master ingénierie des systèmes industriels et des projets
TRANSCRIPT

MASTER Ingénierie des Systèmes Industriels et des Projets
SPECIALITE : SYSTEMES DYNAMIQUES ET SIGNAUX
Année 2008 / 2009
Thèse de Master SDS
Présentée et soutenue par :
Lei XU
le 02 juillet 2009
Au sein de l'Institut des Sciences et Techniques de l'Ingénieurs d'Angers
TITRE
APPORTS D’UN RESEAU BAYESIEN CAUSAL POUR LE DIAGNOSTIC PAR
CLASSIFICATION SUPERVISEE
JURY
Président : Laurent Hardouin Professeur des Université à l’ISTIA
Examinateurs : Fabrice Guérin Professeur des Université à l’ISTIA
Philippe Declerck Maître de Conférences à l’ISTIA
Sylvain Cloupet Maître de Conférences à l’ISTIA
Directeur(s) de thèse : Sylvain Verron Maître de Conférences à l’ISTIA
Laboratoire : LASQUO
LASQUO/ISTIA 62, av. Notre Dame du Lac 49000 Angers

Remerciements
Je tiens à remercier Monsieur Sylvain VERRON d’avoir suivi ce projet de Master 2. Son
aide, j’ai permis de mener à bien ce travail. Je souhaite également la remercier pour
sa disponibilité tout au long des semaines de projet.

1
TABLE DES MATIERES
1 Introduction ............................................................................................................... 2
2 Méthode de diagnostic par classification supervisée................................................... 4
2.1 Diagnostic par classification supervisée ....................................................4
2.2 L’Analyse discriminante ..............................................................................5
2.2.1 L’analyse discriminante quadratique..............................................6
2.2.2 L’analyse discriminante linéaire. ....................................................6
2.3 Méthode des SVM (Support Vector Machines) .........................................7
2.4 Méthode des k plus proches voisins (KNN) ...............................................7
2.5 Méthode des arbres de décision................................................................8
2.6 Méthode des réseaux de neurones ...........................................................9
3 Réseaux bayésiens ................................................................................................... 11
3.1 Présentation des réseaux bayésiens ........................................................11
3.2 Un exemple de réseaux bayésiens...........................................................11
3.3 Réseaux bayésiens conditionnel Gaussien...............................................12
3.4 Proposition de Méthode MYT et Li et al. .................................................12
3.5 Méthode MYT par réseaux bayésiens......................................................15
4 Application des méthodes proposées ....................................................................... 17
4.1 Proposition...............................................................................................17
4.2 Évaluation.................................................................................................17
4.2.1 Présentation du TEP.....................................................................18
4.2.2 Surveillance du TEP par réseaux bayésiens .................................23
4.3 Analyse.....................................................................................................30
5 Conclusion générale ................................................................................................. 32
6 Références : ............................................................................................................. 33

2
1 Introduction
Après un long temps de fonctionnement, il y a certains changements dans la
production de tout système, ce qui influence inévitablement la qualité des produits.
Outre une conception stricte et fiable, la mise en place d'un système de supervision
de processus peut assurer et améliorer la qualité des produits. La surveillance des
procédés est une méthode de modélisation utilisant les dernières données du
processus. En entreprise, avec les progrès de l'automatisation et l'augmentation de
la capacité de la mémoire de l'ordinateur dans le travail, la collecte et le stockage de
données de production permet la surveillance des procédés.
Définition d’un procédé (Selon Montgomery [1]):
X0 : l’entrée du procédé (ex : matières premières, composants)
Xi : les facteurs contrôlables (ex : matière, opérateur)
Zj : les facteurs non-contrôlables (ex : température)
Y : le produit fini (ex : les caractéristiques qualité du produit fini)
La sortie Y est un ensemble de caractéristiques qualité :
Y = (y1, y2,..., yp) (ex : longueur, température, etc.).On suppose que yi suit une loi
normale N (μi, σi2) et que Y suit une loi normale multivariée N (μY, ΣY).
=
p
Y
µ
µµ
µ...
2
1
=
221
22221
11221
2
...
............
...
...
ppp
p
p
Y
σσσ
σσσσσσ
σ
Procédé X0 Y
X1, X2,…, Xn
Z1, Z2,…, Zm
3
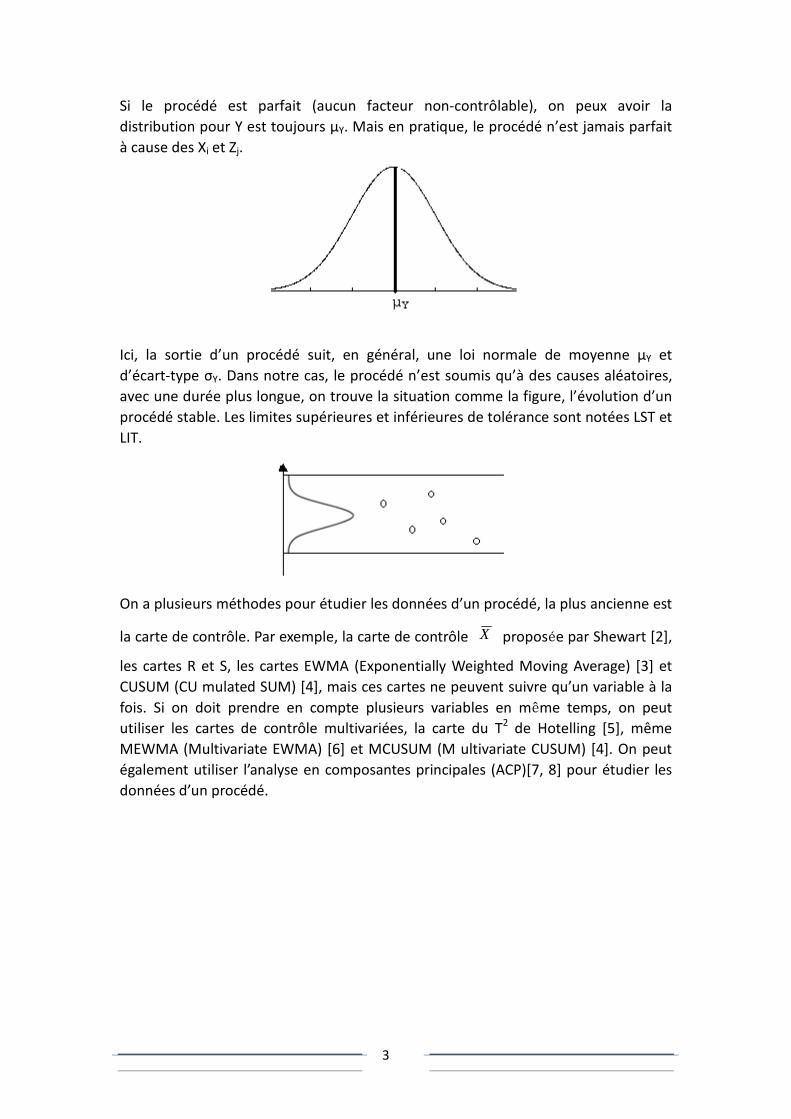
Si le procédé est parfait (aucun facteur non-contrôlable), on peux avoir la
distribution pour Y est toujours μY. Mais en pratique, le procédé n’est jamais parfait
à cause des Xi et Zj.
Ici, la sortie d’un procédé suit, en général, une loi normale de moyenne μY et
d’écart-type σY. Dans notre cas, le procédé n’est soumis qu’à des causes aléatoires,
avec une durée plus longue, on trouve la situation comme la figure, l’évolution d’un
procédé stable. Les limites supérieures et inférieures de tolérance sont notées LST et
LIT.
On a plusieurs méthodes pour étudier les données d’un procédé, la plus ancienne est
la carte de contrôle. Par exemple, la carte de contrôle X proposée par Shewart [2],
les cartes R et S, les cartes EWMA (Exponentially Weighted Moving Average) [3] et
CUSUM (CU mulated SUM) [4], mais ces cartes ne peuvent suivre qu’un variable à la
fois. Si on doit prendre en compte plusieurs variables en même temps, on peut
utiliser les cartes de contrôle multivariées, la carte du T2 de Hotelling [5], même
MEWMA (Multivariate EWMA) [6] et MCUSUM (M ultivariate CUSUM) [4]. On peut
également utiliser l’analyse en composantes principales (ACP)[7, 8] pour étudier les
données d’un procédé.

4
2 Méthode de diagnostic par classification supervisée
On trouve différentes méthodes de classification utilisables pour le diagnostic des
systèmes (classification supervisée à k classes) [9, 10], et il n'existe pas de classifieur
meilleur sur toutes les applications. Donc, nous rappelons tout d'abord le principe de
classification supervisée, et puis nous présentons les différentes méthodes de
classification.
2.1 Diagnostic par classification supervisée
En pratique, sur une production (avec une durée suffisante), on peut obtenir des
données pour différentes classes de fautes. On note ces fautes : F= {F1, F2,…, Fm}, et
chaque faute suit une loi normale: Fi~N (μFi, ΣFi2).
Lorsqu’une nouvelle faute est détectée, noté Y0, on cherche à savoir à quelle région
de faute elle appartient (diagnostic). Pour cela, il faut reconnaître les classes de faute,
on peut les analyser en trois étapes : l’extraction de composantes, l’analyse
discriminante, et la sélection. On étudie chaque probabilité de P (Fi|Y0), et trouve le
plus grande P(F*|Y0), après, on peut dire que Y0 et une faute de F*.
Pour le diagnostic, nous nous intéressons aux différentes classes de fautes. Par
exemple, trois fautes.
L'attribution d'une classe à une nouvelle observation est l'un des buts de la
reconnaissance de forme (classification). Le système type de reconnaissance de
forme se décompose en trois parties : l'extraction de composantes, l'analyse
discriminante (ou calcul des coûts Ki) et la sélection [11].

5
On peut voir le schéma de principe de la reconnaissance de forme :
2.2 L’Analyse discriminante
Se basant sur la règle de Bayes, l’analyse discriminante affecte à un nouvel individu x
la classe Ci qui maximise la probabilité a posteriori P (Ci| x).
( ){ }xCPisiCx iki
i,...,1maxarg
==∈
Par la règle de Bayes : )(
)|()()|(
xP
CxPCPxCP ii
i = , on peut le récrire sous la
forme :
( ) ( ){ }iiki
i CxPCPisiCx,...,1maxarg
==∈
Par la fonction de coût K, on peut trouve que :
{ })(maxarg,...,1
xKisiCx iki
i=
=∈
Avec ))|()((log(2)( iii CxPCPxK −=

6
2.2.1 L’analyse discriminante quadratique
En utilisant la loi normale multivariée, l’équation de coût peut s’écrire :
)2log(|)log(|))(log(2)()()( 1 πµµ pCPxxxK iiiiT
ii +Σ+−−Σ−= −
Si on fait l’hypothèse que tous les variables sont indépendantes, alors, Σi est
diagonale, comme diag (Σi )=(σ12, σ22, … ,σp2), on peut trouver la fonction de coût K
suivante :
)2log()log(2))(log(2||||
)(2
2
πσσ
µppCP
xxK ii
i
ii ++−−=
Le problème de l'analyse discriminante quadratique est qu'elle a besoin d’estimer
beaucoup de paramètres, donc, il faut beaucoup de données. Les problèmes
d'estimation venant principalement des différentes matrices de variance-covariance,
une solution consiste en l'analyse discriminante linéaire.
2.2.2 L’analyse discriminante linéaire.
On fait l’hypothèse que pour toute classe Ci, Σi=Σ, (n=n1+n2+...+nk)
kn
nnn kk
−Σ−++Σ−+Σ−=Σ )1(...)1()1( 2211
On obtient la fonction coût:
CsteCPxxxK iiT
ii +−−Σ−= − ))(log(2)()()( 1 µµ
Cette fonction coût réalise des séparations linéaires (hyperplans) entre les classes.
Bien que l’on puisse faire l’hypothèse que Σ est diagonale, quelque problèmes
subsistent pour l’analyse discriminante, notamment:
- les estimations de matrices de variance-covariance deviennent très variables,
- certains paramètres peuvent ne pas être identifiables,
- certains matrices de variance-covariance deviennent non-inversibles.

7
2.3 Méthode des SVM (Support Vector Machines)
Les SVM sont des outils modernes pour la classification et la régression de données
[12]. Ils sont des classifieurs binaires,et ici, on étudie leur application à la
classification supervisée. Le but d’un SVM est de trouver un classifieur séparant les
données de différentes fautes, et maximisant la distance entre chaque classe. Ce
classifieur est appelé hyperplan. Par exemple pour deux classes :
2.4 Méthode des k plus proches voisins (KNN)
La méthode des k plus proches voisins (k Nearest Neighborhood) est une méthode
de discrimination non-paramétrique [13]. Pour une nouvelle observation à classer,
cette méthode calcule la distance de cette nouvelle observation à chaque
observation présente. On choisit les k voisins ayant la distance la plus faible (plus
proche). En générale, on attribue à la nouvelle observation la même que celle la plus
représentée parmi ses k plus proches voisins.
Un de problèmes principal de la classification par les k plus proches voisins est que
pour chaque nouvel individu à classer, on doit calculer les distances de ce nouvel
individu à chaque individu présent dans la base d’apprentissage, donc, cela prend
beaucoup de mémoire de stockage.
8
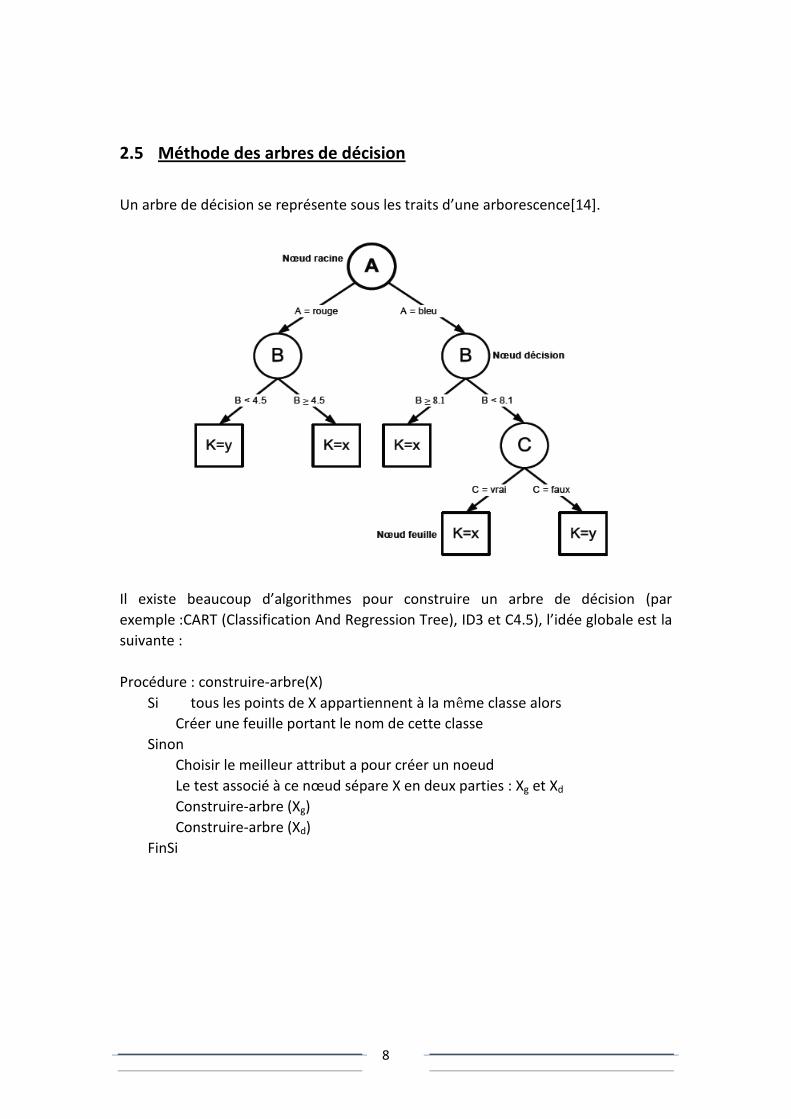
2.5 Méthode des arbres de décision
Un arbre de décision se représente sous les traits d’une arborescence[14].
Il existe beaucoup d’algorithmes pour construire un arbre de décision (par
exemple :CART (Classification And Regression Tree), ID3 et C4.5), l’idée globale est la
suivante :
Procédure : construire-arbre(X)
Si tous les points de X appartiennent à la même classe alors
Créer une feuille portant le nom de cette classe
Sinon
Choisir le meilleur attribut a pour créer un noeud
Le test associé à ce nœud sépare X en deux parties : Xg et Xd
Construire-arbre (Xg)
Construire-arbre (Xd)
FinSi

9
En observant la procédure de construction d'un arbre, on constate qu'une étape
pose problème : choisir le meilleur attribut pour créer un nœud. En effet, le but des
algorithmes d'arbre de décision est de trouver l'ordre adéquat des décisions à
prendre. En d'autres mots, quels attributs doivent être placés dans les premières
décisions et quels autres doivent être placés vers le bout de l'arbre (les feuilles). Le
but est donc de choisir en premier lieu l'attribut séparant au mieux les données dans
l'espace entier d'apprentissage. Ceci équivaut à chercher l'attribut dont
l'homogénéité est la plus faible. Afin de résoudre ce problème, les algorithmes cités
(CART, ID3 et C4.5) se basent sur la notion d'entropie H [15].
Soient les données suivantes : n exemples, réparties en k classes Ck comportant
chacune nj, p attributs binaires notés ai. Pour un attribut binaire a donné (a = vrai ou
a = faux), chaque sous-ensemble nj est divisé en deux parties contenant
respectivement vj (a = vrai) et fj ( a = faux),
∑=
=k
jjnn
1 , ∑
=
=k
jjvv
1 , ∑
=
=k
jjff
1 , nfv =+
L’entropie de l’attribut a est calculée par :
∑∑==
+=k
j
jjk
j
jj
f
f
f
f
n
f
v
v
v
v
n
vaCH
11
)log()log()|(
Donc, on trouve ai qui minimise l’entropie,
))|(min(arg iaCHi =
2.6 Méthode des réseaux de neurones
Les réseaux de neurones constituent une technique non-linéaire prédiction de
données [16].

10
On peut observer qu’un neurone reçoit une information de la part de plusieurs
entrées, avec ses poids propres ωj. On note s la somme de toutes xjωj :
∑=
=n
jjjxs
1
ω
La somme s est transmise à une fonction de transfert nommée fonction d’activation h,
donnant alors la sortie général y du neurone.
)(1∑
=
=n
jjjxhy ω
Les différentes fonctions d’activation h
La mise en relation de plusieurs neurones nous donne un réseau de neurones.
On note la première couche « couche d’entrée » et la dernière couche « couche de
sortie », et il y a une ou plusieurs couches de neurones entre ces deux couches,
notées couche cachées. Il n’y a aucune liaison entre les neurones d’une même
couche.

11
3 Réseaux bayésiens
3.1 Présentation des réseaux bayésiens
Un réseaux bayésien est modèle graphique probabilisé [17]. Il est défini par :
-Un graphe acyclique orienté G, G= (V, E), V est l’ensemble des nœud de G, E
est l’ensemble des arcs de G,
-Un espace probabilité(Ω,Z,P), Ω est un ensemble fini non-vide, Z est ensemble de
sous-espace, P une mesure de probabilité sur Z, P(Z)=1,
-un ensemble de variable aléatoire associées aux nœud du graphe G, telle que :
∏=
=n
iiin VCVPVVVP
121 ))(|(),...,,(
C(Vi) est l’ensemble des causes de Vi dans le graphe G.
Chaque variable est un nœud du graphe et prend ses valeurs dans un ensemble
discret ou continu. Le graphe est toujours dirigé et acyclique. Les arcs dirigés
représentent un lien de dépendance directe (la plupart du temps il s'agit de
causalité). Ainsi un arc allant de la variable X à la variable Y exprimera que Y
dépende directement de X. Les paramètres expriment les poids donnes à ces
relations et sont les probabilités conditionnelles des variables sachant leurs parents
(exemple : P(Y|X)) . Il est possible de réaliser des classifieurs grâce aux réseaux
bayésiens.
3.2 Un exemple de réseau bayésien
( http://bnt.insa-rouen.fr/tutoriels/tutoriel1.html ):

12
3.3 Réseaux bayésiens conditionnel Gaussien
Un réseau bayésien permet de modéliser plusieurs types de nœuds. Dans le cadre
des procèdes, nous sommes principalement en présence de deux types de nœuds :
un nœud représentant une variable discrète que l'on nomme nœud discret et un
nœud représentant une variable continue que l'on nomme nœud continu. Les
réseaux bayésiens traitent de modèles paramétriques. Or, dans le cas discret, un
nœud multinomial permet de modéliser toutes fonctions de densité de probabilité
d'une variable discrète. En effet, une variable binaire (par exemple Vrai-Faux) peut se
représenter grâce à un nœud discret (donc multinomial) de dimension 2 (possédant
2 modalités différentes). Pour les nœuds continus, il est logiquement possible de
pouvoir représenter n'importe quelles fonctions de densité de probabilité d'une
variable continue. Mais, à l'heure actuelle, les moteurs d'inférence ne savent traiter
qu'une seule fonction de densité de probabilité : celle de la loi normale multivariée
de dimension p. Cependant, toute fonction de densité de probabilité d'une variable
continue peut être approchée comme un mélange de plusieurs lois gaussiennes :
∑=
=p
iii CxPaxP
1
)|()( avec 10 << ia ,
11
=∑=
p
iia
3.4 Proposition de Méthode MYT et Li et al.
La méthode MYT a été mise au point par Mason, Young, et Tracy [18], et utilise la
statistique T2 [5] dans un nombre limité de composantes orthogonales qui sont
également des distances statistiques.
21,...,3,2,1
23,2,14
22,13
212
21
2 ... −•••• +++++= ppTTTTTT
Où 2
,. kjiT représente la statistique T2 de Xj, Xk sur Xi.
On fait l’hypothèse que le procédé peut être modélisé sous la forme d’un réseau
bayésien causal (chaque variable du procédé est une variable gaussienne univariée).
Si un réseau bayésien représente uniquement des variables continues normales, il
est appelé modèle linéaire gaussien.
Dans le cadre de la modélisation du procédé par un modèle linéaire gaussien, pour
une décomposition du T2 donnée, s’il existe un terme 2
1,...,1 −• iiT tel que l’ensemble de
variable {X1, … , Xi-1} contient au moins un descendant de Xi, cette décomposition est
de type A, dans le cas contraire, la décomposition est de type B.

13
On voit un exemple de 3 variables, X1, X2, X3 :
Les décompositions possibles sont les suivantes :
Li et al. [19] Prouvent que les décompositions de type A permettent un diagnostic
moins précis que les décompositions de type B. De plus, dans le contexte du modèle
linéaire gaussien, toutes les décompositions de type B convergent vers une unique
décomposition que les auteurs nomment "causation-based T2 décomposition", noté
décomposition causale du T2. Donc, chaque décomposition de type B (dans le cas
d'un modèle linéaire gaussien causal) converge vers la décomposition causale du T2
décrite dans l'équation ∑
=•=
p
iXPAi i
TT1
2)(
2
, où PA(X i) représentent les parents de la
variable X i sur le graphe causal. Ainsi, la décomposition causale du T2 de l'exemple
de { X1, X2, X3} est la suivante : 213
212
21
2•• ++= TTTT .
Suite à ces différentes démonstrations, les auteurs énoncent la procédure de
détection et de diagnostic utilisant la nouvelle décomposition causale. D’abord, pour
représenter les relations causales entre les différentes variables du procédé, on
construit un réseau bayésien linéaire gaussien, suite à cela, le procédé est surveillé
par une carte de contrôle du T2. Lors de la détection d'une situation hors-contrôle, le
T2 est décomposé par la décomposition causale de l’équation précédente. Dans
cette équation, chaque 2
)( iXPAiT • est indépendant et suit une distribution du 2χ
à
un degré de liberté. On compare chaque 2
)( iXPAiT • à la limite 2,1αχ
représentant le
quantile à la valeur α (taux de fausses alertes) de la distribution du 2χ à un degré
de liberté. Un 2
)( iXPAiT • significatif (dépassant la limite de contrôle) implique que la
variable X i a probablement subi un saut de moyenne. La figure représente le
diagramme de surveillance du procédé par la méthode énoncée ci-dessus.

14
Pour démontrer la performance de cette approche, les auteurs utilisent un procède
à 5 variables comme exemple, représenté par le réseau bayésien causal (modèle
linéaire gaussien) de la figure suivante, où la variable X5 représente une
caractéristique qualité, et les 4 autres sont des variables du procédé.
Dans ce contexte (5 variables), il existe 31 situations potentielles de fautes : 5 fautes
potentielles uniques (1 seule variable incriminée) et 26 fautes potentielles multiples
(plusieurs variables incriminées). Chaque faute est représentée comme un saut de
moyenne de 3 écart-types sur chaque variable incriminée. Une fois la situation
hors-contrôle détectée, elle est diagnostiquée. Si le diagnostic correspond
exactement au scénario simulé, le diagnostic est considéré comme correct, sinon il
est considéré comme erroné.
L'approche développe par Li et al. est la seule approche permettant la prise en
compte de variables continues. De plus, cette approche exploite des seuils donnes
par des quantiles de lois statistiques. Donc, elle permet d'améliorer
considérablement les performances de diagnostic par rapport à la méthode MYT,
tout en demandant moins de calcul que celle-ci. Cependant, quelques points
seraient à éclaircir. L'approche proposée possède exactement la même idée
sous-jacente à l'approche MYT, à savoir la régression des variables du procédé. La
différence ici est que l'on apporte une information supplémentaire : les relations
causales entre les différentes variables du procédé. Les auteurs se servent du réseau
bayésien causal. De plus, cette méthode permet juste l'identification des variables
responsables d'une situation hors-contrôle, mais elle n'effectue pas la détection par
réseau bayésien.
15
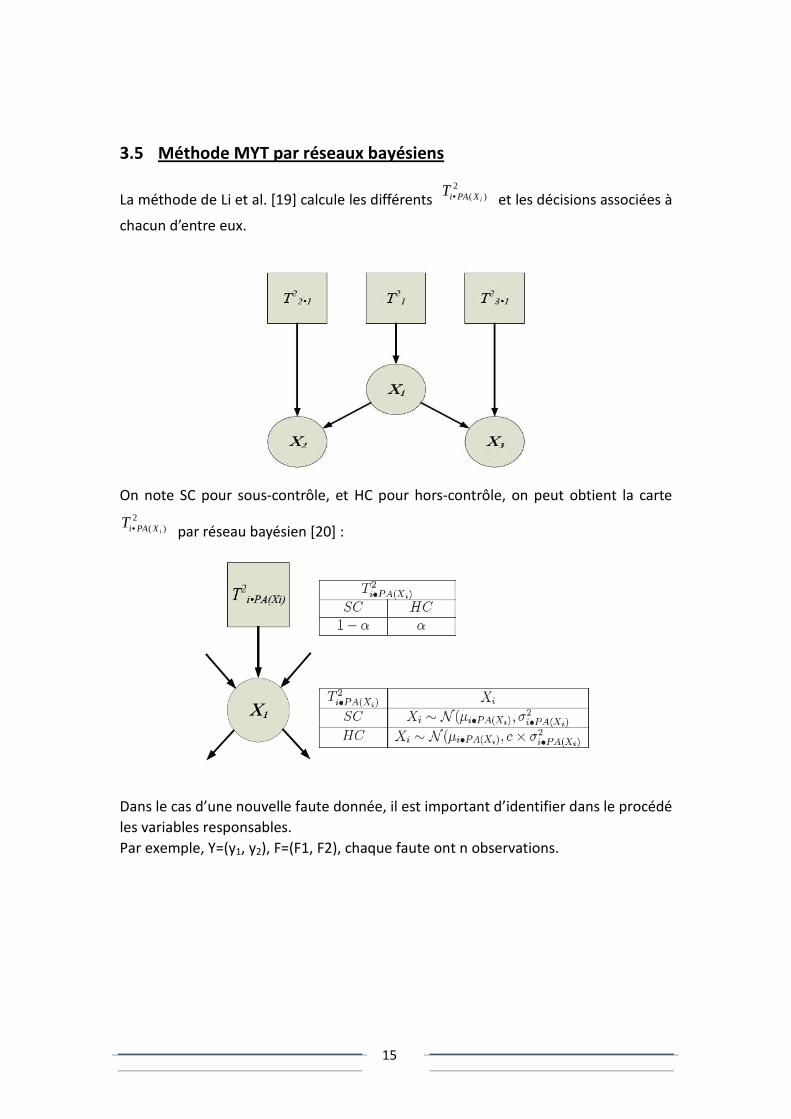
3.5 Méthode MYT par réseaux bayésiens
La méthode de Li et al. [19] calcule les différents 2
)( iXPAiT • et les décisions associées à
chacun d’entre eux.
On note SC pour sous-contrôle, et HC pour hors-contrôle, on peut obtient la carte
2)( iXPAiT • par réseau bayésien [20] :
Dans le cas d’une nouvelle faute donnée, il est important d’identifier dans le procédé
les variables responsables.
Par exemple, Y=(y1, y2), F=(F1, F2), chaque faute ont n observations.
16
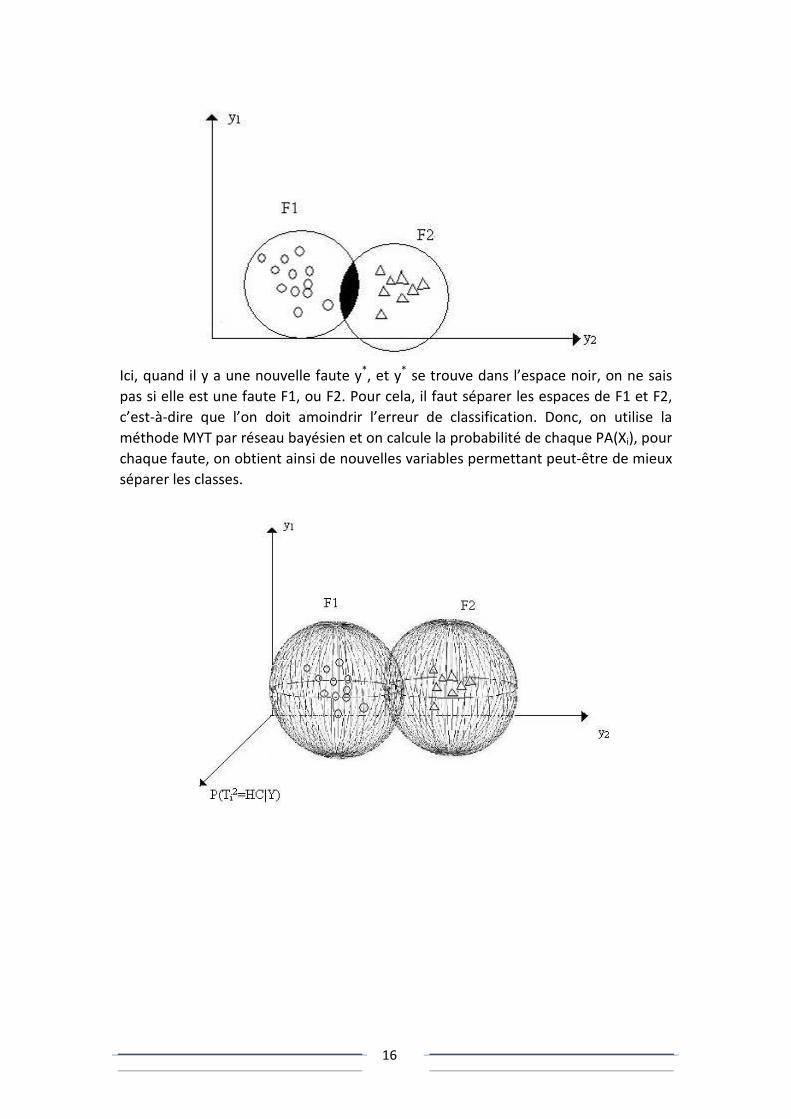
Ici, quand il y a une nouvelle faute y*, et y* se trouve dans l’espace noir, on ne sais
pas si elle est une faute F1, ou F2. Pour cela, il faut séparer les espaces de F1 et F2,
c’est-à-dire que l’on doit amoindrir l’erreur de classification. Donc, on utilise la
méthode MYT par réseau bayésien et on calcule la probabilité de chaque PA(Xi), pour
chaque faute, on obtient ainsi de nouvelles variables permettant peut-être de mieux
séparer les classes.

17
4 Application des méthodes proposées
L'application du réseau présenté demande (comme toute autre méthode de
détection ou de diagnostic basée sur les données) une base de données regroupant
des observations de période de fonctionnement normal ainsi que des observations
des différentes fautes déjà connues.
4.1 Proposition
Comme on possède des données normales (déjà connues), on construit le réseau
bayésien. Par les différentes donnée fautes déjà connues, en les appliquant sur le
réseau bayésien causal, on peut obtenir des probabilités pour chaque faute, après,
on cherche les résultats par les différentes méthodes proposées. Pour chaque
méthode, il y a deux résultats : avec-probabilité, et sans-probabilité. On peut
résumer la proposition par la figure suivante.
4.2 Évaluation
Afin de valider les méthodes sur un exemple réel, nous l'appliquons sur un procédé
chimique complexe : le Tennessee Eastman Process (TEP) [21]. Ce procède complexe
implique 53 variables et 20 types de fautes. Ici, nous étudions les performances du
réseau en diagnostic supervisé.
Données Normales Données fautes
Données fautes avec des probabilités
Diagnostic par classifieur
Réseau Bayésien causal
Diagnostic par classifieur
Comparer
Construire le Réseau Bayésien
Calculer les probabilités
18
4.2.1 Présentation du TEP
Le Tennessee Eastman Process (TEP) est un procédé chimique développé par la
société Eastman Chemical Company afin de fournir une simulation d’un procédé
industriel réel. Il a été utilisé par la communauté de la surveillance des procédés.
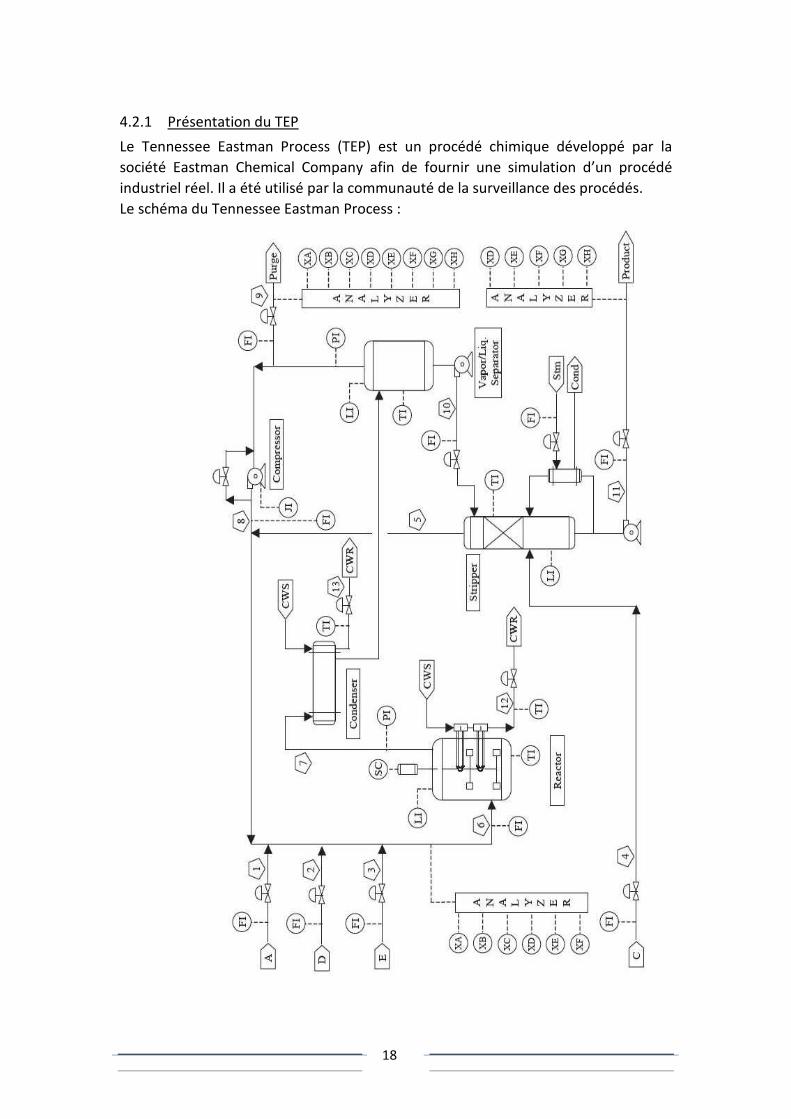
Le schéma du Tennessee Eastman Process :

19
Ce procédé comporte 53 variables : 12 variables d’asservissement et 41 variables
mesurables. Parmi les 41 variables mesurables, 22 sont des variables mesurables en
continu (ce sont les valeurs des capteurs du procédé), les autres sont des mesures de
compositions telles que des concentrations, et ne sont pas disponibles en continu
mais échantillonnées.
Les variables de mesure en continu :
Les variables de mesure échantillonnées :

20
Les variables de contrôle du TEP (variables d’asservissement)
Pour comparer les méthodes de surveillance des procédés, on peut classifier le TEP
par 20 fautes différentes.
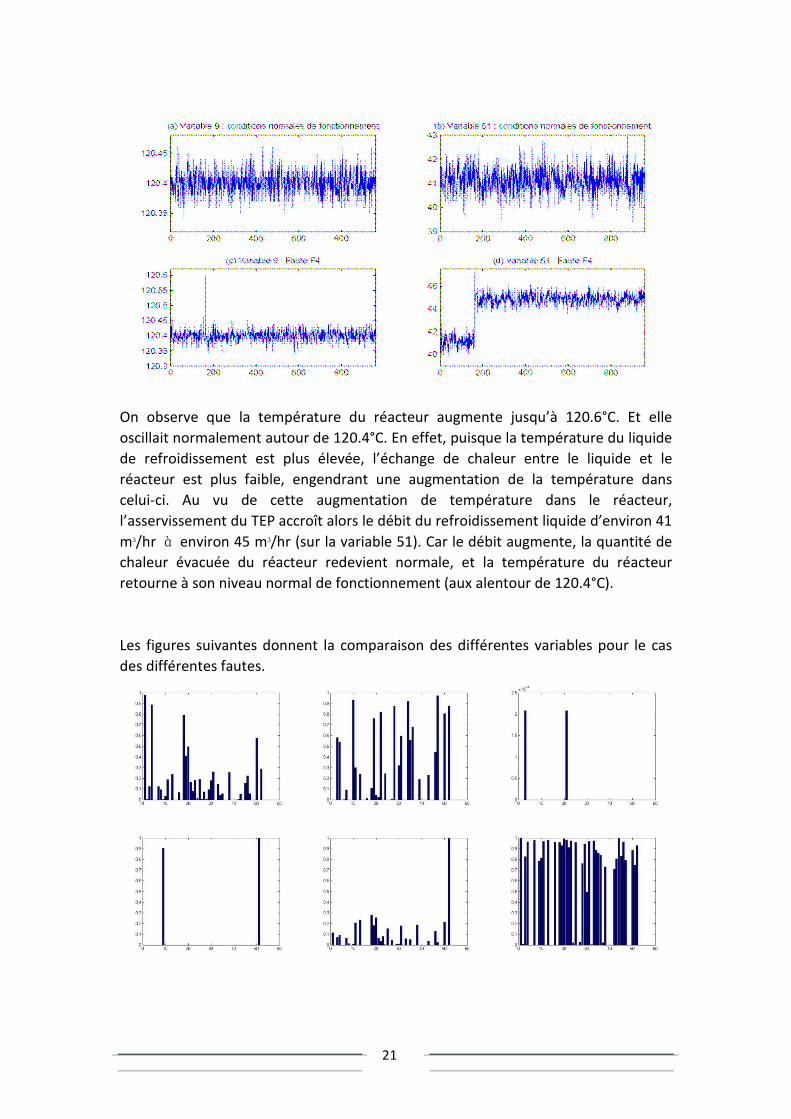
Il est possible de décrire le comportement des variables 9 (température du réacteur)
et 51 (débit du refroidissement liquide au réacteur) en réponse à l’introduction de la
fautes F4 (augmentation de la température d’entrée du liquide de refroidissement
du réacteur).
21
On observe que la température du réacteur augmente jusqu’à 120.6°C. Et elle
oscillait normalement autour de 120.4°C. En effet, puisque la température du liquide
de refroidissement est plus élevée, l’échange de chaleur entre le liquide et le
réacteur est plus faible, engendrant une augmentation de la température dans
celui-ci. Au vu de cette augmentation de température dans le réacteur,
l’asservissement du TEP accroît alors le débit du refroidissement liquide d’environ 41
m3/hr à environ 45 m3/hr (sur la variable 51). Car le débit augmente, la quantité de
chaleur évacuée du réacteur redevient normale, et la température du réacteur
retourne à son niveau normal de fonctionnement (aux alentour de 120.4°C).
Les figures suivantes donnent la comparaison des différentes variables pour le cas
des différentes fautes.
22
23
4.2.2 Surveillance du TEP par réseaux bayésiens
On utilise les données en ligne à l’adresse suivante http://brahms.scs.uiuc.edu . Elles
se présentent ainsi : 480 observation d’apprentissage pour chaque type de faute, et
800 observation de test pour chaque type de faute. Les données d’apprentissage ont
été obtenues par simulation de chacune des fautes sur une période de 24 heures, et
les données de test ont été obtenues sur une durée de 40 heures. La période d’
échantillonnage de toutes les variables a été fixée à 3 minutes. Il faut préciser que
les 53 variables n’ont pas été prises en compte puisque la variable XC(12), la vitesse
de l’agitateur, reste constante dans n’importe quelle situation.
Les données utilisées :
Pour tester les performances en diagnostic supervisé de la méthode proposée, on
prend en compte toutes les fautes, sans sélection de composantes et on suppose
que chaque observation est détectée.
On peut voir la matrice d’occurrence, pour chaque colonne testée, la trace de cette
matrice donne le nombre de bonnes classifications, il nous présente que certaine
fautes sont très bien reconnues par le classifieur (F1, F2, F5, F6, F7, F8, F12, F14 et
F19), avec un taux supérieur à 95%, F3, F9, F15 sont très mal reconnues, avec un
taux inférieur à 25%, les 8 autre fautes restantes sont moyennement reconnues
avec les taux entre 75% et 90%.

24
25
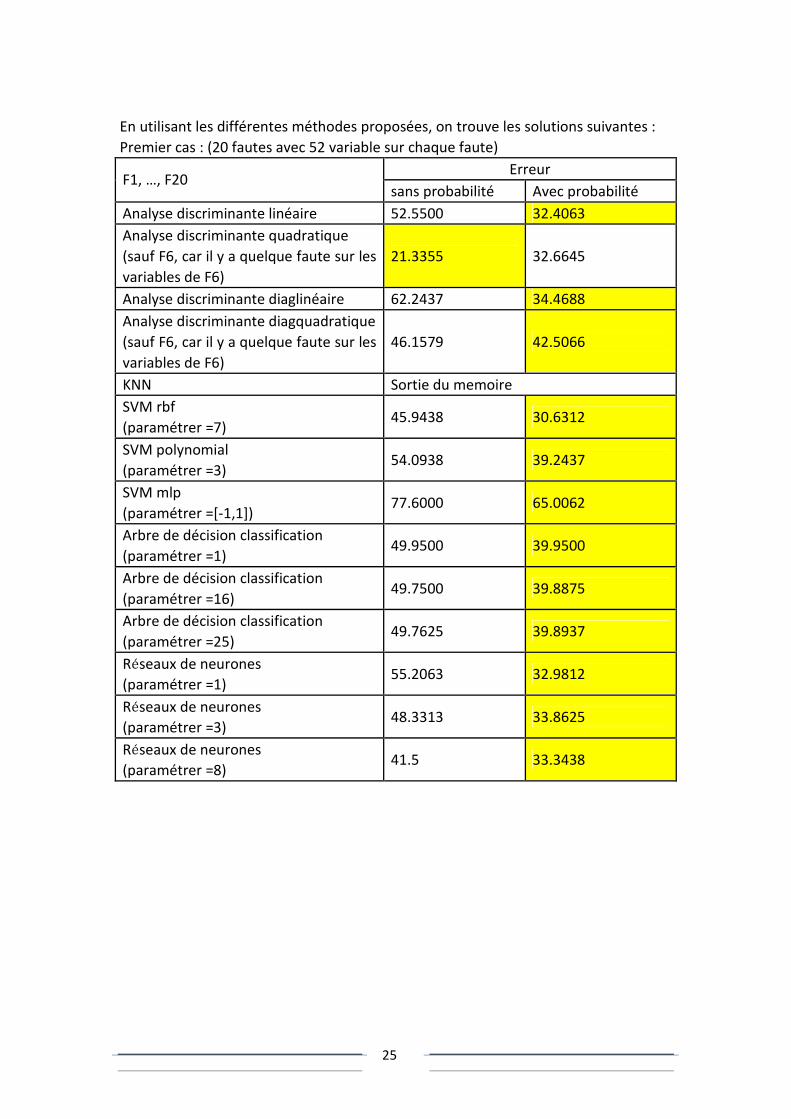
En utilisant les différentes méthodes proposées, on trouve les solutions suivantes :
Premier cas : (20 fautes avec 52 variable sur chaque faute)
Erreur F1, …, F20
sans probabilité Avec probabilité
Analyse discriminante linéaire 52.5500 32.4063
Analyse discriminante quadratique
(sauf F6, car il y a quelque faute sur les
variables de F6)
21.3355 32.6645
Analyse discriminante diaglinéaire 62.2437 34.4688
Analyse discriminante diagquadratique
(sauf F6, car il y a quelque faute sur les
variables de F6)
46.1579 42.5066
KNN Sortie du memoire
SVM rbf
(paramétrer =7) 45.9438 30.6312
SVM polynomial
(paramétrer =3) 54.0938 39.2437
SVM mlp
(paramétrer =[-1,1]) 77.6000 65.0062
Arbre de décision classification
(paramétrer =1) 49.9500 39.9500
Arbre de décision classification
(paramétrer =16) 49.7500 39.8875
Arbre de décision classification
(paramétrer =25) 49.7625 39.8937
Réseaux de neurones
(paramétrer =1) 55.2063 32.9812
Réseaux de neurones
(paramétrer =3) 48.3313 33.8625
Réseaux de neurones
(paramétrer =8) 41.5 33.3438
26
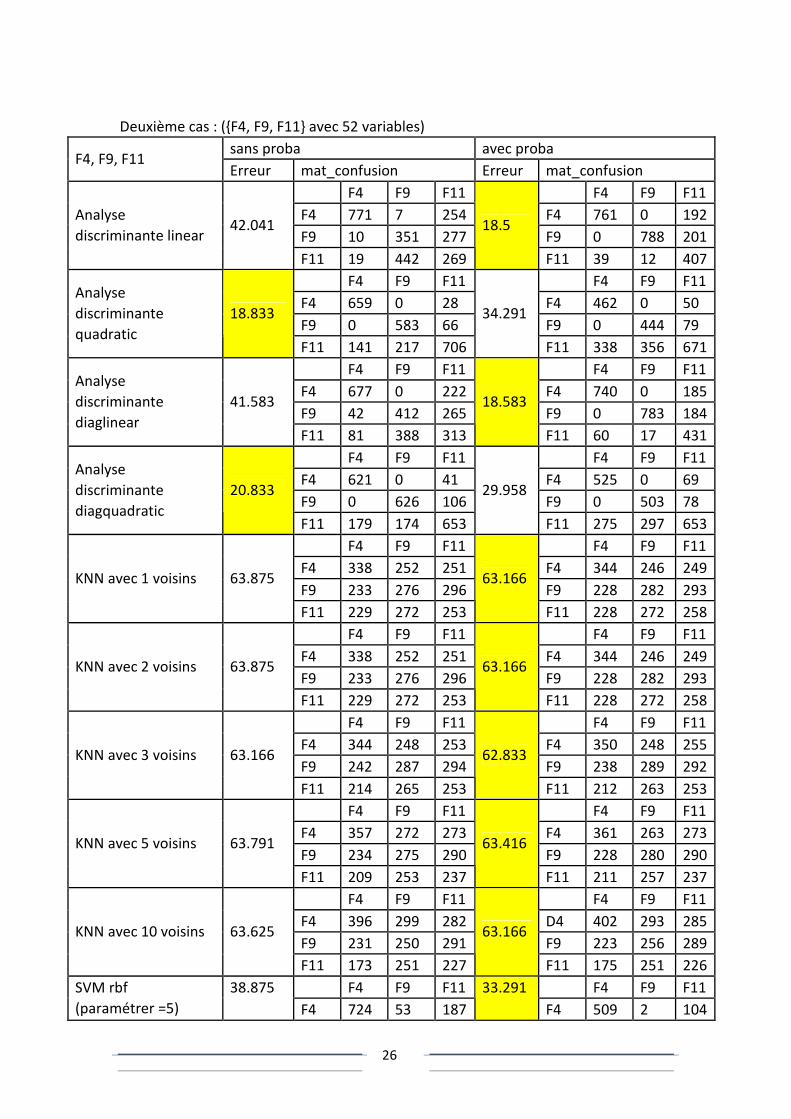
Deuxième cas : ({F4, F9, F11} avec 52 variables)
sans proba avec proba F4, F9, F11
Erreur mat_confusion Erreur mat_confusion
F4 F9 F11 F4 F9 F11
F4 771 7 254 F4 761 0 192
F9 10 351 277 F9 0 788 201
Analyse
discriminante linear 42.041
F11 19 442 269
18.5
F11 39 12 407
F4 F9 F11 F4 F9 F11
F4 659 0 28 F4 462 0 50
F9 0 583 66 F9 0 444 79
Analyse
discriminante
quadratic
18.833
F11 141 217 706
34.291
F11 338 356 671
F4 F9 F11 F4 F9 F11
F4 677 0 222 F4 740 0 185
F9 42 412 265 F9 0 783 184
Analyse
discriminante
diaglinear
41.583
F11 81 388 313
18.583
F11 60 17 431
F4 F9 F11 F4 F9 F11
F4 621 0 41 F4 525 0 69
F9 0 626 106 F9 0 503 78
Analyse
discriminante
diagquadratic
20.833
F11 179 174 653
29.958
F11 275 297 653
F4 F9 F11 F4 F9 F11
F4 338 252 251 F4 344 246 249
F9 233 276 296 F9 228 282 293 KNN avec 1 voisins 63.875
F11 229 272 253
63.166
F11 228 272 258
F4 F9 F11 F4 F9 F11
F4 338 252 251 F4 344 246 249
F9 233 276 296 F9 228 282 293 KNN avec 2 voisins 63.875
F11 229 272 253
63.166
F11 228 272 258
F4 F9 F11 F4 F9 F11
F4 344 248 253 F4 350 248 255
F9 242 287 294 F9 238 289 292 KNN avec 3 voisins 63.166
F11 214 265 253
62.833
F11 212 263 253
F4 F9 F11 F4 F9 F11
F4 357 272 273 F4 361 263 273
F9 234 275 290 F9 228 280 290 KNN avec 5 voisins 63.791
F11 209 253 237
63.416
F11 211 257 237
F4 F9 F11 F4 F9 F11
F4 396 299 282 D4 402 293 285
F9 231 250 291 F9 223 256 289 KNN avec 10 voisins 63.625
F11 173 251 227
63.166
F11 175 251 226
F4 F9 F11 F4 F9 F11 SVM rbf
(paramétrer =5)
38.875
F4 724 53 187
33.291
F4 509 2 104
27
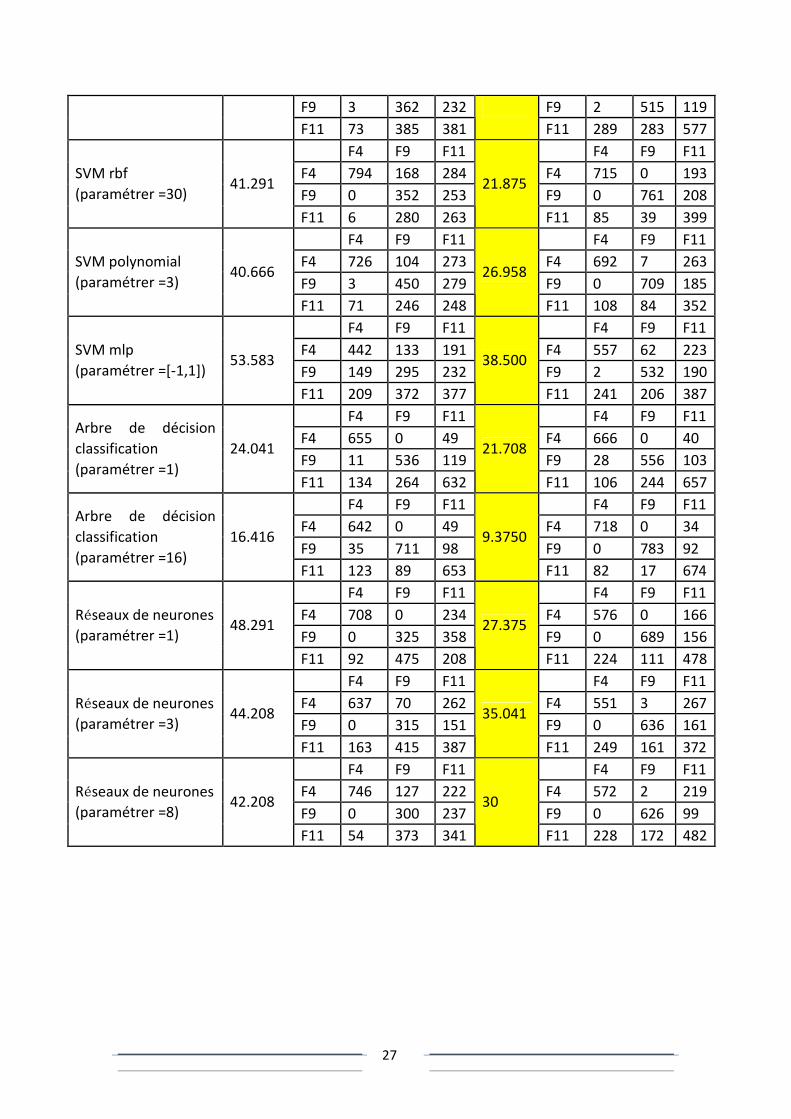
F9 3 362 232 F9 2 515 119
F11 73 385 381
F11 289 283 577
F4 F9 F11 F4 F9 F11
F4 794 168 284 F4 715 0 193
F9 0 352 253 F9 0 761 208
SVM rbf
(paramétrer =30) 41.291
F11 6 280 263
21.875
F11 85 39 399
F4 F9 F11 F4 F9 F11
F4 726 104 273 F4 692 7 263
F9 3 450 279 F9 0 709 185
SVM polynomial
(paramétrer =3) 40.666
F11 71 246 248
26.958
F11 108 84 352
F4 F9 F11 F4 F9 F11
F4 442 133 191 F4 557 62 223
F9 149 295 232 F9 2 532 190
SVM mlp
(paramétrer =[-1,1]) 53.583
F11 209 372 377
38.500
F11 241 206 387
F4 F9 F11 F4 F9 F11
F4 655 0 49 F4 666 0 40
F9 11 536 119 F9 28 556 103
Arbre de décision
classification
(paramétrer =1)
24.041
F11 134 264 632
21.708
F11 106 244 657
F4 F9 F11 F4 F9 F11
F4 642 0 49 F4 718 0 34
F9 35 711 98 F9 0 783 92
Arbre de décision
classification
(paramétrer =16)
16.416
F11 123 89 653
9.3750
F11 82 17 674
F4 F9 F11 F4 F9 F11
F4 708 0 234 F4 576 0 166
F9 0 325 358 F9 0 689 156
Réseaux de neurones
(paramétrer =1) 48.291
F11 92 475 208
27.375
F11 224 111 478
F4 F9 F11 F4 F9 F11
F4 637 70 262 F4 551 3 267
F9 0 315 151 F9 0 636 161
Réseaux de neurones
(paramétrer =3) 44.208
F11 163 415 387
35.041
F11 249 161 372
F4 F9 F11 F4 F9 F11
F4 746 127 222 F4 572 2 219
F9 0 300 237 F9 0 626 99
Réseaux de neurones
(paramétrer =8) 42.208
F11 54 373 341
30
F11 228 172 482
28
Troisième cas: ({F4, F9, F11} avec 2 variables (X9 et X51) pour chaque faute)
sans proba avec proba F4, F9, F11
Erreur mat_confusion Erreur mat_confusion
F4 F9 F11 F4 F9 F11
F4 799 0 257 F4 797 0 196
F9 1 480 180 F9 0 799 162
Analyse
discriminante linear 31.583
F11 0 320 363
15.083
F11 3 1 442
F4 F9 F11 F4 F9 F11
F4 796 0 37 F4 788 0 84
F9 0 775 75 F9 0 776 71
Analyse
discriminante
quadratic
5.8750
F11 4 25 688
7.9583
F11 12 24 645
F4 F9 F11 F4 F9 F11
F4 800 0 276 F4 797 0 220
F9 0 462 144 F9 0 799 130
Analyse
discriminante
diaglinear
31.583
F11 0 338 380
14.750
F11 3 1 450
F4 F9 F11 F4 F9 F11
F4 784 0 44 F4 786 0 102
F9 0 759 86 F9 0 775 71
Analyse
discriminante
diagquadratic
7.7917
F11 16 41 670
8.8333
F11 14 25 627
F4 F9 F11 F4 F9 F11
F4 749 0 70 F4 741 0 57
F9 0 742 130 F9 0 754 92 KNN avec 1 voisins 12.875
F11 51 58 600
10.583
F11 59 46 651
F4 F9 F11 F4 F9 F11
F4 749 0 70 F4 741 0 57
F9 0 742 130 F9 0 754 92 KNN avec 2 voisins 12.875
F11 51 58 600
10.583
F11 59 46 651
F4 F9 F11 F4 F9 F11
F4 780 0 73 F4 774 0 71
F9 0 778 158 F9 0 786 94 KNN avec 3 voisins 11.375
F11 20 22 569
8.5417
F11 26 14 635
F4 F9 F11 F4 F9 F11
F4 779 0 75 F4 777 0 73
F9 0 779 179 F9 0 786 96 KNN avec 5 voisins 12.333
F11 21 21 546
8.5833
F11 23 14 631
F4 F9 F11 F4 F9 F11
F4 773 0 84 D4 782 0 72
F9 0 773 185 F9 0 796 102 KNN avec 10 voisins 13.458
F11 27 27 531
8.1667
F11 18 4 626
F4 F9 F11 F4 F9 F11 SVM rbf
(paramétrer =5)
21.541
F4 799 0 205
11.583
F4 796 0 162
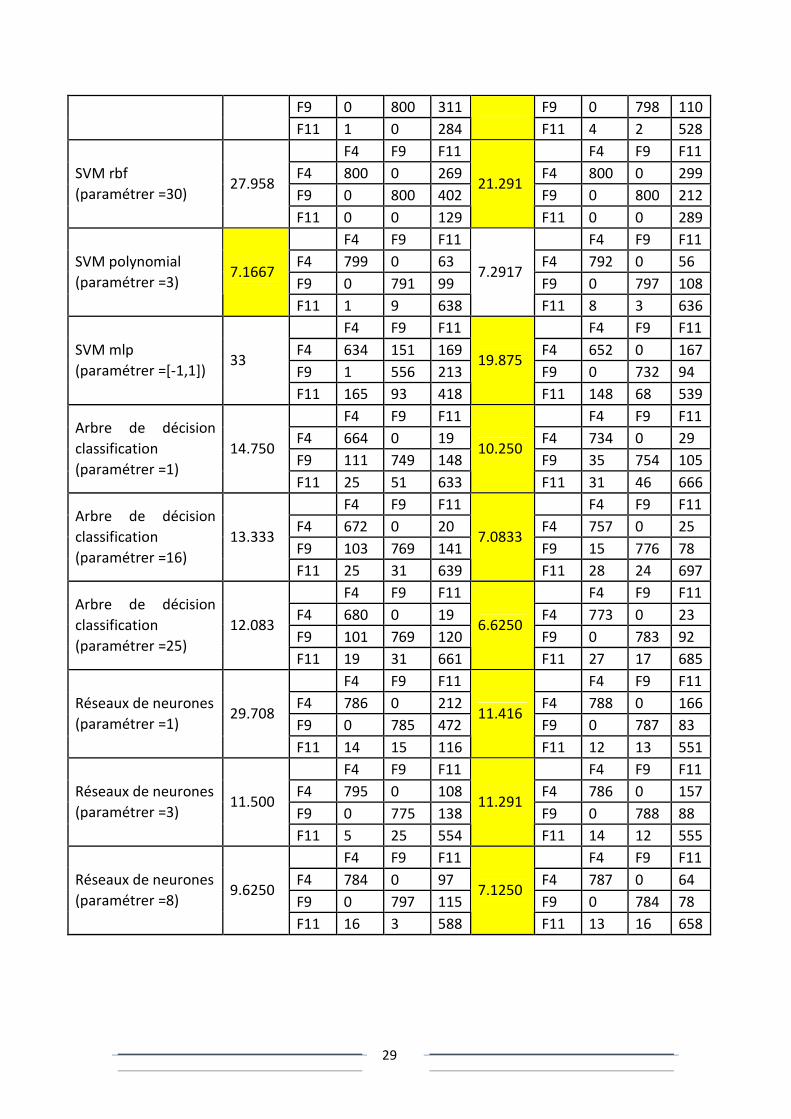
29
F9 0 800 311 F9 0 798 110
F11 1 0 284
F11 4 2 528
F4 F9 F11 F4 F9 F11
F4 800 0 269 F4 800 0 299
F9 0 800 402 F9 0 800 212
SVM rbf
(paramétrer =30) 27.958
F11 0 0 129
21.291
F11 0 0 289
F4 F9 F11 F4 F9 F11
F4 799 0 63 F4 792 0 56
F9 0 791 99 F9 0 797 108
SVM polynomial
(paramétrer =3) 7.1667
F11 1 9 638
7.2917
F11 8 3 636
F4 F9 F11 F4 F9 F11
F4 634 151 169 F4 652 0 167
F9 1 556 213 F9 0 732 94
SVM mlp
(paramétrer =[-1,1]) 33
F11 165 93 418
19.875
F11 148 68 539
F4 F9 F11 F4 F9 F11
F4 664 0 19 F4 734 0 29
F9 111 749 148 F9 35 754 105
Arbre de décision
classification
(paramétrer =1)
14.750
F11 25 51 633
10.250
F11 31 46 666
F4 F9 F11 F4 F9 F11
F4 672 0 20 F4 757 0 25
F9 103 769 141 F9 15 776 78
Arbre de décision
classification
(paramétrer =16)
13.333
F11 25 31 639
7.0833
F11 28 24 697
F4 F9 F11 F4 F9 F11
F4 680 0 19 F4 773 0 23
F9 101 769 120 F9 0 783 92
Arbre de décision
classification
(paramétrer =25)
12.083
F11 19 31 661
6.6250
F11 27 17 685
F4 F9 F11 F4 F9 F11
F4 786 0 212 F4 788 0 166
F9 0 785 472 F9 0 787 83
Réseaux de neurones
(paramétrer =1) 29.708
F11 14 15 116
11.416
F11 12 13 551
F4 F9 F11 F4 F9 F11
F4 795 0 108 F4 786 0 157
F9 0 775 138 F9 0 788 88
Réseaux de neurones
(paramétrer =3) 11.500
F11 5 25 554
11.291
F11 14 12 555
F4 F9 F11 F4 F9 F11
F4 784 0 97 F4 787 0 64
F9 0 797 115 F9 0 784 78
Réseaux de neurones
(paramétrer =8) 9.6250
F11 16 3 588
7.1250
F11 13 16 658
30
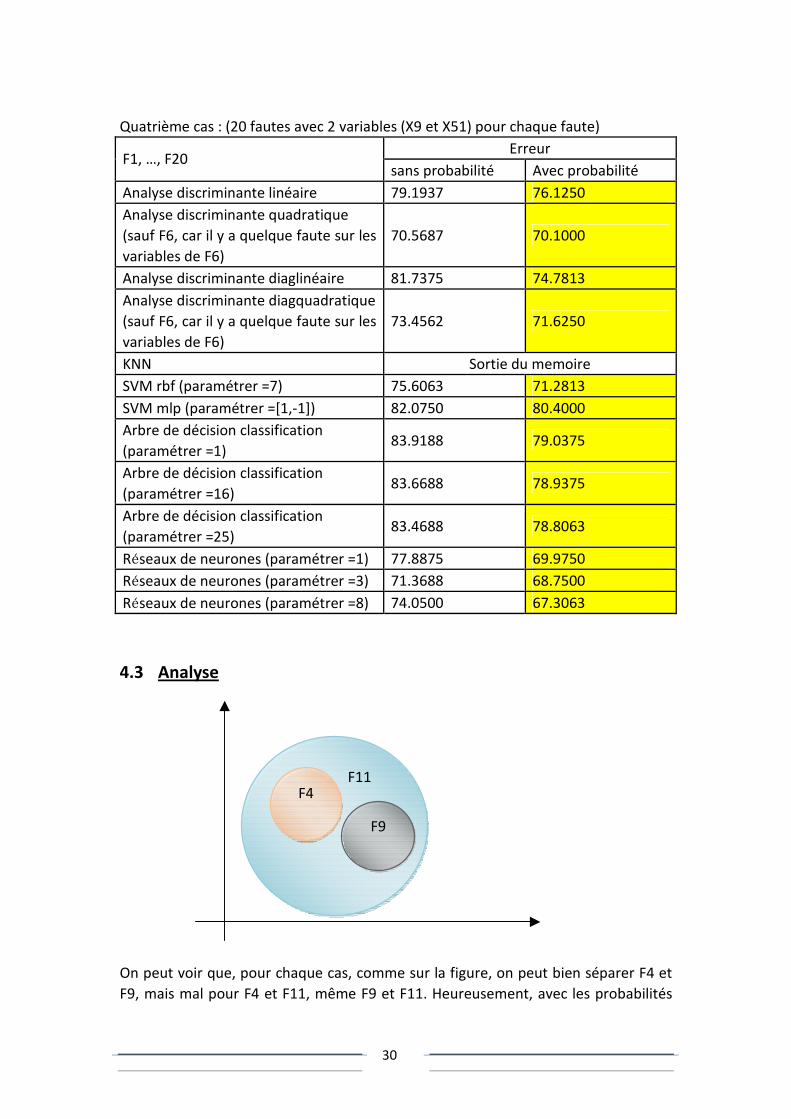
Quatrième cas : (20 fautes avec 2 variables (X9 et X51) pour chaque faute)
Erreur F1, …, F20
sans probabilité Avec probabilité
Analyse discriminante linéaire 79.1937 76.1250
Analyse discriminante quadratique
(sauf F6, car il y a quelque faute sur les
variables de F6)
70.5687 70.1000
Analyse discriminante diaglinéaire 81.7375 74.7813
Analyse discriminante diagquadratique
(sauf F6, car il y a quelque faute sur les
variables de F6)
73.4562 71.6250
KNN Sortie du memoire
SVM rbf (paramétrer =7) 75.6063 71.2813
SVM mlp (paramétrer =[1,-1]) 82.0750 80.4000
Arbre de décision classification
(paramétrer =1) 83.9188 79.0375
Arbre de décision classification
(paramétrer =16) 83.6688 78.9375
Arbre de décision classification
(paramétrer =25) 83.4688 78.8063
Réseaux de neurones (paramétrer =1) 77.8875 69.9750
Réseaux de neurones (paramétrer =3) 71.3688 68.7500
Réseaux de neurones (paramétrer =8) 74.0500 67.3063
4.3 Analyse
On peut voir que, pour chaque cas, comme sur la figure, on peut bien séparer F4 et
F9, mais mal pour F4 et F11, même F9 et F11. Heureusement, avec les probabilités
F11 F4
F9
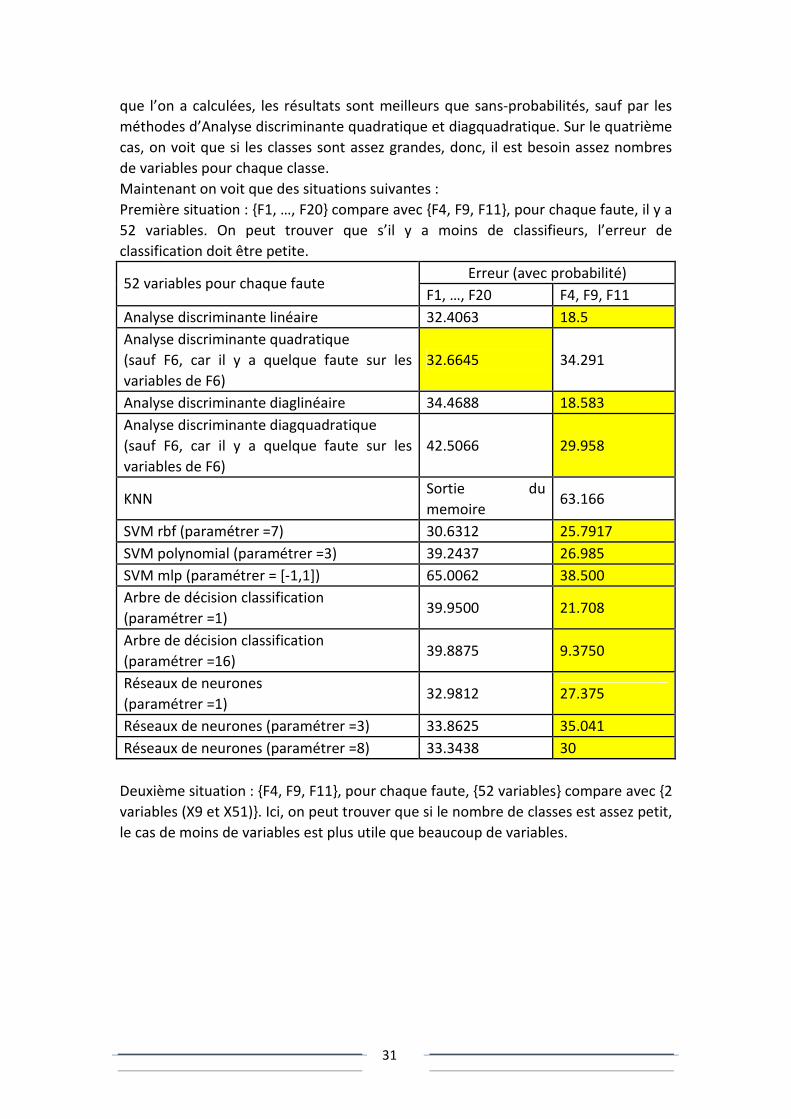
31
que l’on a calculées, les résultats sont meilleurs que sans-probabilités, sauf par les
méthodes d’Analyse discriminante quadratique et diagquadratique. Sur le quatrième
cas, on voit que si les classes sont assez grandes, donc, il est besoin assez nombres
de variables pour chaque classe.
Maintenant on voit que des situations suivantes :
Première situation : {F1, …, F20} compare avec {F4, F9, F11}, pour chaque faute, il y a
52 variables. On peut trouver que s’il y a moins de classifieurs, l’erreur de
classification doit être petite.
Erreur (avec probabilité) 52 variables pour chaque faute
F1, …, F20 F4, F9, F11
Analyse discriminante linéaire 32.4063 18.5
Analyse discriminante quadratique
(sauf F6, car il y a quelque faute sur les
variables de F6)
32.6645 34.291
Analyse discriminante diaglinéaire 34.4688 18.583
Analyse discriminante diagquadratique
(sauf F6, car il y a quelque faute sur les
variables de F6)
42.5066 29.958
KNN Sortie du
memoire 63.166
SVM rbf (paramétrer =7) 30.6312 25.7917
SVM polynomial (paramétrer =3) 39.2437 26.985
SVM mlp (paramétrer = [-1,1]) 65.0062 38.500
Arbre de décision classification
(paramétrer =1) 39.9500 21.708
Arbre de décision classification
(paramétrer =16) 39.8875 9.3750
Réseaux de neurones
(paramétrer =1) 32.9812 27.375
Réseaux de neurones (paramétrer =3) 33.8625 35.041
Réseaux de neurones (paramétrer =8) 33.3438 30
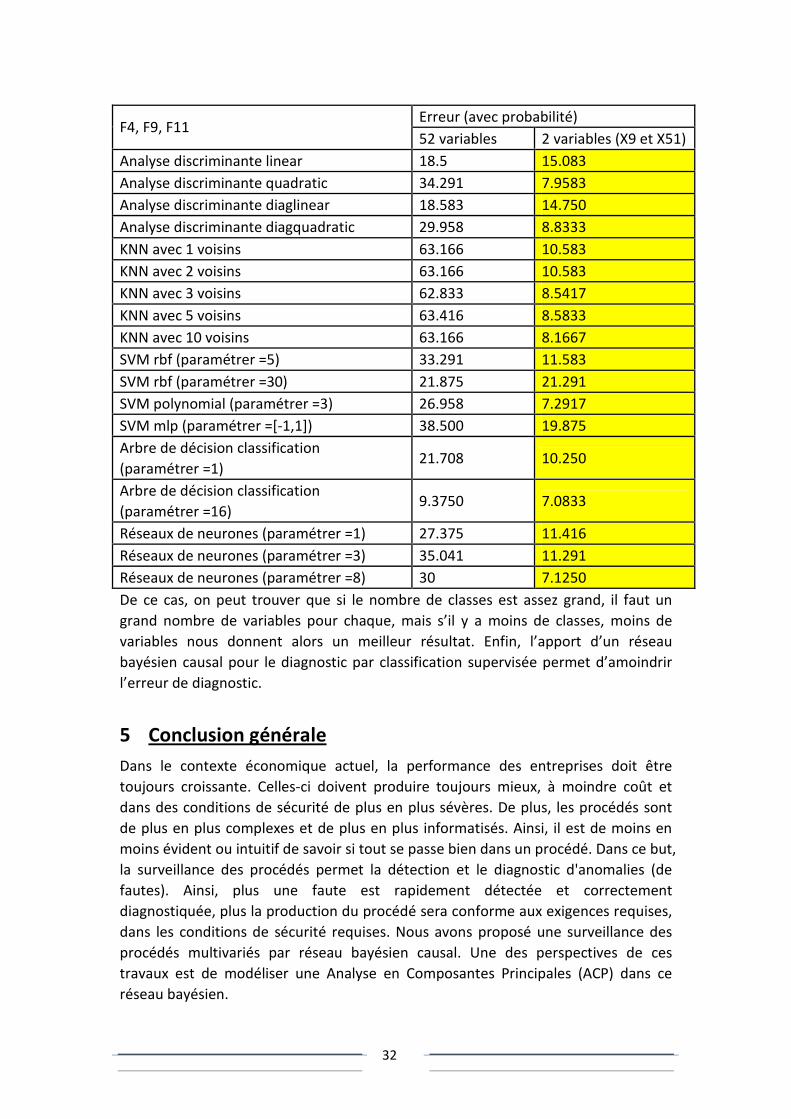
Deuxième situation : {F4, F9, F11}, pour chaque faute, {52 variables} compare avec {2
variables (X9 et X51)}. Ici, on peut trouver que si le nombre de classes est assez petit,
le cas de moins de variables est plus utile que beaucoup de variables.
32
De ce cas, on peut trouver que si le nombre de classes est assez grand, il faut un
grand nombre de variables pour chaque, mais s’il y a moins de classes, moins de
variables nous donnent alors un meilleur résultat. Enfin, l’apport d’un réseau
bayésien causal pour le diagnostic par classification supervisée permet d’amoindrir
l’erreur de diagnostic.
5 Conclusion générale
Dans le contexte économique actuel, la performance des entreprises doit être
toujours croissante. Celles-ci doivent produire toujours mieux, à moindre coût et
dans des conditions de sécurité de plus en plus sévères. De plus, les procédés sont
de plus en plus complexes et de plus en plus informatisés. Ainsi, il est de moins en
moins évident ou intuitif de savoir si tout se passe bien dans un procédé. Dans ce but,
la surveillance des procédés permet la détection et le diagnostic d'anomalies (de
fautes). Ainsi, plus une faute est rapidement détectée et correctement
diagnostiquée, plus la production du procédé sera conforme aux exigences requises,
dans les conditions de sécurité requises. Nous avons proposé une surveillance des
procédés multivariés par réseau bayésien causal. Une des perspectives de ces
travaux est de modéliser une Analyse en Composantes Principales (ACP) dans ce
réseau bayésien.
Erreur (avec probabilité) F4, F9, F11
52 variables 2 variables (X9 et X51)
Analyse discriminante linear 18.5 15.083
Analyse discriminante quadratic 34.291 7.9583
Analyse discriminante diaglinear 18.583 14.750
Analyse discriminante diagquadratic 29.958 8.8333
KNN avec 1 voisins 63.166 10.583
KNN avec 2 voisins 63.166 10.583
KNN avec 3 voisins 62.833 8.5417
KNN avec 5 voisins 63.416 8.5833
KNN avec 10 voisins 63.166 8.1667
SVM rbf (paramétrer =5) 33.291 11.583
SVM rbf (paramétrer =30) 21.875 21.291
SVM polynomial (paramétrer =3) 26.958 7.2917
SVM mlp (paramétrer =[-1,1]) 38.500 19.875
Arbre de décision classification
(paramétrer =1) 21.708 10.250
Arbre de décision classification
(paramétrer =16) 9.3750 7.0833
Réseaux de neurones (paramétrer =1) 27.375 11.416
Réseaux de neurones (paramétrer =3) 35.041 11.291
Réseaux de neurones (paramétrer =8) 30 7.1250

33
6 Références :
[1] Douglas C. Montgomery. Introduction to Statistical Quality Control, Third Edition.
John Wiley and Sons, 1997.
[2] Walter A. Shewhart. Economic control of quality of manufactured product. New York : D. Van Nostrand Co., 1931. [3] S. W. Roberts. Control chart tests based on geometric moving averages. Technometrics, 1(3) :239–250, Aout 1959.
[4] J.J. Pignatiello et G.C. Runger. Comparisons of multivariate cusum charts. Journal of Quality Technology, 22(3) :173-186, 1990. [5] Harold Hotelling. Multivariate quality control. Techniques of Statistical Analysis, :111–184, 1947. [6] Cynthia A. Lowry, William H. Woodall, Charles W. Champ, et Steven E. Rigdon. A multivariate exponentially weighted moving average control chart. Technometrics, 34(1) :46–53, 1992. [7] Brigitte Escofier et Jérôme Pages. Analyses factorielles simples et multiples : Objectifs, méthodes et interprétation, 3ème édition. Dunod, 1998. [8] Ludovic Lebart, Alain Morineau, et Marie Piron. Statistique exploratoire multidimensionnelle. DUNOD, 2000.
[9] Iserman, R. Fault Diagnosis : An introduction from fault detection to fault
tolerance. Springer, 2005.
[10] Chiang, L. H.; Russell, E. L. & Braatz, R. D. Fault detection and diagnosis in
industrial systems. New York: Springer-Verlag, 2001.
[11] L.H. Chiang, M.E. Kotanchek, et A.K. Kordon. Fault diagnosis based on fisher discriminant analysis and support vector machines. Computers and Chemical Engineering, 28(8) :1389–1401, 2004.
[12] Vladimir N. Vapnik. The Nature of Statistical Learning Theory. Springer, 1995.
[13] T.M. Cover et P.E. Hart. Nearest neighbor pattern classification. IEEE Transactions on Information Theory, 13 :21–27, 1967.
[14] Antoine Cornuéjols, Laurent Miclet, et Yves Kodratoff. Apprentissage artificiel : concepts et algorithmes. Eyrolles, 2002.

34
[15] Thomas M. Cover et Joy A. Thomas. Elements of Information Theory. John Wiley and Sons, 1991.
[16] Gérard Dreyfus, Jean-Marc Martinez, Mannuel Samuelides, Mirta Gordon, Fouad Badran, Sylvie Thiria, et Laurent Hérault. Réseaux de neurones : Méthodologie et applications. Eyrolles, 2ème édition, 2004.
[17] Patrick Naim, Pierre-Henri Wuillemin, Philippe Leray, Olivier Pourret, et Anna Becker. Réseaux bayésiens – 2ème édition. Eyrolles, 2004.
[18] Robert L. Mason, Nola D. Tracy, et John C. Young. Decomposition of T² for multivariate control chart interpretation. Journal of Quality Technology, 27(2) :99–108, 1995.
[19] Li, J.; Jin, J. & Shi, J. Causation-Based T² Decomposition for Multivariate Process
Monitoring and Diagnosis. Journal of Quality Technology, Vol. 40, pp. 46-58, 2008.
[20] Verron, S. Diagnostic et surveillance des processus complexes par réseaux
bayésiens. Thèse de doctorat de l’Université d’Angers, 2007
[21] P.R. Lyman et C. Georgakis. Plant-wide control of the tennessee eastman problem. Computers and Chemical Engineering, 19(3) :321-331, 1995.

Titre : Apports d’un réseau bayésien causal pour le diagnostic par classification
supervisée
Mots clés : Surveillance de procédés, réseau bayésien, détection, diagnostic,
surpervisé, analyse discriminante, arbres de décision, SVM, réseaux de
neurones, MYT
Résumé : Cette thèse porte sur la surveillance (détection et diagnostic) des procédés
multivariés par réseau bayésien causal. Ceci présente plusieurs méthodes de
surveillance surpervisées, telles que l’analyse discriminante, la méthode de SVM, de
KNN, des arbres de décision, des réseaux de neurones ou bien la méthode MYT. Par
appliquer ces méthodes sur un exemple classique : le procède Tennessee Eastman,
les performances du réseau bayésien causal pour le diagnostic sont évaluées.
Title :Contribution of causal bayesian network for diagnosis based on supervised
classification
Keywords : process montitoring, Bayesian networks, detection, diagnosis,
supervised, discriminant analysis, Tree method, SVM, KNN, Neural Network
method, MYT
Abstract : This thesis is about the multivariate process montitoring (detection and
diagnosis) with Bayesian networks. It presents some methods like discriminant
analysis, the Tree method, the SVM method, the KNN method, the Neural Network
method and the MYT method. By applying these proposed methods on a benchmark
problem: the Tennesse Eastman Process, efficiency of the Bayesian network is
evaluated for the diagnosis.
Laboratoire : LASQUO
LASQUO/ISTIA 62, av. Notre Dame du Lac 49000 Angers