interception système pour la capture et le rejeu de traces
TRANSCRIPT

ESIALUniversité Henri Poincaré - Nancy 1Campus Aiguillettes - 193, avenue Paul MullerCS 90172 - 54602 Villers-lès-Nancy
Interception systeme pour la capture etle rejeu de traces
Rapport de stage - 2ème annéeLORIA (Laboratoire Lorrain de Recherche en Informatique et ses Applications)
Marion GUTHMULLER2009-2010


ESIALUniversité Henri Poincaré - Nancy 1Campus Aiguillettes - 193, avenue Paul MullerCS 90172 - 54602 Villers-lès-Nancy
Interception systeme pour la capture etle rejeu de traces
Rapport de stage - 2ème annéeLORIA (Laboratoire Lorrain de Recherche en Informatique et ses Applications)Campus Scientifique - BP 239 - 54506 VANDOEUVRE-LES-NANCY Cedex
Effectué du 07 Juin 2010 au 03 Septembre 2010
Marion GUTHMULLEREncadrant Industriel : Martin QUINSONEncadrant Universitaire : Hervé PANETTO


Remerciements
Je tiens à remercier tout particulièrement Martin QUINSON et Lucas NUSSBAUM, cher-cheurs dans l’équipe AlGorille au LORIA, qui m’ont permis d’effectuer ce stage, d’acquérirde nouvelles compétences mais aussi de connaître le monde de la recherche informatique pu-blique.
Je remercie également l’ensemble de l’équipe AlGorille qui a su m’accueillir dans les meilleuresconditions et m’a permise de m’intégrer parfaitement durant ces 10 semaines de stage.
Je souhaite aussi remercier plus particulièrement le «mec génial» du bureau B118 qui n’acessé de nous faire profiter de ses immenses qualités.
Enfin, je voudrais remercier plus largement le LORIA.


Table des matières
Introduction 1
1 Institution d’accueil 31.1 Le LORIA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 L’équipe AlGorille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Travail réalisé 52.1 Présentation du sujet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Évaluation des applications distribuées et calcul scientifique . . . . . . . . 52.1.2 Différentes techniques d’études . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.2.1 Exécution sur plateforme réelle . . . . . . . . . . . . . . . . . . . 62.1.2.2 Simulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.1.2.3 Émulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.3 Objectif final à long terme : émuler avec SimGrid . . . . . . . . . . . . . . 72.1.4 Le projet Simterpose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Interception système . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2.1 Niveaux d’interceptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2.2 Différentes approches d’interception . . . . . . . . . . . . . . . . . . . . . . 11
2.2.2.1 LD_PRELOAD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2.2.2 Valgrind . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.2.2.3 DynInst . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2.2.4 Ptrace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2.2.5 Uprobes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.3 Comparaison des différentes approches . . . . . . . . . . . . . . . . . . . . 162.3 Capture de traces avec ptrace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.1 Extraction des appels système . . . . . . . . . . . . . . . . . . . . . . . . . 162.3.2 Calcul du temps d’exécution . . . . . . . . . . . . . . . . . . . . . . . . . . 182.3.3 Identification des processus communiquants . . . . . . . . . . . . . . . . . 19
2.3.3.1 Lecture des informations sur les sockets . . . . . . . . . . . . . . 192.3.3.2 Identification du processus destinataire . . . . . . . . . . . . . . . 20
2.4 Bilan et perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Conclusion 23
Bibliographie 25


Introduction
De plus en plus populaires, les applications distribuées sont devenues plus complexes, plusgrandes et ont dû faire face à davantage de contraintes et exigences. Cependant, les méthodesutilisées pour leur évaluation n’ont pas vraiment évolué. La plupart des applications sont éva-luées en utilisant les plateformes expérimentales privées, comme les petits clusters dans deslaboratoires ou des universités. Toutefois, ces plateformes ne fournissent qu’une exemple desconditions environnementales et même avec des plateformes à plus grande échelle, il est diffi-cile d’évaluer correctement avec une seule plateforme sur une large gamme de conditions.
Avec le projet SimGrid, qui a débuté en 1999, les chercheurs et développeurs ont pour ob-jectif de faciliter la recherche dans ce domaine de la programmation d’applications distribuéeset parallèles sur les plate-formes de calcul distribué à partir d’un simple réseau. Il s’agit doncde fournir un outil avec les fonctionnalités de base pour la simulation de ces applications hé-térogènes en environnement distribué. Au sein de ce projet, on retrouve le projet Simterposedont l’objectif est de permettre l’émulation d’une application en utilisant un simulateur, enl’occurence, SimGrid. Mon stage a donc porté sur le développement de ce projet au sein deSimGrid.
Pour vous expliquer mon travail réalisé durant ces dix semaines, je commencerai par vousprésenter le contexte dans lequel j’ai effectué mon stage, puis, je procèderai à une présentationdétaillée de ma contribution dans le projet Simterpose. Je terminerai par un bilan sur l’avance-ment actuel du projet et sur les perspectives envisagées.
1


1. INSTITUTION D’ACCUEIL
1 Institution d’accueil
1.1 Le LORIA
Le LORIA[1], Laboratoire Lorrain de Recherche en Informatique et ses Applications, estune Unité Mixte de Recherche commune à plusieurs établissements :
– CNRS, Centre National de Recherche Scientifique– INPL, Institut National Polytechnique de Lorraine– INRIA, Institut National de Recherche en Informatique et en Automatique– UHP, Université Henri Poincaré, Nancy 1– Nancy 2, Université Nancy 2
L’UMR LORIA et le centre de recherche INRIA Nancy - Grand Est ont des services com-muns.
Le LORIA est un laboratoire de plus de 450 personnes organisé :– en équipes de recherche , qui regroupent :
– 150 chercheurs et enseignants-chercheurs– un tiers de doctorants et post-doctorants– des ingénieurs
– en services de support à la recherche, qui regroupent :– des ingénieurs– des techniciens– des personnels administratifs (gestionnaires, juristes, assistantes, ...)
C’est aussi chaque année :– une trentaine de chercheurs étrangers invités– des coopérations internationales avec des pays des cinq continents– une quarantaine de contrats industriels
Les équipes de recherche du LORIA articulent leur travail autour de 4 thématiques scienti-fiques et une thématique transversale :
3

1.2. L’ÉQUIPE ALGORILLE 1. INSTITUTION D’ACCUEIL
– Traitement automatique des langues et des connaissances– Fiabilité et sécurité des systèmes informatiques– Image et géométrie– Perception, action et cognition– Thématique transversale : informatique et science du vivant
Ses principaux domaines d’application sont :
– Réseaux, Internet et Web – Sécurité des systèmes informatiques– Réalité virtuelle – Robotique– Bioinformatique – Santé
1.2 L’équipe AlGorille
Pour ce stage, j’ai été accueillie dans l’équipe AlGorille[2] (Algorithmes pour la Grille) dontle domaine d’application se situe au niveau des Réseaux, systèmes et services et calul distri-bué. Leur thème principal de recherche traite du calcul distribué et applications à très hauteperformance.
Leur travail repose essentiellement sur 3 axes de recherches :
– La gestion transparente des ressources : ordonnancement de tâches, migration de calcul,transfert, distribution et redistribution de données ;
– La structuration des applications pour le passage à l’échelle : modélisation de la localitéet de la granularité ;
– La validation expérimentale : reproductibilité, possibilité d’extension et l’applicabilitédes simulations, des émulations et des expériences in situ.
Pour cela, leur méthodologie s’appuie sur 3 points : la modélisation, la conception et l’ingénie-rie des algorithmes.
L’équipe AlGorille est composée de 4 chercheurs permanents et dirigée par Jens GUSTEDT.Elle accueille également actuellement 2 ingénieurs, 1 Post-Doc et 6 étudiants en thèse.
4

2. TRAVAIL RÉALISÉ
2 Travail réalisé
2.1 Présentation du sujet
Le principe de l’application distribuée est de mettre en place une architecture logiciellepermettant l’exécution d’un programme sur plusieurs ordinateurs communiquant entre euxvia des réseaux locaux ou par Internet en utilisant le protocole IP.
Une architecture N-Tiers (ou distribuée) typique est celle constituée d’un client, d’un ser-veur d’application et d’un serveur de base de données. Certains traitements s’exécutent sur leclient (traitements liés à la gestion de l’interface graphique notamment), d’autres sur le serveurd’application et enfin sur le serveur de base de données (requêtes SQL).
2.1.1 Évaluation des applications distribuées et calcul scientifique
De plus en plus populaires, les applications distribuées sont devenues incontournables. Eneffet, grâce aux applications distribuées, on peut partager des ressources qui ne se trouvent pasau même endroit ou sur la même machine ; elles deviennent donc elles-mêmes distribuées.
Grâce à cela, on obtient tout d’abord une augmentation dans la quantité des ressourcesdisponibles. Le modèle peer-to-peer (P2P) est un exemple de réussite des architectures distri-buées où chaque ordinateur est à la fois serveur de données et client des autres. Ce modèles’applique donc au partage des ressources. L’application la plus répandue du P2P est actuelle-ment le partage de fichiers avec par exemple BitTorrent ou Emule. Dans ce cas, chaque clientayant téléchargé l’information devient aussitôt serveur. Ainsi, les clients eux-mêmes serventles données déjà reçues aux nouveaux destinataires. Le coût et la charge de la distribution desdonnées sont donc considérablement réduits.
Une seconde conséquence de la distribution des ressources est une augmentation de lapuissance de calcul. Les ordinateurs d’aujourd’hui sont tellement puissants que la majeurepartie du temps, une grande partie de leur processeur est disponible pour effectuer des cal-culs. Si on exploite cette disponibilité en même temps pour chaque ordinateur, on peut ob-tenir une puissance de calcul plus importante que les plus gros super-ordinateurs. Ainsi, leprojet BOINC[3] a saisi cette opportunité pour créer un gigantesque parc informatique ré-parti dans le monde afin d’utiliser cette immense puissance de calcul totale pour effectuerdes calculs trop complexes pour être réalisés dans un laboratoire. Le projet BOINC demandedonc au particulier de permettre l’usage de la puissance de calcul dont il n’a pas immédiate-ment besoin pour contribuer à la recherche sur le repliement de protéine (Folding@Home[4])et même la recherche d’intelligence extra-terrestre par analyse de spectre électromagnétique(SETI@home[5]).
Enfin, il est possible de voir des applications telles que Wikipédia[6] comme des systèmesdistribués où les connaissances jouent le rôle des ressources distribuées.
5

2.1. PRÉSENTATION DU SUJET 2. TRAVAIL RÉALISÉ
Pour exploiter ces ressources distribuées et leurs avantages, il faut donc développer des ap-plications distribuées. Cependant, ce n’est pas toujours très simple du fait de leur complexitéet hétérogénéité mais aussi à cause de contraintes et exigences plus fortes.
En effet, les applications distribuées doivent tout d’abord prendre en compte l’hétérogé-néité des ressources connectées au niveau logiciel/matériel : systèmes d’exploitation diffé-rents, logiciels différents, architectures matérielles différentes (PC, processeurs ARM dans lessmartphones ou les ebook readers, ...). On est donc face à une difficulté en terme d’intéropéra-bilité.
Il faut également prendre en compte les différences de performances possibles (connexionsInternet très haut débit vs EDGE/3G sur téléphones portables, vitesses de calcul différentes,...) tout en exploitant au mieux les ressources.
De plus, lors du développement de ces applications, il faut prendre en compte “l’attitude”des utilisateurs. Aujourd’hui, chaque utilisateur cherche à maximiser son revenu de manière“égoiste” (télécharger plus vite en uploadant moins, augmenter son score à seti@home, ...).Il faut, par conséquent, mettre au point des algorithmes qui résistent à des utilisateurs mal-veillants, ou à une collusion d’utilisateurs malveillants.
Enfin, il faut développer des logiciels qui fonctionnent même à une très grande échelle (unnombre important de machines (noeuds) participantes) . Ce point concerne plus particulière-ment les réseaux P2P où il peut y avoir des millions de noeuds pour certains.
Pour répondre à ces contraintes, il est nécessaire de développer des méthodes spécifiquespermettant l’étude des applications distribuées.
2.1.2 Différentes techniques d’études
Pour être en mesure de déterminer le comportement d’une application face à un large éven-tail de conditions environnementales, il est possible de l’exécuter directement sur la plateformeréelle. Cependant pour tester une application sans avoir à trouver des plates-formes fournis-sant ces éléments, les développeurs et les chercheurs ont utilisé 2 autres techniques à la foisdifférentes et complémentaires : la simulation et l’émulation.
2.1.2.1 Exécution sur plateforme réelle
La première technique pour étudier une application distribuée est de l’exécuter directe-ment sur une plateforme réelle telle que PlanetLab 1 ou Grid’5000 2 par exemple : on parlealors d’expérience in situ. Toutefois, une telle expérience peut être lourde à mettre en oeuvredu fait de son déroulement (écrire l’application, construire entièrement la plateforme et exécu-ter l’application sur cette dernière). De plus, il est difficile de reproduire une expérience in situdans des conditions comparables car les plateformes sont partagées avec d’autres utilisateurs,qui influent directement sur les conditions expérimentales.
1. Créé en 2002, PlanetLab est un réseau d’ordinateurs comportant plus de 900 noeuds répartis sur 460 sites,utilisé en tant que plateforme d’essais pour la recherche orientée réseaux et systèmes distribués.
2. Grid’5000 est une plateforme expérimentale, répartie sur 10 sites (9 en France et 1 au Brésil), destinée à l’étudedes systèmes distribués et parallèles à grande échelle.
6

2. TRAVAIL RÉALISÉ 2.1. PRÉSENTATION DU SUJET
2.1.2.2 Simulation
La simulation désigne un procédé selon lequel on exécute un programme sur un ordinateuren vue de simuler, par exemple, un phénomène physique complexe. Elle repose sur la mise enoeuvre de modèles théoriques et sert à étudier le fonctionnement et les propriétés d’un sys-tème modélisé ainsi qu’à en prédire son évolution. Au lieu d’utiliser l’application elle-même,elle est modélisée, et interagit avec un modèle de l’environnement.
La simulation a été l’objet de beaucoup de travail, et des simulateurs génériques ciblant lesapplications distribuées ont été développés. Il est possible de simuler des applications distri-buées avec plusieurs milliers de nœuds, face à des conditions très diverses, avec une modé-lisation très précise de tous les paramètres. Elle apparaît donc comme une solution face à laplupart des problèmes des expérimentations in situ : mise en oeuvre rapide et facile, reproduc-tibilité parfaite des expériences et possibilité d’explorer de nombreux scénarios expérimentauxen temps raisonnable.
Toutefois, la principale limitation de la simulation vient de son principe de base : un mo-dèle de l’application est utilisée au lieu de l’application réelle. Ceci impose donc souvent decoder les applications à évaluer dans un formalisme particulier. Ainsi, la simulation ne permetpas de trouver des bugs ou problèmes de mise en œuvre dans l’application elle-même.
2.1.2.3 Émulation
L’émulation consiste à substituer un élément de l’environnement de l’application par unlogiciel. L’émulateur reproduit le comportement d’un modèle dont toutes les variables sontconnues.
Dans l’évaluation des applications distribuées, l’émulation est une approche intermédiairevisant à résoudre les limitations de la simulation : en émulant l’exécution de l’application surune plate-forme virtuelle (simulée), il est possible d’exécuter l’application réelle sur une largegamme de conditions, dans un environnement entièrement contrôlé. De plus, cela évite dedevoir développer 2 versions de l’application , l’une étant adaptée à l’expérimentation sur si-mulateur tandis que la seconde est utilisée en production. L’émulation d’applications répartiesconsiste à intercepter les actions de l’application et à reporter ces actions dans le simulateur.Dans le cas d’une émulation offline, on sauvegarde ces actions sur disque, puis on les rejoueaprès coup dans le simulateur. Tandis que dans une émulation online, on reporte immédia-tement ces actions dans le simulateur, puis on retarde l’application du temps calculé par lesimulateur.
2.1.3 Objectif final à long terme : émuler avec SimGrid
Le projet SimGrid[7] a débuté en 1999 pour permettre l’étude d’algorithmes d’ordonnan-cement sur des plateformes hétérogènes. Il s’agit d’un outil qui fournit des fonctionnalités debase pour la simulation d’applications distribuées hétérogènes en environnements distribués.
L’objectif spécifique du projet est de faciliter la recherche dans le domaine de la program-mation d’applications distribuées et parallèles sur des plates-formes de calcul distribué à partird’un simple réseau allant du poste de travail aux grilles de calcul.
SimGrid[8] se décompose actuellement en 8 environnements construits au dessus d’un
7

2.1. PRÉSENTATION DU SUJET 2. TRAVAIL RÉALISÉ
noyau de simulation unique, et déjà intégrés, plus 1 en cours de programmation.
FIGURE 2.1 – Ensemble des environnements de SimGrid
On retrouve 4 interfaces utilisateurs à exploiter selon les résultats attendus et le type d’étudeeffectuée :
– SimDag représente la première version développée de SimGrid et est destiné à l’étudedes applications structurées comme des graphes de tâches. Avec cette API, on peut créerdes tâches, ajouter des dépendances entre les tâches, récupérer des informations sur laplateforme ou bien encore calculer le temps d’exécution d’un DAG (Directed AcyclicGraph) ;
– MSG est l’interface permettant l’étude des applications CSP (Concurrent Sequential Pro-cesses). Son utilisation première vise l’étude des algorithmes d’ordonnancement maiselle peut également servir pour les grilles de bureau ;
– GRAS (Grid Reality And Simulation) sert au développement d’applications distribuéesau sein du simulateur mais qui sont ensuite déployées de façon transparente sur lesplateformes réelles, sans modifier le code ;
– SMPI est le module destiné à la simulation d’applications MPI non modifiées en inter-ceptant les primitives MPI.
2.1.4 Le projet Simterpose
Le projet Simterpose s’insère dans un axe de recherche visant à permettre l’étude sur simu-lateur d’applications complètes. L’objectif est d’émuler en utilisant un simulateur, dans notrecas, SimGrid. On souhaite ainsi fournir un émulateur simple et accessible à tous les utilisateursgrâce à sa facilité de déploiement que ce soit sur un simple ordinateur portable personnel oubien sur un petit cluster. Un tel émulateur doit permettre :
– l’exécution d’un grand nombre d’instances d’une application sur un même système envue d’un debuggage ;
– l’évaluation d’applications soumises à une large gamme de conditions telles que descaractéristiques d’un simple noeud ou d’un réseau complet différentes ;
8

2. TRAVAIL RÉALISÉ 2.1. PRÉSENTATION DU SUJET
– la collecte d’information concernant le comportement de l’application pendant son éxe-cution.
L’aspect global du projet peut être représenté de la façon suivante : au lieu d’avoir desapplications distribuées qui communiquent directement entre elles, on “intercale” notre simu-lateur entre les applications. Il joue ainsi le rôle de passerelle lors des échanges. Lorsqu’uneapplication A souhaite communiquer avec une application B, sa demande est en premier lieuétudiée par SimGrid puis, selon l’analyse faite par le simulateur, ce dernier transmet l’infor-mation à l’application B en effectuant éventuellement de nouvelles actions en plus selon les cas.
Application A
Application B
SimGrid
Sans SimGrid
Avec SimGrid
FIGURE 2.2 – Représentation schématique du projet Simterpose
Les objectifs sont d’étudier les moyens d’intercepter les actions des applications et d’im-plémenter une méthode d’interception en interagissant avec le simulateur SimGrid. Pour at-teindre ce but, plusieurs étapes sont définies. La première consiste à déterminer combien detemps les actions d’une application mettent à se réaliser sur la plateforme logique. La secondeconsiste à intercepter les actions de l’application ayant un impact sur son environnement.
Mon travail, lors de ce stage, s’intéresse à la seconde étape, i.e, intercepter les actions del’application (communication, calcul ou autre), tout cela pour chaque processus créé par l’ap-plication lors de son exécution. A chaque interception, je génère une trace contenant les infor-mations nécessaires au simulateur pour le rejeu. Le but est ensuite de reporter cette trace dansle simulateur.
Pour cela, il faut commencer par étudier les moyens d’intercepter les actions de l’applica-tions, puis implémenter une méthode d’interception en interagissant avec le simulateur Sim-Grid.
9

2.2. INTERCEPTION SYSTÈME 2. TRAVAIL RÉALISÉ
2.2 Interception système
2.2.1 Niveaux d’interceptions
Un système d’exploitation est composé d’un ensemble de fonctions (les appels systèmes),elles-mêmes faisant appel aux fonctions internes du noyau. Le tout est structuré de la façonsuivante :
Application
systemes POSIX
Bibliotheques
Appels systemes
NOYAU
Interface des appels
INT $0x80
(open, read, ...)
(printf, fopen, ...)
Au niveau de la couche Bibliothèques se situent les fonctions systèmes de la librairie stan-dard C ainsi que les autres librairies pouvant être éventuellement utilisées par l’application.Ensuite, dans les systèmes UNIX, on retrouve les appels POSIX où les prototypes des fonctionssont normalisés ainsi que les structures de données du système auxquelles elles accèdent. En-fin, juste avant le noyau, il y a les fonctions directement appelées par le noyau via les appelssystèmes et inaccessibles au programmeur. Par exemple, dans le cas d’une application C, lors-qu’on appelle la fonction printf pour afficher un texte sur la sortie standard, c’est la fonctionwrite du noyau qui est appelée par le système.
Cette hiérarchie implique différents niveaux d’interception :– au niveau de l’application– au niveau des bibliothèques– au niveau du noyau
Pour chacun de ces niveaux, il existe une ou plusieurs approches permettant d’intercepterles appels systèmes qui nous intéressent. Mon premier travail consiste à étudier chacune deces approches afin de déterminer laquelle semble la plus adaptée face à nos attentes. Pourcette étude, j’ai commencé par coder plusieurs applications tests sous différents langages (C,Java, Ruby, Python, ...) qui me permettront d’évaluer la bonne interception des appels systèmesavec les différentes appoches.
10

2. TRAVAIL RÉALISÉ 2.2. INTERCEPTION SYSTÈME
2.2.2 Différentes approches d’interception
2.2.2.1 LD_PRELOAD
La première approche qui a été étudiée repose sur l’éditeur de liens dynamiques de Linux(ldd) qui permet d’interposer du code dans l’exécution d’un programme. Dans ce cas, l’inter-ception se fera donc au niveau de la couche Bibliothèques du système.
La dernière phase de construction d’un programme est de réaliser l’édition de liens, ce quiconsiste à assembler tous les morceaux du programme et de chercher ceux qui sont manquants.Les fonctions utilisées par l’application sont fournies sous forme de bibliothèques. Lorsqu’onutilise une bibliothèque statique, l’éditeur de liens cherche le code dont l’application a besoinet en effectue une copie dans le programme physique généré. Pour les bibliothèques parta-gées, c’est le contraire : l’éditeur de liens laisse du code qui lors du lancement du programmechargera automatiquement la bibliothèque. Linux effectue par défaut une édition de liens dy-namique s’il peut trouver les bibliothèques de ce type sinon, il effectue une édition de liensstatique.
Le principe de cette approche est d’utiliser la variable d’environnement LD_PRELOAD[9],qui contient la liste des bibliothèques à précharger avant les autres, pour charger notre proprebibliothèque. Pour intercepter un appel de fonction de bibliothèque, il faut tout d’abord implé-menter la fonction correspondante en utilisant le même nom. Dans notre cas, nous souhaitonsintercepter l’appel système mais pas forcément empêcher son exécution. Il nous faut donc ap-peler la fonction d’origine au sein de notre nouvelle version. Pour cela, on utilise les fonctionsde la famille de dlopen qui permet de charger une bibliothèque dynamique dont le nom estfourni en paramètre. Ensuite, on compile notre fichier contenant toutes les fonctions wrappéespour générer notre propre bibliothèque. On obtient alors un fichier .so. Enfin, pour indiquer àl’application qu’il faut utiliser notre bibliothèque, il suffit d’ajouter cette dernière à la variabled’environnement LD_PRELOAD avant de l’exécuter. Ainsi, notre bibliothèque sera “prioritai-re” face aux autres bibliothèques de base contenant les mêmes fonctions et ce sont nos propresfonctions qui seront utilisées.
Voici un exemple de création de bibliothèque avec une nouvelle fonction dup :
1 # define RTLD_NEXT ( ( void ∗) −1l )23 char ∗error_msg ;45 /∗ On e c r i t dans un f i c h i e r l ’ e n s e m b l e d e s f o n c t i o n s wrappees ∗/6 void LogWrap ( char ∗mess ) {7 FILE ∗ f i l e _ l o g =fopen ( " ./LD_PRELOAD/ f i l e _ l o g " , " a " ) ;8 f p r i n t f ( f i l e _ l o g , "%s " , mess ) ;9 f c l o s e ( f i l e _ l o g ) ;
10 }1112 /∗ La f o n c t i o n dlsym ( ) prend un d e s c r i p t e u r de b i b l i o t h e q u e e t un nom de symbo l e e t r e n v o i e l ’ a d r e s s e ou c e symbo l e a e t e
c h a r g e ∗/13 void DLSym_fonctions ( ) {1415 dup_orig=dlsym (RTLD_NEXT, "dup" ) ;16 i f ( ( error_msg= d l e r r o r ( ) ) !=NULL)17 f p r i n t f ( s tderr , " Erreur dlsym dup !\n" ) ;1819 }2021 /∗ On r e e c r i t l a f o n c t i o n dup en a j o u t a n t d e s m e s s a g e s d ’ i n f o r m a t i o n s e t en a p p e l a n t l ’ o r i g i n a l e ∗/22 i n t dup ( i n t oldfd ) {23 DLSym_fonctions ( ) ;24 LogWrap ( " appel dup ( ) \n" ) ;25 i n t r e t =dup_orig ( oldfd ) ;26 LogWrap ( " appel dup ( ) terminAŠ\n" ) ;27 return r e t ;28 }
11

2.2. INTERCEPTION SYSTÈME 2. TRAVAIL RÉALISÉ
Cette approche permet donc de modifier le comportement d’une application de façon in-directe, sans avoir à recompiler ou rééditer les liens à chaque fois. De plus, les applicationsdistribuées étant généralement multi-process, il faut garantir une interception pour les éven-tuels nouveaux processus créés, ce que fait directement LD_PRELOAD sans ajouter d’optionparticulière. Cependant, cette approche s’avère vite incomplète dans notre cas puisqu’elle nepermet que de surcharger les fonctions des bibliothèques mais pas des appels systèmes. Onn’obtient donc pas de réelle interception et nous n’avons aucune garantie que le système neva pas contourner la nouvelle bibliothèque pour aller directement à la couche des appels sys-tèmes.
2.2.2.2 Valgrind
Valgrind[10] est un outil de programmation libre pour déboguer, effectuer du profilagede code 3 et mettre en évidence des fuites mémoires. Il travaille donc directement au niveaude l’application. Il permet, lors des appels à des fonctions à intercepter, de dérouter vers uneautre fournie par l’utilisateur. Ceci est généralement utilisé pour l’examen des arguments, pourcompter le nombre d’appel à l’originale, et peut-être examiner le résultat.
Le wrapping de fonctions avec Valgrind consiste à créer un wrapper, i.e, une fonction detype identique à celle qui nous intéresse, mais avec un nom particulier qui permet de l’iden-tifier par rapport à l’originale. Pour cela, il faut utiliser les macros fournies par Valgrind, enparticulier les 3 suivantes :
– I_WRAP_SONAME_FNNAME_ZU : génère le vrai nom du wrapper grâce à un encodagespécifique à Valgrind ;
– VALGRIND_GET_ORIG_FN : une fois dans le wrapper, il faut accéder à la fonction origi-nale dont l’adresse est stockée dans OrigFn ;
– CALL_FN_W_WW : permet d’appeler la fonction originale.
Voici un exemple typique de wrapper avec Valgrind dans lequel on s’intéresse à l’appelsystème dup :
1 # include " inc lude/valgr ind . h"2 # include < s t d i o . h>345 i n t I_WRAP_SONAME_FNNAME_ZZ( libcZdsoZd6 , dup ) ( i n t n ) {67 i n t r e t ;8 OrigFn fn ;9 VALGRIND_GET_ORIG_FN( fn ) ; / / on r e c u p e r e l ’ a d r e s s e de l a f o n c t i o n dup o r i g i n a l e
10 p r i n t f ( " wrapper−pre : dup(%d ) \n" , n ) ;11 CALL_FN_W_W( ret , fn , n ) ; / / on e x e c u t e l a f o n c t i o n dup a v e c s e s p a r a m e t r e s e t on s t o c k e l e r e s u l t a t dans r e t12 p r i n t f ( " wrapper−post : dup(%d ) = %d \n" , re t , n ) ;13 return r e t ;14 }1516 i n t main ( ) {1718 dup ( 0 ) ;1920 }
Pour la génération du vrai nom du wrapper avec la première macro, il faut préciser labibliothèque contenant notre fonction originale et encoder selon un Z-encodage défini par Val-grind. Ceci est une opération lourde et complexe et nécessite en plus de connaître la biblio-
3. Le profilage de code consiste à analyser une application afin de connaître la liste des fonctions appelées et letemps passé dans chacune d’elles
12

2. TRAVAIL RÉALISÉ 2.2. INTERCEPTION SYSTÈME
thèque source de chaque appel système. De plus, il est important que le comportement observésur la plateforme virtuelle soit le plus proche possible de celui obtenu sur plateforme réelle. Ilfaut donc faire attention à l’éventuel surcoût de chaque approche afin de garder une efficacitémaximale. Dans ce cas, Valgrind s’est révélé inapproprié pour notre étude à cause d’un facteurde 7.5 lors de l’exécution de l’application avec ce dernier. Pour ces raisons, Valgrind est uneapproche qui a été abandonnée.
2.2.2.3 DynInst
DynInst[11] est une bibliothèque d’exécution multi-plateforme de code correctifs, utiliséedans le développement d’outils de mesure du rendement, des débogueurs, et des simulateurs.Avec son API, il est possible d’injecter directement du code dans une application en coursd’exécution. Le but de cette API est de fournir une machine interface indépendante afin depermettre la création d’outils et d’applications qui utilisent l’exécution de code de correction.Dans notre étude, cette approche travaille donc, comme Valgrind, directement au niveau del’application.
Le fonctionnement de DynInst se décompose de la façon suivante : on commence par choi-sir le processus sur lequel on souhaite travailler. Puis, on crée une image de l’application surlaquelle on effectuera un éventuel travail (interceptions, injection de code, ...). Il “suffit” en-suite de tester la présence d’une fonction qui nous intéresse dans les bibliothèques chargéesavec l’application.
Voici un exemple d’utilisation de DynInst pour intercepter l’appel dup :
1 # include < s t d i o . h>2 # include < f c n t l . h>3 # include " BPatch . h"4 # include " BPatch_process . h"5 # include " BPatch_funct ion . h"6 # include " BPatch_Vector . h"7 # include " BPatch_thread . h"89 void usage ( ) {
10 f p r i n t f ( s tderr , " Usage : e s s a i <filename > <args >\n" ) ;11 }1213 BPatch bpatch ;1415 i n t main ( i n t argc , char ∗argv [ ] ) {1617 i f ( argc <2) {18 usage ( ) ;19 e x i t ( 1 ) ;20 }21 f p r i n t f ( s tderr , " Attaching to process . . . \n" ) ;22 BPatch_process ∗appProc = bpatch . processCreate ( argv [ 1 ] ,NULL) ;23 i f ( ! appProc ) {24 f p r i n t f ( s tderr , " echec c r e a t e process\n" ) ;25 return −1;26 }2728 BPatch_image ∗appImage ;29 BPatch_Vector <BPatch_funct ion ∗> dupFuncs ;30 f p r i n t f ( s tderr , " Opening the programm image . . . \ n" ) ;31 appImage = appProc−>getImage ( ) ;32 appImage−>findFunct ion ( "dup" , dupFuncs ) ;3334 i f ( dupFuncs . s i z e ( ) == 0) {35 f p r i n t f ( s tderr , "ERROR : Unable to f ind funct ion f o r dup ( ) \n" ) ;36 return 1 ;37 } e lse {38 p r i n t f ( "dup trouve !\n" ) ;39 }40 }
13

2.2. INTERCEPTION SYSTÈME 2. TRAVAIL RÉALISÉ
Cependant, l’API fournie par Dyninst semble très bas niveau, avec un niveau d’abstractiontrès élevé. On a donc un code vite complexe, long et difficile à mettre en place. Mon tempsétant limité avec des objectifs à atteindre, nous avons décidé de mettre de côté cette approchesans pour autant l’écarter définitivement car elle offre un surcoût assez faible contrairement àd’autres approches telles que Valgrind travaillant au même niveau dans le système d’exploita-tion.
2.2.2.4 Ptrace
ptrace() est un appel système qui permet d’accéder en lecture/écriture à tout l’espaced’adressage d’un processus, i.e, aussi bien toutes les données que les structures de contrôlecomme les registres du processeur. Toutes les fonctionnalités de ptrace() sont réalisées àpartir d’un appel système unique, tout le travail de dispatching étant réalisé en espace noyau.Pour cela, l’appel système ptrace() fournit au processus parent un moyen de contrôler l’exé-cution d’un autre processus et d’éditer son image mémoire. ptrace() fonctionne grâce à desrequêtes placées en paramètre de l’appel permettant diverses actions sur le processus tracé ousur le processus qui trace.
L’utilisation de cet appel s’effectue de la façon suivante[12] : pour démarrer le suivi d’uneapplication, on commence par créer un processus à tracer (le fils) et un processus traceur (lepère) en appelant fork() . Le fils créé indique qu’il souhaite être tracé grâce à la requêtePTRACE_TRACEME puis exécute l’application grâce à exec. Si le processus fils existe déjà, lepère s’y attache directement en utilisant la requête PTRACE_ATTACH.Pendant l’exécution del’application, le processus père peut laisser s’exécuter le processus fils et ne reprendre la mainqu’à la réception d’un signal ou il peut être interrompu à chaque instruction en utilisant lemode pas à pas ou lors d’un appel système. Ainsi, le processus fils suivi s’arrêtera à chaquefois qu’un signal lui sera délivré, même si le signal est ignoré (à l’exception de SIGKILL quia les effets habituels). Le processus père sera prévenu à son prochain wait et pourra inspec-ter et modifier le processus fils pendant son arrêt. Le processus parent peut également fairecontinuer l’exécution de son fils, éventuellement en ignorant le signal ayant déclenché l’ar-rêt, ou en envoyant un autre signal. Quand le processus père a fini le suivi, il peut terminerle fils avec la requête PTRACE_KILL ou le faire continuer normalement, i.e, non suivi, avecPTRACE_DETACH.
Avant de pouvoir tracer un processus, il est nécessaire de s’attacher à lui, les permissionsrequises sont les mêmes que celles nécessaires à l’envoi d’un signal à un processus, sauf encas de modifications du noyau. Cela signifie qu’il n’est pas nécessaire d’étre root et que toututilisateur peut ptracer ses propres processus. Cette caractéristique fait partie des conditions àrespecter dans le projet Simterpose.
Voici un exemple d’utilisation de ptrace() pour intercepter l’appel dup :
1 # include <sys/ptrace . h>2 # include <sys/types . h>3 # include <sys/wait . h>4 # include <unistd . h>5 # include <l inux/user . h>6 # include <sys/ s y s c a l l . h>78 i n t main ( ) {9 pid_t c h i l d ;
10 long orig_eax , eax ;11 long params [ 3 ] ;12 i n t s t a t u s ;
14

2. TRAVAIL RÉALISÉ 2.2. INTERCEPTION SYSTÈME
13 i n t i n s y s c a l l = 0 ;14 s t r u c t u s e r _ r e g s _ s t r u c t regs ;15 c h i l d = fork ( ) ;16 i f ( c h i l d == 0) {17 ptrace (PTRACE_TRACEME, 0 , NULL, NULL) ;18 e x e c l ( "/bin/ l s " , " l s " , NULL) ;19 } e lse {20 while ( 1 ) {21 wait (& s t a t u s ) ;22 i f (WIFEXITED( s t a t u s ) )23 break ;24 or ig_eax = ptrace (PTRACE_PEEKUSER, chi ld , 4 ∗ ORIG_EAX, NULL) ; / / c o n t i e n t l e numero de l ’ a p p e l s y s t e m e i n t e r c e p t e25 i f ( or ig_eax == SYS_dup ) {26 i f ( i n s y s c a l l == 0) { / / on e s t en e n t r e e de l ’ a p p e l27 i n s y s c a l l = 1 ;28 ptrace (PTRACE_GETREGS, chi ld , NULL, ®s ) ; / / on c o n s u l t e l e s r e g i s t r e s pour o b t e n i r l e s p a r a m e t r e s de l ’ a p p e l29 p r i n t f ( "Dup c a l l e d with %ld\n" , regs . ebx ) ;30 } e lse { / / on s o r t de l ’ a p p e l31 eax = ptrace (PTRACE_PEEKUSER, chi ld , 4 ∗ EAX,NULL) ; / / c o n t i e n t l a v a l e u r r e t o u r de l ’ a p p e l32 p r i n t f ( "Dup returned with %ld\n" , eax ) ;33 i n s y s c a l l = 0 ;34 }35 }36 ptrace (PTRACE_SYSCALL, chi ld ,NULL, NULL) ; / / on f a i t r e p a r t i r l e f i l s37 }38 }39 return 0 ;40 }
Du point de vue du niveau d’interception, ptrace() est donc lié au noyau. Ceci impliqueun éventuel problème de portabilité. En effet, il n’est pas assuré de pouvoir lancer une appli-cation écrite pour une version (majeure) différente du noyau : la mémoire virtuelle vue parun processus peut avoir été complètement remaniée, les alignements, la taille d’un mot peutchanger ou bien encore, la sémantique de certains signaux peut avoir été modifiée, etc ... . Demême, entre différentes architectures, il est difficile d’assurer une quelconque compatibilité :les registres changent, leurs tailles, la capacité du processeur à accéder à des adresses mémoiresnon alignées, etc ... .
2.2.2.5 Uprobes
Avec un surcoût non négligeable et une API non portable et difficile à utiliser, notammentpour le multithreading, ptrace() est entrain d’être concurrencé par une nouvelle interface :Uprobes, dont l’objectif est de fournir une alternative à ptrace() en corrigeant ses défauts.
Uprobes permet de pénétrer dynamiquement dans une routine d’une application et de col-lecter des informations de débogage et les performances sans interruption. Il est possible d’in-tercepter à n’importe quelle adresse de code, en spécifiant un gestionnaire de routine du noyauà invoquer lorsque le point d’arrêt est atteint. Un point d’arrêt peut être inséré sur toute ins-truction dans l’espace virtuel de l’application. La fonction d’enregistrement register_uprobe()indique quel processus est à sonder, où le point d’arrêt doit être inséré et quel gestionnaire doitêtre appelé lorsque le point d’arrêt est touché.
Uprobes fonctionne de la façon suivante : quand un point d’arrêt est enregistré, Uprobesfait une copie de l’instruction sondée, arrête l’application, remplace le(s) premier(s) octet(s) del’instruction sondée avec la routine à invoquer, puis permet à l’application de continuer.
Uprobes supporte l’étude des applications multithreadées et n’impose aucune limite sur lenombre de threads dans une application sondée.
Bien que prometteuse, cette approche n’a pas été approfondie car Uprobes est encore endéveloppement avec peu d’exemple de mise en application et de documentation.
15
2.3. CAPTURE DE TRACES AVEC PTRACE 2. TRAVAIL RÉALISÉ
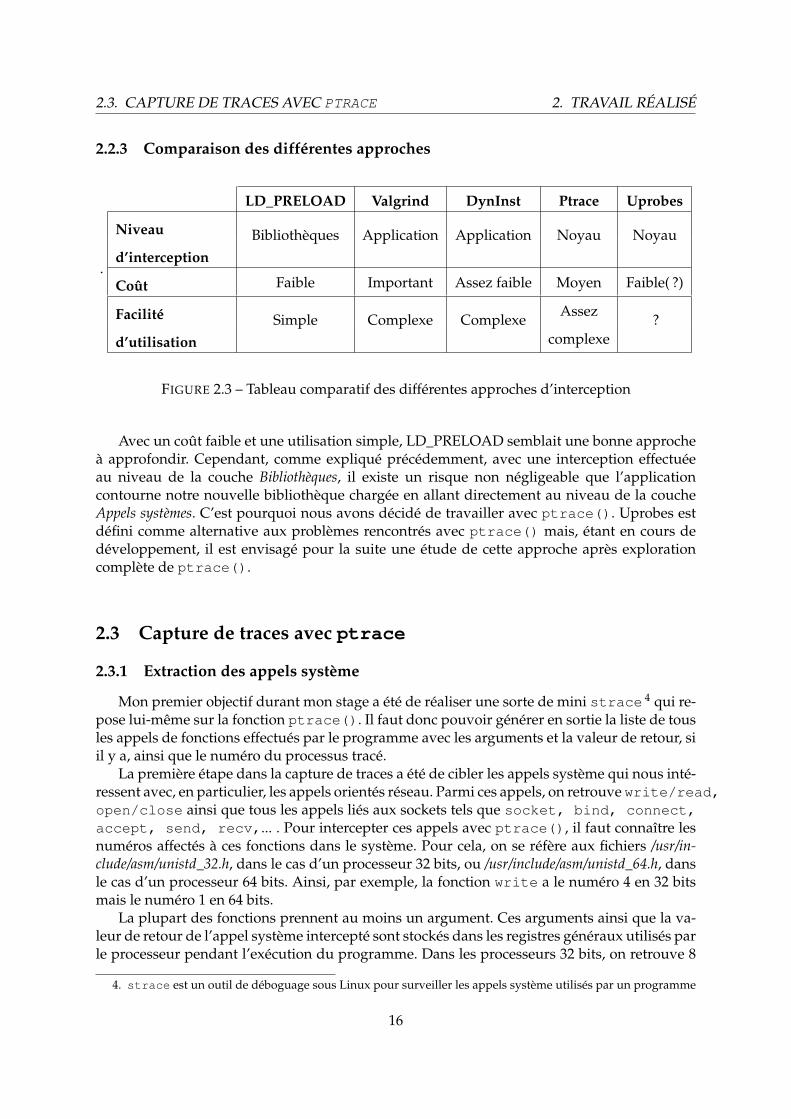
2.2.3 Comparaison des différentes approches
.
LD_PRELOAD Valgrind DynInst Ptrace Uprobes
Niveau Bibliothèques Application Application Noyau Noyaud’interception
Coût Faible Important Assez faible Moyen Faible( ?)
Facilité Simple Complexe ComplexeAssez
?d’utilisation complexe
FIGURE 2.3 – Tableau comparatif des différentes approches d’interception
Avec un coût faible et une utilisation simple, LD_PRELOAD semblait une bonne approcheà approfondir. Cependant, comme expliqué précédemment, avec une interception effectuéeau niveau de la couche Bibliothèques, il existe un risque non négligeable que l’applicationcontourne notre nouvelle bibliothèque chargée en allant directement au niveau de la coucheAppels systèmes. C’est pourquoi nous avons décidé de travailler avec ptrace(). Uprobes estdéfini comme alternative aux problèmes rencontrés avec ptrace() mais, étant en cours dedéveloppement, il est envisagé pour la suite une étude de cette approche après explorationcomplète de ptrace().
2.3 Capture de traces avec ptrace
2.3.1 Extraction des appels système
Mon premier objectif durant mon stage a été de réaliser une sorte de mini strace 4 qui re-pose lui-même sur la fonction ptrace(). Il faut donc pouvoir générer en sortie la liste de tousles appels de fonctions effectués par le programme avec les arguments et la valeur de retour, siil y a, ainsi que le numéro du processus tracé.
La première étape dans la capture de traces a été de cibler les appels système qui nous inté-ressent avec, en particulier, les appels orientés réseau. Parmi ces appels, on retrouve write/read,open/close ainsi que tous les appels liés aux sockets tels que socket, bind, connect,accept, send, recv,... . Pour intercepter ces appels avec ptrace(), il faut connaître lesnuméros affectés à ces fonctions dans le système. Pour cela, on se réfère aux fichiers /usr/in-clude/asm/unistd_32.h, dans le cas d’un processeur 32 bits, ou /usr/include/asm/unistd_64.h, dansle cas d’un processeur 64 bits. Ainsi, par exemple, la fonction write a le numéro 4 en 32 bitsmais le numéro 1 en 64 bits.
La plupart des fonctions prennent au moins un argument. Ces arguments ainsi que la va-leur de retour de l’appel système intercepté sont stockés dans les registres généraux utilisés parle processeur pendant l’exécution du programme. Dans les processeurs 32 bits, on retrouve 8
4. strace est un outil de déboguage sous Linux pour surveiller les appels système utilisés par un programme
16

2. TRAVAIL RÉALISÉ 2.3. CAPTURE DE TRACES AVEC PTRACE
registres généraux tandis que pour les processeurs 64 bits, il y en a 16. Parmi ces registres, cesont les registres de données qui sont utilisés pour stocker les arguments de fonctions et le ré-sultat. Pour manipuler ces registres, ptrace() utilise la requête PTRACE_GETREGS qui récu-prère l’ensemble des registres ainsi que leur contenu dans une structure de type user_regs_struct.Dans le cas des fonctions autres que celles liées aux sockets, pour récupérer les arguments, ilsuffit de lire immédiatement le contenu des registres. Cependant, l’opération est plus com-pliquée dans le cas des fonctions opérant sur les sockets avec les processeurs 32 bits[13]. Eneffet, dans ce cas, les fonctions socket, bind, listen, accept, ... sont gérées par unseul appel système nommé socketcall. Cet appel prend 2 arguments : le premier est le nu-méro de la sous-fonction à exécuter (1 pour socket, 2 pour bind, ...) et le second argumentest l’adresse du fragment de la mémoire contenant les arguments de cette sous-fonction. Auniveau des registres, ceci va donc se traduire par la récupération dans le second registre dedonnées (le premier étant réservé au résultat de l’appel système) de l’adresse du fragment mé-moire contenant tous les arguments, puis il faut aller de case mémoire en case mémoire pourlire chaque argument. Pour cela, ptrace() propose la requête PTRACE_PEEKDATA qui lit unmot à une adresse donnée dans l’espace mémoire du fils. La difficulté avec cette opération estle déplacement dans la mémoire où chaque case est de taille sizeof(long). Ceci nécessite deconnaître chaque type des arguments des fonctions étudiées. Ce travail a été assez compliquépour moi à cause des lectures mémoires qui nécessitent une certaine connaissance des archi-tectures.
Par souci de clarté, il fallait également afficher le nom symbolique associé aux constanteslittérales 5 régulièrement utilisées dans les paramètres de fonctions. Lors de la lecture du contenude la mémoire, j’obtenais pour ce type de paramètre un entier qui peut correspondre à uneseule constante ou bien être le résultat d’un AND entre toutes les constantes utilisées. J’ai doncdu chercher directement dans les fichiers sources du système pour associer dans chaque fonc-tion la valeur littérale à la valeur numérique obtenue.
De plus, lors d’un appel à une fonction, pour la majorité, il y a en fait 2 appels système quisont effectués : un pour l’entrée dans l’appel et un pour la sortie. On ne va donc récupérer lesarguments et surtout le résultat de la fonction une fois que celle-ci a fini de s’exécuter doncen sortie de l’appel. Un simple tableau à 0 ou 1 permet de gérer ce système d’entrée et sortied’appel.
Voici un exemple de résultat obtenu lors d’une capture de trace sur un simple Client/-Serveur TCP avec strace :
1 open ( "/ e t c /ld . so . cache " , O_RDONLY) = 32 f s t a t 6 4 ( 3 , { st_mode=S_IFREG|0644 , s t _ s i z e =74261 , . . . } ) = 03 c l o s e ( 3 ) = 04 open ( "/ l i b / l i b n c u r s e s . so . 5 " , O_RDONLY) = 35 read ( 3 , " \177ELF\1\1\1\0\0\0\0\0\0\0\0\0\3\0\3\0\1\0\0\0\240\223\0\0004\0\0\0 " . . . , 512) = 5126 . .7 . .8 c lone ( Process 29513 at tached9 c h i l d _ s t a c k =0 , f l a g s =CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, c h i l d _ t i d p t r =0xb77ba728 ) = 29513
10 [ pid 29512] rt_sigprocmask (SIG_SETMASK , [ ] , NULL, 8 ) = 011 [ pid 29513] c l o s e (255 <unfinished . . . >12 [ pid 29512] rt_sigprocmask (SIG_BLOCK , [CHLD] , <unfinished . . . >13 [ pid 29513] < . . . c l o s e resumed> ) = 014 [ pid 29513] socket ( PF_INET , SOCK_STREAM, IPPROTO_IP <unfinished . . . >15 [ pid 29514] < . . . r t_sigprocmask resumed> NULL, 8 ) = 016 [ pid 29513] < . . . socket resumed> ) = 317 [ pid 29514] r t _ s i g a c t i o n ( SIGTSTP , { SIG_DFL , [ ] , 0 } , <unf inished . . . >18 [ pid 29513] se tsockopt ( 3 , SOL_SOCKET, SO_REUSEADDR, [ 1 ] , 4 <unfinished . . . >
5. Les constantes littérales représentent des valeurs numériques ou caractères entrées dans le code source duprogramme et réservée et initialisée lors de la phase de compilation de code source.
17

2.3. CAPTURE DE TRACES AVEC PTRACE 2. TRAVAIL RÉALISÉ
19 [ pid 29514] < . . . r t _ s i g a c t i o n resumed> { SIG_DFL , [ ] , 0 } , 8 ) = 020 [ pid 29513] < . . . se t sockopt resumed> ) = 021 [ pid 29514] r t _ s i g a c t i o n ( SIGTTIN , { SIG_DFL , [ ] , 0 } , <unf inished . . . >22 [ pid 29513] getsockopt ( 3 , SOL_SOCKET, SO_REUSEADDR <unfinished . . . >23 [ pid 29514] < . . . r t _ s i g a c t i o n resumed> { SIG_DFL , [ ] , 0 } , 8 ) = 024 [ pid 29513] < . . . getsockopt resumed> , " \1 " , [ 1 ] ) = 025 [ pid 29513] bind ( 3 , { sa_family=AF_INET , s i n _ p o r t=htons ( 2 2 2 6 ) , sin_addr=inet_addr ( " 0 . 0 . 0 . 0 " ) } , 16 <unfinished . . . >26 [ pid 29514] < . . . r t _ s i g a c t i o n resumed> { SIG_DFL , [ ] , 0 } , 8 ) = 027 [ pid 29513] < . . . bind resumed> ) = 028 [ pid 29512] rt_sigprocmask (SIG_SETMASK , [ ] , <unf inished . . . >29 [ pid 29514] r t _ s i g a c t i o n ( SIGINT , { SIG_DFL , [ ] , 0 } , <unf inished . . . >30 [ pid 29513] l i s t e n ( 3 , 128 <unfinished . . . >31 [ pid 29514] < . . . r t _ s i g a c t i o n resumed> { SIG_DFL , [ ] , 0 } , 8 ) = 032 [ pid 29513] < . . . l i s t e n resumed> ) = 0
.Voici un exemple de résultat obtenu lors d’une capture de trace sur un simple Client/Ser-
veur TCP avec notre mini strace :
1 [ 2 4 4 0 1 ] open ( " . . . " , O_RDONLY) = 42 [ 2 4 4 0 1 ] Unknown s y s c a l l 197 = 03 [ 2 4 4 0 1 ] c l o s e ( 4 ) = 04 [ 2 4 4 0 1 ] open ( " . . . " , O_RDONLY) = 45 [ 2 4 4 0 1 ] read ( 4 , . . . , 512) = 5126 . .7 . .8 [ 2 4 4 0 1 ] c lone ( ) = −389 nouveau pid avec ( v ) fork 24403
10 [ 2 4 4 0 3 ] c lone ( ) = 011 [ 2 4 4 0 1 ] c lone ( ) = 2440312 [ 2 4 4 0 2 ] socket ( PF_INET , SOCK_STREAM, IPPROTO_IP ) = 413 [ 2 4 4 0 2 ] se tsockopt ( 4 , SOL_SOCKET, SO_REUSEADDR, 4 ) = 014 [ 2 4 4 0 2 ] getsockopt ( 4 , SOL_SOCKET, SO_REUSEADDR, 1 ) = 015 [ 2 4 4 0 2 ] bind ( 4 , { sa_family=AF_INET , s i n _ p o r t=htons ( 2 2 2 6 ) , sin_addr=inet_addr ( " 0 . 0 . 0 . 0 " ) } , 16 ) = 016 [ 2 4 4 0 2 ] l i s t e n ( 4 , 128 ) = 017 . .18 . .19 [ 2 4 4 0 3 ] c l o s e ( 1 ) = 020 [ 2 4 4 0 3 ] c l o s e ( 2 ) = 021 [ 2 4 4 0 3 ] exi t_group ( 0 ) c a l l e d22 . .23 [ 2 4 4 1 9 ] connect ( 4 , { sa_family=AF_INET , s i n _ p o r t=htons ( 2 2 2 6 ) , sin_addr=inet_addr ( " 1 2 7 . 0 . 0 . 1 " ) } , 16 ) = 024 [ 2 4 4 0 2 ] accept ( 4 , { sa_family=AF_INET , s i n _ p o r t=htons ( 5 6 8 4 2 ) , sin_addr=inet_addr ( " 1 2 7 . 0 . 0 . 1 " ) } , 16 ) = 525 [ 2 4 4 1 9 ] Unknown s y s c a l l 197 =? −3826 [ 2 4 4 1 9 ] send ( 4 , 512 , ) = 51227 [ 2 4 4 0 2 ] recv ( 5 , 512 , ) = 5122829 [ 2 4 4 1 9 ] exi t_group ( 0 ) c a l l e d
.
2.3.2 Calcul du temps d’exécution
En plus de connaître les appels effectués par l’application pendant son exécution, il est né-cessaire de connaître les périodes de calcul pour les transmettre à SimGrid afin qu’il les prenneen compte dans son analyse.
Pour cela, il fallait, à chaque interruption par ptrace(), déterminer le CPU time 6 et leWall time 7. En collaboration avec Tomasz BUCHERT, également en stage dans l’équipe Al-Gorille, j’ai intégré dans mon application existante une fonction permettant de calculer cesvaleurs. Les résultats obtenus réprésentaient les CPU time et Wall time totaux depuis le débutde l’exécution, nous avons donc ajouter un calcul permettant d’obtenir les différentes valeursentre chaque entrée/sortie d’un appel et entre chaque sortie d’un appel et l’entrée dans unnouveau. La difficulté dans ce calcul était de différencier les différents CPU time de chaque
6. Le CPU time correspond au temps d’utilisation du processeur par un processus pendant l’exécution d’unprogramme.
7. Le wall time correspond au temps réellement écoulé entre le début et la fin de l’exécution d’un programme,en incluant les éventuels temps d’attente pour l’utilisation de certaine ressource.
18

2. TRAVAIL RÉALISÉ 2.3. CAPTURE DE TRACES AVEC PTRACE
processus dans le cas de multithreading. Ainsi, pour chaque processus tracé, on a une structurecontenant les derniers CPU time et Wall time calculés, les valeurs totales n’étant pas stockéescar elles sont recalculées à chaque interruption.
De plus, il existe des appels système dit “bloquants”. En effet, lorsqu’un processus est entrain de s’exécuter, il peut exécuter des instructions du processeur (par exemple pour effectuerdes calculs), ou faire des appels système. Parfois, le noyau peut satisfaire l’appel système im-médiatement : par exemple, un appel à gettimeofday calcule l’heure actuelle et retourne im-médiatement au code utilisateur. Cependant, certains appels système ne retournent pas immé-diatement et sont en attente d’un événement. Ils bloquent donc la suite de l’exécution. Parmices appels système, on retrouve en particulier recv, recvfrom et recvmsg, régulièrementutilisés dans nos applications tests. Pour différencier ces périodes d’attente des vraies périodesde calcul, une analyse des CPU time et Wall time ajoutés à la trace doit être effectuée.
2.3.3 Identification des processus communiquants
Pour faire rejouer la trace à SimGrid, en plus de connaître les appels système effectués,nous avons besoin de connaître les processus qui communiquent entre eux via les sockets lorsdes appels du type send et recv.
Pour chaque socket créée, le système attribue un file descriptor 8 unique. Cependant, il ya unicité par processus. Si bien que le file descriptor 4, par exemple, peut être attribué autantde fois qu’il y a de processus en cours d’exécution. Par conséquent, cette information à elleseule n’est pas suffisante pour identifier les processus communiquants entre eux. Nous avonsdonc découper le problème en 2 étapes : la lecture des informations sur les sockets, i.e, lesadresses IP et ports locaux et distants de chaque file descriptor d’une socket, puis une mise enrelation entre tous les file descriptor qui permettra de relier 2 sockets entre elles grâce à leursinformations communes.
2.3.3.1 Lecture des informations sur les sockets
La lecture des informations sur les sockets consiste à récupérer pour chaque socket l’adresseIP par laquelle elle communique (adresse locale) et sur quel port ainsi que l’adresse IP avec quielle communique (adresse distante) sur un certain port.
Lorsqu’on crée une socket via la fonction socket, on commence par indiquer le domainede comunication (INET, UNIX, NETLINK, ...) et le protocole (TCP, UDP, ICMP, IP, ...) qui doitêtre utilisé pour communiquer. Ensuite, dans le cas d’un serveur, on fait appel à la fonctionbind qui fournit à une socket donnée une adresse IP locale et un port : on parle “d’assignationd’un nom à une socket”. À ce moment, la socket se place donc “en attente” grâce à la fonc-tion listen qui indique son désir d’accepter des connexions entrantes. Du côté du client, unefois la socket créée, on fait appel à la fonction connect qui permet de débuter une connexionsur une socket donnée. Par cet appel, le client indique donc au serveur qu’il souhaite entreren communication avec lui. Le client fournit une adresse IP et un port de connexion dans lesparamètres de la fonction. Il s’agit donc pour le client d’une adresse locale comme pour le ser-veur avec le bind. Enfin, pour “sceller” cette liaison et commencer à échanger, le serveur faitun accept qui, comme son nom l’indique, permet d’accepter une connexion entrante. Suiteà cet appel, un nouveau file descriptor est créé avec pour adresse et port locaux ceux du ser-
8. Un file descriptor (descripteur de fichier) est une clé abstraite (un entier) pour accéder à un fichier. Générale-ment, il s’agit d’un index d’une entrée dans le noyau-résident.
19

2.3. CAPTURE DE TRACES AVEC PTRACE 2. TRAVAIL RÉALISÉ
veur et pour adresse et port distants ceux du client connecté. Et du côté du client, suite à lademande de connexion qui a été acceptée, son file descriptor se voit attribuer pour adresseet port distants ceux du serveur avec qui il communique. On obtient donc 2 couples (IP,port)inversement identiques.
Pour obtenir ces informations, nous avons besoin de connaître le numéro de la socket quiest unique sur l’ensemble du système contrairement au file descriptor. Pour cela, on utilise lacommande ls -l /proc/#pid/fd/#fd dans laquelle on indique le pid du processus (#pid)auquel appartient la socket et le file descriptor (#fd) qui lui a été associé lors de sa création. Unefois ce numéro de socket obtenu, selon le protocole utilisé par la socket, nous devons parcourirun fichier : /proc/net/protocol où protocol peut être tcp, udp, raw, netlink, etc ... , qui contient latable des connexions actuellement ouvertes pour le protocole donné. Pour chaque connexion,nous avons, parmi d’autres informations, les deux couples (IP,port) local et (IP,port) distant. Ilsuffit alors de trouver la connexion correspondant à notre socket grâce à son numéro précé-demment obtenu et d’extraire les informations qui nous intéressent. Cette opération se fait parsimple parcours et découpage du fichier.
Pour ne pas avoir à répéter ce travail à chaque appel système, j’ai créé pour chaque so-cket une structure contenant le pid, le file descriptor, le domaine et le protocol, ainsi que les2 couples (IP,port). Ces informations sont enregistrées au fur et à mesure des appels. En effet,lors de la création de la socket, on obtient le file descriptor, le domaine et le protocol. Puis,après un bind on récupère le couple (IP,port) local. Coté client, après un connect, on récu-père les 2 couples (IP,port). Enfin, suite à un accept, on enregistre le nouveau file descriptoravec ses adresses et ports locaux et distants.
2.3.3.2 Identification du processus destinataire
Pour identifier le processus destinataire lors de chaque communication (send, recv, ...),il nous suffit de parcourir le tableau contenant les structures de chaque socket et de chercherquelle socket possède les 2 couples (IP,port) inverses. On en extrait alors le pid.
Voici un exemple de trace obtenue lors d’une capture sur une application distribuée de typeClient/Serveur simple avec le client qui envoie un message au serveur qui répond égalementavec un message.
1 Timestamp pidX wall_t ime cpu_time d i f f _ w a l l d i f f_cpu type s y s c a l l loca l_addr : portremote_addr : port pidY return param
2 2 3 : 1 5 : 1 8 : 9 3 8 0 6 0 6976 19234 12000 0 12000 ( v ) fork6977
3 2 3 : 1 5 : 1 8 : 9 4 4 3 5 4 6976 25537 16000 6303 4000 ( v ) fork6978
4 2 3 : 1 5 : 2 1 : 9 5 6 3 4 6 6978 3012309 12000 0 12000 exit_group0
5 2 3 : 1 5 : 2 1 : 9 5 7 6 4 8 6976 3038838 16000 3013301 0 ( v ) fork6989
6 2 3 : 1 5 : 2 1 : 9 6 9 8 2 3 6977 3031988 0 0 0 in recv 1 2 7 . 0 . 0 . 1 : 22261 2 7 . 0 . 0 . 1 : 3 4 0 2 4 6989
7 2 3 : 1 5 : 2 1 : 9 7 0 1 5 9 6989 12697 0 0 0 in send 1 2 7 . 0 . 0 . 1 : 3 4 0 2 41 2 7 . 0 . 0 . 1 : 2226 6977
8 2 3 : 1 5 : 2 1 : 9 7 0 3 5 6 6989 12895 0 198 0 out send 1 2 7 . 0 . 0 . 1 : 3 4 0 2 41 2 7 . 0 . 0 . 1 : 2226 6977 512 ( 4 , " . . . " , 512)
9 2 3 : 1 5 : 2 1 : 9 7 0 4 7 1 6977 3032640 0 652 0 out recv 1 2 7 . 0 . 0 . 1 : 22261 2 7 . 0 . 0 . 1 : 3 4 0 2 4 6989 512 ( 5 , " . . . " , 512)
10 2 3 : 1 5 : 2 1 : 9 7 0 5 9 4 6989 13133 0 238 0 in recv 1 2 7 . 0 . 0 . 1 : 3 4 0 2 41 2 7 . 0 . 0 . 1 : 2226 6977
11 2 3 : 1 5 : 2 1 : 9 7 0 7 9 1 6977 3032963 0 323 0 in send 1 2 7 . 0 . 0 . 1 : 22261 2 7 . 0 . 0 . 1 : 3 4 0 2 4 6989
12 2 3 : 1 5 : 2 1 : 9 7 0 9 6 6 6977 3033136 0 173 0 out send 1 2 7 . 0 . 0 . 1 : 22261 2 7 . 0 . 0 . 1 : 3 4 0 2 4 6989 512 ( 5 , " . . . " , 512)
13 2 3 : 1 5 : 2 1 : 9 7 1 1 0 4 6989 13643 0 510 0 out recv 1 2 7 . 0 . 0 . 1 : 3 4 0 2 41 2 7 . 0 . 0 . 1 : 2226 6977 512 ( 4 , " . . . " , 512)
20

2. TRAVAIL RÉALISÉ 2.4. BILAN ET PERSPECTIVES
14 2 3 : 1 5 : 2 1 : 9 7 1 4 7 6 6977 3033648 0 512 0 exit_group0
15 2 3 : 1 5 : 2 1 : 9 7 1 9 5 4 6989 14493 0 850 0 exit_group0
16 2 3 : 1 5 : 2 1 : 9 7 2 7 3 7 6976 3053932 16000 15094 0 exit_group0
.
2.4 Bilan et perspectives
L’objectif principal de ce stage, qui était l’interception d’appels système et la générationde trace, a donc été parfaitement atteint. Nous obtenons donc la liste des actions qui ont unimpact sur l’environnement de l’application avec les temps d’exécution et les quantités de don-nées échangées. Nous avons commencé en testant sur les applications que j’avais moi-mêmeécrites. Au fur et à mesure de ces tests, nous avons pu enrichir la trace et élargir le champs decas traités. Parmi les problème soulevés lors de ces tests, il y avait la gestion des applicationsmultithreading, qui créent donc des nouveaux processus en plus de celui de l’application elle-même. Il faut donc que notre traceur soit capable d’intercepter et différencier toutes les actionsde chaque processus. Face à une documentation très succinte sur ce sujet avec ptrace(),cette étape du projet a été difficile à mettre correctement en place et a continué à nous occu-per durant tout le développement, nous retardant parfois dans la mise en place de certainesfonctionnalités. Puis, après validation sur des cas simples, nous avons porter nos tests sur de“vraies” applications telle que BitTorrent. Le but était de tracer le téléchargement d’un fichierde 100Mo. Ceci nous a permis de mettre en avant des failles dans mon traceur, notamment avecdes cas qui n’avaient jamais pu être testés avec mes applications simples, tels que l’utilisationde socket NETLINK, l’utilisation des appels système sendmsg et recvmsg. De même pour lalecture des informations sur les sockets, contrairement à un Client/Serveur simple, dans Bit-Torrent nous avons plusieurs clients qui deviennent eux-mêmes serveurs, ceci n’avait donc pasété géré dans un premier temps. Grâce à cette évolution dans la complexité des applicationstestées, nous avons aujourd’hui un traceur adapté à une large gamme de cas.
Cependant le second objectif durant ce stage était de transmettre la trace obtenue à Sim-Grid pour qu’il rejoue les actions interceptées. Ce dernier n’a pas pu être atteint. En effet, dansle développement actuel de SimGrid pour le rejeu de traces, ce dernier accepte des traces de laforme suivante :
1 # sample a c t i o n f i l e2 tutu send t o t o 1 e103 t o t o recv tutu4 tutu s leep 125 t o t o compute 12
.On retrouve donc les 2 processus communiquants, l’action effectuée (l’appel système) et la
taille des données échangées ou calculées. Il s’agit donc d’une forme plutôt simplifiée en com-paraison avec ma trace générée. Il faut donc décider si on modifie SimGrid pour qu’il rejouema trace dans son état actuel ou bien si on modifie ma trace pour l’adapter au format actuelle-ment accepté par SimGrid. Le choix se porterait aujourd’hui sur le développement de SimGridpour qu’il rejoue ma trace mais nous n’avons malheureusement pas eu le temps de travaillersur cette partie.
21

2.4. BILAN ET PERSPECTIVES 2. TRAVAIL RÉALISÉ
De plus, avec notre traceur actuel, l’émulation avec SimGrid se fera offline, c’est-à dire,que l’on commence par exécuter l’application que l’on trace en même temps. Ensuite, une foisl’exécution terminée et notre trace obtenue, on la transmet à SimGrid qui l’analysera et rejoueratoutes les actions interceptées en ajoutant éventuellement des modifications. L’idée serait doncd’envisager une émulation online où on reporterait immédiatement les actions interceptéesdans le simulateur, puis, on retarderait l’application du temps calculé par le simulateur.
Durant mon stage, j’ai également assisté à une réunion sur un projet d’association entreSimGrid et Glite. Glite[14] est un intergiciel de production nouvelle génération pour le gridcomputing. Il fournit un système pour construire des applications sur grille puisant dans lapuissance de l’informatique distribuée et des ressources de stockage sur Internet. L’objectif decette mise en relation est de définir un environnement contrôlé reproduisant fidèlement le com-portement d’une grille de production pour analyser le fonctionnement du système sous chargeet évaluer différentes stratégies d’optimisation. Pour mettre en place cela, les chercheurs et dé-veloppeurs en charge du projet souhaitent utiliser le projet Simterpose pour la partie Gestion del’infrastructure matérielle où le but est de modéliser et simuler des ressources de stockage, cal-cul et de communication. Il s’agit donc ici d’une nouvelle approche où émulation et simulationsont mélangées, ce qui va impliquer un travail “risqué” mais prometteur dans le partenariatRecherche/Production.
22

Conclusion
Le projet Simterpose a été une excellente occasion pour moi de mettre en pratique les en-seignements vus à l’ESIAL, en particulier les cours de Réseaux et Système. J’ai en effet puapprofondir mes connaissances sur les applications distribuées mais aussi sur la programma-tion orientée Réseaux. J’ai également pu découvrir une certaine organisation dans ce type deprojet avec un système de reporting hebdomadaire permettant de dresser le bilan du travailde la semaine et de discuter en avance des tâches de la semaine suivante. Ceci m’a permis à lafin de mon stage de revoir clairement toute l’évolution du projet durant ces 10 semaines.
J’ai aussi pu expérimenter le logiciel de versions décentralisées Git qui, une fois maîtrisé unminimum, se révèle être un outil indispensable dans le développement de projets de ce type.Le but de l’utilisation de ce type de logiciel est d’obtenir un arbre représentant tout le dérou-lement de développement avec la possibilité de revenir à tout moment à une étape antérieure.Cependant, pour exploiter correctement cette caractéristique, il faut une certaine rigueur dansla mise à jour des fichiers. L’idée est de mettre à jour un fichier dans l’arborescence à chaquemodification de fonctions, structures ou même de variables. J’ai eu beaucoup de mal à intégrercorrectement cette technique et avais tendance à attendre la fin de la journée pour transmettreen une fois toutes les modifications effectuées. Mais après plusieurs tentatives de Lucas, monsecond encadrant au sein de l’équipe, pour me faire comprendre l’intérêt certain d’une tellerigueur, je pense enfin avoir compris comment utiliser correctement cet outil et compte bienm’en resservir pour mes futurs projets.
Durant ces 10 semaines, j’ai également appris à voir à plus long terme que pour les projetsqu’on peut faire à l’ESIAL. Quand je suis arrivée, un travail avait déjà été commencé sur le sujetet il sera encore continué après mon départ. À chaque réunion, on discutait du prochain objectifà atteindre à court terme mais il était toujours évoqué l’objectif final même si on supposait quece ne serait pas fait pendant mon stage. J’ai aussi du me résoudre à accepter ” l’abandon” deplusieurs jours de travail suite à une voie sans issue. Bien que tout travail et toute recherchene sont jamais inutiles, cela reste assez déstabilisant de se dire qu’on n’utilisera finalement pascela pour la suite. Il s’agit là d’une vraie confrontation avec le monde de la recherche.
Enfin, ce stage m’a permis de comparer le monde de l’entreprise, que j’avais découvertdurant mon DUT Informatique, et le monde de la recherche. Ce sont des projets de plusieursannées qui y sont développés avec de nombreuses collaborations. Il m’est apparu une réelleenvie de continuer du côté de la recherche, et même de retravailler plus tard sur le projet sil’opportunité m’était offerte.
23


Bibliographie
[1] «LORIA (Laboratoire Lorrain de Recherche en Informatique et ses Applications)». http://www.loria.fr/.
[2] «AlGorille : Algorithmes pour la grille». http://www.loria.fr/equipes/algorille.
[3] «BOINC, calculer pour la science». http://boinc.berkeley.edu/.
[4] «Folding@Home, Distributing computing». http://folding.stanford.edu/.
[5] «SETI@Home : Search for Extraterrestrial Intelligence». http://setiathome.berkeley.edu/.
[6] «Wikipédia : encyclopédie libre». http://fr.wikipedia.org/.
[7] «SimGrid». http://simgrid.gforge.inria.fr/.
[8] H. Casanova, A. Legrand et M. Quinson. «SimGrid : a Generic Framework for Large-Scale Distributed Experiments». Dans 10th IEEE International Conference on ComputerModeling and Simulation (2008).
[9] «LD_PRELOAD : Intercepting Dynamic Library Function Calls». http://www.uberhip.com/people/godber/interception/html/slide_4.html.
[10] «Valgrind». http://valgrind.org/.
[11] «DynInst : An Application Program Interface (API) for Runtime Code Generation». http://www.dyninst.org/.
[12] P. Padala. «Playing with ptrace». LinuxJournal (2002).
[13] «Shellcode sous Unix - Optimisation des shellcodes sous Linux». http://www.linux-pour-lesnuls.com/.
[14] «gLite : Lightweight Middleware for Grid Computing». http://glite.web.cern.ch/glite/.
25
