prédiction de la défaillance financière des pme marocaines
TRANSCRIPT

18
Revue africaine de management - African management review
ISSN : 2509-0097
VOL.5 (2) 2020 (PP.18-36)
http://revues.imist.ma/?journal=RAM
Prédiction de la défaillance financière des PME marocaines : une
étude comparative.
KHADIR IDRISSI a, AZIZ MOUTAHADDIB
a
a Ecole Nationale de Commerce et de Gestion, Université Ibn Tofail, Kénitra, Maroc*
Résumé
La prédiction de la défaillance est l'une des principales problématiques de classification des entreprises. Cet
article propose une analyse comparative entre deux techniques différentes de prédiction. Il s’agit en effet de
définir le meilleur modèle susceptible de prédire la défaillance des PME marocaines emprunteuses de crédit de
restructuration et ce, à partir des données comptables au titre du dernier exercice clos précédant la constatation
de la survenance (ou non) de la défaillance. Le taux de correspondance de la phase d’apprentissage du jeu de
données retenu ainsi que le score de l’étape de test démontrent la supériorité du modèle des réseaux de neurones
avec un score de 83% contre 61% pour le modèle LOGIT. D’autre part, l’implémentation des deux modèles nous
a permis de relever qu’il existe un sous-ensemble commun de variables explicatives pertinentes de la défaillance
des PME marocaines emprunteuses de crédit de restructuration. Il S’agit principalement de 4 ratios d’autonomie
financière se rapportant surtout au niveau d’endettement de l’entreprise et 1 ratio de gestion correspondant au
délai de règlement des créances clients.
Mots clés : Prédiction de la défaillance, défaillance financière des entreprises, PME marocaines, modèle
LOGIT, modèle des réseaux de neurones, ratios financiers.
Abstract
Predicting business failure is one of the main problems in classification. This article aims to compare between
two different prediction techniques. It is indeed a question of defining the best model able to predict the failure
of Moroccan SMEs that have borrowed restructuring loans. And this, by using accounting data for the last
financial year preceding the recognition of the occurrence (or not) of failure. The training accuracy rate of the
selected dataset as well as the score of the testing step demonstrate the superiority of neural network model with
a score of 83% compared to 61% for LOGIT model. On the other hand, the implementation of the two models
has enabled us to note that there is a common subset of relevant explanatory variables for financial distress of
Moroccan SMEs borrowing restructuring debts. These are mainly 4 financial autonomy ratios relating to the
level of debt of the company and 1 management ratio corresponding to the customer payment terms.
Keys words : Predicting financial distress, business failure, Moroccan SMEs, LOGIT model,
neural network model, financial ratios.

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
19
1. Introduction
Nul ne peut contester que la PME contribue efficacement à la croissance de l’économie.
D’après une recherche effectuée par la Banque Mondiale, 95% des entreprises sont des PME,
qui emploient plus que 60% des salariés, et contribuent à plus de 50% de la valeur ajoutée
brute mondiale1.
La disparition des entreprises peut constituer un événement majeur impactant
significativement la bonne marche de l’économie marocaine. En effet, selon Inforisk2, 8 439
entreprises ont dû mettre la clé sous la porte au cours de l’année 2019, un constat en
augmentation de 5,1% par rapport à 2018.
Dans la pratique courante et afin de favoriser la continuité de l’entreprise en difficulté,
plusieurs Banques lui réitèrent leurs confiances, tout en tenant compte bien entendu de sa
viabilité économique. Pour ce faire, la Banque peut décider l’accompagnement financier de
son entreprise cliente à travers, le cas échéant, par la mise en place d’un crédit de
restructuration. Ce dernier peut avoir plusieurs objets : la consolidation des lignes de crédit à
court terme, le remboursement des dettes fournisseurs ou encore l’acquittement des arriérés
envers les établissements publics. Ainsi, notre sujet sera orienté vers les entreprises ayant opté
pour le crédit de restructuration financière afin de mieux appréhender la défaillance, étant
donné que ces entreprises émettent déjà des signaux de détresse annonçant le risque de
défaillance financière.
Dans ce travail, la définition de la défaillance se base plutôt sur l'incapacité de celles-ci à
honorer leur engagement envers leurs créanciers. D’ailleurs, dans le contexte marocain, la
Circulaire du Gouverneur de Bank Al-Maghrib n°19/G/2002, fait état d’un classement des
créances selon leur santé : créances saines et créances en souffrance. A leur tour, les différents
modèles théoriques de prévision de la défaillance financière ont pour objectif principal de
distinguer les entreprises défaillantes de celles non défaillantes. Notre choix s’est porté sur la
régression LOGIT ainsi que les réseaux de neurones, en tant que modèles ayant démontré
leurs pouvoirs prédictifs. Une fois le modèle au meilleur pouvoir prédictif défini, nous serons
en mesure de faire ressortir les ratios financiers les plus explicatifs de la défaillance.
Ce travail de recherche constitue un réel apport aussi bien sur le plan académique que
managériale. D’une part, il contribuera à enrichir les travaux académiques, qui de par leur
faible nombre, accorde plutôt une importance à l’aspect théorique au détriment de la
vérification empirique. D’autre part, il constitue pour les Banques, l’entreprise elle-même et
toute autre partie prenante, un outil d’aide à la prise de décision afin de prédire la défaillance
financière.
Nous proposons de contribuer à améliorer la compréhension du sujet en orientant cette
recherche en vue de répondre à la problématique suivante : « Comment peut-on prédire la
défaillance des PME marocaines ? ». Cette problématique a été déclinée en plusieurs
questions de recherche : que réservent les travaux de recherche au concept de la modélisation 1 « Le Guide des services bancaires aux PME », Société Financière Internationale 2010. 2 Inforisk : Plateforme de collecte d’informations sur les entreprises marocaines

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
20
de la défaillance ? Quels sont les modèles économétriques capables de prédire la défaillance
financière avant son avènement ? Et quelles sont les variables financières qui expliquent le
mieux cette défaillance ?
Pour ce faire, l’accent sera mis premièrement sur une synthèse intégrative de la littérature
existantes au sujet des modèles de prédiction de la défaillance tout en justifiant le choix
concernant les modèles retenus au niveau de cette étude. Nous exposerons ensuite notre
méthodologie de recherche. Enfin, nous présenterons les résultats obtenus et discuterons leur
interprétation.
2. Revue de la littérature
La variable à expliquer dans la prédiction de la faillite est qualitative et dans la plupart des
cas, elle est d’ordre binaire : défaillante, codée « 1 » et non défaillante, codée « 0 ». Notre
travail consiste à comparer le pouvoir prédictif de la défaillance grâce au modèle LOGIT et
des Réseaux de neurones.
2.1 La régression LOGIT dans la prédiction de défaillance
De nombreux chercheurs ont eu recours au modèle LOGIT pour prévoir les défaillances, car il
convient particulièrement bien pour comprendre la nature de la prédiction des faillites
(Ohlson, 19803, Back et al., 19964).
Comme indiqué par Hair et al. (20065), la régression logistique est la méthode statistique
appropriée lorsque la variable dépendante est une variable catégorique, alors que les variables
indépendantes utilisent des variables non métriques ou métriques. Par conséquent, le LOGIT
est le modèle paramétrique le plus approprié pour interpréter les probabilités avec une
variable de sortie qualitative.
Le modèle LOGIT est basé sur une fonction logistique cumulative. De ce fait, nous obtenons
la probabilité qu'une société appartienne à l'un des deux groupes à priori déterminés, compte
tenu des caractéristiques financières de la société.
L’avantage de ce modèle c’est sa capacité à appliquer la non-linéarité LOGIT au model
linéaire multi-variables. Cela permet de ramener la valeur de sortie dans l’intervalle [0, 1],
facilitant l’interprétation sous forme de probabilité.
2.2 Le réseau de neurones dans la prédiction de défaillance
Avec la révolution technologique, l’intelligence artificielle a permis d’affiner les prévisions
grâce à des algorithmes génétiques et des réseaux de neurones efficients et développés, issus
de l’apprentissage automatique. Ceci fait référence à ce qu’on appelle désormais
3 OHLSON, James A. Financial ratios and the probabilistic prediction of bankruptcy. Journal of accounting research, 1980, p. 109-131. 4 BACK, Barbro, LAITINEN, Teija, SERE, Kaisa, et al. Choosing bankruptcy predictors using discriminant analysis, logit analysis, and genetic algorithms.
Turku Centre for Computer Science Technical Report, 1996, vol. 40, no 2, p. 1-18. 5 HAIR, Joseph F., BLACK, William C., BABIN, Barry J., et al. Multivariate data analysis (Vol. 6). 2006.

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
21
l’apprentissage profond, désigné par l’expression Deep Learning. En effet, la profondeur du
réseau dépend du nombre de neurones.
Comparés à d'autres approches empiriques de la prévision de la faillite, les réseaux de
neurones présentent certains avantages. Premièrement, les réseaux de neurones ne font pas
d’hypothèses sur la distribution des données. Deuxièmement, ce modèle prédictif permet un
ensemble non linéaire de relations. Cette tolérance est particulièrement importante pour les
prévisions de faillite, car la relation entre la probabilité de défaut et les variables explicatives
ne doit pas nécessairement être linéaire. Oreski et Oreski (20146) ont fait valoir qu'une
approche non linéaire surpasse les modèles linéaires pour deux raisons : premièrement, des
effets de saturation peuvent se produire dans la relation entre les ratios financiers et la
prédiction de défaut. Deuxièmement, les facteurs multiplicatifs peuvent devenir
problématiques.
L’essence des modèles fondés sur l’intelligence artificielle est le traitement et l’interprétation
de la complexité des données recueillies. Ils sont capables de formuler des règles
d’interférence et une connaissance généralisée des situations dans lesquelles ils sont censés
prédire ou classer l’objet dans l’une des catégories précédemment observées (Korol, 20137).
L’utilisation du réseau de neurones requiert un solide travail, pour identifier l’architecture, la
structure, l’algorithme et la fonction d’activation la plus adaptée au problème à résoudre ainsi
que d’autres hyperparamètres le rendant plus optimal.
2.3 Choix du modèle prédictif
D’après plusieurs travaux de recherche antérieurs, ces deux modèles sont les plus préconisées
pour prédire la défaillance des entreprises, compte tenu de leur pouvoir prédictif ainsi que la
capacité d’interprétation des résultats obtenus.
La régression LOGIT a été préconisée par Ohlson (19808), en passant par Platt et Platt
(19919) et Mossman et al (199810).
En effet, les prédictions faites grâce au modèle LOGIT donnent lieu à des correspondances de
bonne qualité, à un horizon d’un an. D’ailleurs, Platt et Platt (1991) ont conclu un taux de
bons classements de l’ordre de 88% pour les entreprises saines et de 85% pour les entreprises
défaillantes. Mossman et Al (1998) de leur côté ont abouti à un taux de bons classements de
l’ordre de 70% pour les entreprises saines et de 80% pour les entreprises défaillantes.
Ces dernières années, une vaste liste de modèles de prévision des défaillances d’entreprise a
été développée en appliquant la régression logistique, elle a été appliquée à des échantillons
correspondant à différents pays d'Europe, tels que la Norvège (Westgaard et van der Wijst,
6 ORESKI, Stjepan et ORESKI, Goran. Genetic algorithm-based heuristic for feature selection in credit risk assessment. Expert systems with applications, 2014,
vol. 41, no 4, p. 2052-2064. 7 KOROL, Tomasz. Early warning models against bankruptcy risk for Central European and Latin American enterprises. Economic Modelling, 2013, vol. 31, p.
22-30. 8 OHLSON, James A. Financial ratios and the probabilistic prediction of bankruptcy. Journal of accounting research, 1980, p. 109-131. 9 PLATT, Harlan D. et PLATT, Marjorie B. A note on the use of industry-relative ratios in bankruptcy prediction. Journal of Banking & Finance, 1991, vol. 15,
no 6, p. 1183-1194. 10 MOSSMAN, Charles E., BELL, Geoffrey G., SWARTZ, L. Mick, et al. An empirical comparison of bankruptcy models. Financial Review, 1998, vol. 33, no
2, p. 35-54.

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
22
200111), la Grèce (Konstantaras et Siriopoulos, 201112), l'Allemagne (Jostarndt et Sautner,
200813), et le Royaume-Uni (Polemis et Gounopoulos, 201214), ainsi que dans le reste du
monde, des modèles de prédiction ayant été développés en Australie (Hensher et Jones,
200715). ), aux États-Unis (Hauser et Booth, 201116) et en Chine (Li et al., 201217), et le
Maroc (Kherrazi et Ahsina, 201618), entre autres.
Pour ce qui est de notre champ de recherche portant sur la prédiction de la défaillance des
entreprises, plusieurs chercheurs ont eu recours à la modélisation par le réseau des neurones et
ce depuis 1990, notamment grâce à une étude menée aux Etats-Unis par Odom et Sharda19
qui ont employé une architecture à 2 couches avec 5 entrées, 5 neurones cachés et 1 neurone
de sortie. L’apprentissage de leur modèle s’est basé sur un réseau de type Percepton multi-
couches entrainé à l’aide de l’algorithme de Rétro-propagation de l’erreur.
L’intégration de ces algorithmes d’apprentissage automatique semble prometteuse, par
exemple, Nanni et Lumini (200920) ont utilisé des bases de données financières australiennes,
allemandes et japonaises pour constater que les techniques d'apprentissage automatique,
conduisent à une meilleure classification que les méthodes autonomes.
Tseng, F. M., et Hu, Y. C. (201021) ont mené à leur tour une étude sur les entreprises
anglaises. Les résultats confirment la supériorité du Perceptron multi-couches (Multilayer
percpetron-MLP), qui est un réseau de neurones dense multicouches, sur le modèle de
régression LOGIT.
Compte tenu de ce qui précède, nous retiendrons l’hypothèse suivante qu’il conviendra de
confirmer ou infirmer.
H1 : Le modèle des réseaux de neurones fournit des prévisions de
meilleure qualité que le modèle LOGIT ;
Dans le même contexte, la défaillance a été examinée par différents modèles, parmi lesquels
nous en citons les plus connus, notamment ceux de Fitzpatrick (193222), Beaver (196623) et
Altman (196824). Devant l’insuffisance ou l’inexistence des données qualitatives et
11 WESTGAARD, Sjur et VAN DER WIJST, Nico. Default probabilities in a corporate bank portfolio: A logistic model approach. European journal of
operational research, 2001, vol. 135, no 2, p. 338-349. 12 KONSTANTARAS, Konstantinos et SIRIOPOULOS, Costas. Estimating financial distress with a dynamic model: Evidence from family owned enterprises in
a small open economy. Journal of multinational financial management, 2011, vol. 21, no 4, p. 239-255. 13 JOSTARNDT, Philipp et SAUTNER, Zacharias. Out-of-court restructuring versus formal bankruptcy in a non-interventionist bankruptcy setting. Review of
Finance, 2010, vol. 14, no 4, p. 623-668. 14 POLEMIS, Dionysios et GOUNOPOULOS, Dimitrios. Prediction of distress and identification of potential M&As targets in UK. Managerial Finance, 2012. 15 HENSHER, David A. et JONES, Stewart. Forecasting corporate bankruptcy: Optimizing the performance of the mixed logit model. Abacus, 2007, vol. 43, no
3, p. 241-264. 16 HAUSER, Richard P. et BOOTH, David. Predicting bankruptcy with robust logistic regression. Journal of Data Science, 2011, vol. 9, no 4, p. 565-584. 17 LI, Hui et SUN, Jie. Forecasting business failure: The use of nearest-neighbour support vectors and correcting imbalanced samples–Evidence from the Chinese
hotel industry. Tourism Management, 2012, vol. 33, no 3, p. 622-634. 18 KHERRAZI, Soufiane et AHSINA, Khalifa. Modélisation et Analyse des Défaillances d'Entreprises: Application aux PME Marocaines. Finance and Finance
Internationale, 2016, vol. 442, no 5257, p. 1-16. 19 ODOM, Marcus D. et SHARDA, Ramesh. A neural network model for bankruptcy prediction. In : 1990 IJCNN International Joint Conference on neural
networks. IEEE, 1990. p. 163-168. 20 NANNI, Loris et LUMINI, Alessandra. An experimental comparison of ensemble of classifiers for bankruptcy prediction and credit scoring. Expert systems
with applications, 2009, vol. 36, no 2, p. 3028-3033. 21 TSENG, Fang-Mei et HU, Yi-Chung. Comparing four bankruptcy prediction models: Logit, quadratic interval logit, neural and fuzzy neural networks. Expert
Systems with Applications, 2010, vol. 37, no 3, p. 1846-1853. 22 FITZPATRICK, Paul Joseph. A comparison of the ratios of successful industrial enterprises with those of failed companies. 1932. 23 BEAVER, William H. Financial ratios as predictors of failure. Journal of accounting research, 1966, p. 71-111. 24 ALTMAN, Edward I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. The journal of finance, 1968, vol. 23, no 4, p. 589-
609.

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
23
organisationnelles, ces chercheurs considèrent que les chiffres communiqués par les
entreprises au niveau de leurs états de synthèse reflètent une image fidèle de la santé de
l’entreprise. Ils ont ainsi mis l’accent sur la définition des ratios financiers susceptibles
d’expliquer la défaillance (ou non) d’une entreprise.
Précisons que compte tenu de la spécificité des informations comptables, il n'existe pas
d'approche théorique dans la sélection des variables pour les modèles de prévision de la
défaillance financière. Selon Laitinen et Laitinen (200025), le choix des ratios financiers en
tant que variables dans les modèles de prédiction de la faillite est construit à partir d'une série
de processus d'essais et d'erreurs tels que pratiqués par la plupart des chercheurs dans des
études antérieures.
Ainsi, la défaillance peut être expliquées en fonction d’un certain nombre de variables
d’entrées, qui ne sont autres que les ratios financiers, qu’il convient d’implémenter dans le
modèle de prédiction afin de vérifier leur pertinence. Ceci nous a permis de formuler
l’hypothèse suivante :
H2 : Quelle que soit le modèle de prédiction choisie, il existe un sous-
ensemble commun de variables explicatives pertinentes.
3. Méthodologie
Plusieurs débats ont été ouverts pour se mettre d’accord sur le moment où une entreprise est
jugée défaillante. Les uns pensent qu’elle est considérée ainsi dès qu’un défaut de paiement
survient, alors que d’autres la considère en tant que telle dès l’ouverture d’une procédure
judiciaire.
Garantir une meilleure représentativité pose le double problème de l’homogénéité des
entreprises retenues (Refait, 200426). Ainsi, la démarche est susceptible de se heurter à un
biais statistique causé principalement par un effet de taille, une tendance sectorielle ou encore
une disproportion de l’étendue des entreprises saines et défaillantes.
Tenant compte de ces paramètres, nous présenterons ci-après la démarche suivie pour la
construction de l’échantillon de notre travail de recherche.
3.1 Profil de l’entreprise défaillante
La défaillance reflète la situation de l’entreprise en difficulté, qui englobe selon Casta et
Zerbib (197927
) un pilier juridique (soit la procédure de redressement judiciaire à la suite du
dépôt d’un bilan lié à une situation d’insolvabilité), un pilier économique (absence de
rentabilité traduite par une valeur ajoutée négative), et un pilier financier (problème de
trésorerie qui en découle une impossibilité d’honorer les engagements financiers).
25 LAITINEN, Erkki K. et LAITINEN, Teija. Bankruptcy prediction: Application of the Taylor's expansion in logistic regression. International review of
financial analysis, 2000, vol. 9, no 4, p. 327-349. 26 REFAIT-ALEXANDRE, Catherine. La prévision de la faillite fondée sur l'analyse financière de l'entreprise: un état des lieux. Economie prevision, 2004, no 1,
p. 129-147. 27 Casta JF et Zerbib JP (1979) Prévoir la défaillance des entreprises ?, Revue Française de Comptabilité, Octobre, pp 506–527

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
24
Le crédit de restructuration, en tant que mode de financement bancaire, permet d’accorder à
l’entreprise en difficulté un nouveau souffle afin d’assurer la continuité de son activité.
Toutefois, l’octroi de ce type de crédit suppose une maitrise de risque de par la Banque, afin
de garantir le remboursement de sa créance. Dans le même esprit, ceci constitue de facto, une
alerte aux différentes parties prenantes qui deviennent de plus en plus soucieuses de la
solvabilité de l’entreprise emprunteuse.
Dans une étude effectuée par Kang et Shivdasani (199728
) qui comprend un échantillon de 92
entreprises nippones et 114 américaines qui sont passées par des difficultés de 1985 à 1990. Il
s’avère que celles japonaises recourent à abaisser les taux d’intérêt ou rééchelonner les dettes
plutôt qu’à la liquidation, avec un taux de 25% contre 50% pour les entreprises américaines.
Diverses revues de littérature Petersen et Rajan (199429
) et Cole (199830
), Harhoff et Körting
(199831
) et Elsas et Krahnen (199832
), D’Auria et al. (199933
), Ferri et Messori (200034
),
s’accordent sur le fait qu’il existe une corrélation positive entre l’intensité de relation banque-
entreprise et l’octroi de crédit.
L’originalité de notre travail de recherche tire profit du choix de la population à étudier. En
effet, pour ce qui est du contexte marocain, la défaillance des entreprises a un caractère «
anticipé », c'est-à-dire, observé avant même que les créanciers réclament leurs droits par voie
judiciaire (Kherrazi et Ahsina, 201635
).
Vu l’intérêt du sujet, nous avons retenu la définition financière, du fait qu’elle se rapproche le
plus du risque de solvabilité lié aux entreprises ayant bénéficié d’un crédit de restructuration,
sans pour autant faire appel au redressement ou liquidation judiciaire, qui font plutôt référence
à l’aspect juridique de la défaillance.
3.2 Variables explicatives
A l’issue de notre revue de littérature, nous avons retenu les ratios les plus cités et ayant
contribué à produire des modèles prédictifs pertinents, à savoir : Beaver, 196636
; Altman,
196837
; Ohlson, 198038
; Mensah, 198339
; Laitinen et Laitinen, 200040
; Barniv et al.,
28 KANG, Jun-Koo et SHIVDASANI, Anil. Corporate restructuring during performance declines in Japan. Journal of Financial economics, 1997, vol. 46, no 1,
p. 29-65. 29 PETERSEN, Mitchell A. et RAJAN, Raghuram G. The benefits of lending relationships: Evidence from small business data. The journal of finance, 1994, vol.
49, no 1, p. 3-37. 30 COLE, Rebel A. The importance of relationships to the availability of credit. Journal of Banking & Finance, 1998, vol. 22, no 6-8, p. 959-977. 31 HARHOFF, Dietmar et KOERTING, Tim. How many creditors does it take to tango. Wissenschaftszentrum Berlin, Berlin, 1998. 32 ELSAS, Ralf et KRAHNEN, Jan Pieter. Is relationship lending special? Evidence from credit-file data in Germany. Journal of Banking & Finance, 1998, vol.
22, no 10-11, p. 1283-1316.
33 D’AURIA, Claudio, FOGLIA, Antonella, et REEDTZ, Paolo Marullo. Bank interest rates and credit relationships in Italy. Journal of Banking & Finance,
1999, vol. 23, no 7, p. 1067-1093.
34 FERRI, Giovanni et MESSORI, Marcello. Bank–firm relationships and allocative efficiency in Northeastern and Central Italy and in the South. Journal of
Banking & Finance, 2000, vol. 24, no 6, p. 1067-1095. 35 KHERRAZI, Soufiane et AHSINA, Khalifa. Défaillance et politique d’entreprises: modélisation financière déployée sous un modèle logistique appliqué aux
PME marocaines. La revue gestion et organisation, 2016, vol. 8, no 1, p. 53-64. 36 BEAVER, William H. Financial ratios as predictors of failure. Journal of accounting research, 1966, p. 71-111. 37 ALTMAN, Edward I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. The journal of finance, 1968, vol. 23, no 4, p. 589-
609. 38 OHLSON, James A. Financial ratios and the probabilistic prediction of bankruptcy. Journal of accounting research, 1980, p. 109-131. 39 MENSAH, Yaw M. An examination of the stationarity of multivariate bankruptcy prediction models: A methodological study. Journal of accounting research,
1984, p. 380-395. 40 LAITINEN, Erkki K. et LAITINEN, Teija. Bankruptcy prediction: Application of the Taylor's expansion in logistic regression. International review of
financial analysis, 2000, vol. 9, no 4, p. 327-349.
K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
25
200241
; Charitou et al., 200442
; Wang and Deng, 200643
. La purification des ratios financiers
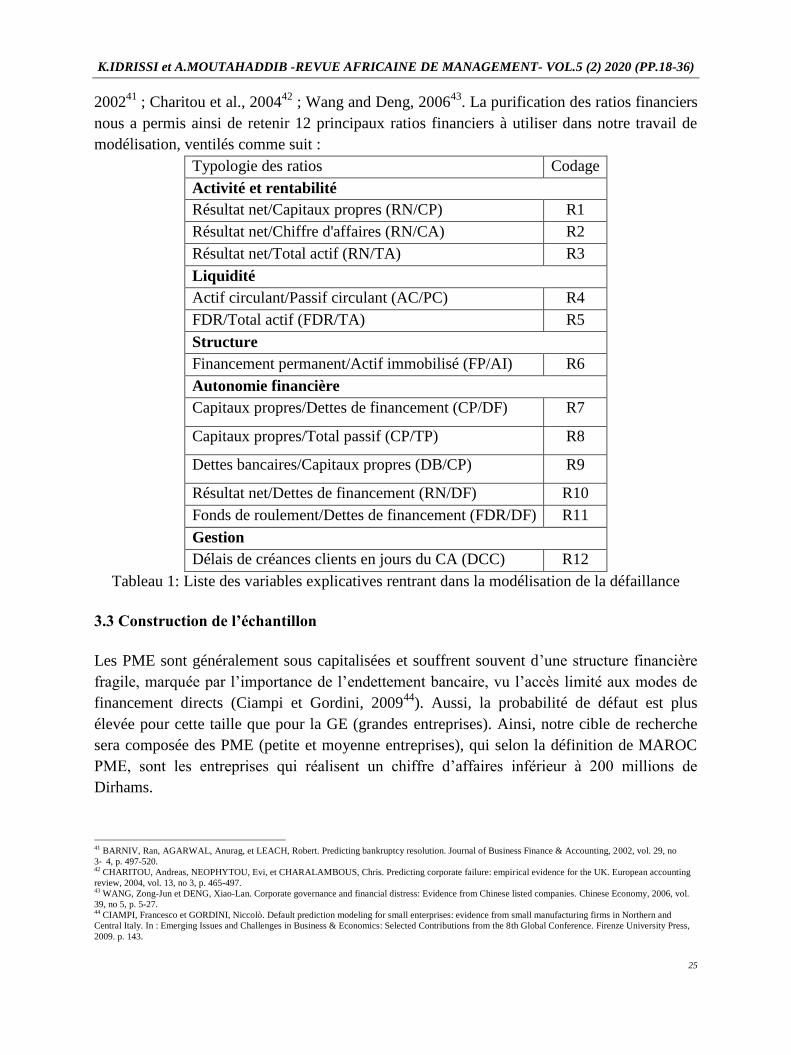
nous a permis ainsi de retenir 12 principaux ratios financiers à utiliser dans notre travail de
modélisation, ventilés comme suit :
Typologie des ratios Codage
Activité et rentabilité
Résultat net/Capitaux propres (RN/CP) R1
Résultat net/Chiffre d'affaires (RN/CA) R2
Résultat net/Total actif (RN/TA) R3
Liquidité
Actif circulant/Passif circulant (AC/PC) R4
FDR/Total actif (FDR/TA) R5
Structure
Financement permanent/Actif immobilisé (FP/AI) R6
Autonomie financière
Capitaux propres/Dettes de financement (CP/DF) R7
Capitaux propres/Total passif (CP/TP) R8
Dettes bancaires/Capitaux propres (DB/CP) R9
Résultat net/Dettes de financement (RN/DF) R10
Fonds de roulement/Dettes de financement (FDR/DF) R11
Gestion
Délais de créances clients en jours du CA (DCC) R12
Tableau 1: Liste des variables explicatives rentrant dans la modélisation de la défaillance
3.3 Construction de l’échantillon
Les PME sont généralement sous capitalisées et souffrent souvent d’une structure financière
fragile, marquée par l’importance de l’endettement bancaire, vu l’accès limité aux modes de
financement directs (Ciampi et Gordini, 200944
). Aussi, la probabilité de défaut est plus
élevée pour cette taille que pour la GE (grandes entreprises). Ainsi, notre cible de recherche
sera composée des PME (petite et moyenne entreprises), qui selon la définition de MAROC
PME, sont les entreprises qui réalisent un chiffre d’affaires inférieur à 200 millions de
Dirhams.
41 BARNIV, Ran, AGARWAL, Anurag, et LEACH, Robert. Predicting bankruptcy resolution. Journal of Business Finance & Accounting, 2002, vol. 29, no
3‐ 4, p. 497-520. 42 CHARITOU, Andreas, NEOPHYTOU, Evi, et CHARALAMBOUS, Chris. Predicting corporate failure: empirical evidence for the UK. European accounting
review, 2004, vol. 13, no 3, p. 465-497. 43 WANG, Zong-Jun et DENG, Xiao-Lan. Corporate governance and financial distress: Evidence from Chinese listed companies. Chinese Economy, 2006, vol.
39, no 5, p. 5-27. 44 CIAMPI, Francesco et GORDINI, Niccolò. Default prediction modeling for small enterprises: evidence from small manufacturing firms in Northern and
Central Italy. In : Emerging Issues and Challenges in Business & Economics: Selected Contributions from the 8th Global Conference. Firenze University Press,
2009. p. 143.

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
26
L’échantillon a été formé par les PME issues de différents secteurs d’activités afin de ne pas
se limiter à un secteur précis mais de favoriser plutôt une visibilité sur la tendance générale
des entreprises cibles. Cependant, il était nécessaire d’exclure les entreprises âgées de moins
de 3 ans, compte tenu de leur fragilité prouvée lors du démarrage et leurs données comptables
insignifiantes.
Notre étude se penche sur l’événement de la défaillance constaté à partir de l’année 2018.
Ainsi, grâce à la collaboration de différentes banques marocaines, notre population a été
constituée d’entreprises ayant contracté des crédits de restructuration durant la période qui
s’étale entre 2014 et 2017. Eu égard de notre modèle de recherche basé sur les ratios
financiers, les informations comptables ont été extraites principalement à partir de deux bases
de données : DirectInfo appartenant à l’OMPIC ainsi que InfoRisk. Nous avons réussi à
constituer une base de données de 600 entreprises, toutes catégories confondues, PME et GE,
parmi lesquelles figurent des entreprises manifestant des créances en souffrances annoncées
en 2018. Ensuite, il était question de garder uniquement les entreprises qui disposent des états
financiers fiscaux au titre de l’exercice comptable de 2017. Une population de 188 entreprises
a été retenue par nos soins. Pour ce qui est des PME, nous avons extrait 171 entreprises parmi
lesquelles 129 entreprises saines et 42 entreprises défaillantes.
Dans un contexte économique normal, étant donné que le nombre d’entreprises défaillantes
est faible, l’une des solutions pertinentes a été préconisée par Mossman et Al (198845
), qui
consiste à adopter une sélection par appariement. En effet, cette méthode consiste
premièrement à définir l’échantillon des entreprises défaillantes puis, à attribuer à chacune,
une entreprise non-défaillante selon différents critères tels que le secteur d’activité, la taille ou
encore l’exercice financier afin de former, in fine, l’échantillon des entreprises saines
(Balcaen and Ooghe, 200646
). Toutefois, les entreprises saines demeurent sous-représentées,
limitées uniquement aux conditions d’appariement choisies. On assiste ici à un
échantillonnage non-aléatoire, donnant lieu à un biais statistique.
Pour contrecarrer le déséquilibre entre le nombre d’entreprises défaillantes et celles saines,
nous avons opté pour un échantillonnage « mixte ». D’une part, afin d’assurer une large
représentativité, nous avons retenu toutes les entreprises défaillantes suivant un
échantillonnage non-aléatoire. D’autre part, nous avons appliqué un appariement aléatoire au
moment de la sélection des entreprises saines, afin de respecter l’inférence statistique de la
population étudiée.
Nous avons retenu premièrement les 42 entreprises défaillantes dont les données comptables
de 2017 sont disponibles. Deuxièmement, l’échantillon des entreprises saines a été tiré
aléatoirement à partir des 129 entreprises saines disposant également des données comptables
de l’exercice 2017.
45 MOSSMAN, Charles E., BELL, Geoffrey G., SWARTZ, L. Mick, et al. An empirical comparison of bankruptcy models. Financial Review, 1998, vol. 33, no
2, p. 35-54. 46 BALCAEN, Sofie et OOGHE, Hubert. 35 years of studies on business failure: an overview of the classic statistical methodologies and their related problems.
The British Accounting Review, 2006, vol. 38, no 1, p. 63-93.
K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
27
Par ailleurs, la littérature préconise la construction d’un échantillon composé d’un nombre
important d’observations. La règle générale recommande l’emploi de deux sous-échantillons
distincts : un échantillon d’apprentissage et un autre réservé au test du modèle. Pour notre cas,
nous disposons d’un jeu de données de petite taille. L’isolation d’un échantillon de test réduit
les chances du modèle pour apprendre davantage en privant une partie des données de
l’apprentissage. Nous exposerons dans la suite du présent travail les méthodes d’apprentissage
et de test adoptées pour chacun des deux modèles déployés.
3.4 Pouvoir discriminant des ratios financiers
Certains ratios présentent des dispersions variables, d’où l’intérêt de valider statistiquement la
significativité de la différence de cette dispersion. Pour ce faire, nous avons opté pour
l’utilisation du rapport de corrélation (Saporta, 200647
). Il s’agit de la force de la liaison entre
une variable qualitative et une variable quantitative. Ainsi, le rapport de corrélation contribue
à mesurer la liaison entre chaque ratio financier retenu et la survenance de la défaillance en
2018.
Une valeur de 1 suppose une très forte liaison entre les deux variables. Plus la valeur est
proche de 0 moins les deux variables sont corrélées. Nous avons appliqué également un test
de nullité du rapport de corrélation afin de déterminer si la valeur de ce dernier est
significativement différente de 0.
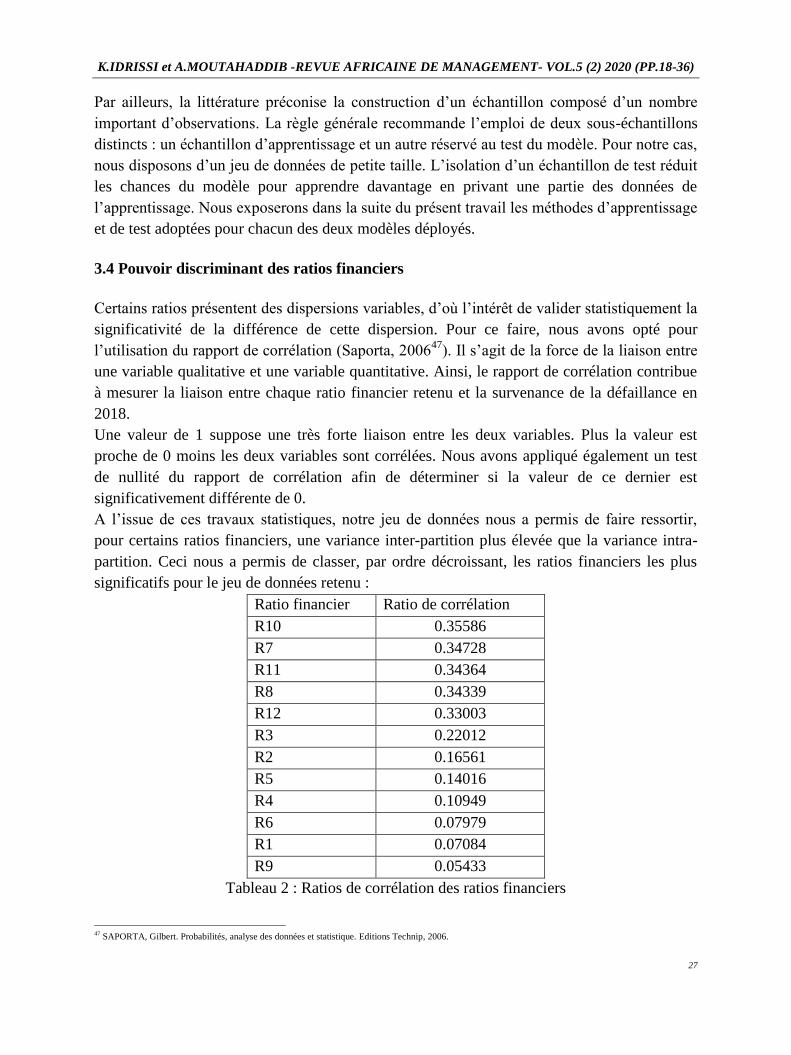
A l’issue de ces travaux statistiques, notre jeu de données nous a permis de faire ressortir,
pour certains ratios financiers, une variance inter-partition plus élevée que la variance intra-
partition. Ceci nous a permis de classer, par ordre décroissant, les ratios financiers les plus
significatifs pour le jeu de données retenu :
Ratio financier Ratio de corrélation
R10 0.35586
R7 0.34728
R11 0.34364
R8 0.34339
R12 0.33003
R3 0.22012
R2 0.16561
R5 0.14016
R4 0.10949
R6 0.07979
R1 0.07084
R9 0.05433
Tableau 2 : Ratios de corrélation des ratios financiers
47 SAPORTA, Gilbert. Probabilités, analyse des données et statistique. Editions Technip, 2006.

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
28
Le calcul du ratio de corrélation permet d’éliminer les ratios financiers les moins corrélés
avec le statut (0 ou 1) et de garder ensuite, en tant que variable d’entrée les « TOP N » de
ratios financiers, c’est-à-dire les ratios ayant les meilleurs classement pour une meilleure
détection de la défaillance. De plus, l’élimination des ratios financiers ayant les rapports de
corrélation les moins puissants favorise la réduction de la dimensionnalité de l’espace
d’entrée des variables explicatives et de simplifier par conséquent la complexité de calcul et
d’atténuer le bruit stochastique introduit par ces ratios peu signifiants.
4. Résultats :
Rappelons que nous disposons de deux sous-ensembles, chacun correspondant à l’une des
deux catégories qui sont identifiées (étiquetées) comme défaillantes ou saines.
Nous avons utilisé pour le modèle de Régression LOGIT et du modèle des Réseaux de
neurones l’implémentation de Scikit-learn, qui a été faite grâce à la bibliothèque
d’apprentissage profond Tensorflow en utilisant le langage de programmation applicative
Python. Il s’agit d’un langage de programmation multiplateforme, placé sous une licence
libre.
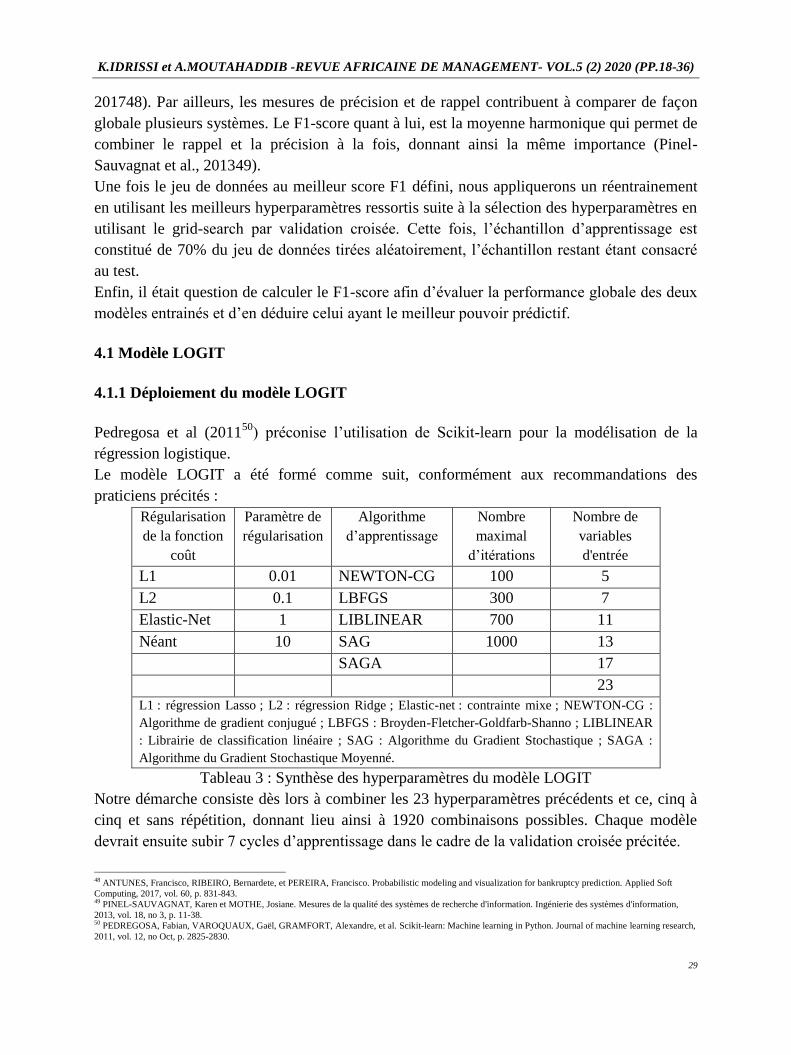
Précisons que notre échantillon subira un apprentissage suivant le modèle à déployer. Pour ce
faire, chaque modèle nécessitera la définition des hyperparamètres qui lui sont propres.
Afin d’optimiser les modèles déployés, nous avons opté pour le Grid Search par validation
croisée (cross-validation). Il s’agit d’une technique d’optimisation permettant de tester la
performance des paramètres d’un modèle pour en déduire la meilleure configuration possible
et ce, par le croisement des données afin de créer un modèle pour chaque combinaison
d’hyperparamètres.
La technique de validation croisée (k-fold cross validation) permet de découper le jeu de
données initial en k échantillons de taille égale. L’apprentissage se fait sur k-1 groupes
d’observations et le score d’apprentissage est reporté sur le groupe de test relatif aux
observations restantes. Cette opération est répétée à k reprises tout en s’assurant que tous les
sous-échantillons ont été utilisés dans le processus d’apprentissage et de test. Enfin, il y a lieu
de comparer le pouvoir prédictif de chaque modèle pour en retenir celui offrant le meilleur
score.
Dans notre cas, étant donné le nombre limité de données, nous avons choisi k=7.
En effet, la sélection du nombre de variable d’entrées se fera conformément à la configuration
suivante : 5, 7, 11, 13, 17 et 23 ratios financiers.
Rappelons également que les prévisions de la faillite se sont basées sur une classification
binaire : saine (0) ou défaillante (1). Les résultats de la classification sont généralement
présentés dans une matrice de confusion. Cette dernière est constituée de quatre résultats
possibles : vrai négatif, faux négatif, vrai positif et faux positif.
Plusieurs méthodes statistiques ont été utilisées pour évaluer la performance de la
modélisation dans le domaine de classification, appelée correspondance (Antunes et al.,
K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
29
201748). Par ailleurs, les mesures de précision et de rappel contribuent à comparer de façon
globale plusieurs systèmes. Le F1-score quant à lui, est la moyenne harmonique qui permet de
combiner le rappel et la précision à la fois, donnant ainsi la même importance (Pinel-
Sauvagnat et al., 201349).
Une fois le jeu de données au meilleur score F1 défini, nous appliquerons un réentrainement
en utilisant les meilleurs hyperparamètres ressortis suite à la sélection des hyperparamètres en
utilisant le grid-search par validation croisée. Cette fois, l’échantillon d’apprentissage est
constitué de 70% du jeu de données tirées aléatoirement, l’échantillon restant étant consacré
au test.
Enfin, il était question de calculer le F1-score afin d’évaluer la performance globale des deux
modèles entrainés et d’en déduire celui ayant le meilleur pouvoir prédictif.
4.1 Modèle LOGIT
4.1.1 Déploiement du modèle LOGIT
Pedregosa et al (201150
) préconise l’utilisation de Scikit-learn pour la modélisation de la
régression logistique.
Le modèle LOGIT a été formé comme suit, conformément aux recommandations des
praticiens précités :
Régularisation
de la fonction
coût
Paramètre de
régularisation
Algorithme
d’apprentissage
Nombre
maximal
d’itérations
Nombre de
variables
d'entrée
L1 0.01 NEWTON-CG 100 5
L2 0.1 LBFGS 300 7
Elastic-Net 1 LIBLINEAR 700 11
Néant 10 SAG 1000 13
SAGA 17
23
L1 : régression Lasso ; L2 : régression Ridge ; Elastic-net : contrainte mixe ; NEWTON-CG :
Algorithme de gradient conjugué ; LBFGS : Broyden-Fletcher-Goldfarb-Shanno ; LIBLINEAR
: Librairie de classification linéaire ; SAG : Algorithme du Gradient Stochastique ; SAGA :
Algorithme du Gradient Stochastique Moyenné.
Tableau 3 : Synthèse des hyperparamètres du modèle LOGIT
Notre démarche consiste dès lors à combiner les 23 hyperparamètres précédents et ce, cinq à
cinq et sans répétition, donnant lieu ainsi à 1920 combinaisons possibles. Chaque modèle
devrait ensuite subir 7 cycles d’apprentissage dans le cadre de la validation croisée précitée.
48 ANTUNES, Francisco, RIBEIRO, Bernardete, et PEREIRA, Francisco. Probabilistic modeling and visualization for bankruptcy prediction. Applied Soft
Computing, 2017, vol. 60, p. 831-843. 49 PINEL-SAUVAGNAT, Karen et MOTHE, Josiane. Mesures de la qualité des systèmes de recherche d'information. Ingénierie des systèmes d'information,
2013, vol. 18, no 3, p. 11-38. 50 PEDREGOSA, Fabian, VAROQUAUX, Gaël, GRAMFORT, Alexandre, et al. Scikit-learn: Machine learning in Python. Journal of machine learning research,
2011, vol. 12, no Oct, p. 2825-2830.
K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
30
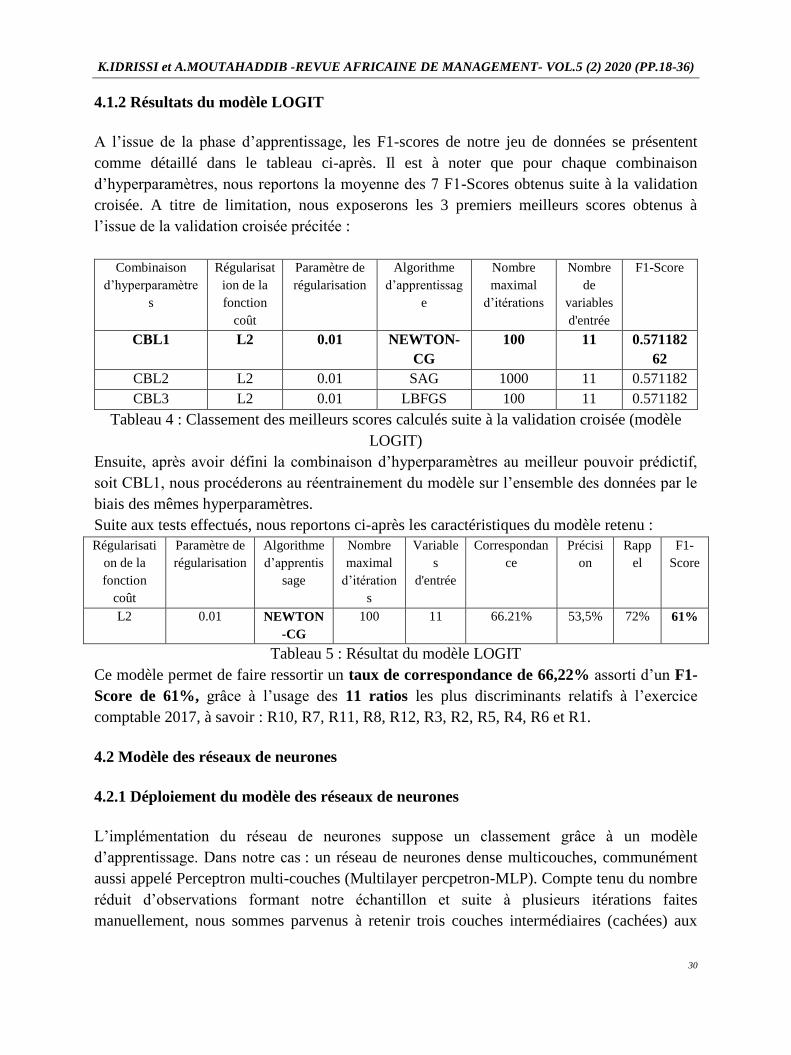
4.1.2 Résultats du modèle LOGIT
A l’issue de la phase d’apprentissage, les F1-scores de notre jeu de données se présentent
comme détaillé dans le tableau ci-après. Il est à noter que pour chaque combinaison
d’hyperparamètres, nous reportons la moyenne des 7 F1-Scores obtenus suite à la validation
croisée. A titre de limitation, nous exposerons les 3 premiers meilleurs scores obtenus à
l’issue de la validation croisée précitée :
Combinaison
d’hyperparamètre
s
Régularisat
ion de la
fonction
coût
Paramètre de
régularisation
Algorithme
d’apprentissag
e
Nombre
maximal
d’itérations
Nombre
de
variables
d'entrée
F1-Score
CBL1 L2 0.01 NEWTON-
CG
100 11 0.571182
62
CBL2 L2 0.01 SAG 1000 11 0.571182
CBL3 L2 0.01 LBFGS 100 11 0.571182
Tableau 4 : Classement des meilleurs scores calculés suite à la validation croisée (modèle
LOGIT)
Ensuite, après avoir défini la combinaison d’hyperparamètres au meilleur pouvoir prédictif,
soit CBL1, nous procéderons au réentrainement du modèle sur l’ensemble des données par le
biais des mêmes hyperparamètres.
Suite aux tests effectués, nous reportons ci-après les caractéristiques du modèle retenu :
Régularisati
on de la
fonction
coût
Paramètre de
régularisation
Algorithme
d’apprentis
sage
Nombre
maximal
d’itération
s
Variable
s
d'entrée
Correspondan
ce
Précisi
on
Rapp
el
F1-
Score
L2 0.01 NEWTON
-CG
100 11 66.21% 53,5% 72% 61%
Tableau 5 : Résultat du modèle LOGIT
Ce modèle permet de faire ressortir un taux de correspondance de 66,22% assorti d’un F1-
Score de 61%, grâce à l’usage des 11 ratios les plus discriminants relatifs à l’exercice
comptable 2017, à savoir : R10, R7, R11, R8, R12, R3, R2, R5, R4, R6 et R1.
4.2 Modèle des réseaux de neurones
4.2.1 Déploiement du modèle des réseaux de neurones
L’implémentation du réseau de neurones suppose un classement grâce à un modèle
d’apprentissage. Dans notre cas : un réseau de neurones dense multicouches, communément
aussi appelé Perceptron multi-couches (Multilayer percpetron-MLP). Compte tenu du nombre
réduit d’observations formant notre échantillon et suite à plusieurs itérations faites
manuellement, nous sommes parvenus à retenir trois couches intermédiaires (cachées) aux
K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
31
dimensions suivantes : C1 : 32 ; C2 : 32 ; C3 : 17. Ces nombres correspondent à la taille de
chaque couche, c’est-à-dire le nombre de neurones par couche.
Pour la modélisation de ce réseau, il est question de prédire la valeur de sortie tenant compte
des valeurs d’entrée et des poids (paramètres appris par le modèle).
L’existence multiple de couches cachées permet à ces dernières d’apprendre des relations
complexes qui existent entre leurs entrées et leurs sorties. Avec un échantillon réduit, on
assiste à un bruit d’échantillonnage présent au moment de l’entrainement, qui ne sera pas
automatiquement détectable au moment du test, quoiqu’il s’agît du même jeu de données. Ce
qui mène vers ce que l’on appelle le surajustement (Srivastava, Hinton et al, 201451
).
Nous avons maintenu la même configuration prévue dans la modélisation par LOGIT, à
savoir : 5, 7, 11, 13, 17 et 23 ratios financiers.
Ainsi, les hyperparamètres rentrant dans la modélisation de la défaillance par le réseau de
neurones se présentent comme suit :
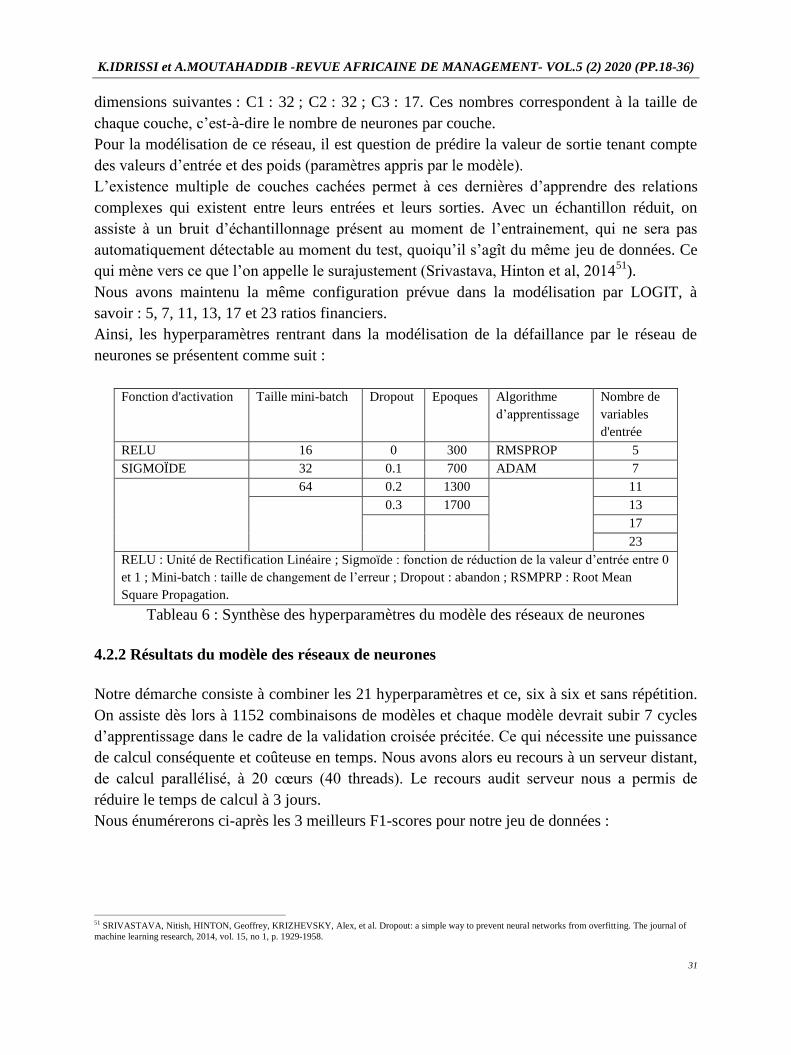
Fonction d'activation Taille mini-batch Dropout Epoques Algorithme
d’apprentissage
Nombre de
variables
d'entrée
RELU 16 0 300 RMSPROP 5
SIGMOÏDE 32 0.1 700 ADAM 7
64 0.2 1300 11
0.3 1700 13
17
23
RELU : Unité de Rectification Linéaire ; Sigmoïde : fonction de réduction de la valeur d’entrée entre 0
et 1 ; Mini-batch : taille de changement de l’erreur ; Dropout : abandon ; RSMPRP : Root Mean
Square Propagation.
Tableau 6 : Synthèse des hyperparamètres du modèle des réseaux de neurones
4.2.2 Résultats du modèle des réseaux de neurones
Notre démarche consiste à combiner les 21 hyperparamètres et ce, six à six et sans répétition.
On assiste dès lors à 1152 combinaisons de modèles et chaque modèle devrait subir 7 cycles
d’apprentissage dans le cadre de la validation croisée précitée. Ce qui nécessite une puissance
de calcul conséquente et coûteuse en temps. Nous avons alors eu recours à un serveur distant,
de calcul parallélisé, à 20 cœurs (40 threads). Le recours audit serveur nous a permis de
réduire le temps de calcul à 3 jours.
Nous énumérerons ci-après les 3 meilleurs F1-scores pour notre jeu de données :
51 SRIVASTAVA, Nitish, HINTON, Geoffrey, KRIZHEVSKY, Alex, et al. Dropout: a simple way to prevent neural networks from overfitting. The journal of
machine learning research, 2014, vol. 15, no 1, p. 1929-1958.
K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
32
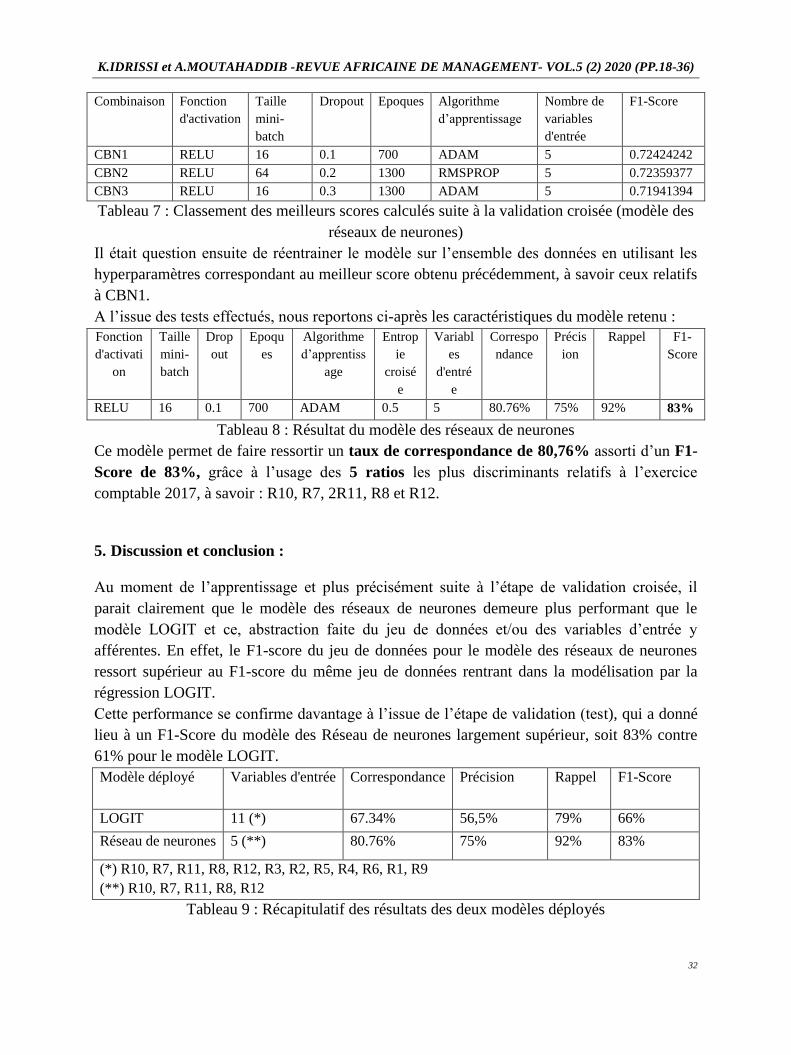
Combinaison Fonction
d'activation
Taille
mini-
batch
Dropout Epoques Algorithme
d’apprentissage
Nombre de
variables
d'entrée
F1-Score
CBN1 RELU 16 0.1 700 ADAM 5 0.72424242
CBN2 RELU 64 0.2 1300 RMSPROP 5 0.72359377
CBN3 RELU 16 0.3 1300 ADAM 5 0.71941394
Tableau 7 : Classement des meilleurs scores calculés suite à la validation croisée (modèle des
réseaux de neurones)
Il était question ensuite de réentrainer le modèle sur l’ensemble des données en utilisant les
hyperparamètres correspondant au meilleur score obtenu précédemment, à savoir ceux relatifs
à CBN1.
A l’issue des tests effectués, nous reportons ci-après les caractéristiques du modèle retenu :
Fonction
d'activati
on
Taille
mini-
batch
Drop
out
Epoqu
es
Algorithme
d’apprentiss
age
Entrop
ie
croisé
e
Variabl
es
d'entré
e
Correspo
ndance
Précis
ion
Rappel F1-
Score
RELU 16 0.1 700 ADAM 0.5 5 80.76% 75% 92% 83%
Tableau 8 : Résultat du modèle des réseaux de neurones
Ce modèle permet de faire ressortir un taux de correspondance de 80,76% assorti d’un F1-
Score de 83%, grâce à l’usage des 5 ratios les plus discriminants relatifs à l’exercice
comptable 2017, à savoir : R10, R7, 2R11, R8 et R12.
5. Discussion et conclusion :
Au moment de l’apprentissage et plus précisément suite à l’étape de validation croisée, il
parait clairement que le modèle des réseaux de neurones demeure plus performant que le
modèle LOGIT et ce, abstraction faite du jeu de données et/ou des variables d’entrée y
afférentes. En effet, le F1-score du jeu de données pour le modèle des réseaux de neurones
ressort supérieur au F1-score du même jeu de données rentrant dans la modélisation par la
régression LOGIT.
Cette performance se confirme davantage à l’issue de l’étape de validation (test), qui a donné
lieu à un F1-Score du modèle des Réseau de neurones largement supérieur, soit 83% contre
61% pour le modèle LOGIT.
Modèle déployé Variables d'entrée Correspondance Précision Rappel F1-Score
LOGIT 11 (*) 67.34% 56,5% 79% 66%
Réseau de neurones 5 (**) 80.76% 75% 92% 83%
(*) R10, R7, R11, R8, R12, R3, R2, R5, R4, R6, R1, R9
(**) R10, R7, R11, R8, R12
Tableau 9 : Récapitulatif des résultats des deux modèles déployés
K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
33
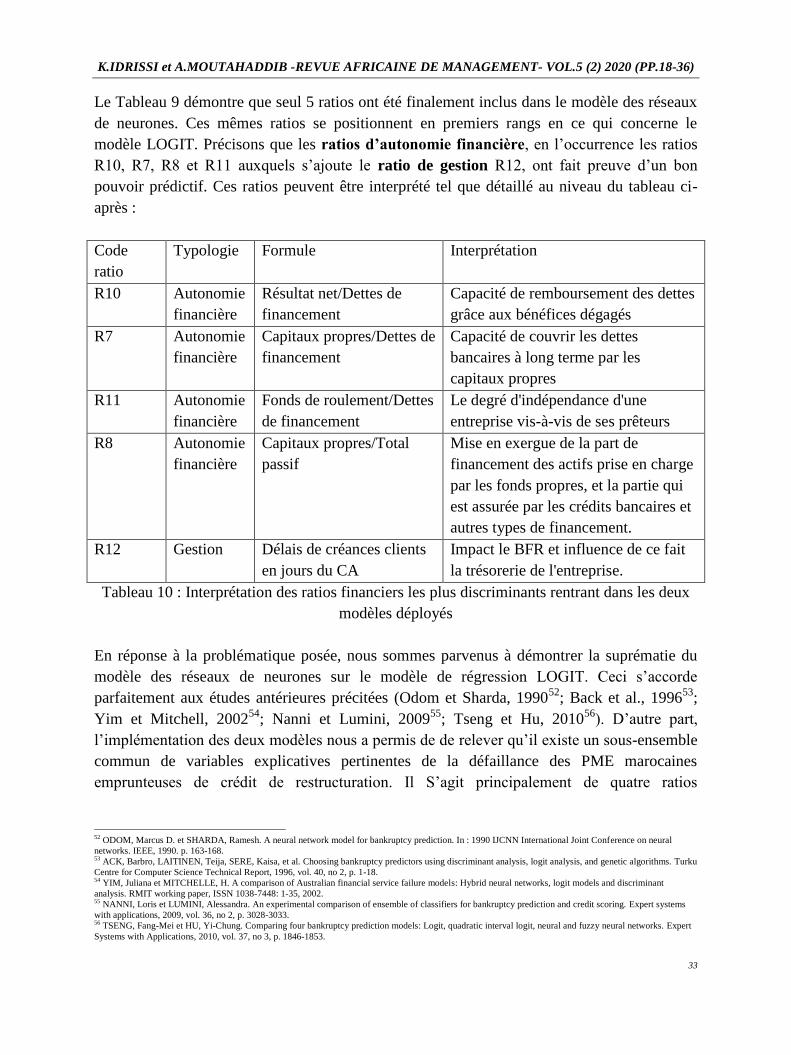
Le Tableau 9 démontre que seul 5 ratios ont été finalement inclus dans le modèle des réseaux
de neurones. Ces mêmes ratios se positionnent en premiers rangs en ce qui concerne le
modèle LOGIT. Précisons que les ratios d’autonomie financière, en l’occurrence les ratios
R10, R7, R8 et R11 auxquels s’ajoute le ratio de gestion R12, ont fait preuve d’un bon
pouvoir prédictif. Ces ratios peuvent être interprété tel que détaillé au niveau du tableau ci-
après :
Code
ratio
Typologie Formule Interprétation
R10 Autonomie
financière
Résultat net/Dettes de
financement
Capacité de remboursement des dettes
grâce aux bénéfices dégagés
R7 Autonomie
financière
Capitaux propres/Dettes de
financement
Capacité de couvrir les dettes
bancaires à long terme par les
capitaux propres
R11 Autonomie
financière
Fonds de roulement/Dettes
de financement
Le degré d'indépendance d'une
entreprise vis-à-vis de ses prêteurs
R8 Autonomie
financière
Capitaux propres/Total
passif
Mise en exergue de la part de
financement des actifs prise en charge
par les fonds propres, et la partie qui
est assurée par les crédits bancaires et
autres types de financement.
R12 Gestion Délais de créances clients
en jours du CA
Impact le BFR et influence de ce fait
la trésorerie de l'entreprise.
Tableau 10 : Interprétation des ratios financiers les plus discriminants rentrant dans les deux
modèles déployés
En réponse à la problématique posée, nous sommes parvenus à démontrer la suprématie du
modèle des réseaux de neurones sur le modèle de régression LOGIT. Ceci s’accorde
parfaitement aux études antérieures précitées (Odom et Sharda, 199052
; Back et al., 199653
;
Yim et Mitchell, 200254
; Nanni et Lumini, 200955
; Tseng et Hu, 201056
). D’autre part,
l’implémentation des deux modèles nous a permis de de relever qu’il existe un sous-ensemble
commun de variables explicatives pertinentes de la défaillance des PME marocaines
emprunteuses de crédit de restructuration. Il S’agit principalement de quatre ratios
52 ODOM, Marcus D. et SHARDA, Ramesh. A neural network model for bankruptcy prediction. In : 1990 IJCNN International Joint Conference on neural
networks. IEEE, 1990. p. 163-168. 53 ACK, Barbro, LAITINEN, Teija, SERE, Kaisa, et al. Choosing bankruptcy predictors using discriminant analysis, logit analysis, and genetic algorithms. Turku
Centre for Computer Science Technical Report, 1996, vol. 40, no 2, p. 1-18. 54 YIM, Juliana et MITCHELLE, H. A comparison of Australian financial service failure models: Hybrid neural networks, logit models and discriminant
analysis. RMIT working paper, ISSN 1038-7448: 1-35, 2002. 55 NANNI, Loris et LUMINI, Alessandra. An experimental comparison of ensemble of classifiers for bankruptcy prediction and credit scoring. Expert systems
with applications, 2009, vol. 36, no 2, p. 3028-3033. 56 TSENG, Fang-Mei et HU, Yi-Chung. Comparing four bankruptcy prediction models: Logit, quadratic interval logit, neural and fuzzy neural networks. Expert
Systems with Applications, 2010, vol. 37, no 3, p. 1846-1853.

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
34
d’autonomie financière se rapportant surtout au niveau d’endettement de l’entreprise et un
ratio de gestion correspondant au délai de règlement des créances clients.
Quant aux apports de ce travail, il permettrait d’une part, d’alimenter la recherche scientifique
grâce à l’originalité du sujet adapté au contexte marocain. D’autre part, sur le plan
professionnel, il offrirait aux Banques, en sus de leur système de scoring, un outil d’aide à la
prise de décision au moment de l’octroi des crédits. Il permettrait également à l’entreprise
concernée de se suivre constamment afin d’assurer une détection précoce de sa défaillance.
Dans la même optique, la disponibilité des bilans comptables sur plusieurs bases de données
constitue un potentiel qu’il convient d’exploiter par toutes les parties prenantes afin de se
prémunir contre tout risque de solvabilité des débiteurs en question.
Alors que les résultats de cette recherche sont acceptables, il présente certes des limites que
nous ne pouvons pas ignorer. Premièrement, l’apprentissage automatique repose sur la
puissance de calcul, alors que la construction de modèles statistiques s’appuie sur les
connaissances et l’expertise humaine. En effet, bien que de nombreuses études aient analysé
la solvabilité des entreprises à l'aide de techniques informatiques modernes, les résultats
n'identifiaient pas la meilleure méthode, car la performance du modèle dépendait des
caractéristiques spécifiques du problème de classification et de la structure des données
(Duéñez-Guzmán & Vose, 201357
). Par ailleurs, l’indisponibilité des informations comptables
pour certaines entreprises présentent un frein majeur à la modélisation de la défaillance.
D’ailleurs, ceci s’avère justifiable étant donné que notre sujet se limite à l’étude de la
défaillance pour le cas des PME, qui contrairement aux GE, ont tendance à ne pas remettre au
public leurs bilans fiscaux. Ceci nous a conduit ainsi à avoir accès à un nombre limité
d’entreprises cibles, qui par ricochet, nous a poussé à réduire la taille de notre échantillon.
Les limites avancées nous animent pour chercher de nouvelles perspectives de recherche.
D’une part nous veilleront à améliorer notre travail en se rapprochant davantage des Banques
afin de recueillir une base de données plus consistantes et mieux ciblée. Ceci nous permettra
de renforcer l’apprentissage de notre modèle et le rendre plus mûr. D’autre part, afin
d’approfondir notre démarche, nous inspirons implémenter de nouvelles variables d’ordre
qualitatif, tels que la forme juridique de l’entreprise, son secteur d’activité, son âge, sa zone
géographique d’implantation ou encore la qualité de son management (entreprise familiale,
expérience du gérant, sa formation, etc.). Au final, la mise à notre de disposition de
l’information exhaustive nous permettra de faire appel à d’autres méthodes économétriques
d’apprentissage automatique qui ont démontré leur performance, du point de vue de la
littérature à l’instar des arbres de décision, les machines à vecteurs de support, etc.
57 DUÉÑEZ-GUZMÁN, Edgar A. et VOSE, Michael D. No free lunch and benchmarks. Evolutionary Computation, 2013, vol. 21, no 2, p. 293-312.

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
35
Bibliographie
- ANTUNES, Francisco, RIBEIRO, Bernardete, et PEREIRA, Francisco. Probabilistic modeling and
visualization for bankruptcy prediction. Applied Soft Computing, 2017, vol. 60.
- BACK, Barbro, LAITINEN, Teija, SERE, Kaisa, et al. Choosing bankruptcy predictors using discriminant
analysis, logit analysis, and genetic algorithms. Turku Centre for Computer Science Technical Report, 1996,
vol. 40, no 2.
- BALCAEN, Sofie et OOGHE, Hubert. 35 years of studies on business failure: an overview of the classic
statistical methodologies and their related problems. The British Accounting Review, 2006, vol. 38, no 1.
- BARNIV, Ran, AGARWAL, Anurag, et LEACH, Robert. Predicting bankruptcy resolution. Journal of
Business Finance & Accounting, 2002, vol. 29, no 3‐ 4.
- Casta JF et Zerbib JP (1979) Prévoir la défaillance des entreprises?, Revue Française de Comptabilité, Octobre.
- CHARITOU, Andreas, NEOPHYTOU, Evi, et CHARALAMBOUS, Chris. Predicting corporate failure:
empirical evidence for the UK. European accounting review, 2004, vol. 13, no 3.
- CIAMPI, Francesco et GORDINI, Niccolò. Default prediction modeling for small enterprises: evidence from
small manufacturing firms in Northern and Central Italy. In : Emerging Issues and Challenges in Business &
Economics: Selected Contributions from the 8th Global Conference. Firenze University Press, 2009.
- DUÉÑEZ-GUZMÁN, Edgar A. et VOSE, Michael D. No free lunch and benchmarks. Evolutionary
Computation, 2013, vol. 21, no 2
- HAIR, Joseph F., BLACK, William C., BABIN, Barry J., et al. Multivariate data analysis (Vol. 6). 2006.
- HAUSER, Richard P. et BOOTH, David. Predicting bankruptcy with robust logistic regression. Journal of
Data Science, 2011, vol. 9, no 4.
- HENSHER, David A. et JONES, Stewart. Forecasting corporate bankruptcy: Optimizing the performance of
the mixed logit model. Abacus, 2007, vol. 43, no 3.
- JOSTARNDT, Philipp et SAUTNER, Zacharias. Out-of-court restructuring versus formal bankruptcy in a non-
interventionist bankruptcy setting. Review of Finance, 2010, vol. 14, no 4.
- KHERRAZI, Soufiane et AHSINA, Khalifa. Défaillance et politique d’entreprises : modélisation financière
déployée sous un modèle logistique appliqué aux PME marocaines. La revue gestion et organisation, 2016, vol.
8, no 1.
- KHERRAZI, Soufiane et AHSINA, Khalifa. Modélisation et Analyse des Défaillances d’Entreprises :
Application aux PME Marocaines. Finance and Finance Internationale, 2016, vol. 442, no 5257.
- KONSTANTARAS, Konstantinos et SIRIOPOULOS, Costas. Estimating financial distress with a dynamic
model: Evidence from family owned enterprises in a small open economy. Journal of multinational financial
management, 2011, vol. 21, no 4.
- KOROL, Tomasz. Early warning models against bankruptcy risk for Central European and Latin American
enterprises. Economic Modelling, 2013, vol. 31.
- LAITINEN, Erkki K. et LAITINEN, Teija. Bankruptcy prediction: Application of the Taylor's expansion in
logistic regression. International review of financial analysis, 2000, vol. 9, no 4.
- LI, Hui et SUN, Jie. Forecasting business failure: The use of nearest-neighbour support vectors and correcting
imbalanced samples–Evidence from the Chinese hotel industry. Tourism Management, 2012, vol. 33, no 3.
- MOSSMAN, Charles E., BELL, Geoffrey G., SWARTZ, L. Mick, et al. An empirical comparison of
bankruptcy models. Financial Review, 1998, vol. 33, no 2.
- MOSSMAN, Charles E., BELL, Geoffrey G., SWARTZ, L. Mick, et al. An empirical comparison of
bankruptcy models. Financial Review, 1998, vol. 33, no 2.
- NANNI, Loris et LUMINI, Alessandra. An experimental comparison of ensemble of classifiers for bankruptcy
prediction and credit scoring. Expert systems with applications, 2009, vol. 36, no 2.

K.IDRISSI et A.MOUTAHADDIB -REVUE AFRICAINE DE MANAGEMENT- VOL.5 (2) 2020 (PP.18-36)
36
- ODOM, Marcus D. et SHARDA, Ramesh. A neural network model for bankruptcy prediction. In : 1990
IJCNN International Joint Conference on neural networks. IEEE, 1990.
- ORESKI, Stjepan et ORESKI, Goran. Genetic algorithm-based heuristic for feature selection in credit risk
assessment. Expert systems with applications, 2014, vol. 41, no 4.
- PEDREGOSA, Fabian, VAROQUAUX, Gaël, GRAMFORT, Alexandre, et al. Scikit-learn: Machine learning
in Python. Journal of machine learning research, 2011, vol. 12, no Oct.
- PINEL-SAUVAGNAT, Karen et MOTHE, Josiane. Mesures de la qualité des systèmes de recherche
d'information. Ingénierie des systèmes d'information, 2013, vol. 18, no 3.
- POLEMIS, Dionysios et GOUNOPOULOS, Dimitrios. Prediction of distress and identification of potential
M&As targets in UK. Managerial Finance, 2012.
- REFAIT-ALEXANDRE, Catherine. La prévision de la faillite fondée sur l'analyse financière de l’entreprise :
un état des lieux. Economie prevision, 2004, no 1.
- SAPORTA, Gilbert. Probabilités, analyse des données et statistique. Editions Technip, 2006.
- TSENG, Fang-Mei et HU, Yi-Chung. Comparing four bankruptcy prediction models: Logit, quadratic interval
logit, neural and fuzzy neural networks. Expert Systems with Applications, 2010, vol. 37, no 3.
- WANG, Zong-Jun et DENG, Xiao-Lan. Corporate governance and financial distress: Evidence from Chinese
listed companies. Chinese Economy, 2006, vol. 39, no 5.
- WESTGAARD, Sjur et VAN DER WIJST, Nico. Default probabilities in a corporate bank portfolio: A logistic
model approach. European journal of operational research, 2001, vol. 135, no 2.