modélisation - accueillibre.act.ulaval.ca/fileadmin/portail_libre/act-2005/recueils d... ·...
TRANSCRIPT

Modélisationdesdistributionsdesinistres
Exercices et solutions


Modélisationdesdistributionsdesinistres
Exercices et solutions
Hélène CossetteVincent GouletMichel JacquesMathieu Pigeon
École d’actuariat, Université Laval

© 2009 Hélène Cossette, Vincent Goulet, Michel Jacques, Mathieu Pigeon
Cette création est mise à disposition selon le contrat Paternité-Partage à l’iden-tique 2.5 Canada disponible en ligne http://creativecommons.org/licenses/by-sa/2.5/ca/ ou par courrier postal à Creative Commons, 171 Second Street, Suite 300, SanFrancisco, California 94105, USA.
Historique de publicationSeptembre 2009 : Première éditionSeptembre 2008 : Première version préliminaire
Code sourceLe code source LATEX de ce document est disponible à l’adresse
http://vgoulet.act.ulaval.ca/distributions_sinistres/
ou en communiquant directement avec les auteurs.
ISBN 978-2-9811416-1-3Dépôt légal – Bibliothèque et Archives nationales du Québec, 2009Dépôt légal – Bibliothèque et Archives Canada, 2009

Introduction
Ce document est le fruit de la mise en commun d’exercices colligés aufil du temps pour nos cours de modélisation des distributions de sinistresà l’Université Laval et à l’Université Concordia. Nous ne sommes toutefoispas les uniques auteurs des exercices ; certains ont, en effet, été rédigés parles Docteurs José Garrido et Jacques Rioux, entre autres. Quelques exercicesproviennent également d’anciens examens de la Society of Actuaries et de laCasualty Actuarial Society.
C’est d’ailleurs afin de ne pas usurper de droits d’auteur que ce docu-ment est publié selon les termes du contrat Paternité-Partage des conditionsinitiales à l’identique 2.5 Canada de Creative Commons. Il s’agit donc d’undocument «libre» que quiconque peut réutiliser et modifier à sa guise, àcondition que le nouveau document soit publié avec le même contrat.
Les exercices sont divisés en six chapitres qui correspondent aux cha-pitres de notre cours. Le chapitre 1 porte sur des rappels de notions de baseen analyse, probabilité et statistique. Le chapitre 2 traite des fondements de lamodélisation en assurance de dommages, en particulier le traitement mathé-matique des franchises, limite supérieure et coassurance ainsi que de l’effetde l’inflation sur la fréquence et la sévérité des sinistres. Les aspects plus sta-tistiques apparaissent au chapitre 3 avec la modélisation non paramétrique.Le chapitre 4 étudie les principales distributions utilisées en assurance dedommages et la création de nouvelles distributions à partir des lois usuelles.Les chapitres 5 et 6 portent quant à eux sur l’estimation paramétrique etles tests d’adéquation des modèles. Enfin, le chapitre 7 propose une brèveincursion dans la modélisation des distributions de fréquence des sinistres.
Les termes anglais ordinary deductible et franchise deductible nous ont poséquelques soucis de traduction. Pour le premier, nous utilisons l’expression«franchise forfaitaire» recommandée par Béguin (1990). Pour le second terme,beaucoup moins répandu, nous avons opté pour l’expression «franchise at-teinte» suggérée, entre autres, dans Charbonnier (2004).
Les réponses des exercices se trouvent à la fin de chacun des chapitres,alors que les solutions complètes sont regroupées à l’annexe E. De plus, ontrouvera à la fin de chaque chapitre (sauf le premier) une liste non exhaustived’exercices proposés dans Klugman et collab. (2008a). Des solutions de cesexercices sont offertes dans Klugman et collab. (2008b).
L’annexe A présente la paramétrisation des lois de probabilité continues
v

vi Introduction
et discrètes utilisée dans les exercices. L’information qui s’y trouve est enplusieurs points similaire à celle des annexes A et B de Klugman et collab.(1998, 2004, 2008a), mais la paramétrisation des lois est dans certains casdifférente. Le lecteur est donc fortement invité à la consulter.
Plusieurs exercices de ce recueil requièrent l’utilisation de R (R Develop-ment Core Team, 2009) et du package actuar (Dutang et collab., 2008). L’an-nexe B explique comment configurer R pour faciliter l’installation et l’admi-nistration de packages externes. Enfin, les annexes C et D contiennent destableaux de quantiles des lois normale et khi carré.
Nous remercions d’avance les lecteurs qui voudront bien nous faire partde toute erreur ou omission dans les exercices ou leurs solutions.
Hélène Cossette <[email protected]>Vincent Goulet <[email protected]>Michel Jacques <[email protected]>Mathieu Pigeon <[email protected]>
Québec, septembre 2009

Table des matières
Introduction v
1 Rappels d’analyse, de probabilité et de statistique 1
2 Modélisation en assurance de dommages 7
3 Modélisation non paramétrique 13
4 Modèles paramétriques potentiels 21
5 Modélisation paramétrique 27
6 Tests d’adéquation 35
7 Modèles de fréquence 39
A Paramétrisation des lois de probabilité 43A.1 Famille bêta transformée . . . . . . . . . . . . . . . . . . . . . . . 44A.2 Famille gamma transformée . . . . . . . . . . . . . . . . . . . . . 47A.3 Autres distributions continues . . . . . . . . . . . . . . . . . . . 49A.4 Distributions discrètes de la famille (a, b, 0) . . . . . . . . . . . . 52
B Installation de packages dans R 55
C Table de quantiles de la loi normale 57
D Table de quantiles de la loi khi carré 59
E Solutions 61Chapitre 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61Chapitre 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73Chapitre 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85Chapitre 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103Chapitre 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114Chapitre 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131Chapitre 7 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
Bibliographie 145vii


1 Rappels d’analyse, de probabilitéet de statistique
1.1 On a l’inégalité
12− x2
24<
1− cos(x)x2 <
12
vraie pour toutes valeurs de x près de 0. Calculer
limx→0
1− cos(x)x2
et faire le graphique de la fonction et des deux bornes pour −2≤ x ≤ 2.
1.2 Calculer
limx→0
xln(x + 1)
.
1.3 Calculer limx→0(1 + x)1/x.
1.4 a) Déterminer laquelle des expressions, x ou ln(x), tend la plus rapide-ment vers l’infini lorsque x tend vers l’infini.
b) Répéter la partie a) avec x et ex.
1.5 Il faut parfois élargir l’ensemble des nombres réels à celui des nombrescomplexes. Un nombre complexe z se présente souvent sous la formed’une somme
z = a + bi
où a et b sont des nombres réels et i est un nombre imaginaire particuliertel que
i2 = −1.
1

2 Rappels d’analyse, de probabilité et de statistique
De là, il découle que
i3 = (i2)(i)= (−1)(i)= −i
i4 = (i2)(i2)= (−1)(−1)= 1
i5 = i
i6 = −1
et ainsi de suite. À partir du développement connu de ex,
ex = 1 + x +x2
2!+
x3
3!+
x4
4!+ . . . ,
démontrer l’identité d’Euler eiπ = −1 en suivant les étapes suivantes.
a) Développer autour de c = 0 la fonction f (x) = cos(x).
b) Développer autour de c = 0 la fonction f (x) = sin(x).
c) Développer, en remplaçant x par ix la fonction f (x) = eix.
d) Démontrer l’identité eix = cos(x) + i sin(x).
e) Démontrer l’identité eiπ = −1.
1.6 Soit la fonctionF(x) =
11 + e−x −∞ < x < ∞.
Démontrer qu’il s’agit d’une fonction de répartition.
1.7 Soit X, une variable aléatoire continue avec fonction de densité f (x) etfonction de répartition F(x). On choisit une valeur quelconque x0 et ondéfinit la fonction
g(x) =
{f (x)
1−F(x0), x ≥ x0
0, x < x0.
On suppose que F(x0) < 1. Démontrer que g(x) est une densité de pro-babilité.
1.8 Soit X, une variable aléatoire avec une distribution de Pareto(α, λ) :
f (x) =αλα
(x + λ)α+1 , x > 0, α > 0, λ > 0.
Calculer la fonction de survie S(x) = 1− F(x) et en faire le graphiquepour α = 2 et λ = 3 000.

Rappels d’analyse, de probabilité et de statistique 3
1.9 Soit X, une variable aléatoire avec une distribution Binomiale(n, p), c’est-à-dire que
Pr(X = x) =(
nx
)px(1− p)n−x , x = 0,1, . . . .
Déterminer la distribution de la variable aléatoire Y = n− X.
1.10 Soit X ∼ N(µ, σ2). La variable aléatoire Y = eX est distribuée selon la loilog-normale.
a) Exprimer la fonction de densité de probabilité et la fonction de ré-partition de Y en fonction de celles de X.
b) Calculer Var[Y].
1.11 La distribution de Cauchy a comme fonction de densité de probabilité
f (x) =1π
11 + x2 , −∞ < x < ∞.
Démontrer que l’espérance de cette distribution n’existe pas, c’est-à-direque E[|X|] = ∞.
1.12 Soit X, une variable aléatoire avec densité Poisson(λ) et soit g(x), unefonction telle que −∞ < E[g(X)] < ∞ et −∞ < g(−1) < ∞. Démontrerque E[λg(X)] = E[Xg(X− 1)].
1.13 Soient X et Y, deux variables aléatoires continues. On définit
M = max(X,Y)m = min(X,Y).
Démontrer que E[M] = E[X] + E[Y]− E[m].
1.14 Soit X, une variable aléatoire avec densité
fX(x) = 7e−7x , 0 < x < ∞,
et soit Y = 4X + 3. Calculer la densité de Y en utilisant la technique dela fonction de répartition.
1.15 Soit X, une variable aléatoire avec densité
fX(x) = x2/9, 0 < x < 3.
Trouver la fonction de densité de probabilité de Y = X3.
1.16 Soit X, une variable aléatoire avec distribution N(0, σ2). Trouver la dis-tribution de Y = X2.
1.17 Pour une densité quelconque, démontrer que si la densité est symé-trique par rapport à un point a, alors le coefficient d’asymétrie est 0.

4 Rappels d’analyse, de probabilité et de statistique
1.18 Soit X, une variable aléatoire avec densité
f (x) = e−x , x > 0.
Calculer son coefficient d’asymétrie.
1.19 Soit X, une variable aléatoire avec densité
f (x) =12
, −1 < x < 1.
Calculer son coefficient d’aplatissement et commenter.
1.20 Déterminer la fonction génératrice des moments de la densité
f (x) =2xc2 , 0 < x < c.
1.21 Soit X1 et X2 les moyennes de deux échantillons aléatoires indépendantsde taille n d’une population avec variance σ2, trouver une valeur de ntelle que
Pr(|X1 − X2| <
σ
5
)≈ 0,99.
1.22 Soit X la moyenne d’un échantillon de taille 100 issu d’une loi χ2(50).
a) Trouver la distribution exacte de X.
b) Calculer à l’aide d’un logiciel statistique la valeur exacte de Pr[49 <X < 51].
c) Calculer une valeur approximative de la probabilité en b).
1.23 Soit Θ, un estimateur de la variance d’une loi de Pareto(3,1 000). Sa-chant que E[Θ] = 749 500 et que Var[Θ] = 750, trouver le biais et l’erreurquadratique moyenne de Θ.
1.24 Soit X1, . . . , Xn, un échantillon aléatoire d’une population avec moyenneµ et variance σ2.
a) Démontrer que l’estimateur T(X) = ∑ni=1 aiXi est un estimateur sans
biais de µ si ∑ni=1 ai = 1.
b) On nomme les estimateurs de la forme en a) des estimateurs sans biaislinéaires. Parmi ceux-ci, trouver celui avec la plus petite variance.
1.25 Soit X1, . . . , Xn un échantillon aléatoire d’une distribution avec moyenneµ et variance σ2. Démontrer que n−1 ∑n
i=1(Xi − µ)2 est un estimateursans biais de σ2.
1.26 Soit X, une observation d’une population dont la densité est
f (x;θ) =(
θ
2
)|x|(1− θ)1−|x|, x = −1,0,1; 0≤ θ ≤ 1.

Rappels d’analyse, de probabilité et de statistique 5
Soit l’estimateur
T(X) =
{2, x = 10, ailleurs.
Démontrer que T(X) est un estimateur sans biais pour θ.
1.27 Soit X ∼ Binomiale(n, p). Démontrer que
nXn
(1− X
n
)est un estimateur biaisé de la variance de X. Calculer le biais de l’esti-mateur ci-dessus.
1.28 Calculer l’efficacité de X comme estimateur du paramètre λ d’une dis-tribution de Poisson.
1.29 Deux experts tentent d’évaluer le montant des dommages causés parun ouragan. La variable aléatoire X représente l’évaluation du premierexpert et la variable aléatoire Y représente l’évaluation faite par le se-cond expert. On suppose que les deux experts travaillent de façon indé-pendante. Les données suivantes sont connues : E[X] = 0,8z, E[Y] = z,Var[X] = z2, et Var[Y] = 1,5z2, où z représente le vrai montant des dom-mages. On considère une classe d’estimateurs pour z de la forme
Z = αX + βY.
Déterminer les valeurs de α et β qui feront de X l’estimateur sans biaisà variance uniformément minimale de z.
1.30 Soitf (x;θ) =
1θ
x(1−θ)/θ , 0 < x < 1, θ > 0.
a) Identifier cette distribution.
b) Démontrer que l’estimateur du maximum de vraisemblance de θ est
θ = − 1n
n
∑i=1
ln Xi.
c) Démontrer que θ est un estimateur sans biais de θ.
Réponses
1.1 12
1.2 1

6 Rappels d’analyse, de probabilité et de statistique
1.3 e
1.4 a) x plus rapide que ln(x) b) ex plus rapide que x
1.8 S(x) =(
xx+λ
)α
1.9 Binomiale(n, 1− p)
1.10 a) FY(x) = FX(ln x), fY(x) = x−1 fX(ln x) b) e2µ+σ2(eσ2 − 1)
1.14 fY(y) = 74 e−
74 (y−3), y > 3
1.15 fY(y) = 127 , 0 < y < 27
1.16 Gamma( 12 , 1
2 σ−2)
1.18 2
1.19 9/5
1.20 2(ct)−2(ct2tc − etc + 1)
1.21 332
1.22 a) Gamma(2 500,50) b) 0,682722 c) 0,6826
1.23 Biais : −500 ; MSE : 250 750
1.24 b) X
1.28 1
1.29 α = 0,6122, β = 0,5102.
1.30 a) Bêta(1/θ, 1)

2 Modélisation en assurance dedommages
Rappelons que l’expression «franchise forfaitaire» correspond au termeanglais ordinary deductible, alors que l’expression «franchise atteinte» corres-pond au terme franchise deductible.
2.1 Les montants suivants représentent les coûts associés aux réparationsautomobiles de 12 contrats :
{579,110,842,213,98,445,1 332,162,131,276,312,482}.
Les contrats présentent une franchise forfaitaire de 250 $. Calculer le rap-port d’élimination de perte (LER) de l’assureur.
2.2 Les montants suivants représentent les coûts associés à des accidents au-tomobiles pour huit contrats :
{86 000,123 000,423 000,43 000,213 000,28 000,52 000,178 000}.
Les contrats présentent une limite supérieure de 100 000 $. Calculer lerapport d’élimination de perte de l’assureur.
2.3 Pour un portefeuille dont le montant d’un sinistre obéit à une loi ex-ponentielle de paramètre 0,02, trouver le rapport d’élimination de pertedécoulant de l’introduction des limites de couvertures suivantes.a) Une franchise atteinte de 10.b) Une franchise forfaitaire de 10.
2.4 On suppose que le montant d’un sinistre obéit à une distribution gammade paramètres α = 4 et λ = 0,1. Un assureur a signé un traité avec unréassureur où ce dernier s’engage à payer l’excédent de 100 sur chacundes sinistres. Trouver le rapport d’élimination de perte de l’assureur.
2.5 Dans un groupe d’assurés, les sinistres suivants sont survenus :
{20,50,80,80,80,85,90,110,150,240,360,400}.
Trouver le rapport d’élimination de perte de l’assureur si celui-ci a ins-tauré une franchise forfaitaire de 70 et s’il limite ses paiements à 200.
7

8 Modélisation en assurance de dommages
2.6 Soit X, la variable aléatoire représentant le montant d’un sinistre. On saitque E[X] = 2 000, que E[X;30 000] = 1 640,79 et que le rapport d’élimina-tion de perte de l’assureur pour un contrat avec une franchise forfaitairede 100 est de 0,0465. Trouver le rapport d’élimination de perte de l’assu-reur pour un contrat avec une franchise forfaitaire de 100 et une limitesupérieure de 30 000.
2.7 Soit X, une variable aléatoire représentant le montant d’un sinistre telque
fX(x) = e−2x +e−x
2, x > 0.
a) Trouver E[X;d].b) Soit N, une variable aléatoire représentant la fréquence des sinistres.
Calculer la prime pure (fréquence moyenne multipliée par la sévéritémoyenne) pour une franchise de d = 0,25 et une fréquence moyennede un sinistre tous les 10 ans.
c) Si on observe un taux d’inflation de 5 %, que devient la prime pure ?
2.8 On suppose que le montant d’un sinistre obéit à une loi Pareto de para-mètres α = 1,5 et λ = 2 500.
a) Calculer le montant moyen des sinistres payé par un assureur pourun contrat de réassurance avec une rétention de 50 000.
b) Trouver le rapport d’élimination de perte pour le réassureur si la ré-tention est de 100 000.
2.9 Soit YP la variable aléatoire du montant payé par paiement pour uncontrat d’assurance avec une franchise forfaitaire de d et X est la variablealéatoire du montant d’un sinistre. Démontrer que
E[YP] =E[X]− E[X;d]
1− FX(d),
où E[X;d] = E[min(X, d)] est l’espérance limitée de X à d. Interpréter lerésultat.
2.10 Un assureur décide de modéliser X, la variable aléatoire du montantd’un sinistre, par une distribution Weibull de paramètres τ = 3 et λ =1/15. Tracer (idéalement de manière informatique, à l’aide du packageactuar) les graphiques des variables aléatoires suivantes.
a) La variable aléatoire du montant payé par sinistre pour un contratavec une franchise forfaitaire de 10.
b) La variable aléatoire du montant payé par paiement pour une fran-chise atteinte de 10 et une limite supérieure de 40.
c) La variable aléatoire du montant du sinistre avec une coassurance de80 %.

Modélisation en assurance de dommages 9
2.11 Un assureur dispose des informations suivantes :– le montant d’un sinistre pour l’année 1990 obéit à une loi Pareto de
paramètres α = 1,5 et λ = 1 500 ;– un taux d’inflation de 5 % par année a été observé entre 1990 et 1992
et de 6 % par année entre 1992 et 1995 ; et– une franchise de 500 est introduite en 1995.
a) Calculer le rapport d’élimination de perte pour l’assureur en 1995.
b) L’assureur paie un sinistre en 1995. Déterminer la probabilité qu’ilpaie plus de 2 000 $
c) Déterminer la charge espérée par sinistre de l’assureur s’il avait dé-cidé en 1995 de ne pas payer plus de 3 500 $ par sinistre (en plus dela franchise de 500 $).
2.12 Le tableau ci-dessous présente, sous forme groupée, les montants payéspar sinistre pour des sinistres en assurance habitation couverts par descontrats ayant une limite supérieure de 300 000 $.
Montant payé Nombre Montant moyen
0 – 2 500 41 1 3892 500 – 7 500 48 4 661
7 500 – 12 500 24 9 99112 500 – 17 500 18 15 48217 500 – 22 500 15 20 23222 500 – 32 500 14 26 61632 500 – 47 500 16 40 27847 500 – 67 500 12 56 41467 500 – 87 500 6 74 985
87 500 – 125 000 11 106 851125 000 – 225 000 5 184 735225 000 – 300 000 4 264 025
300 000 3 300 000
Pour modéliser les données, on utilise une distribution log-normale deparamètres µ et σ2. À l’aide d’une technique d’estimation quelconque,on trouve que µ = 9,356 et σ = 1,596.
a) Estimer le montant payé espéré.
b) Estimer le pourcentage de changement dans le montant payé parpaiement espéré si l’on observe une inflation de 10 % des sinistres.
c) Estimer le pourcentage de réduction dans le montant payé espéré sil’on décide d’ajouter une franchise de 1 000 $ au contrat de base (onne tient plus compte de l’inflation).
2.13 Soit X, la variable aléatoire représentant le montant d’un sinistre en res-ponsabilité professionnelle pour un médecin. On suppose que la com-pagnie d’assurance achète un traité de réassurance de rétention δ par

10 Modélisation en assurance de dommages
réclamation, c’est-à-dire que le réassureur paie l’excédent des pertes au-dessus de δ pour chaque réclamation. Si l’on suppose que X a une distri-bution de Pareto(α, λ), démontrer que la distribution du montant payépar paiement du réassureur a une distribution de Pareto de paramètresα et λ + δ.
2.14 On suppose que le montant d’un sinistre obéit à une loi exponentiellede paramètre 3, c’est-à-dire que
f (x) = 3−3x , x > 0.
On introduit une franchise forfaitaire de 0,2. Lorsque l’assureur effectueun paiement, quelle est la probabilité qu’il soit de plus de 0,50 ?
2.15 Une compagnie décide d’acheter deux contrats d’assurance pour l’annéeà venir. Le montant moyen des sinistres pour une année est de 11 100 $.La police A a une franchise forfaitaire de 5 000 $ et ne présente pasde limite, alors que la police B a une limite de 5 000 $ et ne présentepas de franchise. Pour la police A, l’espérance de la variable aléatoiredu montant payé par sinistre, YS, est de 6 500 $ et l’espérance de lavariable aléatoire du montant payé par paiement, YP, est de 10 000 $.Sachant qu’un sinistre d’un montant plus petit ou égal à 5 000 $ s’estproduit, calculer l’espérance de la variable aléatoire du montant payépar paiement pour le contrat B.
2.16 Un assureur utilise une distribution binomiale négative de paramètresr = 3 et θ = 1/6 pour modéliser la fréquence des sinistres par année etune distribution de Weibull de paramètres τ = 0,3 et λ = 1/1 000 pourmodéliser la sévérité des sinistres. Il décide également d’appliquer unefranchise forfaitaire de 200. Déterminer le nombre espéré de paiementsque fera l’assureur par année.
2.17 Pour un contrat comportant une franchise forfaitaire de d, une limitesupérieure de u et une coassurance de α, la variable aléatoire du mon-tant payé par sinistre, YS, est donnée à partir de la variable aléatoire dumontant d’un sinistre, X, par
YS =
0, X < dα(X− d), d ≤ X < uα(u− d), X ≥ u.
a) Démontrer que E[YS] = α(E[X;u]− E[X;d]).
b) Trouver Var[YS].c) Trouver l’expression générale de l’espérance du montant payé par
sinistre à la suite d’une inflation de 100r %.
2.18 Soient YS, la variable aléatoire du montant payé par sinistre, X, la va-riable aléatoire du montant d’un sinistre, d une franchise forfaitaire et

Modélisation en assurance de dommages 11
u, une limite supérieure. Démontrer la relation E[YS] = E[X;u]− E[X;d]à l’aide d’intégrales, et non par une définition astucieuse de la variablealéatoire YS.
2.19 Le ratio de perte (loss ratio) R est défini comme étant le montant totaldes sinistres payés pendant l’année, S, divisé par le montant total desprimes reçues pendant l’année, π. Une compagnie d’assurance souhaitebien entendu conserver ce ratio sous un certain niveau pour ne pas êtreen difficulté financière. Pour ce faire, elle offre un bonus B à ses agentsà la fin de l’année si le ratio de perte pour l’année est inférieur à 75 %.Le montant du bonus est calculé comme suit :
B = max(
0, π
(0,75− R
3
)).
Calculer le montant espéré du bonus si π = 600 000 et que la distributionde la variable aléatoire S est une Pareto avec paramètres α = 3 et λ =700 000.
2.20 Soit X, une variable aléatoire représentant le montant d’un sinistre. Unassureur souhaite connaître les paiements à sa charge pour un contratd’assurance incluant une franchise décroissante (disappearing deductible).Dans ce type de contrat, l’assuré assume en entier tout sinistre inférieurà d et l’assureur assume en entier tout sinistre supérieur à d∗. Entre det d∗, le paiement effectué par l’assureur est une fonction linéaire dumontant d’un sinistre.
a) Définir la variable aléatoire YP représentant le montant payé parpaiement pour un contrat avec une franchise décroissante.
b) Trouver l’expression générale en termes de E[X], E[X; x] et FX(x) dumontant payé par paiement espéré.
Exercices proposés dans Loss Models
3.5, 3.7, 3.8, 3.9, 3.11, 3.15, 8.1 8.2, 8.3, 8.5 8.7 8.8 8.11, 8.12, 8.14, 8.16, 8.17,8.18, 8.19, 8.23, 8.24, 8.25, 8.26, 8.27. 8.28
Réponses
2.1 0,4946
2.2 0,4686
2.3 a) 0,0175 b) 0,1813
2.4 0,0034
2.5 0,567

12 Modélisation en assurance de dommages
2.6 0,226
2.7 a) (3− e−2d − 2e−d)/4 b) 0,0541 c) 0,0576
2.8 a) 1 091,09 b) 0,8438
2.11 a) 0,1069 b) 0,4107 c) 1 255,23
2.12 a) 33 962 b) +8,04 % c) −2,87 %
2.14 0,22
2.15 3 857
2.16 8,0925
2.17 b) α2(E[X2;u2]−E[X2;d2]− 2dE[X;u]+ 2dE[X;d])− α2(E[X;u]−E[X;d])2
c) α(1 + r)(E[X;u/(1 + r)]− E[X;d/(1 + r)])
2.19 76 559,55
2.20 b) (E[X] + d/(d∗ − d)E[X;d∗]− d∗/(d∗ − d)E[X;d])/(1− FX(d))

3 Modélisation non paramétrique
3.1 Un assureur présente les coûts (en millions de $) créés par les écrase-ments de météorites :
{3,5,5,6,8,8,8,8,9,10,10,11,11,11,16,21,23,26,29,36}.
a) Faire des graphiques de la fonction de répartition empirique et de lafonction de masse de probabilité empirique du coût des écrasements.
b) À partir des bornes c0 = 2, c1 = 7, c2 = 12, c3 = 22 et c4 = 38, écrirel’équation de l’ogive.
c) En utilisant les mêmes bornes qu’en b), écrire l’équation de l’histo-gramme.
3.2 Le tableau ci-dessous présente les sinistres enregistrés par un assureur.
Classe Nombre de sinistres
(0,50] 36(50,150] x
(150,250] y(250,500] 84
(500,1 000] 80(1 000, ∞) 0
Total n
Soit Fn(·) l’ogive correspondant à ces données. Sachant que Fn(90) = 0,21et Fn(210) = 0,51, déterminer la valeur de x.
3.3 Pour 500 sinistres, un assureur a enregistré la distribution présentée autableau ci-dessous.
Classe Nombre de sinistres
(0,500] 200(500,1 000] 110
(1 000,2 000] x(2 000,5 000] y
(5 000,10 000](10 000,25 000]
(25 000, ∞)
13

14 Modélisation non paramétrique
Soit Fn(·) l’ogive correspondant à ces données. Sachant que F500(1 500) =0,689 et F500(3 500) = 0,839, calculer la valeur de y.
3.4 Au cours de la dernière année, la compagnie d’assurance Big Companya remboursé les sinistres présentés dans le tableau ci-dessous.
Classe Nombre de sinistres
0 – 1 000 161 000 – 3 000 223 000 – 5 000 25
5 000 – 10 000 1810 000 – 25 000 1025 000 – 50 000 5
50 000 – 100 000 3100 000 et plus 1
Tracer l’ogive de ces données et calculer, à la main et avec R, la probabilitéque le montant d’une réclamation soit compris entre 2 000 $ et 6 000 $.Expliquer le traitement réservé à la dernière classe.
3.5 Un assureur a enregistré les montants de sinistres suivants au cours dela dernière année :
{80,153,162,267,410}.
Soit F(x) l’estimateur avec noyaux uniformes de bande 50 de la fonctionde répartition et soit F5(x) la fonction de répartition empirique. Calculer|F5(150)− F(150)|.
3.6 Un assureur estime la densité des données {150,210,240,300} à l’aided’un estimateur avec noyaux triangulaires de largeur de bande 50.
a) Calculer la moyenne de f (x).
b) Tracer le graphique de f (x).
3.7 Un échantillon est composé des valeurs {5,7,4,5,9,8,3,5,4,10}. Évaluerau point 6,2 un estimateur de la densité avec
a) noyaux uniformes et largeur de bande 0,5.
b) noyaux uniformes et largeur de bande 1.
c) noyaux uniformes et largeur de bande 2.
d) noyaux uniformes et largeur de bande 3.
e) noyaux triangulaires et largeur de bande 0,5.
f) noyaux triangulaires et largeur de bande 1.
g) noyaux triangulaires et largeur de bande 2.
3.8 Pour l’échantillon {2,4,6,8,10}, on construit un estimateur lissé de ladensité de probabilité avec noyaux triangulaires. Quelle est la plus petitelargeur de bande qui assure que f (5) = 0,01 ?

Modélisation non paramétrique 15
3.9 Un assureur a enregistré les montants suivants (en 1 000 000 $) liés à descatastrophes naturelles :
{2,2,2,2,2,2,2,2,2,2,2,2,3,3,3,3,4,4,4,5,5,5,5,6,6,6,6,8,8,9,15,17,22,23,24,24,25,27,32,43}.
a) Tracer le graphique de la fonction de répartition empirique F40.
b) En utilisant les bornes c0 = 1,5, c1 = 2,5, c2 = 6,5, c3 = 29,5, et c4 = 49,5,tracer l’ogive des données sur le même graphique que pour la sous-question précédente. L’ajustement semble-t-il bon ? Détailler. Le choixdes bornes semble-il correct ?
c) Tracer l’histogramme des données en utilisant les mêmes classes qu’enb).
d) Calculer la moyenne et l’écart type empiriques.
3.10 Un assureur a enregistré les montants de sinistres suivants (en millions) :
{1,2,2,4,6,6,6,8,8,10}.
Construire un intervalle de confiance de niveau 0,95 pour F(4).
3.11 Le tableau ci-dessous présente les sinistres censurés à droite enregistréspar un assureur pendant l’année 2002.
Montant Nombre de sinistres Groupe-risque
500 3 52800 10 40
1 200 11 191 700 2 6
Calculer l’estimateur de F(1 200) basé sur l’estimateur de Nelson-AalenHn(1 200).
3.12 Le tableau ci-dessous présente les sinistres enregistrés par un assureurpendant l’année 2006.
Montant Nombre de sinistres Groupe-risque
1 000 1 203 400 1 194 500 1 187 500 1 17
15 000 1 1617 500 1 15
a) Déterminer l’estimateur de Nelson-Aalen, Hn(x), pour les six valeursdu tableau.

16 Modélisation non paramétrique
b) On va maintenant tenter d’appliquer la méthode d’estimation parnoyaux au taux d’incidence. Pour une fonction de densité, l’estima-teur par noyaux est
f (x) =s
∑j=1
fn(yj)k j(x),
que l’on peut aussi écrire sous la forme
f (x) =1b
s
∑j=1
fn(yj)k j
( x− yj
b
)
en définissant k j sur l’intervalle [−1,1]. Par analogie, pour le tauxd’incidence, on va utiliser
h(x) =1b
s
∑j=1
hn(yj)k j
( x− yj
b
),
en estimant hn(yj) par ∆Hn(yj). En utilisant un noyau uniforme,c’est-à-dire
k(x) =
{1/2, −1≤ x ≤ 10, ailleurs
et une largeur de bande de 6 000, calculer h(10 000).
3.13 Un assureur a enregistré les 30 réclamations suivantes : deux réclama-tions de 2 000 $, six réclamations de 4 000 $, 12 réclamations de 6 000 $et 10 réclamations de 8 000 $. Donner la valeur de l’estimateur empi-rique du coefficient d’asymétrie et son interprétation.
3.14 Le tableau ci-dessous présente les réclamations enregistrées par un petitassureur automobile pendant une année.
Montant enregistré Fréquence
100 1200 4300 10400 4500 1
Calculer les estimateurs empiriques du coefficient d’asymétrie et du co-efficient d’aplatissement.
3.15 Soit l’échantillon suivant
{12,16,20,23,26,28,30,32,33,35,36,38,39,40,41,43,45,47,50,57}.

Modélisation non paramétrique 17
a) Calculer l’estimateur lissé du soixantième centile.
b) Calculer l’estimateur lissé du troisième quartile.
3.16 On a les données groupées présentées dans le tableau ci-dessous. Ensupposant que les données sont distribuées uniformément sur chacundes intervalles, calculer une estimation empirique de E[min(X, 320)].
Classe Nombre de données
(0,50] 20(50,100] 34
(100,200] 22(200,500] 24
3.17 On dispose d’un échantillon de cinq données d’une distribution conti-nue. À partir de cet échantillon, un intervalle de confiance non paramé-trique pour la médiane est construit, dont les bornes sont les 2e et 4e
statistiques d’ordre de l’échantillon. Quel est le niveau de confiance decet intervalle ?
3.18 On dispose d’un échantillon de taille 500 d’une distribution continue.À partir de cet échantillon, un intervalle de confiance non paramé-trique pour la médiane est construit, dont les bornes sont les statistiquesd’ordre X(240) et X(260) de l’échantillon. Quel est le niveau de confiancede cet intervalle ?
3.19 Un assureur a enregistré les montants de sinistres suivants (en milliers) :
{1,1,1,2,2,3,5,6,9,10,12,15,15,20,30,32,33,33,35,40}.
Déterminer le niveau de confiance de l’intervalle [10,20) pour π0,55.
3.20 Soit Y ∼ Gamma(α, λ) et X = eY. On a
fY(y) =λα
Γ(α)yα−1e−λy, y > 0.
a) Déterminer la distribution de X.
b) Soit α = 1 et l’estimateur
λ =X
X− 1.
Évaluer empiriquement le biais de cet estimateur de la façon sui-vante :
1. Choisir une valeur de λ plus grande que 1 (la solution est construiteavec λ = 5).
2. Simuler des observations x(j)1 , . . . , x(j)
n de la variable X dont la dis-tribution a été déterminée en a).

18 Modélisation non paramétrique
3. Répéter les étapes 2 et 3 pour j = 1,2, . . . , r.
4. Calculer le biais moyen
5. Estimer le biais comme suit :
bλ(λ) =1r
r
∑j=1
λ(j) − λ.
Faire cette estimation pour
i) n = 10 et r = 1 000 ;
ii) n = 1 000 et r = 100 ; et
iii) n = 1 000 et r = 1 000.
Discuter de l’impact du nombre d’observations dans l’échantillon etdu nombre de répétitions dans la simulation.
c) En utilisant les estimateurs de la partie b) ii), tracer la fonction derépartition empirique de λ.
d) En utilisant les estimateurs de la partie c) et les classes calculées au-tomatiquement par la fonction hist, tracer l’histogramme et l’ogivede la distribution de λ.
e) Calculer les 45e et 70e quantiles lissés des données de la partie c).
Exercices proposés dans Loss Models
13.2, 13.3, 13.4, 13.6, 13.7, 13.8, 13.9, 14.2, 14.3, 14.6, 14.7, 14.8, 14.11, 14.12,14.14, 14.18, 14.19, 14.22, 14.25, 14.28, 14.29, 14.31, 14.34, 14.35, 3.1, 3.2, 3.4,3.13, 3.14, 3.16, 15.9, 15.10
Réponses
3.1 b)
F20(x) =
0, x ≤ 2(x− 2)/25, 2 < x ≤ 7(x− 5)/10, 7 < x ≤ 12(x + 58)/100, 12 < x ≤ 22(x + 42)/80, 22 < x ≤ 381, x > 38

Modélisation non paramétrique 19
c)
f20(x) =
0, x ≤ 21/25, 2 < x ≤ 71/10, 7 < x ≤ 121/100, 12 < x ≤ 221/80, 22 < x ≤ 380, x > 38.
3.2 120
3.3 81
3.4 0,396
3.5 0,17
3.6 a) 225
3.7 a) 0 b) 0,05 c) 0,125 d) 0,1333 e) 0 f) 0,02 g) 0,095
3.8 1,0264
3.9 d) 9,225 et 10,2369
3.10 (0,0964,0,7036)
3.11 0,5880
3.12 a) 0,05, 0,1026, 0,1582, 0,2170, 0,2795, 0,3462 b) 0,00001449
3.13 −0,559
3.14 γ1 = 0, γ2 = 3,125
3.15 a) 38,6 b) 42,5
3.16 134,54
3.17 0,625
3.18 0,6287
3.19 0,6208
3.20 a) Log-gamma(α, λ)


4 Modèles paramétriques potentiels
4.1 Soit X, une variable aléatoire avec densité Pareto(α, λ) représentant lemontant d’un sinistre et c > 0, une constante. Démontrer que la distribu-tion de Y = cX est une distribution Pareto(α, cλ).
4.2 Soit X, une variable aléatoire avec fonction de densité
f (x) =12θ
e−|x/θ|, −∞ < x < ∞.
Trouver la fonction de répartition de Y = eX .
4.3 Il existe une relation intéressante entre les fonctions de répartition des loisgamma et Poisson. Soit X, une variable aléatoire avec densité Gamma(α, β)et α un entier. Démontrer que
Pr(X ≤ x) = Pr(Y ≥ α),
où Y ∼ Poisson(x/β). Utiliser la paramétrisation de la loi gamma où lesecond paramètre est un paramètre d’échelle.
4.4 Soit X, une variable aléatoire avec densité de Pareto généralisée(α, τ, λ).Démontrer que la distribution de
Y =X
X + λ
est une distribution bêta et identifier les paramètres de cette loi.
4.5 Soit X, une variable aléatoire telle que X ∼ Pareto(α, 1). Trouver la fonc-tion de répartition de la variable aléatoire
Y = 5X−1/4
et identifier cette distribution ainsi que ses paramètres.
4.6 Soit X, une variable aléatoire avec densité Gamma(α, λ).
a) Trouver la fonction de densité de Y = eX .
b) Trouver E[Y] et Var[Y].c) Est-ce que tous les moments existent ?
21

22 Modèles paramétriques potentiels
4.7 Soit X, une variable aléatoire et i (0 ≤ i ≤ 1), le taux d’inflation pourl’année 2006. Pour chacune des lois ci-dessous, trouver la distribution deY = (1 + i)X :
a) X ∼ Pareto(α, λ).
b) X ∼ Burr(α, γ, θ).
c) X ∼ Log-gamma(α, λ).
4.8 Soit X, une variable aléatoire avec densité Pareto(α, λ). Trouver la fonc-tion de densité de
Y = X1/τ , τ > 0.
4.9 Un assureur modélise des données à l’aide de la variable aléatoire X quia une distribution de Pareto de paramètres α et θ. On pose
Y = ln(1 + X/θ).
Déterminer la distribution de Y.
4.10 Un assureur automobile a dans sa base de données les montants dessinistres de 2004. Il estime que les sinistres obéissaient alors à une loiBurr(α = 0,5, γ = 2, θ = 3). Pour s’en servir le premier janvier 2007, il sedoit de les mettre à jour selon les considérations suivantes :– 2005 : inflation de 4 % ;– 2006 : inflation de 4,5 % ; et– nouvelles taxes de 16 %.Quelle est la probabilité d’avoir un sinistre supérieur à 4 en 2007 ?
4.11 Soit X, la variable aléatoire représentant le montant d’un sinistre (enmillions) pour l’année 2006. Sa fonction de densité de probabilité est
f (x) = 3x−4, x ≥ 1.
On observe qu’une inflation de 10 % affecte uniformément tous les si-nistres de 2006 à 2007.
a) Trouver la fonction de répartition du montant des sinistres en 2007.
b) Trouver la probabilité que le montant d’un sinistre en 2007 soit su-périeur à 2 200 000 $.
4.12 Pour un assuré d’un certain groupe, le nombre de sinistres suit une loiBinomiale(10, θ). Sachant que, dans ce groupe, le paramètre θ est tiréd’une distribution uniforme sur l’intervalle (0,1), trouver la probabilitéqu’un assuré pris au hasard ait plus de six sinistres au cours d’unepériode.
4.13 Soit X, une variable aléatoire telle que la distribution conditionnelle deX étant donné le paramètre Θ = θ est une distribution Gamma(τ, θ), oùΘ obéit à une loi gamma de paramètres α et λ. Trouver la distributionde X.

Modèles paramétriques potentiels 23
4.14 On suppose que X a une distribution conditionnelle géométrique telleque
Pr(X = x|Θ = θ) = θ(1− θ)x−1, x = 1,2, . . .
et θ est une réalisation de la variable aléatoire Θ de loi Bêta(α, β). Dé-montrer que la fonction de masse de probabilité de X est
Pr(X = x) =Γ(α + β)Γ(α + 1)Γ(β + x− 1)
Γ(α)Γ(β)Γ(α + β + x).
4.15 On suppose que X a une distribution conditionnelle de Weibull(τ, θ1/τ)telle que
f (x|Θ = θ) = τθxτ−1e−θxτ, x > 0.
Aussi, on suppose que Θ∼Gamma(α, λ). Démontrer que la distributionmarginale de X est une Burr(α, τ, λ1/τ).
4.16 On suppose que le montant d’un sinistre pour un groupe d’assurésa une distribution Burr(5,1, λ). Si λ est une réalisation de la variablealéatoire Λ pour ce groupe d’assurés et que l’on suppose que Λ ∼Gamma(10,2), trouver l’espérance et la variance du montant d’un si-nistre pour un assuré pris au hasard.
4.17 Soit le taux d’échec suivant pour le montant d’un sinistre pour unevaleur donnée de θ,
λ(x|θ) =3
x + θ,
où x est la réalisation de la variable aléatoire X représentant le montantd’un sinistre et θ est la réalisation de la variable aléatoire Θ où Θ ∼Gamma(10,0,01). Trouver l’espérance et la variance du montant d’unsinistre pris au hasard.
4.18 Comparer les queues des lois Gamma(α, λ) et Log-normale(µ, σ2).
4.19 Soit X, une variable aléatoire représentant le montant d’un sinistre etl’espérance de vie résiduelle suivante
e(x) = 2 000 + 2x.
Pour un contrat d’assurance comportant une limite supérieure de 10 000,trouver le ratio d’élimination de perte (LER) de l’assureur.
4.20 Le tableau ci-dessous présente l’espérance de vie résiduelle pour cer-taines valeurs de x.
x e(x)
0 44 79 10,75
14 14,5

24 Modèles paramétriques potentiels
a) À quelle distribution peut-on associer ces données et quelles sont lesvaleurs de ses paramètres ?
b) Trouver E[X;10].
4.21 On construit une distribution raccordée sur les sous-intervalles (0,2),(2,8) et (8,16) avec les poids respectifs 0,5, 0,20 et 0,30. Dans chacundes sous-intervalles, on utilise une distribution gamma, de moyenneégale au point milieu du sous-intervalle et de variance égale à 1. Écrirela densité de probabilité obtenue sur (0,16). La réponse sera en fonctionde la gamma incomplète.
4.22 On construit un modèle raccordé avec une distribution uniforme surl’intervalle (0,10) et une loi de Pareto de paramètres α = 3 et λ = 100sur le reste des valeurs positives. Quels poids doivent être accordés auxdistributions pour que la densité obtenue soit continue ?
4.23 a) Comparer les queues d’une distribution Weibull(λ, τ) et d’une dis-tribution Weibull inverse(θ, α) en utilisant les critères suivants :
i) l’existence des moments ; et
ii) la comparaison des fonctions de survie.
b) En utilisant une distribution Weibull et une distribution Weibull in-verse dont les moyennes et variances sont égales, comparer graphi-quement les queues des distributions.
4.24 Soit Y, une variable aléatoire telle que
fY(y) =SX(y)E[X]
pour une variable aléatoire X quelconque. On dit qu’une telle distribu-tion est équilibrée. Démontrer que
MY(t) =MX(t)− 1
tE[X]
lorsque MX(t) existe. Astuce 1 : intégrer par parties. Astuce 2 : l’existencede MX(t) signifie que l’intégrale
MX(t) =∫ ∞
0etx fX(x)dx
converge.
4.25 Un assureur modélise ses sinistres par une variable aléatoire X avecdensité
f (x) = (1 + 2x2)e−2x , x ≥ 0.
a) Calculer la fonction de survie SX(x).
b) Calculer le taux d’incidence h(x).

Modèles paramétriques potentiels 25
c) Calculer la fonction d’espérance résiduelle e(x).
d) Calculer limx→∞ h(x).
e) Calculer limx→∞ e(x).
f) Démontrer que e(x) est une fonction strictement décroissante, maisque h(x) n’est pas une fonction strictement croissante.
Exercices proposés dans Loss Models
5.1, 5.3, 5.4, 5.5, 5.7, 5.9, 5.13, 5.17, 5.18, 5.19, 5.20, 5.21, 5.22, 5.23, 3.25, 3.26,3.27
Réponses
4.2 FY(y) = 12 eln(y)/θ I{0<y<1} + (1− 1
2 eln(y)/θ)I{y≥1}
4.4 Bêta(τ, α)
4.5 Burr inverse(α, 4, 5)
4.6 a) Log-gamma(α, λ) b) E[Y] = (λ/(λ − 1))α, Var[Y] = (λ/(λ − 2))α −(λ(λ− 1))2α c) Non
4.7 a) Pareto(α, (1 + i)λ) b) Burr(α, γ, (1 + i)θ) c) fY(y) = λα(1 + i)λ(ln(y)−ln(1 + i))α−1y−λ−1/Γ(α)
4.8 Burr(α, τ, λ1/τ)
4.9 Exponentielle(α)
4.10 0,6870
4.11 a) F(x) = 1− 1,331x−3, x ≥ 1,1 b) 0,125
4.12 4/11
4.13 X ∼ Pareto généralisée(α, τ, λ)
4.16 5/4 et 145/48
4.17 500, 850 000
4.18 La distribution log-normale a une queue plus lourde que la distributiongamma.
4.19 0,30
4.20 a) Pareto(7/3,16/3) b) 3,0215

26 Modèles paramétriques potentiels
4.21
fX(x) =
0,5e−x
Γ(1;2), 0 < x ≤ 2
0,2Γ(25;40)− Γ(25;10)
525x25−1e−5x
Γ(25), 2 < x ≤ 8
0,3Γ(144;192)− Γ(144;96)
12144x144−1e−12x
Γ(144), 8 < x ≤ 16
4.22 3/14
4.25 a) (1 + x + x2)e−2x
b) 2− (1 + 2x)/(1 + x + x2)c) (1 + x + 0,5x2)/(1 + x + x2)

5 Modélisation paramétrique
5.1 Soit X, une variable aléatoire représentant le montant d’un sinistre. Onsuppose
X|Λ = λ ∼ Exponentielle(λ)Λ ∼ Gamma(α, β).
Les sinistres suivants ont été observés :
{1,10,200,1 000,5 000}.
Estimer α et β par la méthode des moments.
5.2 On dispose d’un échantillon aléatoire avec deux données inférieures à2 000 et quatre données entre 2 000 et 5 000. Les données supérieures à5 000 n’ont pas été enregistrées. Écrire la fonction de vraisemblance pourun modèle de loi exponentielle.
5.3 Un assureur automobile a enregistré les montants de sinistres suivants :
{1 000,850,750,1 100,1 250,900}.
Il souhaite utiliser une distribution Gamma(α, 1/θ) pour les représenter.Estimer les paramètres de cette distribution à l’aide de la méthode desmoments.
5.4 Un actuaire dispose d’un échantillon aléatoire tiré d’une distribution log-logistique. Dans cet échantillon, 80 % des données sont supérieures à 100et 20 % des données sont supérieures à 400. Calculer les estimateurs desparamètres de la distribution à l’aide de la méthode des quantiles.
5.5 Soit x1, . . . , xn un échantillon aléatoire d’une population dont la fonctionde répartition est
FX(x) = xp, 0 < x < 1.
Déterminer l’estimateur de p par la méthode des moments.
5.6 Pendant une année, un assureur a enregistré les montants de sinistressuivants :
{500,1 000,1 500,2 500,4 500}.Il décide de modéliser ces données par une loi Log-normale(µ, σ). Enutilisant la méthode des moments, estimer les paramètres µ et σ. Calculerensuite la probabilité d’avoir un sinistre supérieur à 4 500.
27

28 Modélisation paramétrique
5.7 Soit X, une variable aléatoire avec densité
f (x) = β−2xe−12 ( x
β )2, x > 0, β > 0.
L’espérance de cette variable aléatoire est donnée par β√
2π/2. On a ob-servé les cinq valeurs suivantes :
{4,9,1,8,3,4,6,9,4,0}.
Déterminer l’estimateur de β à l’aide de la méthode des moments.
5.8 On suppose que la distribution du montant des sinistres obéit à une loiWeibull(τ, λ) de paramètres inconnus.
a) Sachant que 50 % des sinistres sont supérieurs à 1 000 $ et que 75 %des sinistres sont supérieurs à 500 $, estimer τ et λ par la méthodedes quantiles.
b) À partir des estimations obtenues en a), estimer le 80e centile.
5.9 Soit X, la variable aléatoire représentant le montant d’un sinistre. On sup-pose que le montant d’un sinistre pour un λ fixé obéit à une distributionExponentielle(λ) et que λ est une réalisation de la variable aléatoire Λ,où Λ ∼ Gamma(α, β). À la suite d’une expérience, on observe que 0,1 %des sinistres sont supérieurs à 450 et que 87,5 % des sinistres sont infé-rieurs à 50. Trouver l’équation, uniquement fonction de β, que l’on doitrésoudre pour estimer β et qui, après avoir été résolue, permet d’estimerle paramètre α.
5.10 Pour des contrats en assurance automobile avec les modalités suivantes,on a observé pour l’année 1999 :– un rapport d’élimination de perte de 0,56 avec une franchise forfai-
taire de d = 200 ;– un rapport d’élimination de perte de 0,32 avec une franchise atteinte
de d = 200 ;– un rapport d’élimination de perte de 0,79 avec une franchise forfai-
taire de d = 500 ;– un rapport d’élimination de perte de 0,52 avec une franchise atteinte
de d = 500.On a aussi observé que le montant moyen d’un sinistre est de 200 $.Si on suppose une loi de Weibull(τ, λ) pour modéliser le montant d’unsinistre, estimer les paramètres τ et λ par la méthode des quantiles.
5.11 Un assureur a déterminé que 20 % des sinistres de son portefeuille sontsupérieurs à 50 $ et que 10 % des sinistres sont supérieurs à 55 $. D’aprèsces données, estimer A et B (à l’aide de la méthode des quantiles) pour
fX(x) =
1
b− a, a < x < b
0, ailleurs.

Modélisation paramétrique 29
5.12 On a enregistré n essais indépendants X1, . . . , Xn de la variable aléatoireX ∼ Bernoulli(p). Trouver l’estimateur du maximum de vraisemblancepour p.
5.13 Soit X1, . . . , Xn, un échantillon aléatoire provenant d’une loi normale deparamètres µ et σ2 inconnus.a) Trouver les estimateurs du maximum de vraisemblance de µ et σ2.b) Démontrer que µ et σ2 ont approximativement une distribution nor-
male conjointe avec moyennes µ et σ2 et variances σ2/n et 2σ4/n.c) Trouver l’approximation de la distribution de l’estimateur h(µ, σ2)
de
h(µ, σ2) = Pr(X ≤ c) = Φ(
c− µ
σ
).
5.14 Soit X, une variable aléatoire représentant les montants de sinistres donton possède un échantillon de taille n. La fonction de densité de proba-bilité de X est
f (x) = 2θxe−θx2, x > 0.
Déterminer l’estimateur du maximum de vraisemblance de θ.
5.15 Un assureur possède un échantillon aléatoire x1, . . . , xn et il souhaitemodéliser la variable aléatoire sous-jacente à l’aide de la fonction
F(x) = xp, 0 < x < 1.
a) Déterminer l’estimateur du maximum de vraisemblance de p.b) Quelle est la variance asymptotique de l’estimateur du maximum de
vraisemblance de p ?c) À partir de la réponse obtenue en b), déterminer un intervalle de
confiance de niveau 95 % pour p.d) Déterminer l’estimateur du maximum de vraisemblance de E[X].e) À partir de la réponse obtenue en d), déterminer un intervalle de
confiance de niveau 95 % pour E[X].5.16 La variable aléatoire X a la densité suivante :
f (x) = αλα(λ + x)−α−1, x > 0.
On sait que λ = 1 000. À partir de l’échantillon
{43,145,233,396,777},
déterminer l’estimation du maximum de vraisemblance de α.
5.17 Quatre observations sont faites d’une variable aléatoire dont la densitéest
f (x) = 2λxe−λx2, x > 0.
La seule information dont on dispose est qu’une des quatre observa-tions est inférieure à 2. Calculer une estimation du maximum de vrai-semblance de λ.

30 Modélisation paramétrique
5.18 Un échantillon de taille 40 a été tiré d’une population dont la densité est
f (x) = (2πθ)−1/2e−x2/(2θ), −∞ < x < ∞.
À partir de cet échantillon, on détermine une estimation du maximumde vraisemblance de θ : θ = 2. Déterminer une approximation de l’erreurquadratique de θ.
5.19 On suppose que X obéit à une distribution log-gamma :
f (x) =λ2 ln(x)
xλ+1 , x > 1.
a) Trouver l’estimateur des moments de λ.b) Trouver l’estimateur du maximum de vraisemblance de λ.
5.20 Soit l’échantillon suivant provenant d’une distribution Gamma(5, λ) :
{2,20,5,4,19}.
a) Trouver l’estimateur du maximum de vraisemblance de λ et en cal-culer la valeur.
b) Trouver la variance de λ si λ = 58 .
5.21 Le tableau ci-dessous présente les sinistres payés en 1999. On pose l’hy-pothèse que la sévérité d’un sinistre est distribuée selon une loi de Pa-reto de paramètres α et 1. Déterminer l’équation finale permettant detrouver l’estimateur du maximum de vraisemblance de α.
Montant Nombre de sinistres
(0,2] 2(2,5] 0
(5,11] 1(11, ∞) 1
5.22 Le tableau ci-dessous présente les sinistres payés par un assureur. Onpose que la distribution de X est une exponentielle de paramètre β in-connu. Quel est l’estimateur du maximum de vraisemblance de β ?
Montant Nombre de sinistres
(0,1] 1(1,2] 0
(2, ∞) 1
5.23 Soit X1, . . . , Xn un échantillon aléatoire provenant d’une loi Weibull dedensité
f (x) = 2λxe−λx2, x > 0.
On estime Pk = Pr(X ≤ k) par la méthode du maximum de vraisem-blance.

Modélisation paramétrique 31
a) Déterminer Pk.
b) Déterminer la variance de l’estimateur trouvé en a).
c) Si X1 = X2 = 10 et X3 = 15, calculer Pr(P10 ≤ 12 ).
5.24 Sachant qu’un échantillon aléatoire X1, . . . , X50 provenant d’une distri-bution de Pareto(α, λ) a conduit aux estimations α = 1,5 et λ = 1 500par la méthode du maximum de vraisemblance, estimer les variancesdes estimateurs α et λ ainsi que leur covariance.
5.25 On suppose que le montant d’un sinistre obéit à une loi de Pareto(α, λ).Pendant une année, on observe 50 sinistres. À l’aide des montants des50 sinistres, on obtient α = 2, λ = 4, Var[α] = 24 et Var[λ] = 40. Si lacovariance entre les estimateurs α et λ est 10, trouver un intervalle deconfiance de niveau α = 0,15 pour Pr(X > 10).
5.26 Soit X la variable aléatoire représentant le montant d’un sinistre. Onobserve les sinistres suivants en assurance automobile :
{25,88,33,62,44,75,47,53}.
On suppose que X ∼ Exponentielle(λ).
a) Estimer la variance de la distribution de l’estimateur du maximumde vraisemblance de E[X;50].
b) Estimer la variance de la distribution de l’estimateur du maximumde vraisemblance de π0,95.
5.27 Soit X, une variable aléatoire indiquant si une expérience est un succès(1) ou un échec (0) et dont la distribution est une loi de Bernoulli deparamètre α. On sait que la distribution a priori du paramètre α est uneloi U(0,1). On a observé un succès en trois essais.
a) Calculer l’estimateur bayesien α si la fonction de perte choisie estl’erreur quadratique.
b) Trouver l’estimation bayesienne de la probabilité que α se retrouveentre 0,2 et 0,4.
5.28 On suppose que X|Θ = θ obéit à une loi de Poisson(θ) et que la distri-bution a priori de Θ est une loi Gamma(α, λ). Pour un échantillon detaille n, trouver l’estimateur bayesien θ si la fonction de perte choisie estl’erreur quadratique.
5.29 On suppose que X|A = α ∼ Pareto(α, 1) et que la distribution a prioride A est une Exponentielle(3).
a) Trouver la distribution a posteriori de A.
b) Calculer α à partir de l’échantillon {2,1,2,3,3,4} si la fonction deperte choisie est l’erreur quadratique.

32 Modélisation paramétrique
5.30 On suppose que X|B = β ∼ Exponentielle(β) et que la distribution apriori de B est une Gamma(2,3). On a l’échantillon aléatoire suivant :
{6,11,8,13,9}
a) Calculer l’estimateur bayesien du paramètre β si la fonction de perteest l’erreur quadratique.
b) Répéter la partie a) avec la fonction de perte valeur absolue de l’er-reur. On fournit les valeurs
Γ(7;4,734) = 0,2 Γ(7;5,411) = 0,3 Γ(7;6,039) = 0,4Γ(7;6,670) = 0,5 Γ(7;7,343) = 0,6.
5.31 Au cours d’une session, les étudiants en actuariat font des devoirs in-formatiques. En faisant ces devoirs, il leur arrive de rester bloqués. Lenombre de fois où un étudiant reste bloqué dans un devoir suit unedistribution Binomiale(3, θ), où l’on suppose que θ est uniformémentdistribué sur l’intervalle (0,25,0,75). Deux étudiants sont restés bloquéschacun deux fois pendant un certain devoir.a) Trouver l’estimateur bayesien de θ avec une fonction de perte qua-
dratique.b) Déterminer la probabilité a posteriori que θ se retrouve dans l’inter-
valle (0,6,0,7).
5.32 Pour des contrats d’assurance comportant une rétention de 1,5 millions,40 catastrophes ont été déclarées au réassureur. Le réassureur supposeque les montants de sinistres obéissent à une loi de Pareto(α, λ). SoitW la variable aléatoire représentant un montant de sinistre déclaré auréassureur (en millions). À l’aide des montants qui lui ont été déclarés,le réassureur a estimé les paramètres α et λ par la méthode du maximumde vraisemblance. Il a obtenu α = 5,084 et λ = 28,998.a) Trouver, par la méthode du maximum de vraisemblance, l’estimation
de Pr(W > 29,5).b) Si la matrice variance-covariance de (α, λ) est[
23,92 167,07167,07 1 199,32
],
estimer la variance de l’estimateur de Pr(W > 29,5) utilisé en a).
5.33 Soit X la variable aléatoire représentant le montant d’un sinistre. Onsuppose X ∼ Exponentielle(λ). Pour des contrats d’assurance compor-tant une franchise forfaitaire de 100 $ et une limite supérieure de 3 000 $,les montants de sinistres suivants ont été payés par l’assureur :
{100,200,250,425,515,630,1 000,1 500,2 900,2 900}.
Estimer le montant espéré d’un sinistre par la méthode du maximumde vraisemblance.

Modélisation paramétrique 33
5.34 Un assureur signe un traité de réassurance excess-of-loss de plein 150,c’est-à-dire que l’assureur ne paie que les 150 premiers dollars de chaquesinistre et le réassureur se charge de l’excédent. Cet assureur veut cal-culer combien lui coûterait la hausse du plein à 200, mais il ignore ladistribution du coût des sinistres. L’assureur a payé les montants sui-vants :
{10,70,100,105,110,150,150,150}
et il suppose que le coût des sinistres est distribué comme suit :
f (x) =
{λe−λx , x > 00, ailleurs.
Quel est l’estimateur du maximum de vraisemblance de λ en supposantque les trois montants de 150 de l’échantillon proviennent d’un montantpayé supérieur à 150 $ ?
5.35 On dispose d’un échantillon tiré d’une loi exponentielle présentant deuxobservations entre 0 et 2, quatre observations entre 2 et 5 et trois obser-vations entre 5 et 8. Estimer le paramètre de la loi par la méthode deCramér–von Mises avec poids unitaires.
Exercices proposés dans Loss Models
15.1, 15.2, 15.3, 15.4, 15.6, 15.8, 15.11, 15.12, 15.15, 15.20, 15.22, 15.23, 15.24,15.25, 15.26, 15.29, 15.33, 15.37, 15.38, 15.39, 15.40, 15.46, 15.47, 15.48, 15.51,15.52, 15.53, 15.57, 15.58, 15.59, 15.60, 15.62, 15.64, 15.65, 15.66, 15.68, 15.70,15.71, 15.72, 15.73, 15.75
Réponses
5.1 α = 3,45, β = 3 048,87
5.2 L(λ) = [(1− e−2 000λ)2(e−2 000λ − e−5 000λ)4]/(1− e−5 000λ)6
5.3 α = 34,83, θ = 27,99
5.4 γ = 2, θ = 200
5.5 x/(1− x)
5.6 µ = 7,40, σ = 0,6368 et 0,056
5.7 3,3511
5.8 a) τ = 1,2687, λ = 0,000747 b) 1 947
5.9 β(β + 450)0,3010 = β0,3010(β + 50)

34 Modélisation paramétrique
5.10 τ = 0,48, λ = 0,01,
5.11 a = 10, b = 60
5.12 p = X
5.13 a) µ = X, σ2 = S2 c) h(µ, σ2)∼ N(h(µ, σ2), V), V = φ2((c− µ)/σ)(1/n +(c− µ)2/(2nσ2))
5.14 n/ ∑ni=1 x2
i
5.15 a) −n/ ∑ni=1 ln xi b) p2/n c) p± 1,96p/
√n d) p/(1 + p) e) p/(1 + p)±
1,96p(1 + p)−2/√
n
5.16 3,8629
5.17 14 ln 4
3
5.18 0,20
5.19 a)√
X/(√
X− 1) b) 2n/ ∑ni=1 ln(Xi)
5.20 a) 1/2 b) 1/64
5.21 L(α) = (1− (1/3)α)2((1/6)α − (1/12)α)(1/12)α
5.22 ln(1,5)
5.23 a) 1− e−λk2, λ = n/ ∑n
i=1 X2i b) k4λ2e−2λk2
/n c) 0,4875
5.24 Var[α] = 0,28133, Var[λ] = 656 250, Cov(α, λ) = 393,75
5.25 (0,0,7653)
5.26 a) 20,68 b) 3 196
5.27 a) 0,4 b) 0,3432
5.28 (α + ∑ni=1 Xi)/(λ + n)
5.29 a) Gamma(n + 1,3 + ∑ni=1 ln(1 + xi)) b) 0,68
5.30 a) 0,14 b) 0,1334
5.31 a) 0,5668 b) 0,3055
5.32 a) 0,0365 b) 0,00057
5.33 1 302,50
5.34 0,0059
5.35 0,2286

6 Tests d’adéquation
6.1 On suppose que la variable aléatoire représentant le montant d’un si-nistre a une distribution de Pareto avec paramètres α = 2 et λ = 1 000.Un échantillon de taille 10 présente trois données entre 0 et 250, deuxdonnées entre 250 et 500, trois données entre 500 et 1 000 et deux don-nées supérieures à 1 000. Appliquer le test du khi carré à un seuil designification de 10 % même si les nombres de sinistres attendus danschaque classe ne sont pas supérieurs à cinq.
6.2 Le tableau ci-dessous présente un échantillon de 1 000 données groupées.
Intervalle Nombre de données
(0,3] 180(3,7,5] 180
(7,5,15] 235(15,40] 255(40, ∞) 150
Une loi de Pareto a été ajustée à ces données et les estimateurs obtenussont α = 3,5 et λ = 50. Quel est le seuil de signification le plus élevé(parmi 5 %, 2,5 %, 1 % et 0,5 %) auquel on ne rejette pas ce modèle avecle test du khi carré ?
6.3 On dispose de l’échantillon aléatoire {0,1, 0,4, 0,8, 0,8, 0,9} et on veut yajuster la distribution avec fonction de densité de probabilité
f (x) =1 + 2x
2, 0≤ x ≤ 1.
Calculer la statistique de Kolmogorov–Smirnov et réaliser un test avec unseuil de signification de 5 %.
6.4 La compagnie d’assurance Great Company a obtenu les montants de si-nistres suivants :
{1,1,2,2,2,2,3,3,4,8}.a) Trouver la distribution empirique.
b) Si le montant d’un sinistre obéit à une loi de Pareto(2,2), calculer ladistance de Cramér–von Mises avec poids unitaires.
35

36 Tests d’adéquation
c) Un compétiteur sujet aux mêmes sinistres, Greater Company, a perdutoutes les données sur ses sinistres. Dans un élan de sollicitude, GreatCompany lui fournit ses données, mais sous la forme restreinte ci-dessous.
Montants des sinistres Nombre de sinistres
(0,2] 6(0,4] 9(0,8] 10
Calculer la distance de Cramér–von Mises avec poids unitaires.
6.5 Soit la distribution avec fonction de densité de probabilité
f (x) =x2
, 0≤ x ≤ 2,
et soit l’échantillon tiré de cette densité {0,5, 1, 1,25, 1,5}. Calculer la sta-tistique de Kolmogorov–Smirnov.
6.6 On veut tester si
fX(x) =
{x
50 , 0 < x < 100, ailleurs
est un bon modèle pour les données suivantes :
{1, 4, 6, 9, 8, 7, 9,5}.
Utiliser la statistique de Kolmogorov–Smirnov avec un seuil de significa-tion de 5 %. (Utiliser la valeur critique c = 1,36/
√n même si n < 15.)
6.7 En supposant que les données du tableau ci-dessous sont associées à uneloi de Pareto(1,8), calculer la statistique de Pearson.
Intervalle Fréquence
(0,5] 10(5,20] 5
(20, ∞) 5
6.8 On a observé les sinistres suivants en assurance habitation :
{125,550,550,700}.
On hésite entre les distributions Gamma(3,0,01) et Gamma(3,5,0,01) pourmodéliser le montant d’un sinistre. Utiliser la statistique de Kolmogorov–Smirnov pour guider le choix de la distribution. Voici quelques valeursde la Gamma incomplète : Γ(3,5;1,25) = 0,0729, Γ(3,5;5,51) = 0,8614,Γ(3,5;7) = 0,9488. De plus, pour α entier, on a
Γ(α; x) = 1−α−1
∑j=0
xje−x
j!.

Tests d’adéquation 37
6.9 On a observé les sinistres du tableau ci-dessous en assurance médica-ments. Déterminer, à l’aide de la statistique de Pearson, si l’hypothèsed’une distribution avec taux d’échec constant
λ(x) = 0,01, x > 0
est appropriée à un niveau de confiance de 95 %.
Montants des sinistres Nombre de sinistres
[0,25) 10[25,40) 5[40,60) 10[60,80) 5[80, ∞) 20
6.10 On détient les informations du tableau ci-dessous sur l’expérience desinistres d’un portefeuille d’assurance.
Montants de sinistres Fréquence
[0,25) 10[25,50) 12[50,100) 12[100,200) 11[200, ∞) 5
On hésite entre une loi de Pareto(1,5, 50) et une loi de Weibull(0,01, 1)pour la distribution du montant d’un sinistre.
a) Quel modèle privilégier si on utilise la distance de Cramér–von Misesavec poids unitaires pour guider le choix ?
b) Si la statistique de Pearson avait été utilisée au lieu de la distancede Cramér–von Mises, l’hypothèse de la loi Pareto(1,5,50) aurait-elleété rejetée à un niveau de confiance α = 0,05 ?
c) Si l’on obtient une distance de Cramér–von Mises de 0,01 lorsque l’onsuppose X ∼ Log-normale(µ = 65, σ2 = 5 500), est-ce que, selon cettestatistique, le choix de cette distribution est meilleur que le choix dela distribution de Pareto(1,5,50) ?
6.11 Au départ d’une course de chevaux, il y a habituellement huit positionsde départ et la position numéro 1 est la plus proche de la palissade.On soupçonne qu’un cheval a plus de chances de gagner quand il porteun numéro faible, c’est-à-dire lorsqu’il est plus proche de la palissadeintérieure. Le tableau ci-dessous présente les résultats pour 144 courses.
Numéro 1 2 3 4 5 6 7 8
Gains 29 19 18 25 17 10 15 11

38 Tests d’adéquation
a) Poser les hypothèses à tester (hypothèse nulle et hypothèse alterna-tive).
b) La comparaison de la distribution observée à la distribution théo-rique s’effectue par un test de Kolmogorov–Smirnov. Que peut-onen conclure ?
6.12 À partir d’un échantillon contenant 100 données, un assureur obtient lesrésultats présentés dans le tableau ci-dessous pour cinq modèles postu-lés. Déterminer le meilleur modèle selon le critère bayesien de Schwarz.
Modèle Nombre de paramètres Log-vraisemblance
Pareto généralisée 3 −219,1Burr 3 −219,2Pareto 2 −221,2Log-normale 2 −221,4Exponentielle inverse 1 −224,4
Exercices proposés dans Loss Models
16.1, 16.2, 16.3, 16.4, 16.5, 16.8, 16.9, 16.11, 16.12, 16.15, 16.16
Réponses
6.1 Q = 0,7740
6.2 0,5 %
6.3 D = 0,32
6.4 b) 0,3478 c) 0,0242
6.5 0,4375
6.6 D = 0,1329
6.7 1,1667
6.8 Gamma(3,5,0,01)
6.9 Q = 1,8179
6.10 a) Weibull b) oui c) oui
6.11 b) D = 0,132
6.12 Pareto

7 Modèles de fréquence
7.1 Un assureur décide de modéliser la fréquence des sinistres par une dis-tribution N ∼ Binomiale(m, θ) dont le paramètre m est connu.
a) Démontrer que l’estimateur du maximum de vraisemblance de θ estsans biais.
b) Déterminer directement la variance de cet estimateur.
c) Déterminer la variance de cet estimateur en calculant l’information deFisher.
d) Déterminer un intervalle de confiance approximatif de niveau 1− αpour la paramètre θ.
7.2 Un portefeuille de la compagnie Even Greater Company comptant 10 000risques a produit les fréquences de sinistres présentées dans le tableau ci-dessous.
Fréquence Nombre de risques
0 9 0481 9052 453 2
4+ 0
a) Déterminer l’estimateur du maximum de vraisemblance du paramètreλ d’une loi de Poisson ainsi qu’un intervalle de confiance de niveau95 % pour ce paramètre.
b) Soit une distribution géométrique de paramètre β = (1− θ)/θ, c’est-à-dire que
Pr(N = k) =βk
(β + 1)k+1 , k = 0,1, . . .
Déterminer l’estimateur du maximum de vraisemblance du paramètreβ ainsi qu’un intervalle de confiance de niveau 95 % pour ce para-mètre.
c) Déterminer les estimateurs de la méthode des moments des para-mètres d’une distribution binomiale négative avec fonction de masse
39

40 Modèles de fréquence
de probabilité
Pr(N = k) =(
k + r− 1r− 1
)βk
(β + 1)k+r , k = 0,1, . . .
d) Répéter la partie c) pour les estimateurs du maximum de vraisem-blance en utilisant une procédure numérique.
7.3 Un assureur offre un contrat couvrant les accidents automobiles causéspar des hommes et par des femmes. L’information pour 1 000 polices estprésentée dans le tableau ci-dessous.
Fréquence Hommes Femmes
0 901 9471 92 502 5 23 1 14 1 0
5+ 0 0
a) Déterminer l’estimateur du maximum de vraisemblance du paramètreλ d’une loi de Poisson pour la variable N1, le nombre de sinistres cau-sés par des hommes, et la variable N2, le nombre de sinistres causéspar des femmes.
b) En supposant que N1 et N2 sont des variables indépendantes, déter-miner un modèle pour N = N1 + N2.
7.4 Le tableau ci-dessous présente des données de fréquence annuelle d’ac-cidents pour un portefeuille d’assurance automobile.
Fréquence Nombre de risques
0 8611 1212 133 34 15 06 1
7+ 0
a) Ajuster une distribution Binomiale(7, θ) à ces données en estimant leparamètre θ par la méthode du maximum de vraisemblance.
b) Ajuster plutôt une distribution binomiale négative aux données par laméthode des moments. Utiliser la paramétrisation de l’exercice 7.2 c).
c) Répéter la partie b) en estimant plutôt par la méthode du maximumde vraisemblance.

Modèles de fréquence 41
7.5 Démontrer que la distribution Binomiale négative(r, β(β + 1)−1) est lerésultat du mélange continu de distributions de Poisson suivant
N|Λ = λ ∼ Poisson(λ)Λ ∼ Gamma(r, β).
7.6 Un assureur modélise la fréquence des sinistres par une distribution Bi-nomiale négative(3,1/6). La sévérité des sinistres est modélisée par unedistribution Exponentielle(0,01). Si une franchise de 20 $ est ajoutée aucontrat, calculer E[N∗], l’espérance de la fréquence modifiée.
7.7 Un portefeuille d’assurance compte 1 000 contrats. Le tableau ci-dessousrésume l’information connue à propos de la fréquence des sinistres.
Nombre de sinistres Nombre de contrats
0 1001 2672 3113 2084 875 236 4
7+ 0
Parmi les distributions binomiale, Poisson, binomiale négative, normaleet gamma, laquelle semble la plus appropriée pour modéliser ces don-nées ?
7.8 Un assureur enregistre tous les jours d’une année (365 jours) le nombrede réclamations qu’il reçoit. Les données recueillies sont présentées dansle tableau ci-dessous. L’assureur utilise une distribution de Poisson demoyenne 0,6 pour modéliser la variable aléatoire du nombre quotidiende sinistres. Déterminer la statistique de Pearson.
Nombre de sinistres Nombre de jours
0 2091 1112 333 74 35 2
Exercices proposés dans Loss Models
6.1, 6.2, 6.3, 15.18, 15.19, 15.4, 15.104, 15.105, 15.106, 15.109, 15.110, 8.29, 8.32,8.33, 8.34

42 Modèles de fréquence
Réponses
7.1 b) θ(1− θ)/(nm) c) θ(1− θ)/(nm) d) θ ± zα/2
√θ(1− θ)/(mn)
7.2 a) 0,1001± 1,96√
0,1001/10 000 b) 0,1001± 1,96√
0,1001(1,1001)/10 000c) r = 55,67, β = 0,0018 d) r = 52,73, µ = 0,1001
7.3 a) λ1 = 0,109 et λ2 = 0,057 b) N ∼ Poisson(0,166)
7.4 a) 0,0237 b) r = 0,4715, β = 0,3521 c) r = 0,656, µ = 0,166
7.6 12,28
7.7 Binomiale
7.8 2,85

A Paramétrisation des lois deprobabilité
Cette annexe précise la paramétrisation des lois de probabilité continueset discrètes utilisée dans les énoncés des exercices. Dans certains cas, elle estdifférente de celle présentée dans les annexes A et B de Klugman et collab.(2008a). En particulier, nous utilisons toutes les distributions de la famillegamma transformée avec un paramètre de taux (λ) plutôt qu’un paramètred’échelle (θ). De plus, l’ordre des paramètres est différent.
En plus de la fonction de densité de probabilité et de la fonction de répar-tition, l’annexe fournit les éléments suivants pour chaque loi : la racine foodes fonctions dfoo, pfoo, qfoo, rfoo, mfoo et levfoo telles que définiesdans R et actuar ; les noms des arguments de ces fonctions correspondantà chacun des paramètres de la loi ; le ke moment (ainsi que l’espérance etla variance pour les cas les plus usuels) ; l’espérance limitée (lois continuesseulement) ; la fonction génératrice des moments M(t), lorsqu’elle existe ; lafonction génératrice des probabilités P(z) (lois discrètes seulement).
Dans les formules ci-dessous,
Γ(α; x) =1
Γ(α)
∫ x
0tα−1e−t dt, α > 0, x > 0
avec
Γ(α) =∫ ∞
0tα−1e−t dt
est la fonction gamma incomplète, alors que
β(a, b; x) =1
β(a, b)
∫ x
0ta−1(1− t)b−1 dt, a > 0, b > 0, 0 < x < 1
avec
β(a, b) =∫ 1
0ta−1(1− t)b−1 dt =
Γ(a)Γ(b)Γ(a + b)
est la fonction bêta incomplète régularisée.Sauf avis contraire, les paramètres sont strictement positifs et les fonctions
sont définies pour x > 0.
43

44 Paramétrisation des lois de probabilité
A.1 Famille bêta transformée
A.1.1 Bêta transformée (α, γ, τ, θ)
Racine : trbeta, pearson6Paramètres : shape1 (α), shape2 (γ), shape3 (τ), rate (λ = 1/θ),scale (θ)
f (x) =γuτ(1− u)α
xβ(α, τ), u =
v1 + v
, v =( x
θ
)γ
F(x) = β(τ, α;u)
E[Xk] =θkΓ(τ + k/γ)Γ(α− k/γ)
Γ(α)Γ(τ), −τγ < k < αγ
E[X; x] =θΓ(τ + 1/γ)Γ(α− 1/γ)
Γ(α)Γ(τ)β(τ + 1/γ, α− 1/γ;u) + x(1− F(x))
A.1.2 Burr (α, γ, θ)
Racine : burrParamètres : shape1 (α), shape2 (γ), rate (λ = 1/θ), scale (θ)
f (x) =αγuα(1− u)
x, u =
11 + v
, v =( x
θ
)γ
F(x) = 1− uα
E[Xk] =θkΓ(1 + k/γ)Γ(α− k/γ)
Γ(α), −γ < k < αγ
E[X; x] =θΓ(1 + 1/γ)Γ(α− 1/γ)
Γ(α)β(1 + 1/γ, α− 1/γ;u) + xuα
A.1.3 Burr inverse (τ, γ, θ)
Racine : invburrParamètres : shape1 (τ), shape2 (γ), rate (λ = 1/θ), scale (θ)
f (x) =τγuτ(1− u)
x, u =
v1 + v
, v =( x
θ
)γ
F(x) = uτ
E[Xk] =θkΓ(τ + k/γ)Γ(1− k/γ)
Γ(τ), −τγ < k < γ
E[X; x] =θΓ(τ + 1/γ)Γ(1− 1/γ)
Γ(α)β(τ + 1/γ, 1− 1/γ;u) + x(1− uτ)

A.1. Famille bêta transformée 45
A.1.4 Pareto généralisée (α, τ, θ)
Racine : genparetoParamètres : shape1 (α), shape2 (τ), rate (λ = 1/θ), scale (θ)
f (x) =uτ(1− u)α
xβ(α, τ), u =
v1 + v
, v =xθ
F(x) = β(τ, α;u)
E[Xk] =θkΓ(τ + k)Γ(α− k)
Γ(α)Γ(τ), −τ < k < α
E[X] =θτ
α− 1, α > 1
Var[X] =θ2τ(τ + α− 1)(α− 1)2(α− 2)
, α > 2
E[X; x] =θτ
α− 1β(τ + 1, α− 1;u) + x(1− F(x))
A.1.5 Pareto (α, θ)
Racine : pareto, pareto2Paramètres : shape (α), scale (θ)
f (x) =αuα(1− u)
x, u =
11 + v
, v =xθ
F(x) = 1− uα
E[Xk] =θkΓ(k + 1)Γ(α− k)
Γ(α), −1 < k < α
E[X] =θ
α− 1, α > 1
Var[X] =θ2α
(α− 1)2(α− 2), α > 2
E[X; x] =
θ
α− 1
[1−
(θ
x + θ
)α−1]
, α ≠ 1
−θ ln(
θ
x + θ
), α = 1
A.1.6 Pareto inverse (τ, θ)
Racine : invparetoParamètres : shape (τ), scale (θ)
f (x) =τuτ(1− u)
x, u =
v1 + v
, v =xθ
F(x) = uτ

46 Paramétrisation des lois de probabilité
E[Xk] =θkΓ(τ + k)Γ(1− k)
Γ(τ), −τ < k < 1
E[X; x] = θkτ∫ u
0
yτ
1− ydy + x(1− uτ)
A.1.7 Log-logistique (γ, θ)
Racine : llogisParamètres : shape (γ), rate (λ = 1/θ), scale (θ)
f (x) =γu(1− u)
x, u =
v1 + v
, v =( x
θ
)γ
F(x) = u
E[Xk] = θkΓ(1 + k/γ)Γ(1− k/γ), −γ < k < γ
E[X; x] = θΓ(1 + 1/γ)Γ(1− 1/γ)β(1 + 1/γ, 1− 1/γ;u) + x(1− u)
A.1.8 Paralogistique (α, θ)
Racine : paralogisParamètres : shape (α), rate (λ = 1/θ), scale (θ)
f (x) =α2uα(1− u)
x, u =
11 + v
, v =( x
θ
)α
F(x) = 1− uα
E[Xk] =θkΓ(1 + k/α)Γ(α− k/α)
Γ(α), −γ2 < k < α2
E[X; x] =θΓ(1 + 1/α)Γ(α− 1/α)
Γ(α)β(1 + 1/α, α− 1/α;u) + xuα
A.1.9 Paralogistique inverse (τ, θ)
Racine : invparalogisParamètres : shape (τ), rate (λ = 1/θ), scale (θ)
f (x) =τ2uτ(1− u)
x, u =
v1 + v
, v =( x
θ
)τ
F(x) = uτ
E[Xk] =θkΓ(τ + k/τ)Γ(1− k/τ)
Γ(τ), −τ2 < k < τ
E[X; x] =θΓ(τ + 1/τ)Γ(1− 1/τ)
Γ(τ)β(τ + 1/τ, 1− 1/τ;u) + x(1− uτ)

A.2. Famille gamma transformée 47
A.2 Famille gamma transformée
A.2.1 Gamma transformée (α, τ, λ)
Racine : trgammaParamètres : shape1 (α), shape2 (τ), rate (λ), scale (θ = 1/λ)
f (x) =τuαe−u
xΓ(α), u = (λx)τ
F(x) = Γ(α;u)
E[Xk] =Γ(α + k/τ)
λkΓ(α), k > −ατ
E[X; x] =Γ(α + 1/τ)
λΓ(α)Γ(α + 1/τ;u) + x(1− Γ(α;u))
A.2.2 Gamma transformée inverse (α, τ, λ)
Racine : invtrgammaParamètres : shape1 (α), shape2 (τ), rate (λ), scale (θ = 1/λ)
f (x) =τuαe−u
xΓ(α), u = (λx)−τ
F(x) = 1− Γ(α;u)
E[Xk] =Γ(α− k/τ)
λkΓ(α), k < ατ
E[X; x] =Γ(α− 1/τ)
λΓ(α)(1− Γ(α− 1/τ;u)) + xΓ(α;u)
A.2.3 Gamma (α, λ)
Racine : gammaParamètres : shape (α), rate (λ), scale (θ = 1/λ)
f (x) =uαe−u
xΓ(α), u = λx
F(x) = Γ(α;u)
E[Xk] =Γ(α + k)λkΓ(α)
, k > −α
E[X] =α
λ
Var[X] =α
λ2

48 Paramétrisation des lois de probabilité
E[X; x] =Γ(α + 1)
λΓ(α)Γ(α + 1;u) + x(1− Γ(α;u))
M(t) =(
λ
λ− t
)α
A.2.4 Gamma inverse (α, λ)
Racine : invgammaParamètres : shape (α), rate (λ), scale (θ = 1/λ)
f (x) =uαe−u
xΓ(α), u = (λx)−1
F(x) = 1− Γ(α;u)
E[Xk] =Γ(α− k)λkΓ(α)
, k < α
E[X; x] =Γ(α− 1)
λΓ(α)(1− Γ(α + 1;u)) + xΓ(α;u)
A.2.5 Weibull (τ, λ)
Racine : weibullParamètres : shape (τ), scale (θ = 1/λ)
f (x) =τue−u
x, u = (λx)τ
F(x) = 1− e−u
E[Xk] =Γ(1 + k/τ)
λk , k > −τ
E[X; x] =Γ(1 + 1/τ)
λΓ(1 + 1/τ;u) + xe−u
A.2.6 Weibull inverse (τ, λ)
Racine : invweibull, lgompertzParamètres : shape (τ), rate (λ), scale (θ = 1/λ)
f (x) =τue−u
x, u = (λx)−τ
F(x) = e−u
E[Xk] =Γ(1− k/τ)
λk , k < τ
E[X; x] =Γ(1− 1/τ)
λ(1− Γ(1− 1/τ;u)) + x(1− e−u)

A.3. Autres distributions continues 49
A.2.7 Exponentielle (λ)
Racine : expParamètre : rate (λ)
f (x) =ue−u
x, u = λx
F(x) = 1− e−u
E[Xk] =Γ(k + 1)
λk , k > −1
E[X] =1λ
Var[X] =1
λ2
E[X; x] =1− e−u
λ
M(t) =λ
λ− t
A.2.8 Exponentielle inverse (λ)
Racine : invexpParamètres : rate (λ), scale (θ = 1/λ)
f (x) =ue−u
x, u = (λx)−1
F(x) = e−u
E[Xk] =Γ(1− k)
λk , k < 1
A.3 Autres distributions continues
A.3.1 Normale (µ, σ2)
Racine : normParamètres : mean (−∞ < µ < ∞), sd (σ)
f (x) =1√2πσ
exp{− 1
2
(x− µ
σ
)2}, −∞ < x < ∞
F(x) = Φ(
x− µ
σ
), Φ(x) =
1√2π
∫ x
−∞e−y2
dy
E[X] = µ
Var[X] = σ2
M(t) = eµt+σ2t2/2

50 Paramétrisation des lois de probabilité
A.3.2 Log-normale (µ, σ2)
Racine : lnormParamètres : meanlog (α), sdlog (σ)
f (x) =1√2πσ
1x
exp{− 1
2
(ln x− µ
σ
)2}F(x) = Φ
(ln x− µ
σ
)E[Xk] = ekµ+k2σ2/2
E[X] = eµ+σ2/2
Var[X] = e2µ+σ2(eσ2 − 1)
A.3.3 Log-gamma (α, λ)
Racine : lgammaParamètres : shapelog (α), ratelog (λ)
f (x) =λα(ln x)α−1
xλ+1Γ(α), x > 1
F(x) = Γ(α;λ ln x), x > 1
E[Xk] =(
λ
λ− k
)α
E[X] =(
λ
λ− 1
)α
Var[X] =(
λ
λ− 2
)α
−(
λ
λ− 1
)2α
E[X; x] =(
λ
λ− 1
)α
Γ(α; (λ− 1) ln x) + x(1− Γ(α;λ ln x))
A.3.4 Pareto translatée (α, θ)
Racine : pareto1Paramètres : shape (α), min (θ)
f (x) =αθα
xα+1 , x > θ
F(x) = 1−(
θ
x
)α
, x > θ
E[Xk] =αθk
α− k, k < α
E[X; x] =αθ
α− 1− θ
(α− 1)xα−1

A.3. Autres distributions continues 51
Cette loi est également appelée Pareto à un paramètre. Seul α est considérécomme un véritable paramètre de la distribution. Le paramètre θ est la borneinférieure du support de la distribution et est en général considéré connu.
A.3.5 Bêta généralisée (α, β, τ, θ)
Racine : genbetaParamètres : shape1 (α), shape2 (β), shape3 (τ), rate (λ = 1/θ),scale (θ)
f (x) =τuα(1− u)β−1
xβ(α, β), u =
( xθ
)τ, 0 < x < θ
F(x) = β(α, β;u)
E[Xk] =θkΓ(α + β)Γ(α + k/τ)Γ(α)Γ(α + β + k/τ)
, k > −ατ
E[X; x] =θΓ(α + β)Γ(α + 1/τ)Γ(α)Γ(α + β + 1/τ)
β(α + 1/τ, β;u) + x(1− β(α, β;u))
A.3.6 Bêta (α, β)
Racine : betaParamètres : shape1 (α), shape2 (β)
f (x) =Γ(α + β)Γ(α)Γ(β)
xα−1(1− x)β−1, 0 < x < 1
F(x) = β(α, β; x)
E[Xk] =Γ(α + β)Γ(α + k)Γ(α)Γ(α + β + k)
, k > −α
E[X] =α
α + β
Var[X] =αβ
(α + β)2(α + β + 1)
E[X; x] =Γ(α + β)Γ(α + 1)Γ(α)Γ(α + β + 1)
β(α + 1, β;u) + x(1− β(α, β; x))

52 Paramétrisation des lois de probabilité
A.4 Distributions discrètes de la famille (a, b, 0)
A.4.1 Binomiale (n, θ)
Racine : binomParamètres : size (n), prob (θ)
Pr(X = x) =(
nx
)θx(1− θ)n−x , n entier, 0 < θ < 1, x = 0,1, . . .
E[X] = nθ
Var[X] = nθ(1− θ)
M(t) = (1− θ + θet)n
P(z) = (1− θ(z− 1))n
A.4.2 Binomiale négative (r, θ)
Racine : nbinomParamètres : size (r), prob (θ), mu (µ = r(1− θ)/θ)
Pr(X = x) =(
x + r− 1r− 1
)θr(1− θ)x , 0 < θ < 1, x = 0,1, . . .
E[X] =r(1− θ)
θ
Var[X] =r(1− θ)
θ2
M(t) =(
θ
1− (1− θ)et
)r
P(z) = (1− (1− θ)z)−r
A.4.3 Géométrique (θ)
Racine : nbinomParamètre : prob (θ)
Pr(X = x) = θ(1− θ)x , 0 < θ < 1, x = 0,1, . . .
E[X] =1− θ
θ
Var[X] =1− θ
θ2
M(t) =θ
1− (1− θ)et
P(z) = (1− (1− θ)z)−1

A.4. Distributions discrètes de la famille (a, b, 0) 53
A.4.4 Poisson (λ)
Racine : poisParamètre : lambda (λ)
Pr(X = x) =λxe−λ
x!, x = 0,1, . . .
E[X] = λ
Var[X] = λ
M(t) = eλ(et−1)
P(z) = eλ(z−1)


B Installation de packages dans R
Plusieurs exercices de ce recueil requièrent l’utilisation du package actuar(Dutang et collab., 2008). Le package doit être installé depuis le site Compre-hensive R Archive Network (CRAN ; http://cran.r-project.org). Cette an-nexe explique comment configurer R pour faciliter l’installation et l’adminis-tration de packages externes.
Les instructions ci-dessous sont centrées autour de la création d’une bi-bliothèque personnelle où seront installés les packages R téléchargés de CRAN.Il est fortement recommandé de créer une telle bibliothèque. Cela permetd’éviter d’éventuels problèmes d’accès en écriture dans la bibliothèque prin-cipale et de conserver les packages intacts lors des mises à jour de R. Nousmontrons également comment spécifier le site miroir de CRAN pour éviterd’avoir à le répéter à chaque installation de package.
1. Identifier le dossier de départ de l’utilisateur. En cas d’incertitude, exami-ner la valeur de la variable d’environnement HOME 1, soit depuis R avec lacommande
> Sys.getenv("HOME")
ou encore directement depuis Emacs avec
M-x getenv RET HOME RET
Tout comme R et Emacs, nous référerons à ce dossier par le symbole ~.
2. Créer un dossier qui servira de bibliothèque de packages personnelle.Dans la suite, nous utiliserons ~/R/library.
3. Dans un fichier nommé ~/.Renviron (donc situé dans le dossier de dé-part), enregistrer la ligne appropriée ci-dessous selon votre système d’ex-ploitation :
R_LIBS="~/R/library;${R_LIBS}" (Windows)
R_LIBS="~/R/library:${R_LIBS}" (OS X, Linux, Unix)
Au besoin, remplacer le chemin ~/R/library par celui du dossier créé àl’étape précédente. Utiliser la barre oblique avant (/) dans le chemin pourséparer les dossiers.
1. Dans Windows, la variable est créée par l’assistant d’installation de GNU Emacs lorsqu’ellen’existe pas déjà.
55

56 Installation de packages dans R
4. Dans un fichier nommé ~/.Rprofile, enregistrer les options suivantes :
options(repos = "http://cran.ca.r-project.org",menu.graphics = FALSE)
Si désiré, remplacer la valeur de l’option repos par l’URL d’un autre sitemiroir de CRAN.
Consulter la rubriques d’aide de Startup pour les détails sur la syntaxe etl’emplacement des fichiers de configuration, celles de library et .libPathspour la gestion des bibliothèques et celle de options pour les différentesoptions reconnues par R.
Après un redémarrage de R, la bibliothèque personnelle aura préséancesur la bibliothèque principale et il ne sera plus nécessaire de préciser le sitemiroir de CRAN lors de l’installation de packages. Ainsi, la simple com-mande
> install.packages("actuar")
téléchargera le package actuar depuis de le miroir canadien de CRAN etl’installera dans le dossier ~/R/library. Pour charger le package en mémoire,on fera
> library("actuar")
On peut arriver au même résultat sans utiliser les fichiers de configuration.Renviron et .Rprofile. Il faut cependant recourir aux arguments lib etrepos de la fonction install.packages et à l’argument lib.loc de la fonctionlibrary. Consulter les rubriques d’aide de ces deux fonctions pour de plusamples informations.
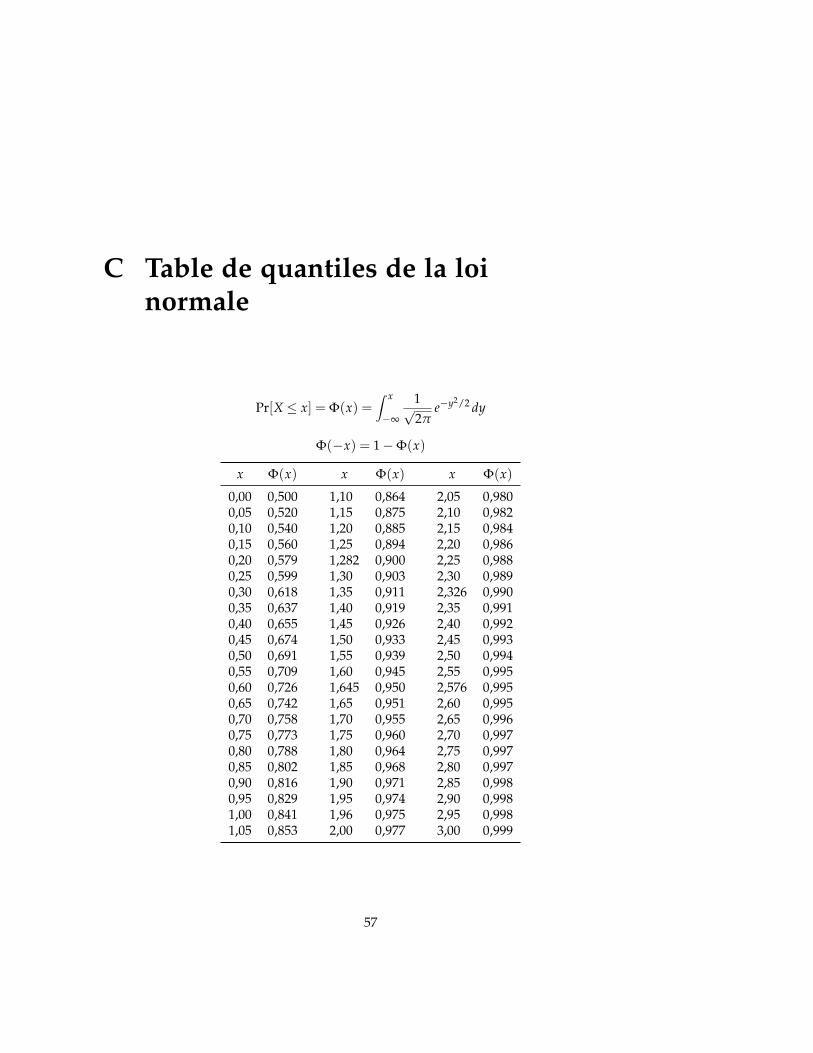
C Table de quantiles de la loinormale
Pr[X ≤ x] = Φ(x) =∫ x
−∞
1√2π
e−y2/2 dy
Φ(−x) = 1−Φ(x)
x Φ(x) x Φ(x) x Φ(x)
0,00 0,500 1,10 0,864 2,05 0,9800,05 0,520 1,15 0,875 2,10 0,9820,10 0,540 1,20 0,885 2,15 0,9840,15 0,560 1,25 0,894 2,20 0,9860,20 0,579 1,282 0,900 2,25 0,9880,25 0,599 1,30 0,903 2,30 0,9890,30 0,618 1,35 0,911 2,326 0,9900,35 0,637 1,40 0,919 2,35 0,9910,40 0,655 1,45 0,926 2,40 0,9920,45 0,674 1,50 0,933 2,45 0,9930,50 0,691 1,55 0,939 2,50 0,9940,55 0,709 1,60 0,945 2,55 0,9950,60 0,726 1,645 0,950 2,576 0,9950,65 0,742 1,65 0,951 2,60 0,9950,70 0,758 1,70 0,955 2,65 0,9960,75 0,773 1,75 0,960 2,70 0,9970,80 0,788 1,80 0,964 2,75 0,9970,85 0,802 1,85 0,968 2,80 0,9970,90 0,816 1,90 0,971 2,85 0,9980,95 0,829 1,95 0,974 2,90 0,9981,00 0,841 1,96 0,975 2,95 0,9981,05 0,853 2,00 0,977 3,00 0,999
57


D Table de quantiles de la loi khicarré
Pr[X ≤ x] =∫ x
0
1Γ(r/2)2r/2 yr/2−1e−r/2 dx
59
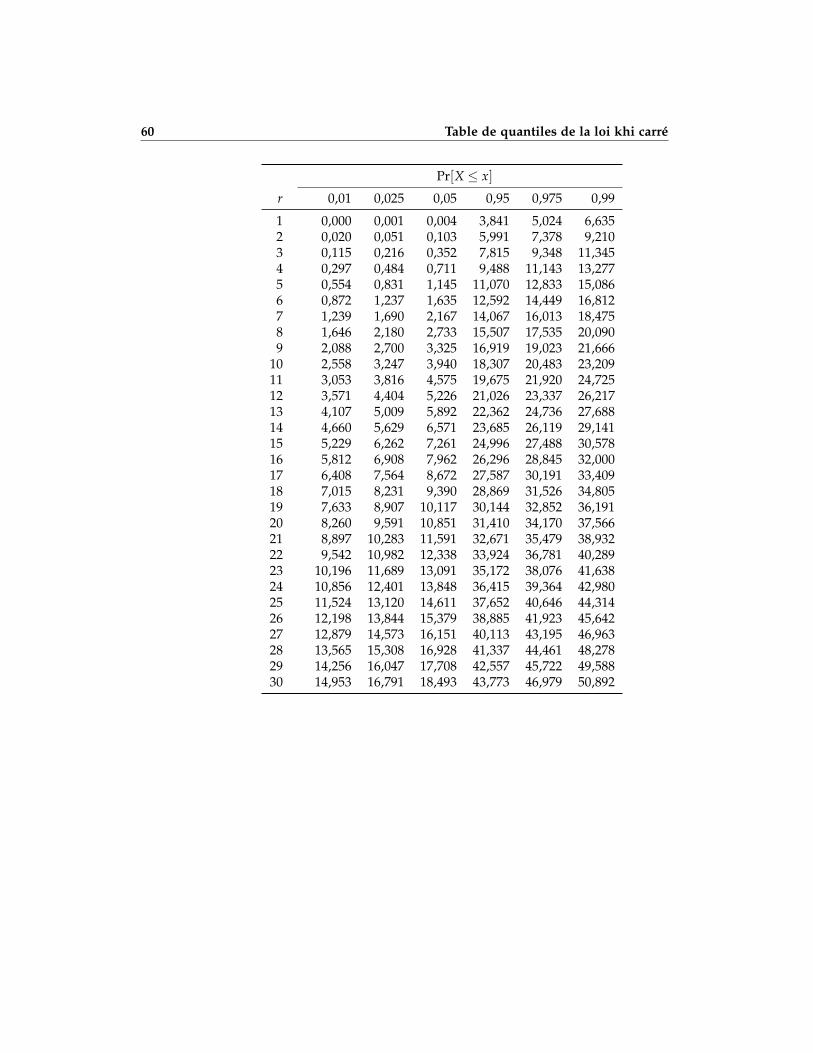
60 Table de quantiles de la loi khi carré
Pr[X ≤ x]
r 0,01 0,025 0,05 0,95 0,975 0,99
1 0,000 0,001 0,004 3,841 5,024 6,6352 0,020 0,051 0,103 5,991 7,378 9,2103 0,115 0,216 0,352 7,815 9,348 11,3454 0,297 0,484 0,711 9,488 11,143 13,2775 0,554 0,831 1,145 11,070 12,833 15,0866 0,872 1,237 1,635 12,592 14,449 16,8127 1,239 1,690 2,167 14,067 16,013 18,4758 1,646 2,180 2,733 15,507 17,535 20,0909 2,088 2,700 3,325 16,919 19,023 21,666
10 2,558 3,247 3,940 18,307 20,483 23,20911 3,053 3,816 4,575 19,675 21,920 24,72512 3,571 4,404 5,226 21,026 23,337 26,21713 4,107 5,009 5,892 22,362 24,736 27,68814 4,660 5,629 6,571 23,685 26,119 29,14115 5,229 6,262 7,261 24,996 27,488 30,57816 5,812 6,908 7,962 26,296 28,845 32,00017 6,408 7,564 8,672 27,587 30,191 33,40918 7,015 8,231 9,390 28,869 31,526 34,80519 7,633 8,907 10,117 30,144 32,852 36,19120 8,260 9,591 10,851 31,410 34,170 37,56621 8,897 10,283 11,591 32,671 35,479 38,93222 9,542 10,982 12,338 33,924 36,781 40,28923 10,196 11,689 13,091 35,172 38,076 41,63824 10,856 12,401 13,848 36,415 39,364 42,98025 11,524 13,120 14,611 37,652 40,646 44,31426 12,198 13,844 15,379 38,885 41,923 45,64227 12,879 14,573 16,151 40,113 43,195 46,96328 13,565 15,308 16,928 41,337 44,461 48,27829 14,256 16,047 17,708 42,557 45,722 49,58830 14,953 16,791 18,493 43,773 46,979 50,892

E Solutions
Plusieurs solutions faisant appel à R utilisent des fonctions des packagesactuar (Dutang et collab., 2008) et MASS (Venables et Ripley, 2002). On sup-pose donc que les packages ont été chargés en mémoire avec
> library("actuar")> library("MASS")
Chapitre 1
1.1 On a
limx→0
12
=12
et
limx→0
12− x2
24=
12
.
En utilisant le théorème «sandwich», on obtient donc directement
limx→0
1− cos(x)x2 =
12
.
La figure E.1 présente le graphique de la fonction et des deux bornes,ainsi que le code R pour créer ce graphique.
1.2 Il suffit d’appliquer la règle de l’Hôpital :
limx→0
xln(x + 1)
= limx→0
dx/dxd ln(x + 1)/dx
= limx→0
11/(x + 1)
= 1.
61
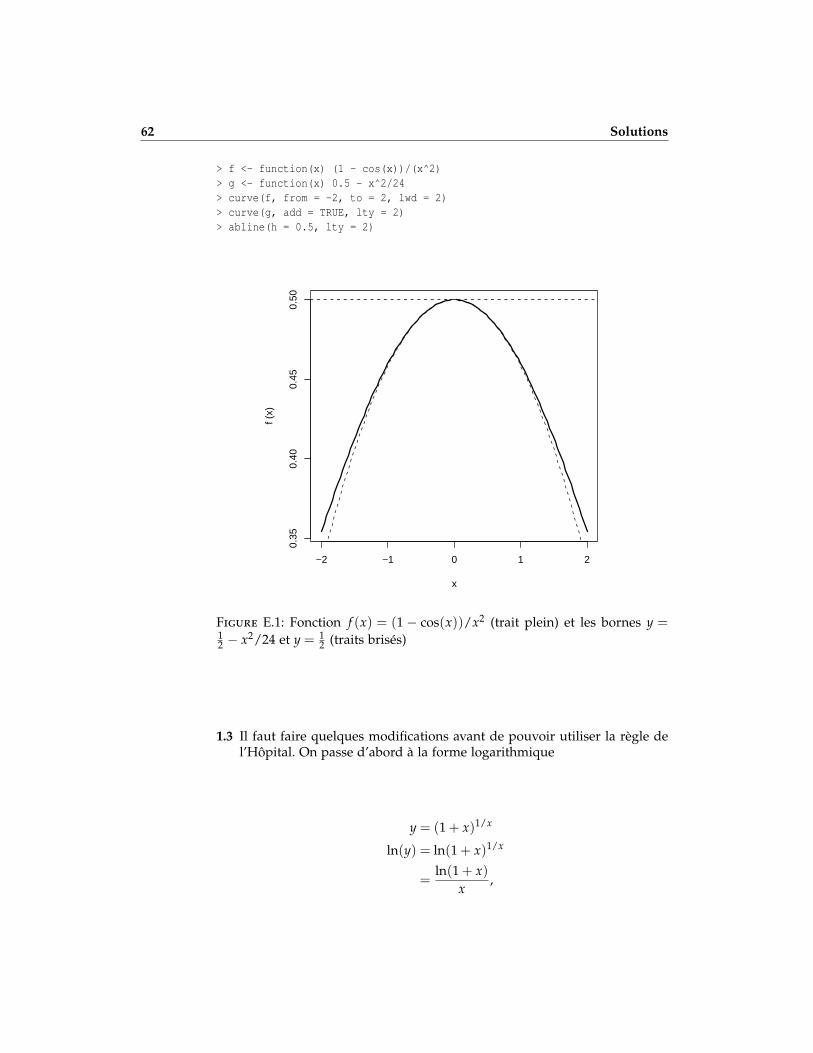
62 Solutions
> f <- function(x) (1 - cos(x))/(x^2)> g <- function(x) 0.5 - x^2/24> curve(f, from = -2, to = 2, lwd = 2)> curve(g, add = TRUE, lty = 2)> abline(h = 0.5, lty = 2)
−2 −1 0 1 2
0.35
0.40
0.45
0.50
x
f (x)
Figure E.1: Fonction f (x) = (1 − cos(x))/x2 (trait plein) et les bornes y =12 − x2/24 et y = 1
2 (traits brisés)
1.3 Il faut faire quelques modifications avant de pouvoir utiliser la règle del’Hôpital. On passe d’abord à la forme logarithmique
y = (1 + x)1/x
ln(y) = ln(1 + x)1/x
=ln(1 + x)
x,

Solutions 63
pour ensuite calculer la limite à l’aide de la règle de l’Hôpital
limx→0
ln(y) = limx→0
d ln(1 + x)/dxdx/dx
= limx→0
ln(1 + x)x
= limx→0
1/(1 + x)1
= 1
et enfin revenir à la forme exponentielle
limx→0
y = limx→0
(1 + x)1/x
= e1
= e.
1.4 a) On utilise la règle de l’Hôpital pour évaluer
limx→∞
xln(x)
= limx→∞
dx/dxd ln(x)/dx
= limx→∞
11/x
= limx→∞
x
= ∞.
Il est donc possible de conclure que le numérateur tend plus rapide-ment vers l’infini que le dénominateur, c’est-à-dire que x tend plusrapidement vers l’infini que ln(x).
b) De manière similaire,
limx→∞
xex = lim
x→∞
dx/dxdex/dx
= limx→∞
1ex
= 0,
d’où ex tend plus rapidement vers l’infini que x.
1.5 a) On a f (x) = cos(x), f (0) = 1, f ′(x) = −sin(x), f ′(0) = 0, f ′′(x) =−cos(x), f ′′(0) = −1, f ′′′(x) = sin(x), f ′′′(0) = 0, et ainsi de suite.On obtient donc
cos(x) = 1− x2
2!+
x4
4!− . . .

64 Solutions
b) On a f (x) = sin(x), f (0) = 0, f ′(x) = cos(x), f ′(0) = 1, f ′′(x) =−sin(x),f ′′(0) = 0, f ′′′(x) =−cos(x), f ′′′(0) =−1, et ainsi de suite. On obtientdonc
sin(x) = x− x3
3!+
x5
5!− . . .
c) On obtient
eix = 1 + ix +i2x2
2!+
i3x3
3!+
i4x4
4!+
i5x5
5!+ . . .
= 1 + ix− x2
2!− i
x3
3!+
x4
4!+ i
x5
5!− . . . .
En regroupant les termes, on obtient
eix =(
1− x2
2!+
x4
4!− . . .
)+ i(
x− x3
3!+
x5
5!− . . .
)d) Des résultats obtenus en a), b) et c), on a directement
eix = cos(x) + i sin(x).
e) En posant x = π dans le résultat en d), on obtient
eiπ = cos(π) + i sin(π)= −1 + i(0)= −1.
1.6 Il faut démontrer que la fonction F(x) est non décroissante, que sa limiteà droite est 1, que sa limite à gauche est 0 et qu’elle est continue (à droite).Clairement, on a limx→−∞ F(x) = 0, et limx→∞ F(x) = 1. De plus,
F′(x) =e−x
(1 + e−x)2 > 0,
qui implique que la fonction est non décroissante.
1.7 La fonction g(x) est clairement positive. Il faut démontrer que l’intégralesur la totalité du domaine de cette fonction est 1 :∫ ∞
x0
g(x)dx =∫ ∞
x0
f (x)1− F(x0)
dx
=
∫ ∞x0
f (x)dx
1− F(x0)
=1− F(x0)1− F(x0)
= 1.
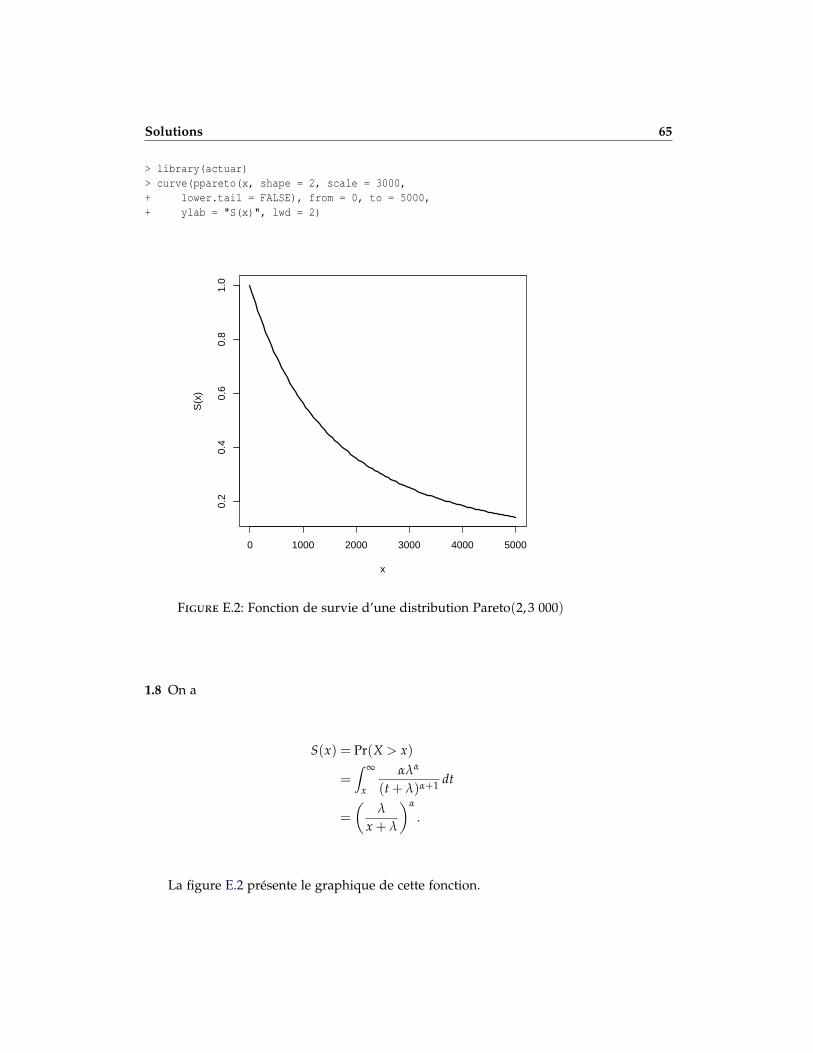
Solutions 65
> library(actuar)> curve(ppareto(x, shape = 2, scale = 3000,+ lower.tail = FALSE), from = 0, to = 5000,+ ylab = "S(x)", lwd = 2)
0 1000 2000 3000 4000 5000
0.2
0.4
0.6
0.8
1.0
x
S(x
)
Figure E.2: Fonction de survie d’une distribution Pareto(2,3 000)
1.8 On a
S(x) = Pr(X > x)
=∫ ∞
x
αλα
(t + λ)α+1 dt
=(
λ
x + λ
)α
.
La figure E.2 présente le graphique de cette fonction.

66 Solutions
1.9 On a que Y = n− X si, et seulement si, X = n−Y. Ainsi,
Pr(Y = y) = Pr(X = n− y)
=(
nn− y
)pn−y(1− p)n−(n−y)
=(
ny
)(1− p)y pn−y, y = 0,1, . . . ,
d’où Y ∼ Binomiale(n, 1− p).
1.10 a) On a Y = eX où X ∼ N(µ, σ2). Par conséquent,
FY(x) = Pr[Y ≤ x]
= Pr[eX ≤ x]= Pr[X ≤ ln x]= FX(ln x)
et
fY(x) = F′Y(x)
=1x
fX(ln x).
b) La fonction génératrice des moments de X est MX(t) = eµt+σ2t2/2. Ona
Var[Y] = E[Y2]− E[Y]2
= E[e2X ]− E[eX ]2
= MX(2)−M2X(1)
= e2µ+2σ2 − e2µ+σ2
= e2µ+σ2(eσ2 − 1).
1.11 On a
E[|X|] =∫ ∞
−∞
|x|π
11 + x2 dx
=∫ 0
−∞
−xπ
11 + x2 dx +
∫ ∞
0
xπ
11 + x2 dx
=2π
∫ ∞
0
x1 + x2 dx
= lima→∞
2π
∫ a
0
x1 + x2 dx
= lima→∞
ln(1 + a2)
= ∞.

Solutions 67
1.12 On utilise la définition de l’espérance :
E[λg(X)] =∞
∑x=0
λg(x)e−λλx
x!
=∞
∑x=0
g(x)(
e−λλx+1
x!
)(x + 1x + 1
)=
∞
∑x=0
(x + 1)g(x)e−λλx+1
(x + 1)!.
Il faut maintenant faire un glissement d’indice et ajouter un terme pourobtenir
E[λg(X)] =∞
∑x=1
xg(x− 1)e−λλx
x!
=∞
∑x=0
xg(x− 1)e−λλx
x!
= E[Xg(X− 1)].
1.13 Il suffit de remarquer que M + m = X + Y. Le résultat découle ensuitedirectement par linéarité de l’espérance : E[M] + E[m] = E[X] + E[Y].
1.14 On utilise la technique de la fonction de répartition :
FY(y) = Pr(Y ≤ y)= Pr(4X + 3≤ y)
= Pr(
X ≤ y− 34
)= FX
(y− 3
4
)= 1− e7
(y−3
4
).
La densité est alors
fY(y) = F′Y(y) =74
e−74 (y−3), y > 3.
1.15 On utilise la technique de la fonction de répartition :
FY(y) = Pr(Y ≤ y)
= Pr(
X3 ≤ y)
= Pr(
X ≤ y13
)=
19
∫ y13
0x2 dx
=y27
.

68 Solutions
On trouve donc que
fY(y) = F′Y(y) =1
27, 0≤ y ≤ 27.
1.16 Selon l’énoncé, X ∼ N(0,σ2) et Y = X2. Il faut voir que Y = X2 n’est pasune transformation bijective (à une valeur de Y correspond plus d’unevaleur de X). On pose W = |X| et on trouve la densité de W à l’aide dela technique de la fonction de répartition :
FW(w) = Pr(|X| ≤ w)= Pr(−w ≤ X ≤ w)= FX(w)− FX(−w)
et donc
fW(w) = fX(w) + fX(−w)
=2
σ√
2πe−x2/(2σ2).
On pose maintenant Y = W2 = |X|2 = X2 et on trouve la densité de Ypar la technique du changement de variable :
fY(y) = fW(y1/2)∣∣∣∣ ddy
y1/2∣∣∣∣
= fW(y1/2)∣∣∣∣ 12√
y
∣∣∣∣=
2σ√
2πe−y/(2σ2)
(1
2√
y
)=
(2σ2)−1/2
Γ( 12 )
y−1/2e−y/(2σ2)
puisque√
π ≡ Γ( 12 ). On a donc que Y ∼ Gamma( 1
2 , 12 σ−2). De manière
équivalente, on peut aussi poser X = σZ, où Z ∼ N(0,1), et utiliser lerésultat connu que Z2 ∼ χ2(1) ≡ Gamma( 1
2 , 12 ).
1.17 Si X est une variable aléatoire dont la distribution est symétrique autourdu point a, alors E[X] = a. On a donc
µ3 = E[(X− a)3]
=∫ ∞
−∞(x− a)3 f (x)dx
=∫ a
−∞(x− a)3 f (x)dx +
∫ ∞
a(x− a)3 f (x)dx.

Solutions 69
En faisant le changement de variable y = x− a, on obtient
µ3 =∫ 0
−∞y3 f (y + a)dy +
∫ ∞
0y3 f (y + a)dy
=∫ ∞
0−y3 f (−y + a)dy +
∫ ∞
0y3 f (y + a)dy
= 0,
puisque f (−y + a) = f (y + a) par symétrie autour du point a. Par consé-quent, γ1 = µ3/µ3/2
2 = 0.
1.18 La distribution de la variable aléatoire X est en fait une Exponentielle(1).Par conséquent, E[X] = Var[X] = 1 et
µ3 = E[(X− 1)3]
=∫ ∞
0(x− 1)3e−x dx
=∫ ∞
0(x3 − 3x2 + 3x− 1)e−x dx
= Γ(4)− 3Γ(3) + 3Γ(2)− Γ(1)= 3!− 3! + 3− 1= 2
en reconnaissant des lois gamma. Ainsi, on obtient γ1 = µ3/µ3/22 = 2.
1.19 On trouve que µ2 = 1/3, µ4 = 1/5 et donc γ2 = µ4/µ22 = 9/5. Comme
γ2 < 3, la distribution a des queues moins lourdes que la distributionnormale.
1.20 Par définition,
MX(t) = E[etX ]
=∫ c
0
2xc2 etx dx
=2
c2t2 (ctect − ect + 1).
1.21 Par le théorème central limite, on sait que X1 ∼ N(µ, σ2/n) et X2 ∼N(µ, σ2/n). Comme les deux variables aléatoires sont indépendantes,X1 − X2 ∼ N(0,2σ2/n). Ainsi,
Pr(|X1 − X2| <
σ
5
)= Pr
(−σ/5
σ/√
n/2<
X1 − X2
σ/√
n/2<
σ/5σ/√
n/2
)= Pr
(15
√n2
< Z <15
√n2
),
où Z ∼ N(0,1). On doit donc trouver une valeur de n tel que Pr(Z ≥√n/(5
√2)) ≈ 0,005. On trouve dans une table de quantiles de la loi
normale que√
n/(5√
2) = 2,576, et donc que n ≈ 332.

70 Solutions
1.22 a) On a Xi ∼ Gamma(25, 12 ). Or, une somme de n lois gamma indépen-
dantes de paramètres αi et λ est une loi gamma de paramètres ∑ni=1 αi
et λ. Par conséquent, ∑ni=1 Xi ∼Gamma(2 500, 1
2 ) et X∼Gamma(2 500,50).
b) On obtient avec R
> diff(pgamma(c(49, 51), 2500, 50))
[1] 0.6827218
c) Pour obtenir une approximation de la probabilité en b), on peut uti-liser le Théorème central limite. On a que E[X] = 2 500/50 = 50 etVar[X] = 2 500502 = 1. Par conséquent,
Pr[49 < X < 51] = Pr[
49− 501
<X− 50
1<
51− 501
]≈ Pr[−1 < Z < 1]= Φ(1)−Φ(−1)= 2Φ(1)− 1= 0,6826,
où Z ∼ N(0,1).
1.23 Par définition, le biais est
bΘ(θ) = E[Θ]− θ
= 749 500−(
2(1 000)2
(2)(1)−(
1 0002
)2)
= −500.
L’erreur quadratique moyenne est
MSE(Θ) = Var[Θ] + bΘ(θ)2
= 750 + (−500)2
= 250 750.
1.24 a) Par linéarité de l’espérance,
E
[n
∑i=1
aiXi
]=
n
∑i=1
aiE[Xi]
=n
∑i=1
aiµ
= µn
∑i=1
ai
= µ.

Solutions 71
b) Étant donné que les variables sont indépendantes, on a
Var
[n
∑i=1
aiXi
]=
n
∑i=1
a2i Var[Xi]
= σ2n
∑i=1
a2i .
Il faut donc minimiser ∑ni=1 a2
i sous la contrainte ∑ni=1 ai = 1. Or,
n
∑i=1
a2i =
n
∑i=1
((ai −
1n
)+
1n
)2
=n
∑i=1
(ai −
1n
)2+
1n
,
étant donné que le produit croisé vaut 0. Ainsi, l’expression ∑ni=1 a2
iest minimisée en choisissant ai = 1/n pour tout i. Par conséquent,
X =n
∑i=1
1n
Xi
possède la plus petite variance parmi tous les estimateurs sans biaislinéaires.
1.25 On a
E
[1n
n
∑i=1
(Xi − µ)2
]=
1n
n
∑i=1
E[(Xi − µ)2]
=1n
n
∑i=1
σ2
= σ2.
1.26 En utilisant la définition de l’espérance, on obtient
E[T(X)] = 0 + 0 + (2)(
θ
2
)1= θ.
1.27 Soit Var[X] = θ et
θ = nXn
(1− X
n
).

72 Solutions
On a
E[θ] = E[X]− E[X2]n
= np− np(1− p) + (np)2
n= np− p(1− p)− np2
= np(1− p)− p(1− p)= θ − p(1− p).
Par conséquent, θ est un estimateur de θ avec un biais de −p(1− p).
1.28 On sait que
Var[X] =Var[X]
n=
λ
n.
De plus,
E
[(∂
∂λln f (X;λ)
)2]
= E
[(X− λ
λ
)2]
=1
λ2 Var[X]
=1λ
.
La borne de Rao–Cramér est doncλ
n= Var[X] .
Comme la variance de l’estimateur est égale à la borne de Rao–Cramér,son efficacité vaut 1 et de X est un estimateur sans biais à varianceminimale du paramètre λ d’une loi de Poisson.
1.29 D’abord, on cherche un estimateur sans biais :
E[Z] = αE[X] + βE[Y]= α0,8z + βz= z,
d’où β = 1− 0,8α. Ensuite, on cherche un estimateur avec une varianceminimale :
Var[Z] = α2Var[X] + β2Var[Y]
= α2z2 + β2(1,5)z2
= (α2 + 1,5(1− 0,8α)2)z2.
Cette dernière expression est minimisée lorsque α2 + 1,5(1− 0,8α)2 estminimisé, c’est-à-dire, lorsque α = 0,6122. On trouve ensuite que β =0,5102.

Solutions 73
1.30 a) On a
f (x;θ) =1θ
x1/θ−1(1− x)1−1, 0 < x < 1, θ > 0,
soit une distribution bêta de paramètres α = 1/θ et β = 1.b) On a ln f (xi;θ) = (θ−1 − 1) ln xi − lnθ et, donc,
`(θ) =(
1θ− 1) n
∑i=1
ln xi − n lnθ.
Par conséquent,
ddθ
`(θ) = −∑ni=1 ln xi
θ2 − nθ
et θ = −n−1 ∑ni=1 ln xi.
c) On a
E[θ] = − 1n
n
∑i=1
∫ 1
0
1θ(ln xi)x1/θ−1
i dxi
= − 1n
n
∑i=1
[x1/θ ln x|10 −
∫ 1
0x1/θ−1
i dxi
]= − 1
n
n
∑i=1
(−θ)
= θ.
Chapitre 2
2.1 La franchise permet à l’assureur d’économiser au plus 250 $ par contrat.L’assureur économise donc, pour les 12 contrats de son portefeuille,
250,110,250,213,98,250,250,162,131,250,250,250,
pour un total de 2 464 $. Le montant total des sinistres sans la franchiseest de 4 982 $. Le rapport d’élimination de perte est donc
LER =2 4644 982
= 0,4946.
2.2 La limite permet à l’assureur d’économiser l’excédent de 100 000 $ parcontrat. L’assureur économise donc, pour les huit contrats de son porte-feuille,
0,23 000,323 000,0,113 000,0,0,78 000,
pour un total de 537 000 $. Le montant total des sinistres sans la limiteest de 1 146 000 $. Le rapport d’élimination de perte est donc
LER =537 000
1 146 000= 0,4686.

74 Solutions
2.3 a) Soit X ∼ Exponentielle(0,02) la variable aléatoire du montant d’unsinistre et soit Y, la variable aléatoire du montant économisé par l’as-sureur. On définit
Y =
{X, X ≤ 100, X > 10.
Le rapport d’élimination de perte est
LER =E[Y]E[X]
=
∫ 100 x fX(x)dx
50
=0,87616
50= 0,0175.
b) Avec une franchise forfaitaire, on a plutôt
Y =
{X, X ≤ 1010, X > 10.
Le rapport d’élimination de perte est
LER =E[Y]E[X]
=
∫ 100 x fX(x)dx +
∫ ∞10 10 fX(x)dx
E[X]
=E[X;10]
E[X]
=9,0634
50= 0,1813.
Il est normal que ce ratio soit supérieur à celui en a) puisque l’assu-reur ne rembourse que la partie du montant du sinistre excédent lafranchise forfaitaire, et non le montant au complet.
2.4 Soit X ∼ Gamma(4,0,1), la variable aléatoire du montant d’un sinistreet soit Y, la variable aléatoire du montant économisé par l’assureur. Ondéfinit
Y =
{0, X ≤ 100X− 100, X > 100.

Solutions 75
Le rapport d’élimination de perte est
LER =E[Y]E[X]
=
∫ ∞100(x− 100) fX(x)dx
E[X]
=0,138
40= 0,0034.
Il est également possible de réécrire la variable aléatoire comme étant
Y =
{X− X, X ≤ 100X− 100, X > 100.
Il est alors aisé de calculer le rapport d’élimination de perte comme suit :
LER =E[Y]E[X]
=E[X]− E[X;100]
E[X]
=(40)Γ(5;10) + (100)(1− Γ(4;10))
40.
Comme la valeur de α est entière, on peut utiliser
Γ(α;y) = 1−α−1
∑j=0
yje−y
j!
pour obtenir
LER =40− 39,862
40= 0,0034.
2.5 Il est dit dans la question que l’assureur «limite ses paiements à 200»,la limite est donc de 270. En introduisant d’abord la limite, l’assureuréconomise, respectivement,
0,0,0,0,0,0,0,0,0,0,90,130,
pour un total de 220. En introduisant ensuite la franchise, l’assureur éco-nomise en plus, respectivement,
20,50,70,70,70,70,70,70,70,70,70,70,
pour un total de 770. Le montant total des sinistres sans la limite et lafranchise est de 1 745. Le rapport d’élimination de perte est donc
LER =770 + 220
1 745= 0,567.

76 Solutions
2.6 On trouve d’abord
LERd=100 =
∫ 1000 x fX(x)dx +
∫ ∞100 100 fX(x)dx
E[X]
=E[X;100]
E[X]
=E[X;100]
2 000= 0,0465
d’où l’on trouve que E[X;100] = 93. Soit Y, la variable aléatoire du mon-tant épargné par l’assureur. On définit
Y =
X, X ≤ 100100, 100 < X ≤ 30 000X− 30 000 + 100, X > 30 000,
ou, de manière équivalente,
Y = X−min(X, 30 000) + min(X, 100)
=
X− X + X, X ≤ 100X− X + 100, 100 < X ≤ 30 000X− 30 000 + 100, X > 30 000.
Ainsi,
LER =E[X]− E[X;30 000] + E[X;100]
E[X]= 0,226.
2.7 a) Il faut voir que la densité donnée peut s’écrire comme une combinai-son linéaire de deux distributions exponentielles :
fX(x) = e−2x +e−x
2
=12(2e−2x) +
12
e−x.
L’espérance limitée est donc, en utilisant les formules pour l’espérancelimitée d’une exponentielle,
E[X;d] =(
12
)(12
)(1− e−2d) +
(12
)(1)(1− e−d)
=1− e−2d
4+
1− e−d
2.

Solutions 77
b) Il faut d’abord évaluer la sévérité moyenne. Soit Y, la variable aléatoiredu montant payé par l’assureur, on a
Y =
{0, X ≤ 0,25X− 0,25, X > 0,25,
ou encore
Y = max(X− 0,25,0)= X−min(X, 0,25)
=
{X− X, X ≤ 0,25X− 0,25, X > 0,25.
À partir de cette représentation, il est facile de voir que
E[Y] = E[X]− E[X;0,25]
=(
14
+12
)− 3− e−0,5 − 2e−0,25
4= 0,541.
L’espérance de la sévérité est de un sinistre tous les dix ans, donc de0,1. Ainsi, la prime pure est
π = (0,541)(0,1) = 0,0541.
c) Soit Z = 1,05X, la variable aléatoire du montant de sinistre après in-flation. On a
FZ(x) = FX(x/1,05)
=12(1− e−(2/1,05)x) +
12(1− e−1/1,05x).
Le calcul de l’espérance de la sévérité est donc
E[Y] = E[Z]− E[Z;0,25]= 0,7875− 0,2107= 0,576.
La prime pure est alors
π = (0,576)(0,1) = 0,0576.
2.8 a) Pour le réassureur, il s’agit d’une franchise de 50 000. Soit Y, la va-riable aléatoire du montant payé par le réassureur. On a
Y =
{0, X ≤ 50 000X− 50 000, X > 50 000,

78 Solutions
ou encore
Y = max(X− 50 000,0)= X−min(X, 50 000)
=
{X− X, X ≤ 50 000X− 50 000, X > 50 000
À partir de cette représentation, il est facile de voir que
E[Y] = E[X]− E[X;50 000]= 1 091,09.
b) Soit Y∗ la variable aléatoire du montant économisé par le réassureur.On définit
Y∗ =
{X, X ≤ 100 000100 000, X > 100 000.
On trouve alors que
E[Y∗] = E[X;100 000]= 4 219,13.
De plus, on a
E[X] =λ
α− 1
=2 500
1,5− 1= 5 000.
Le rapport d’élimination de perte est donc
LER =4 219,13
5 000= 0,8438.
2.9 On sait que YP = X− d|X > d et que
fYP(x) =fX(x + d)1− FX(d)
, x > 0.

Solutions 79
On a donc
E[YP] =1
1− FX(d)
∫ ∞
0x fX(x + d)dx
=1
1− FX(d)
∫ ∞
d(y− d) fX(y)dy
=1
1− FX(d)
(∫ ∞
dy fX(y)dy− d(1− F(d))
)=
11− FX(d)
(∫ ∞
0y fX(y)dy−
∫ d
0y fX(y)dy− d(1− F(d))
)=
E[X]− E[X;d]1− FX(d)
par définition de l’espérance limitée. Le numérateur représente le mon-tant moyen des sinistres au-dessus de la franchise d, alors que la présencedu dénominateur s’interprète comme la sélection des seuls sinistres dé-passant la franchise.
2.10 Pour chaque cas, la fonction coverage du package actuar retourne unefonction pour calculer ou tracer la densité modifiée. Voir la figure E.3pour les graphique demandés. On a superposé, sur chaque graphique,la densité de la distribution sans la modification à la densité modifiée.Le code R pour créer ces graphiques est le suivant :
a) > f <- coverage(dweibull, pweibull, deductible = 10,+ per.loss = TRUE)> curve(dweibull(x, 3, 15), from = 0, to = 50,+ ylim = c(0, f(0, 3, 15)))> curve(f(x, 3, 15), from = 0.01, add = TRUE,+ lwd = 3)> points(0, f(0, 3, 15), pch = 16, lwd = 3)
b) > f <- coverage(dweibull, pweibull, deductible = 10,+ limit = 40, franchise = TRUE)> curve(f(x, 3, 15), from = 10.01, to = 39.99,+ xlim = c(0, 50), lwd = 3)> points(40, f(40, 3, 15), pch = 16, lwd = 3)> curve(dweibull(x, 3, 15), add = TRUE, lty = 2)
c) > f <- coverage(dweibull, pweibull, coins = 0.8)> curve(f(x, 3, 15), from = 0, to = 50)> curve(dweibull(x, 3, 15), add = TRUE, lty = 2)
2.11 a) On a X ∼ Pareto(1,5,1 500). En 1995, la variable aléatoire est, aprèsinflation,
X1995 = (1,05)2(1,06)3X1990
= (1,3131)X1990,
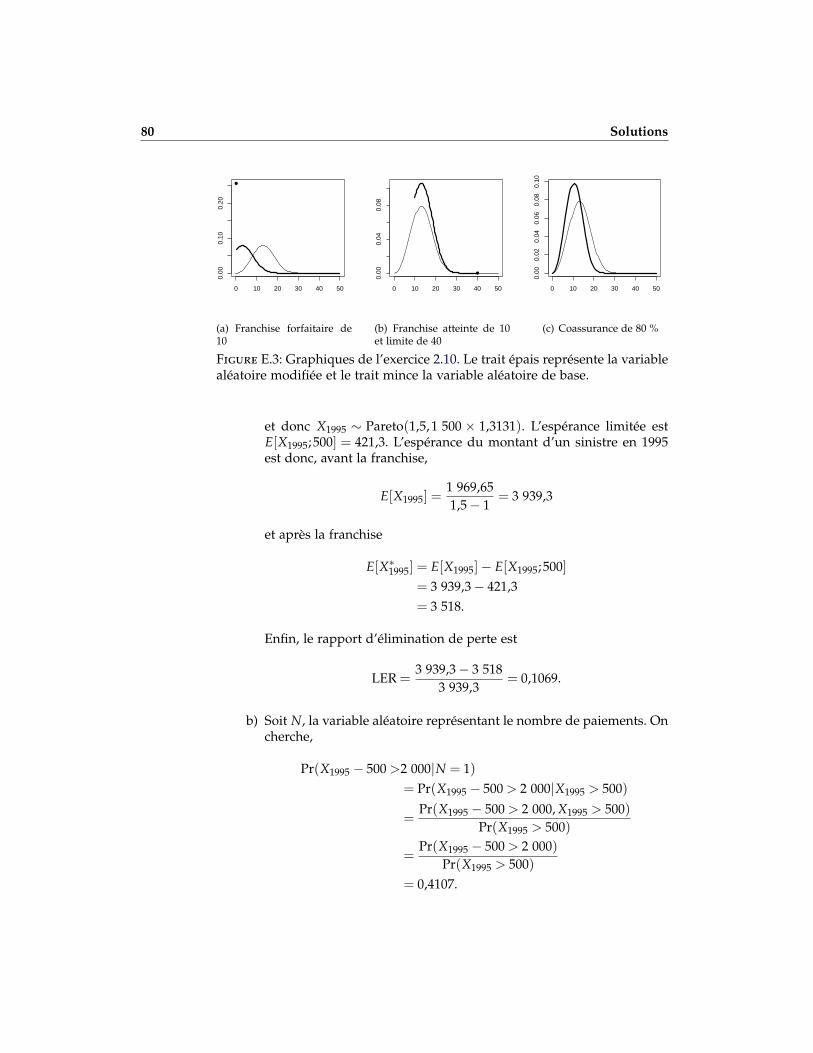
80 Solutions
0 10 20 30 40 50
0.00
0.10
0.20
●
(a) Franchise forfaitaire de10
0 10 20 30 40 50
0.00
0.04
0.08
●
(b) Franchise atteinte de 10et limite de 40
0 10 20 30 40 50
0.00
0.02
0.04
0.06
0.08
0.10
(c) Coassurance de 80 %
Figure E.3: Graphiques de l’exercice 2.10. Le trait épais représente la variablealéatoire modifiée et le trait mince la variable aléatoire de base.
et donc X1995 ∼ Pareto(1,5,1 500 × 1,3131). L’espérance limitée estE[X1995;500] = 421,3. L’espérance du montant d’un sinistre en 1995est donc, avant la franchise,
E[X1995] =1 969,651,5− 1
= 3 939,3
et après la franchise
E[X∗1995] = E[X1995]− E[X1995;500]= 3 939,3− 421,3= 3 518.
Enfin, le rapport d’élimination de perte est
LER =3 939,3− 3 518
3 939,3= 0,1069.
b) Soit N, la variable aléatoire représentant le nombre de paiements. Oncherche,
Pr(X1995 − 500 >2 000|N = 1)= Pr(X1995 − 500 > 2 000|X1995 > 500)
=Pr(X1995 − 500 > 2 000, X1995 > 500)
Pr(X1995 > 500)
=Pr(X1995 − 500 > 2 000)
Pr(X1995 > 500)= 0,4107.

Solutions 81
c) La nouvelle variable aléatoire est
Y∗ =
0, X1995 ≤ 500X1995 − 500, 500 < X1995 ≤ 4 0004 000− 500, X1995 > 4 000,
ou encore,
Y∗ = max(min(X1995, 4 000)− 500,0)= min(X1995, 4 000)−min(X1995, 500)
=
X1995 − X1995, X1995 ≤ 500X1995 − 500, 500 < X1995 ≤ 4 0004 000− 500, X1995 > 4 000,
d’où
E[Y∗] = E[X1995;4 000]− E[X1995;500]= 1 154,07.
2.12 a) On veut calculer
E[X;u] = eµ+σ2/2Φ(
ln(u)− µ− σ2
σ
)+ u
(1−Φ
(ln(u)− µ
σ
))avec u = 300 000, µ = 9,356 et σ = 1,596. On obtient
E[X;300 000] = (41 340,92)(0,671413) + (300 000)(1− 0,9793)= 33 962.
b) Soit Y, le montant payé par sinistre après inflation. On a
E[Y] = (1 + r)E[
X;d
1 + r
]= (1,1)E[X;272 727,272]= (1,1)(33 356)= 36 692.
Puisque 36 692/33 962 = 1,0804, cela représente une augmentationdes coûts de 8,04 %.
c) Soit Y∗ la variable aléatoire du montant payé par sinistre suite àl’introduction d’une franchise de 1 000 $. On a
E[Y∗] = E[X;300 000]− E[X;1 000]= 33 962− 973,92= 32 988,38.
Puisque 32 988,38/33 962 = 0,9713, l’introduction de la franchise en-traîne une baisse des coûts de 2,87 % par rapport à la situation ena).

82 Solutions
2.13 Soit YP la variable aléatoire du montant payé par paiement par le réas-sureur. On a YP = X− δ|X > δ, donc
fYP(x) =fX(x + δ)1− FX(δ)
=αλα/(x + δ + λ)α+1
λα/(δ + λ)α
=α(λ + δ)α
(x + (λ + δ))α+1 , x > 0,
d’où YP ∼ Pareto(α, λ + δ).
2.14 Soit X la variable aléatoire du montant d’un sinistre et YP = X− d|X > d,la variable aléatoire du montant payé par paiement avec une franchiseforfaitaire d. Or, la distribution exponentielle étant sans mémoire, on a,de manière générale,
Pr(YP > x) =Pr(X > x + d)
Pr(X > d)
=e−λ(x+d)
e−λd
= e−λx ,
d’où YP ∼ Exponentielle(λ). Ici, on a donc Pr(YP > 0,5) = e−3(0,5) = 0,22.
2.15 On a
EA[YS] = E[X]− E[X;5 000]= 11 100− E[X;5 000]= 6 500,
d’où E[X;5 000] = 4 600. De même,
EA[YP] =E[X]− E[X;5 000]
1− F(5 000)
=11 100− 6 5001− F(5 000)
= 10 000,
d’où F(5 000) = 0,35. Enfin, on cherche
EB[YP|X ≤ 5 000] = E[X|X ≤ 5 000]
=
∫ 5 0000 x f (x)dx
F(5 000)
=E[X;5 000]− (5 000)(1− F(5 000))
F(5 000)= 3 857.

Solutions 83
2.16 L’espérance de la fréquence annuelle des sinistres est r(1− θ)/θ = 15.Pour qu’il y ait un paiement, le montant du sinistre doit être supérieurà la franchise. Or
Pr(X > 200) = e(200/1 000)0,3= 0,5395.
Ainsi, 53,95 % des sinistres occasionneront un paiement, d’où le nombreespéré de paiements par années est (15)(0,5395) = 8,0925.
2.17 a) Le résultat découle directement de la redéfinition de la variable aléa-toire YS comme suit :
YS = αmax(min(X, u)− d, 0)= α(min(X, u)−min(X, d))
= α
X− X, X < dX− d, d ≤ X < uu− d, X ≥ u.
b) Pour calculer le second moment de la variable aléatoire YS, on écritd’abord
(YS)2 =
0, X ≤ dα2(X2 − 2dX + d2), d < X < uα2(u2 − 2ud + d2), X ≥ u
=
α2(X2 − X2 − 2dX + 2dX), X ≤ dα2(X2 − d2 − 2dX + 2dd), d < X < uα2(u2 − d2 − 2du + 2dd), X ≥ u.
On a alors
E[(YS)2] = α2(E[X2;u2]− E[X2;d2]− 2dE[X;u] + 2dE[X;d]).
La variance est donc
Var[YS] = E[(YS)2]− E[YS]2
= α2(E[X2;u2]− E[X2;d2]− 2dE[X;u] + 2dE[X;d])
− α2(E[X;u]− E[X;d])2.
c) Suite à une inflation de 100r %, la définition de la variable aléatoireYS équivalente à celle utilisée en a) est
YS = α(1 + r)[
min(
X,u
1 + r
)−min
(X,
d1 + r
)]
= α(1 + r)
X− X, X < d/(1 + r)X− d/(1 + r), d/(1 + r) ≤ X < u/(1 + r)u/(1 + r)− d/(1 + r), X ≥ u/(1 + r).

84 Solutions
On obtient donc directement
E[YS] = α(1 + r)(
E[
X;u
1 + r
]− E
[X;
d1 + r
]).
2.18 On remarquera que la relation est un cas spécial du résultat de l’exercice2.17 avec α = 1 et r = 0. On a
YS =
0, X < dX− d, d ≤ X < uu− d, X ≥ u.
Par conséquent,
E[YS] = (0)Pr(X < d) +∫ u−d
0y fYS(y)dy + (u− d)(1− FX(u))
=∫ u−d
0y fYS(y)dy + (u− d)(1− FX(u)).
En faisant le changement de variable x = y + d dans l’intégrale, on ob-tient
E[YS] =∫ u
d(x− d) fX(x)dx + (u− d)(1− FX(u))
=∫ u
0(x− d) fX(x)dx−
∫ d
0(x− d) fX(x)dx
+ (u− d)(1− FX(u))
=∫ u
0x fX(x)dx− d FX(u)−
∫ d
0x fX(x)dx + d FX(d)
+ (u− d)(1− FX(u))
=∫ u
0x fX(x)dx + u(1− FX(u))−
∫ d
0x fX(x)dx− d(1− FX(d))
= E[X;u]− E[X;d].
2.19 Lorsqu’il y a bonus, son montant est
600 000(
0,75− S/600 0003
)=
450 000− S3
.
Il y aura donc un bonus si L < 450 000. On a donc
B = max(
0,450 000− S
3
)= 150 000− 1
3min(S, 450 000),
d’où
E[B] = 150 000− 13
E[S;450 000]
= 150 000− 13
(220 321,36)
= 76 559,55.

Solutions 85
2.20 a) Lorsqu’un sinistre de montant d < x ≤ d∗ survient, l’assureur rem-bourse un montant d∗(x− d)/(d∗ − d). On a donc
YP =
d∗
d∗ − d(X− d), d < X ≤ d∗
X, X > d∗.
b) Pour pouvoir évaluer l’espérance, il est plus facile de réécrire la va-riable sous la forme
YP = X +(
dd∗ − d
)min(X, d∗)−
(d∗
d∗ − d
)min(X, d)
∣∣∣∣X > d
=
X +
(d
d∗ − d
)X−
(d∗
d∗ − d
)d, d < X ≤ d∗
X +(
dd∗ − d
)d∗ −
(d∗
d∗ − d
)d, X > d∗.
Par la définition de l’espérance limitée ou en utilisant le résultat del’exercice 2.9, on obtient directement
E[YP] =E[X] + dE[X;d∗]/(d∗ − d)− d∗E[X;d]/(d∗ − d)
1− FX(d).
Chapitre 3
3.1 a) On peut calculer puis tracer la fonction de répartition empirique aisé-ment avec la fonction ecdf de R ; voir la figure E.4. Quant à la fonctionde masse de probabilité empirique, la façon la plus simple de la cal-culer est à partir de la fonction table ; voir la figure E.5.
b) Il faut d’abord déterminer le nombre de données dans chacune desclasses. On a n1 = 4, n2 = 10, n3 = 2 et n4 = 4. L’équation de l’ogiveest alors
F20(x) =
0, x ≤ 2(x− 2)/25, 2 < x ≤ 7(x− 5)/10, 7 < x ≤ 12(x + 58)/100, 12 < x ≤ 22(x + 42)/80, 22 < x ≤ 381, x > 38
Les fonctions grouped.data et ogive de actuar permettent, dans l’ordre,de définir un objet de données groupées et de calculer son ogive ; voirla figure E.6.
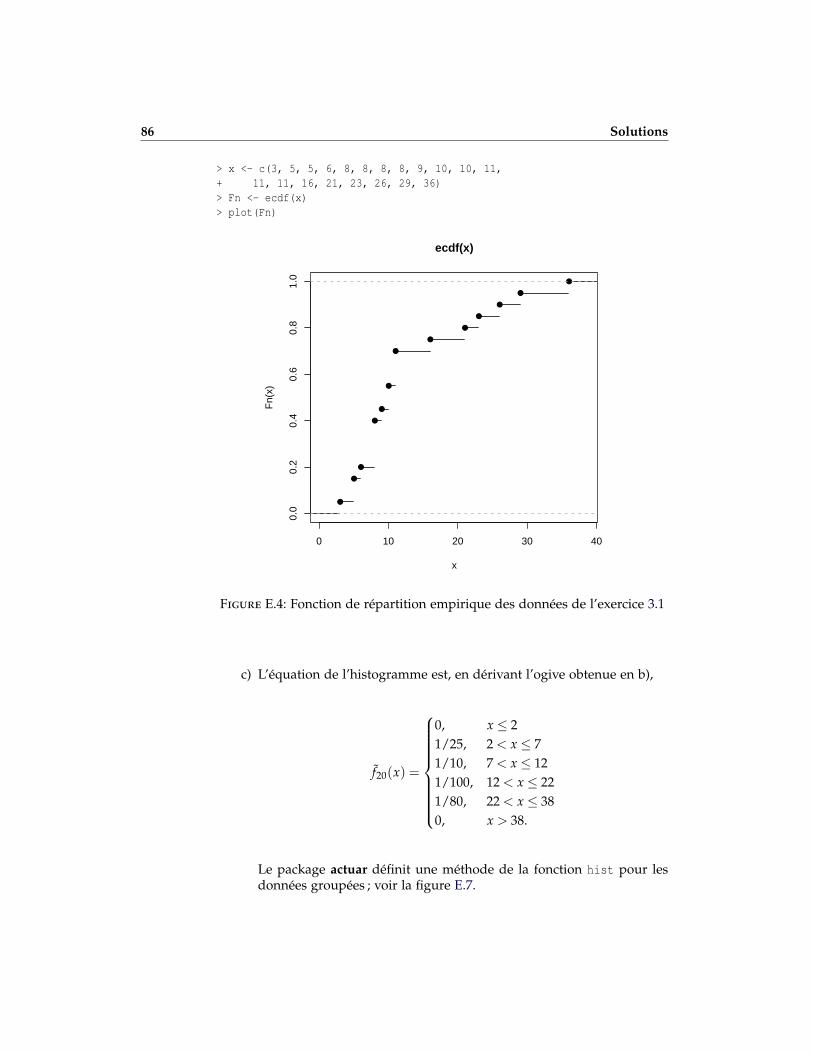
86 Solutions
> x <- c(3, 5, 5, 6, 8, 8, 8, 8, 9, 10, 10, 11,+ 11, 11, 16, 21, 23, 26, 29, 36)> Fn <- ecdf(x)> plot(Fn)
0 10 20 30 40
0.0
0.2
0.4
0.6
0.8
1.0
ecdf(x)
x
Fn(
x)
●
●
●
●
●
●
●
●
●
●
●
●
●
Figure E.4: Fonction de répartition empirique des données de l’exercice 3.1
c) L’équation de l’histogramme est, en dérivant l’ogive obtenue en b),
f20(x) =
0, x ≤ 21/25, 2 < x ≤ 71/10, 7 < x ≤ 121/100, 12 < x ≤ 221/80, 22 < x ≤ 380, x > 38.
Le package actuar définit une méthode de la fonction hist pour lesdonnées groupées ; voir la figure E.7.
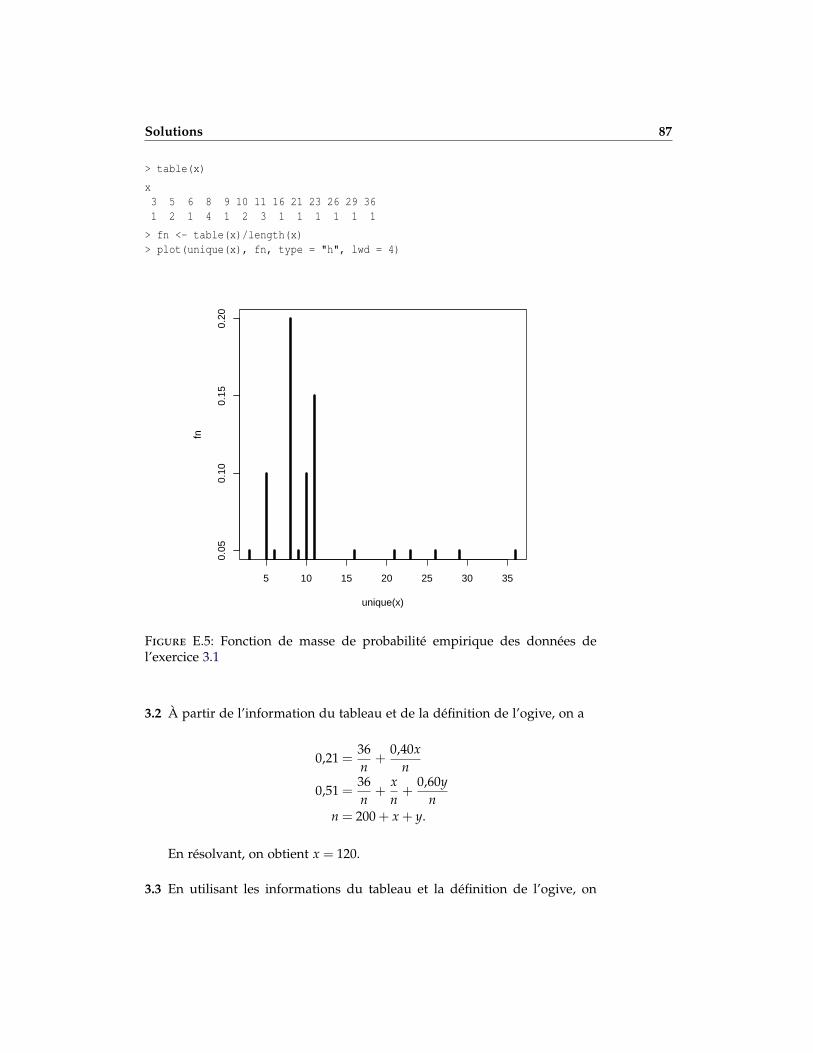
Solutions 87
> table(x)
x3 5 6 8 9 10 11 16 21 23 26 29 361 2 1 4 1 2 3 1 1 1 1 1 1
> fn <- table(x)/length(x)> plot(unique(x), fn, type = "h", lwd = 4)
5 10 15 20 25 30 35
0.05
0.10
0.15
0.20
unique(x)
fn
Figure E.5: Fonction de masse de probabilité empirique des données del’exercice 3.1
3.2 À partir de l’information du tableau et de la définition de l’ogive, on a
0,21 =36n
+0,40x
n
0,51 =36n
+xn
+0,60y
nn = 200 + x + y.
En résolvant, on obtient x = 120.
3.3 En utilisant les informations du tableau et la définition de l’ogive, on
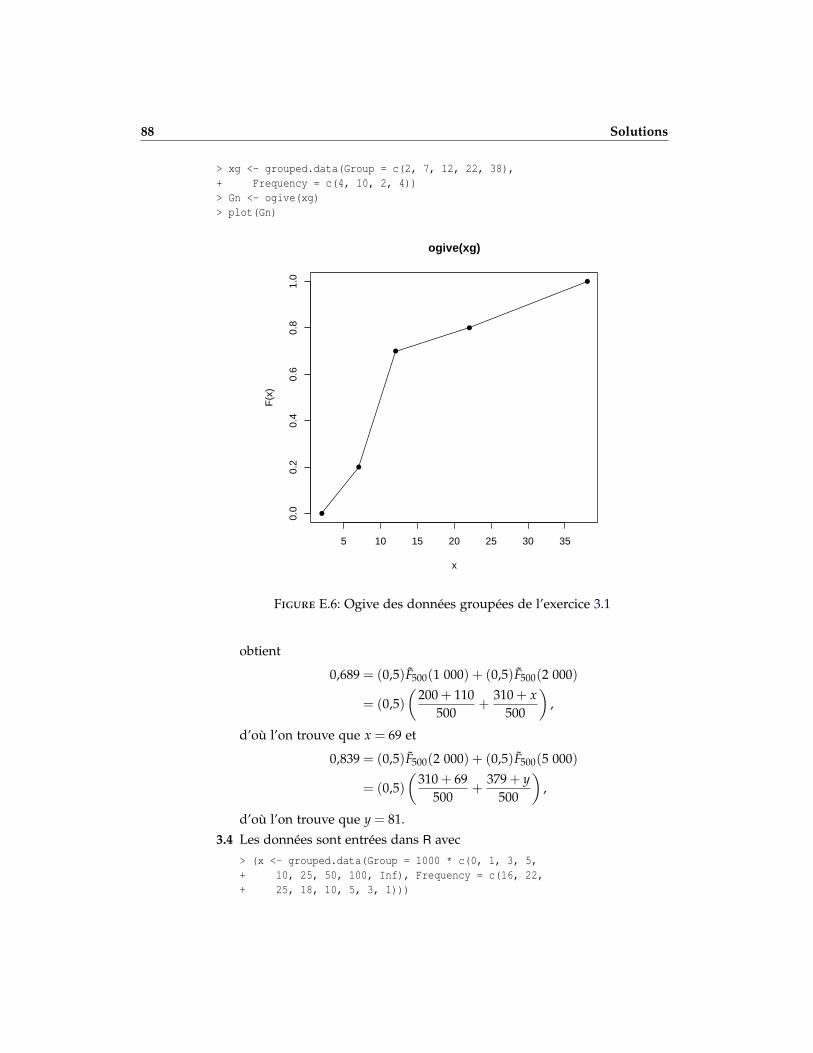
88 Solutions
> xg <- grouped.data(Group = c(2, 7, 12, 22, 38),+ Frequency = c(4, 10, 2, 4))> Gn <- ogive(xg)> plot(Gn)
●
●
●
●
●
5 10 15 20 25 30 35
0.0
0.2
0.4
0.6
0.8
1.0
ogive(xg)
x
F(x
)
Figure E.6: Ogive des données groupées de l’exercice 3.1
obtient
0,689 = (0,5)F500(1 000) + (0,5)F500(2 000)
= (0,5)(
200 + 110500
+310 + x
500
),
d’où l’on trouve que x = 69 et
0,839 = (0,5)F500(2 000) + (0,5)F500(5 000)
= (0,5)(
310 + 69500
+379 + y
500
),
d’où l’on trouve que y = 81.3.4 Les données sont entrées dans R avec
> (x <- grouped.data(Group = 1000 * c(0, 1, 3, 5,+ 10, 25, 50, 100, Inf), Frequency = c(16, 22,+ 25, 18, 10, 5, 3, 1)))
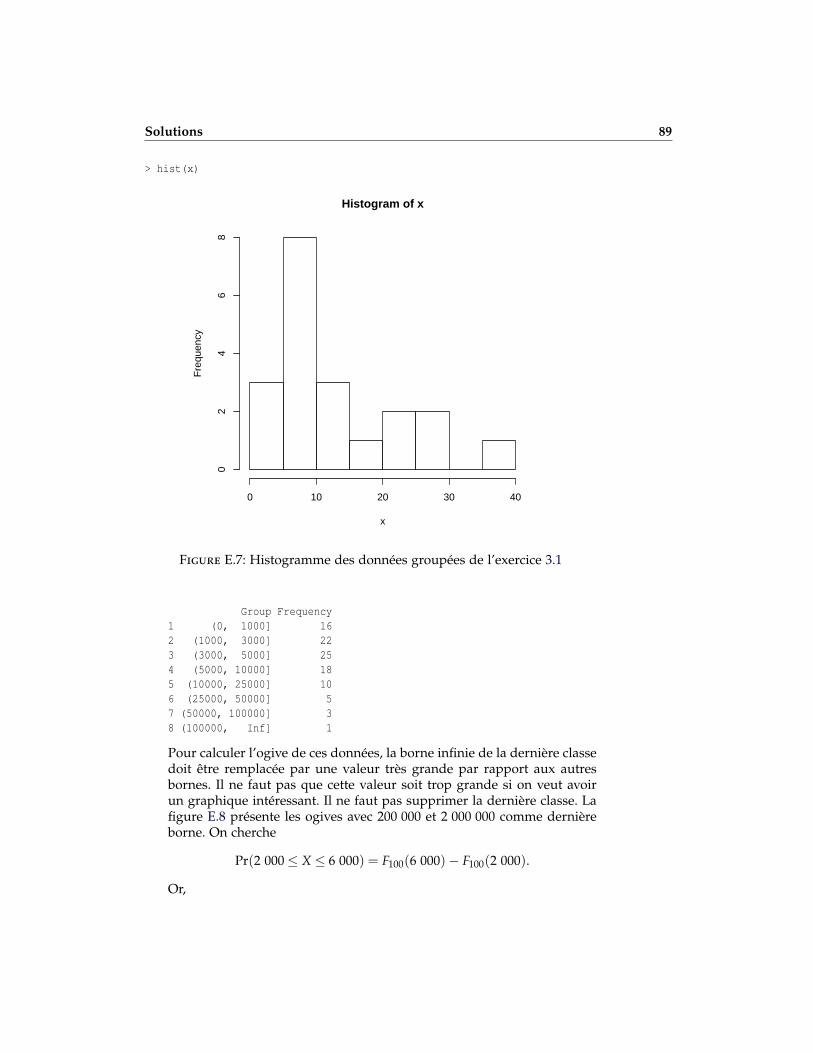
Solutions 89
> hist(x)
Histogram of x
x
Fre
quen
cy
0 10 20 30 40
02
46
8
Figure E.7: Histogramme des données groupées de l’exercice 3.1
Group Frequency1 (0, 1000] 162 (1000, 3000] 223 (3000, 5000] 254 (5000, 10000] 185 (10000, 25000] 106 (25000, 50000] 57 (50000, 100000] 38 (100000, Inf] 1
Pour calculer l’ogive de ces données, la borne infinie de la dernière classedoit être remplacée par une valeur très grande par rapport aux autresbornes. Il ne faut pas que cette valeur soit trop grande si on veut avoirun graphique intéressant. Il ne faut pas supprimer la dernière classe. Lafigure E.8 présente les ogives avec 200 000 et 2 000 000 comme dernièreborne. On cherche
Pr(2 000≤ X ≤ 6 000) = F100(6 000)− F100(2 000).
Or,
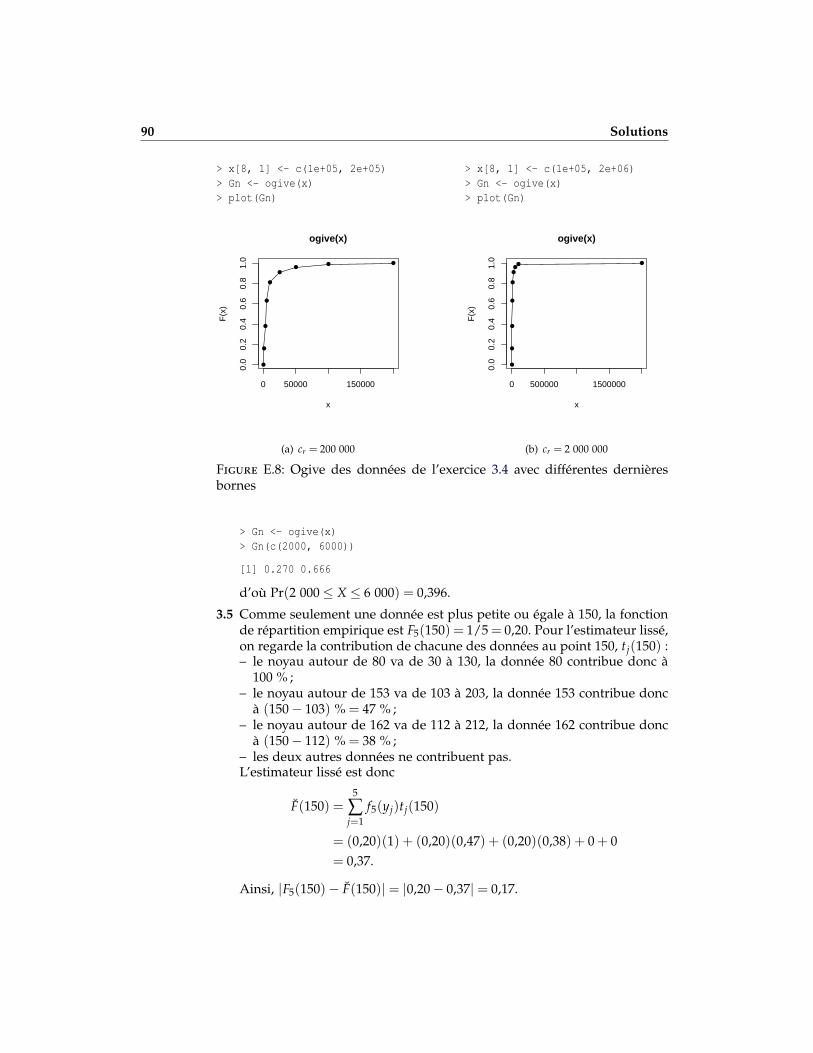
90 Solutions
> x[8, 1] <- c(1e+05, 2e+05)> Gn <- ogive(x)> plot(Gn)
●
●
●
●
●
●●
● ●
0 50000 150000
0.0
0.2
0.4
0.6
0.8
1.0
ogive(x)
x
F(x
)
(a) cr = 200 000
> x[8, 1] <- c(1e+05, 2e+06)> Gn <- ogive(x)> plot(Gn)
●
●
●
●
●
●●
● ●
0 500000 1500000
0.0
0.2
0.4
0.6
0.8
1.0
ogive(x)
x
F(x
)
(b) cr = 2 000 000
Figure E.8: Ogive des données de l’exercice 3.4 avec différentes dernièresbornes
> Gn <- ogive(x)> Gn(c(2000, 6000))
[1] 0.270 0.666
d’où Pr(2 000≤ X ≤ 6 000) = 0,396.
3.5 Comme seulement une donnée est plus petite ou égale à 150, la fonctionde répartition empirique est F5(150) = 1/5 = 0,20. Pour l’estimateur lissé,on regarde la contribution de chacune des données au point 150, tj(150) :– le noyau autour de 80 va de 30 à 130, la donnée 80 contribue donc à
100 % ;– le noyau autour de 153 va de 103 à 203, la donnée 153 contribue donc
à (150− 103) % = 47 % ;– le noyau autour de 162 va de 112 à 212, la donnée 162 contribue donc
à (150− 112) % = 38 % ;– les deux autres données ne contribuent pas.L’estimateur lissé est donc
F(150) =5
∑j=1
f5(yj)tj(150)
= (0,20)(1) + (0,20)(0,47) + (0,20)(0,38) + 0 + 0= 0,37.
Ainsi, |F5(150)− F(150)| = |0,20− 0,37| = 0,17.
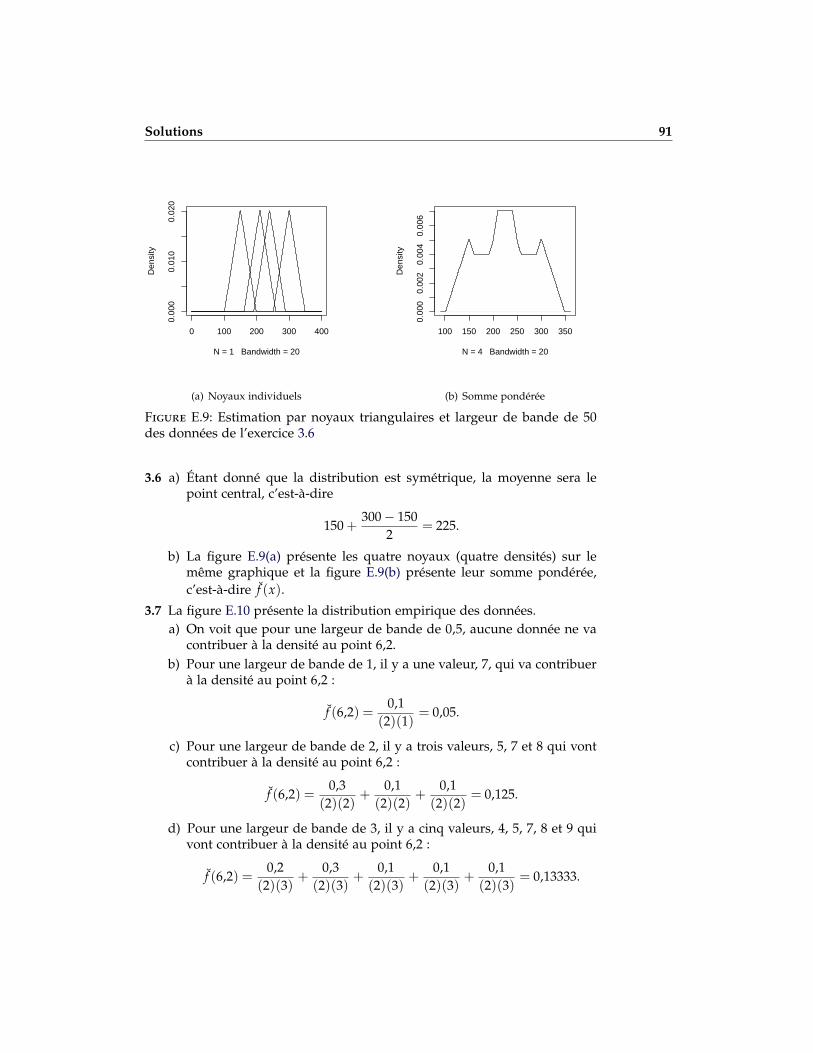
Solutions 91
0 100 200 300 400
0.00
00.
010
0.02
0
N = 1 Bandwidth = 20
Den
sity
(a) Noyaux individuels
100 150 200 250 300 350
0.00
00.
002
0.00
40.
006
N = 4 Bandwidth = 20
Den
sity
(b) Somme pondérée
Figure E.9: Estimation par noyaux triangulaires et largeur de bande de 50des données de l’exercice 3.6
3.6 a) Étant donné que la distribution est symétrique, la moyenne sera lepoint central, c’est-à-dire
150 +300− 150
2= 225.
b) La figure E.9(a) présente les quatre noyaux (quatre densités) sur lemême graphique et la figure E.9(b) présente leur somme pondérée,c’est-à-dire f (x).
3.7 La figure E.10 présente la distribution empirique des données.a) On voit que pour une largeur de bande de 0,5, aucune donnée ne va
contribuer à la densité au point 6,2.b) Pour une largeur de bande de 1, il y a une valeur, 7, qui va contribuer
à la densité au point 6,2 :
f (6,2) =0,1
(2)(1)= 0,05.
c) Pour une largeur de bande de 2, il y a trois valeurs, 5, 7 et 8 qui vontcontribuer à la densité au point 6,2 :
f (6,2) =0,3
(2)(2)+
0,1(2)(2)
+0,1
(2)(2)= 0,125.
d) Pour une largeur de bande de 3, il y a cinq valeurs, 4, 5, 7, 8 et 9 quivont contribuer à la densité au point 6,2 :
f (6,2) =0,2
(2)(3)+
0,3(2)(3)
+0,1
(2)(3)+
0,1(2)(3)
+0,1
(2)(3)= 0,13333.
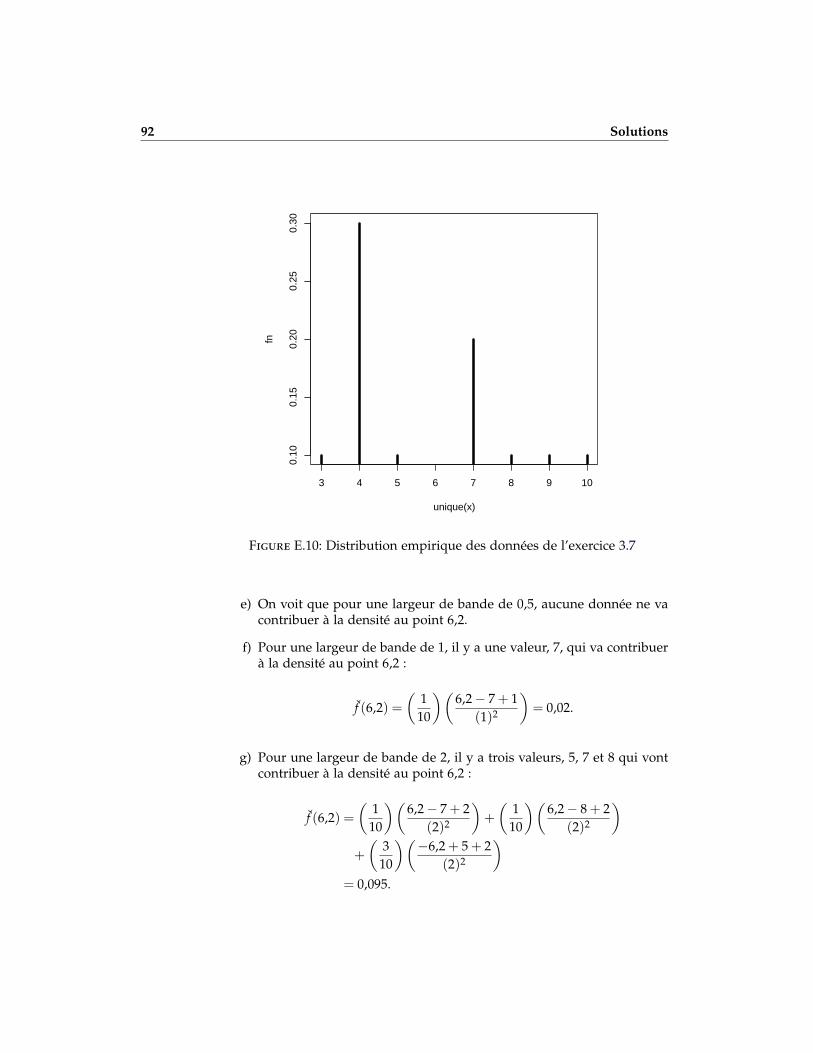
92 Solutions
3 4 5 6 7 8 9 10
0.10
0.15
0.20
0.25
0.30
unique(x)
fn
Figure E.10: Distribution empirique des données de l’exercice 3.7
e) On voit que pour une largeur de bande de 0,5, aucune donnée ne vacontribuer à la densité au point 6,2.
f) Pour une largeur de bande de 1, il y a une valeur, 7, qui va contribuerà la densité au point 6,2 :
f (6,2) =(
110
)(6,2− 7 + 1
(1)2
)= 0,02.
g) Pour une largeur de bande de 2, il y a trois valeurs, 5, 7 et 8 qui vontcontribuer à la densité au point 6,2 :
f (6,2) =(
110
)(6,2− 7 + 2
(2)2
)+(
110
)(6,2− 8 + 2
(2)2
)+(
310
)(−6,2 + 5 + 2
(2)2
)= 0,095.

Solutions 93
3.8 On utilise l’équation d’un estimateur avec noyaux triangulaires :
f (5) =(
1/5a2
)(5− (6− a)) +
(−1/5
a2
)(5− (4 + a))
= 0,01.
En simplifiant, on trouve 0,05a2 − 2a + 2 = 0 et, en choisissant la bonneracine, a = 1,0263.
3.9 On entre les données individuelles de l’exercice dans R avec
> x <- c(2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3,+ 3, 3, 3, 4, 4, 4, 5, 5, 5, 5, 6, 6, 6, 6,+ 8, 8, 9, 15, 17, 22, 23, 24, 24, 25, 27, 32,+ 43)
et les données sous forme groupée avec
> xg <- grouped.data(Group = c(1.5, 2.5, 6.5, 29.5,+ 49.5), Frequency = c(12, 15, 11, 2))
a) La figure E.11 présente la fonction de répartition empirique des don-nées, obtenue à l’aide de la fonction ecdf.
b) La figure figure E.11 présente également l’ogive des données, obtenueavec la fonction ogive du package actuar. On voit que l’ogive et lafonction de répartition empirique correspondent généralement bien.Autour du point x = 22, l’ajustement pourrait être un peu meilleur,par exemple en ajoutant une classe. Pour les deux bornes extrêmes,0 aurait peut-être été un peu plus intuitif comme choix de borne in-férieure que 1,5. La borne supérieure est logique, car supérieure à lavaleur maximale de l’échantillon, mais est totalement arbitraire sinon(on aurait pu choisir, par exemple, 50).
c) La figure E.12 présente l’histogramme des données créé à partir del’objet de données groupées.
d) On a simplement
> mean(x)
[1] 9.225
> sd(x)
[1] 10.23691
3.10 Tout d’abord, on a F10(4) = 0,40, E[F10(4)] = F(4), et Var[F10(4)] = F(4)(1−F(4))/10. En utilisant le Théorème central limite, on peut poser que
Pr
(−1,96≤ F10(4)− E[F10(4)]√
Var[F10(4)]≤ 1,96
)≈ 0,95,
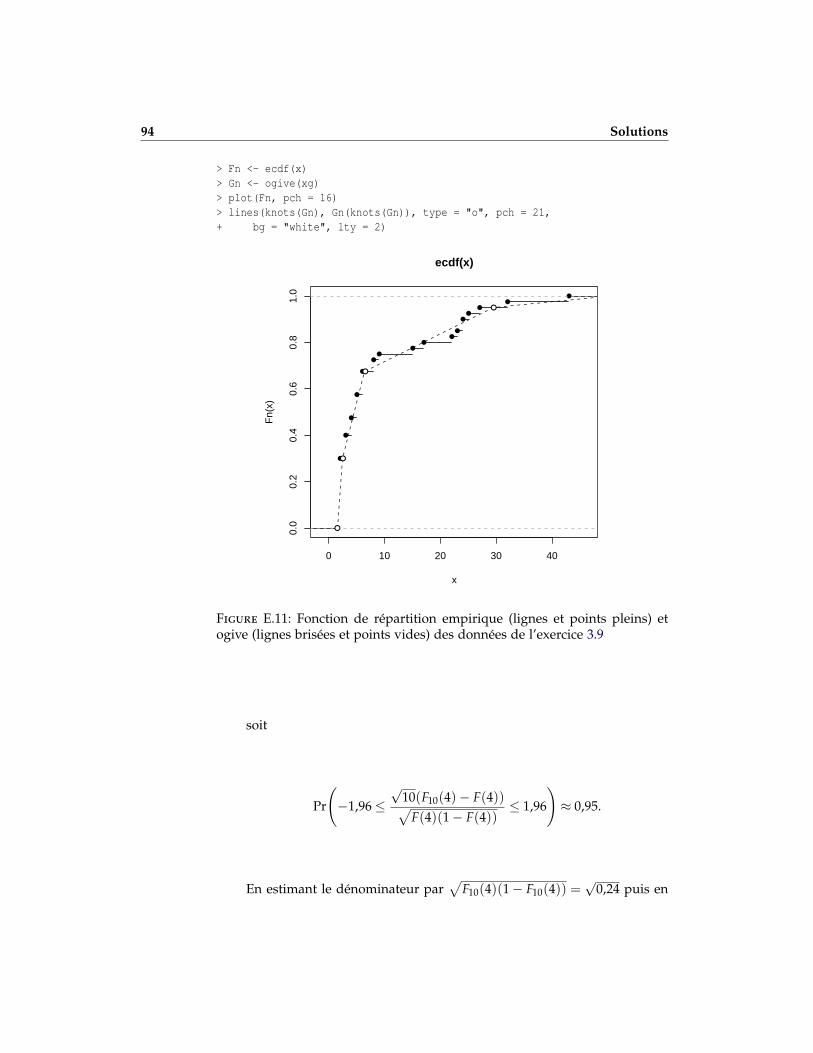
94 Solutions
> Fn <- ecdf(x)> Gn <- ogive(xg)> plot(Fn, pch = 16)> lines(knots(Gn), Gn(knots(Gn)), type = "o", pch = 21,+ bg = "white", lty = 2)
0 10 20 30 40
0.0
0.2
0.4
0.6
0.8
1.0
ecdf(x)
x
Fn(
x)
●
●
●
●
●
●●
●●
●●
●●
●●
●
●
●
●
●
●
Figure E.11: Fonction de répartition empirique (lignes et points pleins) etogive (lignes brisées et points vides) des données de l’exercice 3.9
soit
Pr
(−1,96≤
√10(F10(4)− F(4))√
F(4)(1− F(4))≤ 1,96
)≈ 0,95.
En estimant le dénominateur par√
F10(4)(1− F10(4)) =√
0,24 puis en
Solutions 95
> hist(xg)
Histogram of xg
xg
Den
sity
0 10 20 30 40 50
0.00
0.05
0.10
0.15
0.20
0.25
0.30
Figure E.12: Histogramme des données de l’exercice 3.9
isolant F(4), on trouve
F(4) ∈(
F10(4)± 1,96
√F10(4)(1− F10(4))
10
)
∈(
0,4± (1,96)
√0,2410
)∈ (0,0964,0,7036).
3.11 En utilisant l’équation de l’estimateur de Nelson-Aalen, on obtient
Hn(1 200) =352
+1040
+1119
= 0,8866.
On trouve maintenant la valeur de la fonction de survie évaluée au point1 200,
S(1 200) = e−0,8866 = 0,4120,

96 Solutions
yi (10 000− yi)/(6 000) k ∆Hn
1 000 1,5000 0,0 0,05003 400 1,1000 0,0 0,05264 500 0,9167 0,5 0,05567 500 0,4167 0,5 0,0588
15 000 −0,8333 0,5 0,062517 500 −1,2500 0,0 0,0667
Table E.1: Résultats intermédiaires du calcul de l’estimation par noyaux pourles données de l’exercice 3.12
et finalement la valeur de la fonction de répartition évaluée à ce mêmepoint :
F(1 200) = 1− 0,4120 = 0,5880.
3.12 a) En utilisant l’équation de l’estimateur de Nelson-Aalen, on trouve
Hn(1 000) =120
= 0,0500
Hn(3 400) =120
+1
19= 0,1026
Hn(4 500) =120
+1
19+
118
= 0,1582
Hn(7 500) =120
+1
19+
118
+1
17= 0,2170
Hn(15 000) =120
+1
19+
118
+1
17+
116
= 0,2795
Hn(17 500) =120
+1
19+
118
+1
17+
116
+115
= 0,3462.
b) Le tableau E.1 présente les résultats intermédiaires. L’estimation estdonc
h(10 000) =(
16 000
)(0,5)(0,0556 + 0,0588 + 0,0625)
= 0,00001449.

Solutions 97
3.13 On aγ1 =
µ3
σ3 .
En entrant les données dans R, on peut calculer les troisième et deuxièmemoment centraux facilement :
> x <- 1000 * c(rep(2, 2), rep(4, 6), rep(6, 12),+ rep(8, 10))> (m <- mean(x))
[1] 6000
> mean((x - m)^3)
[1] -3.2e+09
> mean((x - m)^2)
[1] 3200000
On a donc
γ1 =−3 200 000 000
3 200 0003/2
= −0,559.
La distribution des données est donc asymétrique vers la gauche ou, demanière équivalente, la bosse se trouve à droite.
3.14 Étant donné que la distribution empirique est symétrique, l’estimateurdu coefficient d’asymétrie est 0. En entrant les données dans R, on peutcalculer les quatrième et deuxième moment centraux facilement :
> x <- c(100, rep(200, 4), rep(300, 10), rep(400,+ 4), 500)> (m <- mean(x))
[1] 300
> mean((x - m)^4)
[1] 2e+08
> mean((x - m)^2)
[1] 8000
On a donc
γ2 =µ4
σ4
=200 000 000
8 0002
= 3,125.
La distribution empirique des données s’approche donc de celle d’uneloi normale.

98 Solutions
3.15 a) On a (n + 1)p = (20 + 1)(0,60) = 12,6, d’où
π0,60 = 0,4x(12) + 0,6x(13)
= (0,4)(38) + (0,6)(39)= 38,6.
b) On a (n + 1)p = (20 + 1)(0,75) = 15,75, d’où
π0,75 = 0,25x(15) + 0,75x(16)
= (0,25)(41) + (0,75)(43)= 42,5.
3.16 Par définition,
E[min(X, 320)] =∫ 320
0x fX(x)dx + 320(1− FX(320)).
En supposant que les données sont uniformément distribuées à l’inté-rieur des classes, la moyenne de celles-ci est affectée au point milieu.À la classe (200,320], on attribue un nombre de données proportion-nel à la longueur de leur classe par rapport à la classe (200,500], soit(120/300)(24) = (0,4)(24) = 9,6 données. On a au total n = 100 don-nées. On a donc
E100[min(X, 320)] =(
50 + 02
)(20
100
)+(
100 + 502
)(34100
)+(
200 + 1002
)(22100
)+(
320 + 2002
)(9,6100
)+ 320
(24− 9,6
100
)= 5 + 25,5 + 33 + 24,96 + 46,08= 134,54.
On peut vérifier ce résultat à l’aide de la fonction elev de actuar :
> x <- grouped.data(Classe = c(0, 50, 100, 200,+ 500), Frequence = c(20, 34, 22, 24))> elev(x)(320)
[1] 134.54
3.17 Étant donné que l’intervalle est petit, on peut en calculer le niveau deconfiance exactement. En utilisant la loi binomiale avec paramètres n = 5et p = 0,5, on obtient
Pr(X(2) ≤ π0,5 < X(4)) =3
∑k=2
(5k
)(0,5)k(0,5)5−k
= 0,625.

Solutions 99
3.18 Étant donné que l’intervalle est grand, on va utiliser l’approximationnormale avec correction pour la continuité pour déterminer le niveaude confiance. On a, avec Y ∼ N(250,125),
Pr(240≤ π0,50 < 260) ≈ Pr(239,5≤ K < 259,5)= Φ(0,85)−Φ(−0,94)= 0,6287.
3.19 La valeur 10 est la 10e statistique d’ordre et la valeur 20 est la 14e statis-tique d’ordre. Comme l’intervalle est petit, on peut en calculer le degréde confiance exactement. Soit N ∼ Binomiale(20,0,55),
Pr(X(10) ≤ π0,55 < X(14)) = Pr(N = 10,11,12,13)
=13
∑k=10
(20k
)(0,55)k(0,45)20−k
= 0,1593 + 0,1771 + 0,1623 + 0,1221= 0,6208.
3.20 a) On obtient aisément
fX(x) =1x
fY(ln(x))
=λα
Γ(α)x(ln(x))α−1e−λ ln(x), x > 1.
On remarque que comme Y est définie sur [0, ∞), X = eY est définiesur [1, ∞). Cette distribution est la log-gamma de paramètres α et λ.
b) La fonction R de la figure E.13 calcule le biais empirique pour desvaleurs de λ, n et r données. On remarquera que cette fonction définitune fonction interne qui se charge des étapes 2 et 3 de l’algorithmeprésenté dans l’exposé de l’exercice. Cette fonction est ensuite passéeà replicate pour réaliser efficacement l’étape 4 de l’algorithme.
i) Pour n = 10 et r = 1 000 on a> simul.1 <- sim(5, 10, 1000)> simul.1$bias
[1] 0.6603609
ii) Pour n = 1 000 et r = 100 on a> simul.2 <- sim(5, 1000, 100)> simul.2$bias
[1] 0.009779794
iii) Pour n = 1 000 et r = 1 000 on a

100 Solutions
sim <- function(lambda, n, r){
## Fonction interne pour simuler un échantillon## et calculer l’estimateur.f <- function(lambda, n){
## Simulation des données. On pourrait aussi## utiliser la fonction rlgamma() du package## actuar.x <- exp(rgamma(n, shape = 1, rate = lambda))
## Estimateur de lambda1 / (1 - 1/mean(x))
}
## Simulation de ’r’ échantillonslc <- replicate(r, f(lambda, n))
## La fonction retourne une liste contenant le## vecteur d’estimateurs et le biais empirique.list(estimates = lc,
bias = mean(lc) - lambda)}
Figure E.13: Fonction R permettant la création des échantillons et le calculdu biais empirique
> simul.3 <- sim(5, 1000, 1000)> simul.3$bias
[1] 0.005028595
La taille de l’échantillon a un impact sur le biais de l’estimateur. Onvoit qu’au passage d’un petit échantillon (partie i)) à un plus grand(partie ii)) le biais devient moins important et l’estimateur est doncplus proche de sa vraie valeur. En revanche, le nombre de simulationn’a un impact que sur la force de la conclusion. De la partie ii) à lapartie iii), seul le nombre de simulations change. Or, le biais changeassez peu. Nous ne sommes que confortés dans notre conclusion quel’estimateur λ est probablement sans biais pour λ.
c) On a un échantillon de 100 estimations. La figure E.14 présente legraphique de la fonction de répartition empirique de l’estimateur λ.
d) La figure E.15 présente l’histogramme et l’ogive de l’estimateur λ.Tel que suggéré dans l’énoncé de l’exercice, on a utilisé les classes
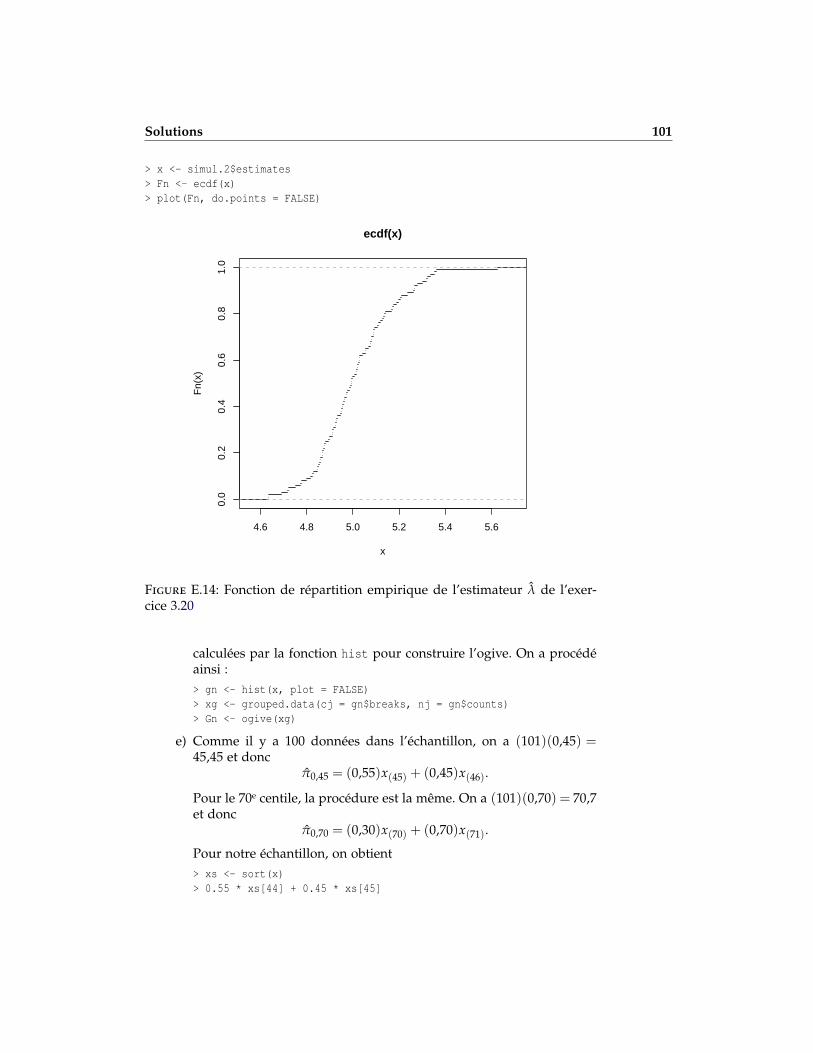
Solutions 101
> x <- simul.2$estimates> Fn <- ecdf(x)> plot(Fn, do.points = FALSE)
4.6 4.8 5.0 5.2 5.4 5.6
0.0
0.2
0.4
0.6
0.8
1.0
ecdf(x)
x
Fn(
x)
Figure E.14: Fonction de répartition empirique de l’estimateur λ de l’exer-cice 3.20
calculées par la fonction hist pour construire l’ogive. On a procédéainsi :> gn <- hist(x, plot = FALSE)> xg <- grouped.data(cj = gn$breaks, nj = gn$counts)> Gn <- ogive(xg)
e) Comme il y a 100 données dans l’échantillon, on a (101)(0,45) =45,45 et donc
π0,45 = (0,55)x(45) + (0,45)x(46).
Pour le 70e centile, la procédure est la même. On a (101)(0,70) = 70,7et donc
π0,70 = (0,30)x(70) + (0,70)x(71).
Pour notre échantillon, on obtient> xs <- sort(x)> 0.55 * xs[44] + 0.45 * xs[45]
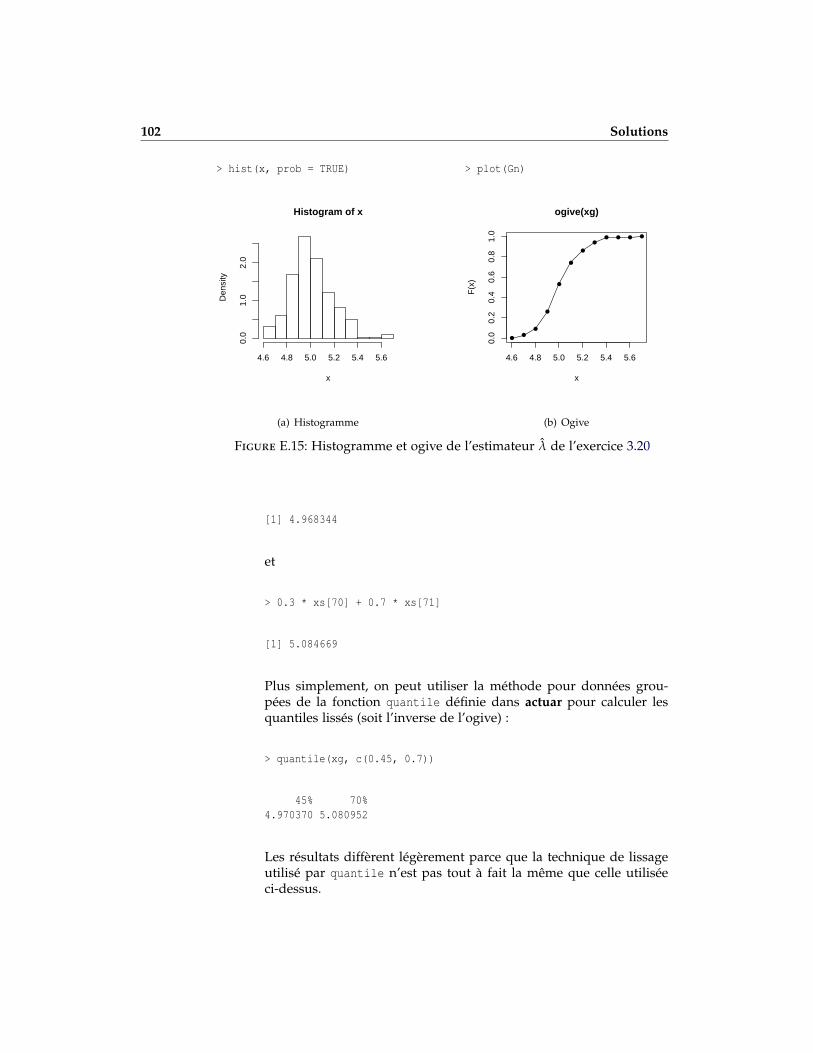
102 Solutions
> hist(x, prob = TRUE)
Histogram of x
x
Den
sity
4.6 4.8 5.0 5.2 5.4 5.6
0.0
1.0
2.0
(a) Histogramme
> plot(Gn)
●●
●
●
●
●
●
●● ● ● ●
4.6 4.8 5.0 5.2 5.4 5.6
0.0
0.2
0.4
0.6
0.8
1.0
ogive(xg)
x
F(x
)
(b) Ogive
Figure E.15: Histogramme et ogive de l’estimateur λ de l’exercice 3.20
[1] 4.968344
et
> 0.3 * xs[70] + 0.7 * xs[71]
[1] 5.084669
Plus simplement, on peut utiliser la méthode pour données grou-pées de la fonction quantile définie dans actuar pour calculer lesquantiles lissés (soit l’inverse de l’ogive) :
> quantile(xg, c(0.45, 0.7))
45% 70%4.970370 5.080952
Les résultats diffèrent légèrement parce que la technique de lissageutilisé par quantile n’est pas tout à fait la même que celle utiliséeci-dessus.

Solutions 103
Chapitre 4
4.1 En utilisant la technique de la fonction de répartition, on a
FY(y) = Pr(Y ≤ y)= Pr(cX ≤ y)= Pr(X ≤ y/c)= FX(y/c)
= 1−(
λ
λ + y/c
)α
= 1−(
cλ
cλ + y
)α
et donc, Y ∼ Pareto(α, cλ).
4.2 En utilisant la technique de la fonction de répartition, on a
FY(y) = Pr(Y ≤ y)= Pr(X ≤ ln(y))= FX(ln(y)).
Étant donné la présence de la valeur absolue dans la densité de X, il fautséparer le domaine. Pour −∞ < x ≤ 0, on a 0 < y < 1, et donc
FX(ln(y)) =∫ ln(y)
−∞
12θ
exθ dx
=12
eln(y)/θ .
Pour 0 < x < ∞, on a 1 < y < ∞, et donc
FX(ln(y)) =∫ 0
−∞
12θ
ex/θ dx +∫ ln(y)
0
12θ
e−x/θ dx
= 1− 12
e− ln(y)
θ .
Par conséquent,
F(y) =
{12 eln(y)/θ , 0 < y < 11− 1
2 eln(y)/θ , y ≥ 1.

104 Solutions
4.3 En utilisant le fait que, pour α entier, Γ(α) = (α− 1)!, on trouve
Pr(X ≤ x) =1
(α− 1)!βα
∫ x
0tα−1e−t/β dt
=1
(α− 1)!βα
(−tα−1βe−t/β
∣∣∣x0+∫ x
0(α− 1)tα−2βe−t/β dt
)= − xα−1e−x/β
(α− 1)!βα−1 +1
(α− 2)!βα−1
∫ x
0tα−2e−t/β dt
= −Pr(Y = α− 1) +1
(α− 2)!βα−1
∫ x
0tα−2e−t/β dt
avec Y ∼ Poisson(x/β). La relation s’obtient en continuant à intégrercomme ci-dessus jusqu’à obtenir
Pr(X ≤ x) = 1− Pr(Y = α− 1)− · · · − Pr(Y = 0)= Pr(Y ≥ α).
4.4 En utilisant la technique de la fonction de répartition, on a
FY(y) = FX
(λy
1− y
)= β
(τ, α;
λy/(1− y)λy/(1− y) + λ
)= β(τ, α;y),
où β(a, b; x) est la fonction de répartition d’une distribution Bêta(a, b)évaluée au point x. On a donc que Y ∼ Bêta(τ, α).
4.5 En utilisant la technique de la fonction de répartition, on obtient
FY(y) = Pr(Y ≤ y)
= Pr(5X−1/4 ≤ y)
= Pr(
X >(y
5
)−4)
= 1− FX
((y5
)−4)=(
11 + (5/y)4
)α
qui est la fonction de répartition d’une variable aléatoire avec distributionBurr inverse de paramètres τ = α, γ = 4 et θ = 5.
4.6 a) Par définition, la distribution de Y est nommée log-gamma. On re-marque que comme X est définie sur [0, ∞), Y = eX est définie sur

Solutions 105
[1, ∞). On a donc
fY(y) =1y
fX(ln(y))
=λα
Γ(α)y(ln(y))α−1e−λ ln(y), y ≥ 1.
b) En utilisant la fonction génératrice des moments de X, on trouve
E[Y] = E[eX ]= MX(1)
=(
λ
λ− 1
)α
, λ > 1
E[Y2] = E[e2X ]= MX(2)
=(
λ
λ− 2
)α
, λ > 2,
d’où
Var[Y] = E[Y2]− E[Y]2
=(
λ
λ− 2
)α
−(
λ
λ− 1
)2α
, λ > 2.
c) De la partie b), on voit que
E[Yk] = MX(k)
=(
λ
λ− k
)α
, λ > k.
Les moments de Y existent donc seulement pour k < λ.
4.7 a) Il suffit de poser c = 1 + i dans le résultat de l’exercice 4.1.
b) En utilisant la technique de la fonction de répartition, on trouve
FY(y) = FX
(y
1 + i
)= 1−
(θγ(1 + i)γ
θγ(1 + i)γ + yγ
)α
et donc, Y ∼ Burr(α, γ, (1 + i)θ).

106 Solutions
c) On a
fY(y) =1
1 + ifX
(x
1 + i
)=
11 + i
λα
Γ(α)(ln(y/(1 + i)))α−1
(y/(1 + i))λ+1
=λα(1 + i))λ(ln(y)− ln(1 + i))α−1
Γ(α)yλ+1 .
4.8 En utilisant la technique de la fonction de répartition, on a
FY(y) = FX(yτ)
= 1−(
λ
λ + yτ
)α
et donc, Y ∼ Burr(α, τ, λ1/τ).
4.9 En utilisant la technique de la fonction de répartition, on a
FY(y) = Pr(Y ≤ y)= Pr(ln(1 + X/θ) ≤ y)= Pr(X ≤ θ(ey − 1))= FX(θ(ey − 1))
= 1−(
θ
θ + θ(ey − 1)
)α
= 1− e−αy, y ≥ 0.
Ainsi, Y ∼ Exponentielle(α).
4.10 Soit Y, la variable aléatoire du montant des sinistres en 2007. On définit
Y = (1,04)(1,045)(1,16)X= 1,260688X.
En se reportant à l’exercice 4.7 b), on a que Y ∼ Burr(α = 0,5, γ = 2, θ =3,7821) et donc que
Pr(Y > 4) = 1− FY(4) = 0,6870.
4.11 a) On observe que la variable aléatoire X obéit à une distribution Paretotranslatée(3,1). En utilisant la technique de la fonction de répartition,on trouve
FY(y) = FX
(y
1,10
)= 1−
(1,10
y
)3.
b) On a Pr(Y > 2,2) = 1− FY(2,2) = 0,125.

Solutions 107
4.12 On a X|Θ ∼ Binomiale(10, Θ) et Θ ∼ Uniforme(0,1). Par la loi des pro-babilités totales,
Pr(X = x) =∫ 1
0
(10x
)θx(1− θ)10−x dθ
=(
10x
)∫ 1
0θx(1− θ)10−x dθ
qui devient, en reconnaissant sous l’intégrale la forme fonctionnelled’une distribution Bêta(x + 1,11− x),
Pr(X = x) =(
10x
)Γ(x + 1)Γ(11− x)
Γ(12)
=10!
(10− x)!x!x!(10− x)!
11!
=1
11.
Par conséquent,
Pr(X > 6) =10
∑i=7
Pr(X = i)
=4
11.
4.13 Par la loi des probabilités totales, on trouve
fX(x) =∫ ∞
0
(θτe−θxxτ−1
Γ(τ)
)(λαe−λθθα−1
Γ(α)
)dθ
=xτ−1λα
Γ(τ)Γ(α)
∫ ∞
0θτ+α−1e−(x+λ)θ dθ
qui devient, en reconnaissant sous l’intégrale la forme fonctionnelled’une distribution Gamma(τ + α, x + λ)
fX(x) =xτ−1λαΓ(τ + α)
Γ(α)Γ(τ)(x + λ)τ+α
et donc, X ∼ Pareto Généralisée(α, τ, λ).
4.14 On a
Pr(X = x) =∫ 1
0θ(1− θ)x−1 Γ(α + β)
Γ(α)Γ(β)θα−1(1− θ)β−1 dθ
=Γ(α + β)Γ(α)Γ(β)
∫ 1
0θα(1− θ)x+β−2 dθ

108 Solutions
qui devient, en reconnaissant sous l’intégrale une distribution Bêta(α +1, β + x− 1),
Pr(X = x) =Γ(α + β)Γ(α + 1)Γ(x + β− 1)
Γ(α)Γ(β)Γ(α + β + x).
4.15 Par la loi des probabilités totales, on obtient
fX(x) =∫ ∞
0τθxτ−1e−θxτ λαxα−1e−λx
Γ(α)dθ
=τxτ−1λα
Γ(α)
∫ ∞
0θαe−(xτ+λ)θ dθ
=ατxτ−1λα
(λ + xτ)α+1 ,
en reconnaissant une distribution Gamma(α + 1, xτ + λ) sous l’intégrale.La densité obtenue est celle d’une loi Burr(α, τ, λ1/τ).
4.16 On a X|Λ ∼ Burr(5,1, Λ) et Λ ∼ Gamma(10,2). On cherche E[X] etVar[X]. Il ne faut pas tenter de trouver la distribution marginale de X,mais plutôt conditionner :
E[X] = E[E[X|Λ]]
= E[
ΛΓ(4)Γ(2)Γ(5)
]=
14
E[Λ]
=54
et
Var[X] = E[Var[X|Λ]] + Var[E[X|Λ]]
= E
[Λ2Γ(3)Γ(3)
Γ(5)−(
ΛΓ(4)Γ(2)Γ(5)
)2]
+ Var[
ΛΓ(4)Γ(2)Γ(5)
]=
548
E[Λ2] +1
16Var[Λ]
=14548
.
4.17 Pour commencer, on utilise le lien entre le taux d’échec et la fonction de

Solutions 109
survie pour trouver
S(x|θ) = e−∫ x
0 λ(x|θ)dt
= exp{−∫ x
0
3θ + t
dt}
= exp{−3ln
(θ
θ + x
)}= exp
{ln(
θ
θ + x
)3}
=(
θ
θ + x
)3.
La fonction de répartition est donc
F(x|θ) = 1−(
θ
θ + x
)3,
d’où X|Θ ∼ Pareto(3, Θ). Par conséquent,
E[X] = E[E[X|Θ]]
= E[
Θ2
]= 500
et
Var[X] = E[Var[X|Θ]] + Var[E[X|Θ]]
= E[
3Θ4
]+ Var
[Θ2
]= 850 000.
4.18 Soit f (·) la fonction de densité de probabilité d’une Log-normale(µ, σ2)et g(·) celle d’une Gamma(α, λ). Pour comparer les queues de ces deuxdistributions, il faut évaluer
limx→∞
f (x)g(x)
.
En éliminant les termes qui ne dépendent pas de x, on obtient
limx→∞
x−1e−(ln(x)−µ)2/2σ2
xα−1e−x/θ= lim
x→∞e−(ln(x)−µ)2/2σ2−α ln(x)+x/θ .
Or, de l’exercice 1.4 on sait que x tend plus rapidement vers l’infini queln(x). L’exposant tend donc vers ∞, d’où la distribution log-normale aune queue plus épaisse que la distribution gamma.

110 Solutions
4.19 Une fonction d’espérance de vie résiduelle linéaire en x indique unedistribution de Pareto telle que
e(x) =(
1α− 1
)x +
λ
α− 1.
À partir de e(x) = 2 000 + 2x, on trouve que α = 1,5 et λ = 1 000. Enutilisant les formules de l’annexe A pour l’espérance limitée d’une loide Pareto, on a que le LER est
LER =E[X]− E[X; x]
1− FX(x)= 0,30115.
4.20 a) Il s’agit d’une fonction linéaire en x, on a donc que X ∼ Pareto. Enutilisant la relation de l’exercice 4.19, on trouve que α = 7/3 et λ =16/3.
b) En utilisant la formule de l’annexe A, on trouve que E[X;10] = 3,0215.
4.21 Pour X ∼ Gamma(α, λ), on a E[X] = α/λ et Var[X] = α/λ2. On trouveles paramètres suivants pour les trois sous-intervalles : α1 = 1, λ1 = 1,α2 = 25, λ2 = 5, α3 = 144 et λ3 = 12. Pour le premier sous-intervalle, ona A ∼ Gamma(1,1) et
Pr(A ≤ 2) = Γ(1;2).
Pour le second sous-intervalle, on a B ∼ Gamma(25,5) et
Pr(2 < B ≤ 8) = Γ(25;40)− Γ(25;10).
Pour le troisième sous-intervalle, on a C ∼ Gamma(144,12) et
Pr(8 < C ≤ 16) = Γ(144,192)− Γ(144;96).
La densité raccordée est donc
fX(x) =
0,5e−x
Γ(1;2), 0 < x ≤ 2
0,2Γ(25;40)− Γ(25;10)
525x25−1e−5x
Γ(25), 2 < x ≤ 8
0,3Γ(144;192)− Γ(144;96)
12144x144−1e−12x
Γ(144), 8 < x ≤ 16.
4.22 On a
fX(x) =
p/10, 0 < x < 10
(1− p)(3)(1003)(100 + x)4
1(100/110)3 , x ≥ 10
=
p/10, 0 < x < 10(3)(1103)(100 + x)4 (1− p), x ≥ 10.

Solutions 111
Pour que la distribution soit continue au point x = 10, on doit avoir
fX(10) =p
10,
soit
3110
(1− p) =p
10.
En résolvant pour p, on trouve p = 3/14.
4.23 a) On pose X ∼ Weibull(λ1, τ1) et Y = X−1 ∼ Weibull inverse(λ2, τ2).On sait de l’annexe A que tous les moments positifs de la distributionWeibull existent, alors que ceux de la distribution Weibull inversen’existent que pour k < τ2. Par ce critère, on voit que la distributionWeibull Inverse possède une queue plus lourde.D’autre part, on a
fY(x)fX(x)
=τ2λ−τ2
2 x−τ2−1e−(λ2x)−τ2
τ1λτ11 xτ1−1e−(λ1x)τ1
∝ x−τ1−τ2 e−(λ2x)−τ2 +(λ1x)τ1 ,
d’où
ln(
fY(x)fX(x)
)∝ (λ1x)τ1 − (λ2x)−τ2 − (τ1 + τ2) ln(x).
Lorsque x → ∞, le terme central tend vers 0. Comme x tend plusrapidement vers ∞ que ln(x), on a que
limx→∞
ln(
fY(x)fX(x)
)= lim
x→∞(λ1x)τ1 − (λ2x)−τ2 − (τ1 + τ2) ln(x)
= ∞,
d’où
limx→∞
SY(x)SX(x)
= limx→∞
fY(x)fX(x)
= ∞.
Ainsi, en comparant les fonctions de survie on arrive aussi à laconclusion que la queue de la loi Weibull inverse est plus lourdeque celle de la Weibull.
b) On fixe τ1 et λ1 de manière arbitraire et on résoud numériquementpour τ2 et θ2. La figure E.16 présente le graphique des deux distribu-tions pour τ1 = 3, λ1 = 0,1, τ2 = 4,4744 et θ2 = 0,1335.
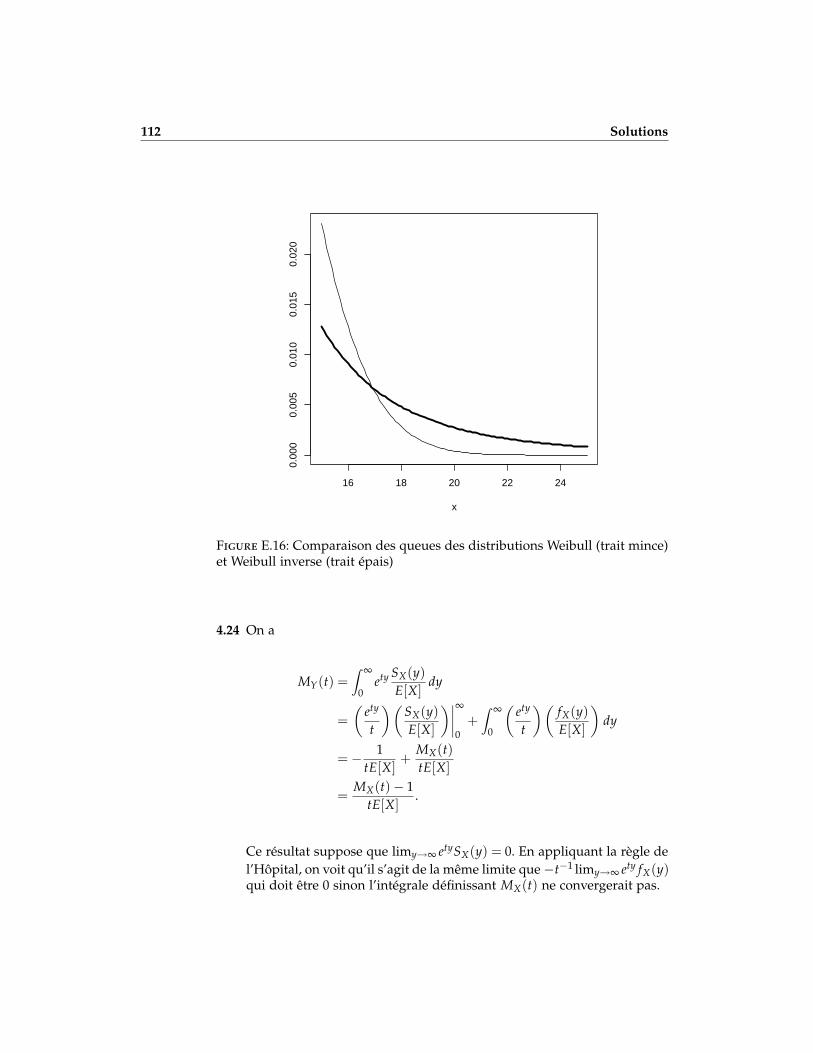
112 Solutions
16 18 20 22 24
0.00
00.
005
0.01
00.
015
0.02
0
x
Figure E.16: Comparaison des queues des distributions Weibull (trait mince)et Weibull inverse (trait épais)
4.24 On a
MY(t) =∫ ∞
0ety SX(y)
E[X]dy
=(
ety
t
)(SX(y)E[X]
)∣∣∣∣∞0
+∫ ∞
0
(ety
t
)(fX(y)E[X]
)dy
= − 1tE[X]
+MX(t)tE[X]
=MX(t)− 1
tE[X].
Ce résultat suppose que limy→∞ etySX(y) = 0. En appliquant la règle del’Hôpital, on voit qu’il s’agit de la même limite que−t−1 limy→∞ ety fX(y)qui doit être 0 sinon l’intégrale définissant MX(t) ne convergerait pas.

Solutions 113
4.25 a) Par définition de la fonction de survie :
S(x) =∫ ∞
x(1 + 2t2)e2t dt
= (1 + x + x2)e−2x , x ≥ 0.
b) Par définition du taux d’incidence :
h(x) = − ddx
lnS(x)
=d
dx(2x)− d
dxln(1 + x + x2)
= 2− 1 + 2x1 + x + x2 .
c) On a d’abord ∫ ∞
xS(t)dt =
∫ ∞
x(1 + t + t2)e−2t dt
= (1 + x + 0,5x2)e−2x
et donc
e(x) =
∫ ∞x S(x)dx
S(x)=
1 + x + 0,5x2
1 + x + x2 .
d) On a
limx→∞
h(x) = limx→∞
(2− 1 + 2x
1 + x + x2
)= 2.
e) On a
limx→∞
e(x) =1
limx→∞ h(x)
=12
.
f) À partir de c), on trouve
ddx
e(x) = − x + 0,5x2
(1 + x + x2)2 < 0,
pour x > 0, d’où e(x) est une fonction strictement décroissante. Ce-pendant, pour h(x), on a h(0) = 1, h(0,5) = 6/7 et h(∞) = 2. On voitdonc que le taux d’incidence n’est pas une fonction strictement crois-sante.

114 Solutions
Chapitre 5
5.1 On a ∑5i=1 xi = 6 211 et ∑5
i=1 x2i = 26 040 101. Pour trouver les estimateurs
des moments de α et β, on pose
E[X] = E[E[X|Λ]] = E[Λ−1] =β
α− 1=
6 2115
et
E[X2] = E[E[X|Λ]] = E[Λ−2] =2β2
(α− 1)(α− 2)=
26 040 1015
.
En résolvant, on trouve α = 3,45 et β = 3 048,87.
5.2 Par définition, la fonction de vraisemblance donne la probabilité d’obte-nir un échantillon tel que celui obtenu. On doit donc avoir deux donnéesentre 0 et 2 000 et quatre données entre 2 000 et 5 000, le tout sachant queles six données sont plus petites que 5 000. On a alors
L(λ) =(1− e−2 000λ)2(e−2 000λ − e−5 000λ)4
(1− e−5 000λ)6 .
5.3 On a ∑5i=1 xi = 5 850 et ∑5
i=1 x2i = 5 867 500. Pour trouver les estimateurs
des moments de α et θ il suffit de poser égaux les deux premiers momentsempiriques et théoriques :
αθ =5 850
6et
αθ2 + α2θ2 =5 867 500
6.
On trouve alors α = 34,83 et θ = 27,99.
5.4 La fonction de répartition de la log-logistique étant
F(x) =(x/θ)γ
1 + (x/θ)γ,
on trouve, après avoir égalisé les quantiles théoriques et empiriques, queγ = 2 et θ = 200.
5.5 La densité de la variable aléatoire sous-jacente est
fX(x) = F′X(x) = pxp−1.
L’espérance est donc
E[X] =∫ 1
0xpxp−1 dx
=p
p + 1.

Solutions 115
En posant E[X] = x pour trouver un estimateur des moments de p, onobtient
p =x
1− x.
5.6 On a ∑5i=1 xi = 10 000 et ∑5
i=1 x2i = 30 000 000. On égalise les deux pre-
miers moments théoriques et empiriques :
eµ+ σ22 =
10 0005
ete2µ+2σ2
=30 000 000
5.
On trouve alors µ = 7,40 et σ = 0,6368. Par conséquent,
Pr(X > 4 500) = 1−Φ(
ln(4 500)− 7,400,6368
)= 1−Φ(1,5919)= 0,056.
5.7 On pose simplementβ√
2π
2= x = 4,2,
d’où β = 3,3511.
5.8 a) Posons λ = λτ . On a
Pr(X ≤ 500) = 1− e−λ500τ
= 0,25
et
Pr(X ≤ 1 000) = 1− e−λ1 000τ
= 0,50
d’où on trouve que ˆλ = 0,000108 et τ = 1,2687. Ainsi, on a λ = 0,000747.b) On cherche π0,80 tel que
1− e−(λπ0,80)τ= 0,80.
On trouve π0,80 = (− ln0,20)1/τ/λ = 1 947.
5.9 La distribution marginale de la variable X est une loi de Pareto(α, β).Ainsi, pour estimer les paramètres α et β par la méthode des quantiles,on pose
SX(450) =(
β
β + 450
)α
= 0,001

116 Solutions
et
SX(50) =(
β
β + 50
)α
= 0,125.
Il suffit maintenant de manipuler les termes pour obtenir
ln(0,125)ln(0,001)
=ln(
ββ+50
)ln(
ββ+450
)ln(
β
β + 450
)0,3010= ln
(β
β + 50
)β0,3010(β + 50) = β(β + 450)0,3010.
5.10 D’abord, le rapport d’élimination de perte avec une franchise forfaitaireest
LER =E[X;d]E[X]
alors qu’avec une franchise atteinte il est
LER =E[X;d]− d(1− F(d))
E[X].
Par conséquent, on a les équations suivantes :
0,56 =E[X;200]
E[X]
0,79 =E[X;500]
E[X]
0,32 =E[X;200]− 200(1− F(200))
E[X]
0,52 =E[X;500]− 500(1− F(500))
E[X]
Puisque E[X] = 200, on trouve F(200) = 0,76 et F(500) = 0,892, d’oùλ ≈ 0,01 et τ ≈ 0,48.
5.11 La fonction de répartition d’une loi U(a, b) étant
F(x) =x− ab− a
,

Solutions 117
on a
50− ab− a
= 0,80
55− ab− a
= 0,90,
d’où on obtient a = 10 et b = 60.
5.12 Pour X ∼ Bernoulli(p), on a la fonction de vraisemblance
L(p; x1, . . . , xn) =n
∏i=1
pxi (1− p)1−xi
= p∑ni=1 xi (1− p)n−∑n
i=1 xi
et la fonction de log-vraisemblance
l(p; x1, . . . , xn) =n
∑i=1
xi ln(p) +
(n−
n
∑i=1
xi
)ln(1− p),
d’où
l′(p; x1, . . . , xn) = ∑ni=1 xi
p− n−∑n
i=1 xi
1− p
=nxp− n− nx
1− p.
On trouve donc p = X.
5.13 a) On a la fonction de log-vraisemblance
l(µ, σ2) = n ln(
1√2πσ
)− 1
2
n
∑i=1
(xi − µ)2
σ2
et les dérivées partielles
∂
∂µl(µ, σ2) =
n
∑i=1
(xi − µ)σ2
∂
∂σ2 l(µ,σ2) = − n2σ2 + ∑n
i=1(xi − µ)2
2σ4 .
En posant ces dérivées égales à 0 et en résolvant pour µ et σ2, onobtient les estimateurs du maximum de vraisemblance
µ =1n
n
∑i=1
Xi = X
σ2 =1n
n
∑i=1
(Xi − X)2 = S2.

118 Solutions
b) À partir des calculs précédents, on trouve
∂2
∂µ2 l(µ, σ2) = − nσ2
∂2
∂σ4 l(µ, σ2) =n
2σ4 −∑n
i=1(xi − µ)2
σ6
∂2
∂µ∂σ2 l(µ, σ2) = −∑ni=1 xi − µ
σ4 .
Or,
E[− n
σ2
]= − n
σ2
E[−∑n
i=1(Xi − µ)σ4
]= 0
et
E[
n2σ4 −
∑ni=1(Xi − µ)2
σ6
]= − n
2σ4
car E[Xi − µ] = 0 et E[(Xi − µ)2] = σ2. On obtient ainsi la matricevariance-covariance :
Σ =[
σ2/n 00 2σ4/n
].
Or, on sait que la distribution asymptotique conjointe des estimateursdu maximum de vraisemblance est une normale multivariée sansbiais et de matrice variance-covariance Σ.
c) On rappelle que Φ(·) et φ(·) sont, dans l’ordre, les fonctions de répar-tition et de densité de probabilité d’une loi N(0,1). Par conséquent,
A =∂
∂µh(µ, σ2) = − 1
σφ
(c− µ
σ
)et
B =∂
∂σ2 h(µ, σ2) = −12
(c− µ
σ3
)φ
(c− µ
σ
),
d’où
Var[h(µ, σ2)] =[A B
][σ2/n 00 2σ4/n
][AB
]=(
φ
(c− µ
σ
))2( 1n
+(c− µ)2
2nσ2
).
Enfin, on sait que, asymptotiquement,
h(µ, σ2) ∼ N(h(µ, σ2),Var[h(µ, σ2)]).

Solutions 119
5.14 En utilisant la technique habituelle :
L(θ) = 2nθn
(n
∏i=1
xi
)e−θ ∑n
i=1 x2i
l(θ) = n ln(2) + n ln(θ) +n
∑i=1
ln xi − θn
∑i=1
x2i
l′(θ) =nθ−
n
∑i=1
x2i .
On trouve alors θ = n/ ∑ni=1 x2
i . En calculant la dérivée seconde de lafonction de log-vraisemblance, on voit qu’il s’agit bien d’un maximum.
5.15 a) On a f (x) = pxp−1, d’où
L(p) = pnn
∏i=1
xp−1i
l(p) = n ln(p) + (p− 1)n
∑i=1
ln(xi)
l′(p) =np
+n
∑i=1
ln(xi).
On trouve alors p =−n/ ∑ni=1 ln(xi). En calculant la dérivée seconde,
on voit qu’il s’agit bien d’un maximum.
b) À partir de a), on calcule
l′′(p; x1, . . . , xn) = − np2
d’où
I(p) = nE[p−2] =np2
et
Var[ p] =1
I(p)=
p2
n.
c) On sait que
p ∈ p± 1,96√
Var[ p].
De a) et b), on a doncp ∈ p± 1,96
p√n
.

120 Solutions
d) On a
E[X] =∫ 1
0xpxp−1 dx
=p
p + 1.
Par la propriété d’invariance, l’estimateur du maximum de vraisem-blance de E[X] est
E[X] =p
1 + p,
où p est l’estimateur du maximum de vraisemblance de p déterminéen a).
e) On pose E[X] = h(p) avec
h(p) =p
1 + p,
d’où
h′(p) =1
(1 + p)2 .
Par la méthode delta,
Var[E[X]
]= h′(p)2Var[ p]
=(
11 + p
)4( p2
n
)et
Var[E[X]
]=(
11 + p
)4( p2
n
)et donc
E[X] ∈ p1 + p
± 1,96(
p(1 + p)2
√n
).
5.16 On a
L(α) = α5λ5α5
∏i=1
(λ + xi)−α−1
l(α) = 5ln(α) + 5α lnλ− (α + 1)5
∑i=1
ln(λ + xi)
l′(α) =5α
+ 5ln(λ)−5
∑i=1
ln(λ + xi).

Solutions 121
On obtient alors α = 5/(∑5i=1 ln(λ + xi)− 5lnλ) = 3,8629. En calculant
la dérivée seconde de la fonction de log-vraisemblance, on vérifie qu’ils’agit bien d’un maximum.
5.17 La probabilité d’avoir une observation inférieure à 2 est
F(2) =∫ 2
02λxe−λx2
dx = 1− e−4λ.
On a ensuite, pour un échantillon aléatoire de taille 4,
L(λ) = F(2)(1− F(2))3
= (1− e−4λ)e−12λ
l(λ) = ln(1− e−4λ)− 12λ
l′(λ) = 4(1− e−4λ)−1e−4λ − 12.
On trouve alors λ = 14 ln 4
3 .
5.18 On aura reconnu la densité d’une N(0, θ). On sait que l’estimateur dumaximum de vraisemblance de θ est sans biais. Ainsi, MSE(θ) = Var[θ].Or, on a
ln f (x) = −12
ln(2πθ)− x2
2θ
d2
dθ2 ln f (x) =1
2θ2 −x2
θ3
I(θ) = nE[
12θ2 −
X2
θ3
]=
2nθ2
et Var[θ] = I−1(θ). Une approximation de l’erreur quadratique moyenneest donc
MSE(θ) = Var[θ]
=2θ2
n= 0,20.
5.19 a) On a une distribution log-gamma de paramètres α = 2 et λ. De l’an-nexe A, on sait que
E[X] =(
λ
λ− 1
)2.
En posant E[X] = X, on trouve que l’estimateur des moments de λest
λ =±√
X
±√
X− 1.

122 Solutions
b) On a
L(λ) =λ2n ∏n
i=1 ln(xi)
∏ni=1 xλ+1
i
l(λ) = 2n ln(λ) +n
∑i=1
ln(ln(xi))− (λ + 1)n
∑i=1
ln(xi)
l′(λ) =2nλ−
n
∑i=1
ln(xi).
On trouve alors que λ = 2n/ ∑ni=1 ln(xi).
5.20 a) On a
L(λ) =(λ5)5(∏5
i=1 x4i )e−λ ∑5
i=1 xi
(Γ(5))5
l(λ) = 25ln(λ) + 45
∑i=1
ln xi − λ5
∑i=1
xi − 5lnΓ(5)
l′(λ) =25λ−
5
∑i=1
xi ,
d’où λ = 25/ ∑5i=1 xi = 1/2.
b) On a
l′′(λ) = − 25λ2
et donc la matrice d’information de Fisher est
I(λ) = E[
25λ2
]=
25(5/8)2
= 64.
Par conséquent, Var[λ] = 164 .
5.21 Par définition de la fonction de vraisemblance :
L(α) = (Pr(X ≤ 2))2Pr(5≤ X ≤ 11)Pr(X ≥ 11)
=(
1−(
13
)α)2((16
)α
−(
112
)α)( 112
)α
.
Étant donné qu’il faudra faire appel à des méthodes numériques pourrésoudre ce problème, on peut tout aussi bien minimiser la fonction devraisemblance au lieu de la fonction de log-vraisemblance.

Solutions 123
5.22 On a
L(β) = Pr(0≤ X ≤ 1)Pr(X ≥ 2)
= (1− e−β)e−2β
l(β) = ln(1− e−β)− 2β
l′(β) =e−β
1− e−β− 2.
On obtient β = ln(1,5).
5.23 a) Par la méthode du maximum de vraisemblance habituelle, on trouve
λ =n
∑ni=1 x2
i.
Or, Pk = FX(k) = 1− e−λk2. Par la propriété d’invariance de l’estima-
teur du maximum de vraisemblance, on a donc Pk = 1− e−λk2.
b) Par la méthode delta, on a que
Var[Pk] =(
∂Pk∂λ
)2Var[λ]
= (k2e−λk2)2Var[λ].
Or, en laissant tomber les termes non fonction de λ,
l(λ) = n ln(λ)− λn
∑i=1
x2i + . . .
l′(λ) =nλ−
n
∑i=1
x2i
l′′(λ) = − nλ2
d’oùE[− n
λ2
]= − n
λ2
et
Var[λ] =λ2
n.
Par conséquent,
Var[Pk] =k4λ2e−2λk2
n.
c) On sait que Pk ∼ N(Pk ,Var[Pk]). Or, si X1 = X2 = 10 et X3 = 15, alorsλ = 3/425, p10 = 0,5063 et
Var[P10] =λ
3= 0,0405.

124 Solutions
Ainsi, approximativement, P10∼N(0,5063,0,0405), d’où Pr(P10≤ 0,5)≈Φ(−0,0313) = 0,4875.
5.24 En premier lieu, on a
l(α, λ; x) = n ln(α) + αn ln(λ)− (α + 1)n
∑i=1
ln(λ + xi)
et
∂2
∂α2 l(α, λ; x) = − nα2
∂2
∂λ2 l(α, λ; x) = −αnλ2 + (α + 1)
n
∑i=1
(1
λ + xi
)2
∂2
∂α∂λl(α, λ; x) =
nλ−
n
∑i=1
(1
λ + xi
).
Pour la suite, on aura besoin des résultats intermédiaires
E
[(1
λ + X
)2]
=∫ ∞
0
1(λ + x)2
αλα
(λ + x)α+1 dx
=α
λ2(α + 2)
E[
1λ + X
]=∫ ∞
0
1λ + x
αλα
(x + λ)α+1 dx
=α
α + 11λ
.
Ainsi,
E[
∂2
∂α2 l(α, λ; X)]
= E[− n
α2
]= − n
α2
E[
∂2
∂λ2 l(α, λ; X)]
= E
[−αn
λ2 + (α + 1)n
∑i=1
(1
λ + Xi
)2]
= − αnλ2(α + 2)
E[
∂2
∂α∂λl(α, λ; X)
]= E
[nλ−
n
∑i=1
(1
λ + Xi
)]=
nλ(α + 1)

Solutions 125
et la matrice d’information de Fisher est
I(α, λ) =
nα2 − n
λ(α + 1)
− nλ(α + 1)
αnλ2(α + 2)
.
La matrice de variance-covariance est donc
Σ = I−1(α, λ)
=
α2(α + 1)2
nα(α + 1)(α + 2)λ
nα(α + 1)(α + 2)λ
nλ2(α + 1)2(α + 2)
nα
.
De là, on obtient
Var[α] =α2(α + 1)2
50= 0,28125
Var[λ] =λ2(α + 1)2(α + 2)
50α= 656 250
Cov(α, λ) =α(α + 1)(α + 2)λ
50= 393,75.
5.25 On a
h(α, λ) = Pr(X > 10)
=(
λ
λ + 10
)α
∂h(α, λ)∂α
=(
λ
λ + 10
)α
ln(
λ
λ + 10
)∂h(α, λ)
∂λ= α
(λ
λ + 10
)α−1( 10(λ + 10)2
).
Or,
h(α, λ) = 0,0816
∂h(α, λ)∂α
∣∣∣∣(α,λ)
= −0,1023
∂h(α, λ)∂λ
∣∣∣∣(α,λ)
= 0,0292
et donc
Var[h(α, λ)] =[−0,1023 0,0292
][24 1010 40
][−0,10230,0292
]= 0,2254.

126 Solutions
L’intervalle de confiance est donc 0,0816± (1,44)√
0,2254. Étant donnéqu’il s’agit d’un intervalle pour une probabilité, la borne inférieure nepeut être plus petite que 0 (et la borne supérieure ne peut être plusgrande que 1). L’intervalle de confiance est donc (0,0,7653).
5.26 On sait que l’estimateur du maximum de vraisemblance de λ est λ =X−1 et il est simple d’établir que Var[λ] = λ2/n. Ici, on a λ = 0,0187.a) On a
h(λ) = E[X;50]
=1− e−50λ
λ
dh(λ)dλ
=e−50λ(50λ + 1)− 1
λ2 ,
d’où
Var[h(λ)] =(
e−50λ(50λ + 1)− 1λ2
)2λ2
n
et
Var[h(λ)] = (−686,57)2(0,000 043 88)= 20,68.
b) On procède comme en a) avec
h(λ) = π0,95
=ln(0,05)
λdh(λ)
dλ= − ln(0,05)
λ2 .
On obtient Var[h(λ)] = 3 196.
5.27 a) On a que X|A = α obéit à une loi de Bernoulli(α) et que A obéit àune loi U(0,1). On cherche
f (α|x1, x2, x3) ∝ α∑3i=1 xi (1− α)3−∑3
i=1 xi (1)
= α(1− α)2.
On reconnaît ici la forme fonctionnelle d’une distribution Bêta(2,3).On sait que, si la fonction de perte choisie est l’erreur quadratique,l’estimateur bayesien est l’espérance de la distribution a posteriori.On a donc
α =2
2 + 3=
25
= 0,4.

Solutions 127
b) On a
Pr(0,2 < A < 0,4|X = x) =∫ 0,4
0,2
Γ(5)Γ(2)Γ(3)
α(1− 2α + α2)dα
= 0,3432.
5.28 On a que X|Θ = θ ∼ Poisson(θ) et que Θ ∼ Gamma(α, λ). On a donc
f (θ|x1, . . . , xn) ∝
(e−θnθ∑n
i=1 xi
∏ni=1 xi!
)(λαe−λθθα−1
Γ(α)
)= e−(λ+n)θθα+∑n
i=1 xi−1.
On reconnaît ici la forme fonctionnelle d’une distribution Gamma deparamètres α∗ = α + ∑n
i=1 xi et λ∗ = λ + n. On sait que, si la fonction deperte choisie est l’erreur quadratique, l’estimateur bayesien est l’espé-rance de la distribution a posteriori. Par conséquent
θ =α + ∑n
i=1 xi
n + λ.
5.29 a) On a que X|A = α obéit à une loi de Pareto(α, 1) et que A obéit à unedistribution Exponentielle(3). On a
f (α|x1, . . . , xn) ∝ 3e−3α
(αn
∏ni=1(1 + xi)α+1
)=
αne−3α
∏ni=1(1 + xi)α+1
= αn(
e−3
∏ni=1(1 + xi)
)α
= αne−λ∗α
avec λ∗ = 3 + ∑ni=1 ln(1 + xi). On reconnaît alors la forme fonction-
nelle d’une loi Gamma. On a donc, comme densité a posteriori, uneloi Gamma de paramètres α∗ = n + 1 et λ∗.
b) On sait que, si la fonction de perte choisie est l’erreur quadratique,l’estimateur bayesien est l’espérance de la distribution a posteriori.On a donc
α =n + 1
3 + ∑ni=1 ln(1 + xi)
=7
3 + 7,27= 0,68.
5.30 a) On a que X|B = β obéit à une loi Exponentielle(β) et que B obéit àune loi Gamma(2,3). On a
f (β|x1, . . . , x5) ∝ β6e−β(3+∑5i=1 xi).

128 Solutions
Puisque ∑5i=1 xi = 47, on reconnaît ici la forme fonctionnelle d’une loi
Gamma(7,50). Avec une fonction de perte quadratique, l’estimateurbayesien est l’espérance de la distribution a posteriori. On a donc
β =7
50= 0,14.
b) Avec une fonction de perte valeur absolue„ l’estimateur bayesien estla médiane de la distribution a posteriori. Il faut donc choisir β telque
Pr(B ≤ β|X = x) = Γ(7;50β) =12
.
Avec les informations données dans l’énoncé, on trouve
β =6,670
50= 0,1334.
5.31 a) Soit X la variable aléatoire du nombre de fois où un étudiant restebloqué dans un devoir. On a X|Θ = θ∼Binomiale(3, p) et Θ∼U(0,25,0,75).On a
f (θ|x1 = 2, x2 = 2) =2((3
2)θ2(1− θ)2)2∫ 0,750,25 2
((3
2)θ2(1− θ)2)2 dθ
=θ4(1− θ)2∫ 0,75
0,25 θ4(1− θ)2 dθ
= 141,22θ4(1− θ)2.
Avec une fonction de perte quadratique, l’estimateur bayesien estl’espérance de la distribution a posteriori. Ainsi,
θ = 141,22∫ 0,75
0,25θ5(1− θ)2 dθ = 0,5668.
b) On a
Pr(0,6 < Θ < 0,7|X1 = 2, X2 = 2) = 1441,22∫ 0,7
0,6θ4(1− θ)2 dp
= 0,3055.
5.32 a) Soit X la variable aléatoire du montant d’un sinistre en millions. Ona W = X− 1,5|X > 1,5. Par conséquent,
Pr(W > 29,5) =FX(29,5)− FX(1,5)
1− FX(1,5).

Solutions 129
Or, par la propriété d’invariance de l’estimateur du maximum devraisemblance, on a
Pr(W > 29,5) = 1−
(λ
λ+1,5
)α−(
λλ+29,5
)α
(λ
λ+1,5
)α
=
(λ + 1,5
λ + 29,5
)α
= 0,0365.
b) On a
h(α, λ) =(
λ + 1,5λ + 29,5
)α
∂h∂α
=(
λ + 1,5λ + 29,5
)α
ln(
λ + 1,5λ + 29,5
)∂h∂λ
= 28α(λ + 1,5)α−1
(λ + 29,5)α+1
et
∂h(α, λ)∂α
∣∣∣∣(α,λ)
= −0,0238
∂h(α, λ)∂λ
∣∣∣∣(α,λ)
= 0,0029,
d’où
Var[h(α, λ)] =[−0,0238 0,0029
][ 23,92 167,07167,07 1 199,32
][−0,02380,0029
]= 0,00057.
5.33 Le montant payé par l’assureur est Y = min(X, 3 000) − 100|X > 100,d’où
fY(y) =
fX(y + 100)1− FX(100)
, 0≤ y < 2 900
SX(3 000)1− FX(100)
, y = 2 900
0, y > 2 900,
=
λe−λy, 0≤ y < 2 900e−2 900λ, y = 2 9000, y > 2 900.

130 Solutions
La fonction de vraisemblance est donc
L(λ) =n
∏i=1
fY(yi)
= λ8e−λ(100+···+1 500)(e−2 900λ)2
= λ8e−10 420λ.
Par la méthode usuelle, on trouve λ = 8/10 420. On cherche une esti-mation de E[X] = λ−1. Par la propriété d’invariance de l’estimateur dumaximum de vraisemblance, on a
E[X] =1λ
=10 420
8= 1 302,50.
5.34 Soit X la variable aléatoire du montant d’un sinistre et Y la variablealéatoire du montant payé par l’assureur. On a Y = min(X, 150), d’où
fY(y) =
fX(y), y < 1501− FX(150), y = 1500, y > 150,
=
λe−λy, y < 150e−150λ, y = 1500, y > 150.
On a donc la fonction de vraisemblance
L(λ) =n
∏i=1
fY(yi)
= λ5e−λ(10+···+110)(e−150λ)3
= λ5e−845λ.
Par la technique usuelle, on trouve λ = 0,0059.5.35 On a la fonction de répartition empirique
F9(x) =
0, x ≤ 029 , 0 < x ≤ 269 , 2 < x ≤ 51, 5 < x ≤ 8.
Il faut maintenant trouver la valeur de λ qui minimise
Q(λ) = ∑x=2,5,8
(F(x)− F9(x))2
=(
1− e−λ2 − 29
)2+(
1− e−λ5 − 69
)2+(
1− e−λ8 − 1)2
.
On trouve numériquement que le minimum est atteint en λ = 0,2286.

Solutions 131
Chapitre 6
6.1 La fonction de répartition théorique est
FX(x) = 1−(
λ
λ + x
)α
= 1−(
1 0001 000 + x
)2.
Ainsi, le nombre espéré de sinistres dans chaque classe est
E1 = 10(F(250)− F(0)) = 3,6E2 = 10(F(500)− F(250)) = 1,9556E3 = 10(F(1 000)− F(500)) = 1,9444E4 = 10(F(∞)− F(1 000)) = 2,5.
On a les nombres de sinistres observés n1 = 3, n2 = 2, n3 = 3 et n4 = 2. Lavaleur de la statistique du test du khi carré est donc
Q =4
∑j=1
(nj − Ej)2
Ej
=(3− 3,6)2
3,6+
(2− 1,9556)2
1,9556+
(3− 1,9444)2
1,9444+
(2− 2,5)2
2,5= 0,7740.
Soit χ23,0,10 = 6,2514 le 90e centile d’une distribution khi carré avec trois
degrés de liberté. Puisque 0,7740 < 6,2514, on ne rejette pas le modèle.
6.2 La fonction de répartition du modèle est
FX(x) = 1−(
λ
λ + x
)α
= 1−(
5050 + x
)3,5.
On a les nombres espérés de sinistres par classe suivants :
E1 = 1 000(F(3)− F(0)) = 184,49E2 = 1 000(F(7,5)− F(3)) = 202,37E3 = 1 000(F(15)− F(7,5)) = 213,93E4 = 1 000(F(40)− F(15)) = 271,40E5 = 1 000(F(∞)− F(40)) = 127,80.
La valeur de la statistique est donc
Q =(180− 184,49)2
184,49+
(180− 202,37)2
202,37+
(235− 213,93)2
213,93
+(255− 271,40)2
271,40+
(150− 127,80)2
127,80= 9,5046.

132 Solutions
Or, Pr(χ22 > 9,5046) = 0,0086 (où χ2
2 est une variable aléatoire avec dis-tribution khi carré avec deux degrés de liberté). Par conséquent, on nerejette pas le modèle avec un seuil de signification de 0,86 %. Des seuilsproposés, seul 0,5 % est donc valide.
6.3 La fonction de répartition empirique est
F5(x) =
0, x < 0,10,2, 0,1≤ x < 0,40,4, 0,4≤ x < 0,80,8, 0,8≤ x < 0,91, x ≥ 0,9.
La fonction de répartition théorique est
F(x) =∫ x
0
1 + 2y2
dy =x2(1 + x), 0≤ x ≤ 1.
La statistique de Kolmogorov–Smirnov est donc
D = maxi=1,...,5
{|F(xi)− F5(xi)|, |F(xi)− F5(xi−1)|}
= max{|F(0,1)− F5(0,1)|, |F(0,1)− F5(0)|,|F(0,4)− F5(0,4)|, |F(0,4)− F5(0,1)|,|F(0,8)− F5(0,8)|, |F(0,8)− F5(0,4)|,|F(0,9)− F5(0,9)|, |F(0,9)− F5(0,8)|}
= 0,32.
La valeur critique du test de Kolmogorov–Smirnov avec un seuil de si-gnification de 5 % est c = 1,36/
√5 = 0,6082. Puisque D < c, on ne rejette
pas le modèle.
6.4 a) La fonction de répartition empirique est
F10(x) =
0, x < 12
10 , 1≤ x < 26
10 , 2≤ x < 38
10 , 3≤ x < 49
10 , 4≤ x < 81, x ≥ 8.
b) La fonction de répartition théorique est
FX(x) = 1−(
22 + x
)2. =

Solutions 133
i |Fn(xi)− F(xi)| |Fn(xi−1)− F(xi)|1 3/16 1/162 1/4 03 0,359375 0,1093754 7/16 3/16
Table E.2: Différences entre les fonctions de répartition théorique et empi-rique pour les données de l’exercice 6.5
On a donc F(1) = 59 , F(2) = 3
4 , F(3) = 2125 , F(4) = 8
9 et F(8) = 2425 La
distance de Cramér–von Mises est
QCvM =10
∑i=1
(F(xi)− F10(xi))2
= 2×(
59− 2
10
)2+ 4×
(34− 6
10
)2+ 2×
(2125− 8
10
)2
+(
89− 9
10
)2+(
2425− 1)2
= 0,3478.
c) On a cette fois une fonction de répartition empirique telle que F10(2) =6
10 , F10(4) = 910 et F10(8) = 1. La valeur de la distance est donc
QCvM =(
34− 6
10
)2+(
89− 9
10
)2+(
2425− 1)2
= 0,0242.
6.5 On trouve d’abord la fonction de répartition théorique :
F(x) =∫ x
0
y2
dy =x2
4, 0≤ x ≤ 2.
On a ensuite F4(0,5) = 1/4, F4(1) = 2/4, F4(1,25) = 3/4, et F4(1,5) = 1. Letableau E.2 présente les différences entre les fonctions de répartition. Lastatistique D4 est donc 7/16 = 0,4375.
6.6 On trouve d’abord la fonction de répartition théorique :
F(x) =∫ x
0
y50
dy =x2
100, 0≤ x ≤ 10.
On a ensuite F7(1) = 1/7, F7(4) = 2/7, F7(6) = 3/7, F7(7) = 4/7, F7(8) =5/7, F7(9) = 6/7 et F7(9,5) = 1. Le tableau E.3 présente les différencesentre les fonctions de répartition. La statistique de Kolmogorov–Smirnovvaut donc D = 0,1329. Puisque la valeur critique du test est c = 1,36/
√7 =
0,5140 > D, on ne rejette pas le modèle.

134 Solutions
xi |Fn(xi)− F(xi)| |Fn(xi−1)− F(xi)|1 0,1329 0,01004 0,1257 0,01716 0,0686 0,07437 0,0814 0,06148 0,0743 0,06869 0,0471 0,0957
9,5 0,0975 0,0454
Table E.3: Différences entre les fonctions de répartition théorique et empi-rique pour les données de l’exercice 6.6
6.7 On a
FX(x) = 1−(
λ
λ + x
)α
= 1− 88 + x
.
On trouve ensuite que
E1 = (20) (F(5)− F(0))= 7,6923
E2 = (20) (F(20)− F(5))= 6,5934
E3 = (20) (F(∞)− F(20))= 5,7143.
Ainsi, la valeur de la statistique est
Q =(10− 7,6923)2
7,6923+
(5− 6,5934)2
6,5934+
(5− 5,7143)2
5,7143= 1,1667.
6.8 On rappelle que FX(x;α, λ) = Γ(α;λx), où Γ(α; x) est la fonction de ré-partition de la distribution Gamma(α, 1). Le calcul de la statistique deKolmogorov–Smirnov requiert donc les valeurs de Γ(α;1,25), Γ(α;5,5) etΓ(α;7) pour α = 3 et α = 3,5. Or, avec la relation donnée dans l’énoncé,on obtient
Γ(3;1,25) = 1− e−1,25(
1 + 1,25 +(1,25)2
2
)= 0,1315
Γ(3;5,5) = 1− e5,5(
1 + 5,5 +(5,5)2
2
)= 0,9116
Γ(3;7) = 1− e−7(
1 + 7 +(7)2
2
)= 0,9704.

Solutions 135
|Fn(xi)− F(xi)| |Fn(xi−1)− F(xi)|xi α = 3 α = 3,5 α = 3 α = 3,5
125 0,1185 0,1771 0,1315 0,0729550 0,1616 0,1114 0,6616 0,6114700 0,0296 0,0512 0,2204 0,1988
Table E.4: Différences entre les fonctions de répartition théorique et empi-rique pour les données de l’exercice 6.8
Le tableau E.4 présente les calculs pour les deux distributions postu-lées. Pour la Gamma(3,0,01), la statistique de Kolmogorov–Smirnov estD = 0,6616 et pour la Gamma(3,5,0,01), la statistique est D = 0,6114. Onchoisit donc la deuxième distribution pour la modélisation les données.
6.9 L’hypothèse de taux d’échec constant correspond à une distribution ex-ponentielle de paramètre λ = 0,01. On a donc FX(x) = 1− e−x/100 et
E1 = 50 (F(25)− F(0)) = 11,0600E2 = 50 (F(40)− F(25)) = 5,4240E3 = 50 (F(60)− F(40)) = 6,0754E4 = 50 (F(80)− F(60)) = 4,9741E5 = 50 (F(∞)− F(80)) = 22,4664.
Étant donné que E4 < 5, on regroupe (arbitrairement) E3 et E4 pour obte-nir E3,4 = 11,0495. On obtient ensuite
Q =(10− 11,06)2
11,06+
(5− 5,4240)2
5,4240
+(15− 11,0495)2
11,0495+
(20− 22,4664)2
22,4664= 1,8179.
Puisque Pr(χ23 > 1,8179) = 0,61 > 0.05, on ne rejette pas l’hypothèse.
6.10 a) On les valeurs suivantes de la fonction de répartition empirique :F50(25) = 0,20, F50(50) = 0,44, F50(100) = 0,68 et F50(200) = 0,90. Pourla distribution de Pareto, on a F(25) = 0,4557, F(50) = 0,6464, F(100) =0,8075 et F(200) = 0,9106. La distance de Cramér–von Mises est alors
QCvM = (0,4557− 0,2)2 + (0,6464− 0,44)2
+ (0,8075− 0,68)2 + (0,9106− 0,9)2
= 0,1244.
136 Solutions
Pour la distribution de Weibull, on a F(25) = 0,2212, F(50) = 0,3935,F(100) = 0,6321 et F(200) = 0,8647. La distance est alors
QCvM = (0,2212− 0,2)2 + (0,3935− 0,44)2
+ (0,6321− 0,68)2 + (0,8647− 0,9)2
= 0,0062.
Comme 0,0062 < 0,1244, la distribution de Weibull est un meilleurmodèle.
b) Pour la distribution de Pareto, on a
E1 = 50 (F(25)− F(0)) = 22,7834E2 = 50 (F(50)− F(25)) = 9,5389E3 = 50 (F(100)− F(50)) = 8,0552E4 = 50 (F(200)− F(100)) = 5,1504E5 = 50 (F(∞)− F(200)) = 4,4721.
Étant donné que E5 < 5, on regroupe E4 et E5 pour obtenir E4,5 =9,6225. On obtient alors
Q =(10− 22,7834)2
22,7834+
(12− 9,5389)2
9,5389
+(12− 8,0552)2
8,0552+
(16− 9,6225)2
9,6225= 13,9662.
Or, χ23,0,05 = 7,815 < Q. On rejette donc le modèle avec distribution
de Pareto.c) Comme 0,10 < 0,1244, le choix de la distribution log-normale serait
meilleur.
6.11 a) On a
H0 : numéros de départ équiprobablesH1 : numéros de départ non équiprobables.
b) Pour un total de 144 courses et une probabilité uniforme de victoirede 1
8 , le nombre de victoires espéré pour chaque numéro est 144/8 =18. Les résultats cumulés observés et espérés sont présentés dans letableau suivant :
Numéro 1 2 3 4 5 6 7 8
Gains observés 29 48 66 91 108 118 133 144Gains théoriques 18 36 54 72 90 108 126 144
Écart absolu 11 12 12 19 18 10 7 0

Solutions 137
La plus grande différence est observée pour le numéro 4. On a doncD = 19/144 = 0,132. La valeur critique du test de Kolmogorov–Smirnovpour une taille d’échantillon n = 144 est 1,36/12 = 0,1133 pour unseuil α = 0,05 et 1,63/12 = 0,1358 pour un seuil α = 0,01. On rejettedonc l’hypothèse H0 à un niveau de confiance de 95 %, mais pas àun niveau de confiance de 99 %.
6.12 On a, dans l’ordre,
−219,1−(
32
)ln(100) = −226,01
−219,2−(
32
)ln(100) = −226,11
−221,2−(
22
)ln(100) = −225,81
−221,4−(
22
)ln(100) = −226,01
−224,4−(
12
)ln(100) = −226,70.
Le meilleur modèle est donc la distribution de Pareto.
Chapitre 7
7.1 a) On trouve d’abord l’estimateur du maximum de vraisemblance duparamètre θ. On a pk = Pr(N = k) = (m
k )θk(1− θ)n−k, k = 0, . . . , m etdonc
L(θ) =m
∏k=0
(pk)nk
l(θ) =m
∑k=0
nk ln pk
=m
∑k=0
nk
(ln(
mk
)+ k ln(θ) + (m− k) ln(1− θ)
)l′(θ) =
m
∑k=0
nk
(kθ− m− k
1− θ
).
En résolvant l’équation l′(θ) = 0, on trouve
θ =1m
∑mk=0 kNk
∑mk=0 Nk
=Nm
.

138 Solutions
Par conséquent,
E[θ] = E[
Nm
]=
E[N]m
=mθ
m= θ.
b) On a
Var[θ] = Var[
Nm
]=
Var[N]nm2
=mθ(1− θ)
nm2
=θ(1− θ)
nm.
c) De la partie a), on a
d2
dθ2 ln pk = − kθ2 −
m− k(1− θ)2
d’où
I(θ) = E[−nd2
dθ2 ln pN ]
=nθ2 E[N] +
n(m− k)(1− θ)2 E[m− N]
=nmθ
+mn(1− θ)(1− θ)2
=nm
θ(1− θ)
et donc
Var[θ] = I−1(θ)
=θ(1− θ)
nm.
d) Un intervalle de confiance de niveau 1− α pour θ est
θ ± zα/2
√Var[θ]

Solutions 139
soit
θ ± zα/2
√θ(1− θ)
mn.
Or, comme le paramètre θ est inconnu, on utilise en pratique l’inter-valle approximatif
θ ± zα/2
√θ(1− θ)
mn.
7.2 a) On a Pr(N = k) = λke−λ/k!, k = 0,1, . . . , et donc les fonctions de vrai-semblance
L(λ) =∞
∏k=0
(λke−λ
k!
)nk
et de log-vraisemblance
l(λ) =∞
∑k=0
nk(k lnλ− λ− lnk!).
Par les techniques habituelles, on trouve
λ = N = ∑∞k=0 knk
∑∞k=0 nk
= 0,1001
puis E[λ] = λ et Var[λ] = Var[N] = λ/n. On a donc λ ∼ N(λ, λ/n).Par conséquent, un intervalle de confiance approximatif à 95 % pourle paramètre λ est
λ± 1,96√
Var[λ],
avec Var[λ] = λ/n. L’intervalle de confiance est donc
0,1001± 1,96
√0,100110 000
.
b) Avec la paramétrisation donnée dans l’énoncé, E[N] = β et Var[N] =β(β + 1). De plus,
L(β) =∞
∏k=0
(βk
(β + 1)k+1
)nk
l(β) =∞
∑k=0
nk(k ln β− (k + 1) ln(β + 1))

140 Solutions
et donc
β = N = ∑∞k=0 knk
∑∞k=0 nk
= 0,1001.
On trouve ensuite que E[β] = 0,1001 et que Var[β] = β(β + 1)/n, d’oùVar[β] = 0,1001(1,1001)/10 000. L’intervalle de confiance est donc
0,1001± 1,96
√0,1001(1,1001)
10 000.
c) En posant θ = (β + 1)−1 dans les formules de l’annexe A, on trouveE[N] = rβ et Var[N] = rβ(β + 1). Les estimateurs des moments de r etβ sont donc les solutions des équations
rβ = ∑∞k=0 knk
∑∞k=0 nk
= 0,1001
et
rβ(1 + β) = ∑∞k=0 k2nk
∑∞k=0 nk
−(
∑∞k=0 knk
∑∞k=0 nk
)2
= 0,10028
d’où on trouve r = 55,67 et β = 0,0018.
d) On peut utiliser la fonction fitdistr du package MASS dans saforme la plus simple pour trouver les estimateurs du maximum devraisemblance de r et µ = rβ :> x <- c(rep(0, 9048), rep(1, 905), rep(2, 45),+ rep(3, 2))> fitdistr(x, "negative binomial")
size mu5.273162e+01 1.001000e-01(3.797344e+02) (3.166543e-03)
7.3 a) De l’exercice 7.2, on sait que l’estimateur du maximum de vraisem-blance du paramètre d’une distribution de Poisson est la moyenneéchantillonale. Pour la variable aléatoire N1, on a λ1 = x = 0,109. Pourla variable aléatoire N2, on a λ2 = x = 0,057.
b) On sait que la distribution de la somme de n variables aléatoires in-dépendantes distribuées selon des lois de Poisson de paramètre λi,i = 1, . . . , n est une Poisson de paramètre λ = ∑n
i=1 λi. On obtient doncN ∼ Poisson(λ1 + λ2 = 0,166).
7.4 a) De l’exercice 7.1, on a
θ =n7
=∑7
k=0 knk
7n= 0,0237.

Solutions 141
b) Comme à l’exercice 7.2 c), on a
rβ = ∑∞k=0 knk
∑∞k=0 nk
= 0,166
et
rβ(1 + β) = ∑∞k=0 k2nk
∑∞k=0 nk
−(
∑∞k=0 knk
∑∞k=0 nk
)2
= 0,2244
On trouve alors r = 0,4715 et β = 0,3521.c) On utilise la fonction fitdistr du package MASS pour trouver les
estimateurs du maximum de vraisemblance de r et µ = rβ :> x <- c(rep(0, 861), rep(1, 121), rep(2, 13),+ rep(3, 3), 4, 6)> fitdistr(x, "negative binomial")
size mu0.65606189 0.16600239
(0.21012471) (0.01442188)
7.5 On a
Pr(N = k) =∫ ∞
0Pr(N = k|Λ = λ) fΛ(λ)dλ
=βr
Γ(r)k!
∫ ∞
0λr+k−1e−λ(β+1) dλ.
Or, en reconnaissant sous l’intégrale la forme fonctionnelle d’une distri-bution Gamma(r + k, β + 1), on obtient
Pr(N = k) =Γ(r + k)βr
Γ(r)k!(β + 1)r+k
=Γ(r + k)
Γ(r)Γ(k− 1)
(β
β + 1
)r( 1β + 1
)k
=Γ(r + k)
Γ(r)Γ(k− 1)θr(1− θ)k ,
avec θ = β(β + 1)−1, soit la fonction de masse de probabilité d’une distri-bution binomiale négative de paramètres r et θ.
7.6 Sans la franchise, l’espérance de la fréquence serait E[N] = r(1− θ)/θ =15. De plus, on a
SX(20) = e−(0,01)(20) = 0,8187.
Cela signifie qu’environ 82 % des sinistres seront d’un montant supérieurà la franchise, c’est-à-dire qu’environ 82 % des sinistres vont produire uneréclamation. On a donc E[N∗] = (0,8187)(15) = 12,28.
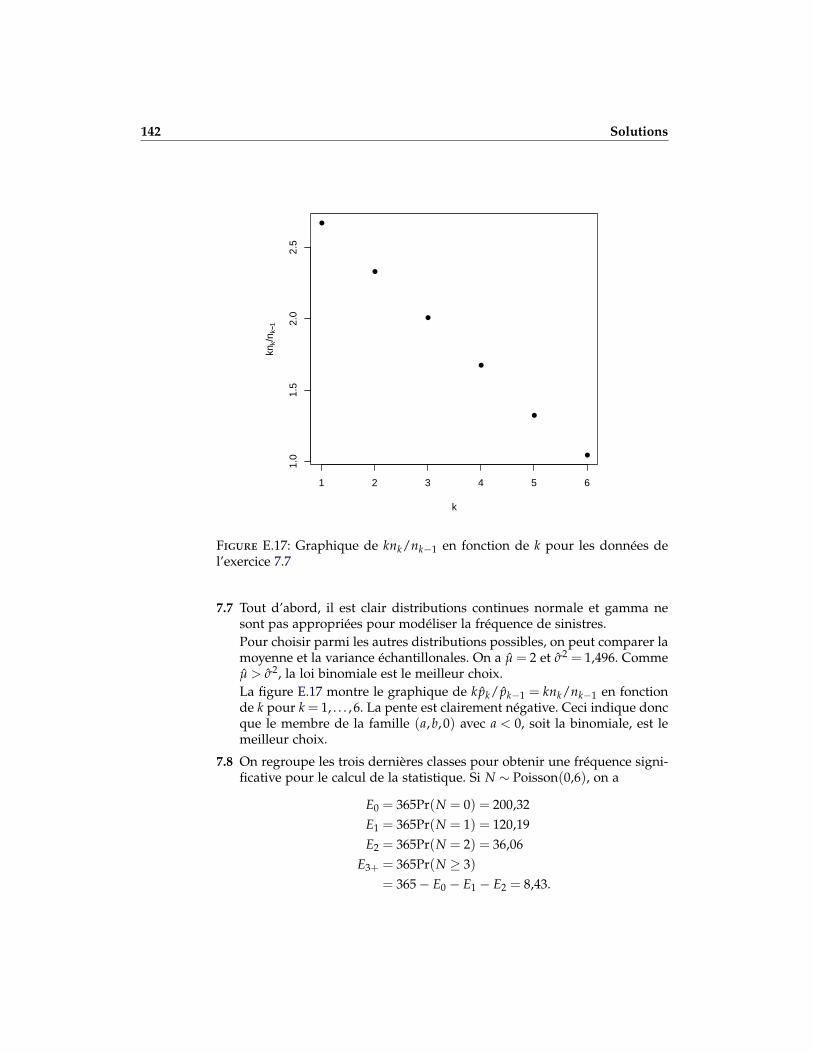
142 Solutions
●
●
●
●
●
●
1 2 3 4 5 6
1.0
1.5
2.0
2.5
k
knk/
n k−−1
Figure E.17: Graphique de knk/nk−1 en fonction de k pour les données del’exercice 7.7
7.7 Tout d’abord, il est clair distributions continues normale et gamma nesont pas appropriées pour modéliser la fréquence de sinistres.Pour choisir parmi les autres distributions possibles, on peut comparer lamoyenne et la variance échantillonales. On a µ = 2 et σ2 = 1,496. Commeµ > σ2, la loi binomiale est le meilleur choix.La figure E.17 montre le graphique de kpk/ pk−1 = knk/nk−1 en fonctionde k pour k = 1, . . . , 6. La pente est clairement négative. Ceci indique doncque le membre de la famille (a, b, 0) avec a < 0, soit la binomiale, est lemeilleur choix.
7.8 On regroupe les trois dernières classes pour obtenir une fréquence signi-ficative pour le calcul de la statistique. Si N ∼ Poisson(0,6), on a
E0 = 365Pr(N = 0) = 200,32E1 = 365Pr(N = 1) = 120,19E2 = 365Pr(N = 2) = 36,06
E3+ = 365Pr(N ≥ 3)= 365− E0 − E1 − E2 = 8,43.

Solutions 143
On a les nombres de sinistres observés n0 = 209, n1 = 111, n2 = 33 etn3+ = 12. La valeur de la statistique de Pearson est donc
Q =3
∑j=0
(nj − Ej)2
Ej
=(209− 209.32)2
209,32+
(111− 120,19)2
120,19
+(33− 36,06)2
36,06+
(12− 8,43)2
8,43= 2,85.


Bibliographie
Béguin, L.-P. 1990, Lexique général des assurances : lexique anglais-français etfrançais-anglais, Cahiers de l’Office de langue française, Publications duQuébec, ISBN 2-55114107-9.
Charbonnier, J. 2004, Dictionnaire de la gestion des risques et des assurances, LaMaison Du Dictionnaire, Paris, ISBN 978-2-85608178-5.
Dutang, C., V. Goulet et M. Pigeon. 2008, «actuar: An R package for ac-tuarial science», Journal of Statistical Software, vol. 25, no 7. URL http://www.jstatsoft.org/v25/i07.
Klugman, S. A., H. H. Panjer et G. Willmot. 1998, Loss Models: From data toDecisions, Wiley, New York, ISBN 0-4712388-4-8.
Klugman, S. A., H. H. Panjer et G. Willmot. 2004, Loss Models: From Data toDecisions, 2e éd., Wiley, New York, ISBN 0-4712157-7-5.
Klugman, S. A., H. H. Panjer et G. Willmot. 2008a, Loss Models: From Data toDecisions, 3e éd., Wiley, New York, ISBN 978-0-470-18781-4.
Klugman, S. A., H. H. Panjer et G. Willmot. 2008b, Solutions Manual to Ac-company Loss Models: From Data to Decisions, 3e éd., Wiley, New York, ISBN978-0-470-38571-5.
R Development Core Team. 2009, R: A Language and Environment for StatisticalComputing, R Foundation for Statistical Computing, Vienna, Austria. URLhttp://www.r-project.org.
Venables, W. N. et B. D. Ripley. 2002, Modern Applied Statistics with S, 4e éd.,Springer, New York, ISBN 0-3879545-7-0.
145



9 782981 141613
ISBN 978-2-9811416-1-3