introduction - isima · introduction la compréhension du fonctionnement cellulaire et de...
TRANSCRIPT

Introduction
La compréhension du fonctionnement cellulaire et de l'évolution biologique ont pour objectif entre autres de développer des stratégies pour le traitement de certaines maladies complexes (cancers...).
Pour cela, l'étude des réseaux biologiques nécessite la mise à disposition d'outils d'analyse pertinents, capables d'extraire des informations significatives pour le biologiste. La quantité de données biologiques disponibles grâce aux efforts des biologistes est telle qu'il devient nécessaire de développer des outils d'analyse efficaces, systématiques et ciblés. [MASON O. & VERWOERD M.]
L'analyse de réseaux biologiques est souvent conduite par des méthodes quantitatives fondées sur l'étude de la stœchiométrie des réactions, les vitesses et les flux des réactions (fluxomique).
Les réseaux biologiques - et en particulier les réseaux métaboliques - peuvent pertinemment être représentés sous forme de graphes. Et les concepts fournis par la Théorie des Graphes constituent une voie d'exploration prometteuse pour l'étude qualitative de ces réseaux. L'étude que nous avons conduite vise à développer en Matlab des outils d'analyse de graphes qui seront intégrés au logiciel "Brume" développé par le professeur Laurent Poughon au LGCB de Polytech'Clermont-Ferrand.
Une première étape du travail a consisté en une recherche documentaire approfondie nécessaire à la compréhension du contexte biologique dans lequel s'inscrit notre projet. Grâce aux publications trouvées et guidées par les explications du professeur L. Poughon et de ses attentes, nous avons pu sélectionner les concepts de graphe pertinents pour l'analyse de réseaux métaboliques. Une seconde phase a été de développer les méthodes d'analyse correspondantes, à partir d'algorithmes de principe ou de définitions, de les implémenter sous Matlab et de les tester au fur et à mesure. Les tests nous ont permis de corriger et d'améliorer ces algorithmes ou de nous rendre compte de l'importance d'une étude approfondie de certains points au-delà du cadre de notre projet. Une troisième phase a été de générer les résultats de tests de ces outils sur les graphes de réseaux fournis, de les analyser et d'essayer de les interpréter.
Ce rapport synthétise le travail réalisé au cours de ce projet. Dans un premier temps, nous commençons par l'étude du cadre dans lequel s'inscrit notre projet, en introduisant quelques éléments de la biologie des réseaux cellulaires et en décrivant une des méthodes d'analyse quantitatives conduites au LGCB. Ensuite, nous exposons la modélisation en graphes des réseaux métaboliques et les concepts de graphes adoptés pour le développement des outils d'analyse. Enfin, la dernière partie est consacrée aux tests des outils et aux résultats obtenus.
1

I. PRESENTATION DU CONTEXTE
1. Définitions et Intérêt de l'étude des réseaux métaboliques
Un réseau biologique est une représentation abstraite d'un système biologique. L'appellation s'inscrit dans une démarche de modélisation. Elle intervient dès lors que l'on s'intéresse à étudier les interactions entre composants biologiques dans l'un des processus biologiques (métabolisme, régulation des gènes, transduction de signaux).
Les "réseaux métaboliques" sont l'application de cette notion dans le cadre du métabolisme cellulaire. Le métabolisme cellulaire est le processus de transformation de matière au niveau cellulaire, par lequel s'élaborent (anabolisme) ou se dégradent (catabolisme) des substances pour assurer le fonctionnement d'un organisme, en faisant intervenir des échanges d'énergie, dans des conditions d'équilibre. En effet, 'rien ne se perd, rien ne se crée, tout se transforme' (Lavoisier); l'énergie reçue de l'extérieure est transformée par des réactions cellulaires pour assurer un ensemble de fonctions cellulaires.
On définit par voie ou cycle métabolique les réactions successives propres à assurer une fonction cellulaire particulière et dans lesquels le produit d'une réaction devient le substrat de la réaction suivante. L'ensemble des voies et cycles métaboliques déterminent le métabolisme, processus ordonné, qui est donc le moteur de l'activité cellulaire.
Dès lors, la cellule peut être vue comme un réseau d'interaction puisque le fonctionnement cellulaire repose sur des séquences d'interactions entre constituants biochimiques et des flux de substances et d'informations. L'analogie peut être faite avec les réseaux d'interaction entre individus (web, réseaux sociaux,...) [VALDIS K.].
La biologie s'intéresse naturellement à étudier les mécanismes cellulaires, à décrire les processus qui assurent la vitalité d'un organisme et à cerner les fonctions particulières accomplies dans le cadre du métabolisme. Par exemple, l'étude du métabolome (concentration des différents métabolites) s'intéresse à étudier les relations entre les entités biologiques et les dynamiques fonctionnelles (dimensions spatiale et temporelle des interactions) et permet de comprendre le comportement biochimique de la cellule à travers la description de l'environnement cellulaire en plus de l'expression de son génome.
Cependant, la complexité des réactions et de leur organisation a rendu nécessaire la modélisation, l'analyse et la simulation de ces réseaux pour mettre en évidence leurs structures et prédire leurs comportements. Ainsi, par exemple, des "cartes métaboliques" ont été établies pour décrire la structure cellulaire. Celles-ci permettraient de :
--> visualiser le cheminement des métabolites intermédiaires, en traçant les raccordements entre voies et cycles ;
--> imaginer le "modèle de circulation" des métabolites intermédiaires et l'effet d'un blocage résultant de la déficience d'une enzyme ou d'administration de drogue.
--> mettre en évidence des modules fonctionnels (partie de voie métabolique, système de régulation), en vue de l'étude de la phylogénie des espèces.
On peut ainsi prédire le comportement de cellules face à des modifications environnementales ou des mutations, ou encore prévoir les effets de perturbations dues à des maladies ou médicaments administrés... appliquées à un réseau d'interaction.
2

La notion de réseau métabolique est introduite pour modéliser la biochimie et la physiologie d'un organisme. Les réseaux métaboliques sont construits à partir des séquences de réactions métaboliques. Selon le niveau de détail disponible/voulu, ces réseaux peuvent être simples (enchaînement de quelques réactions accomplissant une fonction métabolique particulière) ou complexes (enchaînement de l'ensemble des réactions du métabolisme d'une cellule). A chaque réaction peut être associée une vitesse (ou flux) et l'analyse de ces flux est une discipline particulière de la bioinformatique : la fluxomique.
Il s'agit alors d'étudier ces réseaux métaboliques. Plusieurs approches sont possibles (voir annexe A1). Deux grands types d'approches quantitatives :
"dynamique classique" : écrire le système d'équations différentielles basées sur les cinétiques des réactions d'un réseau donné, et calculer les profils des métabolites en fonction du temps;
"pseudo-permanent" : en réalité, absence de données dynamiques fiables et suffisantes... on fait l'hypothèse d'un régime stationnaire, et on ne tient pas compte de l'aspect cinétique. Le réseau est étudié sous l'angle de la modélisation stœchiométrique (méthodes MFA, EFM...) à travers la calcul de la distribution des flux métaboliques par les équations de conservation de la masse des métabolites. (algèbre linéaire)
topologique : étudier la structure cellulaire par des méthodes de graphes (l'objet de ce projet)
Au Laboratoire de Génie Chimique et Biochimique (LGCB), laboratoire avec lequel nous collaborons pour réaliser ce projet, le professeur Laurent Poughon a développé des outils d'analyse fondés sur l'approche qui fait l'hypothèse d'un état stationnaire, à travers un logiciel dédié à l'analyse de Réseaux Métaboliques dénommé "Brume". Il souhaite développer l'analyse structurelle par des méthodes de graphes. Notre travail s'intéresse donc en particulier à cette dernière approche.
2. Le Logiciel Brume
Le LGCB a développé des outils d'analyse de réseaux métaboliques. Dans ce cadre, une application nommée "Brume" a été développée pour permettre le traitement des données fournies par ces réseaux (construction et analyses de données, calculs de flux).
Il y a également une interface associée, nommée 'Brume', développée en HTML et PHP/mySQL qui permet d'interroger et gérer une base de données, où sont stockées des informations sur des métabolites, des enzymes et des réactions métaboliques à partir desquels on peut construire des réseaux métaboliques. La base de donnée a été construite à partir de LIGAND (KEGG), et en particulier de ses tables concernant les métabolites (compound), les réactions (REACTION) et les enzymes (ENZYME).
L'application Brume est destinée à l'analyse de réseaux métaboliques par différentes approches, principalement l'analyse de flux métaboliques (MFA) que nous allons décrire par la suite. Ce programme d'analyse a été développé en langage Matlab et actuellement dans sa version 1.9.0b. Il est composé d'un ensemble d'algorithmes développés au laboratoire et d'autres adaptés des travaux de S. Shuster et du logiciel METATOOL pour l'analyse par méthodes des EFM.
3

Illustration 2: Exemple de Schématisation d'un réseau
4
Illustration 3: Description du réseau sous forme de liste de réactions et de métabolites
Illustration 1: Interface "Brume" de la base de donnée en intranet (LGCB)

Ci-dessous est présentée l'interface graphique du programme 'Brume'. Celui-ci comporte cinq volets :
=============================================================================================================================================== PROGRAMME D'ANALYSE ET DE CALCUL POUR LES RESEAUX METABOLIQUES == Brume C : Version 1.9.0b
== Sky 2008 ===============================================================================================================================================0 : Quitter1 : SAISIE des données/Projet [Inclut analyse préliminaire -
cycles/colinéarités]2 : INFORMATIONS sur le réseau3 : CALCUL DE FLUX [Principe LGCB - DL, Fixer, Résolution, Résultats]4 : ANALYSE des EFM - [Gagneur & Klamt - BMC Bioinformatics 2004, 5:175]5 : ANALYSE Methodes des GraphesIllustration 4: Interface du logiciel Brume en Matlab
Saisie de données : l'utilisateur introduit le nom du dossier dans lequel sont répertoriées les données du réseau métabolique considéré pour l'analyse. Ce volet inclut une analyse préliminaire des cycles présents, par l'étude de colinéarités dans la matrice stœchiométrique.
Informations sur le réseau : Ce menu décrit les informations du réseau, le nombre de métabolites dans le réseau, de réactions, de métabolites échangeables, de réactions réversibles ainsi que le nombre de combinaisons linéaires entre les métabolites, les réactions, le nombre de nœuds du graphe et celui d’arc. De plus, il offre la possibilité d’afficher les résultats de la réduction des relations entre métabolites et le résultat des cycles obtenus avec l’analyse des combinaisons linéaires.
Calcul de flux : Ce menu applique l’analyse des réseaux métaboliques. Pour cela l’utilisateur doit entrer les réactions et/ou les métabolites. Puis il doit fixer les métabolites échangeables, i.e. leur donner une valeur de vitesse. Ensuite l’utilisateur peut choisir de résoudre le système, de sauvegarder les résultats et d’afficher les résultats du calcul de flux.
Analyse des EFM : ce menu affiche les résultats de calculs sur les Elementary Flux Mode.
Analyse par des méthodes de graphes : Cette partie développe les concepts d’analyse de graphe. C'est la partie dans laquelle nous développons nos méthodes d'analyse, tels que la recherche de plus court chemin, de points d’articulation, de cycle et des mesures sur les nœuds.
5

3. Exemple de méthode d'analyse algébrique : MFA
L’analyse des flux métaboliques (Metabolic Flux Analysis (MFA)) est le calcul ainsi que l’analyse de la distribution des flux des réactions biochimiques dans un système étudié. Cette méthode permet d’analyser les flux entre les différentes réactions. Les informations concernant le réseau métabolique sont stockées dans une matrice dont les lignes sont les métabolites mis en jeu et les colonnes les différentes réactions. Cette matrice est appelée matrice stœchiométrique.
Avec cette matrice, on peut représenter mathématiquement les relations intracellulaires grâce à une équation différentielle :
dc/dt = T.v -μ.c (1)Où T est la matrice stœchiométrique, c la concentration des métabolites intracellulaire, v le
vecteur de flux et μ le facteur de croissance de la cellule.
Cependant les mécanismes intracellulaires sont très complexes et peu compris. C’est pourquoi les biologistes ne prennent pas en compte le vecteur des concentrations c. De plus le terme μ.c est négligeable devant le terme T.v. L’équation (1) peut alors se réécrire sous la forme :
T.v = 0 (2)
Cette équation définit une série de contraintes qui lient certains flux avec d’autres et réduisent ainsi l’espace des flux possibles à un hyperplan de Rn, où chaque axe correspond aux flux.
Cet hyperplan est délimité par plusieurs contraintes. Par exemple les flux irréversibles sont positifs : vi ≥ 0
Suite à ce postulat, le système devient alors linaire et l’espace ainsi défini par l’hyperplan devient un polyèdre convexe. Pour finir, une autre condition peu être imposée, on définit un flux maximum vmax d’où la nouvelle contrainte : v < vmax
Celle-ci définit l’hyperplan de manière plus précise en un cône polyédrique limité par la valeur de vmax..
Illustration 5: Représentations des hyperplans solutions
6

A l’aide de la méthode MFA on peut calculer r, le vecteur des taux de formation des métabolites ou bien, connaissant r, calculer le flux des réactions.
Pour ce calcul, on considère un système représentant un ensemble de réactions. Ces réactions sont engendrées par des substrats qui réagissent entre eux et créent d’autres métabolites qui vont interagir entre eux afin de créer des produits. Toutes ces réactions ont un flux associé à leurs réactions.
Le calcul du taux de formation se fait à partir de la formule :
r = Tt.v (1)
Si l’on connait le vecteur v, on peut alors calculer le vecteur des taux de formation des différents composants du système. Cependant, dans la réalité, le plus souvent le vecteur r est connu et on cherche à calculer v.
On décompose r en deux vecteurs : rc, les taux de formation non connus, rm : les taux mesurés ; r = (rc rm) ; ainsi que T= (T1 T2), T1 correspond à rc et T2 à rm.
Soit P la dimension du vecteur r, J le nombre de flux, i.e. la dimension de v, K le nombre de métabolites ayant un taux stationnaire (r = 0), F = J-K correspond aux degrés de liberté du système, i.e. la dimension du vecteur rm .Cette valeur détermine le nombre de valeurs de flux qui doivent être connues afin de résoudre le système. On connait alors la dimension du vecteur rm ainsi que celui de la matrice T2.
D’après (1) et la décomposition des deux vecteurs r et T on obtient deux autres équations :rc = T1.v (2)
(3)
L’équation (3) est alors utilisée afin de calculer v. Suite au calcul de v on peut déterminer rc.[LIDEN G.] et [LLANERAS.F and PICO.J]
En annexe (A2), nous illustrons ce type de calculs par un exemple.
7
Illustration 6: Schéma des réactions cellulaires
Substrats Produits
Création de métabolites

II. ANALYSE DES RESEAUX METABOLIQUES PAR DES METHODES DE GRAPHES
Les mécanismes cellulaires sont la conséquence d'interactions complexes entre plusieurs constituants (ADN, ARN, métabolites..), que l'on identifie en réseau métabolique. En l'absence de données cinétiques et dynamiques complètes ou fiables, il y a un réel intérêt pour des approches d'analyse issue de concepts de théorie de graphes. Les récentes avancées dans le domaine permettent une description structurelle de ces réseaux grâce à ces concepts, indépendamment de l'existence ou non d'informations sur la cinétique des réactions mises en jeu. Les concepts de graphes peuvent donc fournir des informations sur la topologie du réseau.
1. Modélisation des réseaux métaboliques en graphe 1.1 Représentations de réseaux en graphes
A un niveau de représentation simplifié, un réseau métabolique consiste en des réactions se produisant entre des composants (métabolites). Cette structure est semblable à une représentation en graphes. En effet, un graphe est défini par G = (V,E), où V est l'ensemble des sommets (nœuds) et E l'ensemble des arêtes qui les relient. Chaque arête modélisant un lien entre des nœuds. Plusieurs types de graphes peuvent être utilisés en biologie : graphe bipartis, hypergraphes ou graphes simples. Ci-dessous sont représentés pour un même type de réactions les trois représentations différentes. [LACROIX V. et al.]
En l'occurrence, notre étude se base sur la représentation réduite en graphe simple. Suivant les modélisations, les nœuds du graphe peuvent représenter les métabolites et les arêtes les réactions intervenant entre eux ("graphe des composés"), ou bien les nœuds peuvent symboliser les réactions et les arêtes les métabolites qui entrent en jeu ("graphe des réactions").
Notre étude se base sur une représentation en graphes de composés. Le graphe peut alors être orienté ou pas suivant la disponibilité des informations. Un graphe G est orienté lorsque chaque arête est orientée d'un nœud à un autre (donc appelée 'arc'). L'orientation symbolise alors le sens de la réaction. Ainsi, lorsque les informations sont disponibles quant aux sens des réactions intervenant dans un réseau, on utilise une représentation en graphe orienté.
8
Illustration 9: hypergraphe associé
Illustration 8: graphe biparti correspondant
Illustration 7: graphe simple associé à deux réseaux différentes (modélisation comportant l'inconvénient de ne pas distinguer ces cas)

0 0 1 1 1 0 1 0 A = 1 0 0 1 0 0 0 0
Matrice d'adjacence correspondante (représentation en mémoire du graphe)en lignes : métabolites (C,B,A,D)en colonnes : métabolites (C,B,A,D)
La structure de données utilisée pour modéliser le graphe et le stocker en mémoire est la matrice d'adjacence. Il s'agit d'une matrice carrée qui représente en ligne et en colonne les métabolites intervenant dans le réseau. elle est définie par :
A(i,j) = 1 si une réaction Rij existe entre i et j : i ---> j (Rij)A(i,j) = 0 sinon
Cette simplicité de représentation autorise par exemple d'employer les outils d'analyse sur des graphes non orientés (dont les données sur les sens de réaction sont incomplètes et donc inexploitables à un moment donné). Il suffit alors de modéliser un lien entre deux métabolites (existence d'une réaction) par une réaction supposée réversible, ce qui revient à considérer l'existence de deux arcs entre une paire de métabolites. La matrice d'adjacence est alors symétrique.
Il est également possible de mémoriser une "matrice de Coûts" qui est semblable à la matrice d'adjacence à la différence que les valeurs de 1 sont remplacées par des poids sur les arcs. Ceux-ci peuvent modéliser le 'coût' d'une réaction en consommation énergétique ou d'autres composants ou encore représenter une certaine contrainte associée à la réalisation d'une réaction, etc.
La représentation sous forme matricielle présente l'avantage d'être simple, claire et surtout de permettre divers types de calculs et traitements qui peuvent être importants. Les différents modules que nous avons développés font intervenir cette matrice qui représente donc entièrement le réseau métabolique considéré et son graphe associé.
Des noms de métabolites sont associés au réseau dans le logiciel. Ils sont mémorisés sous forme d'un vecteur. Il y a nécessairement correspondance entre les indices de ce vecteur de nomenclature et ceux de la matrice d'adjacence associée au graphe pour permettre entre autre l'affichage des noms de métabolites.
9
Illustration 11: graphes et matrices d'adjacence (correspondance orienté(d.)/non-orienté(g.))
Illustration 10: Graphe du réseau test "bmc_full"

1.2 Simplification de modèles : le sort des 'cofacteurs'
Dans le métabolisme cellulaire, certains composés ont un statut de composés principaux tandis que d'autres peuvent être considérés comme auxiliaires (cofacteurs, par exemple ATP, ADP, H2O,...). Cette distinction est primordiale. En effet, dans certains traitements pour l'analyse, inclure ou non les cofacteurs dans le réseau étudié peut conduire à une interprétation erronée des résultats obtenus. Du fait de leur intervention dans de multiples réactions, certaines mesures sont faussées. Par exemple, lors de calculs sur la prédominance des nœuds, ils apparaitraient comme importants alors qu'en fait ceci est dû à leur intervention dans plusieurs réactions comme composés courants ou communs et occulteraient la présence de métabolites centraux.
Cependant, pour des études plus approfondies (puisqu'il s'agit d'études de prospection), dans différents types de modules, nous conservons ces cofacteurs et plusieurs choix d'élimination (ou non) sont proposés afin que les résultats suivant les cas soient comparés plus tard et permettent de trancher la question.
2. Analyse structurelle des réseaux métaboliques : concepts de Théorie des Graphes
Après avoir présenté les différentes modélisations en graphes possibles et celle que nous avons adoptée dans notre projet, nous consacrons cette partie centrale à la description des concepts de la Théorie des Graphes que nous avons choisis et qui sont à la base des algorithmes implémentés sous Matlab. Des études menées au-delà de ce projet pourront compléter cette liste ou proposer des alternatives plus efficaces. L'analyse plus poussée des résultats permettrait d'étudier plus en détail la topologie des réseaux métaboliques à disposition, en vue de les classer selon leur type (réseau sans-échelle, réseau "small world", [ALBERT R.], [BARABASI A.,ALBERT R. et al.] et [WATTS D. & STROGATZ S.])
2.1 Mesures de connectivités des nœuds
Les graphes sont composés de nœuds connectés entre eux par des arcs. L’étude des liens entre les arcs et les nœuds ainsi que leurs connectivités au sein du graphe peut montrer l’importance de certains nœuds par rapport aux autres.
2.1.1 Degré ( degree centrality )
Le degré d’un nœud est la somme des arcs entrants et sortants d’un nœud. Cette grandeur permet de voir comment un nœud est connecté au réseau. Un nœud dont le degré est élevé est fortement connecté aux autres nœuds. Le degré d’un nœud se décompose en deux parties, le degré entrant, le nombre d’arcs entrants, et le degré sortant, le nombre d’arcs sortants du nœud.
2.1.2 Degré moyen
A l’aide du degré des nœuds on peut calculer le degré moyen d’un graphe. Cette grandeur permet de voir en moyenne à combien d’autres nœuds est relié un nœud. De plus, à l’aide de cette valeur nous avons trié les métabolites selon leurs degrés. Pour cela nous avons choisi arbitrairement un critère (voir algorithme de principe). Avec celui-ci, nous comparons le degré de chaque nœud. Si le degré est supérieur au critère choisi ,on le définit comme ayant un degré élevé par rapport au degré moyen, sinon il fait partie des métabolites ayant un faible degré. Les nœuds fortement connectés, c'est-à-dire ceux qui ont un degré élevé par rapport au degré moyen, sont définis comme étant des Hubs [ALBERT R.].
10

2.1.3 Clustering
Le Clustering d’un graphe est une grandeur qui permet de voir comment sont reliés les voisins d’un nœud. C'est une mesure du nombre de liens entre les différents voisins d’un nœud (i.e. dans les réseaux sociaux cette grandeur calcule la possibilité que deux de vos amis se connaissent). Elle est comprise entre 0 et 1, plus la valeur est grande plus il existe de liens entre les différents nœuds. [GIRVAN M. and NEWMAN M.E.J]
2.1.4 Densité
La densité du graphe est le rapport entre le nombre d’arcs dans le graphe et le nombre de nœuds présents -1. Cette grandeur est comprise entre 0 et 1. Si la densité vaut 1, cela veut dire que tous les liens possibles existent vraiment dans le graphe. [GAY B. and DOUSSET B.]
L'option d'élimination des cofacteurs est également proposée dans ce module.Nous présentons ci-dessous les principes des algorithmes développés à partir des définitions
des notions présentées.
Algorithme de principe du calcul du degré d’un nœud ainsi que du degré entrant et sortant :
Cet algorithme prend en paramètre la matrice associée et retourne trois vecteurs, contenant respectivement le degré, le degré entrant et le degré sortant d'un nœud.
Pour chaque métabolite i de la matrice associé On initialise le degré, le degré entrant ainsi que le degré sortant de i à 0 On regarde les coefficients positifs de la matrice associée afin de voir si le nœud i a des voisins j. Pour chaque coefficient positif de la matrice, on augmente le degré du nœud Si la réaction est dans le sens i-> j on augmente le degré sortant sinon le degré entrant. On stocke dans trois vecteurs les différents degrés du nœud i.Fin pour
Algorithme de principe de calcul du degré moyen d’un nœud :
Il prend en paramètre la matrice associée et retourne le degré moyen et les 3 vecteurs contenant les différents degrés
Initialisation de la somme à 0Appel de la fonction qui calcul les degrés des nœudsSomme des valeurs des degrés contenus dans le vecteur degré et division par le nombre de nœuds.On obtient ainsi le degré moyen, DM, du nœud.
DM = ∑degré/n.
11
Illustration 12: Le clustering d'un noeud est défini comme la probabilité moyenne que deux voisins d'un noeud soient adjacents

Algorithme de principe de la comparaison des degrés :
Il prend en paramètre la matrice triée. Cette matrice contient dans la première colonne les indices des métabolites et dans la deuxième les valeurs des degrés triés par ordre croissant, ainsi que le degré moyen et la liste des noms des métabolites. L’utilisateur peut choisir d’afficher les métabolites dont le degré est élevé ou bien faible.
Soit M = partie entière du degré moyen.% affichage des degrés élevés :
Pour chaque ligne i de la matrice Si la valeur du degré : matrice(i,2) > 3*M/2
afficher le métabolite correspondant ainsi que son degré FinSiFin pour
% affichage des degrés faibles Pour chaque ligne i de la matrice
Si la valeur du degré : matrice(i,2) < M/2afficher le métabolite correspondant ainsi que son degré FinSi
Fin pour
Algorithme de principe de calcul de la densité du graphe :
Il prend en paramètre la matrice associée ainsi que le degré moyen et retourne la densité du graphe :
On divise le degré moyen par le nombre de nœud -1 pour obtenir la densitéDensité = DM/(n-1)
Algorithme de principe de calcul du clustering :
Il prend en paramètre la matrice associée ainsi que le vecteur contenant les degrés des nœuds. Il retourne le clustering du graphe ainsi que celui de chaque nœud.
Pour chaque nœud i calcul du clustering :Création de la liste des voisins du nœud iCalcul du nombre d'arc entre les voisins de i
Tant qu'il existe un voisinOn compare chaque voisin entre euxSi les voisins sont reliés on augment EvFin siPasse au voisin suivant
Fin tant queCalcul du clustering: c= 2*EV/ (degree (i)*degree (i)-1)On stock la valeur dans le vecteur C
Fin pourCalcul du clustering
Sommer toutes les valeurs de clustering des nœuds et diviser par le nombre de nœuds
12

2.2 Ensemble de Points d'Articulation (Cut Vertices, 'Cut')
Un graphe est dit connexe si pour toute paire de sommets u et v distincts il existe un chemin les reliant, c'est-à-dire, il existe une suite d'arêtes (ou d'arcs) permettant d'atteindre v à partir de u, autrement dit où toute paire de sommets distincts u et v est connectée par un chemin. [BOLLOBAS B.]. Une fonction de test de connectivité à été introduite dans le logiciel Brume afin de déterminer la connexité du graphe et par exemple de vérifier les résultats du point suivant (recherche de Points d'articulation). [BALI S. and MOHAMMAD A.J.]
La notion de "point d'articulation" (P.A.) nous a été présentée en cours de Recherche Opérationnelle à travers un exercice où le principe était de trouver un algorithme permettant de répertorier les "points de fragilité" d'un graphe G. Un "Cut" est un ensemble de P.A. dont la suppression rend G déconnecté et fait apparaître des composantes non connexes (i.e. on ne peut pas atteindre tous les sommets à partir de n'importe quel sommet).
Les P.A. sont donc des nœuds critiques au niveau d'un réseau. En effet, s'ils sont affectés par une perturbation quelconque les détruisant et les rendant indisponibles au niveau du réseau, celui-ci en serait affecté d'une manière ou d'une autre (les déconnexions représentent alors des réactions qui ne peuvent plus se faire...).
Nous avons commencé par implémenter un algorithme proposé par [HYUNG-JOON K.]. Cependant, il s'agissait d'une méthode dédiée à l'étude de graphes non orientés. Les résultats seraient donc aléatoires pour les graphes orientés.
Par la suite, Nous avons trouvé un ensemble d'outils proposés par [BALI S. and MOHAMMAD A.J.] permettant d'effectuer cette recherche de "Cut". Celle-ci commence par un parcours en profondeur (Depth-First-Search DFS) qui, pour un graphe donné génère l'arbre DFS correspondant.
Une propriété de base est la suivante :Un nœud u est un P.A. si et seulement si pour tout nœud-fils v, il n' y a pas d'arête-retour partant de v vers un nœud précédent u dans l'arbre DFS. Autrement dit : tout nœud descendant dans l'arbre DFS d'un nœud u, ne peut remonter 'au-dessus' de u sans passer par u.
Algorithme de principe : (CutVertex - DFS)L'algorithme débute à un nœud S de G, qui devient le nœud courant. L'algorithme parcourt le
graphe par n'importe quel arc (u,v) incident au nœud courant. Si l'arc mène à un nœud déjà visité, alors on 'backtrack' (retour-arrière) au nœud courant u. Si au contraire, l'arc (u,v) mène à un nœud non visité, alors v devient le nœud courant. On procède de cette manière jusqu'à ce que tous les nœuds aient été visités. Le processus se termine lorsque le backtracking ramène au point de départ S.
Dans l'arbre DFS généré, la recherche de point d'articulation se fait suivant la propriété ci-dessus. A chaque passage du DFS par un nœud, on calcule dfsnum(v) (représentant l'ordre de parcours des nœuds dans l'arbre) et low(v) qui est la plus petite valeur de dfsnum de tout point du sous-arbre partant de v ou connecté à un nœud de ce sous-arbre par une arête-retour. [HYUNG-JOON K.]
13
Illustration 13: Réseau faisant apparaître des Cut Vertices dont la suppression déconnecterait le réseau en plusieurs composantes

[BALI S. and MOHAMMAD A.J.]
DFS(G) {pour tout v, choisir un nouveau sommet x adjacent (x->v) initialiser un compteur à 0 initialiser une liste L à videconstruire un arbre orienté,
initialement à {x} visite(x) }visite(p) { ajouter p à L dfsnum(p) = N incrémenter N low(p) = dfsnum(p)
pour tout arc p->q →
→ si q n'est pas déjà dans T {
ajouter p->q à T visite(q) low(p) = min(low(p), low(q))
} sinon low(p) = min(low(p), dfsnum(q))
si low(p)=dfsnum(p) { output "Point d'articulation :" répéter
supprimer le dernier élément v de L afficher v supprimer v from G
jusqu'à ce que v=p } }
2.3 Recherche de Cycles
En Théorie des Graphes, la notion de cycle est importante.
Par définition, un graphe G = (V, E) possède un cycle s’il existe un sommet v ϵ E tel que l’on peut trouver un chemin partant de v qui retourne en v.
Illustration 14: Représentation d'un exemple de cycle
De plus dans les réseaux métaboliques la notion de cycle est aussi un point important. Dans ce type de réseaux, un cycle est une suite de réactions qui, partant d’un métabolite réactif va, suite à d’autres réactions, produire ce même métabolite.
La détection de cycles dans un réseau métabolique peut permettre de comprendre comment les réactions interagissent, ou bien de voir des relations entre métabolites. De plus il est possible de détecter un cycle passant par un métabolite donné. Ceci peut permettre de vérifier si un métabolite est inclut dans un cycle ou non.
Nous avons donc implémenté un algorithme qui permet la détection de cycle au sein d’un graphe qui modélise les réseaux métaboliques. Cet algorithme est composé de deux fonctions, l’une appelé cycle et l’autre cherche_cycle. A l'exécution, l'utilisateur peut choisir de supprimer les cofacteurs de la matrice ou non.
14

La fonction cycle :
La fonction cycle prend en paramètre la matrice associée ainsi que le vecteur contenant le nom des métabolites. L’algorithme de principe de la fonction cycle :
Cycle :% recherche de cyclesPour tout les métabolites i initialisation du tableau marque ainsi que source recherche d'un cycle a partir de i : appel de la fonction cherche_cycleFin pour
% affichage de la liste des cycles :Comparaison des cycles afin d’éliminer les doublonsAffichage du nombre de cycle trouvésAffichage du cycle (à l'aide du vecteur nom )
Pour l’affichage d’un cycle passant par un métabolite donné : le cycle n'est affiché que si le métabolite en fait partie
La fonction cherche_cycle :
Elle prend en paramètre un métabolite de départ, la matrice stœchiométrique, le vecteur marque ainsi que celui source, la listecycle et liste_cycle_mark. Cette fonction retourne plusieurs arguments : listecycle, marque, source et liste_cycle_mark.
marque : Vecteur contenant la marque de chaque sommet. Elle vaut 1 si le sommet a été marqué 0, sinon.Source : Contient la liste des sommets présents dans le cyclelistecycle : Vecteur contenant les cycles.liste_cycle_mark : Matrice contenant les cycles.
[listecycle,marque,source,liste_cycle_mark]= cherche_cycle(i,mat,source,marque,listecycle,liste_cycle_mark)
On marque le métabolite i : marque(i)=1 Pour chaque voisin j du sommet i
Si le sommet i possède au moins un voisin : passe =1Fin siSi j non marqué, i.e. marque(j)=0
[listecycle,marque,source,liste_cycle_mark]= cherche_cycle(j,mat,source,marque,listecycle,liste_cycle_mark
SinonOn a trouvé un cycle donc res=1
Fin siFin pour
On vérifie que le cycle trouvé existe On le retourne afin de pouvoir l’afficher
15

2.4 Plus Courts Chemins (PCC) / voies métaboliques
Un chemin entre deux nœuds u et v est une succession de nœuds et d'arcs les reliant.La distance entre u et v est la longueur d'un plus court chemin {u-v} entre eux ; plus précisément c'est la somme des coûts sur les arcs du chemin {u-v}.
Dans le cadre du projet, la matrice de 'Coûts' coïncide avec la matrice d'adjacence. Les poids étant à 1, la distance est le nombre minimal d'arcs reliant la paire de nœuds considérée sur un plus court chemin. [HUBER W., CAREY V.J. et al.]
Un tel chemin peut représenter par exemple, une voie de transformation d'un substrat à un produit donnés dans un réseau métabolique (voie métabolique).
Par ailleurs, des études récentes ont montré que la moyenne des distances (~ log(n)) dans les réseaux biologiques est "petite" par rapport à la taille du réseau (n). Ces réseaux sont ainsi qualifiés de réseaux "small-world". [WATTS D. & STROGATZ S.]
Nous nous sommes basés sur l'algorithme de Dijkstra déjà implémenté dans Brume pour construire nos méthodes d'analyse. Celui-ci permet de trouver le plus court chemin entre un nœud-source et un nœud-destination.
Cependant, nous nous intéressons à trouver tous les plus courts chemins possibles qui existent entre chaque paire de nœuds. En effet, ceci est motivé par le fait de :
1. pouvoir prévoir les voies métaboliques préférentielles et détecter celles effectivement réalisées dans le cadre de la construction des réseaux métaboliques ;
2. pouvoir trouver des voies de reconstitution pour pallier à d'éventuelles destructions de voies métaboliques dues à diverses perturbations possibles (maladies, drogues...).
Après avoir tenté sans succès de développer à partir de l'algorithme de Dijkstra de base notre propre algorithme de recherche de tous les PCC entre deux nœuds, nous avons trouvé un algorithme implémenté en langage C qui affirme trouver tous les plus courts chemins à un nœud [SCVALEX 2008]. Nous avons également trouvé une publication qui propose un pseudo-code pour la recherche optimisée de k- plus courts chemins entre deux nœuds [MACGREGOR M.H. & GROVER W.D.]. Par ailleurs, [VAN HELDEN J.] trouve les cinq plus courts chemins de L-aspartate à L-methionine. Cette recherche semble donc raisonnable d'un point de vue combinatoire et peut être envisagée. Ces documents constituent donc la base d'une étude ultérieure qui consistera à trouver tous ces plus courts chemins entre paires de nœuds, également indispensable pour les calculs sur les centralités d'intermédiaire.
Notons qu'au stade de développement du logiciel Brume et au vu des données actuellement disponibles sur les réseaux, nous considérons les poids sur les arcs du graphe comme positifs, ce qui justifie l'utilisation de l'algorithme de Dijkstra. Comme point d'amélioration de cette méthode d'analyse, il serait intéressant de considérer la possibilité de poids négatifs. Dans ce cas, l'algorithme de Floyd-Warshall est judicieux [FLOYD R.] [SCVALEX 2007].
16
Illustration 15: Chemin de longueur 4 de u à v [MASON O. & VERWOERD M.]

Nous détaillons ci-dessous le principe de l'algorithme de Dijkstra qui se base sur un parcours en largeur (BFS) de graphe pour trouver le PCC de S à D :
S : nœud sourceD : nœud destinationmat : matrice d'adjacence (coûts sur arcs) associée au grapheparent : vecteur des nœuds précédents le nœud courantdist : vecteur des distances de la source au nœud courantqueue : pour le parcours , ensemble des nœuds non traités
[r_path,r_cost] = dijkstra_s(S,D,mat) n = taille(mat)//initialisations des structures :parent = 0dist = Infqueue = videdistance(S) = 0
//débuter au nœud sourcePour tous les nœuds i faire Si un arc existe entre S et i dist(i) = mat(S,i) parent(i) = S
ajouter i à queue finSifinPour
// parcours en largeur BFSTant que queue non vide enlever le 1er élément u de queue pour tout nœud v du graphe faire // un PCC a été trouvé entre u et v si dist(v) > dist(u) + mat(u,v) alors →
→ dist(v) = dist(u) + mat(u,v)parent(v) = uajouter v à queue
finSifinTantque// Bracktrace du PCC (reconstitution)initialiser :r_path à Dparent(D) est le noeud courant
Tantque i n'est pas en S et i>0 faire mettre i en tête de r_path parent(i) devient le noeud courantfinTanque
si on est arrivé à la source S ajouter le noeud courant à r_pathsinon r_path est mis à jour à videfinSi
// retourner la distance r_cost est la valeur de dist(D)
Nous proposons dans le module PCC quatre types d'options possibles dont les algorithmes se basent sur l'algorithme de Dijkstra de base entre paire et fait un filtrage selon le choix opéré :
1. PCC entre toutes les paires de métabolites : pour répertorier tous les PCC possibles (un seul par paire) entre toutes les paires de nœuds du graphe ;
2. PCC "contraint" (passant par un métabolite donné) : l'utilisateur entre le nom du métabolite v dont il souhaite voir tous les chemins qui passent par v (résultat faussé par l'unique chemin trouvé par l'algorithme actuel)
3. PCC entre les métabolites S et P : l'utilisateur souhaite connaître les PCC passant entre deux métabolites dont il spécifie le nom (résultat faussé par l'unique chemin trouvé par l'algorithme actuel)
4. PCC "contraint" entre les métabolites S et P : l'utilisateur désire répertorier l'ensemble des PCC entre deux métabolites S et P, en ajoutant la contrainte d'appartenance d'un troisième métabolite v - dont il entre les noms - à ces chemins. (résultat faussé par l'unique chemin trouvé par l'algorithme actuel)
Nous avons décomposé ce module PCC afin de proposer différentes options de filtre de PCC et permettre de cibler cette recherche.
17

Entre deux nœuds, les différents PCC correspondraient à des voies alternatives à la réalisation d'une succession de réactions possibles, permettant, à partir d'un métabolite S, de produire un autre métabolite P, et par conséquent, permettre la réalisation d'une fonction biologique donnée. Passant par un nœud donné, les différents PCC donneraient une idée sur l'importance de ce nœud. Ainsi, la redondance de chemins est une propriété locale importante. Elle traduit la robustesse de plusieurs réseaux métaboliques. [AITTOKALLIO T. and SCHWIKOWSKI B.]
2.5 Notions de Centralité (betweenness centrality)
En 1977, [Freeman, L.] définit la centralité pour les réseaux sociaux par ce qui suit : "the degree to which a point is on the shortest path between others and therefore has a potential for control of communication." Il existe plusieurs types de mesures de centralités :
la centralité des degrés (degree centrality) : nombre de liens d'un nœud (voir 'Connectivité des nœuds d'un graphe'), mesure par exemple, le risque pour un nœud d'être atteint par tout ce qui peut circuler dans un réseau (virus, information)
la centralité d'intermédiaire (betweenness centrality) la closeness centrality : la distance géodésique moyenne entre un nœud v et tous les autres
nœuds atteignables à partir de v. Elle peut mesurer par exemple, le temps que met une information partant de v à atteindre tous les autres nœuds du graphe.
Nous nous intéressons en particulier à la centralité d'intermédiaire. Notée CB(v) pour un nœud v donné, elle peut être définie comme étant la proportion du nombre de chemins géodésiques entre une paire de nœuds du graphe passant par v, σst(v), par rapport au nombre total de chemins entre cette même paire de nœuds σst :
De manière abstraite, s'il existe m chemins entre deux nœuds s et t d'un graphe, la probabilité qu'une 'information' passe par un de ces chemins est de 1/m. S'il existe p chemins entre s et t passant par un nœud v, alors la probabilité qu'une 'information' passe par v est de p/m.
La centralité d'intermédiaire (Betweenness Centrality BC) d'un nœud v est donc une mesure de son importance en tant qu'intermédiaire dans une succession de réactions. Cette notion peut être mise en œuvre pour mesurer les effets de perturbations sur la redondance des voies métaboliques, tandis que les longueurs de chemins (distance) caractérisent les temps de réponse (réaction) à une perturbation [BRANDES U.].
Le calcul des centralités d'intermédiaires pour les différents nœuds est donc tributaire de l'algorithme de recherche de tous les PCC entre nœuds du graphe. Ainsi, notre projet implémente un algorithme de calcul fiable puisqu'il se base sur les définitions précises proposées, mais les résultats sont biaisés par l'unicité du PCC trouvé en 3.
La mise en œuvre de l'algorithme pour le calcul des indices de centralités est coûteuse d'un point de vue combinatoire. En effet, pour un graphe de n sommets, le calcul se fait en environ O(n3). Néanmoins, pour optimiser le calcul, nous nous basons sur le critère de Bellman : En notant dG(s,t) la distance entre deux nœuds s et t dans G,
Un nœud v du graphe G fait partie d'un plus court chemin entre les nœuds s et t, si et seulement si dG(s,t) = dG(s,v) + dG(v,t)
18

Et nous adoptons la démarche de calcul suivante :
Étant données les distances entre paires de nœuds et les nombres de plus courts chemins, la dépendance (pair-dependency) notée δst(v) d'une paire s-t à un intermédiaire v est la proportion de PCC entre s et t passant par v et est donné par :
et alors, le calcul de la centralité d'intermédiaire se fait par sommation des dépendances :
[BRANDES U.] propose un algorithme 'rapide' qui se fait en un temps O(nm), où m est le nombre de liens entre les nœuds du graphe. Une amélioration de ce module serait donc d'implémenter l'algorithme proposé.
19
Illustration 17: Relative importance des noeuds i et j faiblement connectés, mais intermédiaires indispensables
Illustration 18: Exemple de réseau illustrant les notions de Betwenness Centrality, de connectivité et de points d'articulation
Illustration 16: La "Betweenness Centrality" peut être vue comme une mesure de la résistance physique du réseau

III.ANALYSE DES RESULTATS DE TESTS DES ALGORITHMES SUR LES GRAPHES
1. Quelques éléments sur les réseaux étudiés
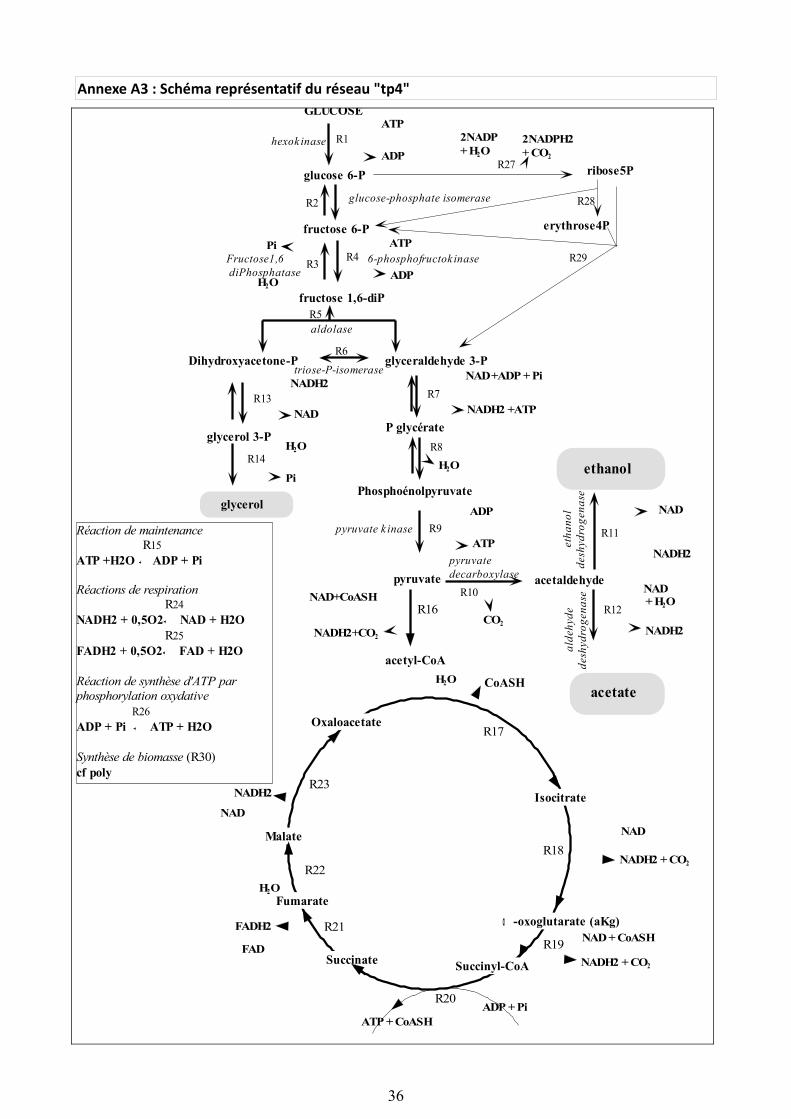
"tp4" est un des réseaux métaboliques utilisés pour tester les algorithmes implémentés. Etant donnée la multitude de réactions métaboliques mises en jeu dans ce réseau, nous identifions un squelette du réseau. Pour cela, il faut considérer les réactions centrales, c'est-à-dire celles qui sont les plus courantes, qui mettent en jeu un grand nombre de métabolites ou qui participent à la réalisation d'une voie ou d'un cycle métabolique. Le glucose est le métabolite de départ du squelette composé de la voie de la glycolyse ainsi que du cycle de Krebs. Ce squelette est représenté en rouge dans l’image ci-dessous. Ce réseau est composé de 41 métabolites intervenant dans 31 réactions.
Illustration 19: Glycolyse et cycle de Krebs
(voir Annexe A3 pour la représentation du réseau "tp4")
Le réseau de test fibro comporte le même squelette que celui du tp4 avec d’autres réactions en complément, ce qui le différencie du tp4. Ce réseau possède 116 métabolites et 102 réactions sont mises en jeu.
20

2. Tests des algorithmes et analyse des résultats
2.1 MESURES DE CONNECTIVITES
"tp4" :L’application des calculs sur la connectivité au réseau tp4 donne plusieurs résultats. Nous
choisissons l’élimination des cofacteurs ou non, les valeurs calculées sont modifiées.Sans élimination de cofacteurs, choix 0, ce réseau possède un degré moyen plus élevé que pour les autres choix. Ceci peut s’expliquer par le fait que les cofacteurs ont des degrés élevés étant donné la fréquence de leurs apparitions dans les réactions. La densité du graphe pour les trois différents choix est plutôt faible ce qui montre que le graphe est peu dense, i.e. tous les liens entre les différents métabolites ne sont pas possibles [GAY B. and DOUSSET B.].
De même la valeur du clustering est faible et varie légèrement, voir tableau, avec les différents choix d'éliminations possibles.
Fichier Choix Nombres de sommets Clustering Degré
moyenDensité du graphe
Tp4 1* 33 0.0524 4.9091 0.1534
2** 31 0.0495 3.7419 0.1247
3*** 31 0.0495 3.7419 0.1247
0**** 41 0.1462 8.1951 0.2049
Tableau 1 : Valeurs des connectivités du réseau tp4 (*) : Élimination des Cofacteurs(**) : Élimination des cofacteurs + PI et H20(***) : Elimination des cofacteurs +FMN+ FMNH2+ CH2__THF+CH0-THF+THF+CH2-THF+DAMP+cytb_red+cytb_ox(****) : Choix par défaut pas d’élimination de cofacteur.
Cette partie du programme permet aussi d’afficher les nœuds ayant un degré faible ou élevé par rapport au degré moyen. Ci-dessous la liste des métabolites ayant un fort degré ainsi que ceux ayant un faible degré (nombre de réactions les faisant intervenir) pour le choix 2 appliqué au réseau tp4.
Nœuds Nb de réac.GA3PCO2
fructose6P fructose1-
6diP ribose5P
CoASHglucose6P erythrose4
PDHAP
1088766655
Tableau 2: Nœuds de forte connectivité (par rapport au degré moyen du graphe)
Nœuds Nb de réac.glycerolethanol acetate fructose
glycerol3P succinate fumarate malate
NH3 H2SO4
1111222222
Tableau 3: Nœuds de faible connectivité (par rapport au degré moyen du graphe)
Ce tableau met en avant d’une part la forte connectivité des métabolites tel que : CO2, GA3P, fructose6P, fructose1-6diP. Ces métabolites peuvent ainsi être considérés comme des hubs. D’autre part la faible connectivité des métabolites : glycerol, ethanol, acetate, fructose.
21
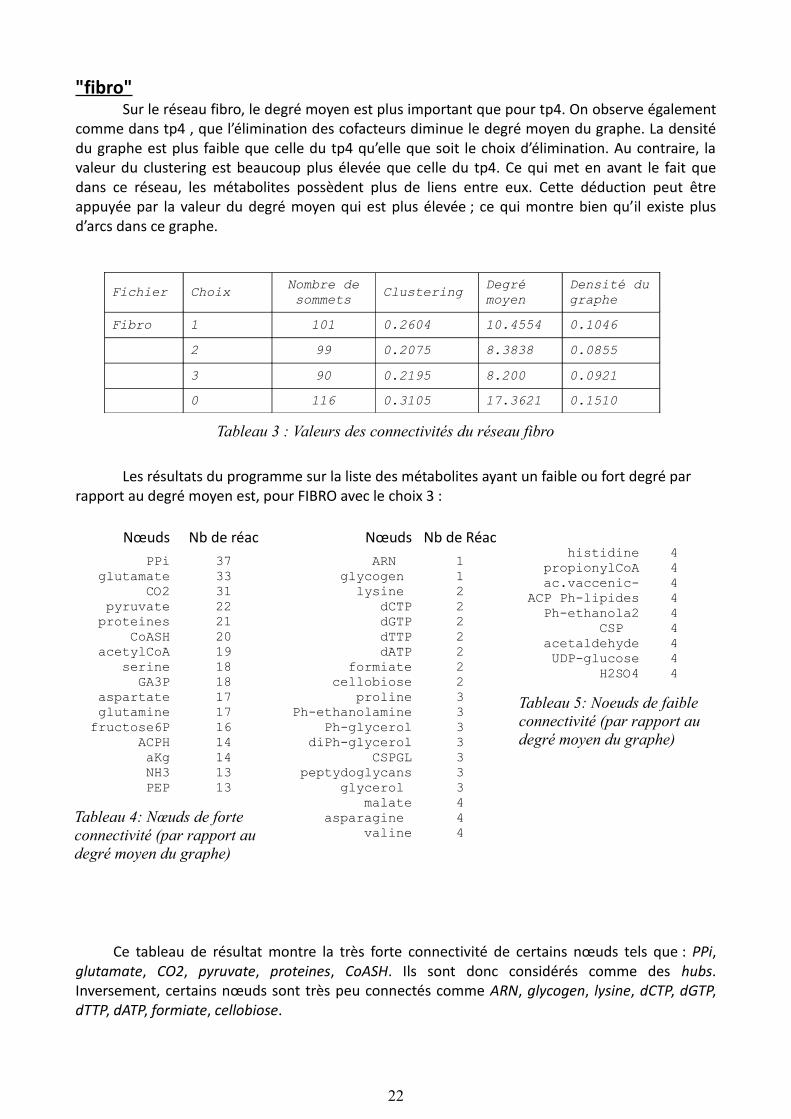
"fibro"Sur le réseau fibro, le degré moyen est plus important que pour tp4. On observe également
comme dans tp4 , que l’élimination des cofacteurs diminue le degré moyen du graphe. La densité du graphe est plus faible que celle du tp4 qu’elle que soit le choix d’élimination. Au contraire, la valeur du clustering est beaucoup plus élevée que celle du tp4. Ce qui met en avant le fait que dans ce réseau, les métabolites possèdent plus de liens entre eux. Cette déduction peut être appuyée par la valeur du degré moyen qui est plus élevée ; ce qui montre bien qu’il existe plus d’arcs dans ce graphe.
Fichier Choix Nombre de sommets Clustering Degré
moyenDensité du graphe
Fibro 1 101 0.2604 10.4554 0.1046
2 99 0.2075 8.3838 0.0855
3 90 0.2195 8.200 0.0921
0 116 0.3105 17.3621 0.1510
Tableau 3 : Valeurs des connectivités du réseau fibro
Les résultats du programme sur la liste des métabolites ayant un faible ou fort degré par rapport au degré moyen est, pour FIBRO avec le choix 3 :
Nœuds Nb de réacPPi
glutamateCO2
pyruvateproteines
CoASHacetylCoA
serineGA3P
aspartateglutaminefructose6P
ACPHaKgNH3PEP
37333122212019181817171614141313
Tableau 4: Nœuds de forte connectivité (par rapport au degré moyen du graphe)
Nœuds Nb de RéacARN
glycogen lysine
dCTPdGTPdTTPdATP
formiatecellobiose
prolinePh-ethanolamine
Ph-glyceroldiPh-glycerol
CSPGLpeptydoglycans
glycerol malate
asparagine valine
1122222223333333444
histidine
propionylCoA ac.vaccenic-
ACP Ph-lipides Ph-ethanola2
CSP acetaldehydeUDP-glucose
H2SO4
444444444
Tableau 5: Noeuds de faible connectivité (par rapport au degré moyen du graphe)
Ce tableau de résultat montre la très forte connectivité de certains nœuds tels que : PPi, glutamate, CO2, pyruvate, proteines, CoASH. Ils sont donc considérés comme des hubs. Inversement, certains nœuds sont très peu connectés comme ARN, glycogen, lysine, dCTP, dGTP, dTTP, dATP, formiate, cellobiose.
22

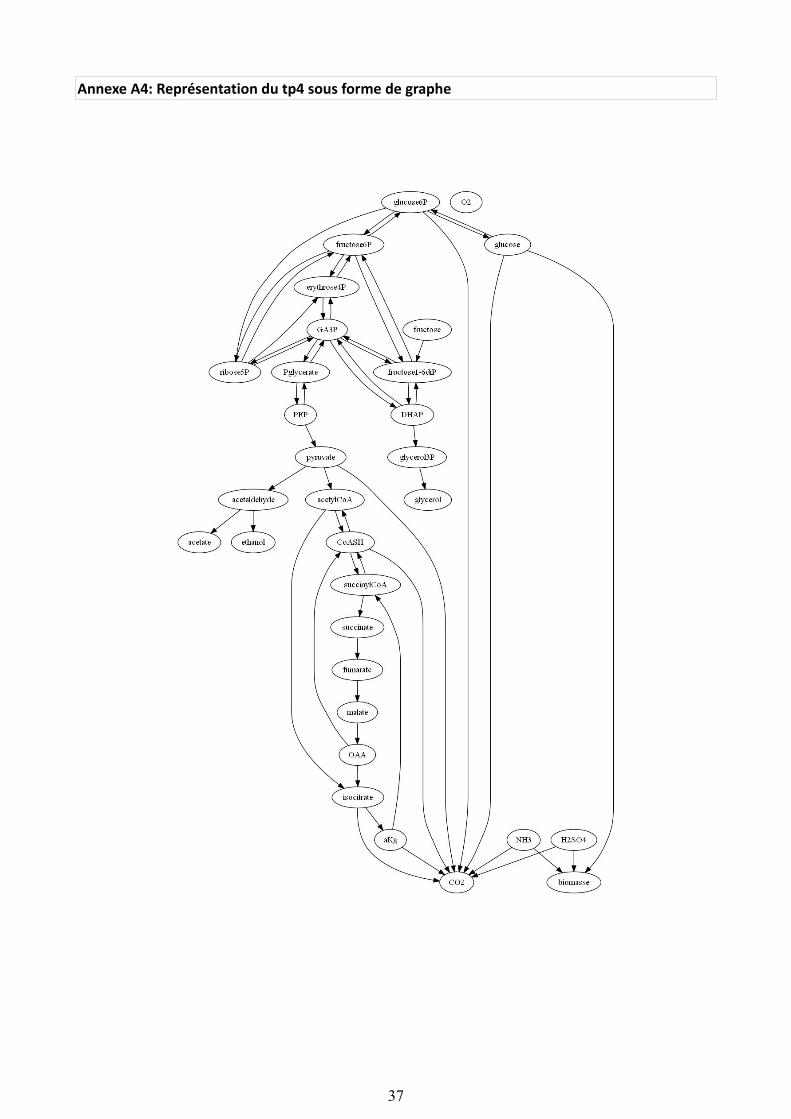
2.2 GENERATION DE DESSIN DE GRAPHE
Nous avons ajouté une fonction qui génère un fichier sous l'extension '.dot' à partir de la matrice d'adjacence afin de générer un dessin de graphe sous Graphviz. Ceci est utile afin de vérifier visuellement quelques résultats obtenus ci-dessous. Nous trouverons en annexe (A4) le dessin du graphe généré pour le réseau tp4.
2.3 RECHERCHE DE CYCLES
"tp4" :
L’algorithme de recherche de cycle appliqué au réseau tp4 après élimination des cofacteurs (choix 2) renvoie 5 cycles :
Nombre de cycles trouves après élimination répétitions: 5
-------Cycle 1GA3P fructose1-6diP fructose6P glucose6P ribose5P erythrose4P -------Cycle 2GA3P fructose1-6diP fructose6P glucose6P ribose5P -------Cycle 3isocitrate aKg succinylCoA succinate fumarate malate OAA -------Cycle 4CoASH acetylCoA isocitrate aKg succinylCoA succinate fumarate malate OAA -------Cycle 5isocitrate aKg succinylCoA CoASH acetylCoA
Sur le graphe représentant le réseau ont peut observer la présence de ces cycles, voir tableau ci-dessous. De plus on retrouve le cycle de Krebs présent dans le squelette du réseau.
Illustration 20: Cycle 1 Illustration 21: Cycle 2
23
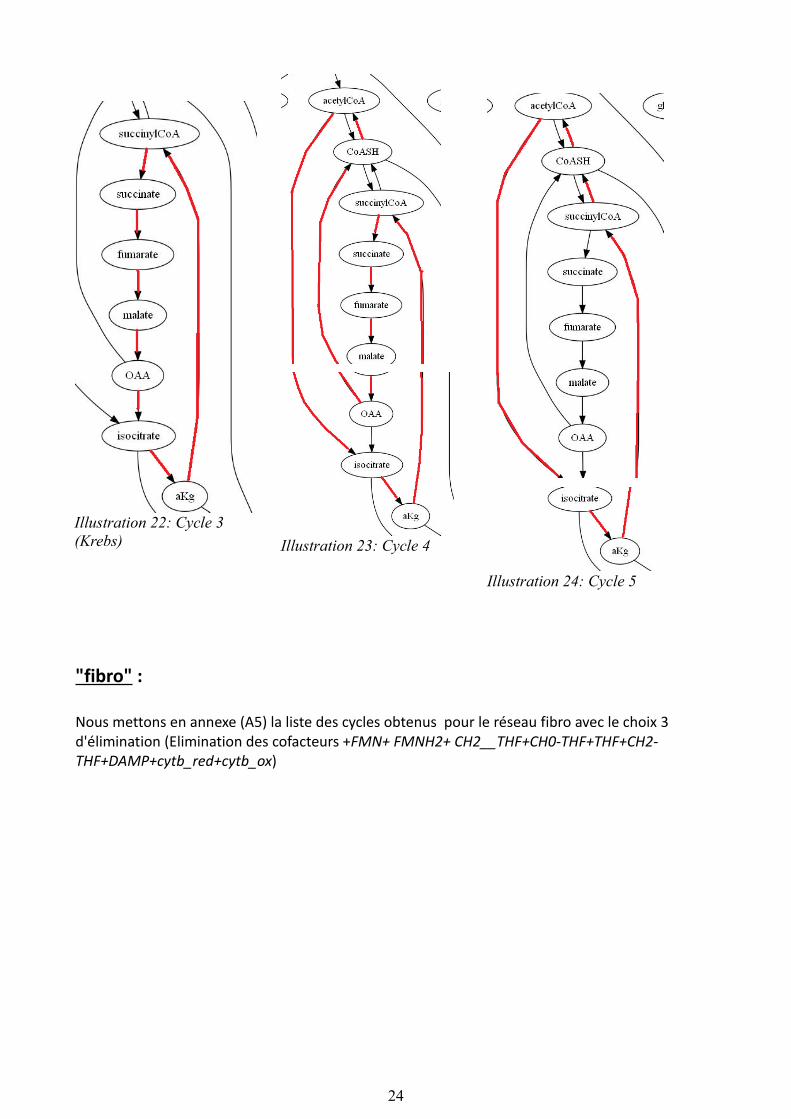
Illustration 22: Cycle 3 (Krebs) Illustration 23: Cycle 4
Illustration 24: Cycle 5
"fibro" :
Nous mettons en annexe (A5) la liste des cycles obtenus pour le réseau fibro avec le choix 3 d'élimination (Elimination des cofacteurs +FMN+ FMNH2+ CH2__THF+CH0-THF+THF+CH2-THF+DAMP+cytb_red+cytb_ox)
24
2.4 POINTS D'ARTICULATION
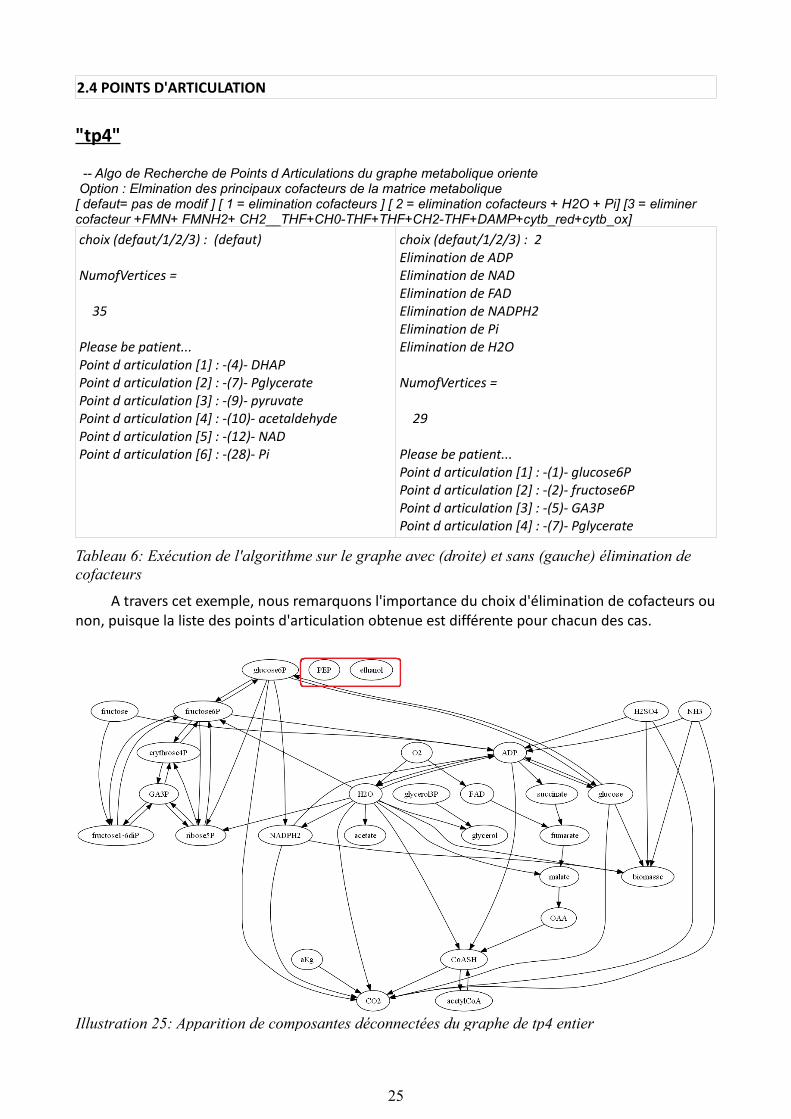
"tp4"
-- Algo de Recherche de Points d Articulations du graphe metabolique oriente Option : Elmination des principaux cofacteurs de la matrice metabolique[ defaut= pas de modif ] [ 1 = elimination cofacteurs ] [ 2 = elimination cofacteurs + H2O + Pi] [3 = eliminer cofacteur +FMN+ FMNH2+ CH2__THF+CH0-THF+THF+CH2-THF+DAMP+cytb_red+cytb_ox]choix (defaut/1/2/3) : (defaut)
NumofVertices =
35
Please be patient...Point d articulation [1] : -(4)- DHAPPoint d articulation [2] : -(7)- PglyceratePoint d articulation [3] : -(9)- pyruvatePoint d articulation [4] : -(10)- acetaldehydePoint d articulation [5] : -(12)- NADPoint d articulation [6] : -(28)- Pi
choix (defaut/1/2/3) : 2Elimination de ADPElimination de NADElimination de FADElimination de NADPH2Elimination de PiElimination de H2O
NumofVertices =
29
Please be patient...Point d articulation [1] : -(1)- glucose6PPoint d articulation [2] : -(2)- fructose6PPoint d articulation [3] : -(5)- GA3PPoint d articulation [4] : -(7)- Pglycerate
Tableau 6: Exécution de l'algorithme sur le graphe avec (droite) et sans (gauche) élimination de cofacteurs
A travers cet exemple, nous remarquons l'importance du choix d'élimination de cofacteurs ou non, puisque la liste des points d'articulation obtenue est différente pour chacun des cas.
25
Illustration 25: Apparition de composantes déconnectées du graphe de tp4 entier
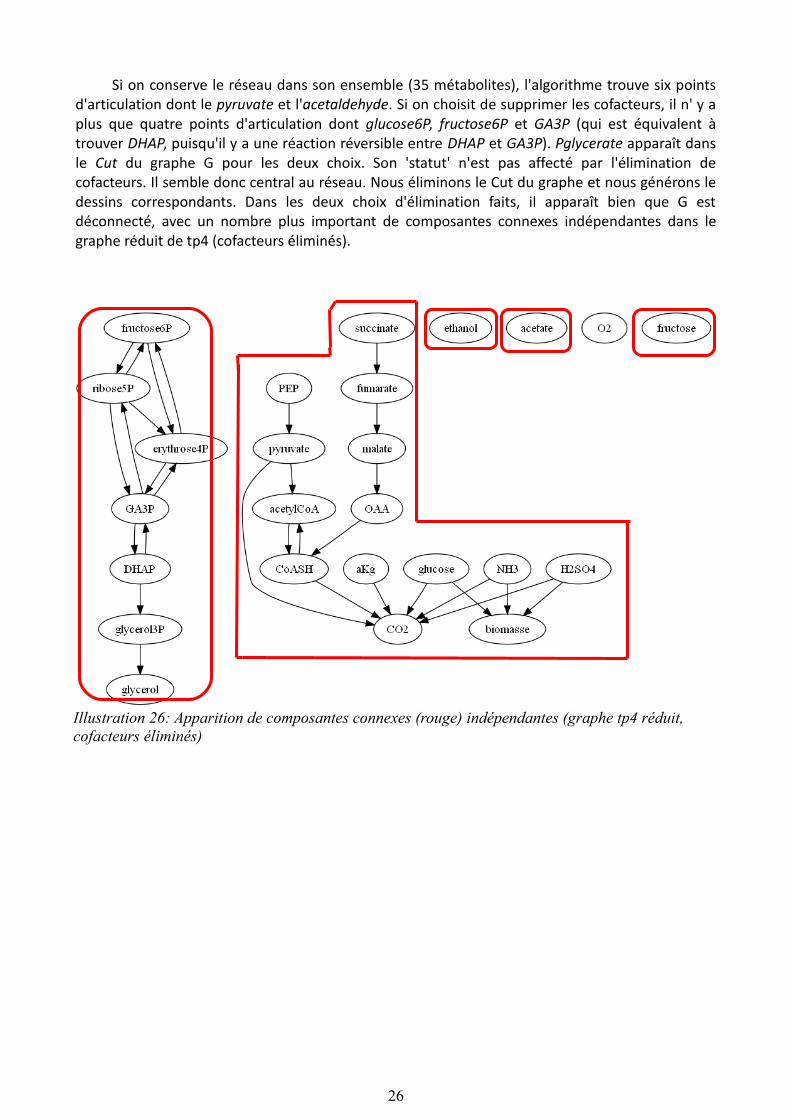
Si on conserve le réseau dans son ensemble (35 métabolites), l'algorithme trouve six points d'articulation dont le pyruvate et l'acetaldehyde. Si on choisit de supprimer les cofacteurs, il n' y a plus que quatre points d'articulation dont glucose6P, fructose6P et GA3P (qui est équivalent à trouver DHAP, puisqu'il y a une réaction réversible entre DHAP et GA3P). Pglycerate apparaît dans le Cut du graphe G pour les deux choix. Son 'statut' n'est pas affecté par l'élimination de cofacteurs. Il semble donc central au réseau. Nous éliminons le Cut du graphe et nous générons le dessins correspondants. Dans les deux choix d'élimination faits, il apparaît bien que G est déconnecté, avec un nombre plus important de composantes connexes indépendantes dans le graphe réduit de tp4 (cofacteurs éliminés).
26
Illustration 26: Apparition de composantes connexes (rouge) indépendantes (graphe tp4 réduit, cofacteurs éliminés)

"fibro"
Dans l'exemple suivant, nous testons la recherche de Cut sur le graphe du réseau fibro.
-- Algo de Recherche de Points d Articulations du graphe metabolique oriente Option : Elmination des principaux cofacteurs de la matrice metabolique[ defaut= pas de modif ] [ 1 = elimination cofacteurs ] [ 2 = elimination cofacteurs + H2O + Pi] [3 = eliminer cofacteur +FMN+ FMNH2+ CH2__THF+CH0-THF+THF+CH2-THF+DAMP+cytb_red+cytb_ox]
choix (defaut/1/2/3) : NumofVertices =
109
Please be patient...Point d articulation [1] : -(4)- DHAPPoint d articulation [2] : -(7)- PglyceratePoint d articulation [3] : -(9)- pyruvatePoint d articulation [4] : -(50)- DAMPPoint d articulation [5] : -(59)- ac.phosphaPoint d articulation [6] : -(63)- ATPPoint d articulation [7] : -(64)- ADPPoint d articulation [8] : -(66)- PPiPoint d articulation [9] : -(71)- CDPPoint d articulation [10] : -(87)- ac.phospha2Point d articulation [11] : -(100)- PiPoint d articulation [12] : -(101)- CO2
choix (defaut/1/2/3) : 2Elimination de ATPElimination de ADPElimination de AMPElimination de UMPElimination de UDPElimination de UTPElimination de CMPElimination de CDPElimination de CTPElimination de GDPElimination de GTPElimination de NADPElimination de NADElimination de PiElimination de H2O
NumofVertices =
94
Please be patient...Point d articulation [1] : -(2)- fructose6PPoint d articulation [2] : -(4)- DHAPPoint d articulation [3] : -(5)- glycerol3PPoint d articulation [4] : -(6)- GA3PPoint d articulation [5] : -(7)- PglyceratePoint d articulation [6] : -(10)- acetylPPoint d articulation [7] : -(13)- OAAPoint d articulation [8] : -(15)- xylulose5PPoint d articulation [9] : -(17)- succinylCoAPoint d articulation [10] : -(18)- fumaratePoint d articulation [11] : -(19)- malatePoint d articulation [12] : -(20)- ribose5PPoint d articulation [13] : -(25)- CH2--THFPoint d articulation [14] : -(27)- CH2-THFPoint d articulation [15] : -(29)- THFPoint d articulation [16] : -(30)- glutamatePoint d articulation [17] : -(34)- aspartatePoint d articulation [18] : -(42)- alaninePoint d articulation [19] : -(43)- serinePoint d articulation [20] : -(55)- propionylCoAPoint d articulation [21] : -(74)- ac.phospha2Point d articulation [22] : -(87)- CO2BridgesElapsed time: 95.3106
Tableau 7: Exécution de l'algorithme sur le graphe avec (droite) et sans (gauche) élimination de cofacteurs
27

Le dessin de graphe ci-dessous a été généré après suppression des points d'articulation sur le réseau tp4 réduit (94 nœuds, option d'élimination 2). Il apparaît bien que les métabolites fructose1-6diP, DHF et FMN (en rouge) ne sont plus reliés au graphe G.
2.5 RECHERCHE DE PLUS COURTS CHEMINS (PCC)
Ce test d'exécution du module de PCC se fait avec l' option qui se base sur la matrice stœchiométrique réduite.
"bmc_full"
Appliquée au graphe-test "bmc_full", la recherche du plus court chemin entre nœuds donne des résultats corrects. Nous l'appliquons sur le graphe complet sans élimination. Comme précédemment évoqué, l'algorithme doit être amélioré afin de proposer une recherche de tous les plus courts chemins entre paire de nœuds. Ceci afin par exemple de trouver les chemins entre A et D qui sont au nombre de 2 sur ce graphe-test : A-->D passant par C et A-->D passant par B.
0 : Retour au menu principal 1 : PCC entre toutes les paires de métabolites 2 : PCC "contraint" (passant par un métabolite v donné) 3 : PCC entre les métabolites S et P 4 : PCC "contraint" entre les métabolites S et P
Selection :1 = PCC entre toutes les paires de métabolites C --> B C B [1]C --> D C D [1]A --> C A C [1]
A --> B A B [1] →
→ A --> D A C D [2]B --> C B C [1]B --> D B D [1]Nombre de PCC entre toutes les pairs : 7 Elapsed time: 0.057
28
Illustration 27: Apparition de composantes connexes (rouge) indépendantes (graphe fibro réduit, cofacteurs éliminés)

Selection : 2 = PCC "contraint" (passant par un métabolite v donné) PCC "contraint" (passant par un métabolite donné) Entrer le nom du metabolite intermédiaire : B
nomNoeud = B Recherche de PCC passant par le métabolite : B(intermédiaire)
C --> B C B [1]A --> B A B [1]B --> C B C [1]B --> D B D [1] Nombre PCC passant par B : 4 Elapsed time: 3.354
Selection :3 = PCC entre les métabolites S et P Entrer le nom du metabolite Source (S) : AnomNoeud = AEntrer le nom du metabolite Puit (P) : DnomNoeud = D
Recherche de PCC de : A à DA --> D A C D [2] Nombre PCC de : A à D 1
Selection : 4 = PCC "contraint" entre les métabolites S et P
Entrer le nom du metabolite Source (S) : A →
→ nomNoeud = AEntrer le nom du metabolite Puit (P) : DnomNoeud =DEntrer le nom du metabolite intermédiaire : CnomNoeud = C Recherche de PCC de : A à Dpassant par le métabolite : C(intermédiaire) A --> D A C D [2] Nombre PCC de : A à Dpassant par le métabolite : C(intermédiaire) 1Elapsed time: 7.293
Selection : 4 = PCC "contraint" entre les métabolites S et P Entrer le nom du metabolite Source (S) : AnomNoeud = AEntrer le nom du metabolite Puit (P) : DnomNoeud = DEntrer le nom du metabolite intermédiaire : BnomNoeud = B
Recherche de PCC de : A à Dpassant par le métabolite : B(intermédiaire) Nombre PCC de : A à Dpassant par le métabolite : B(intermédiaire) 0 Elapsed time: 3.896
Selection :0--->Fin Algo de Recherche de Plus Courts Chemins
"tp4"Nous donnons ci-dessous un extrait des résultats trouvés par cette recherche, les résultats
complets étant en annexe (A6). L'algorithme est exécuté avec l'option d'élimination 2 des cofacteurs. Il trouve des PCC uniques entre métabolites et affiche la distance correspondante entre crochets. Entre autres nous notons qu'il trouve le chemin correpondant à la voie métabolique de la glycolyse (glucose --> pyruvate avec d'autres intermédiaires importants).
Notons qu'avec la sélection 3 nous obtenons un PCC entre glucose et pyruvate passant par le cofacteur ADP, la distance annoncée est de 1.5. Cependant, ce chemin ne présente aucun intérêt puisqu'il occulte la voie métabolique importante de la glycolyse. Nous contraignons donc cette recherche par la sélection 4 qui demande le PCC entre le glucose et le pyruvate passant par le PEP (Phosphoénolpyruvate). La distance entre le glucose et le pyruvate est alors de 6. Ceci correspond bien à la fonction de glycolyse accomplie par cette voie métabolique.
29

Selection :1 = PCC entre toutes les paires de métabolites[...]fructose6P --> OAA fructose6P fructose1-6diP DHAP NAD OAA [4]PEP --> fructose6P PEP Pglycerate H2O fructose6P [3]erythrose4P --> Pglycerate erythrose4P GA3P Pglycerate [2]
Selection : 2 = PCC "contraint" (passant par un métabolite v donné)[...]glucose --> aKg glucose ADP Pglycerate NAD aKg [3.5][...] Nombre PCC passant par Pglycerate : 194
Selection :3 = PCC entre les métabolites S et P Entrer le nom du metabolite Source (S) : glucosenomNoeud = glucoseEntrer le nom du metabolite Puit (P) : pyruvatenomNoeud = pyruvateRecherche de PCC de : glucose à pyruvate glucose --> pyruvate glucose ADP pyruvate [1.5] Nombre PCC de : glucose à pyruvate 1 Selection : 4 = PCC "contraint" entre les métabolites S et P Entrer le nom du metabolite Source (S) : glucosenomNoeud = glucoseEntrer le nom du metabolite Puit (P) : pyruvatenomNoeud = pyruvateEntrer le nom du metabolite intermédiaire : PEPnomNoeud = PEP
Recherche de PCC de : glucose à pyruvatepassant par le métabolite : PEP(intermédiaire) glucose --> pyruvate glucose glucose6P ribose5P GA3P Pglycerate PEP pyruvate [6]
Nombre PCC de : glucose à pyruvatepassant par le métabolite : PEP(intermédiaire) 1 Elapsed time: 62.332
30

2.6 BETWEENNESS CENTRALITY
"tp4"
Les résultats ci-dessous sont générés pour le graphe 'tp4' en choisissant de conserver tous les métabolites du réseau. Ils sont donnés à titre d'exemple. Nous avons précédemment attiré l'attention sur le manque de pertinence de ces résultats, dû à la recherche précédente qui fournit un PCC unique pour chaque paire de nœuds du graphe. On aurait dû obtenir une valeur de centralité d'intermédiaire très élevée pour le Pglycerate par exemple qui est présent sur 194 chemins d'après les résultats donnés précédemment (PCC, sélection 2) pour un total de 672 chemins entre toutes les paires de nœuds du réseau.
Betweenness Centrality BC (Centralité d intermédaire) :
BC | BC normalisé BC(glucose6P) = 89 | 0.11772BC(fructose6P) = 64 | 0.084656BC(fructose1-6diP) = 62 | 0.082011BC(DHAP) = 64 | 0.084656BC(GA3P) = 57 | 0.075397BC(glycerol3P) = 58 | 0.07672BC(Pglycerate) = 57 | 0.075397BC(PEP) = 57 | 0.075397BC(pyruvate) = 57 | 0.075397BC(acetaldehyde) = 57 | 0.075397BC(acetylCoA) = 57 | 0.075397BC(CoASH) = 57 | 0.075397BC(aKg) = 57 | 0.075397BC(succinate) = 57 | 0.075397BC(fumarate) = 57 | 0.075397BC(malate) = 57 | 0.075397BC(OAA) = 57 | 0.075397
BC(ribose5P) = 57 | 0.075397BC(erythrose4P) = 57 | 0.075397BC(glucose) = 57 | 0.075397BC(glycerol) = 57 | 0.075397BC(ethanol) = 57 | 0.075397BC(acetate) = 57 | 0.075397BC(CO2) = 57 | 0.075397BC(O2) = 57 | 0.075397BC(NH3) = 57 | 0.075397BC(H2SO4) = 57 | 0.075397BC(biomasse) = 57 | 0.075397BC(fructose) = 57 | 0.075397 BC moyen (normalisé) = 0.077769 --->Fin Algo de calculs des Centralités Elapsed time: 38.954
31

Conclusion
Les récentes avancées théoriques et technologiques en Biologie ont permis de meilleures analyses des réseaux métaboliques. L'utilisation d'outils de traitement efficaces est d'autant plus utile que la quantité de données disponibles sur ces réseaux est importante. A travers ce projet, nous avons tenté de proposer des méthodes permettant d'analyser les réseaux métaboliques en utilisant les concepts de la Théorie des Graphes que nous avons intégrés au logiciel Brume développé au LGCB.
En premier lieu, nous avons implémenté une méthode qui effectue des calculs sur la connectivité des nœuds. Elle permet d'obtenir des informations sur la relative importance des métabolites , sur la densité du réseau et sur le clustering. A partir de ces résultats, une étude pourra être faite sur la distribution des degrés des nœuds, afin d'en conclure des éléments de topologie du réseau et de fonctions biologiques assurées.
Ensuite, nous avons développé une méthode pour la recherche de points d'articulation qui permet de déterminer les métabolites centraux. Ceux-ci assurent la cohésion au sein du réseau et leur absence entraînerait une perturbation de celui-ci.
De plus, le logiciel intègre un algorithme de recherche de cycles. Celui-ci donne des résultats intéressants. Cependant, certains cycles peuvent ne pas être détectés et la recherche de tous les cycles dans un réseau de grande taille pose un problème combinatoire. Une étude pourra être menée, au-delà du cadre de ce projet pour proposer une solution.
En outre, un algorithme de recherche de plus courts chemins et distances entre paires de nœuds du graphe est proposé. Cependant, cet algorithme trouve un unique plus court chemin alors qu'il peut en exister plusieurs. Par ailleurs, à ce stade de développement, il suppose que les poids sur les arcs soient positifs. Ainsi, les résultats actuellement obtenus sont intéressants puisqu'ils mettent en évidence certaines voies métaboliques. Néanmoins, pour un traitement complet du réseau et dans l'éventualité de poids négatifs, cet algorithme devrait être amélioré à la lumière des publications trouvées pour recenser tous les plus courts chemins entre métabolites dans le réseau.
Enfin, un module de calcul sur les centralités d'intermédiaires permet d'obtenir des mesures traduisant l'importance des métabolites en tant qu'intermédiaires des réactions dans un réseau. Ceci se fait en déterminant la proportion de réactions (chemins) auxquelles ils participent. Les résultats obtenus par ce module sont tributaires des résultats du module de recherche de plus courts chemins, ils ne sont donc pas exploitables à ce stade. Cependant, l'algorithme est pertinent puisqu'il a été développé à partir des définitions des notions impliquées.
A partir du travail réalisé, il serait intéressant d'étudier par exemple des notions de topologie tels que la détection de motifs dans les réseaux métaboliques qui représentent des fonctions biologiques. Ces études permettront une meilleure description des réseaux métaboliques.
32

Bibliographie
[AITTOKALLIO T. and SCHWIKOWSKI B.] Graph-based methods for analyzing networks in cell biology, Briefings in Bioinformatics. Vol. 7 n° 3. 243-255
[ALBERT R.] Scale-free Networks in Cell Biology, Journal of Cell Science, No.118, 4947-4957, the Company of Biologists 2005
[BALI S. and MOHAMMAD A.J.] Implementation of Commonly Used Graph Algorithms in Matlab, www.ittc.ku.edu/~sbali/graphSoftware.htm Department of EECS, University of Kansas, Lawrence, KS
[BARABASI A.,ALBERT R. et al.] the Large-scale Organization of Metabolic Networks, Nature, 407:651-654, 2000
[BOLLOBAS B.] Graph Theory : an Introductory Course.
[BRANDES U.] A Faster Algorithm for Betweenness Centrality, Journal of Mathematical Sociology, 25(2):163-177, (2001)
[FLOYD R.] Algorithm 97: shortest path, Communications of the ACM, 5, 342 (1962)
[FREEMAN L.] A set of measures of centrality based on betweenness. Sociometry, 40:35.41, 1977
[GAY B. and DOUSSET B.] Cartographie de réseaux d’alliances et analyse stratégique, R&D&I Journal, Vol. 1 (2007): Issue 1
[GIRVAN M. and NEWMAN M.E.J] Community Structure in Social and Biological Networks, PNAS, Vol. 99 no. 12 7821-7826 (June 11, 2002)
[HUBER W, CAREY V.J et al.] Graphs in Molecular Biology, BMC Bioinformatics 2007, 8 (Suppl 6):S8 www.biomdecentral.com/1471-2105/8/S6/S8
[HYUNG-JOON K.] Articulation Points Detection Algorithm, www.ibluemojo.com/school/articul_algorithm.html, CSE 417, University of Washington
[LACROIX V. et al.] Motif Search in Graphs : Application to Metabolic Networks, IEEE/ACM Transactions on Computational Biology and Bioinformatics, Vol. 3, No. 4, (October-December 2006)
[LIDEN G.] cours en ligne : KTE071 Biokemisk reaktionsteknik, LUNDS Universitet, Lunds Tekniska Högskola (2008)
[LLANERAS.F and PICO.J] Stoichiometric Modelling of Cell Metabolism Journal of bioscience and Bioengineering Vol. 105, No 1, (November 2008)
[MACGREGOR M.H. & GROVER W.D.] Optimized k-shortest-paths Algorithm for Facility Restoration, Software—Practice and Experience, Vol. 24(9), 823–834, (September 1994)
[MASON O. & VERWOERD M.] Graph Theory and Networks in Biology, Systems Biology, IETVolume 1, Issue 2, P:89 - 119, (March 2007)
[POUGHON.L]
[SCVALEX 2008] Finding All Paths of Minimum Length to a Node Using Dijkstra’s Algorithm, compprog.wordpress.com/2008/01/17/finding-all-paths-of-minimum-length-to-a-node-using-dijkstras-algorithm (2008)
[SCVALEX 2007] All Sources Shortest Path : The Floyd-Warshall Algorithm,compprog.wordpress.com/2007/11/15/all-sources-shortest-path-the-floyd-warshall-algorithm/
[VALDIS K.] Social Network Analysis, A Brief Introduction, www.orgnet.com/sna.html (2009)
[VAN HELDEN J.] Examples of Metabolic Pathways, ESF Workshop-Integrated Approaches for Functional Genomics - Madrid 2005
[WATTS D. & STROGATZ S.] Collective Dynamics of Small-World Networks. Nature, 393: 440-442 (1998)
33

Annexes
Annexe A1 : Schéma représentant les différentes méthodes d'analyses algébriques mises en oeuvre pour l'étude des réseaux métaboliques
Ce document montre les différentes méthodes d'analyse algébriques qui existent dans le domaine de l'analyse des réseaux métaboliques. Au LGCB, le professeur L. Poughon et son équipe travaillent sur les méthodes suivantes :
● Linear algebra● Convex Analysis● Metabolic Flux Analysis
34

Annexe A2 : Exemple d'analyse par la méthode MFA
Prenons l’exemple d’une réaction pour illustrer le calcul de v.Soient les réactions suivantes :
D’après la relation r = Tt .v et
D'où
On définit r et v :r = (rE rC rA rF rB rD rNADH)t avec rc = (rE rC) et rm = (rA rF) et rB = rD = rNADH = 0.v= (v1 v2 v3 v4 v5)
t. .
Pour définir T2 et T1 on détermine à quel sommet correspond chaque ligne
Avec
On a donc v1 = - rA v2 = 2. rF v3 = - rA - 2. rF v4 = - rA - 3. rF v5 = rF On déduit rC de cette relation car rC = T1.v
D’où rE = v4 rC = v2
Ainsi connaissant des valeurs du taux de formation on peut calculer le flux des réactions.
35
Annexe A3 : Schéma représentatif du réseau "tp4"
36
glucose 6-P
GLUCOSEATP
ADP
fructose 6-P
fructose 1,6-diP
glycerol 3-P
glycerol
NAD+ADP + Pi
NADH2 +ATPP glycérate
hexok inase
glucose-phosphate isomerase
Dihydroxyacetone-P glyceraldehyde 3-P
aldolase
triose-P-isomerase
NAD
NADH2
H2O
Phosphoénolpyruvate
pyruvate
CO2
acetaldehyde
NADH2
NAD
ethanol
NADH2
NAD
acetate
etha
nol
desh
ydro
gena
seal
dehy
dede
shyd
roge
nase
pyruvatedecarboxylase
ADP
ATPpyruvate k inase
ATP
ADPH2O
Pi6-phosphofructok inaseFructose1,6
diPhosphatase
R1
R2
R3 R4
R5
R6
R7
R8
R9
R10
R11
R12
R13
Pi
H2OR14
+ H2O
Isocitrate
α -oxoglutarate (aKg)
Succinate
Fumarate
Malate
Oxaloacetate
acetyl-CoA
NADH2+CO2
R21
R18
CoASH
NAD
NADH2 + CO2
NAD + CoASH
NADH2 + CO2Succinyl-CoA
R22
R23
NAD
NADH2
FADH2
FAD
H2O
ADP + PiATP + CoASH
H2O
Réaction de maintenanceR15
ATP +H2O → ADP + Pi
Réactions de respirationR24
NADH2 + 0,5O2→ NAD + H2OR25
FADH2 + 0,5O2→ FAD + H2O
Réaction de synthèse d'ATP parphosphorylation oxydative
R26ADP + Pi → ATP + H2O
Synthèse de biomasse (R30)cf poly
R16
R17
R19
R20
NAD+CoASH
ribose5P
erythrose4P
2NADP+ H2O
2NADPH2+ CO2
R27
R28
R29
Annexe A4: Représentation du tp4 sous forme de graphe
37

Annexe A5 : Résultats de tests sur le réseau fibro de la recherche de cycles
Liste des cycles obtenus par l'exécution de la recherche de cycle sur le réseau fibro avec l'option 3
Nombre de cycles trouves apres elimination repetitions: 31 -------Cycle 1acetylP acetate -------Cycle 2glutamate glutamine CoASH CO2 OAA aKg -------Cycle 3fumarate malate -------Cycle 4CO2 OAA aspartate fumarate succinate succinylCoA propionylCoA ac.penta-ACP ACPH ac.palmitic-ACP ac.palmitol-ACP ac.vaccenic-ACP ac.phospha -------Cycle 5CO2 OAA aKg glutamate glutamine fumarate succinate succinylCoA -------Cycle 6fructose6P fructose1-6diP -------Cycle 7fructose1-6diP DHAP -------Cycle 8sedoheptulose7P erythrose4P -------Cycle 9CO2 fumarate succinate succinylCoA propionylCoA ac.penta-ACP ACPH ac.palmitic-ACP ac.palmitol-ACP ac.vaccenic-ACP ac.phospha -------Cycle 10CO2 OAA aKg glutamate glutamine GA3P fructose6P fructose1-6diP DHAP glycerol3P -------Cycle 11CO2 OAA aKg glutamate glutamine GA3P fructose6P glucose6P -------Cycle 12GA3P fructose6P fructose1-6diP -------Cycle 13CO2 OAA aKg glutamate glutamine GA3P fructose6P sedoheptulose7P xylulose5P ribulose5P -------Cycle 14xylulose5P ribulose5P -------Cycle 15CO2 OAA aKg glutamate glutamine CoASH succinylCoA propionylCoA ac.penta-ACP ACPH ac.palmitic-ACP ac.palmitol-ACP ac.vaccenic-ACP ac.phospha -------Cycle 16CO2 OAA aKg glutamate glutamine fumarate succinate succinylCoA propionylCoA ac.penta-ACP ACPH ac.palmitic-ACP ac.palmitol-ACP ac.vaccenic-ACP ac.phospha -------Cycle 17acetylCoA acetylP -------Cycle 18fumarate succinate -------Cycle 19CO2 OAA aKg glutamate glutamine -------Cycle 20CO2 OAA aspartate fumarate succinate succinylCoA -------Cycle 21glutamate glutamine CoASH acetylCoA acetylP xylulose5P GA3P Pglycerate PEP pyruvate CO2 OAA aKg -------Cycle 22CO2 OAA aKg glutamate fumarate succinate succinylCoA propionylCoA ac.penta-ACP ACPH ac.palmitic-ACP ac.palmitol-ACP ac.vaccenic-ACP ac.phospha -------Cycle 23fumarate succinate succinylCoA CoASH acetylCoA acetylP xylulose5P GA3P fructose6P sedoheptulose7P ribose5P PRPP -------Cycle 24CO2 fumarate succinate succinylCoA
38

-------Cycle 25NH3 alanine -------Cycle 26CO2 OAA aKg glutamate glutamine fumarate succinate succinylCoA propionylCoA ac.penta-ACP ACPH ac.palmitic-ACP ac.phospha -------Cycle 27CO2 OAA aKg glutamate glutamine CoASH acetylCoA acetylP xylulose5P GA3P fructose6P glucose6P -------Cycle 28GA3P fructose6P fructose1-6diP DHAP -------Cycle 29CO2 OAA aKg glutamate glutamine fumarate succinate succinylCoA propionylCoA ac.penta-ACP ac.phospha2 -------Cycle 30CO2 OAA aKg glutamate glutamine CoASH acetylCoA acetylP xylulose5P GA3P fructose6P fructose1-6diP DHAP glycerol3P -------Cycle 31CO2 OAA aKg glutamate glutamine CoASH acetylCoA acetylP xylulose5P GA3P fructose6P sedoheptulose7P ribose5P PRPP
Annexe A6 : Résultats de tests sur le réseau tp4 de la recherche de PCC
0 : Retour au menu principal 1 : PCC entre toutes les paires de métabolites 2 : PCC "contraint" (passant par un métabolite v donné) 3 : PCC entre les métabolites S et P 4 : PCC "contraint" entre les métabolites S et P
Selection : 2 = PCC "contraint" (passant par un métabolite v donné)
Recherche de PCC passant par le métabolite : Pglycerate(intermédiaire) glucose6P --> Pglycerate glucose6P glucose ADP Pglycerate [2.5]glucose6P --> PEP glucose6P glucose ADP Pglycerate PEP [3.5]glucose6P --> NAD glucose6P glucose ADP Pglycerate NAD [3.5]glucose6P --> aKg glucose6P glucose ADP Pglycerate NAD aKg [4.5]glucose6P --> OAA glucose6P glucose ADP Pglycerate NAD OAA [4.5]fructose6P --> Pglycerate fructose6P ADP Pglycerate [2]fructose6P --> PEP fructose6P ADP Pglycerate PEP [3]fructose1-6diP --> Pglycerate fructose1-6diP GA3P Pglycerate [2]fructose1-6diP --> PEP fructose1-6diP GA3P Pglycerate PEP [3]DHAP --> Pglycerate DHAP GA3P Pglycerate [2]DHAP --> PEP DHAP GA3P Pglycerate PEP [3]GA3P --> Pglycerate GA3P Pglycerate [1]GA3P --> PEP GA3P Pglycerate PEP [2]GA3P --> pyruvate GA3P Pglycerate PEP pyruvate [3]GA3P --> acetaldehyde GA3P Pglycerate PEP pyruvate acetaldehyde [4]GA3P --> ADP GA3P Pglycerate ADP [2]GA3P --> malate GA3P Pglycerate H2O malate [3]GA3P --> NADPH2 GA3P Pglycerate H2O NADPH2 [3]GA3P --> glucose GA3P Pglycerate ADP glucose [3]GA3P --> ethanol GA3P Pglycerate PEP pyruvate acetaldehyde ethanol [5]GA3P --> H2O GA3P Pglycerate H2O [2]glycerol3P --> fructose1-6diP glycerol3P Pi Pglycerate GA3P fructose1-
39

6diP [4]glycerol3P --> DHAP glycerol3P Pi Pglycerate GA3P DHAP [4]glycerol3P --> GA3P glycerol3P Pi Pglycerate GA3P [3]glycerol3P --> Pglycerate glycerol3P Pi Pglycerate [2]glycerol3P --> PEP glycerol3P Pi Pglycerate PEP [3]glycerol3P --> NAD glycerol3P Pi Pglycerate NAD [3]glycerol3P --> aKg glycerol3P Pi Pglycerate NAD aKg [4]glycerol3P --> OAA glycerol3P Pi Pglycerate NAD OAA [4]glycerol3P --> erythrose4P glycerol3P Pi Pglycerate GA3P erythrose4P [4]Pglycerate --> glucose6P Pglycerate ADP glucose glucose6P [3]Pglycerate --> fructose6P Pglycerate H2O fructose6P [2]Pglycerate --> fructose1-6diP Pglycerate GA3P fructose1-6diP [2]Pglycerate --> DHAP Pglycerate GA3P DHAP [2]Pglycerate --> GA3P Pglycerate GA3P [1]Pglycerate --> glycerol3P Pglycerate GA3P DHAP glycerol3P [3]Pglycerate --> PEP Pglycerate PEP [1]Pglycerate --> pyruvate Pglycerate PEP pyruvate [2]Pglycerate --> acetaldehyde Pglycerate PEP pyruvate acetaldehyde [3]Pglycerate --> ADP Pglycerate ADP [1]Pglycerate --> NAD Pglycerate NAD [1]Pglycerate --> acetylCoA Pglycerate NAD acetylCoA [2]Pglycerate --> CoASH Pglycerate ADP CoASH [2]Pglycerate --> aKg Pglycerate NAD aKg [2]Pglycerate --> succinate Pglycerate ADP succinate [2]Pglycerate --> fumarate Pglycerate ADP succinate fumarate [3]Pglycerate --> malate Pglycerate H2O malate [2]Pglycerate --> OAA Pglycerate NAD OAA [2]Pglycerate --> NADPH2 Pglycerate H2O NADPH2 [2]Pglycerate --> ribose5P Pglycerate GA3P ribose5P [2]Pglycerate --> erythrose4P Pglycerate GA3P erythrose4P [2]Pglycerate --> glucose Pglycerate ADP glucose [2]Pglycerate --> glycerol Pglycerate H2O glycerol [2]Pglycerate --> ethanol Pglycerate PEP pyruvate acetaldehyde ethanol [4]Pglycerate --> acetate Pglycerate NAD acetate [2]Pglycerate --> Pi Pglycerate Pi [1]Pglycerate --> H2O Pglycerate H2O [1]Pglycerate --> CO2 Pglycerate NAD CO2 [1.25]Pglycerate --> biomasse Pglycerate NAD biomasse [2]PEP --> glucose6P PEP Pglycerate ADP glucose glucose6P [4]PEP --> fructose6P PEP Pglycerate H2O fructose6P [3]PEP --> fructose1-6diP PEP Pglycerate GA3P fructose1-6diP [3]PEP --> DHAP PEP Pglycerate GA3P DHAP [3]PEP --> GA3P PEP Pglycerate GA3P [2]PEP --> glycerol3P PEP Pglycerate GA3P DHAP glycerol3P [4]PEP --> Pglycerate PEP Pglycerate [1]PEP --> ADP PEP Pglycerate ADP [2]PEP --> NAD PEP Pglycerate NAD [2]PEP --> CoASH PEP Pglycerate ADP CoASH [3]PEP --> aKg PEP Pglycerate NAD aKg [3]PEP --> succinate PEP Pglycerate ADP succinate [3]PEP --> fumarate PEP Pglycerate ADP succinate fumarate [4]PEP --> malate PEP Pglycerate H2O malate [3]PEP --> OAA PEP Pglycerate NAD OAA [3]PEP --> NADPH2 PEP Pglycerate H2O NADPH2 [3]PEP --> ribose5P PEP Pglycerate GA3P ribose5P [3]PEP --> erythrose4P PEP Pglycerate GA3P erythrose4P [3]PEP --> glucose PEP Pglycerate ADP glucose [3]PEP --> glycerol PEP Pglycerate H2O glycerol [3]PEP --> acetate PEP Pglycerate NAD acetate [3]PEP --> Pi PEP Pglycerate Pi [2]PEP --> H2O PEP Pglycerate H2O [2]
40

PEP --> biomasse PEP Pglycerate NAD biomasse [3]pyruvate --> fructose6P pyruvate acetaldehyde NAD Pglycerate H2O fructose6P [5]pyruvate --> fructose1-6diP pyruvate acetaldehyde NAD Pglycerate GA3P fructose1-6diP [5]pyruvate --> DHAP pyruvate acetaldehyde NAD Pglycerate GA3P DHAP [5]pyruvate --> GA3P pyruvate acetaldehyde NAD Pglycerate GA3P [4]pyruvate --> glycerol3P pyruvate acetaldehyde NAD Pglycerate GA3P DHAP glycerol3P [6]pyruvate --> Pglycerate pyruvate acetaldehyde NAD Pglycerate [3]pyruvate --> PEP pyruvate acetaldehyde NAD Pglycerate PEP [4]pyruvate --> malate pyruvate acetaldehyde NAD Pglycerate H2O malate [5]pyruvate --> NADPH2 pyruvate acetaldehyde NAD Pglycerate H2O NADPH2 [5]pyruvate --> ribose5P pyruvate acetaldehyde NAD Pglycerate GA3P ribose5P [5]pyruvate --> erythrose4P pyruvate acetaldehyde NAD Pglycerate GA3P erythrose4P [5]pyruvate --> glycerol pyruvate acetaldehyde NAD Pglycerate H2O glycerol [5]pyruvate --> H2O pyruvate acetaldehyde NAD Pglycerate H2O [4]acetaldehyde --> fructose6P acetaldehyde NAD Pglycerate H2O fructose6P [4]acetaldehyde --> fructose1-6diP acetaldehyde NAD Pglycerate GA3P fructose1-6diP [4]acetaldehyde --> DHAP acetaldehyde NAD Pglycerate GA3P DHAP [4]acetaldehyde --> GA3P acetaldehyde NAD Pglycerate GA3P [3]acetaldehyde --> glycerol3P acetaldehyde NAD Pglycerate GA3P DHAP glycerol3P [5]acetaldehyde --> Pglycerate acetaldehyde NAD Pglycerate [2]acetaldehyde --> PEP acetaldehyde NAD Pglycerate PEP [3]acetaldehyde --> malate acetaldehyde NAD Pglycerate H2O malate [4]acetaldehyde --> NADPH2 acetaldehyde NAD Pglycerate H2O NADPH2 [4]acetaldehyde --> ribose5P acetaldehyde NAD Pglycerate GA3P ribose5P [4]acetaldehyde --> erythrose4P acetaldehyde NAD Pglycerate GA3P erythrose4P [4]acetaldehyde --> glycerol acetaldehyde NAD Pglycerate H2O glycerol [4]acetaldehyde --> H2O acetaldehyde NAD Pglycerate H2O [3]ADP --> fructose1-6diP ADP Pglycerate GA3P fructose1-6diP [3]ADP --> DHAP ADP Pglycerate GA3P DHAP [3]ADP --> GA3P ADP Pglycerate GA3P [2]ADP --> glycerol3P ADP Pglycerate GA3P DHAP glycerol3P [4]ADP --> Pglycerate ADP Pglycerate [1]ADP --> PEP ADP Pglycerate PEP [2]ADP --> NAD ADP Pglycerate NAD [2]ADP --> aKg ADP Pglycerate NAD aKg [3]ADP --> OAA ADP Pglycerate NAD OAA [3]ADP --> erythrose4P ADP Pglycerate GA3P erythrose4P [3]NAD --> fructose6P NAD Pglycerate H2O fructose6P [3]NAD --> fructose1-6diP NAD Pglycerate GA3P fructose1-6diP [3]NAD --> DHAP NAD Pglycerate GA3P DHAP [3]NAD --> GA3P NAD Pglycerate GA3P [2]NAD --> glycerol3P NAD Pglycerate GA3P DHAP glycerol3P [4]NAD --> Pglycerate NAD Pglycerate [1]NAD --> PEP NAD Pglycerate PEP [2]NAD --> malate NAD Pglycerate H2O malate [3]NAD --> NADPH2 NAD Pglycerate H2O NADPH2 [3]NAD --> ribose5P NAD Pglycerate GA3P ribose5P [3]
41

NAD --> erythrose4P NAD Pglycerate GA3P erythrose4P [3]NAD --> glycerol NAD Pglycerate H2O glycerol [3]NAD --> H2O NAD Pglycerate H2O [2]NADPH2 --> fructose1-6diP NADPH2 ADP Pglycerate GA3P fructose1-6diP [4]NADPH2 --> DHAP NADPH2 ADP Pglycerate GA3P DHAP [4]NADPH2 --> GA3P NADPH2 ADP Pglycerate GA3P [3]NADPH2 --> glycerol3P NADPH2 ADP Pglycerate GA3P DHAP glycerol3P [5]NADPH2 --> Pglycerate NADPH2 ADP Pglycerate [2]NADPH2 --> PEP NADPH2 ADP Pglycerate PEP [3]NADPH2 --> NAD NADPH2 ADP Pglycerate NAD [3]NADPH2 --> aKg NADPH2 ADP Pglycerate NAD aKg [4]NADPH2 --> OAA NADPH2 ADP Pglycerate NAD OAA [4]NADPH2 --> erythrose4P NADPH2 ADP Pglycerate GA3P erythrose4P [4]ribose5P --> Pglycerate ribose5P GA3P Pglycerate [2]ribose5P --> PEP ribose5P GA3P Pglycerate PEP [3]erythrose4P --> Pglycerate erythrose4P GA3P Pglycerate [2]erythrose4P --> PEP erythrose4P GA3P Pglycerate PEP [3]glucose --> DHAP glucose ADP Pglycerate GA3P DHAP [3.5]glucose --> GA3P glucose ADP Pglycerate GA3P [2.5]glucose --> glycerol3P glucose ADP Pglycerate GA3P DHAP glycerol3P [4.5]glucose --> Pglycerate glucose ADP Pglycerate [1.5]glucose --> PEP glucose ADP Pglycerate PEP [2.5]glucose --> NAD glucose ADP Pglycerate NAD [2.5]glucose --> aKg glucose ADP Pglycerate NAD aKg [3.5]glucose --> OAA glucose ADP Pglycerate NAD OAA [3.5]Pi --> fructose1-6diP Pi Pglycerate GA3P fructose1-6diP [3]Pi --> DHAP Pi Pglycerate GA3P DHAP [3]Pi --> GA3P Pi Pglycerate GA3P [2]Pi --> glycerol3P Pi Pglycerate GA3P DHAP glycerol3P [4]Pi --> Pglycerate Pi Pglycerate [1]Pi --> PEP Pi Pglycerate PEP [2]Pi --> NAD Pi Pglycerate NAD [2]Pi --> aKg Pi Pglycerate NAD aKg [3]Pi --> OAA Pi Pglycerate NAD OAA [3]Pi --> erythrose4P Pi Pglycerate GA3P erythrose4P [3]H2O --> GA3P H2O Pglycerate GA3P [2]H2O --> Pglycerate H2O Pglycerate [1]H2O --> PEP H2O Pglycerate PEP [2]H2O --> NAD H2O Pglycerate NAD [2]H2O --> aKg H2O Pglycerate NAD aKg [3]O2 --> DHAP O2 H2O Pglycerate GA3P DHAP [3.5]O2 --> GA3P O2 H2O Pglycerate GA3P [2.5]O2 --> glycerol3P O2 H2O Pglycerate GA3P DHAP glycerol3P [4.5]O2 --> Pglycerate O2 H2O Pglycerate [1.5]O2 --> PEP O2 H2O Pglycerate PEP [2.5]NH3 --> fructose1-6diP NH3 ADP Pglycerate GA3P fructose1-6diP [4]NH3 --> DHAP NH3 ADP Pglycerate GA3P DHAP [4]NH3 --> GA3P NH3 ADP Pglycerate GA3P [3]NH3 --> glycerol3P NH3 ADP Pglycerate GA3P DHAP glycerol3P [5]NH3 --> Pglycerate NH3 ADP Pglycerate [2]NH3 --> PEP NH3 ADP Pglycerate PEP [3]NH3 --> NAD NH3 ADP Pglycerate NAD [3]NH3 --> aKg NH3 ADP Pglycerate NAD aKg [4]NH3 --> OAA NH3 ADP Pglycerate NAD OAA [4]NH3 --> erythrose4P NH3 ADP Pglycerate GA3P erythrose4P [4]H2SO4 --> fructose1-6diP H2SO4 ADP Pglycerate GA3P fructose1-6diP [4]H2SO4 --> DHAP H2SO4 ADP Pglycerate GA3P DHAP [4]H2SO4 --> GA3P H2SO4 ADP Pglycerate GA3P [3]H2SO4 --> glycerol3P H2SO4 ADP Pglycerate GA3P DHAP glycerol3P
42

[5]H2SO4 --> Pglycerate H2SO4 ADP Pglycerate [2]H2SO4 --> PEP H2SO4 ADP Pglycerate PEP [3]H2SO4 --> NAD H2SO4 ADP Pglycerate NAD [3]H2SO4 --> aKg H2SO4 ADP Pglycerate NAD aKg [4]H2SO4 --> OAA H2SO4 ADP Pglycerate NAD OAA [4]H2SO4 --> erythrose4P H2SO4 ADP Pglycerate GA3P erythrose4P [4] Nombre PCC passant par Pglycerate : 194 Elapsed time: 4.5963 0 : Retour au menu principal 1 : PCC entre toutes les paires de métabolites 2 : PCC "contraint" (passant par un métabolite v donné) 3 : PCC entre les métabolites S et P 4 : PCC "contraint" entre les métabolites S et PSelection :3 Entrer le nom du metabolite Source (S) : glucosenomNoeud = glucoseEntrer le nom du metabolite Puit (P) : pyruvatenomNoeud = pyruvate Recherche de PCC de : glucose à pyruvate glucose --> pyruvate glucose ADP pyruvate [1.5] Nombre PCC de : glucose à pyruvate 1 Elapsed time: 7.7834 0 : Retour au menu principal 1 : PCC entre toutes les paires de métabolites 2 : PCC "contraint" (passant par un métabolite v donné) 3 : PCC entre les métabolites S et P 4 : PCC "contraint" entre les métabolites S et PSelection :4 Entrer le nom du metabolite Source (S) : glucosenomNoeud = glucoseEntrer le nom du metabolite Puit (P) : pyruvatenomNoeud = pyruvateEntrer le nom du metabolite intermédiaire : pglyceratenomNoeud = pglycerate Recherche de PCC de : glucose à pyruvatepassant par le métabolite : Pglycerate(intermédiaire) Nombre PCC de : glucose à pyruvatepassant par le métabolite : Pglycerate(intermédiaire) 0 Elapsed time: 32.9749 0 : Retour au menu principal 1 : PCC entre toutes les paires de métabolites 2 : PCC "contraint" (passant par un métabolite v donné) 3 : PCC entre les métabolites S et P 4 : PCC "contraint" entre les métabolites S et PSelection :4
43

Entrer le nom du metabolite Source (S) : glucosenomNoeud = glucoseEntrer le nom du metabolite Puit (P) : pyruvatenomNoeud = pyruvateEntrer le nom du metabolite intermédiaire : fructose6PnomNoeud = fructose6P Recherche de PCC de : glucose à pyruvatepassant par le métabolite : fructose6P(intermédiaire) Nombre PCC de : glucose à pyruvatepassant par le métabolite : fructose6P(intermédiaire) 0 Elapsed time: 18.2748 Selection :4 Entrer le nom du metabolite Source (S) : glucosenomNoeud = glucoseEntrer le nom du metabolite Puit (P) : glycerolnomNoeud = glycerolEntrer le nom du metabolite intermédiaire : fructose6PnomNoeud = fructose6P Recherche de PCC de : glucose à glycerolpassant par le métabolite : fructose6P(intermédiaire) Nombre PCC de : glucose à glycerolpassant par le métabolite : fructose6P(intermédiaire) 0 Elapsed time: 29.7599 0 : Retour au menu principal 1 : PCC entre toutes les paires de métabolites 2 : PCC "contraint" (passant par un métabolite v donné) 3 : PCC entre les métabolites S et P 4 : PCC "contraint" entre les métabolites S et PSelection :0 --->Fin Algo de Recherche de Plus Courts Chemins
44