informatique décisionnelle décisionnelle
TRANSCRIPT

Informatique
Décisionnelle
Hajer TRABELSI
Mastère de recherche IMD/ISAMM
Mai 2014
1
Michel de rougemontUniversité Parie II
2007

Contexte
But: préciser la robustesse de certains modèles, par rapport à l’incertitude de
données.
Les données économiques sont en effet souvent bruitées (inexactes et
approximatives)
Il est fondamental d’isoler les procédures informatiques robustes au bruit,
c’est à dire qui produisent des résultat approchés lorsque les données sont
bruitées.
2

Plan
Modèles d’automates
Modèle relationnel
Modèle Olap
Data-Mining
Modèle XML
3
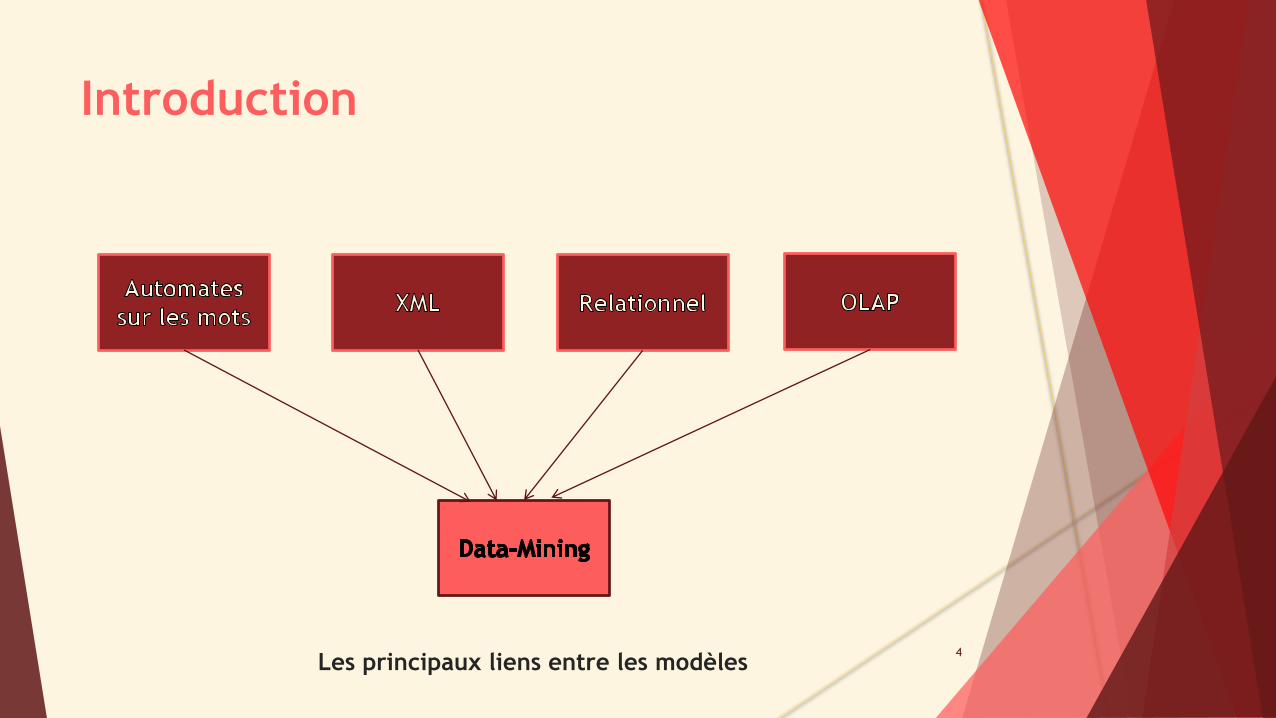
Introduction
4Les principaux liens entre les modèles

Introduction
Les automates sur les mots se généralisent aux arbres et sont le fondement
du langage du XML.
Le modèle relationnel se généralise au modèle OLAP et constitue le cœur des
systèmes d’information.
Le Data-Mining s’applique à tous les modèles, mais décrit son utilisation à
partir du modèle OLAP, qui constitue les fondements du Business Intelligence.
5

Les modèles d’automates
Le traitement de l’information nécessite un modèle de calcul
les automates finis sont un des modèles les plus simples, qui ont des variantesselon les classes de structures considérés.
Un automate fini est défini par (Q, q0, F, )
- Q est un ensemble fini d’états
- q0 Є est l’état initial
- F Ϲ Q est un ensemble d’états finaux
- Ϲ Q x ∑ x Q (∑ alphabet fini)
On présente souvent un automate par un graphe où les nœuds sont les états et lesarêtes sont des transitions possibles lorsque l’automate lit un symbole s.
Chaque arête est étiquetée par un tel symboles s tel que q.s.q’ soit une transition.
6

Les modèles d’automates
Dans cet exemple on a 4 états {0,
1, 2, 3}.
L’état 4 est l’état qui permet de
compléter l’automate pour que la
fonctions soit toujours définie.
On obtient alors la complétion de
l’automates.
7

Modèle relationnel
Les données sont représentées par des tables.
Une table est constituée de plusieurs colonnes appelées attributs et deplusieurs lignes appelées enregistrement ou tuples.
Une requête est une fonction qui associe à un ensemble de tables unenouvelle table.
C’est la représentation mathématique d’une question posée à une BD.
La définition des différentes tables constitue le Schéma.
Pour concevoir un schéma, il est utile d’isoler des entités et des relationsentre entités.
Une entité décrit un objet muni d’attributs.
8

Modèle relationnel - Entité-Relations
La conception d’un schéma est facilitée par un diagramme Entité-Relations.
Il qui décrit de manière graphique des entités munies d’attributs et des
relations entre entités.
9
Buy
Name add Date Item Price

Modèle relationnel - Schéma relationnel
Chaque relation peut être considérée comme une table.
Un attribut est le nom d’une colonne dont les valeurs sont dans un domaine
Di.
L’information spécifiant le domaine de chaque attribut définit le schéma.
10

Modèle Olap
Online Analytic Processing, permet de définir des requêtes.
Effectuer des résumés/ agrégations selon plusieurs critères et sur plusieursdimensions.
Générer des rapports.
Répondre à des questions de gestionnaires et d’économistes, pour analyser desdonnées. Par exemple :
- Quels sont les produits les plus vendus en 2005 ?
- Quels sont les magasins et les produits les plus vendus entre 2004 et 2005 enEurope ?
Ces requêtes généralisent le GROUP BY de SQL mais en l’intégrant à plusieursattributs.
Les requêtes OLAP étendent SQL dans ce sens.
11

Modèle Olap – Intégration des
informations
Le besoin: collecter des informations à partir des plusieurs sources dont le
but est d’exploiter leur synthèse.
Le problème: les sources peuvent être autonomes et hétérogènes.
- autorisations nécessaires pour l’extraction
- utilisation de plusieurs langages pour la définition de l’information à
extraire.
La solution: utiliser un schéma fédérateur, avec ou sans données, que les
utilisateurs manipulent comme s’il s’agissait d’une BD habituelle.
12

Modèle Olap – Intégration des
informations
Avec données courantes provenant d’une seule source (vues matérialisées) ou de
plusieurs sources autonomes et éventuellement hétérogènes (base de données
intégrée).
besoin d’outils pour la conception du schéma, transformation/chargement de
données et propagation de changements.
Avec données historiques (entrepôt de données, données en avance), c’est notre cas.
besoin d’outils pour la conception du schéma, transformation/chargement de
données propagation de changements et rafraîchissement périodique.
Sans données, au sein d’une seule source (vues virtuelles) ou lié à plusieurs sources
autonomes et éventuellement hétérogènes (médiateurs, données à la demande).
besoin d’outils pour la récriture/évaluation des requêtes et la fusion des résultats.
Dans tous les cas, l’accès aux données se fait presque exclusivement en lecture.
13

Modèle Olap – Construction d’un
entrepôt de données
Architecture à trois niveaux : sources – entrepôt – data mart
data mart : ‘petit’ entrepôt orienté sujet, dont les données sont dérivées de l’entrepôt
Extraction, Transformation, Chargement de données outils ETL
Extracteur :
- traduction vers le langage source, évaluation, traduction vers le langage de l’entrepôt
- détection de changements aux sources
Intégrateur :
- réconciliation /correction d’erreurs/filtrage/estampillage pour conformer au schéma de l’entrepôt
- chargement de données, rafraîchissement
14

Modèle Olap – Caractéristiques
principales d’un entrepôt de données
C’est un endroit où les données intégrées sont stockées et exploitées à l’aided’un système de gestion de BD.
Par conséquent, un entrepôt de données est avant tout une BD, même si lescaractéristiques suivantes le distinguent clairement des BD transactionnelleshabituelles.
- Utilisations: Les utilisateurs principaux sont les décideurs de l’entreprise quiont besoin des schémas faciles à lire.
- Mode d’accès: souvent à travers un data mart, en lecture uniquement.
- Volume: de l’ordre de tera octets
- Maintenance: les mises à jour sont propagées de sources vers l’entrepôtimmédiatement ou périodiquement, par construction ou de manièreincrémentale.
15

Modèle Olap – Expressions de chemin
et langage OLAP
Un schéma dimensionnel aussi appelé Schéma Etoile est un graphe connexe,
orienté, acyclique, étiqueté tel que:
Une seule racine, appelé l’origine et notée O.
Chaque nœud a une étiquette (dimension) et chaque arête (flèche) a une
étiquette.
Toutes les flèches ont des étiquettes distinctes.
Les flèches de source O sont d’un de deux types, dimension ou mesure.
16

Modèle Olap – Expressions de chemin
Etant donné un schéma dimensionnel S, une expression de chemin sur S estune expression bien formée dont les opérandes sont des flèches de S et dontles opérateurs sont ceux de l’algèbre fonctionnelle.
Une expression dimensionnelle sur S: toute expression de chemin constituéeuniquement de flèches figurant sur des chemins dimensionnels.
Une évaluation d’une expression de chemin e par rapport à une BDD sur S:se fait en remplaçant chaque flèche f figurant dans e par la fonction (f) quilui est associée par , et en effectuant les opérations de l’algèbrefonctionnelle.
Une vue sur S: schéma dimensionnel S’ dont chaque sommet est un sommetde S et donc chaque flèche est une expression de chemin sur S.
Un data mart est défini comme une vue sur S, pouvant être virtuelle oumatérialisée suivant les besoins de l’application.
17

Modèle Olap – Requête OLAP
Etant donné un schéma dimensionnel S, un ‘OLAP Pattern’ sur S est un couple
P= (u, v), où u est une expression dimensionnelle, v une expression de mesure
et source(u)= source(v)= O.
La cible de u est appelée le niveau d’agrégation de P et la cible de v le niveau
de mesure de P.
Une requête OLAP sur S est alors un couple Q= <P, op>, où P est un OLAP
pattern et op est une opération applicable sur le domaine du niveau de
mesure de P.
18

Modèle Olap – Exemple OLAP
Considérons un entrepôt qui
regroupe toutes factures émises
par une chaine de magasin.
Le schéma pourrait être défini par
cet arbre.
On peut analyser le nombre de
ventes par gamme de produits et
par ville.
Les démentions de cette requête
sont Gamme, Ville.
19

Modèle Olap – Exemple OLAP
On peut exprimer cette requête
par les chemins: f2of1 pour Gamme
et h2oh1 pour Ville.
La mesure est Ventes et
l’opérateur est la somme.
On peut aussi donner des
conditions de sélection: par
exemple Année= 2004, Région=
Europe.
20

Modèle Olap – Exemple OLAP
On affiche alors un tableau ordonné selon les valeurs des attributs.
Dans le cas de l’analyse Gamme, Ville, où Gamme a les valeurs (A,B, C) et
Ville a les valeurs (NY, Paris, Berlin) on aura un tableau comme dans cet
exemple.
21

Data-Mining
Le terme Data-Mining est utilisé dans de nombreux contextes avec un sens
différent.
Dans son interprétation la plus simple, il s’agit de trouver une fonction f sur
la base d’échantillons de valeurs xi, yi= f(xi).
22

Data-Mining – Arbres de décision
Un arbre de décision est une représentation succincte d’une fonction.
Dans le cas d’une fonction booléenne, on imagine une arbre dont les nœuds
sont les variables et les arêtes représentent les valeurs des variables.
Deux nœuds terminaux correspondent aux valeurs de la fonction.
L’arbre de décision est déterminé par l’ordre des variables.
23Deux arbres de décision pour la fonction f= (x1 Λ x2) Λ (x2 V x3), selon deux
ordres différents: x1, x2, x3 et x2, x1, x3.

Data-Mining – Arbres de décision
Dans le cas d’une table T avec les
attributs A, B, C, supposons que la
3ème colonne soit la valeur de la
fonction.
On peut donc représenter la table
suivante par plusieurs arbres
possibles:
24

Data-Mining – Arbres de décision
Approximation et arbre de décision:
Dans un cas réel, on peut imaginer 30 attributs, des valeurs cibles discrètes, par exemple 10, 20, 50, 100.
On cherche alors un arbre de profondeur minimum et chaque feuille correspond à une valeur prépondérante.
Par exemple: la feuille gauche correspond à la valeur prépondérante de 100, à 90%.
Chaque feuille est une distribution de valeurs, qui permet de prédire une valeur et une confiance.
La feuille gauche correspond à la prédiction 100 avec la confiance 90% ou la valeur 20 avec la confiance 10% , ou la valeur 50 avec la confiance 10%.
25

Data-Mining – logiciels de Fouille de
Données
3 trois logiciels qui implémentent les techniques de fouilles de données.
Dtree : ce logiciel est très simple, construit des arbres de décision à partir
d’un fichier de données, sur des valeurs discrètes.
SAS / Entreprise Miner: ce module de SAS intègre les 3 principaux modèles et
permet de les comparer, en sortant des courbes de lift.
26

Data-Mining – logiciels de Fouille de
Données
Weka: ce logiciel libre a une interface, largement inspirée de celle de SAS/
Entreprise Miner.
De très nombreux modèles sont disponibles, ce qui rend le logiciel plus
difficile à utiliser.
27

Modèle XML
Langage générique qui permet d’unifier la manipulation de données sur des
serveurs différents.
Les fonctions essentielles sont:
- La transmission de données semi-structurées entre Client et Serveur.
- L’interrogation de données semi-structurées.
- La transmission de données.
- L’intégration de données.
Ce langage est important dans l’usage du Web, car XML (eXtensible Markup
Langage) est une recommandation du W3C, l’organisme de normalisation de
logiciels pour le Web.
28

Conclusion
Nous avons étudier les Modèles d’automates, le Modèle relationnel, le Modèle
Olap, le Data-Mining et le Modèle XML, qui représentent les principaux
modèles informatiques, afin de connaître les principaux liens entre eux et de
préciser leur robustesse par rapport à l’incertitude de données.
29

Merci pour votre attention
30