrés
théoriques, 2046 sont à échantillonner. Pour ceux dont seulement une petite partie était en mer
ou dans un pays frontalier, les carrés ont été déplacés par les observateurs. Cependant, lorsque
les nouvelles coordonnées fournies par les observateurs semblaient erronées, ces carrés ont été
par précaution supprimés des analyses. Au final, sur les 2046 carrés, 1230 sont échantillonnés
et 1187 sont conservés pour les analyses.
Les données
L’étude s’est déroulée sur trois années, de 2000 à 2002, et concerne 24 espèces de rapaces
diurnes. Sur chaque carré et pour chaque espèce, les observateurs ont noté les indices de
présence et de nidification qui détermineront selon deux catégories un nombre de couples
nicheurs possibles et de nicheurs probables/certains (Thiollay & Bretagnolle 2004). Lorsque
des carrés ont été échantillonnés plusieurs années, l’effectif maximal est retenu. Cependant, il
existe un écart important dans l’effort fourni par les observateurs, cette variable n’étant pas
renseignée pour tous les carrés (644 sur 1230 carrés). Un indice d’effort est donc utilisé,
correspondant au « nombre de couples nicheurs possibles divisé par le nombre de couple total
du carré ». Cet indice est corrélé au nombre d’heures passées sur le carré (corrélation de
Pearson = -0,13 ; p<0,001 ; (n=644)) (Fargettas 2003). Cet indice compris entre zéro et un
avec plus de valeurs aux extrêmes est transformé à l’aide de la fonction asinus
Dans cette étude, le Milan noir (Milvus migrans) une espèce localement abondante, est
utilisée pour le développement de la démarche. C’est une espèce à répartition restreinte d’un
point de vue étendue géographique car la France inclut la limite nord de son aire de
répartition. Au vu des différences de répartition qui existent entre les espèces, d’autres
espèces vont être utilisées pour tester et valider certaines étapes de la démarche. Deux autres
espèces sont donc utilisées : une espèce abondante à répartition très large, la Buse variable
(Buteo buteo) et à l’inverse, une espèce peu abondante à répartition restreinte, le Circaète
Jean-le-Blanc (Circaetus gallicus).
Les variables environnementales
Les données climatiques proviennent de la base de données WORLDCLIM
(www.worldclim.org). 19 variables sont récoltées entre 1960 et 1990 à la résolution de
0,86km2 à l’Equateur. Les données disponibles sont des tendances annuelles (moyenne de
température annuelle, précipitations annuelles), la saisonnalité (écart de température et de
précipitations annuelles) et des données plus précises (température du mois le plus chaud et le

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 22
plus froid, précipitations du mois le plus sec et plus humide, température et précipitations du
¼ le plus chaud, le plus froid, le plus sec et le plus humide de l’année). Les données de
température sont en ‘deca’-degrès celcius (°C x10) et les précipitations en mm. (Hijmans et
al. 2005) Les données d’altitude sont distribuées par l’Institut Géographique National
(www.ign.fr). C’est la base de données BD ALTI, un Modèle Numérique de Terrain (MNT)
au pas de 250m donnant les altitudes en mètre.
Les données Corine Land Cover d’occupation du sol en 2000 proviennent de la base de
données d’European Environment Agency (www.eea.europa.eu), à une résolution de 1ha.
Elles représentent 43 classes d’occupation du sol réparties en 3 niveaux de classification
(Annexe 2). Pour l’étude, elles sont regroupées en 9 variables (Annexe 2). Ce regroupement a
été opéré du point de vue fonctionnel du rapace : les habitats urbains, les zones agricoles
intensives (terres labourés) ; les zones agricoles permanentes (vergers et vignes), hétérogènes
(paysages complexes d’alternance entre terres agricoles et naturelles), extensives (prairies et
pâtures) ; les habitats forestiers fermés (Forêts diverses), ouverts et sols nus (plages,
végétations éparses, affleurements rocheux), intermédiaires (transition, landes) ; les zones en
eau et humides au sens large (lacs, océans, marais, marais salant…). Pour chaque carré
central, on extrait au final la proportion de pixels de chacun des 9 types de regroupement. Les
données de densité de population humaine proviennent de la même base de données (EEA).
Ces données de 2001, à l’étendue de l’Europe, sont à une résolution de 1ha.
Les données environnementales sont résumées pour chaque maille par la valeur moyenne des
pixels du carré. Pour l’altitude, la variance des valeurs des pixels par carré est également
extraite pour fournir un indice de la topographie du carré. Ceci est réalisé à la fois pour les
carrés centraux mais aussi sur une grille de maillage 5x5 km dessinée sur l’étendue de la
France.
Les analyses
Logiciels
La manipulation des données environnementales, leur extraction et les jointures spatiales sont
réalisées à l’aide du Système d’Information Géographique ArcGis. Ceci a nécessité deux
outils additionnels Hawthtools et Xtools. (Environmental Systems Research Institute, Inc.-
ESRI, http://www.esri.com/)
La manipulation du jeu de données et les analyses statistiques, sont réalisées sur le logiciel R
(R Development Core Team 2009). Les analyses ont nécessité des packages supplémentaires :

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 23
nlme (Pinheiro et al. 2008), MASS(Venables & Ripley 2002), mgcv (Wood 2006),
PresenceAbsence (Freeman 2007), gstat (Pebesma 2004).
L’exploration des données
L’exploration de la distribution des données d’abondance en fonction des covariables, montre
qu’il est nécessaire d’effectuer une transformation sur les données utilisées dans le modèle
d’abondance. Une transformation log est utilisée pour les variables de variance d’altitude et
pour la densité moyenne de population humaine. Une transformation logit est utilisée pour les
données de proportion pour les différents types d’occupation du sol car elle donne de
meilleurs résultats que la transformation log qui a été aussi testée. Leur distribution est
concentrée près de 0 et les unités des variables d’altitude, de densité de population, de
proportion d’occupation du sol n’ont pas les mêmes unités. Les données sont donc centrées et
réduites.
Le calcul d’un variogramme indique la présence d’autocorrélation spatiale. Le modèle de
variogramme généralement retenu est de type sphérique et présente un effet pépite. Des
variogrammes directionnels n’indiquent pas de problèmes d’anisotropie (Fig. 2).
Dans l’utilisation des méthodes de régression, la colinéarité entre les variables est un biais
important. La corrélation entre les variables est donc contrôlée par la création d’une matrice
des corrélations de Spearman. Une sélection est faite entre deux variables si celles-ci ont une
corrélation positive ou négative supérieure à rS=0,6.
Figure 2 : Semivariogramme des données d’abondance du Milan noir sur l’aire sélectionnée.
La démarche adoptée
La méthode doit tenir compte de l’autocorrélation spatiale des données ainsi que la
distribution ‘Zéro enflée’. Dans ce jeu de données décrivant la répartition d’abondance de 24
espèces de rapaces, certaines présentent des répartitions larges comme la Buse variable.

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 24
D’autres, comme le Circaète Jean-le-Blanc, présentent des répartitions plus restreintes ce qui
pose le problème de la signification des zéros. Ces espèces sont absentes de grandes zone en
France, même si l’habitat local (occupation du sol) peut être favorable. Ces absences sont
dues au fait que l’espèce est hors de son aire de répartition (elle n’est pas vue dans le carré et
la probabilité d’y être est infime). C’est une forme d’autocorrélation à large échelle.
Cependant, au sein de son aire de répartition l’espèce est inégalement abondante et est parfois
absente. Cette absence en revanche peut s’expliquer par un habitat local défavorable. Il y a
donc deux processus qui agissent à des échelles spatiales différentes, un premier à grande
échelle qui concerne la répartition biogéographique et un second à échelle plus locale qui
implique l’habitat. La démarche proposée va donc permettre de modéliser ces deux processus
en deux étapes. Elle est inspirée de celle de Welsh et al. (1996) qui est améliorée par Barry &
Welsh (2002) qui préconisent l’utilisation de modèles non linéaires (GAM). Elle est
également utilisée par Seoane et al. (2003) sur des rapaces. Les formes non linéaires de
réponses face à un gradient environnemental prédominent dans la nature (Austin 2007). Les
GAM, méthodes semi paramétriques, sont donc très utiles car très flexibles pour modéliser
des réponses complexes (Elith et al. 2006) comme des relations non linéaires et non
monotones entre la variable réponse et les variables explicatives (Guisan et al. 2002).
L’avantage de la démarche en deux étapes est qu’elle permet d’avoir deux modèles séparés,
directement interprétables et permettant de vérifier que l’information est utilisée de manière
appropriée (Barry & Welsh 2002). Dans cet article, les auteurs modélisent deux états : un état
où l’espèce est absente avec un modèle logistique et un où elle est seulement présente et varie
en abondance avec un modèle à distribution tronquée (c'est-à-dire sans la classe ‘zéro’). Dans
la démarche utilisée lors de cette étude, tous les zéros ne sont pas enlevés pour la seconde
étape car une partie d’entre eux représente une source d’information pour décrire les
processus locaux d’évitement de certains habitats.
Ainsi, le but de la première étape est de définir une aire de répartition potentielle de l’espèce à
l’aide des processus à grande échelle qui déterminent la présence ou l’absence de cette
dernière. Le modèle développé a pour but de maximiser l’explication des variations à grande
échelle, en supprimant l’autocorrélation spatiale présente à large échelle comprise dans les
variables explicatives. C’est pour cette raison qu’aucun terme d’autocorrélation n’est inclus
dans le modèle. Comme le climat est censé influencer la distribution des espèces à plus large
échelle que les variables d’habitat (Anderson et al. 2009), sont incorporées dans le modèle
logistique non linéaire (GAM), les variables climatiques de la même manière que l’ont fait
Seoane et al. (2003) sur une autre espèce de rapace en Espagne. En effet, les variables

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 25
climatiques, et en particulier la température, sont parmi les plus importants facteurs de la
distribution des espèces à large échelle. (Hirzel & Le Lay 2008)
Le modèle est ensuite utilisé pour faire des prédictions à l’échelle nationale. Un seuil de
‘vraie’ absence est déterminé et la seconde étape de la démarche n’utilise alors que les carrés
situés dans les bornes de ce seuil. Parmi ces carrés, on trouve des présences mais aussi des
absences qui sont maintenant dues à des processus locaux d’habitats évités. Dans la
littérature, il a déjà été démontré que l’abondance des rapaces entre les habitats varie et que
les rapaces ont des préférences de type d’occupation du sol (Sanchez-Zapata et al. 2003)
(Sanchez-Zapata & Calvo 1999). On utilise un modèle non linéaire d’abondance spatialisé
(GAMM) avec une distribution Binomiale Négative. Ce modèle permet donc au final de
prédire une abondance de couples nicheurs dans les carrés où l’espèce est possiblement
présente. Chacun des modèles produit est validé en inspectant la normalité des résidus à l’aide
d’un ‘QQplot’ et l’homogénéité de la variance à l’aide d’un graphe des résidus en fonction
des valeurs prédites.
La robustesse des prédictions du modèle est validée à l’aide d’une validation croisée. A l’aide
de la même méthode la capacité à prédire dans des régions sous échantillonnées est ensuite
vérifiée.
Le modèle logistique
Pour ce premier modèle s’intéressant au processus se déroulant à grande échelle et
déterminant la présence ou l’absence de l’espèce, 19 variables climatiques et 1 variable
d’altitude moyenne sont disponibles. Cependant, les variables climatiques sont très corrélées
et la présence de colinéarité dans un GAM est très nuisible (Zuur et al. 2009). Il faut donc
procéder à une sélection de variable. La corrélation entre les variables est testée à l’aide d’un
coefficient de corrélation de Spearman qui ne fait aucune hypothèse sur le caractère linéaire
d’une corrélation (Zuur et al. 2009) (Annexe 3). Une analyse multivariée aurait pu être
utilisée comme par exemple une analyse discriminante pour sélectionner les variables.
Cependant, ces méthodes ne sont pas robustes à l’ajout de nouvelles données. De plus, le but
de la démarche est de développer un modèle général et facilement répétable, définissant de
grandes zones géographiques de conditions climatiques globales différentes. C’est pour cette
raison que parmi les variables candidates, une sélection des variables climatiques principales
définissant au mieux des zones bioclimatiques générales est effectuée au regard des
corrélations. Les variables principales retenues sont donc la température annuelle moyenne
ainsi que l’écart annuel et pour les précipitations, la quantité annuelle et la saisonnalité. De
plus, les conditions estivales semblent déterminer énormément la répartition des espèces

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 26
(Lennon et al. 2000). Donc les variables de température moyenne estivale et de précipitations
estivales sont également de bons candidats. Cependant, la température moyenne estivale est
corrélée à la température moyenne (rS=0,9). Donc cette dernière n’est pas incluse dans le
modèle. En revanche, la variable de précipitations estivales est retenue car sa corrélation avec
les autres variables du modèle est acceptable (rS=0,6). Les variables finalement retenues dans
le modèle complet sont donc : l’altitude moyenne, la température annuelle moyenne, l’écart
annuel de température, les précipitations annuelles, la saisonnalité des précipitations et enfin
les précipitations estivales.
Comme le but de ce modèle est de maximiser le pouvoir explicatif (R2), pour prendre en
compte au mieux l’autocorrélation à large échelle, aucune procédure de sélection de variables
n’est faite.
Le seuil de présence
Dans la littérature, la méthode couramment utilisée pour vérifier les capacités de prédiction
des modèles logistiques est l’utilisation de ‘caractéristique de fonctionnement du récepteur’
(ROC). (Brotons et al. 2004; Anderson et al. 2009). Différents seuils de discrimination entre
les présences et les absences sont testés et celui qui maximise l’objectif de l’étude est
conservé (Suarez-Seoane et al. 2002) (Balbontin et al. 2008). Dans cette étude, le ROC est
utilisé pour calculer la sensitivité et la spécificité en fonction du seuil choisi. La sensibilité
correspond à la proportion de carrés où l’espèce est vue et prédite présente (vrai positif) et la
spécificité est la proportion de carrés où l’espèce n’est pas vue et prédite absente par le
modèle (vrai négatif). Le modèle logistique permet d’obtenir pour chaque carré, une
probabilité de présence entre 0 et 1 exclus. Un seuil défini permet alors de discriminer entre
les présences et les absences prédites. L’objectif du modèle logistique dans cette étude est de
minimiser la présence des zéros qui correspondent au processus à grande échelle. Le but est
donc de retirer de l’étude de grandes zones géographiques où l’espèce est largement absente,
hors de son aire de répartition. Cependant, dans de grandes zones où l’espèce a une faible
probabilité d’être présente, il existe quelques carrés épars où l’espèce a été observée. Le seuil
retenu est un compromis entre (1) retirer de l’étude un maximum de vrai négatifs et (2) éviter
les carrés où l’espèce est prédite absente alors qu’elle est présente (faux négatifs). La
sensibilité prédite est calculée pour tous les seuils de discrimination entre absence et présence
prédite. Un graphe est tracé, représentant la diminution de l’aire conservée (en proportion) par
ce seuil en fonction de la sensibilité et donc du nombre de carrés de présence observée
correctement prédits. La tangente à la courbe avec y = x est tracée et définit la sensibilité pour
le seuil qui est retenu (Fig. 6). On peut vérifier visuellement sur la carte représentée que la

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 27
valeur retenue ne morcelle pas l’aire de répartition de l’espèce. Pour contrôler la robustesse de
cette méthode sur différents patterns de distribution, cette méthode est également testée sur la
buse variables et le circaète jean-le-blanc.
Le modèle d’abondance
Ce modèle a pour but de modéliser les processus qui interviennent à plus fine échelle, au sein
de la zone de répartition des rapaces et agissant sur l’abondance. Cependant, les données sont
toujours sur-dispersées (Fig. 3). Le modèle prend en compte une distribution Binomiale
Négative. Une première estimation du paramètre thêta de la distribution est calculée par
itération sur un GAM non spatial et sélectionnée par AIC. Les données présentent également
de l’autocorrélation spatiale à fine échelle selon le variogramme (Fig. 2). Le modèle théorique
du variogramme correspond au type sphérique avec un effet pépite. La formule de la
corrélation dans le modèle est donc de type ~ X+Y + nugget.
Figure 3 : histogramme de distribution des valeurs d’abondance pour le Milan noir, avant la sélection (en haut) et
après la sélection faite par le seuil (en bas). Une grosse partie de zéro à été retirée
Pour le modèle, la taille des matrices de variance/covariance a été limitée par un découpage
de la France en quatre blocs. Le variogramme est estimé sur l’ensemble des données pendant
le processus d’estimation du modèle, il est donc identique pour tous les blocs. L’estimation
des paramètres dans un GAMM se fait par l’approche de ‘quasi-vraisemblance pénalisée’. La
sélection de variables retenues dans le GAMM final ne peut pas être effectuée par sélection de
modèles (AIC ou test d’ANOVA) car la vraisemblance ne peut être estimée pour ce type de

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 28
modèle (Wood 2006; Zuur et al. 2009). La sélection a donc été basée sur les p-values dans le
modèle complet. Préalablement à la procédure de sélection, un GAMM est ajusté
indépendamment pour chaque variable. Ce GAMM nous permet de voir si la relation entre la
covariable et la variable réponse est linéaire ou non. Les variables pour lesquelles le nombre
de degrés de libertés estimé par le modèle est edf=1 sont par la suite introduites comme terme
linéaire dans les modèles. La procédure de sélection utilisée est une procédure mixte
ascendante. (1) La première étape consiste à tester toutes les variables dans le modèle
complet : les 9 variables d’occupation du sol, la variance de l’altitude et la densité de
population humaine. Seules les variables significatives (p<0,05) sont conservées pour ‘le
modèle 0’. (2) Lors de la seconde étape, le ‘modèle 0 + 1 variable’ est testé en ajoutant
indépendamment toutes les variables retirées par la première étape. Si plusieurs d’entre elles
deviennent significatives, cela signifie que leurs effets étaient masqués par une variable
retirée. La variable la plus significative est alors conservée. Le ‘modèle 1’ est ainsi obtenu. (3)
Ensuite, le ‘modèle 1’ est testé indépendamment avec chaque variable précédemment retirée.
L’étape deux est ainsi répétée jusqu’à ce que les variables retirées ne soient plus significatives
indépendamment dans le modèle final.
La validation croisée
Il existe peu de méthodes dans la littérature qui permettent de valider les prédictions d’un
modèle d’abondance. Nous utiliserons donc une méthode principalement utilisée pour valider
les prédictions d’un modèle logistique, la validation croisée. Elle est basée sur l’utilisation
d’un jeu de données indépendant pour valider les prédictions du modèle en découpant le jeu
de données en deux. La première partie est utilisée pour ajuster le modèle, l’autre partie des
données sert à la prédiction et on compare la différence entre le prédit et l’observé. Dans la
littérature certains divisent leur jeu de données en 90-10% (Suarez-Seoane et al. 2002), 75-
25% (Balbontin et al. 2008) ou 70-30% (Brotons et al. 2004). Ici nous désirons tester la
robustesse du modèle à prédire et nous cherchons également à tester sa capacité à prédire dans
des zones sous échantillonnées. Pour ce faire, deux processus de sélection de points sont
utilisés pour la validation croisée, un premier processus spatial aléatoire et un second par bloc
spatialement homogène. La zone d’étude est découpée en cinq zones contenant
approximativement le même nombre de points. Quatre blocs sont utilisés pour ajuster le
modèle et on vérifie les prédictions à l’aide du cinquième, ce qui représente
approximativement 20% du total des données. C’est pour cette raison que pour le processus
aléatoire un découpage 80-20% à été choisi. Ainsi, 5 processus aléatoires et 5 processus par
bloc sont simulés. Une fois le modèle ajusté et les paramètres calculés, on effectue une
Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 29
prédiction sur les carrés restants. La probabilité de tomber exactement sur la valeur observée
est évidement faible et, dans le cas d’une distribution Binomiale négative qui a une grande
variance, cette probabilité n’a plus de signification. Ainsi, 10 000 processus de points sont
générés aléatoirement suivant une loi Binomiale Négative dont les paramètres sont : les
valeurs prédites et les paramètres du modèle estimés. On compare alors les observations avec
ce processus de point généré par le modèle en générant une enveloppe de confiance à 95 %
(0;025 <> 0,975) selon les 10 000 processus de points.
Résultats
Les probabilités de présence
Les probabilités de présence sont obtenues à l’aide d’un GAM logistique utilisant les
variables climatiques et l’altitude moyenne. Ces variables introduites en terme non
paramétriques sont toutes significative (p<0,02). La majorité des termes sont retenus non
linéaires sauf la saisonnalité de la précipitation (nombre de degrés de liberté estimé : edf=1,2)
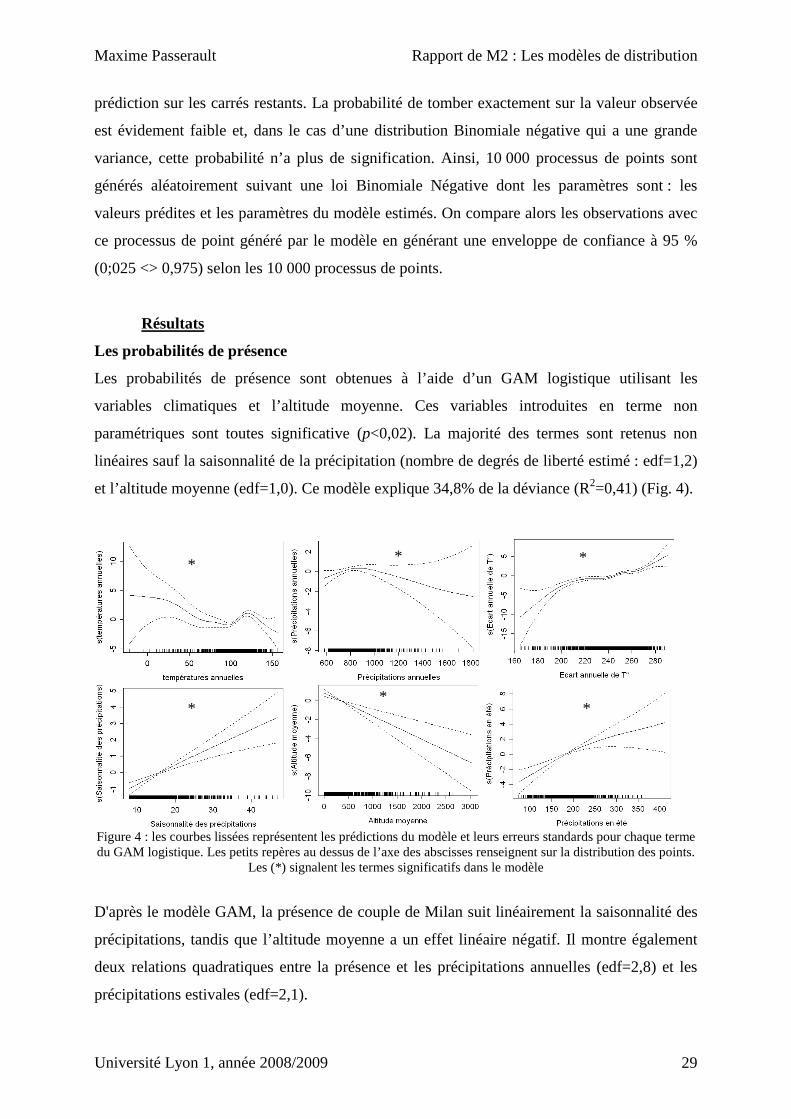
et l’altitude moyenne (edf=1,0). Ce modèle explique 34,8% de la déviance (R2=0,41) (Fig. 4).
Figure 4 : les courbes lissées représentent les prédictions du modèle et leurs erreurs standards pour chaque terme du GAM logistique. Les petits repères au dessus de l’axe des abscisses renseignent sur la distribution des points.
Les (*) signalent les termes significatifs dans le modèle
D'après le modèle GAM, la présence de couple de Milan suit linéairement la saisonnalité des
précipitations, tandis que l’altitude moyenne a un effet linéaire négatif. Il montre également
deux relations quadratiques entre la présence et les précipitations annuelles (edf=2,8) et les
précipitations estivales (edf=2,1).
* *
* *
*
*

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 30
Ce modèle logistique estimé sur les carrés centraux permet de prédire sur la grille nationale la
répartition de la probabilité de présence des Milan noirs en fonction des variables climatiques
et d’altitude moyennes. (Fig. 5).
Figure 5 : Carte des probabilités de présence du Milan noir en France
données par le modèle logistique (blanc p=0,00 ; rouge p=9,99)
Le seuil de discrimination entre présence et absence
Pour déterminer le seuil de sélection des carrés définissant l’aire de répartition de l’espèce, la
diminution de la superficie conservée est étudiée en fonction du nombre de carrés dans
lesquels l’espèce est observée mais prédite absente (correspond à la diminution de la
sensibilité). Cette méthode est testée sur trois espèces présentant des patterns différents de
répartition (Fig. 6).
Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 31
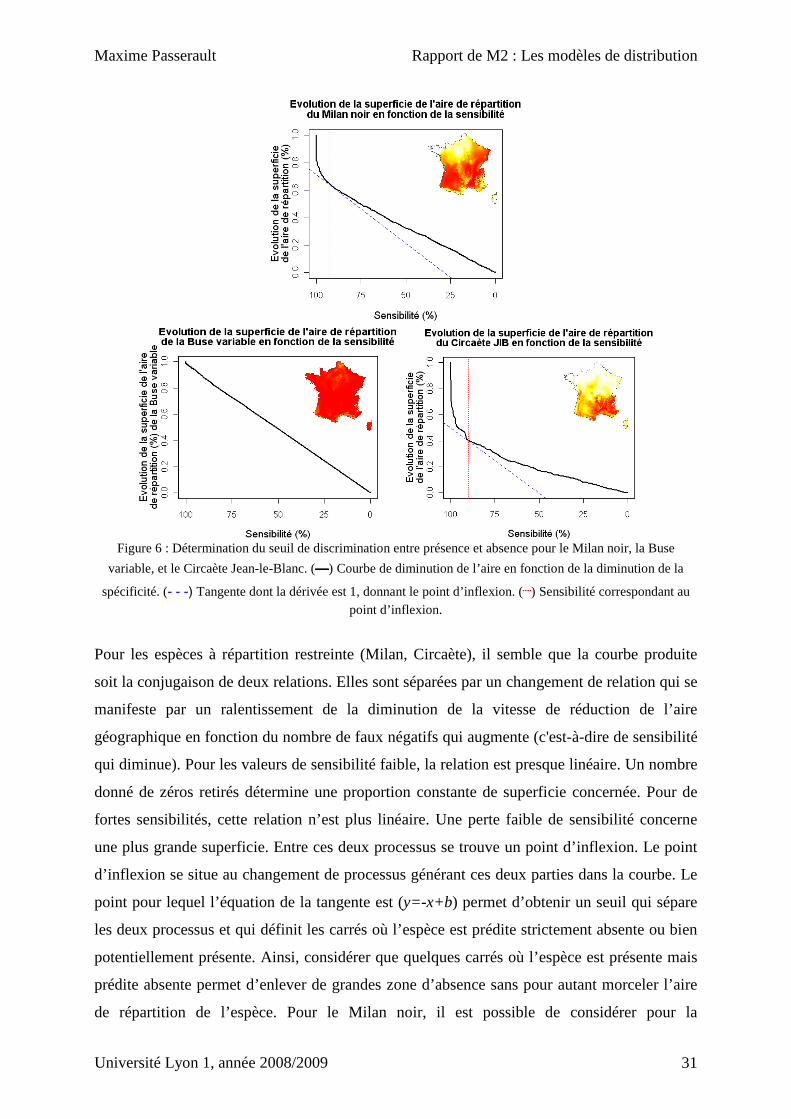
Figure 6 : Détermination du seuil de discrimination entre présence et absence pour le Milan noir, la Buse
variable, et le Circaète Jean-le-Blanc. (————) Courbe de diminution de l’aire en fonction de la diminution de la
spécificité. (- - -) Tangente dont la dérivée est 1, donnant le point d’inflexion. (┈) Sensibilité correspondant au point d’inflexion.
Pour les espèces à répartition restreinte (Milan, Circaète), il semble que la courbe produite
soit la conjugaison de deux relations. Elles sont séparées par un changement de relation qui se
manifeste par un ralentissement de la diminution de la vitesse de réduction de l’aire
géographique en fonction du nombre de faux négatifs qui augmente (c'est-à-dire de sensibilité
qui diminue). Pour les valeurs de sensibilité faible, la relation est presque linéaire. Un nombre
donné de zéros retirés détermine une proportion constante de superficie concernée. Pour de
fortes sensibilités, cette relation n’est plus linéaire. Une perte faible de sensibilité concerne
une plus grande superficie. Entre ces deux processus se trouve un point d’inflexion. Le point
d’inflexion se situe au changement de processus générant ces deux parties dans la courbe. Le
point pour lequel l’équation de la tangente est (y=-x+b) permet d’obtenir un seuil qui sépare
les deux processus et qui définit les carrés où l’espèce est prédite strictement absente ou bien
potentiellement présente. Ainsi, considérer que quelques carrés où l’espèce est présente mais
prédite absente permet d’enlever de grandes zone d’absence sans pour autant morceler l’aire
de répartition de l’espèce. Pour le Milan noir, il est possible de considérer pour la

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 32
modélisation de l’abondance seulement 70% de la zone d’étude. Pour le circaète, on remarque
que le point d’inflexion permet de retirer une aire géographique supérieure, jusqu’à plus de
50% de la France. En revanche pour la Buse variable, espèce à répartition continue sur le
territoire, la courbe est presque linéaire, il n’y a pas de point clair d’inflexion. On peut donc
penser qu’un seul processus intervient sans changement dans la distribution.
Le modèle d’abondance
Le seuil déterminé à l’aide du modèle logistique permet de faire la sélection des carrés
centraux qui se trouvent dans l’aire de répartition et qui doivent être considérés pour le second
processus local qui agit sur l’abondance.
Le GAM d’estimation du paramètre Thêta de la Binomiale Négative calcule un paramètre de
1,001. Ce paramètre est ensuite utilisé dans les modèles additifs mixtes de distribution
Binomiale Négative (GAMM). Le choix d’utiliser des modèles spatiaux est fait car les
données présentent de l’autocorrélation spatiale. Ce choix est appuyé par le fait que les
variations complexes entre l’abondance et l’environnement dans des modèles non spatiaux se
simplifient dans les modèles spatiaux (Tab. 1). Le modèle final estime le ‘range’ à 61km ce
qui donne la distance jusqu’à laquelle l’autocorrélation à un effet.
Le modèle final retient 5 variables (Tab. 1) auxquelles l’indice d’effort est ajouté de manière
linéaire. Un terme non linéaire est retenu, la proportion de zones aquatiques dans le carré.
(R2=0,0594) (Tab. 1).
Tableau 1 : Les degrés de libertés des variables d’occupation du sol obtenus à l’aide d’un modèle Aspatial (GAM) et un modèle spatial (GAMM). Suite à la sélection, les pentes estimée et leur erreur standard pour les variables linéaire retenues (L) sont données, pour la variable non linéaire (nL), c’est le nombre de degrés de liberté de la relation. (n)= variables non retenues codes Significativité : ‘***’ p<0,001 ;‘**’ p<0,01 ; ‘*’ p<0,05 Variables Model
Aspatial Model Spatial
M. Final
Var. Altitude 4,1 1,0 n Densité Pop 7,2 1,0 n Z. Bâti 8,8 1,0 L pente=0,27+/-0,06*** Agri Intensive 5,2 1,0 L pente=0,16+/-0,07* Agri Permanente 7,5 1,0 n Agri. Extensive 5,7 1,0 L pente=0,22+/-0,06** Agri. Hétérogène 8,6 1,0 L pente=0,21+/-0,07** Z. Forestières 5,8 2,8 n Z. Intermédiaires 2,9 1,0 n Z. Ouvertes 3,9 1,0 n Z. Humides 5,8 2,1 nL edf=1,7*** (Fig. 7) Indice Effort L pente=0,29+/-0,11**
Figure 7: graphe de la courbe lissée représentent la prédiction et l’erreur
standard de l’estimation du terme non linéaire ‘Z. Humides’ du GAMM.

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 33
Les zones aquatiques ont un effet prononcé dans le modèle, ce qui est visible sur la
cartographie des prédictions de distribution d’abondance. Les zones humides ressortent donc
très bien. (Fig. 8)
Figure 8 : Cartographie des abondances prédites pour 25km2 par le GAMM.
Attention, les variations de couleurs utilisées sont exacerbées par les valeurs extrêmes prédites.
L’évaluation des prédictions
La comparaison des valeurs prédites par le modèle final et des données observées est utilisée
pour évaluer la robustesse des prédictions, d'après une sélection aléatoire des points retirés
(Fig. 9 et Annexe 1). La comparaison par bloc est utilisée pour évaluer la capacité du modèle
à prédire dans les zones sous-échantillonnées (Fig. 9 et Annexe 1). Cette méthode de
validation permet d’avoir une idée de la probabilité d’observer les données si le modèle ajusté
est vrai.
En moyenne sur les 5 simulations du processus aléatoire 10,4 points sont en dehors de
l’enveloppe de confiance à 95% (1,4% ; n=765) contre 9,6 pour les 5 simulations du
processus par bloc (1,2% n=765). Pour tester si ces moyennes sont significativement
différentes, un test de Student, de comparaison de moyenne, est réalisé après avoir vérifié la
normalité par un test de Shapiro (p(aléatoire)=0,25 n=5 ; p(par bloc)=0,82 n=5). Les résultats du test
indiquent que le nombre de données observées en dehors de l’enveloppe de simulation à 95%
ne sont pas différentes entre les deux processus (t=0,3 ; p=0,78). La qualité des estimations est
donc similaire pour les deux processus de sélection de point (aléatoire et bloc) selon la
validation croisée.
L’estimation moyenne du modèle est proche de la droite y=x de prédiction parfaite. Le
modèle fournit donc des prédictions proches de ce qui est observé. L’estimation moyenne est
300
30
3
0

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 34
parallèle à cette droite mais le modèle a tendance à toujours sous estimer de façon constante le
nombre de couples présents. Donc la moyenne des effectifs observés est toujours légèrement
supérieure à celle prédite. Les observations sont très dispersées autour la droite y=x avec
majoritairement des valeurs faibles et quelques observations avec beaucoup de couples. Les
points sont pour l’essentiel présents au sein de l’enveloppe de prédiction à 95%. Les données
observées sont donc dans l’ensemble bien prédites par le modèle. Il est normal d’observer
cette sur-dispersion car les données suivent à peu près une Binomiale négative. C’est aussi la
raison pour laquelle la variance des prédictions augmente avec les grandes valeurs
d’abondances. Il y a un certain nombre de carrés où aucun Milan n’a été observé et dans
lesquels le modèle prédit un effectif non nul. Cette situation est très variable en fonction des
simulations mais le modèle dans l’ensemble a des difficultés à discriminer les valeurs faibles.
a) b) Figure 9 : figure présentant les résultats d’une réalisation de validation croisée suivant deux processus spatiaux :
(a) un processus aléatoire et (b) un processus par blocs. Les autres réalisations sont disponible en Annexe 1
Discussion
Le but de la démarche est de pouvoir utiliser les données de suivis issus des enquêtes à grande
échelle pour modéliser l’abondance d’une espèce. Pour ce faire, les données ont été
modélisées en deux étapes. La première étape consiste en un modèle logistique prédisant à
l’aide de variables climatiques les probabilités de présence de l’espèce. A l’aide d’un seuil de
discrimination entre les présences et les absences prédites, l’aire de répartition de l’espèce a
été définie. Dans un second temps, l’abondance a été modélisée à l’aide de variables
d’occupation du sol sur les zones de présence prédites par le modèle logistique.

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 35
Le modèle logistique des présences/absences
Les prédictions des probabilités de présence données par le modèle permettent de discriminer
des grandes zones d’absence à l’aide de variables climatiques qui déterminent la répartition
des espèces à grandes échelles (Anderson et al. 2009; Hirzel & Le Lay 2008) par des effets
sur la physiologie, la phénologie de la reproduction ou par un effet indirect en agissant sur
l’abondance des proies (Lennon et al. 2000). Cette méthode présente l’avantage de pouvoir
explorer quels facteurs limitent la répartition globale. Il semble donc que les variables
climatiques peuvent être des prédicteurs fiables de la répartition à grande échelle (Anderson et
al. 2009). Ces outils de prédiction sont de plus, facilement disponibles. Il existe une grande
quantité de données climatiques disponibles, à des échelles mondiales comme locales.
Cependant, à l’échelle locale, il semble que ce ne soit pas les plus déterminantes sur la
répartition des oiseaux (Lopez-Lopez et al. 2006).
Détermination du seuil
Les patrons de distribution pour les espèces à répartition restreinte présentent donc de grandes
zones d’absences où la probabilité de présence prédite par le modèle logistique est très faible.
Mais, au sein de ces grandes zones, il y a quelques carrés épars où l’espèce est notée
observée. Ces points en marges ou très isolés peuvent être des individus observés en
migration, des juvéniles qui sont plus mobiles (Hirzel et al. 2004), des individus non nicheurs
ou des nicheurs exceptionnels. Il peut être alors acceptable de ne pas les considérer, les
principales informations sur la sélection d'habitat étant contenues dans l'aire principale de
l'espèce.
Les études utilisant la démarche en deux étapes ne considèrent, pour la deuxième étape, que
les points où l’espèce a été observée (Welsh et al. 1996; Barry & Welsh 2002). Mais les
processus qui déterminent l’abondance déterminent aussi les absences locales. Ceci est
appuyé par les études à fine échelle qui comparent les méthodes de ‘présences strictes’ avec
des méthodes de ‘présences absences’ concluant que les prédictions à l’aide des données de
présences absences était plus précises grâce à l’information amenée par les absences (Brotons
et al. 2004). Donc pour la deuxième étape de modélisation de distribution de l’abondance à
échelle locale, il est important de considérer les absences qui sont situées au sein de l’aire de
répartition, en conservant un maximum de points de présence mais en éliminant les zones de
probabilité de présence faible prédite par le modèle. Il fallait donc choisir un seuil de
détermination de présence/absence et de caractérisation de l’aire de répartition qui prenne ceci
en considération. Parmi les articles scientifiques travaillant sur la prédiction de la répartition

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 36
spatiale d’une espèce avec l’aide de modèle logistique, beaucoup utilisent la méthode ROC
pour calculer, à différents seuils de discrimination, les capacités du modèle à discriminer les
présences et les absences. La majorité de ces études n’intègrent pas dans leurs critères de
choix de seuil une vision spatiale de la répartition. Certains maximisent le pourcentage de
présence et d’absence correctement prédits (Suarez-Seoane et al. 2002) ou bien le point qui
permette de prédire de manière égale les présences et les absences (Balbontin et al. 2008). Ces
méthodes estiment donc que les faux négatifs et les faux positifs ont des conséquences
identiques sur les prédictions. Or il y a un coût supplémentaire à retirer des présences par
rapport à conserver des absences car, dans l’aire de répartition, ces absences peuvent
correspondre à des zones non occupées avec un habitat non saturé ou non approprié. La
méthode utilisée dans cette étude prend en considération ce biais et ne s’intéresse qu’aux taux
de faux positifs qui sont plus coûteux en termes de prédiction. Ici, le choix du seuil a pris en
compte les caractéristiques spatiales de l’aire de répartition. En optimisant l’aire soustraite et
en maximisant la sensibilité, le seuil choisi a permis de retirer de grandes zones d’absences et
quelques carrés de présence isolés ou très en marge de l’aire de répartition mais sans pour
autant morceler cette dernière.
Les courbes de détermination des seuils permettent de plus de montrer chez les espèces à
répartition restreinte l’existence de deux processus déterminant la distribution, celui à grande
échelle, en retirant quelques observations en marge de l'aire principale de répartition, diminue
fortement l’aire de répartition totale. Une fois le seuil atteint, une courbe presque linéaire est
observée et correspond à une distribution quasiment uniforme, de type espèce à répartition
large comme la Buse. On peut alors considérer que ce sont les processus locaux qui agissent
sur l’abondance.
Le modèle d'abondance
Le modèle d’abondance a des performances relativement faibles pour expliquer les variations
dans l’abondance. Dans la littérature, il est rapporté que les modèles d’abondance ont des
pouvoirs explicatifs plus faibles que les modèles de présence/absence et ce quelles que soient
les méthodes utilisées (Pearce & Ferrier 2001; Nielsen et al. 2005). Ces "mauvaises"
performances sont expliquées par l’absence parmi les variables explicatives des facteurs
jouant sur l’abondance comme l’histoire du site, les interactions avec d’autres espèces…
(Nielsen et al. 2005). Dans cette étude cela peut s’expliquer par une grande variation dans la
pression d’observation qui, n’étant pas renseignée pour tous les carrés, est caractérisée par un
indice approximatif. De plus, lors du processus de modélisation, l’hypothèse est faite que

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 37
l’habitat est saturé. Or, si ce n’est pas le cas, cela ajoute du bruit car beaucoup d’habitats
propices sans oiseaux vont rendre plus difficile la détermination des habitats propices. C’est
une des explications avancée au fait que le modèle prédit des effectifs assez importants pour
beaucoup de carrés où l’espèce est absente. Une autre source d'imprécision tient au fait que
les habitats sont catégorisés grossièrement sans prendre en compte l'aspect fonctionneel
comme la qualité, l’abondance de proies… Il faudrait identifier tous les facteurs importants
pour chaque espèce et les inclure dans le modèle prédictif, mais cela est irréaliste car certains
facteurs sont difficilement accessibles et certains inconnus.
La cartographie des abondances prédites montre des effectifs prédits dépassant les 300
couples par carrés de 25km2 ce qui n’est pas réaliste. Cela peut s’expliquer par des carrés
réunissant en forte proportion deux habitats très favorables et pour lesquels le modèle n’avait
pas de données pour s’ajuster sur une telle association. Il prédit alors des valeurs aberrantes. Il
se peut aussi que ce soit une association d’habitat inconnu pour le modèle et sa prédiction est
alors hasardeuse.
Intérêts et limites de la méthode employée
Les données collectées lors d’enquêtes à grandes échelles présentent différents problèmes à
résoudre. Pour résoudre le problème d’un échantillonnage spatialement hétérogène, avec de
grandes zones sous-échantillonnées, des variables externes ont été utilisées pour affiner les
prédictions dans ces zones. Avec les méthodes classiques s’appuyant seulement sur
l’autocorrélation spatiale, comme le krigeage ordinaire, les prédictions faites hors de portée de
l’autocorrélation ne sont pas pertinentes. Avec la méthode utilisée ici, le modèle est robuste à
la prédiction dans ces zones sous-échantillonnée.
L’autocorrélation des données intervient au sein de processus à échelles différentes. La
démarche employée reprend successivement ces processus, avec un processus définissant de
grande zone de présence et de grandes zones d’absence, et à plus fine échelle, un processus
définissant les variations d’abondance au sein des grandes zones de présences. Ces deux
processus sont conditionnés par des variables de l’environnement différentes (Barry & Welsh
2002). Dans la première étape, la présence absence est modélisée à l’aide de variables
climatiques qui déterminent la répartition des espèces à grande échelle (Anderson et al. 2009;
Hirzel & Le Lay 2008). C’est ce processus qui est en partie responsable de l’importante
proportion de zéro dans le jeu de données. Un des objectifs de l’étude était de prendre en
compte cette distribution ‘Zéro enflée’, qui est un biais important en statistique si elle n’est
pas considérée. De plus en plus d’études y prêtent attention mais seulement de manière

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 38
statistique et non spatiale (Gschlossl & Czado 2008; Welsh et al. 1996; Barry & Welsh 2002).
Dans la présente étude, ce problème voulait être abordé tout en considérant l’hétérogénéité de
distribution présente dans les études de distribution de beaucoup d’espèces à grande échelle.
Ici, les grandes zones d’absence ont été ‘capturées’ par le modèle logistique ce qui a permis
de modéliser l’abondance seulement au sein de l’aire de répartition. L’autocorrélation spatiale
des variables externes utilisées parvient à neutraliser l’autocorrélation des données de
présences absences à grande échelle, satisfaisant l'hypothèse de stationnarité. Cette étape
permet de retirer les grandes zones d’absence par une méthode qui optimise la diminution de
l’aire géographique retirée et minimise la diminution de sensibilité. Pour améliorer cette
méthode, il serait intéressant de trouver un moyen de déterminer le seuil de discrimination de
‘présence-absence’ prédite de manière plus statistique. Il existe des méthodes développées en
médecine qui permettent de définir ce seuil en attribuant un coût différentiel aux ‘faux
négatifs’ et aux ‘faux positifs’. Mais l’évaluation de ce coût n’est pas simple, il faudrait
prendre en compte la probabilité de détection, la probabilité d’erreur d’identification ou de
caractérisation du statut de nicheur certain.
Dans un second temps, l’abondance est modélisée en fonction des variables locales
d’occupation du sol. Cette méthode voulait également considérer de manière explicite le
caractère spatial des données. Dans ce modèle, il a été nécessaire d’ajouter un terme
d’autocorrélation spatiale, qui a neutralisé une partie de la variabilité et des patterns observés.
Avant l’introduction du terme d’autocorrélation, les relations abondance-environnement
étaient très complexes avec des polynômes de degrés 6 qui sont devenues des relations
linéaires une fois le terme ajouté dans modèle.
Globalement, les prédictions du modèle correspondent aux données observées mais, la
variance dans les valeurs prédites est très importante, en particulier pour les fortes valeurs.
Cela tient à la distribution Binomiale Négative. Ainsi, même si en moyenne le modèle prédit
correctement les observations, la distribution Binomiale Négative n’est pas la distribution la
plus adaptée pour faire des prédictions précises de l’abondance dans une fourchette étroite du
fait d'une forte variance. Il ne semble pas y avoir de différences entre les valeurs prédites et
observées suivant les processus de validation croisée aléatoire ou par bloc. La méthode s’est
montrée robuste à la prédiction dans des zones sous-échantillonnées.
Cette méthode présente donc l’avantage de pouvoir prendre en compte l’autocorrélation
spatiale en plus des données ‘zéro enflées’ sans nécessiter trop de capacité de calcul ou de
développement contrairement aux méthodes ‘Zéro-Enflées’ qui doivent s’appuyer sur des
méthodes bayésiennes pour intégrer conjointement ces deux problèmes.

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 39
Conclusion
L’utilisation cette méthode semble limitée dans la production d’estimation précise de la
répartition d’abondance à grande échelle de par la grande variance de ses prédictions même si
en moyenne, ces dernières sont correctes.
Le modèle logistique en revanche est plus puissant que le modèle d’abondance. Si on émet
l’hypothèse que les changements globaux affectent la répartition des espèces, le modèle
logistique utilisant un GAM peut s’avérer un très bon outil pour étudier ces changements. En
effet dans ce contexte, les changements climatiques entraîneraient des changements dans les
aires de répartition. En contrôlant les courbes de réponse de l’espèce aux variables
climatiques estimées par le modèle, il est possible de voir si ces relations espèces – climat ont
changé. De plus, ce modèle est répétable dans le temps et réutilisable pour constater les
déplacements d’aire de répartition dus aux climats. En revanche, si les changements globaux
impactent l’abondance des espèces mais que cette diminution de densité ne se perçoit pas sur
la distribution, alors cette méthode est trop imprécise pour pouvoir constater des évolutions.
Cette étude a pointé les problèmes sous-jacents aux études de distribution d’abondance
spatiale qui sont rarement tous pris en considérations de manière exhaustive. Il est donc
nécessaire de poursuivre le développement de méthodes permettant de produire des
estimations précises. Mais à plus court terme, il serait intéressant de comparer sur le même
jeu de donnée, les résultats obtenus avec différentes méthodes et en particulier avec les
modèles ‘Zéro enflés’ Bayésiens.

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 40
Références
Anderson,B.J., Arroyo,B.E., Collingham,Y.C., Etheridge,B., Fernandez-De-Simon,J., Gillings,S., Gregory,R.D., Leckie,F.M., Sim,I.M.W., Thomas,C.D., Travis,J. & Redpath,S.M. (2009) Using distribution models to test alternative hypotheses about a species' environmental limits and recovery prospects. Biological Conservation, 142, 488-499.
Austin,G.E., Thomas,C.J., Houston,D.C. & Thompson,D.B.A. (1996) Predicting the spatial distribution of buzzard Buteo buteo nesting areas using a geographical information system and remote sensing. Journal of Applied Ecology, 33, 1541-1550.
Austin,M. (2007) Species distribution models and ecological theory: A critical assessment and some possible new approaches. Ecological Modelling, 200, 1-19.
Austin,M.P. (2002) Spatial prediction of species distribution: an interface between ecological theory and statistical modelling. Ecological Modelling, 157, 101-118.
Bahn,V., O'Connor,R.J. & Krohn,W.B. (2006) Importance of spatial autocorrelation in modeling bird distributions at a continental scale. Ecography, 29, 835-844.
Balbontin,J. (2005) Identifying suitable habitat for dispersal in Bonelli's eagle: An important issue in halting its decline in Europe. Biological Conservation, 126, 74-83.
Balbontin,J., Negro,J.J., Sarasola,J.H., Ferrero,J.J. & Rivera,D. (2008) Land-use changes may explain the recent range expansion of the Black-shouldered Kite Elanus caeruleus in southern Europe. Ibis, 150, 707-716.
Barbosa,A.M., Real,R. & Vargas,J.M. (2009) Transferability of environmental favourability models in geographic space: The case of the Iberian desman (Galemys pyrenaicus) in Portugal and Spain. Ecological Modelling, 220, 747-754.
Barry,S.C. & Welsh,A.H. (2002) Generalized additive modelling and zero inflated count data. Ecological Modelling, 157, 179-188.
Brotons,L., Thuiller,W., Araujo,M.B. & Hirzel,A.H. (2004) Presence-absence versus presence-only modelling methods for predicting bird habitat suitability. Ecography, 27, 437-448.
Bustamante,J. (1997) Predictive models for lesser kestrel Falco naumanni distribution, abundance and extinction in southern Spain. Biological Conservation, 80, 153-160.
Bustamante,J. & Seoane,J. (2004) Predicting the distribution of four species of raptors (Aves : Accipitridae) in southern Spain: statistical models work better than existing maps. Journal of Biogeography, 31, 295-306.
Carl,G. & Kuhn,I. (2008) Analyzing spatial ecological data using linear regression and wavelet analysis. Stochastic Environmental Research and Risk Assessment, 22, 315-324.
Dale,M.R.T., Dixon,P., Fortin,M.J., Legendre,P., Myers,D.E. & Rosenberg,M.S. (2002) Conceptual and mathematical relationships among methods for spatial analysis. Ecography, 25, 558-577.
Dormann,C.F. (2007) Effects of incorporating spatial autocorrelation into the analysis of species distribution data. Global Ecology and Biogeography, 16, 129-138.
Dormann,C.F., McPherson,J.M., Araujo,M.B., Bivand,R., Bolliger,J., Carl,G., Davies,R.G., Hirzel,A., Jetz,W., Kissling,W.D., Kuhn,I., Ohlemuller,R., Peres-Neto,P.R., Reineking,B., Schroder,B., Schurr,F.M. & Wilson,R. (2007) Methods to account for spatial autocorrelation in the analysis of species distributional data: a review. Ecography, 30, 609-628.
Dungan,J.L., Perry,J.N., Dale,M.R.T., Legendre,P., Citron-Pousty,S., Fortin,M.J., Jakomulska,A., Miriti,M. & Rosenberg,M.S. (2002) A balanced view of scale in spatial statistical analysis. Ecography, 25, 626-640.

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 41
Elith,J., Graham,C.H., Anderson,R.P., Dudik,M., Ferrier,S., Guisan,A., Hijmans,R.J., Huettmann,F., Leathwick,J.R., Lehmann,A., Li,J., Lohmann,L.G., Loiselle,B.A., Manion,G., Moritz,C., Nakamura,M., Nakazawa,Y., Overton,J.M., Peterson,A.T., Phillips,S.J., Richardson,K., Scachetti-Pereira,R., Schapire,R.E., Soberon,J., Williams,S., Wisz,M.S. & Zimmermann,N.E. (2006) Novel methods improve prediction of species' distributions from occurrence data. Ecography, 29, 129-151.
Engler,R., Guisan,A. & Rechsteiner,L. (2004) An improved approach for predicting the distribution of rare and endangered species from occurrence and pseudo-absence data. Journal of Applied Ecology, 41, 263-274.
Fargettas,A. (2003) Rapport DEA, Université Lyon 1 : Analyse et modélisation de la distribution et de l'abondance d'une communauté de prédateurs.
Ferrier,S. & Guisan,A. (2006) Spatial modelling of biodiversity at the community level. Journal of Applied Ecology, 43, 393-404.
Freeman,E. (2007) PresenceAbsence: An R Package for Presence-Absence Model Evaluation. USDA Forest Service, Rocky Mountain Research Station.
Graham,C.H., Elith,J., Hijmans,R.J., Guisan,A., Peterson,A.T. & Loiselle,B.A. (2008) The influence of spatial errors in species occurrence data used in distribution models. Journal of Applied Ecology, 45, 239-247.
Gschlossl,S. & Czado,C. (2008) Modelling count data with overdispersion and spatial effects. Statistical Papers, 49, 531-552.
Guisan,A., Edwards,T.C. & Hastie,T. (2002) Generalized linear and generalized additive models in studies of species distributions: setting the scene. Ecological Modelling, 157, 89-100.
Guisan,A., Lehmann,A., Ferrier,S., Austin,M., Overton,J.M.C., Aspinall,R. & Hastie,T. (2006) Making better biogeographical predictions of species' distributions. Journal of Applied Ecology, 43, 386-392.
Guisan,A. & Thuiller,W. (2005) Predicting species distribution: offering more than simple habitat models. Ecology Letters, 8, 993-1009.
Guisan,A., Weiss,S.B. & Weiss,A.D. (1999) GLM versus CCA spatial modeling of plant species distribution. Plant Ecology, 143, 107-122.
Guisan,A. & Zimmermann,N.E. (2000) Predictive habitat distribution models in ecology. Ecological Modelling, 135, 147-186.
Hijmans,R.J., Cameron,S.E., Parra,J.L., Jones,P.G. & Jarvis,A. (2005) Very high resolution interpolated climate surfaces for global land areas. International Journal of Climatology, 25, 1965-1978.
Hirzel,A.H., Hausser,J., Chessel,D. & Perrin,N. (2002) Ecological-niche factor analysis: How to compute habitat-suitability maps without absence data? Ecology, 83, 2027-2036.
Hirzel,A.H., Helfer,V. & Metral,F. (2001) Assessing habitat-suitability models with a virtual species. Ecological Modelling, 145, 111-121.
Hirzel,A.H. & Le Lay,G. (2008) Habitat suitability modelling and niche theory. Journal of Applied Ecology, 45, 1372-1381.
Hirzel,A.H., Le Lay,G., Helfer,V., Randin,C. & Guisan,A. (2006) Evaluating the ability of habitat suitability models to predict species presences. Ecological Modelling, 199, 142-152.
Hirzel,A.H., Posse,B., Oggier,P.A., Crettenand,Y., Glenz,C. & Arlettaz,R. (2004) Ecological requirements of reintroduced species and the implications for release policy: the case of the bearded vulture. Journal of Applied Ecology, 41, 1103-1116.
Jaberg,C. & Guisan,A. (2001) Modelling the distribution of bats in relation to landscape structure in a temperate mountain environment. Journal of Applied Ecology, 38, 1169-1181.

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 42
Keitt,T.H., Bjornstad,O.N., Dixon,P.M. & Citron-Pousty,S. (2002) Accounting for spatial pattern when modeling organism-environment interactions. Ecography, 25, 616-625.
Kuhn,I. (2007) Incorporating spatial autocorrelation may invert observed patterns. Diversity and Distributions, 13, 66-69.
Leathwick,J.R., Whitehead,D. & McLeod,M. (1996) Predicting changes in the composition of New Zealand's indigenous forests in response to global warming: A modelling approach. Environmental Software, 11, 81-90.
Legendre,P., Dale,M.R.T., Fortin,M.J., Gurevitch,J., Hohn,M. & Myers,D. (2002) The consequences of spatial structure for the design and analysis of ecological field surveys. Ecography, 25, 601-615.
Lennon,J.J., Greenwood,J.J.D. & Turner,J.R.G. (2000) Bird diversity and environmental gradients in Britain: a test of the species-energy hypothesis. Journal of Animal Ecology, 69, 581-598.
Liebhold,A.M. & Gurevitch,J. (2002) Integrating the statistical analysis of spatial data in ecology. Ecography, 25, 553-557.
Lopez-Lopez,P., Garcia-Ripolles,C., Aguilar,J.M., Garcia-Lopez,F. & Verdejo,J. (2006) Modelling breeding habitat preferences of Bonelli's eagle (Hieraaetus fasciatus) in relation to topography, disturbance, climate and land use at different spatial scales. Journal of Ornithology 147, 97-106.
Maggini,R., Lehmann,A., Zimmermann,N.E. & Guisan,A. (2006) Improving generalized regression analysis for the spatial prediction of forest communities. Journal of Biogeography, 33, 1729-1749.
Manel,S., Dias,J.M., Buckton,S.T. & Ormerod,S.J. (1999) Alternative methods for predicting species distribution: an illustration with Himalayan river birds. Journal of Applied Ecology, 36, 734-747.
Maxwell,D.L., Stelzenmüller,V., Eastwood,P.D. & Rogers,S.I. (2008) Modelling the spatial distribution of plaice (Pleuronectes platessa), sole (Solea solea) and thornback ray (Raja clavata) in UK waters for marine management and planning. Journal of Sea Research.
Miller,J., Franklin,J. & Aspinall,R. (2007) Incorporating spatial dependence in predictive vegetation models. Ecological Modelling, 202, 225-242.
Nielsen,S.E., Johnson,C.J., Heard,D.C. & Boyce,M.S. (2005) Can models of presence-absence be used to scale abundance? - Two case studies considering extremes in life history. Ecography, 28, 197-208.
Osborne,P.E., Alonso,J.C. & Bryant,R.G. (2001) Modelling landscape-scale habitat use using GIS and remote sensing: a case study with great bustards. Journal of Applied Ecology, 38, 458-471.
Palomino,D. & Carrascal,L.M. (2007) Habitat associations of a raptor community in a mosaic landscape of Central Spain under urban development. Landscape and Urban Planning, 83, 268-274.
Pearce,J. & Ferrier,S. (2001) The practical value of modelling relative abundance of species for regional conservation planning: a case study. Biological Conservation, 98, 33-43.
Pebesma,E.J. (2004) Multivariable geostatistics in S: the gstat package. Computers & Geosciences 30, 683-691..
Perry,J.N., Liebhold,A.M., Rosenberg,M.S., Dungan,J., Miriti,M., Jakomulska,A. & Citron-Pousty,S. (2002) Illustrations and guidelines for selecting statistical methods for quantifying spatial pattern in ecological data. Ecography, 25, 578-600.
Pinheiro,J., Bates,D., DebRoy,S., Sarkar,D. & the R Core team. (2008) nlme: Linear and Nonlinear Mixed Effects Models. R package version 3.1-90.
R Development Core Team. (2009) R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org.

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 43
Randin,C.F., Dirnbock,T., Dullinger,S., Zimmermann,N.E., Zappa,M. & Guisan,A. (2006) Are niche-based species distribution models transferable in space? Journal of Biogeography, 33, 1689-1703.
Sanchez-Zapata,J.A. & Calvo,J.F. (1999) Raptor distribution in relation to landscape composition in semi-arid Mediterranean habitats. Journal of Applied Ecology, 36, 254-262.
Sanchez-Zapata,J.A., Carrete,M., Gravilov,A., Sklyarenko,S., Ceballos,O., Donazar,J.A. & Hiraldo,F. (2003) Land use changes and raptor conservation in steppe habitats of Eastern Kazakhstan. Biological Conservation, 111, 71-77.
Schabenberge,O. & Gotway,C.A. (2005) Statistical Methods for Spatial Data Analysis. Taylor & Francis Group
Scott,J.M., Heglund,P.J., Morrison,M.L., Haufler,J.B., Raphael,M.G., Wall,W.A. & Samson,F.B. (2002) Predicting Species Occurences : Issues of Accuracy and Scale. Island Press.
Segurado,P. & Araujo,M.B. (2004) An evaluation of methods for modelling species distributions. Journal of Biogeography, 31, 1555-1568.
Seoane,J., Vinuela,J., Diaz-Delgado,R. & Bustamante,J. (2003) The effects of land use and climate on red kite distribution in the Iberian peninsula. Biological Conservation, 111, 401-414.
Suarez-Seoane,S., Osborne,P.E. & Alonso,J.C. (2002) Large-scale habitat selection by agricultural steppe birds in Spain: identifying species-habitat responses using generalized additive models. Journal of Applied Ecology, 39, 755-771.
Thiollay,J.M. & Bretagnolle,V. (2004) Rapaces Nicheurs de France. Delachaux et Niestlé.
Venables,W.N. & Ripley,B.D. (2002) Modern Applied Statistics with S. Fourth Edition ; Springer, New York.
Welsh,A.H., Cunningham,R.B., Donnelly,C.F. & Lindenmayer,D.B. (1996) Modelling the abundance of rare species: Statistical models for counts with extra zeros. Ecological Modelling, 88, 297-308.
Wood,S.N. (2006) Generalized Additive Models: An Introduction with R. Chapman and Hall/CRC.
Zuur,A.F., Ieno,E.N., Walker,N.J., Saveliev,A.A. & Smith,G.M. (2009) Mixed Effetcts Models and Extensions in Ecology with R. Springer

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 44
A)
B)
ANNEXE 1 : Résultats des simulations de la validation croisée suivant le sélection aléatoire (A) ou suivant la
sélection par blocs (B)

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 45
ANNEXE 2 : Tableau de classification des variables Corine Land Cover
Sea and oceanMarine watersWater bodies
EstuariesMarine watersWater bodies
Coastal lagoonsMarine watersWater bodies
Water bodiesInland watersWater bodies
Water coursesInland watersWater bodies
Intertidal flatsMaritime wetlandsWetlands
SalinesMaritime wetlandsWetlandsHumides
Salt marshesMaritime wetlandsWetlandsZones
Peat bogsInland wetlandsWetlands
Inland marshesInland wetlandsWetlands
Glaciers and perpetual snowOpen spaces with little or no vegetation
Forest and semi natural areas
Burnt areasOpen spaces with little or no vegetation
Forest and semi natural areas
Sparsely vegetated areasOpen spaces with little or no vegetation
Forest and semi natural areasOuvertes
Bare rocksOpen spaces with little or no vegetation
Forest and semi natural areasZones
Beaches, dunes, sandsOpen spaces with little or no vegetation
Forest and semi natural areas
Transitional woodland-shrubScrub and/or herbaceous vegetation associations
Forest and semi natural areas
Sclerophyllous vegetationScrub and/or herbaceous vegetation associations
Forest and semi natural areasIntermédiaires
Moors and heathlandScrub and/or herbaceous vegetation associations
Forest and semi natural areasZones
Mixed forestForestsForest and semi natural areas
Coniferous forestForestsForest and semi natural areasForestières
Broad-leaved forestForestsForest and semi natural areasZones
Agro-forestry areasHeterogeneous agricultural areasAgricultural areas
Land principally occupied by agriculture, with significant areas of natural vegetationHeterogeneous agricultural areasAgricultural areas
Complex cultivation patternsHeterogeneous agricultural areasAgricultural areasHétérogène
Annual crops associated with permanent cropsHeterogeneous agricultural areasAgricultural areasAgriculture
Natural grasslandsScrub and/or herbaceous vegetation associations
Forest and semi natural areasExtensive
PasturesPasturesAgricultural areasAgriculture
Olive grovesPermanent cropsAgricultural areas
Fruit trees and berry plantationsPermanent cropsAgricultural areasPermanente
VineyardsPermanent cropsAgricultural areasAgriculture
Rice fieldsArable landAgricultural areas
Permanently irrigated landArable landAgricultural areasIntensive
Non-irrigated arable landArable landAgricultural areasAgriculture
Sport and leisure facilitiesArtificial, non-agricultural vegetated areasArtificial surfaces
Green urban areasArtificial, non-agricultural vegetated areasArtificial surfaces
Construction sitesMine, dump and construction sitesArtificial surfaces
Dump sitesMine, dump and construction sitesArtificial surfaces
Mineral extraction sitesMine, dump and construction sitesArtificial surfaces
AirportsIndustrial, commercial and transport unitsArtificial surfaces
Port areasIndustrial, commercial and transport unitsArtificial surfacesZones Baties
Road and rail networks and associated landIndustrial, commercial and transport unitsArtificial surfaces
Industrial or commercial unitsIndustrial, commercial and transport unitsArtificial surfaces
Discontinuous urban fabricUrban fabricArtificial surfaces
Continuous urban fabricUrban fabricArtificial surfaces
LABEL3LABEL2LABEL1vaiables
Nomenclature Corline Land CoverRegroupement des
Sea and oceanMarine watersWater bodies
EstuariesMarine watersWater bodies
Coastal lagoonsMarine watersWater bodies
Water bodiesInland watersWater bodies
Water coursesInland watersWater bodies
Intertidal flatsMaritime wetlandsWetlands
SalinesMaritime wetlandsWetlandsHumides
Salt marshesMaritime wetlandsWetlandsZones
Peat bogsInland wetlandsWetlands
Inland marshesInland wetlandsWetlands
Glaciers and perpetual snowOpen spaces with little or no vegetation
Forest and semi natural areas
Burnt areasOpen spaces with little or no vegetation
Forest and semi natural areas
Sparsely vegetated areasOpen spaces with little or no vegetation
Forest and semi natural areasOuvertes
Bare rocksOpen spaces with little or no vegetation
Forest and semi natural areasZones
Beaches, dunes, sandsOpen spaces with little or no vegetation
Forest and semi natural areas
Transitional woodland-shrubScrub and/or herbaceous vegetation associations
Forest and semi natural areas
Sclerophyllous vegetationScrub and/or herbaceous vegetation associations
Forest and semi natural areasIntermédiaires
Moors and heathlandScrub and/or herbaceous vegetation associations
Forest and semi natural areasZones
Mixed forestForestsForest and semi natural areas
Coniferous forestForestsForest and semi natural areasForestières
Broad-leaved forestForestsForest and semi natural areasZones
Agro-forestry areasHeterogeneous agricultural areasAgricultural areas
Land principally occupied by agriculture, with significant areas of natural vegetationHeterogeneous agricultural areasAgricultural areas
Complex cultivation patternsHeterogeneous agricultural areasAgricultural areasHétérogène
Annual crops associated with permanent cropsHeterogeneous agricultural areasAgricultural areasAgriculture
Natural grasslandsScrub and/or herbaceous vegetation associations
Forest and semi natural areasExtensive
PasturesPasturesAgricultural areasAgriculture
Olive grovesPermanent cropsAgricultural areas
Fruit trees and berry plantationsPermanent cropsAgricultural areasPermanente
VineyardsPermanent cropsAgricultural areasAgriculture
Rice fieldsArable landAgricultural areas
Permanently irrigated landArable landAgricultural areasIntensive
Non-irrigated arable landArable landAgricultural areasAgriculture
Sport and leisure facilitiesArtificial, non-agricultural vegetated areasArtificial surfaces
Green urban areasArtificial, non-agricultural vegetated areasArtificial surfaces
Construction sitesMine, dump and construction sitesArtificial surfaces
Dump sitesMine, dump and construction sitesArtificial surfaces
Mineral extraction sitesMine, dump and construction sitesArtificial surfaces
AirportsIndustrial, commercial and transport unitsArtificial surfaces
Port areasIndustrial, commercial and transport unitsArtificial surfacesZones Baties
Road and rail networks and associated landIndustrial, commercial and transport unitsArtificial surfaces
Industrial or commercial unitsIndustrial, commercial and transport unitsArtificial surfaces
Discontinuous urban fabricUrban fabricArtificial surfaces
Continuous urban fabricUrban fabricArtificial surfaces
LABEL3LABEL2LABEL1vaiables
Nomenclature Corline Land CoverRegroupement des

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 46
ANNEXE 3 : Matrice des corrélations de Spearman des variables climatiques et de la moyenne d’altitude.
10.170.660.500.33-0.150.450.350.50-0.67-0.36-0.41-0.010.49-0.77-0.170.52-0.290.17-0.58meanalti
0.1710.260.710.830.080.580.750.840.14-0.040.41-0.60-0.150.09-0.08-0.240.19-0.020.08meanbio19
0.660.2610.680.41-0.230.710.410.64-0.70-0.42-0.570.040.37-0.75-0.280.44-0.240.09-0.62meanbio18
0.500.710.6810.61-0.340.910.550.87-0.30-0.17-0.04-0.420.20-0.39-0.080.140.100.21-0.25meanbio17
0.330.830.410.6110.390.460.960.890.03-0.080.23-0.370.00-0.04-0.10-0.110.02-0.01-0.01meanbio16
-0.150.08-0.23-0.340.391-0.470.450.060.440.230.280.21-0.110.430.12-0.260.08-0.070.35meanbio15
0.450.580.710.910.46-0.4710.400.74-0.41-0.27-0.22-0.420.15-0.46-0.170.150.050.13-0.36meanbio14
0.350.750.410.550.960.450.4010.840.05-0.050.23-0.260.07-0.04-0.06-0.080.030.050.01meanbio13
0.500.840.640.870.890.060.740.841-0.18-0.150.06-0.380.15-0.28-0.100.050.040.12-0.17meanbio12
-0.670.14-0.70-0.300.030.44-0.410.05-0.1810.680.78-0.04-0.310.960.52-0.580.560.150.93meanbio11
-0.36-0.04-0.42-0.17-0.080.23-0.27-0.05-0.150.6810.600.240.330.550.950.100.350.520.89meanbio10
-0.410.41-0.57-0.040.230.28-0.220.230.060.780.601-0.28-0.120.700.50-0.360.430.220.77meanbio9
-0.01-0.600.04-0.42-0.370.21-0.42-0.26-0.38-0.040.24-0.2810.36-0.080.280.36-0.100.200.08meanbio8
0.49-0.150.370.200.00-0.110.150.070.15-0.310.33-0.120.361-0.480.540.86-0.090.69-0.03meanbio7
-0.770.09-0.75-0.39-0.040.43-0.46-0.04-0.280.960.550.70-0.08-0.4810.35-0.670.45-0.070.84meanbio6
-0.17-0.08-0.28-0.08-0.100.12-0.17-0.06-0.100.520.950.500.280.540.3510.260.390.720.76meanbio5
0.52-0.240.440.14-0.11-0.260.15-0.080.05-0.580.10-0.360.360.86-0.670.261-0.490.31-0.30meanbio4
-0.290.19-0.240.100.020.080.050.030.040.560.350.43-0.10-0.090.450.39-0.4910.600.52meanbio3
0.17-0.020.090.21-0.01-0.070.130.050.120.150.520.220.200.69-0.070.720.310.6010.34meanbio2
-0.580.08-0.62-0.25-0.010.35-0.360.01-0.170.930.890.770.08-0.030.840.76-0.300.520.341meanbio1
meanaltimeanbio19
meanbio18
meanbio17
meanbio16
meanbio15
meanbio14
meanbio13
meanbio12
meanbio11
meanbio10
meanbio9
meanbio8
meanbio7
meanbio6
meanbio5
meanbio4
meanbio3
meanbio2
meanbio1
10.170.660.500.33-0.150.450.350.50-0.67-0.36-0.41-0.010.49-0.77-0.170.52-0.290.17-0.58meanalti
0.1710.260.710.830.080.580.750.840.14-0.040.41-0.60-0.150.09-0.08-0.240.19-0.020.08meanbio19
0.660.2610.680.41-0.230.710.410.64-0.70-0.42-0.570.040.37-0.75-0.280.44-0.240.09-0.62meanbio18
0.500.710.6810.61-0.340.910.550.87-0.30-0.17-0.04-0.420.20-0.39-0.080.140.100.21-0.25meanbio17
0.330.830.410.6110.390.460.960.890.03-0.080.23-0.370.00-0.04-0.10-0.110.02-0.01-0.01meanbio16
-0.150.08-0.23-0.340.391-0.470.450.060.440.230.280.21-0.110.430.12-0.260.08-0.070.35meanbio15
0.450.580.710.910.46-0.4710.400.74-0.41-0.27-0.22-0.420.15-0.46-0.170.150.050.13-0.36meanbio14
0.350.750.410.550.960.450.4010.840.05-0.050.23-0.260.07-0.04-0.06-0.080.030.050.01meanbio13
0.500.840.640.870.890.060.740.841-0.18-0.150.06-0.380.15-0.28-0.100.050.040.12-0.17meanbio12
-0.670.14-0.70-0.300.030.44-0.410.05-0.1810.680.78-0.04-0.310.960.52-0.580.560.150.93meanbio11
-0.36-0.04-0.42-0.17-0.080.23-0.27-0.05-0.150.6810.600.240.330.550.950.100.350.520.89meanbio10
-0.410.41-0.57-0.040.230.28-0.220.230.060.780.601-0.28-0.120.700.50-0.360.430.220.77meanbio9
-0.01-0.600.04-0.42-0.370.21-0.42-0.26-0.38-0.040.24-0.2810.36-0.080.280.36-0.100.200.08meanbio8
0.49-0.150.370.200.00-0.110.150.070.15-0.310.33-0.120.361-0.480.540.86-0.090.69-0.03meanbio7
-0.770.09-0.75-0.39-0.040.43-0.46-0.04-0.280.960.550.70-0.08-0.4810.35-0.670.45-0.070.84meanbio6
-0.17-0.08-0.28-0.08-0.100.12-0.17-0.06-0.100.520.950.500.280.540.3510.260.390.720.76meanbio5
0.52-0.240.440.14-0.11-0.260.15-0.080.05-0.580.10-0.360.360.86-0.670.261-0.490.31-0.30meanbio4
-0.290.19-0.240.100.020.080.050.030.040.560.350.43-0.10-0.090.450.39-0.4910.600.52meanbio3
0.17-0.020.090.21-0.01-0.070.130.050.120.150.520.220.200.69-0.070.720.310.6010.34meanbio2
-0.580.08-0.62-0.25-0.010.35-0.360.01-0.170.930.890.770.08-0.030.840.76-0.300.520.341meanbio1
meanaltimeanbio19
meanbio18
meanbio17
meanbio16
meanbio15
meanbio14
meanbio13
meanbio12
meanbio11
meanbio10
meanbio9
meanbio8
meanbio7
meanbio6
meanbio5
meanbio4
meanbio3
meanbio2
meanbio1
BIO1 = Température moyenne annuelle BIO2 = Moyenne mensuelle des variations journalières BIO3 = Isothermatlité (P2/P7) (* 100) BIO4 = Saisonnalité de Température BIO5 = Maximum de Température du mois le plus chaud BIO6 = Minimum de Température du mois le plus froid BIO7 = Ecart annuelle de Température BIO8 = Moyenne de Température de la saison humide BIO9 = Moyenne de Température de la saison la plus sèche
BIO10 = Température moyenne de la saison la plus chaude BIO11 = Température moyenne de la saison la plus froide BIO12 = Précipitations annuelles BIO13 = Précipitations du mois le plus humide BIO14 = Précipitations du mois le plus sec BIO15 = Saisonnalité des Précipitations BIO16 = Précipitations de la saison humide BIO17 = Précipitations de la saison sèche BIO18 = Précipitations de la saison la plus chaude BIO19 = Précipitations de la saison la plus froide

Maxime Passerault Rapport de M2 : Les modèles de distribution
Université Lyon 1, année 2008/2009 47
Résumé
L’étude des distributions de présence et d’abondance d'organismes présente plusieurs
contraintes lors des analyses, notamment liées au caractère spatial comme l’autocorrélation,
un échantillonnage hétérogène, des distributions ‘zéro enflées’. Le but de ce stage est de
développer une démarche qui solutionne ces problèmes, entre autre en intégrant des variables
externes comme l’habitat et le climat à l'aide de GAM mixtes spatialisés. La première étape
modélise la probabilité de présence de l’espèce à large échelle et, avec l’aide d’une méthode
spatialement implicite, détermine un seuil discriminant la présence et l’absence. La deuxième
étape modélise l’abondance conditionnellement à la présence prédite, en prenant en compte
l’autocorrélation spatiale et des variables externes à fine échelle. Au final, cette démarche
parvient à considérer les différents problèmes pour donner une représentation précise de la
répartition d’abondance et étudier les facteurs qui l'affectent. Pour les développements futurs,
cette démarche gagnerait encore en robustesse en adoptant un cadre Bayésien.
Mots clés : abondance ; modèles additifs généralisés ; autocorrélation ; modèle de
distribution ; prédicteurs environnementaux
Abstract
Some problems like spatial autocorrelation, heterogeneous sampling or zero-inflated data,
frequently rise when modelling species presence and abundance. The goal of this study is to
develop a method to account for these problems, for example by integrating external variables
like habitats using spatial mixed GAM. In a first step, occurrence probabilities are modelled at
large scale, and then a cut-off between presence and absence is determinated according to the
distribution pattern. In a second step, abundance is modelled conditionally to presence
predicted at step 1, considering small scale variables like habitats. To conclude, this method
tackled main statistical problems and considered different biological aspects. In the futur, it
would be useful to integrate this approach using a Bayesian framework.
Key-words: abundance; generalized additive models; autocorrelation; distribution modelling; environmental predictors