master biologie intégrative 2017-2018 biostatistiques … · des croissances semblables, et...
TRANSCRIPT

1
Master Biologie Intégrative 2017-2018
Biostatistiques avancées
Responsable du cours : Yves Desdevises
Corrigé
Exercice 1 Un chercheur a créé un hybride entre deux souches de bactéries. Les deux souches d’origine ont des croissances semblables, et répondent de la même façon à une augmentation de la concentration en amidon. Le chercheur veut savoir si l’hybride répond également de la même façon à une telle augmentation. Il met en place une expérience avec 15 concentrations en amidon différentes, et mesure les croissances correspondantes pour un échantillon de chaque souche bactérienne (45 observations au total). 1. Quelle(s) méthode(s) permettent d'appréhender ce problème ? Posez toutes les hypothèses nulles et contraires testées dans le cas de la méthode la plus évidente. On peut faire une ANCOVA, ou une ANOVA à 2 facteurs avec répétitions, mais cela suppose de recoder en classes la variable indépendante quantitative (concentration en amidon). On pourrait aussi faire une régression multiple en recodant la variable qualitative (souche) en variables muettes. Nous allons réaliser l’analyse de covariance : Hypothèses nulles et contraires de l'ANCOVA : H0 : La concentration d’amidon n'a pas d'effet sur la croissance des bactéries. H0 : Le type de souche bactérienne n’affecte pas la relation entre la concentration en amidon et la croissance des bactéries. H0 : Le type de souche bactérienne n'a pas d'effet sur leur croissance. H1 : La concentration d’amidon a un effet sur la croissance des bactéries. H1 : Le type de souche bactérienne a un effet sur la relation entre la concentration en amidon et la croissance des bactéries. H1 : Le type de souche bactérienne a un effet sur leur croissance. Graphique pour l’ANCOVA : bact=read.table(file.choose(),h=T) attach(bact) plot(Amidon,Croissance,type='n') symbols=c(1,2,3) points(Amidon,Croissance,pch=symbols[as.numeric(Souche)]) legend(locator(1),c('S1','S2','H'),pch=c(1,2,3))
Travaux Dirigés n o 5

2
20 40 60 80 100 120 140
200
400
600
800
Amidon
Croissance
S1S2H
2. Réalisez ce test Testons d’abord si la relation linéaire entre Croissance et Amidon est significative (-ment différente de 0) pour chaque souche. Am1=subset(Amidon,Souche=="S1") # pour tous les groupes, les concentrations sont les mêmes Cr1=subset(Croissance,Souche=="S1") Cr2=subset(Croissance,Souche=="S2") CrH=subset(Croissance,Souche=="H") cor.test(Am1,Cr1) p-value = 1.721e-05 0.8775191 cor.test(Am1,Cr2) p-value = 0.001044 0.7585725 cor.test(Am1,CrH) p-value = 1.658e-08 0.9592063 Les trois relations linéaires sont « significatives ». On rejette l 'hypothèse nulle d’absence de relations linéaires entre croissance et concentration en amidon pour les 3 souches. On vérifie aussi que les conditions d’application sont respectées pour les 3 relations, par exemple ici pour la Souche 2 (à faire aussi pour les deux autres) : par(mfrow=c(2,2)) plot(lm(Cr2~Am1))

3
200 300 400 500 600 700
-100
0100
200
Fitted values
Residuals
Residuals vs Fitted
5
1 14
-1 0 1
-10
12
3
Theoretical Quantiles
Sta
ndar
dize
d re
sidu
als
Normal Q-Q
5
1 14
200 300 400 500 600 700
0.0
0.5
1.0
1.5
Fitted values
Standardized residuals
Scale-Location5
114
0.00 0.05 0.10 0.15 0.20 0.25
-10
12
3
Leverage
Sta
ndar
dize
d re
sidu
als
Cook's distance0.5
0.5
1
Residuals vs Leverage
5
115
20 40 60 80 100 120 140
100
200
300
400
500
600
700
Am1
Cr1
NB : l’effet du point 5 est bien visible sur le graphe de la relation à droite. On peut vérifier également la normalité dans chaque groupe pour la variable dépendante (car les moyennes seront comparées comme pour une ANOVA à 1 facteur) : shapiro.test(Cr1) p-value = 0.4628 shapiro.test(Cr2) p-value = 0.381 shapiro.test(CrH) p-value = 0.3094 On effectue le reste de l’ANCOVA avec la fonction ancova.R : source("/Users/yves/…/ancova.R") ancova(Croissance,Souche,Amidon) D.l. SC CM F Prob. Regression (global) 4 122287 30572 3.574 0.0141 Pente 1 983798 983798 115.015 0.0000 Egalite des intercepts (facteur) 2 116818 58409 6.829 0.0029 Egalite des pentes (interaction) 2 5469 2734 0.320 0.7283 Residus 39 333593 8554 NA NA Donc, on accepte l 'hypothèse nulle d'égalité des pentes. Il n'y a pas interaction entre le type de souche et la concentration en amidon. On rejette l 'hypothèse nulle d'égalité des ordonnées à l 'origine, les droites ne sont pas confondues. Les souches ont des croissances différentes. La même chose est obtenue via : anova(lm(Croissance~Amidon*Souche)) Analysis of Variance Table Response: Croissance

4
Df Sum Sq Mean Sq F value Pr(>F) Amidon 1 983798 983798 115.0148 3.403e-13 *** Souche 2 116818 58409 6.8285 0.002867 ** Amidon:Souche 2 5469 2734 0.3197 0.728264 Residuals 39 333593 8554 Exercice 2 Des médecins ont collecté des données pour tenter d’expliquer les variations du taux de mortalité dans les régions rurales (fichier mortalite.txt). 1. Elaborez à l’aide de ces données le meilleur modèle linéaire permettant d’expliquer comment la mortalité est liée aux différentes variables mesurées. Effectuez la sélection des variables par une procédure manuelle, puis par une procédure automatique. Interprétez les résultats quant à l’effet de chaque variable sur la mortalité. On peut commencer par tracer quelques relations 2 à 2 pour détecter un modèle non linéaire : mort=read.table(file.choose(),h=T) attach(mort) par(mfrow=c(2,2)) plot(docteur,mortalite) plot(hopitaux,mortalite) plot(revenu,mortalite) plot(densite,mortalite)
100 150 200
46
810
12
docteur
mortalite
500 1000 1500
46
810
12
hopitaux
mortalite
7 8 9 10 11 12 13
46
810
12
revenu
mortalite
50 100 150 200 250 300
46
810
12
densite
mortalite
Il semble judicieux de faire une régression linéaire multiple de mortalité = f(docteur, hopitaux, revenu, densite). Vérifions d’abord la normalité des données : shapiro.test(mortalite) W = 0.95746, p-value = 0.05679 shapiro.test(docteur)

5
W = 0.9409, p-value = 0.01112 shapiro.test(hopitaux) W = 0.91382, p-value = 0.0009896 shapiro.test(revenu) W = 0.97393, p-value = 0.2965 shapiro.test(densite) W = 0.9217, p-value = 0.001939 Les variables suivantes ne sont pas normales : docteur, hopitaux, densite. On transforme (ici en ln) les variables non normales et on refait le test de Shapiro-Wilk : lndoc=log(docteur) lnhop=log(hopitaux) lnden=log(densite) shapiro.test(lndoc) W = 0.97701, p-value = 0.3954 shapiro.test(lnhop) W = 0.97622, p-value = 0.3677 shapiro.test(lnden) W = 0.9867, p-value = 0.8176 On garde maintenant les variables transformées, dont la distribution est normale. Calcul du modèle : mortalité = a1*lndoc + a2*lnhop + a3*revenu + a4*lnden+ b summary(lm(mortalite~lndoc+lnhop+revenu+lnden)) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 5.97586 4.08123 1.464 0.149651 lndoc 0.23978 0.71470 0.335 0.738711 lnhop 1.52754 0.40792 3.745 0.000484 *** revenu -0.07735 0.21482 -0.360 0.720386 lnden -1.48143 0.47108 -3.145 0.002851 ** Multiple R-squared: 0.3503, Adjusted R-squared: 0.2961 F-statistic: 6.47 on 4 and 48 DF, p-value: 0.0003012 Le modèle est globalement significatif, ce qui n’est pas le cas de toutes les variables explicatives. Il faut les sélectionner. Nous le faisons « à la main » en retirant séquentiellement la moins significative jusqu’à ce qu’il ne reste plus que des variables significatives (élimination descendante) : summary(lm(mortalite~lnhop+revenu+lnden)) Estimate Std. Error t value Pr(>|t|) (Intercept) 6.59805 3.60248 1.832 0.073104 . lnhop 1.56800 0.38615 4.061 0.000176 *** revenu -0.04113 0.18403 -0.223 0.824096 lnden -1.50195 0.46284 -3.245 0.002119 ** Multiple R-squared: 0.3488, Adjusted R-squared: 0.3089 F-statistic: 8.747 on 3 and 49 DF, p-value: 9.476e-05

6
summary(lm(mortalite~lnhop+lnden)) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 6.1709 3.0243 2.040 0.04661 * lnhop 1.5861 0.3740 4.241 9.58e-05 *** lnden -1.5186 0.4525 -3.356 0.00152 ** Multiple R-squared: 0.3481, Adjusted R-squared: 0.322 F-statistic: 13.35 on 2 and 50 DF, p-value: 2.263e-05 Seuls le nombre d’hôpitaux et la densité de population expliquent les variations de la mortalité. Notez que le R2 global baisse très peu (mais il baisse !) quand on enlève les variables non significatives. Par contre le R2 augmente, témoignant de la meilleure qualité du modèle. NB : la procédure automatique via step donne le même résultat. 2. Quelle est la proportion de la variation de la mortalité expliquée par les variables incluses dans le modèle ? Il s’agit simplement du R2 global, 0,348, donc la proportion est de 34,8 %. 3. Pour une densité de population constante, quelle est la contribution de la variable « Hôpitaux/100000 habitants » à la variation de la mortalité ? A densité constante, 1 unité de lnhop fait augmenter la mortalité de 1,586 mort/100000 habitants ! Exercice 3 Des maîtres-nageurs ont noté le nombre de baigneurs présents au cours de l’année sur une petite plage en fonction de la température du sable (fichier baigneurs.txt). 1. Trouvez le meilleur modèle de régression pour expliquer significativement le nombre de baigneurs par la température du sable. Il faut d’abord visualiser le nuage de points : plage=read.table(file.choose(),h=T) attach(plage) plot(Temp,Baigneurs)
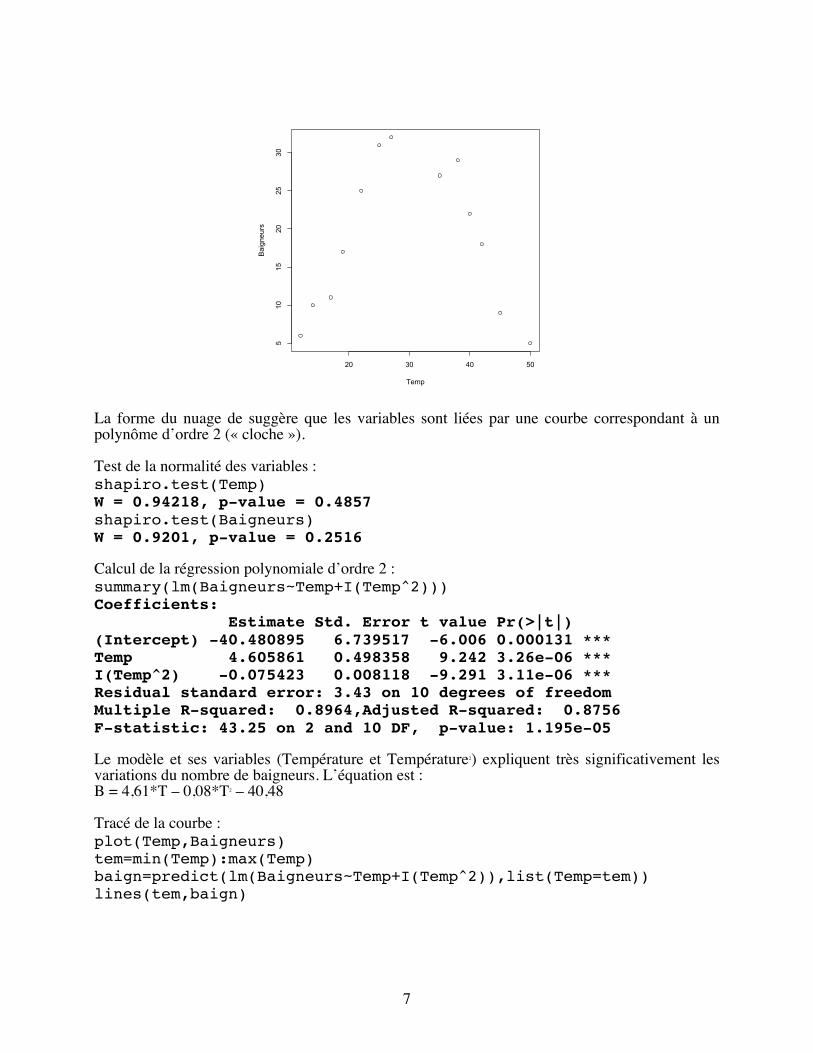
7
20 30 40 50
510
1520
2530
Temp
Baigneurs
La forme du nuage de suggère que les variables sont liées par une courbe correspondant à un polynôme d’ordre 2 (« cloche »). Test de la normalité des variables : shapiro.test(Temp) W = 0.94218, p-value = 0.4857 shapiro.test(Baigneurs) W = 0.9201, p-value = 0.2516 Calcul de la régression polynomiale d’ordre 2 : summary(lm(Baigneurs~Temp+I(Temp^2))) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -40.480895 6.739517 -6.006 0.000131 *** Temp 4.605861 0.498358 9.242 3.26e-06 *** I(Temp^2) -0.075423 0.008118 -9.291 3.11e-06 *** Residual standard error: 3.43 on 10 degrees of freedom Multiple R-squared: 0.8964,Adjusted R-squared: 0.8756 F-statistic: 43.25 on 2 and 10 DF, p-value: 1.195e-05 Le modèle et ses variables (Température et Température2) expliquent très significativement les variations du nombre de baigneurs. L’équation est : B = 4,61*T – 0,08*T2 – 40,48 Tracé de la courbe : plot(Temp,Baigneurs) tem=min(Temp):max(Temp) baign=predict(lm(Baigneurs~Temp+I(Temp^2)),list(Temp=tem)) lines(tem,baign)

8
20 30 40 50
510
1520
2530
Temp
Baigneurs
2. En vous basant sur cet échantillon, calculez la température théorique à laquelle on devrait trouver un maximum de baigneurs. Dans quelle gamme de température les baigneurs préfèrent-ils fréquenter la plage ? Il s’agit de calculer l’optimum et la tolérance des baigneurs (zone de préférence) par rapport à la température : Optimum u = -a1/2a2 : -4.6/(2*-0.075) [1] 30.66667 Tolérance t = 1/√-2a2 : 1/(sqrt(2*0.075)) [1] 2.581989 Les baigneurs se sentent le mieux à 30,67 ± 2,582 °C 3. Ajustez un modèle de régression plus complexe d’un ordre à celui estimé en 1. Que vous inspirent les résultats ? Ajustons un polynôme d’ordre 3 : summary(lm(Baigneurs~Temp+I(Temp^2)+I(Temp^3))) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -4.843e+01 1.740e+01 -2.784 0.0213 * Temp 5.557e+00 1.975e+00 2.814 0.0202 * I(Temp^2) -1.091e-01 6.802e-02 -1.604 0.1432 I(Temp^3) 3.640e-04 7.294e-04 0.499 0.6297 Residual standard error: 3.566 on 9 degrees of freedom Multiple R-squared: 0.8992, Adjusted R-squared: 0.8656 F-statistic: 26.75 on 3 and 9 DF, p-value: 8.135e-05

9
Le R2 global augmente à peine mais les variables individuelles du modèle deviennent beaucoup moins voire pas significatives. On ne gagne donc rien à passer à un modèle plus complexe, au contraire, la diminution de degrés de libertés engendrée fait perdre en précision l’estimation des paramètres.