indicateurs de performance de romeo · eyepitch 0,0175 table 1: couple de maintien articulaire en...
TRANSCRIPT

Indicateurs de performance deRomeo
Philippe SOUERES Patrick DANESFrederic LERASLE Olivier STASSE
Kévin GIRAUD-ESCLASSE Ali MEKONNENLaurent FITTE DUVAL Thomas FORGUE
Dinesh Atchuthan
LAAS-CNRS20 Janvier 2016

Sommaire
1 Indicateurs de performance liés aux capacités motrices de ROMEO 3
1.1 Géométrie du mouvement . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.1.1 Volume de l’espace de travail . . . . . . . . . . . . . . . . . . . . . 3
1.1.2 Précision et stabilité . . . . . . . . . . . . . . . . . . . . . . . . . . 4
Résolution des encodeurs . . . . . . . . . . . . . . . . . . . . . . . 4
Jeu et flexibilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2 Cinématique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2.1 Temps d’initiation du mouvement . . . . . . . . . . . . . . . . . . 5
1.2.2 Caractéristiques cinématiques . . . . . . . . . . . . . . . . . . . . 5
1.3 Dynamique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3.1 Couples articulaires de maintien . . . . . . . . . . . . . . . . . . . 5
1.3.2 Compliance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3.3 Énergie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3.4 Puissance massique . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3.5 Réactivité et réversibilité . . . . . . . . . . . . . . . . . . . . . . . . 6
1.4 Fonctions motrices fondamentales . . . . . . . . . . . . . . . . . . . . . . 7
2 Indicateurs de performance liées aux capacités de perception du robot 8
2.1 Extracteurs/détecteurs visuels . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Extracteurs/détecteurs audio . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Analyse spatio-temporelle . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4 Identification de personnes . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.5 Intentionalité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2 | 15

1 Indicateurs de performance liés aux
capacités motrices de ROMEO
1.1 Géométrie du mouvement
1.1.1 Volume de l’espace de travail
Les espaces de travail de la main gauche au niveau de l’articulation "LWristPitch" et dupied gauche au niveau de l’articulation "LAnklePitch" ont été déterminés. Les limitesarticulaires renvoyées par le middleware naoqi sur le robot ont permis de déterminerle débattement de chaque articulation. Pour chacune, le débattement a été discrétisépar pas de 0.3 à 0.5 rad. La bibliothèque Pinocchio a ensuite été utilisée pour trouverles positions atteintes par les articulations citées. Les résultats de ces simulations ontété joués par le programme Gepetto-viewer. Les images de la Figure 1 représentent cesrésultats.
Vue de 3/4, jambe gauche Vue de face, bras gauche
Vue de droite, jambe gauche Vue de 3/4 dos, bras gauche
Vue de face, jambe gauche Vue de 3/4 face, bras gauche
Figure 1: représentation des volumes de travail de la jambe et du bras gauches
3 | 15
1 Indicateurs de performance liés aux capacités motrices de ROMEO
1.1.2 Précision et stabilité
Résolution des encodeurs
Les erreurs en position de la main et du pied gauches dues à la résolution des en-codeurs ont été estimées. Deux configurations du bras et de la jambe ont été testées:tendus (position zéro) et pliés. Les données ont été calculées à partir du nombre depoints par tour des encodeurs au niveau des articulations (après les flexibilités del’actionneur). Les donées ont été traitées avec la bibliothèque Pinocchio. L’erreur enposition de la main et du pied due aux encodeurs dans l’espace opérationnel est del’ordre de 0.1mm
Jeu et flexibilité
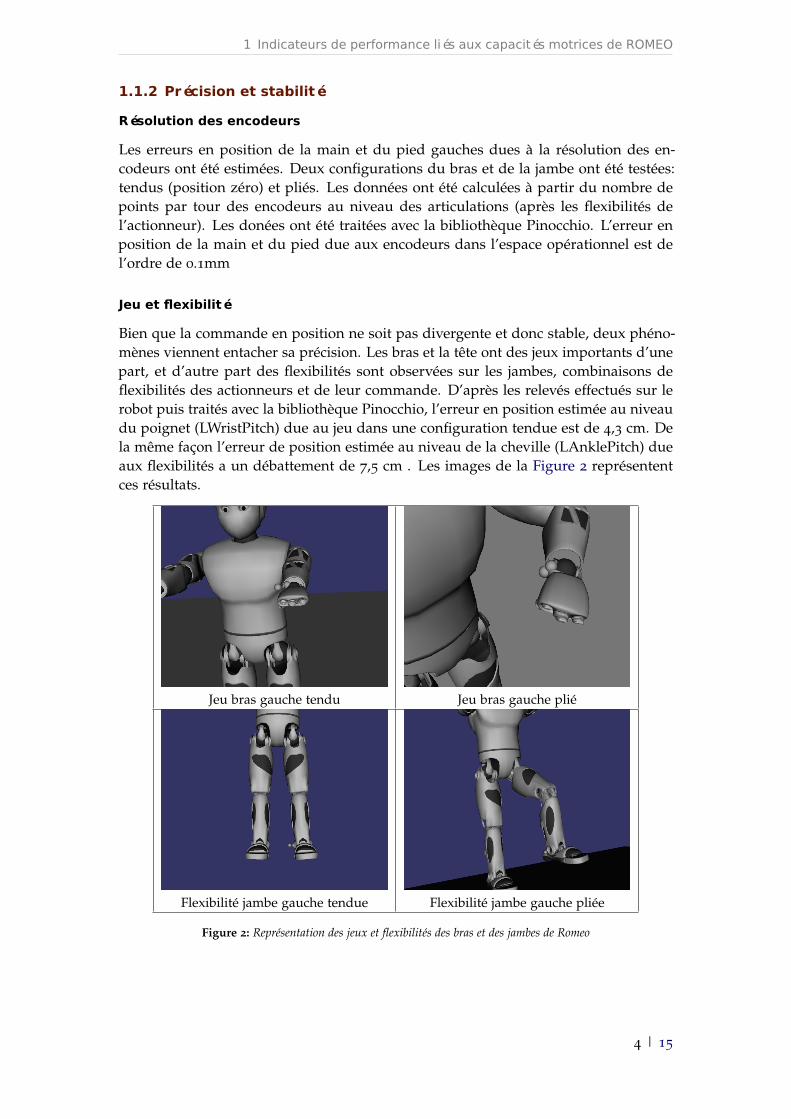
Bien que la commande en position ne soit pas divergente et donc stable, deux phéno-mènes viennent entacher sa précision. Les bras et la tête ont des jeux importants d’unepart, et d’autre part des flexibilités sont observées sur les jambes, combinaisons deflexibilités des actionneurs et de leur commande. D’après les relevés effectués sur lerobot puis traités avec la bibliothèque Pinocchio, l’erreur en position estimée au niveaudu poignet (LWristPitch) due au jeu dans une configuration tendue est de 4,3 cm. Dela même façon l’erreur de position estimée au niveau de la cheville (LAnklePitch) dueaux flexibilités a un débattement de 7,5 cm . Les images de la Figure 2 représententces résultats.
Jeu bras gauche tendu Jeu bras gauche plié
Flexibilité jambe gauche tendue Flexibilité jambe gauche pliée
Figure 2: Représentation des jeux et flexibilités des bras et des jambes de Romeo
4 | 15

1 Indicateurs de performance liés aux capacités motrices de ROMEO
1.2 Cinématique
1.2.1 Temps d’initiation du mouvement
Le temps d’initiation du mouvement a été récupéré sur deux articulations : celledu coude (LElbowYaw) et celle du genou (LKneePitch). La fonction ALMotion:: an-gleInterpolationWithSpeed a été utilisée sur la carte Cogito de Romeo pour initier lemouvement. Les acquisitions ont été effectuées à la fréquence maximale de rafraîchisse-ment des données (10 ms). L’ordre de grandeur du temps d’initiation du mouvementest de 100ms pour les deux articulations testées. La latence d’envoi de la commandeest de l’ordre de 30ms sur le robot.
1.2.2 Caractéristiques cinématiques
La vitesse maximum du pied dans l’espace opérationnel a été estimée. Les vitessesmaximales des articulations de la hanche (LHipPitch) et du genou (LKneePitch) ont étéjouées alors que le robot était suspendu. Les acquisitions (10 ms) ont été traitées avecla bibliothèque Pinocchio. La vitesse maximum linéaire du pied dans ces conditionsest estimée à 2.5 m/s. La trajectoire et le profil de vitesse sont représentés dans laFigure 3.
Trajectoire testée Profil de vitesse obtenu
Figure 3: Vitesse maximale du pied dans l’espace opérationnel
1.3 Dynamique
1.3.1 Couples articulaires de maintien
1.3.2 Compliance
L’élasticité du câble de l’actionneur a été mesurée sur le banc de test fourni par Alde-baran. Des mesures ont été effectuées sur les codeurs du moteur et de l’articulation.Elles ont permis de calculer l’élongation relative du câble. Une fois ramenée à la force
5 | 15

1 Indicateurs de performance liés aux capacités motrices de ROMEO
Articulations Couple de maintien (Nm)
NeckYaw 39,3NeckPitch 32,0HeadPitch 6,0HeadRoll 9,2
ShoulderPitch 67,7ShoulderYaw 32,0
ElbowRoll 39,3ElbowYaw 32,0WristRoll 9,3WristYaw 2,9WristPitch 2,0
Hand 0,65
TrunkYaw 40,4HipYaw 75,5HipRoll 401,1HipPitch 609,3
KneePitch 165-375
AnklePitch 618,3AnkleRoll 421,6EyeYaw 0,0175
EyePitch 0,0175
Table 1: Couple de maintien articulaire en fonction des articulations
exercée pour provoquer cette déformation, la raideur de la transmission (câble et cour-roie) à été estimée à 9, 68.105N/m en raideur linéaire, soit 663, 1Nm/rad en raideurangulaire avec modèle de ressort de torsion entre les encodeurs. D’autre part sonmodule de Young a été estimé à 8, 64.1010Pa.
1.3.3 Énergie
L’énergie des mouvements nominaux ne peut pour l’instant être évaluée de façon fiable.Les mesures du couple pendant le mouvement, accessibles sur le robot suspendu, sonttrès bruitées. De plus, la valeur du courant ne semble pas pouvoir être remontéejusqu’à l’utilisateur. Les travaux en cours permettront éventuellement d’effectuer desmesures plus rapides et plus fiables du courant dans l’actionneur du banc de tests.
1.3.4 Puissance massique
Pour les mêmes raisons que précédemment la puissance massique ne peut pas êtreestimée.
1.3.5 Réactivité et réversibilité
L’actionneur est réversible. Une étude complémentaire pourrait donner une quantifica-tion de l’efficacité de la transmission suivant le sens d’entrée du système.
6 | 15

1 Indicateurs de performance liés aux capacités motrices de ROMEO
1.4 Fonctions motrices fondamentales
Romeo est stable en double support statique grâce au maintien en position des action-neurs. Néanmoins les capacités du robot à ce jour ne lui confèrent pas la possibilité demarcher dans le cas nominal. En l’état actuel, les fonctions locomotrices n’atteignentpas un niveau suffisant pour que le robot puisse se déplacer par lui-même. Sa vitesse,sa précision, sa robustesse aux perturbations ou ses capacités à évoluer sur différentstypes de sols ou en portant des charges ainsi que l’ensemble des fonctions motricesfondamentales ne peuvent donc pas être évaluées.Les travaux en cours permettront éventuellement de générer et planifier en ligne descomportements multi-objectifs et multi-contraints en considérant la cinématique et ladynamique complète du robot.
7 | 15

2 Indicateurs de performance liées aux
capacités de perception du robot
2.1 Extracteurs/détecteurs visuels
[But : détection visuelle mono- ou multi- personnes à différentes distances d’interactiondu robot. Évaluations en termes de taux de détection et fausses alarmes.
Nous avons évalué divers détecteurs visuels de la littérature sur des bases publiquesd’images incluant une ou plusieurs personnes. Nous avons privilégié les détecteursusuels de la littérature : LDCF (pour « Locally Decorrelated Channel Features »), ACF(pour « Agregated Channel Features »), DPM (pour « Deformable Part-based Method»), HOG-SVM (pour « Histogram of Oriented Gradient ») pour la complétude des éval-uations. Ces détecteurs sont décrits dans le livrable L3.2.3. Les évaluations réaliséessont ici qualitatives et quantitatives.
Sur le plan quantitatif, les métriques sont classiquement : « recall » caractérisantla proportion de cibles détectées correctement, et « precision » caractérisant la pro-portion de bonnes cibles. Les évaluations sont menées sur des séquences publiques(« benchmarks »). Il s’agit de 7 séquences vidéo i.e. 4 (respectivement 3) issues decaméras fixes (respectivement embarquées). La Table 2 ci-après montre les perfor-mances obtenues ; les statistiques surlignées correspondent aux meilleures perfor-mances. Nous avons privilégié le détecteur basé ACF qui offre (comparativement) debonnes performances et qui dispose d’une version en code C++ « opensource » (parKU Leuven, https://bitbucket.org/rodrigob/doppia) et adapté au haut du corps.
Table 2: Évaluations quantitatives de détecteurs visuels de personnes.
Le détecteur basé ACF (dans sa version « upper body ») a donc été intégré sousROS puis testé sur le flux vidéo du robot ROMEO en présence de une ou plusieurspersonnes dans son voisinage immédiat. Le détecteur est exécuté sur un PC (déporté)intel core i7 avec protocole ROS pour le transfert du flux vidéo RGB. Seule une évalu-ation qualitative a été menée à ce jour ; elle a permis de montrer que le détecteur est
8 | 15

2 Indicateurs de performance liées aux capacités de perception du robot
fonctionnel. La figure suivante illustre un exemple de détection de personnes depuisROMEO.
Figure 4: Exemple de « snapshot » du flux RGB issu de ROMEO et résultat dudétecteur ACF en superposition (gauche), situation H/R associée (droite).
2.2 Extracteurs/détecteurs audio
[But : Détection audio mono- ou multi- locuteur à différentes distances d’interactiondu robot. Évaluations en termes de taux de détection et fausses alarmes]
Comme indiqué dans le livrable L3.2.2, nous poursuivons l’évaluation quantitativede notre détecteur d’azimuts mono- et multi-locuteurs [10] et [11] en situations réal-istes, sur la base du logiciel de simulation de scènes acoustiques complexes ROOMSIM.Nous considérons une salle de dimensions 6.25x3.75x2.50 mètres, dans laquelle nousplaçons un ensemble tête+torse binaural (“head and torso simulator” – HATS). Qua-tre environnements acoustiques sont simulés : salle parfaitement anéchoïque ; paroisconstituées de divers matériaux, correspondant à des temps de réverbération (RT60)couvrant les intervalles [0.16;0.55], [0.39;0.6], [0.3;1] secondes sur la bande de fréquence[0;5kHz] exploitée pour cette localisation court-terme. Nous exploitons un HATS detype KEMAR, dont le LAAS dispose d’un exemplaire, et pour lequel il existe des basesde réponses impulsionnelles / fonctions de transfert (HRIRs/HRTFs) publiques, e.g.,la base de HRIRs du MIT [5] ou du Quality and Usability Lab de l’Université Tech-nologique de Berlin [12]. Ce HATS est positionné en les situations [1.5625;1.875;1.1],[3.125;1.875;1.1]. Des sources utiles (enregistrements de voix masculines et fémininesfrançaises) ou parasites (autres enregistrements de voix), bruit stationnaire émis parun ventilateur) sont simulées dans le plan du capteur binaural. Elles sont situées dansle demi-espace avant, éventuellement dans le demi-espace arrière, en formant un angled’au moins 10
o avec le HATS et pour des distances pertinentes dans le contexte con-sidéré. En convoluant ces signaux sources avec les HRIRs relatives aux oreilles gaucheet droite, des rendus binauraux élémentaires d’une durée de 15 secondes sont générés.Des combinaisons linéaires de ces signaux binauraux élémentaires, éventuellement en-tachées d’un bruit additif (spatialement et temporellement blanc), permettent d’émulerdes rendus de scènes multi-locuteurs bruitées et réverbérantes, avec des rapports signal
9 | 15
2 Indicateurs de performance liées aux capacités de perception du robot
sur bruit/perturbations variables.
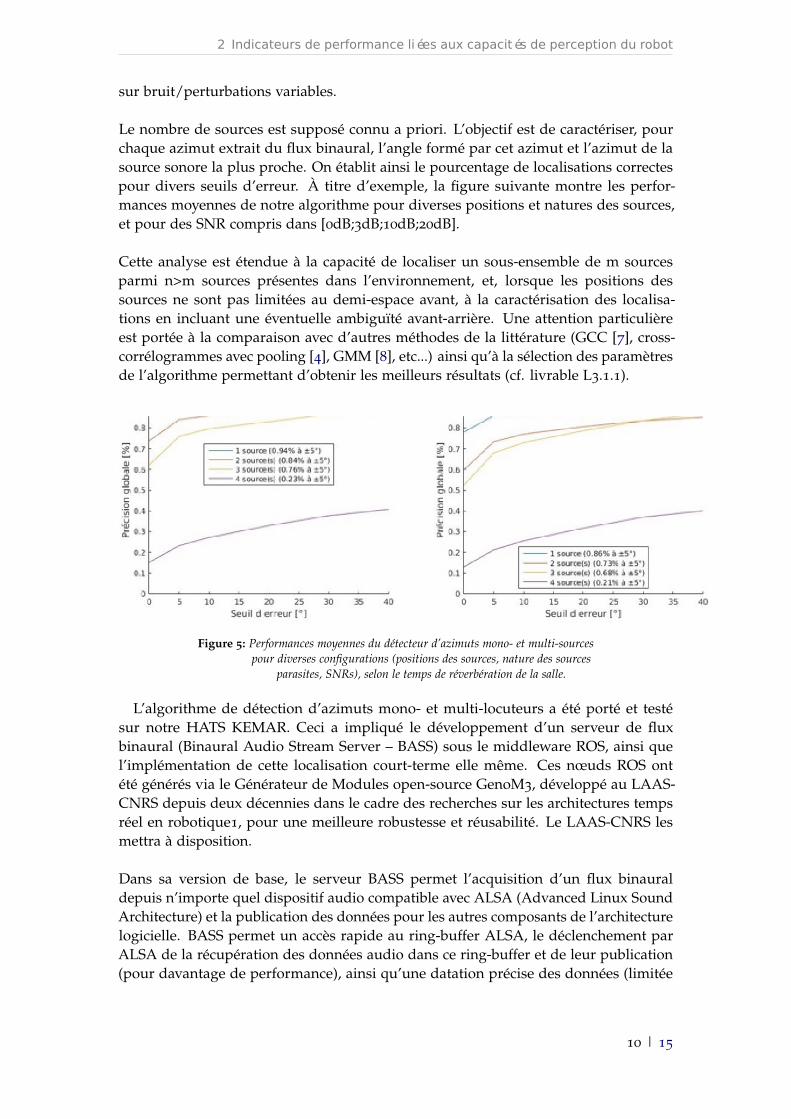
Le nombre de sources est supposé connu a priori. L’objectif est de caractériser, pourchaque azimut extrait du flux binaural, l’angle formé par cet azimut et l’azimut de lasource sonore la plus proche. On établit ainsi le pourcentage de localisations correctespour divers seuils d’erreur. À titre d’exemple, la figure suivante montre les perfor-mances moyennes de notre algorithme pour diverses positions et natures des sources,et pour des SNR compris dans [0dB;3dB;10dB;20dB].
Cette analyse est étendue à la capacité de localiser un sous-ensemble de m sourcesparmi n>m sources présentes dans l’environnement, et, lorsque les positions dessources ne sont pas limitées au demi-espace avant, à la caractérisation des localisa-tions en incluant une éventuelle ambiguïté avant-arrière. Une attention particulièreest portée à la comparaison avec d’autres méthodes de la littérature (GCC [7], cross-corrélogrammes avec pooling [4], GMM [8], etc...) ainsi qu’à la sélection des paramètresde l’algorithme permettant d’obtenir les meilleurs résultats (cf. livrable L3.1.1).
Figure 5: Performances moyennes du détecteur d’azimuts mono- et multi-sourcespour diverses configurations (positions des sources, nature des sources
parasites, SNRs), selon le temps de réverbération de la salle.
L’algorithme de détection d’azimuts mono- et multi-locuteurs a été porté et testésur notre HATS KEMAR. Ceci a impliqué le développement d’un serveur de fluxbinaural (Binaural Audio Stream Server – BASS) sous le middleware ROS, ainsi quel’implémentation de cette localisation court-terme elle même. Ces nœuds ROS ontété générés via le Générateur de Modules open-source GenoM3, développé au LAAS-CNRS depuis deux décennies dans le cadre des recherches sur les architectures tempsréel en robotique1, pour une meilleure robustesse et réusabilité. Le LAAS-CNRS lesmettra à disposition.
Dans sa version de base, le serveur BASS permet l’acquisition d’un flux binauraldepuis n’importe quel dispositif audio compatible avec ALSA (Advanced Linux SoundArchitecture) et la publication des données pour les autres composants de l’architecturelogicielle. BASS permet un accès rapide au ring-buffer ALSA, le déclenchement parALSA de la récupération des données audio dans ce ring-buffer et de leur publication(pour davantage de performance), ainsi qu’une datation précise des données (limitée
10 | 15

2 Indicateurs de performance liées aux capacités de perception du robot
seulement par l’OS). Le portage sur ROMEO est en cours. Si besoin, une implémenta-tion du BASS sur un microcalculateur Raspberry PI2 couplé à une carte FPGA, dédiéeà une paire de microphones MEMS sera exploitée.
Figure 6: Implémentation d’un serveur de flux binaural ROS-compatible surRaspberry PI2 avec codecs câblés sur carte FPGA.
Le portage de l’algorithme de détection d’azimuts de locuteurs est également encours. Les résultats de l’étude simulée présentée plus haut permettront sa paramétrisa-tion optimale. Notons qu’il sera nécessaire de procéder à l’identification des HRIRs/HRTFsgauche et droite de ROMEO pour permettre un fonctionnement optimal. À défaut, desmodèles approximatifs (tête sphérique) seraient utilisés.
2.3 Analyse spatio-temporelle
[But : suivi visuel mono et multi- personnes. Évaluations par les métriques usuellesde la littérature. Suivi auditif mono-locuteur. Idem. Suivi visio-auditif mono- et multi-personnes]
Nous avons proposé un traqueur RGB qui traite indifféremment des scènes inclu-ant une ou plusieurs cibles. Ce traqueur, basé sur du filtrage particulaire décentralisé(noté DPF) et associé à un détecteur de cibles, est décrit dans les livrables L3.2.2 etL3.2.3. Les évaluations réalisées sont ici encore qualitatives et quantitatives.
Sur le plan quantitatif, les métriques pour évaluer les traqueurs multi-cibles sontusuellement CLEAR-MOT [3] : MOTA (« Multi-Object Tracking Accuracy »), MOTP («Multi-Object Tracking Precision »), IdSw (« ID switch » entre cibles), etc. Les évalua-tions associées portent sur les séquences publiques pré-citées.
La Figure 7 montre les statistiques obtenues sur ces 7 séquences pour diverses as-sociations filtre-détecteur visuel. Les meilleures performances sont surlignées. Notretraqueur, dans sa version « mono-template » (noté DPF) ou « multi-template » (DPF-MT), offre de bonnes performances eu égard aux autres filtres mentionnés et issus dela littérature.
Ces évaluations ont donné lieu à une soumission journal [9]. Suite à ces évaluationsquantitatives, nous avons alors porté notre traqueur RGB monoculaire (DPF), associé à
11 | 15

2 Indicateurs de performance liées aux capacités de perception du robot
Table 7: Exemple de « snapshot » du flux vidéo RGB issu de ROMEO et résultatdu traqueur en superposition (gauche), situation H/R associée (droite).
un détecteur ACF (Cf. section précédente), sur ROMEO. Nous avons alors testé (par desévaluations qualitatives) depuis le flux vidéo issu d’une de ces deux caméras. ROMEO,et donc ses capteurs, sont statiques. Ce traqueur visuel RGB est aujourd’hui fonc-tionnel. La figure suivante illustre notre traqueur multi-personnes avec cette caméra:situation homme-robot, « snapshot » issu du flux vidéo. Une vidéo illustrative estaccessible depuis le lien url : http://homepages.laas.fr/aamekonn/romeo/
Figure 8: Exemple de « snapshot » du flux vidéo RGB issu de ROMEO et résultatdu traqueur en superposition (gauche), situation H/R associée (droite)
Les investigations en cours portent sur l’extension du traqueur RGB à sa versionRGB-D afin de fusionner des informations couleur (apparence) et géométrique i.e. deprofondeur (« Depth »). Nous avons implémenté et testé, dans le cadre du stage PFE6 mois de D.Atchuthan [2], ce traqueur RGB-D sur des flux vidéo issus d’un capteurRGB-D certes déporté mais reproduisant le contexte applicatif ROMEO2. Il nous aété impossible d’exploiter le casque de ROMEO2 car : (i) le capteur embarqué est deprofondeur seulement, le recalage (spatial, temporel) avec les caméras RGB par ailleursserait donc à effectuer, (ii) le champ de vue du capteur D est inadapté car dirigé versses mains/pieds. Nous serions intéressés par le nouveau casque prototypé et intégrantun capteur RGB-D. Dans cette perspective, la montre des « snapshots » de séquencedepuis le capteur RGB-D déporté pour un scénario à 2 personnes. Les résultats quali-tatifs observés semblent intéressants ; ce traqueur sera évalué sur des séquences avecvérité terrain pour quantifier ses performances.
12 | 15

2 Indicateurs de performance liées aux capacités de perception du robot
Figure 9: Exemples de « snapshots » de suivi multi-cibles par capteur RGB-D.
2.4 Identification de personnes
[But : exploitation de modalités visuelles et auditives. Évaluations par les métriquesusuelles de la littérature]
L’identification des personnes au voisinage immédiat du robot repose sur la signaturecolorimétrique de leurs vêtements. Il s’agit classiquement de distributions couleursextraites de la boîte englobant la personne durant le processus de suivi spatiotemporel.La Figure 10 montre un exemple de distribution couleur.
Figure 10: Signature couleur apprise (gauche), vraisemblance calculée(représentation fausse couleur) pour deux images données (milieu,
droite).
Cette modalité d’identification n’a pas été évaluée séparément mais à travers le
13 | 15
2 Indicateurs de performance liées aux capacités de perception du robot
traqueur RGB embarqué sur ROMEO. Les performances associées se quantifient àpartir du critère de switch entre cibles i.e. mauvaises association de données doncd’identification.
2.5 Intentionalité
[But : détection visio-auditive de l’intentionnalité d’un partenaire. Évaluations sur desscénarios mettant en jeu des personnes expertes et non expertes]
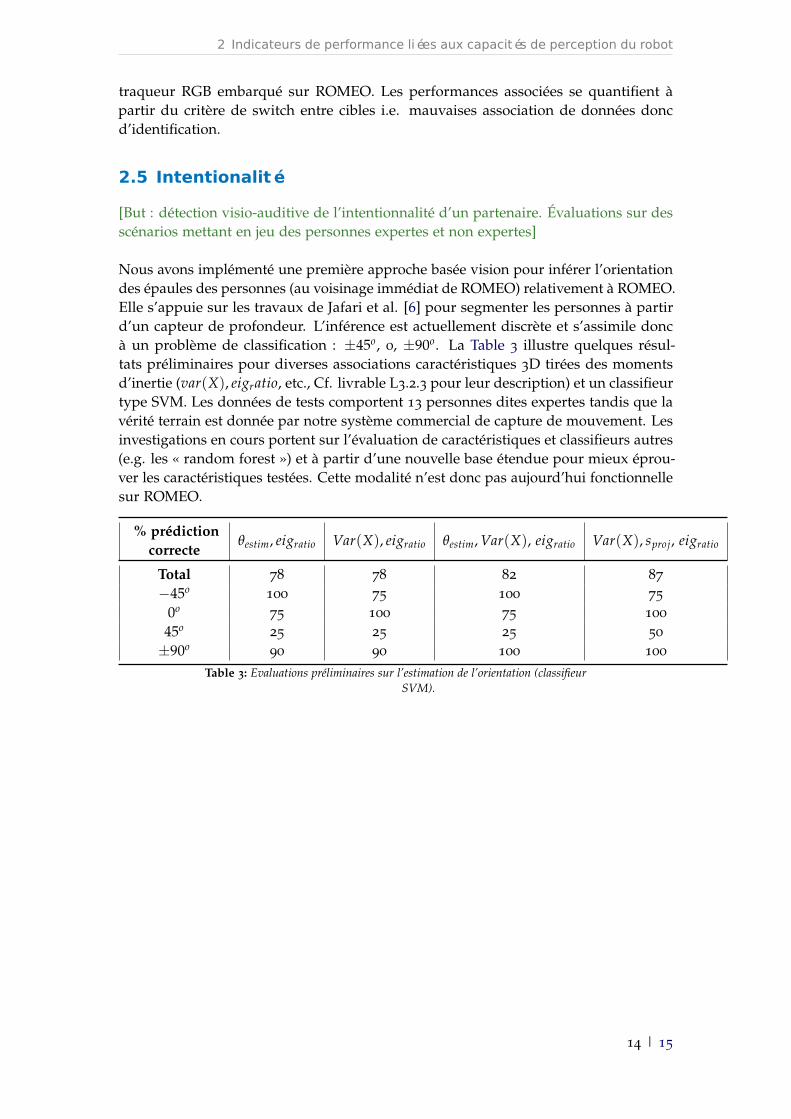
Nous avons implémenté une première approche basée vision pour inférer l’orientationdes épaules des personnes (au voisinage immédiat de ROMEO) relativement à ROMEO.Elle s’appuie sur les travaux de Jafari et al. [6] pour segmenter les personnes à partird’un capteur de profondeur. L’inférence est actuellement discrète et s’assimile doncà un problème de classification : ±45o, 0, ±90o. La Table 3 illustre quelques résul-tats préliminaires pour diverses associations caractéristiques 3D tirées des momentsd’inertie (var(X), eigratio, etc., Cf. livrable L3.2.3 pour leur description) et un classifieurtype SVM. Les données de tests comportent 13 personnes dites expertes tandis que lavérité terrain est donnée par notre système commercial de capture de mouvement. Lesinvestigations en cours portent sur l’évaluation de caractéristiques et classifieurs autres(e.g. les « random forest ») et à partir d’une nouvelle base étendue pour mieux éprou-ver les caractéristiques testées. Cette modalité n’est donc pas aujourd’hui fonctionnellesur ROMEO.
% prédictioncorrecte
θestim, eigratio Var(X), eigratio θestim, Var(X), eigratio Var(X), sproj, eigratio
Total 78 78 82 87
−45o100 75 100 75
0o75 100 75 100
45o25 25 25 50
±90o90 90 100 100
Table 3: Evaluations préliminaires sur l’estimation de l’orientation (classifieurSVM).
14 | 15

Bibliography
[1] @online Projet ROMEO Motor information documentation, http://projetromeo.com/sites/default/files/romeo-documentation/hardware_romeo_motor.
html, Accessed: 2015-12-18
[2] Atchuthan, Détection et suivi de l’homme par capteur RGB-D, application à la robotiquehumanoïde. Rapport de stage, 2015. 12
[3] Bernardin et al., Evaluating multiple object tracking performance: the CLEAR MOT met-rics. K.Bernardin, R.Stiefelhagen. EURASIP Journal on Image and Video Processing,2008, 1:1–1:10. 11
[4] Brown et al., Computational auditory scene analysis. Computer Speech and Language,vol. 8, no. 4, pp. 297–336, Oct. 1994 10
[5] Gardner et al., HRTF Measurements of a KEMAR Dummy-Head Microphone. MITMedia Lab Perceptual Computing, 1994. 9
[6] Jafari et al., Real time RGB-D based people detection and tracking for mobile robotsand head-worn cameras. O.Jafari, D.Mitzel, and B.Leibe. Int. Conf. on Robotics andAutomation (ICRA’14), Hong-Kong, June 2014. 14
[7] Knapp et al., The generalized correlation method for estimation of time delay. IEEETransactions on Acoustics, Speech and Signal Processing, vol. 24, no. 4, pp. 320–327,1976. 10
[8] May et al., A Probabilistic Model for Robust Localization Based on a Binaural AuditoryFront-End. EEE Transactions on Audio, Speech, and Language Processing, vol. 19,no. 1, pp. 1–13, Jan. 2011. 10
[9] Mekonnen et al., Comparative evaluation of selected tracking-by-detection approaches.A.Mekonnen, G.Marion, F.Lerasle. IEEE Trans. On Circuits and Systems for VideoTechnology, 2016. 11
[10] Portello et al., HRTF-based source azimuth estimation and activity detection from abinaural sensor. in 2013 IEEE/RSJ International Conference on Intelligent Robotsand Systems (IROS), 2013, pp. 2908–2913. 9
[11] Portello et al., Localization of multiple sources from a binaural head in a known noisyenvironment. in 2014 IEEE/RSJ International Conference on Intelligent Robots andSystems (IROS 2014), 2014, pp. 3168–3174. 9
[12] Wierstorf et al., A Free Database of Head-Related Impulse Response Measurements inthe Horizontal Plane with Multiple Distances.. 2011. 9
15 | 15