owledge un moteur d’analyse de corpus par concepts · un moteur d’analyse de corpus par...
TRANSCRIPT

OwlEdge Un moteur d’analyse de corpus
par concepts
Pierre Molette LERASS PsyCom
Toulouse mars 2014
www.owledge.org www.lerass.com

2
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
QU’EST-CE QU’UN CORPUS ?
D’après Wikipedia, un « corpus est un ensemble de documents… regroupés dans une optique précise ».
Les corpus ont tous un certain nombre de caractéristiques :
• Date (de création, de mise à jour)
• Type (textes, images, vidéos, tableaux de nombres)
• Quantité (nombre de fichiers, taille sur disque)
• Qualité (parfois difficile à évaluer)
• Et un contenu sémantique…
On peut considérer que les dossiers et les fichiers présents sur les ordinateurs constituent des ensembles de corpus et de sous-corpus.
� Quand on regroupe plusieurs fichiers en un seul, on perd de l’information. Ceci explique pourquoi on est parfois obligé de coder des variables pour conserver certaines modalités. Cette opération n’est pas utile quand les noms des fichiers et des dossiers permettent de transporter l’information.
3
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
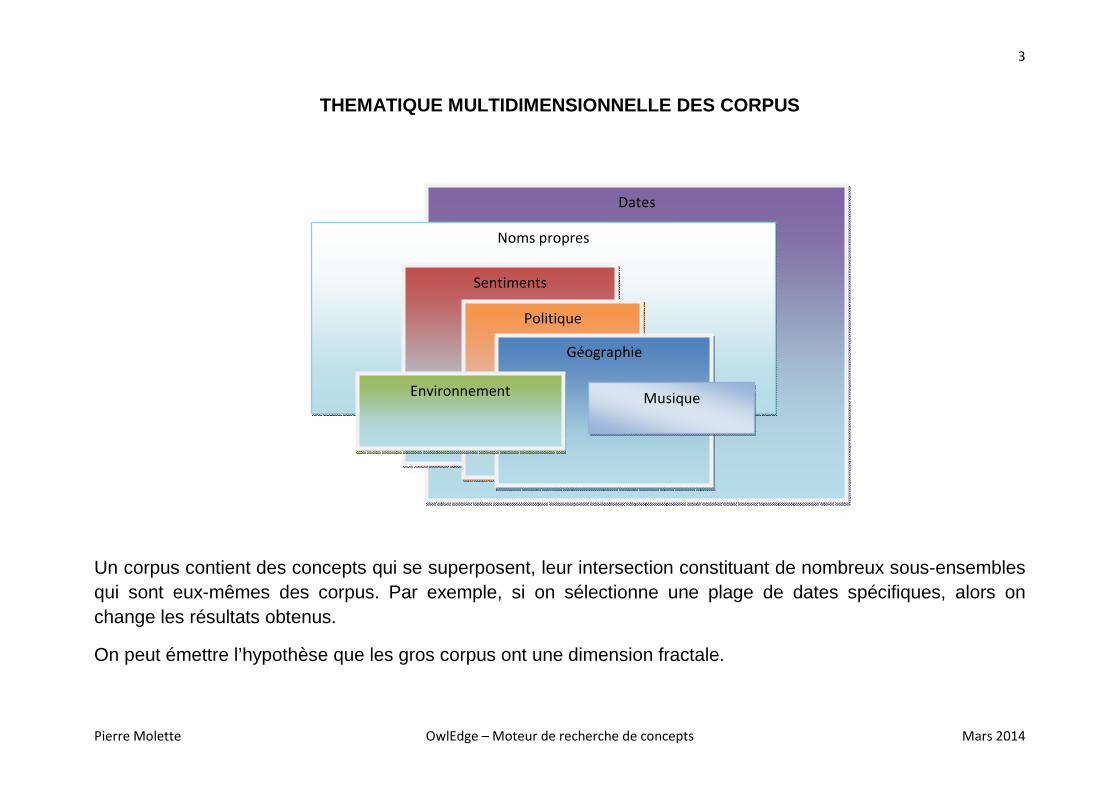
THEMATIQUE MULTIDIMENSIONNELLE DES CORPUS
Un corpus contient des concepts qui se superposent, leur intersection constituant de nombreux sous-ensembles qui sont eux-mêmes des corpus. Par exemple, si on sélectionne une plage de dates spécifiques, alors on change les résultats obtenus.
On peut émettre l’hypothèse que les gros corpus ont une dimension fractale.
Dates
Noms propres
Sentiments
Politique
Géographie
Environnement Musique

4
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
CLASSIFICATION DES DOCUMENTS PAR OWLEDGE
OwlEdge est moteur d’analyse de textes, qui a été conçu dès le départ pour proposer des résultats :
• Sémantiques
• Visuels
• Significatifs
• Lisibles
• Rapidement, sur un gros volume de données
Ces contraintes impliquent des algorithmes optimisés et des représentations graphiques claires.
Dans cette présentation, on appellera « concept » tout regroupement de mots ayant un sens proche ou lié par des relations d’hyperonymie ou d’antonymie.
Pierre Molette
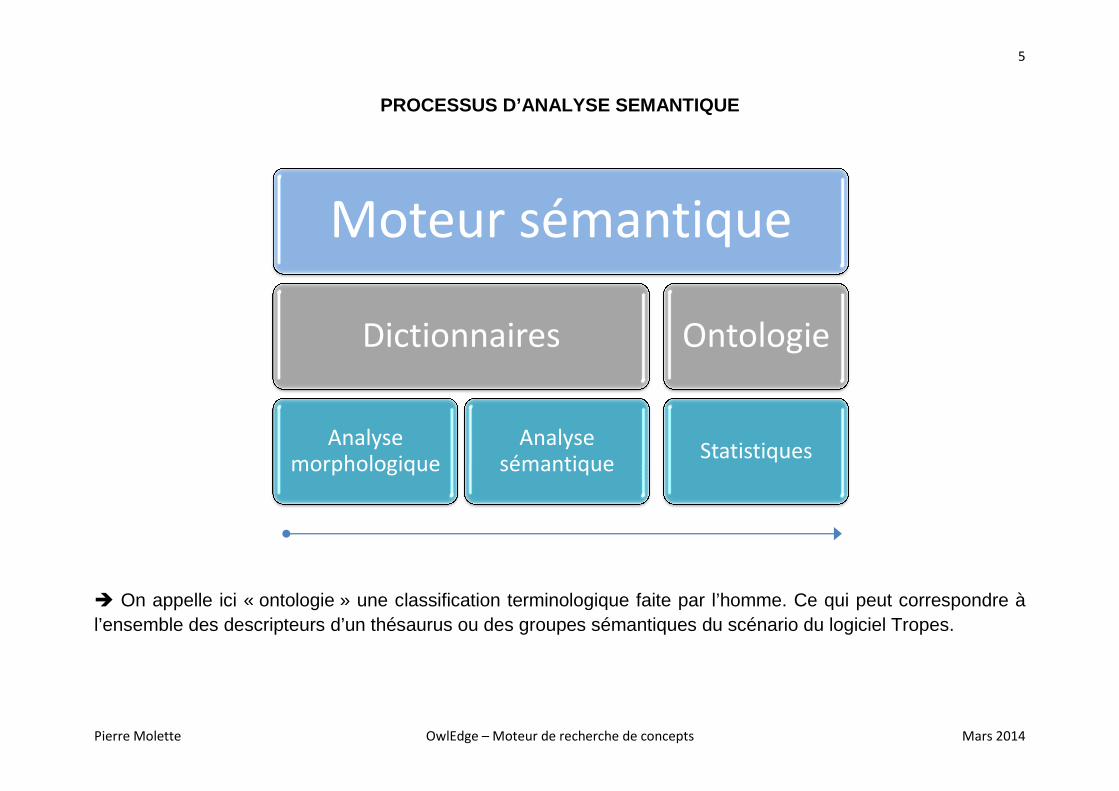
PROCESSUS D’ANALYSE SEMANTIQUE
� On appelle ici « ontologie » une classification terminologique faite par l’homme. l’ensemble des descripteurs d’un thésaurus ou des groupes sémantiques du scénario du logiciel Tropes.
Moteur sémantique
Dictionnaires
Analyse
morphologique
OwlEdge – Moteur de recherche de concepts
PROCESSUS D’ANALYSE SEMANTIQUE
» une classification terminologique faite par l’homme. Ce qui thésaurus ou des groupes sémantiques du scénario du logiciel Tropes.
Moteur sémantique
Dictionnaires
Analyse
morphologique
Analyse
sémantique
Ontologie
Statistiques
5
Mars 2014
Ce qui peut correspondre à thésaurus ou des groupes sémantiques du scénario du logiciel Tropes.
Ontologie
Statistiques
Pierre Molette
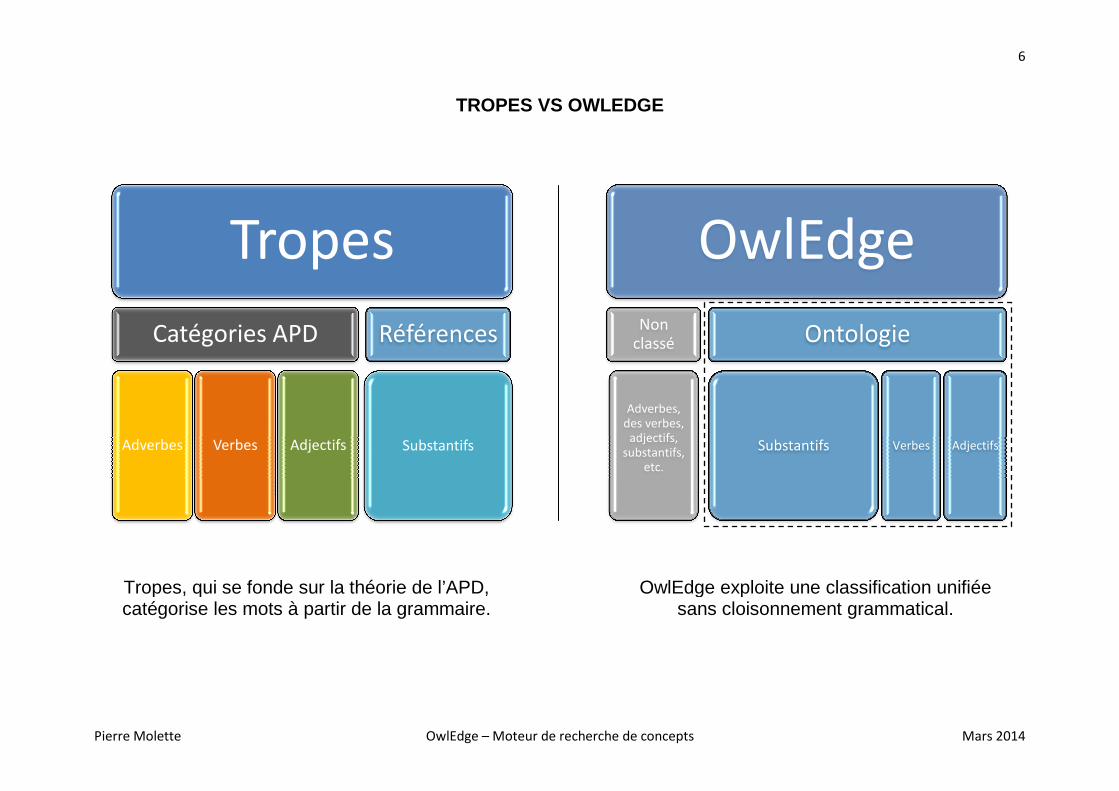
Tropes, qui se fonde sur la théorie de l’APD, catégorise les mots à partir de la grammaire.
Tropes
Catégories APD
Adverbes Verbes Adjectifs
Références
Substantifs
OwlEdge – Moteur de recherche de concepts
TROPES VS OWLEDGE
Tropes, qui se fonde sur la théorie de l’APD, catégorise les mots à partir de la grammaire.
OwlEdge exploite une classification unifiéesans cloisonnement grammatical.
Références
Substantifs
OwlEdge
Non
classé
Adverbes,
des verbes,
adjectifs,
substantifs,
etc.
Ontologie
Substantifs
6
Mars 2014
OwlEdge exploite une classification unifiée sans cloisonnement grammatical.
OwlEdge
Ontologie
Substantifs Verbes Adjectifs
7
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
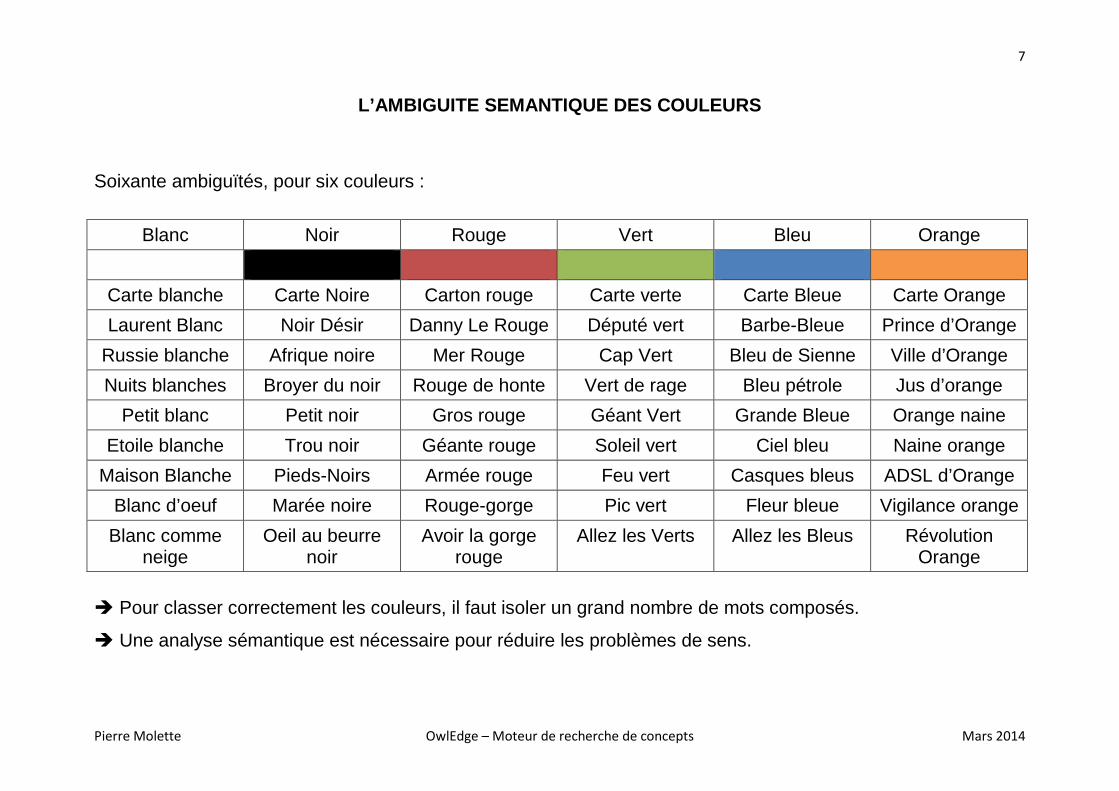
L’AMBIGUITE SEMANTIQUE DES COULEURS
Soixante ambiguïtés, pour six couleurs :
Blanc Noir Rouge Vert Bleu Orange
Carte blanche Carte Noire Carton rouge Carte verte Carte Bleue Carte Orange
Laurent Blanc Noir Désir Danny Le Rouge Député vert Barbe-Bleue Prince d’Orange
Russie blanche Afrique noire Mer Rouge Cap Vert Bleu de Sienne Ville d’Orange
Nuits blanches Broyer du noir Rouge de honte Vert de rage Bleu pétrole Jus d’orange
Petit blanc Petit noir Gros rouge Géant Vert Grande Bleue Orange naine
Etoile blanche Trou noir Géante rouge Soleil vert Ciel bleu Naine orange
Maison Blanche Pieds-Noirs Armée rouge Feu vert Casques bleus ADSL d’Orange
Blanc d’oeuf Marée noire Rouge-gorge Pic vert Fleur bleue Vigilance orange
Blanc comme neige
Oeil au beurre noir
Avoir la gorge rouge
Allez les Verts Allez les Bleus Révolution Orange
� Pour classer correctement les couleurs, il faut isoler un grand nombre de mots composés.
� Une analyse sémantique est nécessaire pour réduire les problèmes de sens.
Pierre Molette
RECHERCHE
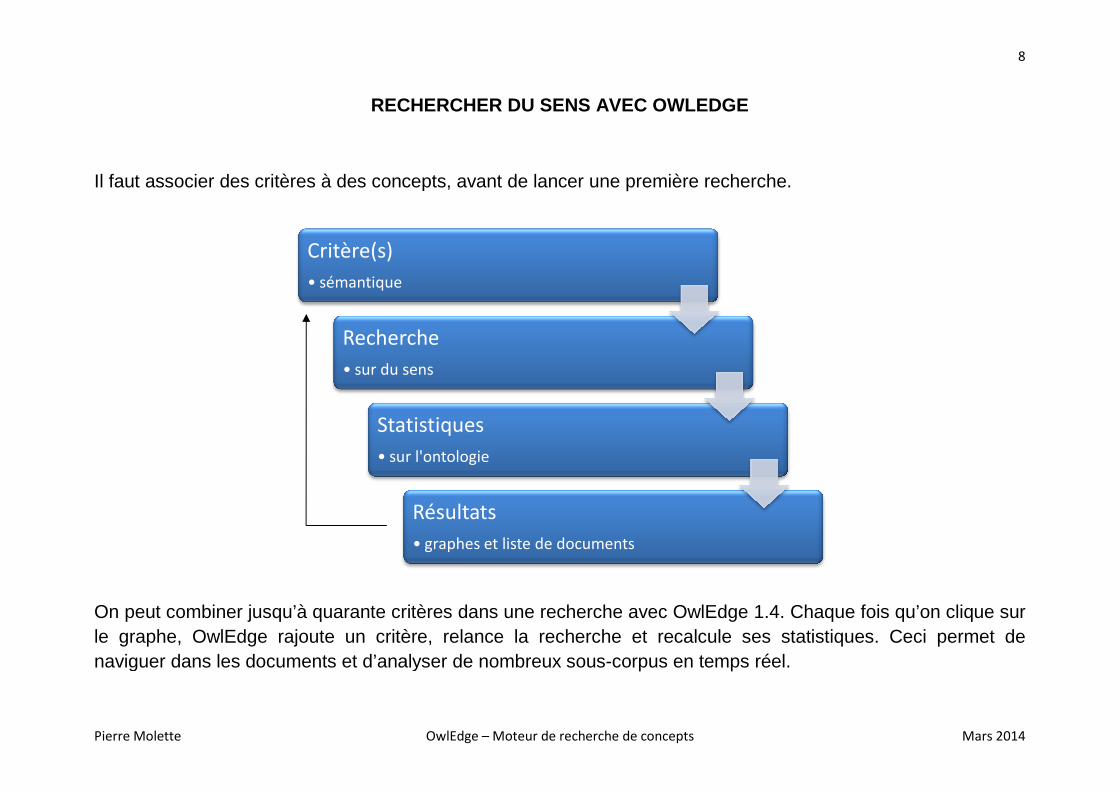
Il faut associer des critères à des concepts
On peut combiner jusqu’à quarante critères dans une recherche avec OwlEdge 1.4. Chaque fois qu’on clique sur le graphe, OwlEdge rajoute un critère, relance la recherche et recalcule ses statistiques. Ceci permetnaviguer dans les documents et d’analyser de nombreux sous
Critère(s)
• sémantique
Recherche
• sur du sens
Statistiques
• sur l'ontologie
OwlEdge – Moteur de recherche de concepts
RECHERCHER DU SENS AVEC OWLEDGE
à des concepts, avant de lancer une première recherche.
On peut combiner jusqu’à quarante critères dans une recherche avec OwlEdge 1.4. Chaque fois qu’on clique sur le graphe, OwlEdge rajoute un critère, relance la recherche et recalcule ses statistiques. Ceci permetnaviguer dans les documents et d’analyser de nombreux sous-corpus en temps réel.
Recherche
sur du sens
Statistiques
sur l'ontologie
Résultats
• graphes et liste de documents
8
Mars 2014
On peut combiner jusqu’à quarante critères dans une recherche avec OwlEdge 1.4. Chaque fois qu’on clique sur le graphe, OwlEdge rajoute un critère, relance la recherche et recalcule ses statistiques. Ceci permet de
9
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
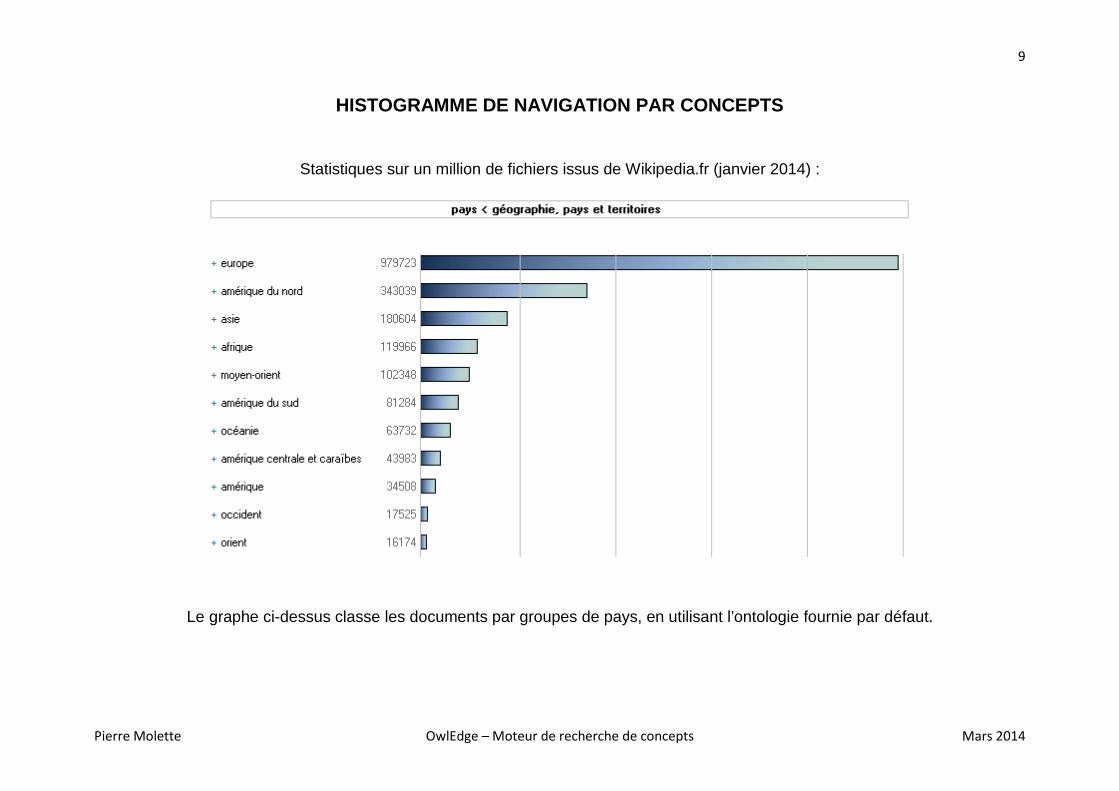
HISTOGRAMME DE NAVIGATION PAR CONCEPTS
Statistiques sur un million de fichiers issus de Wikipedia.fr (janvier 2014) :
Le graphe ci-dessus classe les documents par groupes de pays, en utilisant l’ontologie fournie par défaut.
10
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
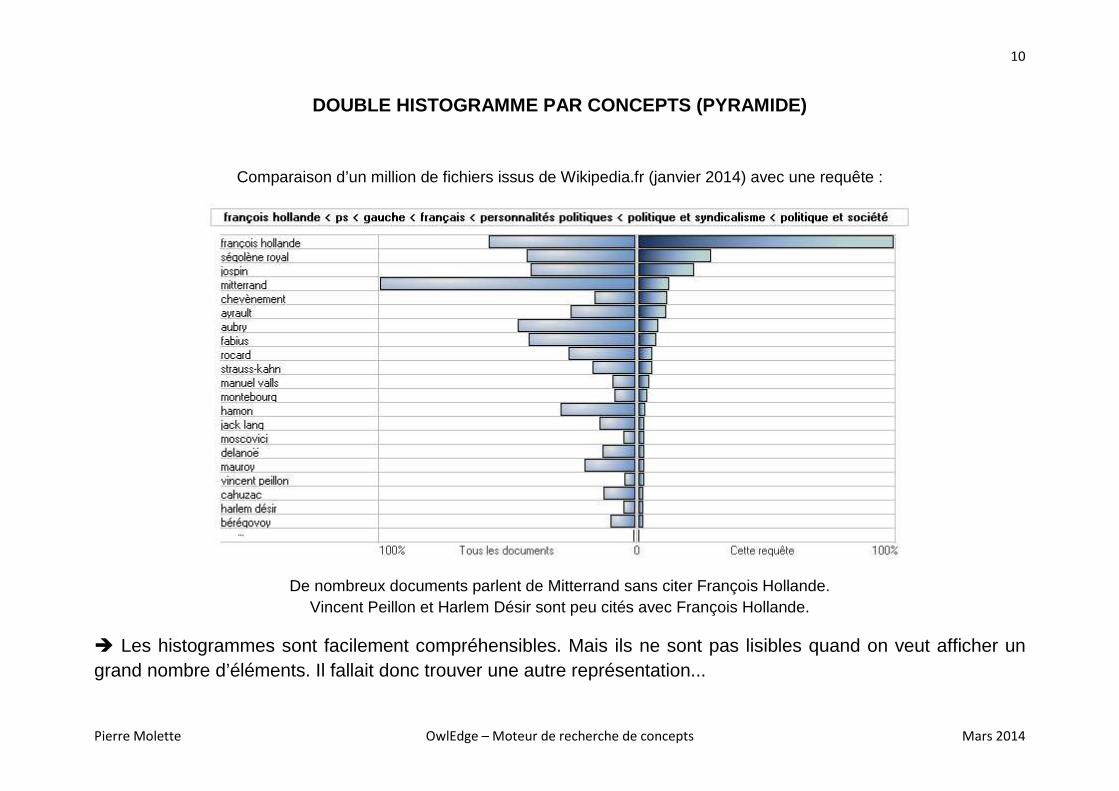
DOUBLE HISTOGRAMME PAR CONCEPTS (PYRAMIDE)
Comparaison d’un million de fichiers issus de Wikipedia.fr (janvier 2014) avec une requête :
De nombreux documents parlent de Mitterrand sans citer François Hollande. Vincent Peillon et Harlem Désir sont peu cités avec François Hollande.
� Les histogrammes sont facilement compréhensibles. Mais ils ne sont pas lisibles quand on veut afficher un grand nombre d’éléments. Il fallait donc trouver une autre représentation...

11
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
TREEMAPS
Les Treemaps (Ben Shneiderman, 1998) permettent des visualisations compactes d’un grand nombre de variables :
Graphe réalisé avec le JavaScript InfoVis Toolkit (Nicolas Garcia Belmonte, 2013)

12
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
TREEMAPS D’OWLEDGE
OwlEdge s’inspire des Treemaps, pour améliorer la lisibilité des ontologies :
Nombre de documents trouvés dans Wikipedia.fr (version de janvier 2014)

13
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
LE CLUSTERING D’OWLEDGE
Le « clustering » est un mot anglais qui peut se traduire par « regroupement » (d’après Robert & Collins) ou « partitionnement de données » (d’après Wikipedia). Dans OwlEdge c’est un traitement statistique qui va :
• Trouver les variables indépendantes
• Identifier les concepts les plus significatifs
• Réduire la collection de données
• Ajuster le résultat pour fabriquer les graphes exploitables
Ce clustering diffère radicalement des analyses sémantiques latentes (LSA) et des analyses factorielles (AFC).
Cette opération est effectuée en temps réel lorsqu’on fait une recherche sur un ou plusieurs critères. Elle peut exploiter la centaine de milliers de termes (lemmes) encapsulés dans l’ontologie par défaut.
� L’objectif est de faire émerger des informations qui resteraient invisibles avec une classification thématique.
14
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
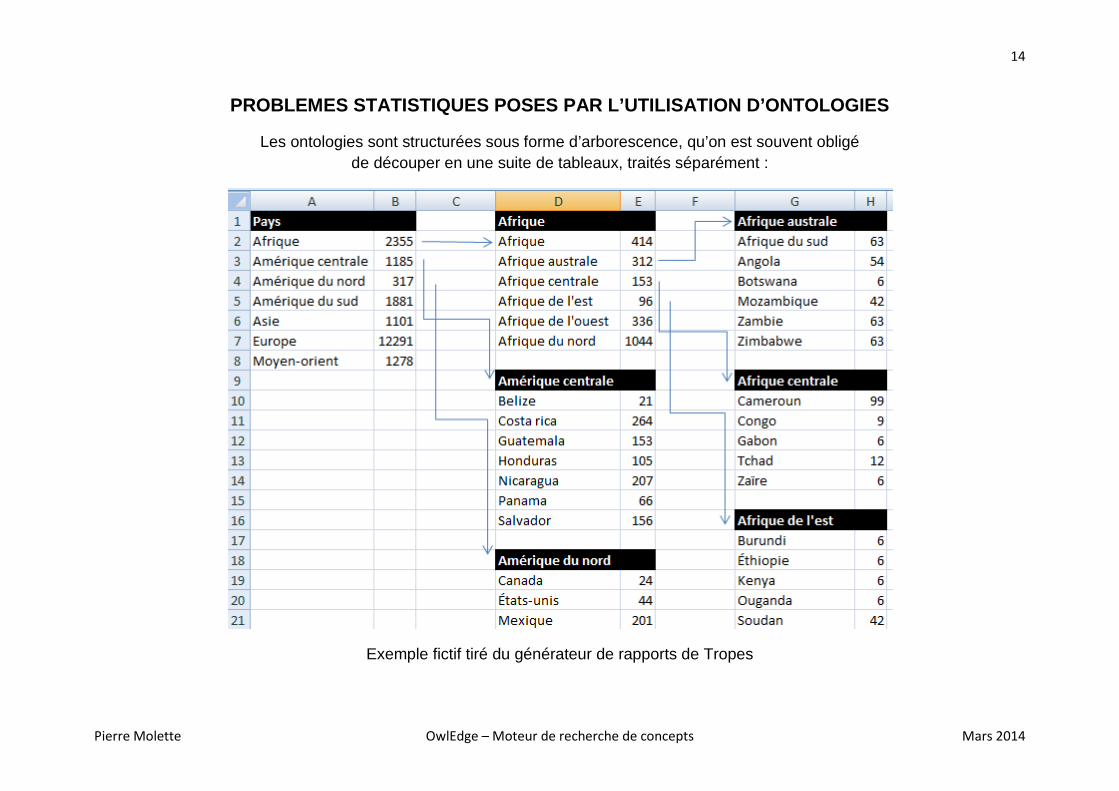
PROBLEMES STATISTIQUES POSES PAR L’UTILISATION D’ON TOLOGIES
Les ontologies sont structurées sous forme d’arborescence, qu’on est souvent obligé de découper en une suite de tableaux, traités séparément :
Exemple fictif tiré du générateur de rapports de Tropes
15
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
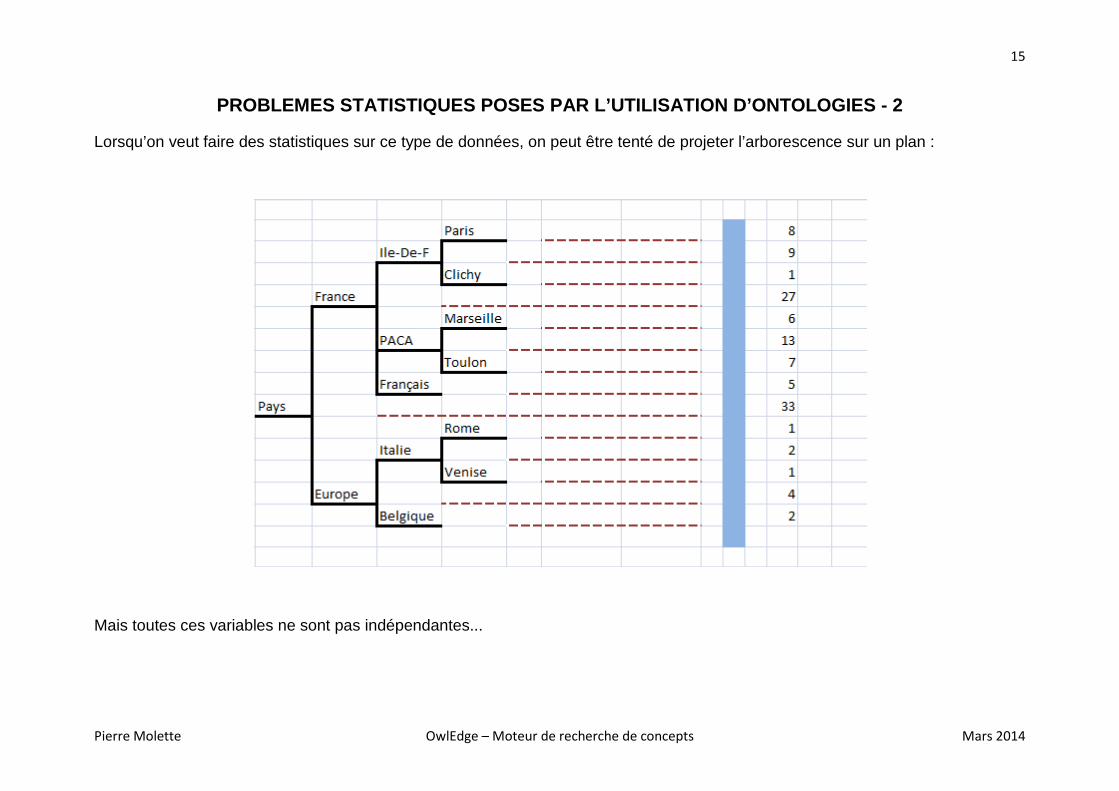
PROBLEMES STATISTIQUES POSES PAR L’UTILISATION D’ON TOLOGIES - 2
Lorsqu’on veut faire des statistiques sur ce type de données, on peut être tenté de projeter l’arborescence sur un plan :
Mais toutes ces variables ne sont pas indépendantes...

16
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
SOLUTION : FAIRE UN TEST DE SIGNIFICATIVITE
Il faut identifier les variables indépendantes et faire un test statistique pour déterminer les concepts significatifs :
Le calcul se fait de façon "classique" en comparant l’effectif observé (ce qui a été trouvé lors d’une recherche) avec l’effectif théorique (ce qui existe dans l’intégralité du corpus). Par la même occasion, on va aussi supprimer les concepts qui en contiennent d’autres sans apporter d’information supplémentaire. Et regrouper les hapax dans des concepts de plus haut niveau.

17
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
REDUCTION DES DONNEES ET AJUSTEMENT DES VISUALISATI ONS
Après le filtrage statistique, on obtient une collection de concepts qu’il faut ajuster :
• Si le nombre d’éléments est trop grand, l’affichage sera illisible.
• S’il est trop petit, le graphe sera sans intérêt, voire inexploitable.
OwlEdge va faire varier automatiquement les intervalles de confiance pour réduire ou augmenter le nombre d’éléments, et adapter le résultat à l’affichage. Dans tous les cas, le clustering affichera toujours les concepts les plus significatifs.
Si aucun concept significatif n’a été trouvé, le logiciel s’arrête et affiche un message d’information.

18
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
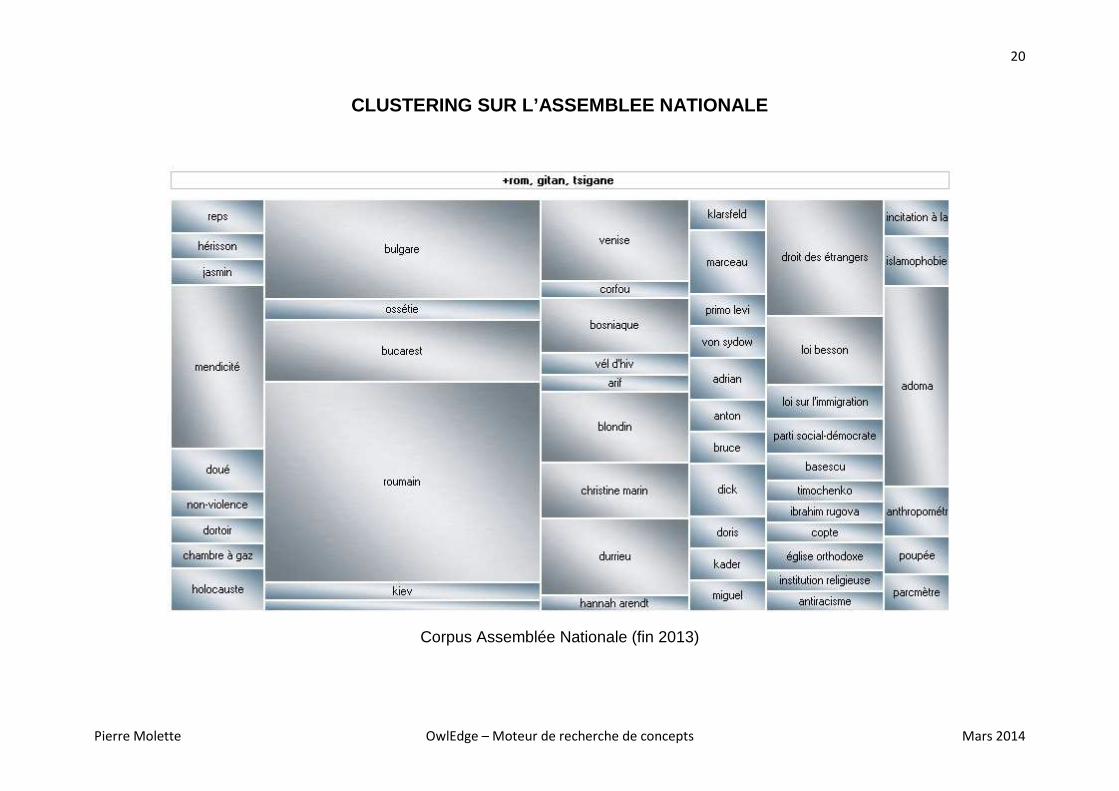
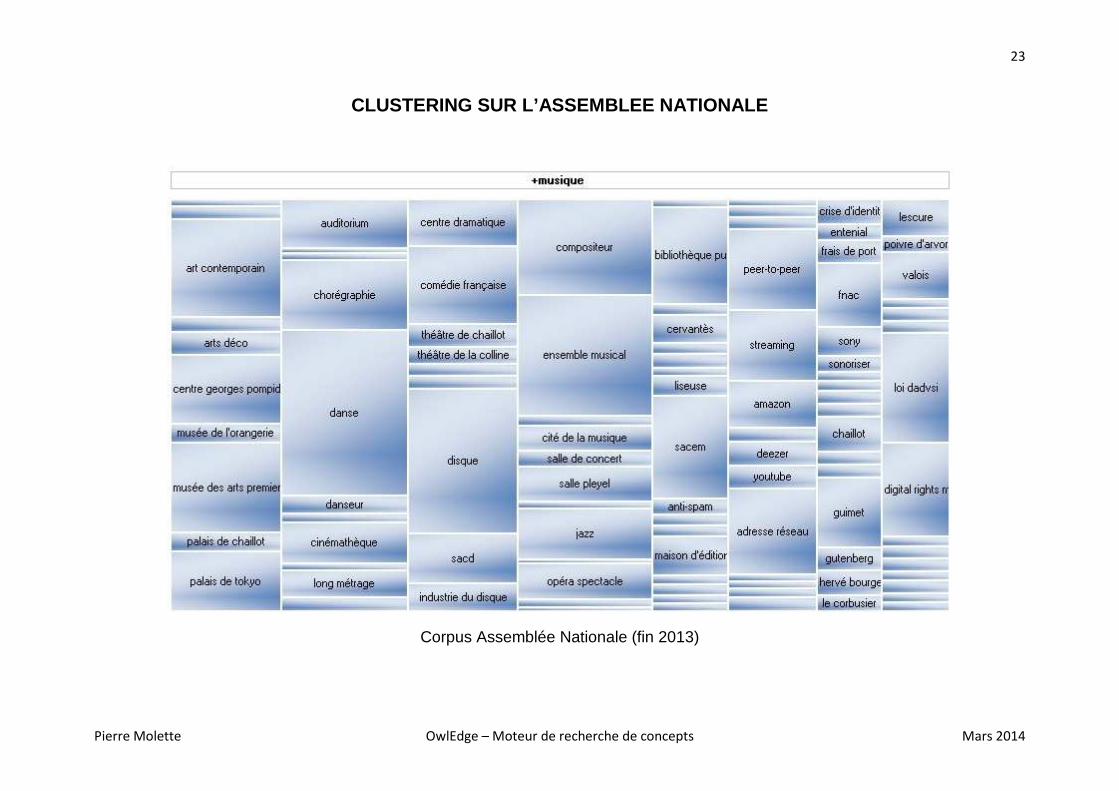
CLUSTERING SUR L’ASSEMBLEE NATIONALE
Corpus Assemblée Nationale (fin 2013)
19
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
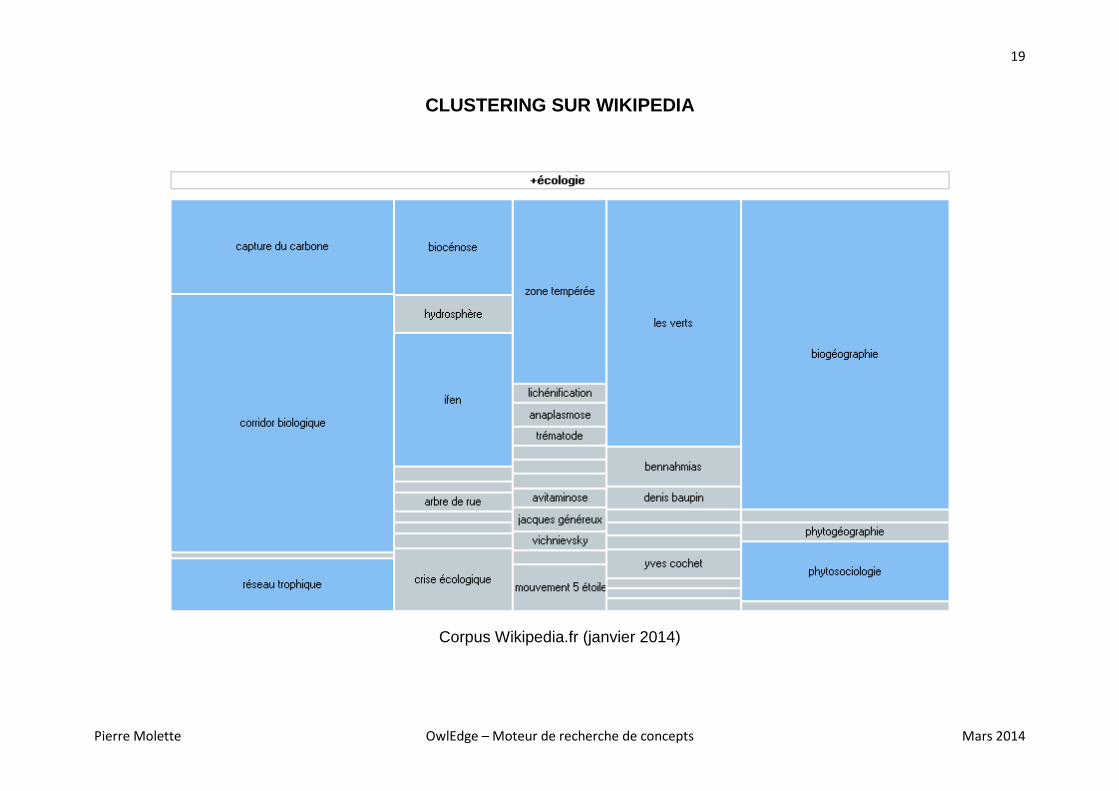
CLUSTERING SUR WIKIPEDIA
Corpus Wikipedia.fr (janvier 2014)
20
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
CLUSTERING SUR L’ASSEMBLEE NATIONALE
Corpus Assemblée Nationale (fin 2013)
21
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
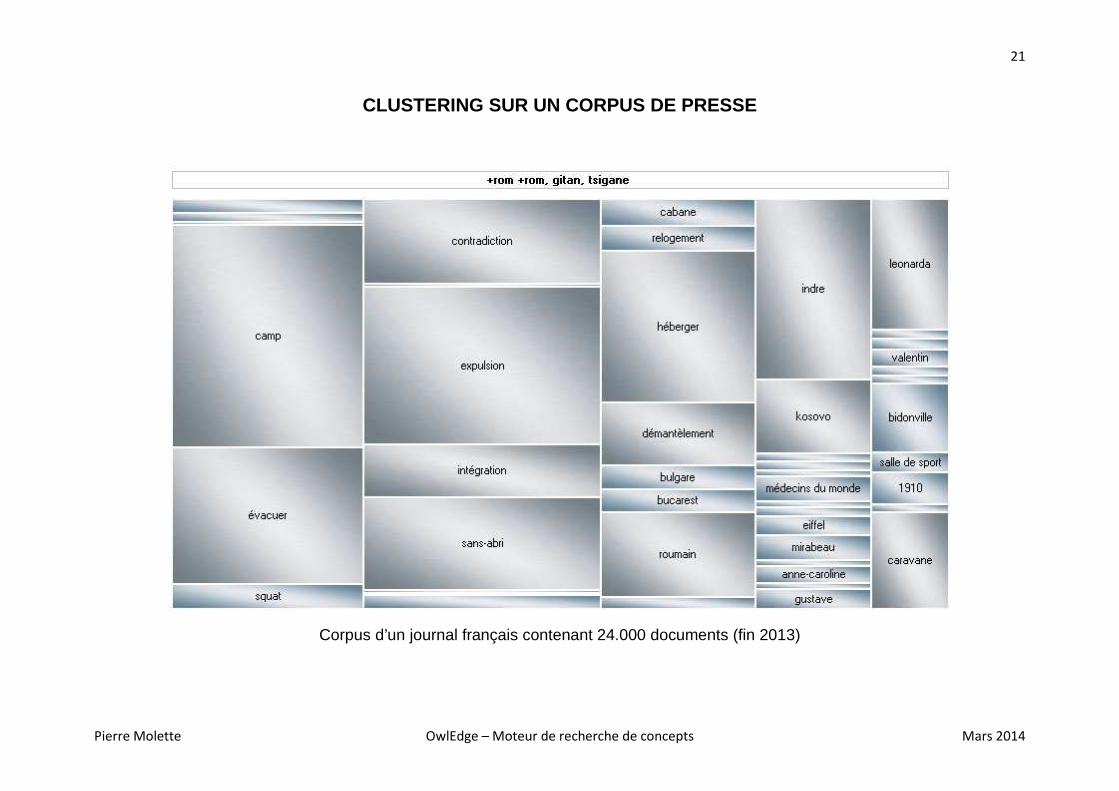
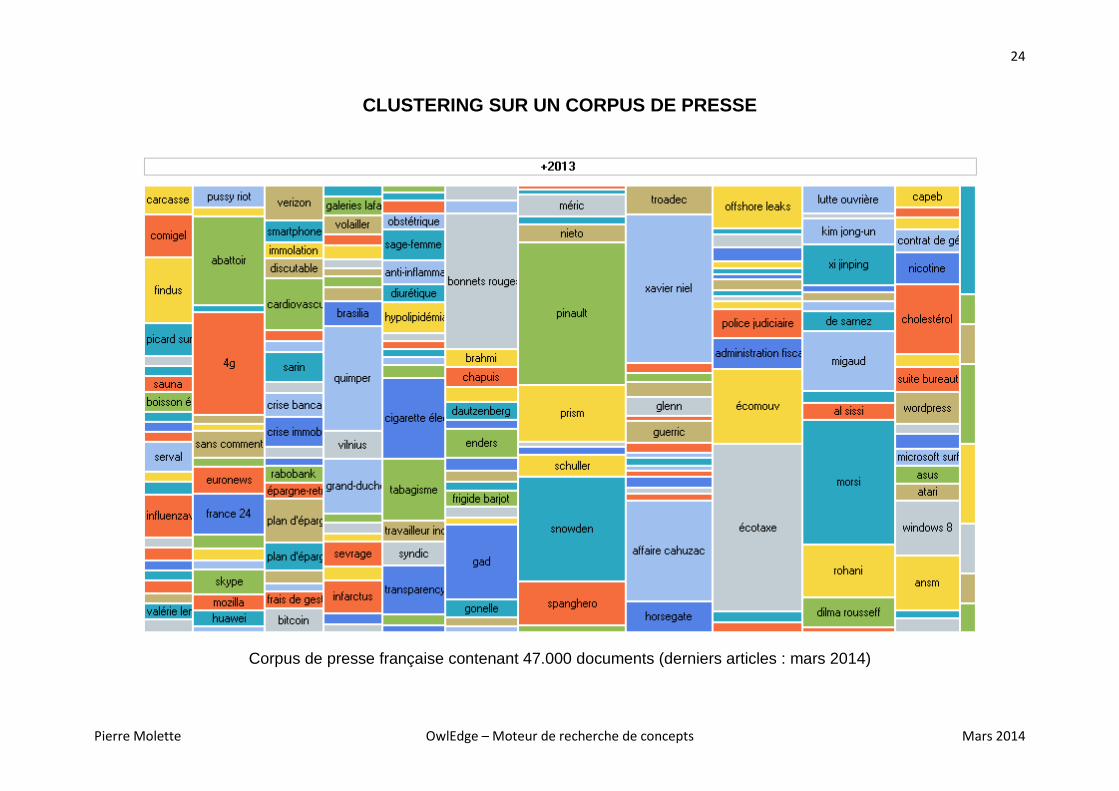
CLUSTERING SUR UN CORPUS DE PRESSE
Corpus d’un journal français contenant 24.000 documents (fin 2013)

22
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
CLUSTERING SUR WIKIPEDIA
Corpus Wikipedia.fr (janvier 2014)
23
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
CLUSTERING SUR L’ASSEMBLEE NATIONALE
Corpus Assemblée Nationale (fin 2013)
24
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
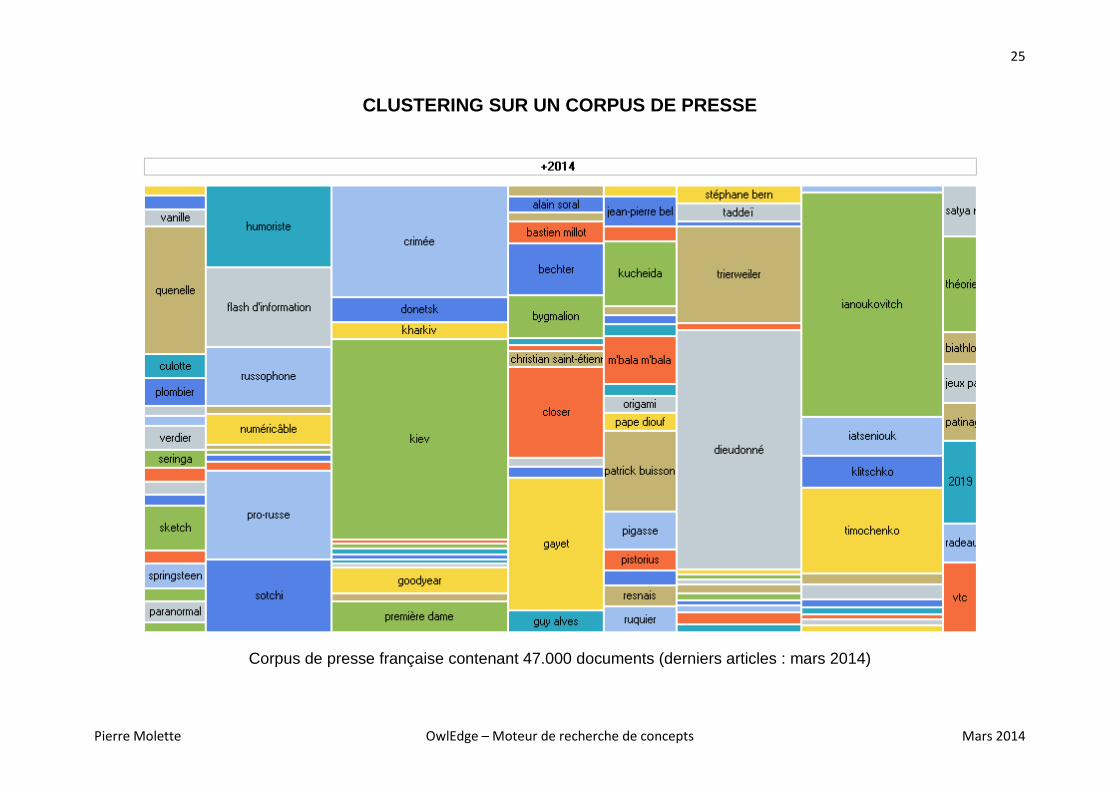
CLUSTERING SUR UN CORPUS DE PRESSE
Corpus de presse française contenant 47.000 documents (derniers articles : mars 2014)
25
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
CLUSTERING SUR UN CORPUS DE PRESSE
Corpus de presse française contenant 47.000 documents (derniers articles : mars 2014)

26
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
ANALYSE ET ANNOTATION D’UN DOCUMENT
La logique du clustering s’adapte quand on affiche l’analyse d’un texte unique :
Un clic sur ce graphe permet de sélectionner les extraits de texte correspondants. Le résultat peut ensuite être enregistré au format HTML et facilement réutilisé.

27
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
UN PARFUM DE BIG DATA
Vincent Blondel définit le Big Data de la façon suivante :
« Le premier critère est le volume, sous-entendu par le mot « big ». Le domaine des Big Data s’intéresse à des ensembles de données digitales qui, de par leur taille, ne peuvent être traitées avec des méthodes traditionnelles ; en fonction des applications, ce peut-être de l’ordre du gigabit, du térabit ou plus encore. Ensuite, ce volume ne cesse de croître à grande vitesse. »
Extrait d’interview publié dans La Recherche, en décembre 2013.
� Un ordinateur grand public est actuellement livré avec un disque dur de plusieurs téraoctets. Il peut stocker des millions de fichiers au format texte.
� Le principal problème est de fabriquer des logiciels capables de traiter ces données.
� OwlEdge peut traiter des corpus qu’on pourrait qualifier de « Little Big Data ».
28
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
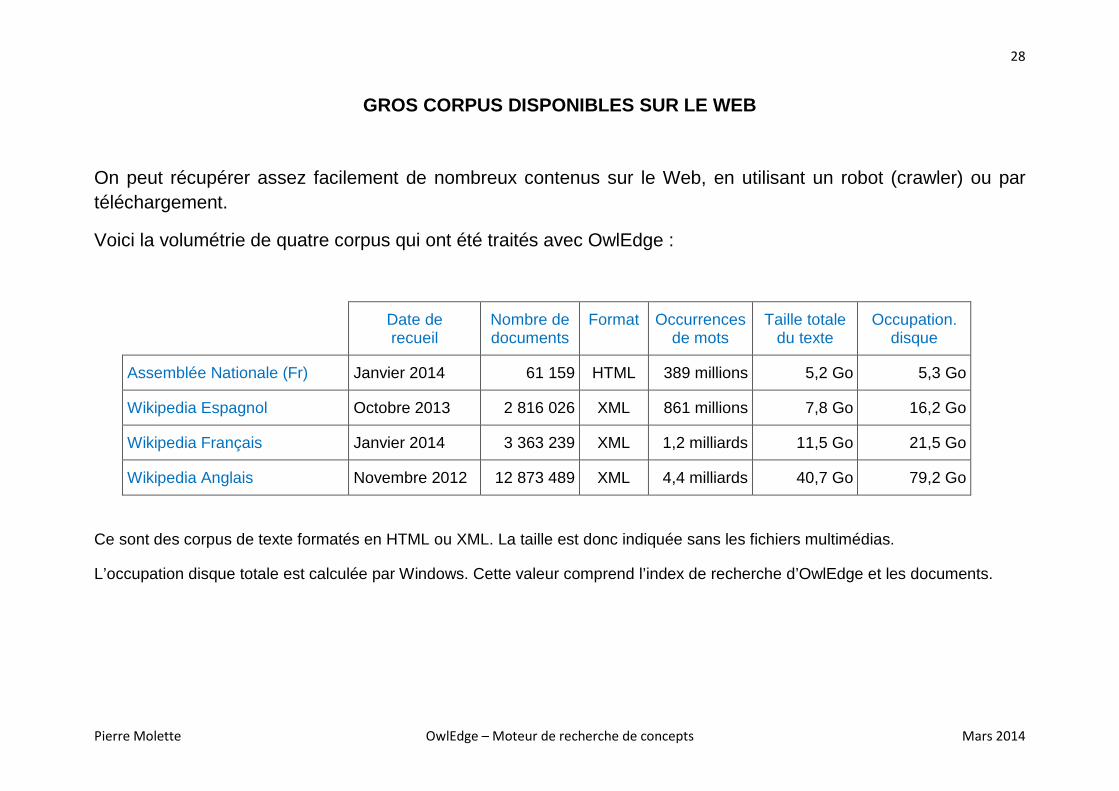
GROS CORPUS DISPONIBLES SUR LE WEB
On peut récupérer assez facilement de nombreux contenus sur le Web, en utilisant un robot (crawler) ou par téléchargement.
Voici la volumétrie de quatre corpus qui ont été traités avec OwlEdge :
Date de recueil
Nombre de documents
Format
Occurrences de mots
Taille totale du texte
Occupation. disque
Assemblée Nationale (Fr) Janvier 2014 61 159 HTML 389 millions 5,2 Go 5,3 Go
Wikipedia Espagnol Octobre 2013 2 816 026 XML 861 millions 7,8 Go 16,2 Go
Wikipedia Français Janvier 2014 3 363 239 XML 1,2 milliards 11,5 Go 21,5 Go
Wikipedia Anglais Novembre 2012 12 873 489 XML 4,4 milliards 40,7 Go 79,2 Go
Ce sont des corpus de texte formatés en HTML ou XML. La taille est donc indiquée sans les fichiers multimédias.
L’occupation disque totale est calculée par Windows. Cette valeur comprend l’index de recherche d’OwlEdge et les documents.
29
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
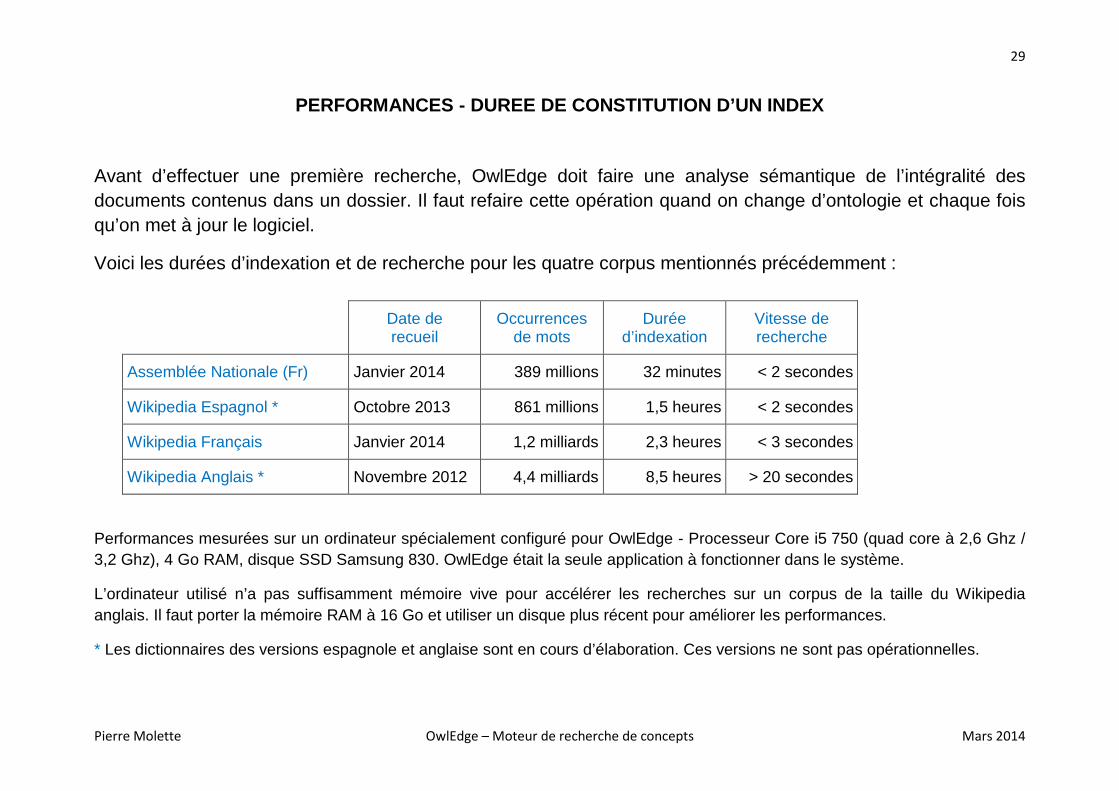
PERFORMANCES - DUREE DE CONSTITUTION D’UN INDEX
Avant d’effectuer une première recherche, OwlEdge doit faire une analyse sémantique de l’intégralité des documents contenus dans un dossier. Il faut refaire cette opération quand on change d’ontologie et chaque fois qu’on met à jour le logiciel.
Voici les durées d’indexation et de recherche pour les quatre corpus mentionnés précédemment :
Date de recueil
Occurrences de mots
Durée d’indexation
Vitesse de recherche
Assemblée Nationale (Fr) Janvier 2014 389 millions 32 minutes < 2 secondes
Wikipedia Espagnol * Octobre 2013 861 millions 1,5 heures < 2 secondes
Wikipedia Français Janvier 2014 1,2 milliards 2,3 heures < 3 secondes
Wikipedia Anglais * Novembre 2012 4,4 milliards 8,5 heures > 20 secondes
Performances mesurées sur un ordinateur spécialement configuré pour OwlEdge - Processeur Core i5 750 (quad core à 2,6 Ghz / 3,2 Ghz), 4 Go RAM, disque SSD Samsung 830. OwlEdge était la seule application à fonctionner dans le système.
L’ordinateur utilisé n’a pas suffisamment mémoire vive pour accélérer les recherches sur un corpus de la taille du Wikipedia anglais. Il faut porter la mémoire RAM à 16 Go et utiliser un disque plus récent pour améliorer les performances.
* Les dictionnaires des versions espagnole et anglaise sont en cours d’élaboration. Ces versions ne sont pas opérationnelles.

30
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
PROBLEMES POSES PAR LE BIG DATA
Il est parfaitement possible de décompresser une archive (Zip) contenant des millions de fichiers sur un ordinateur grand public. Mais de nombreux problèmes vont se poser :
• Il sera impossible de supprimer ou de copier le dossier résultant (sans utiliser la ligne de commande).
• Certaines applications risquent d’afficher un message de dépassement de capacité.
• Des processus en arrière-plan peuvent fonctionner durant des semaines sans s’arrêter.
• La sauvegarde des données deviendra difficile.
Les systèmes d’exploitation actuels ne sont pas paramétrés pour gérer de grandes quantités de fichiers.
� Il faut configurer spécifiquement un ordinateur pour travailler sur ces données, comme sur les serveurs. C’est-à-dire... Faire une installation propre du système. Utiliser des partitions ou des disques dédiés au "Big Data". Désactiver les services d’indexation et de défragmentation de Windows sur les dossiers concernés. Paramétrer un anti-virus léger (ou se placer en DMZ). Limiter le nombre de services fonctionnant en arrière-plan. Compresser dans une archive Zip les fichiers à sauvegarder. Etc.
Ces problèmes ne se posent qu’à partir du moment où on veut stocker des millions de fichiers.
On peut utiliser OwlEdge sur quelques centaines de milliers de documents, sans problème.

31
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
PERSPECTIVES D’AVENIR
Ajout d’autres fonctions d’analyse
Ajout des langues anglaise et espagnole
Développement d’autres langues
Amélioration de l’analyse sémantique
Développement d’un éditeur d’ontologies
Publication des résultats sur le Web
Connexion avec d’autres logiciels
Réécriture des filtres de conversion de fichiers
Evolution vers un projet Open source

32
Pierre Molette OwlEdge – Moteur de recherche de concepts Mars 2014
BIBLIOGRAPHIE
Vincent BLONDEL. Big Data. La Recherche, nº 482, décembre 2013
Rodolphe GHIGLIONE et al. L'analyse automatique des contenus. Paris, Dunod, 1998.
Nicolas GARCIA BELMONTE. JavaScript InfoVis Toolkit – Squarified Treemaps http://philogb.github.io/jit
The Latent Semantic Indexing home page. University of Colorado, Boulder. http://lsa.colorado.edu
John LYONS. Semantics. Cambridge University Press. 1977.
Pierre MOLETTE. De l’APD à Tropes : comment un outil d’analyse de contenu peut évoluer en logiciel de classification sémantique généraliste. Colloque Psychologie Sociale et Communication. Tarbes, 2009.
Arthur Rimbaud. Poésies. Voyelles. Gallimard. 1963.
Ben SHNEIDERMAN. Treemaps for space-constrained visualization of hierarchies. HCIL, University of Maryland Online document, 1998, http://www.cs.umd.edu/hcil/treemap
visualcomplexity.com | A visual exploration on mapping complex networks http://www.visualcomplexity.com/vc