image numérique : le capteur ccd et son optique · digital video jean-philippe. muller...
TRANSCRIPT

jean-philippe muller
Version 05/2002
Image numérique : le capteur CCD et son optique

Digital video
jean-philippe. muller
Sommaire
1. Photoscope et caméscope numérique 2. Le bloc optique 3. La formation de l’image sur le capteur 4. Distance focale et taille de l’image 5. L’objectif standard 6. Les réglages du bloc optique 7. L’autofocus 8. L’objectif à mise au point interne 9. La stabilisation de l’image 10. Le principe du capteur d’image 11. Le transfert des charges dans le capteur CCD 12. La lecture des charges dans le capteur CCD 13. La capteur CCD à transfert interligne IF 14. La production du signal vidéo 15. L’obturateur électronique 16. La technologie HAD de Sony 17. La structure actuelle des capteurs Sony 18. La caméra couleur tri-CCD 19. Le capteur CCD à couleurs primaires 20. Le capteur CCD à couleurs secondaires 21. Le traitement du signal issu du capteur 22. Un mot sur les capteurs CMOS 23. L’équilibrage des couleurs par la balance des blancs 24. Le traitement numérique de l’image
Annexe 1 : les capteurs CCD Sony pour caméscopes Annexe 2 : les capteurs CCD Sony pour photoscopes Annexe 3 : vue d’ensemble de la gamme des capteurs CCD Sony
Digital video
jean-philippe. muller
1-Photoscope et caméscope numériques
Le succès de l’image numérique repose sur trois importantes innovations technologiques :
la faculté de l’industrie des semi-conducteurs de produire des capteurs d’images compacts et de haute qualité (jusqu’à 5 mégapixels en 2002) le développement d’algorithmes de compression très évolués comme le JPEG pour l’image
fixe, et le DV ou le MPEG pour l’image animée, capables de transformer les informations relatives à une image ou à une séquence en un fichier comprimé plus léger l’apparition de cartes mémoires miniatures capables, sous un volume réduit, de stocker une
grande quantité de données (par exemple 128 Mo pour le Mémorystick)
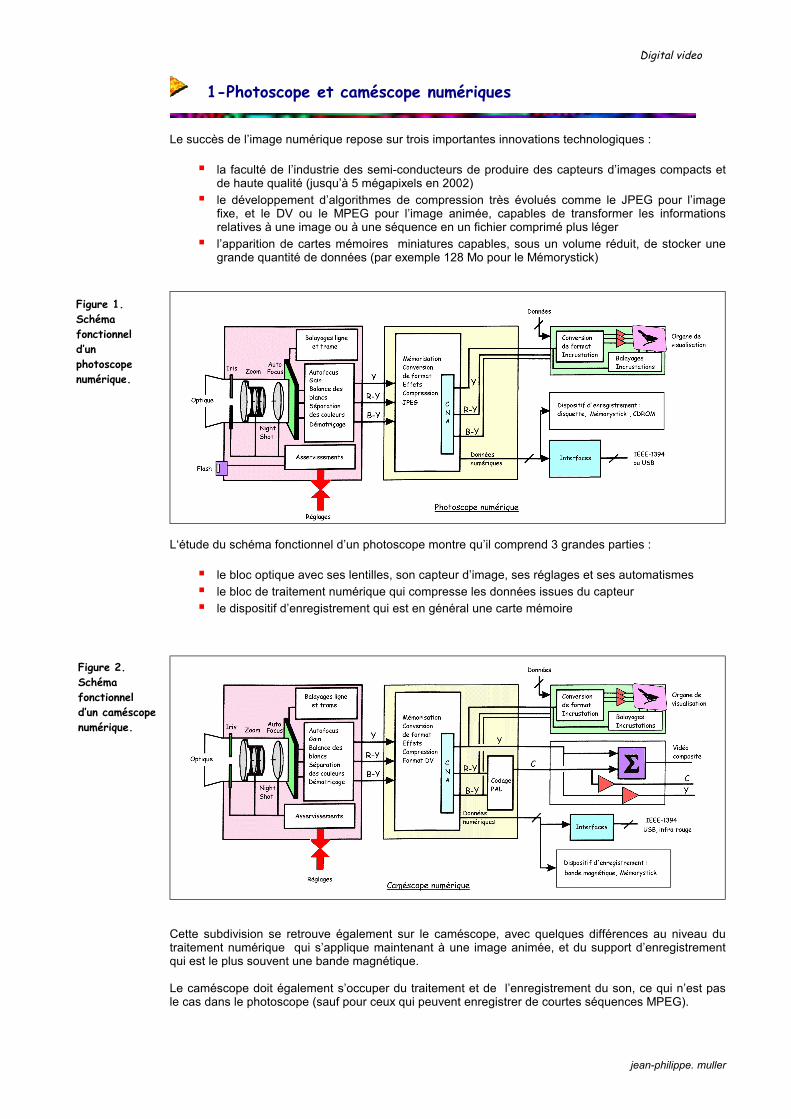
L‘étude du schéma fonctionnel d’un photoscope montre qu’il comprend 3 grandes parties :
le bloc optique avec ses lentilles, son capteur d’image, ses réglages et ses automatismes le bloc de traitement numérique qui compresse les données issues du capteur le dispositif d’enregistrement qui est en général une carte mémoire
Cette subdivision se retrouve également sur le caméscope, avec quelques différences au niveau du traitement numérique qui s’applique maintenant à une image animée, et du support d’enregistrement qui est le plus souvent une bande magnétique. Le caméscope doit également s’occuper du traitement et de l’enregistrement du son, ce qui n’est pas le cas dans le photoscope (sauf pour ceux qui peuvent enregistrer de courtes séquences MPEG).
Figure 1. Schéma fonctionnel d’un photoscope numérique.
Figure 2. Schéma fonctionnel d’un caméscope numérique.

Digital video
jean-philippe. muller
2-Le bloc optique
Le bloc optique d’un photoscope ou d’un caméscope, qui est le premier étage de traitement de l’image est constitué :
des lentilles permettant de projeter l’image sur le capteur CCD, avec le réglage de la mise au point ou focus d’un dispositif de zoom qui déplace certaines des lentilles et permet ainsi de passer d’un plan
large à un plan étroit éventuellement d’un stabilisateur optique qui compense les tremblements de main et fournit
une image filmée stable d’un filtre optique qui adapte le signal lumineux au capteur d’image du capteur CCD (ou parfois CMOS) qui va transformer le signal lumineux reçu en signal
électrique (ce capteur est quelquefois remplacé par un séparateur optique suivi de 3 capteurs)
La sensibilité spectrale des capteurs d’image s’étend assez largement dans l’infrarouge, ce qui constitue un avantage et un inconvénient :
possibilité de photographier ou de filmer sous très faible éclairement, ce qui peut être utile pour les caméras de surveillance (fonction NightShot chez Sony) les IR ne sont pas focalisés au même endroit que la lumière visible, ce qui crée des
interférences au niveau du capteur et du moirage
Le filtre optique est constitué de 3 couches :
un passe-bas fréquentiel au Niobate de lithium qui arrête le rayonnement infrarouge (ce filtre est escamoté lorsqu’on active la fonction NightShot) un filtre quart-d’onde qui redonne une polarisation circulaire à tous les rayons incidents et
permet ainsi un fonctionnement correct du séparateur optique un passe-bas spatial qui introduit un très léger flou en éliminant les détails très fins de la scène
filmée, évitant ainsi des effets parasites liés à l’échantillonnage spatial par le capteur
Figure 3. Structure du bloc optique dans une caméra mono-CCD.
Figure 4. Sensibilité spectrale de l’œil et des capteurs CCD et CMOS.
Digital video
jean-philippe. muller
3-La formation de l’image sur le capteur
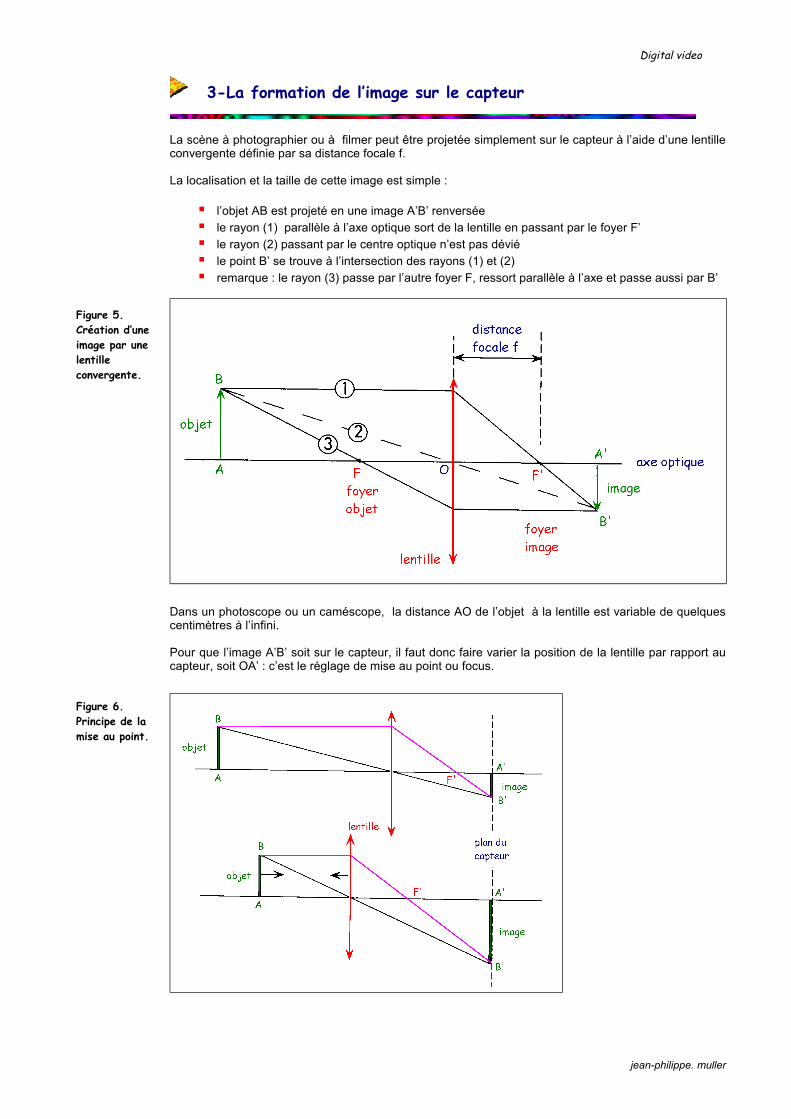
La scène à photographier ou à filmer peut être projetée simplement sur le capteur à l’aide d’une lentille convergente définie par sa distance focale f. La localisation et la taille de cette image est simple :
l’objet AB est projeté en une image A’B’ renversée le rayon (1) parallèle à l’axe optique sort de la lentille en passant par le foyer F’ le rayon (2) passant par le centre optique n’est pas dévié le point B’ se trouve à l’intersection des rayons (1) et (2) remarque : le rayon (3) passe par l’autre foyer F, ressort parallèle à l’axe et passe aussi par B’
Dans un photoscope ou un caméscope, la distance AO de l’objet à la lentille est variable de quelques centimètres à l’infini. Pour que l’image A’B’ soit sur le capteur, il faut donc faire varier la position de la lentille par rapport au capteur, soit OA’ : c’est le réglage de mise au point ou focus.
Figure 5. Création d’une image par une lentille convergente.
Figure 6. Principe de la mise au point.
Digital video
jean-philippe. muller
4-Distance focale et taille de l’image
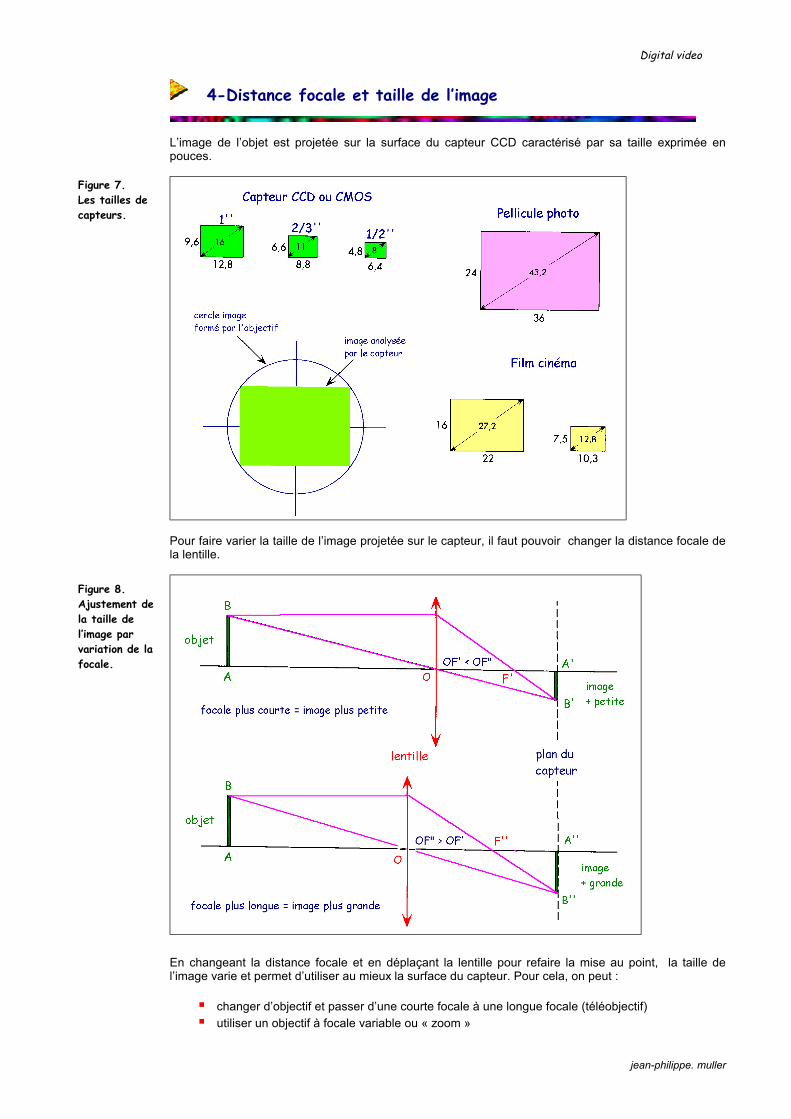
L’image de l’objet est projetée sur la surface du capteur CCD caractérisé par sa taille exprimée en pouces.
Pour faire varier la taille de l’image projetée sur le capteur, il faut pouvoir changer la distance focale de la lentille.
En changeant la distance focale et en déplaçant la lentille pour refaire la mise au point, la taille de l’image varie et permet d’utiliser au mieux la surface du capteur. Pour cela, on peut :
changer d’objectif et passer d’une courte focale à une longue focale (téléobjectif) utiliser un objectif à focale variable ou « zoom »
Figure 7. Les tailles de capteurs.
Figure 8. Ajustement de la taille de l’image par variation de la focale.
Digital video
jean-philippe. muller
5-L’objectif standard
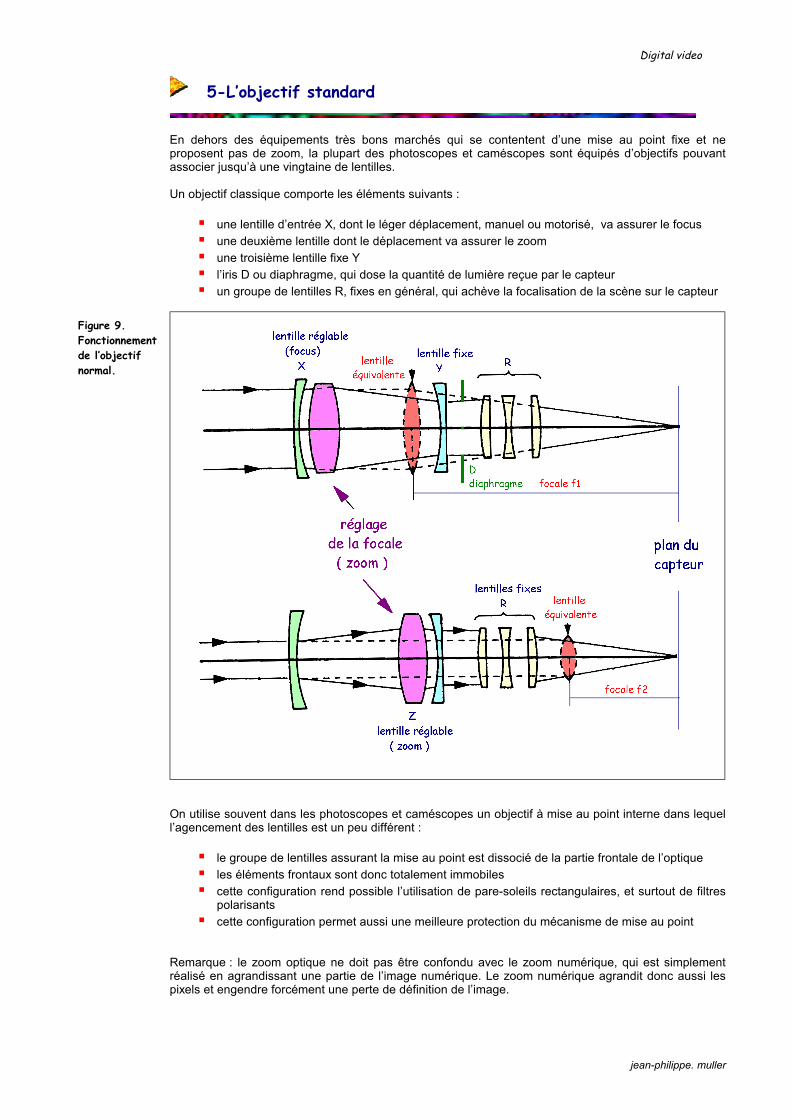
En dehors des équipements très bons marchés qui se contentent d’une mise au point fixe et ne proposent pas de zoom, la plupart des photoscopes et caméscopes sont équipés d’objectifs pouvant associer jusqu’à une vingtaine de lentilles. Un objectif classique comporte les éléments suivants :
une lentille d’entrée X, dont le léger déplacement, manuel ou motorisé, va assurer le focus une deuxième lentille dont le déplacement va assurer le zoom une troisième lentille fixe Y l’iris D ou diaphragme, qui dose la quantité de lumière reçue par le capteur un groupe de lentilles R, fixes en général, qui achève la focalisation de la scène sur le capteur
On utilise souvent dans les photoscopes et caméscopes un objectif à mise au point interne dans lequel l’agencement des lentilles est un peu différent :
le groupe de lentilles assurant la mise au point est dissocié de la partie frontale de l’optique les éléments frontaux sont donc totalement immobiles cette configuration rend possible l’utilisation de pare-soleils rectangulaires, et surtout de filtres
polarisants cette configuration permet aussi une meilleure protection du mécanisme de mise au point
Remarque : le zoom optique ne doit pas être confondu avec le zoom numérique, qui est simplement réalisé en agrandissant une partie de l’image numérique. Le zoom numérique agrandit donc aussi les pixels et engendre forcément une perte de définition de l’image.
Figure 9. Fonctionnement de l’objectif normal.
Digital video
jean-philippe. muller
6-Les réglages du bloc optique
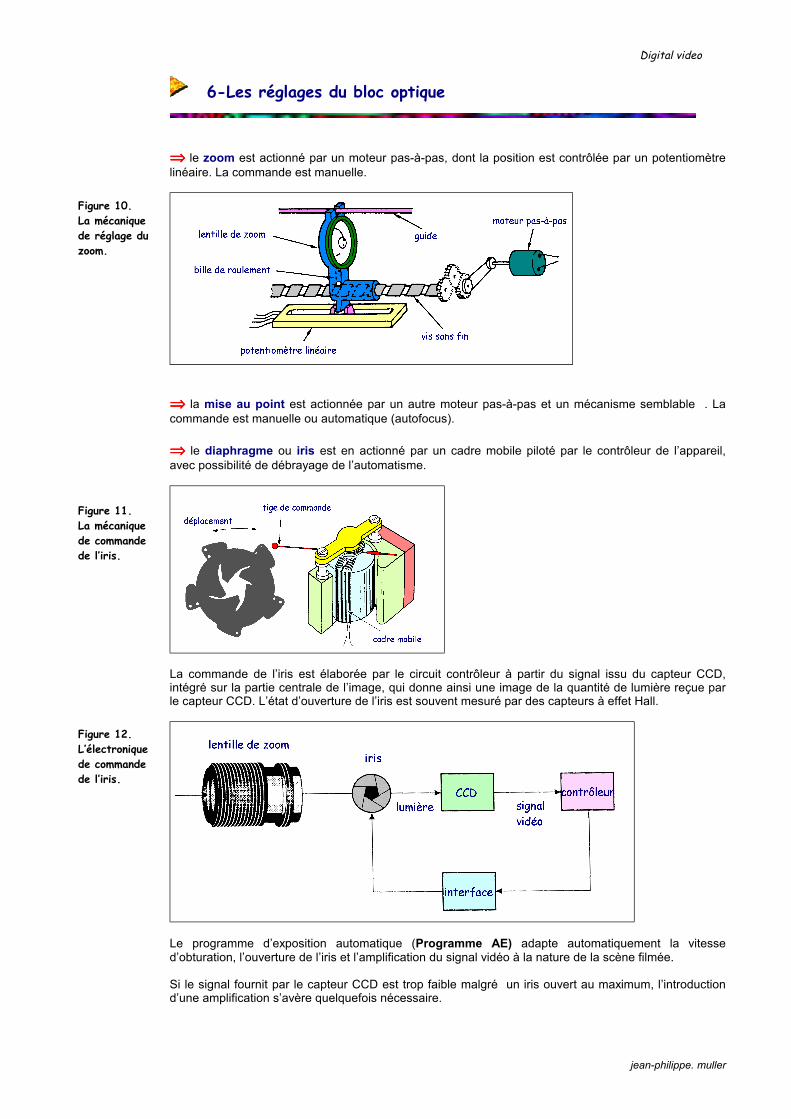
⇒⇒⇒⇒ le zoom est actionné par un moteur pas-à-pas, dont la position est contrôlée par un potentiomètre linéaire. La commande est manuelle.
⇒⇒⇒⇒ la mise au point est actionnée par un autre moteur pas-à-pas et un mécanisme semblable . La commande est manuelle ou automatique (autofocus). ⇒⇒⇒⇒ le diaphragme ou iris est en actionné par un cadre mobile piloté par le contrôleur de l’appareil, avec possibilité de débrayage de l’automatisme.
La commande de l’iris est élaborée par le circuit contrôleur à partir du signal issu du capteur CCD, intégré sur la partie centrale de l’image, qui donne ainsi une image de la quantité de lumière reçue par le capteur CCD. L’état d’ouverture de l’iris est souvent mesuré par des capteurs à effet Hall.
Le programme d’exposition automatique (Programme AE) adapte automatiquement la vitesse d’obturation, l’ouverture de l’iris et l’amplification du signal vidéo à la nature de la scène filmée. Si le signal fournit par le capteur CCD est trop faible malgré un iris ouvert au maximum, l’introduction d’une amplification s’avère quelquefois nécessaire.
Figure 10. La mécanique de réglage du zoom.
Figure 11. La mécanique de commande de l’iris.
Figure 12. L’électronique de commande de l’iris.
Digital video
jean-philippe. muller
7-L’autofocus
Tous les caméscopes et photoscopes modernes sont équipés d’un système de focalisation automatique qui peut être :
actif, par utilisation d’infra rouge ou d’ultra sons (technique de moins en moins utilisée) passif, par analyse du signal vidéo issu du capteur CCD
Lorsqu’une image est bien focalisée, elle contient un maximum de détails, qui correspondent à des fréquences élevées dans le spectre du signal vidéo.
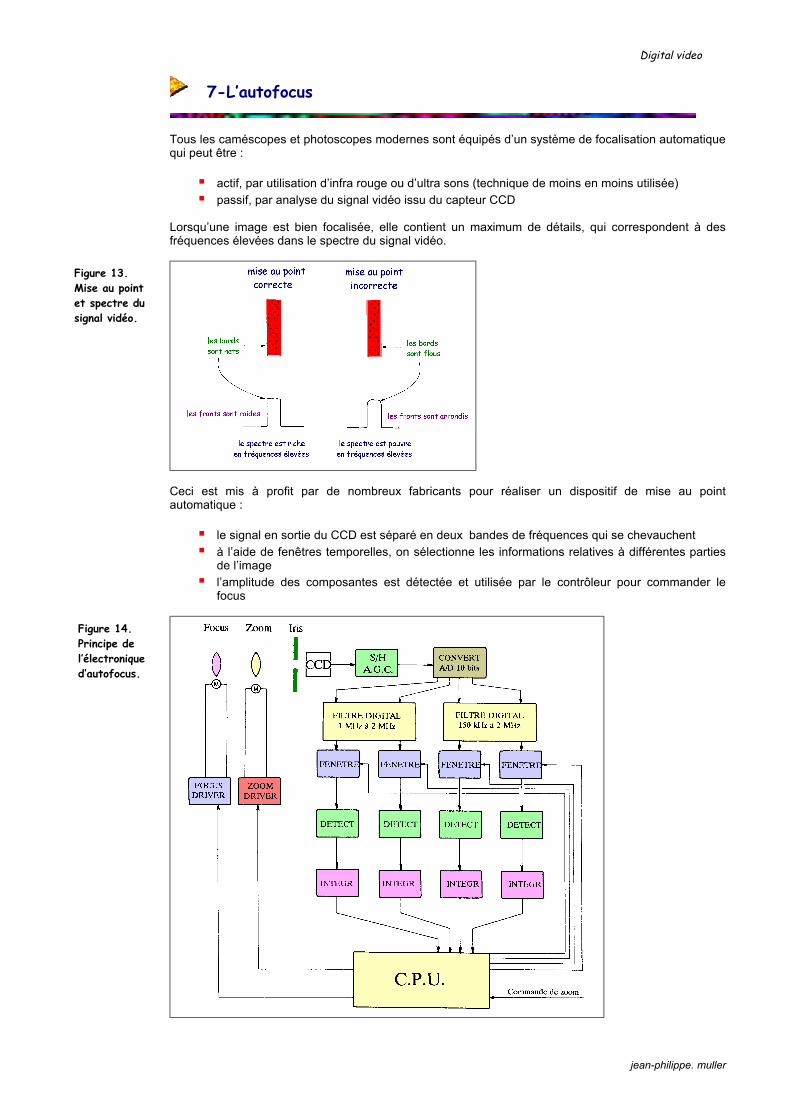
Ceci est mis à profit par de nombreux fabricants pour réaliser un dispositif de mise au point automatique :
le signal en sortie du CCD est séparé en deux bandes de fréquences qui se chevauchent à l’aide de fenêtres temporelles, on sélectionne les informations relatives à différentes parties
de l’image l’amplitude des composantes est détectée et utilisée par le contrôleur pour commander le
focus
Figure 13. Mise au point et spectre du signal vidéo.
Figure 14. Principe de l’électronique d’autofocus.

Digital video
jean-philippe. muller
8-L’objectif à mise au point interne
Sur une optique classique, qu'il s'agisse d'une focale fixe ou d'un zoom, la mise au point se fait par rotation et déplacement de la lentille frontale. Cette structure présente un certain nombres d’inconvénients :
la rotation est commandée par un moteur dont la démultiplication amène une certaine lenteur de l’autofocus impossibilité d’utiliser des filtres polarisants et des pare-soleils rectangulaires fixés sur l’objectif risques de dégradation du mécanisme d’autofocus en cas de choc sur la lentille frontale
Avec l’objectif à mise au interne ou Inner Focus, celle-ci est effectuée par le déplacement d'un groupe de lentilles à l’arrière du zoom.
Ce type d’objectif équipe la grande majorité des caméscopes et photoscopes actuels, avec les avantages et les inconvénients suivants :
« plus » le déplacement est linéaire et la course beaucoup plus courte que dans une optique classique, ce qui assure une mise au point plus rapide
« plus » cette rapidité diminue le pompage et limite la consommation en électricité. La grande
majorité des caméscopes est aujourd’hui équipée de zooms à mise au point interne « moins » les zooms Inner Focus ne gardent pas aussi bien le point sur l'ensemble des
focales que les zooms à mise au point classique Rappelons que lorsque l'on a fait le point avec un zoom traditionnel en position téléobjectif, cette mise au point est valable pour toutes les focales du zoom et n'est pas à refaire tant que la distance sujet-caméscope ne change pas, ce qui n'est plus vrai avec un zoom Inner Focus.
Figure 15. Structure de l’objectif à mise au point interne.
Digital video
jean-philippe. muller
9-La stabilisation de l’image
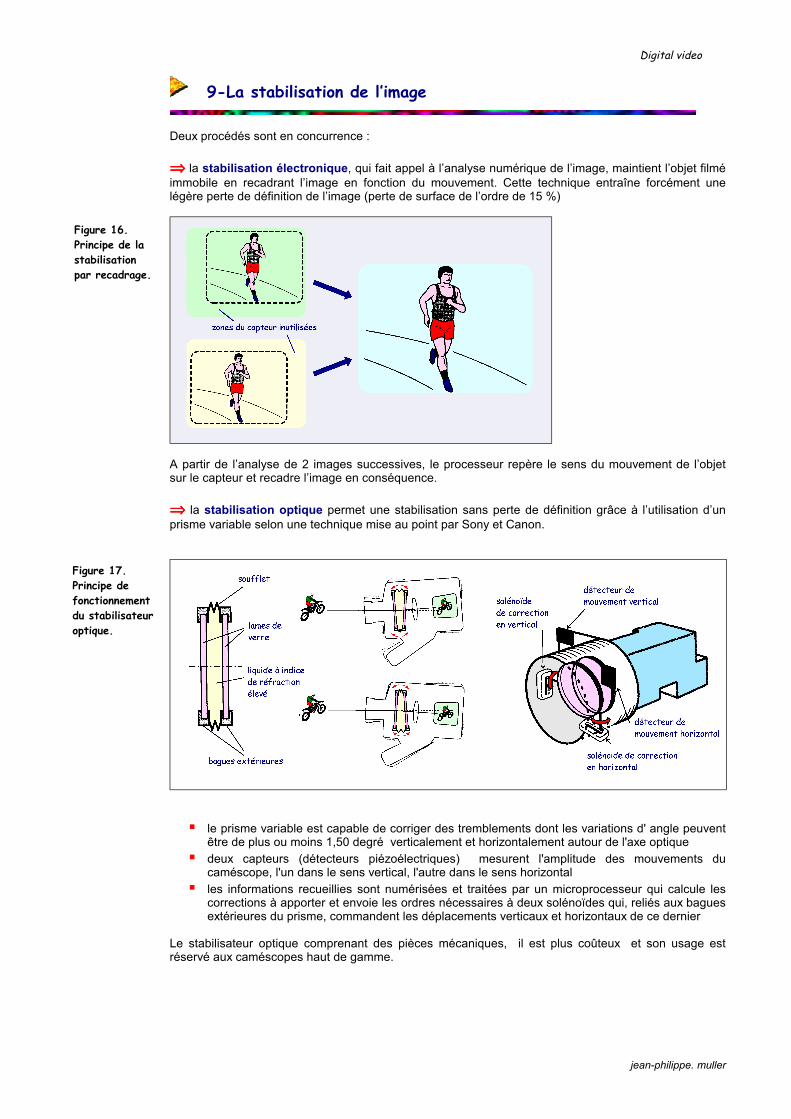
Deux procédés sont en concurrence : ⇒⇒⇒⇒ la stabilisation électronique, qui fait appel à l’analyse numérique de l’image, maintient l’objet filmé immobile en recadrant l’image en fonction du mouvement. Cette technique entraîne forcément une légère perte de définition de l’image (perte de surface de l’ordre de 15 %)
A partir de l’analyse de 2 images successives, le processeur repère le sens du mouvement de l’objet sur le capteur et recadre l’image en conséquence. ⇒⇒⇒⇒ la stabilisation optique permet une stabilisation sans perte de définition grâce à l’utilisation d’un prisme variable selon une technique mise au point par Sony et Canon.
le prisme variable est capable de corriger des tremblements dont les variations d' angle peuvent être de plus ou moins 1,50 degré verticalement et horizontalement autour de l'axe optique deux capteurs (détecteurs piézoélectriques) mesurent l'amplitude des mouvements du
caméscope, l'un dans le sens vertical, l'autre dans le sens horizontal les informations recueillies sont numérisées et traitées par un microprocesseur qui calcule les
corrections à apporter et envoie les ordres nécessaires à deux solénoïdes qui, reliés aux bagues extérieures du prisme, commandent les déplacements verticaux et horizontaux de ce dernier
Le stabilisateur optique comprenant des pièces mécaniques, il est plus coûteux et son usage est réservé aux caméscopes haut de gamme.
Figure 16. Principe de la stabilisation par recadrage.
Figure 17. Principe de fonctionnement du stabilisateur optique.
Digital video
jean-philippe. muller
10-Le principe du capteur d’image
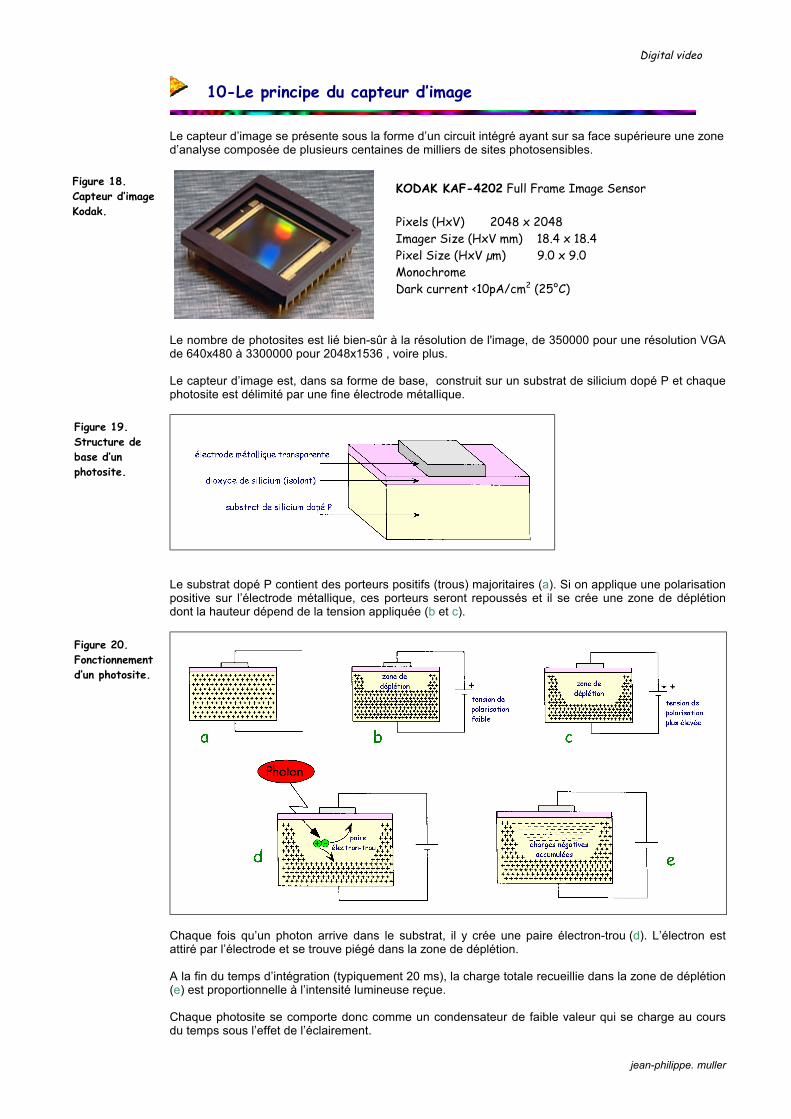
Le capteur d’image se présente sous la forme d’un circuit intégré ayant sur sa face supérieure une zone d’analyse composée de plusieurs centaines de milliers de sites photosensibles.
KODAK KAF-4202 Full Frame Image Sensor Pixels (HxV) 2048 x 2048 Imager Size (HxV mm) 18.4 x 18.4 Pixel Size (HxV µm) 9.0 x 9.0 Monochrome Dark current <10pA/cm2 (25°C)
Le nombre de photosites est lié bien-sûr à la résolution de l'image, de 350000 pour une résolution VGA de 640x480 à 3300000 pour 2048x1536 , voire plus. Le capteur d’image est, dans sa forme de base, construit sur un substrat de silicium dopé P et chaque photosite est délimité par une fine électrode métallique.
Le substrat dopé P contient des porteurs positifs (trous) majoritaires (a). Si on applique une polarisation positive sur l’électrode métallique, ces porteurs seront repoussés et il se crée une zone de déplétion dont la hauteur dépend de la tension appliquée (b et c).
Chaque fois qu’un photon arrive dans le substrat, il y crée une paire électron-trou (d). L’électron est attiré par l’électrode et se trouve piégé dans la zone de déplétion. A la fin du temps d’intégration (typiquement 20 ms), la charge totale recueillie dans la zone de déplétion (e) est proportionnelle à l’intensité lumineuse reçue. Chaque photosite se comporte donc comme un condensateur de faible valeur qui se charge au cours du temps sous l’effet de l’éclairement.
Figure 18. Capteur d’image Kodak.
Figure 19. Structure de base d’un photosite.
Figure 20. Fonctionnement d’un photosite.
Digital video
jean-philippe. muller
11-Le transfert des charges dans le capteur CCD
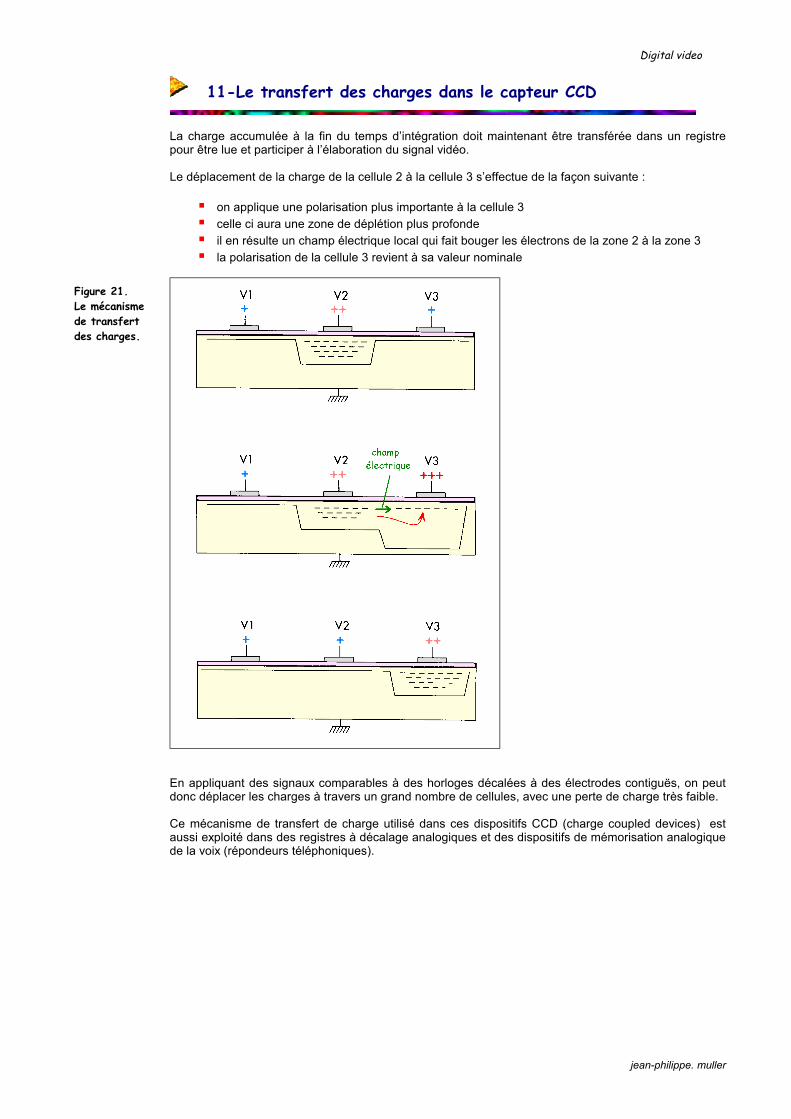
La charge accumulée à la fin du temps d’intégration doit maintenant être transférée dans un registre pour être lue et participer à l’élaboration du signal vidéo. Le déplacement de la charge de la cellule 2 à la cellule 3 s’effectue de la façon suivante :
on applique une polarisation plus importante à la cellule 3 celle ci aura une zone de déplétion plus profonde il en résulte un champ électrique local qui fait bouger les électrons de la zone 2 à la zone 3 la polarisation de la cellule 3 revient à sa valeur nominale
En appliquant des signaux comparables à des horloges décalées à des électrodes contiguës, on peut donc déplacer les charges à travers un grand nombre de cellules, avec une perte de charge très faible. Ce mécanisme de transfert de charge utilisé dans ces dispositifs CCD (charge coupled devices) est aussi exploité dans des registres à décalage analogiques et des dispositifs de mémorisation analogique de la voix (répondeurs téléphoniques).
Figure 21. Le mécanisme de transfert des charges.

Digital video
jean-philippe. muller
12-La lecture des charges dans le capteur CCD
Dans un capteur CCD, chaque photosite est associé à une cellule de stockage :
les cellules de stockage sont organisées en colonnes formant des registres verticaux, qui
alternent avec les colonnes de photocapteurs les cellules photosensibles sont séparées par des stoppeurs de canal (CSG : Channel Stopper
Gate) empêchant la diffusion des charges d' une cellule vers les voisine et par des drains d'évacuation (OFD . Overflow Drain) dans lesquels sont écoulées les charges
en excès produites par une forte illumination chaque cellule photosensible est isolée de sa cellule de stockage par une porte de lecture
(ROG : Read Out Gate) au travers de laquelle les charges vont circuler
Etape 1 : pendant la durée d’intégration ( durée de la trame pour un caméscope) l'énergie lumineuse fournie par l'optique est traduite en énergie électrique et les charges s'accumulent dans les cellules photosensibles proportionnellement à la lumière reçue. Etape 2 : durant un bref instant (dans un caméscope : intervalle de suppression trame séparant la fin de l'analyse d'une trame et le début de la suivante) une impulsion de forte amplitude est appliquée simultanément sur les électrodes de toutes les cellules de stockage. Etape 3 : la différence de potentiel établie entraîne alors un déplacement latéral simultané de toutes les charges des photocapteurs vers les registres de transfert, qui sont évidemment masqués de la lumière. Etape 4 : à l’issue de l' intervalle de suppression trame, les zones de déplétion des photocapteurs sont vidées, et donc prêtes à recevoir de nouvelles charges provenant de l’analyse de l’image suivante.
Figure 22. Détail de la structure d’un capteur CCD.

Digital video
jean-philippe. muller
13-Le capteur CCD à transfert interligne IT
Les capteurs CCD Sony utilisent tous le mode de lecture des photosites à transfert interligne qui fonctionne de la façon suivante :
pendant la durée d’intégration, le photosite se charge sous l’action de la lumière incidente à la fin de cette durée, le contenu de chaque photosite est transféré dans sa cellule de
stockage associée à l’issue de cette phase de transfert rapide, le photosite est disponible pour une nouvelle
analyse pendant cette nouvelle analyse et grâce au mécanisme de transfert de charges, le contenu des
cellules de stockage est progressivement décalé vers le bas dans le registre à décalage horizontal celui-ci est vidé à chaque nouveau décalage et fournit en sortie les informations correspondant
à chaque ligne
Dans un photoscope, le temps d’intégration peut varier dans une large gamme et l’image est lue en une fois ( CCD progressif). Dans un caméscope, l’intégration peut être faite soit pour la durée de l’image ( 40 ms ), soit pour la trame (20 ms ).
Le mode intégration image, à cause de son temps d’intégration plus long, donne une meilleure sensibilité et est donc bien adaptée au traitement des images fixes. Le mode intégration trame, à cause de son temps d’intégration plus court, est plus adapté au traitement des images animées et permet d’éviter le flou dans une certaine mesure. Si les mouvements à analyser sont rapides, il sera nécessaire de diminuer encore le temps d’intégration en faisant intervenir l’obturateur électronique.
Figure 23. Le capteur CCD à transfert interligne.
Figure 24. Les 2 modes d’intégration dans un caméscope.
Digital video
jean-philippe. muller
14-La production du signal vidéo
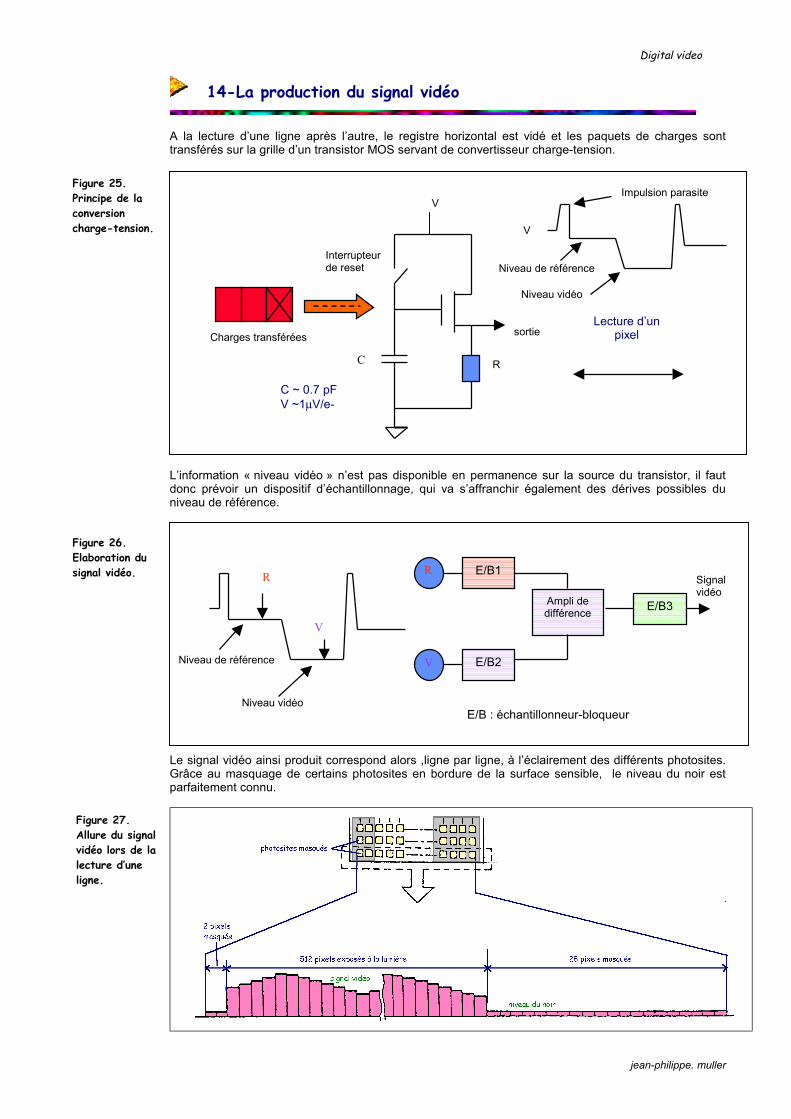
A la lecture d’une ligne après l’autre, le registre horizontal est vidé et les paquets de charges sont transférés sur la grille d’un transistor MOS servant de convertisseur charge-tension. L’information « niveau vidéo » n’est pas disponible en permanence sur la source du transistor, il faut donc prévoir un dispositif d’échantillonnage, qui va s’affranchir également des dérives possibles du niveau de référence. Le signal vidéo ainsi produit correspond alors ,ligne par ligne, à l’éclairement des différents photosites. Grâce au masquage de certains photosites en bordure de la surface sensible, le niveau du noir est parfaitement connu.
Charges transférées
R
Interrupteur de reset
C
Impulsion parasite
Niveau de référence
Lecture d’un pixel
Niveau vidéo
sortie
V
C ~ 0.7 pF V ~1µV/e-
V
Niveau de référence
Niveau vidéo
R R
V
V
E/B1
E/B2
Ampli de différence E/B3
E/B : échantillonneur-bloqueur
Signal vidéo
Figure 25. Principe de la conversion charge-tension.
Figure 26. Elaboration du signal vidéo.
Figure 27. Allure du signal vidéo lors de la lecture d’une ligne.
Digital video
jean-philippe. muller
15-L’obturateur électronique
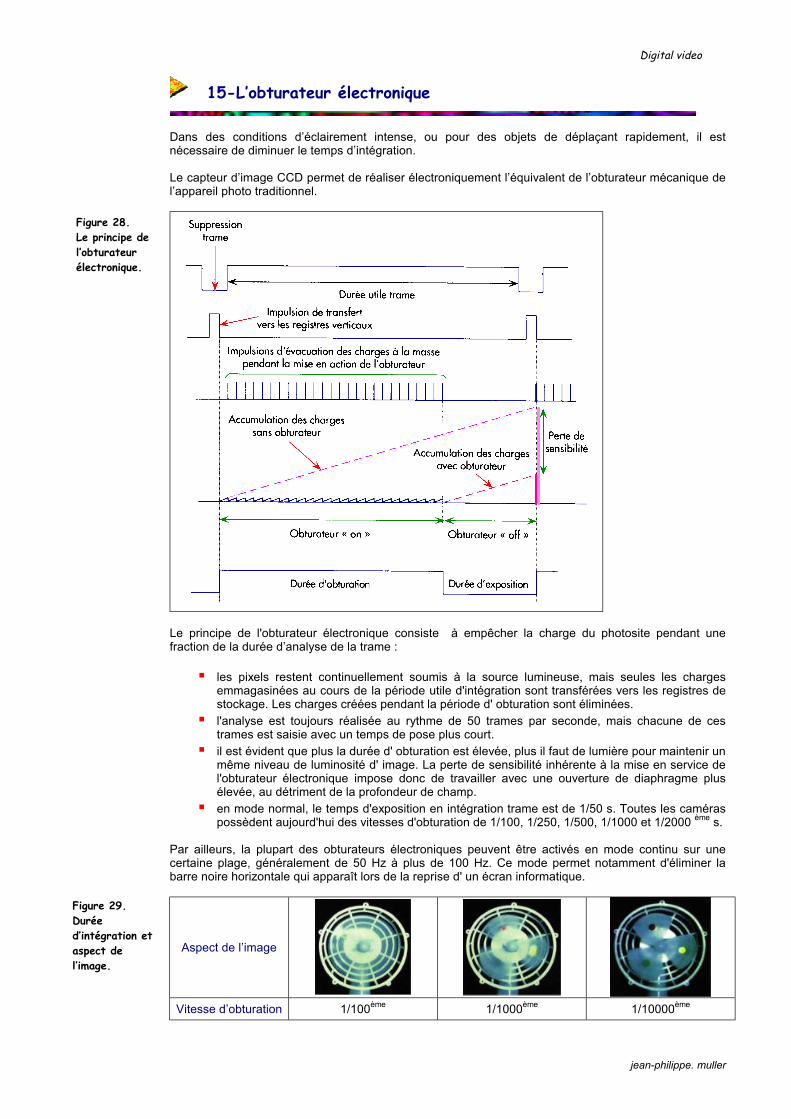
Dans des conditions d’éclairement intense, ou pour des objets de déplaçant rapidement, il est nécessaire de diminuer le temps d’intégration. Le capteur d’image CCD permet de réaliser électroniquement l’équivalent de l’obturateur mécanique de l’appareil photo traditionnel.
Le principe de l'obturateur électronique consiste à empêcher la charge du photosite pendant une fraction de la durée d’analyse de la trame :
les pixels restent continuellement soumis à la source lumineuse, mais seules les charges emmagasinées au cours de la période utile d'intégration sont transférées vers les registres de stockage. Les charges créées pendant la période d' obturation sont éliminées. l'analyse est toujours réalisée au rythme de 50 trames par seconde, mais chacune de ces
trames est saisie avec un temps de pose plus court. il est évident que plus la durée d' obturation est élevée, plus il faut de lumière pour maintenir un
même niveau de luminosité d' image. La perte de sensibilité inhérente à la mise en service de l'obturateur électronique impose donc de travailler avec une ouverture de diaphragme plus élevée, au détriment de la profondeur de champ. en mode normal, le temps d'exposition en intégration trame est de 1/50 s. Toutes les caméras
possèdent aujourd'hui des vitesses d'obturation de 1/100, 1/250, 1/500, 1/1000 et 1/2000 ème s. Par ailleurs, la plupart des obturateurs électroniques peuvent être activés en mode continu sur une certaine plage, généralement de 50 Hz à plus de 100 Hz. Ce mode permet notamment d'éliminer la barre noire horizontale qui apparaît lors de la reprise d' un écran informatique.
Aspect de l’image
Vitesse d’obturation 1/100ème 1/1000ème 1/10000ème
Figure 28. Le principe de l’obturateur électronique.
Figure 29. Durée d’intégration et aspect de l’image.
Digital video
jean-philippe. muller
16-La technologie HAD de SONY
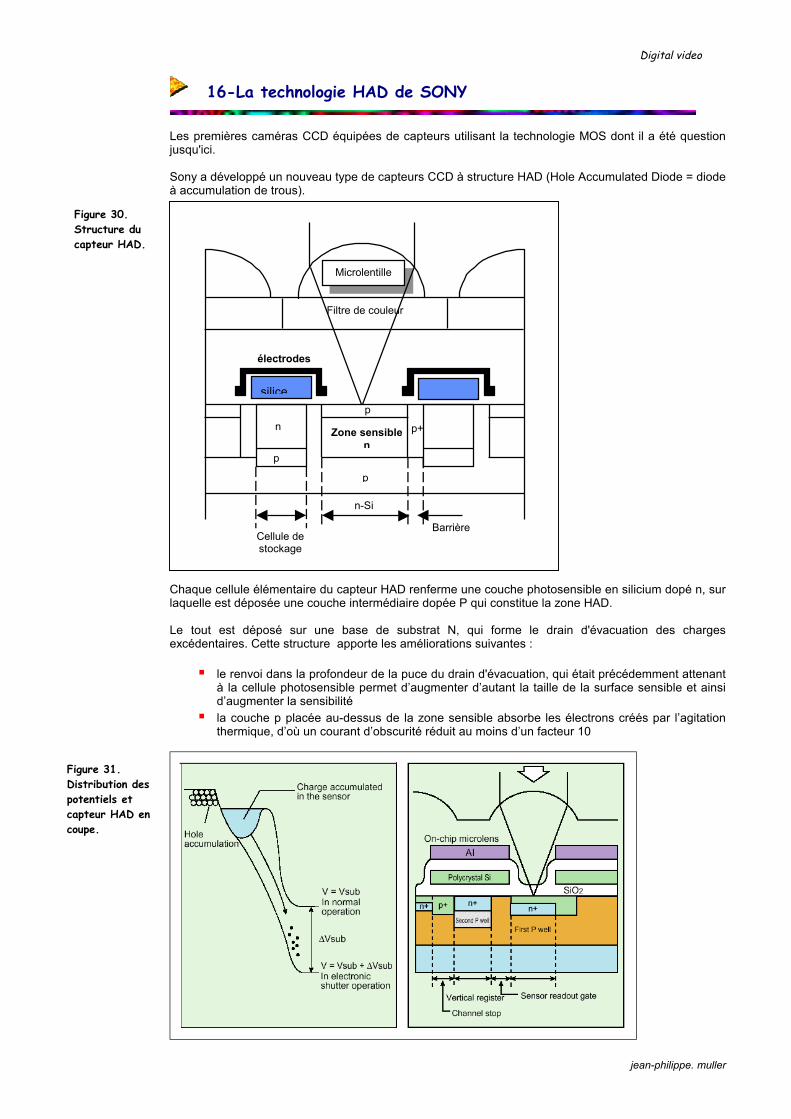
Les premières caméras CCD équipées de capteurs utilisant la technologie MOS dont il a été question jusqu'ici. Sony a développé un nouveau type de capteurs CCD à structure HAD (Hole Accumulated Diode = diode à accumulation de trous). Chaque cellule élémentaire du capteur HAD renferme une couche photosensible en silicium dopé n, sur laquelle est déposée une couche intermédiaire dopée P qui constitue la zone HAD. Le tout est déposé sur une base de substrat N, qui forme le drain d'évacuation des charges excédentaires. Cette structure apporte les améliorations suivantes :
le renvoi dans la profondeur de la puce du drain d'évacuation, qui était précédemment attenant à la cellule photosensible permet d’augmenter d’autant la taille de la surface sensible et ainsi d’augmenter la sensibilité la couche p placée au-dessus de la zone sensible absorbe les électrons créés par l’agitation
thermique, d’où un courant d’obscurité réduit au moins d’un facteur 10
Microlentille
Filtre de couleur
silice
électrodes
p
p
p+
p
n-Si
Cellule de stockage
Barrière
Zone sensible n
n
Figure 30. Structure du capteur HAD.
Figure 31. Distribution des potentiels et capteur HAD en coupe.
Digital video
jean-philippe. muller
17-La structure actuelle des capteurs SONY
La diminution de la taille des capteurs entraîne une diminution de la surface des photosites, et donc de la sensibilité du capteur. L’ajout de microlentilles au-dessus de chaque photosite permet de capter davantage de lumière, et en pratique de doubler la sensibilité du capteur.
L’ajout d’une lentille interne permet de gagner encore en sensibilité en concentrant de façon optimale la lumière arrivant sur le capteur vers le photosite.
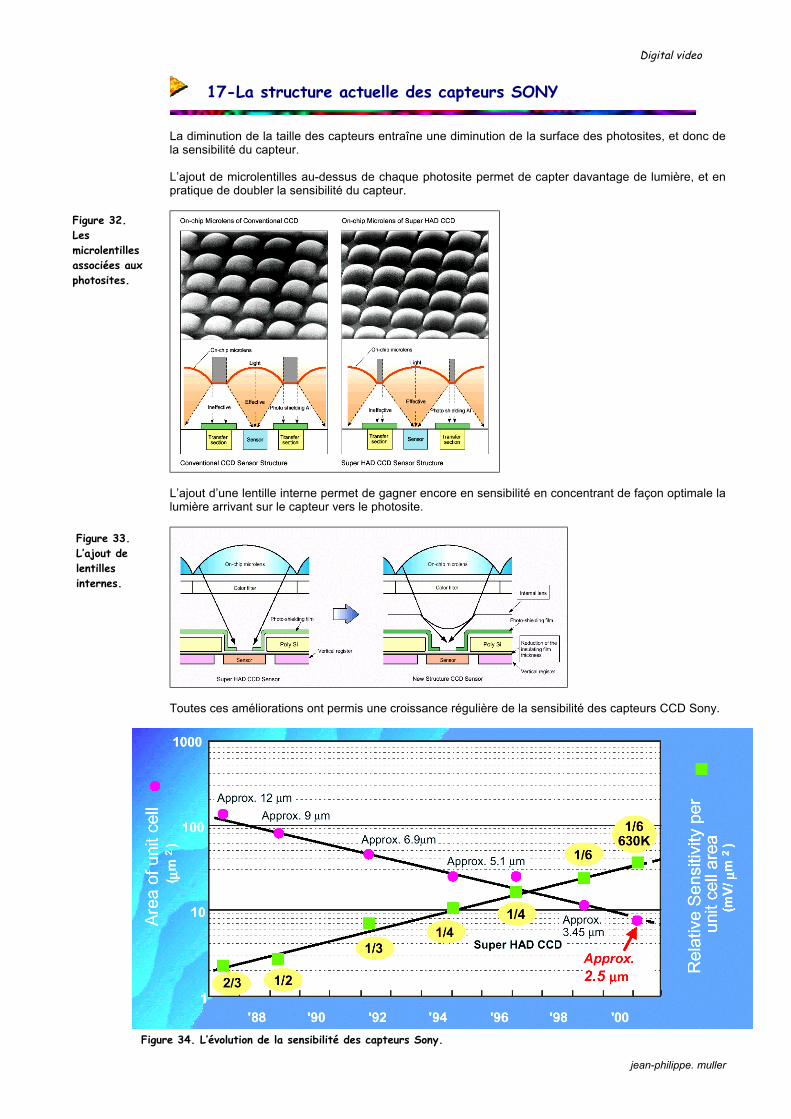
Toutes ces améliorations ont permis une croissance régulière de la sensibilité des capteurs CCD Sony.
Figure 32. Les microlentilles associées aux photosites.
Figure 33. L’ajout de lentilles internes.
Figure 34. L’évolution de la sensibilité des capteurs Sony.

Digital video
jean-philippe. muller
18-La caméra couleur tri-CCD
Pour obtenir une image en couleur, il faut analyser la scène filmée selon les 3 couleurs primaires RVB. Une première solution possible est de placer derrière l’objectif un séparateur optique équipé de miroirs semi-transparents dichroïques qui acheminent vers 3 capteurs CCD identiques les parties du spectre lumineux correspondant à chaque couleur.
Les 3 capteurs CCD fournissent les 3 signaux vidéo RVB, à partir desquels il sera facile de fabriquer le signal de luminance et les 2 signaux de couleur R-Y et B-Y. Cette technique donne les meilleurs résultats, mais reste réservée au matériel haut de gamme, car l’utilisation de 3 capteurs CCD rend la solution onéreuse. Deux exemples de caméscopes Sony tri-CCD :
Modèle Spécificités
Sony DCR-VX2000
zoom optique 12X / objectif fixe 6-72 mm 3 capteurs CCD 1/3" de 450 000 pixels sensibilité 2 Lux en basse lumière petit écran LCD de 2.5" / viseur couleur réglage et contrôle manuel de l'audio entrée et sortie analogique et numérique memory stick et mode photo 640x480
Sony DCR-TRV900
3 capteurs CCD de 450 000 pixels Ecran large de 3,5" / Viseur couleur Super Steady Shot optique Zoom optique x12 Zoom numérique x48 Entrées et sorties numérique / analogique Capture de photos sur disquette (lecteur fourni) ou sur Memory Stick (en option) Son numérique PCM (12 et 16 bits)
Figure 35. La séparation des 3 couleurs dans la caméra tri-CCD.

Digital video
jean-philippe. muller
19-Le capteur CCD à couleurs primaires
Si, pour des raisons de coût, on ne souhaite utiliser qu’un seul capteur, il faudra surmonter chaque photosite d’un filtre pour l’affecter à une couleur donnée. L’introduction d’un filtre RVB de Bayer appelé aussi filtre en mosaïque conduira inévitablement à une perte de définition au niveau de chaque couleur :
le nombre de photosites sensibles au vert est deux fois plus élevé que ceux sensibles au bleu ou au rouge, ce qui correspond à la sensibilité de l’œil le dématriçage permet d’abord de séparer les informations correspondant aux 3 couches de
couleurs une étape suivante d’interpolation utilisant des algorithmes mathématiques plus ou moins
élaborés permet alors d’affecter une valeur RVB à chaque pixel
Les capteurs CCD Sony sont disponibles équipés de différents filtres, et en particulier celui à couleurs primaires RVB.
Ce type de filtre à couleurs primaires a été historiquement le premier filtre en mosaïque utilisé dans les capteurs CCD. Puis il a été une peu délaissé au profit des filtres à couleurs complémentaires, qui donnent au capteur une sensibilité légèrement supérieure. Avec les progrès introduits entre autres par Sony sur le plan de la sensibilité, on assiste actuellement à un retour en force des capteurs à couleurs primaires qui permettent une analyse des couleurs proche de la perfection.
Figure 36. Le filtre RVB de Bayer.
Figure 37. Exemple de capteur Sony muni d’un filtre RVB de Bayer.
Digital video
jean-philippe. muller
20-Le capteur CCD à couleurs secondaires
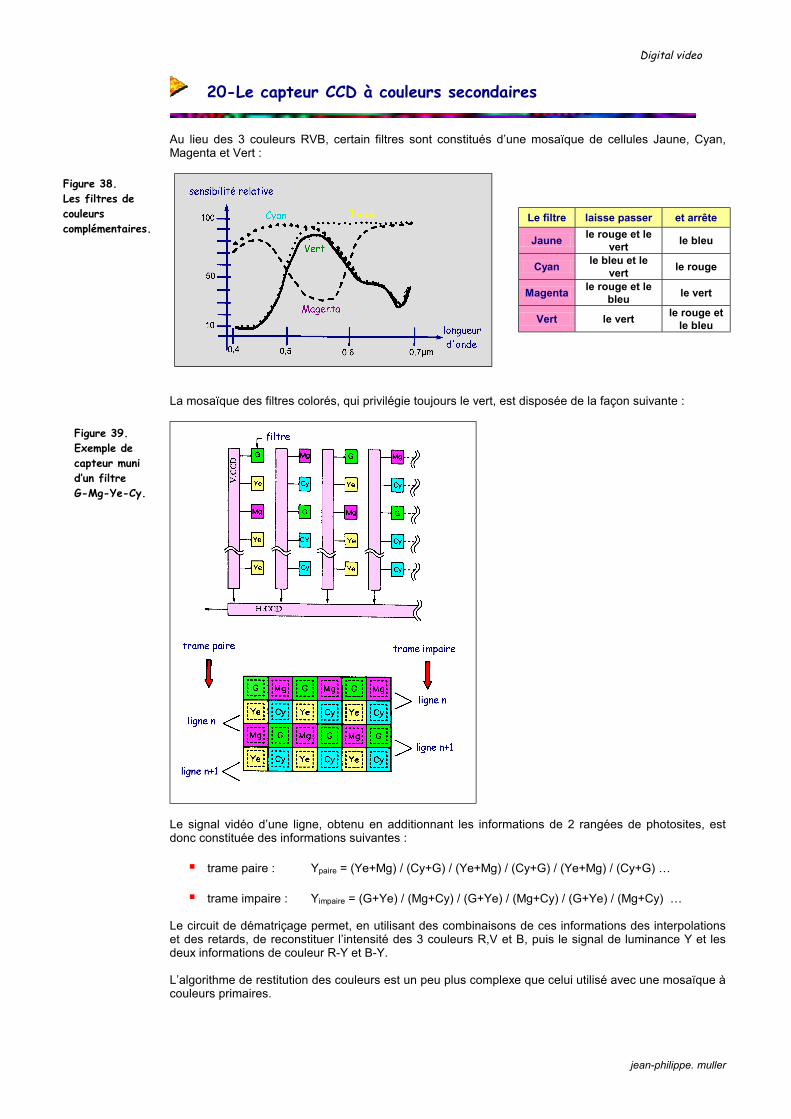
Au lieu des 3 couleurs RVB, certain filtres sont constitués d’une mosaïque de cellules Jaune, Cyan, Magenta et Vert :
Le filtre laisse passer et arrête
Jaune le rouge et le vert le bleu
Cyan le bleu et le vert le rouge
Magenta le rouge et le bleu le vert
Vert le vert le rouge et le bleu
La mosaïque des filtres colorés, qui privilégie toujours le vert, est disposée de la façon suivante :
Le signal vidéo d’une ligne, obtenu en additionnant les informations de 2 rangées de photosites, est donc constituée des informations suivantes : trame paire : Ypaire = (Ye+Mg) / (Cy+G) / (Ye+Mg) / (Cy+G) / (Ye+Mg) / (Cy+G) …
trame impaire : Yimpaire = (G+Ye) / (Mg+Cy) / (G+Ye) / (Mg+Cy) / (G+Ye) / (Mg+Cy) …
Le circuit de dématriçage permet, en utilisant des combinaisons de ces informations des interpolations et des retards, de reconstituer l’intensité des 3 couleurs R,V et B, puis le signal de luminance Y et les deux informations de couleur R-Y et B-Y. L’algorithme de restitution des couleurs est un peu plus complexe que celui utilisé avec une mosaïque à couleurs primaires.
Figure 38. Les filtres de couleurs complémentaires.
Figure 39. Exemple de capteur muni d’un filtre G-Mg-Ye-Cy.
Digital video
jean-philippe. muller
21-Le traitement du signal issu du capteur
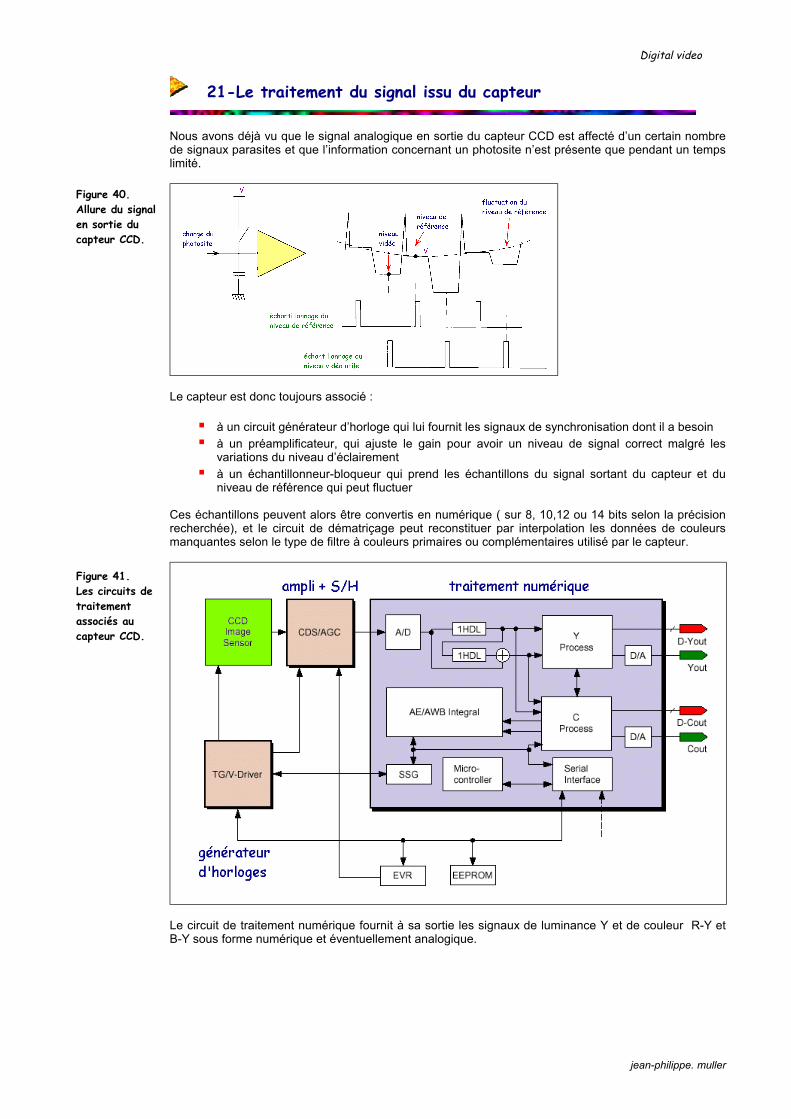
Nous avons déjà vu que le signal analogique en sortie du capteur CCD est affecté d’un certain nombre de signaux parasites et que l’information concernant un photosite n’est présente que pendant un temps limité.
Le capteur est donc toujours associé :
à un circuit générateur d’horloge qui lui fournit les signaux de synchronisation dont il a besoin à un préamplificateur, qui ajuste le gain pour avoir un niveau de signal correct malgré les
variations du niveau d’éclairement à un échantillonneur-bloqueur qui prend les échantillons du signal sortant du capteur et du
niveau de référence qui peut fluctuer Ces échantillons peuvent alors être convertis en numérique ( sur 8, 10,12 ou 14 bits selon la précision recherchée), et le circuit de dématriçage peut reconstituer par interpolation les données de couleurs manquantes selon le type de filtre à couleurs primaires ou complémentaires utilisé par le capteur.
Le circuit de traitement numérique fournit à sa sortie les signaux de luminance Y et de couleur R-Y et B-Y sous forme numérique et éventuellement analogique.
Figure 40. Allure du signal en sortie du capteur CCD.
Figure 41. Les circuits de traitement associés au capteur CCD.

Digital video
jean-philippe. muller
22-Un mot sur les capteurs CMOS
Le coût de revient élevé des capteurs CCD provient de la fabrication spéciale nécessitée par les circuits de transfert de charge. Le capteur CMOS, fabriqué comme un circuit CMOS classique et donc à coût plus faible que le CCD, présente un certain nombre d’avantages :
comme pour le CCD, la cible comporte des photosites organisées en ligne et en colonnes la charge des photosites est validée par l'intermédiaire d'une ligne d'adressage la technologie CMOS permet l'intégration des opérateurs analogiques (amplificateurs) ou
numériques (adressage) sur la même puce de semi-conducteur il est facilement envisageable d'adresser, séparément ou par bloc, les cellules élémentaires la consommation reste très faible ( un CCD demande 2–5 watts, comparé aux 20–50 mW pour
les CMOS avec de même nombre de pixel )
Le gros inconvénient est le mélange entre les signaux de commande et grandeur mesurée source de bruit (parasites) dans l'image finale. C'est la raison pour laquelle :
on a intégré dans la cellule un élément actif qui permet de diminuer cet effet l'intégration d'un élément actif dans la cellule a pour inconvénient de réduire d'autant la
surface sensible offerte, les meilleurs capteurs actuels arrivant à un taux de 30%
Les capteurs CMOS sont surtout utilisés pour le moment dans les appareils à faible coût et ne rivalisent pas encore avec les capteurs CCD. Mais l'intégration sur une seule puce de la matrice de photo-détecteurs, de la commande, du CAN et quelques autres fonctions annexes ( comme dans la puce W6850 de la société VISION ayant une taille d'image de 1000 X 800 pixels) ouvre des horizons intéressants.
Figure 42. Structure de principe du capteur d’image CMOS.
Figure 43. Disposition des photosites dans le capteur CMOS.
Digital video
jean-philippe. muller
23-L’équilibrage des couleurs par la balance des blancs
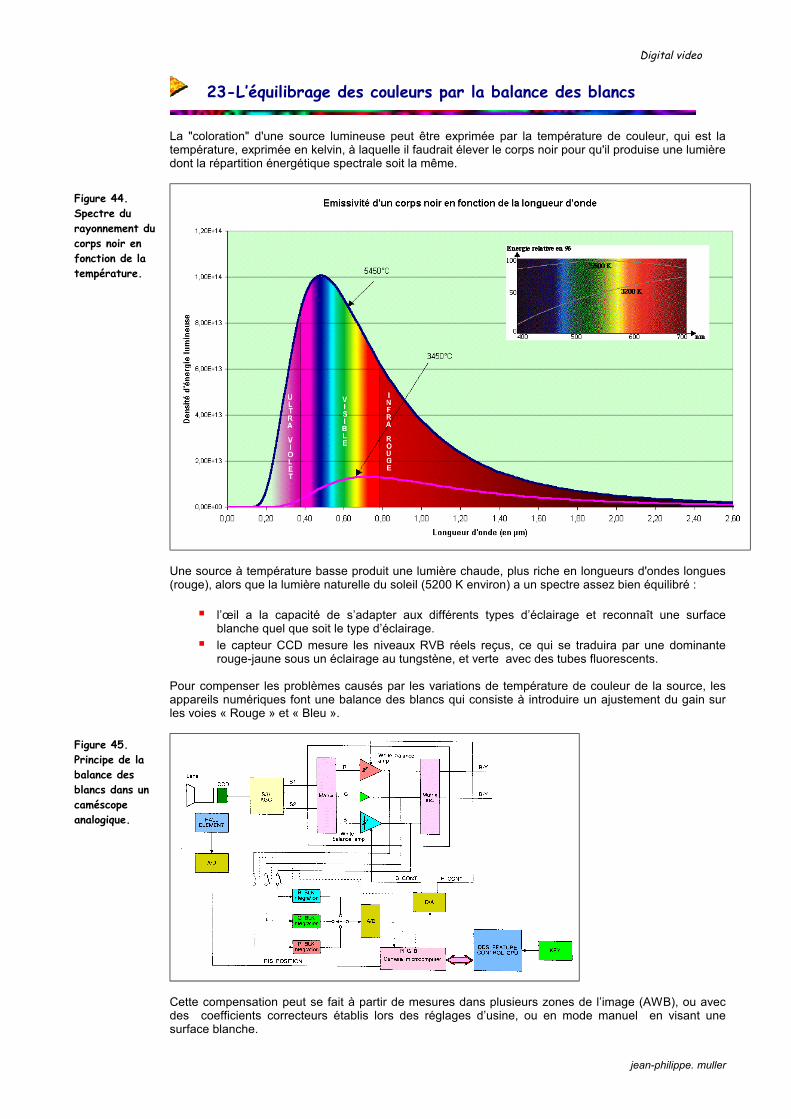
La "coloration" d'une source lumineuse peut être exprimée par la température de couleur, qui est la température, exprimée en kelvin, à laquelle il faudrait élever le corps noir pour qu'il produise une lumière dont la répartition énergétique spectrale soit la même.
Une source à température basse produit une lumière chaude, plus riche en longueurs d'ondes longues (rouge), alors que la lumière naturelle du soleil (5200 K environ) a un spectre assez bien équilibré :
l’œil a la capacité de s’adapter aux différents types d’éclairage et reconnaît une surface blanche quel que soit le type d’éclairage. le capteur CCD mesure les niveaux RVB réels reçus, ce qui se traduira par une dominante
rouge-jaune sous un éclairage au tungstène, et verte avec des tubes fluorescents.
Pour compenser les problèmes causés par les variations de température de couleur de la source, les appareils numériques font une balance des blancs qui consiste à introduire un ajustement du gain sur les voies « Rouge » et « Bleu ».
Cette compensation peut se fait à partir de mesures dans plusieurs zones de l’image (AWB), ou avec des coefficients correcteurs établis lors des réglages d’usine, ou en mode manuel en visant une surface blanche.
Figure 45. Principe de la balance des blancs dans un caméscope analogique.
Figure 44. Spectre du rayonnement du corps noir en fonction de la température.

Digital video
jean-philippe. muller
24-Le traitement numérique de l’image
De nombreux traitements et corrections sont apportés à l’image, dans le photoscope comme dans le caméscope, pour améliorer la qualité de l’image : Parmi les plus importantes, on peut noter :
la correction de « flare », défaut se manifestant par une dégradation du noir en gris quand la quantité de lumière captée par l’objectif est importante. Ce défaut est causé par une diffusion parasite de lumière à l’intérieur de l’objectif.
la correction des « taches au noir », défaut se manifestant par une coloration parasite des
plages noires de l’image et lié au courant d’obscurité des photosites ( dépend de la température)
la correction des « taches au blanc », défaut se manifestant par une coloration parasite des
plages blanches de l’image, lié aux défauts de l’objectif (influence de la longueur d’onde sur la déviation des rayons, vignettage…)
la correction des pixels défectueux. Avec le temps, le courant d’obscurité de certains pixels
peut augmenter, ce qui se traduira par l’apparition permanente de points R, V ou B sur l’image. On peut détecter ces photosites défectueux en comparant la valeur d’un pixels à tous ses voisins (pour une couleur donnée) et remplacer le pixel par le précédent, ou par une moyenne locale.
la correction de contour, qui rajoute du « piqué » à l’image en renforçant électroniquement les
transitions horizontales et verticales la correction de « gamma » dans les caméscopes, qui compense la non-linéarité de la courbe
de transfert tension/lumière du tube cathodique
Interpolation de couleur
Traitement analogique
ADC
Balance des blancs
Détection de seuils
Seuillage
Compression
Stockage
Traitement de l’affichage
Display
Capteur d’image
Transformation RVB/YCrCb
Corrections des couleurs
Figure 46. Traitements et corrections de l’image.
Digital video
jean-philippe. muller
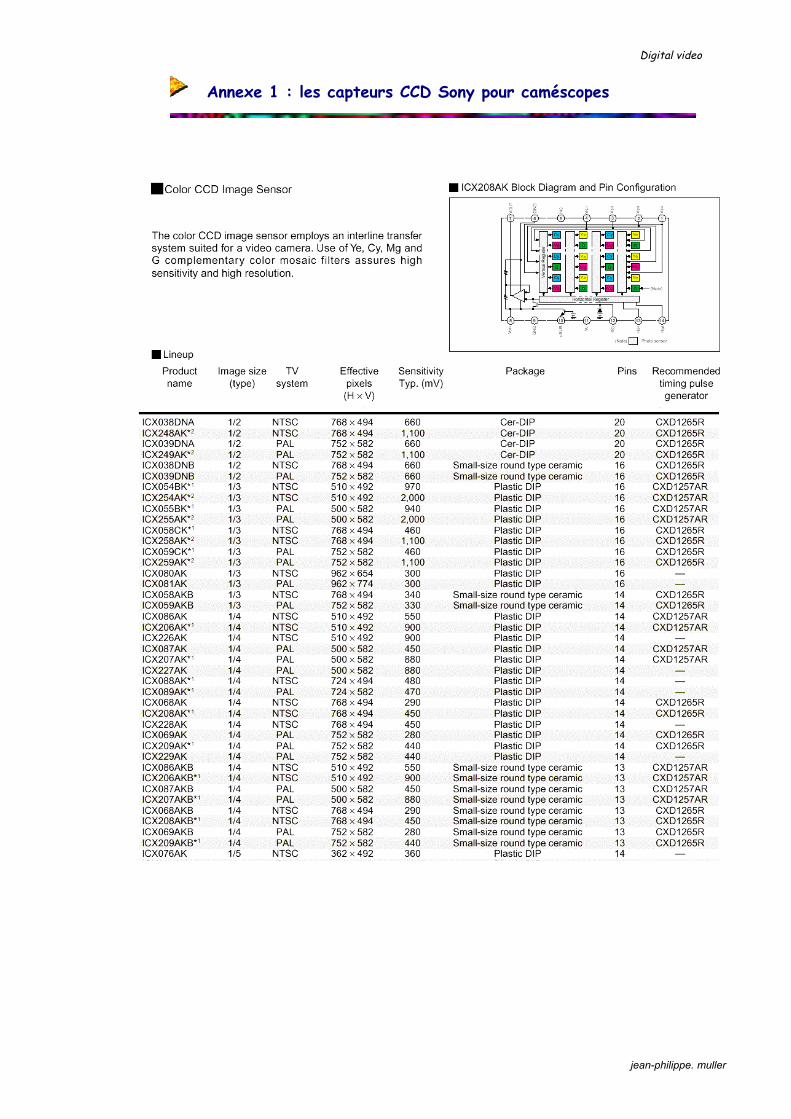
Annexe 1 : les capteurs CCD Sony pour caméscopes
Digital video
jean-philippe. muller
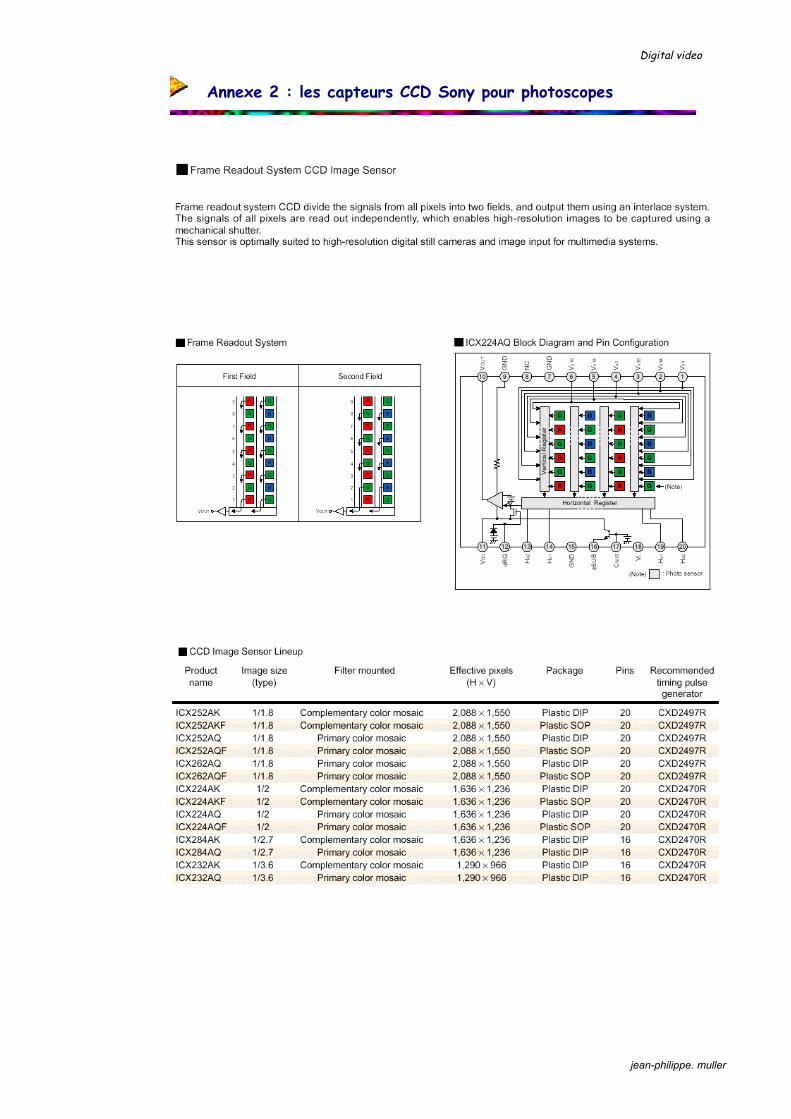
Annexe 2 : les capteurs CCD Sony pour photoscopes
Digital video
jean-philippe. muller
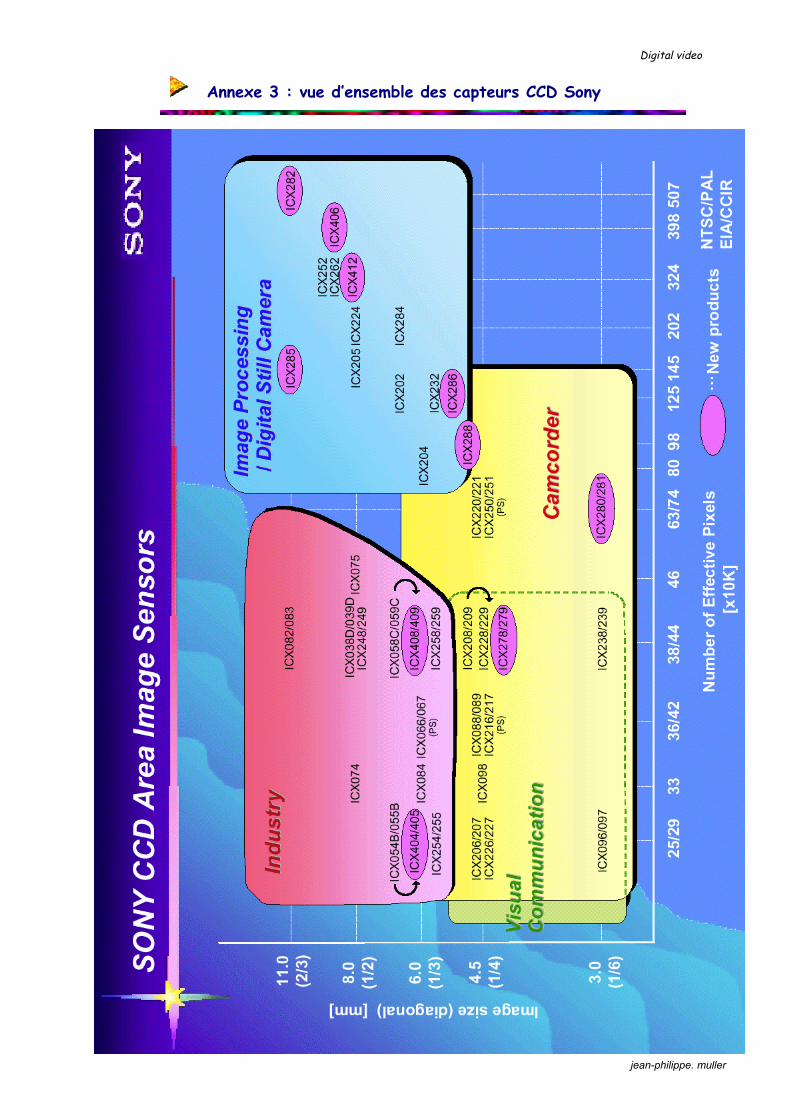
Annexe 3 : vue d’ensemble des capteurs CCD Sony

Image numérique : les compressions JPEG, DV et MPEG2
jean-philippe muller
Version 05/2002

Digital video
jean-philippe. muller
Sommaire
1. Compression des données dans le photoscope 2. Les formats d’enregistrement de l’image 3. La réduction des données de couleur 4. Exemple de conversion RVB-YUV 5. Principe de la compression JPEG d’une image 6. La transformée en cosinus discrète 7. La quantification des blocs DCT 8. Exemple de compression JPEG faible 9. Exemple de compression JPEG forte 10. La sérialisation des coefficients quantifiés 11. Organisation du flux binaire 12. La compression des données dans le caméscope 13. La norme vidéo numérique 4:2:2 14. Le sous-échantillonnage de l’image numérique 15. Effets visuels du sous-échantillonnage de la couleur 16. La compression DV dans le caméscope DV 17. Exemple de circuit de compression DV 18. Le traitement du son dans le caméscope DV 19. Le principe de la compression MPEG1 20. L’estimation de mouvement en MPEG 21. Structure du codeur MPEG 22. La compression MPEG2 du standard microMV 23. Les bases de la compression audio MPEG2 24. Le dispositif de compression audio MPEG2
Digital video
1-Compression des données dans le photoscope
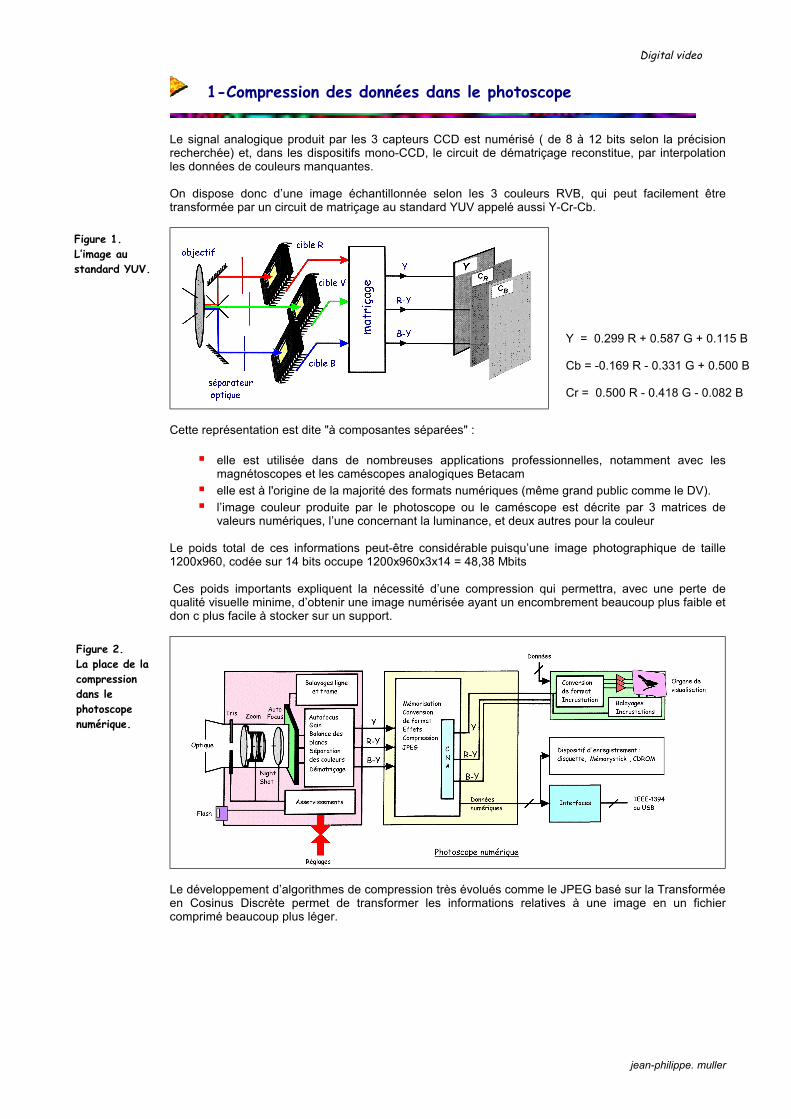
Le signal analogique produit par les 3 capteurs CCD est numérisé ( de 8 à 12 bits selon la précision recherchée) et, dans les dispositifs mono-CCD, le circuit de dématriçage reconstitue, par interpolation les données de couleurs manquantes. On dispose donc d’une image échantillonnée selon les 3 couleurs RVB, qui peut facilement être transformée par un circuit de matriçage au standard YUV appelé aussi Y-Cr-Cb.
Cette représentation est dite "à composantes séparées" :
elle est utilisée dans de nombreuses applications professiomagnétoscopes et les caméscopes analogiques Betacam elle est à l'origine de la majorité des formats numériques (même l’image couleur produite par le photoscope ou le caméscope
valeurs numériques, l’une concernant la luminance, et deux autr Le poids total de ces informations peut-être considérable puisqu’une im1200x960, codée sur 14 bits occupe 1200x960x3x14 = 48,38 Mbits Ces poids importants expliquent la nécessité d’une compression qui qualité visuelle minime, d’obtenir une image numérisée ayant un encombdon c plus facile à stocker sur un support.
Le développement d’algorithmes de compression très évolués comme le en Cosinus Discrète permet de transformer les informations relativecomprimé beaucoup plus léger.
Figure 2. La place de la compression dans le photoscope numérique.
Figure 1. L’image au standard YUV.
Y = 0.299 R + 0.587 G + 0.115 B Cb = -0.169 R - 0.331 G + 0.500 B Cr = 0.500 R - 0.418 G - 0.082 B
jean-philippe. muller
nnelles, notamment avec les
grand public comme le DV). est décrite par 3 matrices de
es pour la couleur
age photographique de taille
permettra, avec une perte de rement beaucoup plus faible et
JPEG basé sur la Transformée s à une image en un fichier
Digital video
jean-philippe. muller
2-Les formats d’enregistrement de l’image
Les images numériques peuvent être enregistrées sous plusieurs formes de fichiers informatiques. Voici les caractéristiques des formats les plus courants. ⇒⇒⇒⇒ le format RAW
cette dénomination désigne le format de fichier brut utilisé par les appareils photographiques numériques et contient les informations directement issues du capteur CCD chaque fabricant d’appareil utilise un format RAW spécifique, et propose un logiciel de lecture
adapté pour lire ses images (interpolation des couleurs manquantes, etc …) les fichiers RAW permettent d'exploiter la totalité des informations issues du capteur CCD : le
codage des données s’effectue généralement sur 12 bits ou plus au lieu de 8 pour les autres types de fichiers
⇒⇒⇒⇒ le format TIFF (Tag Image File Format)
c’est le format des images produites en mode haute qualité par les appareils photo
numériques, qui garde toutes les informations de l’image originale il gère les fichiers en mode RVB ou CMJN (cyan, magenta, jaune, noir), il est très utilisé par les
professionnels de l'image mais donne des fichiers images très volumineux une compression sans perte de données par algorithme LZW est possible, mais le poids de
l'image n'est réduit que de 50% environ. ⇒⇒⇒⇒ le format JPEG (Joint Photographic Expert Group) Ce format à été mis au point spécialement pour les images et les photographies, dans le but de réduire la taille des fichiers produits :
il utilise une méthode de compression des données dite “destructive”, qui consiste à ne retenir que les informations clés de l’image suivant des algorithmes puissants et à supprimer les autres informations un rapport de compression de 1 / 4 permet d’obtenir des fichiers peu volumineux sans perte de
qualité visible un rapport de compression élevé fournira des fichiers peu volumineux mais avec une perte de
qualité importante la norme JPEG permet un taux de compression ajustable, mais ce taux est en général fixé par
le fabriquant dans un photoscope des modifications et enregistrements successifs d’un fichier JPEG dégradent la qualité de
l’image finale, par la répétition des traitements de compression
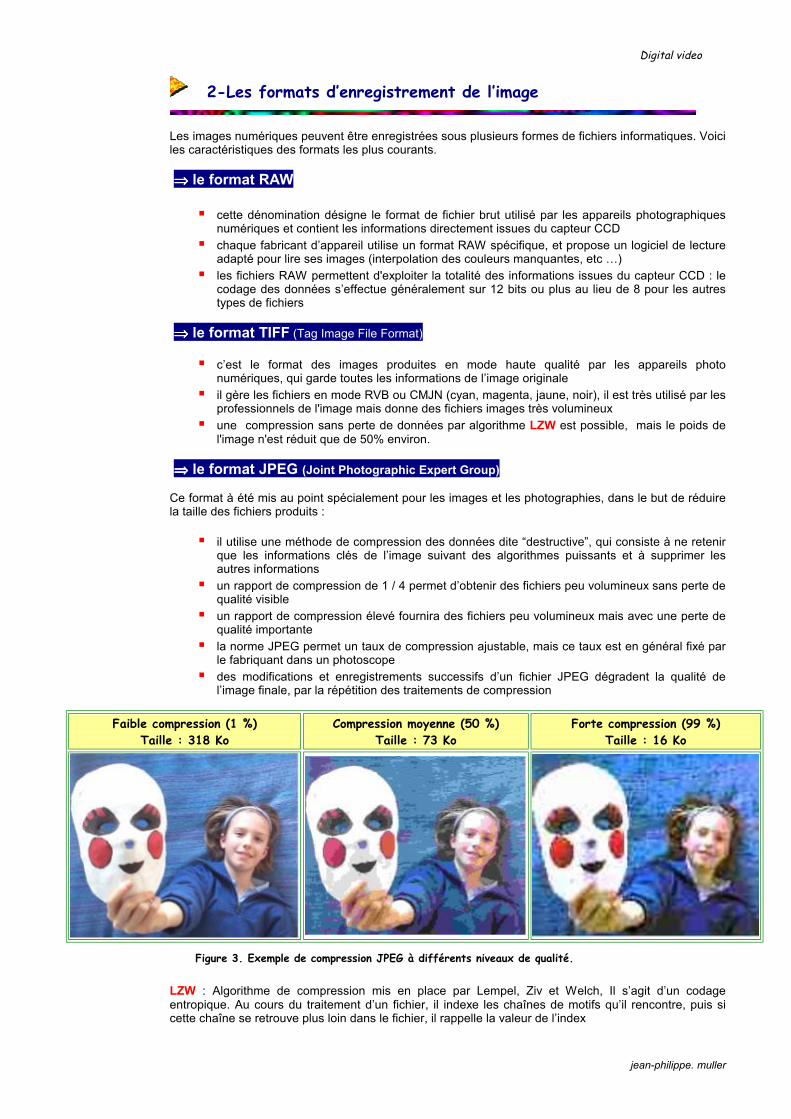
Faible compression (1 %) Taille : 318 Ko
Compression moyenne (50 %) Taille : 73 Ko
Forte compression (99 %) Taille : 16 Ko
LZW : Algorithme de compression mis en place par Lempel, Ziv et Welch, Il s’agit d’un codage entropique. Au cours du traitement d’un fichier, il indexe les chaînes de motifs qu’il rencontre, puis si cette chaîne se retrouve plus loin dans le fichier, il rappelle la valeur de l’index
Figure 3. Exemple de compression JPEG à différents niveaux de qualité.

Digital video
jean-philippe. muller
3-La réduction des données de couleur
L’œil humain n'est pas un organe parfait et certaines de ses caractéristiques ont été mises à profit pour réduire la quantité de données nécessaires pour décrire une image, et ce déjà en télévision analogique :
l’œil est plus sensible aux détails en noir et blanc qu'aux détails colorés la réduction de la bande passante des composantes couleur est bien tolérée par l’œil jusqu'à
une valeur égale à 25 % de celle de la luminance c’est pourquoi la bande passante en télédiffusion analogique a été fixée à 6 MHz pour la
luminance et à 1,5 MHz pour chacune des composantes couleur. Cette réduction de la chrominance reste toujours valable aujourd'hui, même pour les nouveaux formats vidéo numériques grand public. Pour une image numérique couleur, la réduction des informations « couleur » se traduit par un sous-échantillonnage des signaux Cr et Cb :
l’image est découpée en blocs carrés de 2x2 pixels ( quelquefois 4x4) à chaque bloc on affecte 4 échantillons de luminance Y, un échantillon de chrominance rouge
Cr et un échantillon de chrominance bleue Cb ces échantillons Cr et Cb sont des moyennes de ces 2 grandeurs sur les 4 pixels
Une image numérique en couleur de taille 1200x960 par exemple, est décrite en RVB par 3 matrices de 1200x960, soit T = 3456000 valeurs. Après sous-échantillonnage de la couleur, elle est donc décrite par 3 matrices de tailles différentes :
une matrice Y de 1200x960 deux matrices Cr et Cb de 600x480
soit une taille totale de T = 1200x960 + 2x600x480 = 1728000 échantillons
Ce sous-échantillonnage de la couleur introduit une diminution de qualité imperceptible à l’œil et apporte un taux de compression d’un facteur 2.
Figure 4. Réduction des échantillons de couleur.
Figure 5. Codage YUV d’une image couleur.

Digital video
jean-philippe. muller
4-Exemple de conversion RVB-YUV
Image originale en RVB 800x600 24 bits/pixel Taille totale : 34,5 Mbits
Image de luminance 800x600 9 bits/pixel Taille : 4,32 Mbits
Images Cr et Cb 400X300 9 bits/pixel Taille : 1,08 Mbits chacune
Image finale en YCrCb Taille : 800x600 Digitalisée sur 9 bits/pixel Taille totale : 6,48 Mbits

Digital video
jean-philippe. muller
5-Principe de la compression JPEG d’une image
Nous avons vu qu’une image couleur peut être représentée par 3 images à niveaux de gris dans la représentation YCrCb. Chacune de ces 3 matrices est décomposée en blocs de 8x8 pixels qui vont tous subir le même traitement mathématique.
Le principe de l’algorithme JPEG pour une image à niveaux est le suivant :
une transformation linéaire, appelée transformée en cosinus discrète ou DCT (Discret Cosine
Transform) est réalisée sur chaque bloc, ce qui donne chaque fois une nouvelle matrice 8x8 la DCT concentre l’information sur l’image en haut et à gauche de la matrice les coefficients de la transformée sont ensuite quantifiés à l ’aide d‘une table de 64 éléments
définissant les pas de quantification cette table permet de choisir un pas de quantification important pour certaines composantes
jugées peu significatives visuellement et jouer sur le taux de compression de l’image souhaité des codages appropriés sont ensuite appliqués aux données pour produire un flux binaire le
plus léger possible
Figure 7. Les étapes de la compression JPEG.
Figure 6. Découpage des matrices en blocs 8x8.
Digital video
jean-philippe. muller
6-La transformée en cosinus discrète
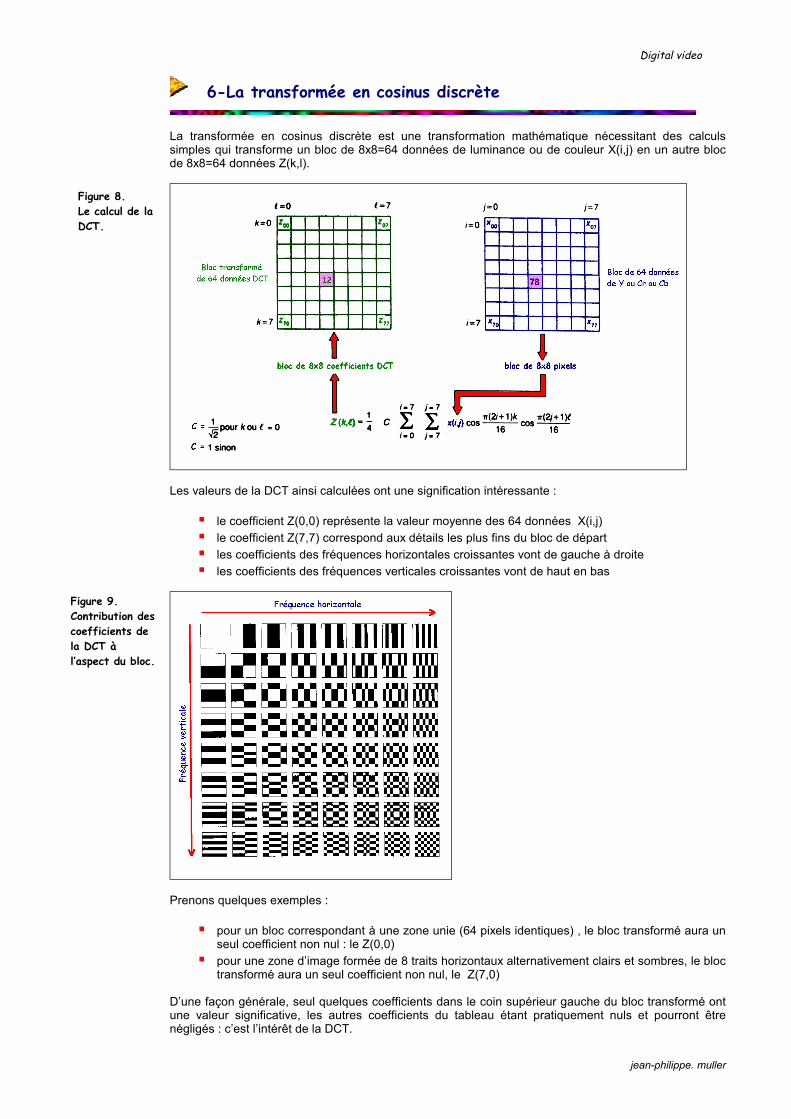
La transformée en cosinus discrète est une transformation mathématique nécessitant des calculs simples qui transforme un bloc de 8x8=64 données de luminance ou de couleur X(i,j) en un autre bloc de 8x8=64 données Z(k,l).
Les valeurs de la DCT ainsi calculées ont une signification intéressante :
le coefficient Z(0,0) représente la valeur moyenne des 64 données X(i,j) le coefficient Z(7,7) correspond aux détails les plus fins du bloc de départ les coefficients des fréquences horizontales croissantes vont de gauche à droite les coefficients des fréquences verticales croissantes vont de haut en bas
Prenons quelques exemples :
pour un bloc correspondant à une zone unie (64 pixels identiques) , le bloc transformé aura un seul coefficient non nul : le Z(0,0) pour une zone d’image formée de 8 traits horizontaux alternativement clairs et sombres, le bloc
transformé aura un seul coefficient non nul, le Z(7,0) D’une façon générale, seul quelques coefficients dans le coin supérieur gauche du bloc transformé ont une valeur significative, les autres coefficients du tableau étant pratiquement nuls et pourront être négligés : c’est l’intérêt de la DCT.
Figure 8. Le calcul de la DCT.
Figure 9. Contribution des coefficients de la DCT à l’aspect du bloc.

Digital video
jean-philippe. muller
7-La quantification des blocs DCT
La quantification représente la phase non conservatrice du processus de compression JPEG et permet, moyennant une diminution de la précision de l‘image, de réduire le nombre de bits nécessaires au stockage. Pour cela, elle réduit chaque valeur de la matrice DCT en la divisant par un nombre (quantum), fixé par une table (matrice 8 x 8) de quantification :
Valeur quantifiée ( i , j ) = valeur DCT ( i, j ) / quantum ( i, j ) La matrice de quantification peut être fixe pour tous les blocs de l’image, ou valable pour une région de l’image (ensemble de blocs). Les coefficients les moins importants pour la restitution de l’image sont "amoindris" en divisant chaque élément par l'élément correspondant de la table de quantification. Ainsi les hautes fréquences s'atténuent rapidement.
1 1 2 4 8 16 32 64 1 1 2 4 8 16 32 64 2 2 2 4 8 16 32 64 4 4 4 4 8 16 32 64 8 8 8 8 8 16 32 64
16 16 16 16 16 16 32 64 32 32 32 32 32 32 32 64 64 64 64 64 64 64 64 64
La valeur du quantum peut être d‘autant plus élevée que l‘élément correspondant de la matrice DCT contribue peu à la qualité de l’image, donc qu‘il se trouve éloigné du coin supérieur gauche ( i=j=0).
150 80 40 14 4 2 1 0 92 75 36 10 6 1 0 0 52 38 26 8 7 4 0 0 12 8 6 4 2 1 0 0 4 3 2 0 0 0 0 0 2 2 1 1 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
150 80 20 4 1 0 0 0 92 75 18 3 1 0 0 0 26 19 13 2 1 0 0 0 3 2 2 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Matrice des coefficients DCT Matrice des coefficients DCT quantifiés
La qualité de l’image compressée, et donc le taux de compression, peuvent être ajustés en choisissant des matrices de quantification adéquates :
en choisissant des tailles de pas de quantification très élevés, le résultat est un taux de compression important pour une qualité d’image médiocre
en choisissant des tailles de pas petites la qualité de l’image reste excellente et les taux de
compression n’auront rien d’extraordinaire.
Figure 10. Exemple de matrice de quantification.
Figure 11. Matrice de coefficients DCT avant et après quantification.

Digital video
jean-philippe. muller
8-Exemple de compression JPEG faible
Figure 12. Les étapes de la compression JPEG d’une image.

Digital video
jean-philippe. muller
9-Exemple de compression JPEG forte
Figure 13. Les étapes de la compression JPEG d’une image.

Digital video
jean-philippe. muller
10-La sérialisation des coefficients quantifiés
Le codage de la matrice DCT quantifiée se fait en parcourant les éléments dans l’ordre imposé par une séquence particulière appelée séquence zigzag :
on lit les valeurs en zigzags inclinés à 45° en commençant par le coin supérieur gauche et en finissant en bas à droite cette séquence a la propriété de parcourir les éléments en commençant par les basses
fréquences et de traiter les fréquences de plus en plus hautes puisque la matrice DCT contient beaucoup de composantes de hautes fréquences nulles,
l’ordre de la séquence zigzag va engendrer de longues suites de 0 consécutives Ceci facilite de nouveau les étapes de compression suivantes : les codages RLC et VLC.
Deux mécanismes sont ensuite mis en œuvre pour comprimer la matrice DCT quantifiée et diminuer sans pertes ma masse des informations présentes: ⇒⇒⇒⇒ le codage RLC (Run Length Coding) :
si une image contient une suite assez longue de pixels identiques, il devient intéressant de répertorier le couple nombre/valeur de couleur les longues suites de « 0 » par exemple sont codées en donnant le nombre de 0 successifs
⇒⇒⇒⇒ le codage DPCM (Differential Pulse Code Modulation) :
le coefficient Z(0,0) correspondant à la valeur moyenne de la teinte du bloc est souvent proche de celui du bloc précédent on code alors simplement la différence avec la valeur du coefficient du bloc précédent
⇒⇒⇒⇒ le codage VLC (Variable Length Coding) ou codage de Huffman :
les valeurs non nulles seront codées en utilisant une méthode de type statistique on a intérêt à coder sur un petit nombre de bits les valeurs qui sont les plus utilisées et à
réserver des mots binaires de plus grande longueur aux valeurs les plus rares.
Figure 14. La lecture en zigzag d’un bloc DCT.
Figure 15. La réduction des données en JPEG.
Digital video
jean-philippe. muller
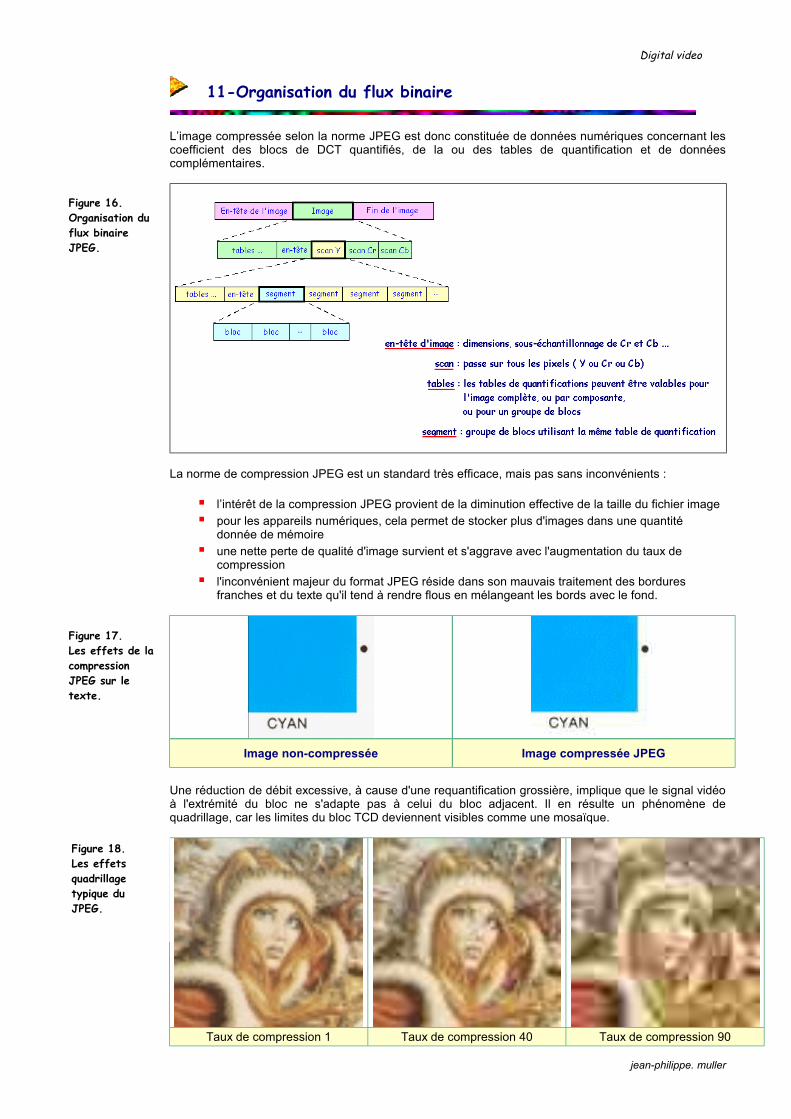
11-Organisation du flux binaire
L’image compressée selon la norme JPEG est donc constituée de données numériques concernant les coefficient des blocs de DCT quantifiés, de la ou des tables de quantification et de données complémentaires.
La norme de compression JPEG est un standard très efficace, mais pas sans inconvénients :
l’intérêt de la compression JPEG provient de la diminution effective de la taille du fichier image pour les appareils numériques, cela permet de stocker plus d'images dans une quantité
donnée de mémoire une nette perte de qualité d'image survient et s'aggrave avec l'augmentation du taux de
compression l'inconvénient majeur du format JPEG réside dans son mauvais traitement des bordures
franches et du texte qu'il tend à rendre flous en mélangeant les bords avec le fond.
Image non-compressée Image compressée JPEG
Une réduction de débit excessive, à cause d'une requantification grossière, implique que le signal vidéo à l'extrémité du bloc ne s'adapte pas à celui du bloc adjacent. Il en résulte un phénomène de quadrillage, car les limites du bloc TCD deviennent visibles comme une mosaïque.
Taux de compression 1 Taux de compression 40 Taux de compression 90
Figure 16. Organisation du flux binaire JPEG.
Figure 17. Les effets de la compression JPEG sur le texte.
Figure 18. Les effets quadrillage typique du JPEG.

Digital video
jean-philippe. muller
12-La compression des données dans le caméscope
Dans le caméscope, la dimension de l’image reste limitée à la taille standard 720x576 et le problème de poids vient surtout de la fréquence de répétition (25 images par seconde) :
pour une image RVB de 720x576, sur 8 bits, le poids est P = 720x560x3x8 = 9,6768 Mbits soit avec 25 images/seconde, un débit de D = 250 Mbits/s
Pour diminuer la taille du flot de données nécessaires à une séquence vidéo, plusieurs standards de compression peuvent être utilisés : ⇒⇒⇒⇒ le Motion JPEG
c’est une extension du JPEG qui permet de traiter des séquences d’images, utilisé dans les caméscopes DV il se contente de considérer une séquence vidéo comme une succession d’images fixes,
chacune d’elles compressée séparément en utilisant le standard JPEG. chaque image étant compressée indépendamment des autres, le MJPEG permet le montage à
l’image près le taux de compression standard obtenu est de 5, soit un débit de 25 Mbits/s pour l’image
⇒⇒⇒⇒ le MPEG (Moving Pictures Experts Group)
il se base sur les similitudes existant entre plusieurs images successives (redondance temporelle) pour atteindre des taux de compression bien plus importants que le MJPEG le MPEG2 a été conçu pour traiter des séquences d’images entrelacées et produire des vidéos
de qualité satisfaisante avec un débit allant de 4 à 15 Mbits/seconde. les utilisations principales de MPEG-2 sont la TV satellite, la TV câble et le DVD le processus de compression est beaucoup plus complexe que le MJPEG et nécessite donc
une puissance de calcul supérieure, ce qui explique son apparition récente dans les caméscopes le MPEG travaille avec sur des groupes d’images (12 en général) et n’est donc pas adapté
pour faire du montage à l’image près
Figure 19. Schéma fonctionnel d’un caméscope numérique.
Digital video
jean-philippe. muller
13-La norme vidéo numérique 4:2:2
L’œil humain n'est pas un organe parfait et certaines de ses caractéristiques ont été mises à profit pour réduire la quantité de données nécessaires pour décrire une image, et ce déjà en télévision analogique :
à cause de la persistance rétinienne, une fréquence de répétition de 25 images/seconde est suffisante pour donner une impression de mouvement continu l’œil est plus sensible aux détails en noir et blanc qu'aux détails colorés la réduction de la bande passante des composantes couleur est bien tolérée par l’œil jusqu'à
une valeur égale à 25 % de celle de la luminance c’est pourquoi la bande passante en télédiffusion a été fixée à 6 MHz pour la luminance et à
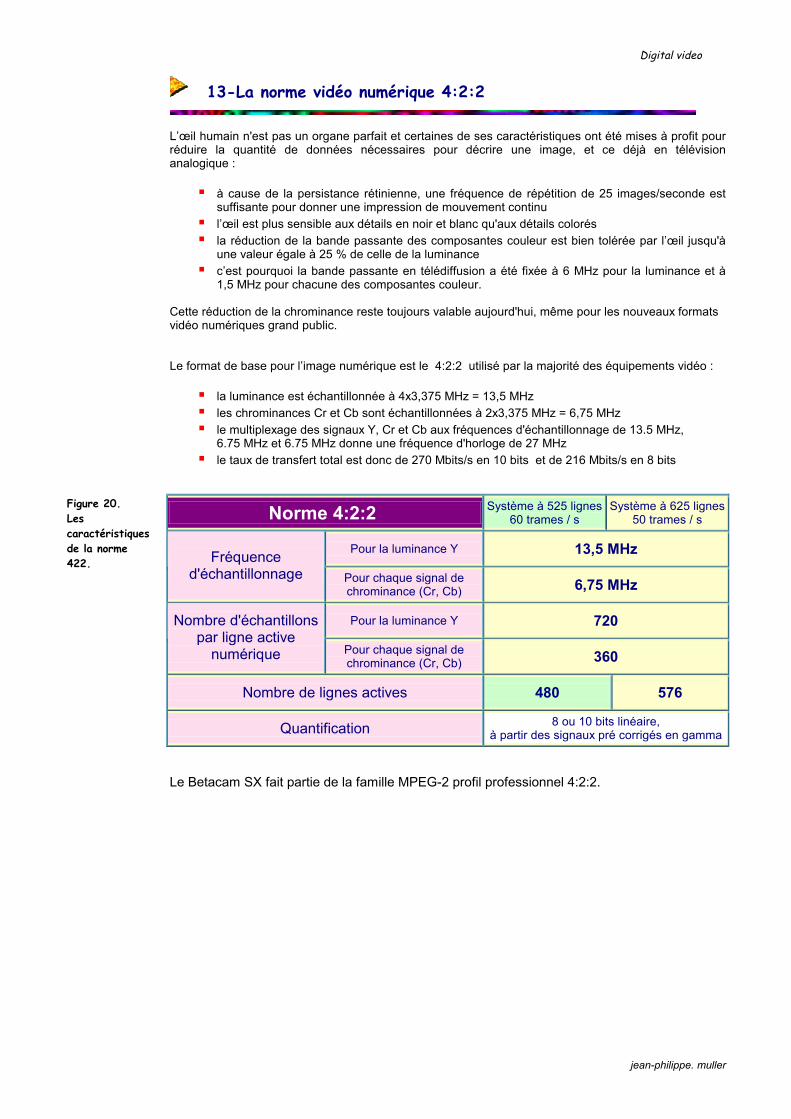
1,5 MHz pour chacune des composantes couleur. Cette réduction de la chrominance reste toujours valable aujourd'hui, même pour les nouveaux formats vidéo numériques grand public. Le format de base pour l’image numérique est le 4:2:2 utilisé par la majorité des équipements vidéo :
la luminance est échantillonnée à 4x3,375 MHz = 13,5 MHz les chrominances Cr et Cb sont échantillonnées à 2x3,375 MHz = 6,75 MHz le multiplexage des signaux Y, Cr et Cb aux fréquences d'échantillonnage de 13.5 MHz,
6.75 MHz et 6.75 MHz donne une fréquence d'horloge de 27 MHz le taux de transfert total est donc de 270 Mbits/s en 10 bits et de 216 Mbits/s en 8 bits
Norme 4:2:2 Système à 525 lignes 60 trames / s
Système à 625 lignes 50 trames / s
Pour la luminance Y 13,5 MHz Fréquence d'échantillonnage Pour chaque signal de
chrominance (Cr, Cb) 6,75 MHz
Pour la luminance Y 720 Nombre d'échantillons par ligne active
numérique Pour chaque signal de chrominance (Cr, Cb) 360
Nombre de lignes actives 480 576
Quantification 8 ou 10 bits linéaire, à partir des signaux pré corrigés en gamma
Le Betacam SX fait partie de la famille MPEG-2 profil professionnel 4:2:2.
Figure 20. Les caractéristiques de la norme 422.
Digital video
jean-philippe. muller
14-Le sous-échantillonnage de l’image numérique
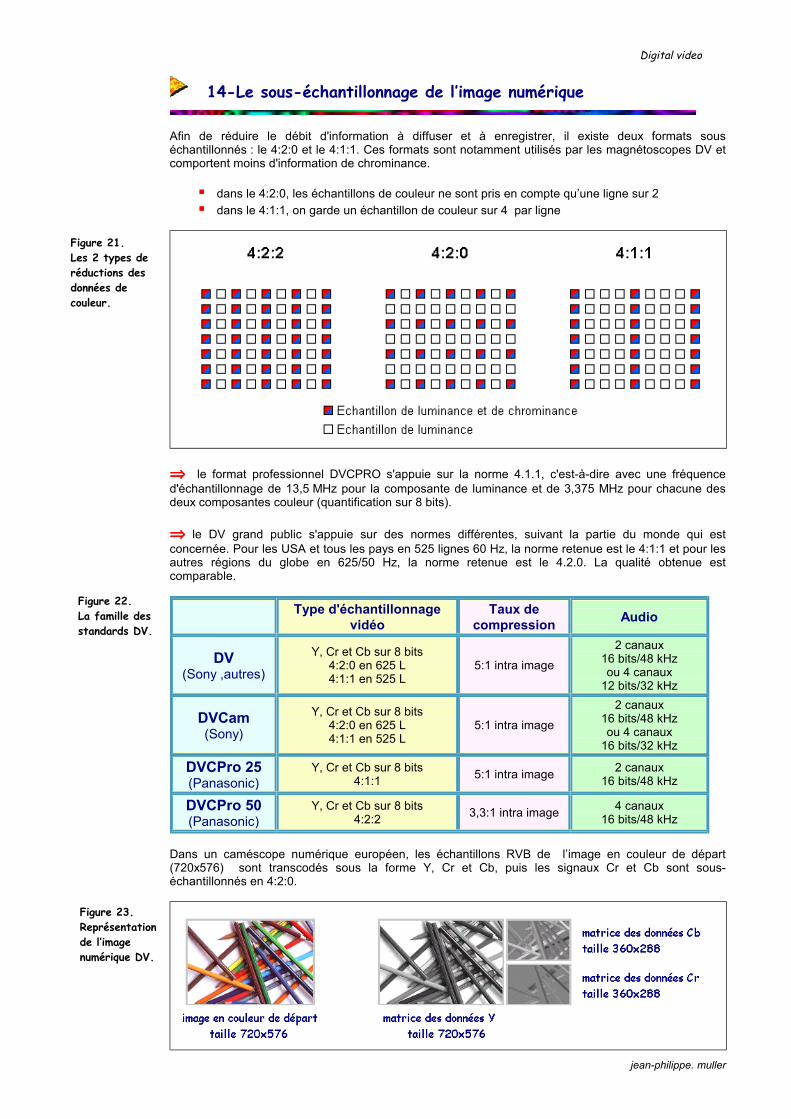
Afin de réduire le débit d'information à diffuser et à enregistrer, il existe deux formats sous échantillonnés : le 4:2:0 et le 4:1:1. Ces formats sont notamment utilisés par les magnétoscopes DV et comportent moins d'information de chrominance.
dans le 4:2:0, les échantillons de couleur ne sont pris en compte qu’une ligne sur 2 dans le 4:1:1, on garde un échantillon de couleur sur 4 par ligne
⇒⇒⇒⇒ le format professionnel DVCPRO s'appuie sur la norme 4.1.1, c'est-à-dire avec une fréquence d'échantillonnage de 13,5 MHz pour la composante de luminance et de 3,375 MHz pour chacune des deux composantes couleur (quantification sur 8 bits). ⇒⇒⇒⇒ le DV grand public s'appuie sur des normes différentes, suivant la partie du monde qui est concernée. Pour les USA et tous les pays en 525 lignes 60 Hz, la norme retenue est le 4:1:1 et pour les autres régions du globe en 625/50 Hz, la norme retenue est le 4.2.0. La qualité obtenue est comparable.
Type d'échantillonnage vidéo
Taux de compression Audio
DV (Sony ,autres)
Y, Cr et Cb sur 8 bits 4:2:0 en 625 L 4:1:1 en 525 L
5:1 intra image 2 canaux
16 bits/48 kHz ou 4 canaux
12 bits/32 kHz
DVCam (Sony)
Y, Cr et Cb sur 8 bits 4:2:0 en 625 L 4:1:1 en 525 L
5:1 intra image 2 canaux
16 bits/48 kHz ou 4 canaux
16 bits/32 kHz
DVCPro 25 (Panasonic)
Y, Cr et Cb sur 8 bits 4:1:1 5:1 intra image 2 canaux
16 bits/48 kHz
DVCPro 50 (Panasonic)
Y, Cr et Cb sur 8 bits 4:2:2 3,3:1 intra image 4 canaux
16 bits/48 kHz
Dans un caméscope numérique européen, les échantillons RVB de l’image en couleur de départ (720x576) sont transcodés sous la forme Y, Cr et Cb, puis les signaux Cr et Cb sont sous-échantillonnés en 4:2:0.
Figure 21. Les 2 types de réductions des données de couleur.
Figure 22. La famille des standards DV.
Figure 23. Représentation de l’image numérique DV.

Digital video
jean-philippe. muller
15-Effets visuels du sous-échantillonnage de la couleur
L’image suivante a été filmée avec un caméscope DV au format 4:1:1.
Le détail (72x48 pixels) fait apparaître clairement l’aspect du sous-échantillonnage 4:1:1 :
horizontalement, la couleur (liée à Cr et Cb) reste identique pour 4 pixels seule l’intensité (liée à Y) peut varier d’un pixel à l’autre verticalement, la couleur peut changer à chaque ligne
L’image suivante représente le même détail, mais filmé avec un caméscope à la norme 4:2:0 et montre que l’information de couleur est valable pour un carré de 4 pixels.
Figure 24. Image au format 4:1:1.
Figure 25. Détail au format 4:1:1.
Figure 26. Détail au format 4:2:0.

Digital video
jean-philippe. muller
16-La compression DV dans le caméscope
Comme pour une compression JPEG, l'image vidéo YUV est découpée en 9720 blocs :
6480 blocs de 8 x 8 pixels pour l’image Y (720x576) 1620 blocs de 8 x 8 pixels pour l’image Cr (360x288) 1620 blocs de 8 x 8 pixels pour l’image Cb (360x288)
Ces blocs sont regroupés par 6 pour former un macrobloc, qui sont eux-mêmes entrelacés, puis assemblés par groupes de 5 pour former des unités de compression caractérisé par la même table de quantification : 1 matrice de quantification / unité de compression = 5 macroblocs = 30 blocs de 8x8 pixels La compression DV d’une image utilise donc 324 matrices de quantifications, pas forcément toutes différentes, et se différencie en cela de la compression MJPEG qui n’utilise qu’une matrice par image, comme en JPEG.
Pour optimiser la réduction de débit par rapport au contenu de la scène à coder, une détection de mouvement est effectuée entre les deux trames d'une image :
s'il y a peu de mouvement d'une trame à l'autre, la compression est réalisée sur l'ensemble des 6480 blocs 8x8 de l'image Y si le mouvement d'une trame à l'autre est trop prononcé, la compression est effectuée
indépendamment sur chaque trame, sur des blocs de 8 x 4 (3240 pour chaque trame) Le codage DV laisse chaque image indépendante des autres et se prête sans aucune difficulté au montage à l'image près. Le reste du processus de compression est voisin du JPEG :
la DCT transforme chaque bloc de 8 x 8 pixels en une matrice de 8 x 8 coefficients de composantes fréquentielles afin de mettre en évidence les données redondantes la quantification non-linéaire divise ces coefficients par des valeurs plus ou moins élevées. Les
matrices de quantification de chaque unité de compression sont optimisées pour assurer un bon compromis « qualité visuelle/efficacité de compression » la matrice obtenue après quantification est soumise à une lecture en zigzag, faisant apparaître
de longues suites de zéros puis un codage à longueur variable est réalisé, attribuant des codes courts aux symboles les
plus fréquents et réservant les codes longs aux symboles plus rares. les données des macroblocs sont enfin mises en paquets dans un bloc de synchronisation de
taille fixe (framing). Tant que l’on se contente de facteurs de compression relativement faibles (de 2 à 5) il peut s’appliquer à du travail de production ou de postproduction de qualité et, optimisé, il est quasi transparent. Toutefois, lorsque le facteur de compression devient plus important (au delà de 10), la dégradation des images devient telle qu’elle est aisément perceptible par l’œil. En outre, ces dégradations s’additionnent d’une génération à l’autre, jusqu’à devenir rapidement inacceptables.
Figure 27. L’image est formée de 2 trames.
Digital video
jean-philippe. muller
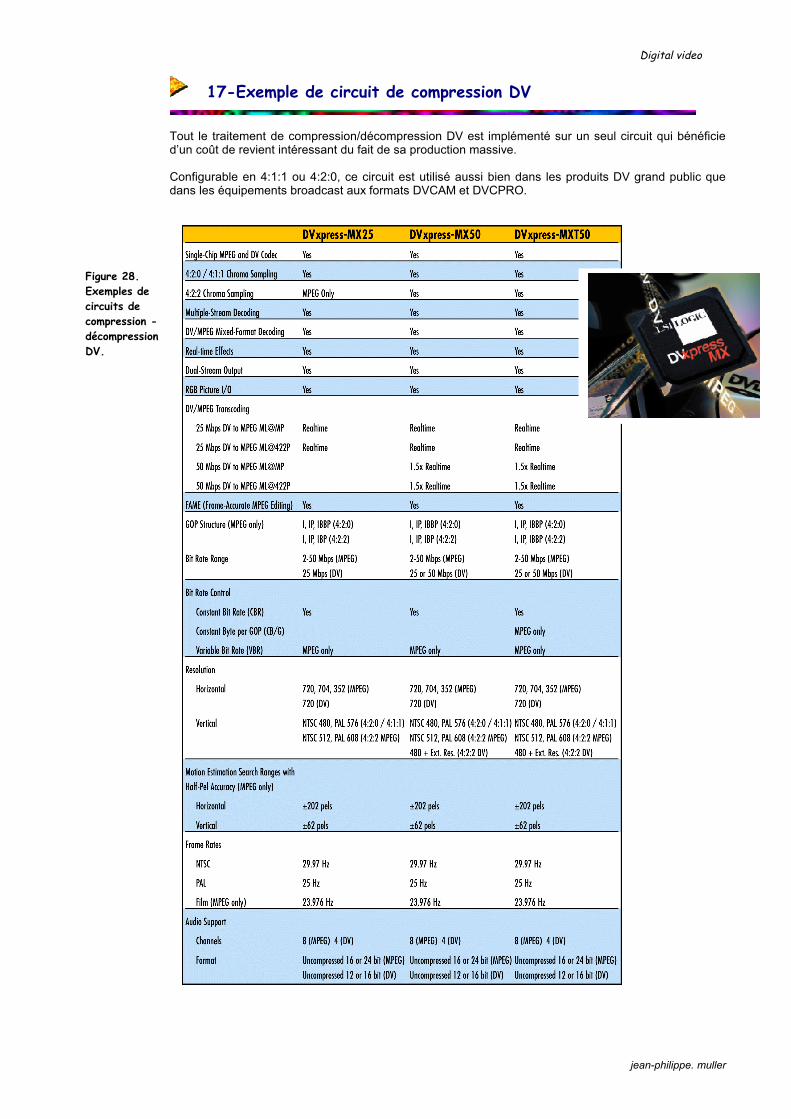
17-Exemple de circuit de compression DV
Tout le traitement de compression/décompression DV est implémenté sur un seul circuit qui bénéficie d’un coût de revient intéressant du fait de sa production massive. Configurable en 4:1:1 ou 4:2:0, ce circuit est utilisé aussi bien dans les produits DV grand public que dans les équipements broadcast aux formats DVCAM et DVCPRO.
Figure 28. Exemples de circuits de compression -décompression DV.
Digital video
jean-philippe. muller
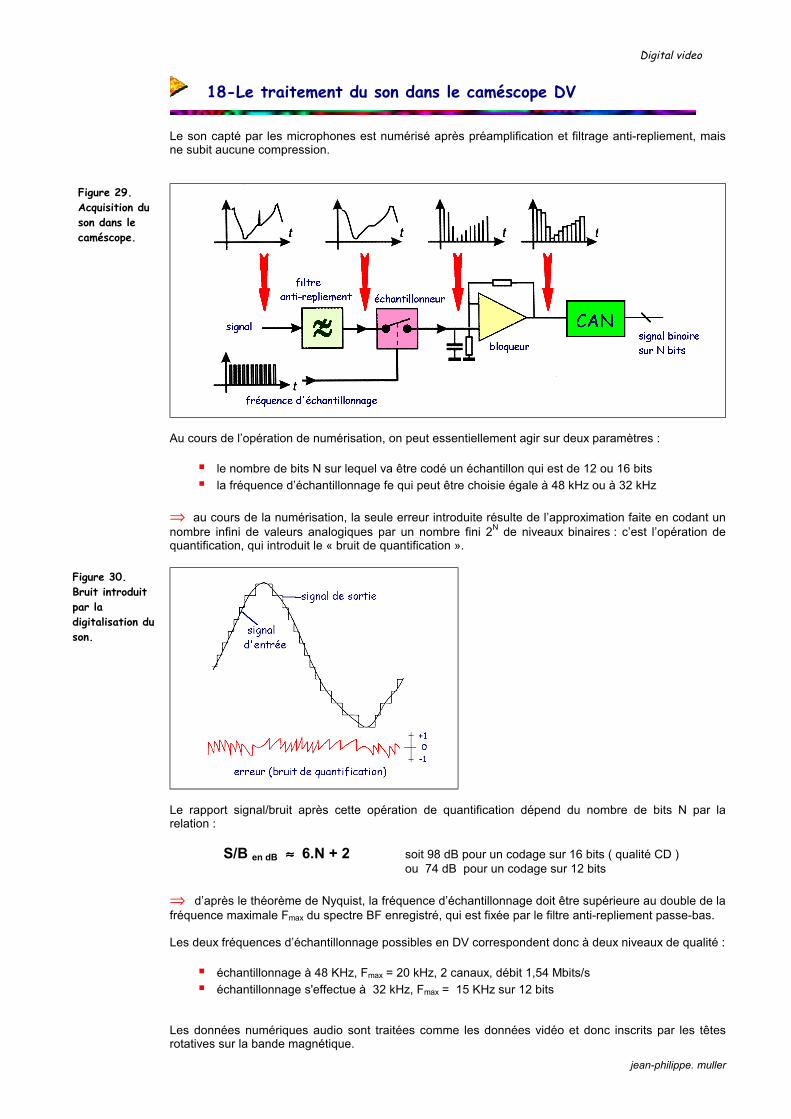
18-Le traitement du son dans le caméscope DV
Le son capté par les microphones est numérisé après préamplification et filtrage anti-repliement, mais ne subit aucune compression.
Au cours de l’opération de numérisation, on peut essentiellement agir sur deux paramètres :
le nombre de bits N sur lequel va être codé un échantillon qui est de 12 ou 16 bits la fréquence d’échantillonnage fe qui peut être choisie égale à 48 kHz ou à 32 kHz
⇒ au cours de la numérisation, la seule erreur introduite résulte de l’approximation faite en codant un nombre infini de valeurs analogiques par un nombre fini 2N de niveaux binaires : c’est l’opération de quantification, qui introduit le « bruit de quantification ».
Le rapport signal/bruit après cette opération de quantification dépend du nombre de bits N par la relation : S/B en dB ≈≈≈≈ 6.N + 2 soit 98 dB pour un codage sur 16 bits ( qualité CD ) ou 74 dB pour un codage sur 12 bits ⇒ d’après le théorème de Nyquist, la fréquence d’échantillonnage doit être supérieure au double de la fréquence maximale Fmax du spectre BF enregistré, qui est fixée par le filtre anti-repliement passe-bas. Les deux fréquences d’échantillonnage possibles en DV correspondent donc à deux niveaux de qualité :
échantillonnage à 48 KHz, Fmax = 20 kHz, 2 canaux, débit 1,54 Mbits/s échantillonnage s'effectue à 32 kHz, Fmax = 15 KHz sur 12 bits
Les données numériques audio sont traitées comme les données vidéo et donc inscrits par les têtes rotatives sur la bande magnétique.
Figure 29. Acquisition du son dans le caméscope.
Figure 30. Bruit introduit par la digitalisation du son.
Digital video
jean-philippe. muller
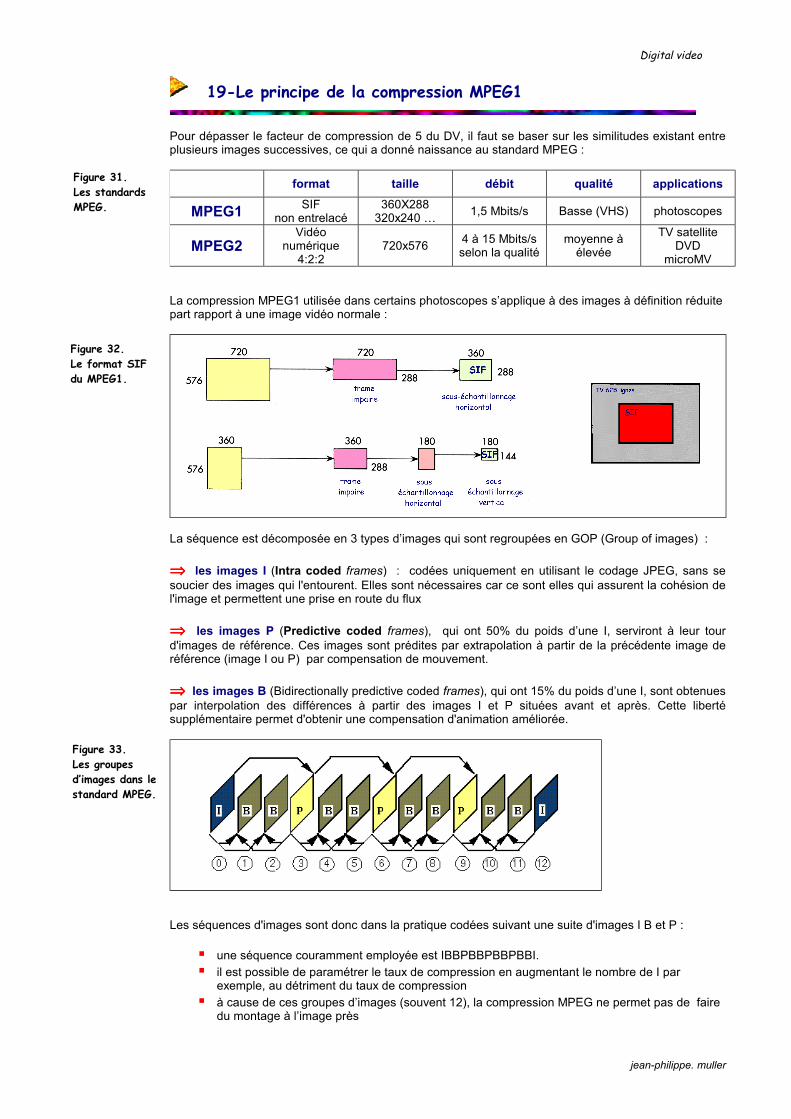
19-Le principe de la compression MPEG1
Pour dépasser le facteur de compression de 5 du DV, il faut se baser sur les similitudes existant entre plusieurs images successives, ce qui a donné naissance au standard MPEG :
format taille débit qualité applications
MPEG1 SIF non entrelacé
360X288 320x240 … 1,5 Mbits/s Basse (VHS) photoscopes
MPEG2 Vidéo
numérique 4:2:2
720x576 4 à 15 Mbits/s selon la qualité
moyenne à élevée
TV satellite DVD
microMV La compression MPEG1 utilisée dans certains photoscopes s’applique à des images à définition réduite part rapport à une image vidéo normale :
La séquence est décomposée en 3 types d’images qui sont regroupées en GOP (Group of images) : ⇒⇒⇒⇒ les images I (Intra coded frames) : codées uniquement en utilisant le codage JPEG, sans se soucier des images qui l'entourent. Elles sont nécessaires car ce sont elles qui assurent la cohésion de l'image et permettent une prise en route du flux ⇒⇒⇒⇒ les images P (Predictive coded frames), qui ont 50% du poids d’une I, serviront à leur tour d'images de référence. Ces images sont prédites par extrapolation à partir de la précédente image de référence (image I ou P) par compensation de mouvement. ⇒⇒⇒⇒ les images B (Bidirectionally predictive coded frames), qui ont 15% du poids d’une I, sont obtenues par interpolation des différences à partir des images I et P situées avant et après. Cette liberté supplémentaire permet d'obtenir une compensation d'animation améliorée.
Les séquences d'images sont donc dans la pratique codées suivant une suite d'images I B et P :
une séquence couramment employée est IBBPBBPBBPBBI. il est possible de paramétrer le taux de compression en augmentant le nombre de I par
exemple, au détriment du taux de compression à cause de ces groupes d’images (souvent 12), la compression MPEG ne permet pas de faire
du montage à l’image près
Figure 31. Les standards MPEG.
Figure 32. Le format SIF du MPEG1.
Figure 33. Les groupes d’images dans le standard MPEG.
Digital video
jean-philippe. muller
20-L’estimation du mouvement en MPEG
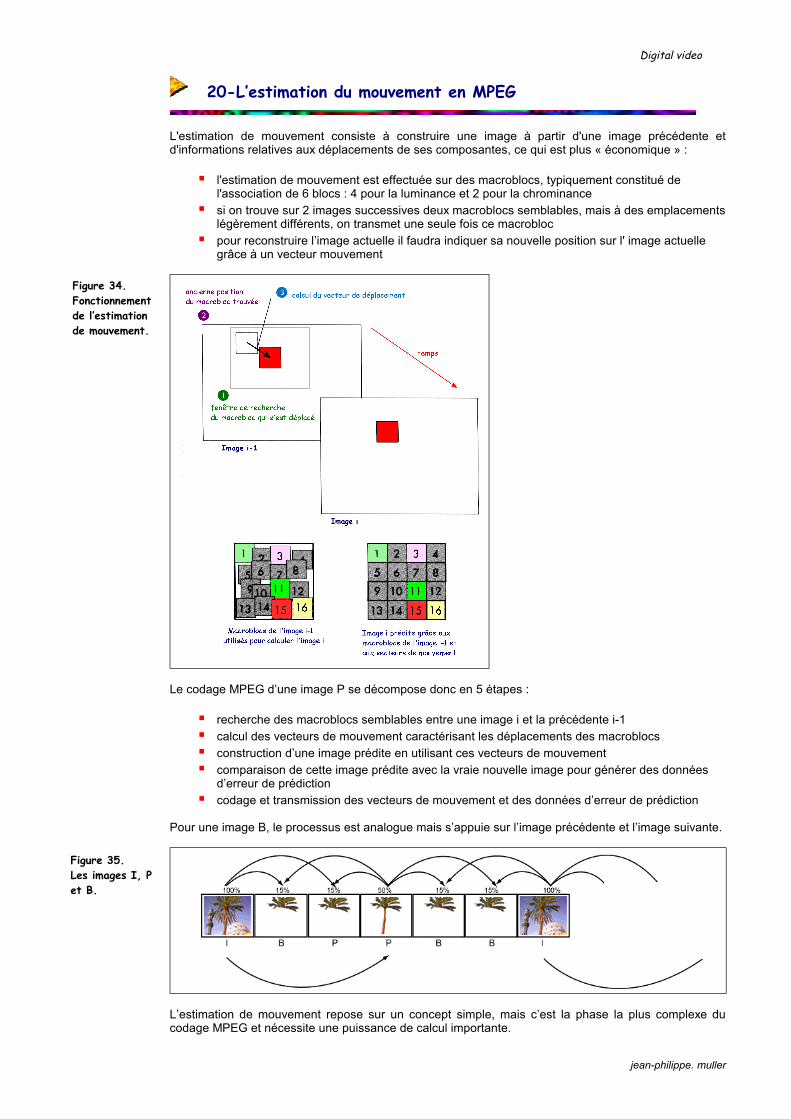
L'estimation de mouvement consiste à construire une image à partir d'une image précédente et d'informations relatives aux déplacements de ses composantes, ce qui est plus « économique » :
l'estimation de mouvement est effectuée sur des macroblocs, typiquement constitué de
l'association de 6 blocs : 4 pour la luminance et 2 pour la chrominance si on trouve sur 2 images successives deux macroblocs semblables, mais à des emplacements
légèrement différents, on transmet une seule fois ce macrobloc pour reconstruire l’image actuelle il faudra indiquer sa nouvelle position sur l' image actuelle
grâce à un vecteur mouvement
Le codage MPEG d’une image P se décompose donc en 5 étapes :
recherche des macroblocs semblables entre une image i et la précédente i-1 calcul des vecteurs de mouvement caractérisant les déplacements des macroblocs construction d’une image prédite en utilisant ces vecteurs de mouvement comparaison de cette image prédite avec la vraie nouvelle image pour générer des données
d’erreur de prédiction codage et transmission des vecteurs de mouvement et des données d’erreur de prédiction
Pour une image B, le processus est analogue mais s’appuie sur l’image précédente et l’image suivante.
L’estimation de mouvement repose sur un concept simple, mais c’est la phase la plus complexe du codage MPEG et nécessite une puissance de calcul importante.
Figure 34. Fonctionnement de l’estimation de mouvement.
Figure 35. Les images I, P et B.
Digital video
jean-philippe. muller
21-Structure du codec MPEG
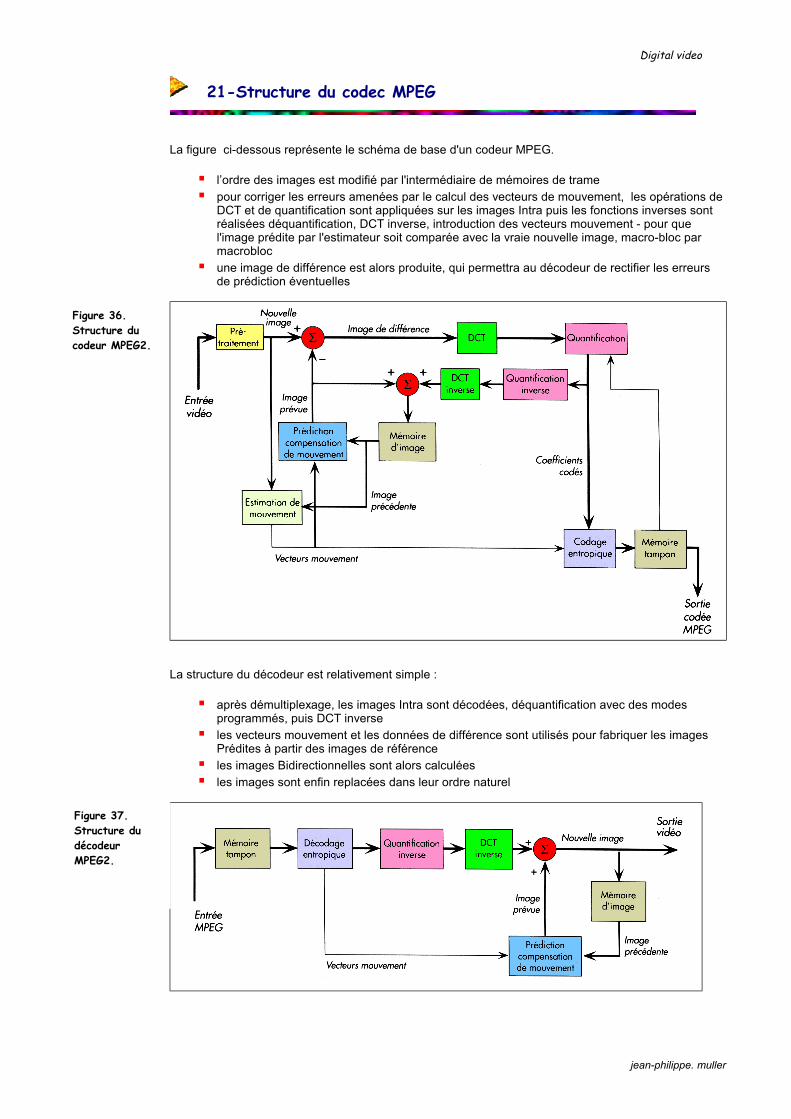
La figure ci-dessous représente le schéma de base d'un codeur MPEG.
l’ordre des images est modifié par l'intermédiaire de mémoires de trame pour corriger les erreurs amenées par le calcul des vecteurs de mouvement, les opérations de
DCT et de quantification sont appliquées sur les images Intra puis les fonctions inverses sont réalisées déquantification, DCT inverse, introduction des vecteurs mouvement - pour que l'image prédite par l'estimateur soit comparée avec la vraie nouvelle image, macro-bloc par macrobloc une image de différence est alors produite, qui permettra au décodeur de rectifier les erreurs
de prédiction éventuelles
La structure du décodeur est relativement simple :
après démultiplexage, les images Intra sont décodées, déquantification avec des modes programmés, puis DCT inverse les vecteurs mouvement et les données de différence sont utilisés pour fabriquer les images
Prédites à partir des images de référence les images Bidirectionnelles sont alors calculées les images sont enfin replacées dans leur ordre naturel
Figure 36. Structure du codeur MPEG2.
Figure 37. Structure du décodeur MPEG2.

Digital video
jean-philippe. muller
22-La compression MPEG2 du microMV
Si le principe de fonctionnement du MPEG2 est très voisin du MPEG, il apporte cependant un grand nombre d’améliorations parmi lesquelles :
il reconnaît des séquences entrelacées, il travaille avec des images au même format que le DV il permet un taux de compression supérieur au DV, au prix d’une légère perte de qualité la diminution de débit (12 Mbits/s au maximum, au lieu des 25 Mbits/s du DV) permet
l’utilisation d’un nouveau modèle de cassettes plus petit les séquences vidéos sont enregistrées sous forme de fichier, et peuvent être manipulés et
échangés facilement
Capteur CCD : 1/6 '' - 800.000 pixels 400.000 effectifs en mode camera Sensibilité : 7 Lux Objectif : Optique Carl Zeiss / filtre de 30mm Obturateur : Mode auto / 1/3 à 1/600 Time code / data code : Non / Oui Doublage son : Non Format image : MPEG2 Format son : Format MPEG1 audio layer 2 Entrée/sortie numérique i.LINK MPEG2
Sony a opté pour ce format MPEG2 pour les nouveaux caméscopes au format microMV :
les cassettes DV sont remplacées par les micro MV, trois fois plus petites. Un gain de place qui permet à Sony de proposer des caméscopes - le DCRIP-5 et le DCR IP-7 - encore plus compacts (47 x 103 x 80 mm) et légers (370 g avec batteries) que les caméscopes miniDV.
plus petites, les cassettes Micro MV ont logiquement une capacité moindre : elles ne stockent
que 6,5 Go, contre 12,2 pour le DV. Mais elles font appel au MPEG-2, qui a un taux de compression au moins deux fois plus élevé que le DV et qui permet d’obtenir des images au moins aussi bonnes.
grâce à MPEG2, le Memory Stick de 64 Mo peut stocker près de cinq minutes de vidéo depuis
le DCR-IP7.
Le Micro MV a un autre atout, car chaque séquence vidéo est enregistrée dans un fichier séparé. Inconvénient :
lorsqu’on se déplace d’une séquence à l’autre sur la bande Micro MV, il faut 0,8 seconde à la tête de lecture pour lire le fichier suivant.
Avantages :
les fichiers séparés permettent de créer des vignettes et d'accéder directement aux séquences directement depuis l’écran LCD en couleurs de 2,5 pouces qui équipe le caméscope.
au moment du transfert sur l’ordinateur, il est possible de travailler séquence par
séquence et fichier par fichier sans difficulté.
Figure 38. Caméscope au standard microMV.
Digital video
jean-philippe. muller
23-Les bases de la compression audio MPEG2
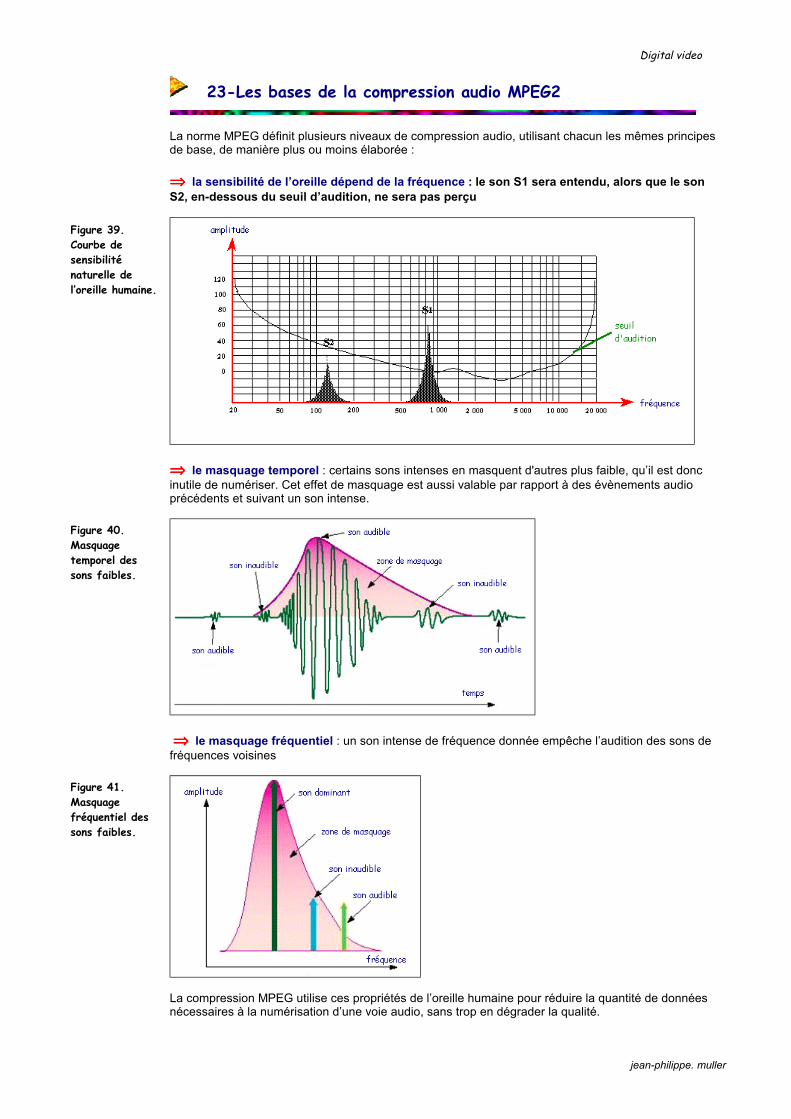
La norme MPEG définit plusieurs niveaux de compression audio, utilisant chacun les mêmes principes de base, de manière plus ou moins élaborée : ⇒⇒⇒⇒ la sensibilité de l’oreille dépend de la fréquence : le son S1 sera entendu, alors que le son S2, en-dessous du seuil d’audition, ne sera pas perçu
⇒⇒⇒⇒ le masquage temporel : certains sons intenses en masquent d'autres plus faible, qu’il est donc inutile de numériser. Cet effet de masquage est aussi valable par rapport à des évènements audio précédents et suivant un son intense.
⇒⇒⇒⇒ le masquage fréquentiel : un son intense de fréquence donnée empêche l’audition des sons de fréquences voisines
La compression MPEG utilise ces propriétés de l’oreille humaine pour réduire la quantité de données nécessaires à la numérisation d’une voie audio, sans trop en dégrader la qualité.
Figure 39. Courbe de sensibilité naturelle de l’oreille humaine.
Figure 40. Masquage temporel des sons faibles.
Figure 41. Masquage fréquentiel des sons faibles.
Digital video
jean-philippe. muller
24-Le dispositif de compression audio MPEG2
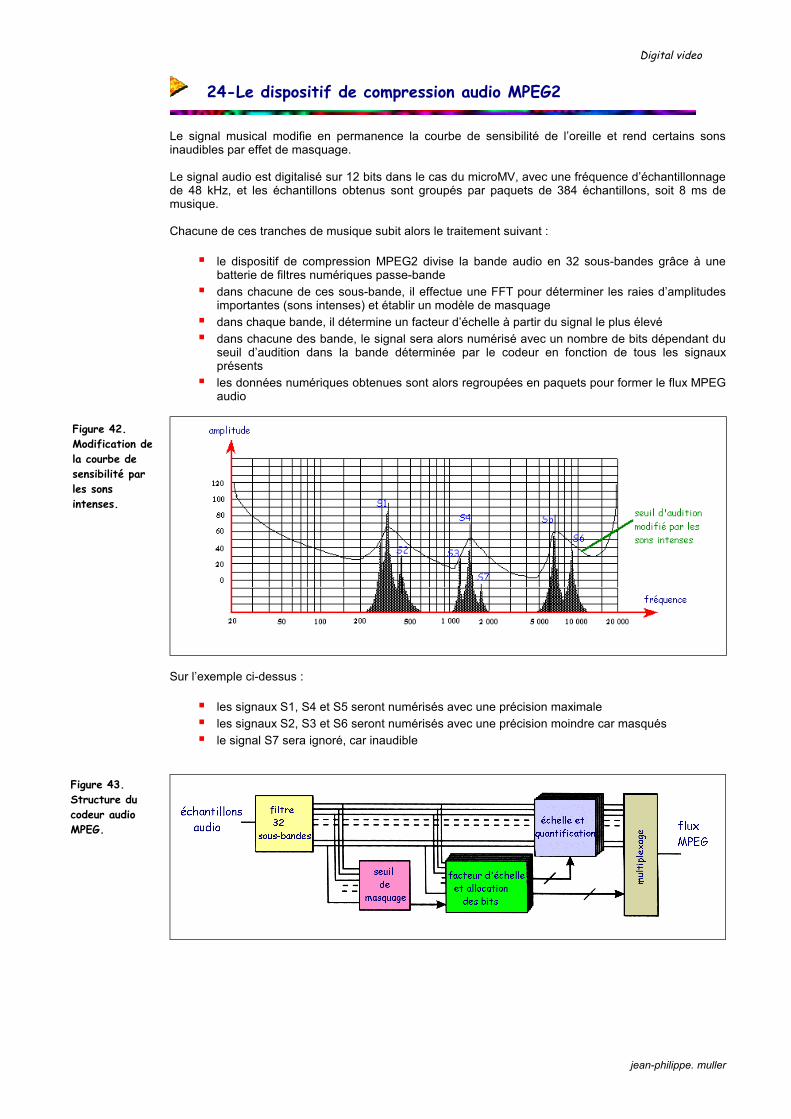
Le signal musical modifie en permanence la courbe de sensibilité de l’oreille et rend certains sons inaudibles par effet de masquage. Le signal audio est digitalisé sur 12 bits dans le cas du microMV, avec une fréquence d’échantillonnage de 48 kHz, et les échantillons obtenus sont groupés par paquets de 384 échantillons, soit 8 ms de musique. Chacune de ces tranches de musique subit alors le traitement suivant :
le dispositif de compression MPEG2 divise la bande audio en 32 sous-bandes grâce à une batterie de filtres numériques passe-bande dans chacune de ces sous-bande, il effectue une FFT pour déterminer les raies d’amplitudes
importantes (sons intenses) et établir un modèle de masquage dans chaque bande, il détermine un facteur d’échelle à partir du signal le plus élevé dans chacune des bande, le signal sera alors numérisé avec un nombre de bits dépendant du
seuil d’audition dans la bande déterminée par le codeur en fonction de tous les signaux présents les données numériques obtenues sont alors regroupées en paquets pour former le flux MPEG
audio
Sur l’exemple ci-dessus :
les signaux S1, S4 et S5 seront numérisés avec une précision maximale les signaux S2, S3 et S6 seront numérisés avec une précision moindre car masqués le signal S7 sera ignoré, car inaudible
Figure 42. Modification de la courbe de sensibilité par les sons intenses.
Figure 43. Structure du codeur audio MPEG.

jean-philippe muller
Version 05/2002
Image numérique : l’enregistrement de l’image

Digital video
jean-philippe. muller
Sommaire ⇒⇒⇒⇒ sur barrette mémoire Memorystick
1. Les dispositifs de stockage de l’image numérique 2. Le stockage des images sur carte mémoire 3. Le principe de la mémoire « Flash » 4. La structure du Memorystick 5. Le brochage et les caractéristiques 6. L’échange des données avec l’hôte 7. Les évolutions du Mémorystick
⇒⇒⇒⇒ sur bande magnétique 8. L’enregistrement de la vidéo sur bande 9. Le support de l’enregistrement au format DV 10. La segmentation des images 11. Les spécificités du format Digital8 12. La courbe de réponse du système d’enregistrement 13. Le codage des données à enregistrer 14. Le spectre du signal enregistré 15. L’utilisation de l’azimut des têtes 16. Schéma fonctionnel du caméscope numérique 17. Le format microMV
⇒⇒⇒⇒ sur disque réinscriptible
18. L’enregistrement sur CDRW 19. La diode laser 20. L’enregistrement des données 21. La lecture des données 22. Le bloc optique 23. L’asservissement de focalisation 24. L’asservissement de suivi de piste

Digital video
jean-philippe. muller
1-Les dispositifs de stockage de l’image numérique
Ce récapitulatif couvre les systèmes de stockage les plus communs pour les appareils numériques.
Disquette (utilisé dans les Mavica) Positifs: le système le plus simple, accessible à la plupart des ordinateurs, facile à distribuer, coût très bas Négatifs: petite capacité qui ne permet de stocker que des petites images ou des photos très comprimées, demande un appareil de grosse taille, plus lent que la majorité des autres systèmes.
Mini CD-Recordable ( dans le MVC-CD300 de Sony) Positifs: facile d'utilisation, disques de 3 1/8 de pouce, plus petits que les CD standards, capacité de 156 Mo, peut être lu par tout ordinateur équipé d'un CD-ROM sans avoir besoin d'un adaptateur spécial, stockage à long terme, coût très faible Négatifs: plus lent que les cartes mémoire.
Microdrive Positifs: utilise le format CompactFlash Type II, capacité élevée de 340 Mo à 1 Go, coût moyen Négatifs: plus fragile que les cartes mémoire, l'enregistrement ralentit au fur et à mesure que le disque se remplit, consomme plus d'électricité.
CompactFlash Type I et II Positifs: très utilisé dans les appareils numériques, petit et très solide, capacité jusqu'à 512Mo Négatifs: demande un ordinateur équipé USB ou un lecteur de carte USB pour être efficace.
SmartMedia Positifs: petit et très mince, très utilisé dans les appareils numériques, capacité allant jusqu'à 128 Mo. Négatifs: un peu plus fragile que d'autres formats de carte mémoire, demande un ordinateur équipé USB ou un lecteur de carte USB pour être efficace.
Memorystick Positifs: petit, utilisable avec une variété de produits, capacité allant jusqu'à 128 Mo. Négatifs: utilisé par peu de fabricants autres que Sony

Digital video
jean-philippe. muller
2-Le stockage des images sur carte mémoire
L'utilisation du numérique dans les domaines du son, de l'image et de la vidéo génère une énorme quantité de données : ⇒⇒⇒⇒ le stockage de ces données nécessite des volumes de stockage et de temps d’accès et de transfert de l’information bien supérieurs à ce que les disquettes de 3.5 pouces peuvent permettre.
⇒⇒⇒⇒ la tendance générale en électronique est à la suppression des éléments mécaniques à cause de leur coût de fabrication ainsi que leur sensibilité aux chocs et vibrations
Ces besoins de stockage ont été à l’origine de différents modèles de cartes mémoires ( CompactFlash, SmartMedia …) offrant des capacités de plus en plus élevée et allant actuellement jusqu’à 512 Moctets. Proposé par Sony et adopté maintenant par d’autres constructeurs, la carte mémoire Mémorystick est utilisée dans les photoscopes et les caméscopes, mais aussi dans un grand nombre de produits comme les ordinateurs portables, les assistants personnels, les lecteurs MP3 et les téléphones cellulaires.
Le nombre d’images qui peuvent être stockées sur un Memorystick dépend évidemment de sa capacité, mais aussi de la taille de l’image et du format d’enregistrement RAW, TIFF ou JPEG.
Carte 16MB Carte 32MB Carte 64MB Type du capteur
TIFF JPEG 1:10 TIFF JPEG 1:10 TIFF JPEG 1:10
1 Mégapixel 5 53 10 106 21 213
3 Mégapixel 1 17 3 35 7 71 Tous les PC n’étant pas équipés de lecteurs Memorystick, il a fallu développer un certain nombre d’interfaces pour pouvoir transférer les images de la carte mémoire vers le PC.
Adaptateur disquette Lecteur souris Lecteur USB
Figure 1. Le Memorystick 16 Mo de Sony.
Figure 2. Les interfaces pour Memorystick.

Digital video
jean-philippe. muller
3-Le principe de la mémoire « Flash »
Les constructeurs de matériel informatique disposaient déjà depuis longtemps de la RAM, moyen de stockage de l'information à la fois électronique et réinscriptible à l'infini, mais ne conservant les données que lorsqu’elle est alimentée. A la charnière des années 80-90, plusieurs fabricants d'électronique parmi les plus importants (Intel, Texas Instruments, Fujitsu) se sont penchés sur ce problème et ont mis au point la technologie de la mémoire flash :
ce type de mémoire comporte les avantages cumulés d'être purement électronique, réinscriptible à l'infini et non-volatile. elle peut être utilisée par exemple au sein des unités centrales d'ordinateur notamment au
niveau du BIOS rendant ce dernier facilement programmable elle s'est surtout rapidement imposée, sous la forme de cartes mémoire amovibles, comme le
support privilégié de stockage de l'information pour de nombreux appareils numériques dont les appareils photo numérique et les caméscopes
La mémoire Flash est basée sur un type de circuit électronique comportant un transistor MOS pour chacune de ces cellules :
ce transistor est composé d’une grille métallique et d’un canal semi-conducteur en l’absence de charges sur la grille, il se crée à l’équilibre une zone isolante qui limite le
passage des électrons dans le circuit principal. lorsque des électrons supplémentaires sont acheminés à la grille, le volume de la zone isolante
augmente jusqu’à totalement bloquer le passage des électrons dans le circuit principal. pour l’écriture, il suffit de charger ou décharger la grille pour la lecture, il faut polariser le canal et l’existence ou l’absence de courant indique l’état de
la grille et donc la donnée « 1 » ou « 0 » stockée dans la cellule Le terme de flash provient ainsi des capacités très rapides d'écriture et d'effacement des données pouvant aller jusqu’à 1.5 Mo/s.
Figure 3. Principe de la cellule de mémoire Flash.
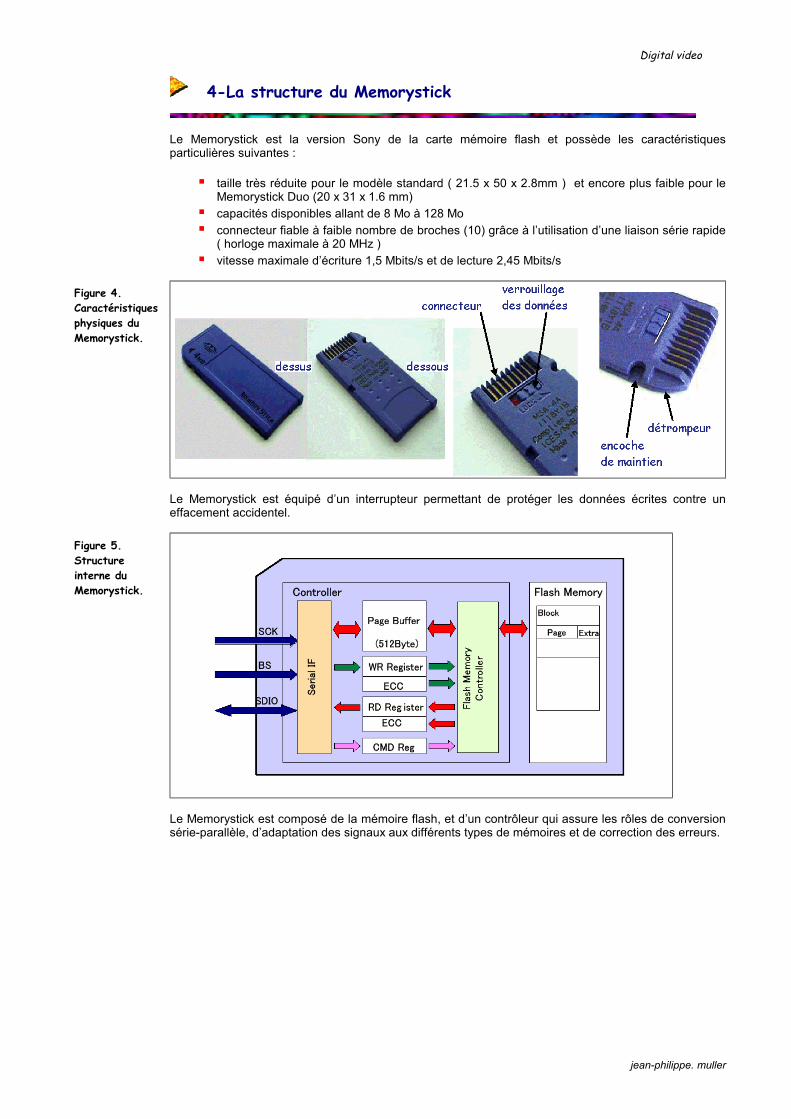
Digital video
jean-philippe. muller
4-La structure du Memorystick
Le Memorystick est la version Sony de la carte mémoire flash et possède les caractéristiques particulières suivantes :
taille très réduite pour le modèle standard ( 21.5 x 50 x 2.8mm ) et encore plus faible pour le Memorystick Duo (20 x 31 x 1.6 mm) capacités disponibles allant de 8 Mo à 128 Mo connecteur fiable à faible nombre de broches (10) grâce à l’utilisation d’une liaison série rapide
( horloge maximale à 20 MHz ) vitesse maximale d’écriture 1,5 Mbits/s et de lecture 2,45 Mbits/s
Le Memorystick est équipé d’un interrupteur permettant de protéger les données écrites contre un effacement accidentel.
Le Memorystick est composé de la mémoire flash, et d’un contrôleur qui assure les rôles de conversion série-parallèle, d’adaptation des signaux aux différents types de mémoires et de correction des erreurs.
Figure 4. Caractéristiques physiques du Memorystick.
Figure 5. Structure interne du Memorystick.
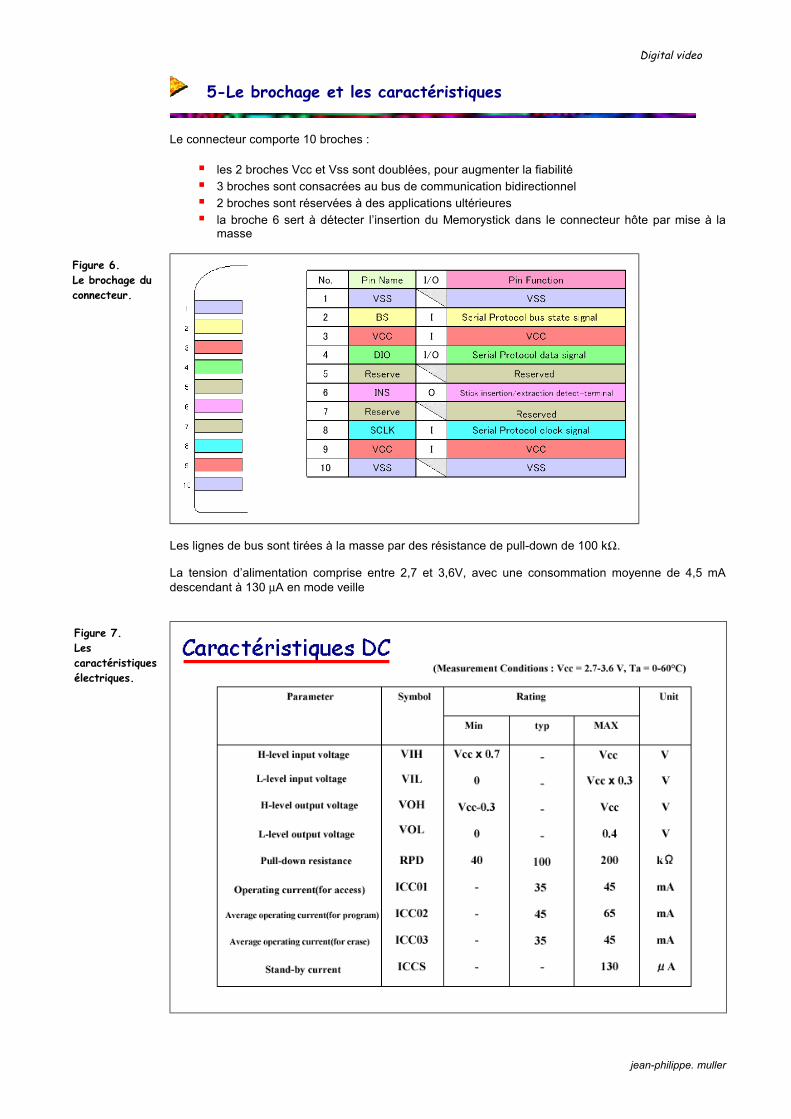
Digital video
jean-philippe. muller
5-Le brochage et les caractéristiques
Le connecteur comporte 10 broches :
les 2 broches Vcc et Vss sont doublées, pour augmenter la fiabilité 3 broches sont consacrées au bus de communication bidirectionnel 2 broches sont réservées à des applications ultérieures la broche 6 sert à détecter l’insertion du Memorystick dans le connecteur hôte par mise à la
masse
Les lignes de bus sont tirées à la masse par des résistance de pull-down de 100 kΩ. La tension d’alimentation comprise entre 2,7 et 3,6V, avec une consommation moyenne de 4,5 mA descendant à 130 µA en mode veille
Figure 6. Le brochage du connecteur.
Figure 7. Les caractéristiques électriques.
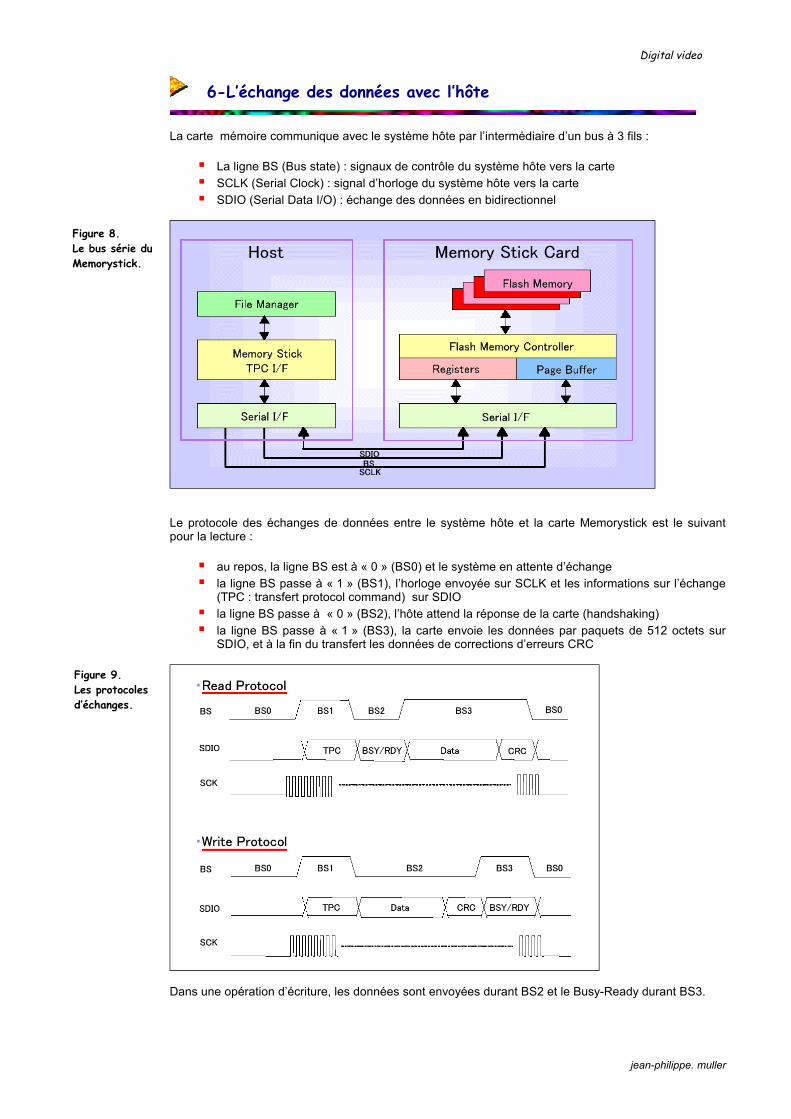
Digital video
jean-philippe. muller
6-L’échange des données avec l’hôte
La carte mémoire communique avec le système hôte par l’intermédiaire d’un bus à 3 fils :
La ligne BS (Bus state) : signaux de contrôle du système hôte vers la carte SCLK (Serial Clock) : signal d’horloge du système hôte vers la carte SDIO (Serial Data I/O) : échange des données en bidirectionnel
Le protocole des échanges de données entre le système hôte et la carte Memorystick est le suivant pour la lecture :
au repos, la ligne BS est à « 0 » (BS0) et le système en attente d’échange la ligne BS passe à « 1 » (BS1), l’horloge envoyée sur SCLK et les informations sur l’échange
(TPC : transfert protocol command) sur SDIO la ligne BS passe à « 0 » (BS2), l’hôte attend la réponse de la carte (handshaking) la ligne BS passe à « 1 » (BS3), la carte envoie les données par paquets de 512 octets sur
SDIO, et à la fin du transfert les données de corrections d’erreurs CRC
Dans une opération d’écriture, les données sont envoyées durant BS2 et le Busy-Ready durant BS3.
Figure 8. Le bus série du Memorystick.
Figure 9. Les protocoles d’échanges.

Digital video
jean-philippe. muller
7-Les évolutions de la Memorystick
De nombreuses évolutions de ces modules mémoire sont envisagées, pour des applications qui vont au-delà de la fonction de mémorisation.
Le Mémorystick Duo 20 x 31 x 1.6 mm C’est une version de taille réduite destinée à des applications nécessitant un très faible encombrement
L'Infostick 4 g pour des dimensions de 21.5 × 55 × 2.8mm Ce module Memorystick est un module Bluetooth et permet une liaison sans fil Rend possible l'accès à Internet pour un appareil photo ou un caméscope, établit ses connexions dans un rayon de 10 mètres et assure un débit de 1 Mbits/s.
Modules de localisation GPS Module appareil photo numérique Module d'identification d'empreintes digitales Sony prévoit d' autres applications de type récepteur TV, récepteur FM …
Figure 10. Quelques évolutions des cartes mémoires Sony.
Figure 11. Insertion du Memorystick dans le photoscope.
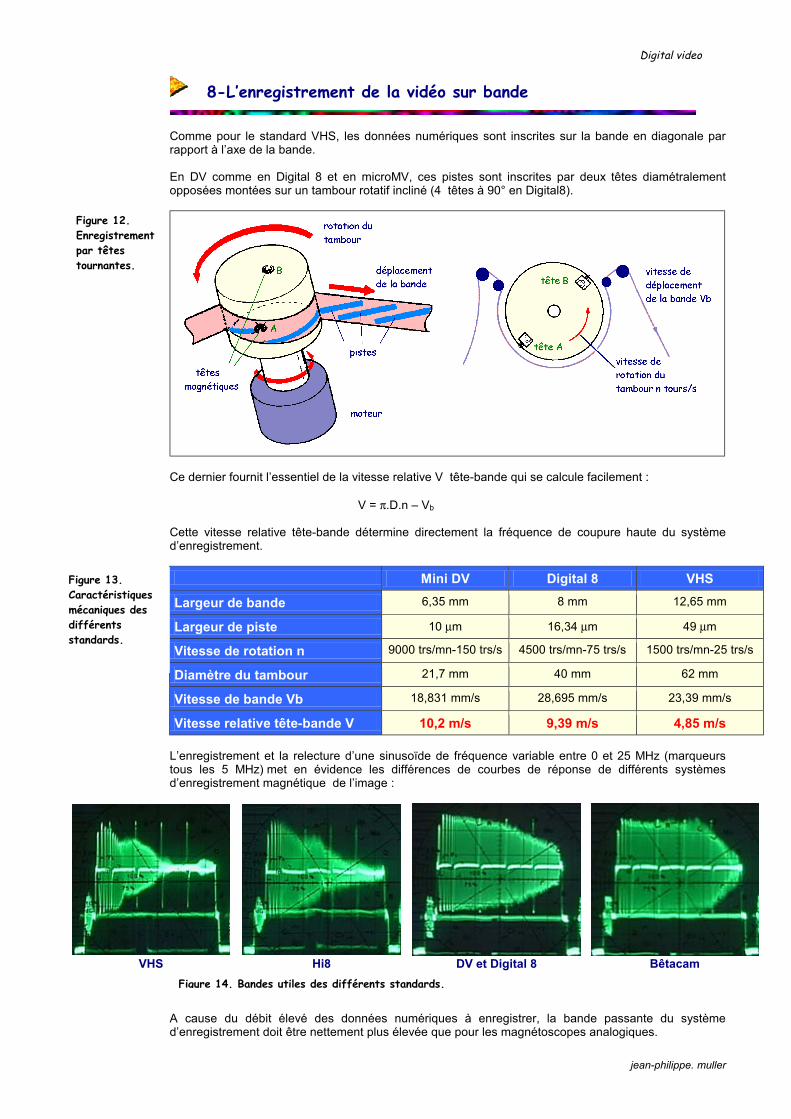
Digital video
8-L’enregistrement de la vidéo sur bande
Comme pour le standard VHS, les données numériques sont inscrites sur la bande en diagonale par rapport à l’axe de la bande. En DV comme en Digital 8 et en microMV, ces pistes sont inscrites par deux têtes diamétralement opposées montées sur un tambour rotatif incliné (4 têtes à 90° en Digital8).
Ce dernier fournit l’essentiel de la vitesse relative V tête-bande qui se calcule facilement :
V = π.D.n – Vb Cette vitesse relative tête-bande détermine directement la fréquence de coupure haute du système d’enregistrement. Mini DV Digital 8 VHS
Largeur de bande 6,35 mm 8 mm 12,65 mm
Largeur de piste 10 µm 16,34 µm 49 µm
Vitesse de rotation n 9000 trs/mn-150 trs/s 4500 trs/mn-75 trs/s 1500 trs/mn-25 trs/s
Diamètre du tambour 21,7 mm 40 mm 62 mm
Vitesse de bande Vb 18,831 mm/s 28,695 mm/s 23,39 mm/s
Vitesse relative tête-bande V 10,2 m/s 9,39 m/s 4,85 m/s L’enregistrement et la relecture d’une sinusoïde de fréquence variable entre 0 et 25 MHz (marqueurs tous les 5 MHz) met en évidence les différences de courbes de réponse de différents systèmes d’enregistrement magnétique de l’image :
VHS Hi8 DV et Digital 8 Bêtacam
Ad
Figure 12. Enregistrement par têtes tournantes.
Figure 13. Caractéristiques mécaniques des différents standards.
.
Figure 14. Bandes utiles des différents standardsjean-philippe. muller
cause du débit élevé des données numériques à enregistrer, la bande passante du système ’enregistrement doit être nettement plus élevée que pour les magnétoscopes analogiques.
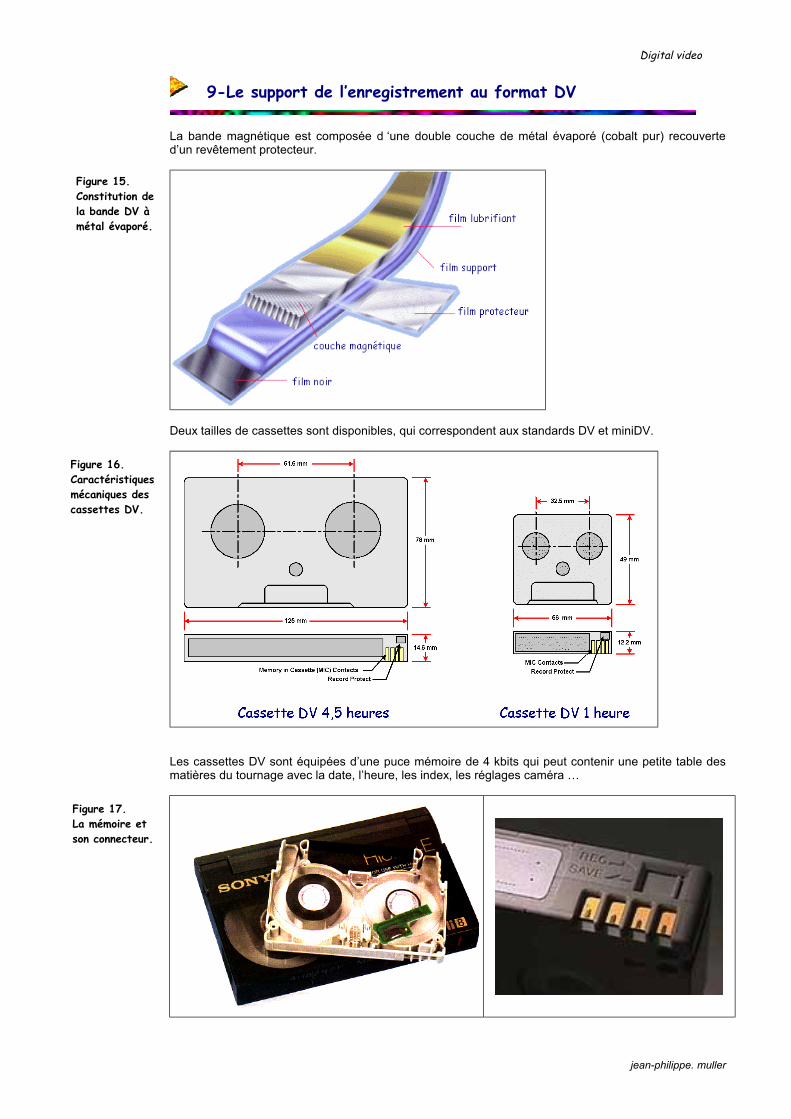
Digital video
jean-philippe. muller
9-Le support de l’enregistrement au format DV
La bande magnétique est composée d ‘une double couche de métal évaporé (cobalt pur) recouverte d’un revêtement protecteur.
Deux tailles de cassettes sont disponibles, qui correspondent aux standards DV et miniDV.
Les cassettes DV sont équipées d’une puce mémoire de 4 kbits qui peut contenir une petite table des matières du tournage avec la date, l’heure, les index, les réglages caméra …
Figure 15. Constitution de la bande DV à métal évaporé.
Figure 16. Caractéristiques mécaniques des cassettes DV.
Figure 17. La mémoire et son connecteur.

Digital video
jean-philippe. muller
10-La segmentation des images
Sur la bande de largeur 6,35 mm, les données sont enregistrées comme en VHS par des têtes placées sur un tambour de diamètre D = 2,17 cm tournant à 9000 tours/minute, soit n = 150 tours/seconde :
la bande défile à une vitesse faible de Vb = 1,88 cm/s les pistes sont longues d'environ 33 mm et inclinées de 9° par rapport à l'axe de la bande chaque piste est divisée en 4 secteurs contenant, dans l'ordre, les données pilotes de suivi de
piste ITI (Insert and Tracking Information), l'audio, la vidéo, et le time code un intervalle de garde sépare tous les secteurs afin de faciliter l'insert audio/vidéo et de
s'accommoder des erreurs de timing durant les opérations de montage
Comme pour tous les formats vidéo numériques et contrairement au VHS, le DV fait appel au processus de segmentation, qui consiste à découper une image en plusieurs segments et à enregistrer chaque segment sur une piste :
une image est découpée en 10 segments dans les systèmes à 525 lignes (elle s'étale donc sur 10 pistes) et en 12 segments dans les systèmes à 625 lignes (répartition sur 12 pistes) dans les deux cas, 300 pistes sont inscrites en une seconde (10 pistes x 30 i/s en 525 lignes,
et 12 pistes x 25 i/s en 625 lignes)
Figure 18. Format d’enregistrement DV.
Figure 19. Segmentation d’une image.

Digital video
jean-philippe. muller
11-Les spécificités du format Digital8
Lancé en I999 par Sony, le DigitaI8 est un format grand public qui établit une passerelle entre le DV et le 8mm/Hi8. Le Digital8 reprend Ies spécifications du DV en termes de traitement vidéo et audio numérique, mais utilise comme support d'enregistrement une cassette Hi8 classique, avec comme atouts :
un coût réduit comparé à celui du DV au niveau de la partie mécanique sa compatibilité en lecture avec le parc de cassettes analogiques accumulées depuis I985
(8mm) et 1989 (Hi8) Côté mécanique, les deux modes de fonctionnement Digital8 et Hi-8 sont prévus :
le tambour, de diamètre 40 mm (comme en 8mm), porte deux têtes diamétralement opposées pour la lecture analogique et quatre têtes à 90° pour l'enregistrement/lecture numérique en mode analogique, le tambour effectue 1500 tr/min en mode numérique, il tourne trois fois plus rapidement, à 4 500 tr/min
Le Digital8 code les données identiquement au DV' avec une segmentation de l'image sur 12 pistes, mais profite de la largeur supérieure de la bande Hi8 (8mm contre 6,35 en DV) pour inscrire les pistes numériques. deux par deux, dans le prolongement l'une de l'autre. Deux fonctions offertes par le DV ne sont pas assurées par les équipements Digital8 :
le doublage son sur la deuxième voie audio 12bits/32 kHz la mémoire sur le boîtier de la cassette DV, facilitant la gestion des séquences vidéo et des
photos
Figure 20. Le format d’enregistrement D8.
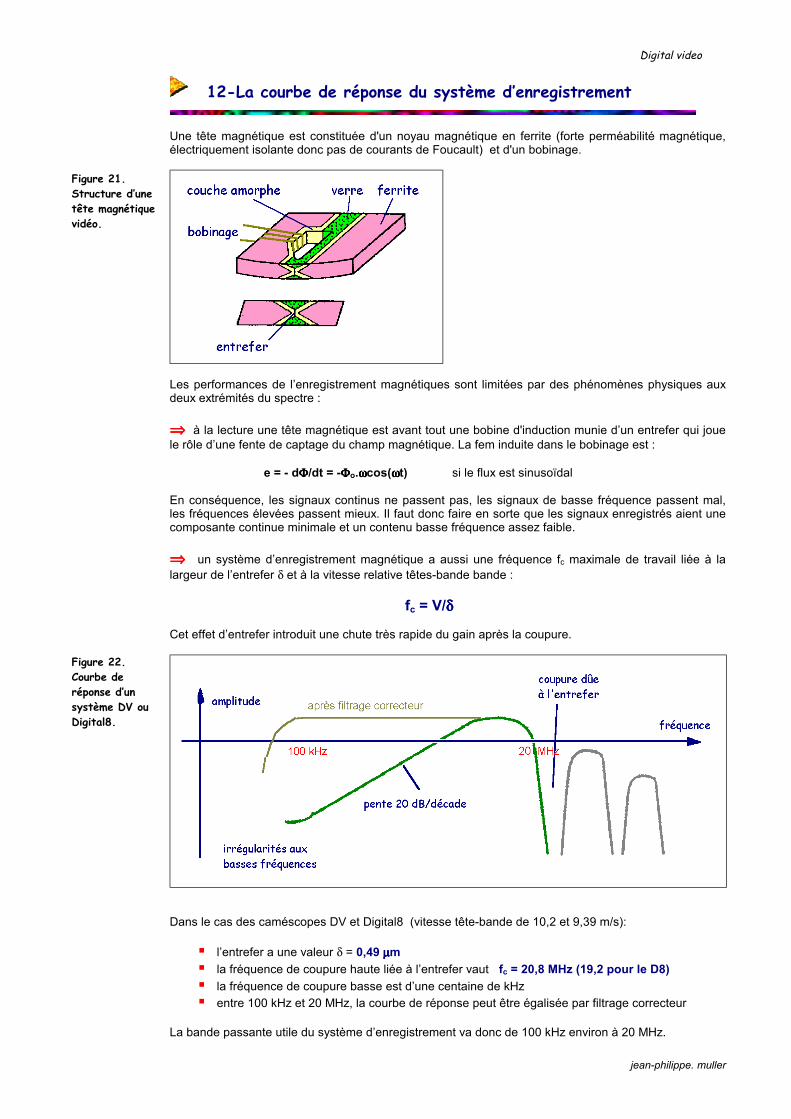
Digital video
jean-philippe. muller
12-La courbe de réponse du système d’enregistrement
Une tête magnétique est constituée d'un noyau magnétique en ferrite (forte perméabilité magnétique, électriquement isolante donc pas de courants de Foucault) et d'un bobinage.
Les performances de l’enregistrement magnétiques sont limitées par des phénomènes physiques aux deux extrémités du spectre : ⇒⇒⇒⇒ à la lecture une tête magnétique est avant tout une bobine d'induction munie d’un entrefer qui joue le rôle d’une fente de captage du champ magnétique. La fem induite dans le bobinage est :
e = - dΦΦΦΦ/dt = -ΦΦΦΦo.ωωωωcos(ωωωωt) si le flux est sinusoïdal En conséquence, les signaux continus ne passent pas, les signaux de basse fréquence passent mal, les fréquences élevées passent mieux. Il faut donc faire en sorte que les signaux enregistrés aient une composante continue minimale et un contenu basse fréquence assez faible. ⇒⇒⇒⇒ un système d’enregistrement magnétique a aussi une fréquence fc maximale de travail liée à la largeur de l’entrefer δ et à la vitesse relative têtes-bande bande : fc = V/δδδδ Cet effet d’entrefer introduit une chute très rapide du gain après la coupure.
Dans le cas des caméscopes DV et Digital8 (vitesse tête-bande de 10,2 et 9,39 m/s):
l’entrefer a une valeur δ = 0,49 µµµµm la fréquence de coupure haute liée à l’entrefer vaut fc = 20,8 MHz (19,2 pour le D8) la fréquence de coupure basse est d’une centaine de kHz entre 100 kHz et 20 MHz, la courbe de réponse peut être égalisée par filtrage correcteur
La bande passante utile du système d’enregistrement va donc de 100 kHz environ à 20 MHz.
Figure 21. Structure d’une tête magnétique vidéo.
Figure 22. Courbe de réponse d’un système DV ou Digital8.
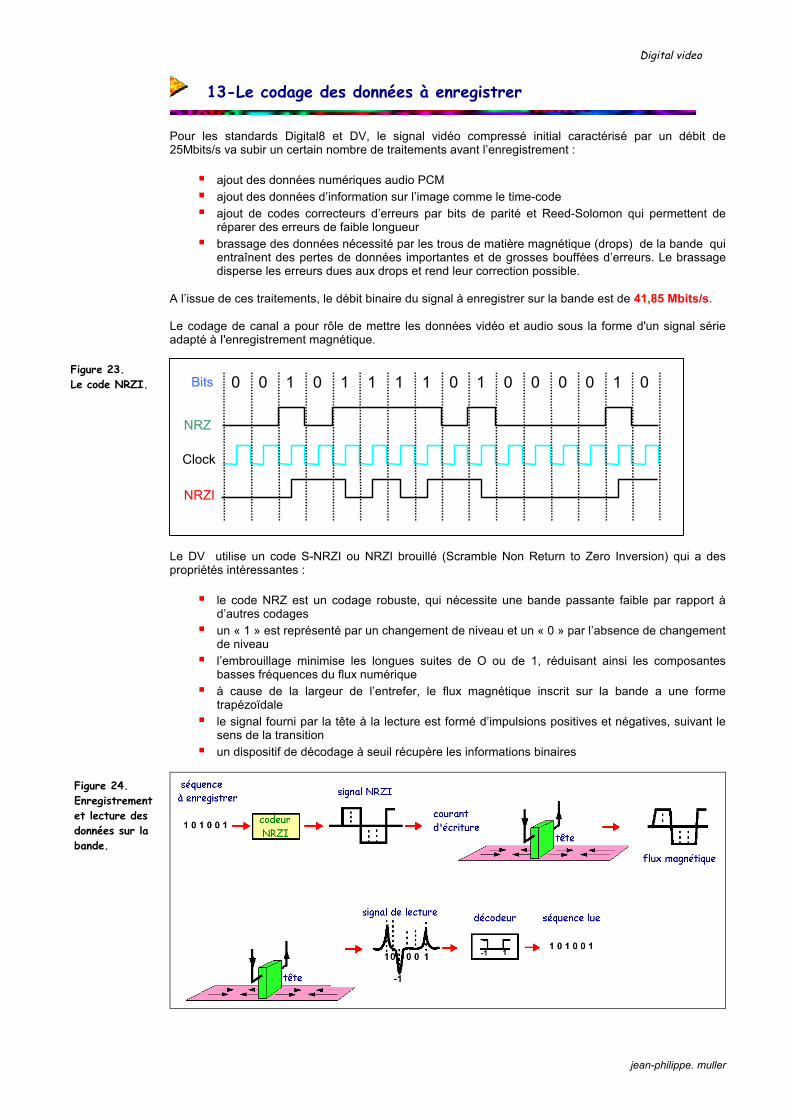
Digital video
jean-philippe. muller
13-Le codage des données à enregistrer
Pour les standards Digital8 et DV, le signal vidéo compressé initial caractérisé par un débit de 25Mbits/s va subir un certain nombre de traitements avant l’enregistrement :
ajout des données numériques audio PCM ajout des données d’information sur l’image comme le time-code ajout de codes correcteurs d’erreurs par bits de parité et Reed-Solomon qui permettent de
réparer des erreurs de faible longueur brassage des données nécessité par les trous de matière magnétique (drops) de la bande qui
entraînent des pertes de données importantes et de grosses bouffées d’erreurs. Le brassage disperse les erreurs dues aux drops et rend leur correction possible.
A l’issue de ces traitements, le débit binaire du signal à enregistrer sur la bande est de 41,85 Mbits/s. Le codage de canal a pour rôle de mettre les données vidéo et audio sous la forme d'un signal série adapté à I'enregistrement magnétique. Le DV utilise un code S-NRZI ou NRZI brouillé (Scramble Non Return to Zero Inversion) qui a des propriétés intéressantes :
le code NRZ est un codage robuste, qui nécessite une bande passante faible par rapport à d’autres codages un « 1 » est représenté par un changement de niveau et un « 0 » par l’absence de changement
de niveau l’embrouillage minimise les longues suites de O ou de 1, réduisant ainsi les composantes
basses fréquences du flux numérique à cause de la largeur de l’entrefer, le flux magnétique inscrit sur la bande a une forme
trapézoïdale le signal fourni par la tête à la lecture est formé d’impulsions positives et négatives, suivant le
sens de la transition un dispositif de décodage à seuil récupère les informations binaires
Bits
NRZ
Clock
NRZI
0 0 1 0 1 1 1 1 0 1 0 0 0 0 1 0 Figure 23. Le code NRZI.
Figure 24. Enregistrement et lecture des données sur la bande.
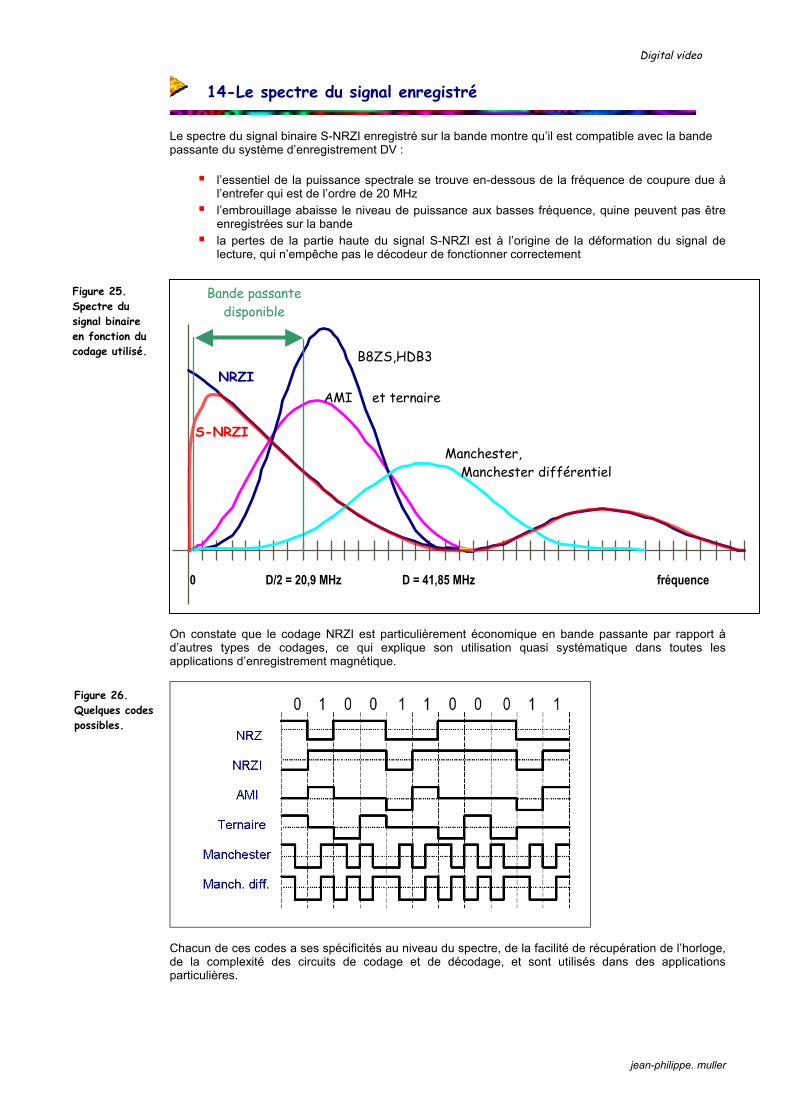
Digital video
jean-philippe. muller
14-Le spectre du signal enregistré
Le spectre du signal binaire S-NRZI enregistré sur la bande montre qu’il est compatible avec la bande passante du système d’enregistrement DV :
l’essentiel de la puissance spectrale se trouve en-dessous de la fréquence de coupure due à l’entrefer qui est de l’ordre de 20 MHz l’embrouillage abaisse le niveau de puissance aux basses fréquence, quine peuvent pas être
enregistrées sur la bande la pertes de la partie haute du signal S-NRZI est à l’origine de la déformation du signal de
lecture, qui n’empêche pas le décodeur de fonctionner correctement On constate que le codage NRZI est particulièrement économique en bande passante par rapport à d’autres types de codages, ce qui explique son utilisation quasi systématique dans toutes les applications d’enregistrement magnétique.
Chacun de ces codes a ses spécificités au niveau du spectre, de la facilité de récupération de l’horloge, de la complexité des circuits de codage et de décodage, et sont utilisés dans des applications particulières.
NRZI S-NRZI
B8ZS,HDB3
AMI et ternaire
Manchester, Manchester différentiel
0 D/2 = 20,9 MHz D = 41,85 MHz fréquence
Bande passante disponible
Figure 25. Spectre du signal binaire en fonction du codage utilisé.
Figure 26. Quelques codes possibles.
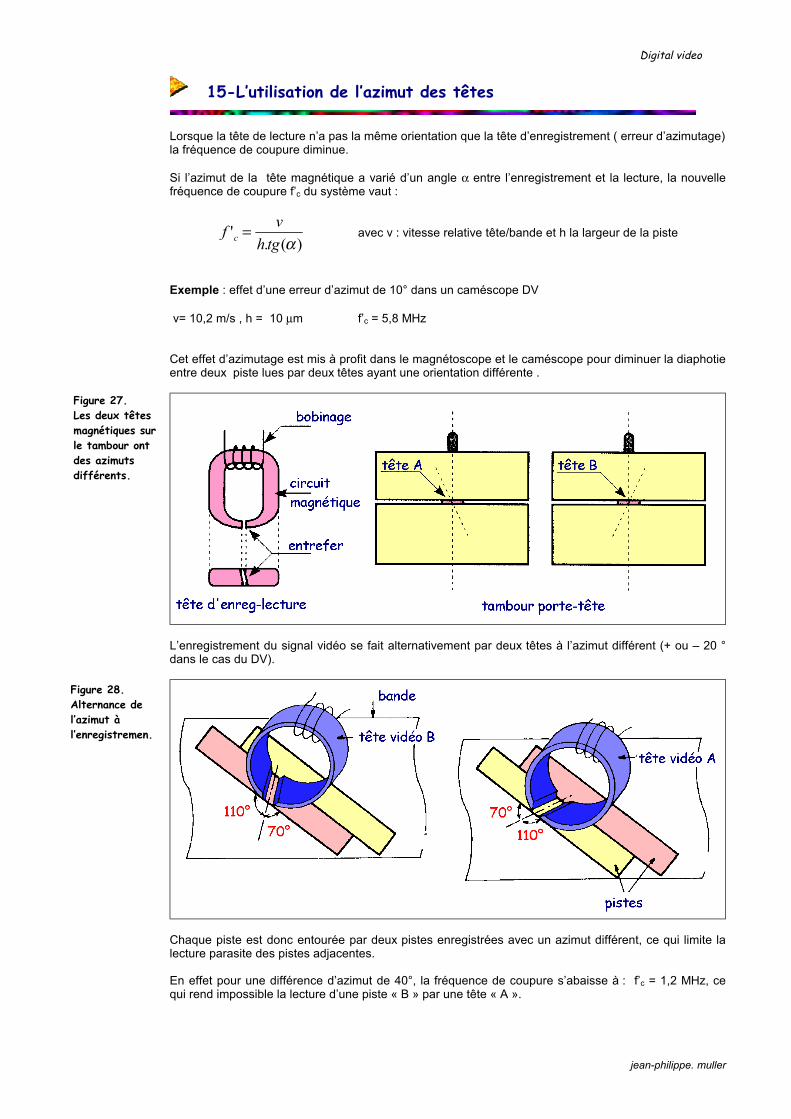
Digital video
jean-philippe. muller
15-L’utilisation de l’azimut des têtes
Lorsque la tête de lecture n’a pas la même orientation que la tête d’enregistrement ( erreur d’azimutage) la fréquence de coupure diminue. Si l’azimut de la tête magnétique a varié d’un angle α entre l’enregistrement et la lecture, la nouvelle fréquence de coupure f’c du système vaut :
)(.
'αtghvf c = avec v : vitesse relative tête/bande et h la largeur de la piste
Exemple : effet d’une erreur d’azimut de 10° dans un caméscope DV v= 10,2 m/s , h = 10 µm f’c = 5,8 MHz Cet effet d’azimutage est mis à profit dans le magnétoscope et le caméscope pour diminuer la diaphotie entre deux piste lues par deux têtes ayant une orientation différente .
L’enregistrement du signal vidéo se fait alternativement par deux têtes à l’azimut différent (+ ou – 20 ° dans le cas du DV).
Chaque piste est donc entourée par deux pistes enregistrées avec un azimut différent, ce qui limite la lecture parasite des pistes adjacentes. En effet pour une différence d’azimut de 40°, la fréquence de coupure s’abaisse à : f’c = 1,2 MHz, ce qui rend impossible la lecture d’une piste « B » par une tête « A ».
Figure 27. Les deux têtes magnétiques sur le tambour ont des azimuts différents.
Figure 28. Alternance de l’azimut à l’enregistremen.
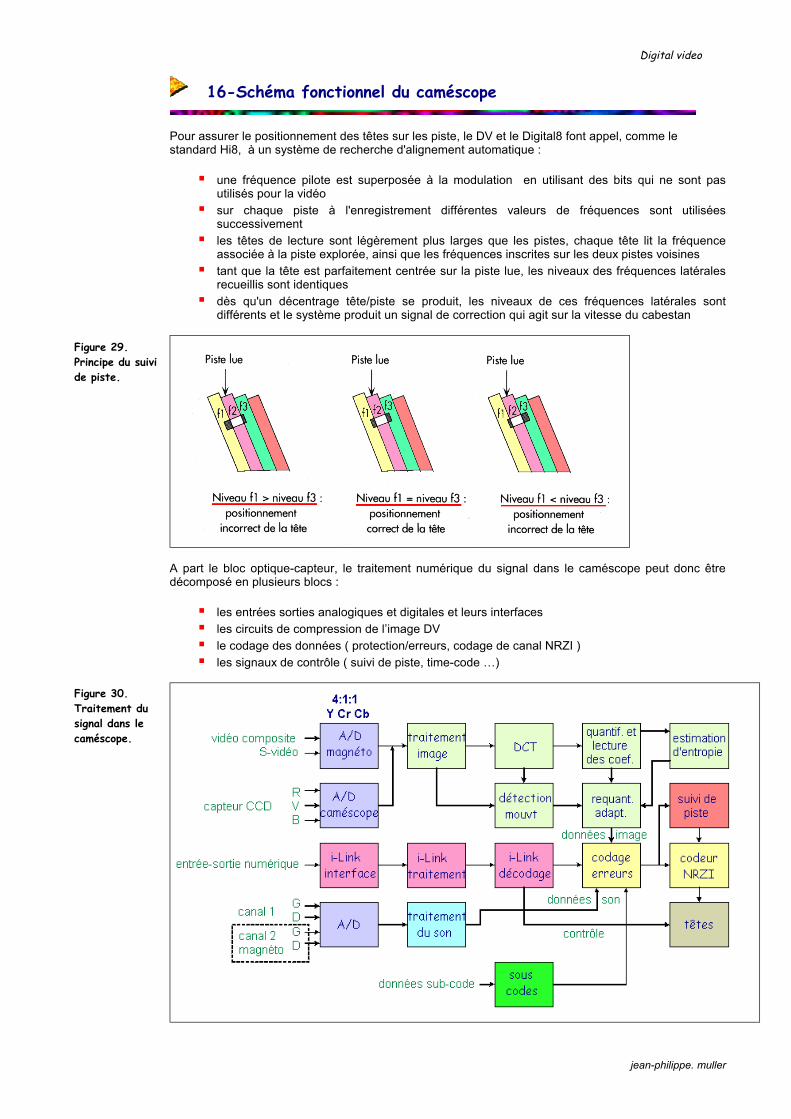
Digital video
jean-philippe. muller
16-Schéma fonctionnel du caméscope
Pour assurer le positionnement des têtes sur les piste, le DV et le Digital8 font appel, comme le standard Hi8, à un système de recherche d'alignement automatique :
une fréquence pilote est superposée à la modulation en utilisant des bits qui ne sont pas utilisés pour la vidéo sur chaque piste à l'enregistrement différentes valeurs de fréquences sont utilisées
successivement les têtes de lecture sont légèrement plus larges que les pistes, chaque tête lit la fréquence
associée à la piste explorée, ainsi que les fréquences inscrites sur les deux pistes voisines tant que la tête est parfaitement centrée sur la piste lue, les niveaux des fréquences latérales
recueillis sont identiques dès qu'un décentrage tête/piste se produit, les niveaux de ces fréquences latérales sont
différents et le système produit un signal de correction qui agit sur la vitesse du cabestan
A part le bloc optique-capteur, le traitement numérique du signal dans le caméscope peut donc être décomposé en plusieurs blocs :
les entrées sorties analogiques et digitales et leurs interfaces les circuits de compression de l’image DV le codage des données ( protection/erreurs, codage de canal NRZI ) les signaux de contrôle ( suivi de piste, time-code …)
Figure 29. Principe du suivi de piste.
Figure 30. Traitement du signal dans le caméscope.
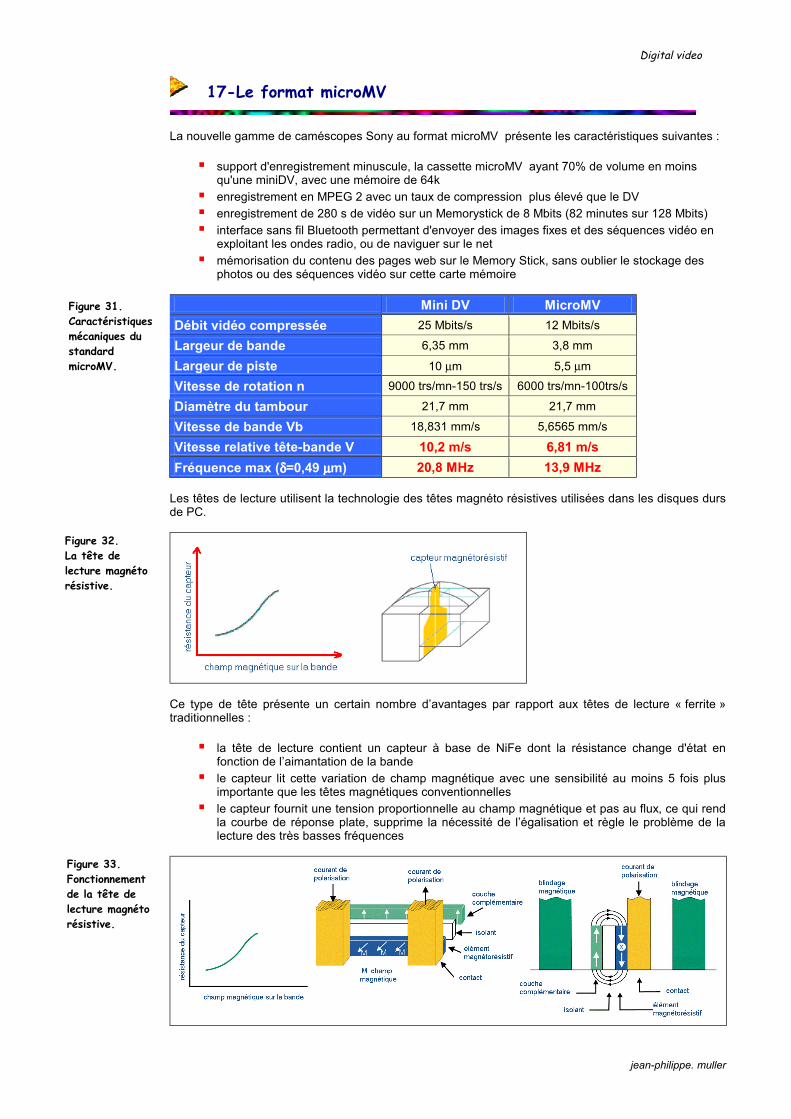
Digital video
jean-philippe. muller
17-Le format microMV
La nouvelle gamme de caméscopes Sony au format microMV présente les caractéristiques suivantes :
support d'enregistrement minuscule, la cassette microMV ayant 70% de volume en moins qu'une miniDV, avec une mémoire de 64k enregistrement en MPEG 2 avec un taux de compression plus élevé que le DV enregistrement de 280 s de vidéo sur un Memorystick de 8 Mbits (82 minutes sur 128 Mbits) interface sans fil Bluetooth permettant d'envoyer des images fixes et des séquences vidéo en
exploitant les ondes radio, ou de naviguer sur le net mémorisation du contenu des pages web sur le Memory Stick, sans oublier le stockage des
photos ou des séquences vidéo sur cette carte mémoire Mini DV MicroMV Débit vidéo compressée 25 Mbits/s 12 Mbits/s
Largeur de bande 6,35 mm 3,8 mm
Largeur de piste 10 µm 5,5 µm
Vitesse de rotation n 9000 trs/mn-150 trs/s 6000 trs/mn-100trs/s
Diamètre du tambour 21,7 mm 21,7 mm
Vitesse de bande Vb 18,831 mm/s 5,6565 mm/s
Vitesse relative tête-bande V 10,2 m/s 6,81 m/s Fréquence max (δδδδ=0,49 µµµµm) 20,8 MHz 13,9 MHz
Les têtes de lecture utilisent la technologie des têtes magnéto résistives utilisées dans les disques durs de PC.
Ce type de tête présente un certain nombre d’avantages par rapport aux têtes de lecture « ferrite » traditionnelles :
la tête de lecture contient un capteur à base de NiFe dont la résistance change d'état en fonction de l’aimantation de la bande le capteur lit cette variation de champ magnétique avec une sensibilité au moins 5 fois plus
importante que les têtes magnétiques conventionnelles le capteur fournit une tension proportionnelle au champ magnétique et pas au flux, ce qui rend
la courbe de réponse plate, supprime la nécessité de l’égalisation et règle le problème de la lecture des très basses fréquences
Figure 31. Caractéristiques mécaniques du standard microMV.
Figure 33. Fonctionnement de la tête de lecture magnéto résistive.
Figure 32. La tête de lecture magnéto résistive.

Digital video
jean-philippe. muller
18-L’enregistrement sur CDRW
Le disque réinscriptible CDRW est un support d’enregistrement de grande capacité, de faible coût, et lisible sur la plupart des lecteurs de CDROM actuels. Il est donc tout à fait normal qu’il soit apparu comme mémoire dans les appareils photos et les caméscopes (Hitachi).
SONY MCV-CD200(CDRW) Appareil photo numérique doté d'un capteur CCD Super HAD de 2,1 millions de pixels, d'un mode film et d'un support d'enregistrement sur CD-RW 153 Mo. Capacité en photos (qualité haute/basse) : 237 (1600x1200) 1300 (640x480)
Le CD-RW utilise les changements de phase de la couche métallique pressée dans l'âme du disque entre deux couches diélectriques:
le métal utilisé étant un alliage d’argent, d’indium, d’antimoine et de tellure si l’on chauffe une petite zone de la surface, elle passe du stade amorphe à l’état cristallin, ce
qui modifie ses propriétés de réflexion et crée l’équivalent d’une cuvette ces variation d’état du métal ont pour conséquence une présence ou une absence de réflexion
lors qu’elles sont balayées par un laser de puissance normale, et le résultat de la réflexion est capté par une photodiode
Afin que le faisceau laser incident puisse se positionner et décrire une spirale lors de l'enregistrement, un sillon (groove) est tracé dans le substrat :
la compatibilité avec les blocs optiques laser standards est assurée quand ce sillon a une largeur typique de 600 nm pour une profondeur de 100 nm, la section étant en forme de U pour asservir la vitesse de rotation du disque à une vitesse linéaire constante, le sillon oscille
autour de la spirale constituant sa position moyenne (wobble of the groove) avec une amplitude typique de 30 nm et une longueur d'onde de 60 µm la vitesse linéaire est nominale quand une longueur d'onde (reproduite par une variation de flux
du faisceau réfléchi) est lue en 45,35 µs, ce qui correspond à une fréquence de référence de 22,05 kHz.
En fait, l'oscillation de la spirale du sillon n'a pas une longueur d'onde constante de 60 µm mais varie en fonction de la position sur le disque. Le graveur est ainsi capable de déterminer la durée enregistrée et la durée restant disponible pour une autre cession d'enregistrement. La modulation de l'oscillation de la spirale du sillon est appelée APIT (absolute time in pre groove).
Figure 34. Photoscope utilisant un CDRW.
Figure 35. Le sillon de guidage inscrit sur le CDRZ vierge.

Digital video
jean-philippe. muller
19-La diode laser
Pour les opérations de lecture et d’écriture, le disque est éclairée par une diode laser à semi-conducteur à arséniure de gallium :
ce composant est réalisé autour d’une jonction P-N polarisée en direct et constituant une cavité résonante. la diode laser émet une puissance lumineuse variable selon l’opération entre 2 et 14 mW et le
courant qu’elle consomme est de l’ordre de 50 à 60 mA. ce courant augmente lors du vieillissement de la diode laser et peut atteindre 100 mA : on peut
alors considérer que la diode laser est épuisée et il faut procéder au remplacement du bloc optique( durée de vie de l’ordre de 6000h)
Pour pouvoir réguler la puissance émise par la diode laser, il faut la mesurer, ce qui se fait par l’intermédiaire d’une photodiode montée dans le boîtier de la diode laser.
Le faisceau principal de la diode laser :
est collimaté et rendu parallèle par un dispositif optique est focalisé précisément sur la surface du disque par un asservissement de position se réfléchit au niveau du disque avec une variation d’intensité liée à un phénomène
d’interférence (CD, CDROM) ou de variation du coefficient de réflexion (CDRW) revient vers le bloc de photodiodes où il est séparé en différents faisceaux servant à la
focalisation, au suivi de piste et à la lecture des données
Figure 37. Structure d’une diode laser.
Figure 36. Effet de la régulation de puissance sur le courant de la diode.
Figure 38. Géométrie du trajet optique dans un lecteur CD.

Digital video
jean-philippe. muller
20-L’enregistrement des données
Avant d’être enregistrées sur le disque, les données binaires relatives à l’image vont subir, comme dans le cas de la bande magnétique, un certain nombre de traitements avant l’enregistrement :
ajout de codes correcteurs d’erreurs par bits de parité et Reed-Solomon qui permettent de
réparer des erreurs de faible longueur brassage des données pour se protéger des macro-défauts (rayure du disque, trace de doigts,
défaut de fabrication, etc.) pouvant entraîner la perte d'un ou plusieurs octets de données transcodage évitant des cuvettes trop courtes (codage 8-14) : par exemple, l'octet 0111 0010
est transposé en 10010010000010 de telle sorte qu'entre deux niveaux 1 successifs il puisse y avoir au moins deux niveaux 0 et au plus dix niveaux 0. codage NRZI : le passage d'une absence de cuvette à une cuvette correspond à un niveau 1.
La longueur des cuvettes enregistrés sur le disque s'en trouve allongée
Lors de l’écriture, le changement de phase nécessite une élévation de température de l’ordre de 500 à 700 ° localisée au point d’impact du faisceau, ce qui correspond à une puissance lumineuse comprise entre 8 et 14 mW. L’envoi d’une impulsion laser de cette puissance :
échauffe localement le matériau polycristallin et le fait passer le l’état cristallin à l’état amorphe il en résulte une perte de réflectivité du « sandwich » qui passe de 25% (cristallin) à 15%
(amorphe) on a ainsi créé l’équivalent d’une cuvette
Figure 39. Codage 8-14 utilisé pour les CD.
Figure 40. L’enregistrement des données sur un CDRW.
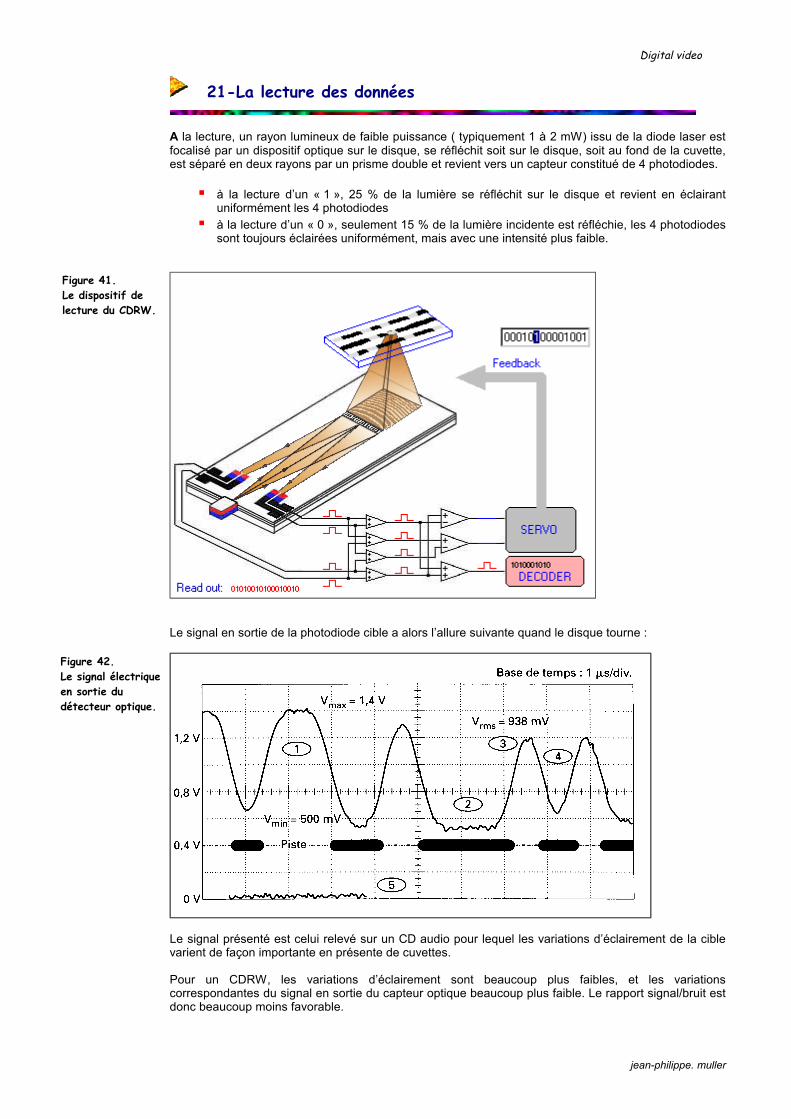
Digital video
jean-philippe. muller
21-La lecture des données
A la lecture, un rayon lumineux de faible puissance ( typiquement 1 à 2 mW) issu de la diode laser est focalisé par un dispositif optique sur le disque, se réfléchit soit sur le disque, soit au fond de la cuvette, est séparé en deux rayons par un prisme double et revient vers un capteur constitué de 4 photodiodes.
à la lecture d’un « 1 », 25 % de la lumière se réfléchit sur le disque et revient en éclairant uniformément les 4 photodiodes à la lecture d’un « 0 », seulement 15 % de la lumière incidente est réfléchie, les 4 photodiodes
sont toujours éclairées uniformément, mais avec une intensité plus faible.
Le signal en sortie de la photodiode cible a alors l’allure suivante quand le disque tourne :
Le signal présenté est celui relevé sur un CD audio pour lequel les variations d’éclairement de la cible varient de façon importante en présente de cuvettes. Pour un CDRW, les variations d’éclairement sont beaucoup plus faibles, et les variations correspondantes du signal en sortie du capteur optique beaucoup plus faible. Le rapport signal/bruit est donc beaucoup moins favorable.
Figure 42. Le signal électrique en sortie du détecteur optique.
Figure 41. Le dispositif de lecture du CDRW.
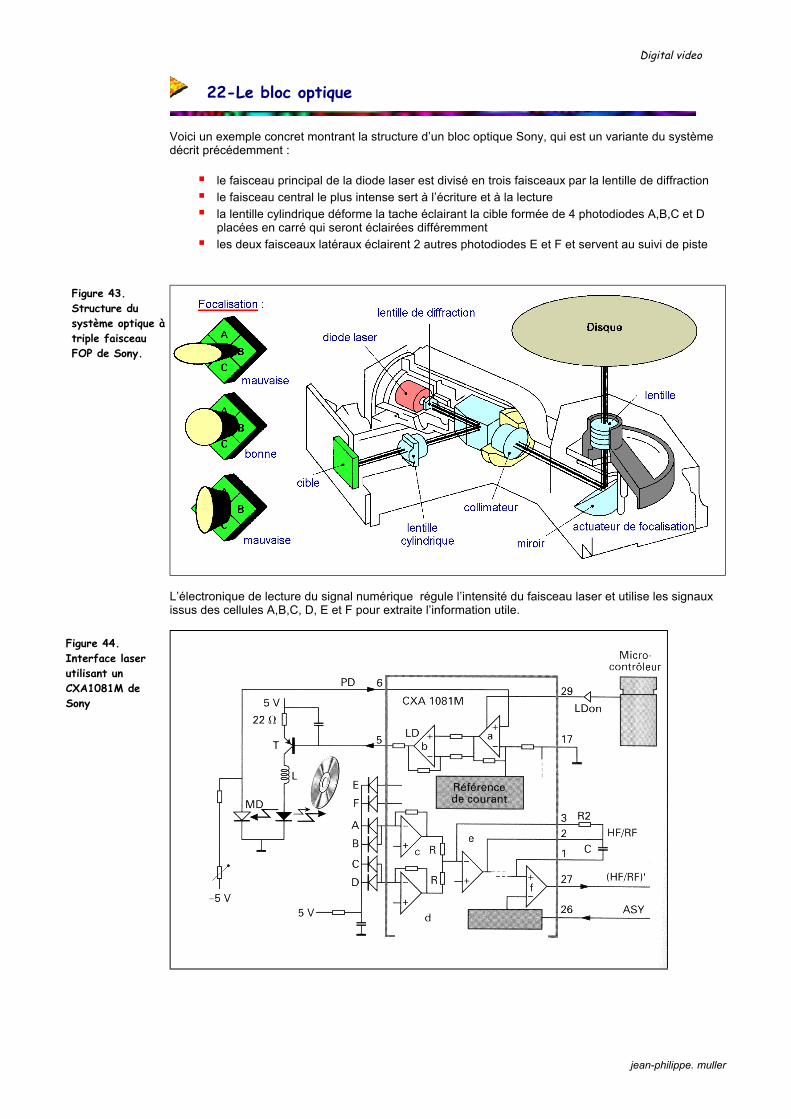
Digital video
jean-philippe. muller
22-Le bloc optique
Voici un exemple concret montrant la structure d’un bloc optique Sony, qui est un variante du système décrit précédemment :
le faisceau principal de la diode laser est divisé en trois faisceaux par la lentille de diffraction le faisceau central le plus intense sert à l’écriture et à la lecture la lentille cylindrique déforme la tache éclairant la cible formée de 4 photodiodes A,B,C et D
placées en carré qui seront éclairées différemment les deux faisceaux latéraux éclairent 2 autres photodiodes E et F et servent au suivi de piste
L’électronique de lecture du signal numérique régule l’intensité du faisceau laser et utilise les signaux issus des cellules A,B,C, D, E et F pour extraite l’information utile.
Figure 43. Structure du système optique à triple faisceau FOP de Sony.
Figure 44. Interface laser utilisant un CXA1081M de Sony
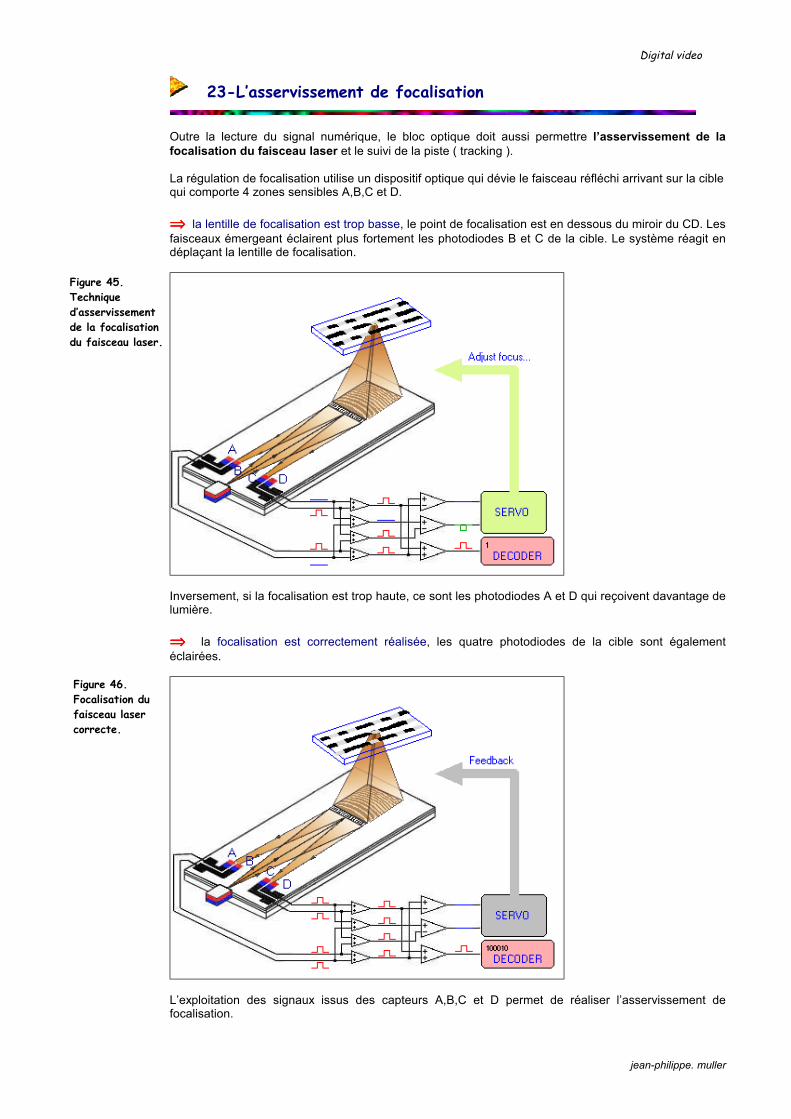
Digital video
jean-philippe. muller
23-L’asservissement de focalisation
Outre la lecture du signal numérique, le bloc optique doit aussi permettre l’asservissement de la focalisation du faisceau laser et le suivi de la piste ( tracking ). La régulation de focalisation utilise un dispositif optique qui dévie le faisceau réfléchi arrivant sur la cible qui comporte 4 zones sensibles A,B,C et D. ⇒⇒⇒⇒ la lentille de focalisation est trop basse, le point de focalisation est en dessous du miroir du CD. Les faisceaux émergeant éclairent plus fortement les photodiodes B et C de la cible. Le système réagit en déplaçant la lentille de focalisation.
Inversement, si la focalisation est trop haute, ce sont les photodiodes A et D qui reçoivent davantage de lumière. ⇒⇒⇒⇒ la focalisation est correctement réalisée, les quatre photodiodes de la cible sont également éclairées.
L’exploitation des signaux issus des capteurs A,B,C et D permet de réaliser l’asservissement de focalisation.
Figure 45. Technique d’asservissement de la focalisation du faisceau laser.
Figure 46. Focalisation du faisceau laser correcte.

Digital video
jean-philippe. muller
24-L’asservissement de suivi de piste
Le même dispositif servant à la lecture et au réglage de focalisation sert également à l’asservissement de suivi de piste. Quand le spot principal est bien placé dans le sillon, la quantité de lumière constituant les faisceaux latéraux réfléchis est identique et les 4 photodiodes reçoivent une quantité de lumière identique.
L’existence d’une erreur de piste entraîne une dissymétrie dans les faisceaux émergents, et les photodiodes A et B sont moins éclairées que les photodiodes C et D. L’asservissement de position de la tête de lecture peut alors réagir et replacer la tête optique exactement sous le sillon.
Figure 47. Eclairement des cibles quand le spot est sur la piste.
Figure 48. Effet d’une erreur de piste.

jean-philippe muller
Version 05/2002
Image numérique : l’afficheur LCD

Digital video
jean-philippe. muller
Sommaire
1. Lumière naturelle et lumière polarisée 2. Les cristaux liquides 3. L’orientation des cristaux liquides 4. Le principe de l’afficheur TN à 2 couleurs 5. Les afficheurs à commande matricielle 6. L’affichage des niveaux de gris 7. L’affichage des couleurs 8. Exemple d’organisation d’afficheur 9. La source de lumière 10. Les signaux de commande 11. Exemple de circuit de commande 12. Les caractéristiques d’un afficheur Sony 13. La technologie des afficheurs OLED
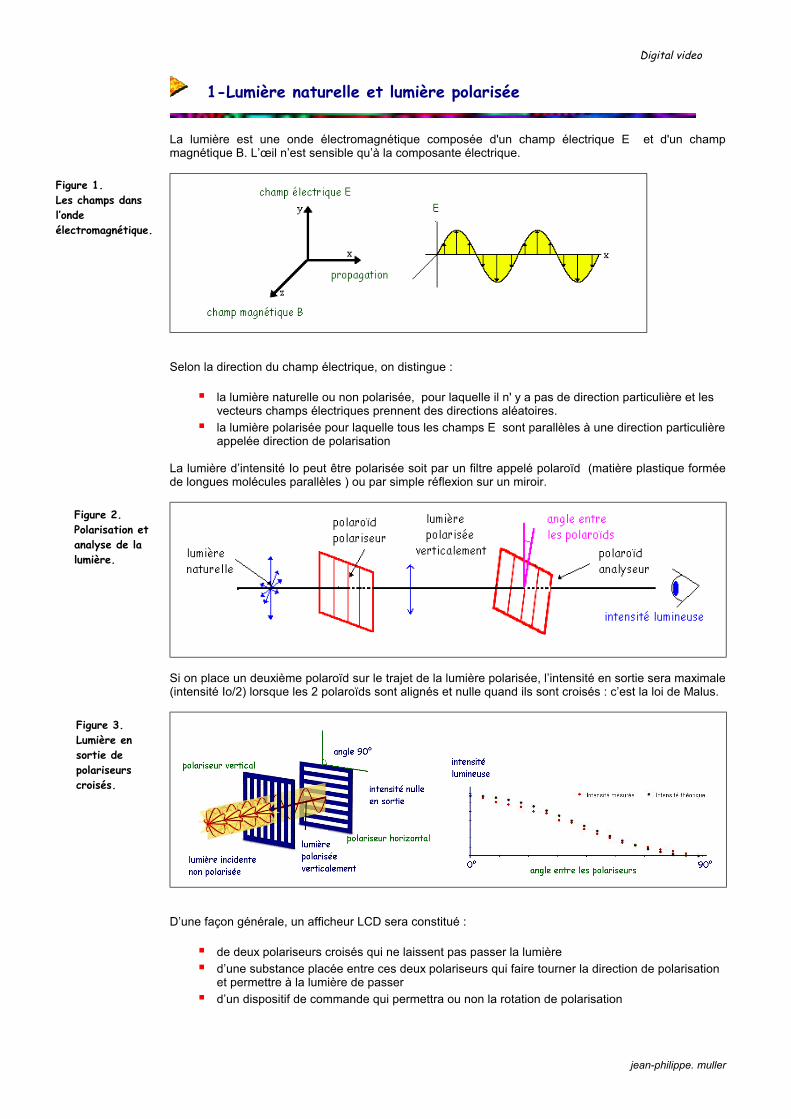
Digital video
jean-philippe. muller
1-Lumière naturelle et lumière polarisée
La lumière est une onde électromagnétique composée d'un champ électrique E et d'un champ magnétique B. L’œil n’est sensible qu’à la composante électrique.
Selon la direction du champ électrique, on distingue :
la lumière naturelle ou non polarisée, pour laquelle il n' y a pas de direction particulière et les vecteurs champs électriques prennent des directions aléatoires. la lumière polarisée pour laquelle tous les champs E sont parallèles à une direction particulière
appelée direction de polarisation La lumière d’intensité Io peut être polarisée soit par un filtre appelé polaroïd (matière plastique formée de longues molécules parallèles ) ou par simple réflexion sur un miroir.
Si on place un deuxième polaroïd sur le trajet de la lumière polarisée, l’intensité en sortie sera maximale (intensité Io/2) lorsque les 2 polaroïds sont alignés et nulle quand ils sont croisés : c’est la loi de Malus.
D’une façon générale, un afficheur LCD sera constitué :
de deux polariseurs croisés qui ne laissent pas passer la lumière d’une substance placée entre ces deux polariseurs qui faire tourner la direction de polarisation
et permettre à la lumière de passer d’un dispositif de commande qui permettra ou non la rotation de polarisation
Figure 1. Les champs dans l’onde électromagnétique.
Figure 2. Polarisation et analyse de la lumière.
Figure 3. Lumière en sortie de polariseurs croisés.

Digital video
jean-philippe. muller
2-Les cristaux liquides
Les cristaux liquides ont été découverts en 1888 par le botaniste autrichien H. Reinitzer. Comme leur nom ne l’indique pas, les cristaux liquides ne sont pas des cristaux :
la plupart des cristaux liquides sont des composés organiques avec des molécules allongées en forme de bâtonnets ils ne présentent ni les arêtes vives, ni les facettes lisses et brillantes qui caractérisent ce qu'on
appelle communément les cristaux. en revanche, ils possèdent des propriétés d'organisation des molécules qui se traduisent par
des caractéristiques optiques particulières et qui les rapprochent de l' état cristallin
Dans l'état naturel, les molécules se disposent spontanément d' une manière ordonnée avec leurs axes grossièrement parallèles. Prenons l'exemple du Cholesteryl Myristate, composé de carbone et d'hydrogène, et utilisé par Reinitzer lors de ses expériences en 1888:
à 20 degrés on est en phase solide, les molécules du cristal sont rangées avec un ordre de position et d' orientation à 71 degrés, le solide fond, mais le " liquide" résultant est trouble, l'ordre positionnel a disparu
mais toutes les molécules ont plus ou moins gardé leur orientation d'origine. à 85 degrés, le liquide trouble devient clair, on a obtenu une phase liquide classique où ne
subsiste aucun ordre
Pour les afficheurs à cristaux liquides, on utilise des substances qui sont à l’état de cristaux liquides à la température ordinaire.
Figure 4. Molécule de cristal liquide et exemple d’alignement.
Figure 5. Les 3 états des cristaux liquides.

Digital video
jean-philippe. muller
3-L’orientation des cristaux liquides
Il est possible de "piloter" la direction des molécules de cristaux liquides par divers moyens : ⇒⇒⇒⇒ par un dispositif mécanique Lorsqu'on dispose une couche de cristal liquide sur une plaque gravée de fins sillons parallèles (couche d'alignement), les molécules s'orientent parallèlement à ces sillons
Lorsqu'on enferme une couche de cristaux liquides entre deux plaques gravées de sillons orientés dans deux directions différentes, l' orientation des molécules (à l' état de repos) passe progressivement de la direction (1) à la direction (2. Elle fait donc apparaître une torsion. C'est ce qu'on appelle un cristal liquide "Twisted Nematic", qu'on pourrait traduire par nématique tordu. Ces molécules alignées vont avoir des propriétés spéciales dans le domaine optique puisqu’elles vont faire tourner la direction de polarisation de la lumière. ⇒⇒⇒⇒ sous l’action d’un champ électrique Si on soumet le cristal liquide à une tension électrique, l’orientation des molécules se modifie sous l’action du champ électrique. Les chaînes moléculaires s’orientent parallèlement aux lignes de champ et se retrouvent perpendiculaires aux électrodes. Dans cette situation, elles ne modifient plus la direction de polarisation de la lumière.
Remarque : en jouant sur la valeur de la tension appliquée, il est possible d’obtenir des situations intermédiaires dans lesquelles seule une partie des rayons incidents voit sa direction de polarisation modifiée.
Figure 6. Alignement mécanique des molécules de cristal liquide.
Figure 7. Alignement électrique des molécules de cristal liquide.

Digital video
jean-philippe. muller
4-Le principe de l’afficheur TN à 2 couleurs
En intercalant une cellule de ce type entre deux polariseurs croisés, on peut fabriquer un dispositif à transmittance optique variable :
au repos, les cristaux liquides font tourner l’axe de polarisation de la lumière qui peut donc traverser le dispositif l’application d’une tension entre les deux plaques de verre aligne les molécules sur le champ et
empêche la rotation de la polarisation : la lumière ne traverse plus le dispositif
La variation de la transmittance en fonction de la tension de polarisation appliquée met en évidence une zone où la transmittance varie rapidement. On pourra donc utiliser l’interrupteur optique ainsi constitué pour afficher sur un écran des zones sombres ou claires : ⇒⇒⇒⇒ qui reproduisent la forme des électrodes : c’est le principe utilisé dans les afficheurs à points ou à segments.
⇒⇒⇒⇒ qui peuvent être adressées de façon matricielle en x,y pour former une image quelconque : c’est la technique utilisée dans les écrans LCD graphiques .
Figure 8. Principe de l’interrupteur à cristaux liquides.
Figure 9. Exemple d’afficheur LCD à segments.
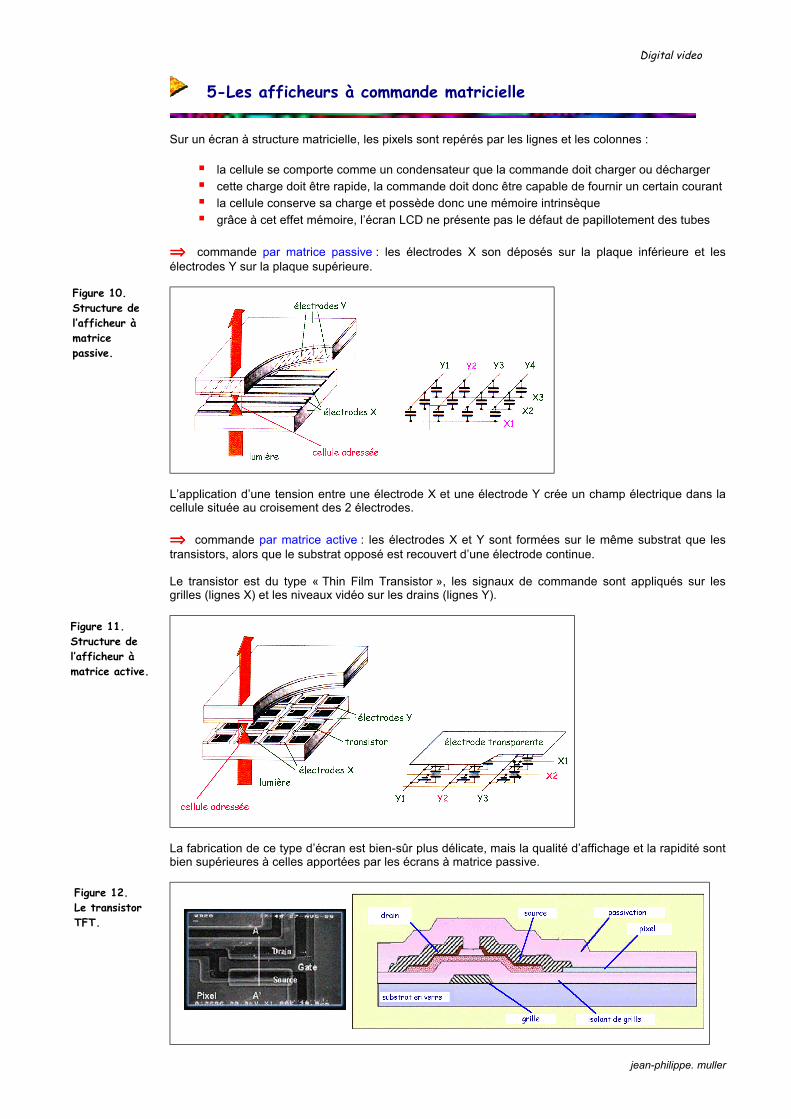
Digital video
jean-philippe. muller
5-Les afficheurs à commande matricielle
Sur un écran à structure matricielle, les pixels sont repérés par les lignes et les colonnes :
la cellule se comporte comme un condensateur que la commande doit charger ou décharger cette charge doit être rapide, la commande doit donc être capable de fournir un certain courant la cellule conserve sa charge et possède donc une mémoire intrinsèque grâce à cet effet mémoire, l’écran LCD ne présente pas le défaut de papillotement des tubes
⇒⇒⇒⇒ commande par matrice passive : les électrodes X son déposés sur la plaque inférieure et les électrodes Y sur la plaque supérieure.
L’application d’une tension entre une électrode X et une électrode Y crée un champ électrique dans la cellule située au croisement des 2 électrodes. ⇒⇒⇒⇒ commande par matrice active : les électrodes X et Y sont formées sur le même substrat que les transistors, alors que le substrat opposé est recouvert d’une électrode continue. Le transistor est du type « Thin Film Transistor », les signaux de commande sont appliqués sur les grilles (lignes X) et les niveaux vidéo sur les drains (lignes Y).
La fabrication de ce type d’écran est bien-sûr plus délicate, mais la qualité d’affichage et la rapidité sont bien supérieures à celles apportées par les écrans à matrice passive.
Figure 10. Structure de l’afficheur à matrice passive.
Figure 11. Structure de l’afficheur à matrice active.
Figure 12. Le transistor TFT.

Digital video
jean-philippe. muller
6-L’affichage des niveaux de gris
L’affichage des différents niveaux de luminance de l’image est basé sur le principe suivant :
en l’absence de champ électrique appliqué (tension de polarisation nulle), les molécules se placent en position « twistée » pour permettre le passage de la lumière. en présence d’un champ électrique faible (tension de polarisation faible), quelques molécules
s’orientent en direction du champ, les autres restant « twistées » : la transmittance a légèrement diminué en présence d’un champ fort (tension de polarisation élevée), la plupart des molécules sont
orientées dans le sens du champ et la transmittance de la cellule est très faible On pourra donc commander la luminosité du pixel en jouant sur la tension de polarisation qui lui est appliquée : les afficheurs à cristaux liquides nécessitent donc une commande analogique.
Remarques :
le maximum de transmittance correspond à une transmittance de 50%, ce qui explique la qualité médiocre des afficheurs sous faible éclairement et la nécessité du rétro éclairage les deux tension V10 et V90 caractérisent la plage de tension utilisée pour passer de l'extinction
au passage maximal. Si on veut une luminosité du pixel proportionnelle à la tension de polarisation, il est important que la courbe de transmittance soit la plus linéaire possible. pour une commande aisée, il est agréable d’avoir une plage de commande assez large.
Malheureusement, l’élargissement de la plage de commande augmente le temps de réponse et introduit le phénomène de « traînée » très gênant pour l’affichage des images animées. si le transistor de commande est abîmé, la cellule est transparente est le pixel est blanc, ce qui
est très visible. Pour pallier à ces problèmes, on a amélioré les écrans TN (Twisted nematic) en utilisant des matériaux sophistiqués dans des écrans qui allient rapidité satisfaisante et plage de commande correcte :
le STN (Super Twisted nematic) dans lesquels les cristaux liquides introduisent une rotation de la polarisation de l’ordre de 210 degrés l’ECB (Electrically controlled birefringence), technique développée par Sony, qui met en œuvre
un seul polariseur et un éclairage par la face avant
Figure 13. Caractéristique de commande d’un afficheur LCD.
Figure 14. Structure de l’afficheur ECB de Sony.

Digital video
jean-philippe. muller
7-L’affichage des couleurs
Les couleurs sont obtenues en utilisant des filtres de couleurs vert rouge et bleu, les trois couleurs primaires, comme sur un tube cathodique. A définition identique, l’afficheur LCD couleur doit donc comporter 3 fois plus de cellules qu’un afficheur monochrome.
En ajustant les intensités des faisceaux sortant des cellules rouge, verte et bleue on pourra afficher un grand nombre de couleurs.
La structure de l’afficheur LCD couleur à rétro éclairage est alors la suivante :
Figure 15. Principe de l’afficheur couleur.
Figure 16. Exemples d’affichages de différentes couleurs.
Figure 17. Structure de l’afficheur couleur à matrice active.
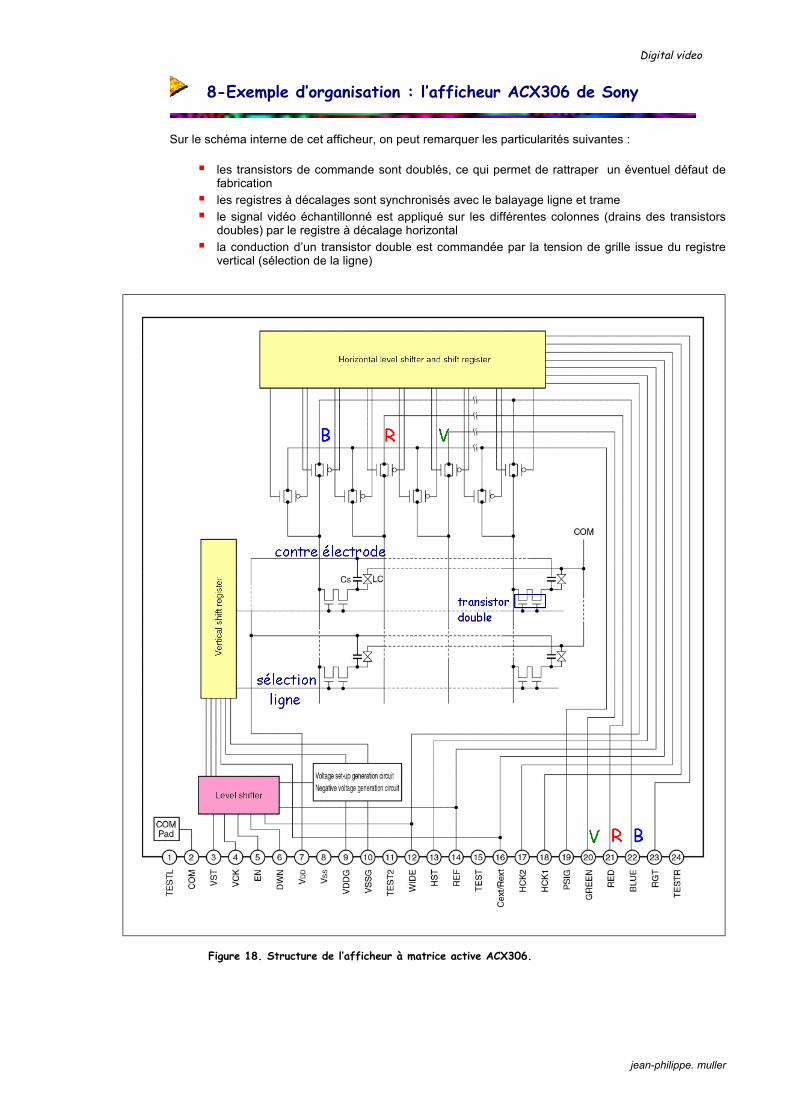
Digital video
jean-philippe. muller
8-Exemple d’organisation : l’afficheur ACX306 de Sony
Sur le schéma interne de cet afficheur, on peut remarquer les particularités suivantes :
les transistors de commande sont doublés, ce qui permet de rattraper un éventuel défaut de fabrication les registres à décalages sont synchronisés avec le balayage ligne et trame le signal vidéo échantillonné est appliqué sur les différentes colonnes (drains des transistors
doubles) par le registre à décalage horizontal la conduction d’un transistor double est commandée par la tension de grille issue du registre
vertical (sélection de la ligne)
Figure 18. Structure de l’afficheur à matrice active ACX306.

Digital video
jean-philippe. muller
9-La source de lumière
Les deux configurations des écrans LCD sont les écrans réflectifs et ceux utilisant un rétro-éclairage. les écrans réflectifs utilisent la lumière ambiante.
Au repos, la lumière traverse le cristal avant de subir une réflexion dans le miroir et de repasser à travers le cristal : on observe un point blanc. Quand on applique une tension, on observe un point noir (la lumière est bloquée avant la réflexion). les écrans avec rétro-éclairage (LED, tube fluorescent).
Cette lumière traverse ou non le cristal en fonction de la polarisation appliquée. Ce type d'écran LCD donne une meilleure intensité de l'écran, surtout avec peu de lumière ambiante, mais consomme plus d'énergie qu'un écran réflectif.
Différents dispositifs comme l’éclairage latéral sont mis en oeuvre pour réduire la profondeur de l’afficheur.
Remarque : alors que les afficheurs monochromes sont disponibles en réflexion ou en transmission, les écrans couleurs, compte tenu des effets de réfraction dans la cellule, ne peuvent être employés qu’en transmission.
Figure 19. Principe de l’afficheur à rétro éclairage.
Figure 20. L’éclairage latéral.
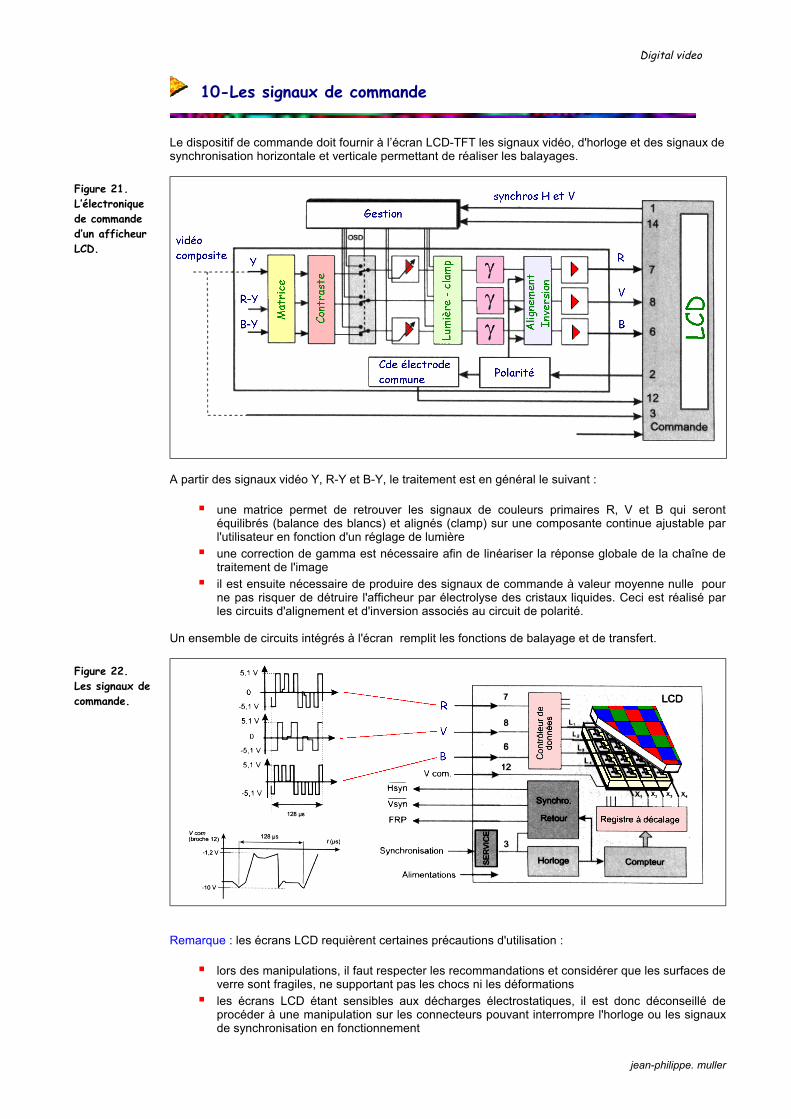
Digital video
jean-philippe. muller
10-Les signaux de commande
Le dispositif de commande doit fournir à l’écran LCD-TFT les signaux vidéo, d'horloge et des signaux de synchronisation horizontale et verticale permettant de réaliser les balayages.
A partir des signaux vidéo Y, R-Y et B-Y, le traitement est en général le suivant :
une matrice permet de retrouver les signaux de couleurs primaires R, V et B qui seront équilibrés (balance des blancs) et alignés (clamp) sur une composante continue ajustable par l'utilisateur en fonction d'un réglage de lumière une correction de gamma est nécessaire afin de linéariser la réponse globale de la chaîne de
traitement de l'image il est ensuite nécessaire de produire des signaux de commande à valeur moyenne nulle pour
ne pas risquer de détruire l'afficheur par électrolyse des cristaux liquides. Ceci est réalisé par les circuits d'alignement et d'inversion associés au circuit de polarité.
Un ensemble de circuits intégrés à l'écran remplit les fonctions de balayage et de transfert.
Remarque : les écrans LCD requièrent certaines précautions d'utilisation :
lors des manipulations, il faut respecter les recommandations et considérer que les surfaces de verre sont fragiles, ne supportant pas les chocs ni les déformations les écrans LCD étant sensibles aux décharges électrostatiques, il est donc déconseillé de
procéder à une manipulation sur les connecteurs pouvant interrompre l'horloge ou les signaux de synchronisation en fonctionnement
Figure 21. L’électronique de commande d’un afficheur LCD.
Figure 22. Les signaux de commande.

Digital video
jean-philippe. muller
11-Exemple de circuit de commande
Le circuit Sony CXA3572R est destiné à piloter les afficheurs LCD pour photoscopes numériques ACX306 et ACX312.
La structure interne de ce circuit de commande est la suivante :
Figure 23. Un chipset d’affichage.
Figure 24. Structure interne du CXA3572.

Digital video
jean-philippe. muller
12-Les caractéristiques d’un afficheur Sony
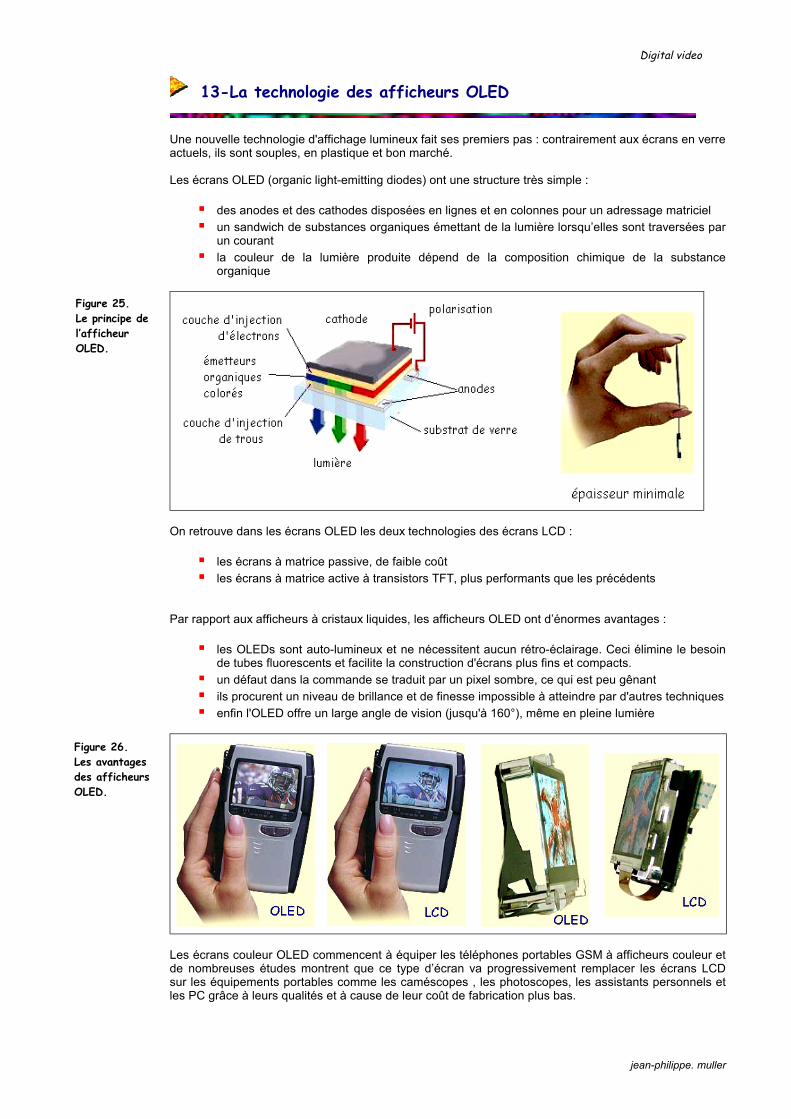
Digital video
jean-philippe. muller
13-La technologie des afficheurs OLED
Une nouvelle technologie d'affichage lumineux fait ses premiers pas : contrairement aux écrans en verre actuels, ils sont souples, en plastique et bon marché. Les écrans OLED (organic light-emitting diodes) ont une structure très simple :
des anodes et des cathodes disposées en lignes et en colonnes pour un adressage matriciel un sandwich de substances organiques émettant de la lumière lorsqu’elles sont traversées par
un courant la couleur de la lumière produite dépend de la composition chimique de la substance
organique
On retrouve dans les écrans OLED les deux technologies des écrans LCD :
les écrans à matrice passive, de faible coût les écrans à matrice active à transistors TFT, plus performants que les précédents
Par rapport aux afficheurs à cristaux liquides, les afficheurs OLED ont d’énormes avantages :
les OLEDs sont auto-lumineux et ne nécessitent aucun rétro-éclairage. Ceci élimine le besoin
de tubes fluorescents et facilite la construction d'écrans plus fins et compacts. un défaut dans la commande se traduit par un pixel sombre, ce qui est peu gênant ils procurent un niveau de brillance et de finesse impossible à atteindre par d'autres techniques enfin l'OLED offre un large angle de vision (jusqu'à 160°), même en pleine lumière
Les écrans couleur OLED commencent à équiper les téléphones portables GSM à afficheurs couleur et de nombreuses études montrent que ce type d’écran va progressivement remplacer les écrans LCD sur les équipements portables comme les caméscopes , les photoscopes, les assistants personnels et les PC grâce à leurs qualités et à cause de leur coût de fabrication plus bas.
Figure 25. Le principe de l’afficheur OLED.
Figure 26. Les avantages des afficheurs OLED.