mémoire parallélisation d'algorithmes de graphes avec mapreduce sur un cluster...
TRANSCRIPT

République Algérienne Démocratique et Populaire
Ministère de l’enseignement supérieur et de la recherche scientifique
Université des Sciences et de la Technologie Houari Boumediene
Faculté d’Electronique et d’Informatique Département Informatique
Mémoire de Master
Option
Réseaux et Systèmes Distribués
Thème
Parallélisation d'algorithmes de graphes
avec MapReduce sur un cluster
d'ordinateurs
Sujet proposé par :
Mme
MEHDI-SILHADI Malika
Présenté par :
Melle
BENHADJ DJILALI Hadjer
Melle
AIT AMEUR Ouerdia Lydia
Soutenu le : 21 / 06 / 2014
Devant le jury composé de :
Mme ALEB Nassima Présidente
Mme
BABA ALI Sadjia Membre
Binôme N° : 114/2016

Dédicace
Toutes les lettres ne sauraienttrouver les mots qu’il faut...Tous les mots ne sauraientexprimer la gratitude,le respect, lareconnaissance...Malgré les obstacles quis’opposaientEn dépit des difficultés quis’interposaientÀ cœur vaillant riend’impossibleÀ conscience tranquille tout estaccessibleNous prions dieu , souhaitantque le fruit de nos effortsfournisJour et nuit, nous mènera vers laréussite.
Aussi, c’est tout simplement que je dédie ce mémoire :À ma famille : mes chères parents, Mohammed et Zahia
À mon oncle Moh et ma tante Baya,À mon frère Sofiane,
Je vous suis très reconnaissante, pour votre soutien , et aide précieuse.À mes professeurs,
À ma binôme Hadjer ,À mes amis, Au Micro-Club, en souvenir de notresincère et profonde amitié et des moments agréables que nous avons passés
ensemble.

Dédicace
Je dédie ce modeste mémoire :À mes parents Nasr Eddine et Zohra qui m’ont aidé et d’avoir crus en
moi et me poussent toujours à faire mieux, par leur soutien, sacrifies, com-préhension, prière ...etc. Je vous aime beaucoup.
À mes deux frères Billel et Khaled et mon unique sœur Asma qui m’avraiment aidé.
À mes chères tantes Hamida, Nacira, Djamila, Salima et meriem. À monchère oncle Moammed Samir et ma chère cousine Nesrine et ainsi qu’a toutla famille.
À mes amies proches : Manel, Amel, Sarah, Amina, Imen, Meriem, Cha-fia, Loubna, Kiki , les tiboukalins surtout Makhlouf. Je vous remercie touspour les beaux moments, souvenir partagé ensemble.
À mes connaissance, amis /amies, collègues, voisin et à tous qui sontchères à mon cœur.

Remerciement
Nous tenons tout d’abord à remercier Dieu le tout puissant et miséricordieux, qui nousa donné la force et la patience d’accomplir ce modeste travail.
En second lieu, nous tenons à remercier notre promotrice : Mme MEHDI-SILHADIMalika pour la confiance qu’elle nous a accordé en acceptant d’encadrer notre travail nousavoir diriger, pour le temps qu’elle nous a consacré et l’ensemble des directives prodiguéesqui nous aidé durant la réalisation de ce mémoire.
Nos vifs remerciements vont également aux membres du jury : Mme ALEB Nassima etMme BABA ALI Sadjia , pour l’intérêt qu’ils ont porté en acceptant d’examiner ce travail.Nous souhaitant adresser nos remerciements les plus sincères aux personnes qui nous ontapporté leur aide et qui ont contribué à l’élaboration de ce mémoire ainsi qu’au corps profes-soral durant ces deux années de master pour la richesse et la qualité de leurs enseignements.
Enfin, nous exprimons nos plus chaleureux remerciements, à nos parents, à tous nosproches et amis, qui nous ont soutenu et encouragé tout au long de ce parcours. Merci àtous et à toutes.

Résumé
Avec l’évolution de l’architecture des ordinateurs, l’architecture parallèle a connu ungrand sucées grâce à ses grandes performances et rentabilités en fonction de calcule et detemps. Cela a permis de résoudre les grands problèmes informatiques qui nécessitent degrandes performances.
Avec l’avènement de l’architecture parallèle des ordinateurs, de nouveaux modèles dedéveloppement informatique sont apparues. Map/Reduce est un nouveau modèle de pro-grammation parallèle dans lequel sont effectués des calculs parallèles distribués de grandmasses de donnés.
L’algorithme Branch and Bound est l’une des méthodes les plus efficaces pour la ré-solution exacte des problèmes d’optimisation combinatoire. Il effectue une énumérationimplicite de l’espace de recherche au lieu d’une énumération exhaustive ce qui réduit consi-dérablement le temps de calcul nécessaire pour explorer l’ensemble de l’espace de recherche.
Le problème Flow Shop de permutation est un problème combinatoire d’ordonnance-ment NP- difficile. Sa résolution consiste à trouver la permutation qui a un temps d’exé-cution minimale.
Pour résoudre le problème Flow Shop de permutation, nous avons procédé à la paral-lélisation de l’algorithme Branch and Bound avec le modèle de programmation parallèleMap/Reduce.
Pour ce faire, nous avons travaillé sur une adaptation des approches classiques de pa-rallélisation de l’algorithme Branch and Bound sur le modèle Map/Reduce en utilisant leframework Hadoop.
Mots clés : Architecture parallèle, Programmation parallèle, Calcul paral-lèle, Cluster, Map/Reduce, Hadoop, Branche and Bound, Flow Shop

Table des matières
Introduction générale
État de l’art
1 Notions sur les architectures et la programmation parallèle 11.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Architecture parallèle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.3 Sources de parallélisme . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3.1 Parallélisme de contrôle . . . . . . . . . . . . . . . . . . . . . . . . 21.3.2 Parallélisme de données . . . . . . . . . . . . . . . . . . . . . . . . 31.3.3 Parallélisme de flux . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Classification des architectures parallèles . . . . . . . . . . . . . . . . . . . 31.4.1 La classification de Michael J. FLYNN (1972) . . . . . . . . . . . . 31.4.2 Classification de Raina . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.5 Classification selon la mémoire . . . . . . . . . . . . . . . . . . . . . . . . . 81.5.1 Machines parallèles à mémoire partagée . . . . . . . . . . . . . . . . 81.5.2 Machines parallèles à mémoire distribuée . . . . . . . . . . . . . . . 8
1.6 Les mesures de performances des architectures parallèles . . . . . . . . . . 91.6.1 Le temps d’exécution . . . . . . . . . . . . . . . . . . . . . . . . . . 91.6.2 L’accélération (SpeedUp) . . . . . . . . . . . . . . . . . . . . . . . . 101.6.3 L’efficacité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.7 Architecture parallèle actuelle . . . . . . . . . . . . . . . . . . . . . . . . . 111.7.1 Processeur graphique . . . . . . . . . . . . . . . . . . . . . . . . . 111.7.2 Cloud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.7.2.1 Les modèles de service de cloud . . . . . . . . . . . . . . . 121.7.3 Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.7.3.1 Concept d’un cluster informatique . . . . . . . . . . . . . 131.7.4 Grille informatique . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.7.4.1 Type de grille . . . . . . . . . . . . . . . . . . . . . . . . . 141.7.4.2 Caractéristique d’une grille informatique . . . . . . . . . . 14
1.7.5 Le cluster IBN BADIS . . . . . . . . . . . . . . . . . . . . . . . . . 141.7.5.1 Architecture du cluster IBN BADIS . . . . . . . . . . . . 15

1.8 La programmation séquentielle et parallèle . . . . . . . . . . . . . . . . . . 161.8.1 La programmation séquentielle . . . . . . . . . . . . . . . . . . . . 161.8.2 La programmation parallèle . . . . . . . . . . . . . . . . . . . . . . 17
1.9 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2 Étude du modèle MapReduce ,du framework qui l’implémente : Ha-doop et le produit de recherche MR-MPI 182.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2 Modèle de programmation MapReduce . . . . . . . . . . . . . . . . . . . . 18
2.2.1 Qu’est ce que MapReduce ? . . . . . . . . . . . . . . . . . . . . . . 182.2.1.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.2.1.2 Principe de fonctionnement . . . . . . . . . . . . . . . . . 19
2.2.2 Caractéristiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.2.3 Utilisateurs de MapReduce . . . . . . . . . . . . . . . . . . . . . . . 22
2.3 Framework Hadoop solution d’Apache . . . . . . . . . . . . . . . . . . . . 232.3.1 Qu’est ce que Hadoop ? . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.3.1.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.3.1.2 Le système de fichier HDFS . . . . . . . . . . . . . . . . . 232.3.1.3 Architecture de Hadoop . . . . . . . . . . . . . . . . . . . 25
2.3.2 Fonctionnement de MapReduce dans l’architecture de Hadoop . . . 262.3.3 Avantages de la solution . . . . . . . . . . . . . . . . . . . . . . . . 27
2.4 Produit de recherche MR-MPI (Map Reduce Message Passing Interface ) . 282.4.0.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.4.0.2 La librairie MR-MPI . . . . . . . . . . . . . . . . . . . . . 29
2.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3 Étude de l’ algorithme Branch and Bound et des stratégies de parallé-lisation 313.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.2 La méthode Branch and Bound . . . . . . . . . . . . . . . . . . . . . . . . 31
3.2.0.3 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.2.1 Principe de fonctionnement : Opérateurs d’un algorithme B & B . 313.2.2 Séparation (Branch) . . . . . . . . . . . . . . . . . . . . . . . . . . 323.2.3 Évaluation (Bound) . . . . . . . . . . . . . . . . . . . . . . . . . . . 323.2.4 Élagage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.2.5 Sélection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.2.6 Algorithme Branch & Bound . . . . . . . . . . . . . . . . . . . . . 34
3.3 Stratégie de parcours . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.3.1 En largeur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.3.2 En profondeur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.3.3 Meilleur évaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . 363.3.4 Plus prioritaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363.3.5 Stratégie mixte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36

3.4 Algorithmes B&B parallèles . . . . . . . . . . . . . . . . . . . . . . . . . . 363.4.1 Notion sur les Algorithmes B&B parallèles . . . . . . . . . . . . . . 37
3.4.1.1 Workpool . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.4.1.2 Base des connaissances d’un algorithme Branch & Bound
parallèle . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.5 Paramètres des algorithmes B&B parallèle . . . . . . . . . . . . . . . . . . 38
3.5.1 Division du travail . . . . . . . . . . . . . . . . . . . . . . . . . . . 383.5.2 Interaction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383.5.3 Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.6 Classification des algorithmes B&B parallèles . . . . . . . . . . . . . . . . 393.6.1 Classification de Melab . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.6.1.1 Modèle multiparamétrique parallèle . . . . . . . . . . . . 393.6.1.2 Le modèle parallèle de l’exploration de l’arbre . . . . . . 393.6.1.3 L’évaluation parallèle des limites . . . . . . . . . . . . . 403.6.1.4 Évaluation parallèle d’une seule limite / Solution . . . . 41
3.7 Mesures de performance pour les algorithmes B&B parallèles . . . . . . . . 413.7.1 Qualité de la solution . . . . . . . . . . . . . . . . . . . . . . . . . 413.7.2 Nombre de sous problème . . . . . . . . . . . . . . . . . . . . . . . 413.7.3 Accélération / efficacité . . . . . . . . . . . . . . . . . . . . . . . . 42
3.8 Complexité d’un algorithme B&B parallèle . . . . . . . . . . . . . . . . . 423.8.1 Complexité en temps de calcul . . . . . . . . . . . . . . . . . . . . 423.8.2 Complexité de mémoire . . . . . . . . . . . . . . . . . . . . . . . . 423.8.3 Complexité de communication . . . . . . . . . . . . . . . . . . . . 43
3.9 Approche de déploiement d’un algorithme B&B parallèle . . . . . . . . . . 433.9.1 Optimisation de communication . . . . . . . . . . . . . . . . . . . 433.9.2 Tolérance aux pannes . . . . . . . . . . . . . . . . . . . . . . . . . 433.9.3 Passage à l’échelle . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.10 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
Contribution
4 Conception d’un algorithme Branch and Bound parallèle basé surMapReduce 454.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.2 Le problème Flow-Shop de permutation . . . . . . . . . . . . . . . . . . . 45
4.2.1 Résolution du Flow-Shop de permutation . . . . . . . . . . . . . . 474.2.1.1 Makespan . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.2.2 Approche du Flow-Shop avec méthode exacte . . . . . . . . . . . . 484.2.2.1 Résolution du Flow-Shop de permutation avec l’algorithme
B&B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484.2.2.2 La borne inférieure . . . . . . . . . . . . . . . . . . . . . . 494.2.2.3 La borne supérieure . . . . . . . . . . . . . . . . . . . . . 50

4.2.3 Résolution parallèle du Flow-Shop de permutation avec MapReduce 514.2.3.1 Application du modèle MapReduce sous Hadoop au FSP 524.2.3.2 Les Stratégies de parcours implémentés . . . . . . . . . . 55
4.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5 Implémentation et tests d’évaluation avec Hadoop 585.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 585.2 Présentation de l’environnement de travail . . . . . . . . . . . . . . . . . . 58
5.2.1 Systèmes d’exploitation . . . . . . . . . . . . . . . . . . . . . . . . . 585.2.2 Le framework Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . 585.2.3 Eclipse , Sun java 6 . . . . . . . . . . . . . . . . . . . . . . . . . . . 585.2.4 Cloudera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.3 Présentation des données utilisées pour les tests "Benchmarks" . . . . . . . 595.4 Implémentation de l’algorithme B&B parallèle sous MapReduce pour le pro-
blème FSP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 615.4.1 Implémentation dans MapReduce . . . . . . . . . . . . . . . . . . . 61
5.4.1.1 Programmation Hadoop et utilisation . . . . . . . . . . . . 615.4.1.2 Diagramme de classes . . . . . . . . . . . . . . . . . . . . 61
5.4.2 Analyse du parcours par profondeur . . . . . . . . . . . . . . . . . . 635.4.3 Analyse du parcours par largeur . . . . . . . . . . . . . . . . . . . 64
5.5 Tests de validation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 655.5.1 Tests sur un cluster à nœud unique (SingleNode) . . . . . . . . . . 655.5.2 Tests sur le cluster IBN BADIS . . . . . . . . . . . . . . . . . . . . 67
5.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
Conclusion générale
Bibliographie
Annexes
Table des figures
1.1 Principe du calcul parallèle [2]. . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Parallélisme de contrôle [3]. . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Parallélisme de flux [3]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.4 Architecture SISD [4]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.5 Architecture de MISD [5]. . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.6 Architecture SIMD [4]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5

1.7 Architecture MIMD à mémoire partagée [4]. . . . . . . . . . . . . . . . . . 51.8 Accès mémoire UMA [2]. . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.9 Accès mémoire CC-NUMA [2]. . . . . . . . . . . . . . . . . . . . . . . . . 71.10 Accès mémoire COMA [2]. . . . . . . . . . . . . . . . . . . . . . . . . . . 71.11 Classification MIMD de Rania [4]. . . . . . . . . . . . . . . . . . . . . . . . 71.12 Machine parallèle à mémoire partagée [3]. . . . . . . . . . . . . . . . . . . 81.13 Machine parallèle à mémoire distribuée [3]. . . . . . . . . . . . . . . . . . 91.14 Différentes architectures de réseau d’interconnexion [3]. . . . . . . . . . . . 91.15 Analyse de résultat de l’accélération [2]. . . . . . . . . . . . . . . . . . . . 101.16 Exemple de processeur graphique NVIDIA avec un CPU [6]. . . . . . . . . 111.17 Image illustre la différence technique entre les 3 modèles de cloud [8]. . . . 121.18 Image d’un cluster de machines cher Yahoo ! [10]. . . . . . . . . . . . . . . 131.19 Image illustre architecture d’une grille informatique [12]. . . . . . . . . . . 141.20 Image du cluster IBN BADIS au CERIST. . . . . . . . . . . . . . . . . . . 151.21 Architecture du cluster IBN BADIS au CERIST. . . . . . . . . . . . . . . 16
2.1 Illustre les deux opérations essentielles dans le modèle MapReduce [21]. . . 202.2 Illustre un aperçu de l’exécution du fonctionnement des étapes de MapRe-
duce [22]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.3 Illustre certaines entreprises et universités qui utilisent le modèle MapRe-
duce [19]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.4 Illustre l’architecture du HDFS [24]. . . . . . . . . . . . . . . . . . . . . . . 252.5 Illustre l’architecture générale de Hadoop [19]. . . . . . . . . . . . . . . . . 26
3.1 Structure général d’un arbre de recherche Branch&Bound [32]. . . . . . . 333.2 Stratégie de parcours par largeur [32] . . . . . . . . . . . . . . . . . . . . . 353.3 Stratégie de parcours en profondeur [32]. . . . . . . . . . . . . . . . . . . . 353.4 Stratégie de parcours par meilleur évaluation [32]. . . . . . . . . . . . . . . 363.5 Illustre le modèle multiparamètrique parallèle [3]. . . . . . . . . . . . . . . 393.6 illustre le modèle parallèle de l’exploration de l’arbre [3]. . . . . . . . . . . 403.7 Illustre le d’évaluation parallèle des limites [3]. . . . . . . . . . . . . . . . 41
4.1 Ilustre un atelier de type Flow-Shop. . . . . . . . . . . . . . . . . . . . . . 464.2 Diagramme de Gantt de l’exécution de la séquence 1-2. . . . . . . . . . . . 464.3 Diagramme de Gantt de l’exécution de la séquence 1-2. . . . . . . . . . . . 474.4 Représentation du problème de Flow-Shop dans l’arbre de recherche Branch
& Bound. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 494.5 Architcture du HDFS qui montre la communication entre NameNode et
DataNodes pour l’application du FSP . . . . . . . . . . . . . . . . . . . . 534.6 Architecture logique de MapReduce pour FSP. . . . . . . . . . . . . . . . 54
5.1 Benchmark artificiel de 6 tâches et 5 machines à partir du benchmark 20*5de E .Taillard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59

5.2 Benchmark artificiel de 7 tâches et 5 machines à partir du benchmark 20*5de E .Taillard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.3 Benchmark artificiel de 8 tâches et 5 machines à partir du benchmark 20*5de E .Taillard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.4 Benchmark artificiel de 9 tâches et 5 machines à partir du benchmark 20*5de E .Taillard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.5 Benchmark artificiel de 10 tâches et 5 machines à partir du benchmark 20*5de E .Taillard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.6 Diagramme de classes pour l’implémentation du FSP sous MapReduce . . 625.7 Graphe représentant le Makespan et temps d’exécution d’instances de pro-
blèmes artificiels issue de E.Taillard pour les différents Benchmarks sur uncluster singleNode pour les deux approches. . . . . . . . . . . . . . . . . . 67
5.8 Graphe représentant le Makespan et temps d’exécution d’instances de pro-blèmes artificiels issue de E.Taillard pour les différents Benchmarks sur lecluster IBN BADIS pour les deux approches. . . . . . . . . . . . . . . . . 68
5.9 Graphe représentant le Makespan et temps d’exécution d’instances de pro-blèmes artificiels issue de E.Taillard pour les différents Benchmarks sur uncluster singlenode et le cluster IBN BADIS pour les deux approches. . . . 69
Liste des tableaux
1.1 Tableau de classification de FLYNN. . . . . . . . . . . . . . . . . . . . . . 4
5.1 Illustration des clefs / valeurs pour une instances de problèmes. . . . . . . 635.2 Makespan d’instances de problèmes artificiels issue de E.Taillard avec une
borne supérieure commune pour les différents benchmarks. . . . . . . . . . 655.3 Makespan d’instances de problèmes artificiels issue de E.Taillard avec une
borne supérieure variables pour les différents Benchmarks. . . . . . . . . . 665.4 Makespan et temps d’exécution d’instances de problèmes artificiels issue de
E.Taillard pour les différents Benchmarks sur un cluster singleNode . . . . 665.5 Makespan et temps d’exécution d’instances de problèmes artificiels issue de
E.Taillard pour les différents Benchmarks sur le cluster IBN BADIS. . . . 67

Liste d’abréviationsAPI Application Programming Interface.
B&B Branch and Bound
CC-NUMA Cache-Coherent NUMA
CERIST Centre de Recherche sur l’Information Scientifique et Technique
COMA Cache Only Memory Access
CPU Central Processing Unit.
CUDA Compute Unified Device Architecture.
DADM Distributed Address space, Distributed Memory.
FD Flot de Données
FI Flot d’Instructions
GFS Google File System.
GPU Graphic Processing Unit.
HDFS Hadoop Distributed File System.
HPC High Performance Computing
IDE Integrated Development Environment
JDK Java Development Kit
KMV Key Multiple Value
KV Key Value
MIMD Multiple-Instruction Multiple-Data.
MISD Multiple-Instruction Single-Data.
MPI/IO Message Passing Interface Input/Output
MPI Message Passing Interface.
MR Map Reduce
NA Nœud Actif

NEH Heuristique de Nawaz, Enscore et Ham
NORMA No Remote Memory Access
NUMA Non Uniform Memory Access.
OSMA Operating System Memory Access
POC Problèmes d’Optimisation Combinatoires
RAM Random Acess Memory
SADM Single Address space, Distributed Memory
SASM Single Address space, Shared Memory.
SIMD Single-Instruction Multiple-Data.
SISD Single-Instruction Single-Data.
TB Tera Byte
UC Unité de Contrôle
UMA Uniform Memory Access.
UM Unité de Mémoire
UT Unité de traitement

Introduction générale
L’optimisation combinatoire est une riche branche de l’informatique et de la rechercheopérationnelle. Elle vise à fournir des techniques pour trouver des solutions optimalesou bonnes pour des problèmes avec des espaces de recherche importants.Les problèmesd’optimisation combinatoire (POC), sont complexes et reconnus NP-difficiles ,plusieursapplications de divers domaines industriels et économiques peuvent être modélisés sousforme de " POC " ,par exemple, on peut citer le problème d’ordonnancement Flow-Shopde permutation (FSP).
Les algorithmes d’optimisation combinatoire peuvent être classés en deux grandes ca-tégories : les méthodes exactes et les méthodes approchées. Les méthodes exactes ontpour objectif de trouver la ou les solutions optimales au problème avec preuve d’optima-lité. Tandis que les méthodes approchée tentent de trouver une bonne solution dans untemps raisonnable.Ces algorithmes ont étés utilisés avec succès pour la résolution de nom-breux problèmes d’optimisation. Néanmoins, leur application à des problèmes difficiles etde grande taille nécessite une grande puissance de calcul et de la mémoire de stockage.
La parallélisation de ces derniers reste un moyen incontournable pour la résolution effi-cace d’instances de très grande taille. Les tendances récentes pour la résolution de grandsproblèmes, ont mis l’accent sur la mise à l’échelle à travers des grappes de machines regrou-pant plusieurs centaines d’unités , voire des milliers de machines ou plus, selon le contexte,liées par un réseau de connexion haut débit, sur lesquelles des tâches de calculs intensespeuvent être effectuées. Dans ce mémoire on s’intéresse particulièrement a la parallélisa-tion d’un algorithme exacte appelé Branch and Bound pour la résolution du problème FSP.
Le B&B est un algorithme basé sur une structure d’arbre représentant l’ensemble dessolutions de l’espace de recherche. En effet, l’arbre est construit au fur et a mesure qu’onavance dans la recherche. les nœuds intermédiaires de l’arbre sont des sous problèmes duproblème a résoudre se trouvant à la racine de l’arbre. Tandis que les feuilles sont les solu-tions du problème. L’algorithme B&B utilise un parcours intelligent de l’arbre de base surdes techniques mathématiques (relaxation des contraintes du problème). En effet, certainesrégirons de l’espace de recherche (c-à-d) certains nœuds de l’arbre) sont exclus de la re-cherche car elles ne sont pas susceptible de contenir la solution optimale. Des stratégies deparallélisation existent pour cet algorithme pour plusieurs types d’architectures parallèles

et infrastructures de calcul distribués (clusters , grilles, GPUs etc).
En plus de ces infrastructures de calcul parallèles traditionnelles, on assiste actuelle-ment a une révolution du domaine des systèmes distribues avec l’émergence des technologiesconnues sous l’appellation " BigData " et le "Cloud". En effet, La croissance exponentielledes données est un des premiers défis des entreprises telles que Google , Yahoo, Amazon etMicrosoft , dans la collecte , analyse et traitement , des téra-octets et pétaoctets de donnéespour savoir les sites plus les populaires, l’indexation , la recherche et d’autre services. Lesoutils existant dés lors devenaient insuffisantes d’où l’apparition de technologies Big Datapermettant de paralléliser ces service sur des milliers de CPUs d’un cloud.
MapReduce est une de ces technologies permettant de paralléliser les traitements faitssur des données a grande échelle.MapReduce a été initialisation inventé par Google pourleurs services de recherche, indexation etc., puis adopte par une large sphère d’entreprisesactivant dans le domaine Big Data pour sa facilite d’utilisation et son efficacité.
L’objectif est de proposer une adaptation des stratégies classiques de parallélisation d’unalgorithme Branch & Bound en utilisant le modèle de programmation MapReduce sous sonimplémentation la plus connue le framework Hadoop. Nous avons aussi fait une étude d’étatde l’art sur le cas d’une autre implémentation issue de la recherche et basée sur le modèleMPI (Message Passing Interface), la bibliothèque MR-MPI. Des expérimentations sontmenées sur le cluster IBN-BADIS du CERIST dans le but de valider notre implémentation.Ce mémoire est structuré comme suit :
Partie I : État de l’art
Chapitre 1 : " Notions sur les architectures et la programmation parallèle "Ce chapitre est consacré aux architectures parallèles et leurs mesures de performances. Oncitera leurs classifications, quelques infrastructures parallèles et on illustrera par les archi-tectures parallèles actuellement utilisées.
Chapitre 2 : " Étude du modèle MapReduce ,du framework qui l’implé-mente : Hadoop et le produit de recherche MR-MPI "Dans ce chapitre, nous allons étudier le modèle MapReduce : un modèle de programmationmis au point par Google à travers l’étude de son principe de fonctionnement, ses caractéris-tiques et la concrétisation de son implémentation dans le framework Hadoop ou le produitde recherche la bibliotheque MR-MPI.
Chapitre 3 : " Étude de l’algorithme Branch and Bound et des stratégies deparallélisation "Ce chapitre présente des notions essentielles sur les algorithmes B&B ensuite les algo-rithmes B&B parallèles , les méthodes de leurs conceptions, et les stratégies de parallélisa-tion classiques sur différentes architectures parallèles comme : les grilles, clusters, mémoire

partagées , ainsi que les mesures de performances , la complexité et l’approche de déploie-ment de ces algorithmes.
Partie II : Contribution
Chapitre 4 : " Conception d’un algorithme Branch and Bound parallèle basésur MapReduce "Dans ce chapitre nous détaillerons notre conception d’un algorithme B&B parallèle baséesur le paradigme MapReduce en utilisant le framework Hadoop et on présentera le pro-blème d’optimisation combinatoire qu’on va traiter avec l’algorithme Branch and Bound.
Chapitre 5 : " Implémentation avec Hadoop et tests sur IBN BADIS "Le dernier chapitre , sera réservé pour l’implémentation et évaluation de notre approchesur le cluster IBN BADIS du CERIST .

Chapitre
1Notions sur les architectures etla programmation parallèle
" Les architectures parallèles sontdevenues le paradigme dominantpour tous les ordinateurs depuisles années 2000. En effet, la vitessede traitement qui est liée àl’augmentation de la fréquence desprocesseurs connaît des limites. Lacréation de processeursmulti-cœurs, traitant plusieursinstructions en même temps ausein du même composant, résoutce dilemme pour les machines debureau depuis le milieu des années2000. "
( citée dans [1] ).

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
1.1 IntroductionDans l’architecture classique des ordinateurs dite de Von Neumann (1945), toute les
opérations sont effectuées de façon séquentielle dans un ordre précis sans parallélisme.Avec l’apparition des problèmes informatique, la technologie ne permet pas de fournirune solution rapide et optimale pour résoudre ces problèmes. Avec la révolution de latechnologie hardware , software et l’établissement du réseau de communication mondial «Internet », l’architecture parallèle des ordinateurs a été introduite pour pouvoir exécuterdes programmes et des algorithmes parallèles sur plusieurs ordinateurs de façon rapide ettransparente aux utilisateurs.
Dans ce chapitre nous allons présenter l’architecture parallèle, les mesures de perfor-mances et tout ce qui est utilisé actuellement comme architecture parallèle pour les grandespuissances de calcul. Dans ce chapitre nous allons en premier approcher la limite de l’ar-chitecture séquentielle puis en étudier l’architecture parallèle avec ces différents types declassification et leurs mesures de performance, ensuite on aborde les deux types de pro-grammation séquentielle et parallèle, après on illustres quelques architectures parallèlesactuelle. A la fin on clôture le chapitre avec une petite description de l’environnement detravail du le cluster IBN BADIS du CERIST.
1.2 Architecture parallèleLes architectures parallèles sont devenues le paradigme dominant pour tous les ordina-
teurs depuis les années 2000. En effet, la vitesse de traitement qui est liée à l’augmentationde la fréquence des processeurs connaît des limites.La création de processeurs multi-cœurs, traitant plusieurs instructions en même temps ausein du même composant [1] . De même une architecture parallèle est un ensemble de pro-cesseurs qui coopèrent et communique pour résoudre les problèmes dans un délais court.Lecalcul parallèle est l’utilisation simultanée de plusieurs ressources de calcul pour résoudreun problème donné : [2]
ä Le problème est donc exécuté en utilisant plusieurs processeurs.
ä Le problème est divisé en parties distinctes qui peuvent être résolues en même temps.
ä Chaque partie est subdivisée en une série d’instructions.
ä Les Instructions de chaque partie sont exécutées simultanément sur des processeursdifférents.
1

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
Figure 1.1: Principe du calcul parallèle [2].
1.3 Sources de parallélismeTrois principales sources de parallélisme sont détectées [3] :
1.3.1 Parallélisme de contrôleFaire plusieurs choses en même temps : l’application est composée d’actions (tâches)
qu’on peut exécuter en même temps. Les tâches peuvent être exécutées de manière, plus oumoins, indépendante sur les ressources de calcul. Si on associe à chaque ressource de calculune action, on aura un gain en temps linéaire. Si on exécute N actions sur N ressources onva N fois plus vite. Toutefois on remarque bien que les dépendances qui existent entre lestâches vont ralentir l’exécution parallèle.
Figure 1.2: Parallélisme de contrôle [3].
2

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
1.3.2 Parallélisme de donnéesRépéter une action sur des données similaires : pour les applications qui sont composées
de données identiques sur lesquelles on doit effectuer une action répétée (exemple : tableauxde données). Les ressources de calcul sont associées aux données.
1.3.3 Parallélisme de fluxTravailler à la chaîne : certaines applications fonctionnent selon le mode de travail à
la chaîne, on dispose d’un flux de données, généralement similaires, sur lesquelles on doiteffectuer une suite d’opérations en cascade ,illustré, par la figure ci-dessus :
Figure 1.3: Parallélisme de flux [3].
Les ressources de calcul sont associées aux actions et chaînées tels que les résultats desactions effectuées au temps T sont passés au temps T+1 au processeur suivant (mode defonctionnement Pipe-Line).
1.4 Classification des architectures parallèlesIl existe plusieurs classifications des architectures parallèles , dont on va mentionner
quelques unes.
1.4.1 La classification de Michael J. FLYNN (1972)Flynn propose une classification suivant deux paramètres, le flux d’instructions, et le
flux de données :
— Flux d’instructions : séquence d’instructions exécutées par la machine.— Flux de données : séquence des données appelées par le flux d’instructions.
3

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
1 flux d’instruction > 1 flux instruction1 flux de données SISD MISD (pipeline)> 1 flux de donnés SIMD MIMD
Table 1.1: Tableau de classification de FLYNN.
S : Single (une seule), M : Multiple (plusieurs)
D : Data (données), I : Instruction (instruction)
SISD : « Single Instruction stream, Single Data stream » , une seule instruction avecune seule donnée en entrée. Cette catégorie correspond aux machines séquentielles conven-tionnelles (modèle de Von Neumann), pour lesquelles chaque opération s’effectue sur unedonnée à la fois. L’unité de contrôle (UC), recevant son flot d’instructions (FI) de l’unité
Figure 1.4: Architecture SISD [4].
mémoire (UM), envoie les instructions à l’unité de traitement (UT), qui effectue ses opéra-tions sur le flot de données (FD) provenant de l’unité mémoire [4]. Exemples de machinesSISD : UNIVAC1, IBM 360, CRAY1, CDC 7600, PDP1, Dell Laptop.
MISD : « Multiple Instruction stream, Single Data stream », plusieurs instructionspour une seule donnée. Cette catégorie regroupe les machines spécialisées de type « systo-lique », dont les processeurs, arrangés selon une topologie fixe, sont fortement synchronisés[4].
Figure 1.5: Architecture de MISD [5].
4

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
SIMD : « Single Instruction stream, Multiple Data stream », une seule instruction pourplusieurs données. Plusieurs données traitées en même temps par une seule instruction.Utilisé dans les gros ordinateurs vectoriels. Une machine SIMD exécute à tout instant uneseule instruction, mais qui agit en parallèle sur plusieurs données, on parle en générale deparallélisme de données [2].
Figure 1.6: Architecture SIMD [4].
MIMD : « Multiple Instruction stream, Multiple Data stream », plusieurs instruc-tions sur plusieurs données. Exécution d’une instruction différente sur chaque processeurpour des données différentes.Il désigne les machines multiprocesseurs où chaque processeurexécute son code de manière asynchrone et indépendante. Pour assurer la cohérence desdonnées, il est souvent nécessaire de synchroniser les processeurs entre eux, les techniquesde synchronisation dépendent de l’organisation de la mémoire. Soit mémoire partagée oubien mémoire distribuée [5].
Figure 1.7: Architecture MIMD à mémoire partagée [4].
1.4.2 Classification de RainaUne sous-Classification étendue des machines MIMD, due à Raina, permet de prendre
en compte de manière fine les architectures mémoire, selon deux critères : l’organisation de
5

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
l’espace d’adressage et le type d’accès mémoire mise en œuvre.L’organisation de l’espaced’adressage [4] :
Û SASM : « Single Address space, Shared Memory » , une seule mémoire partagéeentre tous les processeurs. Le temps mis pour accéder à la mémoire est identique pour tousles processeurs. L’accès simultané à la même zone mémoire par plusieurs processeurs n’estpas possible , un seul accède à la fois.
Û DADM : « Distributed Address space, Distributed Memory » , appelée aussi lesarchitectures distribuées dont chaque processeur a sa propre mémoire (mémoire distribuéesans aucune mémoire partagée entre eux). L’échange de données entre processeurs s’effec-tue nécessairement par passage de messages, au moyen d’un réseau de communication.
Û SADM : « Single Address space, Distributed Memory » , mémoire distribuée,avec espace d’adressage global, autorisant éventuellement l’accès aux données situées surd’autres processeurs.Le temps d’accès pour les divers banc mémoires devient par consé-quent différent.
Types d’accès mémoire mis en œuvre [4] :
Û NORMA (« No Remote Memory Access ») , ce type n’a pas de moyen d’accès auxdonnées distantes, ce qui nécessite le passage de messages.
Û UMA (« Uniform Memory Access ») : accès symétrique à la mémoire avec un coûtidentique pour tous les processeurs.
Figure 1.8: Accès mémoire UMA [2].
Û NUMA (« Non-Uniform Memory Access ») , dans ce cas les performances d’accèsà la mémoire dépendent de la localisation des données.
Û CC-NUMA : (« Cache-Coherent NUMA » , type d’architecture NUMA intégrantla mémoire caches et implémentation de protocole cohérence de cache.
6

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
Figure 1.9: Accès mémoire CC-NUMA [2].
Û OSMA : « Operating System Memory Access » , les accès aux données distantessont gérés par le système d’exploitation, qui traite les défauts de page au niveau logiciel etgère les requêtes d’envoi/copie de pages distantes.
Û COMA : « Cache Only Memory Access » : les mémoires locales se comportentcomme des caches, de telle sorte qu’une donnée n’a pas de processeur propriétaire ni d’em-placement déterminé en mémoire.
Figure 1.10: Accès mémoire COMA [2].
Figure 1.11: Classification MIMD de Rania [4].
7

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
1.5 Classification selon la mémoire
1.5.1 Machines parallèles à mémoire partagéeCes machines sont caractérisées par une horloge indépendante pour chaque processeur,
mais une seule mémoire partagée entre ces processeurs, où tous les processeurs lisent etécrivent dans le même espace d’adressage mémoire, ce qui permet de réaliser un parallélismede données et de contrôles. Le programmeur n’a pas besoin de spécifier l’emplacement desdonnées, il définit seulement la partie du programme que doit exécuter chaque processeuren plus de la gestion de la synchronisation [3]. Ce type d’architecture possède plusieursavantages dont la simplicité, le passage à l’échelle et la parallélisation de haut niveau.Son inconvénient majeur est lié principalement à la limite de la bande passante du réseaud’interconnexion.
Figure 1.12: Machine parallèle à mémoire partagée [3].
1.5.2 Machines parallèles à mémoire distribuéeDans ce type de machine, chaque processeur possède sa propre mémoire locale, où il exé-
cute des instructions identiques ou non aux autres processeurs. Les différents nœuds définispar l’ensemble mémoires plus processeurs sont reliés entre eux par un réseau d’intercon-nexion.Le parallélisme est implémenté par échange de messages [3]. L’avantage principaldes machines parallèles à mémoire distribuée est l’augmentation facile du nombre de pro-cesseurs avec des moyens simples, tels que les clusters. Seulement elles présentent plus dedifficulté dans la programmation.
8
CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
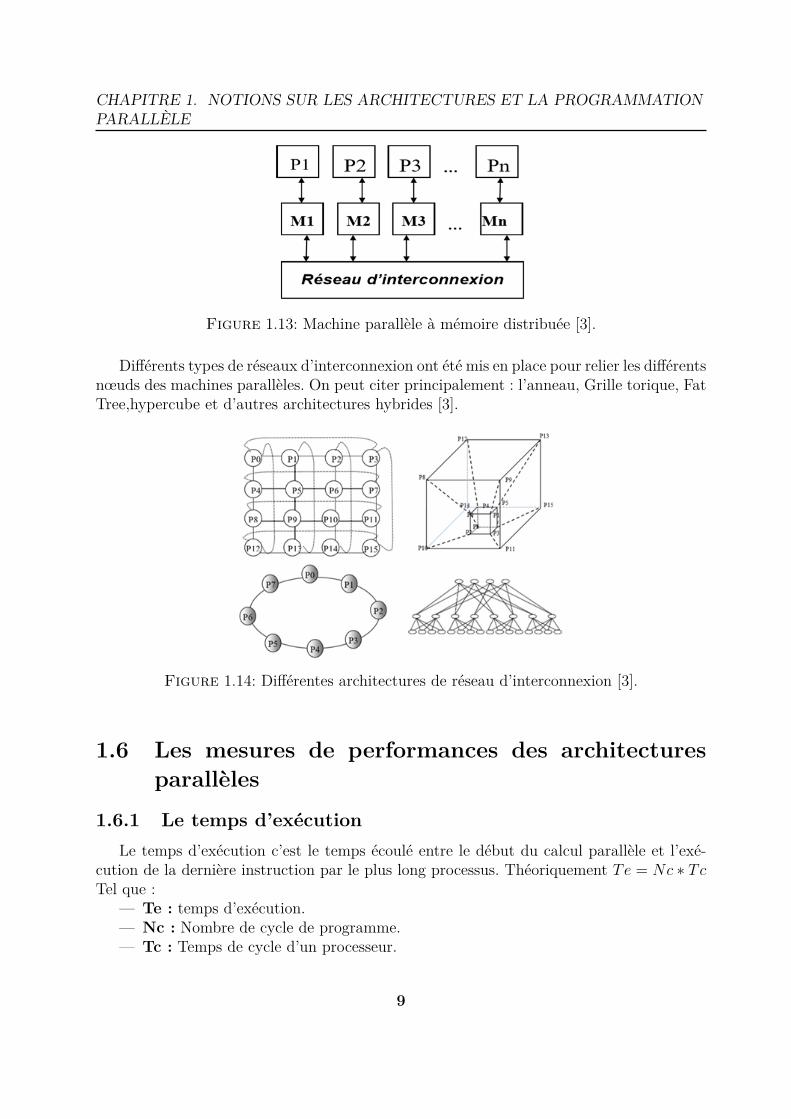
Figure 1.13: Machine parallèle à mémoire distribuée [3].
Différents types de réseaux d’interconnexion ont été mis en place pour relier les différentsnœuds des machines parallèles. On peut citer principalement : l’anneau, Grille torique, FatTree,hypercube et d’autres architectures hybrides [3].
Figure 1.14: Différentes architectures de réseau d’interconnexion [3].
1.6 Les mesures de performances des architecturesparallèles
1.6.1 Le temps d’exécutionLe temps d’exécution c’est le temps écoulé entre le début du calcul parallèle et l’exé-
cution de la dernière instruction par le plus long processus. Théoriquement Te = Nc ∗ TcTel que :
— Te : temps d’exécution.— Nc : Nombre de cycle de programme.— Tc : Temps de cycle d’un processeur.
9

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
1.6.2 L’accélération (SpeedUp)Le gain en performance peut s’exprimer en termes d’accélération. Suivant la loi de
Amdahl l’accélération est le rapport du temps d’exécution séquentielle sur le temps d’exé-cution parallèle.Plus la partie parallélisable d’un programme est grand, plus l’accélérationest meilleure.
S(p) = Ts
Tp
Tel que : S (p) c’est l’accélération, Ts c’est le temps séquentiel, Tp temps parallèle.Þ La loi d’Amdahl s’exprime aussi avec [2] :
S(p) = 1(1− α) + α
P
æ P : Le nombre de processeurs.æ α : La fraction de la partie parallélisable du programme.
Figure 1.15: Analyse de résultat de l’accélération [2].
å S(p) < 1, On ralentit ! mauvaise parallélisation.
å 1< S(p) < p, Normal.
å S(p) > p, Hyper-accélération analyser & justifier.
å S(p)=p , Accélération idéal.
1.6.3 L’efficacitéEfficacité une métrique qui représente le taux d’utilisation des ressources, ou F fraction
de l’accélération idéale dans l’architecture parallèle. L’efficacité est inférieure ou égale à 1.
10

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
E = S(p)p
,ou S(p) et l’accélération (SpeedUp) et p le nombre de processeurs [2].
1.7 Architecture parallèle actuelleDans cette section nous allons présenter quelque architecture parallèle actuelle.
1.7.1 Processeur graphiqueUn processeur graphique, ou GPU (en l’anglais Graphics Processing Unit), est un cir-
cuit intégré la plupart du temps présent sur une carte graphique mais pouvant aussi êtreintégrée sur une carte-mère ou dans un CPU et assurant les fonctions de calcul de l’affi-chage. Un processeur graphique a généralement une structure hautement parallèle qui lerend efficace pour une large palette de tâches graphiques comme le rendu 3D, en Direct3D,en OpenGL, la gestion de la mémoire vidéo, le traitement du signal vidéo, la décompres-sion Mpeg ...etc [5]. Peu d’entreprises conçoivent de tels processeurs : les plus connuessont NVIDIA, AMD et Intel.Il y a aussi d’autre moins connues telles que Qualcomm, S3Graphics, Matrox,3DLabs, et XGI.
Figure 1.16: Exemple de processeur graphique NVIDIA avec un CPU [6].
1.7.2 CloudCloud est l’exploitation de la puissance de calcul ou de stockage de serveurs informa-
tiques distants par l’intermédiaire d’un réseau, généralement l’internet. Ces serveurs sontloués à la demande, le plus souvent par tranche d’utilisation selon des critères techniques(puissance, bande passante, etc.) mais également au forfait. Il se caractérise par sa grandesouplesse : selon le niveau de compétence de l’utilisateur client, il est possible de gérersoi-même son serveur ou de se contenter d’utiliser des applicatifs distants [7]. Les grandesentreprises du secteur informatique comme IBM, Microsoft, Google, Amazon,Dell, Oracle
11

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
ou Apple font la promotion du cloud computing, qui constitue un important changementde paradigme des systèmes informatiques, jusque-là constitués de serveurs situés au seinmême de l’entreprise.
1.7.2.1 Les modèles de service de cloud
Il existe 3 modèles de service de cloud [8] :ã SasS (Software as a Service), Logiciel en tant que service.ã PaaS (Platform as a Service), Plateforme en tant que service.ã Iaas (infrastrure as a Service), Infrastructure en tant que service.
Figure 1.17: Image illustre la différence technique entre les 3 modèles de cloud [8].
1.7.3 ClusterLe cluster « grappe en français » est une architecture de groupe d’ordinateurs, utili-
sée pour former de gros serveurs, chaque machine est un nœud du cluster, l’ensemble estconsidéré comme une seule et unique machine. Toutes les machines du cluster travaillentensemble sur des tâches communes en s’échangeant des données (l’échange est restreintdans une zone géographique étroite), ce type de travail est appelé calcul parallèle [9].
12

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
Figure 1.18: Image d’un cluster de machines cher Yahoo ! [10].
1.7.3.1 Concept d’un cluster informatique
Les concepts d’un cluster informatique est le suivant [11] :l Partage de l’exécution d’une application entre plusieurs machines du cluster.l Redondance.l Haute disponibilité.l Accélération des temps d’exécution de façon significative.l Problème de charge réseau : échange de messages.l Temps de latence.l Communication par échange de message.l Evolutivité.l Délégation des calculs.l Sécurité.
1.7.4 Grille informatiqueGrille informatique est une architecture réseaux qui utilise le calcul distribué en re-
groupant des ressources géographiquement distribuées, et se caractérise par un transfertimportant de données, des logiciels de coordination et d’ordonnancement. La grille infor-matique consiste également à mettre en commun la puissance de toutes les machines d’unemême entreprise ou d’un réseau plus vaste, et de redistribuer la puissance de calcul enfonction des besoins spécifiques de chaque client [12].
13

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
Figure 1.19: Image illustre architecture d’une grille informatique [12].
1.7.4.1 Type de grille
On distingue 3 type de grille [13] :— Grille d’information : À pour but partage d’information comme site web.— Grille de stockage : Partage des données, musique, vidéo, applications à succès,
données scientifiques ...etc.— Grille de calcul : Agrégation de puissance de calcul dont on distingue 3 sous-type
aussi :Ü Supercalculateur Virtuel.Ü Internet computing.Ü MetaComputing.
1.7.4.2 Caractéristique d’une grille informatique
Les grilles informatiques sont caractérisées par [14] :
Ü Existence de plusieurs domaines administratifs.
Ü Hétérogénéité des ressources.
Ü Passage à l’échelle.
Ü Nature dynamique des ressources.
1.7.5 Le cluster IBN BADISLa recherche dans notre projet fin d’études est implémentée sur le cluster IBN BADIS
du CERIST (centre de recherche sur l’information scientifique et technique), un centrede recherche scientifique équipé par du matériel adapté pour le calcul intensif. Le clusterIBNBADIS est une plateforme de calcul haute performance à 32 noeuds de calcul composéchacun de deux processeurs Intel(R) Xeon(R) CPU E5-2650 2.00GHz. Chaque processeur
14

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
est composé de 8 cœurs, ce qui fait 512 cœurs au total (ce qui est 500 fois plus rapidequ’un simple ordinateur à un seul cœur ), La puissance théorique du cluster est d’environs8TFLOPS a une puissance théorique 8 TFlops (8000 milliard d’opérations flottantes parseconde),un linpack de 7.8 TFlops, un système d’exploitation linux Readhat, 36 TB commebais de stockage, 512 coeurs et comme environnement de développement les langages deprogrammation : C++/MPI/FORTRAN/JAVA ... etc, sont utilisés. De plus tout outilnécessaire pour faire de la recherche et de l’expérimentation [15].
Figure 1.20: Image du cluster IBN BADIS au CERIST.
1.7.5.1 Architecture du cluster IBN BADIS
Le cluster " IBN BADIS " est composé d’un noeud d’administration ibnbadis0, un nœudde visualisation ibnbadis10 et 32 noeuds de calcul ibnbadis11-ibnbadis42.Le nœud de visualisation ibnbadis10 est équipé d’un GPU Nvidia Quadro 4000 (6GB, 448cœurs) qui peut être exploité pour les calculs.Les logiciels installés sur "IBN BADIS " sont :
— SLURM pour la gestion des jobs.— C/C++, Fortran— MPI
La figure suivante montre l’architecture interne du cluster " IBN BADIS ".
15

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
Figure 1.21: Architecture du cluster IBN BADIS au CERIST.
Voir l’annexe " D" pour la procédure de connexion et utilisation du cluster "IBN BADIS".
1.8 La programmation séquentielle et parallèleDans cette section nous allons parler de façon générale de la programmation séquentielle
et parallèle.
1.8.1 La programmation séquentielleLa programmation séquentielle et un type de programmation existant actuellement et
le plus ancien. Il s’agit d’écrire un programme en utilisant un ou des algorithmes séquen-tiels. Le nombre d’algorithmes séquentiels dans un programme dépend de la fonctionnalitéet la complexité de la conception du programme. Un algorithme séquentiel est une suited’instructions code machine qui sera exécutée par le processeur une par une, la prochaineinstruction ne s’exécutera pas tant que la précédente n’a pas terminé son exécution. Biensûr, l’exécution de l’algorithme (programme) dépendra de l’ordre des instructions de l’al-gorithme.Le programme séquentiel est exécuté par un seul et unique processeur. Si on veutl’exécuter sur plusieurs processeurs en même temps, comme s’il s’exécute localement, nonpas comme un programme réparti coopération entre les processeurs , pour avoir un résultatfinal.Certains algorithmes séquentiels ont un temps d’exécution très long qui n’est pas accep-table, comme : l’algorithme de calcule de factoriel ou bien les algorithmes de recherche degraphes sur des grandes données leur complexité temporelle et exponentielle ou bien facto-rielle ...etc. Le problème est que la solution existante actuellement est rentable mais aprèsun temps d’attente élevé, et avec l’introduction des architectures parallèles , la nécessitéde paralléliser les algorithmes pour les rendre efficaces en termes de temps d’exécution etde performances de coût et l’exploitation des ressources ... etc s’est imposée.
16

CHAPITRE 1. NOTIONS SUR LES ARCHITECTURES ET LA PROGRAMMATIONPARALLÈLE
1.8.2 La programmation parallèleLe parallélisme est omniprésent dans les ordinateurs d’aujourd’hui. Au niveau micro-
scopique,les processeurs multiplient les unités arithmétiques pipelinées sur un même circuitintégré. Au niveau macroscopique, on interconnecte les stations de travail en grappes pourconstruire des supercalculateurs à peu de frais. Dans les deux cas, l’algorithmique paral-lèle permet de comprendre et de maîtriser les concepts fondamentaux à mettre en œuvrepour l’utilisation de plates-formes distribuées. Elle emprunte beaucoup à l’algorithmiqueclassique dans sa problématique (conception, analyse, étude de complexité), mais s’enrichitd’une nouvelle dimension avec l’exploitation simultanée de plusieurs ressources [16].On écrit des programmes parallèles qui seront exécutées sur plusieurs processeurs répartiesgéographiquement dans le monde connectés via un réseau de télécommunication dans unearchitecture parallèle à mémoire distribuée où la communication entre les processus ,se faitpar échange de messages. Aussi les algorithmes parallèles peuvent s’exécuter sur une seulemachine avec un processeur multi-cœurs dans une architecture parallèle à mémoire parta-gée où le parallélisme se fait par des threads s’exécutant chacun sur de différents cœurs.La programmation parallèle se base sur les algorithmes parallèles, dont le développeur doitconsidérer plusieurs facteurs tels que : la partie du programme qui peut être traitée enparallèle,la manière de distribuer les données, les dépendances des données, la répartitionde charges entre les processeurs, les synchronisations entre les processeurs. Il y a essen-tiellement deux méthodes pour concevoir un algorithme parallèle, l’une consiste à détecteret à exploiter le parallélisme à l’intérieur d’un algorithme séquentiel déjà existant, l’autreconsistant à inventer un nouvel algorithme dédié au problème donné.
1.9 ConclusionA la fin de ce chapitre, nous arrivons à dire que les machines à architecture parallèle
ont bouleversée le monde de la technologie informatique et ont facilité la résolution debeaucoup de problèmes. Devenue une grande puissance technologique moderne qui permetde faire de calcul parallèle, dont on ne peut pas négliger son utilisation due à leur rapiditéet bonne performance. Ils sont devenus indispensables.
17

Chapitre
2Étude du modèle MapReduce,du framework qui l’implémente :Hadoop et le produit de re-cherche MR-MPI
" La quantité de données dumonde digital à la fin de 2011 àété estimée à 1.8 zettabytes (1021)bytes "
(cité dans [17] )
"Une nouvelle génération detechnologies et architecturesconçues pour extraire de la valeuréconomique à une grande variétéde données en permettant leurcapture à haute vitesse, leurdécouverte et/ou analyse "
( firme IDC citée dans [18] ).

CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
2.1 IntroductionLa science, à l’heure actuelle,vit une révolution qui a mené à un nouveau concept,selon
lequel,«la science est dans les données », autrement dit, la connaissance émerge du traite-ment des données. L’extraction de connaissances à partir de grands volumes de données,l’apprentissage statistique, l’agrégation de données hétérogènes, la visualisation et la navi-gation dans de grands espaces de données, sont autant d’outils qui permettent d’observerdes phénomènes, de valider des hypothèses, d’élaborer de nouveaux modèles, la prise dedécisions, dans des situations critiques,ou encore dans le but de servir une application decalcul intensif. Selon une étude faite par : The Economist Intelligence Unit en 2014« 68% des entreprises qui ont systématiquement recours à une analyse de données,dansleurs prises de décision,voient leurs bénéfices augmenter ». La donnée,est donc l’un desprincipaux actifs immatériels,des organisations quelque soit leur domaine : recherche ouindustriel.Le traitement de donnés représente ainsi, un pilier de la science. Tout comme la théorie,l’expérimentation et la simulation, il constitue un défis majeur pour les systèmes de re-cherche d’ information tels que les moteurs de recherche d’information dans le Web connucomme le plus grand dépôt de données , on cite par exemple : Google,Yahoo,Bing ...etc.Un des enjeux,concerne le traitement de grandes quantités de données, et le faite ,qu’ilne peut être réalisé avec les paradigmes classiques de traitement de données,et nécessitel’utilisation de plateformes distribuées de calcul et des mécanismes de parallélisations pouratteindre un débit de production élevé,et un temps de réponse minimal , ce qui nous amèneà la problématique suivante :
Comment effectuer des calculs distribués tout tant assurant la gestion et leparallélisme des différentes tâches appliquées sur ces vastes collections de
données ?
Le modèle MapReduce répond à cette dernière, notamment ce qu’on va présenter dansce chapitre, le framework l’implémentant "Hadoop" utilisé par les grands auteurs du webcomme : Google ,Yahoo ,Facebook ,Twitter,Amazone ,IBM, LinkedIn et d’autres , le pro-duit de recherche MR-MPI.
2.2 Modèle de programmation MapReduce
2.2.1 Qu’est ce que MapReduce ?Pour exécuter un problème large de manière distribuée, une stratégie algorithmique dite
« divide and conquer / diviser pour régner » [19] est appliquée , c’est à dire découperle problème en plusieurs sous problèmes ou sous tâches de taille réduite , puis les répartirsur les machines qui constituent le cluster, pour être exécutés.De multiples approches existent pour cette division d’un problème en plusieurs « sous-tâches » ,parmi elles, MapReduce, qu’on va définir dans la suite.
18

CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
2.2.1.1 Définition
MapReduce est un paradigme (un modèle) attrayant pour le traitement des donnéesen parallèle,dans le calcul de haute performance dans un environnement en cluster [20].L’évolutivité de MapReduce s’est avérée élevée du fait que le travail est partitionné en denombreuses petites tâches, en cours d’exécution sur plusieurs ordinateurs,dans un clusterà grande échelle.Le modèle vise aussi à généraliser les approches existantes pour produire une approcheunique,applicable à tous les problèmes. Il est conçu pour traiter de grands volumes dedonnées en parallèle et cela en divisant le travail en un ensemble de tâche indépendantes.MapReduce existait déjà depuis longtemps , dans les langages fonctionnels (Lisp, Scheme)[19], mais la présentation du paradigme sous une forme rigoureuse, généralisable à tousles problèmes et orientée calcul distribué ,est attribuable au département de recherche deGoogle qui a publié en 2004 un article sous le thème : « MapReduce : Simplified DataProcessing on Large Clusters ».Un des objectifs du modèle MapReduce est la répartition de charge de calcul sur les ma-chines qui constitue le cluster. Le but est d’utiliser suffisamment de ressources tout enoptimisant le temps de calcul et maintenir la fiabilité du système.MapReduce permet de :
— Traiter de grands volumes de données.— Gérer plusieurs processeurs.— La parallélisation automatique.— L’équilibrage de charge.— L’optimisation sur les transferts disques et réseaux.— L’ordonnancement des entrées / sorties.— La surveillance des processus.— La tolérance aux pannes.
2.2.1.2 Principe de fonctionnement
MapReduce définit deux opérations différentes à effectuer sur les données d’entrée :
X Mappage :La première opération « MAP », écrite par l’utilisateur , dans un premier lieu transformeles données d’entrée en une série de couples « clef,valeur » . Ensuite elle regroupe les don-nées en les associant à des clefs, choisies de manière à ce que les couples « clef,valeur »aient une signification par rapport au problème à résoudre.En outre, l’opération « MAP »doit être parallélisable, les données d’entrée sont découpées en plusieurs fragments, et cettedernière est exécutée par chaque machine du cluster sur un fragment distinct [19, 20].
X Réduction :La seconde opération « REDUCE », également écrite par l’utilisateur applique un traite-ment à toutes les valeurs de chacune des clefs différentes produite par l’opération « MAP». À la fin de l’opération « REDUCE », on aura un résultat pour chacune des clefs dif-
19
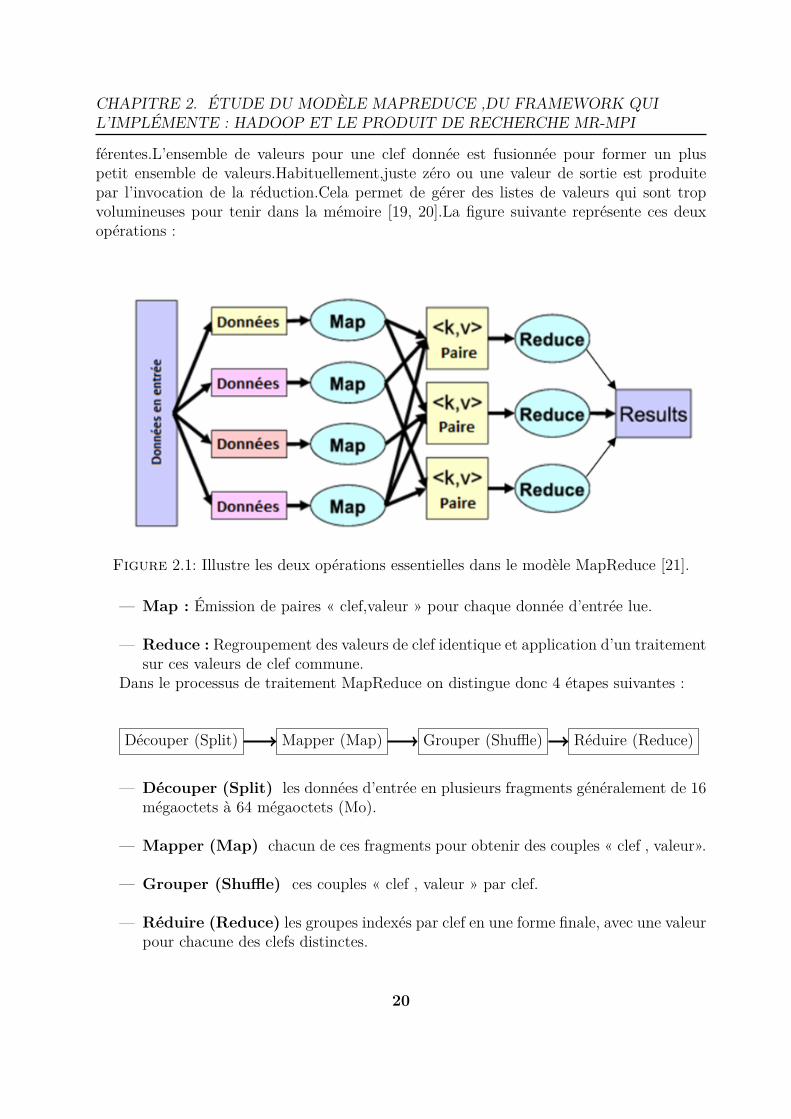
CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
férentes.L’ensemble de valeurs pour une clef donnée est fusionnée pour former un pluspetit ensemble de valeurs.Habituellement,juste zéro ou une valeur de sortie est produitepar l’invocation de la réduction.Cela permet de gérer des listes de valeurs qui sont tropvolumineuses pour tenir dans la mémoire [19, 20].La figure suivante représente ces deuxopérations :
Figure 2.1: Illustre les deux opérations essentielles dans le modèle MapReduce [21].
— Map : Émission de paires « clef,valeur » pour chaque donnée d’entrée lue.
— Reduce : Regroupement des valeurs de clef identique et application d’un traitementsur ces valeurs de clef commune.
Dans le processus de traitement MapReduce on distingue donc 4 étapes suivantes :
Découper (Split) Mapper (Map) Grouper (Shuffle) Réduire (Reduce)
— Découper (Split) les données d’entrée en plusieurs fragments généralement de 16mégaoctets à 64 mégaoctets (Mo).
— Mapper (Map) chacun de ces fragments pour obtenir des couples « clef , valeur».
— Grouper (Shuffle) ces couples « clef , valeur » par clef.
— Réduire (Reduce) les groupes indexés par clef en une forme finale, avec une valeurpour chacune des clefs distinctes.
20
CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
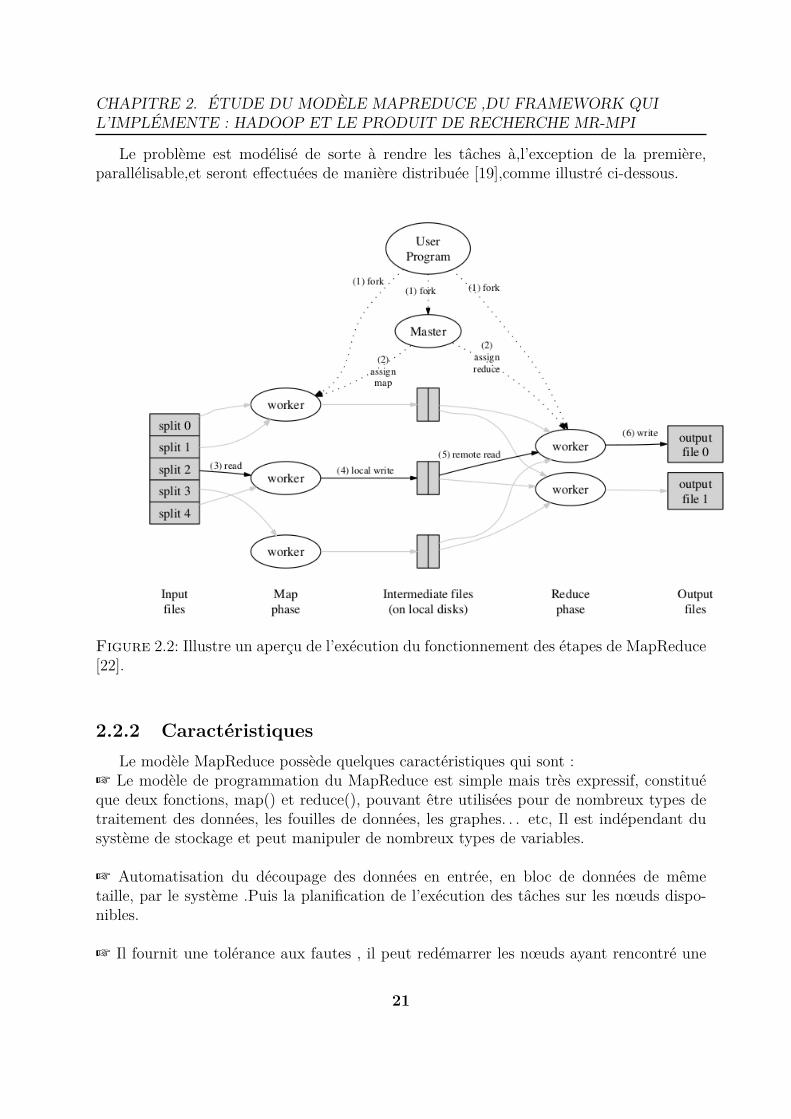
Le problème est modélisé de sorte à rendre les tâches à,l’exception de la première,parallélisable,et seront effectuées de manière distribuée [19],comme illustré ci-dessous.
Figure 2.2: Illustre un aperçu de l’exécution du fonctionnement des étapes de MapReduce[22].
2.2.2 CaractéristiquesLe modèle MapReduce possède quelques caractéristiques qui sont :
+ Le modèle de programmation du MapReduce est simple mais très expressif, constituéque deux fonctions, map() et reduce(), pouvant être utilisées pour de nombreux types detraitement des données, les fouilles de données, les graphes. . . etc, Il est indépendant dusystème de stockage et peut manipuler de nombreux types de variables.
+ Automatisation du découpage des données en entrée, en bloc de données de mêmetaille, par le système .Puis la planification de l’exécution des tâches sur les nœuds dispo-nibles.
+ Il fournit une tolérance aux fautes , il peut redémarrer les nœuds ayant rencontré une
21

CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
erreur ou affecter la tâche à un autre nœud.
+ La parallélisation est transparente à l’utilisateur afin de lui permettre de se concen-trer sur le traitement des données.
2.2.3 Utilisateurs de MapReduceLe modèle MapReduce est très utilisé par plusieurs organismes, on cite :
O Google : pour la construction des index pour « Google Search » et le regroupementdes articles pour « Google News », et cela depuis 2004, où il a remplacé les algorithmesindexation originales et heuristiques, compte tenu de son efficacité, face au traitement degrands masses de données.Un rapport plus récent, en 2008, indique que Google exécute plus de cent mille job MapRe-duce par jour , traite plus de 20 po de données , et en 2010, plus de dix mille programmesdistincts de MapReduce effectuant une variété des fonctions, y compris le traitement àgrande échelle graphique, texte traitement ...etc, ont été créés [20].
O Yahoo ! : utilise Hadoop le framework le plus connu implémentant MapReduce pouralimenter Yahoo ! Search avec « Web Map » aussi de la détection de Spam pour « Yahoo !Mail » .
O Facebook : dans la fouille de données connu sous l’appellation «Data Mining » etdans la détection de spam.
O Laboratoires/ chercheurs : dans le domaine de la recherche on l’utilise aussi pour :
Ø Analyse d’images Astronomiques.
Ø Simulations métrologiques.
Ø Simulations physiques.
Ø Statistiques.
Ø Et bien d’autres . . . .etc [23]
22

CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
Figure 2.3: Illustre certaines entreprises et universités qui utilisent le modèle MapReduce[19].
2.3 Framework Hadoop solution d’Apache
2.3.1 Qu’est ce que Hadoop ?Hadoop est une technologie en plein essor ,de plus en plus de données produites par des
systèmes d’information à une fréquence de plus en plus importante,ces données doiventtoutes être analysées, corrélées,traitées,...etc et puis stockées ce qui est communémentappelé « Big Data ».Hadoop offre une solution idéale et facile à implémenter au problème.
2.3.1.1 Définition
Hadoop est un framework libre, conçu, pour réaliser des traitements sur des volumes dedonnées massifs « Big Data », et destiné à faciliter la création d’applications distribuées etqui passent à l’échelle, permettant aux applications de travailler avec des milliers de nœudset des pétaoctets de données, soit plusieurs milliers de Téraoctets.Hadoop a été inspiré par les publications de Google , la première concernant MapReduceprésenté ci-dessus et la seconde en 2003 sur « Google File System » : un système de fichiersdistribués, conçu pour répondre aux besoins de leurs applications en matière de stockagede données [20].
2.3.1.2 Le système de fichier HDFS
HDFS, Hadoop Distributed File System, est un système de fichiers distribué conçu poursauvegarder de très grande quantités de données, de l’ordre de téra-octets ou même pétaoc-tets, et de fournir un accès en haut débit à ces informations [20]. Pour stocker les donnéesen entrée ainsi que les résultats des traitements, on va utiliser le système de fichiers, le «
23

CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
HDFS » ,Il s’agit du système de fichier standard de Hadoop distribué car les données sontréparties sur tout le cluster de machines, une de ces caractéristiques , aussi :
+ Il est répliqué : Les fichiers sont stockés dans un mode redondant sur plusieurs or-dinateurs afin d’assurer leur durabilité à l’échec et de haute disponibilité à plusieurs ap-plications parallèles,si une des machines du cluster tombe en panne, aucune donnée n’estperdue.
+ Il est conscient du positionnement des serveurs sur les racks. HDFS va répliquer lesdonnées sur des racks différents, pour être certain qu’une panne affectant un rack de ser-veurs entier ne provoque pas ,non plus, de perte de données, même temporaire.
+ HDFS peut aussi optimiser les transferts de données pour limiter la «distance » àparcourir pour la réplication ,et donc,les temps de transfert.
Le HDFS possède une architecture de maître /slave. Il repose sur deux serveurs :— Le NameNode : qui stocke les informations relatives aux noms de fichiers, il y a
un seul NameNode dans tout le cluster.
— Le DataNode : qui stocke les blocs de données eux-mêmes. Il y a un DataNodepour chaque machine du cluster, et ils sont en communication constante avec leNameNode pour recevoir de nouveaux blocs, indiquer quels blocs sont contenus surle DataNode, signaler des erreurs, ...etc[19].
Un cluster HDFS se compose donc d’un seul NameNode, le serveur maître qui gère l’espacede noms du fichier système et réglemente l’accès aux fichiers par clients. En outre, il existeun certain nombre de DataNodes, habituellement un par nœud dans le cluster, qui gère lestockage pour les nœuds en exécution. En interne, un fichier est divisé en un ou plusieursblocs, ces derniers sont stockés dans un ensemble de DataNodes. Le NameNode exécute lesopérations d’espace noms comme l’ouverture, de fermeture et de renommer des fichiers etrépertoires. Il détermine également le mappage des blocs aux DataNodes. Les DataNodessont responsables du service de lecture et demandes d’écriture dans le fichier clients dusystème. Le DataNode effectue également la création de bloc , suppression, et réplicationsur l’ instruction du NameNode [24] .
En outre , le HDFS est en communication constante avec le système de gestion destâches de Hadoop, qui distribue les fragments de données d’entrée au cluster pour lesopérations « MAP » et/ou « REDUCE ». La figure suivante illustre l’architecture dusystème de fichier HDFS.
24

CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
Figure 2.4: Illustre l’architecture du HDFS [24].
2.3.1.3 Architecture de Hadoop
La gestion des tâches de Hadoop se base sur deux serveurs aussi, qui sont :
— Le JobTracker : le serveur responsable de recevoir directement les tâches à exécu-ter ainsi que les données d’entrées , et le répertoire, où stocker les données de sortiesur HDFS . Il y a un seul JobTracker sur une seule machine du cluster Hadoop.Le JobTracker est en communication avec le NameNode de HDFS et sait donc oùsont les données, donc il est conscient de la position des données , il peut facilementdéterminer les meilleures machines auxquelles attribuer les sous-tâches.
— Le TaskTracker : qui est en communication constante avec le JobTracker et varecevoir les opérations simples à effectuer (MAP,REDUCE) ainsi que les blocs dedonnées correspondants stockés sur HDFS. Il y a un TaskTracker sur chaque ma-chine du cluster [19].
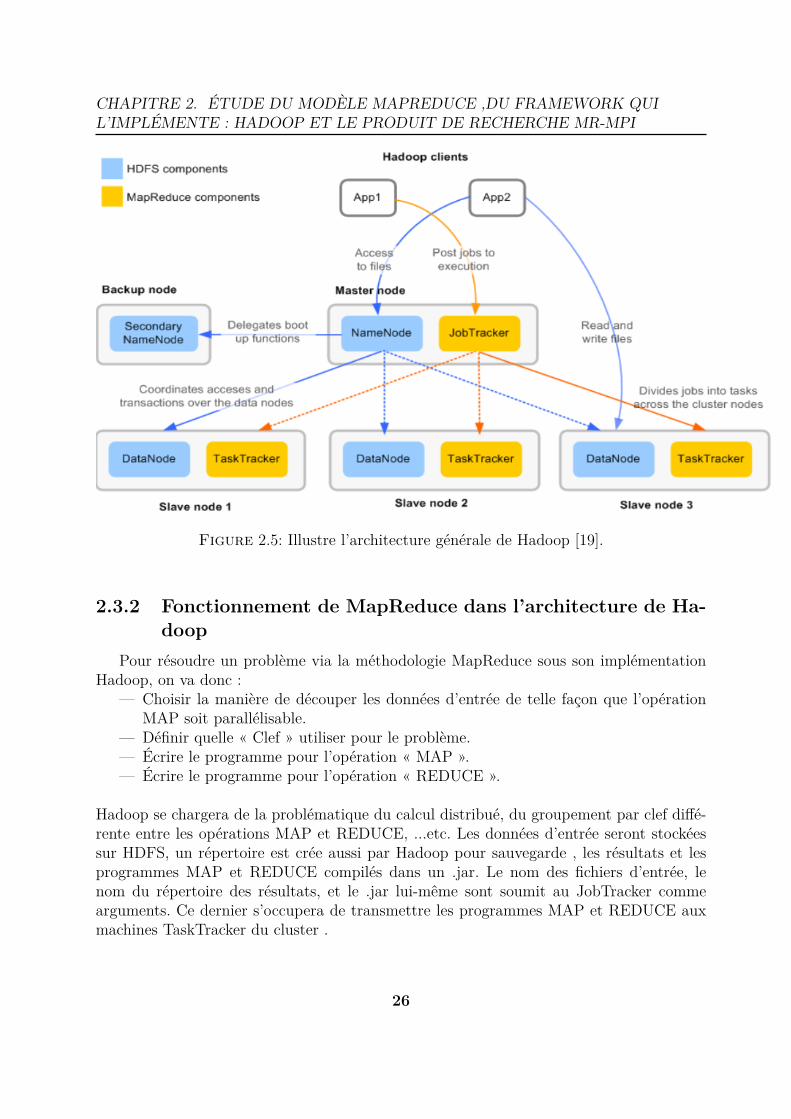
La figure suivante illustre l’architecture générale de Hadoop ainsi que l’interaction avecle système de fichier HDFS.
25
CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
Figure 2.5: Illustre l’architecture générale de Hadoop [19].
2.3.2 Fonctionnement de MapReduce dans l’architecture de Ha-doop
Pour résoudre un problème via la méthodologie MapReduce sous son implémentationHadoop, on va donc :
— Choisir la manière de découper les données d’entrée de telle façon que l’opérationMAP soit parallélisable.
— Définir quelle « Clef » utiliser pour le problème.— Écrire le programme pour l’opération « MAP ».— Écrire le programme pour l’opération « REDUCE ».
Hadoop se chargera de la problématique du calcul distribué, du groupement par clef diffé-rente entre les opérations MAP et REDUCE, ...etc. Les données d’entrée seront stockéessur HDFS, un répertoire est crée aussi par Hadoop pour sauvegarde , les résultats et lesprogrammes MAP et REDUCE compilés dans un .jar. Le nom des fichiers d’entrée, lenom du répertoire des résultats, et le .jar lui-même sont soumit au JobTracker commearguments. Ce dernier s’occupera de transmettre les programmes MAP et REDUCE auxmachines TaskTracker du cluster .
26

CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
Le déroulement de l’exécution d’une tâche Hadoop suit les étapes suivantes :1. Le client, un outil Hadoop console va soumettre le travail à effectuer au JobTracker
ainsi que les opérations MAP et REDUCE, le nom des fichiers d’entrée, et l’endroitoù stocker les résultats.
2. Le JobTracker communique avec le NameNode HDFS pour savoir où se trouvent lesblocs correspondant aux noms de fichiers donnés par le client.
3. Le JobTracker, à partir de ces informations, détermine quels sont les nœuds TaskTra-cker les plus appropriés, c’est à dire ceux qui contiennent les données sur lesquellestravailler sur la même machine, ou le plus proche possible.
4. Pour chaque fragments des données d’entrée, le JobTracker envoie au TaskTrackersélectionné le travail à effectuer (MAP/REDUCE) et les blocs de données corres-pondants.
5. Le JobTracker communique avec les nœuds TaskTracker qui exécutent les tâches. Ilsenvoient régulièrement des message signalant qu’ils travaillent toujours sur la sous-tâche reçue. Si aucun message n’est reçu dans une période donnée, le JobTrackerconsidère la tâche comme ayant échouée et donne le même travail à effectuer à unautre TaskTracker.
6. Si par hasard une tâche échoue , le TaskTracker va signaler au JobTracker quela tâche n’a pas pût être exécutée. Le JobTracker va alors décider de la conduiteà adopter : redonner la sous-tâche à un autre TaskTracker, demander au mêmeTaskTracker de ré-essayer, marquer les données concernées comme invalides, etc. ilpourra même lister le TaskTracker concerné comme non-fiable dans certains cas.
7. Une fois que toutes les opérations envoyées aux TaskTracker (MAP et REDUCE)ont été effectuées et confirmées comme effectuées par tous les nœuds, le JobTrackermarque la tâche comme « effectuée ». Des informations détaillées sont disponibles(statistiques, TaskTracker ayant posé problème,. . . etc).
Dans le cas de travailleurs plus lents, ralentissants l’ensemble du cluster sera redistribuéaux machines qui ont terminé leurs les tâches respectives et /ou ne recevront plus d’autrestâches. Par ailleurs, on peut également obtenir à tout moment de la part du JobTrackerdes informations sur les tâches en train d’être effectuées : étape actuelle (MAP, REDUCE,SHUFFLE), pourcentage de complétion,... etc. Le TaskTracker lorsqu’il reçoit une nou-velle tâche à effectuer (MAP, REDUCE, SHUFFLE) depuis le JobTracker, démarre unenouvelle instance et enverra régulièrement au JobTracker des messages. Lorsqu’une sous-tâche est terminée, le TaskTracker envoie un message au JobTracker pour l’en informer,du déroulement correcte ou non de la tâche et il lui indique le résultat [19].
2.3.3 Avantages de la solutionLes avantages de la solution sont énumérés ci-dessous :
4 Projet de la fondation Apache – Open Source, composants complètement ouverts, tout
27

CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
le monde peut y participer.4 Modèle simple pour les développeurs : il suffit de développer des tâches map-reduce,depuisdes interfaces simples accessibles via des librairies dans des langages multiples (Java, Py-thon, C/C++...).4 Déployable très facilement (paquets Linux pré-configurés), configuration très simple,elle aussi.4 S’occupe de toutes les problématiques liées au calcul distribué, comme l’accès et le par-tage des données, la tolérance aux pannes, ou encore la répartition des tâches aux machinesmembres du cluster : le programmeur a simplement à s’occuper du développement logicielpour l’exécution de la tâche [19].
2.4 Produit de recherche MR-MPI (Map Reduce Mes-sage Passing Interface )
En deuxième lieu , le produit de recherche qui implémente le modèle de programmationMapReduce est MR-MPI [25, 26] mettant en œuvre l’utilisation des fonctionnalités dela bibliothèque MPI (Message Passing Interface) .Un standard destiné à l’industriepour l’écriture de programme de passage de messages sur les plateformes de Calcul hauteperformance (HPC High Performance Computing) [27].
2.4.0.1 Définition
MPI ( Message Passing Interface) est une API (Application ProgrammingInterface) constitué d’un ensemble normalisé de classes, de méthodes ou de fonctions miseen œuvre par une bibliothèque logicielle utilisable avec les langages C ,C++ et Fortran.Elle permet de faire communiquer par passage de messages des processus distants sur unensemble de machines hétérogènes et ne partageant pas de mémoire commune . MPI estadapté à la programmation parallèle distribué et très utilisé dans le calcul intensif.Ellepermet de gérer :
— Les communications point à point.— Les communications collectives.— Les groupes de processus.— Les topologies de processus.— Les communications unidirectionnelles.— La création dynamique de processus.— Les entrées/sorties parallèles (MPI/IO).— Utilisation de différents types de données.
MPI est passée par plusieurs propositions avancées et des versions révisées due au change-ment fréquent des machines parallèles et afin de permettre les principales caractéristiquescités ci- dessous ,aboutie par : MPI version 1 environ 120 fonctions et plus de 200 pourMPI version 2 . Une extension vers MPI version 3 est en cours de discussion [27].
28

CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
2.4.0.2 La librairie MR-MPI
MR-MPI ( Map Reduce Message Passing Interface) est une bibliothèque parallèle avecappels de transmission de messages qui permet aux algorithmes de s’exprimer dans le pa-radigme de MapReduce. La bibliothèque est libre, écrit en C, peut être appelé à partirde C++, Fortran ou langages de script comme Python et peut fonctionner sur n’importequelle plate-forme parallèle qui prend en charge le contexte MPI.La référence de base opérée dans le modèle MapReduce est l’entité paire : clefs/valeurs(KV) qui peuvent être de n’importe quel type de données ou combinaisons de plusieurstypes. Les paires sont stockées dans un objet de MapReduce appelé MR. Un programmeutilisateur peut créer un ou plusieurs objets MR pour implémenter un algorithme. Diversesopérations de MapReduce (MAP, Reduce, etc.) sont appelées sur un objet ainsi que lespaires KV générées par ce dernier, qui peuvent être passées et combinées entre les objetsMR [25].La mémoire physique totale des grosses machines parallèles peut être de plusieurs téraoc-tets, ce qui permet de traiter de grands ensembles de données, en supposant que les pairesKV / KMV demeurent uniformément distribuées tout au long de la séquence d’opéra-tions de MapReduce ,dans le cas contrainte MR-MPI permet d’utiliser des disques pourécrire des fichiers contenant des paires KV ou KMV qui ne peuvent pas être retenus dansla mémoire.Toutefois, aucune tolérance de panne ou de capacité de redondance des données n’est four-nie . MR-MPI propose plusieurs opérations permettant d’effectuer diverses tâches, briève-ment [28] :
— Map : génère les paires (KV) « clef,valeur » en appelant un programme utilisateur, ne nécessite pas de communication entre les processeurs.
— Ajouter : ajoute des paires KV à partir d’un objet à un autre. Ne nécessite pas decommunication et s’effectue en série.
— Convertir : convertit les paires KV en paires « clef,multi-valeur ». Avant d’ap-peler la fonction "convert", les paires KV peuvent contenir un double des clefs etleurs valeurs . Après l’appel de la fonction convertir, les valeurs de la même clé sontconcaténées à être une seule paire KMV.
— Collate : agrégat des paires KV , puis les convertit en paires KMV . Cetteopération nécessite la communication, et est en fait, équivalente à une exploitationd’agrégats , suivie d’une opération de conversion.
— Réduire : Cette opération traiter les paires KMV et ne nécessite pas de commu-nication et traite une paire KMV pour générer la paire de KV. Les paires KMVdétenues sont uniques. À la fin de la réduction, chaque processeur possédera uneliste de paires KV unique.
29

CHAPITRE 2. ÉTUDE DU MODÈLE MAPREDUCE ,DU FRAMEWORK QUIL’IMPLÉMENTE : HADOOP ET LE PRODUIT DE RECHERCHE MR-MPI
Les implémentations de MR-MPI actuelles ne permettent pas de détecter facilement desprocessus morts et ne fournit pas de la redondance des données.Contrairement à Hadoop,et son système de fichiers (HDFS) qui assure la redondance des données.
2.5 ConclusionChaque jour, 2,5 trillions octets de données sont crées.Ces données proviennent de
différentes sources : des capteurs utilisés pour recueillir des informations climatiques,..etc,du Web, le plus grand dépôt de données ( les sites de médias sociaux, achat en ligne,enregistrements des transactions et d’autres,...etc) tel que, au cours des deux dernièresannées seulement, ça représente 90 % des données dans le monde. Pour cela une variétéd’architectures de systèmes,y compris des applications de calcul parallèle et distribué ontété mises en œuvre pour analyser des données volumineuses à grande échelle. Cependantla plupart des données croissantes sont des données non structurées, d’où s’est avéré lanécessité de nouveaux modèles de traitement de données flexibles.Nous avons présenté dans ce chapitre , le modèle de programmation MapReduce mis aupoint par Google à travers l’étude de son principe de fonctionnement ,ses caractéristiqueset la concrétisation de son implémentation dans le framework Hadoop et le produit derecherche MR-MPI. Pour la suite de ce mémoire on a opté pour le framework Hadoop carpour ce qui est de MR-MPI qui ce veut être plus optimiser pour le calcul scientifique maisnon stable et en cours d’élaboration.
30

Chapitre
3Étude de l’ algorithme Branchand Bound et des stratégies deparallélisation
" L’algorithme de Branch etBound est proposé par A. H. Landand A. G. Doig en 1960 pour laprogrammation discrète. Il s’agitd’un algorithme général pourtrouver des solutions optimales desdifférents problèmesd’optimisation "
( citée dans [29] ).

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
3.1 IntroductionAujourd’hui, avec le développement de la technologie et le besoin d’évolutivité on se
trouve face à des problèmes, qui n’existaient pas avant, comme les problèmes d’optimisa-tion combinatoire , qui sont NP-difficiles. Les méthodes de la solution de ces problèmes sontclassées en deux grandes catégories : les méthodes approchées, appelées aussi, heuristiques,et les méthodes exactes. Les heuristiques, qui produisent en un temps raisonnable, des so-lutions de bonne qualité, mais pas forcément optimales.Les méthodes exactes, permettentde trouver des solutions exactes, avec preuve d’optimalité. Parmi les méthodes exactes, ontrouve la méthode Branch&Bound qui est basée sur une énumération intelligente de l’es-pace de recherche. Les méthodes exactes réduisent, considérablement, le temps requis pourl’exploration de tout l’espace de recherche. Cependant elles restent, inefficaces, lorsqu’ellessont appliquées aux problèmes de grandes tailles (possédant un espace de recherche trèsgrand). Vue la limite physique des architectures des ordinateurs actuelle, la parallélisation,de ces méthodes, s’avère un moyen efficace, pour accélérer les calculs et réduire leur tempsd’exécution, sur des ordinateurs à architecture parallèles.
Dans ce chapitre, nous allons décrire la méthode Branch&Bound avec son principede fonctionnement,puis nous étudieront les différentes stratégies de parcours et illustra-tion avec des exemples d’utilisation de cette méthode, ensuite, on énumère les différentesclassifications de l’algorithme B&B parallèle, avec les mesures de performance et leur com-plexité. Enfin de ce chapitre nous exposerons approche de déploiement d’un algorithmeB&B parallèle.
3.2 La méthode Branch and Bound3.2.0.3 Définition
La technique du B&B est une méthode algorithmique classique exacte pour résoudreun problème d’optimisation combinatoire. Il s’agit,de rechercher une solution optimale,dans un ensemble combinatoire de solutions possibles. La méthode repose d’abord, sur laséparation, (Branch) ,de l’ensemble des solutions, en sous-ensembles plus petits. L’explo-ration de ces solutions utilise ensuite ,une évaluation optimiste pour majorer (Bound) lessous-ensembles, ce qui permet de ne plus considérer ,que ceux susceptibles ,de contenir unesolution, potentiellement meilleure, que la solution courante. [30]
3.2.1 Principe de fonctionnement : Opérateurs d’un algorithmeB & B
L’énumération des solutions du problème, consiste à construire un arbre Branch&Bound, dont les nœuds, sont des sous-ensembles de solutions du problème, et les branchessont les nouvelles contraintes à respecter. La taille de l’arbre dépend de la stratégie utilisée
31

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
pour le construire . Pour appliquer la méthode de Branch & Bound, nous devons être enpossession :
1. D’un moyen de calcul d’une borne inférieure d’une une solution partielle.2. D’une stratégie de subdiviser l’espace de recherche pour créer des espaces de re-
cherche de plus en plus petits.3. D’un moyen de calcul d’une borne supérieure pour au moins une solution.
La méthode commence par considérer le problème de départ avec son ensemble de solutions,appelé la racine. Des procédures de bornes inférieures et supérieures sont appliquées à laracine.Si ces deux bornes sont égales, alors une solution optimale est trouvée, et on arrête là.Sinon, l’ensemble des solutions est divisée en deux ou plusieurs sous-problèmes, devenantainsi des fils de la racine. La méthode est ensuite appliquée récursivement à ces sous-problèmes,engendrant ainsi une arborescence. Si une solution optimale est trouvée pourune sous-problème,elle est réalisable, mais pas nécessairement optimale, pour le problèmedépart. Comme elle est réalisable, elle peut être utilisée pour éliminer toute sa descendance :si la borne inférieure d’un nœud dépasse la valeur d’une solution déjà connue, alors on peutaffirmer que la solution optimale globale ne peut être contenue dans le sous-ensemble desolutions représenté par ce nœud. La recherche continue jusqu’à ce que tous les nœuds sontsoit explorés ou éliminés.Les étapes de fonctionnement de la méthode Branch & Boundsont la séparation (Branch),évaluation (Bound), élagage et la sélection.
3.2.2 Séparation (Branch)La séparation consiste à diviser le problème en sous-problèmes. Ainsi, en résolvant
tous les sous-problèmes et en gardant la meilleure solution trouvée, on est assuré d’avoirrésolu le problème initial. Cela revient à construire un arbre permettant d’énumérer toutesles solutions.L’ensemble de nœuds de l’arbre qu’il reste encore à parcourir comme étantsusceptibles de contenir une solution optimale, c’est-à-dire encore à diviser, est appeléensemble des nœuds actifs [31].
3.2.3 Évaluation (Bound)La fonction d’évaluation est spécifique à chaque problème. Elle est dite optimiste car
le coût renvoyé par cette fonction est le coût minimal que peut avoir une solution partielleassociée à ce nœud. La valeur associée à un nœud en utilisant cette fonction s’appelle laborne inférieure (Lower Bound). La borne supérieure (Upper Bound) représente le coûtde la meilleure solution trouvée actuellement. La fonction consiste à évaluer les solutionsd’un sous-ensemble de façon optimiste, c’est-à-dire en majorant la valeur de la meilleuresolution de ce sous-ensemble. L’algorithme propose de parcourir l’arborescence des solutionspossibles en évaluant chaque sous-ensemble de solutions de façon optimiste. Lors de ceparcours, il maintient la valeur M de la meilleure solution trouvée jusqu’à présent. Quandl’évaluation d’un sous-ensemble donne une valeur plus faible que M, il est inutile d’explorerplus loin ce sous-ensemble [30].
32

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
3.2.4 ÉlagageUne fois que la valeur d’un nœud interne est calculée (la borne inférieure d’un nœud),
on peut utiliser cette valeur pour interrompre éventuellement l’exploration de cette partiede l’arbre. En particulier, il est inutile de diviser le nœud dans les cas suivants :
1. L’évaluation a permis de calculer une solution qui a exactement cette valeur. Cettesolution est nécessairement optimale dans ce sous-ensemble de solutions. Si cettesolution est la meilleure trouvée jusque là, elle devient la meilleure solution courante.Ce cas est plutôt rare.
2. L’évaluation est supérieure ou égale à la valeur de la meilleure solution (bornesupérieure actuelle) trouvée jusque là. On n’a donc aucune chance de trouver mieuxdans ce sous-ensemble. Ceci peut permettre des gains importants, car on élimineune partie de l’arbre de recherche.
3. Le sous-ensemble est réduit à un seul élément.Dans les cas 1 et 2, on gagne dans l’exploration de l’arbre puisque la branche suivant lenœud considéré ne sera pas explorée. On dit que cette branche est élaguée (pruning enanglais). A noter que dans le cas 1, si la meilleure solution courante a changé, il convientde parcourir tous les nœuds actifs pour voir s’ils le restent [30].
3.2.5 SélectionLa sélection est une stratégie de recherche utilisée pour sélectionner l’ordre dont lequel
les sous problèmes seront traités. On peut distinguer pendant le déroulement de l’algo-rithme trois types de nœuds dans l’arbre de recherche : le nœud courant qui est le nœuden cours d’évaluation,les nœuds actifs qui sont dans la liste des nœuds qui doivent êtretraités, et les nœuds inactifs qui ont été élagués [32].
Figure 3.1: Structure général d’un arbre de recherche Branch&Bound [32].
33

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
3.2.6 Algorithme Branch & BoundL’algorithme maintient la valeur M de la meilleure solution trouvée jusqu’à présent et
la liste NA des nœuds actifs, susceptibles de contenir de meilleures solutions que M [30].
Algorithm 1 Branch & Bound1: NA ← { racine de l’arbre des solutions } ;2: while NA 6= ∅ do3: Prendre un nœud actif " n " dans NA ;4: Diviser " n " ;5: for Pour chaque fils "f" de "n" do6: Évaluer f et en fonction du résultat, mettre à jour M et ;7: Transformer "f" en nœud actif (le mettre dans NA) ou l’élaguer ;8: end for9: end while
3.3 Stratégie de parcoursEn fonction de la structure de données utilisée pour la liste des nœuds actifs NA,
l’algorithme peut avoir des performances expérimentales très différentes. La façon donton parcourt l’arbre des solutions et donc le choix du prochain nœud actif à diviser sontcruciaux. Plusieurs stratégies sont à envisager. Étant donnée une arborescence en cours deconstruction, il faut choisir le prochain nœud à séparer et une des décisions de séparation quipeuvent lui être appliquées. L’important dans une méthode arborescente est de bien choisirles règles de séparation et d’évaluation. La stratégie d’exploration est plutôt considéréecomme un détail d’implémentation.
3.3.1 En largeurElle permet de visiter les nœuds suivant l’ordre de leur création. Néanmoins, cette mé-
thode représente beaucoup d’inconvénients, parmi eux [32] :l Le temps mis pour arriver aux premières solutions est relativement long, car les solutionsse trouvent dans les feuilles.l Le nombre exponentiel de nœuds actifs.
34
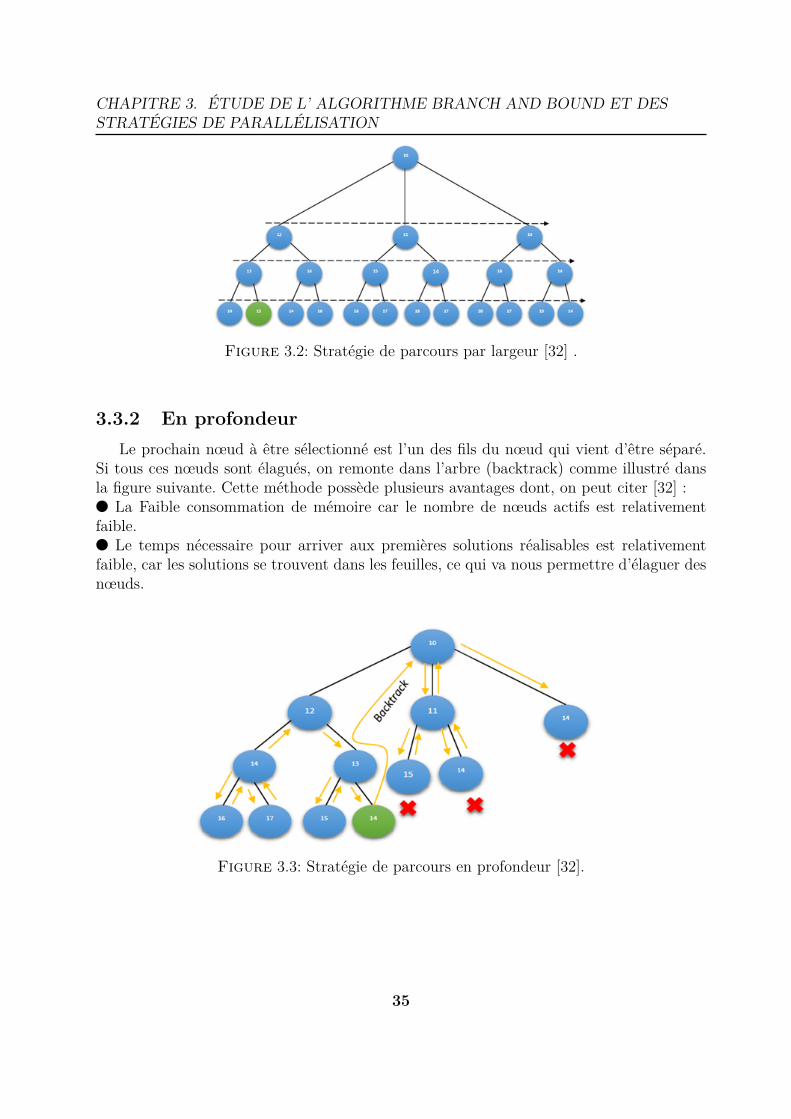
CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
Figure 3.2: Stratégie de parcours par largeur [32] .
3.3.2 En profondeurLe prochain nœud à être sélectionné est l’un des fils du nœud qui vient d’être séparé.
Si tous ces nœuds sont élagués, on remonte dans l’arbre (backtrack) comme illustré dansla figure suivante. Cette méthode possède plusieurs avantages dont, on peut citer [32] :l La Faible consommation de mémoire car le nombre de nœuds actifs est relativementfaible.l Le temps nécessaire pour arriver aux premières solutions réalisables est relativementfaible, car les solutions se trouvent dans les feuilles, ce qui va nous permettre d’élaguer desnœuds.
Figure 3.3: Stratégie de parcours en profondeur [32].
35

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
3.3.3 Meilleur évaluationLa stratégie consiste à explorer des sous problèmes possédant la meilleure borne. Elle
permet aussi d’éviter l’exploration de tous les sous-problèmes qui possèdent une mauvaiseévaluation par rapport à la valeur optimale [31].
Figure 3.4: Stratégie de parcours par meilleur évaluation [32].
3.3.4 Plus prioritaireLa priorité d’un nœud peut être évaluée par la pondération entre son évaluation et sa
profondeur dans l’arbre. En effet il est souvent plus avantageux de diviser un nœud avecune moins bonne évaluation mais qui possède une plus grande profondeur [30].
3.3.5 Stratégie mixteOn va en profondeur tant qu’on le peut, mais quand on ne peut plus on saute au nœud
de meilleure évaluation. On explorera les fils dans l’ordre d’évaluation : le meilleur d’abord[30].
3.4 Algorithmes B&B parallèlesNous avons vu plus haut que les méthodes Branch & Bound étaient des méthodes effi-
caces et attrayantes pour la résolution exacte des problèmes d’optimisation combinatoires(POC) par exploration d’un espace de recherche arborescent. Néanmoins ces méthodes at-teignent leurs limites dès que l’instance du problème s’agrandit , en effet, ces algorithmessont très gourmands en temps de calcul pour des instances de problèmes de grande taille.D’où l’émergence de la parallélisation de ces méthodes a commencé à attirer de l’intérêt,ces dernières années, pour traiter efficacement de telles instances.Le défi est alors, d’utilisertous les niveaux de parallélisme sous-jacents et donc, de repenser les modèles parallèles desalgorithmes B&B.
36

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
Dans cette section, nous allons donner une vue générale sur les algorithmes B&B parallèles, leurs paramètres ainsi que les stratégies de parallélisations et les différentes classifications, aussi décrire les critères utilisés pour mesurer la qualité de ces derniers et les différentesanomalies qui peuvent survenir.
3.4.1 Notion sur les Algorithmes B&B parallèlesLa parallélisation de l’algorithme séquentiel de Branch-and-Bound nécessite en outre
la subdivision de l’espace de recherche en sous-espaces disjointes. Dans ce qui suit, nousallons présenter un ensemble de notions utilisées dans un algorithme B&B parallèle.
3.4.1.1 Workpool
C’est un espace mémoire où les processus sélectionnent et stockent leurs unités de travail"tâches" afin de les traitées , et un processus peut également sélectionné indépendammentses tâches de différents workpools. Il est géré par un processus maître qui contrôle la dis-tribution des tâches aux processus esclaves.Du moment que le workpool est partagé parplusieurs processus, l’accès doit être synchronisé afin d’éviter les conflits. On peut distin-guer deux types d’algorithmes :© Algorithme à pool unique (Single pool) : Dans les algorithmes à pool unique, lesunités de travail sont sauvegardées dans une seule mémoire.Ces algorithmes sont généra-lement implémentés sur des machines à mémoire partagées aussi que sur des machines àmémoire distribuées en utilisant le paradigme « maître/esclave ». Dans ce paradigme leworkpool est géré par le processus maître qui affecte les unités de travail aux autres pro-cessus appelés esclaves. A la fin de leurs traitements , ces derniers renvoient les résultatsau processus maître.© Algorithmes à pool multiple (Multiple pool) : Les algorithmes utilisant des work-pools multiples peuvent être divisés en trois classes : collégiale, groupée et mixte. Dansla première, chaque processus possède son propre workpool. Dans la seconde, les processussont partitionnés en sous-ensembles et à chaque sous ensemble est associé un workpool. Etenfin, la dernière où chaque processus possède son propre workpool, ainsi qu’un workpoolglobal qui est partagé par tous les processus [32].
3.4.1.2 Base des connaissances d’un algorithme Branch & Bound parallèle
Durant l’exécution de chaque instance du problème traité, des connaissances sont gé-nérées et collectées. Ces connaissances sont constituées de tous les sous problèmes générés,séparés et éliminés, les bornes inférieures et supérieures et l’ensemble des solutions réali-sables. C’est à base de ces connaissances, que les décisions sur les prochaines opérations àeffectuer sont prises (sélection du prochain sous problème à séparer,..).
37

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
3.5 Paramètres des algorithmes B&B parallèlePour de meilleures performances, le travail doit être reparti équitablement sur l’en-
semble des processus. Cependant dans un algorithme Branch & Bound il est impossibled’avoir une estimation du travail à exécuter dès le début , donc la division du travail doitêtre de manière dynamique.Dans ce qui suit nous allons détailler ces paramètres.
3.5.1 Division du travailAfin de répartir le travail sur l’ensemble des processus, on définit certaines unités de
travail ainsi qu’un mécanisme permettant d’affecter ces unités aux différents processus,cesunités peuvent être : une séparation d’un sous problème, recherche de la meilleure solutiond’un sous problème, ou le calcul de la borne inférieure. La division du travail est réaliséeen utilisant des workpools auxquels les processus ajoutent les nouveaux travaux crées. Età chaque fois qu’un processus est inactif, il obtient un travail dans un des workpools.
3.5.2 InteractionL’échange des connaissances générées et les mesures à prendre à l’arrivée de nou-
velles sont deux aspects d’interactions dans lesquelles les connaissances sont exploitables.D’abord, lors de la prise de décision afin d’obtenir les connaissances nécessaires pour fondercette décision et deuxièmement, quand les nouvelles connaissances générées par un autreprocédé devient disponible, les processus doivent être en mesure de détecter les mises àjour correspondantes.La stratégie de réaction spécifie comment un processus prend et réagià la mise à jour d’une base de connaissances. Il existe deux manières de base dans lequelun processus peut devenir conscient d’une mise à jour : par interrogation de la base deconnaissances ou par interruption à chaque fois que la base de connaissances est mise àjour.
3.5.3 SynchronisationLorsqu’un processus achève le traitement d’une tâche, deux possibilités se présentent :
commencer immédiatement le traitement d’une nouvelle tâche, ou attendre que tous lesautres processus terminent leurs tâches. La synchronisation permet de faciliter la distri-bution des tâches sur les différents processus.Cependant elle a tendance à augmenter lacomplexité de la communication car les processus doivent savoir si les autres processusont terminé leurs tâches ou non. Par contre, si les processus ne sont pas synchronisés, ladivision du travail sur les processus et l’échange des connaissances générées introduit unnon déterminisme dans l’algorithme si l’ordre de traitement des pools de travail (inser-tion, extraction, élimination) diffère d’un processus à un autre, ou si un processus signaletardivement la découverte d’une nouvelle borne supérieure, et donc deux exécutions consé-cutives d’un même algorithme peuvent être complètement différentes [32, 33].
38

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
3.6 Classification des algorithmes B&B parallèlesLes algorithmes Branch& Bound parallèle sont classés généralement selon leur source
de parallélisation (de contrôle ou de données). Dans la littérature, La parallélisation deB&B est bien étudiée de nombreuses classifications ont été menées parmi elles celle deMELAB. La plus récente , en 2005, est présentée ci-dessous :
3.6.1 Classification de MelabCette taxonomie est basée sur la classification de Gendron et Al, quatre modèles d’al-
gorithmes parallèles B&B sont identifiés :
3.6.1.1 Modèle multiparamétrique parallèle
Ce modèle consiste à considérer simultanément plusieurs processus B&B qui diffèrentpar un ou plusieurs opérateurs (séparation - évaluation -élagage - sélection), ou avoir lesmêmes opérateurs paramétrés distinctement.Le principal avantage du modèle multiparamé-trique est sa généricité permettant son utilisation transparente pour l’utilisateur. Toutefois,elle pourrait conduire à une exploration redondante de certains sous-problèmes qui ralen-tissent le temps d’exploration nécessaire pour parcourir l’arbre de recherche B&B.Enfin, ledegré de parallélisation créé par cette stratégie n’est pas exploitable sur les environnementshautement parallèles sauf s’il est combiné avec d’autres.
Figure 3.5: Illustre le modèle multiparamètrique parallèle [3].
3.6.1.2 Le modèle parallèle de l’exploration de l’arbre
Ce modèle consiste à lancer plusieurs processus de B&B à explorer simultanément deschemins différents (sous-arbres) du même arbre. Les différentes opérations sélection, sépa-ration, élagage sont exécutées en parallèle, soit dans un mode synchrone ou asynchrone. Enmode synchrone, les processus B&B ont besoin d’échanger des informations globales qui
39

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
permettent d’accélérer le parcours de l’arbre comme la meilleure solution courante. Dansun mode asynchrone, les processus B&B communiquent de manière imprévisible.Comparéeaux autres modèles,le degré de parallélisme de ce modèle est effectivement très élevé, princi-palement, pour les grands problèmes qui justifient comme sur des architectures multicœur.Toutefois, cette stratégie de parallélisation , mène à des unités de travail imprévisible etdéséquilibrée , qui suscitent plusieurs défis sur le dessus des données-plates-formes parallèlestels que processeurs graphiques.
Figure 3.6: illustre le modèle parallèle de l’exploration de l’arbre [3].
3.6.1.3 L’évaluation parallèle des limites
L’évaluation parallèle des limites consiste à lancer un seul processus B&B pendantqu’une évaluation parallèle des sous-problèmes générés par l’opérateur de séparation esteffectuée illustré par la figure ci-dessus. Ce modèle utilise le parallélisme de données, princi-palement asynchrone et calcul le coût de l’évaluation de la limite. Cependant, cette parallé-lisation de l’évaluation n’est portable, que si l’opération d’évaluation des limites consommeénormément de temps, principalement ,sur les architectures à forte proportion d’opérationsarithmétiques.
40

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
Figure 3.7: Illustre le d’évaluation parallèle des limites [3].
3.6.1.4 Évaluation parallèle d’une seule limite / Solution
L’évaluation parallèle d’une seule limite / solution est similaire à la précédente (évalua-tion parallèle des limites) où un seul processus est utilisé. Dans ce modèle, un ensemble deprocessus évalue en parallèle la fonction limite / objectif d’un seul nœud. Il nécessite la dé-finition de nouveaux éléments spécifiques pour le problème en cours de traitement, commela fonction objectif partielle et la méthode pour consolider ces résultats partiels. Commela mise en œuvre de ce modèle est naturellement synchrone, il est essentiel de mémorisertoutes les valeurs d’évaluation partielles pour les solutions en cours d’évaluation [3, 34, 35,36].
3.7 Mesures de performance pour les algorithmes B&Bparallèles
Le succès de la parallélisation de l’algorithme B&B peut être mesuré par :
3.7.1 Qualité de la solutionCette mesure est utilisée ,par exemple, pour comparer la meilleure solution trouvée
dans un B & B parallèle, à celle d’un algorithme séquentiel ,pour vérifier si le parallélismeaméliore la qualité de la solution.
3.7.2 Nombre de sous problèmeIl existe deux variantes pour cette mesure, la première variante se base sur le nombre
total des sous problèmes générés, et la seconde ,sur le nombre de sous problèmes générésavant que la meilleure solution ne soit trouvée. La première mesure peut être utilisée dans
41

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
tous les types d’algorithmes, mais ne fournit pas une bonne estimation sur la quantité dutravail effectuée, et ne prends pas en compte le travail supplémentaire du au parallélisme,la seconde introduit la notion du timing et peut être difficile à estimer.
3.7.3 Accélération / efficacitéL’accélération mesure l’amélioration du temps d’exécution de l’algorithme dans le cas
d’utilisation de plusieurs processeurs définis comme suit : S(p) = T (1)T (p) , E(p) = S(p)
Ptel
que : T(p) le temps requis pour résoudre un problème donné en utilisant p>1 processeurs.Pour évaluer l’accélération d’un algorithme, il est nécessaire d’utiliser un algorithme sé-quentiel optimal et respecter la même architecture pour les deux types d’algorithmes i.e.(utilisation des mêmes règles de séparation, d’évaluation, d’élimination)[32, 37].
3.8 Complexité d’un algorithme B&B parallèleL’exécution d’un algorithme parallèle demande la mise à disposition d’un certain nombre
de ressources (nombre de processeurs, espace mémoire,...). Le but de l’analyse de la com-plexité est de mesurer les différentes ressources nécessaires. Pour le parallélisme, les mesuresde complexité sont différentes suivant le modèle parallèle choisi.Les mesures de complexitésdes algorithmes parallèles sont donc ,la complexité en temps, la complexité en communi-cation et la complexité en espace mémoire.Ces évaluations nous permettent de juger de laqualité de l’algorithme.
3.8.1 Complexité en temps de calculLe temps est souvent le premier critère considéré pour évaluer les performances d’un
algorithme parallèle. La définition suivante, qui exprime le temps d’exécution, suppose quecette mesure est effectuée par un observateur extérieur au système. Le temps d’exécutionparallèle est déterminé par le nombre de cycles d’horloge décomptés du début de l’appli-cation à sa terminaison. La complexité en temps d’une application parallèle est égale autemps d’exécution maximale de l’algorithme pour une exécution quelconque [3].
3.8.2 Complexité de mémoireEn algorithmique, la conception d’ un algorithme qui utilise de grandes structures de
données, implique une grande complexité en mémoire surtout pour les problèmes com-plexes. Un compromis entre la taille des structures de données et la complexité en calcul(temps) est nécessaire pour concevoir des algorithmes optimaux [38].
42

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
3.8.3 Complexité de communicationQuand les communications sont explicites, il est possible de définir une complexité en
communication. La définition suivante peut être proposée : « La complexité en commu-nication d’une application parallèle est égale au nombre maximal de messages échangés(ou le nombre maximal d’octets échangés) par les processeurs au cours d’une exécutionquelconque de l’algorithme ». La complexité en communication est fondamentale dans lecas de l’algorithmique distribuée, car ce sont les communications qui déterminent les per-formances de l’application parallèle implique minorer le nombre de communications. Il estparfois utile de dupliquer le calcul d’une valeur sur une partie des processeurs plutôt qued’attendre qu’un processeur diffuse ce résultat [3].
3.9 Approche de déploiement d’un algorithme B&Bparallèle
3.9.1 Optimisation de communicationLes délais de communication sont l’une des sources majeures de perte d’efficacité dans
toute approche parallèle du B& B.La réduction de la taille des messages échangés est doncune des solutions qui améliore l’efficacité parallèle d’un B& B. Les messages communiquésdans un B& B parallèle sont constitués en grande partie de sous problèmes [39].
3.9.2 Tolérance aux pannesDans un algorithme B& B, les sous problèmes en cours de traitement représentent en
grande partie l’état global d’une résolution. En les sauvegardant, il est toujours possible deréinitialiser une résolution en cas de panne et de la relancer à partir de son dernier pointde sauvegarde. Réduire la taille de ces sous problèmes permet d’améliorer une stratégie detolérance aux pannes [39].
3.9.3 Passage à l’échelleLa plupart des algorithmes d’aujourd’hui visent à exploiter des milliers de ressources
informatiques,toutefois la majorité des interfaces parallèles B&B sont basées sur le maître-travailleur paradigme , ainsi des milliers de travailleurs desservis par un seul maître. Ilexiste trois façons d’accroître l’efficacité de ces algorithmes :ä Diminuer le taux de fréquence de demande de tâche en augmentant la granularité ducalcul.ä Alléger le processus maître en attribuant au travailleur des opérations telles que laséparation, l’équilibrage de charge, et une communication directe entre les travailleurs àatteindre un travail de collaboration.
43

CHAPITRE 3. ÉTUDE DE L’ ALGORITHME BRANCH AND BOUND ET DESSTRATÉGIES DE PARALLÉLISATION
ä Développer la décentralisation ou hiérarchique, B&Bs où plusieurs maîtres sont envisagésau lieu d’un unique [40].
3.10 ConclusionL’optimisation combinatoire consiste à trouver une solution parmi un grand nombre
fini de solutions, elle se situe au carrefour de la théorie des graphes, de la programmationmathématique, informatique théorique et de la recherche opérationnelle dont la méthodeexacte est un axe principal de recherche de solutions. Parmi les algorithmes exacts ontrouve l’algorithme séparation et évaluation (Branch and Bound) et qui consiste à énumé-rer implicitement toutes les solutions d’un problème en énumérant ces sous-ensembles etcela en construisant un arbre dont les nœuds sont les sous-problèmes.
Dans ce chapitre nous avons présenté dans une première partie des notions sur lesalgorithmes B&B, le principe de fonctionnement et les stratégies de parcours de l’arbre derecherche, ensuite les algorithmes B&B parallèles , les méthodes de leurs conceptions, et lesstratégies de parallélisation ainsi que comment mesurer les performances de ces algorithmeset enfin nous avons invoqué les facteurs de complexité et l’approche de déploiement . Cesdifférentes notions seront utiles pendant le reste de notre étude concernant Parallélisationd’algorithmes de graphes un cluster d’ordinateurs.
44

Chapitre
4Conception d’un algorithmeBranch and Bound parallèle basésur MapReduce

CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
4.1 IntroductionL’utilisation des méthodes exactes dans la recherche de solutions optimales pour des
problèmes d’optimisation combinatoire est une opération assez lourde, l’exécution de cetteopération sur une seule machine est très contraignant car il faut parfois des heures voirquelques jours pour avoir un résultat.le problème devient plus accru lorsque le volume de l’espace de recherche et les données ensortie est important, d’où le choix de faire appel aux mécanismes de calcul distribués poureffectuer de telles opérations. Cela permet de réduire de façon considérable le temps et laquantité d’efforts nécessaires.Par ailleurs, l’apparition de nouveaux paradigmes liées auxtraitements de grandes masses de données (MapReduce, Hadoop et autres technologies duCloud et Big Data ) très populaire dans le Web, ouvre une nouvelle perspective pour leursutilisation pour les applications du calcul intensif. De ce fait nous avons choisi de combinerles attraits du modèle MapReduce et le framwork Hadoop dans la résolution de problèmesd’optimisation combinatoire.
Dans ce chapitre, nous proposons la conception d’un algorithme B&B parallèle basésur le paradigme MapReduce en utilisant le framework Hadoop. On va d’abord présen-ter le problème de l’optimisation combinatoire (le Flow-Shop de permutations) qu’on vatraiter avec une méthode exacte puis nous exposerons les détails de la conception sous laméthodologie du modèle MapReduce.
4.2 Le problème Flow-Shop de permutationLe Flow-Shop de permutation est un problème d’ordonnancement d’atelier dans lequel
on a " n " jobs (tâches) J1, J2, J3, J4, J5, ..., Jn, qui vont s’exécuter successivement sur " m" machines m1,m2,m3, ...,mm.L’ordre de passage des jobs est identique passer de la machine " 1 " à la machine " m", et chaque machine ne peut exécuter qu’une seule tache à la fois, la prochaine qui veuts’exécuter sur la même machine attend la fin de l’exécution de la tache actuelle en coursd’exécution. Chaque job prend un temps d’exécution sur la machine m qui est différent surles autres machines et des autres jobs, on le représente par Pi,j , "P" le temps d’exécutionde la tâche "i" sur la machine "j" tel que : ( 1<= i < n et 1<= j <= m ) [41].Le problème FSP a pour objectif de trouver la séquence d’ordonnancement "S" qui mini-mise le temps d’exécution (Makespan) de tous les jobs.Un ordre de production est défini par l’ordre des machines. Puisqu’il a n! permutations pos-sible par machine, le nombre total de séquences possibles est n !*m , mais comme l’ordrede passage de job sur les machines est fixe, alors le nombre de séquence possibles est n!.La figure suivante illustre un atelier de type Flow shop pour" n" jobs utilisant "m "machines.
45
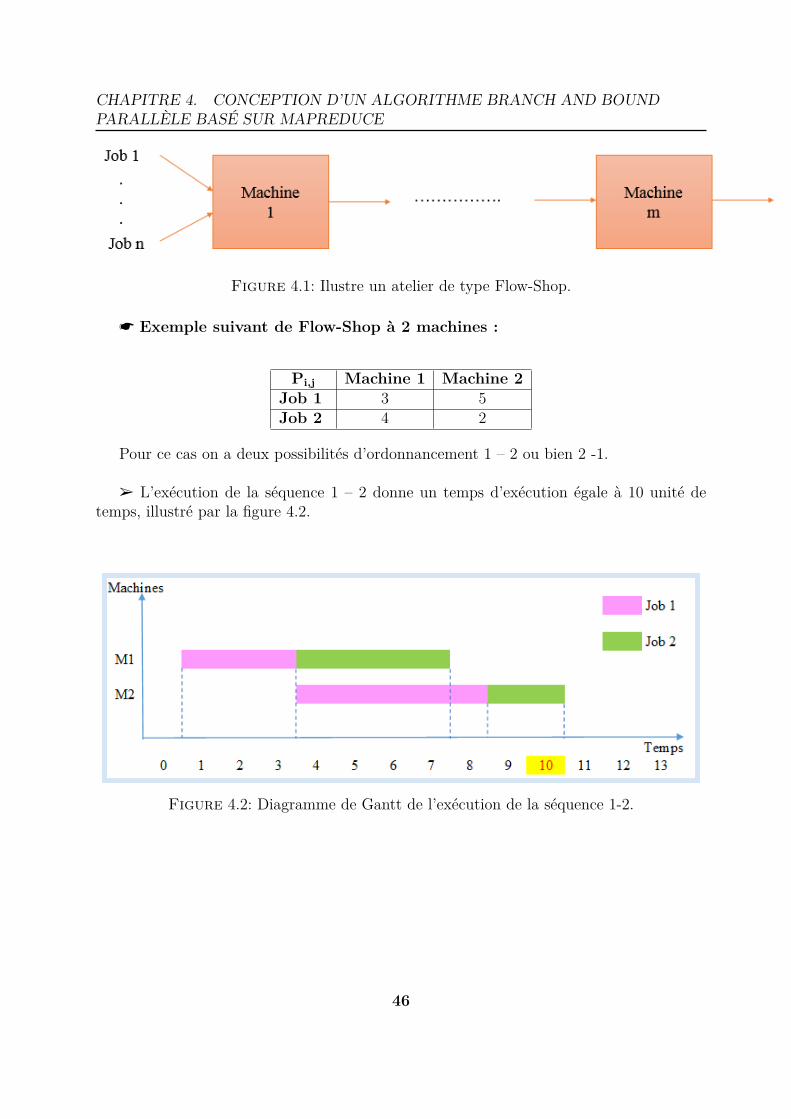
CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
Figure 4.1: Ilustre un atelier de type Flow-Shop.
* Exemple suivant de Flow-Shop à 2 machines :
Pi,j Machine 1 Machine 2Job 1 3 5Job 2 4 2
Pour ce cas on a deux possibilités d’ordonnancement 1 – 2 ou bien 2 -1.
â L’exécution de la séquence 1 – 2 donne un temps d’exécution égale à 10 unité detemps, illustré par la figure 4.2.
Figure 4.2: Diagramme de Gantt de l’exécution de la séquence 1-2.
46

CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
â L’exécution de la séquence 2 – 1 donne un temps d’exécution égale à 12 unité detemps, illustré par la figure 4.3.
Figure 4.3: Diagramme de Gantt de l’exécution de la séquence 1-2.
Donc l’ordonnancement optimal dans le temps est la séquence j 1 – j 2 .
4.2.1 Résolution du Flow-Shop de permutationRésoudre le problème de Flow-Shop consiste à satisfaire certains critères donnés. Ces
critères varient selon la spécificité du problème traité et consistent généralement en laminimisation de l’un des paramètres suivants :/ Cmax : date de fin de l’ordonnancement./ C : flot moyen./ Tmax : maximum des retards./ T : somme des retards./ U : nombre de Jobs en retard.Dans notre travail, nous nous intéressons à la minimisation du temps d’accomplissementdu dernier job sur la dernière machine "Makespan" noté Cmax.
4.2.1.1 Makespan
En recherche opérationnelle, le Makespan correspond au temps total qui s’est écoulédepuis le début d’un projet donné à son extrémité. Le terme communément utilisé appa-raît dans le contexte de la planification. Il s’agit d’un projet complexe qui est composé deplusieurs sous-tâches. Nous tenons à attribuer des tâches aux travailleurs, tel que le projetse termine dans les plus brefs délais [42].Le makespan et le temps exact de l’exécution d’une séquence de problème Flow Shop notépar C.
* Exemple de calcul de Makespan :On considère le problème suivant :
47

CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
J/M P1,j P2,j P3,j1 4 2 12 3 6 23 7 2 24 1 5 8
On a 3 machine et 4 job, on considère l’ordre suivant (1,2,3,4)
J/M C1,j C2,j C3,j1 4 4 + 2 = 6 6 + 1 = 72 4 + 3 = 7 Max(6, 7) + 6 = 13 Max(7, 13) + 2 = 153 7 + 7 = 14 Max(14, 13) + 2 = 16 Max(15, 16) + 3 = 194 14 + 1 = 15 Max(15, 16) + 5 = 21 Max(21 + 19) + 8 = 29
Le Makespan de cette séquence (ordre) (1,2,3,4) est 29.
Ci,j : représente le coût (le temps d’exécution) de la tâche " i " sur la machine " j "suivant un ordre préétabli (une séquence).
Ci,j = Max (Ci,j-1,Ci-1,j)+ Pi,j
Le Makespan de la séquence se trouve à la dernière case du tableau C(3,4) qui est letemps de fin d’exécution de la tâche 4 sur la machine 3. Pour un Flow-Shop de taille n ∗mle Makespan se trouve à la case C(n ,m) .
4.2.2 Approche du Flow-Shop avec méthode exacteLe problème de Flow-Shop est connu pour être fortement NP difficile , les méthodes
exactes sont limitées aux petites instances en raison de la durée d’exécution. Néanmoins,l’importance des solutions exactes étant essentielles pour certains domaines industriels,l’utilisation des approches de calcul distribués permet de résoudre les plus grandes instancesde problèmes en des temps plus raisonnables.
4.2.2.1 Résolution du Flow-Shop de permutation avec l’algorithme B&B
Pour un problème de Flow-Shop de " n " job et " m "machines on a appliqué la méthodeB&B pour trouver la solution optimale du problème. Le principe general de cet algorithmea été precedement décrit dans le chapitre précédant. Pour le cas du Flow-Shop, le nombrede sous problèmes ou noeuds issues de la decomposition (séparation) d’un sous problèmeparent dans l’arbre de recherche est égale au nombre de jobs non encore ordonnancés. Laprofondeur d’un nœud d’un arbre B&B représente le nombre de jobs déjà ordonnancés.L’arbre de la recherche reste indépendant du nombre de machines. La figure 4.4 représenteune représentation d’un problème de Flow-Shop de permutation de trois tâches et troismachines dans l’arbre B&B.
48

CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
Figure 4.4: Représentation du problème de Flow-Shop dans l’arbre de recherche Branch& Bound.
Dans ce qui suit, nous allons détailler les différents composants de l’algorithme B&Bpour le cas du Flow-Shop de permutation, a savoir la borne inférieure, les strategies deparcours de l’arbre et la méthode de calcul de l’evaluation des solutions (ici le Makespan).
4.2.2.2 La borne inférieure
Dans un algorithme Branch& Bound, la borne inférieure d’un sous problème représentele coût minimal qu’une solution issue de ce sous problème. Dans un problème de Flow-Shop, la borne inférieure d’un ordonnancement partiel donné indique qu’il ne peut existerun ordonnancement complet issu ce cet ordonnancement qui peut posséder, un Makespaninférieure à cette borne.Avant de présenter la borne inférieure que nous avons utilisé pour notre algorithme [43,44], nous allons commencer par présenter les théorèmes sur lesquelles cette borne est basée(Algorithme et Théorème de Johnson).
X Algorithme de Johnson :
Algorithme qui permet d’avoir une solution optimale pour un problème flow shop àdeux machines, m=2 en utilisant la règle transitive � [43, 44]
Ji � Jj ⇐⇒Min(pi,1,pj,2) �Min(pi,2,pj,1 )On rappelle que pk ,l désigne le temps d’exécution du job k sur la machine m, à partir dela règle ci-dessus suivant le théorème de Johnson exposé ci-dessous :
49

CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
X Théorème de Johnson :
Étant donnée P un problème Flow-Shop avec m =2, P est résolue avec une complexitétemporelle de O(nlog(n)) (algorithme polynomial). La solution optimale est obtenue enpremier, en triant dans un ordre croissant les jobs ayant un temps de traitement plus courtsur la première machine que la deuxième, et puis un tri d’ordre décroissant des jobs ayantun temps de traitement plus court sur la deuxième machine [43, 44].La règle de Johnson est étendue par Jackson et Mitten avec des décalages (Lags) qui apermis à " Lenstra et Al " de proposer une borne inférieure pour Flow-Shop de permuta-tion avec m � 3. Un décalage Lj désigne la durée minimale entre le temps de début de jobJj dans la deuxième machine et son temps de finition sur la première machine. Jackson etMitten ont démonté que la solution optimale d’un problème Flow-Shop de permutationavec m=2 peut être obtenue en utilisant la règle transitive � [43, 44]
Ji � Jj ⇐⇒Min(pi,1 + li,lj+pj,2) �Min(li + pi,2,pj,1+lj)
On se basant sur cette règle " Lenstra et Al " ont proposé la borne inférieure suivantepour le sous problème associée à un ordonnancement partiel ou un ensemble de job "J"doit être ordonnancé sur "m" machines. P * jα(J,Mk,Ml) représente la solution optimalede Jackson-Mitten du sous-problème obtenu en considérant l’ensemble de jobs J et lesmachines M k et Ml. " B.J. Legwag et Al " ont ainsi obtenue la borne inférieure avecun complexité O(m2nlogn) que nous avons utilisée dans notre travail [43, 44] :
LB = Max1�k�m{P ∗ jα(J,Mk,Ml) +Min(i,j)∈j2,i 6=j(ri,k + qj,l)}
Tels que :è ri,k = ∑
l≺k pi,j qui désigne l’instant de début du job ji peut commencer son opérationsur la machine Mk.è qi,k = ∑
l�k pi,j qui désigne l’instant de début du job ji peut commencer son opérationsur la machine Mk.
X Complexité de la borne inférieure :
Il y a m ∗ m−12 couple de machines à considérer. Et chaque sous problème est calculé
en O(nlog(n)). La complexité de la borne est donc O(m2 ∗ nlog(n)). Donc le problèmeFlow-Shop devient NP-difficile au-delà de trois machines.
4.2.2.3 La borne supérieure
La borne supérieure du problème Flow-Shop représente le coût d’une solution accep-table ou optimale déjà calculée où bien estimée par les algorithmes heuristiques. On peutciter comme exemple : l’heuristique NEH.Une bonne borne supérieure permet d’élaguer plusieurs nœuds intermédiaires qui ne peuventpas mener à une solution meilleure que la borne supérieure, ce qui impliquera un temps derésolution du problème plus rapide.
50

CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
4.2.3 Résolution parallèle du Flow-Shop de permutation avecMapReduce
Dans cette section, nous allons d’abord voir comment on peut implémenter des al-gorithmes de graphes en general, avec le modèle MapReduce et on prend pour exemplel’algorithme du plus court chemin, pour ensuite décrire notre conception d’un algorithmeB&B avec MapReduce.
Les graphes sont des constructions mathématiques qui représentent une interconnexiond’ensemble d’objets. Un graphe se compose d’un certain nombre de nœuds (officiellementappelés sommets) et liens (appelée familièrement les bords) qui connectent les nœuds entreeux.
ä Exemple d’illustration de l’algorithme du plus court chemin avec MapRe-duce :
L’algorithme du plus court chemin est un problème commun en théorie des graphes, oùle but est de trouver le plus court chemin entre deux nœuds et où les bords n’ont pas unpoids, auquel cas le chemin le plus court est le chemin d’accès avec le plus petit nombrede sauts entre la source et la destination.La structure des données produites par "Map" et "Reduce" ne change pas entre les itéra-tions des algorithmes, ce qui facilite le parcours, car le format d’entrée est le même que leformat de sortie.Les deux algorithmes suivants , illustre un pseudo-code pour les deux principales fonctionsdu modèle, soit "Map" et "Reduce" , appliqué pour la recherche parallèle du plus courtchemin en largeur d’abord à l’aide de MapReduce.
Algorithm 2 Map(node-name, node)1: émettre (node-name, node) { pour préserver le nœud } ;2: if node.distance 6=∞ then3: voisins de processus si la distance actuelle a été calculée ;4: neighbor-distance ← node.distance+1 ;5: for all adjacent nodes adjnode ∈ node.adjnodes do6: Output : nœud adjacent, la distance du nœud adjacent , le backpointer chemin
d’accès ;7: émettre (adjnode.name,[neighbor-distance,node.backpointer+node.name]) ;8: end for9: end if
51

CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
Algorithm 3 Reduce(node-name, list-of-nodes)1: node.distance←∞ ;2: node.backpointer ← null ;3: for all reduce-node ∈ nodes do4: distance ← reduce-node.distance ;5: backpointer ← reduce-node.backpointer ;6: if distance < distance.node then7: distance.node ← distance ;8: backpointer.node ← backpointer ;9: end if10: end for11: émettre (node-name, node) ;
Tout d’abord, la fonction "Map" affiche les nœuds afin de préserver la structure originaledu graphe. Puis, pour tous les nœuds adjacents, affiche ces derniers avec leurs distanceset un backpointeur , si seulement la distance du nœud n’est pas infinie. Le backpointerporte l’information sur les nœuds visités à partir du nœud de démarrage, pour sauvegarderle chemin d’accès. Ensuite , la fonction "Reduce" consiste à calculer la distance minimalepour chaque nœud et comme sortie : la distance minimale, le backpointer et les nœudsadjacents originaux [45].
Après avoir donné un exemple sur la manière de modéliser un algorithme de rechercheà travers le modèle MapReduce , continuons avec la modélisation du Flow-Shop de permu-tation (FSP).
4.2.3.1 Application du modèle MapReduce sous Hadoop au FSP
Dans cette sous section nous allons présenter notre solution qui consiste à paralléliserla résolution du Flow-Shop de permutation en utilisant l’algorithme B&B avec le modèleMapReduce sous Hadoop.
La figure suivante illustre la première abstraction logique du système de fichier de Ha-doop.
52
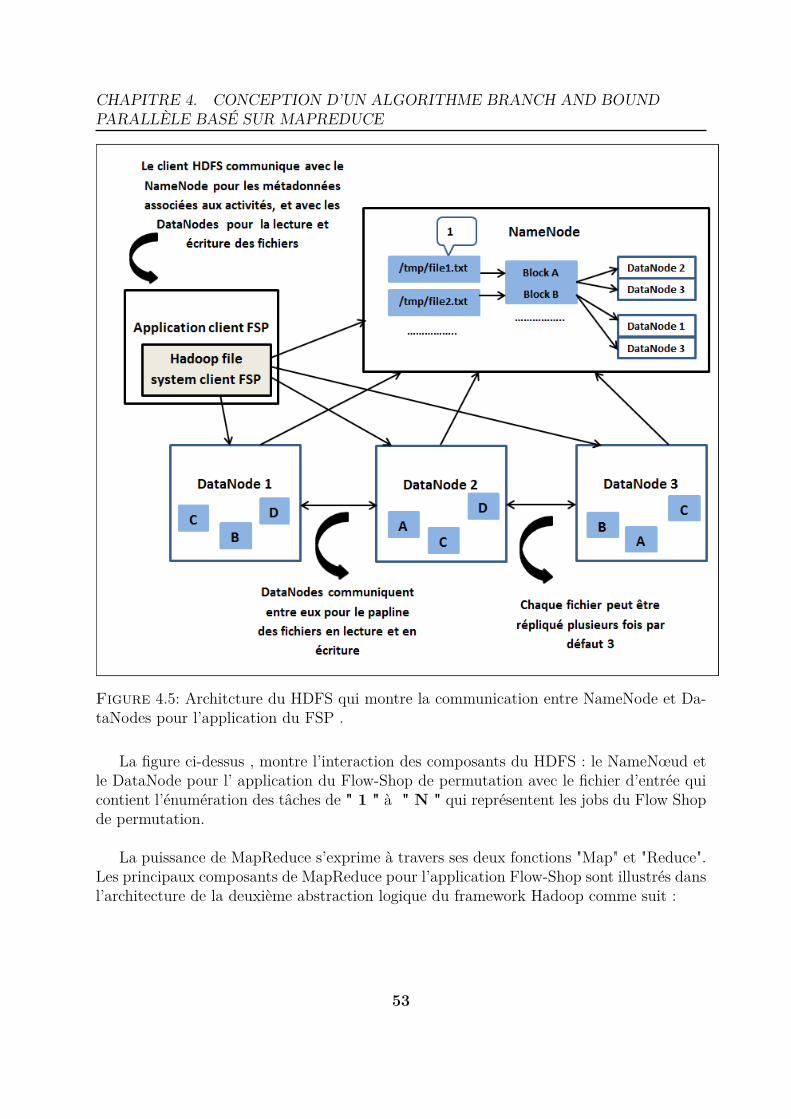
CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
Figure 4.5: Architcture du HDFS qui montre la communication entre NameNode et Da-taNodes pour l’application du FSP .
La figure ci-dessus , montre l’interaction des composants du HDFS : le NameNœud etle DataNode pour l’ application du Flow-Shop de permutation avec le fichier d’entrée quicontient l’énumération des tâches de " 1 " à " N " qui représentent les jobs du Flow Shopde permutation.
La puissance de MapReduce s’exprime à travers ses deux fonctions "Map" et "Reduce".Les principaux composants de MapReduce pour l’application Flow-Shop sont illustrés dansl’architecture de la deuxième abstraction logique du framework Hadoop comme suit :
53
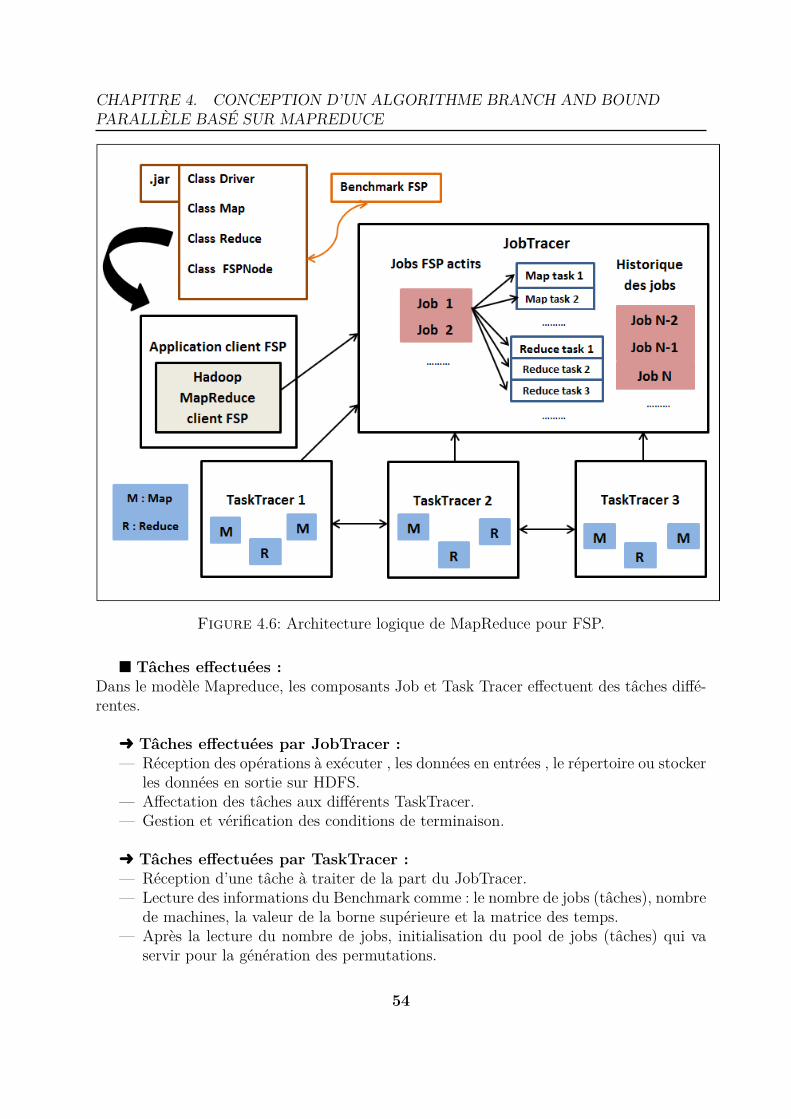
CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
Figure 4.6: Architecture logique de MapReduce pour FSP.
n Tâches effectuées :Dans le modèle Mapreduce, les composants Job et Task Tracer effectuent des tâches diffé-rentes.
Ü Tâches effectuées par JobTracer :— Réception des opérations à exécuter , les données en entrées , le répertoire ou stocker
les données en sortie sur HDFS.— Affectation des tâches aux différents TaskTracer.— Gestion et vérification des conditions de terminaison.
Ü Tâches effectuées par TaskTracer :— Réception d’une tâche à traiter de la part du JobTracer.— Lecture des informations du Benchmark comme : le nombre de jobs (tâches), nombre
de machines, la valeur de la borne supérieure et la matrice des temps.— Après la lecture du nombre de jobs, initialisation du pool de jobs (tâches) qui va
servir pour la génération des permutations.
54

CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
— Initialisation du nœud racine avec la tâche reçu.— Pour chaque job et dépendamment du nombre total de jobs (tâches) " N " du FSP
traité , la profondeur de l’arbre B&B est de N-1 , chaque profondeur représenteun niveau , on commence par générer le premier niveau correspondant à fixer ladeuxième permutation possible avec la racine comme l’ordre de la séquence et ainside suite.
— Un nœud est une liste des permutations fixées. À chaque niveau,ce dernier est évaluépour déterminer si il est intéressant de continuer l’exploration ou pas ,en comparantça borne inférieure avec la borne supérieure en appliquant la règle d’élagage.
— Arriver à la profondeur N-1, la séquence de permutation est complète, on calcule leMakespan qui correspond au coût de la solution.
— Mise à jour de la borne supérieure, si la valeur de la borne inférieure est toujoursinférieure strictement à la borne supérieure courante au niveau N-1.
— Traitement pour rechercher le minimum : la séquence qui a le Makespan le pluspetit est la solution optimale pour notre problème Flow Shop de nombre de jobs(tâches) et machines donné.
— Rendre le résultat au JobTracer.
Les deux algorithmes suivants , illustre un pseudo-code pour les deux principales fonc-tions du modèle, soit "Map" et "Reduce" ,implémentées pour la résolution du Flow Shopde permutation à l’aide de MapReduce.
Algorithm 4 Map( racine-id , racine )1: Récupérer racine =(racine-id) // la racine du sous arbre à partir des fichiers en entrée ;2: Récupère les informations du Benchmarks3: arbre = FSPNode.Set_Racine(racine) //Initialiser le sous l’arbre de recherche ;4: FSPNode.Génération_niveaux // on a N-1 niveaux a généré , Borne_inf(noeud) //
pour chaque noeud généré on calcul la borne inférieure et on applique la règle d’élagagepour le niveau suivant ;
5: FSPNode.Min(arbre) // retourne la solution optimale du sous arbre de recherche ;6: émettre (clef : la racine , valeur : la permutation correspondante à la solution optimale
, son Makesapn ) ;
Algorithm 5 Reduce( racine-id , la permutation et le Makespan)1: Récupère les clefs et valeurs //pour chaque sous arbre de l’arbre de recherche ;2: émettre ( racine-id , la permutation et le Makespan)) ;
4.2.3.2 Les Stratégies de parcours implémentés
Nous avons implémenté deux méthodes de parcours, parcours par profondeur et par-cours par largeurs.
55

CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
l Parcours par profondeur :
Nous avons implémenté une méthode de parcours par profondeur qui consiste de dé-marrer du nœud racine et l’évaluer et de s’approfondir par ses nœuds fils un par un jusqu’àarriver au nœuds feuilles. Pour l’implémentation de cette méthode de parcours nous avonsutilisé une fonction récursive qui génère tous les nœuds de chaque niveau par profondeur.Ci-dessus le Pseudo code :
Algorithm 6 Évaluation profondeur (entier racine) // 1 ère élément de la permutation(job)1: Nœud = GénéréNoeud(racine) // Génération d’un nœud du niveau 1er avec 1er job
fixé2: Borne_inf = Évaluer (Nœud) ;3: if Borne_inf <= Borne_Sup then4: Level (niveau++, Nœud) ; //Fonction qui génère les sous niveaux5: end if
Algorithm 7 Fonction level (niveau,Nœud) // avec cette fonction on génère les sousniveaux1: if niveau == nombre_job then2: MakeSpane (Nœud) ;3: else4: Nœud2 = GénèreNoeud(Niveau) ; // Génération d’un nœud du niveau intermédiaire5: Borne_inf =Evaluer (Nœud2) ;6: if Borne_Inf <=Borne_Sup then Alors7: Level (niveau++, Nœud) ; //Fonction qui génère les sous niveaux8: end if9: end if
Pour des raisons de capacité de mémoire, en pratique, on ne génère pas tous les nœudsde l’arbre à l’avance. On génère qu’un seul nœud fils de chaque niveau, quand la condi-tion de test de la borne inférieure est vérifiée, dans le but de ne pas épuiser la mémoired’exécution en cours (RAM). Dès qu’on arrive aux nœud feuilles on génère le nœud frèredu nœud parent (comme bien illustré dans la figure 3.3 de chapitre 3). Et ainsi de suitejusqu’à avoir généré toutes les permutations possibles.
l Parcours par largeur :
Cet stratégie diffère de la méthode de parcours en profondeur par le fait que, à partird’un nœud source S, il liste d’abord les fils de S pour ensuite les explorer un par un et
56

CHAPITRE 4. CONCEPTION D’UN ALGORITHME BRANCH AND BOUNDPARALLÈLE BASÉ SUR MAPREDUCE
niveau par niveau en fixant une permutation à la fois. Pour ce mode de fonctionnementon a utilisé une liste dont les éléments sont des listes (les nœuds), le premier sommet "laracine " qui correspond à la première permutation fixé , puis on fait appelle à une fonctionqui met à jour la liste en rajoutant les nœuds (fils) découlant du niveau généré, ce quirevient à explorer un nœud source, puis ses successeurs, puis les successeurs non explorésdes successeurs, etc. Ci-dessus un pseudo code de cette méthode.
Algorithm 8 Parcours par largeur : évaluation de la racine // la première permutationfixé1: liste.add(racine) ; // rajouter la racine à la liste2: Nœud = [racine] ;3: Borne_inf = Évaluer (Nœud) ;4: if Borne_inf <= Borne_Sup then5: Génération_niveaux () ; //Fonction qui génère les sous niveaux6: end if
Algorithm 9 Fonction Génération_niveaux // avec cette fonction on génère les sousniveaux1: if Taille(Nœud) == nombre_job then2: MakeSpane (Nœud) ;3: else4: Générer_niveau ; // Génération des nœuds du niveau courant5: Borne_inf = Évaluer (nœud) ; // chaque nœud généré est évalué avant d’être ra-
jouter à la liste6: end if
Le parcours en largeur est très gourmand en ressource mémoire , de ce fait en ne gradedans la liste que les nœuds intéressants dont l’évaluation a été positive pour chaque niveauet de manière récursive pour les autres.
4.3 ConclusionLe Flow-Shop de permutation est un problème NP-difficile qui prend beaucoup de temps
de calcule. Par conséquent, sa resolution par un algorithme exacte nécessite beaucoup detemps de calcul. Dans le but de minimiser le temps d’exécution et remédier au problème,nous pouvons exploiter les ressources physiques du réseaux (système distribué). Dans cechapitre nous avons illustré, la stratégie de parallélisation de l’algorithme Branch& Boundpour résoudre le problème Flow-Shop avec le framwork Hadoop MapReduce .
57

Chapitre
5Implémentation et tests d’éva-luation avec Hadoop

CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
5.1 IntroductionAprès avoir abordé notre conception d’un algorithme parallèle du problème de d’or-
donnancement Flow Shop de permutation sous le modèle de programmation MapReduceavec la méthode de Branch &Bound, dans ce présent chapitre nous allons décrire notreimplémentation avec Hadoop et mener une série de tests pour évaluer l’approche exposéedans le chapitre précédent. Nous commencerons par présenter l’environnement de travailet des données "Benchmarks" sur lesquelles les tests se feront, puis l’implémentation desdeux stratégies de parcours pour la résolution du Flow-Shop de permutation. Après nousdiscuterons les résultats obtenus à l’issu des différents tests d’évaluation.
5.2 Présentation de l’environnement de travail
5.2.1 Systèmes d’exploitationNous utilisons une plateforme Unix de type linux : "ubuntu linux 15.04 LTS" et
"ubuntu linux 14.04 LTS" et linux Readhat au niveau du cluster IBN BADIS, unsystème d’exploitation multitâche et multi-utilisateur Bullx Linux Server release 6.3 (V1),64 bits.
5.2.2 Le framework HadoopHadoop est un framework libre et open source écrit dans le langage Java
destiné à faciliter la création d’applications distribuées (au niveau du sto-ckage des données et de leurs traitements) ainsi que le passage à l’échelle.Tous les modules de Hadoop sont conçus pour prendre en considération lespannes matérielles automatiquement par le framework. Au niveau du clus-ter : le nœud ibnbadis15 est le maître et les nœuds 16-19 sont les es-claves.
5.2.3 Eclipse , Sun java 6Eclipse : est un IDE, Integrated Development Environment (EDI environ-
nement de développement intégré ), un logiciel qui simplifie la programmationsous le langage JAVA en proposant un certain nombre de raccourcis. Il est gra-tuit et disponible pour la plupart des systèmes d’exploitation. nous avons utiliséEclipse pour la programmation et l’implémentation des algorithmes ainsi quel’exportation des projets sous forme de .jar.
58

CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
Sun java 6 : Le Java Development Kit (JDK) désigne un ensemble debibliothèques logicielles de base du langage de programmation Java, ainsique les outils avec lesquels le code Java peut être compilé. Pour l’exécu-tion de Hadoop l’environnement java et prérequis ,nécessitant installationd’une version 5 ou plus , nous avons choisi d’installer la version (Java7).
5.2.4 ClouderaUne distribution de Hadoop (Voir Annexe C).
5.3 Présentation des données utilisées pour les tests"Benchmarks"
Les benchmarks que nous avons utilisé sont des fichiers qui contiennent le nombrede tâches à ordonner, le nombre de machines, la borne supérieure qui représente le coutde la meilleure solution trouvée jusqu’à maintenant. Ces benchmarks sont proposés parE.Taillard dans la référence [46].Nous avons fabriqué cinq autres benchmarks artificiels de petite taille à partir du bench-mark de Taillard, 20 tâches et 5 machines avec une borne supérieur égale à 1278, afin detester notre approche. Les figures suivantes représentent les benchmarks artificiels utilisés.
Figure 5.1: Benchmark artificiel de 6 tâches et 5 machines à partir du benchmark 20*5de E .Taillard
59

CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
Figure 5.2: Benchmark artificiel de 7 tâches et 5 machines à partir du benchmark 20*5de E .Taillard
Figure 5.3: Benchmark artificiel de 8 tâches et 5 machines à partir du benchmark 20*5de E .Taillard
Figure 5.4: Benchmark artificiel de 9 tâches et 5 machines à partir du benchmark 20*5de E .Taillard
60

CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
Figure 5.5: Benchmark artificiel de 10 tâches et 5 machines à partir du benchmark 20*5de E .Taillard
5.4 Implémentation de l’algorithme B&B parallèle sousMapReduce pour le problème FSP
5.4.1 Implémentation dans MapReduce5.4.1.1 Programmation Hadoop et utilisation
Hadoop est développé en Java. Les tâches MAP/REDUCE sont donc implémentéespar le biais d’interfaces Java mais elles peuvent être implémentées dans n’importe quellangage.Un programme Hadoop se compile au sein d’un .jar.Pour développer un programmeHadoop, on va créer trois classes distinctes :Ê Une classe dite « Driver » qui contient la fonction main du programme. Cette classese chargera d’informer Hadoop des types de données « clef,valeur » utilisées, des classesse chargeant des opérations MAP et REDUCE, et des fichiers HDFS à utiliser pour lesentrées/sorties.Ë Une classe MAP (qui effectuera l’opération MAP).Ì Une classe REDUCE (qui effectuera l’opération REDUCE) [19].
5.4.1.2 Diagramme de classes
Pour notre approche , on génère n clef tel que n est égale au nombre de jobs FSP.Nous avons partagé l’arbre de recherche en n sous arbre. Chaque mappeur va traiter un ouplusieurs sous arbres tous dépend du nombre de données en entrée et le nombre de nœudsdisponibles dans le cluster.
Dans la fonction "MAP" : ≺ la clef : le racine, la valeur : la permutation :Makespan �
< Clef , Valueur > : La clef représente la racine du sous arbre de recherche et lavaleur représente la permutation de la solution optimale a ce sous arbre ainsi que le Ma-
61

CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
kespan associée.
Ci-dessous le diagramme de classes pour l’implémentation de la résolution du FlowShop de permutation avec MapReduce.
Figure 5.6: Diagramme de classes pour l’implémentation du FSP sous MapReduce
— La classe Driver, qui s’exécute sur une machine client, est chargé de configurer lejob puis de le soumettre pour exécution.
— La classe Map est chargé de lire les données stockées sur disque et les traiter.Les don-nées lues par le mapper sont définies au niveau du driver. La définition des donnéescomprend :leur localisation (fichier ou répertoire), le type des enregistrements.
— La classe Reduce est chargé de consolider les résultats issus du mapper puis de lesécrire sur disque.
— La classe FSPNode définie les opérations principales pour résoudre le problème FlowShop de permutation tel que : générations des permutations ,calcule de la borne in-férieure pour élagage , calcule du Makespan des solutions feuilles.
Pour un problème de taille 20 jobs – 5 machines, Hadoop divise par égalité entre lesnœuds les données. En supposant ayant 4 nœuds dans le cluster :
— Le nœud 1 reçoit les clefs : 0, 1, 2, 3, 4.
62

CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
— Le nœud 2 reçoit les clefs : 5, 6, 7, 8, 9.— Le nœud 3 reçoit les clefs : 10, 11, 12, 13, 14.— Le nœud 4 reçoit les clefs : 15, 16 ,17 ,18 ,19.Chaque nœud va avoir autant de mappeurs que de nombre de clef qu’il possède, les
mappeurs travaillent en parallèle.
l Exemple :
Pour un exemple un benchmark de taille 6 jobs avec 5 machines à 6 clefs qui sont :0,1,2,3,4,5.
La valeur de chaque clef représente la solution optimale du sous arbre, si elle existe.
clef valeur0 627 – 0, 2, 3, 1, 5, 41 647 – 1, 5, 3, 2, 4, 02 626 – 2, 5 ,4 ,0 ,3 ,13 640 – 3, 1, 5, 0, 4, 24 638 – 4, 3, 1, 0, 5, 25 612 – 5, 3, 1, 0, 2, 4
Table 5.1: Illustration des clefs / valeurs pour une instances de problèmes.
Le mappeur envoie la clef et la valeur associée au reducer.
5.4.2 Analyse du parcours par profondeurDans la méthode de parcours par profondeur nous avons ajouté une fonction qui fait
la mise à jour de la borne supérieure entre les différents mappeurs, la fonction consiste àpartager un fichier entre tous les mappeurs, ce fichier contient la valeur de la borne supé-rieure du problème. Chaque mappeur quand il arrive à un nœud feuille il vérifie d’abord laborne supérieure existante dans le fichier partagé. Si elle est supérieure à celle qu’il possèdeil va mettre à jour le fichier en écrivant sa borne supérieure dans le fichier, sinon si elleest inférieure le mappeur va mettre à jour la borne contenu dans le fichier avec sa bornesupérieure courante.
Une autre mise a jours peut être nécessaire dans la stratégie de parcours par profondeurdans les niveaux intermédiaires. On programme sur chaque k niveau une mise jour tel quek inférieure au nombre de jobs (tâches), par exemple pour un problème de taille 6 : k=2,unproblème de taille 20 : k = 5,et un problème de taille 50 : k = 10 .. etc. La mise à jourse fait par un mappeur qui ouvre le fichier partagé en lecture et lit la borne supérieureexistante dans le fichier, si elle est inférieure de celle de mappeur, le mappeur va mettre
63

CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
à jour le fichier avec sa borne supérieure sinon si elle supérieure le mappeur ne fait rien ilferme le fichier et refait la mise a jours dans les k niveau suivantes.
La mise a jours de k niveau est nécessaire dans la stratégie de parcours par profon-deur parce que les mappeurs quand ils travaillent en parallèle, il y a une possibilité qu’unmappeur arrive à calculer une nouvelle bonne solution plus rapidement que les autres map-peurs de plus ça permettra d’élaguer plus de nœuds ,par conséquence réduction du tempsde calcul gagné par inexplorable des mauvaises branches (des branches qui ne mène pas àune solution optimale).
Donc il est nécessaire de faire les mises à jour de k niveau car ils permettent aux map-peurs de mettre à jours leur borne supérieur à celle meilleure trouvé actuellement par lesautres mappeurs. Ci-dessus un peseudo-code pour la mise à jour de la borne supérieure.
Algorithm 10 Fonction update_feuille(path, Makespan )1: Borne_SupF =LireFichier(path) ; //Ici on récupère la valeur de la borne supérieure
du fichier ;2: if Makespn <Borne_SupF then3: EcrireFichier(path,Makespan) ; //Mettre à jours la borne supérieur du fichier avec
celle du mappeur4: Borne_Sup =Makespn ; // le mappeur met à jour sa propre borne supérieure.5: else6: Borne_Sup =Borne_SupF ; // le mappeur met à jour la borne supérieure avec celle
contenue dans le fichier7: end if
Algorithm 11 Fonction UpdateK (path , Borne_Sup) //Borne_sup représente lavaleur de la borne supérieur du mappeur)1: Borne_SupF=LireFichier(path) ; //Ici on récupère la valeur de borne supérieure du
fichier ;2: if Borne_SupF <Borne_Sup then3: Borne_Sup=Borne_supF ;// le mappeur met à jour sa propre borne supérieure.4: end if
5.4.3 Analyse du parcours par largeurDans la méthode de parcours par largeur, l’évolution des mappeurs est quasiment la
même car chacun d’eux progresse de la même manière, pour notre implémentation niveaupar niveau tel que k= 1 ce qui représente la profondeur de l’arbre et comme les nœuds du
64
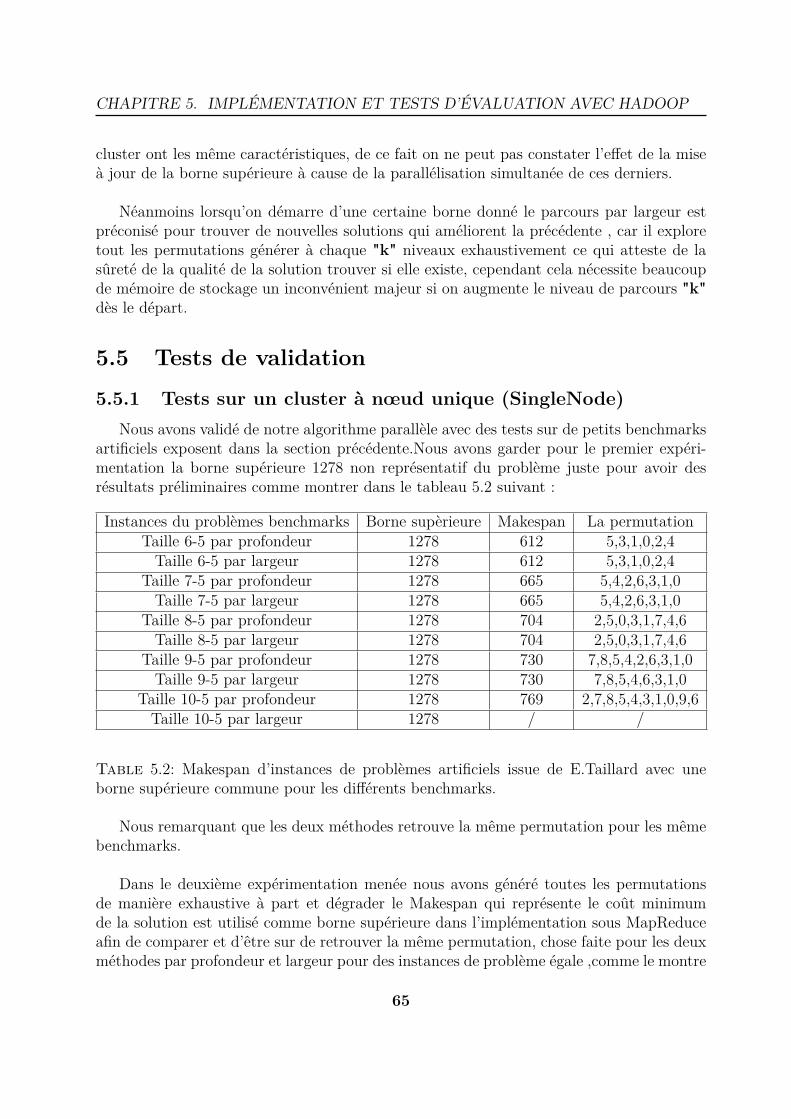
CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
cluster ont les même caractéristiques, de ce fait on ne peut pas constater l’effet de la miseà jour de la borne supérieure à cause de la parallélisation simultanée de ces derniers.
Néanmoins lorsqu’on démarre d’une certaine borne donné le parcours par largeur estpréconisé pour trouver de nouvelles solutions qui améliorent la précédente , car il exploretout les permutations générer à chaque "k" niveaux exhaustivement ce qui atteste de lasûreté de la qualité de la solution trouver si elle existe, cependant cela nécessite beaucoupde mémoire de stockage un inconvénient majeur si on augmente le niveau de parcours "k"dès le départ.
5.5 Tests de validation
5.5.1 Tests sur un cluster à nœud unique (SingleNode)Nous avons validé de notre algorithme parallèle avec des tests sur de petits benchmarks
artificiels exposent dans la section précédente.Nous avons garder pour le premier expéri-mentation la borne supérieure 1278 non représentatif du problème juste pour avoir desrésultats préliminaires comme montrer dans le tableau 5.2 suivant :
Instances du problèmes benchmarks Borne supèrieure Makespan La permutationTaille 6-5 par profondeur 1278 612 5,3,1,0,2,4Taille 6-5 par largeur 1278 612 5,3,1,0,2,4
Taille 7-5 par profondeur 1278 665 5,4,2,6,3,1,0Taille 7-5 par largeur 1278 665 5,4,2,6,3,1,0
Taille 8-5 par profondeur 1278 704 2,5,0,3,1,7,4,6Taille 8-5 par largeur 1278 704 2,5,0,3,1,7,4,6
Taille 9-5 par profondeur 1278 730 7,8,5,4,2,6,3,1,0Taille 9-5 par largeur 1278 730 7,8,5,4,6,3,1,0
Taille 10-5 par profondeur 1278 769 2,7,8,5,4,3,1,0,9,6Taille 10-5 par largeur 1278 / /
Table 5.2: Makespan d’instances de problèmes artificiels issue de E.Taillard avec uneborne supérieure commune pour les différents benchmarks.
Nous remarquant que les deux méthodes retrouve la même permutation pour les mêmebenchmarks.
Dans le deuxième expérimentation menée nous avons généré toutes les permutationsde manière exhaustive à part et dégrader le Makespan qui représente le coût minimumde la solution est utilisé comme borne supérieure dans l’implémentation sous MapReduceafin de comparer et d’être sur de retrouver la même permutation, chose faite pour les deuxméthodes par profondeur et largeur pour des instances de problème égale ,comme le montre
65
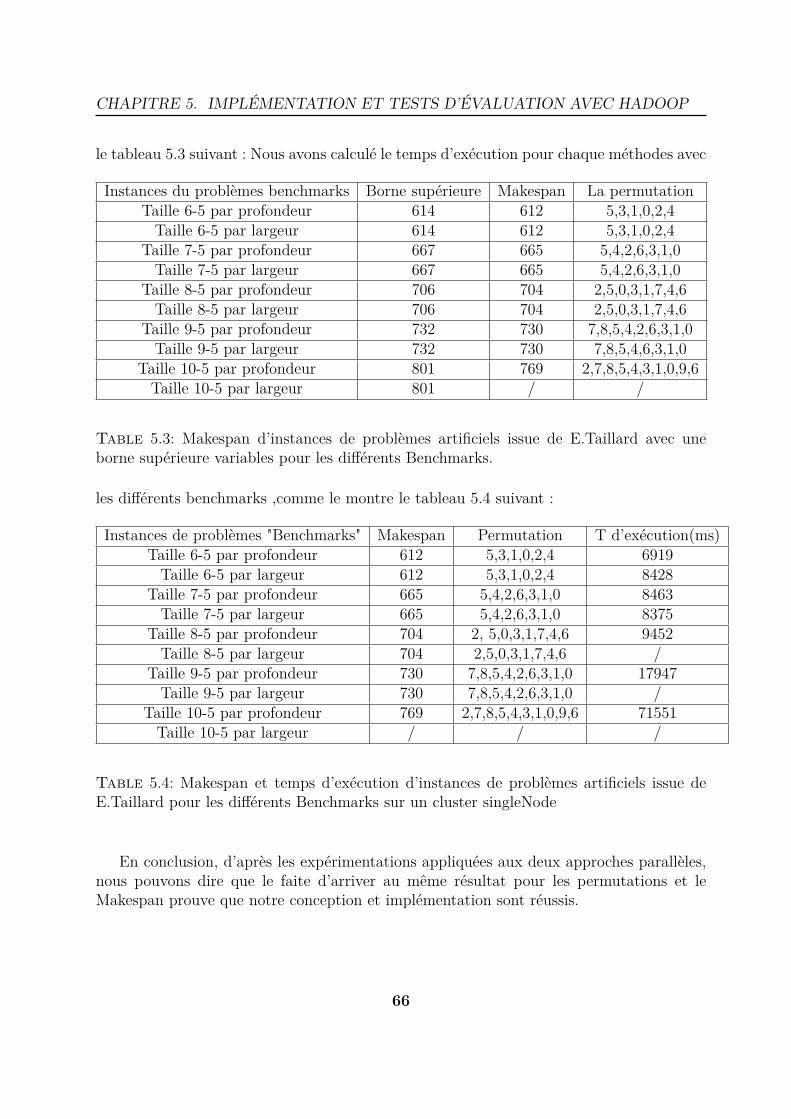
CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
le tableau 5.3 suivant : Nous avons calculé le temps d’exécution pour chaque méthodes avec
Instances du problèmes benchmarks Borne supérieure Makespan La permutationTaille 6-5 par profondeur 614 612 5,3,1,0,2,4Taille 6-5 par largeur 614 612 5,3,1,0,2,4
Taille 7-5 par profondeur 667 665 5,4,2,6,3,1,0Taille 7-5 par largeur 667 665 5,4,2,6,3,1,0
Taille 8-5 par profondeur 706 704 2,5,0,3,1,7,4,6Taille 8-5 par largeur 706 704 2,5,0,3,1,7,4,6
Taille 9-5 par profondeur 732 730 7,8,5,4,2,6,3,1,0Taille 9-5 par largeur 732 730 7,8,5,4,6,3,1,0
Taille 10-5 par profondeur 801 769 2,7,8,5,4,3,1,0,9,6Taille 10-5 par largeur 801 / /
Table 5.3: Makespan d’instances de problèmes artificiels issue de E.Taillard avec uneborne supérieure variables pour les différents Benchmarks.
les différents benchmarks ,comme le montre le tableau 5.4 suivant :
Instances de problèmes "Benchmarks" Makespan Permutation T d’exécution(ms)Taille 6-5 par profondeur 612 5,3,1,0,2,4 6919Taille 6-5 par largeur 612 5,3,1,0,2,4 8428
Taille 7-5 par profondeur 665 5,4,2,6,3,1,0 8463Taille 7-5 par largeur 665 5,4,2,6,3,1,0 8375
Taille 8-5 par profondeur 704 2, 5,0,3,1,7,4,6 9452Taille 8-5 par largeur 704 2,5,0,3,1,7,4,6 /
Taille 9-5 par profondeur 730 7,8,5,4,2,6,3,1,0 17947Taille 9-5 par largeur 730 7,8,5,4,2,6,3,1,0 /
Taille 10-5 par profondeur 769 2,7,8,5,4,3,1,0,9,6 71551Taille 10-5 par largeur / / /
Table 5.4: Makespan et temps d’exécution d’instances de problèmes artificiels issue deE.Taillard pour les différents Benchmarks sur un cluster singleNode
En conclusion, d’après les expérimentations appliquées aux deux approches parallèles,nous pouvons dire que le faite d’arriver au même résultat pour les permutations et leMakespan prouve que notre conception et implémentation sont réussis.
66
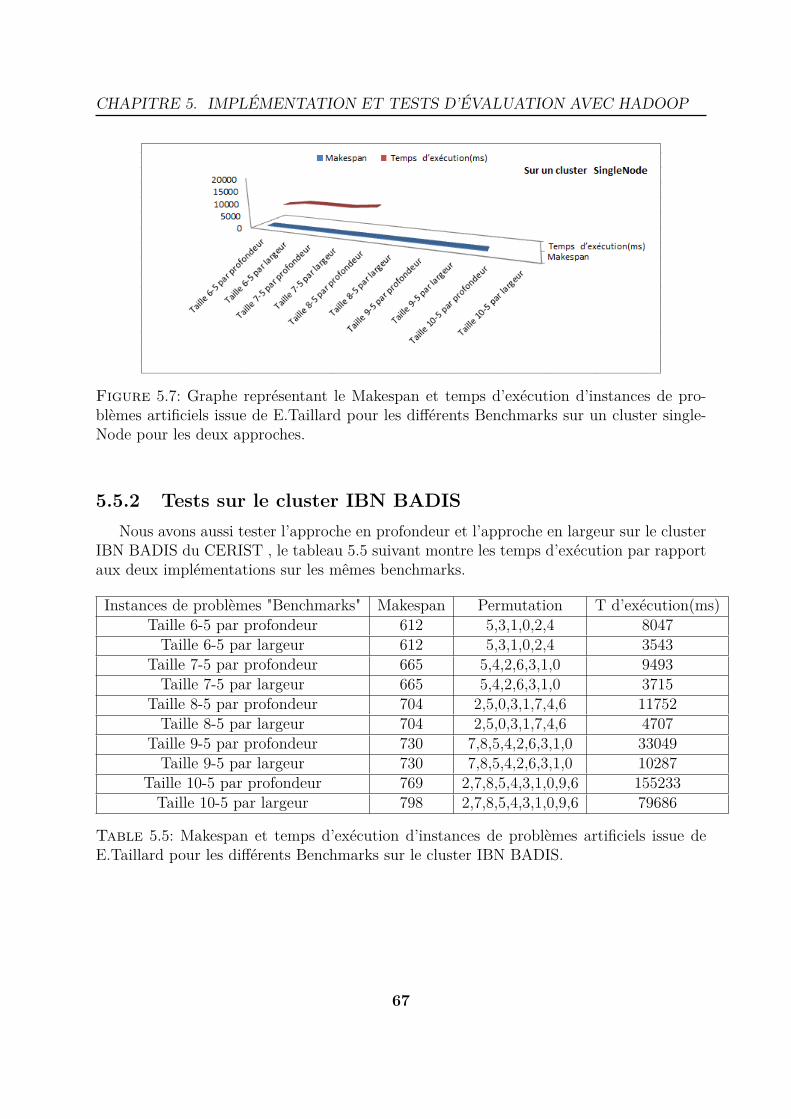
CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
Figure 5.7: Graphe représentant le Makespan et temps d’exécution d’instances de pro-blèmes artificiels issue de E.Taillard pour les différents Benchmarks sur un cluster single-Node pour les deux approches.
5.5.2 Tests sur le cluster IBN BADISNous avons aussi tester l’approche en profondeur et l’approche en largeur sur le cluster
IBN BADIS du CERIST , le tableau 5.5 suivant montre les temps d’exécution par rapportaux deux implémentations sur les mêmes benchmarks.
Instances de problèmes "Benchmarks" Makespan Permutation T d’exécution(ms)Taille 6-5 par profondeur 612 5,3,1,0,2,4 8047Taille 6-5 par largeur 612 5,3,1,0,2,4 3543
Taille 7-5 par profondeur 665 5,4,2,6,3,1,0 9493Taille 7-5 par largeur 665 5,4,2,6,3,1,0 3715
Taille 8-5 par profondeur 704 2,5,0,3,1,7,4,6 11752Taille 8-5 par largeur 704 2,5,0,3,1,7,4,6 4707
Taille 9-5 par profondeur 730 7,8,5,4,2,6,3,1,0 33049Taille 9-5 par largeur 730 7,8,5,4,2,6,3,1,0 10287
Taille 10-5 par profondeur 769 2,7,8,5,4,3,1,0,9,6 155233Taille 10-5 par largeur 798 2,7,8,5,4,3,1,0,9,6 79686
Table 5.5: Makespan et temps d’exécution d’instances de problèmes artificiels issue deE.Taillard pour les différents Benchmarks sur le cluster IBN BADIS.
67
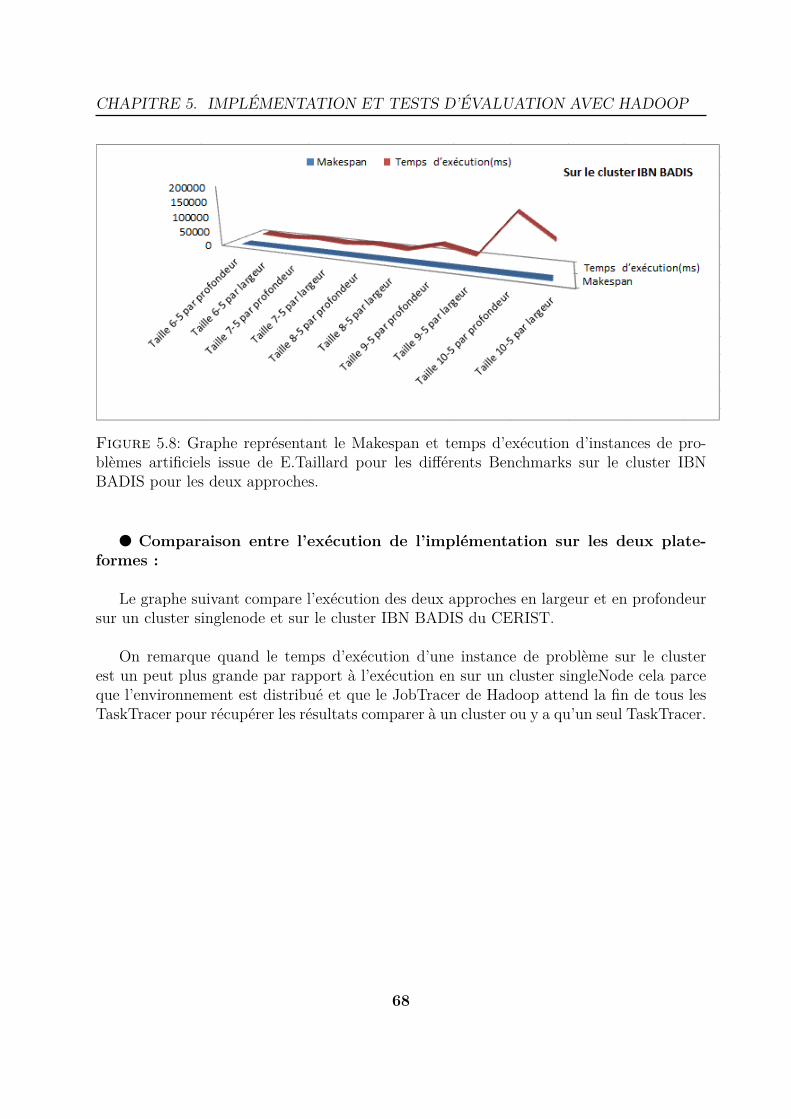
CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
Figure 5.8: Graphe représentant le Makespan et temps d’exécution d’instances de pro-blèmes artificiels issue de E.Taillard pour les différents Benchmarks sur le cluster IBNBADIS pour les deux approches.
l Comparaison entre l’exécution de l’implémentation sur les deux plate-formes :
Le graphe suivant compare l’exécution des deux approches en largeur et en profondeursur un cluster singlenode et sur le cluster IBN BADIS du CERIST.
On remarque quand le temps d’exécution d’une instance de problème sur le clusterest un peut plus grande par rapport à l’exécution en sur un cluster singleNode cela parceque l’environnement est distribué et que le JobTracer de Hadoop attend la fin de tous lesTaskTracer pour récupérer les résultats comparer à un cluster ou y a qu’un seul TaskTracer.
68
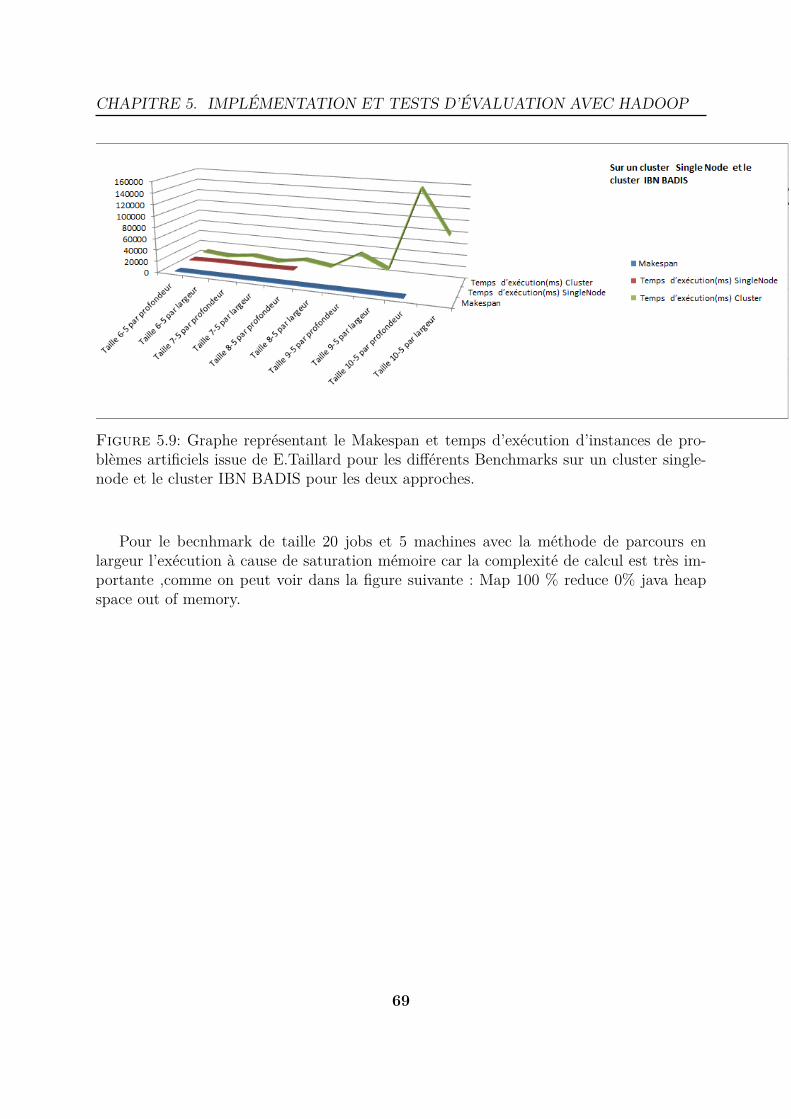
CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
Figure 5.9: Graphe représentant le Makespan et temps d’exécution d’instances de pro-blèmes artificiels issue de E.Taillard pour les différents Benchmarks sur un cluster single-node et le cluster IBN BADIS pour les deux approches.
Pour le becnhmark de taille 20 jobs et 5 machines avec la méthode de parcours enlargeur l’exécution à cause de saturation mémoire car la complexité de calcul est très im-portante ,comme on peut voir dans la figure suivante : Map 100 % reduce 0% java heapspace out of memory.
69

CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
le nombre de nœuds dans le cluster est insuffisant pour de grand instances de problèmes,pour une meilleure résolution du problème il faut augmenté le nombre de nœuds alloués.
5.6 ConclusionDans ce derniers chapitre nous avons présenté l’implémentation des deux stratégies de
parcours en profondeur et en largeur pour un l’algorithme Branch and Bound parallèleavec MapReduce et nous avons validé notre implémentation avec une série de tests sur uncluster à noeud unique (singleNode) (un PC portable ou une machine virtuelle sur un PCportable) et sur le cluster IBN BADIS du CERIST. Nous arrivons à dire que Hadoop est unoutil puissant pour faire des calculs simples d’immense données pour les entreprises maispour les grands calculs scientifiques il n’est pas vraiment adapté car il est d’une architecturecomplexe et lourdes pas facile à la modifier suivant nos contraints. Il lui manque des outilspour supporter le calcul parallèle intensif.
70

Conclusion générale
Dans ce mémoire intitulé ‘Parallélisation d’ algorithmes de graphes sur un cluster d’ordi-nateurs’, nous avons implémenté une version parallèle de l’algorithme Branch and Boundsur le cluster IBN BADIS en utilisant le modèle MapReduce en moyen du frameworkHadoop d’Apache dans le but de résoudre le problème combinatoire Flow Shop de per-mutation. L’algorithme Branch and Bound utilises un parcours intelligent de l’espace derecherche qu’il organise sous forme d’un arbre construit au fur et à mesure qu’on avancedans la recherche. Cet algorithme exact permet de résoudre à l’optimalité des problèmesd’optimisation combinatoire. Sa parallélisation sur divers architectures parallèles a large-ment été étudié dans la littérature. Dans ce mémoire on s’intéresse à l’adaptation des stra-tégies de parallélisation classiques au modèle MapReduce initialement invente par Googlepour la parallélisation des services liés au traitement fait sur des données de grande taille(Big Data). Le portage des algorithmes Branch and Bound sur MapReduce et notammentle framwork Hadoop présente quelques défis qu’il faut soulever afin de profiter pleinementde ces nouvelles technologies en plein essor actuellement.
Dans ce travail, nous avons pu implémenter et avec succès une adaptation des algo-rithmes Branch and Bound parallèle avec le modèle MapReduce que nous avons teste surle cluster IBN BADIS.
Nous avons implémenté l’algorithme Branch and Bound parallèle avec deux stratégiesde parcours de l’arbre : par largeur et par profondeur. Ce qui à donner de bons résultatspour les tests effectuées.
Ce projet nous a permis d’avoir des nouvelles connaissances sur les nouvelles technolo-gies d’architectures parallèle, des notions sur les problèmes combinatoires et une nouvelleapproche de leur résolution. Il nous a aussi permis de faire du calcul parallèle sur un en-semble d’ordinateurs dans un système distribué, en plus de l’apprentissage d’un nouveaumodèle de programmation Map/Reduce en utilisant le framework Hadoop.
Par ailleurs, tout au long de ce travail, nous avons constaté que : bien que MapReducesoit parfaitement adapte pour notre cas d’étude (algorithme de recherche base sur unestructure d’arbre), le framework Hadoop lui ne s’adapte pas bien pour la résolution desproblèmes scientifiques car il est orienté pour le calcule simple qui consiste à faire le comp-

CHAPITRE 5. IMPLÉMENTATION ET TESTS D’ÉVALUATION AVEC HADOOP
tage et l’analyse pour les grands données (Big Data) comme celle des bases de données.Par exemple compter le nombre d’employée, les statistique ..etc . Les difficultés que nousavons rencontrées sont des problèmes internes de l’architecture de Hadoop. En plus de cela,Hadoop n’utilise que les type de données simple propre à lui. Il lui manque des outils poursupporter facilement les applications du calcul intensif.
Comme perspective du projet faire du round-robin sur le job MapReduce autrement ditfaire des itérations de job MapReduce de tell sort que : On génère et on évaluer dans le maptous les nœuds du niveau suivant. On envoie au reducer la liste des nœuds qui présente unebonne évaluation, les nœuds qui sont susceptible d’avoir une solution optimale. Le résultatdu reducer sera traité comme une nouvelle entrée pour le job MapReduce et ainsi de suitejusqu’à arriver aux nœuds feuilles.
Dans le future ré-implémenter la conception en utilisant MR-MPI quand il sera stable.

Bibliographie
[1] Paralélisme (informatique). https://fr.wikipedia.org/wiki/Paral%C3%A9lisme_%28informatique%29. Dernière mise à jour : 4 décembre 2015.
[2] BOUGACI Dalila. Introduction au calcul parallèle. Rapp. tech. université des scienceset de la technologie Houari-Boumédiène, 2015/2016.
[3] Rédha LOUCIF. Mémoire Magister Parallélisation d’Algorithmes d’OptimisationCombinatoire. Rapp. tech. université colonel Hadj Lakhdar-Batna, 13/01/2014.
[4] "François Pellegrini Enseirb". “Livre Architectures et Systèmes des CalculateursParallèles”. In : (2003).
[5] Processeur graphique. https://fr.wikipedia.org/wiki/Processeur_graphique.Dernière mise à jour : 13-03-2016.
[6] GPU, puces graphiques : qui sont-elles et à quoi servent-elles ? http://www.frandroid.com/hardware/processeurs/235635_gpu-puces-graphiques-servent. Dernièreconsultation : 20-03-2016.
[7] Cloud computing. https://fr.wikipedia.org/wiki/Cloud_computing. Dernièremise à jour : 20-03-2016.
[8] "MICHAEL ULRYCK". Les modèles de service du Cloud : SaaS/PaaS/IaaS. http://www.michaelulryck.com/les-modeles-de-service-du-cloud-saas-paas-iaas. Dernière mise à jour : 8-06-2014.
[9] Grappe de serveurs. https://fr.wikipedia.org/wiki/Grappe_de_serveurs.Dernière mise à jour : 30-12-2015.
[10] Running Hadoop on Ubuntu Linux (Single-Node Cluster). http ://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-single-node-cluster/. Dernière consultation : 01-05-2016.
[11] Cédric LHERM. Présentation : Les clusters. 2000.[12] Nezha EL GOURII. Grid Computing. http : / / www . supinfo . com / articles /
single/281-grid-computing. Dernière mise à jour : 13-09-2015.[13] Smaël Laskri" Aurélien Jolly. Les grilles de calcul. http://igm.univ-mlv.fr/
~dr/XPOSE2006/Jolly_Laskri/index.html. Années :2006/2007.[14] MEHDI Malika. Cour Gestion et Administration de grilles de calcul. Rapp. tech.
université des sciences et de la technologie Houari-Boumédiène.

BIBLIOGRAPHIE
[15] "BENDJOUDI Ahmed". “Calcul Haute Performance pour l’optimisation combina-toire”. In : La Journée nationale de calcul intensif et ses applications (2014).
[16] Yves Roberte" "Amaud Legrand. “Livre Algorithmique parallèle : cours et exercicescorrigés”. In : (2013).
[17] Paul Zikopoulos et al. “Harness the power of big data : the IBM big data platform”.In : McGraw-Hill Osborne Media (2012).
[18] John Gantz et David Reinsel. “The digital universe in 2020 : big data, biggerdigital shadows, and biggest growth in the far east.” In : Technical report, IDC(2012).
[19] Benjamin Renaut. Hadoop / Big Data. Rapp. tech. MBDS Université de Nice SO-PHIA ANTIPOLIS, 2013/2014.
[20] Shamil Humbetov. Data-Intensive Computing with Map-Reduce and Hadoop. Rapp.tech. Department of Computer Engineering Qafqaz University, p. 5.
[21] Ludovic Denoyer et Sylvain Lamprier. Introduction à MapReduce/Hadoop et Spark.Rapp. tech. UPMC, p. 36.
[22] Jeffrey Dean et Sanjay Ghemawat. MapReduce : Simplified Data Processing onLarge Clusters. Rapp. tech. Google, Inc, p. 13.
[23] Matei Zaharia. Introduction to MapReduce and Hadoop. Rapp. tech. UC BerkeleyRAD Lab, p. 61.
[24] Dhruba Borthakur. HDFS Architecture Guide. Rapp. tech., p. 13.[25] Steven J. Plimpton et Karen D. Devine. MapReduce in MPI for Large-scale Graph
Algorithms. Rapp. tech. Sandia National Laboratories Albuquerque, NM, p. 39.[26] Message Passing Interface Forum. MPI : A Message-Passing Interface Standard.
Rapp. tech. ARPA et al., 1994, p. 236.[27] Andrew Lumsdaine Torsten Hoefler et Jack Dongarra. “Towards Efficient
MapReduce Using MPI”. In : (), p. 10.[28] Ata Turk R. Oguz Selvitopi Gunduz Vehbi Demirci et Cevdet Aykanat. Petas-
caling Machine Learning Applications with MR-MPI. Rapp. tech. Bilkent University, Computer Engineering Department et 06800 Ankara TURKEY, p. 11.
[29] Jiyao Gao (ChE 345 Spring 2014). Branch and bound (BB). https://optimization.mccormick.northwestern.edu/index.php/Branch_and_bound_%28BB%29. Der-nière mise à jour :26 Mai 2014.
[30] Benjamin Renaut. Méthode de résolution par séparation et évaluation : Branch &Bound, Annexe à l’énoncé du TP 2 Algorithmique et programmation orienté objet.Rapp. tech. École nationale supérieure d’informatique et de mathématiques appli-quées, 2009/2010.

BIBLIOGRAPHIE
[31] Halima Lakhbab Sidi Mohamed Douiri Souad Elbernoussi. Cours des méthodesde résolution exactes heuristiques et métaheuristiques. Rapp. tech. Université Mo-hammed V,Faculté des Sciences de Rabat.
[32] GHARBI Makhlouf CHEKINI Mehdi. Mémoire Parallel B&B Algorithm for Hy-brid Multi-core/GPU Architectures. Rapp. tech. École nationale supérieure d’infor-matique, 2013.
[33] Harry W.J.M. Trienekens et Arie de Bruin. “Towards a Taxonomy of ParallelBranch and Bound Algorithms”. In : (), p. 23.
[34] Mohand Mezmaz. Une approche efficace pour le passage sur grilles de calcul deméthodes d’optimisation combinatoire. Rapp. tech. Soutenu le : 27 Novembre 2007.Université des Siences et Technologies de Lille Laboratoire LIFL/INRIA.
[35] Imen Chakroun. Parallel heterogeneous Branch and Bound algorithms for multi-core and multi-GPU environments. Rapp. tech. Submitted on 8 Jul 2013. Ecole Doc-torale Sciences Pour l’Ingénieur Université Lille 1 Nord-de-France.
[36] Nouredine. MELAB. Contributions à la résolution de problèmes d’optimisation com-binatoire sur grilles de calcul. 2005.
[37] Arie de Bruin Harry W.J.M. Trienekens. B and B survey Crainic. ParallelBranch-and-Bound Algorithms : Survey and Synthesis. Oper. Res., 42(6) :1042–1066(1994). Rapp. tech. Erasmus University Rotterdam, p. 23.
[38] Wolfram Schiffmann Udo Honig. “A Parallel Branch–and–Bound Algorithm forComputing Optimal Task Graph Schedules”. In : (), p. 8.
[39] El-Ghazali Talbi Mohand Mezmaz Nouredine Melab. B and B@Grid : une approcheefficace pour la gridification d’un algorithme Branch and Bound (traduire). Rapp.tech. Centre de recherche INRIA Lille – Nord Europe Parc Scientifique de la HauteBorne, 2009, p. 32.
[40] Ahcne Bendjoudi. SCALABLE AND FAULT TOLERANT HIERARCHICAL B&BALGORITHMS FOR COMPUTATIONAL GRIDS. Rapp. tech. Submitted on 5 Jul2013. Université A.MIRA-BEJAIA.
[41] Flow-shop. https://fr.wikipedia.org/wiki/Flow-shop. Dernière mise à jour le :23 février 2016.
[42] Makespan. https://en.wikipedia.org/wiki/Makespan. Dernière mise à jour le :23 mai 2016.
[43] "Fatos Ajith Abraham (Eds)". “Metaheuristics for Scheduling in Distribted Compu-ting Environments”. In : (2008).
[44] "Raphael Couturier". “Designing Scientific Application on GPUs”. In : (2014).[45] ALEX HOLMES Manning Publications Co Shelter Island NY 11964. Hadoop in
Practice.

BIBLIOGRAPHIE
[46] Scheduling instances "Benchmarks for basic scheduling problems". http://mistic.heig-vd.ch/taillard/problemes.dir/ordonnancement.dir/ordonnancement.html. Dernière mise à jour le : 22.05.2015.

Annexes

Annexe
AImplémentation d’un clusterHadoop à nœud unique
A.1 Prérequis1. Installation de l’environnement Java
û Installation de " sun -java6-jdk " :
û Vérification de l’installation de java :
2. L’ajout d’un compte utilisateur dédié à HadoopDans le but, de facilité administration et par mesure de sécurité il est recommandéd’utiliser un compte et un groupe dédié pour l’exécution du framework Hadoop ,aussi en cas de délégations de tâches ou/et intégration d’autres comptes pour lagestion du cluster :
û Ajouter le groupe :
û Création du compte et l’affecter au groupe :

ANNEXE A. IMPLÉMENTATION D’UN CLUSTER HADOOP À NŒUD UNIQUE
3. Configuration du SSH :Hadoop requière un accès SSH pour gérer les différents nœuds. Pour un cluster ànœud unique la configuration est simple, nous avons besoin d’un l’accès vers local-host pour l’utilisateur " hadoopuser" de créer précédemment.
û Installation des packages SSH :
û Génération d’une paire de clés RSA pour SSH :
û Teste de la configuration SSH :
A.2 Hadoop
A.2.1 InstallationPour cela , il faut télécharger le package d’Hadoop du site officiel , nous avons utilisé la
version 2.7.2 . Après extraction on renomme ce dernier,et on met le dossier dans : /usr/-local/ , pour une meilleure gestion.

ANNEXE A. IMPLÉMENTATION D’UN CLUSTER HADOOP À NŒUD UNIQUE
A.2.2 Configuration & LancementA.2.2.1 Configuration du HDFS
La configuration du HDFS est conntenue dans certains fichiers XML dans le réper-toire etc/. Pour terminer l’installation de Hadoop, ces derniers devront être modifiés ,Lesnouveaux paramètres sont à ajouter entre la balise <configuration> . . . </configuration>.
1. Modifier le fichier " /.bashrc " :Avant ,il faut éditer le fichier .bashrc dans votre répertoire de base, pour rajoutertrouver le chemin d’accès où Java a été installé pour définir la variable d’environ-nement JAVA_HOME .Comme ci-dessus :
2. Modifier le fichier " /usr/local/hadoop/etc/hadoop/hadoop-env.sh " :Dans ce fichier, recherchez la ligne qui exporte la variable JAVA_HOME . Modifiezcette ligne comme suit enregistrez et fermez le fichier. Ajout de l’instruction ci-dessusdans le fichier hadoop-env.sh veille à ce que la valeur de la variable JAVA_HOMEsera disponible à chaque fois que Hadoop est lancé :
3. Modifier le fichier "/usr/local/hadoop/etc/hadoop/core-site.xml " :Le fichier /usr/local/hadoop/etc/hadoop/core-site.xml contient des propriétés deconfiguration que Hadoop utilise lors du démarrage. Ce fichier peut être utilisé poursubstituer les paramètres par défaut.

ANNEXE A. IMPLÉMENTATION D’UN CLUSTER HADOOP À NŒUD UNIQUE
Enregistrez et fermez le fichier.4. Modifier le fichier " /usr/local/hadoop/etc/hadoop/yarn-site.xml " :
Le fichier /usr/local/hadoop/etc/hadoop/yarn-site.xml contient des propriétés deconfiguration que MapReduce utilise lors du démarrage. Ce fichier peut être utilisépour substituer les paramètres par défaut .
Enregistrez et fermez le fichier.

ANNEXE A. IMPLÉMENTATION D’UN CLUSTER HADOOP À NŒUD UNIQUE
5. Modifier le fichier " /usr/local/hadoop/etc/hadoop/mapred-site.xml " :Ce fichier est utilisé pour spécifier quel cadre est utilisé pour MapReduce.
Enregistrez et fermez le fichier.6. Modifier le fichier "/usr/local/hadoop/etc/hadoop/hdfs-site.xml " :
Le /usr/local/hadoop/etc/hadoop/hdfs-site.xml doit être configuré pour chaquehôte du cluster en cours d’utilisation. Il est utilisé pour spécifier les répertoiresqui seront utilisés comme le namenode et le datanode sur cet hôte.Avant d’éditer ce fichier, nous devons créer deux répertoires qui contiendront le na-menode et le datanode pour cette installation de Hadoop. Cela peut être fait enutilisant les commandes suivantes :
Une fois cela fait, ouvrez le /usr/local/hadoop/etc/hadoop/hdfs-site.xml Dans cefichier, entrez le contenu suivant entre le <configuration></configuration> .
Enregistrez et fermez le fichier.

ANNEXE A. IMPLÉMENTATION D’UN CLUSTER HADOOP À NŒUD UNIQUE
A.2.2.2 Formatage du HDFS via le NameNode
Après avoir terminé toutes la configuration le système de fichiers Hadoop qui se trouveau-dessus du système de fichiers local, doit être formaté avant de commencer à l’ utiliser,ceci est réalisé en exécutant la commande suivante :
Cela ne doit être effectué qu’ une fois avant d’utiliser Hadoop. Si cette commande estexécutée à nouveau après que Hadoop a été utilisé, il va détruire toutes les données sur lesystème de fichiers Hadoop.
A.2.2.3 Lancement du cluster à nœud unique :
Tout ce qui reste à faire est de lancer le démarrage du cluster à nœud unique nouvel-lement installé :
1. Lancement du système de fichier HDFS :
Cette commande va démarrer le serveur NameNode sur la machine maître et desDataNodes sur chacune des machines esclaves.
2. Lancement du YARN :
L’idée fondamentale de du YARN est de séparer la problématique de la gestiondes ressources des clusters de celle du traitement des données. La commande ci-dessus permet de le lancer.
3. Vérification du lancement du cluster :

ANNEXE A. IMPLÉMENTATION D’UN CLUSTER HADOOP À NŒUD UNIQUE
û Vérification avec la commande " JPS " :
û Vérification avec la commande " netstat " :
4. Arrêter le cluster :Exécuter la commande, ce qui va arrêter le NameNode, DataNode et Le YARN :
A.2.2.4 Lancer un job Map/Reduce
1. Téléchargement des données en entrées (Input) :On va lancer un job Map/Reduce pour tester notre cluster , pour cela on lance leprogramme WordCount qui calcule le nombre d’occurrence des mots dans un texte. En utilisant le hadoop-mapreduce-examples-2.7.2.jar contenu dans Hadoop .Les données en entrées sont représentées par deux fichiers : file01.txt et file02.txt

ANNEXE A. IMPLÉMENTATION D’UN CLUSTER HADOOP À NŒUD UNIQUE
On définit un dossier "input1" sur la machine locale pour contenir ces fichiers :
2. Relancer le cluster Hadoop suivant les commandes ci-dessus3. Copier les données en entrées sur le système de fichiers HDFS :
û On commence par créer un répertoire sur le HDFS ,comme suite :
û Copier les données en entrées : " file01.txt et file02.txt "
4. Lancer le Job WordCount de Map/Reduce :Avec cette commande , on lance la lecture de tous les fichiers HDFS contenus dansle répertoire donné en entrée "input1" , exécute le programme WordCount , calcu-lant le nombre d’occurrence des mots , et à la fin sauvegarder les résultats dans lerépertoire spécifié en sortie sur le HDFS .
5. Vérification de la sauvegarde du résultat :

ANNEXE A. IMPLÉMENTATION D’UN CLUSTER HADOOP À NŒUD UNIQUE
Avec cette commande , on vérifie que le résultat retourné par le programme Word-Count a bien été sauvegarder au niveau du HDFS dans le dossier spécifier en sortie :
6. Récupération du résultat du HDFS :On récupère le résultat sur la machine locale afin de pouvoir le visualiser .
Annexe
BFramework Hadoop via Eclipsekepler
B.1 Création et configuration d’un projet Hadoop sousEclipse
Voici les instructions pour la mise en place d’un environnement de développement pourHadoop sous l’IDE Eclipse.
B.1.1 Configuration1. Télécharger Eclipse IDE, la dernière version " Kepler" et lancer le.2. Activation de l’onglet perspective "Map/Reduce" : clic droit sur "Window" dans
barre d’outils, puis sélectionnez " open perspective " => "Other" => " Map/Reduce" de la liste des perspectives , puis cliquer sur "ok" pour terminer.Après cela en remarque l’apparition d’un bouton "Map/Reduce " afin de faciliter latransition rentre les applications développées en Java et Map/Reduce.
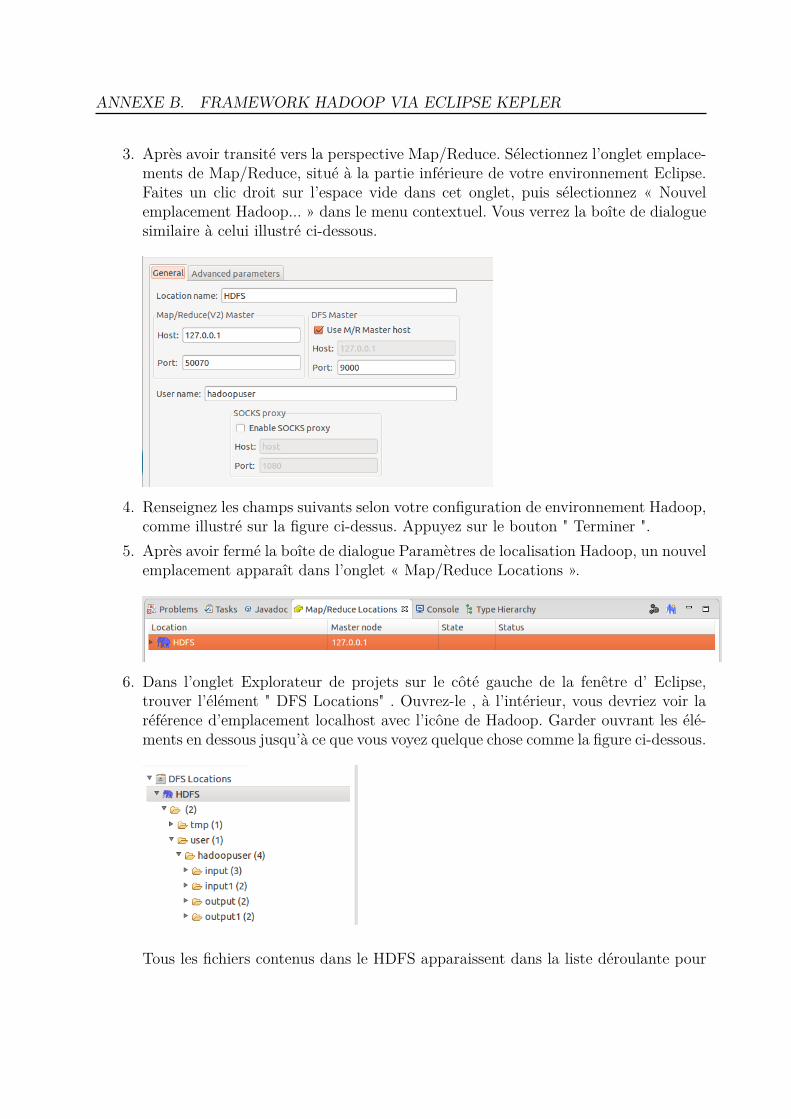
ANNEXE B. FRAMEWORK HADOOP VIA ECLIPSE KEPLER
3. Après avoir transité vers la perspective Map/Reduce. Sélectionnez l’onglet emplace-ments de Map/Reduce, situé à la partie inférieure de votre environnement Eclipse.Faites un clic droit sur l’espace vide dans cet onglet, puis sélectionnez « Nouvelemplacement Hadoop... » dans le menu contextuel. Vous verrez la boîte de dialoguesimilaire à celui illustré ci-dessous.
4. Renseignez les champs suivants selon votre configuration de environnement Hadoop,comme illustré sur la figure ci-dessus. Appuyez sur le bouton " Terminer ".
5. Après avoir fermé la boîte de dialogue Paramètres de localisation Hadoop, un nouvelemplacement apparaît dans l’onglet « Map/Reduce Locations ».
6. Dans l’onglet Explorateur de projets sur le côté gauche de la fenêtre d’ Eclipse,trouver l’élément " DFS Locations" . Ouvrez-le , à l’intérieur, vous devriez voir laréférence d’emplacement localhost avec l’icône de Hadoop. Garder ouvrant les élé-ments en dessous jusqu’à ce que vous voyez quelque chose comme la figure ci-dessous.
Tous les fichiers contenus dans le HDFS apparaissent dans la liste déroulante pour

ANNEXE B. FRAMEWORK HADOOP VIA ECLIPSE KEPLER
cela Hadoop doit etre lancé sur la machine locale suivant les deux commandes "start-dfs.sh" et "start-yarn.sh".
Maintenant, cette étape est terminée vous pouvez passer à l’étape suivante.
B.1.2 Création d’un projet Map/Reduce sous Eclipse1. Clic droit sur "Window" dans Explorateur de projets , puis sélectionnez New->
projet... pour créer un nouveau projet.2. Sélectionnez le projet de Map/Reduce dans la liste des types de projets comme le
montre la figure ci-dessous.3. Appuyez sur le bouton suivant , la fenêtre de propriétés de projet s’affichera.4. Cliquez sur " configure Hadoop install directory ... " ,dans la fenêtre de préférences
de projet, entrez l’emplacement du répertoire Hadoop dans le champ Répertoired’installation de Hadoop comme indiqué ci-dessus.
5. Après avoir entré l’emplacement, fermez la fenêtre de préférences en appuyant surle bouton OK. Puis fermez la fenêtre de projet avec le bouton Terminer.
6. Vous avez maintenant créé votre premier projet Hadoop sous Eclipse , dont le noms’affichera dans l’onglet Explorateur de projets.
B.1.2.1 Création de classes Map/Reduce
1. Clic droit sur le projet Hadoop nouvellement créé dans l’onglet Explorateur deprojets, puis sélectionnez New-> autres dans le menu contextuel.
2. Allez dans le dossier de Map/Reduce, sélectionnez MapReduceDriver, puis appuyezsur le bouton suivant.
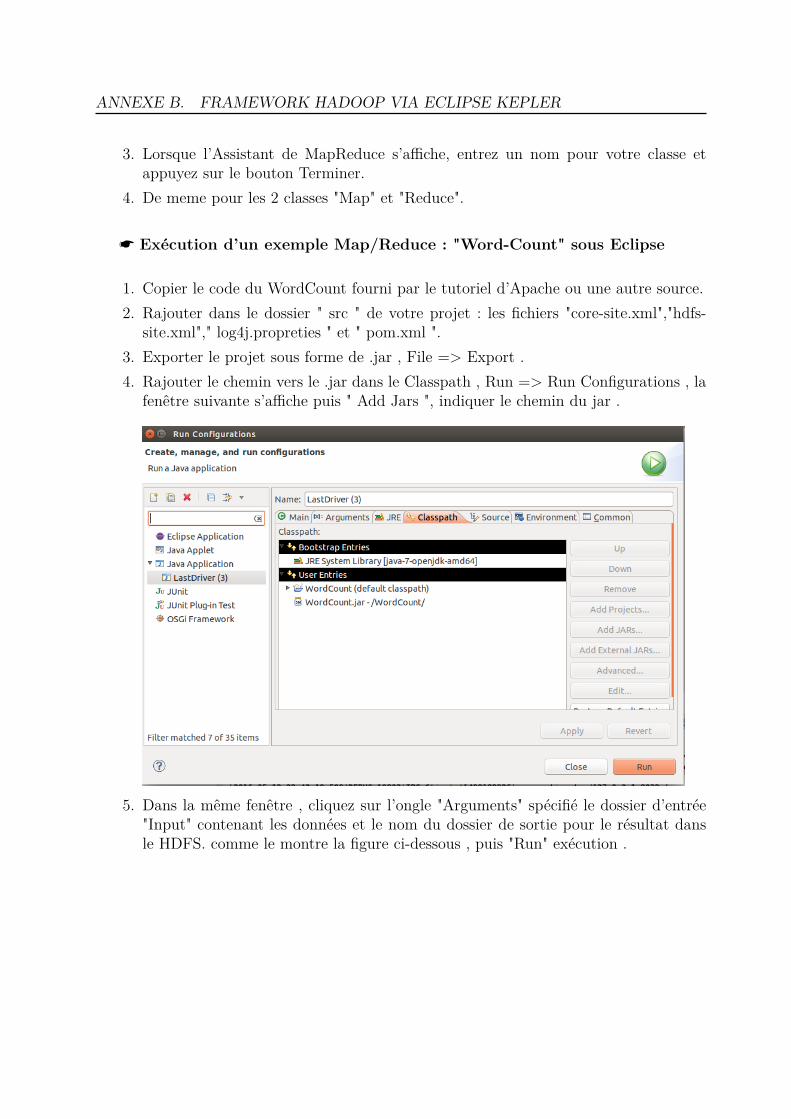
ANNEXE B. FRAMEWORK HADOOP VIA ECLIPSE KEPLER
3. Lorsque l’Assistant de MapReduce s’affiche, entrez un nom pour votre classe etappuyez sur le bouton Terminer.
4. De meme pour les 2 classes "Map" et "Reduce".
* Exécution d’un exemple Map/Reduce : "Word-Count" sous Eclipse
1. Copier le code du WordCount fourni par le tutoriel d’Apache ou une autre source.2. Rajouter dans le dossier " src " de votre projet : les fichiers "core-site.xml","hdfs-
site.xml"," log4j.propreties " et " pom.xml ".3. Exporter le projet sous forme de .jar , File => Export .4. Rajouter le chemin vers le .jar dans le Classpath , Run => Run Configurations , la
fenêtre suivante s’affiche puis " Add Jars ", indiquer le chemin du jar .
5. Dans la même fenêtre , cliquez sur l’ongle "Arguments" spécifié le dossier d’entrée"Input" contenant les données et le nom du dossier de sortie pour le résultat dansle HDFS. comme le montre la figure ci-dessous , puis "Run" exécution .
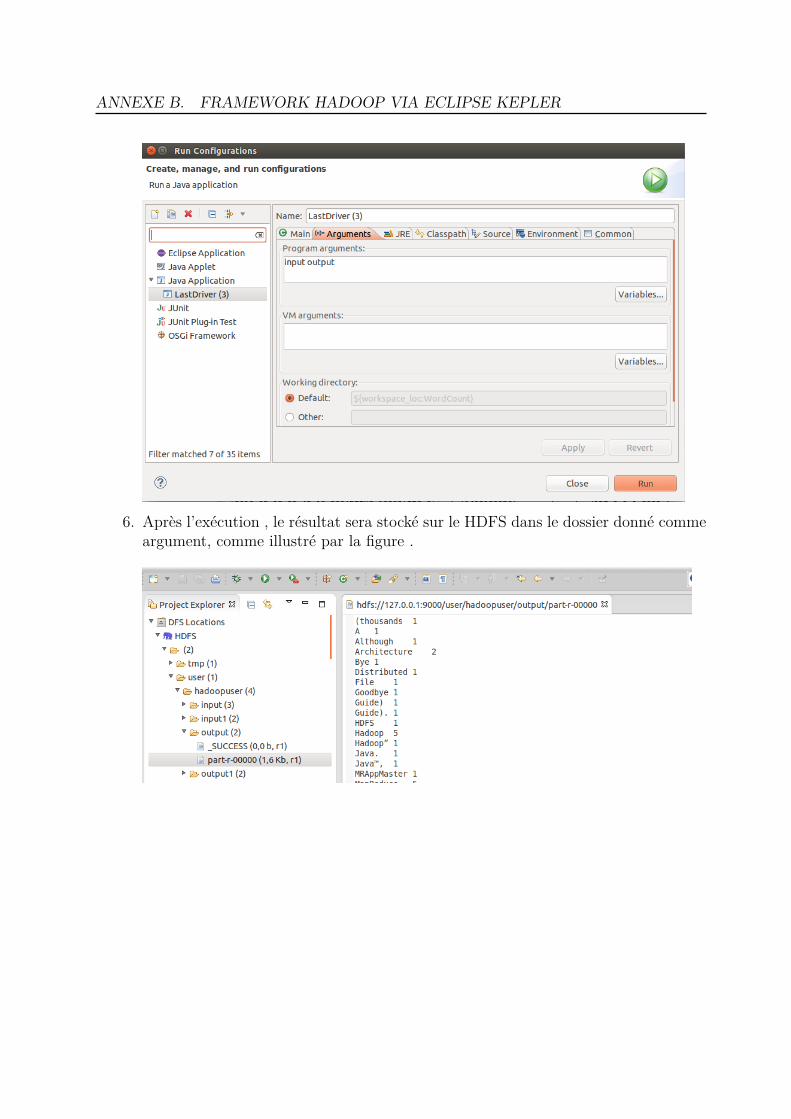
ANNEXE B. FRAMEWORK HADOOP VIA ECLIPSE KEPLER
6. Après l’exécution , le résultat sera stocké sur le HDFS dans le dossier donné commeargument, comme illustré par la figure .

Annexe
CHadoop sous la distributionCloudera
Pour une utilisation directe de Hadoop sans installation et configuration on peut utili-ser la solution Cloudera.Cloudera est un produit d’une start-up de la Silicon Valley, basée BBurlingame (Califor-nie), et cofondée en 2008 par le mathématicien Jeff Hammerbach , CDH contient les prin-cipaux éléments, de base du framework Hadoop (MapReduce et HDFS), ainsi que d’autrescomposants orientés vers les entreprises qui assurent la sécurité, la haute disponibilité, etl’intégration avec le matériel et les autres logiciels (HDFS & MapReduce, Impala, ApacheSpark, HBase, Accumulo, Apache Kafka). Cloudera utilise l’approche de virtualisation,On peut la télécharger sous forme de machine virtuelle ou bien image docker par le liensuivant : http ://www.cloudera.com/downloads.html
L’avantage d’utilisation de cloudera est la simplicité de son utilisation et installation etadministration du cluster de plus on peut directement crée un projet et le lancer sans sesoucier d’avoir lancé les services de hadoop ou de les éteindre après avoir finis le travail,tous les outils de travail car il sont déjà installer , son inconvénient est qu’elle nécessitede grande ressource physique pour pouvoir lancé Cloudera Manager il faut avoir dans lamachine 8 giga de ram pour pouvoir la lancée et administrer le cluster.
Une fois télécharger faut importer la machine et la démarrer.
ANNEXE C. HADOOP SOUS LA DISTRIBUTION CLOUDERA
Comme on peut voir dans la figure le system d’exploitation est linux RedHat entreprise64bit, on a qu’un seul nœud dans le cluster qui en même temps maître et esclave. Ici dansnotre cas on ne peut pas rajouter des nœud esclaves à cause d’insuffisance de mémoire maison s’est servi de lui comme un cluster single node. Sur le bureau on trouve l’icône d’eclipseide de développement de java. Pour se familiarisé pour le développement sous Cloudera(configuration de eclipse pour un projet Map/Reduce) on vous invite de visiter le liensuivant : https ://blog.cloudera.com/blog/2013/08/how-to-use-eclipse-with-mapreduce-in-clouderas-quickstart-vm/Le lien suivant donne exemple de création du projet WordCount dans eclipse avec l’exécu-tion dans Hdfs : http ://www.bogotobogo.com/Hadoop BigData_hadoop_Creating_Java_Wordcount_Project_with_Eclipse_MapReduce2_Part2.php

Annexe
DProcédure de connexion et utili-sation du cluster IBN BADIS
D.1 Première connexionAprès la création de votre compte par l’administrateur de IBNBADIS, vous receverez
un mail du genre :
Bonjour, Voici les détails de votre compte utilisateur sur le cluster IBNBADIS pour vos tests :login : userpasswd : password (merci de respecter la casse)Vous pouvez vous connecter à partir de l’algérie en ssh comme suit :ssh_ [email protected] atterissez sur le noeud de management ibnbadis0. Les noeuds de calculsont ibnbadis11-ibnbadis42.Prières de ne pas lancer des calculs sur le noeud ibnbadis0.Les calculs deveront être lancés sur les noeuds ibnbadis11 à ibnbadis42.Bonne utilisation
À la première connexion au cluster IBN BADIS, vous atterrissez sur le noeud de ma-nagement ibnbadis0 sur lequel vous effectuez toutes vos opérations (reservation de noeuds,lancement de jobs, consultation de résultats, ...).Les connexions au cluster IBN BADIS sefont via ssh comme suit : ssh [email protected] : Le nœud ibnbadis0 n’est pas fait pour les calculs. Prière de ne pas exécuterexplicitement vos programmes sur ce nœud. Utilisez plutôt Slurm qui exclut ce nœud.
D.2 Utilisation du cluster IBN BADISLe cluster IBN BADIS utilise SLURM comme gestionnaire de ressources. SLURM
(Simple Linux Utility for Resource Management) est un outil open source pour la ges-tion de cluster et l’ordonnancement de jobs dans les clusters linux. Plus d’informationspeuvent être trouvées sur le site officiel de SLURM : http ://slurm.schedmd.com/


Résumé :
Nous avons travaillé sur une adaptation des approches classiques de parallélisation
de l'algorithme Branch and Bound sur le modèle Map/Reduce en utilisant le framework
Hadoop pour résoudre le problème combinatoire Flow Shop de permutation sur un
cluster d'ordinateurs.
Summary:
We have worked on an adaptation of the classical approaches of parallelization of
the Branch and Bound algorithm on the model Map/Reduce, using the Hadoop
framework in order to solve of the Flow Shop of permutation combinatorial problem
on a cluster of computers.
الملخص:
/ Mapعلى نموذج Branch and Bound اللوغاريتم موازاةلا على تكييف المناهج الكالسيكية لقد عملن
Reduce، اإلطار" وذلك باستخدام Hadoop مشكل تبديل أجل حل منFlow Shop على مجموعة من أجهزة
.الكمبيوتر